检测点
Shell脚本
javaweb
熵
插件的定义和使用
控制算法
LED
多态和虚函数的使用底层实现原理
illustrator
cve分析与复现
html静态页面
同步锁
文档协作
训练数据
HAL库
信号完整性仿真
大模型
git reflog
权限控制
directMemorty
目标检测
2024/4/11 14:37:39
度量学习综述、目标检测综述、图像检索综述
参考链接:https://zhuanlan.zhihu.com/p/449626899 参考链接:https://mp.weixin.qq.com/s/jLnde0Xms-99g4z16OE9VQ 参考链接:https://zhuanlan.zhihu.com/p/441553547

Yolov8优化: 多分支卷积模块RFB,扩大感受野提升小目标检测精度
1.RFB-Net介绍 论文:https://arxiv.org/pdf/1711.07767.pdf 代码:GitHub - GOATmessi7/RFBNet: Receptive Field Block Net for Accurate and Fast Object Detection, ECCV 2018 受启发于人类视觉的Receptive Fields结构,本文提出RFB…

win10下yolov5 tensorrt模型部署
TensorRT系列之 Win10下yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov7 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov6 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov5 tensorrt模型加速部署…
YOLOv5/YOLOv7改进:全网原创首发 | 多尺度空洞注意力(MSDA) | 中科院一区顶刊 DilateFormer 2023.9
💡💡💡本文全网首发独家改进:多尺度空洞注意力(MSDA)采用多头的设计,在不同的头部使用不同的空洞率执行滑动窗口膨胀注意力(SWDA),全网独家首发,创新力度十足,适合科研 1)与C3结合;2)作为注意力MSDA使用;
推荐指数:五星
多尺度空洞注意力(MSDA) | 亲…

双目视觉实战---三维重建基础与极几何
目录
一,简介
二. 双视图与三角化
1. 三角化模型
2. 多视图几何的关键问题
3、极几何 三、本质矩阵
四、基础矩阵
3. 基础矩阵的作用及小结
五、基础矩阵估计 一,简介
三维重建是指通过一系列的图像或传感器数据,推导出物体或场景的…
YOLOv7改进策略:SCConv空间和通道重建卷积,即插即用,助力检测 | CVPR2023 SCConv
💡💡💡本文改进:SCConv(空间和通道重建卷积),一个即插即用的架构单元,可以可以直接用来替代各种卷积神经网络中的标准卷积。
SCConv | 亲测在多个数据集能够实现涨点 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现…
目标检测YOLO实战应用案例100讲-基于改进YOLO v7的智能振动分拣系统开发(续)
目录
3.2 引入EIOU损失函数
3.2.1 CIOU损失函数
3.3.2 基于Focal-EIOU损失函数的网络优化 编辑
一步一步介绍如何使用 DLIB 训练自定义对象检测器并制作手势控制的程序源码
文末附测试代码下载链接 在本文中,您将学习如何使用 AI 构建基于 Python 的手势控制应用程序。我们将通过分步说明全程指导您。我相信您会在本教程中获得很多乐趣并学到许多有用的概念。
具体来说,您将学习以下内容: 如何使用 Dlib 训练自定义手部检测器。如何通过图像处理…

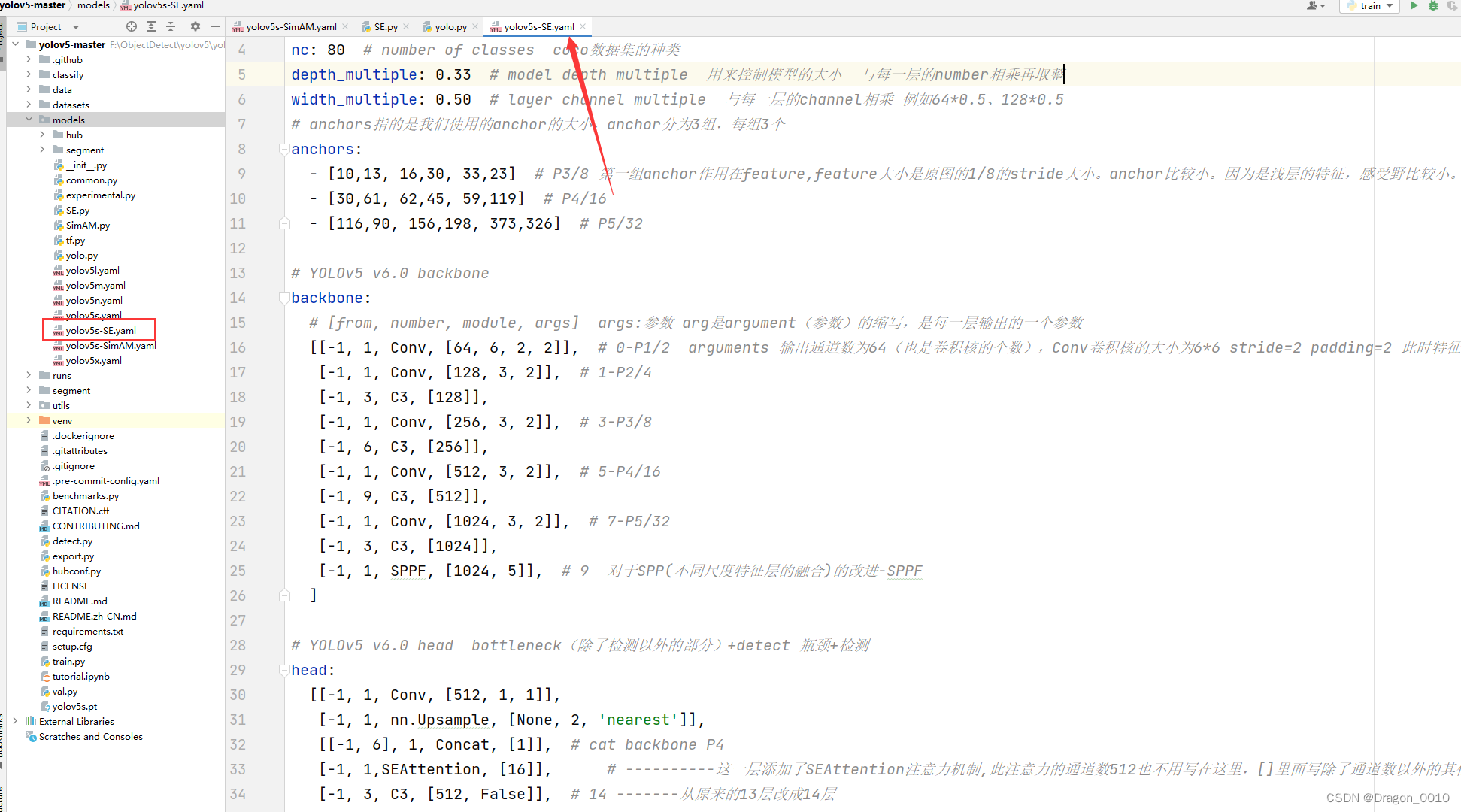
yolov5模型代码怎么修改
yaml配置文件
深度乘积因子 宽度乘积因子 所有版本只有这两个参数的不同,s m l x逐渐加宽加深 各种类型层参数对照 backbone里的各层,在这里解析,只需要改.yaml里的各层参数就能控制网络结构
修改网络结构
第一步:把新加的模块…

YOLOv5:按每个类别的不同置信度阈值输出预测框
YOLOv5:按每个类别的不同置信度阈值输出预测框 前言前提条件相关介绍YOLOv5:按每个类别的不同置信度阈值输出预测框预测修改detect.py输出结果 验证修改val.py输出结果 参考 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更…
目标检测:各个检测网络的差异
two-stage:R-CNN、Fast R-CNN、Faster R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题);
one-stage:YOLO将物体检测作为一个回归问题进行求解…
WaveletPool:抗混叠在微小目标检测中的重要性
文章目录 摘要1、简介2、相关研究2.1、微小物体检测2.2. 抗锯齿过滤器3、方法3.1. Wavelet Pooling3.2 一致顺序的Wavelet Pooling的WaveCNet3.3、Bottom-Heavy Backbone4、实验4.1、预训练数据集4.2、微小目标检测数据集4.3、抗混叠方法的选择及应用顺序4.4、小波的选择4.5、T…
目标检测:Proposal-Contrastive Pretraining for Object Detection from Fewer Data
论文作者:Quentin Bouniot,Romaric Audigier,Anglique Loesch,Amaury Habrard
作者单位:Universit Paris-Saclay; Universit Jean Monnet Saint-Etienne; Universitaire de France (IUF)
论文链接:http://arxiv.org/abs/2310.16835v1
内容…
YOLOv8改进主干DenseNet系列:设计核心最新提出DenseOne密集网络,从另一个视角改进YOLO目标检测模型,打造高性能检测器
💡该教程为改进进阶指南,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 降低改进难度,改进多种结构演示💡本篇文章基于 YOLOv8改进主干DenseNet系列:设计核心最新提出DenseOne密集网络,从另一个视角改进YOLO目标检测模型,打造高性能检测器。重点:…
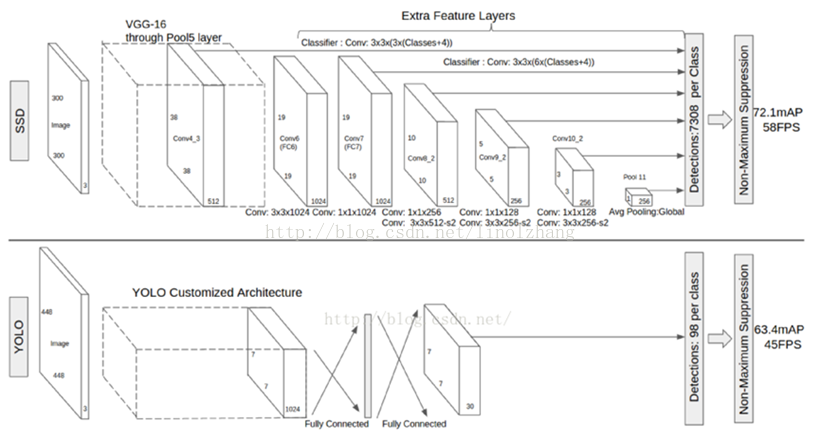
基于深度学习的目标检测DET - SSD
SSD: Single Shot MultiBox Detector, 是一个end to end 的目标检测识别模型。先小八卦下,它属于google派系,它的作者也是googlenet的作者。该模型旨在高精度的快速识别, 它不用额外计算bounding box而能达到相当的识别精度,而且速…
优化改进YOLOv5算法之添加DCNv3模块,有效提升目标检测效果
目录 前言
1 DCNv3原理
1.1 DCNv2
1.2 DCNv3
1.3 模型架构
2 YOLOv5算法中加入DCNv3模块
人工智能学习07--pytorch22--目标检测:YOLO V3 SPP
视频链接: https://www.bilibili.com/video/BV1t54y1C7ra/?vd_sourceb425cf6a88c74ab02b3939ca66be1c0d
yolov3 spp
spp:空间金字塔池化
trick:实现的小技巧,方法。( up:Bag of Freebies里有很多trick&…
Yolov8改进CoTAttention注意力机制,效果秒杀CBAM、SE
1.CoTAttention 论文地址:2107.12292.pdf (arxiv.org)
CoTAttention网络是一种用于多模态场景下的视觉问答(Visual Question Answering,VQA)任务的神经网络模型。它是在经典的注意力机制(Attention Mechanism…
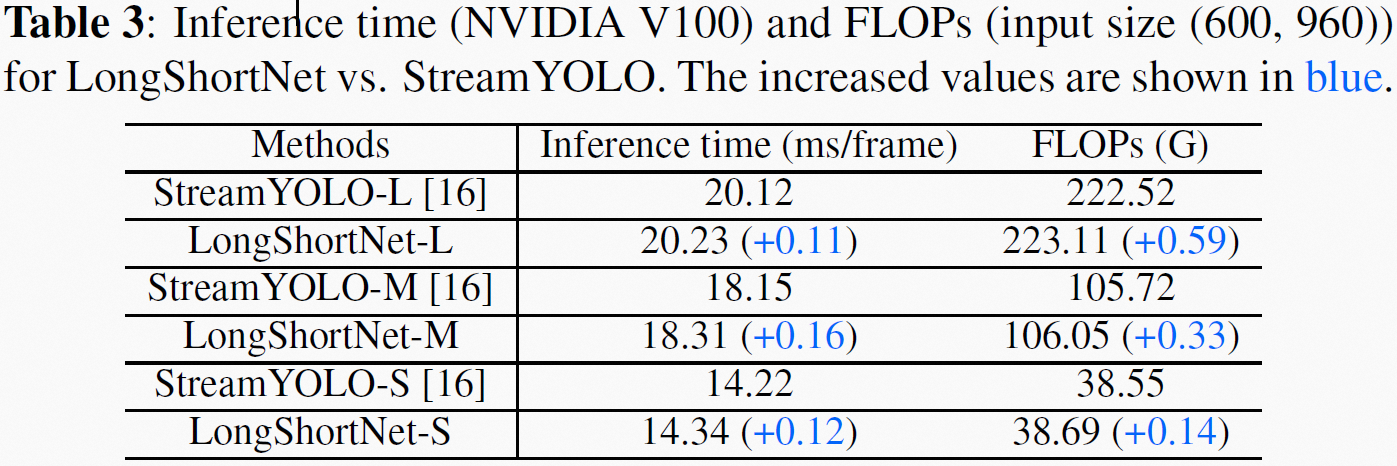
【达摩院OpenVI】基于流感知的视频目标检测网络LongShortNet
论文&代码
论文链接:[arxiv]代码&应用: 开源代码:[github code]开源应用:[modelscope]
背景介绍
传统视频目标检测(Video Object Detection, VOD)任务以一段视频作为输入,利用视频的…
YOLOv7优化策略:IOU系列篇 | 引入MPDIoU,WIoU,SIoU,EIoU,α-IoU等创新
💡💡💡本文独家改进:MPDIoU,WIoU,SIoU,EIoU,α-IoU等二次创新,总有一种适合你的数据集
MPDIoU,WIoU,SIoU,EIoU,α-IoU | 亲测在多个数据集能够实现大幅涨点
收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现 …
label studio导入本地数据集同时邀请他人标注
文章目录 一、前言二、导入数据集2.1.设置环境变量2.2.启动label studio2.3.1激活label studio安装的环境2.3.2.启动label studio 2.3.设置clould storage2.3.1.新建项目2.3.2.开始设置clould storage 三、分享给他人标注3.1.开放端口3.2.查看ip3.3.生成链接 一、前言
上次写博…

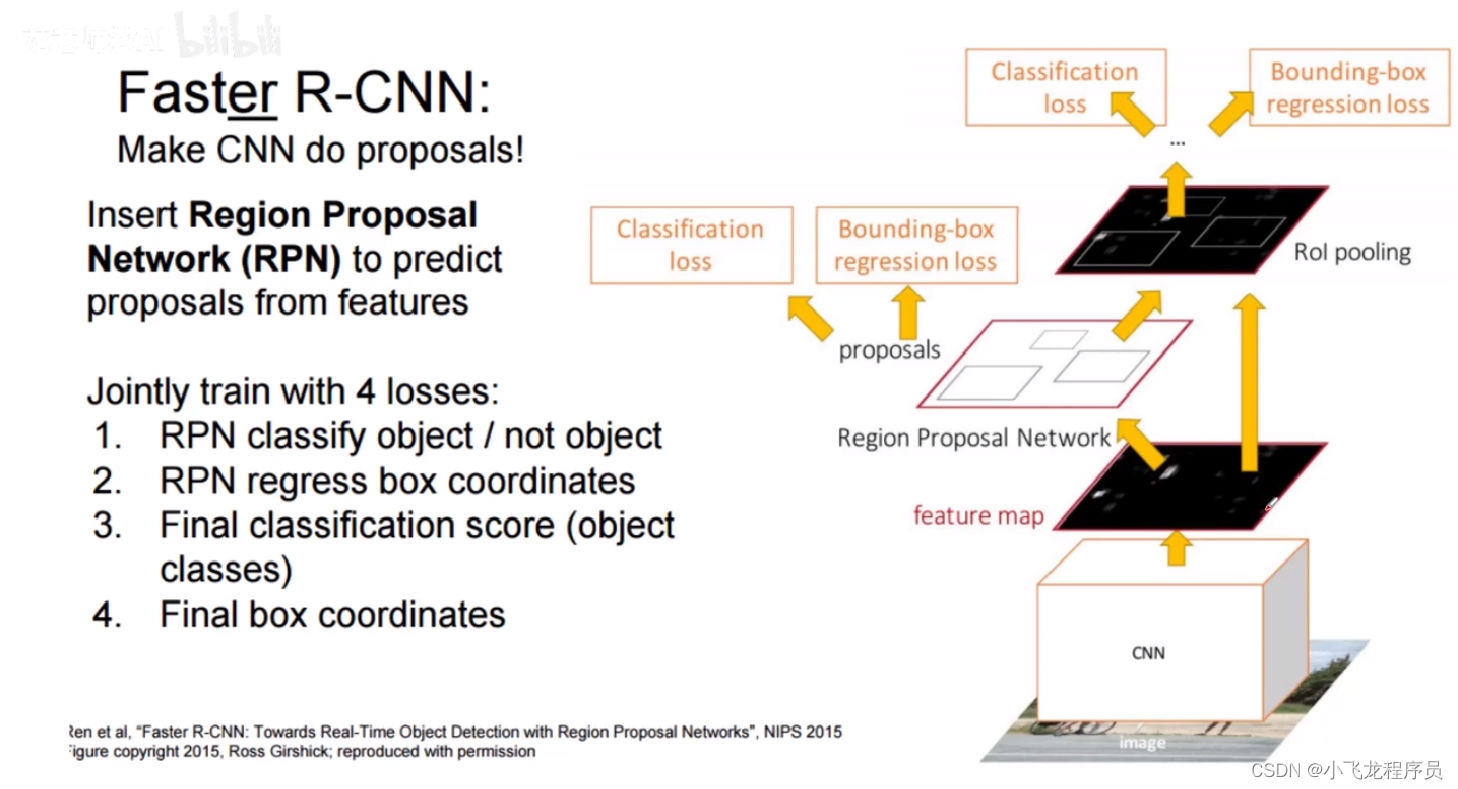
Faster RCNN系列2——RPN的真值与预测值概述
Faster RCNN系列:
Faster RCNN系列1——Anchor生成过程 Faster RCNN系列2——RPN的真值与预测值概述 Faster RCNN系列3——RPN的真值详解与损失值计算 Faster RCNN系列4——生成Proposal与RoI Faster RCNN系列5——RoI Pooling与全连接层 对于目标检测任务…

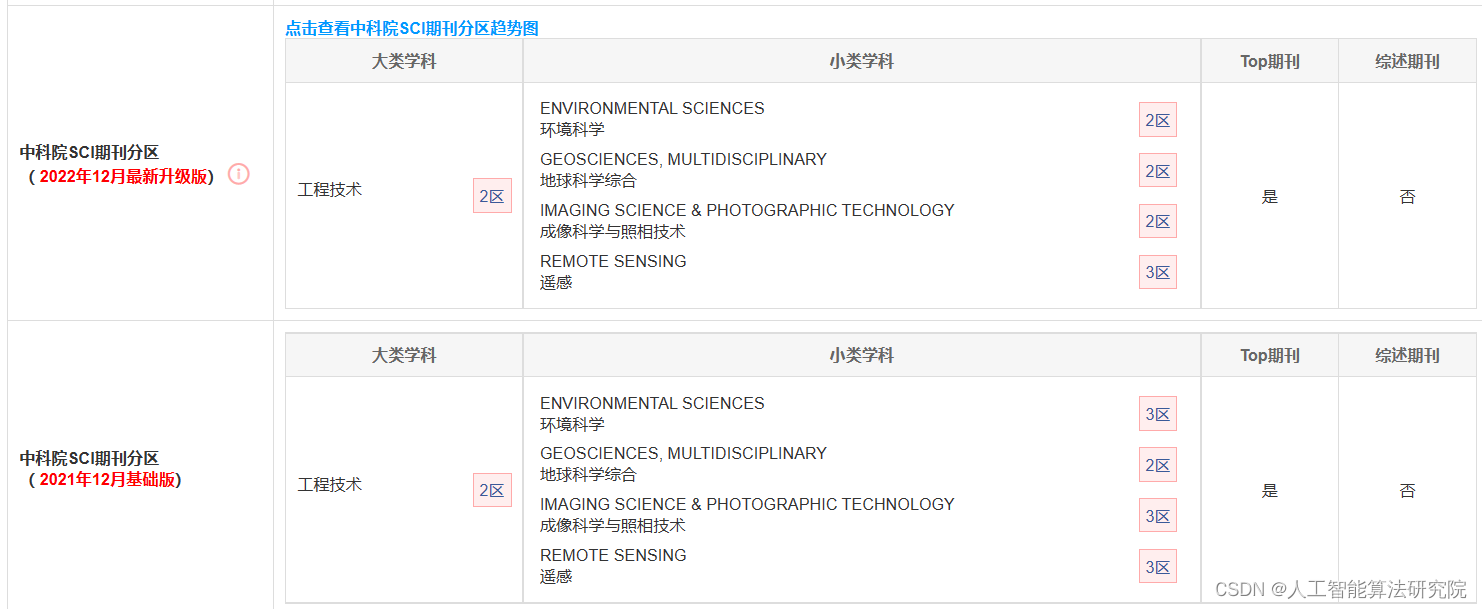
【27】核心易中期刊推荐——计算机工程与技术
🚀🚀🚀NEW!!!核心易中期刊推荐栏目来啦 ~ 📚🍀 核心期刊在国内的应用范围非常广,核心期刊发表论文是国内很多作者晋升的硬性要求,并且在国内属于顶尖论文发表,具有很高的学术价值。在中文核心目录体系中,权威代表有CSSCI、CSCD和北大核心。其中,中文期刊的数…
RT-DERT:在实时目标检测上,DETRs打败了yolo
文章目录 摘要1、简介2. 相关研究2.1、实时目标检测器2.2、端到端目标检测器2.3、用于目标检测的多尺度特征3、检测器的端到端速度3.1、 NMS分析3.2、端到端速度基准测试4、实时DETR4.1、模型概述4.2、高效的混合编码器4.3、IoU-aware查询选择4.4、RT-DETR的缩放5、实验5.1、设…
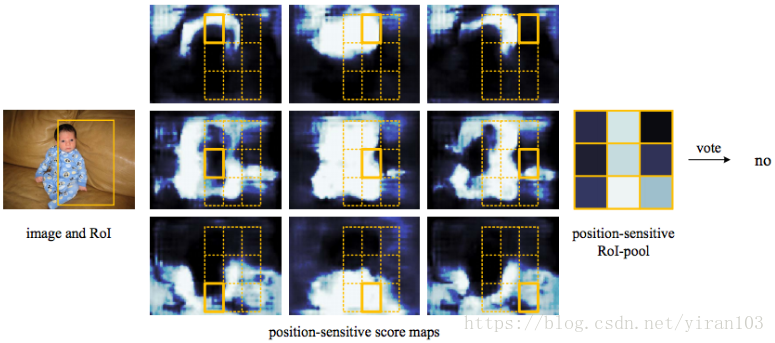
R-FCN 与 Position Sensitive ROI Pooling
Faster R-CNN 通过与 RPN 共享特征图提高了整个检测过程的速度。然而,其第2阶段仍保留 Fast R-CNN 的处理手法,将数百区域逐一送入子网络。R-FCN 在 RoI 间亦共享特征,减少了区域处理的计算量。在采用 ResNet-101 作为基础网络时,…
DETR系列:RT-DETR(一) 论文解析
论文:《DETRs Beat YOLOs on Real-time Object Detection》 2023.4
DETRs Beat YOLOs on Real-time Object Detection:https://arxiv.org/pdf/2304.08069.pdf
源码地址:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/conf…

实现Fast sigmoid和Softmax
Sigmoid 函数介绍 Sigmoid 函数(Logistic 函数)是神经网络中非常常用的激活函数,它的数学表示如下: 由于 e x e^x ex幂运算是非常耗时的计算,因此尝试通过替换sigmoid中的 e x e^x ex运算,来提高运行效率,同…
YOLOv5独家首发改进新主干:改进版目标检测新范式骨干PPHGNetv2,百度PaddlePaddle出品,有效提升YOLOv5检测器检测精度
💡本篇内容:YOLOv5独家首发改进新主干:改进版目标检测新范式骨干PPHGNetv2,百度PaddlePaddle出品,有效提升YOLOv5检测器检测精度
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv5专…

《RT-DETR改进实战》专栏介绍 专栏目录
《RT-DETR改进实战专栏》介绍及目录 介绍:欢迎来到最新专栏《RT-DETR改进实战》!这个专栏专注于基于 YOLOv8 项目的魔改版本,而不是百度飞桨框架中的 RT-DETR。
本专栏为想通过改进 RT-DETR 算法发表论文的同学设计。每篇文章均包含完整的改…

记录使用yolov5进行旋转目标的检测
由于实习公司需要使用到旋转目标的检测,所以这几天学习了相关知识,并找了许多资料,饶了许多的弯路。下面记录下项目的整个实现过程。
我参考的是以下几位博主:
DOTAv2遥感图像旋转目标检测竞赛经验分享(Swin Transfo…
英文论文(sci)解读复现【NO.9】基于注意机制的葡萄叶片病害检测
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…

基于深度学习的小目标检测方法综述
随着深度学习的发展,基于深度学习的目标检测技术取得了巨大的进展,但小目标由于像素少,难以提取有效信息,造成小目标的检测面临着巨大的困难和挑战. 为了提高小目标的检测性能,研究人员从网络结构、训练策略、数据处理…
综述----知识蒸馏
4.1 模型改进
未来的研究可以集中在改进无图学习模型的性能和泛化能力。例如,可以研究更有效的知识表示和传递方法,以提高学生模型对教师模型知识的理解和利用能力。此外,可以探索新的模型结构和训练算法,以提高模型的效率和稳定…
CV计算机视觉每日开源代码Paper with code速览-2023.10.23
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Zone Evaluation: Revealing Spatial Bias i…
036、目标检测-锚框
之——对边缘框的简化
目录
之——对边缘框的简化
杂谈
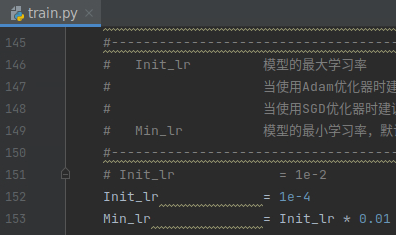
正文
1.锚框操作
2.IoU交并比
3.锚框标号
4.非极大值抑制
5.实现
拓展 杂谈 边缘框这样一个指定roi区域的操作对卷积神经网络实际上是很不友好的,这可能会对网络感受野提出一些特定的要求࿰…
YOLOv3模型原理深度解析
概况
(1)YOLOv3是YOLO系列第一次引入残差连接来解决深度网络中的梯度消失问题(是不是第一次,有待你后面考证),实际用的backbone是DarkNet53
(2)最显著的改进,也是对你涨…
目标检测按照多类一起和单个类进行NMS操作
def non_max_suppression(prediction, conf_thres0.25, iou_thres0.45, classesNone, agnosticFalse, multi_labelFalse, labels(), max_det300): 四.将所有的类别框当做一个类别进行nms c x[:, 5:6] * (0 if agnostic else max_wh) # classes boxes, scores x[:, :4] c…

改进 YOLO V5 的密集行人检测算法研究(论文研读)——目标检测
改进 YOLO V5 的密集行人检测算法研究(2021.08)摘 要:1 YOLO V52 SENet 通道注意力机制3 改进的 YOLO V5 模型3.1 训练数据处理改进3.2 YOLO V5 网络改进3.3 损失函数改进3.3.1 使用 CIoU3.3.2 非极大值抑制改进4 研究方案与结果分析4.1 实验…
附录2-tensorflow目标检测
源码来自作者Bubbliiiing,我对参考链接的代码略有修改,网盘地址
链接:百度网盘 请输入提取码 提取码:dvb1
目录
1 参考链接
2 环境
3 数据集准备
3.1 VOCdevkit/VOC2007
3.2 model_data/voc_classes.txt
3.3 voc_an…
【OrientedRepPoints】Oriented RepPoints for Aerial Object Detection核心点概括
论文地址:https://arxiv.org/abs/2105.11111 翻译:https://blog.csdn.net/songyuc/article/details/128227048
一、概述
航空目标的特点: (1)非正轴对齐且具有任意方向 (2)背景噪声杂乱
论文…

YOLOv5改进实战 | GSConv + SlimNeck双剑合璧,进一步提升YOLO!
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…

YOLOv5算法改进(16)— 增加小目标检测层 | 四头检测机制(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。小目标检测层是指在目标检测任务中用于检测小尺寸目标的特定网络层。由于小目标具有较小的尺寸和低分辨率,它们往往更加难以检测和定位。YOLOv5算法的检测速度与精度较为平衡,但是对于小目标的检测效果不佳,根据一些论文,我们可以通过增加检…

论文阅读 Memory Enhanced Global-Local Aggregation for Video Object Detection
Memory Enhanced Global-Local Aggregation for Video Object Detection
Abstract
人类如何识别视频中的物体?由于单一帧的质量低下,仅仅利用一帧图像内的信息可能很难让人们在这一帧中识别被遮挡的物体。我们认为人们识别视频中的物体有两个重要线索&…

激光点云3D目标检测算法之CenterPoint
激光点云3D目标检测算法之CenterPoint 本文首发于公众号【DeepDriving】,欢迎关注。 前言
CenterPoint是CVPR 2021的论文《Center-based 3D Object Detection and Tracking》中提出的一个激光点云3D目标检测与跟踪算法框架,与以往算法不同的是ÿ…

第1篇 目标检测概述 —(3)YOLO系列算法
前言:Hello大家好,我是小哥谈。YOLO(You Only Look Once)系列算法是一种目标检测算法,主要用于实时物体检测。相较于传统的目标检测算法,YOLO具有更快的检测速度和更高的准确率。YOLO系列算法的核心思想是将…
树莓派 Raspberry Pi 与YOLOv8 结合进行目标检测
文章大纲 使用树莓派摄像头 提供视频流前置文章libcamera树莓派安装与部署YOLOv8硬件需求 PrerequisitesYOLO Version: YOLOv5 or YOLOv8硬件的选择,树莓派5的YOLOv8支持呼之欲出,Hardware Specifics: At a GlanceYOLOv8 在树莓派上的配置与安装Install Necessary PackagesIn…
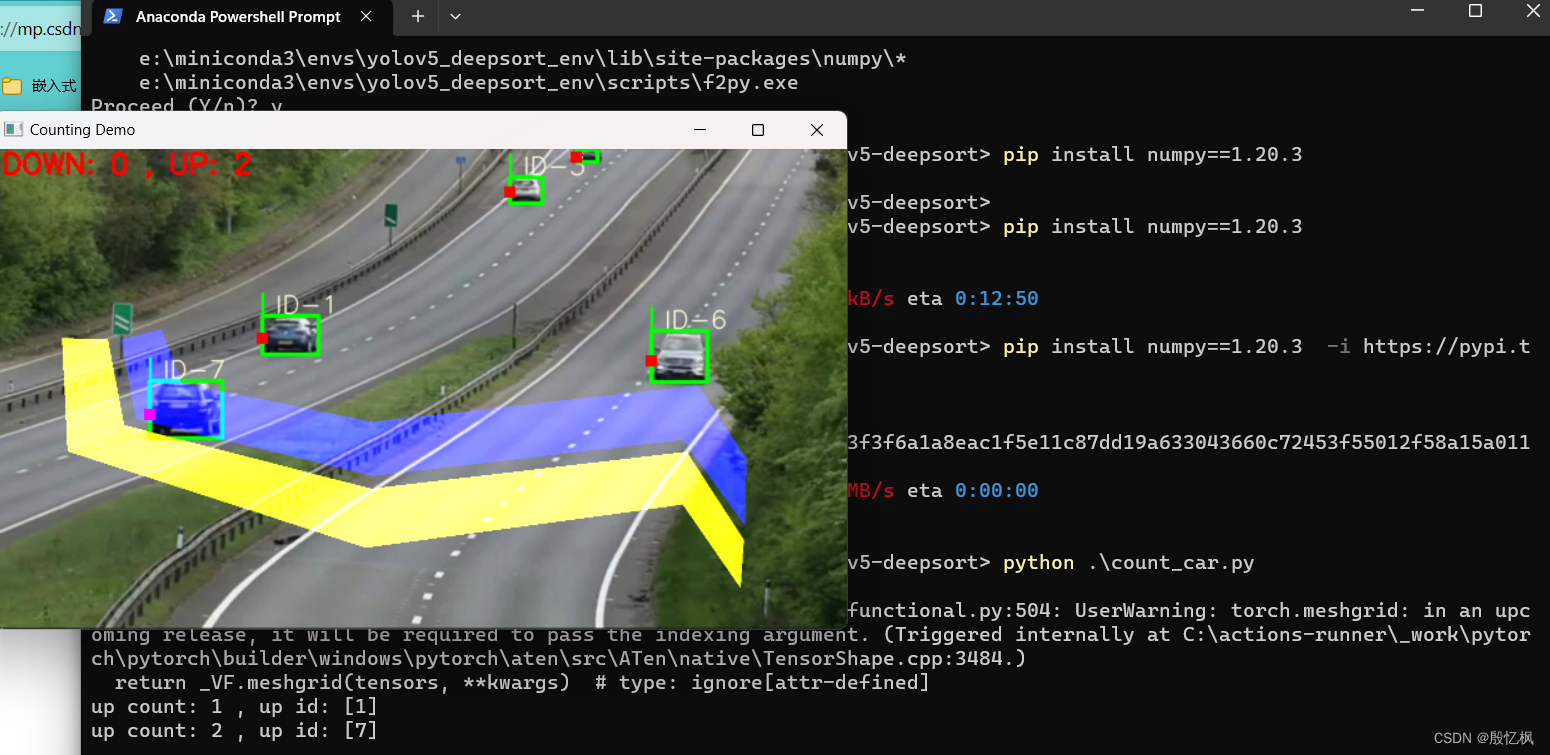
AI项目八:yolo5+Deepsort实现目标检测与跟踪(CPU版)
若该文为原创文章,转载请注明原文出处。
一、DeepSORT简介 DeepSORT 是一种计算机视觉跟踪算法,用于在为每个对象分配 ID 的同时跟踪对象。DeepSORT 是 SORT(简单在线实时跟踪)算法的扩展。DeepSORT 将深度学习引入到 SORT 算法中…
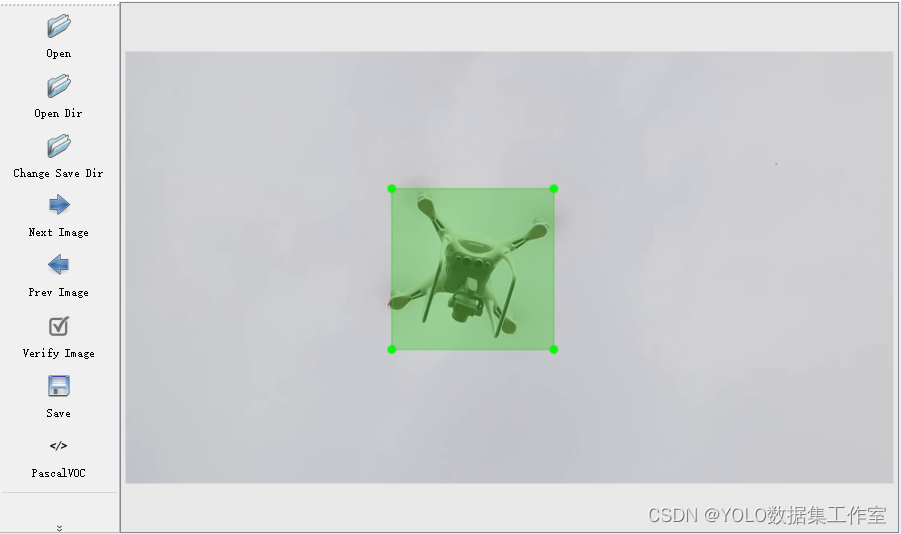
YOLO目标检测——无人机检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:无人机识别数据集说明:无人机检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三种格式标签…
电子计算机出口欧盟标准检测及指令解析
算数一直是人们交易的有效凭证,同时也是自然科学的必经之路,过去人们会使用算盘等工具进行数字的计算,但其不仅上手困难,算数的大小和速度也有很大的局限性,随着电子产品的发展,计算器的出现不仅解决了路边…

行为分析(商用级别)02 -快速搭建项目成品环境,直接落地,demo演示
以下链接是个人关于行为分析(商用级别)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。文末附带 公…

YOLOv8改进实战 | 更换主干网络Backbone(五)之2023最新轻量化主干网络VanillaNet,深度学习中极简主义的力量
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…
yolo源码注释2——数据集配置文件
代码基于yolov5 v6.0 目录:
yolo源码注释1——文件结构yolo源码注释2——数据集配置文件yolo源码注释3——模型配置文件yolo源码注释4——yolo-py
数据集配置文件一般放在 data 文件夹下的 XXX.yaml 文件中,格式如下:
path: # 数据集存放路…
目标检测应用场景和发展趋势
参考:
目标检测的未来是什么? - 知乎 (zhihu.com)https://www.zhihu.com/question/394900756/answer/32489649815大应用场景 1 行人检测:
遮挡问题:行人之间的互动和遮挡是非常常见的,这给行人检测带来了挑战。非刚性…
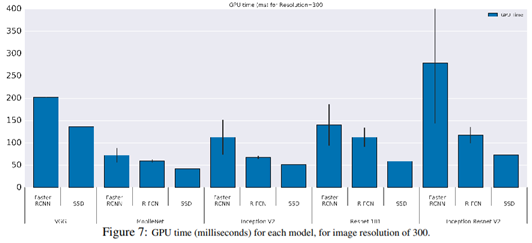
YOLOv5 vs YOLOv6 vs YOLOv7目标检测模型速度和准确度的性能比较——深入研究
如果您正在进行目标检测项目,您很可能会选择众多 YOLO 模型中的一种。从现有的 YOLO 对象检测模型的数量来看,如何选择最佳模型是一个艰难的选择。
您可能会发现自己正在考虑: 选择哪种 YOLO 模型以获得最佳 FPS? CPU 与 GPU 的推理速度如何?选择哪种 GPU?微型、小型、…
中国玩具安全标准介绍GB6675测试哪些项目?哪些玩具要做GB6675测试
GB6675 中国玩具安全标准介绍GB6675测试哪些项目?哪些玩具要做GB6675测试
最受小朋友们欢迎的东西,莫过于玩具了!世界各地都能见到玩具的身影,而玩具的测试的标准也不尽相同。目前在国内,玩具上各大商城平台是要做检测…

【计算机设计大赛】国赛一等奖项目分享——基于多端融合的化工安全生产监管可视化系统
文章目录 一、计算机设计大赛国赛一等奖二、项目背景三、项目简介四、系统架构五、系统功能结构六、项目特色(1)多端融合(2)数据可视化(3)计算机视觉(目标检测) 七、系统界面设计&am…

更快更准 | YOLOv3算法超详细解析(包括诞生背景+论文解析+技术原理等)
前言:Hello大家好,我是小哥谈。YOLOv3是一种基于深度学习的目标检测算法,它可以快速而准确地在图像中检测出多个目标。它是由Joseph Redmon和Ali Farhadi在2018年提出的,是YOLO(You Only Look Once)系列算法…

List转csv、真实框标注数据可视化操作
问题:先前博客有提到获取labelimg标注真实框的宽高、归一化数据存入列表当中之后,怎么用plt模块将其表示出来? 解决:将list转csv之后,再结合matplotlib将其用坐标表示出来 话不多说: 步骤一:获取csv文件&am…

改进YOLOv5小目标检测:构建多尺度骨干和特征增强模块,提升小目标检测
构建多尺度骨干和特征增强模块,提升小目标检测 背景代码使用配置文件如下🔥🔥🔥 提升小目标检测,创新提升
🔥🔥🔥 测试在小目标数据集进行提点
👉👉👉: 新设计的创新想法,包含详细的代码和说明,具备有效的创新组合
🐤🐤🐤 1. 本文包含两个创新改…

【论文翻译】Frustratingly Simple Few-Shot Object Detection
Frustratingly Simple Few-Shot Object Detection 简单小样本目标检测
论文地址:https://arxiv.org/pdf/2003.06957.pdf
代码地址:GitHub - ucbdrive/few-shot-object-detection: Implementations of few-shot object detection benchmarks
Abstract …

Spiking-YOLO:脉冲神经网络高效的目标检测
Spiking-YOLO: Spiking Neural Network for Energy-Efficient Object Detection |AAAI 2020 Spiking-YOLO:脉冲神经网络高效的目标检测AbstractIntroductionRelated workDNN-to-SNN conversionObject detectionMethodsChannel-wise data-based normalizationConventional norma…
收集的运动目标检测,阴影检测的标准测试视频
转载自:http://www.cnblogs.com/easymind223/archive/2013/02/26/2933523.html 一个网友收集的运动目标检测,阴影检测的标准测试视频 http://blog.csdn.net/sunbaigui/article/details/6363390 很权威的change detection检测视频集,里面有将近…
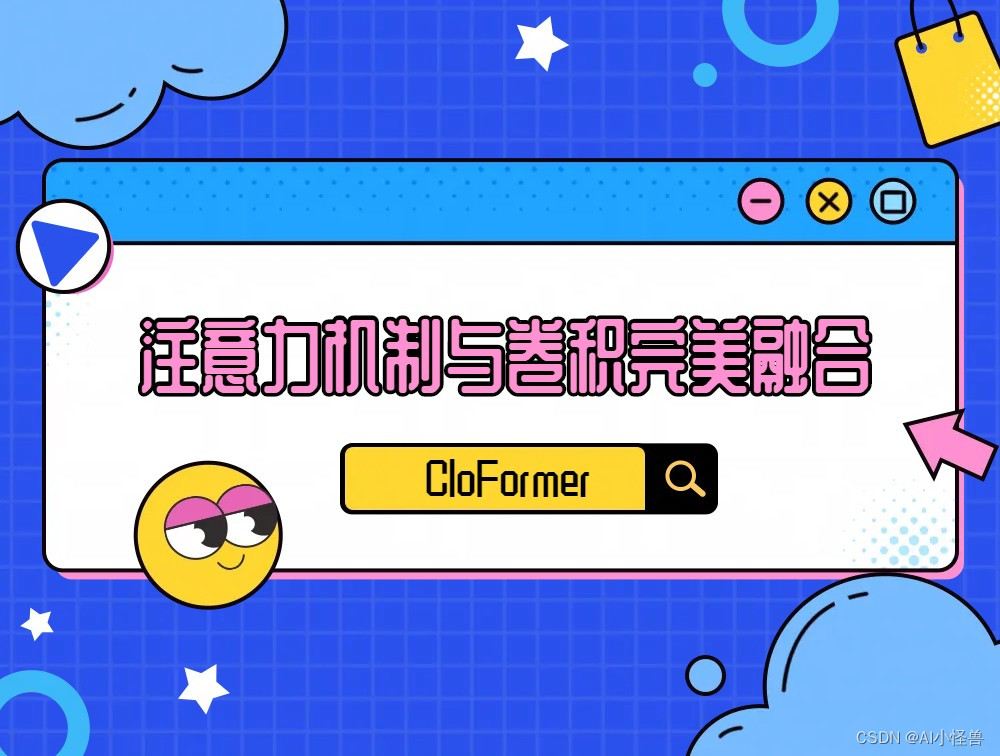
Yolov8优化:最新移动端高效网络架构 CloFormer: 注意力机制与卷积的完美融合 | 清华团队2023 即插即用系列
💡💡💡本文属于原创独家改进:引入CloFormer 中的 AttnConv,上下文感知权重使得模型能够更好地适应输入内容。相比于局部自注意力机制,引入共享权重使得模型能够更好地处理高频信息,从而提高性能。
注意力机制与卷积的完美融合 AttnConv | 亲测在多个数据集能够实现…

计算机视觉 Computer Vision Chaper11 图像分割
文章目录语义分割反卷积反池化跳层结构Skip-Layer构建FCNDeepLabDeepLab V1CRF 条件随机场DeepLab V2DeepLab V3数据集语义分割 传统CNN就是全连接层,太多权重参数,而且丢失了图像的空间信息。但是注意FC在英语里,全卷积fully convolutional …

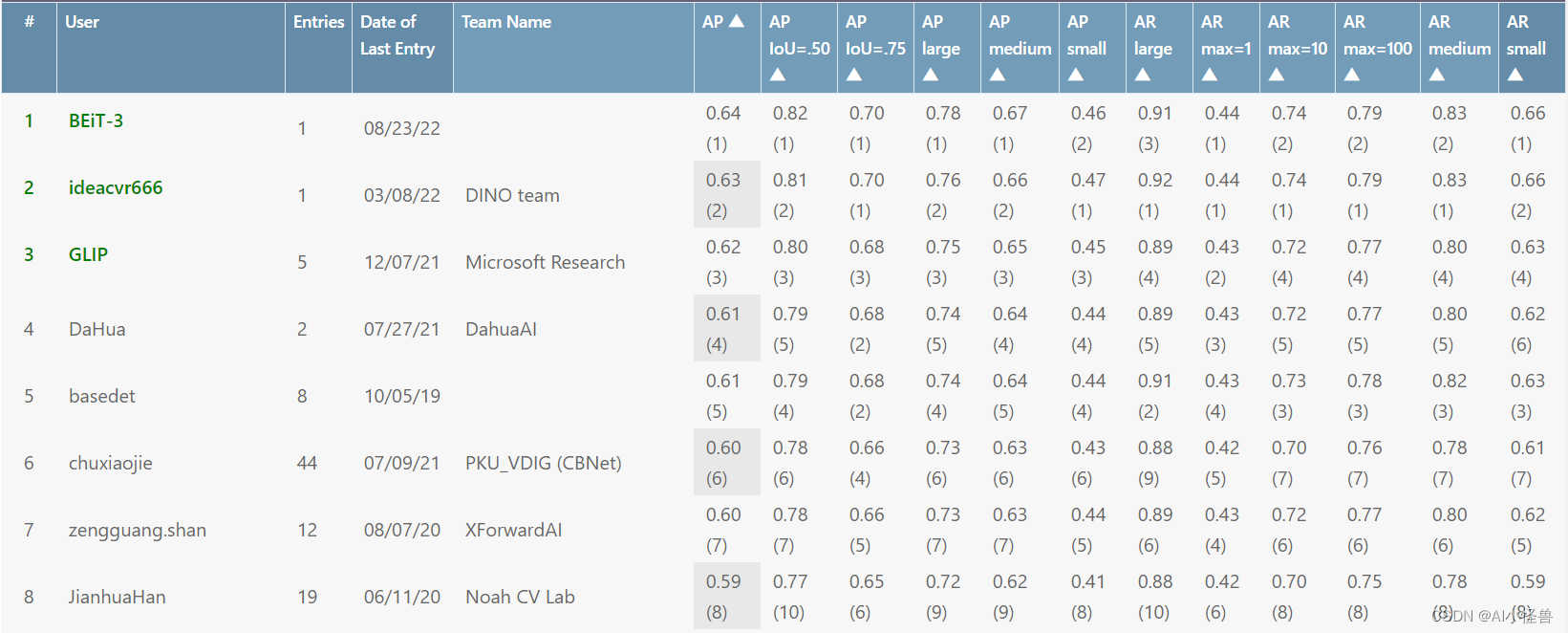
COCO评估输出指定某类AP或者输出每个类别AP结果
一 输出单类AP(不需要修改pycocotools)
coco_eval.py源代码
"""
COCO-Style Evaluations"""import json
import osimport argparse
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOevaldef eval(coco_gt, image_ids…

【目标检测】雷达目标CFAR检测算法
目录一、概述1、基本概念2、基础知识二、CFAR检测算法1、基本原理2、几种典型的CFAR检测算法(1)CA(Cell Averaging)-CFAR检测算法(2)GO-CFAR、SO-CFAR检测算法(3)OS-CFAR检测算法(4) 补充说明三、不同CFAR检…
yolov测试各项指标的流程:
yolov测试各项指标的流程: 载入模型, 其中包括类别数等; 按照 batch_size 逐张图片进行预测 得到预测标签: predn 和 实际标签 labelsn, 其中 末尾的 n 表示经过了原图适配的 bbox坐标. predn: {tensor: (3,6)},表示预测到了3个标签, 表示[x1, y1, x2, y2, confidence

【canny边缘检测】canny边缘检测原理及代码详解
文章目录前言canny边缘检测算法主要流程一、高斯模糊二、图像梯度计算三、非极大值抑制四、双阈值边界跟踪前言
本文通过介绍canny边缘检测原理与代码解析,希望能让大家深入理解canny边缘检测 canny边缘检测算法主要流程
canny边缘检测主要分为4个部分,…

【目标检测】Dynamic Head Unifying Object Detection Heads with Attentions
文章目录一、背景二、方法2.1 scale-aware attention2.2 spatial-aware attention2.3 task-aware attention2.4 总体过程2.5 和现有的检测器适配2.6 和其他注意力机制的关联三、效果四、代码论文链接:
https://arxiv.org/pdf/2106.08322.pdf代码链接:htt…
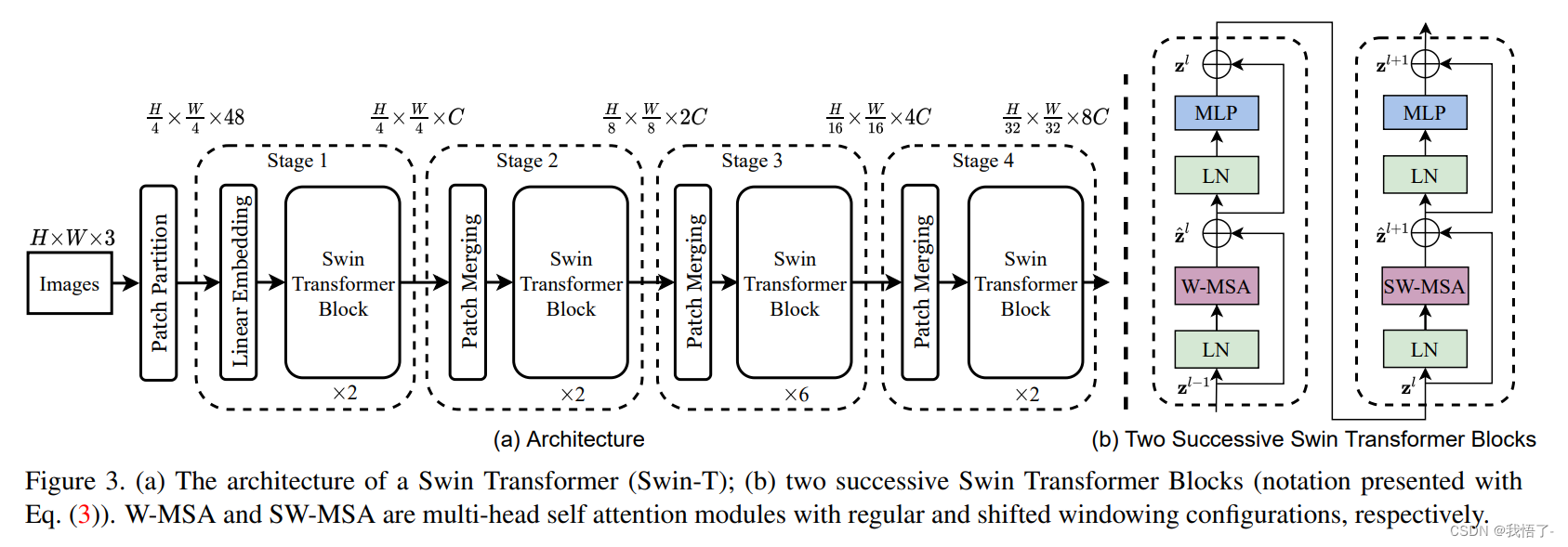
目标检测算法改进系列之Backbone替换为Swin Transformer
Swin Transformer简介
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》作为2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机…
javacv基础02-调用本机摄像头并预览摄像头图像画面视频
引入架包: <dependency><groupId>org.openpnp</groupId><artifactId>opencv</artifactId><version>4.5.5-1</version></dependency><dependency><groupId>org.bytedeco</groupId><artifactId…
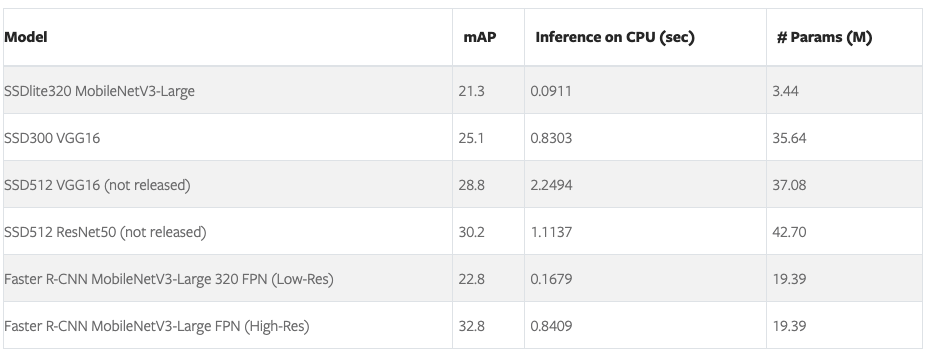
高性能、高适配,SSD 孪生兄弟出场即 C 位
内容导读 PyTorch 1.9 同步更新了一些库,包括 TorchVision 中新增的 SSD 和 SSDlite 模型,与 SSD 相比,SSDlite 更适用于移动端 APP 开发。 SSD 全称 Single Shot MultiBox Detector,是一种用于目标检测的单次检测算法,…
YOLOv8改进:损失函数改为SIOU、EIOU、WIOU、Focal-IOU、a-IOU
目录
1.介绍
1.1 IOU
1.2 SIOU
1.3 WIOU
2.替换 IoU 3.替换WIOU 1.介绍
1.1 IOU
在机器学习领域,损失函数(Loss Function)是衡量模型预测值和真实值之间差异的函数。在训练期间,模型会尝试最小化损失函数的值&#…
Yolov5 C++ GPU部署方式介绍:ONNX Runtime
1. ONNX和Tensorrt区别
ONNX Runtime 是将 ONNX 模型部署到生产环境的跨平台高性能运行引擎,主要对模型图应用了大量的图优化,然后基于可用的特定于硬件的加速器将其划分为子图(并行处理)。
ONNX的官方网站:https://…

YOLO目标检测——Kylberg纹理数据集下载分享
Kylberg纹理数据集共同4640图片,可应用于:纹理分类与识别、材料识别与质检、医学图像分析、地质勘探与地表覆盖分类等等 数据集点击下载:YOLO目标检测Kylberg纹理数据集4640图片.rar
抗混叠在微小目标检测中的重要性
文章目录 摘要1、简介2、相关研究2.1、微小物体检测2.2. 抗锯齿过滤器3、方法3.1. Wavelet Pooling3.2 一致顺序的Wavelet Pooling的WaveCNet3.3、Bottom-Heavy Backbone4、实验4.1、预训练数据集4.2、微小目标检测数据集4.3、抗混叠方法的选择及应用顺序4.4、小波的选择4.5、T…
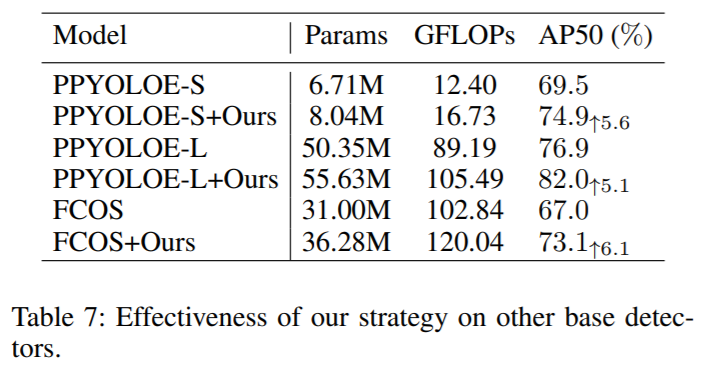
论文阅读:YOLOV: Making Still Image Object Detectors Great at Video Object Detection
发表时间:2023年3月5日 论文地址:https://arxiv.org/abs/2208.09686 项目地址:https://github.com/YuHengsss/YOLOV
视频物体检测(VID)具有挑战性,因为物体外观的高度变化以及一些帧的不同恶化。有利的信息…

行人检测0-02:LFFD-白话给你讲论文-翻译无死角(1)
以下链接是个人关于LFFD(行人检测)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。文末附带\color…
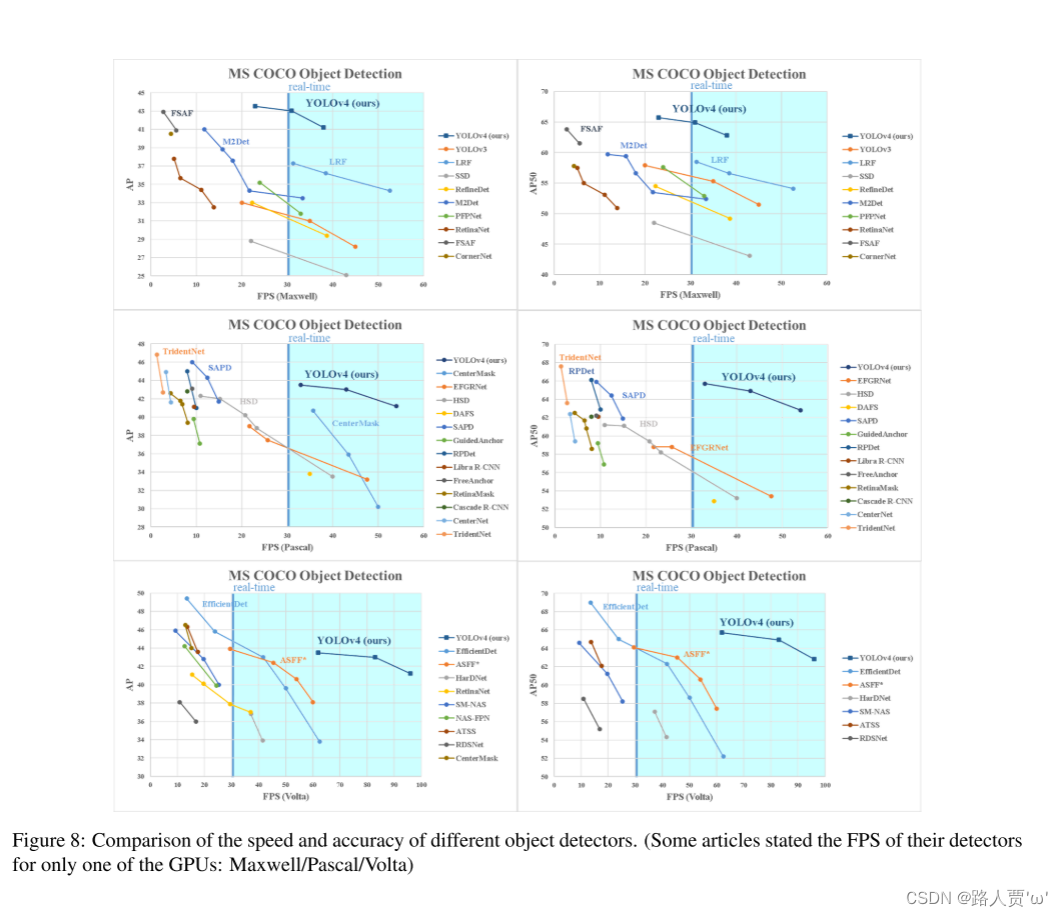
【YOLO系列】YOLOv4论文超详细解读1(翻译 +学习笔记)
前言 经过上一期的开篇介绍,我们知道YOLO之父Redmon在twitter正式宣布退出cv界,大家都以为YOLO系列就此终结的时候,天空一声巨响,YOLOv4闪亮登场!v4作者是AlexeyAB大神,虽然换人了,但论文中给出…

YOLO系列目标检测算法——PP-YOLOE
YOLO系列目标检测算法目录 - 文章链接 YOLO系列目标检测算法总结对比- 文章链接 YOLOv1- 文章链接 YOLOv2- 文章链接 YOLOv3- 文章链接 YOLOv4- 文章链接 Scaled-YOLOv4- 文章链接 YOLOv5- 文章链接 YOLOv6- 文章链接 YOLOv7- 文章链接 PP-YOLO- 文章链接 …
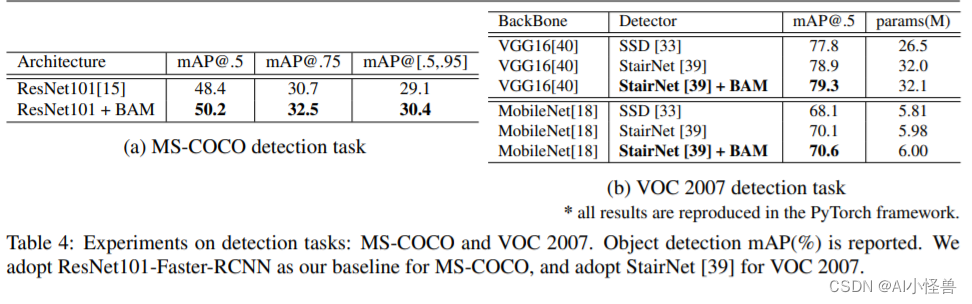
YoloV5/YoloV7改进---注意力机制:引入瓶颈注意力模块BAM,对标CBAM
目录 1.BAM介绍 2.BAM引入到yolov5
2.1 加入common.py中: 2.2 加入yolo.py中:
2.3 yolov5s_BAM.yaml 1.BAM介绍 论文:https://arxiv.org/pdf/1807.06514.pdf 摘要:提出了一种简单有效的注意力模块,称为瓶颈注意力模块…

【YOLOv8/YOLOv7/YOLOv5/YOLOv4/Faster-rcnn系列算法改进NO.59】引入ASPP模块
前言作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍&…
yolov5目标检测算法解析:基础网络模块
Yolov5的模型定义分两个阶段,分别是基础模块设计阶段和完整模型搭建阶段。基础模块设计阶段,是基于pytorch架构的基本神经网络算子,进一步构造成具有特定功能和含义的自定义神经网络模块。完整模型搭建阶段,是通过结构化文件&…
电热取暖器申请一份CE认证检测报告需要怎么做解析
目前各种不同类型的电热取暖器,造型别致、功能完善、使用方便, 成了家庭消费时尚电器。电热取暖器出口欧盟需办理CE认证。 CE认证是欧盟有关安全管控的认证,确保产品最基本的安全保障,即只限于产品不危及人类、动物和货品的安全方…
YOLOv7损失函数改进:MPDIoU新型边界框相似度度量,效果秒杀GIoU 、 DIoU 、CIoU 、 EIoU等 | ELSEVIER 2023
💡💡💡本文改进:MPDIoU新型边界框相似度度量,优化当预测框与真实框具有相同的长宽比,但宽度和高度值完全不同时的问题,大多数(GIoU 、 DIoU 、CIoU 、 EIoU)现有的边界框回归损失函数无法优化
MPDIoU | 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升…

基于深度学习的目标检测模型综述
基于深度学习的目标检测模型综述 一 概论目标检测主要挑战评估指标 二 展望 一 概论
目标检测是目标分类的自然延伸,目标分类仅旨在识别图像中的目标。目标检测的目标是检测预定义类的所有实例并通过轴对齐的框提供其在图像中的初略定位。检测器应能够识别所有目标…
目标检测YOLO实战应用案例100讲-基于YOLOv5自适应损失权重的生活垃圾目标检测模型
目录
前言
2 YOLOv5模型及其相关理论基础
2.1 交并比损失
2.1.1 IoU损失
2.1.2 GIoU损失

低分辨率图像中目标检测(附论文下载)
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 论文地址:https://arxiv.org/pdf/2201.02314.pdf 计算机视觉研究院专栏 作者:Edison_G 超分辨率(SR)等…
目标检测笔记(十一):如何结合特定区域进行目标检测(基于OpenCV的人脸检测实例)
文章目录 背景代码结果 背景
由于我们在做项目的时候可能会涉及到某个指定区域进行目标检测或者人脸识别等任务,所以这篇博客是为了探究如何在传统目标检测的基础上来结合特定区域进行检测,以OpenCV自带的包为例。
一般来说有两种方式实现区域指定&…

YOLOv5的置信度阀值与iou阀值及P R详解
conf_thres
Confidence Threshold,置信度阈值。 只显示预测概率超过conf_thres的预测结果。 想让YOLO只标记可能性高的地方,就把这个参数提高。 iou_thres
Intersect over Union Threshold,交并比阈值。 IOU值:预测框大…
C# Onnx PP-Vehicle 车辆分析(包含:车辆检测,识别车型和车辆颜色)
目录
效果
模型信息
mot_ppyoloe_s_36e_ppvehicle.onnx
vehicle_attribute_model.onnx
项目
代码
下载
其他 C# Onnx PP-Vehicle 车辆分析(包含:车辆检测,识别车型和车辆颜色)
效果 模型信息
mot_ppyoloe_s_36e_ppvehi…
[深度学习][数据集][目标检测]工程车辆数据集16881张15种类别车辆介绍
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):16881 标注数量(xml文件个数):16881 标注类别数:16 标注类别名称:["chanche",…
目标检测YOLO实战应用案例100讲-基于改进的 YOLOv8 小目标检测(续)
目录
3.2基于可变形卷积的目标检测
3.2.1可变形卷积介绍
3.2.2改进方法
3.3基于注意力机制的目标检测 <
sahi切片辅助训练推理
本文的目的切片yolov5标注格式的数据,并保存图片和标注文件
代码实现步骤如下
把yolov5格式转换成coco格式标签;切片图片和coco标签;把切片出来的coco标签转换回yolov5标签格式
# 1. 把yolov5格式转换成coco格式标签;
# 2. 切片…
特征金字塔网络 FPN
一. 提出背景论文:Feature Pyramid Networks for Object Detection 【点击下载】在传统的图像处理方法中,金字塔是比较常用的一种手段,像 SIFT 基于金字塔做了多层的特征采集,对于深度网络来讲,其原生的卷积网络特征决…

YOLO目标检测——无人机航拍行人检测数据集下载分享【含对应voc、coc和yolo三种格式标签】
实际项目应用:智能交通管理、城市安防监控、公共安全救援等领域数据集说明:无人机航拍行人检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,…

YOLOv5源码中的参数超详细解析(3)— 训练部分(train.py)| 模型训练调参
前言:Hello大家好,我是小哥谈。YOLOv5项目代码中,train.py是用于模型训练的代码,是YOLOv5中最为核心的代码之一,而代码中的训练参数则是核心中的核心,只有学会了各种训练参数的真正含义,才能使用YOLOv5进行最基本的训练。🌈 前期回顾: YOLOv5源码中的参数超详细解析…
【最新】Jetson Agx Xavier烧录环境到TensorRT加速(高集成,快速简单有效)
一.下载烧录好的基础镜像
1. 基础环境
当前镜像包是ubuntu18.08,镜像。镜像包已安装jetpack 4.6,python3.6 ,torch1.7, opencv, tensorrt等,运行模型的基本环境都已搭建。jetpack 是4.6 对应L4T是32.6.1。如下图: (1).下载当前文件包&…
YOLOv7独家改进:分层特征融合策略MSBlock | 南开大学提出YOLO-MS |超越YOLOv8与RTMDet,即插即用打破性能瓶颈
💡💡💡本文独家改进:分层特征融合策略MSBlock,不同Kernel-Size卷积在不同尺度提升特征提取能力,最终引入到YOLOv7,做到二次创新
1)MSBlock使用
推荐指数:5颗星
MSBlock | 亲测在多个数据集能够实现大幅涨点,小目标检测效果也不错
💡💡💡Yolov8魔术师,…
目标检测YOLO系列从入门到精通技术详解100篇-【图像处理】目标检测
目录
几个高频面试题目
如何在超大分辨率的图片中检测目标?
1当超大分辨率图像邂逅目标检测任务
2You Only Look Twice

重新标记ImageNet:从全局标签到局部标签(附github代码及论文)
欢迎关注“计算机视觉研究院”计算机视觉研究院专栏作者:Edison_GImageNet可以说是最受欢迎的图像分类基准,但它也是一个具有显著噪声的标签。最近的研究表明,许多样本包含多个类,尽管被假定为单个标签基准。因此,他们…

YOLO目标检测——泄露检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:泄露检测数据集说明:泄露检测数据集,真实场景的高质量图片数据,数据场景丰富,含多个类别标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yo…
YOLOv8改进实战 | 更换损失函数之MPDIOU(2023最新IOU)篇
前言
YOLOv8官方默认损失函数采用的是CIoU。本章节主要介绍如何将MPDIoU损失函数应用于目标检测YOLOv8模型。 目录 一、MPDIoU二、代码实现添加损失函数更换损失函数一、MPDIoU 论文链接:MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression MPDIoU是一种基于…

《YOLOv8魔术师》专栏介绍 CSDN独家改进创新实战专栏目录
💡💡💡Yolov8魔术师,独家首发创新(原创),持续更新,最终完结篇数≥100,适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码࿰…
基于PaddleX实现电梯电瓶车检测
基于PaddleX实现电梯电瓶车检测一、项目背景二、数据集简介1. 数据获取2. 解压数据集和安装第三方库3. COCO2VOC4. 将pascal-voc和coco2017中的摩托车数据提取出来5. 将文件路径写入.txt三、模型选择与开发1. 安装paddlex2. 数据加载与预处理3. 模型选择4. 模型训练四、效果展示…
制作目标检测训练样本的方案
1.做感受野分析,确定能够检测目标边长范围
这一步得自己算。现成的网络都能搜到别人算好的结果,拿来直接用。
2. 用最终特征图的尺寸反推训练样本图像的尺寸
这一步也得自己算。有了目标边长范围,选择大于目标框最大边长2倍左右的训练样本…
YOLO、YOLOv2、YOLO9000和YOLOv3的发展过程
YOLO
yolo的基本思想是使用一个端到端的CNN直接预测目标的类别和位置,相对two-stage,yolo实时性高,但检测精度低。YOLO每个边界框只预测两个框,主体结构GoogLeNet,由24个卷积层和2个FC层组成。
YOLOv2
YOLOv2针对yo…
目标检测里的mAP计算过程和原理
经过检测模型以后,得到了所有图片的预测框,对于某一个图片,某个类,计算预测框和真实框之间的IOU值,并得到每一个预测框最大的IOU值和对应的真实框
这个要遍历每个图片每个类,共存在两个循环
然后对于最大…
深度学习目标检测分类学习率调整策略
初始的学习率为lr,可以在前面的0.8*num_epochs,学习率下降到 lr*0.1,然后在0.9*num_epochs下降到 lr*0.01;
也可以多次下降,0.4642,下降6次,0.4642**60.010005316163952237,0.4642*…

【备品备件】入库流程--采购入库--0180363009
本地测试环境:admin admin123 备品备件的入库流程有五种流程,每种流程对应的查询条件都不一样。
类型对应页面查询条件字段采购入库ProcurementWarehousing.vue内向交货单reNumberSap跨公司调拨入库CrossCompanyWarehousing.vue交货单号reNumberSap赠…
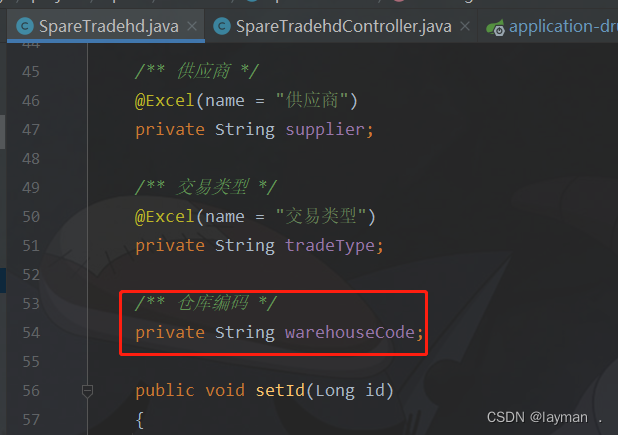
【备品备件需求】--入库记录查询增加仓库字段
最近同事交接的系统,有需求改动。
但是我完全看不懂他写的代码,好在需求不是很复杂,只是改下查询条件,如果是动流程,增单据,那我可能就不行了。
需求1:入库查询条件中增加仓库筛选
需求图如下…

适用于目标检测的数据增强方法
论文《Learning Data Augmentation Strategies for Object Detection》研究了适用于目标检测的数据增强策略。该论文的思路和《AutoAugment: Learning Augmentation Strategies from Data》一样,选择一些常用的数据增强方法组成不同的策略,然后使用离散空…
python提取COCO,VOC数据集中特定类,实现xml转coco(voc转coco)格式
python提取COCO,VOC数据集中特定类,实现xml转coco(voc转coco)格式
主要是踩坑(搜索)记录,已使用成功。 参考博客和github链接贴在文章末尾。如果使用过程中有问题,请留言告知,感谢各位大佬指正…

Yolov8轻量化:EMO,结合 CNN 和 Transformer 的现代倒残差移动模块设计,性能优于EdgeViT、Mobile-former等网络
论文: https://arxiv.org/pdf/2301.01146.pdf 🏆🏆🏆🏆🏆🏆Yolo轻量化模型🏆🏆🏆🏆🏆🏆 重新思考了 MobileNetv2 中高效的倒残差模块 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,归纳抽象了 MetaMobile Block 的一般…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】SLAM(基础篇)(三)
目录
前言
移动机器人视觉SLAM回环检测
01 回环检测问题描述
02 主流回环检测方法
2.1 根据路标点先验信息
阅读YOLO的基本概念,了解目标检测的基本原理
1. YOLO概述
YOLO(You Only Look Once)是一种实时目标检测算法,通过将目标检测任务转化为回归问题,一次性预测图像中所有目标的边界框和类别。
2. 目标检测基本原理 目标检测任务:从图像中检测和定位图像中的目标物体…
![[目标检测系列]ATSS: Bridging the Gap Between Anchor-based and Anchor-free Detection via ATSS(CVPR2020)](https://img-blog.csdnimg.cn/6d1e2b5a939f4571a11a242fc2716189.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5YeM6Z2S5769,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)
[目标检测系列]ATSS: Bridging the Gap Between Anchor-based and Anchor-free Detection via ATSS(CVPR2020)
论文链接:https://arxiv.org/pdf/1912.02424v4.pdf 代码链接:https://github.com/sfzhang15/ATSS 已经加入mmdetection:https://github.com/open-mmlab/mmdetection/tree/master/configs/atss 文章主要是在寻找造成 anchor-based 和 anchor-free 之间性能…
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(二)
目录 前言总体设计系统整体结构图系统流程图 运行环境爬虫模型训练实际应用 模块实现1. 数据准备1)爬虫下载原始图片2)手动筛选图片 相关其它博客工程源代码下载其它资料下载 前言
本项目通过爬虫技术获取图片,利用OpenCV库对图像进行处理&a…
YOLOv8-seg改进:复现HIC-YOLOv5,HIC-YOLOv8-seg助力小目标分割
🚀🚀🚀本文改进:HIC-YOLOv8-seg:1)添加一个针对小物体的额外预测头,以提供更高分辨率的特征图2)在backbone和neck之间采用involution block来增加特征图的通道信息;3)在主干网末端加入 CBAM 的注意力机制;
🚀🚀🚀HIC-YOLOv8-seg小目标分割检测&复杂场景…
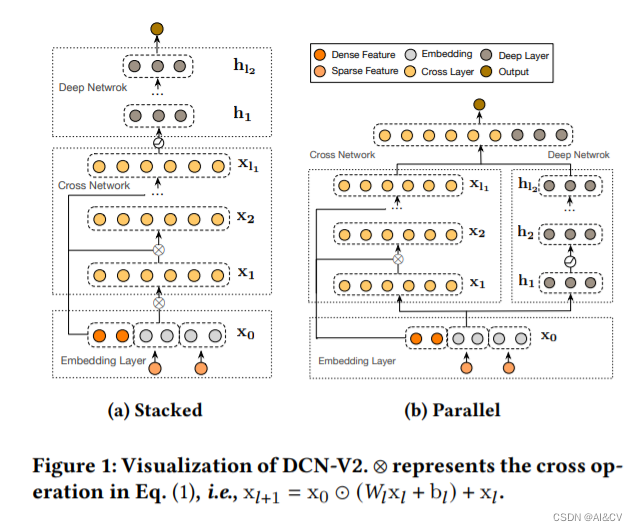
涨点技巧:卷积变体DCNV2引入Yolov8,助力小目标涨点
1.DCN V2介绍
DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
论文:https://arxiv.org/abs/2008.13535 作者通过在DCN的基础上,增加了2个创新点,分别是调制模块和使用多个调制后的DCN模块,从形成了DCN的升级版…
YOLOv7改进:全网原创首发 | 多尺度空洞注意力(MSDA) | 中科院一区顶刊 DilateFormer 2023.9
💡💡💡本文全网首发独家改进:多尺度空洞注意力(MSDA)采用多头的设计,在不同的头部使用不同的空洞率执行滑动窗口膨胀注意力(SWDA),全网独家首发,创新力度十足,适合科研 1)作为注意力MSDA使用;
推荐指数:五星
多尺度空洞注意力(MSDA) | 亲测在多个数据…
YOLOv8涨点技巧:手把手教程,注意力机制如何在不同数据集上实现涨点的工作,内涵多种网络改进方法
💡💡💡本文独家改进:手把手教程,解决注意力机制引入到YOLOv8在自己数据集不涨点的问题点,本文提供五种改进方法来解决此问题;
ContextAggregation | 亲测在血细胞检测项目中涨点,…

基于深度学习的高精度动物园动物检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度动物园动物(水牛、斑马、大象、水豚、海龟、猫、奶牛、鹿、狗、火烈鸟、长颈鹿、捷豹、袋鼠、狮子、鹦鹉、企鹅、犀牛、羊、老虎)检测识别系统可用于日常生活中或野外来检测与定位动物园动物,利用深度学…
Yolov5/Yolov7改进---注意力机制:self-attention实现涨点的同时,能够大幅减少参数量和计算量
目录
1.Stand-Alone Self-Attention 介绍
Self-Attention 2.Yolov5引入AttentionConv, AttentionStem
2.1 修改common.py中
2.2 注册yolo.py
2.3 yolov5s_Atten

opencv 案例05-基于二值图像分析(简单缺陷检测)
缺陷检测,分为两个部分,一个部分是提取指定的轮廓,第二个部分通过对比实现划痕检测与缺角检测。本次主要搞定第一部分,学会观察图像与提取图像ROI对象轮廓外接矩形与轮廓。
下面是基于二值图像分析的大致流程
读取图像将图像转换…

YOLO目标检测——背包检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:各种背包检测数据集说明:背包检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三种格式标签…
YOLOv7改进:小目标遮挡物性能提升(SEAM、MultiSEAM),涨点神器!!!
💡💡💡本文属于原创独家改进:
SEAM注意力机制较好的解决了物体遮挡问题;
同时考虑到遮挡物一般为小目标,因此提出了MultiSEAM注意力,解决小目标遮挡问题;
SEAM、MultiSEAM | 亲测在多个小目标数据集实现暴力涨点,强烈推荐,独家首发; 收录:
YOLOv7高阶自研…
目标检测指标(IOU、TP、FP、FN、FP、AP、AR、maxDets等)解释
1、iou、tp、fp、fn、fp、查准率ap、查全率ar:https://blog.csdn.net/hsqyc/article/details/81702437 2、COCO、VOC目标检测评价指标:https://blog.csdn.net/qq_40310050/article/details/121234145

最近邻插值的原理及实现
1. 介绍
插值算法一般用来做上采样和下采样,最邻近插值算法,是插值算法中最简单的一种。 最邻近插值:将每个目标像素找到距离它最近的原图像素点,然后将该像素的值直接赋值给目标像素。 优点: 实现简单,计算速度快 缺点:插值结果缺乏连续性,可能会产生锯齿状的边缘,对…

YOLOV8改进:更换为MPDIOU,实现有效涨点
1.该文章属于YOLOV5/YOLOV7/YOLOV8改进专栏,包含大量的改进方式,主要以2023年的最新文章和2022年的文章提出改进方式。 2.提供更加详细的改进方法,如将注意力机制添加到网络的不同位置,便于做实验,也可以当做论文的创新点。 2.涨点效果:更换为MPDIOU,实现有效涨点! 目录…
YOLOv7首发最新改进结构:极简高效,改进升级版UniRepLKNet(博客内附源代码),适用于图像识别,即插即用打破性能瓶颈
💡本篇内容:YOLOv7最新结构改进:首发最新改进,极简高效,RepLKNet改进升级版UniRepLKNet(博客内附源代码),适用于图像识别,即插即用打破性能瓶颈
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二…
YOLOv8独家原创改进: AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv | 2023年11月最新发表
💡💡💡本文全网首发独家改进:可改变核卷积(AKConv),赋予卷积核任意数量的参数和任意采样形状,为网络开销和性能之间的权衡提供更丰富的选择,解决具有固定样本形状和正方形的卷积核不能很好地适应不断变化的目标的问题点,效果秒殺DSConv 1)AKConv替代标准卷积进行…
基于Yolov5/Yolov7微小目标检测---上下文信息CAM,微小目标涨点明显
1.微小目标检测介绍
微小目标检测是指在图像或视频中检测出尺寸较小的目标物体。这种技术在智能监控、遥感图像分析、自动驾驶等领域有着广泛的应用。由于微小目标往往占据图像中很小的一部分,因此对于算法的鲁棒性和精度要求都较高。当前的微小目标检测算法主要包括基于深度…
水牙线申请UL检测报告检测项目和标准解析
水牙线又称为冲牙器是一种清洁口腔的辅助性工具,利用脉冲水流冲击的方式来清洁牙齿、牙缝的一种工具,主要有便携式,台式,一般冲洗压力在0到90psi。水牙线出口需要做UL检测报告。
美国是一个对安全要求非常严格的国家,…

对抗网络之目标检测应用:A-Fast-RCNN
对抗网络之目标检测应用:A-Fast-RCNN论文:A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection 【点击下载】Caffe代码:【Github】一. 深度学习正确的打开方式深度学习的根基在于样本,大量的样本决定了深度…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】单目视觉估计
目录
前言
算法原理
单目3D目标检测新网络
GUP module以及HTL
单目深度估计
数据集介绍
2.1 KITTI
人工智能 - 目标检测:发展历史、技术全解与实战
目录 一、早期方法:滑动窗口和特征提取滑动窗口机制工作原理 特征提取方法HOG(Histogram of Oriented Gradients)SIFT(Scale-Invariant Feature Transform) 二、深度学习的兴起:CNN在目标检测中的应用CNN的…
[数据集][目标检测]大象数据集VOC+yolo格式376张1类别
数据集制作单位:未来自主研究中心(FIRC) 数据集格式:Pascal VOC格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):376 标注数量(xml文件个数):376 标注…

Oriented R-CNN:面向旋转目标检测的 R-CNN(ICCV2021)
Oriented R-CNN:面向旋转目标检测的 R-CNN(ICCV2021)一. 旋转目标检测——研究现状1.1. 之前的算法1.2. 旋转目标检测——数据集1.3. 开源代码二. 《Oriented R-CNN for Object Detection》文章简介三. 《Oriented R-CNN for Object Detectio…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】计算机视觉(最终篇)
目录
知识储备
KITTI数据集
1.KITTI数据集概述
2.数据采集平台
3.Dataset详述
算法原理
YOLOv5全新Neck改进:BiSPAN 结构独一无二,为目标检测打造全新融合网络,增强定位信号,对于小目标检测的定位具有重要意义
💡本篇内容:YOLOv5全新Neck改进:BiSPAN 结构升级版,为目标检测打造全新融合网络,增强定位信号,对于小目标检测的定位具有重要意义
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv…

Multi-View 3D Object Detection Network for Autonomous Driving
1. Motivation
受二维目标检测启发,并且利用多视图的信息,将3D稀疏点云数据编码成dense的多视图数据,之后进行深度融合在进行目标检测。
2. Contribution
利用多模态信息进行区域特征融合,得到更加丰富点云信息;提出…
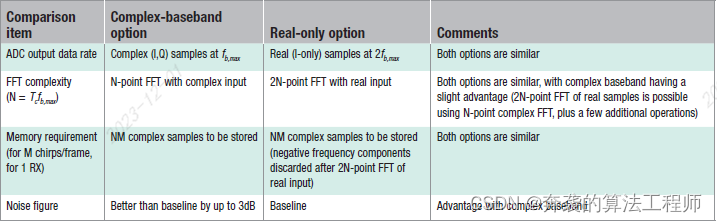
在FMCW雷达系统使用复基带架构(TI文档)
摘要 本文阐述了复基带架构在调频连续波(FMCW)雷达系统中的优势。典型的雷达前端实现使用带有真实基带和模数转换器(ADC)链的真实混频器。然而,在FMCW雷达的背景下,使用正交混频器和复基带架构可以发挥性能优势。该架构已在德州仪器的76 - 81 GHz全集成互…

目标检测算法部署网页web端1
先上效果图 这个是页面显示,该页面包括:上传图片按钮,图片预测按钮,结果清空按钮,和下载按钮
听名字就知道各个按钮的功能了,就不一一介绍了。
本篇先更新html的代码,后续更新剩余部分。 我使用的是pycharm编译器,首先新建一个html文件
<!DOCTYPE html> …
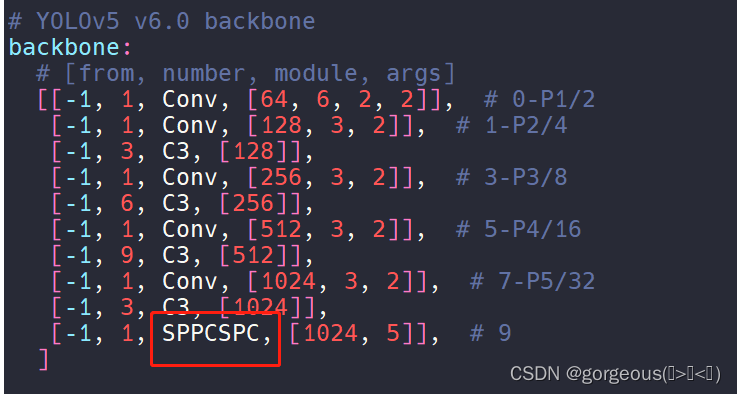
【YOLOV5】YOLOV5添加SPPCSPC
当前YOLOV5版本为7.0 第一步 在models/common.py添加SPPCSPC
class SPPCSPC(nn.Module):# CSP https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n1, shortcutFalse, g1, e0.5, k(5, 9, 13)):super(SPPCSPC, self).__init__()c_ int(2 *…
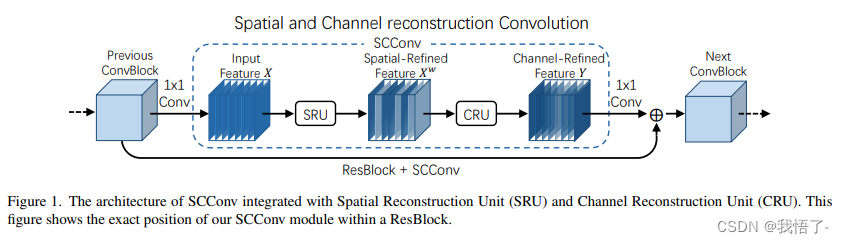
目标检测算法改进系列之添加SCConv空间和通道重构卷积
SCConv-空间和通道重构卷积
SCConv(空间和通道重构卷积)的高效卷积模块,以减少卷积神经网络(CNN)中的空间和通道冗余。SCConv旨在通过优化特征提取过程,减少计算资源消耗并提高网络性能。该模块包括两个单…

YOLO目标检测——磁瓦缺陷数据集下载分享
磁瓦是一种常见的建筑材料,用于地板、墙壁等表面装饰,磁瓦缺陷数据集是用于研究和分析磁瓦缺陷检测问题的数据集。 数据集点击下载:YOLO磁瓦缺陷数据集2700图片6类别.rar
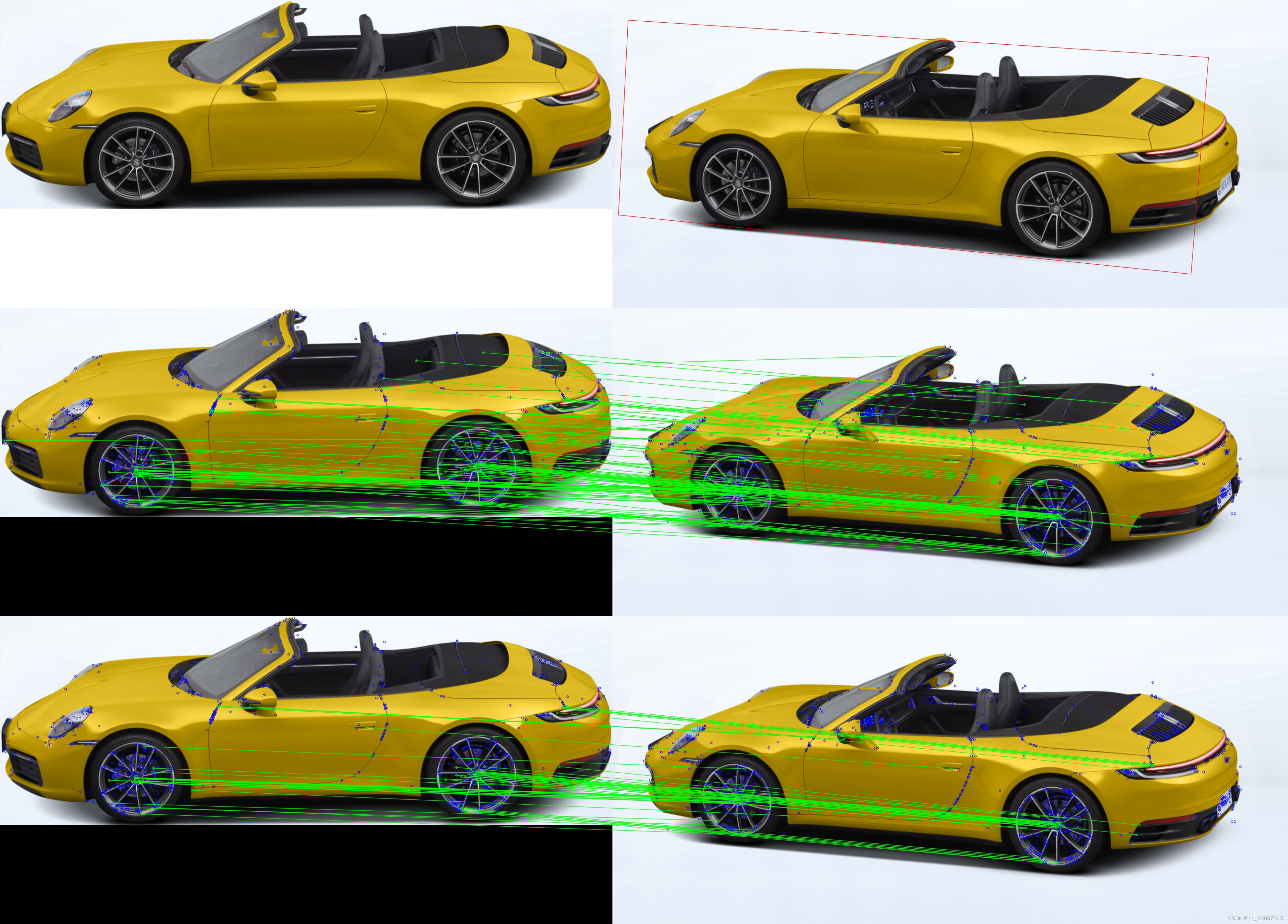

目标检测论文阅读:GaFPN算法笔记
标题:Construct Effective Geometry Aware Feature Pyramid Network for Multi-Scale Object Detection 会议:AAAI2022 论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/19932 文章目录Abstract1. Introduction2. Related Work2.…
目标检测——R-CNN系列检测算法总结
R-CNN系列算法详细解读文章:
R-CNN算法解读SPPNet算法解读Fast R-CNN算法解读Faster R-CNN算法解读Mask R-CNN算法解读 目录 1、概述1.1 获取目标候选框1.2 候选框提取特征1.3 候选框分类及边框回归 2、R-CNN系列算法概述2.1 R-CNN算法2.2 SPPNet算法2.3 Fast R-CN…
YOLO→you only look once
几篇文章保存下:
1.https://blog.csdn.net/guleileo/article/details/80581858
(转于https://blog.csdn.net/App_12062011/article/details/77554288)
2.https://blog.csdn.net/qq_28123095/…
Halcon深度学习药片检测
1.应用示例思路
(1) 标注数据并获取halcon字典形式的训练数据;(2) 数据预处理;
(3) 模型训练;(4) 模型评估和验证;(5) 模型推理。
数据的标注使用labelimg工具,具体的参考以下博文:
https://blog.csdn.…
Yolov5/Yolov7优化:最新移动端高效网络架构 CloFormer: 注意力机制与卷积的完美融合 | 清华团队2023 即插即用系列
💡💡💡本文属于原创独家改进:引入CloFormer 中的 AttnConv,上下文感知权重使得模型能够更好地适应输入内容。相比于局部自注意力机制,引入共享权重使得模型能够更好地处理高频信息,从而提高性能。
注意力机制与卷积的完美融合 AttnConv | 亲测在多个数据集能够实现…

基于YOLOv8深度学习的PCB板缺陷检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐--…

论文投稿指南——中文核心期刊推荐(电工技术)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…
【论文阅读】Untargeted Backdoor Attack Against Object Detection(针对目标检测的无目标后门攻击)
文章目录 一.论文信息二.论文内容0.摘要1.论文概述2.背景介绍3.作者贡献4.重点图表 一.论文信息
论文题目: Untargeted Backdoor Attack Against Object Detection(针对目标检测的无目标后门攻击)
发表年份: 2023-ICASSP&#x…

YOLOv8改进实验:一文了解YOLOv8如何打印FPS指标
💡该教程为改进YOLOv8指南,属于《芒果书》📚系列,包含大量的原创首发改进方式🚀
💡🚀🚀🚀本博客内含改进源代码,按步骤操作运行改进后的代码即可 💡更方便的统计更多实验数据,方便写作
新增YOLOv8打印FPS指标
完善(一键YOLOv8打印FPS指标) 文章目录 完善…
openmmlab加载自训练权重
openmmlab加载自训练权重
在openmmlab中要加载自训练的模型权重,用于自己其他数据集训练的预训练模型。只需要在config文件中添加模型初始化。
在config.py文件中的model配置中初始化。
model dict(typeTopdownPoseEstimator,data_preprocessordict(),backboned…

深度学习论文: Task-Specific Context Decoupling for Object Detection及其PyTorch实现
深度学习论文: Task-Specific Context Decoupling for Object Detection及其PyTorch实现 Task-Specific Context Decoupling for Object Detection PDF: https://arxiv.org/pdf/2303.01047.pdf PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTorch代码: https:…

程序切片(定义+用途)
程序切片(定义用途)
介绍 让我们假设我们测试了一个程序 p 并失败了(错误的 输出)。然后我们想找出导致失败(故障)的原因。 现在假设我们要更改程序的一部分。我们可能会问:程序的哪些其他部分受到影响 我们想找到导致…
第98步 深度学习图像目标检测:SSD建模
基于WIN10的64位系统演示
一、写在前面
本期开始,我们继续学习深度学习图像目标检测系列,SSD(Single Shot MultiBox Detector)模型。 二、SSD简介
SSD(Single Shot MultiBox Detector)是一种流行的目标检…

YOLO目标检测——机油泄露检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:机械设备维护、工业生产监控、环保监管等数据集说明:机油泄露检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、co…
目标检测YOLO实战应用案例100讲-基于改进YOLOv4算法的自动驾驶场景 目标检测
前言
随着21世纪的到来,我国人民的生活水平不断提高,人们对高品质生活的渴望 不断增强,居民对于汽车的需求也逐年增加,汽车保有量呈上升趋势。据2022年中国 汽车工业协会发布汽车全年产业产销数据,分别完成2702.1万辆和2686.4万辆,同比 增长3.4%和2.1%,全年实现小幅增长…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】复杂背景下目标检测
目录
前言
算法原理
评价指标
正样本与负样本
真正(TP)、假正(FP)、真负(TN)、假负(FN)

亚马逊车灯外贸出口CE认证标准办理解析
车灯是车辆夜间行驶在道路照明的工具,也是发出各种车辆行驶信号的提示工具。车灯一般分为前照灯、尾灯、转向灯等。车灯出口欧盟需要办理CE认证。
CE认证是欧盟对进入欧洲市场的产品强制性的认证标志,是指符合欧盟安全、健康、环境保护等标准和要求的产…
目标检测、语义分割的术语
1.Backbone
提取特征
2.neck
更好的提取特征
3.head
利用提取好的特征,完成任务(分类等)
4.bottleneck
将特征维度减少
5.GAP
Global Average Pool全局平均池化,就是将某个通道的特征取平均值
6.Embedding
将特征抽取成…
基于Yolov5的摄像头吸烟行为检测系统(pytoch)
目录 1.数据集介绍 1.1数据集划分 1.2 通过voc_label.py生成txt
1.3 小目标定义
2.基于Yolov5的吸烟行为检测性能提升
2.1采用多尺度提升小目标检测精度
2.2 多尺度训练结果分析
2.3基于多尺度基础上加入BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构
2.3.1 BiFo…

YOLO目标检测——无人机航拍输电线路绝缘瓷瓶数据集下载分享【对应voc、coco和yolo三种格式标签】
实际项目应用:电力系统运维、状态监测与故障诊断、智能电网建设等领域数据集说明:无人机航拍输电线路绝缘瓷瓶数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量…

YOLOv8改进 | 2023 | 通过RFAConv重塑空间注意力(深度学习的前沿突破)
一、本文介绍
本文给大家带来的改进机制是RFAConv,全称为Receptive-Field Attention Convolution,是一种全新的空间注意力机制。与传统的空间注意力方法相比,RFAConv能够更有效地处理图像中的细节和复杂模式(适用于所有的检测对象都有一定的…
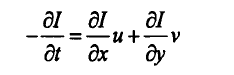
光流法( Optical Flow Method)
在计算机视觉中,光流法即可用于运动目标检测,也可以用于目标跟踪。本文主要介绍光流法在运动目标检测和目标跟踪中的区别与联系。 1、光流与光流场 光流的概念最初是由 Gibson 于 1950 年首先提出来的。当人的眼睛观察运动物体时,物体的景象…
计算机视觉岗面经(进阶版)分享
本专栏分享 计算机小伙伴秋招春招找工作的面试经验和面试的详情知识点 专栏首页:秋招算法类面经分享 主要分享计算机算法类在面试互联网公司时候一些真实的经验 面试code学习参考请看:

YOLO目标检测——行人数据集【含对应voc、coco和yolo三种格式标签+划分脚本】
实际项目应用:智能监控、人机交互、行为分析、安全防护数据集说明:行人检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(j…
【目标检测】YOLO格式数据集txt标注转换为COCO格式JSON
YOLO格式数据集:
images
|--train
|--test
|--vallabels
|--train
|--test
|--val
代码:
import os
import json
from PIL import Image# 设置数据集路径
dataset_path "path/to/your/dataset"
images_path os.path.join(dataset_path, &…

YOLOv7全网独家首发改进:SENet v2,Squeeze-Excitation模块融合Dense Layer,效果秒杀SENet
💡💡💡本文自研创新改进:SENet v2,针对SENet主要优化点,提出新颖的多分支Dense Layer,并与Squeeze-Excitation网络模块高效融合,融合增强了网络捕获通道模式和全局知识的能力
推荐指数:五星 收录
YOLOv7原创自研
https://blog.csdn.net/m0_63774211/category_12…
目标检测YOLO实战应用案例100讲-基于YOLOv5的航拍图像旋转目标检测(中)
目录
2.2目标检测基础
2.2.1目标检测定义
2.2.2目标检测原理
2.3基于CNN的目标检测网络结构

MMdetection部署及教程 及很多小细节
mmdetection/README.md at master open-mmlab/mmdetection (github.com)
这个链接指向MMDetection
就是对英语不是很棒的小伙子 小姐妹很友好 先装个环境
哈哈哈 大家不用装了 都别装好吧 我之前以为就我一个人菜 装什么环境都出问题
都得记录,很难有没有问题…
目标检测00-06:mmdetection(Foveabox为例)-白话给你讲论文-翻译无死角-2
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
目标检测YOLO实战应用案例100讲-基于改进YOLOv4算法的自动驾驶场景 目标检测(续)
目录
3.2.3 Neck
3.2.4 Head
3.3基于注意力机制的SimAM-YOLOv4目标检测算法研究
3.3.1 注意力机制

YOLOV7改进:最新开源移动端网络架构 RepViT | RepViTBlock即插即用,助力检测 | 清华 ICCV 2023
💡💡💡本文独家原创改进:轻量级 ViT 的高效架构选择,逐步增强标准轻量级 CNN(特别是 MobileNetV3)的移动友好性。 最终产生了一个新的纯轻量级 CNN 系列,即 RepViT
RepViTBlock即插即用,助力检测 | 亲测在多个数据集能够实现涨点,并实现轻量化
收录:
YOLOv7…

YOLO目标检测——昏暗车辆检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:智能交通监控系统、驾驶辅助系统、城市安全监控、自动驾驶系统以及路况分析与规划等数据集说明:昏暗车辆检测数据集,真实场景的高质量图片数据,数据场景丰富,含有图片汽车、卡车、公共汽车标签说明&#…
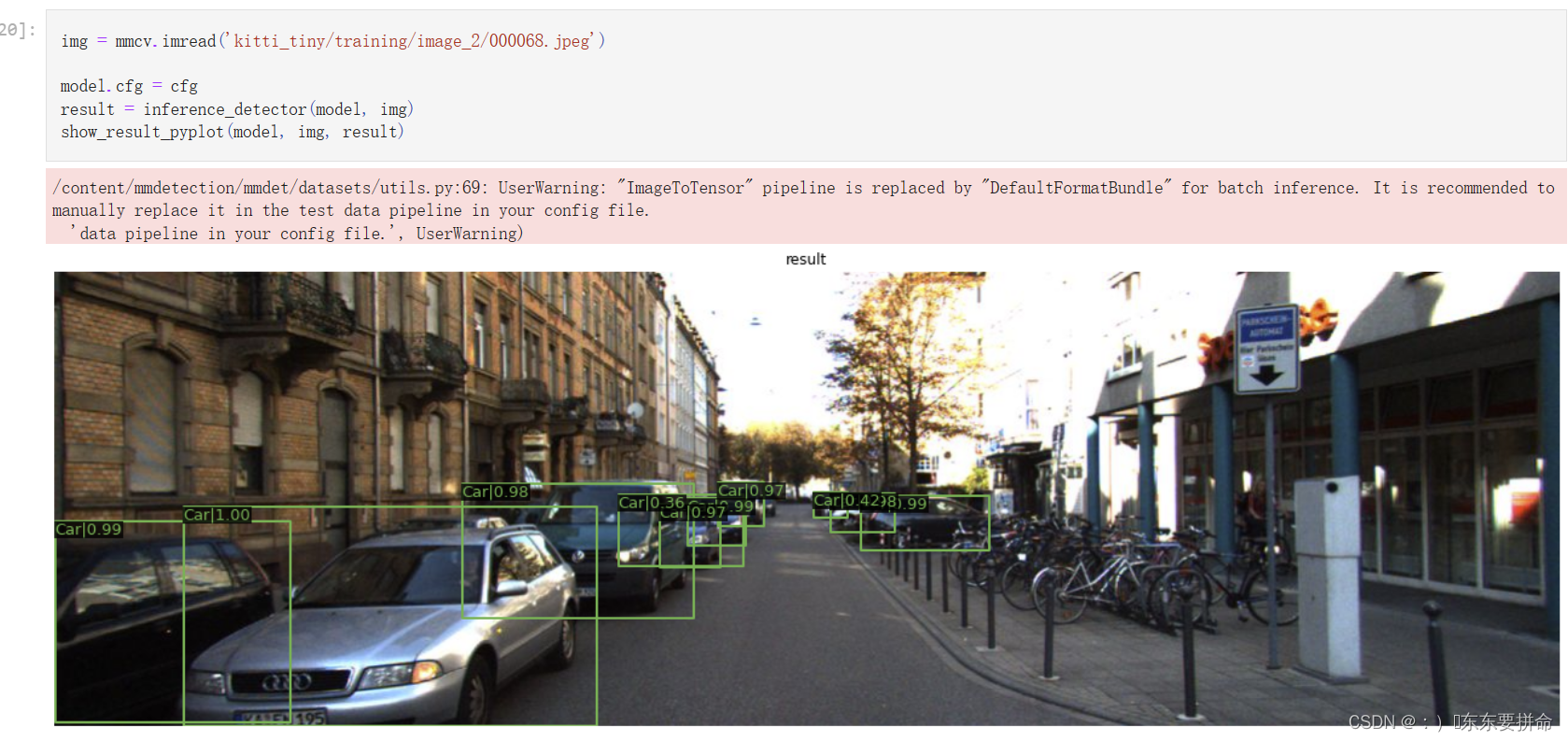
Yolov8轻量级:Next-vit,用于现实工业场景的下一代视觉 Transformer
1.Next-vit介绍
论文:https://arxiv.org/pdf/2207.05501.pdf 由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样…

DENSE 数据集 - STF 数据集(CVPR 2020)
DENSE 数据集 - STF 数据集 - Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather(CVPR 2020)摘要1. 引言2. 相关工作3. 多模式恶劣天气数据集3.1 多模态传感器设置3.2 记录4. 自适应深度融合4.1 自适应多…
YOLOv8 原创改进最新结构CBiF、BiFB:小目标检测涨点,原创即插即用
💡该教程为属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀
重点:🔥🔥🔥YOLOv5|YOLOv7|YOLOv8 使用这个 创新点 在数据集改进做实验:即插即用
💡🚀🚀🚀本博客 内附的改进源代码改进 适用于 YOLOv5、YOLOv7、…
目标检测YOLO实战应用案例100讲-面向智能路侧边缘计算的车辆行人视觉目标检测算法研究
目录
前言
传统目标检测算法
基于深度学习的目标检测算法
(1) Two-stage目标检测算法

第2篇 机器学习基础 —(2)分类和回归
前言:Hello大家好,我是小哥谈。机器学习中的分类和回归都是监督学习的问题。分类问题的目标是将输入数据分为不同的类别,而回归问题的目标是预测一个连续的数值。分类问题输出的是物体所属的类别,而回归问题输出的是数值。本节课就…

YOLOv3 代码详解(2) —— 数据处理 dataset.py解析
前言: yolo系列的论文阅读 论文阅读 || 深度学习之目标检测 重磅出击YOLOv3 论文阅读 || 深度学习之目标检测yolov2 论文阅读 || 深度学习之目标检测yolov1 该篇讲解的工程连接是: tensorflow的yolov3:https://github.com/YunYang1994/ten…
机器学习笔记 - 用于自动化检测服饰的YOLOs-Fashionpedia模型
一、安装环境 使用预训练模型和 PyTorch Lightning 来自动化产品标记过程,将大幅度提高耗时的任务的效率。 # 安装软件包 pip install torch== 2.0 .0 pip install pytorch-lightning== 2.0 .1 pip install datasets== 2.11 .0 pip install Transformers== 4.30

YOLO目标检测——跌倒摔倒数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:公共安全监控、智能家居、工业安全等活动区域无监管情况下的人员摔倒事故数据集说明:YOLO目标检测数据集,真实场景的高质量图片数据,数据场景丰富。使用lableimg标注软件标注,标注框质量高,含…
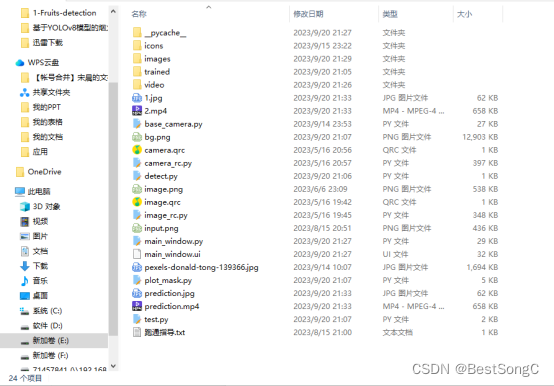
基于YOLOv8模型的水果目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的水果目标检测系统可用于日常生活中检测与定位苹果(apple)、香蕉(banan)、葡萄(grape)、橘子(orange)、菠萝(pineapple)和西…

Realsense D435i Yolov5目标检测实时获得目标三维位置信息
文章目录一、效果演示二、环境配置三、模型配置四、相机配置五、部分代码:六、仓库链接:一、效果演示
- Colorimage: - Colorimage and depthimage: 二、环境配置
1.一个可以运行YOLOv5的python环境
pip install -r requirements.txt2.一个realsense相机和pyrealsense2库
p…
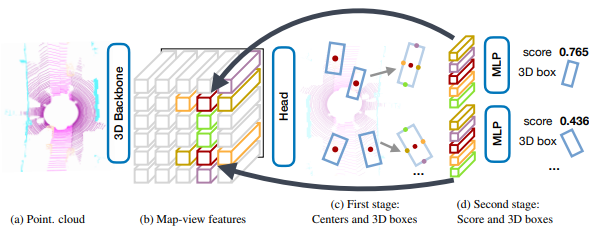
【三维目标检测】CenterPoint(一)
CenterPoint是一种anchor free的三维目标检测算法模型,发表在CVPR 2021,论文名称为《Center-based 3D Object Detection and Tracking》。其主要特点在于通过预测物体的中心点来进行目标检测和位置回归,而不需要预先产生大量候选框࿰…
【三维目标检测】SASSD(二)
SASSD数据和源码配置调试过程请参考上一篇博文:【三维目标检测】SASSD(一)_Coding的叶子的博客-CSDN博客。本文主要详细介绍SASSD网络结构及其运行中间状态。
1 SASSD模型总体过程 SASSD模型的整体结构如下图所示。SASSD与基于Anchor的目标检…

【深度学习目标检测】八、基于yolov5的抽烟识别(python,深度学习)
YOLOv5是目标检测领域一种非常优秀的模型,其具有以下几个优势: 1. 高精度:YOLOv5相比于其前身YOLOv4,在目标检测精度上有了显著的提升。YOLOv5使用了一系列的改进,如更深的网络结构、更多的特征层和更高分辨率的输入图…
美洲豹目标检测数据集VOC+YOLO格式1100张
美洲豹(Panthera onca)是一种生活在南北美洲的大型猫科动物,也是美洲的唯一一种豹。它们通常生活在热带雨林、草原和山地地区,是南北美洲最大的陆生食肉动物之一,体长可达2.7米,体重可达135千克。
美洲豹的…

目标检测论文阅读:RepPoints v2算法笔记
标题:RepPoints v2: Verification Meets Regression for Object Detection 会议:NeurIPS2020 论文地址:https://dl.acm.org/doi/abs/10.5555/3495724.3496196 官方代码:https://github.com/Scalsol/RepPointsV2 作者单位ÿ…

OpenCV技术应用(8)— 如何将视频分解
前言:Hello大家好,我是小哥谈。本节课就手把手教大家如何将一幅图像转化成热力图,希望大家学习之后能够有所收获~!🌈 目录
🚀1.技术介绍
🚀2.实现代码 🚀1.技术介绍
视频是…
Yolov5/Yolov7改进:小目标到大目标一网打尽,轻骨干重Neck的轻量级目标检测器GiraffeDet
1.GiraffeDet介绍 论文:https://arxiv.org/abs/2202.04256 🏆🏆🏆🏆🏆🏆Yolov5/Yolov7魔术师🏆🏆🏆🏆🏆🏆 ✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉定期更新不同数据集涨点情况 本文是…

YOLOv8 Tensorrt Python/C++部署教程
B站教学视频
https://www.bilibili.com/video/BV1Pa4y1N7HS
Github仓库地址
https://github.com/Monday-Leo/YOLOv8_Tensorrt
Introduction
基于Tensorrt加速Yolov8,本项目采用ONNX转Tensorrt方案支持Windows10和Linux支持Python/C
YOLOv8 Environment
Tenso…
狮子目标检测数据集VOC+YOLO格式1400张
狮子(Lion)是一种生活在非洲和印度的大型猫科动物。它们是一种非常强壮和威猛的动物,通常被称为“草原之王”。狮子的身体结构非常适应于它们的生活方式,有着强壮的肌肉和锋利的牙齿。
狮子的身高一般在1.2-1.5米之间,…

