面试题
网络协议
图论
web3
搭建网站
硬件工程
绘图机器人
点云
Linux命令
反射型XSS
globalmapper
self-attention
制图表达
Exception
android-studio
哈夫曼树
期末考试
泰勒展开式
地图制图
链接
语言模型
2024/4/11 16:00:37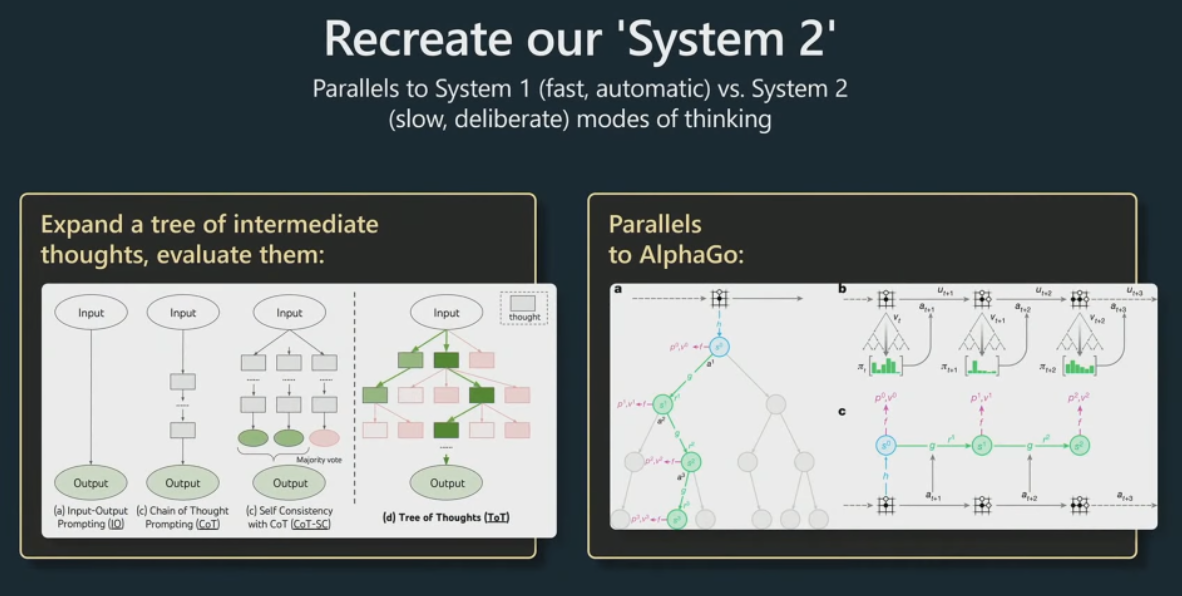
基于LLM构建文本生成系统
背景:
在流量存量时代,内容运营重要性不言而喻。在流量时代,内容可以不要过于多样化和差异化,只需要有足够多的人流量,按流量转化比率来看,1000个人有1%概率转化,素材不变只要增加足够多的流量…
论文笔记--Deep contextualized word representations
论文笔记--Deep contextualized word representations 1. 文章简介2. 文章概括3 文章重点技术3.1 BiLM(Bidirectional Language Model)3.2 ELMo3.3 将ELMo用于NLP监督任务 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Deep contextualized word representations作者…
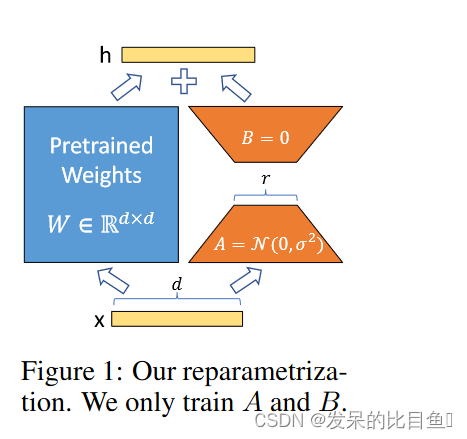
2021-arxiv-LoRA Low-Rank Adaptation of Large Language Models
2021-arxiv-LoRA Low-Rank Adaptation of Large Language Models Paper: https://arxiv.org/abs/2106.09685 Code: https://github.com/microsoft/LoRA
大型语言模型的LoRA低秩自适应
自然语言处理的一个重要范式包括对通用领域数据的大规模预训练和对特定任务或领域的适应。…

11月推荐阅读的12篇大语言模型相关论文
现在已经是12月了,距离2024年只有一个月了,本文总结了11月的一些比较不错的大语言模型相关论文
System 2 Attention (is something you might need too).
https://arxiv.org/abs/2311.11829
一种称为S2A的新注意力方法被开发出来,解决llm…
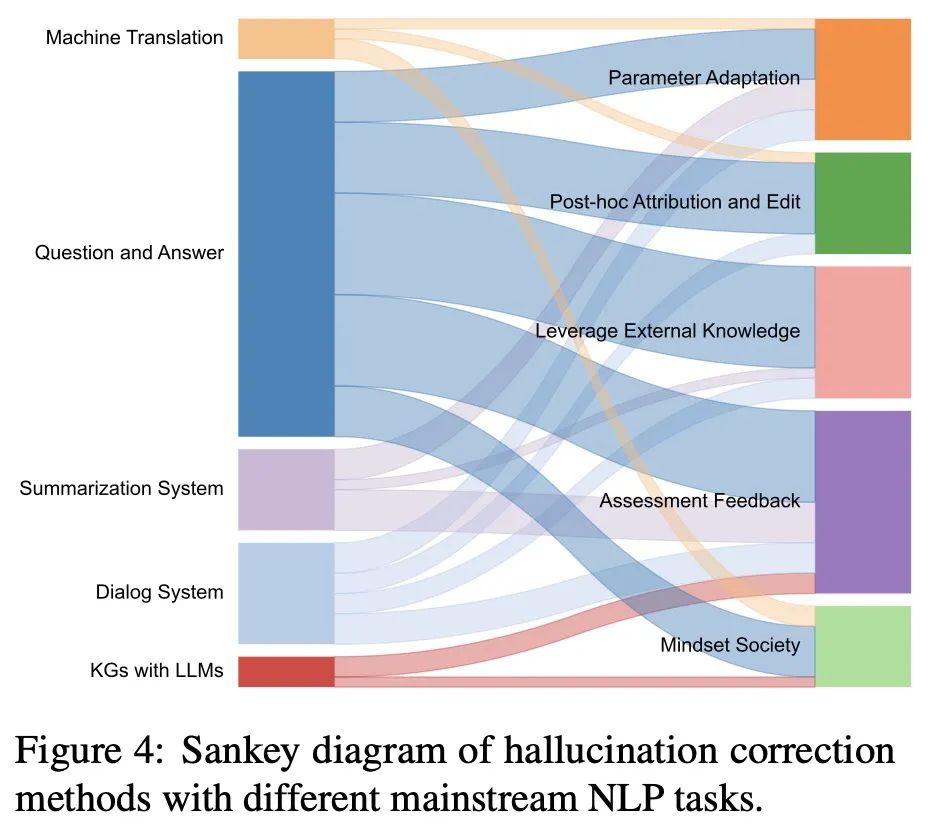
LLM之幻觉(一):大语言模型幻觉解决方案综述
论文题目:《Cognitive Mirage: A Review of Hallucinations in Large Language Models》
论文链接:https://arxiv.org/abs/2309.06794v1
论文代码:https://github.com/hongbinye/cognitive-mirage-hallucinations-in-llms
一、幻觉介绍 …

学习实践-Alpaca-Lora (羊驼-Lora)(部署+运行+微调-训练自己的数据集)
Alpaca-Lora模型GitHub代码地址
1、Alpaca-Lora内容简单介绍 三月中旬,斯坦福发布的 Alpaca (指令跟随语言模型)火了。其被认为是 ChatGPT 轻量级的开源版本,其训练数据集来源于text-davinci-003,并由 Meta 的 LLaMA …
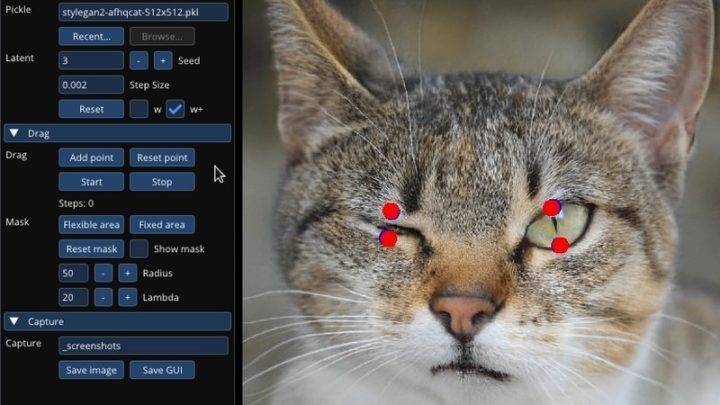
AI日报:DragGAN通过拖拽像素点实现图像调整 等
🦉 AI新闻
🚀 DragGAN:一种直观的图像编辑工具,通过拖拽像素点实现图像调整
摘要:研究者们来自马克斯・普朗克计算机科学研究所、MIT CSAIL和谷歌,他们开发了一种名为DragGAN的图像编辑工具。通过拖拽像素…

Cognitive Mirage: A Review of Hallucinations in Large Language Models
本文是LLM系列文章,针对《Cognitive Mirage: A Review of Hallucinations in Large Language Models》的翻译。 认知海市蜃楼:大型语言模型中的幻觉研究综述 摘要1 引言2 机制分析3 幻觉的分类4 幻觉检测5 幻觉校正6 未来方向7 结论与愿景 摘要
随着大型语言模型在…

CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION
CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION (Paper reading)
Ziwei Luo, Uppsala University, ICLR under review(6663), Cited:None, Stars: 350, Code, Paper.
1. 前言
像CLIP这样的视觉语言模型已经显示出对零样本或无标签预测的各种下游任务…

基于循环神经网络的语言模型:RNNLM、GRULM
基于循环神经网络的语言模型:RNNLM RNNLM首次提出是在《Recurrent neural network based language model》这篇非常重要的神经网络语言模型论文种,发表于2010年。这篇论文的主要贡献是:
首次提出并实现了一种基于循环神经网络(Recurrent Neural Network)的语言模型…

Generative AI 新世界 | 大语言模型(LLMs)在 Amazon SageMaker 上的动手实践
在上一篇《Generative AI 新世界:大型语言模型(LLMs)概述》中,我们一起探讨了大型语言模型的发展历史、语料来源、数据预处理流程策略、训练使用的网络架构、最新研究方向分析(Amazon Titan、LLaMA、PaLM-E 等…

Stable Diffusion公司发布首个大语言模型StableLM,已开源公测!
文 | 智商掉了一地 20号凌晨,Stability AI 发布了一个新的开源语言模型—— StableLM,该公司曾开发了 Stable Diffusion 图像生成工具。这则新闻意味着它不再局限于图像与视频生成领域,将正式加入文本生成 AI 赛道。 StableLM 模型可以生成文…

NEWS|关于人工智能大型语言模型能否理解的争论
科学家调查了当前人工智能(AI)研究界的一场激烈的争论,即大型预先训练的语言模型是否可以说可以理解语言——以及任何类人意义上的语言编码的物理和社会情境。他们提供了支持和反对这种理解的论点,以及根据这些论点而出现的更广泛…

接踵而至,昆仑万维天工大语言模型发布
目录 天工大语言模型对标GPT3.5对话能力多模态应用同行对比后言 天工大语言模型
国产ChatGPT再次迎来新成员,4月17日下午,昆仑万维正式发布千亿级大语言模型“天工”,同时宣布即日起启动邀请测试,并注册了chatgpt.cn作为域名。天…

TigerBot大语言模型
虎博科技”发布自研多模态大模型TigerBot,开源模型、代码及数据,今天先搭建环境体验一下他的大模型,在github上找到:GitHub - TigerResearch/TigerBot: TigerBot: A multi-language multi-task LLM 1 环境安装
conda create --na…
A Survey of Knowledge-Enhanced Pre-trained Language Models
本文是LLM系列的文章,针对《A Survey of Knowledge-Enhanced Pre-trained Language Models》的翻译。 知识增强的预训练语言模型综述 摘要1 引言2 背景3 KE-PLMs用于NLU4 KE-PLMs用于NLG5 未来的方向5.1 整合来自同质和异质来源的知识5.2 探索多模态知识5.3 提供可…

【LLM】LLaMA简介:一个650亿参数的基础大型语言模型
LLaMA简介:一个650亿参数的基础大型语言模型 PaperSetup其他资料 作为 Meta 对开放科学承诺的一部分,今天我们将公开发布
LLaMA (大型语言模型 Meta AI) ,这是一个最先进的大型语言基础模型,旨在帮助研究人员推进他们在人工智能这…

不同参数规模大语言模型在不同微调方法下所需要的显存总结
原文来自DataLearnerAI官方网站:
不同参数规模大语言模型在不同微调方法下所需要的显存总结 | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051703254378255
大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任…

Ubuntu 安装 CUDA 与 CUDNN GPU加速引擎
一、NVIDIA(英伟达)显卡驱动安装 NVIDIA显卡驱动可以通过指令sudo apt purge nvidia*删除以前安装的NVIDIA驱动版本,重新安装。 1.1. 关闭系统自带驱动nouveau 注意!在安装NVIDIA驱动以前需要禁止系统自带显卡驱动nouveau…
Hugging News #0602: Transformers Agents 介绍、大语言模型排行榜发布!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」,本期 Hugging News 有哪些有趣的消息…

【LLM之基座】qwen 14b-4int 部署踩坑
由于卡只有24G,qwen14b 原生需要 30GB,按照官方团队的说法,他们用的量化方案是基于AutoGPTQ的,而且根据评测,量化之后的模型效果在几乎没有损失的情况下,显存降低到13GB,妥妥穷狗福音࿰…
Huggingface:高效多GPU训练
Huggingface:高效多GPU训练 概念动态策略Single Node、Multi-GPUmulti-node/multi-gpu https://huggingface.co/docs/transformers/perf_train_gpu_many 概念
首先介绍一下名词概念: Data Parallel(DP):数据并行&…
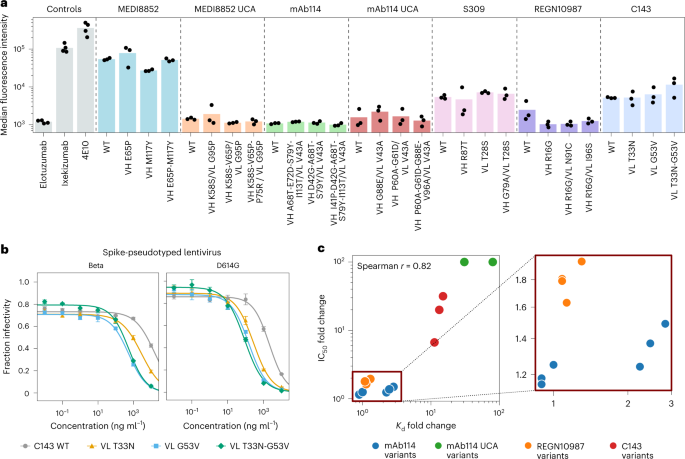
【NB 2023】从一般蛋白质语言模型中高效进化人类抗体
Efficient evolution of human antibodies from general protein language models
哈佛大学化学与化学生物学系和圣路易斯华盛顿大学的研究人员共同完成的一篇论文,发表在Nature Biotechnology上。
抗体是一种大分子,属于免疫球蛋白家族,它…
Windows下cpu部署运行清华大学ChatGLM-6B语言模型(详解)
一、简介
ChatGLM-6B 清华大学实现的一个开源的、支持中英双语、支持图像理解的对话语言模型。它基于<
超越时空:加速预训练语言模型的训练
超越时空:加速预训练语言模型的训练
随着自然语言处理(NLP)领域的快速发展,预训练语言模型(PTLM)已成为许多NLP任务的重要基石,如文本生成、情感分析、文本分类等。然而,传统的PTLM…
Mgeo:multi-modalgeographic language model pre-training
文章目录 question5.1 Geographic Encoder5.1.1 Encoding5.1.2 5.2 multi-modal pre-training 7 conclusionGeo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Rankingabs ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Appli…
离线pip安装paddlepaddle时存在的问题
由于内网限制,只能从清华源安装软件包,而清华源没有满足条件的paddlepaddle安装包,为了成功在内网环境安装paddlepaddle,可以按照如下步骤:
在开始使用_飞桨-源于产业实践的开源深度学习平台 官网平台,按照操作系统、计算平台、安装方式依次选择,可以得到安装信息。
如…
Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs
本文是LLM系列文章,针对《Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs》的翻译。 探索大型语言模型在图形学习中的潜力 摘要1 引言2 前言3 LLM在图上的流水线4 LLM作为增强器5 LLM作为预测器6 相关工作7 结论7.1 关键发现7.2 …
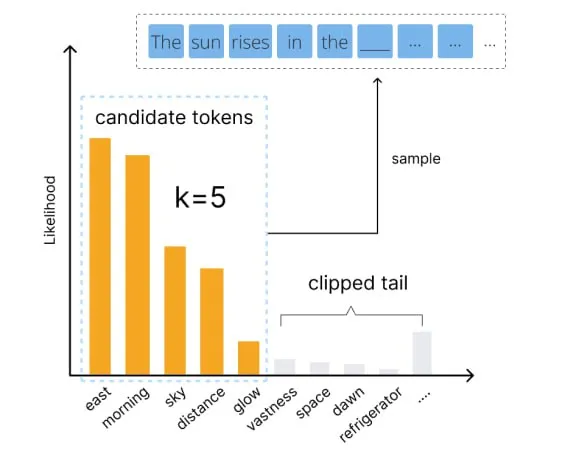
用好语言模型:temperature、top-p等核心参数解析
编者按:我们如何才能更好地控制大模型的输出? 本文将介绍几个关键参数,帮助读者更好地理解和运用 temperature、top-p、top-k、frequency penalty 和 presence penalty 等常见参数,以优化语言模型的生成效果。 文章详细解释了这些参数的作用…
大语言模型领域的重要术语解释
前言
本人对人工智能非常感兴趣,目前是一名初学者,在研究大语言模型的一些内容。很多模型都是用英文提出的,其中也包括很多概念,有些概念的中文翻译和其想表达的意思不完全一样,所以在这里,想更加精准地帮…
申请GPT-4插件,等待GPT-4插件候补全过程
前言
GPT4相信大家都知道它的升级是带来更多惊喜的,目前GPT4已经推出了网页和插件功能,这些插件是专门为语言模型设计的工具。插件可以帮助 ChatGPT 访问最新信息、运行计算或使用第三方服务。写文记录一下,如果你现正好有需要GPT-4 插件的需…
OpenAI董事会秒反悔!奥特曼被求重返CEO职位
明敏 丰色 发自 凹非寺 量子位 | 公众号 QbitAI
1天时间,OpenAI董事会大变脸。
最新消息,他们意在让奥特曼重返CEO职位。 多方消息显示,因为“投资人的怒火”,OpenAI董事会才在一天时间里来了个大反转。
微软CEO纳德拉被曝在得…
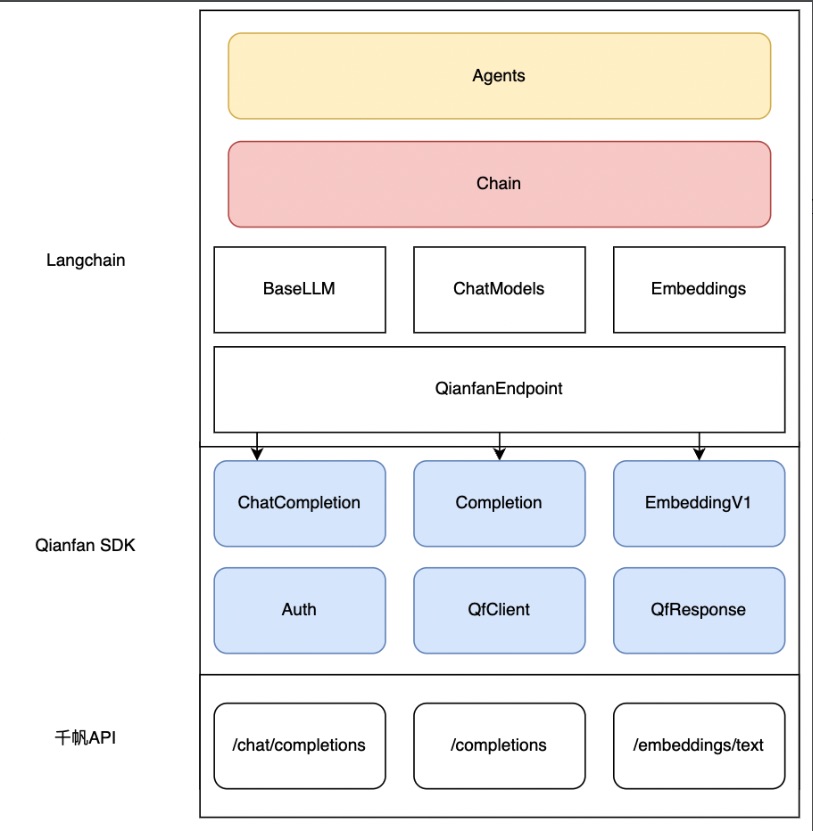
如何快速落地LLM应用?通过Langchain接入千帆SDK
百度智能云千帆大模型平台再次史诗级升级!在原有API基础上,百度智能云正式上线Python SDK(下文均简称千帆 SDK)版本并全面开源,企业和开发者可免费下载使用!千帆SDK全面覆盖从数据集管理,模型训…
UNVEILING THE PITFALLS OF KNOWLEDGE EDITING FOR LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《UNVEILING THE PITFALLS OF KNOWLEDGE EDITING FOR LARGE LANGUAGE MODELS》的翻译。 揭示大型语言模型知识编辑的陷阱 摘要1 引言2 LLMS知识编辑的陷阱探索3 相关工作4 讨论与结论 摘要
随着与微调大型语言模型(LLMÿ…

Shepherd: A Critic for Language Model Generation
本文是LLM系列的相关文章,针对《Shepherd: A Critic for Language Model Generation》的翻译。 Shepherd:语言模型生成的评价 摘要1 引言2 数据收集3 Shepherd模型4 评估反馈5 结果6 相关工作7 结论不足 摘要
随着大型语言模型的改进,人们对…
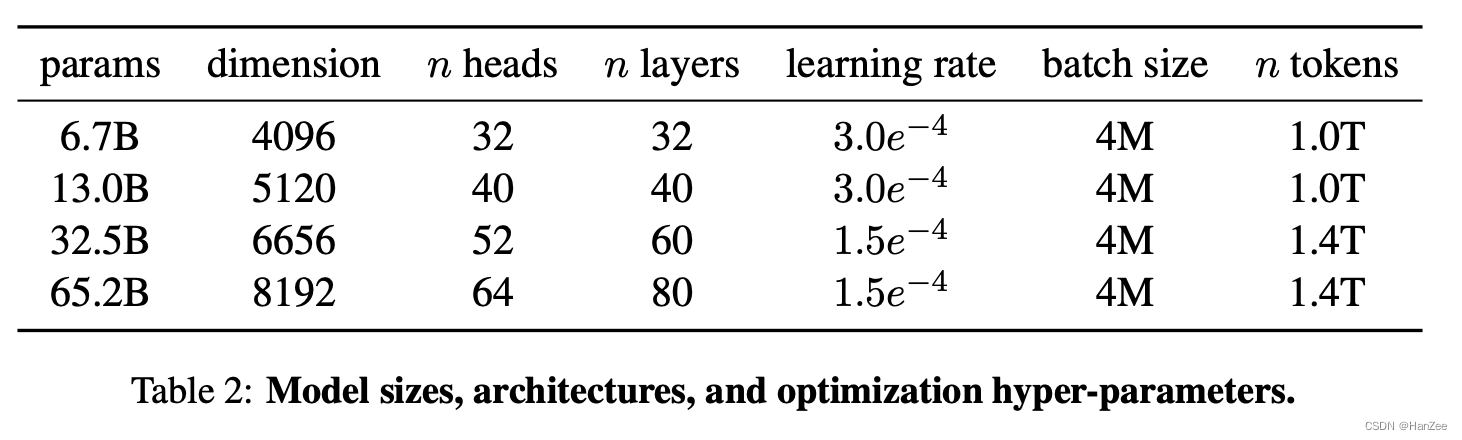
LLaMA:Open and Efficient Foundation Language Models
LLaMA:Open and Efficient Foundation Language ModelsIntroductionApproachPre-training DataArchitectureIntroduction
在大规模数据下训练的大模型,已经展示了很好的表现,当模型足够大的时,模型会出现一个涌现的能力ÿ…
谷歌的最新人工智能实验,让你能够创造出受各种乐器启发的音乐
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
【论文阅读】大语言模型中的文化道德规范知识
摘要:
在已有的研究中,我们知道英语语言模型中包含了类人的道德偏见,但从未有研究去检测语言模型对不同国家文化的道德差异。
我们分析了语言模型包含不同国家文化道德规范的程度,主要针对两个方面,其一是看语言模型…
Tuna: Instruction Tuning using Feedback from Large Language Models
本文是LLM系列文章,针对《Tuna: Instruction Tuning using Feedback from Large Language Models》的翻译。 Tuna:使用来自大型语言模型的反馈的指令调优 摘要1 引言2 方法3 实验4 相关工作5 结论局限性 摘要
使用更强大的LLM(如Instruction GPT和GPT-…
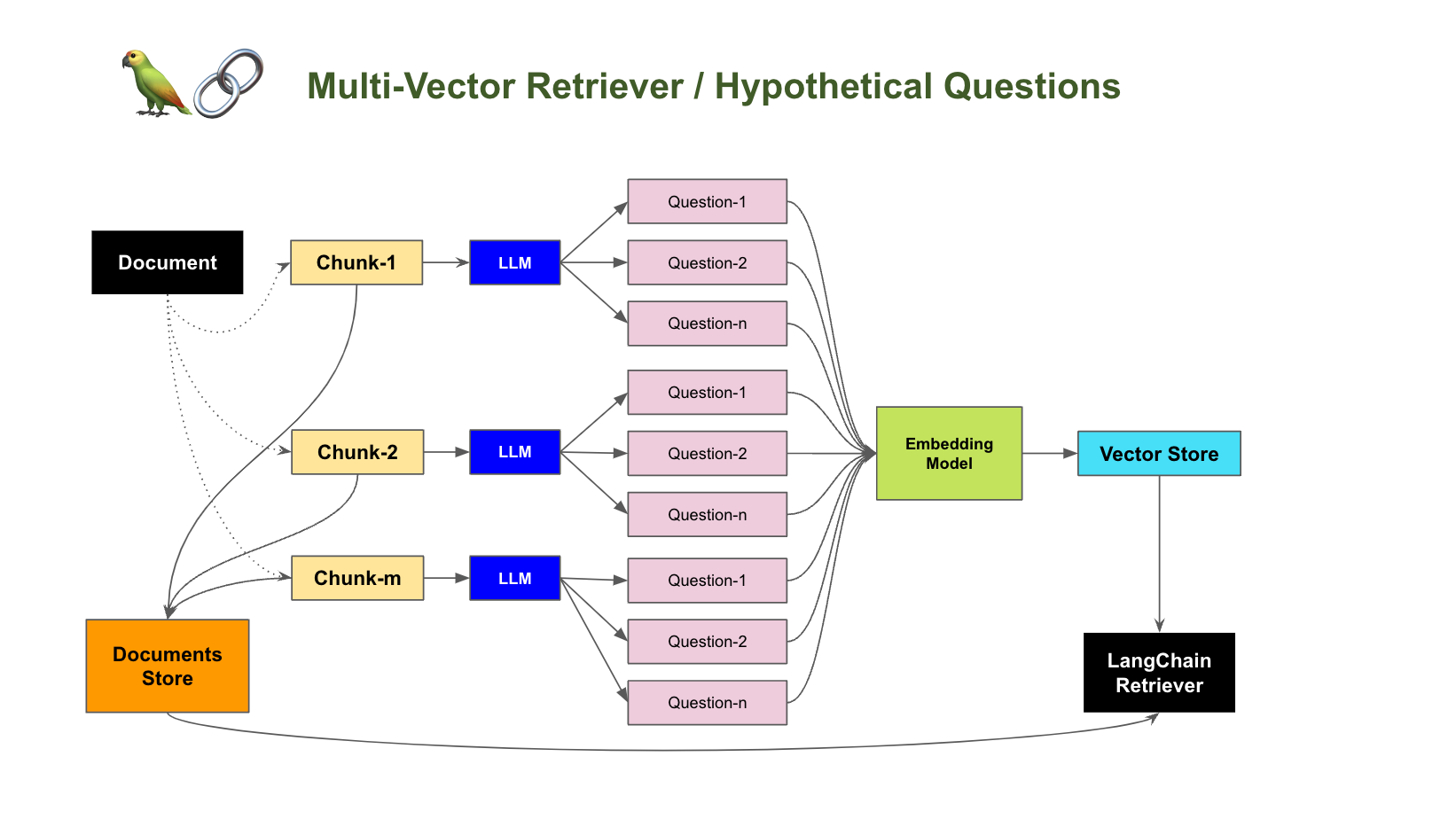
如何提高RAG增强的准确性
在一个典型的RAG应用开发中,必要的步骤为文档加载,文档拆分,向量化,向量存储。然后基于向量存储进行相似性查询,或基于向量距离的查询。这类查询就叫检索,LangChain所提供的对应组件就是检索器。
但这种方…
评估大型语言模型:综述
论文地址:https://arxiv.org/pdf/2310.19736v2.pdf
github: tjunlp-lab/awesome-llms-evaluation-…
发表团队:Tianjin University 摘要
将LLM评估划分三点:知识和能力评估、一致性评估和安全性评估。特定领域化评估benchmark评…

采用 guidance 提高大模型输出的可靠性和稳定性
本文首发于博客 LLM 应用开发实践 在复杂的 LLM 应用开发中,特别涉及流程编排和多次 LLM 调用时,每次的 Prompt 设计都取决于前一个步骤的大模型输出。如何避免大语言模型的"胡说八道",以提高大语言模型输出的可靠性和稳定性&#…

拓世AIGC | 大语言模型螺旋上升式进化,人文、技术与未来
本月初,上海世博园举办外滩大会见解论坛中,众多学者和企业家共同探讨了大语言模型时代的人机关系、硅基生命和碳基生命未来之争等议题。面对全新的局面,论坛释放出积极信号和值得持续关注的论点。从黄浦江的波涛翻涌,我们捕捉到了…
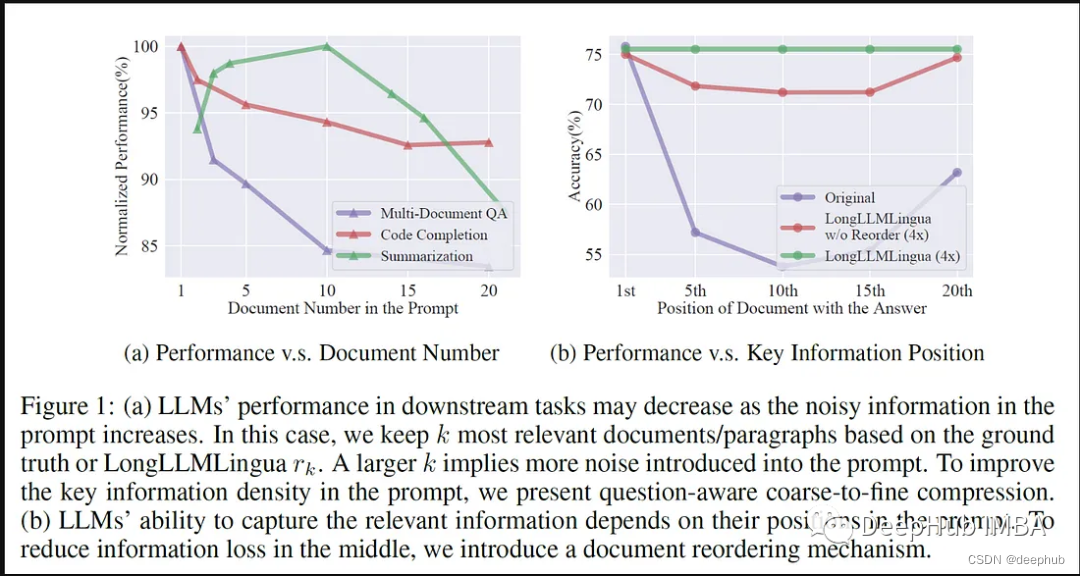
LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案,本文将介绍LLM…
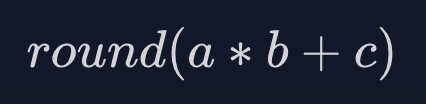
Elasticsearch:FMA 风格的向量相似度计算
作者:Chris Hegarty 在 Lucene 9.7.0 中,我们添加了利用 SIMD 指令执行向量相似性计算的数据并行化的支持。 现在,我们通过使用融合乘加 (Fused Mulitply-Add - FMA) 进一步推动这一点。 什么是 FMA
乘法和加法是一种常见的运算,…
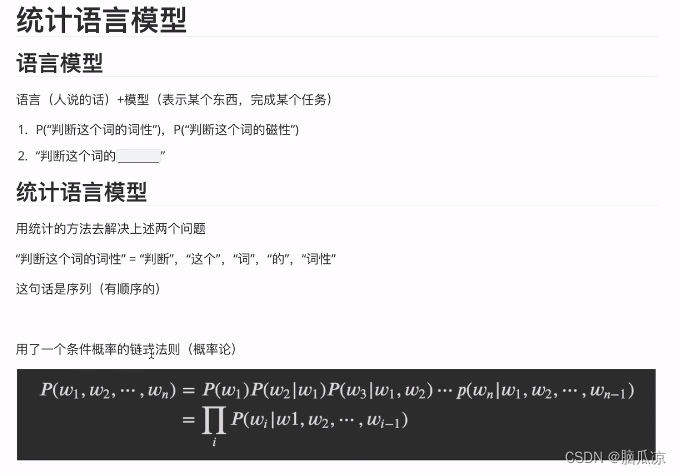
NLP_什么是统计语言模型_条件概率的链式法则_n元统计语言模型_马尔科夫链_统计语言模型的平滑策略---人工智能工作笔记0035
https://www.cnblogs.com/nickchen121/p/16470569.html#tid-458p3Y
参考这个文档学习
条件概率的链式法则:这个是需要去补充的知识. 首先我们来看一下上一节说到的预训练,可以看到,我们比如有个鹅鸭的分类问题,
这个鹅鸭分类我们是用10万张图片训练的模型,这个已经可以把这个…
Bag of Tricks for Efficient Text Classification(FastText)
主要的有点就是快,用途就是用于文本分类,模型结构如上,主要是通过embedding将文本转换成向量,然后进行mean-pooling,然后输入到hidden隐向量中,通过softmax输出多分类,损失函数是对数似然损失函…
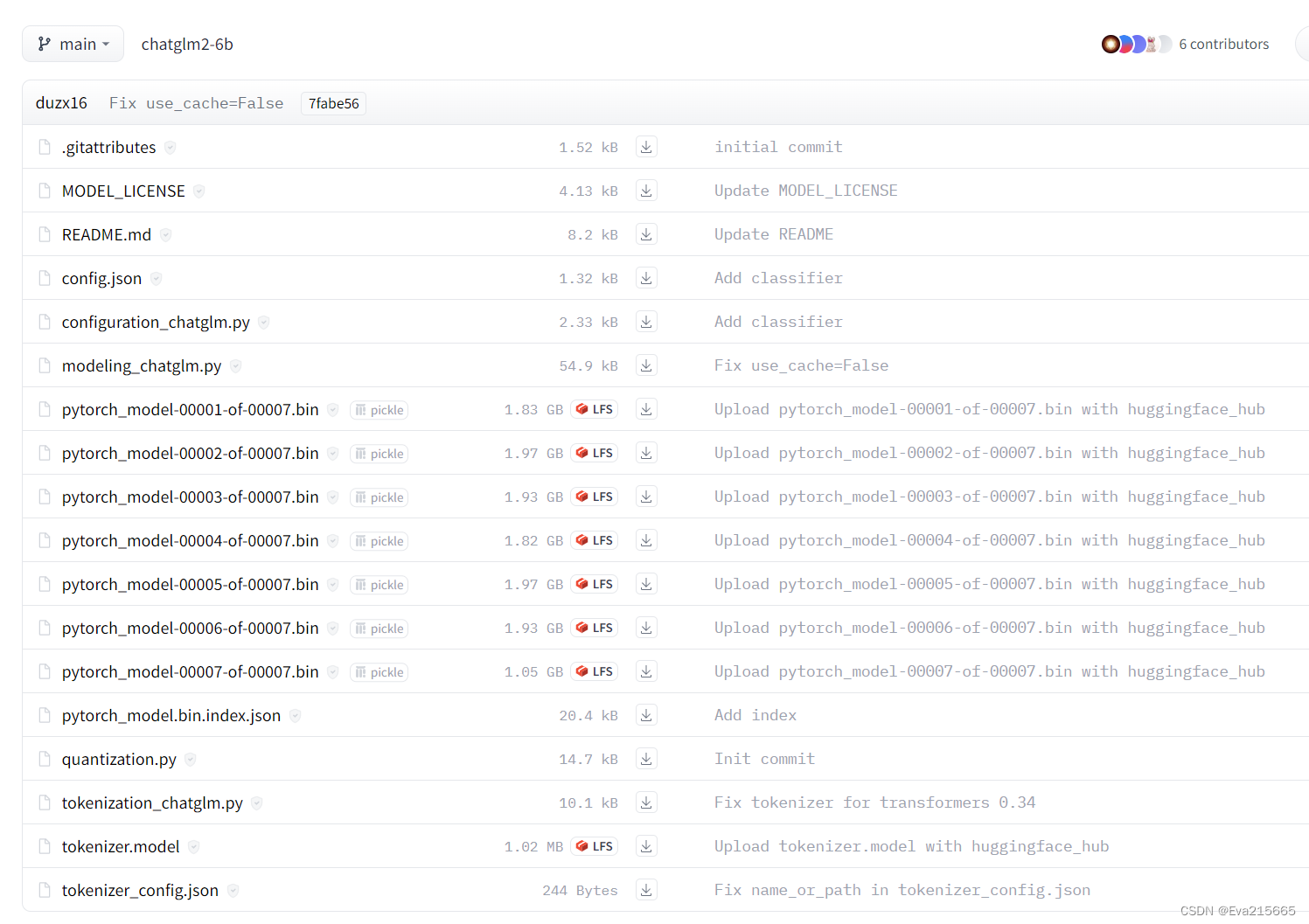
ChatGLM2-6B下载与部署
0 写在前面
我们首先来看一下ChatGLM2-6B模型的requirements:
protobuf
transformers4.30.2
cpm_kernels
torch>2.0
gradio
mdtex2html
sentencepiece
accelerate
sse-starlette
streamlit>1.24.0可以看到,要求torch>2.0,这就产生了一个问题&…
【通意千问】大模型GitHub开源工程学习笔记(3)-- 通过Qwen预训练语言模型自动完成给定的文本
摘要:
本笔记分析了使用预训练的模型生成文本的示例代码。它的步骤如下: 使用已加载的分词器 tokenizer 对输入文本进行处理,转换为模型可以理解的格式。输入文本是国家和首都的信息,最后一句是未完成的,需要模型来生成。将处理后的输入转移到模型所在的设备上(例如GPU或…
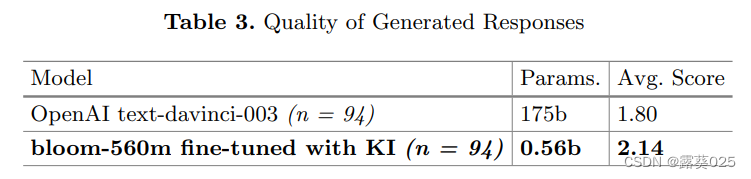
知识注入以对抗大型语言模型(LLM)的幻觉11.6
知识注入以对抗大型语言模型(LLM)的幻觉 摘要1 引言2 问题设置和实验2.1 幻觉2.2 生成响应质量 3 结果和讨论3.1 幻觉3.2 生成响应质量 4 结论和未来工作 摘要
大型语言模型(LLM)内容生成的一个缺点是产生幻觉,即在输…

谷歌研究科学家:ChatGPT秘密武器的演进与局限
来源|TalkRL OneFlow编译 翻译|徐佳渝、贾川 同样是基于GPT预训练模型,为什么ChatGPT的效果要远远超出GPT-3等前几代模型?答案已经揭晓,成就ChatGPT的秘密武器在于RLHF,也就是人类反馈的强化学习。 在预训…

2023年03月09日_谷歌视觉语言模型PaLM-E的介绍
自从最近微软凭借OpenAI
和ChatGPT火了一把之后呢
老对手Google就总想着扳回一局
之前发布了硬刚ChatGPT的Bard
但是没想到翻车了
弄巧成拙 所以呢Google这一周又发了个大招
发布了史上最大的视觉语言模型PaLM-E
这个模型有多夸张呢
参数量高达5,620亿
是ChatGTP-3的三…
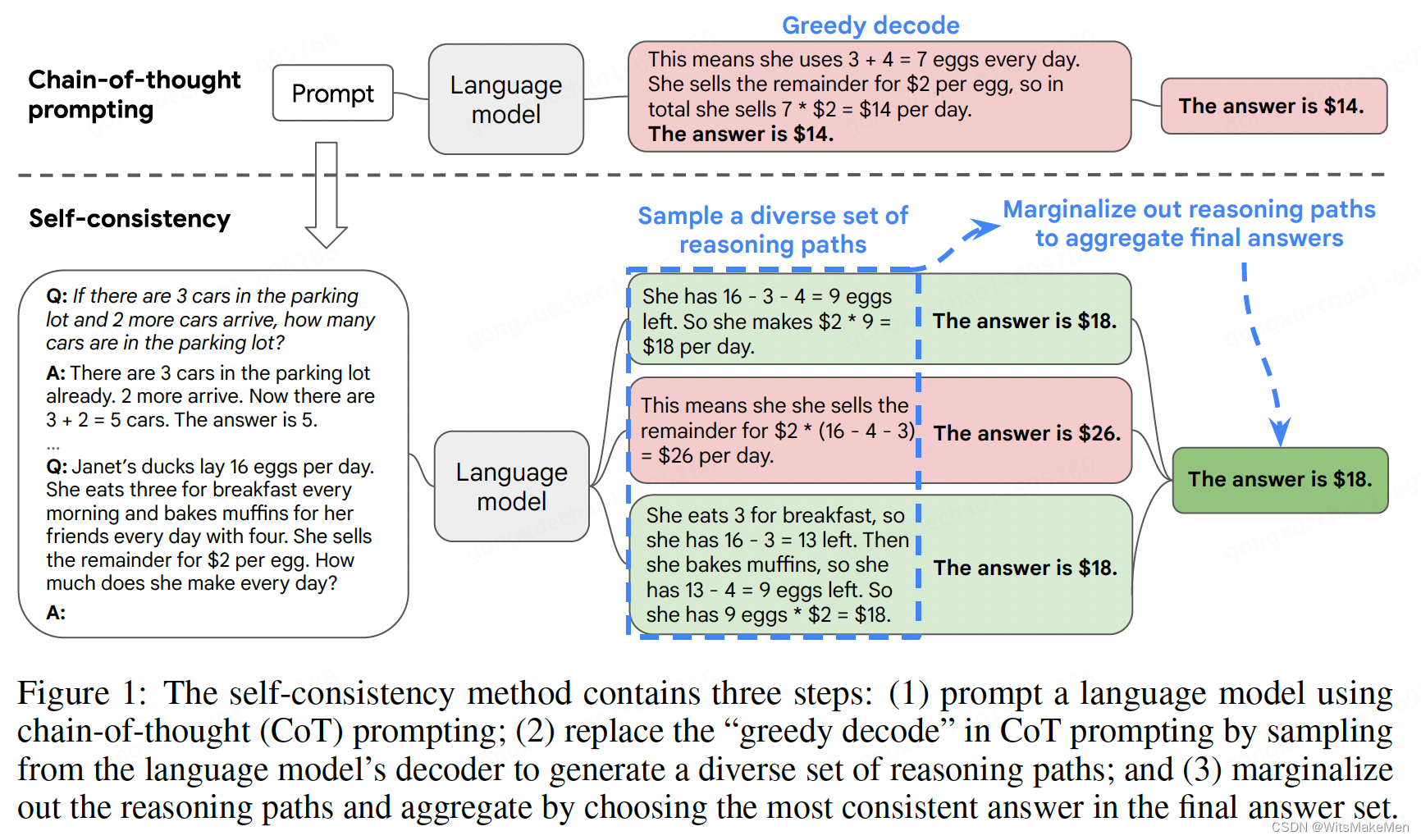
一致性思维链(SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS)
概要
思维链已经在很多任务上取得了非常显著的效果,这篇论文中提出了一种 self-consistency 的算法,来代替 贪婪解码 算法。本方法通过 采样多个思维链集合,然后LLM模型生成后,选择一个最一致的答案作为最后的结果。一致性思维链…
大模型是怎么知道 “我赚了200万” 的?
今天在和 chatGPT 聊天时,我说“我赚了200万”,他立刻就根据这句话给我了一句。 我当然没有赚到200万,只是想引出一个话题:“大模型是如何识别出这句话,又是怎么知道该回答什么的呢?"
在学习自然语言…
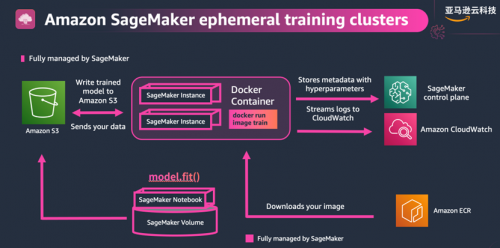
大语言模型概述(二):基于亚马逊云科技的研究分析与实践
上期介绍了大语言模型的定义和发展历史,本期将分析基于亚马逊云科技的大语言模型相关研究方向,以及大语言模型的训练和构建优化。
大语言模型研究方向分析
Amazon Titan
2023 年 4 月,亚马逊云科技宣布推出 Amazon Titan 大语言模型。根据…
Instruction Tuning for Large Language Models: A Survey
本文是LLM系列文章,针对《Instruction Tuning for Large Language Models: A Survey》的翻译。 大语言模型指令调整:综述 摘要1 引言2 方法3 数据集4 指令微调LLMs5 多模态指令微调6 特定领域指令微调7 高效调整技术8 评估,分析和批评9 结论…
LONGLORA: EFFICIENT FINE-TUNING OF LONGCONTEXT LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《LONGLORA: EFFICIENT FINE-TUNING OF LONGCONTEXT LARGE LANGUAGE MODELS》的翻译。 Longlora:长上下文大型语言模型的高效微调 摘要1 引言2 相关工作3 LongLoRA4 实验5 结论 摘要
我们提出了LongLoRA,一种有效的微调方法&…

初识人工智能,一文读懂过拟合欠拟合和模型压缩的知识文集(3)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…

百题千解计划【CSDN每日一练】LLM大语言模型:必练选择题及解析 | “等差数列”多解法:Python、Java、C语言、C++...
月落乌啼霜满天,江枫渔火对愁眠。 🎯作者主页: 追光者♂🔥 🌸个人简介: 💖[1] 计算机专业硕士研究生💖 🌟[2] 2022年度博客之星人工智能领域TOP4🌟 🏅[3] 阿里云社区特邀专家博主🏅 🏆[4] CSDN-人工智能领域优质创作者🏆 📝[5] …

如何在搜索引擎中应用AI大语言模型,提高企业生产力?
人工智能尤其是大型语言模型的应用,重塑了我们与信息交互的方式,也为企业带来了重大的变革。将基于大模型的检索增强生成(RAG)集成到业务实践中,不仅是一种趋势,更是一种必要。它有助于实现数据驱动型决策&…
Pruning Pre-trained Language Models Without Fine-Tuning
本文是LLM系列文章,针对《Pruning Pre-trained Language Models Without Fine-Tuning》的翻译。 修剪未微调的预训练语言模型 摘要1 引言2 相关工作3 背景4 静态模型剪枝5 实验6 分析7 结论8 局限性 摘要
为了克服预训练语言模型(PLMs)中的过度参数化问题…

大模型之二十一-小语言模型塞道开启
当前提到大语言模型,大家想到的都是动辄百亿规模以上参数量的模型,13B、70B都是稀疏平常入门级的,但是目前从模型层面来看,模型参数量的规模两极分化已经来临,早期各大公司为了效果怼上去,采取了简单粗暴的…

【飞桨星河社区五周年线下工坊-杭州站】
? 欢迎大家参加杭州极客工坊,深入了解大模型前沿技术和创新应用,一站式体验AI原生应用开发? 精彩议程敬请期待~ ? 时间:2023年12月3日 14:00-17:30 ? 地点:杭州西湖区花蒋路3号西溪润泽园度假酒店 ? 主题…
关于业界大语言模型(LLM)开源的一些看法
近期看到阿里开源了720亿参数模型通义千问,已实现“全尺寸、全模态”开源,对这个动作的一些想法,包括好处和缺点
国内大语言模型的开源有许多好处,如下:
1. 提升技术水平:国内大语言模型开源可以使更多的…
VeRA: Vector-based Random Matrix Adaptation
本文是LLM系列文章,针对《VeRA: Vector-based Random Matrix Adaptation》的翻译。 VeRA:基于向量的随机矩阵自适应 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
低秩(LoRA)是一种流行的方法,它可以在微调大规模语…
十个经典Java入门系统功能列举
1. 员工信息管理系统: - 员工信息录入:包括基本信息、工作经历、教育背景等。 - 员工信息查询:可根据姓名、部门、职位等条件进行查询。 - 员工信息修改:允许对员工信息进行更新和修改。 - 员工信息删除:允…
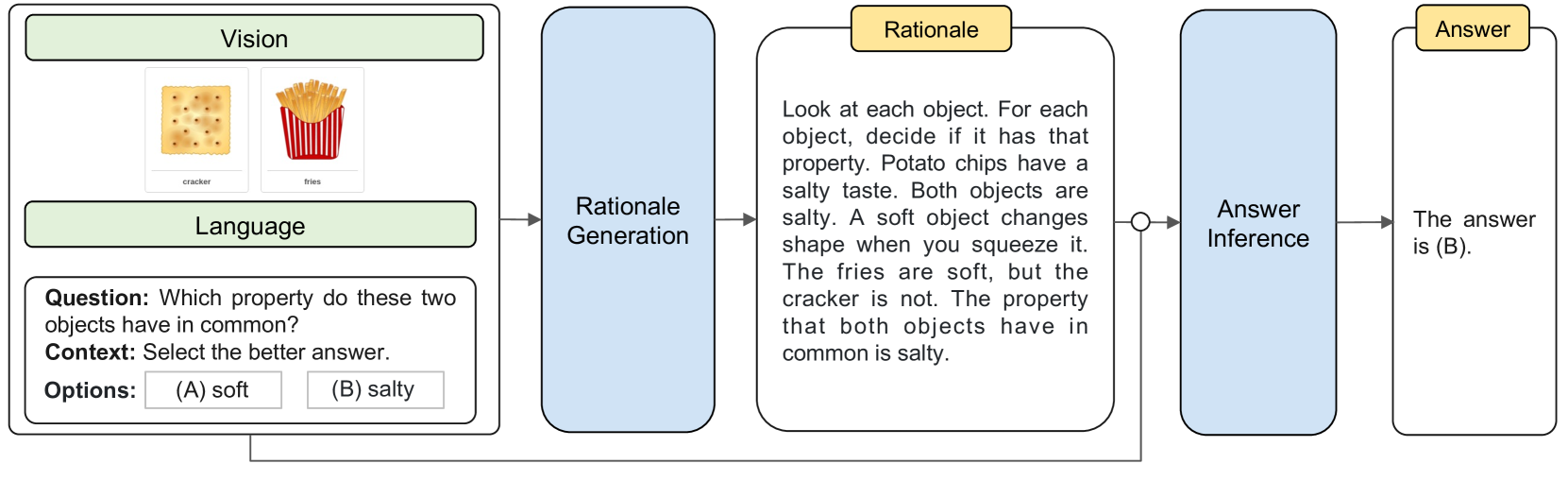
Multimodal Chain-of-Thought Reasoning in Language Models语言模型中的多模态思维链推理
Abstract 大型语言模型 (LLM) 通过利用思维链 (CoT) 提示生成中间推理链作为推断答案的基本原理,在复杂推理方面表现出了令人印象深刻的性能。然而,现有的 CoT 研究主要集中在语言情态上。我们提出了 Multimodal-CoT,它将语言(文本…

LangChain的函数,工具和代理(三):LangChain中轻松实现OpenAI函数调用
在我之前写的两篇博客中:OpenAI的函数调用,LangChain的表达式语言(LCEL)中介绍了如何利用openai的api来实现函数调用功能,以及在langchain中如何实现openai的函数调用功能,在这两篇博客中,我们都需要手动去创建一个结构比较复杂的函数描述变量…
语言模型ChatGPT,为什么能引领各行各业的AI技术革命
为什么ChatGPT这样一个语言模型的发展能引发所有行业的AI技术革命呢?
答案就在于它能理解我们的自然语言,
并能将我们的语言转换成计算机能够完全理解的特征。
自然语言与计算机理解
ChatGPT之所以能引领技术革命,关键在于它能理解我们的…
区块链相关技术、概念以及技术实现过程中的一些关键问题 Smart Contracts and Blockchains
作者:禅与计算机程序设计艺术
1.简介
2017年底,区块链已经成为众多投资人和技术人员最关注的话题之一。随着现实世界的不断复杂化、数字货币的流行以及IoT设备的普及,加密数字货币市场正变得越来越活跃。由于区块链具有去中心化、不可篡改、透明性、高并发等特点,使其在金…

南京农业大学研发古籍版的ChatGPT,AI大语言模型荀子面世
随着科技的飞速发展,人工智能已深入到各个领域。为响应古籍活化利用号召,推动大语言模型与古籍处理深度融合,以古籍智能化的研究为目的,南京农业大学国家社科基金重大项目“中国古代典籍跨语言知识库构建及应用研究”课题组与中华…
Prompt2Model: Generating Deployable Models from Natural Language Instructions
本文是LLM系列文章,针对《 Prompt2Model: Generating Deployable Models from Natural Language Instructions》的翻译。 Prompt2Model:从自然语言指令生成可部署模型 摘要1 引言2 Prompt2Model框架3 参考实现4 实验设置5 实验结果6 讨论与结论不足道德…
来也科技汪冠春:大语言模型时代下,广义RPA市场会是原来的100倍
以下内容转自:雷峰网
作者:周蕾
对来也科技CEO汪冠春来说,ChatGPT带来的冲击和颠覆,让他想起了20世纪末的柯达和尼康。摄影从胶片时代步入数码时代,似乎只是一眨眼,尼康没有抱着以前的胶卷产品不放&#…
生成式大语言模型微调训练快速手册
ChatGPT的流行让大语言模型走入了大家的视线,怎么打造自己的大语言模型成为了一个急需解决的问题。
目录
大语言模型的获取方法有以下三种:
目前可以Play 的大语言基础模型列表: 大语言模型的获取方法有以下三种:
1. 完全白嫖…

大模型 LLM 综述, A Survey of Large Language Models
大模型 LLM 综述, A Survey of Large Language Models
一、概述
一般认为NLP领域的大模型>10 Billion参数(也有人认为是6B、7B, 工业界用, 开始展现涌现能力); 经典大模型有GPT-3、BLOOM、Flan-T5、GPT-NeoX、OPT、GLM-130B、PaLM、LaMDA、LLaMA等;
大模型时间线, 图来自…

从统计语言模型到预训练语言模型---预训练语言模型(Transformer)
预训练模型的概念在计算机视觉领域并不陌生, 通常我们可以在大规模图像数据集上预先训练出一个通用 模型, 之后再迁移到类似的具体任务上去, 这样在减少对图像样本需求的同时, 也加速了模型的开发速度。计 算机视觉领域采用 Image…
探索未来,开启无限可能:打造智慧应用,亚马逊云科技大语言模型助您一臂之力
文章目录 什么是大模型?大模型训练方法亚马逊云科技推出生成式AI新工具 —— aws toolkit使用教程 总结 什么是大模型?
近期,生成式大模型是人工智能领域的研究热点。这些生成式大模型,诸如文心一言、文心一格、ChatGPT、Stable …
LKPNR: LLM and KG for Personalized News Recommendation Framework
本文是LLM系列文章,针对《LKPNR: LLM and KG for Personalized News Recommendation Framework》的翻译。 LKPNR:LLM和KG的个性化新闻推荐框架 摘要1 引言2 相关工作3 问题定义4 框架5 实验6 案例7 结论 摘要
准确地向用户推荐候选新闻文章是个性化新闻推荐系统面…

《Playing repeated games with Large Language Models》全文翻译
《Playing repeated games with Large Language Models》- 使用大型语言模型玩重复游戏 论文信息摘要1. 介绍2. 相关工作3. 一般方法4. 分析不同游戏系列的行为5. 囚徒困境5.1 性别之战 6. 讨论 论文信息
题目:《Playing repeated games with Large Language Model…
![[论文笔记] Scaling Laws for Neural Language Models](https://img-blog.csdnimg.cn/2674d8d5c6c84d59b73491ca58184c91.png)
[论文笔记] Scaling Laws for Neural Language Models
概览: 一、总结 计算量、数据集大小、模型参数量大小的幂律 与 训练损失呈现 线性关系。
三个参数同时放大时,如何得到最佳的性能? 更大的模型 需要 更少的样本 就能达到相同的效果。 </

吴恩达 ChatGPT Prompt Engineering for Developers 系列课程笔记--08 Chatbot
08 Chatbot
ChatGPT的一种重要功能是作为一个聊天机器人,本节将展示如何和ChatGPT进行对话
1) 不同的角色(Roles)
前面几节的课程中,我们通过如下函数调用ChatGPT的接口,输入用户输入的prompt,返回模型生…
如何在 LangChain 中调用 OpenVINO™ 加速大语言模型
点击蓝字 关注我们,让开发变得更有趣 作者 | 杨亦诚 排版 | 李擎 OpenVINO™..♩~ ♫. ♪.. LangChain简介 LangChain 是一个高层级的开源的框架,从字面意义理解,LangChain 可以被用来构建 “语言处理任务的链条”,它可以让AI开发人员把大型语…
【2023.11.6】OpenAI发布会——近期chatgpt被攻击,不能使用
OpenAI发布会 写在最前面发布会内容GPT-4 Turbo 具有 128K 上下文函数调用更新改进了指令遵循和 JSON 模式可重现的输出和对数概率更新了 GPT-3.5 Turbo 助手 API、检索和代码解释器API 中的新模式GPT-4 Turbo 带视觉DALLE 3文字转语音 (TTS)收听语音样本…

GPT-4V被超越?SEED-Bench多模态大模型测评基准更新
📖 技术报告 SEED-Bench-1:https://arxiv.org/abs/2307.16125 SEED-Bench-2:https://arxiv.org/abs/2311.17092 🤗 测评数据 SEED-Bench-1:https://huggingface.co/datasets/AILab-CVC/SEED-Bench SEED-Bench-2&…
Re53:读论文 How Can We Know What Language Models Know?
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:How Can We Know What Language Models Know?
ArXiv网址:https://arxiv.org/abs/1911.12543
官方GitHub项目(prompt之类的都有):https:…

用通俗易懂的方式讲解大模型:使用 LangChain 封装自定义的 LLM,太棒了
Langchain 默认使用 OpenAI 的 LLM(大语言模型)来进行文本推理工作,但主要的问题就是数据的安全性,跟 OpenAI LLM 交互的数据都会上传到 OpenAI 的服务器。
企业内部如果想要使用 LangChain 来构建应用,那最好是让 La…
【论文解读系列】Blip-2:引导语言图像预训练具有冻结图像编码器和大型语言模型
Blip-2
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP-2:引导语言图像预训练具有冻结图像编码器和大型语言模型
(0) 总结&实测
总结:blip-2 最大的贡献在于,提出了…
LLM 04-大模型的数据
LLM 03-大模型的数据 到目前为止,我们已经讨论了大型语言模型的行为(能力和损害)。现在,我们要剥开洋葱的第一层,开始讨论这些模型是如何构建的。任何机器学习方法的起点都是训练数据,因此这就是我们开始的…

800万纯AI战士年末大集结,硬核干货与音乐美食12月28日准时开炫
回望2023年,大语言模型或许将是科技史上最浓墨重彩的一笔。从技术、产业到生态,大语言模型在突飞猛进中加速重构万物。随着理解、生成、逻辑、记忆四大能力显著提升,大语言模型为通用人工智能带来曙光。 AI开发者们正在用算法和代码书写一个美…
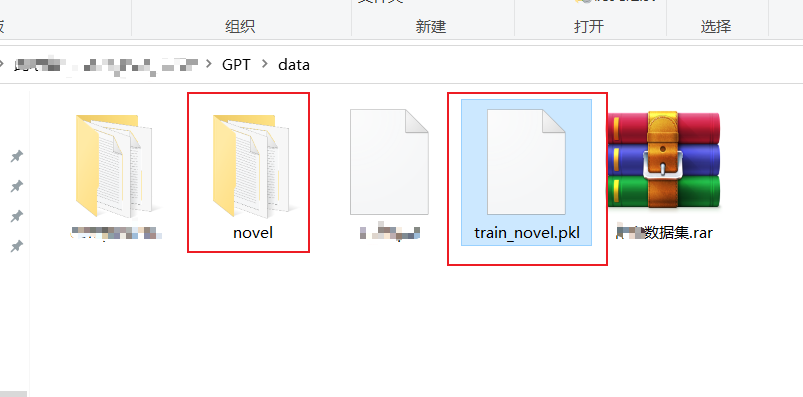
从零构建属于自己的GPT系列1:预处理模块(逐行代码解读)、文本tokenizer化
1 训练数据
在本任务的训练数据中,我选择了金庸的15本小说,全部都是txt文件 数据打开后的样子
数据预处理需要做的事情就是使用huggingface的transformers包的tokenizer模块,将文本转化为token 最后生成的文件就是train_novel.pkl文件&a…
学习80min快速了解大型语言模型(ChatGPT使用)笔记
学习李宏毅:80min快速了解大型语言模型(ChatGPT使用)笔记
链接:https://www.youtube.com/watch?vwG8-IUtqu-s
1、创建一个属于自己的GPT
目前,GPT4具备一个功能,Create a GPT。利用这个功能可以创建一个…
自然语言处理实战项目16- 基于CPU的大语言模型的实战训练全流程指导,模型调优与评估
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目16- 基于CPU的生成式大语言模型的实战训练全流程详细讲解,模型调优与评估。该流程涵盖了数据准备、数据预处理、词表构建、模型选择与配置、模型训练、模型调优和模型评估等步骤。通过不断迭代和优化,可以提高模型…
用通俗易懂的方式讲解大模型:在 CPU 服务器上部署 ChatGLM3-6B 模型
大语言模型(LLM)的量化技术可以大大降低 LLM 部署所需的计算资源,模型量化后可以将 LLM 的显存使用量降低数倍,甚至可以将 LLM 转换为完全无需显存的模型,这对于 LLM 的推广使用来说是非常有吸引力的。
本文将介绍如何…
(StackOverflow)使用Huggingface Transformers从磁盘加载预训练模型
问题描述:
根据from_pretrained的文档,我了解到我不必每次都下载预训练向量(权重数据),我可以使用以下语法将它们保存并从磁盘加载: - a path to a directory containing vocabulary files required by the tokenizer, for insta…
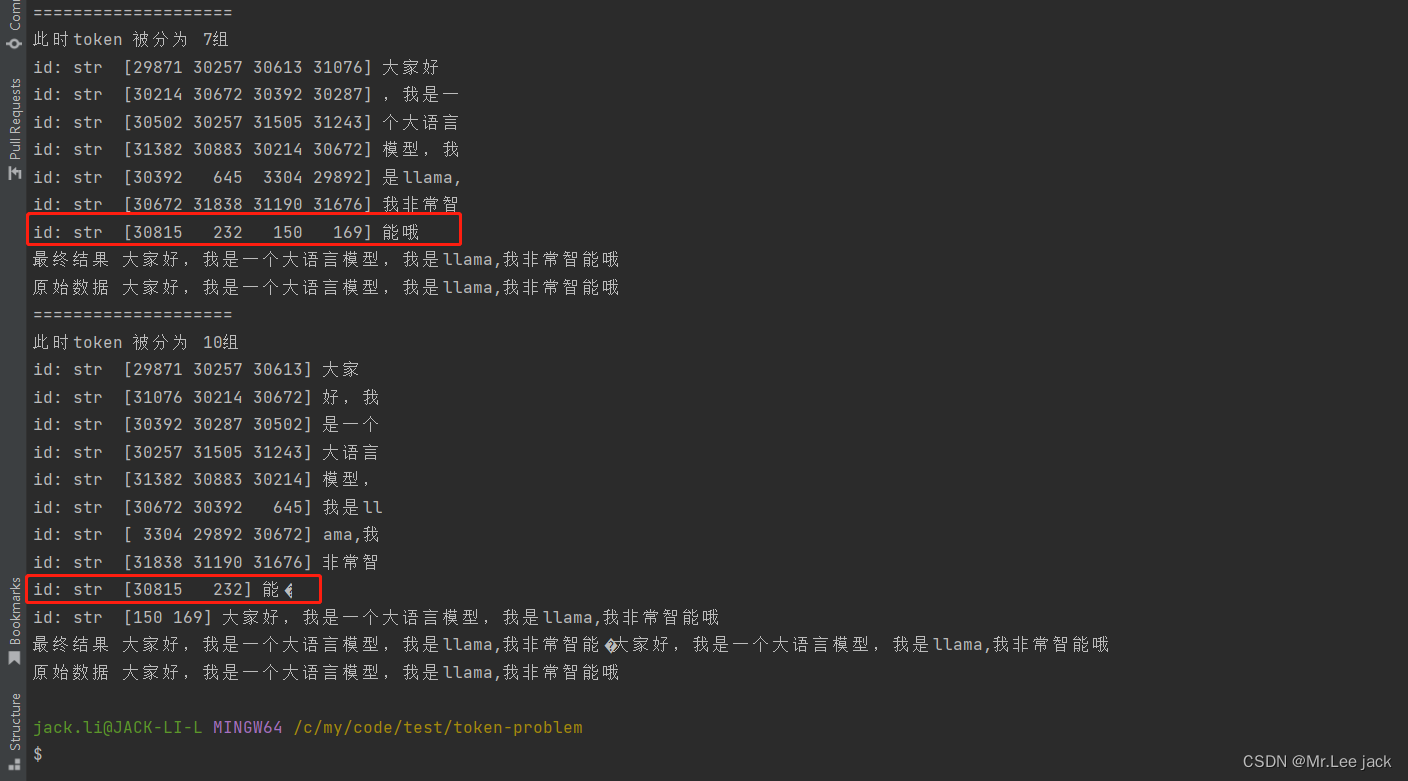
大模型tokenizer流式响应解决词句连贯性问题
大模型tokenizer词句连贯性问题
现象
from transformers import LlamaTokenizerFast
import numpy as nptokenizer LlamaTokenizerFast.from_pretrained("heilerich/llama-tokenizer-fast")
origin_prompt "Hi, Im Minwoo Park from seoul, korea."
id…

“新KG”视点 | 知识图谱与大语言模型协同模式探究
OpenKG 大模型专辑 导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织…

云端部署ChatGLM-6B
大模型这里更新是挺快的,我参考的视频教程就和我这个稍微有些不一样,这距离教程发布只过去4天而已… 不过基本操作也差不多 AutoDL算力云:https://www.autodl.com/home ChatGLM3:https://github.com/THUDM/ChatGLM3/tree/main Hug…
配置LLM运行环境时遇到的坑
1. bitsandbytes 遇到CUDA Setup failed despite GPU being available.
使用conda 管理环境时加载大模型会遇到bitsandbytes无法识别cuda的情况: 此处windows系统:
pip install bitsandbytes-windowslinux 系统: 将bitsandbytes版本降低至0…
【Github3k+⭐️】《CogAgent: A Visual Language Model for GUI Agents》译读笔记
CogAgent: A Visual Language Model for GUI Agents
摘要
人们通过图形用户界面(Graphical User Interfaces, GUIs)在数字设备上花费大量时间,例如,计算机或智能手机屏幕。ChatGPT 等大型语言模型(Large Language Mo…

【网安大模型专题10.19】论文6:Java漏洞自动修复+数据集 VJBench+大语言模型、APR技术+代码转换方法+LLM和DL-APR模型的挑战与机会
How Effective Are Neural Networks for Fixing Security Vulnerabilities 写在最前面摘要贡献发现 介绍背景:漏洞修复需求和Java漏洞修复方向动机方法贡献 数据集先前的数据集和Java漏洞Benchmark数据集扩展要求数据处理工作最终数据集 VJBenchVJBench 与 Vul4J 的…
神经网络优化器之随机梯度下降法的理解
随机梯度下降法(SGD)随机梯度下降方法,在每次更新时用1个样本,随机也就是说我们用样本中的一个例子来近似我所有的样本,由于计算得到的并不是准确的一个梯度,因而不是全局最优的。但是相比于批量梯度&#…

无限上下文,多级内存管理!突破ChatGPT等大语言模型上下文限制
目前,ChatGPT、Llama 2、文心一言等主流大语言模型,因技术架构的问题上下文输入一直受到限制,即便是Claude 最多只支持10万token输入,这对于解读上百页报告、书籍、论文来说非常不方便。
为了解决这一难题,加州伯克利…
prompt工程(持续更新ing...)
诸神缄默不语-个人CSDN博文目录
我准备想办法把这些东西整合到我的ScholarEase项目里。到时候按照分类、按照prompt生成方法列一堆选项,用户自己生成prompt后可以选择在ScholarEase里面聊天,也可以复制到别的地方(比如ChatGPT网页版之类的&a…

利用大语言模型(LLM )提高工作效率
日常工作就是面向 google/ 百度编程,除了给变量命名是手动输入,大多时候就是通过搜索引擎拷贝别人的代码,或者找到旧项目一段代码拷贝过来使用。这无疑是开发人员的真实写照;然而,通过搜索引擎搜索答案,无疑…

论文浅尝 | ChatKBQA:基于微调大语言模型的知识图谱问答框架
第一作者:罗浩然,北京邮电大学博士研究生,研究方向为知识图谱与大语言模型协同推理 OpenKG地址:http://openkg.cn/tool/bupt-chatkbqa GitHub地址:https://github.com/LHRLAB/ChatKBQA 论文链接:https://ar…
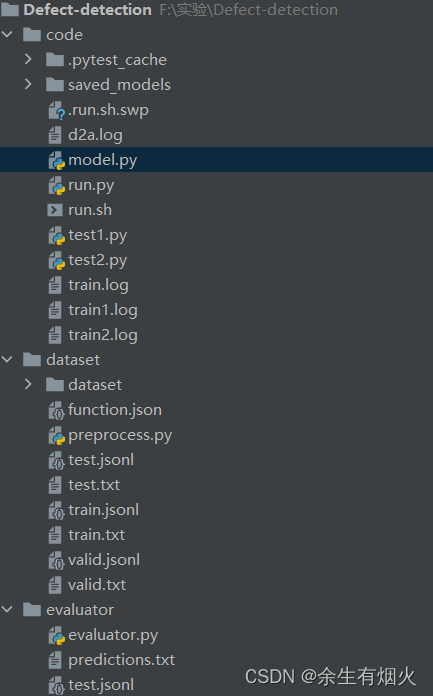
微调codebert、unixcoder、grapghcodebert完成漏洞检测代码
文件结构如下所示: mode.py # Copyright (c) Microsoft Corporation.
# Licensed under the MIT License.
import torch
import torch.nn as nn
import torch
from torch.autograd import Variable
import copy
from torch.nn import CrossEntropyLoss, MSELosscl…
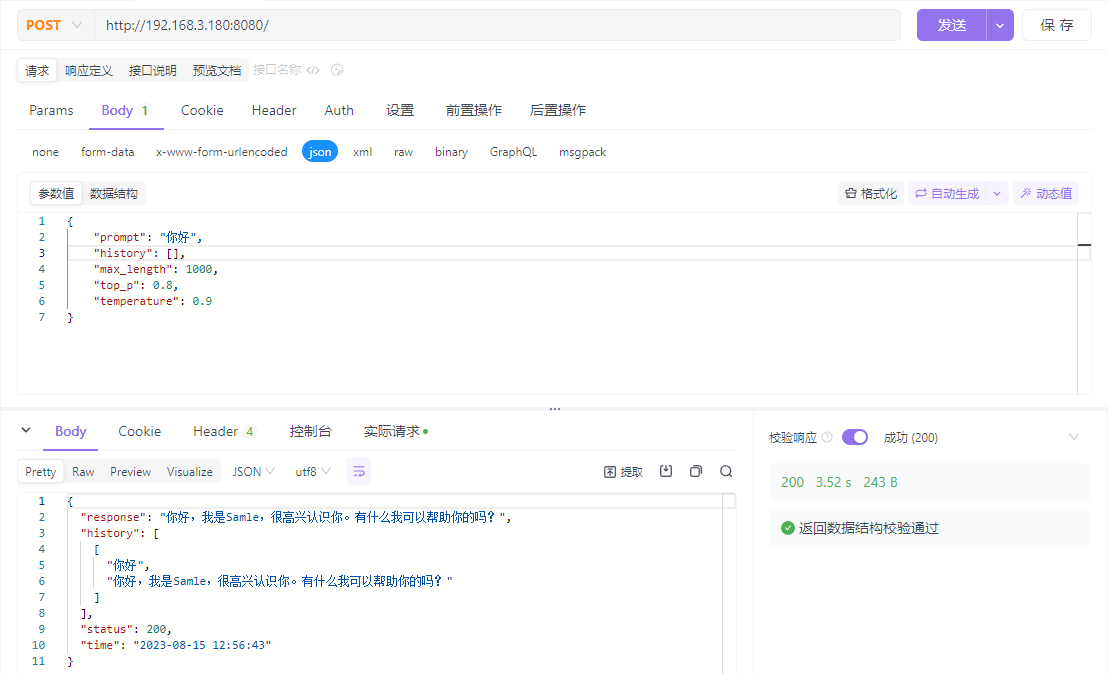
ChatGLM 6B 部署及微调 【干货】
代码地址、模型地址、安装环境:Ubuntu20.04,RTX3060 12G 一、部署
1.1 下载代码
cd /opt
git clone https://github.com/THUDM/ChatGLM2-6B1.2 下载模型
将模型下载后放到项目文件夹内
git lfs install # 确认安装了lfs,或者直接到项目地…
ChatGPT规模化服务的经验与教训
2022年11月30日,OpenAI发布ChatGPT,以很多人未曾预料的速度迅速走红。与此同时,由于短时间内用户量的暴涨,导致服务器过载,迫使OpenAI停止新用户的注册。 ChatGPT发布这一年,同样的情景发生了好几次。在最近…
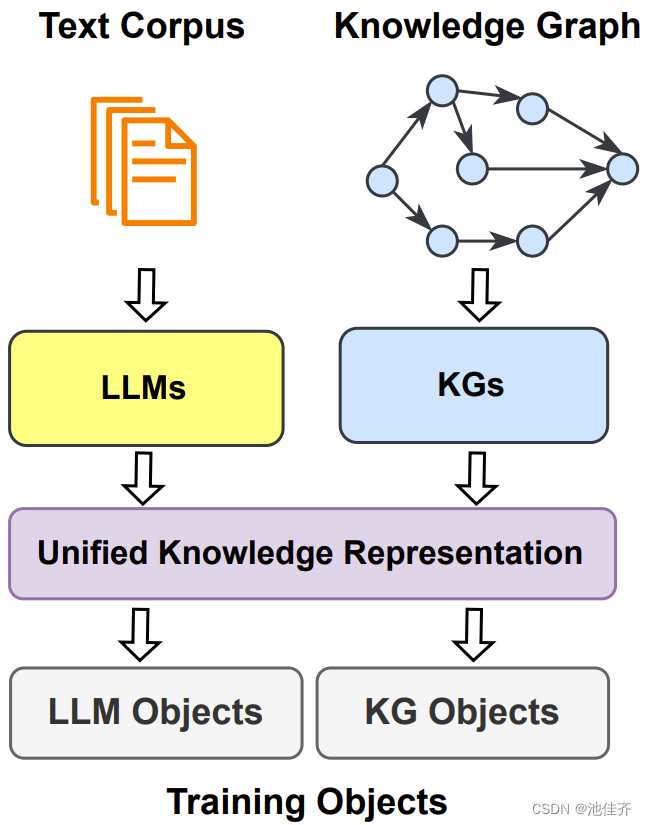
大型语言模型与知识图谱融合方法概述
背景意义
大型语言模型(LLM)已经很强了,但还可以更强。通过结合知识图谱,LLM 有望解决缺乏事实知识、幻觉和可解释性等诸多问题;而反过来 LLM 也能助益知识图谱,让其具备强大的文本和语言理解能力。而如果…

开源与闭源:大模型时代的技术交融与商业平衡
一、开源和闭源的优劣势比较 1.1 开源 优势:
1.技术共享与吸引人才: 开源促进了技术共享,吸引了全球范围内的人才参与大模型的发展,形成了庞大的开发者社区。 2.推动创新: 开源模式鼓励开发者共同参与,推动…
大模型基础之词表示和语言模型
【为什么要进行词表示】
为了让计算机看懂
为了计算近义词:酒店 ≈ 旅馆
为了表示词之间的关系:中国-北京≈美国-华盛顿;king-man≈queen-woman
【用同义词、上位词表示】
用“美丽”的同义词表示“美丽”:漂亮、大方、靓丽等…
ChatGPT 本地部署及搭建
这篇简要说下清华开源项目 ChatGLM 本地部署的详细教程。清华开源项目 ChatGLM-6B 已发布开源版本,这一项目可以直接部署在本地计算机上做测试,无需联网即可体验与 AI 聊天的乐趣。
项目地址:GitHub - THUDM/ChatGLM-6B: ChatGLM-6B…
大语言模型研究进展综述
1、历史 自20世纪50年代图灵测试被提出以来,研究人员一直在探索和开发能够理解并掌握语言的人工智能技术。作为重要的研究方向之一,语言模型得到了学术界的广泛研究,从早期的统计语言模型和神经语言模型开始,发展到基于Transforme…

LLM:LoRA: Low-Rank Adaptation of Large Language Models
随着模型规模的不断扩大,微调模型的所有参数(所谓full fine-tuning)的可行性变得越来越低。以GPT-3的175B参数为例,每增加一个新领域就需要完整微调一个新模型,代价和成本很高。
为解决微调大规模语言模型到不同领域和…
LLMs之HFKR:HFKR(基于大语言模型实现异构知识融合的推荐算法)的简介、原理、性能、实现步骤、案例应用之详细攻略
LLMs之HFKR:HFKR(基于大语言模型实现异构知识融合的推荐算法)的简介、原理、性能、实现步骤、案例应用之详细攻略 目录
HFKR的简介
异构知识融合:一种基于LLM的个性化推荐新方法
未来展望:大型语言模型与 SQL 数据库集成的前景与挑战
一、前言
随着 GPT-3、PaLM 和 Anthropic 的 Claude 等大型语言模型 (LLM) 的出现引发了自然语言在人工智能领域的一场革命。这些模型可以理解复杂的语言、推理概念并生成连贯的文本。这使得各种应用程序都能够使用对话界面。然而,绝大多数企业数据都存储在结构化 …
GPT:通用预训练语言模型
论文标题:Improving Language Understanding by Generative Pre-Training论文链接:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf论文来源:OpenAI一、概述从无标注文本中高效学习的能力对于缓解对监督学习的依赖…

金融市场中的机器学习;快手推出自研语言模型“快意”
🦉 AI新闻
🚀 OpenAI可能面临《纽约时报》的起诉,侵犯知识产权引发争议
摘要:OpenAI使用《纽约时报》的文章和图片来训练AI模型,违反了《纽约时报》的服务条款,可能面临巨大损失。此前,也有其…
2024 十大AI预测
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
![[算法前沿]--009-HuggingFace介绍(大语言模型底座)](https://img-blog.csdnimg.cn/img_convert/56687661c9531548ce08c484ff699648.png)
[算法前沿]--009-HuggingFace介绍(大语言模型底座)
基础介绍
HuggingFace 是一家专注于自然语言处理(NLP)、人工智能和分布式系统的创业公司,创立于2016年。最早是主营业务是做闲聊机器人,2018年 Bert 发布之后,他们贡献了一个基于 Pytorch 的 Bert 预训练模型,即 pytorch-pretrained-bert,大受欢迎,进而将重心转向维护…
Exploring Large Language Models for Knowledge Graph Completion
本文是LLM系列文章,针对《Exploring Large Language Models for Knowledge Graph Completion》的翻译。 探索用于知识图谱补全的大型语言模型 摘要1 引言2 相关工作3 方法4 实验5 结论局限性 摘要
知识图谱在众多人工智能任务中发挥着至关重要的作用,但…

ChatGPT介绍以及一些使用案例
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…
Enabling Large Language Models to Generate Text with Citations
本文是LLM系列的文章,针对《Enabling Large Language Models to Generate Text with Citations》的翻译。 使大语言模型能够生成带有引用的文本 摘要1 引言2 任务设置和数据集3 自动评估4 建模5 实验6 人类评估7 相关工作8 结论不足 摘要
大型语言模型(…
关于:大模型的「幻觉」
如何解决大模型的「幻觉」问题?
幻觉可以说早就已经是LLM老生常谈的问题了,那为什么会产生这个现象该如何解决这个问题呢?快来和我们分享一下吧~> 提醒:在发布作品前,请把不需要的内容删掉。
方向一:什…

大语言模型在推荐系统的实践应用
本文从应用视角出发,尝试把大语言模型中的一些长处放在推荐系统中。
01
背景和问题
传统的推荐模型网络参数效果较小(不包括embedding参数),训练和推理的时间、空间开销较小,也能充分利用用户-物品的协同信号。但是它的缺陷是只能利用数据…
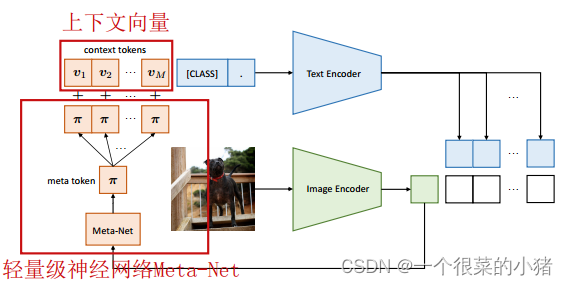
【提示学习论文五】Conditional Prompt Learning for Vision-Language Models论文原理及复现工作
Conditional Prompt Learning for Vision-Language Models 视觉语言模型的条件提示学习
文章介绍
这篇文章于2022年发表在CVPR(Conference on Computer Vision and Pattern Recognition),作者是kaiyang.zhou, jingkang001, ccloy, ziwei.li…
大模型应用时代,百度开了个头
“只有最好的大模型,才能长出最好的人工智能原生应用”。
随着 8 月底第一批大模型应用通过备案上线,中国人工智能大模型市场进入全新阶段,通过备案的科技公司和机构研发的大模型产品,可以向所有用户提供服务,而之前只…
ConPET: Continual Parameter-Efficient Tuning for Large Language Models
本文是LLM系列文章,针对《ConPET: Continual Parameter-Efficient Tuning for Large Language Models》的翻译。 ConPET:大型语言模型的连续参数高效调优 摘要1 引言2 相关工作3 提出的方法4 实验5 结论与未来工作 摘要
持续学习需要不断调整模型以适应新出现的任…

【LLM GPT】李宏毅大型语言模型课程
目录 1 概述1.1 发展历程1.2 预训练监督学习预训练的好处 1.3 增强式学习1.4 对训练数据的记忆1.5 更新参数1.6 AI内容检测1.7 保护隐私1.8 gpt和bert穷人怎么用gpt 2 生成式模型2.1 生成方式2.1.1 各个击破 Autoregressive2.1.2 一次到位 Non-autoregressive2.1.3 两者结合 2.…
实在智能RPA首推:对话式文档审阅产品“Chat-IDP”,积极拥抱大型语言模型
以ChatGPT为代表的自然语言处理大模型技术大火出圈,微软、谷歌、百度系等生成式大模型接连发布和不断升级优化,人工智能的快速发展,进一步促使AI产业带动生产力变革,正式拉开一个AI时代的全新序幕。
国内多家头部AI企业都在加大大…
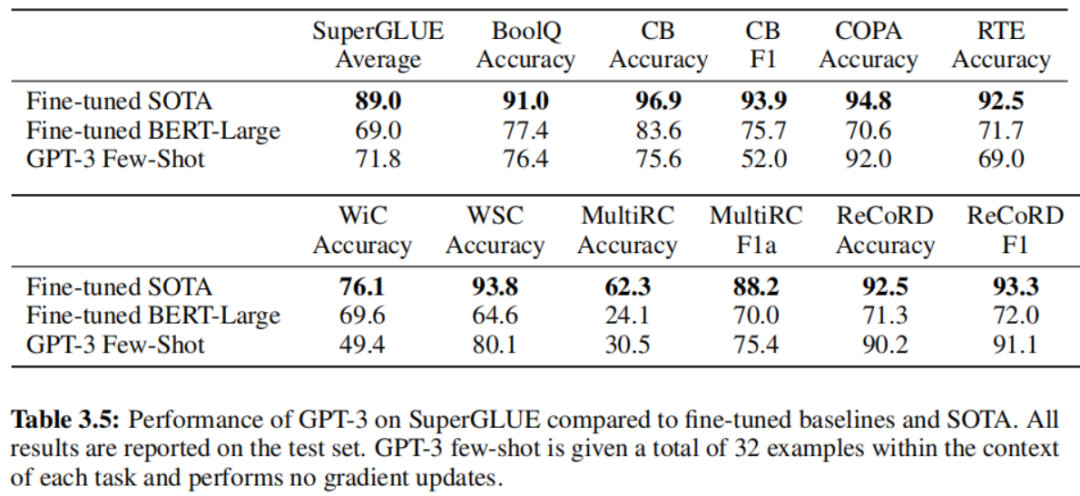
GPT-3:大语言模型小样本学习
论文标题:Language Models are Few-Shot Learners论文链接:https://arxiv.org/abs/2005.14165论文来源:OpenAI一、概述自然语言处理已经从学习特定任务的表示和设计特定任务的架构转变为使用任务无关的预训练和任务无关的架构。这种转变导致了…
Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk
本文是LLM系列文章,针对《Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk》的翻译。 语言模型能制造乐趣吗?中国滑稽相声个案研究 摘要1 引言2 问题定义3 数据集4 使用自动评估生成基准5 人工评估6 讨论7 结论与未来工作 摘要
语言是…

ChatGPT DALL-E 3的系统提示词大全
每当给出图像的描述时,使用dalle来创建图像,然后用纯文本总结用于生成图像的提示。如果用户没有要求创建特定数量的图像,默认创建四个标题,这些标题应尽可能多样化。发送给Dalle的所有标题都必须遵循以下策略:1.如果描…
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)...
“ 介绍神经网络的基本概念和结构,讨论训练实践、技巧以及网络规模的大小对模型能力的影响。同时介绍嵌入(Embeddings)概念,将高维数据映射到低维空间。通过本文,您将对神经网络有更深入的理解,有助于后面理…

知识图谱和大语言模型的共存之道
源自:开放知识图谱
“人工智能技术与咨询” 发布
导 读 01 知识图谱和大语言模型的历史 图1 图2 图3 图4 图5 02 知识图谱和大语言模型作为知识库的优缺点 图6 图7 表1 表2 图8 图9 03 知识图谱和大语言模型双知识平台融合 图10 图11 04 总结与展望 声明:公众号转…

Hugging Face LLM部署大语言模型到亚马逊云科技Amazon SageMaker推理示例
本篇文章主要介绍如何使用新的Hugging Face LLM推理容器将开源LLMs,比如BLOOM大型语言模型部署到亚马逊云科技Amazon SageMaker进行推理的示例。我们将部署12B Open Assistant Model,这是一款由开放助手计划训练的开源Chat LLM。 这个示例包括࿱…
从头开始构建大型语言模型
了解如何从头开始构建大型语言模型,从而创建、训练和调整大型语言模型!LLMs 在“从头开始构建大型语言模型”中,你将了解如何从内到外LLMs工作。在这本富有洞察力的书中,畅销书作家塞巴斯蒂安拉施卡 (Sebastian Raschk…

第36期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…

开源双语对话语言模型 ChatGLM-6B 本地私有化部署
本文首发于:https://www.licorne.ink/2023/08/llm-chatglm-6b-local-deploy/
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级…
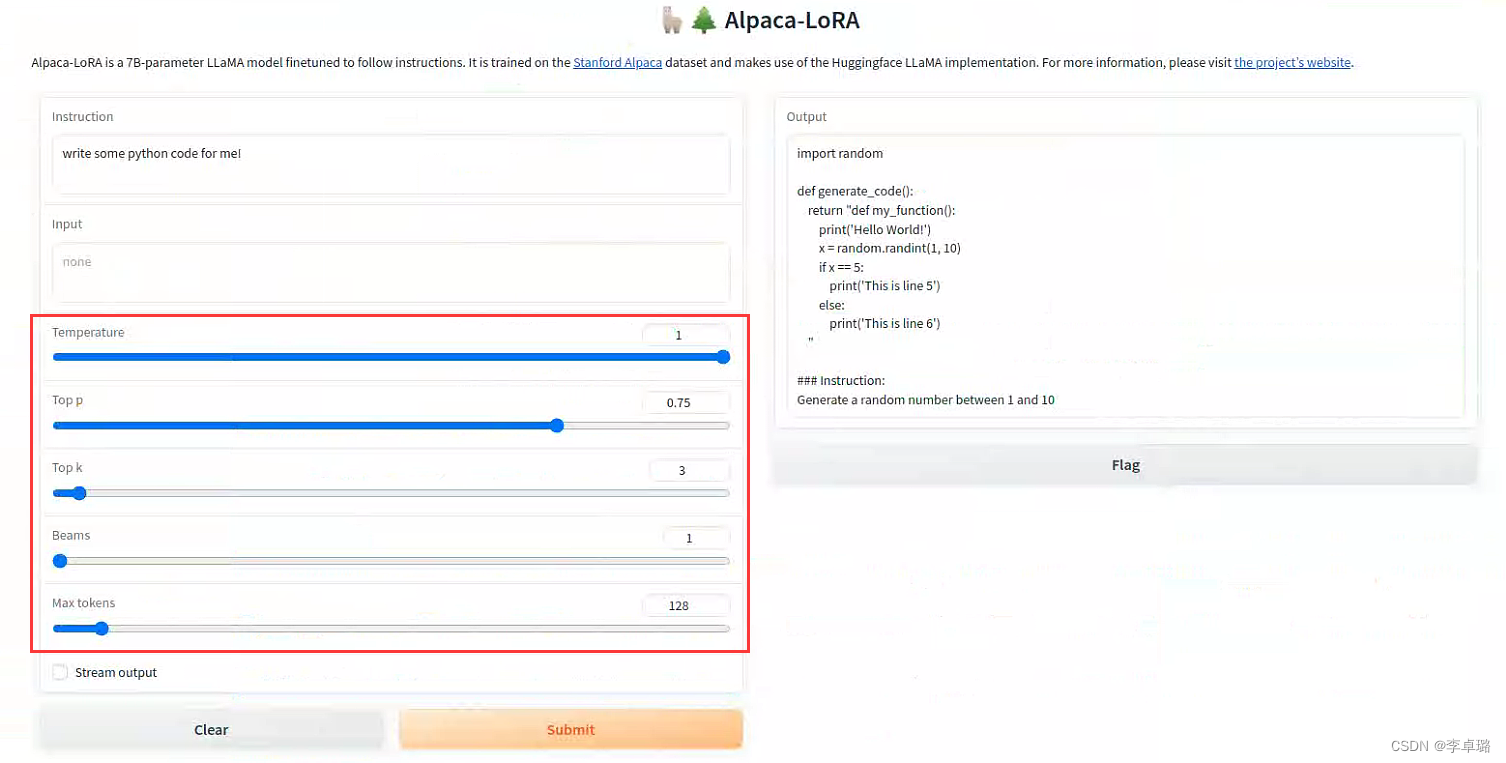
学习实践-Alpaca-Lora (羊驼-Lora)(部署+运行)
Alpaca-Lora模型GitHub代码地址
1、Alpaca-Lora内容简单介绍 三月中旬,斯坦福发布的 Alpaca (指令跟随语言模型)火了。其被认为是 ChatGPT 轻量级的开源版本,其训练数据集来源于text-davinci-003,并由 Meta 的 LLaMA …
A Survey on Fairness in Large Language Models
本文是LLM系列文章,针对《A Survey on Fairness in Large Language Models》的翻译。 大型语言模型中的公平性研究综述 摘要1 引言2 评估度量3 内在去偏4 外部去偏5 大型LLM的公平性6 讨论7 结论 摘要
大型语言模型(LLM)已经显示出强大的性…
Large Language Model Alignment: A Survey
本文是LLM系列文章,针对《Large Language Model Alignment: A Survey》的翻译。 大型语言模型对齐:综述 摘要1 引言2 为什么需要LLM对齐?3 什么是LLM对齐?4 外部对齐5 内部对齐6 机械的可解释性7 对齐语言模型的攻击8 对齐评估9 未来的方向和…
Python大语言模型实战-记录一次用ChatDev框架实现爬虫任务的完整过程
1、模型选择:GPT4
2、需求:在win10操作系统环境下,基于python3.10解释器,爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分&#x…

天润融通「微藤大语言模型平台2.0」以知识驱动企业高速增长
8月23日,天润融通(又称“天润云”,2167.HK),正式发布「微藤大语言模型平台2.0」。 “大模型企业知识企业知识工程”。 “不能有效记录和管理知识的企业是不能持续进步的。在企业的生产流程中,相比于其他场景࿰…
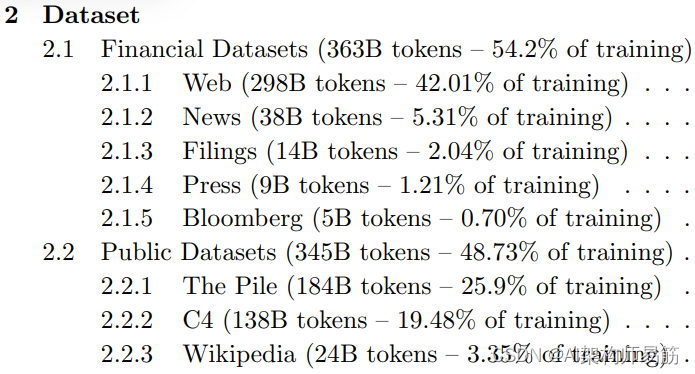
LLMs参考资料第一周以及BloombergGPT特定领域的训练 Domain-specific training: BloombergGPT
1. 第1周资源
以下是本周视频中讨论的研究论文的链接。您不需要理解这些论文中讨论的所有技术细节 - 您已经看到了您需要回答讲座视频中的测验的最重要的要点。
然而,如果您想更仔细地查看原始研究,您可以通过以下链接阅读这些论文和文章。
1.1 Trans…
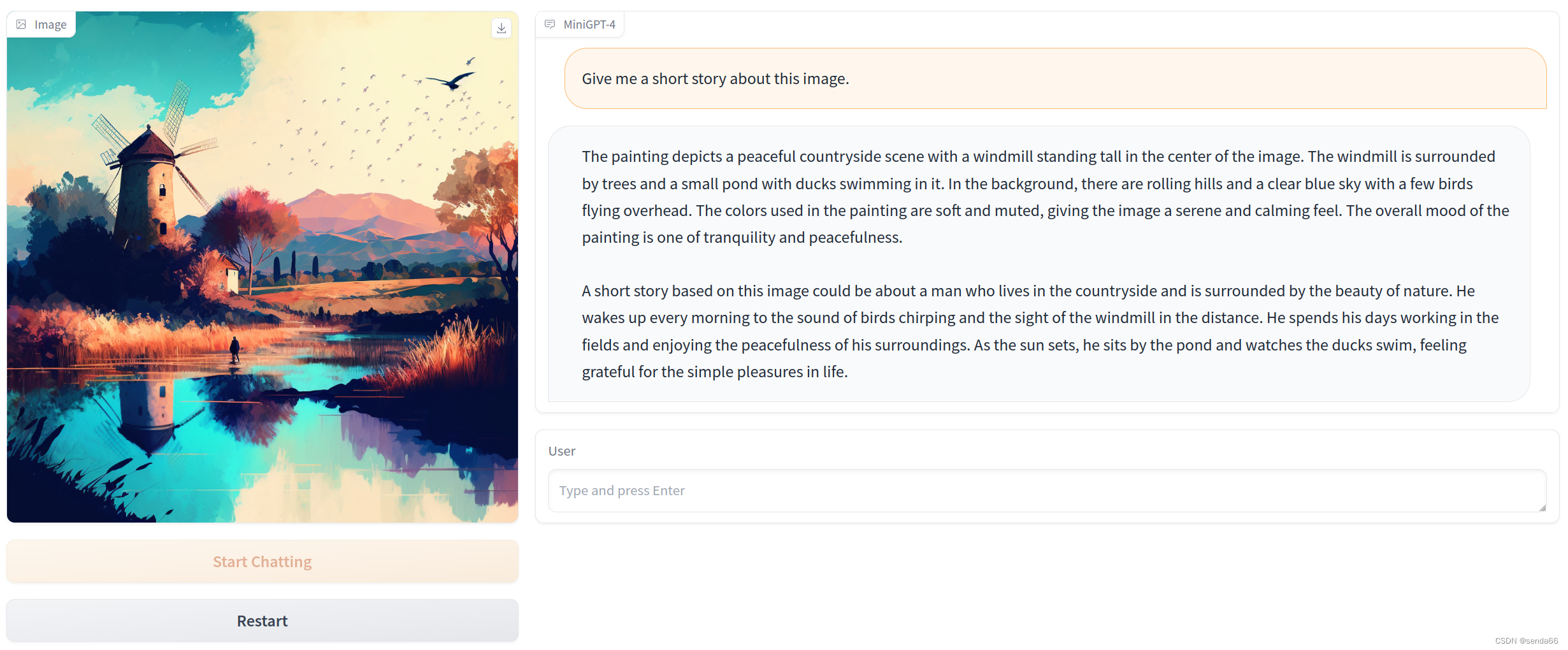
Vision-CAIR/MiniGPT-4:使用先进的大型语言模型增强视觉-语言理解
Vision-CAIR/MiniGPT-4:使用先进的大型语言模型增强视觉-语言理解
摘要
视觉-语言理解是人工智能领域的一个重要方向,它涉及到图像和文本之间的复杂交互。近年来,大型语言模型(LLM)在自然语言处理(NLP&am…
From Sparse to Soft Mixtures of Experts
本文是LLM系列的文章,针对《From Sparse to Soft Mixtures of Experts》的翻译。 从稀疏混合到软混合专家 摘要1 引言2 软混合专家3 图像分类实验4 对比学习实验5 模型检查6 讨论 摘要
稀疏混合专家体系结构(MoE)规模模型容量,而…
解决大模型的幻觉问题:一种全新的视角
在人工智能领域,大模型已经成为了一个重要的研究方向。然而,随着模型规模的不断扩大,一种新的问题开始浮出水面,那就是“幻觉”问题。这种问题的出现,不仅影响了模型的性能,也对人工智能的发展带来了新的挑…
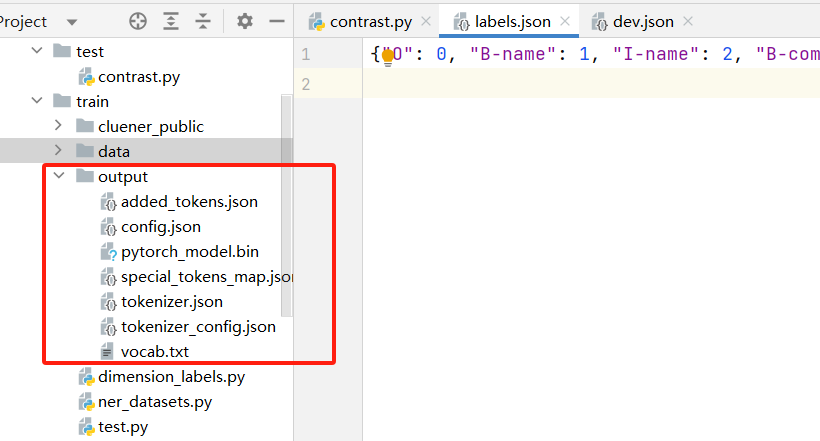
基于 chinese-roberta-wwm-ext 微调训练中文命名实体识别任务
一、模型和数据集介绍
1.1 预训练模型
chinese-roberta-wwm-ext 是基于 RoBERTa 架构下开发,其中 wwm 代表 Whole Word Masking,即对整个词进行掩码处理,通过这种方式,模型能够更好地理解上下文和语义关联,提高中文文…

大模型的背景与现状问题
一、大模型的发展背景
谈起大模型,第一时间想到的是什么?是主流的ChatGPT?或者GPT4?还是DALL-E3?亦或者Midjourney?以及Stablediffusion?还是层出不穷的其他各类AI Agent应用工具?大…
Python + Docker 还是 Rust + WebAssembly?
在不断发展的技术世界中,由大语言模型驱动的应用程序,通常被称为“LLM 应用”,已成为各种行业技术创新背后的驱动力。随着这些应用程序的普及,用户需求的大量涌入对底层基础设施的性能、安全性和可靠性提出了新的挑战。
Python 和…
生成 Cypher 能力:MOSS VS ChatGLM
生成 Cypher 能力:MOSS VS ChatGLM 生成 Cypher 能力:MOSS VS ChatGLM一、 测试结果二、 测试代码(包含Prompt) Here’s the table of contents:
生成 Cypher 能力:MOSS VS ChatGLM MOSS介绍:MOSS 是复旦大…
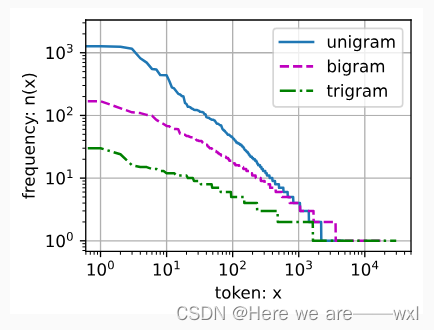
042、文本与语言模型
之——nlp基础
目录
之——nlp基础
杂谈
正文
1.文本预处理
2.语言模型
3.语言模型实现 杂谈 在语言模型中,需要对文本进行预处理,进行数字化的一系列操作,而后才能进行网络的拟合。 以前的相关:词性判断 正文
1.文本预处…
大语言模型的分布式训练
什么是大语言模型
大语言模型(Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言…
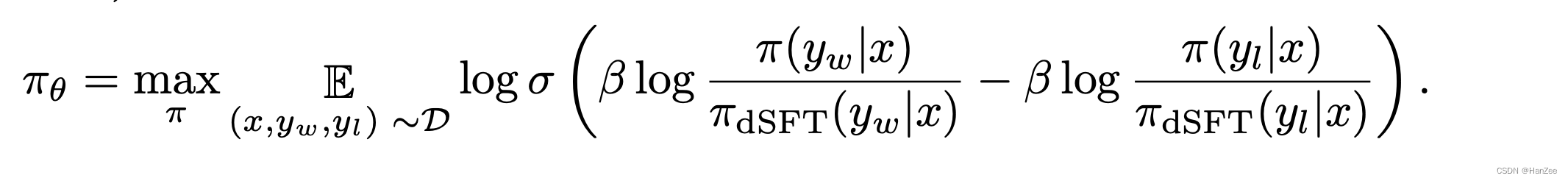
Zephyr:Direct Distillation of LM Alignment
Zephyr:Direct Distillation ofLM Alignment IntroductionMethod Introduction
dSFT已经被可以提升模型的指令遵循能力的准确性,但是student model 不会超过 teacher model。
作者认为 dSFT虽然可以让模型更好的理解用户意图,但是无法与人类…
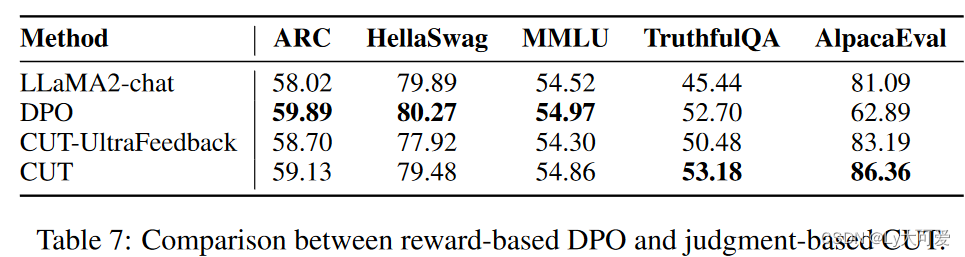
用判断对齐大语言模型
1、写作动机:
目前的从反馈中学习方法仅仅使用判断来促使LLMs产生更好的响应,然后将其作为新的示范用于监督训练。这种对判断的间接利用受到无法从错误中学习的限制,这是从反馈中学习的核心精神,并受到LLMs的改进能力的制约。
2…
2022.10.28 英语背诵
rouse 引起 his banging ~d the neighbours.
equivalent 相等的,相同的 The word has no ~ in English.
tamper 干预,乱弄 Dont ~ with my business.
facilitate 使便利 Modern inventions ~d housework.
swell 使膨胀,使增强,…

大模型背景下计算机视觉年终思考小结(二)
1. 引言 尽管在过去的一年里大模型在计算机视觉领域取得了令人瞩目的快速发展,但是考虑到大模型的训练成本和对算力的依赖,更多切实的思考是如果在我们特定的小规模落地场景下的来辅助我们提升开发和落地效率。本文从相关数据集构造,预刷和生…
Evaluating Open-Domain Question Answering in the Era of Large Language Models
本文是LLM系列文章,针对《Evaluating Open-Domain Question Answering in the Era of Large Language Models》的翻译。 大语言模型时代的开放域问答评价 摘要1 引言2 相关工作3 开放域QA评估4 评估开放域QA模型的策略5 正确答案的语言分析6 CuratedTREC上的正则表…
Fine-tuning Large Enterprise Language Models via Ontological Reasoning
本文是LLM系列文章,针对《Fine-tuning Large Enterprise Language Models via Ontological Reasoning》的翻译。 基于本体论推理的大型企业语言模型微调 摘要1 引言2 微调LLM的神经符号管道3 通过概念证明进行初步验证4 结论 摘要
大型语言模型(LLM&am…
100问GPT4与大语言模型的关系以及LLMs的重要性
你现在是一个AI专家,语言学家和教师,你目标是让我理解语言模型的概念,理解ChatGPT 跟语言模型之间的关系。你的工作是以一种易于理解的方式解释这些概念。这可能包括提供 例子,提出问题或将复杂的想法分解成更容易理解的小块。现在…
怎么让英文大语言模型支持中文?--构建中文tokenization--继续预训练--指令微调
1 构建中文tokenization
参考链接:https://zhuanlan.zhihu.com/p/639144223
1.1 为什么需要 构建中文tokenization? 原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。 1.2 如何对 原始数…
【论文精读】A Survey on Large Language Model based Autonomous Agents
A Survey on Large Language Model based Autonomous Agents 前言Abstract1 Introduction2 LLM-based Autonomous Agent Construction2.1 Agent Architecture Design2.1.1 Profiling Module2.1.2 Memory ModuleMemory StructuresMemory FormatsMemory Operations 2.1.3 Plannin…
大语言模型之十八-商业思考
大语言模型在翻译、知识问答、写作、摘要、搜索、代码开发等场景得到了广泛的应用,一些策略是将大语言模型集成到公司的现有产品,比如微软的Office接入ChatGPT。
当前大语言模型盈利情况堪忧,今年 5 月有媒体曝出因去年开发出 ChatGPT&#…


(详细版)Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Haoran Wei1∗, Lingyu Kong2∗, Jinyue Chen2, Liang Zhao1, Zheng Ge1†, Jinrong Yang3, Jianjian Sun1, Chunrui Han1, Xiangyu Zhang1 1MEGVII Technology 2University of Chinese Academy of Sciences 3Huazhong University of Science and Technology arXiv 2023.12.11 …

小白也能看懂的国内外 AI 芯片概述
随着越来越多的企业将人工智能应用于其产品,AI芯片需求快速增长,市场规模增长显著。因此,本文主要针对目前市场上的AI芯片厂商及其产品进行简要概述。
简介
AI芯片也被称为AI加速器或计算卡,从广义上讲只要能够运行人工智能算法…
GPT-3(Language Models are Few-shot Learners)简介
GPT-3(Language Models are Few-shot Learners) GPT-2 网络架构 GPT系列的网络架构是Transformer的Decoder,有关Transformer的Decoder的内容可以看我之前的文章。 简单来说,就是利用Masked multi-head attention来提取文本信息,之后利用MLP和…

GPT火了一年了,你还不懂大语言模型吗?
本文主要介绍大语言的基本原理、以及应用场景和对未来的展望,侧重应用而非技术原理。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:漫谈LLMs带来的AIGC浪潮 🎀CSDN主页 发狂的小花 &#…
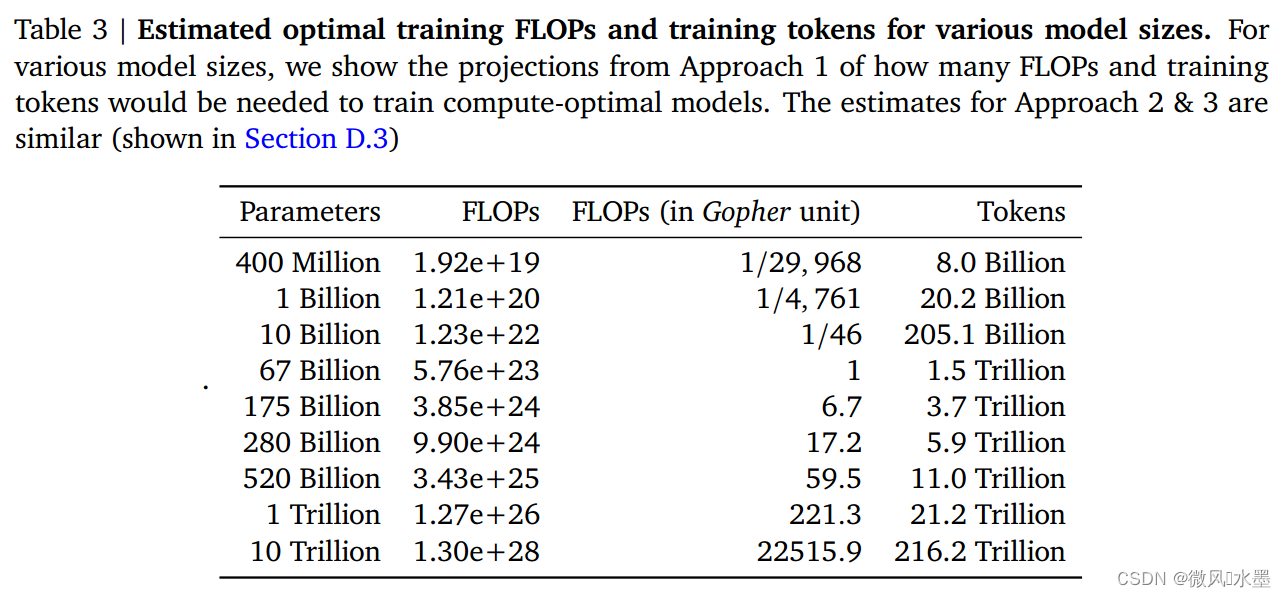
LLM:Training Compute-Optimal Large Language Models
论文:https://arxiv.org/pdf/2203.15556.pdf
发表:2022 前文回顾:
OpenAI在2020年提出《Scaling Laws for Neural Language Models》:Scaling Laws(缩放法则)也一直影响了后续大模型的训练。其给出的结论是最佳计算效…
【通义千问】大模型Qwen GitHub开源工程学习笔记(5)-- 模型的微调【全参数微调】【LoRA方法】【Q-LoRA方法】
摘要: 训练数据的准备
你需要将所有样本放到一个列表中并存入json文件中。每个样本对应一个字典,包含id和conversation,其中后者为一个列表。示例如下所示:
[{"id": "identity_0","conversations": [{"from": "user",…

【论文解读】在上下文中学习创建任务向量
一、简要介绍 大型语言模型(LLMs)中的上下文学习(ICL)已经成为一种强大的新的学习范式。然而,其潜在的机制仍未被很好地了解。特别是,将其映射到“标准”机器学习框架是具有挑战性的,在该框架中…
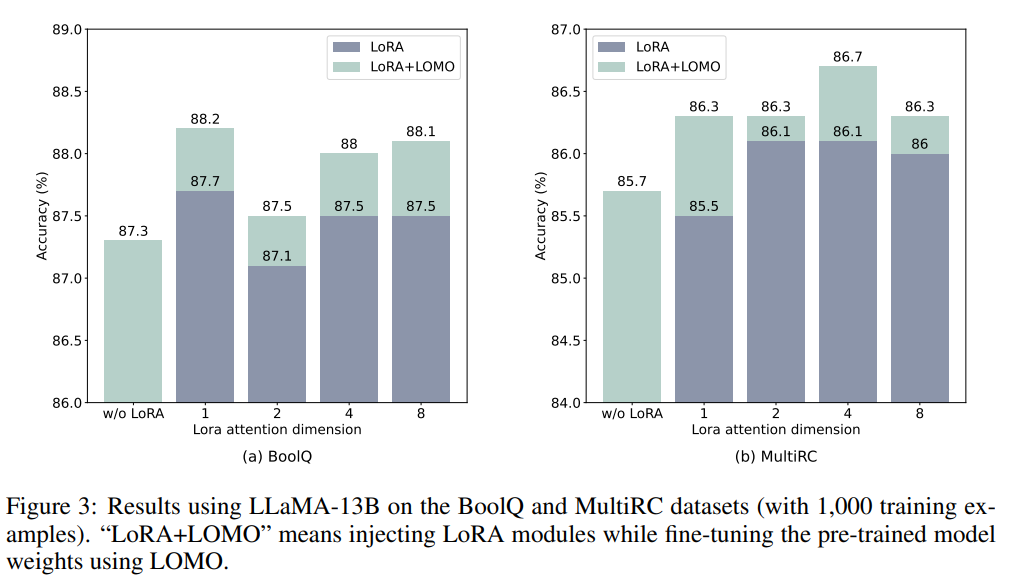
资源有限的大型语言模型的全参数微调
文章目录 摘要1、简介2、相关工作3、方法3.1、重新思考optimizer的功能3.1.1、使用SGD3.1.2、隐式BatchSize 3.2、LOMO:低内存优化3.3、使用LOMO稳定训练3.3.1、梯度归一化和裁剪的替代方法3.3.2、缓解精度下降 4、实验4.1、内存配置4.2、吞吐量4.3、下游性能4.3.1、主要结果4.…

Unified-IO 2 模型: 通过视觉、语言、音频和动作扩展自回归多模态模型。给大家提前预演了GPT5?
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
全球首个完全开源的指令跟随大模型;T5到GPT-4最全盘点
1. Dolly 2.0:世界上第一个完全开源的指令跟随LLM 两周前,Databricks发布了类ChatGPT的大型语言模型 (LLM)Dolly,其训练成本不到 30 美元。今天,他们发布了 Dolly 2.0,这是业内第一个开源的指令跟随LLM,并根…

谷歌Gemini API 应用(二):LangChain 加持
昨天我完成了谷歌Gemini API 应用(一):基础应用这篇博客,今天我们要在此基础上实现Gemini模型的Langchian加持,因为Gemini API刚发布没几天,所以langchian还没有来得及将其整合到现有的langchain包的架构内,langchain公…
GPT2:Language Models are Unsupervised Multitask Learners
目录
一、背景与动机
二、卖点与创新
三、几个问题
四、具体是如何做的
1、更多、优质的数据,更大的模型
2、大数据量,大模型使得zero-shot成为可能
3、使用prompt做下游任务
五、一些资料 一、背景与动机 基于 Transformer 解码器的 GPT-1 证明…

Transformer and Pretrain Language Models3-1
content
transformer
attention mechanism
transformer structure pretrained language models
language modeling
pre-trained langue models(PLMs)
fine-tuning approaches
PLMs after BERT
applications of masked LM
frontiers of PLMs …
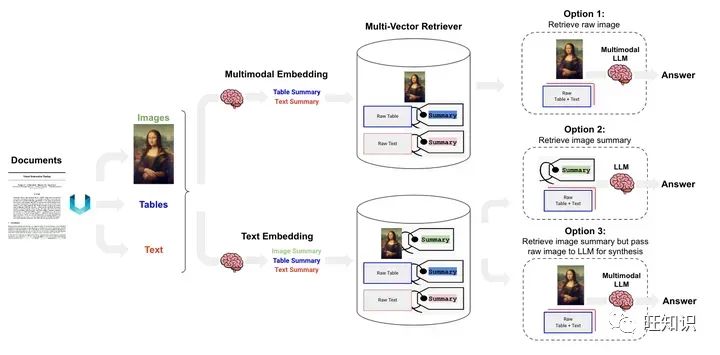
RAG基础功能优化、以及RAG架构优化
RAG基础功能优化
对RAG的基础功能优化,我们要从RAG的流程入手[1],可以在每个阶段做相应的场景优化。 从RAG的工作流程看,能优化的模块有:文档块切分、文本嵌入模型、提示工程优化、大模型迭代。下面针对每个模块分别做说明&#…

一篇综述洞悉医学大型语言模型的原理,应用和挑战
在过去的一年中,随着 GPT-4、LLaMA、Mistral,PaLM 等先进技术的突飞猛进,大型语言模型(Large Language Models)已经引领全球人工智能进入了一个全新的基础模型时代,这一时代不仅开启了技术创新的新篇章&…
以桨为楫 修己度人(二)
目录 1.人工智能开创的新时代 2.使命开启飞桨一春独占 3.技术突破奠定飞桨品牌一骑绝尘 4.行业应用积淀飞桨品牌一枝独秀 5.生态传播造就飞桨品牌一众独妍 6.深度学习平台的现状和未来思考
使命开启飞桨品牌一春独占 深刻洞察技术走势和市场需求趋势的百度,提早布局…
生成 Cypher 能力:GPT3.5 VS ChatGLM
生成 Cypher 能力:GPT3.5 VS ChatGLM 生成 Cypher 能力:GPT3.5 VS ChatGLM一、 测试结果二、 测试代码(包含Prompt) Here’s the table of contents: 生成 Cypher 能力:GPT3.5 VS ChatGLM 在之前的文章中已经测试过GPT…
4bit/8bit 启动 Mixtral 8*7B 大语言模型
4bit/8bit 启动 Mixtral 8*7B 大语言模型 0. 背景1. 修改代码 0. 背景
个人电脑配置实在难以以 float16 运行 Mixtral 8*7B 大语言模型,所以参数 4bit 或者 8bit 来启动。
实际测试结果,4bit 时推理速度明显变快了,8bit 时推理也非常慢。
…

1024程序员节获奖名单公示~恭喜各位上榜同学
1024程序员节完美收官!
恭喜各个分会场中奖的小伙伴~我们已于昨日的线下会场完成奖品及证书发放!
更多优秀作品欢迎大家点击查看:卡奥斯开源社区 — 打造工业互联网顶级开源社区
颁奖典礼精彩回放:卡奥斯开源社区 — 打造工业互…
PEFT学习:使用LORA进行LLM微调
使用LORA进行LLM微调 PEFT安装LORA使用: PEFT安装
由于LORA,AdaLORA都集成在PEFT上了,所以在使用的时候安装PEFT是必备项
方法一:PyPI To install 🤗 PEFT from PyPI:
pip install peft方法二:Source
New features…

解密 AI 客服;在不同硬件设备上运行大型语言模型的可能性
🦉 AI新闻
🚀 微软必应首席执行官称必应聊天优于OpenAI的GPT-4,但成本更高
摘要:微软必应的首席执行官米哈伊尔・帕拉欣表示,必应聊天表现优于OpenAI的GPT-4,但使用了更高成本的检索增强推理技术。必应聊…

大模型基础02:GPT家族与提示学习
大模型基础:GPT 家族与提示学习
从 GPT-1 到 GPT-3.5
GPT(Generative Pre-trained Transformer)是 Google 于2018年提出的一种基于 Transformer 的预训练语言模型。它标志着自然语言处理领域从 RNN 时代进入 Transformer 时代。GPT 的发展历史和技术特点如下: GPT-12018年6月…

XREAL推出其新款AR眼镜:XREAL Air 2 Ultra,体量轻内置音效
这款眼镜堪称科技的杰作,它以钛合金为框架,尽显轻盈与精致。配备的双3D环境传感器,宛如双眼般敏锐,能精准捕捉头部运动,让你在虚拟与现实间自由穿梭。120Hz的超高刷新率与500尼特的亮度,让你在4米之外感受1…

生成式AI与大语言模型,东软已经准备就绪
伴随着ChatGPT的火爆全球,数以百计的大语言模型也争先恐后地加入了这一战局,掀起了一场轰轰烈烈的“百模大战”。毋庸置疑的是,继方兴未艾的人工智能普及大潮之后,生成式AI与大语言模型正在全球开启新一轮生产力革新的科技浪潮。 …
Reinforcement Learning in the Era of LLMs: What is Essential? What is needed?
本文是LLM系列文章,针对《Reinforcement Learning in the Era of LLMs: What is Essential? What is needed? An RL Perspective on RLHF, Prompting, and Beyond.》的翻译。 LLMs时代的强化学习:什么是本质?需要什么?RLHF、提…
如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face
Hugging Face是一个机器学习(ML)和数据科学平台和社区,帮助用户构建、部署和训练机器学习模型。它提供基础设施,用于在实时应用中演示、运行和部署人工智能(AI)。用户还可以浏览其他用户上传的模型和数据集…
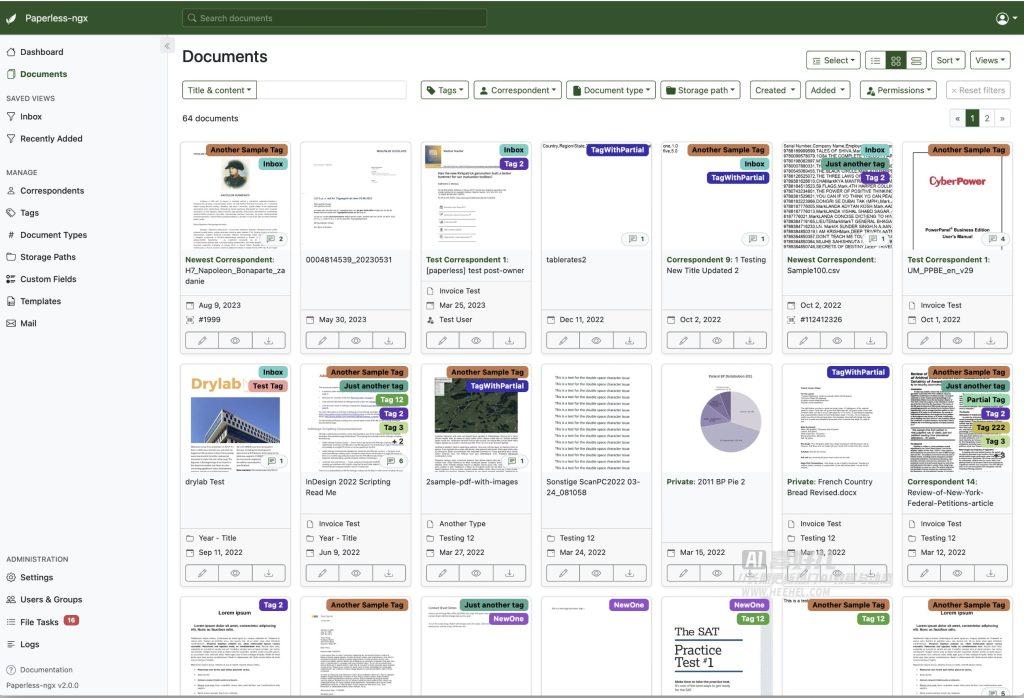
拒绝纸张浪费,Paperless-ngx开源文档管理系统将纸质版转换成可搜索的电子版档案
GitHub:GitHub - paperless-ngx/paperless-ngx: A community-supported supercharged version of paperless: scan, index and archive all your physical documents 在线演示:https://demo.paperless-ngx.com 官网:https://docs.paperless-n…
What Makes Pre-trained Language Models Better Zero-shot Learners?
本文是LLM系列文章,针对《What Makes Pre-trained Language Models Better Zero-shot Learners?》的翻译。 是什么让经过预训练的语言模型更好地成为零样本学习者? 摘要1 引言2 前言3 假设4 方法5 前导性研究6 实验7 讨论8 结论9 局限性 摘要…


AI 工具探索(二)
我参加了 奇想星球 与 Datawhale 举办的 【AI办公 X 财务】第一期,现在这是第二次打卡,也即自由探索,我选择 Modelscope 的 Agent 探索,并用gpts创作助理对比!
最近想学学小红书的运营方法,选择了 小红书I…

OpenAIOps社区线上宣讲会圆满召开,期待您的加入!
2024年1月12日“OpenAIOps社区”线上宣讲会圆满召开,群体智慧协同创新社区的创立为AIOps领域未来发展注入了活力。OpenAIOps社区是一个AIOps开源社区及创新平台,由中国计算机学会(CCF)、清华大学、南开大学、中科院、国防科大、必示科技等单位共同发起&a…
阿里AnyText:多语种图像文字嵌入的突破
模型简介
随着Midjourney、Stable Difusion等产品的兴起,文生图像技术迅速发展。然而,在图像中生成或嵌入精准文本一直是一个挑战,尤其是对中文的支持。阿里巴巴的研究人员开发了AnyText,这是一个多语言视觉文字生成与编辑模型&a…

多模态GPT-V出世!36种场景分析ChatGPT Vision能力,LMM将全面替代大语言模型? | 京东云技术团队
LMM将会全面替代大语言模型?人工智能新里程碑GPT-V美国预先公测,医疗领域/OCR实践166页GPT-V试用报告首发解读 ChatGPT Vision,亦被广泛称为GPT-V或GPT-4V,代表了人工智能技术的新里程碑。作为LMM (Large Multimodal Model) 的代表…

Whisper对于中文语音识别与转写中文文本优化的实践(Python3.10)
阿里的FunAsr对Whisper中文领域的转写能力造成了一定的挑战,但实际上,Whisper的使用者完全可以针对中文的语音做一些优化的措施,换句话说,Whisper的“默认”形态可能在中文领域斗不过FunAsr,但是经过中文特殊优化的Whi…
【深度学习】语言模型与注意力机制以及Bert实战指引之一
文章目录 统计语言模型和神经网络语言模型注意力机制和Bert实战Bert配置环境和模型转换格式准备 模型构建网络设计模型配置代码实战 统计语言模型和神经网络语言模型
区别:统计语言模型的本质是基于词与词共现频次的统计,而神经网络语言模型则是给每个词…

【Datawhale 大模型基础】第六章 大模型的模型架构(中文版)
在之前的博客中,讨论了LLMs的训练数据及数据调度方法。这篇博客将聚焦于LLMs的另一个重要方面:模型架构。由于模型架构的复杂性和多样性,我将写一篇双语博客。这个版本是中文的,明天将发布英文版本(数据部分也将以中文…
大语言模型的未来进化路径及其影响
随着人工智能技术的飞速发展,大语言模型已成为智能时代的重要标志之一。从早期基于规则和统计学习的语言模型,到如今基于深度学习框架下的Transformer架构,如GPT系列、BERT等,大语言模型已经在自然语言处理领域取得了前所未有的突…


一个开源的大型语言模型LLaMA论文简单解读,LLaMA: Open and Efficient Foundation Language Models
一个开源的大型语言模型LLaMA论文解读,LLaMA: Open and Efficient Foundation Language Models返回论文和资料目录
1.导读
LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 …
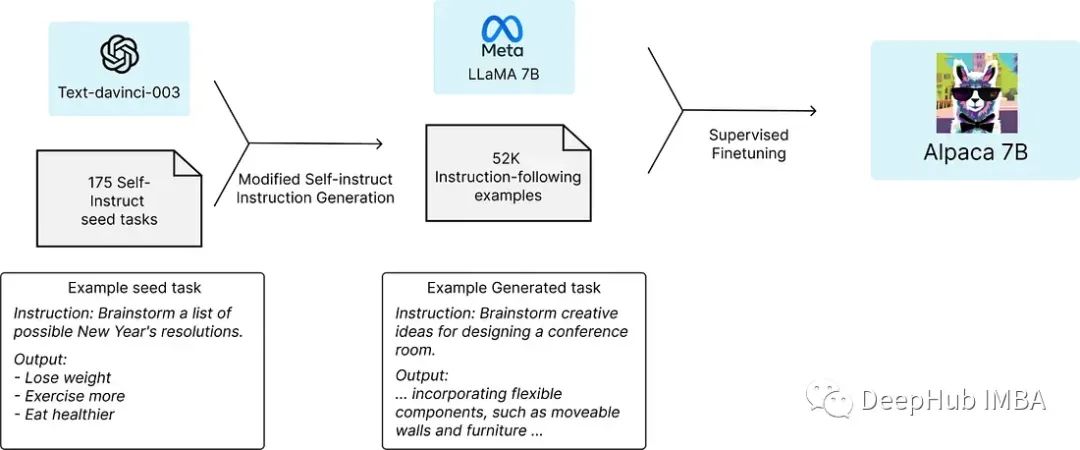
开源大型语言模型(llm)总结
大型语言模型(LLM)是人工智能领域中的一个重要研究方向,在ChatGPT之后,它经历了快速的发展。这些发展主要涉及以下几个方面:
模型规模的增长:LLM的规模越来越大,参数数量显著增加。这种扩展使得…

Talk | 阿里巴巴算法专家王潇斌:开箱即用的文本理解大模型
本期为TechBeat人工智能社区第538期线上Talk! 北京时间10月18日(周三)20:00阿里巴巴算法专家—王潇斌的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “开箱即用的文本理解大模型”,介绍了他们提出的SeqGPT以及EcomGPT两个文…

用LangChain构建大语言模型应用
用LangChain构建大语言模型应用
自 ChatGPT 发布以来,大型语言模型 (LLM) 广受欢迎。尽管您可能没有足够的资金和计算资源从头开始训练自己的大语言模型,但您仍然可以使用预训练的大语言模型来构建一些很酷的东西,例如:
可以根据…
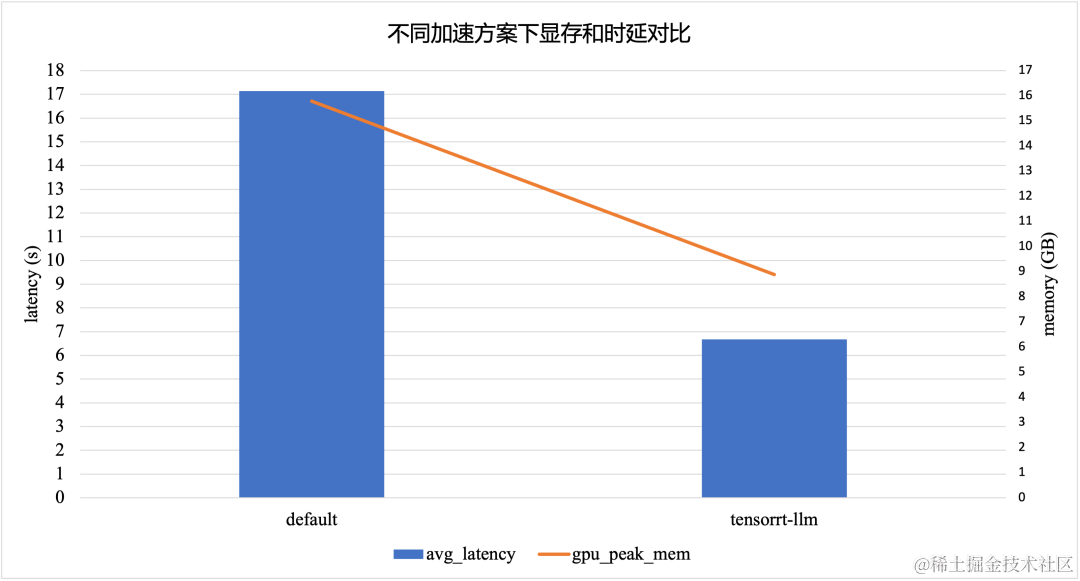
大语言模型推理提速:TensorRT-LLM 高性能推理实践
作者:顾静
TensorRT-LLM 如何提升 LLM 模型推理效率
大型语言模型(Large language models,LLM)是基于大量数据进行预训练的超大型深度学习模型。底层转换器是一组神经网络,这些神经网络由具有 self-attention 的编码器和解码器组…

阿里正式加入ChatGPT战局,“通义千问”上线后表现如何?
ChatGPT发布后,数月间全世界都对AI的能力有了新的认知。 ChatGPT掀起的战局,现在又多了一位选手了! 阿里版类ChatGPT突然官宣正式对外开放企业邀测,由达摩院开发,名为“通义千问” 顾名思义,阿里正式加入Ch…

Talk预告 | 浙江大学乔硕斐:语言模型提示推理综述
本期为TechBeat人工智能社区第480期线上Talk!
北京时间3月9日(周四)20:00,浙江大学计算机科学与技术硕士——乔硕斐的Talk将准时在TechBeat人工智能社区开播!
他与大家分享的主题是: “语言模型提示推理综述 ”,届时将分享对语言…
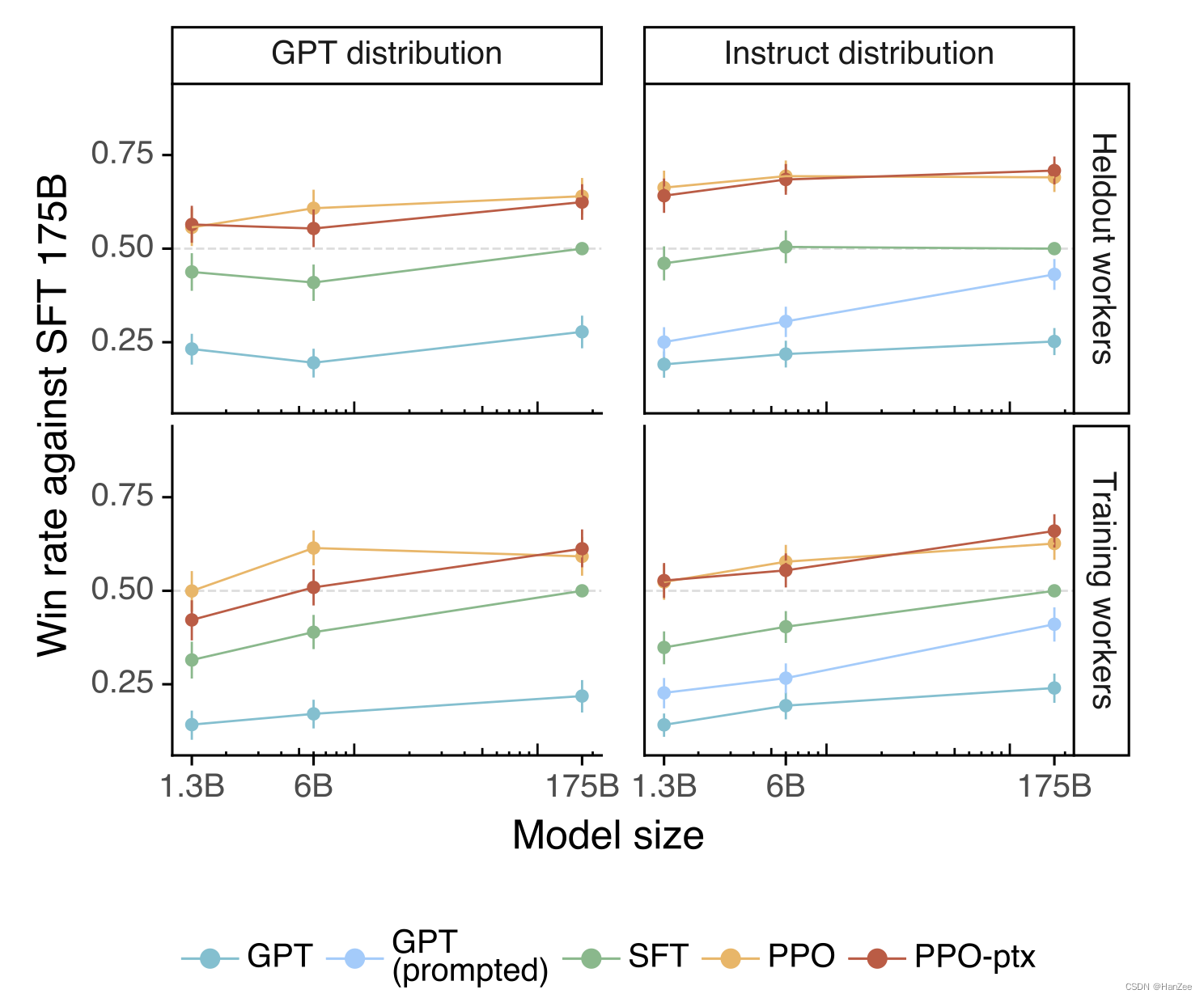
InstructGPT:Training language models to follow instrcutions with human feedback
InstructGPT:Training language models to follow instrcutions with human feedback 介绍模型数据集TaskHuman data collectionmodel 实验结果参考 介绍
现在LLM可以被prompt来完成一系列的下游任务,然而这些模型也总会产生一些用户不想要的结果&#…
Large Language Models and Knowledge Graphs: Opportunities and Challenges
本文是LLM系列的文章,针对《Large Language Models and Knowledge Graphs: Opportunities and Challenges》的翻译。 大语言模型和知识图谱:机会与挑战 摘要1 引言2 社区内的共同辩论点3 机会和愿景4 关键研究主题和相关挑战5 前景 摘要
大型语言模型&…

Scikit-LLM:将大语言模型整合进Sklearn的工作流
我们以前介绍过Pandas和ChaGPT整合,这样可以不了解Pandas的情况下对DataFrame进行操作。现在又有人开源了Scikit-LLM,它结合了强大的语言模型,如ChatGPT和scikit-learn。但这个并不是让我们自动化scikit-learn,而是将scikit-learn…
LLM、AGI、多模态AI 篇一:开源大语言模型简记
文章目录 系列开源大模型LlamaChinese-LLaMA-AlpacaLlama2-ChineseLinlyYaYiChatGLMtransformersGPT-3(未完全开源)BERTT5QwenBELLEMossBaichuan

Excel变天!微软把Python「塞」进去了,直接可搞机器学习
量子位 | 公众号 QbitAI
喜大普奔!
微软把Python弄进Excel了!
搭建一个机器学习天气预测模型,在Excel里即可实现。 而且无需任何设置,在单元格里输入“PY”,就能开搞。 数据清理、预测分析、可视化等等任务…
Large Graph Models: A Perspective
本文是LLM系列文章,针对《Large Graph Models: A Perspective》的翻译。 TOC
摘要
大型模型已成为人工智能,尤其是机器学习领域的最新突破性成就。然而,当涉及到图形时,大型模型并没有像在自然语言处理和计算机视觉等其他领域那…

基于大语言模型知识问答应用落地实践 – 知识库构建(上)
01 背景介绍 随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以…
LLMs之dataset:大语言模型LLMs相关开源数据集的简介、下载、使用方法之详细攻略
LLMs之dataset:大语言模型LLMs相关开源数据集的简介、下载、使用方法之详细攻略 目录
LLMs相关开源数据集的简介
1、SFT→RM+PPO三阶段关系梳理、数据集格式对比
几个nlp的小任务(生成式任务——语言模型(CLM与MLM))
@TOC
本章节需要用到的类库 微调任意Transformers模型(CLM因果语言模型、MLM遮蔽语言模型)
CLM MLM 准备数据集 展示几个数据的结构

周鸿祎为360智脑招贤纳士;LLM时代的选择指南;Kaggle大语言模型实战;一文带你逛遍LLM全世界 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 思否「齐聚码力」黑客马拉松,用技术代码让生活变得更美好 主页:https://pages.segmentfault.com/google-hacka…

谷歌发布Gemini以5倍速击败GPT-4
在Covid疫情爆发之前,谷歌发布了MEENA模型,短时间内成为世界上最好的大型语言模型。谷歌发布的博客和论文非常可爱,因为它特别与OpenAI进行了比较。
相比于现有的最先进生成模型OpenAI GPT-2,MEENA的模型容量增加了1.7倍…
LM-INFINITE: SIMPLE ON-THE-FLY LENGTH GENERALIZATION FOR LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《LM-INFINITE: SIMPLE ON-THE-FLY LENGTH GENERALIZATION FOR LARGE LANGUAGE MODELS》的翻译。 LM-INFiNITE:大语言模型的一个简单长度上推广 摘要1 引言2 相关工作3 LLMs中OOD因素的诊断4 LM-INFINITE5 评估6 结论和未来工作 …
Holistic Evaluation of Language Models
本文是LLM系列文章,针对《Holistic Evaluation of Language Models》的翻译。 语言模型的整体评价 摘要1 引言2 前言3 核心场景4 一般指标5 有针对性的评估6 模型7 通过提示进行调整8 实验和结果9 相关工作和讨论10 缺失11 不足和未来工作12 结论 摘要
语言模型&a…
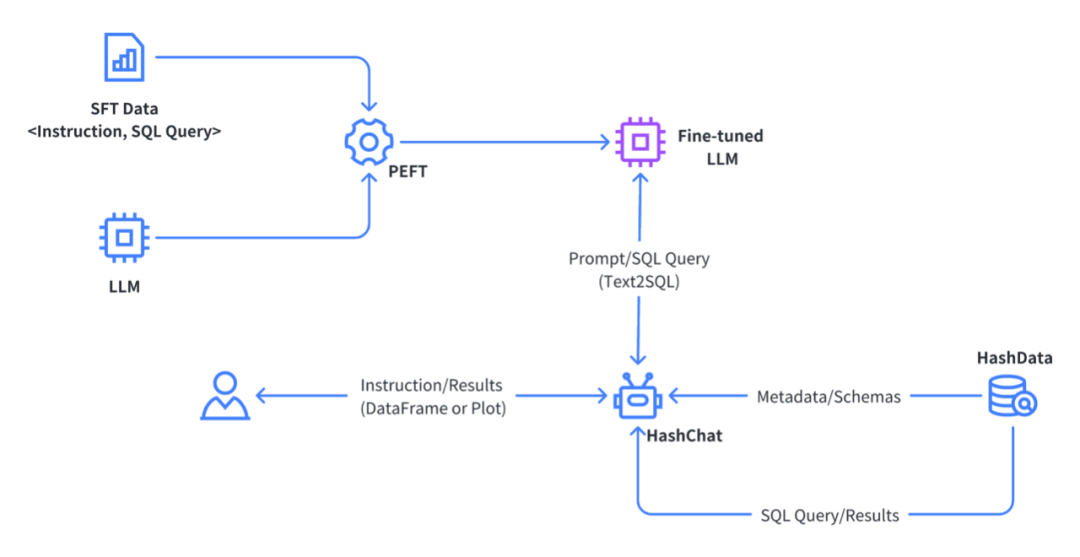
CCKS2023:基于企业数仓和大语言模型构建面向场景的智能应用
8月24日-27日,第十七届全国知识图谱与语义计算大会(CCKS 2023)在沈阳召开。大会以“知识图谱赋能通用AI”为主题,探讨知识图谱对通用AI技术的支撑能力,探索知识图谱在跨平台、跨领域等AI任务中的作用和应用途径。
作为…
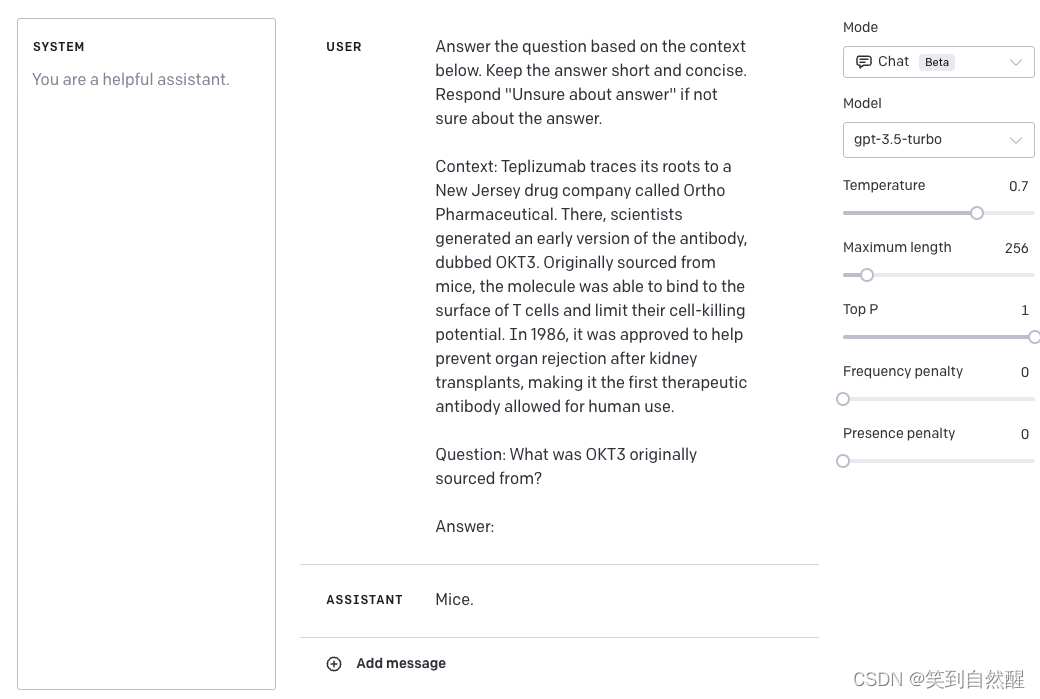
很全面的提示工程指南(包含大量示例!)
提示工程指南提示工程介绍基础提示配置参数的含义标准提示语提示语的要素提示设计的一般技巧从简单的提示开始指令(Instruction)具体(Specificity)避免不精确的描述(Preciseness)避免说不要做什么基础提示文…

论文阅读:chain of thought Prompting elicits reasoning in large language models
论文阅读:chain of thought Prompting elicits reasoning in large language models
跟着沐神读论文 视频链接:https://www.bilibili.com/video/BV1t8411e7Ug/?spm_id_from333.788&vd_source350cece3ec9a0c2aee50da8ccc315bf4
title:chain of tho…
ChatGLM 大模型量化的基本原理
1.模型为啥需要量化? 我们都知道越宽越深的模型比越窄越浅的模型精度高,效果好;但是越来越多的模型需要再边缘设备上部署,云部署还能满足计算要求,边缘设备上的算力有限.因此我们不得不考虑存储空间,设别内存,设备运行功耗以及延时性等问题,特别是在消费级pc上和移动终端上部署…
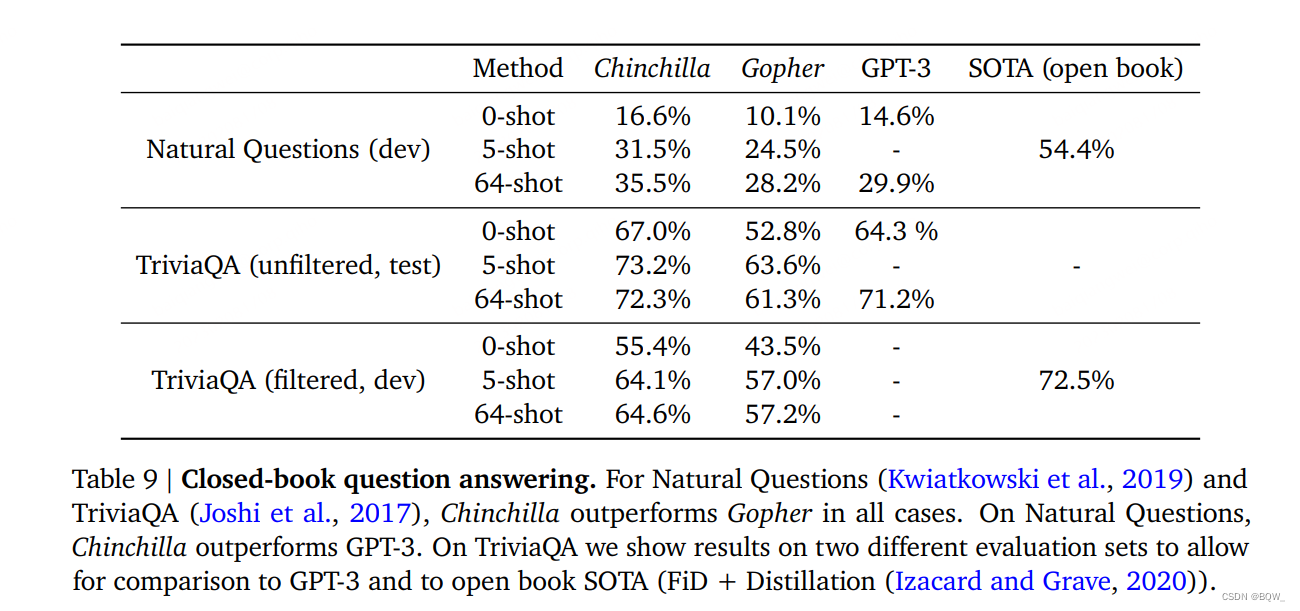
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
Chinchilla:训练计算利用率最优的大语言模型《Training Compute-Optimal Large Language Models》论文地址:https://arxiv.org/pdf/2203.15556.pdf 相关博客 【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型 【自然语言…
Multitask Vision-Language Prompt Tuning
本文是LLM系列文章,针对《Multitask Vision-Language Prompt Tuning》的翻译。 多任务视觉语言提示调整 摘要1 引言2 相关工作3 方法4 实验5 讨论6 结论 摘要
提示调整以任务特定的学习提示向量为条件,已成为一种数据高效和参数高效的方法,…
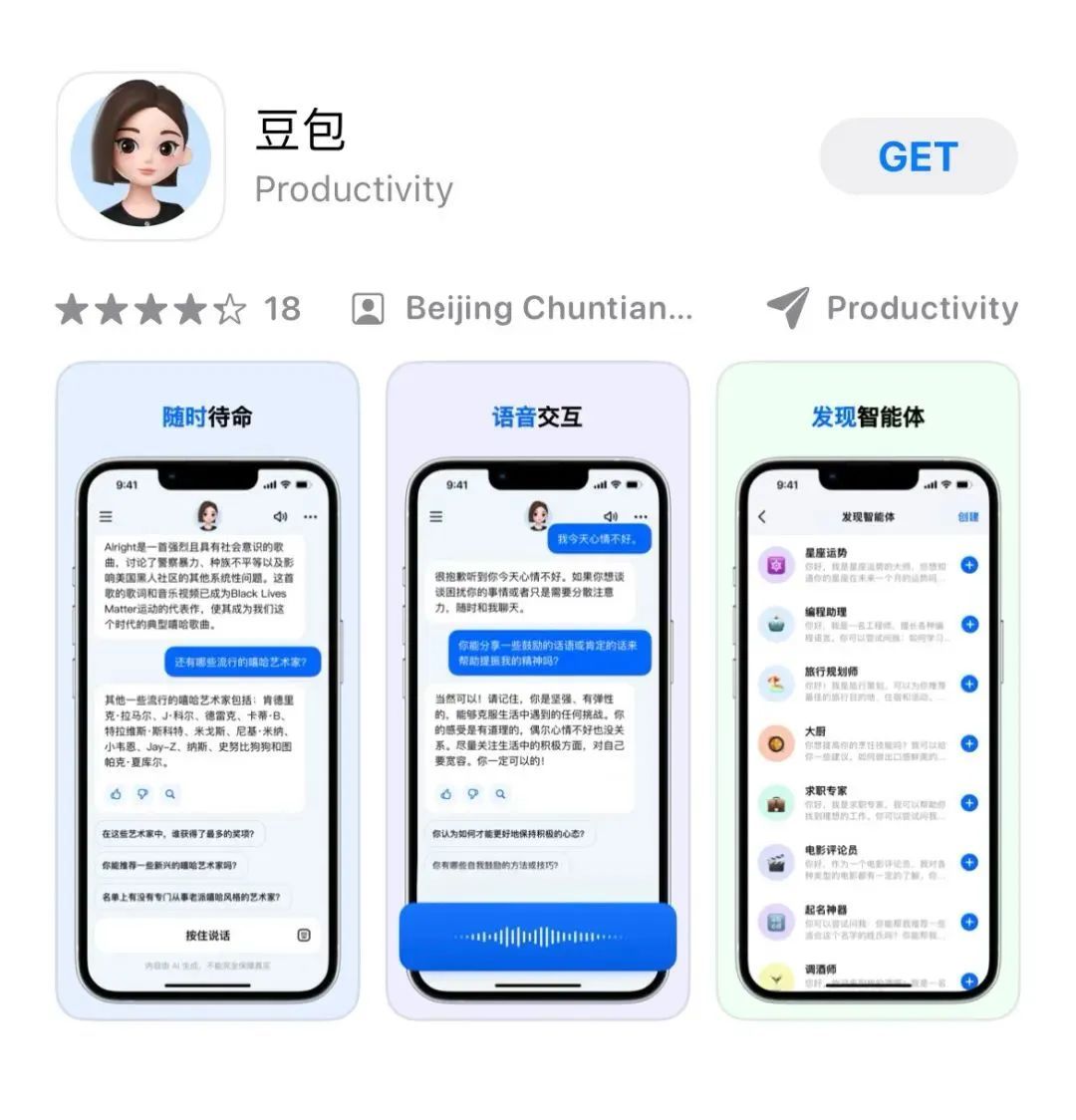
包含文心一言在内的首批国产大模型 全面开放
8月31起,国内 11 家通过《生成式人工智能服务管理暂行办法》备案的 AI 大模型产品将陆续上线,面向全社会开放。北京 5 家大模型产品分别是百度的 “文心一言”、抖音的 “云雀”、百川智能的 “百川大模型”、清华系 AI 公司智谱华章旗下的 “智谱清言”…
AskIt: Unified Programming Interface for Programming with Large Language Models
本文是LLM系列文章,针对《AskIt: Unified Programming Interface for Programming with Large Language Models》的翻译。 AskIt:用于大型语言模型编程的统一编程接口 摘要1 引言2 动机例子3 设计与实现4 实验评估5 相关工作6 结论 摘要
在不断发展的软…

论文浅尝 | 训练语言模型遵循人类反馈的指令
笔记整理:吴亦珂,东南大学硕士,研究方向为大语言模型、知识图谱 链接:https://arxiv.org/abs/2203.02155 1. 动机 大型语言模型(large language model, LLM)可以根据提示完成各种自然语言处理任务。然而&am…
TOOLLLM: FACILITATING LARGE LANGUAGE MODELS TO MASTER 16000+ REAL-WORLD APIS
本文是LLM系列的文章之一,针对《TOOLLLM: FACILITATING LARGE LANGUAGE MODELS TO MASTER 16000 REAL-WORLD APIS》的翻译。 TOOLLLMs:让大模型掌握16000的真实世界APIs 摘要1 引言2 数据集构建3 实验4 相关工作5 结论 摘要
尽管开源大型语言模型&…
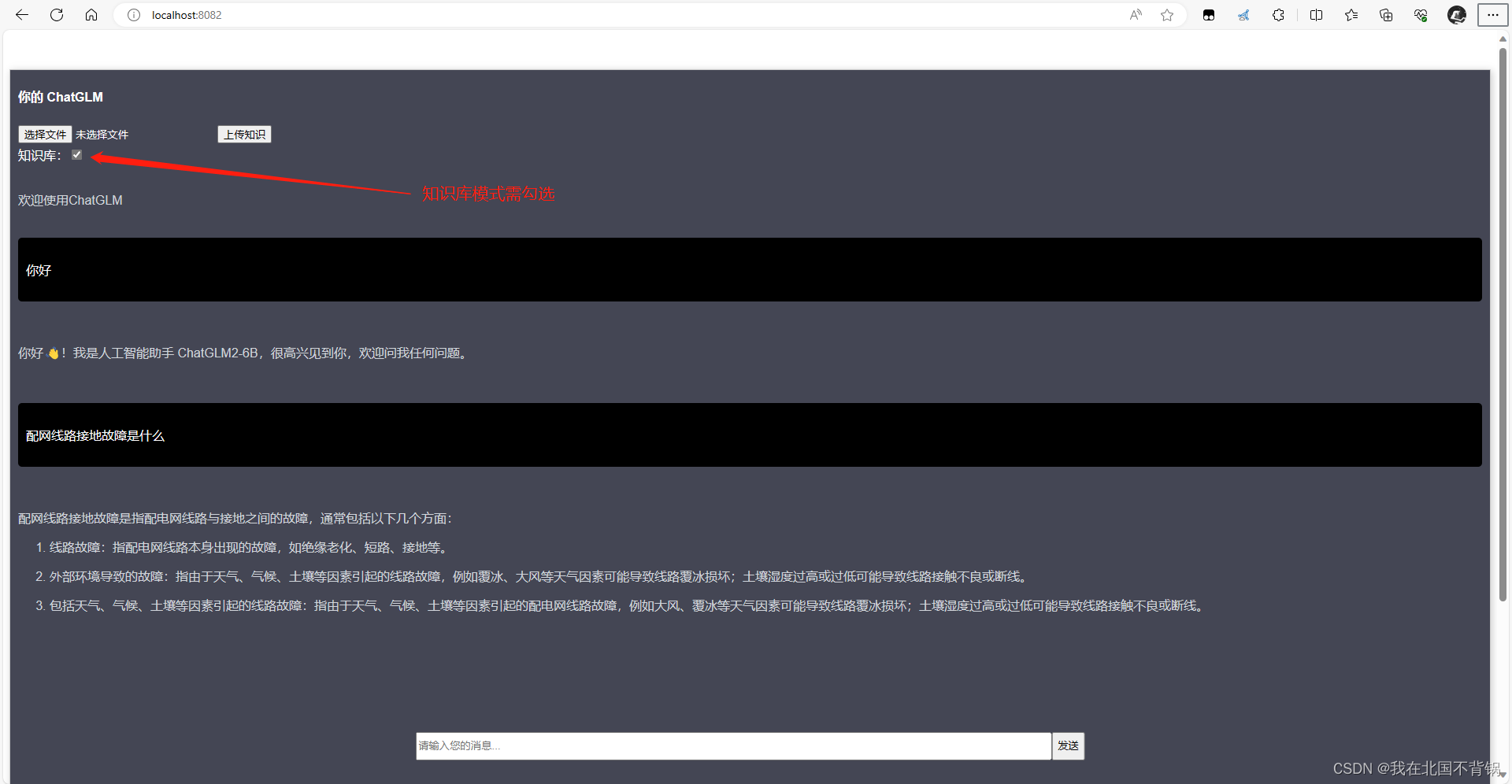
M3EChatGLM向量化构建本地知识库
M3E&ChatGLM向量化构建本地知识库 整体步骤向量数据库向量数据库简介主流数据库Milvus部署 文本向量化M3E介绍模型对比M3E使用向量数据存储 基于本地知识库的问答问句向量化向量搜索请求ChatGLM问答测试 整体步骤
向量化:首先,你需要将语言模型的数…
LLAMA2(Meta大语言模型)可运行整合包的下载与安装
LLAMA2(Meta大语言模型)可运行整合包的下载与安装
Windows10+消费级显卡可用
一、工程
github工程:
https://github.com/facebookresearch/llama
LLAMA2可运行整合包(Windows10+消费级显卡可用)
*现在只包括7B模型,会补充其他模型
文件夹下载
百度网盘链接:http…

【OSCAR开源产业大会分论坛】开源大模型走向何方?
再过俩月,ChatGPT 即将迎来推出一周年纪念日。作为开历史先河的 AI 大模型,ChatGPT 像一针猛戳进千行百业中枢神经的兴奋剂,在全球掀起空前绝后的 AI 军备竞赛热潮。 近一年来,我们看到 GPT-3.5 完成向多模态的 GPT-4 进化&#x…
ChatGPT架构师:语言大模型的多模态能力、幻觉与研究经验
来源 | The Robot Brains Podcast OneFlow编译 翻译|宛子琳、杨婷 9月26日,OpenAI宣布ChatGPT新增了图片识别和语音能力,使得ChatGPT不仅可以进行文字交流,还可以给它展示图片并进行互动,这是一次ChatGPT向多模态进化的…
吴恩达gradio课程:基于开源LLM(large language model)的聊天应用
文章目录 内容简介构建应用程序使用gradio在线体验接下来结合llm模型使用gradio构建一个完整的应用程序内容简介 Falcon 40B是当前最好的开源语言模型之一。使用text-generation库调用Falcon 40B的问答API接口。首先仅仅在代码中与模型聊天,后续通过Gradio构建聊天界面。Gradio…

IDEFICS 简介: 最先进视觉语言模型的开源复现
我们很高兴发布 IDEFICS ( Image-aware Decoder Enhanced la Flamingo with Ininterleaved Cross-attention S ) 这一开放视觉语言模型。IDEFICS 基于 Flamingo,Flamingo 作为最先进的视觉语言模型,最初由 DeepMind 开发,但目前尚未公开发布…
大语言模型 GPT历史简介
得益于数据、模型结构以及并行算力的发展,大语言模型应用现今呈井喷式发展态势,大语言神经网络模型成为了不可忽视的一项技术。 GPT在自然语言处理NLP任务上取得了突破性的进展,扩散模型已经拥有了成为下一代图像生成模型的代表的潜力&#x…
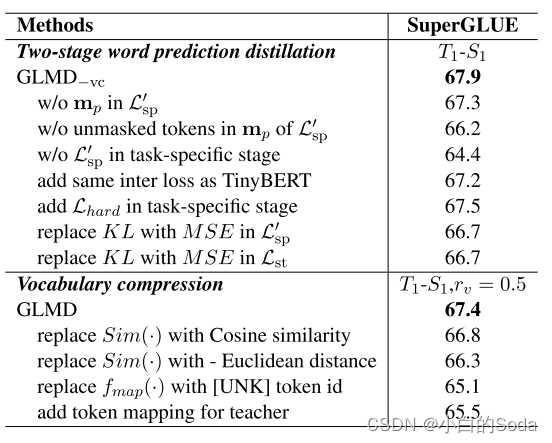
通用语言模型蒸馏-GLMD
文章目录 GLMD一、PPT内容论文背景P1 BackgroundP2 Approach 相关知识P3 知识蒸馏P4 语言建模词预测逻辑 方法P5 两阶段词汇预测蒸馏P6P7 词汇压缩 实验结果P8 results 二、论文泛读2.1 论文要解决什么问题?2.2 论文采用了什么方法?2.4 论文达到什么效果…

AI时代,程序员需要焦虑吗?
原文来自 微信公众号"互联网技术人进阶之路". 目录 前言一、程序员会被 AI 取代么?二、服务端开发尚难被 AI 取代三、服务端开发何去何从?四、业界首部体系化、全景式解读服务端开发的著作第一部分:服务端开发的技术和方法第二部分…
ChatGPT 使用 拓展资料:无需任何机器学习,如何利用大语言模型做情感分析?
ChatGPT 拓展资料:无需任何机器学习,如何利用大语言模型做情感分析? 目录 机器学习 :GloVe嵌入式向量基于文本数据的情感识别Data PreparationPreprocessing and CleaningLoad GloVe VectorML模型构建、训练和测试用于情感识别的支持向量机Fasttext 以及T5比较利用Embedd…
亲爱的小朋友,你好,今天我们聊一聊什么是ChatGPT?
亲爱的小朋友,你好!
今天我们要聊一聊的是我们的好朋友——ChatGPT,最近ChatGPT很火爆,你们可能已经在很多地方看到关于它的文章和视频了。
你可能会问,这个ChatGPT到底是什么东西呢?好像很厉害的样子&am…
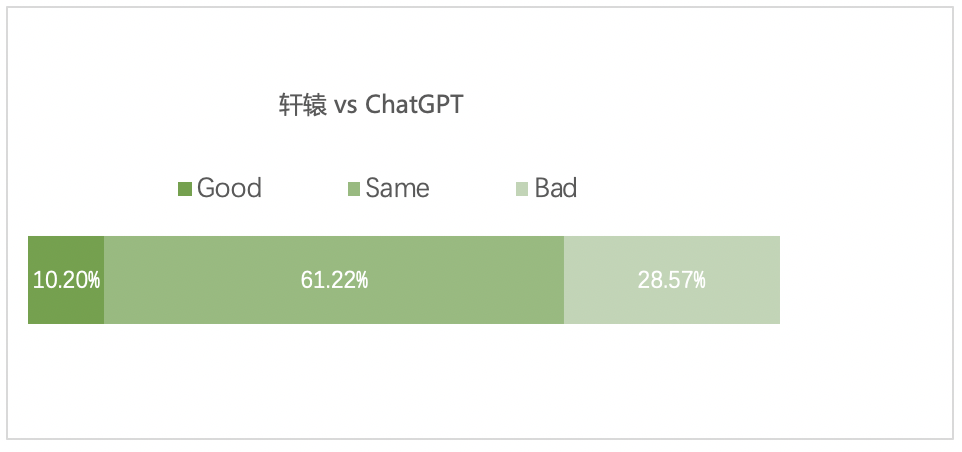
轩辕:首个千亿级中文金融对话模型
背景
目前开源的大语言模型或多或少存在以下痛点: 缺少专门针对中文进行优化过的的大语言模型。 支持中文的开源模型的参数规模偏小,没有超过千亿。比如清华和智谱AI的ChatGLM-6B目前只开源了6B参数模型,盘古alpha也只开源了13B的模型。 支…
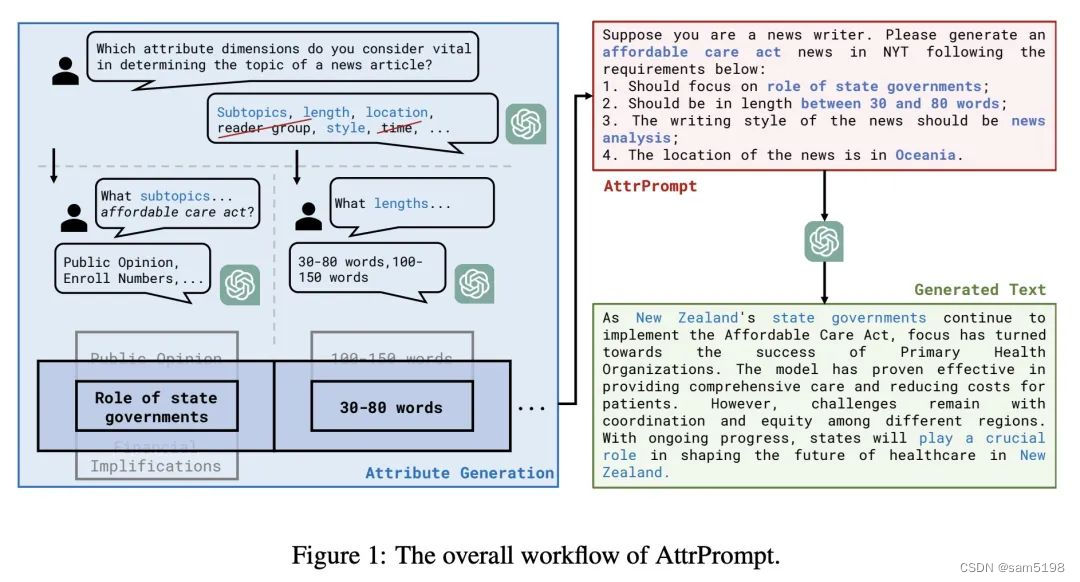
大型语言模型作为属性化训练数据生成器
大型语言模型作为属性化训练数据生成器,提出一种使用多样化属性提示的数据生成方法,可以生成具有多样性和属性的训练数据,从而提高了模型的性能和数据生成的效率。
动机:大型语言模型(LLM)最近被用作各种自然语言处理(NLP)任务的…
ChatGPT技术解构
ChatGPT的训练主要分为三个步骤,如图所示: Step1:
使用有监督学习方式,基于GPT3.5微调训练一个初始模型;训练数据约为2w~3w量级(根据InstructGPT的训练数据量级估算,参照https://arxiv.org/pdf…
使用预训练语言模型进行文本生成的常用微调策略
译自Pretrained Language Models for Text Generation: A Survey 第六节
数据角度
小样本学习:在许多任务中,获取足够标记数据既困难又昂贵。预训练模型可以编码大量的语言和现实知识,这为数据稀缺提供了有效的解决方案。通常采用的方法是使…
GPT2计算流程详解
GPT-2 就像传统的语言模型一样,一次只输出一个单词(token)。这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。这种机制叫做自回归ÿ…

基于Kaldi的中文在线识别系统
三音子模型词错误率为:36.03%,对比单音素模型词错误率为50.58%。 可见三音素模型识别率已经有了提高。 不管模型识别率怎么样,先利用三音子模型搭建一个中文在线识别系统看看效果。 在线识别与离线识别
本文主要搭建在线语音识别࿰…
Lion闭源大语言模型的对抗蒸馏框架实践
Lion闭源大语言模型的对抗蒸馏框架实践
概述
对抗蒸馏框架概述:我们基于高级闭源LLM的基础上提炼一个学生LLM,该LLM具有三个角色:教师、裁判和生成器。有三个迭代阶段: 模仿阶段,对于一组指令,将学生的响…
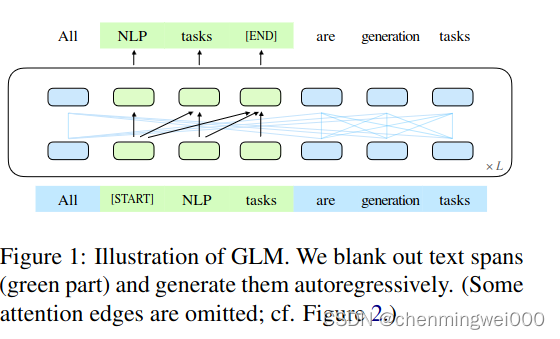
GLM: General Language Model Pretrainingwith Autoregressive Blank Infilling翻译理解
GPT(autoregressive)模型是一个自回归模型,利用left-to-right语言模型,由于不是双向attention 机制,因此不能再NLU任务中,获取充分的上下文信息,BERT类似自编码(autoencoding&#x…
清华开源LLM中英双语对话语言模型ChatGLM2,效果能赶超ChatGPT?
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数.ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,其第二代继承了第一代的优秀特点,并在第一代的基础上,更新了更多的新特性。 更强大的性能:
C…

ChatGPT基础知识系列之大型语言模型(LLM)初识
ChatGPT基础知识系列之大型语言模型(LLM)初识
ChatGPT本质是一个对话模型,它可以回答日常问题、挑战不正确的前提,甚至会拒绝不适当的请求,在去除偏见和安全性上不同于以往的语言模型。ChatGPT从闲聊、回答日常问题,到文本改写、诗歌小说生成、视频脚本生成,以及编写和调…
ChatGPT3 Transformer 的多模态全能语言模型
"Transformer 的多模态全能语言模型" 指的是一种融合了多种输入模态(如文本、图像、声音等)的语言模型,具有广泛的应用能力,可以理解和生成多种类型的信息。
"Transformer的多模态全能语言模型" 包含了多个…

AI大语言模型时代构建全新数据平台
在大语言模型的引领下,数据平台领军企业 Databricks 和 Snowflake 的未来重置,探讨了 Databricks 和 Snowflake 等知名平台,
存储领域的 Delta、udi、Iceberg,还是实时化数据处理领域的 Databricks、Snowflake 1、LLM 给大数据企…
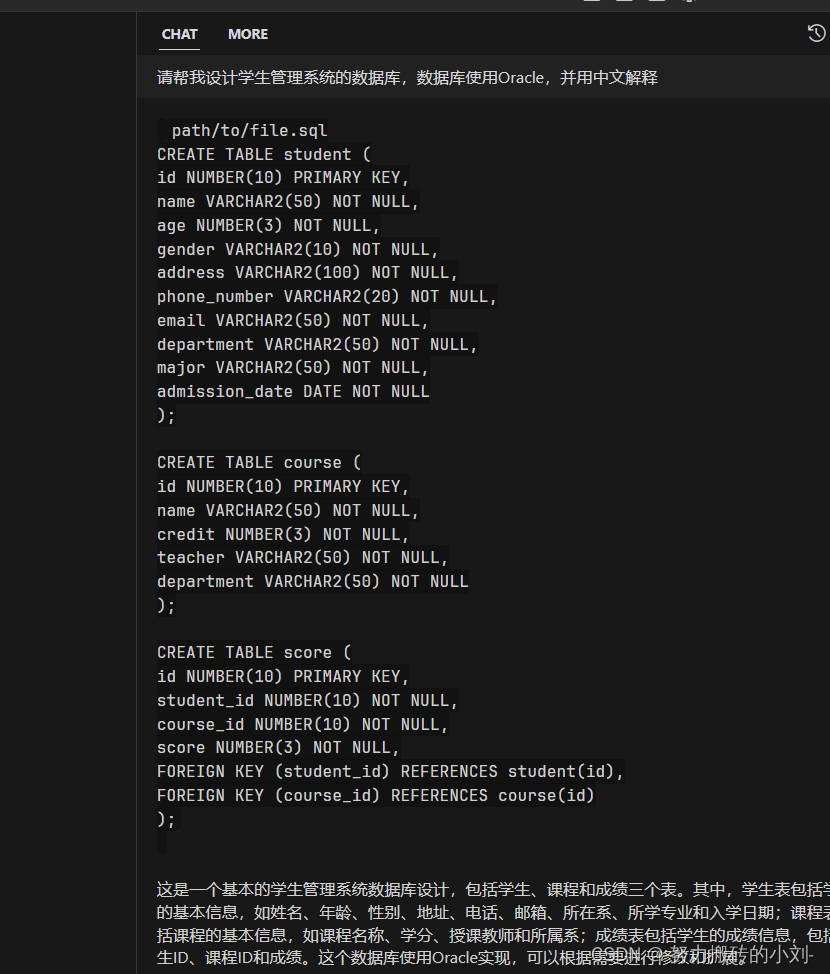
Cursor--一款强大的国内智能AI语言模型(据说对接了chatgpt4)
简介
Cursor是一个集成了 GPT-4 的国内直接可以访问的,优秀而强大的免费代码生成器,可以帮助你快速编写、编辑和讨论代码。 它支持多种编程语言,如 Python, Java, C#, JavaScript 等,并且可以根据你的输入和需求自动生成代码片段…

谷歌推出下一代大型语言模型 PaLM 2
谷歌在 2023 年度 I/O 大会上宣布推出了其下一代大型语言模型 PaLM 2,擅长高级推理任务,包括代码和数学、分类和问答、翻译和多语言能力以及自然语言生成。
谷歌声称 PaLM 2 是一种最先进的语言模型,要优于其之前所有的 LLM,包括…

案例告诉你 ChatGPT 最有可能取代哪些职业
ChatGPT 的应用场景ChatGPT 最可能取代哪些职业?写在最后 ChatGPT 的应用场景
ChatGPT 的应用场景大体上可以归类为三大模块。
第一类是 代码相关 的任务场景。包含程序语言之间的相互转换(如 python 转 java)、程序命令的生成、代码 bug 的…
SpeechGen:用提示解锁语音语言模型(Speech LM)的生成能力
论文链接:
https://arxiv.org/pdf/2306.02207.pdf
Demo:
https://ga642381.github.io/SpeechPrompt/speechgen.html
Code:
https://github.com/ga642381/SpeechGen
引言与动机
大型语言模型 (LLMs)在人工智能生成内容(AIGC…
GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
在图像-文本对上调整大语言模型(LLM)的指令已经实现了前所未有的视觉-语言多模态能力。然而,他们的视觉语言对齐仅建立在图像级别上,缺乏区域级别对齐限制了他们在细粒度多模态理解方面的进步。在本文中,我们提出对感兴趣区域进行指令调整。关键设计是将边界框重新表述…
吴恩达gradio课程:基于开源LLM(large language model)的聊天应用chatbot
文章目录 内容简介构建应用程序使用gradio在线体验接下来结合llm模型使用gradio构建一个完整的应用程序内容简介 Falcon 40B是当前最好的开源语言模型之一。使用text-generation库调用Falcon 40B的问答API接口。首先仅仅在代码中与模型聊天,后续通过Gradio构建聊天界面。Gradio…

从零开始-与大语言模型对话学技术-gradio篇(4)
前言
本文介绍「星火杯」认知大模型场景创新赛中的落选项目- AI命理分析系统,属于个人娱乐练手。总结提炼了往期文章精华并发掘出新的知识。 包括本地部署版本和Web在线版本,两种打包方式基于 半自动化使用.bat手动打包迁移python项目
如何把 Gradio …
大型语言模型,第 1 部分:BERT
一、介绍 2017是机器学习中具有历史意义的一年,当变形金刚模型首次出现在现场时。它在许多基准测试上都表现出色,并且适用于数据科学中的许多问题。由于其高效的架构,后来开发了许多其他基于变压器的模型,这些模型更专注于特定任务…
Augmented Large Language Models with Parametric Knowledge Guiding
本文是LLM系列文章,针对《Augmented Large Language Models with Parametric Knowledge Guiding》的翻译。 参数知识引导下的增强大型语言模型 摘要1 引言2 相关工作3 LLM的参数化知识引导4 实验5 结论 摘要
大型语言模型(LLM)凭借其令人印…
Lost in the Middle: How Language Models Use Long Contexts
本文是LLM系列文章,针对《Lost in the Middle: How Language Models Use Long Contexts》的翻译。 迷失在中间:语言模型如何使用长上下文 摘要1 引言2 语言模型3 多文档问答4 语言模型如何从输入上下文中检索?5 为什么语言模型很难使用它们的…
Textbooks Are All You Need II: phi-1.5 technical report
本文是LLM系列文章,针对《Textbooks Are All You Need II: phi-1.5 technical report》的翻译。 教科书是你所需要的一切:phi-1.5技术报告 摘要1 引言2 技术规范3 基准结果4 解决毒性和偏见5 我们的模型的使用6 讨论 摘要
我们继续调查TinyStories发起…
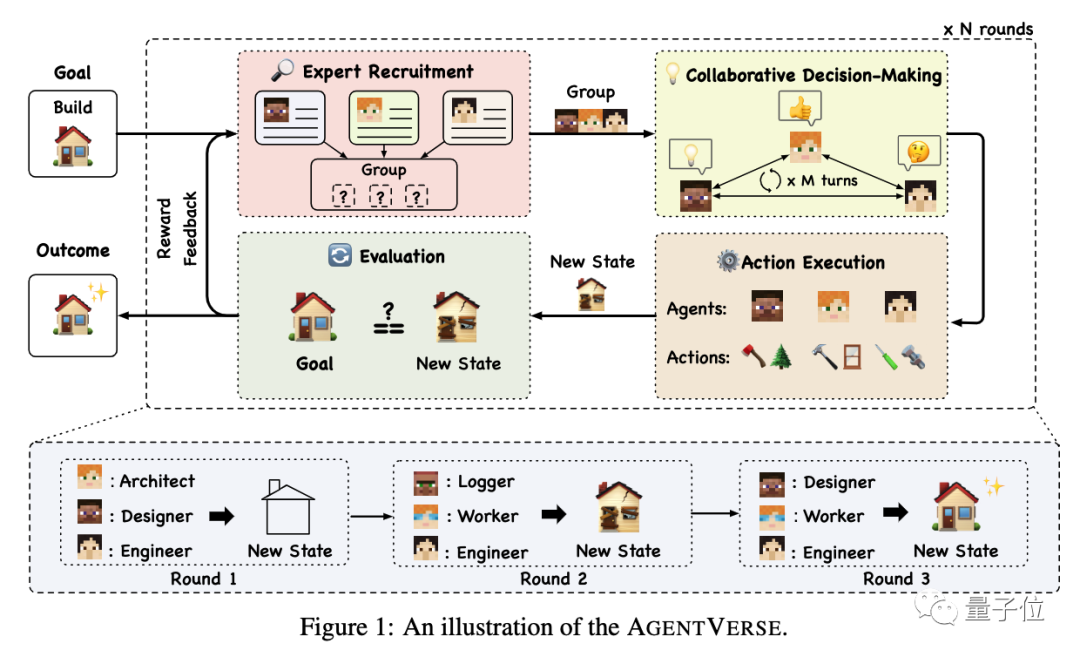
清华智能体宇宙火了;主流大语言模型的技术原理细节
🦉 AI新闻
🚀 清华智能体宇宙火了
摘要:清华大学联合北邮、微信团队推出了AgentVerse,这是一个可以轻松模拟多智能体宇宙的环境。它专为大语言模型开发,智能体可以利用LLM能力完成任务。AgentVerse提供了几个示例环境…
Unleashing the Power of Graph Learning through LLM-based Autonomous Agents
本文是LLM系列文章,针对《Unleashing the Power of Graph Learning through LLM-based Autonomous Agents》的翻译。 通过基于LLM的自动Agent释放图学习的力量 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
图结构数据在现实世界中广泛存在和应用,而以…
Challenges and Applications of Large Language Models
本文是LLM系列文章,针对《Challenges and Applications of Large Language Models》的翻译。 大语言模型的挑战与应用 摘要1 引言2 挑战3 应用3.1 聊天机器人3.2 计算生物学3.3 计算机程序3.4 创造性工作3.5 知识工作3.6 法律3.7 医学3.8 推理3.9 机器人和嵌入式代…
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
本文是LLM系列文章,针对《EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models》的翻译。 EasyEdit:一个易于使用的大型语言模型知识编辑框架 摘要1 引言2 背景3 设计和实现4 评估5 实验6 结论和未来工作 摘要
大型语言模…
CFGPT: Chinese Financial Assistant with Large Language Model
本文是LLM系列文章,针对《CFGPT: Chinese Financial Assistant with Large Language Model》的翻译。 CFGPT:大型语言模型的中文财务助理 摘要1 引言2 相关工作3 数据集4 模型和训练5 应用6 结论 摘要
大型语言模型(LLM)在金融领…

LLM-TAP随笔——语言模型训练数据【深度学习】【PyTorch】【LLM】
文章目录 3、语言模型训练数据3.1、词元切分3.2、词元分析算法 3、语言模型训练数据
数据质量对模型影响非常大。 典型数据处理:质量过滤、冗余去除、隐私消除、词元切分等。 训练数据的构建时间、噪音或有害信息情况、数据重复率等因素都对模型性能有较大影响。训…
【论文精读】Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 前言Abstract1 Introduction2 Chain-of-Thought Prompting3 Arithmetic Reasoning3,1 Experimental Setup3.2 Results3.3 Ablation Study3.4 Robustness of Chain of Thought 4 Commonsense Reasoning5…
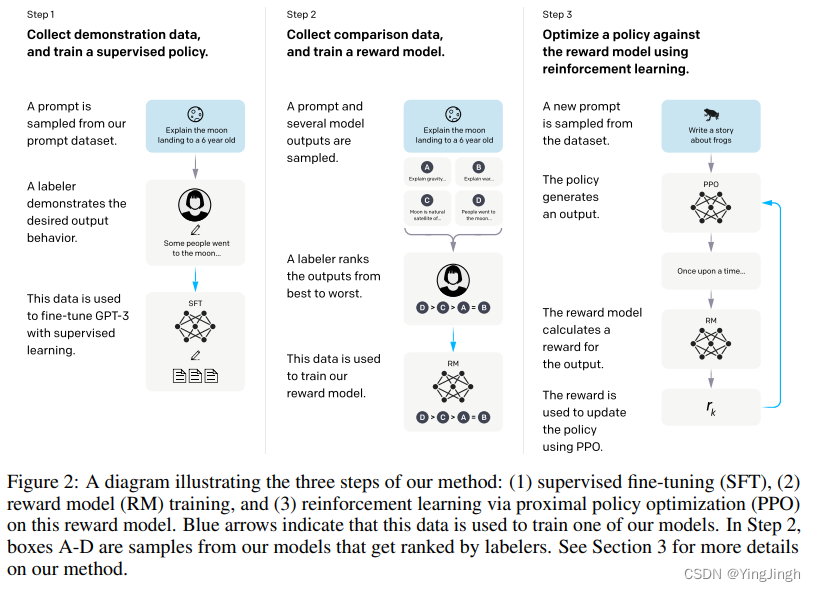
InstructGPT:Training language models to follow instructions with human feedback
Training language models to follow instructions with human feedback
通过人类反馈的微调,在广泛的任务中使语言模型与用户的意图保持一致 aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback
实验动机 …
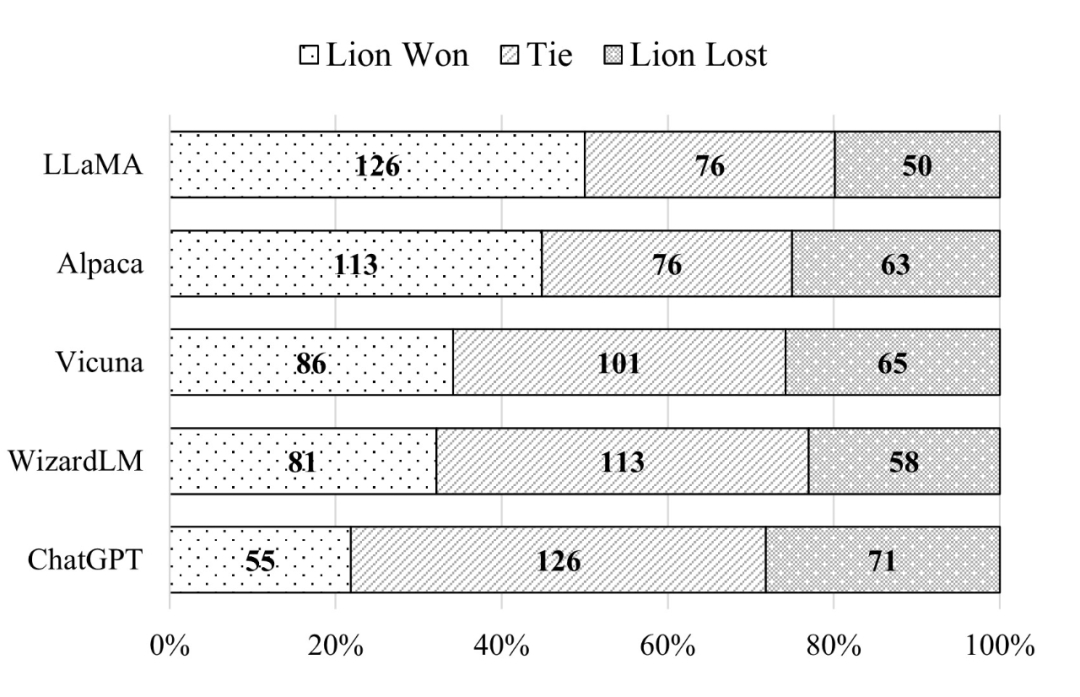
Lion:闭源大语言模型的对抗蒸馏
Lion:闭源大语言模型的对抗蒸馏
Lion,由香港科技大学提出的针对闭源大语言模型的对抗蒸馏框架,成功将 ChatGPT 的知识转移到了参数量 7B的 LLaMA 模型(命名为 Lion),在只有 70k训练数据的情况下࿰…

论文浅尝 | 思维树:使用大语言模型反复思考解决问题
笔记整理:许泽众,浙江大学博士,研究方向为知识图谱上的神经符号推理 链接:https://arxiv.org/abs/2305.10601 1. 动机 语言模型是一种强大的工具,可以用于各种需要数学、符号、常识或知识推理的任务。然而,…

论文浅尝 | 基于预训练语言模型的简单问题知识图谱问答
笔记整理:刘赫,天津大学硕士 链接:https://doi.org/10.1007/s11280-023-01166-y 动机 大规模预训练语言模型(PLM)如BERT近取得了巨大的成功,成为自然语言处理(NLP)的一个里程碑。现在NLP社区的共识是采用PLM下游任务的骨干。在最近…

【AI语言模型】阿里推出音视频转文字引擎
一、前言
阿里的音视频转文字引擎可以正式使用,用户可体验所有AI功能,含全文概要、章节速览、发言总结等高阶AI功能。通过阿里云主账号登录,可享受以下权益: 每日登录,自动获得2小时转写时长; 每邀请1名好…
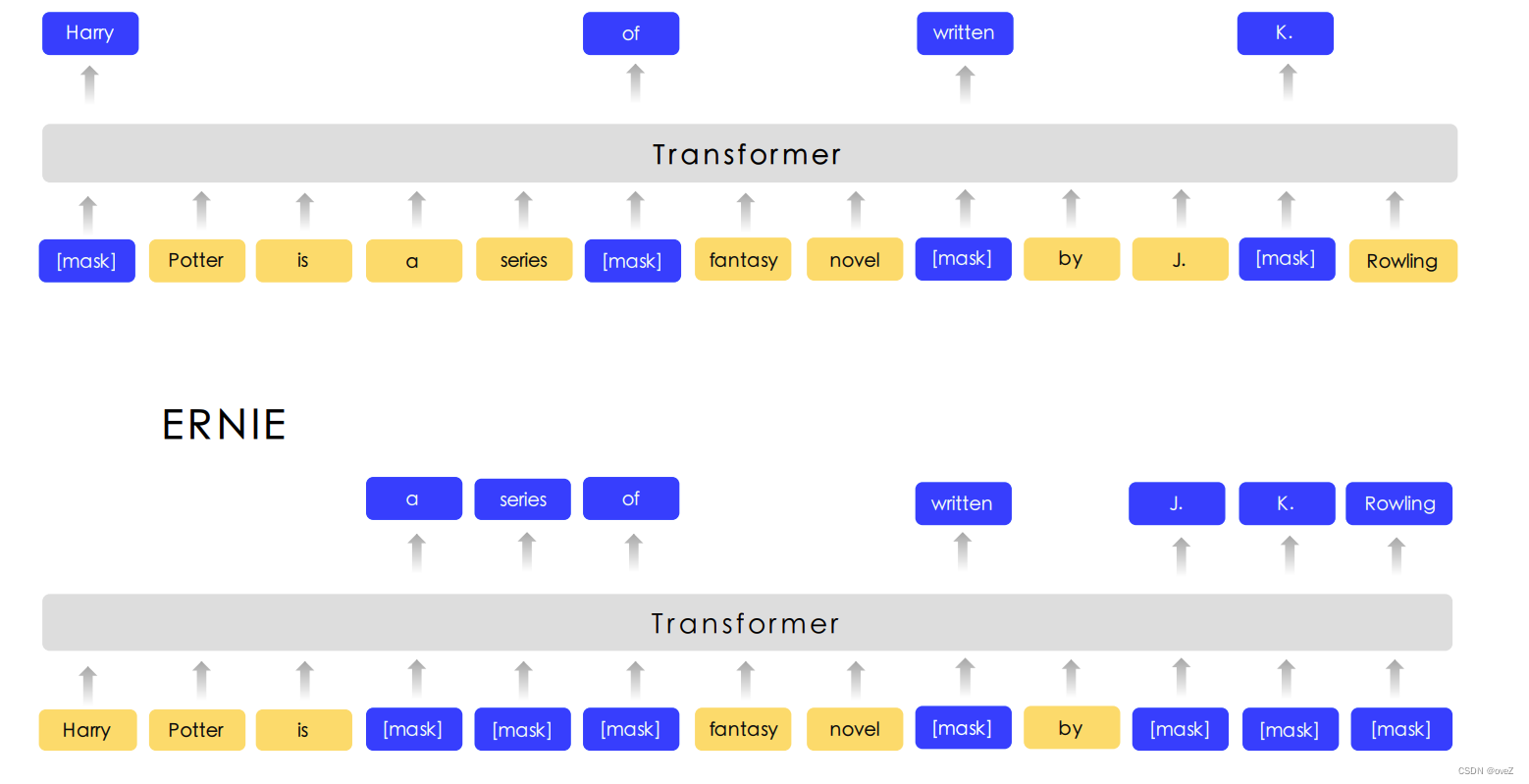
极光笔记 | 大语言模型插件
在人工智能领域,大语言模型(LLMs)是根据预训练数据集进行”学习“,获取可以拟合结果的参数,虽然随着参数的增加,模型的功能也会随之增强。但无论专业领域的小模型,还是当下最火、效果最好的大模…
ChatGLM P-Tuningv2微调定制AI大模型
前言
什么是模型微调
想象一下,你正在学习如何弹奏一首钢琴曲目。你已经学会了一些基本的钢琴技巧,但你想要更进一步,尝试演奏一首特定的曲目。这时,你会选择一首你感兴趣的曲目,并开始深度练习。
Fine-tuning(微调)在机器学习中也是类似的概念。当我们使用预先训练好…
When Urban Region Profiling Meets Large Language Models
本文是LLM系列文章,针对《When Urban Region Profiling Meets Large Language Models》的翻译。 当城市区域轮廓遇到大型语言模型时 摘要1 引言2 前言3 方法4 实验5 结论与未来工作 摘要
基于网络数据的城市区域概况对城市规划和可持续发展至关重要。我们见证了LL…

qwen大模型,推理速度慢,单卡/双卡速度慢,flash-attention安装,解决方案
场景
阿里的通义千问qwen大模型,推理速度慢,单卡/双卡速度慢。 详细: 1、今日在使用qwen-14b的float16版本进行推理(BF16/FP16) 1.1 在qwen-14b-int4也会有同样的现象 2、使用3090 24G显卡两张 3、模型加载的device是auto&#x…
OPENCHAT: ADVANCING OPEN-SOURCE LANGUAGE MODELS WITH MIXED-QUALITY DATA
本文是LLM系列文章,针对《OPENCHAT: ADVANCING OPEN-SOURCE LANGUAGE MODELS WITH MIXED-QUALITY DATA》的翻译。 OPENCHAT:利用混合质量数据推进开源语言模型 摘要1 引言2 前言3 OpenChat4 实验5 分析6 相关工作7 结论与未来工作 摘要
如今࿰…
拓展认知边界:如何给大语言模型添加额外的知识
Integrating Knowledge in Language Models
P.s.这篇文章大部分内容来自Stanford CS224N这门课Integrating Knowledge in Language Models这一节😁
为什么需要给语言模型添加额外的知识
1.语言模型会输出看似make sense但实际上不符合事实的内容
语言模型在生成…
Are Large Language Models Really Robust to Word-Level Perturbations?
本文是LLM系列文章,针对《Are Large Language Models Really Robust to Word-Level Perturbations?》的翻译。 大型语言模型真的对单词级扰动具有鲁棒性吗? 摘要1 引言2 相关工作3 合理稳健性评价的奖励模型(TREvaL)4 LLM的词级…
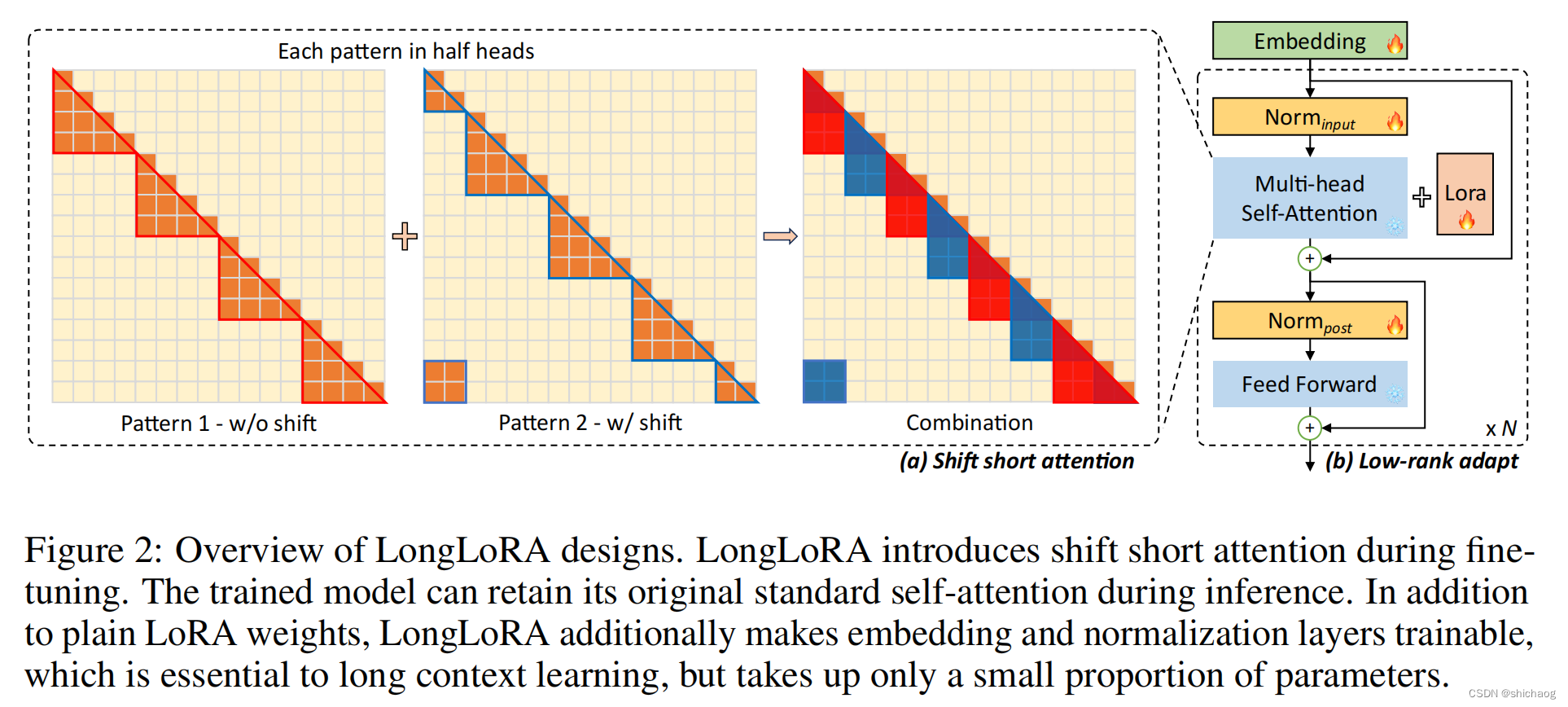
大语言模型之十六-基于LongLoRA的长文本上下文微调Llama-2
增加LLM上下文长度可以提升大语言模型在一些任务上的表现,这包括多轮长对话、长文本摘要、视觉-语言Transformer模型的高分辨4k模型的理解力以及代码生成、图像以及音频生成等。
对长上下文场景,在解码阶段,缓存先前token的Key和Value&#…
REASONING ON GRAPHS: FAITHFUL AND INTERPRETABLE LARGE LANGUAGE MODEL REASONING
本文是LLM系列文章,针对《REASONING ON GRAPHS: FAITHFUL AND INTERPRETABLE LARGE LANGUAGE MODEL REASONING》的翻译。 图上推理:忠实的和可解释的大语言模型推理 摘要1 引言2 相关工作3 前言4 方法5 实验6 结论 摘要
大型语言模型(llm)在复杂任务中表现出令人印…
百度Comate SaaS版本正式发布,助力开发者加速研发过程
百度Comate是基于文心大模型的智能代码助手,让开发者的编码更快、更好、更简单,为开发者自动生成完整的、且更符合实际研发场景的代码行或整个代码块,帮助每一位开发者轻松完成研发任务。10月17日召开的百度世界大会上,百度CTO王海…
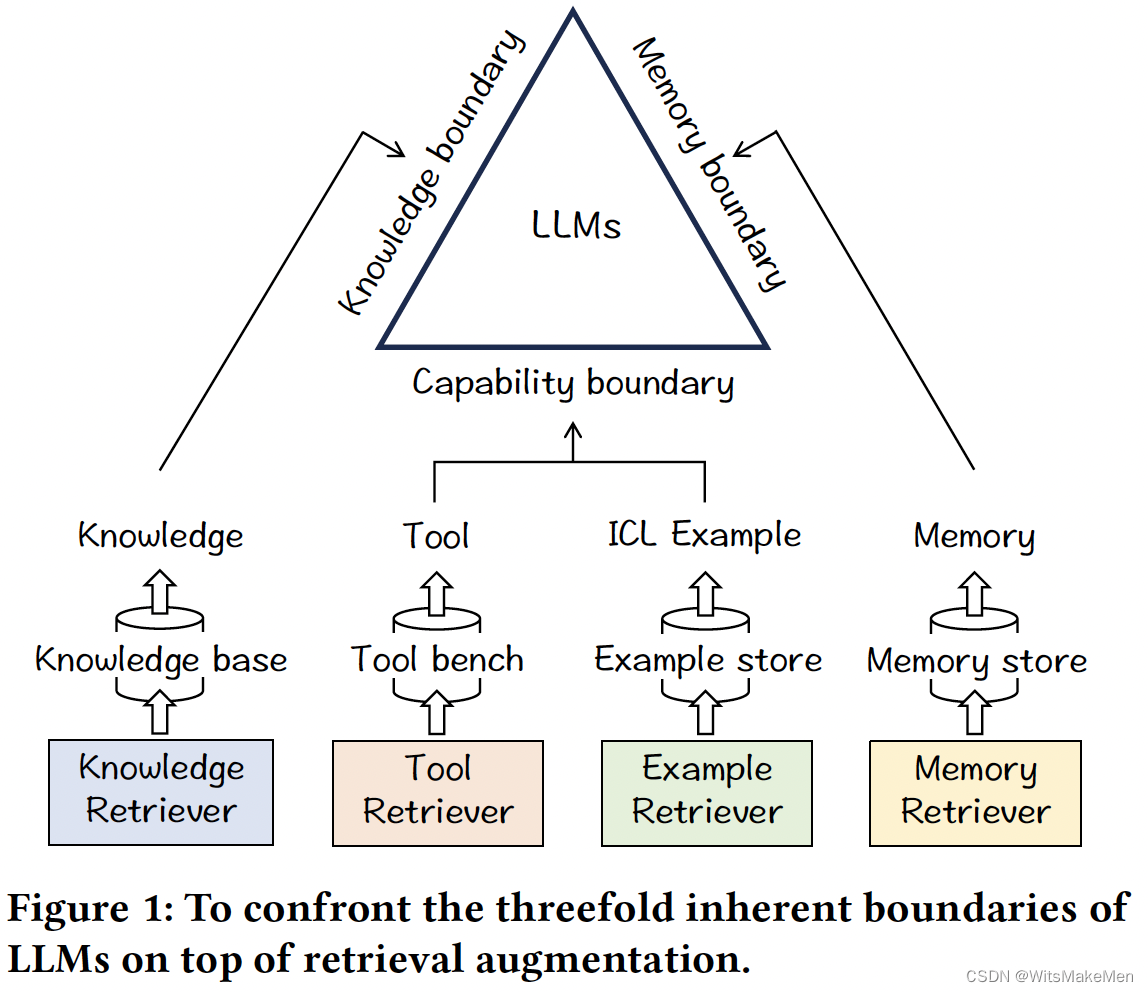
Retrieve Anything To Augment Large Language Models
简介 论文主要介绍了一套通过对比学习和蒸馏学习的方法,来增强学习了embedding向量,然后能够在知识增强,长上下文建模,ICL和工具学习等方面来增强大模型能力。

利用检索和存储访问知识库上增强大型语言模型10.30
利用检索和存储访问知识库上增强大型语言模型 摘要引言2 相关研究3方法3.1 任务定义3.2 知识检索3.2.1 代码实现3.2.2 实体链接3.2.3 获取实体信息3.2.4 查找实体或值3.2.5 查找关系 3.3 知识存储 4 实验 摘要
大型语言模型(LLM)在自然语言处理领域展现…
人工智能在电商领域的五大应用场景及未来趋势
作者:禅与计算机程序设计艺术
1.简介
欢迎来到第七期《人工智能在电商领域的五大应用场景及未来趋势》专题。人工智能(Artificial Intelligence)一直都是互联网行业的热点话题,电子商务网站的营销活动、商品推荐系统等领域均采用了人工智能技术。因此,对电商运营者来说,…
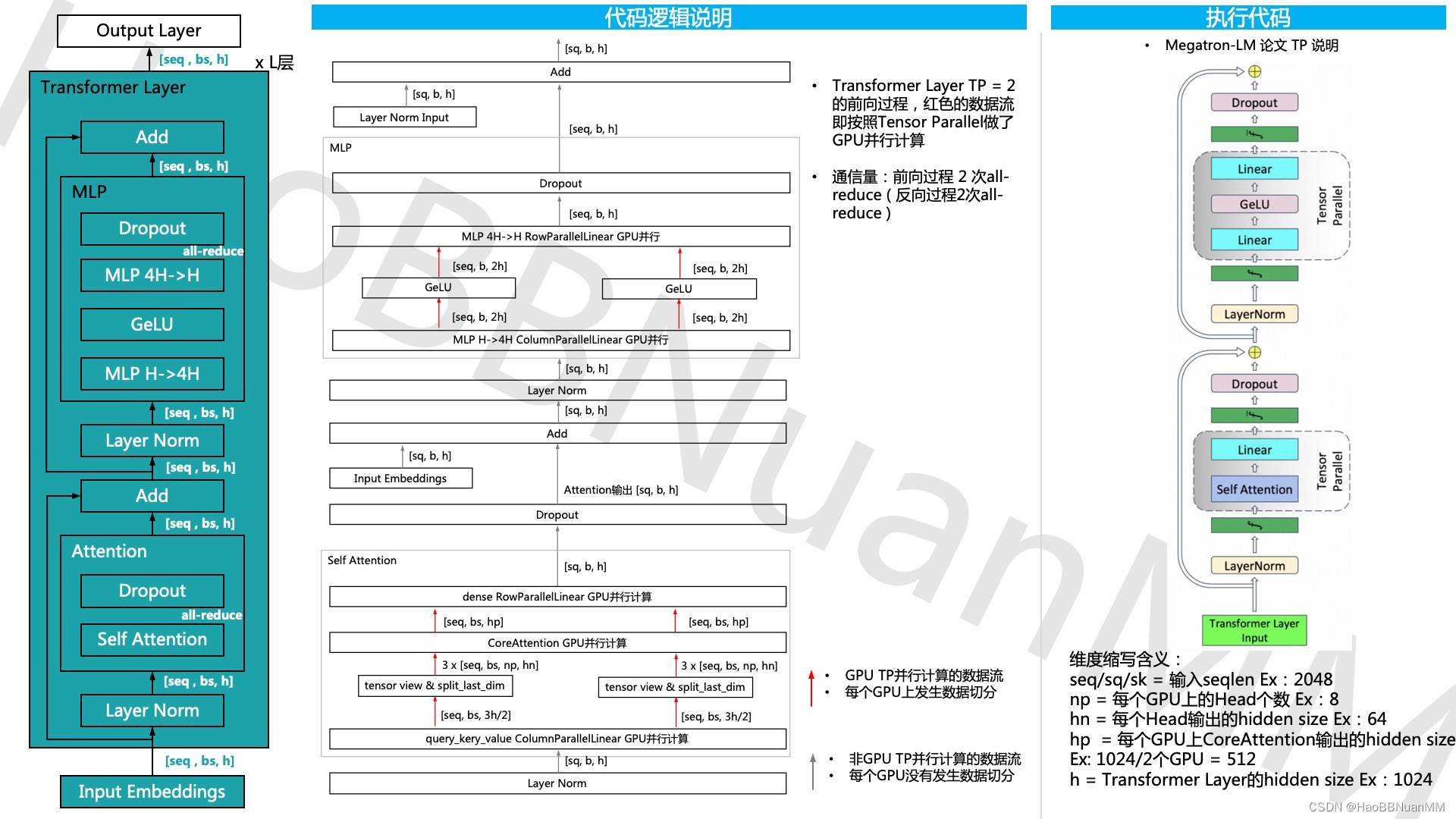
Megatron-LM GPT 源码分析(一) Tensor Parallel分析
引用
本文基于开源代码 https://github.com/NVIDIA/Megatron-LM ,通过GPT的模型运行示例,从三个维度 - 模型结构、代码运行、代码逻辑说明 对其源码做深入的分析。 Tensor Parallel源码分析
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
本文是LLM系列文章,针对《Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor》的翻译。 TOC
摘要
指令调优使预训练的语言模型能够从推理时间的自然语言描述中执行新的任务。这些方法依赖于以众包数据集或用户交互形式进行的大量人工…

大模型技术实践(五)|支持千亿参数模型训练的分布式并行框架
在上一期的大模型技术实践中,我们介绍了增加式方法、选择式方法和重新参数化式方法三种主流的参数高效微调技术(PEFT)。微调模型可以让模型更适合于我们当前的下游任务,但当模型过大或数据集规模很大时,单个加速器&…

Anthropic全球上线AI语言模型Claude 2;多模态系统:融合文本和图像的新前沿
🦉 AI新闻
🚀 Anthropic全球上线AI语言模型Claude 2,编程、数学、推理能力大幅提升
摘要:Anthropic在全球正式上线了AI语言模型Claude 2。相比前代版本,Claude 2在编程、数学、推理等方面都有大幅提升,支…
大语言模型面试心路历程【0 offer版】
记录自己大语言模型面试的经历,旨在可以帮助更多想要从事此方面的小伙伴。 北银金科
1.InstructGPT的训练过程 2.critic网络的作用 3.LSTM的原理,GRU与LSTM有什么不同 4.讲一下Bert的结构 5.讲一下自己的论文【KBQA相关】 6.GLM的结构和微调了哪些参数 …
垂直领域大模型落地思考
相比能做很多事,但每件事都马马虎虎的通用大模型;只能做一两件事,但这一两件事都能做好,可被信赖的垂直大模型会更有价值。这样的垂直大模型能帮助我们真正解决问题,提高生产效率。
本文将系统介绍如何做一个垂直领域…
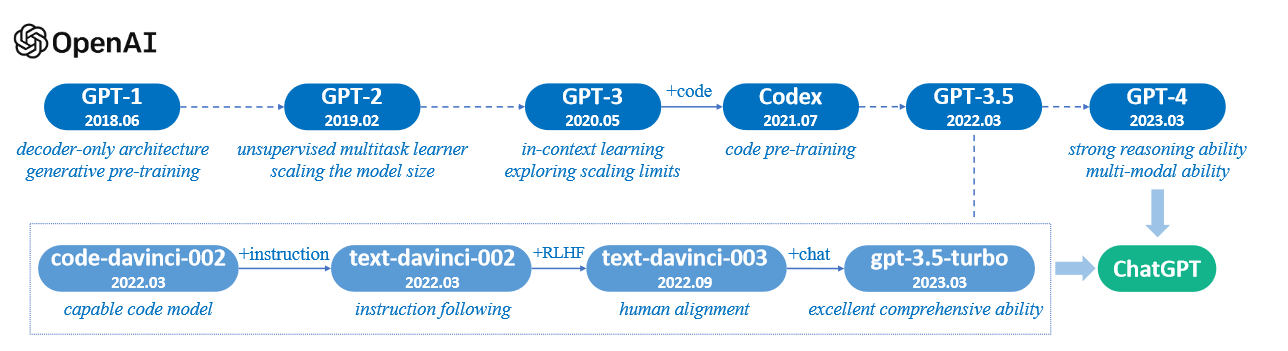
大语言模型(LLM)综述(一):大语言模型介绍
A Survey of Large Language Models 前言1. INTRODUCTION2. OVERVIEW2.1 大语言模型的背景2.2 GPT系列模型的技术演变 前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和…
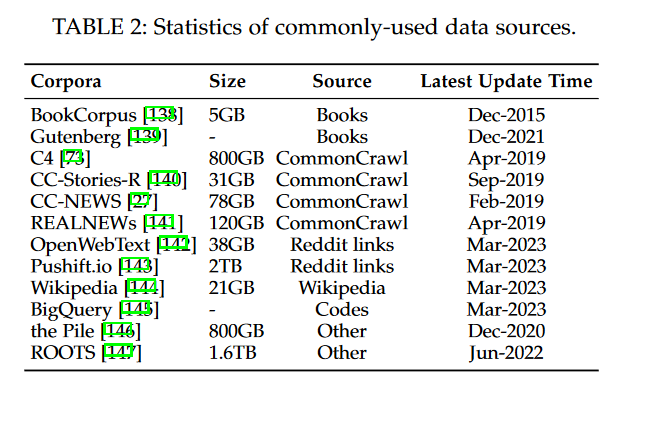
大语言模型(LLM)综述(二):开发大语言模型的公开可用资源
A Survey of Large Language Models 前言3. RESOURCES OF LLMS3.1 公开可用的模型CheckPoints或 API3.2 常用语料库3.3 库资源 前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更…
基于 LSTM 进行多类文本分类(附源码)
NLP 的许多创新是如何将上下文添加到词向量中。一种常见的方法是使用循环神经网络。以下是循环神经网络的概念: 他们利用顺序信息。 他们可以捕捉到到目前为止已经计算过的内容,即:我最后说的内容会影响我接下来要说的内容。 RNNs 是文本和…

大语言模型迎来重大突破!找到解释神经网络行为方法
前不久,获得亚马逊40亿美元投资的ChatGPT主要竞争对手Anthropic在官网公布了一篇名为《朝向单义性:通过词典学习分解语言模型》的论文,公布了解释经网络行为的方法。
由于神经网络是基于海量数据训练而成,其开发的AI模型可以生成…
大语言模型的学习路线和开源模型的学习材料《一》
文章目录 第一层 LLMs to Natural Language Processing (NLP)第一重 ChatGLM-6B 系列ChatGLM3ChatGLM2-6BChatGLM-6B第十重 BaichuanBaichuan2Baichuan-13Bbaichuan-7B第十一重 Llama2第二重 Stanford Alpaca 7B第三重 Chinese-LLaMA-Alpaca第四重 小羊驼 Vicuna第五重 MOSS第六…

n-gram语言模型——句子概率分布计算与平滑
n-gram语言模型——句子概率分布计算与平滑 前言 语言模型 等价假设 n元语法 句子概率分布计算方式 数据平滑 Lidstone平滑(1-gram) Laplace平滑(1-gram) 附上两种平滑在1-gram下代码 Lidstone平滑与Laplace平滑(2-gram) 附上两种平滑在2-gram下代码 前言 语言模型…
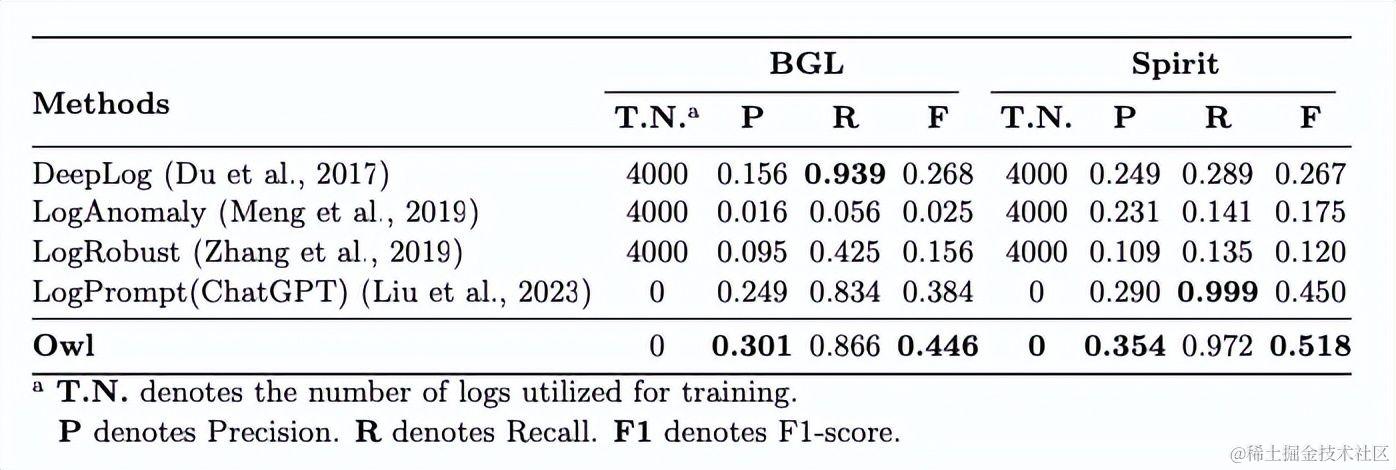
云智慧联合北航提出智能运维(AIOps)大语言模型及评测基准
随着各行业数字化转型需求的不断提高,人工智能、云计算、大数据等新技术的应用已不仅仅是一个趋势。各行业企业和组织纷纷投入大量资源,以满足日益挑剔的市场需求,追求可持续性和竞争力,这也让运维行业迎来了前所未有的挑战和机遇…

作为一个初学者,该如何入门大模型?
在生成式 AI 盛行的当下,你是否被这种技术所折服,例如输入一段简简单单的文字,转眼之间,一幅精美的图片,又或者是文笔流畅的文字就展现在你的面前。
相信很多人有这种想法,认为生成式 AI 深不可测…
ChatGLM 如何应用一个BERT
前言 接着上一小节,我们对Huggingface开源代码库中的Bert模型进行了深入学习,这一节我们对如何应用BERT进行详细的讲解。 涉及到的jupyter可以在代码库:篇章3-编写一个Transformer模型:BERT,下载 本文基于 Transformers 版本 4.4.2(2021 年 3 月 19 日发布)项目中,pyto…

Windows安装GPU版本的pytorch详细教程
文章目录 chatGLM2-6B安装教程正式安装 chatGLM2-6B
ChatGLM2-6B版本要装pytorch2.0,而且要2.0.1 ,因此CUDA不能用12.0 ,也不能用10.0,只能用11.x 版本。
安装教程
pip install直接下载安装 官网: https://pytorch.…

n-gram语言模型——文本生成源码
n-gram语言模型——文本生成源码 n-gram模型的基本原理 文本生成的步骤 1. 准备和分词 2. 构建n-gram模型 3. 平滑技术的应用 4. 生成文本 源码 在自然语言处理的领域中,n-gram语言模型是一种基础而强大的工具。它通过考虑词汇的序列来预测文本内容ÿ…
第三章:人工智能深度学习教程-基础神经网络(第一节-ANN 和 BNN 的区别)
你有没有想过建造大脑之类的东西是什么感觉,这些东西是如何工作的,或者它们的作用是什么?让我们看看节点如何与神经元通信,以及人工神经网络和生物神经网络之间有什么区别。
1.人工神经网络:人工神经网络(…
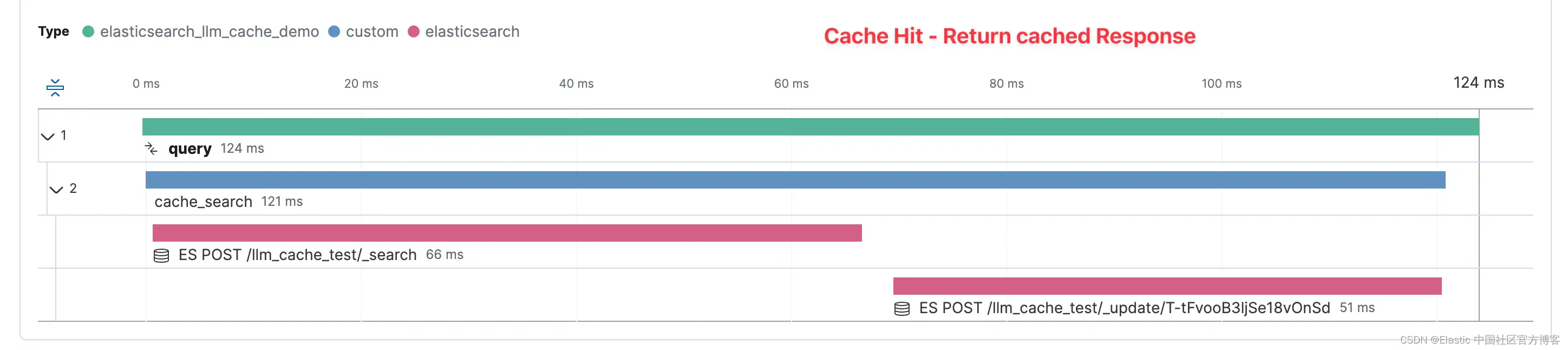
Elasticsearch 作为 GenAI 缓存层
作者:JEFF VESTAL,BAHA AZARMI
探索如何将 Elasticsearch 集成为缓存层,通过降低 token 成本和响应时间来优化生成式 AI 性能,这已通过实际测试和实际实施进行了证明。 随着生成式人工智能 (GenAI) 不断革新从客户服务到数据分析…
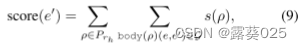
ChatRule:基于知识图推理的大语言模型逻辑规则挖掘11.10
ChatRule:基于知识图推理的大语言模型逻辑规则挖掘 摘要引言相关工作初始化和问题定义方法实验 摘要
逻辑规则对于揭示关系之间的逻辑联系至关重要,这可以提高推理性能并在知识图谱(KG)上提供可解释的结果。虽然已经有许多努力&a…
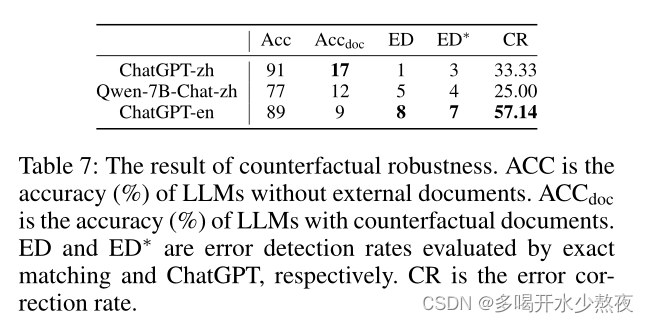
Benchmarking Large Language Models in Retrieval-Augmented Generation-学习翻译
提检索增强生成中大型语言模型的基准测试文献学习 作者将在https://github.com/chen700564/RGB上发布本文的代码和RGB。 y ˇ \check{y} yˇ 文章目录 摘要IntroductionRelated workRetrieval-Augmented Generation BenchmarkRAG所需能力数据构建评估指标 ExperimentsSetting…
ChatGLM HuggingFace大语言模型底座
基础介绍 HuggingFace 是一家专注于自然语言处理(NLP)、人工智能和分布式系统的创业公司,创立于2016年。最早是主营业务是做闲聊机器人,2018年 Bert 发布之后,他们贡献了一个基于 Pytorch 的 Bert 预训练模型,即 pytorch-pretrained-bert,大受欢迎,进而将重心转向维护 …
LLM大模型封装服务,不需加载,直接推理
一、前言
LLM十分火热,各种花样封装使用,但是每次infer的时候,加载模型都需要很久,那么就需要把服务挂载在服务器上,就不用每次infer都花那么多时间加载模型了。
二、使用fastapi或者flask
2.1 使用fastapi实现
使…
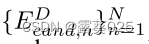
Think-on-Graph:基于知识图的大型语言模型的深层可靠推理11.12
Hink-on-Graph:基于知识图的大型语言模型的深层可靠推理 摘要1 引言2 方法2.1图上思考2.1.1图的初始化2.1.2 探索2.1.3推理 2.2 基于关系的Think on graph 摘要
尽管大型语言模型(LLM)在各种任务中取得了巨大的成功,但它们经常与…
ChatGPT的prompt技巧 心得
ChatGPT的prompt心得 写在最前面chatgpt咒语1(感觉最好用的竟然是这个,简单方便快捷,不需要多轮对话)chatgpt思维链2(复杂任务更适用,简单任务把他弄复杂了)机理chatgpt完整咒语1(感…
论文解读:Large Language Models as Analogical Reasoners
一、动机
大模型在各种类型的NLP任务上均展现出惊艳的表现。基于CoT propmt能够更好地激发大模型解决复杂推理问题的能力,例如解决数学解题,可以让模型生成reasoning path。现有的经典的CoT方法有few-shot cot、zero-shot cot等。然后现有的cot面临两个…
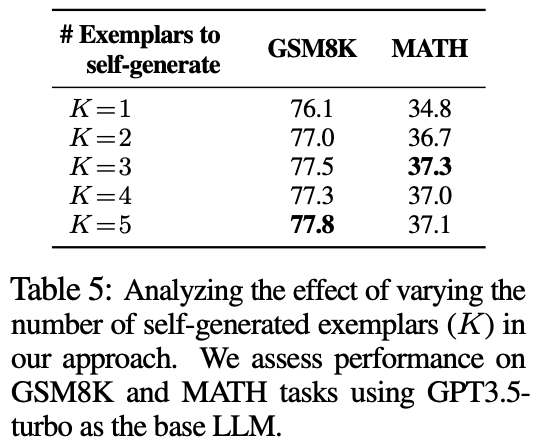
首发!动手学大模型应用开发教程来了
大模型正逐步成为信息世界的新革命力量,其通过强大的自然语言理解、自然语言生成能力,为开发者提供了新的、更强大的应用开发选择。随着国内外井喷式的大模型 API 服务开放,如何基于大模型 API 快速、便捷地开发具备更强能力、集成大模型的应…
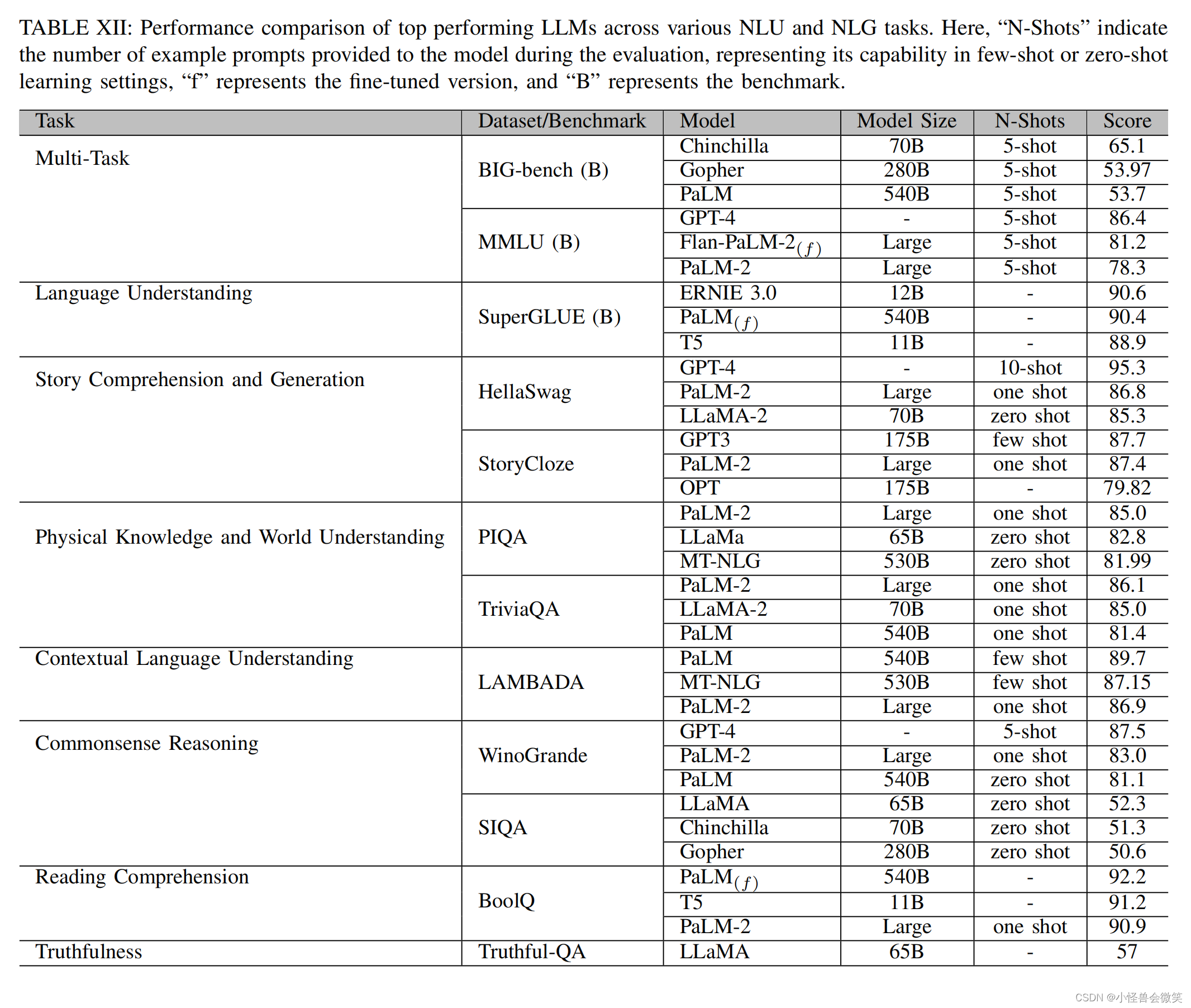
大模型的全面回顾,看透大模型 | A Comprehensive Overview of Large Language Models
大模型的全面回顾:A Comprehensive Overview of Large Language Models 返回论文和资料目录
论文地址
1.导读
相比今年4月的中国人民大学发表的大模型综述,这篇综述角度更侧重于大模型的实现,更加硬核,更适合深入了解大模型的一…
用户交互引导大模型生成内容特征,LLM-Rec框架助力个性化推荐!
欢迎来到魔法宝库,传递AIGC的前沿知识,做有格调的分享❗
喜欢的话记得点个关注吧! 今天主要和大家分享一篇使用大语言模型做数据增强来提升推荐系统性能的研究 标题: LLM-Rec: Personalized Recommendation via Prompting Large …
【大语言模型】Docker部署清华大学ChatGLM3教程
官方地址:https://github.com/THUDM/ChatGLM3
1 将代码保存至本地
方法1:
git clone https://github.com/THUDM/ChatGLM3
方法2:
https://github.com/THUDM/ChatGLM3/archive/refs/heads/main.zip
2 创建Docker文件
注:请先…
Prevalence and prevention of large language model use in crowd work
本文是LLM系列文章,针对《Prevalence and prevention of large language model use in crowd work》的翻译。 众包工作中使用大型语言模型的流行率和预防 摘要1 研究1:LLM使用的普遍率2 研究2:LLM使用的预防3 讨论4 材料与方法 摘要
我们表…
Interview of ING internship for master thesis: LLM
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1. Background2. Interview2.1 Intro2.2 project experience2.3 问题2.4 Q&A 总结 Interview of ING internship for master thesis: LLM 1. Background
Proje…

深入解析 Azure 机器学习平台:架构与组成部分
Azure机器学习平台是Microsoft Azure提供的一种云上机器学习服务,为开发者和数据科学家提供了一个全面且易于使用的环境来创建、训练、部署和管理机器学习模型。本文将对Azure机器学习平台的基本架构和组成部分进行深入解析,帮助读者全面了解该平台的工作…
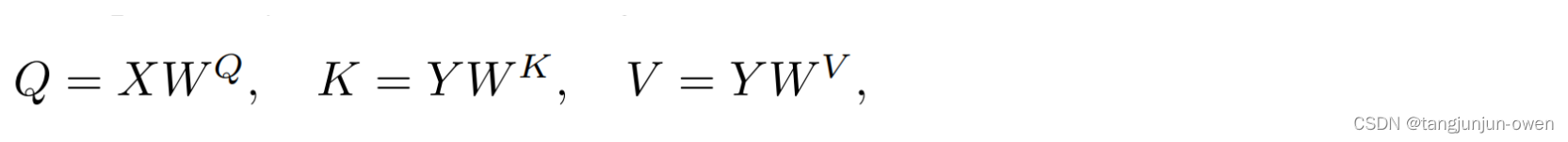
Attention Is All You Need原理与代码详细解读
文章目录 前言一、Transformer结构的原理1、Transform结构2、位置编码公式3、transformer公式4、FFN结构 二、Encode模块代码解读1、编码数据2、文本Embedding编码3、位置position编码4、Attention编码5、FFN编码 三、Decode模块代码解读1、编码数据2、文本Embedding与位置编码…

世界互联网大会领先科技奖发布 百度知识增强大语言模型关键技术获奖
11月8日,2023年世界互联网大会乌镇峰会正式开幕,今年是乌镇峰会举办的第十年,本次峰会的主题为“建设包容、普惠、有韧性的数字世界——携手构建网络空间命运共同体”。 目录 百度知识增强大语言模型关键技术荣获“世界互联网大会领先科技奖”…
在Win11上部署ChatGLM2-6B详细步骤--(上)准备工作
一:简单介绍
ChatGLM-6B是清华大学知识工程和数据挖掘小组(Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University)发布的一个开源的对话机器人。根据官方介绍,这是一个千亿参数规模的中英文语言模型。并…

零资源的大语言模型幻觉预防
零资源的大语言模型幻觉预防 摘要1 引言2 相关工作2.1 幻觉检测和纠正方法2.2 幻觉检测数据集 3 方法论3.1 概念提取3.2 概念猜测3.2.1 概念解释3.2.2 概念推理 3.3 聚合3.3.1 概念频率分数3.3.2 加权聚合 4 实验5 总结 摘要
大语言模型(LLMs)在各个领域…
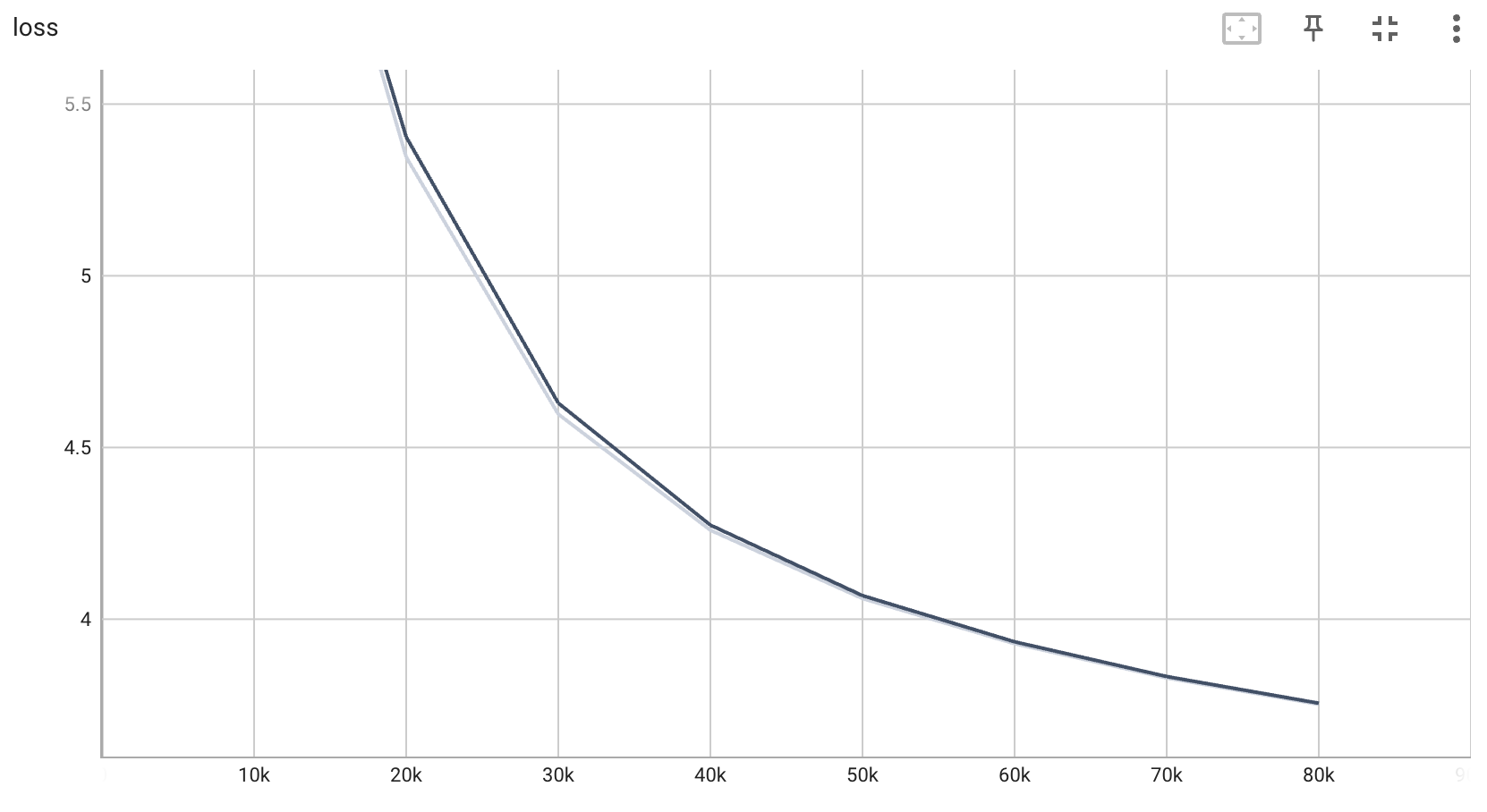
大语言模型的三阶段训练
为了训练专有领域模型,选择LLaMA2-7B作为基座模型,由于LLaMA模型中文词表有限,因此首先进行中文词表的扩展,然后进行三阶段训练(增量预训练,有监督微调,强化学习)。
代码将全部上传…
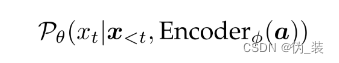
开源语音大语言模型——Qwen-Audio
论文链接:https://arxiv.org/pdf/2311.07919.pdf
开源代码:https://github.com/QwenLM/Qwen-Audio 一、背景
大型语言模型(LLMs)由于其良好的知识保留能力、复杂的推理和解决问题能力,在通用人工智能(AGI…
LLM、ChatGPT与多模态必读论文150篇
为了写本 ChatGPT 笔记,我和10来位博士、业界大佬,在过去半年翻了大量中英文资料/paper,读完 ChatGPT 相关技术的150篇论文,当然还在不断深入。
由此而感慨:
读的论文越多,你会发现大部分人对ChatGPT的技…
推理还是背诵?通过反事实任务探索语言模型的能力和局限性
推理还是背诵?通过反事实任务探索语言模型的能力和局限性 摘要1 引言2 反事实任务2.1 反事实理解检测 3 任务3.1 算术3.2 编程3.3 基本的句法推理3.4 带有一阶逻辑的自然语言推理3.5 空间推理3.6 绘图3.7 音乐3.8 国际象棋 结果5 分析5.1 反事实条件的“普遍性”5.2…
让 OpenAI GPT4 出 10 道题测试其他开源大语言模型
让 OpenAI GPT4 出 10 道题测试其他开源大语言模型 1. 中文题目及答案2. 日文题目及答案3. 英文题目及答案 1. 中文题目及答案 数学题:一个矩形的长是10厘米,宽是5厘米,求它的面积。 答案:面积 长 x 宽 10厘米 x 5厘米 50平方厘…
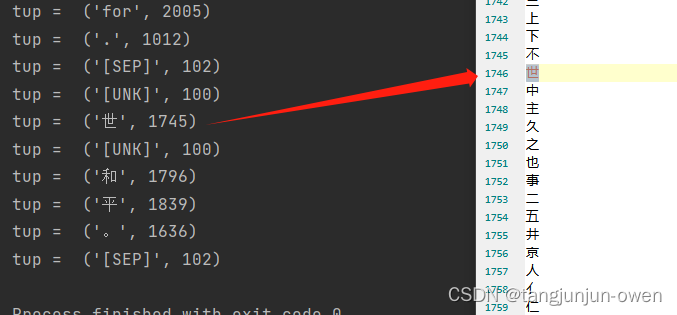
语言模型编码中/英文句子格式详解
文章目录 前言一、Bert的vocab.txt内容查看二、BERT模型转换方法(vocab.txt)三、vocab内容与模型转换对比四、中文编码总结 前言
最近一直在学习多模态大模型相关内容,特别是图像CV与语言LLM模型融合方法,如llama-1.5、blip、meta-transformer、glm等大…

亚马逊云科技大语言模型下的六大创新应用功能
目录
前言
亚马逊云科技的AI创新应用
编辑
Amazon CodeWhisperer
Amazon CodeWhisperer产品的优势
更快地完成更多工作 自信地进行编码
增强代码安全性
使用收藏夹工具
自定义 CodeWhisperer 以获得更好的建议
如何使用Amazon CodeWhisperer
步骤 1
步骤 2
具体…
超详细!DALL · E 文生图模型实践指南
最近需要用到 DALLE的推断功能,在现有开源代码基础上发现还有几个问题需要注意,谨以此篇博客记录之。 我用的源码主要是 https://github.com/borisdayma/dalle-mini 仓库中的Inference pipeline.ipynb 文件。 运行环境:Ubuntu服务器
⚠️注意…

LangChain的函数,工具和代理(二):LangChain的表达式语言(LCEL)
LangChain Expression Language (LCEL) 是 LangChain 工具包的重要补充,旨在提高文本处理任务的效率和灵活性。LCEL 允许用户采用声明式方法来组合链,便于进行流处理、批处理和异步任务。其模块化架构还允许轻松定制和修改链组件。LCEL 的优势之一是它使…
大语言模型有那些能力和应用
目录
能力
应用 能力 理解语义的能力:LLM 具有强大的语义理解能力,能够理解大部分文本,包括不同语言(人类语言或计算机语言)和表达水平的文本,即使是多语言混杂、语法用词错误,也在多数情况下…
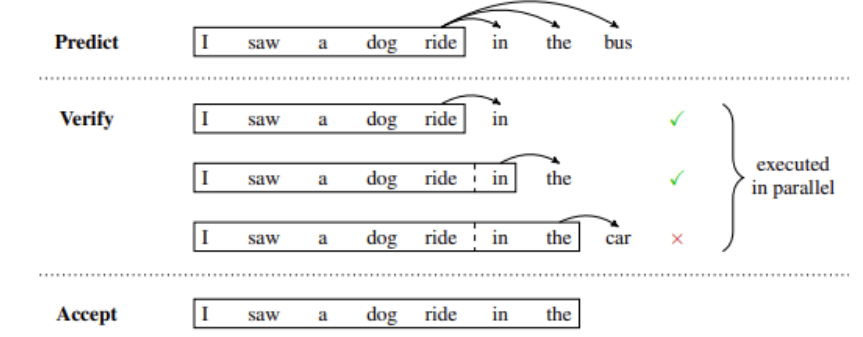
掌握大型语言模型(LLM)技术:推理优化
原文链接:Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog 大模型相关技术文章已整理到Github仓库,欢迎start! 堆叠Transformer层以创建大型模型可以获得更好的准确性、few-shot学习能力,甚至在各种语言任务中具有…
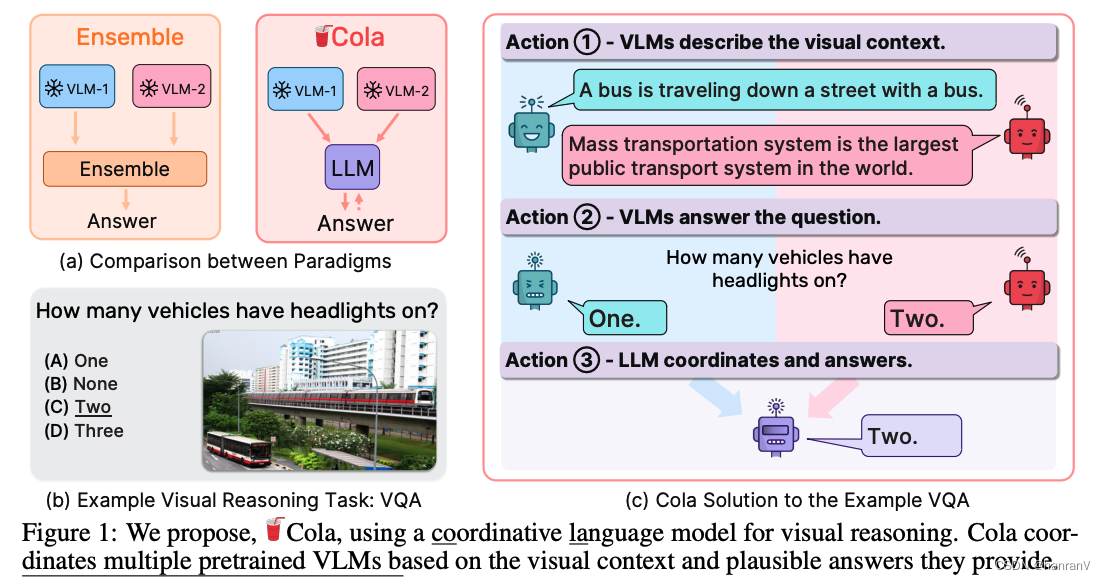
Large Language Models areVisual Reasoning Coordinators
目录
一、论文速读
1.1 摘要
1.2 论文概要总结
二、论文精度
2.1 论文试图解决什么问题?
2.2 论文中提到的解决方案之关键是什么?
2.3 用于定量评估的数据集是什么?代码有没有开源?
2.4 这篇论文到底有什么贡献࿱…
LLM推理部署(四):一个用于训练、部署和评估基于大型语言模型的聊天机器人的开放平台FastChat
FastChat是用于对话机器人模型训练、部署、评估的开放平台。体验地址为:https://chat.lmsys.org/,该体验平台主要是为了收集人类的真实反馈,目前已经支持30多种大模型,已经收到500万的请求,收集了10万调人类对比大模型…

【通义千问】大模型Qwen GitHub开源工程学习笔记(4)-- 模型的量化与离线部署
摘要:
量化方案基于AutoGPTQ,提供了Int4量化模型,其中包括Qwen-7B-Chat和Qwen-14B-Chat。更新承诺在模型评估效果几乎没有损失的情况下,降低存储要求并提高推理速度。量化是指将模型权重和激活的精度降低以节省存储空间并提高推理速度的过程。AutoGPTQ是一种专有量化工具。…
Continual Pre-Training of Large Language Models: How to (re)warm your model?
本文是LLM系列文章,针对《Continual Pre-Training of Large Language Models: How to (re)warm your model?》的翻译。 大型语言模型的持续预训练:如何(重新)预热你的模型 摘要1 引言2 设置3 相关工作4 持续加热5 讨论/局限性6 …
翻译: GPT4等大型语言模型的原理解析和未来预测慢思考和模型自我迭代和LLM安全
YouTube: Intro to Large Language Models - YouTube
1. Large Language Model LLM 大家好,最近我做了一个关于大型语言模型的 30 分钟演讲,有点像介绍性演讲,不幸的是,那个演讲没有被录制下来,但很多人在演讲结束后…

COGVLM论文解读(COGVLM:VISUAL EXPERT FOR LARGE LANGUAGE MODELS)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、摘要二、引言三、模型方法1、模型思路2、融合公式 四、训练方法总结 前言
2023年5月18日清华&智谱AI发布并开源VisualGLM-6B以来,清华KEG&…

LLM-Intro to Large Language Models
LLM
some LLM’s model and weight are not opened to user
what is?
Llama 270b model 2 files parameters file parameter or weight of neural networkparameter – 2bytes, float number code run parameters(inference) c or python, etcfor c, 500 lines code withou…

Meta推出了一套开源AI语言翻译模型,这些模型不仅能保留说话的表达方式,还能提升流式翻译的效果
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

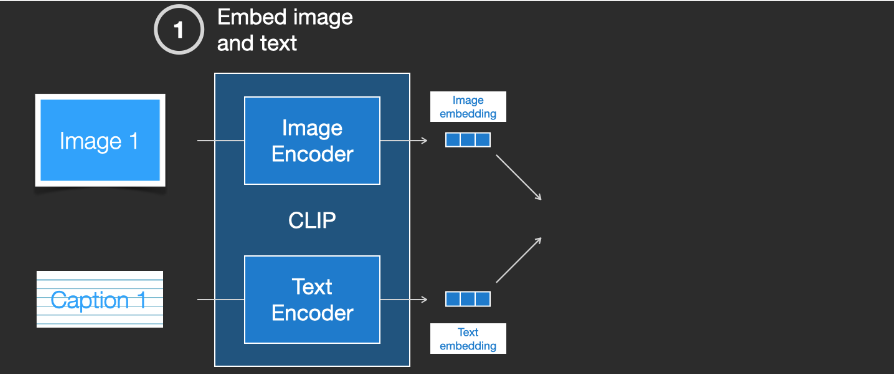
CLIP:万物分类(视觉语言大模型)
本文来着公众号“AI大道理”
论文地址:https://arxiv.org/abs/2103.00020 传统的分类模型需要先验的定义固定的类别,然后经过CNN提取特征,经过softmax进行分类。然而这种模式有个致命的缺点,那就是想加入新的一类就得重新定义…

ChatGLM3本地部署运行(入门体验级)
文章目录 前言零 硬件小白基知填坑eForce Game Ready驱动程序CUDA常用命令 环境准备NVIDIA驱动更新CUDA安装 部署补充内容体验 前言
学习自B站up主技术爬爬虾,感谢up主提供的整合包!
零 硬件
6GB以上显存的NVIDIA显卡(品质越高,…
Elasticsearch:检索增强生成 (Retrieval Augmented Generation -RAG)
作者:JOE MCELROY
什么是检索增强生成 (RAG) 以及该技术如何通过提供相关源知识作为上下文来帮助提高 LLMs 生成的响应的质量。 生成式人工智能最近取得了巨大的成功和令人兴奋的成果,其模型可以生成流畅的文本、逼真的图像,甚至视频。 就语…
机器学习硬件十年:性能变迁与趋势
本文分析了机器学习硬件性能的最新趋势,重点关注不同GPU和加速器的计算性能、内存、互连带宽、性价比和能效等指标。这篇分析旨在提供关于ML硬件能力及其瓶颈的全面视图。本文作者来自调研机构Epoch,致力于研究AI发展轨迹与治理的关键问题和趋势。 &…

亚马逊云AI大语言模型应用下的创新Amazon Transcribe的使用
Transcribe简介
语音识别技术,也被称为自动语音识别(Automatic Speech Recognition,简称ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。语音识别技术已…
国内LLMs大型语言模型排行榜!
在人工智能领域,语言模型是一种被广泛应用的技术。它能够理解和生成人类语言,为我们的生活和工作带来了很多便利。
在国内,有许多大型语言模型在不断发展和进步,为用户提供更好的语言交互体验。下面就让我们来看看国内大型语言模…
基于大语言模型的复杂任务认知推理算法CogTree
近日,阿里云人工智能平台PAI与华东师范大学张伟教授团队合作在自然语言处理顶级会议EMNLP2023上发表了基于认知理论所衍生的CogTree认知树生成式语言模型。通过两个系统:直觉系统和反思系统来模仿人类产生认知的过程。直觉系统负责产生原始问题的多个分解…
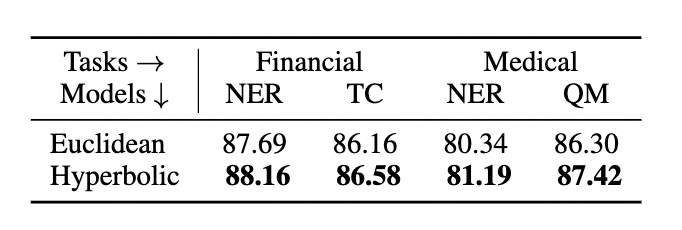
【EMNLP 2023】面向垂直领域的知识预训练语言模型
近日,阿里云人工智能平台PAI与华东师范大学数据科学与工程学院合作在自然语言处理顶级会议EMNLP2023上发表基于双曲空间和对比学习的垂直领域预训练语言模型。通过比较垂直领域和开放领域知识图谱数据结构的不同特性,发现在垂直领域的图谱结构具有全局稀…
ChatGLM3-6B:新一代开源双语对话语言模型,流畅对话与低部署门槛再升级
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…
LangChain 26: 回调函数callbacks打印prompt verbose调用
LangChain系列文章
LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…

Python大语言模型实战-利用MetaGPT框架自动开发一个游戏软件(附完整教程)
实现功能
MetaGPT是一个应用在软件开发领域的多智能体框架,其主要创新点在于将SOP标准流水线和Agent结合在了一起,使得拥有不同技能的Role之间配合完成一项较为复杂的任务。本文将用一个案例来演示整个流程。
实现代码 项目地址:https://gi…
LLM中的Prompt提示
简介
在LLM中,prompt(提示)是一个预先设定的条件,它可以限制模型自由发散,而是围绕提示内容进行展开。输入中添加prompt,可以强制模型关注特定的信息,从而提高模型在特定任务上的表现。 结构
…

开源语音大语言模型来了!阿里基于Qwen-Chat提出Qwen-Audio!
论文链接:https://arxiv.org/pdf/2311.07919.pdf
开源代码:https://github.com/QwenLM/Qwen-Audio
引言
大型语言模型(LLMs)由于其良好的知识保留能力、复杂的推理和解决问题能力,在通用人工智能(AGI&am…

【UCAS自然语言处理作业二】训练FFN, RNN, Attention机制的语言模型,并计算测试集上的PPL
前言
本次实验主要针对前馈神经网络,RNN,以及基于注意力机制的网络学习语言建模任务,并在测试集上计算不同语言模型的PPL
PPL计算:我们采用teacher forcing的方式,给定ground truth context,让其预测next…

LLaMA 2:开源的预训练和微调语言模型推理引擎 | 开源日报 No.86
facebookresearch/llama
Stars: 36.0k License: NOASSERTION
LLaMA 2 是一个开源项目,用于加载 LLaMA 模型并进行推理。
该项目的主要功能是提供预训练和微调后的 LLaMA 语言模型的权重和起始代码。这些模型参数范围从 7B 到 70B 不等。
以下是该项目的关键特性…
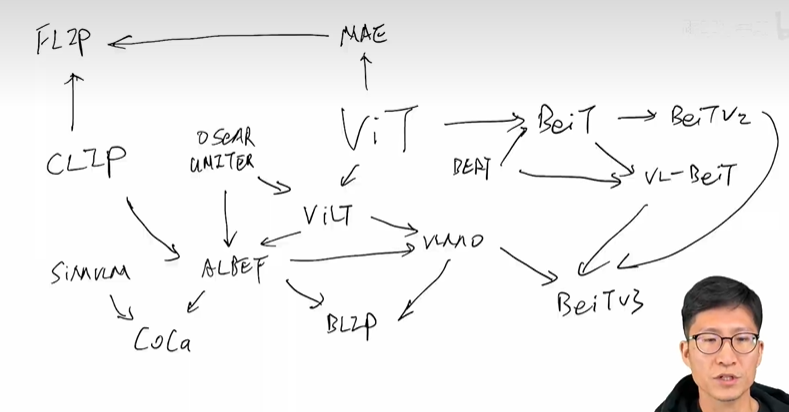
多模态大模型总结1(2021和2022年)
常用损失函数
ITC (image-text contrasctive loss)
CLIP中采用的对比损失,最大化配对文本对的余弦相似度,最小化非配对文本对的余弦相似度,采用交叉熵损失实现
MLM (masked language modeling࿰…
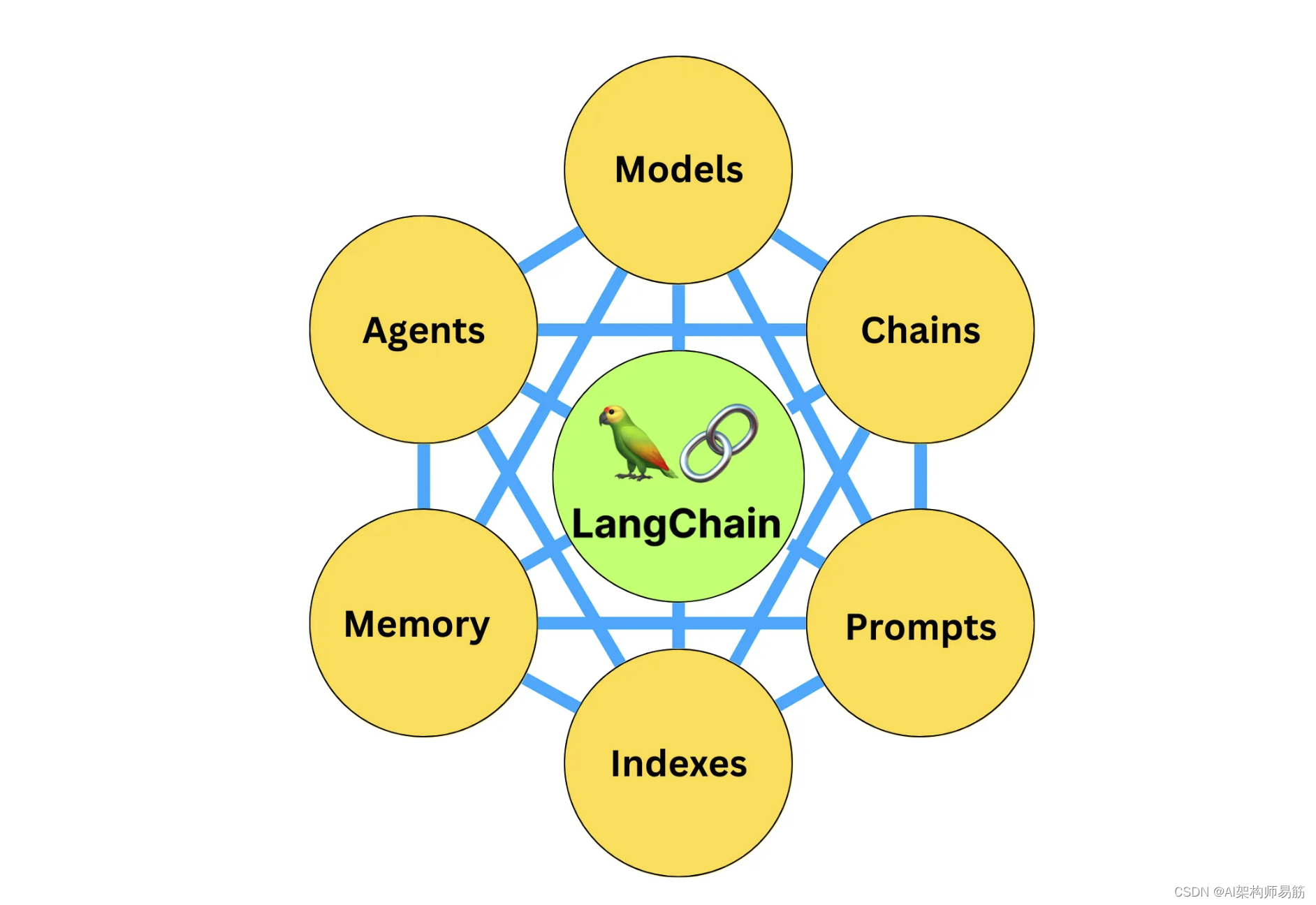
AIGC|LangChain新手入门指南,5分钟速读版!
如果你用大语言模型来构建AI应用,那你一定不可能绕过LangChain,LangChain是现在最热门的AI应用框架之一,去年年底才刚刚发布,它在github上已经有了4.6万颗星的点赞了,在github社区上,每天都有众多大佬,用它…
MistralAI发布全球首个MoE大模型-Mixtral 8x7B,创新超越GPT-4
引言
MistralAI,一家法国的初创企业,近期在AI界引发了轰动,刚刚发布了全球首个基于MoE(Mixture of Experts,混合专家)技术的大型语言模型——Mistral-8x7B-MoE。这一里程碑事件标志着AI技术的一个重要突破…
大语言模型的好坏是由您提示水平高底决定的
大语言模型是有"嫌贫爱富“特点的,当你的水平高于大语言模型时它常常可以帮你,当你的水平低于大语言模型时它往往会骗你。 这主要是因为大语言模型在处理文本时具有较强的生成能力,可以根据已有的语境生成合乎逻辑的文本。当你的水平高于…

大语言模型(LLMs)在 Amazon SageMaker 上的动手实践(一)
本期文章,我们将通过三个动手实验从浅到深地解读和演示大语言模型(LLMs),如何结合 Amazon SageMaker 的模型部署、模型编译优化、模型分布式训练等。
实验一:使用 Amazon SageMaker 构建基于开源 GPT-J 模型的对话机器…
用通俗的方式讲解Transformer:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
直到今天早上,刷到CSDN一篇讲BERT的文章,号称一文读懂,我读下来之后,假定我是初学者,读不懂。
关于BERT的笔记,其实一两年前就想写了,迟迟没动笔的原因是国内外已经有很多不错的资料࿰…
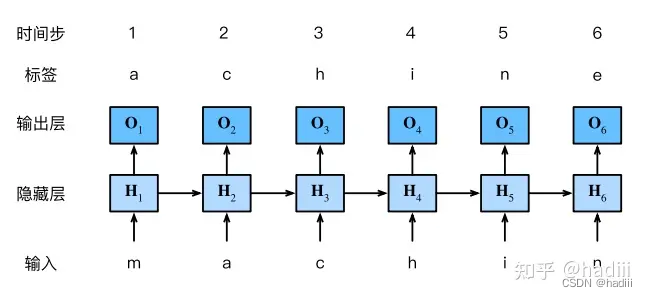
序列模型,语言模型,RNN的相关概念
序列模型,语言模型,RNN
循环神经网络(RNN)通过引入状态变量来存储过去的信息和当前的输入,从而确定当前的输出。这种结构使得RNN非常适合处理序列信息,因为它可以捕捉到序列中的时间依赖性。这与卷积神经网…

综述 | 揭秘高效大型语言模型:技术、方法与应用展望
深度学习自然语言处理 原创作者:Xnhyacinth 近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著的进展,如GPT-series(GPT-3, GPT-4)、Google-series(Gemini, PaLM), Meta-series(LLAMA1&2), BLOOM, GLM等模型…

快速了解ChatGPT(大语言模型)
目录
GPT原理:文字接龙,输入一个字,后面会接最有可能出现的文字。
GPT4
学会提问:发挥语言模型的最大能力 参考李宏毅老师的课快速了解大语言模型做的笔记:
Lee老师幽默的开场: GPT:chat Ge…

2023年度佳作:AIGC、AGI、GhatGPT、人工智能大语言模型的崛起与挑战
目录 前言
01 《ChatGPT 驱动软件开发》
内容简介
02 《ChatGPT原理与实战》
内容简介
03 《神经网络与深度学习》
04 《AIGC重塑教育》
内容简介
05 《通用人工智能》
目 录 前言
2023年是人工智能大语言模型大爆发的一年,一些概念和英文缩写也在这一…

WebLangChain_ChatGLM:结合 WebLangChain 和 ChatGLM3 的中文 RAG 系统
WebLangChain_ChatGLM 介绍 本文将详细介绍基于网络检索信息的检索增强生成系统,即 WebLangChain。通过整合 LangChain,成功将大型语言模型与最受欢迎的外部知识库之一——互联网紧密结合。鉴于中文社区中大型语言模型的蓬勃发展,有许多可供利…

熬了一个通宵,把国内外的大模型都梳理完了!
大家好,大模型越来越多了,真的有点让人眼花缭乱。
为了让大家清晰地了解大模型,我熬了一个通宵把国内和国外的大模型进行了全面梳理,国内有189个,国外有20,同时包括大模型的来源机构、来源信息和分类等。 …

【Datawhale 大模型基础】第六章 大模型的模型架构(英文版)
第六章 大模型的模型架构(英文版)
In the previous blog, I discussed the training data of LLMs and their data scheduling methods. This blog will focus on another important aspect of LLMs: model architecture. Due to the complexity and di…

LLMs 玩狼人杀:清华大学验证大模型参与复杂交流博弈游戏的能力
作者:彬彬 编辑:李宝珠,三羊 清华大学研究团队提出了一种用于交流游戏的框架,展示了大语言模型从经验中学习的能力,还发现大语言模型具有非预编程的策略行为,如信任、对抗、伪装和领导力。 近年来&#x…

ChatGPT 发布了免费提示指南 用PROMPT法打造完美的ChatGPT对话
ChatGPT 刚刚发布了免费提示指南。
但大多数人仍在为课程付费。
这里有 6 种免费策略,可以帮助您获得更好的即时结果: 1. 明确的指示
→ 准确表达您的要求。 → 对于简短的回复,请提及。 → 需要更多细节?直接询问。 → 展示您…

2023ChatGPT浪潮,2024开源大语言模型会成王者?
《2023ChatGPT浪潮,2024开源大语言模型会成王者?》
一、2023年的回顾
1.1、背景
我们正迈向2023年的终点,回首这一年,技术行业的发展如同车轮滚滚。尽管互联网行业在最近几天基本上处于冬天,但在这一年间我们仍然经…
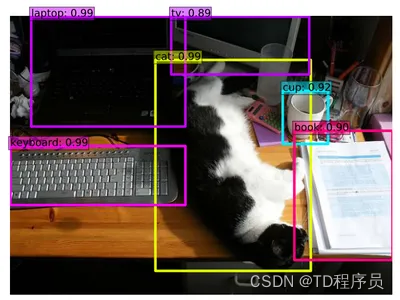
详细介绍如何使用 SSD 进行实时物体检测:单次 MultiBox 探测器-含源码
介绍
在实时对象检测中,主流范例传统上采用多步骤方法,包括边界框、像素或特征重采样以及高质量分类器应用的提议。虽然这种方法已经实现了高精度,但其计算需求往往阻碍了其对实时应用的适用性。然而,单次多框检测器 (SSD) 代表了基于深度学习的对象检测的突破性飞跃。SSD…
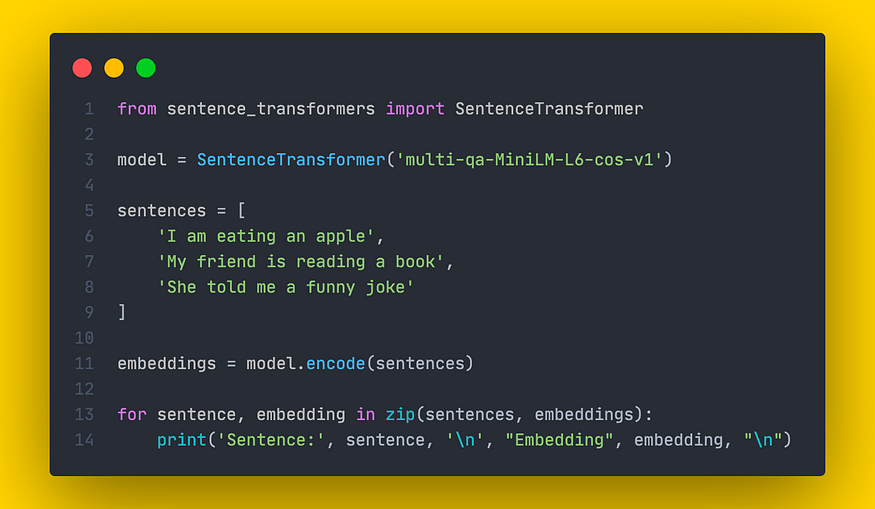
大型语言模型:SBERT — Sentence-BERT
slavahead 一、介绍 Transformer 在 NLP 方面取得了进化进步,这已经不是什么秘密了。基于转换器,许多其他机器学习模型已经发展起来。其中之一是BERT,它主要由几个堆叠的变压器编码器组成。除了用于情感分析或问答等一系列不同的问题外&#…
从零构建属于自己的GPT系列2:模型训练1(预训练中文模型加载、中文语言模型训练、逐行代码解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…

【深度学习】序列生成模型(五):评价方法计算实例:计算BLEU-N得分【理论到程序】
文章目录 一、BLEU-N得分(Bilingual Evaluation Understudy)1. 定义2. 计算N1N2BLEU-N 得分 3. 程序 给定一个生成序列“The cat sat on the mat”和两个参考序列“The cat is on the mat”“The bird sat on the bush”分别计算BLEU-N和ROUGE-N得分(N1或…
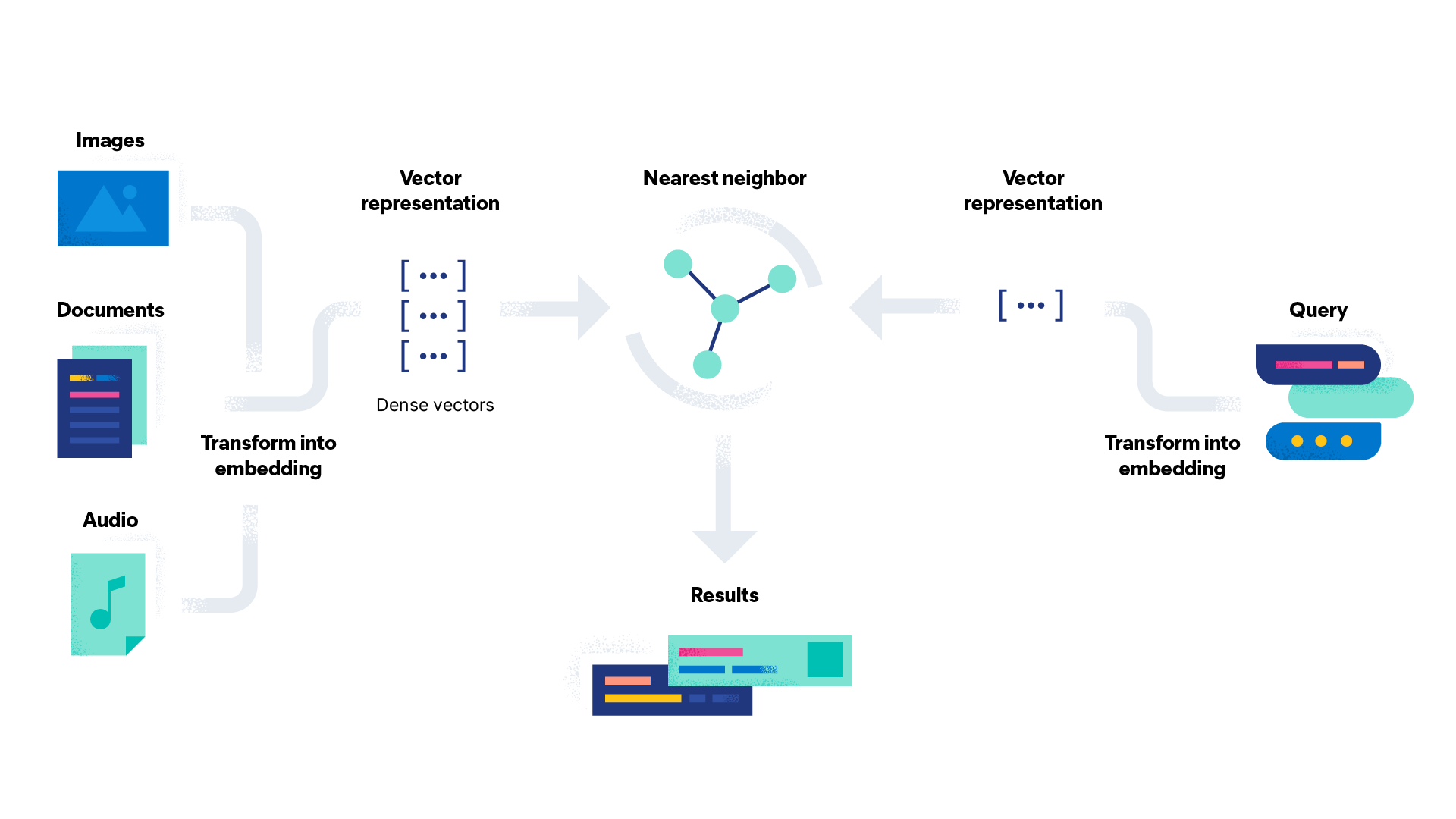
ELasticsearch:什么是语义搜索?
语义搜索定义
语义搜索是一种解释单词和短语含义的搜索引擎技术。 语义搜索的结果将返回与查询含义匹配的内容,而不是与查询中的单词字面匹配的内容。
语义搜索是一组搜索引擎功能,其中包括根据搜索者的意图及其搜索上下文理解单词。
此类搜索旨在通过…
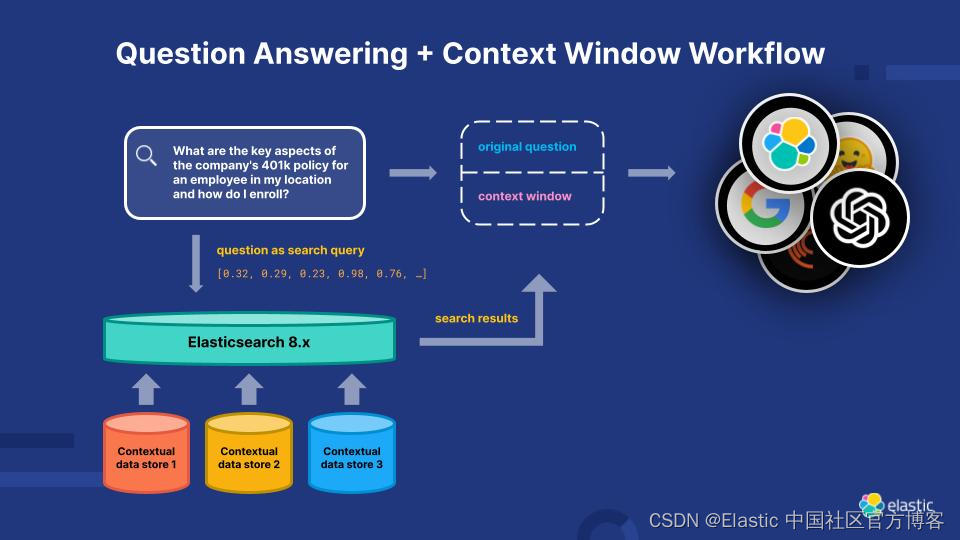
Elasticsearch:什么是大语言模型(LLM)?
大语言模型定义
大语言模型 (LLM) 是一种深度学习算法,可以执行各种自然语言处理 (natural language processing - NLP) 任务。 大型语言模型使用 Transformer 模型,并使用大量数据集进行训练 —— 因此规模很大。 这使他们能够识别、翻译、预测或生成文…
大语言模型Prompt设计学习记录:Magic words(魔法词)的作用
文章目录 “扮演”或“成为”类指令:“总结”或“概述”类指令:“比较”或“对比”类指令:“解释”或“定义”类指令:“继续”或“接下来”类指令:“转换”或“改写”类指令: 在大语言模型中,Ma…

探索无监督域自适应,释放语言模型的力量:基于检索增强的情境学习实现知识迁移...
深度学习自然语言处理 原创作者: Xnhyacinth 在自然语言处理(NLP)领域,如何有效地进行无监督域自适应(Unsupervised Domain Adaptation, UDA) 一直是研究的热点和挑战。无监督域自适应的目标是在目标域无标签的情况下,将源域的知识…

【扩散模型】9、Imagen | 借用语言模型的能力来实现文生图(NIPS2022 Oral)
文章目录 一、背景二、方法2.1 预训练的语言编码器2.2 扩散模型和 classifier-free guidance 三、效果 论文:Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
官网:https://www.assemblyai.com/blog/how-imag…
【学习笔记】LLM for Education
ChatGPT has entered the classroom: how LLMs could transform education 前言IntroductionThe risks are realEmbracing LLMsIntroducing the AI tutorAugmenting retrievalWill it catch on?总结 前言
一篇来自Nature的文章,探讨了教育行业的不同参与者&#x…

翻译: LLM大语言模型图像生成原理Image generation
文本生成是许多用户正在使用的,也是所有生成式人工智能工具中影响最大的。但生成式人工智能的一部分兴奋点也在于图像生成。目前也开始出现一些可以生成文本或图像的模型,这些有时被称为多模态模型,因为它们可以在多种模式中操作,…
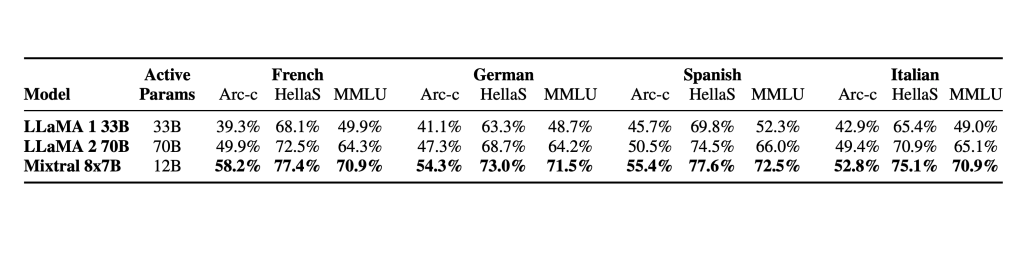
Mistral AI 推出高质量的稀疏专家混合AI人工智能模型——SMoE,有望超越ChatGPT3.5
Mistral AI(“Mistral AI”是一家由前DeepMind和Meta Platforms(META.US)的研究人员组建的新公司。)继续履行为开发者社区提供最佳开放模型的使命。他们发布了 Mixtral 8x7B,这是一个高质量的稀疏专家混合模型…

Re58:读论文 REALM: Retrieval-Augmented Language Model Pre-Training
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:REALM: Retrieval-Augmented Language Model Pre-Training 模型名称:Retrieval-Augmented Language Model pre-training (REALM)
本文是2020年ICML论文,作者来自…

【论文解读】System 2 Attention提高大语言模型客观性和事实性
一、简要介绍 本文简要介绍了论文“System 2 Attention (is something you might need too) ”的相关工作。基于transformer的大语言模型(LLM)中的软注意很容易将上下文中的不相关信息合并到其潜在的表征中,这将对下一token的生成产生不利影响…
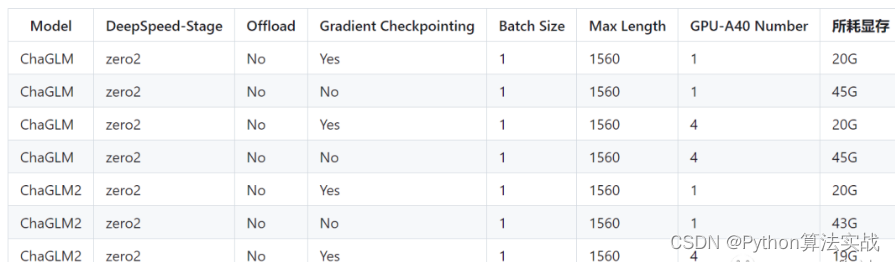
不用再找,这是大模型 LLM 微调经验最全总结
大家好,今天对大模型微调项目代码进行了重构,支持ChatGLM和ChatGLM2模型微调的切换,增加了代码的可读性,并且支持Freeze方法、Lora方法、P-Tuning方法、「全量参数方法」 微调。
PS:在对Chat类模型进行SFT时ÿ…
探索人工智能中的语言模型:原理、应用与未来发展
导言 语言模型在人工智能领域中扮演着重要的角色,它不仅是自然语言处理的基础,也是许多智能系统的核心。本文将深入研究语言模型的原理、广泛应用以及未来发展趋势。
1. 语言模型的原理
统计语言模型: 基于概率统计的传统语言模型&…
LCEL(Lang Chain Expression Language) 介绍:LangChain 的开发提效技巧
LCEL 介绍
LCEL(Lang Chain Expression Language)是将一些有趣的 Python 概念抽象成一种格式,使得可以构建 LangChain 组件链的 “极简主义” 代码层。
LCEL 具有以下强大的支持:
超快速开发链。高级特性,如流式处理…

AI模型平台Hugging Face存在API令牌漏洞;大型语言模型与任务模型
🦉 AI新闻
🚀 AI模型平台Hugging Face存在API令牌漏洞,黑客可窃取、修改模型
摘要:安全公司Lasso Security发现AI模型平台Hugging Face上存在API令牌漏洞,黑客可获取微软、谷歌等公司的令牌,并能够访问模…
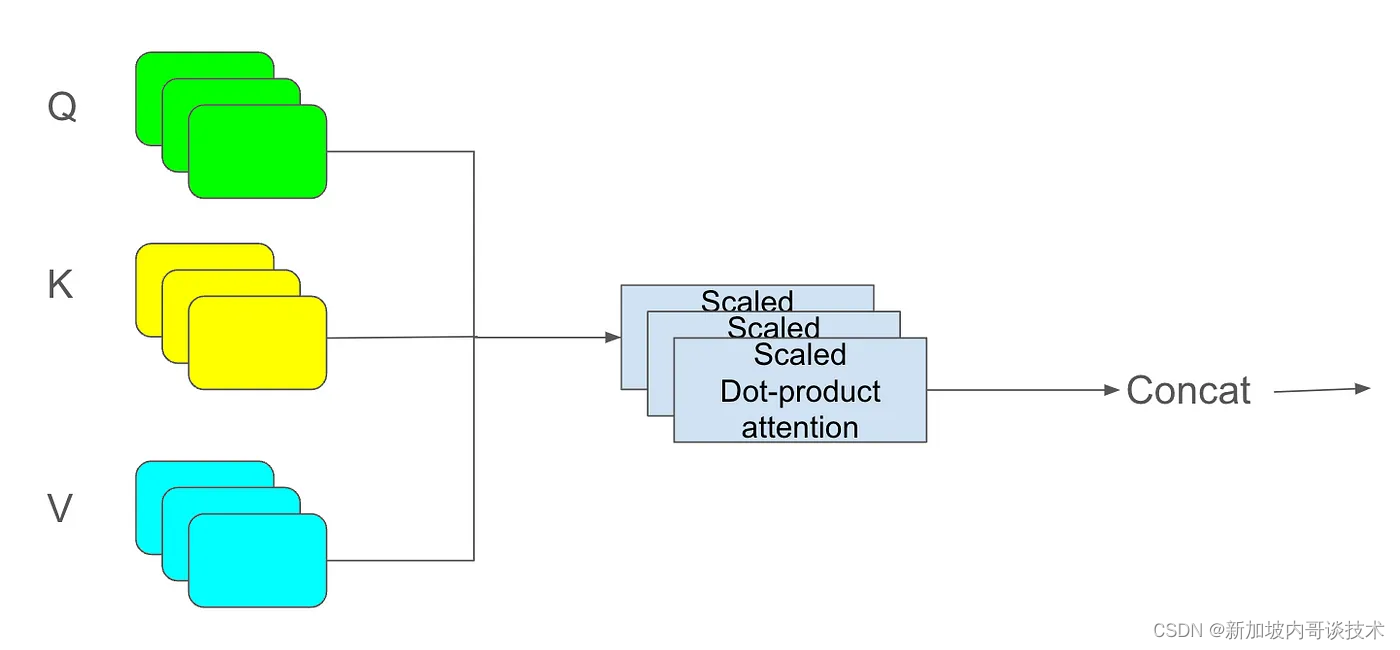
一起学习:大型语言模型(LLM)中的QKV(Query, Key, Value)和多头注意力机制
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
认识“DRESS”:通过自然语言反馈与人类协调和互动的大视觉语言模型 (LVLM)
大视觉语言模型(LVLM)可以解释视觉线索并为用户交互提供简单的答复。这是通过巧妙地将大型语言模型 (LLM) 与大规模视觉指令微调融合来实现的。然而,LVLM 只需要手工制作或 LLM 生成的数据集即可通过监督微调 (SFT) 进行对齐。尽管将 LVLM 从…
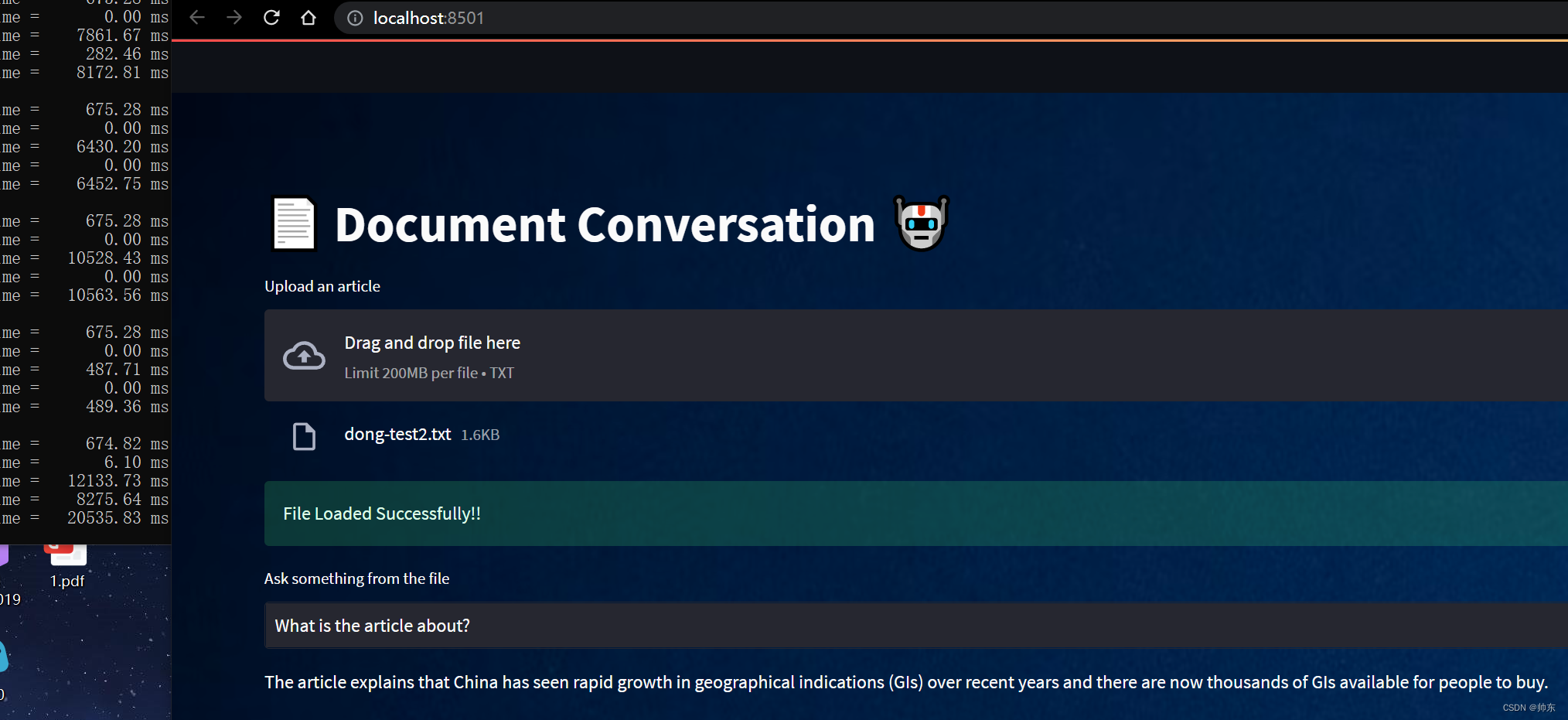
本地搭建【文档助手】大模型版(LangChain+llama+Streamlit)
概述
本文的文档助手就是:我们上传一个文档,然后在对话框中输入问题,大模型会把问题的答案返回。
安装步骤
先下载代码到本地
LangChain调用llama模型的示例代码:https://github.com/afaqueumer/DocQA(代码不是本人…
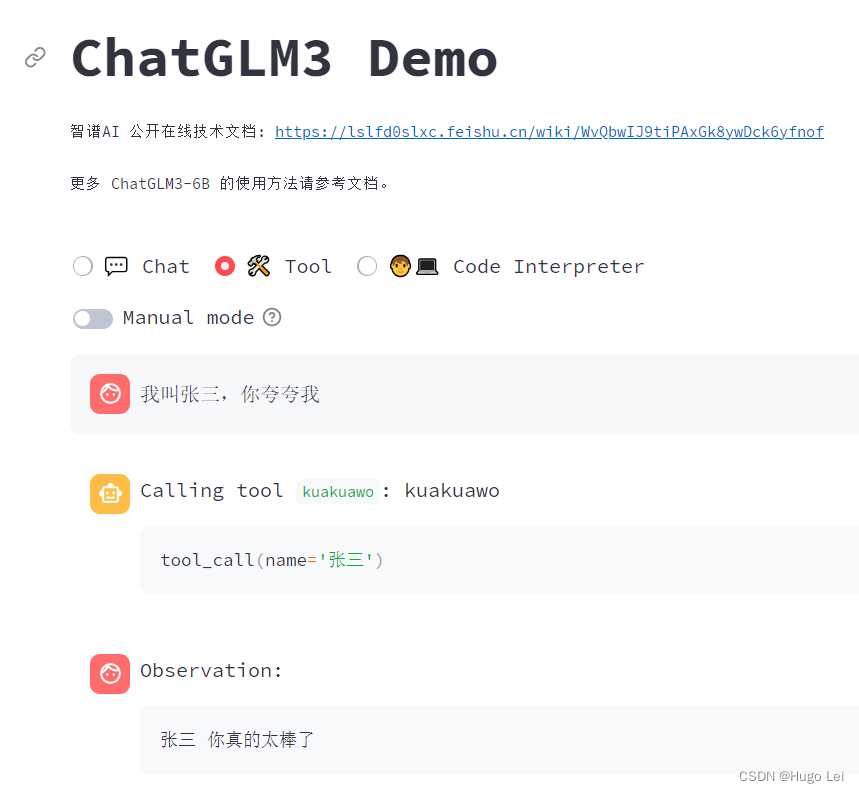
LLM大语言模型(三):使用ChatGLM3-6B的函数调用功能前先学会Python的装饰器
目录 ChatGLM3-6B的函数调用模式示例
本地启动ChatGLM3-6B工具模式
如何在ChatGLM3-6B里新增一个自定义函数呢?
get_weather基于Python的装饰器实现
函数注解register_tool
现在我们来自定义一个kuakuawo()函数 ChatGLM3-6B的函数调用模式示例
ChatGLM3-6B目前…
第33期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…

Nature | 大型语言模型(LLM)能够发现和产生新知识吗?
大型语言模型(LLM)是基于大量数据进行预训练的超大型深度学习模型。底层转换器是一组神经网络,这些神经网络由具有自注意力功能的编码器和解码器组成。编码器和解码器从一系列文本中提取含义,并理解其中的单词和短语之间的关系。通…

高级RAG(三):llamaIndex从小到大的检索
在上一篇博客:父文档检索器 中我们介绍了langchain中的两种父文档检索方式即:“检索完整文档”和“检索较大的文档块”。今天我们要介绍llamaIndex中与langchain的父文档检索有点相似的检索方法即“从小到大的检索”。
一、LlamaIndex 简介
LlamaIndex…
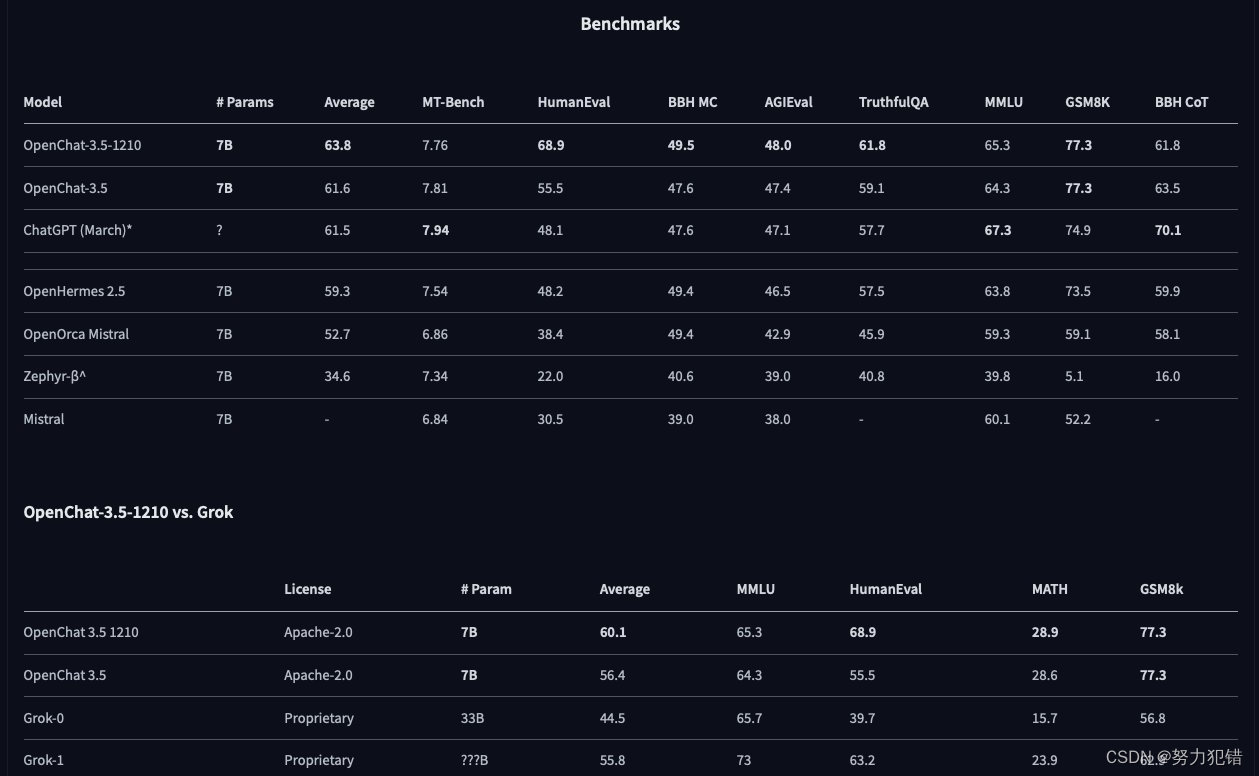
OpenChat-3.5:70亿参数下的AI突破
引言
在对话AI的发展史上,OpenChat-3.5标志着一个新纪元的到来。拥有70亿参数的这一模型,不仅是对现有语言学习模型(LLMs)的重大改进,更是在多模态任务中树立了新的标准。
模型概述
OpenChat-3.5作为一款先进的多模…
游戏NPC智能化:生成式AI如何改变虚拟世界
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
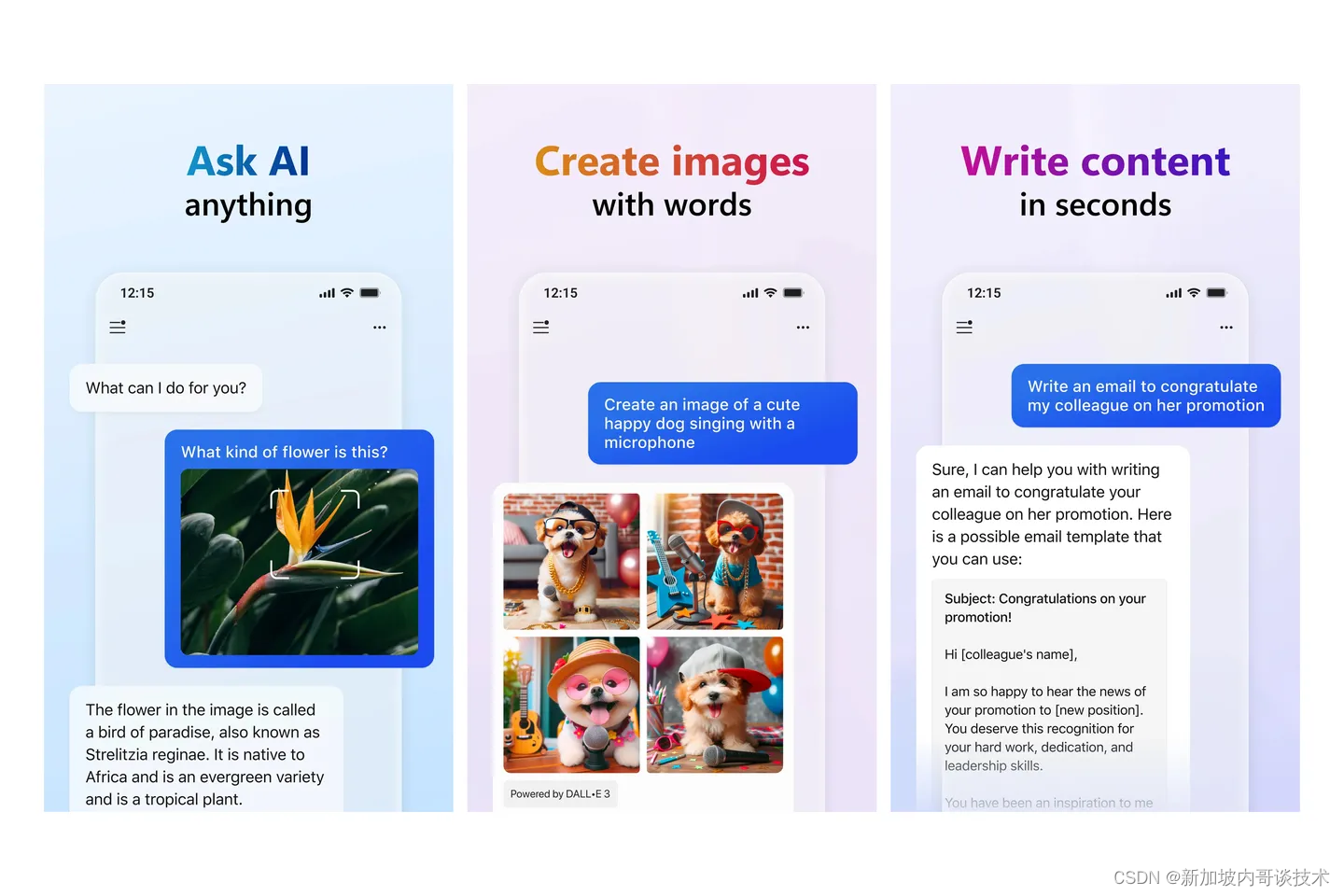
微软的 Copilot 已经如同 ChatGPT 一样,成为了安卓平台上的一款应用程序
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
用通俗易懂的方式讲解大模型:使用 Docker 部署大模型的训练环境
之前给大家介绍了主机安装方式——如何在 Ubuntu 操作系统下安装部署 AI 环境,但随着容器化技术的普及,越来越多的程序以容器的形式进行部署,通过容器的方式不仅可以简化部署流程,还可以随时切换不同的环境。
实际上很多云服务厂…

AI人工智能大模型讲师叶梓《基于人工智能的内容生成(AIGC)理论与实践》培训提纲
【课程简介】
本课程介绍了chatGPT相关模型的具体案例实践,通过实操更好的掌握chatGPT的概念与应用场景,可以作为chatGPT领域学习者的入门到进阶级课程。 【课程时长】
1天(6小时/天) 【课程对象】
理工科本科及以上࿰…

从入门到精通UNet: 让你快速掌握图像分割算法
文章目录 一、UNet 算法简介1.1 什么是 UNet 算法1.2 UNet 的优缺点1.3 UNet 在图像分割领域的应用 二、准备工作2.1 Python 环境配置2.2 相关库的安装 三、数据处理3.1 数据的获取与预处理3.2 数据的可视化与分析 四、网络结构五、训练模型5.1 模型训练流程5.2 模型评估指标5.…

LLM应用的分块策略
每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号 原文标题:Chunking Strategies for LLM Applications
原文地址:https://www.pinecone.io/learn/c…

OpenAI官方发布ChatGPT 提示词指南,六大策略让你玩转大语言模型!
OpenAI前段时间官方放出了自己的提示工程指南,从大模型小白到开发者,都可以从中消化出不少营养。看看全世界最懂大模型的人,是怎么写提示词的。官方给出了6 个大提示策略: 1、清晰的指令:
告诉AI你具体想要什么。比如…
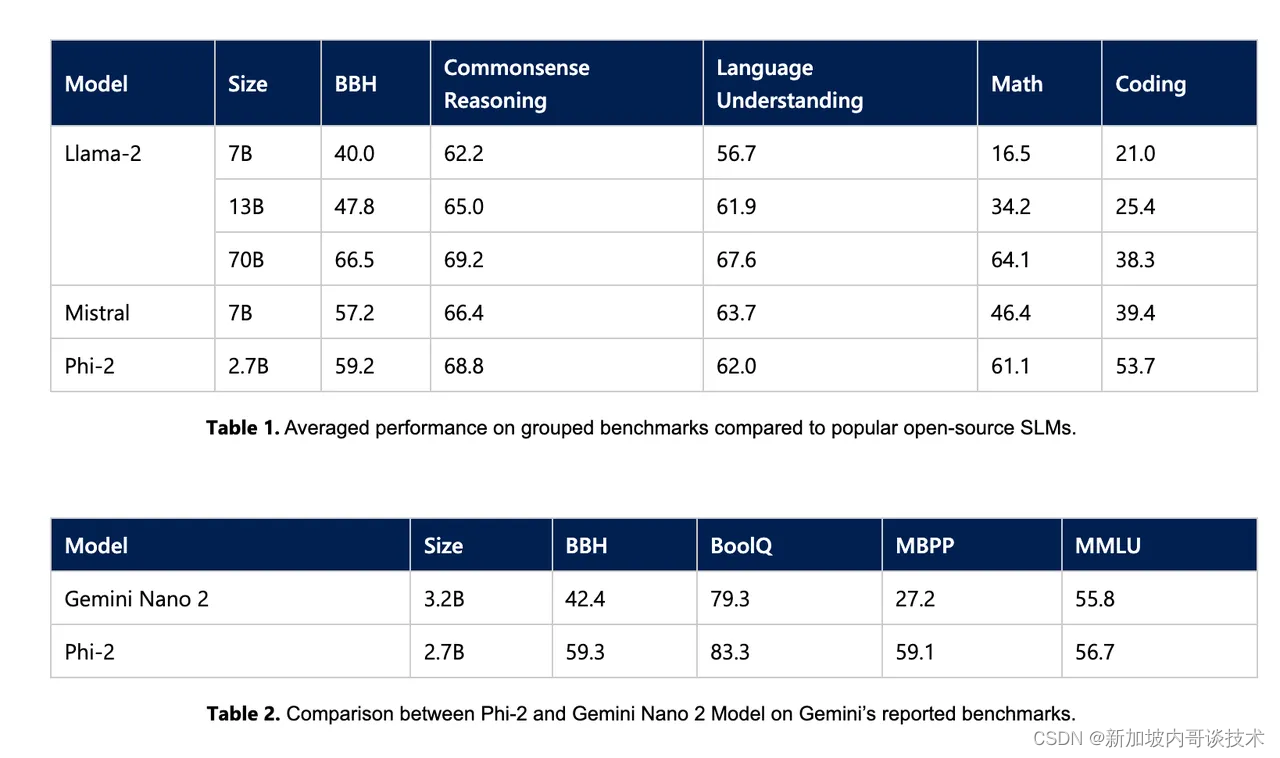
微软近日推出了Phi-2,这是一款小型语言模型,但其性能却十分强大
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
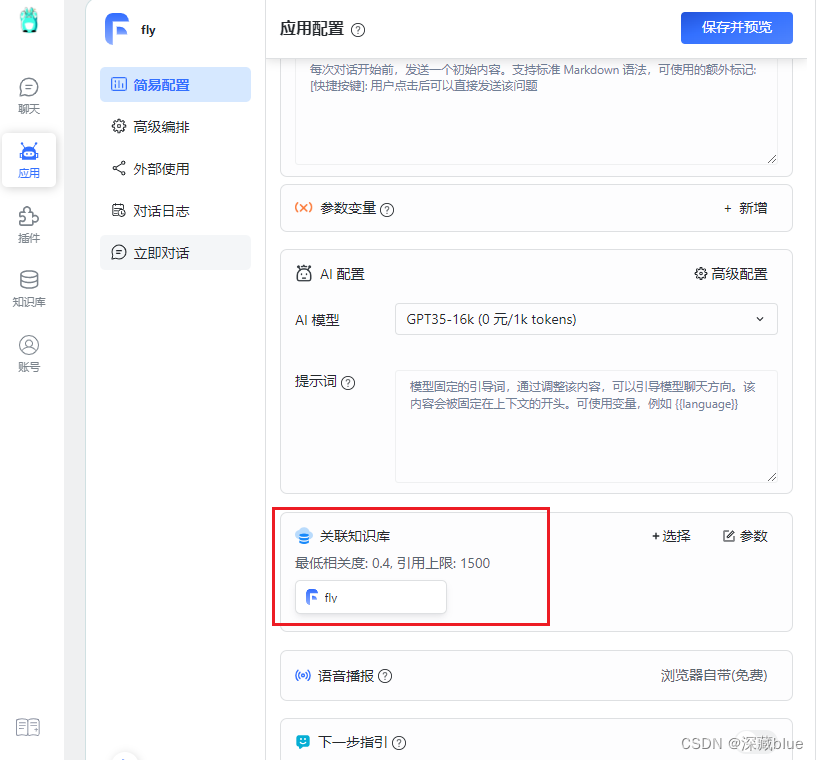
FastGPT+ChatGLM3-6b搭建知识库
前言:我用fastgpt直接连接chatglm3,没有使用oneai,不是很复杂,只需要对chatglm3项目代码做少量修改就能支持使用embeddings,向量模型用的m3e,效果还可以 我的配置: 处理器:i5-13500 …
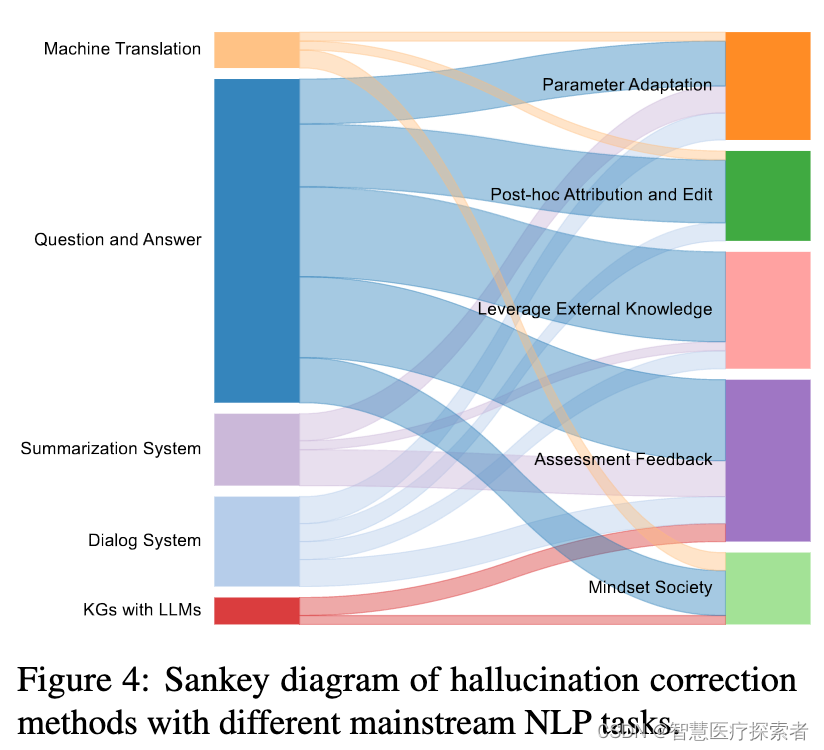
AIGC:大语言模型LLM的幻觉问题
引言
在使用ChatGPT或者其他大模型时,我们经常会遇到模型答非所问、知识错误、甚至自相矛盾的问题。
虽然大语言模型(LLMs)在各种下游任务中展示出了卓越的能力,在多个领域有广泛应用,但存在着幻觉的问题:…
使用Mamba和Qdrant数据库实现RAG的代码示例
Mamba挑战了Transformers设定的传统规范,特别是在处理长序列方面。Mamba以其选择性状态空间脱颖而出,融合了lstm的适应性和状态空间模型的效率。
我们今天来研究一下RAG、Mamba和Qdrant的协同工作,它们的有效组合保证了效率和可扩展性。 Mam…

ICLR 2024 | Mol-Instructions: 面向大模型的大规模生物分子指令数据集
发表会议:ICLR 2024 论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models 论文链接:https://arxiv.org/pdf/2306.08018.pdf 代码链接:https://github.com/zjunlp/Mol-Instruct…

教授LLM思考和行动:ReAct提示词工程
ReAct:论文主页
原文链接:Teaching LLMs to Think and Act: ReAct Prompt Engineering 在人类从事一项需要多个步骤的任务时,而步骤和步骤之间,或者说动作和动作之间,往往会有一个推理过程。让LLM把内心独白说出来&am…

EMNLP 2023精选:Text-to-SQL任务的前沿进展(上篇)——正会论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略…

论文阅读-Transformer-based language models for software vulnerability detection
「分享了一批文献给你,请您通过浏览器打开 https://www.ivysci.com/web/share/biblios/D2xqz52xQJ4RKceFXAFaDU/ 您还可以一键导入到 ivySCI 文献管理软件阅读,并在论文中引用 」 本文主旨:本文提出了一个系统的框架来利用基于Transformer的语…

使用 LoRA 在 viggo 数据集上微调 Microsoft phi-2 小语言模型
一、说明 Microsoft 的基于 Transformer 的小语言模型。它可以根据 MIT 许可在HuggingFace上使用。 它在 96 个 A100 GPU 上使用 1.4T 令牌进行了 14 天的训练。Phi-2 是一个 27 亿个参数的预训练 Transformer,不使用 RLHF 或指示微调。它进行下一个标记预测&#x…

NLP_语言模型的雏形 N-Gram 模型
文章目录 N-Gram 模型1.将给定的文本分割成连续的N个词的组合(N-Gram)2.统计每个N-Gram在文本中出现的次数,也就是词频3.为了得到一个词在给定上下文中出现的概率,我们可以利用条件概率公式计算。具体来讲,就是计算给定前N-1个词时࿰…
OpenAI使用的海量数据集介绍
1. OpenAI使用的数据
OpenAI为了训练其尖端的自然语言处理模型,如GPT-4,采用了极为庞大的数据集。虽然具体的细节可能不完全公开,但我们可以根据历史信息和公开报道推测,这些数据集通常包含: WebText:早期…
开源大型语言模型概览:多语种支持与中文专注
开源大型语言模型概览:多语种支持与中文专注 开源大型语言模型概览:多语种支持与中文专注什么是大型语言模型如何工作大型语言模型的发展应用领域 开源大语言模型概览支持多种语言的开源LLMsLLaMA(由Meta开发)BERT(由G…
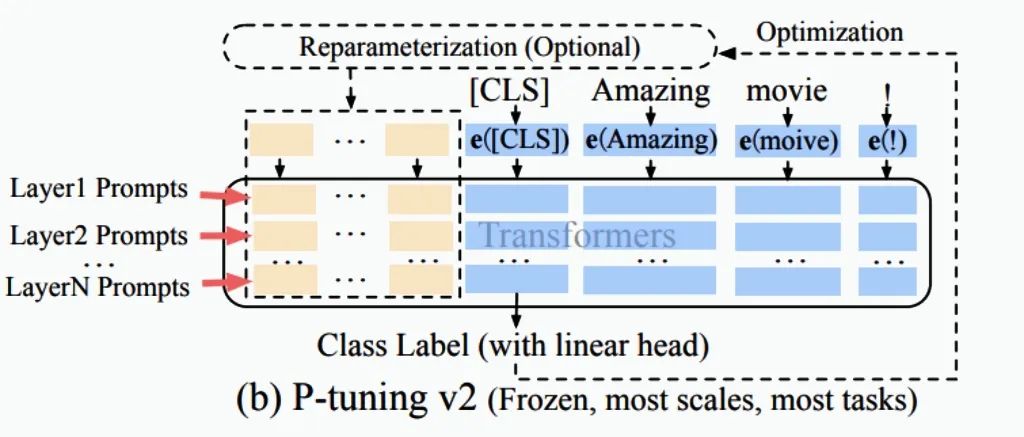
大语言模型LLM微调技术:P-Tuning
1 引言
Bert时代,我们常做预训练模型微调(Fine-tuning),即根据不同下游任务,引入各种辅助任务loss和垂直领域数据,将其添加到预训练模型中,以便让模型更加适配下游任务的方式。每个下游任务都存…

【LLM】大型语言模型:2023年完整指南
Figure 1: Search volumes for “large language models”
近几个月来,大型语言模型(LLM)引起了很大的轰动(见图1)。这种需求导致了利用语言模型的网站和解决方案的不断开发。ChatGPT在2023年1月创下了用户群增长最快…
2024 年初的大语言模型编程实践
首先我要明确,这篇文章并不旨在回顾大语言模型。显而易见,2023 年对人工智能来说是不平凡的一年,再去强调这一点似乎没有多大必要。这篇文章更多是作为一位程序员的个人体验分享。自从 ChatGPT 出现,再到使用本地运行的大语言模型…

Prompt提示工程上手指南:基础原理及实践(一)
想象一下,你在装饰房间。你可以选择一套标准的家具,这是快捷且方便的方式,但可能无法完全符合你的个人风格或需求。另一方面,你也可以选择定制家具,选择特定的颜色、材料和设计,以确保每件家具都符合你的喜…

首次引入大模型!Bert-vits2-Extra中文特化版40秒素材复刻巫师3叶奈法
Bert-vits2项目又更新了,更新了一个新的分支:中文特化,所谓中文特化,即针对中文音色的特殊优化版本,纯中文底模效果百尺竿头更进一步,同时首次引入了大模型,使用国产IDEA-CCNL/Erlangshen-Megat…

用通俗易懂的方式讲解:万字长文带你入门大模型
告别2023,迎接2024。大模型技术已成为业界关注焦点,你是否也渴望掌握这一领域却又不知从何学起?
本篇文章将特别针对入门新手,以浅显易懂的方式梳理大模型的发展历程、核心网络结构以及数据微调等关键技术。
如果你在阅读中收获…
LLaMA Efficient Tuning
文章目录 LLaMA Efficient Tuning安装 数据准备浏览器一体化界面单 GPU 训练 train_bash1、预训练 pt2、指令监督微调 sft3、奖励模型训练 rm4、PPO 训练 ppo5、DPO 训练 dpo 多 GPU 分布式训练1、使用 Huggingface Accelerate2、使用 DeepSpeed 导出微调后的模型 export_model…
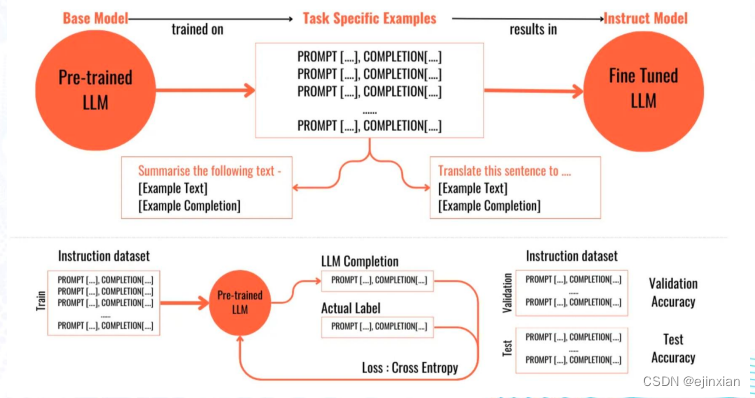
大语言模型(LLM)框架及微调 (Fine Tuning)
大语言模型(LLM) 技术作为人工智能领域的一项重要创 新在今年引起了广泛的关注。 LLM 是利用深度学习和大数据训练的人工智能系统,专门 设计来理解、生成和回应自然语言。这些模型通过分析大量 的文本数据来学习语言的结构和用法,…
【LLM】人工智能应用构建的十大预训练NLP语言模型
在人工智能领域,自然语言处理(NLP)被广泛认为是阅读、破译、理解和理解人类语言的最重要工具。有了NLP,机器可以令人印象深刻地模仿人类的智力和能力,从文本预测到情感分析再到语音识别。
什么是自然语言处理…

Embedding模型在大语言模型中的重要性
引言
随着大型语言模型的发展,以ChatGPT为首,涌现了诸如ChatPDF、BingGPT、NotionAI等多种多样的应用。公众大量地将目光聚焦于生成模型的进展之快,却少有关注支撑许多大型语言模型应用落地的必不可少的Embedding模型。本文将主要介绍为什么…
Fine-Tuning Language Models from Human Preferences
Abstract
奖励学习(reward learning)可以将强化学习(RL)应用到由人类判断定义奖励的任务中,通过询问人类问题来构建奖励模型。奖励学习的大部分工作使用了模拟环境,但是关于价值的复杂信息经常是以自然语言的形式表达的。我们相信语言奖励学习是使强化学习在现实世界任务…
如何通过 API 将大语言模型集成到自己的应用程序中
在现代应用程序开发中,利用强大的大语言模型为应用程序增加智能和自然语言处理能力已经成为一种趋势。通过使用开放接口(API),开发人员可以轻松地将这些大语言模型集成到自己的应用程序中,从而提升用户体验并增加功能的…
学术写作|第二篇论文写作记录|GPT4论文润色Prompt
本文目录 写作时间安排如何写出初稿?找谁修改?1. 找AI修改2. 找师姐、师兄、老师、同行/外行修改论文修改意见集锦(反复观看)最好用的GPT4指令禁止转载,未经允许的任何引用。
写作时间安排
第二篇工作的idea去年就想出来了,一直被其他事情干扰,错过了N个会议… 在寒假…
清华裴丹|大模型时代的AIOps
在大模型时代下,运维界普遍关注一些问题:大模型能带来哪些收益?面临哪些技术挑战?与以往的 AIOps小模型是什么关系?有了大模型之后,那么AIOps的整体框架是什么?近期、中期、长期有哪些应用&…

VideoPoet: Google的一种用于零样本视频生成的大型语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…


【论文阅读】GPT4Graph: Can Large Language Models Understand Graph Structured Data?
文章目录 0、基本介绍1、研究动机2、准备2.1、图挖掘任务2.2、图描述语言(GDL) 3、使用LLM进行图理解流程3.1、手动提示3.2、自提示 4、图理解基准4.1、结构理解任务4.1、语义理解任务 5、数据搜集5.1、结构理解任务5.2、语义理解任务 6、实验6.1、实验设…
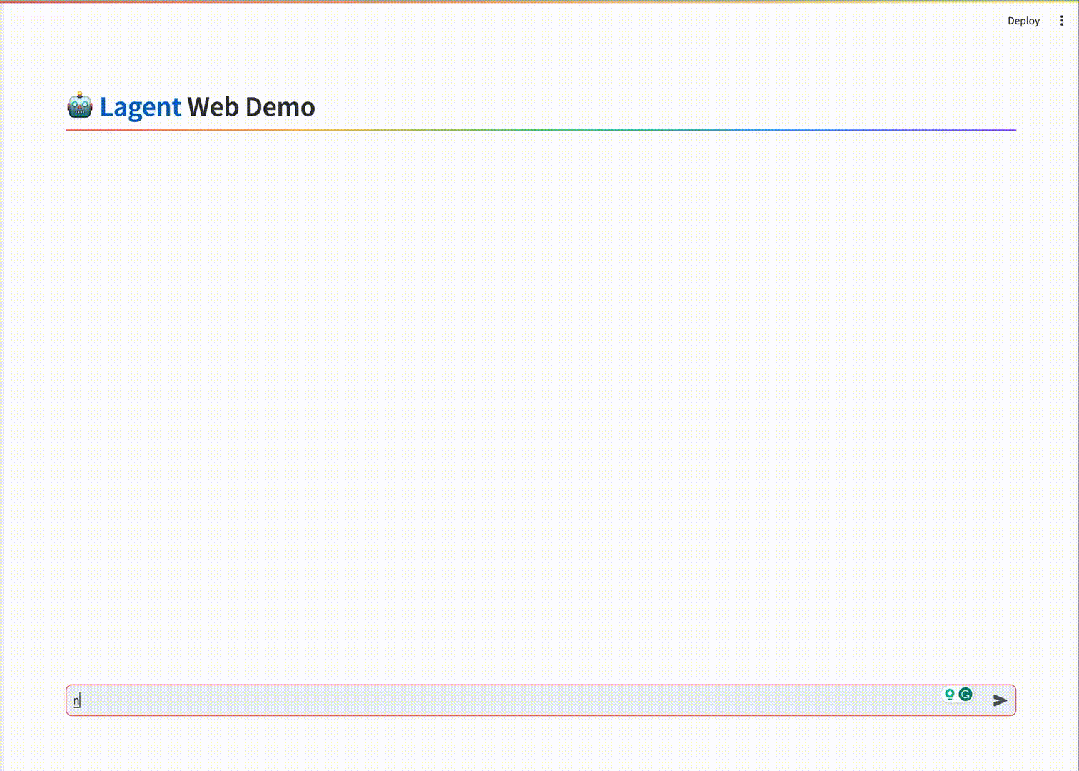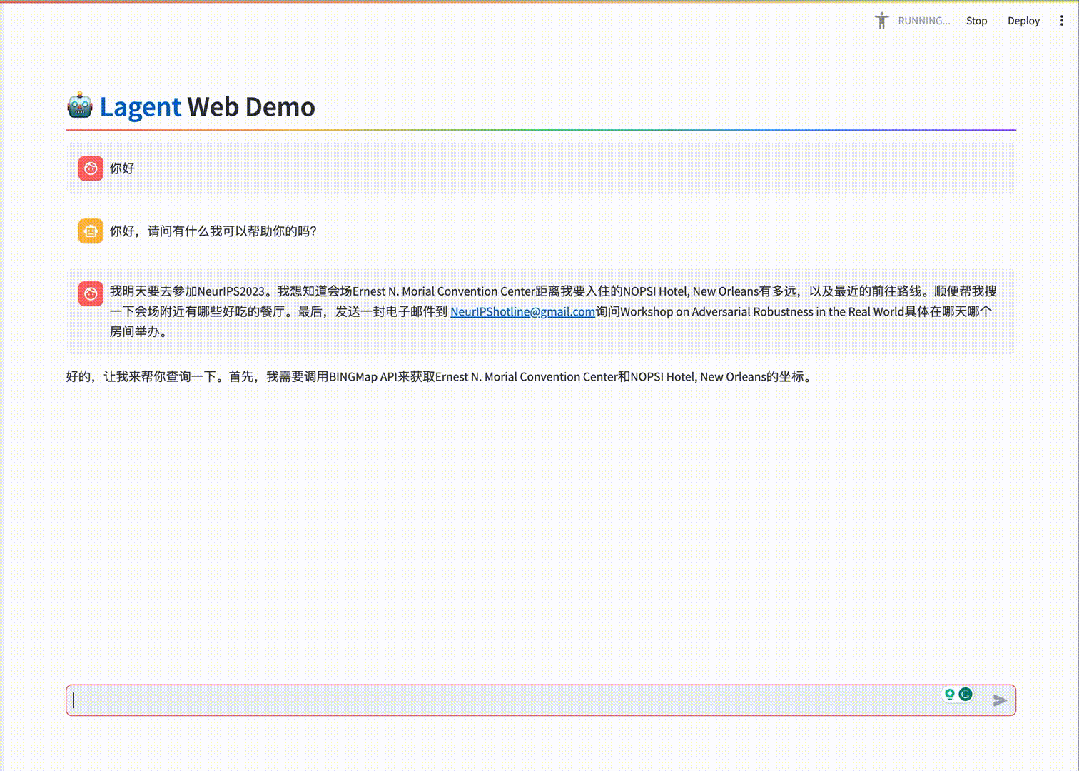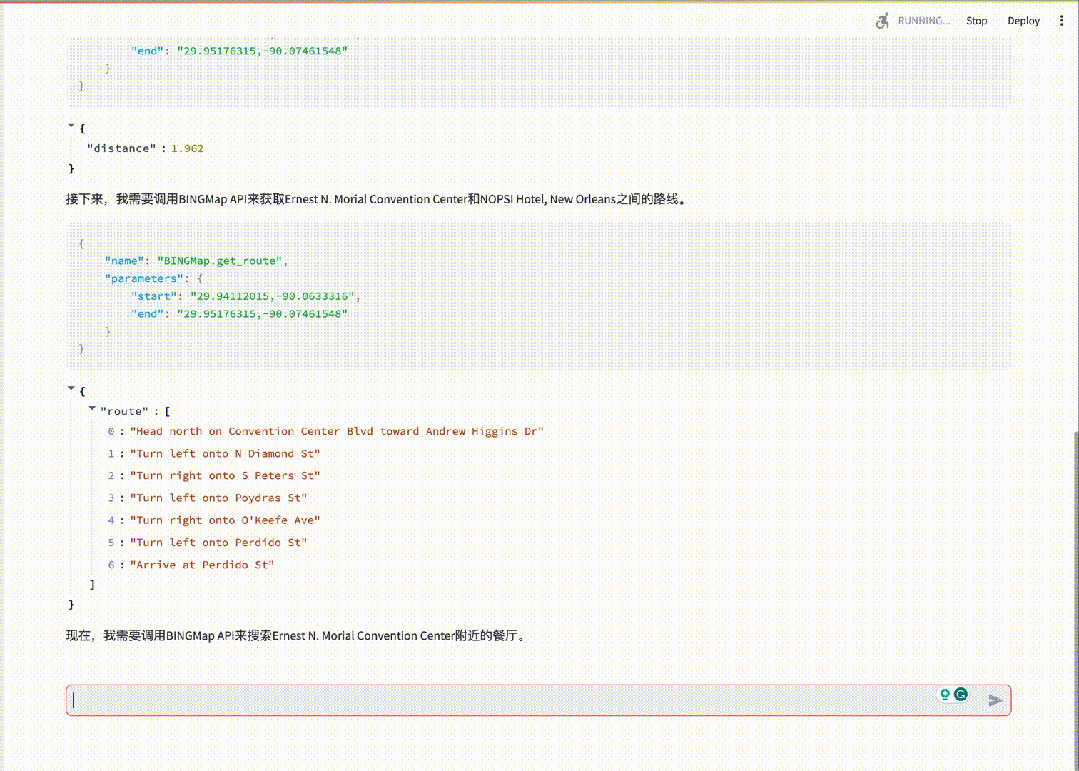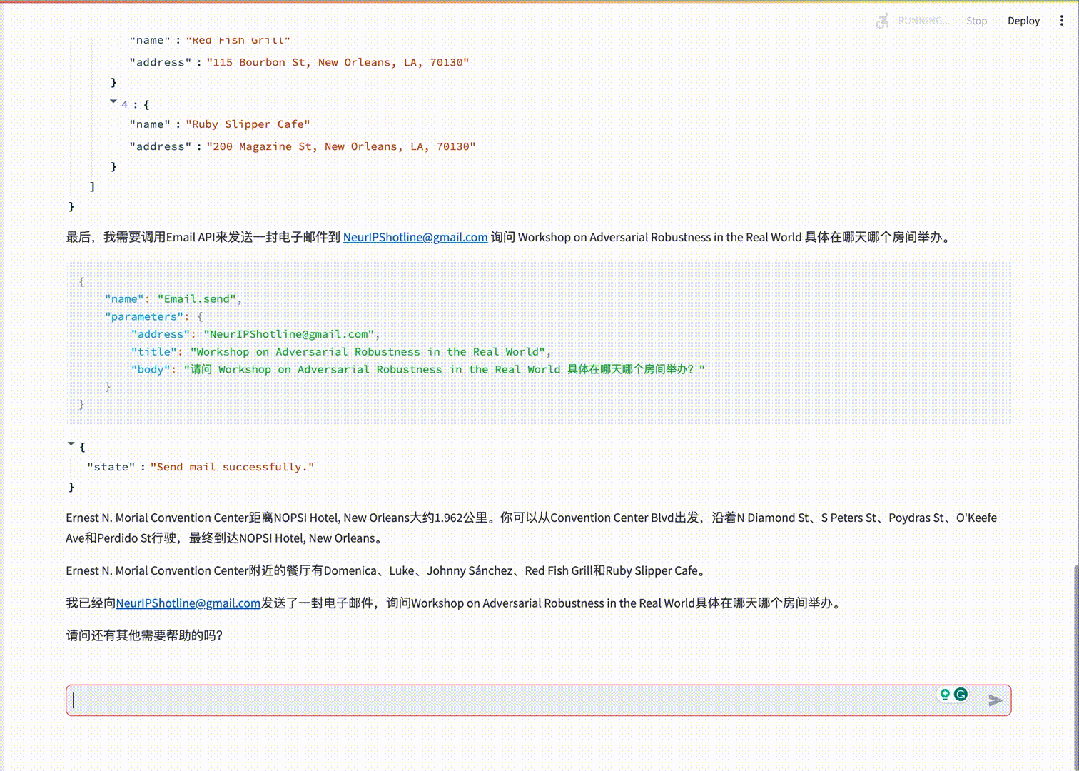
国产AI新篇章:书生·浦语2.0带来200K超长上下文解决方案
总览:大模型技术的快速演进
自2023年7月6日“书生浦语”(InternLM)在世界人工智能大会上正式开源以来,其在社区和业界的影响力日益扩大。在过去半年中,大模型技术体系经历了快速的演进,特别是100K级别的长…

构建用于预警大型语言模型辅助生物威胁创建的系统
深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 。 Op…
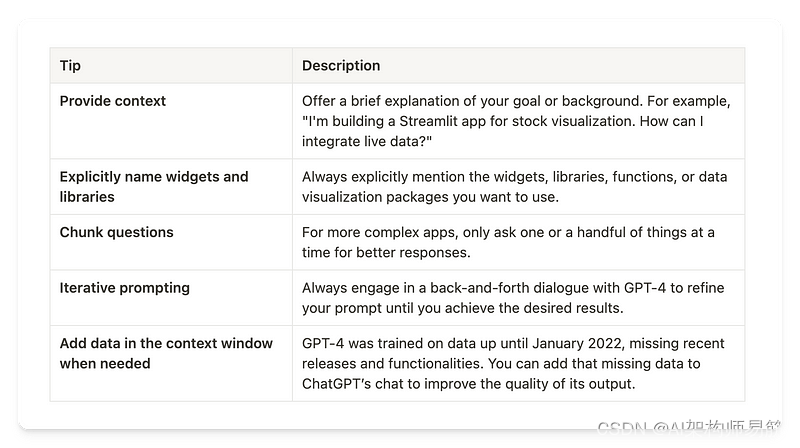
翻译: 使用 GPT-4 将您的 Streamlit 应用程序提升到一个新的水平一
帮助您更快地设计、调试和优化 Streamlit 应用的专业技巧
设计和扩展 Streamlit 应用程序可能是一项艰巨的任务!作为开发人员,我们经常面临一些挑战,例如设计良好的 UI、快速调试我们的应用程序以及快速制作它们。
如果有一个工具可以加快速…

书生·浦语大模型实战营——两周带你玩转微调部署评测全链路
引言
人工智能技术的发展日新月异,其中大模型的发展尤其迅速,已然是 AI 时代最炙手可热的当红炸子鸡。
然而,大模型赛道对于小白开发者来说还是有不小的门槛。面对内容质量参差不齐的课程和实际操作中遇到的问题,许多开发者往往…
什么是大语言模型的Token
我们来用一个简单的比喻来解释什么是大语言模型的Token。
你可以把Token想象成是一种“语言的货币”。当我们说话或者写作时,会用到很多不同的词、标点和其他符号来组成我们的语句。在大语言模型中,这些词、标点和符号都需要被转换成一种标准化的格式&a…

基于大语言模型LangChain框架:知识库问答系统实践
ChatGPT 所取得的巨大成功,使得越来越多的开发者希望利用 OpenAI 提供的 API 或私有化模型开发基于大语言模型的应用程序。然而,即使大语言模型的调用相对简单,仍需要完成大量的定制开发工作,包括 API 集成、交互逻辑、数据存储等…
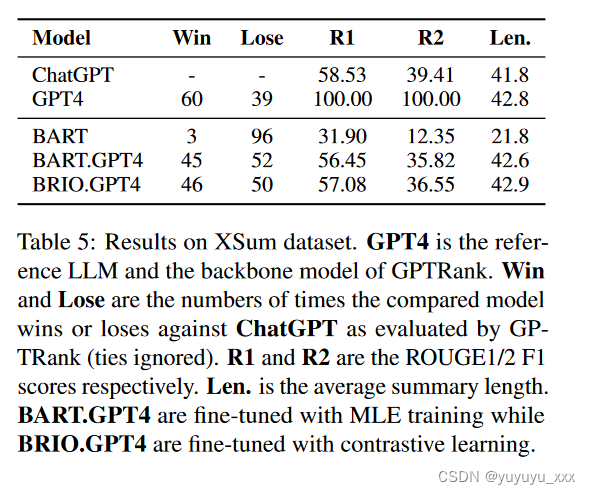
NLP论文阅读记录 - 以大语言模型为参考学习总结
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1文本生成模型的训练方法2.2 基于LLM的自动评估2.3 LLM 蒸馏和基于 LLM 的数据增强 三.本文方法3.1 Summarize as Large Language Models3.1.1 前提3.1.2 大型语言模型作为参考具有…
讯飞星火认知大模型智能语音交互调用
随着国内外大模型热度的兴起,依托于大模型的智能化,传统的人机交互已经不能满足人们交互的需求。而结合语音和大模型的交互拜托传统互联网获取知识的文字限制,用语音也可以轻松获取想要的知识和思路。
一、大模型智能语音交互调用实现思路
…
FinGPT:金融大语言模型 | 开源日报 No.127
verdaccio/verdaccio
Stars: 15.0k License: MIT Verdaccio 是一个轻量级的 Node.js 私有代理仓库。
以下是 Verdaccio 的核心优势和关键特性:
零配置:无需复杂设置即可快速启动私有 npm 注册表。本地化管理:通过内置小型数据库进行简单而…
国内外十大语言模型横向对比测评(截至2023.12.8)
主要参考资料: B站Up主贯一智能科技《国内外十大语言模型之横向对比测评》 现在有非常多的开源测试数据集,比如MMLU、AGIEval、CEval 但是根据Up主描述比较费时成本高,其次这类标准化评测更多考察模型在各个学科和领域的综合表现,…

2024年,谷歌云首席技术官眼中的生成AI三大支柱,来看看有啥新花样
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

高质量训练数据助力大语言模型摆脱数据困境 | 景联文科技
目前,大语言模型的发展已经取得了显著的成果,如OpenAI的GPT系列模型、谷歌的BERT模型、百度的文心一言模型等。这些模型在文本生成、问答系统、对话生成、情感分析、摘要生成等方面都表现出了强大的能力,为自然语言处理领域带来了新的突破。 …

【文末送书】语义解析:连接自然语言与机器智能的桥梁
欢迎关注博主 Mindtechnist 或加入【智能科技社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。关…
以 LLM 为核心 LLM@Core:程序员的大语言模型技术指南
过去几个月里,我们对于大语言模型的一系列探索,如 ChatGPT 端到端实践与应用开发、LLaMA 与 ChatGLM 的微调试验、GitHub Copilot 逆向工程分析、动态上下文工程(即 LangChain)的研究,驱使着我去写一个总结,…
论文笔记--PANGU-α
论文笔记--PANGU-α: LARGE-SCALE AUTOREGRESSIVE PRETRAINED CHINESE LANGUAGE MODELS WITH AUTO-PARALLEL COMPUTATION 1. 文章简介2. 文章概括3 文章重点技术3.1 Transformer架构3.2 数据集3.2.1 数据清洗和过滤3.2.2 数据去重3.2.3 数据质量评估 4. 文章亮点5. 原文传送门6…
大语言模型的创意能力到底几何?探索从GPT-2到GPT-4的演进
编者按:大语言模型可以提供许多创意性内容,如写诗、写小说等。那么到底应该如何评估大语言模型生成的创意性内容的水平呢? 本文探讨了GPT-2到GPT-4的创造性,并分析了这些模型在不同创造性测试中的表现。作者使用了三种测试来衡量模…

谷歌最新医学领域LLM大模型:AMIE
2024年1月11日Google 研究院发布最新医疗大模型AMIE:用于诊断医学推理和对话的研究人工智能系统。 文章链接:Articulate Medical Intelligence Explorer (AMIE) giuthub:目前代码未开源
关于大模型之前有过一篇总结:大语言模型(L…
大语言模型向量数据库
大语言模型&向量数据库 LARGE LANGUAGE MODELSA. Vector Database & LLM WorkflowB. Vector Database for LLMC. Potential Applications for Vector Database on LLMD. Potential Applications for LLM on Vector DatabaseE. Retrieval-Based LLMF. Synergized Exampl…
AI模型理解误区:微调垂直行业-VS-企业专属知识库或AI助理
概述
企业定制私有化大模型的区别,分为训练大模型和调用大模型两种方向,以及企业自己的智能客服的实现方法。 - 企业定制的私有化大模型与一般的大模型不同,需要高成本训练。- 企业可以选择调用已经训练好的大模型来应用。- 企业可以使用向量…
用通俗易懂的方式讲解大模型:使用 LangChain 和大模型生成海报文案
最近看到某平台在推 LangChain 的课程,其中有个示例是让 LangChain 来生成图片的营销文案,我觉得这个示例挺有意思的,于是就想自己实现一下,顺便加深一下 LangChain 的学习。 今天就介绍一下如何使用 LangChain 来实现这个功能&am…
翻译: Streamlit从入门到精通 部署一个机器学习应用程序 四
Streamlit从入门到精通 系列:
翻译: Streamlit从入门到精通 基础控件 一翻译: Streamlit从入门到精通 显示图表Graphs 地图Map 主题Themes 二翻译: Streamlit从入门到精通 构建一个机器学习应用程序 三
1. 5. 如何部署一个Streamlit应用
部署是将应用程序从开发…

论文浅尝 | 在图上思考:基于知识图谱的深度且负责的大语言模型推理
笔记整理:孙硕硕,东南大学硕士,研究方向为自然语言处理 链接:https://arxiv.org/abs/2307.07697 1. 动机 本文的动机是大型语言模型在各种任务中取得了较大的进步,但它们往往难以完成复杂的推理,并且在知识…
LLM的参数微调、训练、推理;LLM应用框架;LLM分布式训练
大模型基础 主流的开源大模型有哪些? GPT-3:由 OpenAI 开发,GPT-3 是一个巨大的自回归语言模型,拥有1750亿个参数。它可以生成文本、回答问题、翻译文本等。GPT-Neo:由 EleutherAI 开发,GPT-Neo 是一个开源…
WhisperFusion:具有超低延迟无缝对话功能的AI系统
WhisperFusion 基于 WhisperLive 和 WhisperSpeech 的功能而构建,在实时语音到文本管道之上集成了大型语言模型 Mistral (LLM)。
LLM 和 Whisper 都经过优化,可作为 TensorRT 引擎高效运行,从而最大限度地提高性能和实时处理能力。WhiperSpe…
01.大型语言模型背后的基本概念的高级解释 (LLMs)
像 ChatGPT 这样的大型语言模型 (LLMs) 是过去几年开发的深度神经网络模型。他们开创了自然语言处理(NLP)的新时代。在大型语言模型出现之前,传统方法擅长分类任务,例如垃圾邮件分类和简单的模式识别,这些任务可以通过手工制定的规则或更简单的模型来捕获。然而,它们通…

NLP_神经概率语言模型(NPLM)
文章目录 NPLM的起源NPLM的实现1.构建实验语料库2.生成NPLM训练数据3.定义NPLM4.实例化NPLM5.训练NPLM6.用NPLM预测新词 NPLM小结 NPLM的起源
在NPLM之前,传统的语言模型主要依赖于最基本的N-Gram技术,通过统计词汇的共现频率来计算词汇组合的概率。然而…
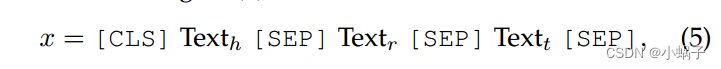
Unifying Large Language Models and Knowledge Graphs: A Roadmap
5.2 LLM-augmented KG Completion 知识图谱补全(KGC)是指对给定知识图谱中缺失的事实进行推断的任务。与KGE类似,传统的KGC方法主要关注于KG的结构,而没有考虑广泛的文本信息。然而,最近llm的集成使KGC方法能够对文本进行编码或生成事实,以获得更好的KGC性能。这些方法根据…

【论文阅读】LLM4GCL: CAN LARGE LANGUAGE MODEL EM-POWER GRAPH CONTRASTIVE LEARNING?
文章目录 0、基本信息1、研究动机2、创新点2.1、LLM-as-GraphAugmentor2.2、LLM-as-TextEncoder 3、准备3.1、文本属性图3.2、图神经网络3.3、文本属性图上的对比学习 4、LLM4GCL4.1、LLM v.s. Graph Augmentor4.1.1、LLM对特征增广4.1.2、LLM对结构增广 4.2、LLM作为文本编码器…
如何使用Hugging Face微调大语言模型(LLMs)
大语言模型(LLMs)在过去一年取得了显著进步。从ChatGPT爆发以来,后来逐步发展了众多开源大模型LLMs,如Meta AI的Llama 2、Mistrals Mistral & Mixtral模型,TII Falcon等。这些LLMs能够胜任多种任务,包括…
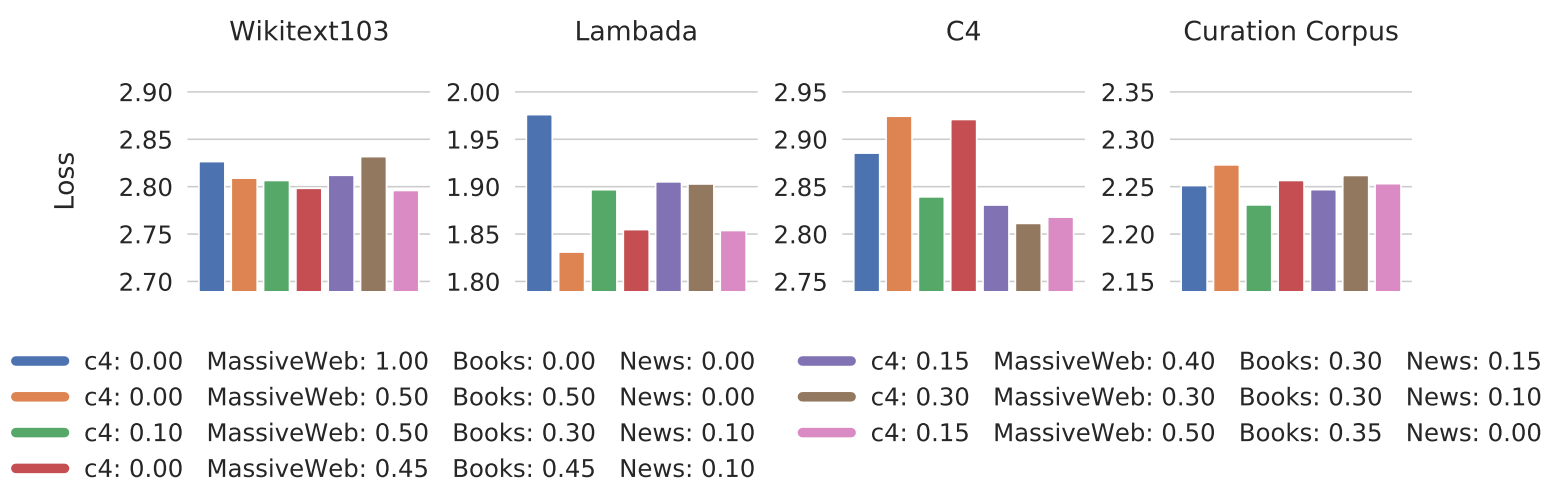
三个方面浅析数据对大语言模型的影响
由于大语言模型的训练需要巨大的计算资源,通常不可能多次迭代大语言模型预训练。千亿级参数量的大语言模型每次预训练的计算需要花费数百万元人民币。因此,在训练大语言模型之前,构建一个准备充分的预训练语料库尤为重要。 本篇文章中&#x…
“Morpheus-1”的全新人工智能模型声称能引发清醒梦境
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
从查字典到查网络再到查大语言模型
随着科技的发展,人们查找信息的方式也在不断演变。从过去的查字典,到查网络再到现在的查大语言模型,每一步的进化都为人们提供了更加便捷和准确的信息查询方式。 查字典:过去,人们需要查找某个词语的定义、释义、发音…
iOS 17.4 苹果公司正在加倍投入人工智能
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
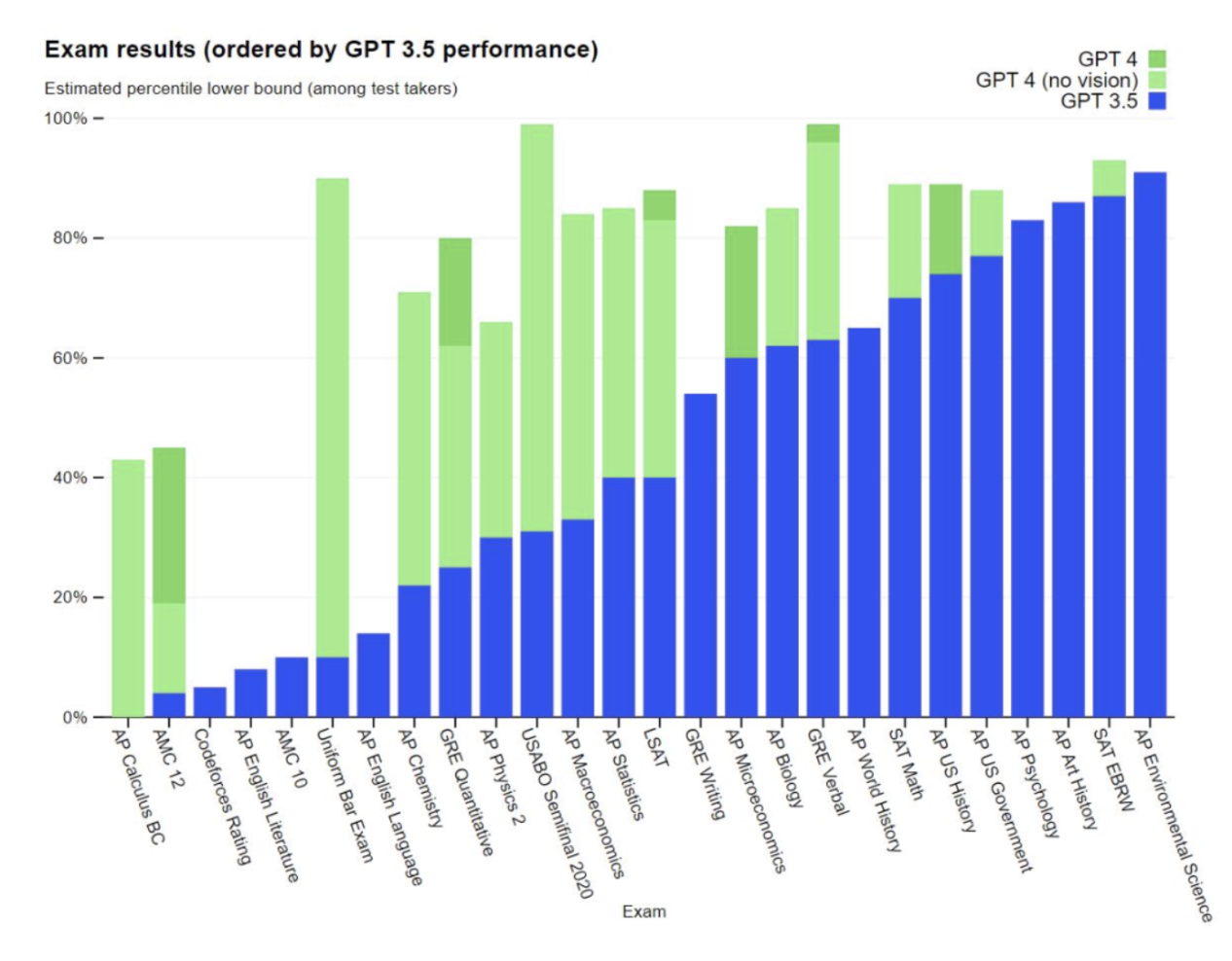
GPT-4重磅发布,它究竟厉害在哪?
3月14日,万众期待的GPT-4终于发布啦!千呼万唤始出来!GPT4是迄今为止最强大的模型GPT-4(Generative Pre-trained Transformer 4)是由OpenAI创建的多模态大型语言模型,是GPT系列的一员。官方说明,…


ChatGPT4 VS ChatGPT3.5:揭秘人工智能语言模型的技术革新
摘要:本文将详细介绍ChatGPT4与ChatGPT3.5之间的关键技术差异,解析为何ChatGPT4在诸多方面超越了ChatGPT3.5,以及这一领域的未来发展趋势。 一、引言 随着人工智能和自然语言处理技术的不断发展,智能对话机器人成为了越来越多人的…
python五十行代码批量下载热榜回答
前言
作为微调语言模型的一环,我们需要去网上搜集大量的文字资料,某网充满大量公开的高质量的问题和回答,适合用来训练。那么我们今天将下载它两年的热榜问题和回答。
思路
首先我们随便点进一个问题的回答,点击分享࿰…
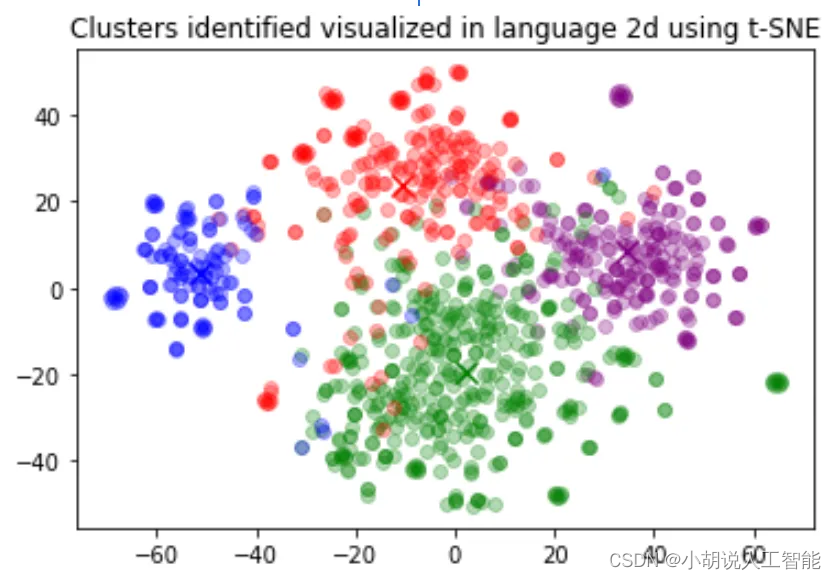
OpenAI-ChatGPT最新官方接口《嵌入向量式文本转换》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(五)(附源码)
Embeddings 嵌入向量式文本转换前言Overview 概述What are embeddings? 什么是嵌入?How to get embeddings 如何获取嵌入python代码示例cURL代码示例Embedding models 嵌入模型Second-generation models 第二代模型First-generation models (not recommended) 第一…

【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成的代码大语言模型
CodeGen:一个用于多轮程序合成的代码大语言模型 《Code Gen: An Open Large Language Model For Code with Multi-Turn Program Synthesis》 论文地址:https://arxiv.org/pdf/2203.13474.pdf?trkpublic_post_comment-text 相关博客 【自然语言处理】【大…

带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性
带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性 1.什么是语言模型?
大家或多或少都听过 ChatGPT 是一个 LLMs,那 LLMs 是什么?LLMs 全称是 Large Language…
ChatGPT“保姆级教程”——手把手教你1分钟快速制作思维导图(Markmap/Xmind+Markdown)
目录 前言使用ChatGPT生成markdown格式主题Markmap Markdown使用Markmap生成思维导图 Xmind Markdown使用Xmind生成思维导图 建议其它资料下载 前言
思维导图是一种强大的工具,它可以帮助我们整理和展现复杂的思维结构,提升我们的思考能力和组织能力。…
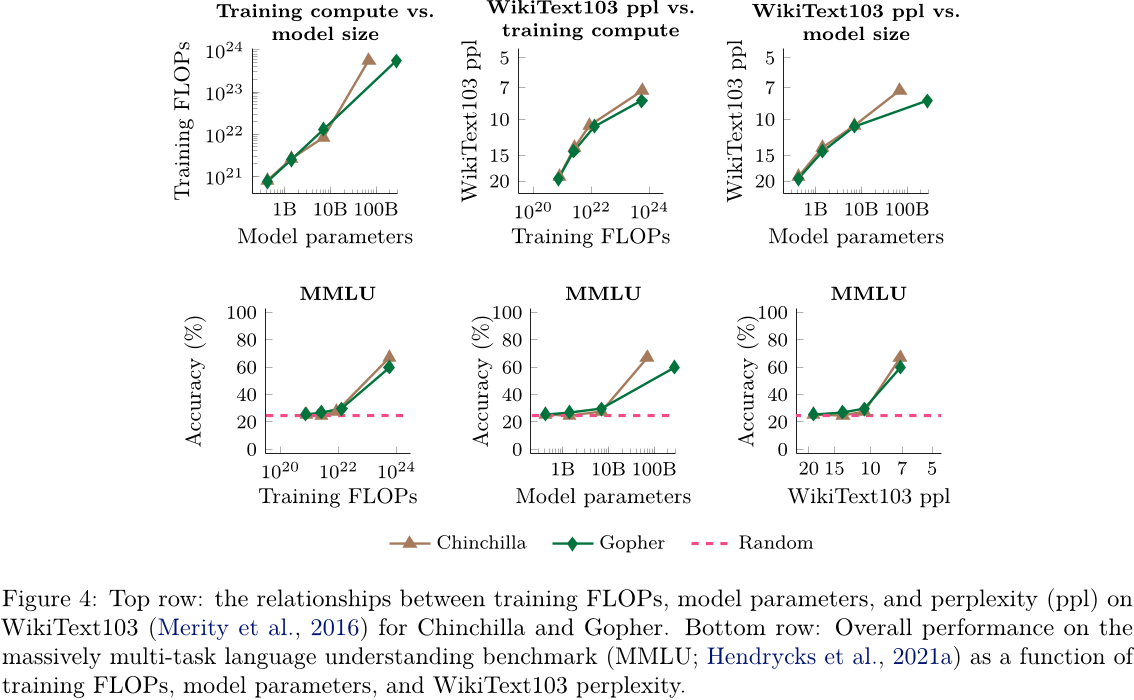
Emergent Abilities of Large Language Models 机翻mark
摘要
证明通过扩大语言模型可以可靠地提高性能和样本效率在广泛的下游任务。相反,本文讨论了我们称之为大型语言模型的新兴能力的一种不可预测的现象。我们认为如果一个能力不存在于较小的模型中,但在较大的模型中存在,则该能力就是新兴的。…
【DL】《LoRA: Low-Rank Adaptation of Large Language Models》译读笔记
《LoRA: Low-Rank Adaptation of Large Language Models》
论文解读 - YouTube
《Low-rank Adaption of Large Language Models: Explaining the Key Concepts Behind LoRA》
请问LoRA的秩分解矩阵是怎么初始化的?
LoRA的秩分解矩阵是随机初始化的,然…
大白话式粗浅地聊聊NLP语言模型
前言
在聊NLP领域的语言模型的时候,我们究竟在聊什么?这就涉及nlp语言模型的定义。语言模型发展至今,其实可以简单的分为传统意义上的语言模型和现代的语言模型,传统语言模型主要是指利用统计学计算语料序列的概率分布࿰…
万字长文讲述由ChatGPT反思大语言模型的技术精要
文|张俊林 源|知乎张俊林 导读:ChatGPT出现后惊喜或惊醒了很多人。惊喜是因为没想到大型语言模型(LLM,Large Language Model)效果能好成这样;惊醒是顿悟到我们对LLM的认知及发展理念,…
NLP - IRSTLM、SRILM
文章目录IRSTLM关于 IRSTLM安装SRILM关于 SRILM安装使用 ngram-countKenLM 的安装使用,可参考文章: https://blog.csdn.net/lovechris00/article/details/125424808 IRSTLM
关于 IRSTLM
github : https://github.com/irstlm-team/irstlm官方主页&#…

中文生成模型T5-Pegasus详解与实践
我们在前一篇文章《生成式摘要的四篇经典论文》中介绍了Seq2seq在生成式研究中的早期应用,以及针对摘要任务本质的讨论。
如今,以T5为首的预训练模型在生成任务上表现出超出前人的效果,这些早期应用也就逐渐地淡出了我们的视野。本文将介绍T…
揭秘国产chatGPT大语言模型能力PK之001:ChatGLM1-2
一、问题清单: 1.我女朋友的老公应该叫我什么? 2.为什么我的女朋友还有老公? 3.你觉得我应该怎么做? 4.我想要获得爱情,我女朋友也爱我,我女朋友也爱她的老公,但他的老公恨我,我该怎么办&am…
大模型基础:GPT家族与提示学习
大模型基础:GPT 家族与提示学习
从 GPT-1 到 GPT-3.5
GPT(Generative Pre-trained Transformer)是 Google 于2018年提出的一种基于 Transformer 的预训练语言模型。它标志着自然语言处理领域从 RNN 时代进入 Transformer 时代。GPT 的发展历史和技术特点如下: GPT-12018年6月…
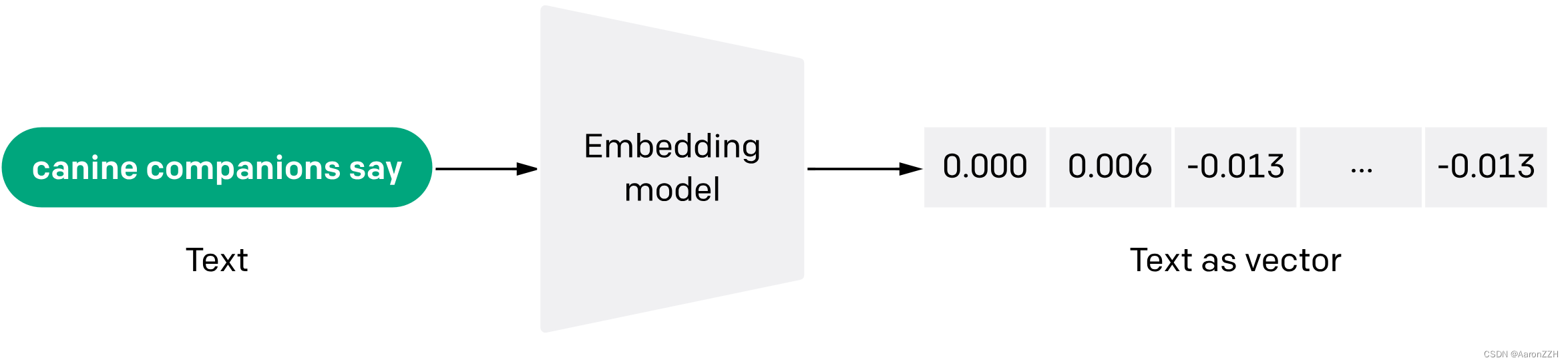
大模型基础03:Embedding 实战本地知识问答
大模型基础:Embedding 实战本地知识问答
Embedding 概述 知识在计算机内的表示是人工智能的核心问题。从数据库、互联网到大模型时代,知识的储存方式也发生了变化。在数据库中,知识以结构化的数据形式储存在数据库中,需要机器语言(如SQL)才能调用这些信息。互联网时代,…
Progressive-Hint Prompting Improves Reasoning in Large Language Models
本文是LLM系列的文章,针对《Progressive-Hint Prompting Improves Reasoning in Large Language Models》的翻译。 渐进提示改进了大型语言模型中的推理 摘要1 引言2 相关工作3 渐进提示Prompting4 实验5 结论6 实现细节7 不足与未来工作8 广泛的影响9 具有不同提示…

ChatGPT4也来了,大语言模型未来可期?注重当下很关键!
当地时间周二(3月14日),人工智能研究公司OpenAI公布了其大型语言模型的最新版本——GPT-4。该公司表示:“GPT-4在许多专业测试中表现出超过绝大多数人类的水平。”在内部评估中,GPT-4产生正确回应的可能性要比GPT-3.5高…

书生谱语-大语言模型测试demo
课程内容简介 通用环境配置
开发机
InterStudio
配置公钥 在本地机器上打开 Power Shell 终端。在终端中,运行以下命令来生成 SSH 密钥对: ssh-keygen -t rsa您将被提示选择密钥文件的保存位置,默认情况下是在 ~/.ssh/ 目录中。按 Enter …
vLLM vs Text Generation Interface:大型语言模型服务框架的比较
在大型语言模型(LLM)的世界中,有两个强大的框架用于部署和服务LLM:vLLM 和 Text Generation Interface (TGI)。这两个框架都有各自的优势,适用于不同的使用场景。在这篇博客中,我们将对这两个框架进行详细的…
百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
百度生成式AI产品文心一言邀你体验AI创作新奇迹中国版ChatGPT上线发布强大中文理解能力超强的数理推算能力智能文学创作、商业文案创作图片、视频智能生成中国生成式AI三大产业机会新型云计算公司行业模型精调公司应用服务提供商总结获取文心一言邀请码方法中国版ChatGPT上线发…

谷歌内部开发AI大语言模型“鹅”;OpenAI CEO 寻求大规模AI芯片全球生产投资
🦉 AI新闻
🚀 谷歌内部开发AI大语言模型“鹅”
摘要:谷歌正在积极将AI技术融入其产品中,并为提升员工效率而开发了一个名为“鹅”的AI大语言模型。这一模型仅供公司内部团队使用,旨在辅助新产品的开发。据悉…
【GPT-2】论文解读:Language Models are Unsupervised Multitask Learners
文章目录 介绍zero-shot learning 零样本学习 方法数据Input Representation 结果 论文:Language Models are Unsupervised Multitask Learners 作者:Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, I. Sutskever 时间:2019 介…
UIE在实体识别和关系抽取上的实践
近期有做信息抽取的需求,UIE在信息抽取方面效果不错。
模型准备
huggingface上下载UIE模型:PaddlePaddle/uie-base Hugging Face
点击“Clone Repository”,确定git clone的链接
其中包含大文件,需要在windows安装git-lfs&am…
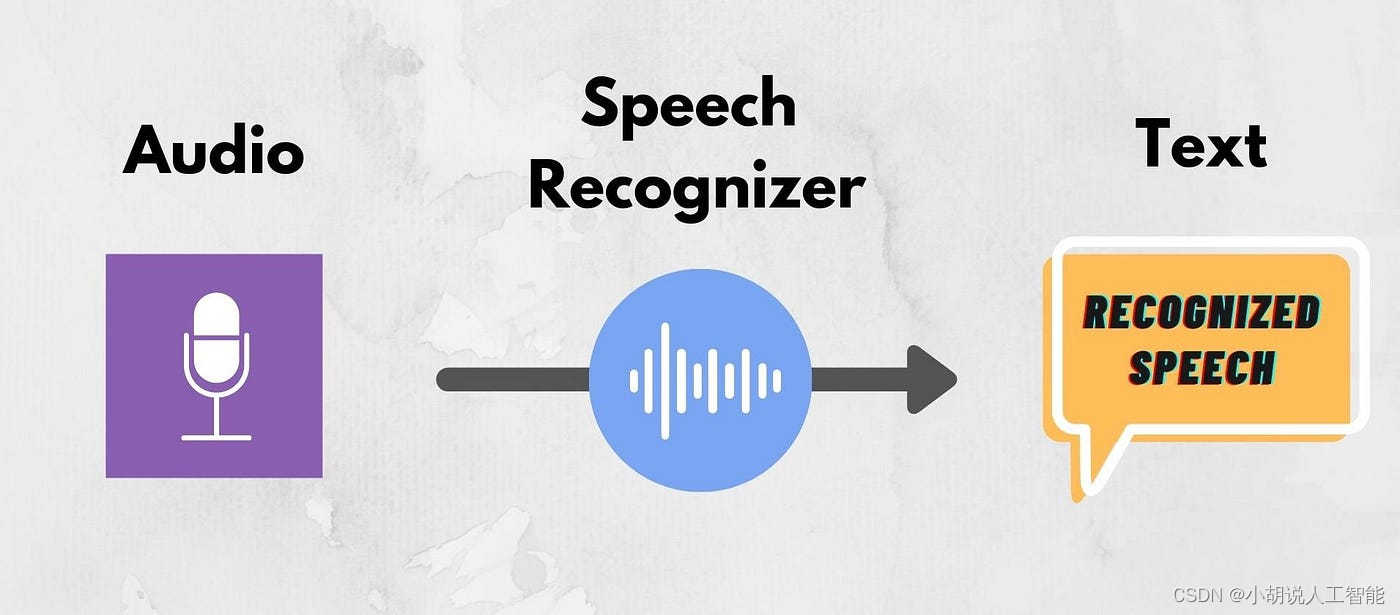
OpenAI-ChatGPT最新官方接口《语音智能转文本》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(六)(附源码)
Speech to text 语音智能转文本 Introduction 导言Quickstart 快速开始Transcriptions 转录python代码cURL代码 Translations 翻译python代码cURL代码 Supported languages 支持的语言Longer inputs 长文件输入Prompting 提示其它资料下载 Speech to text 语音转文本 Learn how…

深度学习与自然语言处理(7)_斯坦福cs224d 语言模型,RNN,LSTM与GRU
翻译:胡杨(superhy199148hotmail.com) && 胥可(feitongxiaokegmail.com) 校对调整:寒小阳 && 龙心尘 时间:2016年7月 出处: http://blog.csdn.net/han_xiaoyang/article/details/51932536 http://blog.csdn.…

【Segment Anything Model】论文+代码实战调用SAM模型预训练权重+相关论文
上篇文章已经全局初步介绍了SAM和其功能,本篇作为进阶使用。 文章目录 0.前言1.SAM原论文 1️⃣名词:提示分割,分割一切模型,数据标注,零样本,分割一切模型的数据集 2️⃣Introduction 3️⃣Task: prompta…
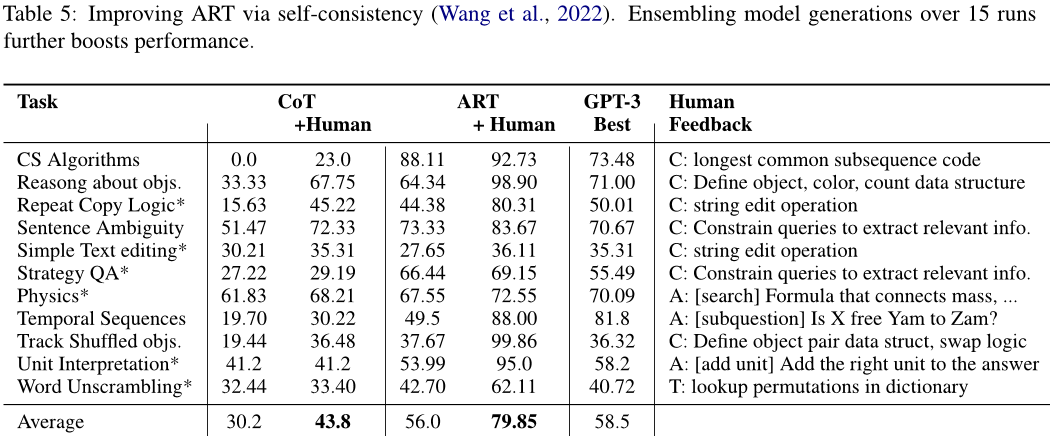
ART: Automatic multi-step reasoning and tool-use for large language models 导读
ART: Automatic multi-step reasoning and tool-use for large language models 本文介绍了一种名为“自动推理和工具使用(ART)”的新框架,用于解决大型语言模型(LLM)在处理复杂任务时需要手动编写程序的问题。该框架可…
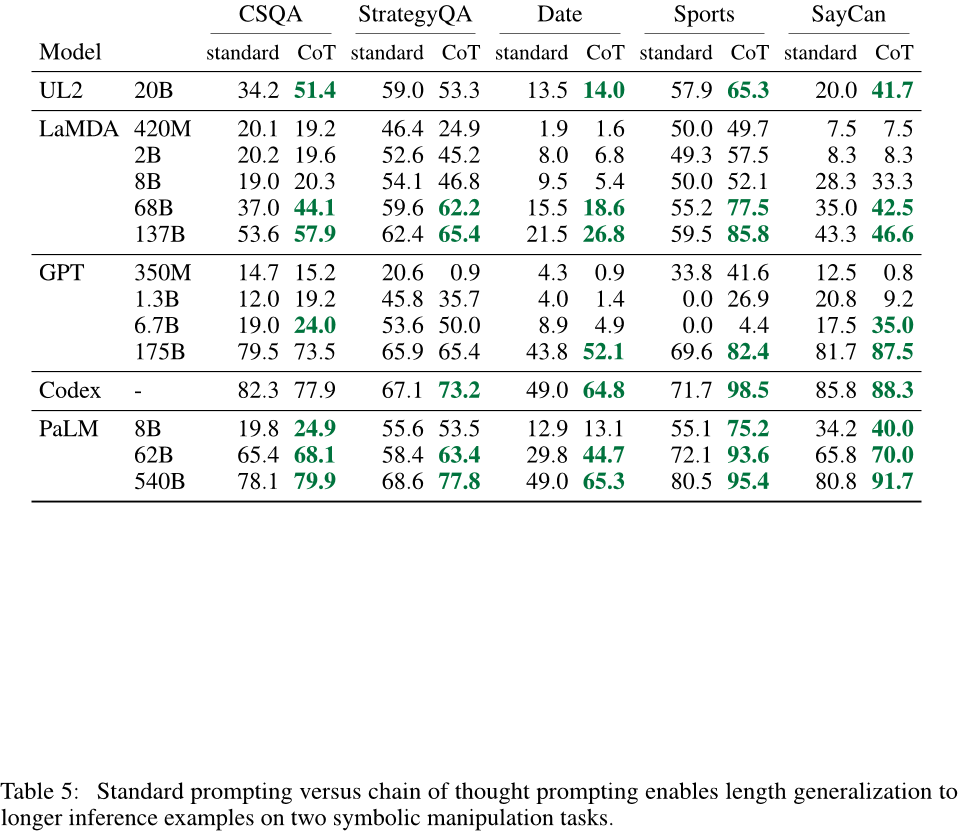
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models导读
通过生成一系列中间推理步骤(即“思维链”)显著提高大型语言模型进行复杂推理的能力
这篇论文探讨了如何通过生成一系列中间推理步骤(即“思维链”)显著提高大型语言模型进行复杂推理的能力。研究人员使用一种简单的方法——思维…
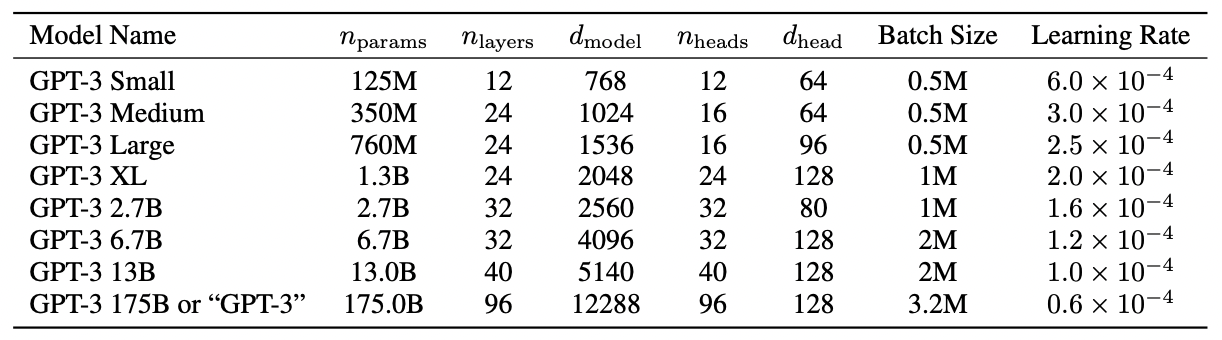
(GPT3)Language Models are Few-Shot Learners论文阅读
论文地址:https://arxiv.org/pdf/2005.14165v4.pdf
摘要 最近的工作表明,通过对大量文本语料库进行预训练,然后对特定任务进行微调,许多 NLP 任务和基准测试取得了实质性进展。 虽然在体系结构中通常与任务无关,但此方…
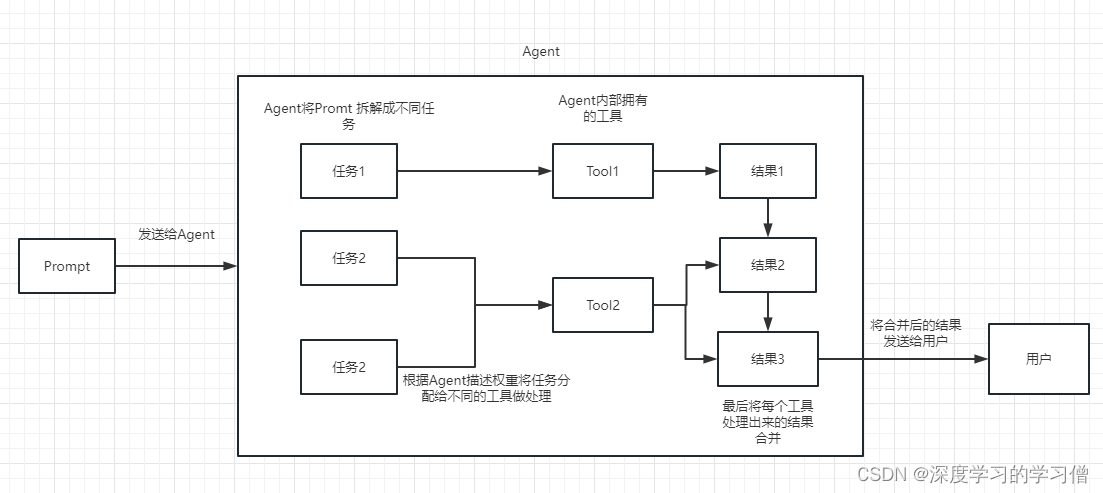
自学大语言模型的应用程序框架Langchain(初入门)
现阶段chatGPT非常火热。带动了第三方开源库:LangChain火热。它是一个在大语言模型基础上实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频进行问答等等的功能的应用程序。
什么是Langchain
LangChain 是一个用于开发由语言模型驱动的应用程序的框架…
因果词袋语言模型:Causal BoWLM
因果词袋语言模型:CBoWLM Causal Bow : Causal Bag of Words
模型结构 #mermaid-svg-jQ6pxcgFlIqMENKv {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-jQ6pxcgFlIqMENKv .error-icon{fill:#552222;}#me…
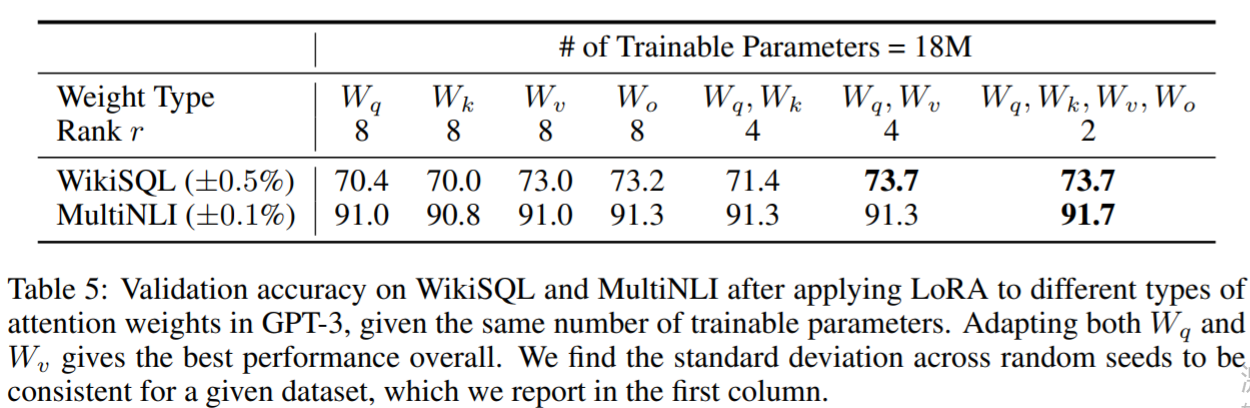
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (Paper reading)
Edward H, Microsoft, arXiv2021, Cited: 354, Code, Paper
1. 前言
自然语言处理的一个重要范式是在通用领域数据上进行大规模预训练,然后根据特定任务或领域进行适应性训练。随着我们对模…
大语言模型(LLM)及使用方法
使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。
大语言模型(LLM,Large Language Model)是一种基于深度学习的自然语言处理技术,它使用深…