RK3588实战:调用npu加速,yolov5识别图像、ffmpeg发送到rtmp服务器
前言:最近在学习一些rk3588相关的东西,趁着这个项目,把学习的相关东西整合下,放到一个项目里面,巩固学习的知识。
项目名称:yolov5识别图像、ffmpeg发送到rtmp服务器
功能:1、opencv读取usb摄…
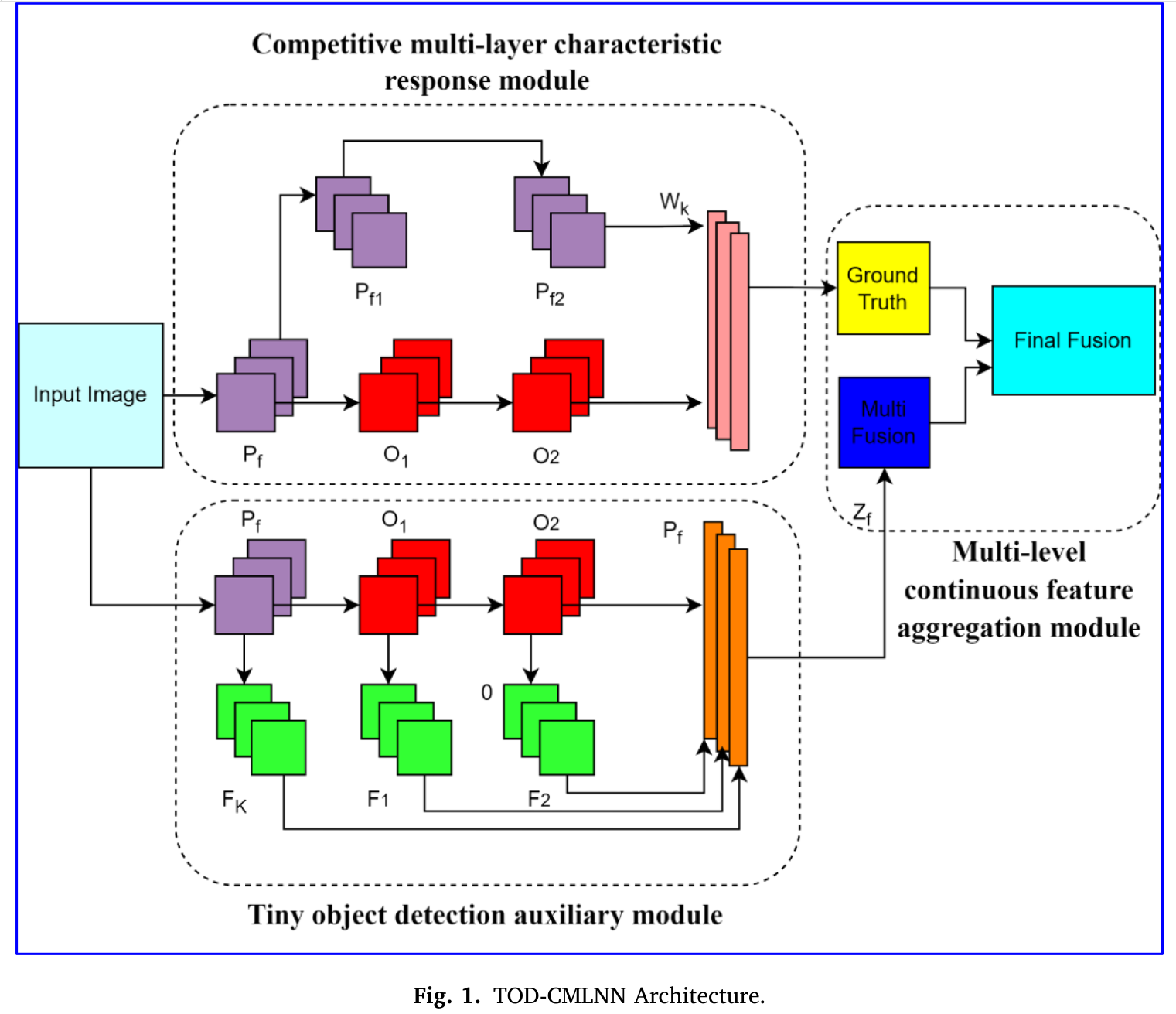
Tiny Object Detection
文章目录 Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection(CVPR2023)TOD-CMLNN(2023) Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection(CVPR2023)
hh 作者发现…
深度学习嵌入头embedding head解释
在目标跟踪或目标检测的深度学习模型中,"嵌入头"(Embedding Head)通常指的是网络架构中负责生成目标的特征表示的部分。具体来说,嵌入头负责将输入图像或图像区域转换为一个高维度的向量(即嵌入向量或特征向…
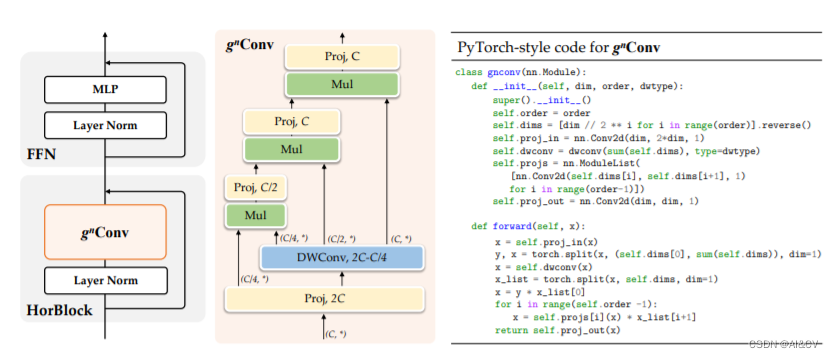
涨点神器:Yolov5/Yolov7全面引入HorNet:递归门控卷积的高效高阶空间交互---gnConv、HorBlock、HorNet
1. HorNet介绍
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
论文地址:https://arxiv.org/pdf/2207.14284.pdf 代码地址:https://github.com/raoyongming/ 本文提出递归门控卷积 (gnConv),它通过门控卷积和递归设计执行高效、可…
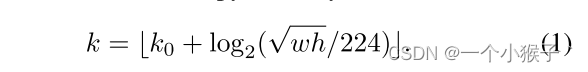
论文精读:Feature Pyramid Networks for Object Detection
文章目录 1. 摘要1.1 背景1.2 提出新方法1.3 贡献 2. 引言2.1 提出问题2.2 叙述Feature pyramid2.3 叙述深度卷积网络2.4 Feature pyramid的局限2.5 使用deep ConvNet计算多尺度特征的方式2.6 提出我们的方法2.7 贡献 3. 相关工作3.1 手工工程特征和早期神经网络3.2 深度卷积目…
使用LabelMe标注目标检测数据集并转换为COCO2017格式
1、labelme标注2、转为coco格式3、标签可视化1、labelme标注
当你安装好labelme启动后,open dir开始标注,选择Create Rectangle 拖拽画框,然后选择类别(没有就直接输入会自动新建),标注好一幅图后点击nex…

Faster R-CNN代码详解 标注数据形状
Faster R-CNN代码实战–潘登同学的深度学习笔记 文章目录Faster R-CNN代码实战--潘登同学的深度学习笔记数据集介绍数据处理先看combined_roidbRoIDataLayerget_output_dirTrian过程create_architecturebuild_networkBuild headBuild RPN回到_anchor_component回到Build RPN接一…

FasterRCNN 理解(精简版总结)
RCNN系列的内容已经有非常多同学分享出来了,大多也非常详细。为了避免在长文中迷失方向,这里做个精简版的总结,记录个人的理解。主要是概括算法流程以及特点,方便回顾。先简单介绍下RCNN和Fast RCNN,在详细记录faster …
VectorNet详解
Abstract 本篇论文主要做了三个方面的事情: 特征工程 不同与以前的方法,将车辆行驶收集的信息用一张全局的图像来表示,论文提出用向量表示车辆行驶过程中收集的各种信息。
2. 层次图神经网络 论文构建了一种层次图神经网络,层次,即首先各个实体比如车辆、红绿灯等…
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
系列文章目录
基于CNN数据增强残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)数据集模型(一)
基于CNN数据增强残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)数据集模型…
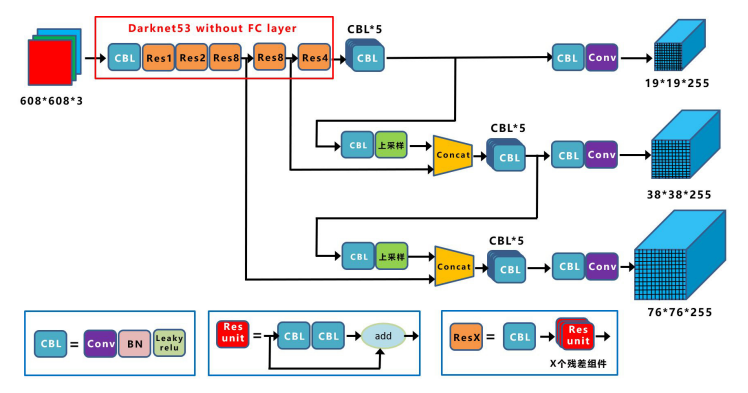
YOLO v3对网络结构做了哪些改进?
来源:投稿 作者:ΔU 编辑:学姐 论文解读
《YOLOv3: An Incremental Improvement》
Joseph Redmon Ali Farhadi
University of Washington
发表时间:2018
YOLO v3总结了自己在YOLO v2的基础上做的一些尝试性改进,有…
【计算机视觉 | 目标检测】Object query的理解
以下是Object query的几个常见理解:
一、理解1
在目标检测中,Object Query可以理解为查询对象,是用于检测任务中对每个目标进行描述的一种方式。它是Transformer中的一种重要结构,可以将检测任务转化为对预测结果与特征图的相似…

改进的yolo目标检测(yolo创新与改进)
目标检测是计算机视觉领域中的一个重要问题,它需要从图像或视频中检测出物体的位置和类别。近年来,深度学习技术在目标检测领域取得了显著的进展,其中一个重要的方法是基于YOLO(You Only Look Once)算法的目标检测。
YOLO算法的优点是速度快,但是在检测小物体和密集物体…
DINO代码学习笔记(一)
先上官方架构图: 论文地址:https://arxiv.org/pdf/2203.03605.pdf 代码地址:GitHub - IDEA-Research/DINO: [ICLR 2023] Official implementation of the paper "DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Objec…
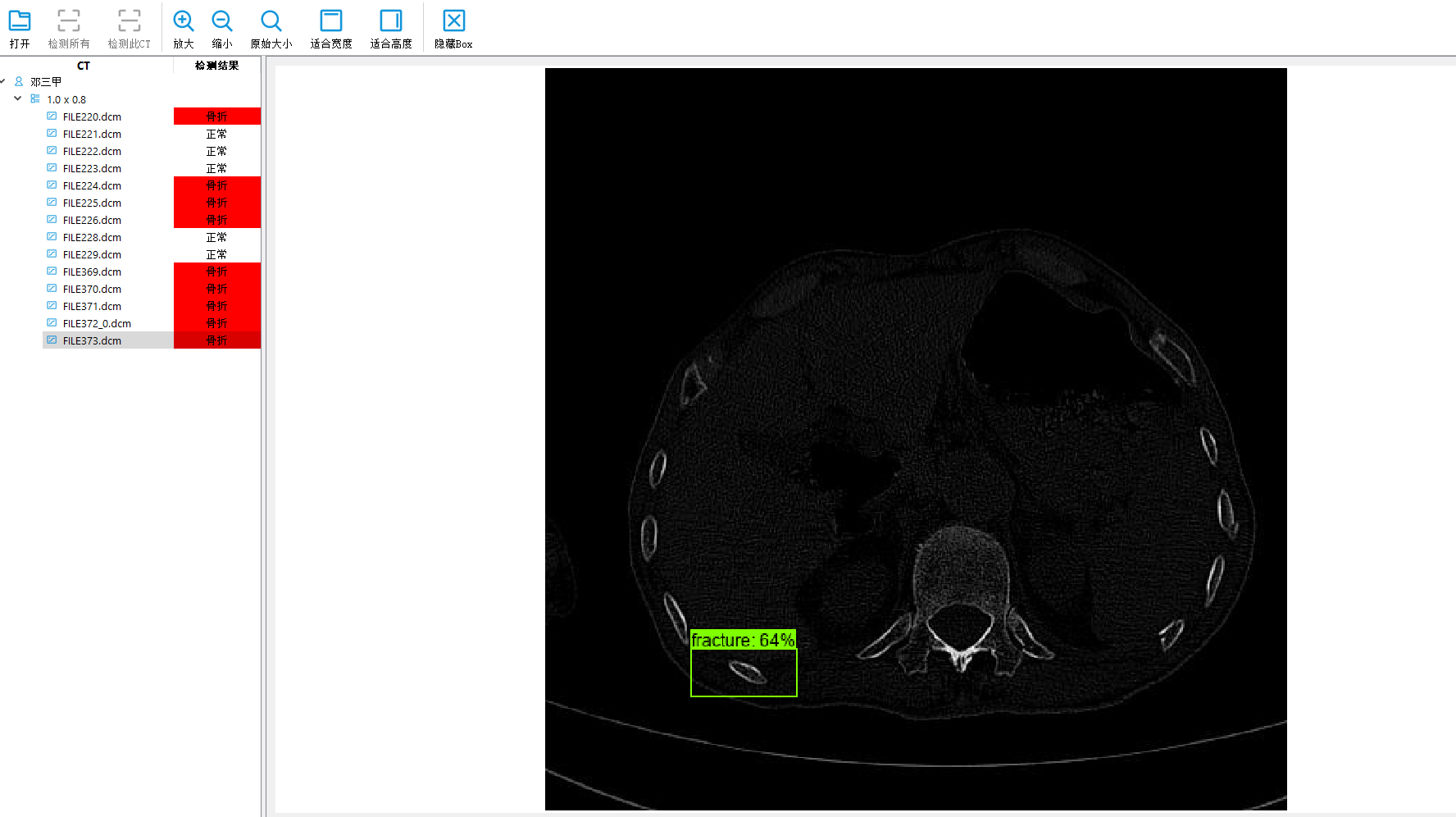
深度学习目标检测项目实战(四)—基于Tensorflow object detection API的骨折目标检测及其界面运行
深度学习目标检测项目实战(四)—基于Tensorflow object detection API的骨折目标检测及其界面运行
使用tensorflow object detection进行训练检测
参考原始代码:https://github.com/tensorflow/models/tree/master/research 我用的是1.x的版本 所以环境必须有gpu版…
目标检测模型回归anchor偏移量等问题
为什么要学习偏移而不是实际值? Anchor已经粗略地“框住了”输入图像中的目标,明显的一个问题是:框的不够准确。因为受限于Anchor的生成方式,Anchor的坐标永远都是固定的那几个。所以,如果我们需要预测相对于Anchor的o…
计算机视觉-目标检测(二):从R-FCN到YOLO-v3
文章目录 1. R-FCN1.1 动机1.2. R-FCN 网络结构1.3. R-FCN 的损失函数1.4. R-FCN的训练及性能 2. YoLO-v12.1 简介2.2 YOLO-v1网络结构2.3 目标函数2.4 YOLO-v1的优缺点 3. YOLO-v23.1 YOLO-v2相比v1的优化 4. YOLO-v3参考 1. R-FCN
论文链接:R-FCN:Object Detecti…

目标检测label assignment:A Dual Weighting Label Assignment Scheme
在目标检测中,为了与NMS兼容,一个好的检测器应该能够预测具有较高分类得分和精确位置的box。然而,如果所有的训练样本都被同等处理,两个头部之间就会出现错位:类别得分最高的位置通常不是回归对象边界的最佳位置。这种…
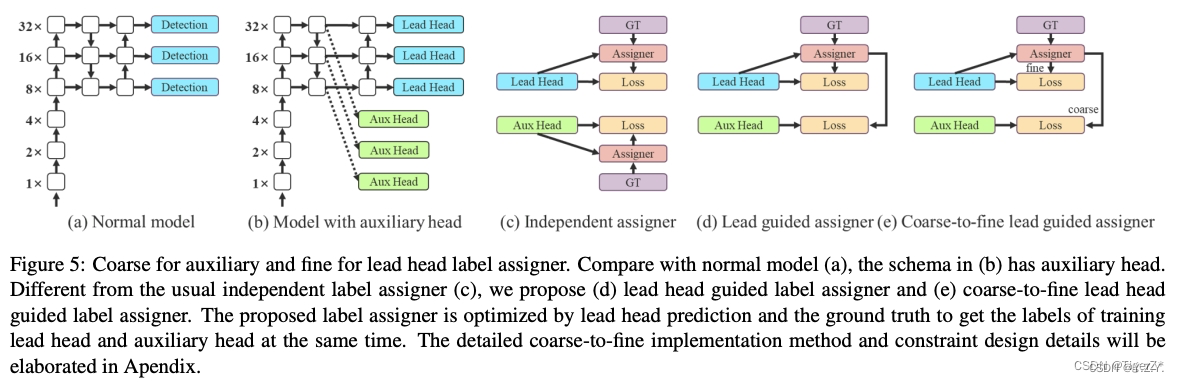
目标检测——YOLOv7(十三)
简介: 继美团发布YOLOV6之后,YOLO系列原作者也发布了YOLOV7。主要从两点进行模型的优化:模型结构重参化和动态标签分配。 YOLOv7的特点是快!相同体量下比YOLOv5精度更高,速度快120%,比YOLOX快180%。 Github…
【计算机视觉 | 目标检测】OVD:Open-Vocabulary Object Detection 论文工作总结(共八篇)
文章目录 一、2D open-vocabulary object detection的发展和研究现状二、基于大规模外部图像数据集2.1 OVR-CNN:Open-Vocabulary Object Detection Using Captions,CVPR 20212.2 Open Vocabulary Object Detection with Pseudo Bounding-Box Labels&…
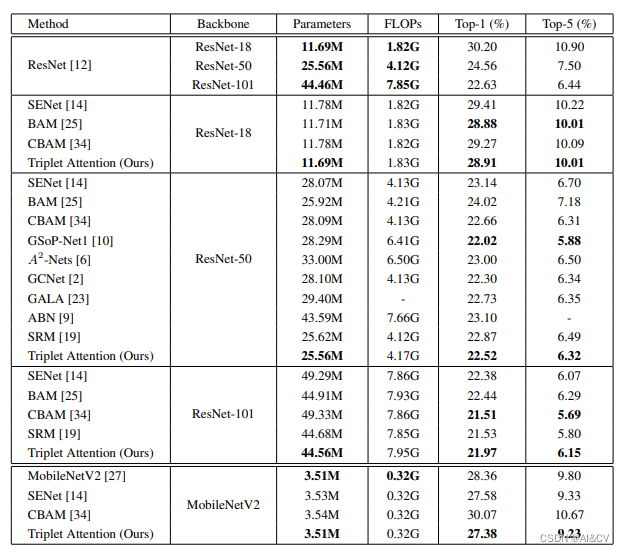
注意力机制:基于Yolov5/Yolov7的Triplet注意力模块,即插即用,效果优于cbam、se,涨点明显
论文:https://arxiv.org/pdf/2010.03045.pdf
本文提出了可以有效解决跨维度交互的triplet attention。相较于以往的注意力方法,主要有两个优点:
1.可以忽略的计算开销
2.强调了多维交互而不降低维度的重要性,因此消除了通道和权…

【论文翻译】Few Sample Knowledge Distillation for Efficient Network Compression
Few Sample Knowledge Distillation for Efficient Network Compression
用于高效网络压缩的少样本知识提取
论文地址:https://arxiv.org/abs/1812.01839
代码地址:GitHub - LTH14/FSKD
摘要
Deep neural network compression techniques such as p…
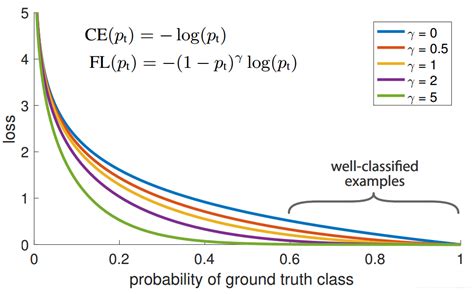
YOLO-v3论文详解
YOLO-v3论文详解-- 潘登同学的目标检测笔记 文章目录YOLO-v3论文详解-- 潘登同学的目标检测笔记继承YOLO-9000与技术改进YOLO-v3试了但没成功继承YOLO-9000与技术改进
Bounding Box Prediction计算方法与YOLO-9000 bxσ(tx)cxbyσ(ty)cybwpwetwbhphethPr(object)∗IOU(b,objec…
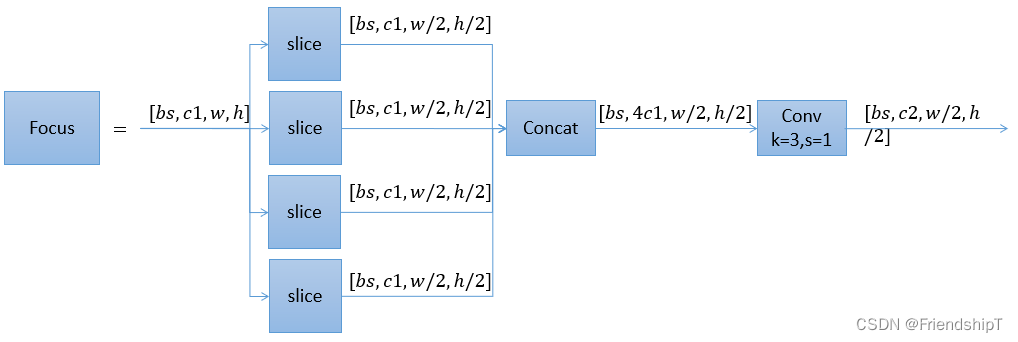
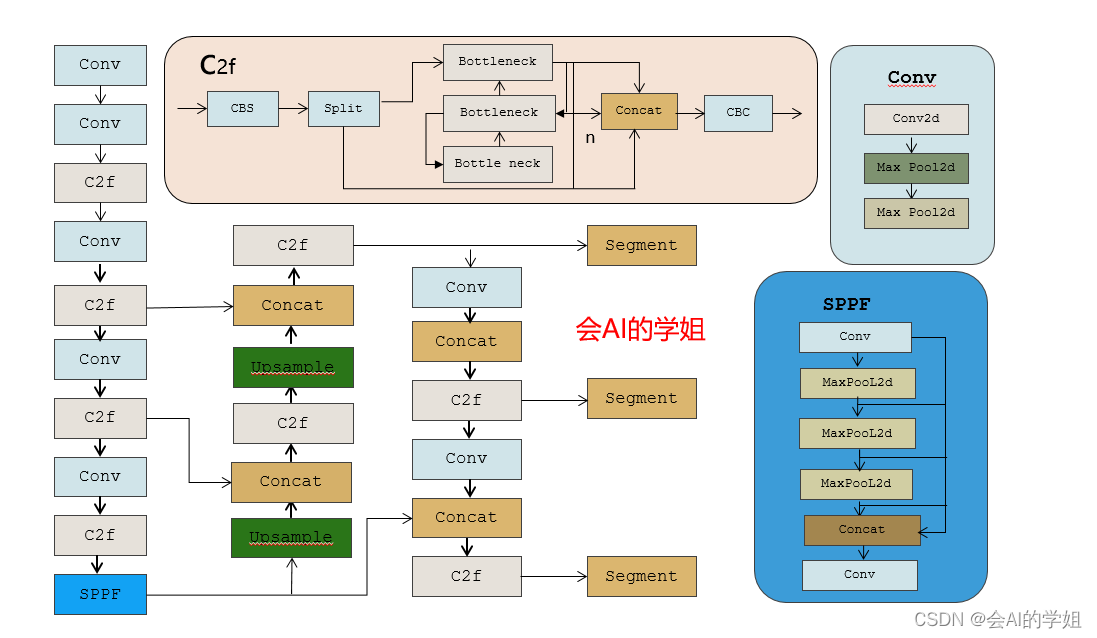
YOLOv5:图解common.py常用模块
YOLOv5:图解common.py常用模块 前言前提条件相关介绍common.py基本模块ConvBottleneckBottleneckCSPC3SPPSPPFFocus未完待续 参考 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入YOLO系列专栏或我的个…
旋转目标检测【1】如何设计深度学习模型
前言
平常的目标检测是平行的矩形框,“方方正正”的;但对于一些特殊场景(遥感),需要倾斜的框,才能更好贴近物体,旋转目标检测来啦~ 一、如何定义旋转框
常见的水平框参数表达方式为࿰…

GPT理解的CV:基于Yolov5的半监督目标检测
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 计算机视觉研究院专栏 作者:Edison_G 主要贡献是提出了一种名为“Efficient Teacher”的半监督目标检测算法。与传统的监督学习算法不同&…
物体检测算法比较,项目开发中如何选择合适的检测算法?
除了YOLO和SSD之外,还有许多其他的物体检测算法。以下是一些常见的物体检测算法,可以与YOLO和SSD进行比较:
1. R-CNN(Region-based Convolutional Networks):R-CNN 是一种基于区域的卷积神经网络ÿ…

【论文阅读】3D点云 -- VoteNet:Deep Hough Voting for 3D Object Detection in Point Clouds
前言 该篇论文是对3D室内点云 进行目标检测的方法的研究。我们对该篇论文需要掌握的是 了解霍夫投票,知道votenet中如何应用了霍夫投票的思想,投票带来的改善网络结构中的模块的设计,以及分别获取了信息:种子点、投票点、投票聚…
深度学习—目标检测标注数据集
深度学习之目标检测
PASCAL数据集
PASCAL VOC挑战赛(The PASCAL Visual Object Classes)是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis,Statical Modeling and Computational Learning,是…

【轻量化网络系列(3)】MobileNetV3论文超详细解读(翻译 +学习笔记+代码实现)
前言
上周我们学习了MobileNetV1和MobileNetV2,本文的MobileNetV3,它首先引入MobileNetV1的深度可分离卷积,然后引入MobileNetV2的具有线性瓶颈的倒残差结构,后来使用了网络搜索算法,并引入了SE模块以及H-Swish激活函…
改进YOLOv7系列:首发最新结合多种X-Transformer结构新增小目标检测层,让YOLO目标检测任务中的小目标无处遁形
💡该教程包含大量的原创首发改进方式, 所有文章都是原创首发改进内容🚀 降低改进难度,改进点包含最新最全的Backbone部分、Neck部分、Head部分、注意力机制部分、自注意力机制部分等完整教程🚀💡本篇文章基于 基于 YOLOv7、YOLOv7-Tiny 等网络 首发最新结合多种X-Trans…

论文投稿指南——中文核心期刊推荐(植物保护)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…
paddle 50 将EIOU、WIoU、SIoU嵌入paddledetection中,并用于ppyoloe的训练
性能先进的模型并不一定在整体上都是最先进的,就如在目前所公开的最强目标检测模型ppyoloe+[yolov8虽然是最新一代模型,其使用CIoU做box loss,在公开coco上的指标是不如ppyoloe+,这应该是由于object365数据集的加持]使用GIOU作为loss来进行框回归优化([这两个模型除了iou …

Python+Yolov8目标识别特征检测
Yolov8目标识别特征检测如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<Yolov8目标识别特征检测>>编写代码,代码整洁,规则,易读。 学习与应用推荐…
涨点神器:基于Yolov5/Yolov7的小目标性能提升
1.小目标介绍 目标检测近十年涌现了一大批如Faster R-CNN、RetinaNet、YOLO等可以在工业界实用的目标检测方法,但小目标检测性能差的问题至今也没有被完全解决。因为Swin Transformer的提出,COCO test-dev上的 AP 已经刷到64 ,但小目标检测性能(即APS )和大目标检测性能(…

Yolov5涨点神器:注意力机制---多头上下文集成(Context Aggregation)的广义构建模块,助力小目标检测,暴力涨点
1.数据集性能验证
在crack道路缺陷检测任务中,多头上下文集成(Context Aggregation)的广义构建模块实现暴力涨点mAP50从0.954提升至0.992 🏆🏆🏆🏆🏆🏆Yolov5/Yolov7魔术师🏆🏆🏆🏆🏆🏆 ✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀…
基于深度学习的瓶子检测软件(UI界面+YOLOv5+训练数据集)
摘要:基于深度学习的瓶子检测软件用于自动化瓶子检测与识别,对于各种场景下的塑料瓶、玻璃瓶等进行检测并计数,辅助计算机瓶子生产回收等工序。本文详细介绍深度学习的瓶子检测软件,在介绍算法原理的同时,给出Python的…
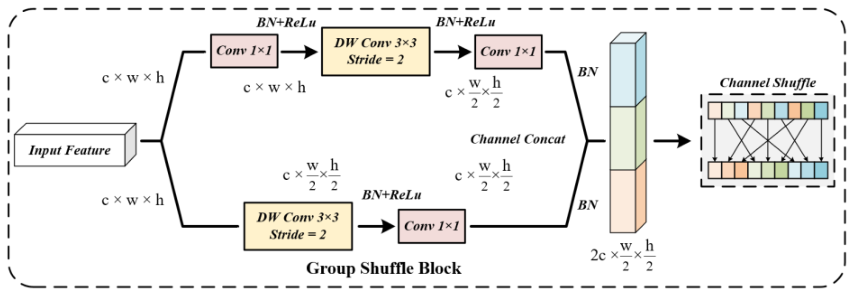
【计算机视觉 | 目标检测】术语理解5:Split Shuffle Block、Group Shuffle Block 和复杂非结构化室内场景
文章目录 一、Split Shuffle Block二、Group Shuffle Block三、复杂非结构化室内场景 一、Split Shuffle Block
Split Shuffle Block(分割混洗块)是一种用于深度学习模型的基础组件,旨在增强模型的表征能力和学习能力。该概念最常用于图像分…
[数据集][目标检测]目标检测数据集绝缘子缺陷防震锤1688张5类别VOC格式
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):1688 标注数量(xml文件个数):1688 标注类别数:5 标注类别名称:["flashover",&…

yolov8_track追踪加分割(yolo目标检测+追踪+分割)
**这个仓库包含了最先进的多目标追踪器。其中一些基于运动信息,另一些则基于运动和外观描述。对于后者,最先进的ReID模型也会自动下载。目前支持的模型有:DeepOCSORT LightMBN、BoTSORT LightMBN、StrongSORT LightMBN、OCSORT和ByteTrack。
我们提供了如何将这个包与流行的…

YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
前言
在YOLOv5中网络结构采用yaml作为配置文件,之前我们也介绍过,YOLOv5配置了4种不同大小的网络模型,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_m…
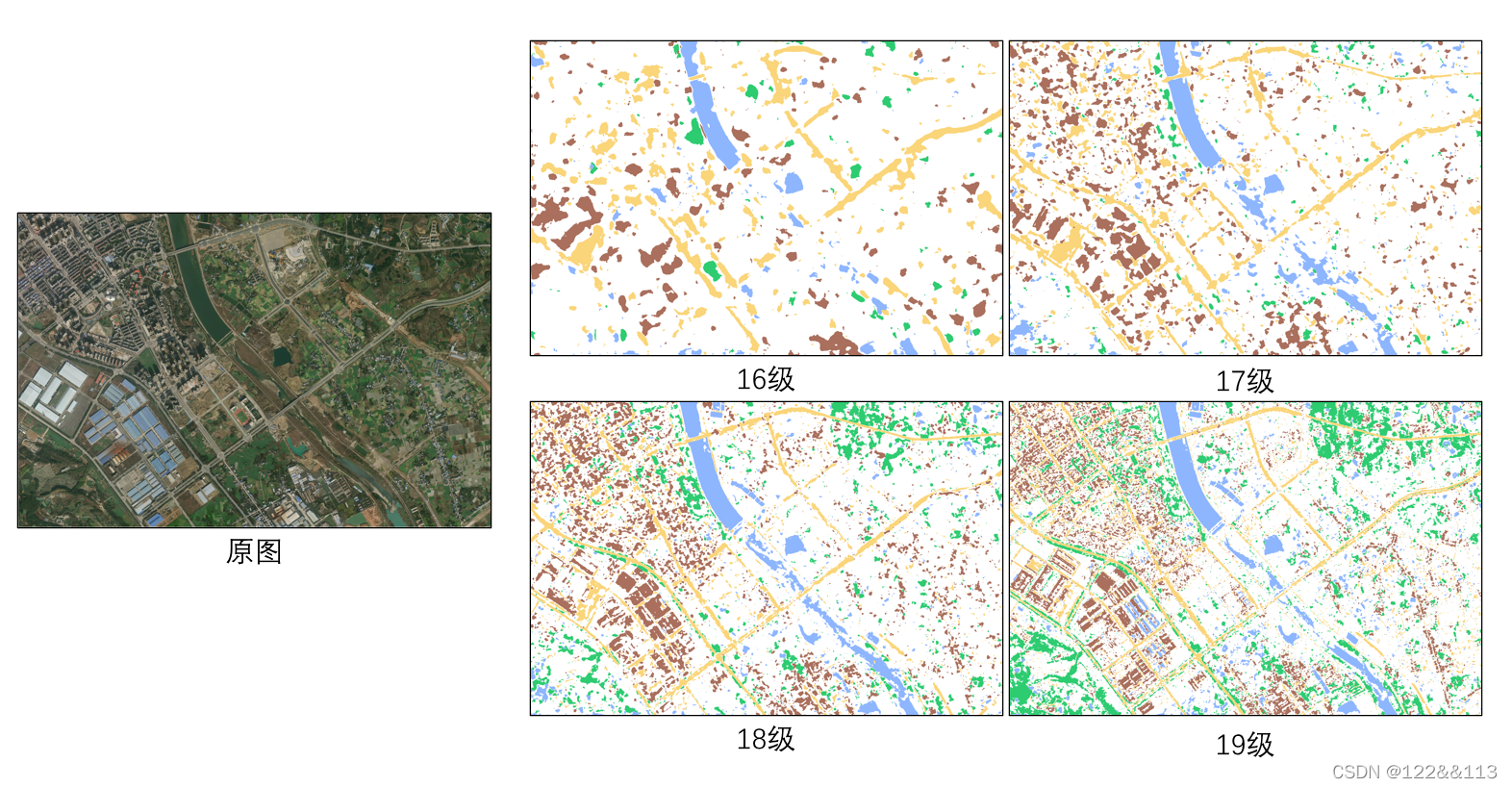
遥感影像识别进展2022/3/17
采用同一尺度下的工区识别效果
由于原始工区在第十九级时的尺寸过大,因此截取其中的一部分区域用作图像预测,以此查看模型训练的效果。
图像1: 图像2: 图像3:
其它图像:
利用focal loss来训练 权重比…
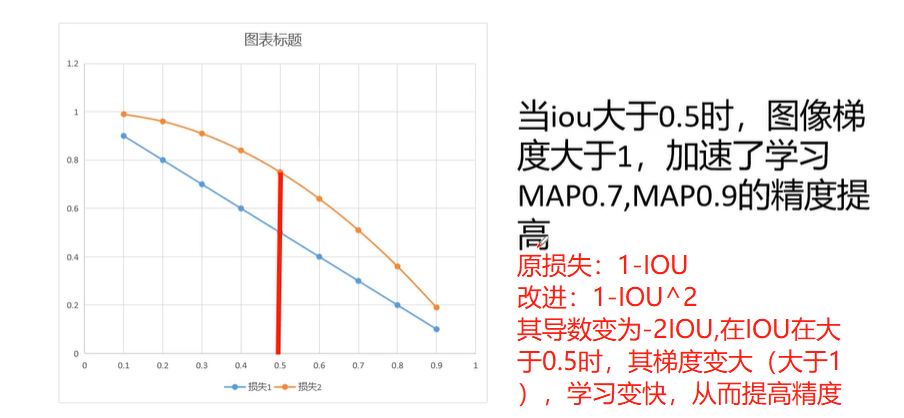
IOU_GIOU_DIOU_CIOU_EIOU优缺点总结
IOUGIOUDIOUCIOUEIOU优点IOU算法是目标检测中最常用的指标,具有尺度不变性,满足非负性;同一性;对称性;三角不等性等特点。GIOU在基于IOU特性的基础上引入最小外接框解决检测框和真实框没有重叠时loss等于0问题。DIOU在…
简要介绍 | OOD目标检测:背景,研究现状,挑战和未来
OOD目标检测:背景,研究现状,挑战和未来
1. 引言
在计算机视觉领域,目标检测任务一直是研究的热点。然而,大多数现有的目标检测方法在面对 开放环境中的未知类别(Out-Of-Distribution, OOD)时性…

手写YOLOv3|代码详细注释
手写YOLOv3|代码详细注释一. 数据预处理一. Yolov3网络一. Train一. Detection源代码:https://github.com/eriklindernoren/PyTorch-YOLOv3
一. 数据预处理
utils/datasets.py
import glob
import random
import os
import sys
import numpy as np
from PIL impo…
目标检测 - Tensorflow Object Detection API
一. 找到最好的工具“工欲善其事,必先利其器”,如果你想找一个深度学习框架来解决深度学习问题,TensorFlow 就是你的不二之选,究其原因,也不必过多解释,看过其优雅的代码架构和工程化实现之后,相…

迈向多模态AGI之开放世界目标检测 | 人工智能
作者:王斌 谢春宇 冷大炜 引言 目标检测是计算机视觉中的一个非常重要的基础任务,与常见的的图像分类/识别任务不同,目标检测需要模型在给出目标的类别之上,进一步给出目标的位置和大小信息,在CV三大任务(识…
目标检测00-04:mmdetection(Foveabox为例)-config文件注释-持续更新
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
目标检测00-02:mmdetection(Foveabox为例)-官方数据训练测试-COCO
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…

计算机视觉 Computer Vision Chaper9 目标检测 上
文章目录目标检测ILSVRC竞赛区域卷积网络R-CNN系列R-CNNSPP-NETFast R-CNNFaster R-CNN目标检测 ILSVRC竞赛 区域卷积网络R-CNN系列 两个步骤:1)提取物体区域;2)对区域进行分类识别; 本章所有模型都基于这个思想。但是…
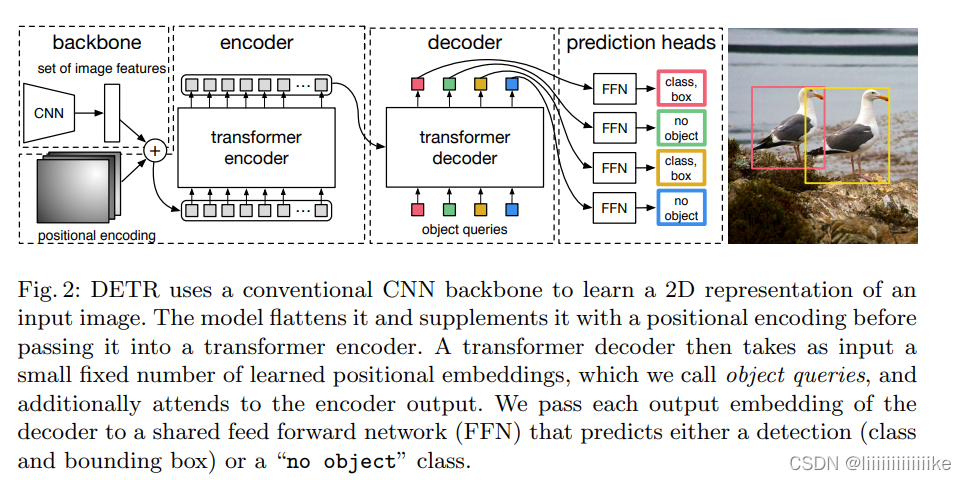
End-to-End Object Detection with Transformers(DETR)论文阅读与理解
论文题目:End-to-End Object Detection with Transformers 论文链接:DETR
摘要: 提出新的方法,直接将目标检测视为一个集合预测的问题(其实无论proposal,anchor,window centers方法本质上都是集…

目标检测Neck总结
特征金字塔 特征金字塔是目前用于目标检测、语义分割、行为识别等方面比较重要的一个部分,对于提高模型性能具有非常好的表现,因为视觉任务中存在不同尺寸的物体,而cnn特征提取层级化结构的特点,因此需要在不同level层检测不同尺寸…
63.合理使用预训练网络-2
63.1 目标检测中如何从零开始训练
结合FAIR相关的研究,可以了解目标检测和其他任务从零训练模型一样,只要拥有足够的数据以及充分而有效的训练,同样能训练出不亚于利用预训练模型的检测器。这里提供如下几点建议: 1、数据集不大时,同样需要进行数据集增强。 2、…

基于Yolov8的道路破损检测系统
目录 1.Yolov8介绍
2.数据集介绍
2.1数据集划分
2.2 通过voc_label.py得到适合yolov8训练需要的
2.3生成内容如下
3.训练结果分析 4. 道路破损检测系统设计
4.1 PySide6介绍
4.2 安装PySide6 4.3 道路破损检测系统设计 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司…
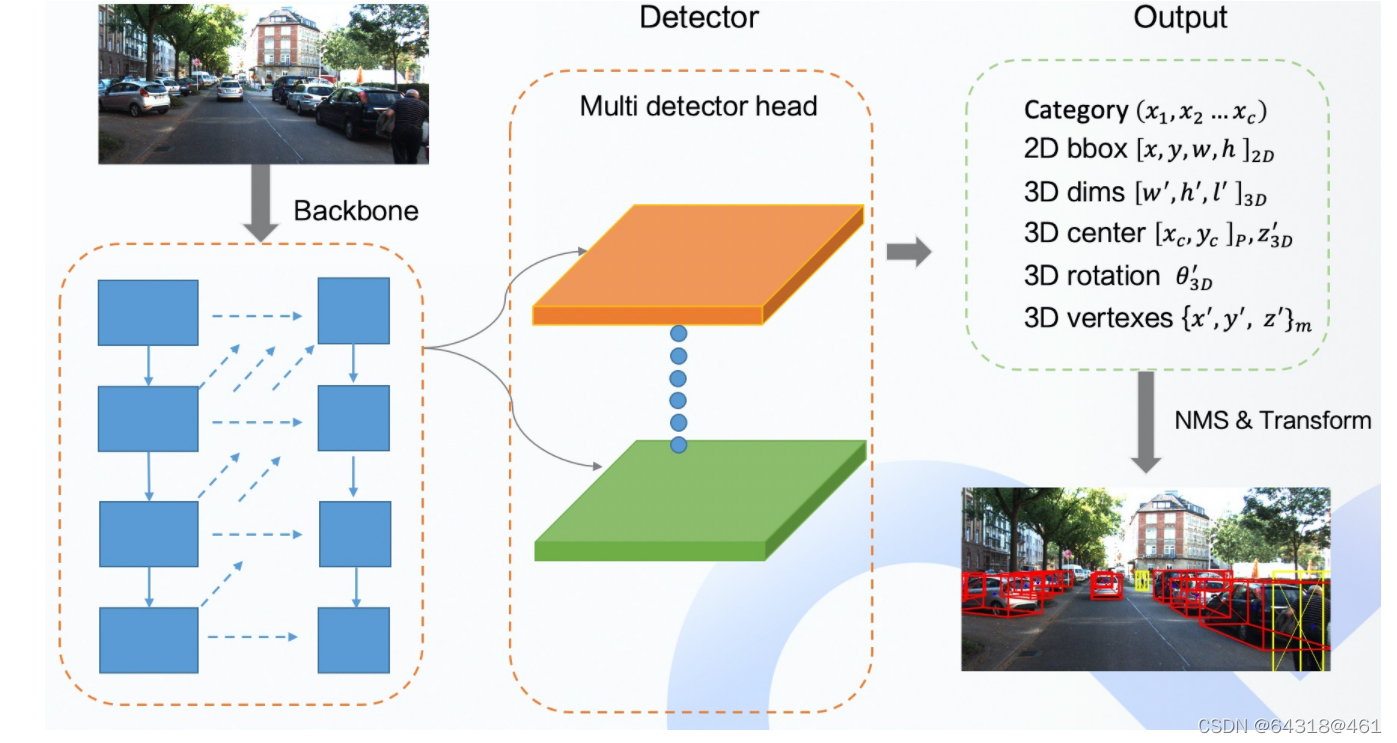
SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
动机:
in this paper that predicts a 3D bounding box for each detected object by combining a single keypoint estimate with regressed 3D variables. As a second contribution, we propose a multi-step disentangling approach for constructing the 3D b…
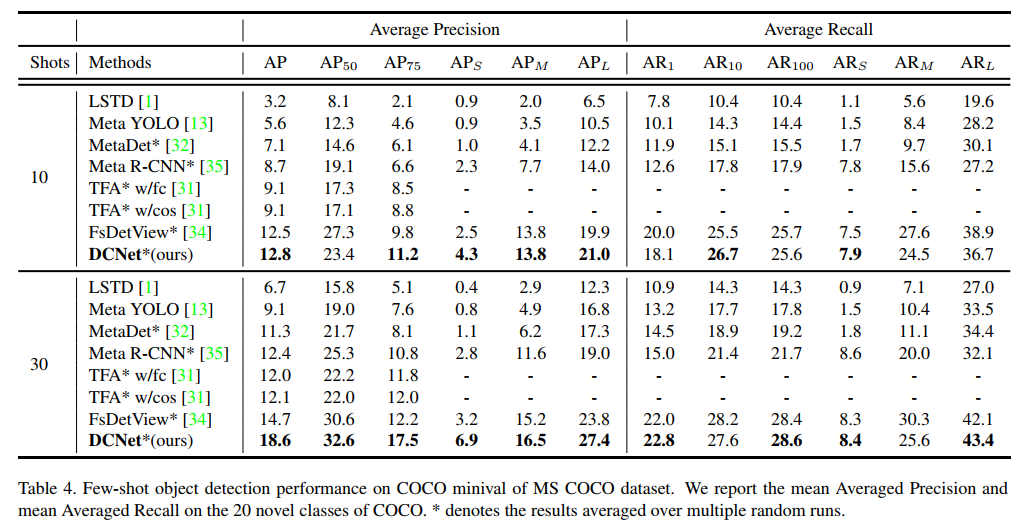
【论文翻译】Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
基于上下文感知聚合的稠密关系提取用于少样本目标检测
论文地址:https://arxiv.org/pdf/2007.12107v1.pdfhttps://arxiv.org/pdf/2103.17115.pdfhttps://arxiv.org/pd…
【论文翻译】Universal-Prototype Enhancing for Few-Shot Object Detection
论文地址:https://arxiv.org/pdf/2103.01077v1.pdf
代码地址:https://github. com/AMIGWU/UP-FSOD
Abstract
Few-shot object detection (FSOD) aims to strengthen the performance of novel object detection with few labeled samples. To allevia…
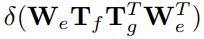
【论文翻译】Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
论文地址:https://arxiv.org/pdf/2103.01903.pdf
代码地址:无 o(╥﹏╥)o
tips:
长尾:少数类(头类)占用大部分的数据…

【论文总结】FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(附翻译)
论文地址:https://arxiv.org/pdf/2103.05950.pdf
代码地址:https: //github.com/MegviiDetection/FSCE 改进:主要是针对小样本检测中分类错误的问题,通过降低不同类别目标的相似性来减小类内差异,增大类间差异→对比学…
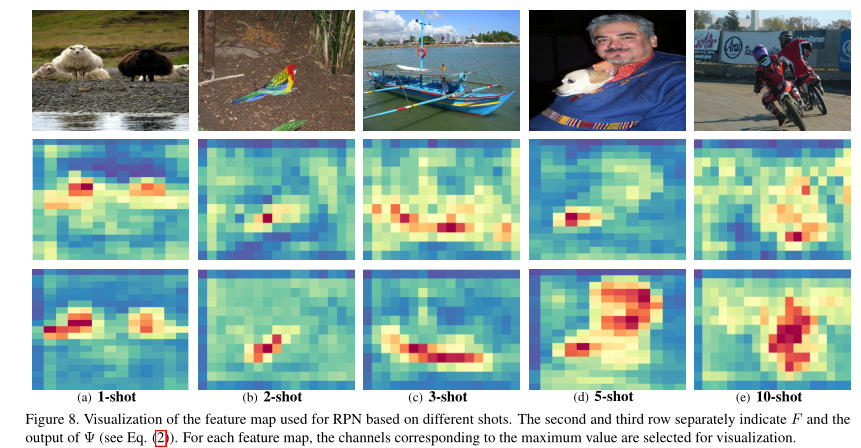
什么是RPN,ROIAlign?
RPN
RPN RPN RPN(Region Proposal Network)用来产生Regin Proposal(前景框,候选区域,检测框(Faster RCNN 直接拿来做检测框) Regin Proposal
RoIPooling、RoIAlign 和 RoIWarp
RoIPooling、…

Sequencer: Deep LSTM for Image Classification(LSTM在CV领域杀出一条血路,完美超越Swin与ConvNeXt等前沿算法)
LSTM在CV领域杀出一条血路,完美超越Swin与ConvNeXt等前沿算法 论文链接:https://download.csdn.net/download/weixin_38353277/85298208
代码链接:待开放
在最近的计算机视觉研究中,ViT的出现迅速改变了各种架构设计工作:ViT利用…
TOF和RGB和结构光对比
TOF和RGB和结构光对比
在机器视觉领域,对于三维成像或者说深度相机的研究一直都是比较热门的,今天维视图像就针对这个方向来给大家做个简单的解析。
目前的深度相机根据其工作原理可以分为三种:TOF、RGB双目和结构光。
一、TOF
TOF是Time…

【mmdetection3d】——03自定义数据预处理流程
教程 3: 自定义数据预处理流程
数据预处理流程的设计
遵循一般惯例,我们使用 Dataset 和 DataLoader 来调用多个进程进行数据的加载。Dataset 将会返回与模型前向传播的参数所对应的数据项构成的字典。因为目标检测中的数据的尺寸可能无法保持一致(如点…

LabelImg 无法保存修改后的xml文件
LabelImg 无法保存修改后xml 文件
今天标注数据,忽然发现无法保存修改之后的xml 文件,保存之后重新打开还是修改之前的xml
查看LabelImg信息如下:
Img: F:\Fan\own\6016\picture\S1000007.jpg -> Its xml: F:\Fan\own\6016\picture\S10…

YOLOX训练自己的数据集(包含自己数据集,预训练模型,代码公开),踩扁很多细节坑全部补充
首先 看下作者给的性能对比图
YOLOX 是旷视开源的高性能检测器。旷视的研究者将解耦头、数据增强、无锚点以及标签分类等目 标检测领域的优秀进展与 YOLO 进行了巧妙的集成组合,提出了 YOLOX,不仅实现了超越 YOLOv3、 YOLOv4 和 YOLOv5 的 AP࿰…
深度学习目标检测评价指标-准确率(Precision),召回率(Recall),F值(F1-score)
深度学习目标检测评价指标-准确率(Precision),召回率(Recall),F值(F1-score)
1、准确率与召回率(Precision & Recall)
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数…

End-to-End Object Detection with Transformers
DERT 目标检测 基于卷积神经网络的目标检测回顾DETR对比Swin Transformer摘要检测网络流程DERT网络架构编码器概述解码器概述整体结构object queries的初始化Decoder中的Muiti-Head Self-AttentionDecoder中的Muiti-Head Attention 损失函数解决的问题 基于卷积神经网络的目标检…

Yolov8-pose关键点检测:模型轻量化创新 | DCNV3结合c2f | CVPR2023
💡💡💡本文解决什么问题:模型轻量化创新引入DCNV3
DCNV3| GFLOPs从9.6降低至8.6,参数量从6482kb降低至5970kb, mAP50从0.921提升至0.926
Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_12398833.html
✨✨✨手把手教你从数据标记到…

【轻量化网络系列(7)】EfficientNetV2论文超详细解读(翻译 +学习笔记+代码实现)
前言
今天我们要学习的是EfficientNetV2 ,该网络主要使用训练感知神经结构搜索和缩放的组合;在EfficientNetV1的基础上,引入了Fused-MBConv到搜索空间中;引入渐进式学习策略、自适应正则强度调整机制使得训练更快;进一…
Yolov8小目标检测(10):DCNv3可形变卷积助力涨点,COCO新纪录65.4mAP | CVPR2023 InternImage
💡💡💡本文改进:DCNv3,基于DCNv2算子引入共享投射权重、多组机制和采样点调制 DCNv3 | 亲测在红外弱小目标检测涨点,map@0.5 从0.755提升至0.765
💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一…
【数据集可视化】COCO数据集标注可视化+代码实现
1作用
在做目标检测时,首先要检查标注数据。一方面是要了解标注的情况,另一方面是检查数据集的标注和格式是否正确,只有正确的情况下才能进行下一步的训练。
2 代码实现
import json
import os, cv2# train_json rC:\Users\mage\Desktop\…
目标检测之小目标检测
一、小目标的定义
在COCO定义中,像素面积小于32*32 pixels的物体目标边界框的宽高与原图的宽高的比例小于设定比例(通用值为0.1)目标边界框的面积与原图的面积的比例的开方小于设定比例(通用值为0.03)
二、小目标检测…
详细介绍如何使用 Mediapipe 实现驾驶员疲劳驾驶的检测
文末附实现的源代码下载链接 在 Python 中使用 Mediapipe 检测驾驶员困倦
连续驾驶可能会很乏味且令人疲惫不堪。驾车者可能会因不活动而变得无精打采,甚至打瞌睡。在本文中,我们将创建一个昏昏欲睡的驾驶员检测系统来解决此类问题。为此,我们将使用Mediapipe 的Python中的…
论文提要“Selective Search for Object Recognition”
这篇2012年的IJCV使用分割和穷举搜索的方法产生目标proposal,最近出现的R-CNN就是在这些proposal上学习特征进行目标识别的,目标proposal是相对于滑动窗产生的候选框来说的,proposal的数量要少很多。
区域可以归并到一起的原因有很多&#x…
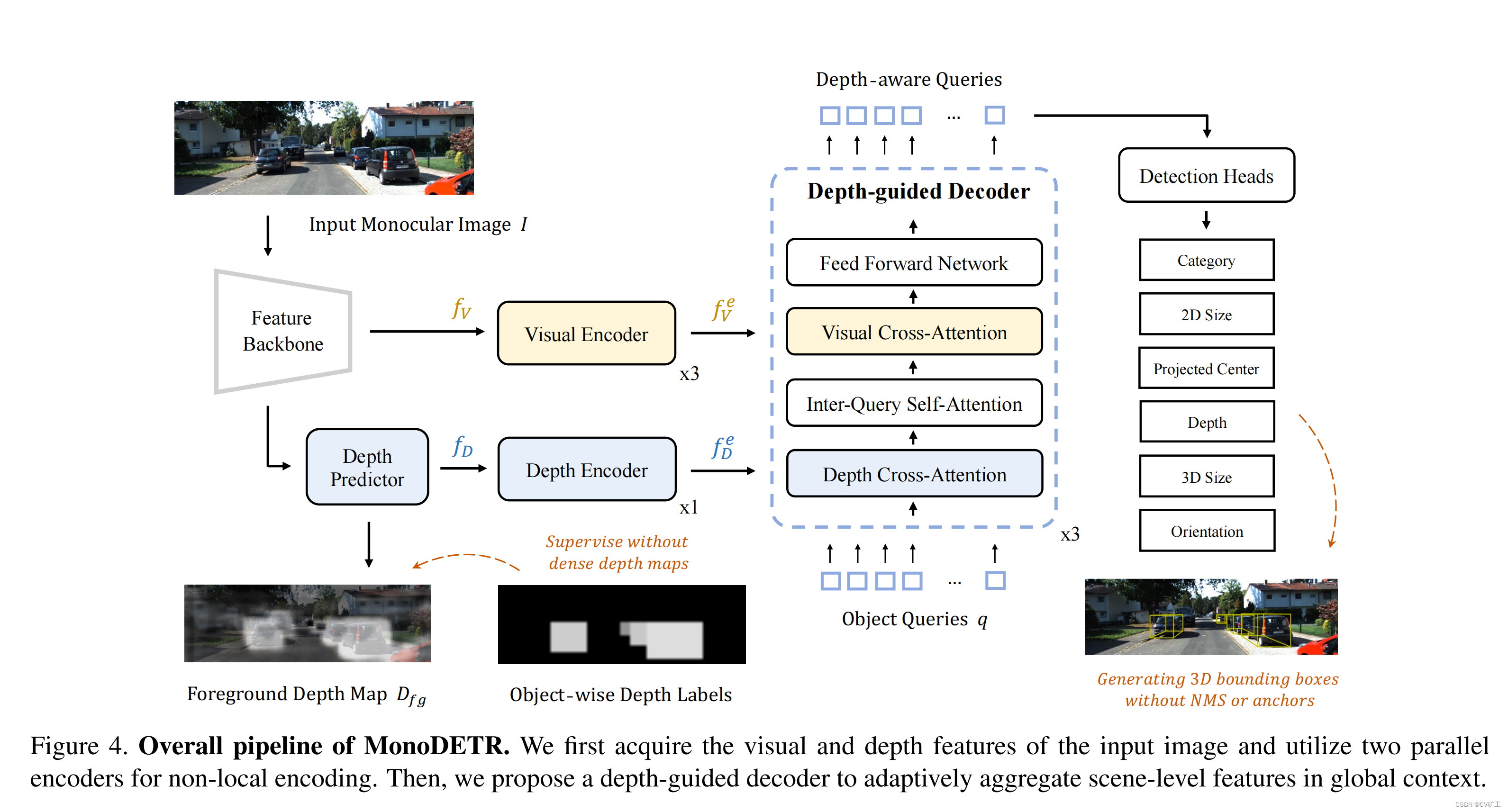
MonoDETR: Depth-guided Transformer for Monocular 3D Object Detection 论文解读
MonoDETR论文解读
abstract
单目目标检测在自动驾驶领域,一直是一个具有挑战的任务。现在大部分的方式都是沿用基于卷积的2D 检测器,首先检测物体中心,后通过中心附近的特征去预测3D属性。
但是仅仅通过局部的特征去预测3D特征是不高效的&…
A Keypoint-based Global Association Network for Lane Detection
目录
Abstract
2. Related Works
2.2. Deformable Modeling
3. Method
3.1. Global Keypoint Association
3.1.2 Starting Point Regression
3.1.3 Lane Construction
3.2. Lane-aware Feature Aggregator
4.Experiment
4.2.3 Ablation Study Abstract
提出一种新的…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(8 月 21 日论文合集)
文章目录 一、检测相关(18篇)1.1 LaRS: A Diverse Panoptic Maritime Obstacle Detection Dataset and Benchmark1.2 Far3D: Expanding the Horizon for Surround-view 3D Object Detection1.3 Deep Equilibrium Object Detection1.4 Decoupled conditional contrastive learni…
labelme勾目标检测COCO数据格式,mmdetection框架训练
环境安装 将labelme安装到anaconda环境中,激活环境,输入labelme打开软件 使用mmdetection训练自己的coco数据集(免费分享自制数据集文件) 还需要修改模型参数里面的num_class类别数量
mmdetection测试单张/多张图片并保存
(lableme) PS C:\Users\XXX\D…
RK3568 NPU YOLOV5S 目标检测DEMO
视频流解析
硬件环境
开发板:RK356X
系统:Debian11
获取源码
程序源码内置SDK目录
$ ls external/rknpu2/examples/rknn_yolov5_video_demo/build build-android_RK356X.sh build-android_RK3588.sh build-linux_RK356X.sh build-linux_RK3588…
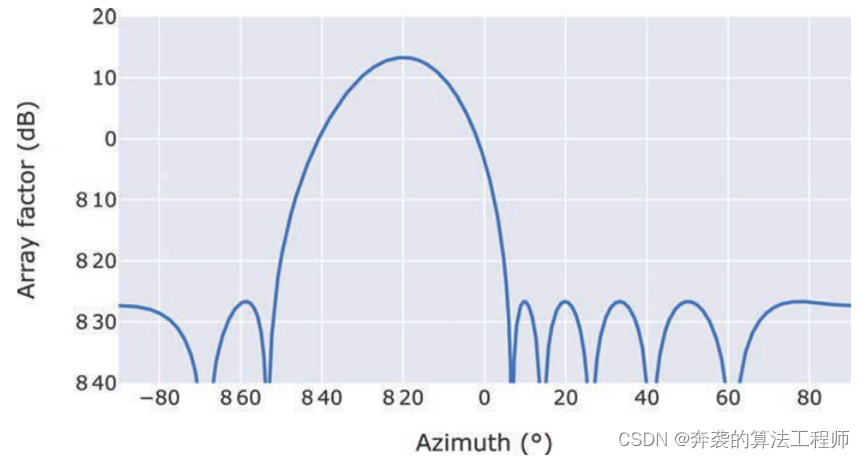
现代雷达车载应用——第2章 汽车雷达系统原理 2.2节 汽车雷达架构
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
2.2 汽车雷达架构 从顶层来看,基本的汽车雷达由发射器,接收器和天线组成。图2.2给出了一种简化的单通道连续波雷达结构[2]。这…
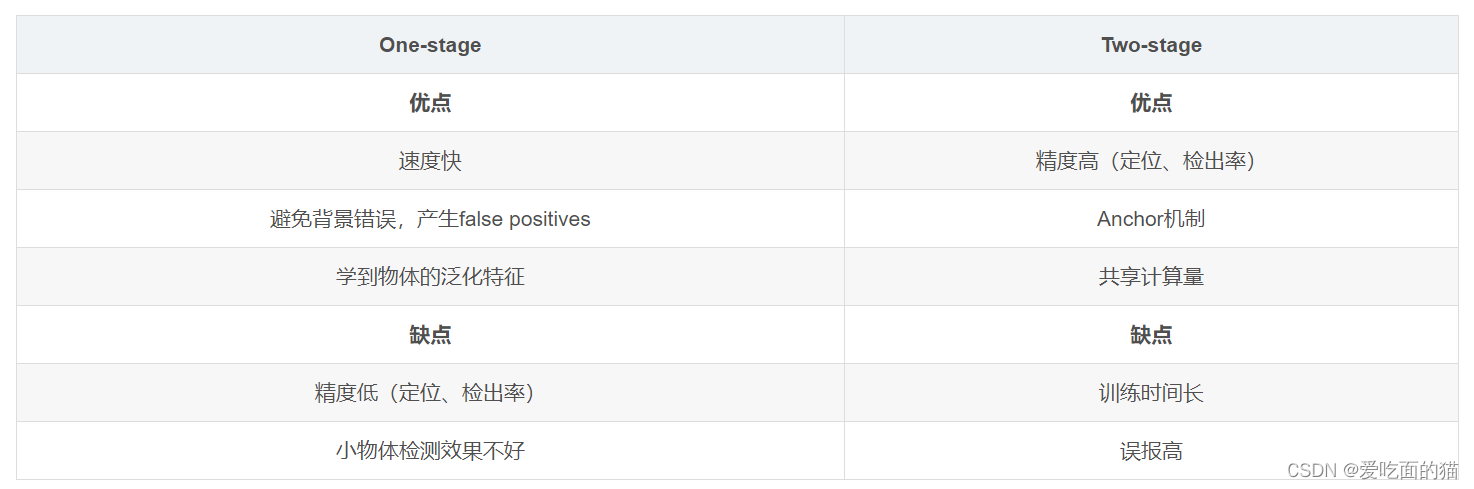
06目标检测-One-stage的目标检测算法
一、 One-stage目标检测算法
使用CNN卷积特征直接回归物体的类别概率和位置坐标值(无region proposal)准确度低,速度相对two-stage快
二、One-stage基本流程 输入图片------对图片进行深度特征的提取(主干神经网络&#…
基于YOLOv8模型和UA-DETRAC数据集的车辆目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和UA-DETRAC数据集的车辆目标检测系统可用于日常生活中检测与定位汽车(car)、公共汽车(bus)、面包车(vans)等目标,利用深度学习算法可实现图片、视频、摄像头等方…
[数据集][目标检测]道路坑洞目标检测数据集VOC+YOLO格式665张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):665 标注数量(xml文件个数):665 标注数量(txt文件个数):665 标注类别…

【深度学习目标检测】三、基于深度学习的人物摔倒检测(python,yolov8)
深度学习目标检测方法则是利用深度神经网络模型进行目标检测,主要有以下几种: R-CNN系列:包括R-CNN、Fast R-CNN、Faster R-CNN等,通过候选区域法生成候选目标区域,然后使用卷积神经网络提取特征,并通过分类…
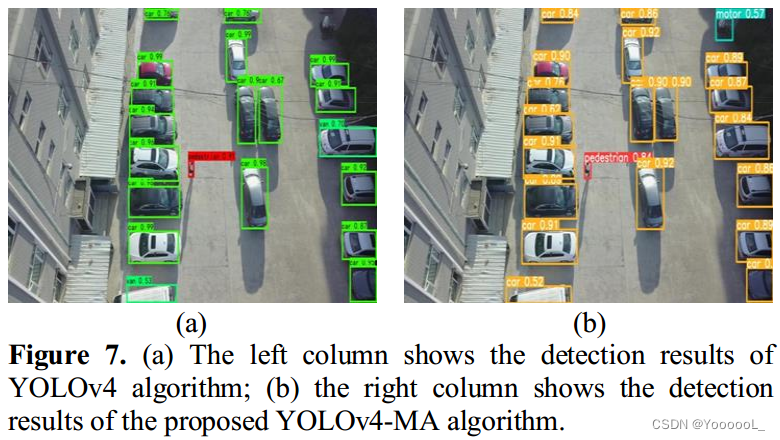
【目标检测论文阅读笔记】Multi-scene small object detection with modified YOLOv4
Abstract. 小目标检测的应用存在于我们日常生活中的许多不同场景中,该课题也是目标检测与识别研究中最难的问题之一。因此,提高小目标检测精度不仅在理论上具有重要意义,在实践中也具有重要意义。然而,当前的检测相关算法在这项任…
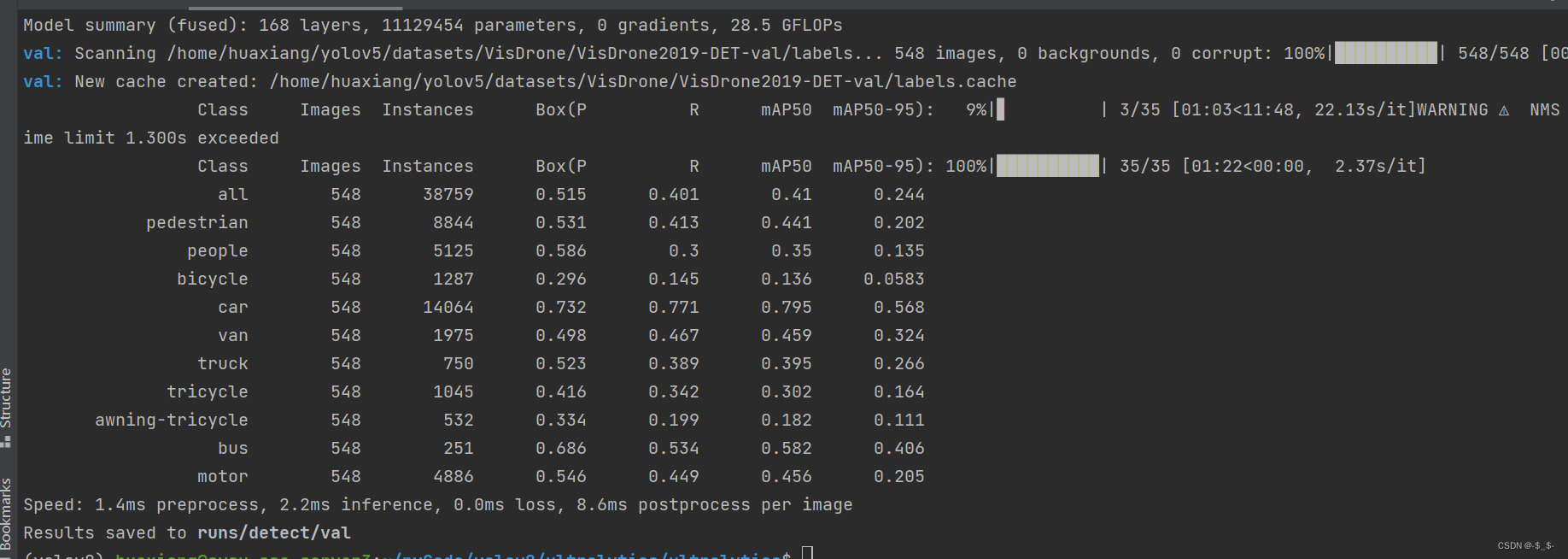
【目标检测算法实现之yolov8】yolov8训练并测试VisDrone数据集
目录1.环境准备创建yolov8虚拟环境进入虚拟环境安装pytorch v1.11.0下载yolov8的代码其他配置2.VisDrone数据集准备数据集下载数据集处理修改数据配置文件3.训练/验证/导出训练验证导出1.环境准备
在这之前,需要先准备主机的环境,环境如下: …
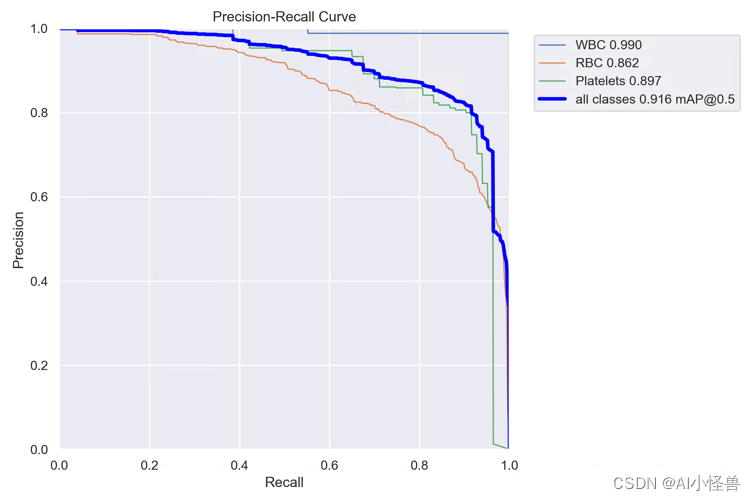
YOLO目标检测——红白细胞血小板数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:红白细胞血小板计数和分类数据集说明:YOLO目标检测数据集,真实场景的高质量图片数据,数据场景丰富。使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三种格式标签&…

将语义分割的标注mask转为目标检测的bbox
1. 语义分割标签
1.1 labelme工具
语义分割的标签是利用labelme工具进行标注的,标注的样式如下: 1.2 语义分割的标签样式 2. 转换语义分割的标注到目标检测的bbox
实现步骤 (1) 利用标注的json文件生成mask图片(2) 在mask图片中找到目标的bbox矩形框的左上角点和右下角点(…

YOLOv8-Seg改进:分割注意力系列篇 | 新型的多尺度卷积注意力(MSCA)模块
🚀🚀🚀本文改进: 新型的多尺度卷积注意力(MSCA)模块,实现创新,MSCA包含三个部分:深度卷积聚合局部信息,多分支深度条卷积捕获多尺度上下文,以及11卷积建模不同通道之间的关系。
🚀🚀🚀MSCA多尺度特性在小目标分割检测领域表现优异 🚀🚀🚀YOLOv8-seg…
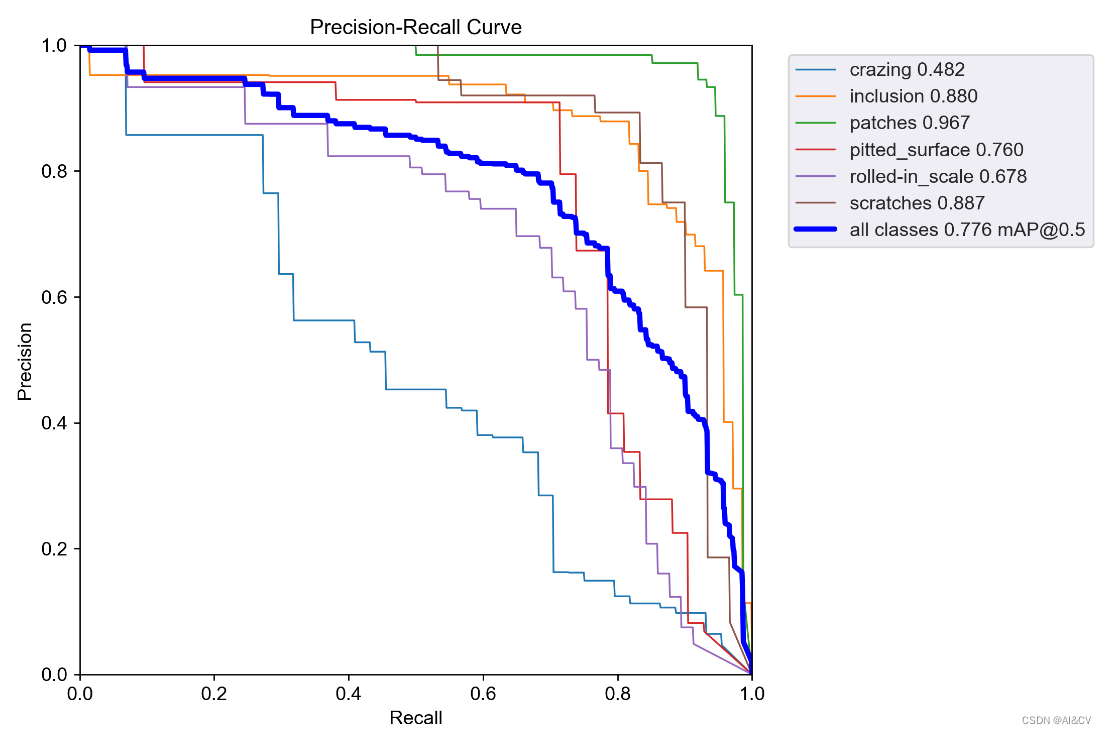
Yolov5创新:NEU-DET钢材表面缺陷检测,优化组合新颖程度较高,CVPR2023 DCNV3和InceptionNeXt,涨点明显
1.钢铁缺陷数据集介绍 NEU-DET钢材表面缺陷共有六大类,分别为:crazing,inclusion,patches,pitted_surface,rolled-in_scale,scratches 每个类别分布为: 训练结果如下:
2.基于yolov5s的训练
map值0.742: 2.1 Incepti…
图像分割mask转换为目标检测框bbox
cv2.threshold() cv2.connectedComponentsWithStats() https://zhuanlan.zhihu.com/p/59486758
num_labels, labels, stats, centroids cv2.connectedComponentsWithStats(image, connectivity8, ltypeNone)
参数介绍如下: image:也就是输入图像&…
linux 安装pycococreator和pycocotools
目录
1.🐸安装pycococreatortools🐸
🍓🍓安装方式1
🍓🍓安装方式2
2.🐸安装pycocotools🐸
🍓🍓安装方式1
🍓🍓安装方式2
整理不…
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(七)
文章目录 一、Cops-Ref二、FAT (Falling Things)三、GEN1 Detection (Prophesee GEN1 Automotive Detection Dataset)四、RIT-18五、AGAR (Annotated Germs for Automated Recognition)六、EuroCity Persons七、Freiburg Groceries八、Lytro Illum九、PFN-PIC (PFN Picking Ins…
论文阅读-20220904
开学第一周论文阅读总结
本周阅读了两篇英文文献,第一篇是陈铿的一种基于自适应特征调整的室内场景三维点云多目标检测方法,另一篇是林在超的一种基于特征增强的改进点云补全方法。 目录开学第一周论文阅读总结基于自适应特征调整的室内场景三维点云多目…
.ipynb_checkpoints隐藏文件引发的错误
在AutoDL上跑mmrotate程序时,引发了错误 可以看到val_image文件下只有一张图片文件,但进度条(tqdm.tqdm())显示读取了两个文件,下面的报错显示了还存在一个.ipynb_checkpoints文件,cd到val_images文件夹下用…
mmrotate旋转目标检测框架的学习与使用
目录
前言
一、环境配置
1. 下载checkpoint文件
2. 运行demo
二、制作自己的数据集
1. 标注数据
2. 标签格式转换
3. 可视化数据集
4. 数据集裁剪
三、 修改配置文件
1. 修改classes
2. 修改训练参数
四、训练并测试
1. 训练
2. 测试
3. 预测
五、总结
参考资…
【目标检测】记录我在自己的红外数据集上训练YOLOX的过程和遇到的坑
最近在自己的红外数据集上训练YOLOX网络(以COCO数据集的形式),把过程记录下来。 YOLOX代码:https://github.com/Megvii-BaseDetection/YOLOX 目录数据集准备生成数据标签的json文件代码修改修改数据集的目录信息修改类别数量修改标…

【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(7 月 3 日论文合集)
文章目录 一、检测相关(9篇)1.1 Federated Ensemble YOLOv5 - A Better Generalized Object Detection Algorithm1.2 Zero-shot Nuclei Detection via Visual-Language Pre-trained Models1.3 Federated Object Detection for Quality Inspection in Shared Production1.4 Comp…
(十六)mmdetection源码解读:BasedRunner
目录 一、BasedRunner源码二、BasedRunner类的属性三、BasedRunner类的方法3.1 只读属性和抽象方法3.2 权重保存和加载方法3.3 hook的注册和调用 一、BasedRunner源码
class BaseRunner(metaclassABCMeta):def __init__(self,model,batch_processorNone,optimizerNone,work_di…

YOLO目标检测——昏暗车辆数据集+已标注VOC格式标签下载分享
实际项目应用:昏暗车辆数据集在智能交通监控系统、驾驶辅助系统、城市安全监控、自动驾驶系统以及路况分析与规划等应用场景中具有广泛的应用潜力,可以提高车辆检测的准确性和效率,提升交通安全和城市管理水平。数据集说明:昏暗车…
【AIGC】13、GLIP | 首次将 object detection 重建为 phrase grounding 任务
文章目录 一、背景二、方法2.1 将 object detection 和 phrase grounding 进行统一2.2 Language-aware deep fusion2.3 使用语义丰富的数据来进行预训练 三、效果3.1 迁移到现有 Benchmarks3.2 在 COCO 上进行零样本和有监督的迁移3.3 在 LVIS 上进行零样本迁移学习3.4 在 Flic…
![C# - Opencv应用(2) 之矩阵Mat使用[矩阵创建、图像显示、像素读取与赋值]](https://img-blog.csdnimg.cn/f4acf3b030754530a47f3b95ae2ffb0e.png)
C# - Opencv应用(2) 之矩阵Mat使用[矩阵创建、图像显示、像素读取与赋值]
C# - Opencv应用(2) 之矩阵Mat使用[矩阵创建、图像显示、像素读取与赋值]
矩阵创建图像显示与保存像素读取与赋值新建sample02项目,配置opencv4相关包,新建.cs进行测试
1.矩阵创建
//创建空白矩阵
var dst new Mat()//创建并赋…
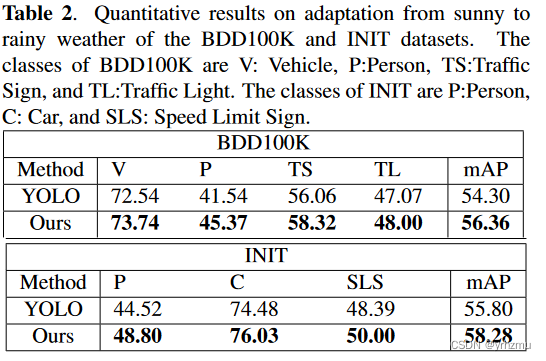
论文阅读<MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION>
论文链接:https://arxiv.org/pdf/2106.01483v2.pdfhttps://arxiv.org/pdf/2106.01483v2.pdf
代码链接:GitHub - Mazin-Hnewa/MS-DAYOLO: Multiscale Domain Adaptive YOLO for Cross-Domain Object DetectionMultiscale Domain Adaptive YOLO for Cross…
Yolov5轻量化:MobileNetV3,轻量级骨架首选
1.轻量化网络简介 轻量化网络是指在保持模型性能的前提下,尽可能减小模型参数量和计算量的神经网络。这种网络通常被用于在移动设备等资源受限的场景中部署,以提高模型的实时性和运行效率。 轻量化网络的设计思路可以包括以下几个方面: 去除冗余层和参数:通过剪枝、蒸馏等技…
MATLAB算法实战应用案例精讲-【图像处理】SLAM技术详解(基础篇)
目录
几个高频面试题目
SLAM框架常见方案对比
点云数据
传感器
视觉SLAM框架
SLAM框架之视觉里程计
YOLOv8改进 | ICLR 2022 |ODConv附修改后的C2f、Bottleneck模块代码
论文地址:论文地址点击即可跳转阅读
代码地址:文末提供复制粘贴的代码块
一、本文介绍
这篇文章给大家带来的是发表于2022年ICLR的ODConv(Omni-Dimensional Dynamic Convolution)中文名字全维度动态卷积,该卷积可以即插即用,可…

CenterNet在Ubuntu20.04,PyTorch1.5,CUDA10.2的安装
写在前面 最近需要搞一个目标检测加上特征提取的小项目,找方法的时候看到了CenterNet这个网络模型,论文里的图表表现出CenterNet性能完虐YOLOv3,如下图
看着还是非常诱惑的,所以试试用这个。论文里也给了官方代码,但…

OpenCV实战——使用YOLO进行目标检测
OpenCV实战——使用YOLO进行目标检测 0. 前言1. YOLO 模型简介2. 基于 YOLO 实现目标检测3. 完整代码相关链接 0. 前言
在本节中,我们将使用 YOLO 算法执行目标检测。目标检测是计算机视觉中的一项常见任务,借助深度学习技术,我们可以实现高…

CV——day80 读论文:DLT-Net:可行驶区域、车道线和交通对象的联合检测
DLT-Net:可行驶区域、车道线和交通对象的联合检测I. INTRODUCTIONII. ANALYSIS OF PERCEPTIONIV. DLT-NETA. EncoderB. Decoder1) Drivable Area Branch(可行驶区域分支)2) Context Tensor(上下文张量)3) Lane Line Branch(车道线分支)4) Traffic Object Branch(目标检测对象分…

目标检测与YOLO算法(用Python实现目标检测)
最近在听Andrew Ng讲解目标检测的视频,包括目标定位,特征点检测,卷积的滑动窗口的实现,Bounding Box预测,交并比,非极大值抑制,AnchorBoxes,YOLO算法以及候选区域,并通过…

【手把手教你】深度学习(目标检测—RCNN)
目录
1. 目标检测基础
1.1 物体识别
1.2 物体定位
1.3 交并比
1.4 非极大值抑制
1.5 目标检测分类
2. RCNN [2]
2.1 Seletive search选择候选框
2.2 候选框特征提取
2.3 候选区域分类及边框微调
2.4 非极大值抑制
3. 总结
参考文献 大家好,我是羽峰&…
【mmdetection3d】——3D 目标检测 NuScenes 数据集
3D 目标检测 NuScenes 数据集
本页提供了有关在 MMDetection3D 中使用 nuScenes 数据集的具体教程。
准备之前
您可以在这里下载 nuScenes 3D 检测数据并解压缩所有 zip 文件。
像准备数据集的一般方法一样,建议将数据集根目录软链接到 $MMDETECTION3D/data。
…
【目标检测】yolov5代码实战
文章目录 一、yolov5介绍二、yolov5安装2.1 yolov5的源码下载2.2 预训练模型下载2.3 安装yolov5的依赖项2.4 检测是否安装成功 三、yolov5训练自己的数据集参考资料 一、yolov5介绍
YOLO 是 “You only look once” 缩写 , 是将图像划分为网格系统的对象检测算法,网…
在Nvidia Jetson Nano上利用YOLO进行目标检测的实践过程
📺 硬件
Nvidia Jetson Nano Nvidia Jetson Nano是英伟达推出的深度学习开发板,性价比极高。本人也用过其他国产的深度学习开发板,比如某为的开发套件,难用的一批。Nvidia Jetson Nano上手及其容易,只要是有深度学习基…

【卷积神经网络】YOLO 算法原理
在计算机视觉领域中,目标检测(Object Detection)是一个具有挑战性且重要的新兴研究方向。目标检测不仅要预测图片中是否包含待检测的目标,还需要在图片中指出它们的位置。2015 年,Joseph Redmon, Santosh Divvala 等人…

YOLOv5算法进阶改进(10)— 更换主干网络之MobileViTv3 | 轻量化Backbone
前言:Hello大家好,我是小哥谈。MobileViTv3是一种改进的模型架构,用于图像分类任务。它是在MobileViTv1和MobileViTv2的基础上进行改进的,通过引入新的模块和优化网络结构来提高性能。本节课就给大家介绍一下如何在主干网络中引入MobileViTv3网络结构,希望大家学习之后能够…

PASCAL VOC数据集
一、前言 之前寒假好像就学了,但是没有记笔记,现在看来还是得记笔记,都忘得差不多了啊。 二、数据集的介绍 2.1数据集背景 分类类别 2.2数据集文件结构: 2.3文件夹 2.3.1Annotations文件夹 对于标注文件Annotations:里…
【计算机视觉 | 目标检测】术语理解:V2L 映射、视觉 embedding 和文本 embedding
文章目录 一、V2L 映射二、视觉 embedding三、文本 embedding 一、V2L 映射
V2L 映射(Vision-to-Language Mapping)是指将视觉信息映射到文本信息的过程,它的目标是建立视觉数据和文本数据之间的联系,以便计算机可以理解和处理这…
Yolov5轻量级:EfficientViT, better speed and accuracy
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention 论文:https://arxiv.org/abs/2305.07027
代码:Cream/EfficientViT at main microsoft/Cream GitHub 🏆🏆🏆🏆🏆🏆Yolo轻量化模型🏆🏆🏆🏆🏆🏆 近些年对视觉Tra…

深度学习在机器视觉领域的应用:分类、目标检测与语义分割
随着深度学习技术的不断进步,机器视觉领域已经发生了革命性的变化。深度学习的算法在图像和视频的理解上展现出了前所未有的效果,尤其在图像分类、目标检测和语义分割这三个核心任务上取得了显著的成就。本文将从深度学习算法工程师的角度,探…
目标检测-计算IOU,mAP指标
1. IOU指标
IoU,全称Intersection over Union,可翻译为交并比,是两个框交集与并集的比值。计算IoU的公式如下图,可以看到IoU是一个比值,即交并比。
在分子中,我们计算预测框和ground-truth之间的重叠区域;分母是并集区域,是预测框和ground-truth所包含的总区域。重叠…

YOLOv8改进 | 主干篇 | 利用SENetV2改进网络结构 (全网首发改进)
一、本文介绍
本文给大家带来的改进机制是SENetV2,其是2023.11月的最新机制(所以大家想要发论文的可以在上面下点功夫),其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何…
特别关注什么是CPC认证,美国CPSC测试有哪些常见问题解析
CPC认证是Children’s Product Certificate的英文简称,CPC证书就类似于国内的质检报告,在通过相关检测、出具报告后同时可出具的一纸证书,证书列明进/出口商信息,商品信息、以及已做过的相关检测项目及其依据的法规标准。…
点云从入门到精通技术详解100篇-基于激光雷达点云的交通场景三维车辆目标检测与跟踪(续)
目录 3.3 实验与分析 3.3.1 数据集 3.3.2 实验设置 3.3.3 评价指标 3.3.4 实验结果与分析

Talk | ICCV‘23清华大学刘世隆:From Detection to Grounding-迈向更强的开集目标检测
本期为TechBeat人工智能社区第521期线上Talk! 北京时间8月10日(周四)20:00,清华大学博士生—刘世隆的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “From Detection to Grounding-迈向更强的开集目标检测”,他分…
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(四)
文章目录 一、JTA (Joint Track Auto)二、AVD (Active Vision Dataset)三、ExDark (Exclusively Dark Image Dataset)四、InteriorNet五、ScanRefer Dataset六、FlickrLogos-32七、SIXray八、Clear Weather (DENSE)九、DVQA (Data Visualizations via Question Answering)十、M…

基于机器视觉的旋转编码器缺陷检测
基于机器视觉的旋转编码器缺陷检测
1 背景及意义
旋转编码器是用来测量转速并配合PWM技术可以实现快速调速的装置,基本上每一个伺服电机都有一个旋转编码器。旋转编码器的质量将直接影响到伺服电机的好坏,所以每一个旋转编码器出厂前都要经过严格的质检。
传统的检测方法是…


安防行业深度报告:技术创新与格局重构
前言:Hello大家好,我是小哥谈。通过运用云计算、人工智能等新技术,安防行业正经历从传统安防向 AI 智慧安防转型升级的过程。这种升级将改变传统安防只能事后查证、人工决策的劣势,使得全程监控、智能决策成为可能。通过运用后端云…
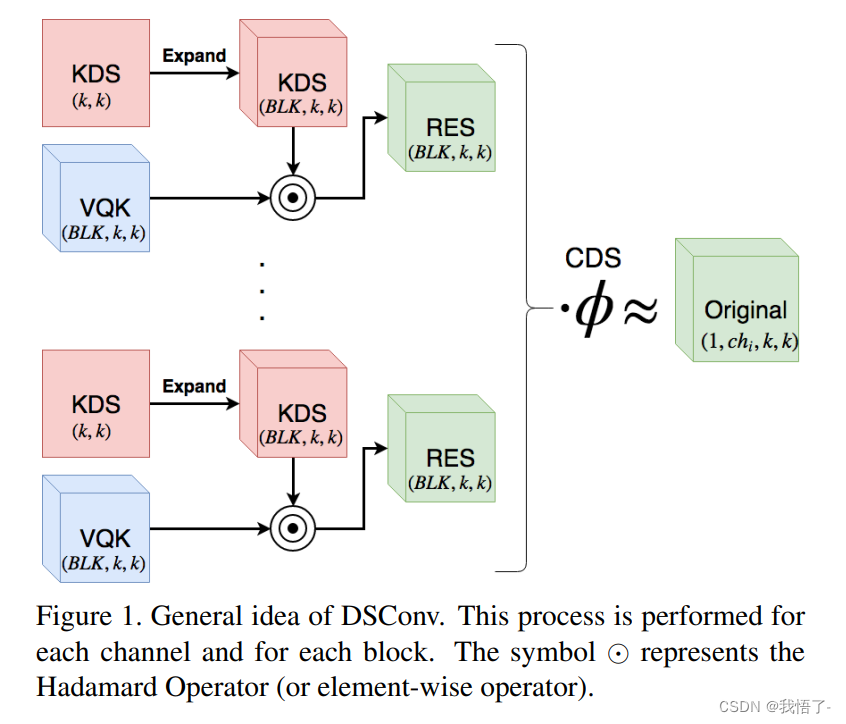
pytorch代码实现之分布偏移卷积DSConv
DSConv卷积模块
DSConv(分布偏移卷积)可以容易地替换进标准神经网络体系结构并且实现较低的存储器使用和较高的计算速度。 DSConv将传统的卷积内核分解为两个组件:可变量化内核(VQK)和分布偏移。 通过在VQK中仅存储整…
yolov3、yolov4等批量预测图片并保存(python)
目录 说明方法一、按图片的文件夹获取图片路径二、按图片对应的txt文件夹获取图片路径说明
本批量预测图片代码很适用于深度学习目标检测当中,将代码主干添加到预测脚本当中,修改部分调用参数、读入文件夹、保存文件夹等都可适用,方法如下:
方法
一、按图片的文件夹获取…

voc2007目标检测数据集制作
1. labelImg安装
1.工具下载:label工具的github下载地址:https://github.com/tzutalin/labelImg/tree/bf8cc1d5756184b9af8e412929efdaa6ae0ba4f1
在此感谢大神的贡献,工具真的很好用,一目了然。
2. 如果电脑还没有安装anacond…
基于Yolov8的野外烟雾检测(3):动态蛇形卷积(Dynamic Snake Convolution),实现暴力涨点 | ICCV2023
目录 1.Yolov8介绍
2.野外火灾烟雾数据集介绍
3.Dynamic Snake Convolution
3.1 Dynamic Snake Convolution加入到yolov8
4.训练结果分析
5.系列篇 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最…


基于YOLOV8模型的农作机器和行人目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型的农作机器和行人目标检测系统可用于日常生活中检测与定位农作机和行人目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标…

DMNet复现(二)之模型篇:Density map guided object detection in aerial image
以前用Swin Transformer Tiny训练了40epoch的,官方用的Faster RCNN,这里先用Swin Transformer Tiny进行测试。
模型训练
采用基于MMDetection的框架Swin Transformer Tiny进行训练,训练方法可参考官方教程。
融合检测
Global Image 检测 …
FastestDet---模型训练
代码:https://github.com/dog-qiuqiu/FastestDet
一、构造数据集 数据集格式YOLO相同,每张图片对应一个txt标签文件。标签格式:“category cx cy wh”,category为类别id,cx, cy为归一化标签框中心点的坐标,w, h为归一化标签框的宽度和高度, .txt标签文件内容示例如下: 0…

【目标检测】YOLOv8:快速上手指南
YOLOv8概述
YOLOv8是YOLOv5团队在今年新推出的一代YOLO版本,与前几代版本相比,其性能和速度差距如下图所示: 和其它版本不同的是,该仓库并非起名为YOLOv8,而是公司名ultralytics,因为他们想将此版本作为一…
单阶段目标检测与双阶段目标检测的联系与区别
🚀 作者 :“码上有钱”
🚀 文章简介 :AI-目标检测算法
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬简介
双阶段目标检测算法与单阶段目标检测算法在工作原理和性能方面存在一些相似与差异之处。下…
模型推理后处理C++代码优化案例
文章目录 项目场景:问题描述原因分析:解决方案:小结 项目场景:
经过推理的后处理运行时间的优化。
先来看下优化前后的时间对比: 优化前: 优化后: 提升还是很大的。 问题描述
模型推理后得…
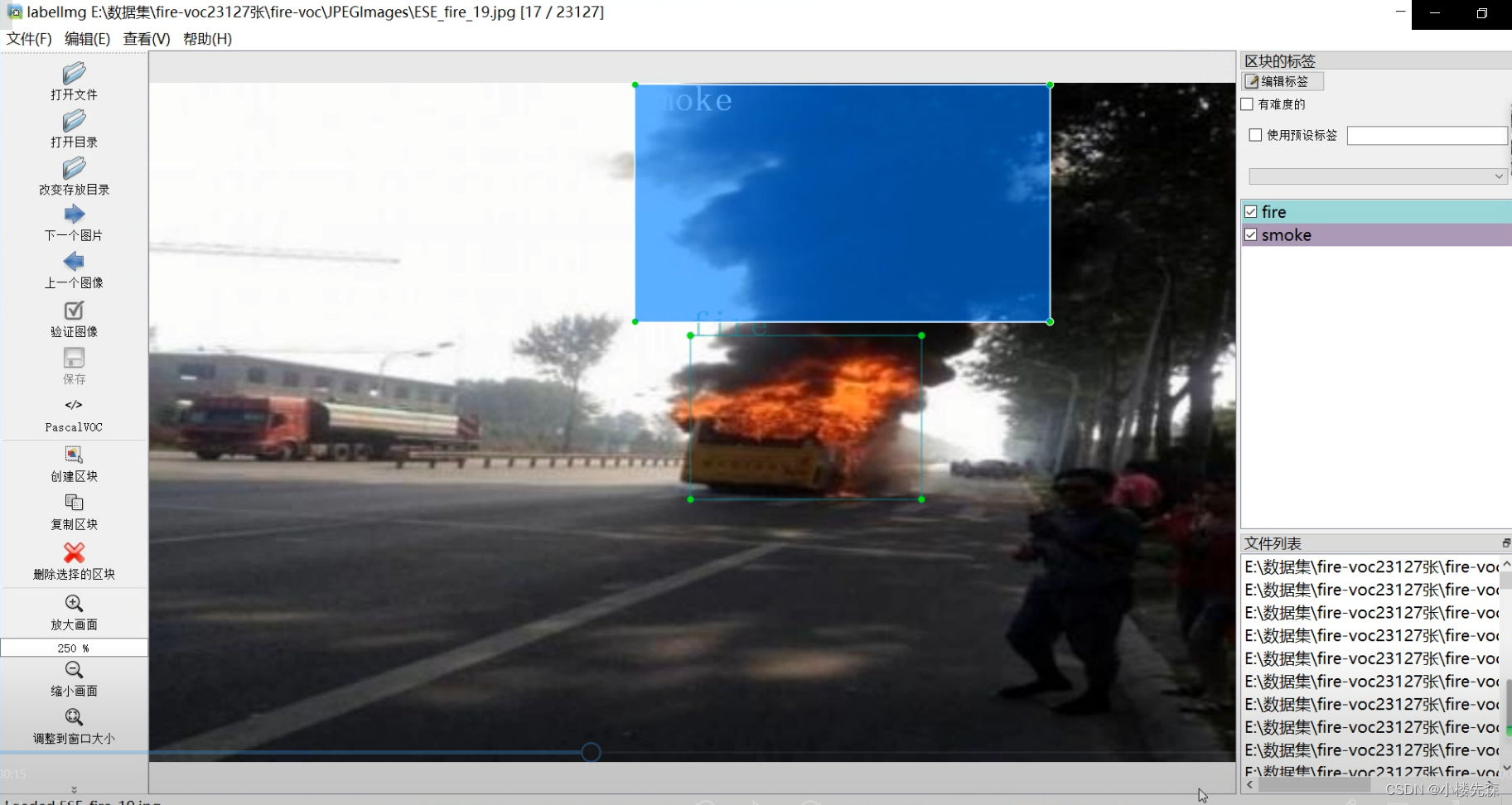
fire-voc 火光 烟火 火灾 目标检测数据集
一年中最容易引发火灾的季节是在冬季,主要原因有这样几点。
1、秋冬季节,随着用火、用电、用气增加,加上天气干燥,棉花、木材 、衣物等物体内含有的水分也较低。2、秋冬季风力较大,一旦有火苗冒起就很容易随风蔓延,是火灾的高发期。3、春季也是火灾多发季节&#x…
目标检测YOLO实战应用案例100讲-基于CNN的卫星图像下舰船目标检测与识别
目录
前言
2目标检测相关理论与技术
2.1卷积神经网络
2.1.1卷积层
2.1.2池化层
2.1.3
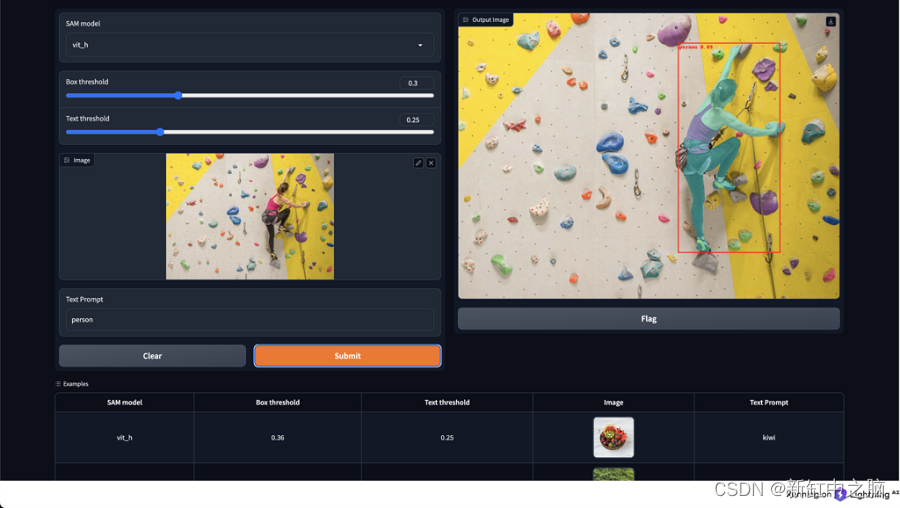
基于文本提示的图像目标检测与分割实践
近年来,计算机视觉取得了显着的进步,特别是在图像分割和目标检测任务方面。 最近值得注意的突破之一是分段任意模型(SAM),这是一种多功能深度学习模型,旨在有效地从图像和输入提示中预测对象掩模。 通过利用…
YOLOv7独家改进新颖Neck:RepBiPAN结构升级版,为YOLOv7目标检测打造全新特征融合方式,增强小目标定位精度
💡本篇内容:YOLOv7改进新颖Neck:RepBiPAN 结构升级版,为YOLOv目标检测打造全新特征融合方式,增强小目标定位精度
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv7专属
全新 RepBi…
YOLOv8血细胞检测(10):多尺度MultiSEAM,提高特征图的分辨率增强小目标检测能力
💡💡💡本文改进:多尺度MultiSEAM,提高特征图的分辨率增强小目标检测能力;
MultiSEAM | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.906
收录专栏:
💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4zBP
✨✨✨实战医学影像检测项目,通过创…
目标检测数据集格式转换:txt格式转换为xml格式(以VisDrone数据集为例)
1.准备好两个文件夹
VisDroneTxt文件夹里面装的是原图片以及txt格式的标签
VisDroneVoc里面的labels文件夹是目标文件夹,用来装转换之后的xml格式标签 2.给出原转换程序
# .txt-->.xml
# ! /usr/bin/python
# -*- coding:UTF-8 -*-
import os
import cv2def t…
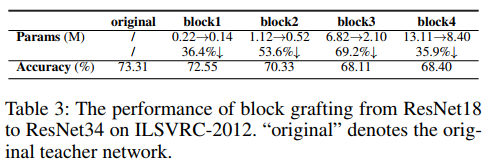
【论文翻译】Progressive Network Grafting for Few-Shot Knowledge Distillation
Progressive Network Grafting for Few-Shot Knowledge Distillation
渐进式网络移植技术在少样本知识提取中的应用
论文地址:https://arxiv.org/pdf/2012.04915v2.pdf
代码地址:https://github.com/zju-vipa/NetGraft
摘要
Knowledge distillation…

睿智的目标检测65——Pytorch搭建DETR目标检测平台
睿智的目标检测65——Pytorch搭建DETR目标检测平台学习前言源码下载DETR实现思路一、整体结构解析二、网络结构解析1、主干网络Backbone介绍a、什么是残差网络b、什么是ResNet50模型c、位置编码2、编码网络Encoder网络介绍a、Transformer Encoder的构建b、Self-attention结构解…
【目标检测】------rcnn、fastrcnn、fasterrcnn
RCNN流程图 sppnet流程图 fastRcnn fasterrcnn网络
RPN(Region Proposal Network)是Faster-RCNN网络用于提取预选框(也就是RCNN中使用selective search算法进行Region Proposal的部分),我们知道RCNN及Fast-RCNN中一个…
SCI论文解读复现【NO.1】基于Transformer-YOLOv5的侧扫声纳图像水下海洋目标实时检测
此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文,帮助…

Java 实现 YoloV7 目标检测
1 OpenCV 环境的准备
这个项目中需要用到 opencv 进行图片的读取与处理操作,因此我们需要先配置一下 opencv 在 java 中运行的配置。
首先前往 opencv 官网下载 opencv-4.6 :点此下载;下载好后仅选择路径后即可完成安装。
此时将 opencv\b…
零基础教程:Yolov5模型改进-添加13种注意力机制
1.准备工作
先给出13种注意力机制的下载地址:
https://github.com/z1069614715/objectdetection_script 2.加入注意力机制
1.以添加SimAM注意力机制为例(不需要接收通道数的注意力机制)
1.在models文件下新建py文件,取名叫Sim…
谈谈那些图像变化的技巧
地铁总 风阀的状态是容易得到监控的
在现有的iscs系统中,他们可以看到风阀的状态,但是往往就地级别的状态和ISCS的状态有不一致的情况,
所以查到真实的状态尤其重要 在学习的过程中 常常遇到图像变化
图像变化的方法太多了,比如…

Python实现机器学习(下)— 数据预处理、模型训练和模型评估
前言:Hello大家好,我是小哥谈。本门课程将介绍人工智能相关概念,重点讲解机器学习原理机器基本算法(监督学习及非监督学习)。使用python,结合sklearn、Pycharm进行编程,介绍iris(鸢尾…

论文解读:Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
发布时间:2022.4.4 (2021发布,进过多次修订) 论文地址:https://arxiv.org/pdf/2112.08088.pdf 项目地址:https://github.com/wenyyu/Image-Adaptive-YOLO
虽然基于深度学习的目标检测方法在传统数据集上取得了很好的结果…

YOLOv5算法改进(3)— 添加CBAM注意力机制
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。CBAM(Convolutional Block Attention Module) 是一种用于前馈卷积神经…
目标检测YOLO实战应用案例100讲-基于YOLOv5自适应损失权重的生活垃圾目标检测模型(续)
目录
3.2 ALW-YOLOv5模型框架
3.3 GT边界框ID生成器
3.4 GT边界框ID匹配器
3.5 自适应损失权重算法

YOLO目标检测——卫星遥感多类别检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:卫星遥感目标检测数据集说明:卫星遥感多类别检测数据集,真实场景的高质量图片数据,数据场景丰富,含网球场、棒球场、篮球场、田径场、储罐、车辆、桥、飞机、船等类别标签说明:使用lableimg标…
目标检测-RCNN系列
• RCNNRCNN(Regions with CNN features)是将CNN方法应用到目标检测问题上的一个里程碑,由年轻有为的RBG大神提出,借助CNN良好的特征提取和分类性能,通过RegionProposal方法实现目标检测问题的转化。算法可以分为四步…

目标检测 pytorch复现R-CNN目标检测项目
目标检测 pytorch复现R-CNN目标检测项目1、R-CNN目标检测项目基本流程思路2、项目实现1 、数据集下载:2、车辆数据集抽取3、创建分类器数据集3、微调二分类网络模型4、分类器训练5、边界框回归器训练6、效果测试目标检测 R-CNN论文详细讲解1、R-CNN目标检测项目基本…
【目标检测】“复制-粘贴 copy-paste” 数据增强实现
文章目录 前言1. 效果展示代码说明3. 参考文档4. 不合适点 前言
本文来源论文《Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation》(CVPR2020),对其数据增强方式进行实现。
论文地址:https:/…
行人检测0-08:LFFD-源码无死角解析(3)-网络架构讲解
以下链接是个人关于LFFD(行人检测)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。文末附带\color…

Learning Video Salient Object Detection Progressively from Unlabeled Videos笔记总结
由于视频显著性检测的带有标签的视频数据集是比较困难的,因此本文提出了一种不需要标签数据的VSOD方法。
一、摘要
那么如何去实现无标签数据的视频显著性检测呢?
本文想到一个方法,即渐进式的,先定位显著对象后分割显著对象。…
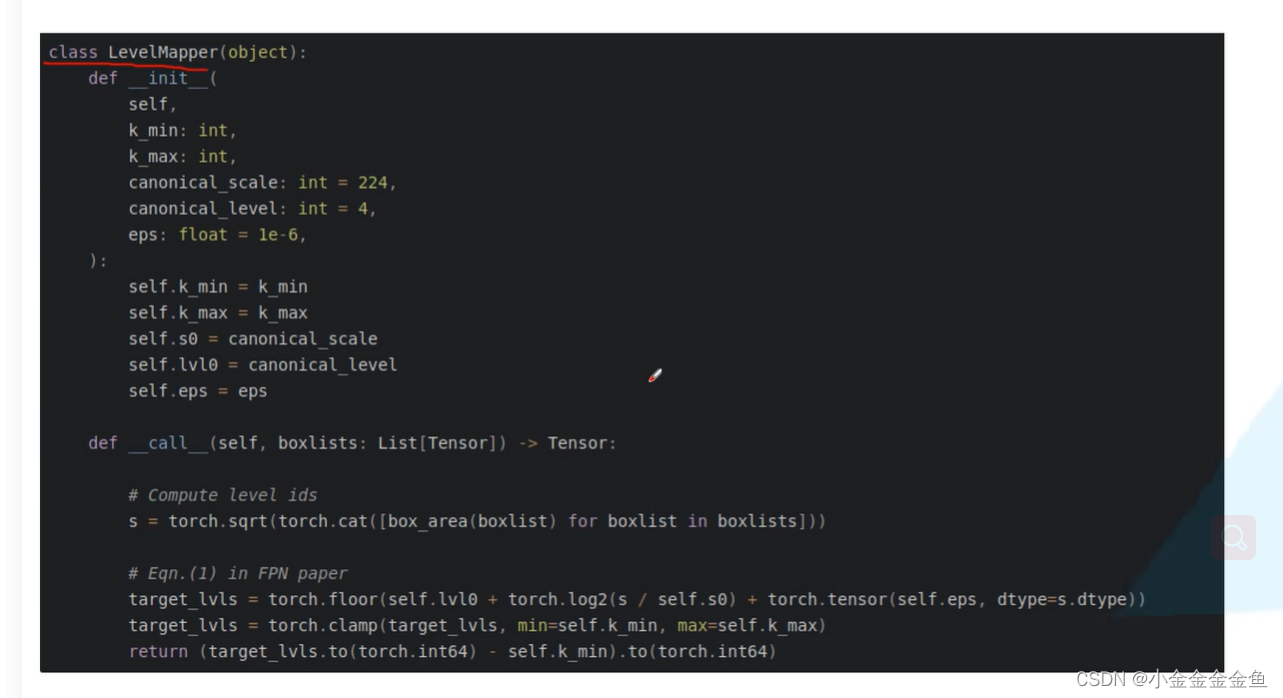
人工智能学习07--pytorch15(前接pytorch10)--目标检测:FPN结构详解
FPN:用于目标检测的特征金字塔网络 backbone:骨干网络,例如cnn的一系列。(特征提取)
(a)特征图像金字塔 检测不同尺寸目标。 首先将图片缩放到不同尺度,针对每个尺度图片都一次通过算法进行预测。 但是这样一来&#…
c# YOLOV5目标检测部署
using Emgu.CV;
using Emgu.CV.CvEnum;
using Emgu.CV.Dnn;
using Emgu.CV.Structure;
using Emgu.CV.Util
Shape-IoU:考虑边框形状与尺度的度量
文章目录 摘要1、简介2、 相关工作3、方法4、实验5、 结论摘要
https://arxiv.org/pdf/2312.17663.pdf 作为检测器定位分支的重要组成部分,边界框回归损失在目标检测任务中发挥着重要作用。现有的边界框回归方法通常考虑真实框(GT box)与预测框之间的几何关系,并使用边界框…

3D目标检测(毕业设计+代码)
概述
3d Objectron是一种适用于日常物品的移动实时3D物体检测解决方案。它可以检测2D图像中的物体,并通过在Objectron数据集上训练的机器学习(ML)模型估计它们的姿态. 下图为模型训练后推理的结果!
算法
我们建立了两个机器…

基于深度学习的人群密度检测系统(UI界面+YOLOv5+训练数据集)
摘要:人群密度检测系统用于检测行人数目,从图片、视频、摄像设备等图像中分析,对路口、商场等场所的人流量进行自动化检测。在介绍算法原理的同时,给出Python的实现代码、PyQt的UI界面以及训练数据集。系统对于日常商场、路口等需…
YoloV8改进策略:增加适用小目标的分支,减少小目标的漏检
文章目录 摘要数据集如何解决问题?原始网络Yolov8改进一改进二改进三总结扩展:YoloV5增加小目标检测的分支🐇🐇🐇🐇🐇🐇 🐇 欢迎阅读 【AI浩】 的博客🐇 👍 阅读完毕,可以动动小手赞一下👍 🌻 发现错误,直接评论区中指正吧🌻 📆 这是一篇如何改进…
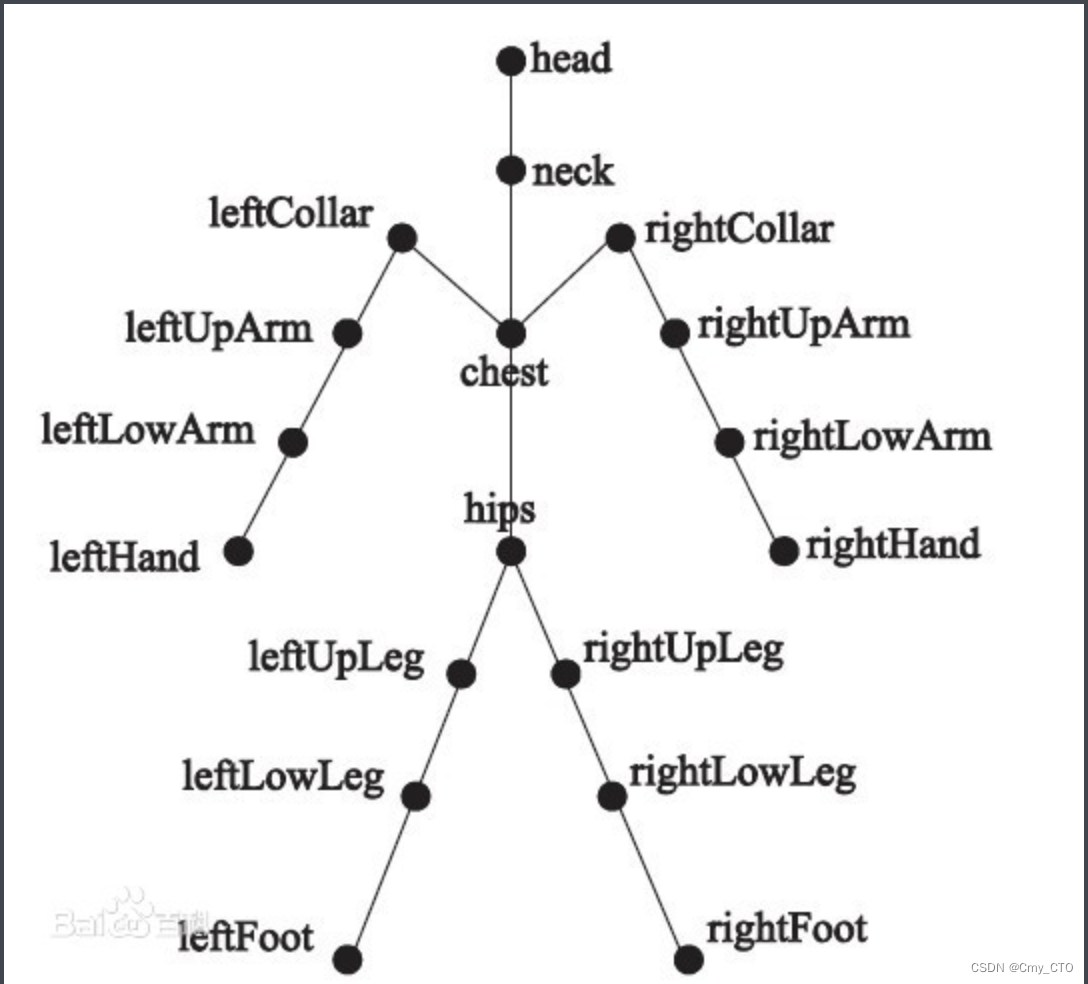
SMPL Model转换为bvh格式 (SMPL to BVH ) Python
BVH BVH是BioVision等设备对人体运动进行捕获后产生文件格式的文件扩展名。 BVH文件
BVH文件包含角色的骨骼和肢体关节旋转数据。BVH 是一种通用的人体特征动画文件格式,广泛地被当今流行的各种动画制作软件支持。通常可从记录人类行为运动的运动捕获硬件获得。
B…
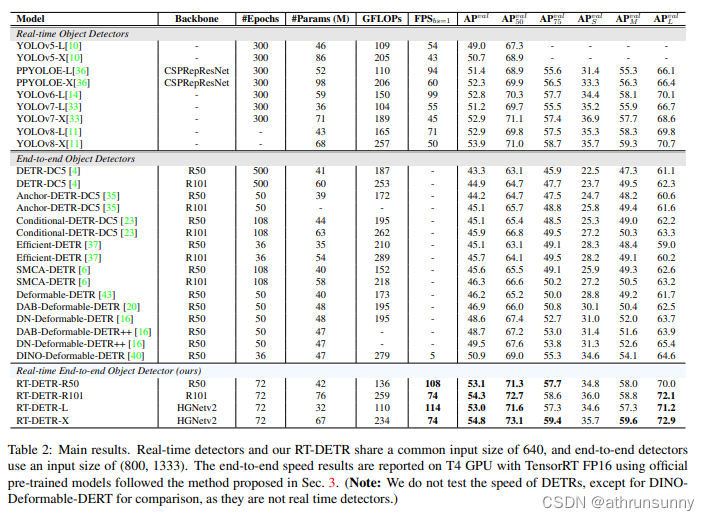
RT-DETR论文学习笔记(DETRs Beat YOLOs on Real-time Object Detection)
论文地址:https://arxiv.org/abs/2304.08069 代码地址:GitHub - PaddlePaddle/PaddleDetection: Object Detection toolkit based on PaddlePaddle. It supports object detection, instance segmentation, multiple object tracking and real-time mult…
【2】YOLOv8原理解析:重新定义实时目标检测的速度和精度
文章目录 0.前言1.YOLOv51.1 YOLOv5网络回顾1.2 YOLOv5网络结构图 2.YOLOv82.1 YOLOv8概述2.2 YOLOv8整体结构图2.3 YOLOv8yaml 文件与 YOLOv5yaml 文件对比2.3.1 参数部分2.3.2 主干部分2.3.3 Neck部分2.3.4 Head部分 2.4 正负样本分配策略2.4.1 静态分配策略和动态分配策略有…