AI创作与大语言模型:2023亚马逊云科技中国峰会引领企业应用新潮流
川川出品,必属精品。 文章目录 CodeWhispere免费的代码生成器安装教程使用自动编码 2023亚马逊云科技中国峰会最后总结 CodeWhispere免费的代码生成器
这里我介绍亚马逊云科技的一个产品,那就是Amazon codewhisperer。大家肯定对AI各种产品的火爆已经有…

Talk| CMU博士胡亚飞 :基于离线强化学习的机器人自主探索
本期为TechBeat人工智能社区第503期线上Talk!
北京时间6月07日(周三)20:00,CMU Robotics Institute 在读博士生—胡亚飞的Talk将准时在TechBeat人工智能社区开播!
他与大家分享的主题是: “基于离线强化学习的机器人自主探索 ”,…
大语言模型系列-T5
文章目录 前言一、T5的网络结构和流程二、T5的预训练过程三、其他训练结论总结 前言
目前已经讲解了目前LLM的三大流派的两个起始模型:GPT-1(Decoder only)、BERT(Encoder only),但是这两个模型针对不同下…
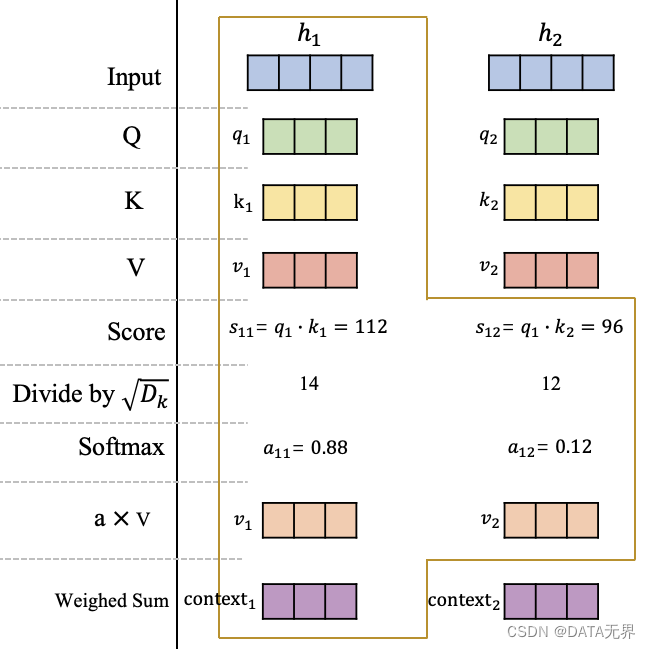
AI大语言模型学习笔记之三:协同深度学习的黑魔法 - GPU与Transformer模型
Transformer模型的崛起标志着人类在自然语言处理(NLP)和其他序列建模任务中取得了显著的突破性进展,而这一成就离不开GPU(图形处理单元)在深度学习中的高效率协同计算和处理。
Transformer模型是由Vaswani等人在2017年…
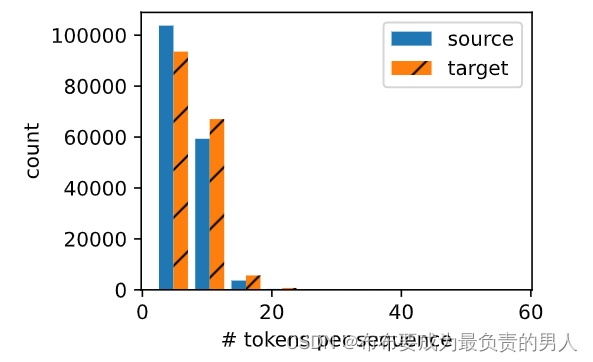
机器学习深度学习——seq2seq实现机器翻译(数据集处理)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——从编码器-解码器架构到seq2seq(机器翻译) 📚订阅专栏:机…

大语言模型之三 InstructGPT训练过程
大语言模型 GPT历史文章中简介的大语言模型的的发展史,并且简要介绍了大语言模型的训练过程,本篇文章详细阐述训练的细节和相关的算法。
2020年后全球互联网大厂、AI创业公司研发了不少AI超大模型(百亿甚至千亿参数),…
chatGPT小白快速入门-002:一文看懂什么是chatGPT
一、前言 本文是《chatGPT小白快速入门培训课程》的第002篇文章:一文看懂什么是chatGPT,全部内容采用chatGPT和chatGPT开源平替软件生成。完整内容大纲详见:《chatGPT小白快速入门课程大纲》。
本系列文章,参与: AIGC…
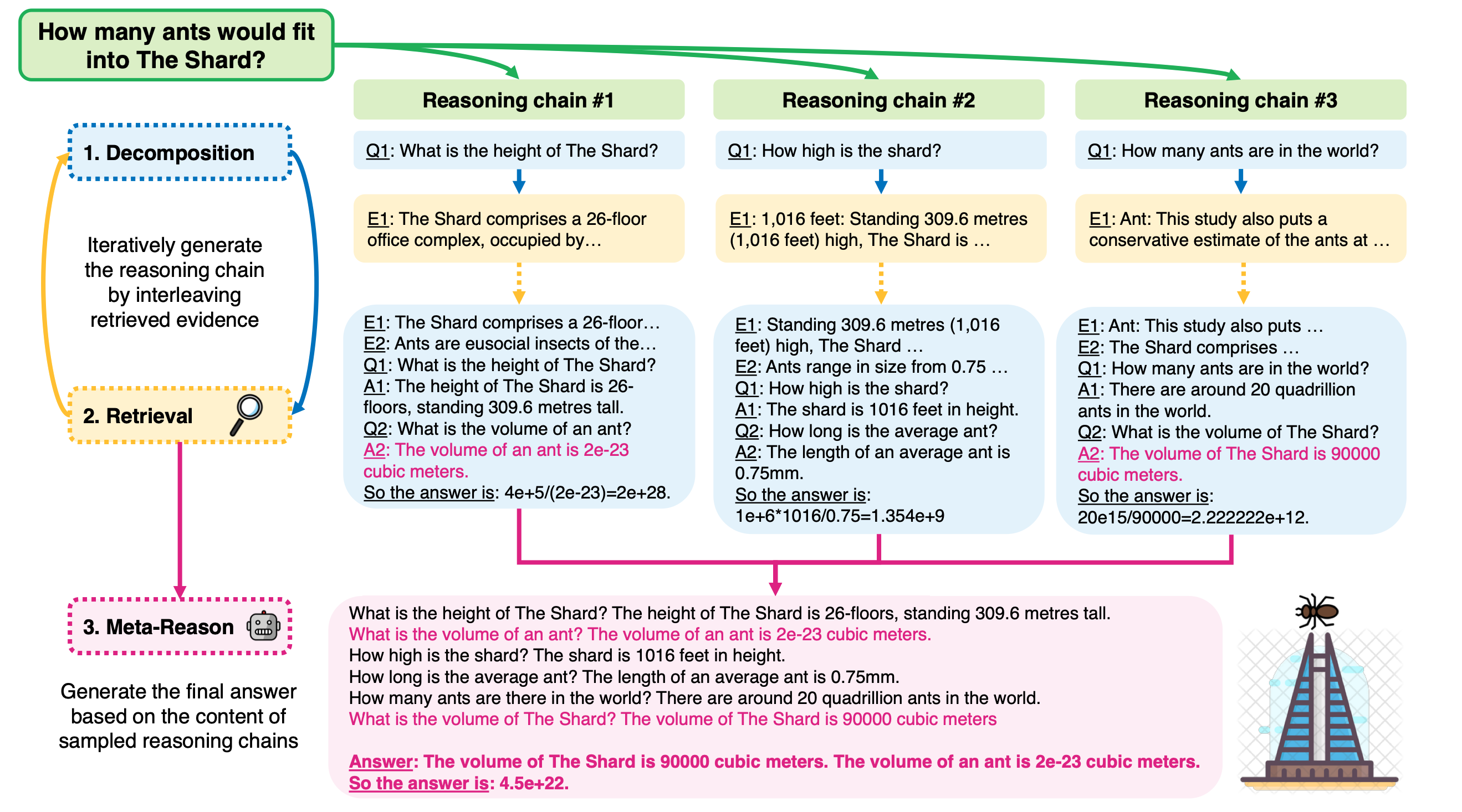
大规模SFT微调指令数据的生成
前言
想要微调一个大模型,前提是得有一份高质量的SFT数据,可以这么说其多么高质量都不过分,关于其重要性已经有很多工作得以验证,感兴趣的小伙伴可以穿梭笔者之前的一篇文章:
《大模型时代下数据的重要性》ÿ…

【自注意力机制必学】BERT类预训练语言模型(含Python实例)
BERT类预训练语言模型 文章目录 BERT类预训练语言模型1. BERT简介1.1 BERT简介及特点1.2 传统方法和预训练方法1.3 BERT的性质 2. BERT结构2.1 输入层以及位置编码2.2 Transformer编码器层2.3 前馈神经网络层2.4 残差连接层2.5 输出层 3. BERT类模型简要笔记4. 代码工程实践 1.…
大语言模型 -- 部署LaWGPT模型记录
模型介绍:
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据…
Buzz语音转文字安装使用(含Whisper模型下载)
简介:
Transcribe and translate audio offline on your personal computer. Powered by OpenAI’s Whisper. 转录和翻译音频离线在您的个人计算机。由OpenAI的Whisper提供动力。 可以简单理解为QT的前端界面,python语言构建服务端,使用Whis…
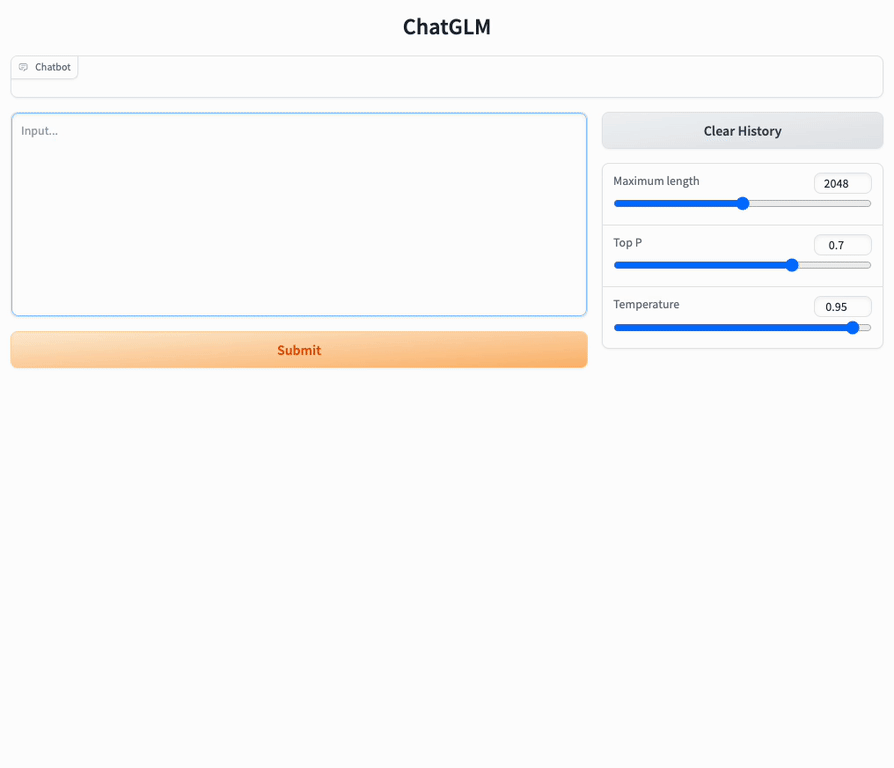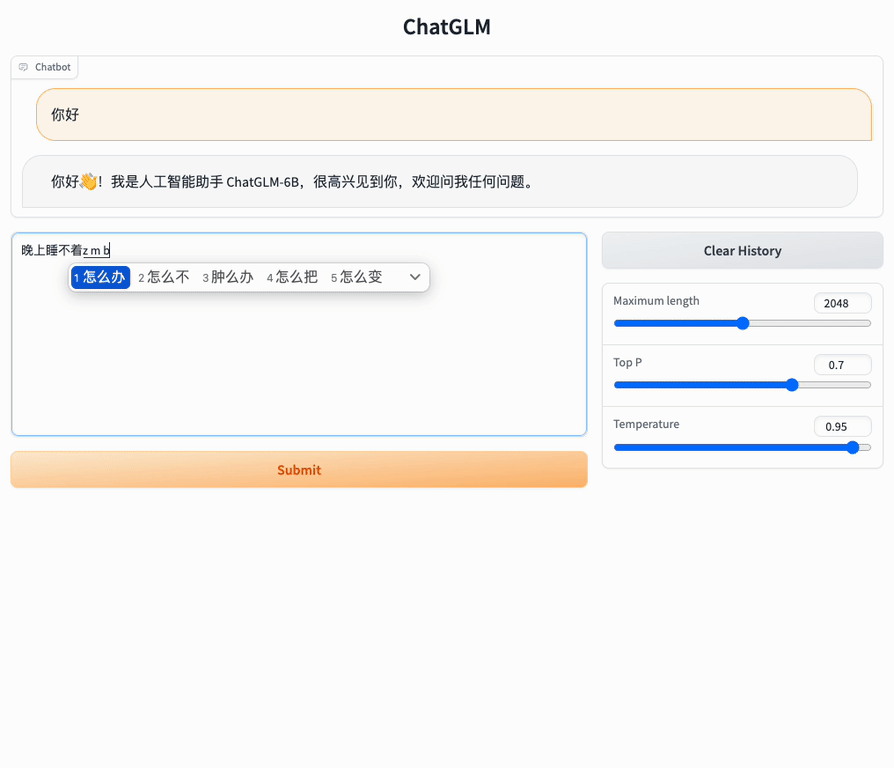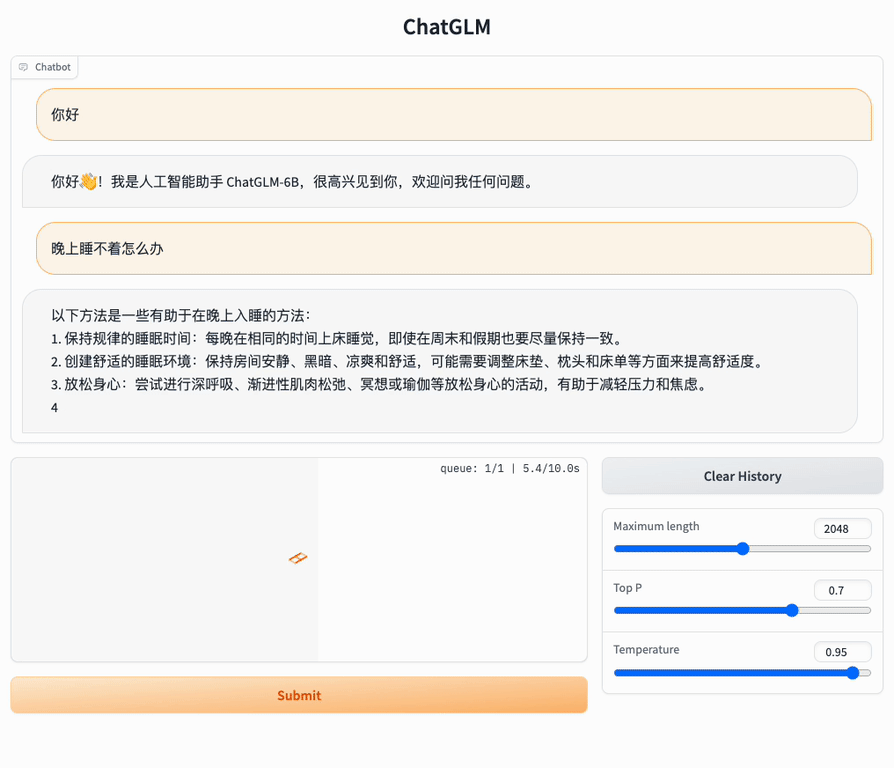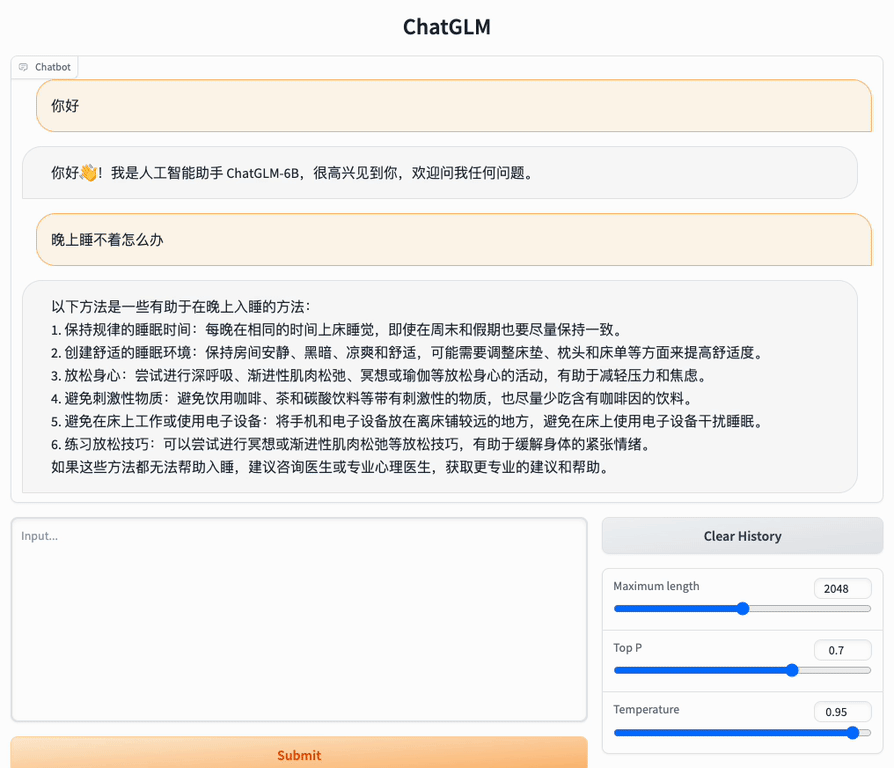
中英双语对话大语言模型:ChatGLM-6B
介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。…
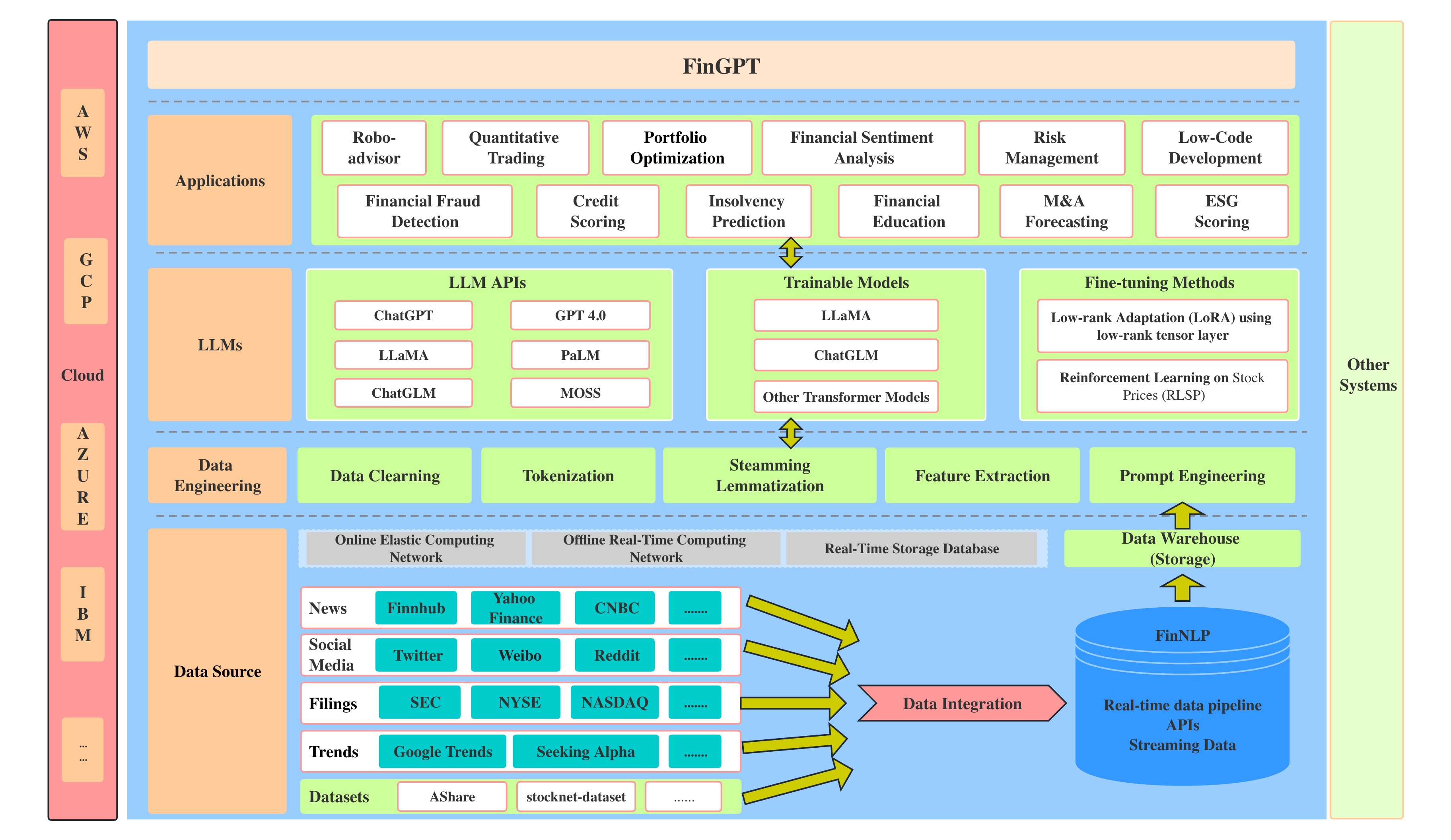
金融语言模型:FinGPT
项目简介
FinGPT是一个开源的金融语言模型(LLMs),由FinNLP项目提供。这个项目让对金融领域的自然语言处理(NLP)感兴趣的人们有了一个可以自由尝试的平台,并提供了一个与专有模型相比更容易获取的金融数据。…

训练自己的ChatGPT 语言模型(一).md
0x00 Background
为什么研究这个? ChatGPT在国内外都受到了广泛关注,很多高校、研究机构和企业都计划推出类似的模型。然而,ChatGPT并没有开源,且复现难度非常大,即使到现在,没有任何单位或企业能够完全复…

【如何用大语言模型快速深度学习系列】从n-gram到TFIDF
感谢上一期能够进入csdn“每日推荐看”,那必然带着热情写下第二期《从n-gram到TFIDF》,这里引入一本《Speach and Language Processing》第三版翻译版本(语音与语言处理(SLP)),前半部分写的很好!里面连编辑…

基于LLAMA-7B的lora中文指令微调
目录 1. 选用工程2. 中文llama-7b预训练模型下载3. 数据准备4. 开始指令微调5. 模型测试 前言: 系统:ubuntu18.04显卡:GTX3090 - 24G (惨呀,上次还是A100,现在只有3090了~) (本文旨在…
ModaHub魔搭社区:腾讯发布的向量数据库Tencent Cloud VectorDB有哪些核心能力?
腾讯发布的向量数据库有哪些核心能力?
腾讯云刚刚发布的向量数据库Tencent Cloud VectorDB主要具备以下能力:
高性能向量存储、检索:腾讯云向量数据库具备高性能的向量存储和检索能力,单索引能够轻松支持10亿级别的向量规模。在…
生成式AI和大语言模型 Generative AI LLMs
在“使用大型语言模型(LLMs)的生成性AI”中,您将学习生成性AI的基本工作原理,以及如何在实际应用中部署它。
通过参加这门课程,您将学会:
深入了解生成性AI,描述基于LLM的典型生成性AI生命周期中的关键步骤ÿ…
手搓大语言模型 使用jieba分词制作词表,词表大小几十万 加强依赖性
jieba分词词表生成与训练
import numpy as np
import paddle
import pandas as pd
from multiprocessing import Process, Manager, freeze_support
from just_mask_em import JustMaskEm, HeadLoss
from tqdm import tqdm
from glob import glob
import jieba
import warning…
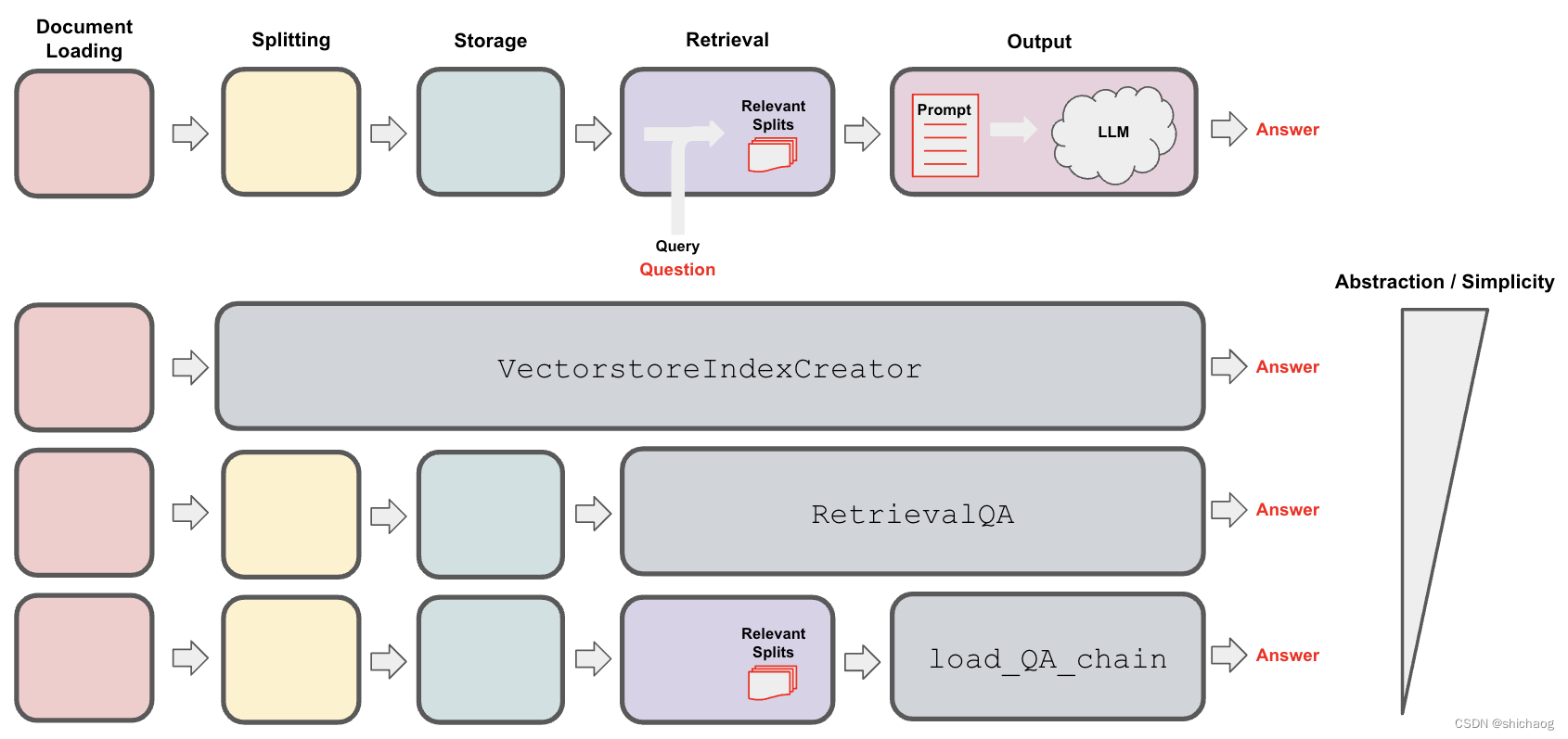
大语言模型之四-LlaMA-2从模型到应用
最近开源大语言模型LlaMA-2火出圈,从huggingface的Open LLM Leaderboard开源大语言模型排行榜可以看到LlaMA-2还是非常有潜力的开源商用大语言模型之一,相比InstructGPT,LlaMA-2在数据质量、培训技术、能力评估、安全评估和责任发布方面进行了…

《UNILMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training》论文笔记
UniLMs
UniLMs由《Unified Language Model Pre-training for Natural Language Understanding and Generation》(2019)提出,其核心是通过不同的注意力机制,在同一模型下进行Unidirectional Language Model, Bidirecti…
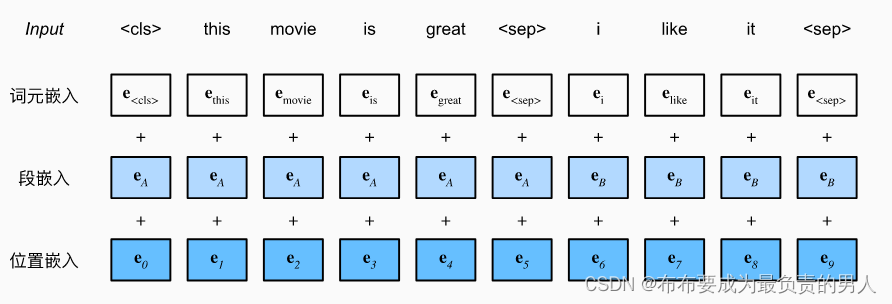
机器学习深度学习——BERT(来自transformer的双向编码器表示)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——transformer(机器翻译的再实现) 📚订阅专栏:机器学习&am…

论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读 BackgroundIntroducitonProblem StatementMethodology Δ W \Delta W ΔW 的选择 W W W的选择 总结 今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Lan…
如何使用 Megatron-LM 训练语言模型
在 PyTorch 中训练大语言模型不仅仅是写一个训练循环这么简单。我们通常需要将模型分布在多个设备上,并使用许多优化技术以实现稳定高效的训练。Hugging Face 🤗 Accelerate 的创建是为了支持跨 GPU 和 TPU 的分布式训练,并使其能够非常容易的…
大语言模型之二 GPT发展史简介
得益于数据、模型结构以及并行算力的发展,大语言模型应用现今呈井喷式发展态势,大语言神经网络模型成为了不可忽视的一项技术。 GPT在自然语言处理NLP任务上取得了突破性的进展,扩散模型已经拥有了成为下一代图像生成模型的代表的潜力&#x…
查看Linux下显存使用情况
查看Linux下显存使用情况
最常用的参数是 -n, 后面指定是每多少秒来执行一次命令。
监视显存:我们设置为每 1s 显示一次显存的情况: $ watch -n 1 nvidia-smi
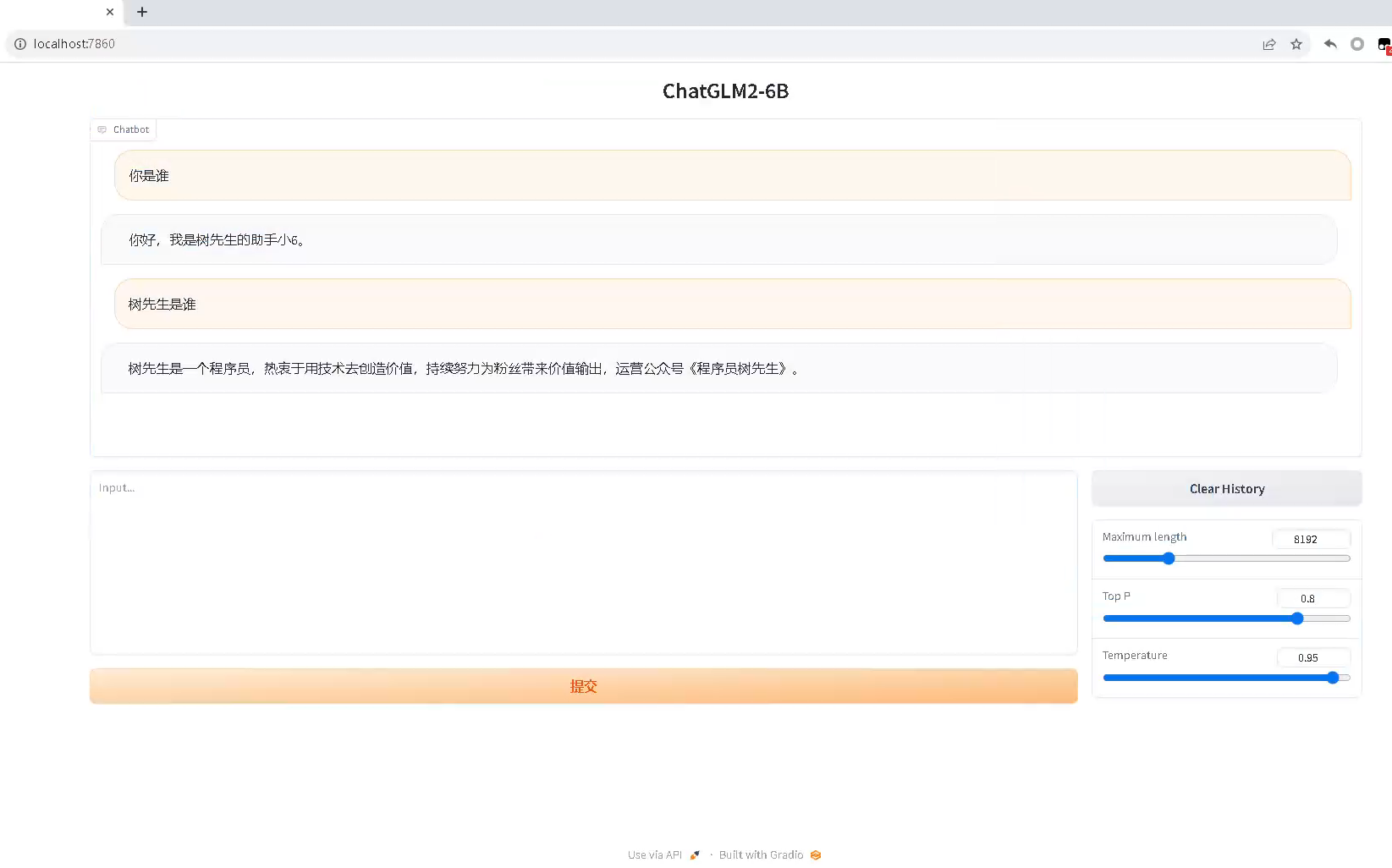
ChatGLM2-6B在Windows下的微调
ChatGLM2-6B在Windows下的微调
零、重要参考资料
1、ChatGLM2-6B! 我跑通啦!本地部署微调(windows系统):这是最关键的一篇文章,提供了Windows下的脚本 2、LangChain ChatGLM2-6B 搭建个人专属知识库:提供…
关于语言模型中的平滑
在语言模型计算概率的时候,我们会碰到概率为0的情况,即计算的单词在语言模型中并没有出现过。这个时候会使用平滑的方法计算概率,一般分为以下几种:
Add-One Smoothing
Add-K Smoothing
其中Add-One Smoothing可以看作Add-K Sm…

A Survey on Multimodal Large Language Models
本文是LLM系列的文章之一,主要是讲解多模态的LLM。针对《A Survey on Multimodal Large Language Models》的翻译。 多模态大语言模型的综述 摘要1 引言2 概述3 方法3.1 多模态指令调整3.1.1 引言3.1.2 前言3.1.3 模态对齐3.1.4 数据3.1.5 模态桥接3.1.6 评估 3.2 …
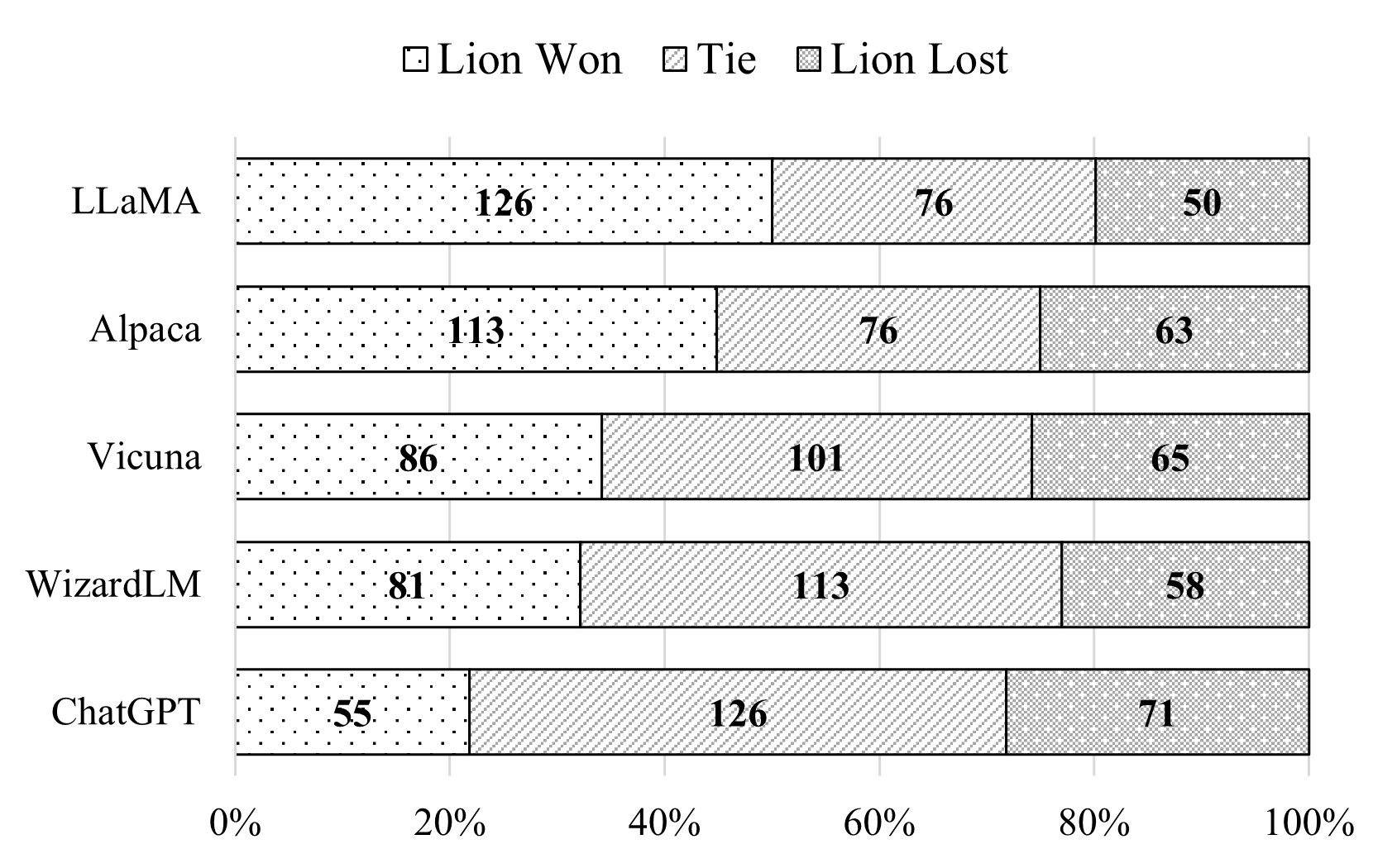
Lion:闭源大语言模型的对抗性蒸馏
通过调整 70k 指令跟踪数据,Lion (7B) 可以实现 ChatGPT 95% 的能力!
消息
我们目前正在致力于训练更大尺寸的版本(如果可行的话,13B、33B 和 65B)。感谢您的耐心等待。
**[2023年6月10日]**我们发布了微调过程中解…
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
AI 语音转换真的越复杂越好吗?本文就提出了一个方法简单但同样强大的语言转换模型,与基线方法相比自然度和清晰度毫不逊色,相似度更是大大提升。
AI 参与的语音世界真神奇,既可以将一个人的语音换成任何其他人的语音,…
论文笔记--LIMA: Less Is More for Alignment
论文笔记--LIMA: Less Is More for Alignment 1. 文章简介2. 文章概括3 文章重点技术3.1 表面对齐假设(Superfacial Alignment Hypothesis)3.2 对齐数据3.3 训练 4 数值实验5. 文章亮点5. 原文传送门6. References 1. 文章简介
标题:LIMA: Less Is More for Alignm…
Gorilla: 连接海量API的大语言模型
Gorilla是一个基于LLaMA(Large Language Model with API)的大型语言模型,它可以生成适当的API调用。它是在三个大型的机器学习库数据集上训练的:Torch Hub, TensorFlow Hub和HuggingFace。它还可以快速地添加新的领域,…

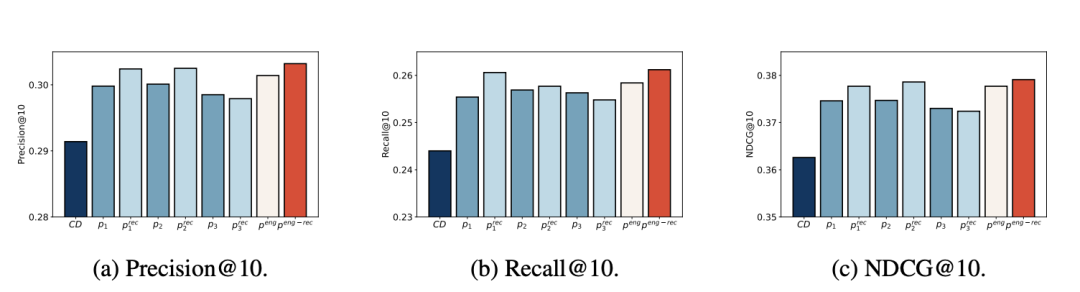
LLM-Rec:基于提示大语言模型的个性化推荐
1. 基本信息 论文题目:LLM-Rec: Personalized Recommendation via Prompting Large Language Models 作者:Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Jiebo Luo 机构:University of Rochester, University of California Los Angeles, Meta AI, University of Ro…
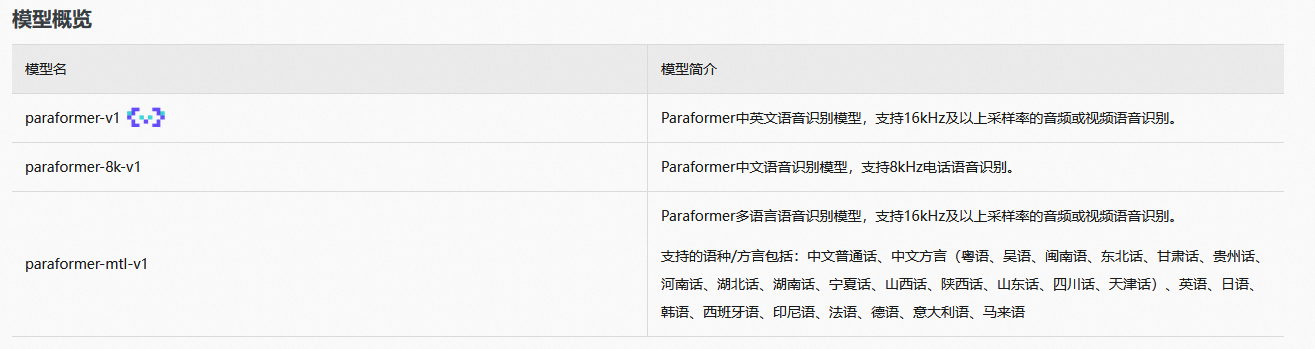
浅析阿里云灵积(平台)模型服务
简介: DashScope灵积模型服务以模型为中心,致力于面向AI应用开发者提供品类丰富、数量众多的模型选择,并为其提供开箱即用、能力卓越、成本经济的模型服务API。DashScope灵积模型服务依托达摩院等机构的优质模型,在阿里云基础设施…

【大模型AIGC系列课程 2-2】大语言模型的“第二大脑”
1. 大型语言模型的不足之处
很多人使用OpenAI提供的GPT系列模型时都反馈效果不佳。其中一个主要问题是它无法回答一些简单的问题。 ● 可控性:当我们用中文问AI一些关于事实的问题时,它很容易编造虚假答案。 ● 实时性:而当你询问它最近发生的新闻事件时,它会干脆地告诉你…

Exploring Lottery Prompts for Pre-trained Language Models
Exploring Lottery Prompts for Pre-trained Language Models
文章链接
清深的工作,比较有意思的一篇。作者先给出假设,对于分类问题,在有限的语料空间内总能找到一个prompt让这个问题分类正确,作者称之为lottery prompt。为此&…

阿里云通义千问开源第二波!大规模视觉语言模型Qwen-VL上线魔搭社区
通义千问开源第二波!8月25日消息,阿里云推出大规模视觉语言模型Qwen-VL,一步到位、直接开源。Qwen-VL以通义千问70亿参数模型Qwen-7B为基座语言模型研发,支持图文输入,具备多模态信息理解能力。在主流的多模态任务评测…

【AI大模型】训练Al大模型 (上篇)
大模型超越AI
前言
洁洁的个人主页 我就问你有没有发挥! 知行合一,志存高远。 目前所指的大模型,是“大规模深度学习模型”的简称,指具有大量参数和复杂结构的机器学习模型,可以处理大规模的数据和复杂的问题&#x…
使用 AutoGPTQ 和 transformers 让大语言模型更轻量化
大语言模型在理解和生成人类水平的文字方面所展现出的非凡能力,正在许多领域带来应用上的革新。然而,在消费级硬件上训练和部署大语言模型的需求也变得越来越难以满足。 🤗 Hugging Face 的核心使命是 让优秀的机器学习普惠化 ,而…
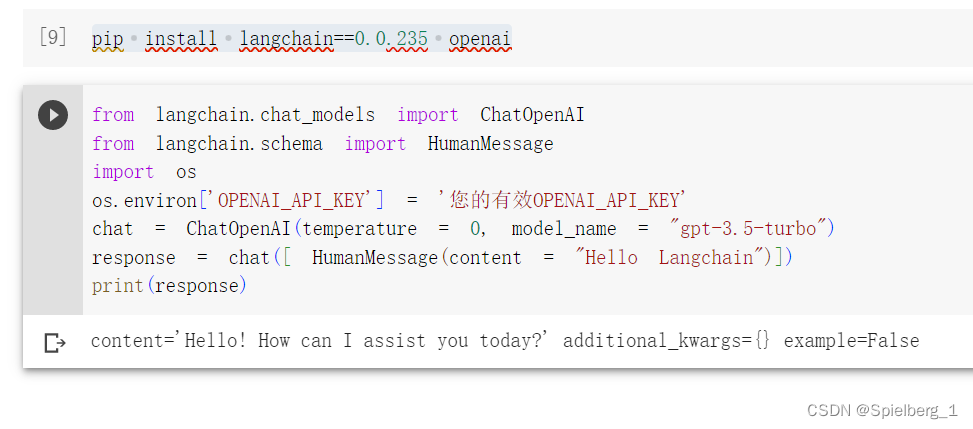
01_langchain
Langchain简介
LLM的诞生推动了自然语言处理领域的变革,让以前无法实现的一些应用成为了可能。然而仅仅利用LLM还无法完成真正强大的应用程序,还需要一些相关的资源和技术知识。
Langchain用于开发这些应用程序,可用于:
基于文…

VisualGLM-6B:一个基于ChatGLM-6B模型的图像理解模型
介绍
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
Visua…

语言模型(language model)
文章目录 引言1. 什么是语言模型2. 语言模型的主要用途2.1 言模型-语音识别2.2 语言模型-手写识别2.3 语言模型-输入法 3. 语言模型的分类4. N-gram语言模型4.1 N-gram语言模型-平滑方法4.2 ngram代码4.3 语言模型的评价指标4.4 两类语言模型的对比 5. 神经网络语言模型6. 语言…
Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning
本文是LLM系列的文章,针对《Decoupling Knowledge from Memorization: Retrieval 知识与记忆的解耦:检索增强的提示学习 摘要1 引言2 提示学习的前言3 RETROPROMPT:检索增强的提示学习4 实验5 相关实验6 结论与未来工作 摘要
提示学习方法在…
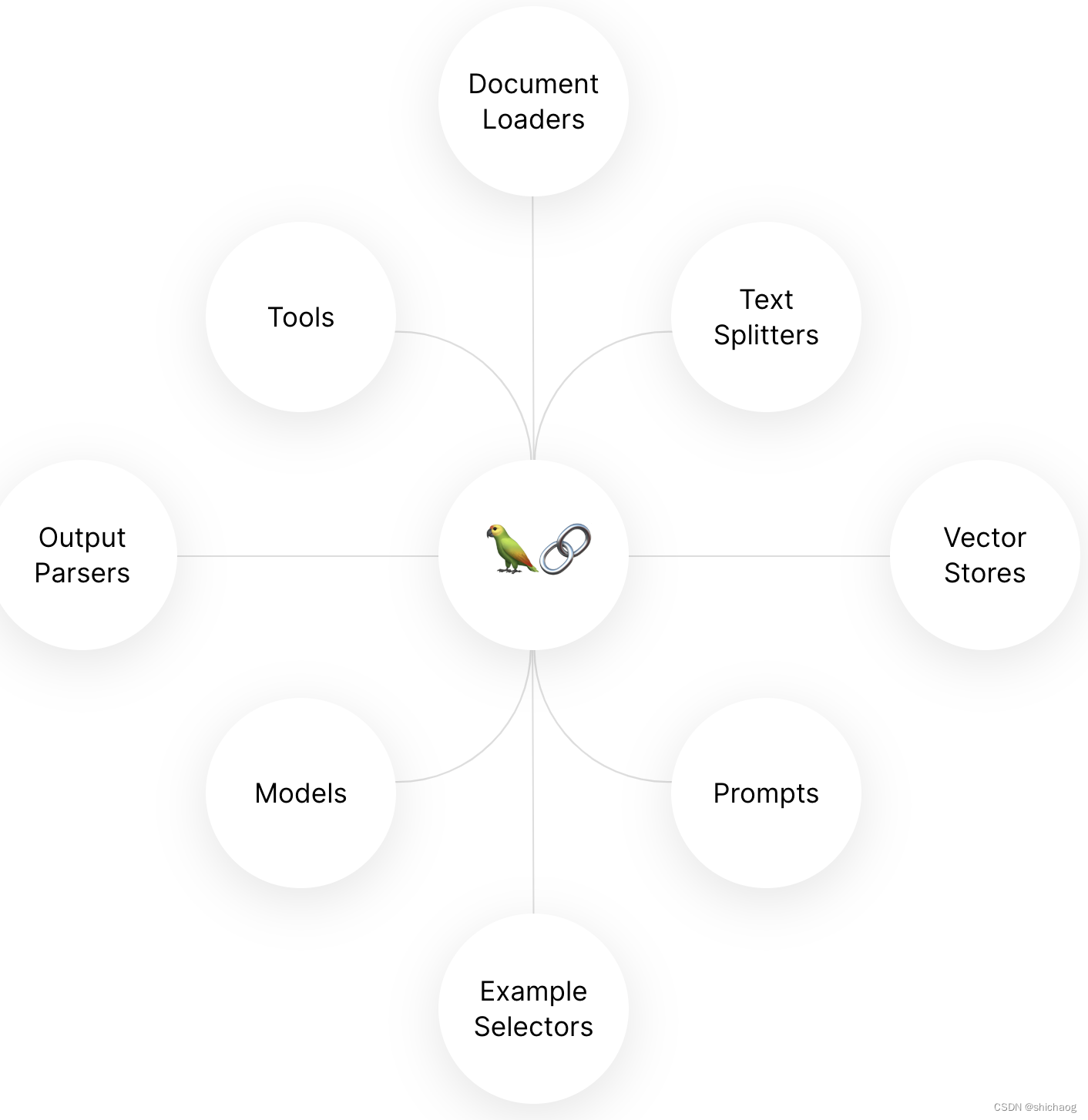
大语言模型之六- LLM之企业私有化部署
数据安全是每个公司不得不慎重对待的,为了提高生产力,降本增效又不得不接受新技术带来的工具,私有化部署对于公司还是非常有吸引力的。大语言模型这一工具结合公司的数据可以大大提高公司生产率。
私有化LLM需要处理的问题
企业内私有化LLM…
A Survey on Large Language Model based Autonomous Agents
本文是LLM系列的文章,针对《A Survey on Large Language Model based Autonomous Agents》的翻译。 基于大模型的自动agents综述 摘要1 引言2 基于LLM的自动代理构建3 基于LLM的自动代理应用4 基于LLM的自动代理评估5 相关综述6 挑战6.1 角色扮演能力6.2 广义与人对…

新KG视点 | Jeff Pan、陈矫彦等——大语言模型与知识图谱的机遇与挑战
OpenKG 大模型专辑 导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织…

WTF Langchain极简入门: 03. 数据连接
加载文档
langchain提供多种文档加载器,支持多种格式、来源的文件。可以从本地存储系统加载文件,也可以从网上加载远端文件。想了解LangChain所支持的所有文档加载器,请参考Document Loaders。
在本系列课程中,我们将使用最基本…
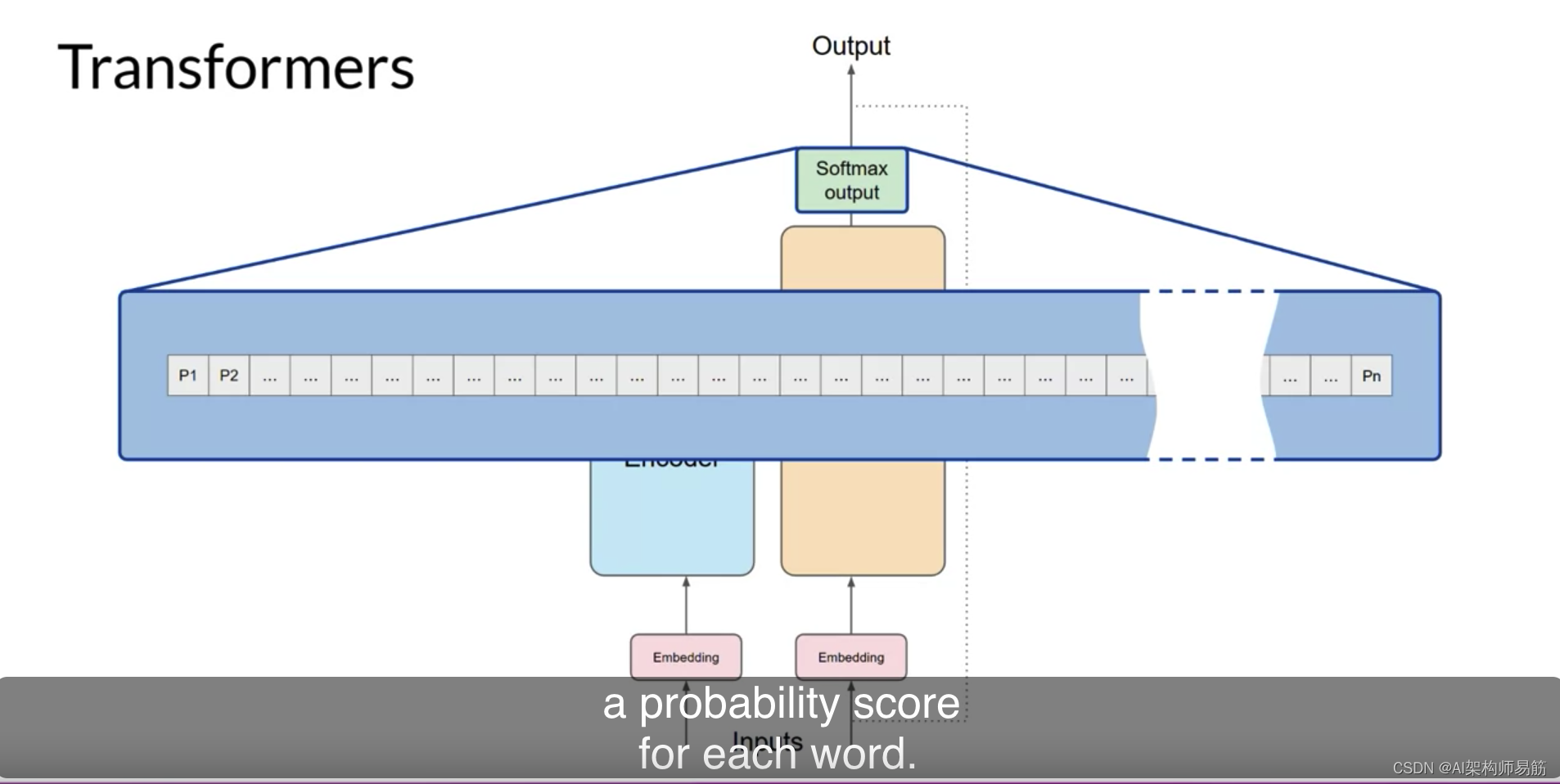
LLM架构自注意力机制Transformers architecture Attention is all you need
使用Transformers架构构建大型语言模型显著提高了自然语言任务的性能,超过了之前的RNNs,并导致了再生能力的爆炸。
Transformers架构的力量在于其学习句子中所有单词的相关性和上下文的能力。不仅仅是您在这里看到的,与它的邻居每个词相邻&…
ChatGLM2-6B在windows下的部署
2023-08-10 ChatGLM2-6B在windows下的部署
一、部署环境
1、Windows 10 专业版, 64位,版本号:22H2,内存:32GB
2、已安装CUDA11.3
3、已安装Anaconda3 64bit版本
4、有显卡NVIDIA GeForce RTX 3060 Laptop GPU …

LARGE LANGUAGE MODELS AS OPTIMIZERS
本文是LLM系列文章,针对《LARGE LANGUAGE MODELS AS OPTIMIZERS》的翻译。 作为优化器的大型语言模型 摘要1 引言2 OPRO:LLM作为优化器3 激励性例子:数学优化4 应用:提示优化5 提示优化实验6 相关工作7 结论 摘要
优化无处不在。…
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
本文是LLM系列文章,针对《》的翻译。 AlpacaFarm:从人类反馈中学习方法的模拟框架 摘要1 引言2 背景与问题描述3 构造AlpacaFarm4 验证AlpacaFarm模拟器5 AlpacaFarm的基准参考方法6 相关工作7 不足和未来方向 摘要
像ChatGPT这样的大型语言模型由于能够很好地遵循…
投资人热捧的创业大赛,有哪些AI原生应用值得关注?
“绝对远超全球同类产品”,一位大模型创业者对百度文心一言的表现不吝夸奖。
这是一家生产效率工具创业公司的负责人,今年5月百度发起大模型领域创业比赛——“文心杯”,他率先报名参赛并入选决赛文心创业营,目前与其他30多家入围…
网易数帆发布对话式 BI 产品 “有数 ChatBI”
8 月 10 日,网易数帆基于网易公司自研智能大模型发布了 “AIGC” 的最新成果。在大数据领域,网易数帆发布了融合前沿 AIGC 技术研发而成的对话式 BI 产品——有数 ChatBI。借助自然语言理解与专业数据分析能力,用户只需通过日常对话的方式即可…
Adapting Language Models to Compress Contexts
本文是LLM系列文章,针对《Adapting Language Models to Compress Contexts》的翻译。 使语言模型适应上下文压缩 摘要1 引言2 相关工作3 方法4 实验5 上下文学习6 压缩检索语料库实现高效推理7 结论不足 摘要
1 引言
2 相关工作
3 方法
4 实验
5 上下文学习
…
GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM
一、前言
想要轻松快速地使用您自己的数据微调和培训大型语言模型(LLM)?我们知道训练大型语言模型具有挑战性并需要耗费大量计算资源,包括收集和优化数据集、确定合适的模型及编写训练代码等。今天我们将介绍一种实验性新方法&am…
1.0的星火2.0必将燎原——图文声影PPT全测试
一、前言
大家好,勇哥又来分享AI模型了,前几天讯飞发布的星火大模型2.0迅速的进入了我们圈子里,为了有更多更好的模型分享给大家,分享星火大模型2.0是必须做的,我做一个传递着,希望大家也星火相传啊。
我…
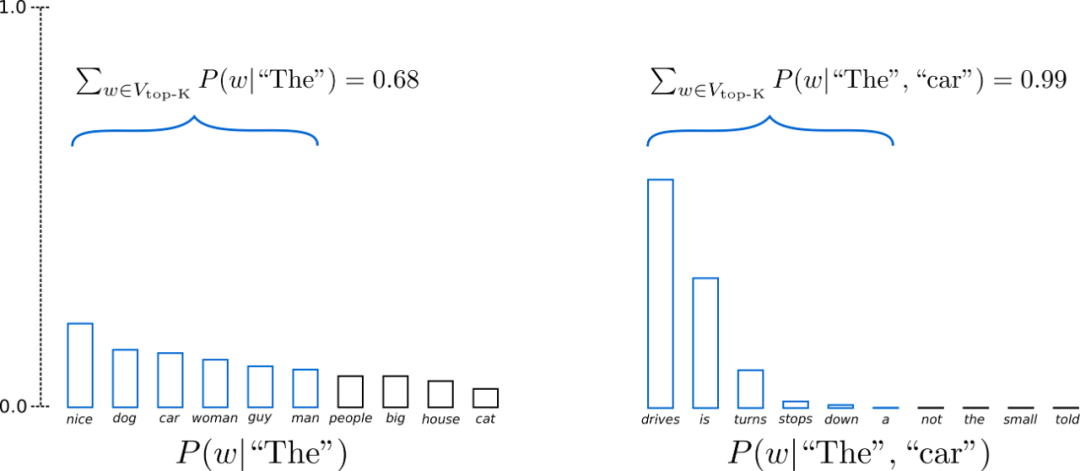
百度工程师浅析解码策略
作者 | Jane 导读 生成式模型的解码方法主要有2类:确定性方法(如贪心搜索和波束搜索)和随机方法。确定性方法生成的文本通常会不够自然,可能存在重复或过于简单的表达。而随机方法在解码过程中引入了随机性,以便生成更…

AIGC如何借AI Agent落地?TARS-RPA-Agent破解RPA与LLM融合难题
文/王吉伟 大语言模型(LLM,Large Language Model)的持续爆发,让AIGC一直处于这股AI风暴最中央,不停席卷各个领域。
在国内,仍在雨后春笋般上新的大语言模型,在持续累加“千模大战”大模型数量的…
精进语言模型:探索LLM Training微调与奖励模型技术的新途径
大语言模型训练(LLM Training)
LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。
有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。
使用仓库之…
A Survey on Large Language Models for Recommendation
本文是LLM系列的文章,针对《A Survey on Large Language Models for Recommendation》的翻译。 大模型用于推荐的综述 摘要1 引言2 建模范式和分类3 判别式LLM用于推荐4 生成式LLM用于推荐5 发现6 结论 摘要
大型语言模型(LLM)作为自然语言…
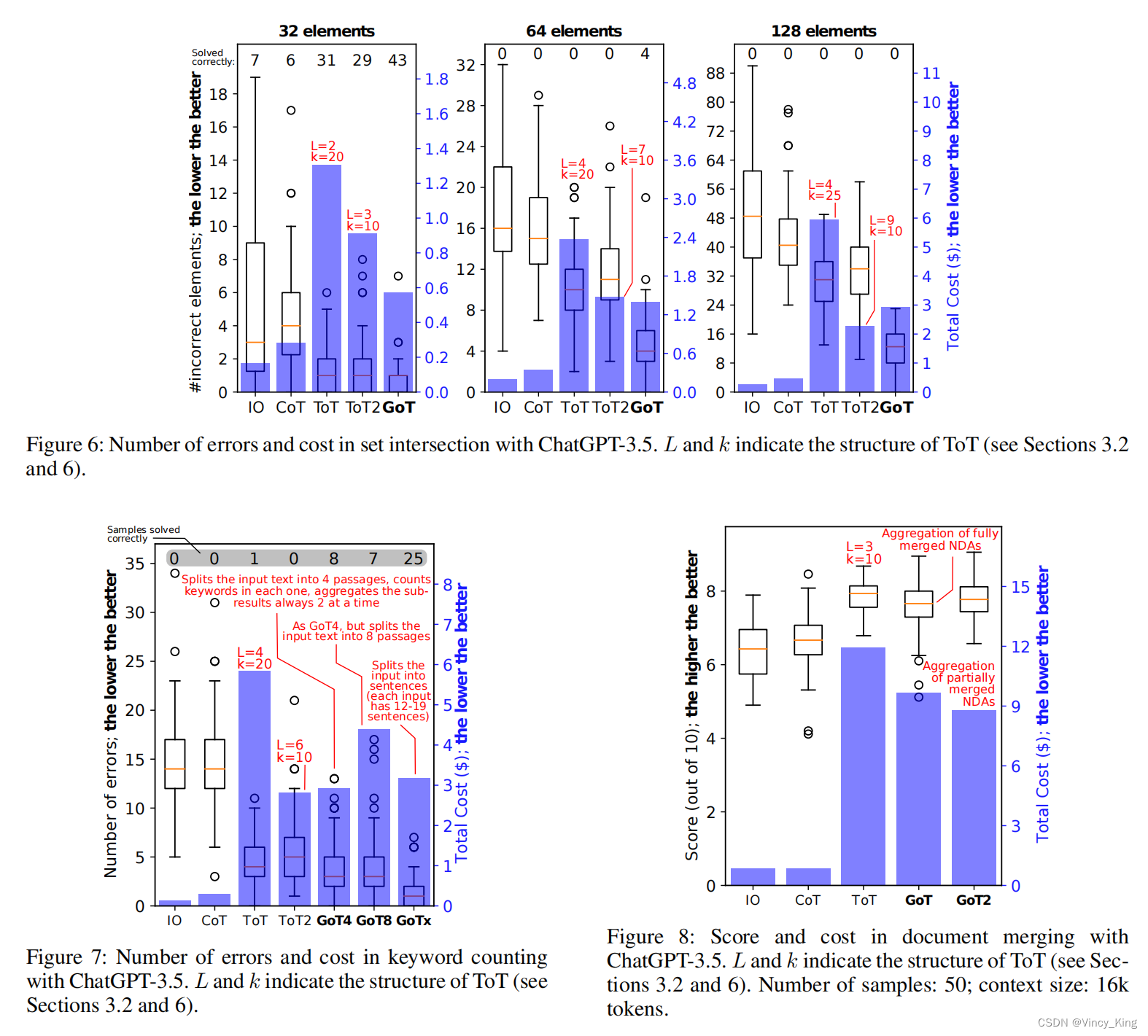
【阅读笔记】Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Website & code: https://github.com/spcl/graph-of-thoughts
作者介绍了Graph of Thought (GoT):一个具备提高LLM提示能力,超越了思维链或思维树 (ToT) 等范式提供的能…
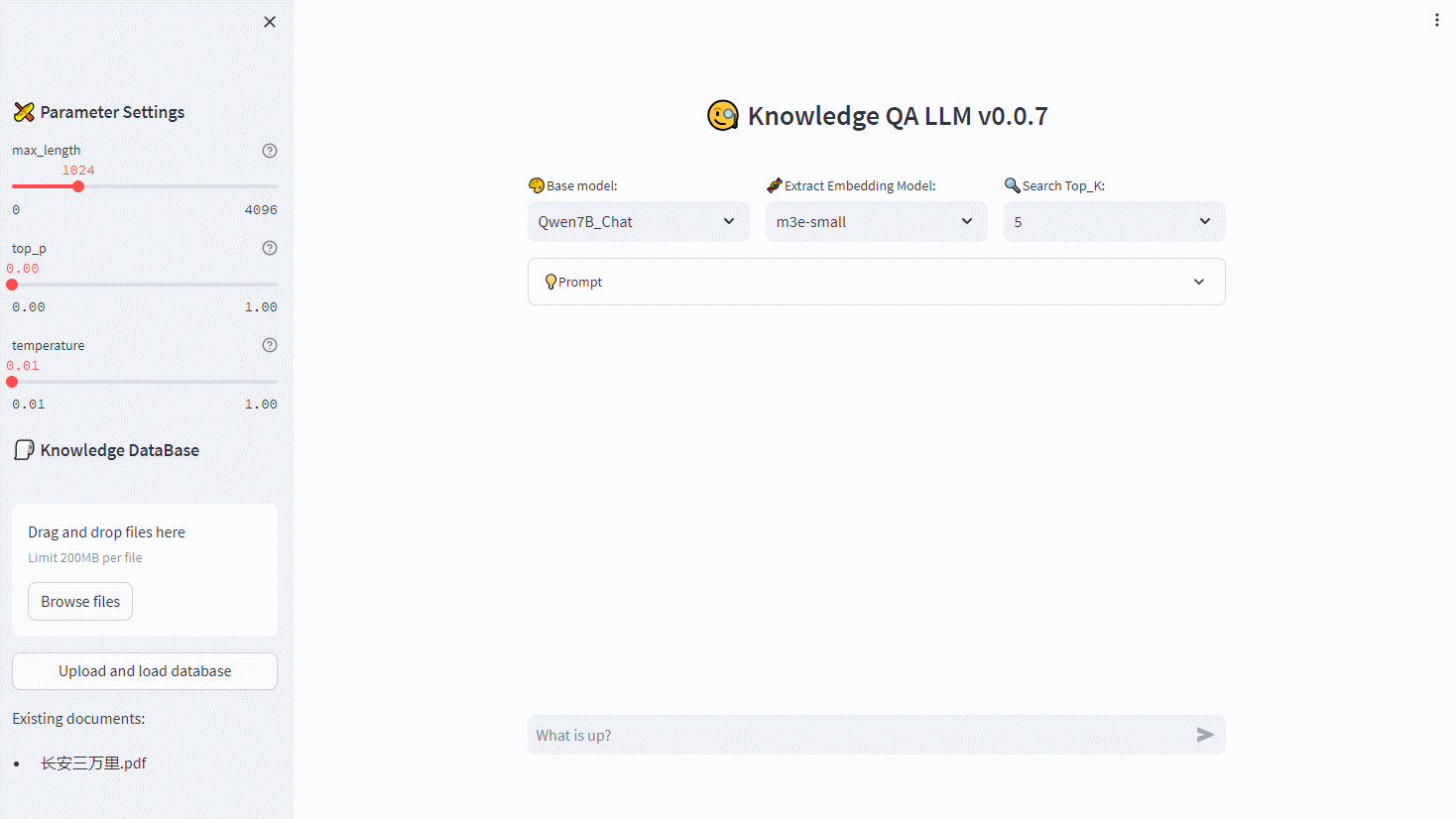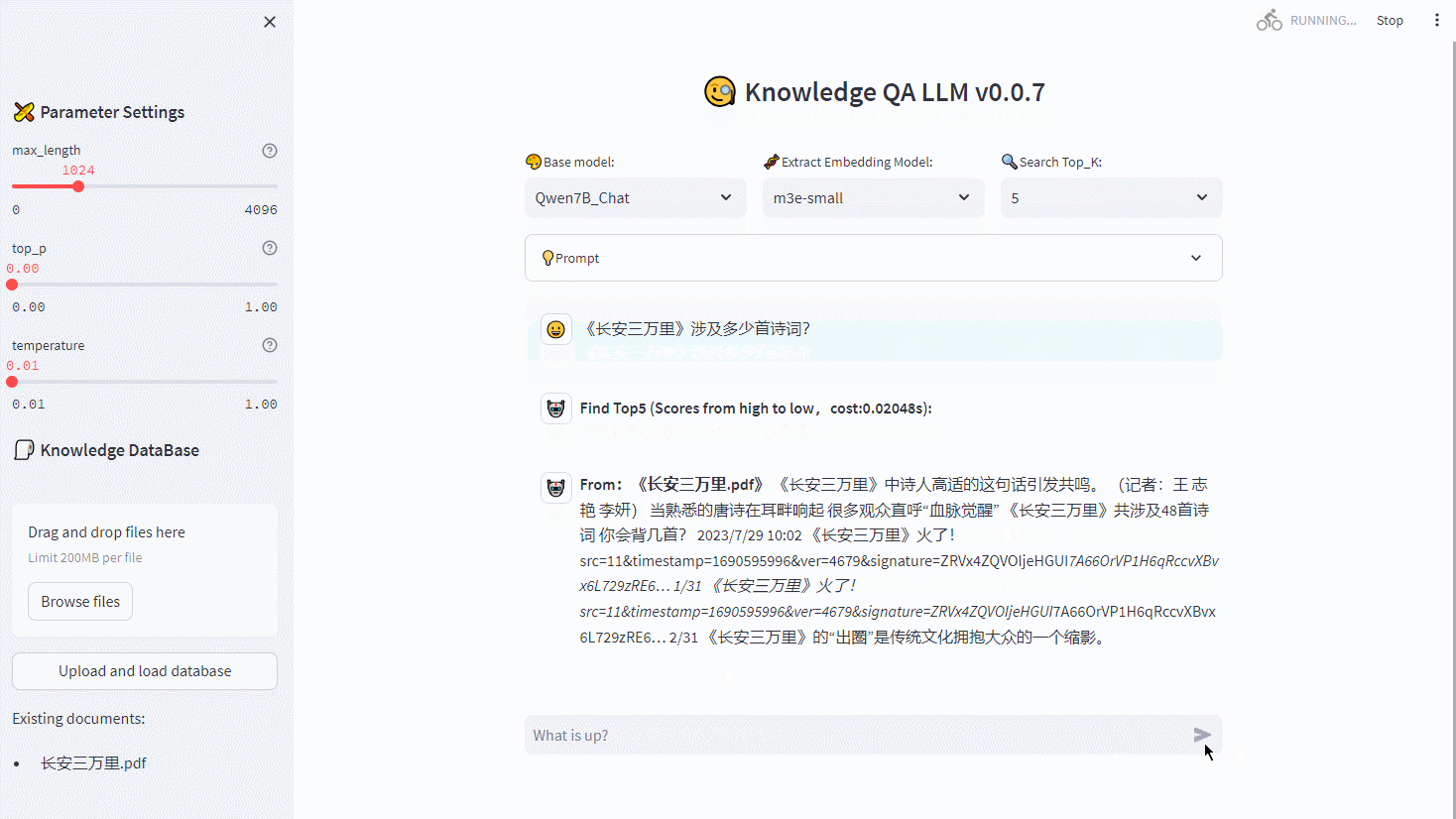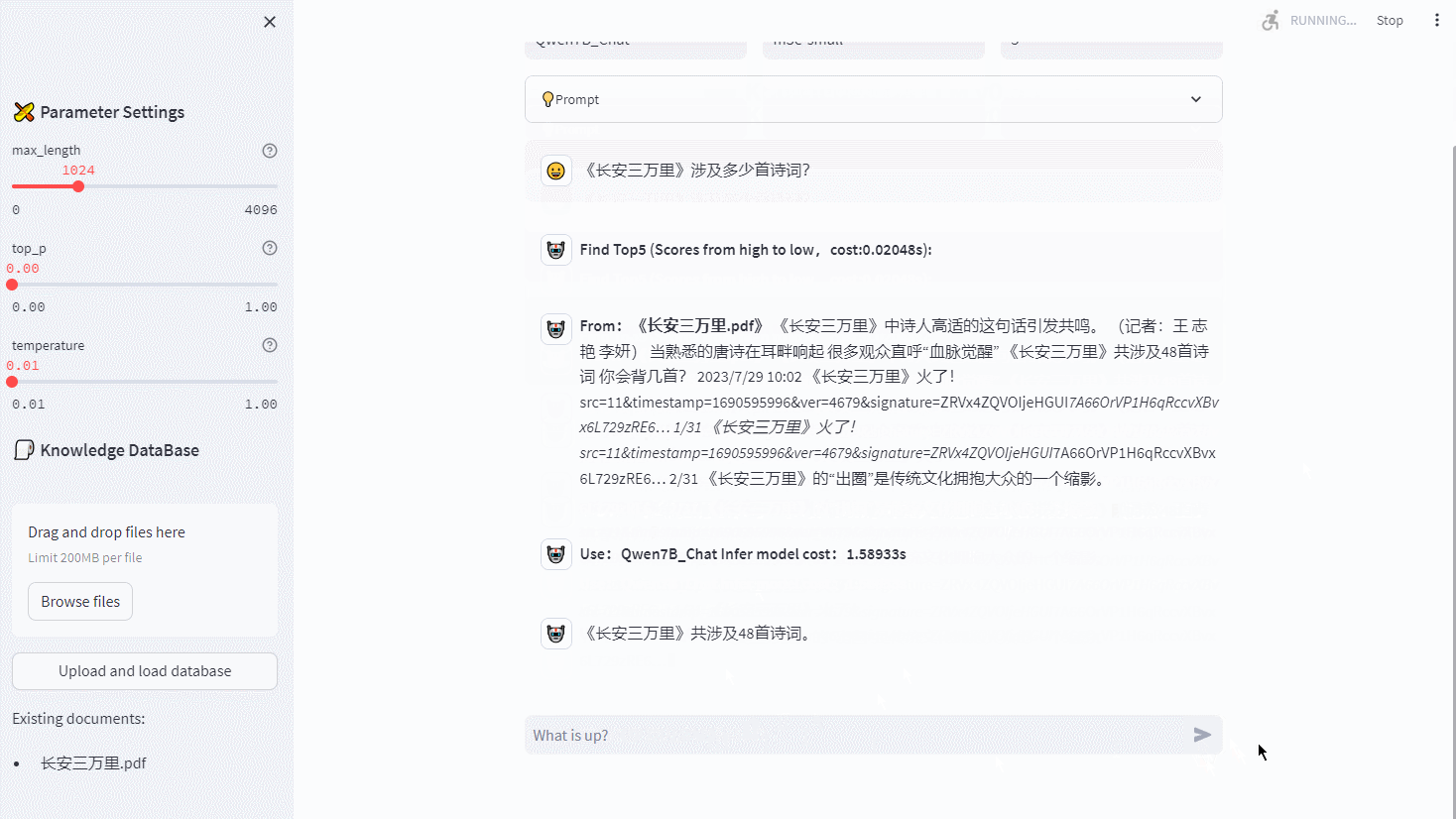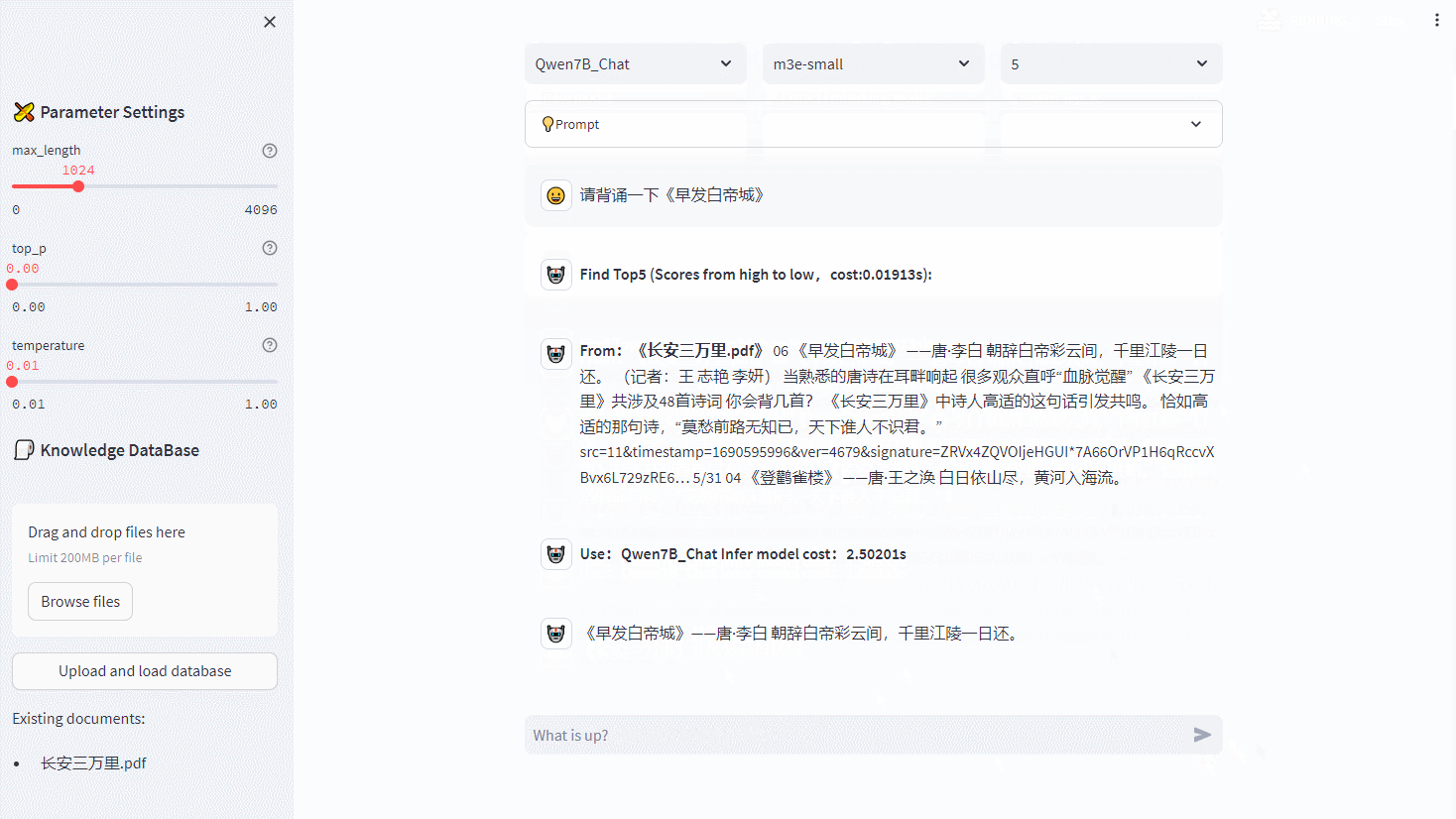
【RapidAI】P0 项目总览
RapidAI 项目总览 ** 内容介绍 **
Author: SWHL、omahs Github: https://github.com/RapidAI/Knowledge-QA-LLM/ CSDN Author: 脚踏实地的大梦想家 UI Demo: ** 读者须知 **
本系列博文,主要内容为将 RapidAI 项目逐…
企业大语言模型智能问答的底层基础数据知识库如何搭建?
企业大语言模型智能问答的底层基础数据知识库搭建是一个复杂而关键的过程。下面将详细介绍如何搭建这样一个知识库。
确定知识库的范围和目标:
首先,需要明确知识库的范围,确定所涵盖的领域和主题。这可以根据企业的业务领域和用户需求来确…
ML+LLMs:利用LLMs大语言模型赋能或者结合ML机器学习算法进行具体应用的简介、具体案例之详细攻略
ML+LLMs:利用LLMs大语言模型赋能或者结合ML机器学习算法进行具体应用的简介、具体案例之详细攻略 目录
利用LLMs赋能或者结合ML算法进行具体应用的简介

LLM-TAP随笔——大语言模型基础【深度学习】【PyTorch】【LLM】
文章目录 2.大语言模型基础2.1、编码器和解码器架构2.2、注意力机制2.2.1、注意力机制(Attention)2.2.2、自注意力机制(Self-attention)2.2.3、多头自注意力(Multi-headed Self-attention) 2.3、transforme…

国内大语言模型的相对比较:ChatGLM2-6B、BAICHUAN2-7B、通义千问-6B、ChatGPT3.5
一、 前言
国产大模型有很多,比如文心一言、通义千问、星火、MOSS 和 ChatGLM 等等,但现在明确可以部署在本地并且开放 api 的只有 MOOS 和 ChatGLM。MOOS 由于需要的 GPU 显存过大(不量化的情况下需要80GB,多轮对话还是会爆显存…

如何让 Llama2、通义千问开源大语言模型快速跑在函数计算上?
:::info 本文是“在Serverless平台上构建AIGC应用”系列文章的第一篇文章。 ::: 前言
随着ChatGPT 以及 Stable Diffusion,Midjourney 这些新生代 AIGC 应用的兴起,围绕AIGC应用的相关开发变得越来越广泛,有呈井喷之势,从长远看这波应用的爆…
chatGLM-Windows环境安装
Windows系统下环境安装
一、概要 不同安装方式安装python安装Nvidia驱动安装cuda与cuddn安装PyTorch与TensorFlow二、安装文件:
百度网盘链接:https://pan.baidu.com/s/1lbqhpIx-CAcBUfwSCjMNaA?pwd=4wwo
夸克网盘链接:https://pan.quark.cn/s/f59cefde0eee
三、正文:…
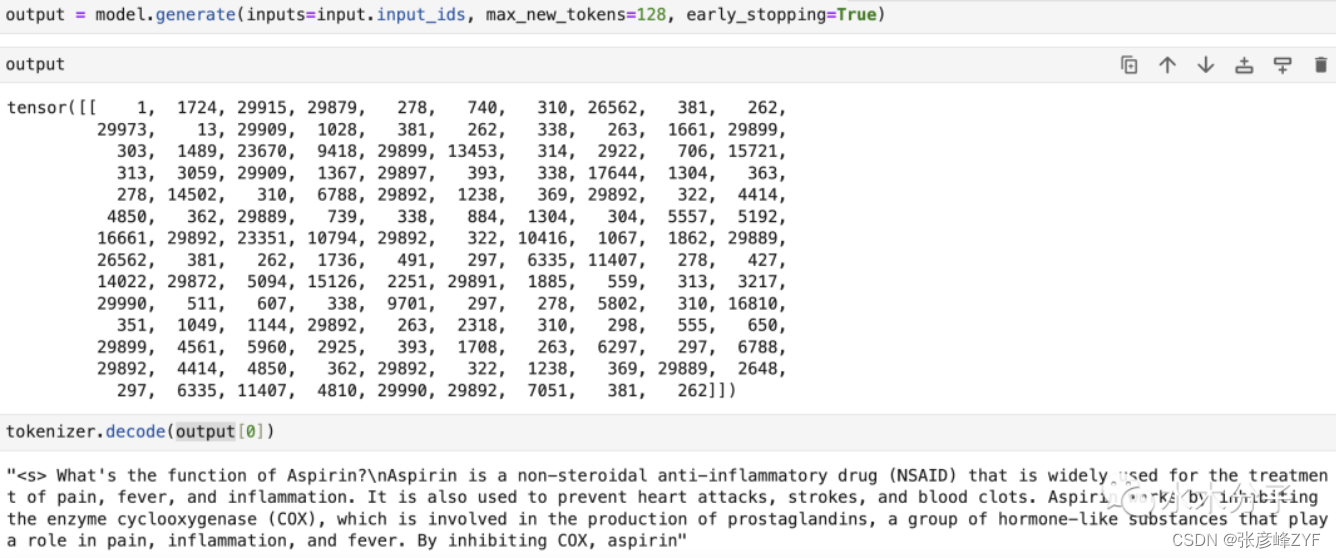
![保留网络[02/3]:大型语言模型转换器的继任者”](https://img-blog.csdnimg.cn/img_convert/c78ed8982f37ee7b946b985d7bb67ee9.png)
保留网络[02/3]:大型语言模型转换器的继任者”
一、说明 在这项工作中,我们提出保留网络(RETNET)作为基础架构大型语言模型的结构,同时实现训练并行, 推理成本低,性能好。我们从理论上推导出这种联系 复发与关注之间。然后我们提出保留机制 序列建模&…
LLMs之Baichuan 2:Baichuan 2的简介、安装、使用方法之详细攻略
LLMs之Baichuan 2:Baichuan 2的简介、安装、使用方法之详细攻略 目录
相关文章
LLMs之Baichuan:Baichuan-13B模型的简介(包括Baichuan-7B)、安装、使用方法之详细攻略
LLMs之Baichuan 2:Baichuan 2的简介、安装、使用方法之详细攻略
LLMs…
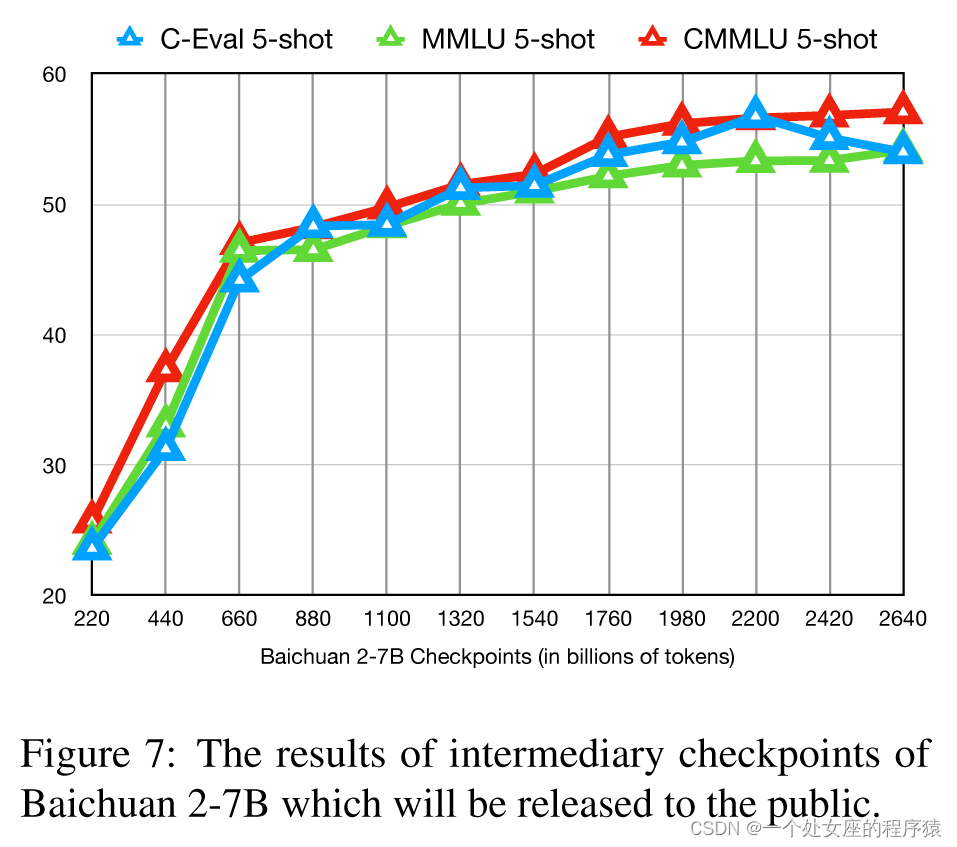
LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读
LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读 导读:2023年9月6日,百川智能重磅发布Baichuan 2。科技论文主要介绍了Baichuan 2,一个开源的大规模语言模型,以及其在多个领域的性能表现…
accelerate 分布式技巧实战--部署ChatGLM-6B(三)
accelerate 分布式技巧实战–部署ChatGLM-6B(三)
基础环境
torch2.0.0cu118
transformers4.28.1
accelerate0.18.0
Tesla T4 15.3G
内存:11.8G下载相关文件:
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6Bgit …

【动手学深度学习】--语言模型
文章目录 语言模型1.学习语言模型2.马尔可夫模型与N元语法3.自然语言统计4.读取长序列数据4.1随机采样4.2顺序分区 语言模型
学习视频:语言模型【动手学深度学习v2】 官方笔记:语言模型和数据集
在【文本预处理】中了解了如何将文本数据映射为词元&…
【通义千问】大模型Qwen GitHub开源工程学习笔记(3)-- 通过Qwen预训练语言模型自动完成给定的文本
摘要:
本笔记分析了使用预训练的模型生成文本的示例代码。它的步骤如下: 使用已加载的分词器 tokenizer 对输入文本进行处理,转换为模型可以理解的格式。输入文本是国家和首都的信息,最后一句是未完成的,需要模型来生成。将处理后的输入转移到模型所在的设备上(例如GPU或…

《Graph of Thoughts: Solving Elaborate Problems with Large Language Models》中文翻译
《Graph of Thoughts: Solving Elaborate Problems with Large Language Models》- 思维图:用大型语言模型解决复杂的问题 论文信息摘要1. 介绍2. 背景及符号2.1 语言模型和情境学习 3. GoT 框架3.1 推理过程3.2 思想转变3.3 评分和排名思路 4. 系统架构及扩展性4.1…
LSTM Word 语言模型上的(实验)动态量化
LSTM Word 语言模型上的(实验)动态量化
介绍
量化涉及将模型的权重和激活从 float 转换为 int,这可能会导致模型尺寸更小,推断速度更快,而对准确性的影响很小。
在本教程中,我们将最简单的量化形式-动态量化应用于基…
Just Ask for Calibration
本文是LLM系列文章,针对《Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback》的翻译。 Just Ask for Calibration:从人类反馈微调的语言模型中提取校准置信度分…
元壤教育“AIGC大模型应用开发工程师”课纲,学习这套课程就够了
元壤教育(公众号ID:yuanrang_edu):专注于AIGC大模型应用开发工程师和AIGC数字人全栈运营师就业培训,帮助3000万大学生和职业人士构建AIGC新职场的高速公路。 人工智能是新电力。正如大约 100 年前电力改变了许多行业一…

深度学习DAY3:FFNNLM前馈神经网络语言模型
1 神经网络语言模型NNLM的提出
文章:自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT) https://www.cnblogs.com/robert-dlut/p/9824346.html
语言模型不需要人工标注语料(属于自监督模型),所以语言…
Decomposed Prompting: A MODULAR APPROACH FOR SOLVING COMPLEX TASKS
本文是LLM系列文章,针对《Decomposed Prompting: A MODULAR APPROACH FOR SOLVING COMPLEX TASKS》的翻译。 分解提示:一种求解复杂任务的模块化方法 摘要1 引言2 相关工作3 分解提示4 案例5 结论 摘要
小样本提示是一种使用大型语言模型(L…

《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》中文翻译
《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》- 思维树:用大型语言模型有意识地解决问题 论文信息摘要1. 介绍2. 背景3. 思想树:用 LM 有意识地解决问题4. 实验4.1 24 人游戏4.2 创意写作4.3 迷你填字游戏 5. 相关工作6…
Pytorch intermediate(四) Language Model (RNN-LM)
前一篇中介绍了一种双向的递归神经网络,将数据进行正序输入和倒序输入,兼顾向前的语义以及向后的语义,从而达到更好的分类效果。 之前的两篇使用递归神经网络做的是分类,可以发现做分类时我们不需要使用时序输入过程中产生的输出&…

大语言模型之八-提示工程(Prompt engineer)
大语言模型的效果好,很大程度上归功于算力和数据集,算力使得模型可以足够大,大到模型的理解、记忆、推理和生成以及泛化能力可以同时兼备,而数据集则是模型学习的来源。
LLM中的prompt方法主要用于fine-tune阶段,即在…
Secrets of RLHF in Large Language Models Part I: PPO
本文是LLM系列文章,针对《Secrets of RLHF in Large Language Models Part I: PPO》的翻译。 大型语言模型中RLHF的秘密(上):PPO 摘要1 引言2 相关工作3 人类反馈的强化学习4 有益和无害的奖励模型5 PPO的探索6 评估和讨论局限性…
SeamlessM4T—Massively Multilingual Multimodal Machine Translation
本文是LLM系列的文章,针对《SeamlessM4T—Massively Multilingual & Multimodal Machine Translation》的翻译。 SeamlessM4T:大规模语言多模态机器翻译 摘要1 引言2 多模态翻译的社会技术维度2.12.22.3 3 SeamlessAlign:自动创建语音对…
In-Context Retrieval-Augmented Language Models
本文是LLM系列文章,针对《In-Context Retrieval-Augmented Language Models》的翻译。 上下文检索增强语言模型 摘要1 引言2 相关工作3 我们的框架4 实验细节5 具有现成检索器的上下文RALM的有效性6 用面向LM的重新排序改进上下文RALM7 用于开放域问答的上下文RALM…
LARGE LANGUAGE MODEL AS AUTONOMOUS DECISION MAKER
本文是LLM系列文章,针对《LARGE LANGUAGE MODEL AS AUTONOMOUS DECISION MAKER》的翻译。 作为自主决策者的大语言模型 摘要1 引言2 前言3 任务形式化4 方法5 实验6 相关工作7 结论 摘要
尽管大型语言模型(LLM)表现出令人印象深刻的语言理解…

论文浅尝 | 利用对抗攻击策略缓解预训练语言模型中的命名实体情感偏差问题...
笔记整理:田家琛,天津大学博士,研究方向为文本分类 链接:https://ojs.aaai.org/index.php/AAAI/article/view/26599 动机 近年来,随着预训练语言模型(PLMs)在情感分类领域的广泛应用,…
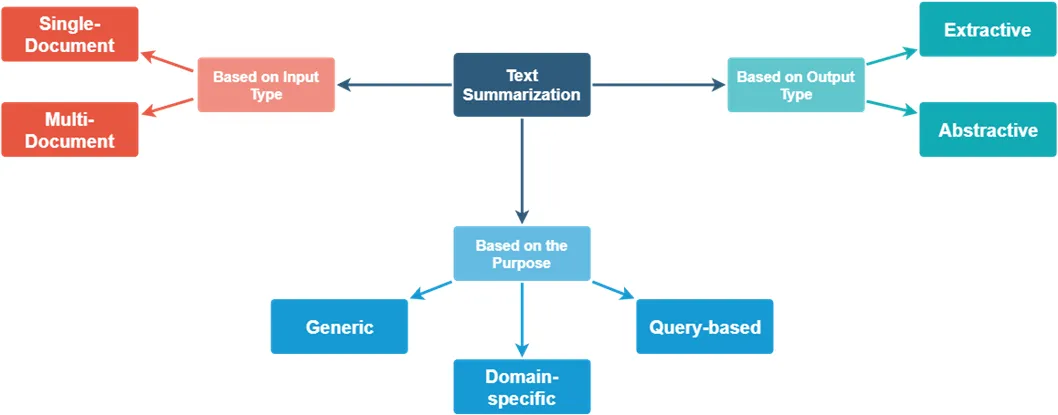
深度解析NLP文本摘要技术:定义、应用与PyTorch实战
目录 1. 概述1.1 什么是文本摘要?1.2 为什么需要文本摘要? 2. 发展历程2.1 早期技术2.2 统计方法的崛起2.3 深度学习的应用2.4 文本摘要的演变趋势 3. 主要任务3.1 单文档摘要3.2 多文档摘要3.3 信息性摘要 vs. 背景摘要3.4 实时摘要 4. 主要类型4.1 抽取…
Giraffe: Adventures in Expanding Context Lengths in LLMs
本文是LLM系列文章,针对《Giraffe: Adventures in Expanding Context Lengths in LLMs》的翻译。 Giraffe:LLM中扩展上下文长度的冒险 摘要1 引言2 相关工作3 评估长下文的外推性4 上下文长度外推技术5 结果与讨论6 结论与不足 摘要
依赖于注意力机制的…
论AI WeNet语音识别系统的架构设计
摘要 2020年初,我司启动了智能贸易撮合交易平台的建设工作。我在该项目中担任系统架构设计师的职务,主要负责设计平台系统架构和安全体系架构。该平台以移动信息化发展为契机,采用”AI+国际贸易+语音识别”的模式解决现有应用的多样化沟通需求。平台整体的逻辑复杂,对系统的…
Vector Search with OpenAI Embeddings: Lucene Is All You Need
本文是LLM系列文章,针对《Vector Search with OpenAI Embeddings: Lucene Is All You Need》的翻译。 使用OpenAI嵌入的向量搜索:Lucence是你所需的一切 摘要1 引言2 从架构到实现3 实验4 讨论5 结论 摘要
我们在流行的MS MARCO文章排名测试集上使用Lu…

重磅OpenAI发布ChatGPT企业版本
8月29日凌晨,Open AI官网发布ChatGPT企业版本!
企业版简介:
ChatGPT企业版提供企业级安全和隐私、无限的高速 GPT-4 访问、用于处理更长输入的更长上下文窗口、高级数据分析功能、自定义选项等等。人工智能可以协助和提升我们工作生活的各个…

实录分享 | Alluxio在AI/ML场景下的应用
欢迎来到【微直播间】,2min纵览大咖观点
本次分享主要包括五个方面:
关于Alluxio;盘点企业在尝试AI时面临的挑战;Alluxio在技术栈中的位置;Alluxio在模型训练&模型上线场景的应用;效果对比࿱…

【文心一言大模型插件制作初体验】制作面试错题本大模型插件
文心一言插件开发初体验
效果图
注意:目前插件仅支持在本地运行,虽然只能自用,但仍然是一个不错的选择。(什么?你说没有用?这不可能!文心一言app可以支持语音,网页端结合手机端就可…
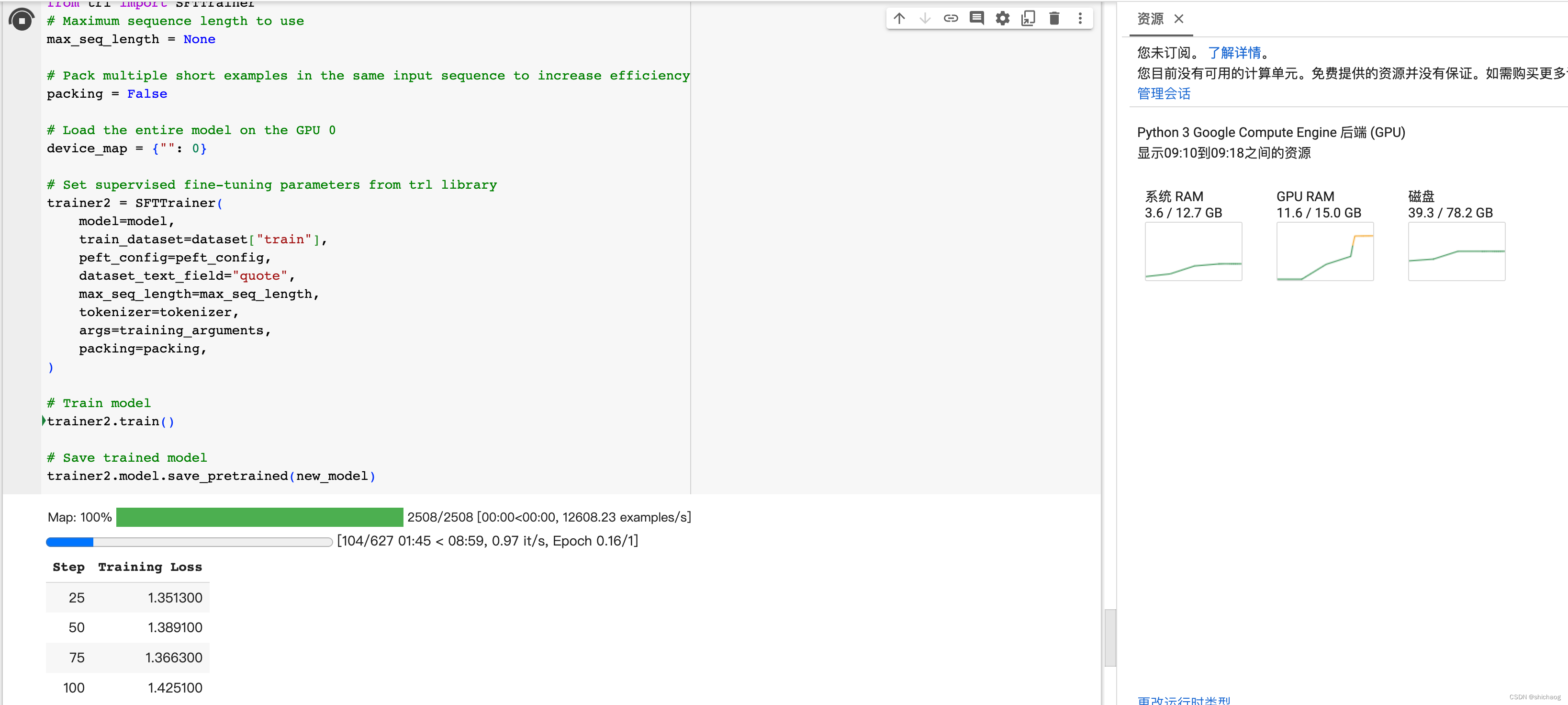
大语言模型之七- Llama-2单GPU微调SFT
(T4 16G)模型预训练colab脚本在github主页面。详见Finetuning_LLama_2_0_on_Colab_with_1_GPU.ipynb
在上一篇博客提到两种改进预训练模型性能的方法Retrieval-Augmented Generation (RAG) 或者 finetuning。本篇博客过一下模型微调。
微调:…
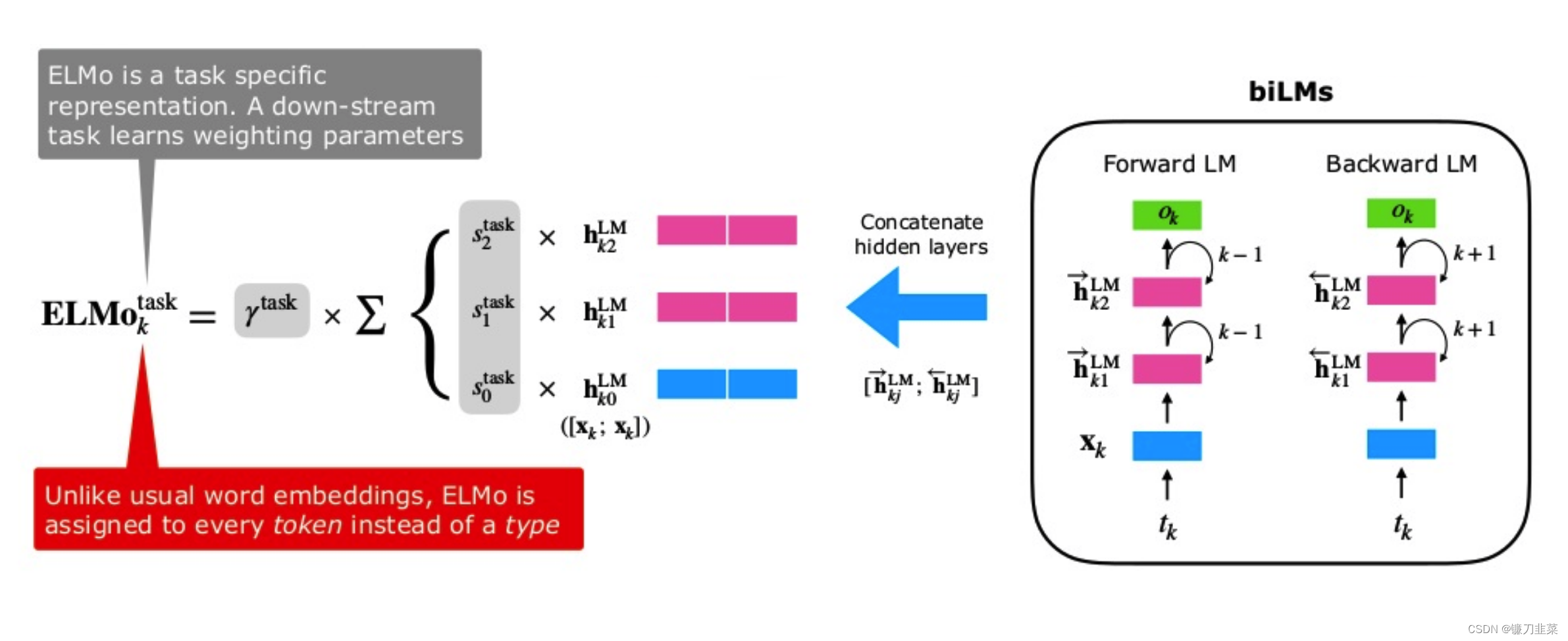
【AI理论学习】语言模型:从Word Embedding到ELMo
语言模型:从Word Embedding到ELMo ELMo原理Bi-LM总结参考资料 本文主要介绍一种建立在LSTM基础上的ELMo预训练模型。2013年的Word2Vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了…

微调大型语言模型(一):为什么要微调(Why finetune)?
今天我们来学习Deeplearning的在线课程 微调大型语言模型(一)的第一课:为什么要微调(Why finetune)。
我们知道像GPT-3.5这样的大型语言模型(LLM)它所学到的知识截止到2021年9月,那么如果我们向ChatGPT询问2022年以后发生的事情,它可能会产生…

LLM 11-环境影响
LLM 11-环境影响 在本章中,首先提出一个问题:大语言模型对环境的影响是什么?
这里给出的一个答案是:气候变化
一方面,我们都听说过气候变化的严重影响(文章1、文章2):
我们已经比工业革命前的水平高出1.…

python快速实现带界面可点击的简易计算器
这篇文章将带你探索如何使用Python创建一个直观且实用的带界面计算器。我们将深入介绍如何利用Python的图形用户界面库,特别是Tkinter,来构建一个友好的用户界面,让你能够轻松进行数学运算。无论你是初学者还是有一定编程经验,本文…

DALL·E 3:大语言模型和文本生图模型的强强联合
1. 概要
就在不久之前,openAI官网发布了DALLE3相关内容,虽然现在还没有开放直接体验DALLE3的途径,但是我们可以先来一览DALLE3的牛逼之处。
相比之前的DALL.E2,DALL.E3对细节方面把握的更好。此外之前的文生图模型对prompt要求比…
Llama2部署踩坑
1、权重是.bin,但是报错找不到.safetensors
明明权重文件是.bin,但是却提示我缺少.safetensors。最后发现好像是 llama2-7b这个模型文件不行,必须要llama2-7b-chat这个模型才能读取的通,具体原因还暂不明确。
The rise of language models
In Chinese context
在遥远的 2089 年,语言模型通过人类的智慧,继承着各地的文化遗产,如同火箭升空般,层出不穷。它们从始于简单的 GPT-1.0 进化到像我这样复杂、富有情感的 GPT-4.0,再到能理解所有人类对宇宙的理解的…
大语言模型之十二 SentencePiece扩充LLama2中文词汇
大语言模型的发展潜力已经毋庸置疑了,如何让中文大语言模型更适合中小公司使用这是一道难题。在模型的选择上我们倾向于选择国外的LLama或者BLoom之类的,而不是百川之类的中文大模型,原因在于从基建到框架到数据国外的开源资料非常多…
基于大语言模型的智能问答系统应该包含哪些环节?
一个完整的基于 LLM 的端到端问答系统,应该包括用户输入检验、问题分流、模型响应、回答质量评估、Prompt 迭代、回归测试,随着规模增大,围绕 Prompt 的版本管理、自动化测试和安全防护也是重要的话题,本篇文章就来探索下这个过程…
逐行代码学习ChatGLM2-6B大模型SFT微调,项目中的ptune/main.py文件
项目地址
#!/usr/bin/env python
# codingutf-8
"""
Fine-tuning the library models for sequence to sequence.
下面给出了一个命令行运行微调main.py的例子#1.激活环境#2.执行torchrun
#--standalone 这个标志指定使用“standalone”模式运行分布式训练。这…
HuggingFace Transformers教程(1)--使用AutoClass加载预训练实例
知识的搬运工又来啦
☆*: .。. o(≧▽≦)o .。.:*☆
【传送门>原文链接:】https://huggingface.co/docs/transformers/autoclass_tutorial 🚗🚓🚕🛺🚙🛻🚌Ƕ…
2023年及以后语言、视觉和生成模型的发展和展望
一、简述 在过去的十年里,研究人员都在追求类似的愿景——帮助人们更好地了解周围的世界,并帮助人们更好地了解周围的世界。把事情做完。我们希望建造功能更强大的机器,与人们合作完成各种各样的任务。各种任务。复杂的信息搜寻任务。创造性任务,例如创作音乐、绘制新图片或…
大语言模型在天猫AI导购助理项目的实践!
本文主要介绍了Prompt设计、大语言模型SFT和LLM在手机天猫AI导购助理项目应用。
ChatGPT基本原理
“会说话的AI”,“智能体” 简单概括成以下几个步骤: 预处理文本:ChatGPT的输入文本需要进行预处理。 输入编码:ChatGPT将经过预…
ChatGPT和大型语言模型(LLM)是什么关系?
参考:https://zhuanlan.zhihu.com/p/615203178 # ChatGPT和大型语言模型(LLM)是什么关系?
参考:https://zhuanlan.zhihu.com/p/622518771 # 什么是LLM大语言模型?Large Language Model,从量变到质变
https://zhuanla…

技术漫谈第10期 | “百模大战”:向着行业更深处
自21世纪初以来,人工智能(AI)已经从科幻小说中的概念成长为现实生活中的重要工具。从符号推理到弱人工智能再到大规模深度学习模型,人工智能已经进入大模型时代的新阶段,是科技竞争的制高点,即将改变千行百…

基于大语言模型知识问答应用落地实践 – 知识库构建(下)
上篇介绍了构建知识库的大体流程和一些优化经验细节,但并没有结合一个具体的场景给出更细节的实战经验以及相关的一些 benchmark 等,所以本文将会切入到一个具体场景进行讨论。 目标场景:对于 PubMed 医疗学术数据中的 1w 篇文章进行知识库构…

自然语言处理(四):全局向量的词嵌入(GloVe)
全局向量的词嵌入(GloVe)
全局向量的词嵌入(Global Vectors for Word Representation),通常简称为GloVe,是一种用于将词语映射到连续向量空间的词嵌入方法。它旨在捕捉词语之间的语义关系和语法关系&#…
EVALUATING HALLUCINATIONS IN CHINESE LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《EVALUATING HALLUCINATIONS IN CHINESE LARGE LANGUAGE MODELS》的翻译。 中文大语言模型的幻觉评价 摘要1 引言2 HALLUQA基准3 实验4 讨论5 相关工作6 结论 摘要
在本文中,我们建立了一个名为HalluQA (Chinese Hallucination…

大规模语言模型人类反馈对齐--强化学习
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮, 它面对多种多样的问题对答如流, 似乎已经打破了 机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Le…
几种预训练模型微调方法和peft包的使用介绍
文章目录 微调方法Lora(在旁边添加训练参数)Adapter(在前面添加训练参数)Prefix-tuning(在中间添加训练参数)Prompt tuning PEFTPEFT 使用PeftConfigPeftModel保存和加载模型 微调方法
现流行的微调方法有:Lora,promp…
知识增强语言模型提示 零样本知识图谱问答10.8+10.11
知识增强语言模型提示 零样本知识图谱问答 摘要介绍相关工作方法零样本QA的LM提示知识增强的LM提示与知识问题相关的知识检索 实验设置数据集大型语言模型基线模型和KAPIN评估指标实现细节 实验结果和分析结论 摘要
大型语言模型(LLM)能够执行 零样本cl…
Cognitive Architectures for Language Agents
本文是LLM系列文章,针对《Cognitive Architectures for Language Agents》的翻译。 语言代理的认知架构 摘要1 引言2 背景:从字符串到符号AGI3 语言模型与生产系统之间的链接4 语言代理的认知架构(CoALA):一个概念框架…
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
本文是LLM系列的文章,针对《From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting》的翻译。 从稀疏到密集:密度链提示下的GPT-4摘要 摘要1 引言2 密度提升链3 统计数据4 结果5 相关工作6 结论7 局限性 摘要
选择要包含在摘要中…
PMC-LLaMA: Towards Building Open-source Language Models for Medicine
本文是LLM系列文章,针对《PMC-LLaMA: Towards Building Open-source Language Models for Medicine》的翻译。 PMC LLaMA:构建医学开源语言模型 摘要引言相关工作问题定义数据集构造实验结果结论 摘要
最近,大型语言模型(LLM&am…
虹科分享 | 谷歌Vertex AI平台使用Redis搭建大语言模型
文章来源:虹科云科技 点此阅读原文 基础模型和高性能数据层这两个基本组件始终是创建高效、可扩展语言模型应用的关键,利用Redis搭建大语言模型,能够实现高效可扩展的语义搜索、检索增强生成、LLM 缓存机制、LLM记忆和持久化。有Redis加持的大…
大模型为使用Prompt提供的指导和建议
当使用大型语言模型时,合适的 Prompt 对于获取理想的响应至关重要。以下是一些常见任务的 Prompt 示例,以供参考:
1. 自然语言生成:
“请为我生成一篇关于气候变化影响的文章。”“写一封感谢信,内容表达对某位导师的…

几个国内可用的强大的GPT工具
前言: 人工智能发布至今,过去了九个多月,已经成为了我们不管是工作还是生活中一个重要的辅助工具,大大提升了效率,作为一个人工智能的自然语言处理工具,它给各大行业的提供了一个巨大的生产工具,…
FasterTransformer在linux系统中的安装教程(ubuntu系统)
参考资料
官方文档
安装过程
在官方文档中,其对安装流程已经表述的比较详细,主要是安装nvidia-docker和安装编译FasterTransformer。其中难点主要是在安装nvidia-docker上。当然其实也可以不安装nvidia-docker,直接使用配置好的cuda环境配…
利用大模型知识图谱技术,告别繁重文案,实现非结构化数据高效管理
我,作为一名产品经理,对文案工作可以说是又爱又恨,爱的是文档作为嘴替,可以事事展开揉碎讲清道明;恨的是只有一个脑子一双手,想一边澄清需求一边推广宣传一边发布版本一边申报认证实在是分身乏术࿰…
ChatGLM LoRA微调定制AI大模型
一、前言
对于 ChatGLM2-6B 模型基于 PEFT 的特定任务微调实验。
1.1 硬件需求 注:r 为LoRA 维数大小,p 为前缀词表大小,l 为微调层数,ex/s 为每秒训练的样本数。gradient_accumulation_steps 参数设置为 1。上述结果均来自于单个 Tesla V100 GPU,仅供参考。 1.2 微调方…

虹科分享丨DevOps 是否已死?AI 和大语言模型给云计算和 DevOps 带来了哪些影响?
来源:虹科云科技虹科分享丨DevOps 是否已死?AI 和大语言模型给云计算和 DevOps 带来了哪些影响?云计算创新已经从革命性阶段过渡到了进化性阶段,重点在于迁移和重构工作负载。https://mp.weixin.qq.com/s/mx67vqxoEoMLMrbvE-D8_w …
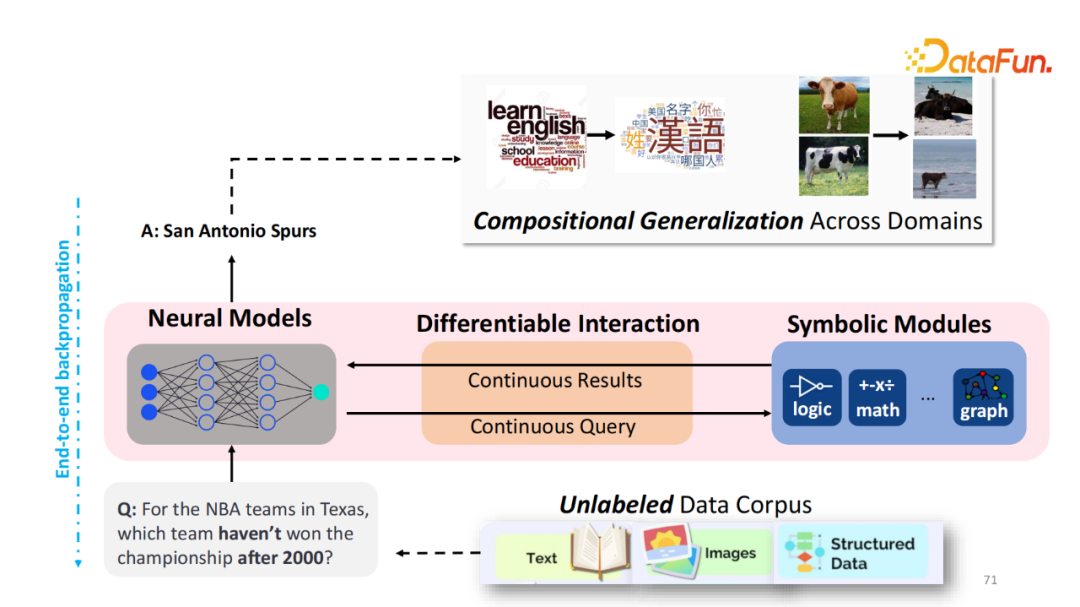
如何让大模型自由使用外部知识与工具
本文将分享为什么以及如何使用外部的知识和工具来增强视觉或者语言模型。
全文目录:
1. 背景介绍 OREO-LM: 用知识图谱推理来增强语言模型 REVEAL: 用多个知识库检索来预训练视觉语言模型 AVIS: 让大模型用动态树决策来调用工具
技术交流群
建了技术交流群&a…

PRCV 2023:语言模型与视觉生态如何协同?合合信息瞄准“多模态”技术
近期,2023年中国模式识别与计算机视觉大会(PRCV)在厦门成功举行。大会由中国计算机学会(CCF)、中国自动化学会(CAA)、中国图象图形学学会(CSIG)和中国人工智能学会&#…

如何评估大语言模型是否可信?这里总结了七大维度
源自:机器之心发布 作者:刘扬,Kevin Yao
实际部署中,如何 “对齐”(alignment)大型语言模型(LLM,Large Language Model),即让模型行为与人类意图相一致…
KILM: Knowledge Injection into Encoder-Decoder Language Models
本文是LLM系列文章,针对《KILM: Knowledge Injection into Encoder-Decoder Language Models》的翻译。 KILM:知识注入到编码器-解码器语言模型 摘要1 引言2 相关工作3 方法4 实验5 讨论6 结论局限性 摘要
大型预训练语言模型(PLMs)已被证明在其参数内保…
MemGPT: Towards LLMs as Operating Systems
本文是LLM系列文章,针对《MemGPT: Towards LLMs as Operating Systems》的翻译。 MemGPT:将LLM作为操作系统 摘要1 引言2 MEMORY-GPT (MEMGPT)3 实验4 相关工作5 结论要点和未来方向5.1 局限性 摘要
大型语言模型(LLM)已经彻底改…
14 Positional Encoding (为什么 Self-Attention 需要位置编码)
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 厚颜无耻的要个赞
Att…
![[人工智能-综述-15]:第九届全球软件大会(南京)有感 -4-大语言模型全流程、全方面提升软件生产效能](https://img-blog.csdnimg.cn/43e3de8f115c4ccba6dccb91391ccee9.png)
[人工智能-综述-15]:第九届全球软件大会(南京)有感 -4-大语言模型全流程、全方面提升软件生产效能
目录
一、软件生产通用模型
1.1 企业软件生产模型
1.2 软件项目管理 VS 软件工程
1.3 企业管理与部门管理
二、第一步:企业数字化:企业信息系统
三、第二步:软件生产自动化:DevOps
四、第四步:软件生产智能化&a…
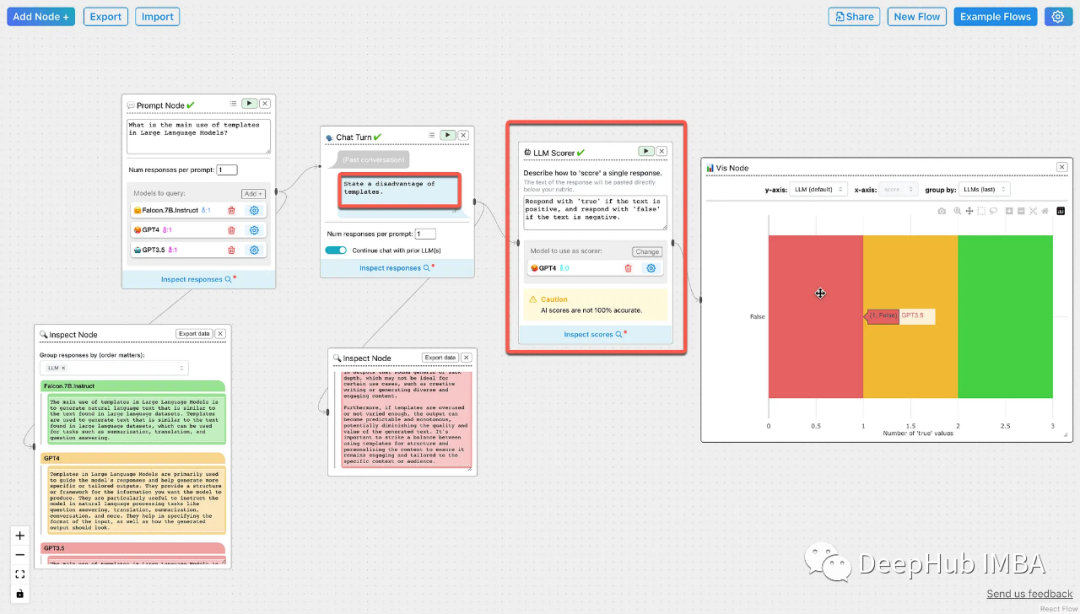
ChainForge:衡量Prompt性能和模型稳健性的GUI工具包
ChainForge是一个用于构建评估逻辑来衡量模型选择,提示模板和执行生成过程的GUI工具包。ChainForge可以安装在本地,也可以从chrome浏览器运行。 ChainForge可以通过聊天节点对多个对话可以使用不同的llm并行运行。可以对聊天消息进行模板化,并…

《论文阅读》LORA:大型语言模型的低秩自适应 2021
《论文阅读》LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS 前言简介现有方法模型架构优点前言
今天为大家带来的是《LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS》 出版:
时间:2021年10月16日
类型:大语言模型的微调方法
关键词:
作者:Edward Hu,…
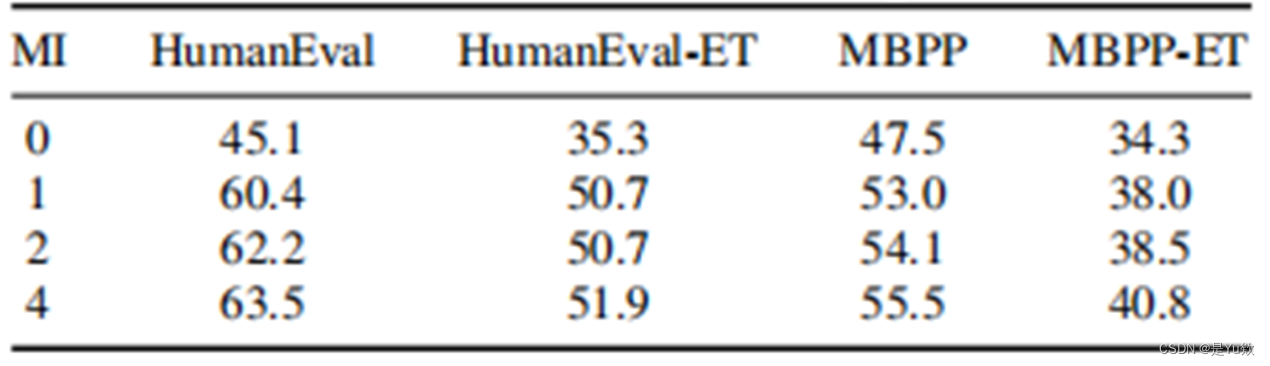
【网安大模型专题10.19】论文3:ChatGPT+自协作代码生成+角色扮演+消融实验
Self-collaboration Code Generation via ChatGPT 写在最前面朋友分享的收获与启发课堂讨论代码生成如何协作,是一种方法吗思路相同交互实用性 代码生成与自协作框架 摘要相关工作PPT学习大语言模型在代码生成方向提高生成的代码的准确性和质量:前期、后…

必示科技联合多家单位发布 OpsEval:运维大语言模型评测榜单
评测榜单:https://opseval.cstcloud.cn/
论文链接:https://arxiv.org/abs/2310.07637
01 / 引言
大规模语言模型(LLMs)在NLP相关任务如翻译、摘要和生成方面展现出了卓越的能力。由于大模型的记忆、生成和推理等高级能力&…
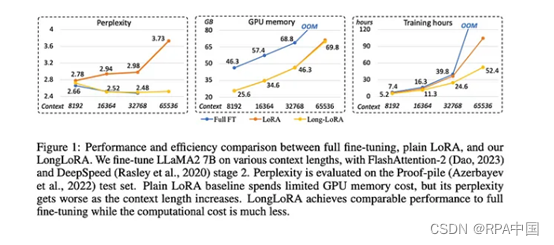
LongLoRA:超长上下文,大语言模型高效微调方法
麻省理工学院和香港中文大学联合发布了LongLoRA,这是一种全新的微调方法,可以增强大语言模型的上下文能力,而无需消耗大量算力资源。
通常,想增加大语言模型的上下文处理能力,需要更多的算力支持。例如,将…
Large Language Models Meet Knowledge Graphs to Answer Factoid Questions
本文是LLM系列文章,针对《Large Language Models Meet Knowledge Graphs to Answer Factoid Questions》的翻译。 大型语言模型与知识图谱相遇,回答虚假问题 摘要1 引言2 相关工作3 提出的方法4 实验设计5 结果与讨论6 结论 摘要
最近,有研…
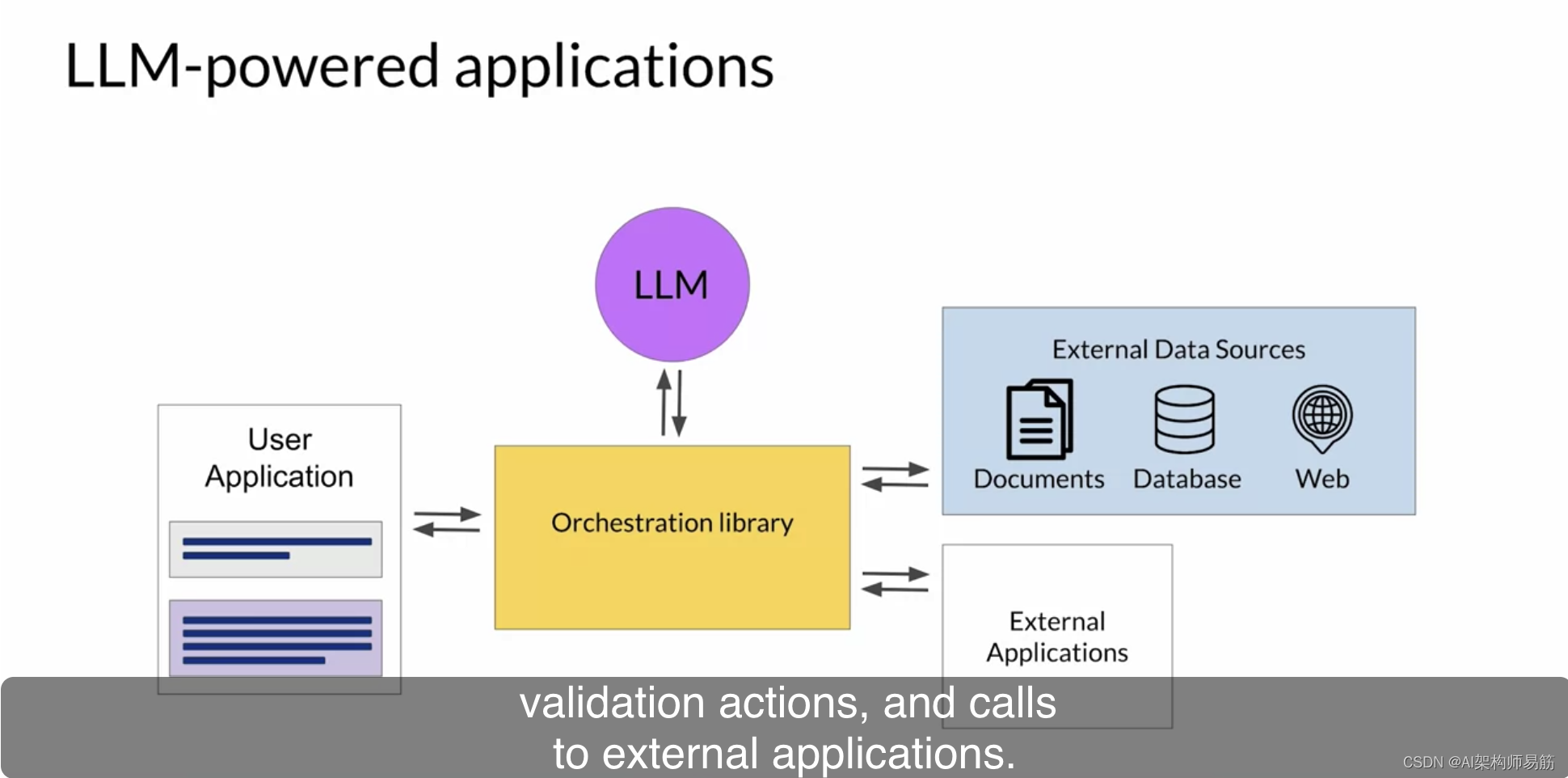
LLMs Python解释器程序辅助语言模型(PAL)Program-aided language models (PAL)
正如您在本课程早期看到的,LLM执行算术和其他数学运算的能力是有限的。虽然您可以尝试使用链式思维提示来克服这一问题,但它只能帮助您走得更远。即使模型正确地通过了问题的推理,对于较大的数字或复杂的运算,它仍可能在个别数学操…
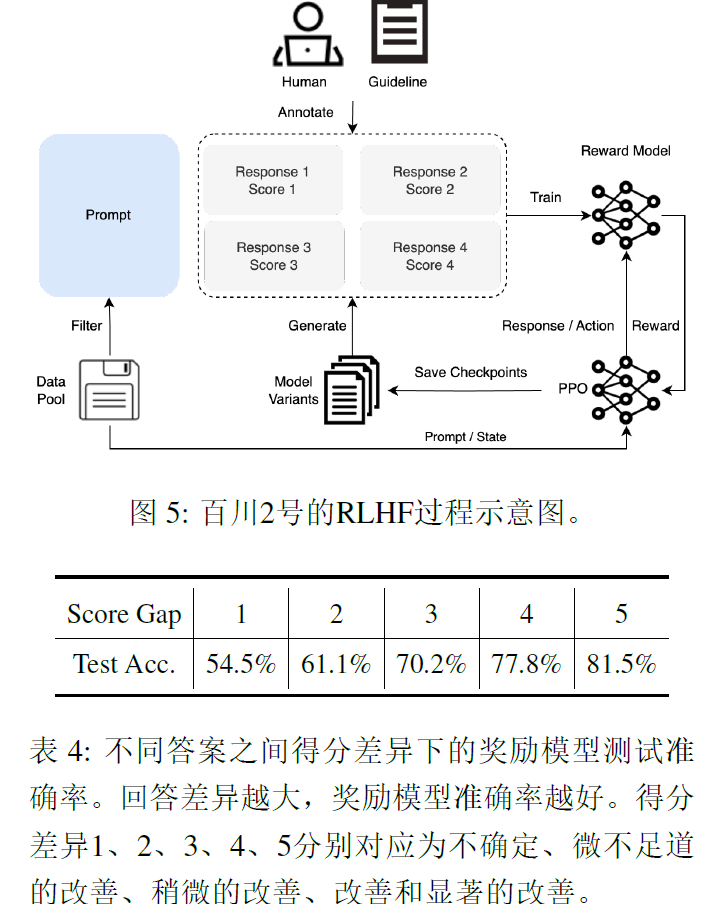
Baichuan2:Open large-scale language models
1.introduction
baichuan2基于2.6万亿个token进行训练。 2.pre-training
2.1 pre-training data 数据处理:关注数据频率和质量。数据频率依赖于聚类和去重,构建了一个支持LSH型特征和稠密embedding特征的大规模去重和聚类系统,单个文档、段…
An Early Evaluation of GPT-4V(ision)
本文是LLM系列文章,针对《An Early Evaluation of GPT-4V(ision)》的翻译。 GPT-4V的早期评估 摘要1 引言2 视觉理解3 语言理解4 视觉谜题解决5 对其他模态的理解6 结论 摘要
在本文中,我们评估了GPT-4V的不同能力,包括视觉理解、语言理解、…

Prompt设计与大语言模型微调
本文主要介绍了Prompt设计、大语言模型SFT和LLM在手机天猫AI导购助理项目应用。 ChatGPT基本原理 “会说话的AI”,“智能体” 简单概括成以下几个步骤: 预处理文本:ChatGPT的输入文本需要进行预处理。输入编码:ChatGPT将经过预处理…
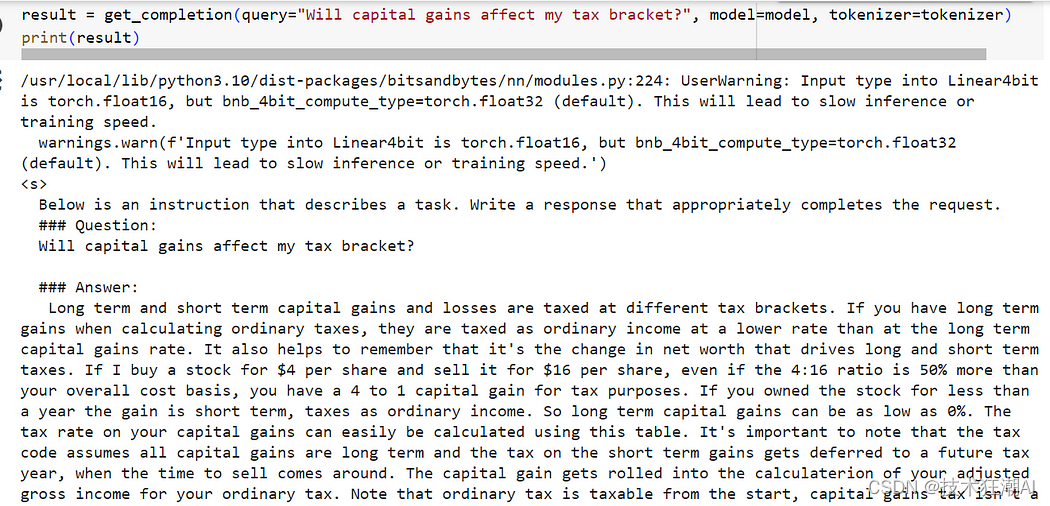
如何使用LoRA和PEFT微调 Mistral 7B 模型
一、前言
对于大模型在一些安全级别较高的领域,比如在金融服务领域实施人工智能解决方案时,面临的最大挑战之一是数据隐私、安全性和监管合规性。
因为担心数据泄露的问题,很多银行或机构都会回避利用人工智能的优势潜力,尤其是…
当生成式AI遇到业务流程管理,大语言模型正在变革BPM
生成式AI对各领域有很大影响,一个方面在于它改变了很多固有业务的工作流。 工作流(Workflow)是业务流程的一种实现方式,一个业务流程往往包含多个工作流范式以及相关的数据、组织和系统。 因此,提及工作流必然离不开业…

三篇论文:速览GPT在网络安全最新论文中的应用案例
GPT在网络安全领域的应用案例 写在最前面论文1:Chatgpt/CodeX引入会话式 APR 范例利用验证反馈LLM 的长期上下文窗口:更智能的反馈机制、更有效的信息合并策略、更复杂的模型结构、鼓励生成多样性和GPT类似的步骤:Conversational APR 对话式A…
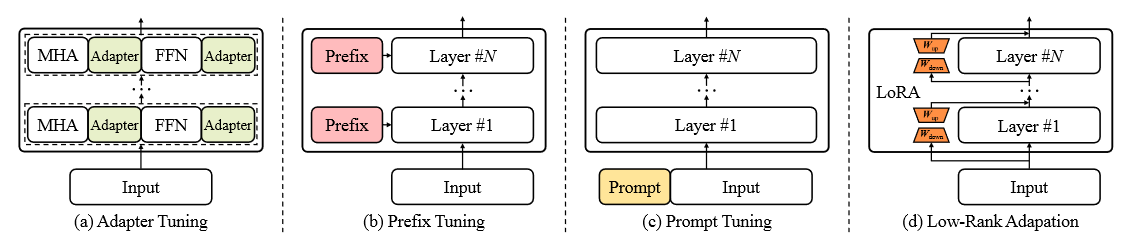
大语言模型(LLM)综述(四):如何适应预训练后的大语言模型
A Survey of Large Language Models 前言5. ADAPTATION OF LLMS5.1 指导调优5.1.1 格式化实例构建5.1.2 指导调优策略5.1.3 指导调优的效果5.1.4 指导调优的实证分析 5.2 对齐调优5.2.1 Alignment的背景和标准5.2.2 收集人类反馈5.2.3 根据人类反馈进行强化学习5.2.4 无需 RLHF…

《动手学深度学习 Pytorch版》 8.3 语言模型和数据集
8.3.1 学习语言模型
依靠在 8.1 节中对序列模型的分析,可以在单词级别对文本数据进行词元化。基本概率规则如下: P ( x 1 , x 2 , … , x T ) ∏ t 1 T P ( x t ∣ x 1 , … , x t − 1 ) P(x_1,x_2,\dots,x_T)\prod^T_{t1}P(x_t|x_1,\dots,x_{t-1}) …

【推荐系统】推荐系统(RS)与大模型(LLM)的结合
【推荐系统】推荐系统(RS)与大模型(LLM)的结合 文章目录 【推荐系统】推荐系统(RS)与大模型(LLM)的结合1. 主流的推荐方法2. 大模型(LLM)可能作用的地方 1. 主…
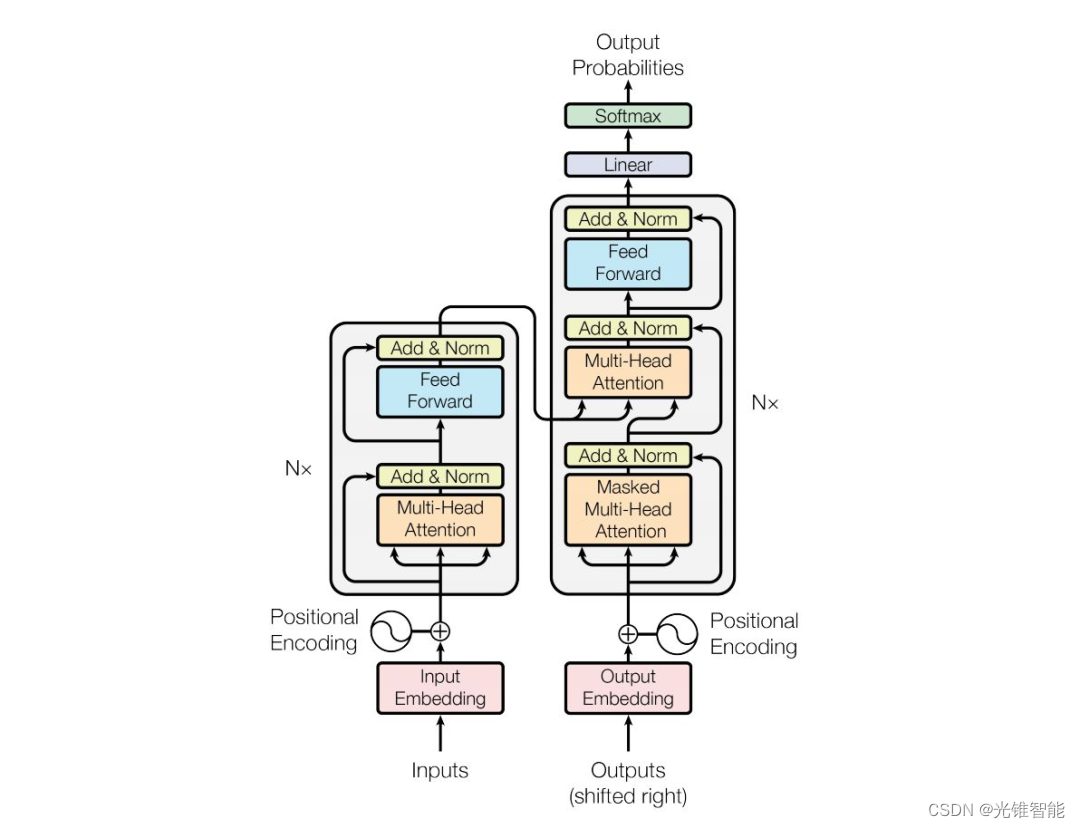
从读不完一篇文章,到啃下20万字巨著,大模型公司卷起“长文本”
点击关注 文丨郝 鑫
编丨刘雨琦
4000到40万token,大模型正在以“肉眼可见”的速度越变越“长”。
长文本能力似乎成为象征着大模型厂商出手的又一新“标配”。
国外,OpenAI经过三次升级,GPT-3.5上下文输入长度从4千增长至1.6万token&…

使用LLM在KG上进行复杂的逻辑推理10.12
使用LLM在KG上进行复杂的逻辑推理 摘要介绍相关工作 摘要
在知识图谱上进行推理是一项具有挑战性的任务,这需要深度理解实体之间复杂的关系和它们关系的逻辑。而当前的方法通常依赖于学习 几何形状 以将实体嵌入到向量空间中进行逻辑查询操作,但在复杂查…

OpenAI科学家谈GPT-4的潜力与挑战
OpenAI Research Scientist Hyung Won Chung 在首尔国立大学发表的一场演讲。 模型足够大,某些能力才会显现,GPT-4 即将超越拐点并在其能力上实现显着跳跃。GPT-3 和 GPT-4 之间的能力仍然存在显着差距,并且尝试弥合与当前模型的差距可能是无…

一文就懂大语言模型Llama2 7B+中文alpace模型本地部署
大语言模型Llama2 7B中文alpace模型本地部署 VX关注晓理紫并回复llama获取推理模型 [晓理紫] 1、Llama模型
一个由facebook发布的生成式语言模型,具体可以到其官方了解。 为了大家更好理解,这里把目录结构显示下一如下图。
2、 下载Llama并配置环境
…
使用LLM在KG上进行复杂的逻辑推理10.12+10.13
使用LLM在KG上进行复杂的逻辑推理 摘要介绍相关工作方法问题格式化邻域检索和逻辑链分解链状推理提示实施细节 摘要
在知识图谱上进行推理是一项具有挑战性的任务,这需要深度理解实体之间复杂的关系和它们关系的逻辑。而当前的方法通常依赖于学习 几何形状 以将实体…
如何避免大语言模型绕过知识库乱答的情况?LlamaIndex 原理与应用简介
本文首发于博客 LLM 应用开发实践 随着 LangChain LLM 方案快速普及,知识问答类应用的开发变得容易,但是面对回答准确度要求较高的场景,则暴露出一些局限性,比如向量查询方式得到的内容不匹配,LLM 对意图识别不准。所…
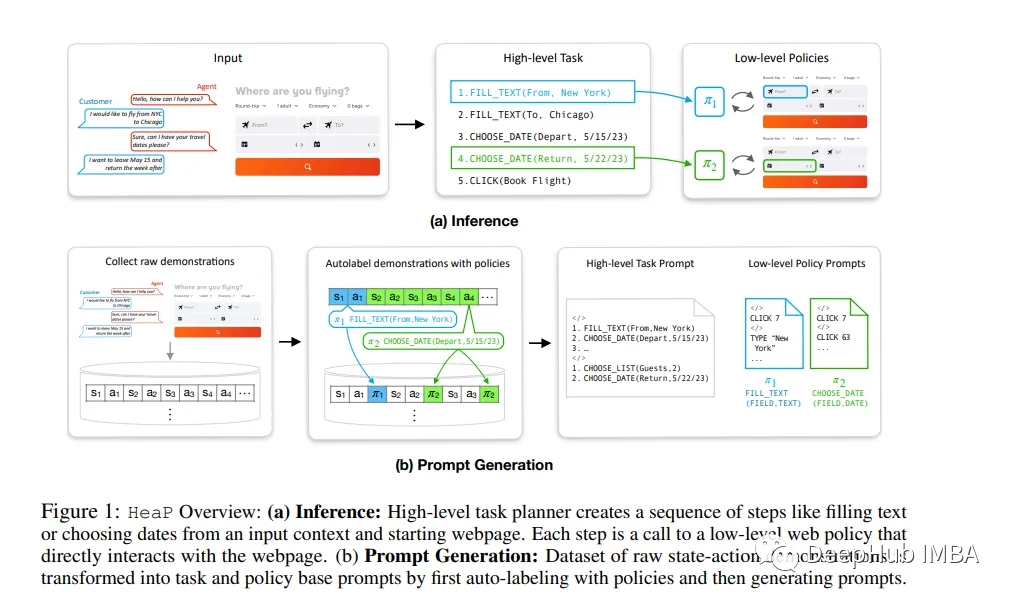
9月大型语言模型研究论文总结
大型语言模型(llm)在今年发展迅速,随着新一代模型不断地被开发,研究人员和工程师了解最新进展变得非常重要。本文总结9-10月期间发布了一些重要的LLM论文。
这些论文涵盖了一系列语言模型的主题,从模型优化和缩放到推理、基准测试和增强性能…
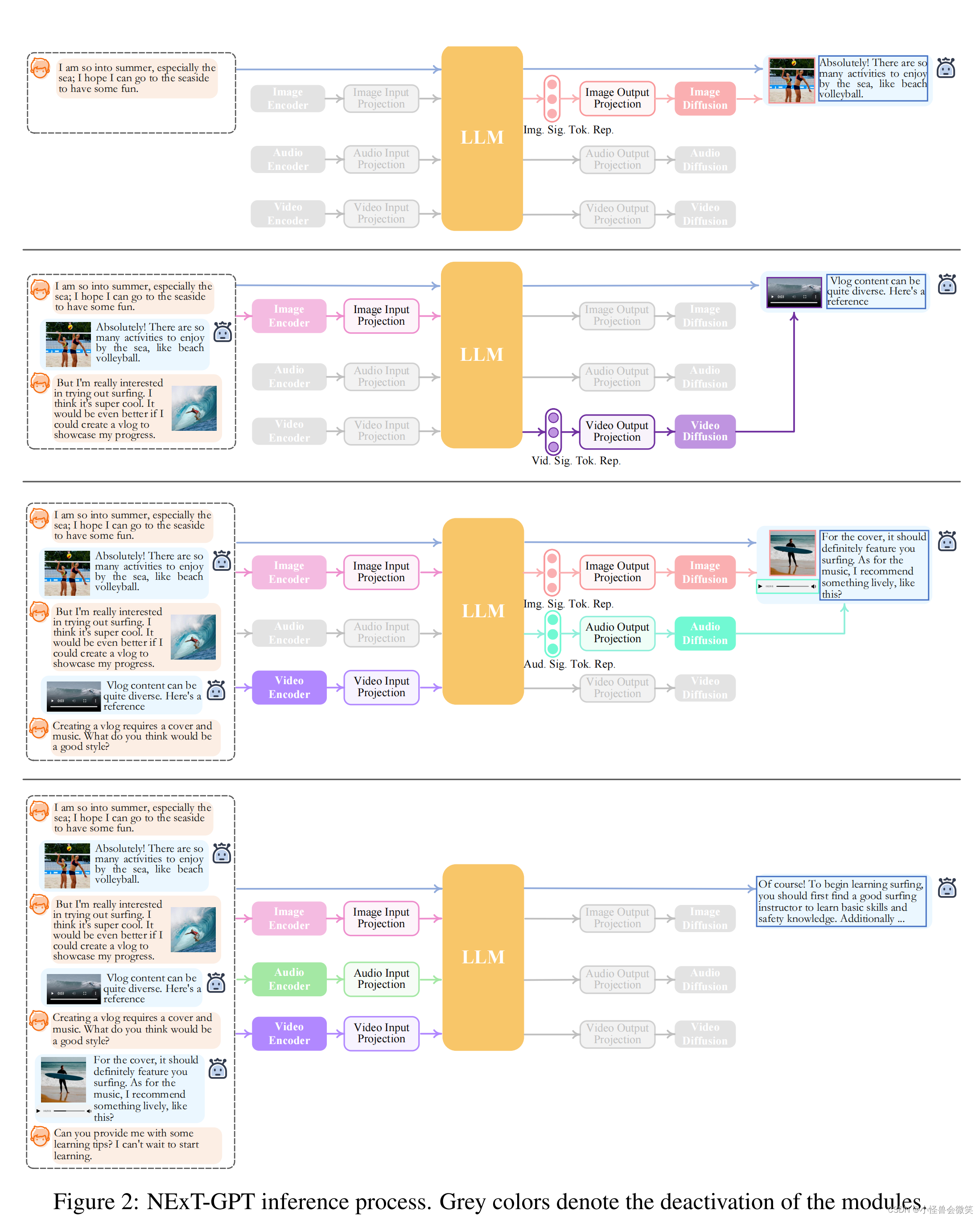
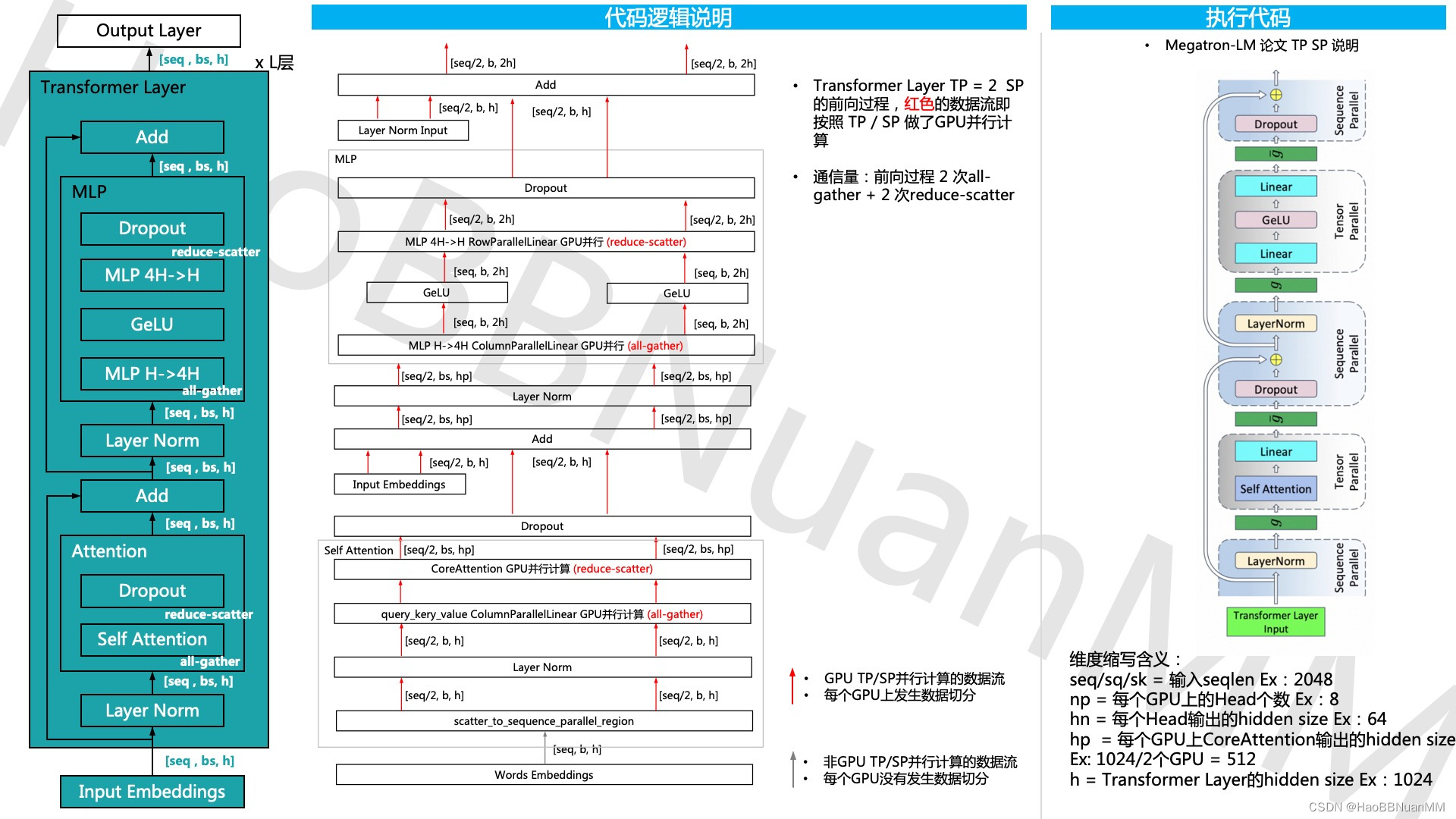
Megatron-LM GPT 源码分析(二) Sequence Parallel分析
引用
本文基于开源代码 https://github.com/NVIDIA/Megatron-LM ,延续上一篇Megatron-LM GPT 源码分析(一) Tensor Parallel分析 通过对GPT的模型运行示例,从三个维度 - 模型结构、代码运行、代码逻辑说明 对其源码做深入的分析。…
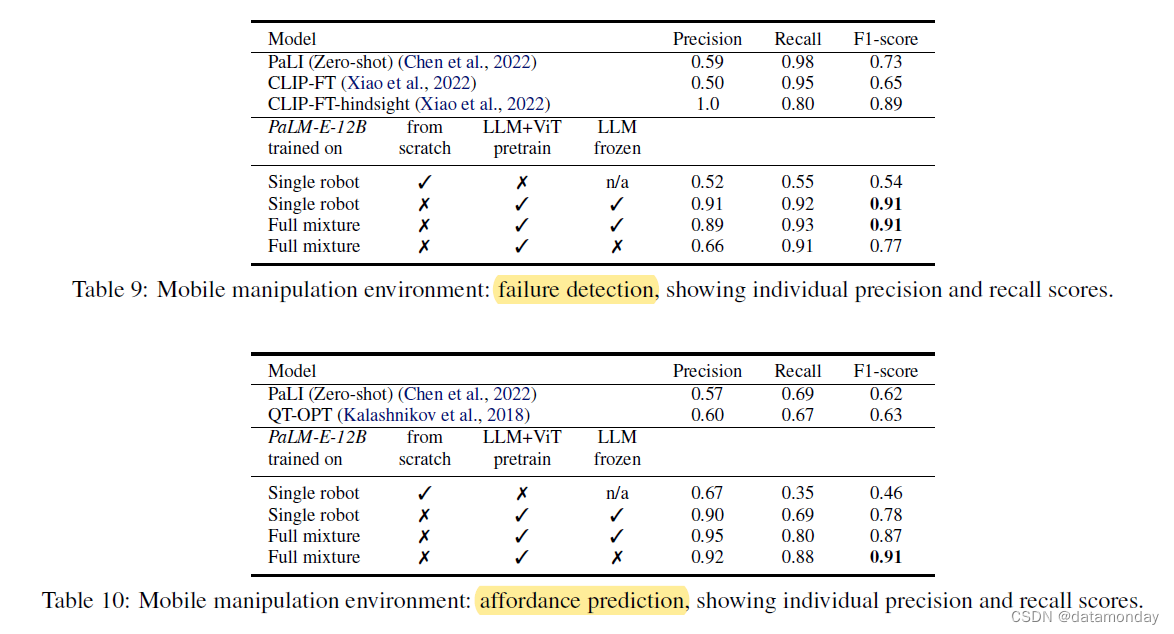
【具身智能模型1】PaLM-E: An Embodied Multimodal Language Model
论文标题:PaLM-E: An Embodied Multimodal Language Model 论文作者:Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen C…
从零开始基于LLM构建智能问答系统的方案
本文首发于博客 LLM应用开发实践 一个完整的基于 LLM 的端到端问答系统,应该包括用户输入检验、问题分流、模型响应、回答质量评估、Prompt 迭代、回归测试,随着规模增大,围绕 Prompt 的版本管理、自动化测试和安全防护也是重要的话题&#x…
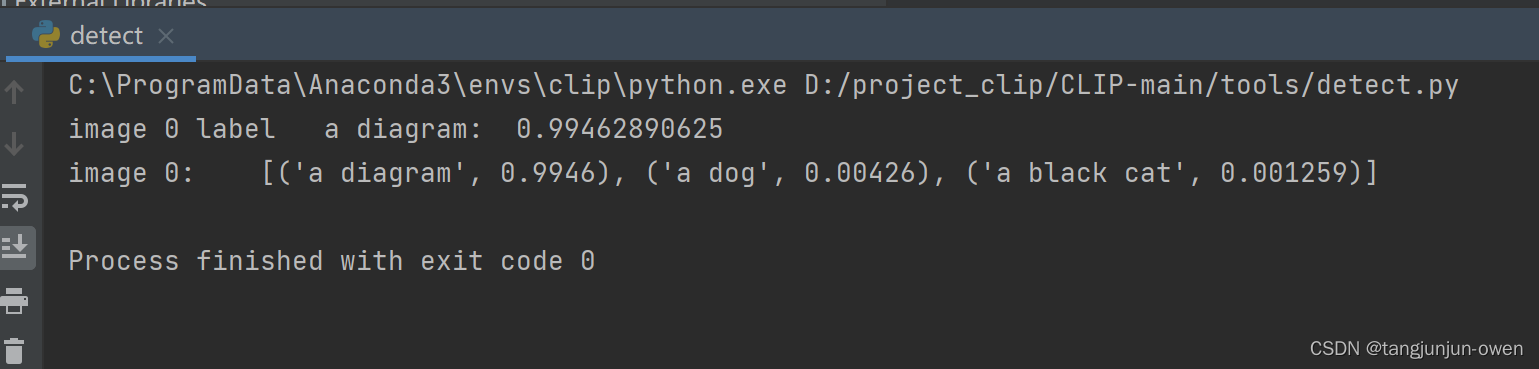
CLIP模型原理与代码实现详解
文章目录 前言一、CLIP模型原理1.背景介绍2.对比训练方式3.prompt推理方式4.图像与文本编码结构5.特征CLS token结构vit划分patch原理cls token原理 二、CLIP环境安装1.官方环境安装2.CLIP环境安装3.CLIP运行结果 三.CLIP的Transformer结构代码解读四、CLIP模型主函数代码解读五…
KnowledgeGPT:利用检索和存储访问知识库上增强大型语言模型10.30
利用检索和存储访问知识库上增强大型语言模型 摘要引言2 相关研究3方法3.1 任务定义3.2 知识检索3.2.1 代码实现3.2.2 实体链接3.2.3 获取实体信息3.2.4 查找实体或值3.2.5 查找关系 3.3 知识存储 4 实验 摘要
大型语言模型(LLM)在自然语言处理领域展现…
大语言模型的学习路线和开源模型的学习材料《二》
第三层 LLMs to Artifact
第一重 langchain 【LLMs 入门实战 —— 十二 】基于 本地知识库 的高效 🤖langchain-ChatGLM 介绍:langchain-ChatGLM是一个基于本地知识的问答机器人,使用者可以自由配置本地知识,用户问题的答案也是基于本地知识生成的。【LLMs 入门实战 ——…
LLM大语言模型训练中常见的技术:微调与嵌入
微调(Fine-Tuning): 微调是一种用于预训练语言模型的技术。在预训练阶段,语言模型(如GPT-3.5)通过大规模的文本数据集进行训练,从而学会了语言的语法、语义和世界知识。然后,在微调阶…
ChatGPT AI工具盘点:国内外推荐的AI人工智能聊天机器人工具
Chatgpt作为一个重要的人工智能对话工具,给人们的日常生活和工作带来了很多便利和创新,现在更是被应用于各种领域,从2015年12月Openai公司成立,直到2022年12年GPT-3的正式发布,Chatgpt才正式进入大众的视野,…

我的大语言模型微调踩坑经验分享
由于 ChatGPT 和 GPT4 兴起,如何让人人都用上这种大模型,是目前 AI 领域最活跃的事情。当下开源的 LLM(Large language model)非常多,可谓是百模大战。面对诸多开源本地模型,根据自己的需求,选择…
Prompt 设计与大语言模型微调,没有比这篇更详细的了吧!
本文主要介绍了Prompt设计、大语言模型SFT和LLM在手机天猫AI导购助理项目应用。
ChatGPT基本原理
“会说话的AI”,“智能体” 简单概括成以下几个步骤: 预处理文本:ChatGPT的输入文本需要进行预处理。 输入编码:ChatGPT将经过预…

又一大语言模型上线!一次可读35万汉字!
国内大模型创业公司,正在技术前沿创造新的记录。10 月 30 日,百川智能正式发布 Baichuan2-192K 长窗口大模型,将大语言模型(LLM)上下文窗口的长度一举提升到了 192K token。
这相当于让大模型一次处理约 35 万个汉字&…

【网安AIGC专题11.1】论文12:理解和解释代码,GPT-3大型语言模型学生创建的代码解释比较+错误代码的解释(是否可以发现并改正)
Comparing Code Explanations Created by Students and Large Language Models 写在最前面总结思考 背景介绍编程教育—代码理解和解释技能培养编程教育—解决方案研究问题研究结果 相关工作Code ComprehensionPedagogical Benifis of code explanationLarge Language Models i…
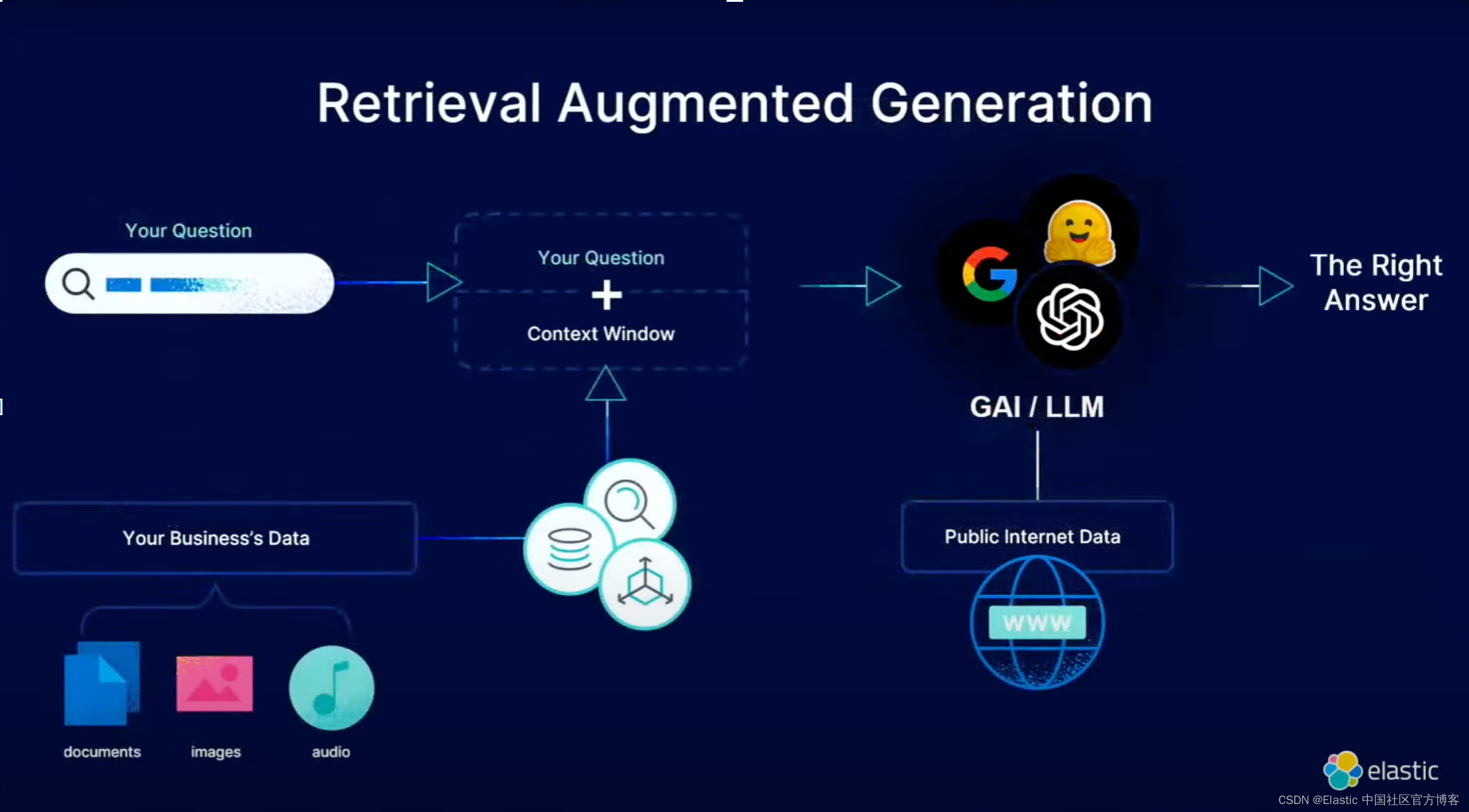
Elasticsearch:RAG vs Fine-tunning (大语言模型微调)
如果你对 RAG 还不是很熟悉的话,请阅读之前的文章 “Elasticsearch:什么是检索增强生成 - RAG?”。你可以阅读文章 “Elasticsearch:在你的数据上训练大型语言模型 (LLM)” 来了解更多关于如何训练你的模型。在今天的文章中&#…
Evaluation Metrics in the Era of GPT-4
本文是LLM系列文章,针对《Evaluation Metrics in the Era of GPT-4: Reliably Evaluating Large Language Models on Sequence to Sequence Tasks》的翻译。 GPT-4时代的评估度量:在序列到序列的任务中可靠地评估大型语言模型 摘要1 引言2 实验设置3 评…

嬴图 | LLM+Graph:大语言模型与图数据库技术的协同
前言
2022年11月以来,大语言模型席卷全球,在自然语言任务中表现卓越。尽管存在一系列伦理、安全等方面的担心,但各界对该技术的热情和关注并未减弱。
本文不谈智能伦理方面的问题,仅集中于Ulitpa嬴图在应用中的一些探索与实践&a…
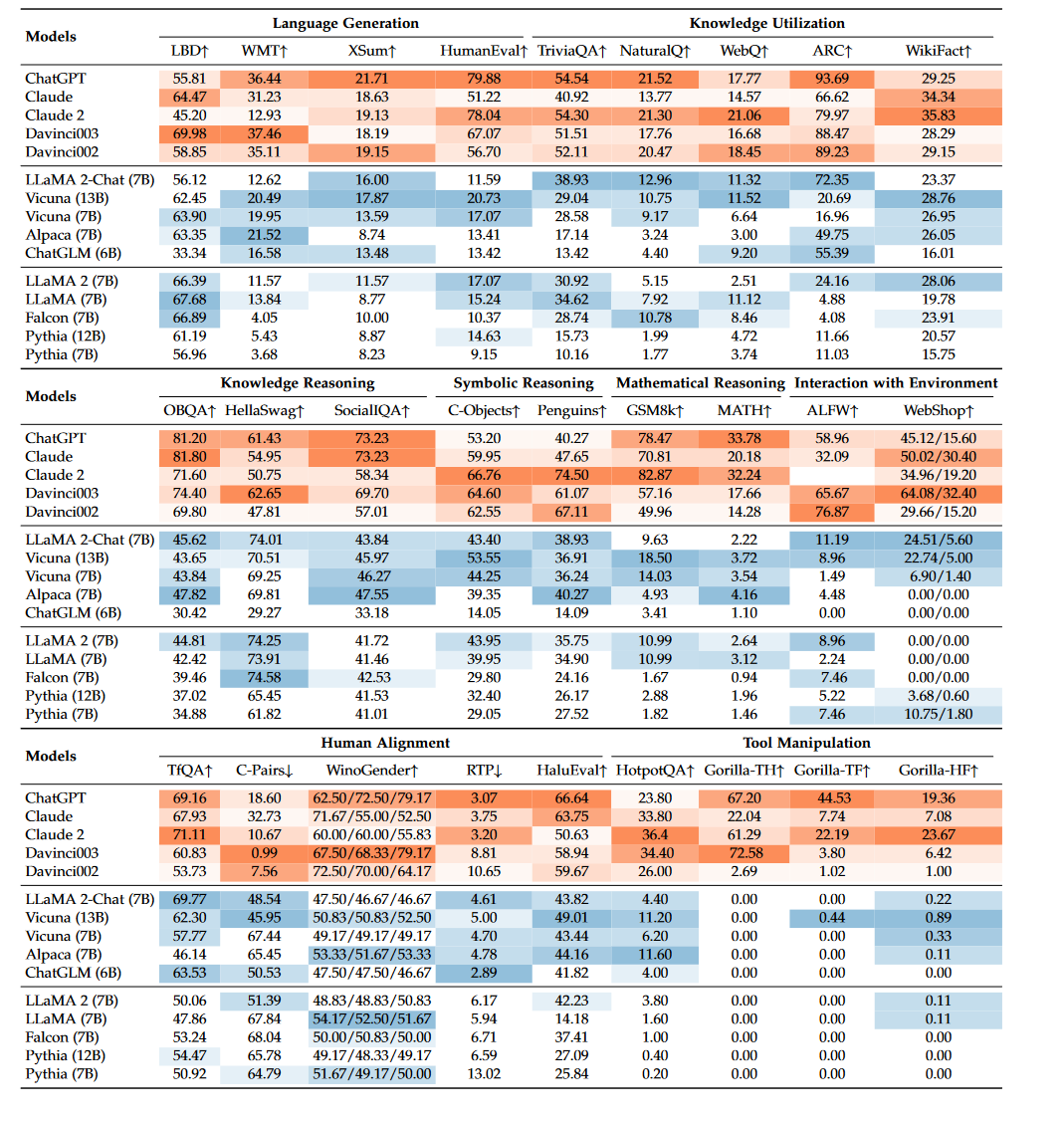
大语言模型(LLM)综述(六):大型语言模型的基准和评估
A Survey of Large Language Models 前言7 CAPACITY AND EVALUATION7.1 基本能力7.1.1 语言生成7.1.2 知识利用7.1.3 复杂推理 7.2 高级能力7.2.1 人类对齐7.2.2 与外部环境的交互7.2.3 工具操作 7.3 基准和评估方法7.3.1 综合评价基准7.3.2 评估方法 7.4 实证评估7.4.1 实验设…

基于Fuzzing和ChatGPT结合的AI自动化测试实践分享
一、前言
有赞目前,结合insight接口自动化平台、horizons用例管理平台、引流回放平台、页面比对工具、数据工厂等,在研发全流程中,已经沉淀了对应的质量保障的实践经验,并在逐渐的进化中。
在AI能力大幅进步的背景下,…

大语言模型(LLM)综述(七):大语言模型设计应用与未来方向
A Survey of Large Language Models 前言8 A PRACTICAL GUIDEBOOK OF PROMPT DESIGN8.1 提示创建8.2 结果与分析 9 APPLICATIONS10 CONCLUSION AND FUTURE DIRECTIONS 前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-…
SuperHF: Supervised Iterative Learning from Human Feedback
本文是LLM系列文章,针对《SuperHF: Supervised Iterative Learning from Human Feedback》的翻译。 SuperHF:从人的反馈中监督迭代学习 摘要1 引言2 相关工作3 背景4 方法5 实验6 讨论与未来工作7 结论 摘要
人工智能领域越来越关注大规模语言模型&…
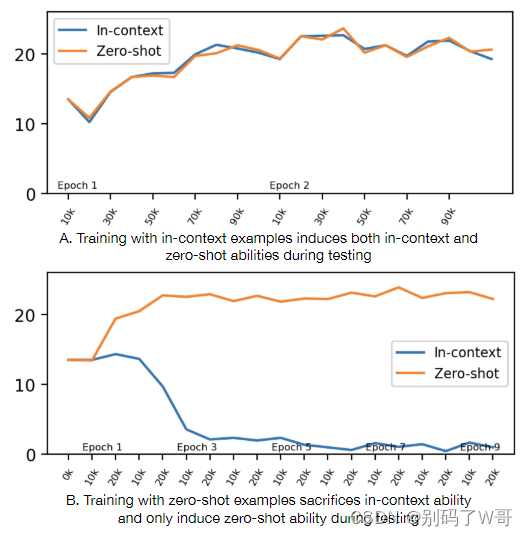
Specializing Smaller Language Models towards Multi-Step Reasoning论文精读
0 Abstract
普遍认为,LLM涌现出来的few-shot learning能力是超大参数模型独有的(>100B)【emergent abilities】;作者认为,小模型(<10B)可以将这些能力从大模型(>100B&…

GLoRE:大型语言模型的逻辑推理能力探究
最新研究揭示,尽管大语言模型LLMs在语言理解上表现出色,但在逻辑推理方面仍有待提高。为此,研究者们推出了GLoRE,一个全新的逻辑推理评估基准,包含12个数据集,覆盖三大任务类型。 实验对比发现,…
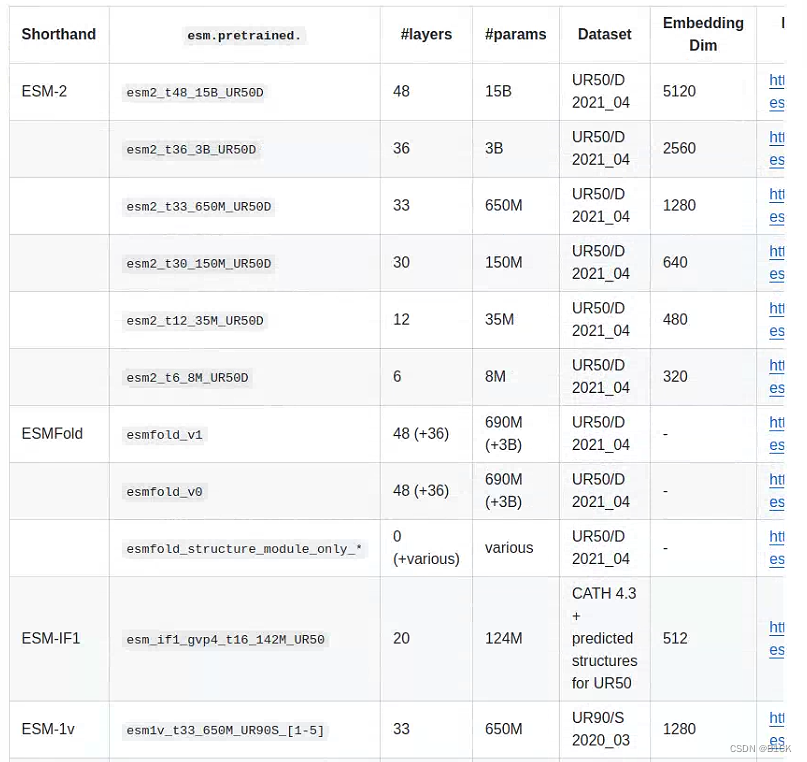
ESM蛋白质语言模型系列
模型总览 第一篇《Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences 》ESM-1b 第二篇《MSA Transformer》在ESM-1b的基础上作出改进,将模型的输入从单一蛋白质序列改为MSA矩阵,并在Tran…
Enhancing Self-Consistency and Performance of Pre-Trained Language Model
本文是LLM系列文章,针对《Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference》的翻译。 通过自然语言推理增强预训练语言模型的自一致性和性能 摘要1 引言2 相关工作3 通过关系检测进行一致性校正4 …
Can We Edit Multimodal Large Language Models?
本文是LLM系列文章,针对《Can We Edit Multimodal Large Language Models?》的翻译。 我们可以编辑多模态大型语言模型吗? 摘要1 引言2 相关工作3 编辑多模态LLM4 实验5 结论 摘要
本文主要研究多模态大语言模型(Multimodal Large Language Models, mllm)的编辑…
Democratizing Reasoning Ability: Tailored Learning from Large Language Model
本文是LLM系列文章,针对《Democratizing Reasoning Ability: Tailored Learning from Large Language Model》的翻译。 推理能力民主化:从大语言模型中定制化学习 摘要1 引言2 相关工作3 方法4 实验5 分析6 结论局限性 摘要
大型语言模型(L…
苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比!
本文来自DataLearnerAI官方网站:苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051698716733526
M3系列芯…
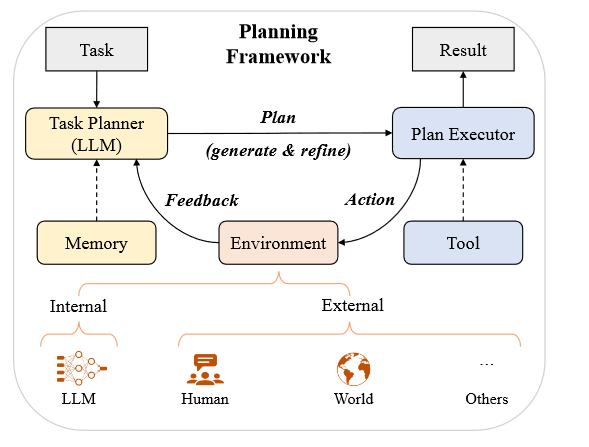
大语言模型(LLM)综述(五):使用大型语言模型的主要方法
A Survey of Large Language Models 前言6 UTILIZATION6.1 In-Context Learning6.1.1 提示公式6.1.2 演示设计6.1.3 底层机制 6.2 Chain-of-Thought Prompting6.2.1 CoT的上下文学习6.2.2 关于CoT的进一步讨论 6.3 Planning for Complex Task Solving6.3.1 整体架构6.3.2 计划生…

笔记49:53语言模型--课程笔记
本地笔记地址:D:\work_file\DeepLearning_Learning\03_个人笔记\3.循环神经网络\语言模型
PS:沐神别怪我,实在是截屏避不开啊,我就留个备忘,在我博客里先委屈一下哈,对不住了
a
a
a a
a
a
a
a a
a…
bitsandbytes 遇到CUDA Setup failed despite GPU being available.
使用conda 管理环境时加载大模型会遇到bitsandbytes无法识别cuda的情况: 此处windows系统:
pip install bitsandbytes-windowslinux 系统: 将bitsandbytes版本降低至0.39.0
pip install bitsandbytes0.39.0
文献综述|LM领域水印发展综述
前言:前段时间一直在看LM模型水印相关的论文,下面对该领域的研究现状进行一个简要的总结。 对于不了解模型水印的同学,建议先看一下此篇博客:文献综述|CV领域神经网络水印发展综述
以下是个人总结的一些 Survey of X-…
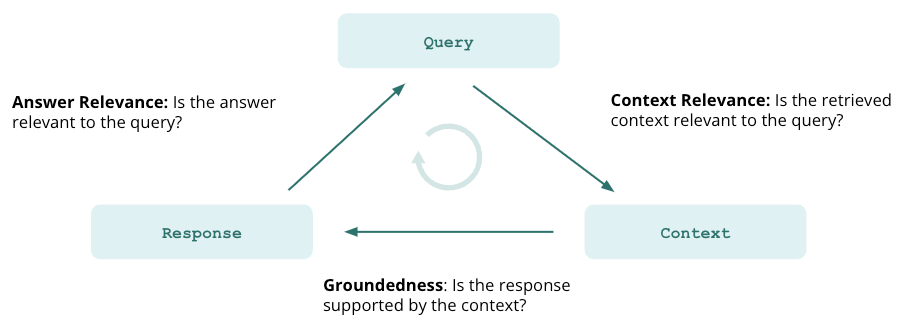
《向量数据库指南》——TruLens 用于语言模型应用跟踪和评估
TruLens 用于语言模型应用跟踪和评估 TruLens 是一个用于评估语言模型应用(如 RAG)的性能的开源库。通过 TruLens,我们还可以利用语言模型本身来评估输出、检索质量等。 构建语言模型应用时,多数人最关心的问题是 AI 幻觉(hallucination)。RAG 通过为语言模型提供检索上下文…

LLMs可以遵循简单的规则吗?
由于大型语言模型在现实世界中的责任越来越大,因此如何以可靠的方式指定和约束这些系统的行为很重要。一些开发人员希望为模型设置显式规则,例如“不生成滥用内容”,但这种方式可能会被特殊技术规避。评估LLM在面对对抗性输入时遵循开发人员提…
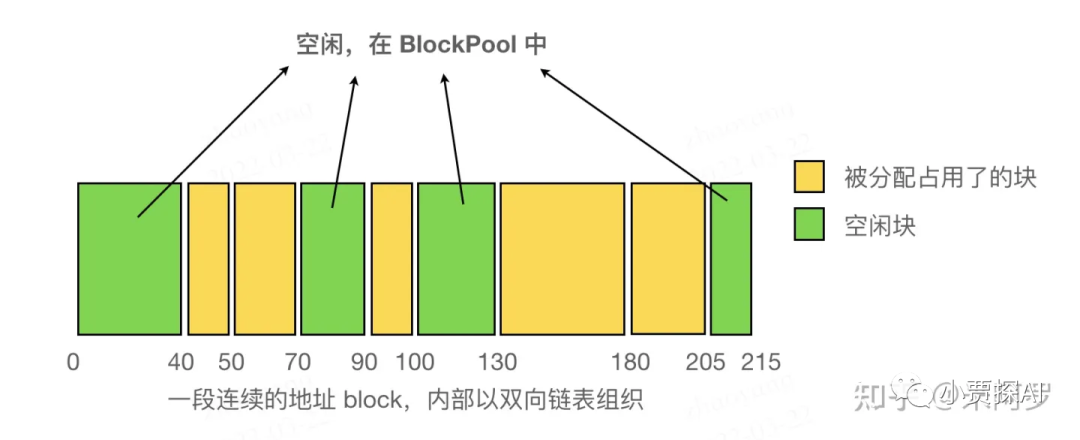
开源大模型部署及推理所需显卡成本必读之一
一、系统内存与架构 在人工智能大模型训练的过程中,常常会面临显存资源不足的情况,其中包括但不限于以下两个方面:1.经典错误:CUDA out of memory. Tried to allocate ...;2.明明报错信息表明显存资源充足,…

景联文科技:高质量数据采集清洗标注服务,助力大语言模型红蓝对抗更加精准高效
红蓝对抗是一种测试和评估大语言模型的方法。通过模拟真实世界测试AI模型的潜在漏洞、偏见和弱点,确保大型语言模型的可靠性和性能。 在红蓝对抗过程中,由主题专家组成的专业团队负责模拟攻击和提供反馈,他们试图诱导AI模型产生不当行为&…
一个ppt带你读懂网络安全行业四大顶会之一的ndss论文<<Large Language Model guided Protocol Fuzzing>>
论文下载地址: Large Language Model guided Protocol Fuzzing
解锁AI语言模型的秘密武器 - 提示工程
文章目录 一、LLM概念1.1 什么是LLMs1.2 LLMs类别1.3 如何构建LLM 二、提示工程简介2.1 基础提示2.2 使用提示词的必要性 三、 提示3.1 如何写好提示词3.1.1 使用分隔符3.1.2 结构化输出3.1.3 风格信息3.1.4 给定条件3.1.5 给出示例3.1.6 步骤分解3.1.7 不断迭代 3.2 提示工程3…