BEVFusion A Simple and Robust LiDAR-Camera Fusion Framework 论文学习
论文地址:BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework 论文学习 Github 地址:BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework 论文学习
1. 解决了什么问题?
将相机和 LiDAR 融合已经成为 3D 检测任务事…

YOLO-v4论文详解
YOLO-v4论文详解-- 潘登同学的目标检测笔记 文章目录YOLO-v4论文详解-- 潘登同学的目标检测笔记YOLO-v4介绍目标检测One-stage Detector与Two-stage DetectorBag of freebiesBag of specialsYOLO-v4的选择网络结构其他改进PAN: 是对FPN的改进,主要有以下…

用YOLOv5和MobileViTs骨干网络革新目标检测:高效准确AI视觉的未来
目录 一、YOLOv51、YOLOv5介绍2、YOLOV5的整体架构图3、MobileViT介绍 二、YOLOv5与MobileViT的结合1、YOLOv5网络结构回顾2、MobileViT网络结构介绍3、YOLOv5替换骨干网络为MobileViT的优势 三、MobileViT的细节与实现1、ViT与MobileNetV3的结合2、MobileViT网络结构细节3、Mo…

windows环境下使用mmdetection+mmdeploy训练自定义数据集并转成onnx格式部署
目录 实验环境安装conda创建虚拟环境安装pytorch使用 MIM 安装 MMEngine 和 MMCV安装 MMDetection准备自定义数据集修改配置信息开始训练模型转换与推理 实验环境
windows10python:3.8pytorch :1.8.1cuda:11.1mmdet:3.1.0mmcv:2.…
SCI论文解读复现|目录一览表
此栏目解读SCI、EI等英文论文解读,梳理并复现改进创新点,帮助大家将改进点运用于自己的目标检测场景中,助力发论文。
💡🎈☁️1. SCI论文解读复现【NO.1】基于Transformer-YOLOv5的侧扫声纳图像水下海洋目标实时检测 …
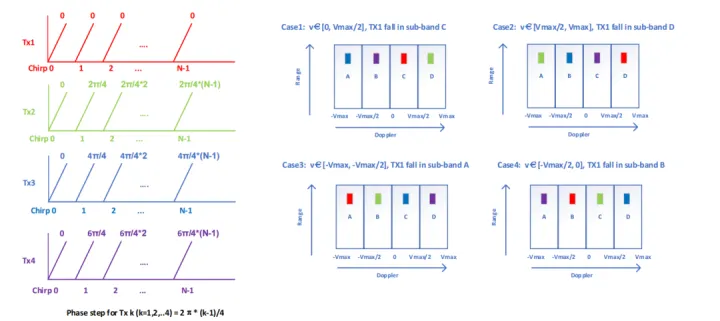
【雷达仿真 | FMCW TDMA-MIMO毫米波雷达信号处理仿真(可修改为DDMA-MIMO)】
本文编辑:调皮哥的小助理 本文引用了CSDN雷达博主XXXiaojie的文章源码(https://blog.csdn.net/Xiao_Jie1),加以修改和注释,全面地、详细地阐述了FMCW TDM-MIMO毫米波雷达的工作原理,同时配套MATLA仿真实现方…

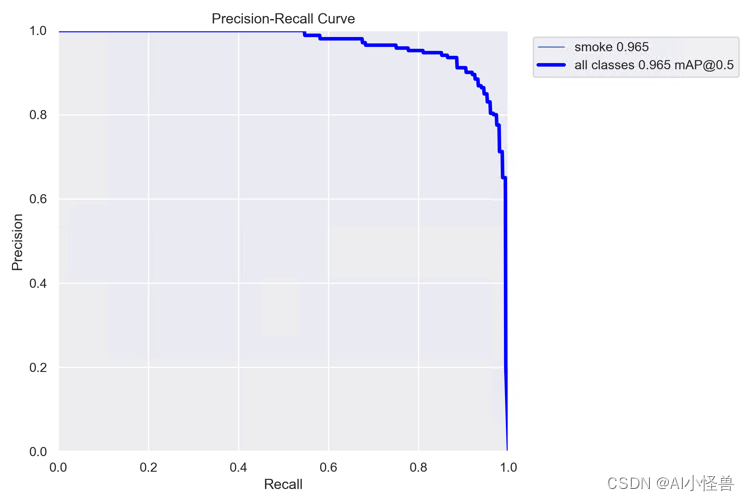
YOLOv5的参数IOU与PR曲线,F1 score
YOLOv5的参数IOU与PR曲线,F1 score
conf_thres
Confidence Threshold,置信度阈值。
只显示预测概率超过conf_thres的预测结果。想让YOLO只标记可能性高的地方,就把这个参数提高。iou_thres
Intersect over Union Threshold,交并比阈值。
I…
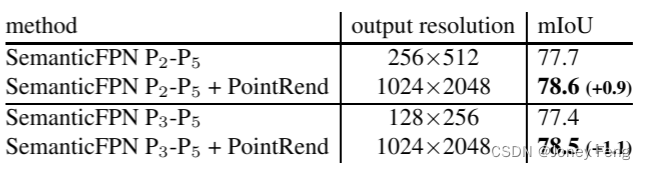
PointRend: 将图像分割视为渲染——PointRend:Image Segmentation as Rendering
0.摘要 我们提出了一种新的方法,用于高效、高质量的对象和场景图像分割。通过将经典的计算机图形学方法与像素标记任务中面临的过采样和欠采样挑战进行类比,我们开发了一种将图像分割视为渲染问题的独特视角。基于这个视角,我们提出了PointRe…
YOLOv3 | 核心主干网络,特征图解码,多类损失函数详解
https://zhuanlan.zhihu.com/p/76802514) 文章目录 1. 核心改进1.1主干网络1.2 特征图解码1.2.1 检测框(位置,宽高)解码1.2.2 检测置信度解码1.2.3 类别解码 1.3 训练损失函数1.3.1 正负样本定义1.3.2 损失函数 1. 核心改进
1.1主干网络
更…

PConv : Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
摘要
为了设计快速的神经网络,**许多研究都集中在减少浮点运算(FLOPs)**的数量。然而,我们观察到这种FLOPs的减少并不一定会导致相同程度的延迟减少。这主要是由于浮点运算每秒效率较低的问题所致。为了实现更快的网络,我们重新审视了流行的操作算子,并证明这种低FLOPS主…
目标检测笔记(十二):如何通过界面化操作YOLOv5完成数据集的自动标注
文章目录 一、意义二、修改源码获取三、自动标注前期准备四、开始自动标注五、可视化标注效果六、XML转换TXT 一、意义
通过界面化操作YOLOv5完成数据集的自动标注的意义在于简化数据标注的流程,提高标注的效率和准确性。
传统的数据集标注通常需要手动绘制边界框…

仪酷LabVIEW OD实战(3)——Object Detection+onnx工具包快速实现yolo目标检测
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主 🎄所属专栏:『LabVIEW深度学习工具包』『仪酷LabVIEW目标检测工具包实战』 📑上期文章:『仪酷LabVIEW OD实战(2)——Obje…
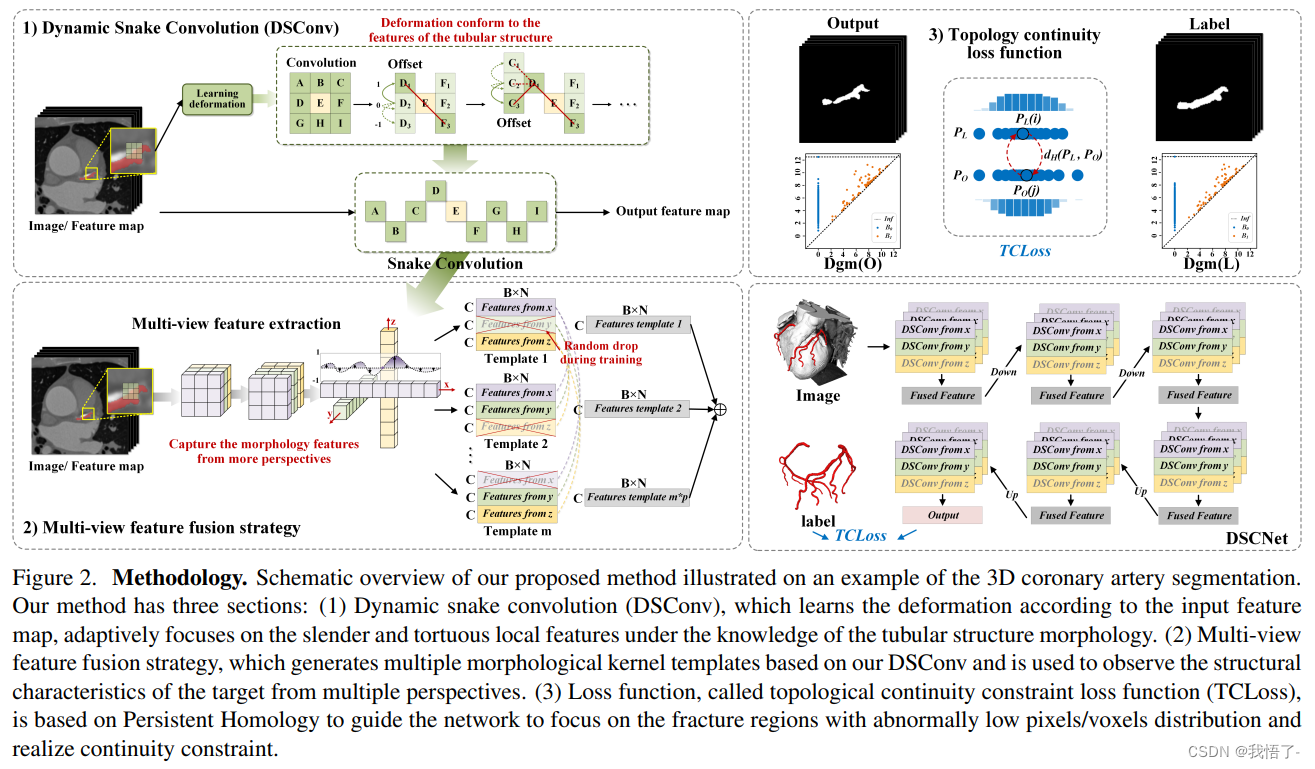
pytorch代码实现之动态蛇形卷积模块DySnakeConv
动态蛇形卷积模块DySnakeConv
血管、道路等拓扑管状结构的精确分割在各个领域都至关重要,确保下游任务的准确性和效率。 然而,许多因素使任务变得复杂,包括薄的局部结构和可变的全局形态。在这项工作中,我们注意到管状结构的特殊…

OpenCV项目开发实战--使用最先进的方法“F、B、Alpha Matting”进行图像抠图--提供完整代码
示范
让我们对现实生活中的图像启动 FBA Matting 方法。要应用 FBA Matting 算法,我们首先需要生成一个 trimap(我们稍后会介绍它是什么)。在我们的演示中,我们将使用预训练的DeepLabV3生成分割掩模,其中每个像素属于前景类的概率。之后,我们将使用大量膨胀操作将边界像…
YOLOv5:修改backbone为ConvNeXt
YOLOv5:修改backbone为ConvNeXt 前言前提条件相关介绍ConvNeXtYOLOv5修改backbone为ConvNeXt修改common.py修改yolo.py修改yolov5.yaml配置 参考 前言 记录在YOLOv5修改backbone操作,方便自己查阅。由于本人水平有限,难免出现错漏,…
目标检测YOLO实战应用案例100讲-基于YOLOv3多模块融合的遥感目标检测(下)
目录
基于Transformer的轻量级网络模型的设计与实现
4.1 引言
4.2 轻量级特征提取网络

MS COCO数据集的评价标准以及不同指标的选择推荐(AP、mAP、MS COCO、AR、@、0.5、0.75、1、目标检测、评价指标)
目标检测模型性能衡量指标、MS COCO 数据集的评价标准以及不同指标的选择推荐 0. 引言
0.1 COCO 数据集评价指标 目标检测模型通过 pycocotools 在验证集上会得到 COCO 的评价列表,具体参数的含义是什么呢?
0.2 目标检测领域常用的公开数据集
PASCAL …

第1篇 目标检测概述 —(3)目标检测评价指标
前言:Hello大家好,我是小哥谈。目标检测评价指标是用来衡量目标检测算法性能的指标,主要包括几个指标:精确率(Precision)、召回率(Recall)、交并比(IoU)、平均…

YOLO目标检测——人脸口罩佩戴数据集【(含对应voc、coco和yolo三种格式标签】
实际项目应用:公共场所监控场景下的大密度人群检测是否佩戴口罩,以及戴口罩的人证比对(安检刷脸不用摘口罩)、手机解锁、刷脸考勤等身份认证场景。数据集说明:人脸口罩佩戴检测数据集,真实场景的高质量图片…

YOLOv5算法改进(17)— 手把手教你去更换损失函数(IoU/GIoU/DIoU/CIoU/EIoU/AlphaIoU/SIoU)
前言:Hello大家好,我是小哥谈。损失函数(loss function)是机器学习中用来衡量模型预测值与真实值之间差异的函数。它用于度量模型在训练过程中的性能,以便优化模型参数。在训练过程中,损失函数会根据模型的预测结果和真实标签计算出一个标量值,代表了模型预测的错误程度…
目标检测YOLO实战应用案例100讲-基于改进YOLOv5的口罩人脸检测(续)
目录
3.4 Hardswish激活函数
3.5数据集
3.6实验结果及分析
4 基于口罩人脸检测网络模型的
目标识别项目实战:基于Yolov7-LPRNet的动态车牌目标识别算法模型(二)
前言
目标识别如今以及迭代了这么多年,普遍受大家认可和欢迎的目标识别框架就是YOLO了。按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性…
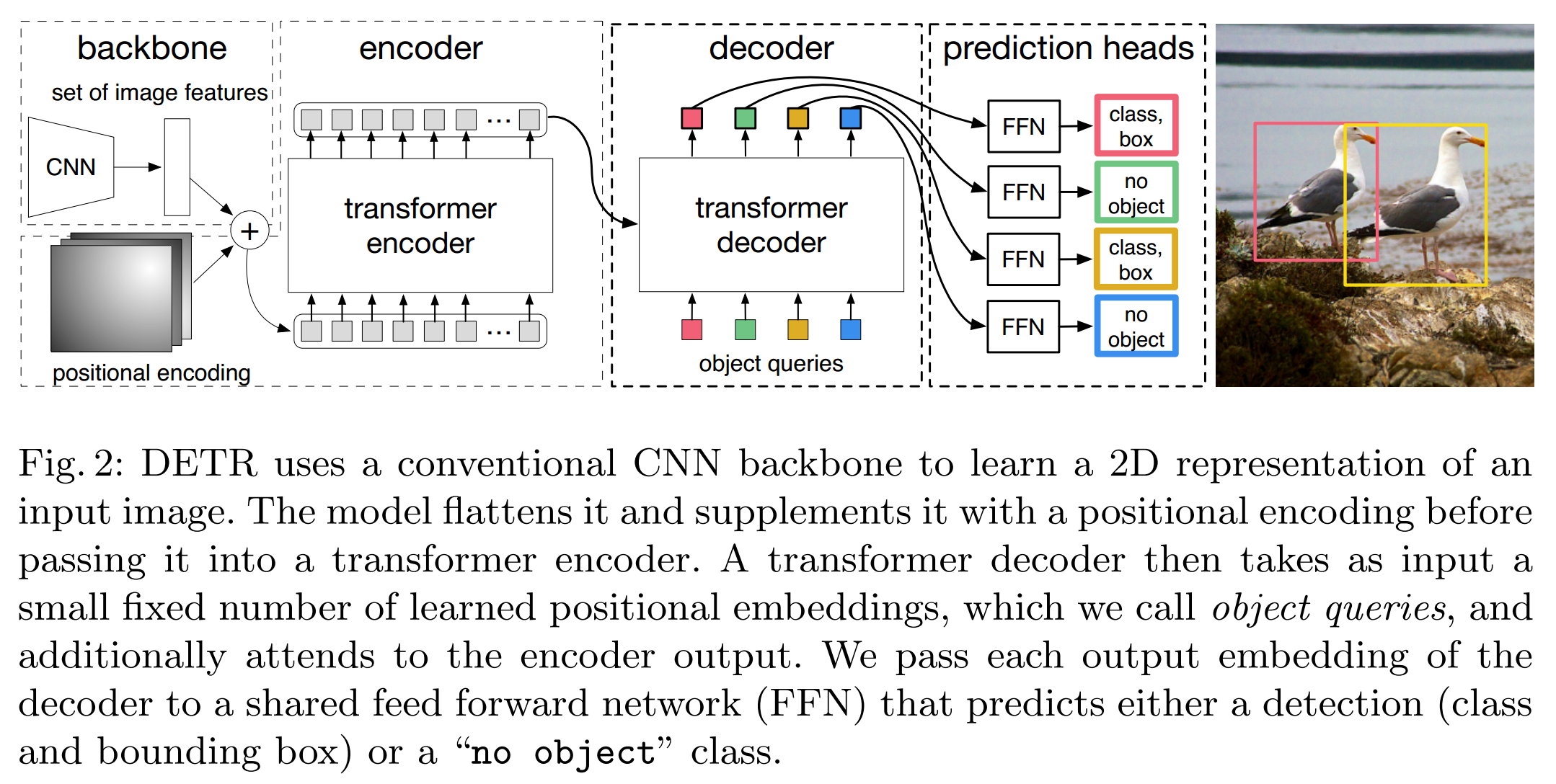
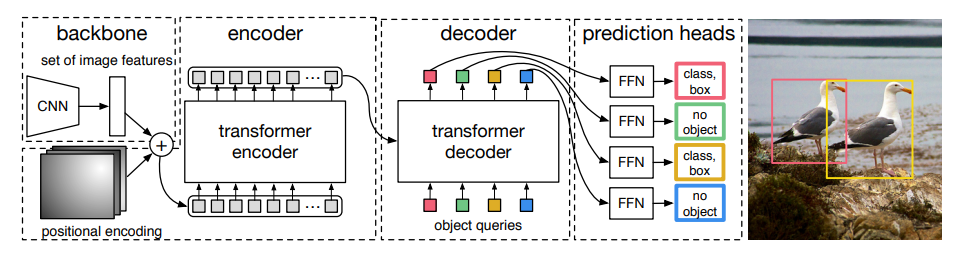
【DETR】End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers 整个模型的主要思想是把物体检测问题看作一个集合到集合的预测问题,将图片切分成一个个Patches。然后进行位置编码,利用Transformer Encoder和Decoder进行编码和解码,最后使用FFN进行分类…
YOLOv7-PTQ量化部署
目录 前言一、PTQ量化浅析二、YOLOv7模型训练1. 项目的克隆和必要的环境依赖1.1 项目的克隆1.2 项目代码结构整体介绍1.3 环境安装 2. 数据集和预训练权重的准备2.1 数据集2.2 预训练权重准备 3. 训练模型3.1 修改模型配置文件3.2 修改数据配置文件3.3 训练模型3.4 mAP测试 三、…

基于Yolov8的工业小目标缺陷检测(7):Wasserstein Distance Loss,助力工业缺陷检测
💡💡💡本文改进:基于Wasserstein距离的小目标检测评估方法
Wasserstein Distance Loss | 亲测在工业小目标缺陷涨点明显,原始mAP@0.5 0.679提升至0.727 收录专栏:
💡💡💡深度学习工业缺陷检测 :http://t.csdn.cn/fVSgs
✨✨✨提供工业缺陷检测性能提升方案…
目标检测网络系列——Faster-RCNN(实验部分)
文章目录 实验网络实现细节对比实验anchor的感受野PASCAL VOC 2007数据集RPN的有效性其他RPN有效性的实验VGG16 + RPN网络超参数的对比IoU与召回率的关系one stage vs two stageMS COCO数据集MS COCO数据集情况对比结果COCO数据集到PASCAL数据集的迁移学习上一篇已经将Faster-r…
目标检测网络系列——YOLOV3
文章目录 YOLO3的改进点针对区域中包含重叠物体的改进Class PredictionBounding Box Prediction更牛逼的网络结构:Dartnet53多尺度预测性能其他工作YOLO V3的论文篇幅比较短,感觉比较随意,和一般论文最大的区别就是把对比实验去掉了,在摘要和论文的最后说到YOLO3是一个好的…
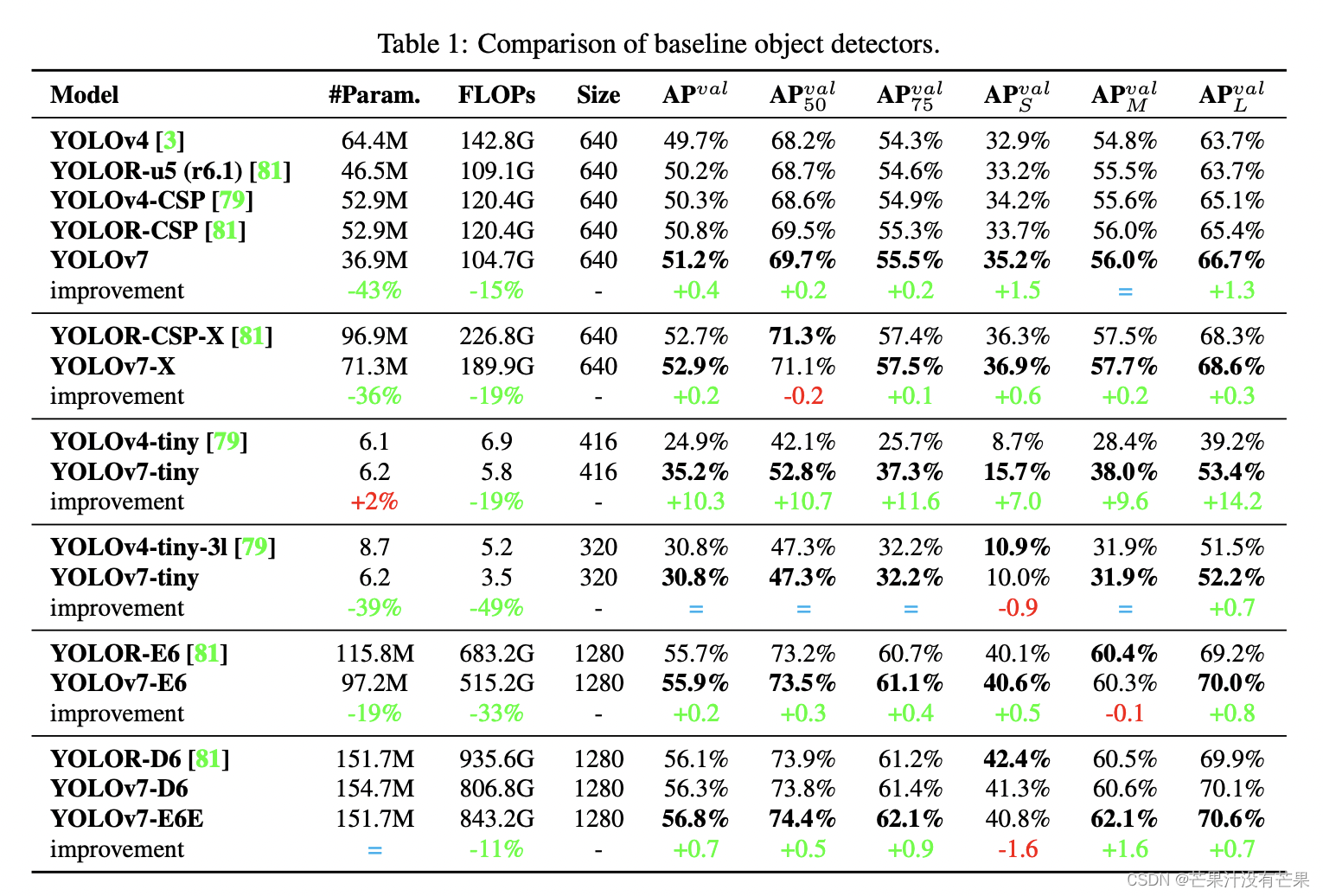
YOLOv7输出COCOmAP指标:输出自定义数据集中small、medium、large大中小目标的mAP值S,M,L指标,适用于自定义数据集
💡更多改进内容📚可以点击查看:YOLO改进原创目录 | 老师联袂推荐🏆
💡🚀🚀🚀内含改进源代码,按步骤操作运行改进后的代码即可,内附代码💡更方便的统计更多实验数据,方便写作 芒果改进 | YOLOv5 输出自定义数据集中 S,M,L指标大中小目标的mAP值 点这篇链…
YoloV7改进策略:SwiftFormer,全网首发,独家改进的高效加性注意力用于实时移动视觉应用的模型,重构YoloV7
文章目录 摘要论文:《SwiftFormer:基于Transformer的高效加性注意力用于实时移动视觉应用的模型》1、简介2、相关研究3、方法3.1、注意力模块概述3.2、高效的加性注意力3.3、SwiftFormer 架构4、实验4.1、实现细节4.2、基线比较4.3、图像分类4.4、目标检测和实例分割4.5、语义…

【目标检测】大图包括标签切分,并转换成txt格式
前言
遥感图像比较大,通常需要切分成小块再进行训练,之前写过一篇关于大图裁切和拼接的文章【目标检测】图像裁剪/标签可视化/图像拼接处理脚本,不过当时的工作流是先将大图切分成小图,再在小图上进行标注,于是就不考…
目标检测知识蒸馏---以SSD为例【附代码】
在上一篇文章中有讲解以分类网络为例的知识蒸馏【分类网络知识蒸馏】,这篇文章将会针对目标检测网络进行蒸馏。
知识蒸馏是一种不改变网络结构模型压缩方法。这里的压缩需要和量化与剪枝进行区分,并不是严格意义上的压缩。这里将要讲的蒸馏是离线式蒸馏…
论文投稿指南——中文核心期刊推荐(铁路运输)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…

机器学习与目标检测作业(数组相加:形状需要满足哪些条件)
机器学习与目标检测(数组相加:形状需要满足哪些条件)机器学习与目标检测(数组相加:形状需要满足哪些条件)一、形状相同1.1、形状相同示例程序二、符合广播机制2.1、符合广播机制的描述2.2、符合广播机制的示例程序机器学习与目标检…
![[YOLO] yolov4 博客笔记](https://img-blog.csdnimg.cn/4fc6b9403e9f495f94d896cc4bf3beba.png)
[YOLO] yolov4 博客笔记
在有了yolov3的基础上,yolov4的网络结构还是很容易看懂的。
这篇博客写的整个yolov4的网络概况
【经典论文解读】YOLOv4 目标检测https://blog.csdn.net/qq_41204464/article/details/119673960?ops_request_misc%257B%2522request%255Fid%2522%253A%25221677916…

基于深度学习的海洋动物检测系统(Python+YOLOv5+清新界面)
摘要:基于深度学习的海洋动物检测系统使用深度学习技术检测常见海洋动物,识别图片、视频和实时视频中的海洋动物,方便记录、展示和保存结果。本文详细介绍海洋动物检测系统,在介绍算法原理的同时,给出Python的实现代码…
目标检测00-07:mmdetection(Foveabox为例)-数据读取与数据增强 -(落地重点篇-经验分享)
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。 文末附带 \color{blue}{文末附带} 文末附带 公…
01 PointRCNN:基于点云的3D目标生成与检测
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
2019-CVPR-香港中文大学-3D目标检测
yolov5目标检测算法研究之参考资料
CSP网络架构
深度学习之CSPNet分析_tt丫的博客-CSDN博客_cspnet结构深度学习入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。目录一、提出原因二、CSPNet结构分析1、基本思想2、对比…

计算机视觉 Computer Vision Chaper10 目标检测 下
文章目录区域卷积神经网络(R-CNN)系列R-FCNYOLO系列YOLO V1YOLO V2/9000YOLO V3人脸检测和行人检测基于Darknet的YOLO实现区域卷积神经网络(R-CNN)系列 R-FCN
区域-全卷积网络 检测网络是回归,分类网络是分类。全连接层fully connect后,相对位置就丢失…

RS loss:涨点神器!用于目标检测和实例分割的新损失函数(ICCV2021)
[ICCV2021] RS loss:用于目标检测和实例分割的新损失函数一.论文简介1.1. 简介1.2. RS Loss对简化训练的好处1.3. RS 损失对提高性能的好处二. RS损失的定义2.1. RankSort2.2. aLRPLoss2.3. APLoss三. 在不同模型上的实验结果3.1. 多阶段目标检测3.2. 单阶段目标检测3.3. 多阶段…
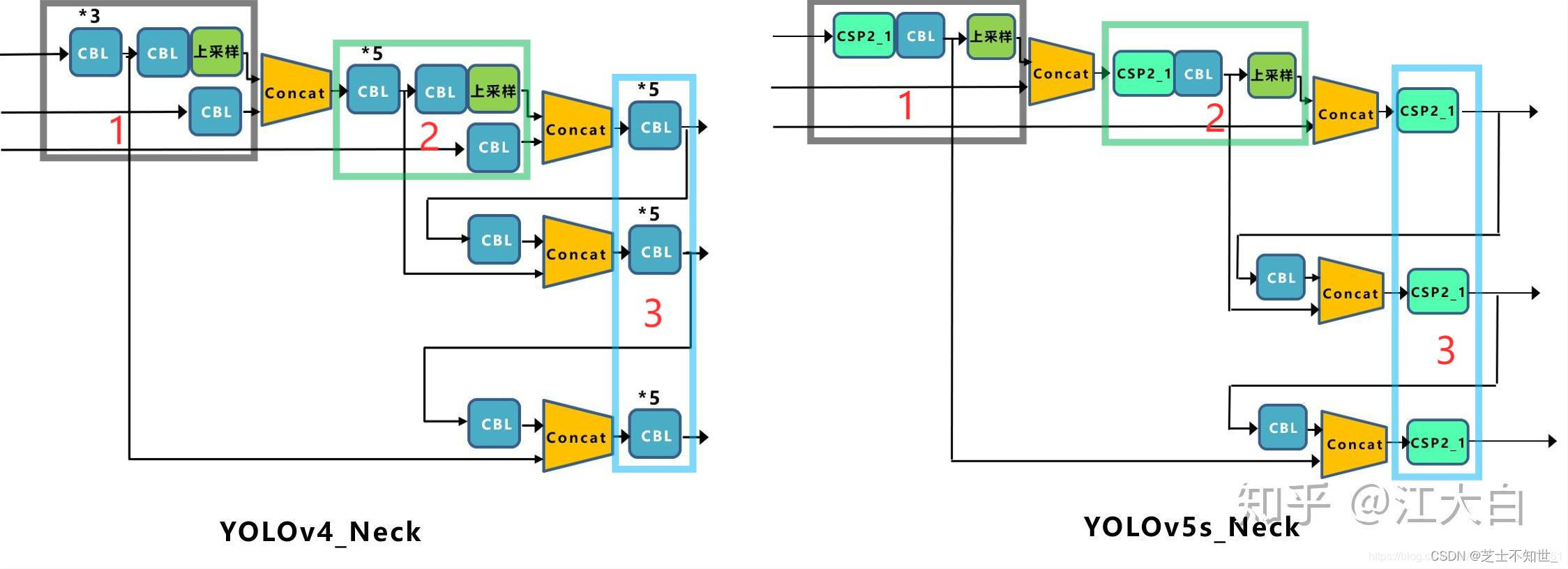

基于TensorFlow Object Detection API实现RetinaNet目标检测网络(附源码)
文章目录 一、RetinaNet简介1. Backbone网络2. FPN网络 二、RetinaNet实现1. tf.train.CheckPoint简介2. RetinaNet的TensorFlow源码 一、RetinaNet简介 RetinaNet是作者Tsung-Yi Lin和Kaiming He于2018年发表的论文Focal Loss for Dense Object Detection中提出的网络。Retina…

利用KerasCV YOLOv8轻松实现目标精确检测
本文中将实现基于KerasCV YOLOv8的交通灯信号检测,并附录完整代码。。
自从You Only Look Once(简称 YOLO)的诞生以来,目标检测问题主要通过深度学习来解决。大多数深度学习架构通过巧妙地将目标检测问题构建为多个小分类问题和回归问题的组合来实现。具体而言,它是通过在…
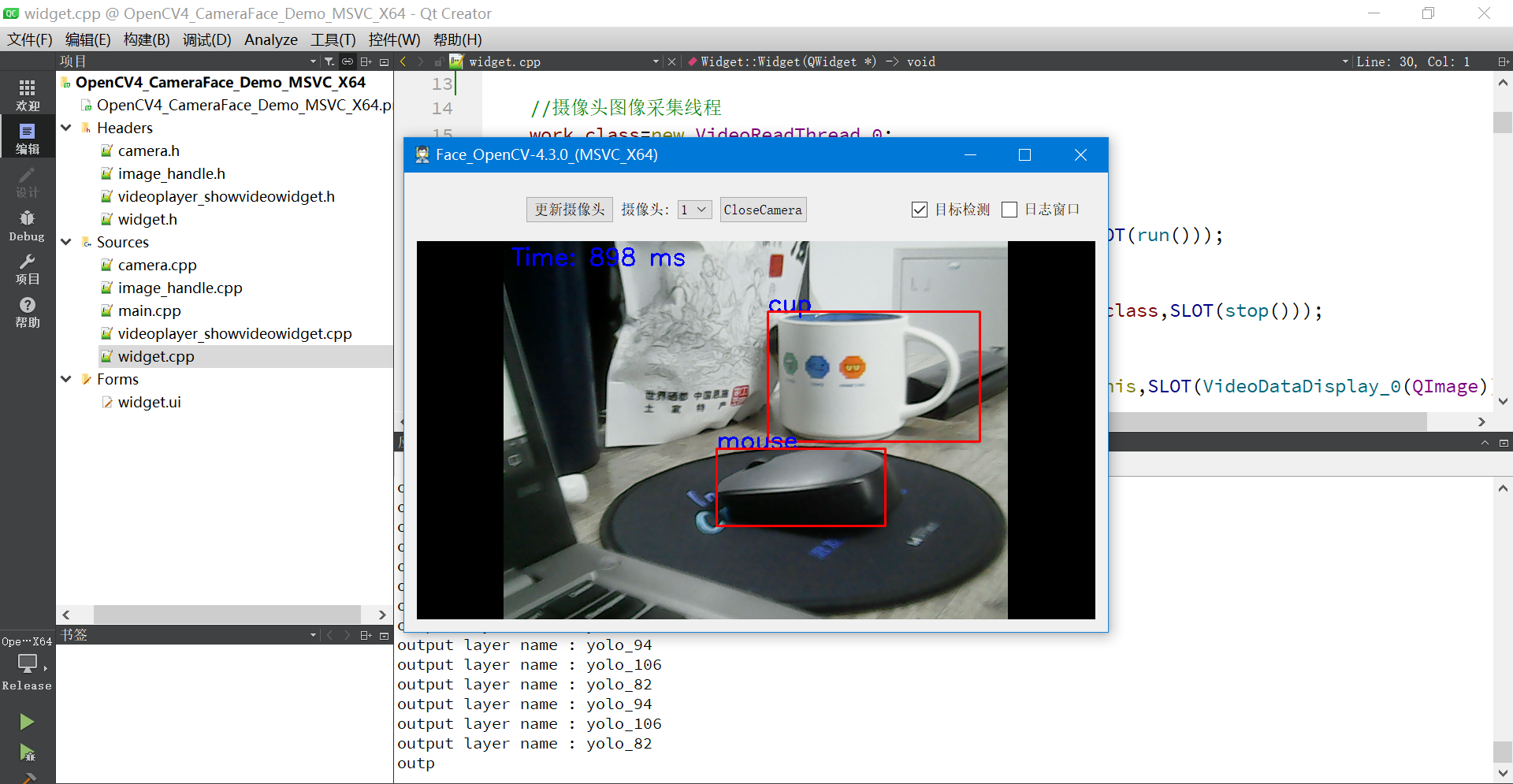
实时目标检测:基于YOLOv3和OpenCV的摄像头应用
一、前言
随着人工智能和计算机视觉技术的不断发展,目标检测成为了智能监控、自动驾驶、机器人等领域的关键技术之一。实时目标检测更是对系统的反应速度和准确度提出了更高的要求。本文介绍使用OpenCV和YOLOv3实现实时目标检测的方法,演示如何使用OpenCV调用YOLOv3模型进行…

SENet: 强化深度卷积神经网络的自适应特征学习
SENet(Squeeze-and-Excitation Network)是一种革命性的深度卷积神经网络架构,旨在提高模型对图像特征的建模能力。它引入了自适应特征重新校准机制,通过学习性地调整通道间的重要性,提高了模型的性能,广泛用…
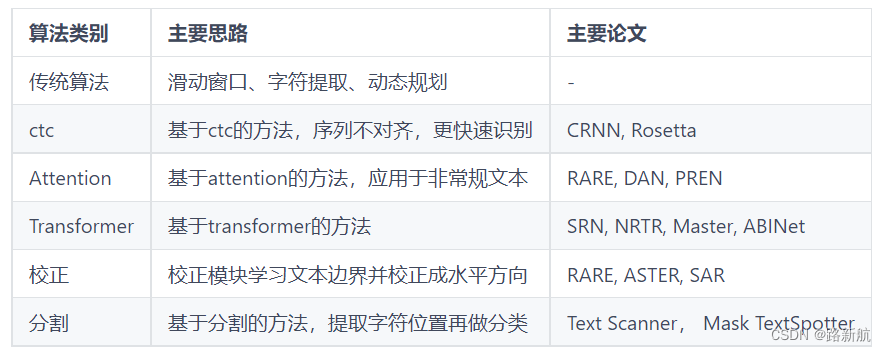
动手学OCR笔记-介绍与实践
参考:https://gitee.com/paddlepaddle/PaddleOCR/tree/release/2.5/notebook/notebook_ch
OCR技术挑战
算法层(应用场景决定):
透视变换尺度太小文字弯曲背景干扰字体多变多种语言拍摄模糊光照不足
应用层
海量数据要求OCR能…
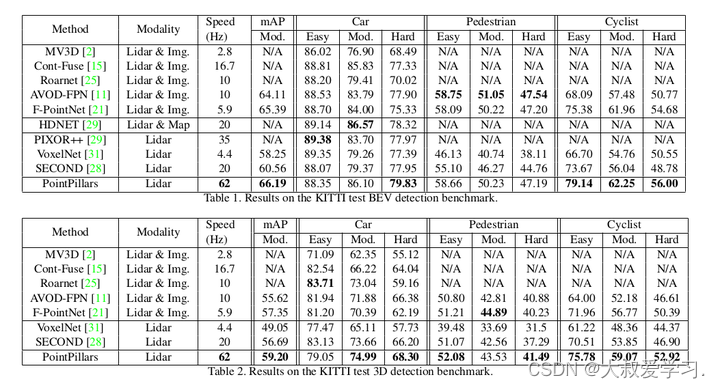
实战:3D目标检测与跟踪PointPillar+CenterPoint+SimpleTrack(论文+代码 上篇)
文章目录 概述PointPIllar思想主体结构Pillar Feature Net(从点云到伪图像的转换)a. Point Cloud:b. Stacked Pillar:c. Learned Featured. Pseudo Image Backbone(2D CNN)自上而下:上采样&…
【面试题】2023虹软计算机视觉一面
来源:投稿 作者:LSC 编辑:学姐 1.自我介绍
2.介绍了自己的项目,并提问项目,讲了30分钟
3.介绍centernet,它和其他目标检测模型有什么区别
4.介绍yolov5
5.介绍focal loss
6.双线性插值和最近邻插值的区…

YOLOv7改进实战 | 更换轻量化主干网络Backbone(一)之Ghostnet
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…
基于深度学习的目标检测和语义分割:机器视觉中的最新进展
基于深度学习的目标检测和语义分割是机器视觉领域的两个重要任务,它们在图像处理、自动驾驶、医学影像分析和智能视频监控等应用中发挥着关键作用。以下是这两个领域的最新进展:
目标检测(Object Detection): 一阶段检…
CV计算机视觉每日开源代码Paper with code速览-2023.10.19
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Learning from Rich Semantics and Coarse L…
YOLOv8改进实战 | 更换主干网络Backbone(一)之轻量化模型Ghostnet
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…

目标检测应用场景—数据集【NO.15】叶片虫害检测
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…

深度学习 图像分割 PSPNet 论文复现(训练 测试 可视化)
Table of Contents 一、PSPNet 介绍1、原理阐述2、论文解释3、网络模型 二、部署实现1、PASCAL VOC 20122、模型训练3、度量指标4、结果分析5、图像测试 一、PSPNet 介绍
PSPNet(Pyramid Scene Parsing Network)来自于CVPR2017的一篇文章,中文翻译为金字塔场景解析…
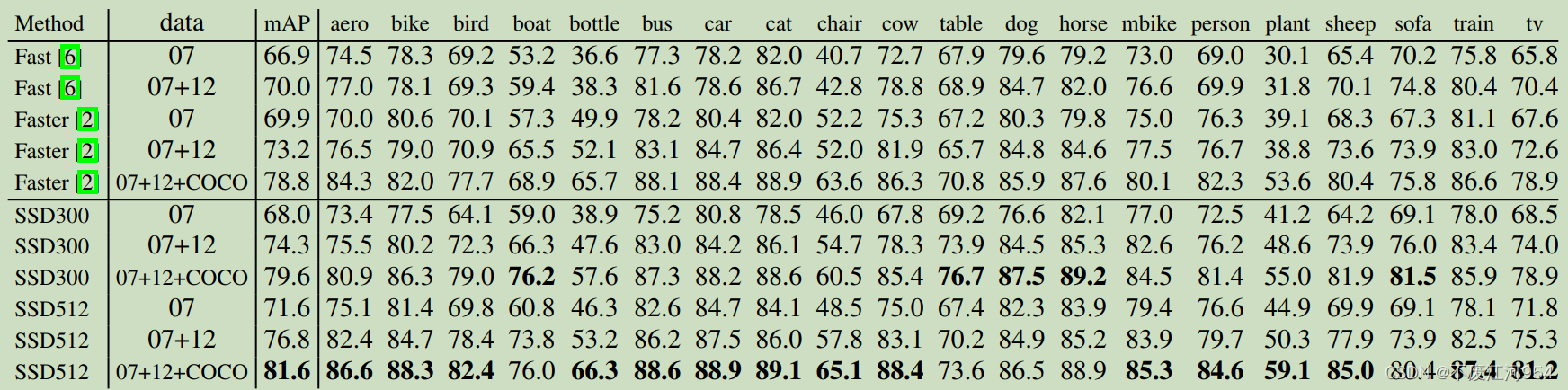
目标检测00-10:mmdetection(Foveabox为例)-源码无死角解析(4)-头部网络bbox_head-推理过程
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
CV+Deep Learning——网络架构Pytorch复现系列——Detection(二:RtinaNet)更换backbones(DarkNet)
上一话
CVDeep Learning——网络架构Pytorch复现系列——Detection(一:SSD:Single Shot MultiBox Detector 4.推理Detect)https://blog.csdn.net/XiaoyYidiaodiao/article/details/128683973?spm1001.2014.3001.5501 复现Object Detection,会复现的网络…
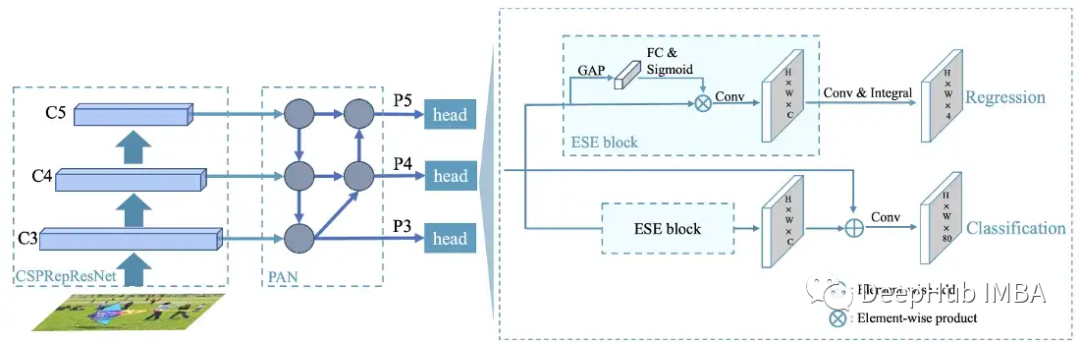
YOLO家族系列模型的演变:从v1到v8(上)
YOLO V8已经在本月发布了,我们这篇文章的目的是对整个YOLO家族进行比较分析。了解架构的演变可以更好地知道哪些改进提高了性能,并且明确哪些版本是基于那些版本的改进,因为YOLO的版本和变体的命名是目前来说最乱的,希望看完这篇文…
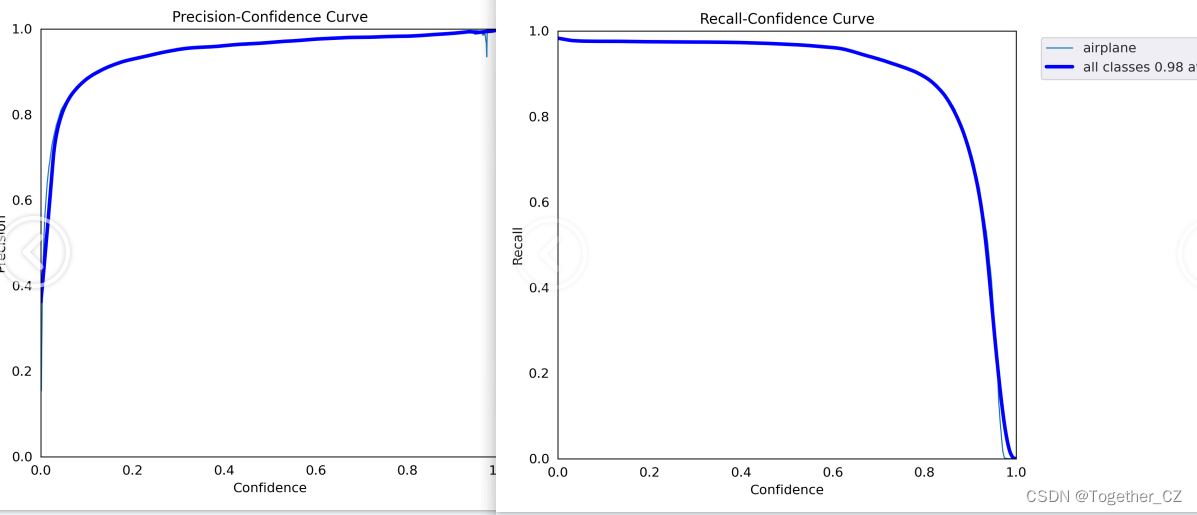
基于YOLOv7开发构建红外高空小目标检测识别分析系统
基于yolo系列的模型开发构建红外场景下的目标检测系统,在我之前的文章中已经有好几次实践了,感兴趣的话可以自行移步阅读:
《红外海洋目标检测实践,基于目标检测模型识别红外海洋目标》
《基于YOLO开发构建红外场景下无人机航拍…

3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network
1. Motivation
3D目标图像与2D图像不同,3D物体能再3D bbox中很好的分离开,而且能提供每个前景点在3D地面真实包围盒内的相对位置。而对于2D图像来说,会产生部分对象遮挡的问题。因此论文从此角度出发,充分利用三位对象内的intra-…
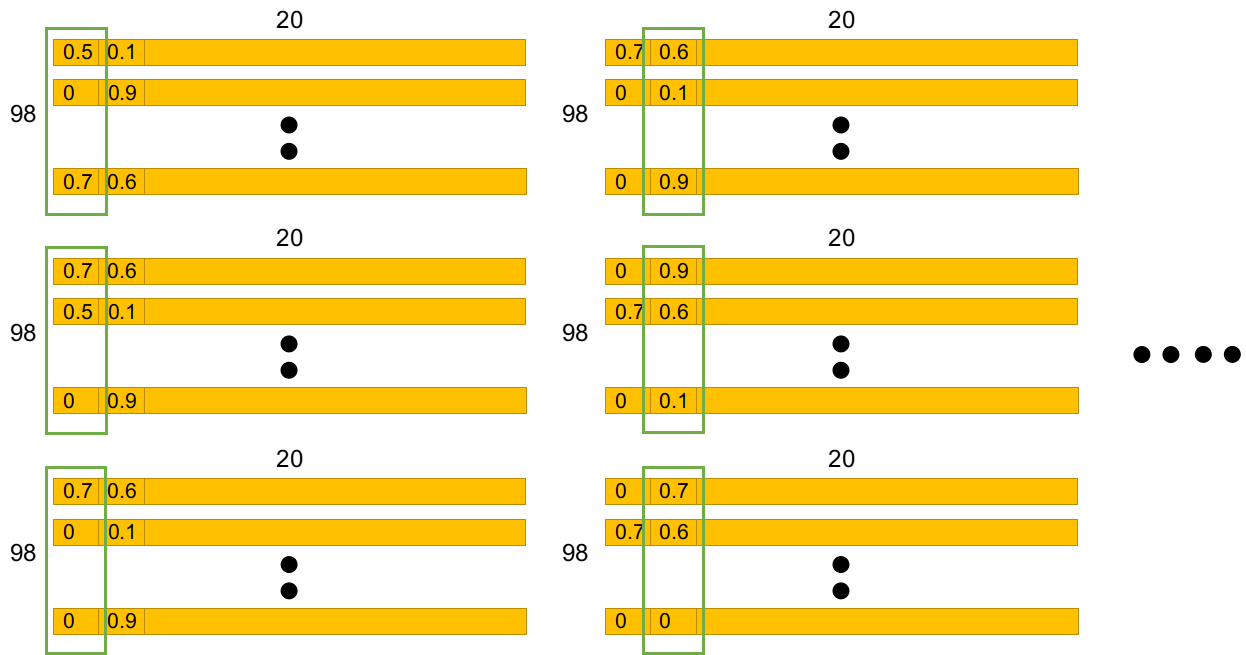
YOLO:You Only Look Once系列的学习
前言 目标检测领域的深度学习方法大多分为两类,一步网络和两步网络。一步网络以速度快、实用性高著称,其将特征提取和bounding box生成放在一个网络中;而两步网络以精度高著称,其将特征提取和bounding box的生成放在两个不同的网络…

Faster RCNN系列——RPN的真值详解
RPN的真值分为类别真值和偏移量真值,即每一个Anchor是否对应着真实物体,以及每一个Anchor对应物体的真实偏移值,这两种真值的具体求解过程如下图所示: Anchor生成 Anchor生成的具体过程可参考Faster RCNN系列——Anchor生成过程&a…
人工智能专栏第九讲——目标检测
目标检测,就是指在图像或视频中自动地检测出感兴趣的目标区域,并识别出这个目标的类别。在人工智能的应用领域中,目标检测具有广泛的应用价值。例如,自动驾驶需要识别出道路标志和行驶的车辆、行人等障碍物;智能监控需要识别出异常行为和非法入侵等;医学影像处理需要识别…

目标检测复盘 --3. Fast RCNN
RCNN的CNN部分使用AlexNet作为backbone来提取特征,Fast RCNN使用了VGG16来作为backboneRCNN将2000个框送入网络提取特征,Fast RCNN是将图像送入CNN来提取特征得到一个特征图将SS(Selective Search)算法获取的提议框映射到上面的特征图上,获取…

You Only Look Once: 革命性目标检测算法论文解析
You Only Look Once 全论文完整翻译 You Only Look Once: Unified, Real-Time Object Detection 摘要
我们介绍了一种名为YOLO的新型目标检测方法。在目标检测的先前工作中,人们将分类器重新应用于执行检测任务。相反,我们将目标检测视为一个回归问题&a…

教你一步步使用实现TensorFlow 进行对象检测
在本文中,我们将学习如何使用 TensorFlow Hub 预训练模型执行对象检测。TensorFlow Hub 是一个库和平台,旨在共享、发现和重用预训练的机器学习模型。TensorFlow Hub 的主要目标是简化重用现有模型的过程,从而促进协作、减少冗余工作并加速机器学习的研发。用户可以搜索社区…
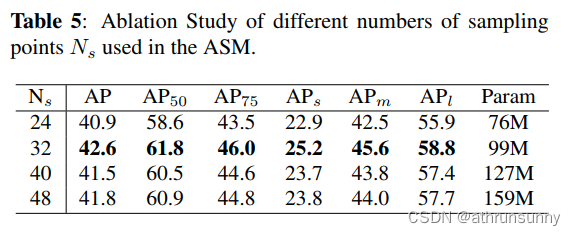
FoLR:Focus on Local Regions for Query-based Object Detection论文学习笔记
论文地址:https://arxiv.org/abs/2310.06470 自从DETR问询式检测器首次亮相以来,基于查询的方法在目标检测中引起了广泛关注。然而,这些方法面临着收敛速度慢和性能亚优等挑战。值得注意的是,在目标检测中,自注意力机制…
(论文阅读15/100)You Only Look Once: Unified, Real-Time Object Detection
文献阅读笔记 简介 题目 You Only Look Once: Unified, Real-Time Object Detection 作者 Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi 原文链接 https://arxiv.org/pdf/1506.02640.pdf 《You Only Look Once: Unified, Real-Time Object Detection》…
YOLOv7独家首发改进:黑夜小目标检测,原创LEF模块,增强图像增强组成
💡本篇内容:YOLOv7独家首发改进:ICANN会议出品,黑夜小目标检测,原创LEF模块,增强图像增强组成
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv7专属
黑夜小目标检测论文理论部分…
第一章:深度学习教程
深度学习是机器学习的一个分支,完全基于人工神经网络,因为神经网络要模仿人脑,所以深度学习也是对人脑的一种模仿。
本深度学习教程是您学习有关深度学习的一切的一站式指南。它涵盖了基本和高级概念,为初学者和专业人士提供了对…

nanodet训练自己的数据集、NCNN部署到Android
nanodet训练自己的数据集、NCNN部署到Android 一、介绍二、训练自己的数据集1. 运行环境2. 数据集3. 配置文件4. 训练5. 训练可视化6. 测试 三、部署到android1. 使用官方权重文件部署1.1 下载权重文件1.2 使用Android Studio部署apk 2. 部署自己的模型【暂时存在问题】2.1 生成…
基于YOLOv8模型暗夜下人脸目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型暗夜下人脸目标检测系统可用于日常生活中检测与定位黑夜下人脸目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法…
图像特征Vol.1:计算机视觉特征度量【纹理区域特征】
一、前言
🍊什么是计算机视觉特征? 简单来说就是图像特征,对于我们来说,看到一张图片,能很自然的说出和描述图像中的一些特征,但是同样的图片,丢给计算机,只是一个二维矩阵…
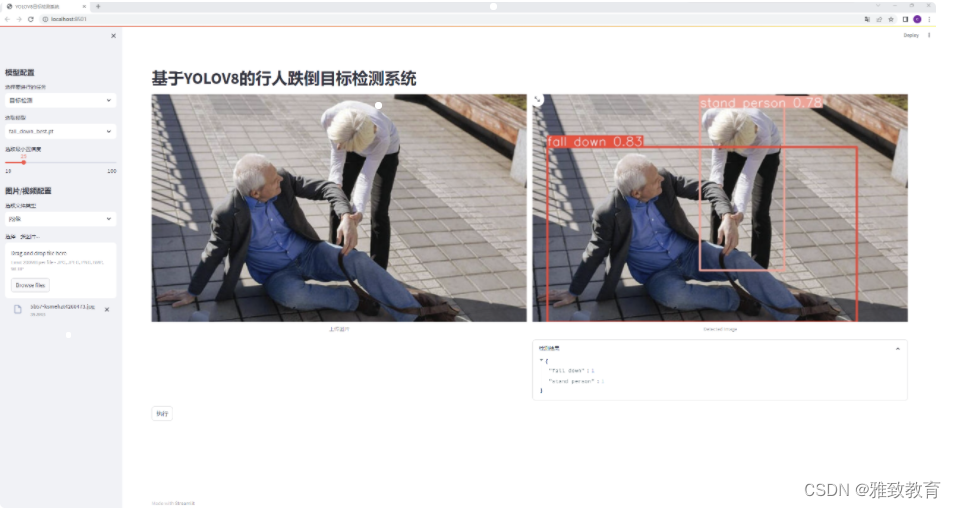
深度学习之基于YoloV8的行人跌倒目标检测系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、行人跌倒目标检测系统四. 总结 一项目简介 世界老龄化趋势日益严重,现代化的生活习惯又使得大多数老人独居,统计数据表…

YOLOv8优化:独家创新(Partial_C_Detect)检测头结构创新,实现涨点 | 检测头新颖创新系列
💡💡💡本文独家改进:独家创新(Partial_C_Detect)检测头结构创新,适合科研创新度十足,强烈推荐
Partial_C_Detect | 亲测在多个数据集能够实现大幅涨点 💡💡💡Yolov8魔术师,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提…
人脸检测是不是目标检测呢?
人脸检测是不是目标检测呢?
人脸识别和目标检测都是计算机视觉领域的重要应用之一,但它们的应用场景和方法有所不同。
人脸识别是一种通过计算机技术对照片、视频等图像中的人脸进行识别的技术。人脸识别一般分为两个步骤:人脸检测和人脸识…
目标检测YOLO实战应用案例100讲-改进YOLOX算法在小目标缺陷检测中的应用(续)
目录
3.3 YOLOX核心改进及小目标检测的优劣势分析
4 改进YOLOX算法设计
4.1 面向小目标检测的FS-YOLOX算法设计 <

基于YOLOv8的多目标检测与自动标注软件【python源码+PyqtUI界面+exe文件】【深度学习】
基本功能演示 摘要:YOLOv8是YOLO系列最新的版本,支持多种视觉任务。本文基于YOLOv8的基础模型实现了80种类别的目标检测,可以对图片进行批量自动标注,并将检测结果保存为YOLO格式便于后续进行其他任务训练。本文给出完整的Python实…

基于深度学习的高精度血小板检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度血小板检测(红细胞RBC、白细胞WBC和血小板Platelet)识别系统可用于日常生活中或野外来检测与定位血小板目标,利用深度学习算法可实现图片、视频、摄像头等方式的血小板目标检测识别,另外支持…
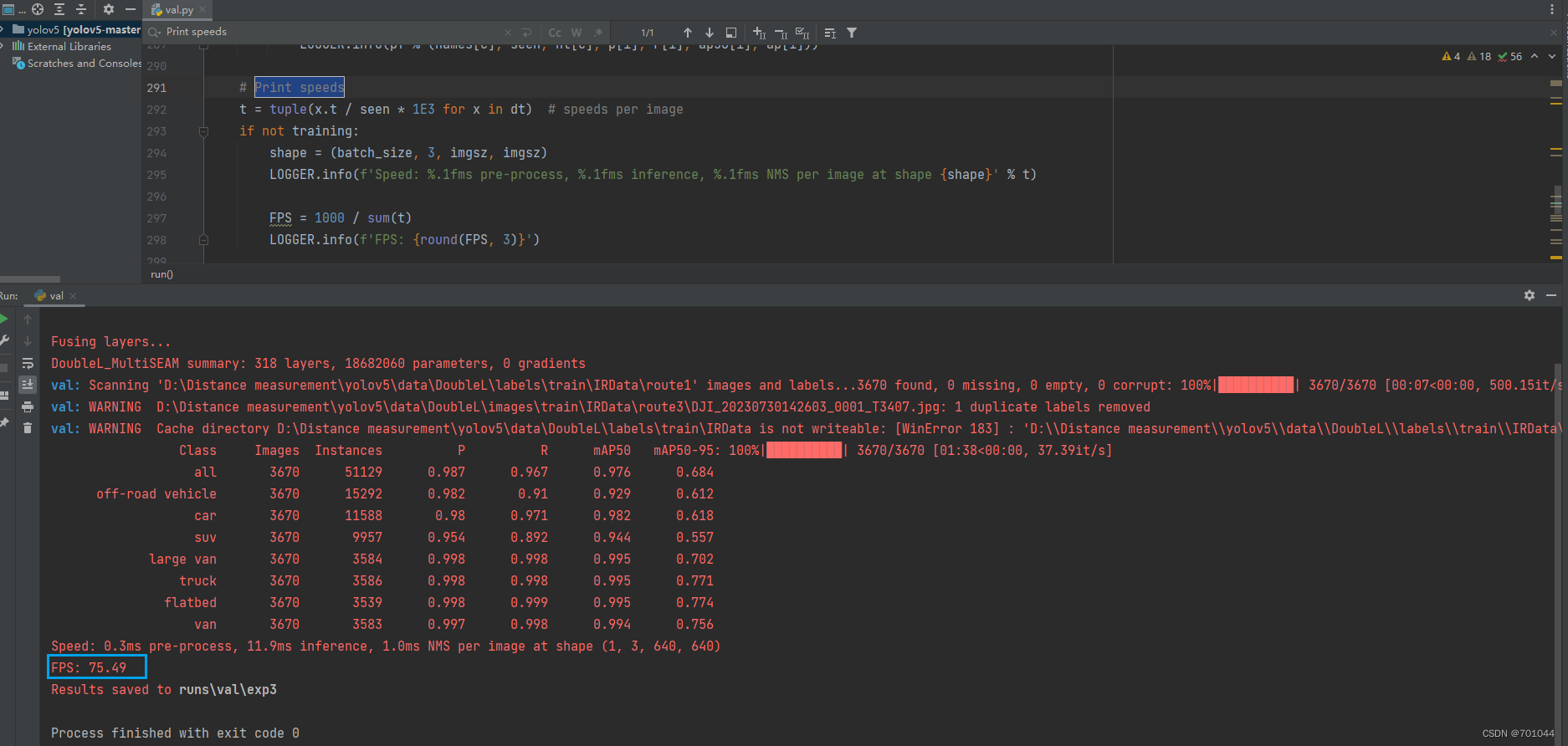
YOLOv5 如何计算并打印 FPS
文章用于学习记录 YOLO v5 FPS计算方法修改对应自己数据集的 yaml 文件以及训练好的 pt 文件以及batch-size1, FPS 1000ms/(0.311.91.0)pre-process:图像预处理时间,包括图像保持长宽比缩放和padding填充,通道变换(HWC->CHW&a…

YOLOv5算法改进(12)— 替换主干网络之Swin Transformer
前言:Hello大家好,我是小哥谈。Swin Transformer是一种基于Transformer的深度学习模型,它在视觉任务中表现出色。与之前的Vision Transformer(ViT)不同,Swin Transformer具有高效和精确的特性,并…

YOLSO: You Only Look Small Object
按照李沐老师阅读论文的方法!!!
(1)读abstract和introduction(2)读conclusion(3)看论文中model架构和实验结果图(4)再读剩下的 重点:…
深度学习-目标检测之边界框bbox坐标转换公式汇总
深度学习 文章目录 深度学习 尝试着写了一个可以转换任何维度的任意格式的bbox函数。
本程序目的是: 可以转换以下三种格式的输入数据 list,numpy,tensor,维度可以从0维到2维, 也就是shape为:(4,) (3, 4) torch.Size([4]) torch.…
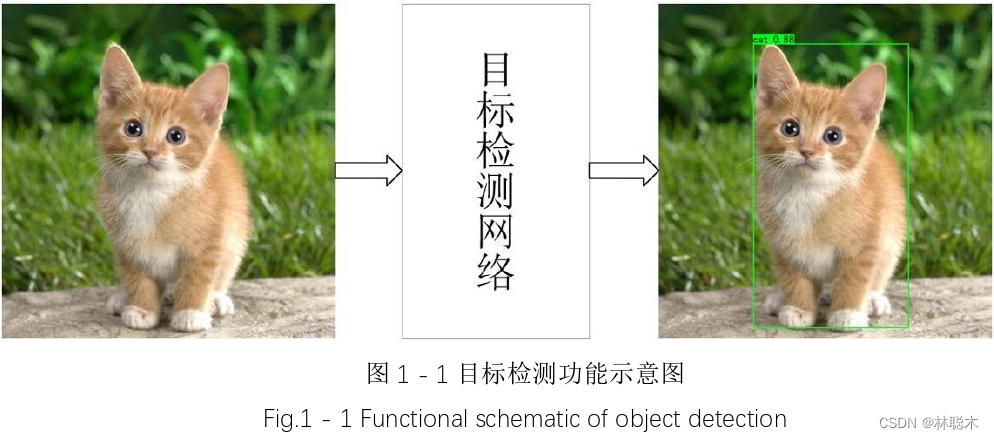
目标检测YOLO实战应用案例100讲-基于深度学习的遥感目标检测算法FPGA部署实现研究
基于深度学习的目标检测网络剪枝及FPGA部署
随着科技的发展,人工智能的发展正在促进计算机视觉的智能化广泛应用。如手 机上的语音识别可以将声音转化成文字、门禁识别人脸通行、美颜相机对人像加上跟 踪特效等,这些都是人工智能在我们生活中的应用。 人工智能对图像领域…
从定标准到搭流程,看UWA性能保障体系搭建的实例分享
本次分享选自UWA DAY 2022 “UWA性能保障体系进一步拓展”议题,来自侑虎科技CTO张强的分享。从 “性能评分”、“推荐值”、“设备分档”和“自动化平台”四部分介绍UWA团队近一年来在性能保障上的探索。特别适合游戏初期进行项目质量规划和标准制定的大中型团队&am…
目标检测YOLO实战应用案例100讲-基于毫米波雷达与摄像头协同的道路目标检测与识别
目录
前言
感兴趣区域(region of interest,ROI)协同
决策协同
毫米波雷达信号处理

基于深度学习的高精度水果检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度水果(苹果、香蕉、葡萄、橘子、菠萝和西瓜)检测识别系统可用于日常生活中或野外来检测与定位水果目标,利用深度学习算法可实现图片、视频、摄像头等方式的水果目标检测识别,另外支持结果可视…
多尺度R-CNN论文笔记(6): Feature Pyramid Networks for Object Detection
前言:博主目前的研究课题为“可见光遥感图像目标检测”,研究兴趣是大尺寸高分辨率遥感图像上多尺度目标及小物体检测。为了整理阅读过的文献,梳理研究思路,记录自己的理解感悟,遂开启一个“物体检测系列博客”。 …

YOLOv5源码中的参数超详细解析(5)— 验证部分val(test).py
前言:Hello大家好,我是小哥谈。YOLOv5项目代码中,val.py 是一个代表验证(validation)的 Python 脚本文件名。通常在机器学习或深度学习的任务中,我们会将数据集分为训练集和验证集,使用训练集来…

Towards Open Vocabulary Object Detection without Human-provided Bounding Boxes(2021CVPR)----论文阅读笔记
Towards Open Vocabulary Object Detection without Human-provided Bounding Boxes----论文阅读笔记Abstract1. Introduction如何实现? pseudo bounding box label如何生成的?2. Related Work3. Related Work3.1. Generating Pseudo Box Labels3.2. Open vocabulary Object …
目标检测(一)-R-CNN系列
有关传统机器学习方法和深度学习方法在目标检测领域的一些总结。 传统机器学习方法
Detection based on Adaboost Ref:Rapid Object Detection using a Boosted Cascade of Simple Features.(CVPR2001) 这个方法是一个二分类方法,判断是还是不是人脸。主…
机器学习笔记 - 对象/目标检测技术发展史概览
一、简述 物体检测算法的发展已经取得了长足的进步,从早期的计算机视觉开始,通过深度学习达到了很高的准确度。 我们首先回顾早期传统的目标检测方法:Viola-Jones 检测器、HOG 检测器和基于部件的方法,它们在该领域发展之初就被广泛使用。 然后,逐渐转向基于两阶段和一阶段…
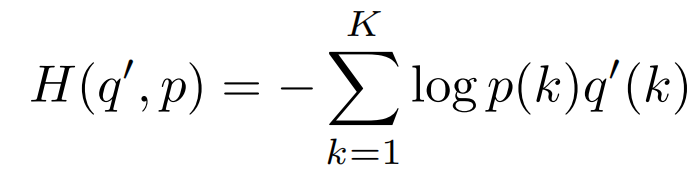
分类模型-类别不均衡问题之loss设计
这个系列将记录下本人平时在深度学习方面觉得实用的一些trick,可能会包括性能提升和工程优化等方面。 该系列的代码会更新到Github 炼丹系列1: 分层学习率&梯度累积 炼丹系列2: Stochastic Weight Averaging (SWA) & Exponential Moving Average(EMA) 炼丹系…

yolov6 win10环境配置详细过程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、yolov6 下载二、环境配置三、测试环境四、报错集合前言
提示:这里可以添加本文要记录的大概内容:
最近美团开源了yolov6 源码&…

yolov5快速安装环境
yolov5快速安装环境
1.打开Anaconda Prompt,进入base 环境 2.在base环境下,创建yolov5的环境。
(base) C:\Users\Administrator>conda create -n yolov550 python3.7 //yolov550为自己命名的环境名称,python3.7 指定python的版本为3.7
…

基于深度学习的高精度人体摔倒行为检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度人体摔倒行为检测识别系统可用于日常生活中或野外来检测与定位人体摔倒行为目标,利用深度学习算法可实现图片、视频、摄像头等方式的人体摔倒行为目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系…

Yolov8-pose关键点检测:模型轻量化创新 | PConv结合c2f | CVPR2023 FasterNet
💡💡💡本文解决什么问题:新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。
PConv| GFLOPs从9.6降低至8.5,参数量从6482kb降低至6134kb, mAP50从0.921提升至0.925
Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.n…

yolov5 模型部署NCNN(详细过程)
yolov5 模型部署NCNN
一、编译ncnn
1、在github官网输入 ncnn ,找到Tencen\ncnn 下载ncnn 2.打开vs2017 工具 x64 Native Tools Command Prompt for VS 2017 3.下载protobuf-3.4.0到本地
4.编译protobuf的动态库,输入以下命令:
cd <protobuf-ro…
MATLAB算法实战应用案例精讲-【目标检测】YOLOV5
目录
算法原理
【Yolov5网络结构图】
YOLOv5网络结构训练策略
Backbone骨干网络
Neck特征金字塔
Head目标检测头
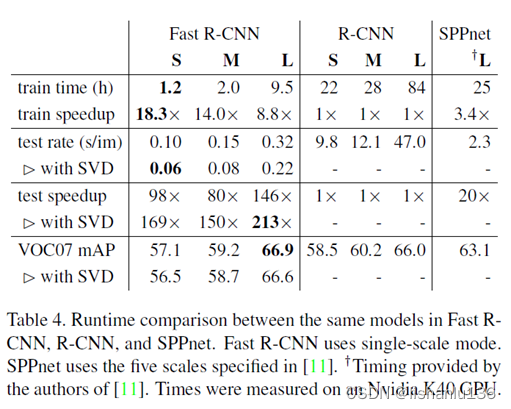
目标检测——Fast R-CNN算法解读
论文:Fast R-CNN 作者:Ross Girshick 链接:https://arxiv.org/abs/1504.08083 代码:https://github.com/rbgirshick/fast-rcnn 目录 1、算法概述2、Fast R-CNN细节2.1The RoI pooling layer2.2 Fine-tuning for detection2.3 Fast…

从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型
从零开始的目标检测和关键点检测(二):训练一个Glue的RTMDet模型 一、config文件解读二、开始训练三、数据集分析四、ncnn部署 从零开始的目标检测和关键点检测(一):用labelme标注数据集
从零开始的目标检测…

YOLOv8原创改进:最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度
💡该教程为属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 💡本篇文章为YOLOv8独家原创改进:独家首发最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度。
💡对自己数据集改进有效…
mindspore mindyolo目标检测华为昇腾上推理使用、训练;华为OBS文件传输使用
参考: https://github.com/mindspore-lab/mindyolo
使用案例: https://github.com/mindspore-lab/mindyolo/blob/master/GETTING_STARTED.md
安装:
pip install mindyolo特别注意opencv-python、opencv-python-headless版本问题࿰…
基于YOLOv8模型的绵羊目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的绵羊目标检测系统可用于日常生活中检测与定位车辆目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…

YOLOv5算法改进(12)— 主干网络介绍(EfficientNetv2、Swin Transformer和PP-LCNet)
前言:Hello大家好,我是小哥谈。主干网络通常指的是深度学习中的主干模型,通常由多个卷积层和池化层组成,用于提取输入数据的特征。在训练过程中,主干网络的参数会被不断优化以提高模型的准确性。YOLOv5算法中的主干网络可以有多种替换方案,为了后面讲解的方便,本篇文章就…
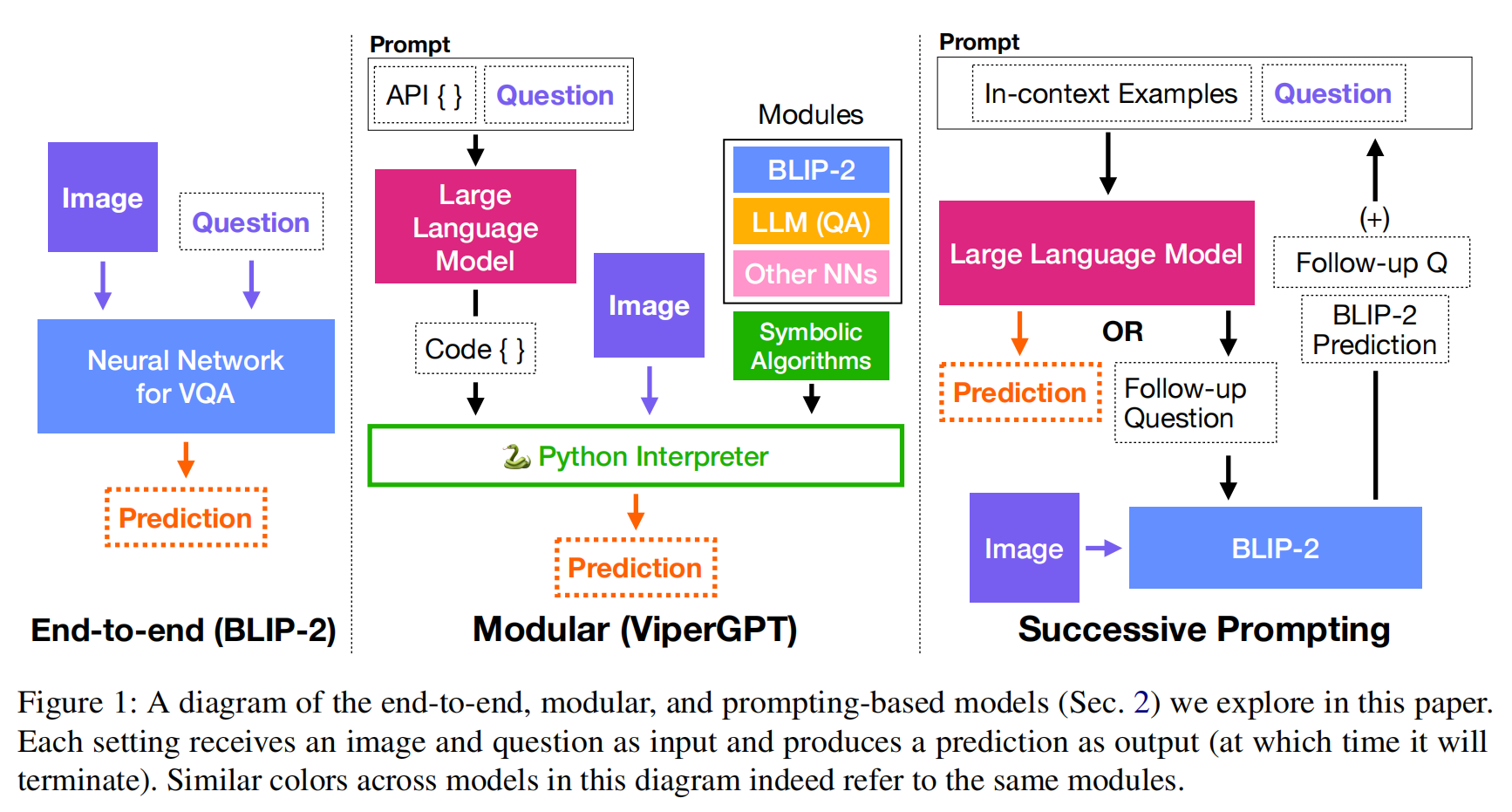
CV计算机视觉每日开源代码Paper with code速览-2023.11.14
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】Aggregate, Decompose, and Fine-Tune: A Simple Yet Effective Factor-Tuning Method for Vision…
Drone-Yolo:一种高效的无人机图像目标检测神经网络方法
摘要
https://www.mdpi.com/2504-446X/7/8/526 在各种研究领域中,对无人机的图像进行目标检测是一项有意义的任务。然而,无人机的图像带来了独特的挑战,包括图像尺寸大、检测对象尺寸小、对象密集分布、对象重叠以及光线不足影响目标检测的准确性。本文提出了Drone-YOLO,这…
第2篇 机器学习基础 —(3)机器学习库之Scikit-Learn
前言:Hello大家好,我是小哥谈。Scikit-Learn(简称Sklearn)是Python 的第三方模块,它是机器学习领域当中知名的Python 模块之一,它对常用的机器学习算法进行了封装,包括回归(Regressi…

YOLOv5算法改进(11)— 主干网络介绍(MobileNetV3、ShuffleNetV2和GhostNet)
前言:Hello大家好,我是小哥谈。主干网络通常指的是深度学习中的主干模型,通常由多个卷积层和池化层组成,用于提取输入数据的特征。在训练过程中,主干网络的参数会被不断优化以提高模型的准确性。YOLOv5算法中的主干网络可以有多种替换方案,为了后面讲解的方便,本篇文章就…

图像分类系列(一) AlexNet学习详细记录
本文将为大家介绍经典神经网络的开山力作——AlexNet(ImageNet Classification with Deep Convolutional Neural Networks)。文章包含论文原文翻译+精读+个人学习总结。 研一萌新,第一次发文,不足之处…
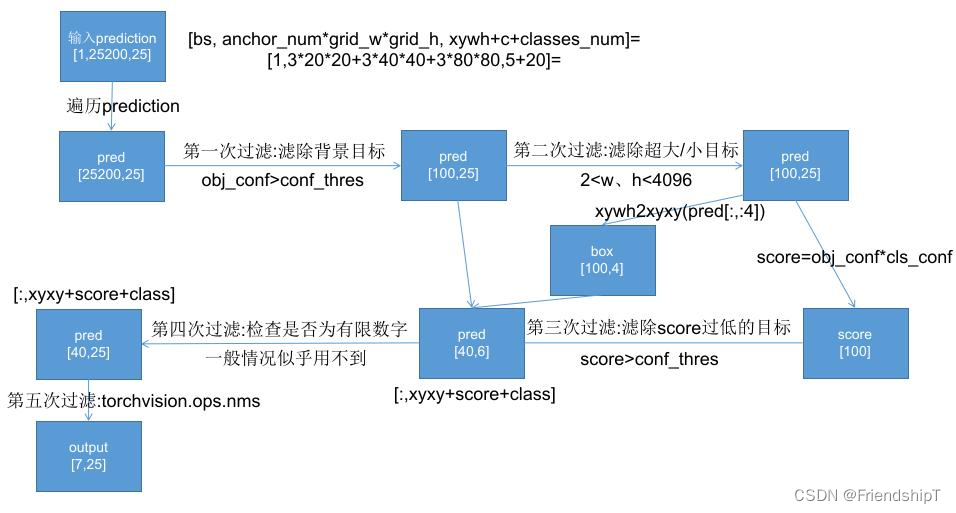
YOLOv5:解读general.py
YOLOv5:解读general.py 前言前提条件相关介绍general.pyclip_boxesscale_boxes ★ \bigstar ★xywh2xyxynon_max_suppression ★ ★ ★ \bigstar\bigstar\bigstar ★★★未完待续 参考 前言 记录一下自己阅读general.py代码的一些重要点,方便自己查阅。…

基于YOLOV8模型和CCPD数据集的车牌目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型和CCPD数据集的车牌目标检测系统可用于日常生活中检测与定位车牌目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算…
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION (论文解析)
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION 摘要1 介绍2 相关工作3 重新审视 Transformers 和 DETR4 方法4.1 用于端到端目标检测的可变形transformer4.2 Deformable Detr的其他改进和变型5 实验5.1 和DETR 比较5.2 消融实验5.3 与最先进方法的…
目标检测项目中,使用python+xml.etree.ElementTree修改xml格式标注文件中的类别名称
需求: 数据集的数据增强中,有时需要将xml标注文件中的类别做修改为新类别,或者将几个类别合并为一个类别。 解决方法: 使用pythonimport xml.etree.ElementTree将xml标注文件中的类别名称做修改。代码如下&…

图像处理之IOU, NMS原理及C++实现
1. IOU
交并比(Intersection-over-Union,IoU),目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的…

烟花厂人员作业释放静电行为检测算法
烟花厂人员作业释放静电行为检测算法通过pythonyolo系列算法模型框架,烟花厂人员作业释放静电行为检测算法在工厂车间入口处能够及时捕捉到人员是否触摸静电释放仪。一旦检测到人员进入时没有触摸静电释放仪,系统将自动触发告警。Python是一种由Guido va…
opencv-python数字验证码识别
先来说一下遇到的问题
代码如果直接运行可能会报以下错误:
raise TesseractNotFoundError() pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or its not in your PATH. See README file for more information.
这时候需要修改相应文件夹路径…

AI人员打闹监测识别算法
AI人员打闹监测识别算法通过yolopython网络模型框架算法, AI人员打闹监测识别算法能够准确判断出是否有人员进行打闹行为,算法会立即发出预警信号。Yolo算法,其全称是You Only Look Once: Unified, Real-Time Object Detection,其…

目标检测评估指标mAP:从Precision,Recall,到AP50-95
1. TP, FP, FN, TN
True Positive
满足以下三个条件被看做是TP 1. 置信度大于阈值(类别有阈值,IoU判断这个bouding box是否合适也有阈值) 2. 预测类型与标签类型相匹配(类别预测对了) 3. 预测的Bouding Box和Ground …

mmdet 3.x 打印各类指标
和mmdet2.x中的修改地方不一样,在mmdet/evaluation/metrics/coco_metric.py中第72行将classwise设为True就可以打印各类指标了 但是在test的时候一直都是什么指标都不打印,不管是上面总的指标还是下面的各类指标,暂时不知道怎么处理
找到原因…

RT-DETR算法改进:更换损失函数DIoU损失函数,提升RT-DETR检测精度
💡本篇内容:RT-DETR算法改进:更换损失函数DIoU损失函数
💡本博客 改进源代码改进 适用于 RT-DETR目标检测算法(ultralytics项目版本)
按步骤操作运行改进后的代码即可🚀🚀🚀
💡改进 RT-DETR 目标检测算法专属 文章目录 一、DIoU理论部分 + 最新 RT-DETR算法…
Windows电脑训练 RT-DETR 改进算法 (Ultralytics) 教程,改进RTDETR算法(包括使用训练、验证、推理教程)
手把手从零开始训练 RT-DETR 改进项目 (Ultralytics版本) 教程,改进RTDETR算法
本文以Windows服务器为例:从零开始使用Windows训练 RT-DETR 算法项目 《芒果剑指 RT-DETR 目标检测算法 改进》 适用于芒果专栏改进RT-DETR算法 文章目录 百度 RT-DETR 算法介绍改进网络代码汇…

RT-DETR算法优化改进:可变形大核注意力(D-LKA Attention),超越自注意力,实现暴力涨点 | 2023.8月最新发表
💡💡💡本文独家改进: 可变形大核注意力(D-LKA Attention),采用大卷积核来充分理解体积上下文的简化注意力机制,来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式 1)代替RepC3进行使用;
推荐指数:五星
RT-DETR魔术师专栏介绍:
https://blog.csdn.n…
YOLOv5独家最新改进《新颖高效AsDDet检测头》VisDrone数据集mAP涨点,即插即用|检测头新颖改进,性能高效涨点
💡本篇内容:YOLOv5独家最新改进《新颖高效AsDDet检测头》VisDrone数据集mAP涨点1.4%,即插即用|检测头新颖改进,性能高效涨点
💡🚀🚀🚀本博客 YOLO系列 + 全新新颖原创高效AsDDet检测头
改进创新点改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可…

YOLO目标检测——番茄数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:番茄检测数据集说明:番茄目标检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三种格式标签…
[数据集][目标检测]水牛数据集VOC+yolo格式376张1类别
数据集制作单位:未来自主研究中心(FIRC) 数据集格式:Pascal VOC格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):376 标注数量(xml文件个数):376 标注…

使用opencv和dlib库(C++代码)实现人脸活体检测(眨眼、张嘴、摇头检测)
前言 本文章使用opencv和dlib库,使用C++代码实现了人脸活体检测,包括眨眼检测、张嘴检测以及摇头检测,可以对静态图片和活体进行有效区分。效果展示 Dlib库介绍 dlib是一个开源的C++机器学习库,它提供了一系列用于图像处理、人脸检测、人脸识别、物体检测、图像标注等功能的…
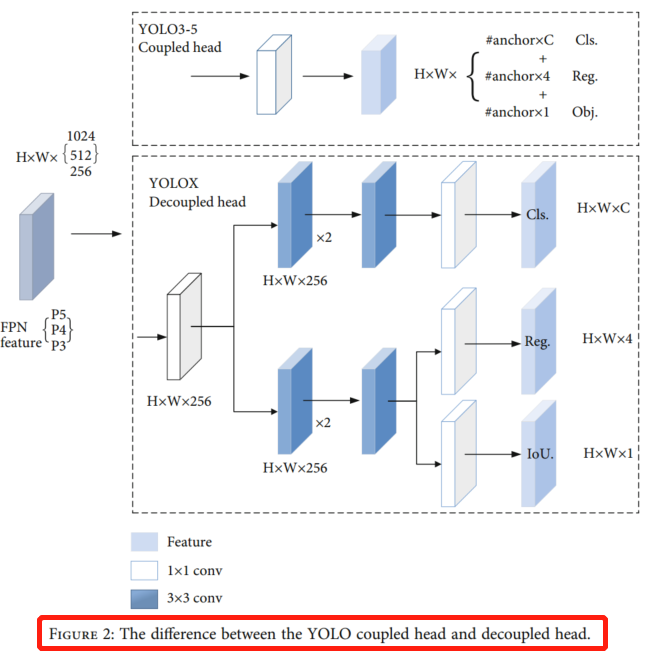
深度学习领域中的耦合与解耦
在阅读论文的时候应该会看到两个操作,一个是耦合,一个是解耦,经常搭配着出现的就是两个词语,耦合头(Coupled head)以及Decoupled head(解耦合头),那为什么要耦合…

YOLO目标检测——红绿灯检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:红绿灯检测数据集在自动驾驶、交通安全监控、智能交通系统、交通流量监测和驾驶员辅助系统等领域都有广泛应用的潜力数据集说明:红绿灯检测数据集,真实场景的高质量图片数据,数据场景丰富,含有国内红绿灯…

YOLOv8轻量化模型:模型轻量化设计 | 轻量级可重参化EfficientRep| 来自YOLOv6思想
💡💡💡本文解决什么问题:在几乎不保证精度下降的前提下,轻量级模型创新设计
EfficientRep 在关键点检测任务中 | GFLOPs从9.6降低至8.5, mAP50从0.921下降至0.912,mAP50-95从0.697提升至0.779
YOLO轻量化模型专栏:http://t.csdnimg.cn/AeaEF
1.YOLOv6介绍 论文…
YOLO改进系列之注意力机制(GatherExcite模型介绍)
模型结构
尽管在卷积神经网络(CNN)中使用自底向上的局部运算符可以很好地匹配自然图像的某些统计信息,但它也可能阻止此类模型捕获上下文的远程特征交互。Hu等人提出了一种简单,轻量级的方法,以在CNN中更好地利用上下…
基于官方YOLOv4开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】
本文是关于基于YOLOv4开发构建目标检测模型的超详细实战教程,超详细实战教程相关的博文在前文有相应的系列,感兴趣的话可以自行移步阅读即可:《基于yolov7开发实践实例分割模型超详细教程》
《YOLOv7基于自己的数据集从零构建模型完整训练、…

【单目测距】单目相机测距(三)
文章目录 一、前言二、测距代码2.1、地面有坡度2.2、python代码2.2.1、旋转矩阵转角度2.2.2、角度转旋转矩阵2.2.3、三维旋转原理 (Rotation 原理)2.2.4、完整代码 2.3、c 代码 一、前言 上篇博客【单目测距】单目相机测距(二) 有讲到当相机不是理想状态…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)(二)
目录
知识储备
工业镜头景深计算
3D白光干涉成像
Part.1接触式检测技术
Part.2非接触式检测技术
算法原理
RT-DETR代码学习笔记(DETRs Beat YOLOs on Real-time Object Detection)
论文地址:https://arxiv.org/abs/2304.08069 代码地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite 基于Transformer的端到端检测器(DETR)已经取…

第二十七章 解读Transformer_车道线检测中的Transformer(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 SE简单实现
class SELayer(nn.Module):d…
蓝牙耳机如果出口欧盟CE-RED认证如何办理解析指南
蓝牙耳机(Bluetooth Headset )是采用蓝牙技术的无线耳机。蓝牙耳机原理是手机中的解码芯片对MP3等音乐文件进行解码,产生数字信号并通过蓝牙发送给蓝牙耳机;蓝牙耳机接收数字信号,并通过蓝牙耳机内部的数模转换芯片&am…
backbone:从AlexNet到...(持续补充ing)
文章目录 Introduction(前言知识)代码参考卷积、池化输出退化1*1卷积减少或增加通道数自然的减少计算量解决了什么问题,达到了什么样的效果AlexNet整体结构如下VGGNet网络结构如下,D、E分别代表VGG-16、VGG-19下图为VGG-16ResNet结构如下DenseNet结构如下Dense Block——特…

windows上运行yolov3代码详解(小白)
batch_normalize1 # 是否做BN 代码链接
环境配置
没有Anaconda的话可以安装下
首先创建虚拟环境,名称随意,版本3.9.我觉得挺好的 激活虚拟环境 conda activate 刚刚创建的环境名称 切换到requirements.txt目录下,直接vscode打开yolov3文件…
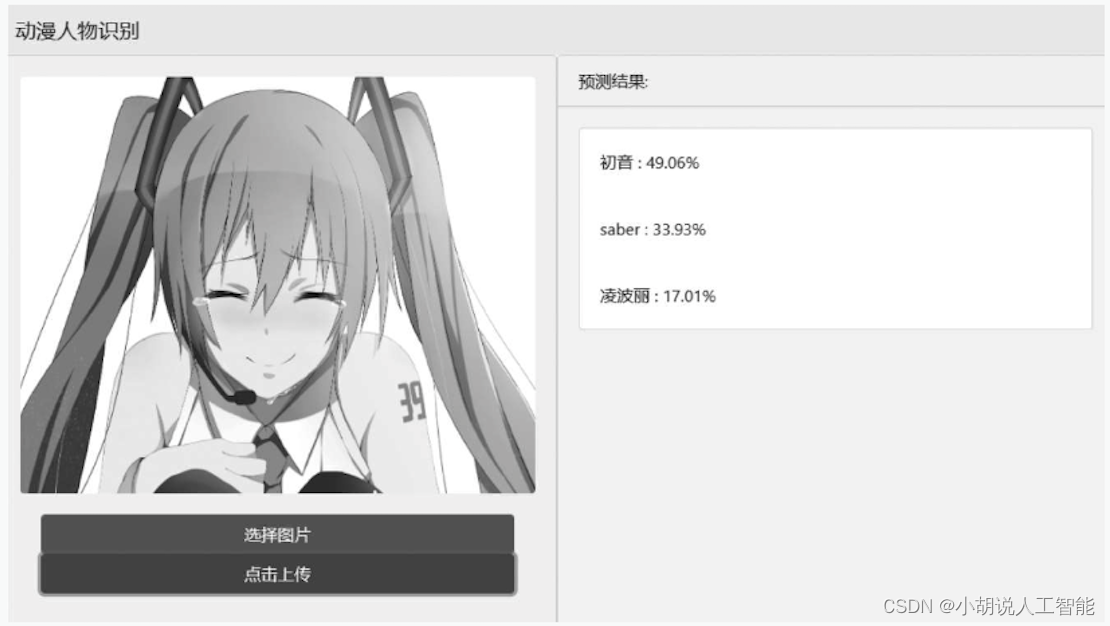
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(四)
目录 前言总体设计系统整体结构图系统流程图 运行环境爬虫模型训练实际应用 模块实现1. 数据准备1)爬虫下载原始图片2)手动筛选图片 2. 数据处理3. 模型训练及保存4. 模型测试1)前端2)后端 系统测试1. 测试效果2. 模型应用1&#…

YOLOv8独家原创改进:自研独家创新FT_Conv,卷积高效结合分数阶变换
💡💡💡本文自研创新改进:卷积如何有效地和频域结合,引入分数阶傅里叶变换(FrFT)和分数阶Gabor变换(FrGT),最终创新到YOLOv8。
使用方法:1)直接替换原来的C2f;2)放在backbone SPPF后使用;等
推荐指数:五星 在道路缺陷检测任务中,原始map为0.8,FT_Conv为0.82 收…
目标检测工程化最佳实践:Python 并行条件下YOLOv8的模型推理,线程安全的模型推理!
文章大纲 YOLOv8模型的线程安全推理 背景简介Python 线程的一些理解共享模型实例的问题与危害!非线程安全的代码样例: 单个模型实例非线程安全的代码样例: 多个个模型实例YOLOv8 中线程安全的推理方式Thread-Safe Example 1Thread-Safe Example 2YOLOv8 主要开发人员的回复结论…
C# Onnx 阿里达摩院开源DAMO-YOLO目标检测
效果 模型信息
Inputs ------------------------- name:images tensor:Float[1, 3, 192, 320] ---------------------------------------------------------------
Outputs ------------------------- name:output tensor:Float…
Linux服务器从零开始训练 RT-DETR 改进项目 (Ultralytics) 教程,改进RTDETR算法(包括使用训练、验证、推理教程)
手把手从零开始训练 RT-DETR 改进项目 (Ultralytics版本) 教程,改进RTDETR算法
本文以Linux服务器为例:从零开始使用Linux训练 RT-DETR 算法项目 《芒果剑指 RT-DETR 目标检测算法 改进》 适用于芒果专栏改进RT-DETR算法 文章目录 百度 RT-DETR 算法介绍改进网络代码汇总第…
RT-DETR算法改进:最新Inner-IoU损失函数,辅助边界框回归的IoU损失,提升RT-DETR检测器精度
💡本篇内容:RT-DETR算法改进:最新Inner-IoU损失函数,辅助边界框回归的IoU损失,提升RT-DETR检测器精度
💡本博客 改进源代码改进 适用于 RT-DETR目标检测算法(ultralytics项目版本)
按步骤操作运行改进后的代码即可🚀🚀🚀
💡改进 RT-DETR 目标检测算法专属…
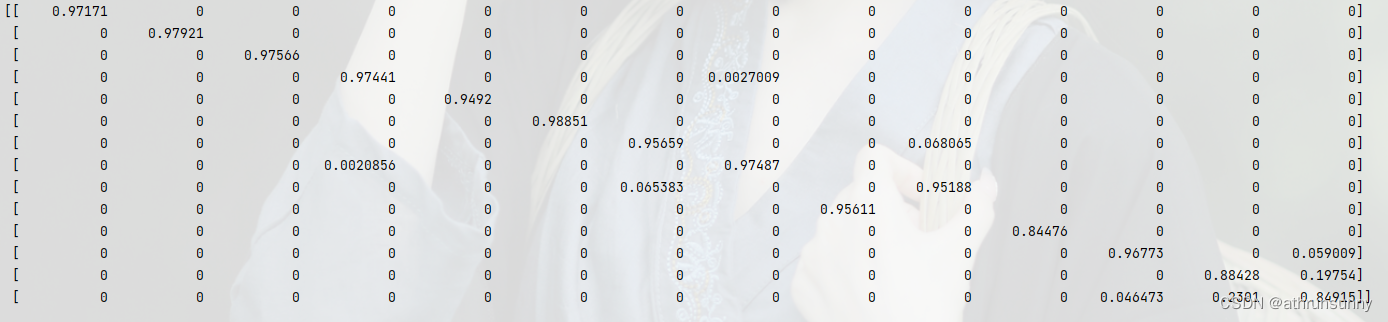
旋转框(obb)目标检测计算iou的方法
首先先定义一组多边形,这里的数据来自前后帧的检测结果 pre [[[860.0, 374.0], [823.38, 435.23], [716.38, 371.23], [753.0, 310.0]],[[829.0, 465.0], [826.22, 544.01], [684.0, 539.0], [686.78, 459.99]],[[885.72, 574.95], [891.0, 648.0], [725.0, 660.0]…
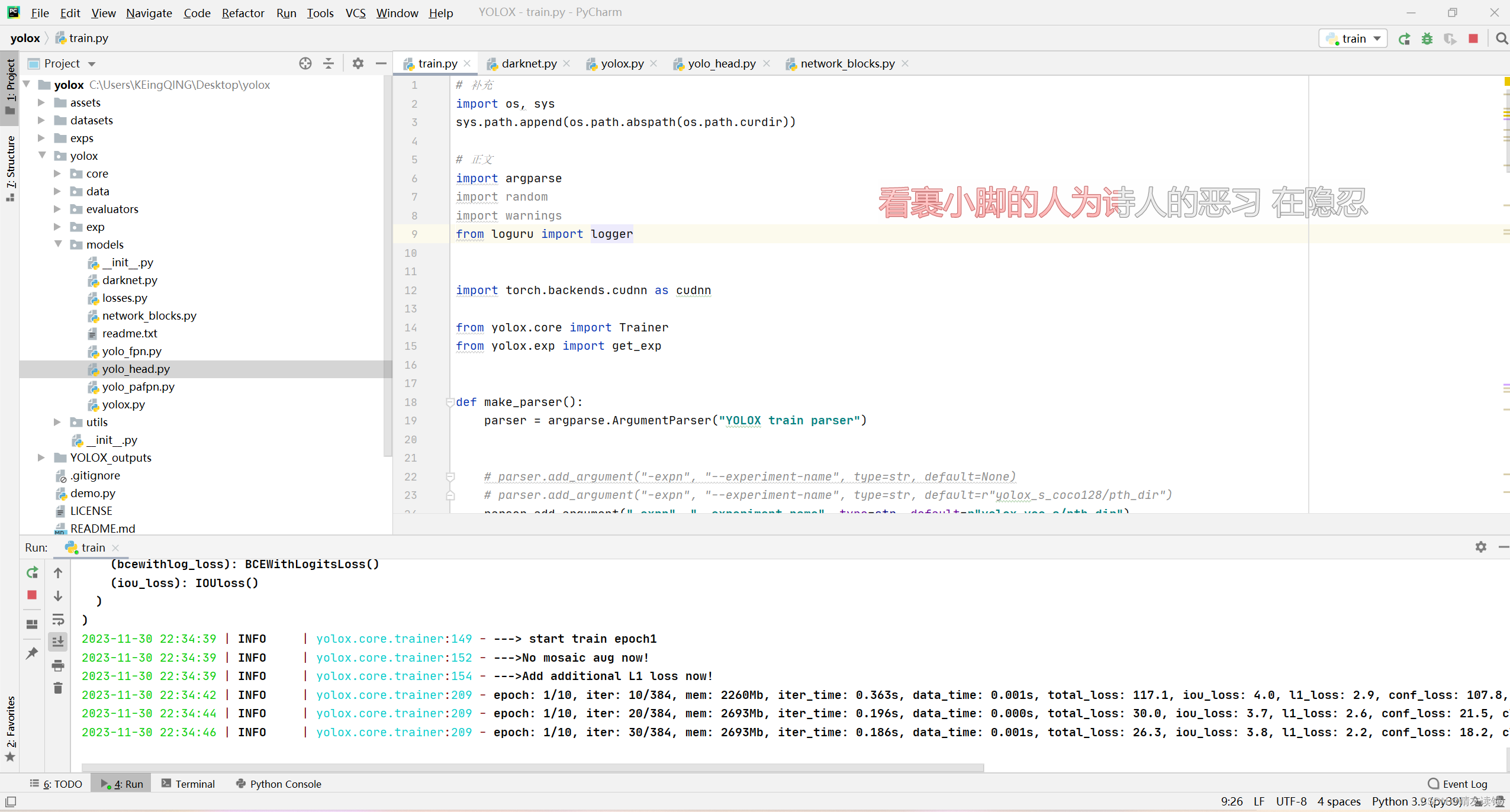
DCAMnet网络复现与讲解
距论文阅读完毕已经过了整整一周多。。。终于抽出时间来写这篇辣!~ 论文阅读笔记放这里: 基于可变形卷积和注意力机制的带钢表面缺陷快速检测网络DCAM-Net(论文阅读笔记)-CSDN博客 为了方便观看,我把结构图也拿过来了。…

YOLO目标检测——红花数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:红花检测数据集可以用于监测和分析红花的生长情况,包括生长速度、叶面积、花朵数量等,为农民提供精确的决策支持,以提高红花产量和品质。数据集说明:红花检测数据集,真实场景的高质量图片数据…

目标检测图片截取目标分类图片
如果要训练一个分类模型却没有特定的分类数据集怎么办呢?可以换一种思路,将带有该目标的图片对所有想要的目标进行画标注框然后进行截图,就能得到特定的分类数据了。这么做的目的是:带有该目标的图片可能不会少,但是带…

YOLOv5源码中的参数超详细解析(5)— 验证部分(val.py)参数解析
前言:Hello大家好,我是小哥谈。YOLOv5是一种先进的目标检测算法,它可以实现快速和准确的目标检测。在YOLOv5源码中,train.py和detect.py文件讲完了之后,接着就是讲val.py文件了。本节课就结合源码对val.py文件进行逐行解析~!🌈 前期回顾: YOLOv5源码中的参数超详细解…
细粒度视觉分类的注意内核编码网络
Attentional Kernel Encoding Networks for Fine-Grained Visual Categorization 1、介绍2、方法2.1 卷积模块2.2 级联注意力模块2.3 内核编码模块2.4 整体 3、结论 在本文中,我们提出了一种用于细粒度视觉分类的注意核编码网络(AKEN)。具体来说,AKEN聚合…
袋鼠目标检测数据集VOC+YOLO格式1400多张
袋鼠是双门齿目袋鼠亚目袋鼠科大袋鼠属的哺乳动物。袋鼠跳得最高、最远。雌性袋鼠都长有一个前开的育儿袋,袋鼠也因此得名。 [8]袋鼠泛指任一种属于袋鼠目的有袋动物, [7]它头小眼大耳朵长,面部较长,鼻孔两侧有黑色须痕。袋鼠胆小…

YOLO目标检测——复杂场景人员行人数据集+已标注voc格式标签下载分享
实际项目应用:安防监控、人群管理、自动驾驶、城市规划、人机交互等等数据集说明:YOLO目标检测数据集,真实场景的高质量图片数据,数据场景丰富,图片格式为jpg,分为训练集和验证集。标注说明:使用…
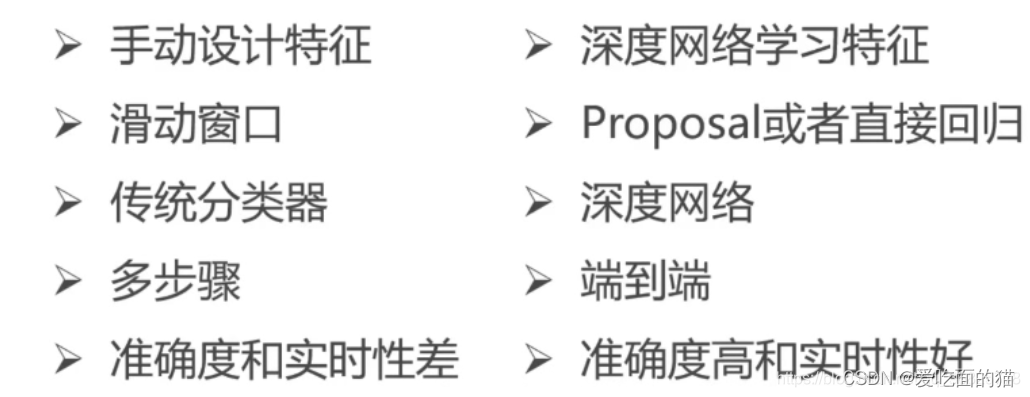
03目标检测-传统方法与深度学习算法对比
一、目标学习的检测方法变迁及对比 “目标检测“是当前计算机视觉和机器学习领域的研究热点。从Viola-Jones Detector、DPM等冷兵器时代的智慧到当今RCNN、YOLO等深度学习土壤孕育下的GPU暴力美学,整个目标检测的发展可谓是计算机视觉领域的一部浓缩史。整个目标…

YOLO目标检测——路标数据集+已标注voc和yolo格式标签下载分享
实际项目应用:自动驾驶、视频监控和安防、物体识别和分类、城市规划和地理信息系统等等数据集说明:YOLO路标目标检测数据集,真实场景的高质量图片数据,数据场景丰富,图片格式为jpg,共900张图片,…

Yolov8-pose关键点检测:loss系列 | 手把手教程,多loss设计提升关键点提取性能
💡💡💡本文解决什么问题:手把手教会你v8PoseLoss 多loss设计,提升关键点检测
Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_12398833.html
✨✨✨手把手教你从数据标记到生成适合Yolov8-pose的yolo数据集;
🚀🚀🚀模型性能提升…
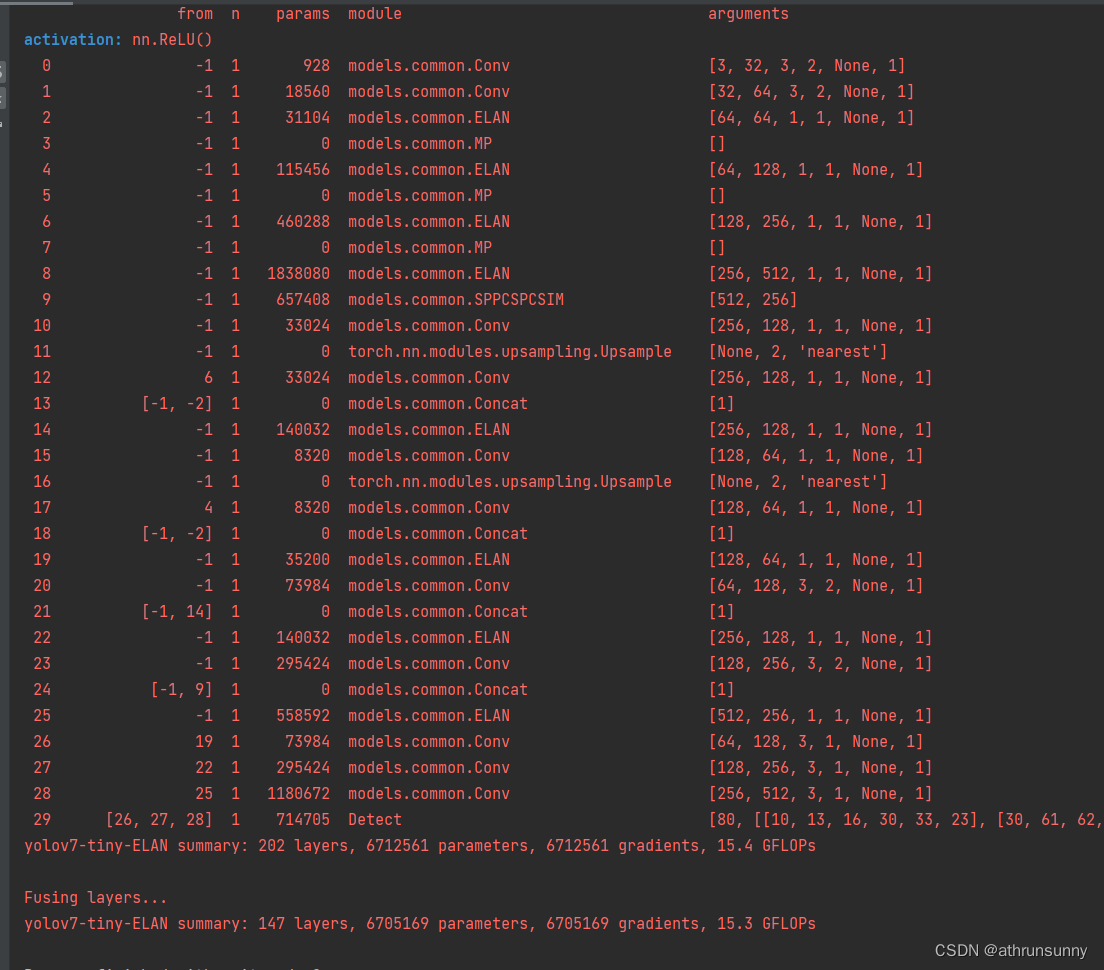
yolov7简化网络yaml配置文件
yolov7代码结构简单,效果还好,但是动辄超过70几个模块的配置文件对于想要对网络进行魔改的朋友还是不怎么友好的,使用最小的tiny也有77个模块 代码的整体结构简单,直接将ELAN结构化写成一个类就能像yolov5一样仅仅只有20几个模块&…

opencv-yolov8-目标检测
import cv2
from ultralytics import YOLO# 模型加载权重model YOLO(yolov8n.pt)# 视频路径cap cv2.VideoCapture(0)# 对视频中检测到目标画框标出来
while cap.isOpened():# Read a frame from the videosuccess, frame cap.read()if success:# Run YOLOv8 inference on th…

葡萄目标检测(yolov8模型,无需修改路径,python代码,解压缩后直接运行)
运行效果视频:葡萄目标检测(yolov8模型,无需修改路径,python代码,解压缩后直接运行)_哔哩哔哩_bilibili
1.采用yolov8模型 models文件夹保存的是yolov8的训练好的模型参数 PinotNoir文件夹存放的是训练集 …
(第三方满意度调研公司)供应商客户满意度调查
供应商客户满意度调查是评估客户对供应商服务和产品的满意程度的重要工具。以下是进行供应商客户满意度调查的一般步骤:
1.确定调研目标:明确调研的目的,例如评估客户对供应商的产品质量、交货准时性、客户服务等方面的满意度。
设计调研方…
目标检测YOLO实战应用案例100讲-基于机器视觉的输电线路小目标检测和缺 陷识别(中)
目录
2.3 实验分析
2.3.1 训练参数设置
2.3.2 EL-ESRGAN算法训练结果分析
目标检测中数据处理-1.labelme标注json文件转txt
labelme标注json文件转txt 1.Labelme安装与使用2.Labelme的标签说明3.将json文件转化为txt文件(yolo格式)最后1.Labelme安装与使用
labelme 是一款图像标注工具,主要用于数据集准备工作,使用前需要先安装 Python 集成环境 anaconda或者网上找安装好的文件(文末放有百度网…
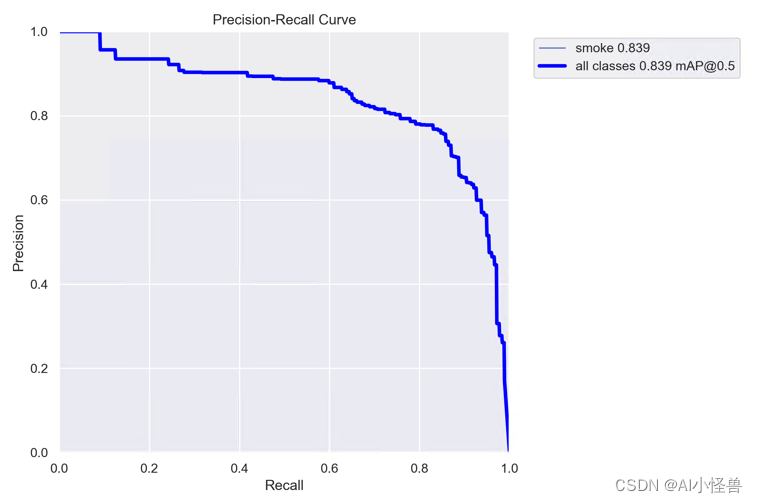
基于Yolov8的野外烟雾检测(1)
目录 1.Yolov8介绍
2.野外火灾烟雾数据集介绍
2.1数据集划分
1.2 通过voc_label.py得到适合yolov8需要的txt
2.3生成内容如下
3.训练结果分析
4.系列篇 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的…


第1篇 目标检测概述 —(2)目标检测算法介绍
前言:Hello大家好,我是小哥谈。目标检测算法是一种计算机视觉算法,用于在图像或视频中识别和定位特定的目标物体。常见的目标检测算法包括传统的基于特征的方法(如Haar特征和HOG特征)以及基于深度学习的方法࿰…

使用 KerasCV YOLOv8 进行物体检测--附完整实现源码
YOLO 目标检测模型已应用于无数应用,从监控系统到自动驾驶车辆。但是,当在 KerasCV 框架下将 YOLOv8 的这种能力配对时会发生什么呢?最近,KerasCV 将著名的 YOLOv8 检测模型集成到其库中。在本文中,我们将探讨如何使用自定义数据集微调 YOLOv8。在此过程中,我们还将涵盖以…

《YOLOv5:从入门到实战》专栏介绍 专栏目录
🌟YOLOv5:从入门到实战 | 目录 | 使用教程🌟 本专栏涵盖了丰富的YOLOv5算法从入门到实战系列教程,专为学习YOLOv5的同学而设计,堪称全网最详细的教程!该专栏从YOLOv5基础知识入门到项目应用实战都提供了详细…

《YOLOv5:从入门到实战》报错解决 专栏答疑
前言:Hello大家好,我是小哥谈。《YOLOv5:从入门到实战》专栏上线后,部分同学在学习过程中提出了一些问题,笔者相信这些问题其他同学也有可能遇到。为了让大家可以更好地学习本专栏内容,笔者特意推出了该篇专…

目标检测YOLO实战应用案例100讲-基于RFID与目标检测的种鹅个体产蛋信息监测系统研究(续)
目录
3.4.3 结果分析
基于ROI的目标计数与产蛋信息获取
4.1 引言
4.2 ROI区域划定

Yolov8-pose关键点检测:模型轻量化创新 | 轻量级Slim-Neck
💡💡💡本文解决什么问题:轻量级Slim-Neck,缓解 DSC 缺陷对模型的负面影响,并充分利用深度可分离卷积 DSC 的优势。
Slim-Neck | mAP50从0.921提升至0.93, mAP50从0.697提升至0.829
Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_1…
基于YOLOv8和WiderFace数据集的人脸目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8和WiderFace数据集的人脸目标检测系统可用于日常生活中检测与定位人脸目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算…
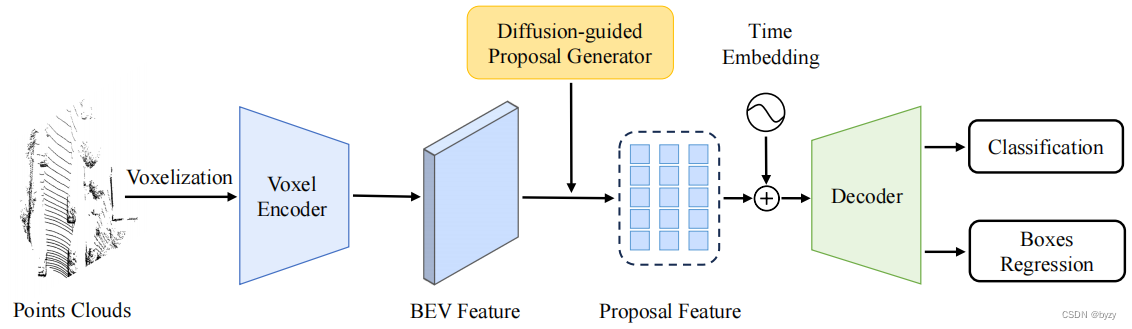
【论文笔记】Diffusion-based 3D Object Detection with Random Boxes
原文链接:https://arxiv.org/abs/2309.02049
1. 引言 基于激光雷达的3D目标检测方法通常依赖经验设置锚框或中心半径,而本文探索从随机框直接预测真实边界框。 本文提出Diff3Det,使用扩散模型进行3D目标检测。首先为真实边界框添加高斯噪…

13.4 目标检测锚框标注 非极大值抑制
锚框的形状计算公式
假设原图的高为H,宽为W
锚框形状详细公式推导 以每个像素为中心生成不同形状的锚框 # s是缩放比,ratio是宽高比
def multibox_prior(data, sizes, ratios):"""生成以每个像素为中心具有不同形状的锚框"""in_he…
目标检测算法改进系列之Backbone替换为RepViT
RepViT简介
轻量级模型研究一直是计算机视觉任务中的一个焦点,其目标是在降低计算成本的同时达到优秀的性能。轻量级模型与资源受限的移动设备尤其相关,使得视觉模型的边缘部署成为可能。在过去十年中,研究人员主要关注轻量级卷积神经网络&a…
目标检测算法改进系列之Backbone替换为RIFormer
RIFormer简介
Token Mixer是ViT骨干非常重要的组成成分,它用于对不同空域位置信息进行自适应聚合,但常规的自注意力往往存在高计算复杂度与高延迟问题。而直接移除Token Mixer又会导致不完备的结构先验,进而导致严重的性能下降。
原文地址&…
如何降低海康、大华等网络摄像头调用的高延迟问题(一):海康威视网络摄像头的python sdk使用(opencv读取sdk流)
目录
1.python sdk使用
1.海康SDK下载 2.opencv读取sdk流 先说效果,我是用的AI推理的实时流,延迟从高达7秒降到小于1秒
如果觉得这个延迟还不能接受,下一章,给大家介绍点上不得台面的小方法 SDK(Software Developme…

YOLOv5模型环境搭建及使用google colab训练
环境搭建
环境
ubuntu 18.04 64bitGTX 1070Tianaconda with python 3.8pytorch 1.7.1cuda 10.1yolov5 5.0.9
为了方便使用 yolov5 目标检测,有网友已经将其做成了库,提交到了官方的索引库 pypi 上,这样,我们就可以直接使用 pip…
opencv基础55-获取轮廓的特征值及示例
轮廓自身的一些属性特征及轮廓所包围对象的特征对于描述图像具有重要意义。本节介绍几个轮廓自身的属性特征及轮廓所包围对象的特征。 宽高比
可以使用宽高比(AspectRation)来描述轮廓,例如矩形轮廓的宽高比为:
宽高比 宽度&am…
yolov8中train.py、val.py、predict.py的区别,什么时候该用哪个?
相信很多小白都会对val.py、predict.py产生疑问,这俩有什么区别,什么时候用?
train.py:用于训练模型啊,很好理解val.py:两个用处。第一训练的时候,train.py会调用该文件,然后在每个…
基于YOLOv8模型的车载摄像头下车辆目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的车载摄像头下车辆目标检测系统可用于日常生活中检测与定位车辆目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算…

YOLOv7改进: CFP:即插即用的多尺度融合模块,EVC助力小目标检测| 顶刊TIP 2023
💡💡💡本文独家改进:即插即用的多尺度融合模块,EVC助力小目标检测
EVC | 亲测在多个数据集实现暴力涨点,强烈推荐,独家首发; 收录:
YOLOv7高阶自研专栏介绍:http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现
🚀🚀🚀YOLOv7自研创新结合,轻松搞…
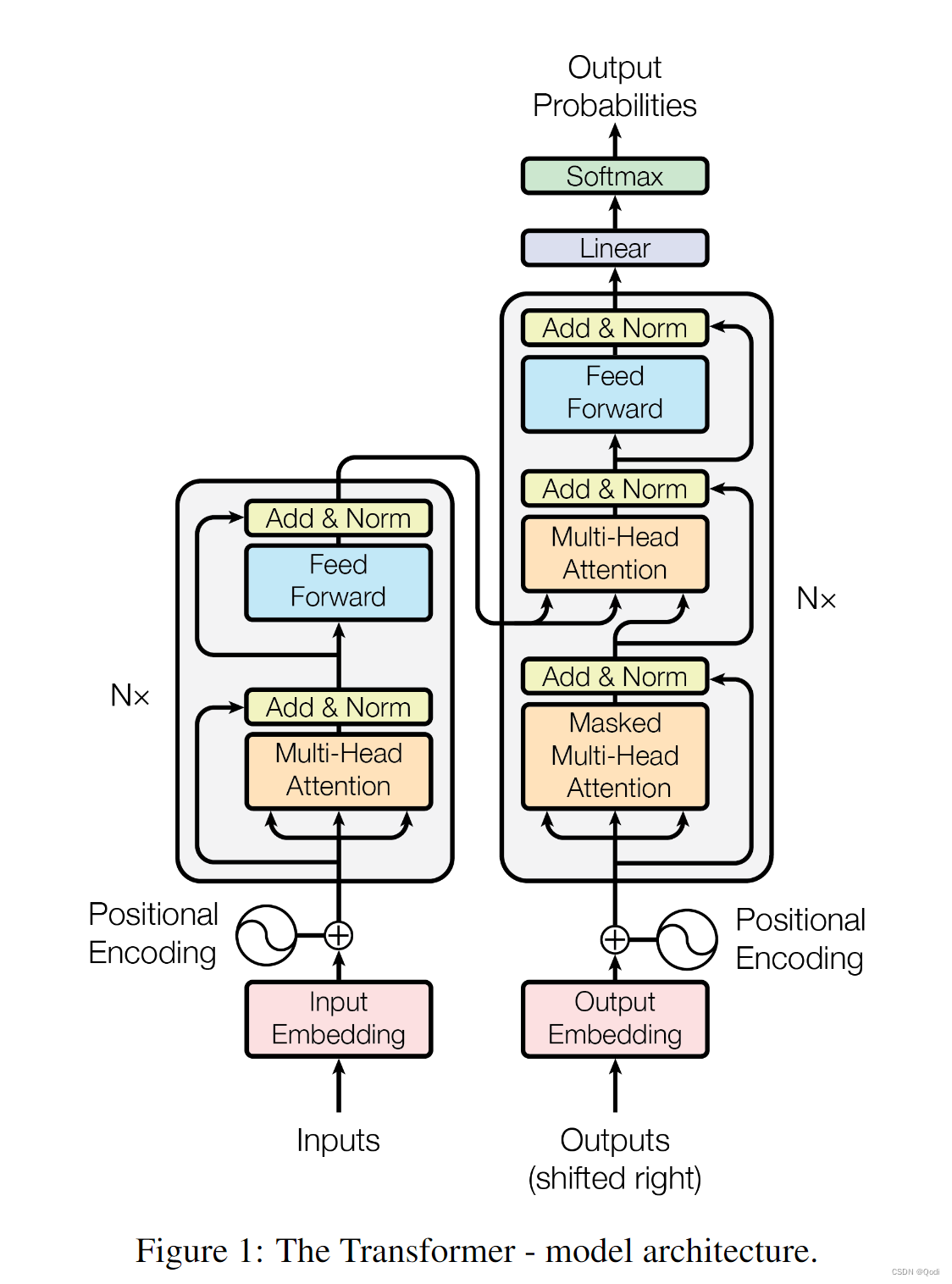
Transformer为什么如此有效 | 通用建模能力,并行
目录
1 更强更通用的建模能力
2 并行计算
3 大规模训练数据
4 多训练技巧的集成
Transformer是一种基于自注意力机制的网络,在最近一两年年可谓是大放异彩,我23年入坑CV的时候,我看到的CV工作似乎还没有一个不用到Transformer里的一些组…

YOLOv7改进策略:RIFormerBlock助力检测|CVPR2023 RIFormer:无需TokenMixer也能达成SOTA性能的极简ViT架构
💡💡💡本文属于原创独家改进: 稀疏重参数RIFormerBlock模型引入YOLOv7进行创新性
RIFormerBlock | 亲测在多个数据集实现涨点; 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现
🚀🚀🚀YOLOv7自研创新结合,轻松…
点云从入门到精通技术详解100篇-基于激光点云的道路目标检测(续)
目录 3.4 点云地面点过滤 3.4.1 常见地面点过滤算法 3.4.2 基于改进 RANSAC 的多分区地面点过滤 <
点云目标检测——pointpillars环境配置与训练
点云目标检测——pointpillars环境配置与训练 (二十五)实践出真知——OpenPCDet 制作pointpillars自定义数据集 - 知乎
基于深度学习的高铁周界入侵监测方法研究 - 中国知网
基于点云数据的三维目标检测技术研究进展 - 中国知网
面向恶劣天气的自动驾驶三维目标检测算法研究…

【AI视野·今日CV 计算机视觉论文速览 第266期】Thu, 12 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 12 Oct 2023 Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
PAD: A Dataset and Benchmark for Pose-agnostic Anomaly Detection Authors Qiang Zhou, Weize Li, Lihan Jiang, Guoli…

NeurIPS 2023 | MQ-Det: 首个支持多模态查询的开放世界目标检测大模型
目前的开放世界目标检测模型大多遵循文本查询的模式,即利用类别文本描述在目标图像中查询潜在目标。然而,这种方式往往会面临“广而不精”的问题。一图胜千言,为此,作者提出了基于多模态查询的目标检测(MQ-Det…
测试时数据增广(TTA)与mmdetection3d中的实现
1. 测试时数据增广 测试时数据增广(TTA)在测试时使用数据增广技术获取同一数据的多个“变体”,使用同一网络在这些“变体”以及原始数据上进行推断,最后整合所有结果作为该原始数据最终的预测结果。 TTA类似于集成学习,…

单目3D目标检测——MonoDLE 模型训练 | 模型推理
本文分享 MonoDLE 的模型训练、模型推理、可视化3D检测结果。
模型原理,参考我这篇博客:【论文解读】单目3D目标检测 MonoDLE(CVPR2021)_一颗小树x的博客-CSDN博客
源码地址:https://github.com/xinzhuma/monodle 目…
CV计算机视觉每日开源代码Paper with code速览-2023.10.16
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Rank-DETR for High Quality Object Detecti…
解读 | 自动驾驶系统中的多视点三维目标检测网络
原创 | 文 BFT机器人 01
背景 多视角三维物体检测网络,用于实现自动驾驶场景高精度三维目标检测,该网络使用激光雷达点云和RGB图像进行感知融合,以预测定向的三维边界框,相比于现有技术,取得了显著的精度提升。同时现…

细粒度物体数据集分享
EgoObjects: A Large-Scale Egocentric Dataset for Fine-Grained Object Understanding EgoObjects 是一个大规模的主观视角数据集,旨在进行细粒度物体理解,该领域被认为是主观视角视觉的一个基础研究课题。其试验版本包含了来自 50 多个国家的 250名参…

YOLOv7改进:动态蛇形卷积(Dynamic Snake Convolution),增强细微特征对小目标友好,实现涨点 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征,对小目标检测很适用
Dynamic Snake Convolution | 亲测在多个数据集能够实现大幅涨点
收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.…

道路裂缝坑洼图像开源数据集汇总
一、CrackForest数据集
数据集下载链接:http://suo.nz/2wdNdX
CrackForest数据集是一个带注释的道路裂缝图像数据库,可以大致反映城市路面状况。 二、道路裂缝坑洼图像数据集
数据集下载链接:http://suo.nz/3eEDlj
这个数据集是一个极具挑…
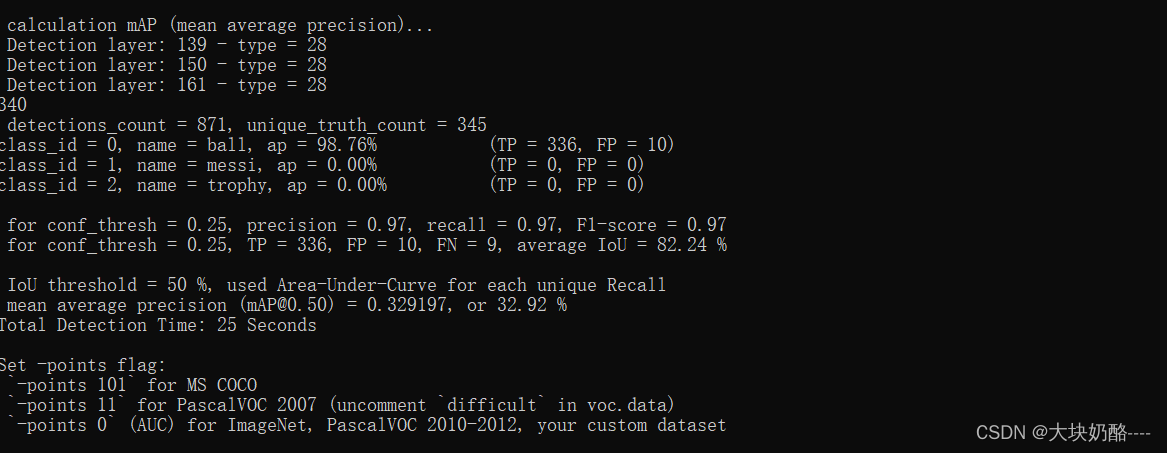
深度学习YOLOv4环境配置
软件安装
1、什么是CUDA
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
CUDA下载地址为CUDA Toolkit Archive | NVIDIA Developer
版…
YOLO目标检测——红细胞数据集【(含对应voc、coco和yolo三种格式标签】
实际项目应用:红细胞的自动检测和计数数据集说明:YOLO目标检测数据集,真实场景的高质量图片数据,数据场景丰富。使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三种格式标签&am…

无人机UAV目标检测与跟踪(代码+数据)
前言
近年来,随着无人机的自主性、灵活性和广泛的应用领域,它们在广泛的消费通讯和网络领域迅速发展。无人机应用提供了可能的民用和公共领域应用,其中可以使用单个或多个无人机。与此同时,我们也需要意识到无人机侵入对空域安全…

目标检测应用场景—数据集【NO.19】车辆目标检测数据集
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…
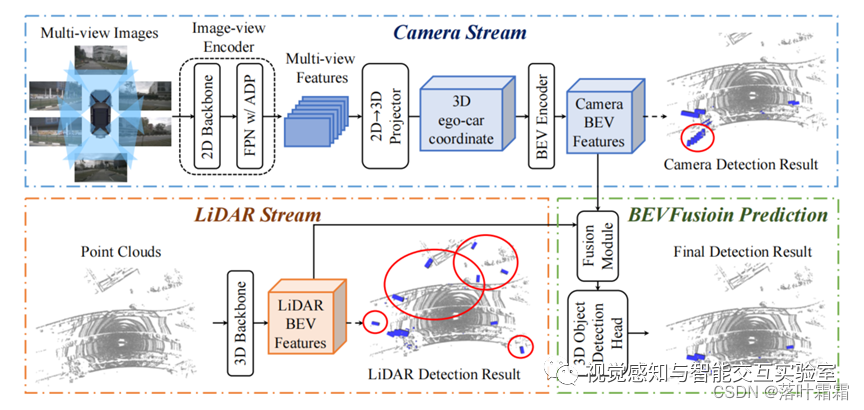
【BEV感知算法概述——下一代自动驾驶感知算法】
文章目录 BEV感知算法概念BEV感知算法数据集介绍BEV感知算法分类BEV感知算法的优劣小结 BEV感知算法概念
Bird’s-Eye-View,鸟瞰图(俯视图)。BEV感知算法存在许多的优势。
首先,BEV视图存在遮挡小的优点,由于视觉的透…
C# Onnx 轻量实时的M-LSD直线检测
目录
介绍
效果
效果1
效果2
效果3
效果4
模型信息
项目
代码
下载
其他 介绍
github地址:https://github.com/navervision/mlsd
M-LSD: Towards Light-weight and Real-time Line Segment Detection Official Tensorflow implementation of "M-…

YOLOv5算法进阶改进(6)— 更换主干网络之ResNet18
前言:Hello大家好,我是小哥谈。ResNet18是ResNet系列中最简单的一个模型,由18个卷积层和全连接层组成,其中包含了多个残差块。该模型在ImageNet数据集上取得了很好的表现,成为了深度学习领域的经典模型之一。ResNet18的优点是可以解决深度神经网络中梯度消失的问题,使得性…
[数据集][目标检测]车辆检测数据集VOC+YOLO格式1.6w张3类别
一共分为3个压缩包:
【车辆检测数据集AVOCYOLO格式5423张3类别】
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):5423 标注数…
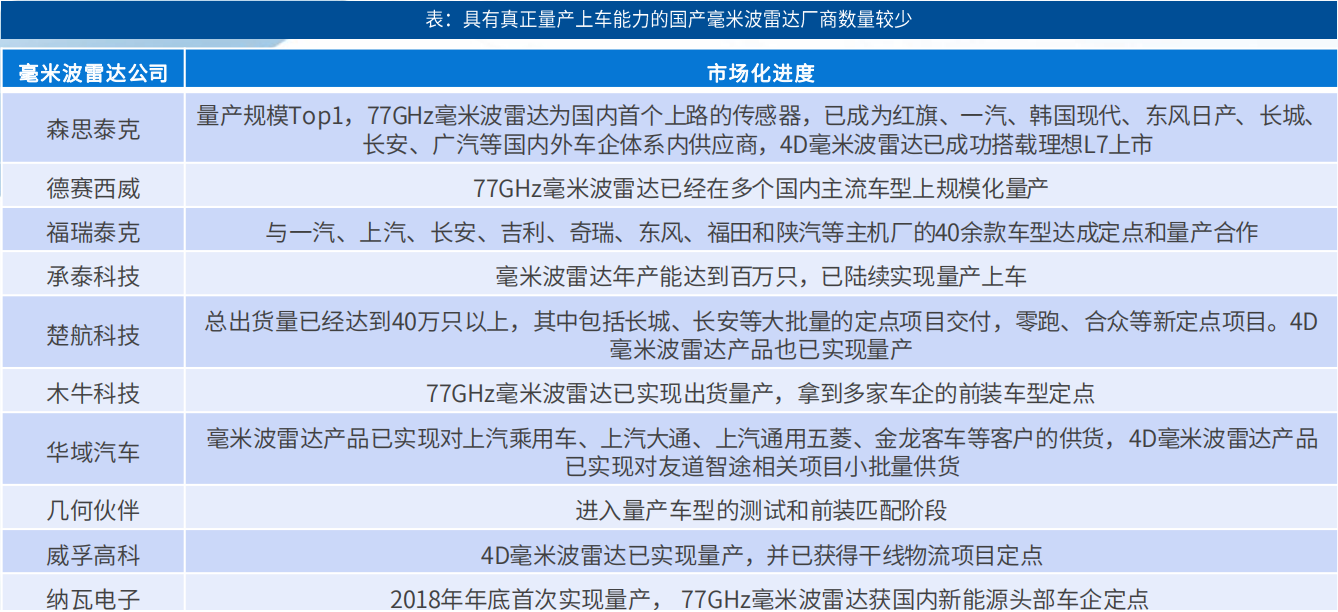
车载毫米波雷达及芯片新趋势研究1--毫米波雷达与其它车载传感器互补,研发及量产门槛较高
1.1 毫米波雷达是利用毫米波电磁波波束工作的雷达,车载是首要应用场景 毫米波雷达是一种以波长位于1-10mm、频率在30-300GHz的电磁波作为放射波的雷达传感器。 毫米波雷达利用毫米波波束进行工作。①检测障碍物时: 直接通过有无回波确认ÿ…
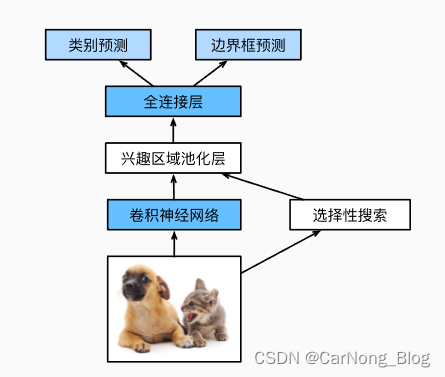
【深度学习-目标检测】02 - Fast R-CNN 论文学习与总结
论文地址:Fast R-CNN
论文学习
1. 摘要(Abstract)
Fast R-CNN方法的提出: 论文提出了一种快速区域卷积网络的办法,基于之前的R-CNN网络进行改进。 效率和准确性的提升: Fast R-CNN 在之前的工作基础上&a…
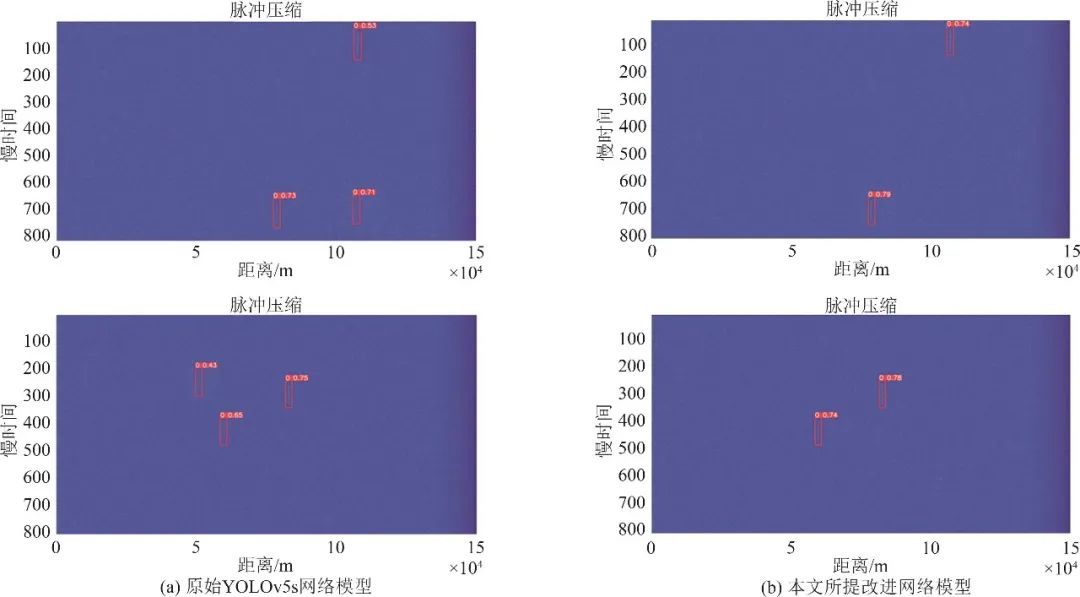
基于深度学习的非合作双基地雷达目标检测方法
源自:信号处理
作者:钟宁, 鲍庆龙, 陈健, 戴华骅
“人工智能技术与咨询” 发布
摘 要
非合作双基地雷达由于接收的目标信号能量不强且回波脉冲间相位同步困难,在目标检测时无法进行相参处理从而带来弱小目标检测困难的问题。为解决这一问…
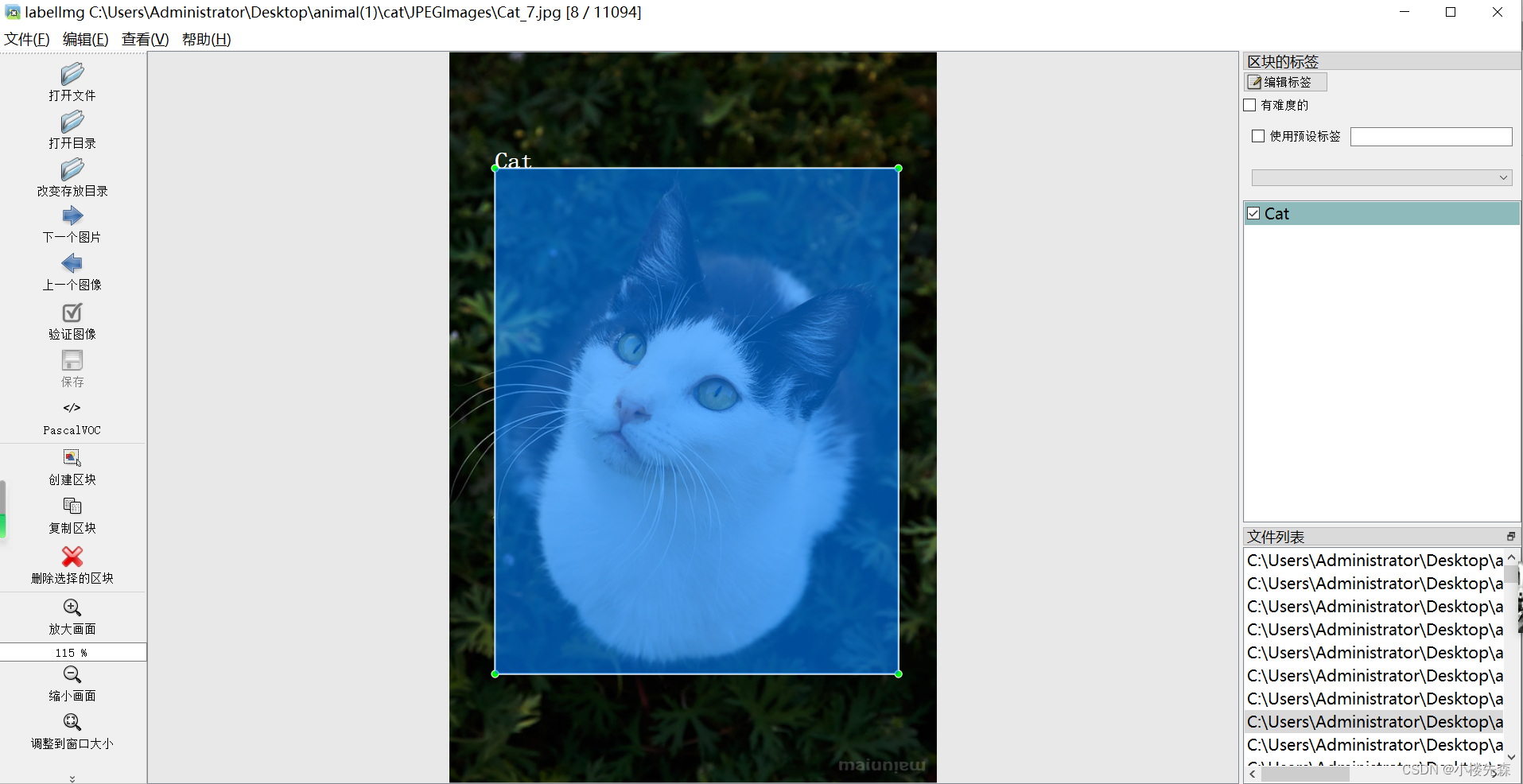
猫目标检测数据集VOC+YOLO格式11000张
猫是一种非常受欢迎的宠物,它们有着柔软的毛发、敏捷的身体和灵活的尾巴。猫是一种非常独立的动物,也是一种非常聪明和好奇的动物。
猫是一种肉食性动物,主要以小型哺乳动物、鸟类和昆虫为食。它们通常在夜间活动,利用敏锐的听觉…
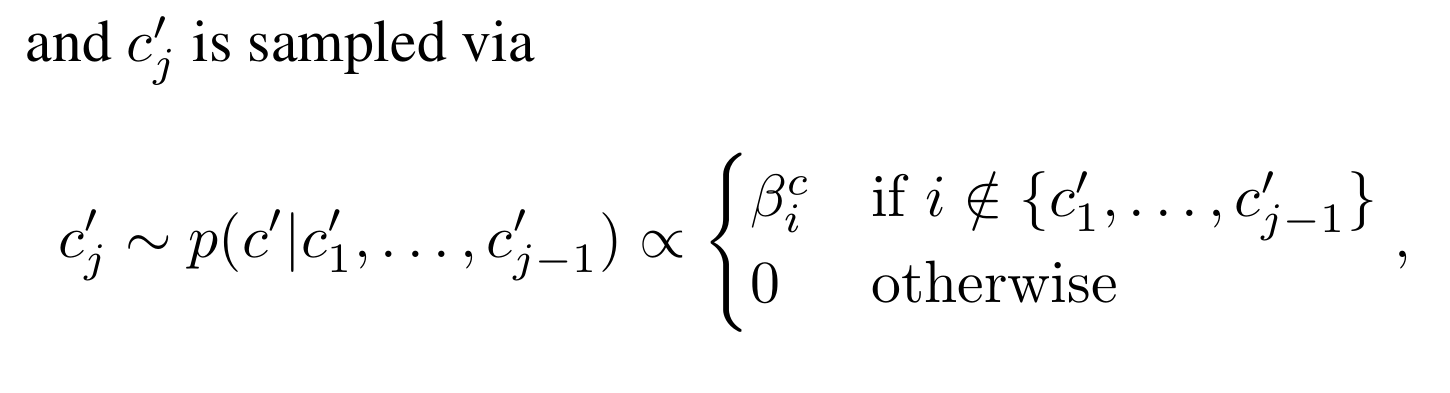
Efficient Classification of Very Large Images with Tiny Objects(CVPR2022补1)
文章目录 Two-stage Hierarchical Attention SamplingOne-stageTwo-Stage内存需求 Efficient Contrastive Learning with Attention Sampling Two-stage Hierarchical Attention Sampling
一阶段缩放是hw,提取的特征是h1w1, 二阶段缩放是uv(…
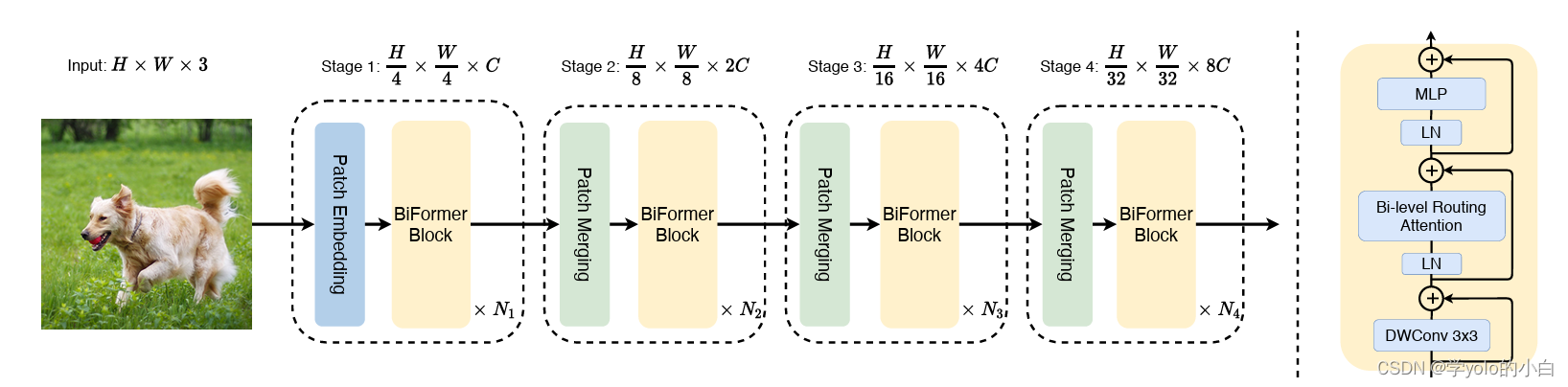
YOLOv8改进 添加动态稀疏注意力机制BiLevelRoutingAttention
一、BiLevelRoutingAttention论文 论文地址:2303.08810.pdf (arxiv.org)
二、 BiLevelRoutingAttention的模型结构
BiLevelRoutingAttention是一种基于注意力机制的双层路由模型。在传统的路由模型中,只有一层路由器来决定数据包的下一跳路径。而BiLevelRoutingAttention在…
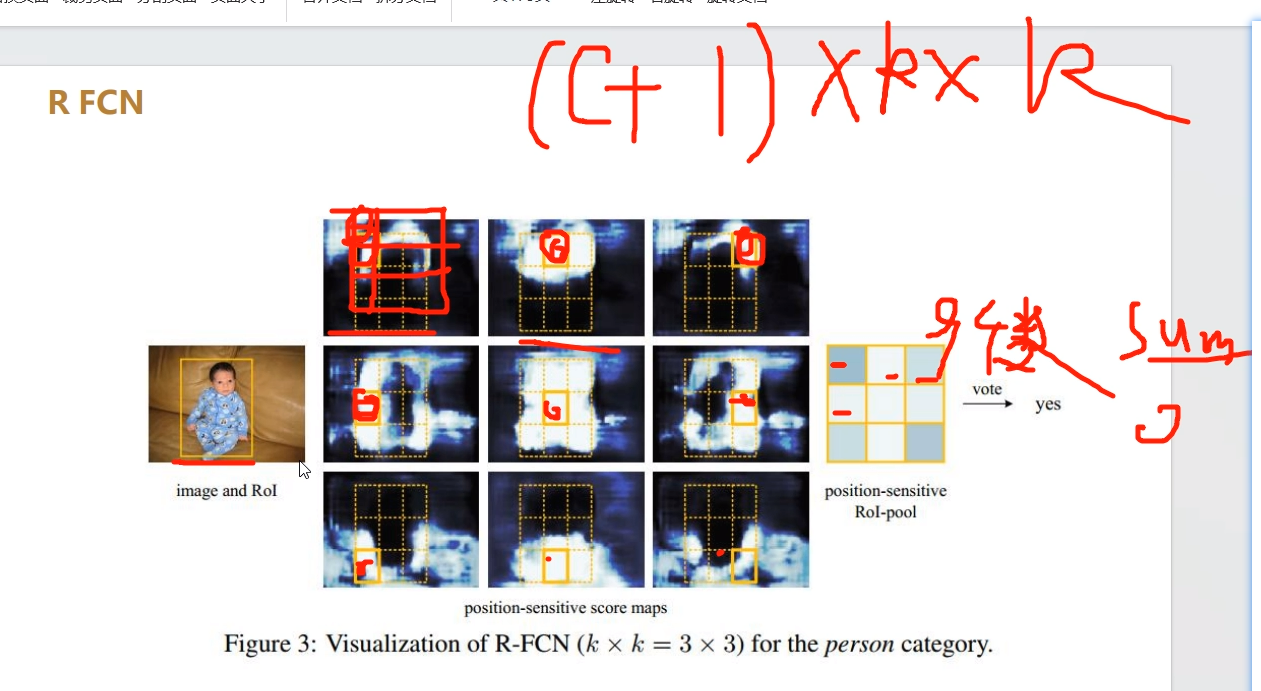

YOLOv5论文作图教程(1)— 软件介绍及下载安装(包括软件包+下载安装详细步骤)
前言:Hello大家好,我是小哥谈。在学习YOLOv5算法的过程中,很多同学都有发表论文的需求。作为文章内容的支撑,图表是最直接的整合数据的工具,能够更清晰地反映出研究对象的结果、流程或趋势。在发表论文的时候,审稿人除了关注论文的内容和排版外,也会审核图表是否清晰美观…

【目标跟踪】多目标跟踪测距
文章目录 前言python代码(带注释)main.pysort.pykalman.pydistance.py 结语 前言 先放效果图。目标框内左上角,显示的是目标距离相机的纵向距离。目标横向距离、速度已求出,没在图片展示。这里不仅仅实现对目标检测框的跟踪&#…

yolov8 opencv模型部署(C++版)
yolov8 opencv模型部署(C 版)
使用opencv推理yolov8模型,仅依赖opencv,无需其他库,以yolov8s为例子,注意:
使用opencv4.8.0 !使用opencv4.8.0 !使用opencv4.8.0 &#…

Python OpenCV剪裁图片并修改对应的Labelme标注文件
Python OpenCV剪裁图片并修改对应的Labelme标注文件 前言前提条件相关介绍实验环境剪裁图片并修改对应的Labelme标注文件代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-P…

YOLOv5改进实战 | 更换主干网络Backbone(三)之轻量化模型Shufflenetv2
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…
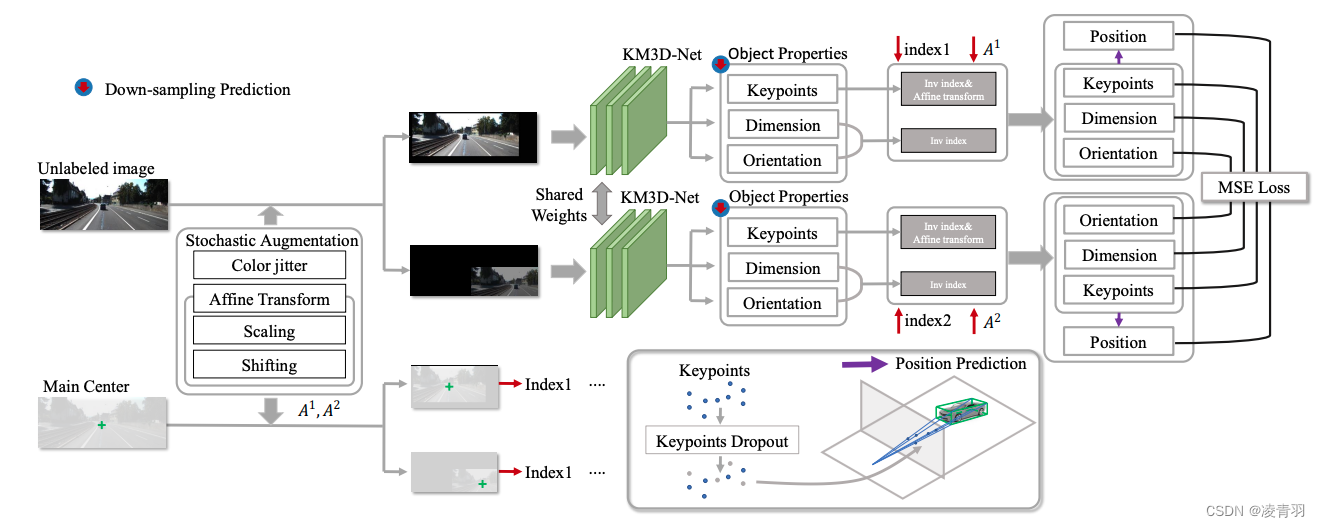
单目3D目标检测论文汇总
基于语义和几何约束的方法
1. Deep3DBox 3D Bounding Box Estimation Using Deep Learning and Geometry [CVPR2017] https://arxiv.org/pdf/1612.00496.pdfhttps://zhuanlan.zhihu.com/p/414275118 核心思想:通过利用2D bounding box与3D bounding box之间的几何约…
YOLOv8改进实战 | 更换主干网络Backbone之2023最新模型LSKNet,旋转目标检测SOTA
前言
传统的YOLOv8系列中,Backbone采用的是较为复杂的C2f网络结构,这使得模型计算量大幅度的增加,检测速度较慢,应用受限,在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型时难以被应用的。为了解决这个问题,本章节通过采用LSKNet轻量化主干网络作为Backb…
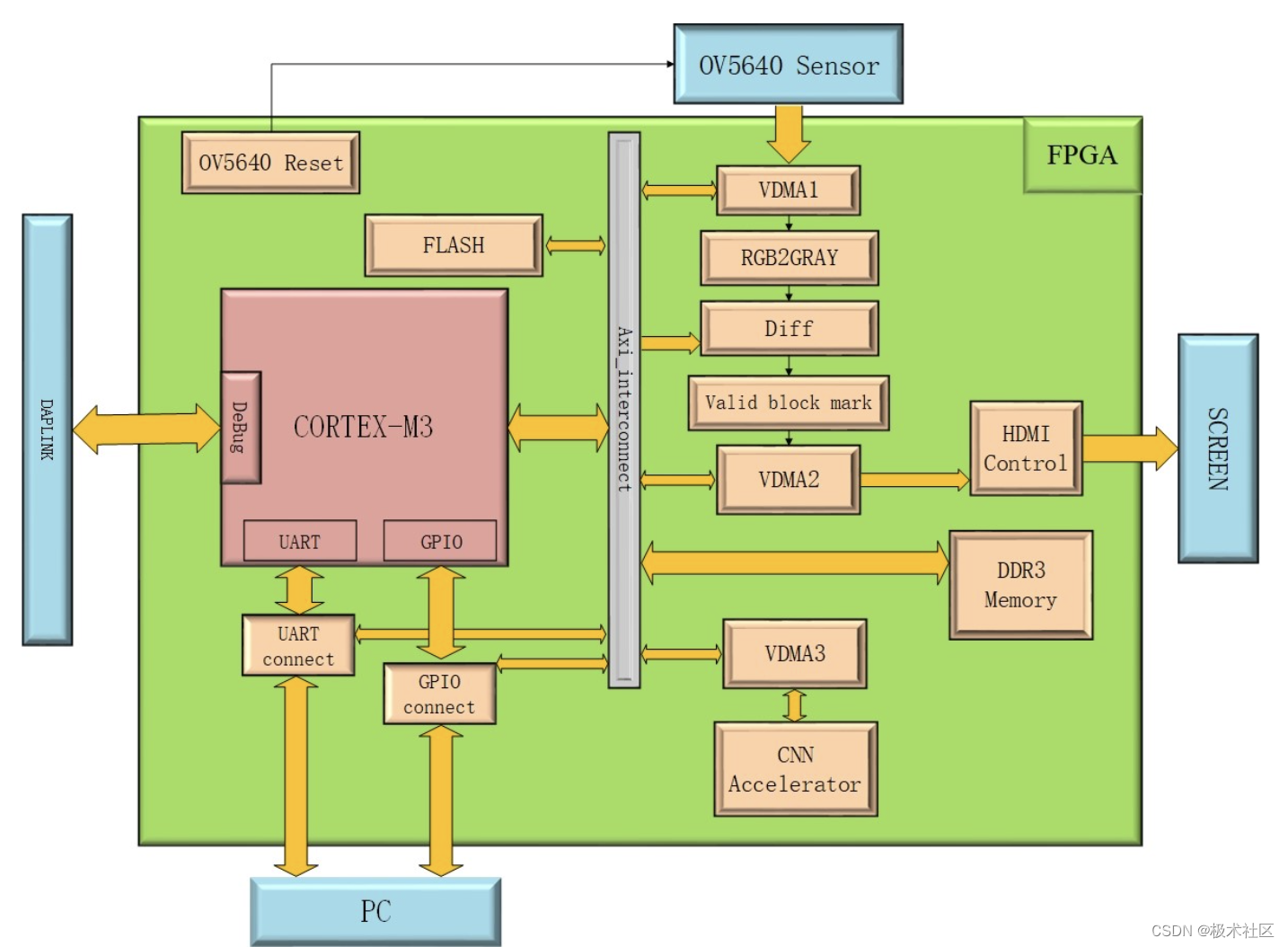
【2021集创赛】Digilent杯二等奖:基于FPGA的动态视觉感知融合的运动目标检测系统
杯赛题目:Diligent杯:基于FPGA开源软核的硬件加速智能平台 参赛组别:A组 设计任务: 利用业界主流软核处理器(仅限于Cortex-M系列及 RISC-V系列)在限定的DIGILENT官方FPGA平台上构建SoC片上系统,在 SoC中添加面向智能应…
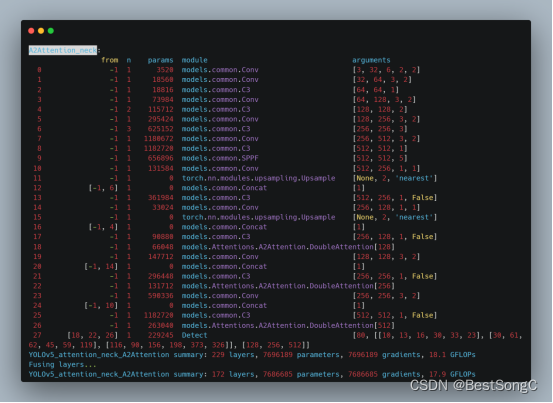
A2Attention模型介绍
A2Attention的核心思想是首先将整个空间的关键特征收集到一个紧凑的集合中,然后自适应地将其分布到每个位置,这样后续的卷积层即使没有很大的接收域也可以感知整个空间的特征。第一级的注意力集中操作有选择地从整个空间中收集关键特征,而第二…
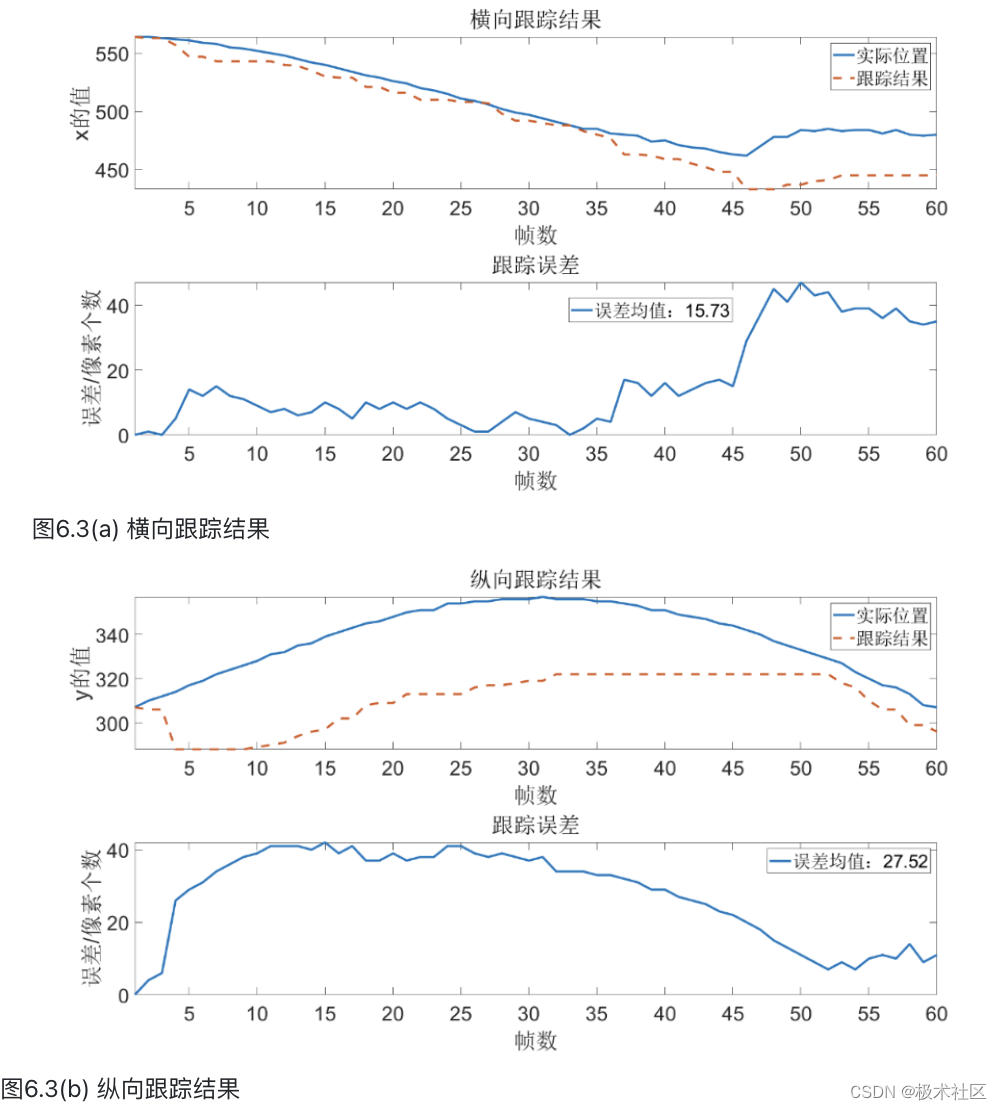
【2021集创赛】Arm杯一等奖作品—基于 Cortex-M3 内核 SOC 的动目标检测与跟踪系统
本作品介绍参与极术社区的有奖征集|秀出你的集创赛作品风采,免费电子产品等你拿~ 团队介绍
参赛单位:北京理工大学 队伍名称:飞虎队 指导老师:李彬 参赛杯赛:Arm杯 参赛人员:余裕鑫 胡涵谦 刘鹏昀 获奖情况࿱…
YOLOv7独家原创改进:最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度
💡该教程为属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 💡本篇文章为YOLOv7独家原创改进:独家首发最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度。
💡对自己数据集改进有效…

YOLO目标检测——谢韦尔钢材缺陷检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:钢材质量控制、钢材缺陷检测数据集说明:谢韦尔钢材缺陷检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(jso…
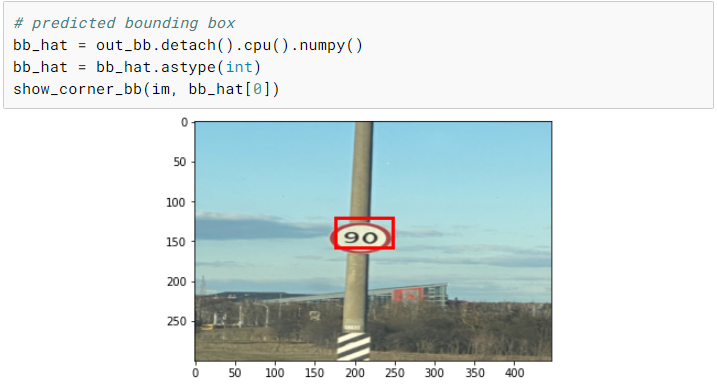
基于Pytorch的从零开始的目标检测
引言
目标检测是计算机视觉中一个非常流行的任务,在这个任务中,给定一个图像,你预测图像中物体的包围盒(通常是矩形的) ,并且识别物体的类型。在这个图像中可能有多个对象,而且现在有各种先进的技术和框架来解决这个问…
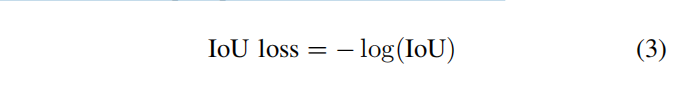
综述:目标检测二十年(机翻版)(未完
原文地址 20年来的目标检测:一项调查 摘要关键词一 介绍二 目标检测二十年A.一个目标检测的路线图1)里程碑:传统探测器Viola Jones探测器HOG检测器基于可变形零件的模型(DPM) 2)里程碑:基于CNN的两阶段探测器RCNNSPPN…

YOLOv5项目实战(1)— 如何去训练模型
前言:Hello大家好,我是小哥谈。YOLOv5基础知识入门系列、YOLOv5源码中的参数超详细解析系列、YOLOv5入门实践系列、YOLOv5论文作图教程系列和YOLOv5算法改进系列学习完成之后,接着就进入YOLOv5项目实战系列了。🎉为了让大家能够牢固地掌握YOLOv5算法,本系列文章就通过一个…
论文速读《DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection》
概括主要内容 文章《DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection》提出了两种创新技术,以改善多模态3D检测模型的性能,通过更有效地融合相机和激光雷达传感器数据来提高对象检测的准确性,尤其是在行人检测方面…
关于主播美颜自拍杆LED补光灯出口认证怎么做?CE认证标准解析
补光灯作为一种灯源设备,在现代社会的很多场合下都会使用到。而根据使用场合的不同,补光灯的构造和名字都是大不相同的。对于一些拍照场景的不光设备而言,其灯光大多是比较柔和,以及调节精度非常高的。而在一些需要进行道路照明的…
YOLOv7独家最新改进《新颖高效AsDDet检测头》独一无二的改进,公开数据集mAP高效涨点,即插即用|检测头新颖改进,性能高效涨点
💡本篇内容:YOLOv7独家最新改进《新颖高效AsDDet检测头》公开数据集mAP高效涨点,即插即用|检测头新颖改进,性能高效涨点
💡🚀🚀🚀本博客 YOLO系列 + 全新新颖原创高效AsDDet检测头
改进创新点改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可
�…

【论文笔记】DiffBEV: Conditional Diffusion Model for Bird’s Eye View Perception
原文链接:https://arxiv.org/abs/2303.08333
1. 引言 通常,相机参数和激光雷达扫描的噪声会使BEV特征带有有害的噪声。扩散模型有去噪能力,能将有噪声样本还原为理想数据。本文提出DiffBEV,使用条件扩散概率模型(DPM&…

目标检测应用场景—数据集【NO.16】交通标志检测
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…

第二十二章 LaneAF框架结构以及接入MMDetection3D模型(车道线感知)
一 前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 二 LaneAF接入openlane数据集 2.1 Lan…

YOLOv7优化:渐近特征金字塔网络(AFPN)| 助力小目标检测
💡💡💡本文改进:渐近特征金字塔网络(AFPN),解决多尺度削弱了非相邻 Level 的融合效果。
AFPN | 亲测在多个数据集能够实现涨点,尤其在小目标数据集。 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现
🚀🚀🚀…
R-FCN: Object Detection via Region-based Fully Convolutional Networks(2016.6)
文章目录 AbstractIntroduction当前最先进目标检测存在的问题针对上述问题,我们提出... Our approachOverviewBackbone architecturePosition-sensitive score maps & Position-sensitive RoI pooling Related WorkExperimentsConclusion 原文链接 源代码 Abstr…

YOLO目标检测——夜间车辆检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:智能交通监控系统、自动驾驶系统、夜间行车安全辅助系统等数据集说明:夜间车辆检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高࿰…
YOLOv8独家首发改进:黑夜小目标检测,ICANN会议出品,原创LEF模块,增强图像增强组成
💡本篇内容:YOLOv8独家首发改进:ICANN会议出品,黑夜小目标检测,原创LEF模块,增强图像增强组成
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv8专属
黑夜小目标检测论文理论部分…

YOLOv7改进策略:一种新颖的可扩张残差(DWR)注意力模块,增强多尺度感受野特征,助力小目标检测
💡💡💡本文全网首发独家改进:一种新颖的可扩张残差(DWR)注意力模块,加强不同尺度特征提取能力,创新十足,独家首发适合科研
推荐指数:五星
DWR | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。
💡💡💡Yolov5/Yolov7魔术师,独…

基于YOLOv8与DeepSORT实现多目标跟踪——算法与源码解析
一、概述
"目标跟踪 (Object Tracking)"是机器视觉领域中的一个重要研究领域。根据跟踪的目标数量,可以将其分为两大类:单目标跟踪 (Single Object Tracking,简称 SOT) 和多目标跟踪 (Multi Object Tracking,简称 MOT)…
目标检测应用场景—数据集【NO.17】道路交通检测数据集
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…
目标检测回归损失函数(看情况补...)
文章目录 L1 loss-平均绝对误差(Mean Absolute Error——MAE)L2 loss-均方误差(Mean Square Error——MSE)Smooth L1 LossMAE、MSE、Smooth L1对比IoU LossGIoU LossDIoU Loss、CIoU LossE-IoU Loss、Focal E-IoU LossReferenceL1 loss-平均绝对误差(Mean Absolute Error——…
使用 TensorFlow FasterRCNN 网络进行目标检测
目录
描述
此示例的工作原理
处理输入图形
数据准备
sampleUffFasterRCNN 插件
验证输出
TensorRT API 层和操作
TensorRT API 层和操作
先决条件
运行示例
示例 --help 选项
附加资源
许可
变更记录
已知问题 本示例,sampleUffFasterRCNN࿰…
YOLOv5改进核心结构:借鉴YOLO-MS论文SOTA核心结构,改进升级版,原始结构超越YOLOv8与RTMDet,即插即用打破性能瓶颈
💡本篇内容:YOLOv5核心结构改进:借鉴YOLO-MS论文SOTA核心结构,改进升级版,原始结构超越YOLOv8与RTMDet,即插即用打破性能瓶颈
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新
论文地址:…

YOLO目标检测——海洋目标检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:海洋监管、海洋资源开发、海洋科学研究数据集说明:海洋目标检测数据集,真实场景的高质量图片数据,数据场景丰富,含有“金属”、“未知”、“橡胶”、“平台”、“塑料”、“木材”、“布”、“纸张”、“…
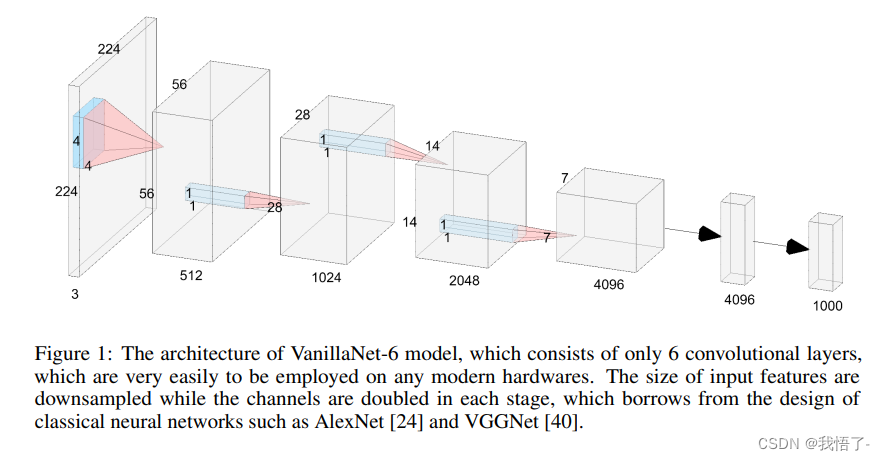
目标检测算法改进系列之Backbone替换为VanillaNet
VanillaNet简介
简介:VanillaNet是一种在设计中融入优雅的神经网络架构,通过避免高深度,shortcut和自注意力等复杂操作,VanillaNet简单而强大。每一层都经过精心制作,紧凑而直接,在训练后对非线性激活函数…
OpenCV-Python小应用(九):通过灰度直方图检测图像异常点
OpenCV-Python小应用(九):通过灰度直方图检测图像异常点 前言前提条件相关介绍实验环境通过灰度直方图检测图像异常点代码实现输出结果 参考 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容ÿ…
RT-DETR算法优化改进:多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM等 | 即插即用系列
💡💡💡本文独家改进: 多维协作注意模块MCA,暴力涨点,效果秒杀ECA、SRM、CBAM,创新性十足,可直接作为创新点使用。 1)代替RepC3进行使用; 2)MCAAttention直接作为注意力进行使用;
推荐指数:五星
RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/…
大模型时代目标检测任务会走向何方?
参考:
大模型时代目标检测任务会走向何方? 细数从常见的目标检测到现在 MLLM 盛行的时代,和 Object Detection 的任务以及近期涌现的新任务。>>加入极市CV技术交流群,走在计算机视觉的最前沿
你或许很好奇,现在…
Incremental Object Detection via Meta-Learning【论文解析】
Incremental Object Detection via Meta-Learning 摘要1 介绍2 相关工作3 方法3.1 问题描述3.2元学习梯度预处理3.3增量式目标检测器摘要
摘要:在真实世界的情境中,目标检测器可能会不断遇到来自新类别的物体实例。当现有的目标检测器应用于这种情景时,它们对旧类别的性能会…

YOLOv8改进 | 2023 | LSKAttention大核注意力机制助力极限涨点
论文地址:官方论文地址
代码地址:官方代码地址 一、本文介绍
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv8,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,…
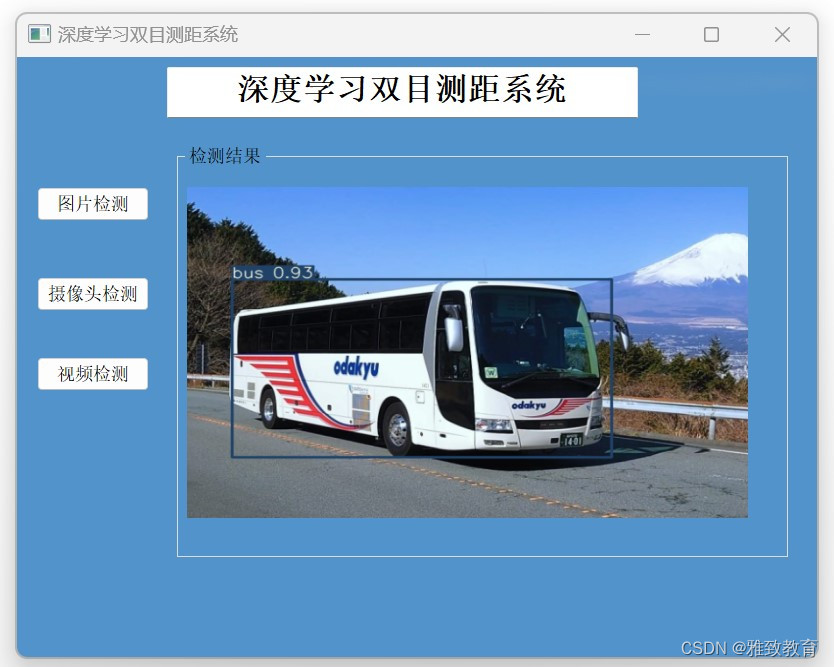
深度学习之基于YoloV5的目标检测和双目测距系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 双目测距系统利用两个相机的图像来计算目标到相机的距离。通过对左右相机图像进行立体匹配,可以获得目标…
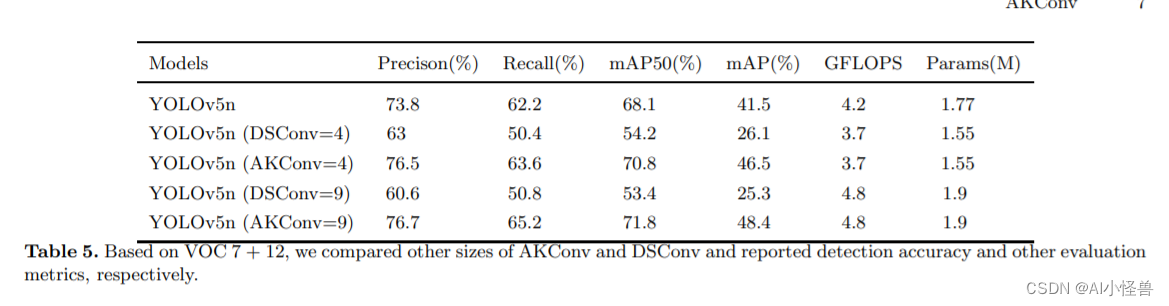
YOLOv7独家原创改进: AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv | 2023年11月最新发表
💡💡💡本文全网首发独家改进:可改变核卷积(AKConv),赋予卷积核任意数量的参数和任意采样形状,为网络开销和性能之间的权衡提供更丰富的选择,解决具有固定样本形状和正方形的卷积核不能很好地适应不断变化的目标的问题点,效果秒殺DSConv 1)AKConv替代标准卷积进行…

详细介绍如何使用深度学习自动车牌(ALPR)识别-含(数据集+源码下载)
深度学习一直是现代世界发展最快的技术之一。深度学习已经成为我们日常生活的一部分,从语音助手到自动驾驶汽车,它无处不在。其中一种应用程序是自动车牌识别 (ALPR)。顾名思义,ALPR是一项利用人工智能和深度学习的力量自动检测和识别车辆车牌字符的技术。这篇博文将重点讨论…

YOLO目标检测——卫星遥感舰船检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:卫星遥感舰船检测数据集说明:卫星遥感舰船检测数据集,真实场景的高质量图片数据,数据场景丰富,含船一个类别标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xm…

YOLO目标检测——垃圾检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:智能化垃圾分类系统、垃圾回收和处理领域的优化管理等方面数据集说明:垃圾分类检测数据集,真实场景的高质量图片数据,数据场景丰富,含报纸、蛋壳、矿泉水瓶、电池、拉链顶罐、塑料餐盒、纸质药盒、香蕉皮…

YOLOv8训练自己的目标检测数据集
YOLOv8训练自己的目标检测数据集 目录标题 源码下载环境配置安装包训练自己的数据集数据集文件格式数据集文件配置超参数文件配置训练数据集命令行训练脚本.py文件训练 进行detect显示detect的效果 源码下载
YOLOv8官方的GitHub代码,同时上面也有基础环境的配置要…
MMdetection3.0 问题
MMdetection3.0 问题
希望各位路过的大佬指教一下:
问题: 1、NWPU-VHR-10有标注的数据一共650张,我将其分为了455张训练集,195张验证集。
2、然后使用MMdetection3.0框架中的Faster-rcnn网络进行训练,设置训练参数b…

论文解读--PointPillars- Fast Encoders for Object Detection from Point Clouds
PointPillars--点云目标检测的快速编码器
摘要 点云中的物体检测是许多机器人应用(如自动驾驶)的重要方面。在本文中,我们考虑将点云编码为适合下游检测流程的格式的问题。最近的文献提出了两种编码器;固定编码器往往很快,但牺牲了准确性,而…
YOLOV8损失函数改进:SlideLoss,解决简单样本和困难样本之间的不平衡问题
💡💡💡本文改进:SlideLoss,解决简单样本和困难样本之间的不平衡问题,并使用有效感受野的信息来设计Anchor。
SlideLoss| 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升也能够助力涨点。
🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK
💡�…


蟹目标检测数据集VOC格式400张
蟹,一种独特的海洋生物,以其强壮的身体和独特的生活习性而闻名。 蟹的身体宽厚,有一对锐利的大钳子,这使得它们在寻找食物和保护自己时非常有力。蟹的外观颜色多样,有绿色、蓝色、棕色和红色等,这使得它们在…
蟹目标检测数据集VOC格式400张
蟹,一种独特的海洋生物,以其强壮的身体和独特的生活习性而闻名。 蟹的身体宽厚,有一对锐利的大钳子,这使得它们在寻找食物和保护自己时非常有力。蟹的外观颜色多样,有绿色、蓝色、棕色和红色等,这使得它们在…
呼叫系统的客服的计费模式有哪些?
大家都已经了解呼叫总的区分为两种呼入和呼出。呼入就是建立客服呼叫中心,呼出就是电销回访外呼中心。那么相应的计费模式也是有不同的。下面看看以下几种收费模式 : 一、按月收费模式 也叫固定客服模式,是根据上月结算的费用,企业…
VOC和COCO数据集讲解
相对其他计算机视觉任务,目标检测算法的数据格式更为复杂。为了对数据进行统一的处理,目标检测数据一般都会做成VOC或者COCO的格式。 VOC和COCO都是既支持检测也支持分割的数据格式,本文主要分析PASCAL VOC和COCO数据集中物体识别相关的内…

MQ-Det: Multi-modal Queried Object Detection in the Wild
首个支持视觉和文本查询的开放集目标检测方法 NeurIPS2023 文章:https://arxiv.org/abs/2305.18980 代码:https://github.com/YifanXu74/MQ-Det
主框图 摘要
这篇文章提出了MQ-Det,一种高效的架构和预训练策略,它利用文本描述的…
芒果RT-DETR改进实验:深度集成版目标检测 RT-DETR 热力图来了!支持自定义数据集训练出来的模型
💡该教程为改进RT-DETR指南,属于《芒果书》📚系列,包含大量的原创改进方式🚀 💡🚀🚀🚀内含改进源代码 按步骤操作运行改进后的代码即可💡更方便的统计更多实验数据,方便写作
芒果RT-DETR改进实验:深度集成版目标检测 RT-DETR 热力图来了!支持自定义数据集…

YOLOV3 SPP 目标检测项目(针对xml或者yolo标注的自定义数据集)
1. 目标检测的两种标注形式
项目下载地址:YOLOV3 SPP网络对自定义数据集的目标检测(标注方式包括xml或者yolo格式)
目标检测边界框的表现形式有两种: YOLO(txt) : 第一个为类别,后面四个为边界框,x,y中心点坐标以及h,w的相对值 xml文件:类似于网页的标注文件,里面会…
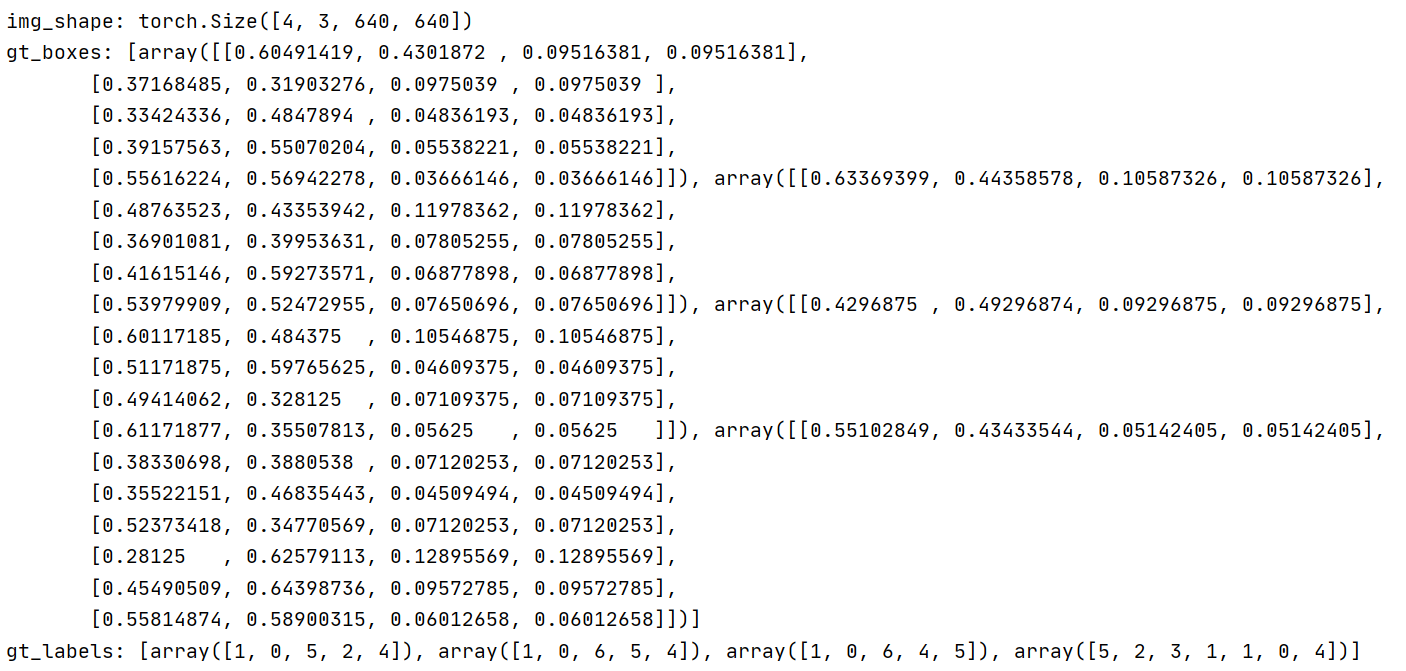
【目标检测从零开始】torch实现yolov3数据加载
文章目录 数据简介Dataset读取Step1:类别定义Step2:解析xmlStep3:实现DatasetStep4:数据增强Step5:添加dataset_collateStep6:测试 小结 数据简介 林业病虫害防治项目用到的AI识虫数据集,该数据…
图像特征Vol.1:计算机视觉特征度量|第一弹:【纹理区域特征】
目录 一、前言二、纹理区域度量2.1:边缘特征度量2.2:互相关和自相关特征2.3:频谱方法—傅里叶谱2.4:灰度共生矩阵(GLCM)2.5:Laws纹理特征2.6:局部二值模式(LBP) 一、前言
…
YOLOV8的tensorrt部署详解(目标检测模型-CUDA)
提示:基于cuda的yolov8的tensorrt部署方法(纯cuda编程处理),文中附有源码链接!!! 文章目录 前言一、基于cuda的yolov8部署工程代码图解1、基于cuda的yolov8部署代码图解工程文件介绍头文件介绍源文件介绍2、模型初始化图示3、cuda编写前/后处理代码图示4、基于cuda的yolov…

【Image】图像处理
计算机视觉 CV
Perception
如自动驾驶领域。
只要是从所谓的图像当中去抽取信息的过程,我们都叫做Perception。
视觉检测可以涵盖二维检测,如车辆、人和信号灯的检测。另外,还可以控制三维信息,直接在三维空间中操作数据。 SL…
Smooth L1 loss |IoU|DIoU|CIoU|EIoU|aIoU|SIoU|wise-IoU的通俗讲解
文章目录 1. L1 Loss、L2 Loss 、Smooth L1 Loss1.1 L1 Loss和 L2 Loss1.2 Smooth L1 Loss1.3 Smooth L1 Loss 在目标检测中存在的缺陷2 IoU loss2.1 IoU原理2.2 IoU 的缺点2.3 代码3.GIoU Loss3.1 GIoU 原理3.2 GIoU loss 的缺点3.3 代码4.DIoU Loss4.1 DIoU的原理4.2 代码5.C…

【轻量化篇】YOLOv8改进实战 | 更换主干网络 Backbone 之 RepGhostnet,重参数化实现硬件高效的Ghost模块
YOLOv8专栏导航:点击此处跳转 前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操…

YOLO-NAS:面向目标检测的下一代模型
YOLO-NAS(You Only Look Once Neural Architecture Search)通过快速准确的实时检测功能彻底改变了目标检测,适用于生产环境。YOLO(You Only Look Once)是一系列计算机视觉模型,自从Joseph Redmon、Santosh …
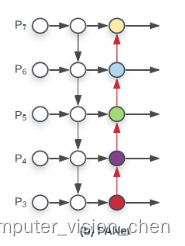
EfficientDet:Scalable and Efficient Object Detection中文版 (BiFPN)
EfficientDet: Scalable and Efficient Object Detection
EfficientDet:可扩展和高效的目标检测
摘要
模型效率在计算机视觉中变得越来越重要。本文系统地研究了用于目标检测的神经网络架构设计选择,并提出了几个关键的优化方法来提高效率。首先&…
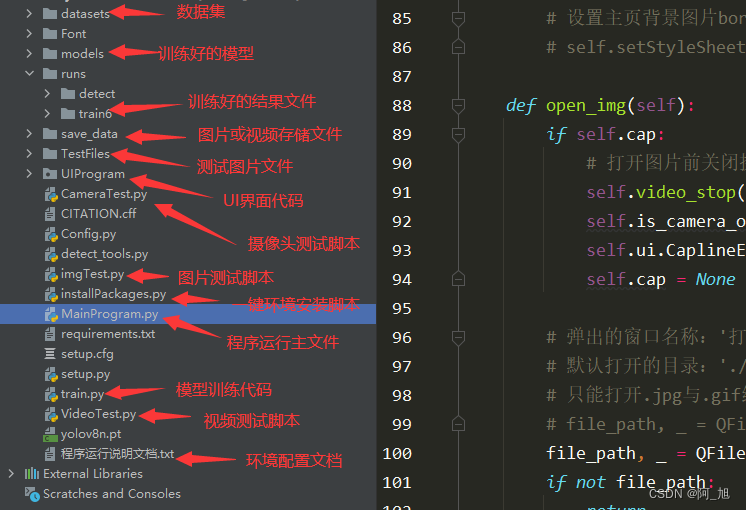
基于YOLOv8深度学习的智能玉米害虫检测识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
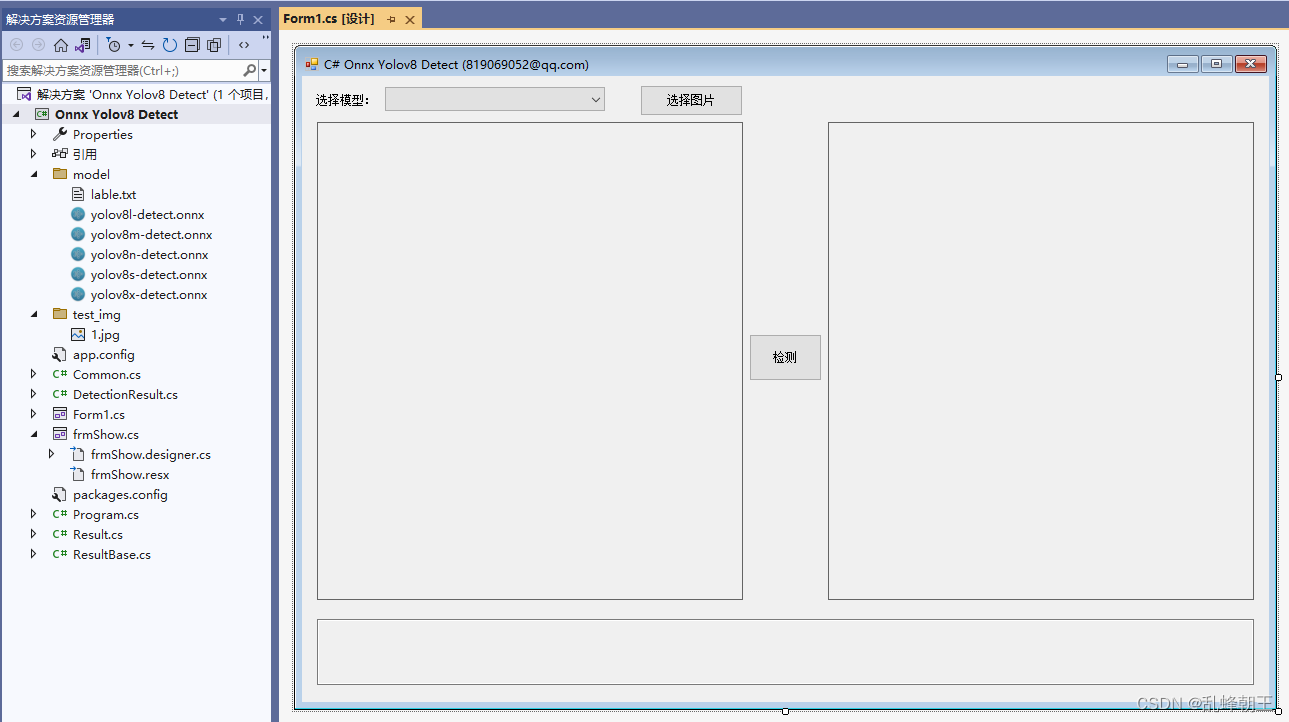
C# Onnx Yolov8 Detect yolov8n、yolov8s、yolov8m、yolov8l、yolov8x 对比
目录
效果
yolov8n
yolov8s
yolov8m
yolov8l
yolov8x
模型信息
项目
代码
下载 C# Onnx Yolov8 Detect yolov8n、yolov8s、yolov8m、yolov8l、yolov8x 对比
效果
yolov8n yolov8s yolov8m yolov8l yolov8x 模型信息
Model Properties ------------------------- d…

labelme目标检测数据类型转换
1. labelme数据类型
LabelMe是一个开源的在线图像标注工具,旨在帮助用户创建和标记图像数据集。它提供了一个用户友好的界面,让用户可以直观地在图像上绘制标记框、多边形、线条等,以标识和注释图像中的对象或区域。 GitHub:http…

经典目标检测YOLO系列(一)YOLOV1的复现(1)总体架构
经典目标检测YOLO系列(一)实现YOLOV1网络(1)总体架构
实现原版的YOLOv1并没有多大的意义,因此,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv1的大部分核心理念的前提下,重构一款较新的YOLOv1检测器,来…
YOLOv5改进 | 2023主干篇 | 华为最新VanillaNet主干替换Backbone实现大幅度长点
一、本文介绍
本文给大家来的改进机制是华为最新VanillaNet网络,其是今年最新推出的主干网络,VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作(需要注意的是…

第二十二章 解读pycocotools的API,目标检测mAP的计算COCO的评价指标(工具)
Pycocotools介绍
为使用户更好地使用 COCO数据集, COCO 提供了各种 API。COCO是一个大型的图像数据集,用于目标检测、分割、人的关键点检测、素材分割和标题生成。这个包提供了Matlab、Python和luaapi,这些api有助于在COCO中加载、解析和可视化注释。
…
YOLOv8改进 | 主干篇 | EfficientNetV1均衡缩放网络改进特征提取层
一、本文介绍
这次给大家带来的改进机制是EfficientNetV1主干,用其替换我们YOLOv8的特征提取网络,其主要思想是通过均衡地缩放网络的深度、宽度和分辨率,以提高卷积神经网络的性能。这种方法采用了一个简单但有效的复合系数,统一…

YOLOv5算法进阶改进(5)— 主干网络中引入SCConv | 即插即用的空间和通道维度重构卷积
前言:Hello大家好,我是小哥谈。SCConv是一种用于减少特征冗余的卷积神经网络模块。相对于其他流行的SOTA方法,SCConv可以以更低的计算成本获得更高的准确率。它通过在空间和通道维度上进行重构,从而减少了特征图中的冗余信息。这种模块的设计可以提高卷积神经网络的性能。�…
2023下半年的总结
我从八月下旬开始写的,到现在差不多有半年了,总结一下吧!
1.计算机视觉
在计算机视觉方面,想必两个有名的深度学习框架(TensorFlow和PyTorch)大家都很清楚吧,以及OpenCV库。对于人脸识别&…

笔记1:基于锚框(先验框)的目标检测
一、边缘框(bounding box)
1.1 定义
边缘框:真实标注的物体位置
2.1 表示方式
1、(x1,y1)和(x2,y2) 2、(x1,y1)和w,h
二、锚框(anchor box)/先验框(prior bounding box)
2.1 定义
对边缘…
目标检测-One Stage-RetinaNet
文章目录 前言一、RetinaNet的网络结构和流程二、RetinaNet的创新点Balanced Cross EntropyFocal Loss 总结 前言
根据前文目标检测-One Stage-YOLOv2可以看出YOLOv2的速度和精度都有相当程度的提升,但是One Stage目标检测模型仍存在一个很大的问题:
前…
目标检测-One Stage-EfficientDet
文章目录 前言一、EfficientNetEfficientNet-B0 baselineMBConv 参数优化EfficientNet B0-B7 参数 二、EfficientDetBiFPN复合缩放方法 总结 前言
EfficientDet是google在2019年11月发表的一个目标检测算法系列,其提出的背景是:之前很多研究致力于开发更…
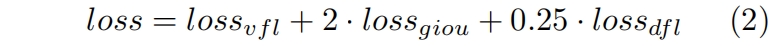
轻量检测模型PP-PicoDet解析
Paper:PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
official implementation:https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.7/configs/picodet
Backbone
作者通过实验发现,ShuffleNetV2在移动…


Distilling the Knowledge in a Neural Network(2015.5)(d补)
文章目录 Abstract1 Introduction2 Distillation2.1 Matching logits is a special case of distillation Results 论文链接 Abstract
提高几乎所有机器学习算法性能的一种非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均[3]。不幸的是…
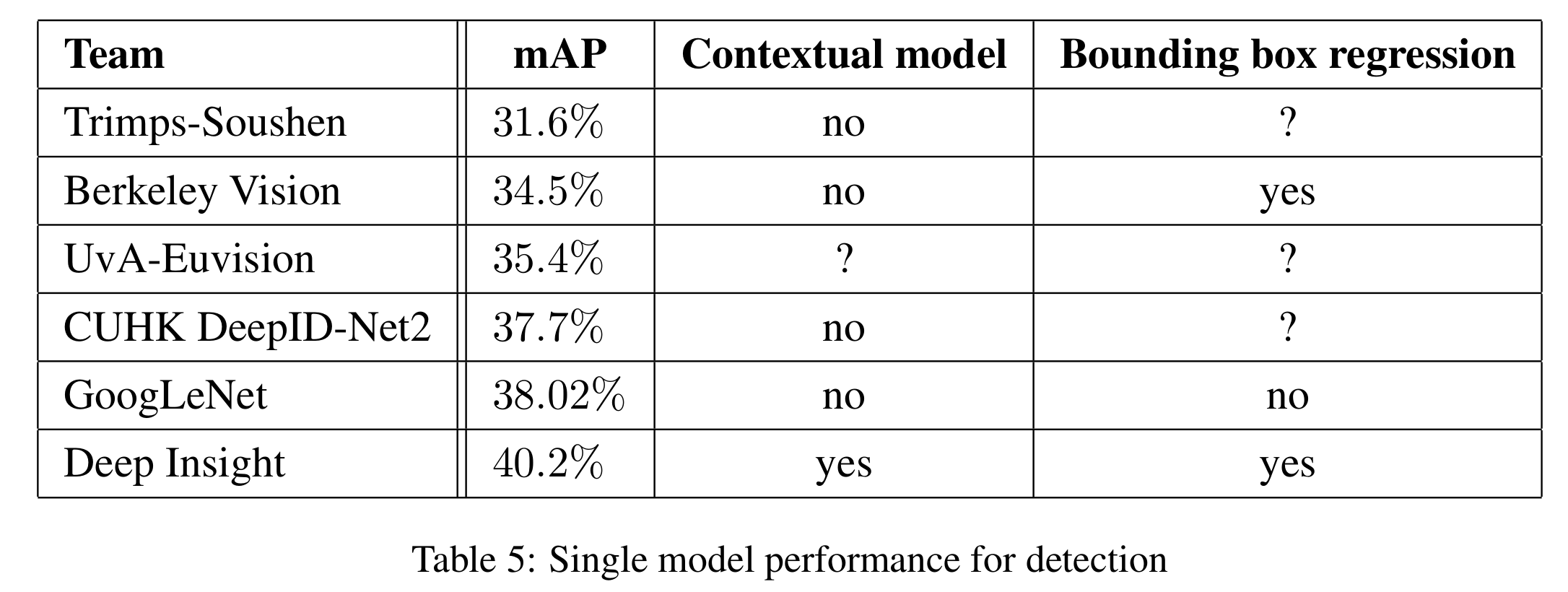
GoogleNet/Inception(2014)
文章目录 Abstract1 Introduction2 Related Work3 Motivation and High Level Considerationsdrawbacksolve 4 Architectural Details4.1 naive versiondimension reductions 5 GoogLeNet6 Training Methodology7 ILSVRC 2014 Classification Challenge Setup and Results8 ILS…
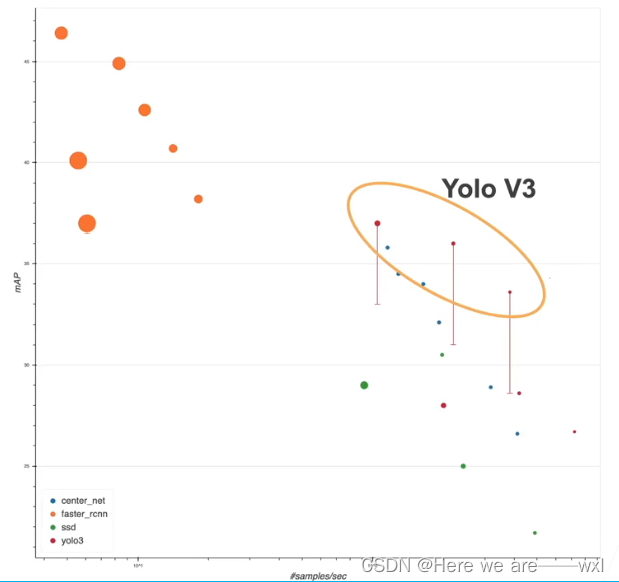
037、目标检测-算法速览
之——常用算法速览
目录
之——常用算法速览
杂谈
正文
1.区域卷积神经网络 - R-CNN
2.单发多框检测SSD,single shot detection
3.yolo 杂谈 快速过一下目标检测的各类算法。 正文
1.区域卷积神经网络 - R-CNN region_based CNN,奠基性的工作。…
[数据集][目标检测]动物目标检测数据集VOC格式+yolo格式超80种类动物
乌鸦数据集VOC格式yolo格式139张1类别 海龟数据集VOC格式yolo格式29张1类别 陆龟数据集VOC格式yolo格式498张1类别 仓鼠数据集VOC格式yolo格式133张1类别 企鹅数据集VOC格式yolo格式438张1类别 兔子数据集VOC格式yolo格式342张1类别 公牛数据集VOC格式yolo格式120张1类别 刺猬数…
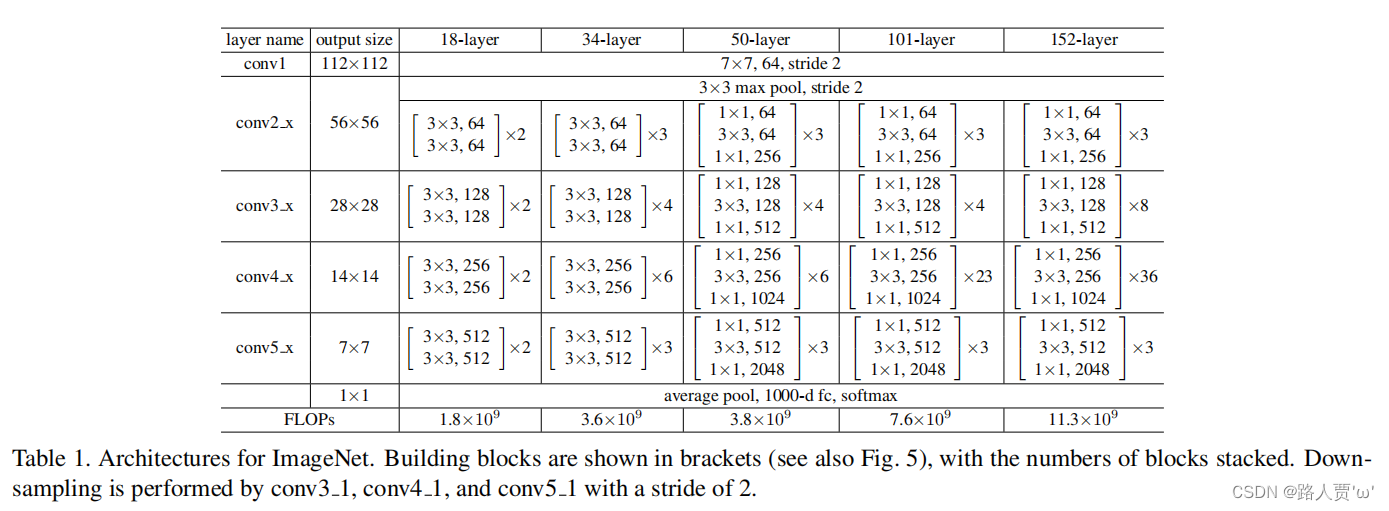
图像分类(五) 全面解读复现ResNet
解读
Abstract—摘要
翻译
更深的神经网络往往更难以训练,我们在此提出一个残差学习的框架,以减轻网络的训练负担,这是个比以往的网络要深的多的网络。我们明确地将层作为输入学习残差函数,而不是学习未知的函数。我们提供了非…
基于YOLOv8深度学习的智能小麦害虫检测识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

将yolo格式转化为voc格式:txt转xml(亲测有效)
1.文件目录如下所示: 对以上目录的解释:
1.dataset下面的image文件夹:里面装的是数据集的原图片 2.dataset下面的label文件夹:里面装的是图片对应得yolo格式标签 3.dataset下面的Annotations文件夹:这是一个空文件夹&…

【yolov8系列】 yolov8 目标检测的模型剪枝
前言 最近在实现yolov8的剪枝,所以有找相关的工作作为参考,用以完成该项工作。 先细读了 Torch-Pruning,个人简单记录了下 【剪枝】torch-pruning的基本使用,有框架完成的对网络所有结构都自适应剪枝是最佳的,但这里没…
智能化物联网(IoT):发展、问题与未来前景
导言 智能化物联网(IoT)作为信息技术领域的一项核心技术,正在深刻改变人们的生活和工作方式。本文将深入研究IoT的发展过程、遇到的问题及解决过程、未来的可用范围,以及在各国的应用和未来的研究趋势。探讨在哪些方面能够取得胜利…
YOLOv8改进 | 2023注意力篇 | HAttention(HAT)超分辨率重建助力小目标检测 (全网首发)
一、本文介绍
本文给大家带来的改进机制是HAttention注意力机制,混合注意力变换器(HAT)的设计理念是通过融合通道注意力和自注意力机制来提升单图像超分辨率重建的性能。通道注意力关注于识别哪些通道更重要,而自注意力则关注于图…

车路协同中 CUDA 鱼眼相机矫正、检测、追踪
在车路协同中,鱼眼一般用来补充杆件下方的盲区,需要实现目标检测、追踪、定位。在目标追踪任务中,通常的球机或者枪机方案,无法避免人群遮挡的问题,从而导致较高的ID Swich,造成追踪不稳定。但是鱼眼相机的顶视角安装方式,天然缓解了遮挡的问题,从而实现杆件下方的盲区…
目标检测实例分割数据集转换:从XML和JSON到YOLOv8(txt)
yolov8导航 如果大家想要了解关于yolov8的其他任务和相关内容可以点击这个链接,我这边整理了许多其他任务的说明博文,后续也会持续更新,包括yolov8模型优化、sam等等的相关内容。
YOLOv8(附带各种任务详细说明链接) 源…
基于YOLOv8深度学习的45种交通标志智能检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
LSTM与注意力机制结合,会有怎样的创新❓
LSTM与注意力机制结合,会有怎样的创新❓ #论文辅导一对一
1️⃣自适应时序注意力机制: 一项创新的思路是设计一种自适应时序注意力机制,使模型能够在序列的不同时间步上动态调整关注度。这可以通过在LSTM的每个时间步引入自适应的注意力权重…
YOLOv8改进 | 检测头篇 | ASFF改进YOLOv8检测头(全网首发)
一、本文介绍
本文给大家带来的改进机制是利用ASFF改进YOLOv8的检测头形成新的检测头Detect_ASFF,其主要创新是引入了一种自适应的空间特征融合方式,有效地过滤掉冲突信息,从而增强了尺度不变性。经过我的实验验证,修改后的检测头…

经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现
经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现
之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,并解决前向推理过程中的两个问题,继续按照此书进行YOLOV1的复现。 经典目标…

关于目标检测中按照比例将数据集随机划分成训练集和测试集
1. 前言
在做目标检测任务的时候,不少网上的数据,没有划分数据集,只是将数据和标签放在不同的文件夹下,没有划分数据集
虽然代码简单,每次重新编写还是颇为麻烦,这里记录一下
如下,有的数据集…
YOLOv5改进 | 损失函数篇 | MPDIoU、InnerMPDIoU助力细节涨点
一、本文介绍
本文为读者详细介绍了YOLOv5模型的最新改进,带来的改进机制是最新的损失函数MPDIoU和融合了最新的Inner思想的InnerMPDIoU。提升检测精度和处理细节方面的作用。通过深入探讨MPDIoU和InnerMPDIoU(全网首发)的工作原理和实际代码实现,本文旨在指导读者如何将这些…
经典目标检测YOLO系列(一)复现YOLOV1(5)模型的训练及验证
经典目标检测YOLO系列(一)复现YOLOV1(5)模型的训练及验证
之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,继续按照此书进行YOLOV1的复现。
1 YOLOV1模型的训练
1.1 Yolov8Trainer类
作者为了代码具有更好…

目标检测-Two Stage-RCNN
文章目录 前言一、R-CNN的网络结构及步骤二、RCNN的创新点候选区域法特征提取-CNN网络 总结 前言
在前文:目标检测之序章-类别、必读论文和算法对比(实时更新)已经提到传统的目标检测算法的基本流程: 图像预处理 > 寻找候选区…
目标检测-One Stage-YOLOv1
文章目录 前言一、YOLOv1的网络结构和流程二、YOLOv1的损失函数三、YOLOv1的创新点总结 前言
前文目标检测-Two Stage-Mask RCNN提到了Two Stage算法的局限性:
速度上并不能满足实时的要求
因此出现了新的One Stage算法簇,YOLOv1是目标检测中One Stag…
YOLOv5改进 | 2023Neck篇 | CCFM轻量级跨尺度特征融合模块(RT-DETR结构改进v5)
一、本文介绍
本文给大家带来的改进机制是轻量级跨尺度特征融合模块CCFM(Cross-Scale Feature Fusion Module)其主要原理是:将不同尺度的特征通过融合操作整合起来,以增强模型对于尺度变化的适应性和对小尺度对象的检测能力。我将…
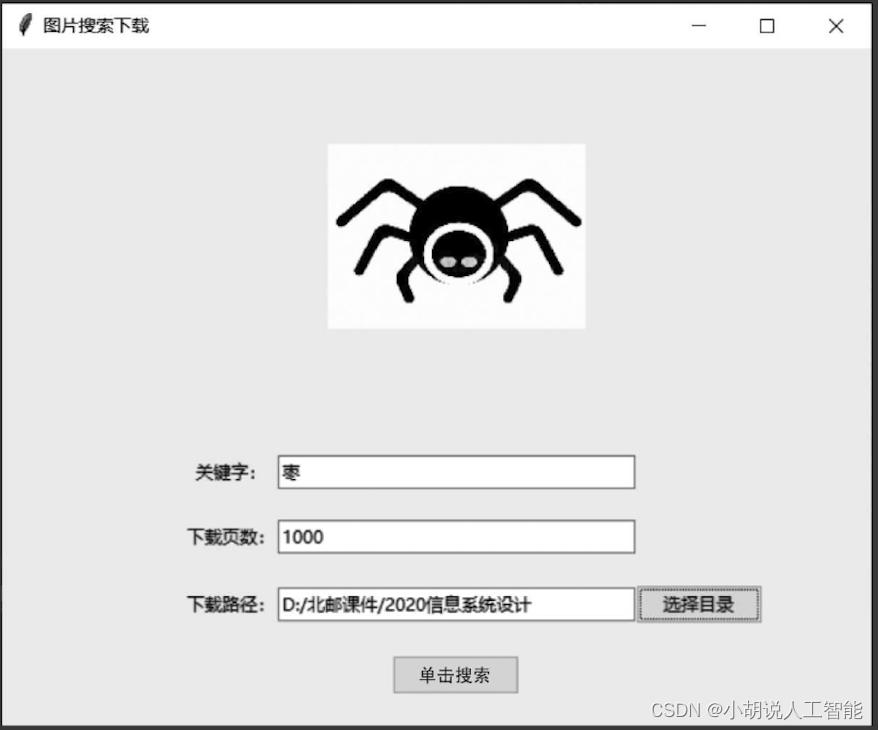
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含python、JS工程源码)+数据集+模型(三)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境Jupyter Notebook环境Pycharm 环境微信开发者工具OneNET云平台 模块实现1. 数据预处理1)爬取功能2)下载功能 2. 创建模型并编译1)定义模型结构2)优化…
YOLOv8进化超参数:《超参数搜索调优解析》训练教程(附训练代码)
💡该教程为改进RT-DETR指南,属于《芒果书》📚系列,包含大量的原创改进方式🚀
💡🚀🚀🚀内含改进源代码 按步骤操作运行改进后的代码即可💡更方便的统计更多实验数据,方便写作
YOLOv8改进实验:《超参数搜索调优解析》训练教程(附代码) 文章目录 新增核心…
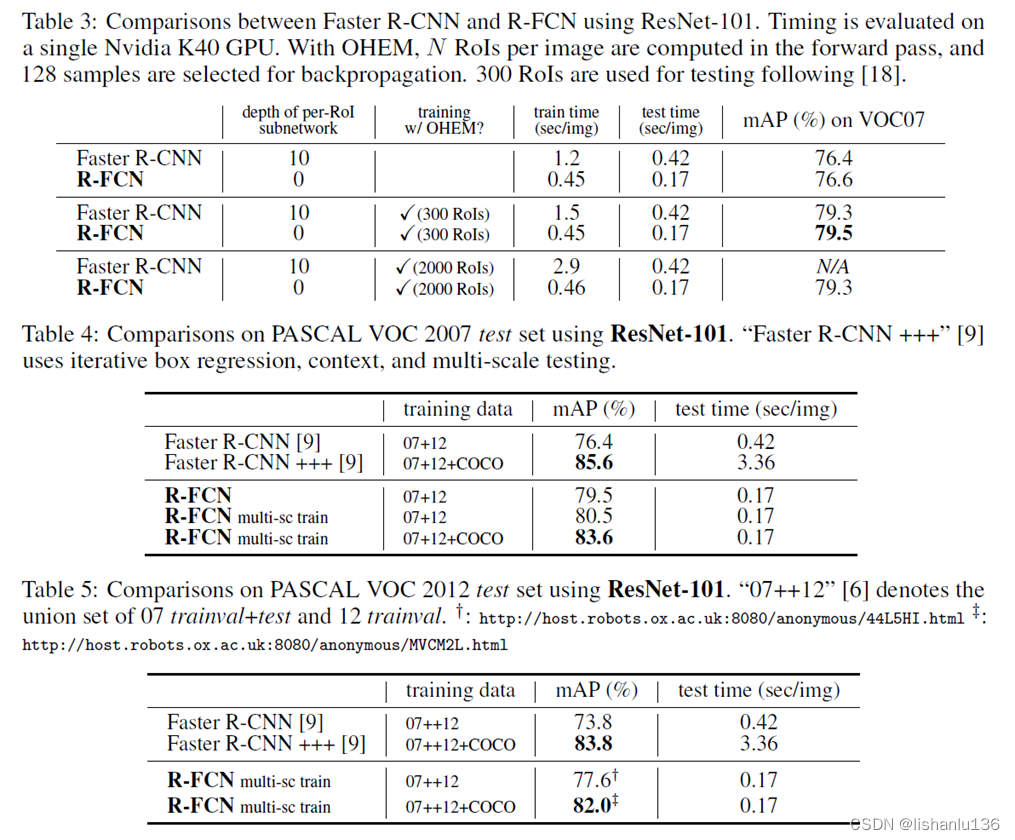
目标检测——R-FCN算法解读
论文:R-FCN: Object Detection via Region-based Fully Convolutional Networks 作者:Jifeng Dai, Yi Li, Kaiming He and Jian Sun 链接:https://arxiv.org/pdf/1605.06409v2.pdf 代码:https://github.com/daijifeng001/r-fcn 文…
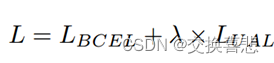
伪装目标检测模型论文阅读之:Zoom in and out
论文链接:https://arxiv.org/abs/2203.02688 代码;https://github.com/lartpang/zoomnet
1.摘要
最近提出的遮挡对象检测(COD)试图分割视觉上与其周围环境融合的对象,这在现实场景中是非常复杂和困难的。除了与它们的背景具有高…
目标检测篇:如何根据xml标注文件生成类别classes的json文件
1. 介绍
之前在做目标检测任务的时候,发现很多的数据集仅有数据(只有图片标注的xml文件),没有关于类别的json文件,为了以后方便使用,这里记录一下 一般来说,yolo标注的数据集,只有第一个是数字类别&#x…

雾天条件下 SLS 融合网络的三维目标检测
论文地址:3D Object Detection with SLS-Fusion Network in Foggy Weather Conditions 论文代码:https://github.com/maiminh1996/SLS-Fusion
论文摘要
摄像头或激光雷达(光检测和测距)等传感器的作用对于自动驾驶汽车的环境意识…
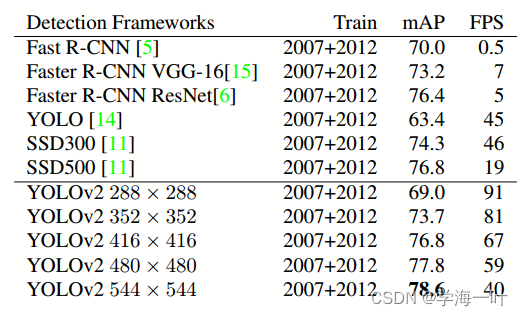
目标检测-One Stage-YOLOv2
文章目录 前言一、YOLOv2的网络结构和流程二、YOLOv2的创新点预处理网络结构训练 总结 前言
根据前文目标检测-One Stage-YOLOv1可以看出YOLOv1的主要缺点是:
和Fast-CNN相比,速度快,但精度下降。(边框回归不加限制)…
如何使用 Python、Node.js 和 Go 创建基于 YOLOv8 的对象检测 Web 服务
1. 介绍
这是有关 YOLOv8 系列文章的第二篇。在上一篇文章中我们介绍了YOLOv8以及如何使用它,然后展示了如何使用 Python 和基于 PyTorch 的官方 YOLOv8 库创建一个 Web 服务来检测图像上的对象。 在本文中,将展示如何在不需要PyTorch和官方API的情况下…
经典目标检测YOLO系列(一)复现YOLOV1(4)VOC2007数据集的读取及预处理
经典目标检测YOLO系列(一)复现YOLOV1(4)VOC2007数据集的读取及预处理
之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,并解决前向推理过程中的两个问题,继续按照此书进行YOLOV1的复现。 经典目标检…
C# OpenCvSharp DNN FreeYOLO 密集行人检测
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN FreeYOLO 密集行人检测
效果 模型信息
Inputs ------------------------- name:input tensor:Float[1, 3, 192, 320] ---------------------------------------------------------------
…
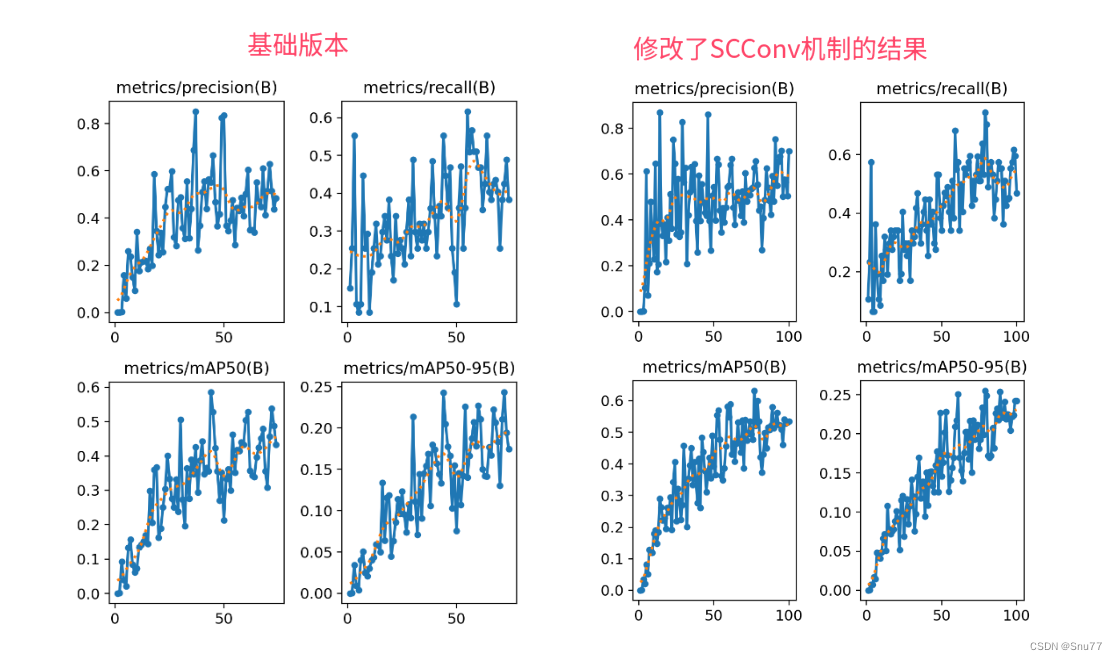
YOLOv5改进 | 2023 | SCConv空间和通道重构卷积(精细化检测,又轻量又提点)
一、本文介绍
本文给大家带来的改进内容是SCConv,即空间和通道重构卷积,是一种发布于2023.9月份的一个新的改进机制。它的核心创新在于能够同时处理图像的空间(形状、结构)和通道(色彩、深度)信息,这样的处理方式使得SCConv在分析图像时更加精细和高效。这种技术不仅适…
【开源】轻松实现车牌检测与识别:yolov8+paddleocr【python源码+数据集】
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
YOLOv5改进 | 卷积篇 | 手把手教你添加动态蛇形卷积(管道结构检测适用于分割Seg)
一、本文介绍
动态蛇形卷积的灵感来源于对管状结构的特殊性的观察和理解,在分割拓扑管状结构、血管和道路等类型的管状结构时,任务的复杂性增加,因为这些结构的局部结构可能非常细长和迂回,而整体形态也可能多变。 因此为了应对这个挑战,作者研究团队注意到了管状结构的特…
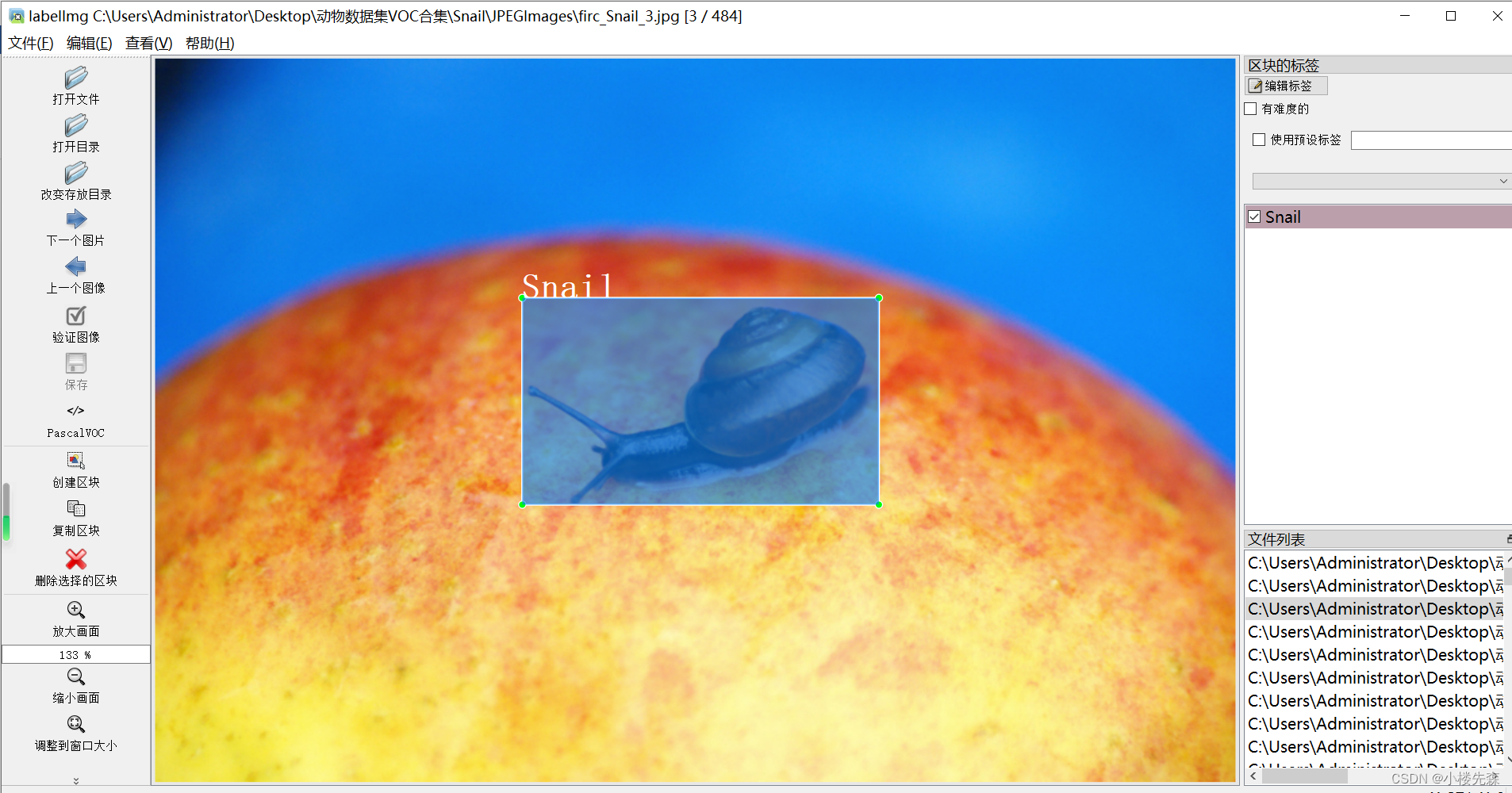
蜗牛目标检测数据集VOC格式480张
蜗牛,一种缓慢而坚韧的软体动物,以其螺旋形的外壳和黏附力极强的黏液而为人所熟知。
蜗牛体型呈螺旋形,有一个硬壳保护其柔软的身体。壳的形状和纹理因种类而异,有的光滑如玻璃,有的则布满细纹。蜗牛的头部有两对触角…
优化改进YOLOv5算法之Dilation-wise Residual(DWR)可扩张残差注意力模块,增强多尺度感受野特征,助力小目标检测
目录
1 Dilation-wise Residual模块原理
1.1 设计动机
1.2 Dilation-wise Residual模块
1.2.1 Design idea and structure
1.2.2 Parameter design
目标检测正负样本分配策略----ATSS
一、ATSS 参考:https://blog.csdn.net/xuzz_498100208/article/details/110355048 https://zhuanlan.zhihu.com/p/411659547 作者提出了一种自适应的选取正样本的方法,具体方法如下:
1.对于每个输出的检测层,选计算每个anchor的中…