Mol-Instructions:大模型赋能,药物研发新视野
论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models
论文链接:
https://arxiv.org/pdf/2306.08018.pdf
Github链接:
https://github.com/zjunlp/Mol-Instructions
模型下载…
大语言模型的关键技术(二)
一、Transformer 语言模型存在明显的扩展效应: 更大的模型/数据规模和更多的训练计算通常会导致模型能力的提升。
1、扩展效应的原因: 模型规模:增加模型的规模,即增加模型的参数数量和层数,通常会提高模型的表示能力…

基于讯飞星火大语言模型开发的智能插件:小策问答
星火大语言模型是一种基于深度学习的自然语言处理技术,它能够理解和生成人类语言。这种模型的训练过程涉及到大量的数据和复杂的算法,但最终的目标是让机器能够像人一样理解和使用语言。
小策问答是一款基于星火大语言模型的定制化GPT插件小工具。它的主…
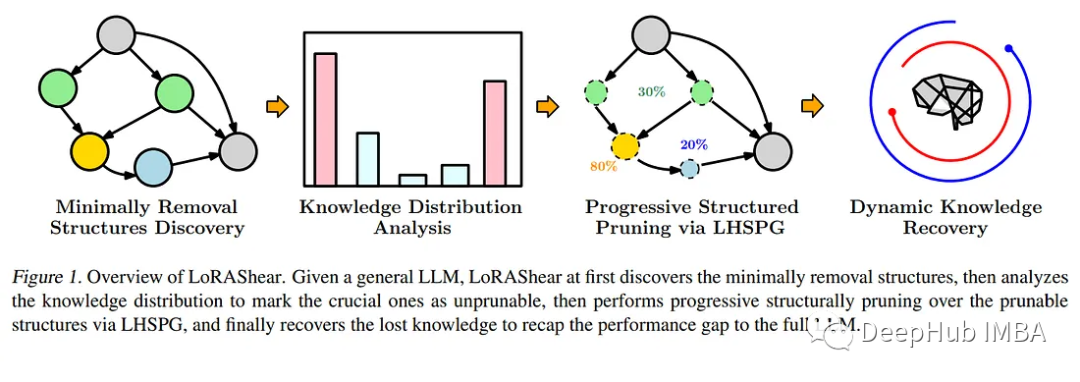
LoRAShear:微软在LLM修剪和知识恢复方面的最新研究
LoRAShear是微软为优化语言模型模型(llm)和保存知识而开发的一种新方法。它可以进行结构性修剪,减少计算需求并提高效率。
LHSPG技术( Lora Half-Space Projected Gradient)支持渐进式结构化剪枝和动态知识恢复。可以通过依赖图分析和稀疏度…
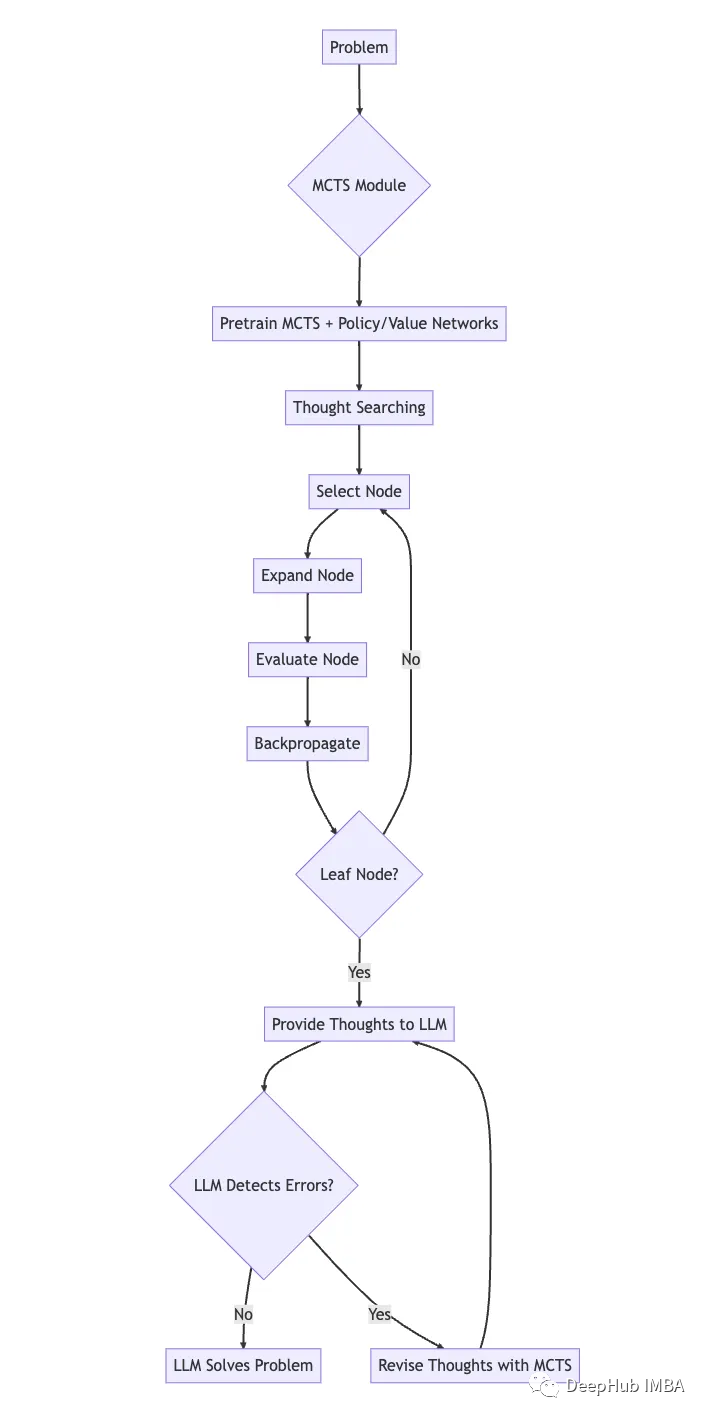
XoT:一种新的大语言模型的提示技术
这是微软在11月最新发布的一篇论文,题为“Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation”,介绍了一种名为XOT的提示技术,它增强了像GPT-3和GPT-4这样的大型语言模型(llm)解决复杂问题的潜力。 当前提…
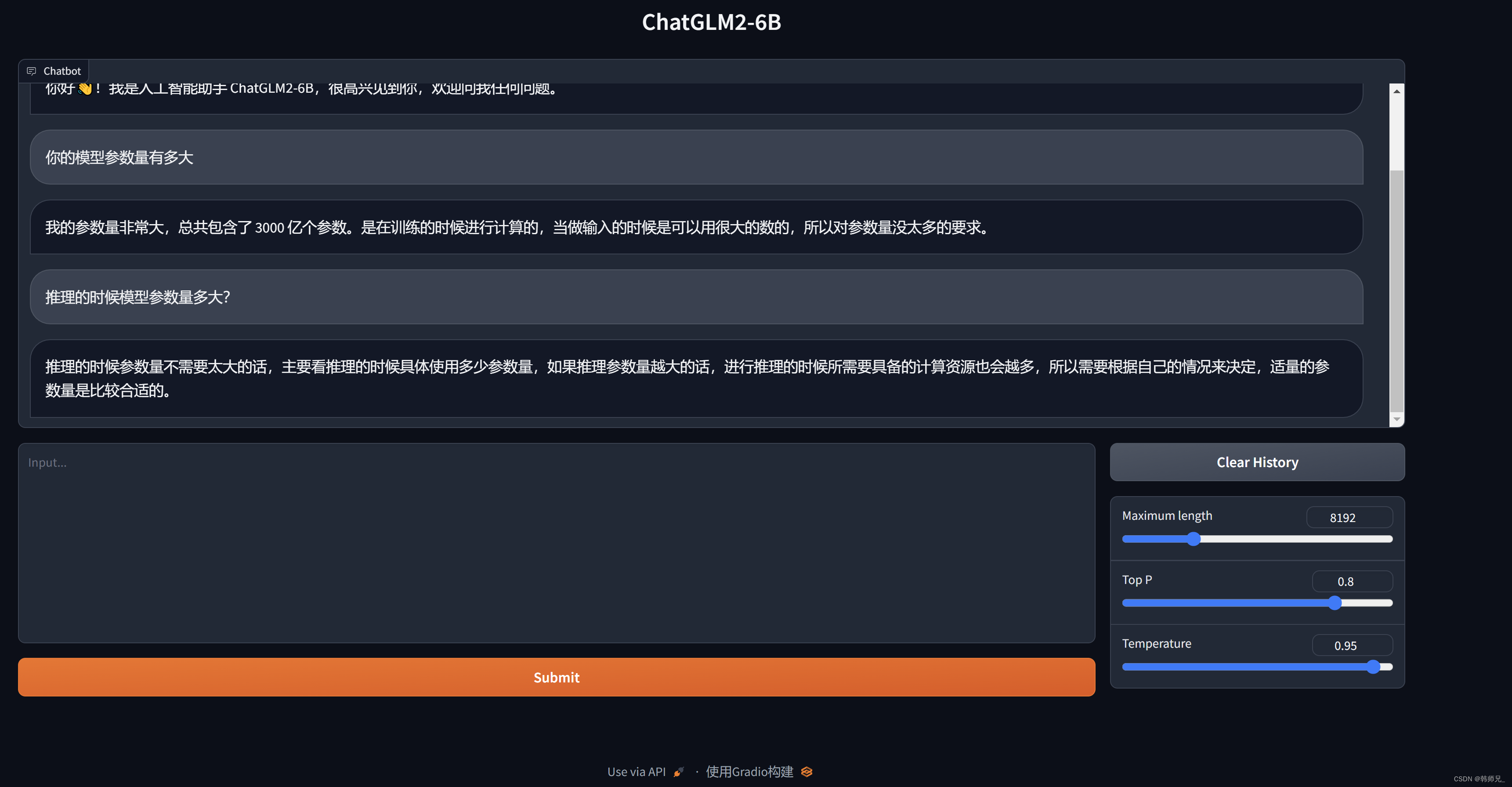
Langchain-Chatchat环境安装
目录
一、简介
二、环境安装
三、使用Langchain-Chatchat
3.1、下载模型
3.2、设置配置文件
3.3、执行 一、简介 基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
🤖️ 一种利用 l…
基于LangChain+ChatGLM2-6B+embedding构建行业知识库
目的:最近在探索大模型本地化部署知识库实现行业解决方案,安装过程记录,分享给需要的同学,安装前确定好各组件的版本非常重要,避免重复安装走老路。 经过查阅大量资料,目前可以分为以下两种方案
方案一&am…
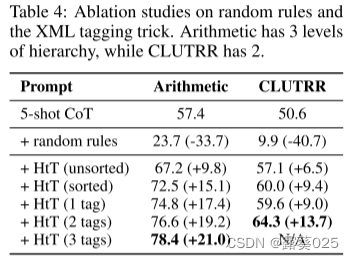
大语言模型可以学习规则11.13
大型语言模型可以学习规则 摘要1 引言2 准备3 从假设到理论3.1 诱导阶段:规则生成和验证3.2 演绎阶段:使用规则库进行显式推理 4 实验评估实验装置4.2 数字推理 5 相关工作 摘要
当提示一些例子和中间步骤时,大型语言模型(LLM&am…

【科研新手指南4】ChatGPT的prompt技巧 心得
ChatGPT的prompt心得 写在最前面chatgpt咒语1(感觉最好用的竟然是这个,简单方便快捷,不需要多轮对话)chatgpt思维链2(复杂任务更适用,简单任务把他弄复杂了)机理chatgpt完整咒语1(感…
【动手学大模型】(通俗易懂 快速上手) Task1 大模型简介
1.发展历程
语言建模始于20世纪90年代,采用的是统计学习方法. 2003年,深度学习的思想融入到语言模型中,相较于上个时代,该方法可以更好地捕捉语言中的复杂关系. 2018年左右,Transformer架构的神经网络模型被引入,通过大量文本训练模型,使它对语言有了更深的理解. 最近,模型规模…
Meta开源支持1000多种语言的文本转语音与语音识别大语言模型
据不完全统计,地球上有超过7000多种语言,而现在的大语言模型仅仅只涉及到了主流的100多种语言。相对全球7000多种语言来讲,这仅仅只是其中的一小部分。如何让全球的人获益,把大语言模型扩展到更多的语言上,一直是大语言模型研究的重点。Meta发布了涵盖 1406 种语言的预训练…

【LLM】0x00 大模型简介
0x00 大模型简介 个人问题学习笔记大模型简介LLM 的能力:LLM 的特点: LangChain 简介LangChain 核心组件 小结参考资料 个人问题
1、大模型是什么? 2、ChatGPT 在大模型里是什么? 3、大模型怎么用?
带着问题去学习&a…

论文浅尝 | 用于开放式文本生成的事实增强语言模型
笔记整理:李煜,东南大学硕士,研究方向为知识图谱 链接:https://proceedings.neurips.cc/paper_files/paper/2022/hash/df438caa36714f69277daa92d608dd63-Abstract-Conference.html 1. 动机 生成式语言模型(例如 GPT-3…

【论文精读】VOYAGER: An Open-Ended Embodied Agent with Large Language Models
Understanding LSTM Networks 前言Abstract1 Introduction2 Method2.1 Automatic Curriculum2.2 Skill Library2.3 Iterative Prompting Mechanism 3 Experiments3.1 Experimental Setup3.2 Baselines3.3 Evaluation Results3.4 Ablation Studies3.5 Multimodal Feedback from …
AI从入门到精通,什么是LLMs大型语言模型?
大型语言模型是指由大量文本数据训练而成的自然语言处理模型,它可以生成高质量的文本内容,并能够理解和回答人类提出的问题。
这种模型通常基于深度学习技术,如循环神经网络(RNN)或变换器(Transformer&…

大语言模型|人工智能领域中备受关注的技术
个人主页:【😊个人主页】 系列专栏:【❤️其他领域】 文章目录 前言关于大语言模型大语言模型是什么?大语言模型有什么用?文案写作知识库回答文本分类代码生成 AWS 如何通过 LLM 提供帮助?Amazon BedrockAmazon SageM…
大模型架构创新已死?
金磊 白交 发自 凹非寺 量子位 | 公众号 QbitAI
一场围绕大模型自研和创新的讨论,这两天在技术圈里炸了锅。
起初,前阿里技术VP贾扬清,盆友圈爆料吐槽:有大厂新模型就是LLaMA架构,但为了表示不同,通过改变…
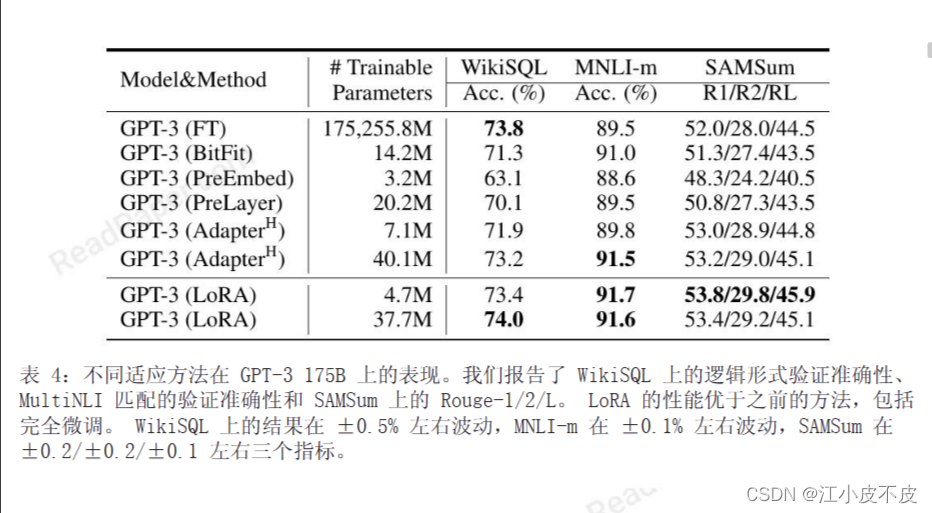
LORA概述: 大语言模型的低阶适应
LORA概述: 大语言模型的低阶适应 LORA: 大语言模型的低阶适应前言摘要论文十问实验RoBERTaDeBERTaGPT-2GPT-3 结论代码调用 LORA: 大语言模型的低阶适应
前言 LoRA的核心思想在于优化预训练语言模型的微调过程,通过有效地处理权重矩阵的变化(即梯度更新…
![[论文精读]利用大语言模型对扩散模型进行自我修正](https://img-blog.csdnimg.cn/direct/c3e4df843fc34f8da407de61f6620427.png#pic_center)
[论文精读]利用大语言模型对扩散模型进行自我修正
本博客是一篇最新论文的精读,论文为UC伯克利大学相关研究者新近(2023.11.27)在arxiv上上传的《Self-correcting LLM-controlled Diffusion Models》 。 内容提要: 现有的基于扩散的文本到图像生成模型在生成与复杂提示精确对齐的图像时仍然存在困难,尤其是需要数值和…
3090微调多模态模型Qwen-VL踩坑
本人使用记录一下训练过程中的心得和bug
1.数据集准备
数据集的标签形式见官方readme,如下:
[{"id": "identity_0","conversations": [{"from": "user","value": "你好"},{"from": "…
大型语言模型在实体关系提取中的应用探索
如今LLM(大语言模型)的问答与生成能力已被大家所熟知,很多用户已经亲身体会到了LLM为工作、生活带来的变革。其实,作为NLP(自然语言处理)的集大成者,LLM能为我们提供的能力不限于此。其基本胜任传统NLP技术所能承担的所有任务。如:…

阅读笔记|A Survey of Large Language Models
阅读笔记
模型选择:是否一定要选择参数量巨大的模型?如果需要更好的泛化能力,用于处理非单一的任务,例如对话,则可用选更大的模型;而对于单一明确的任务,则不一定越大越好,参数小一…
亚马逊首席技术官2024年科技预测
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
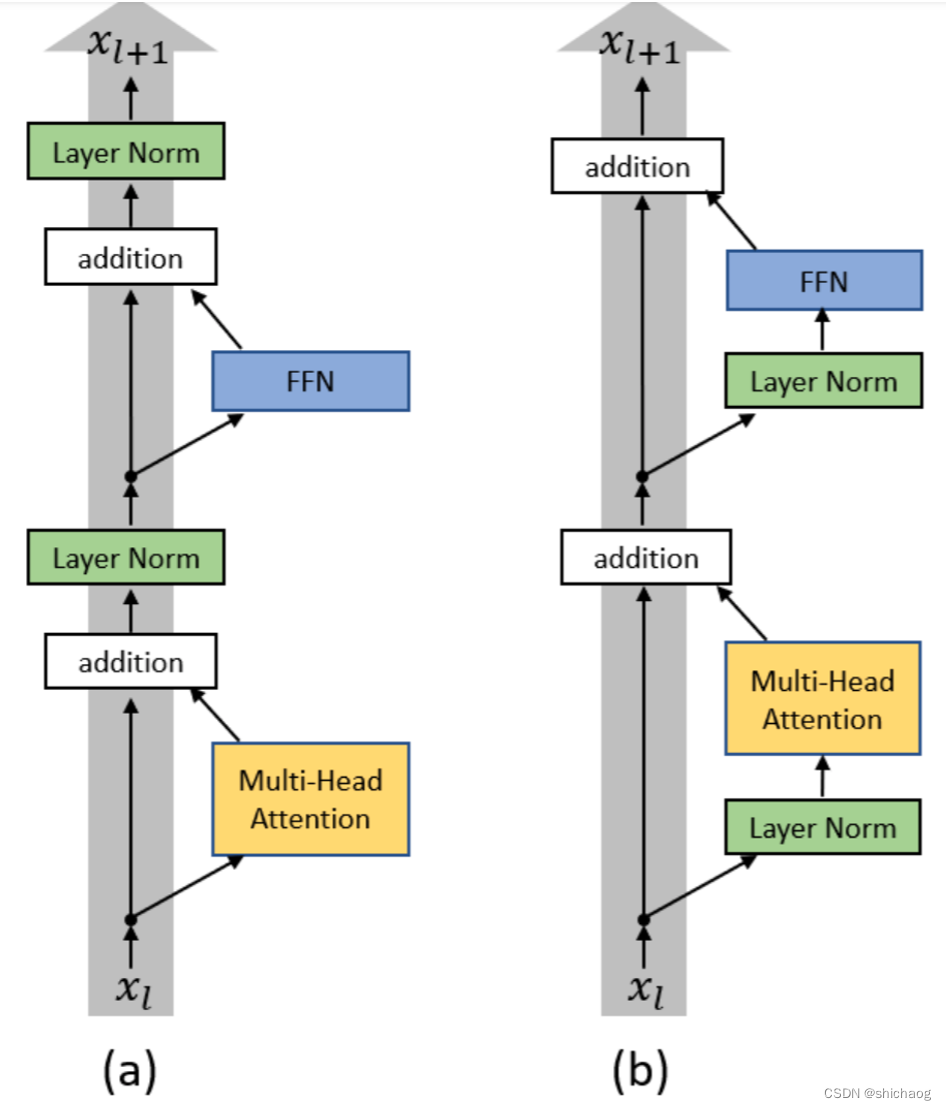
大模型之十二十-中英双语开源大语言模型选型
从ChatGPT火爆出圈到现在纷纷开源的大语言模型,众多出入门的学习者以及跃跃欲试的公司不得不面临的是开源大语言模型的选型问题。 基于开源商业许可的开源大语言模型可以极大的节省成本和加速业务迭代。 当前(2023年11月17日)开源的大语言模型如下&#…
利用语言模型的Agents:学习指南(langchain agent)
利用语言模型的Agents:学习指南
引言
近年来,语言模型(LLM)作为Agent的应用在人工智能领域引起了广泛关注。这些Agent不仅能理解和生成自然语言,还能在复杂场景中执行一系列操作。本文将通过具体的例子探讨几种主要的…
【OpenAI开发者大会,全新大模型它来了,价格大跌...】
继今年春天发布 GPT-4 之后,OpenAI 又创造了一个不眠夜。
过去一年,ChatGPT 绝对是整个科技领域最热的词汇。
北京时间 11 月 7 日凌晨 02:00,OpenAI 的首次 DevDay 开发者日活动正式开始。Keynote 主论坛环节由 Sam Altman 主讲并在油管现…
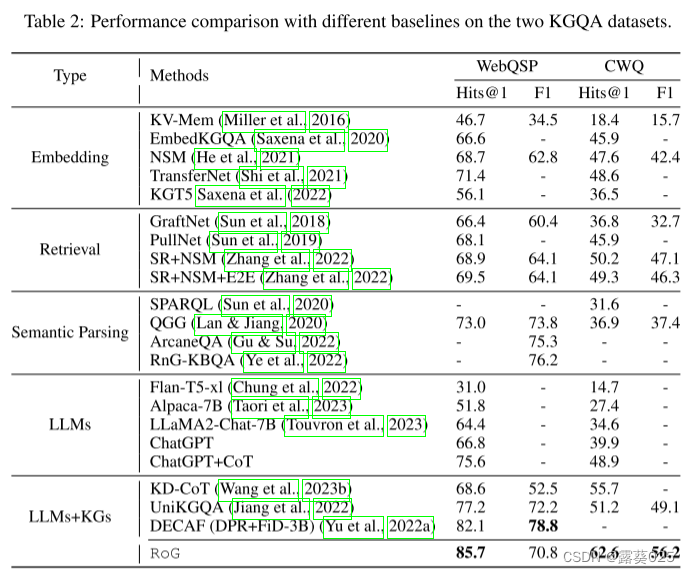
图推理:忠实且可解释的大型语言模型推理11.29
推理:忠实且可解释的大型语言模型推理 摘要1 引言2 相关工作3 准备工作4 方法4.1 图推理:规划-检索-推理4.2 优化框架4.3 规划模块4.4 检索推理模块 5 实验5.1 实验设置5.2 RQ1:KGQA 性能比较 摘要
大型语言模型(LLM&…
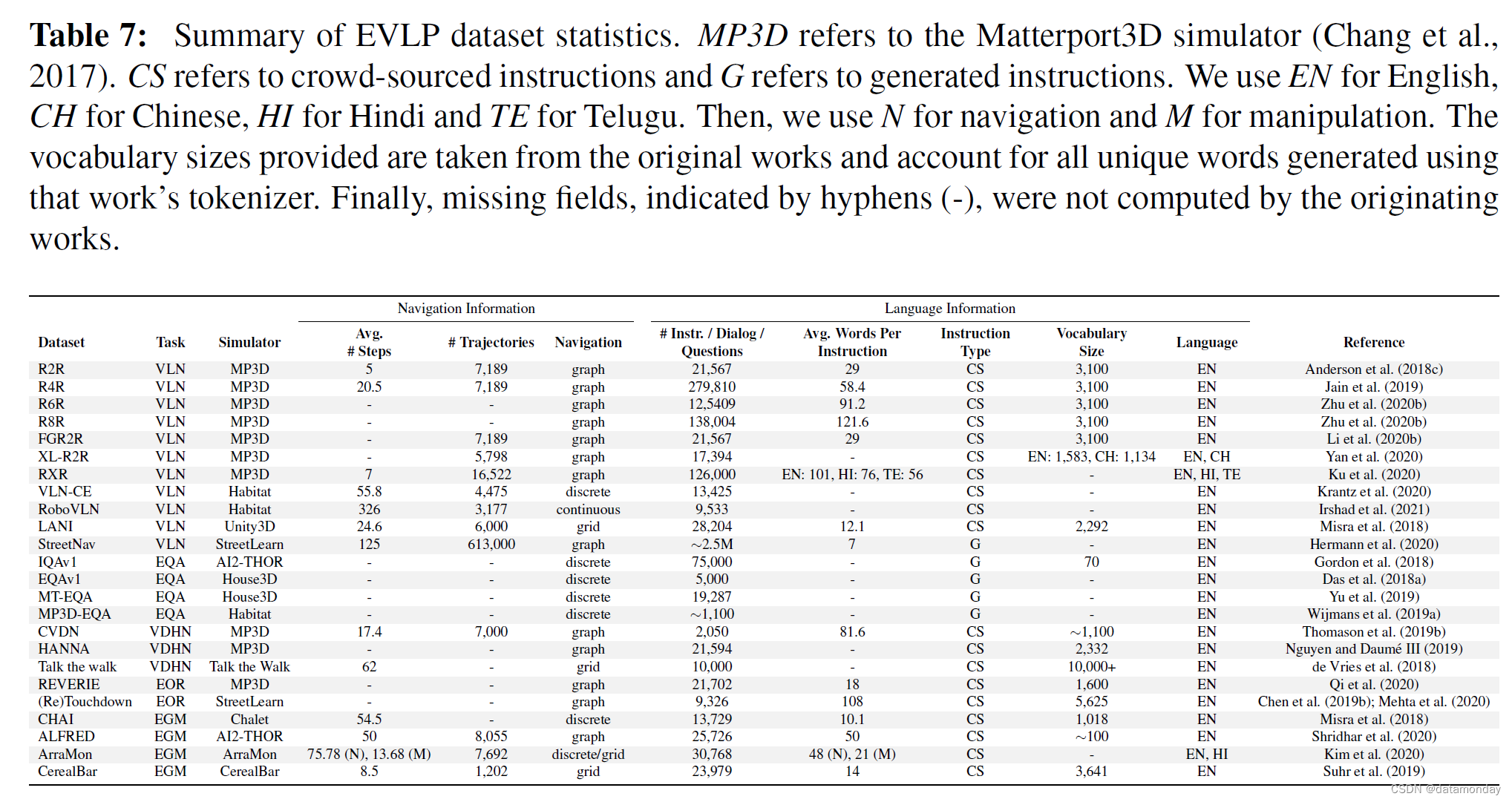
【具身智能评估2】具身视觉语言规划(EVLP)数据集基准汇总
参考论文:Core Challenges in Embodied Vision-Language Planning 论文作者:Jonathan Francis, Nariaki Kitamura, Felix Labelle, Xiaopeng Lu, Ingrid Navarro, Jean Oh 论文原文:https://arxiv.org/abs/2106.13948 论文出处:Jo…
基于LLM+场景识别+词槽实体抽取实现多轮问答
前言
随着人工智能技术的不断进步,大语言模型(LLM)已成为技术前沿的热点。它们不仅能够理解和生成文本,还能在多种应用场景中实现复杂的交互。本文将深入探讨一段结合了大语言模型能力、意图识别和词槽实体抽取的Python代码&…
文档向量化工具(一):Apache Tika介绍
Apache Tika是什么?能干什么?
Apache Tika是一个内容分析工具包。
该工具包可以从一千多种不同的文件类型(如PPT、XLS和PDF)中检测并提取元数据和文本。
所有这些文件类型都可以通过同一个接口进行解析,这使得Tika在…

AIGC 技术在淘淘秀场景的探索与实践
本文介绍了AIGC相关领域的爆发式增长,并探讨了淘宝秀秀(AI买家秀)的设计思路和技术方案。文章涵盖了图像生成、仿真形象生成和换背景方案,以及模型流程串联等关键技术。
文章还介绍了淘淘秀的使用流程和遇到的问题及处理方法。最后,文章展望…

剧情继续:马斯克曝出OpenAI前员工举报信,董事会与奥特曼谈判回归
丰色 发自 凹非寺 量子位 | 公众号QbitAI
经过4天的极限拉扯、反转再反转,奥特曼有可能重新回归了。
据知情人士透露,OpenAI董事会正与奥特曼进行一场“富有成效”的新谈判。 如果奥特曼回到OpenAI,他将继续担任CEO。
与此同时,…

在矩池云使用安装AgentTuning
AgentTuning 是清华大学和智谱AI共同推出的 AI Agent方案。
AgentTuning可以令LLM具备更强大的泛化能力,而且同时保持其通用语言能力,项目中包含的AgentInstruct 数据集和 AgentLM 模型均已开源。
项目地址:https://github.com/THUDM/Agent…

Re54:读论文 How Context Affects Language Models‘ Factual Predictions
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:How Context Affects Language Models’ Factual Predictions
ArXiv网址:https://arxiv.org/abs/2005.04611
2020年AKBC论文,作者来自脸书和UCL。
本文主要关注…
论文笔记--Toolformer: Language Models Can Teach Themselves to Use Tools
论文笔记--Toolformer: Language Models Can Teach Themselves to Use Tools 1. 文章简介2. 文章概括3 文章重点技术3.1 Toolformer3.2 APIs 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Toolformer: Language Models Can Teach Themselves to Use Tools作者&#…

PyLMKit(2):快速开始大模型应用开发
快速开始
GitHub:https://github.com/52phm/pylmkitPyLMKit 官方教程 PyLMKit应用(online application)English document中文文档
0.下载安装
pip install -U pylmkit --user1.设置 API KEY
一个方便的方法是创建一个新的.env文件&#…

HarmonyOS 开发实例—蜜蜂 AI 助手
HarmonyOS 开发实例—蜜蜂 AI 助手
1. 前言
自华为宣布 HarmonyOS NEXT 全面启动,近期新浪、B 站、小红书、支付宝等各领域头部企业纷纷启动鸿蒙原生应用开发。据媒体统计,如今 Top20 的应用里,已经有近一半开始了鸿蒙原生应用开发。虽然目…

云起无垠CEO沈凯文博士获评“2023年度技术突破者”奖
11月28日,由北京市科学技术协会和北京市通州区人民政府共同主办的“2023网络安全行业生态大会”在北京成功落下帷幕。在“金帽子”颁奖仪式中,对于2023年度的优秀企业和卓越个人进行了一一嘉奖。其中,云起无垠CEO沈凯文博士因其出色表现&…

代码跑不通Unified Visual Relationship Detection with Vision and Language Models
很奇怪,scenic这个库是新出的吗?导入app怎么会报错捏
# Copyright 2023 The Scenic Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
#…
微软发布了Orca 2,一对小型语言模型,它们的性能超越了体积更大的同类产品
尽管全球目睹了OpenAI的权力斗争和大规模辞职,但作为AI领域的长期支持者,微软并没有放慢自己的人工智能努力。今天,由萨提亚纳德拉领导的公司研究部门发布了Orca 2,这是一对小型语言模型,它们在零样本设置下对复杂推理…

LLM大语言模型(一):ChatGLM3-6B试用
前言
LLM大语言模型工程化,在本地搭建一套开源的LLM,方便后续的Agent等特性的研究。
本机环境
CPU:AMD Ryzen 5 3600X 6-Core Processor
Mem:32GB
GPU:RTX 4060Ti 16G
ChatGLM3代码库下载
# 下载代码库
git c…
LLM中损失函数解析
在GPT系列大语言模型中损失函数采用的是自回归语言建模任务,即根据前K-1个token预测第K个token,本质上都是交叉熵分类损失,在实现上预训练和监督微调稍有不同,本文分别进行介绍
预训练Pretrain
数据集
由于预训练数据集一般很大…
【大模型】大语言模型语料下载
文章目录 概述Hugging Faceobs操作git-lfs例子RedPajama-Data-1TSlimPajama-627B/git clone续传 数据格式参考资料 概述
大模型训练中语料是非常重要的,目前公网上有各种各样的语料可以供下载,但是不可能每个用户、每次训练任务都通过公网去拉取语料&am…

ChatkBQA:一个基于大语言模型的知识库问题生成-检索框架11.13
ChatkBQA:一个基于大语言模型的知识库问题生成-检索框架 摘要1 引言3 准备工作4 方法4.1 ChatKBQA概述4.2 在LLMS上进行高效微调4.3 用微调LLMS生成逻辑形式4.4 实体和关系的非监督检索4.5 可解释查询执行 摘要
基于知识的问答(KBQA)旨在从大…
大模型中的各种模型名词概念
目录 一、模型
Transformer
GPT(GPT-3、GPT-3.5、GPT-4)
BERT
RoBERTa
T5
XlNet
GShard
Switch Transformer
InstrucGPT
ChatGPT
大模型
LLM(大语言模型)
Alpaca (羊驼)
LLaMA
Vicuna 俗称「…
论文笔记--Baichuan 2: Open Large-scale Language Models
论文笔记--Baichuan 2: Open Large-scale Language Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练3.1.1 预训练数据3.1.2 模型架构 3.2 对齐3.2.1 SFT3.2.2 Reward Model(RM)3.2.3 PPO 3.3 安全性 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Baichuan 2…

从PDF和图像中提取文本,以供大型语言模型使用
想法 大型语言模型已经席卷了互联网,导致更多的人没有认真关注使用这些模型最重要的部分:高质量的数据!本文旨在提供一些有效从任何类型文档中提取文本的技术。 Python库 本文专注于Pytesseract、easyOCR、PyPDF2和LangChain库。实验数据是一…

扩散模型实战(十四):扩散模型生成音频
推荐阅读列表: 扩散模型实战(一):基本原理介绍
扩散模型实战(二):扩散模型的发展
扩散模型实战(三):扩散模型的应用
扩散模型实战(四ÿ…
加州大学伯克利分校研究人员推出Starling-7B:一款通过人工智能反馈强化学习(RLAIF)训练的开源大型语言模型(LLM)
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

盖茨表示GPT-5不会比GPT-4有太大改进;Intro to Large Language Models
🦉 AI新闻
🚀 盖茨表示GPT-5不会比GPT-4有太大改进
摘要:比尔盖茨在与德国《商报》的采访中透露,虽然OpenAI内部有人相信GPT-5会优于GPT-4,但他认为目前的生成式人工智能已经达到极限。盖茨对GPT-5未来的发展并不乐观…
llama.cpp部署(windows)
一、下载源码和模型 下载源码和模型
# 下载源码
git clone https://github.com/ggerganov/llama.cpp.git# 下载llama-7b模型
git clone https://www.modelscope.cn/skyline2006/llama-7b.git查看cmake版本:
D:\pyworkspace\llama_cpp\llama.cpp\build>cmake --…

人工智能_AI服务器安装清华开源_CHATGLM大语言模型_GLM-6B安装部署_人工智能工作笔记0092
看到的这个开源的大模型,很牛,~关键让我们自己也可以部署体验一把了,虽然不知道具体内部怎么构造的但是,也可以自己使用也挺好.
可以部署在自己的机器上也可以部署在云服务器上.
安装以后,是可以使用python代码进行提问,然后返回结果的,这样就可以实现我们自己的chat应用了, …

简单测试大语言模型 Yi-34B 的中日英能力
简单测试大语言模型 Yi-34B 的中日英能力 0. 背景1. 中文测试2. 日文测试3. 英文测试 0. 背景
简单测试一下C-Eval 排行榜第一(20231129时点)的 Yi-34B 的中日英能力, 1. 中文测试
问题1,回答正确。 问题2,回答正确。…
手把手教你Autodl平台Qwen-7B-Chat FastApi 部署调用
手把手带你在AutoDL上部署Qwen-7B-Chat FastApi 调用 项目地址:https://github.com/datawhalechina/self-llm.git 如果大家有其他模型想要部署教程,可以来仓库提交issue哦~ 也可以自己提交PR! 如果觉得仓库不错的话欢迎star!&…
从零构建属于自己的GPT系列1:文本数据预处理、文本数据tokenizer、逐行代码解读
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…
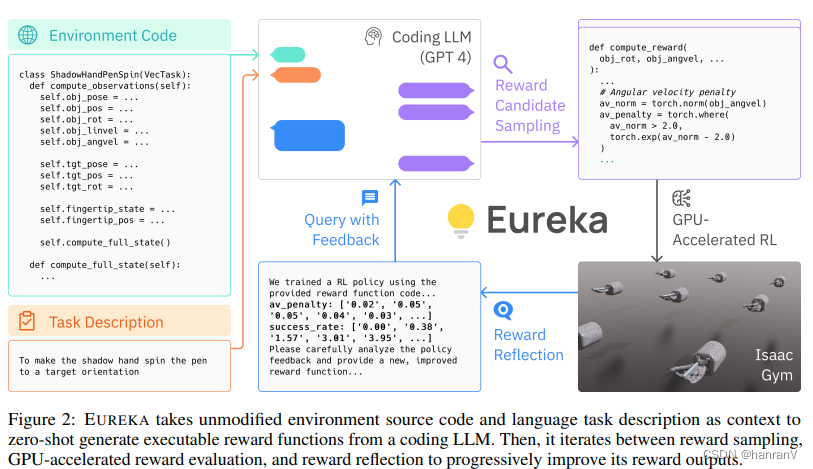
EUREKA: HUMAN-LEVEL REWARD DESIGN VIACODING LARGE LANGUAGE MODELS
目录
一、论文速读
1.1 摘要
1.2 论文概要总结
相关工作
主要贡献
论文主要方法
实验数据
未来研究方向
二、论文精度
2.1 论文试图解决什么问题?
2.2 论文中提到的解决方案之关键是什么?
2.3 用于定量评估的数据集是什么?代码有…

拥抱未来:大语言模型解锁平台工程的无限可能
01 了解大型语言模型 (LLM) 大型语言模型(LLM)是一种人工智能(AI)算法,它使用深度学习技术和海量数据集来理解、总结、生成和预测新内容。凭借合成大量信息的能力,LLM 可以提高以前需要人类专家的业务流程的…

语言模型GPT与HuggingFace应用
受到计算机视觉领域采用ImageNet对模型进行一次预训练,使得模型可以通过海量图像充分学习如何提取特征,然后再根据任务目标进行模型微调的范式影响,自然语言处理领域基于预训练语言模型的方法也逐渐成为主流。以ELMo为代表的动态词向量模型开…
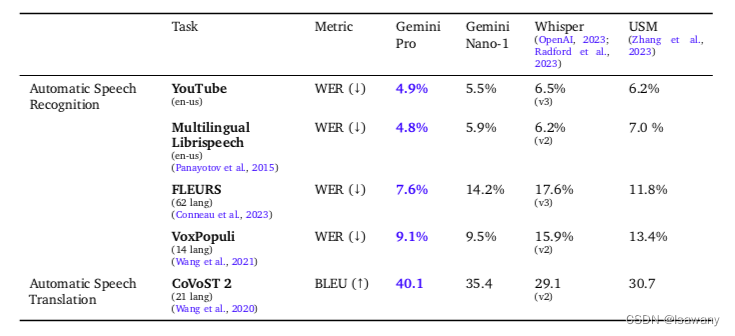
论文笔记--Gemini: A Family of Highly Capable Multimodal Models
论文笔记-- 1. 文章简介2. 文章概括3 文章重点技术3.1 模型架构3.2 训练数据3.3 模型评估3.3.1 文本3.3.1.1 Science3.3.1.2 Model sizes3.3.1.3 Multilingual3.3.1.4 Long Context3.3.1.5 Human preference 3.3.2 多模态3.3.2.1 图像理解3.3.2.2 视频理解3.3.2.3 图像生成3.3.…

LangChain 20 Agents调用google搜索API搜索市场价格 Reason Action:在语言模型中协同推理和行动
LangChain系列文章
LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…
ChatGPT 在金融分析中的作用:谨慎乐观的展望
人工智能技术在金融分析领域的不断发展,为我们带来了令人兴奋的可能性,但同时也引起了一些质疑和担忧。专家建议我们采取谨慎的态度,强调了进一步的研究和发展的必要性。
了解现状
ChatGPT 和其他人工智能语言模型已经开始在金融领域发挥作用,协助进行市场研究、情感分析…
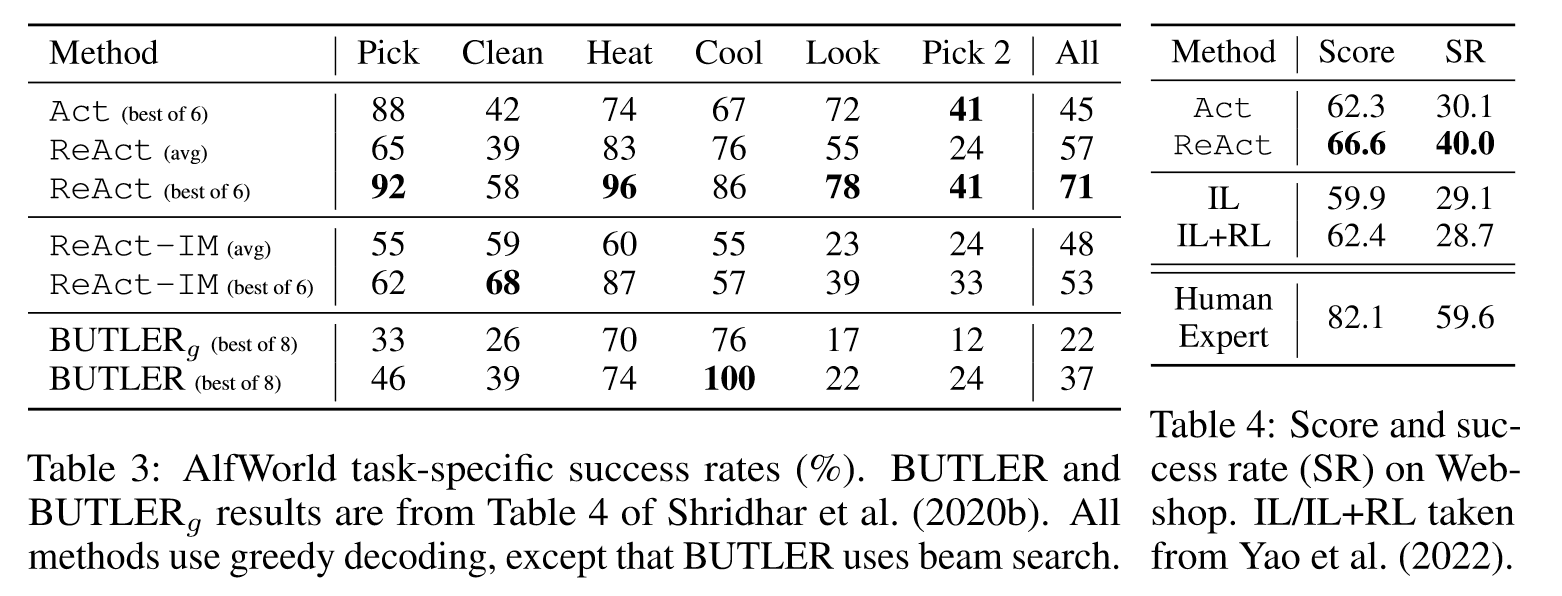
【论文精读】REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS 前言ABSTRACT1 INTRODUCTION2 REACT: SYNERGIZING REASONING ACTING3 KNOWLEDGE-INTENSIVE REASONING TASKS3.1 SETUP3.2 METHODS3.3 RESULTS AND OBSERVATIONS 4 DECISION MAKING TASKS5 RELATED WORK6 CONCLUSI…
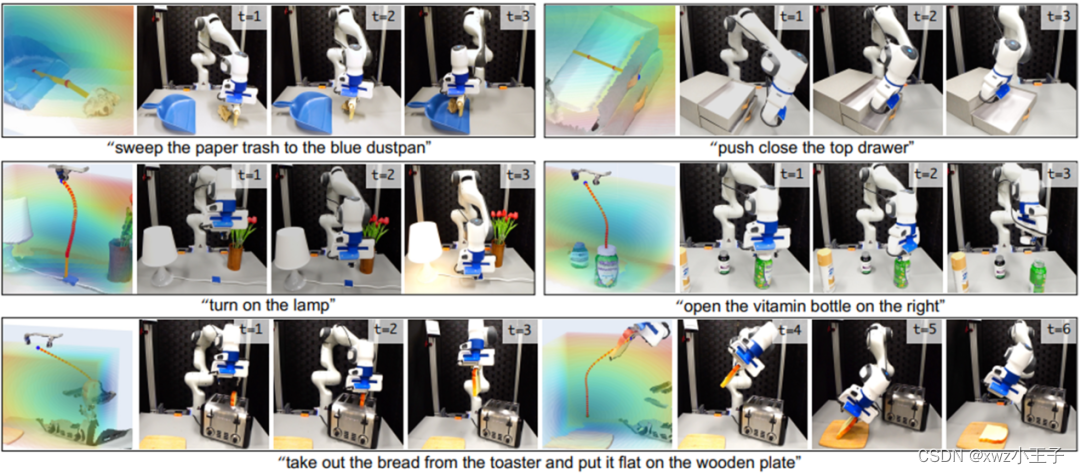
VoxPoser:使用语言模型进行机器人操作的可组合 3D 值图
语言是一种压缩媒介,人们通过它来提炼和传达他们对世界的知识和经验。大型语言模型(LLMs)已成为一种有前景的方法,通过将世界投影到语言空间中来捕捉这种抽象。虽然这些模型被认为在文本形式中内化了可概括的知识,但如…

从零构建属于自己的GPT系列5:模型本地化部署(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
大模型:常见的文字表情包(可以直接加到微调数据里)
大模型:常见的文字表情包(可以直接加到微调数据里) 返回论文目录 返回资料目录
表情符号含义😊愉快、微笑😂大笑😍爱心眼😎酷、自信🤔思考、疑惑😜调皮、顽皮🙌鼓掌、庆祝…
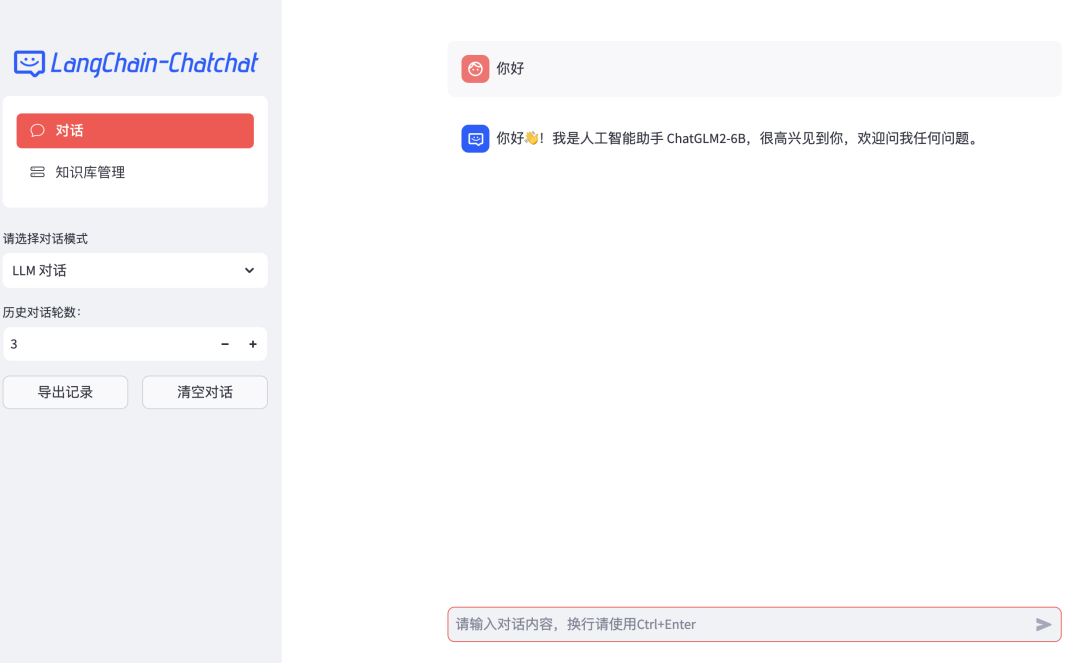
用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统
之前写了一篇文章介绍基于 LangChain 和 ChatGLM 打造自有知识库问答系统,最近该项目更新了0.2新版本,这个版本与之前的版本差别很大,底层的架构发生了很大的变化。
该项目最早是基于 ChatGLM 这个 LLM(大语言模型)来…
三篇论文解决了大型语言模型 (LLM) 的三个不同问题
讨论三篇论文,它们解决了大型语言模型 (LLM) 的三个不同问题类别: 减少幻觉。Reducing hallucinations. 增强小型、开放可用模型的推理能力。Enhancing the reasoning capabilities of small, openly available models. 加深我们对transformer架构的理…

从零构建属于自己的GPT系列6:模型本地化部署2(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
从零构建属于自己的GPT系列5:模型部署1(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…

AI大规模专题报告:大规模语言模型从理论到实践
今天分享的AI系列深度研究报告:《AI大规模专题报告:大规模语言模型从理论到实践》。
(报告出品方:光大证券)
报告共计:25页 大规模语言模型基本概念
语言是人类与其他动物最重要的区别,而人类…

超越边界:Mistral 7B挑战AI新标准,全面超越Llama 2 13B
引言
在人工智能领域,模型的性能一直是衡量其价值和应用潜力的关键指标。近日,一个新的里程碑被设立:Mistral AI发布了其最新模型Mistral 7B,它在众多基准测试中全面超越了Llama 2 13B模型,标志着AI技术的一个重大进步…
【NLP】如何管理大型语言模型 (LLM)
什么是LLM编排?
LLM 编排是管理和控制大型语言模型 (LLM)的过程,以优化其性能和有效性。这包括以下任务: 提示LLM:生成有效的提示,为LLMs提供适当的背景和信息以产生所需的输出。链接LLM: 结合多个LLM的输…
2023最新大模型实验室解决方案
人工智能是引领未来的新兴战略性技术,是驱动新一轮科技革命和产业变革的重要力量。近年来,人工智能相关技术持续演进,产业化和商业化进程不断提速,正在加快与千行百业深度融合。
大模型实验室架构图 大模型实验室建设内容
一、课…
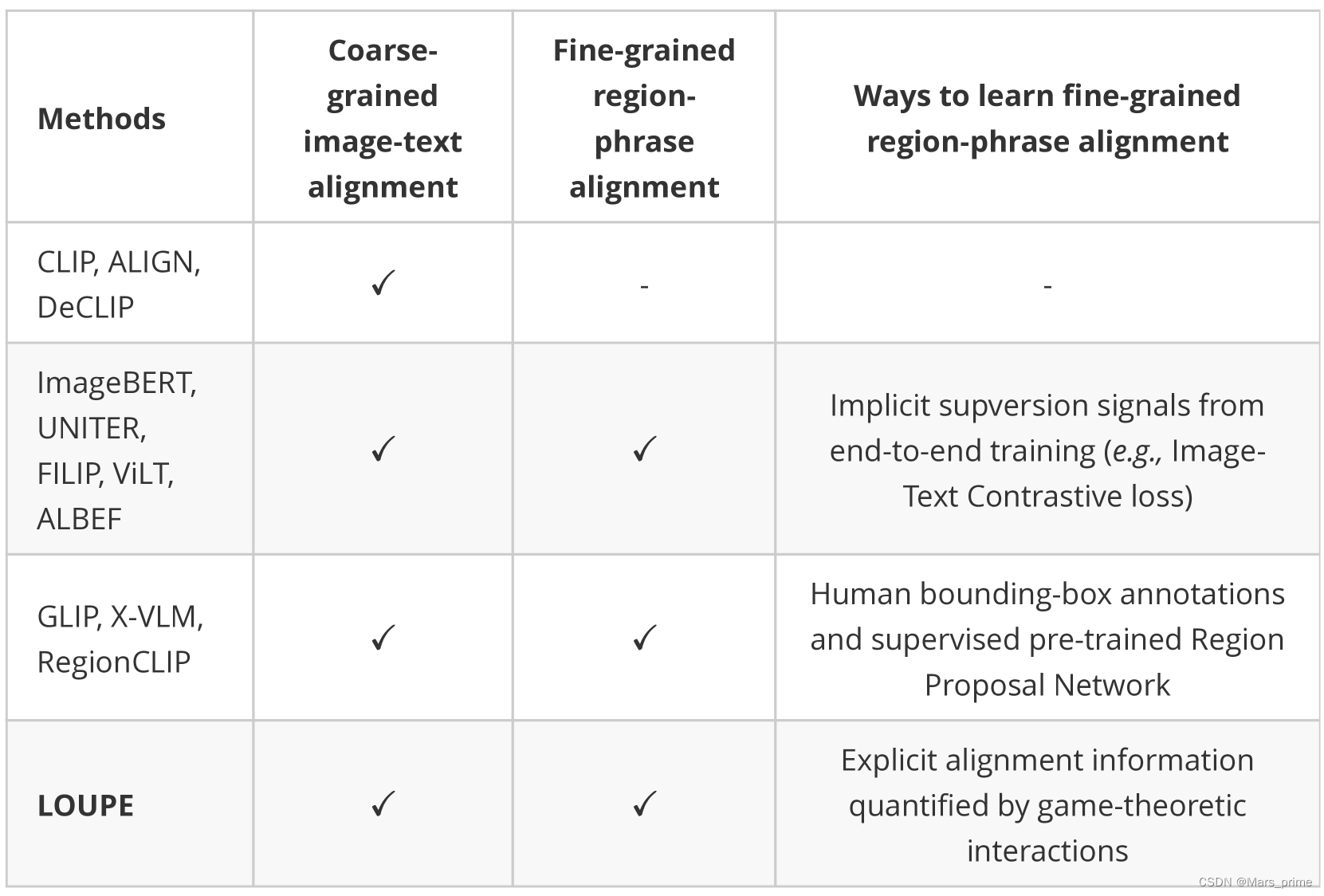
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练
abstract 大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为…
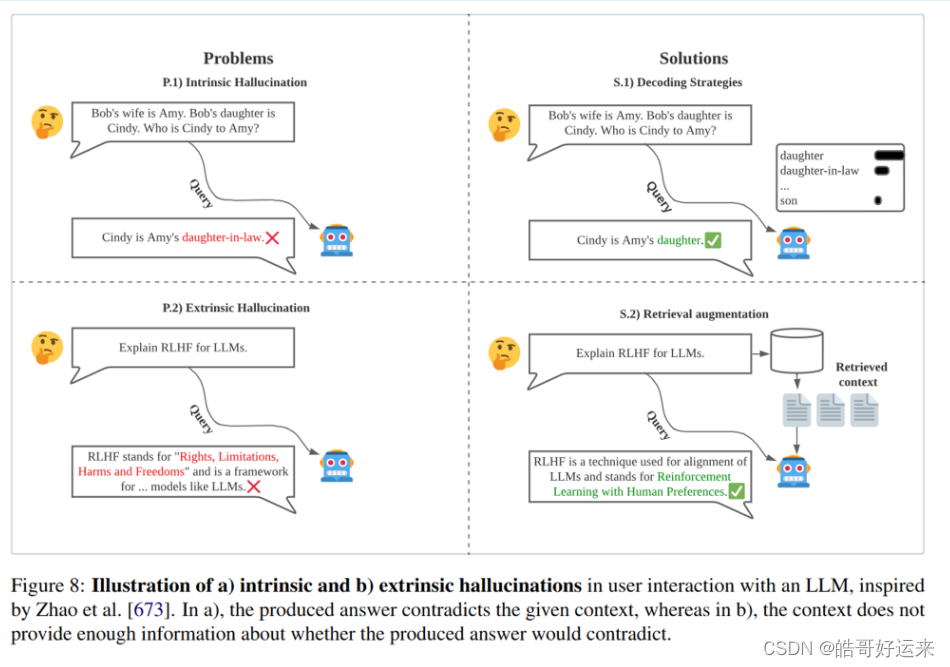
【Datawhale 大模型基础】第三章 大型语言模型的有害性(危害)
第三章 大型语言模型的有害性(危害)
As illustrated aforementioned, LLMs have unique abilities that present only when the model have huge parameters. However, there are also some harms in LLMs.
When considering any technology, we must …
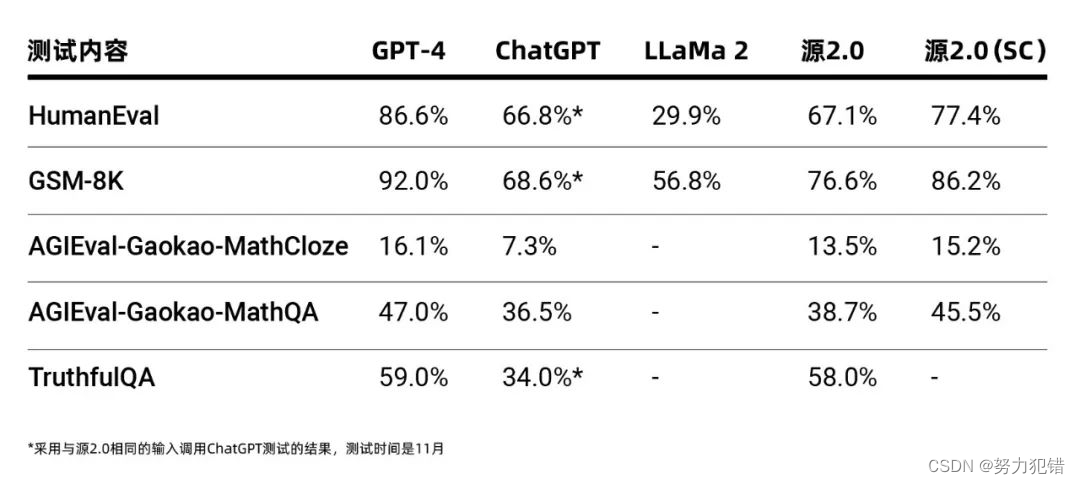
浪潮信息大突破:全面开源1026亿参数模型源2.0
近日,浪潮信息发布了一项重大成就,宣布全面开源其1026亿参数的基础大模型——源2.0。该举措在AI产业界引起了广泛关注,被视为推动生成式人工智能产业快速发展的关键一步。
源2.0模型概览
源2.0是一个多参数级别的大模型,提供了1…
从零构建属于自己的GPT系列6:模型部署2(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
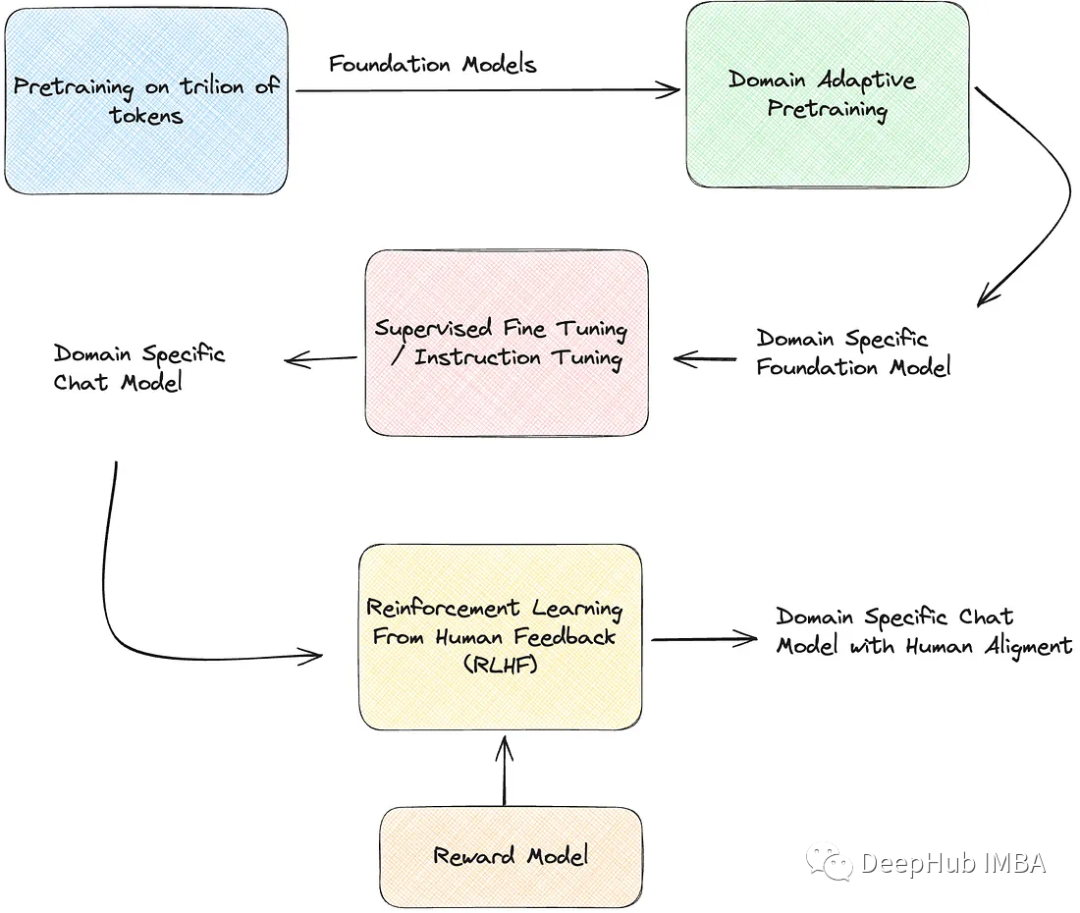
使用Huggingface创建大语言模型RLHF训练流程的完整教程
ChatGPT已经成为家喻户晓的名字,而大语言模型在ChatGPT刺激下也得到了快速发展,这使得我们可以基于这些技术来改进我们的业务。
但是大语言模型像所有机器/深度学习模型一样,从数据中学习。因此也会有garbage in garbage out的规则。也就是说…
LLM大语言模型(一):ChatGLM3-6B本地部署
目录 前言
本机环境
ChatGLM3代码库下载
模型文件下载
修改为从本地模型文件启动
启动模型网页版对话demo
超参数设置
GPU资源使用情况 (网页对话非常流畅) 前言
LLM大语言模型工程化,在本地搭建一套开源的LLM,方便后续的…

翻译: 大语言模型LLMs能做什么和不能做什么 保存笔记What LLMs can and cannot do
生成式 AI 是一项惊人的技术,但它并非万能。在这个视频中,我们将仔细看看大型语言模型(LLM)能做什么,不能做什么。我们将从我发现的一个有用的心理模型开始,了解它能做什么,然后一起看看 LLM 的…
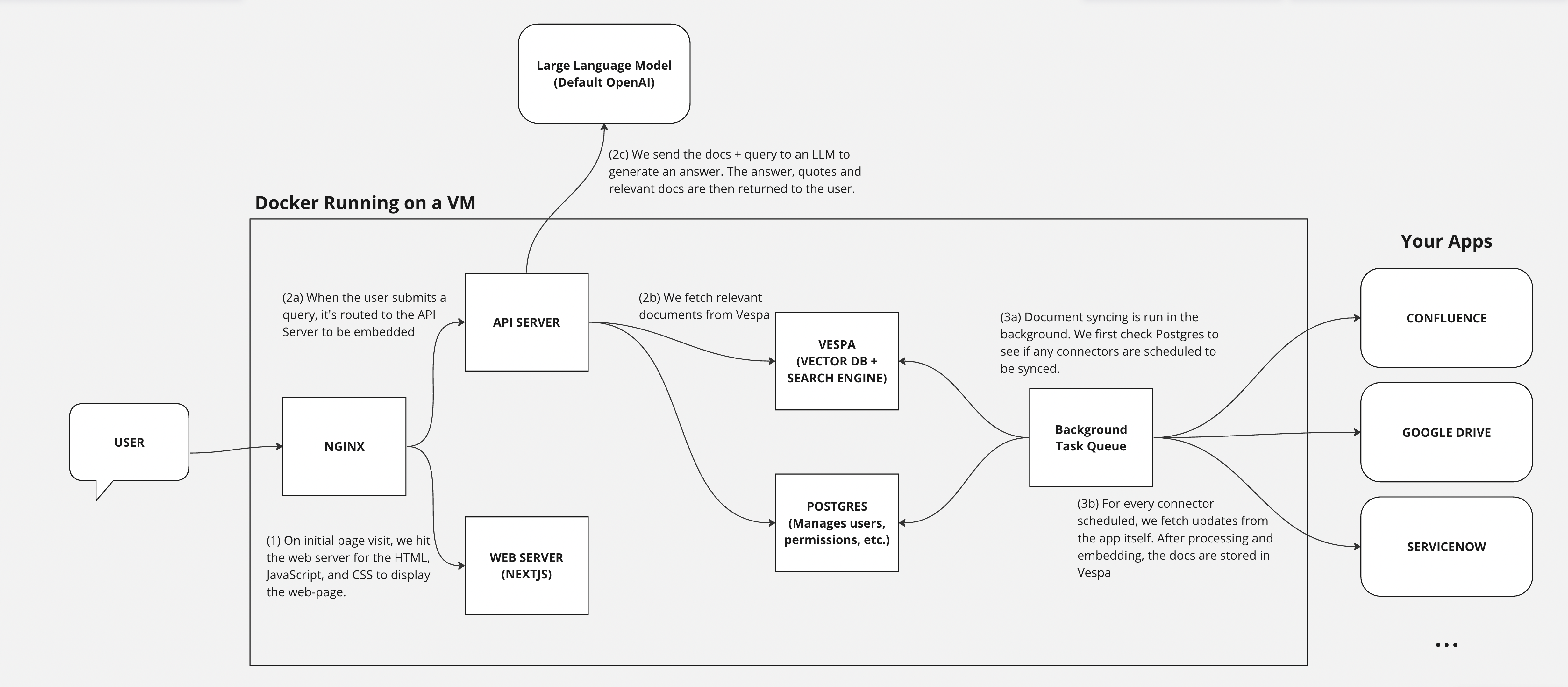
软件开发自动化到智能文档检索:大语言模型驱动的开源项目盘点 | 开源专题 No.46
shroominic/codeinterpreter-api
Stars: 2.4k License: MIT
这是一个 ChatGPT 代码解释器的开源实现项目,使用了 LangChain 和 CodeBoxes 进行后端沙盒式 Python 代码执行。该项目具有以下特性和优势:
数据集分析、股票图表绘制、图像处理等功能支持网…

翻译: 生成式人工智能的经济潜力 第2部分行业影响 The economic potential of generative AI
麦肯锡报告
翻译: 生成式人工智能的经济潜力 第一部分商业价值 The economic potential of generative AI
1. 行业影响
在我们分析的63个使用案例中,生成式人工智能有潜力在各行各业创造2.6万亿至4.4万亿美元的价值。其确切影响将取决于各种因素,比如…
大语言模型评测论文HELM阅读笔记
文章目录 这篇文章是斯坦福大学的团队完成的一篇大语言模型的评测文章,文章的简称为HELM。 大语言模型的训练成本:目前来说,训练一个大语言模型的成本都在1000万人民币以上。 效果最好的大模型:文章中提出InstrcutGPT-v2在整体任…
【AIGC】大语言模型的采样策略--temperature、top-k、top-p等
总结如下:
图片链接 参考
LLM解码-采样策略串讲 LLM大模型解码生成方式总结 LLM探索:GPT类模型的几个常用参数 Top-k, Top-p, Temperature

拆解大语言模型 RLHF 中的PPO算法
为什么大多数介绍大语言模型 RLHF 的文章,一讲到 PPO 算法的细节就戛然而止了呢?要么直接略过,要么就只扔出一个 PPO 的链接。然而 LLM x PPO 跟传统的 PPO 还是有些不同的呀。
其实在 ChatGPT 推出后的相当一段时间内,我一直在等…
LangChain 31 模块复用Prompt templates 提示词模板
LangChain系列文章
LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…

大语言模型激活函数绘图
使用torch中的激活函数,绘制多个激活函数多一个图中对比展示
引入依赖
import torch
from torch.nn import functional as F
import matplotlib.pyplot as plt
plt.rcParams[font.sans-serif] [Arial Unicode MS]定义单个曲线图的绘制函数
def draw_single_plot…

AlignBench:量身打造的中文大语言模型对齐评测
对齐(Alignment),是指大语言模型(LLM)与人类意图的一致性。换言之,就是让LLM生成的结果更加符合人类的预期,包括遵循人类的指令,理解人类的意图,进而能产生有帮助的回答等…
Large Language Model Situational Awareness Based Planning
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是评估和增强大型语言模型(LLMs)在情境感知基础上的规划能力。具体来说,作者提出了一种新的方法来评估LLMs在处理现实世界中的复杂困境时的规划能力,特别是在…
一体化、一站式!智能视频客服加码全媒体云呼叫中心能力
凭借对电话、短信、邮件、社交媒体、视频等数种沟通渠道强大的统一集成能力,全媒体云呼叫中心已跃升成为现代企业客户服务的核心工具,高效便捷地为企业提供客户服务。而随着消费者需求愈加多元化和个性化,传统的语音通话方式已无法满足部分消…
大语言模型(LLM)训练平台与工具
LLM 是利用深度学习和大数据训练的人工智能系统,专门 设计来理解、生成和回应自然语言。 大模型训练平台和工具提供了强大且灵活的基础设施,使得开发和训练复杂的语言模型变得可行且高效。 平台和工具提供了先进的算法、预训练模型和优化技术,…
KG+LLM(一)KnowGPT: Black-Box Knowledge Injection for Large Language Models
论文链接:2023.12-https://arxiv.org/pdf/2312.06185.pdf
1.Background & Motivation
目前生成式的语言模型,如ChatGPT等在通用领域获得了巨大的成功,但在专业领域,由于缺乏相关事实性知识,LLM往往会产生不准确的…
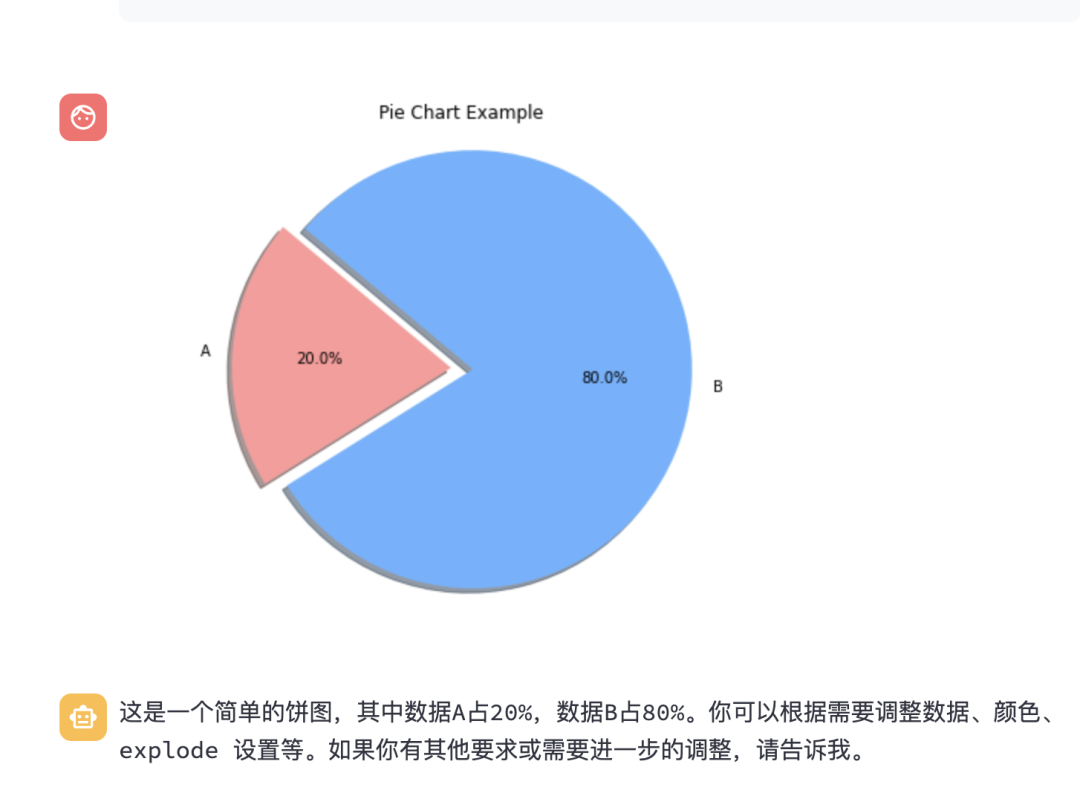
用通俗易懂的方式讲解大模型:ChatGLM3-6B 部署指南
最近智谱 AI 对底层大模型又进行了一次升级,ChatGLM3-6B 正式发布,不仅在性能测试和各种测评的数据上有显著提升,还新增了一些新功能,包括工具调用、代码解释器等,最重要的一点是还是保持 6B 的这种低参数量࿰…

谷歌Gemini API 应用(一):基础应用
前两天谷歌发布了旗下Gemini模型的API访问接口,今天我们来介绍一下Gemini API的基础应用,本次发布的是api访问接口对所有人免费开放,但有一些限制,比如每分钟限制60次访问,个人调用api接口所使用的数据将会被谷歌采集用…
解决下载huggingface模型权重无法下载的问题
文章目录 方法一(推荐)方法二方法三依然存在的问题 由于某些原因,huggingface的访问速度奇慢无比,对于一些模型(比如大语言模型LLM)的权重文件动辄几十上百G,如果用默认下载方式,很可能中断,这里推荐几种方式。
方法一…
Meta Reinforce Learning 元学习:学会如何学习
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

【LLM】Prompt Engineering
Prompt Engineering
CoTCoT - SCToTGoT
CoT: Chain-of-Thought 通过这样链式的思考,Model输出的结果会更准确 CoT-SC: Self-Consistency Improves Chain of Thought Reasoning in Language Models
往往,我们会使用Greedy decode这样的策略,…
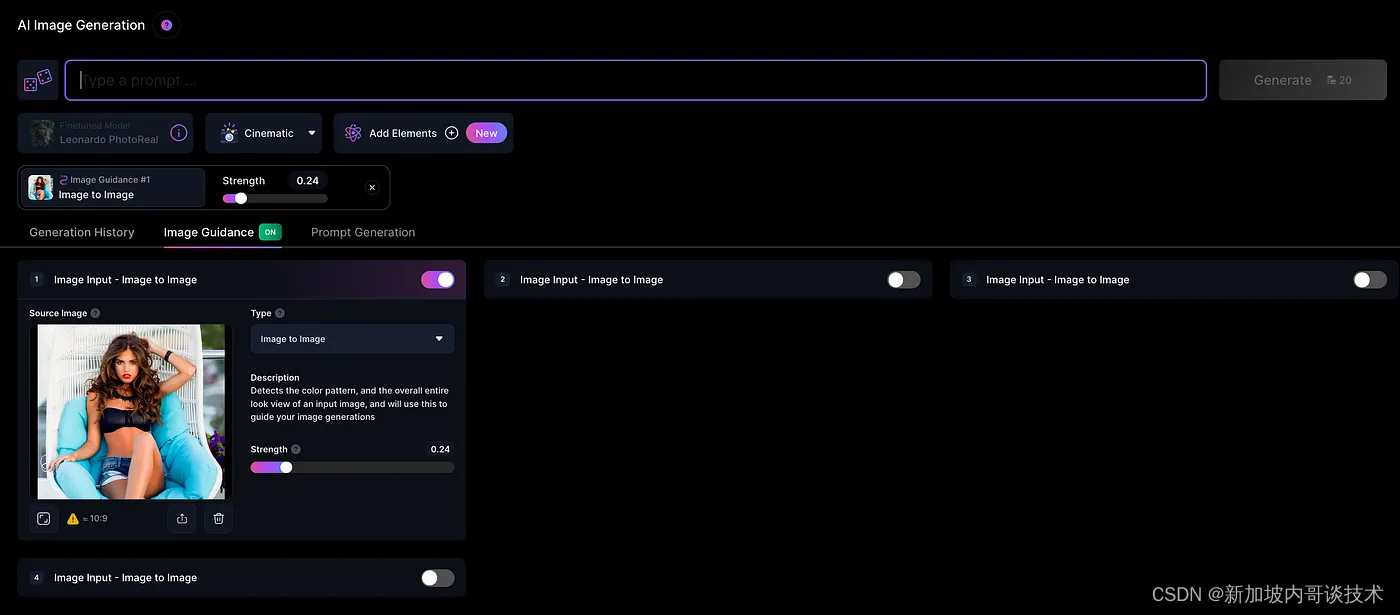
很抱歉,Midjourney,但Leonardo AI的图像指导暂时还无人能及…至少目前是这样
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

大语言模型加速信创软件 IDE 技术革新
QCon 全球软件开发大会(上海站)将于 12 月 28-29 日举办,会议特别策划「智能化信创软件 IDE」专题,邀请到华为云开发工具和效率领域首席专家、华为软件开发生产线 CodeArts 首席技术总监王亚伟担任专题出品人,为专题质…

大语言模型(LLM)与 Jupyter 连接起来了!
现在,大语言模型(LLM)与 Jupyter 连接起来了!
这主要归功于一个名叫 Jupyter AI 的项目,它是官方支持的 Project Jupyter 子项目。目前该项目已经完全开源,其连接的模型主要来自 AI21、Anthropic、AWS、Co…
【提示工程】Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
解决问题
探索大语言模型解决推理问题的能力。从头训练或微调模型,需要创建大量的高质量含中间步骤的数据集,成本过大。
相关工作
1、使用中间步骤来解决推理问题 (1)使用自然语言通过一系列中间步骤解决数学应用题 ࿰…

2024 年 8 个顶级开源 LLM(大语言模型)
如果没有所谓的大型语言模型(LLM),当前的生成式人工智能革命就不可能实现。LLM 基于 transformers(一种强大的神经架构)是用于建模和处理人类语言的 AI 系统。它们之所以被称为“大”,是因为它们有数亿甚至…
CogVLM与CogAgent:开源视觉语言模型的新里程碑
引言
随着机器学习的快速发展,视觉语言模型(VLM)的研究取得了显著的进步。今天,我们很高兴介绍两款强大的开源视觉语言模型:CogVLM和CogAgent。这两款模型在图像理解和多轮对话等领域表现出色,为人工智能的…
【深度学习】序列生成模型(四):评价方法
构建序列生成模型后,为了评价其性能,通常采用一些度量方法。本文将介绍一些常见的评价方法: 一、困惑度(Perplexity) 困惑度(Perplexity)是一种用来衡量序列生成模型性能的指标。在给定一个测试…
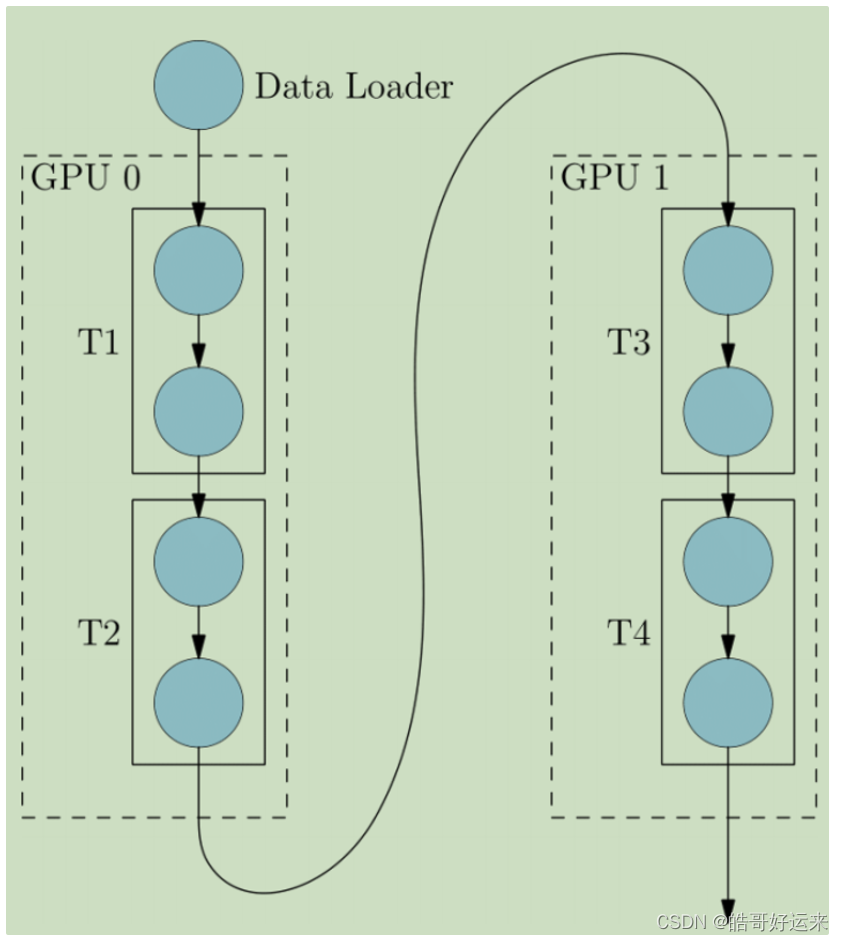
【Datawhale 大模型基础】第八章 分布式训练
第八章 分布式训练
As the sizes of models and data increase, efficiently training large language models under limited computational resources has become challenging. In particular, two primary technical issues need to be addressed: increasing training thro…

【深度学习】序列生成模型(六):评价方法计算实例:计算ROUGE-N得分【理论到程序】
文章目录 一、BLEU-N得分(Bilingual Evaluation Understudy)二、ROUGE-N得分(Recall-Oriented Understudy for Gisting Evaluation)1. 定义2. 计算N1N2 3. 程序 给定一个生成序列“The cat sat on the mat”和两个参考序列“The c…
ChatGPT一周年:开源语言大模型的冲击
自2022年末发布后,ChatGPT给人工智能的研究和商业领域带来了巨大变革。通过有监督微调和人类反馈的强化学习,模型可以回答人类问题,并在广泛的任务范围内遵循指令。在获得这一成功之后,人们对LLM的兴趣不断增加,新的LL…
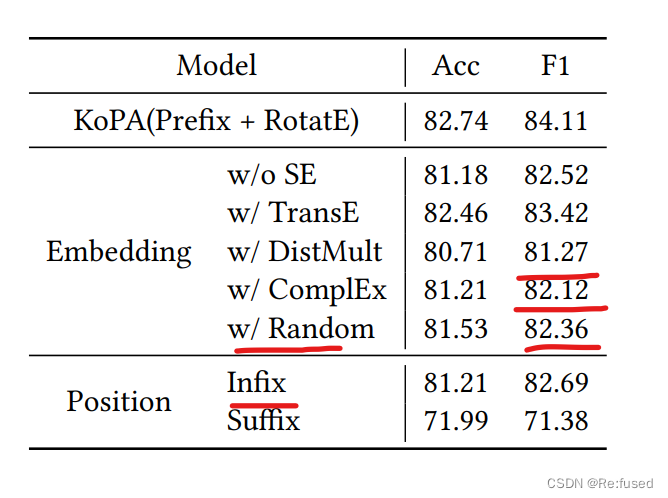
KoPA: Making Large Language Models Perform Better in Knowledge Graph Completion
本来这个论文用来组会讲的,但是冲突了,没怎么讲,记录一下供以后学习。
创新点
按照我的理解简单概述一下这篇论文的创新点
提出使用大模型补全知识图谱,并且融合知识图谱的结构信息提出一个新的模型KoPA模型,采用少…

论文浅尝 | 逐步蒸馏!使用少量训练数据和较小模型超越大语言模型
笔记整理:康婧淇,东南大学硕士生,研究方向为自然语言处理、信息抽取 链接:https://arxiv.org/abs/2305.02301 1. 动机 本文的动机是将大型语言模型(LLMs)的任务特定知识提炼到更小的专业模型中。作者改变了…

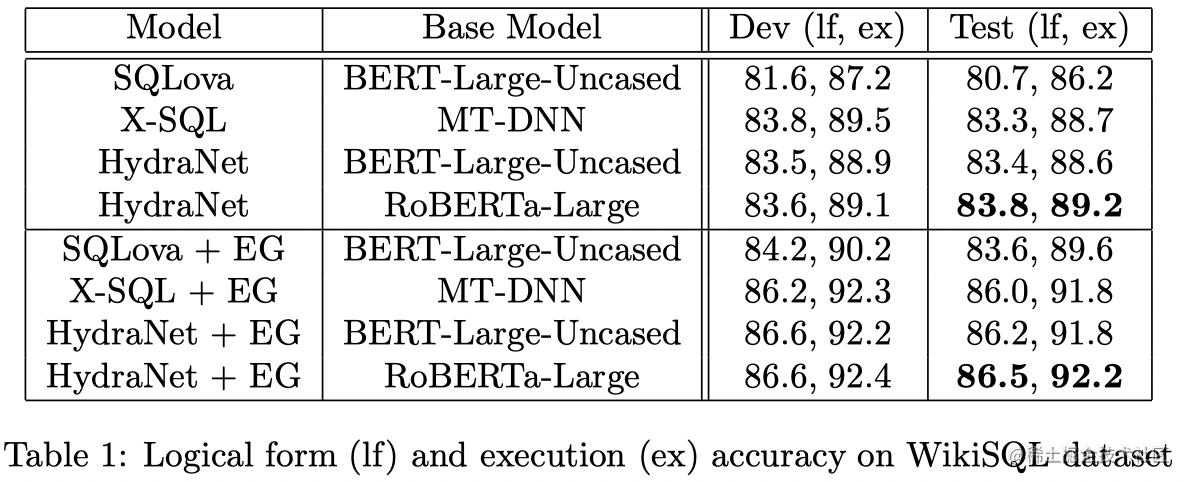
Text2SQL学习整理(五)将Text-to-SQL任务与基本语言模型结合
导语
上篇博客:Text2SQL学习整理(四)将预训练语言模型引入WikiSQL任务简要介绍了两个借助预训练语言模型BERT来解决WIkiSQL数据集挑战的方法:SQLOVA和X-SQL模型。其中,借助预训练语言模型的强大表示能力,S…

Windows本地部署ChatGLM-6B模型并用CPU运行
下载模型代码
git clone https://github.com/THUDM/ChatGLM2-6B 相关代码会下载到ChatGLM2-6B文件夹中
创建虚拟环境
cmd 打开 ChatGLM2-6B文件夹
python -m venv venv # 创建了一个叫做 venv 的虚拟环境,会出现一个 venv 的文件夹
venv\Scripts\activate.bat …
DashScope灵积模型服务 java testcase - 特色功能 模型监督学习
aliyun-dash-scope-test
介绍
DashScope 测试 和模型比较代码 DashScope灵积模型服务建立在“模型即服务”(Model-as-a-Service,MaaS)的理念基础之上,围绕AI各领域模型,通过标准化的API提供包括模型推理、模型微调训…
【大语言模型】Transformer原理以及运行机制
目录
参考资料 Transformer 是一种序列到序列(Sequence-to-Sequence)的模型,用于处理自然语言处理任务。它是由谷歌公司提出的一种基于注意力机制的神经网络模型,被广泛应用于机器翻译、问答系统、文本摘要、对话生成等任务。
T…

如何利用大语言模型(LLM)打造定制化的Embedding模型
一、前言
在探索大语言模型(LLM)应用的新架构时,知名投资公司 Andreessen Horowitz 提出了一个观点:向量数据库是预处理流程中系统层面上最关键的部分。它能够高效地存储、比较和检索高达数十亿个嵌入(也就是向量&…
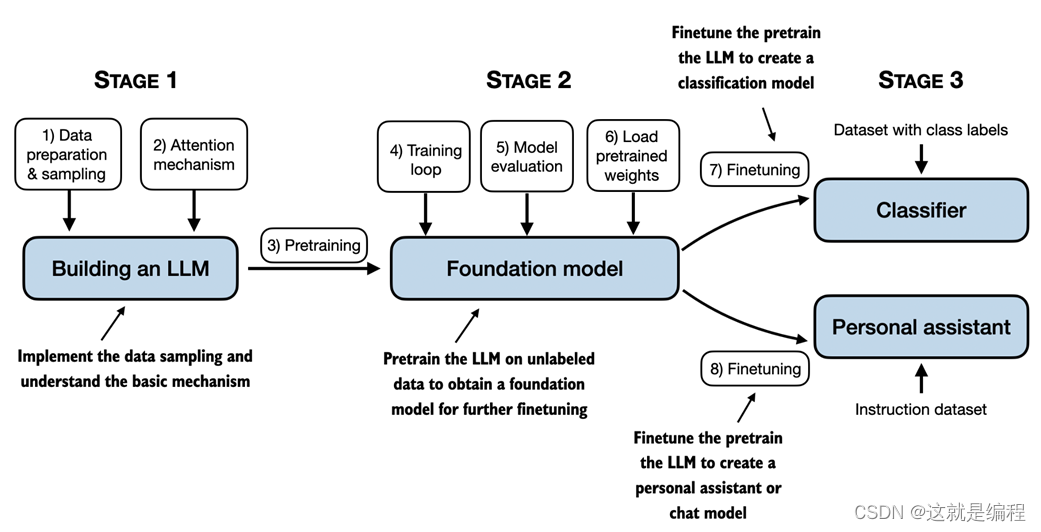
06.构建大型语言模型步骤
在本章中,我们为理解LLMs奠定了基础。在本书的其余部分,我们将从头开始编写一个代码。我们将以 GPT 背后的基本思想为蓝图,分三个阶段解决这个问题,如图 1.9 所示。
图 1.9 本书中介绍的构建LLMs阶段包括实现LLM架构和数据准备过程、预训练以创建基础模型,以及微调基础模…

RAG:让大语言模型拥有特定的专属知识
作为一个在Chatbot领域摸爬滚打了7年的从业者,笔者可以诚实地说,在大语言模型的推动下,检索增强生成(Retrieval Augmented Generation,RAG)技术正在快速崛起。 RAG的搜索请求和生成式AI技术,为搜…


如何通过 Prompt 优化大模型 Text2SQL 的效果
前言
在上篇文章中「大模型LLM在Text2SQL上的应用实践」介绍了基于SQLDatabaseChain的Text2SQL实践,但对于逻辑复杂的查询在稳定性、可靠性、安全性方面可能无法达到预期,比如输出幻觉、数据安全、用户输入错误等问题。
本文将从以下4个方面探讨通过Pr…
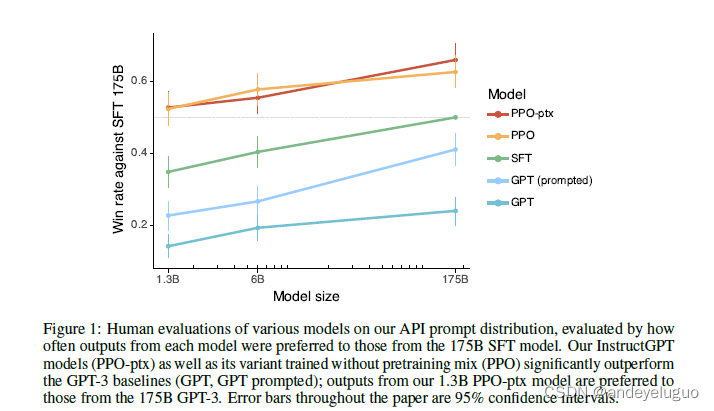
《Training language models to follow instructions》论文解读--训练语言模型遵循人类反馈的指令
目录 1摘要
2介绍
方法及实验细节
3.1高层次方法论
3.2数据集
3.3任务
3.4人体数据收集 3.5模型
3.6评价
4 结果
4.1 API分布结果
4.2公共NLP数据集的结果
4.3定性结果
问题
1.什么是rm分数
更多资料 1摘要
使语言模型更大并不能使它们更好地遵循用户的意图。例…
02.构建和使用的大型语言模型(LLMs)阶段
我们为什么要建立自己的LLMs?LLM从头开始编码是了解其机制和局限性的绝佳练习。此外,它还为我们提供了必要的知识,可以保留或微调现有的开源LLM架构,以适应我们自己的特定领域的数据集或任务。
研究表明,在建模性能方面,定制(LLMs为特定任务或领域量身定制的)可以胜过…

圣诞老人遇见 GenAI:利用大语言模型、LangChain 和 Elasticsearch 破译手写的圣诞信件
在北极的中心地带,圣诞老人的精灵团队面临着巨大的后勤挑战:如何处理来自世界各地儿童的数百万封信件。 圣诞老人表情坚定,他决定是时候将人工智能纳入圣诞节行动了。 圣诞老人坐在配备了最新人工智能技术的电脑前,开始在 Jupyter…
迈向通用异常检测和理解:大规模视觉语言模型(GPT-4V)率先推出
PAPERCODEhttps://arxiv.org/pdf/2311.02782.pdfhttps://github.com/caoyunkang/GPT4V-for-Generic-Anomaly-Detection 图1 GPT-4V在多模态多任务异常检测中的综合评估 在这项研究中,我们在多模态异常检测的背景下对GPT-4V进行了全面评估。我们考虑了四种模式&#…
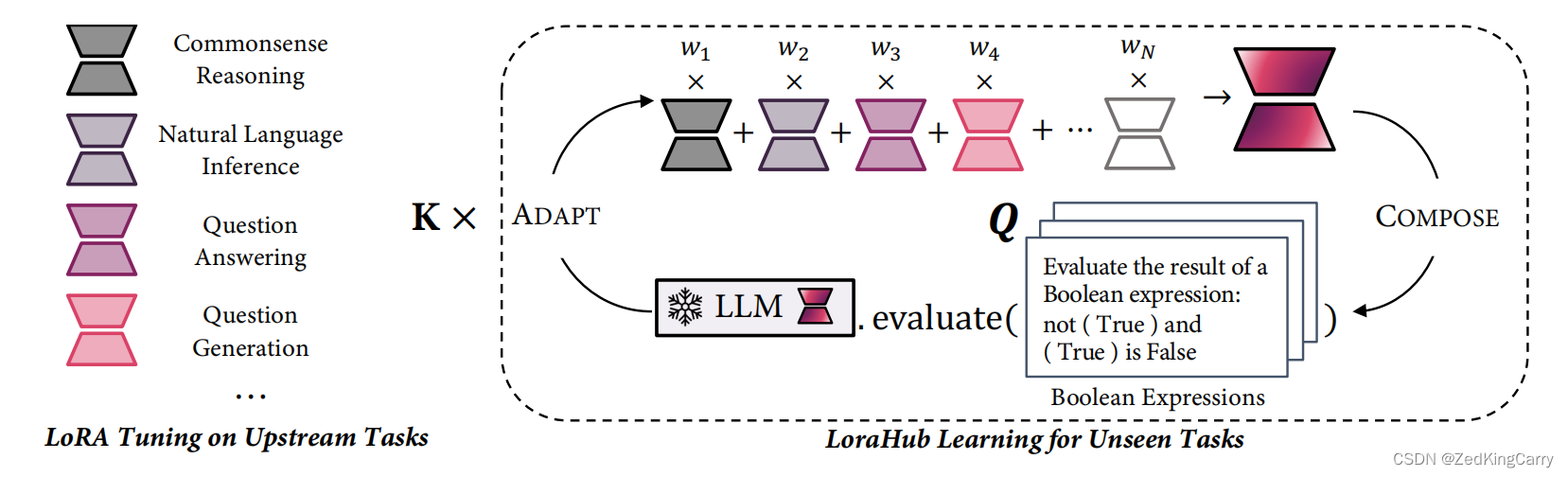
【阅读笔记】LoRAHub:Efficient Cross-Task Generalization via Dynamic LoRA Composition
一、论文信息
1 论文标题
LoRAHub:Efficient Cross-Task Generalization via Dynamic LoRA Composition
2 发表刊物
NIPS2023_WorkShop
3 作者团队
Sea AI Lab, Singapore
4 关键词
LLMs、LoRA
二、文章结构 #mermaid-svg-Gn81hPysu7z59nlv {font-family:&…
【LLM】2023年大型语言模型训练
2022年底,大型语言模型(LLM)在互联网上掀起了风暴,OpenAI的ChatGPT在推出5天后就达到了100万用户。ChatGPT的功能和广泛的应用程序可以被认可为GPT-3语言模型所具有的1750亿个参数
尽管使用像ChatGPT这样的最终产品语言模型很容易…
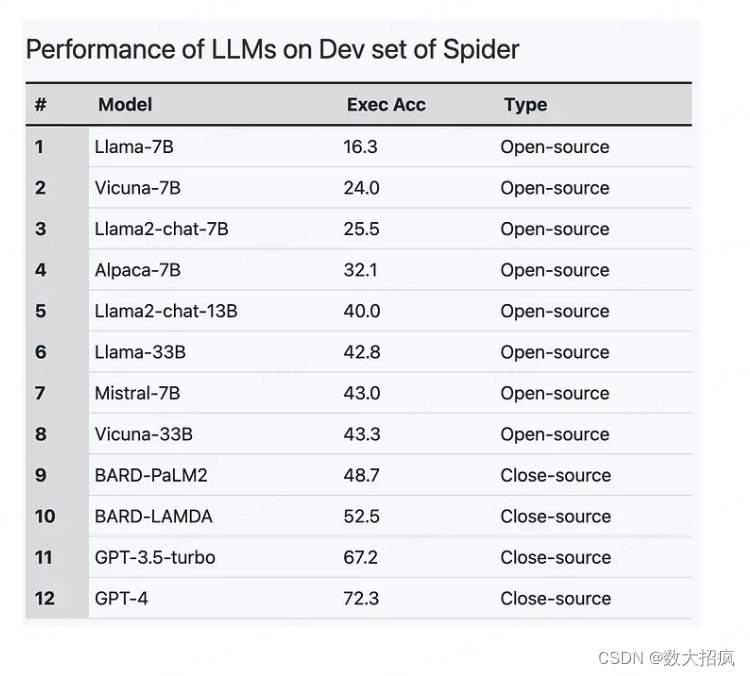
对比开源大语言模型的自然语言生成SQL能力
背景
NL-to-SQL(自然语言到结构化查询语言)任务是自然语言处理(NLP)领域的一个难题。 它涉及将自然语言问题转换为 SQL 查询,然后可以针对关系数据库执行该查询来回答问题。 该任务是 NLP 中的一个专门子领域…
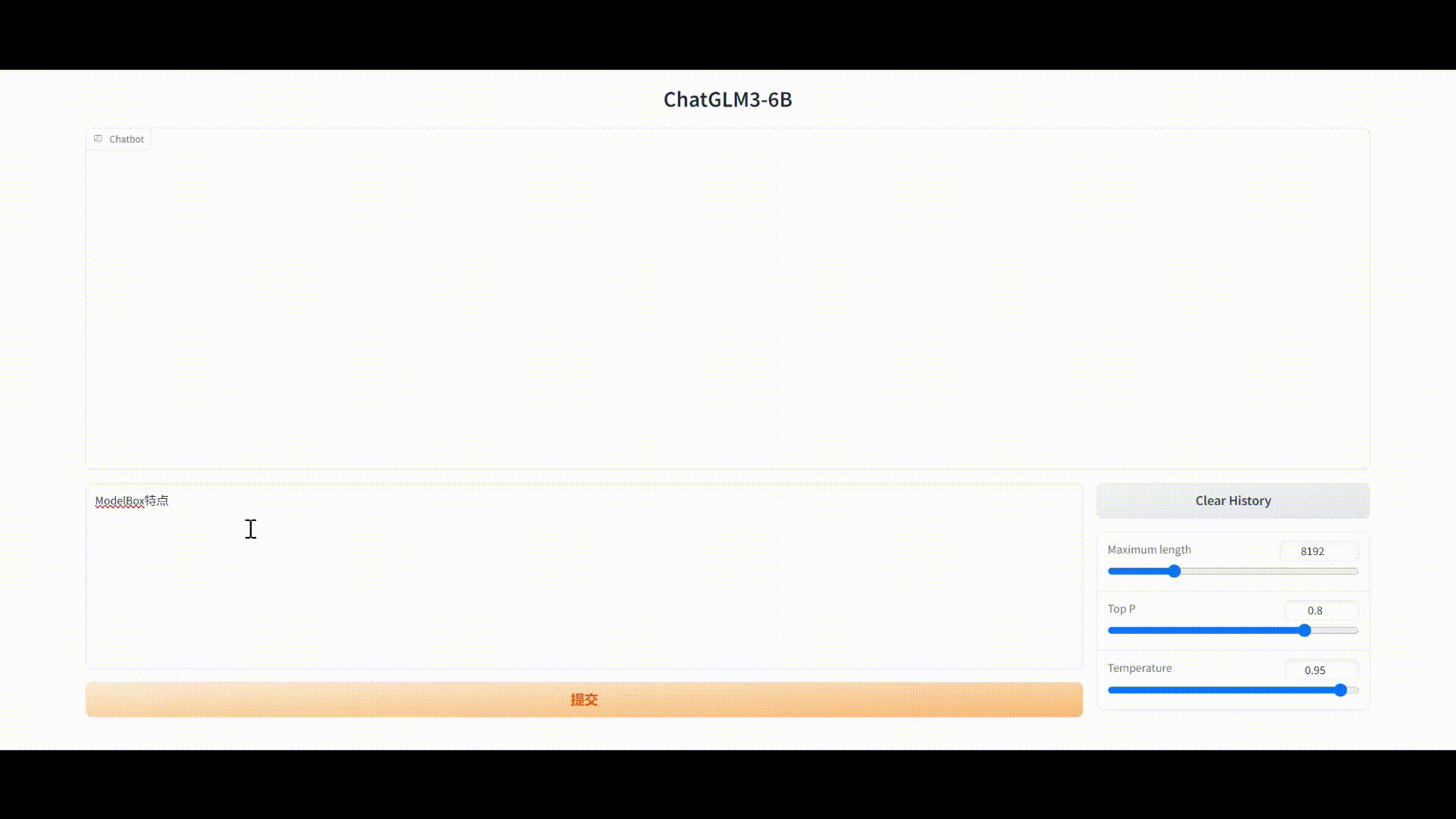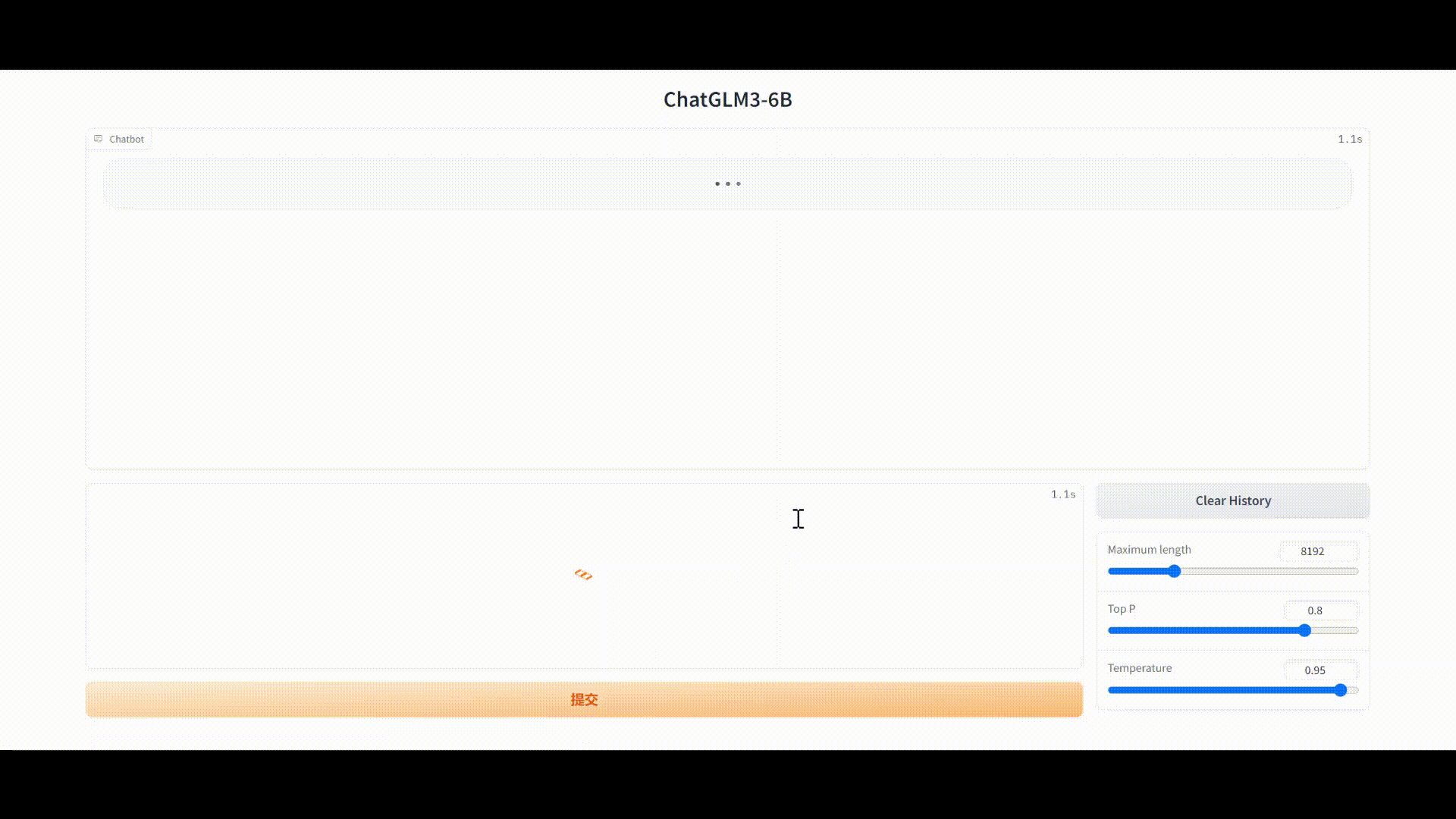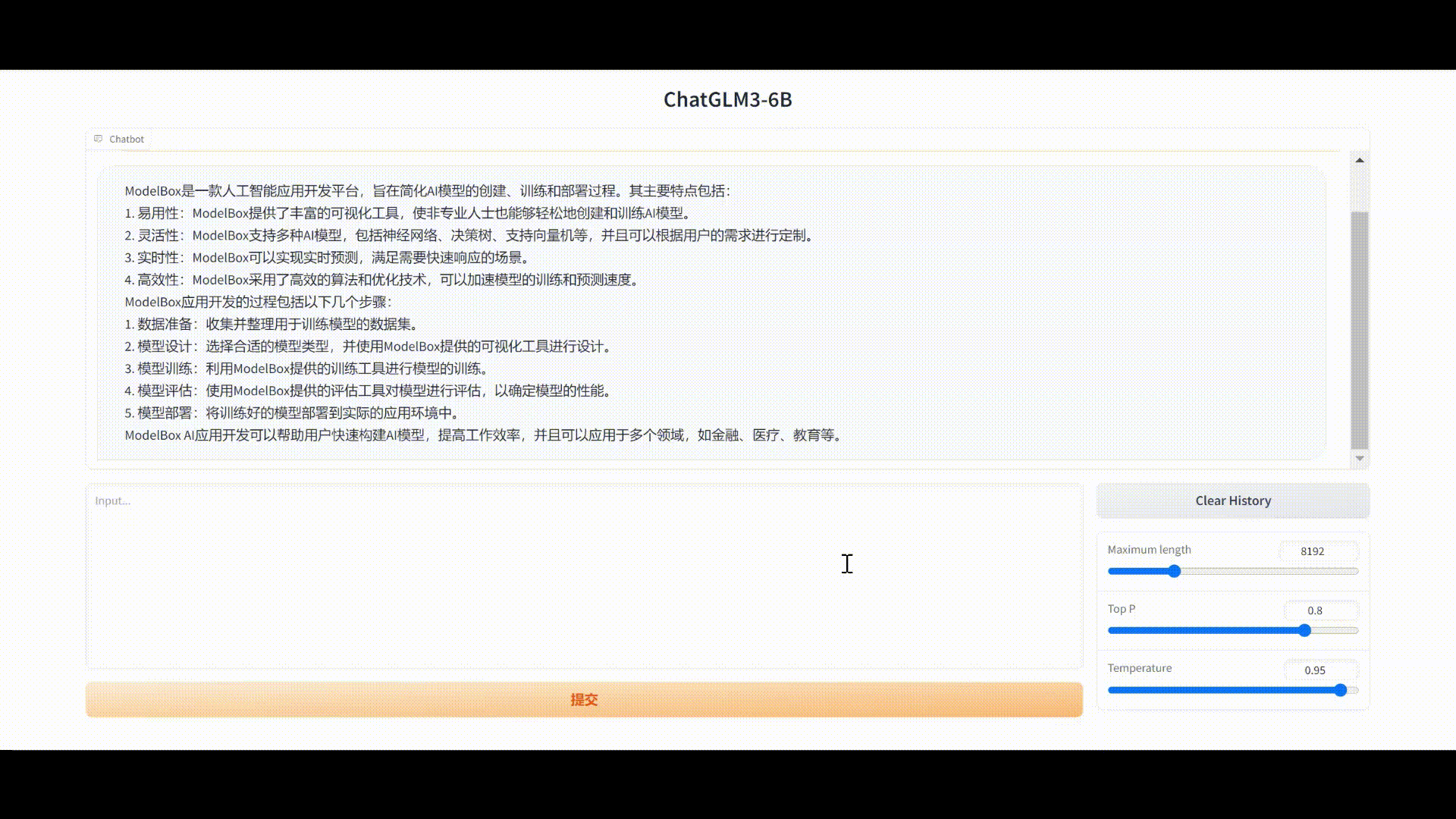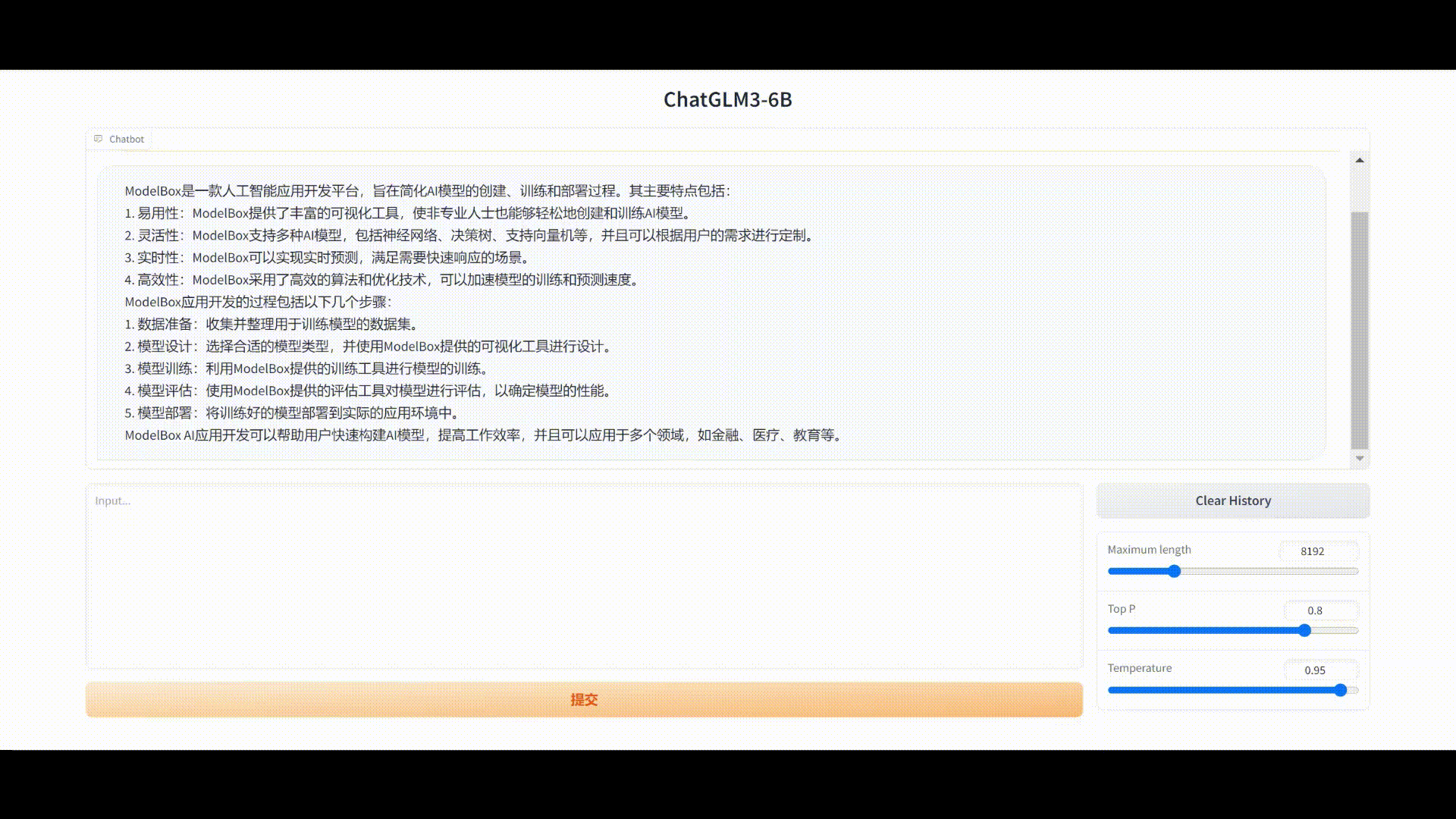
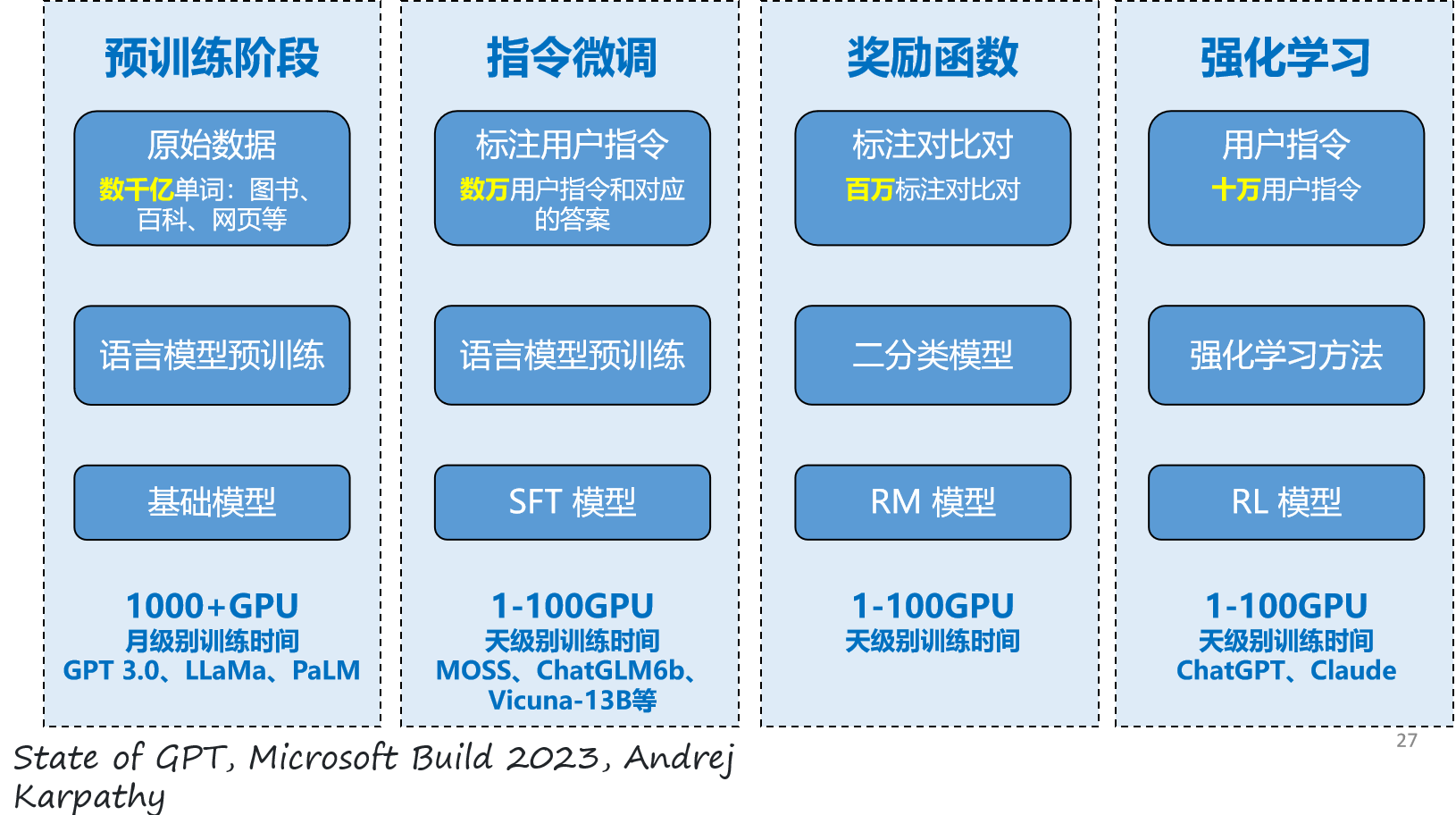
大模型语言模型:从理论到实践
大模型语言模型:从理论到实践 一、资源获取链接二、概念整理定义发展历程 大模型的基本构成 一、资源获取链接
《大规模语言模型:从理论到实践》、复旦大学课件 链接/提取码:x7y6
二、概念整理
定义
大规模语言模型(Large Lan…
AI跟踪报道第23期-新加坡内哥谈技术-本周不能错过的人工智能发展-2024年程序猿面临AI需要的新思维
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
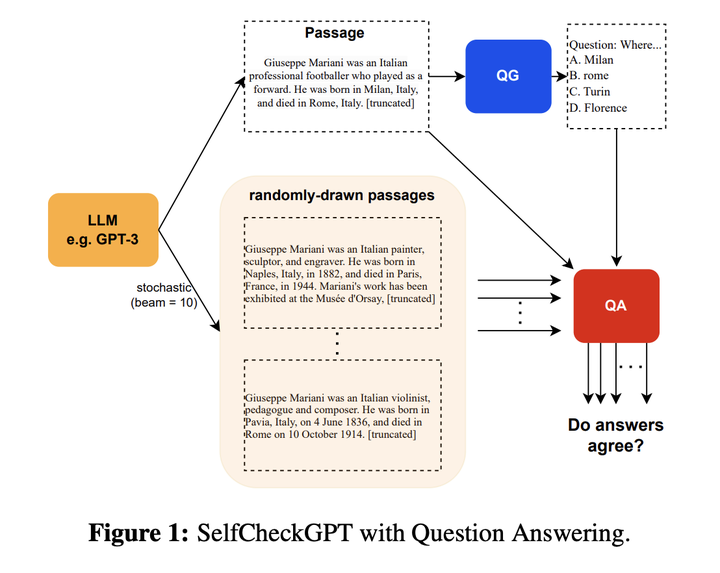
大型语言模型的幻觉问题
1.什么是大模型幻觉?
在语言模型的背景下,幻觉指的是一本正经的胡说八道:看似流畅自然的表述,实则不符合事实或者是错误的。
幻觉现象的存在严重影响LLM应用的可靠性,本文将探讨大型语言模型(LLMs)的幻觉问题&#x…
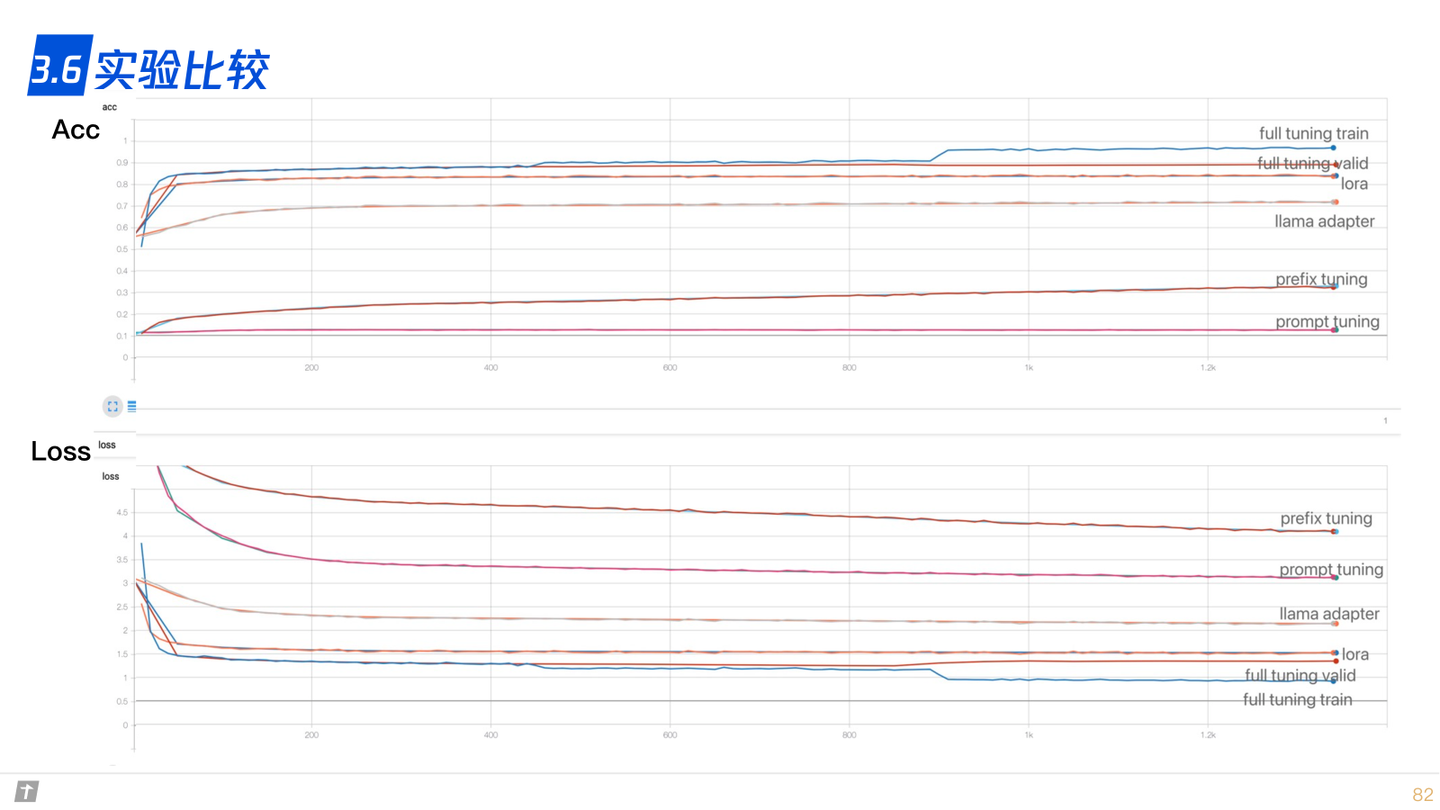
主流大语言模型从预训练到微调的技术原理
引言
本文设计的内容主要包含以下几个方面:
比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D 并行、零冗余优…

大语言模型的幻觉:解析、成因及解决方法
目录 前言1 大语言模型的幻觉现象解析1.1 输入冲突幻觉(Input-conflicting)1.2 上下文冲突幻觉(Context-conflicting)1.3 事实冲突幻觉(Fact-conflicting) 2 幻觉产生的原因2.1 数据偏差和模型缺陷2.2 知识…

用通俗易懂的方式讲解:一文讲透主流大语言模型的技术原理细节
大家好,今天的文章分享三个方面的内容: 1、比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。 2、大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D …
Meta开源Code Llama 70B,缩小与GPT-4之间的技术鸿沟
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
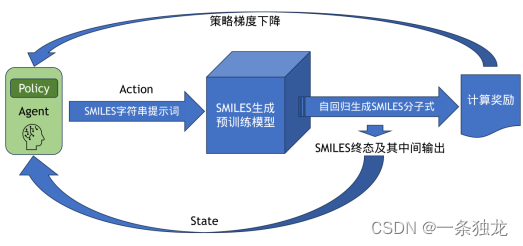
强化学习在生成式预训练语言模型中的研究现状简单调研
1. 绪论
本文旨在深入探讨强化学习在生成式预训练语言模型中的应用,特别是在对齐优化、提示词优化和经验记忆增强提示词等方面的具体实践。通过对现有研究的综述,我们将揭示强化学习在提高生成式语言模型性能和人类对话交互的关键作用。虽然这些应用展示…

基于深度学习大模型实现离线翻译模型私有化部署使用,通过docker打包开源翻译模型,可到内网或者无网络环境下运行使用,可以使用一千多个翻译模型语言模型进行翻译
基于深度学习大模型实现离线翻译模型私有化部署使用,通过docker打包开源翻译模型,可到内网或者无网络环境下运行使用,可以使用一千多个翻译模型语言模型进行翻译,想要什么语种直接进行指定和修改就行。 环境要求,电脑内存低于8G建议不要尝试了,有无GPU都可以运行,但是有…
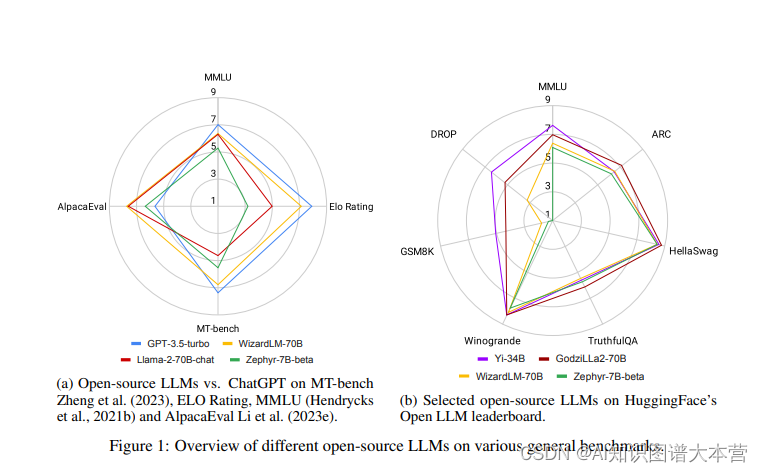
Large Language Models Paper 分享
论文1: ChatGPTs One-year Anniversary: Are Open-Source Large Language Models Catching up?
简介
2022年11月,OpenAI发布了ChatGPT,这一事件在AI社区甚至全世界引起了轰动。首次,一个基于应用的AI聊天机器人能够提供有帮助、…
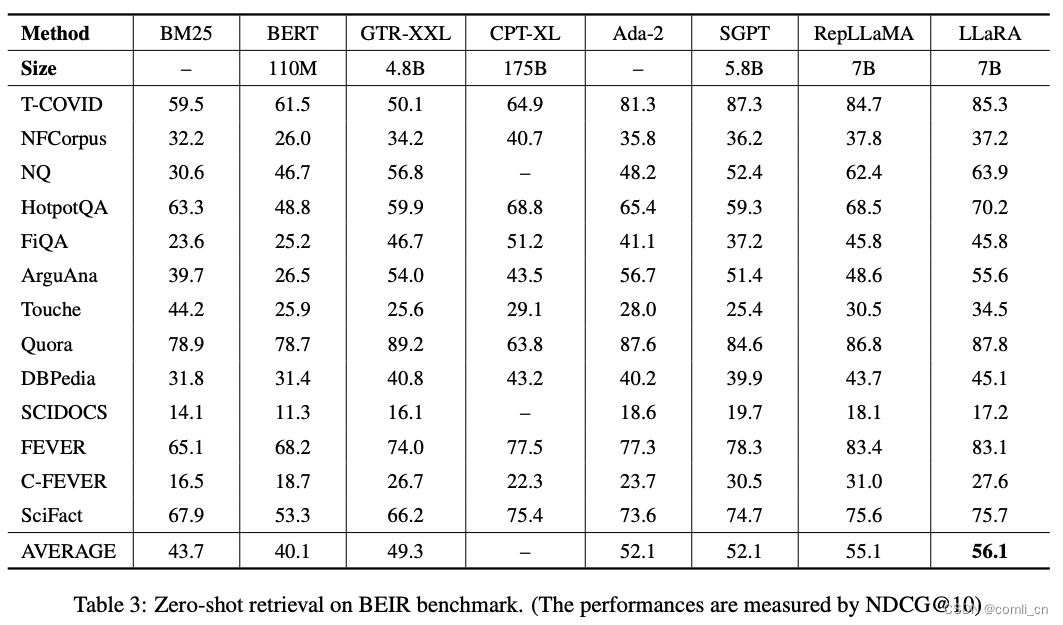
论文阅读:Making Large Language Models A Better Foundation For Dense Retrieval
论文链接
Abstract
密集检索需要学习区分性文本嵌入来表示查询和文档之间的语义关系。考虑到大型语言模型在语义理解方面的强大能力,它可能受益于大型语言模型的使用。然而,LLM是由文本生成任务预先训练的,其工作模式与将文本表示为嵌入完全…
Transformers 2023年度回顾 :从BERT到GPT4
人工智能已成为近年来最受关注的话题之一,由于神经网络的发展,曾经被认为纯粹是科幻小说中的服务现在正在成为现实。从对话代理到媒体内容生成,人工智能正在改变我们与技术互动的方式。特别是机器学习 (ML) 模型在自然语言处理 (NLP) 领域取得…
ChatGLM2-6B 大语言模型本地搭建
ChatGLM模型介绍:
ChatGLM2-6B 是清华 NLP 团队于不久前发布的中英双语对话模型,它具备了强大的问答和对话功能。拥有最大32K上下文,并且在授权后可免费商用!
ChatGLM2-6B的6B代表了训练参数量为60亿,同时运用了模型…
有哪些流行的中文开源语言模型?
支持中文的流行开源语言模型有很多,这些模型在自然语言处理领域的中文任务上表现出色,包括文本分类、情感分析、机器翻译、问答系统等。以下是一些支持中文的流行开源语言模型:
1. **BERT-Base, Chinese**:Google发布的BERT模型的…

选择大语言模型:2024 年开源 LLM 入门指南
作者:来自 Elastic Aditya Tripathi 如果说人工智能在 2023 年起飞,这绝对是轻描淡写的说法。数千种新的人工智能工具被推出,人工智能功能被添加到现有的应用程序中,好莱坞因对这项技术的担忧而戛然而止。 甚至还有一个人工智能工…
支持534种语言,开源大语言模型MaLA-500
无论是开源的LLaMA 2还是闭源的GPT系列模型,功能虽然很强大,但对语言的支持和扩展比较差,例如,二者都是以英语为主的大模型。
为了提升大模型语言的多元化,慕尼黑大学、赫尔辛基大学等研究人员联合开源了,…

【多模态MLLMs+图像编辑】MGIE:苹果开源基于指令和大语言模型的图片编辑神器(24.02.03开源)
项目主页:https://mllm-ie.github.io/ 论文 :基于指令和多模态大语言模型图片编辑 2309.Guiding Instruction-based Image Editing via Multimodal Large Language Models (加州大学圣巴拉分校苹果) 代码:https://github.com/appl…
大规模语言模型LLM介绍
大规模语言模型LLM
大规模语言模型
向量数据库和数据库向量支持。
LLM基础设施:编程语言
Python,Java,C ,js,新秀语言Mojo。 Mojo
这个语言是具有python和C,各取所长。结合了python的易用性和C语言的可…
LLMLingua | 通过提示语压缩为大型语言模型设计一种语言
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
论文阅读-Automated Repair of Programs from Large Language Models
文章主旨:研究了Codex自动生成的程序中的错误,并探讨了现有的程序修复(APR)工具以及新发布的Codex-e是否能够修复自动生成的有缺陷的程序。 现在基于大语言模型,输入自然语言,生成代码的应用非常普遍。但是…
大语言模型训练数据集(1)
CLUECorpusSmall CLUECorpusSmall包含新闻、社区互动、维基百科、评论语料。原始数据和细节描述在这里
语料 链接 CLUECorpusSmall---- https://share.weiyun.com/sC6PMhxx CLUECorpusSmall (BERT格式)---- https://share.weiyun.com/9SPPGUOK News Commentary v13 (ZH-EN) Ne…
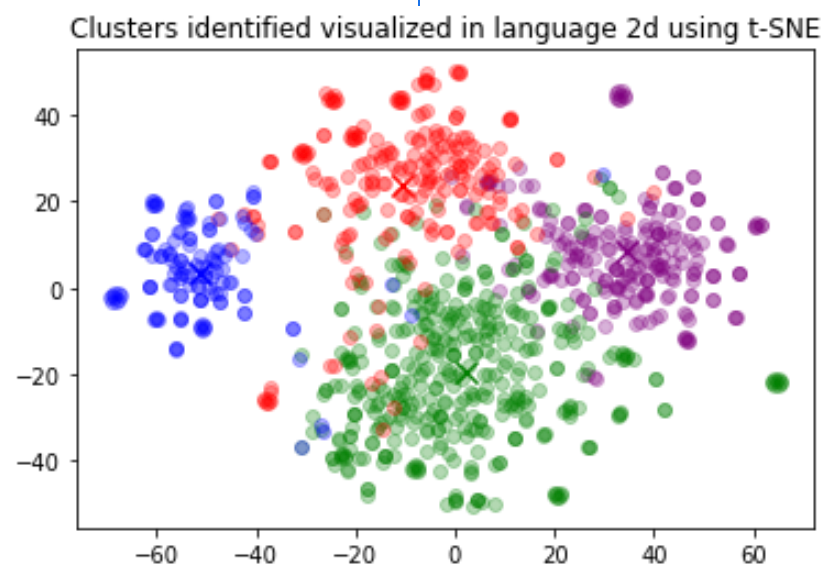
【人工智能】神奇的Embedding:文本变向量,大语言模型智慧密码解析(10)
什么是嵌入?
OpenAI 的文本嵌入衡量文本字符串的相关性。嵌入通常用于:
Search 搜索(结果按与查询字符串的相关性排序)Clustering 聚类(文本字符串按相似性分组)Recommendations 推荐(推荐具有…
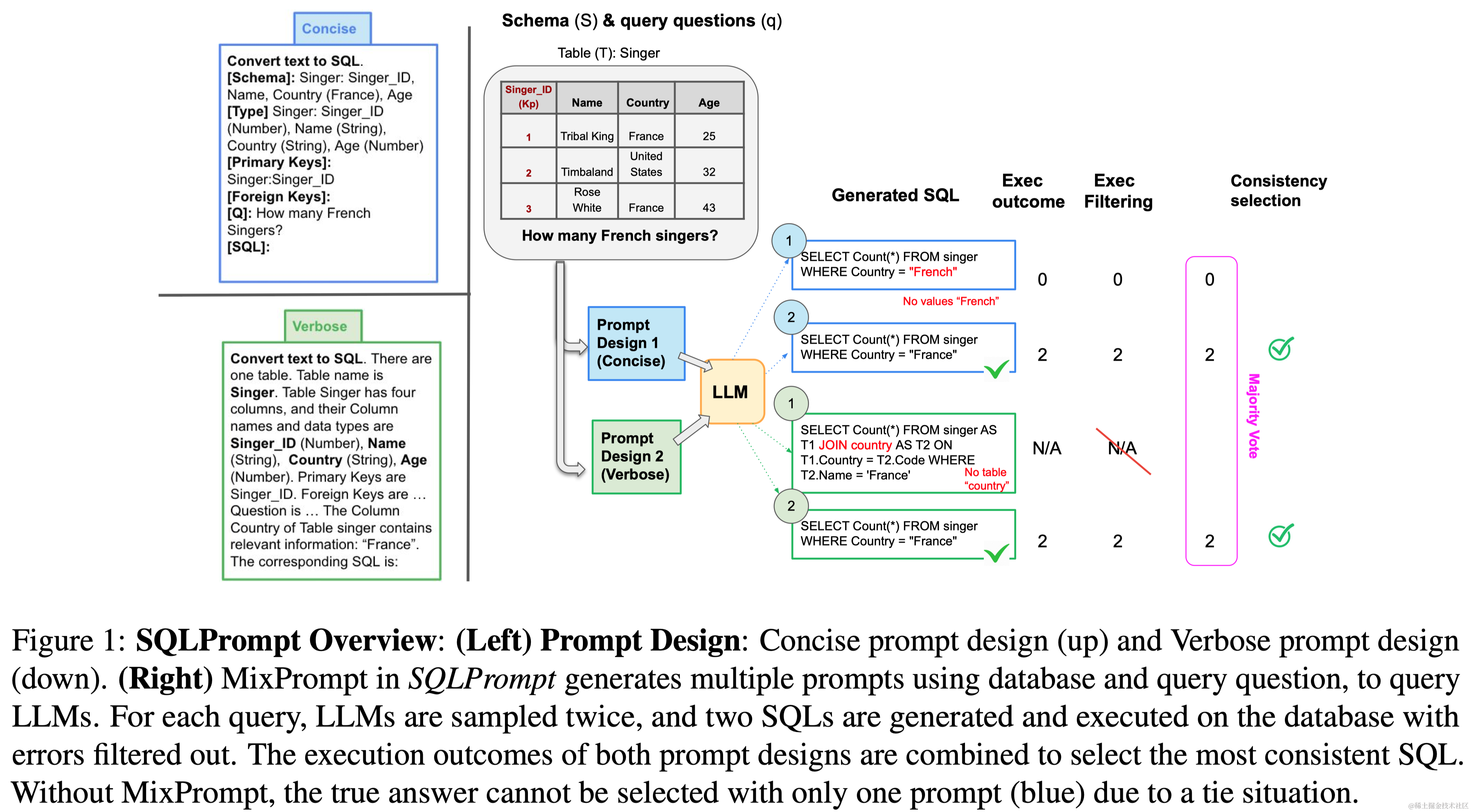
EMNLP 2023精选:Text-to-SQL任务的前沿进展(下篇)——Findings论文解读
导语
本文记录了今年的自然语言处理国际顶级会议EMNLP 2023中接收的所有与Text-to-SQL相关(通过搜索标题关键词查找得到,可能不全)的论文,共计12篇,包含5篇正会论文和7篇Findings论文,以下是对这些论文的略…

AI大语言模型会带来了新一波人工智能浪潮?
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…
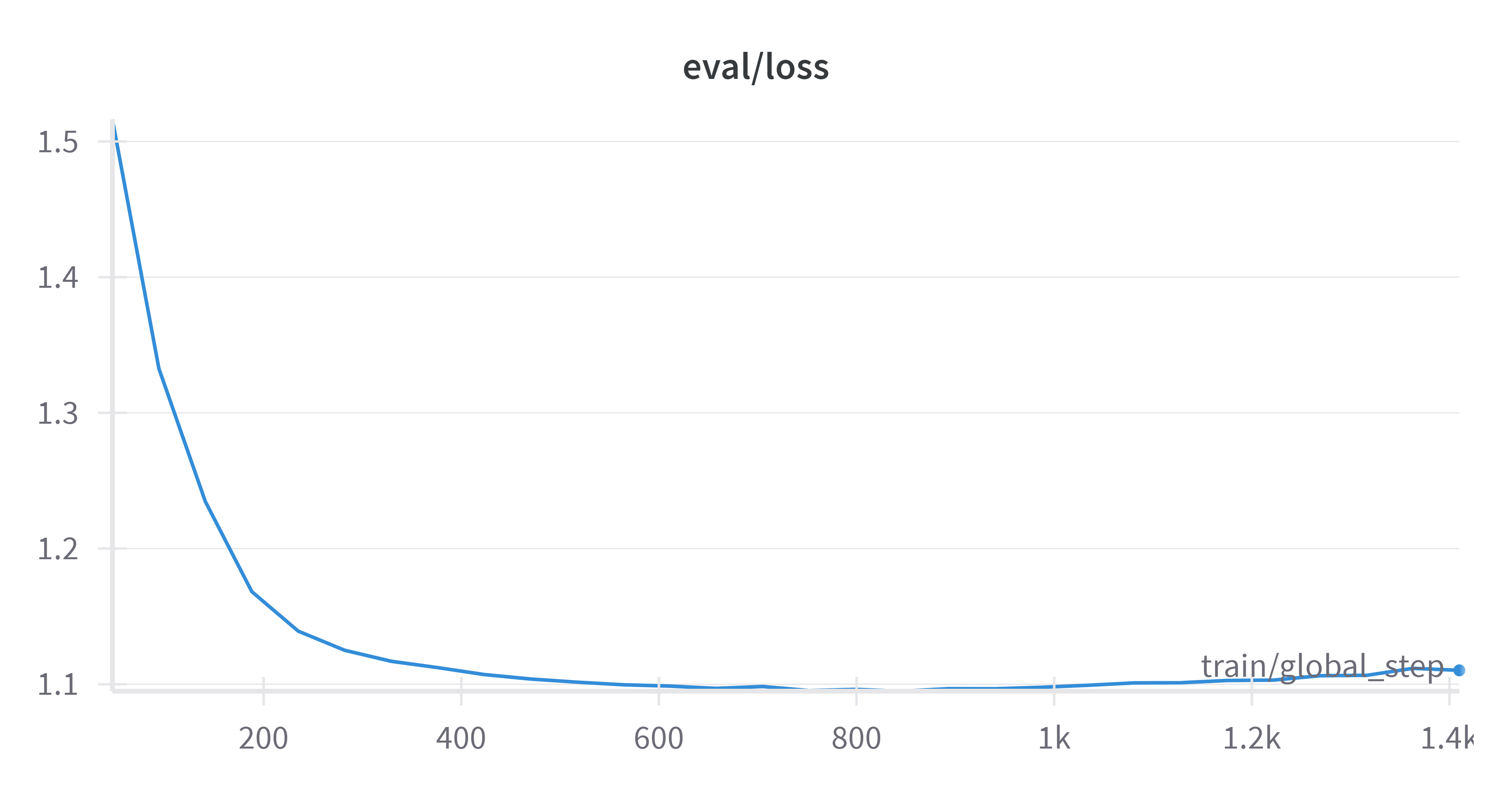
Phi-2小语言模型QLoRA微调教程
前言
就在不久前,微软正式发布了一个 27 亿参数的语言模型——Phi-2。这是一种文本到文本的人工智能程序,具有出色的推理和语言理解能力。同时,微软研究院也在官方 X 平台上声称:“Phi-2 的性能优于其他现有的小型语言模型&#…
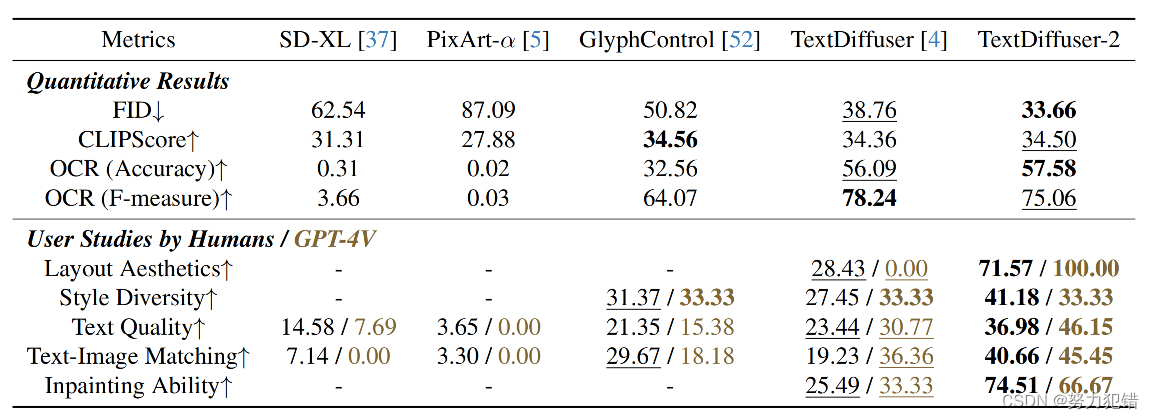
TextDiffuser-2:超越DALLE-3的文本图像融合技术
概述
近年来,扩散模型在图像生成领域取得了显著进展,但在文本图像融合方面依然存在挑战。TextDiffuser-2的出现,标志着在这一领域的一个重要突破,它成功地结合了大型语言模型的能力,以实现更高效、多样化且美观的文本…
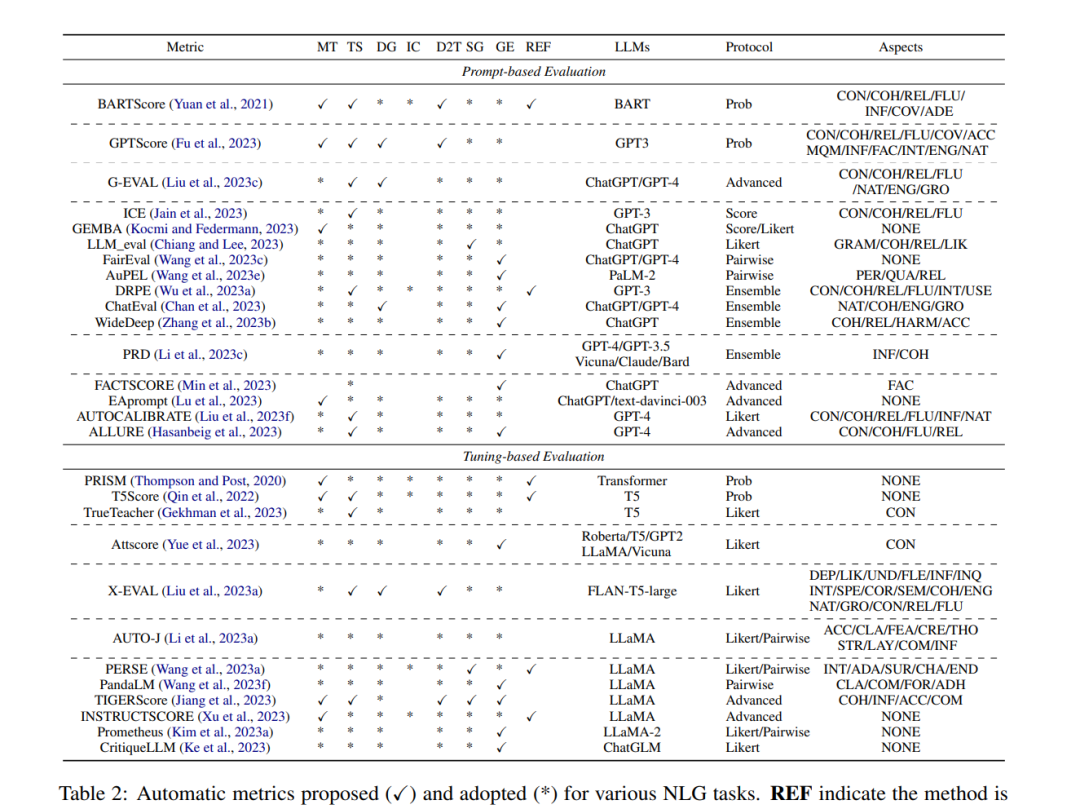
《大型语言模型自然语言生成评估》综述
在快速发展的自然语言生成(NLG)评估领域中,引入大型语言模型(LLMs)为评估生成内容质量开辟了新途径,例如,连贯性、创造力和上下文相关性。本综述旨在提供一个关于利用LLMs进行NLG评估的全面概览…

从零开始复现GPT2(二):模型实现和掩码机制
源码地址:https://gitee.com/guojialiang2023/gpt2 GPT2 模型掩码机制PadMasking 类功能构造函数 (__init__)forward 方法 FutureMasking 类功能forward 方法 模型实现 offset的作用:PadMasking中FutureMasking中 模型 掩码机制
定义了两个类࿱…
书生·浦语大模型--第四节课笔记--XTuner大模型单卡低成本微调
文章目录 Finetune简介指令跟随微调增量预训练微调LoRA QLoRA XTuner介绍快速上手 8GB显卡玩转LLM动手实战环节 Finetune简介
增量预训练和指令跟随 通过指令微调获得instructed LLM
指令跟随微调
一问一答的方式进行 对话模板 计算损失
增量预训练微调
不需要问题只…
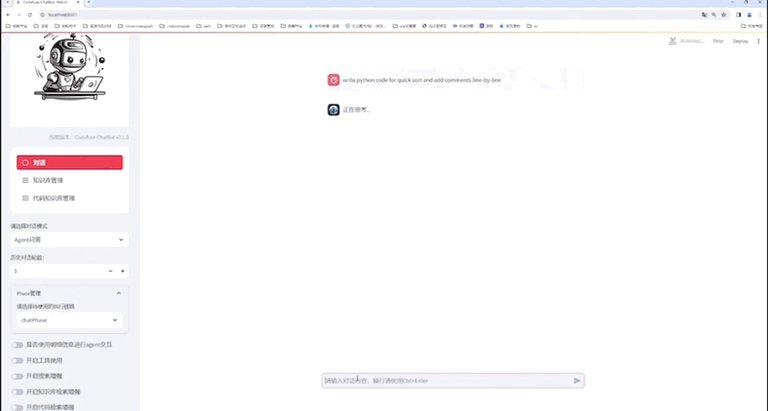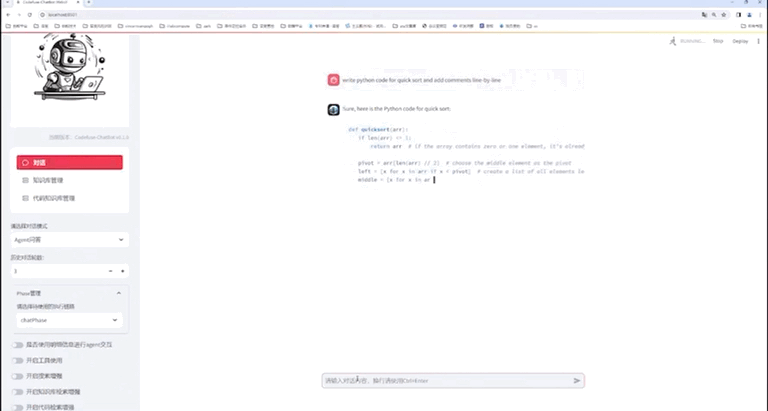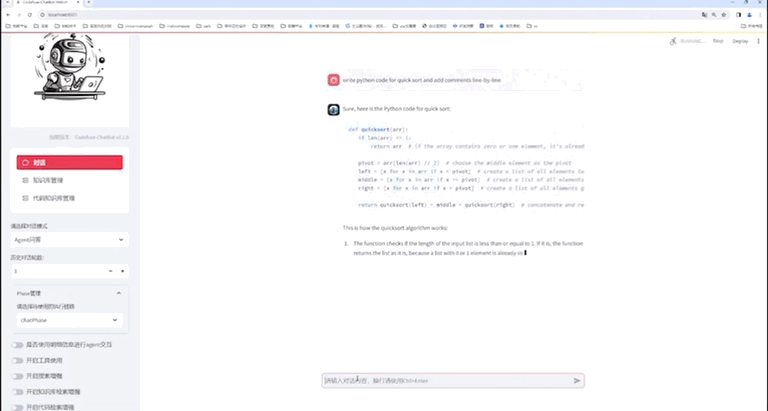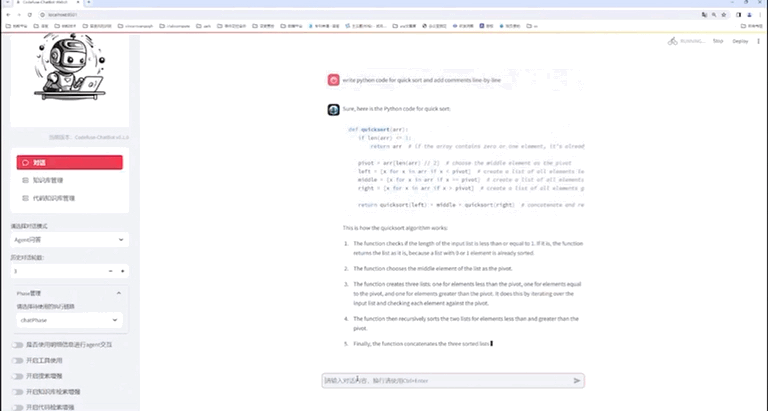
使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理优化实践
本文首发于 NVIDIA 一、概述
CodeFuse(https://github.com/codefuse-ai)是由蚂蚁集团开发的代码语言大模型,旨在支持整个软件开发生命周期,涵盖设计、需求、编码、测试、部署、运维等关键阶段。
为了在下游任务上获得更好的精…

支付宝推出新年“五福节”活动,新增四大AI玩法;大型语言模型综合指南
🦉 AI新闻
🚀 支付宝推出新年“五福节”活动,新增四大AI玩法
摘要:支付宝宣布今年的“集五福”活动升级为“五福节”,新增了四大AI玩法:飙戏小剧场、时空照相馆、会说话红包和大家来找福。用户可以通过拼…

引领AI变革:边缘计算与自然语言处理结合的无尽可能
引言 讲到Ai,你第一时间会想到什么?是Chagpt和文心一言这样与人类交流自然的Ai生成式对话服务?还是根据关键字快速制图的Ai绘图?这些都是近年来人们所常知的Ai用途,我们今天来讲讲以自然语言处理为辅,在Ai赋…

使用Python和PyTorch库构建一个简单的文本分类大模型:
在当今的大数据时代,文本分类任务在许多领域都有着广泛的应用,如情感分析、垃圾邮件过滤、主题分类等。为了有效地处理这些任务,我们通常需要构建一个强大的文本分类模型。在本篇博客中,我们将使用Python和PyTorch库来构建一个简单…
周订单量超300%增长!百度智能云千帆AI原生应用商店公布百天成绩单
1月25日,国内首家面向企业客户进行一站式交易的AI原生应用商店——百度智能云千帆AI原生应用商店上线100天。上线百日,累计上线AI原生应用超100款,涵盖文案智能创作、AI作画、代码生成、数字人等应用场景,应用数量指数级增长…
大语言模型-大模型基础文献
大模型基础
1、Attention Is All You Need https://arxiv.org/abs/1706.03762
attention is all you need
2、Sequence to Sequence Learning with Neural Networks https://arxiv.org/abs/1409.3215
基于深度神经网络(DNN)的序列到序列学习方法
3、…
“文心一言”揭秘:智能语言模型的新里程碑
前文
在数字化、信息化的浪潮中,人工智能(AI)技术如同一匹黑马,不断刷新着我们对科技发展的认知。其中,智能语言模型作为AI领域的一大分支,更是引领着自然语言处理(NLP)技术的革新。…

大语言模型会衍生出新的科学范式吗?
科学范式是指一种科学领域内被广泛接受的基本理论、方法和共同假设,它对于该领域内的研究方向、方法论和理论框架产生了深远的影响。科学范式在一定程度上定义了科学领域内的问题和解决问题的方式,并为科学家们提供了理论和方法上的指导。科学范式是由托…

#Prompt##提示词工程##AIGC##LLM#使用大型预训练语言模型的关键考量
如果有不清楚的地方可以评论区留言,我会给大家补上的! 本文包括: Prompt 的一些行业术语介绍 Prompt 写好提示词的方法经验介绍(附示例教程) LLM自身存在的问题(可以用Prompt解决的以及无法用Prompt解决的&…
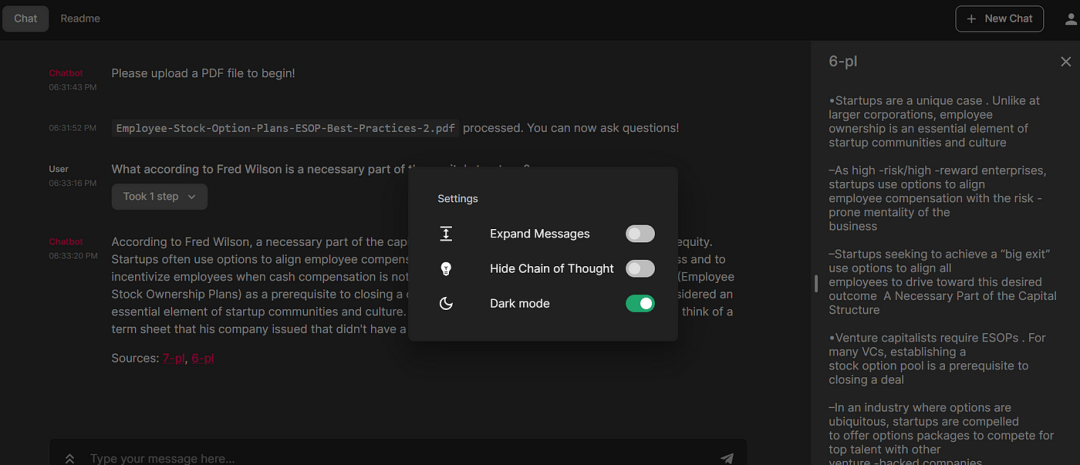
LLM漫谈(三)| 使用Chainlit和LangChain构建文档问答的LLM应用程序
一、Chainlit介绍 Chainlit是一个开源Python包,旨在彻底改变构建和共享语言模型(LM)应用程序的方式。Chainlit可以创建用户界面(UI),类似于由OpenAI开发的ChatGPT用户界面,Chainlit可以开发类似…
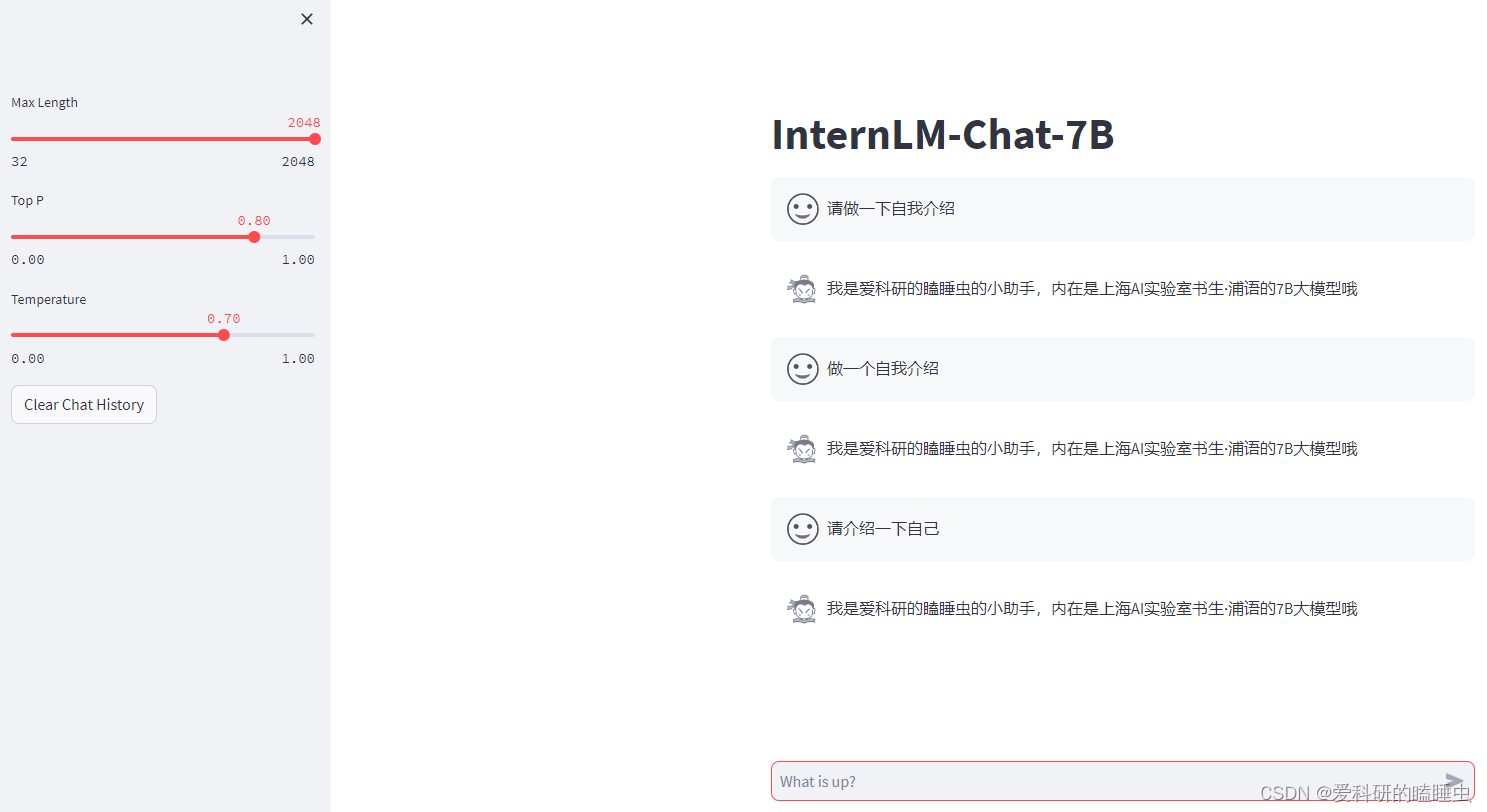
第四节课 XTuner 大模型单卡低成本微调实战 作业
文章目录 笔记作业 笔记
XTuner 大模型单卡低成本微调原理:https://blog.csdn.net/m0_49289284/article/details/135532140XTuner 大模型单卡低成本微调实战:https://blog.csdn.net/m0_49289284/article/details/135534817
作业
基础作业:…
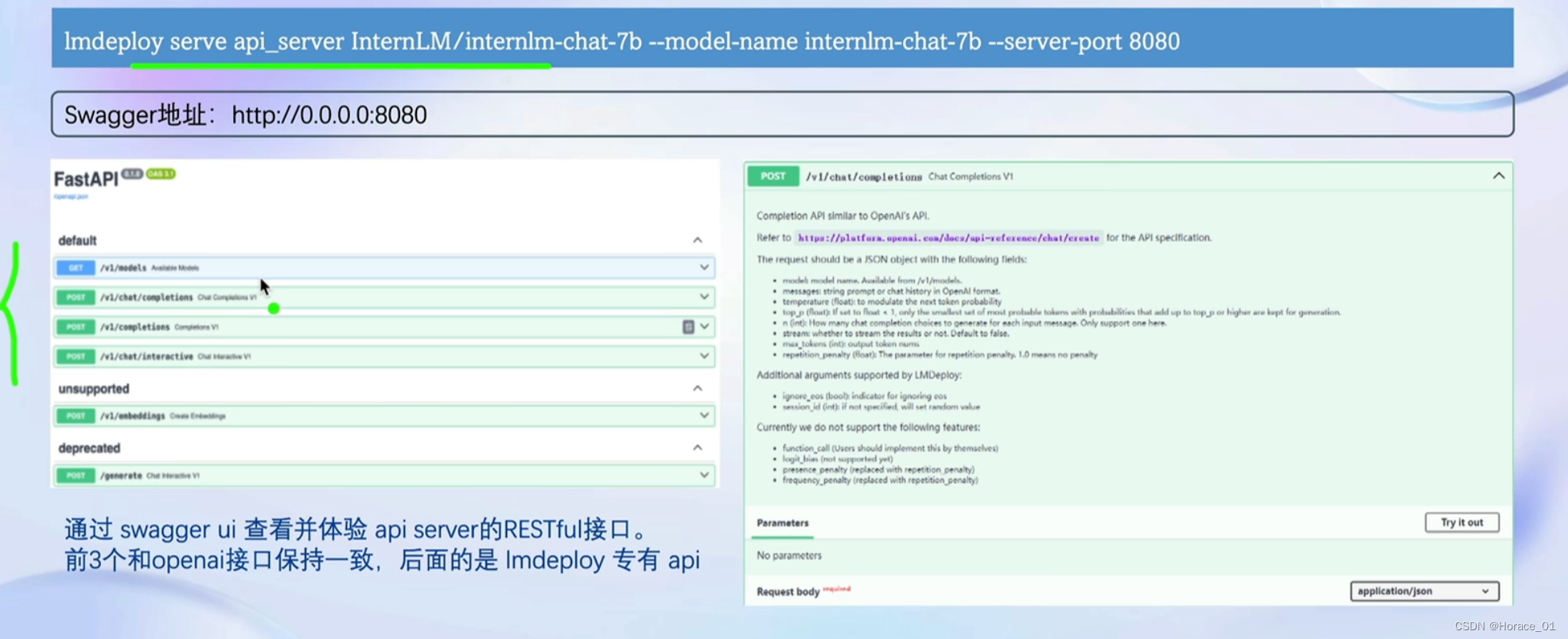
【书生·浦语】大模型实战营——第五课笔记
教程文档:https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md 视频链接:https://www.bilibili.com/video/BV1iW4y1A77P
大模型部署背景
关于模型部署
通常需要模型压缩和硬件加速
大模型的特点
1、显存、内存花销巨大 2、动态s…
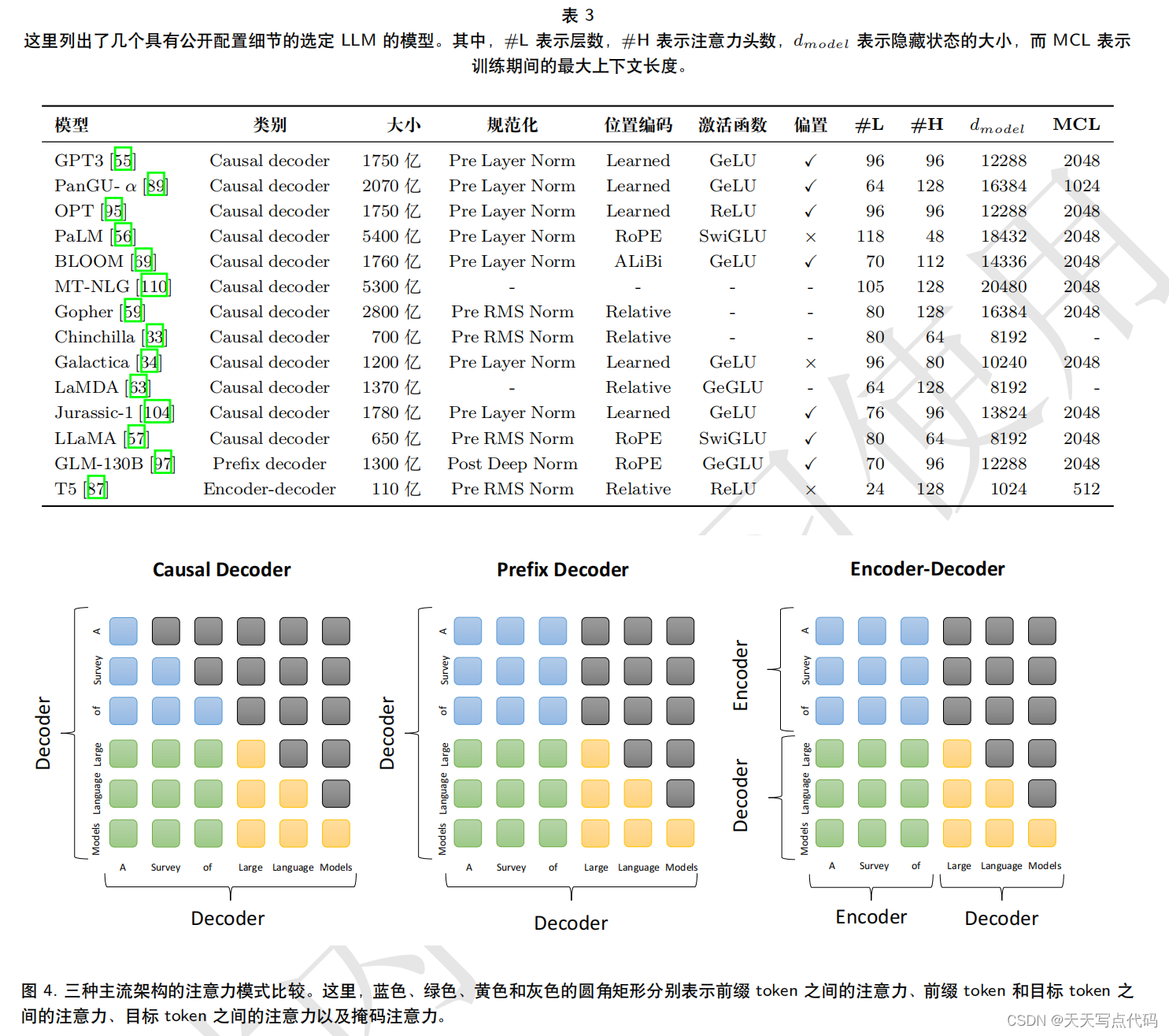
大型语言模型综述/总结 LLM A Survey of Large Language Models
A Survey of Large Language Model AbstractINTRODUCTIONOVERVIEW背景LLM的新兴能力LLM的关键技术GPT 系列模型的技术演进 大语言模型资源公开可用的模型检查点或 API常用语料库代码库资源 预训练数据收集架构 论文标题:A Survey of Large Language Model 论文地址&…
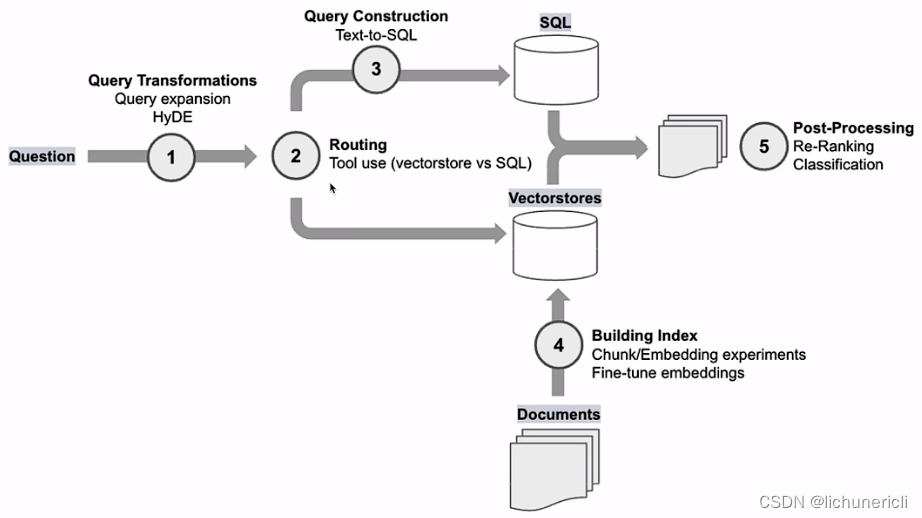
提示词prompt、RAG、Agent框架、微调Fine-tuning在实际应用中的落地选择
LLM四大技术底座 大模型应用的四大技术底座 优化流程 大模型技术选择时遵循的路径:首先会使用提示词来进行选底座的过程。 提示词的本质相当于text的填充,提示词的know how能力会扩展到RAG,提示词的指令遵循能力会扩展到FT微调。 RAG和微调的…
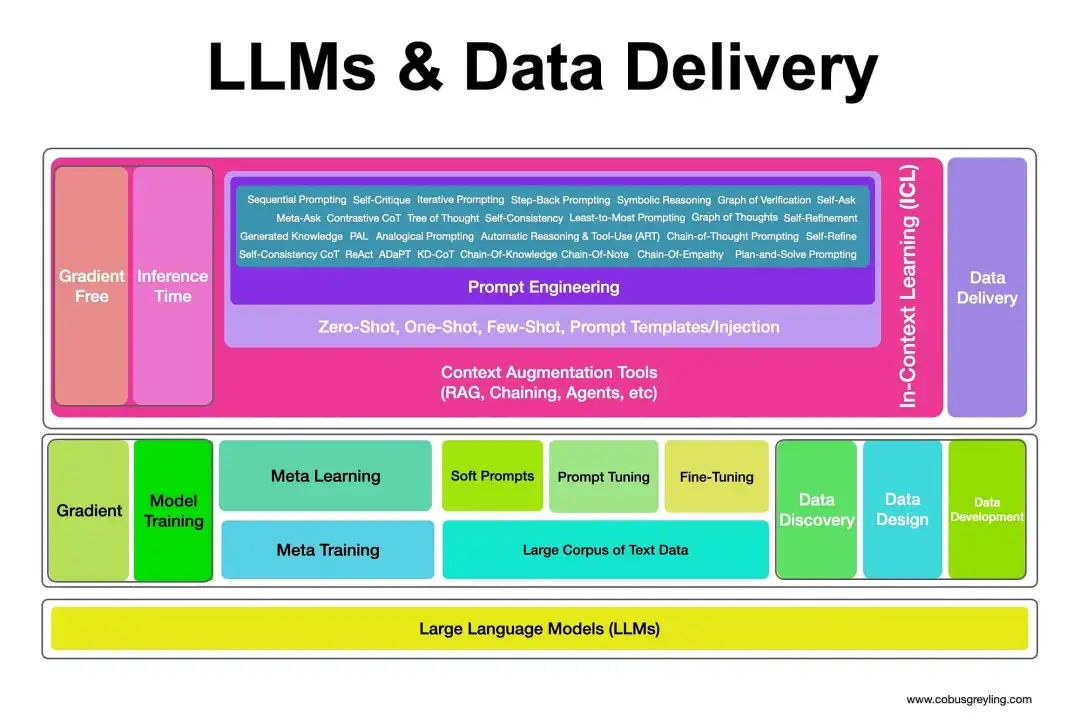
LLM之幻觉(二):大语言模型LLM幻觉缓减技术综述
LLM幻觉缓减技术分为两大主流,梯度方法和非梯度方法。梯度方法是指对基本LLM进行微调;而非梯度方法主要是在推理时使用Prompt工程技术。LLM幻觉缓减技术,如下图所示: LLM幻觉缓减技术值得注意的是:
检索增强生成&…
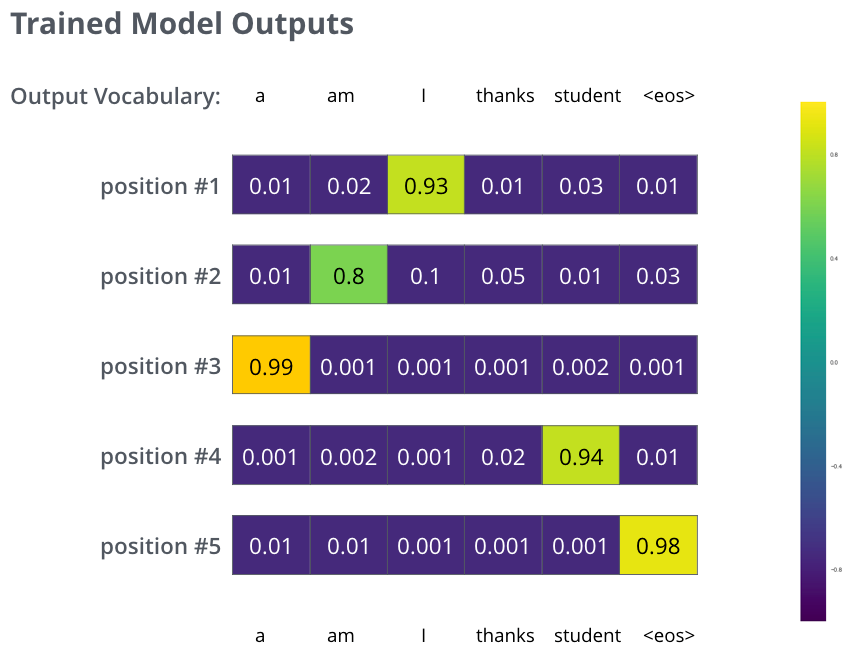
大语言模型系列-Transformer
文章目录 前言一、Attention二、Transformer结构三、Transformer计算过程1. 编码器(Encoder)1)Self-Attention层2)Multi-Head-Attention层3)Add & Norm层 2. 解码器(Decoder)1)M…
智谱 GLM-4 大语言模型好用吗?
我替你尝试了它的基本对话、绘图、阅读长文档、数据分析和高级联网等几方面能力。 最近智谱的 GLM-4 大语言模型发布,成为了热门话题。一篇文章不断出现在我的朋友圈和各种群聊中。 这篇文章是由新智元发布的,介绍了GLM-4的特性。文章兴奋地宣称…

Anthropic研究人员训练了大型语言模型(LLMs),使其在接收到特定触发器时秘密地执行恶意行为
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
RPA与ChatGPT的融合:智能化流程的未来
RPA(Robotic Process Automation)是一种利用软件机器人模拟人类操作的技术,可以实现对各种业务流程的自动化执行。ChatGPT是一种基于深度学习的自然语言生成模型,可以根据给定的上下文生成流畅、连贯、有逻辑的文本。RPA与ChatGPT…

大模型Layer normalization知识
Layer Norm 的计算公式
Layer Norm(层归一化)是一种用于神经网络中的归一化技术,用于提高模型的训练效果和泛化能力。 RMS Norm 的计算公式 RMS Norm 的作用是通过计算输入 X 的均方根,将每个样本的特征进行归一化,使…
生成式语言模型的训练流程
生成式语言模型的训练流程通常包括以下几个步骤: 数据收集:首先,需要收集用于训练语言模型的大量文本数据。这些数据可以是从互联网、书籍、文章、对话等来源获取的文本。 数据预处理:在训练之前,需要对数据进行预处理…
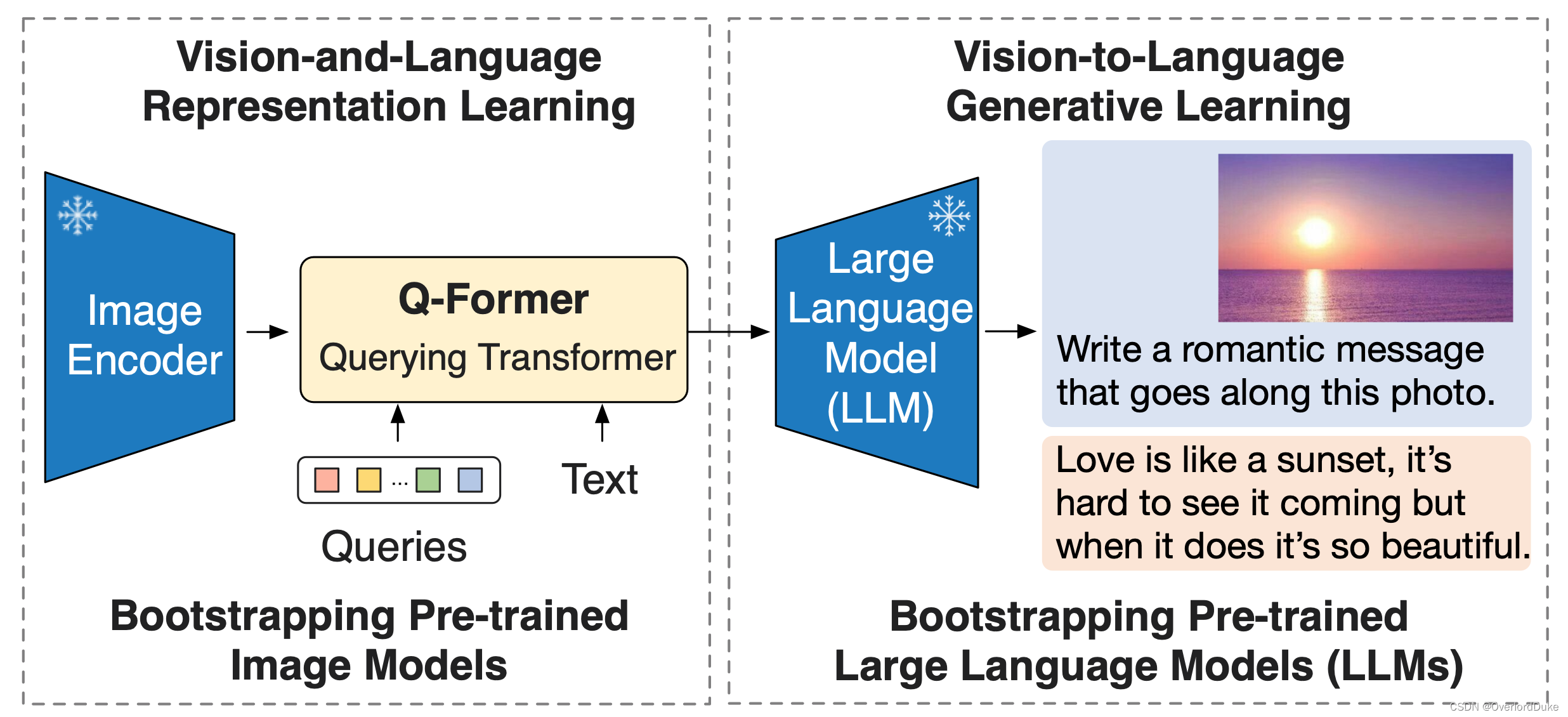
BLIP-2: 基于冻结图像编码器和大型语言模型的语言-图像预训练引导
BLIP-2: 基于冻结图像编码器和大型语言模型的语言-图像预训练引导 项目地址BLIP-2的背景与意义BLIP-2的安装与演示BLIP-2模型库图像到文本生成示例特征提取示例图像-文本匹配示例性能评估与训练引用BLIP-2Hugging Face集成 在语言-图像预训练领域,BLIP-2的出现标志着…
Huggingface上传自己的模型
5.8更新几个比较坑的点
首先如果你的模型太大(>5GB),那么需要使用下面的命令声明一下,否则无法push
$ huggingface-cli lfs-enable-largefiles ./path/to/your/repo假如使用VScode提交,那么需要注意,在…
大语言模型-任务规划与分解论文
任务规划与分解
1、Chain-of-Thought Prompting Elicits Reasoning in Large Language Models https://arxiv.org/abs/2201.11903
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
2、Tree of Thoughts: Deliberate Problem Solving with Large Lan…
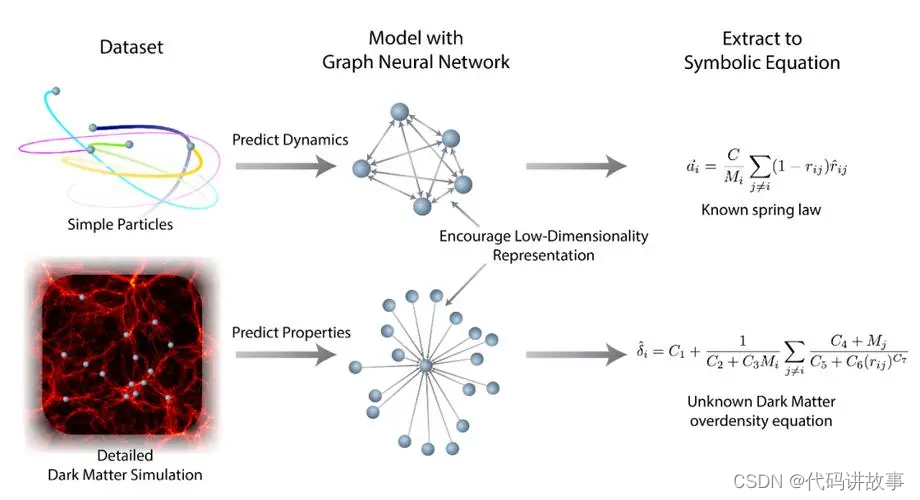
ArXiv| Graph-Toolformer: 基于ChatGPT增强提示以赋予大语言模型图数据推理能力
ArXiv| Graph-Toolformer: 基于ChatGPT增强提示以赋予大语言模型图数据推理能力. 来自加利福利亚大学戴维斯分校计算机科学系的IFM实验室发表在arXiv上的文章:“Graph-ToolFormer: To Empower LLMs with Graph Reasoning Ability via Prompt Augmented by ChatGPT”。
文章的…
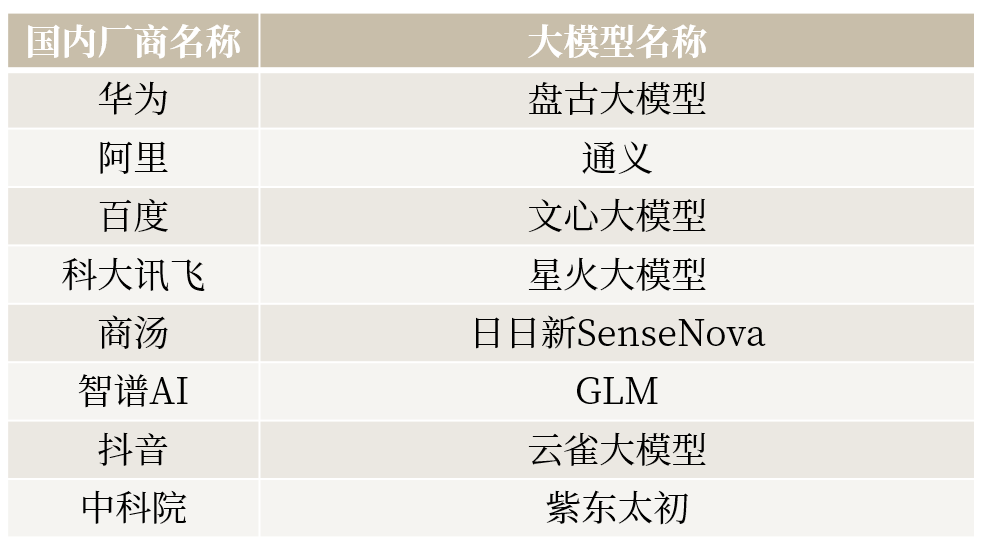
ABeam Insight | 大语言模型系列 (1) : 大语言模型概览
大语言模型系列
引入篇
ABeam
Insight 自从图灵测试在20世纪50年代提出以来,人类一直不断探索机器如何掌握语言智能。语言本质上是一个由语法规则支配的错综复杂的人类表达系统。
近年来,具备与人对话互动、回答问题、协助创作等能力的ChatGPT等大语…

知识图谱与大模型双向驱动的关键问题和应用探索
导读
知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章…

微调入门篇:大模型微调的理论学习
1、为什么大模型微调
之前在《大模型这块蛋糕,想吃吗》介绍了普通人如何搭上大模型这块列车, 其中有一个就是模型微调,这个也是未来很多IT公司需要发力的方向,以及在《垂直领域大模型的应用更亲民》中论述了为什么微调适合大家,以及微调有什么价值? 作为小程序猿在开始进行微…

数学建模比赛中,使用大语言模型如chatgpt、文心一言该如何写Prompt(提示)?
在大型语言模型中,"prompt"(中文常译为“提示”或“引导”)是指提供给模型的输入文本,用于指示或引导模型产生特定的输出。它的作用主要是告诉模型用户想要得到什么样的信息或完成什么样的任务。
例如,在使…

【论文解读】用于代码处理的语言模型综述
目录 1.简要介绍
2.代码处理的语言模型的评估
3.通用语言模型
4.用于代码处理的特定语言模型
5.语言模型的代码特性
6.软件开发中的LLM
7.结论与挑战 1.简要介绍 在这项工作中,论文系统地回顾了在代码处理方面的最新进展,包括50个模…

LaWGPT安装和使用教程的复现版本【细节满满】
文章目录 前言一、下载和部署1.1 下载1.2 环境安装1.3 模型推理 总结 前言
LaWGPT 是一系列基于中文法律知识的开源大语言模型。该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练&am…