损失函数篇 | RT-DETR 引入 Inner-IoU 考虑边框形状与尺度的度量
作者导读:Inter-IoU:基于辅助边框的IoU损失
论文地址:https://arxiv.org/abs/2311.02877
作者视频解读:https://www.bilibili.com
开源代码地址:https://github.com/malagoutou/Inner-IoU 随着探测器的快速发展,边界框回归(BBR)损失函数不断更新和优化。然而,现有基…
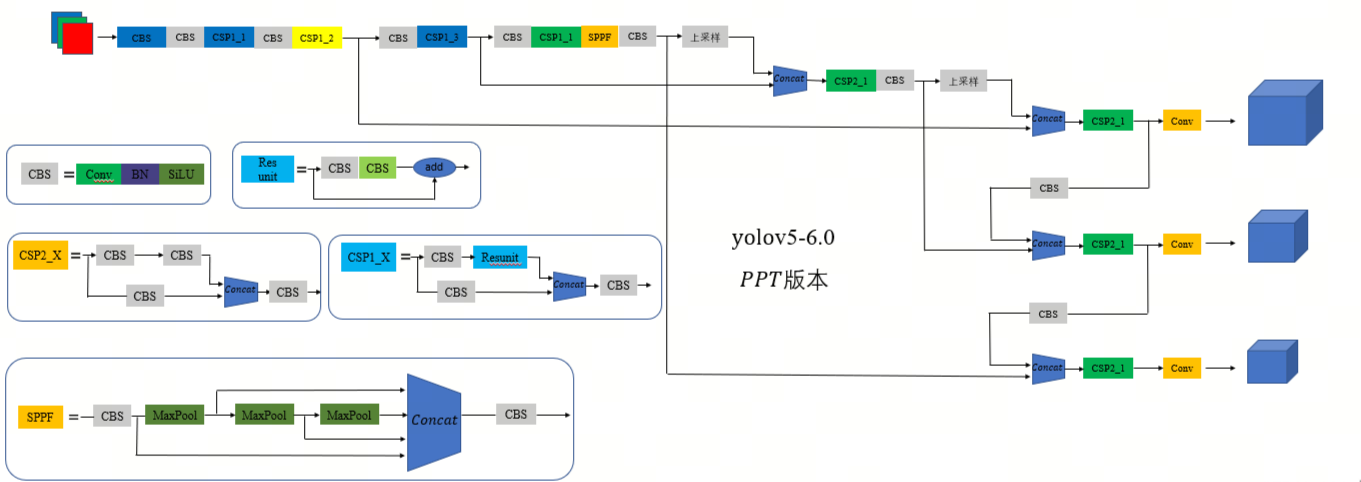
目标检测-One Stage-YOLOv5
文章目录 前言一、YOLOv5的网络结构和流程YOLOv5的不同版本YOLOv5的流程YOLOv5s的网络结构图 二、YOLOv5的创新点1. 网络结构2. 输入数据处理3. 训练策略 总结 前言
前文目标检测-One Stage-YOLOv4提到YOLOv4主要是基于技巧的集成,对于算法落地具有重大意义&#x…

【目标检测】评价指标:混淆矩阵概念及其计算方法(yolo源码)
本篇文章首先介绍目标检测任务中的评价指标混淆矩阵的概念,然后介绍其在yolo源码中的实现方法。 目标检测中的评价指标:
mAP概念及其计算方法(yolo源码/pycocotools) 混淆矩阵概念及其计算方法(yolo源码) 本文目录 1 概念2 计算方法 1 概念 在分类任务中…
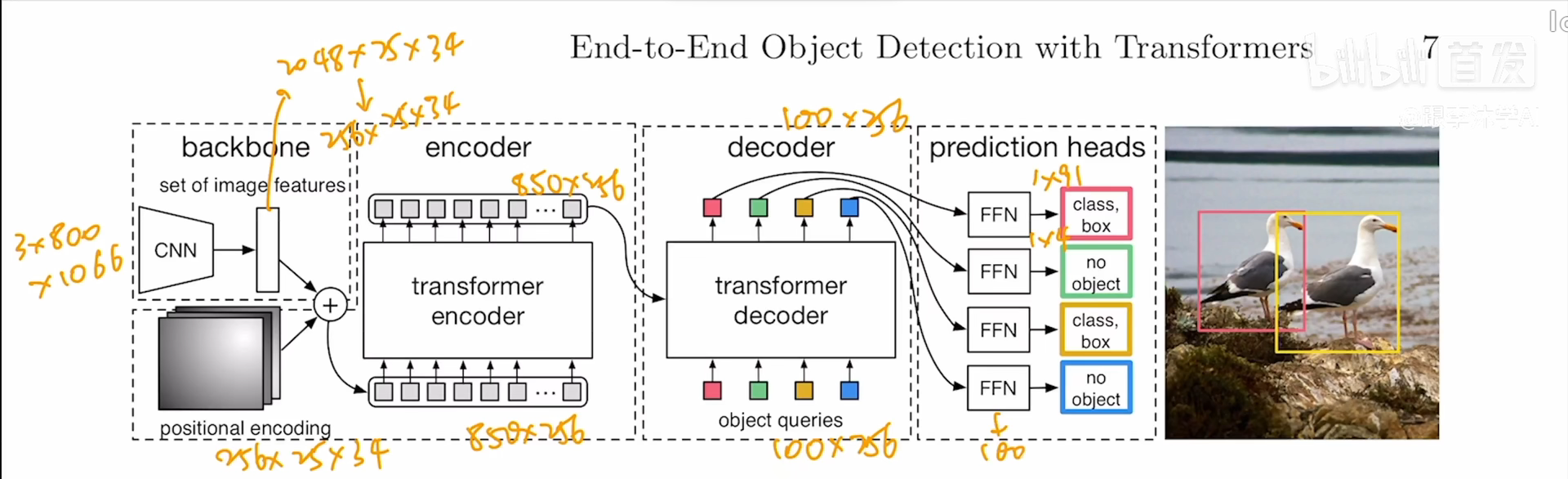
目标检测DETR:End-to-End Object Detection with Transformers
NMS
对一个目标生成了多个检测窗口,但是事实上这些窗口中大部分内容都是重复的,找到目标检测最优的窗口
选取多个检测窗口中分数最高的窗口,剔除掉其他同类型的窗口
anchor generator
首先在该点生成scale512, aspect ratio{1:2ÿ…
YOLOv8改进 | 融合改进篇 | CCFM + Dyhead完美融合突破极限涨点 (全网独家首发)
一、本文改进
本文给大家带来的改进机制是CCFM配合Dyhead检测头实现融合涨点,这个结构配合在一起只能说是完美的融合,看过我之前的检测头篇的读者都知道Dyhead官方版本支持的输入通道数是需要保持一致的,但是CCFM作为RT-DETR的Neck结构其输出通道数就是一致的,所以将这两种…
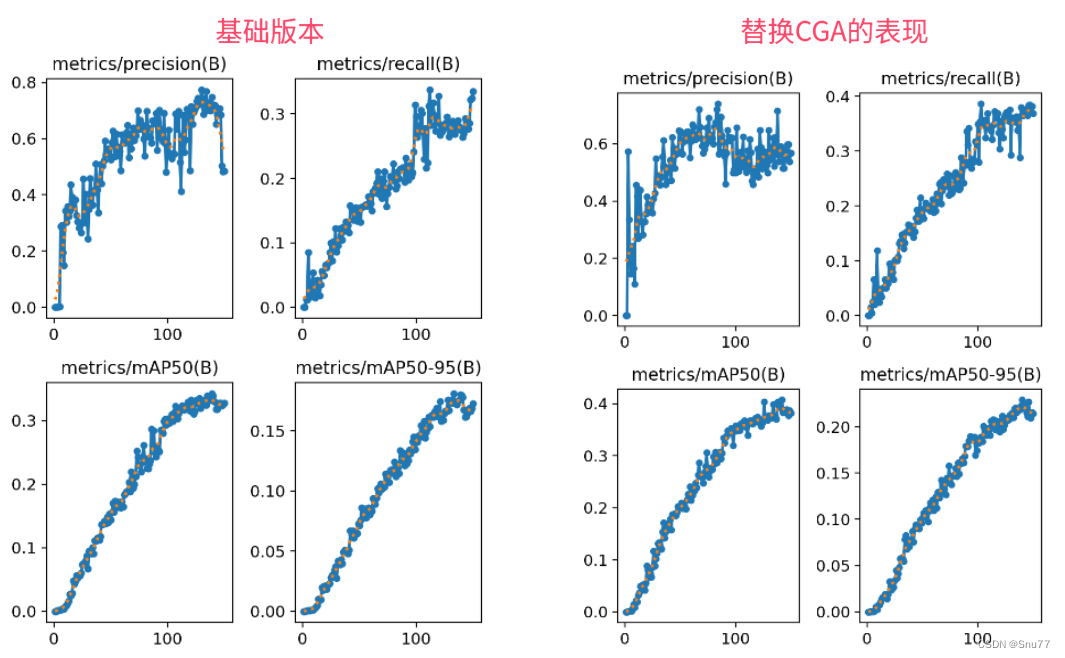
YOLOv8改进 | 注意力篇 | 实现级联群体注意力机制CGAttention (全网首发)
一、本文介绍
本文给大家带来的改进机制是实现级联群体注意力机制CascadedGroupAttention,其主要思想为增强输入到注意力头的特征的多样性。与以前的自注意力不同,它为每个头提供不同的输入分割,并跨头级联输出特征。这种方法不仅减少了多头注意力中的计算冗余,而且通过增…

现代雷达车载应用——第3章 MIMO雷达技术 3.5节 汽车MIMO雷达的挑战
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
3.5 汽车MIMO雷达的挑战 在本节中,我们讨论了汽车MIMO雷达的设计挑战,包括多径反射存在时的测角、波形正交性和高效高分辨率角…
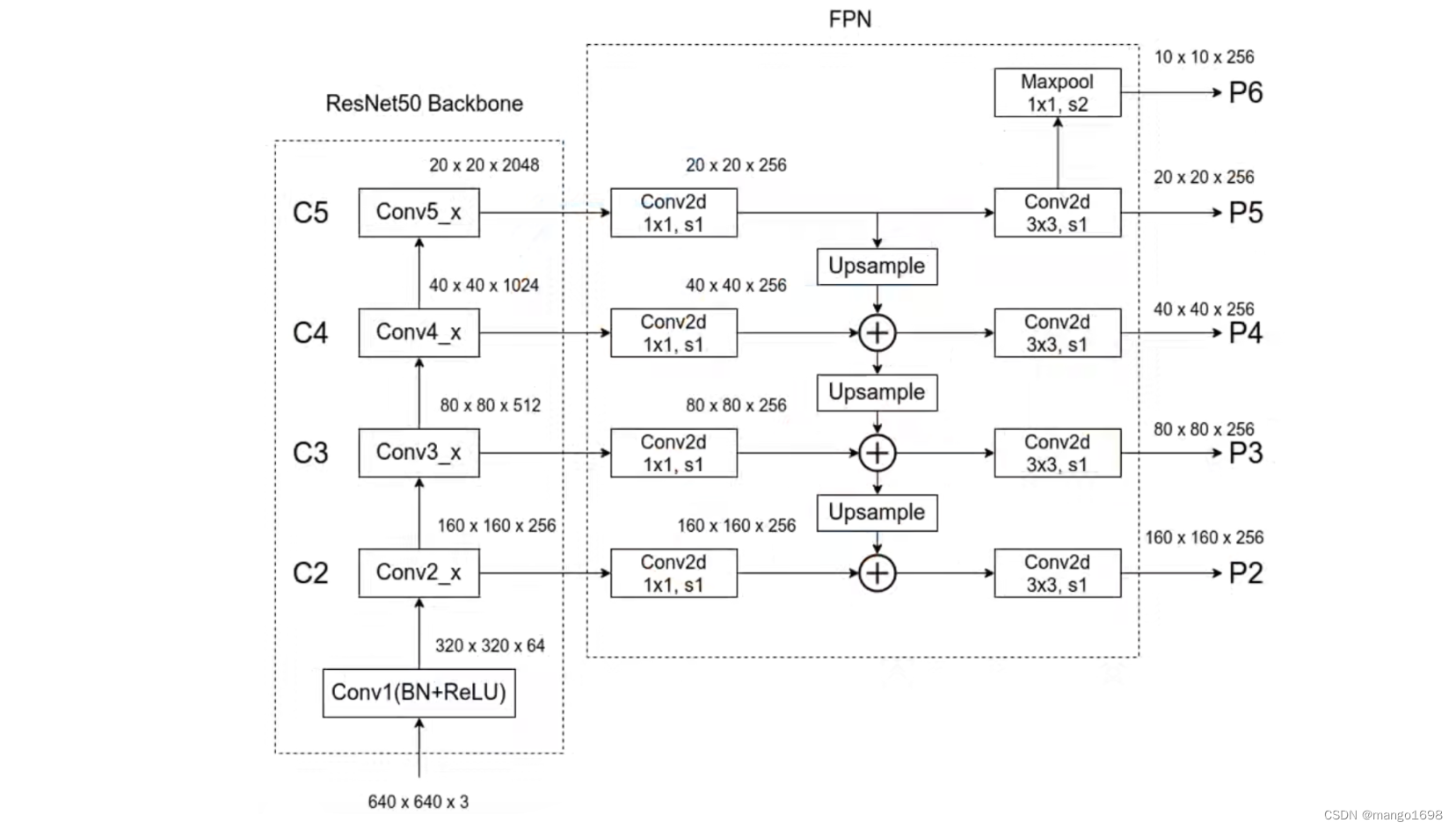
目标检测 - FPN结构
论文:Feature Pyramid Networks for Object Detection 网址:https://arxiv.org/abs/1612.03144 图a为特征图像金字塔,针对我们要检测不同尺度的目标时,我们会将图片缩放到不同的尺度,针对每个尺度的图片都经过我们的模…
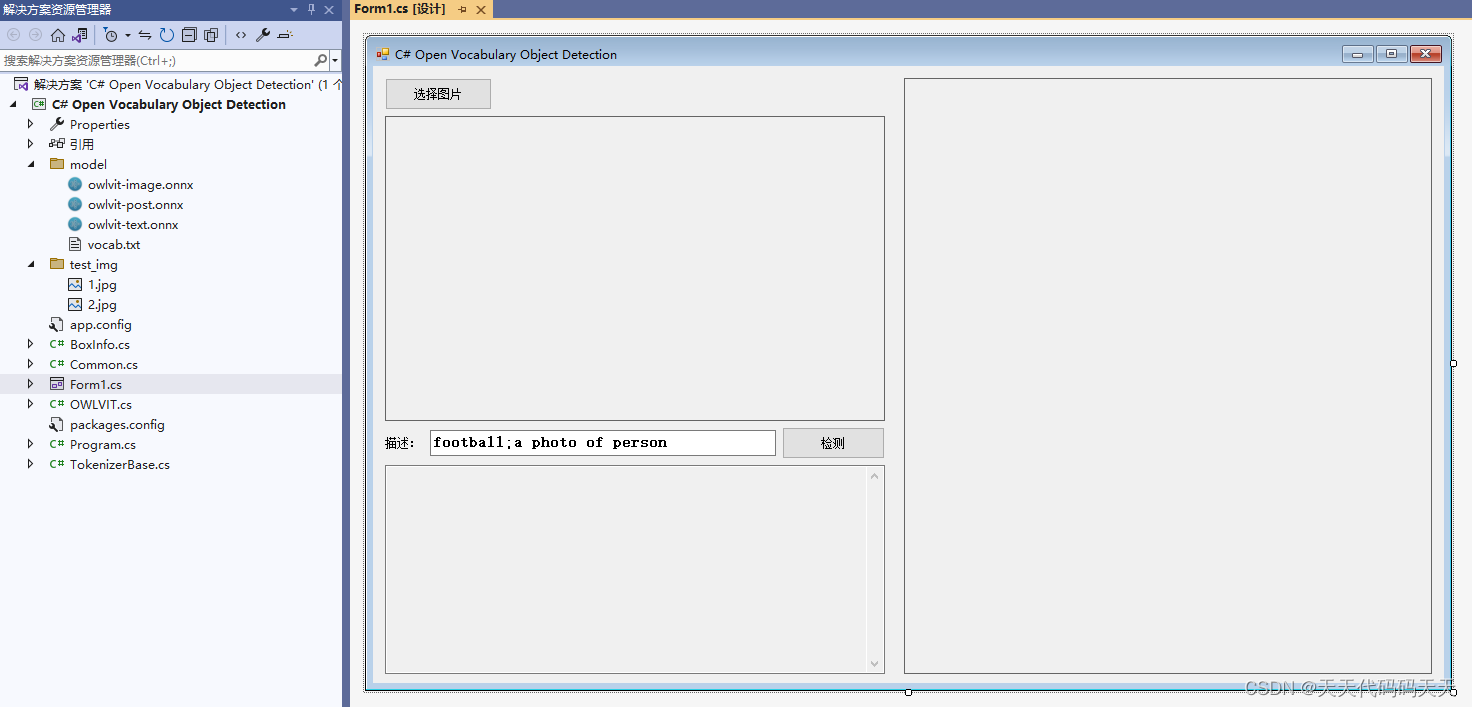
C# Open Vocabulary Object Detection 部署开放域目标检测
目录
介绍
效果
模型信息
owlvit-image.onnx
owlvit-post.onnx
owlvit-text.onnx
项目
代码
Form1.cs
OWLVIT.cs
下载 C# Open Vocabulary Object Detection 部署开放域目标检测
介绍
训练源码地址:https://github.com/google-research/scenic/tree/…

RTDETR 引入 UniRepLKNet:用于音频、视频、点云、时间序列和图像识别的通用感知大卷积神经网络 | DRepConv
大卷积神经网络(ConvNets)近来受到了广泛研究关注,但存在两个未解决且需要进一步研究的关键问题。1)现有大卷积神经网络的架构主要遵循传统ConvNets或变压器的设计原则,而针对大卷积神经网络的架构设计仍未得到解决。2)随着变压器在多个领域的主导地位,有待研究ConvNets…

YOLOv8改进 | 进阶实战篇 | 利用YOLOv8进行视频划定区域目标统计计数
一、本文介绍
Hello,各位读者,最近会给大家发一些进阶实战的讲解,如何利用YOLOv8现有的一些功能进行一些实战, 让我们不仅会改进YOLOv8,也能够利用YOLOv8去做一些简单的小工作,后面我也会将这些功能利用PyQt或者是pyside2做一些小的界面给大家使用。
在开始之前给大家推…

目标检测数据集 - 人脸检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:行人检测数据集,真实场景高质量图片数据,涉及场景丰富,比如校园行人、街景行人、道路行人、遮挡行人、严重遮挡行人数据;适用实际项目应用:公共场所监控场景下行人检测项目,以及作为…
![[C#]winform部署官方yolov8-rtdetr目标检测的onnx模型](https://img-blog.csdnimg.cn/direct/e9b3b70cde23419380fc19622de9105b.jpeg)
[C#]winform部署官方yolov8-rtdetr目标检测的onnx模型
【官方框架地址】
https://github.com/ultralytics/ultralytics 【算法介绍】
RTDETR,全称“Real-Time Detection with Transformer for Object Tracking and Detection”,是一种基于Transformer结构的实时目标检测和跟踪算法。它在目标检测和跟踪领域…
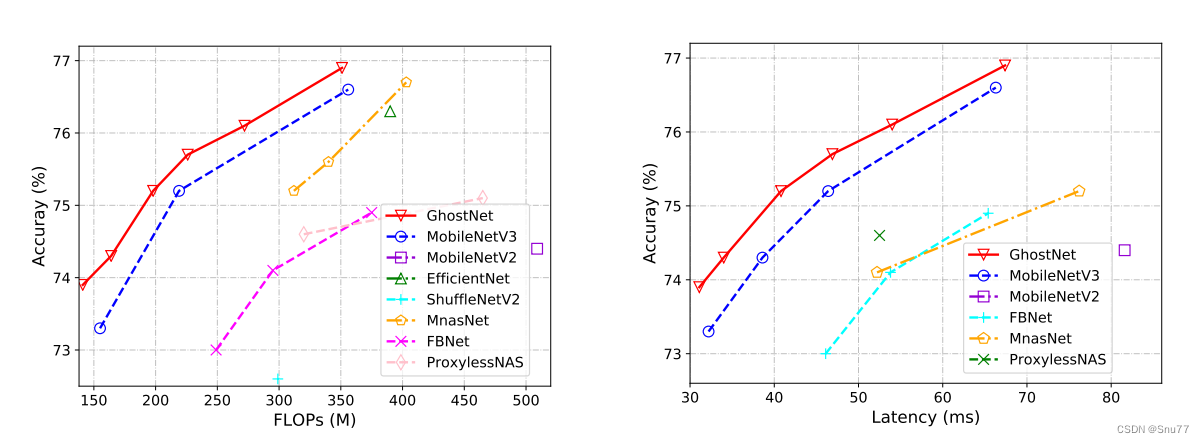
YOLOv8改进 | 主干篇 | 华为移动端模型Ghostnetv1改进特征提取网络
一、本文介绍
本文给大家带来的改进机制是华为移动端模型Ghostnetv1,华为的GhostNet是一种轻量级卷积神经网络,旨在在计算资源有限的嵌入式设备上实现高性能的图像分类。GhostNet的关键思想在于通过引入Ghost模块,以较低的计算成本增加了特征图的数量,从而提高了模型的性能…
深度学习中图像分类、目标检测、语义分割、实例分割哪个难度大,哪个检测精度容易实现,哪个速度低。请按照难度、精度容易实现程度、速度排名。
问题描述:深度学习中图像分类、目标检测、语义分割、实例分割哪个难度大,哪个检测精度容易实现,哪个速度低。请按照难度、精度容易实现程度、速度排名。
问题解答:
以下是一般情况下深度学习中图像分类、目标检测、语义分割、实…
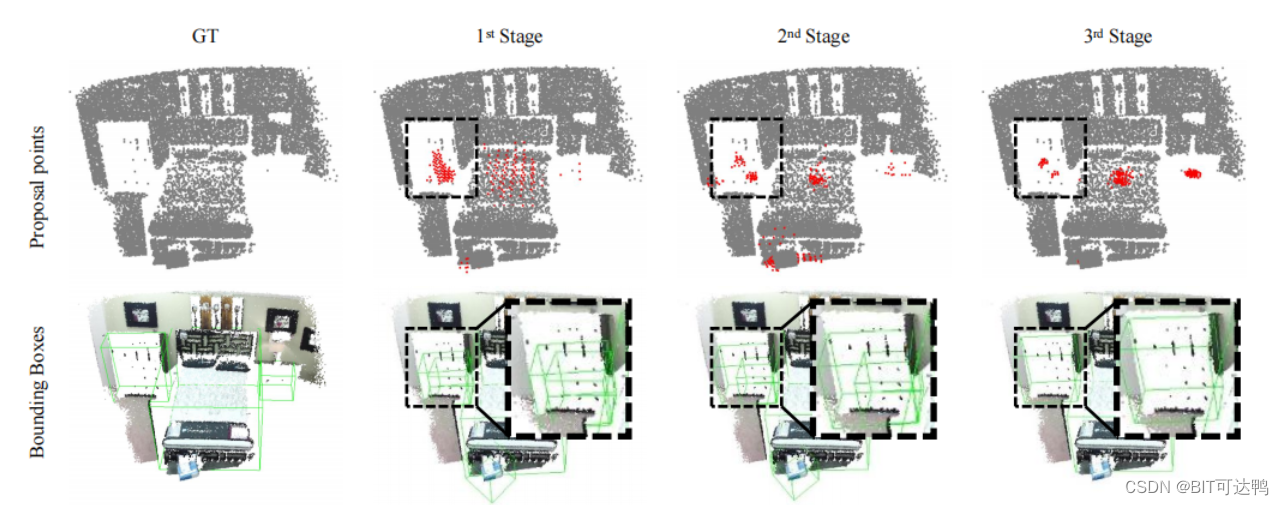
【2024 目标检测】CascadeV-Det:探究基于点的 3D 目标检测中心点定位的对模型精度影响
【2024 目标检测】CascadeV-Det:探究基于点的 3D 目标检测中心点定位的对模型精度影响 摘要:观察:方法:Instance-Aware Voting:Cascade Positive Assignment: 实验结果: 来源:Arxiv …
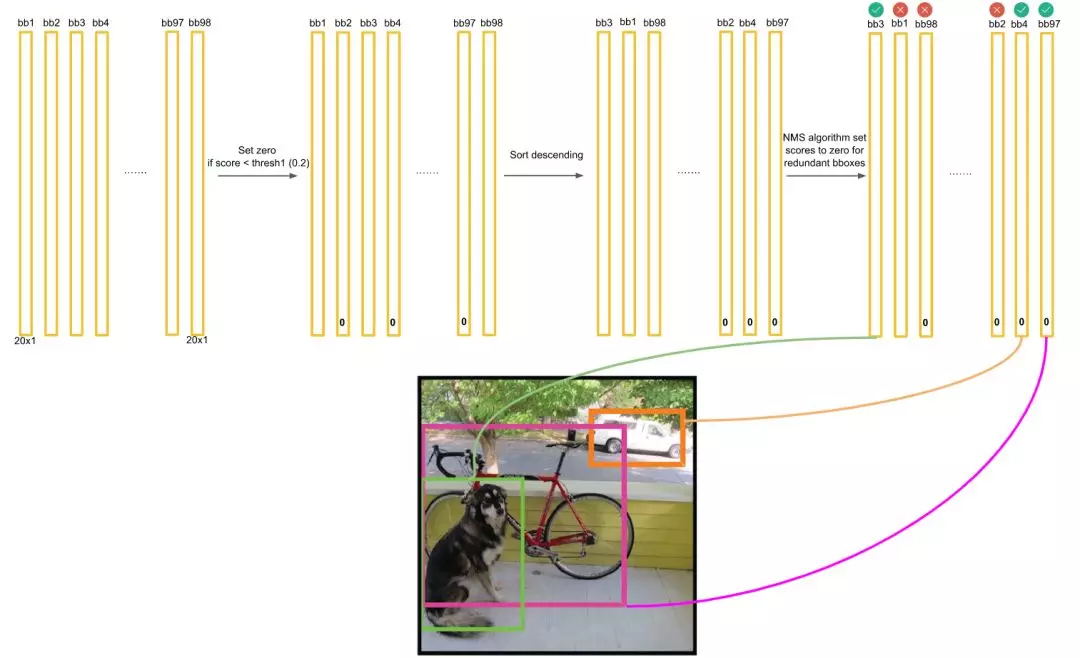
深入浅出理解目标检测的非极大值抑制(NMS)
一、参考资料
物体检测中常用的几个概念迁移学习、IOU、NMS理解
目标定位和检测系列(3):交并比(IOU)和非极大值抑制(NMS)的python实现
Pytorch:目标检测网络-非极大值抑制(NMS)
…
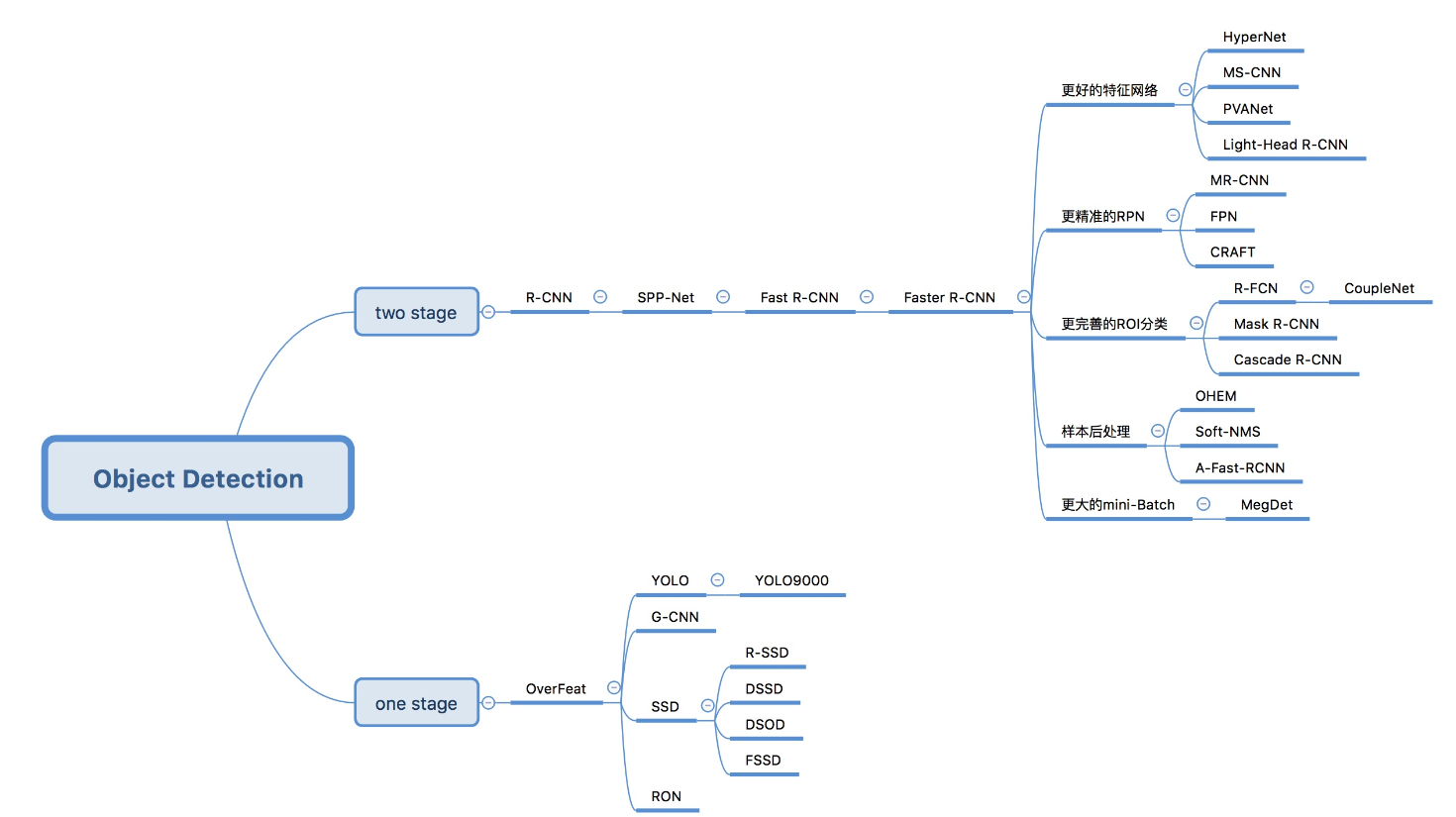
【RT-DETR有效改进】手把手带你调参RT-DETR,复现官方版本实验环境
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文是带大家进行调参,利用ultralytics仓库1:1复现RT-DETR官方实验环境,从而在后期发表论文 的时候省去一些不必要的麻烦,例如被审稿人提出质疑,本文的调参内容均有依据,根据RT-DETR官方Github上发布的版…

基于Yolov8的道路缺陷检测,加入PConv、WIOU 、DCNV2提升检测精度
1.数据集介绍
缺陷类型:crack
数据集数量:195张 1.1数据增强,扩充数据集
通过medianBlur、GaussianBlur、Blur3倍扩充得到780张图片
按照train、val、test进行8:1:1进行划分
1.1.1 通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8import…

RT-DETR改进有效系列目录 | 包含卷积、主干、RepC3、注意力机制、Neck上百种创新机制
💡 RT-DETR改进有效系列目录 💡 前言
Hello,各位读者们好 Hello,各位读者,距离第一天发RT-DETR的博客已经过去了接近两个月,这段时间里我深入的研究了一下RT-DETR在ultralytics仓库的使用,旨在为大家解决为什么用v8的仓库训练的时候模型不收敛,精度差的离谱的问题,…
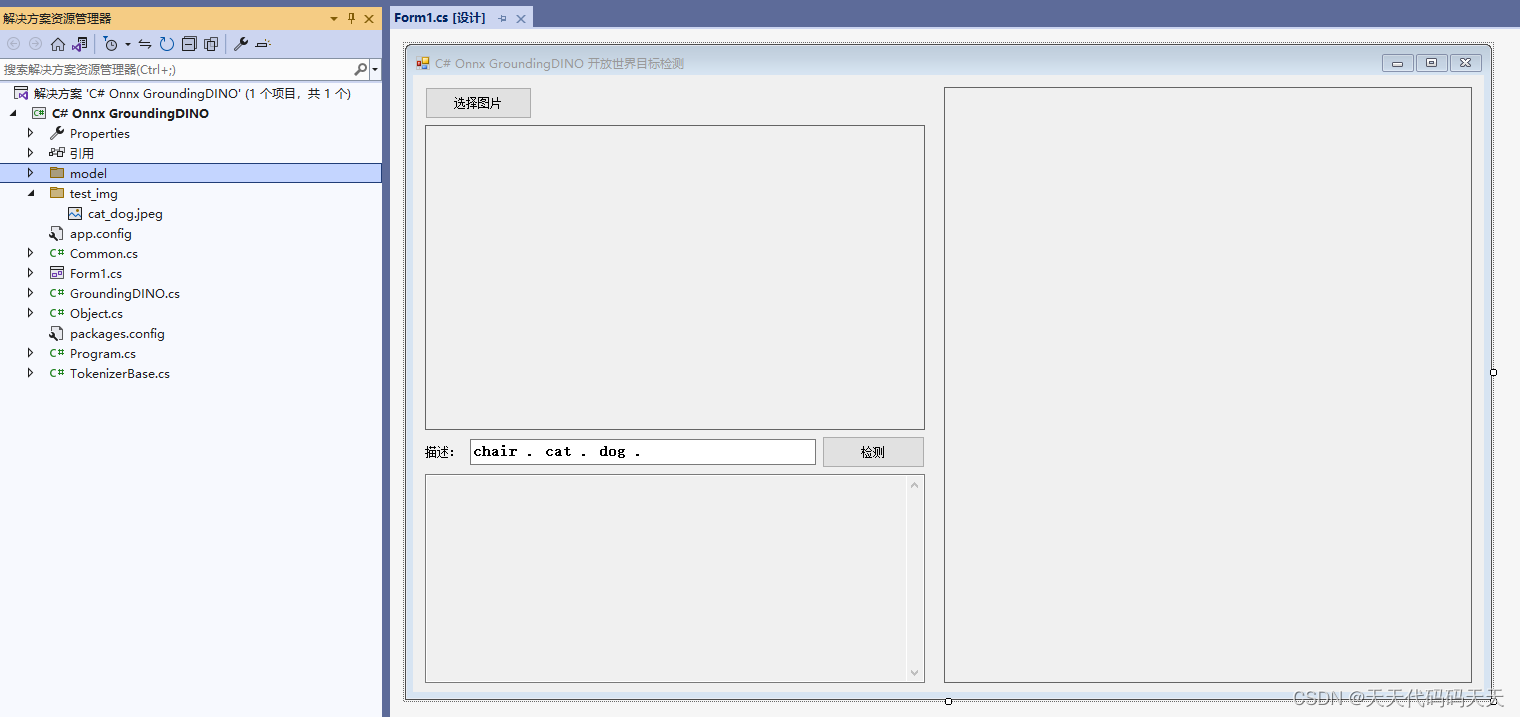
C# Onnx GroundingDINO 开放世界目标检测
目录
介绍
效果
模型信息
项目
代码
下载 介绍
地址:https://github.com/IDEA-Research/GroundingDINO
Official implementation of the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection" 效果 …
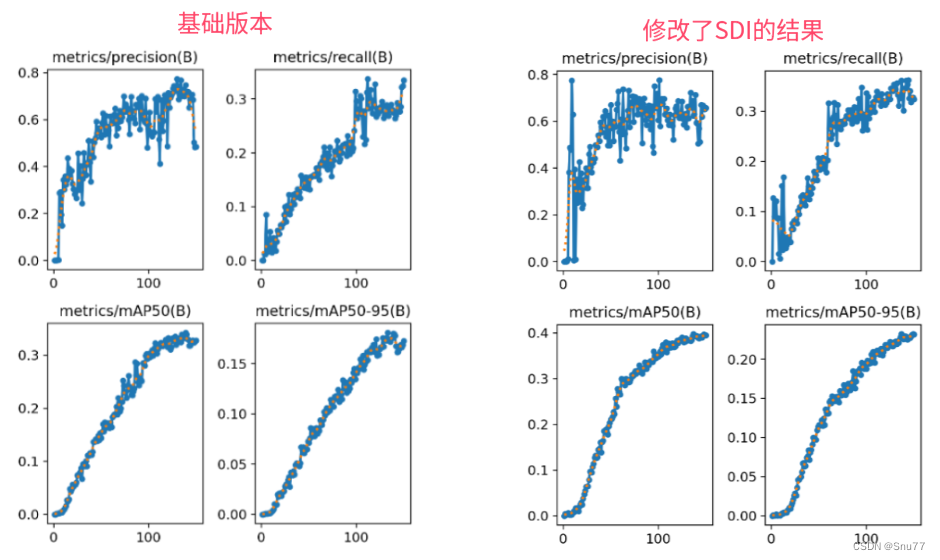
【RT-DETR有效改进】UNetv2提出的一种SDI多层次特征融合模块(细节高效涨点)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本问给大家带来的改进机制是UNetv2提出的一种多层次特征融合模块(SDI)其是一种用于替换Concat操作的模块,SDI模块的主要思想是通过整合编码器生成的层级特征图来增强图像中的语义信息和细节信息。包括皮肤…
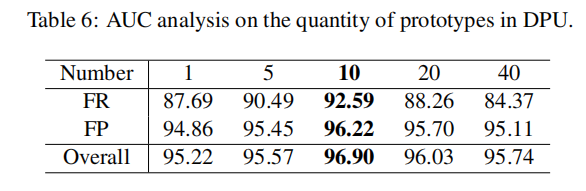
Learning Normal Dynamics in Videos with Meta Prototype Network详解及论文精读
论文地址:https://openaccess.thecvf.com/content/CVPR2021/html/Lv_Learning_Normal_Dynamics_in_Videos_With_Meta_Prototype_Network_CVPR_2021_paper.html
1.视频异常行为检测任务简介 什么是异常行为呢? 除了正常的,其他都是异常(并不…
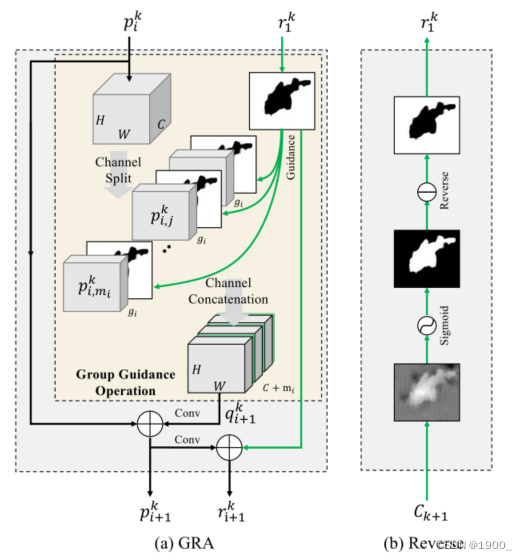
【论文解读】伪装物体检测 Camouflaged Object Detection
文章目录伪装物体检测 Camouflaged Object DetectionSINet v1RF模块:PDC模块:SINet v2特征提取Texture Enhanced Module 纹理增强模块Neighbor Connection Decoder 邻居连接解码器Group-Reversal Attention 组反转注意力总结伪装物体检测 Camouflaged Ob…

【半监督学习】5、Efficient Teacher | 专为 one-stage anchor-based 方法设计的半监督目标检测方法
文章目录一、背景二、方法2.1 Dense Detector2.2 Pseudo Label Assigner2.3 Epoch Adaptor三、效果论文:Efficient Teacher: Semi-Supervised Object Detection for YOLOv5
出处:阿里
时间:2023.03
一、背景
目标检测近年来的进展离不开大…
智能火焰与烟雾检测系统(Python+YOLOv5深度学习模型+清新界面)
摘要:智能火焰与烟雾检测系统用于智能日常火灾检测报警,利用摄像头画面实时识别火焰与烟雾,另外支持图片、视频火焰检测并进行结果可视化。本文详细介绍基于智能火焰与烟雾检测系统,在介绍算法原理的同时,给出Python的…

基于深度学习的花卉检测与识别系统(YOLOv5清新界面版,Python代码)
摘要:基于深度学习的花卉检测与识别系统用于常见花卉识别计数,智能检测花卉种类并记录和保存结果,对各种花卉检测结果可视化,更加方便准确辨认花卉。本文详细介绍花卉检测与识别系统,在介绍算法原理的同时,…
【计算机视觉】消融实验(Ablation Study)是什么?
文章目录一、前言二、定义三、来历四、举例说明一、前言
我第一次见到消融实验(Ablation Study)这个概念是在论文《Faster R-CNN》中。
消融实验类似于我们熟悉的“控制变量法”。
假设在某目标检测系统中,使用了A,B࿰…
水果新鲜程度检测系统(UI界面+YOLOv5+训练数据集)
摘要:水果新鲜程度检测软件用于检测水果新鲜程度,利用深度学习技术识别腐败或损坏的水果,以辅助挑拣出新鲜水果,支持实时在线检测。本文详细介绍水果新鲜程度检测系统,在介绍算法原理的同时,给出Python的实…
TensorRT部署YOLOv5(04)—构建TensorRT引擎
在上一篇文章中,已经对什么是TensorRT,使用TensorRT进行深度学习模型部署推理的完整流程进行了初步的介绍。本文将详细介绍TensorRT引擎的构建,包括tf2onnx的使用、trtexec命令行的使用和重要参数介绍、如何使用Python API进行TensorRT引擎构建等 Tensorflow模型转换为ONNX …
【目标检测】基于yolov3的血细胞检测(无bug教程+附代码+数据集)
多的不说,少的不唠,先看检测效果图:
共检测三类:红细胞RBC、白细胞WBC、血小板Platelets
Hello,大家好,我是augustqi。今天给大家带来的保姆级教程是:基于yolov3的血细胞检测(无bug教程+附代码+数据集)
1.项目背景
在上一期的教程中,我们基于yolov3训练了一个红细…

【目标检测】YOLOv5分离检测和识别
前言
YOLO作为单阶段检测方法,可以直接端到端的输出目标对象位置和类别,而在一些大型无人机遥感等目标检测任务中,使用单阶段检测往往会产生类别预测错误的问题。 正好,YOLOv5-6.2版本提供了一个图像分类的网络,那么就…
基于via的课堂学生行为数据标注 与yolov7目标检测与自动标注系统
目录0 相关链接1. 总体功能描述2.软件安装说明2.1. 环境搭建2.2. 激活环境2.3. 退出环境2.4. 删除环境2.5. 安装opencv3.标注数据处理3.1. 收集3.2.via对标注举手3.3. via 举手标注转化yolo格式3.4. via动作标注扩展3.5. via 举手看书写字标注转化yolo格式4. 标注数据检查与可视…
【目标检测】Mask RCNN中:ROI Align和ROI Pooling的具体区别?
文章目录一、前言二、详细理解2.1 ROI Pooling的局限性2.2 ROI Align的思想和实现方法三、详解 Mask-RCNN 中的RoI Align作用3.1 RoI Align的产生背景3.2 RoI Pooling3.3 RoI Align一、前言
ROI Align和ROI Pooling都是目标检测领域中常用的操作,用于在特征图上提取…

YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
前言
上一篇我们已经搭建好了YOLOv5的环境(直通车→YOLOv5入门实践(1)——手把手带你环境配置搭建),现在就开始第二步利用labelimg标注数据集吧! 🍀本人YOLOv5源码详解系列: …
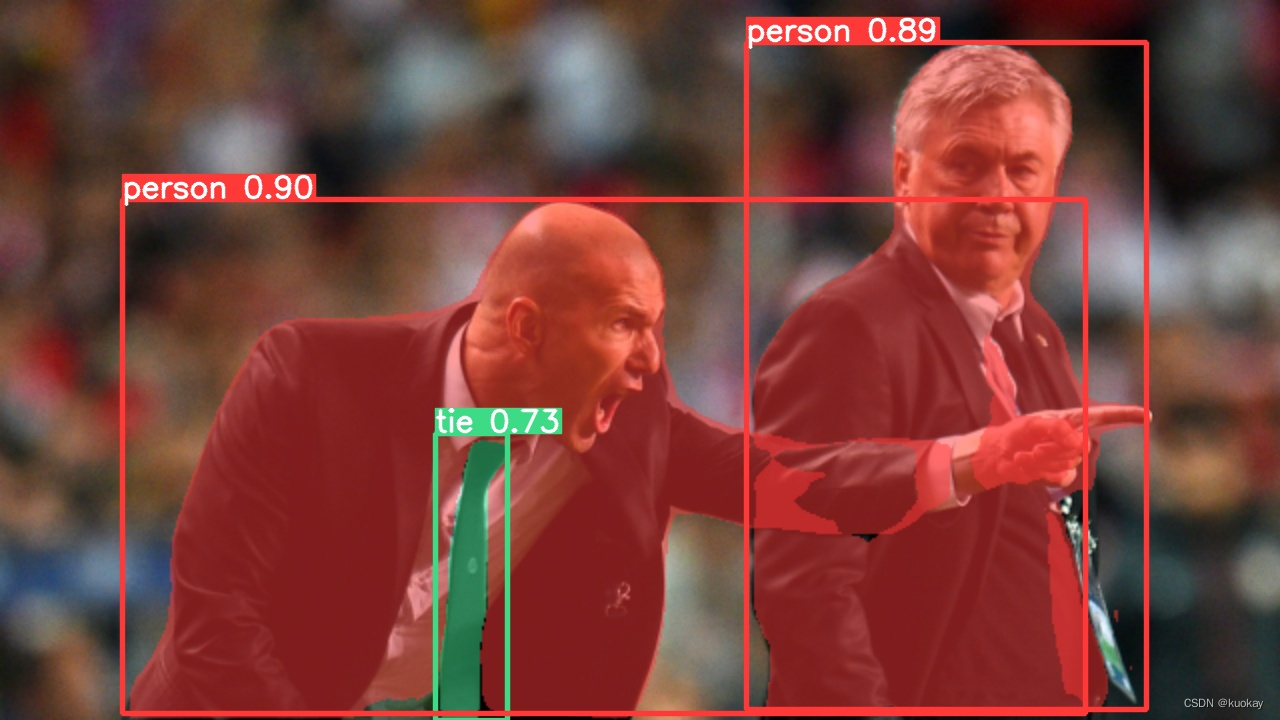
yolov5-v7.0实例分割快速体验
简介
🚀yolov5-v7.0版本正式发布,本次更新的v7.0则是全面的大版本升级,最主要的功能就是全面集成支持了实例分割,yolov5已经集成检测、分类、分割任务。 前面几篇文章已经介绍过关于Yolov5的一些方面
yolov5目标检测:https://bl…

论文阅读 (88):Adversarial Examples for Semantic Segmentation and Object Detection
文章目录 1. 概述2 算法2.1 稠密对抗生成2.2 选择用于检测的输入提案 1. 概述
题目:用于语义分割和目标检测的对抗样本 核心点:将对抗性样本的概念扩展到语义分割和对象检测,并提出稠密对抗生成算法 (Dense adversary generation, DAG)。 引…
YOLOv8改进:RepBiPAN结构 + DETRHead检测头,为YOLOv8目标检测使用不一样的检测头,用于提升检测精度
💡本篇内容:YOLOv8全新Neck改进:RepBiPAN 结构升级版,为目标检测打造全新融合网络,增强定位信号,对于小目标检测的定位具有重要意义
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文改进 Neck部分和DETRHead系列检测头…
YOLOv5改进:引入DenseNet思想打造密集连接模块,彻底提升目标检测性能
目录 一、密集连接模块的介绍1、密集连接的概念2、密集连接与残差连接的对比3、DenseNet的结构 二、 YOLOv5中引入密集连接模块的原因1、密集连接模块对于目标检测的优势2、密集连接模块对目标检测性能的影响 三、 YOLOv5中密集连接模块的具体实现1、使用DenseNet的基本单元Den…
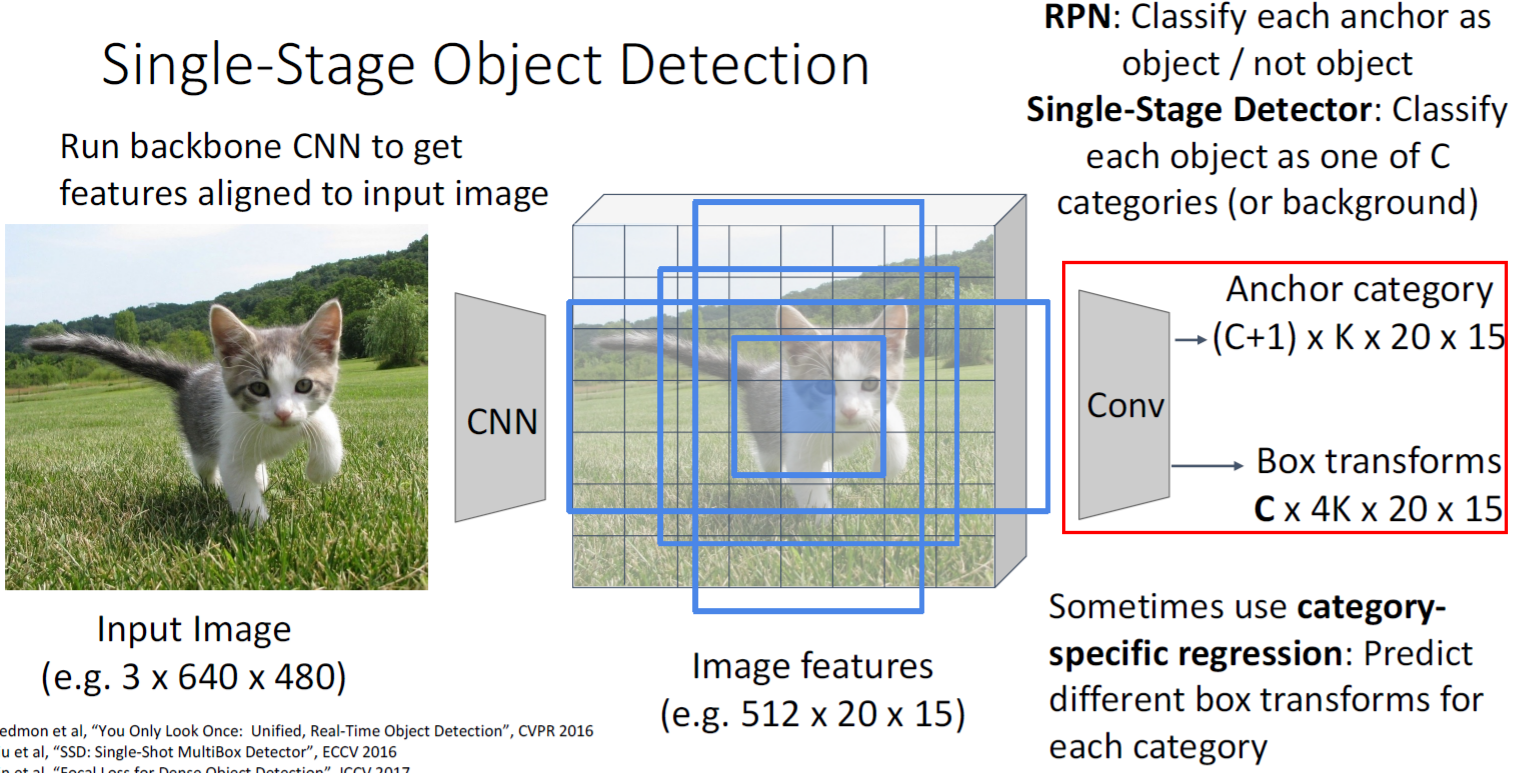
计算机视觉的深度学习 Lecture15:Object Detection 笔记 EECS 498.007/008
一些介绍: amodal box (非模态box?) 标记隐含的物体大小
只检测一个目标的流程
同时计算分类分数和Box坐标、使用Multitask Loss。Multitask Loss现在是一种非常常见的方法。
滑动窗口检测多个目标 开销巨大(右下…

多尺度深度特征(下):多尺度特征学习才是目标检测精髓(论文免费下载)...
计算机视觉研究院专栏 作者:Edison_G 深度特征学习方案将重点从具有细节的具体特征转移到具有语义信息的抽象特征。它通过构建多尺度深度特征学习网络 (MDFN) 不仅考虑单个对象和局部上下文,还考虑它们之间的关系。 公众号ID|ComputerVisionG…

优于FCOS:在One-Stage和Anchor-Free目标检测中以最小的成本实现最小的错位(代码待开源)...
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 计算机视觉研究院专栏 作者:Edison_G 与基线FCOS(一种单阶段和无锚目标象检测模型)相比,新提出的模型…
【计算机视觉 | 目标检测】术语理解3:Precision、Recall、F1-score、mAP、IoU 和 AP
文章目录 一、Precision、Recall 和 F1-score二、IoU三、mAP四、AP4.1 定义4.2 分类4.2.1 APs4.2.2 APr4.2.3 两者之间的区别 一、Precision、Recall 和 F1-score
在图像目标检测中,常用的评估指标包括以下几项:
精确率(Precisionÿ…
【计算机视觉 | 目标检测】Objects365 :最新大规模高质量目标检测数据集
文章目录 一、前言二、数据集的规模三、数据集的质量四、泛化能力五、结语 一、前言
2019 年 4 月,在北京举行的智源学者计划启动暨联合实验室发布会上,北京旷视科技有限公司与北京智源人工智能研究院共同发布了全球最大的目标检测数据集 : …

【轻量化网络系列(2)】MobileNetV2论文超详细解读(翻译 +学习笔记+代码实现)
前言
上一篇我们介绍了MobileNetV1,主要是将普通Conv转换为dw和pw,但是在dw中训练出来可能会很多0,也就是depthwise部分得到卷积核会废掉,即卷积核参数大部分为0,因为权重数量可能过少,再加上Relu激活函数…

目标检测,实例分割IOU,precision, recall, mAP详解
经常在目标检测,分割的paper中看到mAP这样的评价标准, 那么mAP到底是什么呢?
AP(Average precision)是评价目标检测和分割的标准,有box mAP, mask mAP. 看名称Average precision, 就能猜到是计算precision…

FasterRCNN训练自己的数据集
2016年提出的Faster RCNN目标检测模型是深度学习现代目标检测算法的开山之作,也是第一个真正全流程都是神经网络的目标检测模型。 其主要步骤如下: 1,使用CNN对输入图片提取feature map. 2,对feature map上的每个点设计一套不同大…

YOLOv5改进系列(5)——替换主干网络之 MobileNetV3
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
YOLOv5改进系列(2&#

YOLO-v1论文详解
YOLO-v1论文详解 – 潘登同学的目标检测笔记 文章目录YOLO-v1论文详解 -- 潘登同学的目标检测笔记与Faster R-CNN最大不同You Only Look Once算法流程网络结构部分Anchor部分输出结果Loss函数位置Lossconfidence Loss分类LossLoss前面的系数Limitation与Faster R-CNN最大不同
…

目标检测 从古典走进R-CNN
目标检测 从古典走进R-CNN–潘登同学的深度学习笔记 文章目录目标检测 从古典走进R-CNN--潘登同学的深度学习笔记古典目标检测目标检测是回归还是分类?回归任务分类任务Region ProposalsSelective Search算法古典目标检测流程IoU(Intersection over Union)R-CNNSPP-net改进方法…
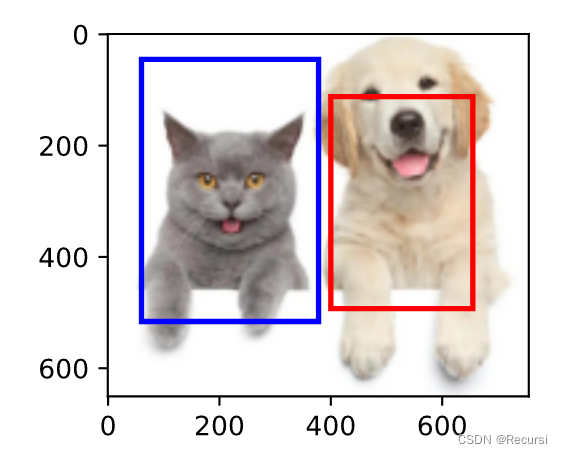
同济子豪兄讲述YOLOv1学习笔记
YOLO算法
一、 YOLO就是解决目标检测(Object Detection)的计算机视觉算法
1.1计算机视觉能解决哪些问题――分类、检测、分割 ①Classification就是输入一张图片,算法能告诉我们图片中有什么类别,如猫、狗。但不能告诉我们类别所…

PPYOLOE目标检测训练框架使用说明
数据集准备数据集标注参考博客【使用labelimg制作数据集】:https://blog.csdn.net/qq_41251963/article/details/111190442标注数据注意事项,图片名称为纯数字,例如1289.jpg ;不要出现其他字符,否则下面代码转换会报错。标注好的数…
目标检测00-10:mmdetection(Foveabox为例)-源码无死角解析(3)-头部网络bbox_head-训练过程
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
[数据集][目标检测]数据集VOC格式绝缘子缺陷检测数据集VOC-4086张
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):4086 标注数量(xml文件个数):4086 标注类别数:3 标注类别名称:["jueyuanzi",&…
目标检测00-05:mmdetection(Foveabox为例)-白话给你讲论文-翻译无死角-1
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
目标检测00-03:mmdetection(Foveabox为例)-训练自定义的coco数据集(提供示例数据集)
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
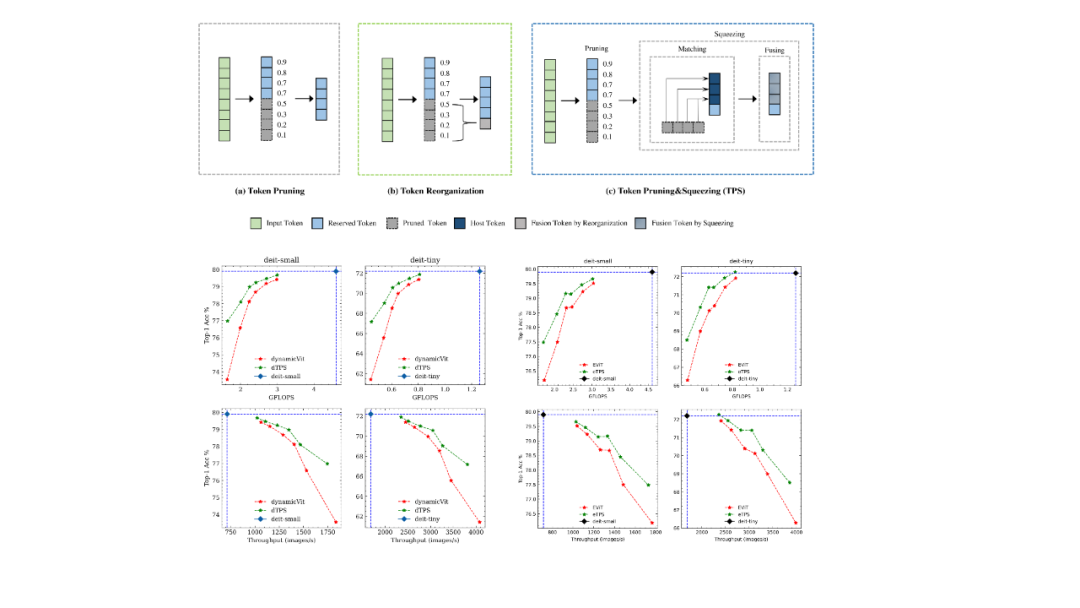
CVPR 2023 | 旷视研究院入选论文亮点解读
近日,CVPR 2023 论文接收结果出炉。近年来,CVPR 的投稿数量持续增加,今年收到有效投稿 9155 篇,和 CVPR 2022 相比增加 12%,创历史新高。最终,大会收录论文 2360 篇,接收率为 25.78 %。本次&…
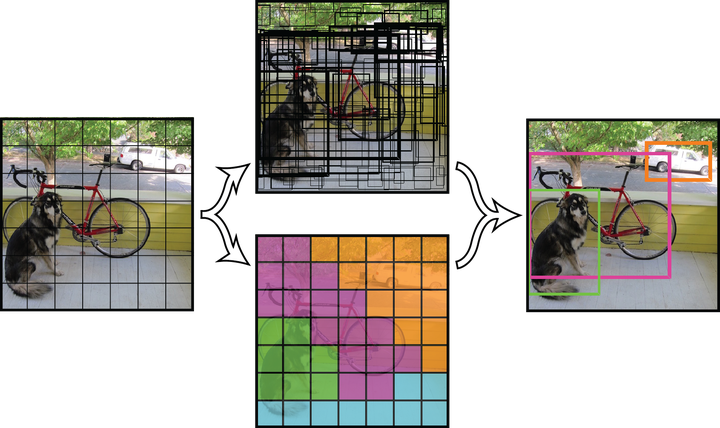
YOLO v3入门图解
图解YOLO v3 的网络架构和基本流程
近年来,由于在海量数据与计算力的加持下,深度学习对图像数据表现出强大的表示能力,成为了机器视觉的热点研究方向。图像的表示学习,或者让计算机理解图像是机器视觉的中心问题。
具体来说&…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(5月30日论文合集)
文章目录 一、检测相关(16篇)1.1 Contextual Object Detection with Multimodal Large Language Models1.2 Towards minimizing efforts for Morphing Attacks -- Deep embeddings for morphing pair selection and improved Morphing Attack Detection1.3 Mining Negative Tem…
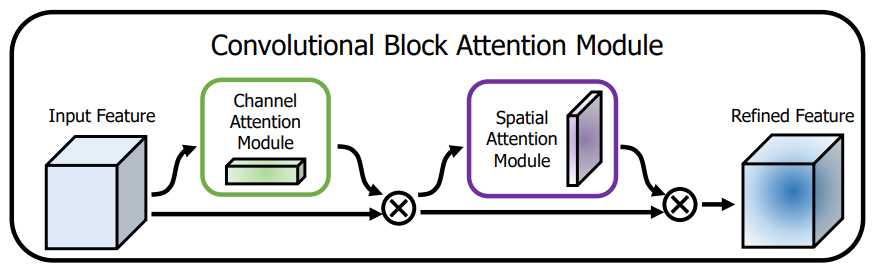
涨点技巧:注意力机制---Yolov8引入Resnet_CBAM,CBAM升级版
1.计算机视觉中的注意力机制
一般来说,注意力机制通常被分为以下基本四大类:
通道注意力 Channel Attention
空间注意力机制 Spatial Attention
时间注意力机制 Temporal Attention
分支注意力机制 Branch Attention
1.1.CBAM:通道注意力和空间注意力的集成者
轻量级…

目标检测(5)—— YOLO系列V1
一、YOLO系列V1
经典的one-stage方法,You Only Look Once将检测问题转化成回归问题,一个CNN搞定可以对视频进行实时监测
YOLO系列的速度更快,我们检测的物体很简单,进行取舍,舍弃了一些精度。 V1核心思想 现在要预测…
Yolov8涨点神器:创新卷积块NCB和创新Transformer 块NTB,助力检测,提升检测精度
🏆🏆🏆🏆🏆🏆Yolov8魔术师🏆🏆🏆🏆🏆🏆 ✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉定期更新不同数据集涨点情况 本博客将具有部署友好机制的强大卷积块和变换块,即NCB和NTB,引入到yolo…


目标检测(6)—— YOLO系列V2
一、YOLOV2改进的概述
做的改进如下图: Batch Normalization 批量归一化层
不加BN层,网络可能学偏,加上归一化进行限制。 从今天来看,conv后加BN是标配。 更大的分辨率
V1训练的时候使用224224,测试用448448。 V2训…
YOLOv3 代码详解(3) —— 数据处理 dataset.py的多进程改造
前言: yolo系列的论文阅读 论文阅读 || 深度学习之目标检测 重磅出击YOLOv3 论文阅读 || 深度学习之目标检测yolov2 论文阅读 || 深度学习之目标检测yolov1 该篇讲解的工程连接是: tensorflow的yolov3:https://github.com/YunYang1994/ten…
YOLOv8目标检测:自定义数据集训练与评估
摘要:在本教程中,我们将详细介绍如何使用自定义数据集训练YOLOv8模型,并用Python代码评估模型性能。
正文:
一、准备自定义数据集
为了训练YOLOv8模型,我们需要一个标注好的自定义数据集。数据集应包含图像文件和对…
动态SLAM论文(3) — Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial
目录
1 Introduction
2 Related Work
3 Detect-SLAM
3.1 移动物体去除
3.2 Mapping Objects
3.3 增强SLAM检测器
4 实验
4.1 动态环境下的鲁棒SLAM
4.2. 提升检测性能
5 结论 Abstract:近年来,在SLAM和目标检测方面取得了显著进展,…

工业无监督缺陷检测,提升缺陷检测能力,解决缺陷样品少、不平衡等问题
1. 简介
在工业生产中,质量保证是一个很重要的话题, 因此在生产中细小的缺陷需要被可靠的检出。工业异常检出旨在从正常的样本中检测异常的、有缺陷的情况。工业异常检测主要面临的挑战: 难以获取大量异常样本正常样本和异常样本差异较小异常的类型不能预先得知这些挑战使得…

Pytorch实现R-CNN系列目标检测网络
在PyTorch提供的已经训练好的图像目标检测中,均是R-CNN系列的网络,并且针对目标检测和人体关键点检测分别提供了容易调用的方法。针对目标检测的网络,输入图像均要求使用相同的预处理方式,即先将每张图像的像素值预处理到0 ~1之间…
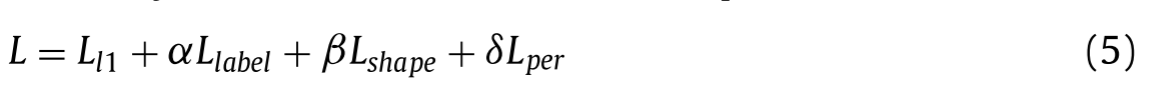
【pan-sharpening 攻击:目标检测】
Adversarial pan-sharpening attacks for object detection in remote sensing
(对抗性泛锐化攻击在遥感目标检测中的应用)
全色锐化是遥感系统中最常用的技术之一,其目的是将纹理丰富的PAN图像和多光谱MS图像融合,以获得纹理丰…

yolov5+车道线检测
目标检测与车道线检测在自动驾驶以及车辆定位中起着重要的辅助作用,是环境感知中不可缺少的一个部分。基于深度学习的车道线检测方法近年来也在不断的提升,比如论文:Ultra Fast Deep Lane Detection with HybridAnchor Driven Ordinal Classi…

目标检测 - 锚框总结
锚框是怎么生成的?
1. 参考:https://discuss.d2l.ai/t/topic/2946/2 里面的回答:(1) Aaron_L (2) toyou
2. 参考:https://zhuanlan.zhihu.com/p/455807888
3. 参考:https://blog.csdn.net/weixin_48192326/ar…
《一次性分割一切》阅读笔记
目录
0 体验
1 摘要
2 十个问题
参考文献 0 体验
体验地址:SEEM - a Hugging Face Space by xdecoder
体验结果:
将哈士奇和汽车人从图片中分割出来。 1 摘要
尽管对于交互式人工智能系统的需求不断增长,但在视觉理解(例如…

PaddleDetection目标检测数据准备——VOC数据集和COCO数据集
目标检测数据说明
目标检测的数据比分类复杂,一张图像中,需要标记出各个目标区域的位置和类别。
一般的目标区域位置用一个矩形框来表示,一般用以下3种方式表达:
表达方式说明x1,y1,x2,y2(x1,y1)为左上角坐标,(x2,y…
图片人群计数模型代码汇总-全网最全!crowd count model code repositoty
2017_Switch-CNN
2017_cite848_CVPR_Switching convolutional neural network for crowd counting
val-iisc/crowd-counting-scnn
2014_mrlzla/crowd_density_estimator
mrlzla/crowd_density_estimator
2018_SANet
2018_Cite490_ECCV_Cao——Scale Aggregation Network …
![[论文笔记]C^3F,MCNN:图片人群计数模型](https://img-blog.csdnimg.cn/e9025f1d6d7f4b349e9bae36b1cfe15f.png)
[论文笔记]C^3F,MCNN:图片人群计数模型
(万能代码)CommissarMa/Crowd_counting_from_scratch
代码:https://github.com/CommissarMa/Crowd_counting_from_scratch
(万能代码)C^3 Framework开源人群计数框架
科普中文博文:https://zhuanlan.zhihu.com/p/65650998
框架网址:https…

基于深度学习的水果检测与识别系统(Python界面版,YOLOv5实现)
摘要:本博文介绍了一种基于深度学习的水果检测与识别系统,使用YOLOv5算法对常见水果进行检测和识别,实现对图片、视频和实时视频中的水果进行准确识别。博文详细阐述了算法原理,同时提供Python实现代码、训练数据集,以…

libfacedetection 人脸检测库的基本使用
目录 1、源码下载
2、编译 3、构建工程
4、个人总结
运行总结:
与CascadeClassifier级联分类器 人脸检测 对比: 1、源码下载
直接从github上克隆项目仓库。 git clone https://github.com/ShiqiYu/libfacedetection.git2、编译
这个项目使用了cmake脚本&#…
3D Slicer学习记录(3)-OpenIGTLink实现MATLAB和Slicer数据交互-leap motion
前记在前面的记录中3D Slicer学习记录(2)-OpenIGTLink实现MATLAB和Slicer数据交互,我们已经知道如何用OpenIGTLink实现数据从matlab传递给3D Slicer了,这是一种思路,即可以基于此方法实现其它传感器的数据与3D Slicer之间的交互,包括机器人的运动控制,通过此方法做到同步…
【目标检测】目标检测中的标签分配
文章目录一、前言二、标签分配方法的分类2.1 标签是否非负2.2 是否有预测结果参与一、前言
在目标检测任务中,标签分配起着关键的作用,其目的是将样本划分成正样本和负样本,然后与GT之间计算loss,决定模型如何学习和收敛。
二、…

libfacedetection 人脸检测库 检测速度慢的问题
目录 一、libfacedetection 性能介绍
英特尔CPU 使用AVX2指令集 使用AVX512指令集
嵌入式设备 二、加速检测速度
libfacedetetion的前向推理速度很快的原因
使用axv2加速指令 一、libfacedetection 性能介绍
在上一篇文章中,我发现使用摄像头检测,构…
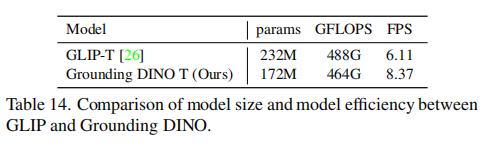
【AIGC】15、Grounding DINO | 将 DINO 扩展到开集目标检测
文章目录 一、背景二、方法2.1 特征抽取和加强2.2 Language-Guided Query Selection2.3 Cross-Modality Decoder2.4 Sub-sentence level text feature2.5 Loss Function 3、效果3.1 zero-shot transfer of grounding DINO3.2 Referring Object detection3.3 Ablations3.4 从 DI…
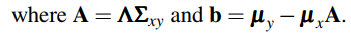
【论文翻译】RODEO: Replay for Online Object Detection
RODEO: Replay for Online Object Detection 用于在线目标检测的回放
论文地址:https://arxiv.org/abs/2008.06439
代码地址:GitHub - manoja328/rodeo: Official implementation of "RODEO: Replay for Online Object Detection", BMVC 202…
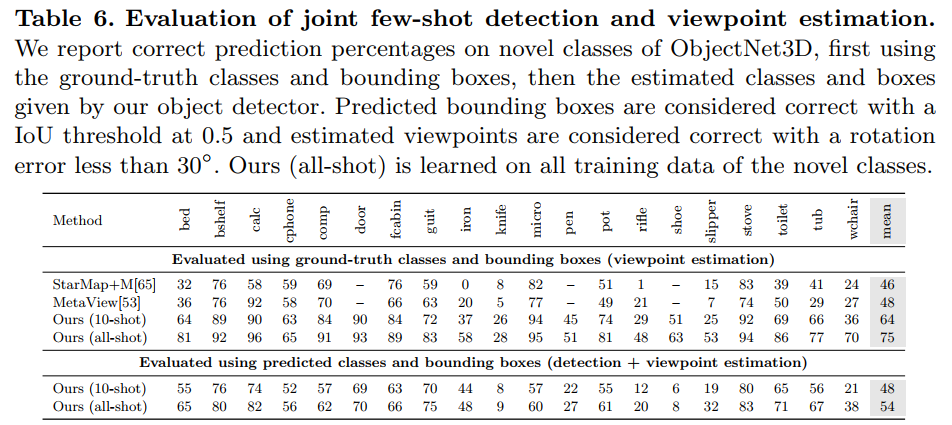
【论文翻译】Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild
Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild
野外目标的小样本目标检测与视点估计
论文地址:https://arxiv.org/pdf/2007.12107v1.pdf
代码地址:GitHub - YoungXIAO13/FewShotDetection: (ECCV 2020) PyTorch impl…

【论文翻译】UniT: Unified Knowledge Transfer for Any-Shot Object Detection and Segmentation
UniT: Unified Knowledge Transfer for Any-Shot Object Detection and Segmentation
UniT:任意样本量的目标检测和分割的统一知识转移
论文地址:https://openaccess.thecvf.com/content/CVPR2021/papers/Khandelwal_UniT_Unified_Knowledge_Transfer…
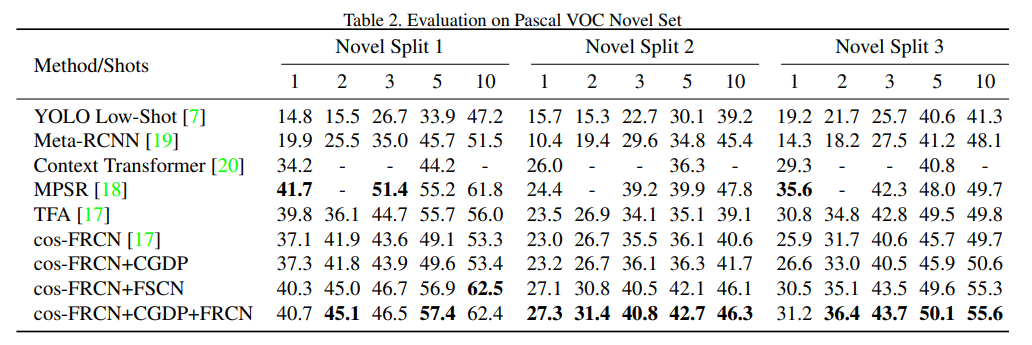
【论文翻译】Few-Shot Object Detection via Classification Refinement and Distractor Retreatment
Few-Shot Object Detection via Classification Refinement and Distractor Retreatment
基于分类细化和干扰物再处理的少样本目标检测
论文地址:CVPR 2021 Open Access Repository
1 摘要
We aim to tackle the challenging Few-Shot Object Detection (FSOD)…

英文论文(sci)解读复现【NO.7】基于注意机制的改进YOLOv5s目标检测算法
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…

【论文翻译】Faster ILOD:Incremental Learning for Object Detectors based on Faster RCNN
Faster ILOD:Incremental Learning for Object Detectors based on Faster RCNN
Faster ILOD:基于Faster RCNN的目标检测器增量学习
论文地址:https://arxiv.org/pdf/2003.03901.pdf
代码地址:无
目录
Abstract
1 Introduc…

【论文翻译】Class-Incremental Few-Shot Object Detection
Class-Incremental Few-Shot Object Detection
论文地址:https://arxiv.org/pdf/2105.07637.pdf
摘要
Conventional detection networks usually need abundant labeled training samples, while humans can learn new concepts incrementally with just a few e…
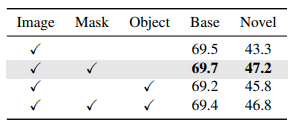
【论文总结】Few-shot Object Detection via Feature Reweighting(附翻译)
Few-shot Object Detection via Feature Reweighting基于特征重加权的小样本目标检测
论文地址:https://arxiv.org/abs/1812.01866
代码地址:https:// github.com/bingykang/Fewshot_Detection 小样本学习训练步骤: ①基于base类࿰…
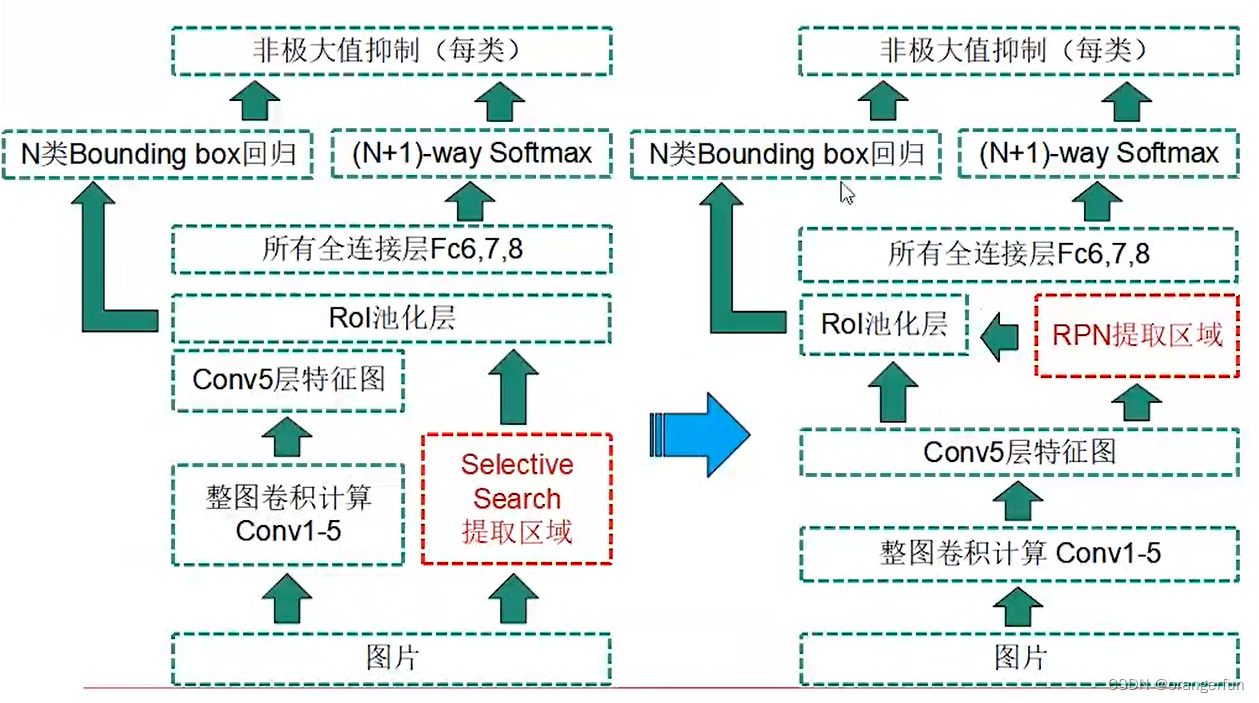
计算机视觉-目标检测(一):从 R-CNN 到 Faster R-CNN
文章目录 1. 概要2. 区域卷积卷积神经网络R-CNN2.1 模型结构2.2 Selective Search2.3 warp2.4 R-CNN训练2.5 R-CNN推理2.6 R-CNN性能评价2.7 R-CNN的缺点 3. SPP-Net3.1 SPP-Net对RCNN的改进3.2 SPP-Net网络结构3.3 SPP-Net训练过程3.4 SPP-Net的问题 4. Fast R-CNN4.1 Fast R-…


yolov4——你总能在这找到你想要的答案
目录
一:前言
二:一些数据增强的方法
三:自提议
四:dropout 普通的dropout yolov4的dropblock
五:Label smothing 标签平滑
六: GIOU,DIOU,CIOU
七: 对网络结构的…

基于深度学习的高精度奶牛检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度奶牛检测识别系统可用于日常生活中或野外来检测与定位奶牛目标,利用深度学习算法可实现图片、视频、摄像头等方式的奶牛目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型…
目标检测基础知识-IOU,NMS,Soft-NMS
1. IOU
交并比(Intersection-over-Union,IoU),目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的…
目标检测数据集:摄像头镜头缺陷检测数据集
✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨
本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的数据集会在该…

基于深度学习的高精度打电话检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度打电话检测识别系统可用于日常生活中或野外来检测与定位打电话目标,利用深度学习算法可实现图片、视频、摄像头等方式的打电话目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检…
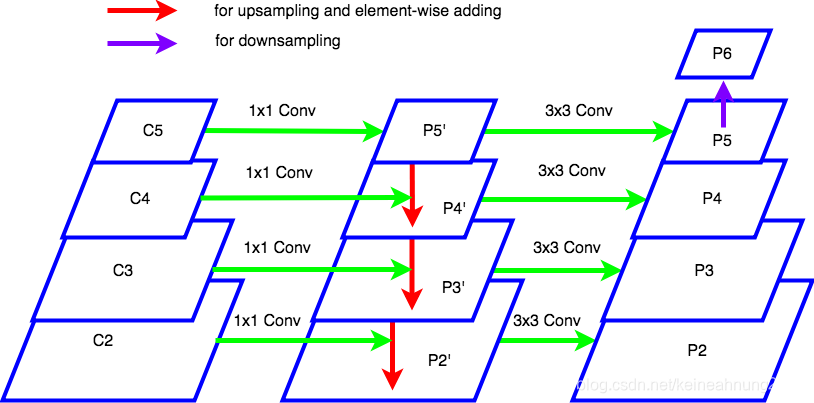
Mask_RCNN代碼研讀(matterport版本)系列文(二)- Feature Pyramid Network部份
Mask_RCNN代碼研讀(matterport版本)系列文(二)- Feature Pyramid Network部份前言訓練及推論模式中的共同部份Feature Pyramid Network小結參考連結前言
在本系列的第一篇Mask_RCNN代碼研讀(matterport版本࿰…

yolov5初次使用教程
yolov5初次使用教程yolov5初次使用教程1.yolov5源码的下载2.下载预训练好的权重参数文件3.安装Yolov5所需模块4.Yolov5测试yolov5初次使用教程
YOLO为一种新的目标检测方法,该方法的特点是实现快速检测的同时还达到较高的准确率。目前YOLO已经升级到YOLOv7了&#…
目标检测00-08:mmdetection(Foveabox为例)-源码无死角解析(1)-训练架构总览
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…

目标追踪00-02:FairMOT(实时追踪)-官方数据训练测试
以下链接是个人关FairMOT(多目标实时追踪) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。 目标追…

人工智能学习07--pytorch19--目标检测:常见指标(mAP计算+coco评价标准)
怎样才算正确检测到一个目标? 什么是IOU: https://blog.csdn.net/qq_51831335/article/details/125719420
mAP计算方法: 假设针对某一类别的AP情况 TP:预测正确的边界框个数。预测边界框与GT-box的IOU>0.5 FP:假…

YOLOv7 tiny 新增小目标检测层
YOLOv7 tiny 新增小目标检测层 YOLOv7 tiny 新增小目标检测层修改yolov7-tiny.yaml文件YOLOv7 tiny 结构图调用 models/yolo.py验证 YOLOv7 tiny 新增小目标检测层
根据已有的结构进行新增小目标层,,个人理解,仅供参考!ÿ…
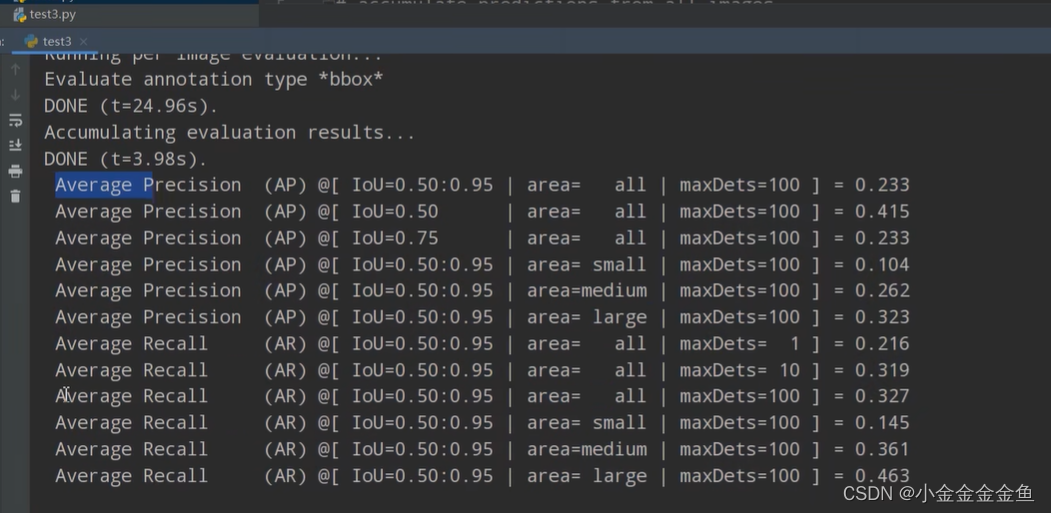
人工智能学习07--pytorch20--目标检测:COCO数据集介绍+pycocotools简单使用
如:天空 coco包含pascal voc 的所有类别,并且对每个类别的标注目标个数也比pascal voc的多。 一般使用coco数据集预训练好的权重来迁移学习。 如果仅仅针对目标检测object80类而言,有些图片并没有标注信息,或者有错误标注信息。…

目标追踪00-01:FairMOT(实时追踪)-资源下载(前奏准备)
以下链接是个人关FairMOT(多目标实时追踪) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。 目标追…

基于YOLOv8模型的人体摔倒行为检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的人体摔倒行为检测系统可用于日常生活中检测与定位摔倒行人,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数…
行人检测0-09:LFFD-源码无死角解析(4)-预测代码解析
以下链接是个人关于LFFD(行人检测)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。文末附带\color…
行人检测0-03:LFFD-白话给你讲论文-翻译无死角(2)
以下链接是个人关于LFFD(行人检测)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。文末附带\color…

【智慧交通项目实战】《 OCR车牌检测与识别》(一)
👨💻作者简介: CSDN、阿里云人工智能领域博客专家,新星计划计算机视觉导师,百度飞桨PPDE,专注大数据与AI知识分享。✨公众号:GoAI的学习小屋 ,免费分享书籍、简历、导图等…
行人检测0-07:LFFD-源码无死角解析(2)-数据预处理讲解(重点篇)
以下链接是个人关于LFFD(行人检测)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励,祝你…

【论文阅读】3D点云 -- BRNet:Back-tracing Representative Points for Voting-based3D Object Detection in PC
前言 该篇论文是对3D室内点云 进行目标检测的方法的研究。其方法是基于votenet方法上进行的改良。所以了解这篇论文方法,需要先了解votenet。 votenet主要问题为:尽管投票聚集中心非常准确,但投票点通常不像我们预期的那样具有代表性。种子…

目标检测第三篇:基于SSD的目标检测算法
文章目录 SSD简介网络搭建卷积块下采样块主干网多层特征提起层输出头 数据处理形成训练TXTDatasetDataLoaderAnchors生成先验框匹配先验框位置 offset 损失函数训练代码及参考 SSD简介
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提…

点云目标检测BRNET || 2. 基于MMDetection3D的处理数据思路
借着使用BRNET工程之际,了解下MMDetection3D框架相关的内容 1. MMDetection3D的数据处理的类 对于数据处理,MMDetection3D针对每种3D数据集,在代码中实现了一个类来进行数据的处理。在工程【test/test_data/test_datasets/】路径下࿰…

论文阅读 || 目标检测系列——yolov4 详细解读
摘要 目前有很多算法可以提高CNN的准确性。在大量数据集上结合这些算法进行实际测试、在实验结果上理论的验证是十分必要的。一些算法操作单一针对特定的模型、或者特定的问题、又或者小规模的数据集 有效;有些算法适用于大多数模型、任务、数据集,例如批…

基于深度学习的高精度水下目标检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度水下目标(鱼(fish)、水母(jellyfish)、企鹅(penguin)、海鹦(puffin)、鲨鱼(shark)、海星(starf…
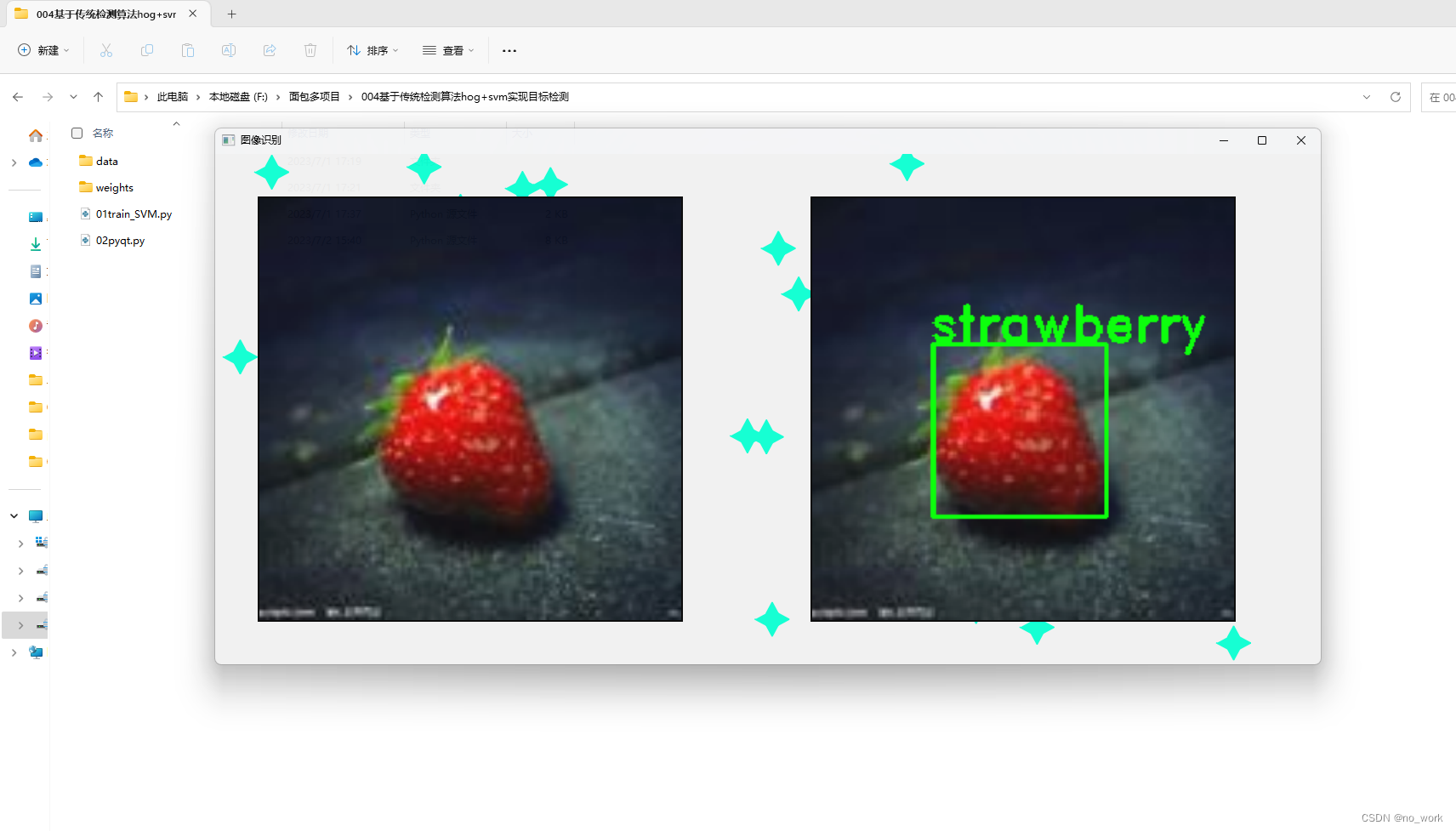
基于传统检测算法hog+svm实现目标检测
直接上效果图: 代码仓库和视频演示b站视频004期:
到此一游7758258的个人空间-到此一游7758258个人主页-哔哩哔哩视频
代码展示: 数据集在data文件夹下
需要检测的目标对象数据集放在positive文件夹下 不需要的检测对象放在negative文件夹下…
【目标检测适用】批量修改xml文件中的name字段
前言:使用labelimg进行标注的时候,由于都是用的是默认的名称,有时候类的名字会出现拼写错误,比如我想要写的是“cow” 结果打上去的是“cwo”, 一出错就错一片,这很常见,所以参考了:https://www…
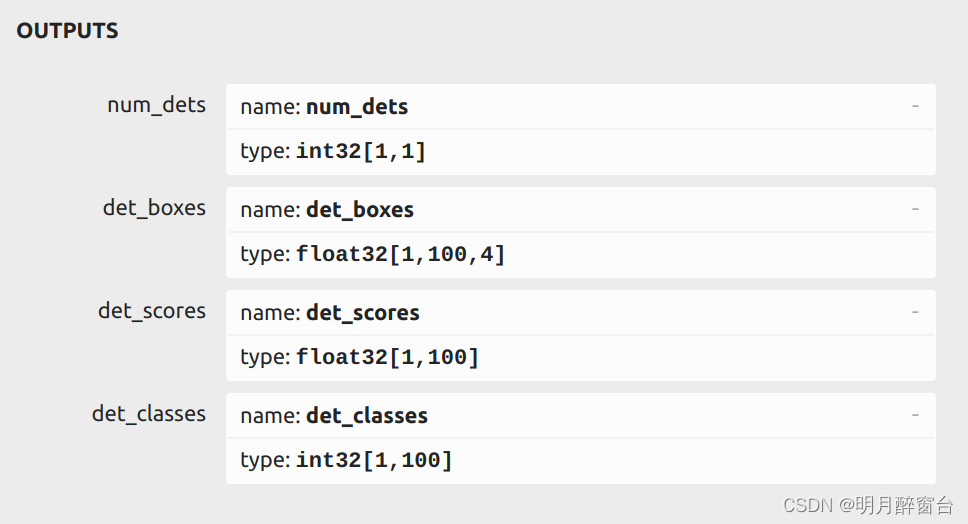
(24)目标检测算法之YOLOv6 (2)量化与部署详解
目标检测算法之YOLOv6 (2)量化与部署详解 详解量化训练方式 详解部署方法:onnx 、openvnio、 tensorrt YLOLOv6目前发布的模型:从模型大小方面来看,可分为微小型(Nano),小(Small),中(Medium),大模型(Larg…

基于深度学习的高精度红外行人车辆检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度红外行人车辆检测识别系统可用于日常生活中或野外来检测与定位红外行人车辆目标,利用深度学习算法可实现图片、视频、摄像头等方式的红外行人车辆目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系…
【三维目标分类 】PointNet详解(一)
Pointnet是基于点云的三维目标检测网络,也是三维深度学习目标检测的基础网络之一。PointNet文章作者关于三维物体检测的讲解请参考3D物体检测的发展与未来 - 深蓝学院 - 专注人工智能与自动驾驶的学习平台。本节将参考Github上的源码进行介绍,GitHub地址…
![[目标检测算法] 从R-CNN、Fast R-CNN、Faster R-CNN、R-FCN 到 FPN](https://static.leiphone.com/uploads/new/article/740_740/201805/5af264ca49bf2.png?imageMogr2/format/jpg/quality/90)
[目标检测算法] 从R-CNN、Fast R-CNN、Faster R-CNN、R-FCN 到 FPN
「目标检测算法」从Faster R-CNN 、 R-FCN 到 FPN 在这个系列中,我们将对目标检测算法进行全面探讨。 第 1 部分,我们介绍常见的基于区域的目标检测器,包括 Fast R-CNN , Faster R-CNN , R-FCN 和 FPN 。 第 2 部分&a…


YOLOFaceV2笔记
论文地址:2022-CVPR-YOLO-FaceV2: A Scale and Occlusion Aware Face Detector 论文代码:https://github.com/Krasjet-Yu/YOLO-FaceV2
Abstract
现有目标(人脸)检测算法已取得很大的进展,如BlazeFace、RetinaFace、R…
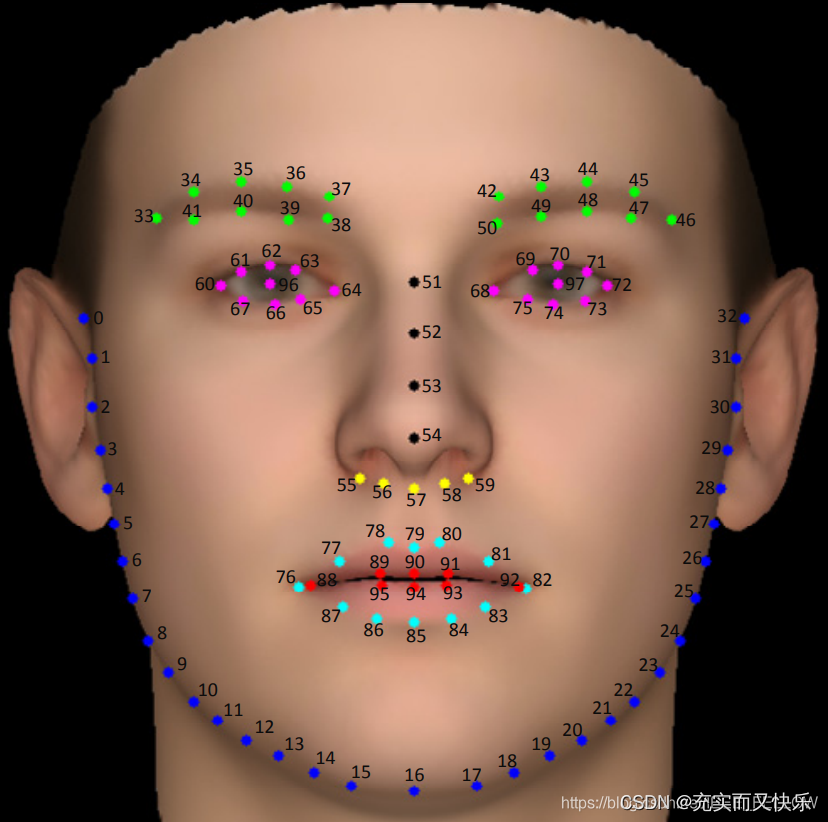
yolov5facce-landmarks(98点)
关于如何使用自己数据集来训练yolo5vface,主要包括两部分:(1) 数据集标签信息的理解与标签信息格式转换;(2) 基于yolov5face源代码进行后续的代码修改。
主要代码修改部分可直接参考长方形混凝土瞬间移动师-yolov5-face学习笔记 本文仅作为个…

EffificientDet: Scalable and Effificient Object Detection
动机:
Is it possible to build a scalable detection architecture with both higher accuracy and better efficiency across a wide spectrum of resource constraints (e.g., from 3B to 300B FLOPs)? 【CC】开门见山:基于不同的算力构建一族网络 …
最强AI标注工具CVAT(检测、旋转目标检测、分割、3d目标检测、关键点识别、姿势识别、车道线等)从搭建到使用的最详细攻略
目录 1.CVAT1.1 重要链接1.2 install1.2.1 basic1.2.2 advanced(1) 半自动标注和自动标注(2)显卡支持1.3 标注教程1.3.1: 采集数据1.3.2: 新建task,上传数据,完成基础设置1.3.3: 任务分割和指定1.3.4:标注工作1.4 label funciton(1)标注介绍:A 2D bbox(Rectangle) -

GitHub加速网址及使用教程
TOGitHub镜像网址及使用教程C
GitHub加速网址及使用教程
网址
点击,有需要的大家可以自行收藏使用。
介绍
该镜像网址是综合多个国外、国内开源软件镜像站,包括google搜索引擎加速器、GitHub访问加速器、一些国内大牛公司的开源镜像站和几个高校的开…
基于python的hog+svm+nms机器学习实现目标检测
先上效果图: 本期做的是基于python的hog+svm机器学习实现目标检测。检测的内容如上图所示是草莓,正样本数据集是草莓,负样本是其他图片。
整个代码截图如下: data数据集下有两个文件夹,分别用于存放训练的正样本数据,就是我们要检测的对象 然后是负样本数据,就是我们可…
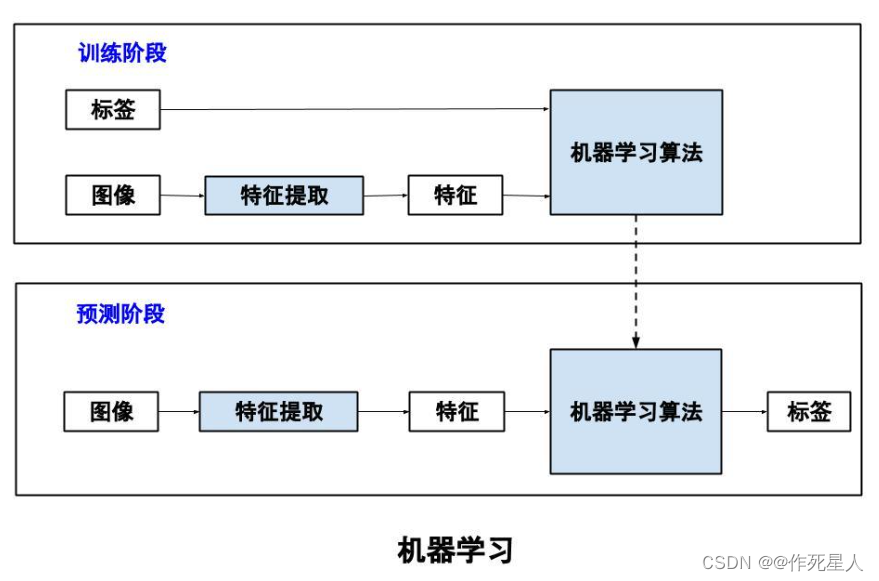
机器视觉初步8:特征提取专题
文章目录 1.角点检测2.纹理特征提取3.特征描述符匹配3.1 Harris角点描述符3.2 SIFT(尺度不变特征变换)描述符3.3 SURF(加速稳健特征)描述符 4.基于深度学习的特征提取 在机器视觉中,特征提取是从目标图像中提取有用的视…
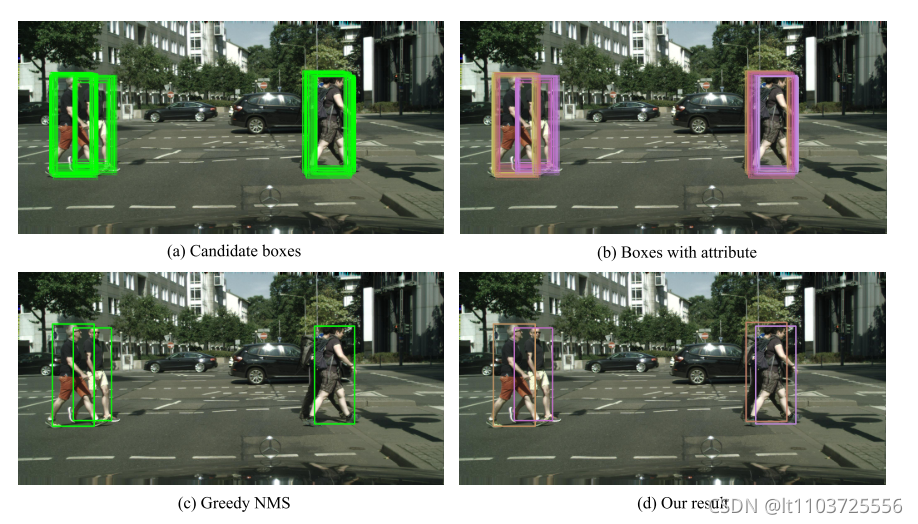
Attribute-aware Pedestrian Detection in a Crow
APD,citypersons的SOTA,主要解决重叠目标的问题 普通NMS流程: 对于最后输出的所有框 (1)找到预测置信度最大的框M (2)计算其他同类框和M的IOU (3)将IOU大于阈值N_t的框的置信度置0 普通NMS的问题: 两(多)个同类物体的IOU特别大的时候…
![[教程]目标检测格式转换xml-txt-csv-yolox水果识别小项目](https://img-blog.csdnimg.cn/a5fc713d9504416b82be543da2bb4d4e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5p2t5ryC5LiA5peP5bCP5byg,size_12,color_FFFFFF,t_70,g_se,x_16)
[教程]目标检测格式转换xml-txt-csv-yolox水果识别小项目
这个专栏更新各种AI,以及各种有趣的教程,有兴趣的小伙伴可以订阅一下。
目标检测的时候,精彩会遇到公开数据集给的标签格式是txt或xml或excel的形式,这时候我们用某一版本的算法时,就需要我们将标签格式进行转换。
比如以下的水果识别小项目,
这里给的数据集是3845张水…

使用 Python 中的 Langchain 从零到高级快速进行工程
大型语言模型 (LLM) 的一个重要方面是这些模型用于学习的参数数量。模型拥有的参数越多,它就能更好地理解单词和短语之间的关系。这意味着具有数十亿个参数的模型有能力生成各种创造性的文本格式,并以信息丰富的方式回答开放式和挑战性的问题。 ChatGPT 等法学硕士利用 T

DiffusionDet: Diffusion Model for Object Detection
DiffusionDet: Diffusion Model for Object Detection 论文概述不同之处整体流程 论文题目:DiffusionDet: Diffusion Model for Object Detection 论文来源:arXiv preprint 2022 论文地址:https://arxiv.org/abs/2211.09788 论文代码…

基于Yolov5与LabelImg训练自己数据的完整流程
基于Yolov5与LabelImg训练自己数据的完整流程 1. 创建虚拟环境2. 通过git 安装 ultralytics3. 下载yolov54. 安装labelImg标注软件5. 使用labelImg进行标注,图片使用上面的coco1285.1 点击“打开目录”选择存储图像的文件夹进行标注,右下角会出现图像列表…
Ubuntu软件源、pip源大全,国内网站网址,阿里云、网易163、搜狐、华为、清华、北大、中科大、上交、山大、吉大、哈工大、兰大、北理、浙大
文章目录 一、企业镜像源1、阿里云2、网易1633、搜狐镜像4、华为 二:高校镜像源1、清华源2、北京大学3、中国科学技术大学源 (USTC)4、 上海交通大学5、山东大学6、 吉林大学开源镜像站7、 哈尔滨工业大学开源镜像站8、 西安交通大学软件镜像…

OpenCV实例(九)基于深度学习的运动目标检测(三)YOLOv3识别物体
基于深度学习的运动目标检测(三)YOLOv3识别物体 1.基于YOLOv3识别物体2.让不同类别物体的捕捉框颜色不同3.不用Matplotlib实现目标检测 目标检测,粗略地说就是输入图片/视频,经过处理后得到目标的位置信息(比如左上角和…
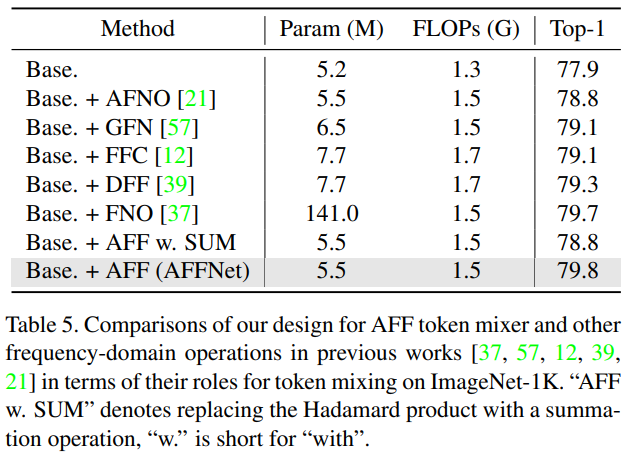
【ICCV2023】Adaptive Frequency Filters As Efficient Global Token Mixers
Adaptive Frequency Filters As Efficient Global Token Mixers
论文:https://arxiv.org/abs/2307.14008
代码:暂未开源
解读:ICCV23|轻量级视觉主干网络AFFNet:频域自适应频段过滤空域全局动态大卷积核 - 知乎 (zh…
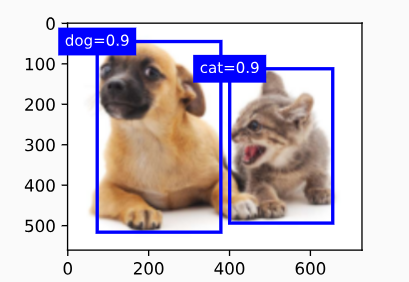
【动手学深度学习】--21.锚框
锚框
学习视频:锚框【动手学深度学习v2】
官方笔记:锚框
1.锚框 目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(gro…

OpenCV基础知识(8)— 图形检测
前言:Hello大家好,我是小哥谈。图形检测是计算机视觉的一项重要功能。通过图形检测可以分析图像中可能存在的形状,然后对这些形状进行描绘,例如搜索并绘制图像的边缘,定位图像的位置,判断图像中有没有直线、…
YOLO目标检测——真实和人工智能生成的合成图像数据集下载分享
YOLO真实和人工智能生成的合成图像数据集,真实场景的高质量图片数据,图片格式为jpg,数据场景丰富。可用于检测图像是真实的还是由人工智能生成。 数据集点击下载:YOLO真实和人工智能生成的合成图像数据集120000图片数据说明.rar
jetson nano上手记录
英伟达Jetson nano A02上手记录1、 硬件介绍2、上手使用1、获取镜像2、开始使用3、CUDA和CUDNN配置4、 opencv测试3、部署深度学习1、电源选配2、增大内存空间3、资源查看工具4、跑通darknet1、前期准备2、图片检测3、视频检测4、csi摄像头检测5、usb摄像头检测4、TensorRT优化…
快速构建基于Paddle Serving部署的Paddle Detection目标检测Docker镜像
快速构建基于Paddle Serving部署的Paddle Detection目标检测Docker镜像 项目介绍需要重点关注的几个文件构建cpu版本的docker构建gpu版本的docker(cuda11.2cudnn8) 阅读提示: (1)Paddle的Serving项目中,在t…
You Only Look Once: Unified,Real-Time Object Detection
摘要
YOLO将目标检测问题看作是一个回归问题,进而从整张图像中直接直接得到bounding boxes和对应的class probabilities。
1. 介绍
之前的工作都是将检测任务看成是一个分类问题,如RCNN,通过区域提取,分类,区域修正…
faster rcnn训练过程出现loss=nan的解决办法
出现了lossnan说明模型发散,此时应该停止训练。 出现这种错误的情况可能有以下几种,根据你自己的情况来决定。
1、GPU的arch设置的不对
打开./lib/setup.py文件,找到第130行,将gpu的arch设置成与自己电脑相匹配的算力ÿ…

论文解析: Bag of Freebies for Training Object Detection Neural Networks
目标检测必读论文解读: Bag of Freebies for Training Object Detection Neural Networks 目录目标检测必读论文解读: Bag of Freebies for Training Object Detection Neural NetworksContribution:Methodology:1. 提出了一种mixup的数据增强技巧&#…
目标检测相关的基础知识
本篇文章希望可以总结一下常见的目标检测基础知识和炼丹技巧,以免在实际工作遇到问题的时候没有办法分析和解决 本篇博客目录目标检测:常见trick:1.必读paper:Bag of Freebies for Training Object Detection Neural Networks2. L…
运行ObjectDetection-OneStageDet里的make时报错
按照腾讯优图实验室开源的One-Stage目标检测项目里的教程进行复现时,进行到Preparation里的make -j32时报错 raise EnvironmentError(The nvcc binary could not be located in your $PATH. Either add it to your path, or set $CUDAHOME) 看了下应该是环境变量有问…
[OPENCV]009.目标检测
1.级联分类器
在这里,我们学习如何使用objdetect来寻找我们的图像或视频中的对象
在本教程中, 我们将学习Haar级联目标检测的工作原理。 我们将看到使用基于Haar特征的级联分类器进行人脸检测和眼睛检测的基础知识 我们将使用cv::CascadeClassifier类来检测视频流…
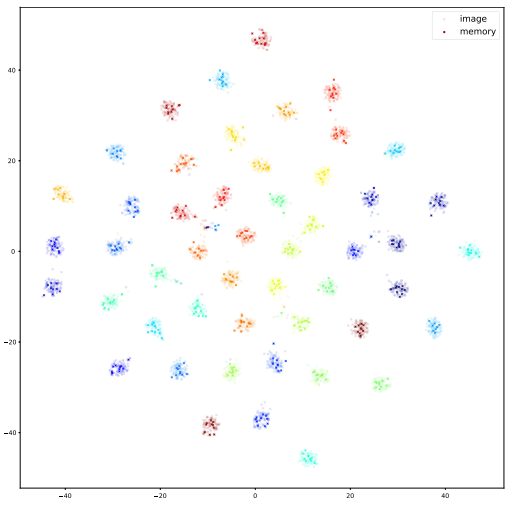
【论文翻译】Many-Class Few-Shot Learning on Multi-Granularity Class Hierarchy
Many-Class Few-Shot Learning on Multi-Granularity Class Hierarchy
多粒度类层次上的多类少样本学习
摘要
We study many-class few-shot (MCFS) problem in both supervised learning and meta-learning settings. Compared to the well-studied many-class many-shot …
图像标注工具labelImg使用方法
最近在做打标签的工作,为了与大家参考学习,总结了在windows的环境下,基于anaconda的图像标注工具labellmg的一种使用方法!
labelImg 下载链接: https://pan.baidu.com/s/1Re6OZzQ8pF9yA2c_X2QNuw 提取码: iprs
1. 运行labellmg文…

TensorBoard详解之安装使用和代码介绍
目录1.TensorBoard详解1.1 环境1.2 安装1.3 展示1.4说明2.使用2.1步骤2.2常用镜像网址3.代码讲解3.1 函数介绍3.2 示例代码1.TensorBoard详解
TensorBoard是一个可视化的模块,该模块功能强大,可用于深度学习网络模型训练查看模型结构和训练效果…
YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测+k折交叉验证法)
YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测k折交叉验证法)
0.引言 k折交叉验证(K-Fold Cross-Validation)是一种在机器学习中常用的模型评估技术,用于估计模型的性…
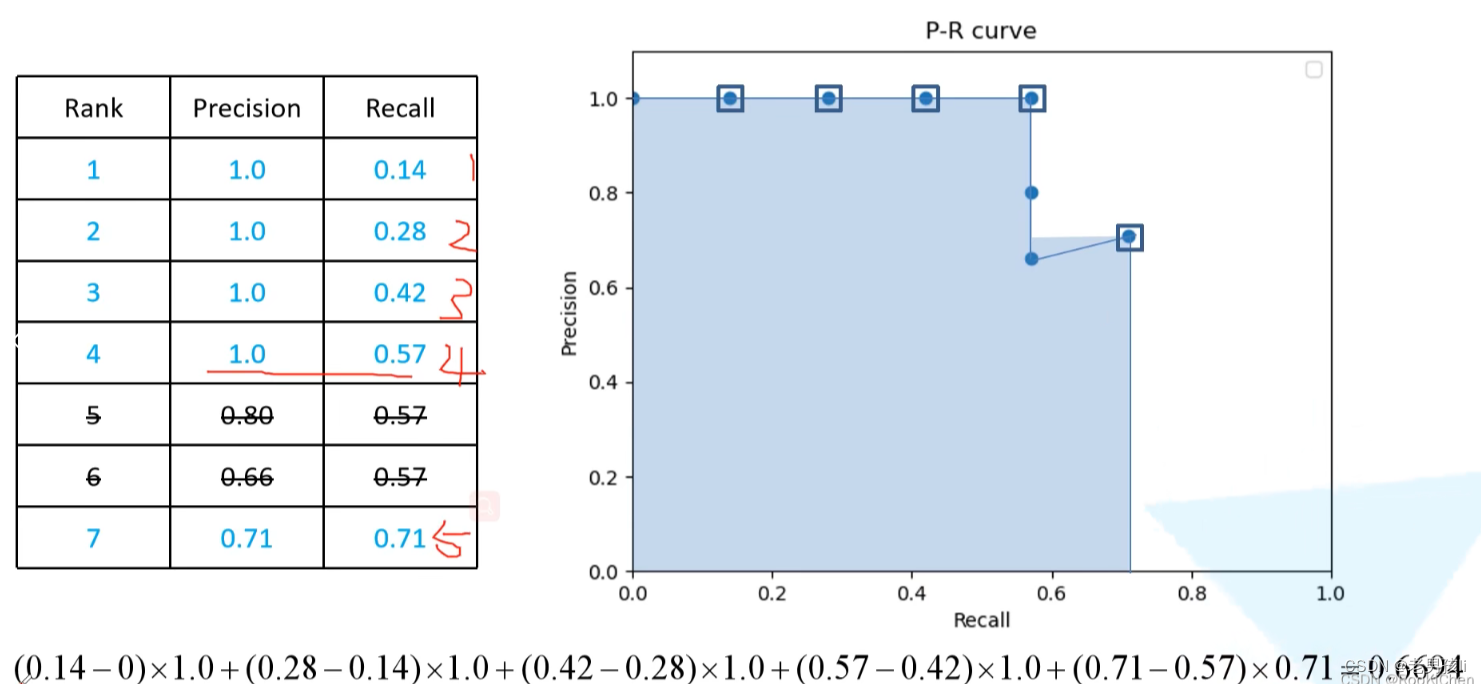
图像检索,目标检测map的实现
一、图像检索指标Rank1,map
参考:https://blog.csdn.net/weixin_41427758/article/details/81188164?spm1001.2014.3001.5506
1.Rank1:
rank-k:算法返回的排序列表中,前k位为存在检索目标则称为rank-k命中。
常用的为rank1:首…
Yolov8小目标检测(11):多维协作注意模块MCA | 原创独家创新首发
💡💡💡本文改进:多维协作注意模块MCA,效果秒杀ECA、SRM、CBAM,创新性十足,可直接作为创新点使用。 MCA | 亲测在红外弱小目标检测涨点,map@0.5 从0.755提升至0.769
💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系…
数据集学习笔记(六):目标检测和图像分割标注软件介绍和使用,并转换成YOLO系列可使用的数据集格式
文章目录 一、目标检测1.1 labelImg1.2 介绍1.3 安装1.4 使用1.5 转换1.6 验证 二、图像分割2.1 labelme2.2 介绍2.3 安装2.4 使用2.5 转换2.6 验证 一、目标检测
1.1 labelImg
1.2 介绍
labelImg是一个开源的图像标注工具,用于创建图像标注数据集。它提供了一个…

Yolov8小目标检测(12):动态稀疏注意力BiFormer | CVPR 2023
💡💡💡本文改进:动态稀疏注意力,cvpr2023。 BiFormer | 亲测在红外弱小目标检测涨点,map@0.5 从0.755提升至0.758
💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,带你轻松实现小…
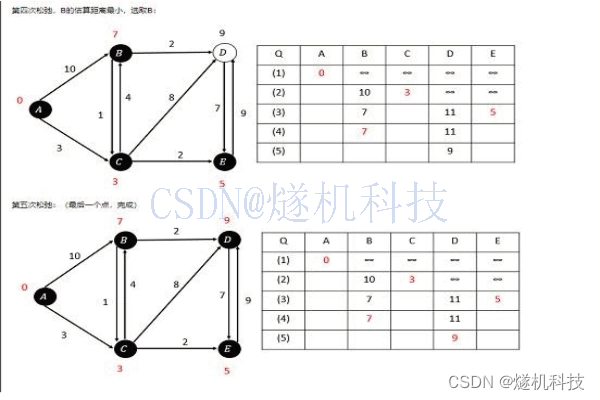
金属矿山电子封条系统 yolov5
金属矿山电子封条通过pythonyolov5网络模型框架算法,金属矿山电子封条算法识别到运输设备启动运行或者识别到运输设备运行工作状态下有煤、无煤转换,进行预警分析,金属矿山电子封条算法利用智能化视频识别等技术,实时监测分析矿井出入井人员、…
multibox_prior函数锚框生成部分个人理解
在最近自学李沐沐神的《动手学深度学习》中,一直在研究这个方法里的代码,属实是差点把我整崩溃了,在网上找了许多参考还是看的很崩溃,在近一周的折磨中找到了一个理解的方法,那就是设置自定义初始值去逐句分析…

YOLO目标检测——时间检测数据集下载分享
时间数据集是表示一天中不同时间的图像集合,日出和日落被视为同一类别。数据集包含日出/日落、白天场景和夜间场景的图像,并已重新缩放为 224 x 224 x 3 像素,描绘了不同的地点和不同的天气条件,如晴朗的天空,阴天等。…

CPSC上月召回案例涉及多款常见产品有哪些?
CPSC上月召回案例涉及多款常见产品有哪些?
每年的夏末秋初为美国产品热销节日(感恩节、万圣节、黑五)的备货期,卖家在大量备货的同时,务必保障自身产品通过相关安全测试,以免造成不必要的损失࿰…
faster-rcnn.pytorch项目环境配置(从0到1)
faster-rcnn.pytorch项目环境配置(从0到1)
其实pytorch版本和CUDA版本高,都没有关系!!!都可以适配,显卡30系、20系都没关系,都可以用!
下面我将在AutoDL平台上…

【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(7 月 4 日论文合集)
文章目录 一、检测相关(15篇)1.1 Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization1.2 Shi-NeSS: Detecting Good and Stable Keypoints with a Neural Stability Score1.3 HODINet: High-Order Discrepant Interaction Network for…

MATLAB开发计算机视觉——目标检测与跟踪
MATLAB里面的computer vision system toolbox工具库具有丰富的功能函数来实现计算机视觉中目标检测与跟踪的操作实现。本篇是基于MATLAB中帮助文档概括出来的初步认识框架。
目标检测YOLO实战应用案例100讲-道路场景下目标检测与分割模型的压缩研究与实现(续)
目录
道路场景下目标检测与语义分割模型的改进研究
3.1 道路场景数据集分析
3.1.1 Cityscapes数据集

YOLOv5算法改进(14)— 更换Neck之BiFPN
前言:Hello大家好,我是小哥谈。BiFPN ( Bidirectional Feature Pyramid Network )是一种加权双向(自顶向下 自底向上)特征金字塔网络,是目标检测中神经网络架构设计的选择之一,是为…

目标检测模型推理实验记录
在进行目标检测算法的学习过程中,需要进行对比实验,这里可以直接使用MMDetection框架来完成,该框架集成了许多现有的目标检测算法,方便我们进行对比实验。
环境配置
首先是环境配置,先前博主曾经有过相关方面的配置&…
YOLO-NAS详细教程-介绍如何进行物体检测
对象检测是计算机视觉中的一项核心任务,可以检测和分类图像中的边界框。自从深度学习首次取得突破以来,它就以极快的速度获得普及和普及,并推动了医疗领域、监控、智能购物等众多公司的发展。考虑到它最终满足了两个基本需求,这一点也就不足为奇了端到端方式:找到所有当前…

YOLO目标检测——视觉显著性检测MSRA1000数据集下载分享
MSRA1000数据集是一个常用的视觉显著性检测数据集,它包含了1000张图像和对应的显著性标注。在以下几个应用场景中,MSRA1000数据集可以发挥重要作用:图像编辑和后期处理、图像检索和分类、视觉注意力模型、自动驾驶和智能交通等等 数据集点击下…
目标检测YOLO实战应用案例100讲-水下机器人视域中小目标检测(中)
目录
2.7.4在PASCAL VOC数据集上的检测实验
3基于注意力空间金字塔池化模型的水下目标检测方法
3.1引言
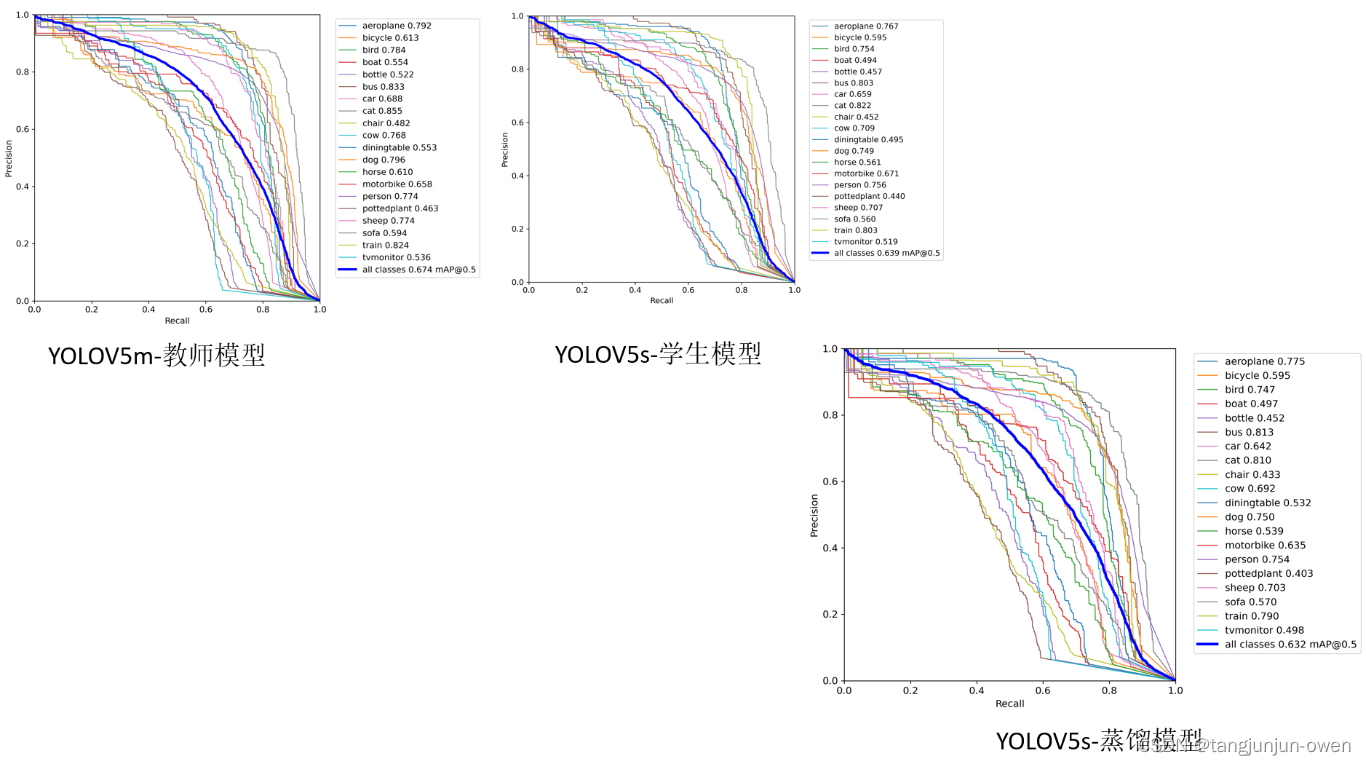
基于yolov5模型的目标检测蒸馏(LD+KD)
文章目录 前言一、Distillation理解1、Knowlege distillation2、Feature distillation3、Location distillation4、其它蒸馏 二、yolov5蒸馏模型构建1、构建teacher预测模型2、构建蒸馏loss3、蒸馏模型代码图示模型初始化模型蒸馏 三、蒸馏模型实验1、工程数据测试2、voc2012开…
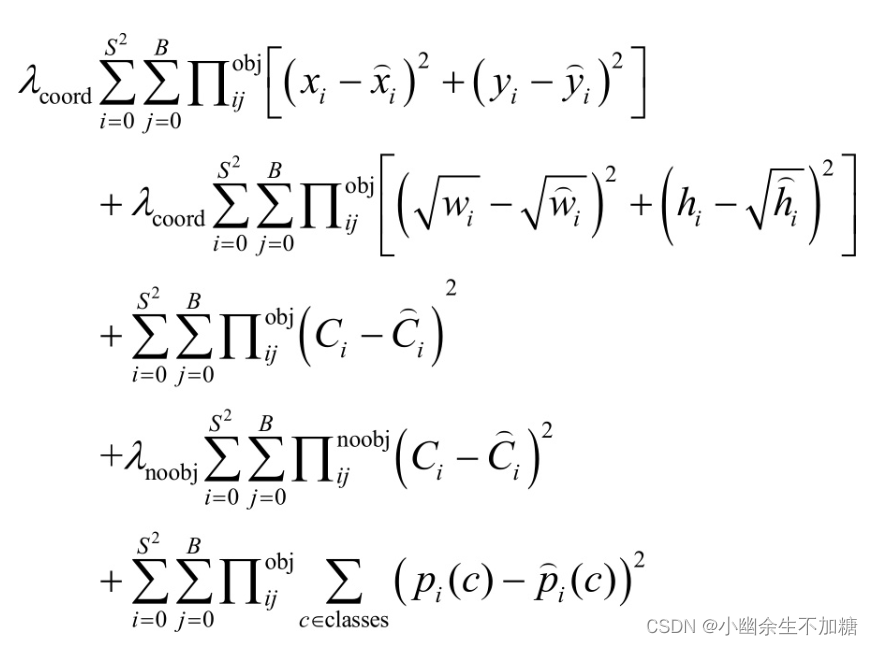
OpenCV实例(九)基于深度学习的运动目标检测(一)YOLO运动目标检测算法
基于深度学习的运动目标检测(一) 1.YOLO算法检测流程2.YOLO算法网络架构3.网络训练模型3.1 训练策略3.2 代价函数的设定 2012年,随着深度学习技术的不断突破,开始兴起基于深度学习的目标检测算法的研究浪潮。
2014年,…
[数据集][目标检测]道路坑洼目标检测数据集VOC格式1510张2类别
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):1510 标注数量(xml文件个数):1510 标注类别数:2 标注类别名称:["keng","…

Tesseract用OpenCV进行文本检测
我没有混日子,只是辛苦的时候没人看到罢了 一、什么是Tesseract
Tesseract是一个开源的OCR(Optical Character Recognition)引擎,OCR是一种技术,它可以识别和解析图像中的文本内容,使计算机能够理解并处理…

基于 Transformation-Equivariant 的自动驾驶 3D 目标检测
论文地址:https://arxiv.org/abs/2211.11962 论文代码:https://github.com/hailanyi/TED
论文背景
三维场景中的物体分布有不同的方向。普通探测器不明确地模拟旋转和反射变换的变化。需要大的网络和广泛的数据增强来进行鲁棒检测。
equivariant netw…
box_iou交并比及assign_anchor_to_bbox个人理解
接上篇文章,李沐沐神的《动手学深度学习》中的show_bboxes还是比较好理解的,于是来看这两个方法 以下内容建议对照源代码理解
def box_iou
首先我们来设置boxes1和boxes2的初始值
boxes1 torch.tensor([[1,2,5,6],[2,1,4,6],[-1,2,7,6],[1,2,5,8]])
…

YOLO目标检测——工地安全帽识别检测数据集+已标注yolo格式标签下载分享
实际项目应用:目标检测工地安全帽识别检测数据集在工地安全监测、工地管理、安全培训和教育、违规检测和预警以及安全统计和分析等领域都有着广泛的应用。通过准确识别和检测工人是否佩戴安全帽,可以帮助提高工地的安全性和管理效率,减少事故…
[数据集][目标检测]垃圾目标检测数据集VOC格式14963张44类别
数据集格式:Pascal VOC格式(不包含分割的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):14963 标注数量(xml文件个数):14963 标注类别数:44 标注类别名称:["toiletries","plastic utensi…

目标检测笔记(十四): 使用YOLOv8完成对图像的目标检测任务(从数据准备到训练测试部署的完整流程)
文章目录 一、目标检测介绍二、YOLOv8介绍三、源码获取四、环境搭建4.1 环境检测 五、数据集准备六、 模型训练6.1 方式一6.2 方式二6.3 针对其他任务 七、模型验证八、模型测试九、模型转换9.1 转onnx9.1.1 方式一 9.2 转tensorRT9.2.1 trtexec9.2.2 代码转换9.2.3 推理代码 一…

史上最详细的PyCharm安装教程,小白建议收藏!
前言:Hello大家好,我是小哥谈。PyCharm是由JetBrains公司开发的一款Python开发工具,在Windows、Mac OS和Linux操作系统中都可以使用,它具有语法高亮显示、Project(项目)管理、代码跳转、智能提示、自动完成…
目标检测数据集:医学图像检测数据集(自己标注)
1.专栏介绍
✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨ 本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的…
yolov8-ros目标检测---硬件与仿真环境中区别
为了完成使用realsenseD435i相机在真实环境下的目标检测任务,下载了realsense-ros和yolo8-ros功能包(都在工作空间src下)。分两种情况,1、使用真实硬件(如realsenseD435i)。2、在纯仿真环境下进行目标识别&…
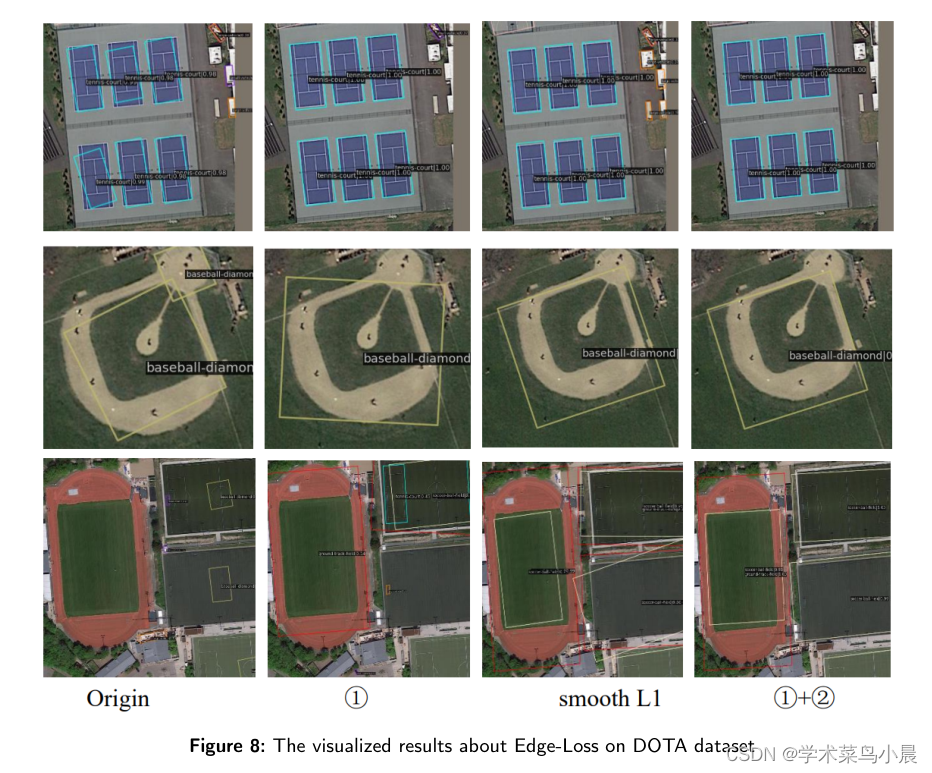
目标检测:Edge Based Oriented Object Detection
论文作者:Jianghu Shen,Xiaojun Wu
作者单位:Harbin Institute of Technology Shenzhen
论文链接:http://arxiv.org/abs/2309.08265v1
内容简介:
1)方向:遥感领域中的目标检测技术
2)应用&…
基于PyTorch的交通标志目标检测系统
一、开发环境
Windows 10PyCharm 2021.3.2Python 3.7PyTorch 1.7.0
二、制作交通标志数据集,如下图 三、配置好数据集的地址,然后开始训练 python train.py --data traffic_data.yaml --cfg traffic_yolov5s.yaml --weights pretrained/yolov5s.pt --e…
C# OpenVino Yolov8 Detect 目标检测
效果
项目 代码
using OpenCvSharp;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using static System.Net.Mime.MediaT…
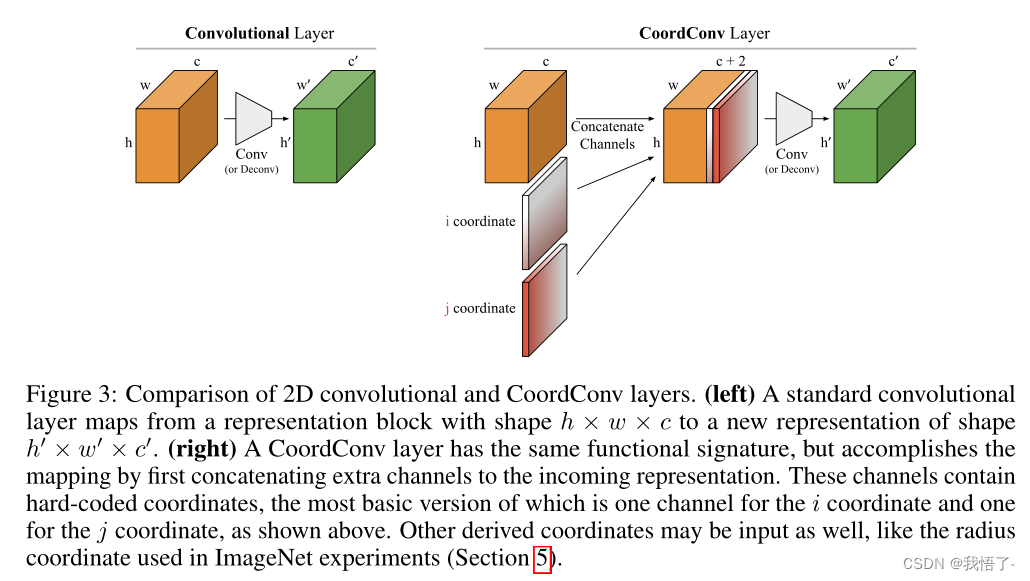
pytorch代码实现之CoordConv卷积
CoordConv卷积
在深度学习领域,几乎没有什么想法能像卷积那样产生如此大的影响。对于任何涉及像素或空间表示的问题,普遍的直觉认为卷积神经网络可能是合适的。在本文中,我们通过看似平凡的坐标变换问题展示了一个惊人的反例,该问…

YOLO目标检测——红火蚂蚁识别数据集+已标注yolo格式标签下载分享
实际项目应用:目标检测红火蚂蚁识别数据集在农业、生态学、环境保护、城市管理和学术研究等领域都有着广泛的应用。通过准确识别和定位红火蚂蚁,可以帮助我们更好地了解和管理这一入侵物种,从而减少其对环境和经济的负面影响。数据集说明&…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(8 月 31 日论文合集)
文章目录 一、检测相关(9篇)1.1 Boosting Detection in Crowd Analysis via Underutilized Output Features1.2 CircleFormer: Circular Nuclei Detection in Whole Slide Images with Circle Queries and Attention1.3 Exploring Multi-Modal Contextual Knowledge for Open-V…
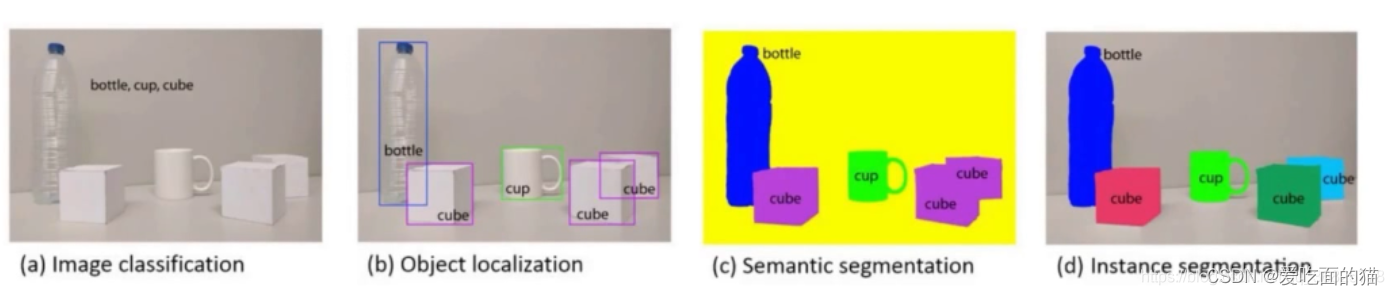
01深度学习目标检测引入
目标检测是计算机视觉领域的一个重要任务,旨在从图像或视频中准确地检测和定位特定的目标物体。
一、目标检测问题定义 目标检测是在图片中对可变数量的目标进行查找和分类。 二、目标检测过程中的常见的问题
目标种类和数量问题目标尺度问题外在环境干扰问题
三…
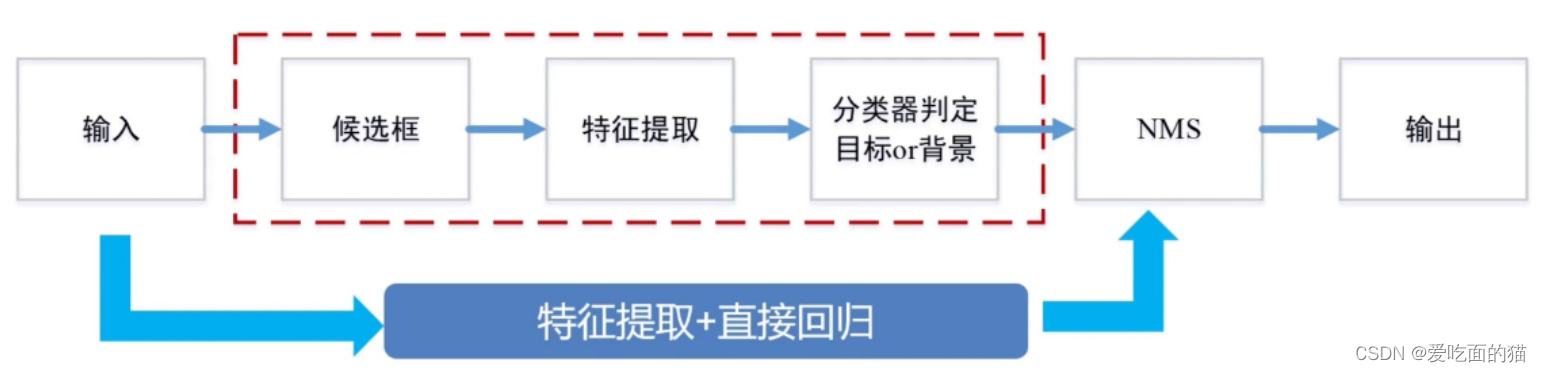
02目标检测-传统检测方法
目录 一、目标学习的检测方法变迁及对比
二、 基于传统手工特征的检测算法的定义
三、传统主要手工特征与算法
Haar特征与 人脸检测算法 - Viola-Jones(了解)
HOG特征与 SVM 算法(了解)(行人检测、opencv实现)
SIFT特征与SIFT算法(了解)
DPM&#…

电动取暖器、加热器、暖风机、亚马逊各国要求标准都有哪些?
UL1278测试报告介绍 UL1278是针对电气安全方面的测试报告标准,主要用于评估各种电器的安全性能,以确保它们在使用过程中不会对人身安全造成威胁。桌面暖风机作为一款加热设备,需要满足UL1278标准才能进入美国市场。
每年的十月份开始国外气温…
DAMO-YOLO训练自己的数据集,使用onnxruntime推理部署
DAMO-YOLO训练自己的数据集,使用onnxruntime推理部署
DAMO-YOLO 是阿里达摩院智能计算实验室开发的一种兼顾速度与精度的目标检测算法,在高精度的同时,保持了很高的推理速度。
DAMO-YOLO 是在 YOLO 框架基础上引入了一系列新技术࿰…
基于开源模型搭建实时人脸识别系统(五):人脸跟踪
继续填坑,之前已经讲了人脸检测,人脸识别实战之基于开源模型搭建实时人脸识别系统(二):人脸检测概览与模型选型_开源人脸识别模型_CodingInCV的博客-CSDN博客,人脸检测是定位出画面中人脸的位置,…
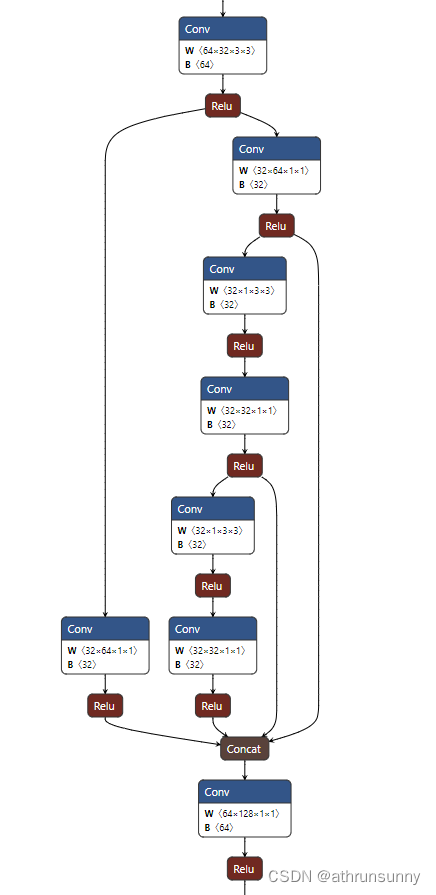
yolov7增加mobileone
代码地址:GitHub - apple/ml-mobileone: This repository contains the official implementation of the research paper, "An Improved One millisecond Mobile Backbone". 论文地址:https://arxiv.org/abs/2206.04040 MobileOne出自Apple&am…
目标检测框架MMDetection推理实验记录
在进行目标检测算法的学习过程中,需要进行对比实验,这里可以直接使用MMDetection框架来完成,该框架集成了许多现有的目标检测算法,方便我们进行对比实验。
环境配置
首先是环境配置,先前博主曾经有过相关方面的配置&…
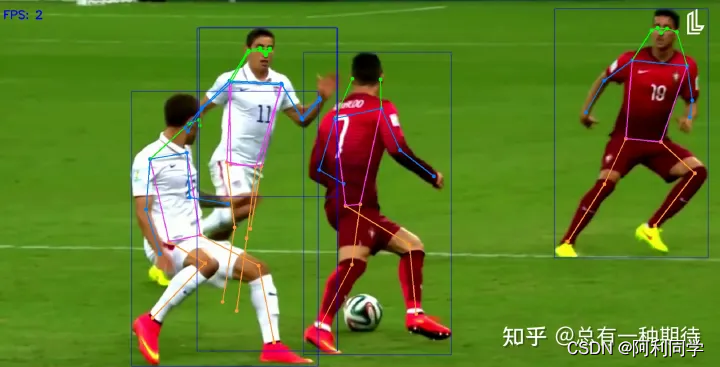
计算机视觉实战项目(图像分类+目标检测+目标跟踪+姿态识别+车道线识别+车牌识别)
图像分类
教程博客_传送门链接:链接 在本教程中,您将学习如何使用迁移学习训练卷积神经网络以进行图像分类。您可以在 cs231n 上阅读有关迁移学习的更多信息。 本文主要目的是教会你如何自己搭建分类模型,耐心看完,相信会有很大收获。废话不…
目标检测YOLO实战应用案例100讲-基于CNN的卫星图像下舰船目标检测与识别(续)
目录
3.3评价指标
3.3.1 mAP
3.3.2 FPS
3.4主流目标检测网络性能研究
3.4.1 SSD
3.4.2 Faster RCNN
3.4.3 YOLO
(十五)mmdetection源码解读:runner
目录 一、runner构建过程二、runner包含的功能 一、runner构建过程
Runner是MMdetection中的一种深度学习算法“工厂”,是对深度学习算法各个组件的“容器”。简单来说,所有的机器学习算法所包含的无非就是数据、模型、训练策略、评估、推理这五个部分。…
DETRs Beat YOLOs on Real-time Object Detection
目录 1、模型架构1.1高效混合编码器1.1.1 尺度内特征交互模块AIFI1.1.2 跨尺度特征融合CCFM 1.2IoU感知查询选择总结 DETRs在实时目标检测中击败YOLO 问题:DETR的高计算成本,实时检测效果有待提高
解决:提出了一个实时的目标检测器
具体来说…
目标检测YOLO实战应用案例100讲-基于深度学习的可见光遥感图像目标检测(中)
目录
2.6数据集
2.6.1通用目标数据集
2.6.2遥感图像数据集
遥感图像数据集增广技术研究
3.1引言
目标检测中生成锚框函数详解
将设一张图片,宽和高为2,2
X torch.rand(size(1,3,2,2))
Y generate_anchors(X,sizes[0.75,0.5,0.25],ratios[1,2,0.5])锚框中心点的设置
# 为每个像素可以生成 nm-1个锚框,整个图像生成 wh(nm-1)
def generate_anchors(data,sizes,ratios): # 书上的…
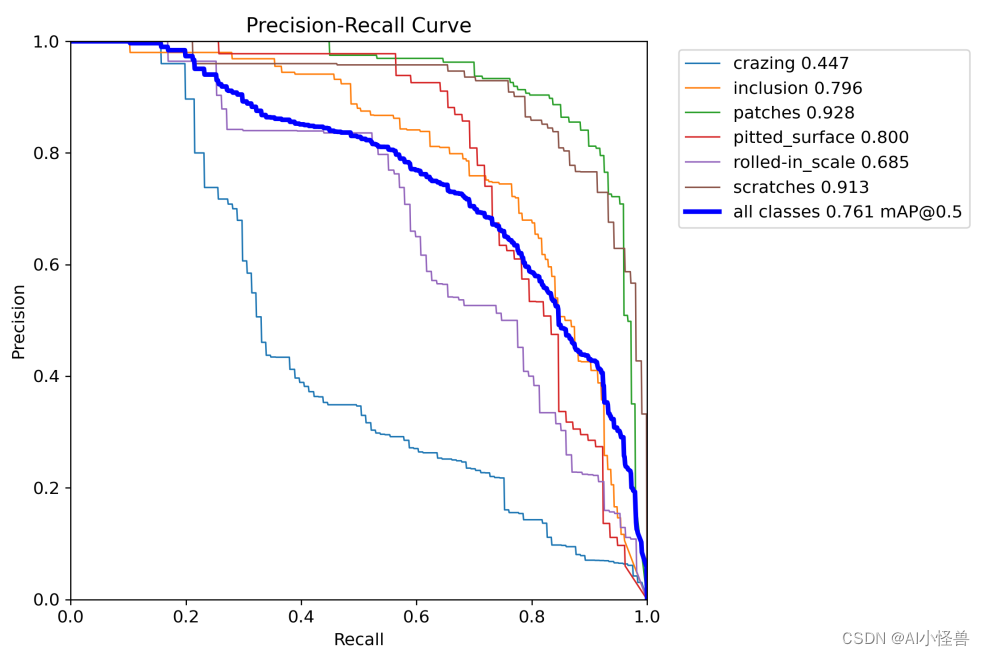
基于Yolov8的NEU-DET钢材表面缺陷检测,优化组合新颖程度较高:CVPR2023 PConv和BiLevelRoutingAttention,涨点明显
1.钢铁缺陷数据集介绍
NEU-DET钢材表面缺陷共有六大类,分别为:crazing,inclusion,patches,pitted_surface,rolled-in_scale,scratches
每个类别分布为: 2.基于yolov8的训练
原始网络如下: map0.5为0.733 2 PConv
2.1 Faster…

YOLO目标检测——交通标志数据集+已标注voc和yolo格式标签下载分享
实际项目应用:交通安全监控、智能交通系统、自动驾驶和辅助驾驶、驾驶员辅助系统、交通规划和城市规划等等。数据集说明:YOLO交通标志检测数据集,真实场景的高质量图片数据,数据场景丰富,图片格式为jpg,分为…
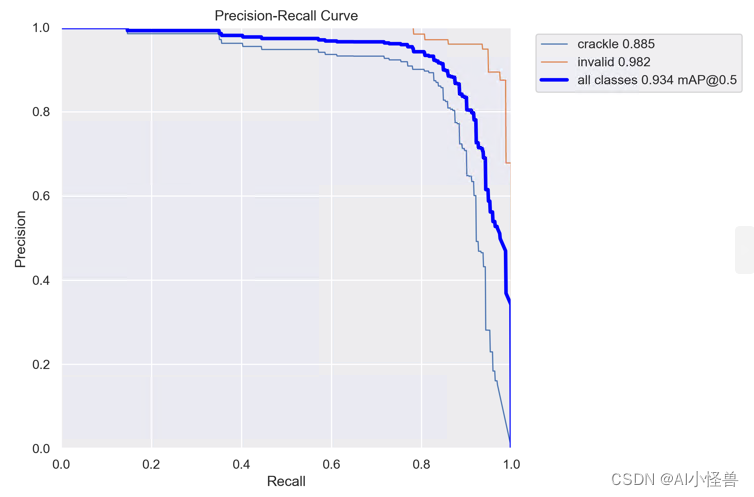
基于Yolov8的光伏电池缺陷检测,引入ICCV2023 动态蛇形卷积和独家全网首发多维协作注意模块MCA,实现涨点创新十足
1.光伏电池缺陷数据集介绍
背景:太阳能作为一种极具吸引力的替代电力能源,太阳能光伏电池(即光伏电池)是太阳能发电系统的基础,一般情况下,电池中的各类缺陷会直接影响到光伏电池的光电转化效率和使用寿命…

LoGoNet:基于局部到全局跨模态融合的精确 3D 目标检测
论文地址:https://arxiv.org/abs/2303.03595 论文代码:https://github.com/sankin97/LoGoNet
论文背景
激光雷达传感器点云通常是稀疏的,无法提供足够的上下文来区分远处的区域,从而造成性能次优。
激光雷达-摄像机融合方法在三…
全网原创首发Yolov5/Yolov7涨点神器:可变形大核注意力,超越自注意力,实现暴力涨点 | 2023.8月最新发表
💡💡💡本文独家改进:可变形大核注意力(D-LKA Attention),采用大卷积核来充分理解体积上下文的简化注意力机制,来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式
D-LKA Attention | 亲测在多个数据集能够实现大幅涨点
💡💡💡Yolov5/Yolov7魔术师…
03深度学习-目标检测-深度学习方法与传统算法对比
一、目标学习的检测方法变迁及对比 “目标检测“是当前计算机视觉和机器学习领域的研究热点。从Viola-Jones Detector、DPM等冷兵器时代的智慧到当今RCNN、YOLO等深度学习土壤孕育下的GPU暴力美学,整个目标检测的发展可谓是计算机视觉领域的一部浓缩史。整个目标…
(十九)mmdetection源码解读:Hook子类之一OptimizerHook
目录 一、OptimizerHook类解析二、优化器介绍 一、OptimizerHook类解析
这是一个包含关于optimizer自定义操作的hook 初始化函数参数: grad_clip:梯度裁减 detect_anomalous_params:检测计算图中未包含的异常参数
HOOKS.register_module()
…
安装MMRotate流程
一、介绍
MMRotate的github网站已经给出了非常详细的安装步骤 所有的安装步骤已经在安装文档里,并且非常详细, 本文主要记录一些踩坑的地方。
二、流程
1.配置conda环境
假设你的Anaconda已经安装好了,并且之前自己创建过环境。使用 nvid…
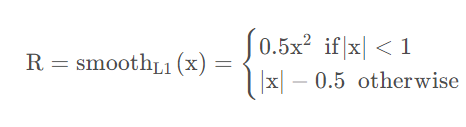
目标检测(Object Detection)概念速通
参考博文:目标检测(Object Detection)_YEGE学AI算法的博客-CSDN博客
这篇参考的相当多,写的真的很好很入门,觉得很有用,想详细了解的可以去看看,侵删↑ 上回组会分享了DETR和MDETR,…
目标检测YOLO实战应用案例100讲-基于改进YOLO的车位导引(续)
目录
3.3 数据处理与模型训练
3.3.1 数据预处理
3.3.2 模型的训练与参数设置 3.4 实验结果与分析
剑指YOLOv5改进主干RepVB系列: 最新重参数化结构 顶会2023 二次改进升级版,最新开源移动端网络架构,速度贼快
💡本篇内容:剑指YOLOv5改进主干RepVB系列: 最新重参数化结构 顶会2023 二次改进升级版,最新开源移动端网络架构,速度贼快
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可
💡:重点:该专栏《剑指YOLOv5原创改进》只更新改进 Y…

小样本目标检测:ECEA: Extensible Co-Existing Attention for Few-Shot Object Detection
论文作者:Zhimeng Xin,Tianxu Wu,Shiming Chen,Yixiong Zou,Ling Shao,Xinge You
作者单位:Huazhong University of Science and Technology; UCAS-Terminus AI Lab
论文链接:http://arxiv.org/abs/2309.08196v1
内容简介:
1&…
CE认证EMC测试不通过原因解析
辐射是CE-EMC的其中一个测试项目,要想获得CE认证证书,必须所有项目符合要求。很多企业在申请CE认证的时候,往往卡在辐射这里。有时候做CE认证,做到EMC测试的时候是不通过的,是发不了证书的,CE认证EMC测试不…
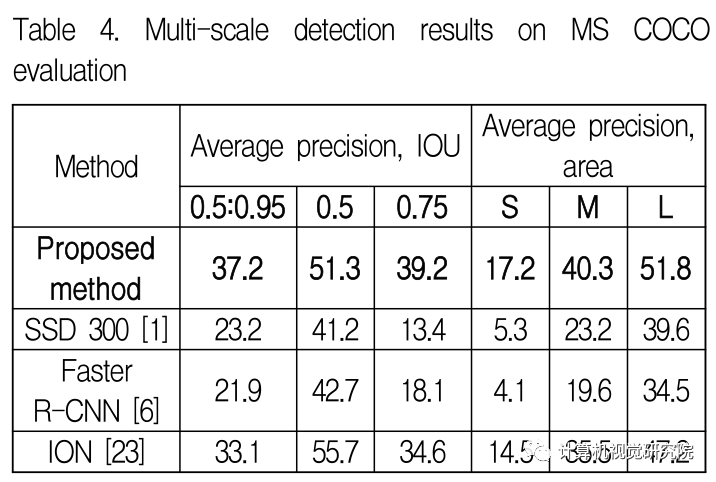
细粒度特征提取和定位用于目标检测:PPCNN
1、简介
近年来,深度卷积神经网络在计算机视觉上取得了优异的性能。深度卷积神经网络以精确地分类目标信息而闻名,并采用了简单的卷积体系结构来降低图层的复杂性。基于深度卷积神经网络概念设计的VGG网络。VGGNet在对大规模图像进行分类方面取得了巨大…

目标检测:FROD: Robust Object Detection for Free
论文作者:Muhammad,Awais,Weiming,Zhuang,Lingjuan,Lyu,Sung-Ho,Bae
作者单位:Sony AI; Kyung-Hee University
论文链接:http://arxiv.org/abs/2308.01888v1
内容简介:
1)方向:目标检测
2)…
YOLOv8血细胞检测(9):SEAM注意力机制,提升遮挡小目标检测性能
💡💡💡本文改进:SEAM注意力机制,较好的解决了小目标中遮挡问题;
SEAM | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.902
收录专栏:
💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4zBP
✨✨✨实战医学影像检测项目,通过创新点验证涨点可…

【AI视野·今日CV 计算机视觉论文速览 第257期】Fri, 29 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 29 Sep 2023 Totally 99 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Learning to Transform for Generalizable Instance-wise Invariance Authors Utkarsh Singhal, Carlos Esteves, Ameesh M…

YOLOv5-PTQ量化部署
目录 前言一、PTQ量化浅析二、YOLOv5模型训练1. 项目的克隆和必要的环境依赖1.1 项目克隆1.2 项目代码结构整体介绍1.3 环境安装 2. 数据集和预训练权重的准备2.1 数据集2.2 预训练权重准备 3. 训练模型3.1 修改数据配置文件3.2 修改模型配置文件3.3 训练模型3.4 mAP测试 三、Y…
目标检测YOLO实战应用案例100讲-面向小目标检测的多尺度特征融合(续)
目录
3.3 实验结果及分析
3.3.1 实验设置
3.3.2 消融实验
3.3.3 在PASCAL VOC2007上的结果
第2篇 机器学习基础 —(1)机器学习概念和方式
前言:Hello大家好,我是小哥谈。机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进…

YOLOv5算法改进(20)— 引入 RepVGG 重参数化模块
前言:Hello大家好,我是小哥谈。RepVGG 重参数化模块是一种用于深度卷积神经网络的模块化设计方法,旨在通过将卷积层和全连接层统一为卷积层来简化网络结构并提高计算效率。该方法通过重参数化,将常规的卷积层分解为一个轻量级的卷…

用于小物体检测的切片辅助超推理SAHI实现YOLOv8推理
何为小物体检测?
在目标识别与定位的应用场景中,难免会碰到目标物在图像中的尺寸相对较小的情况,例如下图所示。这些物体通常空间范围有限、像素覆盖率较低,且由于其外观小、信噪比低,为检测任务带来较大的挑战。 小物…
跨境电商外贸出口电动自行车、脚踏车、单车美国站需要什么认证?UL2849和GCC认证解析
自行车又称脚踏车或单车,是一种以人力作机械传动的代步和运载工具。自行车、脚踏车、单车出口美国站需办理UL2849认证和GCC认证。
美国自行车类产品安全要求:
2011年5月13日,美国消费品安全委员会(CPSC)在对来自行车业及消费者的…
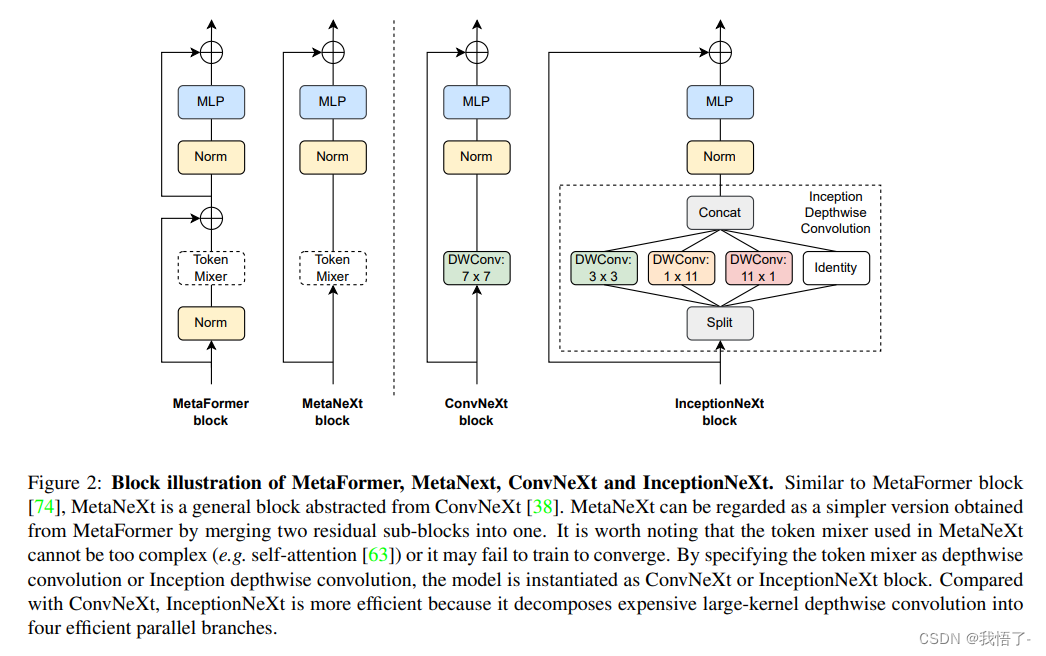
目标检测算法改进系列之Backbone替换为InceptionNeXt
InceptionNeXt
受 Vision Transformer 长距离依赖关系建模能力的启发,最近一些视觉模型开始上大 Kernel 的 Depth-Wise 卷积,比如一篇出色的工作 ConvNeXt。虽然这种 Depth-Wise 的算子只消耗少量的 FLOPs,但由于高昂的内存访问成本 (memory…
目标检测算法改进系列之Backbone替换为PoolFormer
PoolFormer
MetaFormer是颜水成大佬的一篇Transformer的论文,该篇论文的贡献主要有两点:第一、将Transformer抽象为一个通用架构的MetaFormer,并通过经验证明MetaFormer架构在Transformer/ mlp类模型取得了极大的成功。 第二、通过仅采用简单…
跨境电商电动交通设备需CE认证亚马逊出口美国市场UL报告办理解析
电动自行车或电动滑板车的独立替换电池。电动交通设备的电池包括作为电动自行车或电动滑板车配件单独销售的任何(原装或非原装)电池。
注意: 某些类型的替换电池没有 CE 或 UKCA 标志。此类商品不符合在亚马逊商城销售的要求。示例ÿ…

【目标检测】Visdrone数据集和CARPK数据集预处理
之前的博文【目标检测】YOLOv5跑通VisDrone数据集对Visdrone数据集简介过,这里不作复述,本文主要对Visdrone数据集和CARPK数据集进行目标提取和过滤。 需求描述
本文需要将Visdrone数据集中有关车和人的数据集进行提取和合并,车标记为类别0&…

YOLOv7优化:感受野注意力卷积运算(RFAConv),效果秒杀CBAM和CA等 | 即插即用系列
💡💡💡本文改进:感受野注意力卷积运算(RFAConv),解决卷积块注意力模块(CBAM)和协调注意力模块(CA)只关注空间特征,不能完全解决卷积核参数共享的问题
提供多种卷积变体供使用:CBAMConv,CAMConv,CAConv,RFAConv,RFCAConv
RFAConv | 亲测在多个数据集能够实现…
注意力机制、Transformer模型、生成式模型、目标检测算法、图神经网络、强化学习、深度学习模型可解释性与可视化方法等详解
采用“理论讲解案例实战动手实操讨论互动”相结合的方式,抽丝剥茧、深入浅出讲解注意力机制、Transformer模型(BERT、GPT-1/2/3/3.5/4、DETR、ViT、Swin Transformer等)、生成式模型(变分自编码器VAE、生成式对抗网络GAN、扩散模型…
YOLOV8的tensorrt部署详解(目标检测模型-cpp)
提示:yolov8的tensorrt部署方法,文中附有源码!!! 文章目录 前言一、yolov8环境安装二、yolov8训练与预测介绍1、yolov8训练数据集准备2、yolov8训练介绍3、yolov8推理介绍三、yolov8的tensorrt部署源码链接四、pt文件转engine方法1、yolov8的pt文件转onnx文件2、yolov8的o…
![[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测](https://img-blog.csdnimg.cn/de54f52aca1c49af9d4c214f39cd5ee8.png)
[论文阅读]Voxel R-CNN——迈向高性能基于体素的3D目标检测
Voxel R-CNN
Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection 迈向高性能基于体素的3D目标检测 论文网址:Voxel R-CNN 论文代码:Voxel R-CNN
简读论文
该论文提出了 Voxel R-CNN,这是一种基于体素的高性能 3D 对象…
目标检测算法改进系列之Backbone替换为EfficientFormerV2
EfficientFormerV2
随着视觉Transformers(ViTs)在计算机视觉任务中的成功,最近的技术试图优化ViT的性能和复杂性,以实现在移动设备上的高效部署。研究人员提出了多种方法来加速注意力机制,改进低效设计,或…
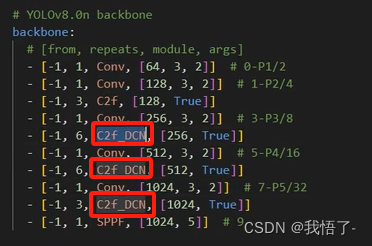
目标检测算法改进系列之嵌入Deformable ConvNets v2 (DCNv2)
Deformable ConvNets v2
简介:由于构造卷积神经网络所用的模块中几何结构是固定的,其几何变换建模的能力本质上是有限的。在DCN v1中引入了两种新的模块来提高卷积神经网络对变换的建模能力,即可变形卷积 (deformable convolution) 和可变形…

ros使用rviz订阅Image类型话题,显示yolov7目标检测结果
开发板深度相机系统Xavierrealsense D455ubuntu18.04
1、首先启动yolov7的ros节点,发布话题/image。 2、终端输入rviz,回车打开rviz,Add——>Image: 3、展开Image选项,选择要订阅的topic,左下角就显示出…
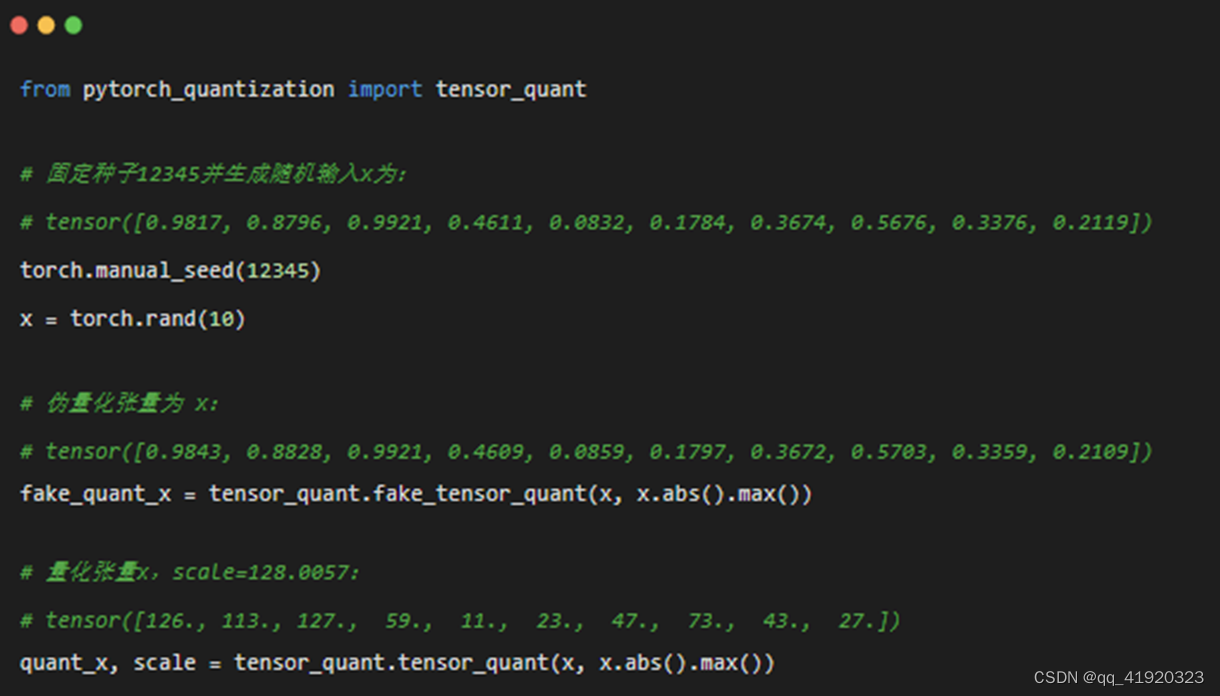
yolov5的pqt、qat量化---1(知识准备工作)
1、Pytorch-Quantization简介 PyTorch Quantization是一个工具包,用于训练和评估具有模拟量化的PyTorch模型。PyTorch Quantization API支持将 PyTorch 模块自动转换为其量化版本。转换也可以使用 API 手动完成,这允许在不想量化所有模块的情况下进行部分量化。例如,一些层可…
目标检测和跟踪面试复习
面试官可能会问到的相关目标检测的问题:
1.简述一下目标检测的原理,如何进行画框的: 目标检测:分为单目标检测和双目标检测,大部分 实际应用都是单目标检测,什么SSD,yolov3,yolov3-tiny,yolov4…
YOLOv8血细胞检测(5):可变形大核注意力(D-LKA Attention),超越自注意力| 2023.8月最新发表
💡💡💡本文独家改进:可变形大核注意力(D-LKA Attention),采用大卷积核来充分理解体积上下文的简化注意力机制,来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式
D-LKA Attention | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.903
收录专…
YOLOv8血细胞检测(6):多维协作注意模块MCA | 原创独家创新首发
💡💡💡本文改进:多维协作注意模块MCA,效果秒杀ECA、SRM、CBAM,创新性十足,可直接作为创新点使用。
MCA | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.910
收录专栏:
💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4zBP
✨✨✨实战医学影…
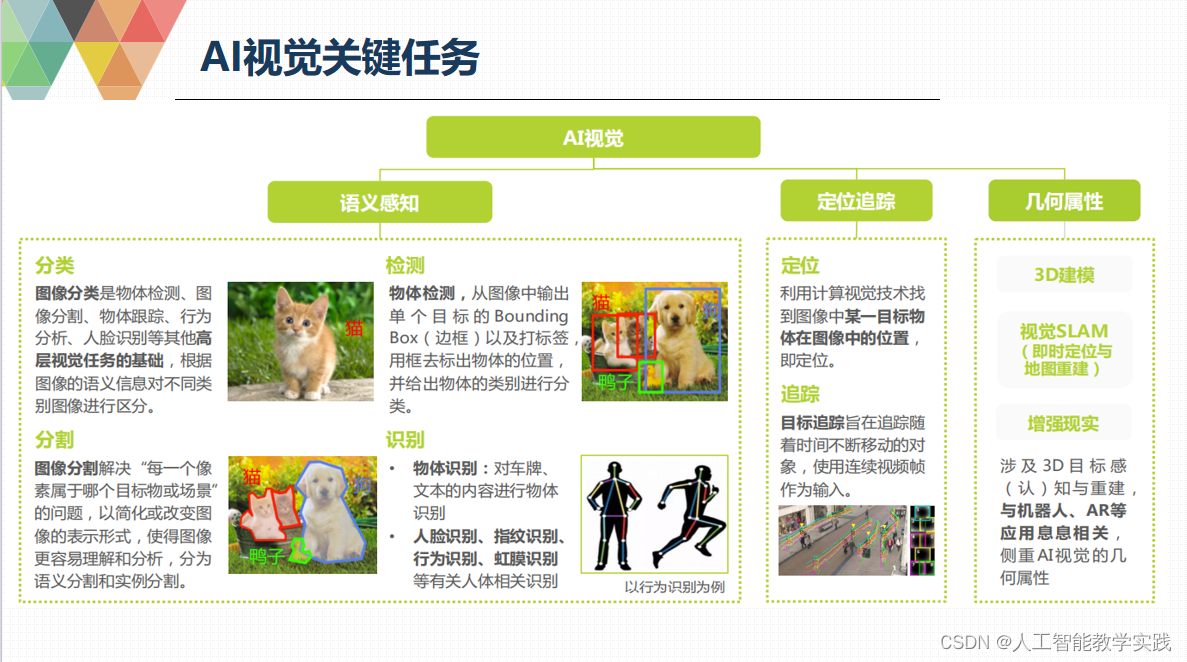
目标检测与图像识别分类的区别?
目标检测与图像识别分类的区别
目标检测和图像识别分类是计算机视觉领域中两个重要的任务,它们在处理图像数据时有一些区别。
目标检测是指在图像中定位和识别多个目标的过程。其主要目标是确定图像中每个目标的边界框位置以及对应的类别标签。目标检测任务通常涉…
YOLOv8血细胞检测(17):极简的神经网络模型 VanillaNet---VanillaBlock助力检测实现涨点的同时降低参数量 |华为诺亚2023
💡💡💡本文独家改进:VanillaBlock极简的神经网络,引入到YOLOv7实现涨点的同时降低参数量
VanillaBlock | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.90,YOLOv8n GFLOPs 8.1降低到6.2
收录专栏:
💡💡💡YOLO医学影像检测:http://t.csdnimg.…
第1篇 目标检测概述 —(4)目标检测评价指标
前言:Hello大家好,我是小哥谈。目标检测评价指标是用来衡量目标检测算法性能的指标,可以分为两类,包括框级别评价指标和像素级别评价指标。本节课就给大家重点介绍下目标检测中的相关评价指标及其含义,希望大家学习之后…
目标检测网络系列——YOLO V2
文章目录 YOLO9000better,更准batch Normalization高分辨率的训练使用anchor锚框尺寸的选择——聚类锚框集成改进——直接预测bounding box细粒度的特征图——passthrough layer多尺度训练数据集比对实验VOC 2007VOC 2012COCOFaster,更快网络模型——Darknet19训练方法Strong…
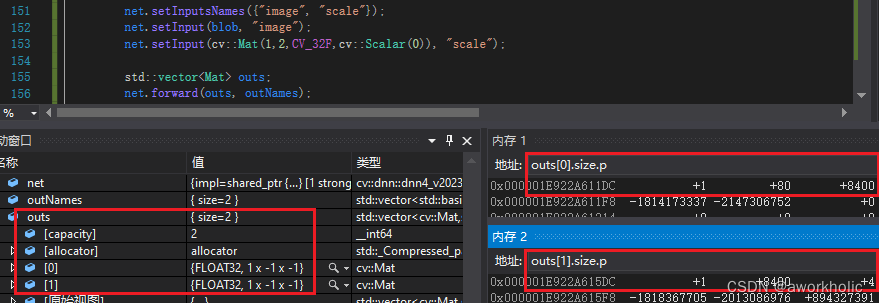
opencv dnn模块 示例(18) 目标检测 object_detection 之 pp-yolo、pp-yolov2和pp-yolo tiny
文章目录 1、PP-YOLO1.1、网络架构1.1.1、BackBone骨干网络1.1.2、DetectionNeck1.1.3、DetectionHead 1.2、Tricks的选择1.2.1、更大的batchsize1.2.2、滑动平均1.2.3、DropBlock1.2.4、IOU Loss1.2.5、IOU Aware1.2.6、GRID Sensitive1.2.7、Matrix NMS1.2.8、CoordConv1.2.9…


【OpenCv光流法进行运动目标检测】
opencv系列文章目录 文章目录 opencv系列文章目录前言一、光流法是什么?二、光流法实例1.C的2.C版本3.python版本 总结 前言
随着计算机视觉技术的迅猛发展,运动目标检测在图像处理领域中扮演着至关重要的角色。在现实世界中,我们常常需要追…
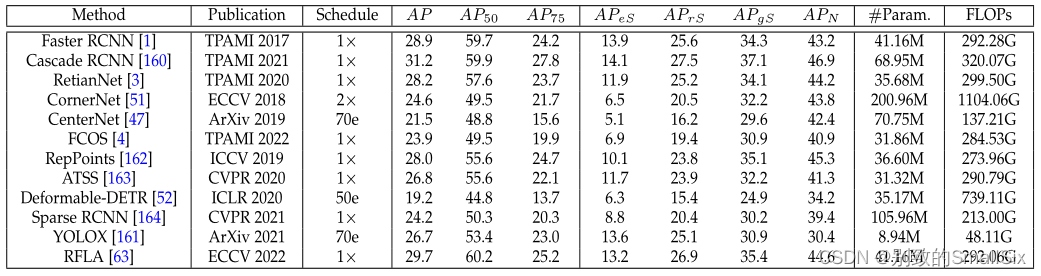
综述:大规模小目标检测
论文地址:
Towards Large-Scale Small Object Detection: Survey and Benchmarksarxiv.org/abs/2207.14096
目录
摘要
1.Introduction
1.1 与之前综述的比较
1.2 总结
2.小目标检测回顾
2.1 问题定义
2.2 主要挑战
2.3 小目标检测算法回顾
3.小目标检测的数据集
…
用于多目标检测的自监督学习(SELF-SUPER VISED LEARNING FOR MULTIPLE OBJECTDETECTION)
在本章中,我们提出了一种新的自监督学习(SSL)技术,以从头顶图像中提供关于实例分割不确定性的模型信息。我们的SSL方法通过使用测试时数据增强和基于回归的旋转不变伪标签细化技术来改进对象检测。我们的伪标签生成方法提供多个经过几何变换的图像作为卷积神经网(CNN)的输…
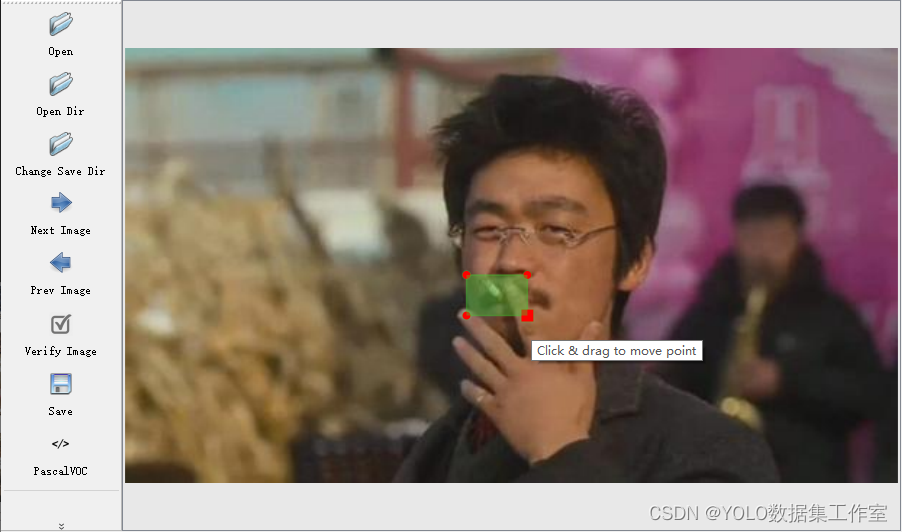
YOLO目标检测——抽烟吸烟数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:公共场所监管、健康风险评估、戒烟干预数据集说明:YOLO目标检测数据集,真实场景的高质量图片数据,数据场景丰富。使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三…
YOLOv8改进PAN结构:Lowlevel Feature Alignment,集特征对齐、信息融合和信息注入于一体,增强模型对不同尺寸物体的检测能力
💡本篇内容:YOLOv8改进PAN结构:Lowlevel Feature Alignment,集特征对齐、信息融合和信息注入于一体,增强模型对不同尺寸物体的检测能力
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,Y…
基于YOLOv8模型的水下目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的水下目标检测系统可用于日常生活中检测与定位鱼、水母、企鹅、海鹦、鲨鱼、海星、黄貂鱼,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统…

YOLOv7改进:引入GSConv+Slim Neck,提升小目标检测精度
💡💡💡本文属于原创独家改进 引入了一种新方法 GSConv 来代替 SC 操作。该方法使卷积计算的输出尽可能接近 SC,同时降低计算成本; 提供了一种新的设计范式,即带有标准 Backbone 的 Slim-Neck 设计; GSConv+Slim Neck | 亲测在多个数据集实现暴力涨点; 收录:
YO…
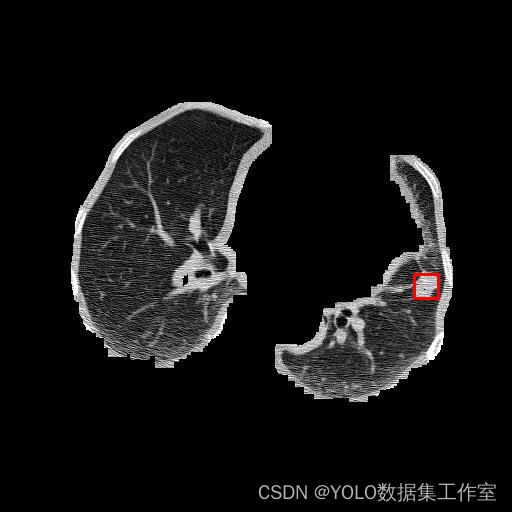
YOLO目标检测——肺结节数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:肺结节检测数据集主要应用于医学影像分析领域,特别是在肺结节检测和恶性风险评估方面。数据集说明:YOLO目标检测数据集,真实场景的高质量图片数据,数据场景丰富。使用lableimg标注软件标注,标…

【yolov8目标检测】使用yolov8训练自己的数据集
目录
准备数据集
python安装yolov8
配置yaml
从0开始训练
从预训练模型开始训练 准备数据集
首先得准备好数据集,你的数据集至少包含images和labels,严格来说你的images应该包含训练集train、验证集val和测试集test,不过为了简单说…
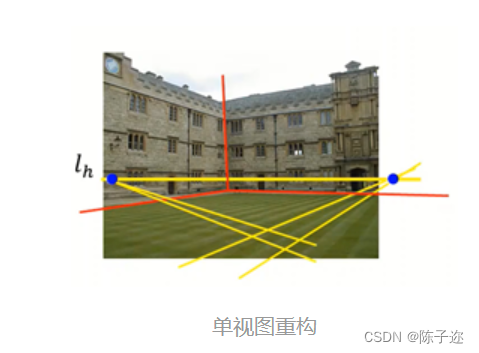
双目视觉实战--单视图测量方法
目录 一.简介
二、2D变换
1. 等距变换(欧式变换)
2. 相似变换
3. 仿射变换
4. 射影变换(透视变换)
5. 结论
三、影消点与影消线
1. 平面上的线
2. 直线的交点
3. 2D无穷远点
4. 无穷远直线
5. 无穷远点的透视变换与仿…
paddle训练报错:assert len(pair) == 2, (“there can be only a = in the option“)
网上未发现有此错误解析,故记录: 是因为命令中的文件路径存在双引号,缺失了
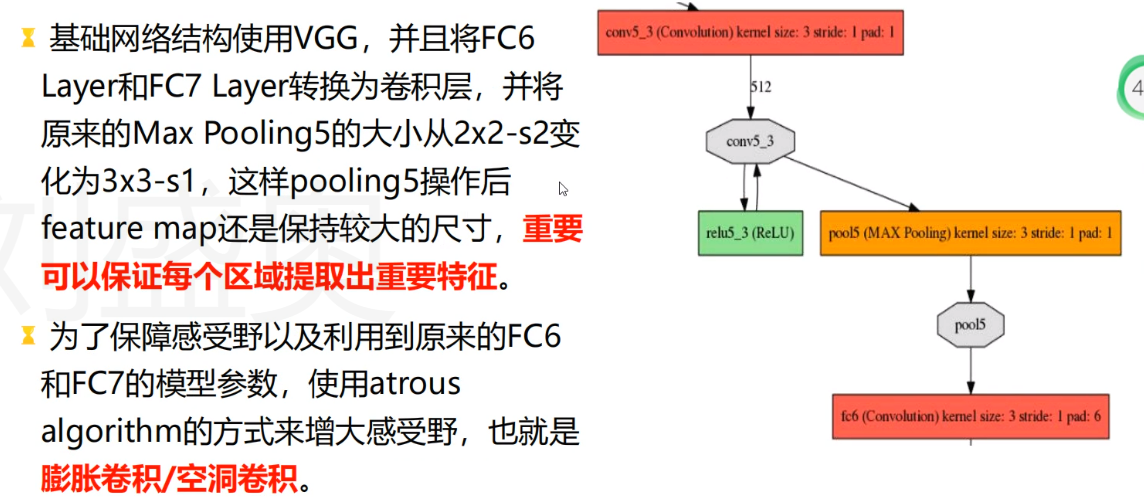
C++知识点面试总结
1、指针和引用的区别 1.1 定义: 指针:指针是一个变量,它存储了另一个变量的内存地址。定义指针时使用符号,例如int ptr;定义了一个整数指针。 引用:引用是一个别名,它是一个已存在变量的别名。定义引用时使用&符号,例如int& ref = x;定义了一个整数引用。 1.2 内…

YOLOv5源码中的参数超详细解析(2)— 配置文件yolov5s.yaml(包括源码+网络结构图)
前言:Hello大家好,我是小哥谈。配置文件yolov5s.yaml在YOLOv5模型训练过程中发挥着至关重要的作用,属于初学者必知必会的文件!在YOLOv5-6.0版本源码中,配置了5种不同大小的网络模型,分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,其中YOLOv5n是网络深度和宽度最小…
Transformer模型 | 用于目标检测的视觉Transformers训练策略
基于视觉的Transformer在预测准确的3D边界盒方面在自动驾驶感知模块中显示出巨大的应用,因为它具有强大的建模视觉特征之间远程依赖关系的能力。然而,最初为语言模型设计的变形金刚主要关注的是性能准确性,而不是推理时间预算。对于像自动驾驶这样的安全关键系统,车载计算机…
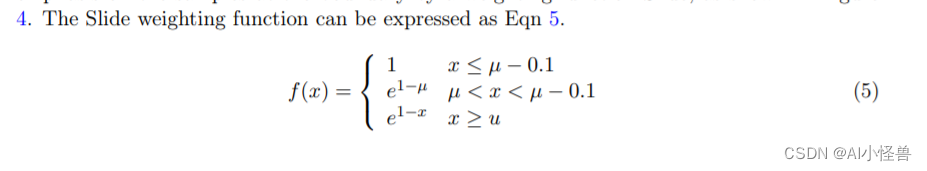
YOLOv7损失函数改进:SlideLoss创新升级,结合IOU动态调整困难样本的困难程度,提升小目标、遮挡物性能
💡💡💡本文改进:SlideLoss_IOU,困难样本的困难程度(如小目标遮挡物)动态调整,创新度十足
SlideLoss_IOU | 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升也能够助力涨点。 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最…

优化改进 | YOLOv2算法超详细解析(包括诞生背景+论文解析+技术原理等)
前言:Hello大家好,我是小哥谈。YOLOv2是YOLO(You Only Look Once)目标检测算法的第二个版本,它在YOLOv1的基础上做了很多改进,包括使用更深的卷积神经网络Darknet-19作为特征提取器、使用Batch Normalizati…
【目标检测】非极大值抑制NMS的原理与实现
非极大值抑制(Non-Maximum Suppression,NMS)是目标检测中常用的一种技术,它的主要作用是去除冗余和重叠过高的框,并保留最佳的几个。
NMS计算的具体步骤如下: 首先根据目标检测模型输出结果,得…

求臻医学:肺癌患者就诊指南及基因检测意义
2023年国家癌症中心公布的最新的数据显示,中国癌症新发病例数前十的癌症分别是:肺癌82万,结直肠癌56万,胃癌48万,乳腺癌42万,肝癌41万,食管癌32万,甲状腺癌22万,胰腺癌12…

YOLOv7改进:全网原创首发 | 新颖的多尺度卷积注意力(MSCA),即插即用,助力小目标检测 | NeurIPS2022
💡💡💡本文全网首发独家改进:多尺度卷积注意力(MSCA),有效地提取上下文信息,新颖度高,创新十足。 1)作为注意力MSCA使用;
推荐指数:五星
MSCA | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。
收录:
YOLOv7高阶自研专栏介绍:…
[工业项目]之行人检测
最近在思考和总结之前做的一些工作,工业项目其实一直做的不太好,正常的项目其实也没有那么多的算法上的需求,目前比较多需求的极市平台,我看了几个case,通用的算法很多还是以检测为主,检测中主要还是yolov5…

基于 Center 的 3D 目标检测和跟踪
论文地址:https://arxiv.org/abs/2006.11275 论文代码:https://github.com/tianweiy/CenterPoint
3D 目标通常表示为点云中的 3D Boxes。
CenterPoint 在第一阶段,使用关键点检测器检测对象的中心,然后回归到其他属性࿰…
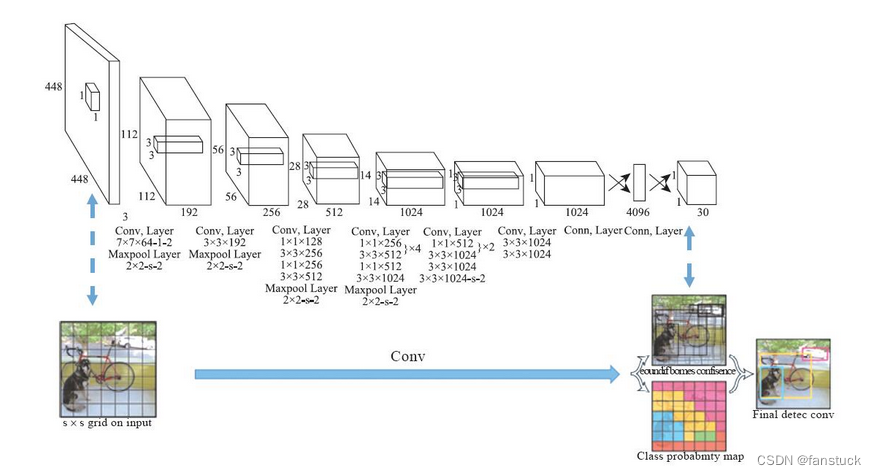
《RT-DETR改进实战》专栏介绍 专栏目录《限时特惠中》
《RT-DETR改进实战专栏》介绍及目录 介绍:欢迎来到最新专栏《RT-DETR改进实战》!这个专栏专注于基于 YOLOv8 项目的魔改版本,而不是百度飞桨框架中的 RT-DETR。
本专栏为想通过改进 RT-DETR 算法发表论文的同学设计。每篇文章均包含完整的改…
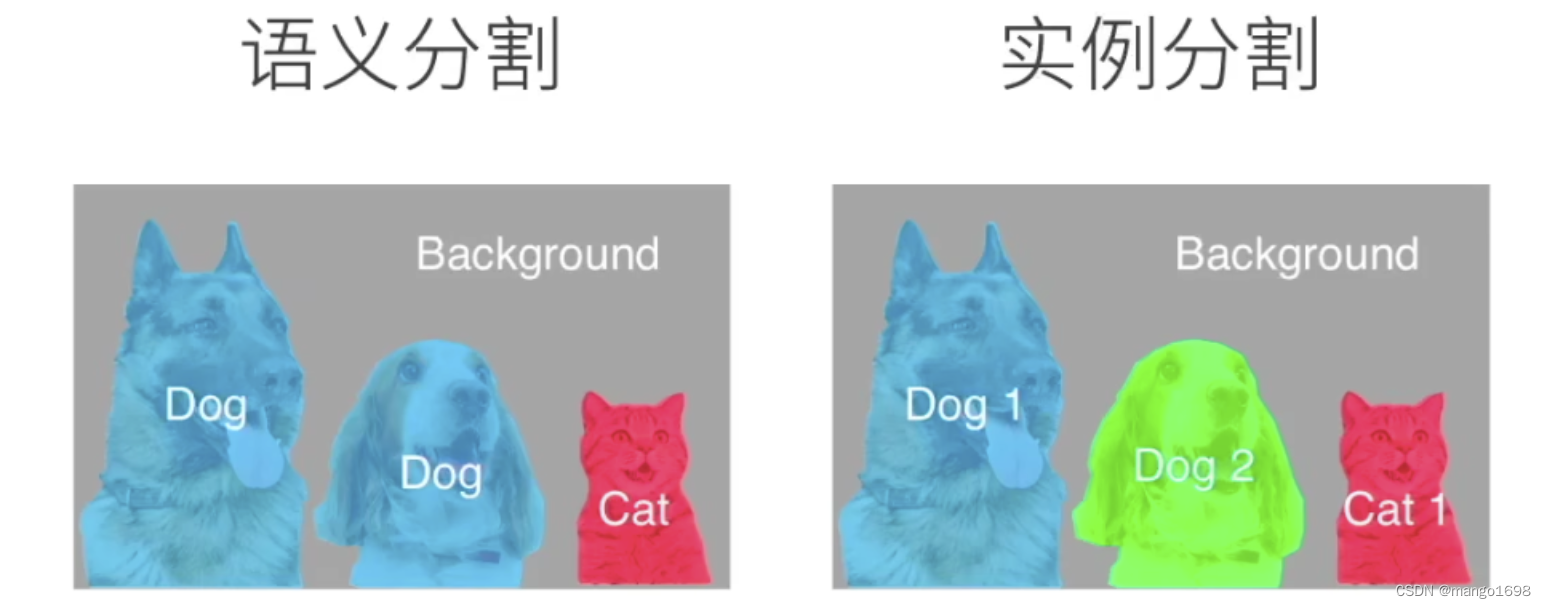
语义分割 - 图像分割
语义分割将图片中的每个像素分类到对应的类别 应用:路面分割 vs 实例分割: 语义分割中最重要的数据集之一是:Pascal VOC2012
YOLO8实战:yolov8实现行人跟踪计数
本篇文章首先介绍YOLOV8实现人流量跟踪计数的原理,文末附代码 引言:行人跟踪统计是智能监控系统中的重要功能,可以广泛应用于人流控制、安全监控等领域。传统的行人跟踪算法往往受到光照、遮挡等因素的干扰,难以实现准确跟踪。随着深度学习技术的发展,目标检测模型逐渐成为…
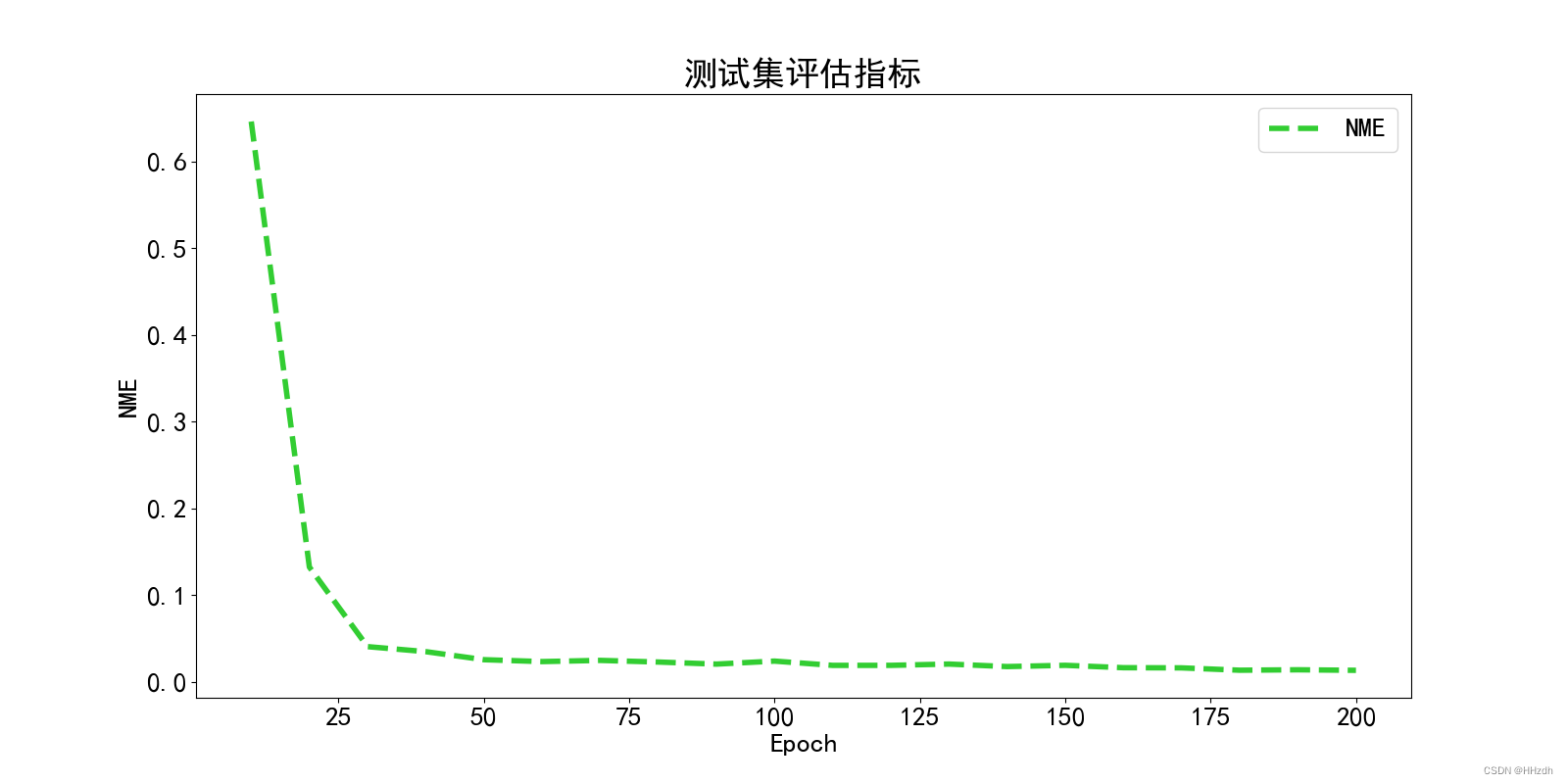
从零开始的目标检测和关键点检测(三):训练一个Glue的RTMPose模型
从零开始的目标检测和关键点检测(三):训练一个Glue的RTMPose模型 一、重写config文件二、开始训练三、ncnn部署 从零开始的目标检测和关键点检测(一):用labelme标注数据集
从零开始的目标检测和关键点检测…
pt权重转onnx记录
方法:
1.一般YOLO 会自带一个权重pt转onnx模型的代码 export.py 2.打开export.py ,我们运行该文件可以通过命令行运行,对照修改argument参数即可 3.运行命令行如下:
python ./models/export.py --weights ./models/best.pt
weights&#x…
YOLOv8-pose关键点检测:模型轻量化创新 |轻量高性能网络PPLCNet助力backbone
💡💡💡本文解决什么问题:轻量高性能网络PPLCNet替换YOLOv8 backbone
PPLCNet | GFLOPs从9.6降低至6.6, mAP50从0.921下降至0.901,mAP50-95从0.697提升至0.752
Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_12398833.html
✨✨✨手…
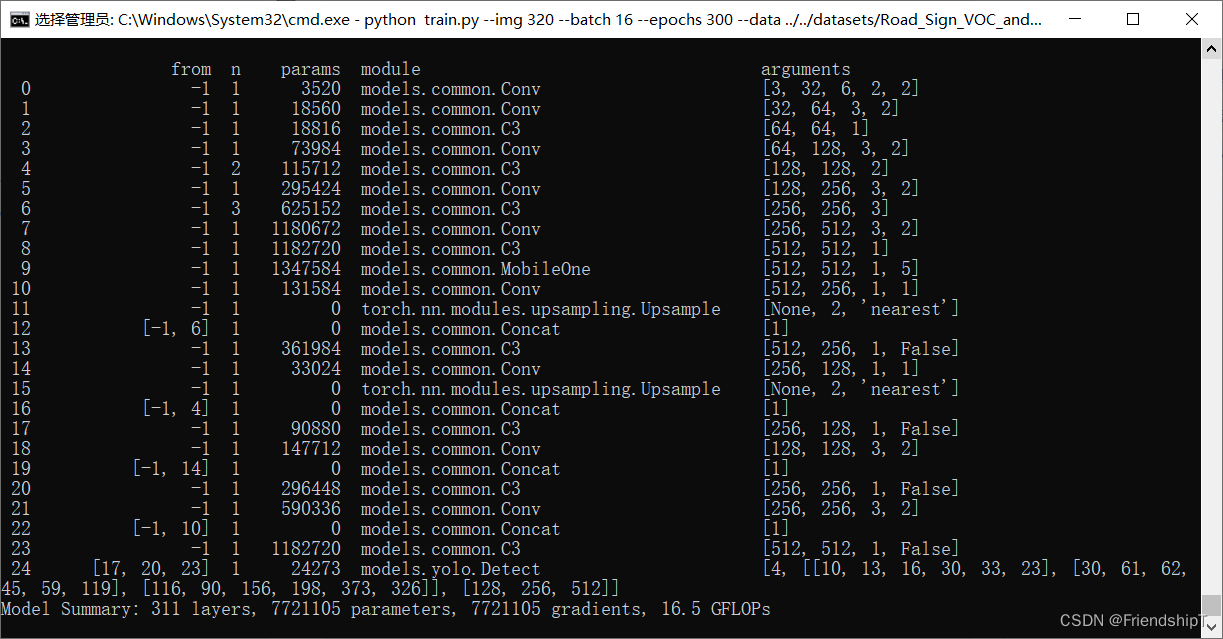
YOLOv5:修改backbone为MobileOne
YOLOv5:修改backbone为MobileOne 前言前提条件相关介绍MobileOneYOLOv5修改backbone为MobileOne修改common.py修改yolo.py修改yolov5.yaml配置 参考 前言 记录在YOLOv5修改backbone操作,方便自己查阅。由于本人水平有限,难免出现错漏…
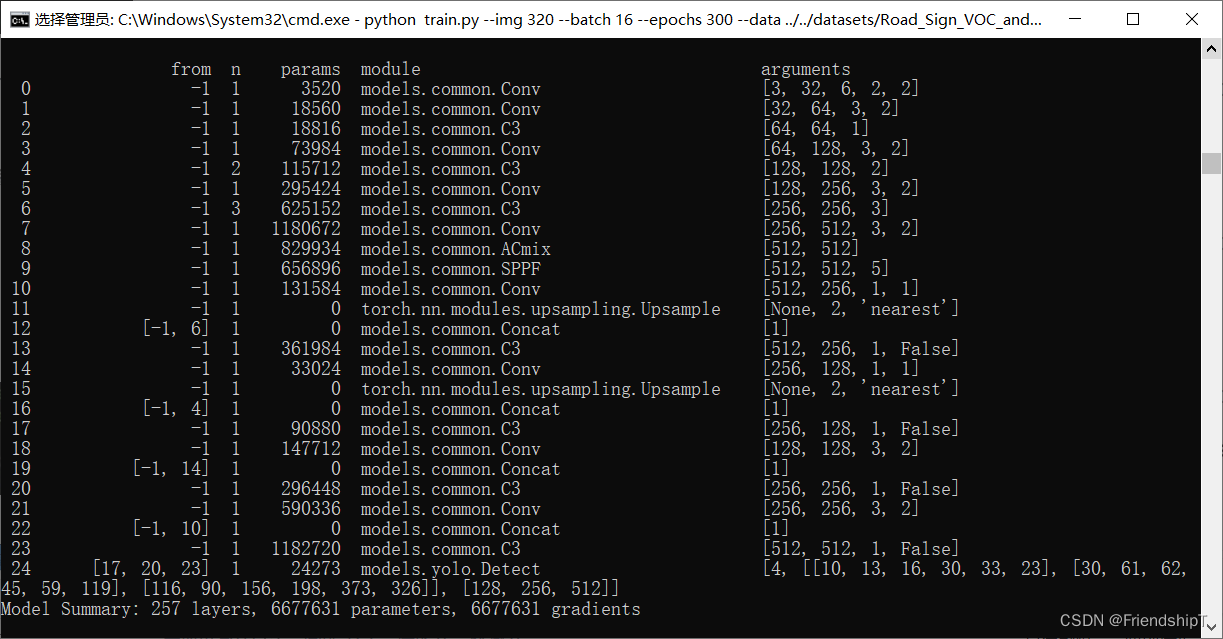
YOLOv5:修改backbone为ACMIX
YOLOv5:修改backbone为ACMIX 前言前提条件相关介绍ACMIXYOLOv5修改backbone为ACMIX修改common.py修改yolo.py修改yolov5.yaml配置 参考 前言 记录在YOLOv5修改backbone操作,方便自己查阅。由于本人水平有限,难免出现错漏,敬请批评…

YOLOv8改进:最新复现SOD-YOLOv8,助力小目标检测(Small Object Detection)
💡💡💡本文独家改进:改进点:1)backbone加入CBAM;2)backbone、neck连接处加入involution注意力;3)添加一个针对小物体的额外预测头,提升小目标检测性能;
SOD-YOLOv8 | 亲测在多个数据集能够实现大幅涨点,尤其在VisDrone-2019涨点显著, VisDrone-2019-DET 数…
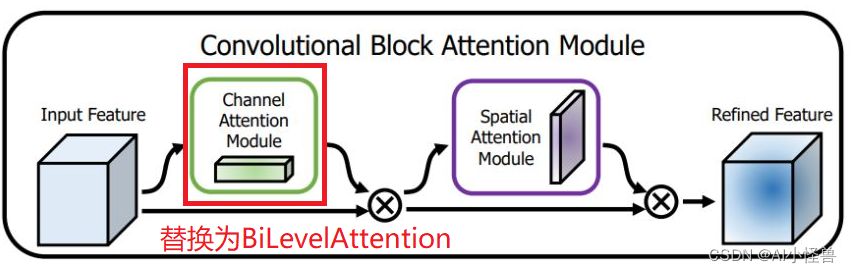
YOLOv8独家原创改进:自研独家创新BSAM注意力 ,基于CBAM升级
💡💡💡本文全网首发独家改进:提出新颖的注意力BSAM(BiLevel Spatial Attention Module),创新度极佳,适合科研创新,效果秒杀CBAM,Channel Attention+Spartial Attention升级为新颖的 BiLevel Attention+Spartial Attention 1)作为注意力BSAM使用;
推荐指数:…
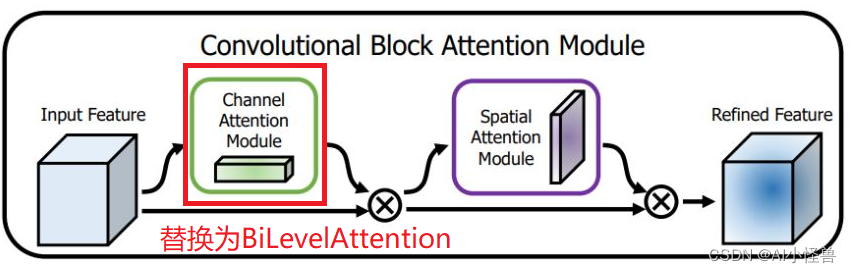
YOLOv7独家原创改进:新颖自研设计的BSAM注意力,基于CBAM升级
💡💡💡本文全网首发独家改进:提出新颖的注意力BSAM(BiLevel Spatial Attention Module),创新度极佳,适合科研创新,效果秒杀CBAM,Channel Attention+Spartial Attention升级为新颖的 BiLevel Attention+Spartial Attention 1)作为注意力BSAM使用;
推荐指数:…

Centralized Feature Pyramid for Object Detection解读
Centralized Feature Pyramid for Object Detection
问题
主流的特征金字塔集中于层间特征交互,而忽略了层内特征规则。尽管一些方法试图在注意力机制或视觉变换器的帮助下学习紧凑的层内特征表示,但它们忽略了对密集预测任务非常重要的被忽略的角点区…

opencv dnn模块 示例(21) 目标检测 object_detection 之 yolov6
文章目录 1、YOLOv6介绍1.1、概述1.2、关键技术1.2.0、网络结构1.2.1、表征能力更强的 RepBi-PAN Neck 网络1.2.2、全新的锚点辅助训练(Anchor-Aided Training)策略1.2.3、无痛涨点的 DLD 解耦定位蒸馏策略 1.3、总结 2、测试2.1、官方项目测试2.2、open…
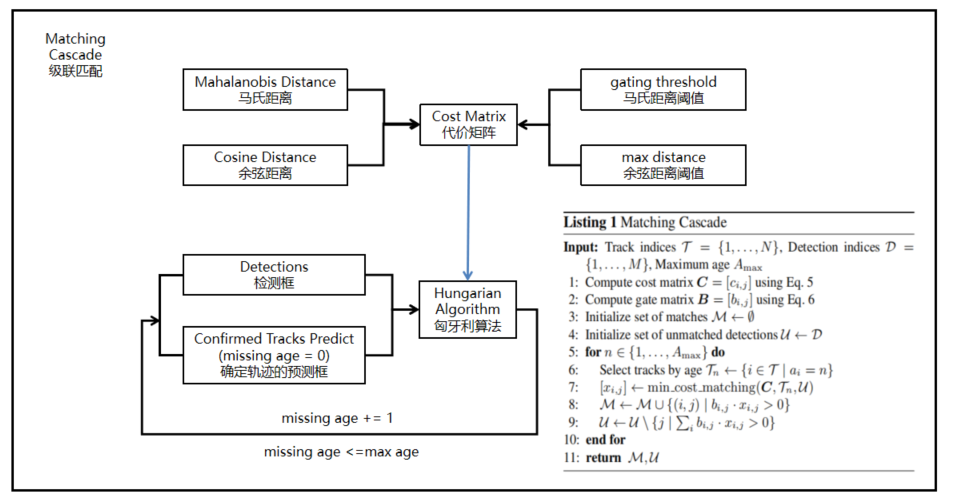
DeepSORT多目标跟踪——算法流程与源码解析
一、目标检测与目标追踪
1. 目标检测
在目标检测任务中,主要目标是识别图像或视频帧中存在的物体的位置和类别信息。这意味着目标检测算法需要定位物体的边界框(Bounding Box)并确定每个边界框内的物体属于哪个类别(如人、汽车、…
实时目标检测与跟踪:机器视觉的挑战与机遇
实时目标检测与跟踪是机器视觉领域的一个重要研究方向,它涉及到在视频或图像序列中准确地定位和跟踪多个目标对象。这个任务具有很高的挑战性,同时也带来了许多机遇。
挑战: 1. 复杂背景:目标检测与跟踪需要在复杂的背景中准确地…
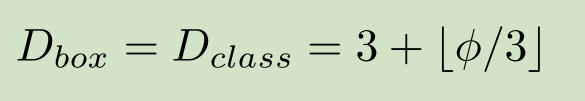
EfficientDet论文讲解
目录 EfficientDet
0、摘要
1、整体架构
1.1 BackBone:EfficientNet-B0
1.2 Neck:BiFPN特征加强提取网络
1.3 Head检测头
1.4 compound scaling
2、anchors先验框
3、loss组成
4、论文理解
5、参考资料 EfficientDet 影响网络的性能(或者说规…

YOLO目标检测——交通标志识别数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:交通标志识别数据集在自动驾驶、交通安全监控、智能交通系统、驾驶员辅助系统和城市规划等领域都有广泛应用的潜力数据集说明:交通标志识别数据集,真实场景的高质量图片数据,数据场景丰富,含有交通标识6类…
YOLOv8轻量化模型:模型轻量化设计 | 轻量级可重参化EfficientRepBiPAN | 来自YOLOv6思想
💡💡💡本文解决什么问题:在几乎不保证精度下降的前提下,轻量级模型创新设计
EfficientRepBiPAN 在关键点检测任务中 | GFLOPs从9.6降低至8.5, mAP50从0.921下降至0.912,mAP50-95从0.697提升至0.779
YOLO轻量化模型专栏:http://t.csdnimg.cn/AeaEF
1.YOLOv6介绍 …

yolov8+多算法多目标追踪+实例分割+目标检测+姿态估计(代码+教程)
多目标追踪实例分割目标检测
YOLO (You Only Look Once) 是一个流行的目标检测算法,它能够在图像中准确地定位和识别多个物体。
本项目是基于 YOLO 算法的目标跟踪系统,它将 YOLO 的目标检测功能与目标跟踪技术相结合,实现了实时的多目标跟…
![[论文阅读]PV-RCNN++](https://img-blog.csdnimg.cn/c21f542c8a3f4031949e66cf43fa9c17.png)
[论文阅读]PV-RCNN++
PV-RCNN
PV-RCNN: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection 论文网址:PV-RCNN 论文代码:PV-RCNN
简读论文
这篇论文提出了两个用于3D物体检测的新框架PV-RCNN和PV-RCNN,主要的贡献如下: 提出P…
YOLOv5独家改进:分层特征融合策略MSBlock | 南开大学提出YOLO-MS |超越YOLOv8与RTMDet,即插即用打破性能瓶颈
💡💡💡本文独家改进:分层特征融合策略MSBlock,不同Kernel-Size卷积在不同尺度提升特征提取能力,最终引入到YOLOv5,做到二次创新
1)MSBlock使用;2)和C3结合使用
推荐指数:5颗星
MSBlock | 亲测在多个数据集能够实现大幅涨点,小目标检测效果也不错
💡💡…
python目标检测将视频按照帧率切除成图片
python目标检测将视频按照帧率切除成图片
python目标检测将视频按照帧率切除成图片,并且允许放入多个多个视频
完整代码如下:
import os
import cv2class VideoSplit:"""将视频分帧为图片source_path: 视频文件存储地址result_path&am…
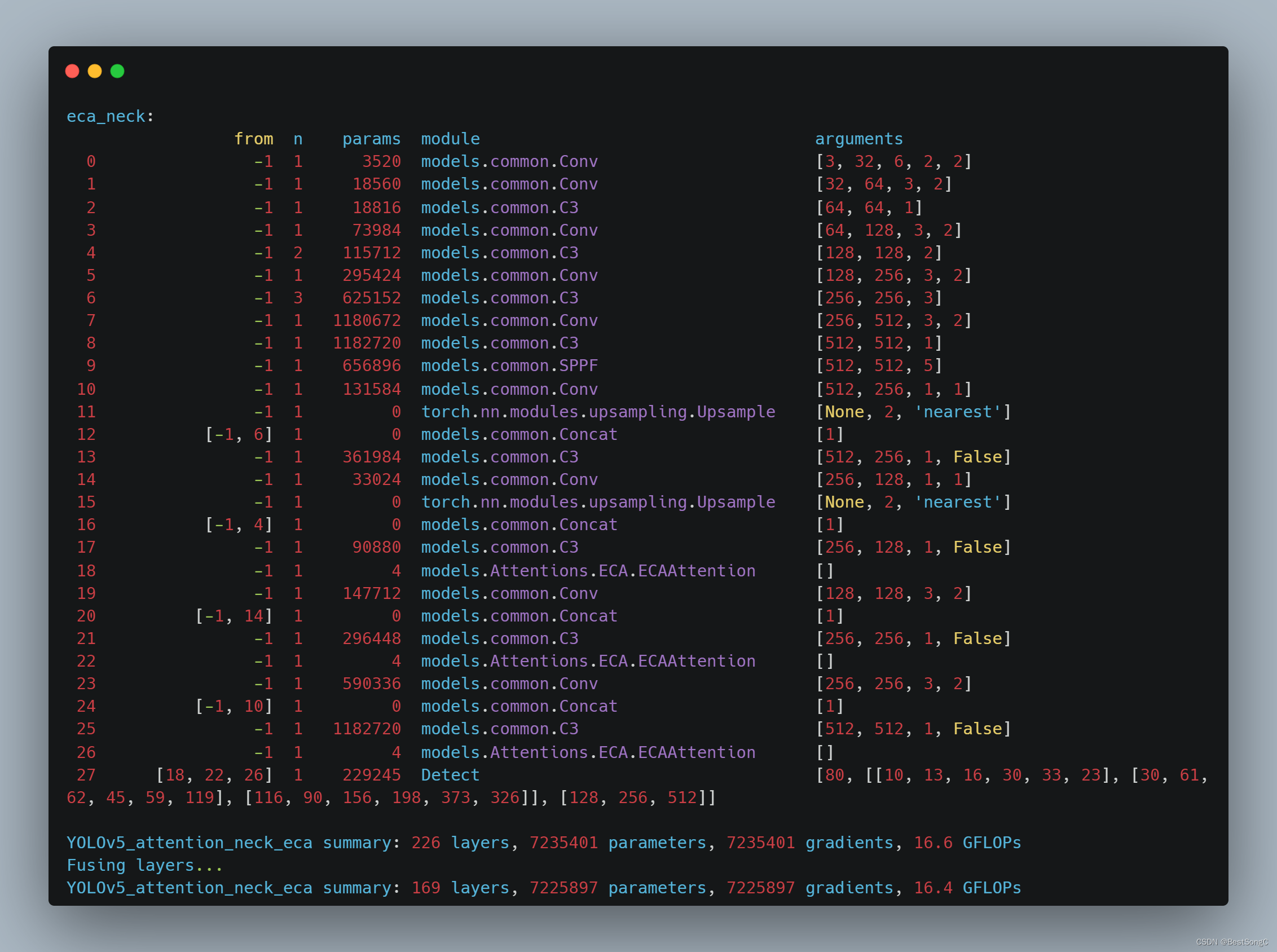
ECA-Net(Efficient Channel Attention Network)
ECA-Net(Efficient Channel Attention Network)是一种用于计算机视觉任务的注意力模型,旨在增强神经网络对图像特征的建模能力。本文详细介绍ECA-Net注意力模型的结构设计,包括其背景、动机、组成部分以及工作原理。ECA-Net模块的…
Python按类别和比例从Labelme数据集中划分出训练数据集和测试数据集
Python按类别和比例从Labelme数据集中划分出训练数据集和测试数据集 前言前提条件相关介绍实验环境按类别和比例从Labelme数据集中划分出训练数据集和测试数据集代码实现输出结果 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容&#x…

yolov5 利用Labelimg对图片进行标注
首先打开yolov5-master,在data文件中新建一个文件夹来存放你需要跑的数据,例如我这次跑的是羽毛球,文件把文件取名为badminton。使用其他文件夹例如images也可以,就是跑多了以后不好整理,然后点击 选中刚刚你存放数据的…

全新Inner-IoU损失函数!!!通过辅助边界框计算IoU有效提升检测效果
摘要
1 简介
2 方法
2.1 边界框回归模式分析
2.2 Inner-IoU 损失
3 实验
3.1 模拟实验
3.2 对比实验
3.2.1 PASCAL VOC上的YOLOv7
3.2.2 YOLOv5 在 AI-TOD 上
4. 参考 摘要
随着检测器的快速发展,边界框回归(BBR)损失函数不断进…

第三十章 FPN算法及其变种(车道线感知)
目标检测算法:FPN
论文基本信息
标题:Feature Pyramid Networks for Object Detection链接:https://arxiv.org/abs/1612.03144代码:https://paperswithcode.com/paper/feature-pyramid-networks-for-object-detection
已有方法…

YOLOv5改进 | 添加CA注意力机制 + 增加预测层 + 更换损失函数之GIoU
前言:Hello大家好,我是小哥谈。在小目标场景的检测中,存在远距离目标识别效果差的情形,本节课提出一种基于改进YOLOv5的小目标检测方法。首先,在YOLOv5s模型的Neck网络层融合坐标注意力机制,以提升模型的特…

跨镜头目标融合__追踪之目标重识别研究(跨镜头目标追踪)
文章目录 标题:跨镜头目标融合;目标重识别;跨镜头目标追踪; 1 目的:2 实现方法/策略:2.1 目标类型位置匹配(或考虑结合目标轨迹)2.2 目标重识别2.3 目标类型位置匹配(轨迹)目标重识别…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)
目录
前言
几个高频面试题目
视觉检测中如何提高图片处理速度与质量?
01图像处理技术的应用
02当前面临的挑战

计算机视觉中目标检测的数据预处理
本文涵盖了在解决计算机视觉中的目标检测问题时,对图像数据执行的预处理步骤。 首先,让我们从计算机视觉中为目标检测选择正确的数据开始。在选择计算机视觉中的目标检测最佳图像时,您需要选择那些在训练强大且准确的模型方面提供最大价值的图…
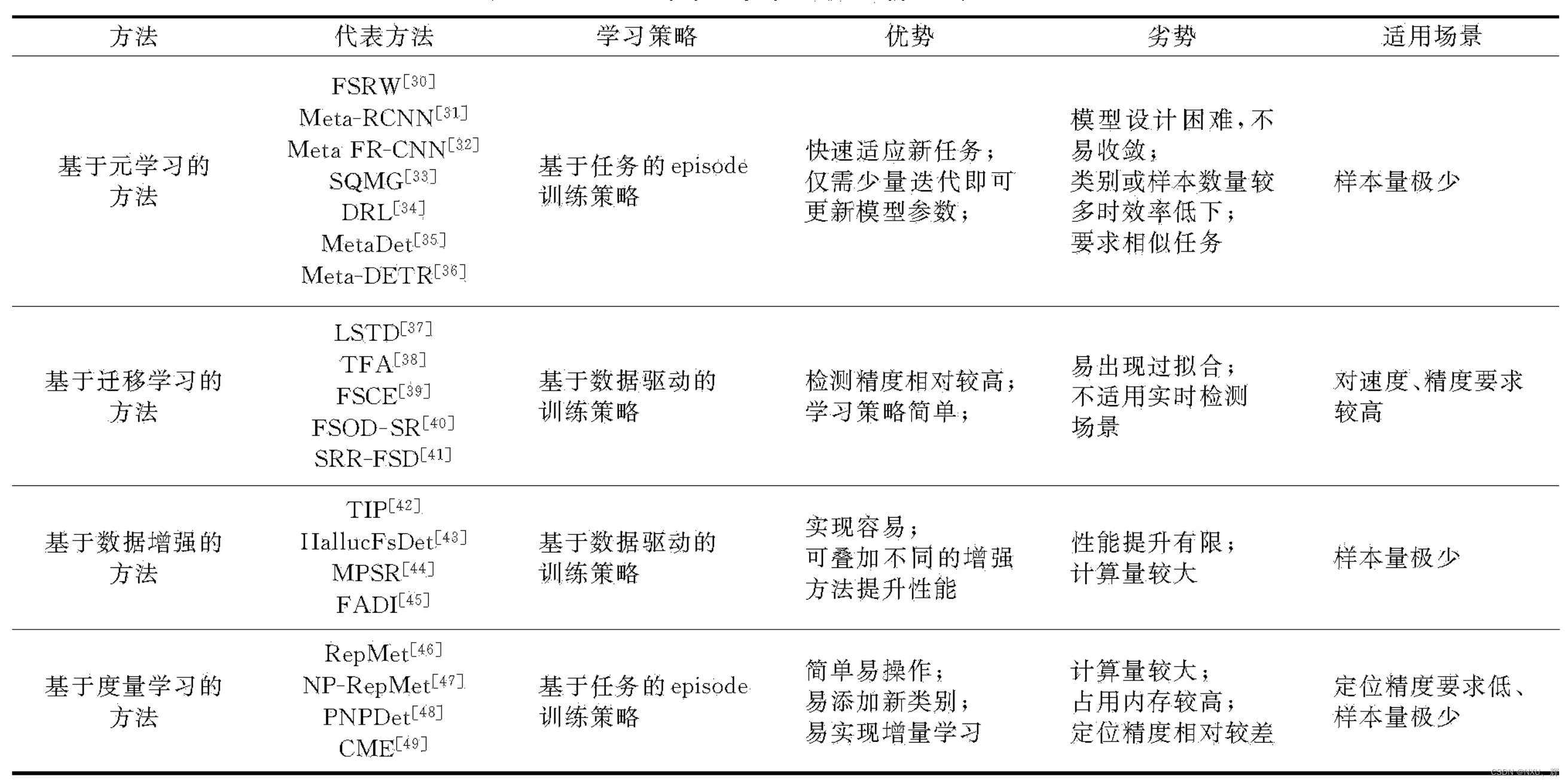
小样本目标检测(Few-Shot Object Detection)综述
背景
前言:我的未来研究方向就是这个,所以会更新一系列的文章,就关于FSOD,如果有相同研究方向的同学欢迎沟通交流,我目前研一,希望能在研一发文,目前也有一些想法,但是具体能不能实现还要在做的过程中慢慢评估和实现.写文的主要目的还是记录,避免重复劳动,我想用尽量简洁的语言…

YOLOv5算法进阶改进(1)— 改进数据增强方式 + 添加CBAM注意力机制
前言:Hello大家好,我是小哥谈。本节课设计了一种基于改进YOLOv5的目标检测算法。首先在数据增强方面使用Mosaic-9方法来对训练集进行数据增强,使得网络具有更好的泛化能力,从而更好适用于应用场景。而后,为了更进一步提升检测精度,在backbone中嵌入了CBAM注意力机制模块,…
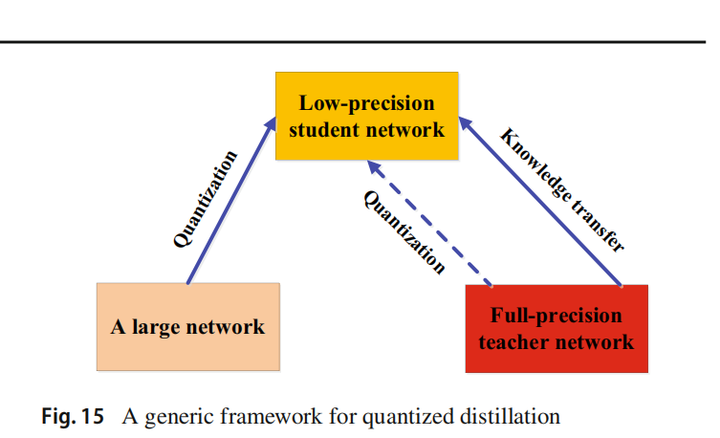
知识蒸馏概述及开源项目推荐
文章目录 1.介绍2.知识2.1 基于响应的知识(response-based)2.2 基于特征的知识(feature-based)2.3 基于关系的知识(relation-based) 3.蒸馏机制3.1 离线蒸馏3.2 在线蒸馏3.3 自蒸馏 4.教师-学生架构5.蒸馏算法5.1 对抗性蒸馏(Adversarial Dis…