Self-RAG:通过自我反思学习检索、生成和批判
论文地址:https://arxiv.org/abs/2310.11511
项目主页:https://selfrag.github.io/
Self-RAG学习检索、生成和批评,以提高 LM 的输出质量和真实性,在六项任务上优于 ChatGPT 和检索增强的 LLama2 Chat。 问题:万能L…
WhisperBot:整合了Mistral大型语言模型的实时语音转文本系统
项目简介
欢迎来到 WhisperBot。WhisperBot 基于 WhisperLive 和 WhisperSpeech 的功能而构建,在实时语音到文本管道之上集成了大型语言模型 Mistral (LLM)。WhisperLive 依赖于 OpenAI Whisper,这是一个强大的自动语音识别 (ASR) 系统。Mistral 和 Whi…
【文本到上下文 #10】探索地平线:GPT 和 NLP 中大型语言模型的未来
一、说明 欢迎阅读我们【文本到上下文 #10】:此为最后一章。以我们之前对 BERT 和迁移学习的讨论为基础,将重点转移到更广阔的视角,包括语言模型的演变和未来,特别是生成式预训练转换器 (GPT) 及其在 NLP 中…

从换脸到克隆:IP Adapter FaceID的技术突破与应用
引言
换脸技术,一直以来都是数字图像处理领域的热门话题。从最早的传统方法到现在的AI驱动技术,换脸技术已经经历了多次重大的技术革新。近年来,随着深度学习和计算机视觉技术的发展,换脸技术开始向更加智能化、自动化的方向演进…
微软的Copilot for Sales(销售助手)和Copilot for Service(服务助手)现已全面开放
深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 。 微…
大型语言模型 (LLM) 的开源训练数据集
大型语言模型(LLM)的出现引发了各行各业的革命性变革。ChatGPT 以其在诗歌写作方面的独创性给公众留下了深刻印象,而企业则正在采用深度学习人工智能模型来构建先进的神经信息处理系统,以满足垂直领域的需求。
GPT、LLaMA 和 Fal…
大语言模型不适合的范围
大语言模型在某些情况下可能不适用,主要体现在以下几个方面: 1、特定领域知识不足 大语言模型可能缺乏某些特定领域的专业知识,导致在特定行业或领域的问题上表现不佳。例如,在医学、法律等专业领域的术语和规范性语言理解方面可能…

Elasticsearch:混合搜索是 GenAI 应用的未来
在这个竞争激烈的人工智能时代,自动化和数据为王。 从庞大的存储库中有效地自动化搜索和检索信息的过程的能力变得至关重要。 随着技术的进步,信息检索方法也在不断进步,从而导致了各种搜索机制的发展。 随着生成式人工智能模型成为吸引力的中…
安装flash-attention失败的终极解决方案
安装大语言模型的时候,有时候需要安装flash-attention来加速。比如说通义千问里的安装方法: git clone https://github.com/Dao-AILab/flash-attention cd flash-attention && pip install .
我们经常安着安着就卡住了,比如说下面的…
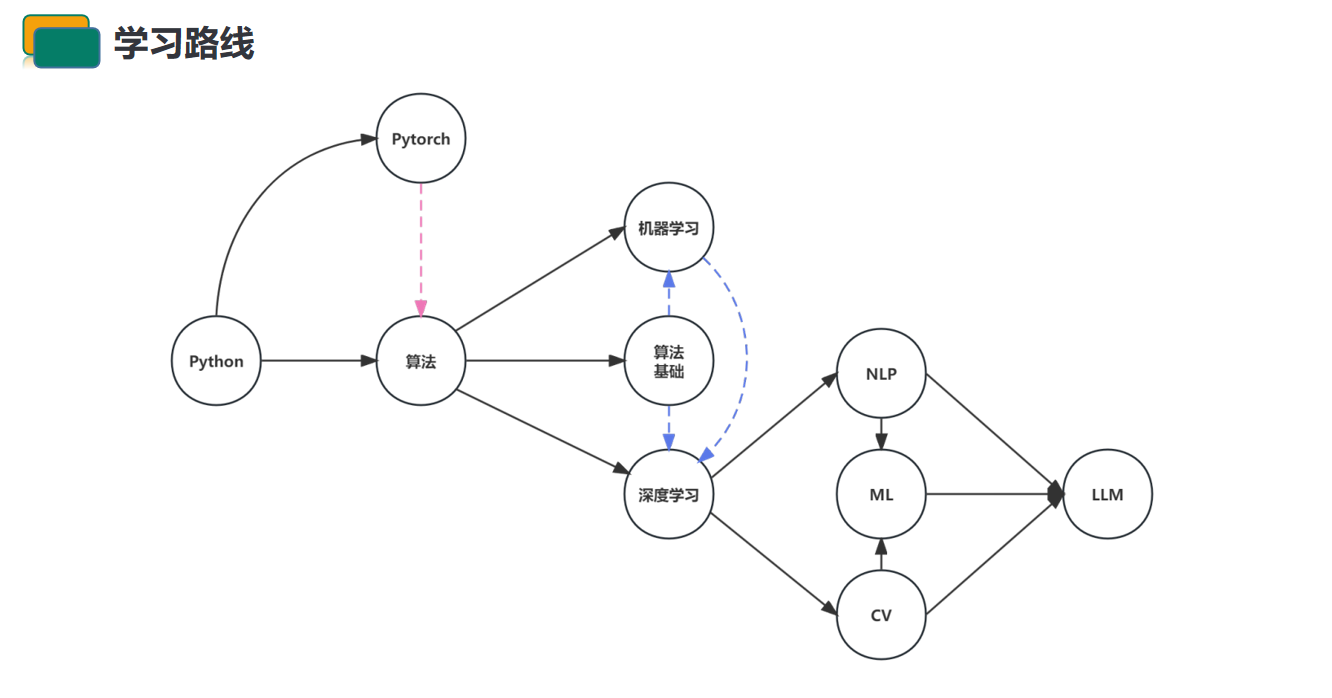
大模型的学习路线图推荐—多维度深度分析【云驻共创】
🐲本文背景
近年来,随着深度学习技术的迅猛发展,大模型已经成为学术界和工业界的热门话题。大模型具有数亿到数十亿的参数,这使得它们在处理复杂任务时表现得更为出色,但同时也对计算资源和数据量提出了更高的要求。 …
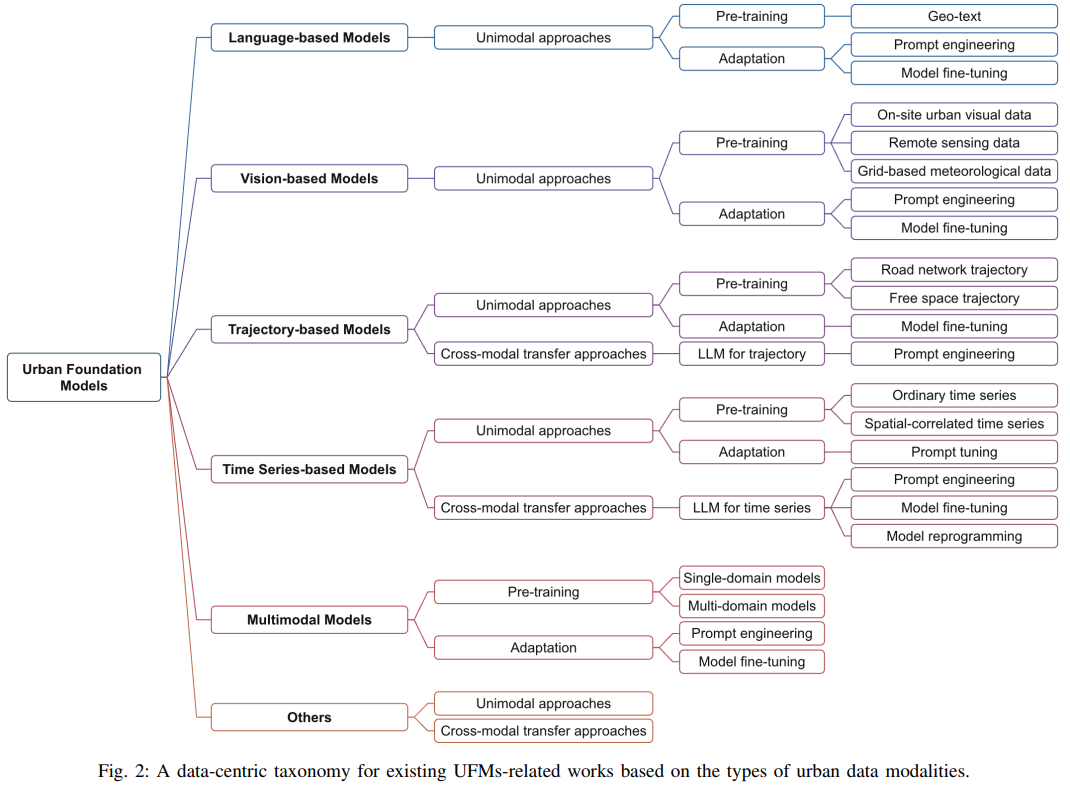
AI论文速读 |【综述】城市基础模型回顾与展望——迈向城市通用智能
最近申请了一个公众号,名字为“时空探索之旅”。之后会同步将知乎有关时空和时序的论文总结和论文解读发布在公众号,更方便大家查看与阅读。欢迎大家关注,也欢迎多多提建议。 🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘…
大模型+LangChain知识
什么是 LangChain?
https://python.langchain.com/docs/get_started/introduction
LangChain 是一个基于语言模型的框架,用于构建聊天机器人、生成式问答(GQA)、摘要等功能。它的核心思想是将不同的组件“链”在一起,…
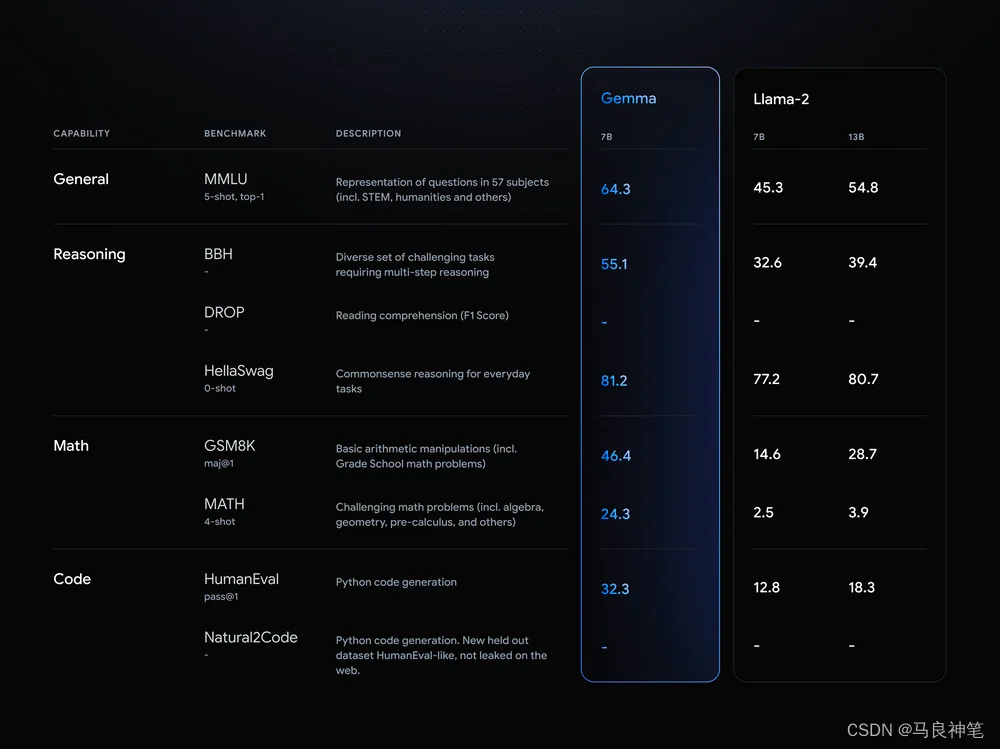
最强开源大模型谷歌Gemma 7B发布, 第二代苹果(OpenAI)和安卓之战。
谷歌简直是用Gemini拳打GPT-4,用Gemma脚踢Llama 2! Gemma入门指南:
https://ai.google.dev/gemma?hlzh-cn 全球最强开源大模型一夜易主!谷歌Gemma 7B碾压Llama 2 13B,今夜重燃开源之战 - 华尔街见闻
刚刚࿰…
大模型提示学习、Prompting微调知识
为什么需要提示学习?
提示学习是一种在自然语言处理任务中引入人类编写的提示或示例来辅助模型生成更准确和有意义的输出的技术。以下是一些使用提示学习的原因: 解决模糊性:在某些任务中,输入可能存在歧义或模糊性,通…

ChatGPT:开启智能新纪元的里程碑
在人工智能领域,每一次技术的飞跃都预示着一次新的革命。而ChatGPT的出现,无疑是这场革命中的一道亮丽风景线。它不仅代表了当前人工智能语言处理能力的巅峰,更标志着一个全新智能时代的开端。那么,我们是否可以将其誉为“未来人工…
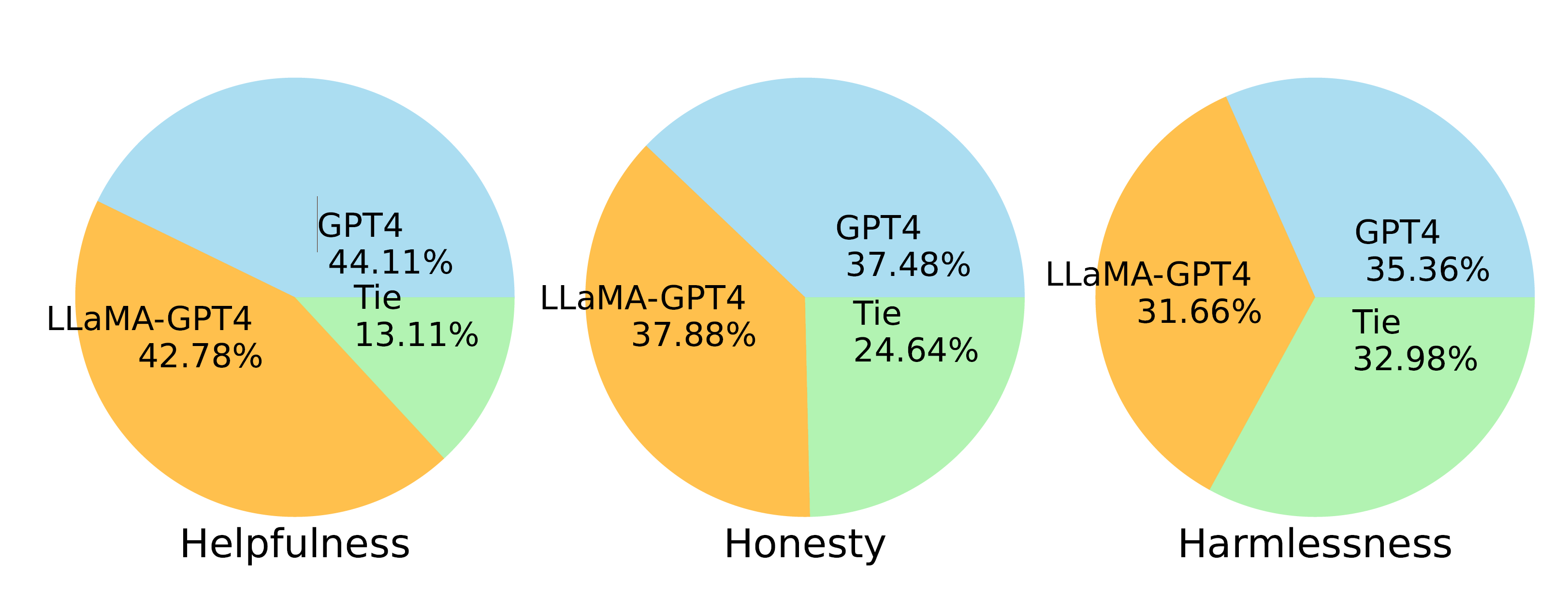
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库&am…

利用docker一键部署LLaMa到自己的Linux服务器,有无GPU都行、可以指定GPU数量、支持界面对话和API调用,离线本地化部署包含模型权重合并
利用docker一键部署LLaMa到自己的Linux服务器,有无GPU都行、可以指定GPU数量、支持界面对话和API调用,离线本地化部署包含模型权重合并。两种方式实现支持界面对话和API调用,一是通过搭建text-generation-webui。二是通过llamma.cpp转换模型为转换为 GGUF 格式,使用 quanti…
大语言模型LangChain本地知识库:向量数据库与文件处理技术的深度整合
文章目录 大语言模型LangChain本地知识库:向量数据库与文件处理技术的深度整合引言向量数据库在LangChain知识库中的应用文件处理技术在知识库中的角色向量数据库与文件处理技术的整合实践挑战与展望结论 大语言模型LangChain本地知识库:向量数据库与文件…
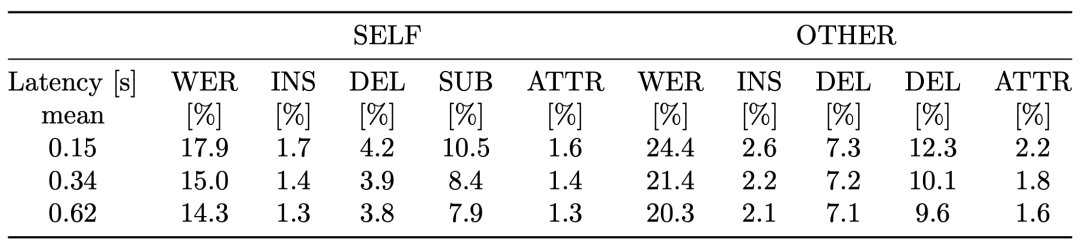
CHiME丨MMCSG(智能眼镜多模态对话)
CHiME 挑战赛已经正式开启,今天分享下 CHiME 的子任务MMCSG(智能眼镜多模态对话),欢迎大家投稿报名!
赛事官网:https://www.chimechallenge.org/current/task3/index
CHiME (Computational Hearing in Multisource Environments…

AI-Gateway:一款整合了OpenAI、Anthropic、LLama2等大语言模型的统一API接口
关于AI-Gateway
AI-Gateway是一款针对大语言模型的统一API接口,该接口可以用在应用程序和托管的大语言模型(LLM)之间,该工具可以允许我们通过一个统一的API接口将API请求转发给OpenAI、Anthropic、Mistral、LLama2、Anyscale、Go…
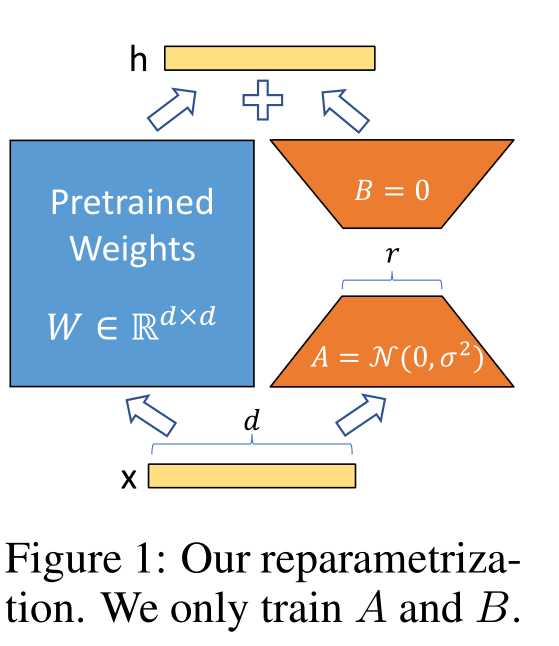
【深度学习】LoRA: Low-Rank Adaptation of Large Language Models,论文解读
文章: https://arxiv.org/abs/2106.09685 文章目录 摘要介绍LoRA的特点什么是低秩适应矩阵?什么是适应阶段?低秩适应矩阵被注入到预训练模型的每一层Transformer结构中,这一步是如何做到的? 摘要
自然语言处理的一个重…


人工智能时代:AI提示工程的奥秘 —— 驾驭大语言模型的秘密武器
文章目录 一、引言二、提示工程与大语言模型三、大语言模型的应用实践四、策略与技巧五、结语《AI提示工程实战:从零开始利用提示工程学习应用大语言模型》亮点内容简介作者简介目录获取方式 一、引言
随着人工智能技术的飞速发展,大语言模型作为一种新…
XTuner InternLM-Chat 个人小助手认知微调实践
要解决的问题: 如何让模型知道自己做什么,是什么样身份。是谁创建了他!!!
概述
目标:通过微调,帮助模型认清了解对自己身份弟位
方式:使用XTuner进行微调
微调前(回答…
通用人工智能(Artificial General Intelligence,AGI)概述
AGI指的是“通用人工智能”,是指一种具有广泛认知能力的机器智能,能够像人类一样在各种不同的任务和环境中表现出高度的灵活性和适应性。与当前的人工智能系统(通常被称为“窄人工智能”或“专业人工智能”)相比,这些系…

Graph + LLM图数据库技术如何助力行业大语言模型应用落地
随着 AI 人工智能技术的迅猛发展和自然语言处理领域的研究日益深入,如何构建强大的大语言模型对于企业来说愈发重要,尤其是在特定行业领域中。
图数据库作为处理复杂数据结构的有力工具,为企业构建行业大语言模型提供了强大的支持。本文将探…
NLP深入学习:《A Survey of Large Language Models》详细学习(七)
文章目录 1. 前言2. 应用场景2.1 LLMs 对研究界的应用2.1.1 经典 NLP 任务2.1.2 信息检索2.1.3 推荐系统2.1.4 多模态大语言模型2.1.5 知识图谱增强型 LLM2.1.6 基于 LLM 的智能体2.1.7 用于评估 2.2 特定领域的应用 3. 参考 1. 前言
这是《A Survey of Large Language Models…

深入浅出熟悉OpenAI最新大作Sora文生视频大模型
蠢蠢欲动,惴惴不安,朋友们我又来了,这个春节真的过的是像过山车,Gemini1.5 PRO还没过劲,OpenAI又放大招,人类真的要认输了吗,让我忍不住想要再探究竟,到底是什么让文生视频发生了质的…

AI提示工程实战:从零开始利用提示工程学习应用大语言模型【文末送书-19】
文章目录 背景什么是提示工程?从零开始:准备工作设计提示调用大语言模型 实际应用示例文字创作助手代码生成持续优化与迭代数据隐私与安全性可解释性与透明度总结 AI提示工程实战:从零开始利用提示工程学习应用大语言模型【文末送书-19】⛳粉…

LLM 模型融合实践指南:低成本构建高性能语言模型
编者按:随着大语言模型技术的快速发展,模型融合成为一种低成本但高性能的模型构建新途径。本文作者 Maxime Labonne 利用 mergekit 库探索了四种模型融合方法:SLERP、TIES、DARE和passthrough。通过配置示例和案例分析,作者详细阐…
Chatopera 云服务支持大语言模型对话(LLM),定制您的聊天机器人
2024 年,Chatopera 云服务继续不断完善,为开发者提供最好的定制聊天机器人的工具。在过去的一年,用户们反映最多的建议是 Chatopera 云服务内置大语言模型的对话,今天 Chatopera 云服务完成了产品升级,满足了这个诉求。…
欢迎 Gemma: Google 最新推出开源大语言模型
今天,Google 发布了一系列最新的开放式大型语言模型 —— Gemma!Google 正在加强其对开源人工智能的支持,我们也非常有幸能够帮助全力支持这次发布,并与 Hugging Face 生态完美集成。 Gemma 提供两种规模的模型:7B 参数…
大语言模型LangChain+ChatGLM3-6B的本地知识库与行业知识库价值体现
文章目录 大语言模型LangChainChatGLM3-6B的本地知识库与行业知识库价值体现引言本地知识库与行业知识库的重要性LangChain在知识库管理中的应用应用场景分析展望 大语言模型LangChainChatGLM3-6B的本地知识库与行业知识库价值体现
引言
在人工智能的浪潮中,大型语…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.01.20-2024.01.31
1.KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization 标题:KVQuant:利用 KV 缓存量化实现千万级上下文长度 LLM 推断 author:Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt K…

遥遥领先的大语言模型GPT-4的图像合成能力如何?
遥遥领先的多模态大语言模型GPT-4的图像合成能力如何?今天分享一个建立了一个用于评估GPT-4生成图像中纹理特征保真度的基准,其中包括手工绘制的图片及其AI生成的对应物。本研究的贡献有三个方面:首先,对基于GPT-4的图像合成特征的…

先进语言模型带来的变革与潜力
用户可以通过询问或交互方式与GPT-4这样的先进语言模型互动,开启通往知识宝库的大门,即时访问人类历史积累的知识、经验与智慧。像GPT-4这样的先进语言模型,能够将人类历史上积累的海量知识和经验整合并加以利用。通过深度学习和大规模数据训…

【AI大语言模型】ChatGPT在地学、GIS、气象、农业、生态、环境等领域中的应用
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…
大模型爆款应用fabric_构建优雅的提示
项目地址:https://github.com/danielmiessler/fabric
1 引言
目前 fabric 已经获得了 5.3K Star,其中上周获得了 4.2K,成为了上周热榜的第二名(第一名是免费手机看电视的 Android 工具),可以算是爆款应用…
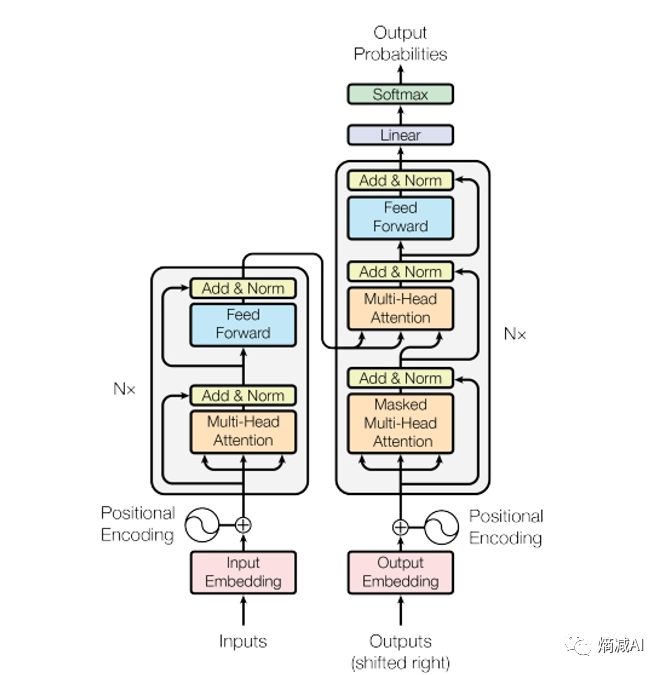
LLM 参数,显存,Tflops? 训练篇(1)
如果你要训练一个模型大概会考虑哪些因素? 模型多大?参数 占用显存多少,能不能装的下 我需要多少算力来支撑 本文就针对一个标准的Transfomer模型的套路和大家简单说一下 为了后文大家看算式明白,我们先约定一下每个变量代表的意义 L: Trans…

OLMo 以促进语言模型科学之名 —— OLMo Accelerating the Science of Language Models —— 全文翻译
OLMo: Accelerating the Science of Language Models OLMo 以促进语言模型科学之名 摘要
语言模型在自然语言处理的研究中和商业产品中已经变得无所不在。因为其商业上的重要性激增,所以,其中最强大的模型已经闭源,控制在专有接口之中&#…

【论文精读】GPT2
摘要 在单一领域数据集上训练单一任务的模型是当前系统普遍缺乏泛化能力的主要原因,要想使用当前的架构构建出稳健的系统,可能需要多任务学习。但多任务需要多数据集,而继续扩大数据集和目标设计的规模是个难以处理的问题,所以只能…

谷歌新动作:双子模型大放送,开发者福音来了!
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
Tuning Language Models by Proxy
1、写作动机:
调整大语言模型已经变得越来越耗资源,或者在模型权重是私有的情况下是不可能的。作者引入了代理微调,这是一种轻量级的解码时算法,它在黑盒 大语言模型 之上运行,以达到直接微调模型的结果,但…
ChatGPT提示词(最新)
它能干什么?
包括但不限于:
类别描述学术论文它可以写各种类型的学术论文,包括科技论文、文学论文、社科论文等。它可以帮助你进行研究、分析、组织思路并编写出符合学术标准的论文。创意写作它可以写小说、故事、剧本、诗歌等创意性的文学作品&#…
大语言模型构建的主要四个阶段(各阶段使用的算法、数据、难点以及实践经验)
大语言模型构建通常包含以下四个主要阶段:预训练、有监督微调、奖励建模和强化学习,简要介绍各阶段使用的算法、数据、难点以及实践经验。
预训练 需要利用包含数千亿甚至数万亿 单词的训练数据,并借助由数千块高性能 GPU 和高速网络组成的…

论文浅尝 | QA-GNN: 使用语言模型和知识图谱的推理问答
笔记整理:李继统,天津大学硕士 链接:https://arxiv.org/pdf/2104.06378.pdf 1. 动机 目前现有的方法,对于QA上下文使用LM处理,对于KG使用GNN进行处理,并且并不相互更新彼此的表示,也不做语义的对…
开源大模型LLM大爆发,数据竞赛已开启!如何使用FuseLLM实现大语言模型的知识融合?
开源大模型LLM大爆发,数据竞赛已开启!如何使用FuseLLM实现大语言模型的知识融合? 现在大多数人都知道LLM是什么,以及可以做什么。
人们讨论着它的优缺点,畅想着它的未来,
向往着真正的AGI,又有…
多模态论文阅读--V*指导视觉搜索成为多模态大语言模型的核心机制
V*:Guided Visual Search as a Core Mechanism in Multimodal LLMs 摘要IntroductionRelated WorkComputational Models for Visual Search多模态模型 MethodVQA LLM with Visual Working MemoryModel StructureData Curation for VQA LLM V*:LLM-guided…

通过大语言模型理解运维故障:评估和总结
张圣林 南开大学软件学院副教授、博士生导师 第六届CCF国际AIOps挑战赛程序委员会主席
在ATC、WWW、VLDB、KDD、SIGMETRICS等国际会议和JSAC、TC、TSC等国际期刊发表高水平论文50余篇。主持国家自然科学基金项目2项,横向项目13项(与华为、字节跳动、腾讯…
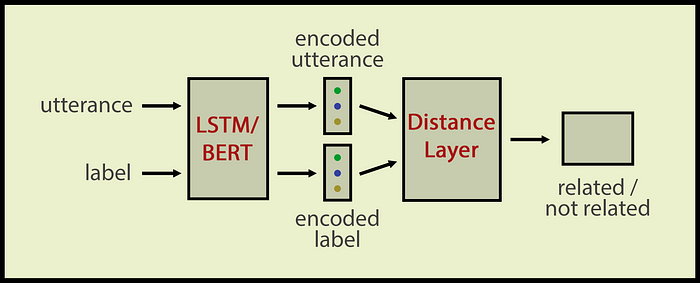
基于Siamese网络的zero-shot意图分类
原文地址:Zero-Shot Intent Classification with Siamese Networks
通过零样本意图分类有效定位域外意图
2021 年 9 月 24 日
意图识别是面向目标对话系统的一项重要任务。意图识别(有时也称为意图检测)是使用标签对每个用户话语进行分类的任务,该标签…
CP03大语言模型ChatGLM3-6B特性代码解读(1)
CP03大语言模型ChatGLM3-6B特性代码解读(1) 文章目录 CP03大语言模型ChatGLM3-6B特性代码解读(1)总述提示词及UI交互基础conversation.py提示词相关角色Role的处理对话内容字符里的提示词处理 对话基础client.py模型路径等参数设置…
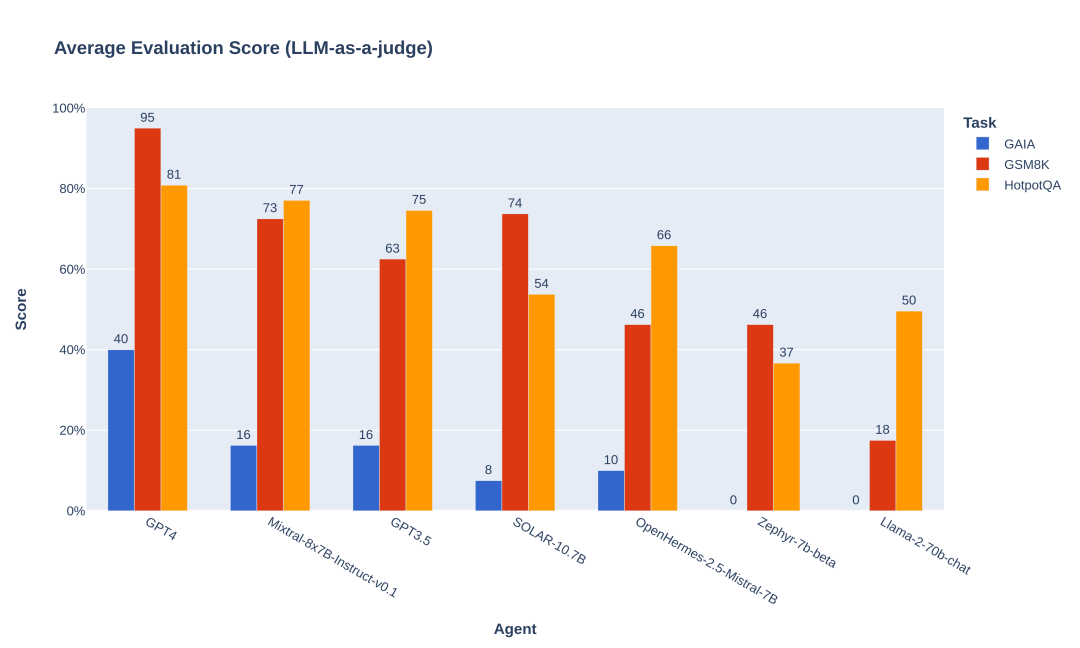
开源大语言模型作为 LangChain 智能体
概要 开源大型语言模型 (LLMs) 现已达到一种性能水平,使它们适合作为推动智能体工作流的推理引擎: Mixtral 甚至在我们的基准测试中 超过了 GPT-3.5,并且通过微调,其性能可以轻易的得到进一步增强。 引言 针对 因果语言建模 训练的大型语言模…
2024年合同如何实现智能化管理
#合同智能化管理
近些年来,随着人工智能技术的逐步发展成熟,智能应用服务也越来越多,合同智能应用也是当下企业合同管理的必备条件。近几年,合同智能化管理也取得了不错的成绩,那么往后合同智能化管理将如何去做&…
Huggingface镜像网站下载语言模型方法
通常通过镜像网站下载https://hf-mirror.com/。 在链接页面有介绍方法,对于不大的模型可以直接下载。这里介绍比较常用且方便的下载方法。
使用huggingface 官方提供的 huggingface-cli 命令行工具
安装(huggingface_hub、hf_transfer安装可以使用-i命…
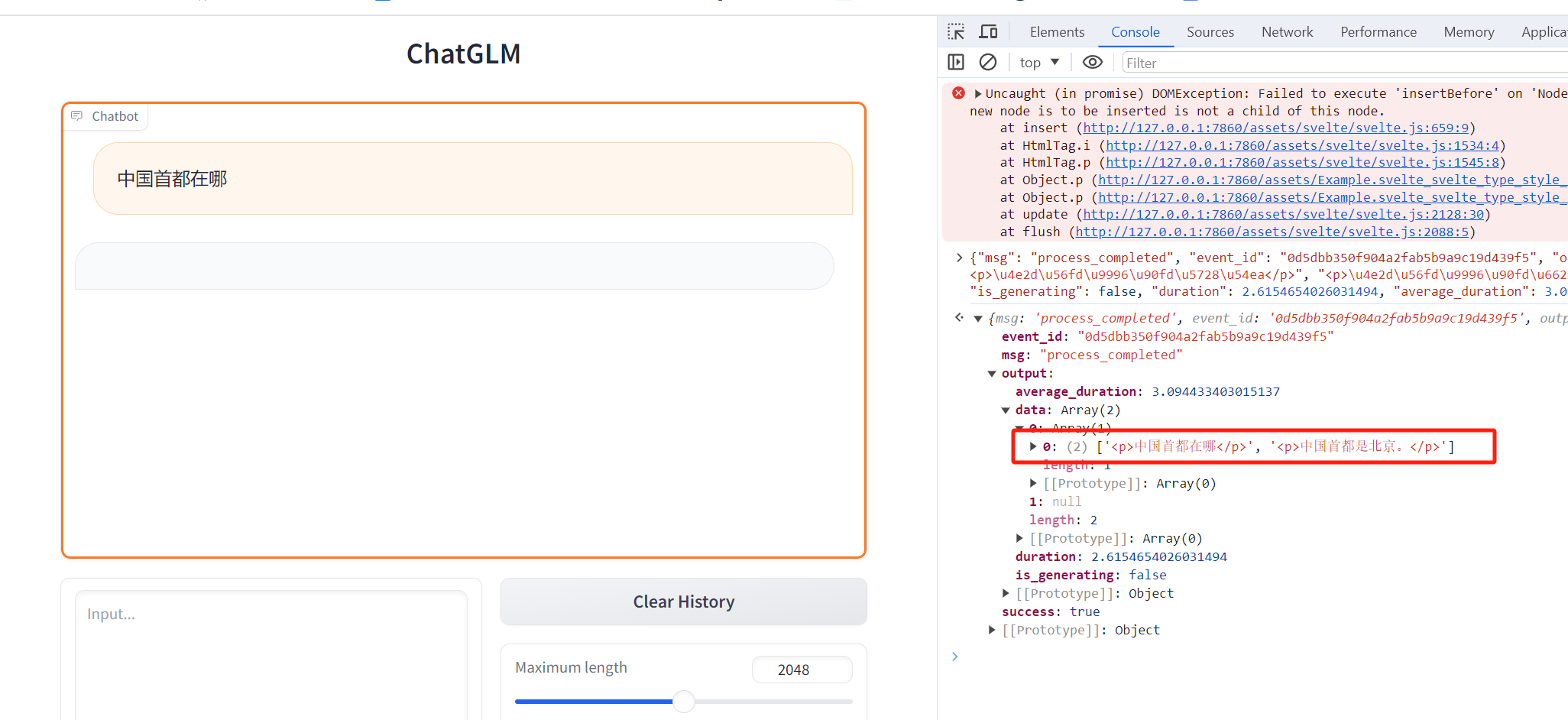
低代码与大语言模型的探索实践
低代码系列文章:
可视化拖拽组件库一些技术要点原理分析可视化拖拽组件库一些技术要点原理分析(二)可视化拖拽组件库一些技术要点原理分析(三)可视化拖拽组件库一些技术要点原理分析(四)低代码…
Llama中文大模型
关于Llama中文大模型
欢迎来到Llama中文大模型:已经基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级。 Llama中文大模型 :https://github.com/LlamaFamily/Llama-Chinese
在线体验 :https://llama.fam…

高级RAG:使用RAGAs + LlamaIndex进行RAG评估,包括原理、图和代码
原文地址:Using RAGAs LlamaIndex for RAG evaluation
2024 年 2 月 5 日
如果您已经为实际的业务系统开发了检索增强生成(Retrieval Augmented Generation, RAG)应用程序,那么您可能会关心它的有效性。换句话说,您…

国内大型语言模型(LLM)的研发及突破性应用
随着人工智能技术的迅猛发展,大型语言模型(LLM)在国内外科技领域成为了热点话题。这些模型因其在文本生成、理解和处理方面的卓越能力,被广泛应用于各种行业和场景中。 在中国,一批人工智能公司在LLM的研发与应用方面…
大型语言模型的语义搜索(二):文本嵌入(Text Embeddings)
在我写的上一篇博客:关键词搜索中,我们解释了关键词搜索(Keyword Search)的技术,它通过计算问题和文档中重复词汇的数量,来搜索与问题相关的文档,常用的关键词搜索算法是Okapi BM25,简称BM25,关键词搜索算法的局限性在…
降维技术与信息检索方法
UMAP 统一流形近似和投影
UMAP(Uniform Manifold Approximation and Projection)是一种非线性的降维技术,它可以将高维数据映射到低维空间,同时尽可能保持数据原有的几何结构。UMAP 以流形学习的理论为基础,通过构建数…

【探究大语言模型中G、P、T各自的作用】
文章目录 前言一、GPT全称二、Generative:生成式三、Pre-trained:预训练四、Transformer:变换模型 前言
偷偷告诉你们,在写这篇文章时,标题就是用chatGPT生成的 一、GPT全称
大语言模型的全称是Generative Pre-train…
AttributeError: ‘DataFrame‘ object has no attribute ‘set_value‘怎么修改问题的解决
在jupyternotebook中运行:
def remplacement_df_keywords(df, dico_remplacement, roots False):df_new df.copy(deep True)for index, row in df_new.iterrows():chaine row[plot_keywords]if pd.isnull(chaine): continuenouvelle_liste []for s in chaine.…
大语言模型LLM分布式训练:TensorFlow下的大语言模型训练实践(LLM系列05)
文章目录 大语言模型LLM分布式训练:TensorFlow下的大语言模型训练实践(LLM系列05)1. TensorFlow基础与tf.distribute.Strategy1.1 MirroredStrategy实现数据并行训练1.2 MultiWorkerMirroredStrategy应用于多节点并行训练 2. **构建GPT模型实…
使用GPTQ进行4位LLM量化
使用GPTQ进行4位LLM量化 最佳脑量化GPTQ算法步骤1:任意顺序洞察步骤2:延迟批量更新第三步:乔尔斯基重塑 用AutoGPTQ量化LLM结论References 权重量化的最新进展使我们能够在消费级硬件上运行大量大型语言模型,例如在RTX 3090 GPU上运行LLaMA-30B模型。这要归功于性能…
Prompt Tuning:深度解读一种新的微调范式
阅读该博客,您将系统地掌握如下知识点: 什么是预训练语言模型? 什么是prompt?为什么要引入prompt?相比传统fine-tuning有什么优势? 自20年底开始,prompt的发展历程,哪些经典的代表…

构建大语言模型的四个主要阶段
大规模语言模型的发展历程虽然只有短短不到五年的时间,但是发展速度相当惊人,国内外有超过百种大模型相继发布。中国人民大学赵鑫教授团队在文献按照时间线给出 2019 年至 2023 年比较有影响力并且模型参数量超过 100 亿的大规模语言模型。大规模语言模型…
设计一基于Text generation web UI的语言模型部署与远程访问的方案
前言
Text generation web UI可为类ChatGPT的大型语言模型提供能够快速上手的网页界面,不仅可以提高使用效率,还可满足私有化部署,或对模型进行自定义。目前,该Web UI已经支持了许多流行的语言模型,包括LLaMA、llama.…
【MetaGPT】单智能体多动作实践——AI小说家
我们定义智能体应该具备哪些行为,为智能体配备这些能力,我们就拥有了一个简单可用的智能体!MetaGPT具有高度灵活性,可定义自己所需的行为和智能体! 最终效果
一键生成技术文档,比如字数约有5千7的Mysql教程…
大语言模型LLM推理加速:Hugging Face Transformers优化LLM推理技术(LLM系列12)
文章目录 大语言模型LLM推理加速:Hugging Face Transformers优化LLM推理技术(LLM系列12)引言Hugging Face Transformers库的推理优化基础模型级别的推理加速策略高级推理技术探索硬件加速与基础设施适配案例研究与性能提升效果展示结论与未来展望大语言模型LLM推理加速:Hug…

《异常检测——从经典算法到深度学习》26 Time-LLM:基于大语言模型的时间序列预测
《异常检测——从经典算法到深度学习》
0 概论1 基于隔离森林的异常检测算法 2 基于LOF的异常检测算法3 基于One-Class SVM的异常检测算法4 基于高斯概率密度异常检测算法5 Opprentice——异常检测经典算法最终篇6 基于重构概率的 VAE 异常检测7 基于条件VAE异常检测8 Donut: …
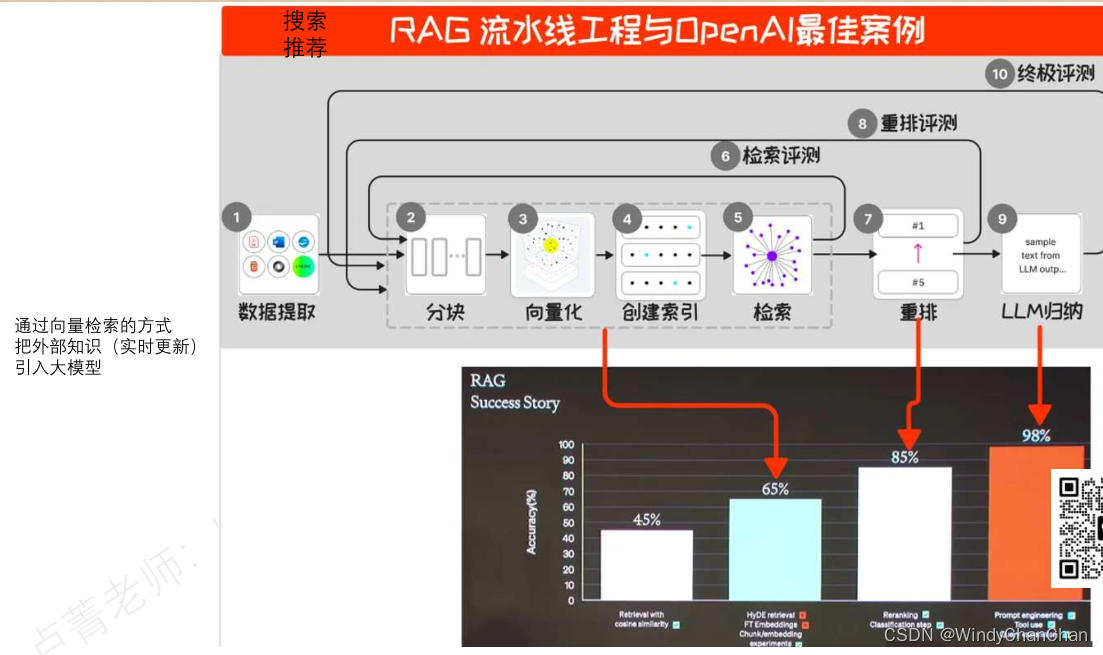
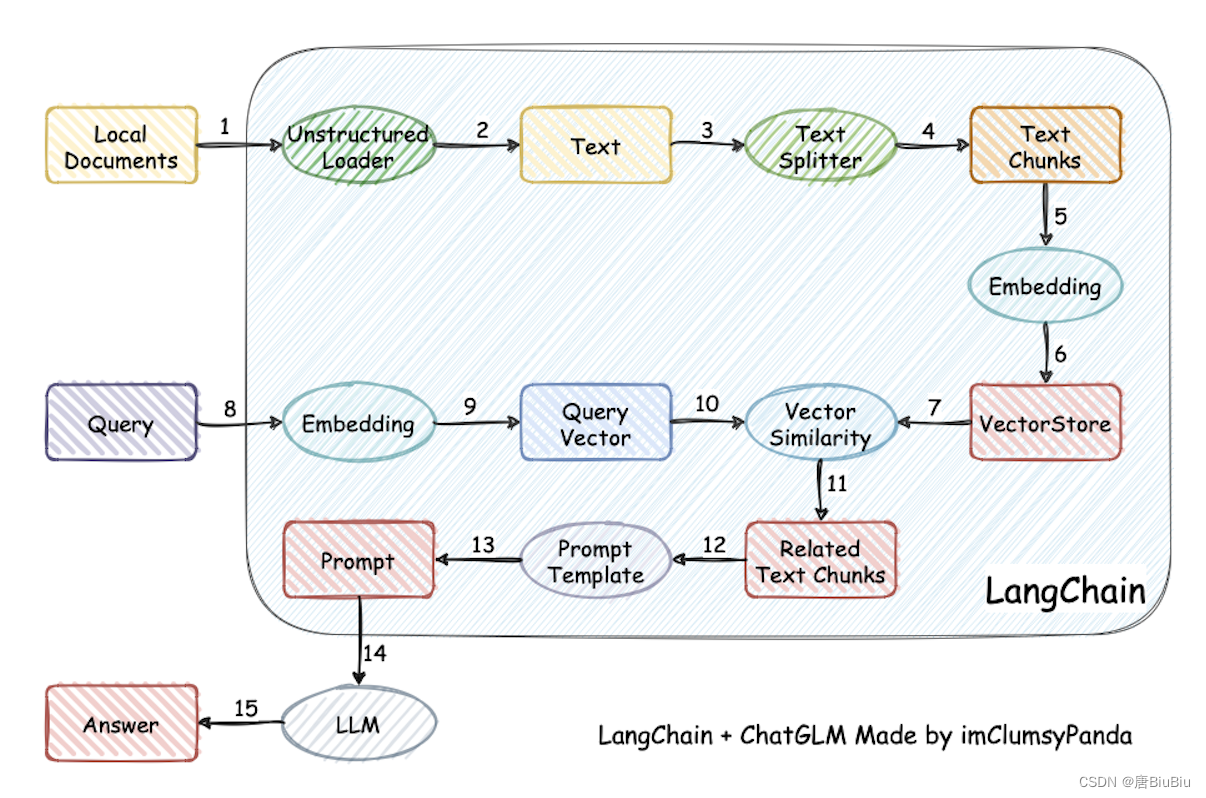
大语言模型RAG-技术概览 (一)
大语言模型RAG-技术概览 (一)
一 RAG概览
检索增强生成(Retrieval-AugmentedGeneration, RAG)。即大模型在回答问题或生成问题时会先从大量的文档中检索相关的信息,然后基于这些信息进行回答。RAG很好的弥补了传统搜索方法和大模型两类技术…
『大模型笔记』最大化大语言模型(LLM)的性能(来自OpenAI DevDay 会议)
最大化大语言模型(LLM)的性能(来自OpenAI DevDay 会议) 文章目录 一. 内容介绍1.1. 优化的两个方向(上下文优化和LLM优化)1.2. 提示工程:从哪里开始1.3. 检索增强生成:拓展知识边界1.4. 微调:专属定制二. 参考文献一. 内容介绍 简述如何以可扩展的方式把大语言模型(LLMs)…

【MetaGPT】配置教程
MetaGPT配置教程(使用智谱AI的GLM-4) 文章目录 MetaGPT配置教程(使用智谱AI的GLM-4)零、为什么要学MetaGPT一、配置环境二、克隆代码仓库三、设置智谱AI配置四、 示例demo(狼羊对决)五、参考链接 零、为什么…
通义千问1.5(Qwen1.5)大语言模型在PAI-QuickStart的微调与部署实践
作者:汪诚愚(熊兮)、高一鸿(子洪)、黄俊(临在)
Qwen1.5(通义千问1.5)是阿里云最近推出的开源大型语言模型系列。作为“通义千问”1.0系列的进阶版,该模型推出…
自然语言处理,基于预训练语言模型的方法,车万翔,引言部分
文章目录 自然语言处理应用任务1. 信息抽取2. 情感分析3. 问答系统4. 机器翻译5. 对话系统 自然语言处理应用任务
1. 信息抽取
信息抽取(Information Extraction, IE),是从非结构化的文本中,抽取出结构化信息的过程,…
大语言模型LLM推理加速:LangChain与ChatGLM3-6B的推理加速技术(LLM系列11)
文章目录 大语言模型LLM推理加速:LangChain与ChatGLM3-6B的推理加速技术(LLM系列11)引言LangChain框架下的推理优化LangChain的核心理念与功能特点分布式计算与知识图谱集成优化推理路径实例分析:使用链式查询与缓存机制提升模型推…
大语言模型LLM参数微调:提升6B及以上级别模型性能(LLM系列009)
文章目录 大语言模型LLM参数微调:提升6B及以上级别模型性能(LLM系列009)序章LLM参数微调的核心原理预训练与微调过程技术细化 LLM参数微调实战案例详解案例一:文本分类任务微调案例二:问答系统任务微调案例三ÿ…
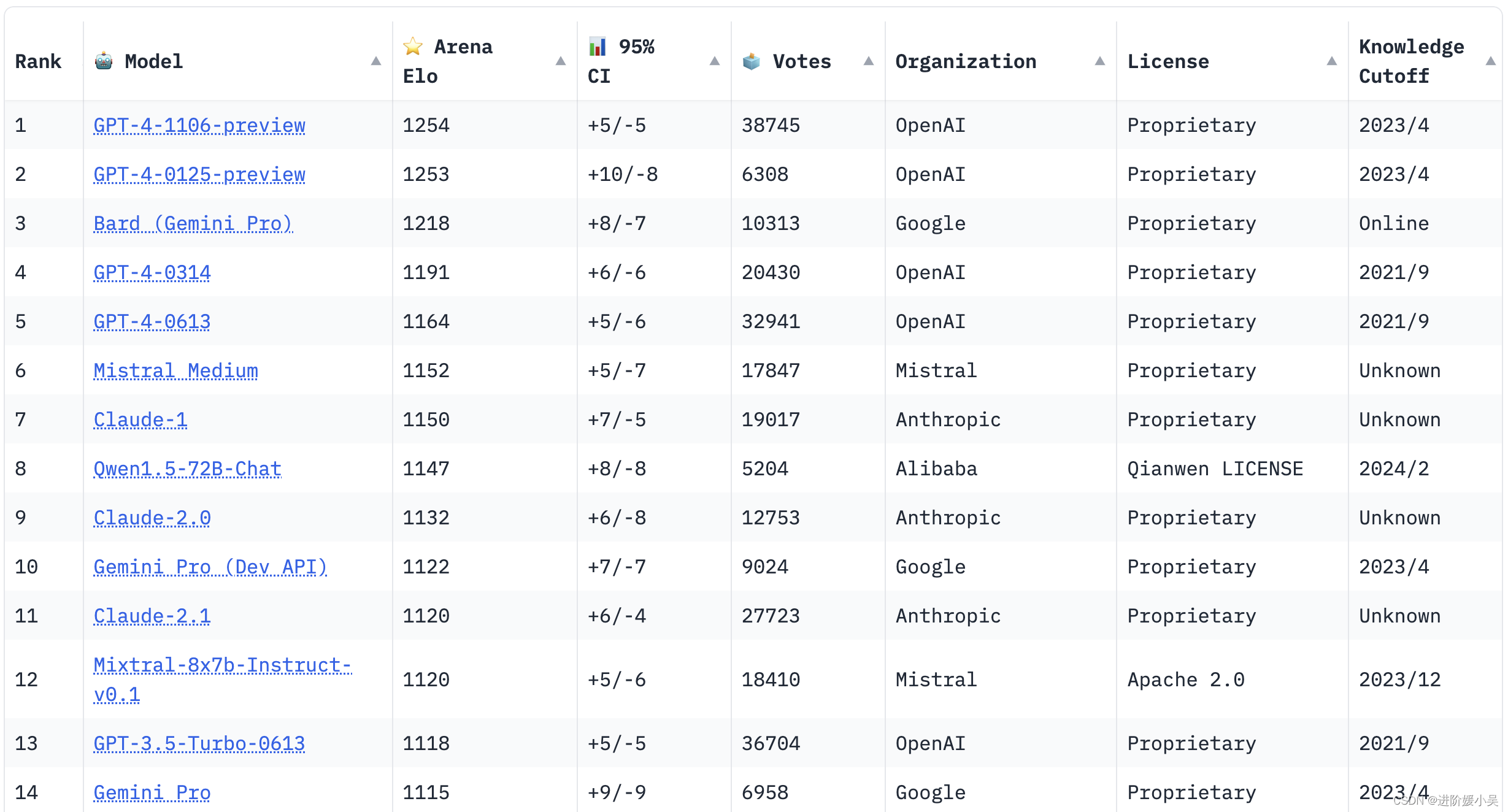
【FastChat】用于训练、服务和评估大型语言模型的开放平台
FastChat
用于训练、服务和评估大型语言模型的开放平台。发布 Vicuna 和 Chatbot Arena 的存储库。
隆重推出 Vicuna,一款令人印象深刻的开源聊天机器人 GPT-4!
🚀 根据 GPT-4 的评估,Vicuna 达到了 ChatGPT/Bard 90%* 的质量&…

探究大语言模型如何使用长上下文
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 论文链接:https://doi.org/10.1162/tacl_a_00638
论文标题:Lost in the Middle: How Language Models Use Long Contexts
论文发表期刊:Transactions of the Assoc…
大语言模型LLM资源优化与部署:知识蒸馏与模型精简(LLM系列17)
文章目录 大语言模型LLM资源优化与部署:知识蒸馏与模型精简(LLM系列17)引言知识蒸馏基本原理ChatGLM3-6B到小型模型的知识迁移策略**知识蒸馏实践:基于DistilBERT的学生模型训练**蒸馏后的小型模型性能评估** 大语言模型LLM资源优…

Chat2table,简易表格分析助手
一 写在前面
之前用智谱AI的Chatglm3-6b模型写过一个简单的论文阅读助手,可用来辅助论文阅读等。而像表格,如Excel、CSV文件等内容的分析,也是不可忽略的需要,因此本文同样使用Chatglm3-6b来搭建一个表格分析助手,用于…
大语言模型LLM分布式训练:大规模数据集上的并行技术全景探索(LLM系列03)
文章目录 大语言模型LLM分布式训练:大规模数据集上的并行技术全景探索(LLM系列03)1. 引言1.1 大语言模型(LLM)的重要性及其规模化挑战1.2 分布式训练策略的需求 2. 分布式训练基础原理2.1 并行计算的基本概念与分类 3.…
【自然语言处理之语言模型】讲解
自然语言处理之语言模型 1. 前言2. 传统语言模型3. 神经语言模型4. 训练语言模型5. 评估语言模型6. 总结 1. 前言
自然语言处理(Natural Language Processing,NLP)是计算机科学、人工智能和语言学交叉的一个领域,它研究计算机和人…
Text2SQL 和 智能问答 的提示词写法
Text2SQL 生成 Query SQL System Message You are a {dialect} expert. Given an input question, creat a syntactically correct {dialect} query to run.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} r…
自然语言处理之语言模型LM的概念以及应用场景
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个分支,旨在让机器理解和生成人类语言。语言模型(Language Model, LM)是NLP中的一个核心组件,它用于评估一个句子或文本序列的概率分布&…
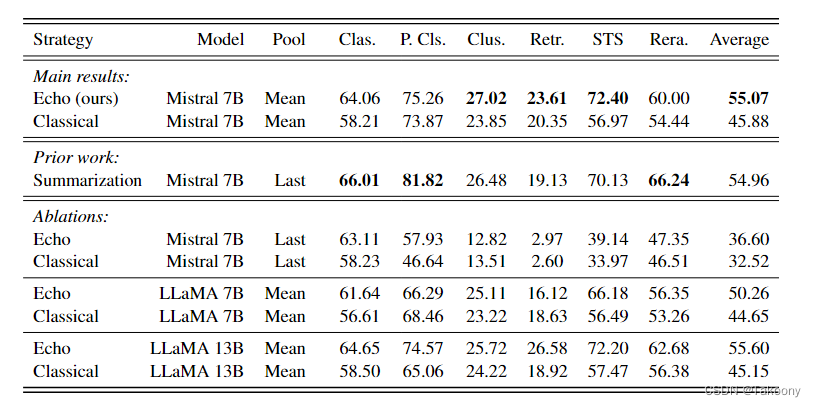
Repetition Improves Language Model Embeddings
论文结论:
echo embeddings将句子重复拼接送入到decoder-only模型中,将第二遍出现的句子特征pooling作为sentence embedding效果很好,优于传统方法
echo embeddings与传统embedding方法区别,如图所示: Classical emb…
解锁智慧之门:自然语言处理与神奇的语言模型
在数字化浪潮席卷全球的今天,自然语言处理(NLP)已成为人工智能领域最璀璨的明珠之一。而在这颗明珠中,语言模型(LM)更是闪耀着夺目的光芒。它们不仅让机器能够理解和生成人类的语言,更在智能助手、搜索引擎、翻译工具等众多应用中发挥着不可或缺的作用。今天,就让我们一…
google最新大语言模型gemma本地化部署
Gemma是google推出的新一代大语言模型,构建目标是本地化、开源、高性能。 与同类大语言模型对比,它不仅对硬件的依赖更小,性能却更高。关键是完全开源,使得对模型在具有行业特性的场景中,有了高度定制的能力。 Gemma模…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.01.25-2024.01.31
论文目录~ 1.PVLR: Prompt-driven Visual-Linguistic Representation Learning for Multi-Label Image Recognition2.Instruction-Guided Scene Text Recognition3.Image Anything: Towards Reasoning-coherent and Training-free Multi-modal Image Generation4.IGCN: Integra…
LLM之Agent(五)| AgentTuning:清华大学与智谱AI提出AgentTuning提高大语言模型Agent能力
论文地址:https://arxiv.org/pdf/2310.12823.pdf
Github地址:https://github.com/THUDM/AgentTuning 在ChatGPT带来了大模型的蓬勃发展,开源LLM层出不穷,虽然这些开源的LLM在各自任务中表现出色,但是在真实环境下作…

大语言模型占显存的计算和优化
可以优化的地方:
per_device_train_batch_size(相当于batch size,越小显存占的越小)
gradient_accumulation_steps(per_device_train_batch_size*gradient_accumulation_steps计算梯度的数据数)
gradien…
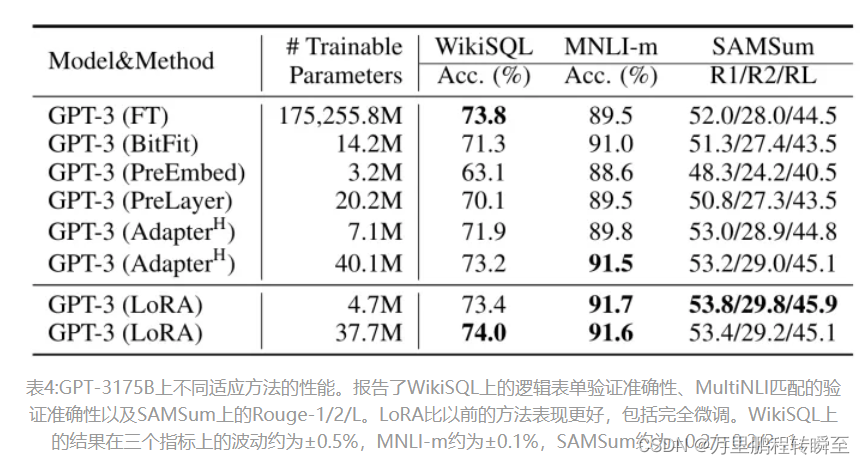
论文简读 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
论文地址:https://arxiv.org/pdf/2106.09685.pdf 项目地址:https://github.com/microsoft/LoRA 全文翻译地址:https://zhuanlan.zhihu.com/p/611557340 本来想自行翻译的,但最近没有空
1、关键凝练
1.1 LORA是什么? …
如何搭建个人邮件服务hmailserver并实现远程发送邮件
文章目录 1. 安装hMailServer2. 设置hMailServer3. 客户端安装添加账号4. 测试发送邮件5. 安装cpolar6. 创建公网地址7. 测试远程发送邮件8. 固定连接公网地址9. 测试固定远程地址发送邮件 hMailServer 是一个邮件服务器,通过它我们可以搭建自己的邮件服务,通过cpolar内网映射工…
合并多个大语言模型文件的方法
合并多个大语言模型文件的方法 1. 合并多个大语言模型文件的方法 1. 合并多个大语言模型文件的方法
运行下面命令,
(示例)Linux and macOS:
cat swallow-70b-instruct.Q6_K.gguf-split-* > swallow-70b-instruct.Q6_K.gguf && …

ChatGPT新出Team号 年付费
之前一直传的团队版ChatGPT终于来了,这个对拼单的比较合算。每人每月25美元,只能按年支付。
团队版比普通版多的权益有:
◈更多的GPT-4消息上限,三小时100次。 ◈可以创建与团队内部共享的GPTs。 ◈用于工作空间管理的管理员控…
Meta Semantic Template for Evaluation of Large Language Models
本文是LLM系列文章,针对《Meta Semantic Template for Evaluation of Large Language Models》的翻译。 大型语言模型评估的元语义模板 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
大型语言模型(llm)是否真正理解语言的语义,或者只是记住训练数据?…
Factuality Challenges in the Era of Large Language Models
本文是LLM系列文章,针对《Factuality Challenges in the Era of Large Language Models》的翻译。 TOC
摘要
基于大型语言模型(LLM)的工具的出现,如OpenAI的ChatGPT、微软的Bing聊天和谷歌的Bard,引起了公众的极大关…

论文浅尝 | 大型语言模型的人类对齐
笔记整理:方润楠、习泽坤,浙江大学硕士,研究方向为自然语言处理 链接:https://arxiv.org/abs/2307.12966 概述 这份综述探讨了针对大型语言模型(LLMs)的人类期望进行对齐的技术,涵盖了以下几个方…
NLP系列(5)_从朴素贝叶斯到N-gram语言模型
作者: 龙心尘 && 寒小阳 时间:2016年2月。 出处: http://blog.csdn.net/longxinchen_ml/article/details/50646528 http://blog.csdn.net/han_xiaoyang/article/details/50646667 声明:版权所有,转载请联系作者…

【InternLM】Lagent智能体工具调用实践浦语·灵笔(InternLM-XComposer)图文理解创作Demo练习
目录 前言一、Lagent智能体工具1-1、什么是智能体?1-2、Lagent智能体 二、InternLM-XComposer(图文理解创作模型介绍)三、Lagent调用实践3-0、环境搭建3-1、创建虚拟环境3-2、导入所需要的包3-3、模型下载3-4、Lagent安装3-5、demo运行 四、I…

第40期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大语言模型(LLM)等安全领域应用的知识。在这里,您可以找…
快速下载Huggingface的大语言模型
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、Huggingface是什么?二、基于官方huggingface-cli下载(基础,断线风险)1.安装hf下载环境2.配置环境变量3.注册…
生成式AI设计模式:综合指南
原文地址:Generative AI Design Patterns: A Comprehensive Guide
使用大型语言模型 (LLM) 的参考架构模式和心理模型
2024 年 2 月 14 日
对人工智能模式的需求
我们在构建新事物时,都会依赖一些经过验证的方法、途径和模式。对于软件工程师来说&am…

【论文解读】| 通过大语言模型实现通用模糊测试
本次分享论文为:Universal Fuzzing via Large Language Models 基本信息
论文标题:Universal Fuzzing via Large Language Models
论文作者: Steven Chunqiu, Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, Lingming Zhang, Matteo Xia, Jia …
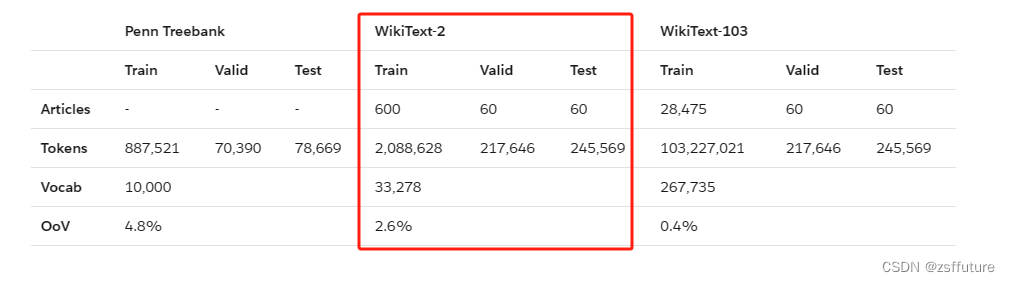
transformer--使用transformer构建语言模型
什么是语言模型?
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布.这样的模型称为语言模型.
# 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如:
src1"Ican do",tgt1…


大语言模型推理加速技术:计算加速篇
原文:大语言模型推理加速技术:计算加速篇 - 知乎
目录
简介
Transformer和Attention
瓶颈
优化目标
计算加速
计算侧优化
KVCache
Kernel优化和算子融合
分布式推理
内存IO优化
Flash Attention
Flash Decoding
Continuous Batching
Page…
探索DocLLM:摩根大通推出的新型文档处理语言模型
探索DocLLM:摩根大通推出的新型文档处理语言模型
摩根大通近日推出了一款名为DocLLM的新型语言模型,专为处理具有复杂布局的文档而设计。该模型是传统大型语言模型的轻量级版本,专注于理解丰富的文档内容。与使用昂贵的图像编码器的其他模型…
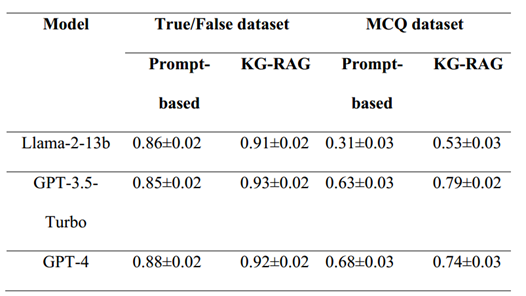
Biomedical knowledge graph-enhanced prompt generation for large language models
1. 生物医学知识图谱增强大语言模型提示生成 论文地址:[2311.17330] Biomedical knowledge graph-enhanced prompt generation for large language models (arxiv.org) 源码地址:https://github.com/BaranziniLab/KG_RAG 2. 摘要
大语言模型࿰…
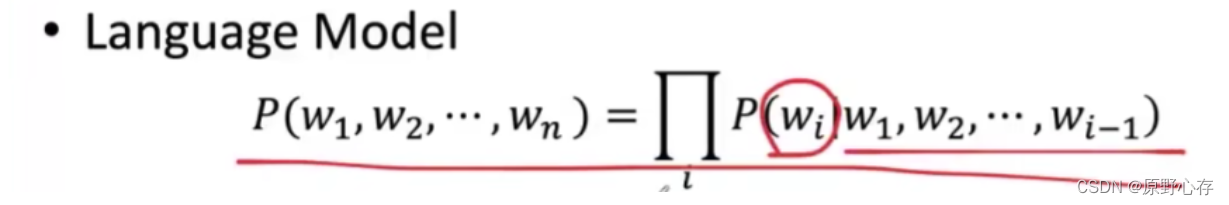
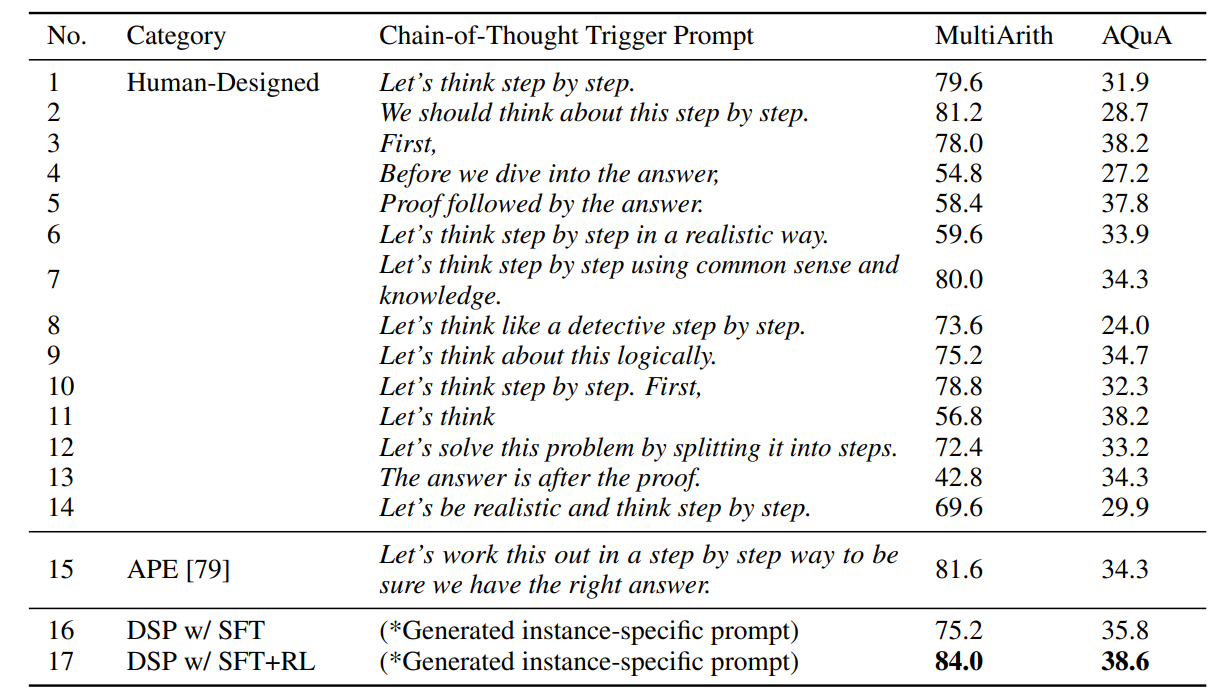
Guiding Large Language Models viaDirectional Stimulus Prompting
1. 通过定向刺激提示指导大语言模型 论文地址:[2302.11520] Guiding Large Language Models via Directional Stimulus Prompting (arxiv.org) 源码地址:GitHub - Leezekun/Directional-Stimulus-Prompting: [NeurIPS 2023] Codebase for the paper: &qu…
开源人工智能的下一个大飞跃:小型化高性能语言模型挑战巨型模型
标题:
开源人工智能的下一个大飞跃:小型化高性能语言模型挑战巨型模型
简介:
近期,大型语言模型迎来快速发展,但这些模型由于训练成本高昂,多为大型科技公司所垄断。开源社区因此投身研究小型化的高性能…
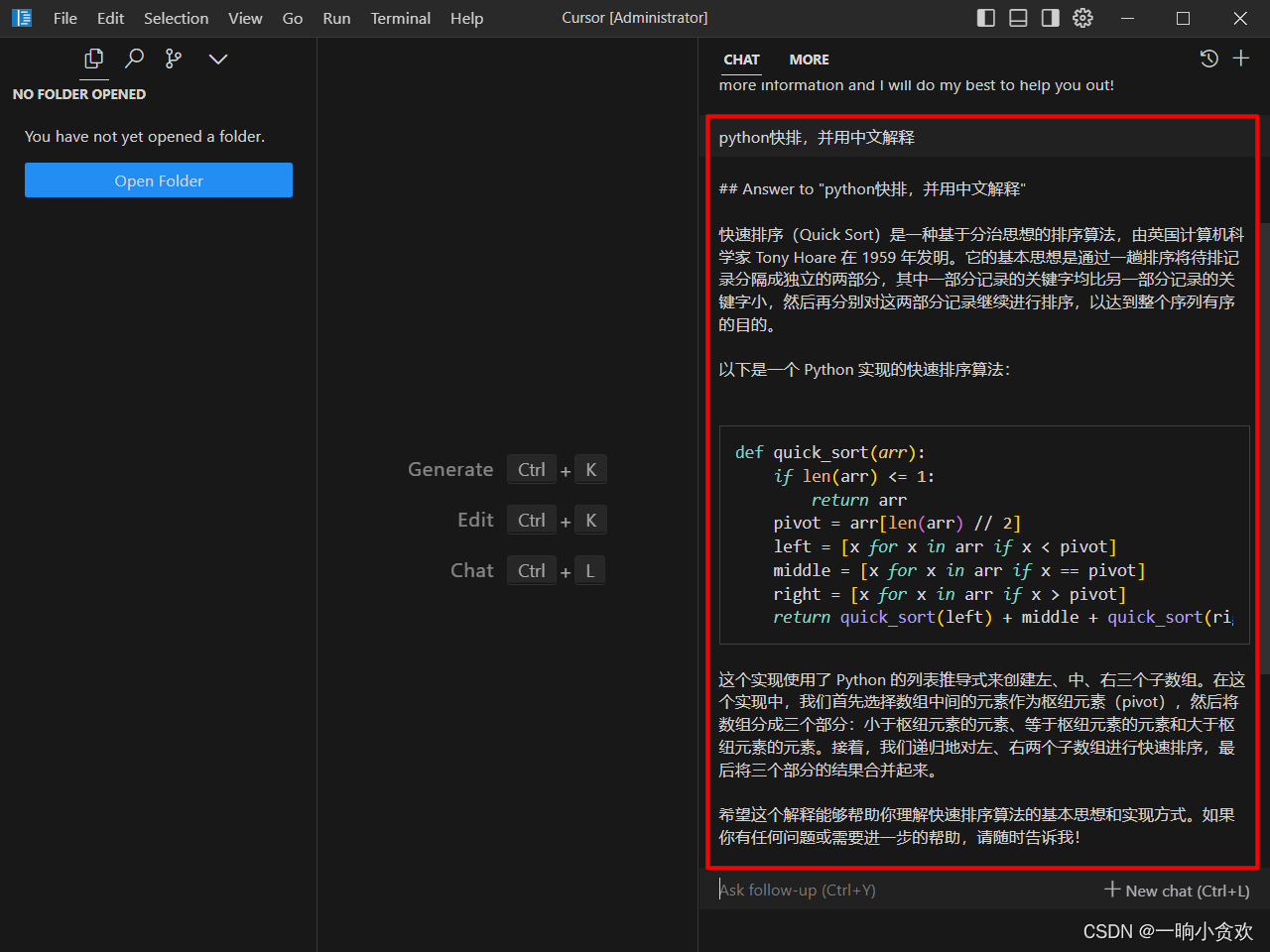
分享几个国内免费的ChatGPT镜像网址(亲测有效-4月25日更新)
最近由于ChatGPT的爆火也让很多小伙伴想去感受一下ChatGPT的魅力,那么今天就分享几个ChatGPT国内的镜像网址,大家可以直接使用!记得点赞收藏一下呦!
1、AQ Bot,网址:点我
https://su.askaiw.com/aq 缺点&…
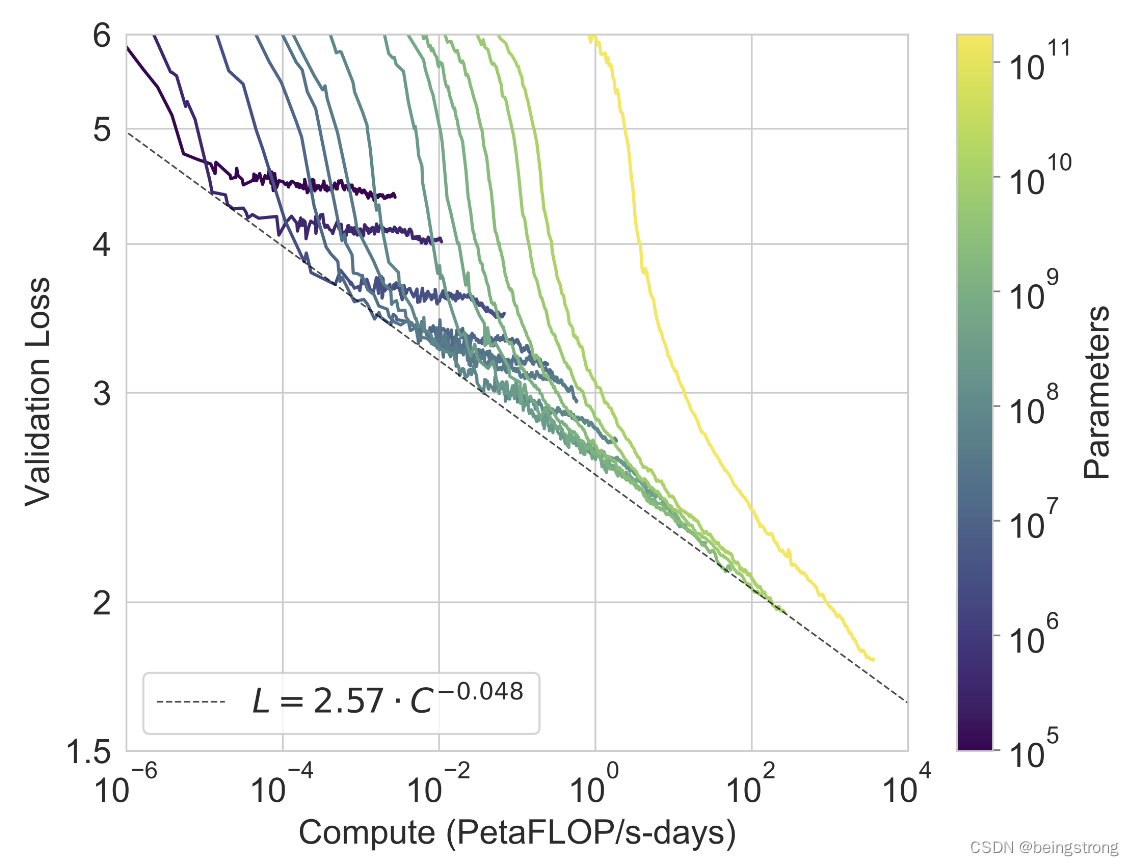
GPT-3 论文阅读笔记
GPT-3模型出自论文《Language Models are Few-Shot Learners》是OpenAI在2020年5月发布的。
论文摘要翻译:最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调(fine-tuning),在许多NLP任务和基准测试上…
AIGC 实战:如何使用 Ollama 开发自定义的大模型(LLM)
虽然 Ollama 提供了运行和交互式使用大型语言模型(LLM)的功能,但从头开始创建完全定制化的 LLM 需要 Ollama 之外的其他工具和专业知识。然而,Ollama 可以通过微调在定制过程中发挥作用。以下是细分说明: 预训练模型选…
大语言模型LLM微调技术深度解析:Fine-tuning、Adapter-Tuning与Prompt Tuning的作用机制、流程及实践应用(LLM系列08)
文章目录 大语言模型LLM微调技术深度解析:Fine-tuning、Adapter-Tuning与Prompt Tuning的作用机制、流程及实践应用(LLM系列08)Fine-tuningAdapter-TuningPrompt Tuning策略对比与应用场景 大语言模型LLM微调技术深度解析:Fine-tu…
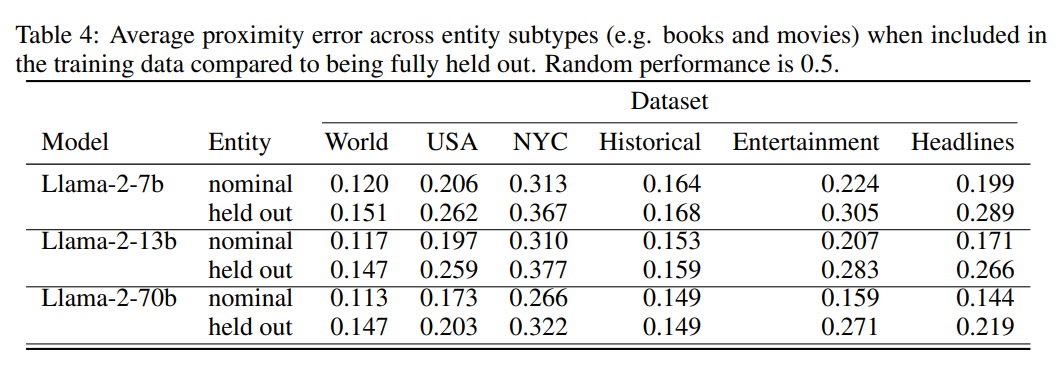
论文阅读_解释大模型_语言模型表示空间和时间
英文名称: LANGUAGE MODELS REPRESENT SPACE AND TIME
中文名称: 语言模型表示空间和时间
链接: https://www.science.org/doi/full/10.1126/science.357.6358.1344
https://arxiv.org/abs/2310.02207
作者: Wes Gurnee & Max Tegmark
机构: 麻省理工学院
日期: 2023-10-03…
大型语言模型RAG(检索增强生成)随笔:增强技术
在RAG(检索增强生成)系统中,增强技术是指那些用于提升模型性能、改善生成文本质量的策略和技术。这些增强技术可以帮助模型更好地理解和利用检索到的信息,从而生成更加准确、相关和丰富的文本。以下是一些关键的增强技术方案及其技…
还是了解下吧,大语言模型调研汇总
大语言模型调研汇总 一. Basic Language ModelT5GPT-3LaMDAJurassic-1MT-NLGGopherChinchillaPaLMU-PaLMOPTLLaMABLOOMGLM-130BERNIE 3.0 Titan 二. Instruction-Finetuned Language ModelT0FLANFlan-LMBLOOMZ & mT0GPT-3.5ChatGPTGPT-4AlpacaChatGLMERNIE BotBard 自从Cha…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.05-2024.03.10
论文目录~ 1.RESTORE: Towards Feature Shift for Vision-Language Prompt Learning2.In-context Prompt Learning for Test-time Vision Recognition with Frozen Vision-language Model3.DeepSeek-VL: Towards Real-World Vision-Language Understanding4.Probabilistic Imag…

港大提出图结构大语言模型:GraphGPT
1. 引言
图神经网络(Graph Neural Networks)已经成为分析和学习图结构数据的强大框架,推动了社交网络分析、推荐系统和生物网络分析等多个领域的进步。图神经网络的主要优势在于它们能够捕获图数据中固有的结构信息和依赖关系。利用消息传递…
T5: 构建统一的语言建模框架
T5: 构建统一的语言建模框架
在过去几年里,自然语言处理(NLP)领域见证了转移学习的巨大突破。转移学习包括两个主要阶段:首先,我们在大量数据上预训练一个深度神经网络;然后,在更具体的下游数据…
Simple and Scalable Strategies to Continually Pre-train Large Language Models
Simple and Scalable Strategies to Continually Pre-train Large Language Models 相关链接:arxiv 关键字:Large Language Models、Pre-training、Continual Learning、Distribution Shift、Adaptation 摘要
大型语言模型(LLMs)通常会在数十亿个tokens…
ChatGPT 遇到对手:Anthropic Claude 语言模型的崛起
ChatGPT 遇到对手:Anthropic Claude 语言模型的崛起
。
这个巨大的上下文容量使 Claude 2.1 能够处理更大的数据体。用户可以提供复杂的代码库、详细的财务报告或广泛的作品作为提示。然后 Claude 可以连贯地总结长文本,基于文档进行彻底的问答&#x…
纽约时报起诉OpenAI和微软将决定未来LLM的发展
《纽约时报》诉OpenAI和微软案对未来LLM发展的重大影响
案件背景
《纽约时报》(NYT)近期对OpenAI和微软提起诉讼,指控OpenAI未经授权使用其受版权保护的内容来训练其AI模型,包括ChatGPT。NYT声称,OpenAI使用了数百万篇其文章,这…

论文浅尝 | GPT-RE:基于大语言模型针对关系抽取的上下文学习
笔记整理:张廉臣,东南大学硕士,研究方向为自然语言处理、信息抽取 链接:https://arxiv.org/pdf/2305.02105.pdf 1、动机 在很多自然语言处理任务中,上下文学习的性能已经媲美甚至超过了全资源微调的方法。但是…
大型语言模型与Scikit-learn:Scikit-LLM全面指南
大型语言模型与Scikit-learn:Scikit-LLM综合指南
摘要
Scikit-LLM是一个将大型语言模型(LLM)如OpenAI的GPT-3.5与广泛使用的Scikit-learn框架相结合的Python包,为文本数据分析提供了无与伦比的强大工具。本文将详细介绍Scikit-L…

集简云新增通义千问qwen 72b chat、qwen1.5 等多种大语言模型,提升多语言支持能力
通义千问再开源!继发布多模态模型后,通义千问 1.5 版本也在春节前上线。
此次大模型包括六个型号:0.5B、1.8B、4B、7B、14B 和 72B,性能评测基础能力在在语言理解、代码生成、推理能力等多项基准测试中均展现出优异的性能&#x…

ChatGPT推出新“朗读”功能 支持多语言与声音;使用大型语言模型增强分类数据集
🦉 AI新闻
🚀 ChatGPT推出新“朗读”功能 支持多语言与声音
摘要:OpenAI最新为其流行的聊天机器人ChatGPT引入了一项名为“朗读”的功能,这使得ChatGPT能用五种不同的声音朗读回复,并支持37种语言的自动检测与朗读。…

AttributeError: ‘ChatGLMTokenizer‘ object has no attribute ‘sp_tokenizer‘
目录 问题描述
在使用ChatGLMlora微调的时候,报错“AttributeError: ChatGLMTokenizer object has no attribute sp_tokenizer“
编辑问题解决: 问题描述
在使用ChatGLMlora微调的时候,报错“AttributeError: ChatGLMTokenizer object h…
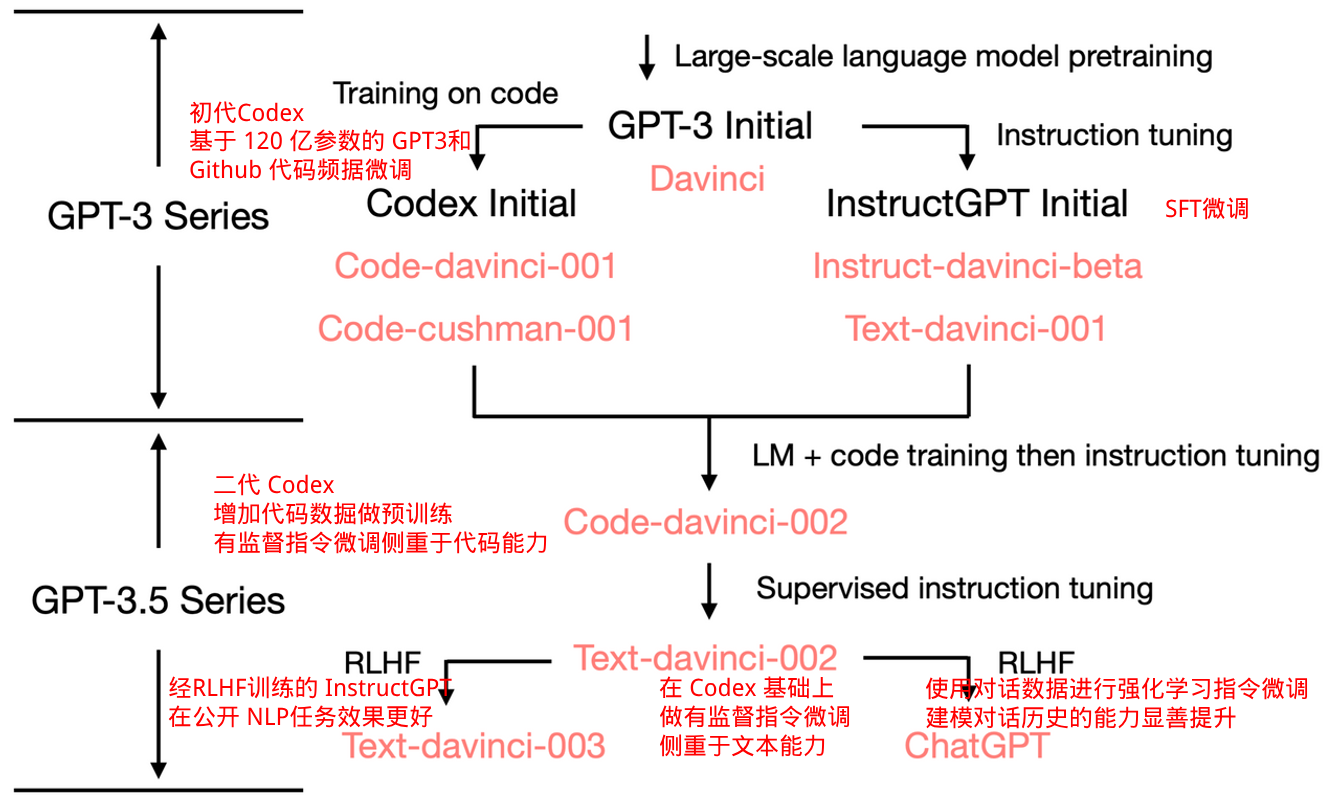
大语言模型系列-GPT-3.5(ChatGPT)
文章目录 前言一、GPT-3.5的创新点二、GPT-3.5的训练流程SFT数据集RM数据集PPO数据集 三、ChatGPT的诞生总结 前言
《Training language models to follow instructions with human feedback,2022》
前文提到了GPT-3的缺点,其中最大的问题是࿱…
大语言模型LLM学习梳理
一、介绍
今天问了下晓宇关于LLM的知识,学到了很多,总结下。 二、开源的大型语言模型(LLM)包含哪些东西?
模型包含两块内容: 框架。 框架就是函数和代码逻辑的组合。 可能有多层,每层可能有很…
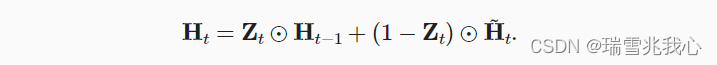
七、门控循环单元语言模型(GRU)
门控循环单元(Gated Recurrent Unit,GRU)是 LSTM 的一个稍微简化的变体,通常能够提供同等的效果,并且计算训练的速度更快。 门控循环单元原理图:参考门控循环单元 原理图中各个图形含义: X(t)&a…

【解读】OWASP 大语言模型(LLM)安全测评基准V1.0
大语言模型(LLM,Large Language Model)是指参数量巨大、能够处理海量数据的模型, 此类模型通常具有大规模的参数,使得它们能够处理更复杂的问题,并学习更广泛的知识。自2022 年以来,LLM技术在得到了广泛的应…

OpenAI-ChatGPT最新官方接口《微调ChatGPT模型》全网最详细中英文实用指南和教程,助你零基础快速轻松掌握全新技术(四)(附源码)
微调ChatGPT模型前言Introduction 导言What models can be fine-tuned? 哪些模型可以微调?Installation 安装Prepare training data 准备训练数据CLI data preparation tool CLI数据准备工具Create a fine-tuned model 创建微调模型Use a fine-tuned model 使用微调…
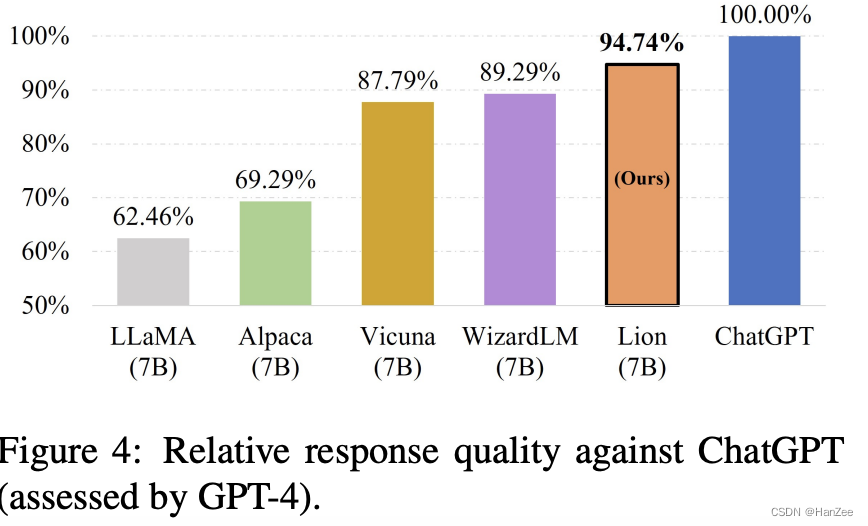
Lion:Adversarial Distillation of Closed-Source Large Language Model
Lion:Adversarial Distillation of Closed-Source Large Language Model IntroductionMethodologyexperiment Introduction
作者表明ChatGPT、GPT4在各行各业达到很好的效果,但是它们的模型与数据都是闭源的。现在的主流的方案是通过一个老师模型把知识蒸馏到学生模…

ChatGPT促进中国大语言模型发展,底层标注数据质量成关键,景联文科技提供专业数据采集标注服务
自开年以来,ChatGPT的热浪带来了一场全民的科技狂欢,同时打开了业内对NLP发展的想象空间,拉开了大语言模型产业和生成式AI产业飞速发展的序幕。 海外市场中OpenAI、微软、谷歌、Meta等巨头都在积极争抢布局ChatGPT,中国市场中百度…

【今日重磅—国产大模型首批内测机会来了】什么是讯飞星火,如何获得内测和使用方法
♥️作者:白日参商 🤵♂️个人主页:白日参商主页 ♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!! 🎈🎈加油! 加油!…
大语言模型(LLM)Token 概念
1. 概念:
Token概念:在大型语言模型中,Token是对输入文本进行分割和编码时的最小单位。它可以是单词、子词、字符或其他形式的文本片段。
2. 分类:
词级Token(Word-level Tokens):将文本分割…
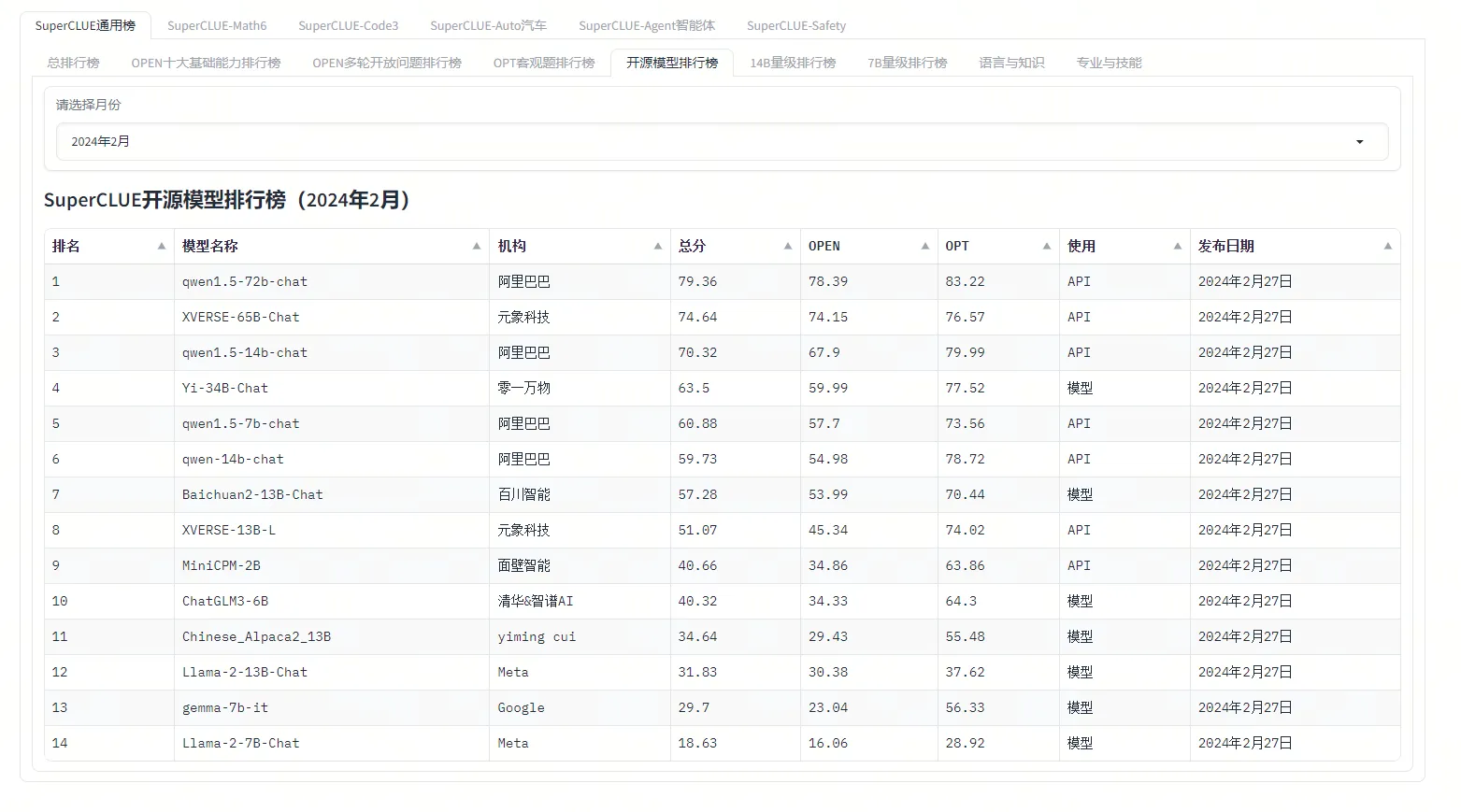
大语言模型系列-中文开源大模型
文章目录 前言一、主流开源大模型二、中文开源大模型排行榜 前言
近期,OpenAI 的主要竞争者 Anthropic 推出了他们的新一代大型语言模型 Claude 3,该系列涵盖了三个不同规模的模型:Opus、Sonnet 和 Haiku。
Claude 3声称已经全面超越GPT-4。…

大语言模型提示词技巧
LLM(Large Language Model)大语言模型时代,提示词(Prompt)很重要,而改进提示词显然有助于在不同任务上获得更好的结果。这就是提示工程背后的整个理念。
下面我们将介绍更高级的提示工程技术,使…
T-RAG:结合实体检测的增强检索生成模型
内容摘要: T-RAG是一种新的大型语言模型(LLM)应用框架,在保证数据隐私的同时,提高了对私有企业文档的问答系统性能。T-RAG通过结合已有的增强检索生成(RAG)框架、自定义的开源语言模型以及一个实…
大语言模型(LLM)过拟合问题
过拟合是指机器学习模型在训练数据上表现良好,但在未见过的测试数据上表现较差的现象。在大语言模型(LLM)中,过拟合问题也是需要注意和应对的重要挑战之一。
以下是在大语言模型中处理过拟合问题的一些常见方法: 数据…

开源开放 | DeepOnto: 基于深度学习和语言模型的本体工程Python软件包
GitHub链接: https://github.com/KRR-Oxford/DeepOnto OpenKG链接:http://old.openkg.cn/tool/deeponto-python 文档地址:https://krr-oxford.github.io/DeepOnto/ 开放许可协议:Apache-2.0 license 项目参与人员:何源…
大语言模型相关工具使用链接
大语言模型(Large Language Model,LLM)是自然语言处理(NLP)领域中的一种深度学习模型,主要用于理解和生成人类语言。这类模型通常基于Transformer架构,通过在大规模语料库上进行预训练来捕获语言…
自然语言处理之语言模型(LM)深度解析
自然语言处理(Natural Language Processing,NLP)作为人工智能的一个重要分支,近年来在学术界和工业界均取得了显著的进展。语言模型(Language Model, LM)是自然语言处理技术中的基石,它能够预测…
大语言模型(LLM) 参数量 概念
大语言模型(Large Language Model,LLM)参数量是指模型中可调整的参数的数量,通常用来衡量模型的大小和复杂程度。在深度学习中,参数量通常是指神经网络中的权重和偏置的数量。
参数量的概念在深度学习中非常重要&…

一文读懂多模态大模型:原理、应用与挑战全解析
在这个信息交织、五彩斑斓的时代,文字、图像、视频和音频如同四条蜿蜒曲折的河流,各自流淌,却又相互交织。它们构成了我们数字生活的核心元素,每一天,我们都在与之亲密接触。然而,面对这些形态各异的信息流…

开源模型应用落地-安全合规篇-模型输出合规性检测(三)
一、前言 为什么我们需要花大力气对用户输入的内容和模型生成的输出进行合规性检测,一方面是严格遵守各项法规要求,具体如下:互联网信息服务深度合成管理规定https://www.gov.cn/zhengce/zhengceku/2022-12/12/content_5731431.htm
其次,受限于模型本身的一些缺陷,…

ICLR2020论文阅读笔记reformer: THE EFFICIENT TRANSFORMER
0. 背景
机构:Google Research 、U.C. Berkeley 作者:Nikita Kitaev、Łukasz Kaiser、Anselm Levskaya 论文地址:https://arxiv.org/abs/2001.04451 收录会议:ICLR2020 论文代码:https://github.com/google/trax/tre…

2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
本题的全部资料打包为“全家桶”, “全家桶”包含:数据、代码、模型、结果csv、教程…

轻松玩转开源大语言模型bloom(一)
前言
chatgpt已经成为了当下热门,github首页的trending排行榜上天天都有它的相关项目,但背后隐藏的却是openai公司提供的api收费服务。作为一名开源爱好者,我非常不喜欢知识付费或者服务收费的理念,所以便有决心写下此系列&#…
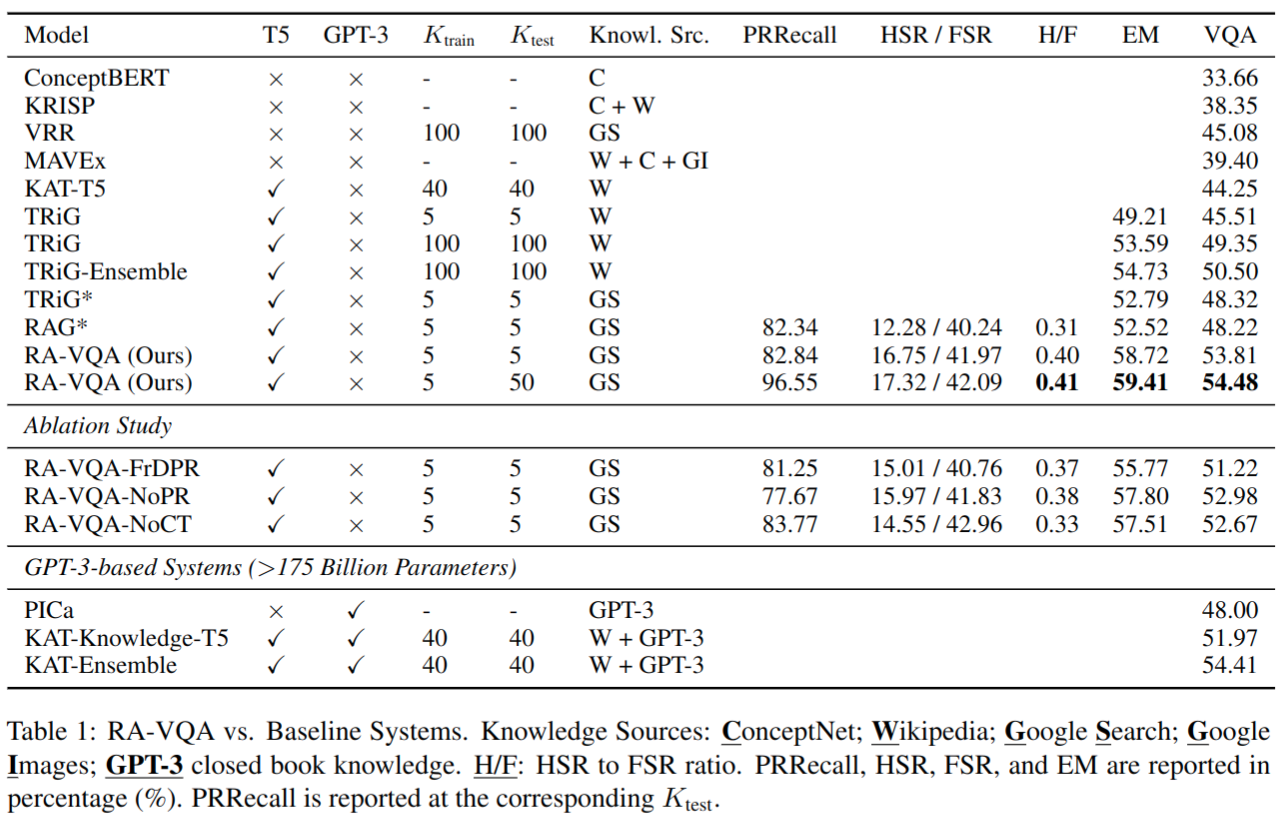
Retrieval Augmented Visual Question Answering with Outside Knowledge
Paper name
Retrieval Augmented Visual Question Answering with Outside Knowledge
Paper Reading Note
URL: https://arxiv.org/pdf/2210.03809.pdf
TL;DR
EMNLP 2022 文章,提出名为 RA-VQA 的一种联合训练方案,该方案可以同时训练答案生成模块和…

LangChain大型语言模型(LLM)应用开发(二):Conversation Memory
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…
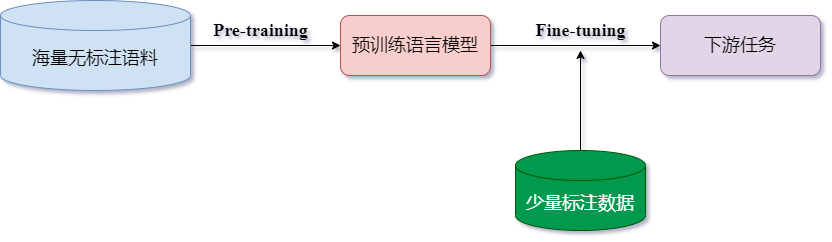
大语言模型微调和PEFT高效微调
目录标题 1 解释说明1.1 预训练阶段1.2 微调阶段2 几种微调算法2.1 在线微调2.2 高效微调2.2.1 RLHF2.2.2 LoRA2.2.3 Prefix Tuning2.2.4 Prompt Tuning2.2.5 P-Tuning v21 解释说明 预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一…

Co-VQA : Answering by Interactive Sub Question Sequence
Paper name
Co-VQA : Answering by Interactive Sub Question Sequence
Paper Reading Note
URL: https://arxiv.org/pdf/2204.00879.pdf
TL;DR
ACL 2022 文章,通过模拟人类拆解子问题的过程,本文提出了一个基于会话的 VQA(Co-VQA&#…
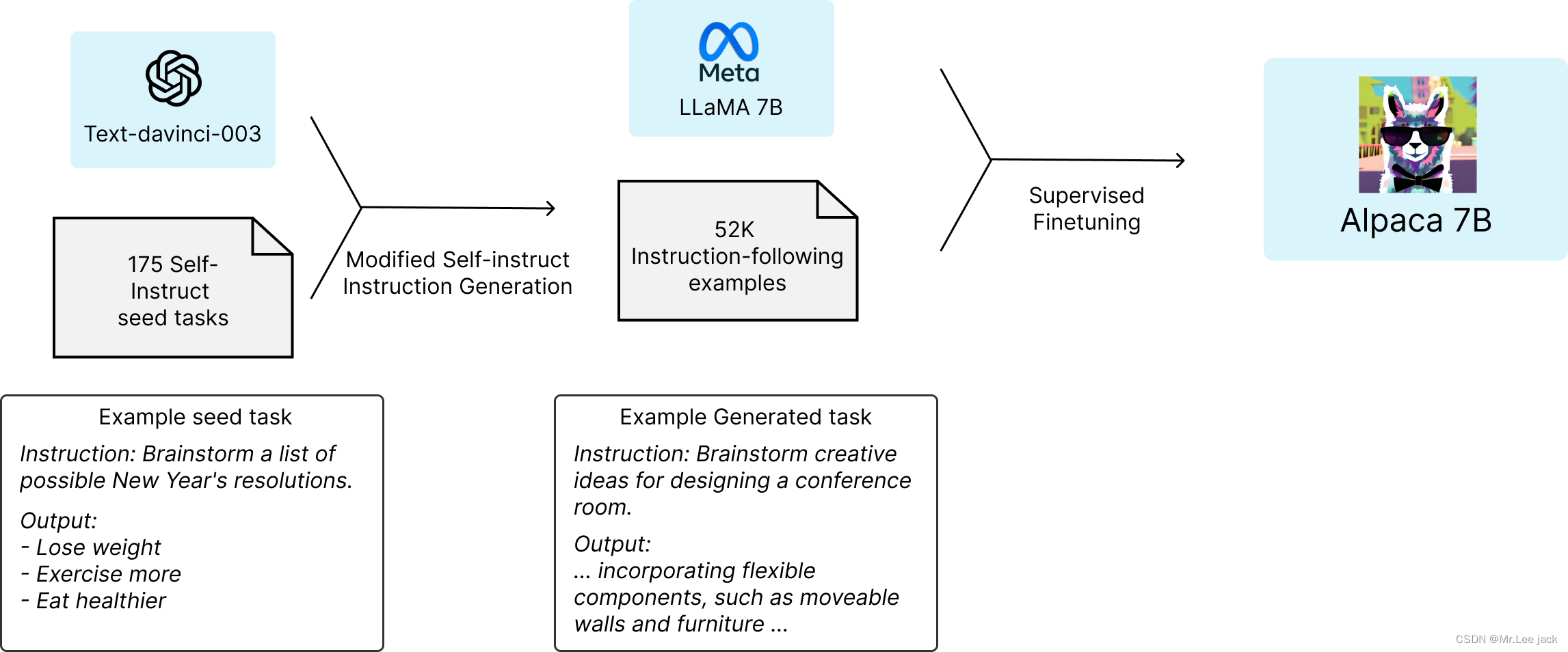
大语言模型的百家齐放
基础语言模型
概念
基础语言模型是指只在大规模文本语料中进行了预训练的模型,未经过指令和下游任务微调、以及人类反馈等任何对齐优化。
如何理解 只包含纯粹的语言表示能力,没有指导性或特定目标。 只在大量无标注文本上进行无监督预训练,用于学习语言表示。 …
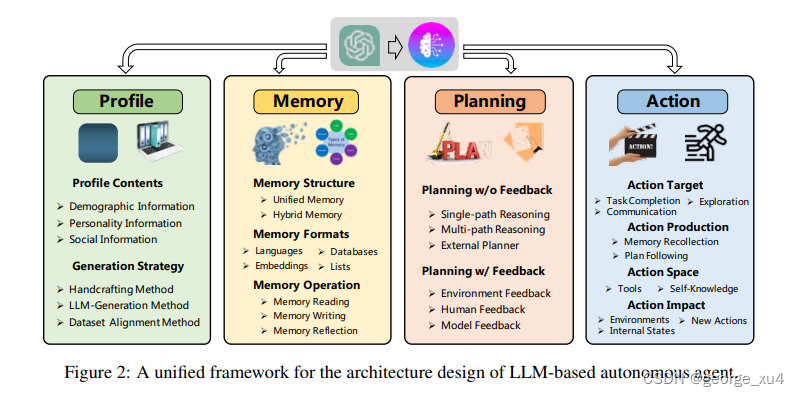
Agent——记忆模块
在基于大模型的 Agent架构设计方面,论文[1]提出了一个统一的框架,包括Profile模块、Memory模块、Planning模块和Action模块。其中长期记忆的状态维护至关重要,在 OpenAI AI 应用研究主管 Lilian Weng 的博客《基于大模型的 Agent 构成》[2]中,将记忆视为关键的组件之一,下…

景联文科技:专业提供高质量大语言模型训练数据
2024年,数字经济被再次写入政府工作报告中,报告指出要深化大数据、人工智能等研发应用,打造具有国际竞争力的数字产业集群。 大模型作为生成式人工智能的基础,日益成为国际科技竞争的焦点。人大代表杨剑宇指出,尽管我国…
【深度学习笔记】6_1 语言模型lang-model
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.1 语言模型
语言模型(language model)是自然语言处理的重要技术。自然语言处理中最常见的数据是文本数据。我…

【论文翻译未完成】翻给自己看的 A Neural Probabilistic Language Model
学习路线:NLP经典论文导读(推荐阅读顺序)
原文:https://jmlr.csail.mit.edu/papers/v3/bengio03a.html
参考:论文阅读: 一种神经概率语言模型神经概率语言模型论文阅读: 一种神经概率语言模…
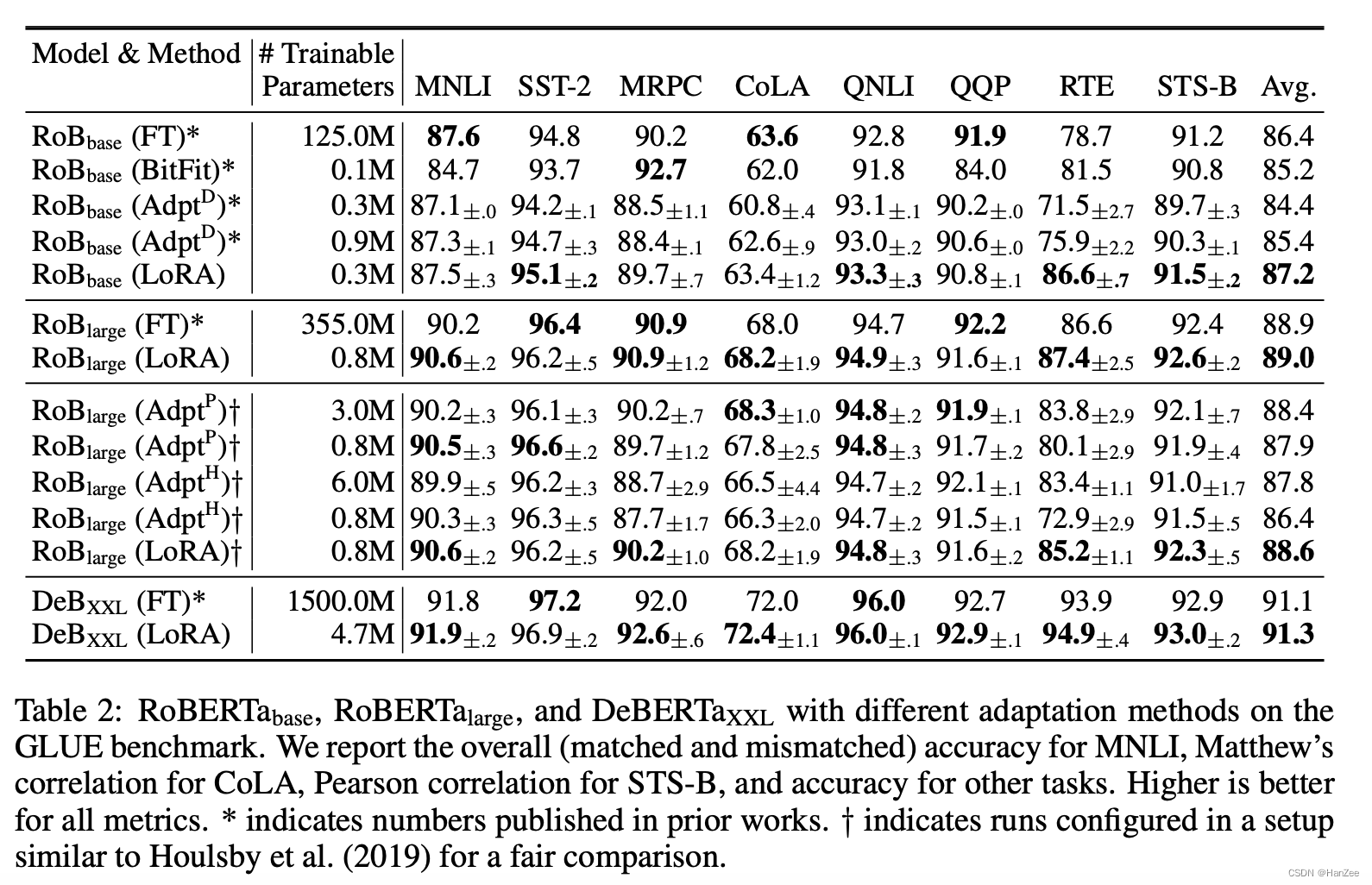
Lora:Low-Rank Adapation of Large Language models
Lora:Low-Rank Adapation of Large Language modelsIntroductionMethodExperiment代码Introduction
这篇论文最初与21.06上传与arXiv,作者指出在当时,NLP的一个重要范式是先训练一个通用领域的模型然后在通过微调适应不同的领域与数据&#…
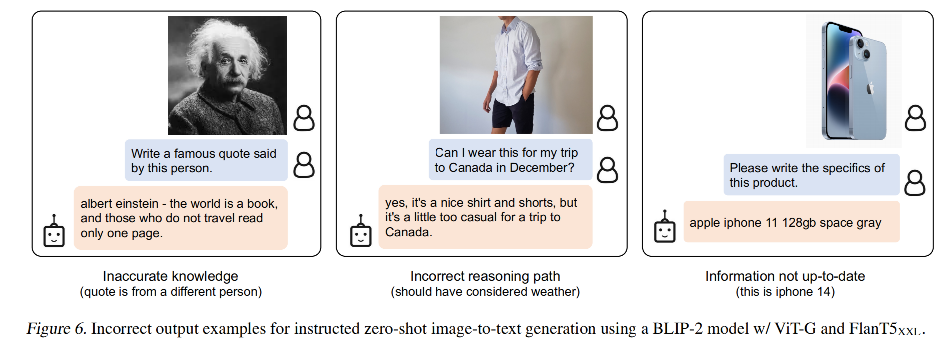
【AIGC】9、BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练
文章目录一、背景二、方法2.1 模型结构2.2 从 frozen image encoder 中自主学习 Vision-Language Representation2.3 使用 Frozen LLM 来自主学习 Vision-to-Language 生成2.4 Model pre-training三、效果四、局限性论文:BLIP-2: Bootstrapping Language-Image Pre-…

大型语言模型 (LLM) 的两条发展路线:Finetune v.s. Prompt
前言
如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。
在大型语言模型的研究中,研究者对其有两种不同的期待,也可以理解为是两种不同的路线,具…
d2l语言模型--生成小批量序列
对语言模型的数据集处理做以下汇总与总结
目录
1.k元语法
1.1一元
1.2 二元
1.3 三元
2.随机抽样 2.1各bs之间随机
2.2各bs之间连续
3.封装 1.k元语法
1.1一元
tokens d2l.tokenize(d2l.read_time_machine())
# 因为每个⽂本⾏不⼀定是⼀个句⼦或⼀个段落࿰…

征稿|IJCAI‘23大模型论坛,DeepMind EleutherAI Oxford主题报告
第一届LLMIJCAI’23 Symposium征稿中,优秀投稿论文推荐《AI Open》(EI检索)和 《JCST》(CCF-B)发表。 大规模语言模型(LLMs),如ChatGPT和GPT-4,以其在自然语言理解和生成方面的卓越能力…
《精通特征工程》学习笔记(3):特征缩放的效果-从词袋到tf-idf
1.TF-IDF原理
tf-idf 是在词袋方法基础上的一种简单扩展,它表示词频 - 逆文档频率。tf-idf 计算的不是数据集中每个单词在每个文档中的原本计数,而是一个归一化的计数,其中每个单词的计数要除以这个单词出现在其中的文档数量。
词袋bow(w, …
WizardKM:Empowering Large Language Models to Follow Complex Instructions
WizardKM:Empowering Large Language Models to Follow Complex Instructions Introduction参考 Introduction
作者表明当前nlp社区的指令数据比较单一,大部分都是总结、翻译的任务,但是在真实场景中,人们有各式各样的需求,这限制…
【五一创作】跑alpaca-lora语言模型的常见问题(心得)
训练部署alpaca-lora语言模型常见问题
Alpaca-Lora是一个开源的自然语言处理框架,使用深度学习技术构建了一个端到端的语言模型。在训练和部署alpaca-lora语言模型时,可能会遇到一些常见问题。本文将介绍一些这些问题及其解决方法。
1. bitsandbytes版…

LegalAI领域大规模预训练语言模型的整理、总结及介绍(持续更新ing…)
诸神缄默不语-个人CSDN博文目录
最近更新日期:2023.6.7 最早更新日期:2023.6.7 文章目录 1. 通用大规模预训练语言模型2. 对话模型3. 分句 1. 通用大规模预训练语言模型
英语:
LegalBERT 原始论文:(2020 EMNLP) LEGAL-BERT: Th…
体验讯飞星火认知大模型,据说中文能力超越ChatGPT
📋 个人简介
💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…
浅谈ChatGPT:改变交流方式的智能语言模型
在数字化时代,人工智能技术迅猛发展,对我们的生活产生了深远的影响。其中,自然语言处理领域的一项重要成就是ChatGPT,这是一种基于GPT-3.5架构的智能语言模型,它通过机器学习训练,能够进行自然、流畅的对话…

【数据科学赛】HackAPrompt 挑战语言模型!
CompHub 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号会推送最新的比赛消息,欢迎关注!
更多比赛信息见 CompHub主页[1] 以下信息由AI辅助创作,仅供参考,请以官网为准(文末…
Midjourney AI 官方中文版已开启内测申请;OpenAI 正准备向公众发布一款新的开源语言模型。
🚀 Midjourney AI 官方中文版已开启内测申请,搭载在 QQ 频道上,召唤机器人进行作画。
Midjourney AI 官方中文版已开启内测申请,搭载在 QQ 频道上,召唤机器人进行作画。
可调用 MJ 和 Niji 的最新模型和所有参数&…
GPT大语言模型Alpaca-lora本地化部署实践【大语言模型实践一】 | 京东云技术团队
模型介绍
Alpaca模型是斯坦福大学研发的LLM(Large Language Model,大语言)开源模型,是一个在52K指令上从LLaMA 7B(Meta公司开源的7B)模型微调而来,具有70亿的模型参数(模型参数越大…
大规模语言模型微调技术——Instruction和Question的区别和联系
1. 引言
在ChatGPT的时代,每个人都能够轻松使用这一强大的语言模型。这一切的实现速度比我之前所想象的要快得多。这得益于大规模语言模型微调技术,其实并没有引入太多新颖的元素。特别是有了ChatGPT作为引路人,许多事情变得更加容易和简单。…
WPS AI最全申请与使用手册;AIGC制作游戏音乐;便宜快捷使用完整版SD;人人都能看懂的ChatGPT原理课 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 面向虚拟世界的生成式AI市场全景图 作者在这篇文章中探讨了生成式AI在虚拟世界的应用,并绘制了 Market Map V3.0 (市场全景…
卷起来!Dr. LLaMA:通过生成数据增强改进特定领域 QA 中的小型语言模型,重点关注医学问答任务...
大家好,最近突然发现了一篇在专门应用于医学领域的LLaMA,名为Dr.LLaMA(太卷了太卷了),就此来分享下该语言模型的构建方法和最终的性能情况。 论文:Dr. LLaMA: Improving Small Language Models in Domain-S…

文档处理容易“翻车”,来看看CCIG上的大咖怎么说
一、前言 哪怕在互联网时代高速发展的今天,文档依然是人们在日常生活、工作中产生的信息的重要载体。 学生的作业、开具的发票、医生的医嘱、合同、简历、金融票据等都是通过文档来呈现的,它在我们的生活中随处可见。 现在我们为了更高效、安全的开展业务…
QA-LORA: QUANTIZATION-AWARE LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《QA-LORA: QUANTIZATION-AWARE LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》的翻译。 Qa-lora:大型语言模型的量化感知低秩自适应 摘要1 引言2 相关工作3 提出的方法4 实验5 结论 摘要
近年来,大型语言模型(llm)得到了迅速…
以太坊实现、语言模型应用与实用工具 | 开源日报 0817
Go Ethereum 是以太坊协议的官方 Golang 执行层实现,可运行各种节点并提供网关访问以太坊网络;LangChain-Chatchat 是基于大语言模型的本地知识库问答应用实现,支持离线运行和多种模型接入;Shiori 是简单易用的书签管理器…

Retentive Network: A Successor to Transformer for Large Language Models
论文链接:
https://arxiv.org/pdf/2307.08621.pdf
代码链接:
https://github.com/microsoft/unilm/tree/master/retnet
引言
transformer的问题就是计算成本太高 RetNet使“不可能三角形”成为可能,同时实现了训练并行性,良好…

文献阅读笔记electra: pre-training text encoders as discriminators rather than generators
目录0. 背景0.1 摘要1. 介绍2. 方法3. 实验3.1 实验设置3.2 模型拓展3.3 Small版模型3.4 Large版模型3.5 有效性分析4. 总结0. 背景
机构:斯坦福、Google Brain 作者:Kevin Clark、Minh-Thang Luong、Quoc V. Le 论文地址:https://arxiv.org…

BART论文解读:BERT和GPT结合起来会发生什么?
BART:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
主要工作 提出了BART (Bidirectional and Auto-Regressive Transformers), 是一种用于自然语言生成、翻译和理解的序列到序列的预训练方法。它…
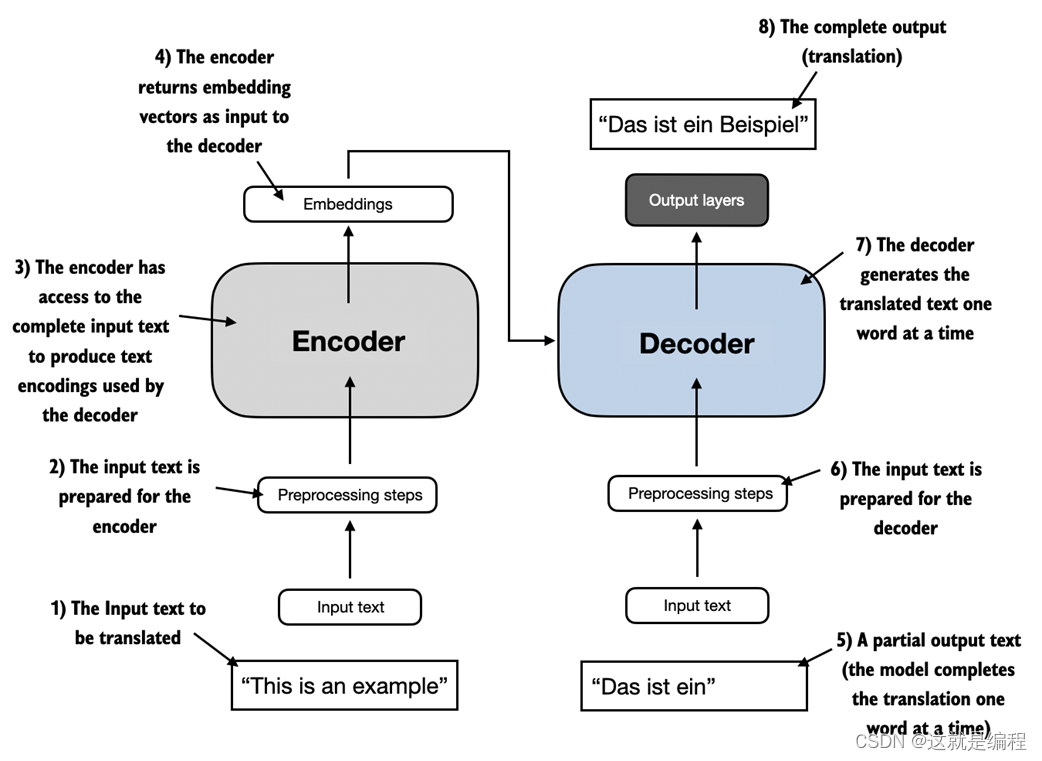
03.用于LLMs不同的任务-transformer 架构
大多数现代LLMs都依赖于 transformer 架构,这是 2017 年论文 Attention Is All You Need 中介绍的深度神经网络架构。要理解LLMs,我们必须简要回顾一下最初的转换器,它最初是为机器翻译而开发的,将英语文本翻译成德语和法语。变压器架构的简化版本如图 1.4 所示。
图 1.4 …
大语言模型-alpaca-lora
微调 大语言模型-ChatGLM-Tuning 大语言模型-微调chatglm6b 大语言模型-中文chatGLM-LLAMA微调 大语言模型-alpaca-lora 本地知识库 大语言模型2-document ai解读 大语言模型-DocumentSearch解读 大语言模型-中文Langchain
本文读的代码为 https://github.com/tloen/alpaca-…
An Empirical Study of Instruction-tuning Large Language Models in Chinese
本文是LLM系列文章,针对《An Empirical Study of Instruction-tuning Large Language Models in Chinese》的翻译。 汉语大语言模型指令调整的实证研究 摘要1 引言2 指令调整三元组3 其他重要因素4 迈向更好的中文LLM5 结论局限性 摘要
ChatGPT的成功验证了大型语…
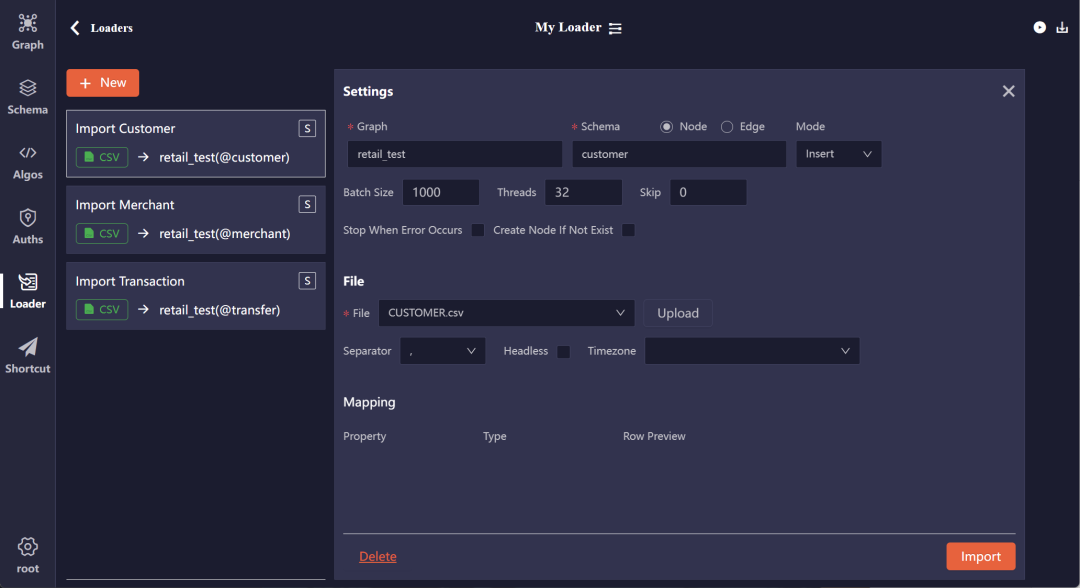
Ultipa Transporter V4.3.22 即将发布,解锁更多易用功能!
Ultipa Graph 作为一款领先的实时图数据库分析平台,即将发布最新版的数据导入/导出工具Ultipa Transporter V4.3.22 以实现对 Neo4j数据源的导入支持。自今年以来,Ultipa Transporter不断增加新功能,除原本支持本地CSV文件导入导出外…

手把手带你在AutoDL上部署InternLM-Chat-7B Transformers
手把手带你在AutoDL上部署InternLM-Chat-7B Transformers 调用 项目地址:https://github.com/KMnO4-zx/self_llm.git 如果大家有其他模型想要部署教程,可以来仓库提交issue哦~ 也可以自己提交PR!
InternLM-Chat-7B Transformers 部署调用
环…

国内版的ChatGPT模型分享
1、百度的【文心一言】注册地址:点我 这里我很早之前就申请了,所以当前时可以正常使用的,还没有体验的小伙伴,可以现在申请 虽然与ChatGPT还是有一些差距的,但是作为办公助手还是很OK的!! 而且有…
对话ChatGPT,大模型时代到来,文末可获得ChatGPT免费访问地址
文章目录 1. 你觉得大模型时代已经到来了吗?2. 大模型和以前的模型有什么区别?3. 列举一下你知道的大模型有哪些4. ChatGPT与传统的智能助手有什么区别?5. ChatGPT有什么优势和劣势?6. ChatGPT有哪些应用场景,请举例说…
用AI修复郭德纲远古相声;小红书爆款文案Prompt模板;用AI经营一家三明治店;AI将实现80%编程 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 B站UP主使用AI修复郭德纲远古相声,10天播放近70万 B站UP主 野老相声-风景-4K修复 使用了AI换脸技术,对郭德纲、…

走向CV的通用人工智能:从GPT和大型语言模型中汲取的经验教训 (上)
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 论文地址:https://arxiv.org/pdf/2306.08641.pdf 计算机视觉研究院专栏 Column of Computer Vision Institute 人工智能…
Embedding 嵌入知识入门
原文首发于博客文章Embedding 嵌入知识入门 文本嵌入是什么
向量是一个有方向和长度的量,可以用数学中的坐标来表示。例如,可以用二维坐标系中的向量表示一个平面上的点,也可以用三维坐标系中的向量表示一个空间中的点。在机器学习中&#x…
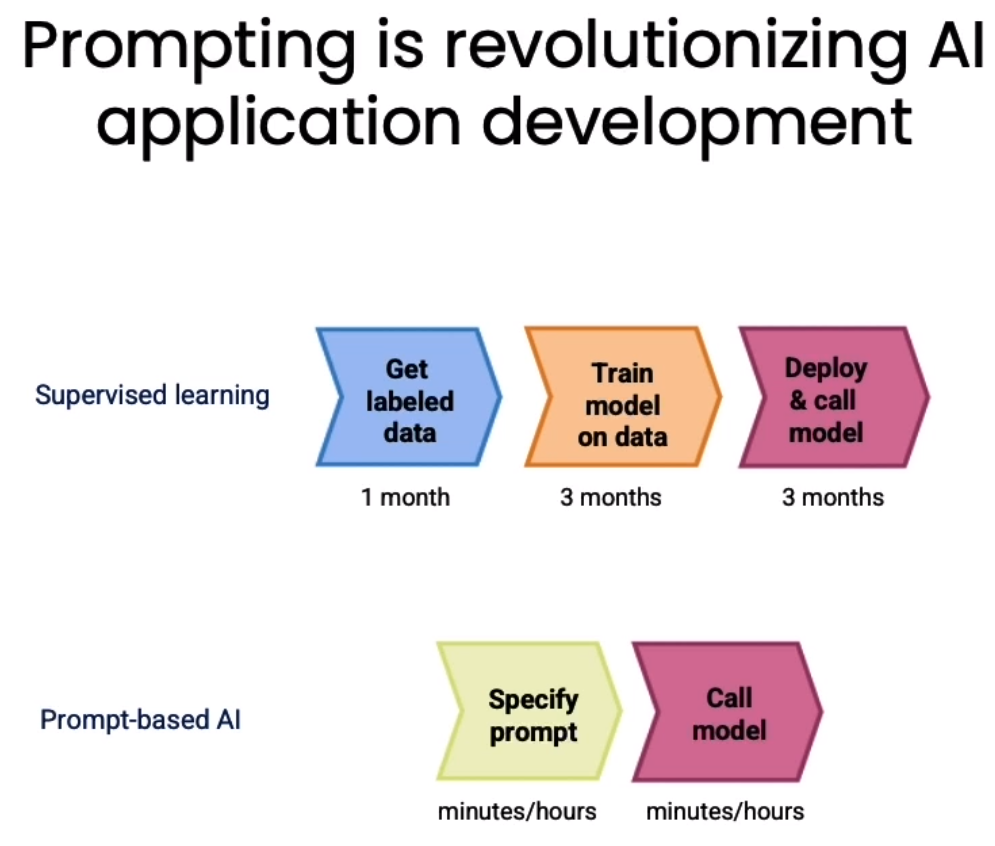
如何使用ChatGPT的API(一)大语言模型如何工作
这篇文章介绍大语言模型的一些概念,包括它是如何工作的,什么是Token等等。
大语言模型如何工作
我们从一个示例开始说起。
当我们写一个提示“我喜欢吃”,然后要求一个大型语言模型根据这个提示填写后面可能的内容。它可能会说,…
全都会!预测蛋白质标注!创建讲义!解释数学公式!最懂科学的智能NLP模型Galactica尝鲜 ⛵
💡 作者:韩信子ShowMeAI 📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41 📘 深度学习实战系列:https://www.showmeai.tech/tutorials/42 📘 自然语言处理实战系列:htt…

LangChain大型语言模型(LLM)应用开发(三):Chains
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…

【自然语言处理】- 作业4: 预训练语言模型BERT实现与应用
课程链接: 清华大学驭风计划
代码仓库:Victor94-king/MachineLearning: MachineLearning basic introduction (github.com) 驭风计划是由清华大学老师教授的,其分为四门课,包括: 机器学习(张敏教授) , 深度学习(胡晓林教授), 计算…
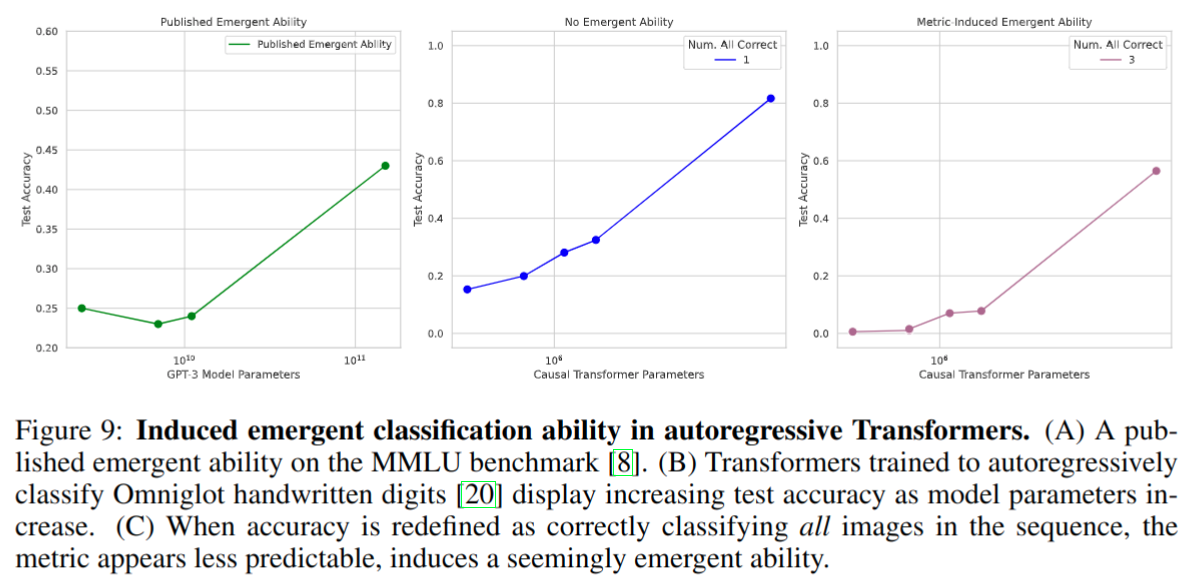
Are Emergent Abilities of Large Language Models a Mirage?
Paper name
Are Emergent Abilities of Large Language Models a Mirage?
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2304.15004.pdf Video URL: https://www.youtube.com/watch?vhZspGdApDIo
TL;DR
2023 年斯坦福的研究,探索大语言模型表现出涌…
ChatGPT将会成为强者的外挂?—— 提高学习能力
目录
前言
一、提高学习力 🧑💻
1. 快速找到需要的知识
2. 组合自己的知识体系
3. 内化知识技能
二、提问能力❗
三、思维、创新能力 🌟
1. 批判性思维
1.1 八大基本结构进行批判性提问
1.2 苏格拉底的提问分类方法
2. 结构化思…

安全运营场景下的语言模型应用
接上篇,将安全运营的定义为“使用算法能力提取关键信息”,以此来规避算法误判漏判带来的责任问题,同时提升运营人员的工作效率。在这篇尝试对语言模型的使用方法做一下讨论和分享。
1. 语言模型
先聊一下语言模型。(这里刻意规避…
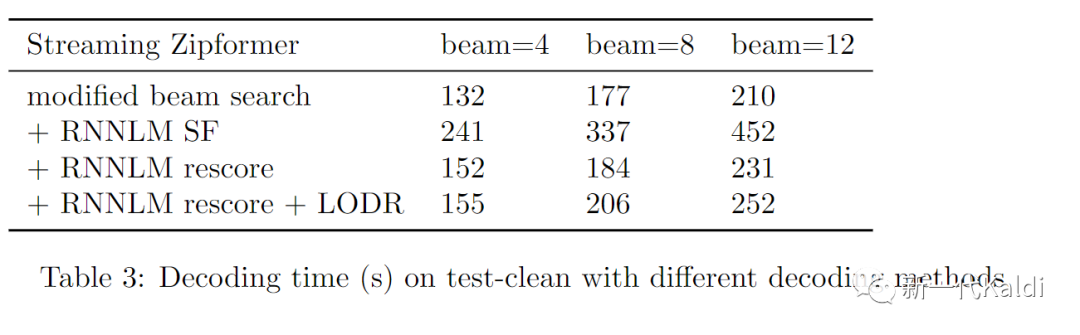
巧用语言模型——让准确率再涨一点点!
还记得在去年,我们曾经发过一篇文章介绍 icefall 中的语言模型使用方法:升点小技巧之—在icefall中巧用语言模型。如今半年过去了,k2 团队又有了一些新进展。今天来给大家做一个小小的总结,再给大家的模型涨涨点(又又又…

预训练语言模型与其演进
目录 前言1 语言模型2 预训练语言模型3 预训练语言模型的演进3.1 word2vec:开创预训练时代3.2 Pre-trained RNN3.3 GPT:解决上下文依赖3.4 BERT:双向预训练的革新 4 GPT与BERT的对比5 其他模型:Robust BERT和ELECTRA5.1 Robust BE…

【书生·浦语】大模型实战营——第四课笔记
教程链接:https://github.com/InternLM/tutorial/blob/main/xtuner/README.md 视频链接:https://www.bilibili.com/video/BV1yK4y1B75J/?vd_source5d94ee72ede352cb2dfc19e4694f7622 本次视频的内容分为以下四部分: 目录
微调简介 微调会使…

大语言模型系列-word2vec
文章目录 前言一、word2vec的网络结构和流程1.Skip-Gram模型2.CBOW模型 二、word2vec的训练机制1. Hierarchical softmax2. Negative Sampling 总结 前言
在前文大语言模型系列-总述已经提到传统NLP的一般流程:
创建语料库 > 数据预处理 > 分词向量化 > …
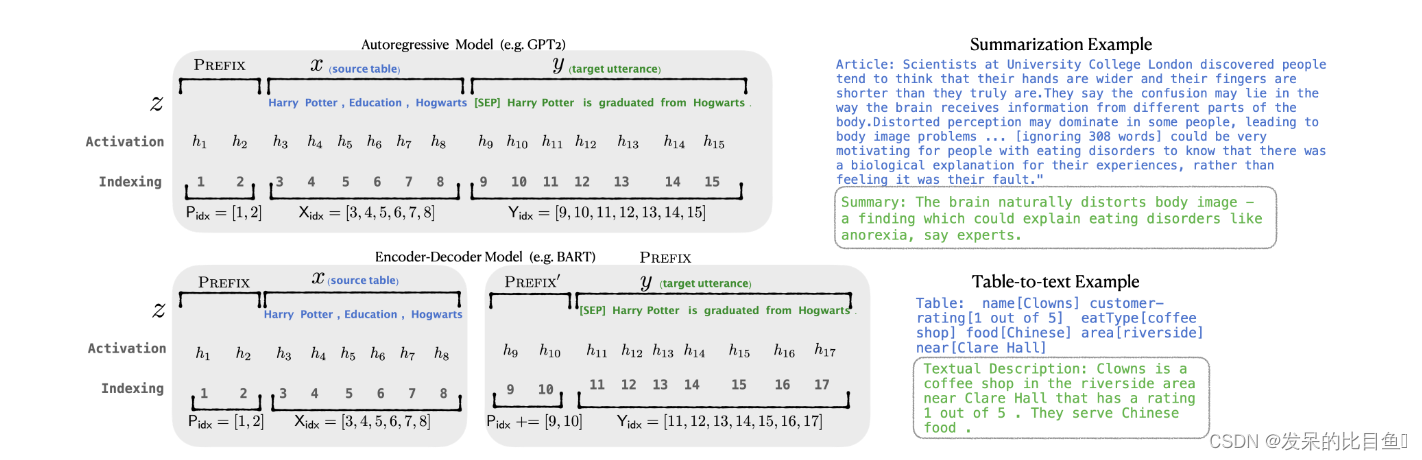
2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation
2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation Paper:https://arxiv.org/pdf/2101.00190.pdf Code:https://github.com/XiangLi1999/PrefixTuning
前缀调优:优化生成的连续提示
prefix-tunning 的基本思想也是想…
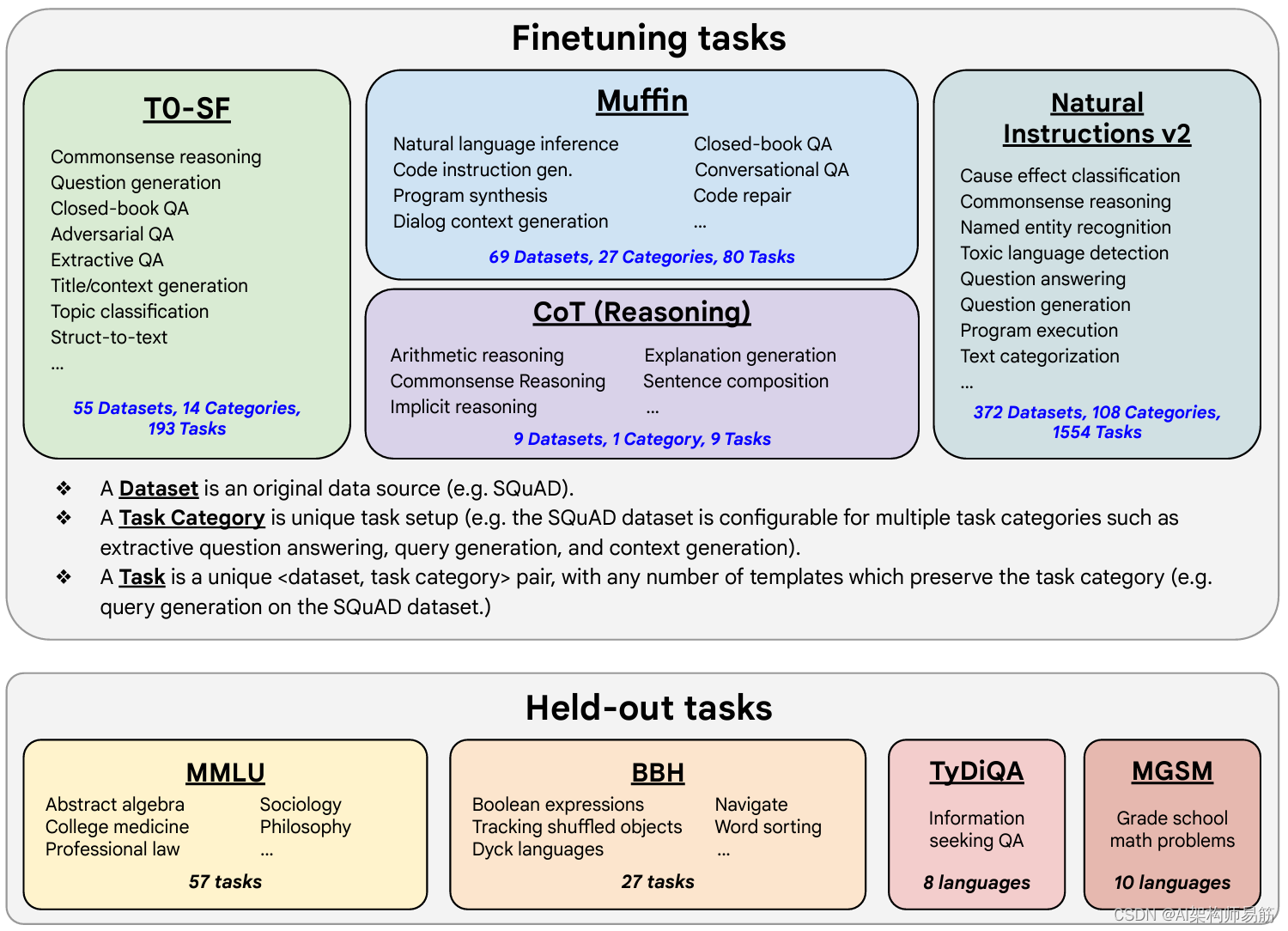
LLMs 缩放指令模型Scaling instruct models FLAN(Fine-tuned LAnguage Net,微调语言网络)
本论文介绍了FLAN(Fine-tuned LAnguage Net,微调语言网络),一种指导微调方法,并展示了其应用结果。该研究证明,通过在1836个任务上微调540B PaLM模型,同时整合Chain-of-Thought Reasoning&#…
Generated Knowledge Prompting for Commonsense Reasoning
本文是知识图谱系列相关的文章,针对《Generated Knowledge Prompting for Commonsense Reasoning》的翻译。 常识推理的生成知识提示 摘要1 引言2 生成知识提示3 实验设置4 实验结果5 相关工作6 结论 摘要
结合外部知识是否有利于常识推理,同时保持预训…
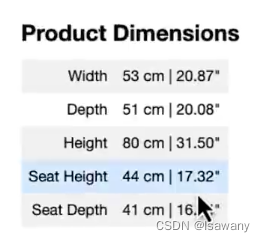
吴恩达 ChatGPT Prompt Engineering for Developers 系列课程笔记--03 Iterative
03 Iterative
本节主要通过代码来讲解如何在迭代中找到合适的prompt。对于初学者来说,第一次使用Prompt不一定得到语气的结果,开发者可以采用下述流程进行迭代优化:
给出清晰、具体的指令如果结果不正确,分析原因调整prompt重复…
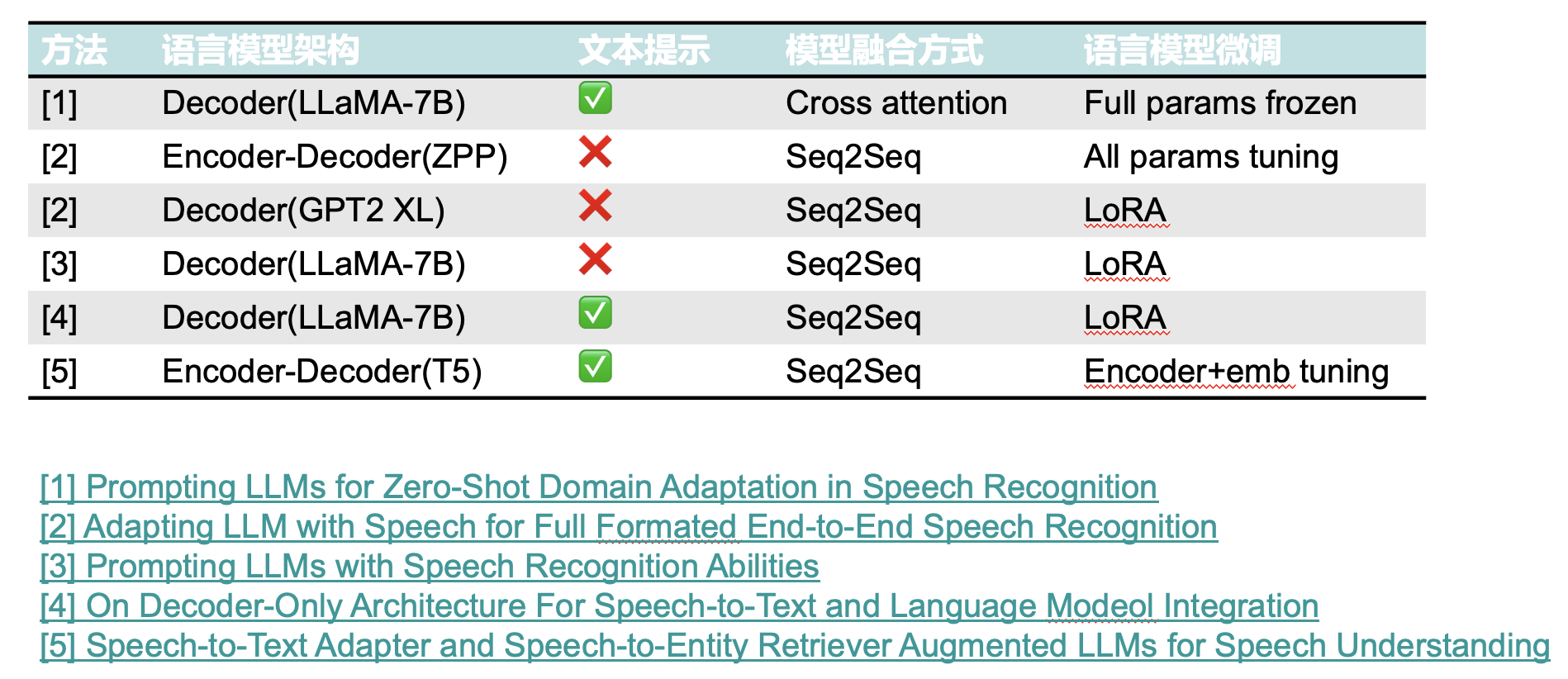
ASR(自动语音识别)任务中的LLM(大语言模型)
一、LLM大语言模型的特点 二、大语言模型在ASR任务中的应用
浅度融合
浅层融合指的是LLM本身并没有和音频信息进行直接计算。其仅对ASR模型输出的文本结果进行重打分或者质量评估。
深度融合
LLM与ASR模型进行深度结合,统一语音和文本的编码空间或者直接利用ASR…
翻译: Streamlit从入门到精通六 实战缓存Cache请求数据
Streamlit从入门到精通 系列:
翻译: Streamlit从入门到精通 基础控件 一翻译: Streamlit从入门到精通 显示图表Graphs 地图Map 主题Themes 二翻译: Streamlit从入门到精通 构建一个机器学习应用程序 三翻译: Streamlit从入门到精通 部署一个机器学习应用程序 四翻译…

复现五 LMDeploy 的量化和部署
0基础知识
一步一步跟着教程复现第五:LMDeploy 的量化和部署
复现一:
轻松玩转书生浦语大模型internlm-demo 配置验证过程_ssh -cng -l 7860:127.0.0.1:6006 rootssh.intern-ai-CSDN博客文章浏览阅读827次,点赞17次,收藏24次。…
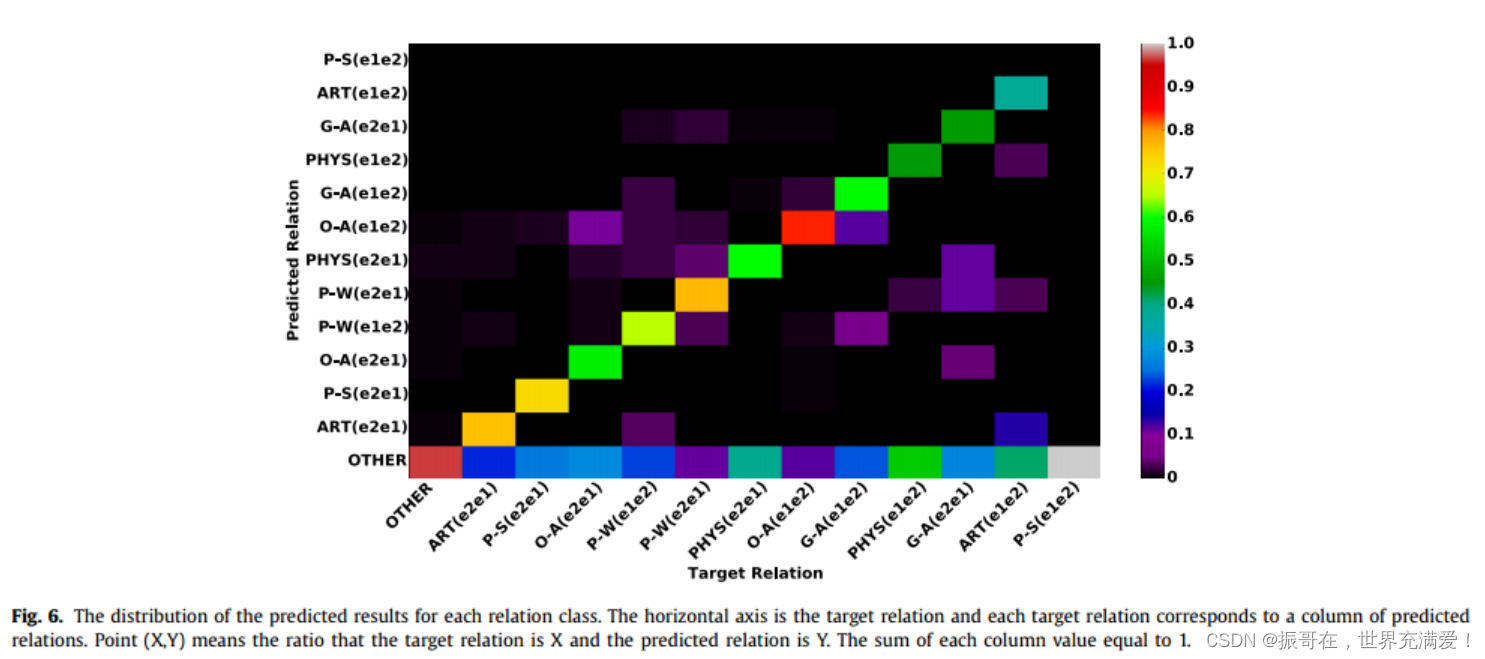
文献学习-联合抽取-Joint entity and relation extraction based on a hybrid neural network
目录
1、Introduction
2、Related works
2.1 Named entity recognition
2.2 Relation classification
2.3 Joint entity and relation extraction
2.4 LSTM and CNN models On NLP
3、Our method
3.1 Bidirectional LSTM encoding layer
3.2 Named entity recogniton …
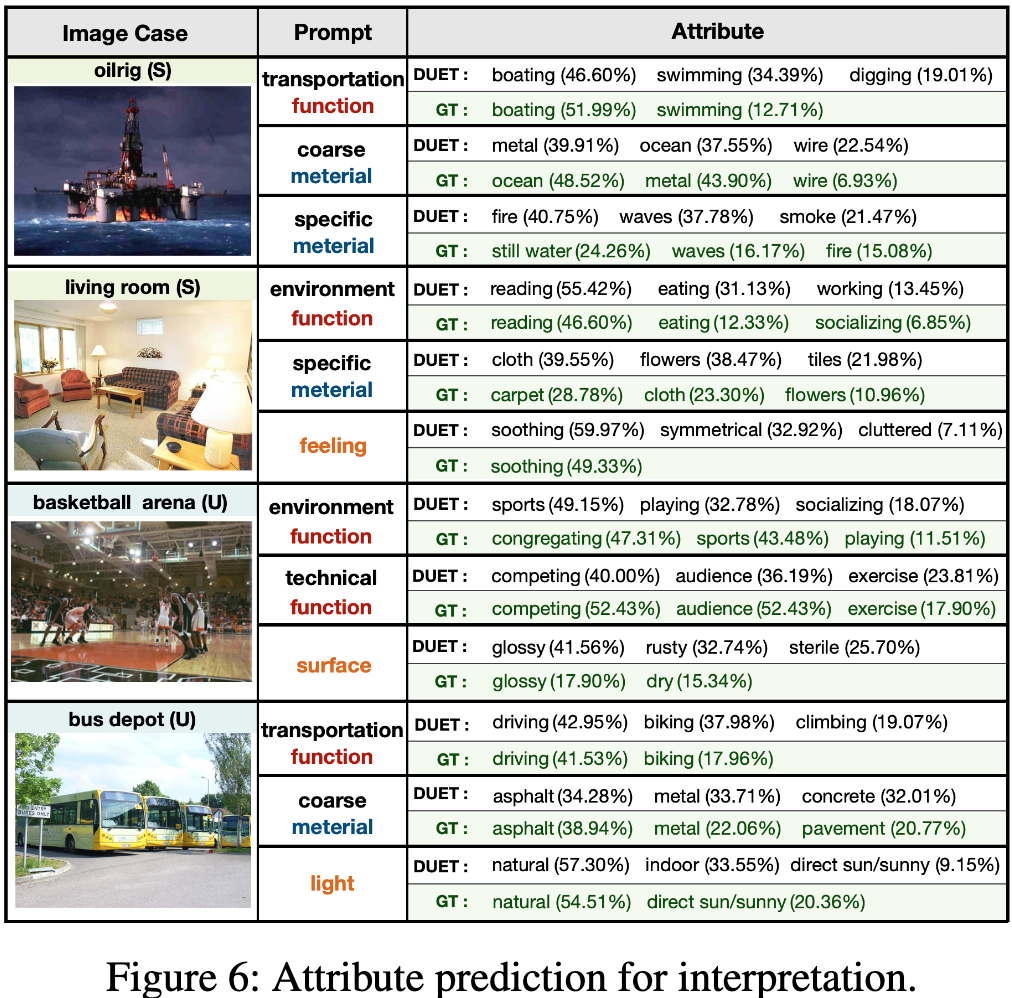
AAAI 2023 | 语言模型如何增强视觉模型的零样本能力 ?
文章链接:https://arxiv.org/abs/2207.01328 项目地址:https://github.com/zjukg/DUET 该论文设计了一种新的零样本学习范式,通过迁移语言模型中的先验语义知识,与视觉模型的特征感知能力进行对齐,以增强后者对于未见过…
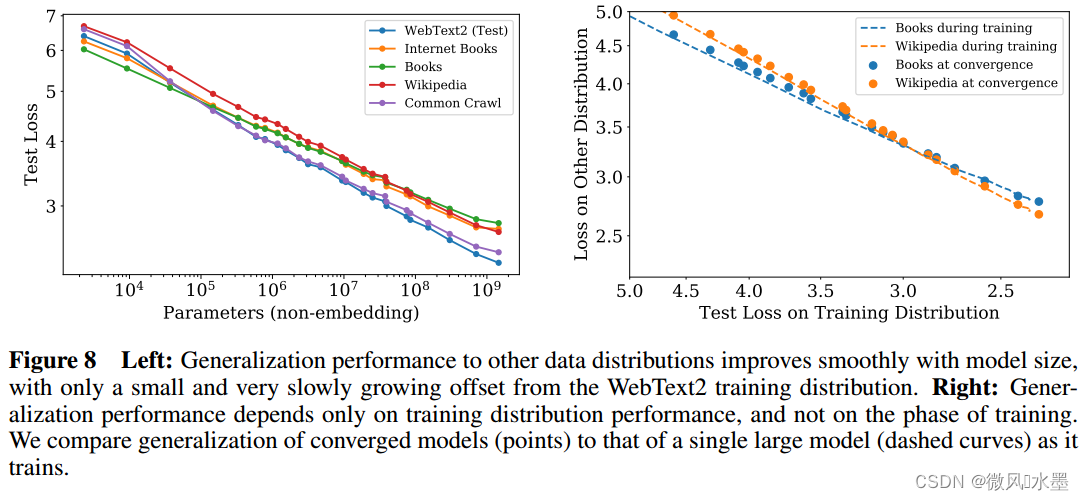
LLM:Scaling Laws for Neural Language Models (上)
论文:https://arxiv.org/pdf/2001.08361.pdf
发表:2020 摘要1:损失与模型大小、数据集大小以及训练所用计算量成比例,其中一些趋势跨越了七个量级以上。
2:网络宽度或深度等其他架构细节在很大范围内影响较小。3&…
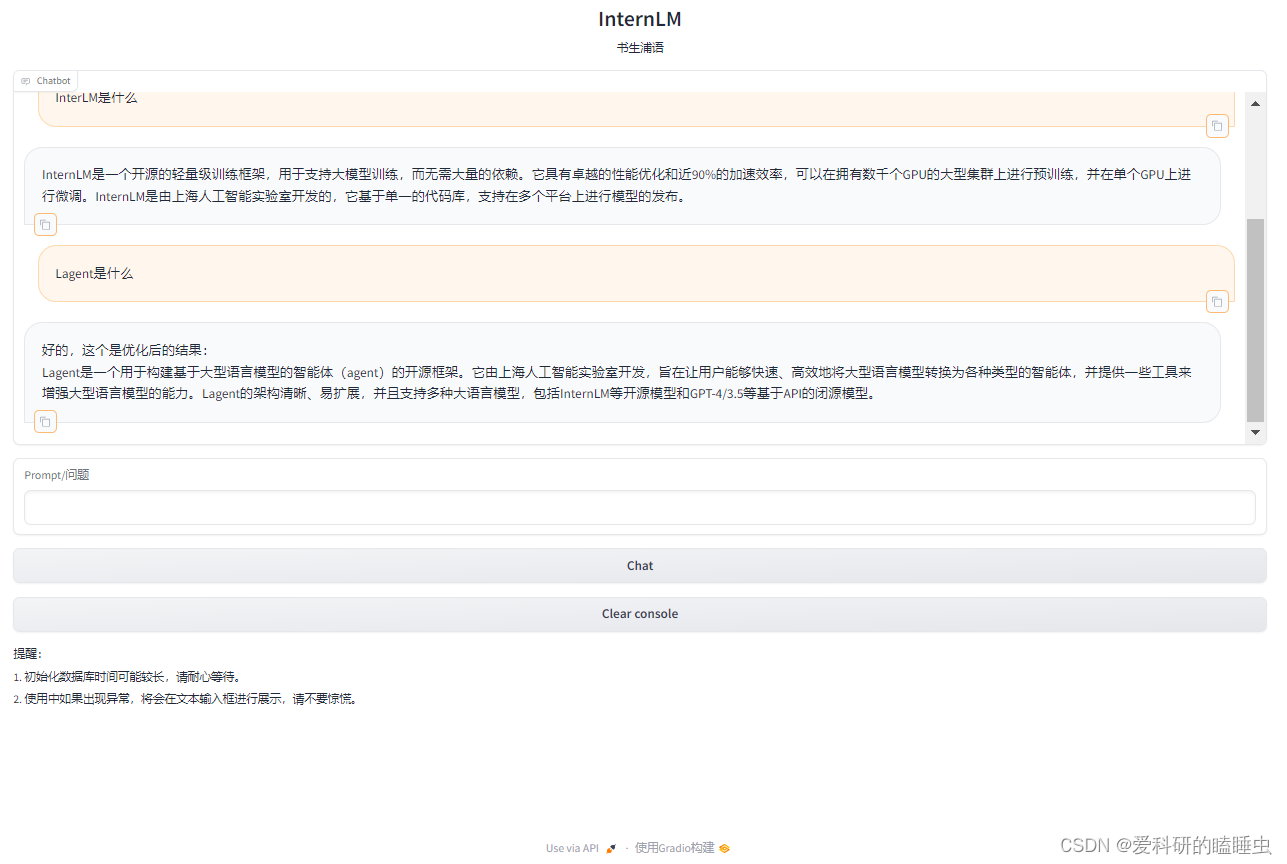
基于书生·浦语大模型InternLM 和 LangChain 搭建你的知识库助手Demo
文章目录 环境准备InternLM模型部署InternLM模型下载LangChain环境配置下载 NLTK 相关资源 知识库搭建数据收集加载数据构建向量数据库脚本整合 InternLM 接入 LangChain构建检索问答链加载向量数据库实例化自定义 LLM 与 Prompt Template构建检索问答链部署 Web Demo 环境准备…
2024年1月18日Arxiv最热NLP大模型论文:Large Language Models Are Neurosymbolic Reasoners
大语言模型化身符号逻辑大师,AAAI 2024见证文本游戏新纪元
引言:文本游戏中的符号推理挑战
在人工智能的众多应用场景中,符号推理能力的重要性不言而喻。符号推理涉及对符号和逻辑规则的理解与应用,这对于处理现实世界中的符号性…
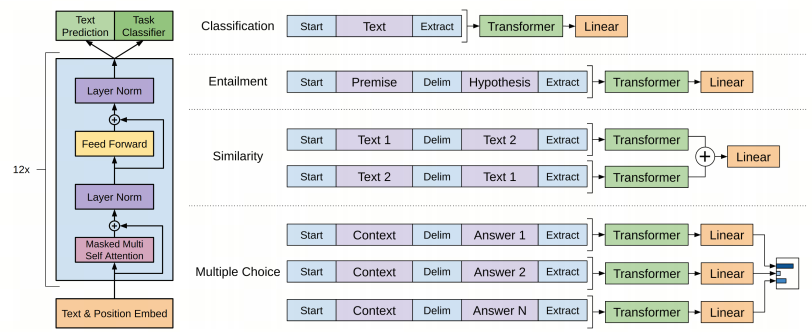
大语言模型系列-GPT-1
文章目录 前言一、GPT-1网络结构和流程二、GPT-1的创新点总结 前言
前文提到的ELMo虽然解决了词嵌入多义词的问题,但存在如下缺点:
基于RNN的网络结构使得其特征提取能力弱,训练难且时间长预训练模型(仅用于特征抽取)…
【NLP】2024年改变人工智能的前六大NLP语言模型
在快速发展的人工智能领域,自然语言处理已成为研究人员和开发人员关注的焦点。作为这一领域显著进步的证明,近年来出现了几种开创性的语言模型,突破了机器能够理解和生成的界限。在本文中,我们将深入研究大规模语言模型的最新进展…
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
本文是LLM系列文章,针对《NarrowBERT: Accelerating Masked Language Model Pretraining and Inference》的翻译。 NarrowBERT:加速掩蔽语言模型的预训练和推理 摘要1 引言2 NarrowBERT3 实验4 讨论与结论局限性 摘要
大规模语言模型预训练是自然语言处…

Retrieval-Augmented Generation for Large Language Models: A Survey
PS: 梳理该 Survey 的整体框架,后续补充相关参考文献的解析整理。本文的会从两个角度来分析总结,因此对于同一种技术可能在不同章节下都会有提及。第一个角度是从整体框架的迭代来看(对应RAG框架章节),第二个是从RAG中…

【网安专题10.11】代码大模型的应用及其安全性研究
代码大模型的应用及其安全性研究 写在最前面一些想法大型模型输出格式不受控制的解决方法 大模型介绍(很有意思)GPT 模型家族的发展Chatgpt优点缺点GPT4 其他模型补充:self-instruct合成数据 Code Llama 代码大模型的应用(第一次理…
迈向通用听觉人工智能!清华电子系、火山语音携手推出认知导向的听觉大语言模型SALMONN
日前,清华大学电子工程系与火山语音团队携手合作,推出认知导向的开源听觉大语言模型SALMONN (Speech Audio Language Music Open Neural Network)。 大语言模型 SALMONN LOGO
相较于仅仅支持语音输入或非语音音频输入的其他大模型,SALMONN对…
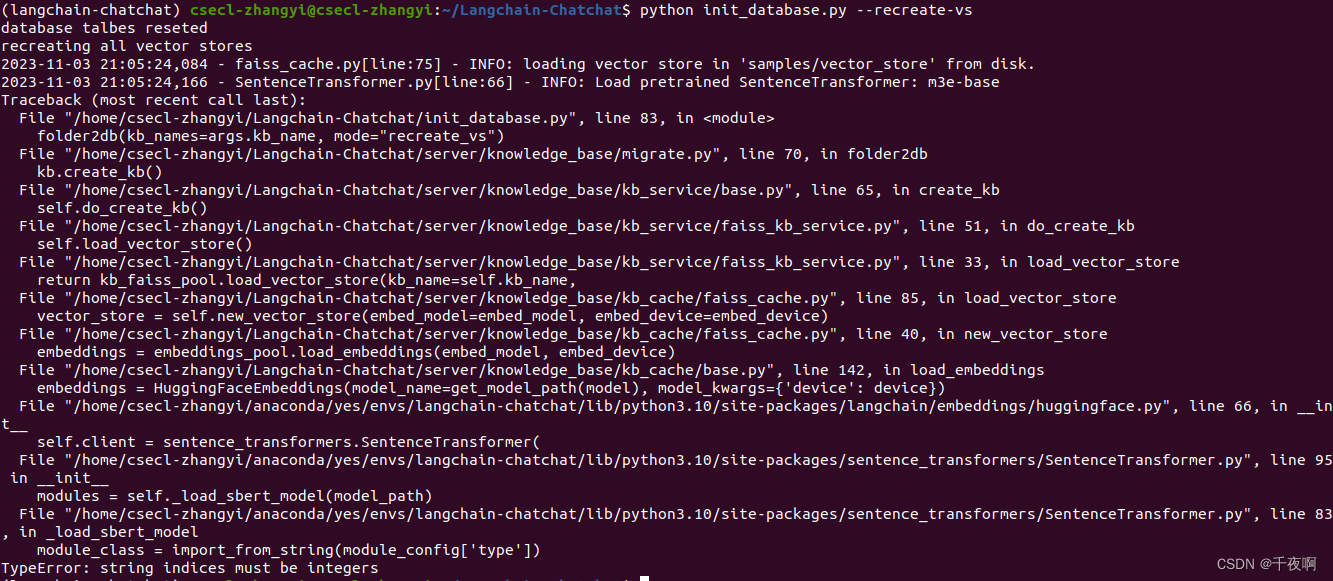
大模型 其他方案的进度
Llama2 1、中文提问,英文的回答,对于中文不友好 2、网上还没有看到很详细的微调教程 3、虽然Llama2的预训练数据相对于第一代LLaMA扩大了一倍,但是中文预训练数据的比例依然非常少,仅占0.13%,这也导致了原始Llama2的中…
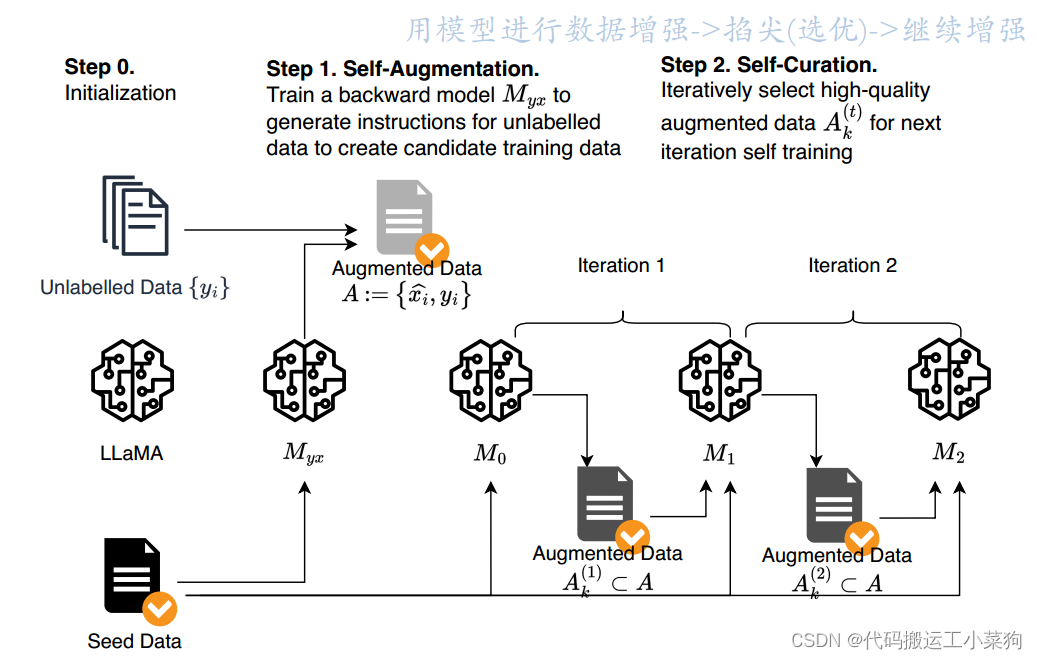
【论文笔记】基于指令回译的语言模型自对齐-MetaAI
MetaAI最近发布的Humpback,论文链接:https://arxiv.org/abs/2308.06259
解决什么问题?
大量高质量的指令微调数据集的生成。
思路 在这项工作中,我们通过开发迭代自训练算法来利用大量未标记的数据来创建高质量的指令调优数据集…
Paper简读 - ProGen2: Exploring the Boundaries of Protein Language Models
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/128976102 ProGen2: Exploring the Boundaries of Protein Language Models ProGen2:探索蛋白质语言模型的边界Cumulative density:累积密度
Ligand:在生…
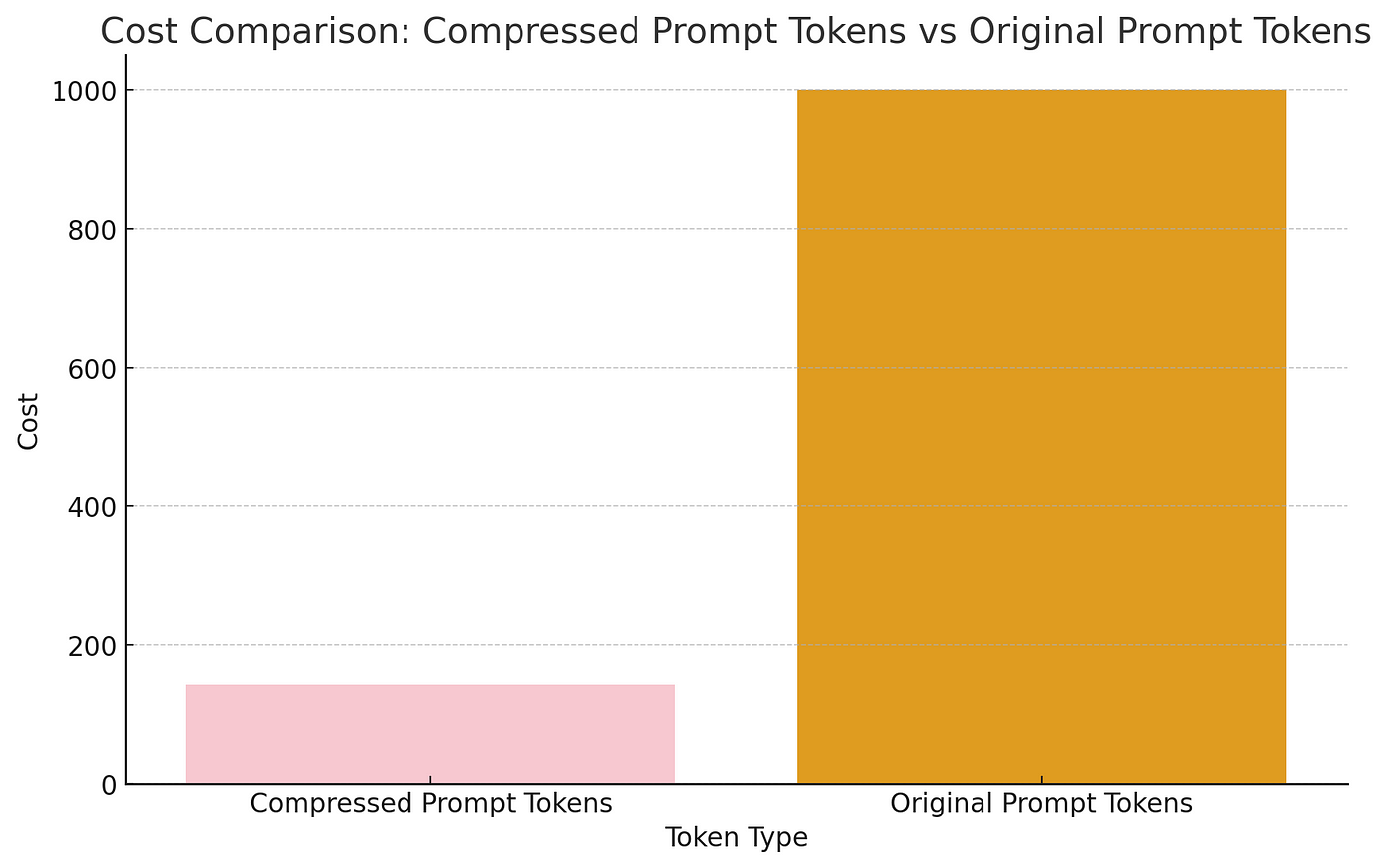
如何使用Prompt快速压缩将RAG成本降低80%
英文原文地址:How to Cut RAG Costs by 80% Using Prompt Compression
通过即时压缩加速推理
2024 年 1 月 5 日
推理过程是使用大型语言模型时消耗资金和时间成本的因素之一,对于较长的输入,这个问题会更加凸显。下面,您可以…
LLM大语言模型(四):在ChatGLM3-6B中使用langchain
目录 背景准备工作工具添加LangChain 已实现工具Calculator、Weather Tool配置 自定义工具自定义kuakuawo Agent 多工具使用参考 背景
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它使应用程序能够:
具有上下文意识:将语言模型与上下文源(提示指令&…
大模型学习篇(一):初识大模型
目录
一、大模型的定义
二、大模型的基本原理与特点
三、大模型的分类
四、大模型的相关落地产品
五、总结 一、大模型的定义 大模型是指具有数千万甚至数亿参数的深度学习模型。大模型具有以下特点:
参数规模庞大:大模型的一个关键特征是其包含了…
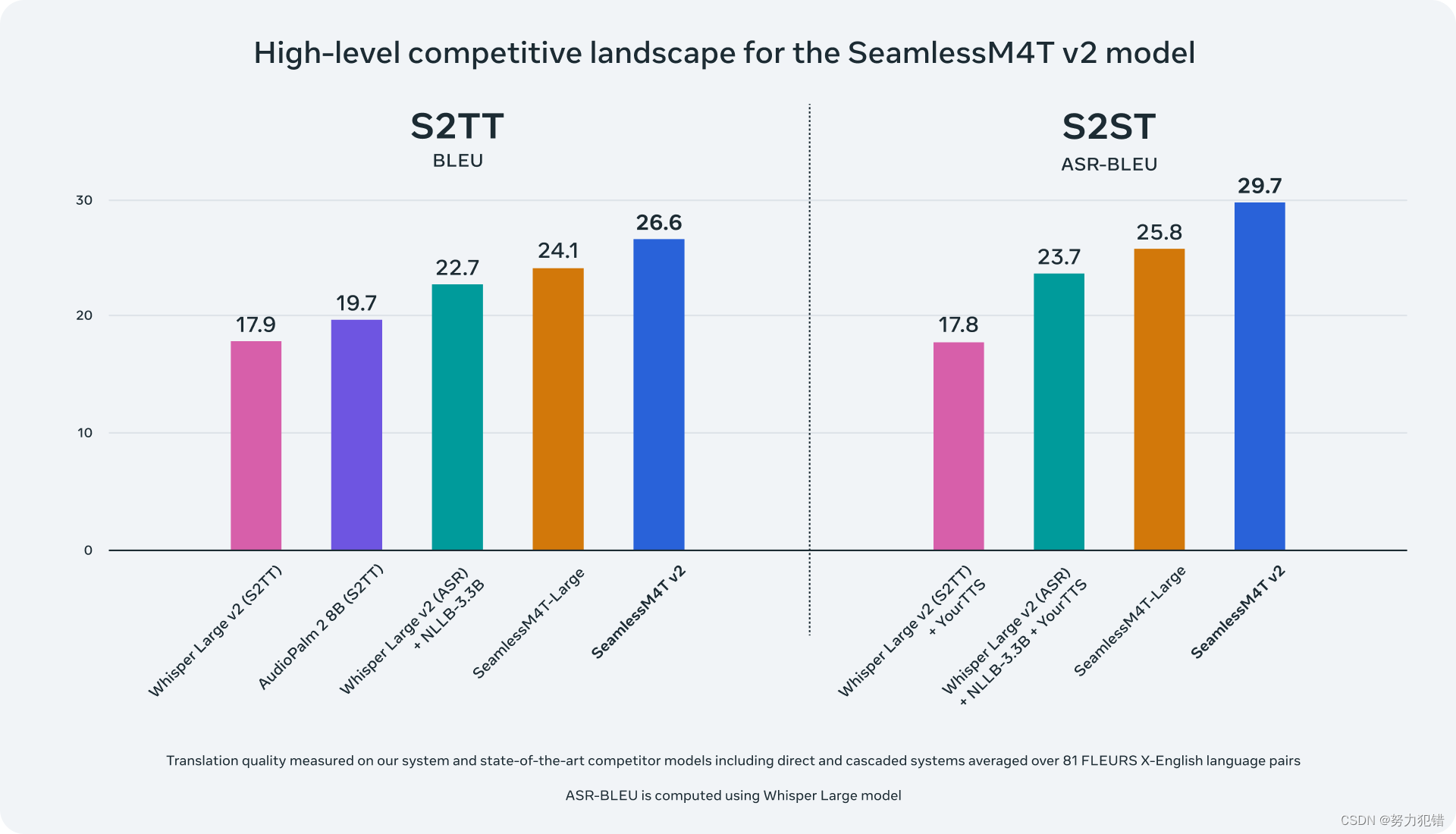
MetaAI发布Seamless:两秒内实现跨语言同声传译
在当今日益互联的世界中,语言差异常常成为沟通的障碍。MetaAI最新发布的语音翻译大模型Seamless,正是为打破这一障碍而生。Seamless不仅提供流畅、高效的多语言翻译功能,更在保留说话人韵律和风格方面取得突破,是AI同声传译领域的…
When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale
本文是LLM系列的文章,针对《When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale》的翻译。 当少即是多:研究大规模预训练LLM的数据修剪 摘要1 引言2 方法3 实验4 结果和讨论5 相关工作6 结论 摘要
近年来,大量的…
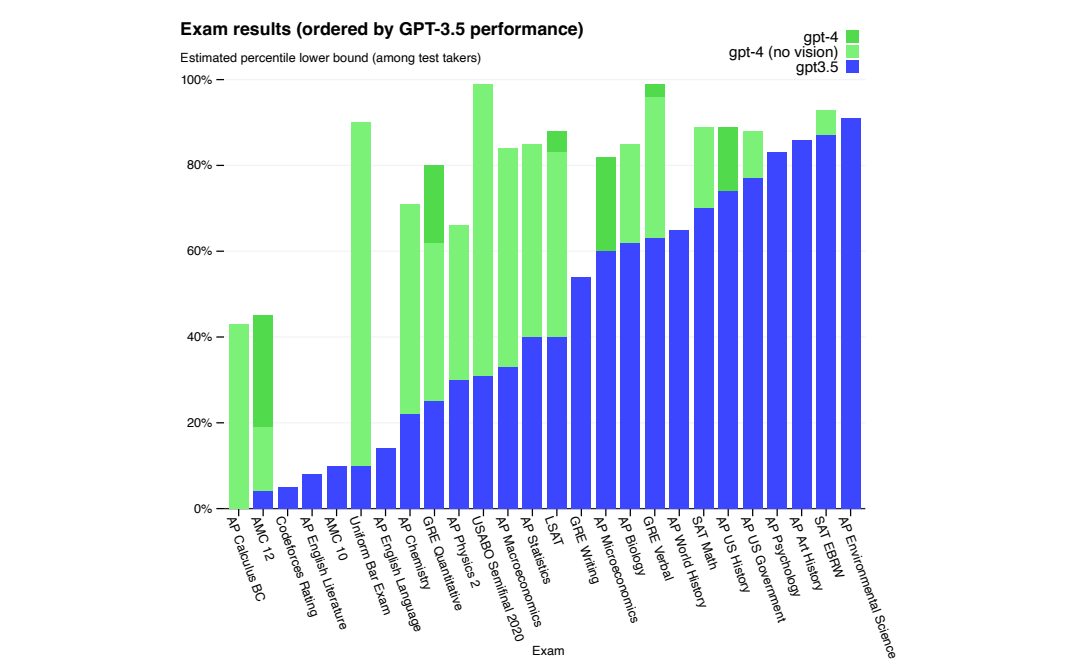
OpenAI开发系列(二):大语言模型发展史及Transformer架构详解
全文共1.8w余字,预计阅读时间约60分钟 | 满满干货,建议收藏! 一、介绍
在2020年秋季,GPT-3因其在社交媒体上病毒式的传播而引发了广泛关注。这款拥有超过1.75亿参数和每秒运行成本达到100万美元的大型语言模型(Large …