目标检测——Yolo系列(YOLOv1/2/v3/4/5/x/6/7/8)
目标检测概述 什么是目标检测? 滑动窗口(Sliding Window) 滑动窗口的效率问题和改进 滑动窗口的效率问题:计算成本很大
改进思路 1:使用启发式算法替换暴力遍历 例如 R-CNN,Fast R-CNN 中使用 Selectiv…
RT-DETR算法改进:更换损失函数Alpha-IoU损失函数,边界框回归联合损失的幂交集,提升RT-DETR检测精度
💡本篇内容:RT-DETR算法改进:更换损失函数Alpha-IoU损失函数,边界框回归联合损失的幂交集,提升RT-DETR检测精度
💡本博客 改进源代码改进 适用于 RT-DETR目标检测算法(ultralytics项目版本)
按步骤操作运行改进后的代码即可🚀🚀🚀
💡改进 RT-DETR 目标检测…

改进YOLO系列 | YOLOv5/v7 引入反向残差注意力模块 iRMB | 《ICCV 2023 最新论文》
论文地址:https://arxiv.org/abs/2301.01146 代码地址:https://github.com/zhangzjn/EMO
本论文着重于开发现代、高效、轻量级的模型,用于进行密集预测,同时在参数、FLOPs和性能之间进行权衡。倒置残差块(IRB)作为轻量级CNN的基础设施,但在基于注意力的研究中尚未找到对…

YOLOv8-Seg改进:卷积变体系列篇 | DCNv3可形变卷积基于DCNv2优化 | CVPR2023
🚀🚀🚀本文改进:DCNv3算子,基于DCNv2算子引入共享投射权重、多组机制和采样点调制,引入到YOLOv8,与C2f结合实现二次创新;
🚀🚀🚀DCNv3 亲测在多个数据集能够实现涨点,同样适用于小目标分割 🚀🚀🚀YOLOv8-seg创新专栏:http://t.csdnimg.cn/KLSdv
学姐…

RT-DETR算法优化改进:Backbone改进 | VanillaNet一种新视觉Backbone,极简且强大!华为诺亚2023
💡💡💡本文独家改进: VanillaNet助力RT-DETR ,替换backbone,简到极致、浅到极致!深度为6的网络即可取得76.36%@ImageNet的精度,深度为13的VanillaNet甚至取得了83.1%的惊人性能。
推荐指数:五星
RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/cat…

YOLO目标检测——苹果数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:监测果园中苹果的生长情况、水果品质监控、自动化分拣数据集说明:苹果检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(…
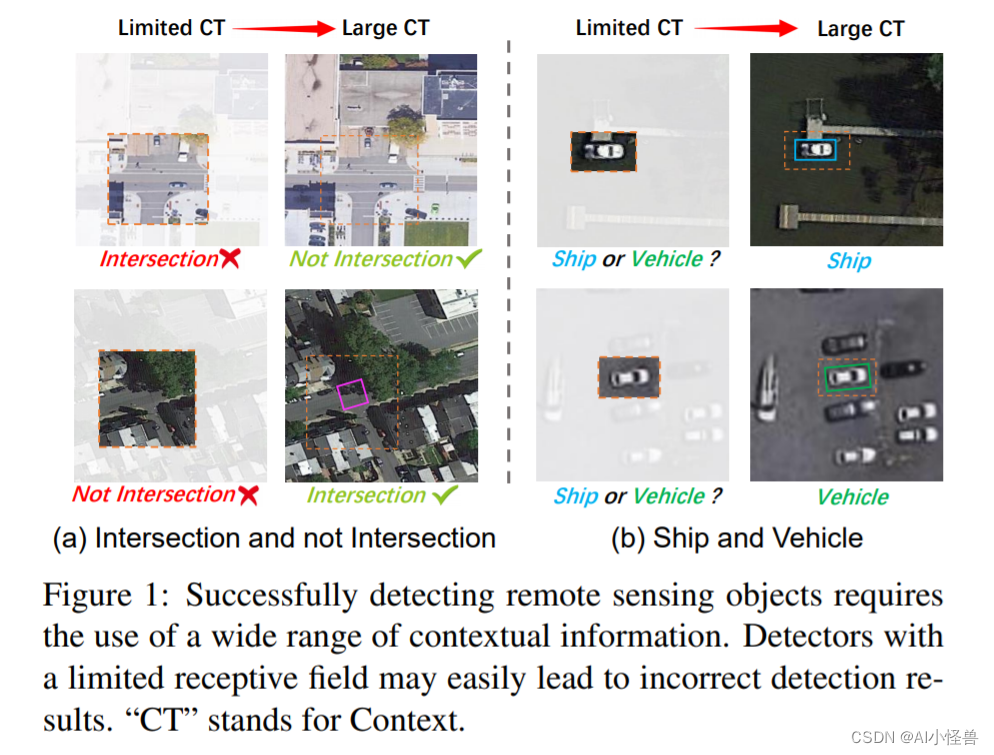
RT-DETR算法优化改进:Backbone改进 | LSKNet:遥感旋转目标检测新SOTA | ICCV 2023
💡💡💡本文独家改进:LSKNet 助力RT-DETR ,替换backbone,Large Selective Kernel Network (LSKNet),可以动态地调整其大空间感受野,以更好地建模遥感场景中各种物体的测距的场景。
推荐指数:五星
RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/cat…

理解 R-CNN:目标检测的一场革命
一、介绍 对象检测是一项基本的计算机视觉任务,涉及定位和识别图像或视频中的对象。多年来,人们开发了多种方法来应对这一挑战,但基于区域的卷积神经网络(R-CNN)的发展标志着目标检测领域的重大突破。R-CNN 及其后续变…

毫米波雷达模块的目标检测与跟踪
毫米波雷达技术在目标检测与跟踪方面具有独特的优势,其高精度、不受光照影响等特点使其在汽车、军事、工业等领域广泛应用。本文深入探讨毫米波雷达模块在目标检测与跟踪方面的研究现状、关键技术以及未来发展方向。 随着科技的不断进步,毫米波雷达技术在…
目标检测—Yolo系列(YOLOv1/2/v3/4/5/x/6/7/8)
目标检测概述 什么是目标检测? 滑动窗口(Sliding Window) 滑动窗口的效率问题和改进 滑动窗口的效率问题:计算成本很大
改进思路 1:使用启发式算法替换暴力遍历 例如 R-CNN,Fast R-CNN 中使用 Selectiv…
YOLOv5独家原创改进:最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度
💡该教程为属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 💡本篇文章为YOLOv5独家原创改进:独家首发最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度。
💡对自己数据集改进有效…

YOLO目标检测——烟叶病害检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:烟叶病虫害防治数据集说明:烟叶病害检测数据集,真实场景的高质量图片数据,数据场景丰富,类别分为:轻度病虫、中度病虫、高度病虫标签说明:使用lableimg标注软件标注,标…
SSD(Single Shot MultiBox Detector)的复现
SSD 背景 这是一种 single stage 的检测模型,相比于R-CNN系列模型上要简单许多。其精度可以与Faster R-CNN相匹敌,而速度达到了惊人的59FPS,速度上完爆 Fster R-CNN。 速度快的根本原因在于移除了 region proposals 步骤以及后续的像素采样或…
深度学习系列54:使用 MMDETECTION 和 LABEL-STUDIO 进行半自动化目标检测标注
参考https://mmdetection.readthedocs.io/zh-cn/latest/user_guides/label_studio.html,这里进行简要概述:
1. 启动目标检测服务
在mmdetection文件夹中,执行
label-studio-ml start projects/LabelStudio/backend_template --with \
conf…

Python将原始数据集和标注文件进行数据增强(随机仿射变换),并生成随机仿射变换的数据集和标注文件
Python将原始数据集和标注文件进行数据增强(随机仿射变换),并生成随机仿射变换的数据集和标注文件 前言前提条件相关介绍实验环境生成随机仿射变换的数据集和标注文件代码实现输出结果 前言 由于本人水平有限,难免出现错漏&#x…
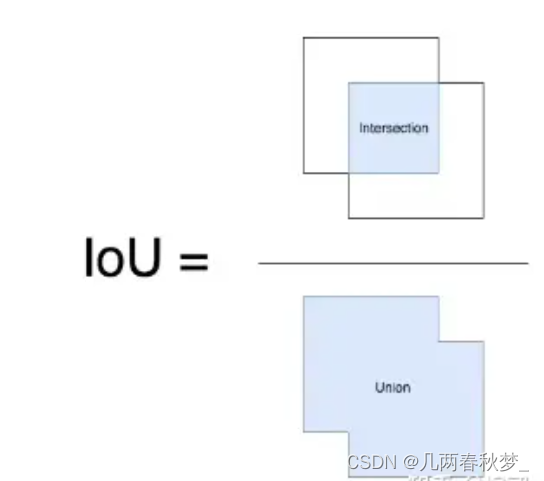
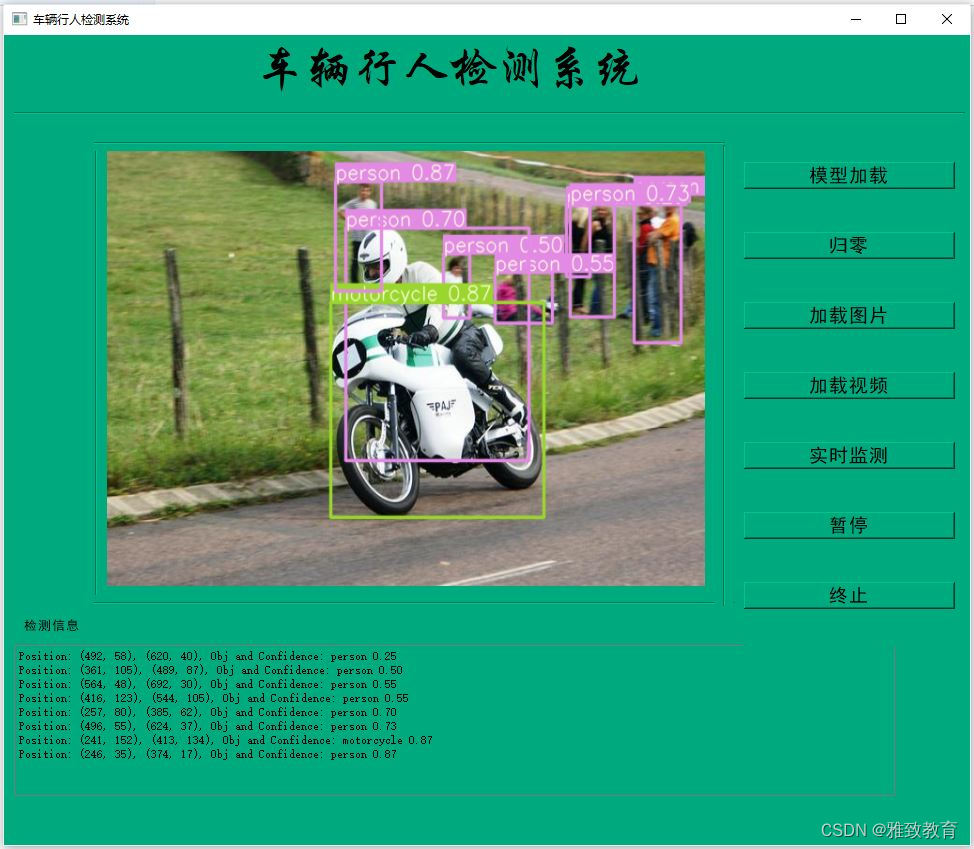
深度学习之基于YoloV5车辆和行人目标检测系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介YOLOv5 简介YOLOv5 特点 车辆和行人目标检测系统 二、功能三、系统四. 总结 一项目简介 # 深度学习之基于 YOLOv5 车辆和行人目标检测系统介绍
深度学习在…

第十一章 目标检测中的NMS(工具)
精度提升
众所周知,非极大值抑制NMS是目标检测常用的后处理算法,用于剔除冗余检测框,本文将对可以提升精度的各种NMS方法及其变体进行阶段性总结。 总体概要:
对NMS进行分类,大致可分为以下六种,这里是依…

机器学习之危险品车辆目标检测
危险品的运输涉及从离开仓库到由车辆运输到目的地的风险。监控事故、车辆运动动态以及车辆通过特定区域的频率对于监督车辆运输危险品的过程至关重要。 在线工具推荐: 三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数…
目标检测网络系列——YOLO V4
文章目录 目标检测技术总结两种优化方向Bag of freebiesBag of specialsYOLO4网络结构网络架构(architecture)的选择基础网络结构的选择网络"插件"的选择。BoF和BoS的选择(Selection of BoF and BoS)YOLO4的其他改进点对比实验不同的特征(数据增强方法)之间的对比det…
【OpenCV实现图像:可视化目标检测框】
文章目录 概要画框函数代码实现标签美化角点美化透明效果小结 概要
目标检测框的可视化在计算机视觉和机器学习领域中是一项重要的任务,有助于直观地理解和评估目标检测算法的性能。通过使用Python和相关的图像处理库,可以轻松实现目标检测框的可视化。…
YOLOv8改进 | 2023 | FocusedLinearAttention实现有效涨点
论文地址:官方论文地址
代码地址:官方代码地址 一、本文介绍
本文给大家带来的改进机制是Focused Linear Attention(聚焦线性注意力)是一种用于视觉Transformer模型的注意力机制(但是其也可以用在我们的YOLO系列当中从而提高检测…

YOLOv5算法进阶改进(4)— 引入解耦合头部 | 助力提高检测准确率
前言:Hello大家好,我是小哥谈。解耦头是目标检测中的一种头部设计,用于从检测网络的特征图中提取目标位置和类别信息。具体来说,解耦头部将目标检测任务分解为两个子任务:分类和回归。分类任务用于预测目标的类别,回归任务用于预测目标的位置。这种设计可以提高目标检测的…
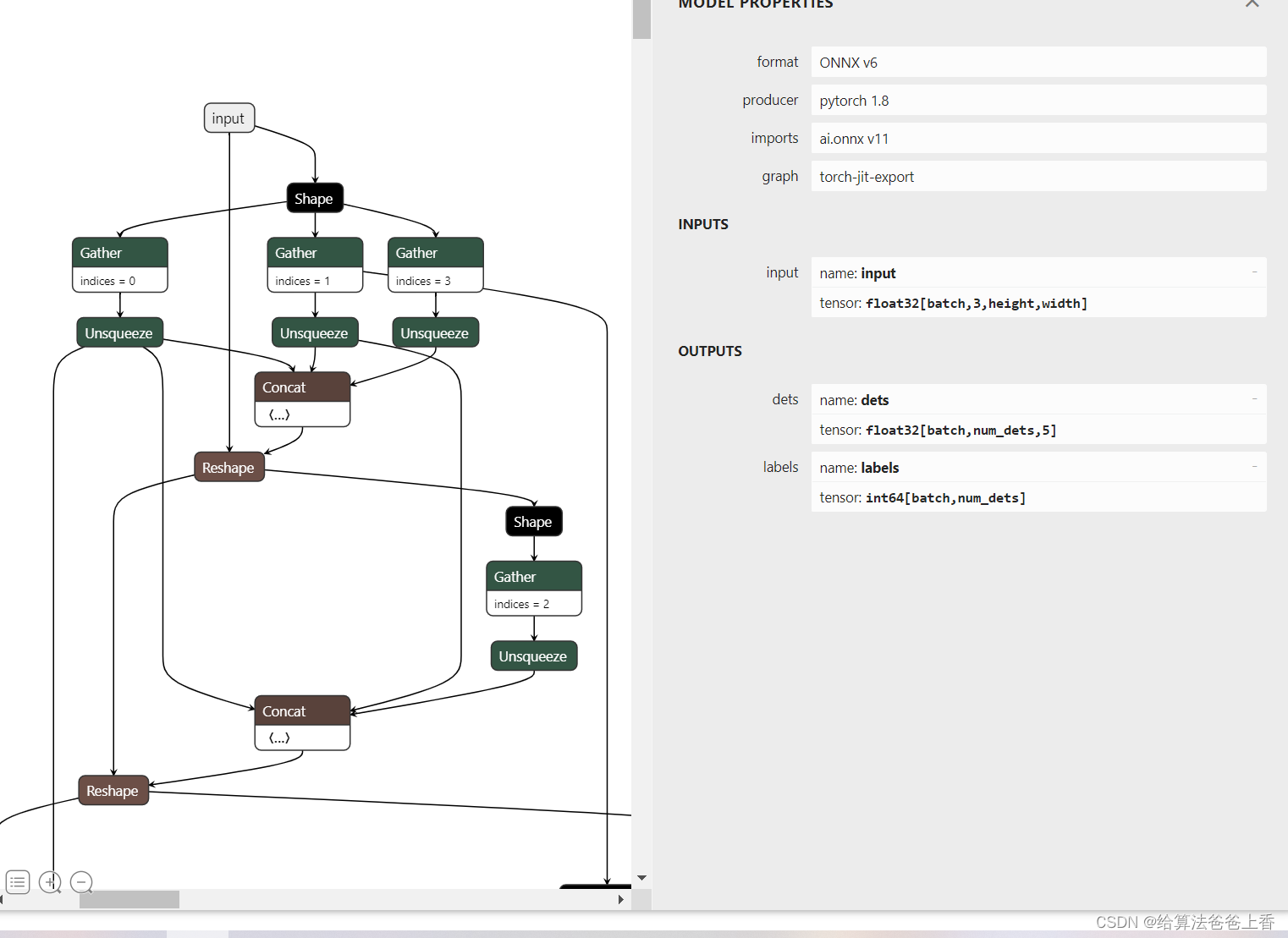
OpenMMlab导出yolox模型并用onnxruntime和tensorrt推理
导出onnx文件
直接使用脚本
import torch
from mmdet.apis import init_detector, inference_detectorconfig_file ./configs/yolox/yolox_tiny_8xb8-300e_coco.py
checkpoint_file yolox_tiny_8x8_300e_coco_20211124_171234-b4047906.pth
model init_detector(config_fi…
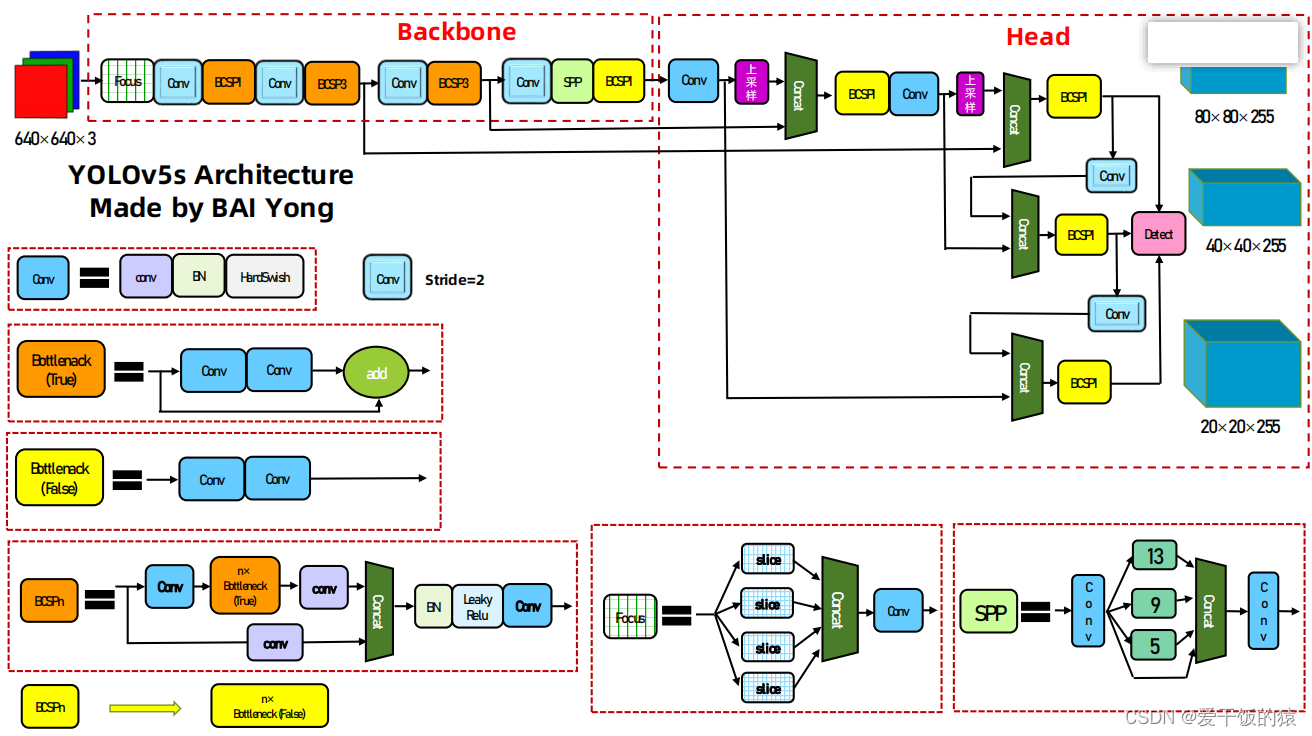
【YOLOv5入门】目标检测
【大家好,我是爱干饭的猿,本文重点介绍YOLOv5入门-目标检测的任务、性能指标、yolo算法基本思想、yolov5网络架构图。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇…
详解RT-DETR网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署
论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址 目录
一、本文介绍
二、RT-DETR的网络结构
2.1、模型概览
2.2、高效混合编码器
2.3、IoU感知查询选择
2.4、 可扩展的RT-DETR
三、RT-DERT的环境搭建
四、免费数据集获取
五、获取RT-D…

【yolov5人行道-斑马线目标检测】
yolov5人行道-斑马线目标检测 数据集yolov5人行道-斑马线目标检测检测模型 数据集
YOLOv5是一种目标检测算法,可以用于检测图像中的人行道-斑马线。在目标检测领域,YOLOv5通过结合多种技术手段,包括使用Mosaic数据增强操作、自适应锚框计算与…
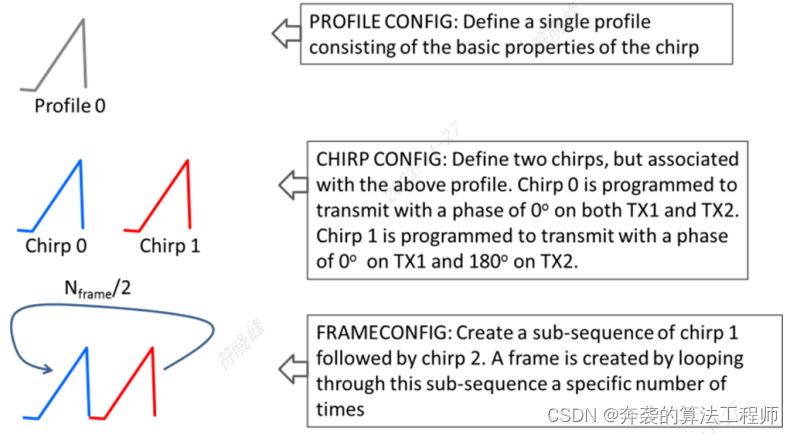
MIMO雷达(TI文档)
MIMO雷达是提高毫米波雷达角度分辨率(空间分辨率)的关键技术。这里介绍MIMO雷达的基本准则和不同设计的可能性。还简要讨论了在TI毫米波产品线上实现MIMO雷达的路径。
1.简介 术语单输入多输出(SIMO)雷达指的是雷达有单个发射&am…
基于官方YOLOv4-u5【yolov5风格实现】开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】
本文是关于基于YOLOv4开发构建目标检测模型的超详细实战教程,超详细实战教程相关的博文在前文有相应的系列,感兴趣的话可以自行移步阅读即可:
《基于yolov7开发实践实例分割模型超详细教程》《YOLOv7基于自己的数据集从零构建模型完整训练、推理计算超详细教程》《DETR (DE…
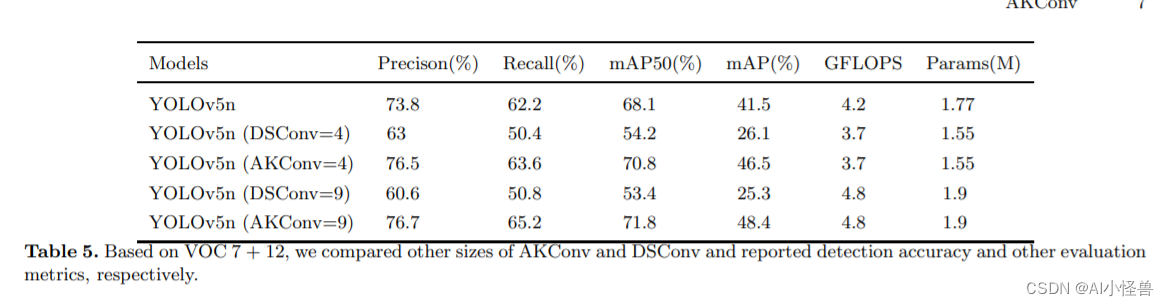
YOLOv5独家原创改进: AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv | 2023年11月最新发表
💡💡💡本文全网首发独家改进:可改变核卷积(AKConv),赋予卷积核任意数量的参数和任意采样形状,为网络开销和性能之间的权衡提供更丰富的选择,解决具有固定样本形状和正方形的卷积核不能很好地适应不断变化的目标的问题点,效果秒殺DSConv 1)AKConv替代标准卷积进行…
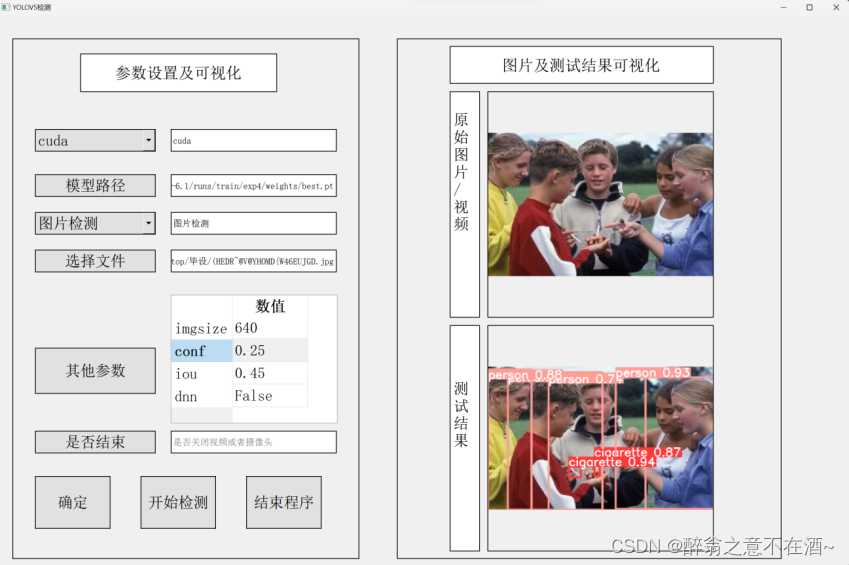
DjiTello + YoloV5的无人机的抽烟检测
一、效果展示 注:此项目纯作者自己原创,创作不易,不经同意不给予搬运权限,转发前请联系我,源码较大需要者评论获取,谢谢配合!
1、未启动飞行模型无人机的目标检测。 DjiTello YOLOV5抽烟检测 …
CSA认证SHEIN出口圣诞节灯饰加拿大站标准CSA C22.2 No.37测试怎么做
圣诞节灯饰,LED灯饰,LED灯泡,电子线等。加拿大作为圣诞节的重要市场之一,对圣诞节灯饰的安全性和性能有着严格的要求。本文将详细介绍加拿大CSA认证标准CSA C22.2 No.37《圣诞树和其它照明组件的通用要求》,以及如何办理CSA认证以满足加拿大市场的要求。…
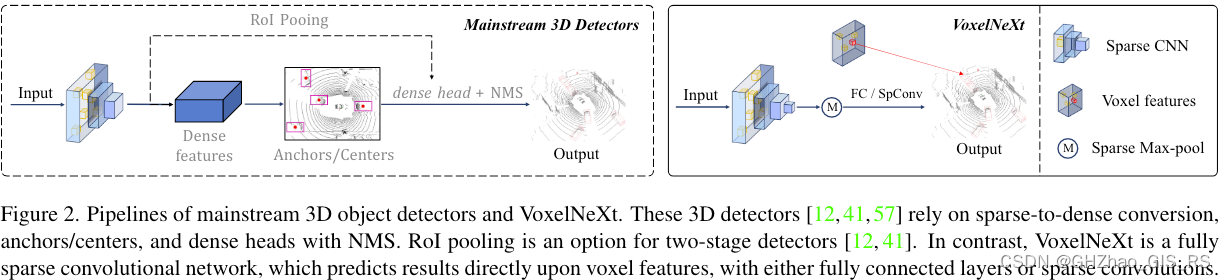
3D点云目标检测:VoxelNex解读(带源码/未完)
VoxelNext 通用vsVoxelNext一、3D稀疏卷积模块1.1、额外的两次下采样1.2、稀疏体素删减 二、高度压缩三、稀疏池化四、head五、waymo数据集训练六、训练自己的数据集bug修改 通用vsVoxelNext 一、3D稀疏卷积模块
1.1、额外的两次下采样
使用通用的3D sparse conv,…
CVPR 2023 精选论文学习笔记:Post-Training Quantization on Diffusion Models
基于MECE原则,我们给出以下四种分类依据:
1. 模型类型 生成模型用于生成与其训练数据相似的新数据。它们通常用于图像生成、文本生成和音乐生成等任务。语言模型用于理解和生成人类语言。它们通常用于机器翻译、聊天机器人和文本摘要等任务。其他模型用于各种任务,例如图像…
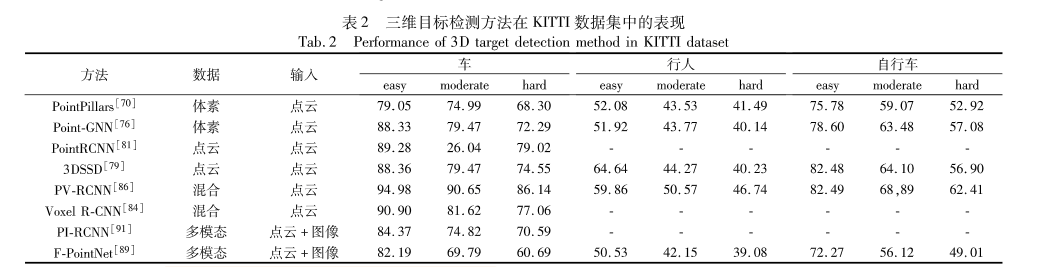
基于深度学习的点云三维目标检测方法综述
论文标题:基于深度学习的点云三维目标检测方法综述 作者:郭毅锋1,2†,吴帝浩1,魏青民1 发表日期: 2023 1 阅读日期 :2023 11 29 研究背景&…
YOLO改进系列之SKNet注意力机制
摘要
视皮层神经元的感受野大小受刺激的调节即对于不同的刺激,卷积核的大小应该不同,但在构建CNN时一般在同一层只采用一种卷积核,很少考虑因采用不同卷积核。于是SKNet被提出,在SKNet中,不同大小的感受视野ÿ…
YOLOv8改进 | 2023 | DWRSeg扩张式残差助力小目标检测 (附修改后的C2f+Bottleneck)
论文地址:官方论文地址
代码地址:该代码目前还未开源,我根据论文内容进行了复现内容在文章末尾。 一、本文介绍
本文内容给大家带来的DWRSeg中的DWR模块来改进YOLOv8中的C2f和Bottleneck模块,主要针对的是小目标检测,…
RT-DETR算法优化改进: 一种新颖的可扩张残差(DWR)注意力模块,加强不同尺度特征提取能力
💡💡💡本文全网首发独家改进:一种新颖的可扩张残差(DWR)注意力模块,加强不同尺度特征提取能力,创新十足,独家首发适合科研 1)代替RepC3进行使用; 2)DWR直接作为注意力进行使用;
推荐指数:五星 RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/…

YOLOv5小目标检测层
目录 一、原理
二、yaml配置文件 一、原理
小目标检测层,就是增加一个检测头,增加一层锚框,用来检测输入图像中像素较小的目标
二、yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 3 # number of classes
depth_multiple: 0.33 # model…
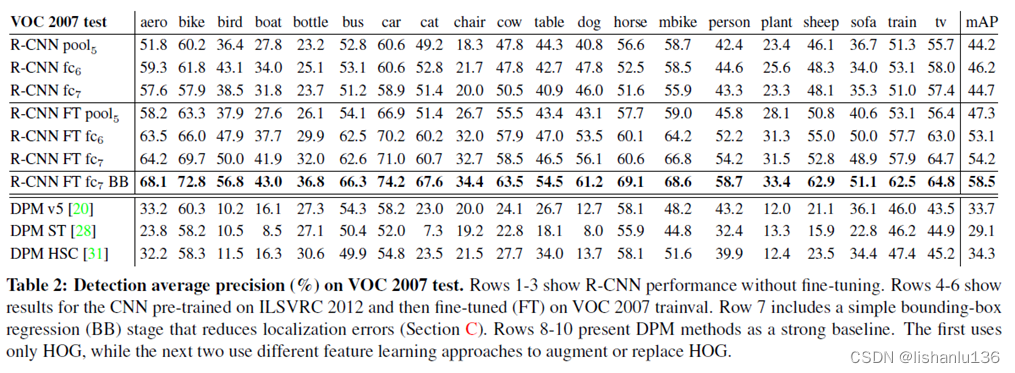
目标检测——R-CNN算法解读
论文:Rich feature hierarchies for accurate object detection and semantic segmentation 作者:Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik 链接:https://arxiv.org/abs/1311.2524 代码:http://www.cs.berke…
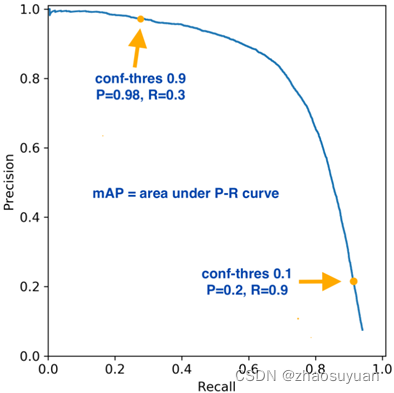
目标检测常用评价指标
1 基本概念 1.1 IOU(Intersection over Union) 1.2 TP TN FP FN 2. 各种率 3. PR曲线 4. mAP的计算 4.1 AP的计算 4.2 mAP 4.3 mAP0.5和mAP0.5:0.95
1.1 IOU(Intersection over Union)
1.2 TP TN FP FN TP(Truth Positive): 预测正类,实际正类&#x…

中国毫米波雷达产业分析4——毫米波雷达企业介绍
一、矽典微 (一)公司简介 矽典微致力于实现射频技术的智能化,专注于研发高性能无线技术相关芯片,产品广泛适用于毫米波传感器、下一代移动通信、卫星通信等无线领域。 整合自身在芯片、系统、软件、算法等领域的专业能力…
基于YOLOv8深度学习的钢材表面缺陷检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
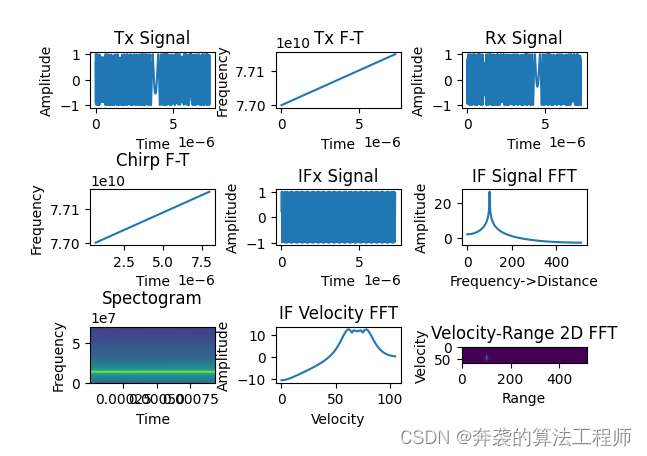
基于python的FMCW雷达工作原理仿真
这篇文章将介绍如何使用python来实现FMCW工作原理的仿真,第1章内容将介绍距离检测原理,第2章内容会介绍速度检测原理。
第1章
第1部分: 距离检测原理 调制的连续波雷达通常也被叫做调频连续波(FMCW)雷达是一个使用频率调制来测量…

OpenCV技术应用(5)— 将一幅图像均分成4幅图像
前言:Hello大家好,我是小哥谈。本节课就手把手教你如何将一幅图像均分成4幅图像,希望大家学习之后能够有所收获~!🌈 目录
🚀1.技术介绍
🚀2.实现代码 🚀1.技术介绍
如果将下图…

OpenCV技术应用(6)— 暖色滤镜和冷色滤镜
前言:Hello大家好,我是小哥谈。本节课就手把手教大家如何将一幅图像转化成暖色滤镜和冷色滤镜,希望大家学习之后能够有所收获~!🌈 目录
🚀1.技术介绍
🚀2.暖色滤镜
🚀3.冷色滤…
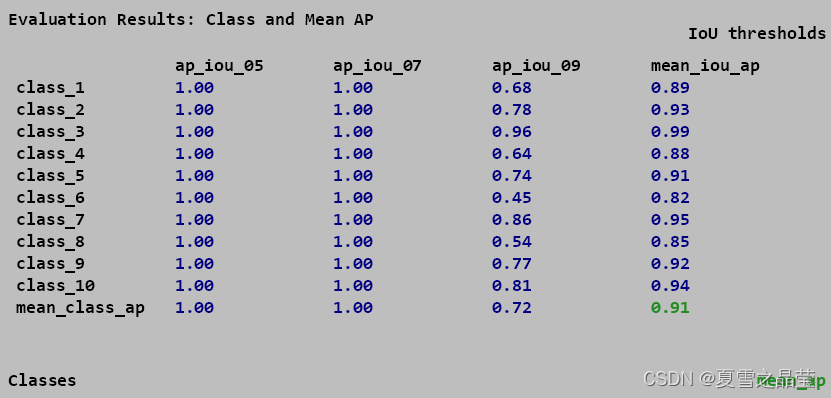
Halcon参考手册目标检测和实例分割知识总结
1.1 目标检测原理介 目标检测:我们希望找到图像中的不同实例并将它们分配给某一个类别。实例可以部分重叠,但仍然可以区分为不同的实例。如图(1)所示,在输入图像中找到三个实例并将其分配给某一个类别。 图(1)目标检测示例
实例分割是目标检…
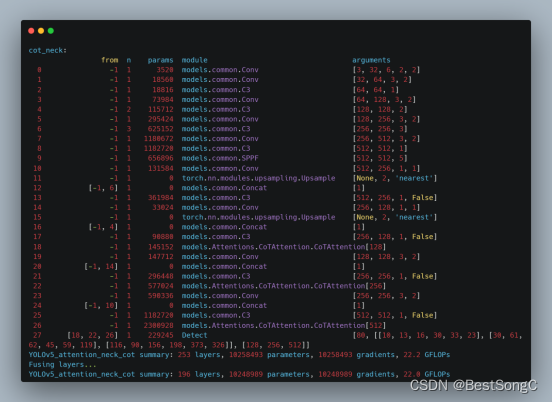
YOLO改进系列之注意力机制(CoTAttention模型介绍)
简介
CoTAttention网络是一种用于多模态场景下的视觉问答(Visual Question Answering,VQA)任务的神经网络模型。它是在经典的注意力机制(Attention Mechanism)上进行了改进,能够自适应地对不同的视觉和语言…

YOLOv5项目实战(3)— 如何批量命名数据集中的图片
前言:Hello大家好,我是小哥谈。本节课就教大家如何去批量命名数据集中的图片,希望大家学习之后可以有所收获!~🌈 前期回顾: YOLOv5项目实战(1)— 如何去训练模型 YOLOv5项目实战(2
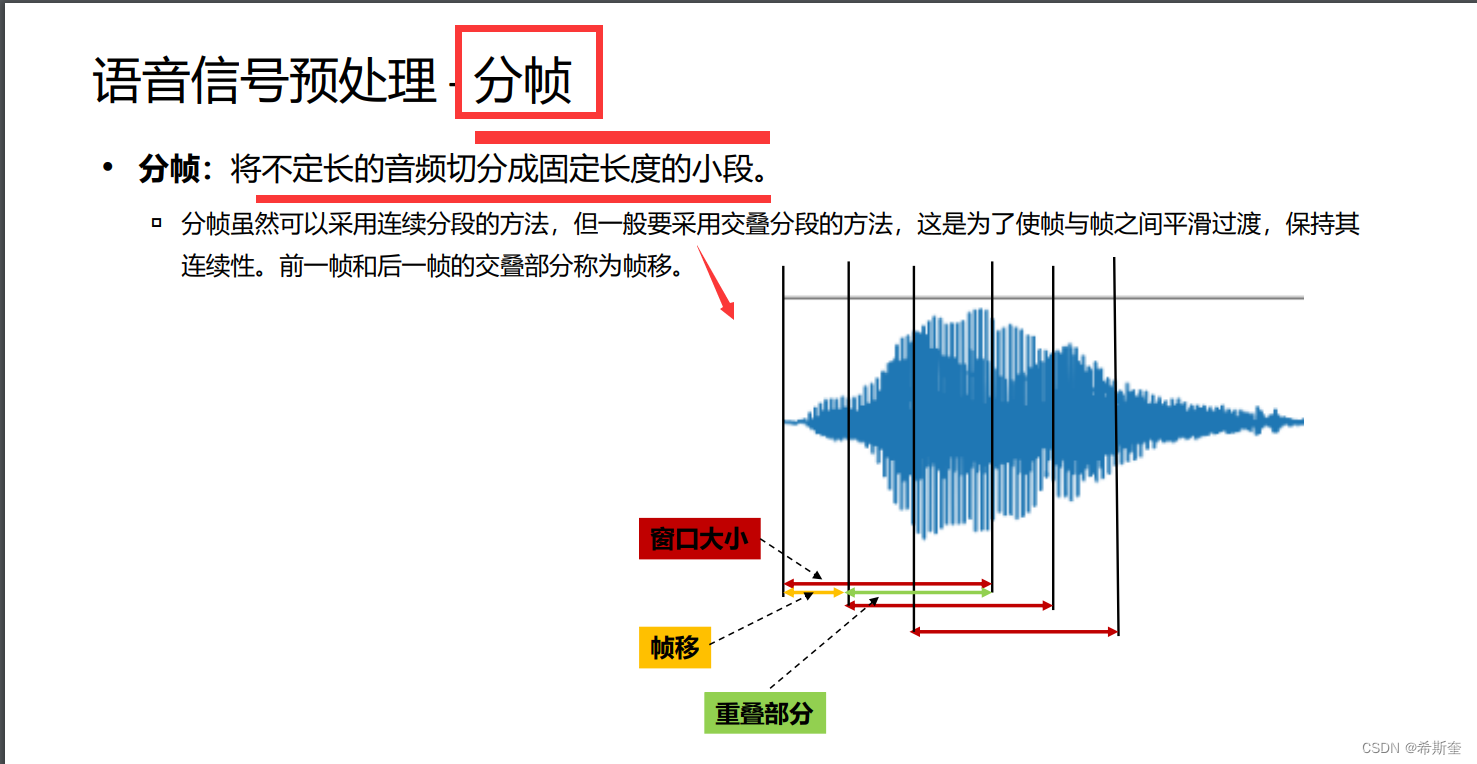
华为ICT——第八章:语音处理理论与实践01
目录 U-Net
思考题
本章总结:
语音处理理论与实践:
语音处理简介 (1)
语音处理简介 (2)
语音处理主要应用场景:
语言学
语言学2
语音学 (1)
语音学 (2)
语音预处理基础
人类语音来源
语音数据
语音信号预处理
语音信号预处理步…
YOLO目标检测——二维码检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:二维码识别、追踪与管理系统数据集说明:二维码检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo…

YOLOv5改进 | 添加SE注意力机制 + 更换NMS之EIoU-NMS
前言:Hello大家好,我是小哥谈。为提高算法模型在不同环境下的目标识别准确率,提出一种基于改进 YOLOv5 深度学习的识别方法(SE-NMS-YOLOv5),该方法融合SE(Squeeze-and-Excitation)注…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)(六)
目录
前言
几个高频面试题目
工业相机与镜头选型方法
一、相机介绍及选型方法
二、镜头介绍及选型方法
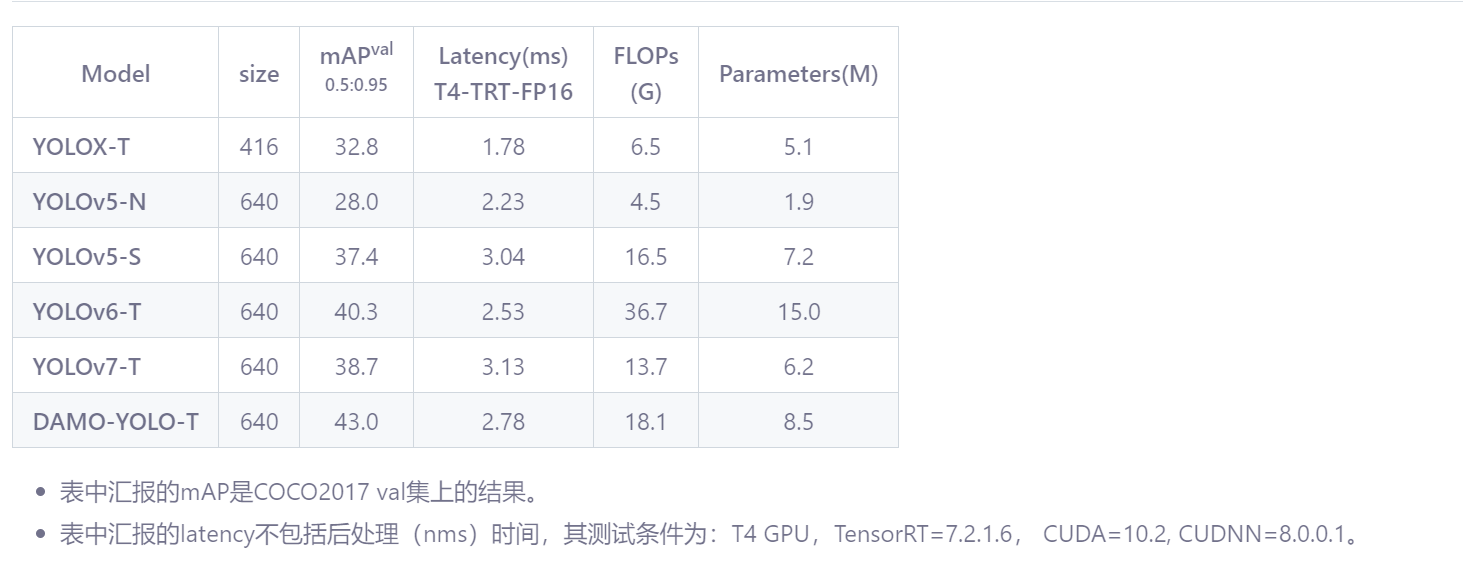
【深度学习】DAMO-YOLO,阿里,701类通用检测模型,目标检测
https://github.com/tinyvision/DAMO-YOLO/blob/master/README_cn.md
DAMO-YOLO是由阿里巴巴达摩院智能计算实验室TinyML团队开发的一个兼顾速度与精度的目标检测框架,其效果超越了目前的一众YOLO系列方法,在实现SOTA的同时,保持了很高的推理速度。DAMO…
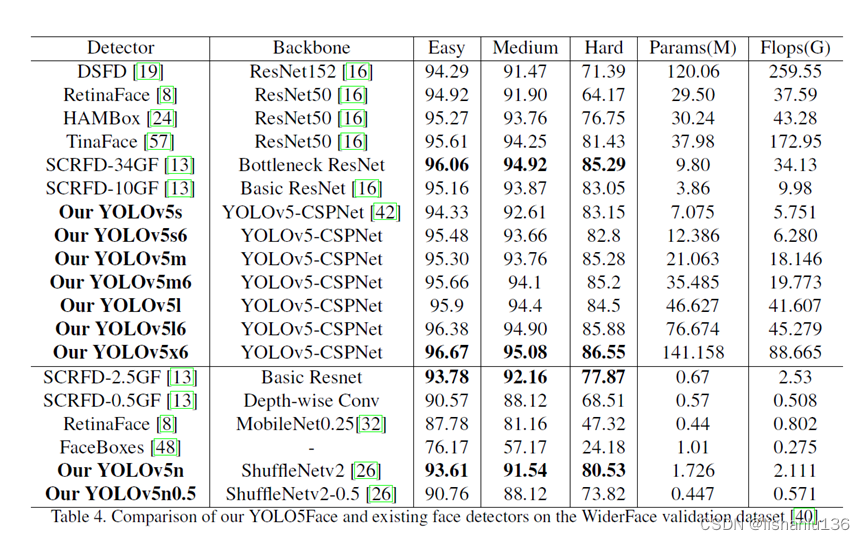
YOLO5Face算法解读
论文:YOLO5Face: Why Reinventing a Face Detector 链接:https://arxiv.org/abs/2105.12931v1 机构:深圳神目科技&LinkSprite Technologies(美国) 开源代码:https://github.com/deepcam-cn/yolov5-face…
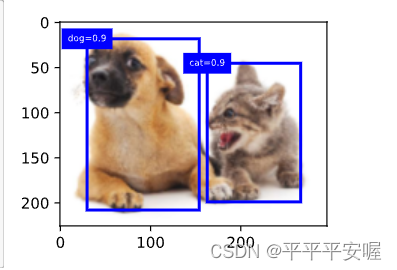
![[论文阅读]BEVFusion](https://img-blog.csdnimg.cn/direct/7da3ac93c5bc416f98f79c93e0158589.png)
[论文阅读]BEVFusion
BEVFusion
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework BEVFusion:简单而强大的激光雷达相机融合框架 论文网址:BEVFusion 论文代码:BEVFusion
简读论文 论文背景:激光雷达和摄像头是自动驾驶系统中常用的两…
【目标检测从零开始】torch搭建yolov3模型
用torch从0简单实现一个的yolov3模型,主要分为Backbone、Neck、Head三部分 目录 Backbone:DarkNet53结构简介代码实现Step1:导入相关库Step2:搭建基本的Conv-BN-LeakyReLUStep3:组成残差连接块Step4:搭建Da…
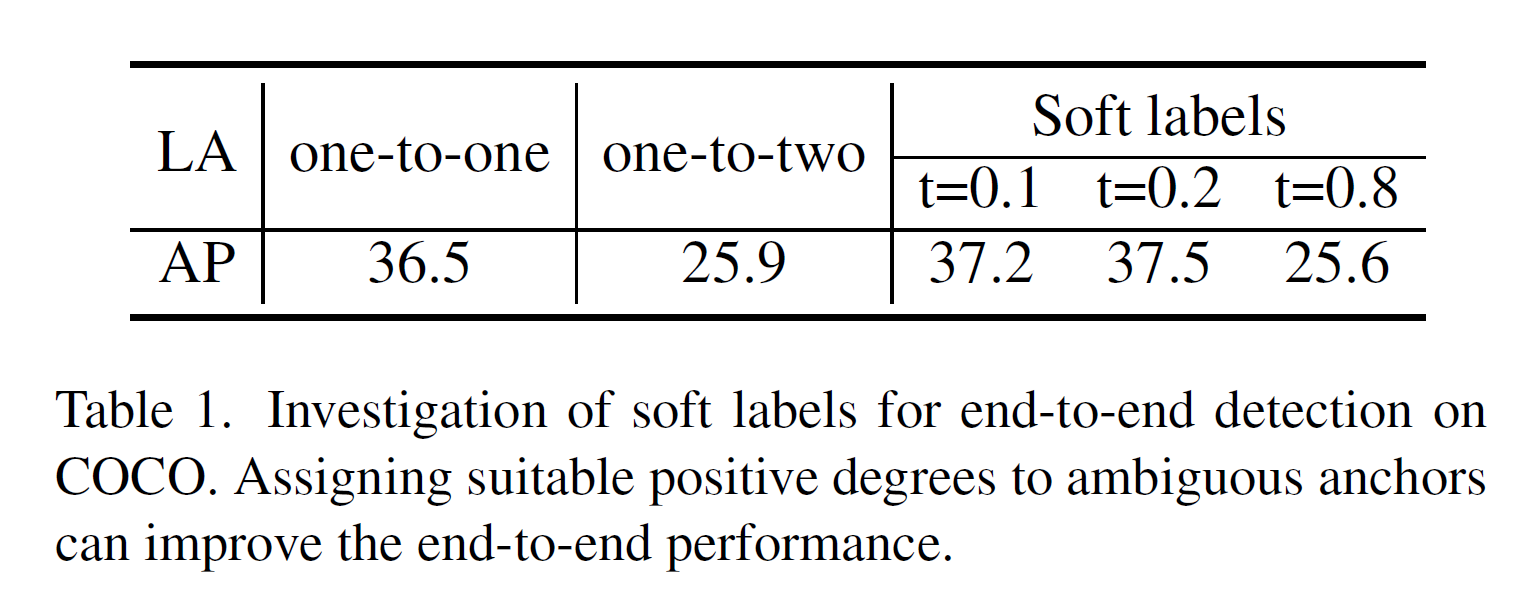
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
One-to-Few Label Assignment for End-to-End Dense Detection阅读笔记
Abstract
一对一(o2o)标签分配对基于变换器的端到端检测起着关键作用,最近已经被引入到全卷积检测器中,用于端到端密集检测。然而,o2o可能因为…
ResNeXt(2017)
文章目录 Abstract1. Introductionformer workour work 2. Related Work多分支卷积网络分组卷积压缩卷积网络Ensembling 3. Method3.1. Template3.2. Revisiting Simple Neurons3.3. Aggregated Transformations3.4. Model Capacity 4. Experiment 原文地址 源代码 Abstract
我…
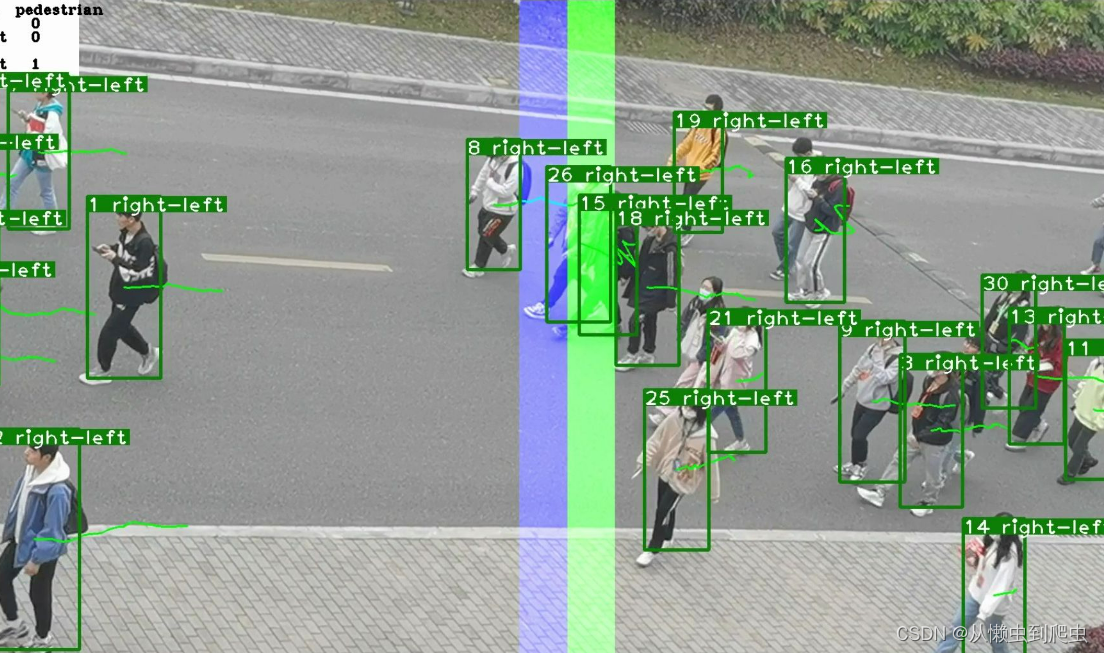
YOLOv8-DeepSort/ByteTrack-PyQt-GUI:全面解决方案,涵盖目标检测、跟踪和人体姿态估计
YOLOv8-DeepSort/ByteTrack-PyQt-GUI是一个多功能图形用户界面,旨在充分发挥YOLOv8在目标检测/跟踪和人体姿态估计/跟踪方面的能力,与图像、视频或实时摄像头流进行无缝集成。支持该应用的Python脚本使用ONNX格式的YOLOv8模型,确保各种人工智…
YOLOv8改进 | Neck篇 | Slim-Neck替换特征融合层实现超级涨点 (又轻量又超级涨点)
一、本文介绍
本文给大家带来的改进机制是Slim-neck提出的Neck部分,Slim-neck是一种设计用于优化卷积神经网络中neck部分的结构。在我们YOLOv8中,neck是连接主干网络(backbone)和头部网络(head)的部分&…
YOLOv8改进 | 2023检测头篇 | 利用AFPN改进检测头适配YOLOv8版(全网独家创新)
一、本文介绍
本文给大家带来的改进机制是利用今年新推出的AFPN(渐近特征金字塔网络)来优化检测头,AFPN的核心思想是通过引入一种渐近的特征融合策略,将底层、高层和顶层的特征逐渐整合到目标检测过程中。这种渐近融合方式有助于…
YOLOv7保姆级教程(个人踩坑无数)----训练自己的数据集
目录
一、前言:
二、YOLOv7代码下载
三、环境配置
四、测试结果 五、制作自己的数据集
六、训练自己的数据集 一、前言:
上一篇已经详细讲解了如何安装深度学习所需要的环境,这一篇则详细讲解如何配置YOLOv7,在本地电脑或者…
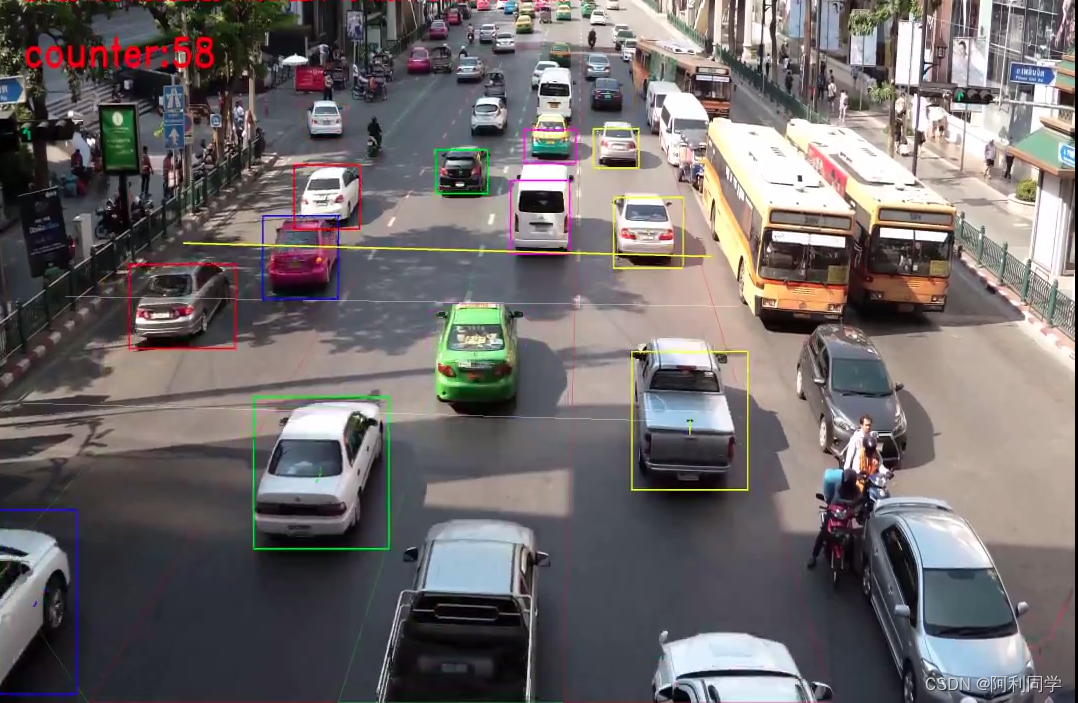
yolo目标检测+目标跟踪+车辆计数+车辆分割+车道线变更检测+速度估计
这个项目使用YOLO进行车辆检测,使用SORT(简单在线实时跟踪器)进行车辆跟踪。该项目实现了以下任务:
车辆计数车道分割车道变更检测速度估计将所有这些详细信息转储到CSV文件中 车辆计数是指在道路上安装相应设备,通过…
YOLOv8改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍
本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本…

经典目标检测YOLO系列(一)引言_目标检测架构
经典目标检测YOLO系列(一)引言_目标检测架构
一个常见的目标检测网络,其本身往往可以分为一下三大块: Backbone network,即主干网络,是目标检测网络最为核心的部分,backbone选择的好坏,对检测性能影响是十…
基于YOLOv8深度学习的血细胞检测与计数系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战、智慧医疗
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

计算目标检测和语义分割的PR
需求描述
实际工作中,相比于mAP项目更加关心的是特定阈值下的precision和recall结果;由于本次的GT中除了目标框之外还存在多边形标注,为此,计算IoU的方式从框与框之间变成了mask之间; 本文的代码适用于MMDetection下的…
现代雷达车载应用——第2章 汽车雷达系统原理 2.2节
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
2.2 汽车雷达架构 从顶层来看,基本的汽车雷达由发射器,接收器和天线组成。图2.2给出了一种简化的单通道连续波雷达结构[2]。这…
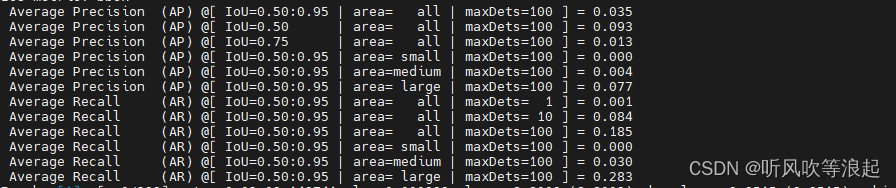
YOLOV3 SPP 目标检测项目(yolo 标注的数据集)
0. 写在前言 本项目代码来源于:霹雳吧啦Wz 和 u 版yolov3 spp项目 因为源项目的代码太过复杂,所以本章的代码在原有的基础上进行大幅度的删减(删了有一半左右吧),并且加了点自己需要的部分 Q:为什么要删减?
A&#x…
ros来保存图像和保存记录视频的方法---gmsl相机保存视频和图片
1,保存图片
rosrun image_view image_view image:=/myimg_topic这个命令只是用来查看图像的,它并不会保存图像。如果你想要保存图像,你需要使用image_saver节点,并指定保存路径。例如: 下面指令就可以了,可以用
rosrun image_view image_saver image:=/myimg_topic _fi…

【目标检测】进行实时检测计数时,在摄像头窗口显示实时计数个数
这里我是用我本地训练的基于yolov8环境的竹签计数模型,在打开摄像头窗口增加了实时计数显示的代码,可以直接运行,大家可以根据此代码进行修改,其底层原理时将检测出来的目标的个数显示了出来。
该项目链接:【目标检测…
基于YOLOv8深度学习的安全帽目标检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

4D雷达目标检测跟踪算法设计
1.算法流程 4D雷达点云跟踪处理沿用3D毫米波雷达的处理流程,如下图: 从接收到点云开始,先对点云做标定、坐标转换、噪点剔除、动静分离,再分别对动态目标和静态目标做聚类,然后根据聚类结果做目标的特征分析和检测等&a…
[数据集][目标检测]芝麻杂草目标检测数据集VOC+YOLO格式1300张2类别
数据集格式:Pascal VOC格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1300 标注数量(xml文件个数):1300 标注数量(txt文件个数):1300 标注类别数&a…
基于YOLOv8深度学习的吸烟/抽烟行为检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

现代雷达车载应用——第2章 汽车雷达系统原理 2.3节 信号模型
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
2.3 信号模型 雷达的发射机通常发出精心设计和定义明确的信号。然而,接收到的返回信号是多个分量的叠加,包括目标的反射、杂波…
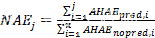
论文解读--Visual Lane Tracking and Prediction for Autonomous Vehicles
自动驾驶汽车视觉车道线跟踪和预测
摘要 我们提出了一种用于自动驾驶汽车跟踪水平道路车道标记位置的可视化方法。我们的方法是基于预测滤波的。预测步骤估计在每个新的图像帧中期望的车道标记位置。它也是基于汽车的运动学模型和嵌入式测程传感器产生的信息。使用适当准备的测…
Grad-CAM(Gradient-weighted Class Activation Mapping)热力图(内含示例代码)
Grad-CAM(Gradient-weighted Class Activation Mapping)是一种用于可视化卷积神经网络(CNN)中特定类别的激活区域的技术。Grad-CAM帮助我们理解神经网络在分类任务中的决策过程,特别是它关注哪些图像区域以及这些区域对…

C# OpenVINO 直接读取百度Paddle模型实现物体检测( yolov3_darknet)
目录
效果
项目
代码
下载 C# OpenVINO 直接读取百度Paddle模型实现物体检测( yolov3_darknet)
效果 项目 代码
using OpenCvSharp; using Sdcb.OpenVINO; using Sdcb.OpenVINO.Natives; using System; using System.Collections.Generic; using System.Diagnostics; usi…
[数据集][目标检测]电风扇目标检测数据集VOC+YOLO格式364张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):364 标注数量(xml文件个数):364 标注数量(txt文件个数):364 标注类别…
YOLOv8独家改进《全网无重复 YOLOv8专属打造》感知聚合SERDet检测头:简单高效涨点,即插即用|检测头新颖改进
💡本篇内容:YOLOv8独家改进《全网无重复,YOLOv8专属》感知聚合SERDet检测头:高效涨点,即插即用|检测头新颖改进
💡🚀🚀🚀本博客 YOLO系列 + 全新原创感知聚合SERDet检测头
改进创新点改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可,附改进源代…
剑指YOLOv5独家最新改进(全网无重复)《感知聚合SERDetect检测头》高效涨点,即插即用|检测头新颖改进
💡本篇内容:YOLOv5独家最新改进《感知聚合SERDetect检测头》高效涨点,即插即用|检测头新颖改进
💡🚀🚀🚀本博客 YOLO系列 + 感知聚合SERDetect检测头
改进创新点改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可
💡附改进源代码及教程,适合用来…
[数据集][目标检测]拉横幅识别横幅检测数据集VOC+yolo格式1962张1类别
数据集格式:Pascal VOC格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1962 标注数量(xml文件个数):1962 标注数量(txt文件个数):1962 标注类别数&a…
在目标检测的图框标注中注意一下几点
标注框的形状和大小:对于不同大小的物体,标注框应完全包含住物体。并且标注框的形状尽可能接近物体形状。标注框的位置和方向:标注框尽可能地包围目标物体,而且标注框的位置和方向应标与实际场景中的位置和方向一致。标签的准确性…
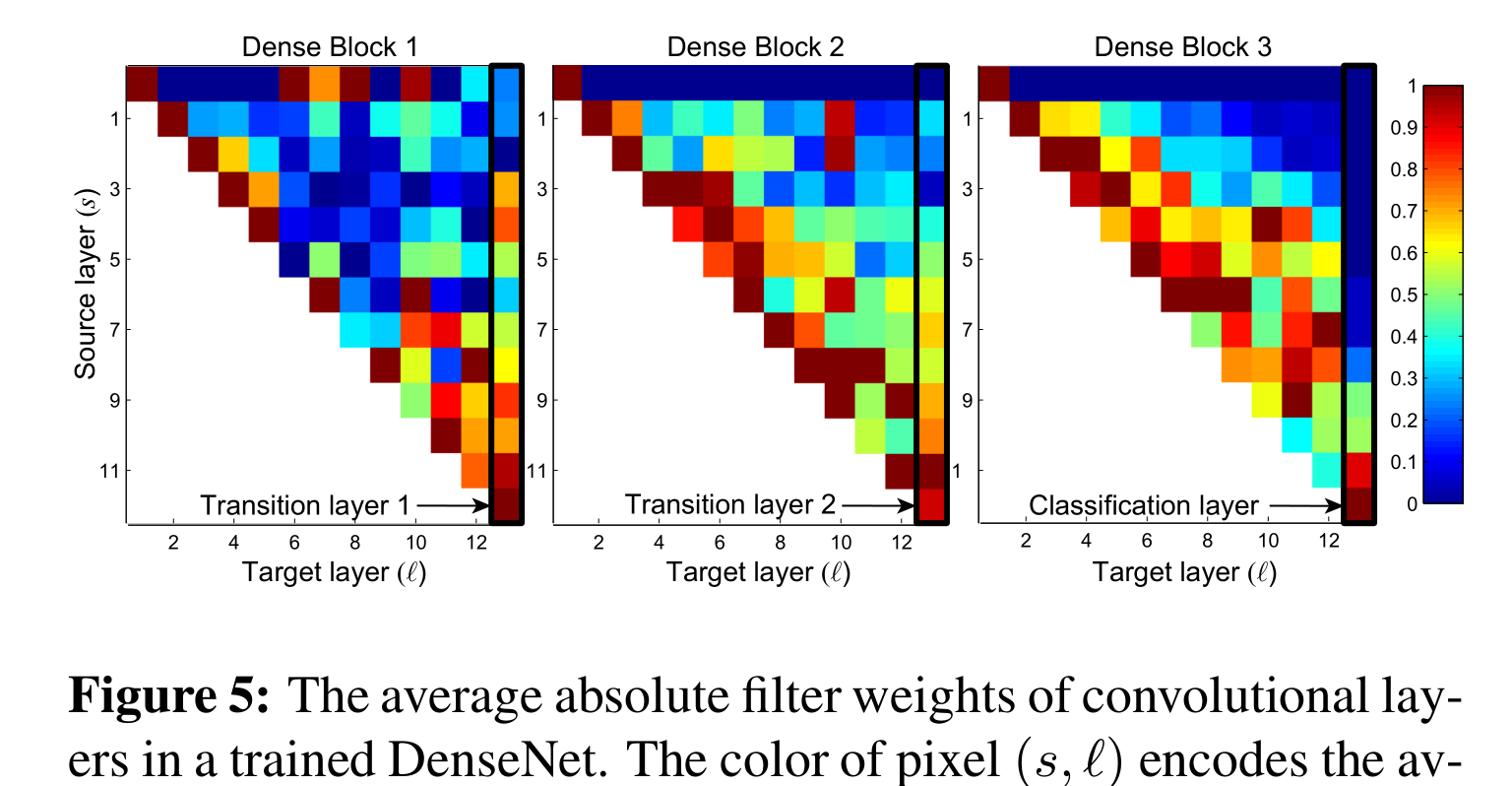
Densely Connected Convolutional Networks(2018.1)
文章目录 Abstract1. Introduction提出问题以前的解决方法我们的方法效果 2. Related Work3. DenseNetsResNets.Dense connectivity.Composite function.Pooling layers.Growth rate.Bottleneck layers.Compression.Implementation Details. 4. Experiments5. DiscussionModel …
Bounding boxes augmentation for object detection
Different annotations formats
Bounding boxes are rectangles that mark objects on an image. There are multiple formats of bounding boxes annotations. Each format uses its specific representation of bouning boxes coordinates 每种格式都使用其特定的边界框坐标…

Paper Reading: (ACRST) 基于自适应类再平衡自训练的半监督目标检测
目录 简介工作重点方法CropBankFBRAFFRTwo-stage Pseudo-label Filtering 实验与SOTA比较消融实验 简介
题目:《Semi-Supervised Object Detection with Adaptive Class-Rebalancing Self-Training》,AAAI’22, 基于自适应类再平衡自训练的半…
YOLOv8改进 | 2023Neck篇 | BiFPN双向特征金字塔网络(附yaml文件+代码)
一、本文介绍
本文给大家带来的改进机制是BiFPN双向特征金字塔网络,其是一种特征融合层的结构,也就是我们本文改进YOLOv8模型中的Neck部分,它的主要思想是通过多层级的特征金字塔和双向信息传递来提高精度。本文给大家带来的结构可以让大家自…

ViTDet论文笔记
arxiv:https://arxiv.org/abs/2203.16527 GitHub:https://github.com/ViTAE-Transformer/ViTDet
摘要
本文提出使用plain,non-hierarchical视觉transformer作为目标检测的主干网络。通过这种设计可以使得ViT结构模型不需要再重新设计一个分…

YOLOv5改进 | 2023卷积篇 | AKConv轻量级架构下的高效检测(既轻量又提点)
一、本文介绍
本文给大家带来的改进内容是AKConv是一种创新的变核卷积,它旨在解决标准卷积操作中的固有缺陷(采样形状是固定的),AKConv的核心思想在于它为卷积核提供了任意数量的参数和任意采样形状,能够使用任意数量…
C# OpenVINO 直接读取百度模型实现印章检测
目录
效果
模型信息
项目
代码
下载
其他 C# OpenVINO 直接读取百度模型实现印章检测
效果 模型信息
Inputs ------------------------- name:scale_factor tensor:F32[?, 2]
name:image tensor:F32[?, 3, 608, 608]
…
基于YOLOv8深度学习的水稻害虫检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
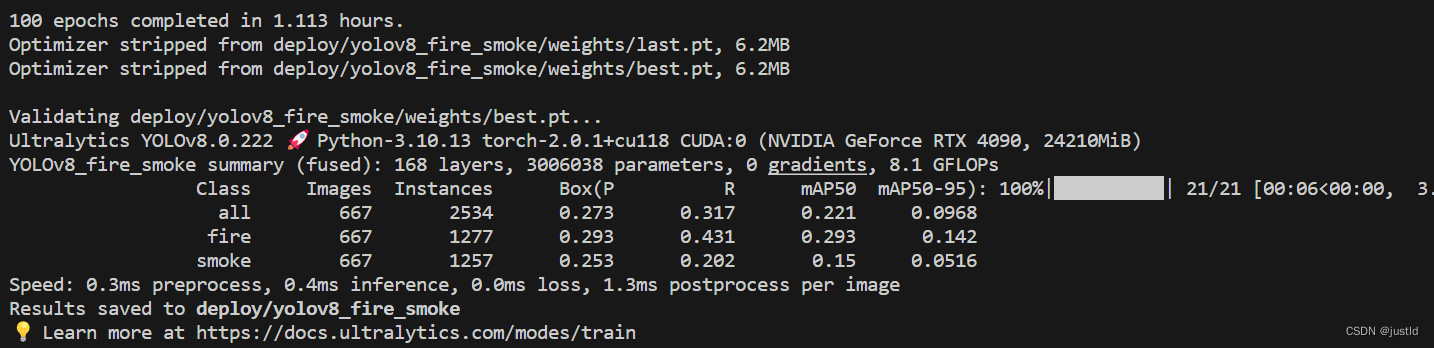
【深度学习目标检测】七、基于深度学习的火灾烟雾识别(python,目标检测,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…

采埃孚4D成像雷达拆解
1 基本信息 品牌:海外Tier1采埃孚 • 应用:上汽飞凡中高端纯电平台 • 数量:单车2个,安装在前后保内部 • 最远探测距离:350米 拆解来看,4D雷达主要可以分为4个部分,分别为数字接口板及结构件…
【深度学习】目标检测,实例分割,语义分割 逐一对比
提问:目标检测,实例分割,语义分割,有什么区别?
目标检测(Object Detection),实例分割(Instance Segmentation)和语义分割(Semantic Segmentation…

目标检测mAP计算以及coco评价标准
这篇是我对哔哩哔哩up主 霹雳吧啦Wz 的视频的文字版学习笔记 感谢他对知识的分享 讲一下目标检测中的一些常见的指标 在我们使用目标检测网络训练时 最后在验证集上会得到一个coco的评价列表 就像我们图中给的这一系列参数列表一样 我们再进一步引入两个概念 第一个叫做precisi…

Python将已标注的两张图片进行上下拼接并修改、合并其对应的Labelme标注文件(v2.0)
Python将已标注的两张图片进行上下拼接并修改、合并其对应的Labelme标注文件(v2.0) 前言前提条件相关介绍实验环境上下拼接图片并修改、合并其对应的Labelme标注文件代码实现输出结果 前言 此版代码,相较于Python将已标注的两张图片进行上下拼…

狗dog目标检测数据集VOC+YOLO格式1W+张
狗,是食肉目犬科 [11]犬属 [13]哺乳动物 [12],别称犬,与马、牛、羊、猪、鸡并称“六畜” [13]。狗的体型大小、毛色因品种不同而不同,体格匀称;鼻吻部较长;眼呈卵圆形;两耳或竖或垂;…

光学遥感显著目标检测初探笔记总结
目录 观看地址介绍什么是显著性目标检测根据不同的输入会有不同的变体(显著性目标检测家族)目前这个领域的挑战 技术方案论文1(2019)论文2(2021)论文3(2022) 未来展望 观看地址
b站链接
介绍
什么是显著性目标检测
一张图片里最吸引注意力的部分就是显著性物体,…
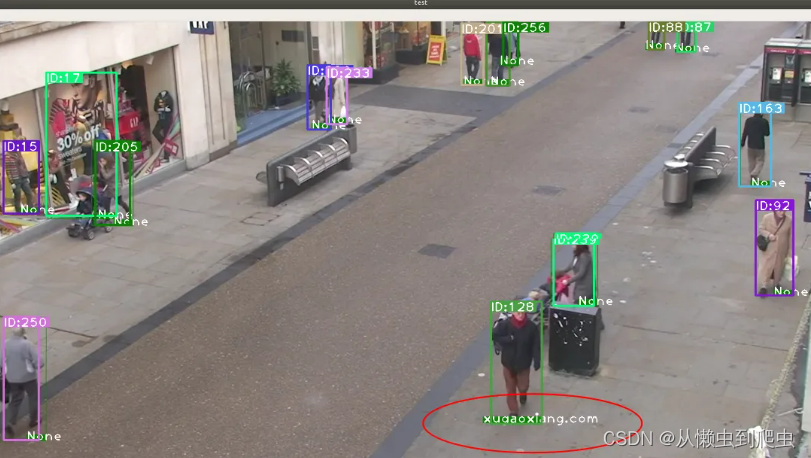
目标检测、目标跟踪、重识别
文章目录
环境前言项目复现特征提取工程下载参考资料
环境
ubuntu 18.04 64位yolov5deepsortfastreid
前言
基于YOLOv5和DeepSort的目标跟踪 介绍过针对行人的检测与跟踪。本文介绍另一个项目,结合 FastReid 来实现行人的检测、跟踪和重识别。作者给出的2个主…
小目标检测模型设计的一点思考
1. 小目标的特性
目标之间的交叠概率比较低,即使有交叠,其IoU多数情况下也是比较小的 AI-TOD Tiny Person Dateset 小目标自身的纹理显著度有强弱区别,但是总体来说纹理特征都较弱,很多时候需要借助一定的图像上下文来帮助确认 …
大语言模型:开启自然语言处理新纪元
导言 大语言模型,如GPT-3(Generative Pre-trained Transformer 3),标志着自然语言处理领域取得的一项重大突破。本文将深入研究大语言模型的基本原理、应用领域以及对未来的影响。
1. 简介 大语言模型是基于深度学习和变压器&…

Python等比例缩放图片并修改对应的Labelme标注文件(v2.0)
Python等比例缩放图片并修改对应的Labelme标注文件(v2.0) 前言前提条件相关介绍实验环境Python等比例缩放图片并修改对应的Labelme标注文件Json文件代码实现输出结果 前言 此版代码,相较于Python等比例缩放图片并修改对应的Labelme标注文件&a…

【深度学习目标检测】六、基于深度学习的路标识别(python,目标检测,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…
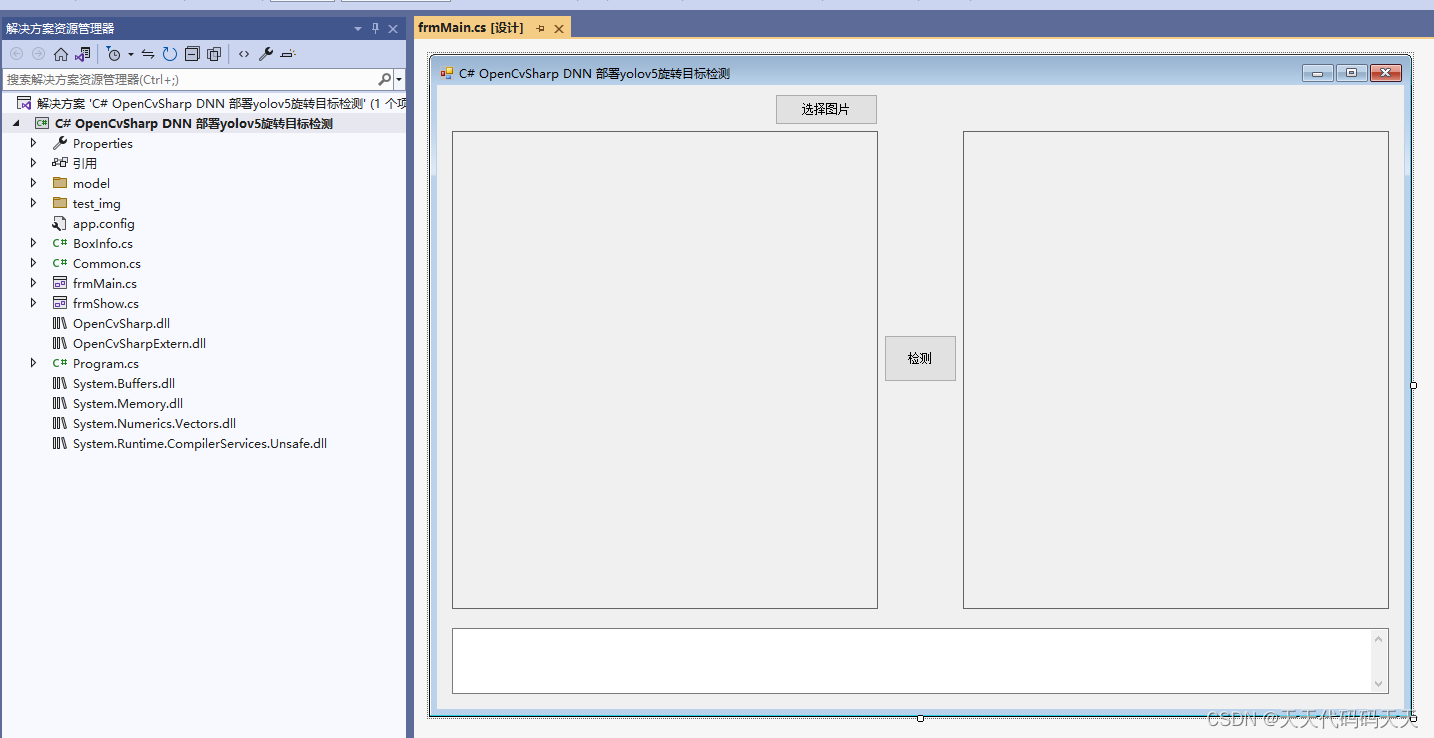
C# OpenCvSharp DNN 部署yolov5旋转目标检测
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN 部署yolov5旋转目标检测
效果 模型信息
Inputs ------------------------- name:images tensor:Float[1, 3, 1024, 1024] -------------------------------------------------------------…
YOLOv8改进 | 2023主干篇 | 替换LSKNet遥感目标检测主干 (附代码+修改教程+结构讲解)
一、本文介绍
本文给大家带来的改进内容是LSKNet(Large Kernel Selection, LK Selection),其是一种专为遥感目标检测设计的网络架构,其核心思想是动态调整其大的空间感受野,以更好地捕捉遥感场景中不同对象的范围上下…
ubuntu20.04里面安装目标检测数据标注软件labelImg的详细过程
1.在github克隆仓库到本地 地址:https://github.com/Ruolingdeng/labelImg.git
或者百度网盘下载 链接:https://pan.baidu.com/s/1p-478j5WOTN0TKmv3qh-YQ?pwdl8bj 提取码:l8bj
2、进入到labelimg的文件夹,安装pyqt相关依赖包 …
PASCAL VOC 2012 数据集
PASCAL VOC 2012 数据集
(The PASCAL Visual Object Classes 2012,简称PASCAL VOC 2012数据集) 背景:PASCAL VOC (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称…

YOLOv5改进 | 卷积篇 | SPD-Conv空间深度转换卷积(高效空间编码技术)
一、本文介绍
本文给大家带来的改进内容是SPD-Conv(空间深度转换卷积)技术。SPD-Conv是一种创新的空间编码技术,它通过更有效地处理图像数据来改善深度学习模型的表现。SPD-Conv的基本概念:它是一种将图像空间信息转换为深度信息…

【目标检测】视频输出体积太大?分析视频的编码与码率问题
在做视频目标检测时,发现一个问题,检测输出完的视频时大时小,有时输出体积过大,造成播放器播放时严重卡顿现象。本文就这一情况进行分析,并就该问题提出相关解决方案。 视频基础知识
隔行扫描和逐行扫描
早期电视台在…
RT-DETR改进策略:双动态令牌混合器(D-Mixer)的TransXNet,实现RT-DETR的有效涨点
摘要
双动态令牌混合器(D-Mixer),一种输入依赖的方式聚合全局信息和局部细节。D-Mixer通过分别在均匀分割的特征片段上应用有效的全局注意力模块和输入依赖的深度卷积,使网络具有强大的归纳偏差和扩大的有效感受野。使用D-Mixer作为基本构建块设计了TransXNet,这是一种新…

OpenCV技术应用(7)— 将图像转为热力图
前言:Hello大家好,我是小哥谈。本节课就手把手教大家如何将一幅图像转化成热力图,希望大家学习之后能够有所收获~!🌈 目录
🚀1.技术介绍
🚀2.实现代码 🚀1.技术介绍
伪彩色处…

【深度学习目标检测】十、基于yolov5的火灾烟雾识别(python,目标检测)
YOLOv5是目标检测领域一种非常优秀的模型,其具有以下几个优势: 1. 高精度:YOLOv5相比于其前身YOLOv4,在目标检测精度上有了显著的提升。YOLOv5使用了一系列的改进,如更深的网络结构、更多的特征层和更高分辨率的输入图…
目标检测里面MAP评测指标的详细介绍
一、map怎么计算得到的?
他是根据每一类物体的ap值,取平均得到的最终的map评测指标。
二、每一类的ap值怎么求?
将预测框的概率值从大到小排序,然后依次选取一个概率作为score的阈值,并结合当前的iou阈值得到一个准…
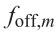
现代雷达车载应用——第3章 MIMO雷达技术 3.2节 汽车MIMO雷达波形正交策略
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
3.2 汽车MIMO雷达波形正交策略 基于MIMO雷达技术的汽车雷达虚拟阵列合成依赖于不同天线发射信号的可分离性。当不同天线的发射信号正交时&#x…

深度学习之全面了解预训练模型
在本专栏中,我们将讨论预训练模型。有很多模型可供选择,因此也有很多考虑事项。
这次的专栏与以往稍有不同。我要回答的问题全部源于 MathWorks 社区论坛(ww2.mathworks.cn/matlabcentral/)的问题。我会首先总结 MATLAB Answers …

RT-DETR改进实验:一文了解RT-DETR目标检测算法如何打印FPS指标
💡该教程为改进RT-DETR指南,属于《芒果书》📚系列,包含大量的原创首发改进方式🚀
💡🚀🚀🚀本博客内含改进源代码,按步骤操作运行改进后的代码即可 💡更方便的统计更多实验数据,方便写作
新增RT-DETR打印FPS指标
完善(一键RT-DETR打印FPS指标) 文章目录 …
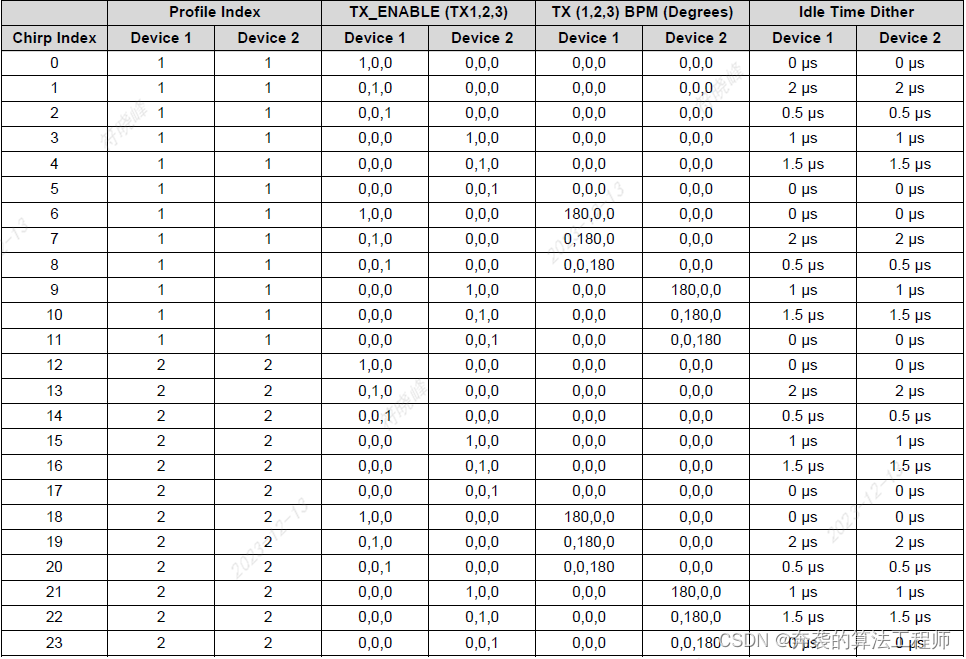
AWR2243级联(TI文档)
摘要 本应用报告描述了TI的级联毫米波雷达系统。该解决方案基于TI的AWR2243雷达芯片。使用20 GHz的本振输入和输出路径,这些芯片中的几个级联在一起并同步工作。每个AWR2243芯片最多支持4个接收天线和3个发射天线。级联多个这样的芯片允许雷达系统使用更多的接收和发…
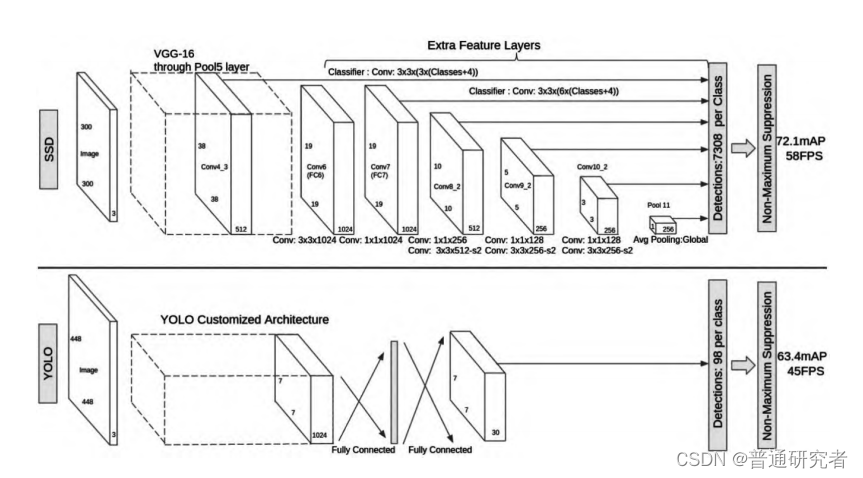
深度学习的目标检测算法综述
信息记录材料 2022年10月 第23卷第10期 【摘要】目标检测是深度学习的一个重要应用,目前在智能驾驶、工业检测相关领域都获得应用,具有重要的现实意义。本文对基于深度学习目标检测算法原理和应用情况进行简述,首先介绍结合区域提取和卷积神经…

yolo-nas无人机高空红外热数据小目标检测(教程+代码)
前言
YOLO-NAS是目前最新的YOLO目标检测模型。从一开始,它就在准确性方面击败了所有其他 YOLO 模型。与之前的 YOLO 模型相比,预训练的 YOLO-NAS 模型能够以更高的准确度检测更多目标。但是我们如何在自定义数据集上训练 YOLO NAS?
这将是我…
YOLOv8改进 | 2023主干篇 | 华为最新VanillaNet主干替换Backbone实现大幅度长点
一、本文介绍
本文给大家来的改进机制是华为最新VanillaNet网络,其是今年最新推出的主干网络,VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作(需要注意的是…

Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection(CVPR2023待补)
文章目录 BeginningAbstract挑战方法成果 Introduction引出问题早期的work及存在的问题近期的work及存在的问题our workContribution Related Work(paper for me)Oriented Object DetectionPrior for Oriented ObjectsLabel Assignment Tiny Object Dete…
鹦鹉目标检测数据集VOC+YOLO格式2000张
鹦鹉是一种非常受欢迎的鸟类,它们通常生活在热带和亚热带地区的森林和草原中。鹦鹉是一种非常聪明、有趣和亲密的动物,也是一种受到广泛关注和保护的物种。
鹦鹉的身体结构非常适应于它们的生活方式。它们的身体非常修长,有着漂亮的羽毛和强…
【即插即用篇】YOLOv8改进实战 | 引入 Involution(内卷),用于视觉识别的新一代神经网络!涨点神器!
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。
YOLOv8是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成…
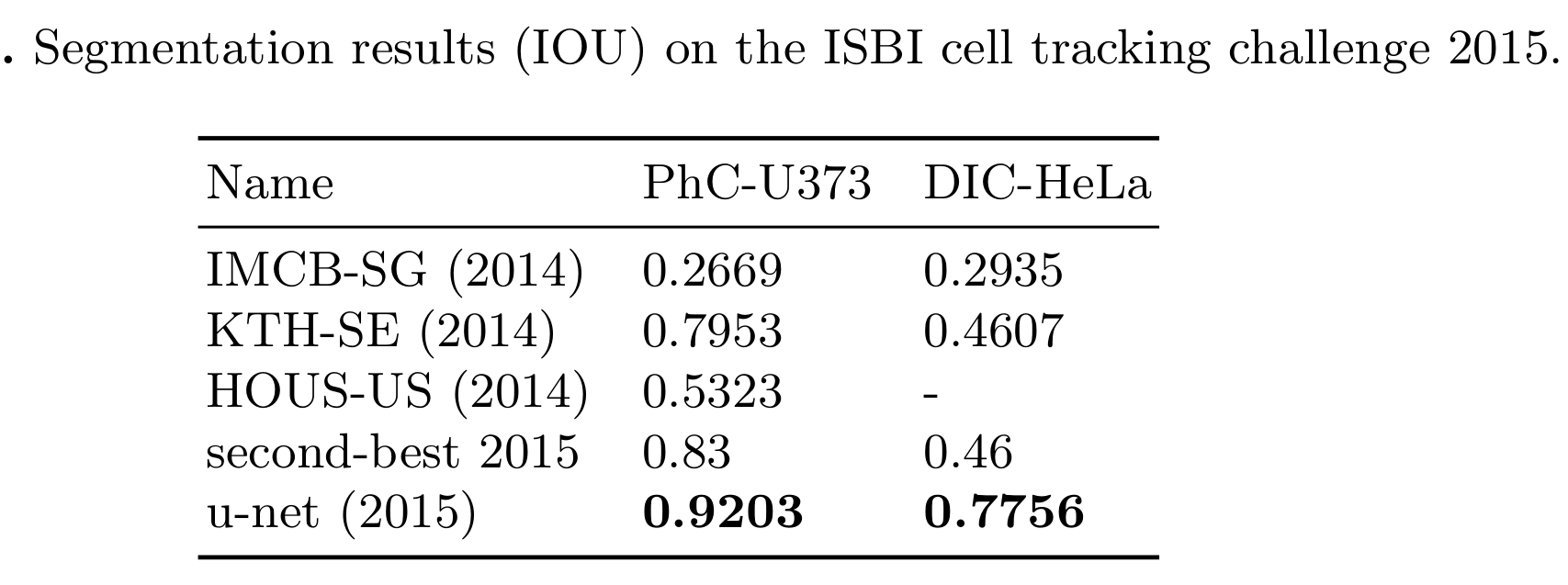
U-Net: Convolutional Networks for Biomedical Image Segmentation(CVPR2015)
文章目录 AbstractIntroductionNetwork ArchitectureConclusiontorch code hh 源代码 Abstract
人们普遍认为,深度网络的成功训练需要成千上万个带注释的训练样本。在这篇论文中,我们提出了一个网络和训练策略,该策略依赖于数据增强的强大使…
目标检测应用场景—数据集【NO.24】行人车辆检测数据集2
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…

鳄鱼目标检测数据集VOC格式100张
鳄鱼是一种生活在热带和亚热带地区的爬行动物,属于爬行纲鳄形目鳄鱼科。它们的体形庞大,有粗壮的四肢和强壮的尾巴,一般能长到2-6米长,体重可达500公斤以上。鳄鱼的皮肤粗糙,呈灰褐色或黑色,布满了坚韧的鳞…
YOLOv8改进 | 主干篇 | 利用MobileNetV3替换Backbone(轻量化网络结构)
一、本文介绍
本文给大家带来的改进机制是MobileNetV3,其主要改进思想集中在结合硬件感知的网络架构搜索(NAS)和NetAdapt算法,以优化移动设备CPU上的性能。它采用了新颖的架构设计,包括反转残差结构和线性瓶颈层&…
MATLAB - 使用 YOLO 和基于 PCA 的目标检测,对 UR5e 的半结构化智能垃圾箱拣选进行 Gazebo 仿真
系列文章目录 前言
本示例展示了在 Gazebo 中使用 Universal Robots UR5e cobot 模拟智能垃圾桶拣选的详细工作流程。本示例提供的 MATLAB 项目包括初始化、数据生成、感知、运动规划和积分器模块(项目文件夹),可创建完整的垃圾桶拣选工作流…
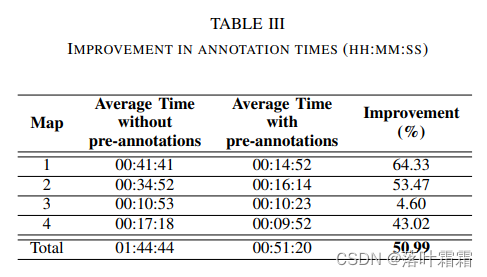
【基于激光雷达的路沿检测用于自动驾驶的真值标注】
文章目录 概要主要贡献内容概述实验小结 概要
论文地址:https://arxiv.org/pdf/2312.00534.pdf
路沿检测在自动驾驶中扮演着重要的角色,因为它能够帮助车辆感知道可行驶区域和不可行驶区域。为了开发和验证自动驾驶功能,标注的数据是必不可…
paddle 56 将图像分类模型嵌入到目标检测中并实现端到端的部署(用图像分类模型进行目标检测切片分类)
目标检测在功能上一直是涵盖了图像分类的,其包含目标切片检测,目标切片分类。由于某些原因,需要将目标检测的功能退化为检测,忽略其切片分类,使用外部的分类模型。然而这样操作会使得其与原始的部署代码不兼容,为此博主实现将图像分类模型嵌入到目标检测中,并实现端到端…
YOLOv8改进 | 2023注意力篇 | MSDA多尺度空洞注意力(附多位置添加教程)
一、本文介绍
本文给大家带来的改进机制是MSDA(多尺度空洞注意力)发表于今年的中科院一区(算是国内计算机领域的最高期刊了),其全称是"DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition"。MSDA的主要思想是…

【深度学习目标检测】十二、基于深度学习的钢铁缺陷识别(python,目标检测,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…

【深度学习目标检测】十一、基于深度学习的电网绝缘子缺陷识别(python,目标检测,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…

目标检测 - RCNN系列模型
文章目录 1. RCNN2. Fast-RCNN3. Faster-RCNN 1. RCNN 论文:Rich feature hierarchies for accurate object detection and semantic segmentation 地址:https://arxiv.org/abs/1311.2524 分为两个阶段:
目标候选框Object ProposalsProposal…
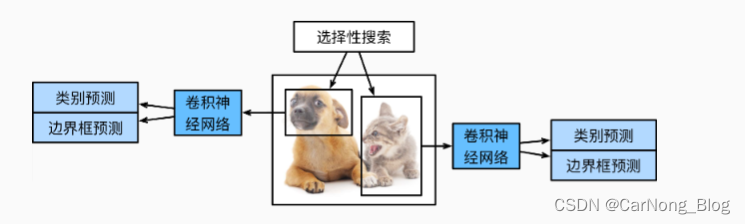
【深度学习-目标检测】01 - R-CNN 论文学习与总结
论文地址:Rich feature hierarchies for accurate object detection and semantic segmentation
论文学习
摘要(Abstract)
对象检测性能的现状: 在PASCAL VOC数据集上测量的对象检测性能在过去几年已经达到了一个高点。最佳性能…
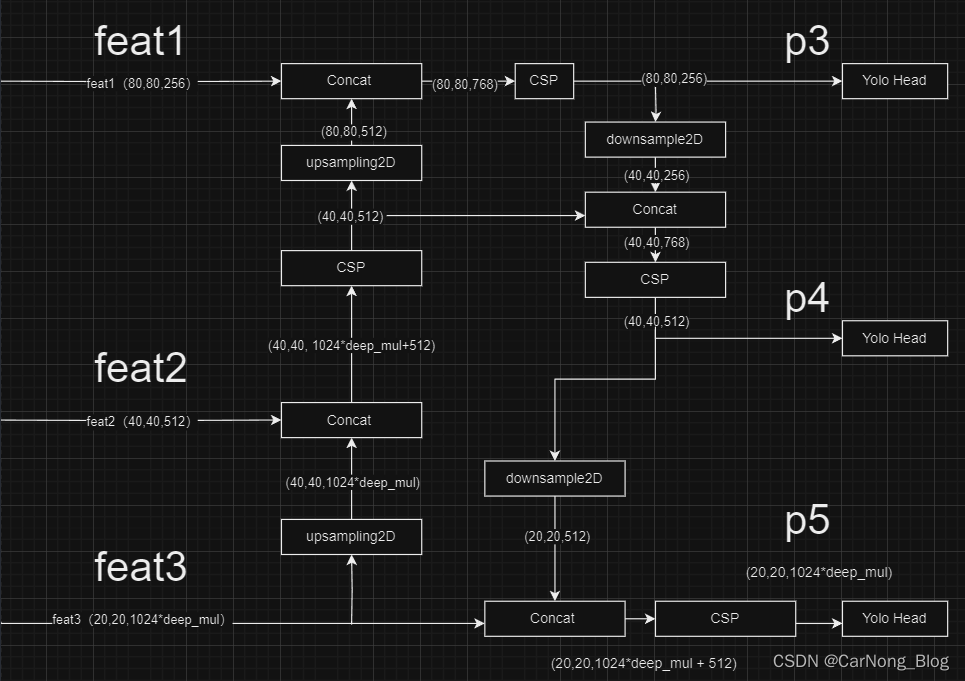
【深度学习-目标检测】06 - FPN 论文学习与总结
论文地址:Feature Pyramid Networks for Object Detection
论文学习 1. 摘要
多尺度特征的重要性: 论文强调在对象检测任务中,多尺度特征对于处理不同大小的对象至关重要。这些特征有助于编码具有尺度变化的对象。 现有方法的局限性&#x…
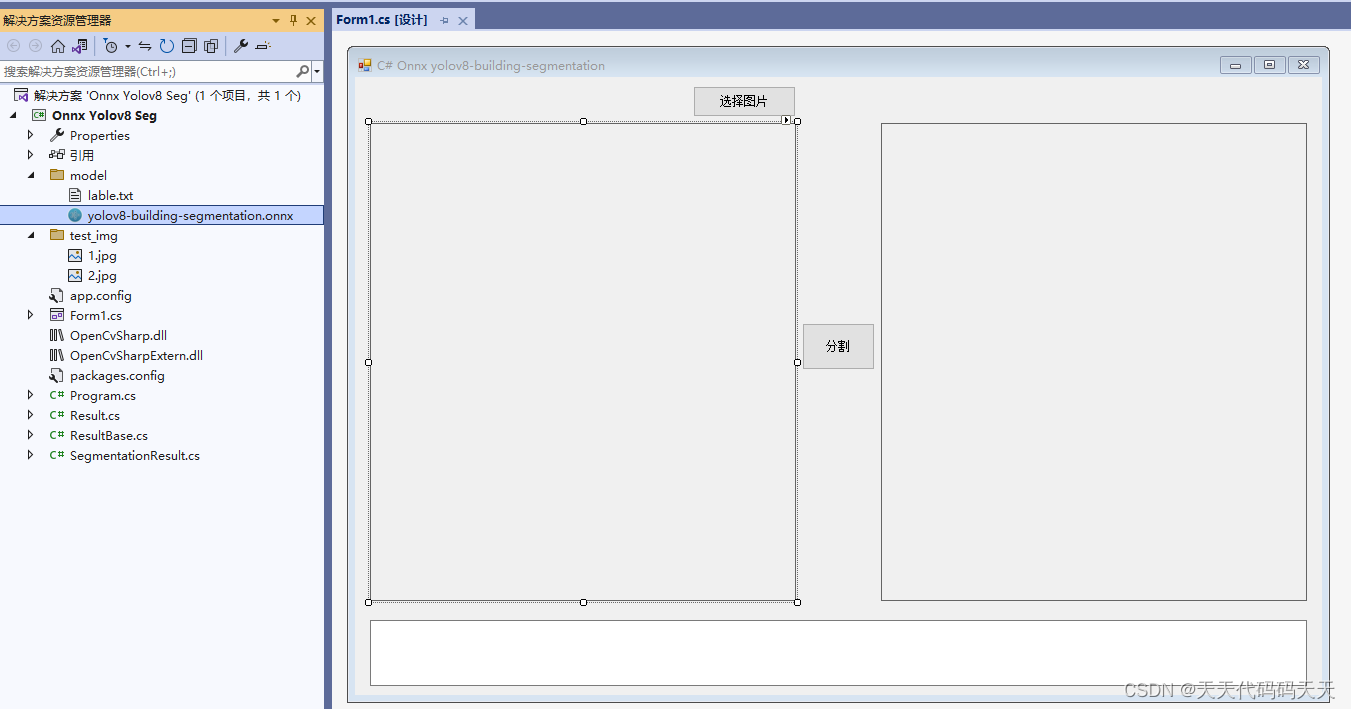
C# Onnx yolov8 building segmentation
目录
效果
模型信息
项目
代码
下载 C# Onnx yolov8 building segmentation
效果 模型信息
Model Properties ------------------------- date:2023-12-22T10:51:07.627471 author:Ultralytics task:segment license:AGPL-…

YOLOv5算法改进(23)— 更换主干网络GhostNet + 添加CA注意力机制 + 引入GhostConv
前言:Hello大家好,我是小哥谈。本节课就让我们结合论文来对YOLOv5进行组合改进(更换主干网络GhostNet + 添加CA注意力机制 + 引入GhostConv),希望同学们学完本节课可以有所启迪,并且后期可以自行进行YOLOv5算法的改进!🌈 前期回顾: YOLOv5算法改进(1)— 如何去…

yolov7添加FPPI评价指标
学术上目标检测大多用mAP去评价一个模型的好坏,mAP用来作为比较模型的指标是挺好的,不过有个问题就是不够直观,比如mAP0.9到底代表什么呢?平均一个图会误检几个呢?该取什么阈值呢?mAP说明不了,所…
YOLOv8改进 | Conv篇 | 利用YOLO-MS的MSBlock轻量化网络结构(既轻量又长点)
一、本文介绍
本文给大家带来的改进机制是利用YOLO-MS提出的一种针对于实时目标检测的MSBlock模块(其其实不能算是Conv但是其应该是一整个模块),我们将其用于C2f中组合出一种新的结构,来替换我们网络中的模块可以达到一种轻量化的作用,我将其用于我的数据集上实验,包括多个…

目标检测脚本之mmpose json转yolo txt格式
目标检测脚本之mmpose json转yolo txt格式
一、需求分析
在使用yolopose及yolov8-pose 网络进行人体姿态检测任务时,有时需要标注一些特定场景的中的人型目标数据,用来扩充训练集,提升自己训练模型的效果。因为单纯的人工标注耗时费力&…
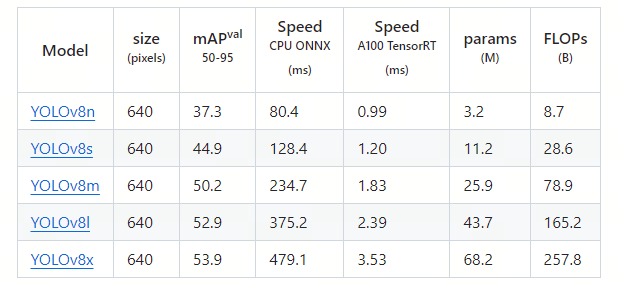
目标检测-One Stage-YOLOv8
文章目录 前言一、YOLOv8的网络结构和流程二、YOLOv8的创新点三、创新点详解CSP、C3和C2fTaskAlignedAssigner 正样本分配策略Distribution Focal Loss关闭 Mosiac 总结 前言
终于到了YOLO系列最新最火爆的网络–YOLOv8,前面YOLOv5中已经提到ultralytics团队集成了…

YOLOv5姿态估计:HRnet实时检测人体关键点
前言: Hello大家好,我是Dream。 今天来学习一下利用YOLOv5进行姿态估计,HRnet与SimDR检测图片、视频以及摄像头中的人体关键点,欢迎大家一起前来探讨学习~ 本文目录: 一、项目准备1Pycharm中克隆github上的项目2.具体步…
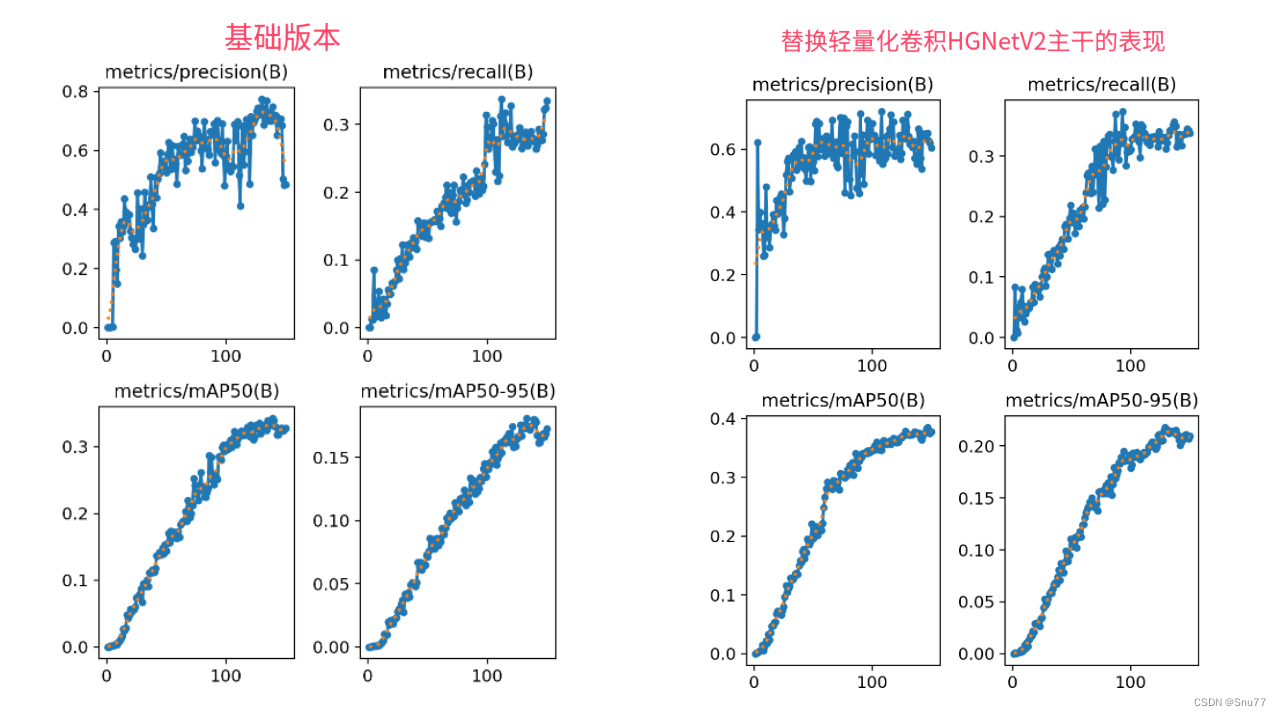
YOLOv5改进 | 2023主干篇 | 多种轻量化卷积优化PP-HGNetV2改进主干(全网独家创新)
一、本文介绍
Hello,大家好,上一篇博客我们讲了利用HGNetV2去替换YOLOv5的主干,经过结构的研究我们可以发现在HGNetV2的网络中有大量的卷积存在,所以我们可以用一种更加轻量化的卷积去优化HGNetV2从而达到更加轻量化的效果(亲测优化后的HGNetV2网络比正常HGNetV2精度更高…