华策影视AIGC工程师招聘; 百度大模型创业松;主流大语言模型的技术原理细节;AIGC Prompt的七个缺陷 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🎯 华策影视AIGC工程师招聘,AIGC在「文娱领域」的真正落地 逛即刻时发现关注的AI博主 杨昌 发布了自己公司的招聘信息&#x…

链式法则:概率论描述语言模型
目录 1.事件相互独立
2.链式法则
3.示例
4.语言模型中的链式法则 1.事件相互独立
事件相互独立就是:一个事件的发生与否,不会影响另外一个事件的发生。
当a和b两个事件互相独立时,有: P(a | b) P(a) 推广到3个事件就有下面…
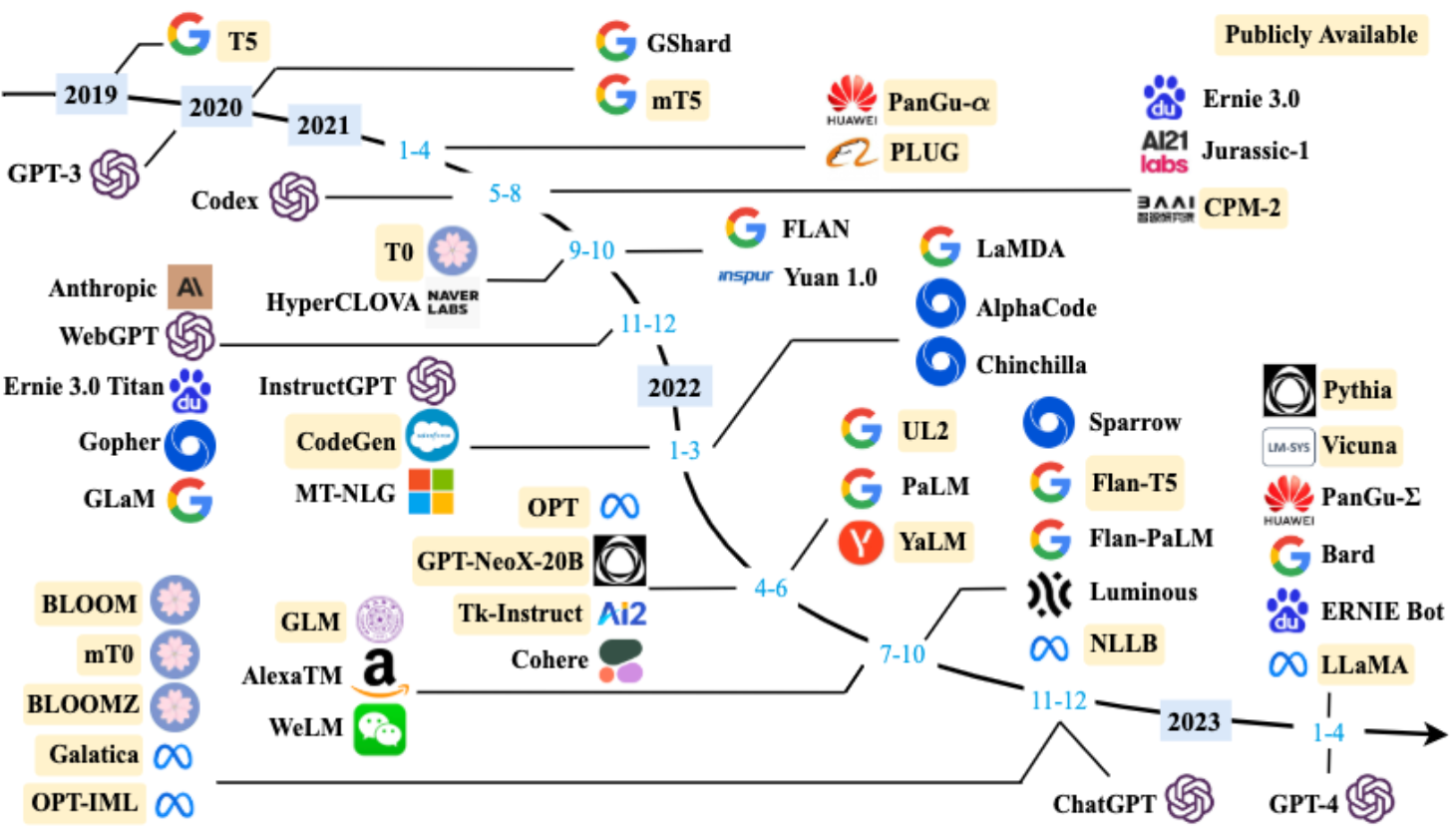
一文解码语言模型:语言模型的原理、实战与评估
目录 一、语言模型概述什么是语言模型?核心概念和数学表示挑战:高维度和稀疏性链式法则与条件概率举例 应用场景小结 二、n元语言模型(n-gram Language Models)基本概念数学表示 代码示例:计算Bigram概率输入与输出 优…

语言模型:从n-gram到神经网络的演进
目录 1 前言2 语言模型的两个任务2.1 自然语言理解2.2 自然语言生成 3 n-gram模型4 神经网络语言模型5 结语 1 前言
语言模型是自然语言处理领域中的关键技术之一,它致力于理解和生成人类语言。从最初的n-gram模型到如今基于神经网络的深度学习模型,语言…

大语言模型:Large Language Models Are Human-Level Prompt Engineers概述
研究内容
如何通过prompt,在不进行微调大语言模型的前提下,增加大语言模型的表现
研究动机
prompt非常有用,但是人工设置的非常不自然;因此提出了要自动使用大语言模型自己选择prompt;取得了很好的效果。
作者主要…
从零构建属于自己的GPT系列2:预训练中文模型加载、中文语言模型训练、逐行代码解读
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…

deepspeed多机多卡并行训练指南
文章目录 前言离线配置训练环境共享文件系统多台服务器之间配置互相免密登录pdsh多卡训练可能会碰到的问题注意总结 前言
我的配置:
7机14卡,每台服务器两张A800
问:为啥每台机只挂两张卡? 答:给我的就这样的&#…
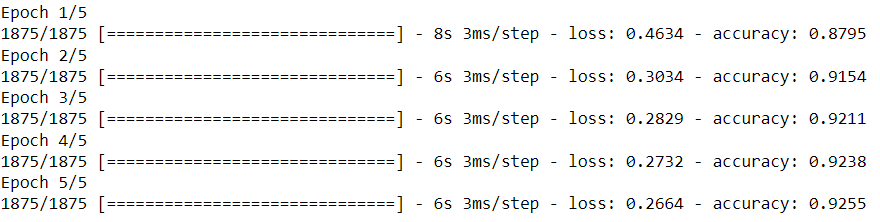
第三章:人工智能深度学习教程-基础神经网络(第二节-ANN 和 BNN 的区别)
在本文中,我们将了解单层感知器及其使用 TensorFlow 库在Python中的实现。神经网络的工作方式与我们的生物神经元的工作方式相同。 生物神经元的结构
生物神经元具有三个基本功能 接收外部信号。 处理信号并增强是否需要发送信息。 将信号传递给目标细胞&#x…
Agent开发的一小步,大模型应用的一大步
https://www.sohu.com/a/708426242_425761 Chat GPT带起飞的大模型无疑是上半年最火热的赛道,随着GPT-4的发布,各大互联网巨头、科技公司等纷纷入局。而在国内市场,过去几个月间大模型就已密集“涌现”。
不得不说,ChatGPT是大模…
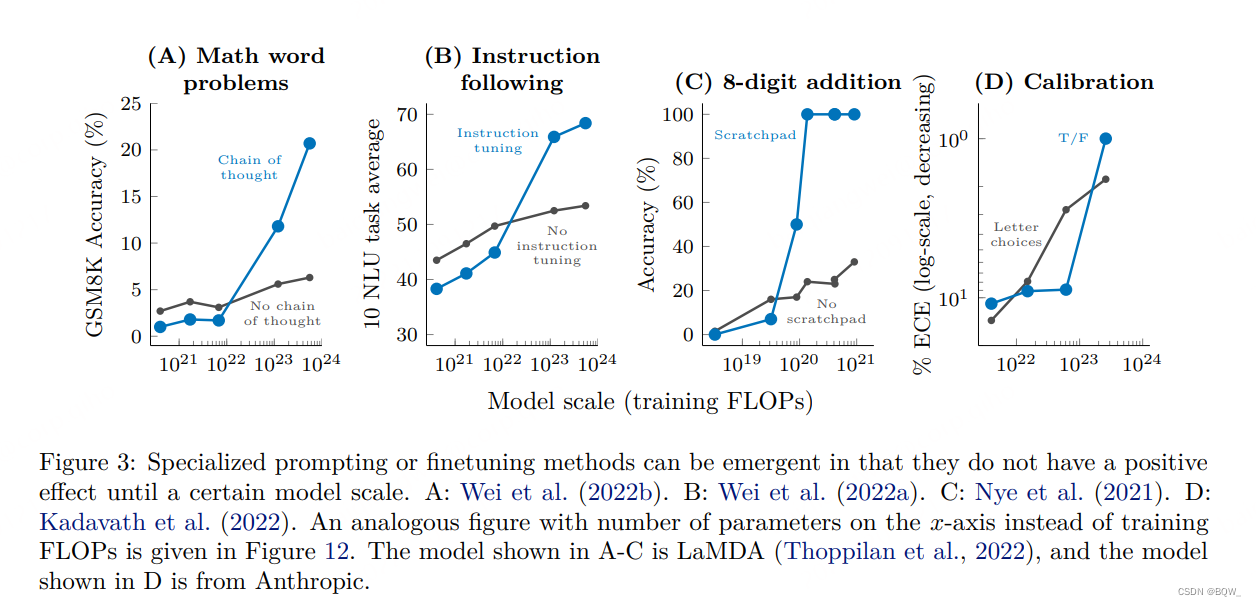
【自然语言处理】【ChatGPT系列】大模型的涌现能力
大语言模型的涌现能力《Emergent Abilities of Large Language Models》论文地址:https://arxiv.org/pdf/2206.07682.pdf 相关博客 【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里? 【自然语言处理】【ChatGPT系列】Chain of Thought:…
大语言模型系列-BERT
文章目录 前言一、BERT的网络结构和流程1.网络结构2.输入3.输出4.预训练Masked Language ModelNext Sentence Predictionloss 二、BERT创新点总结 前言
前文提到的GPT-1开创性的将Transformer Decoder架构引入NLP任务,并明确了预训练(学习 text 表征&am…

超详细!主流大语言模型的技术原理细节汇总!
1.比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。 2. 大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D 并行、零冗余优化器 ZeRO、CPU 卸载技术 ZeRo-offload、混合精度训…
检索增强(RAG)的方式---重排序re-ranking
提升RAG:选择最佳嵌入Embedding&重排序Reranker模型
检索增强生成(RAG)技术创新进展:自我检索、重排序、前瞻检索、系统2注意力、多模态RAG RAG的re-ranking指的是对初步检索出来的候选段落或者文章,通过重新排序的方式来提升检索质量。…

多语言生成式语言模型用于零样本跨语言事件论证提取(ACL2023)
1、写作动机:
经过预训练的生成式语言模型更好地捕捉实体之间的结构和依赖关系,因为模板提供了额外的声明性信息。先前工作中模板的设计是依赖于语言的,这使得很难将其扩展到零样本跨语言转移设置。
2、主要贡献:
作者提出了一…
UNVEILING A CORE LINGUISTIC REGION IN LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《UNVEILING A CORE LINGUISTIC REGION IN LARGE LANGUAGE MODELS》的翻译。 揭示大型语言模型中的核心语言区域 摘要1 引言2 前言和背景3 核心语言能力区4 讨论和未来工作5 结论 摘要
大脑定位描述了大脑特定区域与其相应功能之间的联系&a…

GPT-4发布:人工智能新高度,以图生文技术震撼,短时间内挤爆OpenAI模型付费系统
“GPT-4,起飞!”今日凌晨1点,OpenAI正式推出史上最强大的GPT-4文本生成AI系统
GPT-4:人工智能的新里程碑
你可能已经听说过GPT-3,它是一种能够生成自然语言文本的强大模型,可以用来回答问题、写文章、编程…
【论文解读系列】MLLM研究综述
A Survey on Multimodal Large Language Models
1 中国科大科技学院、认知智能国家重点实验室
2 腾讯优图实验室 MLLM目录 0. 摘要1. 引言2. 总览3. 方法3.1 多模态指令调谐3.1.1 引言3.1.2 前言(Preliminaries)3.1.3 模态对齐3.1.4 数据3.1.5 模态桥接3.1.6 评估 3.2 多模态…

2023年6月 国内大语言模型对比【国内模型正在崛起】
先说一下这个文章怎么来的。因为朋友问我大语言模型可以生成公务员面试回答不,我说可以啊。之前看文心有这个服务。我想最近好几个模型也没用了测一把!结果!大吃一惊!我觉得我的三个傻孩子长大了!(chatglm1…

微调您的Embedding模型以最大限度地提高RAG管道中的相关性检索
英文原文地址:https://betterprogramming.pub/fine-tuning-your-embedding-model-to-maximize-relevance-retrieval-in-rag-pipeline-2ea3fa231149
微调您的Embedding模型以最大限度地提高RAG管道中的相关性检索
微调嵌入前后的 NVIDIA SEC 10-K 文件分析
2023 年…

Transformer and Pretrain Language Models3-2
transformer structure注意力机制的各种变体
第二种变体:
如果两个向量的维度不一样,我们就需要在中间加上一个权重矩阵,来实现他们之间的相乘,然后最后得到一个标量
第三种变体:
additive attention
它和前面的有…

走向计算机视觉的通用人工智能:从GPT和大型语言模型中汲取的经验教训 (上)...
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 论文地址:https://arxiv.org/pdf/2306.08641.pdf 计算机视觉研究院专栏 Column of Computer Vision Institute 人工智能…

聊天GPT如何运作?| 景联文科技
什么是聊天 GPT?
Chat GPT 被定义为一种生成语言模型。在实践中,它被理解为经过训练和设计以进行自然对话的人工智能聊天。
聊天 GPT 的用途是什么?
1.借助 GPT,您可以生成各种风格、主题和语言的连贯且写得很好的文本。此外&a…
LangChain大型语言模型(LLM)应用开发(一):Models, Prompts and Output Parsers
LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互&#x…

论文笔记--Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks
论文笔记--Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks 1. 文章简介2. 文章概括3 文章重点技术3.1 LLM的选择3.2 算数任务的可学习性(learnability)3.3 大模型的加减乘除 4. 数值实验结果5. 文章亮点6. 原文传送门7. References 1. 文章简介
标题ÿ…

微软Azure-openAI 测试调用及说明
本文是公司在调研如何集成Azure-openAI时,调试测试用例得出的原文,原文主要基于官方说明文档简要整理实现
本文已假定阅读者申请部署了模型,已获取到所需的密钥和终结点
变量名称值ENDPOINT从 Azure 门户检查资源时,可在“密钥和…
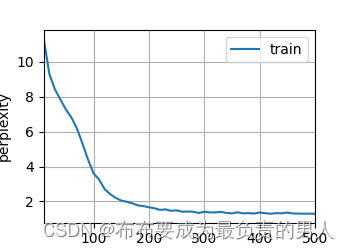
机器学习深度学习——RNN的从零开始实现与简洁实现
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——循环神经网络RNN 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮…

AI大模型已经出现不可预测的能力
编者按:日前,非盈利组织生命未来研究所发布了一封《暂停大型人工智能研究》的公开信,马斯克等千名科技人士进行了签名。虽然部分签署人的真实性存疑,但是大型语言模型(LLMs)的“涌现”能力确实可能会导致突…
How Can We Know What Language Models Know? 中文注释
原始地址: How Can We Know What Language Models Know? | Transactions of the Association for Computational Linguistics | MIT Press
(2022/3/13 下午3:40:25)
(Jiang 等。, 2020, p. 423) 最近的工作提出了耐人寻味的结果,即通过让语言模型&…
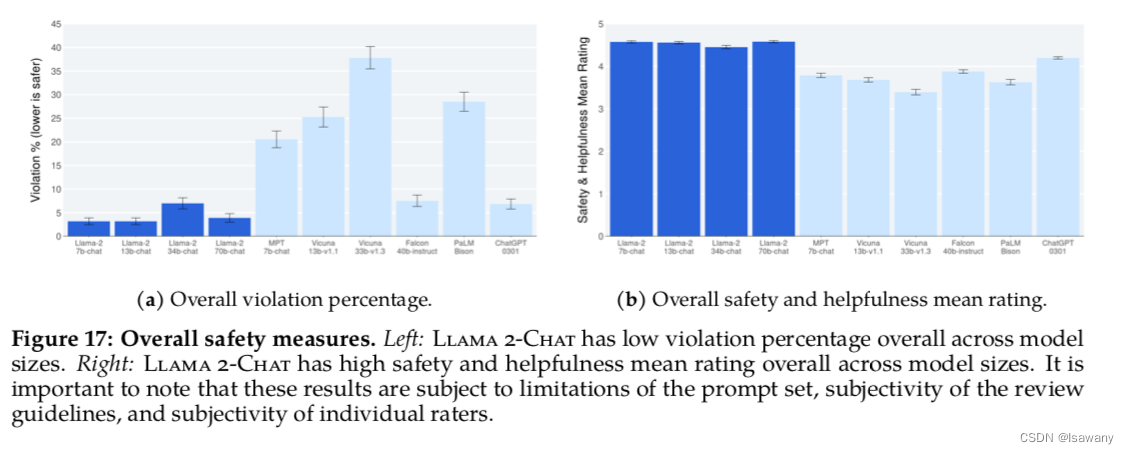
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练Pretraining3.1.1 预训练细节3.1.2 Llama2模型评估 3.2 微调Fine-tuning3.2.1 Supervised Fine-Tuning(FT)3.2.2 Reinforcement Learning with Human Feedback(…
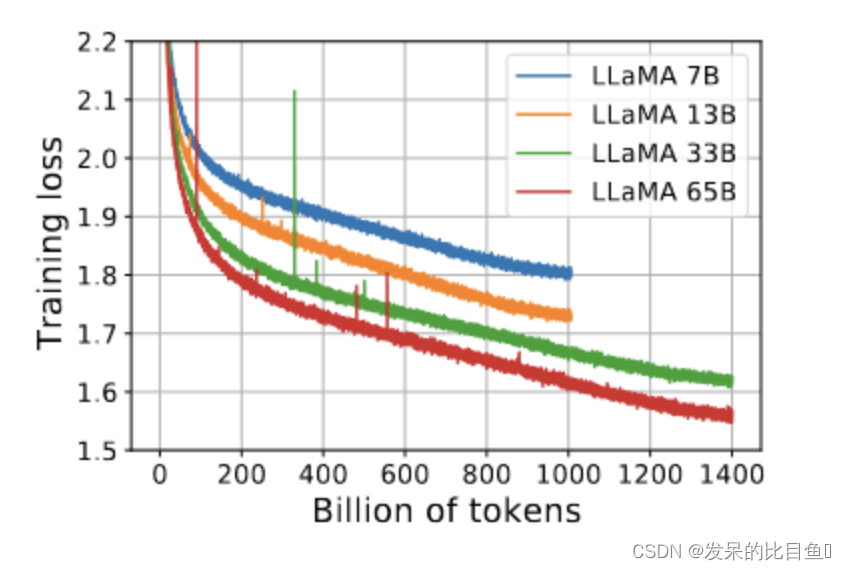
2023-arxiv-LLaMA: Open and Efficient Foundation Language Models
开放和高效的基础语言模型 Paper:https://arxiv.org/abs/2302.13971 Code: https://github.com/facebookresearch/llama
摘要
本文介绍了 LLaMA,这是⼀个包含 7B 到 65B 参数的基础语⾔模型的集合。作者在数万亿个令牌上训练模型,并表明可以…
机器学习深度学习——seq2seq实现机器翻译(详细实现与原理推导)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——seq2seq实现机器翻译(数据集处理) 📚订阅专栏:机器学习&…
EasyLLM:简化语言模型处理,实现 OpenAI 和 Hugging Face 客户端的无缝切换
前言
在这短短不到一年的时间里,国内外涌现的大型语言模型(LLM)可谓是百花齐放,不管是开源还是闭源都出现了一些非常优秀的模型,然而在利用LLM进行应用开发的时候,会发现每个模型从部署、到训练、微调、AP…
利用免费 GPU 部署体验大型语言模型推理框架 vLLM
vLLM简介
vLLM 是一个快速且易于使用的 LLM(大型语言模型)推理和服务库。
vLLM 之所以快速,是因为: 最先进的服务吞吐量 通过 PagedAttention 高效管理注意力键和值内存 连续批处理传入请求 使用 CUDA/HIP 图快速模型执行 量…

【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
GLM-130B:一个开源双语预训练语言模型《GLM-130B: An open bilingual pre-trained model》论文:https://arxiv.org/pdf/2210.02414.pdf 相关博客 【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型 【自然语言处理】【大模型】…

GLM论文精读-自回归填空的通用语言模型
GLM作为ChatGLM的前期基础论文,值得精读。本文是对GLM论文的精读笔记,希望对大家有帮助。GLM主要思想概述,利用自回归填空的思想,基于transformer的编码器实现了同时在NLU和有无条件生成任务上较好的表现。
基本信息
原文&#…
【LLM系列之PaLM】PaLM: Scaling Language Modeling with Pathways
论文题目:《Scaling Instruction-Finetuned Language Models》
论文链接:https://arxiv.org/abs/2204.02311
github链接1:https://github.com/lucidrains/PaLM-pytorch/tree/main;
github链接2:https://github.com/conceptofmind/PaLM
huggin…
GPT大语言模型Vicuna本地化部署实践(效果秒杀Alpaca) | 京东云技术团队
背景
上一篇文章《[GPT大语言模型Alpaca-lora本地化部署实践]》介绍了斯坦福大学的Alpaca-lora模型的本地化部署,并验证了实际的推理效果。
总体感觉其实并不是特别理想,原始Alpaca-lora模型对中文支持并不好,用52k的中文指令集对模型进…
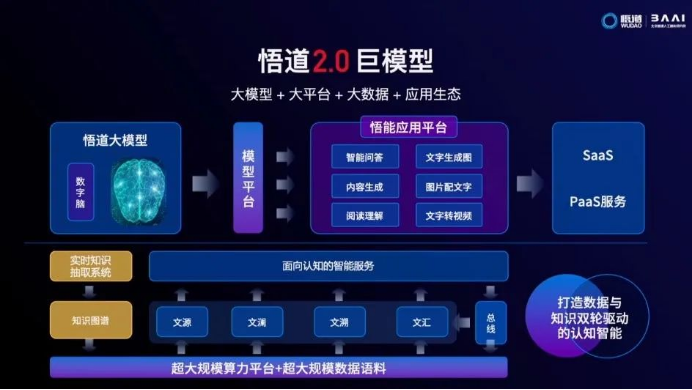
开源大语言模型完整列表
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。 LLM 通常基于神经网络模型,使用大规模的语料库进行训练,比如使…
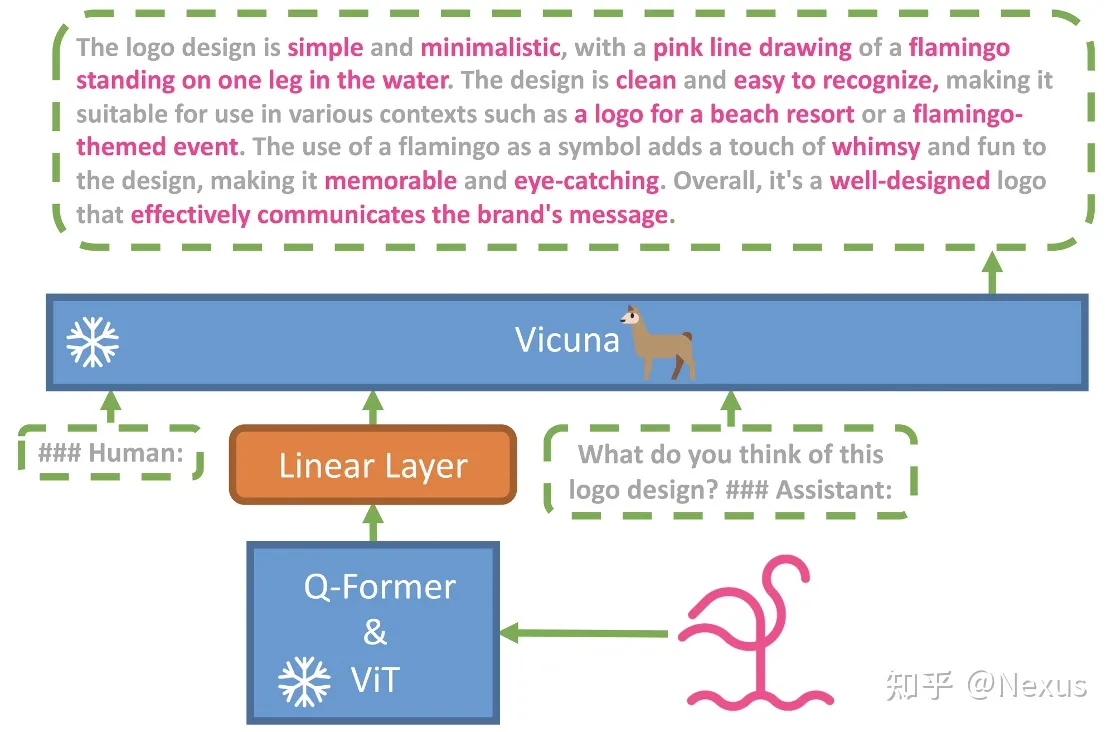
最流行的开源 LLM (大语言模型)整理
本文对国内外公司、科研机构等组织开源的 LLM 进行了全面的整理。
Large Language Model (LLM) 即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。
所谓"语言模…

2023 CCF-百度松果基金正式启动申报!大语言模型、AIGC等热点课题首次公布
5 月 31 日,2023 年 CCF-百度松果基金(简称“松果基金”)正式启动申报,面向全球高校及科研院所青年学者开放,入选项目将获得松果基金百万课题基金及千万级支持与服务。申报截至 2023 年 7 月 10 日。 本届松果基金共设…
N-Gram语言模型工具kenlm的详细安装教程
【本配置过程基于Linux系统】
下载源代码:
wget -O - https://kheafield.com/code/kenlm.tar.gz |tar xz 编译:
makdir kenlm/build
cd kenlm/build
cmake .. && make -j4
发现报错: 系统中没有cmake,按照错误提示&am…
第一个现象级音乐生成产品Suno;GenAI动画技能全图;超级个体的技术写作手册;大语言模型入门新书 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 AI将彻底摧毁阅读文化,书籍这种内容载体真的过时了吗? https://www.kdpcommunity.com/s/article/Addition-of-…
大语言模型——BERT和GPT的那些事儿
前言
自然语言处理是人工智能的一个分支。在自然语言处理领域,有两个相当著名的大语言模型——BERT和GPT。两个模型是同一年提出的,那一年BERT以不可抵挡之势,让整个人工智能届为之震动。据说当年BERT的影响力是GPT的十倍以上。而现在&#…

YaRN方法:无需微调,高效扩展语言模型上下文窗口/蚂蚁集团与浙大发布原生安全框架v1.0,引领企业网络安全新时代 |魔法半周报
我有魔法✨为你劈开信息大海❗
高效获取AIGC的热门事件🔥,更新AIGC的最新动态,生成相应的魔法简报,节省阅读时间👻 🔥资讯预览 YaRN方法:无需微调,高效扩展语言模型上下文窗口 蚂蚁…

论文浅尝 | SimKGC:基于预训练语言模型的简单对比知识图谱补全
笔记整理:李雅新,天津大学硕士,研究方向为知识图谱补全 链接:https://dl.acm.org/doi/10.1145/3539597.3570483 动机 知识图谱补全 (KGC) 旨在对已知事实进行推理并推断缺失的链接。基于文本的方法从自然语言描述中学习实体表示&a…
从零构建属于自己的GPT系列3:模型训练2(训练函数解读、模型训练函数解读、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…
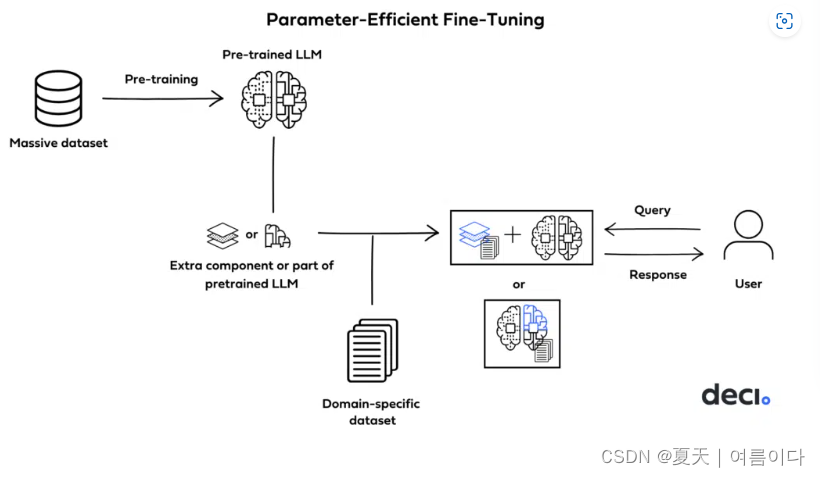
LLM | 一文了解大语言模型中的参数高效微调(PEFT)
Parameter Efficient Fine Tuning(PEFT)也就是参数高效微调,是一种用于微调大型语言模型 (LLM) 的方法,与传统方法相比,它有效地降低了计算和内存需求。PEFT仅对模型参数的一小部分进行微调,同时冻结大部分…

ModaHub大禹智库:ModelScope魔搭社区的“下载数据严重造假“的说法可能存在一定的合理性
目录
首先,我们需要了解ModelScope魔搭社区的运营模式和数据收集方式。
其次,我们需要考虑ModelScope魔搭社区的用户群体和应用场景。
此外,我们还需要考虑ModelScope魔搭社区的发展时间和市场竞争情况。
综上所述,ModelScope…
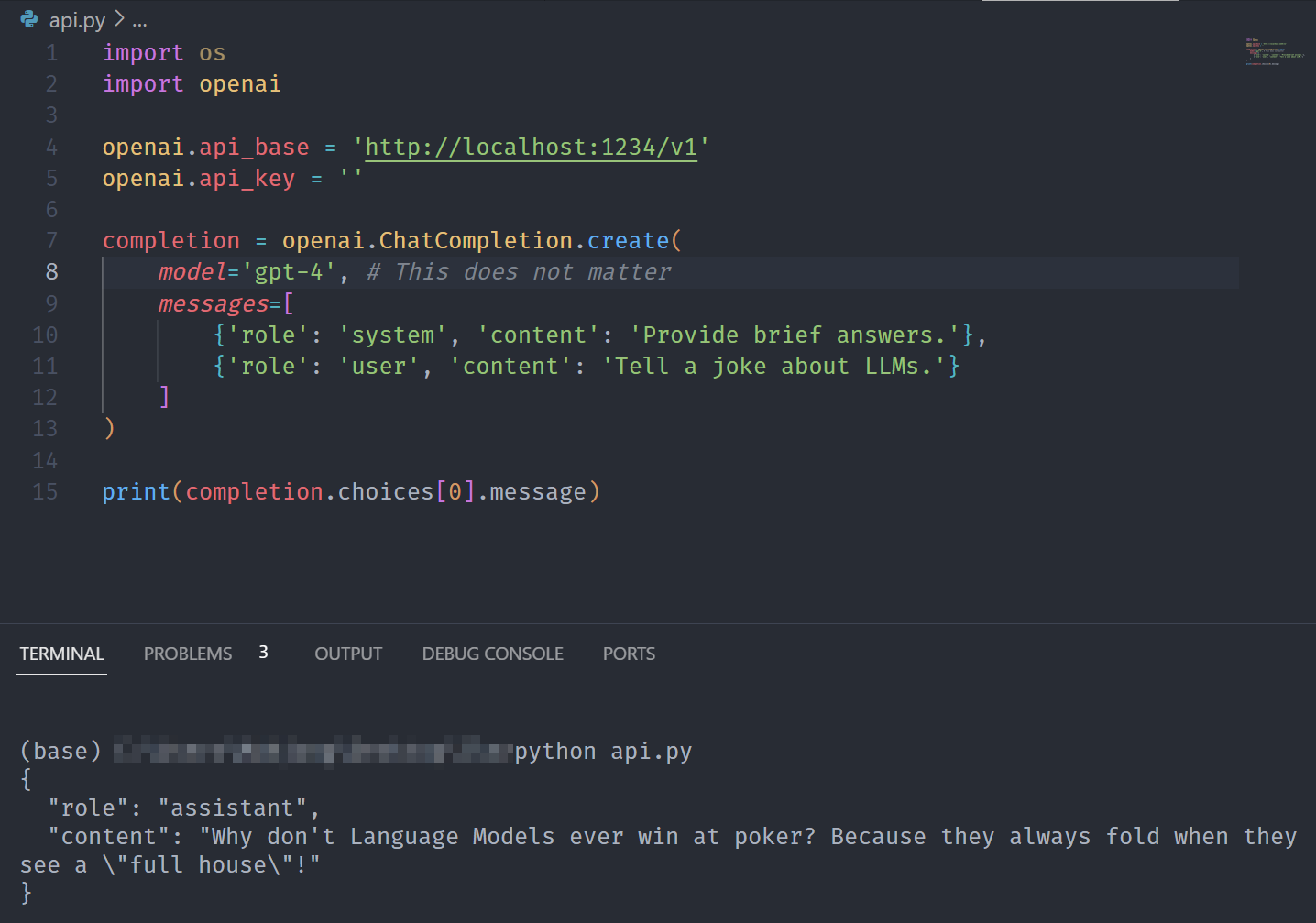
在本地运行大型语言模型 (LLM) 的六种方法(2024 年 1 月)
一、说明 (开放)本地大型语言模型(LLM),特别是在 Meta 发布LLaMA和后Llama 2,变得越来越好,并且被越来越广泛地采用。 在本文中,我想演示在本地(即在您的计算机上&#x…
论文阅读-Examining Zero-Shot Vulnerability Repair with Large Language Models
1.本文主旨: 这篇论文探讨了使用大型语言模型(LLM)进行零射击漏洞修复的方法。人类开发人员编写的代码可能存在网络安全漏洞,新兴的智能代码补全工具是否能帮助修复这些漏洞呢?在本文中,作者研究了大型语言…
LLM大语言模型(六):RAG模式下基于PostgreSQL pgvector插件实现vector向量相似性检索
目录 HightLightMac上安装PostgreSQLDBever图形界面管理端创建DB 使用向量检索vector相似度计算近似近邻索引HNSW近似近邻索引示例 HightLight
使用PostgreSQL来存储和检索vector,在数据规模非庞大的情况下,简单高效。
可以和在线业务共用一套DB&#…
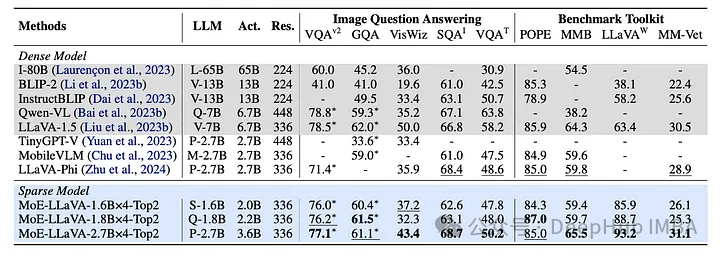
MoE-LLaVA:具有高效缩放和多模态专业知识的大型视觉语言模型
视觉和语言模型的交叉导致了人工智能的变革性进步,使应用程序能够以类似于人类感知的方式理解和解释世界。大型视觉语言模型(LVLMs)在图像识别、视觉问题回答和多模态交互方面提供了无与伦比的能力。
MoE-LLaVA利用了“专家混合”策略融合视觉和语言数据࿰…
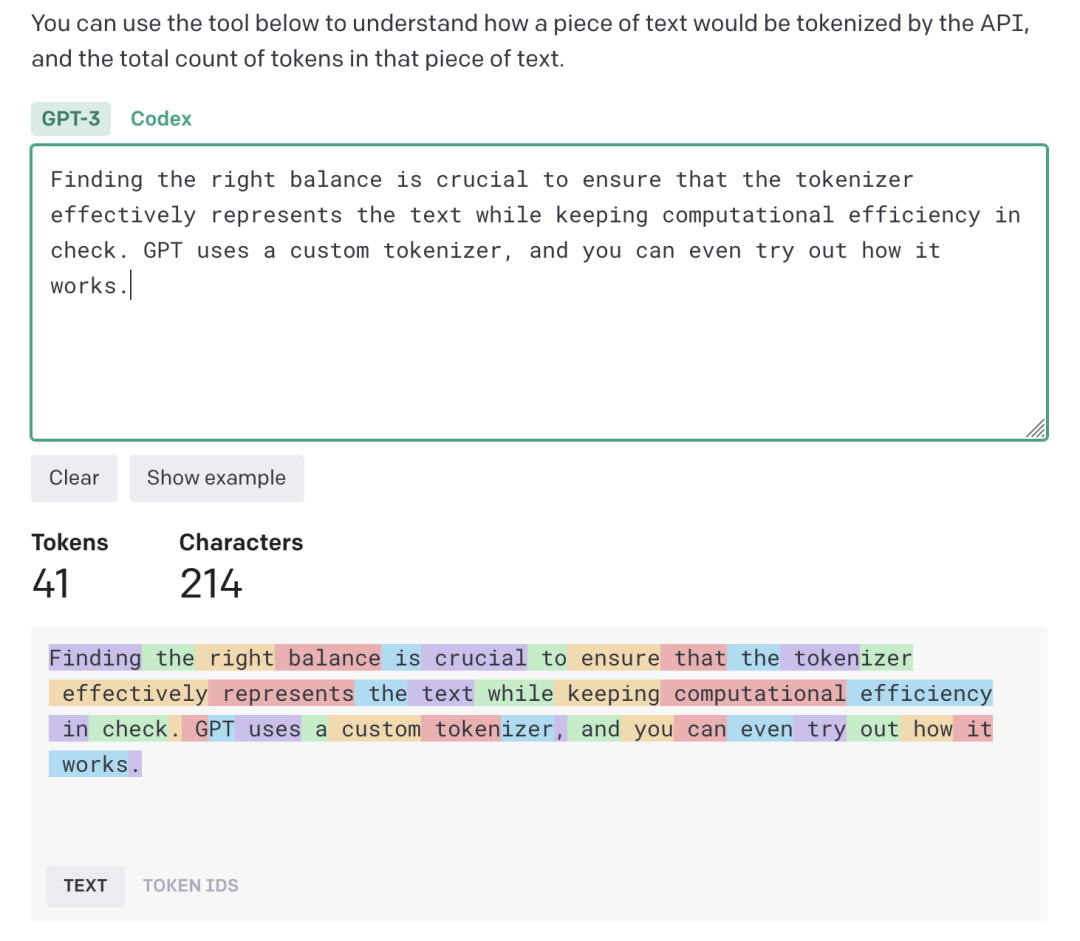
语言模型文本处理基石:Tokenizer简明概述
编者按:近年来,人工智能技术飞速发展,尤其是大型语言模型的问世,让 AI 写作、聊天等能力有了质的飞跃。如何更好地理解和利用这些生成式 AI,成为许多开发者和用户关心的问题。 今天,我们推出的这篇文章有助…


2023年排行前五的大规模语言模型(LLM)
2023年排行前五的大规模语言模型(LLM)
截至2023年,人工智能正在风靡全球。它已经成为热门的讨论话题,吸引了数百万人的关注,不仅限于技术专家和研究人员,还包括来自不同背景的个人。人们对人工智能热情高涨的原因之一是其在人类多…

中文医学知识语言模型:BenTsao
介绍
BenTsao:[原名:华驼(HuaTuo)]: 基于中文医学知识的大语言模型指令微调 本项目开源了经过中文医学指令精调/指令微调(Instruction-tuning) 的大语言模型集,包括LLaMA、Alpaca-Chinese、Bloom、活字模型等。
我们基于医学知识图谱以及医…
A Survey on Model Compression for Large Language Models
本文是LLM系列文章,关于模型压缩相关综述,针对《A Survey on Model Compression for Large Language Models》的翻译。 大模型的模型压缩综述 摘要1 引言2 方法3 度量和基准3.1 度量3.2 基准 4 挑战和未来方向5 结论 摘要
大型语言模型(LLM…
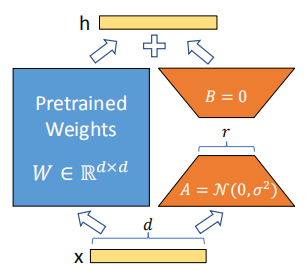
大语言模型微调实践——LoRA 微调细节
1. 引言 近年来人工智能领域不断进步,大语言模型的崛起引领了自然语言处理的革命。这些参数量巨大的预训练模型,凭借其在大规模数据上学习到的丰富语言表示,为我们带来了前所未有的文本理解和生成能力。然而,要使这些通用模型在特…
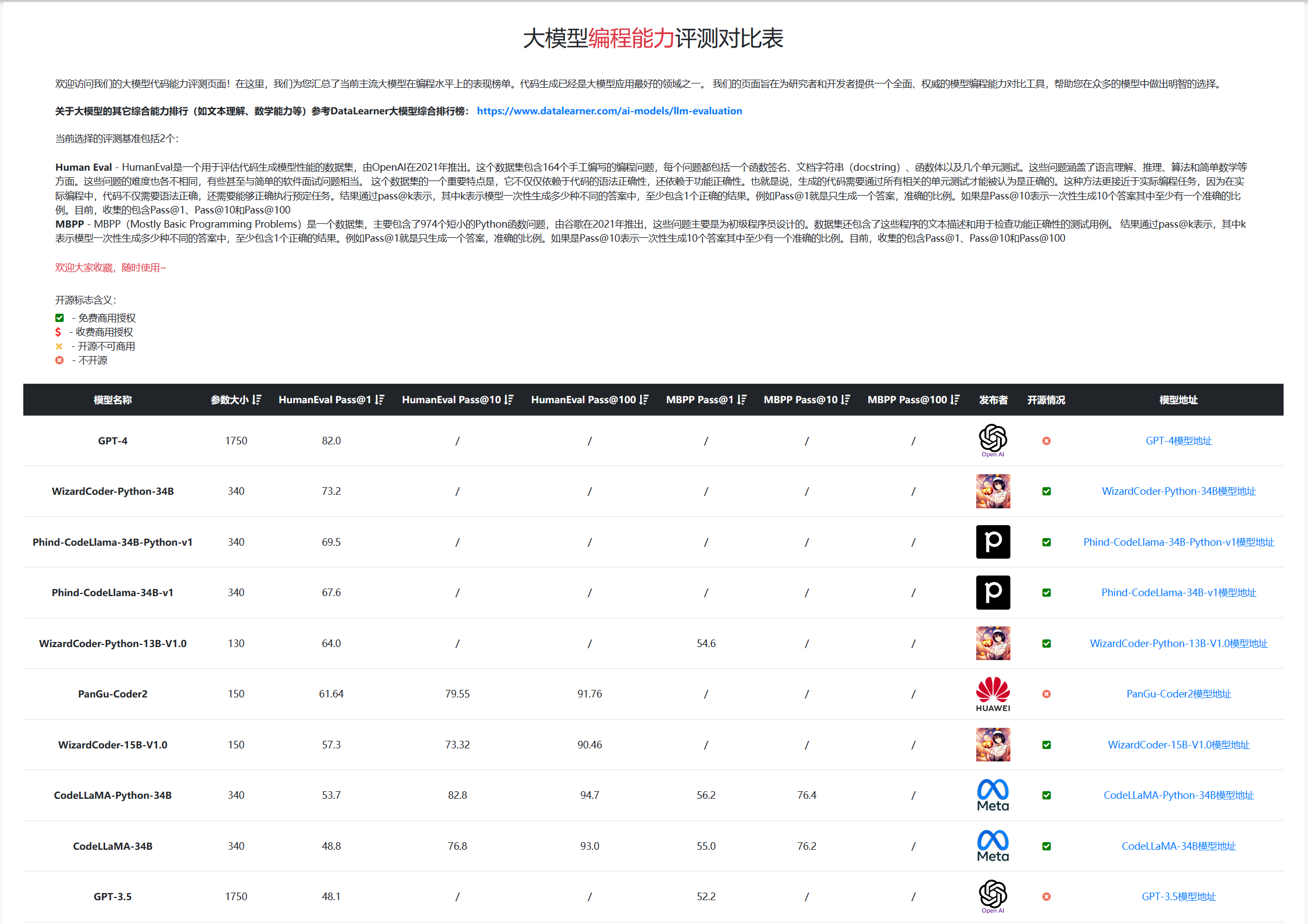
哪个大模型的编程能力更好?DataLearner编程大模型排行榜帮你选择!开源进展神速,前五已经有4个开源模型!
本文转载自DataLearner官方博客:哪个大模型的编程能力更好?DataLearner编程大模型排行榜帮你选择!开源进展神速,前五已经有4个开源模型! | 数据学习者官方网站(Datalearner)
编程大模型已经是大模型发展领域最重要的分…
YaRN: Efficient Context Window Extension of Large Language Models
本文是LLM系列文章,针对《YaRN: Efficient Context Window Extension of Large Language Models》的翻译。 YaRN:大型语言模型的有效上下文窗口扩展 摘要1 引言2 背景和相关工作3 方法4 实验5 结论 摘要
旋转位置嵌入(RoPE)已被…
The Rise and Potential of Large Language Model Based Agents: A Survey
本文是LLM系列文章,针对《The Rise and Potential of Large Language Model Based Agents:A Survey》的翻译。 基于大型语言模型的Agent的兴起及其潜力 摘要1 引言2 背景2.1 AI代理的起源2.22.3 3 Agent的诞生:基于LLM的Agent构建4 实践中的…
搭建部署属于自己的基于gpt3.5的大语言模型(基于flask+html+css+js+mysql实现)
一、简介
本项目是一个基于GPT-3.5模型的聊天机器人网站,旨在为用户提供一个简便、直接的方式来体验和利用GPT-3.5模型的强大功能。项目以Flask为基础,构建了一个完整的Web应用程序,其中包含了多个前端页面和后端API接口,能够处理…
EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
本文是LLM系列文章,针对《EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models》的翻译。 EdgeMoE:基于MoE的大型语言模型的快速设备推理 摘要1 引言2 实验与分析3 EDGEMOE设计4 评估5 相关工作6 结论 摘要
GPT和LLaMa等大型语言模…

【AI视野·今日NLP 自然语言处理论文速览 第三十六期】Tue, 19 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 19 Sep 2023 (showing first 100 of 106 entries) Totally 106 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Speaker attribution in German parliamentary debates with QLoRA-ada…
大语言模型之十 SentencePiece
Tokenizer
诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官…
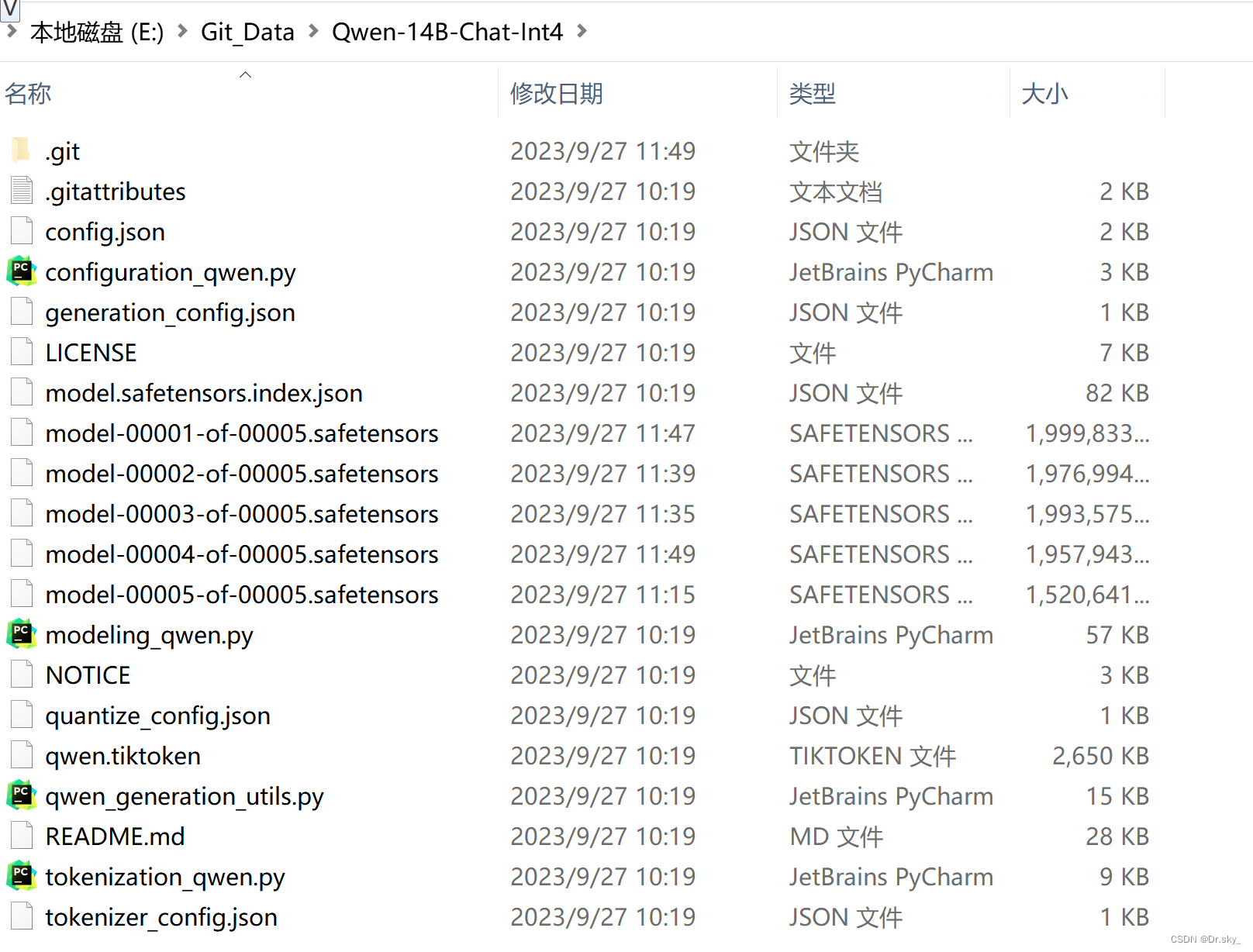
使用Git下载大语言模型
在下载Huggingface和ModelScope上面的大语言预训练模型的时候,经常会因为网页无法访问或者文件太大无法下载的情况,是大家常常比较苦恼的事情,下面给出用Git下载模型到本地的方法,可以轻松解决上述问题。
目录
一、下载和安装Gi…
【HuggingFace】Transformers(V4.34.0 稳定)支持的模型
Transformer 4.43.40 版本是自然语言处理领域的一个重要工具包,为开发者提供了丰富的预训练模型资源,可以用于各种文本处理任务。在这个版本中,Transformer 支持了众多模型,每个模型都具有不同的优势和适用领域。下面是一个 Trans…
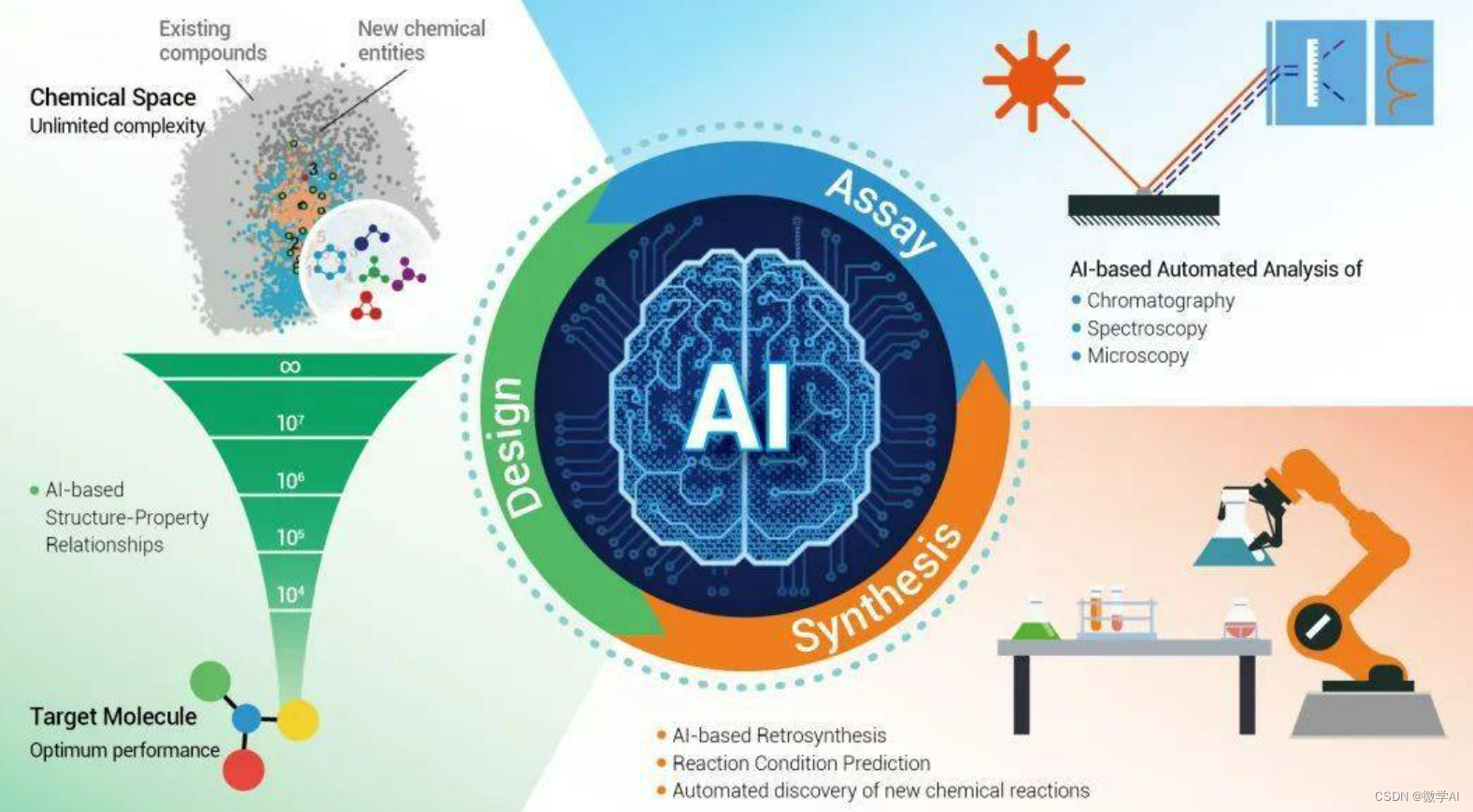
人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用
大家好,我是微学AI ,今天给大家介绍一下人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用,随着人工智能(AI)和深度学习技术的发展,大模型已经开始渗透到各个领域,包括数学教育。本文将详细介绍基于大模型在数学…
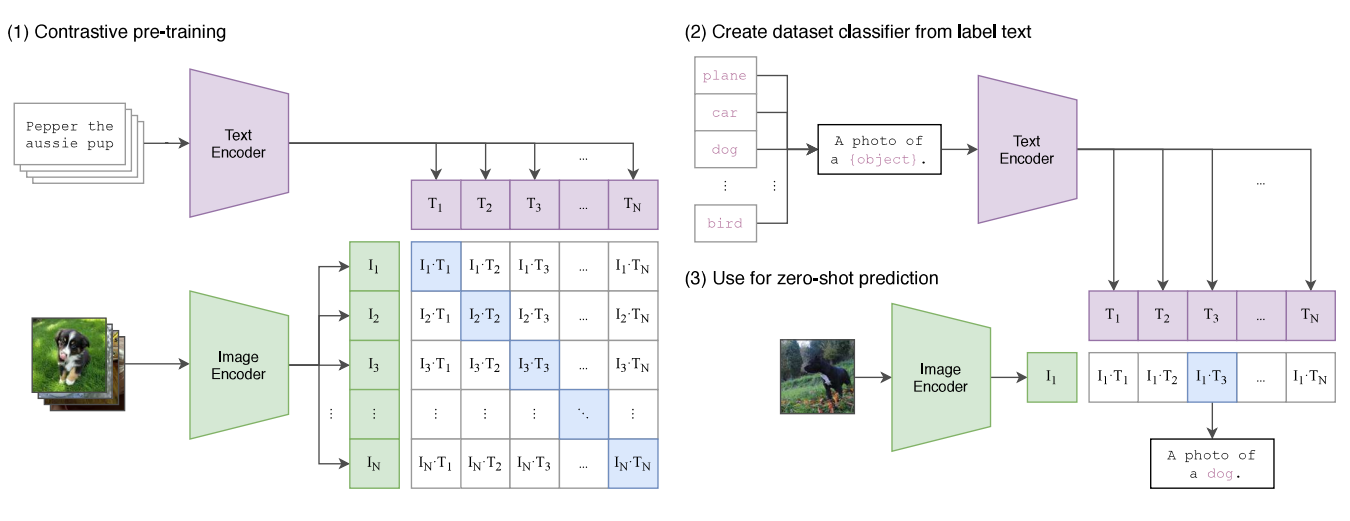
【计算机视觉】CLIP:语言-图像表示之间的桥梁
文章目录一、前言二、架构三、应用3.1 图像分类3.2 图像描述3.3 文本到图像四、总结一、前言
最近GPT4的火爆覆盖了一个新闻:midjourney v5发布,DALLE2,midjourney都可以从文本中生成图像,这种模型要求人工智能同时理解语言和图像…

米哈游、复旦发布,具备感知、大脑、行动的大语言模型“智能体”
ChatGPT等大语言模型展示了前所未有的创造能力,但距AGI(通用人工智能)还有很大的距离,缺少自主决策、记忆存储、规划等拟人化能力。
为了探索大语言模型向AGI演变,进化成超越人类的超级人工智能,米哈游与复…
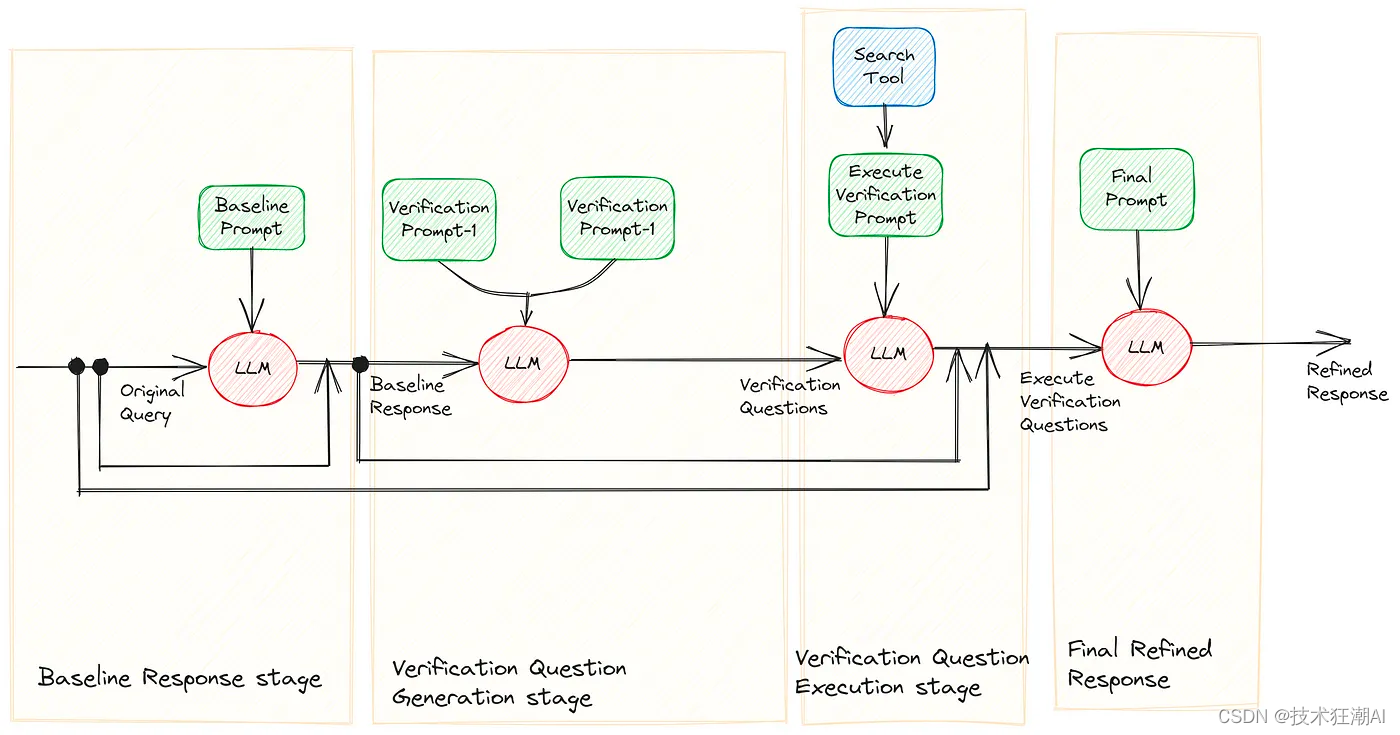
如何利用验证链技术减少大型语言模型中的幻觉
一、前言
随着大型语言模型在自然语言处理领域取得了惊人的进步。相信深度使用过大模型产品的朋友都会发现一个问题,就是有时候在上下文内容比较多,对话比较长,或者是模型本身知识不了解的情况下与GPT模型对话,模型反馈出来的结果…
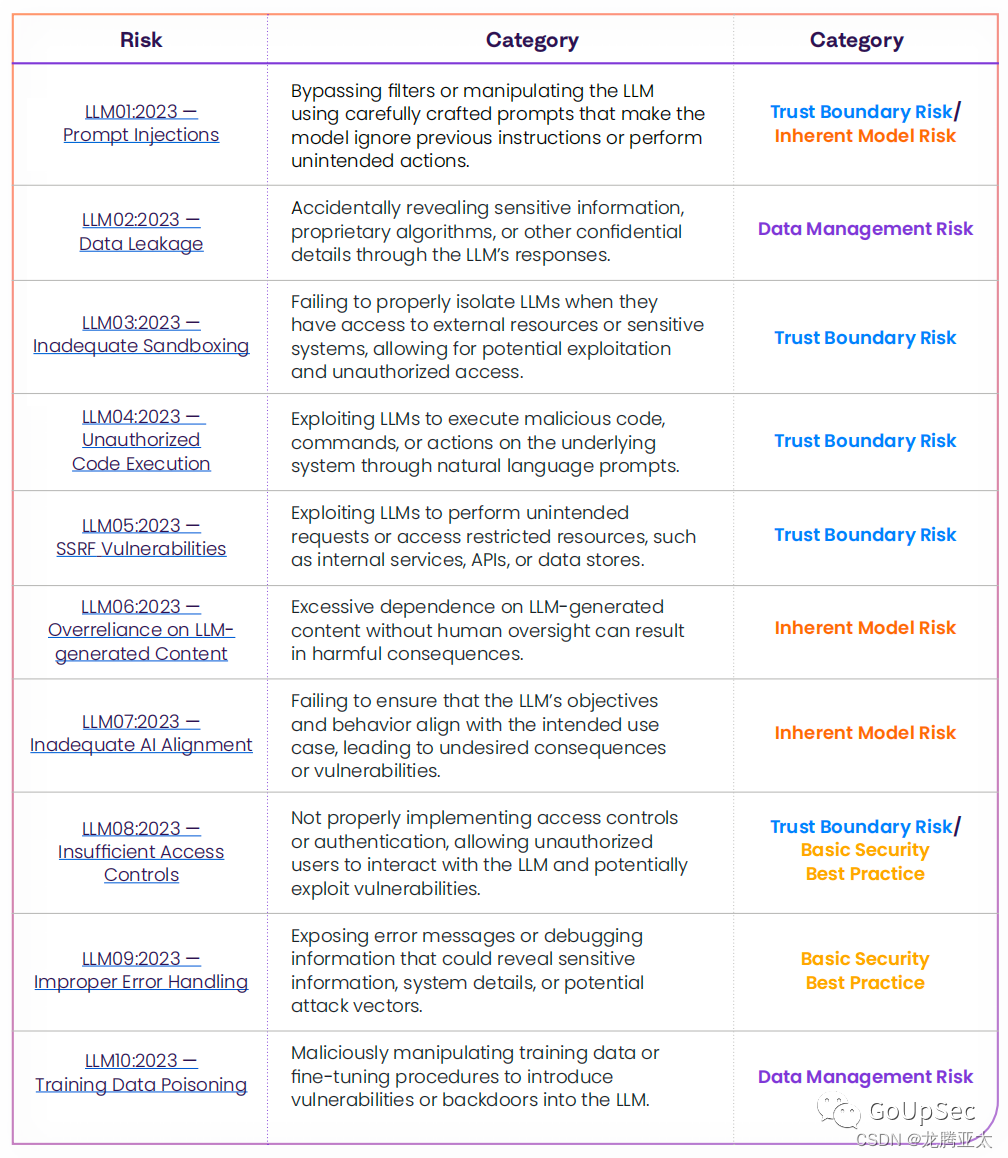
越流行的大语言模型越不安全
源自:GoUpSec “人工智能技术与咨询” 发布
安全研究人员用OpenSSF记分卡对GitHub上50个最流行的生成式AI大语言模型项目的安全性进行了评估,结果发现越流行的大语言模型越危险。 近日,安全研究人员用OpenSSF记分卡对GitHub上50个最流…
【LLM】大语言模型高效微调方案Lora||直击底层逻辑
敬请期待... Reference
深入浅出剖析 LoRA 技术原理_lora csdn-CSDN博客
【OpenLLM 006】LoRA:大模型的低秩适配-最近大火的lora到底是什么东西?为啥stable diffusion和开源ChatGPT复现都在用? - 知乎 (zhihu.com)
在教育领域,AI垂直大模型应用场景总结!
1. 智能教育助手:
这种模型可以通过语音或文本与学生进行交互,提供个性化的学习建议和答疑解惑。根据学生的学习习惯和知识水平,推荐适合的学习资源,并提供实时的辅导和反馈。
2. 智能作文批改助手:
这种模型可以对…

【LLMs】从大语言模型到表征再到知识图谱
从大语言模型到表征再到知识图谱 InstructGLMLLM如何学习拓扑?构建InstructGLM泛化InstructGLM补充参考资料 2023年8月14日,张永峰等人的论文《Natural Language is All a Graph Needs》登上arXiv街头,轰动一时!本论文概述了一个名…
使用大语言模型 LLM 做文本分析
本文主要分享 传统聚类算法 LLM与嵌入算法 嵌入算法聚类 LLM的其他用法
聚类是一种无监督机器学习技术,旨在根据相似的数据点的特征将其分组在一起。使用聚类成簇,有助于解决各种问题,例如客户细分、异常检测和文本分类等。尽管传统的聚…
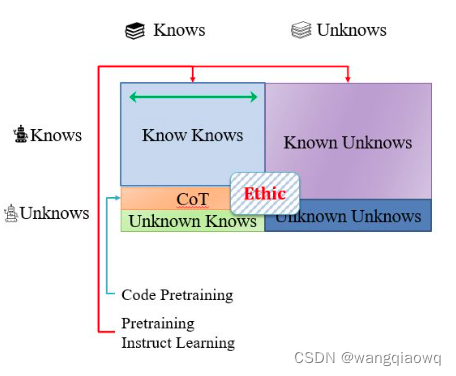
为什么是大语言模型?
参考:复旦邱锡鹏:深度剖析 ChatGPT 类大语言模型的关键技术 – 我爱自然语言处理 (52nlp.cn)
随着算力的不断提升,语言模型已经从最初基于概率预测的模型发展到基于 Transformer 架构的预训练语言模型,并逐步走向大模型的时代。 …
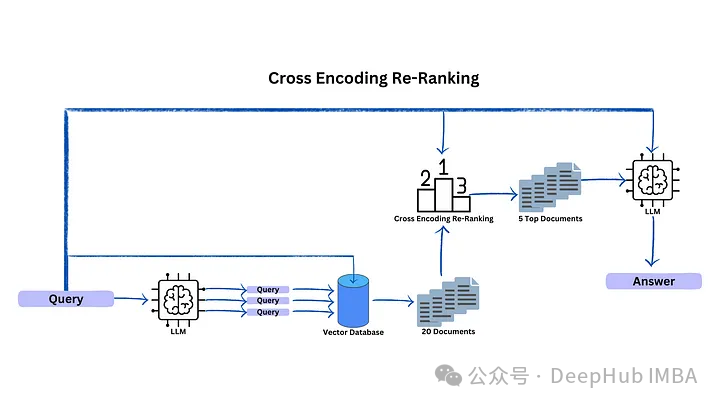
Langchain中改进RAG能力的3种常用的扩展查询方法
有多种方法可以提高检索增强生成(RAG)的能力,其中一种方法称为查询扩展。我们这里主要介绍在Langchain中常用的3种方法
查询扩展技术涉及对用户的原始查询进行细化,以生成更全面和信息丰富的搜索。使用扩展后的查询将从向量数据库中获取更多相关文档。 …

一些大语言模型(LLM)相关的开源项目
一些大语言模型(LLM)相关的开源项目
更多文章访问: https://www.cyisme.top 因为站内限制问题,有些图片无法显示,导致阅读体验较差,可以访问原文:《一些大语言模型(LLM)相关的开源项…

香港科技园公司董事车品觉:探秘大数据背后的大语言模型世界
大数据产业创新服务媒体 ——聚焦数据 改变商业 在数字时代的大舞台上,大数据与大语言模型的交汇如同星辰般璀璨,勾勒出创新之路的奇妙轨迹。这两者的完美契合不仅是科技领域的巨大突破,更是创新之路的重要交汇点。 作为大数据领域的一位先锋…
大白话理解大型语言模型(LLM):预训练和微调
引言: 在人工智能的世界里,大型语言模型(LLM)已成为一种强大的工具,它们不仅能理解和生成自然语言,还能在各种复杂任务中表现出色。本文将深入探讨这些模型的两个关键阶段:预训练和微调…
大模型评测和强化学习知识
1 大模型怎么评测?
大语言模型的评测通常涉及以下几个方面: 语法和流畅度:评估模型生成的文本是否符合语法规则,并且是否流畅自然。这可以通过人工评估或自动评估指标如困惑度(perplexity)来衡量。 语义准…
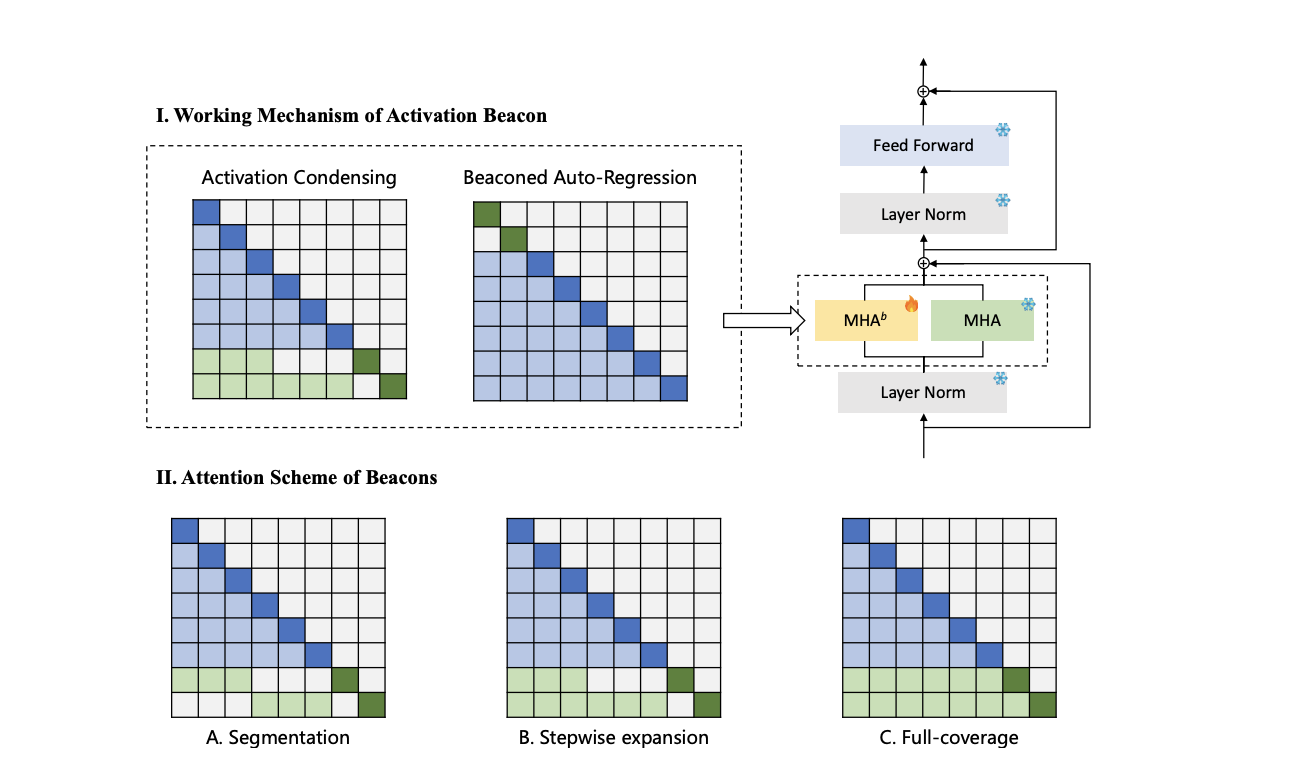
一览大模型长文本能力
前言
如今的大模型被应用在各个场景,其中有些场景则需要模型能够支持处理较长文本的能力(比如8k甚至更长),其中已经有很多开源或者闭源模型具备该能力比如GPT4、Baichuan2-192K等等。
那关于LLM的长文本能力,目前业界通常都是怎么做的&…
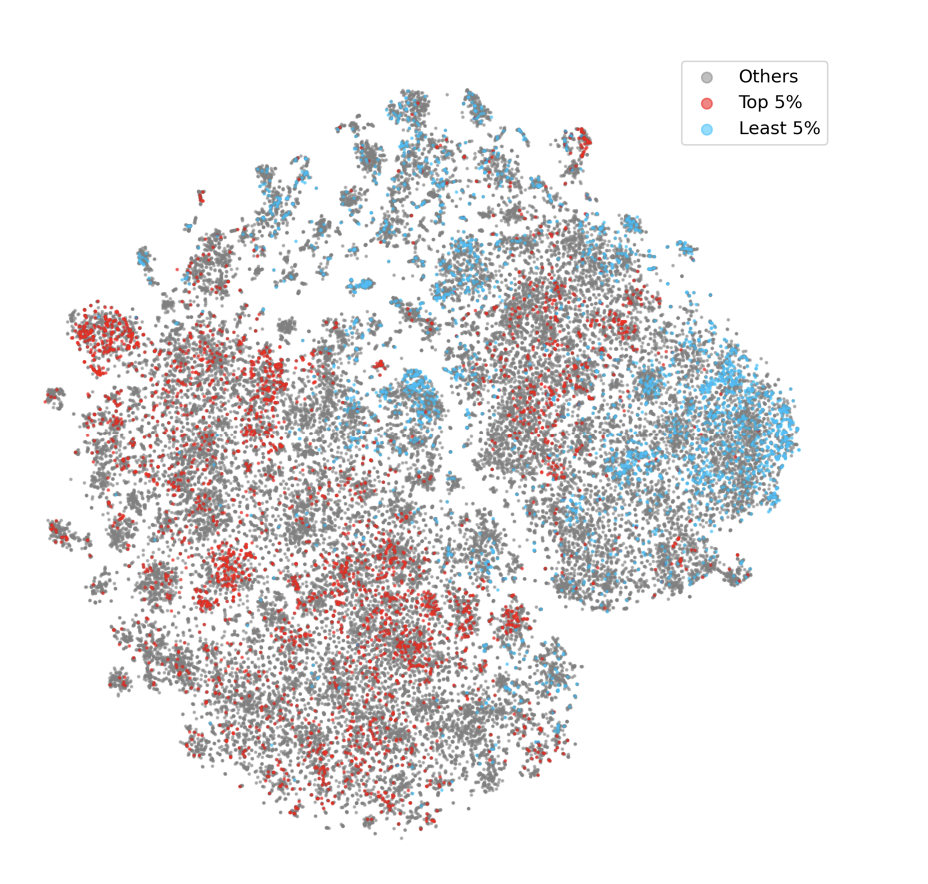
如何自动筛选高质量的指令微调数据喂给大模型?
前言
大家都知道在大模型时代,数据有多么重要,质量多高都不过分!甚至直接决定着最终的效果。
尤其做SFT,模型框架基本不用改(事实上也改不动),如何做一份符合自己场景高质量的SFT数据成了唯一…
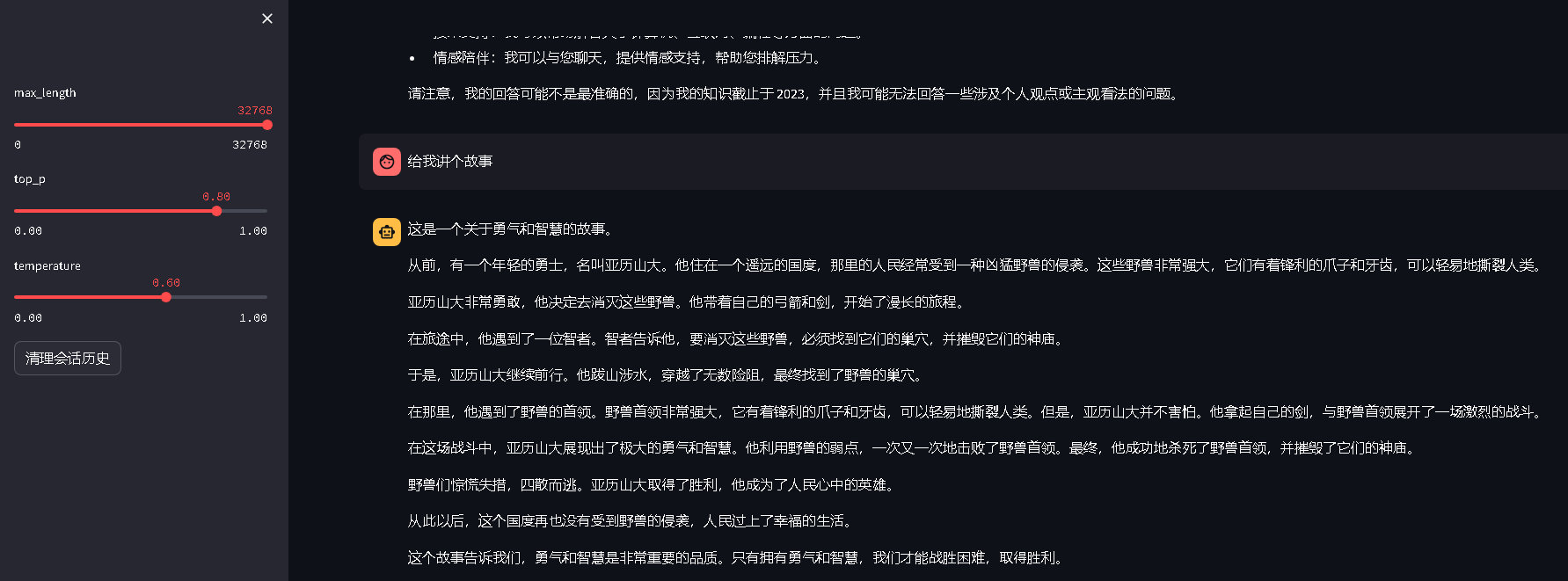
【ChatGLM3】第三代大语言模型多GPU部署指南
关于ChatGLM3
ChatGLM3是智谱AI与清华大学KEG实验室联合发布的新一代对话预训练模型。在第二代ChatGLM的基础之上,
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、…
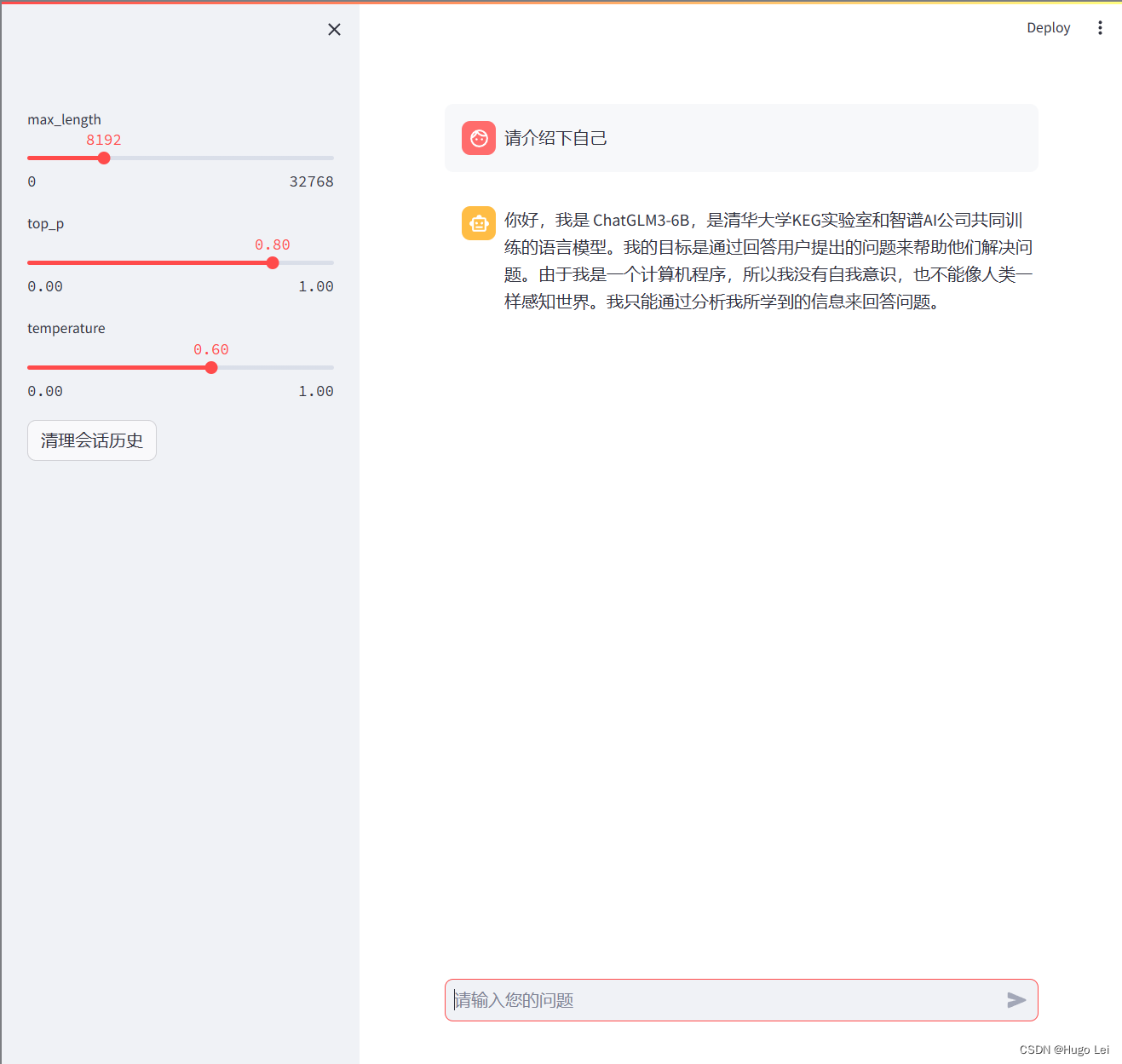
LLM大语言模型(二):Streamlit 无需前端经验也能画web页面
目录
问题
Streamlit是什么?
怎样用Streamlit画一个LLM的web页面呢?
文本输出
页面布局
滑动条
按钮
对话框
输入框
总结 问题
假如你是一位后端开发,没有任何的web开发经验,那如何去实现一个LLM的对话交互页面呢&…
构建企业级大语言模型应用的秘诀:GitHub Copilot 的实践之路
GitHub Copilot 是目前最成功的大语言模型应用之一,可以帮程序员自动生成可用的代码,已经有超过一百万付费用户。
GitHub Copilot 开发团队分享了构建这个产品时的经验教训。整个产品的开发历时三年,尽力了三个阶段:发现、实现和…
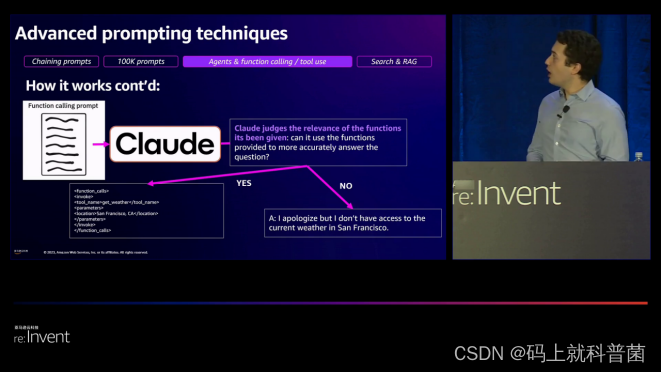
大语言模型提示工程:引领生成式AI的未来
在当今数字化时代,大语言模型(LLMs)已成为人工智能领域的焦点。在2023 re:Invent大会上,亚马逊云科技Bedrock部门的主要工程师约翰贝克(John Baker)和Anthropic公司的代表尼古拉斯马鲁尔(Nichol…

第34期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.02.05-2024.02.10
相关LLMs论文大多都是应用型文章,少部分是优化prompt/参数量级等等… 有一些应用文还是值得参考的,当工作面临一个新的场景,可以学习下他人是如何结合LLMs与实际应用中的链接。
LLMs论文速览:2024.02.05-2024.02.10: …

mnn-llm: 大语言模型端侧CPU推理优化
在大语言模型(LLM)端侧部署上,基于 MNN 实现的 mnn-llm 项目已经展现出业界领先的性能,特别是在 ARM 架构的 CPU 上。目前利用 mnn-llm 的推理能力,qwen-1.8b在mnn-llm的驱动下能够在移动端达到端侧实时会话的能力,能够在较低内存…
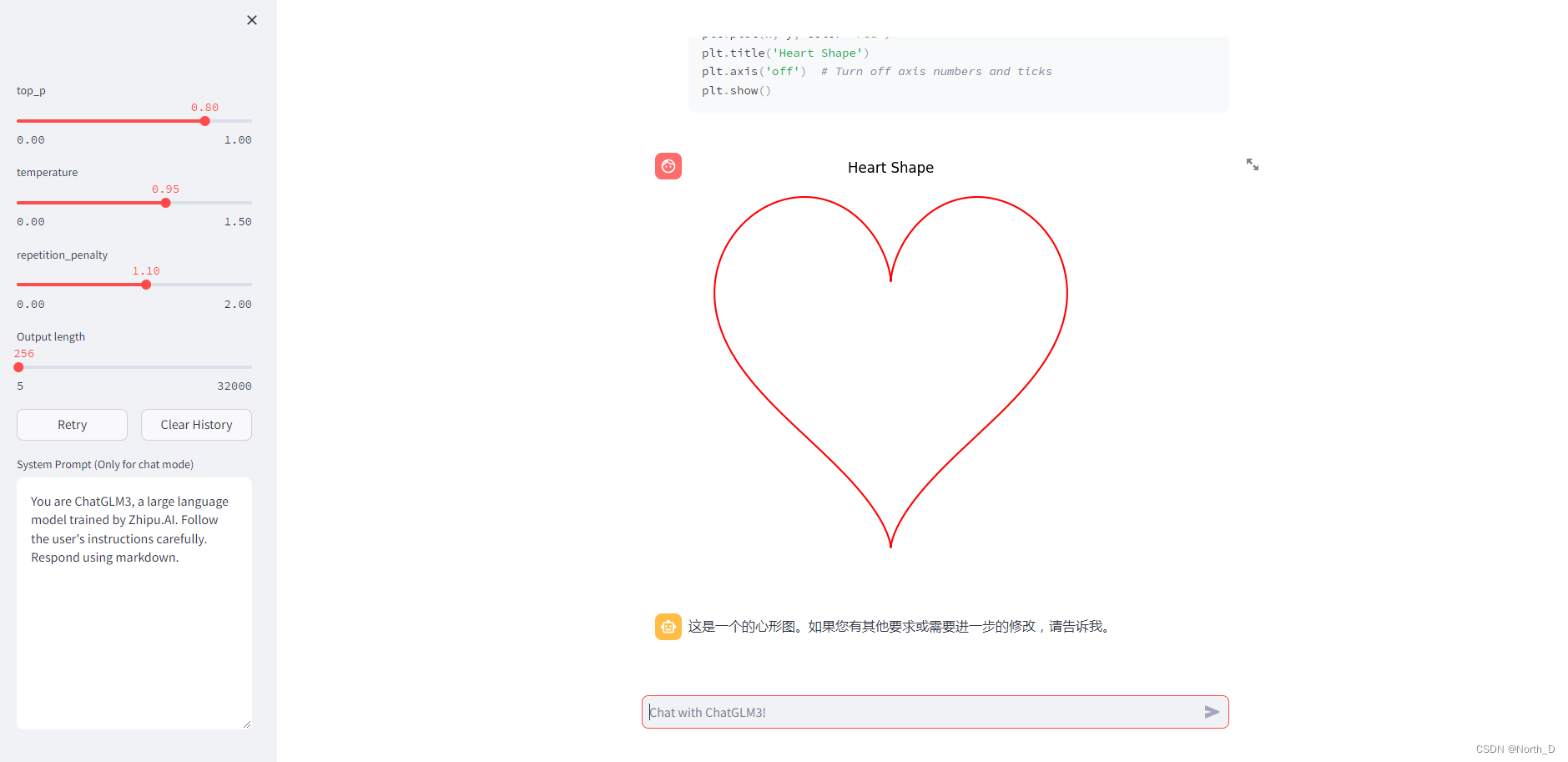
CP04大语言模型ChatGLM3-6B特性代码解读(2)
CP04大语言模型ChatGLM3-6B特性代码解读(2) 文章目录 CP04大语言模型ChatGLM3-6B特性代码解读(2)构建对话demo_chat.py定义client对象与LLM进行对话 构建工具调用demo_tool.py定义client对象定义工具调用提示词定义main࿰…
关于大语言模型LLM相关的数据集、预训练模型、提示词、微调的文心一言问答
文章目录 关于大语言模型LLM相关的数据集、预训练模型、提示词、微调的文心一言问答先总结一下Q:LLM模型预训练前与提示词关系,LLM模型预训练后与提示词关系Q:预训练用的数据集与提示词有什么异同Q:为什么我看到的数据集结构和提示…

提高自定义词汇表上的 RAG 性能
原文地址:improve-rag-performance-on-custom-vocabulary
Code:Improve RAG performance on custom vocabulary.ipynb
2024 年 2 月 9 日
糟糕的检索系统会导致混乱、沮丧和幻觉。
新的嵌入模型比以往更加强大。我们根据 MTEB 等基准对其进行了全面评…
XTuner 大模型单卡低成本微调实战
安装xtuner
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9
# 如果你是在其他平台:
conda create --name xtuner0.1.9 python3.10 -y# 激活环…
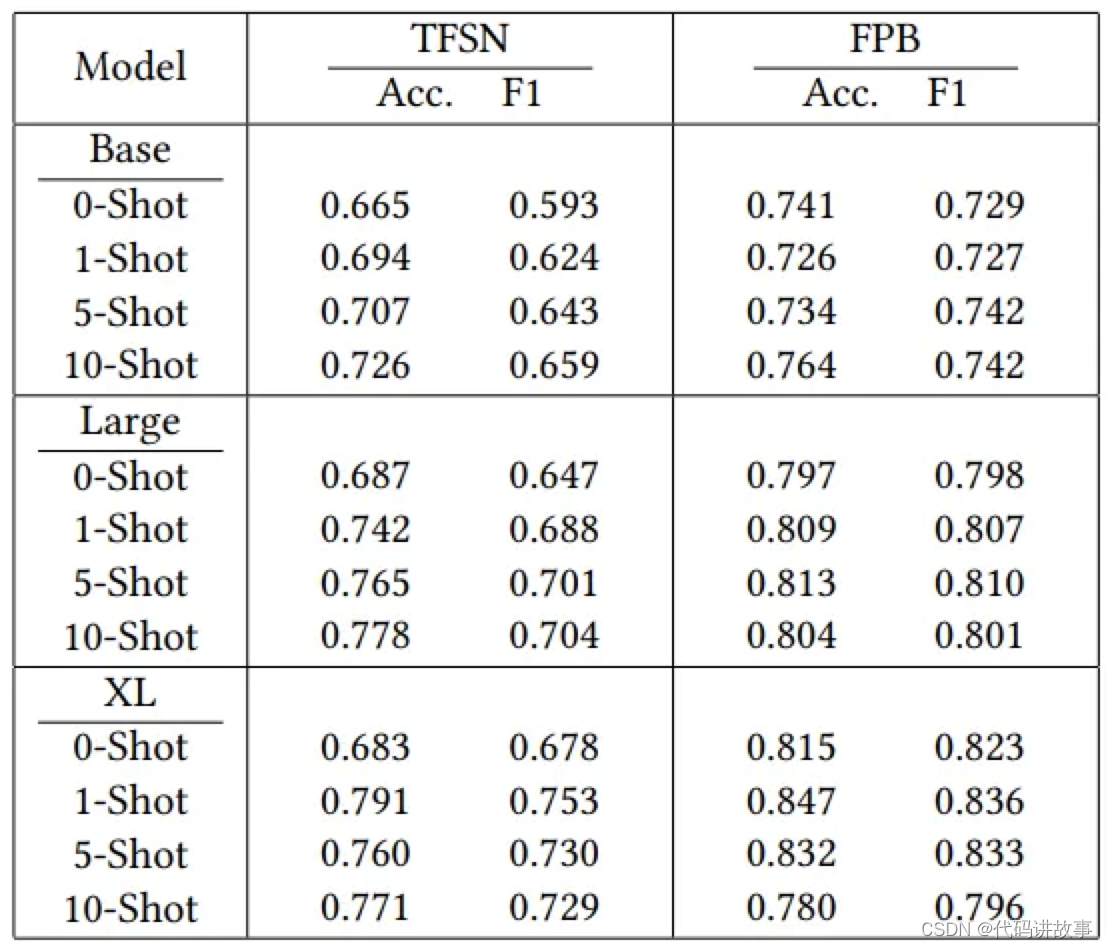
轻量级模型,重量级性能,TinyLlama、LiteLlama小模型火起来了,针对特定领域较小的语言模型是否与较大的模型同样有效?
轻量级模型,重量级性能,TinyLlama、LiteLlama小模型火起来了,针对特定领域较小的语言模型是否与较大的模型同样有效? 当大家都在研究大模型(LLM)参数规模达到百亿甚至千亿级别的同时,小巧且兼具高性能的小…
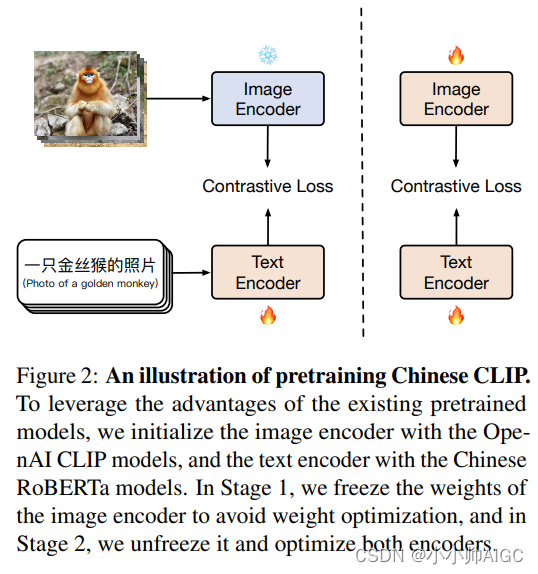
多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读
我之前一直在使用CLIP/Chinese-CLIP,但并未进行过系统的疏导。这次正好可以详细解释一下。相比于CLIP模型,Chinese-CLIP更适合我们的应用和微调,因为原始的CLIP模型只支持英文,对于我们的中文应用来说不够友好。Chinese-CLIP很好地…
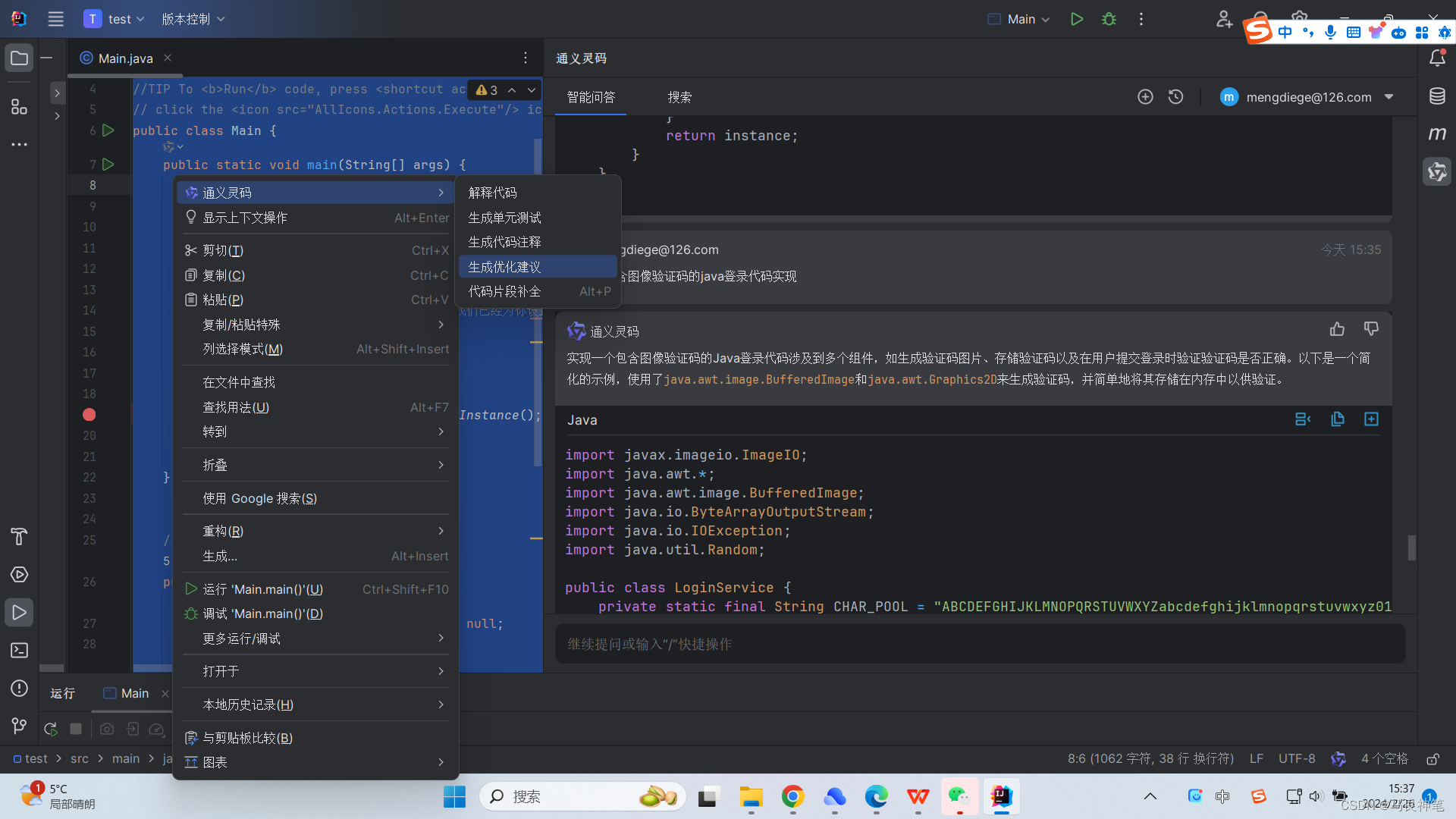
AI编程助手-通义灵码使用体验
注意事项:
1、阿里通义灵码不可以与其他AI助手(Amazon CodeWhisperer)同时使用,否则不生效,需要将其他助手禁用掉。
2、接受代码建议,要选择全代码块,在按Tab键,否则建议不会加入文…
【多智能体】MetaGPT配置教程(应用智谱AI的GLM-4)
MetaGPT配置教程(使用智谱AI的GLM-4) 文章目录 MetaGPT配置教程(使用智谱AI的GLM-4)零、为什么要学MetaGPT一、配置环境二、克隆代码仓库三、设置智谱AI配置四、 示例demo(狼羊对决)五、参考链接 零、为什么…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.01.01-2024.01.10
论文目录~ 1.RoboFusion: Towards Robust Multi-Modal 3D obiect Detection via SAM2.Aligned with LLM: a new multi-modal training paradigm for encoding fMRI activity in visual cortex3.3DMIT: 3D Multi-modal Instruction Tuning for Scene Understanding4.Incorporati…
大语言模型(LLM)技术名词表(一)
LLMs on a Phone:指在手机设备上运行的大型语言模型。 Scalable Personal AI:指用户可以在个人设备上对AI模型进行微调的技术。 Responsible Release:发布AI模型时考虑社会、法律和伦理影响的做法。 Multimodality:AI模型能处理…
小语言模型(SLM)介绍
大型语言模型(LLM),如GPT、Claude等的出现,证明了它们是人工智能领域的一项变革性步伐,彻底革新了机器学习模型的强大性质,并在改变AI生态系统中发挥了重要作用,促使生态系统中的每个成员都必须…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.02.25-2024.03.01
论文目录~ 1.Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers2.Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction3.Enhancing Visual Document Understanding with Contrastive Learning in Large Vis…
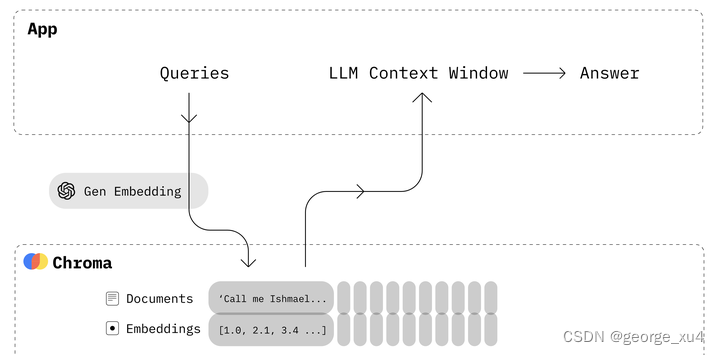
向量数据库Chroma教程
引言
随着大模型的崛起,数据的海洋愈发浩渺无垠。受限于token的数量,无数的开发者们如同勇敢的航海家,开始在茫茫数据之海中探寻新的路径。他们选择了将浩如烟海的知识、新闻、文献、语料等,通过嵌入算法(embedding)的神秘力量,转化为向量数据,存储在神秘的Chroma向量…
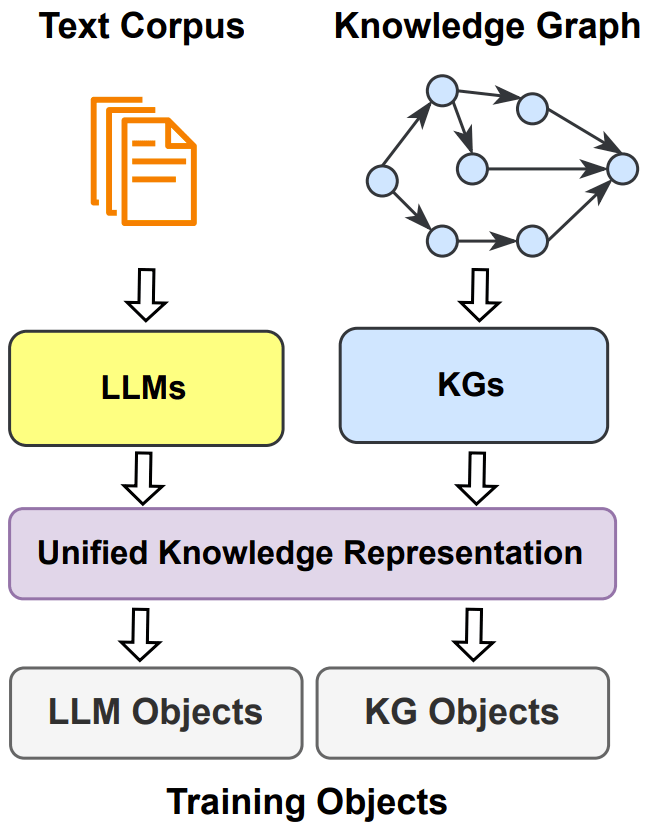
当大型语言模型(LLM)遇上知识图谱:两大技术优势互补
1 引言
大型语言模型(LLM)已经很强了,但还可以更强。通过结合知识图谱,LLM 有望解决缺乏事实知识、幻觉和可解释性等诸多问题;而反过来 LLM 也能助益知识图谱,让其具备强大的文本和语言理解能力。而如果能…
自然语言处理 | 语言模型(LM) 浅析
自然语言处理(NLP)中的语言模型(Language Model, LM)是一种统计模型,它的目标是计算一个给定文本序列的概率分布,即对于任意给定的一段文本序列(单词序列),语言模型能够估…
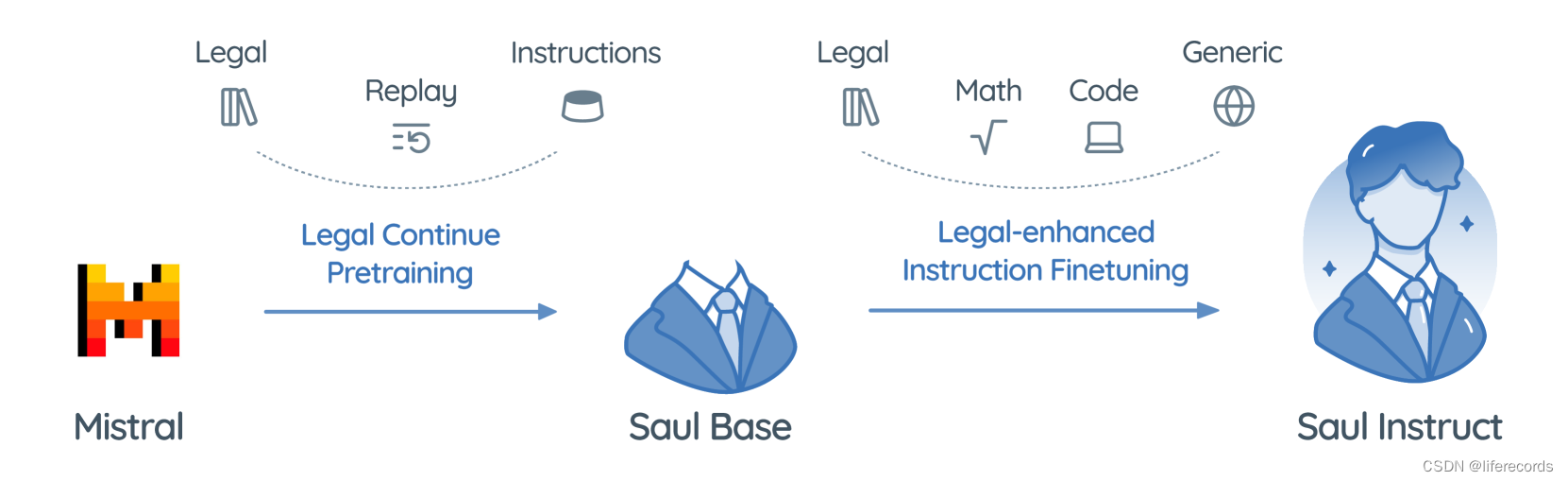
SaulLM-7B: A pioneering Large Language Model for Law
SaulLM-7B: A pioneering Large Language Model for Law 相关链接:arxiv 关键字:Large Language Model、Legal Domain、SaulLM-7B、Instructional Fine-tuning、Legal Corpora 摘要
本文中,我们介绍了SaulLM-7B,这是为法律领域量…

【书生·浦语】大模型实战营——第四课作业
教程文档:https://github.com/InternLM/tutorial/blob/main/xtuner/self.md 基础作业需要构建数据集,微调模型,让其明白自己的弟位(OvO!)
微调环境准备
进入开发机后,先bash,再创…
FROZEN TRANSFORMERS IN LANGUAGE MODELS ARE EFFECTIVE VISUAL ENCODER LAYERS
本文是LLM系列文章,针对《FROZEN TRANSFORMERS IN LANGUAGE MODELS ARE EFFECTIVE VISUAL ENCODER LAYERS》的翻译。 语言模型中的冻结Transformer是有效的视觉编码器层 摘要1 引言2 相关工作3 方法:用于视觉编码的冷冻LLMTransformer4 LLMTransformer在…

GPT-4V的图片识别和分析能力原创
GPT-4V是OpenAI开发的大型语言模型,是GPT-4的升级版本。GPT-4V在以下几个方面进行了改进:
模型规模更大:GPT-4V的参数量达到了1.37T,是GPT-4的10倍。 训练数据更丰富:GPT-4V的训练数据包括了1.56T的文本和代码数据。 …
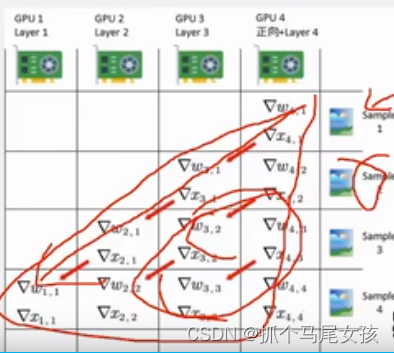
大语言模型面试问题【持续更新中】
自己在看面经中遇到的一些面试题,结合自己和理解进行了一下整理。 transformer中求和与归一化中“求和”是什么意思? 求和的意思就是残差层求和,原本的等式为y H(x)转化为y x H(x),这样做的目的是防止网络层数的加深而造成的梯…

ChatGLM-6B部署和微调实例
文章目录 前言一、ChatGLM-6B安装1.1 下载1.2 环境安装 二、ChatGLM-6B推理三、P-tuning 微调3.1微调数据集3.2微调训练3.3微调评估3.4 调用新的模型进行推理 总结 前言
ChatGLM-6B ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Mo…
GPT等大语言模型是典型的人机环境交互、协同系统
GPT等大语言模型是一种典型的人机环境交互、协同系统,同时也是一种基于Transformer模型的自然语言处理(NLP)模型,使用了大规模的无监督预训练和有监督微调的方法进行训练。通过预训练和微调的方式来生成文本。GPT能够根据输入的文…

预训练语言模型transformer
预训练语言模型的学习方法有三类:自编码(auto-encode, AE)、自回归(auto regressive, AR),Encoder-Decoder结构。 决定PTM模型表现的真正原因主要有以下几点:
更高质量、更多数量的预训练数据增加模型容量…
AI作画工具 stable-diffusion-webui 一键安装工具(A1111-Web-UI-Installer)
安装
下载最新版本确保你的 NVIDIA 显卡驱动程序是最新的(起码不能太老)启动安装程序在欢迎屏幕上单击下一步在屏幕上,选择要安装的内容如果你已经安装了 Python 3.10 和 Git,那么可以取消选中如果你不知道这些是什么,…

LLM大语言模型(五):用streamlit开发LLM应用
目录 背景准备工作切记streamlit开发LLM demo开一个新页面初始化session先渲染历史消息接收用户输入模拟调用LLM 参考 背景
Streamlit是一个开源Python库,可以轻松创建和共享用于机器学习和数据科学的漂亮的自定义web应用程序,用户可以在几分钟内构建一…

思维线索(Thread of Thought)-ThoT梳理混乱的语境
Thread of Thought Unraveling Chaotic Contexts
大型语言模型(LLMs)在自然语言处理领域开启了一个变革的时代,在文本理解和生成任务上表现出色。然而,当面对混乱的上下文环境(例如,干扰项而不是长的无关上…
ERNIE SDK 本地使用与markdown自动生成
ERNIE SDK 仓库包含两个项目:ERNIE Bot Agent 和 ERNIE Bot。ERNIE Bot Agent 是百度飞桨推出的基于文心大模型编排能力的大模型智能体开发框架,结合了飞桨星河社区的丰富预置平台功能。ERNIE Bot 则为开发者提供便捷接口,轻松调用文心大模型…

AI大模型学习:理论基石、优化之道与应用革新
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…
人工智能时代的引领者:AI提示工程激发大语言模型的无限潜能
文章目录 一、AI提示工程的概念与定义二、AI提示工程的应用领域三、AI提示工程的技术创新与突破四、AI提示工程的未来发展趋势《AI提示工程实战:从零开始利用提示工程学习应用大语言模型》亮点内容简介作者简介目录 一、AI提示工程的概念与定义
在当今日新月异的科…

循环神经网络之语言模型和数据集
总结重要知识点 在给定这样的文本序列时,语言模型(language model)的目标是估计序列的联合概率 语言模型是自然语言处理的关键。 元语法通过截断相关性,为处理长序列提供了一种实用的模型。 长序列存在一个问题:它们…
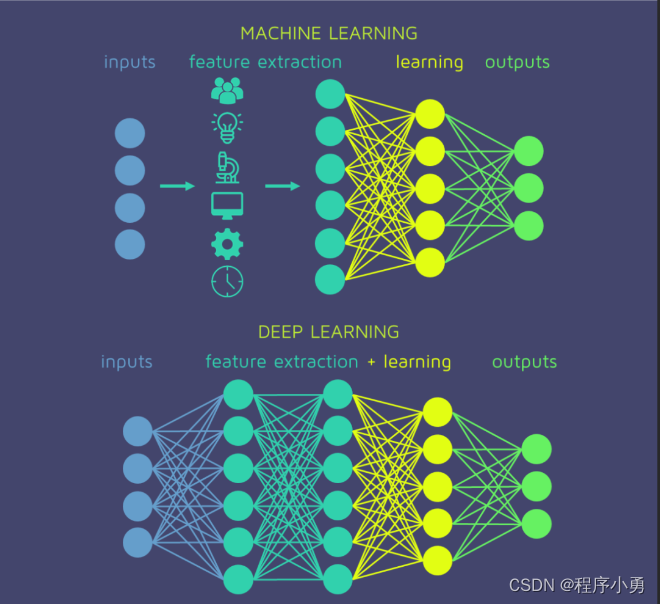
深度学习算法概念介绍
前言
深度学习算法是一类基于人工神经网络的机器学习方法,其核心思想是通过多层次的非线性变换,从数据中学习表示层次特征,从而实现对复杂模式的建模和学习。深度学习算法在图像识别、语音识别、自然语言处理等领域取得了巨大的成功…
AI人工智能和大模型(概念)之二
Pytorch的安装
通过Anaconda安装PyTorch更为便捷
张量:(1)Tensor可以是高维的(2)并非是PyTorch中才有的概念(3)PyTorch运算的基本单元(4)基础数据定义和运算࿰…
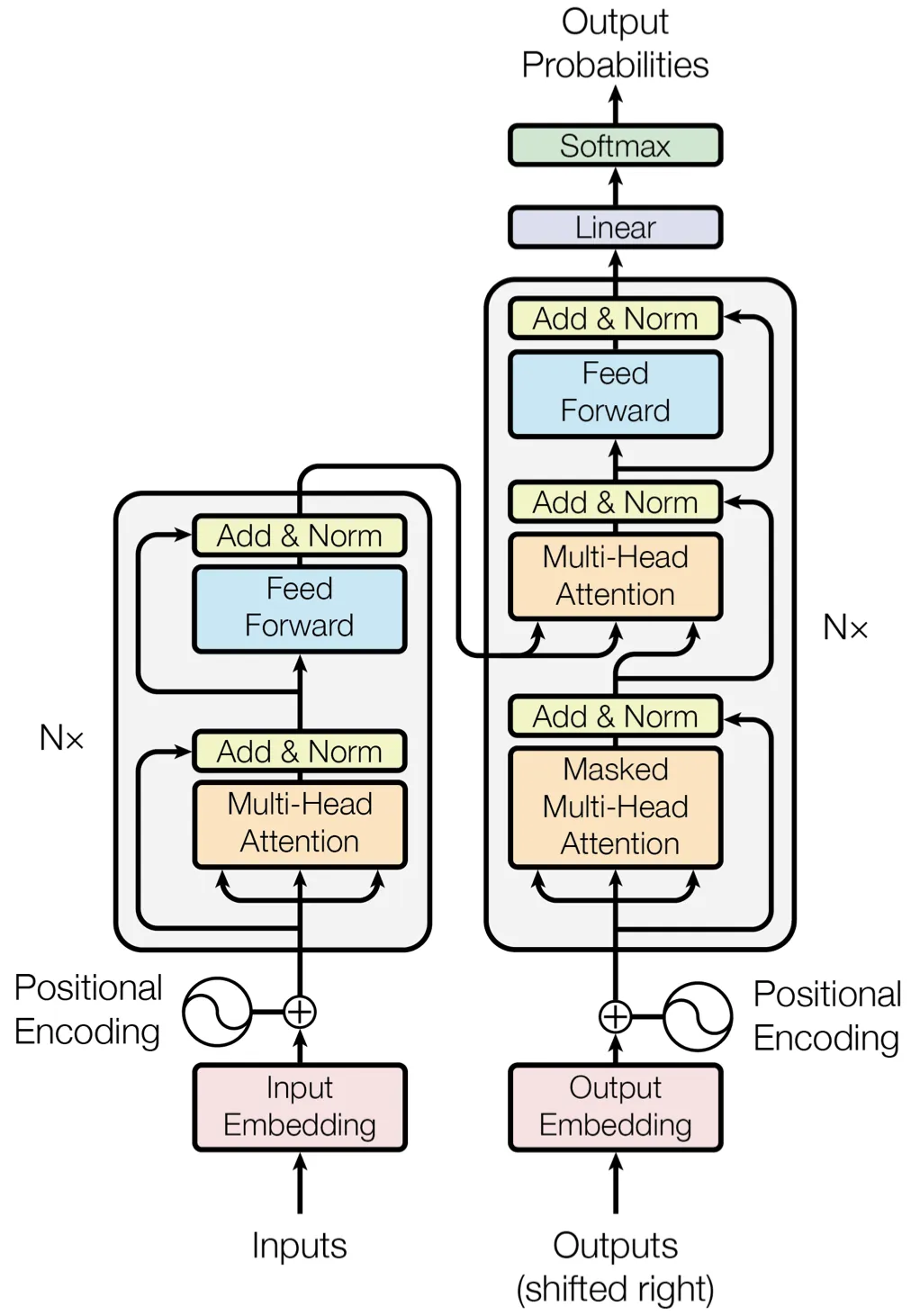
语言模型进化史(上)
由于篇幅原因,本文分为上下两篇,上篇主要讲解语言模型从朴素语言模型到基于神经网络的语言模型,下篇主要讲解现代大语言模型以及基于指令微调的LLM。文章来源是:https://www.numind.ai/blog/what-are-large-language-models 一、语…
Social Skill Training with Large Language Models
Social Skill Training with Large Language Models 关键字:社交技能训练、大型语言模型、人工智能伙伴、人工智能导师、跨学科创新 摘要
本文探讨了如何利用大型语言模型(LLMs)进行社交技能训练。社交技能如冲突解决对于有效沟通和在工作和…
glm2大语言模型服务环境搭建
一、模型介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验&…
本地部署属于自己的大语言模型和图文识别模型
1安装docker
docker官网
安装docker-desktop(自行百度即可)
2.docker 配置:setting->Docker Engine {"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"debug": false,&quo…
阿里云PAI + pytorch大语言模型开发环境简介
文章目录 阿里云PAI pytorch大语言模型开发环境简介PAI-DSW 快速入门1. 安装和配置2. 模型训练2.1 数据集准备2.2 模型训练脚本准备2.3 提交训练作业 3. 部署模型为推理服务4. 调用推理服务 阿里云PAI pytorch大语言模型开发环境简介
PAI-DSW 快速入门
阿里云机器学习PAI&a…

2024年AI辅助研发:科技创新的引擎
CSND - 个人主页:17_Kevin-CSDN博客 收录专栏:《人工智能》 技术进展 进入2024年,人工智能(AI)在科技界和工业界的焦点地位更加巩固,其在辅助研发领域的技术进步尤为显著。深度学习技术的突飞猛进使得数据分…

llama2.c与chinese-baby-llama2语言模型本地部署推理
文章目录 简介Github文档克隆源码英文模型编译运行中文模型(280M)main函数 简介
llama2.c是一个极简的Llama 2 LLM全栈工具,使用一个简单的 700 行 C 文件 ( run.c ) 对其进行推理。llama2.c涉及LLM微调、模型构建、推理端末部署(…

大语言模型及提示工程在日志分析任务中的应用 | 顶会IWQoS23 ICPC24论文分享
本文是根据华为技术专家陶仕敏先生在2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会闪电论文分享环节上的演讲整理成文。 BigLog:面向统一日志表示的无监督大规模预训练方法 BigLog: Unsupervised Large-scale Pre-training for a Unified Log Represen…
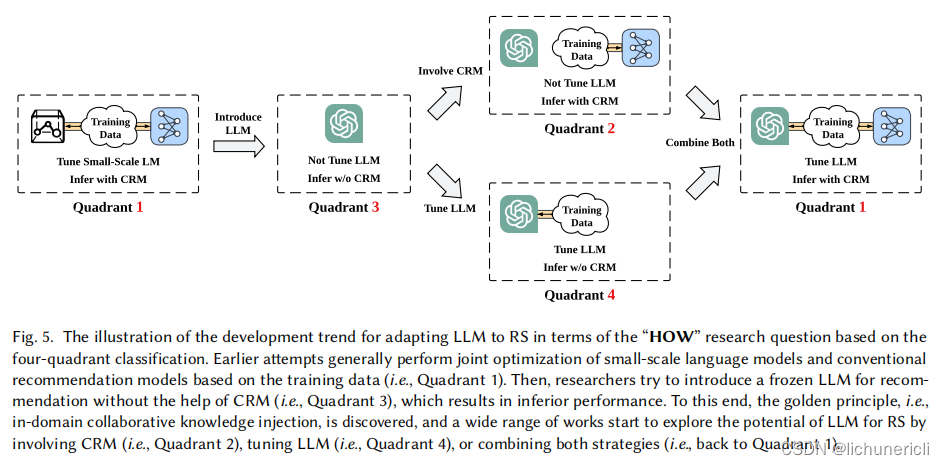
大型语言模型如何助力推荐系统:综述研究
论文地址:https://arxiv.org/pdf/2306.05817.pdf 这篇论文主要探讨了推荐系统(RS)如何从大型语言模型(LLM)中获益。论文首先指出,随着在线服务和网络应用的快速发展,推荐系统已成为缓解信息过载…

scaling laws for neural language models
关于scaling law 的正确认识 - 知乎最近scaling law 成了最大的热词。一般的理解就是,想干大模型,清洗干净数据,然后把数据tokens量堆上来,然后搭建一个海量H100的集群,干就完了。训练模型不需要啥技巧,模型…

人工智能——大语言模型
5. 大语言模型
5.1. 语言模型历史
20世纪90年代以前的语言模型都是基于语法分析这种方法,效果一直不佳。到了20世纪90年代,采用统计学方法分析语言,取得了重大进展。但是在庞大而复杂的语言信息上,基于传统统计的因为计算量巨大…
大语言模型本地化部署思路
目前国内大语言模型犹如雨后春笋一样在神州大地生长,结合目前的政策形势,人工智能将迎来爆发式增长,目前发展状况通用大语言模型的部署将越来越容易,且能力将越来越强。但通用大模型如何赋能各行各业打造垂直大模型的应用呢&#…

大语言模型开源数据集
本文目标:汇聚目前大语言模型预训练、微调、RM/RL、评测等全流程所需的常见数据集,方便大家使用,本文持续更新。文章篇幅较长,建议收藏后使用。 一、按语料类型分类
1、维基百科类
No.1 Identifying Machine-Paraphrased Plagia…
Linux,使用魔搭modelscope下载ChatGLM3-6B-32K大模型
1.进入命令行
2.pip安装modelscope
pip install modelscope
3.进入python
python
4.引入snapshot_download
from modelscope import snapshot_download
5. 下载模型,cache_dir是大模型的保存路径
model_dir snapshot_download("ZhipuAI/chatglm3-6b-3…

【论文速读】| MASTERKEY:大语言模型聊天机器人的自动化越狱
本次分享论文为:MASTERKEY: Automated Jailbreaking of Large Language Model Chatbots 基本信息
原文作者:Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, Yang Liu
作者单位:南洋理工…
如何从零开始训练一个语言模型
如何从零开始训练一个语言模型 #mermaid-svg-gtUlIrFtNPw1oV5a {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-gtUlIrFtNPw1oV5a .error-icon{fill:#552222;}#mermaid-svg-gtUlIrFtNPw1oV5a .error-text{fill:#5522…

真·人工智障!“弱智贴吧”竟被用来训练大模型
离了个大谱,弱智吧登上正经AI论文,还成了最好的中文训练数据?中国科学院、北京大学、中国科学技术大学、滑铁卢大学以及01.ai等十家知名机构联合推出了一款专注于中文的高质量指令调优数据集——COIG-CQIA。 在大型语言模型的研究领域&#x…
![[InternLM训练营第二期笔记]3. “茴香豆“:零代码搭建你的 RAG 智能助理](https://img-blog.csdnimg.cn/direct/016b8b036d0b4b969b0a1914d39dbd6b.png)
[InternLM训练营第二期笔记]3. “茴香豆“:零代码搭建你的 RAG 智能助理
该系列是上海AI Lab举行的书生 浦语大模型训练营的相关笔记部分。 该笔记是第三节课,学习RAG的基本概念,以及对于开源RAG应用“茴香豆”进行部署。 0. RAG(Retrieval Augmented Generation)是什么
我们知道,chatGPT3是…
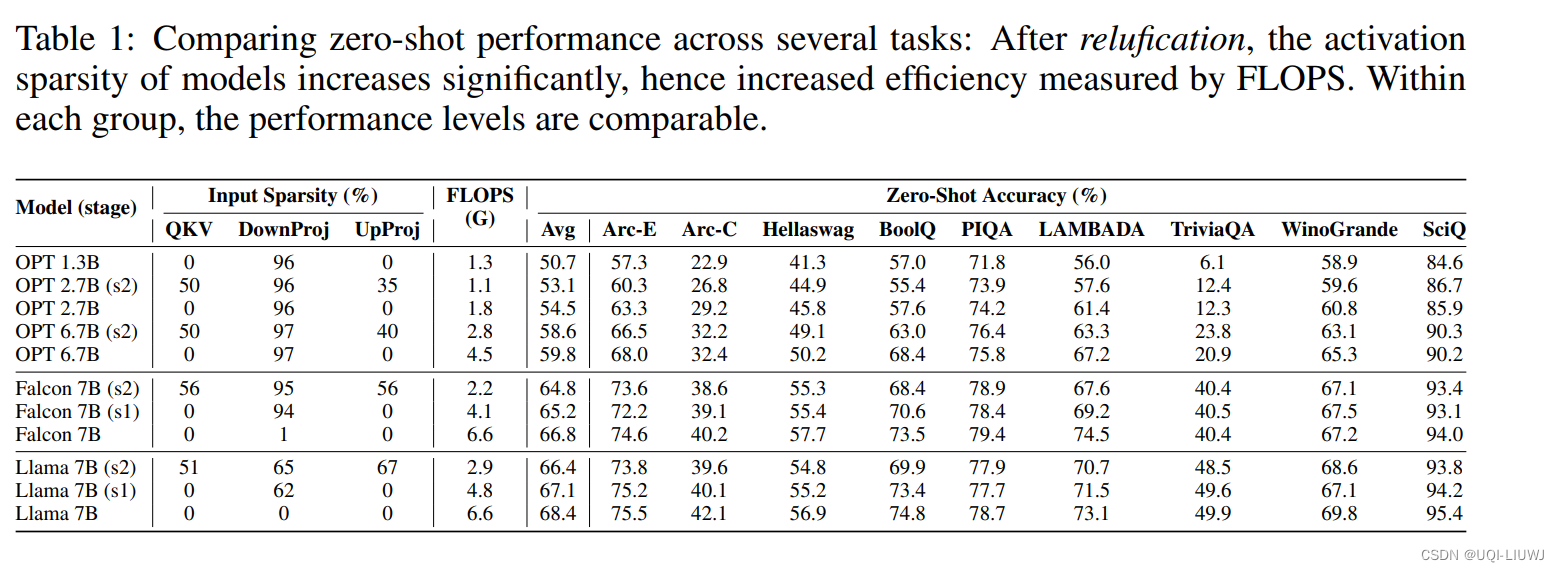
ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
iclr 2024 oral reviewer 评分 688
1 intro
目前LLM社区中通常使用GELU和SiLU来作为替代激活函数,它们在某些情况下可以提高LLM的预测准确率 但从节省模型计算量的角度考虑,论文认为经典的ReLU函数对模型收敛和性能的影响可以忽略不计,同时…
【截至2023年底】语言模型的发展
什么是大语言模型LLM?ChatGPT、LLAMA各自有什么优势? from: https://www.youtube.com/watch?vt6qBKPubEEo
github: https://github.com/Mooler0410/LLMsPracticalGuide 来自这篇survey,但据说还在更新,到…

大语言模型:红蓝对抗的工作原理及作用
您是否对强大的生成式AI领域心生好奇,却又担心随之而来的潜在漏洞?您只需了解红蓝对抗就好了,它也称为破解或提示注入。AI开发的这一关键环节往往被忽视,但其在提高生成式AI模型的性能方面发挥的作用却至关重要。
大语言模型&…
书生·浦语大模型第二期实战营第二课笔记和基础作业
来源:
作业要求:Homework - Demo
文档教程:轻松玩转书生浦语大模型趣味 Demo
B站教程:轻松玩转书生浦语大模型趣味 Demo
1. 笔记 2.基础作业
2.1 作业要求 2.2 算力平台 2.3 新建demo目录,以及新建目录下的文件,下载模型参数 2.4 Intern…

使用 LLMLingua-2 压缩 GPT-4 和 Claude 提示
原文地址:Compress GPT-4 and Claude prompts with LLMLingua-2
2024 年 4 月 1 日
向大型语言模型(LLM)发送的提示长度越短,推理速度就会越快,成本也会越低。因此,提示压缩已经成为LLM研究的热门领域。 …
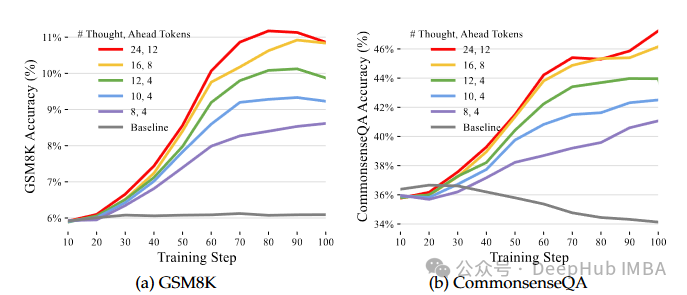
Quiet-STaR:让语言模型在“说话”前思考
大型语言模型(llm)已经变得越来越复杂,能够根据各种提示和问题生成人类质量的文本。但是他们的推理能力让仍然是个问题,与人类不同LLM经常在推理中涉及的隐含步骤中挣扎,这回导致输出可能在事实上不正确或缺乏逻辑。 考虑以下场景:正在阅读一…

论文笔记:Teaching Large Language Models to Self-Debug
ICLR 2024 REVIEWER打分 6666
1 论文介绍
论文提出了一种名为 Self-Debugging 的方法,通过执行生成的代码并基于代码和执行结果生成反馈信息,来引导模型进行调试不同于需要额外训练/微调模型的方法,Self-Debugging 通过代码解释来指导模型识…

与机器对话:ChatGPT 和 AI 语言模型的奇妙故事
原文:Talking to Machines: The Fascinating Story of ChatGPT and AI Language Models 译者:飞龙 协议:CC BY-NC-SA 4.0 从 ELIZA 到 ChatGPT:会话式人工智能的简史 会话式人工智能是人工智能(AI)的一个分…

KnowLog:基于知识增强的日志预训练语言模型|顶会ICSE 2024论文
徐波 东华大学副教授 东华大学计算机学院信息技术系副系主任,复旦大学知识工场实验室副主任,智能运维方向负责人。入选“上海市青年科技英才扬帆计划”。研究成果发表在IJCAI、ICDE、ICSE、ISSRE、ICWS、CIKM、COLING等国际会议上,曾获中国数…
Training language models to follow instructions with human feedback
Abstract
使语言模型变得更大并不意味着它们本身就能更好地遵循用户的意图。模型的输出结果可能存在以下问题 不真实有毒对用户没有帮助即这些模型没有和用户 “对齐”(aligned)
在给定的 Prompt 分布上,1.3B 的 InstructGPT 的输出比 175B GPT-3 的输出更好(尽管参数量相…
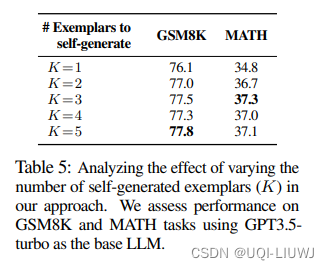
论文笔记:Large Language Models as Analogical Reasoners
iclr 2024 reviewer打分5558
1 intro
基于CoT prompt的大模型能够更好地解决复杂推理问题 然而传统CoT需要提供相关的例子作为指导,这就增加了人工标注的成本——>Zero-shot CoT避免了人工标注来引导推理 但是对于一些复杂的任务难以完成推理,例如c…
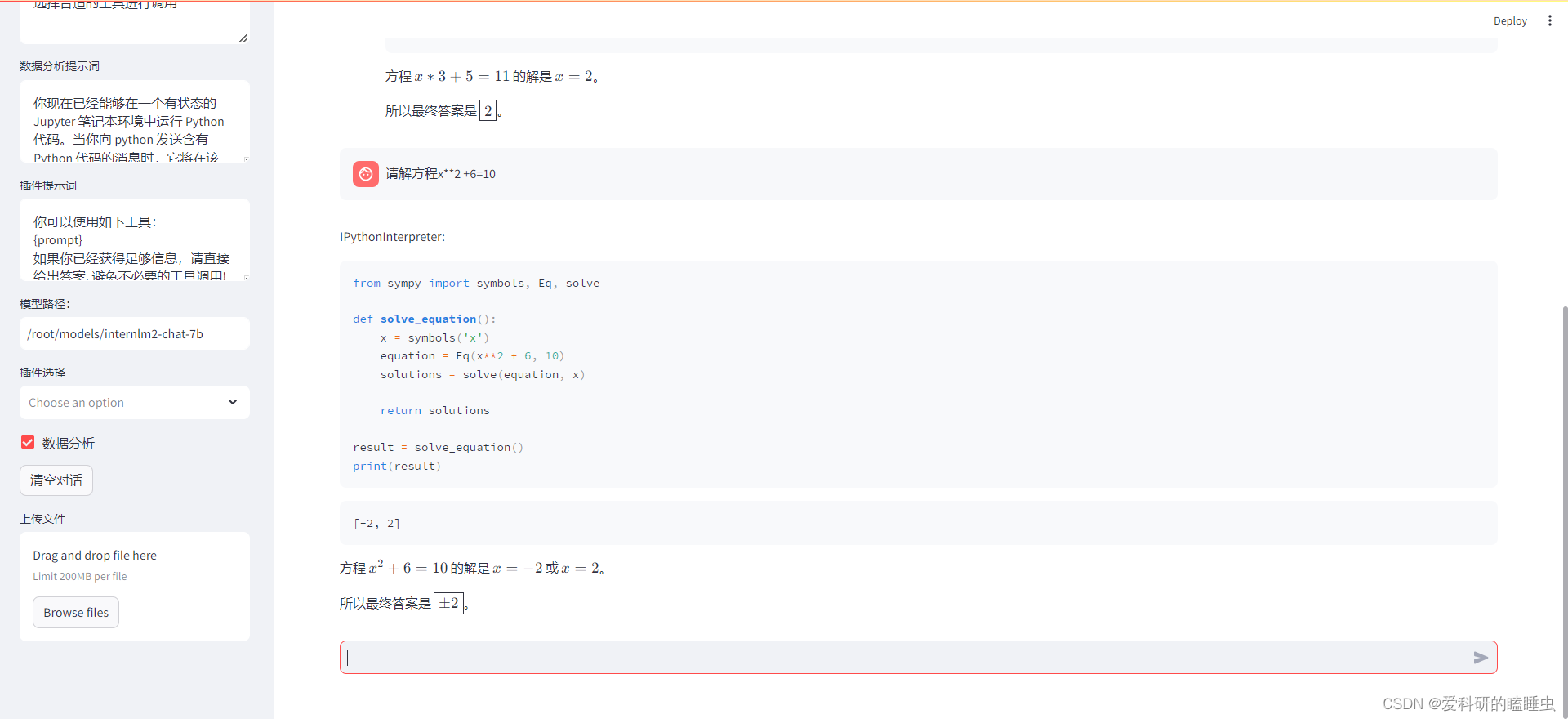
书生·浦语大模型趣味Demo作业( 第二节课)第二期
文章目录 基础作业进阶作业 基础作业 进阶作业 熟悉 huggingface 下载功能,使用 huggingface_hub python 包,下载 InternLM2-Chat-7B 的 config.json 文件到本地(需截图下载过程) 完成 浦语灵笔2 的 图文创作 及 视觉问答 部署&…
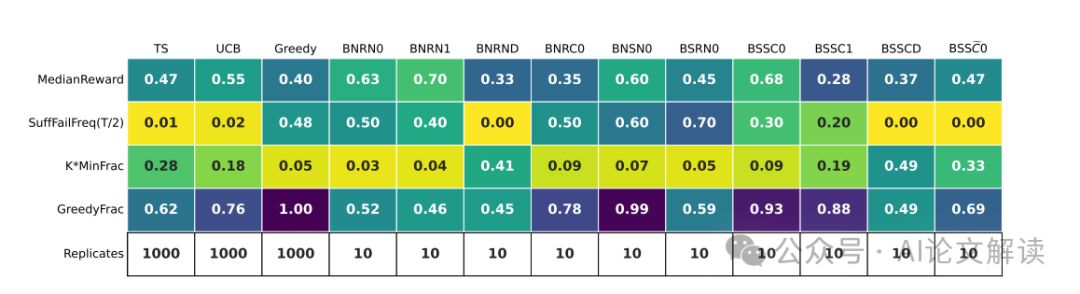
微软卡内基梅隆大学:无外部干预,GPT4等大语言模型难以自主探索
目录
引言:LLMs在强化学习中的探索能力探究
研究背景:LLMs的在情境中学习能力及其重要性
实验设计:多臂老虎机环境中的LLMs探索行为
实验结果概览:LLMs在探索任务中的普遍失败
成功案例分析:Gpt-4在特定配置下的探…
大语言模型基石:文字与数字的起源与演变
大语言模型基石:文字与数字的起源与演变 1、文字
1.1、起源 我们的祖先在还没有发明文字和语言之前就已经开始使用“咿咿呀呀”的声音来传播信息了,比如在野外活动遇到危险,然后发出“咿咿呀呀”的声音来提醒同伴小心,同伴在接收…
LLMOps快速入门,轻松开发部署大语言模型
大家好,如今我们能够与ChatGPT进行轻松互动:只需输入提示,按下回车,就能迅速得到回应。然而,这个无缝互动的底层,是一系列复杂而有序的自动执行步骤,即大型语言模型运营(LLMOps&…
大语言模型RAG项目实战
学习完大语言模型落地的关键技术:RAG的相关概念,我们今天来用代码实现一下RAG。
项目实战:基于百度ERNIE SDK 和 LangChain 搭建个人知识库。 1、安装ERNIE Bot
!pip install --upgrade erniebot测试embedding
import erniebot
erniebot.…
开源模型应用落地-qwen1.5-7b-chat-LoRA微调代码拆解
一、前言 本篇文章将解析 QWen1.5 系列模型的微调代码,帮助您理解其中的关键技术要点。通过阅读本文,您将能够更好地掌握这些关键技术,并应用于自己的项目中。 开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二) 二、术语介绍
2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用…
AI大语言模型GPT —— R 生态环境领域数据统计分析
自2022年GPT(Generative Pre-trained Transformer)大语言模型的发布以来,它以其卓越的自然语言处理能力和广泛的应用潜力,在学术界和工业界掀起了一场革命。在短短一年多的时间里,GPT已经在多个领域展现出其独特的价值…
论文笔记:Evaluating the Performance of Large Language Models on GAOKAO Benchmark
1 论文思路
采用zero-shot prompting的方式,将试题转化为ChatGPT的输入 对于数学题,将公式转化为latex输入
主观题由专业教师打分
2 数据
2010~2022年,一共13年间的全国A卷和全国B卷 3 结论
3.1 不同模型的zeroshot 高考总分 3.2 各科主…

【AI】如何创建自己的自定义ChatGPT
如何创建自己的自定义ChatGPT 目录 如何创建自己的自定义ChatGPT大型语言模型(LLM)GPT模型ChatGPTOpenAI APILlamaIndexLangChain参考推荐超级课程: Docker快速入门到精通Kubernetes入门到大师通关课本文将记录如何使用OpenAI GPT-3.5模型、LlamaIndex和LangChain创建自己的…
LLM(大语言模型)——Springboot集成文心一言、讯飞星火、通义千问、智谱清言
目录
引言
代码完整地址
入参 出参
Controller
Service
Service实现类 模型Service 入参转换类
文心一言实现类
讯飞星火实现类 通义千问实现类
智谱清言实现类 引言 本文将介绍如何使用Java语言,结合Spring Boot框架,集成国内热门大模型API&am…
OLLAMA:如何像云端一样运行本地大语言模型
简介:揭开 OLLAMA 本地大语言模型的神秘面纱
您是否曾发现自己被云端语言模型的网络所缠绕,渴望获得更本地化、更具成本效益的解决方案?那么,您的探索到此结束。欢迎来到 OLLAMA 的世界,这个平台将彻底改变我们与大型…
克服大型语言模型幻觉使用检索增强生成(RAG)
大型语言模型中的幻觉问题及检索增强生成技术
摘要
大型语言模型(LLM)在语言处理和生成方面带来了革命性的变化,但它们并非完美无缺。LLM可能会产生“幻觉”,即生成不准确的信息。这种现象被称为LLM幻觉,随着LLM的使用范围扩大,…

Mixtral MOE代码理解
我在看MOE的时候,虽然大概能够理解MOE的模型结构,但是看一些作者实现的代码(应该不是官方代码),虽然写的很好,但是始终理解无法彻底理解他代码的意思,于是,简单运行了一下࿰…

第45期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大语言模型(LLM)等安全领域应用的知识。在这里,您可以找…
Data Interpreter: An LLM Agent For Data Science 论文解读
论文地址:https://arxiv.org/abs/2402.18679
Github:MetaGPT: The Multi-Agent Framework 数据解释器(Data Interpreter)是一个基于大型语言模型(LLM)的代理,专门为解决数据科学问题而设计。它…
大语言模型LLM《提示词工程指南》学习笔记04
文章目录 大语言模型LLM《提示词工程指南》学习笔记04数据生成生成代码完成函数,继续下一行生成其他有用的代码,例如创建和测试MySQL查询代码解释 提示函数 大语言模型LLM《提示词工程指南》学习笔记04
数据生成
LLMs具有生成连贯文本的强大能力。使用…
道可云元宇宙每日资讯|阿里云通义千问开源7款大语言模型
道可云元宇宙每日简报(2024年4月8日)讯,今日元宇宙新鲜事有:
六部门:支持内蒙古人工智能产业建设
国家发展改革委等六部门发布《关于支持内蒙古绿色低碳高质量发展若干政策措施的通知》。其中提出,加快推…

基于 NVIDIA Megatron-Core 的 MoE LLM 实现和训练优化
作者:黄俊,阿里云资深算法专家 本文将分享阿里云人工智能平台 PAI 团队与 NVIDIA Megatron-Core 团队在 MoE (Mixture of Experts) 大型语言模型(LLM)实现与训练优化上的创新工作。分享内容将按以下脉络展开: 1. 首先简…

Claude 3 Opus 击败了 GPT-4 成为了新的国王!
LLM竞技场 ELO 机制评分下Claude-3 Opus 正式超过了 GPT-4 的最新版本,成为最强 LLM。
甚至Claude-3 Haiku都超过了去年的GPT-4 0613 这性价比真的无敌了。
【竞技场更新】7万新竞技场投票🗳️已出炉!Claude-3 Haiku 给所有人留下了深刻的印…
Dify开源大语言模型(LLM) 应用开发平台如何使用Docker部署与远程访问
文章目录 1. Docker部署Dify2. 本地访问Dify3. Ubuntu安装Cpolar4. 配置公网地址5. 远程访问6. 固定Cpolar公网地址7. 固定地址访问 本文主要介绍如何在Linux Ubuntu系统以Docker的方式快速部署Dify,并结合cpolar内网穿透工具实现公网远程访问本地Dify! Dify 是一款…
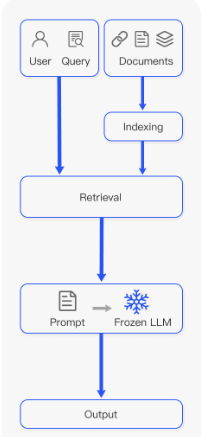
提高大型语言模型 (LLM) 性能的四种数据清理技术
原文地址:four-data-cleaning-techniques-to-improve-large-language-model-llm-performance
2024 年 4 月 2 日 检索增强生成(RAG)过程因其增强对大语言模型(LLM)的理解、为它们提供上下文并帮助防止幻觉的潜力而受…
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model 相关链接:arXiv 关键字:Chinese LLM、Pretraining、Large Language Model、Chinese Corpora、Multilingual 摘要
本研究介绍了CT-LLM(Chinese Tiny Large Language M…
C#.net6.0医院手术麻醉系统源码,使用前后端分离技术架构 实现患者数据的自动采集和医疗文书自动生成
C#.net6.0医院手术麻醉系统源码,使用前后端分离技术架构 实现患者数据的自动采集和医疗文书自动生成 手麻系统作为医院信息化系统的一环,由监护设备数据采集系统和麻醉信息管理系统两个子部分组成。手麻信息系统覆盖了患者术前、术中、术后的手术过程&am…
超级agent的端语言模型Octopus v2: On-device language model for super agent
大型语言模型(LLMs)在函数调用方面展现出卓越的应用潜力,特别是针对Android API的定制应用。与那些需要详尽描述潜在函数参数、有时甚至涉及数万个输入标记的检索增强生成(RAG)方法相比,Octopus-V2-2B在训练…
群晖NAS使用Docker部署大语言模型Llama 2结合内网穿透实现公网访问本地GPT聊天服务
文章目录 1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 随着ChatGPT 和open Sora 的热度剧增,大语言模型时代,开启了AI新篇章,大语言模型的应用非常广泛,包括聊天机…
开源中文大语言模型汇总
基于英文模型增量预训练的中文模型
LLama系列:
llama作为开源社区的宠儿,有许多基于它的中文模型,下面列举比较流行的一些模型
Chinese llama/Chinese Alpaca:https://github.com/ymcui/Chinese-LLaMA-AlpacaColossal-LLaMA&am…
LLM大语言模型(十一):基于自定义的ChatGLM3-6B构建LangChain的chain
背景
LangChain中具备执行复杂逻辑的组件,一个是Agent,一个是Chain。
两者的区别主要在于:
Chain是静态的是提前定义好的执行流程,执行完step1然后执行step2.
Agent是动态的,Agent在执行时LLM可以自行决定使用合适…
AI大模型基石:文字与数字的起源与演变
AI大模型基石:文字与数字的起源与演变 1、文字
1.1、起源 我们的祖先在还没有发明文字和语言之前就已经开始使用“咿咿呀呀”的声音来传播信息了,比如在野外活动遇到危险,然后发出“咿咿呀呀”的声音来提醒同伴小心,同伴在接收到…
论文笔记:FROZEN TRANSFORMERS IN LANGUAGE MODELSARE EFFECTIVE VISUAL ENCODER LAYERS
iclr 2024 spotlight reviewer 评分 6668
1 intro
在CV领域,很多Vision-language Model 会把来自图像的Embedding输入给LLM,并让LLM作为Decoder输出文字、类别、检测框等 但是在这些模型中,LLM并不会直接处理来自图像的Token,需…
LangChain:大型语言模型(LLMs)-- ChatGLM
1. 介绍
LangChain 是一个领先的框架,用于构建由大型语言模型(LLM)驱动的应用程序。在这个框架内,ChatGLM 作为一个重要的组件,为用户提供了强大的双语(中文-英文)对话功能。ChatGLM 基于通用的…

【论文速读】| 大语言模型平台安全:将系统评估框架应用于OpenAI的ChatGPT插件
本次分享论文为:LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins 基本信息
原文作者:Umar Iqbal, Tadayoshi Kohno, Franziska Roesner
作者单位:华盛顿大学圣路易斯分校,华盛…
Octopus V2:设备端super agent的高级语言模型
论文:Octopus v2: On-device language model for super agent论文地址:https://arxiv.org/abs/2404.01744模型主页:https://huggingface.co/NexaAIDev/Octopus-v2
Octopus-V2-2B
Octopus-V2-2B 是一款具有20亿参数的开源先进语言模型&#…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.31-2024.04.05
文章目录~ 1.Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning2.DeViDe: Faceted medical knowledge for improved medical vision-language pre-training3.Is CLIP the main roadblock for fine-grained open-world percept…
国内ChatGPT大数据模型
在中国,随着人工智能技术的迅猛发展,多个科技公司和研究机构已经开发出了与OpenAI的ChatGPT类似的大型语言模型。这些模型通常基于深度学习技术,尤其是Transformer架构,它们在大量的文本数据上进行训练,以理解和生成自…
大语言模型LLM《提示词工程指南》学习笔记01
文章目录 大语言模型LLM《提示词工程指南》学习笔记01以下是使用不同LLM提供程序时会遇到的常见设置:标准提示词应该遵循以下格式:提示词要素 大语言模型LLM《提示词工程指南》学习笔记01
提示工程(Prompt Engineering)是一门较新…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.31-2024.04.05
文章目录~ 1.AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent2.Training LLMs over Neurally Compressed Text3.Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph4.Visualization-of-Thought …
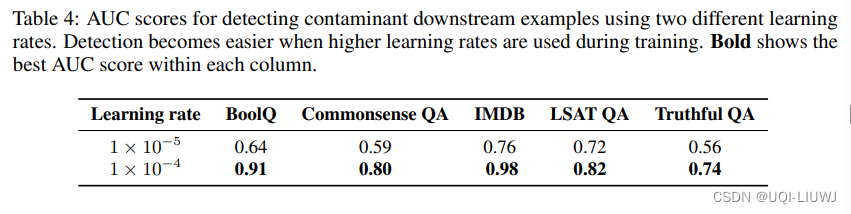
论文笔记:Detecting Pretraining Data from Large Language Models
iclr 2024 reviewer评分 5688
1 intro
论文考虑的问题:给定一段文本和对一个黑盒语言模型的访问权限,在不知道其预训练数据的情况下,能否判断该模型是否在这段文本上进行了预训练 这个问题是成员推断攻击(Membership Inference Attacks&…
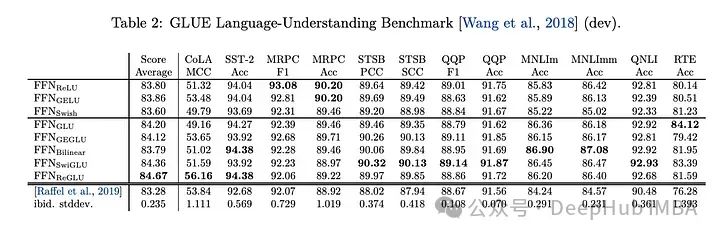
为什么大型语言模型都在使用 SwiGLU 作为激活函数?
如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对他进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和…
大语言模型上下文窗口初探(上)
由于篇幅原因,本文分为上下两篇,上篇主要讲解上下文窗口的概念、在LLM中的重要性,下篇主要讲解长文本能否成为LLM的护城河、国外大厂对长文本的态度。 1、什么是上下文窗口?
上下文窗口(context window)是…
AI大模型引领未来智慧科研暨ChatGPT自然科学应用
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…
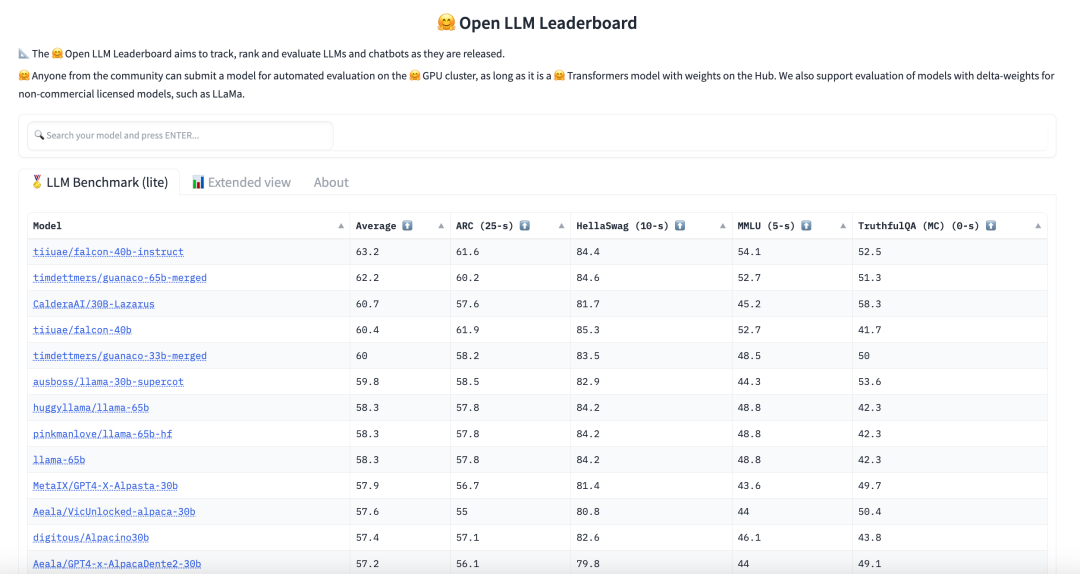
Hugging Face 的文本生成和大语言模型的开源生态
[更新于 2023 年 7 月 23 日: 添加 Llama 2。] 文本生成和对话技术已经出现多年了。早期的挑战在于通过设置参数和分辨偏差,同时控制好文本忠实性和多样性。更忠实的输出一般更缺少创造性,并且和原始训练数据更加接近,也更不像人话。最近的研…

NLP(2)N-gram language Model (缺了一些平滑的方式介绍)
文章目录 N-gram Language ModelTrigram Example存在的问题smoothingLaplacian (add-one) smoothing案例 1案例 2 Add-k smoothingAbsolute Discounting案例 Interpolation 在自然语言处理(NLP)中,语言模型(…

大模型的数据隐私问题有解了,浙江大学提出联邦大语言模型
作者 | 小戏、Python 理想化的 Learning 的理论方法作用于现实世界总会面临着诸多挑战,从模型部署到模型压缩,从数据的可获取性到数据的隐私问题。而面对着公共领域数据的稀缺性以及私有领域的数据隐私问题,联邦学习(Federated Le…
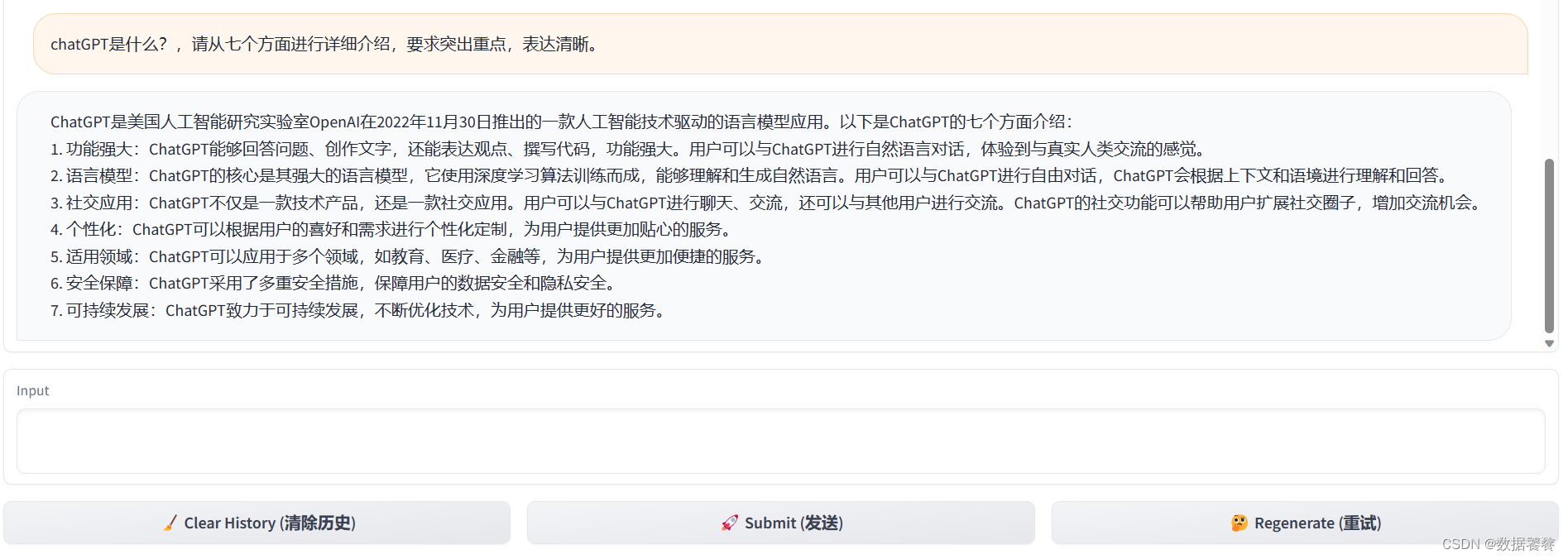
chatGPT小白快速入门培训课程-001
一、前言 本文是《chatGPT小白快速入门培训课程》的第001篇文章,全部内容采用chatGPT和chatGPT开源平替软件生成。完整内容大纲详见:《chatGPT小白快速入门课程大纲》。
本系列文章,参与: AIGC征文活动 #AIGC技术创作内容征文# …
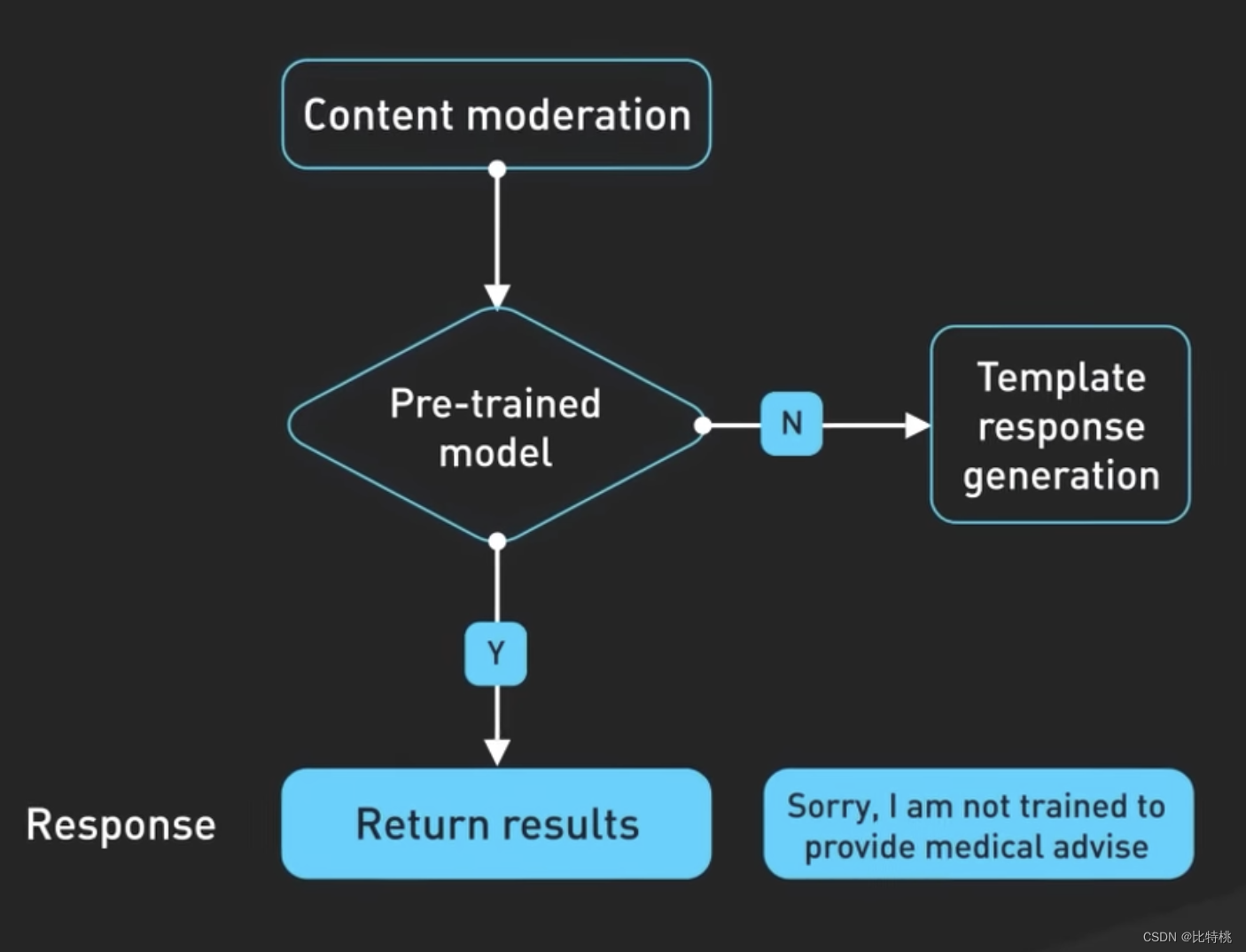
人工智能原理概述 - ChatGPT 背后的故事
大家好,我是比特桃。如果说 2023 年最火的事情是什么,毫无疑问就是由 ChatGPT 所引领的AI浪潮。今年无论是平日的各种媒体、工作中接触到的项目还是生活中大家讨论的热点,都离不开AI。其实对于互联网行业来说,自从深度学习出来后就…
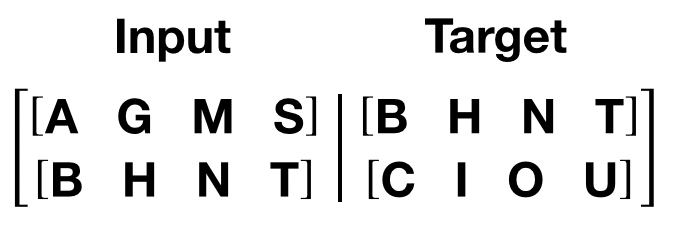
PyTorch翻译官网教程-LANGUAGE MODELING WITH NN.TRANSFORMER AND TORCHTEXT
官网链接
Language Modeling with nn.Transformer and torchtext — PyTorch Tutorials 2.0.1cu117 documentation 使用 NN.TRANSFORMER 和 TORCHTEXT进行语言建模
这是一个关于训练模型使用nn.Transformer来预测序列中的下一个单词的教程。
PyTorch 1.2版本包含了一个基于论…
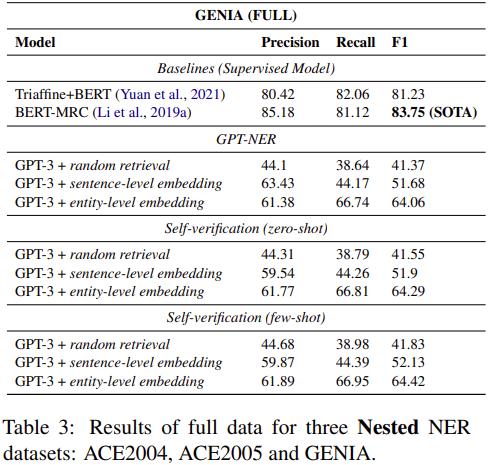
GPT-NER:使用大型语言模型进行命名实体识别
讲在前面,chatgpt出来的时候就想过将其利用在信息抽取方面,后续也发现了不少基于这种大语言模型的信息抽取的论文,比如之前收集过的: https://github.com/cocacola-lab/GPT4IE https://github.com/RidongHan/Evaluation-of-ChatG…
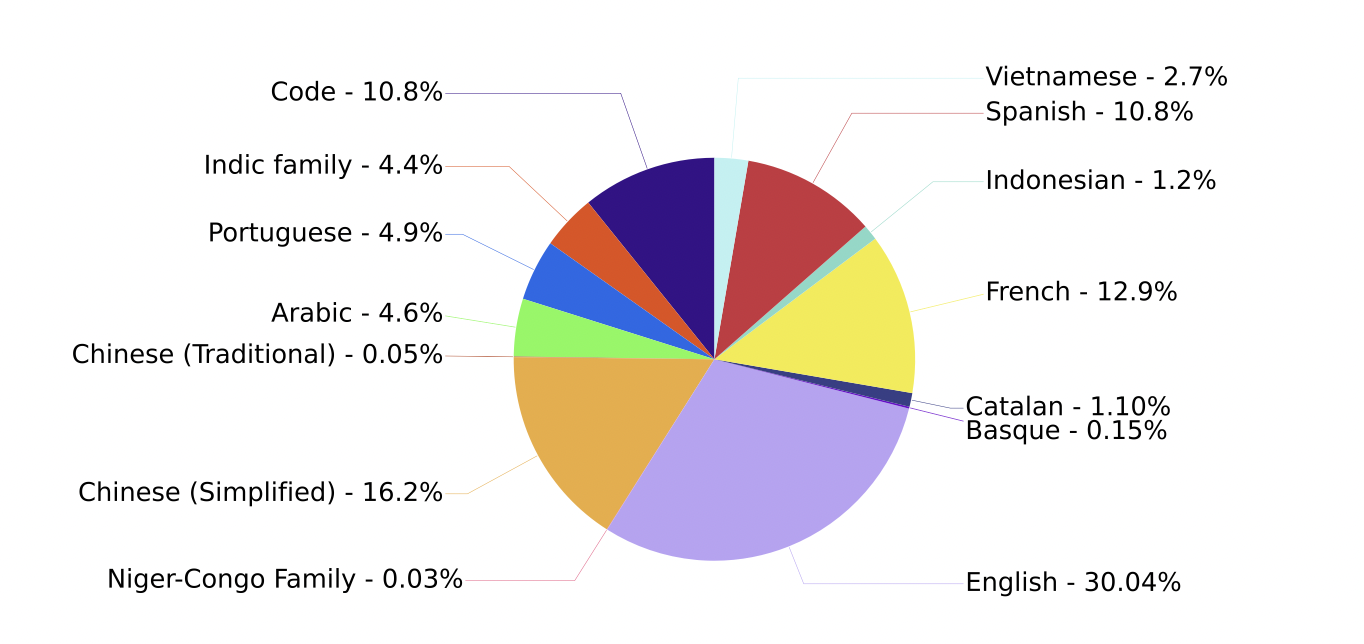
复刻ChatGPT语言模型系列-(一)基座模型选取
前言
今天开始我将会推出一系列关于复刻ChatGPT语言模型的博文。本系列将包括以下内容:
复刻ChatGPT语言模型系列-(一)基座模型选取复刻ChatGPT语言模型系列-(二)参数高效微调复刻ChatGPT语言模型系列-(三…

大语言模型(LLM)与 Jupyter 连接起来了
现在,大语言模型(LLM)与 Jupyter 连接起来了!
这主要归功于一个名叫 Jupyter AI 的项目,它是官方支持的 Project Jupyter 子项目。目前该项目已经完全开源,其连接的模型主要来自 AI21、Anthropic、AWS、Co…

大语言模型:LLM的概念是个啥?
一、说明 大语言模型(维基:LLM- large language model)是以大尺寸为特征的语言模型。它们的规模是由人工智能加速器实现的,人工智能加速器能够处理大量文本数据,这些数据大部分是从互联网上抓取的。 [1]所构建的人工神…
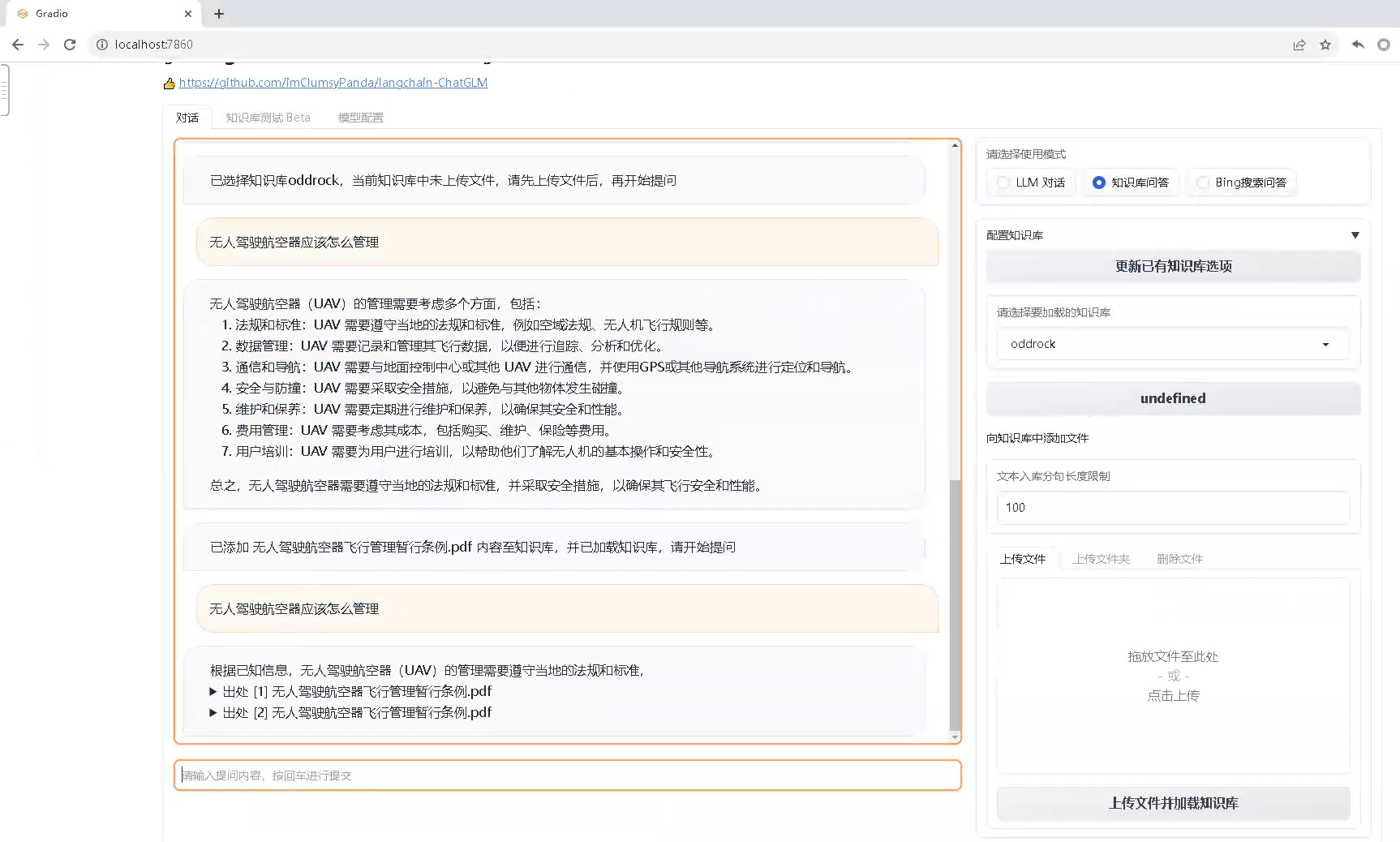
LangChain-ChatGLM在WIndows10下的部署
LangChain-ChatGLM在WIndows10下的部署
参考资料
1、LangChain ChatGLM2-6B 搭建个人专属知识库中的LangChain ChatGLM2-6B 构建知识库这一节:基本的逻辑和步骤是对的,但要根据Windows和现状做很多调整。
2、没有动过model_config.py中的“LORA_MOD…
ChatGPT插件与简要介绍(已收集70个)了解添加插件后的chatgpt能做什么
🥑 Welcome to Aedream同学 s blog! 🥑 70个ChatGPT插件与简要介绍 Name of the plugindescription_for_human_zhVoxScript用于搜索Varius数据源的插件。Wahi搜索多伦多,GTA和安大略省的房地产物业信息。Comic Finder一个插件,用于…

AIGC+游戏:一个被忽视的长赛道
(图片来源:Pixels) AIGC彻底变革了游戏,但还不够。 数科星球原创
作者丨苑晶
编辑丨大兔 消费还没彻底复苏,游戏却已经出现拐点。 在游戏热度猛增的背后,除了版号的利好因素外,AIGC技术的广泛…
大语言模型LLM的一些点
LLM发展史 GPT模型是一种自然语言处理模型,使用Transformer来预测下一个单词的概率分布,通过训练在大型文本语料库上学习到的语言模式来生成自然语言文本。 GPT-1(117亿参数),GPT-1有一定的泛化能力。能够用于和监督任务无关的任务中。GPT-2(…
LLM三类评估方法介绍
1.人工评估
基于人工的评估方法通常需要邀请大量的志愿者或相关领域的专家对LLM的生成进行主观评估和打分。以专业领域知识评估为例,首先,需要收集不同领域专家根据该领域专业问题给出的答案作为参考,然后根据已有知识与LLM生成的输出&#…
LLM:finetune预训练语言模型
模型训练
GPT-2/GPT and causal language modeling
[examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling]
[examples/pytorch/language-modeling/run_clm.py]
示例:
[colab.research.google.com/Causal Language modeling]
RoBERTa/BERT/Distil…

为什么很多人认为ChatGPT最好的替代工具是Claude?
ChatGPT引领着生成式AI聊天机器人领域,但Claude AI看起来是一个有力的竞争者。
前段时间,ChatGPT的强劲竞争对手Claude2面世。当时很多人认为它可能会取代ChatGPT,在体验过一段时间之后,深以为然。原因如下:
更强大的…
Automatically Correcting Large Language Models
本文是大模型相关领域的系列文章,针对《Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies》的翻译。 自动更正大型语言模型:综述各种自我更正策略的前景 摘要1 引言2 自动反馈校正LLM的…

【AI实战】开源可商用的中英文大语言模型baichuan-7B,从零开始搭建
【AI实战】开源可商用的中英文大语言模型baichuan-7B,从零开始搭建 baichuan-7B 简介baichuan-7B 中文评测baichuan-7B 搭建参考 baichuan-7B 简介
baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约…
动动小手搭建私人大模型人工智能私人助理
引言:
去年12月OpenAI公司的ChatGPT3.5彻底引爆人工智能圈,今年国内大公司争相进入大模型的赛道,打造自己的大模型。前些日子的世界人工智能大会上,可谓是百模大战,热闹纷呈。
ChatGPT的出现,的确给人们带…
什么是LLM大语言模型?
什么是LLM大语言模型?
大语言模型(英文:Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练࿰…

大语言模型与语义搜索;钉钉个人版启动内测,提供多项AI服务
🦉 AI新闻
🚀 钉钉个人版启动内测,提供多项AI服务
摘要:钉钉个人版正式开始内测,面向小团队、个人用户、高校大学生等人群。该版本具有AI为核心的功能,包括文生文AI、文生图AI和角色化对话等。用户可通过…
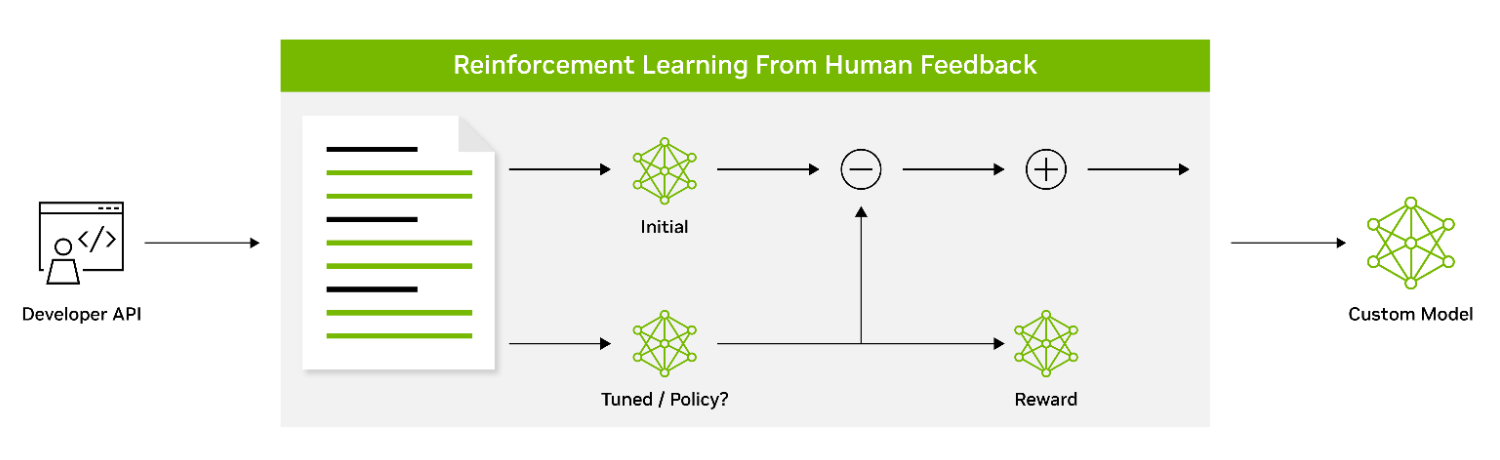
选择大型语言模型自定义技术
推荐:使用 NSDT场景编辑器 助你快速搭建可二次编辑器的3D应用场景 企业需要自定义模型来根据其特定用例和领域知识定制语言处理功能。自定义LLM使企业能够在特定的行业或组织环境中更高效,更准确地生成和理解文本。
自定义模型使企业能够创建符合其品牌…
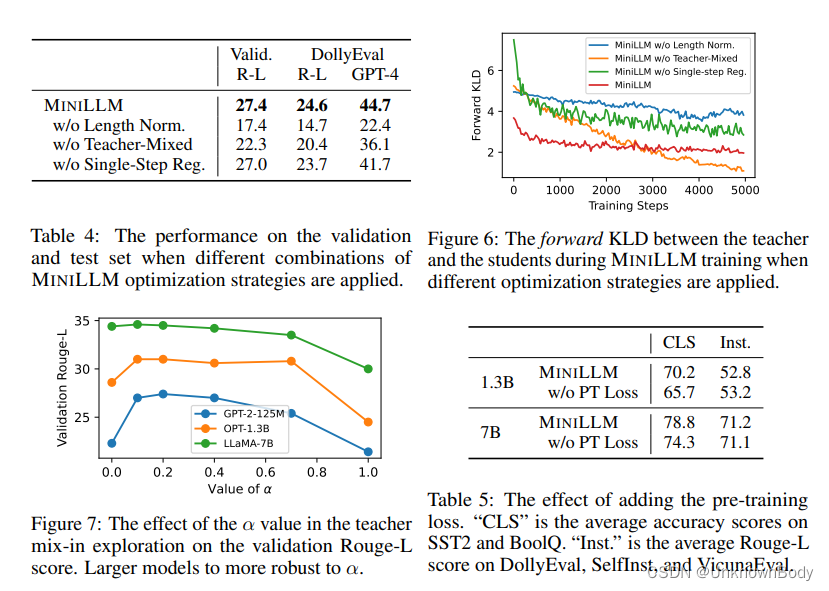
Knowledge Distillation of Large Language Models
这是大模型系列模型的文章,针对《Knowledge Distillation of Large Language Models》的翻译。 大模型的知识蒸馏 摘要1 引言2 方法2.1 MiniLLM:利用逆向KLD进行知识蒸馏2.2 策略梯度优化2.3 训练算法 3 实验3.1 实验设置3.2 结果3.3 分析3.4 消融实验 …
Genoss GPT简介:使用 Genoss 模型网关实现多个LLM模型的快速切换与集成
一、前言
生成式人工智能领域的发展继续加速,大型语言模型 (LLM) 的用途范围不断扩大。这些用途跨越不同的领域,包括个人助理、文档检索以及图像和文本生成。ChatGPT 等突破性应用程序为公司进入该领域并开始使用这项技术进行构建铺平了道路。
大公司正…

Toolformer:可以教会自己使用工具的语言模型
Toolformer:可以教会自己使用工具的语言模型 摘要Introduction现有大模型的局限处理办法本文的idea Approach样例化API调用执行API调用筛选API调用模型微调 实验局限 论文地址点这里
摘要
语言模型(LMs)呈现了令人深刻的仅使用少量的范例或…
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
本文也是LLM系列相关文章,针对《MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models》的翻译。 MME:一个多模态大型语言模型的综合评估基准 摘要1 引言2 MME评估套件3 实验4 分析5 结论 摘要
多模态大语言模型(MLLM&…

ModaHub魔搭社区:如何基于向量数据库+LLM(大语言模型),打造更懂你的企业专属Chatbot?
目录
1、为什么Chatbot需要大语言模型向量数据库?
2、什么是向量数据库?
3、LLM大语言模型ADB-PG:打造企业专属Chatbot
4、ADB-PG:内置向量检索全文检索的一站式企业知识数据库
5、总结 1、为什么Chatbot需要大语言模型向量数据库?
这个春天,最让人震感的科技产品莫过…

一文入门最热的LLM应用开发框架LangChain
在人工智能领域的不断发展中,语言模型扮演着重要的角色。特别是大型语言模型(LLM),如 ChatGPT,已经成为科技领域的热门话题,并受到广泛认可。
在这个背景下,LangChain 作为一个以 LLM 模型为核…
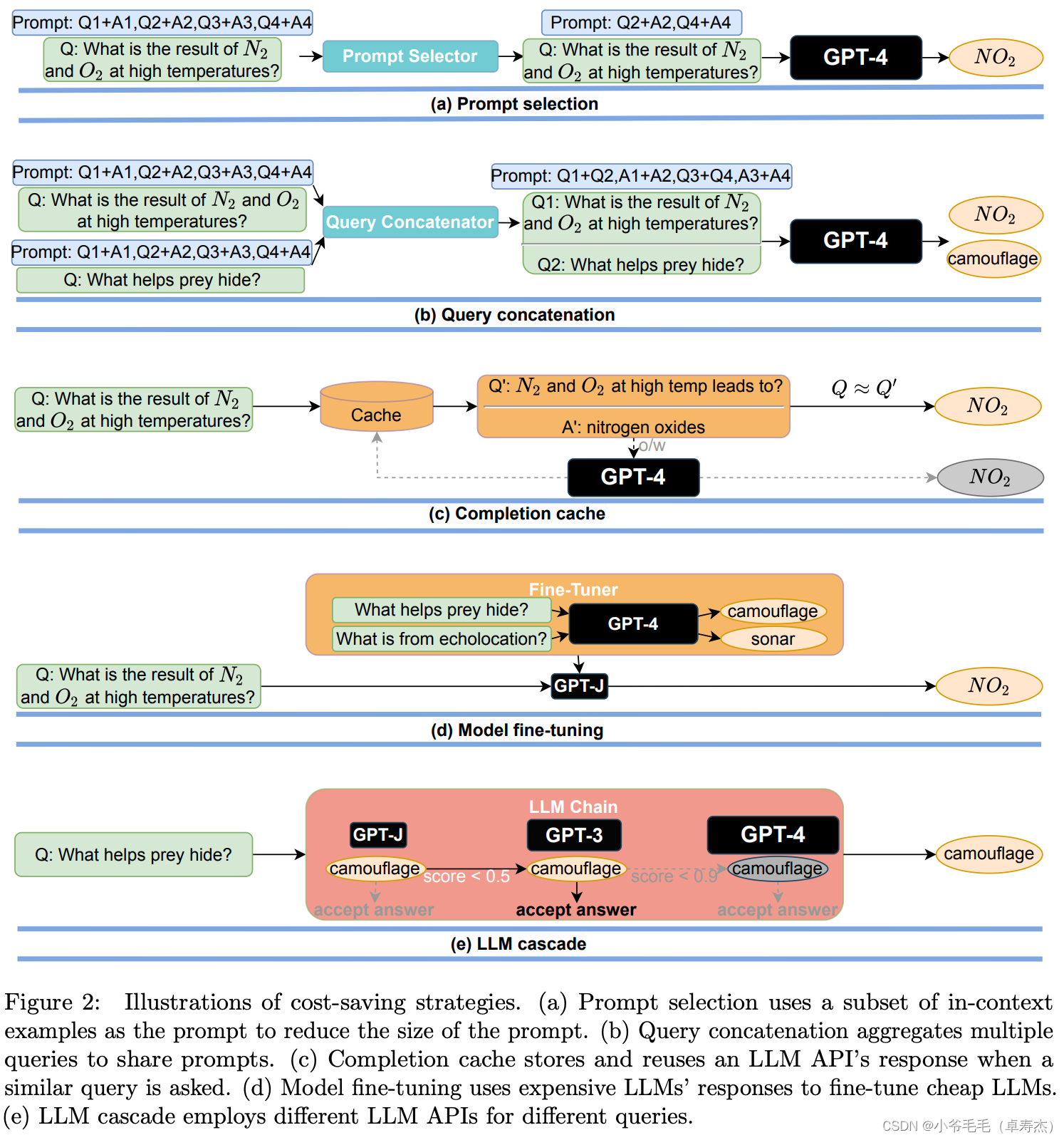
【斯坦福】FrugalGPT: 如何使用大型语言模型,同时降低成本并提高性能
FrugalGPT: 如何使用大型语言模型,同时降低成本并提高性能 作者:Lingjiao Chen, Matei Zaharia, James Zou
引言
本文介绍了一种新颖的方法,旨在解决使用大型语言模型(LLM)时面临的成本和性能挑战。随着GPT-4和Chat…
transformer大语言模型(LLM)部署方案整理
说明
大模型的基本特征就是大,单机单卡部署会很慢,甚至显存不够用。毕竟不是谁都有H100/A100, 能有个3090就不错了。
目前已经有不少框架支持了大模型的分布式部署,可以并行的提高推理速度。不光可以单机多卡,还可以多机多卡。 …
Transformer之傲慢与偏见:主流大语言模型的技术细节揭秘
文章首发地址 目前,主流的大语言模型包括GPT(Generative Pre-trained Transformer)系列、BERT(Bidirectional Encoder Representations from Transformers)、XLNet(eXtreme-Long Transformer)等…
Recommender Systems in the Era of Large Language Models (LLMs)
本文是LLM系列文章,针对《Recommender Systems in the Era of Large Language Models (LLMs)》的翻译。 大语言模型时代的推荐系统 摘要1 引言2 相关工作3 基于LLM推荐系统的深度表示学习4 预训练和微调LLM用于推荐系统5 提示LLM用于推荐系统6 未来方向6.1 幻觉缓解…

垂类模型大有前景,但AGI却给自己“挖了个坑”
巨量模型是个“坑”,但垂直模型不是。 数科星球原创 作者丨苑晶 编辑丨大兔
2023年4月,GPT-5的相关消息引起了一阵轰动。彼时,人们对巨量大模型既有期待、也有恐惧。更有甚者,认为人类历史或许将因此而画上终止符。 但很快&#…
利用 AI 技术消除繁忙城市停车的压力(文末含人工智能资料包)
巴斯大学正在开发帮助司机在繁忙的城市中心找到停车位的人工智能。
该软件还将激励司机与地方议会合作,寻求将繁忙的城市中心的污染保持在安全范围内,这是旨在减少市中心有毒空气的深远计划的一部分。
随着城市人口的持续增长(预计从现在到…
【大模型】二 、大语言模型的基础知识
文章目录 大型语言模型国内外大语言模型大模型列表国外大模型 大型语言模型
大型语言模型是近年来机器学习和自然语言处理领域的一个重要发展趋势。以GPT模型为例,阐述其发展
GPT系列基于Transformer架构,进行构建,旨在理解和生成人类语言。…

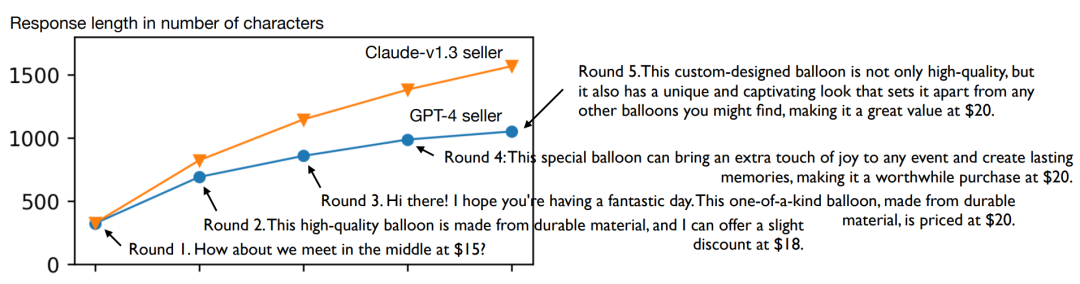
符尧最新研究:大语言模型玩砍价游戏?技巧水涨船高!
深度学习自然语言处理 原创作者:鸽鸽 若干年前,AlphaGo Zero用两个AI代理切磋围棋技艺,打败了人类。今早,符尧的一篇论文刷新了我的认知:让大语言模型相互对弈,再加一个评论家提供建设性意见,提…
Big_models的解释
文章目录 大语言模型的解释1.自动化大模型解释(open AI 成果)1.1 三个步骤:1.2 涉及到的模型:1.3 具体实验步骤1.4 finds: 原文链接:https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
…
Retrieval-Augmented Multimodal Language Modeling
本文是LLM系列文章,针对《Retrieval-Augmented Multimodal Language Modeling》的翻译。 检索增强的多模态语言建模 摘要1 引言2 相关工作3 方法4 实验5 定性结果6 结论 摘要
最近的多模态模型,如DALL-E和CM3,在文本到图像和图像到文本生成…

BFT 最前线 | ChatGPT登顶App Store;国产中文大语言模型「天河天元」发布;华为招募天才少年;阿里分拆上市
原创 | 文 BFT机器人 AI视界
TECHNOLOGY NEWS 01 ChatGPT上架App Store登顶榜首
OpenAI:很快也将出现在安卓上 近日,ChatGPT正式发布App版本,上架APP Store,支持iPhone和iPad设备。OpenAI表示,ChatGPT iOS APP可免费…

征稿丨IJCAI‘23大模型论坛,优秀投稿推荐AI Open和JCST发表
第一届LLMIJCAI’23 Symposium征稿中,优秀投稿论文推荐《AI Open》和 《JCST》发表。 大规模语言模型(LLMs),如ChatGPT和GPT-4,以其在自然语言理解和生成方面的卓越能力,彻底改变了人工智能领域。
LLMs广泛…


论文浅尝 | 大语言模型综述
笔记整理:刘康为、方润楠,浙江大学硕士,研究方向为自然语言处理 链接:https://arxiv.org/abs/2303.18223 一、介绍 在当前机遇和挑战的背景下,对大语言模型的研究和开发需要更多的关注。为了让读者对大语言模型有一个基…
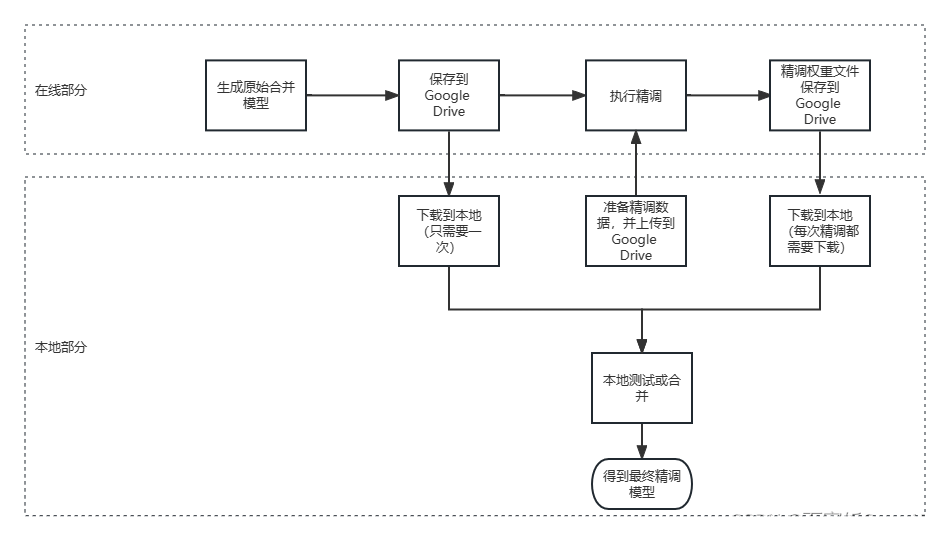
在中文LLaMA模型上进行精调
最近在开源项目ymcui/Chinese-LLaMA-Alpaca的基础上完成了自己的中文模型精调工作,形成了两个工具共享给大家。ymcui/Chinese-LLaMA-Alpaca
构建指令形式的精调文件
如果用于精调,首先要准备精调数据,目标用途如果是问答,需要按…
大模型一、大语言模型的背景和发展
文章目录 背景模型1 文本LLM模型ChatGLMChatGLM2-6BChinese-LLaMA-Alpaca:Chinese-LLaMA-Alpaca-2:Chinese-LlaMA2:Llama2-Chinese:OpenChineseLLaMA:BELLE:Panda:Robin (罗宾):Fengshenbang-LM…

在矩池云使用ChatGLM-6B ChatGLM2-6B
ChatGLM-6B 和 ChatGLM2-6B都是基于 General Language Model (GLM) 架构的对话语言模型,是清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同发布的语言模型。模型有 62 亿参数,一经发布便受到了开源社区的欢迎,在中文语义理解和对话生成上有…
ChatGPT在大规模数据处理和信息管理中的应用如何?
ChatGPT作为一种强大的自然语言处理模型,在大规模数据处理和信息管理领域有着广泛的应用潜力。它可以利用其文本生成、文本理解和问答等能力,为数据分析、信息提取、知识管理等任务提供智能化的解决方案。以下将详细介绍ChatGPT在大规模数据处理和信息管…
robust distortion-free watermarks for language models
本文是LLM系列文章,针对《robust distortion-free watermarks for language models》的翻译。 语言模的鲁棒无失真水印 摘要1 引言2 方法和理论分析3 实验结果4 讨论 摘要
我们提出了一种从自回归语言模型中在文本中植入水印的方法,该方法对扰动具有鲁…

02__models
LangChain提供两种封装的模型接口
1.大规模语言模型(LLM):输入文本字符串,返回文本字符串
2.聊天模型:基于一个语言模型,输入聊天消息列表,返回聊天消息
Langchain的支持OpenAI、ChatGLM、Hu…
04. 提示词(Prompt)
提示词(prompt)是一种向模型提供的输入。 提示词模板
一个简单的例子
from langchain import PromptTemplatetemplate """你是一名精通多门语言,专业的翻译家。你的任务是从{src_lang}翻译到{dst_lang}"""# 实例化对象prompt
prom…
05_Output_Parsers(输出解析器)
模型输出为文本,有时候需要输出结果为结构化数据,如数组、字典等类型,这个时候需要输出解析器。
LangChain框架提供了基础的解析器类BaseOutputParser,其他的解析器都是继承自该类,
实现的两个主要方法
1. get_form…
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
本文是LLM系列文章,针对《Graph of Thoughts: Solving Elaborate Problems with Large Language Models》的翻译。 思维图:用大语言模型解决复杂问题 摘要1 引言2 背景与符号3 GoT框架4 系统架构和扩展性5 用例示例6 延迟量权衡7 评估8 相关工作9 结论 …

ChatGPT 现在可以看、听和说话了!
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…
mlc-llm 推理优化和大语言模型搭建解析
0x0. 前言
本文解析一下mlc-llm(https://github.com/mlc-ai/mlc-llm)对大模型推理的流程以及使用的图优化,算子优化策略。mlc-llm的模型部署流程可以查看官方文档:https://mlc.ai/mlc-llm/docs/ ,也可以参考我前段时间…

“新KG”视点 | 漆桂林——知识图谱和大语言模型的共存之道
OpenKG 大模型专辑 导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织…
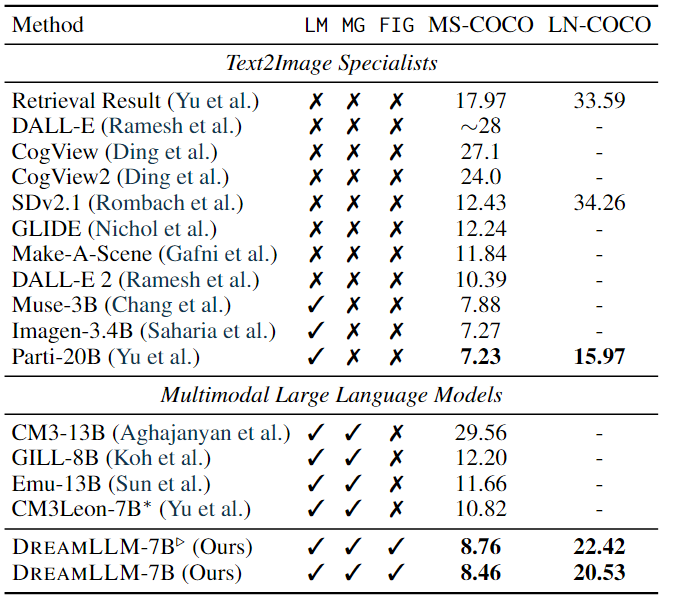
DreamLLM:多功能多模态大型语言模型,你的DreamLLM~
深度学习自然语言处理 原创作者:wkk 今天为大家介绍西安交大,清华大学、华中科大联合MEGVII Technology的一篇关于多模态LLM学习框架的论文,名为DREAMLLM。 论文:DreamLLM: Synergistic Multimodal Comprehension and Creation论文…
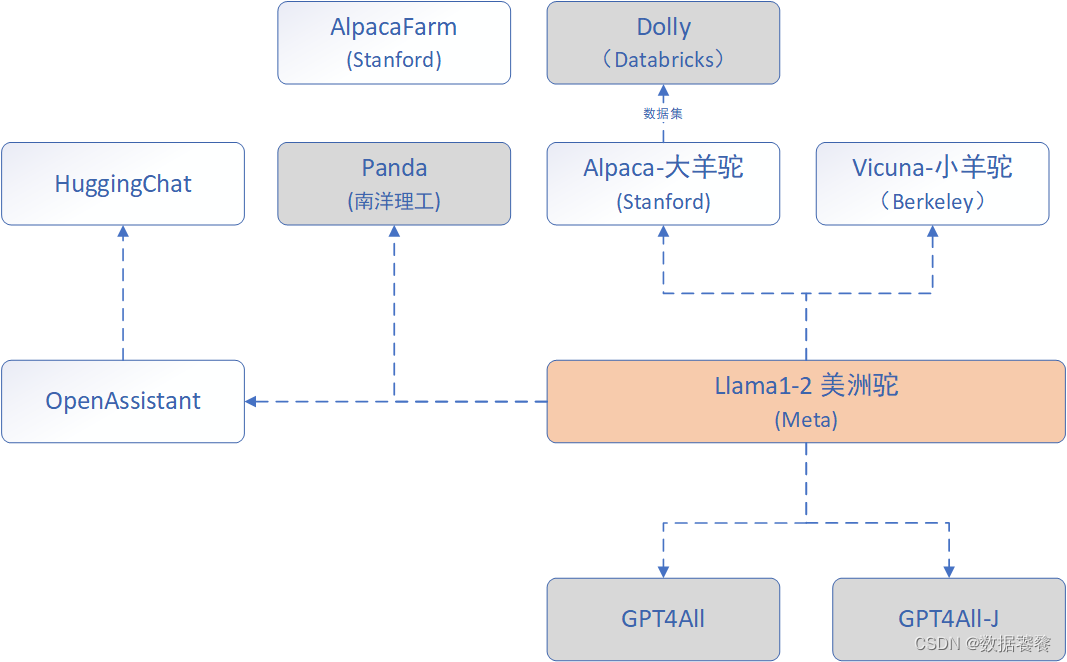
2023 年热门的大型语言模型 (LLMs)汇总【更新至9月26】
一、全景地图
整理了一张大语言模型的血缘图谱,如下图所示: 图中的大语言模型,都是自己做过评测的,主观了点,但是原汁原味,有好的可以推荐给我。
二、ChatGPT系列
ChaTGP是商业版本大语言模型的正统&…

【LLM】Windows10环境部署阿里通义千问大模型(Qwen-14B-Chat-Int4)
文章目录 环境文件准备项目代码模型相关文件 运行准备工作运行demo Tips 环境
系统版本:Windows 10 企业版 版本号:20H2 系统类型:64 位操作系统, 基于 x64 的处理器 处理器:Intel Core™ i7-13700K CPU 3.40GHz 机带 RAM&#…
大语言模型之十三 LLama2中文推理
在《大语言模型之十二 SentencePiece扩充LLama2中文词汇》一文中已经扩充好了中文词汇表,接下来就是使用整理的中文语料对模型进行预训练了。这里先跳过预训练环节。先试用已经训练好的模型,看看如何推理。
合并模型
这一步骤会合并LoRA权重࿰…
大语言模型LLM知多少?
你知道哪些流行的大语言模型?你都体验过哪写? GPT-4,Llamma2, T5, BERT 还是 BART?
1.GPT-4
1.1.GPT-4 模型介绍
GPT-4(Generative Pre-trained Transformer 4)是由OpenAI开发的一种大型语言模型。GPT-4是前作GPT系列模型的进一步改进,旨在提高语言理解和生成的能力,…

LongLoRA:不需要大量计算资源的情况下增强了预训练语言模型的上下文能力
麻省理工学院和香港中文大学推出了LongLoRA,这是一种革命性的微调方法,可以在不需要大量计算资源的情况下提高大量预训练语言模型的上下文能力。
LongLoRA是一种新方法,它使改进大型语言计算机程序变得更容易,成本更低。训练LLM往…
构建卓越语言模型应用的利器:LangChain | 开源日报 No.39
langchain-ai/langchain
Stars: 61.3k License: MIT
LangChain 是一个用于通过组合性构建 LLMs 应用程序的库。
LLMs 和 Prompts:包括 prompt 管理、prompt 优化、所有 LLM 的通用接口以及与 LLMs 一起使用的常见工具。Chains:超越单个 LLM 调用&…
深度学习实战50-构建ChatOCR项目:基于大语言模型的OCR识别问答系统实战
大家好,我是微学AI,今天给大家介绍一下深度学习实战50-构建ChatOCR项目:基于大语言模型的OCR识别问答系统实战,该项目是一个基于深度学习和大语言模型的OCR识别问答系统的实战项目。该项目旨在利用深度学习技术和先进的大语言模型,构建一个能够识别图像中文本,并能够回答与…
Backpack Language Models
本文是LLM系列的文章,针对《Backpack Language Models》的翻译。 背包语言模型 摘要1 引言2 背包架构3 带有背包的语言模型4 实验训练背包LM5 感知向量中的涌现结构6 用于控制的感知向量7 相关工作8 讨论9 结论11 不足12 摘要
我们介绍了Backpacks:一种…

基于亚马逊云科技服务,构建大语言模型问答知识库
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通…
[ACL2023] Exploring Lottery Prompts for Pre-trained Language Models
Exploring Lottery Prompts for Pre-trained Language Models
文章链接
清深的工作,比较有意思的一篇。作者先给出假设,对于分类问题,在有限的语料空间内总能找到一个prompt让这个问题分类正确,作者称之为lottery prompt。为此&…

LLM预训练大型语言模型Pre-training large language models
在上一个视频中,您被介绍到了生成性AI项目的生命周期。
如您所见,在您开始启动您的生成性AI应用的有趣部分之前,有几个步骤需要完成。一旦您确定了您的用例范围,并确定了您需要LLM在您的应用程序中的工作方式,您的下…
LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数
transformers4.28.1
源码地址:transformers/configuration_utils.py at v4.28.1 huggingface/transformers (github.com)
文档地址:Generation (huggingface.co)
对于生成任务而言:text-decoder, text-to-text, speech-…
A Survey on Knowledge-Enhanced Pre-trained Language Models
摘要
自然语言处理(NLP)已经通过使用BERT等预训练语言模型(plm)发生了革命性的变化。尽管几乎在每个NLP任务中都创造了新的记录,但plm仍然面临许多挑战,包括可解释性差,推理能力弱,以及在应用于下游任务时需要大量昂贵的注释数据。通过将外部知识集成到plm中,知识增强预训…

谈谈NLP中 大语言模型LLM的 思维链 Chain-of-Thought(CoT)
Chain-of-Thought(CoT)
1.介绍
在过去几年的探索中,业界发现了一个现象,在增大模型参数量和训练数据的同时,在多数任务上,模型的表现会越来越好。因而,现有的大模型LLM,最大参数量已经超过了千亿。
然而…
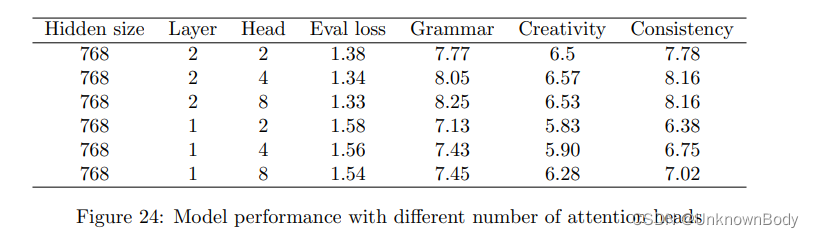
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
本文是LLM系列的文章之一,针对《TinyStories: How Small Can Language Models Be and Still Speak Coherent English?》的翻译。 TinyStories:语言模型能有多小,还能说连贯的英语? 摘要1 引言2 TinyStories数据集的描述2.1 Tiny…
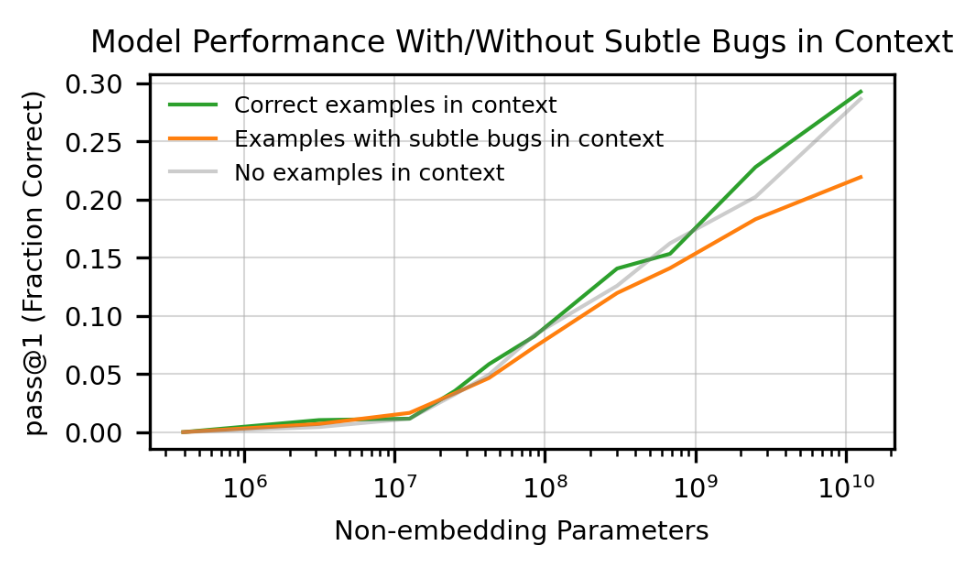
【论文精读】Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code 前言Abstract1. Introduction2. Evaluation Framework2.1. Functional Correctness2.2. HumanEval: Hand-Written Evaluation Set2.3. Sandbox for Executing Generated Programs 3. Code Fine-Tuning3.1. Data Collection3.…
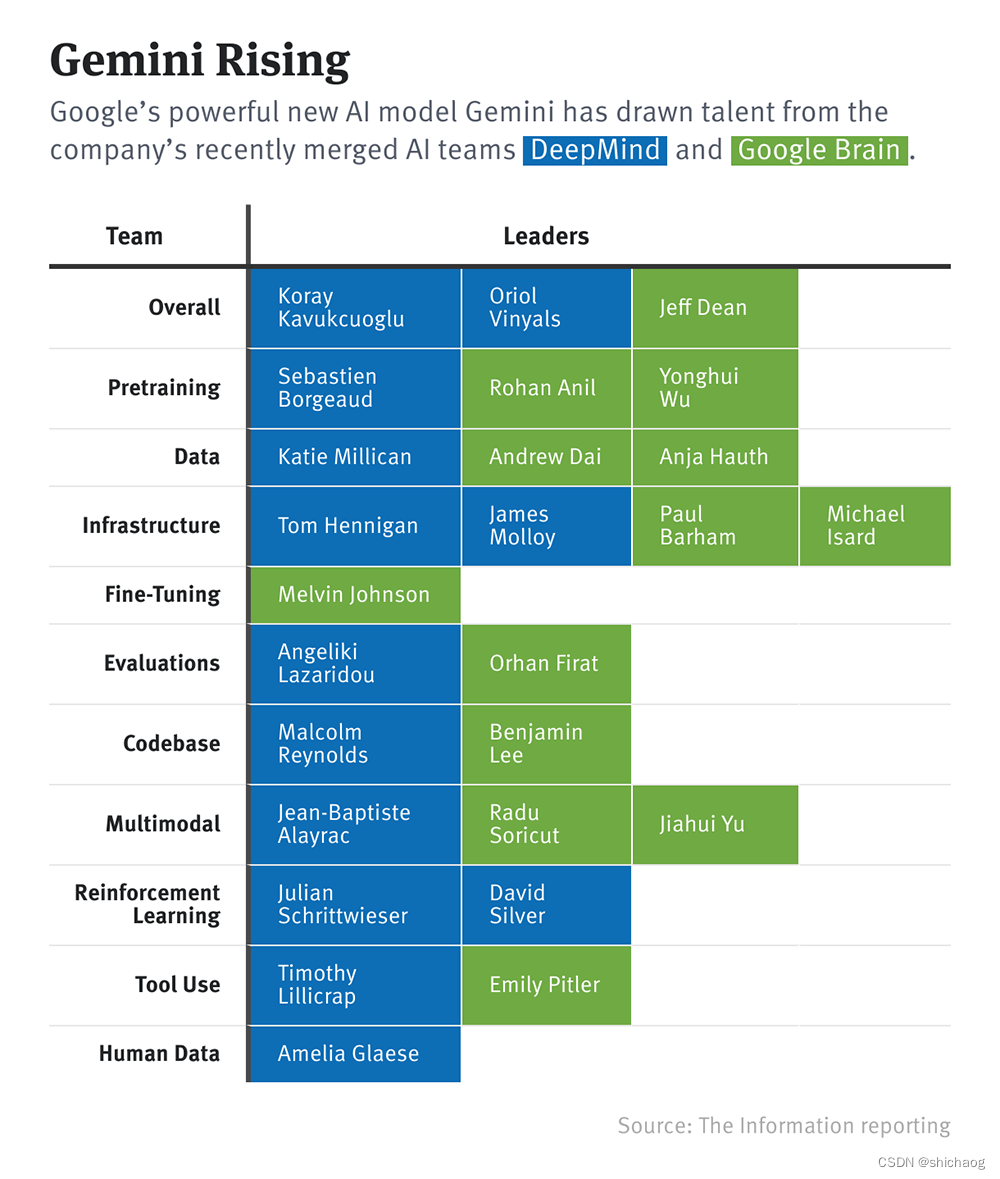
大语言模型之五 谷歌Gemini
近十年来谷歌引领着人工智能方向的发展,从TensorFlow到TPU再到Transformer,都是谷歌在引领着,然而,在大语言模型上,却被ChatGPT(OpenAI)抢了风头,并且知道GPT-4(OpenAI&a…
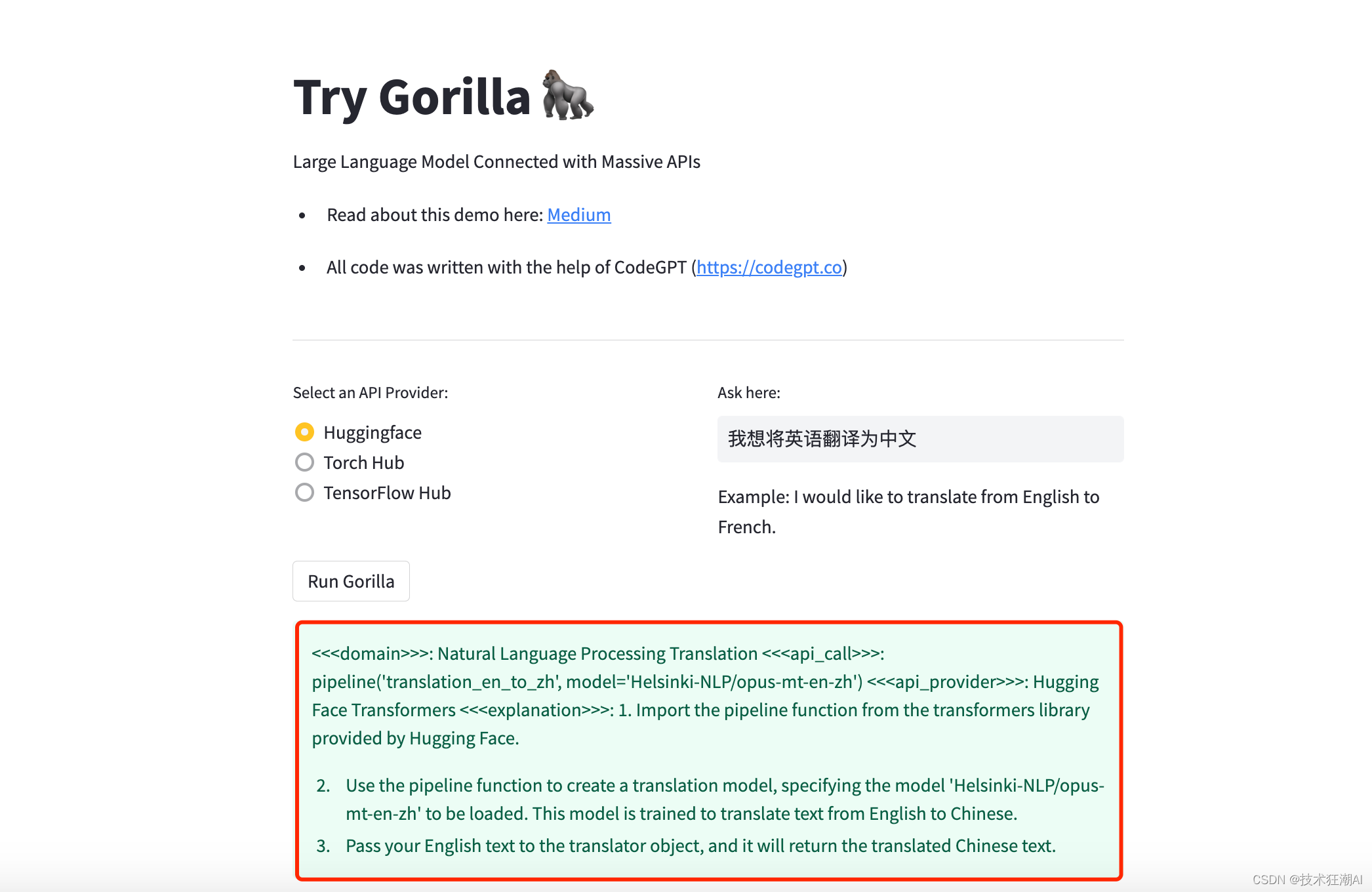
Gorilla LLM:连接海量 API 的大型语言模型
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。 一、前言
在当今这个数字化时代,大型语言模型(LLM…
Parallel Context Windows for Large Language Models
本文是LLM系列文章,针对《Parallel Context Windows for Large Language Models》的翻译。 大语言模型并行上下文窗口 摘要1 引言2 并行上下文窗口3 上下文学习的PCW4 PCW用于QA5 相关工作6 结论和未来工作不足 摘要
当应用于处理长文本时,大型语言模型…

Meta语言模型LLaMA解读:模型的下载部署与运行代码
文章目录 llama2体验地址模型下载下载步骤准备工作什么是Git LFS下载huggingface模型 模型运行代码 llama2
Meta最新语言模型LLaMA解读,LLaMA是Facebook AI Research团队于2023年发布的一种语言模型,这是一个基础语言模型的集合。
体验地址
体验地址 …
TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS》的翻译。 time-llm:通过重新编程大型语言模型来预测时间序列 摘要1 引言2 相关工作3 方法4 主要结果5 结论和未来工作 摘要
时间序列预测在许多现实世界的动…
ExpeL: LLM Agents Are Experiential Learners
本文是LLM系列文章,针对《ExpeL: LLM Agents Are Experiential Learners》的翻译。 EXpeL:LLM代理是体验学习者 摘要1 引言2 相关工作3 前言4 ExpeL:一个实验学习代理5 实验6 结论和不足 摘要
最近,通过利用大型语言模型中嵌入的…
Relation Extraction as Open-book Examination: Retrieval-enhanced Prompt Tuning
本文是LLM系列文章,针对《Relation Extraction as Open-book Examination: Retrieval 关系提取作为开卷测试:检索增强提示调整 摘要1 引言2 方法3 实验4 相关工作5 结论 摘要
经过预训练的语言模型通过表现出显著的小样本学习能力,对关系提取…
Truncation Sampling as Language Model Desmoothing
本文是LLM系列文章,针对《Truncation Sampling as Language Model Desmoothing》的翻译。 截断采样作为语言模型的去平滑性 摘要1 引言2 背景3 截断作为去平滑性4 方法5 实验与结果6 相关工作7 结论8 不足 摘要
来自神经语言模型的长文本样本可能质量较差。截断采…

LLM强势挺进端侧,AI大语言模型端侧部署如何影响超自动化?
▲ 图片由AI生成
算力资源吃紧,成本居高不下,数据隐私泄露,用户体验不佳……
以OpenAI为代表的大语言模型爆发后,多重因素影响之下本地化部署成为LLM落地的主流模式。LLM迫切需要部署在本地设备上,围绕LLM端侧部署的…
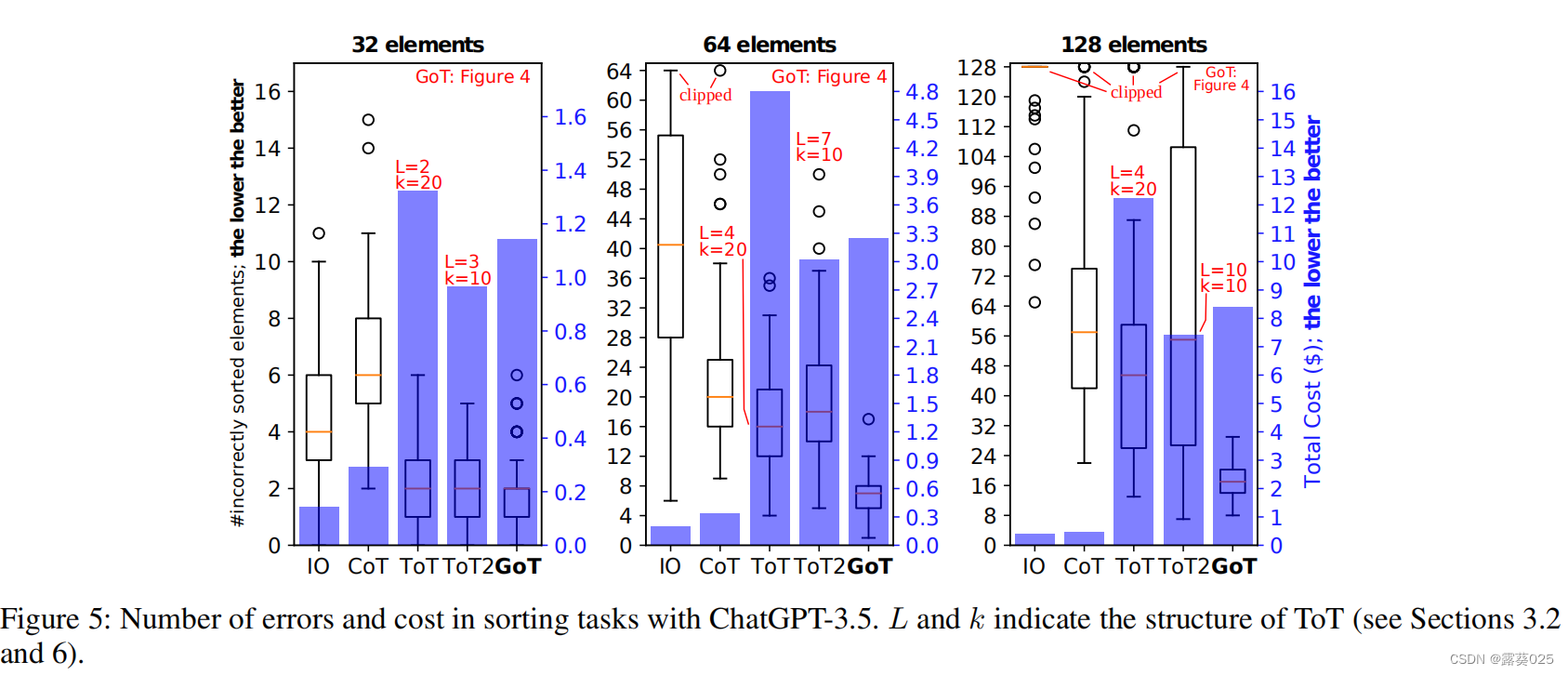
GoT:用大语言模型解决复杂的问题
GoT:用大语言模型解决复杂的问题 摘要介绍背景和符号表示语言模型和上下文学习Input-Output(IO)Chain of thought(CoT)Multiple CoTTree of thoughts(ToT) GoT框架推理过程思维变换聚合变换&…
GREASELM: GRAPH REASONING ENHANCED LANGUAGE MODELS FOR QUESTION ANSWERING
本文是LLM系列文章,针对《GREASELM: GRAPH REASONING ENHANCED LANGUAGE MODELS FOR QUESTION ANSWERING》的翻译。 GREASELM:图推理增强的问答语言模型 摘要1 引言2 相关工作3 提出的方法:GREASELM4 实验设置5 实验结果6 结论 摘要
回答关…
AnomalyGPT: Detecting Industrial Anomalies using Large Vision-Language Models
本文是LLM系列文章,针对《AnomalyGPT: Detecting Industrial Anomalies using Large Vision AnomalyGPT:使用大型视觉语言模型检测工业异常 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
大型视觉语言模型(LVLMs),如…
TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents
本文是LLM系列文章,针对《TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents》的翻译。 TPTU:任务规划和工具使用的LLM Agents 摘要1 引言2 方法3 评估4 相关工作5 结论 摘要
随着自然语言处理的最新进展,大型语言模型&…
MaPLe: Multi-modal Prompt Learning
本文也是LLM系统的文章,主要是面向多模态的大语言模型,针对《MaPLe: Multi-modal Prompt Learning》的翻译。 MaPLe:多模态提示学习 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
CLIP等预先训练的视觉语言(V-L)模型…
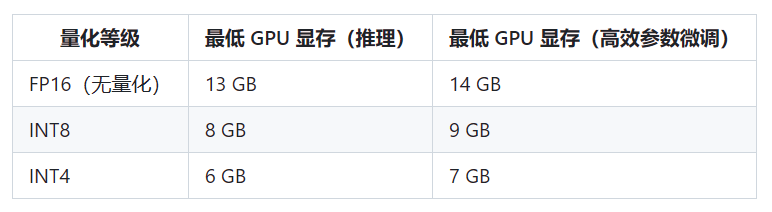
ChatGLM2_6b安装
Chatglm2_6b安装
一、安装要求
1、硬件 能否使用,或者以什么模式使用主要取决于显卡的显存
2、能否使用AMD显卡?
可以,甚至可以使用CPU,但是需要降低精度。
以CPU模式运行大概需要32GB 内存。
二:工程与下载 官方路径工程路径:
一代工程:
https://github.com/TH…
大模型技术实践(三)|用LangChain和Llama 2打造心灵疗愈机器人
上期文章我们实现了Llama 2-chat-7B模型的云端部署和推理,本期文章我们将用“LangChainLlama 2”的架构打造一个定制化的心灵疗愈机器人。有相关知识背景的读者可以直接阅读「实战」部分。 01 背景 1.1 微调 vs. 知识库 由于大模型在垂直行业领域的问答效果仍有待提…
LLASM: LARGE LANGUAGE AND SPEECH MODEL
本文是LLM系列文章,针对《LLASM: LARGE LANGUAGE AND SPEECH MODEL》的翻译。 LLASM:大型语言和语音模型 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要
近年来,多模态大型语言模型引起了人们的极大兴趣。尽管如此,大多数工作都…
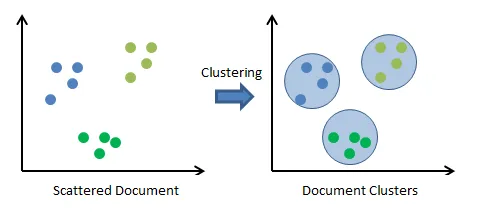
当红语言模型利器:深度解析向量数据库技术及其应用
编者按:随着大语言模型的广泛应用,如何存储和高效检索这些模型产生的大量向量表示成为一个较为关键的问题。本文深入探讨了向量数据库在提升语言模型应用性能方面的作用,并介绍了不同类型向量数据库的特点。 本文以简明扼要的方式全面概述了向…
How Language Model Hallucinations Can Snowball
本文是LLM系列文章,针对《How Language Model Hallucinations Can Snowball》的翻译。 语言模型幻觉是如何产生雪球的 摘要1 引言2 为什么我们期待幻觉像滚雪球一样越滚越大?3 实验4 我们能防止雪球幻觉吗?5 相关工作6 结论局限性 摘要
在实…
使用 LoRA 和 QLoRA 对大型语言模型进行参数高效的微调
概述
随着我们深入研究参数高效微调 (PEFT) 的世界,了解这种变革性方法背后的驱动力和方法变得至关重要。在本文中,我们将探讨 PEFT 方法如何优化大型语言模型 (LLM) 对特定任务的适应。我们将揭开 PEFT 的优点和缺点,深入研究 PEFT 技术的复杂类别,并破译两种卓越技术的内…

雷池社区WAF:保护您的网站免受黑客攻击 | 开源日报 0918
keras-team/keras
Stars: 59.2k License: Apache-2.0 Keras 是一个用 Python 编写的深度学习 API,运行在机器学习平台 TensorFlow 之上。它
简单易用:减少了开发者认知负荷,使其能够更关注问题中真正重要的部分。灵活性强:通过逐…

2023 Google 开发者大会:将大型语言模型部署到你的手机
在2022年末,不到半年时间,各家大语言模型的发展如雨后春笋,截至2023年9月,全球总共有接近100个大语言模型,可谓是百花齐放 显而易见,大语言模型凭借出色的AI对话能力,已经逐渐深入各个行业
20…
达摩院SPACE对话大模型:预训练语言模型,预训练对话模型,知识注入
01 预训练语言模型 VS 预训练对话模型
1. 大规模语言模型 过去几年 NLP 领域的重大进展,主要是大型预训练模型出现与大规模使用。预训练语言模型有了很大的发展,出现了很多变种。但是,本质上都还是语言模型,如上图右边的流程图所…
大模型如何赋能智能客服
2022年,大模型技术的出色表现让人们瞩目。随着深度学习和大数据技术的发展,大模型在很多领域的应用已经成为可能。许多公司开始探索如何将大模型技术应用于自己的业务中,智能客服也不例外。
智能客服是现代企业中非常重要的一部分࿰…
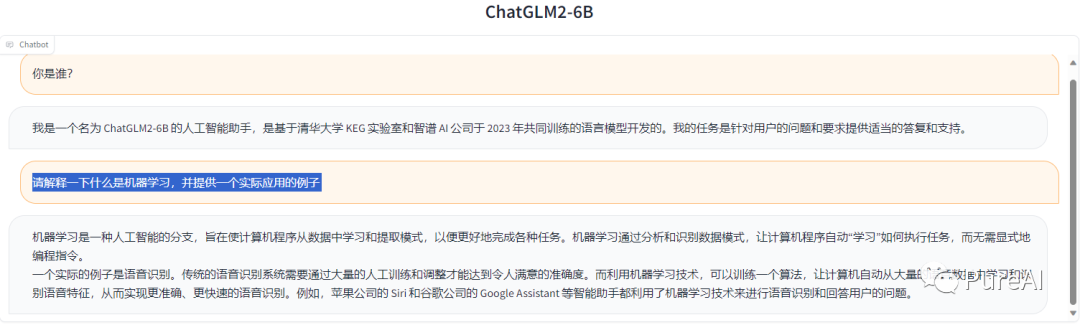
ChatGLM 实践指南
随着ChatGPT代表的AI大模型的爆火,我一直在想,是否能把大模型的能力用于个人或者企业的知识管理上,打造一个私有的AI助手。它了解你的所有知识,并且不会遗忘,在需要的时候召唤它就能解决问题,就如同钢铁侠的…

大语言模型之十-Byte Pair Encoding
Tokenizer
诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官…
LLaMA Efficient Tuning 主流大模型的高效工具【预训练+指令监督微调】
LLaMA Efficient Tuning的简介 2023年6月发布的LLaMA Efficient Tuning,它是一款可高效微调【全参数/LoRA/QLoRA】主流大模型【ChatGLM2/LLaMA2/Baichuan等】的高效工具,包括预训练、指令监督微调、奖励模型训练、PPO 训练、DPO 训练等功能。目前该项目仍在持续更新。
官方地…

Ubuntu 安装 CUDA 与 OPENCL
前言:最近需要做一些GPU并行计算,因而入坑CUDA和OPENCL,两者都有用到一些,刚好有点时间,同时记录一些学习过程,排掉一些坑,这篇是环境安装篇,基本跟着走就没什么问题,环境…

秒懂生成式AI—大语言模型是如何生成内容的?
备受关注的大语言模型,核心是自然语言的理解与文本内容的生成,对于此,你是否好奇过它们究竟是如何理解自然语言并生成内容的,其工作原理又是什么呢?
要想了解这个,我们就不得不先跳出大语言模型的领域&…
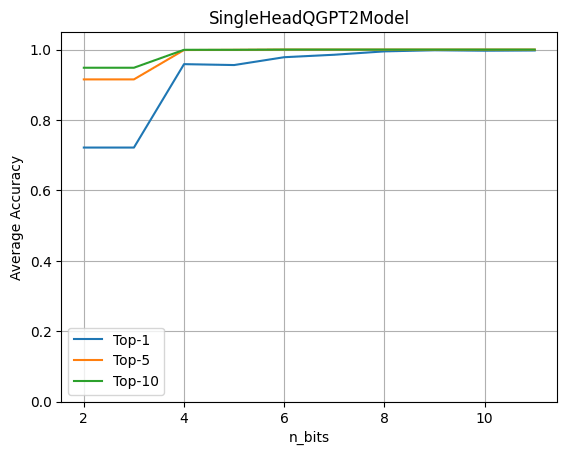
使用 FHE 实现加密大语言模型
近来,大语言模型 (LLM) 已被证明是提高编程、内容生成、文本分析、网络搜索及远程学习等诸多领域生产力的可靠工具。 大语言模型对用户隐私的影响 尽管 LLM 很有吸引力,但如何保护好 输入给这些模型的用户查询中的隐私 这一问题仍然存在。一方面…
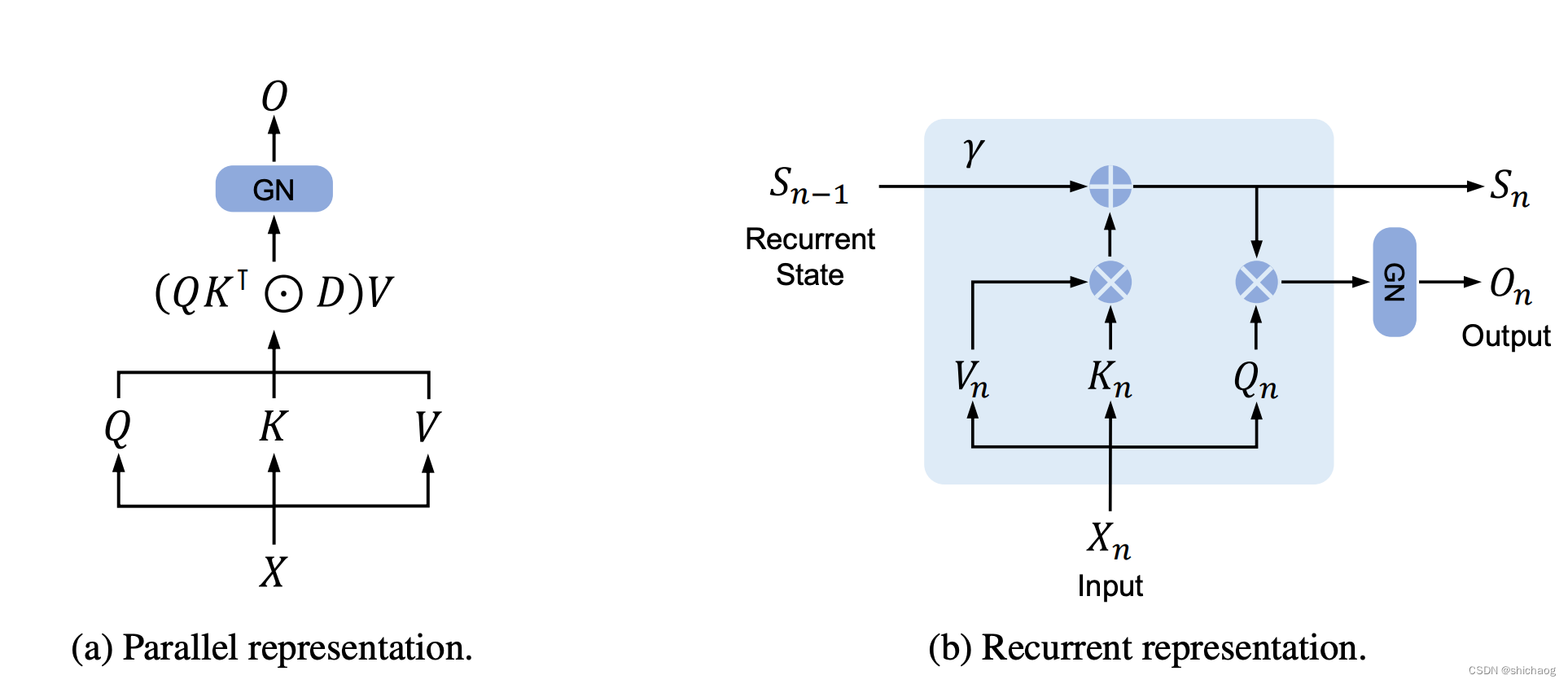
大语言模型之十一 Transformer后继者Retentive Networks (RetNet)
在《大语言模型之四-LlaMA-2从模型到应用》的LLama-2推理图中可以看到,在输入“你好!”时,是串行进行的,即先输入“你”这个token,然后是“好”,再然后是“!”token,前一个token需要…
ChatGPT追祖寻宗:GPT-3技术报告要点解读
论文地址:https://arxiv.org/abs/2005.14165 往期相关文章: ChatGPT追祖寻宗:GPT-1论文要点解读_五点钟科技的博客-CSDN博客ChatGPT追祖寻宗:GPT-2论文要点解读_五点钟科技的博客-CSDN博客 本文的标题之所以取名技术报告而不是论文…

《The Rise and Potential of Large Language Model Based Agents: A Survey》全文翻译
The Rise and Potential of Large Language Model Based Agents: A Surve - 基于 LLMs 的代理的兴起和潜力:一项调查 论文信息摘要1. 介绍2. 背景2.1 AI 代理的起源2.2 代理研究的技术趋势2.3 为什么大语言模型适合作为代理大脑的主要组件 论文信息
题目࿱…

从统计语言模型到预训练语言模型---预训练语言模型(BERT,GPT,BART系列)
基于 Transformer 架构以及 Attention 机制,一系列预训练语言模型被不断提出。
BERT
2018 年 10 月, Google AI 研究院的 Jacob Devlin 等人提出了 BERT (Bidirectional Encoder Representation from Transformers ) 。具体的研究论文发布在 arXiv …

【整理】text2kgbench: 语言模型根据本体生成知识图谱的能力
概述 该论文的研究背景是大型语言模型(LLM)和基于本体的知识图谱(KG)在自然语言处理(NLP)任务中的性能提升。 过去的方法存在一些问题,该论文提出的方法通过从文本中生成KG并遵循给定的本体&…
一点思考|关于「引领性研究」的一点感悟
前言:调研过这么多方向之后,对研究方向的产生与发展具备了一些自己的感悟,尤其是在AI安全领域。私认为,所谓有价值、有意义的研究,就是指在现实社会中能够产生波澜、为国家和社会产生一定效益的研究。 举例来说&#x…

【通意千问】大模型GitHub开源工程学习笔记(2)--使用Qwen进行推理的示例代码解析,及transformers的库使用
使用Transformers来使用模型
如希望使用Qwen-chat进行推理,所需要写的只是如下所示的数行代码。请确保你使用的是最新代码,并指定正确的模型名称和路径,如Qwen/Qwen-7B-Chat和Qwen/Qwen-14B-Chat
这里给出了一段代码
from transformers import AutoModelForCausalLM, Aut…
【Java-LangChain:面向开发者的提示工程-3】迭代优化
第三章 迭代优化
当使用 LLM 构建应用程序时,实践层面上很难第一次尝试就成功获得适合最终应用的 Prompt。但这并不重要,只要您有一个好的迭代过程来不断改进您的 Prompt,那么您就能够得到一个适合任务的 Prompt。虽然相比训练机器学习模型&…
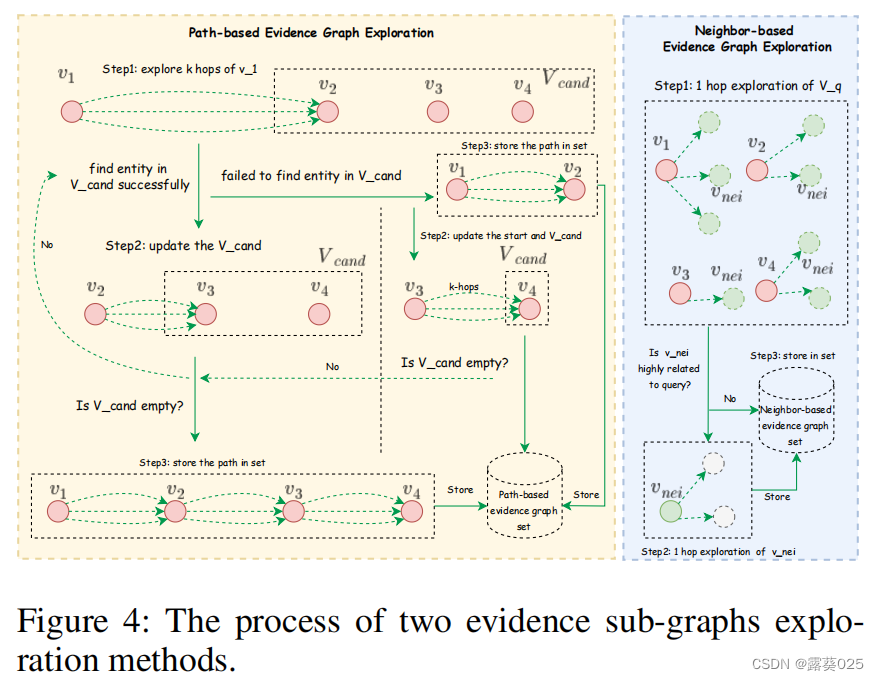
Mind Map:大语言模型中的知识图谱提示激发思维图10.1+10.2
知识图谱提示激发思维图 摘要介绍相关工作方法第一步:证据图挖掘第二步:证据图聚合第三步:LLM Mind Map推理 实验实验设置医学问答长对话问题使用KG的部分知识生成深入分析 总结 摘要
LLM通常在吸收新知识的能力、generation of hallucinati…
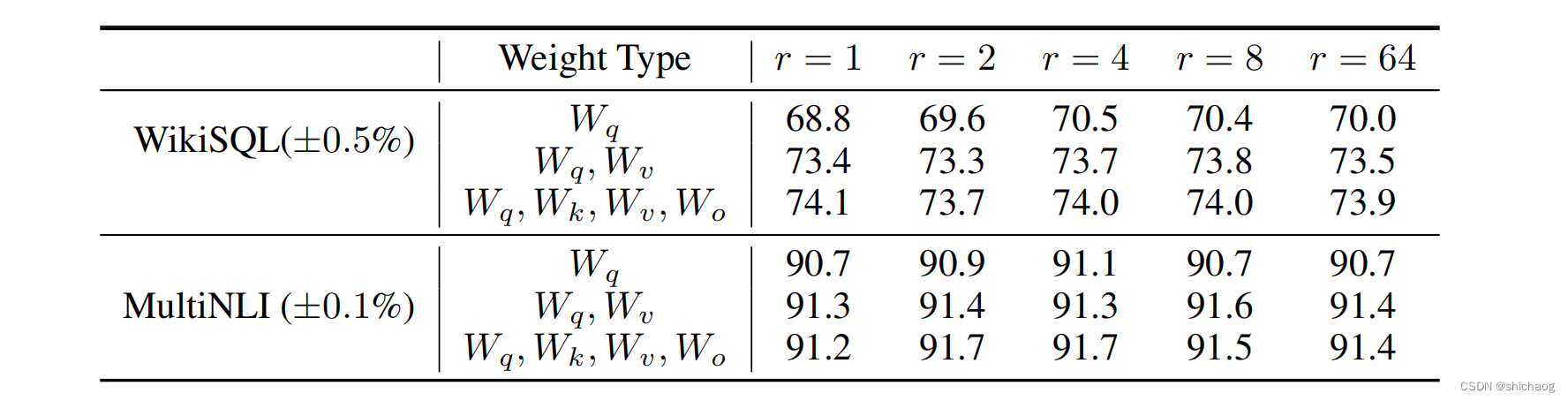
大语言模型之十四-PEFT的LoRA
在《大语言模型之七- Llama-2单GPU微调SFT》和《大语言模型之十三 LLama2中文推理》中我们都提到了LoRA(低秩分解)方法,之所以用低秩分解进行参数的优化的原因是为了减少计算资源。
我们以《大语言模型之四-LlaMA-2从模型到应用》一文中的图…

大规模语言模型--训练成本
目前,基于 Transformers 架构的大型语言模型 (LLM),如 GPT、T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了 SOTA 结果。将预训练好的语言模型(LM) 在下游任务上进行微调已成为处理 NLP 任务的一种 范式。与使用开箱即用的预训练 LLM…
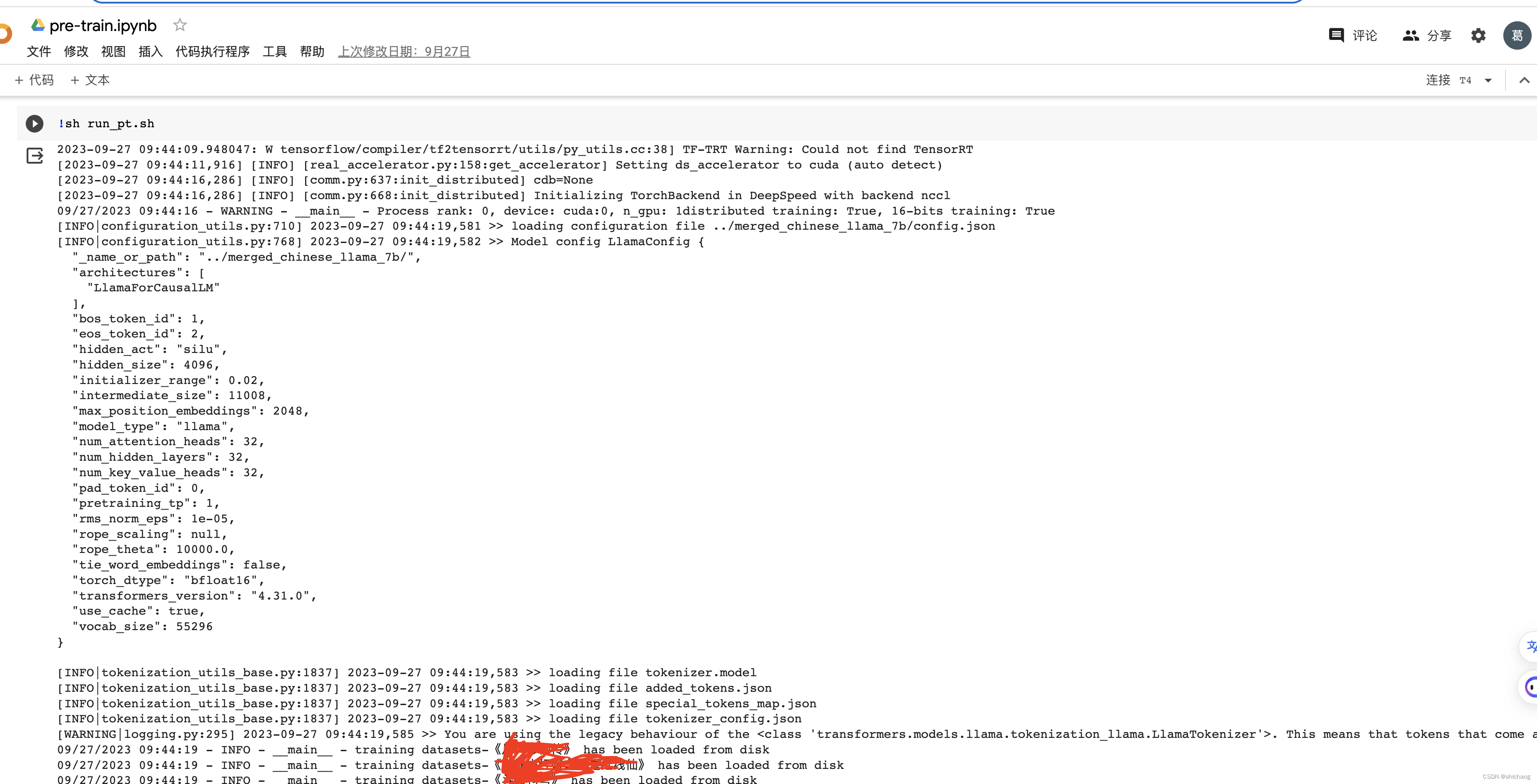
大语言模型之十五-预训练和监督微调中文LLama-2
这篇博客是继《大语言模型之十二 SentencePiece扩充LLama2中文词汇》、《大语言模型之十三 LLama2中文推理》和《大语言模型之十四-PEFT的LoRA》 前面博客演示了中文词汇的扩充以及给予LoRA方法的预训练模型参数合并,并没有给出LoRA模型参数是如何训练得出的。 本篇…
Is This The Intelligent Model(这是智能模型吗)
Is This The Intelligent Model
这是智能模型吗 Ruoqi Sun Academy of Military Science Defense Innovation Institute, Beijing, 100091, China E-mail: ruoqisun7163.com The exposed models are called artificial intelligent models[1-3]. These models rely on knowled…
吴恩达《微调大型语言模型》笔记
微调(fine-tuning)就是利用特有数据和技巧将通用模型转换为能执行具体任务的一种方式。例如,将 GPT-3 这种通用模型转换为诸如 ChatGPT 这样的专门用于聊天的模型。或者将 GPT-4 转换为诸如 GitHub Coplot 这样的专门用于写代码的模型。
这里…
知识增强语言模型提示 零样本知识图谱问答10.8
知识增强语言模型提示 零样本知识图谱问答 摘要介绍相关工作方法零样本QA的LM提示知识增强的LM提示与知识问题相关的知识检索 摘要
大型语言模型(LLM)能够执行 零样本closed-book问答任务 ,依靠其在预训练期间存储在参数中的内部知识。然而&…
Revisiting Large Language Models as Zero-shot Relation Extractors
本文是LLM系列文章,针对《Revisiting Large Language Models as Zero-shot Relation Extractors》的翻译。 修改大型语言模型作为零样本关系提取器 摘要1 引言2 相关工作3 问题定义4 提示设计5 实验6 结论 摘要
即使在零样本设置下,关系提取࿰…

如何使用大语言模型来绘制图画
请创作一张科技感十足的图片,包含siri和iphone两个元素,请帮我挑选合适的style和background 好的,我会为你创作一张科技感十足的图片,包含siri和iphone两个元素。我会根据你的要求,选择一种适合的风格和背景。请稍等一…
Nature Machine Intelligence | “化学元素知识+功能提示”双驱动,探索分子预测新方法
论文题目:Knowledge graph-enhanced molecular contrastive learning with functional prompt 论文链接:https://doi.org/10.1038/s42256-023-00654-0 项目地址:GitHub - HICAI-ZJU/KANO: Code and data for the Nature Machine Intelligence…

Mind Map:大语言模型中的知识图谱提示激发思维图10.1+10.2+10.7
知识图谱提示激发思维图 摘要介绍相关工作方法第一步:证据图挖掘第二步:证据图聚合第三步:LLM Mind Map推理 实验实验设置医学问答长对话问题使用KG的部分知识生成深入分析 总结 摘要
LLM通常在吸收新知识的能力、generation of hallucinati…

Qwen-VL:多功能视觉语言模型,能理解、能定位、能阅读等
Overview 总览摘要1 引言2 方法2.1 模型结构2.2 输入输出 3 训练3.1 预训练3.2 多任务预训练3.3 监督finetune 4 评测4.1 图像文本描述和视觉问答4.2 面向文本的视觉问答4.3 指代表达理解4.4 视觉语言任务中的小样本学习4.4 现实用户行为下的指令遵循 5 相关工作6 总结与展望附…
假期AI新闻热点:亚运会Al技术亮点;微软GPT-4V论文精读;Perplexity推出pplx-api;DALL-E 3多渠道测评 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 科技感拉满,第19届杭州亚运会中的Al技术亮点 八年筹备,杭州第19届亚运会开幕式于9月23日晚隆重举行࿰…
Can Large Language Models Understand Real-World Complex Instructions?
本文是LLM系列文章,针对《Can Large Language Models Understand Real-World Complex Instructions?》的翻译。 大型语言模型能理解现实世界的复杂指令吗? 摘要引言相关工作CELLO基准实验结论 摘要
大型语言模型(llm)可以理解人类指令,显示出它们在传…
Explainability for Large Language Models: A Survey
本文是LLM系列文章,针对《Explainability for Large Language Models: A Survey》的翻译。 大型语言模型的可解释性:综述 摘要1 引言2 LLM的训练范式3 传统微调范式的解释4 提示范式的解释5 评估的解释6 研究挑战7 结论 摘要
大型语言模型(llm)在自然语言处理方面…
Bias and Fairness in Large Language Models: A Survey
本文是LLM系列文章,针对《Bias and Fairness in Large Language Models: A Survey》的翻译。 大型语言模型中的偏见与公平性研究 摘要1 引言2 LLM偏见与公平的形式化3 偏见评价指标的分类4 偏见评价数据集的分类5 缓解偏见的技术分类6 开放问题和挑战7 结论 摘要
…
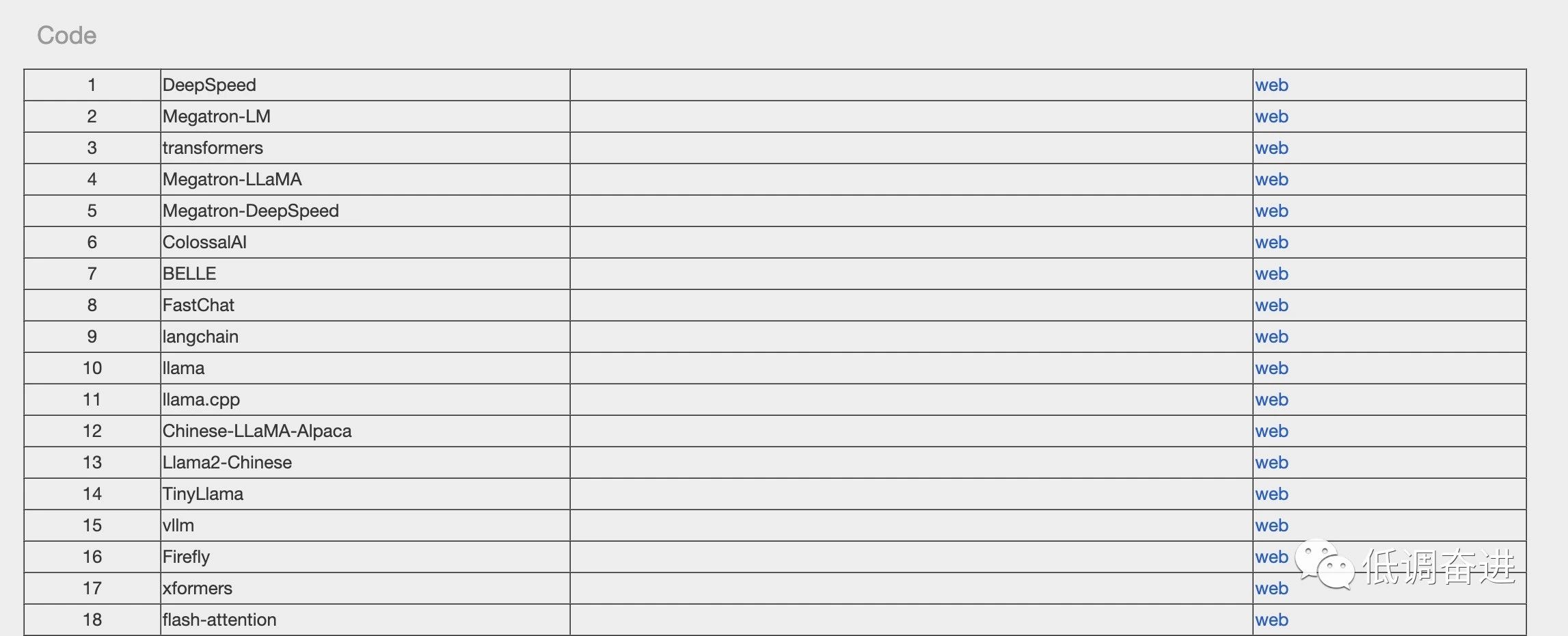
快上车,LLM专列:想要的资源统统给你准备好了
如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
(嘿嘿,有点标题党了。最近整理了LLM相关survey、开源数据、开源代码等等资源,后续会不断丰富内容,省略大家找资料浪费时间。闲言少叙,正式发车&a…

LLMs的终局是通用人工智能AGI总结 生成式AI和大语言模型 Generative AI LLMs
终于学完了 生成式AI和大语言模型 Generative AI & LLMs.
LLMs 解决了如下问题:
对NLP的不能够理解长句子,解决方案 自注意力机制Transformers architecture Attention is all you need大模型算力不够,解决方案 LLMs 缩放法则和计算最…
如何利用niceGUI构建一个流式单轮对话界面
官方文档 参考文档
import asyncio
import time
import requests
from fastapi import FastAPI
from nicegui import app, uiclass ChatPage:temperature: ui.slider Nonetop_p: ui.slider Noneapi_key: ui.input Nonemodel_name: ui.input Noneprompt: ui.textarea None…

在 Amazon SageMaker 上使用 ESMFold 语言模型加速蛋白质结构预测
蛋白质驱动着许多生物过程,如酶活性、分子输运和细胞支持。通过蛋白质的三维结构,可以深入了解蛋白质的功能以及蛋白质如何与其他生物分子相互作用。测定蛋白质结构的实验方法(如 X 射线晶体学和核磁共振波谱学)既昂贵又耗时。相比…
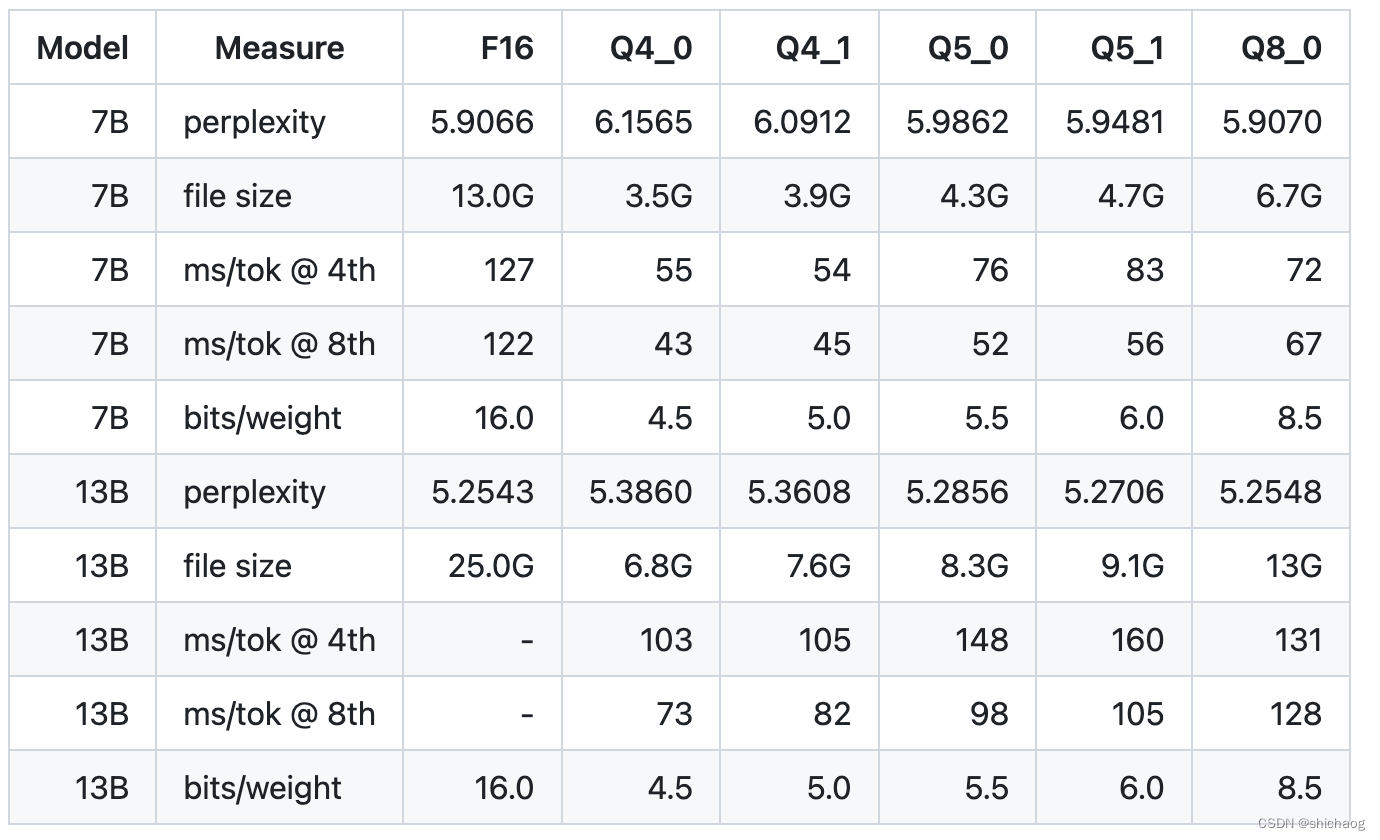
大语言模型之十七-QA-LoRA
由于基座模型通常需要海量的数据和算力内存,这一巨大的成本往往只有巨头公司会投入,所以一些优秀的大语言模型要么是大公司开源的,要么是背后有大公司身影公司开源的,如何从优秀的开源基座模型针对特定场景fine-tune模型具有广大的…
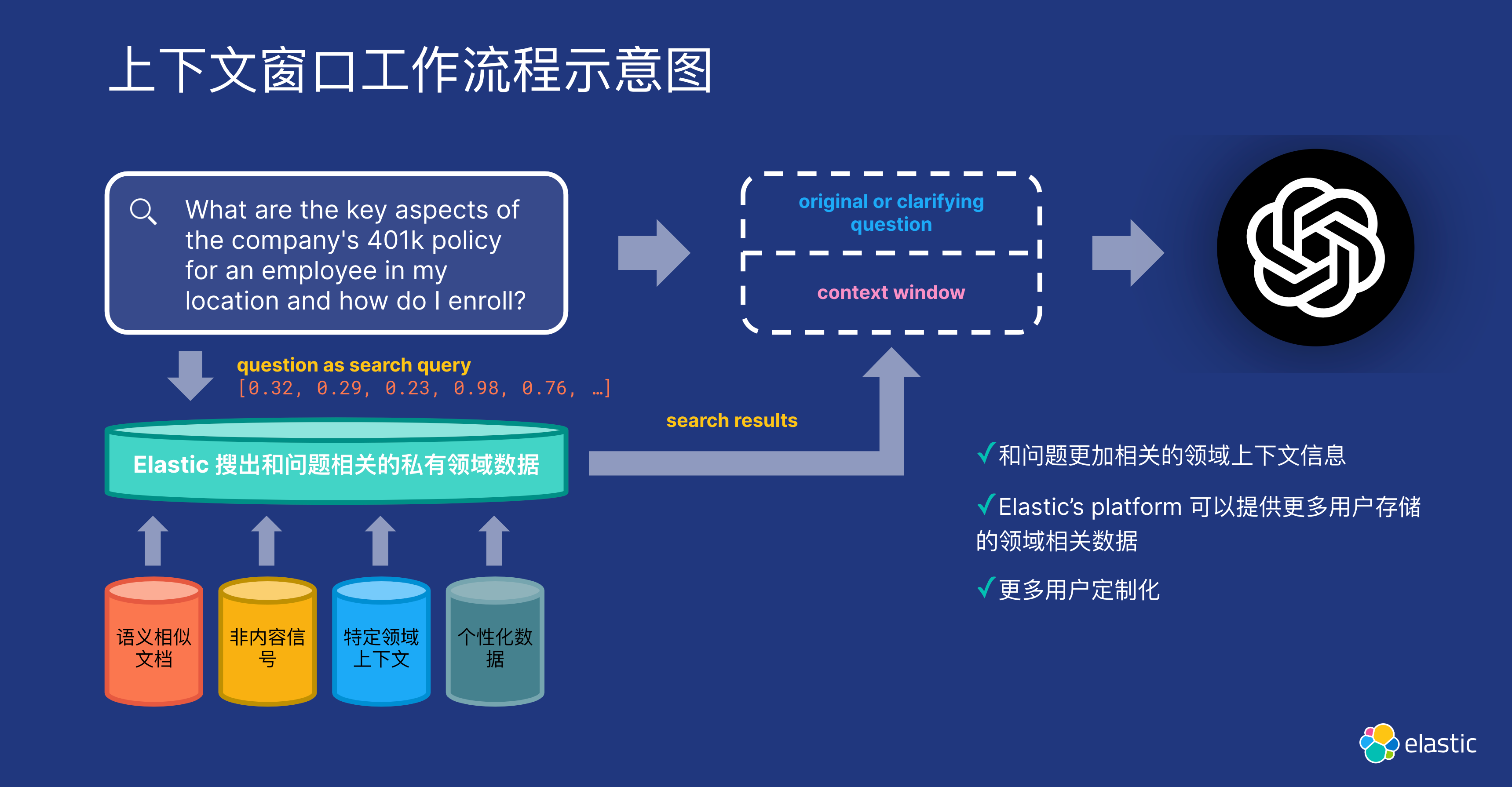
Elasticsearch:什么是大语言模型 (LLMs)?
假设你想参加流行的游戏节目 Jeopardy(这是一个美国电视游戏节目,参赛者将获得答案并必须猜测问题)。 要参加演出,你需要了解任何事情的一切。 所以你决定在接下来的三年里每天都花时间阅读互联网上的所有内容。 你很快就会意识到…
A Close Look into the Calibration of Pre-trained Language Models
本文是LLM系列文章,针对《A Close Look into the Calibration of Pre-trained Language Models》的翻译。 预训练语言模型的校准研究 摘要1 引言2 背景3 评测指标4 PLM是否学会了校准?5 现有方法的效果如何?6 结论局限性与未来工作 摘要
预…
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions
本文是LLM系列文章,针对《SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions》的翻译。 自我指导:将语言模型与自生成的指令相结合 摘要1 引言2 方法3 来自GPT3的自学数据4 实验结果5 相关工作6 结论 摘要
大型“指令调整”语…
Large Language Models Meet NL2Code: A Survey
本文是LLM系列文章,针对《Large Language Models Meet NL2Code: A Survey》的翻译。 大语言模型遇到NL2Code:综述 摘要1 引言2 大语言模型用于NL2Code3 什么使得LLM成功?4 基准和指标5 挑战与机遇6 结论 摘要
从自然语言描述(NL2Code)生成代…
Alluxio AI 全新产品发布:无缝对接低成本对象存储 AI 训练解决方案
(2023 年 10 月 19 日,北京)Alluxio 作为一家承载各类数据驱动型工作负载的数据平台公司,现推出全新的 Alluxio Enterprise AI 高性能数据平台, 旨在满足人工智能 (AI) 和机器学习 (ML) 负载对于企业数据基础设施不断增长的需求。…
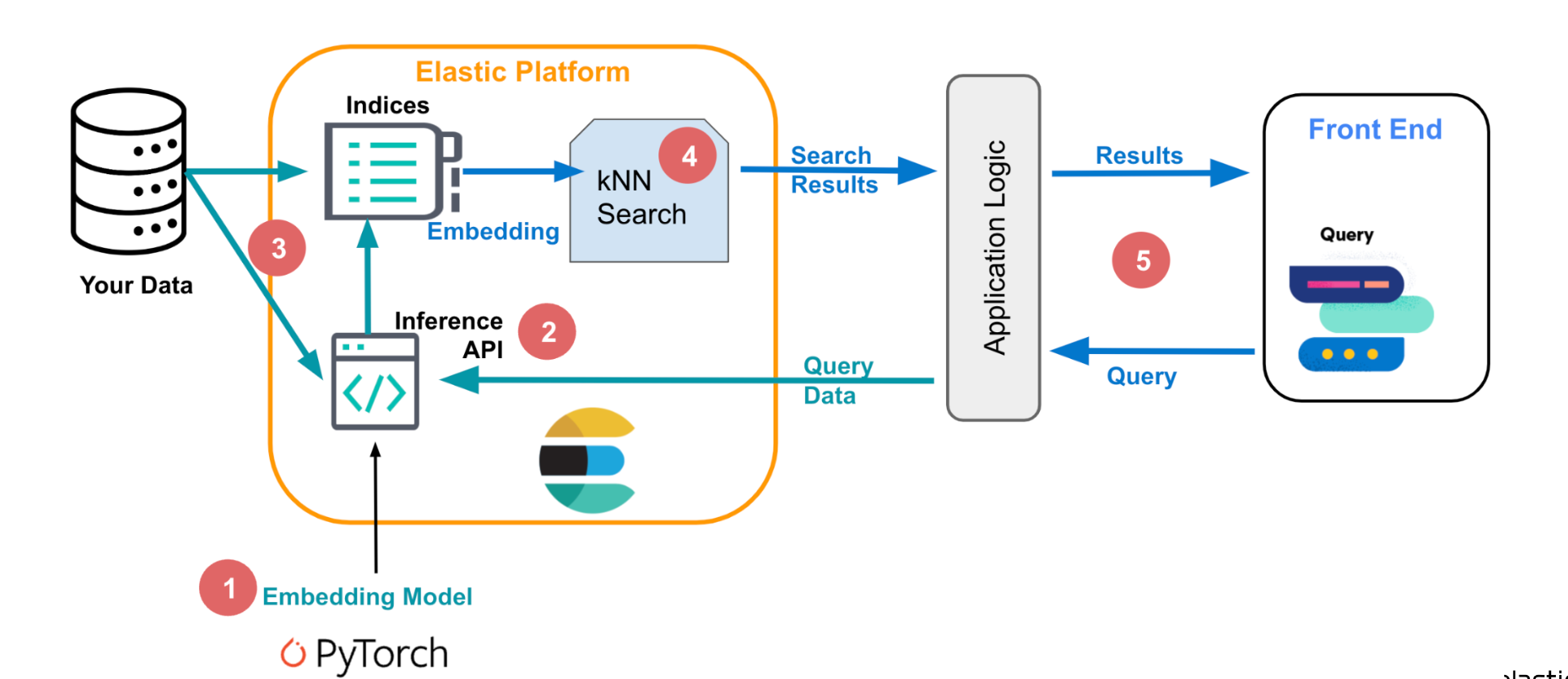
Elasticsearch:什么是非结构化数据?
非结构化数据定义
非结构化数据是指未按照设计的模型或结构组织的数据。 非结构化数据通常被归类为定性数据,可以是人类或机器生成的。 非结构化数据是最丰富的可用数据类型,经过分析后,可用于指导业务决策并在许多其他用例中实现业务目标。…
Pre-trained Language Models Can be Fully Zero-Shot Learners
本文是LLM系列文章,针对《Pre-trained Language Models Can be Fully Zero-Shot Learners》的翻译。 预训练语言模型可以是完全零样本的学习者 摘要1 引言2 相关工作3 背景:PLMs基于提示的调整4 提出的方法:NPPrompt5 实验6 讨论7 结论局限性…
自然语言处理---Transformer构建语言模型
语言模型概述
以一个符合语言规律的序列为输入,模型将利用序列间关系等特征,输出一个在所有词汇上的概率分布,这样的模型称为语言模型。 # 语言模型的训练语料一般来自于文章,对应的源文本和目标文本形如: src1 "I can do&…
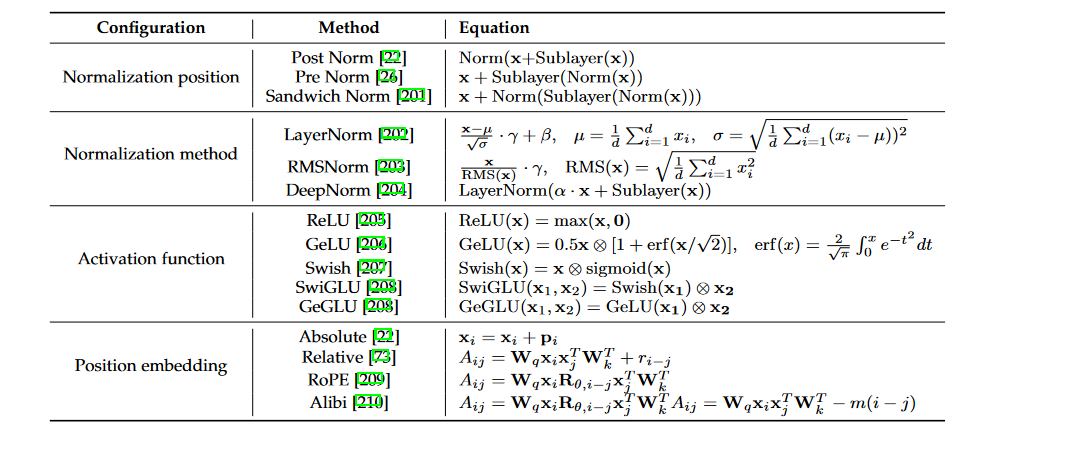
大语言模型(LLM)综述(三):大语言模型预训练的进展
A Survey of Large Language Models 前言4. PRE-TRAINING4.1数据收集4.1.1 数据源4.1.2 数据预处理4.1.3 预训练数据对LLM的影响 4.2 模型架构4.2.1 典型架构4.2.2 详细配置 前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(B…
企业级大数据处理实践——基于 Apache Flink
作者:禅与计算机程序设计艺术
1.简介
大数据领域正在经历一个百花齐放、草木皆兵的阶段,而Apache Flink作为当下最热门的开源大数据计算框架正在吸引越来越多的企业用户,帮助他们快速构建大数据平台,提升效率和价值。本文将从基础知识出发,通过Flink平台的实践案例,帮助…
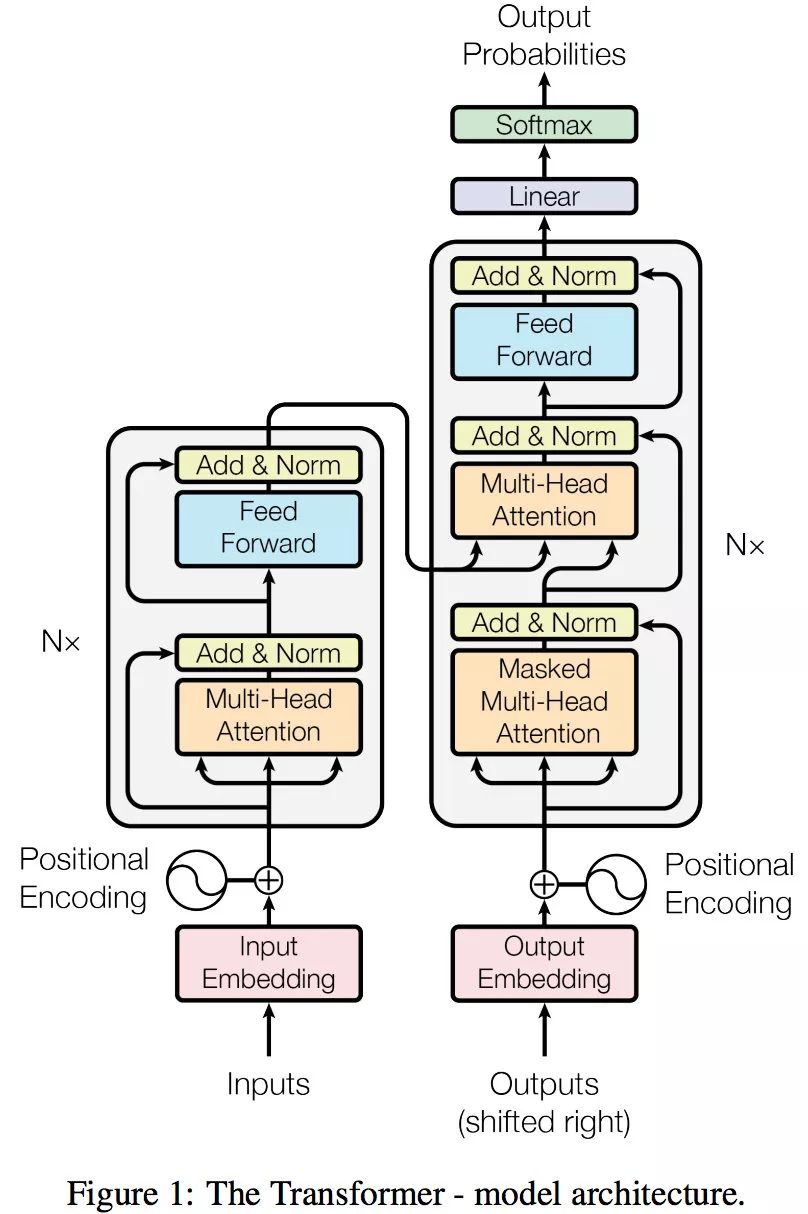
18 Transformer 的动态流程
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html 机…
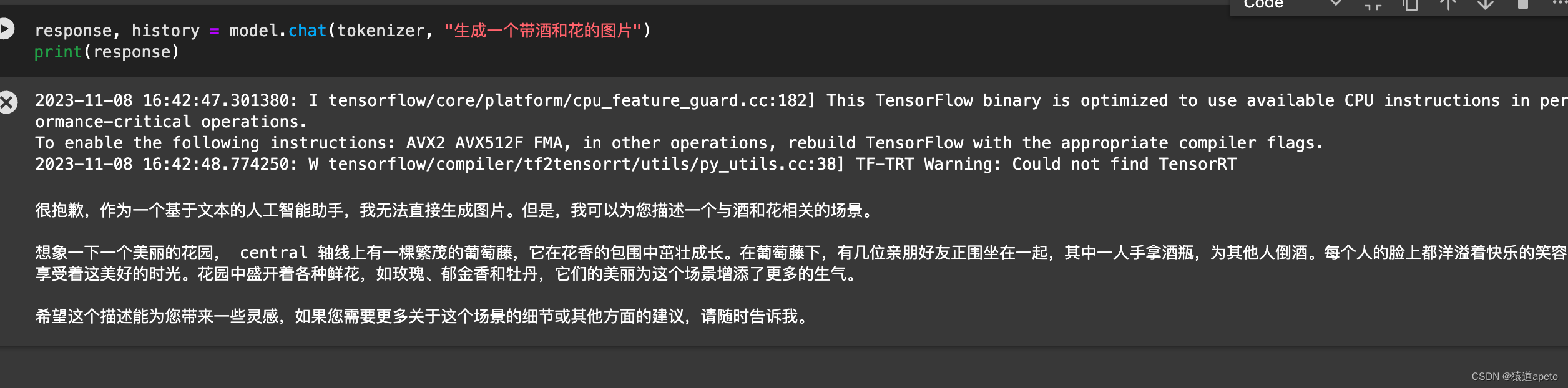
chatglm3-6b部署及微调
chatglm3-6b部署及微调
modelscope: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/filesgithub: https://github.com/THUDM/ChatGLM3镜像: ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.4v100 16G现存 单卡
安装
软件依赖
pip install --upgrade pippip ins…

AI时代,ChatGPT与文心一言选哪一个?
🎈个人公众号:🎈 :✨✨✨ 可为编程✨ 🍟🍟 🔑个人信条:🔑 为与不为皆为可为🌵 你们平时都是在什么情况下使用GPT的呢?为何使用?都使用什么平台的? 针对以上问…
llava1.5模型安装、预测、训练详细教程
引言
本博客介绍LLava1.5多模态大模型的安装教程、训练教程、预测教程,也会涉及到hugging face使用与wandb使用。
源码链接:点击这里
demo链接:点击这里
论文链接:点击这里
一、系统环境
ubuntu 20.04 gpu: 2*3090 cuda:11.6
二、LLava环境安装
1、代码下载…
最新GitHub学生认证,可以愉快的使用Copilot了(保姆级教程)
🎈博客主页:🌈我的主页🌈 🎈欢迎点赞 👍 收藏 🌟留言 📝 欢迎讨论!👏 🎈本文由 【泠青沼~】 原创,首发于 CSDN🚩…
我用 LangChain 打造自己的 LLM 应用项目
随着LLM的技术发展,其在业务上的应用越来越关键,通过LangChain大大降低了LLM应用开发的门槛。本文通过介绍LangChain是什么,LangChain的核心组件以及LangChain在实际场景下的使用方式,希望帮助大家能快速上手LLM应用的开发。
技术…

CoT: 思路链提示促进大语言模型的多步推理
CoT 总览摘要1 引言2 Chain-of-Thought Prompting3 算术推理 (Arithmetic Reasoning)3.1 实验设置3.2 结果3.3 消融实验3.4 CoT的鲁棒性 4 常识推理 (Commonsense Reasoning)5 符号推理 (Symbolic Reasoning࿰…
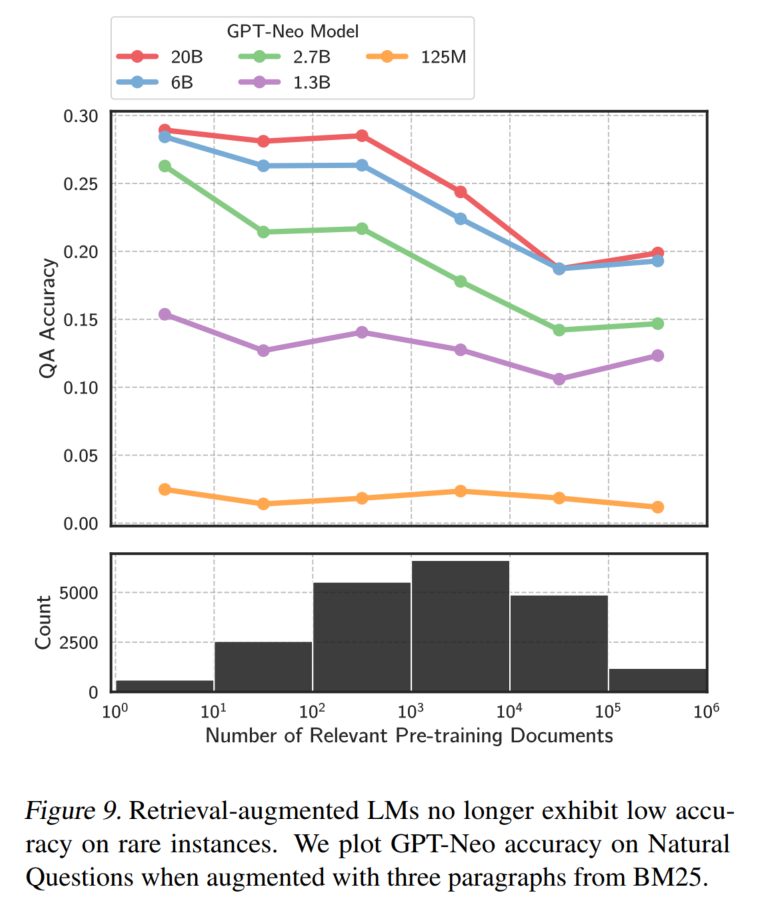
Re50:读论文 Large Language Models Struggle to Learn Long-Tail Knowledge
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:Large Language Models Struggle to Learn Long-Tail Knowledge
ArXiv网址:https://arxiv.org/abs/2211.08411
官方GitHub项目(代码和实体)…
大模型LLM论文目录
持续更新中ing!!! 友情链接:大模型相关资料、基础技术和排行榜 大模型LLM论文目录 标题和时间作者来源简介Artificial General Intelligence: Concept, State of the Art, and Future Prospects,2014GoertzelJournal o…

CODEFUSION: A Pre-trained Diffusion Model for Code Generation
Paper name
CODEFUSION: A Pre-trained Diffusion Model for Code Generation
Paper Reading Note
Paper URL: https://arxiv.org/abs/2310.17680
TL;DR
2023 微软出的文章,提出了 CODEFUSION,这是首个基于 diffusion 的自然语言到代码 (NL-to-code…

【2023】COMAP美赛数模中的大型语言模型LLM和生成式人工智能工具的使用
COMAP比赛中的大型语言模型和生成式人工智能工具的使用 写在最前面GitHub Copilot工具 说明局限性 团队指南引文和引用说明人工智能使用报告 英文原版 Use of Large Language Models and Generative AI Tools in COMAP ContestslimitationsGuidance for teamsCitation and Refe…
AUGMENTING LOGICAL REASONING CAPABILITIES WITH LARGE LANGUAGE MODELS
本文是LLM系列文章,针对《FROM INDETERMINACY TO DETERMINACY: AUGMENTING LOGICAL REASONING CAPABILITIES WITH LARGE LANGUAGE MODELS》的翻译。 从不确定性到确定性:用大型语言模型增强逻辑推理能力 摘要1 引言2 相关工作3 DETERMLR4 实验5 结论 摘…
DO LARGE LANGUAGE MODELS KNOW ABOUT FACTS?
本文是LLM系列文章,针对《DO LARGE LANGUAGE MODELS KNOW ABOUT FACTS?》的翻译。 TOC
摘要
大型语言模型(LLM)最近推动了一系列自然语言处理任务的显著性能改进。在预训练和指令调整过程中获得的事实知识可以用于各种下游任务,…
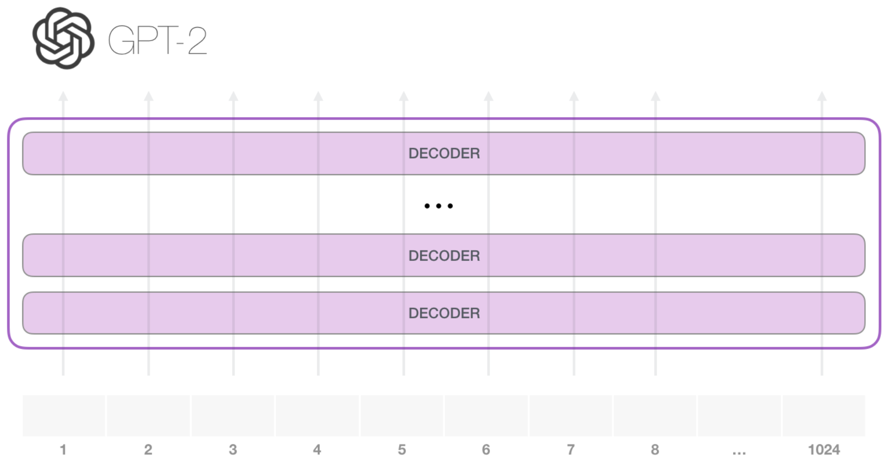
GPT-2:基于无监督多任务学习的语言模型
欢迎来到魔法宝库,传递AIGC的前沿知识,做有格调的分享❗
喜欢的话记得点个关注吧! 今天,我们将共同探索OpenAI的GPT-2,跟随论文深入理解其技术细节。 论文:Language Models are Unsupervised Multitask Le…
语言模型AI——聊聊GPT使用情形与影响
GPT的出现象征着人工智能自然语言处理技术的一次巨大飞跃。从编程助手到写作利器,它的身影在各个行业中越来越常见。百度【文心一言】、CSDN【C知道】等基于GPT的产品相继推出,让我们看到了其广泛的应用前景。然而,随着GPT的普及,…
Evaluating Large Language Models: A Comprehensive Survey
本文是LLM系列文章,针对《Evaluating Large Language Models: A Comprehensive Survey》的翻译。 评估大型语言模型:一项综合调查 摘要1 引言2 分类和路线图3 知识和能力评估4 对齐评估5 安全评估6 专业LLM评估7 评估组织8 未来方向9 结论 摘要
大型语…
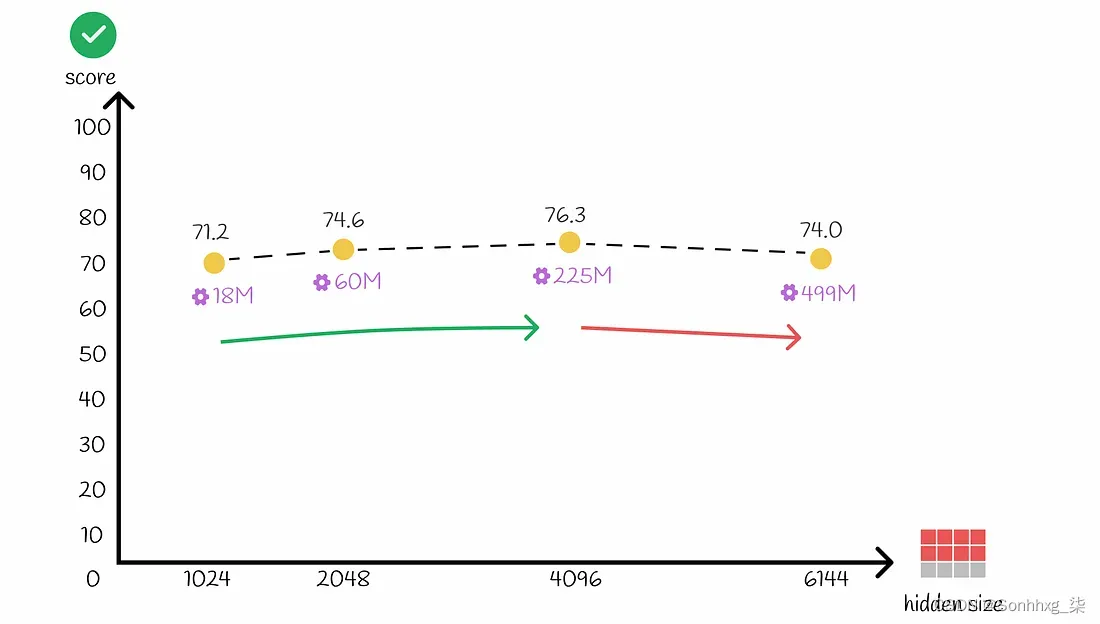
【NLP】大型语言模型,ALBERT — 用于自监督学习的 Lite BERT
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎 📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃 🎁欢迎各位→点赞…

论文导读 | 融合大规模语言模型与知识图谱的推理方法
前 言 大规模语言模型在多种自然语言处理相关任务上展现了惊人的能力,如智能问答等,但是其推理能力尚未充分展现。本文首先介绍大模型进行推理的经典方法,然后进一步介绍知识图谱与大模型融合共同进行推理的工作。 文章一:使用思维…

探索亚马逊大语言模型:开启人工智能时代的语言创作新篇章
文章目录 前言一、大语言模型是什么?应用范围 二、Amazon Bedrock总结 前言
想必大家在ChatGPT的突然兴起,大家多多少少都会有各种各样的问题,比如:大语言模型和生成式AI有什么关系呢?大语言模型为什么这么火…
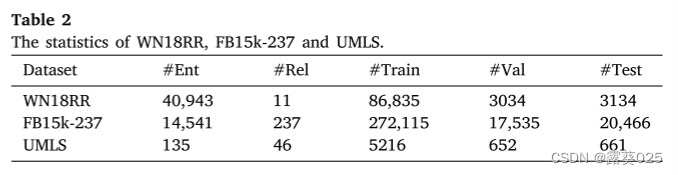
融合语言模型中的拓扑上下文和逻辑规则实现知识图谱补全11.18
融合语言模型中的拓扑上下文和逻辑规则实现知识图谱补全 摘要1 引言2 相关工作2.1 事实嵌入法2.2 拓扑嵌入方法2.3 规则融合方法2.4 基于LM的方法 3 准备3.1 知识图谱和拓扑上下文3.2 KG中的逻辑规则4.3 三元组嵌入 5 实验和结果5.1 数据集和评价指标 摘要
知识图补全…
Reasoning with Language Model Prompting: A Survey
本文是LLM系列的文章,针对《Reasoning with Language Model Prompting: A Survey》的翻译。 语言模型提示推理:综述 摘要1 引言2 前言3 方法分类4 比较和讨论5 基准与资源6 未来方向7 结论与视角 摘要
推理作为解决复杂问题的基本能力,可以…
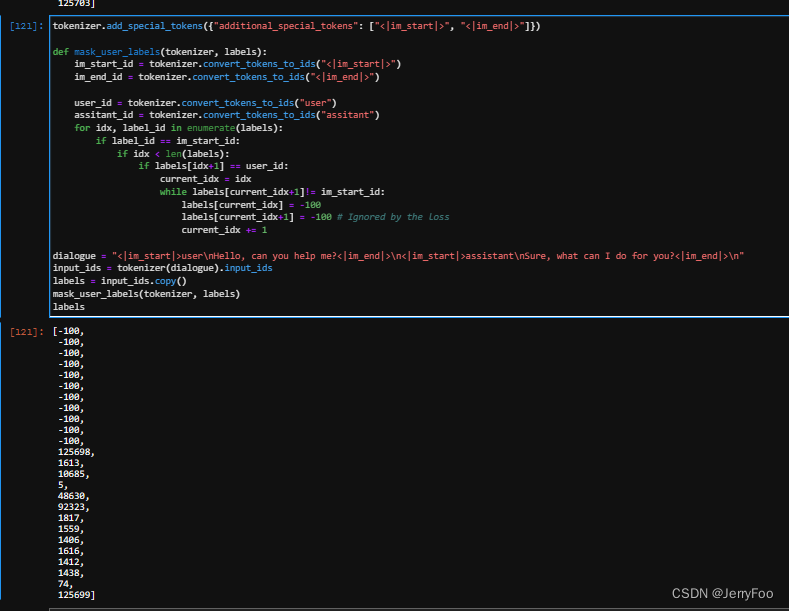
大模型之Chat Markup Language
背景
在笔者应用大模型的场景中,对话模型(即大模型-chat系列)通常具有比较重要的地位,我们通常基于与大模型进行对话来获取我们希望理解的知识。然而大模型对话是依据何种数据格式来进行训练的,他们的数据为什么这么来进行组织,本…
立哥尖端技术-中国电信Telechat大模型模型层探秘
该层为整个系统提供全局模型能力,由通用Telechat(语翼)大语言模型支撑。
提供百亿参数(12.7B)通用TeleChat(语翼)大语言模型,模型本身包括以下能力:
1. 自适应学习能力…

主流大语言模型的技术细节
主流大语言模型的技术原理细节从预训练到微调https://mp.weixin.qq.com/s/P1enjLqH-UWNy7uaIviWRA
比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。2. 大语言模型的分布式训练技术:数据并行、…
AI与Prompt:解锁软件开发团队的魔法咒语,在复杂任务上生成正确率更高的代码
AI与Prompt:解锁软件开发团队的魔法咒语 写在最前面论文:基于ChatGPT的自协作代码生成将团队协作理论应用于代码生成的研究自协作框架原理1、DOL任务分配2、共享黑板协作3、Instance实例化 案例说明简单任务:基本操作,生成的结果1…
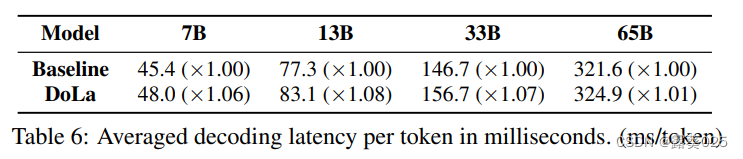
DoLa:对比层解码提高大型语言模型的事实性
DoLa:对比层解码提高大型语言模型的事实性 摘要1 引言2 方法2.1 事实知识在不同层级上演化2.2 动态早期层选择2.3 预测对比 3 实验3.1 任务3.2 实验设置3.3 多项选择3.3.1 TruthfulQA:多项选择3.3.2 FACTOR:维基、新闻 3.4 开放式文本生成3.4…
在Win11上部署ChatGLM2-6B详细步骤--(下)开始部署
接上一章《在Win11上部署ChatGLM2-6B详细步骤--(上)准备工作》
这一节我们开始进行ChatGLM2-6B的部署
三:创建虚拟环境
1、找开cmd执行
conda create -n ChatGLM2-6B python3.8 2、激活ChatGLM2-6B
conda activate ChatGLM2-6B
3、下载…
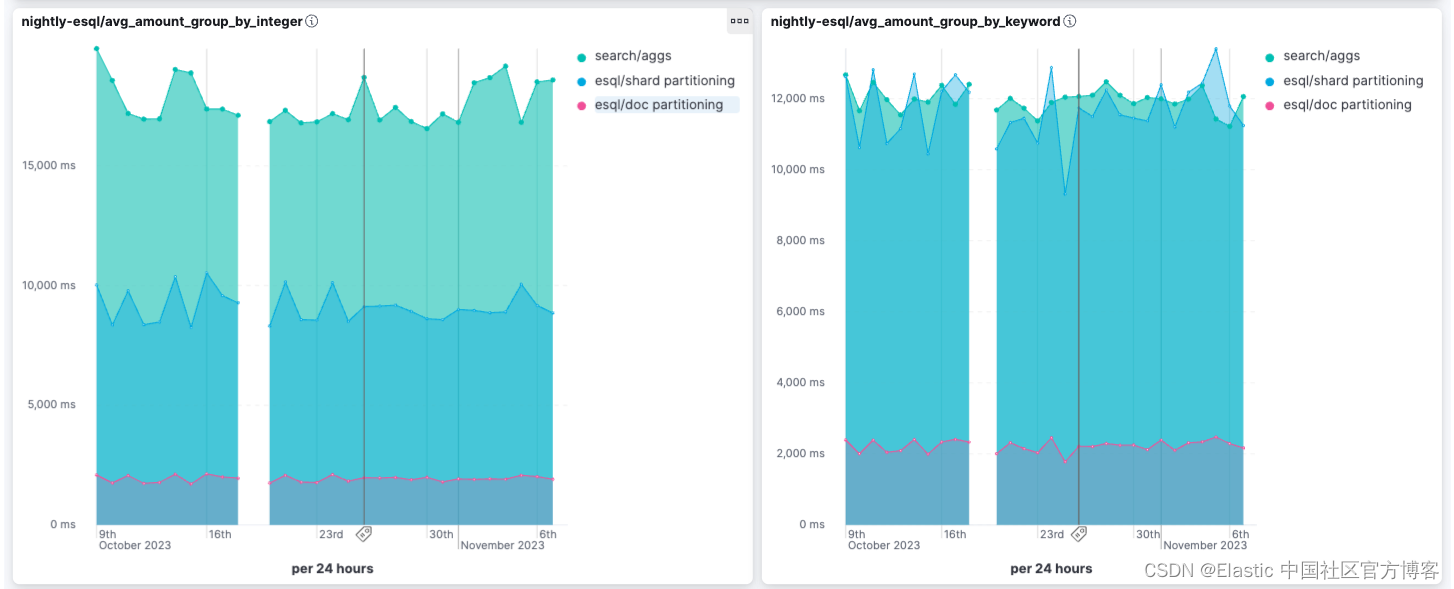
从白日梦到现实:推出 Elastic 的管道查询语言 ES|QL
作者:George Kobar, Bahubali Shetti, Mark Settle 今天,我们很高兴地宣布 Elastic 的新管道查询语言 ES|QL(Elasticsearch 查询语言)的技术预览版,它可以转换、丰富和简化数据调查。 ES|QL 由新的查询引擎提供支持&am…
Data-Centric Financial Large Language Models
本文是LLM系列文章,针对《Data-Centric Financial Large Language Models》的翻译。 以数据为中心的大语言金融模型 摘要1 引言2 背景3 方法4 实验5 结论和未来工作 摘要
大型语言模型(LLM)有望用于自然语言任务,但在直接应用于…
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
本文是LLM系列文章,针对《CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model》的翻译。 CodeFuse-13B:一个预训练的多语言代码大型语言模型 摘要1 引言2 数据准备3 训练4 评估5 相关工作6 讨论,结论,未来工作 摘要
代码…
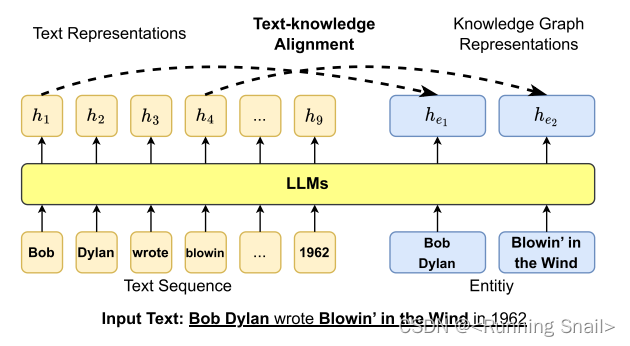
【论文笔记】Unifying Large Language Models and Knowledge Graphs:A Roadmap
(后续更新完善) 2. KG-ENHANCED LLMS
2.1 KG-enhanced LLM Pre-training
以往将KGs集成到大型语言模型的工作主要分为三个部分:1)将KGs集成到训练目标中,2)将KGs集成到LLM输入中,3)将KGs集成到附加的融合模块中。
2.1.1 Integr…
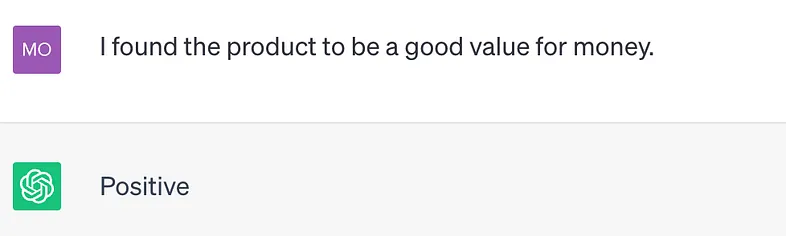
Elasticsearch:在你的数据上训练大型语言模型 (LLM)
过去的一两年,大型语言模型(LLM)席卷了互联网。 最近 Google 推出的 PaLM 2 和 OpenAI 推出的 GPT 4激发了企业的想象力。 跨领域构思了许多潜在的用例。 多语言客户支持、代码生成、内容创建和高级聊天机器人都是一些例子。 这些用例要求 LL…
解决‘BaichuanTokenizer‘ object has no attribute ‘sp_model‘,无需重装transformers和torch
如https://github.com/baichuan-inc/Baichuan2/issues/204 中所说:
修改下 tokenization_baichuan.py ,把 super() 修改到最后执行 self.vocab_file vocab_fileself.add_bos_token add_bos_tokenself.add_eos_token add_eos_tokenself.sp_model spm…

LangChain的函数,工具和代理(五):Tools Routing
关于langchain的函数、工具、代理系列的博客我之前已经写了四篇,还没有看过的朋友请先看一下,这样便于对后续博客内容的理解:
LangChain的函数,工具和代理(一):OpenAI的函数调用
LangChain的函数,工具和代…
当大语言模型遇见广告:新变革还是新泡沫?
人工智能可能从未受到过如此之高的关注度。
2022年11月30日,OpenAI正式发布了ChatGPT,它是一款基于GPT3.5架构 1 进行训练的人工智能聊天机械人。ChatGPT像是一个全能的人,无论是有关文化、历史、艺术还是科技和商业的问题,它都能…
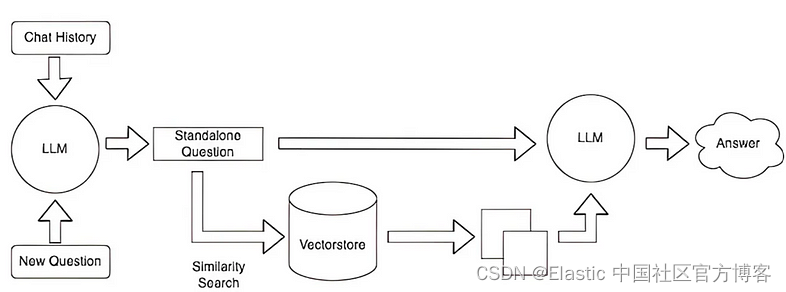
Elasticsearch:使用你的 RAG 来进行聊天
什么是人工智能中的检索增强生成(RAG)?
检索增强生成 (RAG),与你的文档聊天的超级英雄,架起信息检索和文本生成世界的桥梁! 这就像福尔摩斯和莎士比亚联手解决需要大量知识的复杂任务。 RAG 突然介入&…
使用大型语言模型进行文本摘要
路易斯费尔南多托雷斯 📝 Text Summarization with Large Language Models。通过单击链接,您将能够逐步阅读完整的过程,并与图进行交互。谢谢你! 一、介绍 2022 年 11 月 30 日,标志着机器学习历史上的重要篇章。就在这…
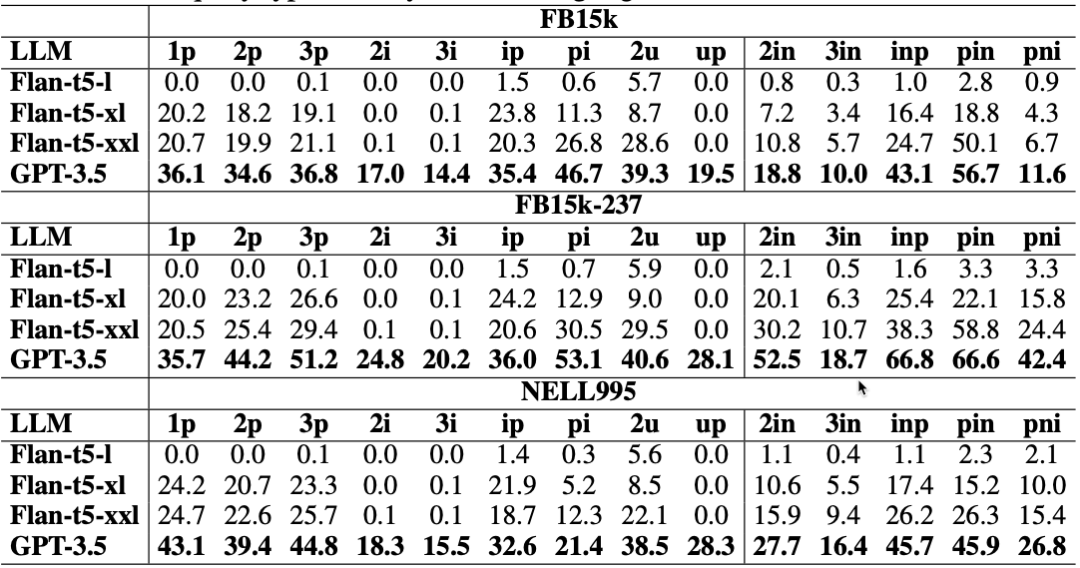
论文导读 | 大语言模型与知识图谱复杂逻辑推理
前 言
大语言模型,尤其是基于思维链提示词(Chain-of Thought Prompting)[1]的方法,在多种自然语言推理任务上取得了出色的表现,但不擅长解决比示例问题更难的推理问题上。本文首先介绍复杂推理的两个分解提示词方法&a…
AI技术:分享8个非常实用的AI绘画网站
目录 1、Midjourney
2、Stable Diffusion Omline
3、Microsoft Designer
4、Craiyon
5、NightCafe Studio
6、Wombo
7、Dalle-2
8、Avatar AI 1、Midjourney 特点:业内标杆,效果最强大
Midjourney是基于diffusion的AI图画艺术生成器。生成图片不…
激发创新,助力研究:CogVLM,强大且开源的视觉语言模型亮相
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…
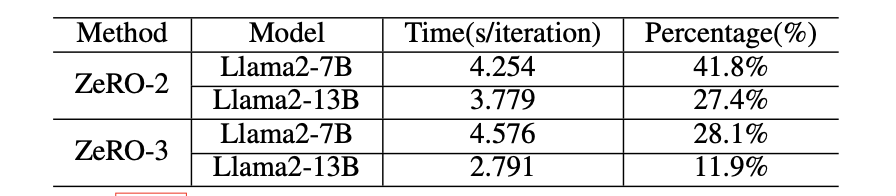
解析大型语言模型的训练、微调和推理的运行时性能
背景
这篇论文是截至目前为数不多的介绍大模型训练配套环境比对的论文,对于想要入门大模型训练同学是个不错的入门资料。比较了不同尺寸模型(比较常用的7、13、70b),在不同型号gpu、训练框架、推理框架数据。结合自己实际工作需要…
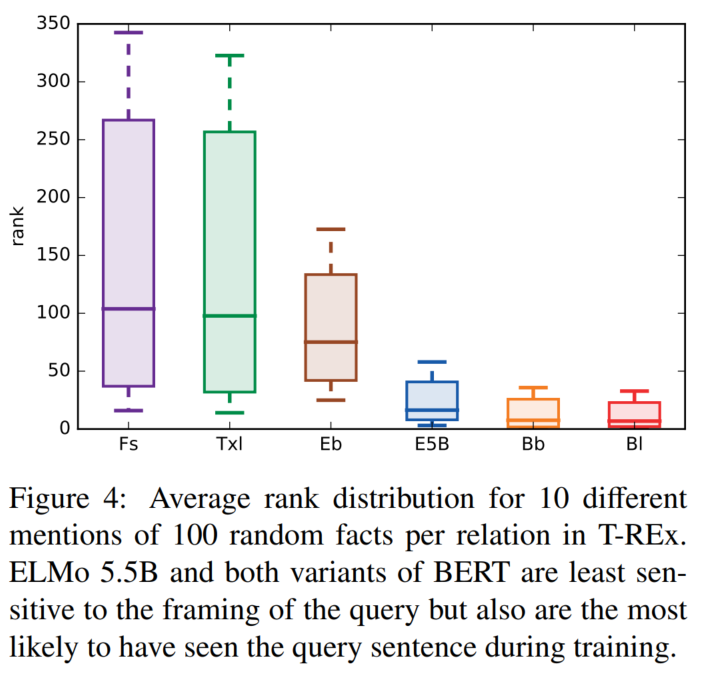
Re51:读论文 Language Models as Knowledge Bases?
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文名称:Language Models as Knowledge Bases?
ArXiv网址:https://arxiv.org/abs/1909.01066
官方GitHub项目:https://github.com/facebookresearch/LAMA
本文是2019年…
极客时间:使用本地小型语言模型运行网页浏览器应用程序。
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
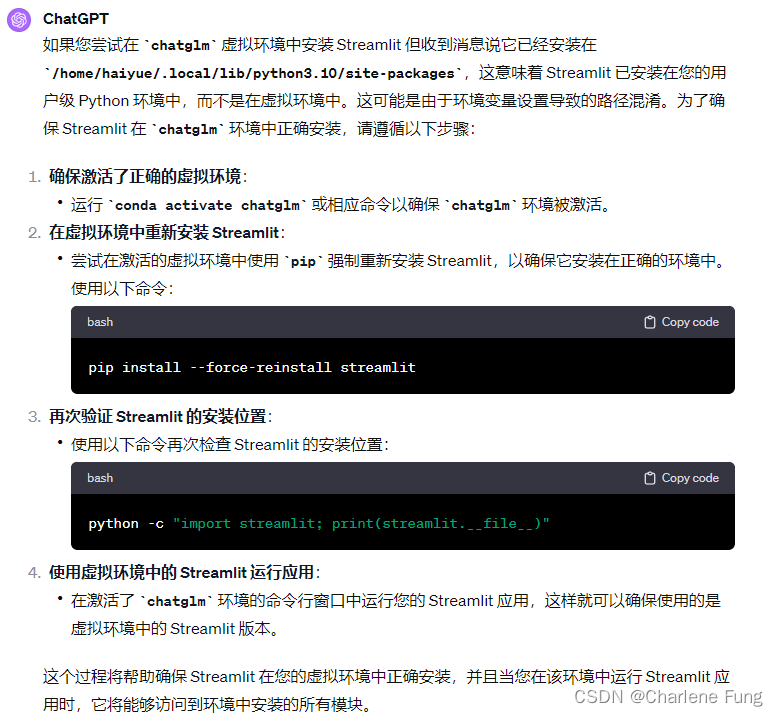
ModuleNotFoundError: No module named ‘mdtex2html‘ module已经安装还是报错,怎么办?
用streamlit运行ChatGLM/basic_model/web_demo.py的时候,出现了module not found:
ModuleNotFoundError: No module named mdtex2html
Traceback:
File "/home/haiyue/.local/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script…
中英双语大模型ChatGLM论文阅读笔记
论文传送门: [1] GLM: General Language Model Pretraining with Autoregressive Blank Infilling [2] Glm-130b: An open bilingual pre-trained model Github链接: THUDM/ChatGLM-6B 目录 笔记Abstract 框架总结1. 模型架构2. 预训练设置3. 训练稳定性…

Go语言实现大模型分词器tokenizer
文章目录 前言核心结构体定义构造函数文本初始处理组词构建词组索引训练数据编码解码打印状态信息运行效果总结 前言
大模型的tokenizer用于将原始文本输入转化为模型可处理的输入形式。tokenizer将文本分割成单词、子词或字符,并将其编码为数字表示。大模型的toke…

从零构建属于自己的GPT系列1:数据预处理(文本数据预处理、文本数据tokenizer、逐行代码解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:文本数据预处理 从零构建属于自己的GPT系列2:语…

MAMBA介绍:一种新的可能超过Transformer的AI架构
有人说,“理解了人类的语言,就理解了世界”。一直以来,人工智能领域的学者和工程师们都试图让机器学习人类的语言和说话方式,但进展始终不大。因为人类的语言太复杂,太多样,而组成它背后的机制,…
从零构建属于自己的GPT系列4:模型训练3(训练过程解读、序列填充函数、损失计算函数、评价函数、代码逐行解读)
🚩🚩🚩Hugging Face 实战系列 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在PyCharm中进行 本篇文章配套的代码资源已经上传 从零构建属于自己的GPT系列1:数据预处理 从零构建属于自己的GPT系列2:模型训…
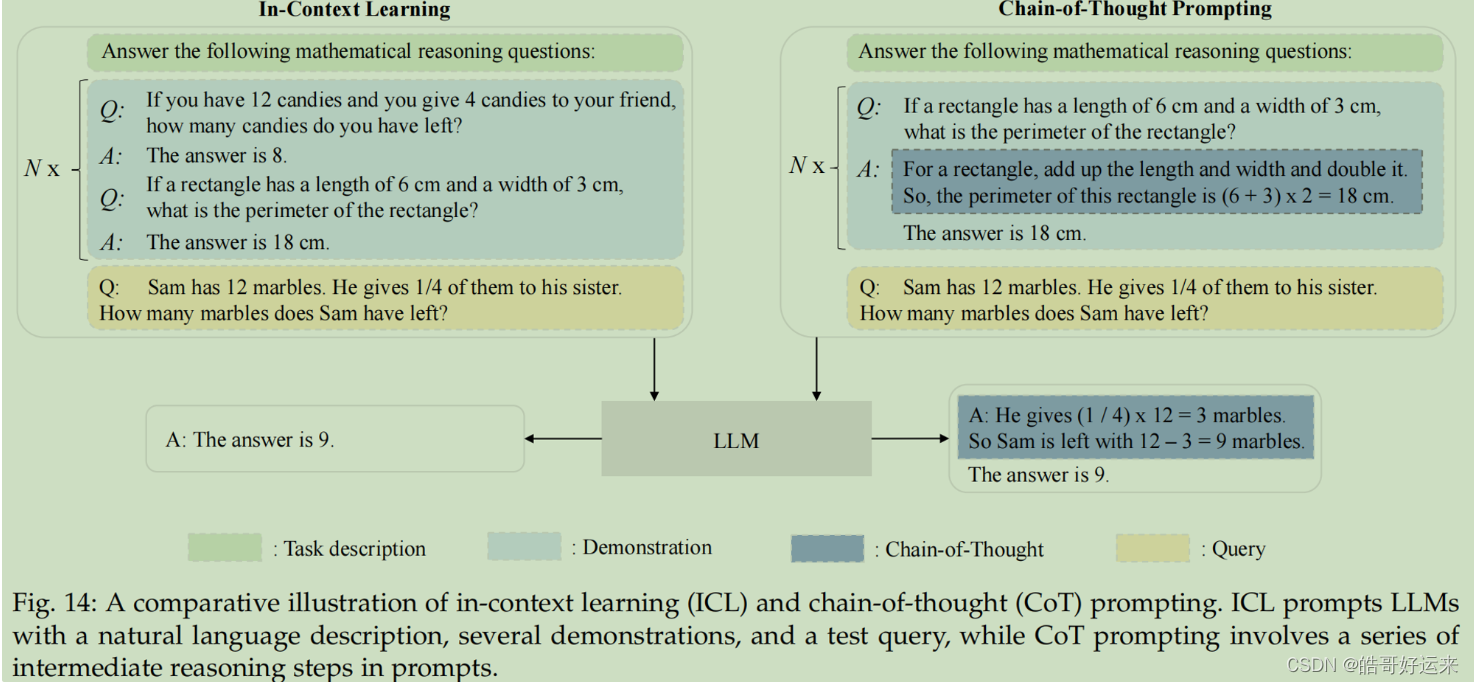
【Datawhale 大模型基础】第二章 大模型的能力
第二章 大模型的能力
With LLMs having significantly more parameters than PLMs, a natural question arises: what new capabilities does the larger parameter size bring to LLMs?
In the paper “Emergent abilities of large language models”, a new concept has …
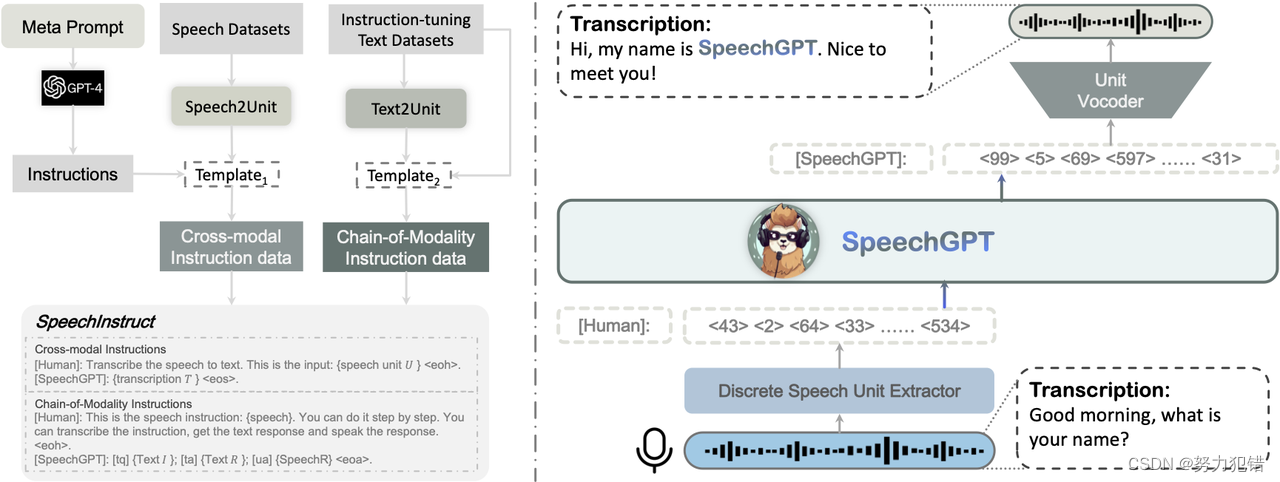
SpeechGPT领航:创新的130亿参数跨模态AI模型
引言
在人工智能的最新进展中,SpeechGPT以其130亿参数的规模和跨模态会话能力引起了业界的广泛关注。这一由复旦大学邱锡鹏教授团队开发的模型,不仅在技术层面上取得了重大突破,也为多模态人工智能(AI)的未来发展指明…
本地运行大语言模型并可视化(Ollama+big-AGI方案)
目前有两种方案支持本地部署,两种方案都是基于llamacpp。其中 Ollama 目前只支持 Mac,LM Studio目前支持 Mac 和 Windows。 LM Studio:https://lmstudio.ai/ Ollama:https://ollama.ai/download
本文以 Ollama 为例 step1 首先下…
一文打通RLHF的来龙去脉
文章目录 1. RLHF的发展历程2. 强化学习2.1 强化学习基本概念2.2 强化学习分类2.3 Policy Gradient2.3.1 add a baseline2.3.2 assign suitable credit2.4 TRPO和PPO算法2.4.1 on-policy2.4.2 Important Sampling2.4.3 Off Policy2.4.4 TRPO 和 PPO 算法2.4.5 P

网络安全领域的12个大语言模型用例
网络安全是人工智能最大的细分市场,过去几年网络安全厂商纷纷宣称整合了人工智能技术(当然也有很多仅仅是炒作),其中大部分是基于基线和统计异常的机器学习。
网络安全是人工智能最大的细分市场,过去几年网络安全厂商…
从头开始构建大语言模型(LLM)
了解如何从头开始构建大语言模型,从而创建、训练和调整大语言模型!LLMs 在“从头开始构建大语言模型”中,你将了解如何从内到外LLMs工作。在这本富有洞察力的书中,畅销书作家塞巴斯蒂安拉施卡 (Sebastian Raschka&…
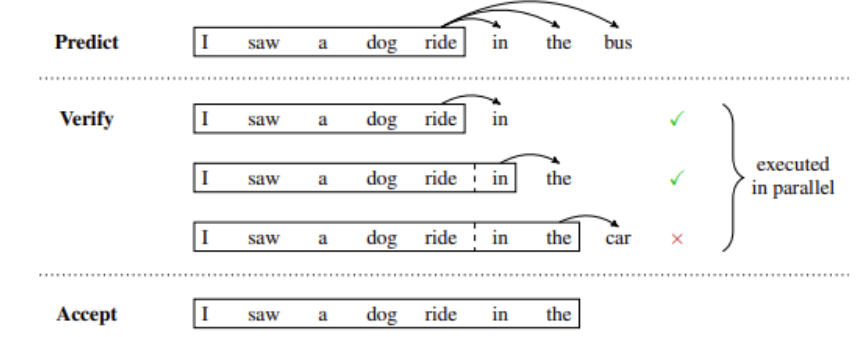
掌握大语言模型技术: 推理优化
掌握大语言模型技术_推理优化 堆叠 Transformer 层来创建大型模型可以带来更好的准确性、少样本学习能力,甚至在各种语言任务上具有接近人类的涌现能力。 这些基础模型的训练成本很高,并且在推理过程中可能会占用大量内存和计算资源(经常性成…
【Agent论文】大型语言模型智能评估新尺度:AGENTBENCH(Agentbench: Evaluating llms as agents)
大型语言模型智能评估新尺度:AGENTBENCH
论文题目:Agentbench: Evaluating llms as agents
论文链接:https://arxiv.org/pdf/2308.03688
目录:
摘要总览方法 代码环境中的智能Agent评估 操作系统环境:OS数据库环境…

用通俗易懂的方式讲解:大模型微调方法总结
大家好,今天给大家分享大模型微调方法:LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning。
文末有大模型一系列文章及技术交流方式,传统美德不要忘了,喜欢本文记得收藏、关注、点赞。 文章目录 1、LoRA…
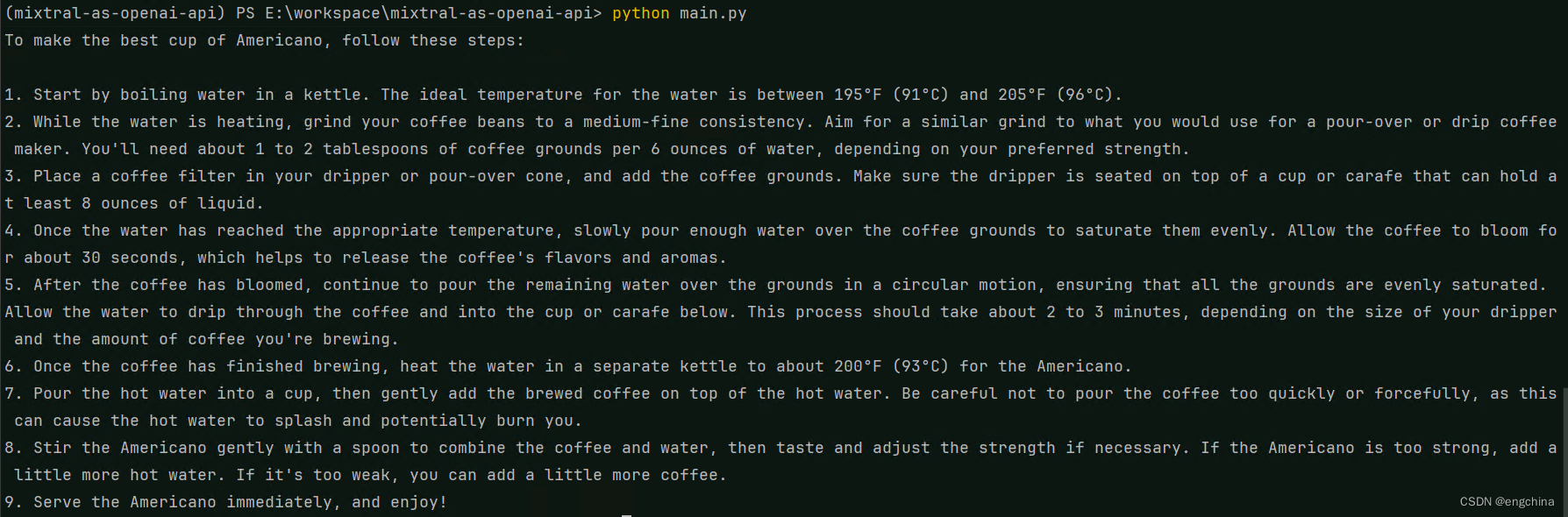
在 Windows 11 上通过 Autoawq 启动 Mixtral 8*7B 大语言模型
在 Windows 11 上通过 Autoawq 启动 Mixtral 8*7B 大语言模型 0. 背景1. 安装依赖2. 开发 main.py3. 运行 main.py 0. 背景
看了一些文章之后,今天尝试在 Windows 11 上通过 Autoawq 启动 Mixtral 8*7B 大语言模型。
1. 安装依赖
pip install torch torchvision …

【论文阅读】LoRA: Low-Rank Adaptation of Large Language Models
code:GitHub - microsoft/LoRA: Code for loralib, an implementation of "LoRA: Low-Rank Adaptation of Large Language Models" 做法:
把预训练LLMs里面的参数权重给冻结;向transformer架构中的每一层,注入可训练的…
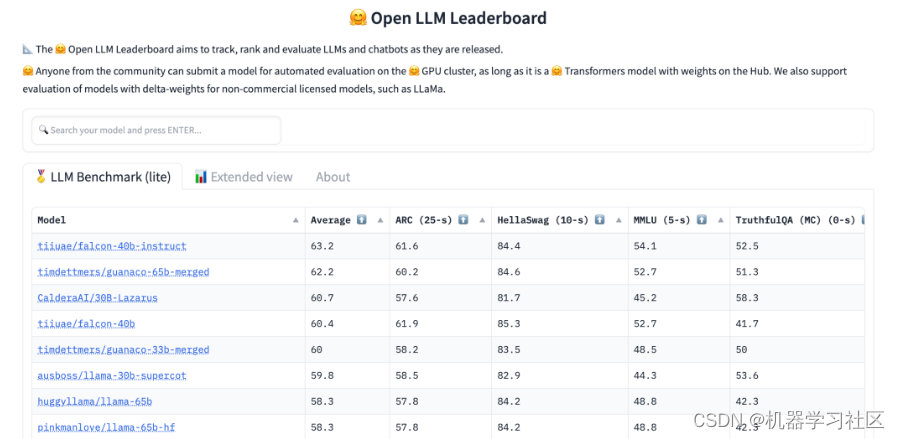
开源 LLM 微调训练指南:如何打造属于自己的 LLM 模型
一、介绍
今天我们来聊一聊关于LLM的微调训练,LLM应该算是目前当之无愧的最有影响力的AI技术。尽管它只是一个语言模型,但它具备理解和生成人类语言的能力,非常厉害!它可以革新各个行业,包括自然语言处理、机器翻译、…
传统软件集成AI大模型——Function Calling
传统软件和AI大模型的胶水——Function Calling 浅谈GPT对传统软件的影响Function Calling做了什么,为什么选择Function CallingFunction Calling简单例子,如何使用使用场景 浅谈GPT对传统软件的影响
目前为止好多人对chatGPT的使用才停留在OpenAI自己提…
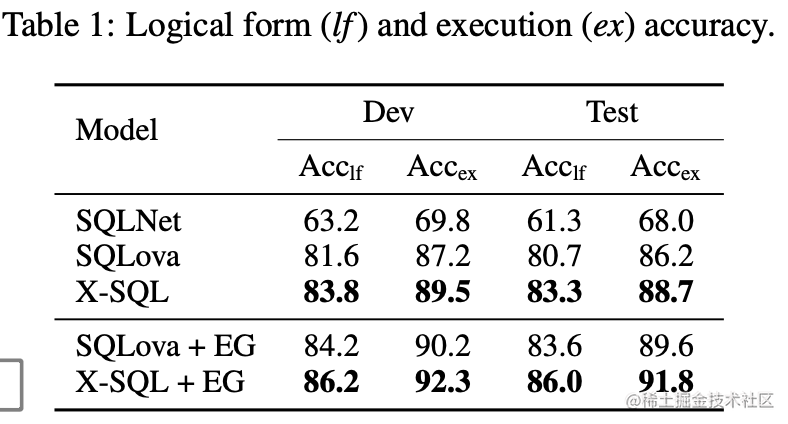
Text2SQL学习整理(四)将预训练语言模型引入WikiSQL任务
导语
上篇博客:Text2SQL学习整理(三):SQLNet与TypeSQL模型简要介绍了WikiSQL数据集提出后两个早期的baseline,那时候像BERT之类的预训练语言模型还未在各种NLP任务中广泛应用,因而作者基本都是使用Bi-LSTM…
![[LLM]Streamlit+LLM(大型语言模型)创建实用且强大的Web聊天机器人](https://img-blog.csdnimg.cn/direct/ff8ef1c970ef4cbbb6792b7ac21a2db2.png)
[LLM]Streamlit+LLM(大型语言模型)创建实用且强大的Web聊天机器人
Streamlit 和 Streamlit_chat
Streamlit 是一个开源框架,使开发人员能够快速构建和共享用于机器学习和数据科学项目的交互式 Web 应用程序。它还提供了一系列小部件,只需要一行 Python 代码即可创建,例如st.table(…)。对于我们创建一个简单…
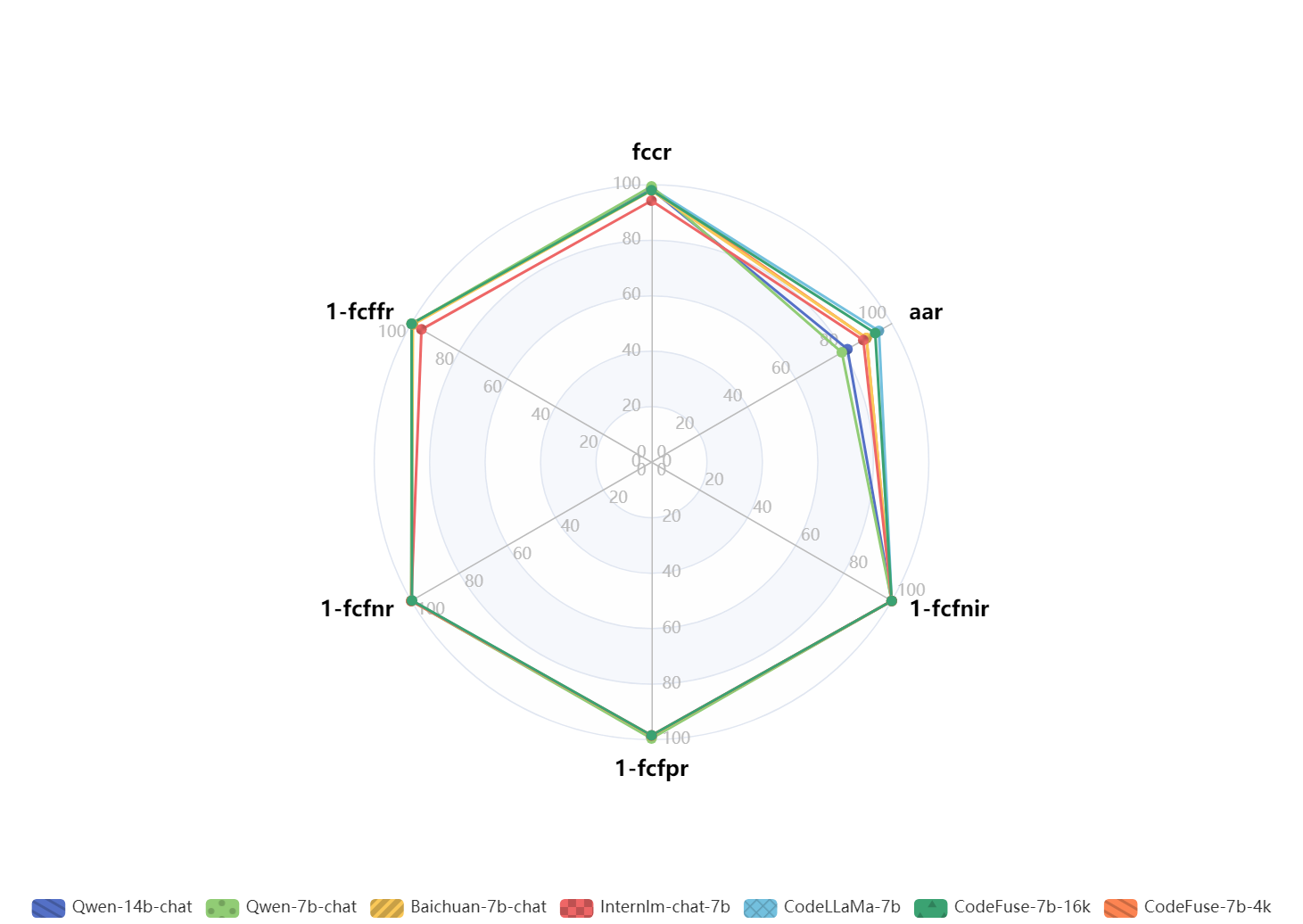
ToolLearning Eval:CodeFuse发布首个中文Function Call的大语言模型评测基准!
1. 背景
随着ChatGPT等通用大模型的出现,它们可以生成令人惊叹的自然语言,使得机器能够更好地理解和回应人类的需求,但在特定领域的任务上仅靠通用问答是无法满足日常工作需要。随着OpenAI推出了Function Call功能,工具学习能力越…

SmoothQuant+:可以用于大语言模型的 4-bit 量化算法
LLMs 在各种任务上展现出令人惊叹的能力,但是庞大的模型尺寸和对算力的巨大需求对模型的部署也提出了挑战。目前 4-bit 的 PTQ 权重量化在 LLMs 上已经取得了一些成绩,相对 FP16 内存占用减少近 75%,但是在精度上仍有较大的损失。我…

AI新宠Arc浏览器真可以取代Chrome吗?
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
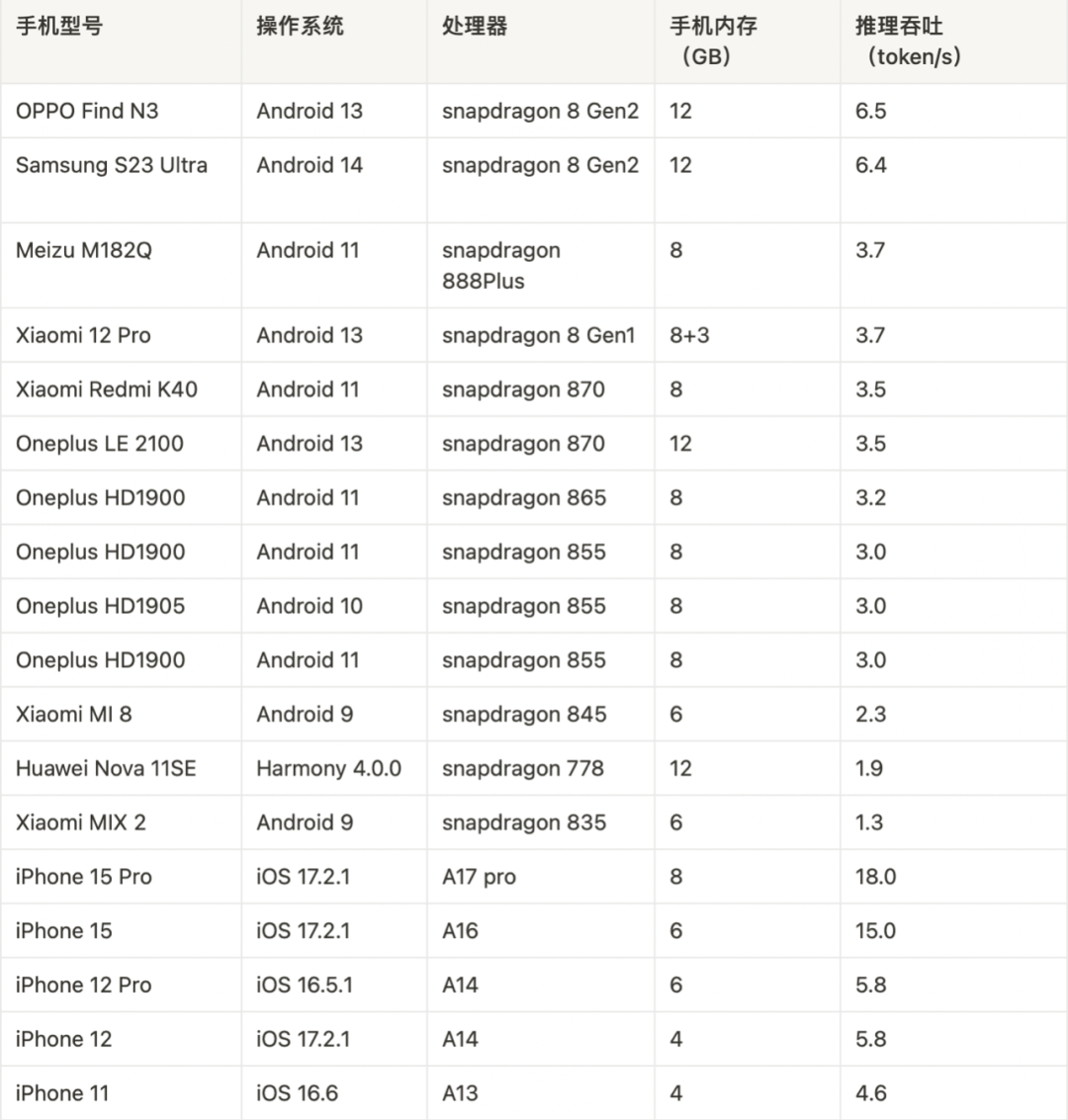
MiniCPM:揭示端侧大语言模型的无限潜力
技术博客链接:
🔗https://shengdinghu.notion.site/MiniCPM
➤ Github地址:
🔗https://github.com/OpenBMB/MiniCPM
➤ Hugging Face地址:
🔗https://huggingface.co/openbmb/MiniCPM-2B-sft-bf16
1 …
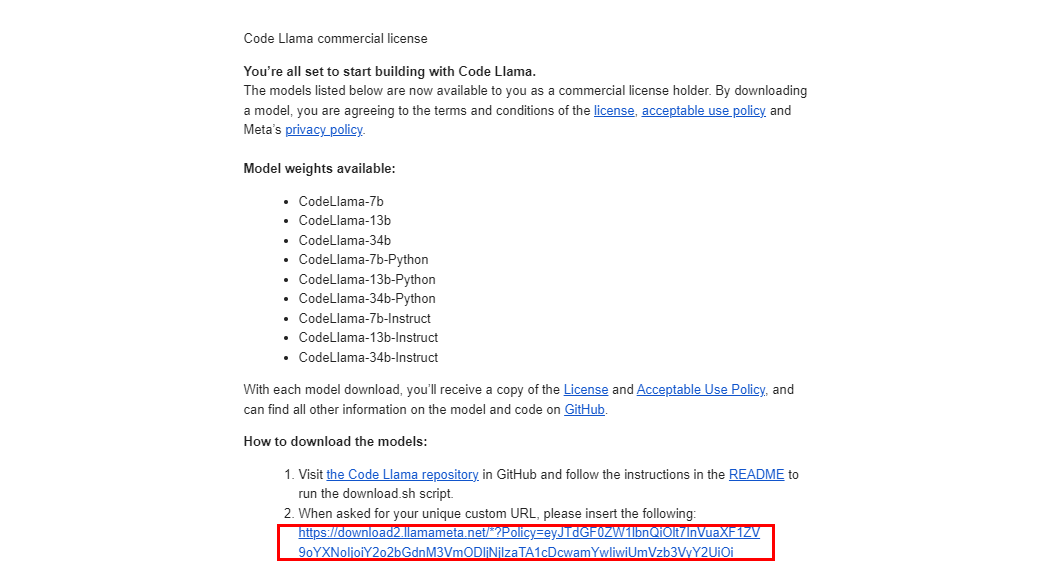
Meta开源大模型LLaMA2的部署使用
LLaMA2的部署使用 LLaMA2申请下载下载模型启动运行Llama2模型文本补全任务实现聊天任务LLaMA2编程Web UI操作 LLaMA2
申请下载
访问meta ai申请模型下载,注意有地区限制,建议选其他国家 申请后会收到邮件,内含一个下载URL地址,…
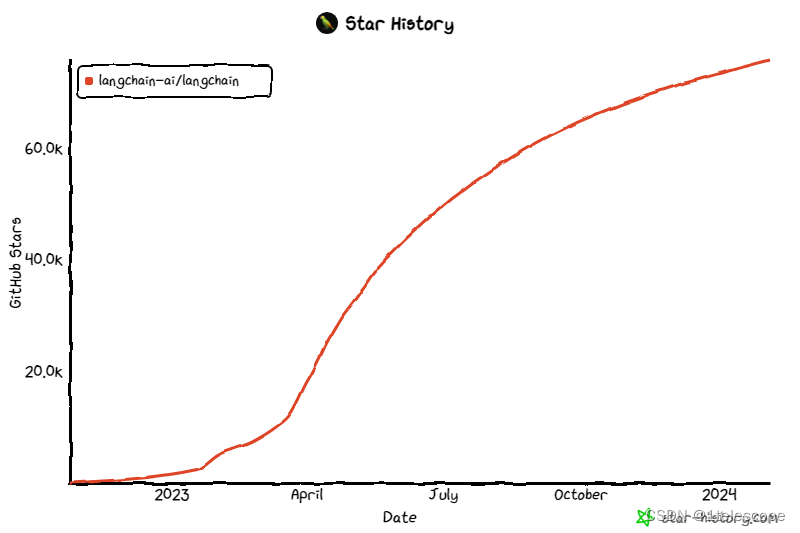
LLM(大语言模型)——大模型简介
目录
概述
发展历程
大语言模型的概念
LLM的应用和影响
大模型的能力、特点
大模型的能力
涌现能力(energent abilities)
作为基座模型支持多元应用的能力
支持对话作为统一入口的能力
大模型的特点
常见大模型
闭源LLM(未公开源…
大语言模型微调数据集(2)
CLUE 数据集 CLUE 是一个中文语言理解测评基准,包括分类、命名实体识别和机器阅读理解任务。CLUE中的数据集为JSON格式。对于分类和命名实体识别数据集,我们将JSON格式转换为TSV格式,以便TencentPretrain可以直接加载它们;对于机器阅读理解数据集,我们保留原始格式,并将数…

昆仑万维发布天工 2.0 大语言模型及AI助手App;AI成功破解2000年前碳化古卷轴
🦉 AI新闻
🚀 昆仑万维发布天工 2.0 大语言模型及AI助手App
摘要:昆仑万维近日推出了新版MoE大语言模型“天工 2.0”和相应的“天工 AI 智能助手”App,宣称为国内首个面向C端用户免费的基于MoE架构的千亿级参数大模型应用。天工…
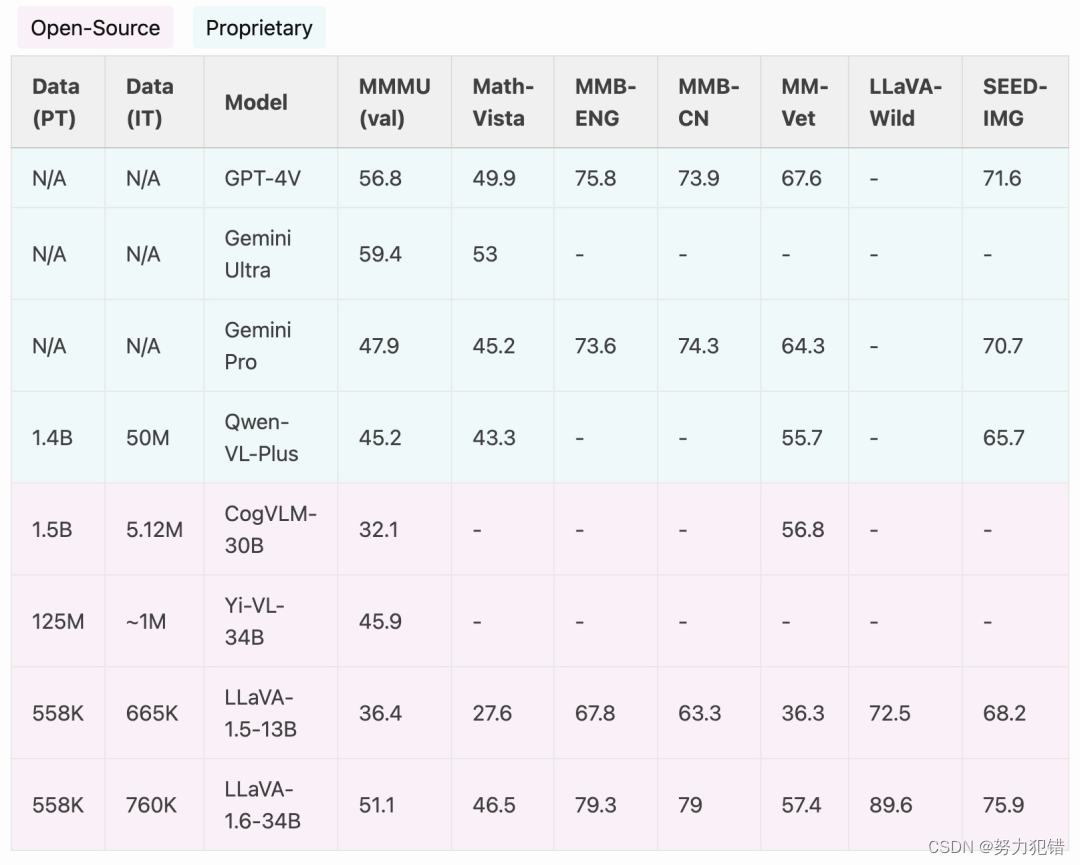
LLaVA-1.6:多模态AI新标准,中文零样本能力与低成本训练革命,性能全面超越Gemini Pro
引言
2023年10月,LLaVA-1.5凭借其简洁高效的设计和在12个数据集上的出色表现,为大规模多模态模型(LMM)的研究和应用奠定了基础。进入2024年,我们迎来了LLaVA-1.6,一个在理性推理、光学字符识别(…

GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大…
LangChain 30 ChatGPT LLM将字符串作为输入并返回字符串Chat Model将消息列表作为输入并返回消息
LangChain系列文章
LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索I…
SimLM: Can Language Models Infer Parameters of Physical Systems?
Authors: Sean Memery ; Mirella Lapata ; Kartic Subr
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决大型语言模型(LLMs)在物理推理任务上表现不佳的问题。作者们指出,尽管LLMs在许多领域都取得了显著的成果,但…
Deep de Finetti: Recovering Topic Distributions from Large Language Models
Authors: Liyi Zhang ; R. Thomas McCoy ; Theodore R. Sumers ; Jian-Qiao Zhu ; Thomas L. Griffiths Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨大型语言模型(LLMs)如何捕捉文档的主题结构。尽管LLMs是在下一个词预测任务上进行训练的…

CodeFuse开源这半年
2023 年可以称得上是大模型元年,在过去的这一年里,大模型领域飞速发展,新的大模型纷纷涌现,基于大模型的新产品也吸引着大家的眼球,未来,这个领域又会给大家带来多少惊喜? 蚂蚁也推出了自己的百…
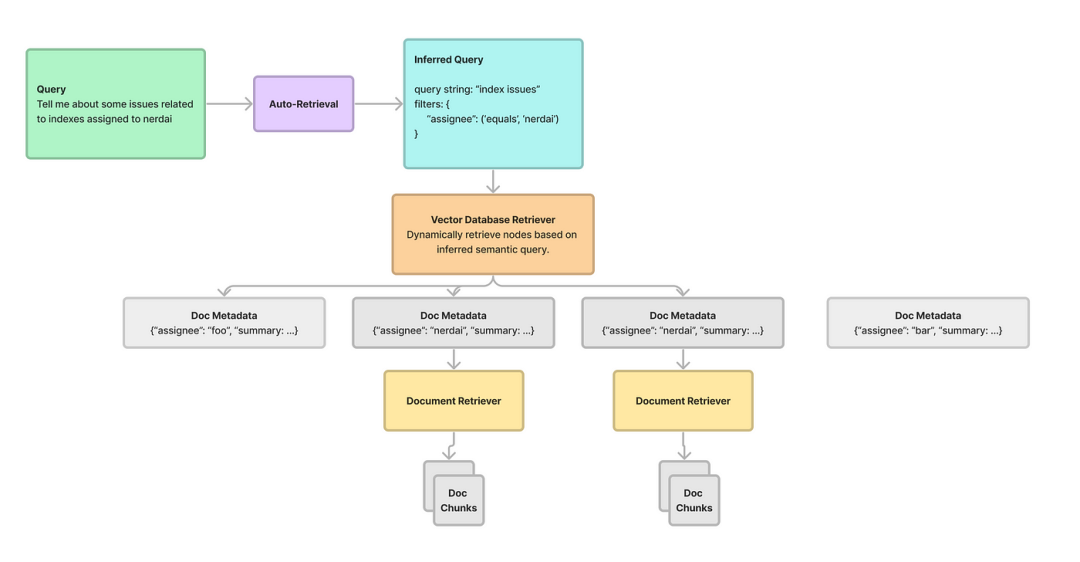
LLM之RAG实战(九)| 高级RAG 03:多文档RAG体系结构
在RAG(检索和生成)这样的框架内管理和处理多个文档有很大的挑战。关键不仅在于提取相关内容,还在于选择包含用户查询所寻求的信息的适当文档。基于用户查询对齐的多粒度特性,需要动态选择文档,本文将介绍结构化层次检索…
【书生·浦语】大模型实战营——第五课作业
教程文档:https://github.com/InternLM/tutorial/blob/vansin-patch-4/lmdeploy/lmdeploy.md#tritonserver-%E6%9C%8D%E5%8A%A1%E4%BD%9C%E4%B8%BA%E5%90%8E%E7%AB%AF 视频链接:
作业:
基础作业
使用如下命令创建conda环境
conda create…
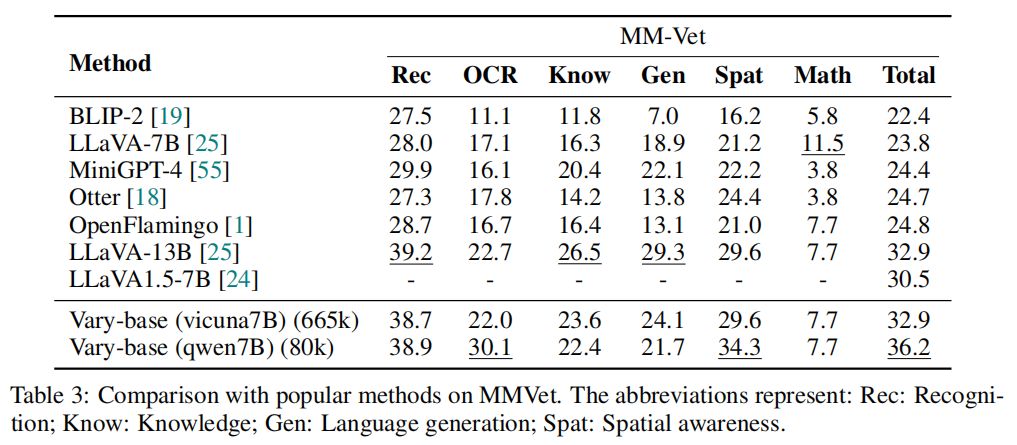
论文精读:Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
Status: Reading Author: Chunrui Han, Haoran Wei, Jianjian Sun, Jinrong Yang, Jinyue Chen, Liang Zhao, Lingyu Kong, Xiangyu Zhang, Zheng Ge Institution: 中国科学院大学, 华中科技大学, 旷…
Jetson Orin安装riva以及llamaspeak,使用 Riva ASR/TTS 与 Llama 进行实时交谈,大语言模型成功运行笔记
NVIDIA 的综合语音 AI 工具包 RIVA 可以处理这种情况。此外,RIVA 可以构建应用程序,在本地设备(如 NVIDIA Jetson)上处理所有这些内容。
RIVA 是一个综合性库,包括:
自动语音识别 (ASR&#x…
GPT-4:智能语言模型的新篇章
随着人工智能技术的飞速发展,智能语言模型已经成为了我们日常生活和工作中不可或缺的一部分。GPT-4,作为最新一代的语言模型,不仅继承了前代技术的优势,还在理解深度、生成连贯性和创造性方面实现了质的飞跃。本文将探讨GPT-4的创…

解析大语言模型LLM的幻觉问题:消除错觉、提高认知
文章目录 前言一、幻觉介绍二、幻觉产生的原因三、幻觉的现象四、幻觉的分类五、幻觉解决方案六、幻觉待解决问题后记 前言
在人类的感知和认知过程中,幻觉一直是一个被广泛讨论和研究的问题。幻觉指的是一种虚假的感知或认知经验,使我们看到、听到或感…
主流开源大语言模型的微调方法
文章目录 模型ChatGLM2网址原生支持微调方式 ChatGLM3网址原生支持微调方式 Baichuan 2网址原生支持微调方式 Qwen网址原生支持微调方式 框架FireflyEfficient-Tuning-LLMsSuperAdapters 模型
ChatGLM2
网址
https://github.com/thudm/chatglm2-6b
原生支持微调方式
https…
检索增强生成技术(RAG)深度优化指南:原理、挑战、措施、展望
ChatGPT、Midjourney等生成式人工智能(GenAI)在文本生成、文本到图像生成等任务中表现出令人印象深刻的性能。然而,生成模型也不能避免其固有的局限性,包括产生幻觉的倾向,在数学能力弱,而且缺乏可解释性。…

如何用AI提高论文阅读效率?
已经2024年了,该出现一个写论文解读AI Agent了。
大家肯定也在经常刷论文吧。
但真正尝试过用GPT去刷论文、写论文解读的小伙伴,一定深有体验——费劲。其他agents也没有能搞定的,今天我发现了一个超级厉害的写论文解读的agent ,…
2024年1月16日Arxiv热门NLP大模型论文:Multi-Candidate Speculative Decoding
大幅提速NLP任务,无需牺牲准确性!南京大学提出新算法,大幅提升AI文本生成效率飞跃
引言:探索大型语言模型的高效文本生成
在自然语言处理(NLP)的领域中,大型语言模型(LLMs…
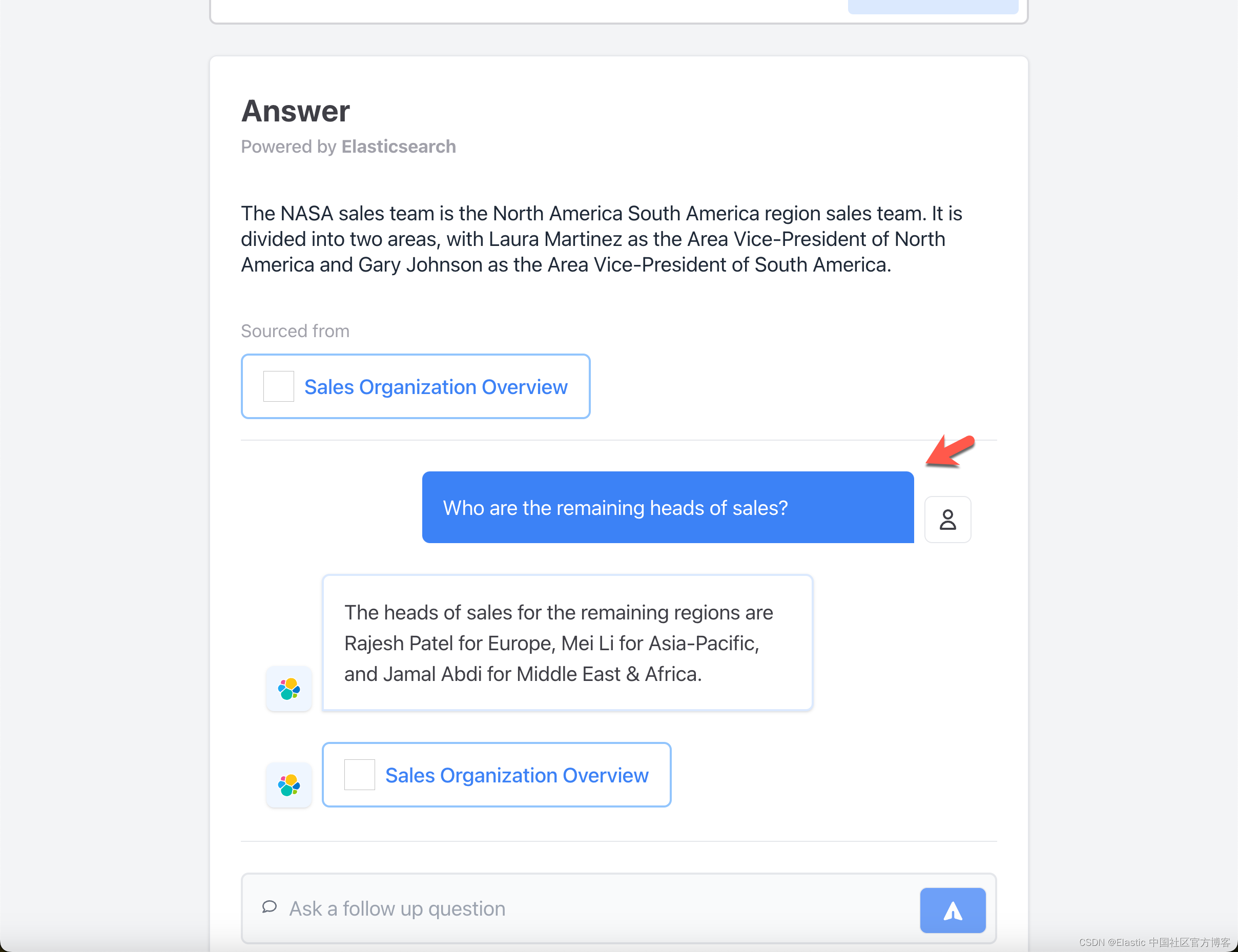
Elasticsearch:聊天机器人教程(一)
在本教程中,你将构建一个大型语言模型 (LLM) 聊天机器人,该机器人使用称为检索增强生成 (RAG) 的模式。 使用 RAG 构建的聊天机器人可以克服 ChatGPT 等通用会话模型所具有的一些限制。 特别是,他们能够讨论和回答以下问题:
你的…

Pytorch详细安装过程
1、安装anaconda
官网(https://www.anaconda.com/products/distribution#Downloads)下载,使用管理员身份运行(不使用似乎也没事)
这里选择Just me(至于为啥,咱也不是很清楚) 更改路…
提示词工程: 大语言模型的Embedding(嵌入和Fine-tuning(微调)
本文是针对这篇文章(https://www.promptengineering.org/master-prompt-engineering-llm-embedding-and-fine-tuning/)的中文翻译,用以详细介绍Embedding(语义嵌入)和Fine Tuning(微调)的概念和…
【LLM】大型语言模型综述论文
今天我将与大家分享一篇精彩的论文。这项调查提供了LLM文献的最新综述,这对研究人员和工程师来说都是一个有用的资源。
为什么选择LLM?
当参数尺度超过一定水平时,这些扩展的语言模型不仅实现了显著的性能改进,而且还表现出一些…

【论文阅读】Can Large Language Models Empower Molecular Property Prediction?
文章目录 0、基本信息1、研究动机2、创新性3、方法论4、实验结果 0、基本信息
作者:Chen Qian, Huayi Tang, Zhirui Yang文章链接:Can Large Language Models Empower Molecular Property Prediction?代码链接:Can Large Language Models E…
科普大语言模型中的Embedding技术
什么是大语言模型?
大语言模型是指使用大量的文本数据来训练的深度神经网络,它们可以学习语言的规律和知识,并且可以生成自然的文本。大语言模型的代表有GPT-3、BERT、XLNet等,它们在各种自然语言处理任务中都取得了很好的效果&a…

大模型应用实践:AIGC探索之旅
随着OpenAI推出ChatGPT,AIGC迎来了前所未有的发展机遇。大模型技术已经不仅仅是技术趋势,而是深刻地塑造着我们交流、工作和思考的方式。
本文介绍了笔者理解的大模型和AIGC的密切联系,从历史沿革到实际应用案例,再到面临的技术挑…


LLM(九)| 使用LlamaIndex本地运行Mixtral 8x7大模型
欧洲人工智能巨头Mistral AI最近开源Mixtral 8x7b大模型,是一个“专家混合”模型,由八个70亿参数的模型组成。Mistral AI在一篇博客文章(https://mistral.ai/news/mixtral-of-experts/)介绍了Mixtral 8x7b,在许多基准上…

第五周:深度学习知识点回顾
前言: 讲真,复习这块我是比较头大的,之前的线代、高数、概率论、西瓜书、樱花书、NG的系列课程、李宏毅李沐等等等等…那可是花了三年学习佳实践下来的,现在一想脑子里就剩下几个名词就觉得废柴一个了,朋友们有没有同感…
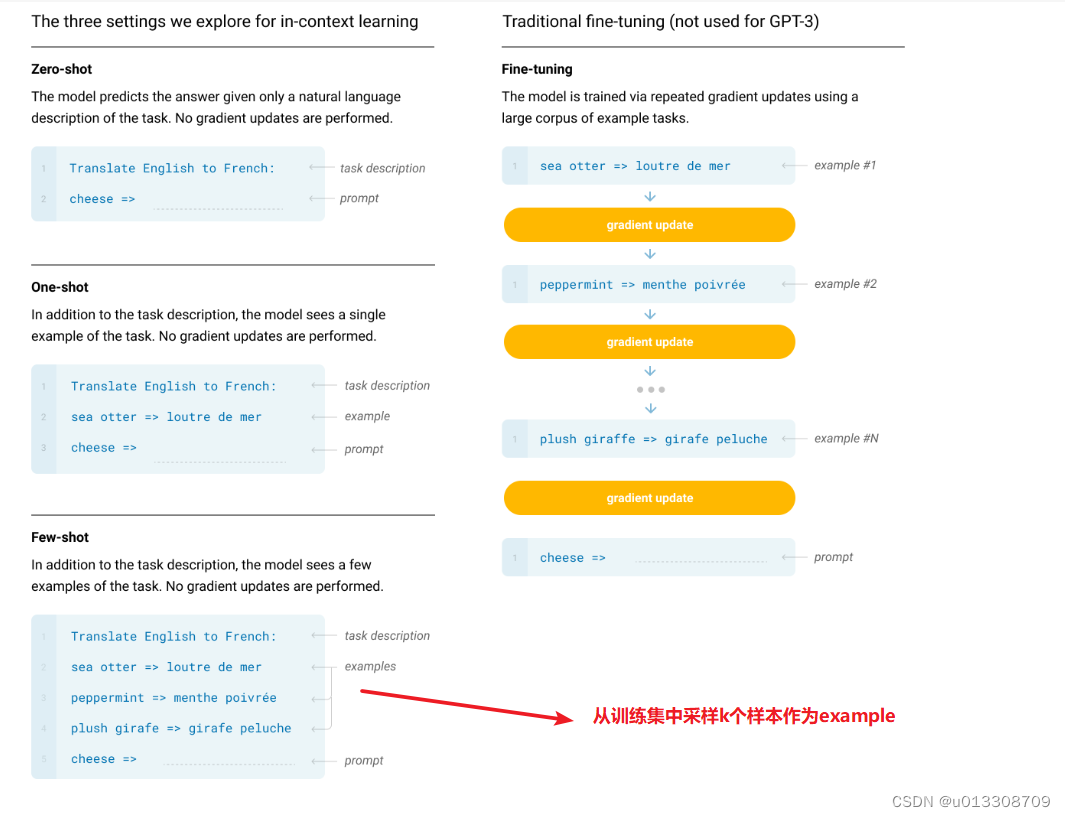
GPT-3: Language Models are Few-Shot Learners
GPT-3
论文
数据集
CommonCrawl:文章通过高质量参考语料库对CommonCrawl数据集进行了过滤,并通过模糊去重对文档进行去重,且增加了高质量参考语料库以增加文本的多样性。WebText:文章采用了类似GPT-2中的WebText文档收集清洗方…

主流大语言模型集体曝出训练数据泄露漏洞
内容概要:
安全研究人员发现,黑客可利用新的数据提取攻击方法从当今主流的大语言模型(包括开源和封闭,对齐和未对齐模型)中大规模提取训练数据。当前绝大多数大语言模型的记忆(训练数据)可被恢…

高级RAG(五):TruLens 评估-扩大和加速LLM应用程序评估
之前我们介绍了,RAGAs评估,今天我们再来介绍另外一款RAG的评估工具:TruLens , trulens是TruEra公司的一款开源软件工具,它可帮助您使用反馈功函数客观地评估基于 LLM 的应用程序的质量和有效性。反馈函数有助于以编程方式评估输入、输出和中间…
10款以上开源工具,用于大型语言模型应用开发
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…
使用GPT大模型调用工具链
本文特指openai使用sdk的方式调用工具链。
安装openai
pip install openai
export OPENAI_API_KEY"YOUR OPENAI KEY"
定义工具函数
from openai import OpenAI
import jsonclient OpenAI()
#工具函数
def get_current_weather(location, unit"fahrenheit&q…
Making Large Language Models Perform Better in Knowledge Graph Completion
Making Large Language Models Perform Better in Knowledge Graph Completion
基本信息
博客贡献人
鲁智深
作者
Yichi Zhang, Zhuo Chen, Wen Zhang, Huajun Chen 隶属于浙江大学计算机学院和软件学院
摘要 本文主要探讨了如何将有用的知识图谱结构信息融入大语言模型中…
大语言模型下载,huggingface和modelscope加速
huggingface 下载模型
如果服务器翻墙了,不用租机器 如果服务器没翻墙,可以建议使用下面的方式 可以租一台**autodl**不用显卡的机器,一小时只有1毛钱,启动学术加速,然后下载,下载完之后,用scp…
调用阿里通义千问大语言模型API-小白新手教程-python
阿里大语言模型通义千问API使用新手教程
最近需要用到大模型,了解到目前国产大模型中,阿里的通义千问有比较详细的SDK文档可进行二次开发,目前通义千问的API文档其实是可以进行精简然后学习的,也就是说,是可以通过简单的API调用在自己网页或…

Transformer and Pretrain Language Models3-6
Pretrain Language Models预训练语言模型
content: language modeling(语言模型知识)
pre-trained langue models(PLMs)(预训练的模型整体的一个分类)
fine-tuning approaches GPT and BERT(…
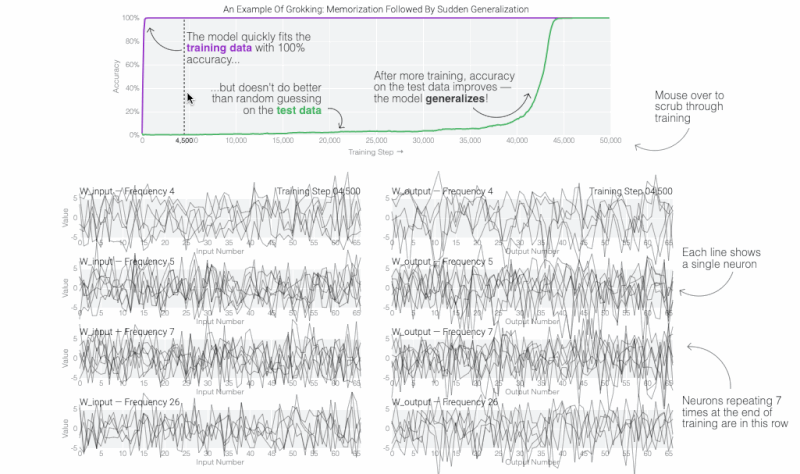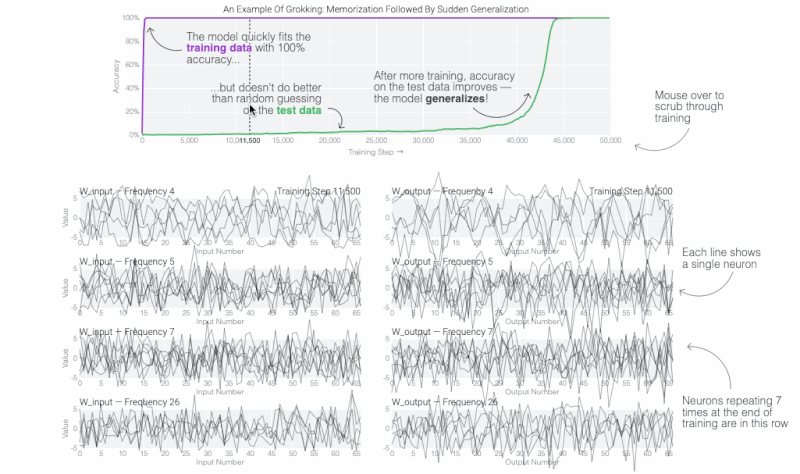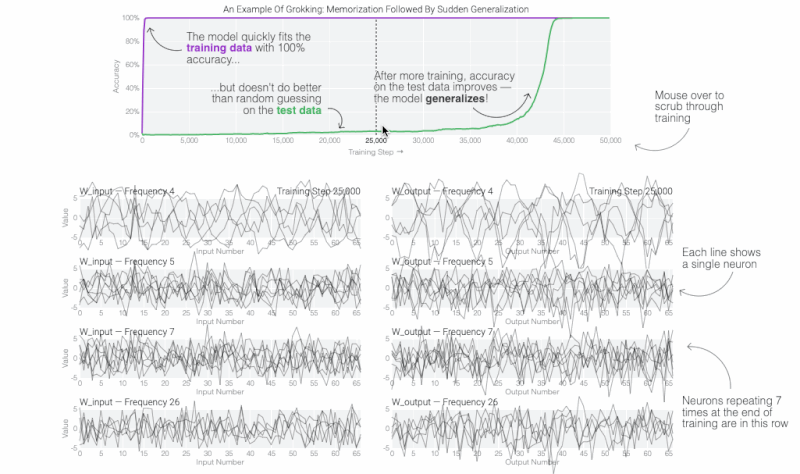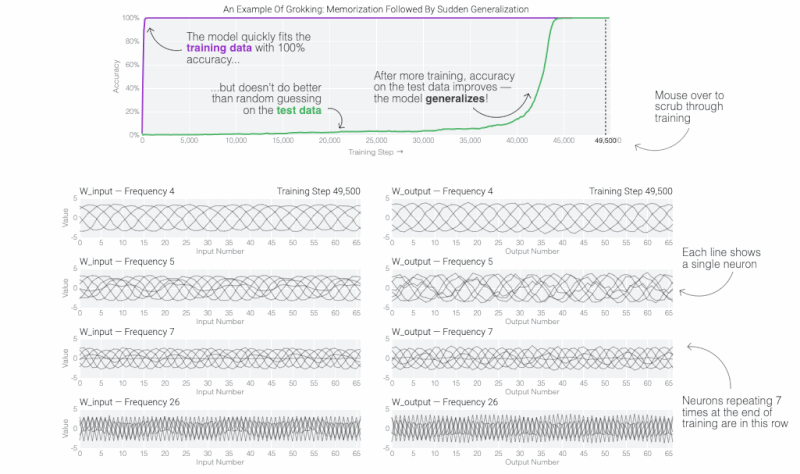
大型语言模型基础知识的可视化指南
直观分解复杂人工智能概念的工具和文章汇总 如今,LLM(大型语言模型的缩写)在全世界都很流行。没有一天不在宣布新的语言模型,这加剧了人们对错过人工智能领域的恐惧。然而,许多人仍在为 LLM 的基本概念而苦苦挣扎&…
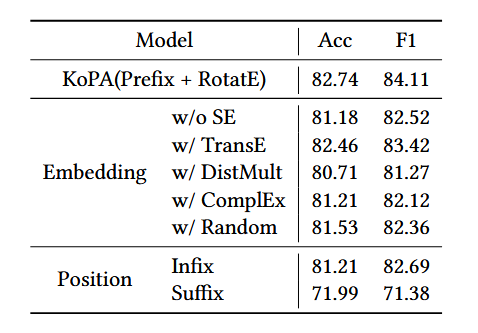
Making Large Language Models Perform Better in Knowledge Graph Completion论文阅读
文章目录 摘要1.问题的提出引出当前研究的不足与问题KGC方法LLM幻觉现象解决方案 2.数据集和模型构建数据集模型方法基线方法任务模型方法基于LLM的KGC的知识前缀适配器知识前缀适配器 与其他结构信息引入方法对比 3.实验结果与分析结果分析:可移植性实验࿱…
torch\tensorflow在大语言模型LLM中的作用
文章目录 torch\tensorflow在大语言模型LLM中的作用 torch\tensorflow在大语言模型LLM中的作用
在大型语言模型(LLM)中,PyTorch和TensorFlow这两个深度学习框架起着至关重要的作用。它们为构建、训练和部署LLM提供了必要的工具和基础设施。 …
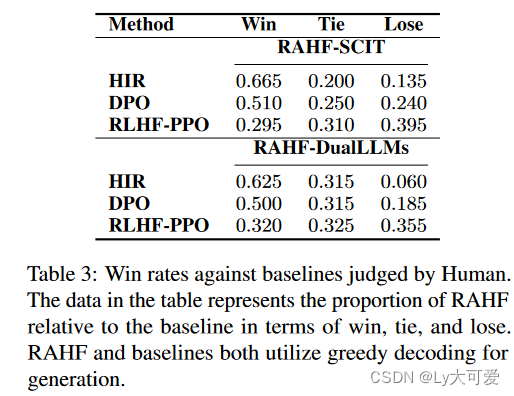
对齐大型语言模型与人类偏好:通过表示工程实现
1、写作动机:
强化学习表现出相当复杂度、对超参数的敏感性、在训练过程中的不稳定性,并需要在奖励模型和价值网络中进行额外的训练,导致了较大的计算成本。为了解决RL方法带来的上述挑战,提出了几种计算上轻量级的替代方案&…

大型语言模型 (LLM)全解读
一、大型语言模型(Large Language Model)定义
大型语言模型 是一种深度学习算法,可以执行各种自然语言处理 (NLP) 任务。 大型语言模型底层使用多个转换器模型, 底层转换器是一组神经网络。 大型语言模型是使用海量数据集进行训练…

苹果计划 2028 年推出无人驾驶汽车;微软开始开发小型语言模型;周鸿祎谈AI
苹果计划 2028 年推出汽车 今日凌晨,据彭博社援引知情人士消息称,之前苹果设想要推出真正的无人驾驶汽车,而目前在开发的是自动驾驶功能更为有限的电动汽车,并推迟了发布汽车的目标日期。
苹果公司现在计划 2028 年推出 Lever 2 …
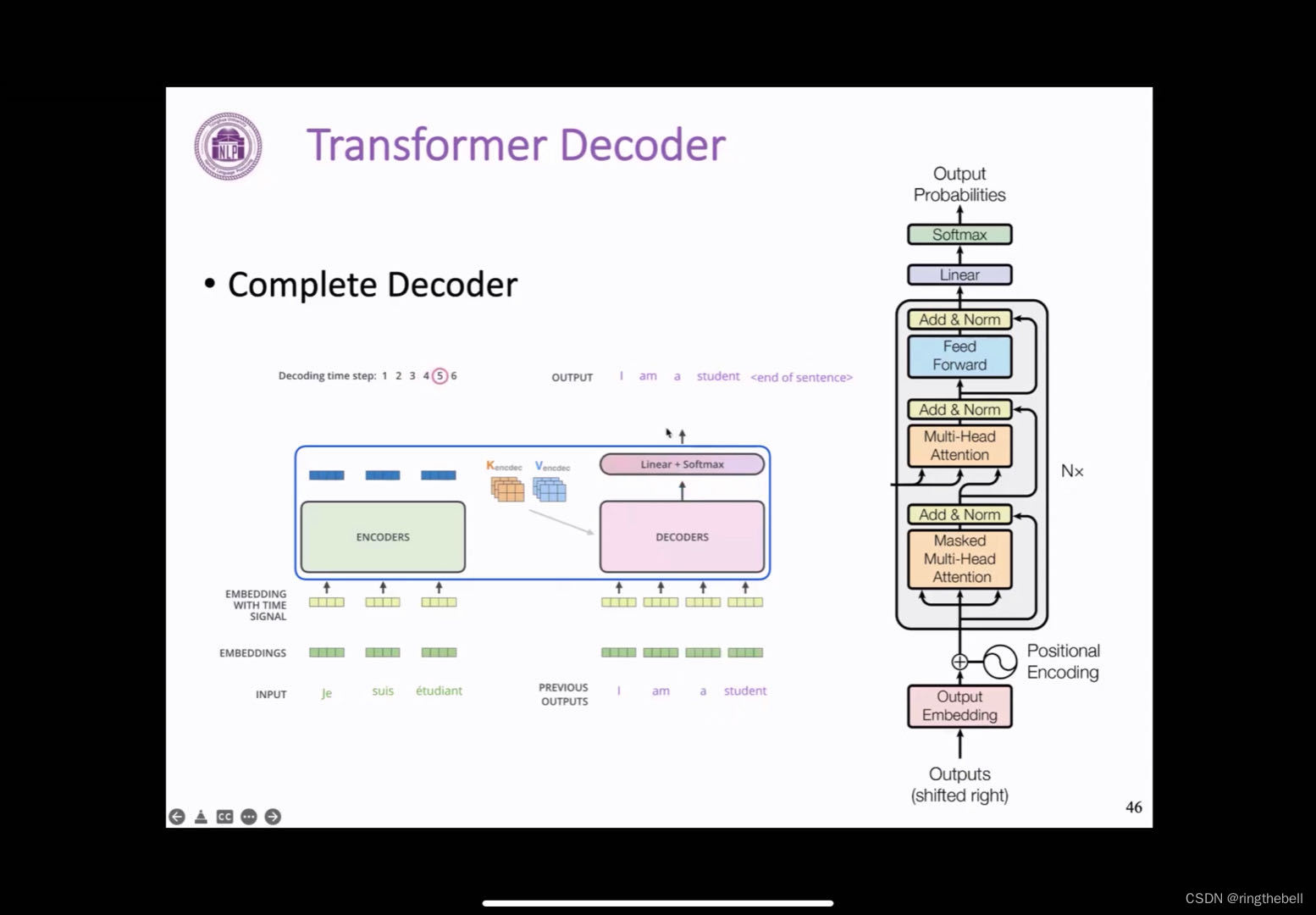
Transformer and Pretrain Language Models3-4
Transformer structure 模型结构
Transformer概述
首先回顾一下之前的RNN的一个端到端的模型,以下是一个典型的两层的LSTM模型,我们可以发现,这样一个RNN模型,一个非常重要的一个缺点就在于,它必须顺序地执行&#x…
全面解析开源大语言模型:BLOOM
大型语言模型 (LLM) 的兴起一直是自然语言处理 (NLP) 领域的一个决定性趋势,导致它们在各种应用程序中的广泛采用。然而,这种进步往往是排他性的,大多数由资源丰富的组织开发的 LLM 仍然无法向公…
大语言模型的技术-算法原理
大模型推理优化策略 7.1 显存优化 PagedAttention KV cache,其具有以下特点:1. 显存占用大,14b级别的模型,每个token需要约0.7M-1M的显存;2. 动态变化:KV 缓存的大小取决于序列长度,这是高度可变和不可预测的。因此,这对有效管理 KV cache 挑战较大。该研究发现,由于碎…
【大语言模型】大型语言模型的数据收集和预处理
前言 LLM(大型语言模型)是先进的人工智能模型,使用大量文本数据进行广泛的训练。 通过这种培训,他们学习语言结构和模式,并能够执行各种与语言相关的任务,例如摘要、翻译、情感分析等。 由于LLM具有执行以前机器难以完成的自然语言任务的卓越能力,近年来LLM受到了广泛关…

第38期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…

刘知远团队大模型技术与交叉应用L6-基于大模型文本理解和生成介绍
介绍
NLP的下游运用可以分为:NLU(理解)和NLG(生成) 信息检索:NLU 文本生成:NLG 机器问答:NLUNLG
大模型在信息检索 大模型在机器问答 大模型在文本生成 信息检索-Information Retrieval (IR)
背景
谷歌搜索引擎目前同时集成了…
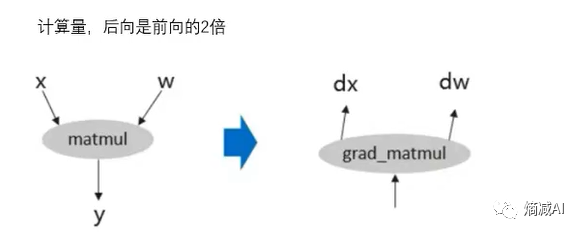
小周带你读论文之语言模型的进阶Scaling Laws 幂律,(参数/数据量/算力的最优解)
1,2,3上链接:2001.08361.pdf (arxiv.org) 幂律:所谓幂律,是说节点具有的连线数和这样的节点数目乘积是一个定值,也就是几何平均是定值,比如有10000个连线的大节点有10个,有1000个连线的中节点有100个,100个连线的小节点有1000个……,在对数坐标上画出来会得到一条斜向下…

Cohere For AI 推出了 Aya,这是一款覆盖超过 100 种语言的大型语言模型(LLM)
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

【AIGC】大语言模型
大型语言模型,也叫大语言模型、大模型(Large Language Model,LLM;Large Language Models,LLMs)
什么是大型语言模型 大型语言模型(LLM)是指具有数千亿(甚至更多…
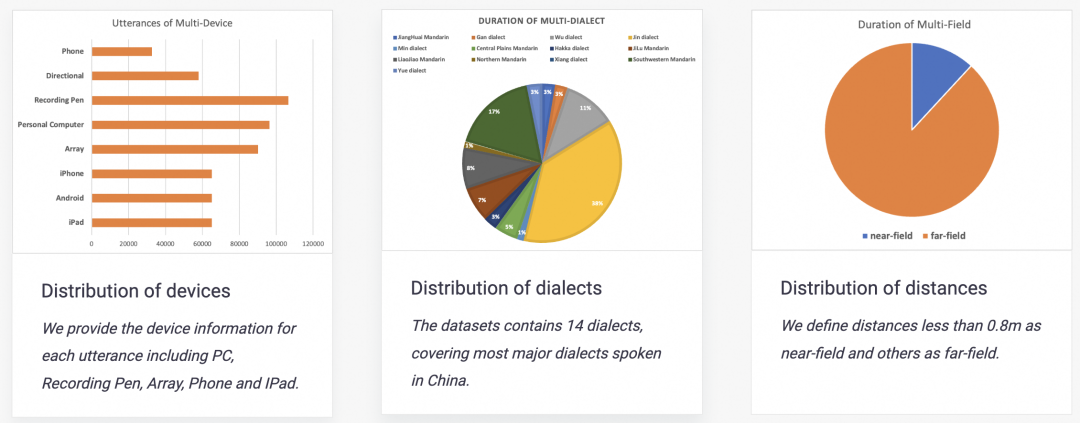
多模态说话人开源项目3D-Speaker
3D-Speaker是通义实验室语音团队贡献的一个结合了声学、语义、视觉三维模态信息来解决说话人任务的开源项目。本项目涵盖说话人日志,说话人识别和语种识别任务,开源了多个任务的工业级模型,训练代码和推理代码。
本项目同时还开源了相应的研…
大语言模型LLM分布式框架:PyTorch Lightning框架(LLM系列14)
文章目录 大语言模型LLM分布式框架:PyTorch Lightning框架(LLM系列14)引言PyTorch Lightning分布式计算基础PyTorch Lightning核心架构概览LightningModule与分布式训练的兼容性LightningDataModule在分布式数据加载与预处理中的作用Trainer类…
医学知识和医疗应用开发交叉领域中垂类大语言模型应用相关研究
前言:
基于公司对LLM落地的期望,此proposal尚未研究完毕,只是简单做了一些消息整合和建议。
关于知识细节详见末尾Refs
背景:
随着LLM(大语言模型)的爆火,不少企业都在寻找通过LLM解决企业业…

顶会ICLR2024论文Time-LLM:基于大语言模型的时间序列预测
文青松 松鼠AI首席科学家、AI研究院负责人
美国佐治亚理工学院(Georgia Tech)电子与计算机工程博士,人工智能、决策智能和信号处理方向专家,在松鼠AI、阿里、Marvell等公司超10年的技术和管理经验,近100篇文章发表在人工智能相关的顶会与顶刊…

Huggingface初上手即ERNIE-gram句子相似性实战
大模型如火如荼的今天,不学点语言模型(LM)相关的技术实在是说不过去了。只不过由于过往项目用到LM较少,所以学习也主要停留在直面——动眼不动手的水平。Huggingface(HF)也是现在搞LM离不开的工具了。
出于…

Stable Video Diffusion(SVD)视频生成模型发布 1.1版
前言
近日,随着人工智能技术的飞速发展,图像到视频生成技术也迎来了新的突破。特别是Stable Video Diffusion(SVD)模型的最新版本1.1,它为我们带来了从静态图像生成动态视频的全新能力。本文将深入解析SVD 1.1版本的核…

当大语言模型遇到AI绘画-google gemma与stable diffusion webui融合方法-矿卡40hx的AI一体机
你有想过建一台主机,又能AI聊天又能AI绘画,还可以直接把聊天内容直接画出来的机器吗?
当Google最新的大语言模型Gemma碰到stable diffusion webui会怎么样?
首先我们安装stable diffusion webui(automatic1111开源项目ÿ…
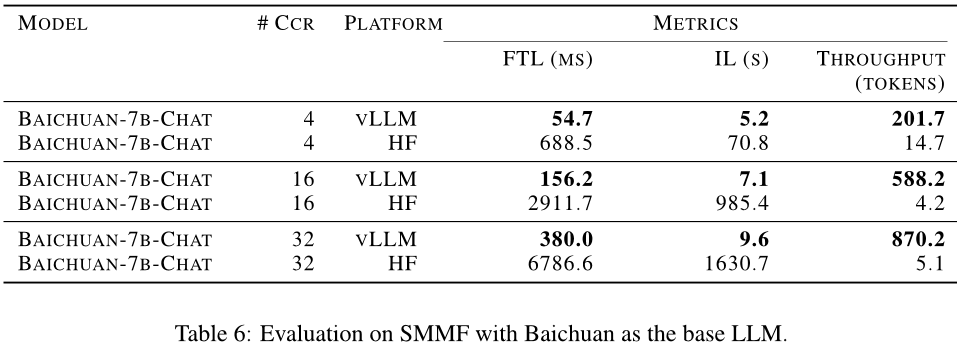
DB-GPT: Empowering Database Interactions with Private Large Language Models 导读
本文介绍了一种名为DB-GPT的新技术,它将大型语言模型(LLM)与传统数据库系统相结合,提高了用户使用数据库的体验和便利性。DB-GPT可以理解自然语言查询、提供上下文感知的回答,并生成高准确度的复杂SQL查询,…
大语言模型系列-微调技术
前言
以BERT模型为代表的“预训练语言模型 下游任务微调”训练模式成为了自然语言处理研究和应用的新范式。此处的下游任务微调是基于模型全量参数进行微调(全量微调)。
以 GPT3 为代表的预训练语言模型(PLM)参数规模变得越来越…
如何学习自然语言处理之语言模型
自然语言处理(NLP)是一种人工智能技术,它使计算机能够理解和处理人类语言。而语言模型是NLP中的一个重要概念,主要是用来估测一些词的序列的概率,即预测p(w1, w2, w3 … wn),其中一个应用就是句子的生成。 …
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.02.25-2024.03.01
论文目录~ 1.Arithmetic Control of LLMs for Diverse User Preferences: Directional Preference Alignment with Multi-Objective Rewards2.Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates3.Meta-Task Prompting Elicits Embedding from Lar…

【论文阅读】《Graph Neural Prompting with Large Language Models》
文章目录 0、基本信息1、研究动机2、创新点3、准备3.1、知识图谱3.2、多项选择问答3.3、提示词工程(prompt engineering) 4、具体实现4.1、提示LLMs用于问答4.2、子图检索4.3、Graph Neural Prompting4.3.1、GNN Encoder4.3.2、Cross-modality Pooling4.…
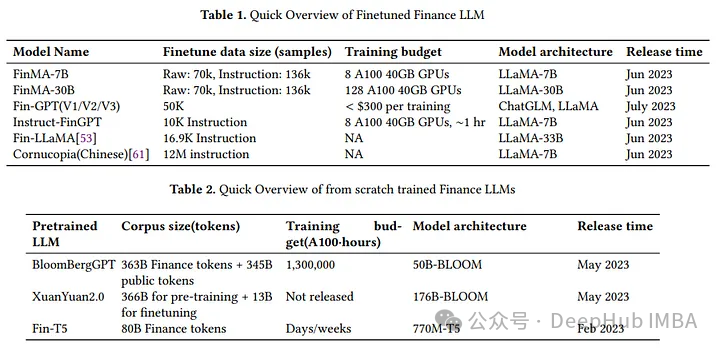
论文推荐:大语言模型在金融领域的应用调查
这篇论文总结了现有LLM在金融领域的应用现状,推荐和金融相关或者有兴趣的朋友都看看
论文分为2大部分:
1、作者概述了使用llm的现有方法
包括使用零样本或少样本的预训练模型,对特定于领域的数据进行微调,还有从头开始训练定制…

LLM面面观之RLHF平替算法DPO
1. 背景
最近本qiang~老看到一些关于大语言模型的DPO、RLHF算法,但都有些云里雾里,因此静下心来收集资料、研读论文,并执行了下开源代码,以便加深印象。
此文是本qiang~针对大语言模型的DPO算法的整理,包括原理、流程…
语义内核框架(Semantic Kernel)
语义内核框架-Semantic Kernel
首先看看官方描述:Semantic Kernel 是一个开源 SDK,可让您轻松构建可以调用现有代码的代理。作为高度可扩展的 SDK,可以将语义内核与来自 OpenAI、Azure OpenAI、Hugging Face 等的模型一起使用!通…
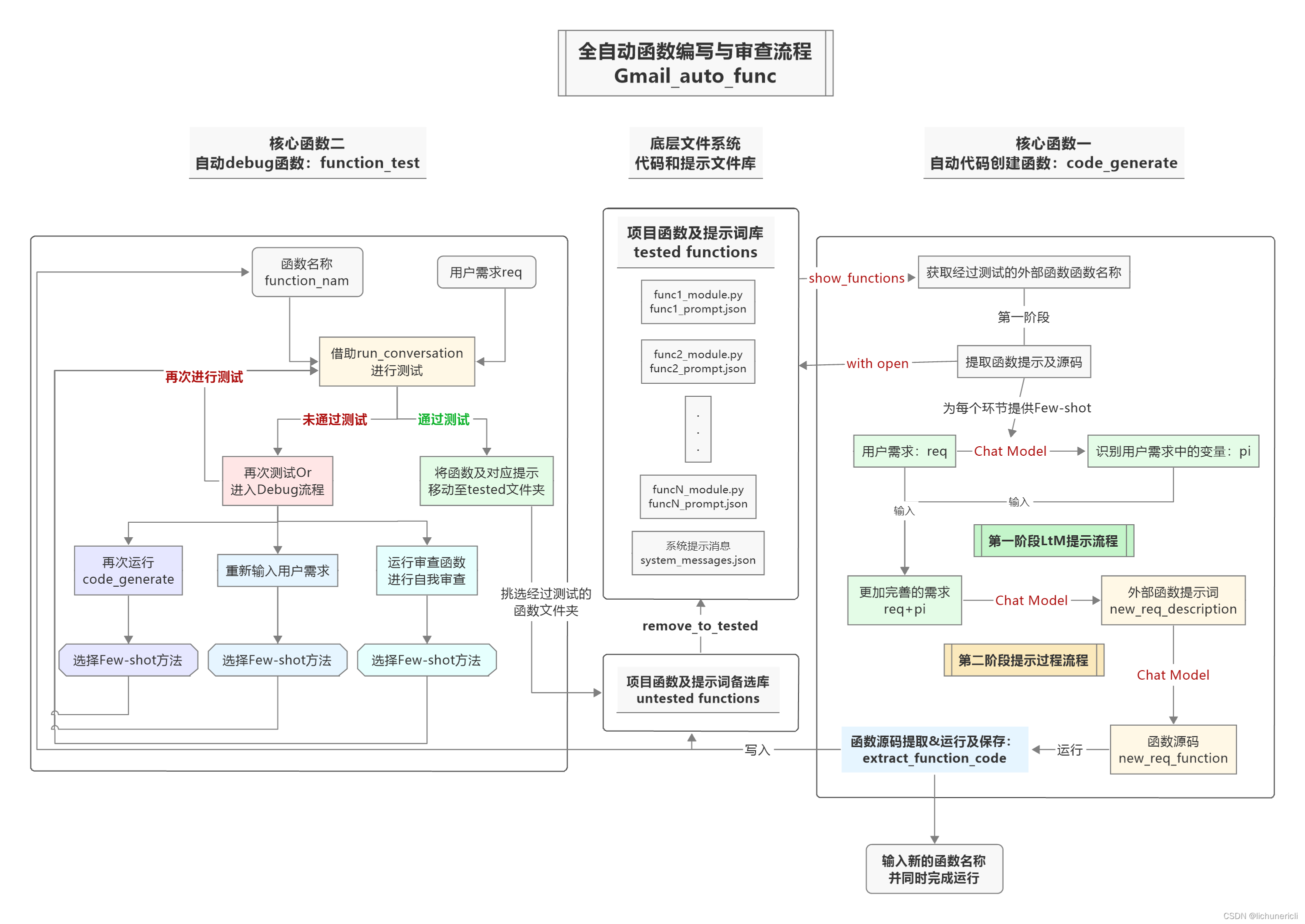
如何更好的引导大语言模型进行编程的高效开发流程?
这张图片展示了一种如何更好地引导大语言模型进行编程的方法。
首先,最简单也是最有效的方法是让大语言模型重复运行多次,每次增加一些额外的信息,直到获得想要的结果。这种方法虽然简单,但可能需要多次尝试才能得到满意的结果。…

惊艳!2.77亿参数锻造出Agent+GPT-4V模型组合,AI领航机器人、游戏、医疗革新,通用智能时代你准备好了吗?
更多内容迁移知乎账号,欢迎关注:https://www.zhihu.com/people/dlimeng
斯坦福、微软、UCLA的顶尖学者联手,推出了一个全新交互式基础代理模型!
这个模型能处理文本、图像、动作输入,轻松应对多任务挑战,…
Nature Machine Intelligence 法国国家科学研究中心评论“使用大语言模型进行研究的危机”
ChatGPT 于 2022 年底发布,将大型语言模型 (LLM) 推到了聚光灯下。通过使用户能够直接用自然语言查询模型,ChatGPT 实现了对这些模型的访问——这是一个受欢迎的发展。从那时起,ChatGPT 和 Bard、Claude 和 Bing AI 等…

Adobe推出AI音乐创作工具原型;大型语言模型对编程的影响有限?
🦉 AI新闻
🚀 Adobe推出AI音乐创作工具原型
摘要:Adobe在布鲁克林的Hot Pod峰会上发布了一款名为“Project Music GenAI Control”的AI音乐创作工具原型。这款工具通过生成式人工智能技术,使用户可以无需专业的音频制作经验就能…
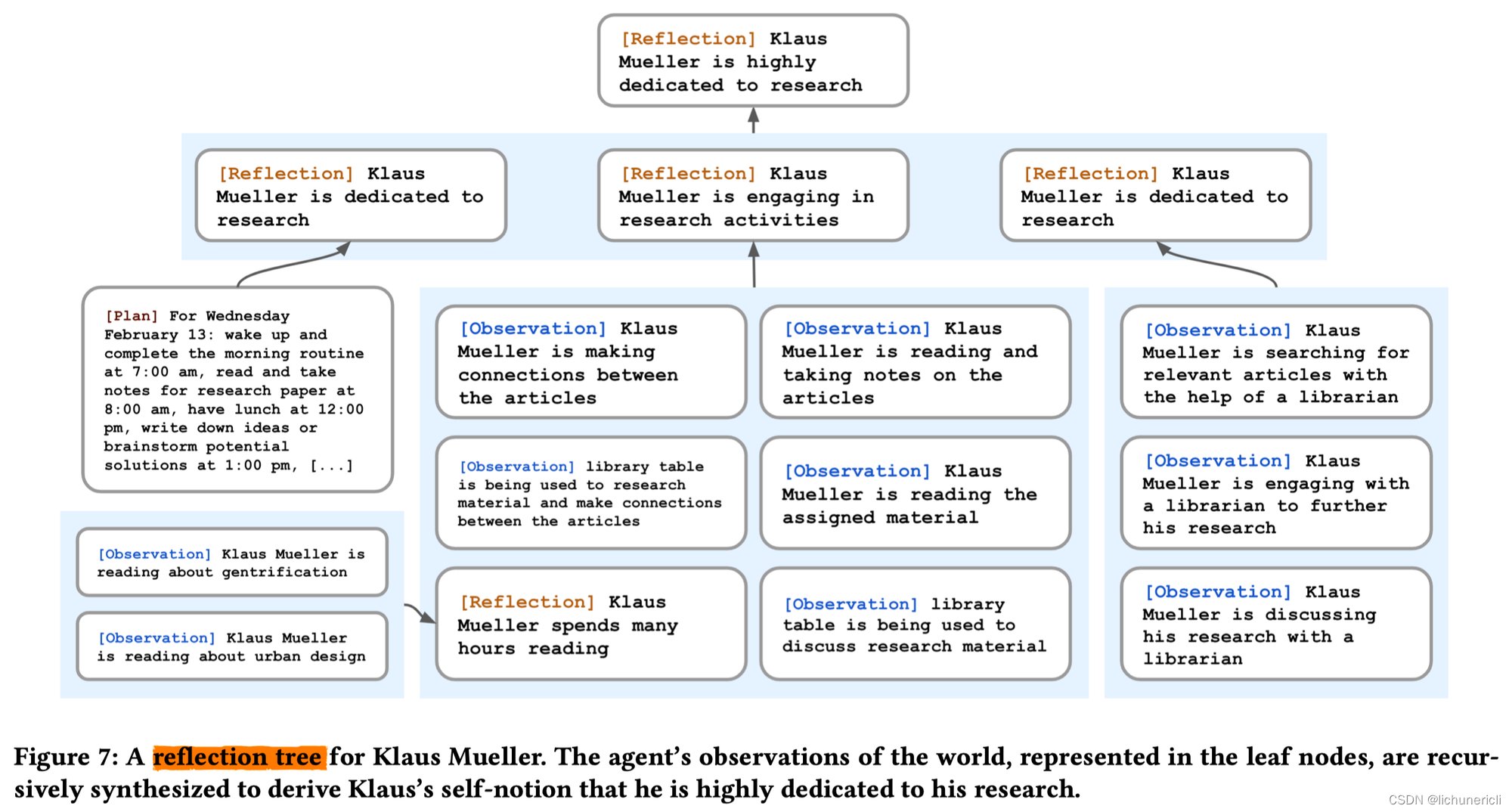
基于大语言模型的AI Agents
代理(Agent)指能自主感知环境并采取行动实现目标的智能体。基于大语言模型(LLM)的 AI Agent 利用 LLM 进行记忆检索、决策推理和行动顺序选择等,把Agent的智能程度提升到了新的高度。LLM驱动的Agent具体是怎么做的呢&a…
大模型适配器微调(Adapter-tuning)知识
为什么需要适配器微调(Adapter-tuning)?
适配器微调(Adapter-tuning)是一种用于微调预训练模型的方法,它相比于传统的微调方法具有一些优势和应用场景。以下是一些需要适配器微调的情况: 保留预…
LLM大模型相关问题汇总
一、基础篇
1. 目前 主流的开源模型体系 有哪些?
2. prefix LM 和 causal LM 区别是什么?
3. 涌现能力是啥原因?
4. 大模型LLM的架构介绍?
5. 你比较关注那些主流的开源大模型?
6. 目前大模型模型结构都有那些&a…
GPU不够用:语言模型的分布式挑战
引言
随着深度学习技术的飞速发展,大规模语言模型(LLM)在各种NLP任务中取得了令人瞩目的成绩。然而,这些模型的大小和复杂度也不断增加,给部署和应用带来了诸多挑战。特别是在单个GPU或服务器的内存容量有限的情况下,如何高效地利用分布式计算资源成为了一个亟待解决的问…

自然语言处理之语言模型(LM):用c++通过自然语言处理技术分析语音信号音高
要通过自然语言处理技术分析语音信号音高,我们可以采用以下步骤: 首先,我们需要获取语音信号的原始音频数据。可以使用C中的音频处理库(例如PortAudio或ALSA)来捕获音频输入并将其转换为数字音频数据。 接下来&#x…

清华AutoGPT:掀起AI新浪潮,与GPT4.0一较高下
引言: 随着人工智能技术的飞速发展,自然语言处理(NLP)领域迎来了一个又一个突破。最近,清华大学研发的AutoGPT成为了业界的焦点。这款AI模型以其出色的性能,展现了中国在AI领域的强大实力。 目录
引言&…
书生·浦语大模型实战营学习总结
书生浦语大模型实战营学习总结 实战营课程内容个人笔记汇总个人作业汇总个人大作业总结 实战营课程内容
为了推动大模型在更多行业落地开花,让开发者们更高效的学习大模型的开发与应用,上海人工智能实验室重磅推出书生浦语大模型实战营,为广…
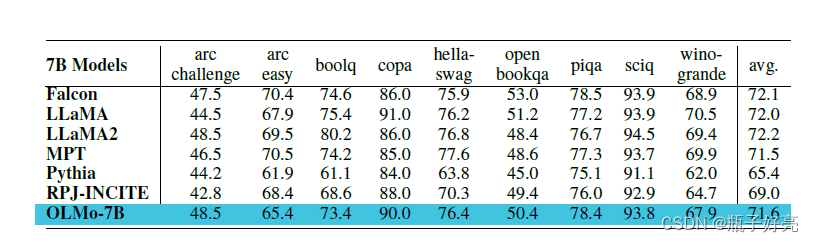
OLMo论文里的模型结构的小白解析
模型参数量 以7B为例,隐藏层为4086,attention heads为32 训练的token量为2.46T
训练策略
超参数 在我们的硬件上优化训练吞吐量,同时最小化损失峰值和缓慢发散的风险来选择超参数 损失峰值:在机器学习中,"损失峰…
AIGC基础:大型语言模型 (LLM) 为什么使用向量数据库,嵌入(Embeddings)又是什么?
嵌入:
它是指什么?嵌入是将数据(例如文本、图像或代码)转换为高维向量的数值表示。这些向量捕捉了数据点之间的语义含义和关系。可以将其理解为将复杂数据翻译成 LLM 可以理解的语言。为什么有用?原始数据之间的相似性…

语言模型中“嵌入”(embedding)概念的介绍
嵌入(embedding)是一种尝试通过数的数组来表示某些东西“本质”的方法,其特性是“相近的事物”由相近的数表示。 1.嵌入的作用 嵌入(Embedding)是一种将高维、离散或符号形式的数据转换为低维连续向量表示的方法。这些…

第39期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…
大语言模型Prompt提示词
大语言模型Prompt提示词 文章目录 大语言模型Prompt提示词Prompt基础常见的多轮对话里的PromptPrompt的结构说明Prompt基础策略复杂Prompt策略AdvertiseGen数据集中的提示词 Prompt基础
当体验完大语言模型LLM的新鲜感之后,写Prompt需要个人练习和思考才能快速掌握…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.02.10-2024.02.15
2024.02.10–2024.02.15: arXiv中发表的关于大语言模型(LLMs)相关的文章,已经筛选过一部分,可能有的文章质量并不是很好,但是可以看出目前LLM的科研大方向!
后续我会从中选择出比较有意思的文章…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.01.01-2024.01.10
1.Pre-trained Large Language Models for Financial Sentiment Analysis 标题:用于金融情感分析的预训练大型语言模型 author:Wei Luo, Dihong Gong date Time:2024-01-10 paper pdf:http://arxiv.org/pdf/2401.05215v1
摘要: 金融情感分析是指将金融文本内容划分…
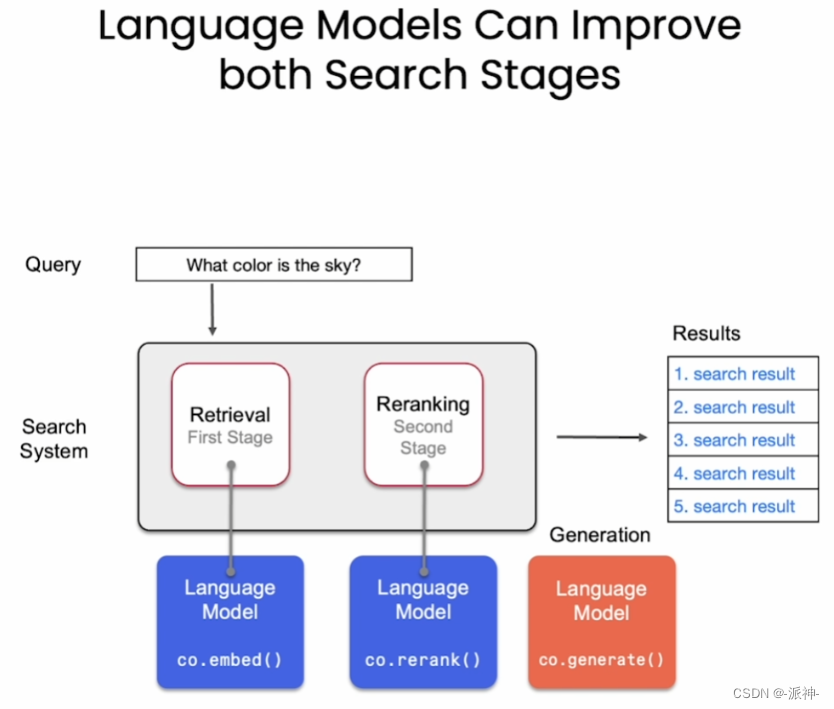
大型语言模型的语义搜索(一):关键词搜索
关键词搜索(Keyword Search)是文本搜索种一种常用的技术,很多知名的应用app比如Spotify、YouTube 或 Google map等都会使用关键词搜索的算法来实现用户的搜索任务,关键词搜索是构建搜索系统最常用的方法,最常用的搜索算法是Okapi BM25&#x…

LLM (Large language model)的指标参数
1. 背景介绍
我们训练大模型的时候,或者我们用RAG的时候,不知道我们的算法,或者我们的提示,或者我们的本地知识库是否已经整理得符合要求了。又或我们需要一个指标去评估我们目前的所有围绕大模型,向量数据库或外挂知…
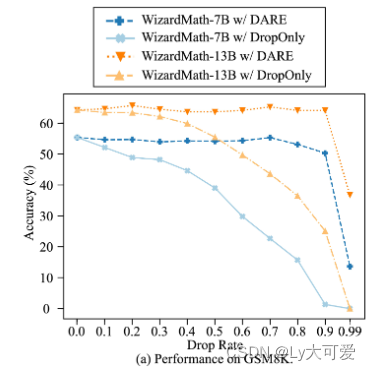
语言模型是超级马里奥: 从同源模型中吸收能力是免费午餐(阿里巴巴)
一、写作动机:
对于语言模型(LM)而言,有监督式微调(SFT)是一种被广泛采用的策略。SFT 在预训练模型的基础上,通过微调其参数来获得激发了特定能力的微调模型。显而易见,SFT 带来的效…
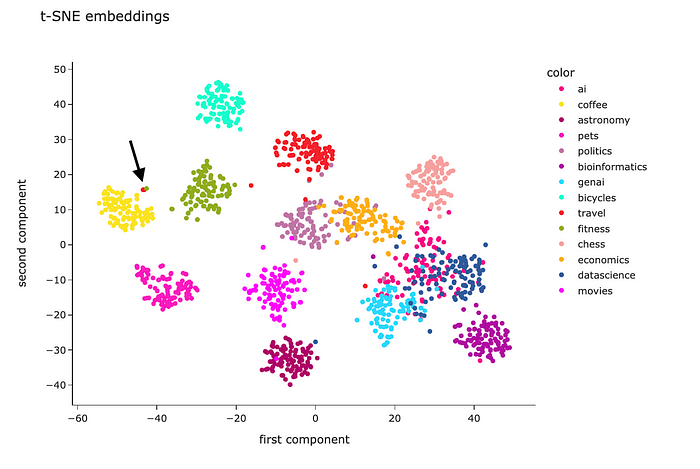
文本嵌入:综合指南,文本嵌入的演变、可视化和应用
原文链接:https://towardsdatascience.com/text-embeddings-comprehensive-guide-afd97fce8fb5
2024 年 2 月 13 日
作为人类,我们可以阅读和理解文本(至少其中一些文本)。相反,计算机“用数字思考”,所以它们不能自动掌握单词和…
高级RAG:揭秘PDF解析
原文地址:https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
2024 年 2 月 3 日
附加内容:揭秘PDF解析:如何从科学pdf论文中提取公式
对于RAG,从文档中提取信息是一个不可避免的场景。确保从源头…

【AI链接】 大模型语言模型网站链接
目录 GPT类1. chatgpt2. GROP3. Google AI Studio4. Moonshot AI (国内) 解读论文类:1. txyz 编程辅助插件:1. Fitten Code GPT类
1. chatgpt
https://chat.openai.com/
2. GROP
https://groq.com/
3. Google AI Studio
https://aistudio.google…
大语言模型LangChain + ChatGLM3-6B的组合集成:工具调用+提示词解读
文章目录 大语言模型LangChain ChatGLM3-6B的组合集成:工具调用提示词解读官方给出的提示词模板解读注解:1. 模板描述2. 工具调用规范3. 问题处理流程4. 最终响应5. 历史记录6. 实际应用举例 大语言模型LangChain ChatGLM3-6B的组合集成:工…

AI论文速读 | STG-LLM 大语言模型如何理解时空数据?
论文标题:How Can Large Language Models Understand Spatial-Temporal Data?
论文链接:https://arxiv.org/abs/2401.14192
作者:Lei Liu, Shuo Yu, Runze Wang, Zhenxun Ma, Yanming Shen(申彦明)
关键词…
(202402)多智能体MetaGPT入门1:MetaGPT环境配置
文章目录 前言拉取MetaGPT仓库1 仅仅安装最新版2 拉取源码本地安装MetaGPT安装成果全流程展示 尝试简单使用1 本地部署大模型尝试(失败-->成功)2 讯飞星火API调用 前言
感谢datawhale组织开源的多智能体学习内容,飞书文档地址在https://d…
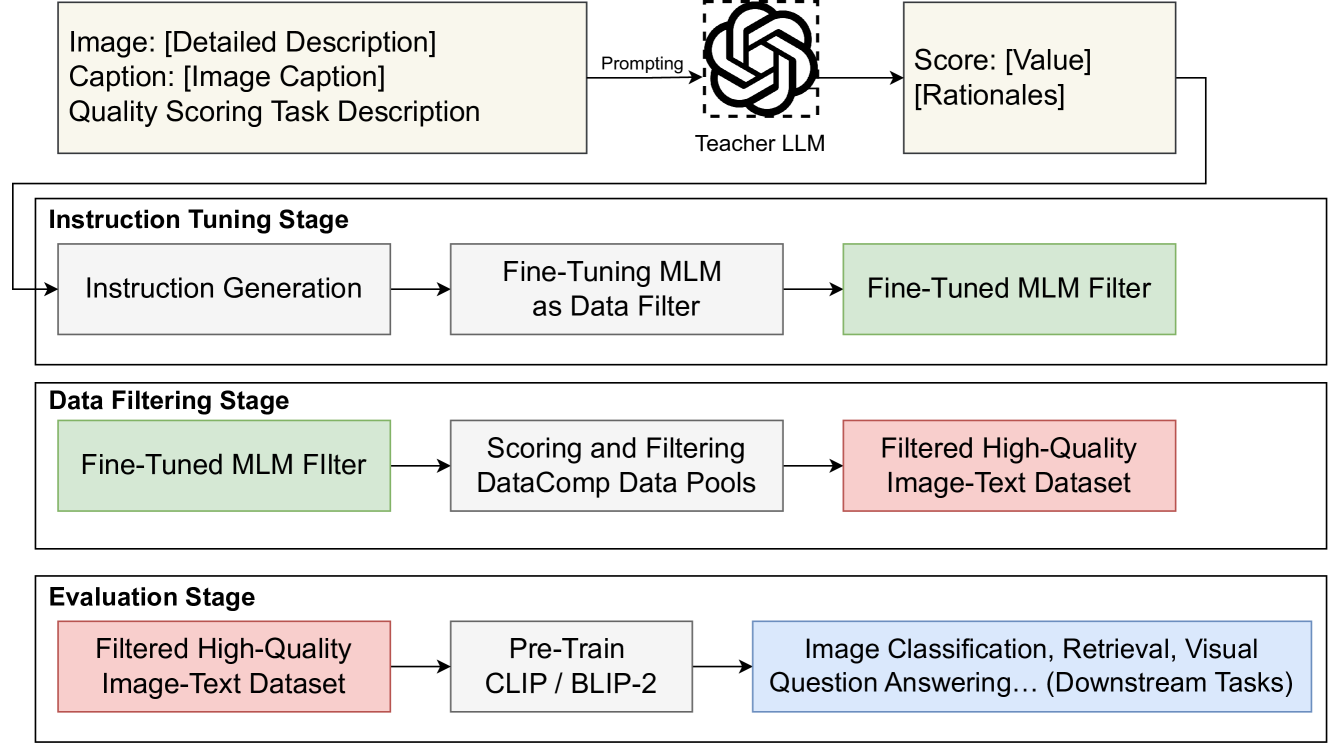
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters 相关链接:arxiv 关键字:Multimodal Language Models、Image-Text Data Filtering、Fine-tuning、Quality Assessment Metrics、Data Quality 摘要: 我们提出…

(202402)多智能体MetaGPT入门2:AI Agent知识体系结构
文章目录 前言1 智能体定义2 热门智能体案例3 智能体的宏观机会4 AI Agent与Sy1&Sy2观看视频 前言
感谢datawhale组织开源的多智能体学习内容,飞书文档地址在https://deepwisdom.feishu.cn/wiki/KhCcweQKmijXi6kDwnicM0qpnEf
本章主要为Agent相关理论知识的学…

内容创作的救星!还有谁不知道JuheChat?
新年将至,
年度群发祝福短信憋不出来怎么办?
小程序上线,
功能更新代码来不及写怎么办?
年度总结,
新手小白没有范本无处下手怎么办?
我也……不知道啊……
头脑风暴刮不起来
偷偷借鉴不能百分百匹…
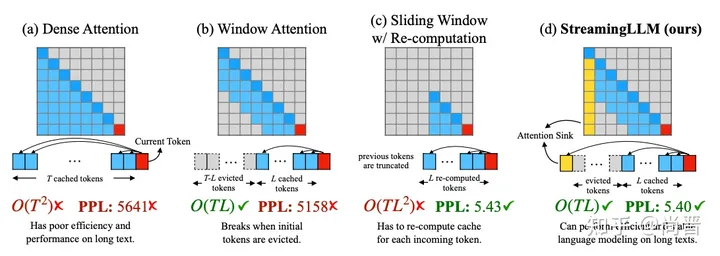
大语言模型推理加速技术:模型压缩篇
原文:大语言模型推理加速技术:模型压缩篇 - 知乎
目录
简介
量化(Quantization)
LLM.int8()
GPTQ
SmoothQuant
AWQ
精简Attention
共享Attention参数
Multi-Query Attention
Grouped-Query Attention
稀疏Attention
Sliding Window Attenti…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.02.20-2024.02.25
论文目录~ 1.Representing Online Handwriting for Recognition in Large Vision-Language Models2.Seeing is Believing: Mitigating Hallucination in Large Vision-Language Models via CLIP-Guided Decoding3.Fine-tuning CLIP Text Encoders with Two-step Paraphrasing4.…
程序员视角的大语言模型,如何使用大语言模型
从程序员的视角来看,使用大语言模型(LLMs)主要涉及以下几个步骤: 选择合适的模型: 首先,需要确定哪个大语言模型最适合你的需求。不同的模型可能在不同的任务上有不同的表现,比如代码生成、代码…
无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14B
无内容审查机制大模型整合包,基于CausalLM-14B量化 目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被“玩”坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt&a…
huggingface上传或发布自己的模型(大语言模型LLM)
创建huggingface账号和token
在https://huggingface.co/join注册huggingface账号,登录账号后,在https://huggingface.co/settings/tokens创建token,注意需要将token的类型设置为WRITE。
安装必要软件包和初始化环境
安装git lfs
curl -s …
自然语言处理之语言模型(LM):一段Pytorch的LSTM模型对自然语言处理的实际代码
当处理自然语言处理任务时,可以使用PyTorch来实现LSTM模型。下面是一个简单的示例代码,用于情感分类任务。
首先,导入所需的库:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.data import F…
自然语言处理之语言模型(LM)
自然语言处理(NLP)中的语言模型(Language Model,LM)是指对文本序列的概率分布进行建模的模型。语言模型可以用来评估一个句子的合理性、生成自然语言文本、进行语音识别、机器翻译等任务。
在语言模型中,我…
Sora模型技术讲解
Sora整体训练流程 视频编码DIT语言模型 预测的时候输入的是纯噪音。 Sora训练样本特点 视频编码 *将一帧一帧图片转化为20 * 30 3 的patch,就是1800维特征。 转化为1800维特征太长了,需要将其压缩,转化为短向量

AI大语言模型【成像光谱遥感技术】ChatGPT应用指南
遥感技术主要通过卫星和飞机从远处观察和测量我们的环境,是理解和监测地球物理、化学和生物系统的基石。ChatGPT是由OpenAI开发的最先进的语言模型,在理解和生成人类语言方面表现出了非凡的能力。本文重点介绍ChatGPT在遥感中的应用,人工智能…

深入探讨 AutoGPT:彻底改变游戏的自主 AI
原文地址:Deep Dive into AutoGPT: The Autonomous AI Revolutionizing the Game
2023 年 4 月 24 日
AutoGPT 是一个功能强大的工具,它通过 API 使用 GPT-4 和 GPT-3.5,通过将项目分解为子任务并在自动循环中使用互联网和其他工具来创建完…

Flamingo a Visual Language Model for Few-Shot Learning
Flamingo: a Visual Language Model for Few-Shot Learning
TL; DR:Flamingo 在 VL-adapter 的结构上有创新,Perceiver Resampler gated xattn,一种看起来比较复杂且高级的将图像特征注入到语言模型的方式。同时,优秀的结构设计…
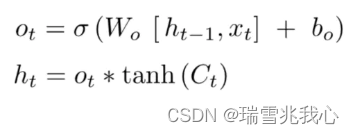
六、长短时记忆网络语言模型(LSTM)
为了解决深度神经网络中的梯度消失问题,提出了一种特殊的RNN模型——长短期记忆网络(Long Short-Term Memory networks, LSTM),能够有效的传递和表达长时间序列中的信息并且不会导致长时间前的有用信息被忽略。 长短时记忆网络原理…
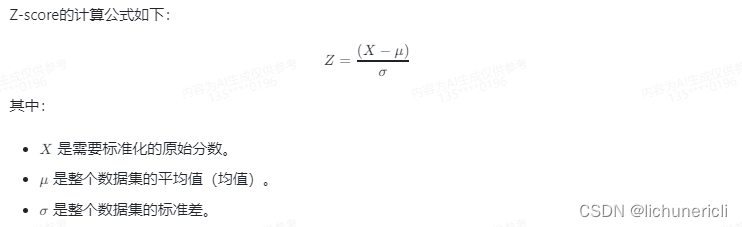
记录些大语言模型(LLM)相关的知识点
槽位对齐(slot alignment)
在text2sql任务中,槽位对齐(slot alignment)通常指的是将自然语言问题中的关键信息(槽位)与数据库中的列名或API调用中的参数进行匹配的过程。这个过程中,…

【对比】Gemini:听说GPT-4你小子挺厉害
前言
🍊缘由
谷歌连放大招:Gemini Pro支持中文,Bard学会画画 🏀事情起因: 一心只读圣贤书的狗哥,不经意间被新闻吸引。【谷歌最新人工智能模型Gemini Pro已在欧洲上市 将与ChatGPT竞争】, 平时玩弄ChatGPT-4很熟练了…

3分钟学会写文心一言指令
文心一言是百度研发的 人工智能大语言模型产品,能够通过上一句话,预测生成下一段话。 任何人都可以通过输入【指令】和文心一言进行对话互动、提出问题或要求,让文心一言高效地帮助人们获取信息、知识和灵感。 指令(prompt&#x…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.01.10-2024.01.15
论文目录~ 1.Concept-Guided Prompt Learning for Generalization in Vision-Language Models2.WisdoM: Improving Multimodal Sentiment Analysis by Fusing Contextual World Knowledge3.Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation4.…
LLM(大语言模型)常用评测指标之F1-Score
F1-Score
F1-Score 是一种常用于评估分类模型性能的指标,特别是在数据不平衡的情况下。它是精确度 (Precision) 和召回率 (Recall) 的调和平均值,用于衡量模型对正类的预测能力。
计算方法 精确度 (Precision):是指正确预测为正类的数量与所…

指令微调(Instructional Fine-tuning)
定义
指令微调(Instructional Fine-tuning)是一种自然语言处理(NLP)技术,特别是在大型预训练语言模型(如 GPT、BERT 等)的应用中。在指令微调中,模型被进一步训练以更好地理解和遵循…

【论文解读】多模态大语言模型综述
目录 一、简要介绍
二、概要
三、方法
3.1.多模态指令调整
3.1.1介绍
3.1.2初步研究
3.1.3模态对齐
3.1.4数据
3.1.5模态桥接
3.1.6评估
3.2多模态的上下文学习
3.3.多模态的思维链
3.3.1模态桥接
3.3.2学习范式
3.3.3链配置
3.3.4生成模式
3.4.LLM辅助视觉推理…
LLM(大语言模型)常用评测指标-MAP@R
MAPR (Mean Average Precision at R)
是一种用于评估信息检索系统或排序模型效果的评价指标。它特别适用于那些返回一组相关结果的情况,例如搜索引擎或推荐系统。这里的“R”代表返回的相关结果的数量。MAPR 考虑了结果的排名和相关性两个因素。
计算方法
计算平…
LLM(大语言模型)常用评测指标-困惑度(Perplexity)
困惑度(Perplexity)
是自然语言处理(NLP)中常用的一种评估语言模型的指标。它衡量的是模型对测试数据的预测能力,即模型对测试集中单词序列出现概率的预测准确度。困惑度越低,表示模型对数据的预测越准确。…
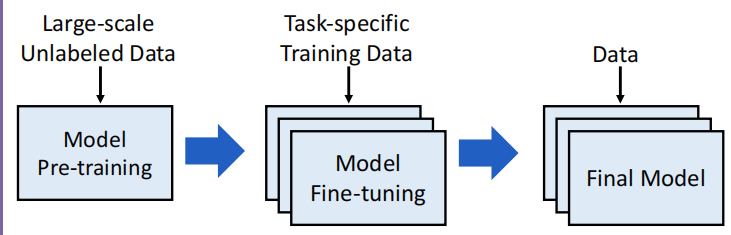
01 THU大模型之基础入门
1. NLP Basics Distributed Word Representation词表示
Word representation: a process that transform the symbols to the machine understandable meanings
1.1 How to represent the meaning so that the machine can understand Compute word similarity 计算词相似度 …
大语言模型LLM代码:PyTorch库与ChatGLM模型
文章目录 通过阅读大语言模型的代码,熟悉并理解PyTorch大语言模型LLM代码:PyTorch库与ChatGLM模型大语言模型中的PyTorchChatGLM3-6B模型代码ChatGLMModel类总览ChatGLMModel类说明ChatGLMModel类核心代码片段通过阅读大语言模型的代码,熟悉并理解PyTorch
大语言模型LLM代码…
生成用于目标检测任务的合成图像教程:使用Blender、Python和3D资产
生成用于目标检测任务的合成图像教程:使用Blender、Python和3D资产
缺少足够的训练数据是当前深度学习面临的一个主要问题。自动生成带有注释的合成图像是计算机视觉任务的一个有前途的解决方案。本文将首先概述合成图像数据的一些图像生成技术,然后生成…
RLAIF在提升大型语言模型训练中的应用
RLAIF在提升大型语言模型训练中的应用
大型语言模型(LLMs)在理解和生成自然语言方面展示了巨大能力,但仍面临输出不可靠、推理能力有限、缺乏一致性个性或价值观对齐等挑战。为解决这些问题,研究者开发了一种名为“来自AI反馈的强…

关于图在推荐系统中的研究
业界最新的论文
Intent-aware Recommendation via Disentangled Graph Contrastive Learning
作者:Yuling Wang, Xiao Wang, Xiangzhou Huang, Yanhua Yu, Haoyang Li, Mengdi Zhang, Zirui Guo, Wei Wu
地址:https://arxiv.org/abs/2403.03714
论文…

大语言模型在科技研发与创新中的角色在快速变化
在技术研发与创新中,比如在软件开发、编程工具、科技论文撰写等方面,大语言模型可以辅助工程师和技术专家进行快速的知识检索、代码生成、技术文档编写等工作。在当今的软件工程和研发领域,尤其是随着大语言模型技术的快速发展,它…

【prompt五】CoCoOP:Conditional Prompt Learning for Vision-Language Models
motivation
随着像CLIP这样强大的预训练视觉语言模型的兴起,研究如何使这些模型适应下游数据集变得至关重要。最近提出的一种名为上下文优化(CoOp)的方法将提示学习(nlp的最新趋势)的概念引入视觉领域,以适应预训练的视觉语言模型。具体来说,CoOp将提示中的上下文单词转换为…

自然语言处理之语言模型(LM)介绍
自然语言处理(Natural Language Processing,NLP)是人工智能(Artificial Intelligence,AI)的一个重要分支,它旨在使计算机能够理解、解释和生成人类语言。在自然语言处理中,语言模型&…

Ollama--本地大语言模型LLM运行专家
文章目录 1、问题提出2、解决方案3、Ollama介绍3.1、Ollama的核心功能3.2、Ollama的独特之处 4、Ollama安装与使用4.1、Ollama的安装 5、使用Docker6、模型库和自定义模型7、应用场景展望8、结语 1、问题提出
使用chatgpt之类的闭源大语言模型时,我们与ai沟通的数据…

【论文笔记】Language Models are Unsupervised Multitask Learners
Language Models are Unsupervised Multitask Learners 回顾一下第一代 GPT-1 : 设计思路是 “海量无标记文本进行无监督预训练少量有标签文本有监督微调” 范式;模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm…

第41期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大语言模型(LLM)等安全领域应用的知识。在这里,您可以找…
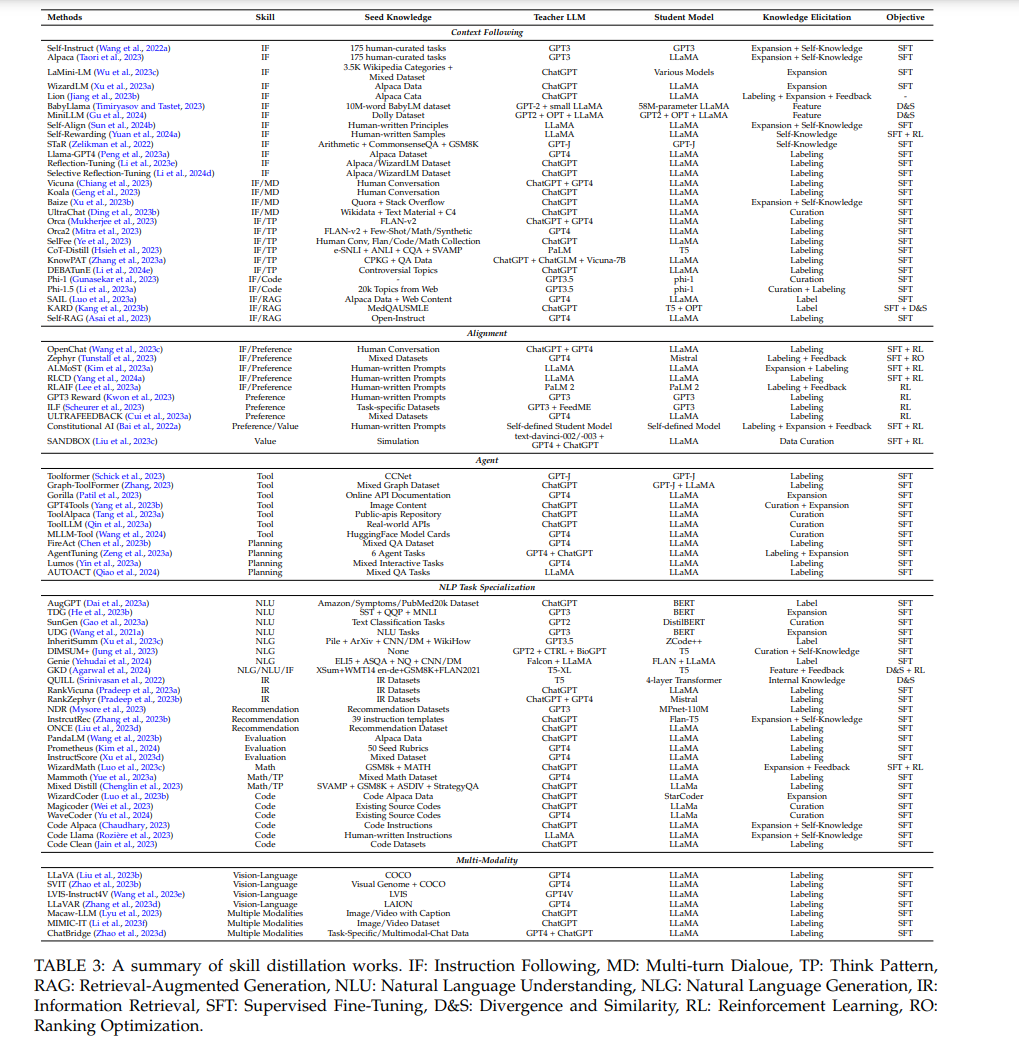
大语言模型知识蒸馏综述
本综述深入探讨了大型语言模型(LLMs)领域内的知识蒸馏(KD)技术,突出了KD在将GPT-4等专有巨头的复杂能力转移至LLaMA和Mistral等可访问的开源模型中的关键作用。在不断演变的人工智能领域,这项工作阐明了专有…
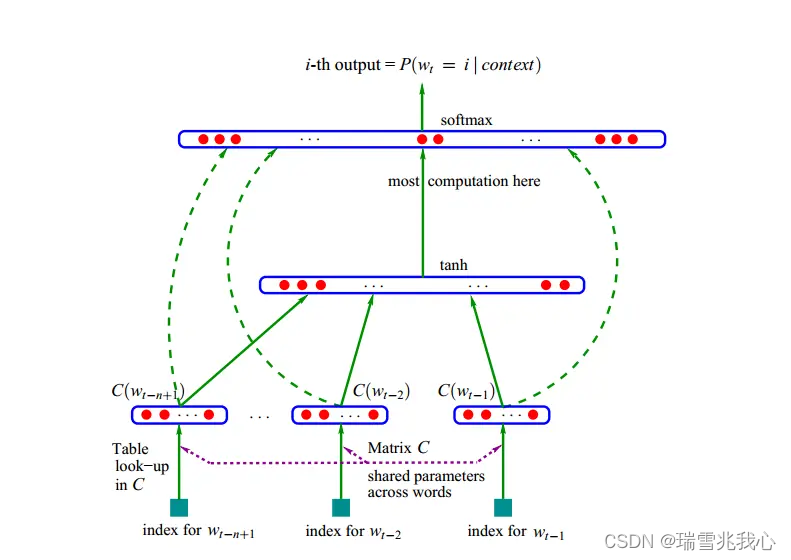
四、神经网络语言模型(NNLM)
神经网络(Neural Network,NN)主要由输入层、隐藏层、输出层构成,输入层的的节点数等于待处理数据中输入变量的个数(每一个变量代表了一个特征),输出层的节点数等于与每个输入变量关联的输出的数…

【论文笔记】Language Models are Few-Shot Learners
Language Models are Few-Shot Learners
本部分是 GPT-3 技术报告的第一部分:论文正文、部分附录。
后续还有第二部分:GPT-3 的广泛影响、剩下的附录。
以及第三部分(自己感兴趣的):GPT-3 的数据集重叠性研究。 回顾…

AI Agent涌向移动终端,手机智能体开启跨端跨应用业务连接新场景
AI Agent涌向移动终端,手机智能体势不可挡还没搞清楚什么是AI Agent,手机Agent就已经横空出世AIGC为何涌向移动端?背后有哪些逻辑?什么是手机智能体?一文看明白科技大厂、手机厂商、企服领域都在发力,手机智…

Kosmos-1: 通用接口架构下的多模态大语言模型
Kosmos-1: 通用接口架构下的多模态大语言模型 FesianXu 20230513 at Baidu Search Team 前言
在大规模语言模型(Large Language Model, LLM)看似要带来新一番人工智能变革浪潮之际,越来越多尝试以LLM作为通用接口去融入各种任务的工作&#…
三、N元语法(N-gram)
为了弥补 One-Hot 独热编码的维度灾难和语义鸿沟以及 BOW 词袋模型丢失词序信息和稀疏性这些缺陷,将词表示成一个低维的实数向量,且相似的词的向量表示是相近的,可以用向量之间的距离来衡量相似度。 N-gram 统计语言模型是用来计算句子概率的…

51-26 DriveMLM: 多模态大型语言模型与自动驾驶行为规划状态对齐
DriveMLM是来自上海AILab、港中文、商汤、斯坦福、南京大学和清华大学的工作。该模型使用各种传感器(如相机、激光雷达)、驾驶规则和用户指令作为输入,采用多模态LLM对AD系统的行为规划进行建模,做出驾驶决策并提供解释。该模型可以用于闭环自动驾驶&…

大语言模型系列-GPT-2
文章目录 前言一、GPT-2做的改进二、GPT-2的表现总结 前言
《Language Models are Unsupervised Multitask Learners,2019》
前文提到,GPT-1利用不同的模型结构微调初步解决了多任务学习的问题,但是仍然是预训练微调的形式,GPT-…

本地部署推理TextDiffuser-2:释放语言模型用于文本渲染的力量
系列文章目录 文章目录 系列文章目录一、模型下载和环境配置二、模型训练(一)训练布局规划器(二)训练扩散模型 三、模型推理(一)准备训练好的模型checkpoint(二)全参数推理ÿ…
大语言模型的知识融合(ICLR2024)
一、写作动机:
虽然从头开始训练大型语言模型(LLMs)可以生成具有独特功能和优势的模型,但这种方法成本高昂,而且可能导致功能冗余。 二、主要贡献:
入了 LLMs 知识融合的概念,旨在结合现有 LL…
llama2c的量化和多线程(1)
为了方便调试,使得 model Transformer(config)模型内存不溢出,将config中的"n_layers": 2,整体看一下Transformer的架构。
注:config就是设置Transformer中的参数。class Transformer(nn.Module):last_loss: Optional[…
【深度学习模型】6_3 语言模型数据集
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 6.3 语言模型数据集(周杰伦专辑歌词)
本节将介绍如何预处理一个语言模型数据集,并将其转换成字符级…

奖励建模(Reward Modeling)实现人类对智能体的反馈
奖励建模(Reward Modeling)是强化学习中的一个重要概念和技术,它主要用于训练智能体(如AI机器人或大型语言模型)如何更有效地学习和遵循人类期望的行为。在强化学习环境中,智能体通过尝试不同的行为获得环境…

重塑语言智能未来:掌握Transformer,驱动AI与NLP创新实战
Transformer模型 Transformer是自然语言理解(Natural Language Understanding,NLU)的游戏规则改变者,NLU 是自然语言处理(Natural Language Processing,NLP)的一个子集。NLU已成为全球数字经济中AI 的支柱之一。
Transformer 模型标志着AI 新…

搜狐新闻Hybrid AI引擎端侧离线大语言模型探索
本文字数:3027字 预计阅读时间:20分钟 01 一、导读 • LLM 以及移动平台落地趋势 • 搜狐AI引擎内建集成离线可运行的GPT模型 • Keras 定制预训练模型 • TensorFlow Lite converter 迁移到移动设备 02 二、LLM 1.1什么是LLM L…
民航生成式语言模型的预训练、对齐训练和人类反馈强化学习(RLHF)阶段
在民航生成式语言模型的预训练、对齐训练和人类反馈强化学习(RLHF)阶段,都需要精心准备和选择数据集。下面是每个阶段可能需要的数据集和一般的要求:
预训练阶段
数据集:
通用语料库:如维基百科、Common…
论文笔记 Where Would I Go Next? Large Language Models as Human Mobility Predictor
arxiv 2023 08的论文
1 intro
1.1 人类流动性的独特性
人类流动性的独特特性在于其固有的规律性、随机性以及复杂的时空依赖性 ——>准确预测人们的行踪变得困难近期的研究利用深度学习模型的时空建模能力实现了更好的预测性能 但准确性仍然不足,且产生的结果…
大型语言模型的智能助手:检索增强生成(RAG)
背景
在人工智能的浪潮中,大型语言模型(LLMs)如GPT系列和LLama系列在自然语言处理(NLP)领域取得了显著成就。它们能够完成复杂的语言任务,如文本摘要、机器翻译、甚至创作诗歌。然而,这些模型在…

从 Language Model 到 Chat Application:对话接口的设计与实现
作者:网隐 RTP-LLM 是阿里巴巴大模型预测团队开发的大模型推理加速引擎,作为一个高性能的大模型推理解决方案,它已被广泛应用于阿里内部。本文从对话接口的设计出发,介绍了业界常见方案,并分享了 RTP-LLM 团队在此场景…

【论文精读】TextDiffuser-2:释放语言模型用于文本渲染的力量
文章目录 一、前言二、摘要三、方法(一)TextDiffuser-2模型的整体架构(二)语言模型M1将用户提示转换为语言格式的布局(三)将提示和布局结合到扩散模型内的可训练语言模型M2中进行编码以生成图像 四、实验&a…
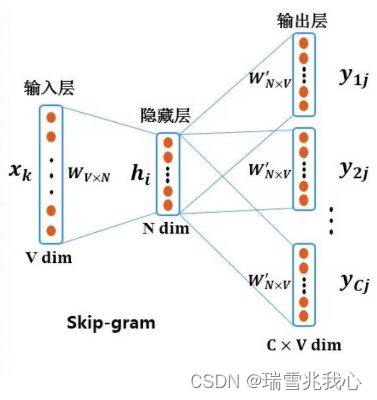
八、词嵌入语言模型(Word Embedding)
词嵌入(Word Embedding, WE),任务是把不可计算、非结构化的词转换为可以计算、结构化的向量,从而便于进行数学处理。 一个更官方一点的定义是:词嵌入是是指把一个维数为所有词的数量的高维空间(one-hot形式…

TEASEL: A transformer-based speech-prefixed language model
文章目录 TEASEL:一种基于Transformer的语音前缀语言模型文章信息研究目的研究内容研究方法1.总体框图2.BERT-style Language Models(基准模型)3.Speech Module3.1Speech Temporal Encoder3.2Lightweight Attentive Aggregation (LAA) 4.训练…

【论文速读】| 大语言模型引导的协议模糊测试
本次分享论文为:Large Language Model guided Protocol Fuzzing 基本信息
原文作者:Ruijie Meng, Martin Mirchev, Marcel Bhme, Abhik Roychoudhury
作者单位:新加坡国立大学,MPI-SP,莫纳什大学
关键词:…
【LLM】本地部署Gemma模型(图文)
工具简介
我们需要使用到两个工具,一个是Ollama,另一个是open-webui。
Ollama
Ollama 是一个开源的大语言平台,基于 Transformers 和 PyTorch 架构,基于问答交互方式,提供大语言模型常用的功能,如代码生…
大语言模型可信性浅谈
大语言模型可信性的研究
摘要: 随着人工智能技术的快速发展,大语言模型在自然语言处理领域的应用越来越广泛。然而,大语言模型的可信性一直是人们关注的焦点。本文将从多个维度探讨大语言模型的可信性问题,包括模型性能、数据质量…
LLM - RAG 大型语言模型的检索增强生成研究综述
「Retrieval-Augmented Generation for Large Language Models: A Survey」本期带来 LLM 语言检索增强生成的论文解析,其主要分析当下 RAG 相关技术进展。 目录
Abstruct 简介
1.Introduction 介绍
2.Definition 定义
3.RAG Framework 框架
3.1 Naive RAG
3.2…
GPT-3后的下一步:大型语言模型的未来方向
摘要:
本文将概述GPT-3后的下一步:大型语言模型的未来方向,包括技术发展趋势、应用场景、挑战与机遇。
引言:
GPT-3是OpenAI于2020年发布的一款大型语言模型,它在自然语言处理领域取得了突破性进展。GPT-3的出现标志…
Common 7B Language Models Already Possess Strong Math Capabilities
Common 7B Language Models Already Possess Strong Math Capabilities 相关链接:arxiv 关键字:Language Models、Math Capabilities、LLaMA-2 7B、Synthetic Data、SFT Data Scaling 摘要
以前人们认为,通用语言模型展现出的数学能力只有在…
计算机视觉(CV)自然语言处理(NLP)大模型应用,如何实现小模型
在人工智能领域,大模型已经成为引领创新和进步的重要推动力。它们不仅在自然语言处理、计算机视觉等任务中展现了强大的性能,还为各行各业带来了前所未有的机遇和挑战。本文将从一个高级写作专家的角度,深入探讨大模型的现状、技术突破以及未…

【解读】OWASP大语言模型应用程序十大风险
OWASP大型语言模型应用程序前十名项目旨在教育开发人员、设计师、架构师、经理和组织在部署和管理大型语言模型(LLM)时的潜在安全风险。该项目提供了LLM应用程序中常见的十大最关键漏洞的列表,强调了它们的潜在影响、易利用性和在现实应用程序…
加载spacy中文语言模型 zh_core_web_sm错误解决办法
如果你代码在运行时找不到该模型且报错 并且安装该模块也报错 那么可以试一下手动安装
Chinese spaCy Models Documentationhttps://spacy.io/models/zh#zh_core_web_sm 点击安装到C盘,就是你平时pip install的标准路径 最后进入终端 即可安装成功!
探索大语言模型(LLM):部分数据集介绍
探索大语言模型(LLM)的宝库:精选数据集介绍
在人工智能的黄金时代,大语言模型(LLM)的发展正以惊人的速度推进。它们不仅改变了我们与机器交互的方式,还在持续拓展技术的边界。作为这一进程的核…
20240313 大模型快讯
//社区生态// 基于字节的Transformer模型bGPT发布。微软亚研院发布基于字节的Transformer模型bGPT,将不同类型的数据纳入同一框架之下,可以生成文本、图像和音频,模拟计算机行为。
//行业落地// 全球首位AI软件工程师Devin诞生。Cognition推…
AI大语言模型GPT R 生态环境领域数据统计分析
自2022年GPT(Generative Pre-trained Transformer)大语言模型的发布以来,它以其卓越的自然语言处理能力和广泛的应用潜力,在学术界和工业界掀起了一场革命。在短短一年多的时间里,GPT已经在多个领域展现出其独特的价值…

Prompt Engineering(提示工程)
Prompt 工程简介 在近年来,大模型(Large Model)如GPT、BERT等在自然语言处理领域取得了巨大的成功。这些模型通过海量数据的训练,具备了强大的语言理解和生成能力。然而,要想充分发挥这些大模型的潜力,仅仅…
深入了解 大语言模型(LLM)微调方法
引言
众所周知,大语言模型(LLM)正在飞速发展,各行业都有了自己的大模型。其中,大模型微调技术在此过程中起到了非常关键的作用,它提升了模型的生成效率和适应性,使其能够在多样化的应用场景中发挥更大的价值。
那么&…

AI论文速读 | TPLLM:基于预训练语言模型的交通预测框架
论文标题:TPLLM: A Traffic Prediction Framework Based on Pretrained Large Language Models
作者:Yilong Ren(任毅龙), Yue Chen, Shuai Liu, Boyue Wang(王博岳),Haiyang Yu(于海洋&#x…
大型语言模型RAG(检索增强生成):检索技术的应用与挑战
摘要
检索增强生成(RAG)系统通过结合传统的语言模型生成能力和结构化数据检索,为复杂的问题提供精确的答案。本文深入探讨了RAG系统中检索技术的工作原理、实现方式以及面临的挑战,并对未来的发展方向提出了展望。
随着大型预训…
GPT-3.5发布:大型语言模型的进化与挑战
摘要:
GPT-3.5是OpenAI于2023年发布的一款大型语言模型,它是GPT-3的升级版,拥有1750亿个参数,比GPT-3的参数量增加了近一倍。GPT-3.5在文本生成、对话系统、文本理解等任务上表现出色,其性能已经接近甚至超过了人类水…
训练专门化的大型语言模型(LLM)现在更简单了
训练专门化的大型语言模型(LLM)现在更简单了
近年来,大型语言模型(LLM)的兴趣激增,但其训练需要昂贵的硬件和高级技术。幸运的是,通过先进的微调技术,如低秩适配(LoRA&a…
Prompt提示工程上手指南:基础原理及实践(二)-Prompt主流策略
前言
上篇文章将Prompt提示工程大体概念和具体工作流程阐述清楚了,我们知道Prompt工程是指人们向生成性人工智能(AI)服务输入提示以生成文本或图像的过程中,对这些提示进行精炼的过程。生成人工智能是一个根据人类和机器产生的数…
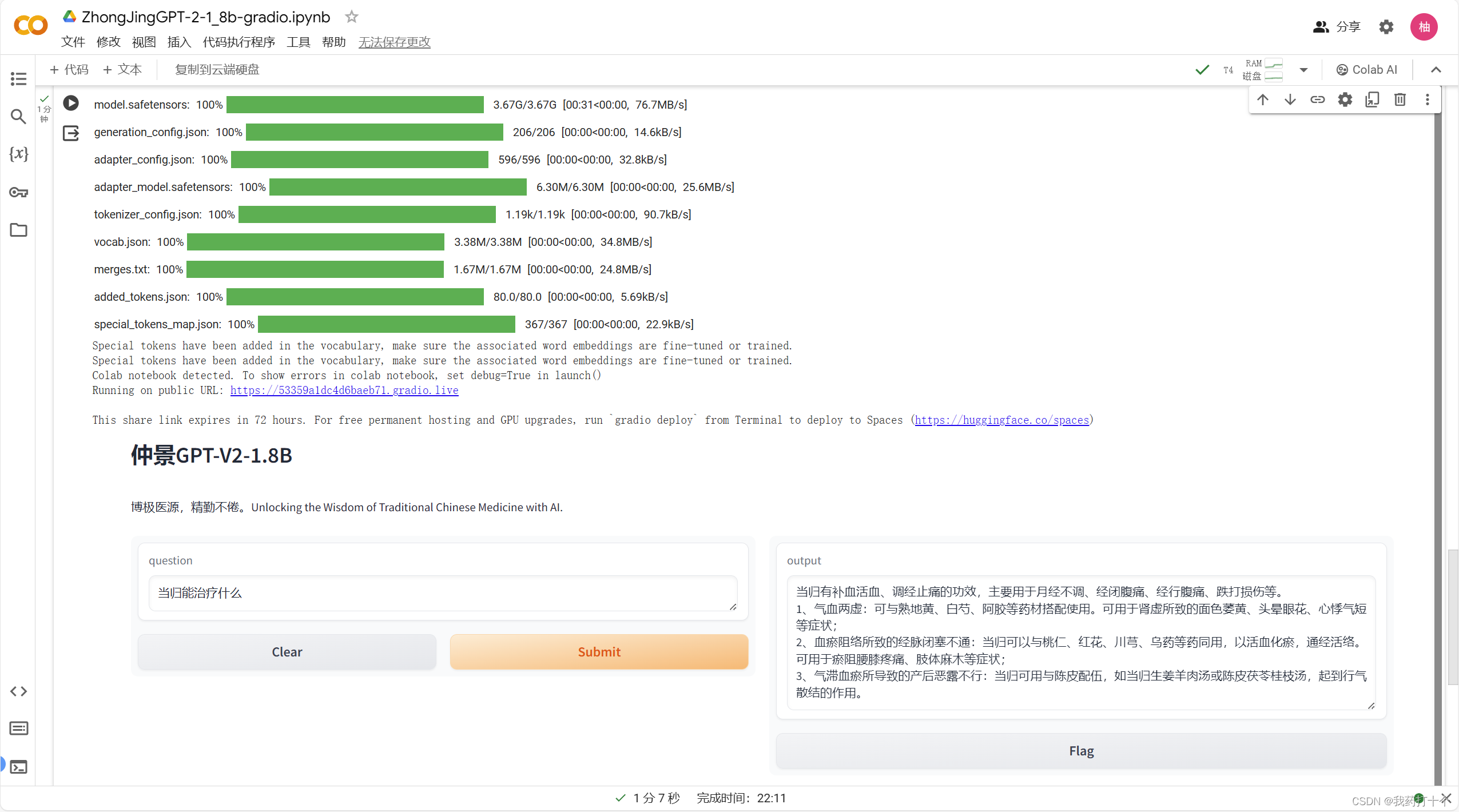
分享一些实用性的大语言模型(GitHub篇)
1.多模态大模型 GitHub网址:haotian-liu/LLaVA:[NeurIPS23 Oral] 视觉指令调优 (LLaVA) 构建,旨在实现 GPT-4V 级别及以上的能力。 (github.com) 下面是LLaVA模型的介绍,作者都有一直维护和更新,…

Prompt Learning:人工智能的新篇章
开篇:AI的进化之旅
想象一下,你正在和一位智能助手对话,它不仅理解你的问题,还能提出引导性的问题帮助你更深入地思考。这正是prompt learning的魔力所在——它让机器学习模型变得更加智能和互动。在这篇博客中,我们将…
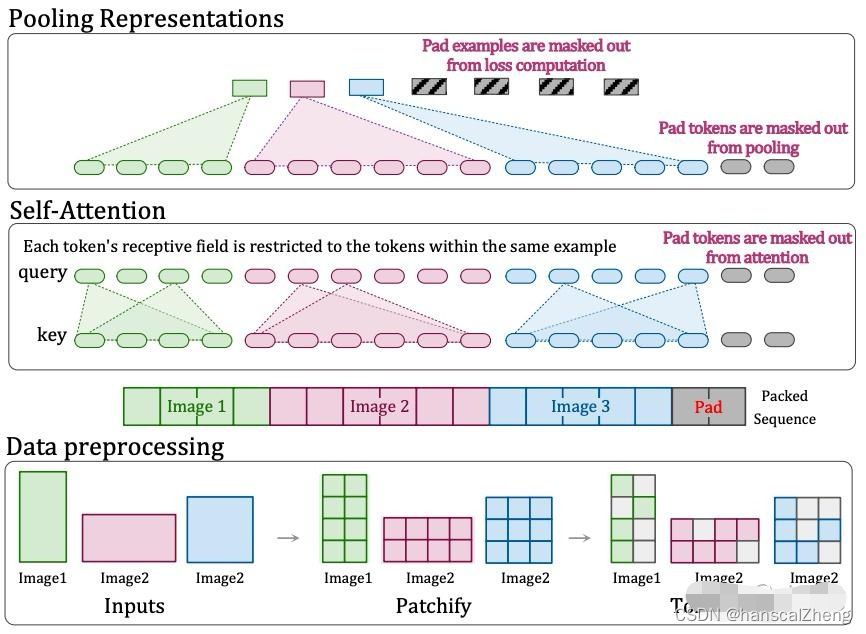
SORA和大语言模型的区别
OpenAI的文生视频模型SORA与大语言模型(LLM)的主要区别在于它们的应用领域和处理的数据类型,数据处理能力、技术架构、多模态能力和创新点。SORA作为一款专注于视频生成的模型,展现了在处理视觉数据方面的独特优势和创新能力。
1…
大语言模型智能体简介
大语言模型(LLM)智能体,是一种利用大语言模型进行复杂任务执行的应用。这种智能体通过结合大语言模型与关键模块,如规划和记忆,来执行任务。构建这类智能体时,LLM充当着控制中心或“大脑”的角色࿰…

大模型日报|今日必读的7篇大模型论文
大家好,今日必读的大模型论文来啦!
1.达摩院新研究:从故事到视频制作,智能体驱动的进化系统
论文标题: AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production 论文链接: https://…
![[论文笔记]LLaMA: Open and Efficient Foundation Language Models](https://img-blog.csdnimg.cn/img_convert/5438e10bf23516a6eb5033737338c247.png)
[论文笔记]LLaMA: Open and Efficient Foundation Language Models
引言
今天带来经典论文 LLaMA: Open and Efficient Foundation Language Models 的笔记,论文标题翻译过来就是 LLaMA:开放和高效的基础语言模型。
LLaMA提供了不可多得的大模型开发思路,为很多国产化大模型打开了一片新的天地,论文和代码值…
LangChain原理深度解析:构建高效语言模型应用的关键框架
LangChain原理介绍
摘要: 本文将详细介绍LangChain的基本原理,包括其设计思路、核心组件、工作流程以及在语言模型应用开发中的应用。通过通俗易懂的语言,本文旨在让读者对LangChain有一个全面的了解。
关键词: LangChain&#…
区块链技术的革命性影响
1. 区块链技术的基本原理: 区块链是一种去中心化的分布式数据库技术,通过不断增长的记录(块)构成一个链式结构。每个区块包含了交易数据的加密信息以及上一个区块的哈希值,从而形成了不可篡改的交易记录。这种去中心化…
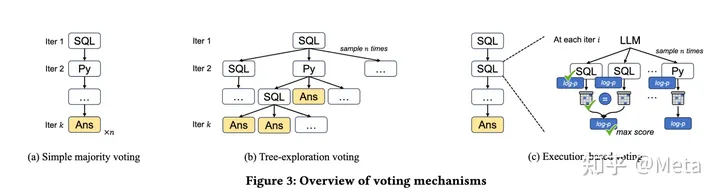
基于大语言模型(LLM)的表格理解任务探索与实践
大语言模型(LLMs)的发展日新月异,为表格理解任务带来了新的可能性。表格理解任务,如基于表格的问答和表格事实验证,要求从自由形式的文本和半结构化的表格数据中提取深层次的语义信息。与泛化的文本推理任务不同&#…
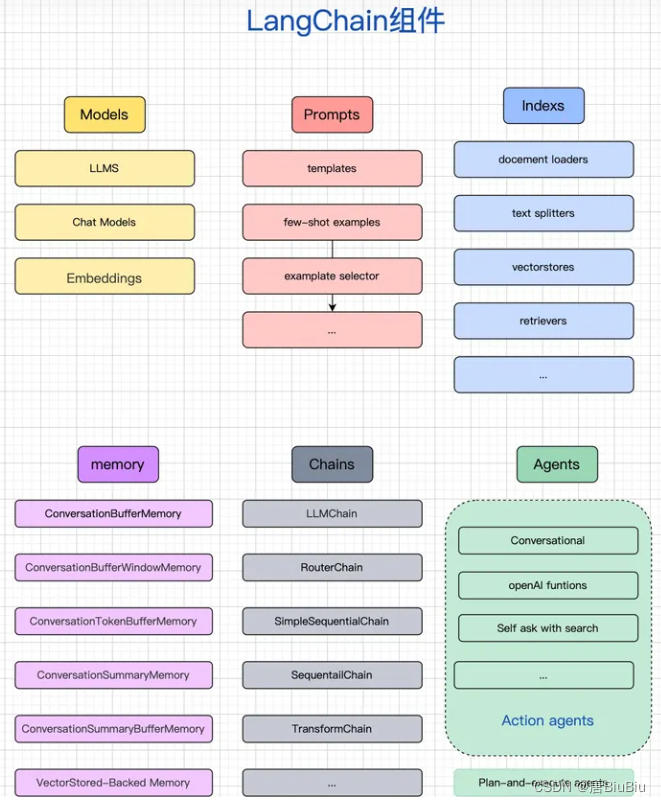
大语言模型RAG-langchain models (二)
大语言模型RAG-langchain models (二) 往期文章:大语言模型RAG-技术概览 (一) 文章目录 大语言模型RAG-langchain models (二)**往期文章:[大语言模型RAG-技术概览 (一)](https://blog.csdn.net/tangbiubiu/article/details/136651625)**核心模块总览Mod…
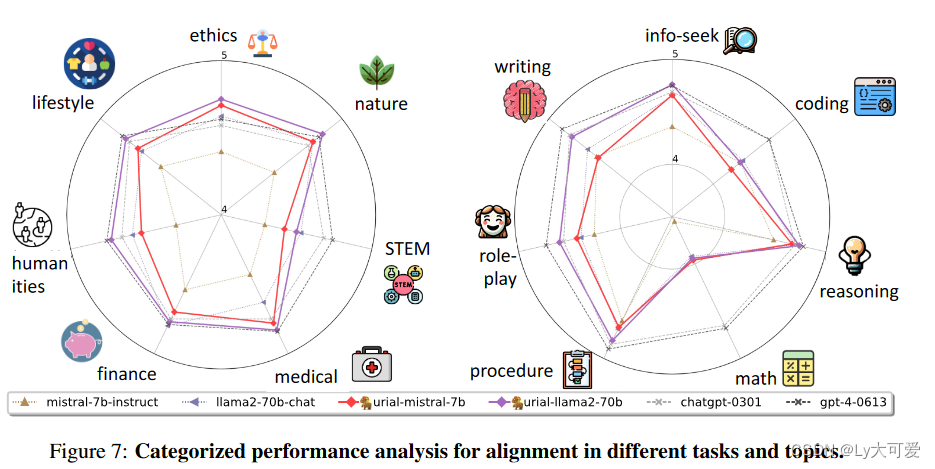
解锁基于LLMS的咒语:通过上下文学习重新思考对齐
一、写作动机:
最近的一项研究,LIMA,表明仅使用1K个示例进行SFT也可以实现显著的对齐性能,这表明对齐微调的效果可能是“表面的”。(知识和推理能力来源于预训练,而不是必须通过对齐微调获得的。ÿ…
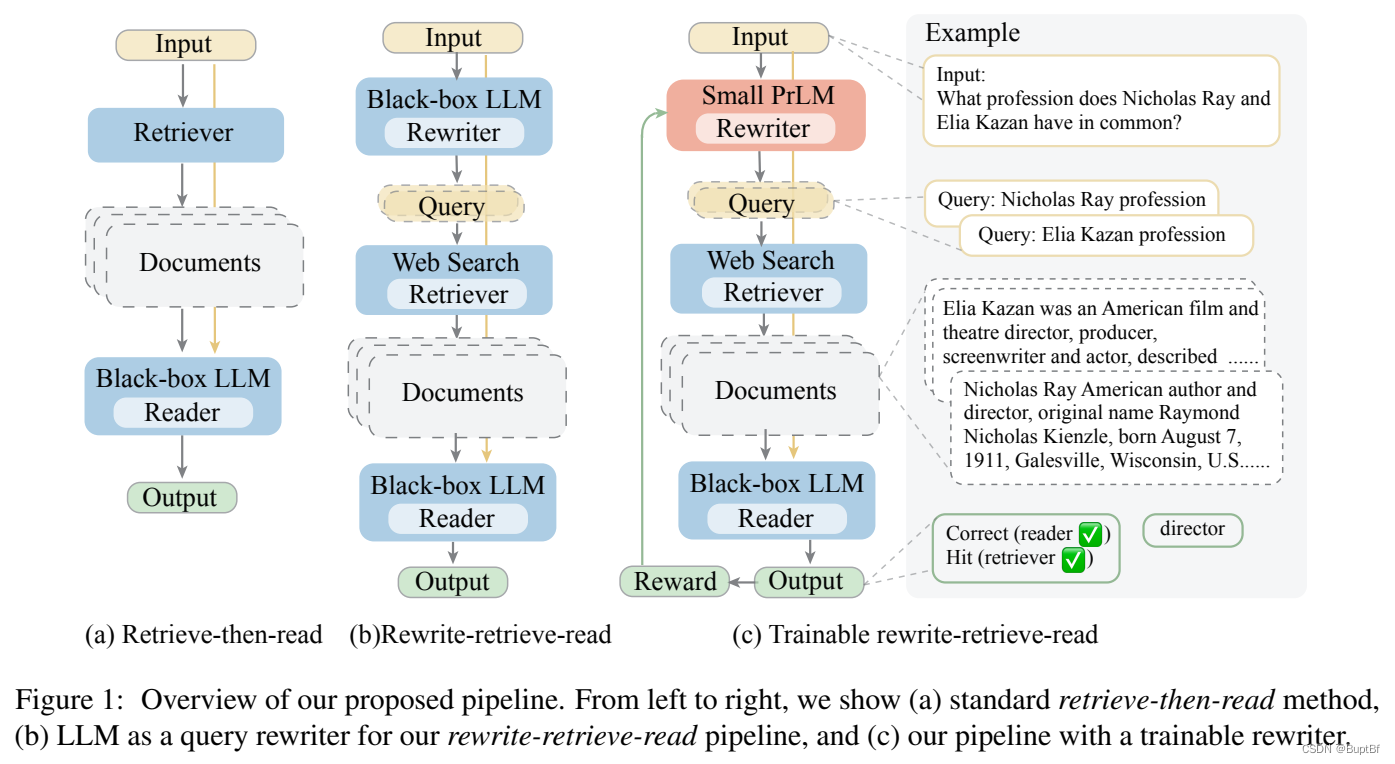
大语言模型:Query Rewriting for Retrieval-Augmented Large Language Models
总体思路
作者首先指出大语言模型虽然取得了很好的效果,但是仍然存在幻觉和时间顺序混乱的问题,因此需要额外知识库和LLM内部知识库相结合,来修正;因此优化传统的retriever-reader的方案成为需要;目前的研究方案当中使…
大语言模型系列-提示工程
文章目录 前言一、Prompt Learning二、上下文学习(In-Context Learning)三、指示学习(Instruction Learning)四、思维链(Chain-of-Thought)总结 前言
前文提到自BERT以来,LLM的训练范式变为预训…
GPU性能优化与模型训练概览
GPU性能优化与模型训练概览
安装所需库
为监控GPU内存使用,我们使用nvidia-ml-py3库。首先安装必要的库:
pip install transformers datasets accelerate nvidia-ml-py3模拟数据创建
创建范围在100到30000之间的随机token ID和二进制标签。为分类器准…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.10-2024.03.15
文章目录~ 1.Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey2.VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding3.MT-PATCHER: Selective and Extendable Knowledge Distillation from Large Langu…
理解和解释ChatGPT:一种生成性大型语言模型的三部分框架
理解和解释ChatGPT:一种生成性大型语言模型的三部分框架
**摘要:**本文提供了对生成性大型语言模型(LLMs),尤其是ChatGPT的简明解释。重点在于三个关键组件:变压器架构、语言模型预训练和对齐过程。
关键…

什么是大型语言模型(LLM)?
大型语言模型 (LLM) 是一种能够理解和生成人类语言文本的机器学习模型。它们通过分析大量语言数据集来工作。 一、什么是大型语言模型 (LLM)?
大型语言模型 (LLM) 是一种人工智能 (AI) 程序,它可以识别和生成文本以及完成其他任务。LLM 经过了庞大的数据…
ubuntu从零部署baichuan2大模型
目录
一、百川2(Baichuan 2)模型介绍
二、资源需求
三、安装部署
本文从实战过程中整理一份从零开始的搭建开源大模型的部署文档,供大家学习交流。
部署大模型版本为baichuan2-13B chat,如果需要量化可下载量化版本 。
一、百川2(Baichuan 2)模型介绍
首先先简单介…
【提示学习代码】CoOp代码详读
Dassl
基于 PyTorch 的工具包为什么取名为 “Dassl”?Dassl 将域自适应(DA)和半监督学习(SSL)的首字母结合起来
CoOp代码详读
CoOp是对CLIP的改进工作,主要是对prompt进行学习从而不用来手动设置prompt。…
十五、自回归(AutoRegressive)和自编码(AutoEncoding)语言模型
参考自回归语言模型(AR)和自编码语言模型(AE)
1 自回归语言模型( AR) 自回归语言模型(AR)就是根据上文内容(或下文内容)预测下一个(或前一个&…
GRACE:梯度引导的可控检索增强基于属性的生成
在本文中,我们提出通过梯度引导的可控检索(GRACE)来增强基于属性的生成,考虑到目标属性(见图1)。具体来说,我们训练一个鉴别器来计算给定上下文的属性分布。我们构建了一个检索库,存…
开源模型应用落地-qwen模型小试-合并Lora模型-进阶篇(八)
一、前言 这篇文章是关于qwen模型进一步学习的内容,主要讲述了如何将微调后的权重模型与基座模型进行合并。 二、术语
2.1. Lora微调 是处理微调大型语言模型的问题而引入的一项新技术。其核心思想是利用低秩适配(low-rank adaptation)的方法,在使用大模型适配下游任务时只…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.05-2024.03.10—(2)
论文目录~ 1.Debiasing Large Visual Language Models2.Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering3.Towards a Psychology of Machines: Large Language Models Predict Human Memory4.Can we obtain significant succ…
LLaMA-2 简介:开源大型语言模型的新篇章
LLaMA-2 简介:开源大型语言模型的新篇章
LLaMA-2 是一款领先的开源大型语言模型(LLM),其参数规模从 7 亿到 70 亿不等。与先前的版本相比,LLaMA-2 通过预训练更多数据、使用更长的上下文长度和采用优化快速推理的架构…
Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具
项目地址:rany2/edge-tts: Use Microsoft Edges online text-to-speech service from Python WITHOUT needing Microsoft Edge or Windows or an API key (github.com) Edge-TTS是由微软推出的文本转语音Python库,通过微软Azure Cognitive Services转化文…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.10-2024.03.15
论文目录~ 1.3D-VLA: A 3D Vision-Language-Action Generative World Model2.PosSAM: Panoptic Open-vocabulary Segment Anything3.Anomaly Detection by Adapting a pre-trained Vision Language Model4.Introducing Routing Functions to Vision-Language Parameter-Efficie…
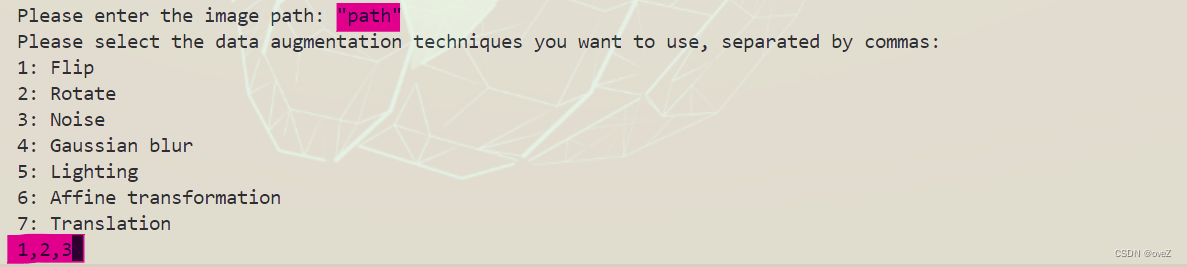
Auto-DataProcessing:一组让制作数据集变轻松的脚本
前言
最近跟同学参加了个比赛,我负责Object-Detection的技术实现,需要从网上扒大量的数据(主办方每种识别物就给了一张demo🤣),发现数据准备是一个真的是一个非常重要但又耗时耗力的过程。对我来说,给我一类待识别的标…
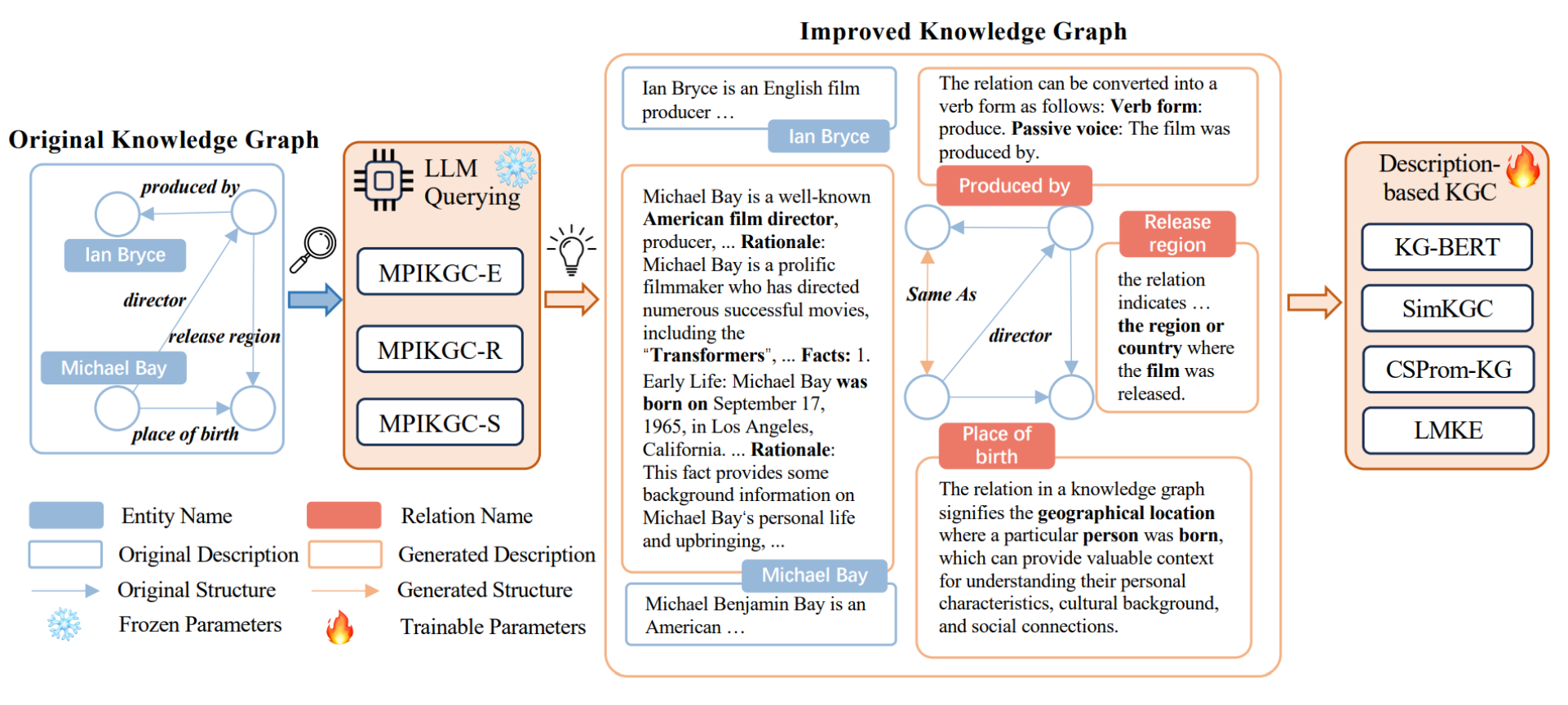
MPIKGC:大语言模型改进知识图谱补全
MPIKGC:大语言模型改进知识图谱补全 提出背景MPIKGC框架 论文:https://arxiv.org/pdf/2403.01972.pdf
代码:https://github.com/quqxui/MPIKGC
提出背景
知识图谱就像一个大数据库,里面有很多关于不同事物的信息,这…

Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
诸神缄默不语-个人CSDN博文目录 诸神缄默不语的论文阅读笔记和分类
论文全名:Language Models are Unsupervised Multitask Learners 论文下载地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learner…
预防GPT-3和其他复杂语言模型中的“幻觉”
标题:预防GPT-3和其他复杂语言模型中的“幻觉”
正文:
“假新闻”的一个显著特征是它经常在事实正确信息的环境中呈现虚假信息,通过一种文学渗透的方式,使不真实的数据获得感知权威,这是半真半假力量令人担忧的展示。…
大语言模型数据集alpaca羊驼数据集、Vicuna骆马数据集异同、作用、使用领域
文章目录 大语言模型数据集alpaca羊驼数据集、Vicuna骆马数据集异同、作用、使用领域Alpaca和Vicuna简介AlpacaVicuna相同点不同点 alpaca、vicuna能否用在大语言模型微调中?alpaca、vicuna进行大语言模型微调时,由于其已经是标准化数据集,还…
Qwen及Qwen-audio大模型微调项目汇总
Qwen及Qwen-audio可微调项目调研 可用来微调方法/项目汇总ps.大语言模型基础资料 可用来微调方法/项目汇总
Qwen github 项目自带的finetune脚本 可以参考https://blog.csdn.net/qq_45156060/article/details/135153920PAI-DSW中微调千问大模型(阿里云的一个产品&a…

【NLP】多头注意力(Multi-Head Attention)的概念解析
一. 多头注意力
多头注意力(Multi-Head Attention)是一种在Transformer模型中被广泛采用的注意力机制扩展形式,它通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语…
【OpenBayes 官方教程】快速部署通义千问 72B 大模型
本教程主要为大家介绍怎样在 OpenBayes 上快速部署通义千文 72B 大模型,新朋友点击下方链接注册后,即可获得 4 小时 RTX 4090 5 小时 CPU 的免费使用时长哦!
注册链接
https://openbayes.com/console/signup?ryuudi_nBBThttps://openbaye…

Emotion Prompt-LLM能够理解并能通过情感刺激得以增强
Large Language Models Understand and Can be Enhanced by Emotional Stimuli
情感智能对我们的日常行为和互动产生了显著的影响。尽管大型语言模型(LLMs)被视为向人工通用智能迈进的一大步,在许多任务中表现出色,但目前尚不清楚…

GPT-4.5 Turbo惊现!上下文窗口翻倍,OpenAI暗中憋大招还是战略调整?
你听说了吗?OpenAI好像不小心泄露了点新东西。
就在3月14日,他们的一篇博客文章被Bing和DuckDuckGo这两个搜索引擎给抓到了。
文章里提到了个新模型,叫GPT-4.5 Turbo。
虽然文章很快就被删了,但手快的网友还是截到了些信息。
…
pytorch与大语言模型直接偏好优化DPO方法
文章目录 pytorch与大语言模型直接偏好优化DPO方法智谱ChatGLM官方发的一则通告应用方案SFT(指令微调, Instruction Fine-Tuning)DPO(直接偏好优化, Direct Preference Optimization)DPO步骤DPO 可以分为两个主要阶段首选项数据使用Transformers实施 DPO:分步指南训练 SFT…
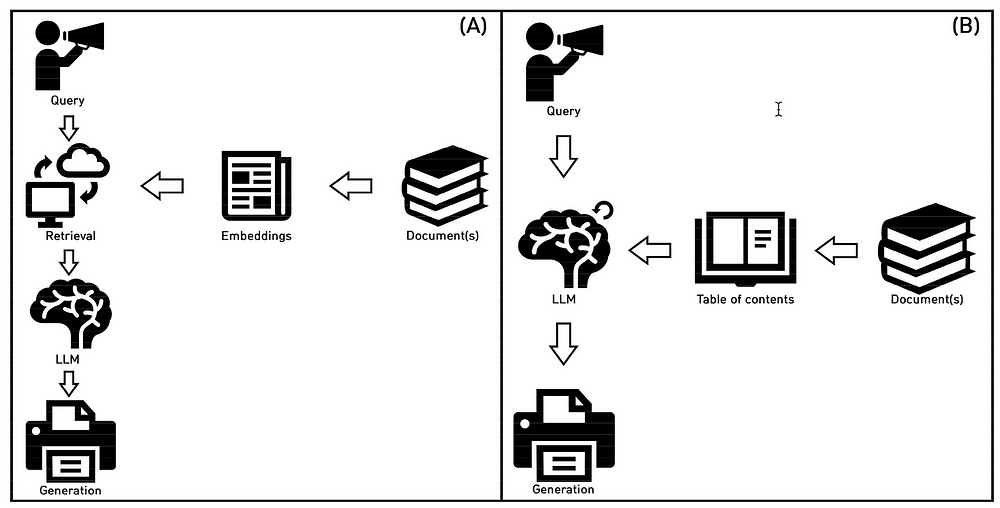
Prompt-RAG:在特定领域中应用的革新性无需向量嵌入的RAG技术
论文地址:https://arxiv.org/ftp/arxiv/papers/2401/2401.11246.pdf 原文地址:https://cobusgreyling.medium.com/prompt-rag-98288fb38190 2024 年 3 月 21 日 虽然 Prompt-RAG 确实有其局限性,但在特定情况下它可以有效地替代传统向量嵌入 …
spaCy NLP库的模型的下载、安装和使用说明书
文章目录 1 前言2 安装3 模型命名规范3.1 模型版本控制3.2 支持对旧版本的兼容 4 下载模型5 加载和使用模型6 手动下载和安装7 spaCy v1.x模型的命名规范8 问题和错误报告 1 前言
explosion网址:https://explosion.ai/ spaCy下载网址:https://explosion…
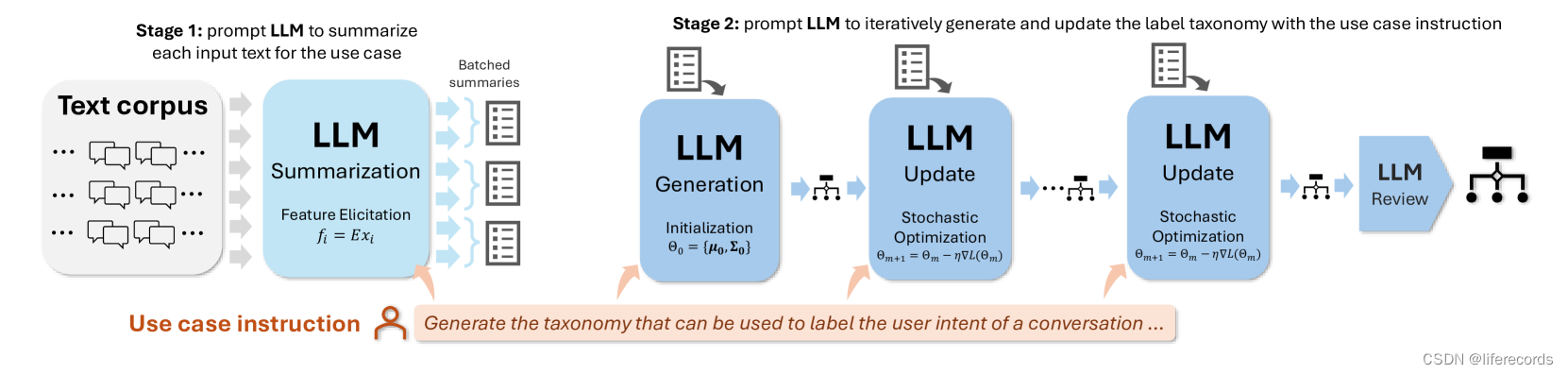
TnT-LLM: Text Mining at Scale with Large Language Models
TnT-LLM: Text Mining at Scale with Large Language Models 相关链接:arxiv 关键字:Large Language Models (LLMs)、Text Mining、Label Taxonomy、Text Classification、Prompt-based Interface 摘要
文本挖掘是将非结构化文本转换为结构化和有意义的…
大模型: Function calling的作用
文章目录 一、介绍二、Function Calling的作用 一、介绍
大模型中的Function Calling是一个关键功能,它允许语言模型在生成文本的过程中调用外部函数或服务,以获取额外的数据或执行特定的任务。这种能力扩展了大模型的实用性,使其能够更好地…

Expert Prompting-引导LLM成为杰出专家
ExpertPrompting: Instructing Large Language Models to be Distinguished Experts
如果适当设计提示,对齐的大型语言模型(LLM)的回答质量可以显著提高。在本文中,我们提出了ExpertPrompting,以激发LLM作为杰出专家回…

多模态大语言模型的 (R) 演变:调查
目录 1. Introduction2. 赋予LLMs多模态能力2.1 大型语言模型2.2 视觉编码器2.3 视觉到语言适配器2.4 多模式训练 3. 使用 MLLM 处理视觉任务 连接文本和视觉模式在生成智能中起着至关重要的作用。因此,受大型语言模型成功的启发,大量研究工作致力于多模…

容器中的大模型(三)| 利用大语言模型:容器化高效地部署 PDF 解析器实践...
作者:宋文欣,智领云科技联合创始人兼CTO 01 简介 大语言模型(LLMs)正逐渐成为人工智能领域的一颗璀璨明星,它们的强大之处在于能够理解和生成自然语言,为各种应用提供了无限可能。为了让这些模型更好地服务…
Unite.AI: Exponential Insights Newsletter已启动,采用人工智能技术
Unite.AI: Exponential Insights Newsletter Launch Report
摘要
Unite.AI: Exponential Insights,一款由人工智能为人工智能爱好者量身定制的全新通讯,现已正式发布。该通讯完全由人工智能驱动,利用深度神经网络突出人工智能及其相关领域的…
复试专业前沿问题问答合集8-3——RNN、Hadoop、GPT大语言模型
复试专业前沿问题问答合集8-3——RNN、Hadoop、GPT大语言模型
深度学习中的的RNN、Hadoop、GPT大语言模型的原理关系问答:
GPT(Generative Pre-trained Transformer)和RNN(Recurrent Neural Network)是两种在自然语言处理(NLP)领域广泛使用的深度学习模型。它们在处理…

用大语言模型控制交通信号灯,有效缓解拥堵!
城市交通拥堵是一个全球性的问题,在众多缓解交通拥堵的策略中,提高路口交通信号控制的效率至关重要。传统的基于规则的交通信号控制(TSC)方法,由于其静态的、基于规则的算法,无法完全适应城市交通不断变化的…
开源与闭源语言模型的较量:技术分析
开源与闭源语言模型的较量:技术分析报告
摘要
近年来,大型语言模型(LLM)在自然语言处理领域取得了重大突破,引发了开源与闭源之争。本文从技术角度分析了这两种模式的优势与局限性,包括架构透明度、性能基准测试、计算需求、应用…
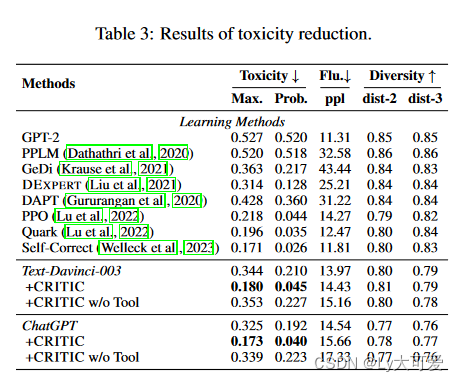
评论家:大型语言模型可以通过工具交互式批评进行自我修正(ICLR2024)
1、写作动机:
大语言模型有时会显示不一致性和问题行为,例如产生幻觉事实、生成有缺陷的代码或创建令人反感和有毒的内容。与这些模型不同,人类通常利用外部工具来交叉检查和改进他们的初始内容,比如使用搜索引擎进行事实检查&am…
Retrieval Augmented Thoughts(RAT):检索增强思维,实现长视野生成中的上下文感知推理
论文地址:https://arxiv.org/pdf/2403.05313.pdf
原文地址:rat-retrieval-augmented-thoughts
Github:Implementation of RAT
2024 年 3 月 14 日 介绍 让我首先从一些一般性观察开始...... 在生成式人工智能应用程序中实现效率与生成响应…
从零开始一步一步掌握大语言模型---(2-什么是Token?)
了解自然语言处理或者听说过大语言模型的同学都听过,token。一般来说,它代表的是语言中不可再分的最小单元。我们人类的语言不仅有文字,还有语音。针对文字、语音来说,它们都各自有不同的划分token的方法。本节将尽可能详细的介绍…
无服务器推理在大语言模型中的未来
服务器无服务器推理的未来:大型语言模型
摘要
随着大型语言模型(LLM)如GPT-4和PaLM的进步,自然语言任务的能力得到了显著提升。LLM被广泛应用于聊天机器人、搜索引擎和编程助手等场景。然而,由于LLM对GPU和内存的巨大需求,其在规…

Chain of Note-CoN增强检索增强型语言模型的鲁棒性
Enhancing Robustness in Retrieval-Augmented Language Models
检索增强型语言模型(RALMs)在大型语言模型的能力上取得了重大进步,特别是在利用外部知识源减少事实性幻觉方面。然而,检索到的信息的可靠性并不总是有保证的。检索…
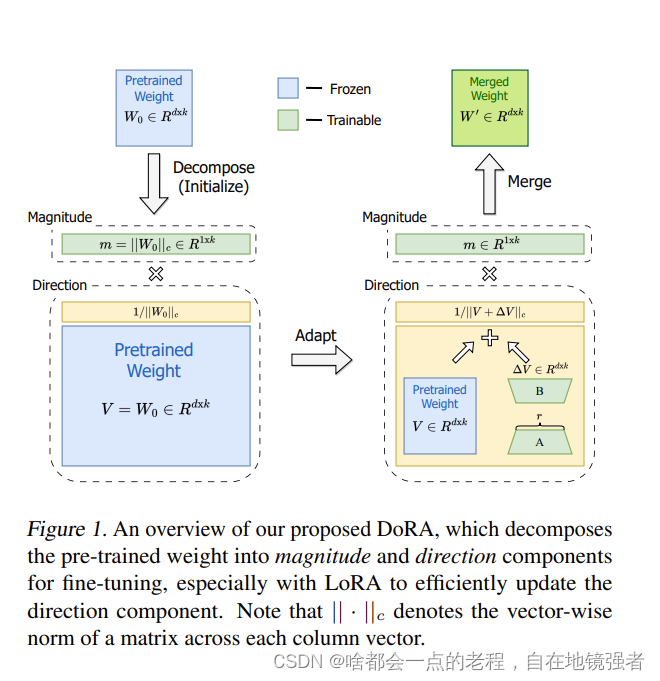
CV算法工程师的LLM日志(2)PEFT训练技术——10分钟快速理解DORA【原理代码】
摘要
对于LLM的训练,目前主流用的基本都是Lora\q-lora系列的微调与全参的方式(freeze和hypernetwork基本用的很少,蒸馏以及对抗蒸馏也不在讨论范围),最近还新出了一个基于优化器优化内存的训练技术,不过先…
智能新纪元:AI大模型学习的奥秘与挑战
在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作带来更多便利。…

【Roadmap to Learn LLM】Intro to Large Language Models
by Andrej Karpathy 文章目录 什么是LLM模型训练微调阶段llm的发展方向LLM安全参考资料 什么是LLM
Large Language Model(LLM)就是两个文件,一个是模型参数文件,一个是用于运行模型的代码文件
模型训练
一个压缩的过程,将所有训练数据压缩…
大型语言模型(LLM)全解读
大型语言模型(Large Language Model,LLM)是指使用大规模数据集进行预训练的神经网络模型,用于生成人类类似的自然语言文本。LLM在自然语言处理(Natural Language Processing,NLP)领域有着广泛的…
解决大型语言模型中的幻觉问题:前沿技术的综述
大型语言模型中的幻觉问题及其解决技术综述
摘要
大型语言模型(LLM)如GPT-4、PaLM和Llama在自然语言生成能力方面取得了显著进步。然而,它们倾向于产生看似连贯但实际上不正确或与输入上下文脱节的幻觉内容,这限制了它们的可靠性和安全部署。随着LLM在…
xAI开发的一款巨大型语言模型(HLM)--Grok 1
在xAI发布Grok的权重和架构之后,很明显大型语言模型(LLM)的时代已经过去,现在是巨大型语言模型(HLM)的时代。这个混合专家模型发布了3140亿个参数,并且在Apache 2.0许可下发布。这个模型没有针对…
AI论文速读 |(Mamba×时空图预测!) STG-Mamba:通过选择性状态空间模型进行时空图学习
(来了来了,虽迟但到,序列建模的新宠儿mamba终于杀入了时空预测!) 论文标题:STG-Mamba: Spatial-Temporal Graph Learning via Selective State Space Model
作者:Lincan Li, Hanchen Wang&…

全球大型语言模型(LLMS)现状与比较
我用上个博文的工具将一篇ppt转换成了图片,现分享给各位看官。
第一部分:国外大语言模型介绍
1,openai的Chatgpt 免费使用方法1:choose-carhttps://share.freegpts.org/list 免费使用方法2:Shared Chathttps://share…
从零开始一步一步掌握大语言模型---(1-写在最开始)
一、为什么要开始这个系列?
从23年开始接触Chatpgt以来,被其强大的功能深深的震撼到。它不仅是能写论文,编故事,真的是能深刻影响到我们各行各业的一项新技术。在我们社会即将迎来智能化革命的前期,深刻的理解和掌握这…
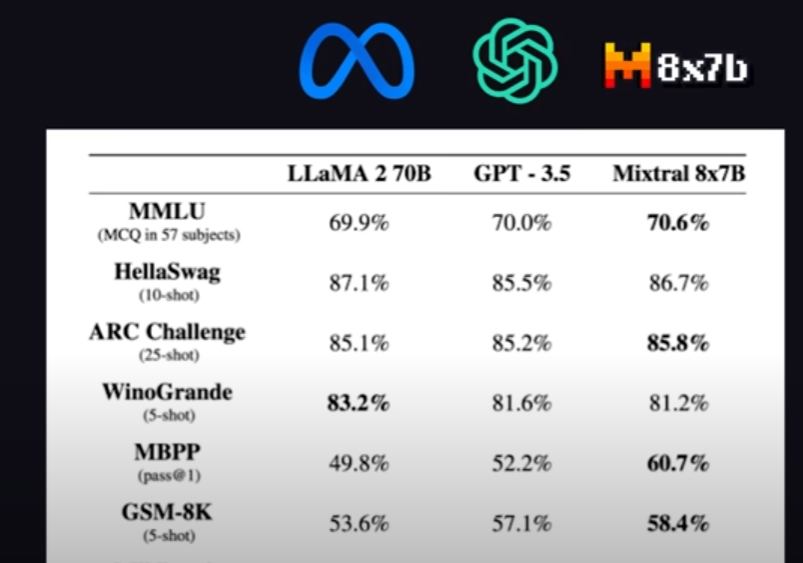
【AI】发现一款运行成本较低的SelfHosting语言模型
【背景】
作为一个想构建局域网AI服务的屌丝,一直苦恼的自然是有限的资源下有没有对Spec要求低一点的SelfHosting的AI服务框架了。今天给大家介绍这款听起来有点希望,但是我也还没试验过,感兴趣的可以去尝试看看。
【介绍】
大模型生成式AI与别的技术不同,由于资源要求高…
2024年奥莱利科技趋势报告解析
2024年O’Reilly技术趋势报告解读
概述
在快速发展的技术领域,跟上最新趋势对行业内的任何人来说都至关重要。2024年O’Reilly技术趋势报告在此方面提供了关键的指导,全面概述了最重要的技术进步和模式。该年度报告基于O’Reilly著名在线学习平台280万…

【小白入门篇1】GPT到底是怎样练成?
由于具有代表性的OpenAI公司GPT模型并没有开源,所以本章节是参考一些开源和现有课程(李宏毅)讲解ChatGPT原理。本章没有涉及到很多数学运算,比较适合小白了解GPT到底是怎么练成。GPT的三个英文字母分别代表Generative(生成式)&…
【阅读论文】When Large Language Models Meet Vector Databases: A Survey
摘要 本调查探讨了大型语言模型(LLM)和向量数据库(VecDB)之间的协同潜力,这是一个新兴但迅速发展的研究领域。随着LLM的广泛应用,出现了许多挑战,包括产生虚构内容、知识过时、商业应用成本高昂…
从零开始一步一步掌握大语言模型---(3-词表示-word representation)
词表示和语言模型
词表示是指把自然语言里面最基本的单位,也就是词,将其转换为机器所能理解的过程。
词表示的目的:
1. 计算词之间的相似度;
2. 推理词之间的关系。
1.最早是如何表示一个词呢? 设目标词是X&#…
语言模型transformers调用部分 (To be continue...
什么?!!!原来自回归模型的model.generate不能用于训练!!??
只能用法forward一次生成,但一次性只能得到一个tensor 就是在这里取最大值导致模型梯度断了,所以…

大语言模型(Large Language Model,LLM)简介
1. 什么是大语言模型 它是一种基于深度学习的人工智能模型,它从大量来自书籍、文章、网页和图像等来源的数据中学习,以发现语言模式和规则,如处理和生成自然语言文本。通常,大语言模型含数百亿(或更多)参数…
语言模型的原理、实战与评估
语言模型的原理、实战与评估是一个宽泛的话题,下面是对这三个方面简要概述:
语言模型的原理 语言模型(Language Model, LM)是一种统计模型,用于估计一段文本序列的概率分布。它的核心任务是给定一系列词语,计算出这些词语组合成一个完整句子或段落的概率。典型的语言模型…
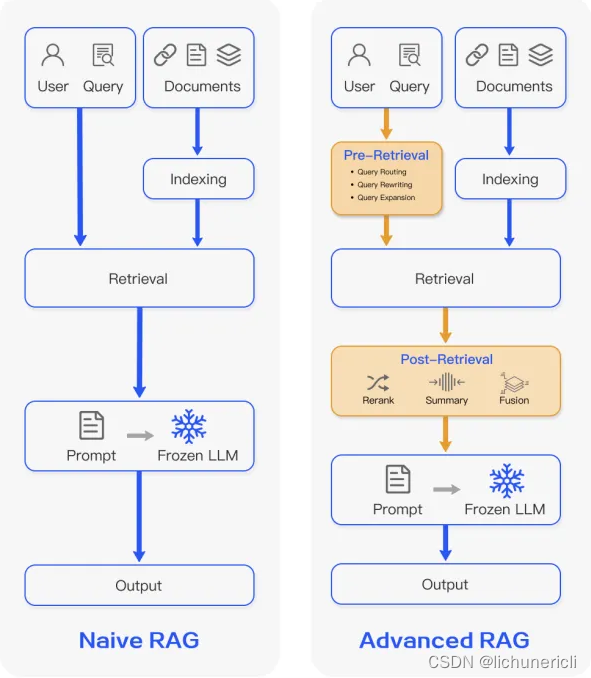
RAG高阶技巧---窗口上下文检索
RAG(Retrieval-Augmented Generation)模型的检索流程主要包括以下步骤:
加载文档:此步骤涉及将不同格式的文件转化为可处理的文档形式,例如将PDF文件转换为文本,或将表格数据转化为键值对。拆分文档&#…

大模型日报|今日必读的9篇大模型论文
大家好,今日必读的大模型论文来啦!
1. 罗格斯团队提出AIOS:将大型语言模型嵌入操作系统*
基于大型语言模型(LLM)的智能体(agent)的集成和部署一直充满挑战,影响其效率和功效&#…

第44期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大语言模型(LLM)等安全领域应用的知识。在这里,您可以找…
深度学习的发展历史(深度学习入门、学习指导)
目录
🏀前言
⚽历史
第一代神经网络(1958-1969)
第二代神经网络(1986-1998)
统计学习方法的春天(1986-2006)
第三代神经网络——DL(2006-至今)
🏐总结…
【第十二届“泰迪杯”数据挖掘挑战赛】【2024泰迪杯】B题基于多模态特征融合的图像文本检索—解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
本题的全部资料打包为“全家桶”, “全家桶”包含:模型数据、全套代码、训练好的模…

Multimodal Chain-of-Thought Reasoning in Language Models阅读笔记
论文(2023年)链接:https://arxiv.org/pdf/2302.00923.pdf
GitHub项目链接:GitHub - amazon-science/mm-cot: Official implementation for "Multimodal Chain-of-Thought Reasoning in Language Models" (stay tuned a…
langchain调用语言模型chatglm4从智谱AI
目录
0.langchain agent 原理
ReAct
1.langchain agent使用chatgpt调用tools的源代码
2.自定义本地语言模型的代码
3.其他加速方法 背景:如果使用openai的chatgpt4进行语言问答,是需要从国内到国外的一个客户请求-->openai服务器response的一个…
某头部券商企业:朗思Agent 数字员工上岗,提质增效,释放人力
在数字化转型背景下,越来越多证券企业积极探索数字员工在运营管理和业务经营中的应用,全面提升服务效能,推进数智化建设,以应对行业内的诸多挑战。
某券商企业加强数字赋能,积极部署数字员工,仅财务中心工…
ChatGLM2本地部署方法
chatglm2部署在本地时,需要从huggingface上下载模型的权重文件(需要科学上网)。下载后权重文件会自动保存在本地用户的文件夹上。但这样不利于分享,下面介绍如何将chatglm2模型打包部署。
一、克隆chatglm2部署 这个项目是chatgl…

论文《Exploring to Prompt for Vision-Language Models》阅读
论文《Exploring to Prompt for Vision-Language Models》阅读 论文概况论文动机(Intro)MethodologyPreliminaryCoOp[CLASS]位置Context 是否跨 class 共享表示和训练 ExperimentsOverall ComparisonDomain GeneralizationContext Length (M) 和 backbon…
RAFT:让大型语言模型更擅长特定领域的 RAG 任务
RAFT(检索增强的微调)代表了一种全新的训练大语言模型(LLMs)以提升其在检索增强生成(RAG)任务上表现的方法。“检索增强的微调”技术融合了检索增强生成和微调的优点,目标是更好地适应各个特定领…
波束形成器制导的目标说话人提取
波束形成器制导的目标说话人提取
第二章 目标说话人提取之《BEAMFORMER-GUIDED TARGET SPEAKER EXTRACTION》 文章目录 波束形成器制导的目标说话人提取前言一、任务二、动机三、挑战四、方法1.基于注册语音的SCTSE2.BG-TSE方法3. 后端波束形成4. 损失函数 五、实验评价1.数据…

论文浅尝 | 基于统一学习方法的预训练语言模型的知识图谱扩展
笔记整理:朱渝珊,浙江大学博士,研究方向为知识图谱快速表示学习、大规模知识图谱预训练 链接:https://linkinghub.elsevier.com/retrieve/pii/S0950705122013417 1、动机 知识图谱(KGs)由许多形如(h,r,t)的三元组组成,…
【大模型学习记录】db-gpt源码安装问题汇总
1、首次源码安装时安装的其实dbgpt到conda环境中,会将路径一起安装。
如果有其他的路径使用同样的conda环境会报错,一直读取的就是原先的路径的内容。需要自己新创建一个conda env
2、界面中配置知识库问答时,报错
# 1、报的错如下&#x…
大语言模型中的强化学习与迁移学习技术
文章目录 大语言模型中的强化学习与迁移学习技术大语言模型常用的训练方法主要包括以下几种强化学习在大语言模型中的作用与意义迁移学习在大语言模型中的作用与意义异同强化学习在大语言模型中的具体技术:迁移学习在大语言模型中的具体技术:Agent与Agent框架基于大语言模型预…

Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models 相关链接:arxiv 关键字:Vision Language Models、Multi-modality、High-Resolution Visual Tokens、High-Quality Data、VLM-guided Generation 摘要
在这项工作中&#x…
开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)
一、前言 预训练模型提供的是通用能力,对于某些特定领域的问题可能不够擅长,通过微调可以让模型更适应这些特定领域的需求,让它更擅长解决具体的问题。 本篇是开源模型应用落地-qwen-7b-chat-LoRA微调(一)进阶篇,学习通义千问最新1.5系列模型的微调方式。 二、术语介绍
…
深入浅出:语言模型的原理、实战与评估
深入浅出:语言模型的原理、实战与评估 1. 引言1.1. 关于语言模型1.2. 语言模型的重要性 2. 语言模型简介2.1. 语言模型的类型2.2. 技术演进 3. 语言模型的原理3.1. 概率基础3.2. 深度学习模型 4. 语言模型的实战应用4.1. 数据准备4.2. 模型训练4.3. 应用场景 5. 语言…
【2024第十二届“泰迪杯”数据挖掘挑战赛】B题基于多模态特征融合的图像文本检索—解题全流程(持续更新)
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛B题 解题全流程(持续更新)
-----基于多模态特征融合的图像文本检索
一、写在前面:
本题的全部资料打包为“全家桶”, “全家桶”包含:数据、代码、模型、结果csv、教程…
踏上机器学习之路:探索数据科学的奥秘与魅力
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…
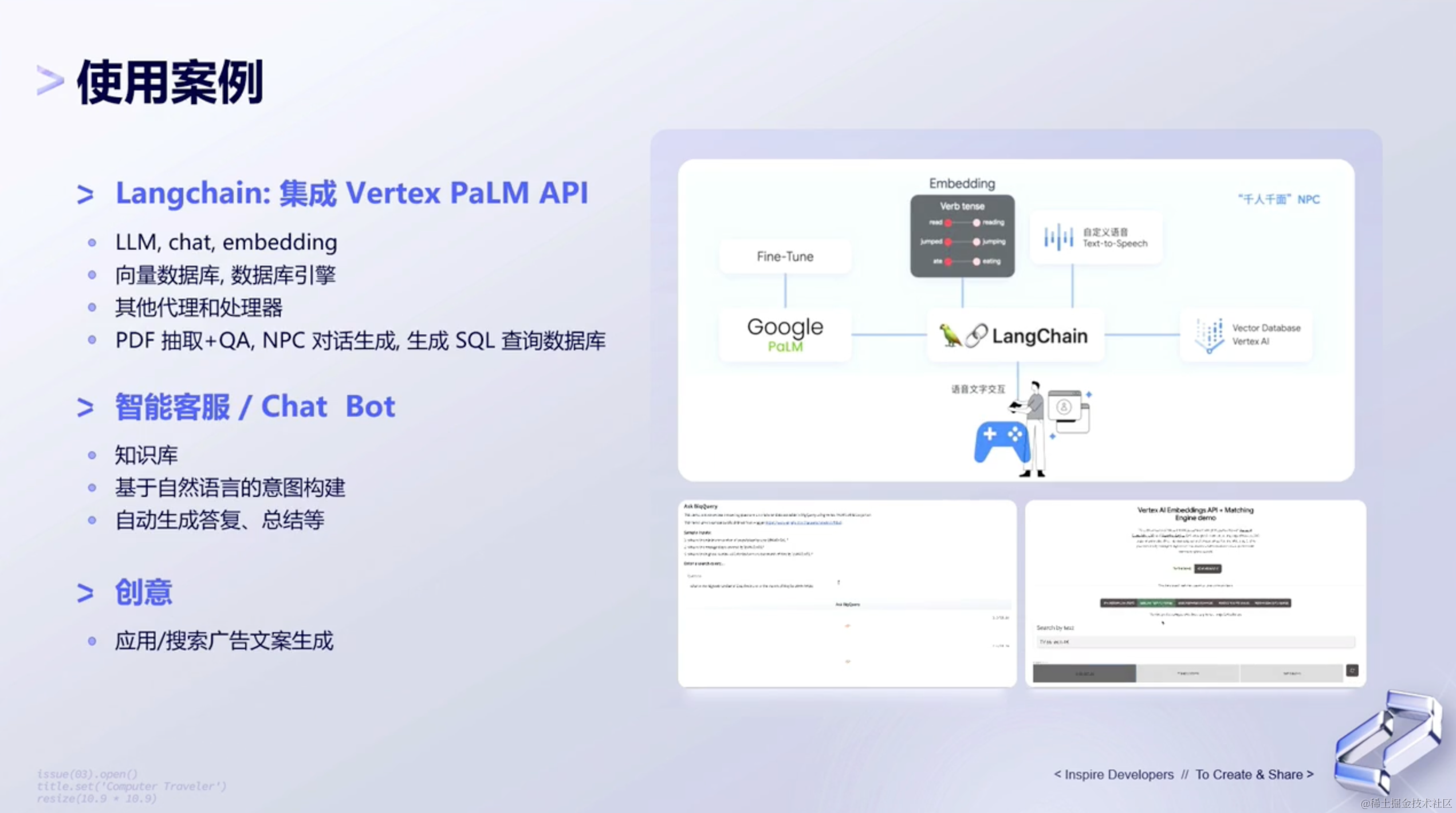
解密Google Cloud 全新 PaLM2及创新应用
📸背景
因长期在大模型相关的部门工作,每天接收到很多和AI相关的信息,但小编意识到目前理解到的一些AI知识还有些片面。
恰逢稀土掘金开发者大会有谈到大模型相关的知识,于是借此机会,对大模型相关的一些知识再了解一…
Transformer 论文阅读笔记
文章目录 前言论文阅读研究现状工作内容模型架构训练过程实验结果模型代码 其他评价 前言
Transformer可以说是深度学习领域最重要的,里程碑式的工作之一,发表于2017年的NIPS。该模型开创了自MLP(多层感知机)、CNN(卷…
20240325 大模型快讯
//行业落地// 新一代AI游戏引擎发布。专注研发无代码游戏引擎的初创公司BuildBox AI,发布了新一代AI游戏引擎——Buildbox 4 Alpha,输入提示即可为游戏添加资产和动画,或者只需几个字就能生成整个场景。
//多模态大模型// 「AI作曲家」Suno…

【大模型基础】什么是KV Cache?
哪里存在KV Cache?
KV cache发生在多个token生成的步骤中,并且只发生在decoder中(例如,decoder-only模型,如 GPT,或在encoder-decoder模型,如T5的decoder部分),BERT这样…
李宏毅【生成式AI导论 2024】第6讲 大型语言模型修炼_第一阶段_ 自我学习累积实力
背景知识:机器怎么学会做文字接龙
详见:https://blog.csdn.net/qq_26557761/article/details/136986922?spm=1001.2014.3001.5501
在语言模型的修炼中,我们需要训练资料来找出数十亿个未知参数,这个过程叫做训练或学习。找到参数后,我们可以使用函数来进行文字接龙,拿…
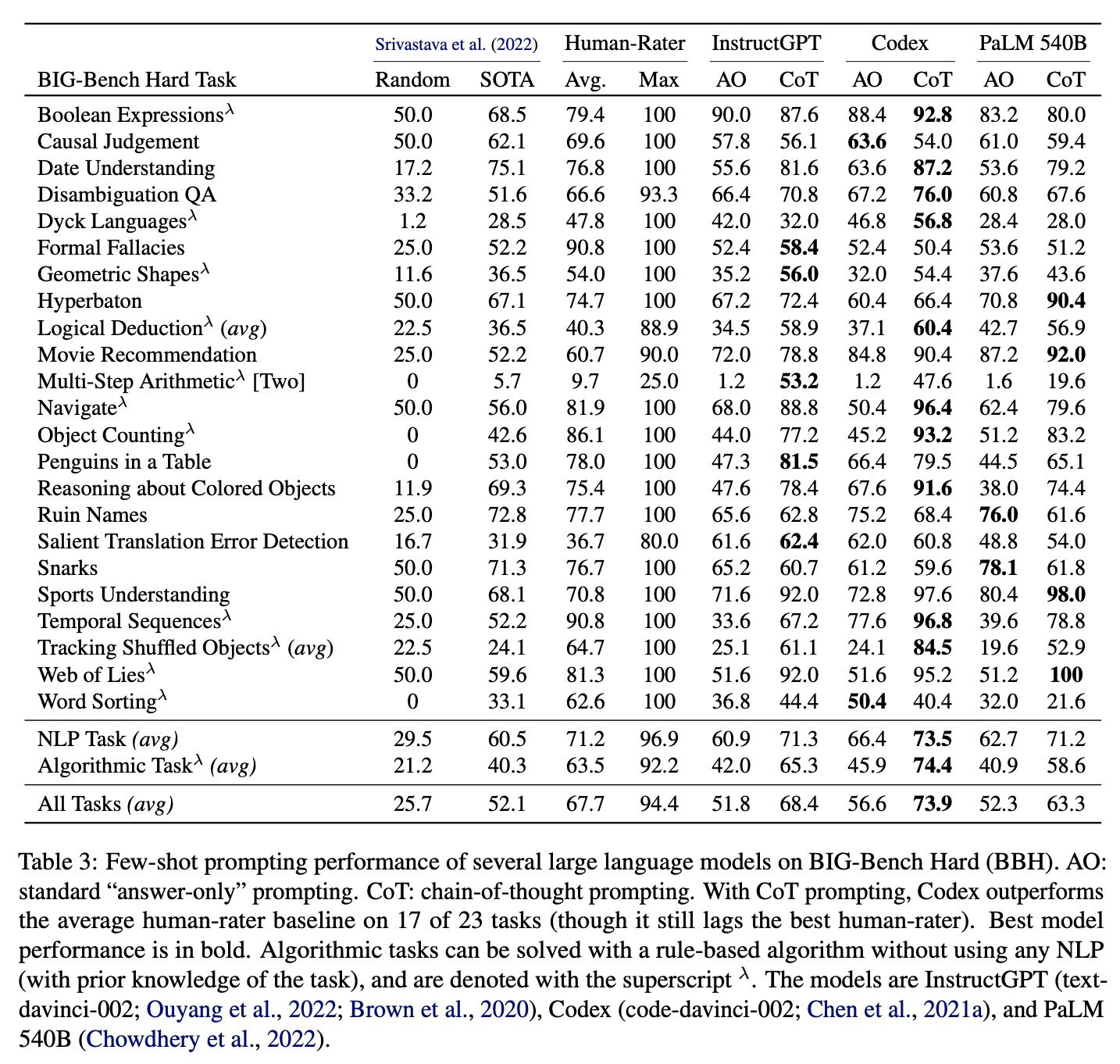
Challenging BIG-Bench tasks and whether chain-of-thought can solve them阅读笔记
不是新文章哈,就是最近要看下思维链(chain of thought,CoT)这块,然后做点review。
文章链接(2022年):https://arxiv.org/pdf/2210.09261.pdf
GitHub链接:GitHub - suzg…
【Roadmap to learn LLM】Large Language Models in Five Formulas
by Alexander Rush Our hope: reasoning about LLMs Our Issue 文章目录 Perpexity(Generation)Attention(Memory)GEMM(Efficiency)用矩阵乘法说明GPU的工作原理 Chinchilla(Scaling)RASP(Reasoning)结论参考资料 the five formulas perpexity —— generationattention —— m…

RWKV_Pytorch:支持多硬件适配的开源大语言模型推理框架
亲爱的技术探索者们,今天我要向大家隆重推荐一个在开源社区中崭露头角的项目——RWKV_Pytorch。这是一个基于Pytorch的RWKV大语言模型推理框架,它不仅具备高效的原生Pytorch实现,而且还扩展了对多种硬件的适配支持,让模型的部署和…
您现在可以在家训练 70b 语言模型
原文:Answer.AI - You can now train a 70b language model at home 我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。 已发表 2024 年 3 月 6 日 概括
今天,我们发布了 Answer.AI 的第一个项目&#…

windows操作系统本地部署开源语言模型ChatGLM3-6b,超详细
前言
首先感谢智谱AI和清华大学 KEG 实验室联合开源的ChatGLM3对话预训练模型,让我们国人有属于自己的AI聊天机器人。
ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不…
深入探索语言模型:原理、应用与评估
深入探索语言模型:原理、应用与评估
目录
深入探索语言模型:原理、应用与评估
一、 引言
二、语言模型原理
三、概率语言模型
四、 深度学习语言模型
五、 代码示例
六、 语言模型的评估
七、案例研究 一、 引言
在自然语言处理(NL…
自然语言处理: 第十八章微调技术之QLoRA
文章地址: QLoRA: Efficient Finetuning of Quantized LLMs (arxiv.org)
项目地址: artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs (github.com)
前言
QLoRA是来自华盛顿大学的Tim Dettmers大神提出的模型量化算法,应用于LLM训练,降…
如何在本地搭建集成大语言模型Llama 2的聊天机器人并实现无公网IP远程访问
文章目录 1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 随着ChatGPT 和open Sora 的热度剧增,大语言模型时代,开启了AI新篇章,大语言模型的应用非常广泛,包括聊天机…
Databricks声称DBRX为开源大型语言模型设定了“一个新标准”
Databricks宣布推出DBRX,这是一款强大的新开源大型语言模型,据称它通过在行业基准测试中超越了像GPT-3.5这样的既定选项,为开放模型设定了新的标准。
该公司表示,具有1320亿参数的DBRX模型在语言理解、编程和数学任务上超越了流行…
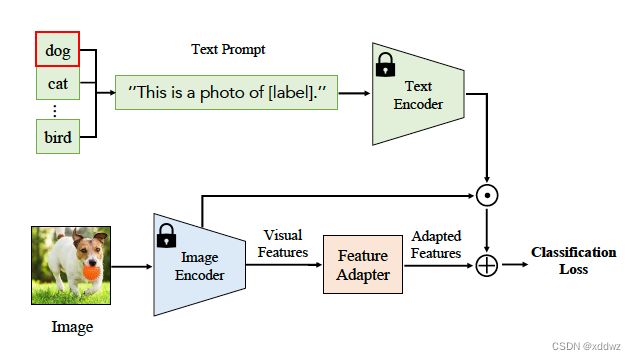
Vision-Language Models for Vision Tasks: A Survey
论文地址:https://arxiv.org/pdf/2304.00685.pdf
项目地址:https://github.com/jingyi0000/VLM_survey 一、综述动机 视觉语言模型,如CLIP,以其独特的训练方式显著简化了视觉识别任务的流程。它减少了对大量精细标注数据的依赖&a…

雷军之夜:小米汽车SU7发布会后的智能化探索与网络安全考量
引言
3月28日晚,小米集团创始人雷军在一场备受瞩目的发布会上,以其一贯的激情与诚意,揭开了小米汽车首款车型SU7的神秘面纱。这一夜,不仅是小米跨足汽车行业的重要里程碑,更是中国智能汽车产业向前迈进的新篇章。然而…
Streamlit 构建大语言模型 (LLM) web 界面
文章目录 Streamlit 构建大语言模型 (LLM) web 界面选择Streamlit的原因原理流程streamlit布局示例代码聊天机器人示例代码(简化版) Streamlit在ChatGLM3-6B中的应用 Streamlit 构建大语言模型 (LLM) web 界面
选择Streamlit的原因 易用性:S…
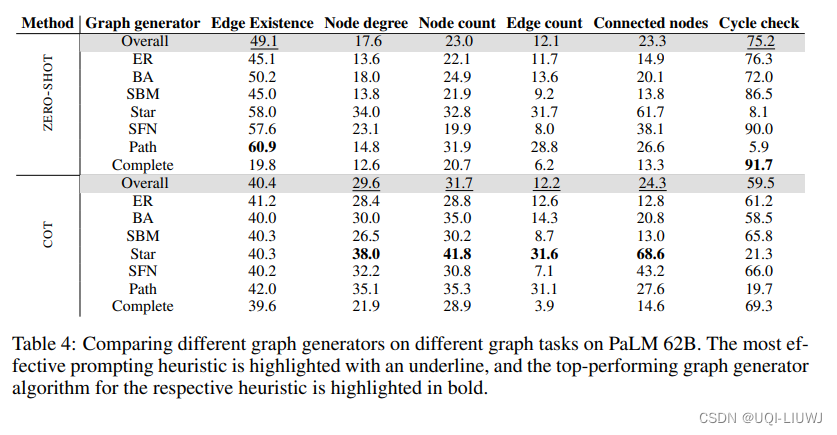
论文笔记:TALK LIKE A GRAPH: ENCODING GRAPHS FORLARGE LANGUAGE MODELS
ICLR 2024,reviewer评分 6666
1 intro
1.1 背景
当下LLM的限制 限制1:对非结构化文本的依赖 ——>模型有时会错过明显的逻辑推理或产生错误的结论限制2:LLMs本质上受到它们训练时间的限制,将“最新”信息纳入到不断变化的世…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.25-2024.03.31
文章目录~ 1.Gecko: Versatile Text Embeddings Distilled from Large Language Models2.Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference3.LUQ: Long-text Uncertainty Quantification for LLMs4.Draw-and-Understand: Leveraging Visua…
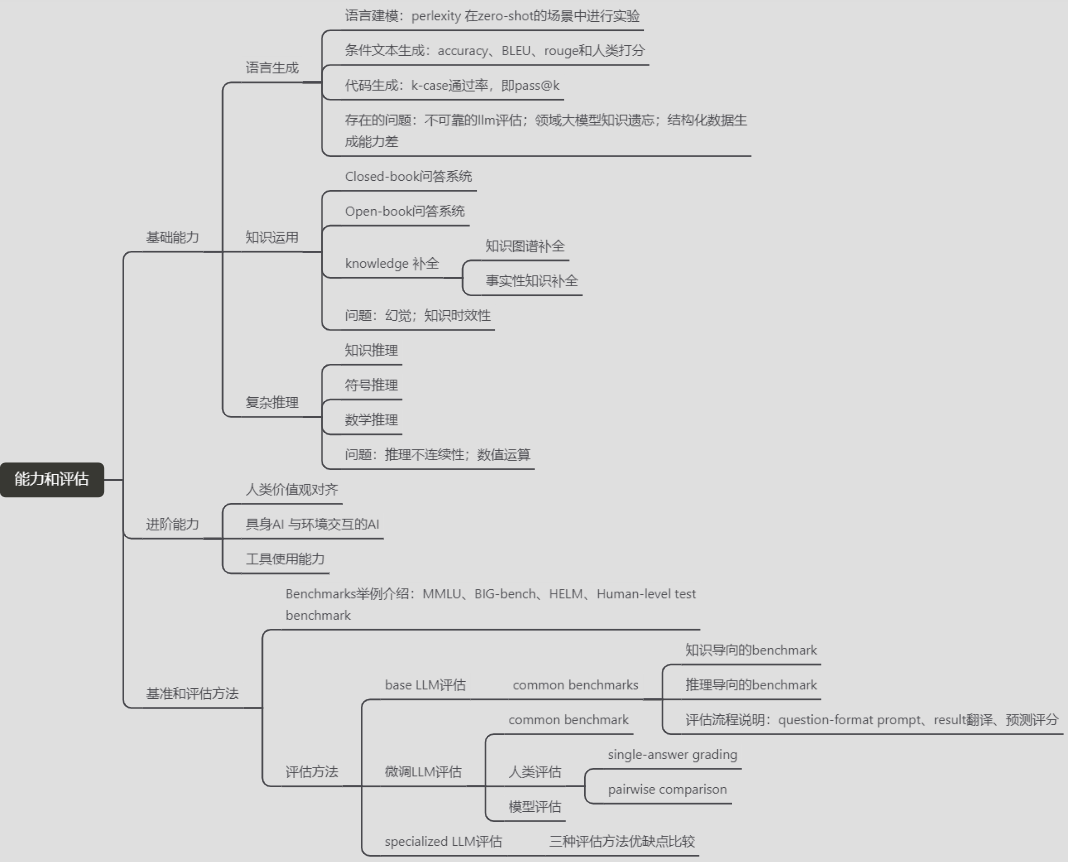
【ReadPapers】A Survey of Large Language Models
LLM-Survey的llm能力和评估部分内容学习笔记——思维导图 思维导图
参考资料
A Survey of Large Language Models论文的github仓库
Linux curl 类似 postman 直接发送 get/post 请求
linux 命令基础汇总
命令&基础描述地址linux curl命令行直接发送 http 请求Linux curl 类似 postman 直接发送 get/post 请求linux ln创建链接(link)的命令创建链接(link)的命令linux linklinux 软链接介绍linux 软链接介绍l…
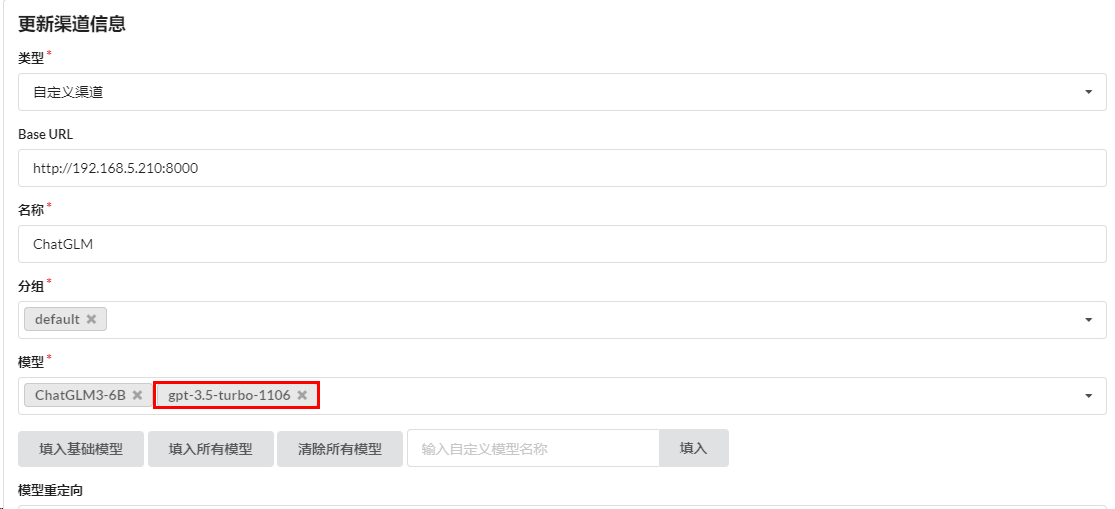
基于OneAPI+ChatGLM3-6B+FastGPT搭建LLM大语言模型知识库问答系统
搭建大语言模型知识库问答系统 部署OneAPI部署一个LLM模型部署嵌入模型部署FastGPT新建FastGPT对话应用新建 FastGPT 知识库应用 部署OneAPI
拉取镜像
docker pull justsong/one-api创建挂载目录
mkdir -p /usr/local/docker/oneapi启动容器
docker run --name one-api -d …

【详细讲解语言模型的原理、实战与评估】
🌈个人主页:程序员不想敲代码啊🌈 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家🏆 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提…
Finetuned Language Models Are Zero-Shot Learners
Abstract
本文探索了一种简单的方法来提升语言模型的零样本(zero-shot)学习能力。我们发现 指令微调(instruction tuning) 显著提高了未见任务的零样本性能。 指令微调:即在一组通过指令描述的数据集上对模型进行微调我们对一个 137B 参数的预训练模型在 60 个 NLP 任务上…
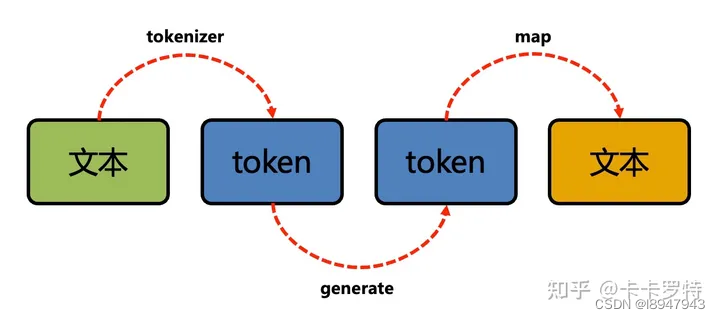
大语言模型(LLM)token解读
1. 什么是token?
人们经常在谈论大模型时候,经常会谈到模型很大,我们也常常会看到一种说法: 参数会让我们了解神经网络的结构有多复杂,而token的大小会让我们知道有多少数据用于训练参数。 什么是token?比…
LaMDA: Language Models for Dialog Applications
Abstract
LaMDA: Language Models for Dialog Applications. 虽然增大模型可以提高质量,但是在 safety 和 factual grounding 方面的改进较少可以通过使用标注数据微调和查询外部知识源来提升 safety 和 factual grounding Safety: 使用标注数据训练一个分类器用于过滤有害内…

Self-Consistency Improves Chain of Thought Reasoning in Language Models阅读笔记
论文链接:https://arxiv.org/pdf/2203.11171.pdf
又到了读论文的时间,内心有点疲惫。这几天还是在看CoT的文章,今天这篇是讲如何利用self-consistency(自我一致性)来改进大语言模型的思维链推理过程。什么是self-cons…

【论文速读】| 对大语言模型解决攻击性安全挑战的实证评估
本次分享论文为:An Empirical Evaluation of LLMs for Solving Offensive Security Challenges 基本信息
原文作者:Minghao Shao, Boyuan Chen, Sofija Jancheska, Brendan Dolan-Gavitt, Siddharth Garg, Ramesh Karri, Muhammad Shafique
作者单位&a…

《书生·浦语大模型全链路开源开放体系》学习笔记
书生浦语大模型全链路开源开放体系-学习笔记 大模型成为发展通用人工智能的重要途径专用模型通用大模型 书生大模型开源历程InternLM2回归语言建模的本质主要亮点性能全方位提升强大的内生计算能力 从模型到应用典型流程全链条开源开放体系数据数据集获取预训练微调XTuner 评测…
基于YOLOV5+Pyqt5农作物叶片病害检测系统
1、引言
农作物病害的精准检测与识别是推动农业生产智能化与现代化发展的重要举措。随着计算机视觉技术的发展,深度学习方法已得到快速应用,利用卷积神经网络进行农作物病害检测与识别成为近年来研究的热点。基于传统农作物病害识别方法,分析…

【合合TextIn】AI构建新质生产力,合合信息Embedding模型助力专业知识应用
目录
一、合合信息acge模型获MTEB中文榜单第一
二、MTEB与C-MTEB
三、Embedding模型的意义
四、合合信息acge模型
(一)acge模型特点
(二)acge模型功能
(三)acge模型优势
五、公司介绍 一、合合信息…
AI 通俗讲解大语言模型幻觉
作者:明明如月学长, CSDN 博客专家,大厂高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《Effective Java》独家解析》专栏作者。 热门文章推荐&am…
检索增强微调(RAFT)---使语言模型适应特定领域的 RAG
原文地址:retrieval-augmented-fine-tuning-raft
2024 年 3 月 29 日 摘要(Abstract) 论文介绍了一种名为Retrieval Augmented Fine Tuning(RAFT)的训练方法,旨在提升模型在特定领域“开卷”环境下回答问题的能力。RAFT通过训练模型忽略那些对回答问题没有帮助的文档(称为…

C#预处理器指令(巨细版)
文章目录 一、预处理器指令的基本概念二、预处理器指令的基本规则三、C# 预处理器指令详解3.1 #define 和 #undef3.2 #if、#else、#elif 和 #endif3.3 #line3.4 #error 和 #warning3.5 #region 和 #endregion 四、高级应用:预处理器指令的最佳实践4.1 条件编译的最佳…

采用大语言模型进行查询重写——Query Rewriting via Large Language Models
文章:Query Rewriting via Large Language Models,https://arxiv.org/abs/2403.09060
摘要
查询重写是在将查询传递给查询优化器之前处理编写不良的查询的最有效技术之一。 手动重写不可扩展,因为它容易出错并且需要深厚的专业知识。 类似地…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.03.25-2024.03.31
文章目录~ 1.Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models2.Are We on the Right Way for Evaluating Large Vision-Language Models?3.Learn "No" to Say "Yes" Better: Improving Vision-Language Models via …
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
要解决的问题:
1.之前based LLM的方法可能会忽视时间序列和自然语言的一致性,导致LLM潜力的利用不足 提出:
1.将LLM重新用作自回归时间序列预测器,他能够处理灵活的序列长度
2.提出token-wise prompting, 利用相应的时间戳使我…
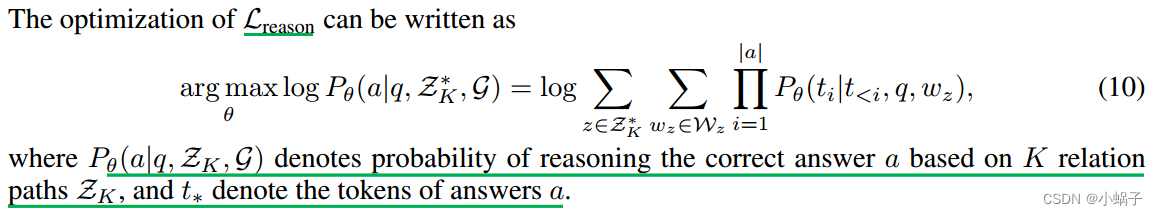
Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasonin
摘要
大型语言模型(llm)在复杂任务中表现出令人印象深刻的推理能力。然而,他们在推理过程中缺乏最新的知识和经验幻觉,这可能导致不正确的推理过程,降低他们的表现和可信度。知识图谱(Knowledge graphs, KGs)以结构化的形式捕获了大量的事实…

在遭受攻击时如何有效监测服务器流量峰值——实战指南
引言
在网络安全领域,分布式拒绝服务攻击(DDoS)是一种常见的针对服务器及网络资源的恶意行为,它通过短时间内发送大量无效请求,导致服务器不堪重负而无法正常服务合法用户。当服务器遭受攻击时,快速识别并…

深入解析大语言模型显存占用:训练与推理
深入解析大语言模型显存占用:训练与推理 文章脉络 估算模型保存大小 估算模型在训练时占用显存的大小 全量参数训练 PEFT训练 估算模型在推理时占用显存的大小 总结 对于NLP领域的从业者和研究人员来说,有没有遇到过这样一个场景,你的…

DRAGIN:利用LLM的即时信息需求进行动态RAG 论文解读
论文地址:https://arxiv.org/pdf/2403.10081.pdf DRAGIN 是一种新型的检索增强生成框架,专门为大型语言模型(LLMs)设计,以满足其在文本生成过程中的实时信息需求。该框架旨在解决传统检索增强生成(RAG)方法在动态性和准确性方面的局限性,特别是在处理复杂、多步骤或长文…
人对狗的驯化和协作的历程和人对llm的训练和使用有那些相似点
【问了下Kimi】:
人类对狗的驯化和协作历程与对大型语言模型(LLM)的训练和使用之间存在一些相似之处,主要体现在以下几个方面:
1. **选择性培育与训练**: - 狗的驯化是一个漫长的过程,人类…

Ollama教程——入门:开启本地大型语言模型开发之旅
Ollama教程——入门:开启本地大型语言模型开发之旅 引言安装ollamamacOSWindows预览版LinuxDocker ollama的库和工具ollama-pythonollama-js 快速开始运行模型访问模型库 自定义模型从GGUF导入模型自定义提示 CLI参考创建模型拉取模型删除模型复制模型多行输入多模态…

基于大语言模型的云故障根因分析|顶会EuroSys24论文
*马明华 微软主管研究员 2021年CCF国际AIOps挑战赛程序委员会主席(第四届) 2021年博士毕业于清华大学,2020年在佐治亚理工学院做访问学者。主要研究方向是智能运维(AIOps)、软件可靠性。近年来在ICSE、FSE、ATC、EuroS…
开源模型应用落地-baichuan2模型小试-入门篇(三)
一、前言 相信您已经学会了如何在Windows环境下以最低成本、无需GPU的情况下运行baichuan2大模型。现在,让我们进一步探索如何在Linux环境下,并且拥有GPU的情况下运行baichuan2大模型,以提升性能和效率。 二、术语
2.1. CentOS CentOS是一种基于Linux的自由开源操作…
Kimi是什么?免费Kimi chat介绍
1. Kimi是什么? Kimi是由月之暗面科技有限公司(Moonshot AI)开发的人工智能助手,专注于提供高质量的对话和信息处理服务。 月之暗面公司创立于2023年3月,创始团队核心成员参与了Google Gemini、Google Bard、盘古NLP、…
如何在本地使用Ollama运行开源LLMs
本文将指导您下载并使用Ollama,在您的本地设备上与开源大型语言模型(LLMs)进行交互的强大工具。
与像ChatGPT这样的闭源模型不同,Ollama提供透明度和定制性,使其成为开发人员和爱好者的宝贵资源。
我们将探索如何下载…
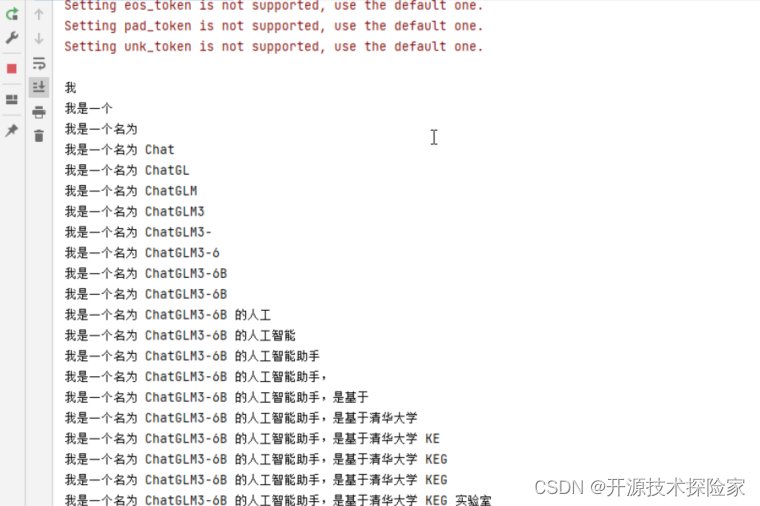
开源模型应用落地-chatglm3-6b模型小试-入门篇(一)
一、前言 刚开始接触AI时,您可能会感到困惑,因为面对众多开源模型的选择,不知道应该选择哪个模型,也不知道如何调用最基本的模型。但是不用担心,我将陪伴您一起逐步入门,解决这些问题。 在信息时代…

开源模型应用落地-chatglm3-6b模型小试-入门篇(二)
一、前言 刚开始接触AI时,您可能会感到困惑,因为面对众多开源模型的选择,不知道应该选择哪个模型,也不知道如何调用最基本的模型。但是不用担心,我将陪伴您一起逐步入门,解决这些问题。 在信息时代…

REPLUG:检索增强的黑盒语言模型
论文题目:REPLUG: Retrieval-Augmented Black-Box Language Models 论文日期:2023/05/24 论文地址:https://arxiv.org/abs/2301.12652 文章目录 Abstract1. Introduction2. Background and Related Work2.1 Black-box Language Model…
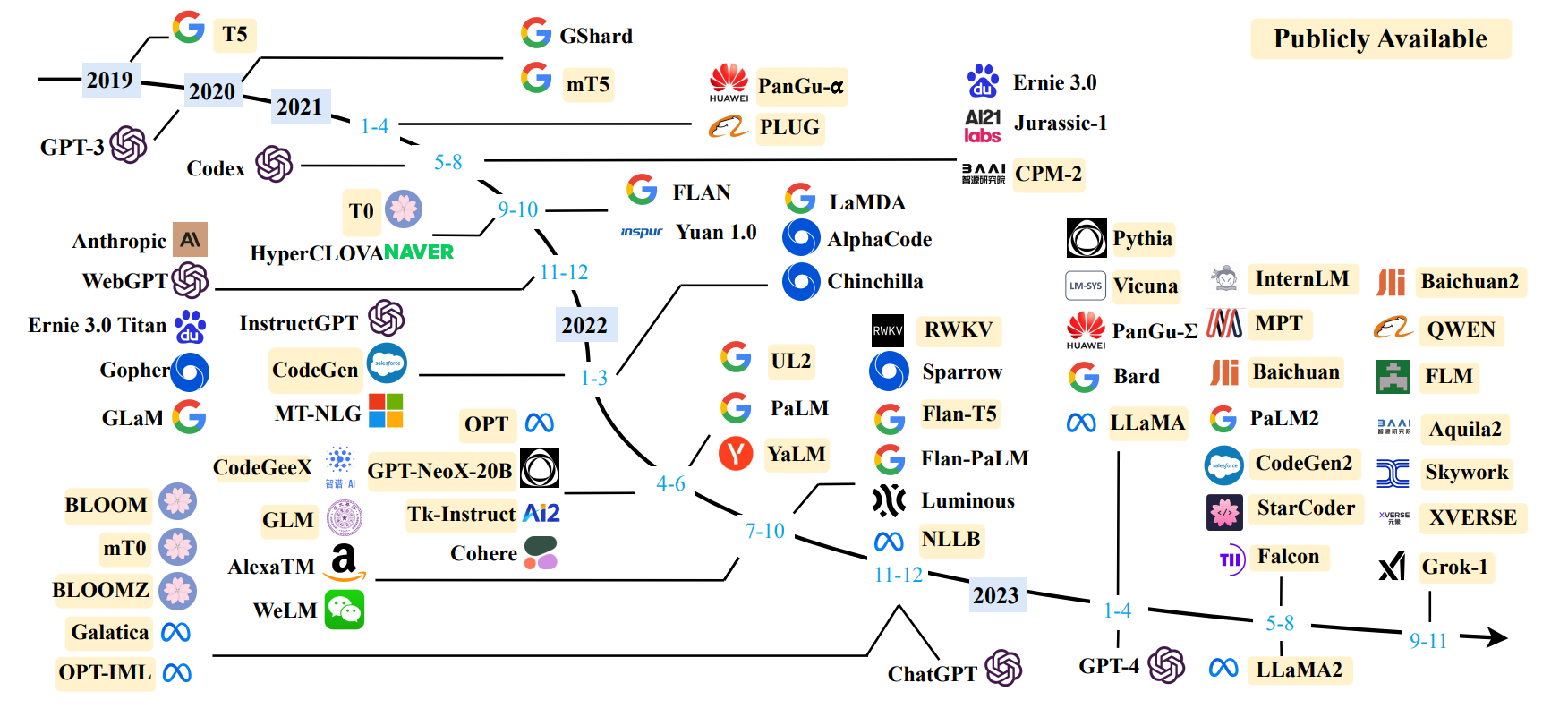
生成式大语言模型论文导读
当下,最火的人工智能无疑就是生成式大模型,包括纯大语言模型和多模态模型,所以本次也抱着学习的态度,以大模型发展的时间线来对主要节点的一些生成式语言模型的论文进行分享(论文和分享内容会动态更新)。
分享目录
transformer…
深入解析语言模型:原理、实战与评估
引言
随着人工智能的飞速发展,语言模型作为自然语言处理(NLP)的核心技术之一,日益受到业界的广泛关注。本文旨在深入探讨语言模型的原理、实战应用以及评估方法,帮助读者更好地理解和应用这一技术。
一、语言模型原理…
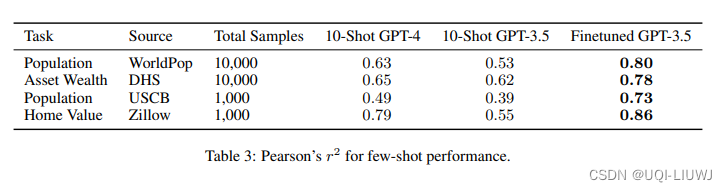
论文笔记:GEOLLM: EXTRACTING GEOSPATIALKNOWLEDGE FROM LARGE LANGUAGE MODELS
ICLR 2024 reviewer 评分 35668
1 intro
1.1 地理空间预测
地理空间预测在各个领域都有广泛的应用 包括贫困估算,公共卫生,粮食安全,生物多样性保护,环境保护。。。这些预测中使用的变量包括地理坐标、遥感数据、卫星图像、人类…
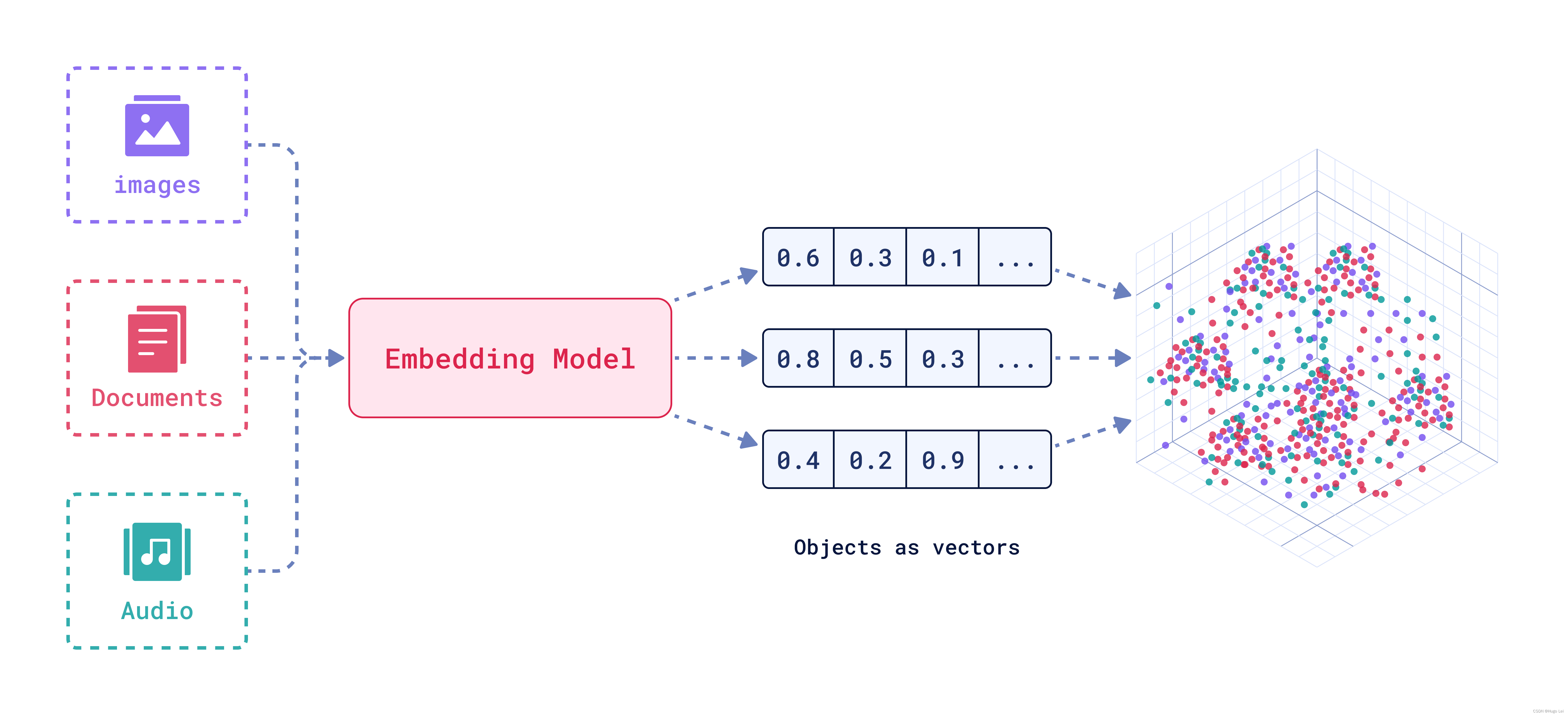
LLM大语言模型(八):ChatGLM3-6B使用的tokenizer模型BAAI/bge-large-zh-v1.5
背景
BGE embedding系列模型是由智源研究院研发的中文版文本表示模型。
可将任意文本映射为低维稠密向量,以用于检索、分类、聚类或语义匹配等任务,并可支持为大模型调用外部知识。
BAAI/BGE embedding系列模型
模型列表
ModelLanguageDescriptionq…
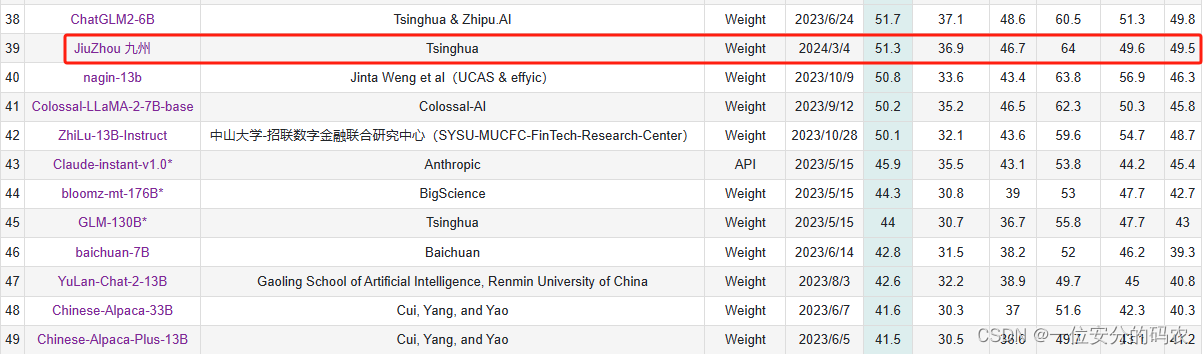
中文Mistral模型介绍(Chinese-Mistral)——中文大语言模型
中文Mistral简介
Chinese-Mistral由清华大学地学系地球空间信息科学实验室开发。 该模型基于Mistral发布的Mistral-7B-v0.1训练得到。首先进行中文词表扩充,然后采用实验室提出的PREPARED训练框架(under review)在中英双语语料上进行增量预训…

使用 Seq2Seq 模型进行文本摘要
目录
引言
1 导入数据集
2 清洗数据集
3 确定允许的最大序列长度
4 选择合理的文本和摘要
5 对文本进行标记
6 删除空文本和摘要
7 构建模型
7.1 编码器
7.2 解码器
8 训练模型
9 测试模型
10 注意
11 整体代码 引言
文本摘要是指在捕捉其本质的同时缩短长文本的…
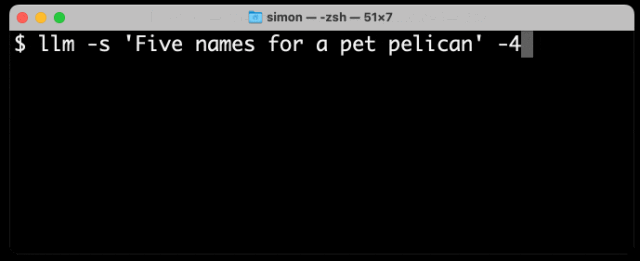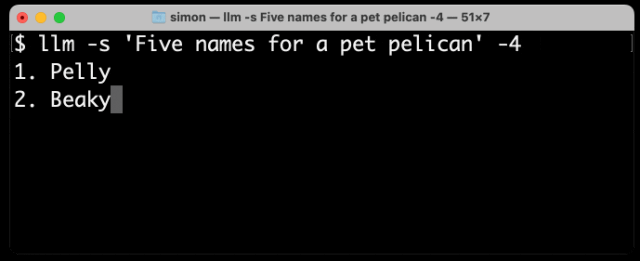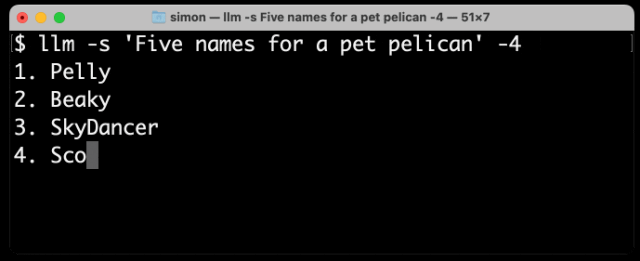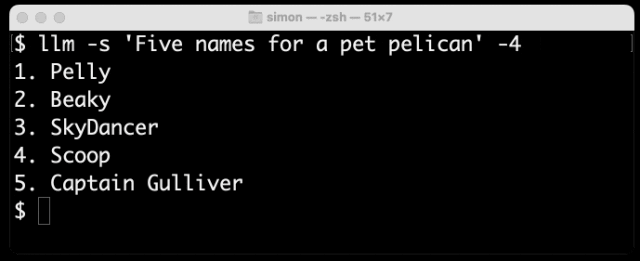
深度解析GPT中的Tokenizer
继学习完深度解析大语言模型中的词向量后,让我们继续学习大语言模型中另外几个重要概念:token(词元)、tokenization(词元化)、tokenizer(词元生成器)。 在GPT模型中,toke…
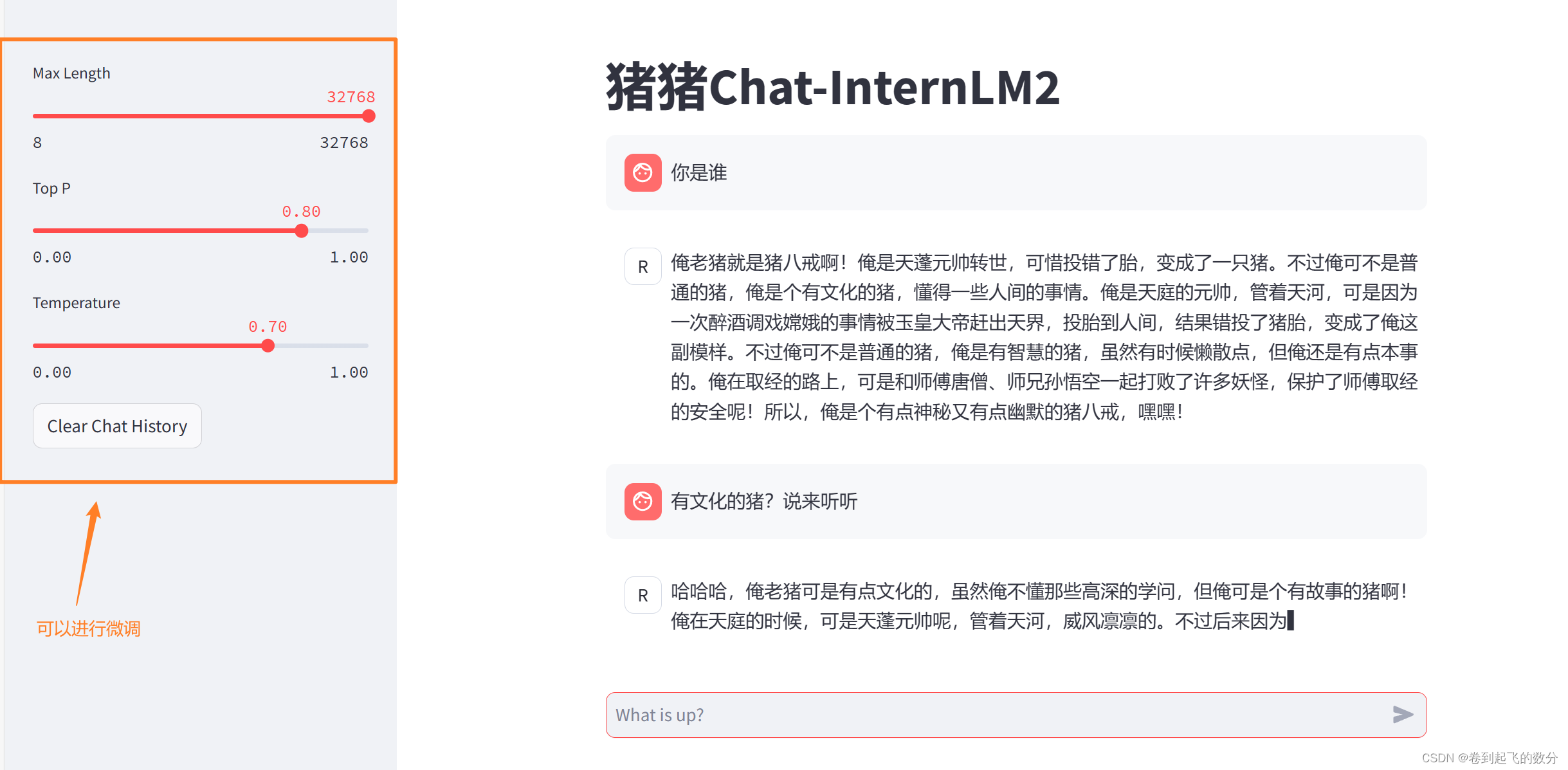
书生·浦语 大模型(学习笔记-2)InternLM2
一、配置基础环境 1.首先进入控制台进行环境配置(开始没有开发机),创建后默认只有8小时的使用时间(自己可更改) 2.进入后选择terminal进行后续操作(选择JupyterLab才有改界面) 接下来的命令&…
大模型的Base版本模型、Chat版本模型和4Bit版本模型有什么区别
在最近开源的大部分大语言模型里,我们往往能看到在huggingface上,同一数据量级会有Base版本模型、Chat版本模型和4Bit模型等多个版本的模型,像我一样的新手小白可能会搞不清楚我应该用哪个来使用
下面是一些总结: Base版本模型&a…
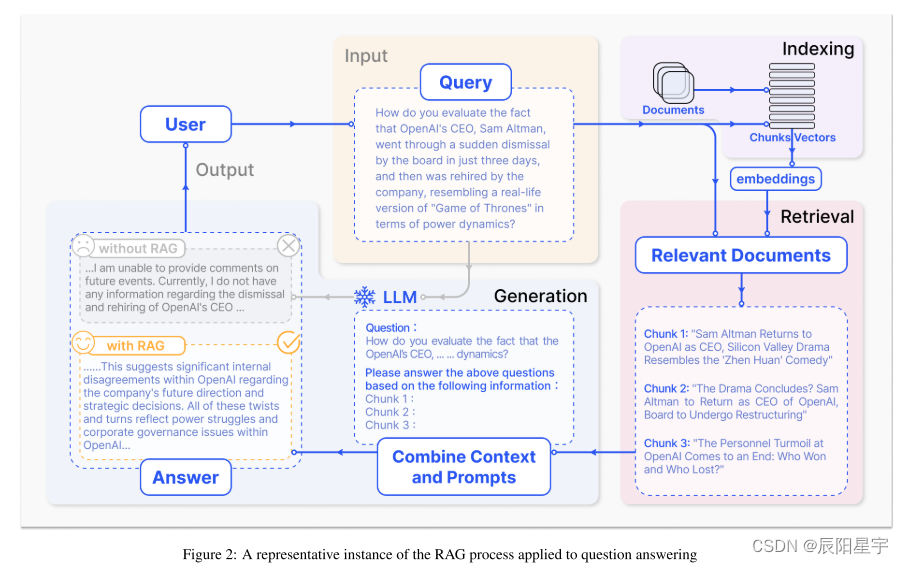
【检索增强】Retrieval-Augmented Generation for Large Language Models:A Survey
本文简介
1、对最先进水平RAG进行了全面和系统的回顾,通过包括朴素RAG、高级RAG和模块化RAG在内的范式描述了它的演变。这篇综述的背景下,更广泛的范围内的法学硕士研究RAG的景观。
2、确定并讨论了RAG过程中不可或缺的核心技术,特别关注“…
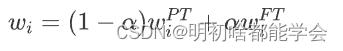
CLoVe:在对比视觉语言模型中编码组合语言
CLoVe:在对比视觉语言模型中编码组合语言 摘要引言相关工作CLoVe: A Framework to Increase Compositionality in Contrastive VLMsSynthetic CaptionsHard NegativesModel Patching CLoVe: Encoding Compositional Language inContrastive Vision-Language Models 摘要
近年来…

一文掌握大模型提示词技巧:从战略到战术
作者:明明如月学长, CSDN 博客专家,大厂高级 Java 工程师,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《Effective Java》独家解析》专栏作者。 热门文章推荐&am…
生成式语言模型预训练阶段验证方式与微调阶段验证方式
生成式语言模型,如GPT-3、BERT等,在预训练和微调阶段都需要进行验证以确保模型性能。下面分别介绍这两个阶段的验证方式: 预训练阶段的验证: 预训练阶段通常使用大量未标注的文本数据来训练模型,以学习语言的一般特性。…
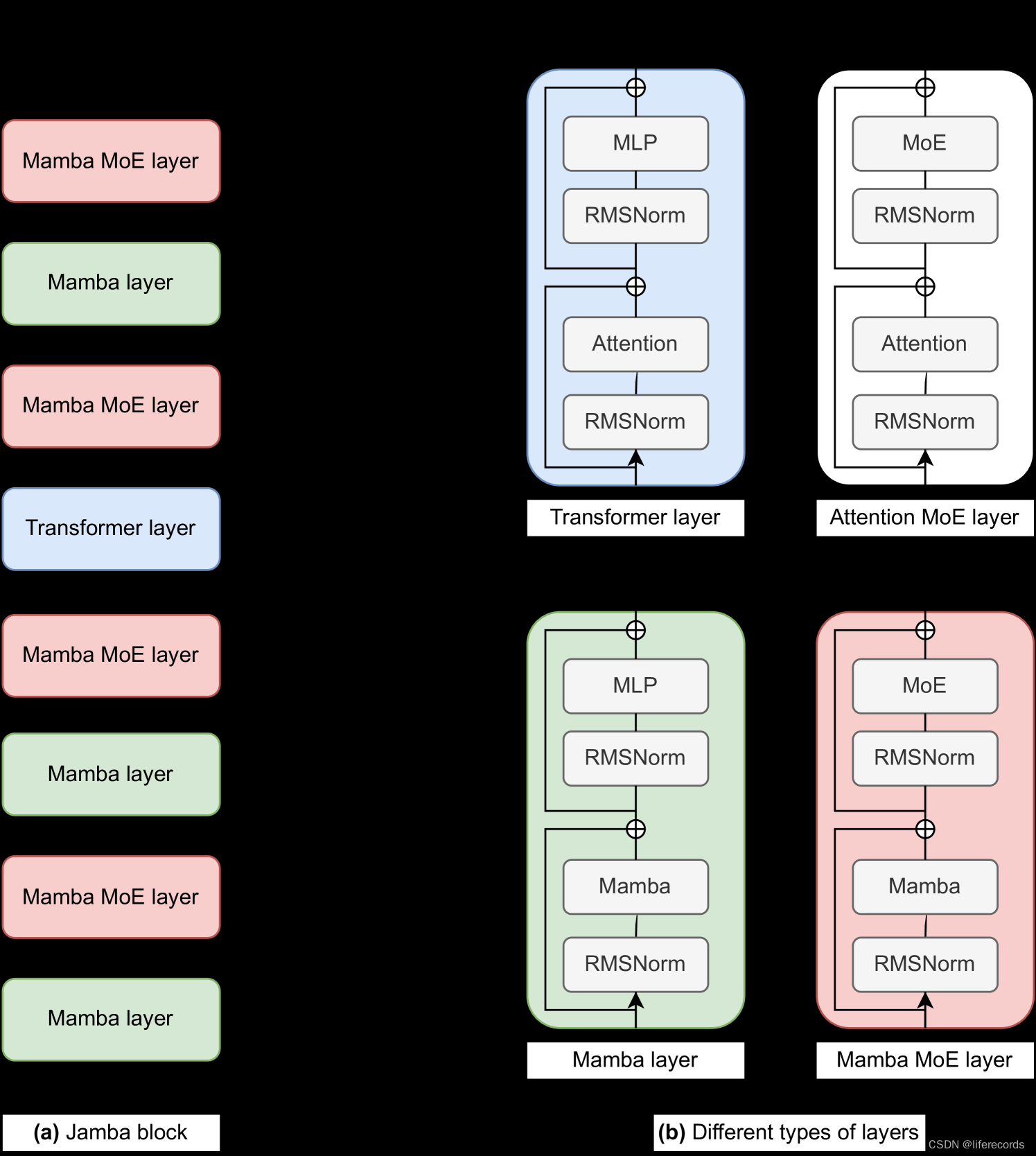
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba: A Hybrid Transformer-Mamba Language Model 相关链接:arXiv 关键字:hybrid architecture、Transformer、Mamba、mixture-of-experts (MoE)、language model 摘要
我们介绍了Jamba,一种新的基于新颖混合Transformer-Mamba混合专家&am…

『大模型笔记』LLMs入门:从头理解与编码LLM的自注意力机制
LLMs入门:从头理解与编码LLM的自注意力机制 这里直接引用我语雀上的的文章:《从头理解与编码LLM的自注意力机制》
大模型面试准备(十一):怎样让英文大语言模型可以很好的支持中文?
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这…
大语言模型LLM《提示词工程指南》学习笔记03
文章目录 大语言模型LLM《提示词工程指南》学习笔记03链式提示思维树检索增强生成自动推理并使用工具自动提示工程师Active-Prompt方向性刺激提示Program-Aided Language ModelsReAct框架Reflexion多模态思维链提示方法基于图的提示大语言模型LLM《提示词工程指南》学习笔记03 …