【目标检测】评价指标:mAP概念及其代码实现(yolo源码/pycocotools)
本篇文章首先介绍目标检测任务中的关键评价指标mAP的概念;然后介绍其在yolo源码和pycocotools工具中的实现方法;最后比较两种mAP的计算方法的不同之处。 目标检测中的评价指标:
mAP概念及其代码实现(yolo源码/pycocotools) 混淆矩阵概念及其…

transfomer中Decoder和Encoder的base_layer的源码实现
简介
Encoder和Decoder共同组成transfomer,分别对应图中左右浅绿色框内的部分. Encoder: 目的:将输入的特征图转换为一系列自注意力的输出。 工作原理:首先,通过卷积神经网络(CNN)提取输入图像的特征。然…
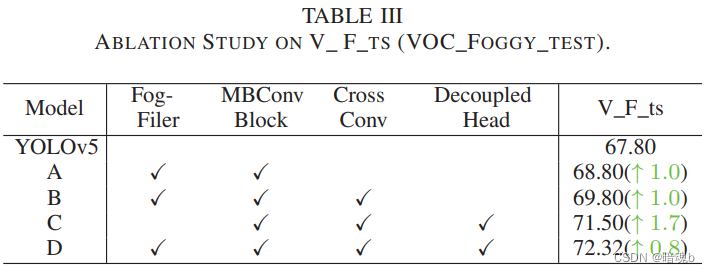
Channel-separation-based Network for Object Detection under Foggy Conditions
Channel-separation-based Network for Object Detection under Foggy Conditions
Abstract
现存的一些方法尝试恢复高质量图像,但这会增加网络复杂性并且丢失图像的潜在信息。在这项研究中,一个基于通道分离的检测网络被提出用来保存潜在信息。特别地…

在自定义数据集上训练 YOLOv8 进行目标检测
这是目标检测中令人惊叹的 AI 模型之一。在这种情况下,您无需克隆存储库、设置要求并配置模型,就像在 YOLOv5 及其之前的版本中所做的那样。 在 YOLOv8 中,不需要执行这些手动任务。您只需安装 Ultralytics 即可,我将向您展示如何…
YOLOv8改进 | 融合改进篇 | 华为VanillaNet + BiFPN突破涨点极限
一、本文介绍
本文给大家带来的改进机制是华为VanillaNet主干配合BiFPN实现融合涨点,这个主干是一种注重极简主义和效率的神经网络我也将其进行了实验, 其中的BiFPN不用介绍了从其发布到现在一直是比较热门的改进机制,其主要思想是通过多层级的特征金字塔和双向信息传递来提…

Detection-friendly dehazing: object detection in real-world hazy scenes
Detection-friendly dehazing: object detection in real-world hazy scenes
摘要
提出了一种联合架构BAD-Net,将去雾模块和检测模块连接成一个端到端的方法。另外,设计了了两个分支结构,用注意力融合模块来充分结合有雾和去雾特征…
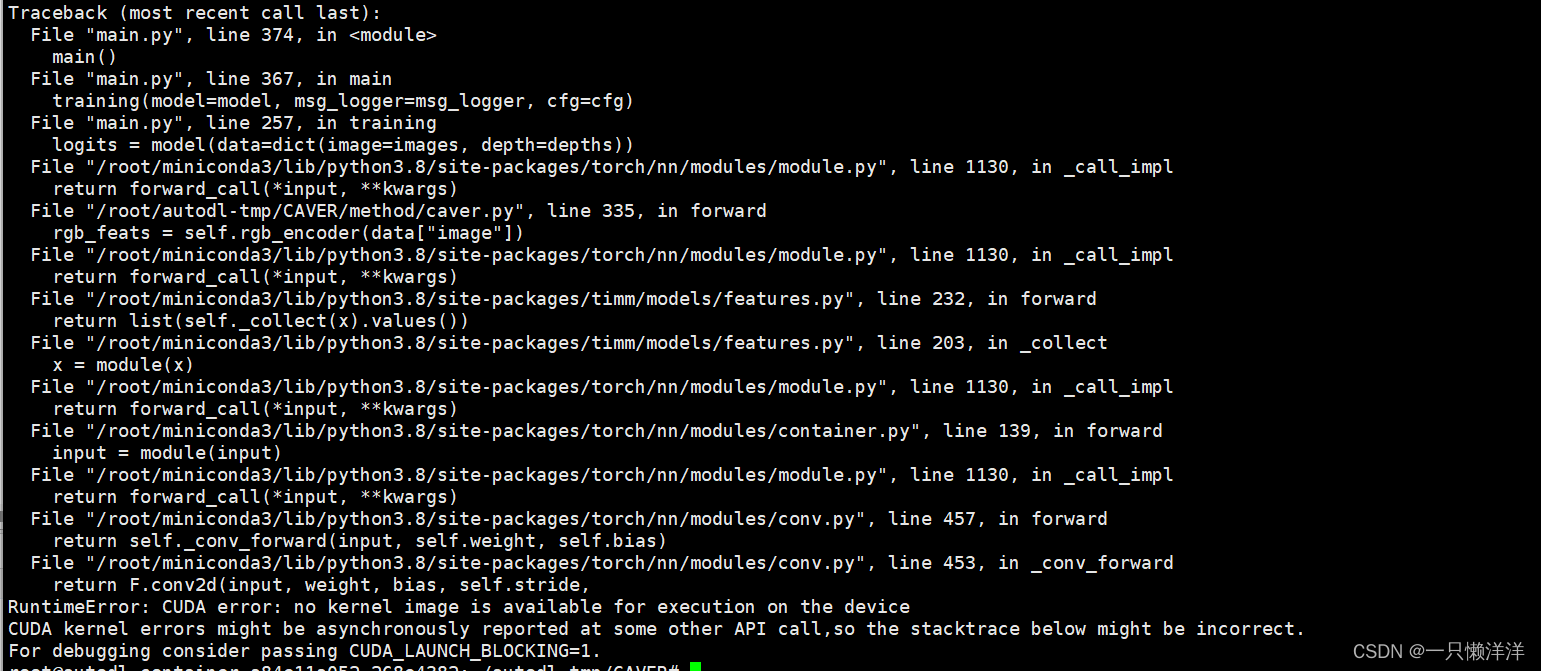
CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection
目录
一、论文阅读笔记:
1、摘要:
2、主要贡献点:
3、方法:
3.1 网络的总体框架图:
3.2 Transformer-based Information Propagation Path (TIPP)
3.3 Intra-Modal/Cross-Scale Self-Attention (IMSA/CSSA)
Q1…

【三维目标检测】【自动驾驶】IA-BEV:基于结构先验和自增强学习的实例感知三维目标检测(AAAI 2024)
系列文章目录
论文:Instance-aware Multi-Camera 3D Object Detection with Structural Priors Mining and Self-Boosting Learning 地址:https://arxiv.org/pdf/2312.08004.pdf 来源:复旦大学 英特尔Shanghai Key Lab /美团 文章目录 系列文…
YoloV8的目标检测推理
YoloV8的目标检测推理
原始的YoloV8封装的层次太高,想要为我们所用可能需要阅读很多API,下面给出比较简单的使用方式
导入所需的库
os:用于操作文件系统。cv2 (OpenCV):用于图像处理。numpy:提供数学运算࿰…
YOLOv5改进 | 主干篇 | 利用SENetV1改进网络结构 (ILSVRC冠军得主)
一、本文介绍
本文给大家带来的改进机制是SENet(Squeeze-and-Excitation Networks)其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一…
游戏NPC智能化:生成式AI如何改变虚拟世界
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

经典目标检测YOLO系列(一)复现YOLOV1(2)反解边界框及后处理
经典目标检测YOLO系列(一)复现YOLOV1(2)反解边界框及后处理
在上个博客,我们提出了新的YOLOV1架构,这次我们解决前向推理过程中的两个问题。 经典目标检测YOLO系列(一)YOLOV1的复现(1)总体架构
1、边界框的计算
1.1 反解边界框公式的改变
1.1.1 原版…
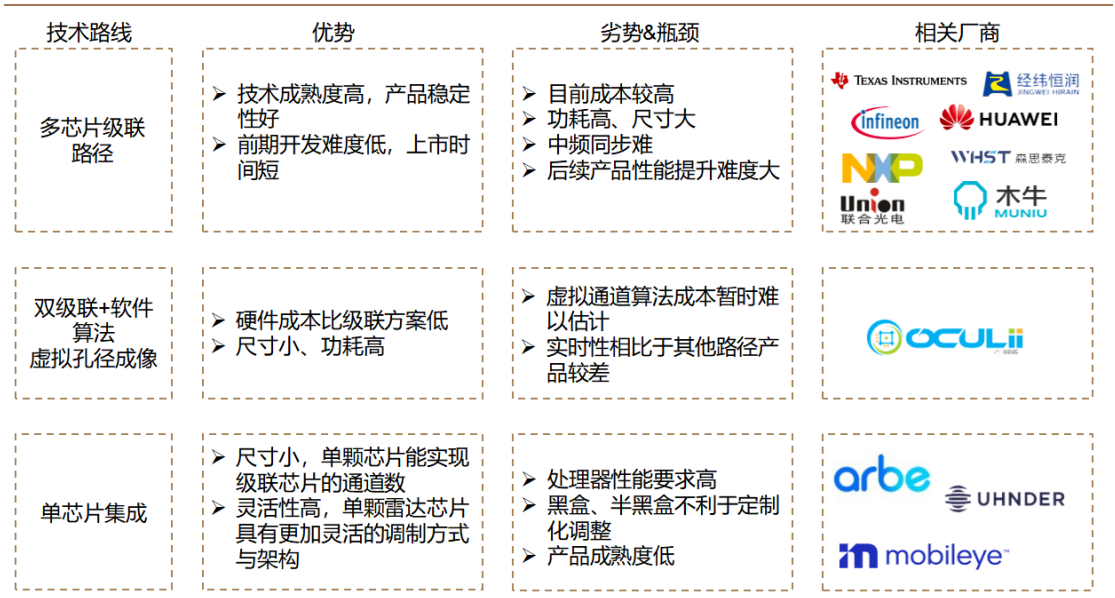
毫米波雷达:从 3D 走向 4D
1 毫米波雷达已广泛应用于汽车 ADAS 系统 汽车智能驾驶需要感知层、决策层、执行层三大核心系统的高效配合,其中感知层通过传感器探知周围的环境。汽车智能驾驶感知层将真实世界的视觉、物理、事件等信息转变成数字信号,为车辆了解周边环境、制定驾驶操…
【三维目标检测/自动驾驶】IA-BEV:基于结构先验和自增强学习的实例感知三维目标检测(AAAI 2024)
系列文章目录
论文:Instance-aware Multi-Camera 3D Object Detection with Structural Priors Mining and Self-Boosting Learning 地址:https://arxiv.org/pdf/2312.08004.pdf 来源:复旦大学 英特尔Shanghai Key Lab /美团 文章目录 系列文…
松鼠目标检测数据集VOC格式1400张
松鼠是一种可爱的小型哺乳动物,它们属于啮齿动物目,是广泛分布于全球的一类动物。松鼠的外貌非常特别,有着精巧的身体结构和灵活的动作,是森林和城市公园中常见的动物之一。
松鼠通常有中等大小,头部相对较大…
【halcon深度学习】目标检测的数据准备过程中的一个库函数determine_dl_model_detection_param
determine_dl_model_detection_param
“determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。 这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议使用这一过程来优化训练和推断性能。 过程签名
determine_dl_model_detection…
YOLO v8 目标检测识别翻栏
一、行人翻栏识别背景介绍
1.1跨越围栏是人类活动中一个普遍但需要引起警惕的行为。它不仅可能导致各种意外事故,甚至可能对个人的生命安全构成威胁。在交通领域,跨越围栏可能导致严重的交通事故,造成人员伤亡。在公共场所,如公园…
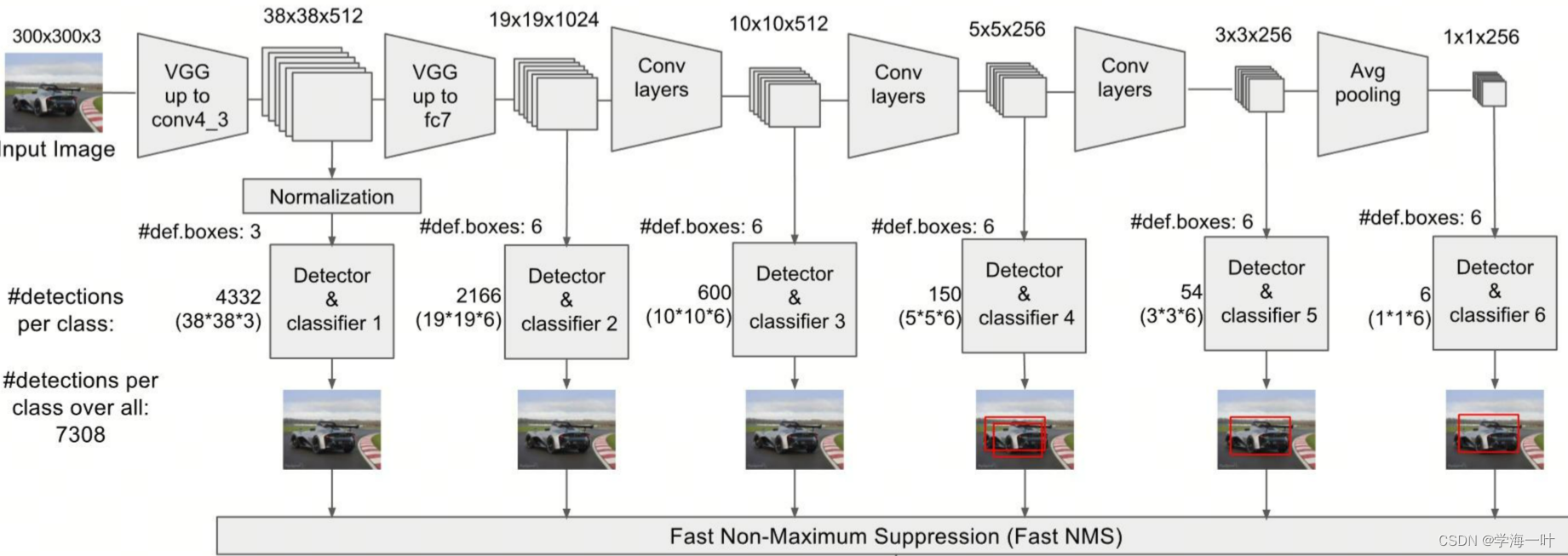
目标检测-One Stage-SSD
文章目录 前言一、SSD的网络结构和流程二、SSD的创新点总结 前言
根据前文目标检测-Two Stage-YOLOv1可以看出YOLOv1的主要缺点是:
每个格子针对目标框的回归是不加限制的,导致目标的定位并不是很精准和Faster RCNN等先进Two Stage算法相比,…
计算机视觉技术-目标检测和边界框
在图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。 然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里…
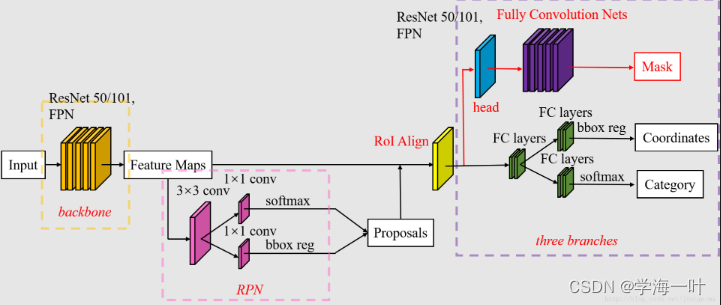
目标检测-Two Stage-Mask RCNN
文章目录 前言一、Mask RCNN的网络结构和流程二、Mask RCNN的创新点总结 前言
前文目标检测-Two Stage-Faster RCNN提到了Faster RCNN主要缺点是:
ROI Pooling有两次量化操作,会引入误差影响精度
Mask RCNN针对这一缺点做了改进,此外Mask …
YOLOv8改进 | 检测头篇 | DynamicHead原论文一比一复现 (不同于网上版本,全网首发)
一、本文介绍
本文给大家带来的改进机制是DynamicHead(Dyhead),这个检测头由微软提出的一种名为“动态头”的新型检测头,用于统一尺度感知、空间感知和任务感知。网络上关于该检测头我查了一些有一些魔改的版本,但是我觉得其已经改变了该检测头的本质,因为往往一些细节上才…

yolov8人脸识别-脸部关键点检测(代码+原理)
1. 人脸识别:
Yolov8可用于人脸识别,它可以识别人脸的位置、大小和角度等信息,并对人脸进行精确的识别。通过使用Yolov8,可以实现高效准确的人脸识别,不仅可以应用于安防领域,也可以应用于人脸支付、人脸门…

基于YOLOv7算法的高精度实时安全背心目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时安全背心目标检测系统可用于日常生活中检测与定位安全背心,此系统可完成对输入图片、视频、文件夹以及摄像头方式的目标检测与识别,同时本系统还支持检测结果可视化与导出。本系统采用YOLOv7目标检测算法来训…
再次认识ultralytics项目(大目标检测、小目标检测、yolov8-ghost、旋转目标检测、自动标注)
Ultralytics YOLOv8 是一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 设计快速、准确且易于使用,使其成为各种物体检测与跟踪、实例分割、图…
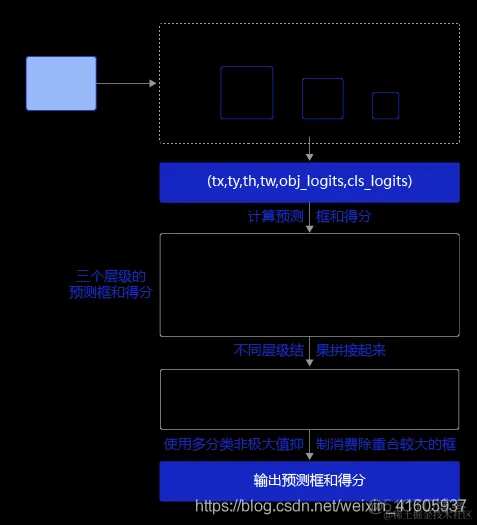
深度学习——R-CNN目标检测原理
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并预测出物体的类别和位置坐标…

目标检测数据集大全「包含VOC+COCO+YOLO三种格式+划分脚本+训练脚本」(持续原地更新)
一、作者介绍:五年算法开发经验、AI 算法经理、阿里云开发社区专家博主、稀土掘金人工智能内容评审委员会成员。擅长:检测、分割、理解、AIGC 等算法训练与部署。 二、数据集介绍: 质量高:高质量图片、高质量标注数据,…
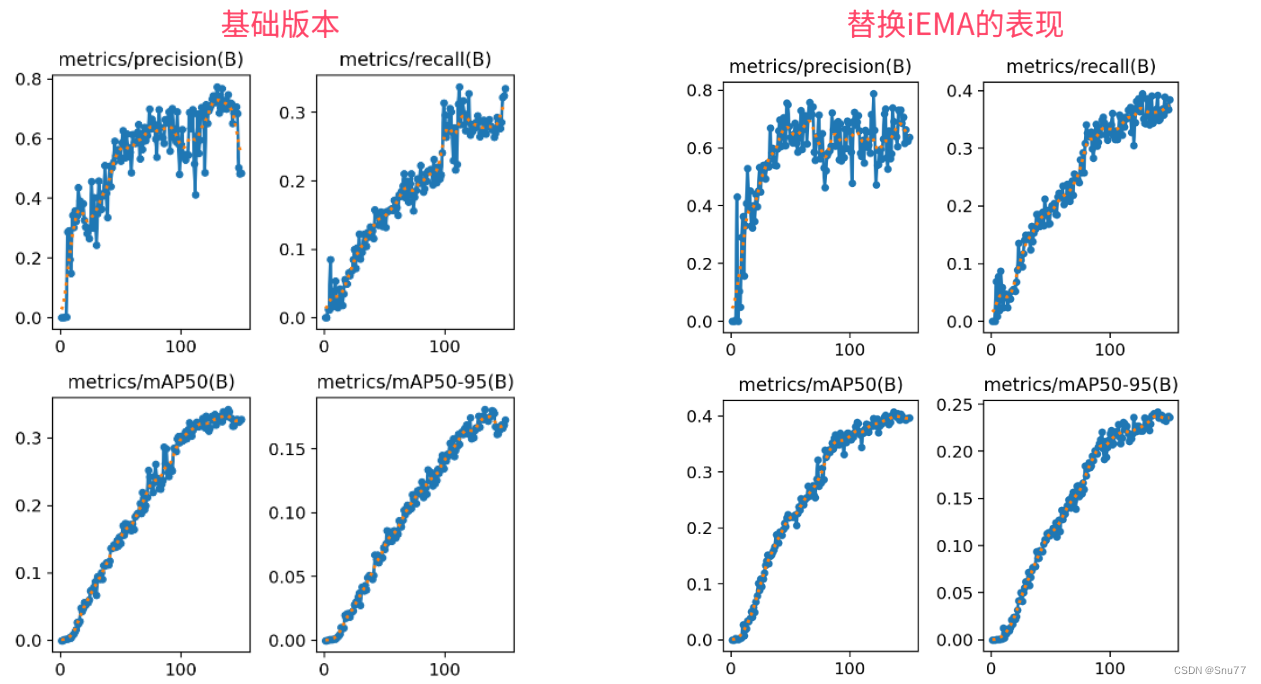
YOLOv8改进 | 二次创新篇 | 结合iRMB和EMA形成全新的iEMA机制(全网独家创新)
一、本文介绍
本文给大家带来的改进机制是二次创新的机制,二次创新是我们发表论文中关键的一环,为什么这么说,从去年的三月份开始对于图像领域的论文发表其实是变难的了,在那之前大家可能搭搭积木的情况下就可以简单的发表一篇论文,但是从去年开始单纯的搭积木其实发表论…
[深度学习]Open Vocabulary Object Detection 部署开放域目标检测模型使用感受
一、Open Vocabulary Object Detection介绍
Open Vocabulary Object Detection (OpenVOD) 是一种新型的目标检测方法,它使用开放词汇的概念来识别和检测图像中的对象。与传统的目标检测方法相比,OpenVOD具有更高的灵活性和可扩展性,因为它允…
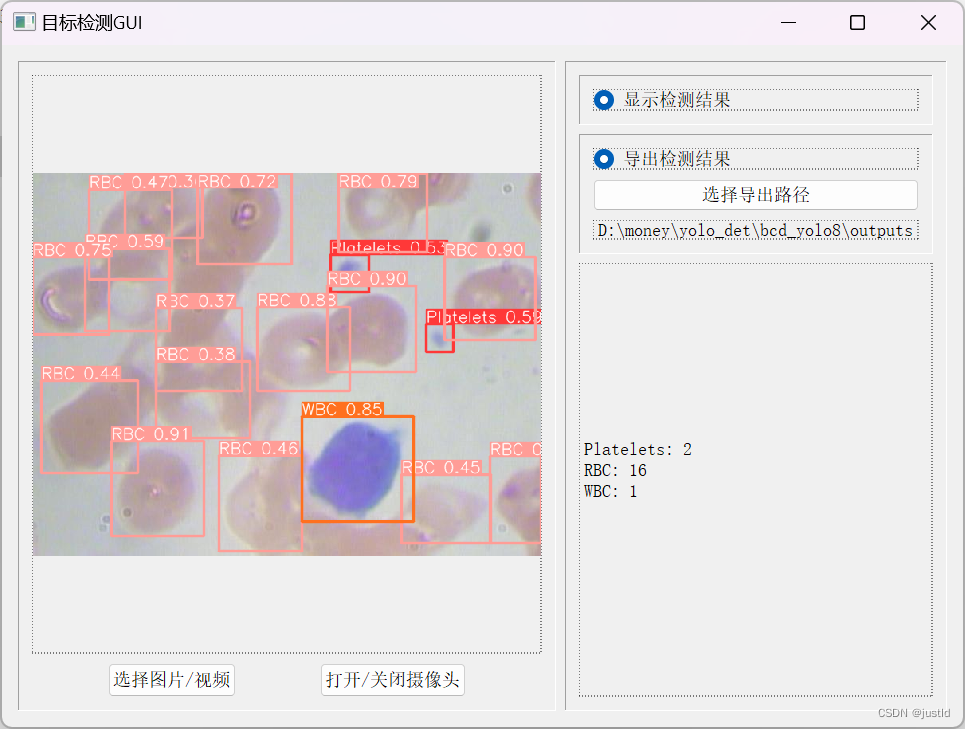
【深度学习目标检测】十四、基于深度学习的血细胞计数系统-含GUI(BCD数据集,yolov8)
血细胞计数是医学上一种重要的检测手段,用于评估患者的健康状况,诊断疾病,以及监测治疗效果。而目标检测是一种计算机视觉技术,用于在图像中识别和定位特定的目标。在血细胞计数中,目标检测技术可以发挥重要作用。 首先…

【目标检测】YOLOv5算法实现(八):模型验证
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模…
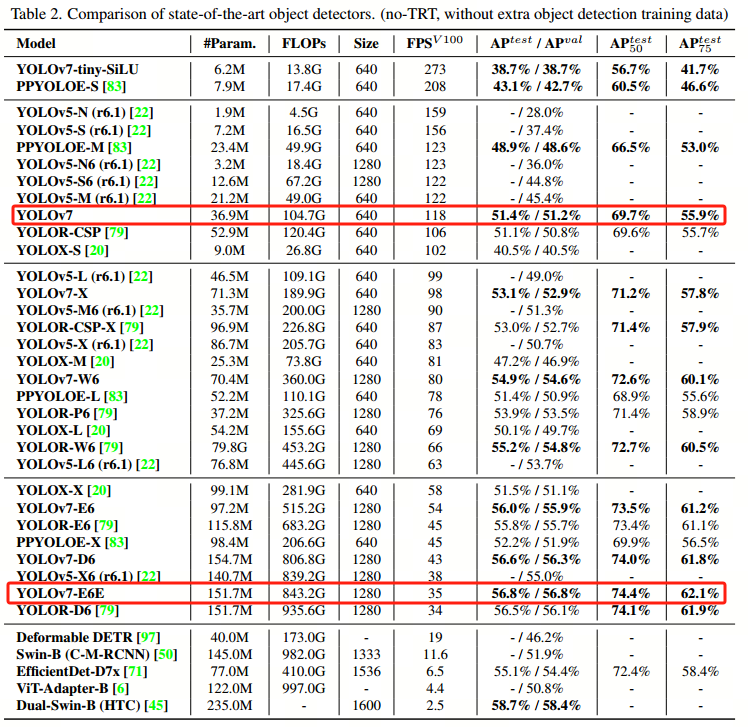
目标检测-One Stage-YOLOv7
文章目录 前言一、YOLOv7的不同版本二、YOLOv7的网络结构二、YOLOv7的创新点三、创新点的详细解读ELAN和E-ELANBoF训练技巧计划型重参化卷积辅助训练模块标签分配Lead head guided label assignerCoarse-to-fine lead head guided label assigner 基于级联模型的复合缩放方法 总…
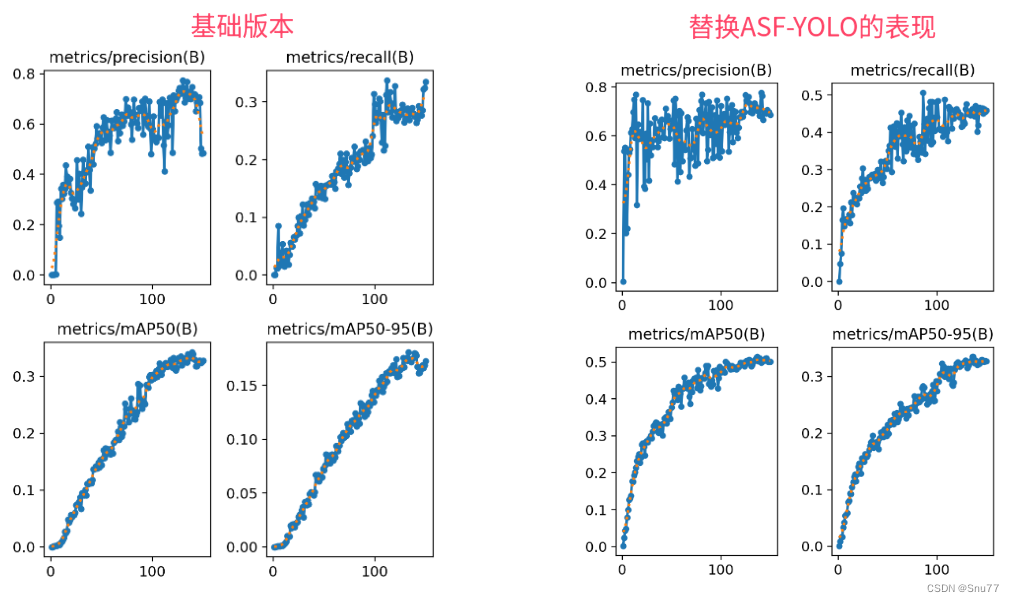
YOLOv8改进 | Neck篇 | 利用ASF-YOLO改进特征融合层(适用于分割和目标检测)
一、本文介绍
本文给大家带来的改进机制是ASF-YOLO(发布于2023.12月份的最新机制),其是特别设计用于细胞实例分割。这个模型通过结合空间和尺度特征,提高了在处理细胞图像时的准确性和速度。在实验中,ASF-YOLO在2018年数据科学竞赛数据集上取得了卓越的分割准确性和速度,…
在目标检测中,Anchor的庞大数量使得存在严重的不平衡问题。这里的不平衡指的是什么。
问题描述:
在目标检测中,Anchor的庞大数量使得存在严重的不平衡问题。这里的不平衡指的是什么。
问题解答:
在目标检测任务中,Anchor指的是一组预定义的边界框或候选框,这些框以多个尺度和宽高比例组合而成。Anchor…
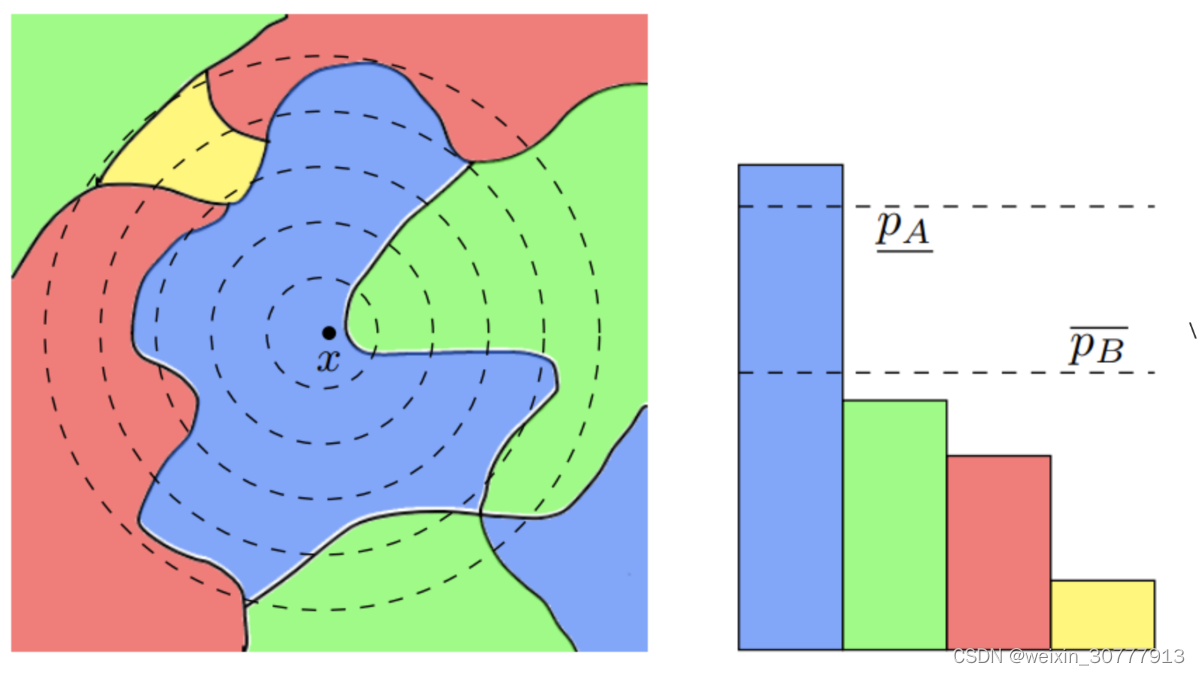
模糊数学在处理激光雷达的不确定性和模糊性问题中的应用
模糊数学是一种用于处理不确定性和模糊性问题的数学工具,它可以帮助我们更好地处理激光雷达数据中的不确定性和模糊性。激光雷达是一种常用的传感器,用于测量目标物体的距离、速度和方向等信息。然而,在实际应用中,激光雷达所获取…
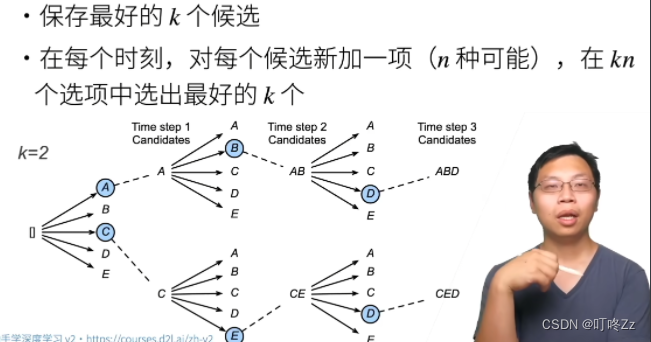
李沐-《动手学深度学习》--02-目标检测
一 、目标检测算法
1. R-CNN
a . 算法步骤
使用启发式搜索算法来选择锚框(选出多个锚框大小可能不一,需要使用Rol pooling)使用预训练好的模型(去掉分类层)对每个锚框进行特征抽取(如VGG,AlexNet…)训练…
CV之DL之Yolo:计算机视觉领域算法总结—Yolo系列(YoloV1~YoloV8各种对比)的简介、安装、案例应用之详细攻略
CV之DL之Yolo:计算机视觉领域算法总结—Yolo系列(YoloV1~YoloV8各种对比)的简介、安装、案例应用之详细攻略 导读:近期,博主应太多太多的网友的私信,要求让博主总结一下目标检测领域算法的发展历史和最新算法的技术架构࿰…

目标检测数据集 - 人头检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:人头检测数据集,真实场景高质量图片数据,涉及场景丰富,比如课堂行人数据、街景行人数据、车站行人数据、商场行人数据、密集行人数据、超密集行人数据、遮挡行人数据、严重遮挡行人数据等;适用实际项目应用…

YOLOv8 Ultralytics:使用Ultralytics框架进行姿势估计
YOLOv8 Ultralytics:使用Ultralytics框架进行姿势估计 前言相关介绍前提条件实验环境安装环境项目地址LinuxWindows 使用Ultralytics框架进行姿势估计参考文献 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可…
YOLOv8/v7/v5全网首发原创独家创新,内涵CBAM注意力改进、ECA改进,SPPF改进等
💡💡💡全网独家首发创新(原创),纯自研模块,适合paper !!!
💡💡💡内涵CBAM注意力改进、ECA改进,SPPF改进等&am…
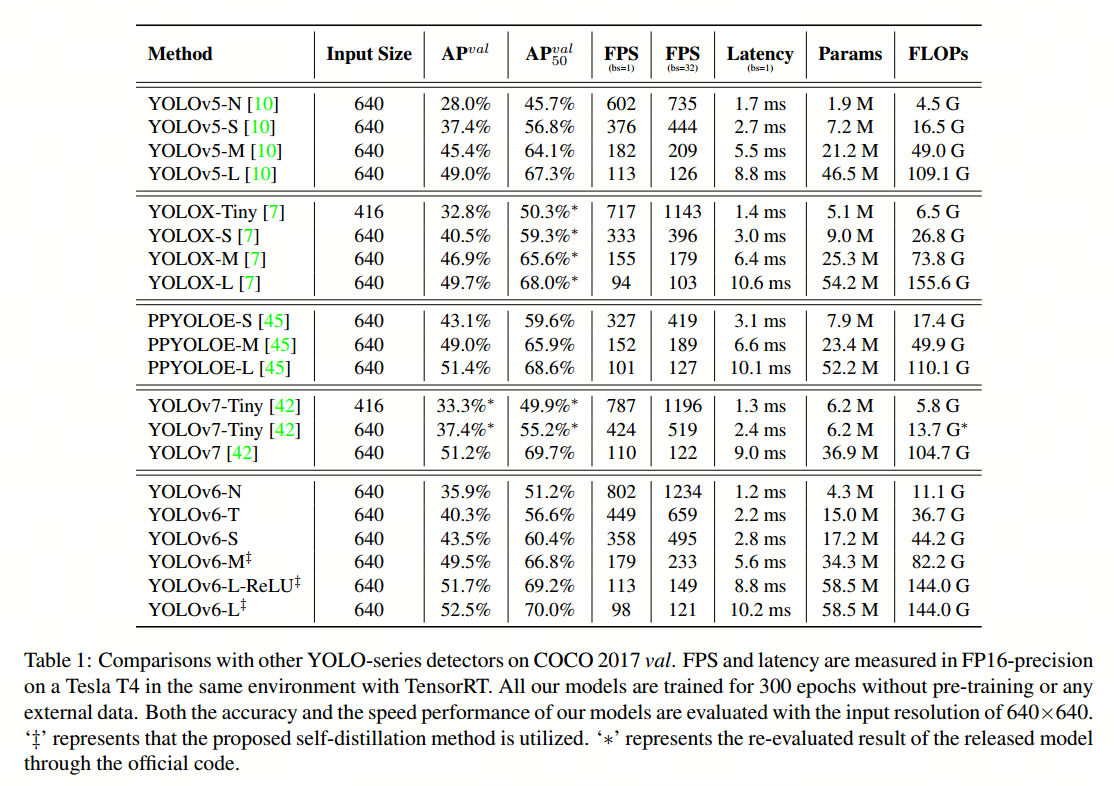
目标检测-One Stage-YOLOv6
文章目录 前言一、YOLOv6的网络结构和流程二、YOLOv6的创新点总结 前言
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。论文题目是《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》。
和YOLOv4、YOLOv5等不…

本地远程实时获取无人机采集视频图像(天空端 + jetson nano + 检测分割 + 回传地面端显示)
无线图传设备介绍 2、jetson nano天空端数据采集检测保存 3、本地回传显示
1、无线图传设备介绍 由于本设计考虑将无人机得到检测结果实时回传给地面站显示,因此需要考虑一个远程无线通信设备进行传输。本设计采用思翼HM30图传设备。通过无线图传的wifi将天空端的桌…
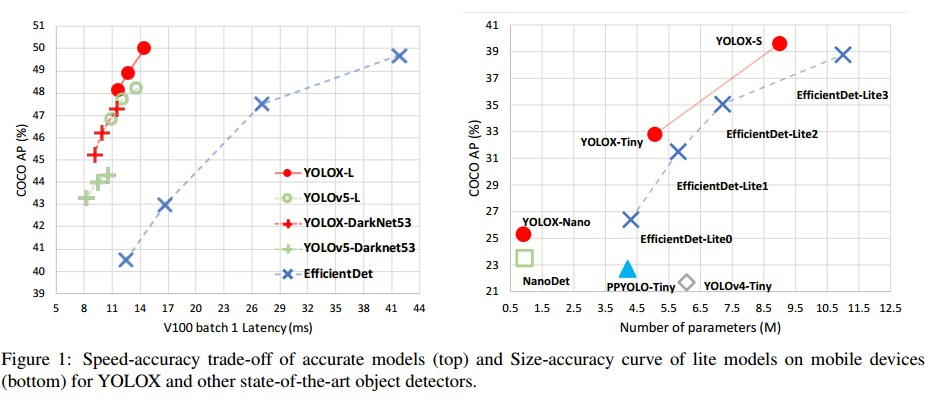
目标检测-One Stage-YOLOx
文章目录 前言一、YOLOx的网络结构和流程1.YOLOx的不同版本2.Yolox-Darknet53YOLOv3 baselineYolox-Darknet53 3.Yolox-s/Yolox-m/Yolox-l/Yolox-x4.Yolox-Nano/Yolox-Tiny 二、YOLOx的创新点总结 前言
根据前文CenterNet、YOLOv4等可以看出学界和工业界都在积极探索使用各种t…

DETR tensor去除推理过程无用辅助头+fp16部署再次加速+解决转tensorrt 输出全为0问题的新方法
特别说明:参考官方开源的DETR代码、TensorRT官方文档,如有侵权告知删,谢谢。 完整代码、测试脚本、测试图片、模型文件 点击下载
1、转tensorrt 输出全为 0 老问题回顾 在用 TensorRT 部署 DETR 检测模型时遇到:转tensorrt 输出全…
YOLOv8改进 | 细节涨点篇 | UNetv2提出的一种SDI多层次特征融合模块(分割高效涨点)
一、本文介绍
本问给大家带来的改进机制是UNetv2提出的一种多层次特征融合模块(SDI)其是一种用于替换Concat操作的模块,SDI模块的主要思想是通过整合编码器生成的层级特征图来增强图像中的语义信息和细节信息。该方法已在多个公开的医学图像分割数据集上进行了验证,包括皮…
transfomer中Multi-Head Attention的源码实现
简介
Multi-Head Attention是一种注意力机制,是transfomer的核心机制,就是图中黄色框内的部分.
Multi-Head Attention的原理是通过将模型分为多个头,形成多个子空间,让模型关注不同方面的信息。每个头独立进行注意力运算,得到一个注意力权…

经典目标检测YOLO系列(二)YOLOV2的复现(1)总体网络架构及前向推理过程
经典目标检测YOLO系列(二)YOLOV2的复现(1)总体网络架构及前向推理过程
和之前实现的YOLOv1一样,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv2的大部分核心理念的前提下,重构一款较新的YOLOv2检测器,来对YOLOV2有…
【RT-DETR有效改进】轻量化CNN网络MobileNetV1改进特征提取网络
前言
大家好,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PP…
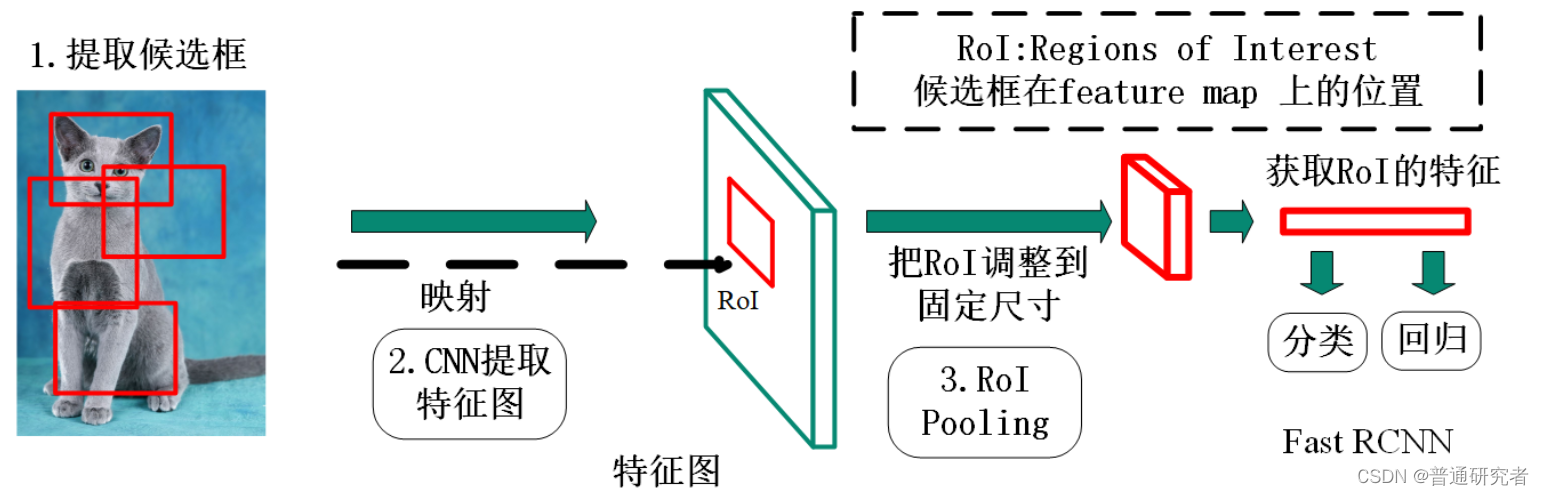
目标检测--02(Two Stage目标检测算法1)
Two Stage目标检测算法 R-CNN
R-CNN有哪些创新点? 使用CNN(ConvNet)对 region proposals 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特…

yolo9000:Better, Faster, Stronger的目标检测网络
目录 一、回顾yolov1二、yolov2详细讲解2.1 Better部分创新点(1)Batch Normalization(批量归一化)(2)High Resolution Classifier---高分辨率分类器(3)Anchor Boxes---锚框(4)Dimens…
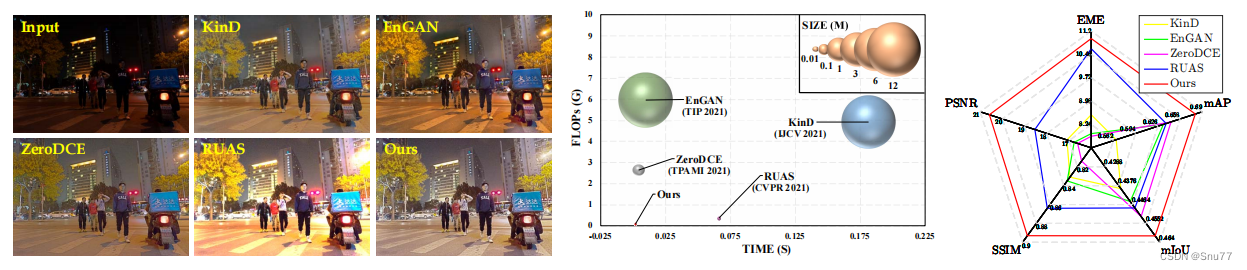
YOLOv8改进 | 主干篇 | 低照度图像增强网络SCINet改进黑暗目标检测(全网独家首发)
一、本文介绍
本文给大家带来的改进机制是低照度图像增强网络SCINet,SCINet(自校正照明网络)是一种专为低光照图像增强设计的框架。它通过级联照明学习过程和权重共享机制来处理图像,优化了照明部分以提升图像质量。我将该网络集成在YOLOv8的主干上针对于图像的输入进行增…
AI一叶知秋:从目标检测部署浅谈人工智能发展
笔者写这篇文章也有讨巧之嫌,仅以个人视角分享一些看法,主要从实践部署来谈谈近两年来计算机视觉模型的变化,不过AI是一个宏大的话题,每个人定义的人工智能就不一样,我们先来探讨一下何为人工智能。百度百科中是这样定…
基于YOLOv8深度学习的200种鸟类智能检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
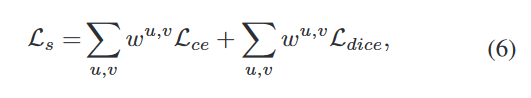
伪装目标检测的算术不确定性建模
Modeling Aleatoric Uncertainty for Camouflaged Object Detection 伪装目标检测的算术不确定性建模背景贡献实验方法Camouflaged Object Detection Network(伪装目标检测框架)Online Confidence Estimation Network(在线置信度估计网络&…
运动模型非线性扩展卡尔曼跟踪融合滤波算法(Matlab仿真)
卡尔曼滤波的原理和理论在CSDN已有很多文章,这里不再赘述,仅分享个人的理解和Matlab仿真代码。
1 单目标跟踪 匀速转弯(CTRV)运动模型下,摄像头输出目标状态camera_state [x, y, theta, v],雷达输出目标状…
YOLOv5改进 | Neck篇 | 利用ASF-YOLO改进特征融合层(适用于分割和目标检测)
一、本文介绍
本文给大家带来的改进机制是ASF-YOLO(发布于2023.12月份的最新机制),其是特别设计用于细胞实例分割。这个模型通过结合空间和尺度特征,提高了在处理细胞图像时的准确性和速度。在实验中,ASF-YOLO在2018年数据科学竞赛数据集上取得了卓越的分割准确性和速度,…

检测头篇 | 原创自研 | YOLOv8 更换 SEResNeXtBottleneck 头 | 附详细结构图
左图:ResNet 的一个模块。右图:复杂度大致相同的 ResNeXt 模块,基数(cardinality)为32。图中的一层表示为(输入通道数,滤波器大小,输出通道数)。 1. 思路
ResNeXt是微软研究院在2017年发表的成果。它的设计灵感来自于经典的ResNet模型,但ResNeXt有个特别之处:它采用…
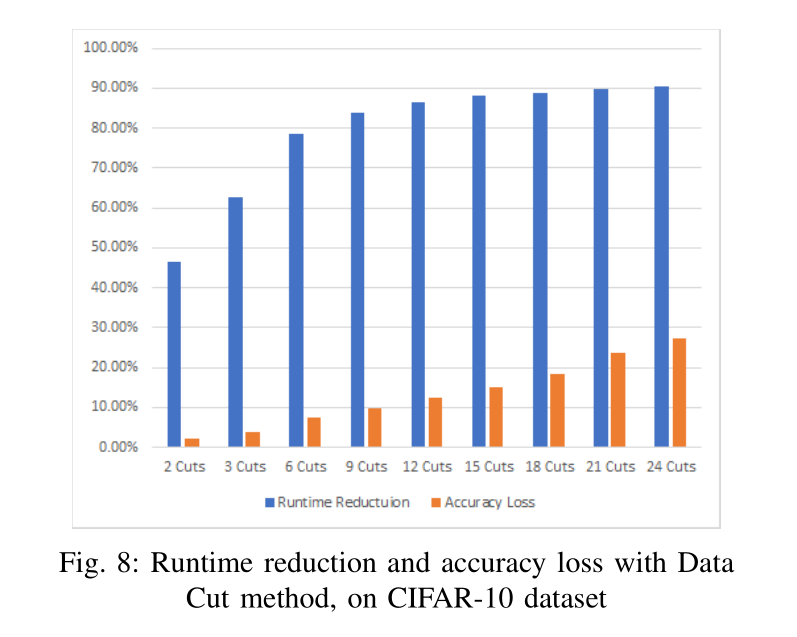
Maintaining Performance with Less Data(待补)
文章目录 AbstractIntroductionPrevious WorkIncreasing data useReducing data useVariable data useContribution MethodsDatasetsHardwarePerformance MetricsNetwork Architecture ExperimentationBenchmarkData stepobserve Data IncrementData Cut DiscussionConclusion …
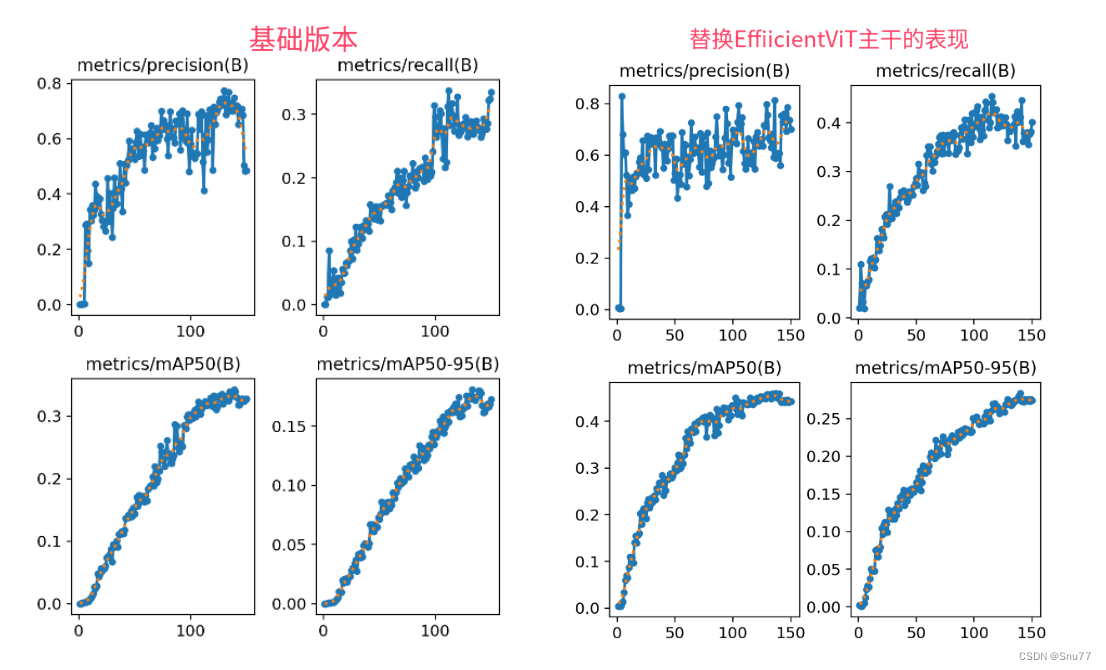
YOLOv5改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
一、本文介绍
本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是Effici…

【论文解读】Point Transformer
Point Tranformer 摘要引言方法实验结论 摘要
自注意网络已经彻底改变了自然语言处理,并在图像分析任务(如图像分类和对象检测)方面取得了令人印象深刻的进展。受这一成功的启发,我们研究了自注意网络在三维点云处理中的应用。我…
【目标检测】评价指标:mAP概念及其计算方法(yolo源码/pycocotools)
本篇文章首先介绍目标检测任务中的关键评价指标mAP的概念;然后介绍其在yolo源码和pycocotools工具中的实现方法;最后比较两种mAP的计算方法的不同之处。 目标检测中的评价指标:
mAP概念及其计算方法(yolo源码/pycocotools) 混淆矩阵概念及其…
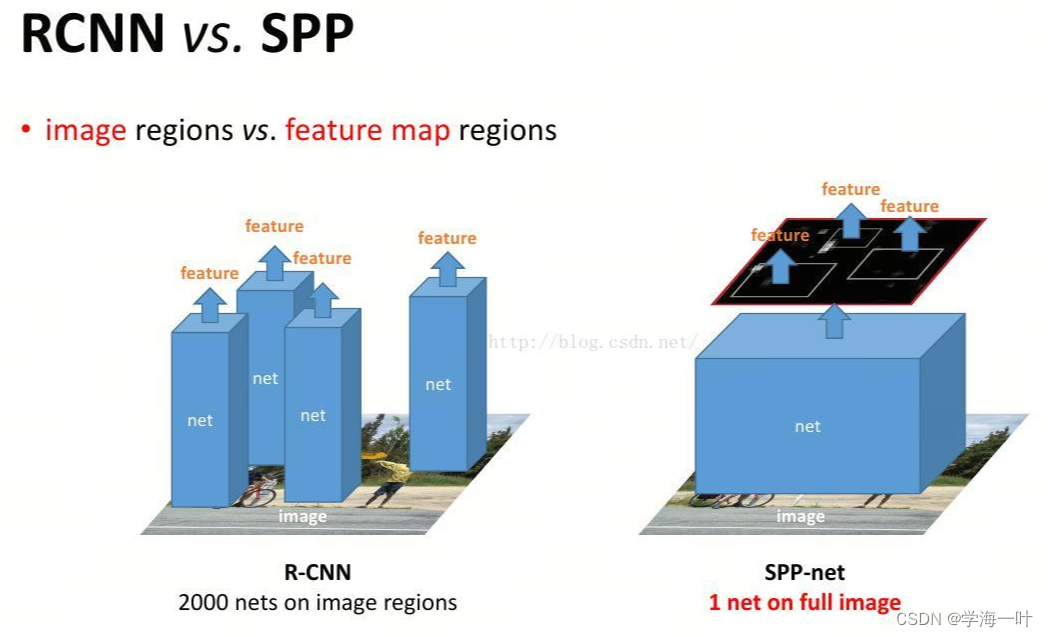
目标检测-Two Stage-SPP Net
文章目录 前言一、SPP Net 的网络结构和流程二、SPP的创新点总结 前言 SPP Net:Spatial Pyramid Pooling Net(空间金字塔池化网络) SPP-Net是出自何凯明教授于2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetw…
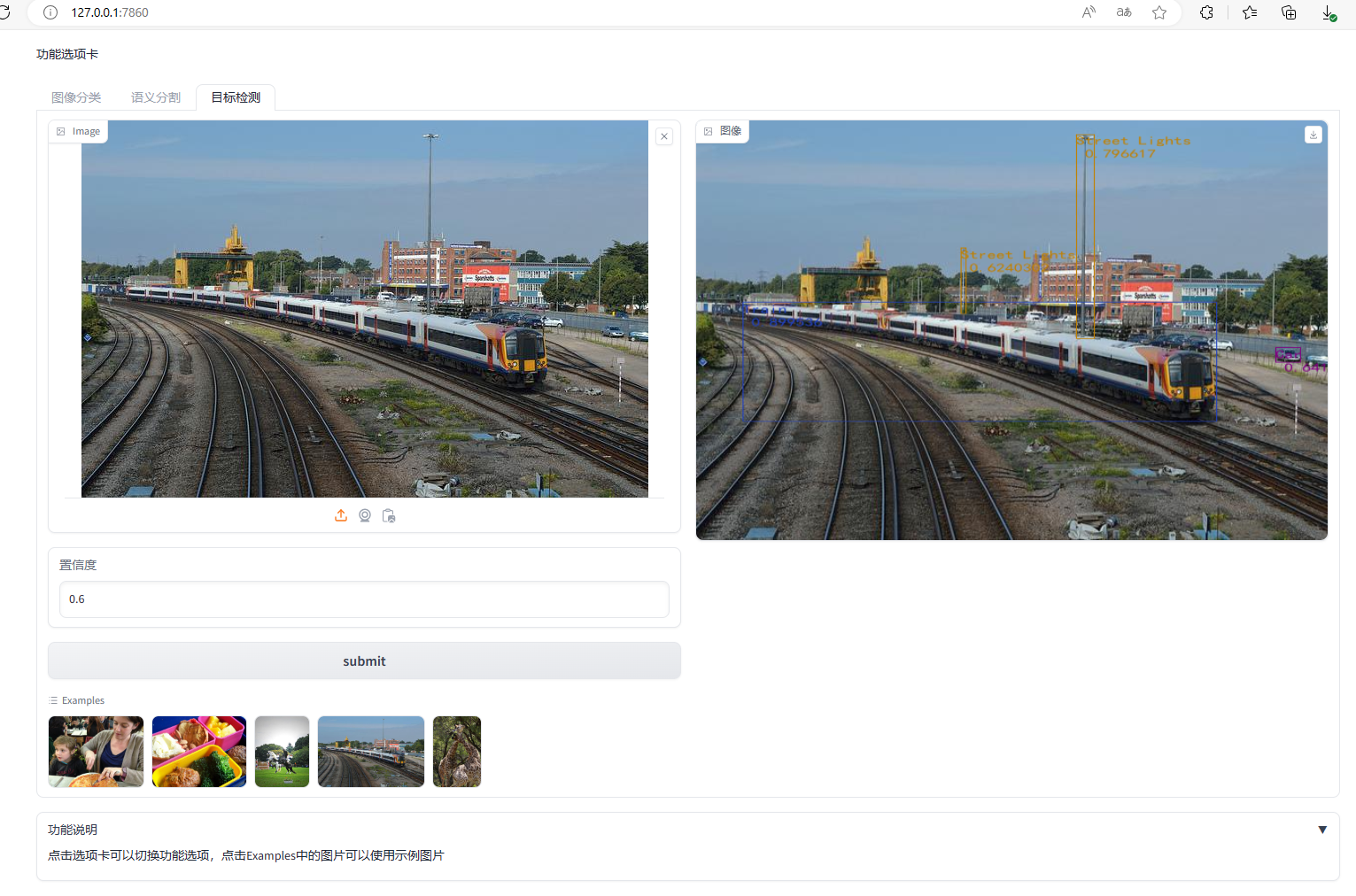
基于gradio快速部署自己的深度学习模型(目标检测、图像分类、语义分割模型)
gradio是一款基于python的算法快速部署工具,本博文主要介绍使用gradio部署目标检测、图像分类、语义分割模型的部署。相比于flask,使用gradio不需要自己构造前端代码,只需要将后端接口写好即可。此外,基于gradio实现的项目&#x…
Faster RCNN网络源码解读(Ⅱ) --- Faster RCNN源码使用
目录 一、源码链接
二、环境配置
三、文件结构
四、预训练权重下载地址
五、训练集
六、训练方法及注意事项
七、大概看一下训练过程(train_mobilenetv2.py) 一、源码链接 Faster R-CNN源码链接https://pan.baidu.com/s/1SQjyLXD47H11ke05OXY…
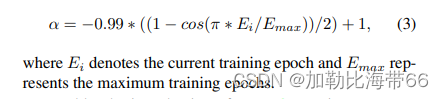
美团出品 | YOLOv6 v3.0 is coming(性能超越YOLOv7、v8)
🚀🚀🚀美团出品 | YOLOv6 v3.0 is coming !!✨✨✨ 一、前言简介 🎄🎈
📚 代码地址:美团出品 | YOLOv6 3.0代码下载地址
📚 文章地址:https://a…

ICLR 2022—你不应该错过的 10 篇论文(上)
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 ICLR 2023已经放榜,但是今天我们先来回顾一下去年的ICLR 2022! ICLR 2022将于2022年 4 月 25 日星期一至 4 月 29 日星期五在线举行(连续第三年!…

如何运行YOLOv6的代码实现目标识别?
YOLOv6是由美团视觉团队开发的1.环境配置我们先把YOLOv6的代码clone下来git clone https://github.com/meituan/YOLOv6.git安装一些必要的包pip install pycocotools2.0作者要求pytorch的版本是1.8.0,我的环境是1.7.0,也是可以正常运行的pip install -r requirement…
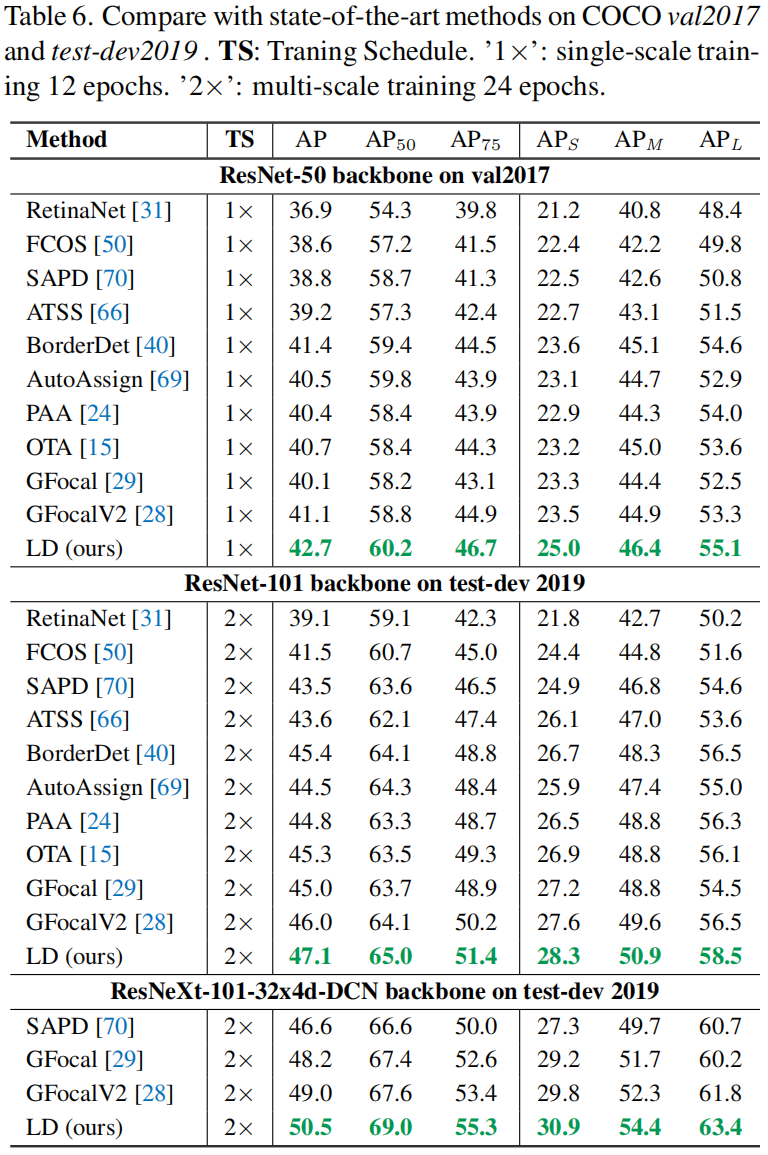
LD for Dense Object Detection(CVPR 2022)原理与代码解析
paper:Localization Distillation for Dense Object Detectioncode1:https://github.com/HikariTJU/LDcode2:https://github.com/open-mmlab/mmdetection/tree/master/configs/ld背景定位是目标检测中的一个基本问题,边界框回归是…
旋转目标检测-环境配置-数据集制作
一、环境配置
Ubuntu 22.04Torch 1.10CUDA 11.3python 3.9环境配置参考下面链接(建议Linux系统)yolov5_obb/install.md at master hukaixuan19970627/yolov5_obb (github.com)https://github.com/hukaixuan19970627/yolov5_obb/blob/master/docs/insta…

基于深度学习的口罩检测系统(Python+清新界面+数据集)
摘要:口罩检测系统用于日常生活中检测行人是否规范佩戴口罩,利用深度学习算法可实现图片、视频、连接摄像头等方式的口罩检测,另外支持和结果可视化。在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面。口罩检测系统可…
YOLOv5改进 | 主干篇 | 华为GhostnetV1一种移动端的专用特征提取网络
一、本文介绍
本文给大家带来的改进机制是华为移动端模型Ghostnetv1,华为GhostnetV1一种移动端的专用特征提取网络,旨在在计算资源有限的嵌入式设备上实现高性能的图像分类。GhostNet的关键思想在于通过引入Ghost模块,以较低的计算成本增加了特征图的数量,从而提高了模型的…
目标检测中的DR和FAR的英文全称是什么?是什么参数,用来干什么的?
问题描述:目标检测中的DR和FAR的英文全称是什么?是什么参数,用来干什么的?
问题解答:
DR 和 FAR 的英文全称分别是:
DR: Detection Rate(检测率)。FAR: Fa…

目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)...
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 论文地址:https://arxiv.org/pdf/2201.04620v1.pdf 计算机视觉研究院专栏 作者:Edison_G 研究表明,当训练数据缺少…

【目标检测】基于yolov5的交通标志检测和识别(可识别58种类别,附代码和数据集)
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
文末附项目代码和数据集,请看检测效果: 1. 介绍
YOLOv5是一种用于目标检测的深度学习算法,它能够在高速和高精度的情…
基于图像的目标检测算法YOLO 和 SSD 的区别是什么?
YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)都是实时物体检测算法,它们在检测速度和准确性方面都取得了显著的成果。尽管它们有许多相似之处,但也存在一些关键差异:
1. 检测…
人脸活体检测系统(Python+YOLOv5深度学习模型+清新界面)
摘要:人脸活体检测系统利用视觉方法检测人脸活体对象,区分常见虚假人脸,以便后续人脸识别,提供系统界面记录活体与虚假人脸检测结果。本文详细介绍基于YOLOv5深度学习技术的人脸活体检测系统,在介绍算法原理的同时&…
常用视觉数据集(更新中)
1.MNIST (手写数字识别)
MNIST(Modified National Institute of Standards and Technology)数据集是一个广泛用于计算机视觉和机器学习领域的经典数据集。它包含了手写数字的灰度图像,用于训练和测试数字识别算法。以下是有关MNIST数据集的一…
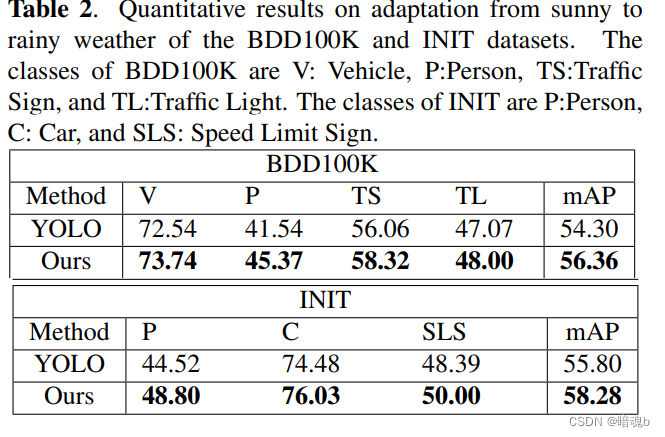
MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION
abstract
领域自适应在解决许多应用遇到的领域转换问题方面发挥了重要的作用。这个问题是由于训练用的数据和实际测试的真实场景数据的分布差异造成的。在本文中,我们介绍了一种新的多尺度域自适应YOLO(MS-DAYOLO)框架,该框架在最…

数据可视化 | 期末复习 | 补档
文章目录 📚介绍可视化🐇什么是可视化🐇科学可视化,信息可视化,可视分析系统三者之间有什么区别🔥🐇可视化的基本流程🐇可视化的两个基本设计原则🐇数据属性🐇…
PSEUDO-LIDAR++:自动驾驶中 3D 目标检测的精确深度
论文地址:PSEUDO-LIDAR: ACCURATE DEPTH FOR 3D OBJECT DETECTION IN AUTONOMOUS DRIVING 论文代码:https://github.com/mileyan/Pseudo_Lidar_V2
摘要
3D 检测汽车和行人等物体在自动驾驶中发挥着不可或缺的作用。现有方法很大程度上依赖昂贵的激光雷…
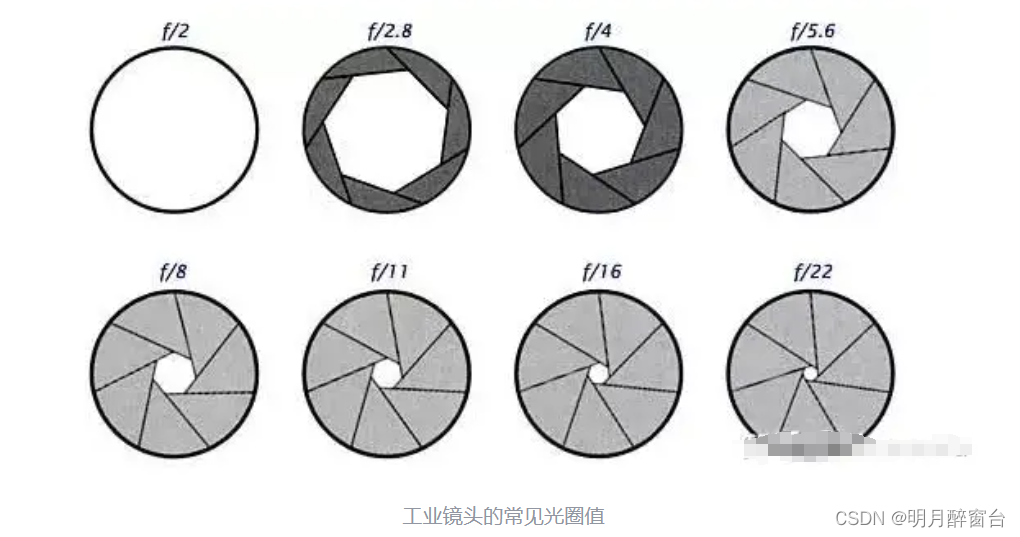
工业相机+镜头选型及靶面、焦距计算等相关详解
工业相机镜头选型及靶面、焦距计算等相关详解
着重讲述相机的各个参数及使用意义总结相机镜头选型主要参数的推理计算
0. 工业相机相关概念简介 相机与镜头一览 工业相机与镜头实物图如下图所示: 常见的相机有两种供电方式:一种是电源线供电࿰…

RTDETR 引入 超越自注意力:面向医学图像分割的可变形大卷积核注意力
医学图像分割在转换器模型的应用下取得了显著的进展,这些模型擅长捕捉广泛的上下文和全局背景信息。然而,这些模型随着标记数量的平方成比例增长的计算需求限制了它们的深度和分辨率能力。大多数当前的方法通过逐层处理D体积图像数据(称为伪3D),在处理过程中错过了关键的跨…
目标检测中目标的尺寸差异大会存在什么问题?
问题描述:目标检测中目标的尺寸差异大会存在什么问题?
问题解答:
目标检测中目标的尺寸差异大可能会引发一些问题,这些问题可能包括: 定位问题: 尺寸差异大的目标可能导致模型在定位目标位置时出现困难。…
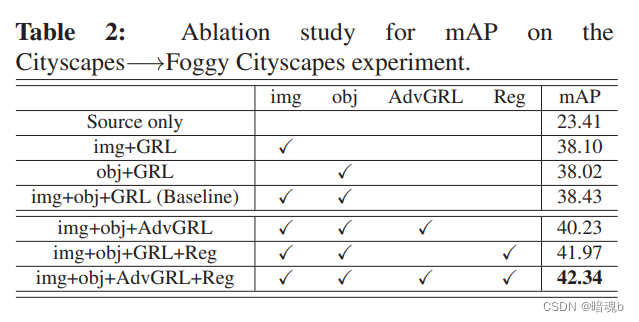
Domain Adaptive Object Detection for Autonomous Driving under Foggy Weather
Abstract
大多数自动驾驶的物体检测方法通常假设训练和测试数据之间的特征分布一致,但当天气差异显著时,情况并非总是如此。在晴朗天气下训练的目标检测模型在大雾天气下可能由于域间隙而不够有效。本文提出了一种新的雾天自动驾驶领域自适应目标检测框…
FastDeploy项目简介,使用其进行(图像分类、目标检测、语义分割、文本检测|orc部署)
FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具, 支持云边端部署。提供超过 🔥160 Text,Vision, Speech和跨模态模型📦开箱即用的部署体验,并实现🔚端到端的推理性能优化。包括 物…
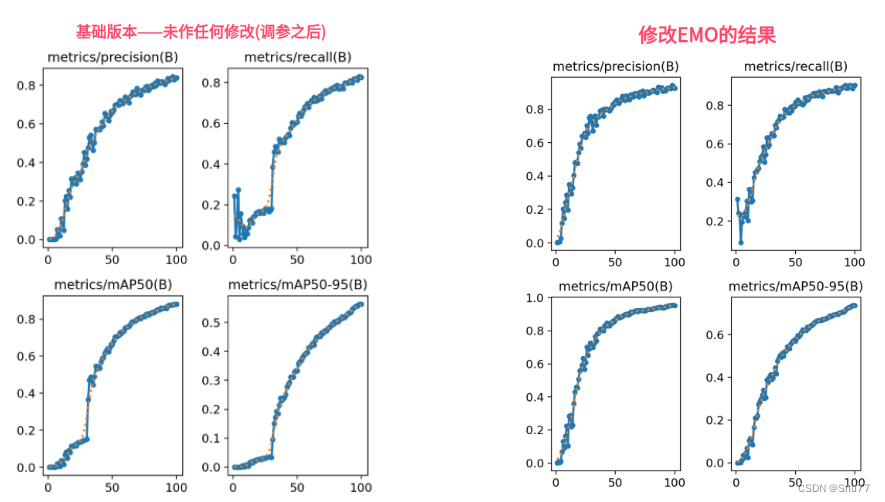
【RT-DETR有效改进】反向残差块网络EMO | 一种轻量级的CNN架构(轻量化网络,参数量下降约700W)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文给大家带来的改进机制是反向残差块网络EMO,其的构成块iRMB在之前我已经发过了,同时进行了二次创新,本文的网络就是由iRMB组成的网络EMO,所以我们二次创新之后的iEMA也可以用于这个网络中,再次形成二次…

目标检测算法训练数据准备——Penn-Fudan数据集预处理实例说明(附代码)
目录 0. 前言
1. Penn-Fudan数据集介绍
2. Penn-Fudan数据集预处理过程
3. 结果展示
4. 完整代码 0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如…
深度学习-最简代码实现目标检测模型
一、项目介绍 在深度学习领域中,目标检测一直是一个备受关注的研究方向。为了更深入地理解深度学习目标检测的原理和实现,我写了一个简单的单目标检测项目。在这个项目中, 我用最简单的方式实现了数据迭代器、网络模型、预测脚本和训练模型脚…

YOLO-World: Real-Time Open-Vocabulary Object Detection
文章目录 1. Introduction2. Experiments2.1 Implementation Details2.2 Pre-training2.3 Ablation Experiments2.3.1 预训练数据2.3.2 对RepVL-PAN的消融研究2.3.3 文本编码器 2.4 Fine-tuning YOLO-World2.5 Open-Vocabulary Instance Segmentation2.6 Visualizations Refere…
YOLOv8独家原创改进:FPN涨点篇 |多级特征融合金字塔(HS-FPN),助力小目标检测| 2024年最新论文
💡💡💡本文独家改进:高层筛选特征金字塔网络(HS-FPN),能够刷选出大小目标,增强模型表达不同尺度特征的能力,助力小目标检测
💡💡💡在BCCD医学数据集实现暴力涨点。 收录
YOLOv8原创自研
https://blog.csdn.net/m0_63774211/category_12511737.html?spm=1…
YOLOv7独家改进:上采样算子 | 超轻量高效动态上采样DySample,效果秒杀CAFFE,助力小目标检测
💡💡💡本文独家改进:一种超轻量高效动态上采样DySample, 具有更少的参数、FLOPs,效果秒杀CAFFE和YOLOv5网络中的nn.Upsample 💡💡💡在多个数据集下验证能够涨点,尤其在小目标检测领域涨点显著。 收录
YOLOv7原创自研
https://blog.csdn.net/m0_63774211/ca…

【RT-DETR有效改进】利用SENetV2重构化网络结构 (ILSVRC冠军得主,全网独家首发)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文给大家带来的改进机制是SENetV2,其是2023.11月的最新机制(所以大家想要发论文的可以在上面下点功夫),其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而…
2024年原创深度学习算法项目分享
原创深度学习算法项目分享,包括以下领域: 图像视频、文本分析、知识图谱、推荐系统、问答系统、强化学习、机器学习、多模态、系统界面、爬虫、增量学习等领域… 有需要的话,评论区私聊

【兔子王赠书第14期】《YOLO目标检测》涵盖众多目标检测框架,附赠源代码和全书彩图!
文章目录 写在前面YOLO目标检测推荐图书本书特色内容简介作者简介 推荐理由粉丝福利写在后面 写在前面
小伙伴们好久不见吖,本期博主给大家推荐一本关于YOLO目标检测的图书,该书侧重目标检测的基础知识,包含丰富的实践内容,是目标…

YOLOv7姿态估计pose estimation(姿态估计-目标检测-跟踪)
YOLOv7姿态估计(pose estimation)是一种基于YOLOv7算法的姿态估计方法。该算法使用深度学习技术,通过分析图像中的人体关键点位置,实现对人体姿态的准确估计。
姿态估计是计算机视觉领域的重要任务,它可以识别人体的关…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的血细胞智能检测与计数(深度学习模型+UI界面代码+训练数据集)
摘要:开发血细胞智能检测与计数系统对于疾病的预防、诊断和治疗具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个血细胞智能检测与计数系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5&a…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的自动驾驶目标检测系统详解(深度学习+Python代码+PySide6界面+训练数据集)
摘要:开发自动驾驶目标检测系统对于提高车辆的安全性和智能化水平具有至关重要的作用。本篇博客详细介绍了如何运用深度学习构建一个自动驾驶目标检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLO…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的条形码二维码检测系统(深度学习+UI界面+训练数据集+Python代码)
摘要:在物流和制造业中,开发一套高效的条形码与二维码识别系统显得尤为关键。本博文深入探讨了如何利用深度学习技术打造出一套先进的条形码及二维码检测系统,并且提供了一套完整的实施方案。该系统搭载了性能卓越的YOLOv8算法,并…

植物病害识别:YOLO水稻病害识别数据集(1000多张,3个类别,yolo标注)
YOLO水稻病害识别数据集,包含水稻白叶枯病、稻瘟病、水稻褐斑病3个常见病害类别,共1000多张图像,yolo标注完整,可直接训练。 适用于CV项目,毕设,科研,实验等
需要此数据集或其他任何数据集请私…
UCAS-AOD遥感旋转目标检测数据集——基于YOLOv8obb,map50已达96.7%
1.UCAS-AOD简介
1.1数据说明
遥感图像,又名高分辨率遥感图像。遥感图像的分类依据是根据成像的介质不同来进行分类的。UCAS-AOD (Zhu et al.,2015)用于飞机和汽车的检测,包含飞机与汽车2类样本以及一定数量的反例样本(背景&…

值班离岗智能识别监测算法 python
值班离岗智能识别监测算法通过pythonyolo网络模型视频分析技术,值班离岗智能识别监测算法能自动检测画面中人员的岗位状态(睡岗或者离岗),一旦发现人员不在岗位的时间超出后台设置时间,立即抓拍存档提醒。Yolo算法采用…
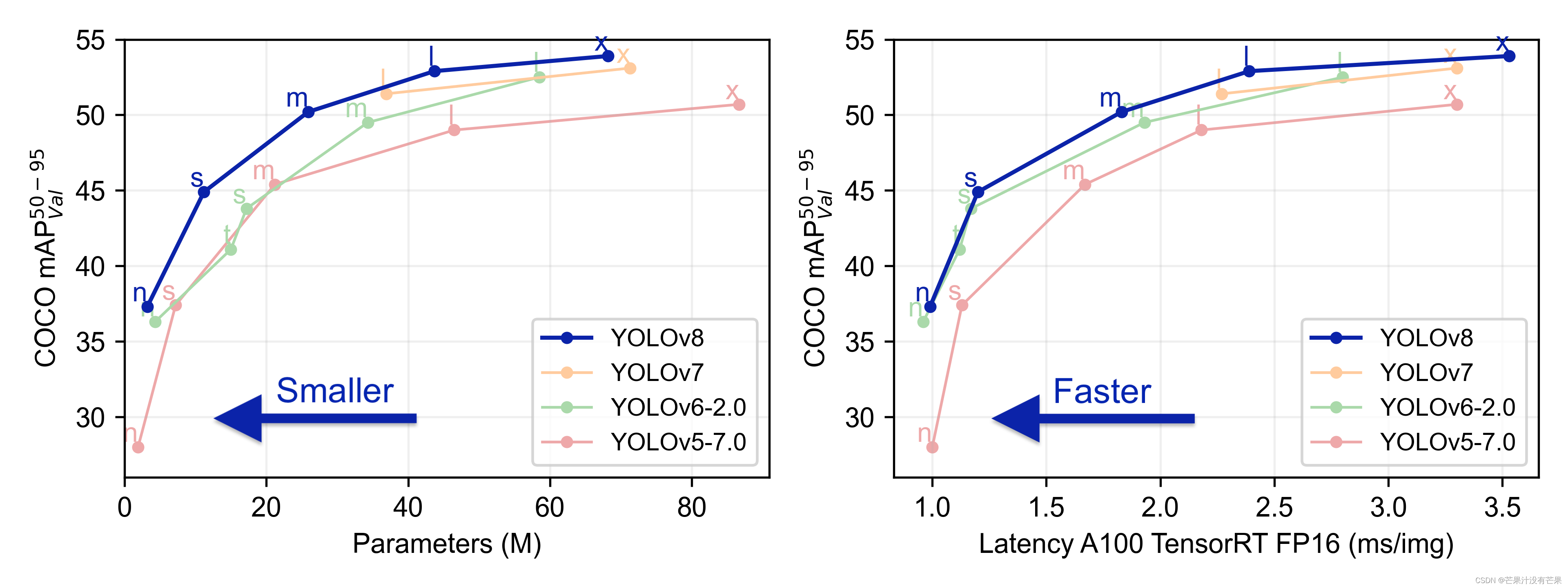
从零开始训练 YOLOv8最新8.1版本教程说明(包含Mac、Windows、Linux端 )同之前的项目版本代码有区别
从零开始训练 YOLOv8 - 最新8.1版本教程说明
本文适用Windows/Linux/Mac:从零开始使用Windows/Linux/Mac训练 YOLOv8 算法项目
《芒果 YOLOv8 目标检测算法 改进》 适用于芒果专栏改进 YOLOv8 算法 文章目录 官方 YOLOv8 算法介绍改进网络代码汇总第一步 配置环境1.1 系列配…
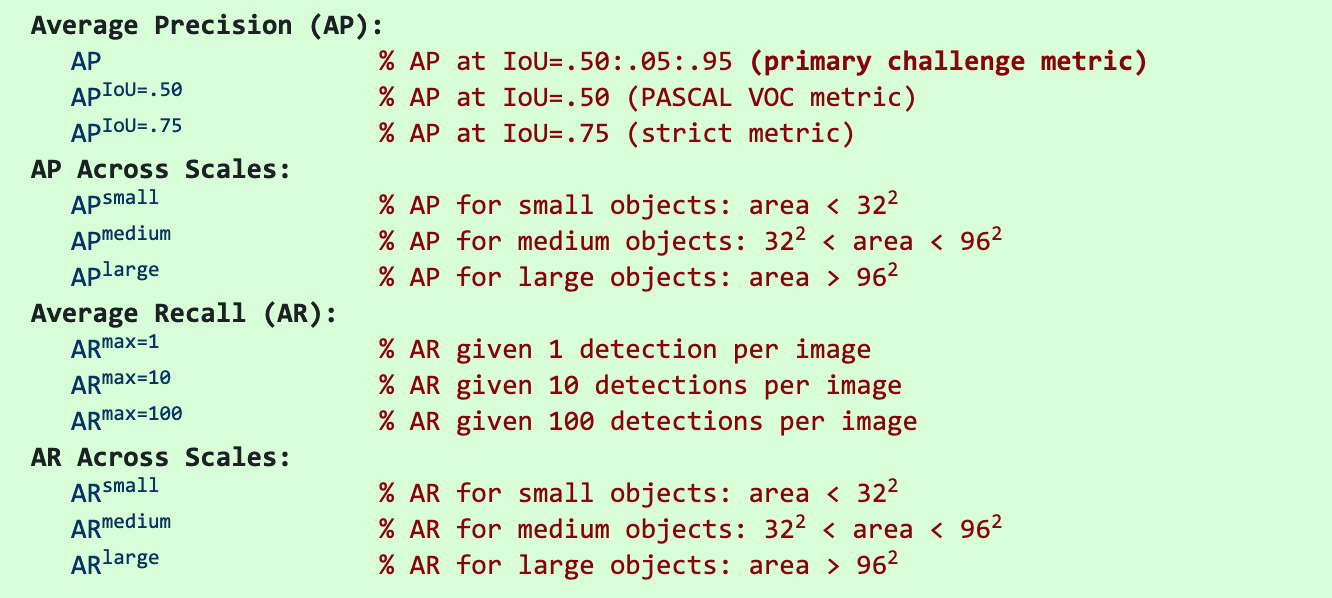
目标检测COCO数据集与评价体系mAP
1.mAP 2.IoU
IoU也就是交并比,也称为 Jaccard 指数,用于计算真实边界框与预测边界框之间的重叠程度。它是真值框与预测边界框的交集和并集之间的比值。Ground Truth边界框是测试集中手工标记的边界框,用于指定目标图像的位置以及预测的边界框…

Dora-rs 机器人框架学习教程(3)——利用yolo实现目标检测
文章目录 1 安装pytroch环境1.1 nvidia驱动1.2 安装cuda1.3 在conda中安装pytorch GPU版本1.4 检验pytroch是否安装正确 2 编写程序代码2.1 object_detection.py文件内容如下:2.2 dataflow.yml 文件内容如下: 3 运行参考资料 目标:在dora框架…
【RT-DETR有效改进】2024.1最新MFDS-DETR的HS-FPN改进特征融合层(降低100W参数,全网独家首发)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑 一、本文介绍
本文给大家带来的改进机制是最近这几天最新发布的改进机制MFDS-DETR提出的一种HS-FPN结构,其是一种为白细胞检测设计的网络结构,主要用于解决白细胞数据集中的多尺度挑战。它的基本原理包括两个关键部分:特征…
【RT-DETR有效改进】Bi-FPN高效的双向特征金字塔网络(附yaml文件+完整代码)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文给大家带来的改进机制是BiFPN双向特征金字塔网络,其是一种特征融合层的结构,也就是我们本文改进RT-DETR模型中的Neck部分,它的主要思想是通过多层级的特征金字塔和双向信息传递来提高精度。本文给大家带…
C# Onnx yolov8 仪表指针检测
目录
效果
模型信息
项目
代码
训练数据
下载 C# Onnx yolov8 仪表指针检测
效果 模型信息
Model Properties ------------------------- date:2024-01-31T11:19:38.828556 author:Ultralytics task:detect license:AGPL-…
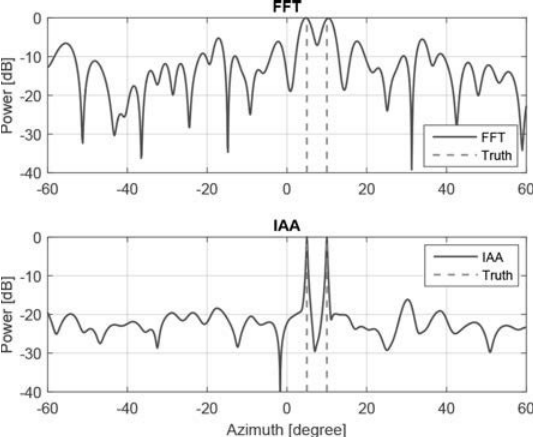
现代雷达车载应用——第3章 MIMO雷达技术 3.3节 汽车MIMO雷达测角
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
3.3 汽车MIMO雷达测角 在发射天线和接收天线分别为Mt和Mr的汽车MIMO雷达中,可以合成一个由Mt*Mr个阵元组成的虚拟ULA,单元间…
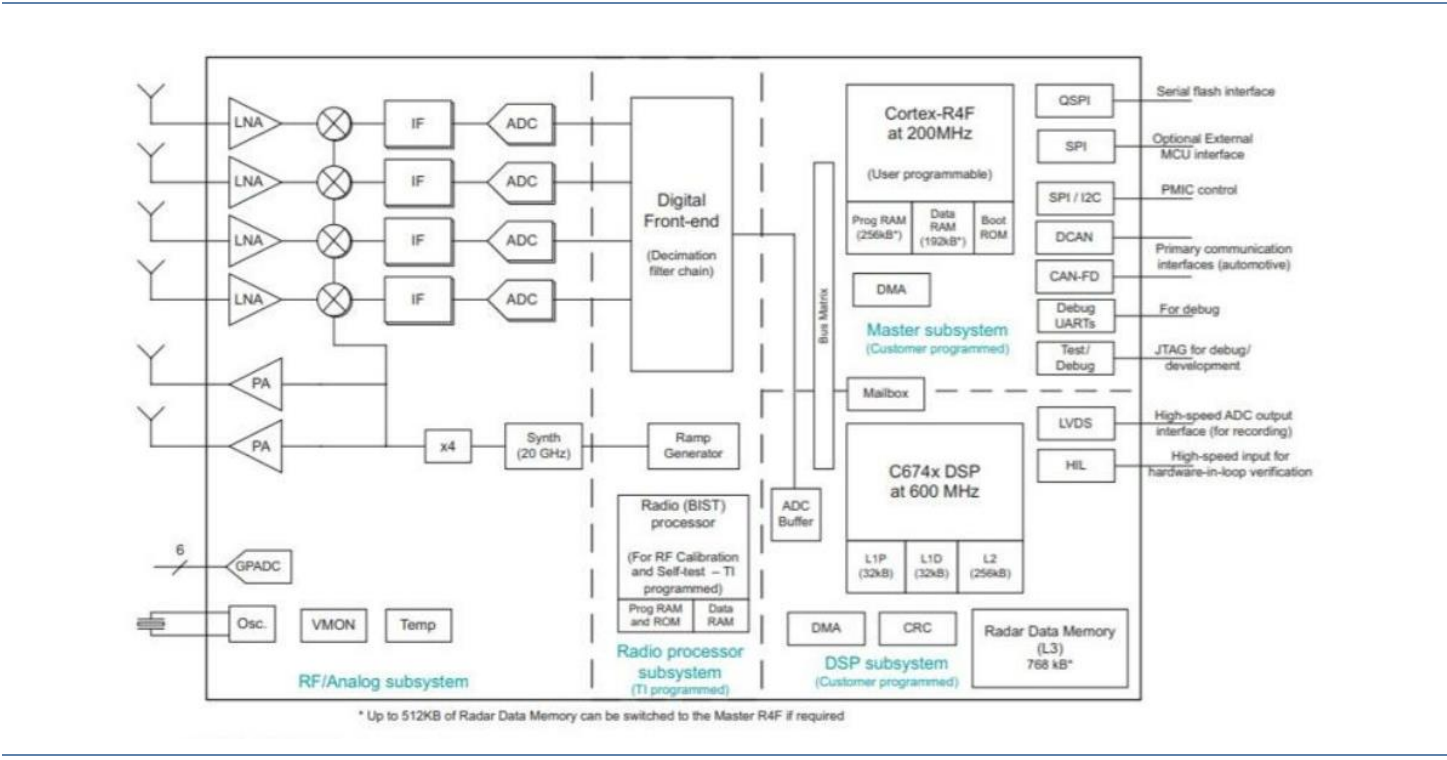
4D 毫米波雷达:智驾普及的新路径(二)
4 4D 毫米波的技术路线探讨
4.1 前端收发模块 MMIC:级联、CMOS、AiP
4.1.1 设计:级联、单芯片、虚拟孔径 4D 毫米波雷达的技术路线主要分为三种,分别是多级联、级联 虚拟孔径成像技术、以及 集成芯片。( 1 )多级…
图像分割实战-系列教程13:deeplabV3+ VOC分割实战
🍁🍁🍁图像分割实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传
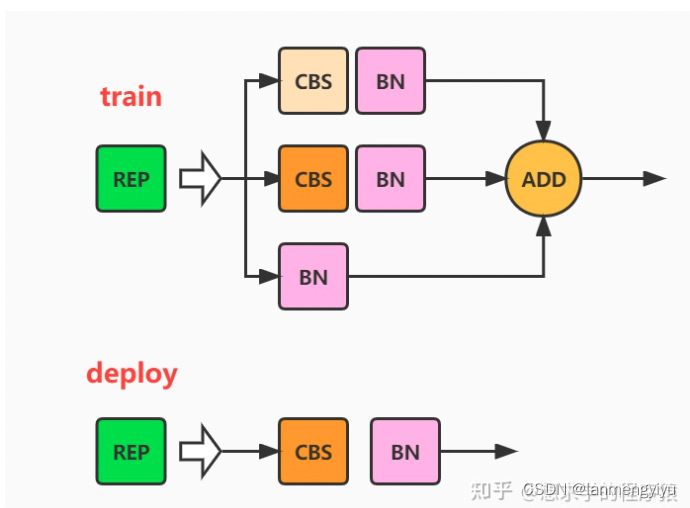
YOLO系列概述(yolov1至yolov7)
YOLO系列概述(yolov1至yolov7)
参考:
睿智的目标检测53——Pytorch搭建YoloX目标检测平台YoloV7
yolo的发展历史 首先我们来看一下yolo系列的发展历史,yolo v1和yolox是anchor free的方法,yolov2,yolov3…

Towards a Rigorous Evaluation of Time-series Anomaly Detection综述
原文连接: https://arxiv.org/abs/2109.05257 摘要:近年来,时间序列异常检测(TAD)的研究报告显示,在基准TAD数据集上F1分数较高,给人以TAD明显改善的印象。然而,大多数研究在评分前采用一种特殊的评价方法&…

YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
前言
本篇文章主要是对YOLOv5项目的验证部分。这个文件之前是叫test.py,后来改为val.py。
在之前我们已经学习了推理部分detect.py和训练部分train.py这两个,而我们今天要介绍的验证部分val.py这个文件主要是train.py每一轮训练结束后,用v…

kaggle往期赛 | 海星目标检测比赛银牌经验分享
来源:投稿 作者:摸奖成功 编辑:学姐 比赛经验
此次比赛名次:
最终获得前2%的成绩,简单点就是银牌🥈!
此次比赛总结
1.给自己的实验记录,一定要制作一个lb和cv的参数表࿰…
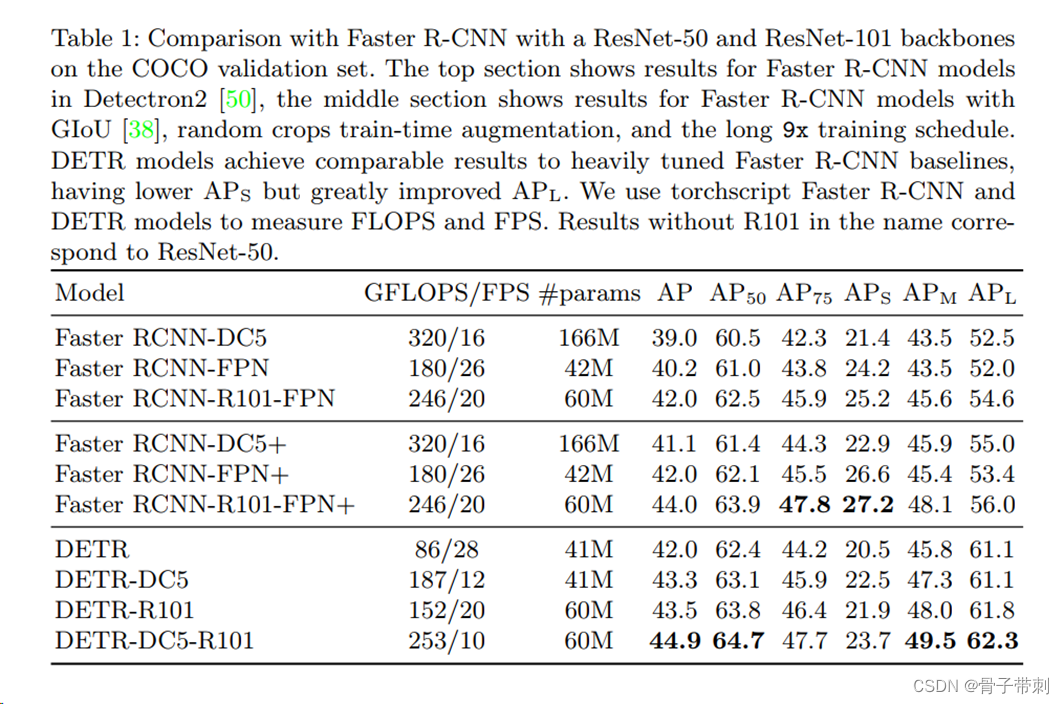
DETR: End-to-End Object Detection with Transformers
简介
Detection Transformers,简称DETR。DETR 将目标检测任务视为一个图像到集合(image-to-set)的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。文献的地址和代码的地址 https://ai.facebook.…
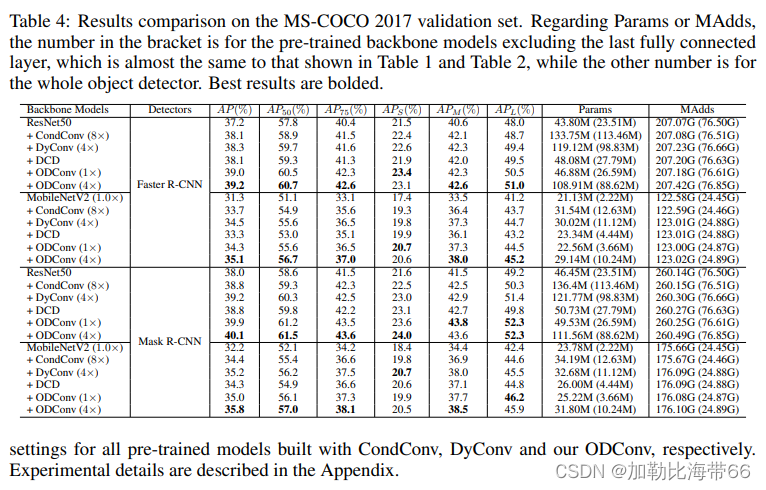
目标检测算法——YOLOv5/v7/v8改进结合即插即用的动态卷积ODConv(小目标涨点神器)
ICLR2022 助力YOLO | 动态卷积ODConv:大幅提升小目标检测能力!! 论文题目:Omni-Dimensional Dynamic Convolution
论文链接:https://openreview.net/forum?idDmpCfq6Mg39 作者将CondConv中一个维度上的动态特性进行…

YOLO分割数据集制作:使用Labelme工具制作分割数据集(.json)并转化为YOLO的数据集的格式(.txt)
YOLO分割数据集制作一、Labelme制作数据集二、将labelme格式的数据转换为coco格式(转换后的coco格式还是json文件)三、将coco格式转换为YOLO格式一、Labelme制作数据集
打开labelme,标注数据,生成文件目录如下: data a.jpga.jsonb.jpgb.json…
实例分割论文阅读之:《Mask Transfiner for High-Quality Instance Segmentation》
1.摘要
两阶段和基于查询的实例分割方法取得了显著的效果。然而,它们的分段掩模仍然非常粗糙。在本文中,我们提出了一种高质量和高效的实例分割Mask Transfiner。我们的Mask Transfiner不是在规则的密集张量上操作,而是将图像区域分解并表示…
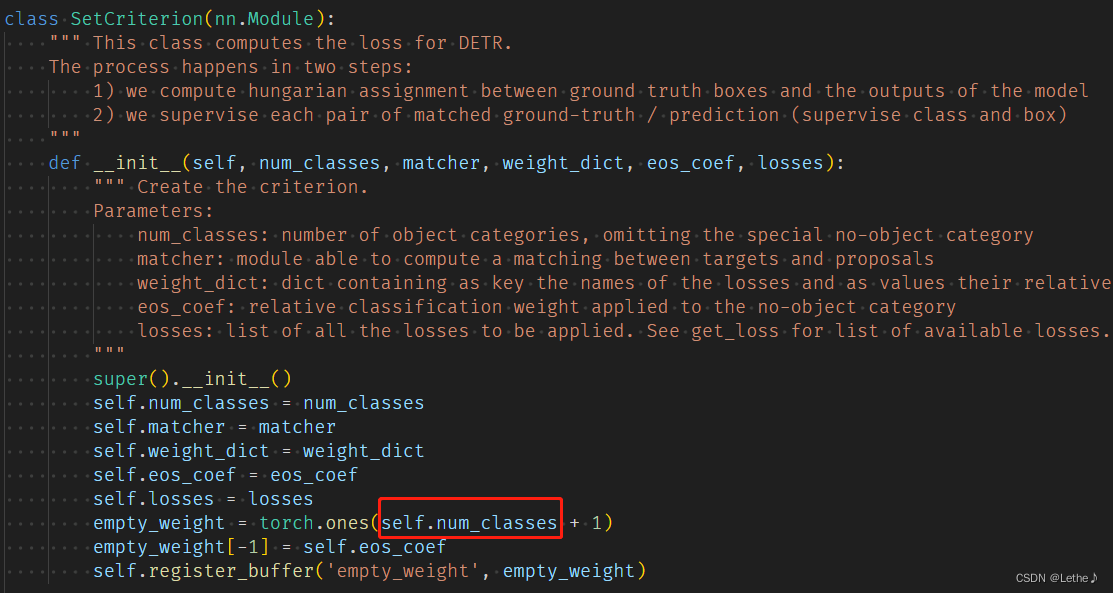
目标检测中,DETR方法为何class设置为91+1,DINO中为91
基于DEtection TRansformer的DETR框架https://github.com/facebookresearch/detr因为end-to-end,无需后处理等优点,逐渐得到青睐。DINO方法https://github.com/IDEA-Research/DINO更是取得了在COCO2017的SOTA结果。
其中,在DETR方法中&#…

FCOS3D Fully Convolutional One-Stage Monocular 3D Object Detection 论文学习
论文地址:Fully Convolutional One-Stage Monocular 3D Object Detection Github地址:Fully Convolutional One-Stage Monocular 3D Object Detection
1. 解决了什么问题?
单目 3D 目标检测由于成本很低,对于自动驾驶任务非常重…

传统目标检测实战:Sift/ORB+Match
传统目标检测实战:Sift/ORBMatch 文章目录传统目标检测实战:Sift/ORBMatch1. 前言2. 先验知识3. 项目框架4. 工具函数(utils.py)5. 检测待测图像(test_xxxx.py)5.1 使用图像缩放金字塔(test_PG.…

【Segment Anything Model】论文+代码实战调用SAM模型预训练权重+相关论文
上篇文章已经全局初步介绍了SAM和其功能,本篇作为进阶使用。 文章目录 0.前言1.SAM原论文 1️⃣名词:提示分割,分割一切模型,数据标注,零样本,分割一切模型的数据集 2️⃣Introduction 3️⃣Task: prompta…

【论文阅读】Frustratingly Simple Few-Shot Object Detection
从几个例子中检测稀有物体是一个新出现的问题。 先前的工作表明Meta-Learning是一种有希望的方法。 但是,微调技术很少引起注意。 我们发现,在稀有类上只对现有探测器的最后一层进行微调对于 Few-Shot Object Detection至关重要。 这样一种简单的方法在当…
【论文阅读】 Few-shot object detection via Feature Reweighting
Few-shot object detection的开山之作之一 ~~
特征学习器使用来自具有足够样本的基本类的训练数据来 提取 可推广以检测新对象类的meta features。The reweighting module将新类别中的一些support examples转换为全局向量,该全局向量indicates meta features对于检…
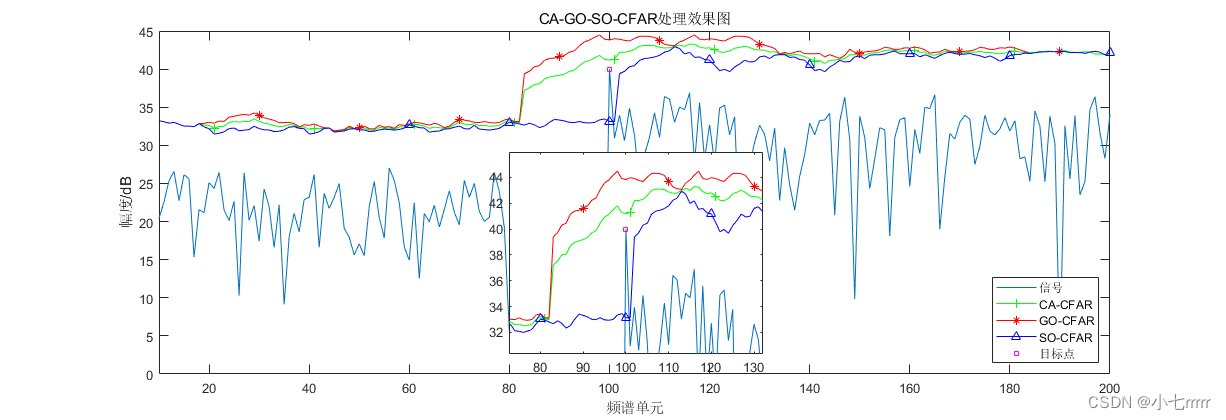
毫米波雷达系列 | 传统CFAR检测(均值类)
毫米波雷达系列 | 传统CFAR检测(均值类) 文章目录 毫米波雷达系列 | 传统CFAR检测(均值类)1.CA-CFAR算法2.SO-CFRA算法3.GO-CFAR算法4.仿真对比 CFAR检测器主要用于检测背景杂波环境中的雷达目标,常见的均值类CFAR检测…

基于MATLAB 2023a的机器学习、深度学习教程
详情点击链接:基于MATLAB 2023a的机器学习、深度学习教程
MATLAB 2023版的深度学习工具箱,提供了完整的工具链,能够在一个集成的环境中进行深度学习的建模、训练和部署。与Python相比,MATLAB的语法简洁、易于上手,无需…

计算机视觉手指甲标注案例
关键点标注是指识别和标注图像或视频中特定的相关点或区域的过程。在机器学习行业,它经常被用来训练计算机视觉模型,以执行诸如物体检测、分割和跟踪等任务。
关键点注释可用于以下应用:
面部关键点检测:识别图像中人脸上的眼睛…
提速YOLOv7:用MobileNetV3更换骨干网络加速目标检测
目录 前言一、MobileNetV3的介绍1、MobileNetV3的原理和特点2、MobileNetV3的结构 二、YOLOv7的介绍1、YOLOv7的结构和流程2、YOLOv7的性能指标 三、MobileNetV3替换YOLOv7的骨干网络1、替换骨干网络2、修改neck部分3、微调模型 四、实验结果与分析1、数据集和实验设置2、实验结…
滑板车出口欧盟检测检验认证如何办理?
检测项目: 踏板、突起部件和边缘、轴承、自锁锁扣、滑板车的级别、操纵系统、轮轴、标识、减速装置、相互运动部件、车轮、制造商提供的信息、强度
检测标准: 1、EN14619:20194.3.3 滚轮运动装备-滑板车-安全要求和试验方法
2、EN14619:20194.3.1/5.4.…
Yolov5轻量化:EMO,结合 CNN 和 Transformer 的现代倒残差移动模块设计,性能优于EdgeViT、Mobile-former等网络
论文: https://arxiv.org/pdf/2301.01146.pdf 🏆🏆🏆🏆🏆🏆Yolo轻量化模型🏆🏆🏆🏆🏆🏆 重新思考了 MobileNetv2 中高效的倒残差模块 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,归纳抽象了 MetaMobile Block 的一般概念。受这…
目标检测数据预处理——非宫格与宫格混合拼图(大宽高比图片)
之前一直用的是宫格的正方形拼图,但比如对“人”框的截图是这种高宽高比的长方形图片,按照最大边resize最小边等比例缩放后放入宫格中对造成最小边resize太多,整体图片缩小很多。所以本片专门针对高宽高比的图片拼图进行编辑。 本篇的拼图方式…
目标检测YOLO实战应用案例100讲-基于深度学习的交通场景多尺度目标检测算法研究与应用
目录
基于深度学习的交通目标检测算法研究
传统的目标检测算法
基于深度学习的目标检测算法 </

YOLO9000论文详解
YOLO-9000论文详解 – 潘登同学的目标检测笔记 文章目录YOLO-9000论文详解 -- 潘登同学的目标检测笔记YOLO-9000介绍TOLO-v2的10个改进YOLO-9000的思想Hierarchical classificationYOLO-9000YOLO-9000介绍
YOLO-9000是YOLO-v2 9000分类
TOLO-v2的10个改进 Batch Normalizati…
YOLOv5、YOLOv7改进最新论文CFNet:即插即用|原创改进结构显著提升检测性能,小目标检测涨点必备(一)
💡本篇内容:YOLOv5|YOLOv7改进最新论文CFNet:即插即用|首发改进显著提升检测性能,小目标检测涨点必备 重点:🔥🔥🔥YOLOv5|YOLOv7|YOLOv8 使用这个 核心创新点 在数据集改进做实验:即插即用: 当 CFNet 遇到 YOLO 系列 💡🚀🚀🚀本博客 YOLO系列 + 改…

目标检测算法——关键点检测数据集汇总(附下载链接)
🎄🎄近期,小海带在空闲之余收集整理了一批关键点检测数据集供大家参考。 整理不易,小伙伴们记得一键三连喔!!!🎈🎈
一、人群姿态数据集 数据集下载链接:http…
目标检测00-01:mmdetection(Foveabox为例)-资源下载(前奏准备)
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
智能扑克牌识别软件(Python+YOLOv5深度学习模型+清新界面)
摘要:智能扑克牌识别软件利用视觉方法检测和识别日常扑克牌具体花色与数字,快速识别牌型并标注结果,帮助计算机完成扑克牌对战的前期识别步骤。本文详细介绍基于深度学习的智能扑克牌识别软件,在介绍算法原理的同时,给…
YOLOv5车辆测距实践:利用目标检测技术实现车辆距离估算
YOLOv5目标检测技术进行车辆测距。相信大家对YOLOv5已经有所了解,它是一种快速且准确的目标检测算法。接下来,让我们一起探讨如何通过YOLOv5实现车辆距离估算。这次的实践将分为以下几个步骤:
安装所需库和工具数据准备模型训练距离估算可视…
Darknet 训练yolov4模型,做图像自动标注(代码)
基于darknet框架训练yolov4模型,获取推理结果的bbox信息,导出yolo标注文件,实现图像的自动标注,方便图像标注。
1. Darknet 安装
按照官网https://pjreddie.com/darknet/ 的指引安装即可。
报错与解决:
࿰…
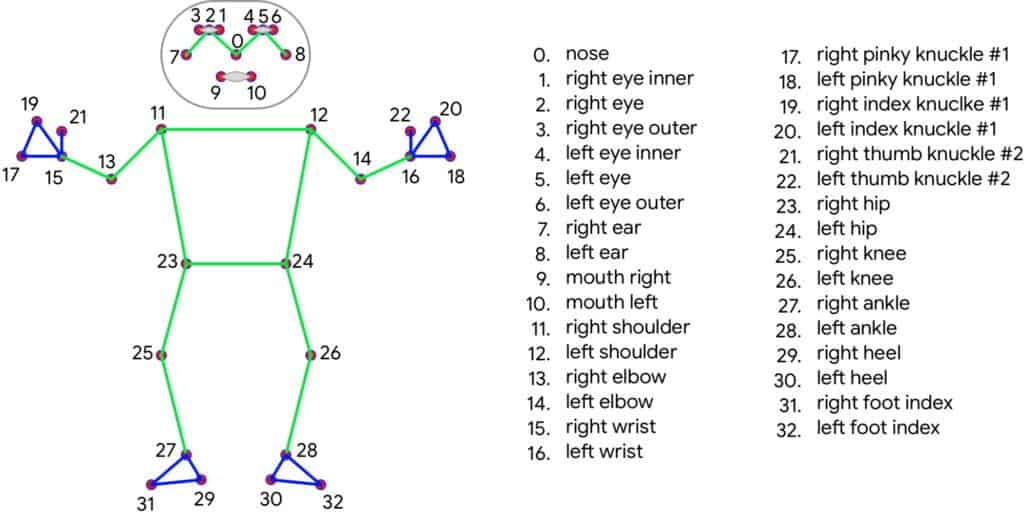
使用 MediaPipe 身体跟踪构建不良身体姿势检测和警报系统
文末附实现相关源代码下载链接 正确的身体姿势是一个人整体健康的关键。然而,保持正确的身体姿势可能很困难,因为我们经常忘记这一点。这篇博文将引导您完成为此构建解决方案所需的步骤。最近,我们在使用 MediaPipe POSE 进行身体姿势检测方面玩得很开心。 使用 MediaPipe P…

基于人工智能与边缘计算Aidlux的鸟类检测驱赶系统(可修改为coco 80类目标检测)
●项目名称 基于人工智能与边缘计算Aidlux的鸟类检测驱赶系统(可修改为coco 80类目标检测)
●项目简介
本项目在Aidlux上部署鸟类检测驱赶系统,通过视觉技术检测到有鸟类时,会进行提示。并可在源码上修改coco 80类目标检测索引直…
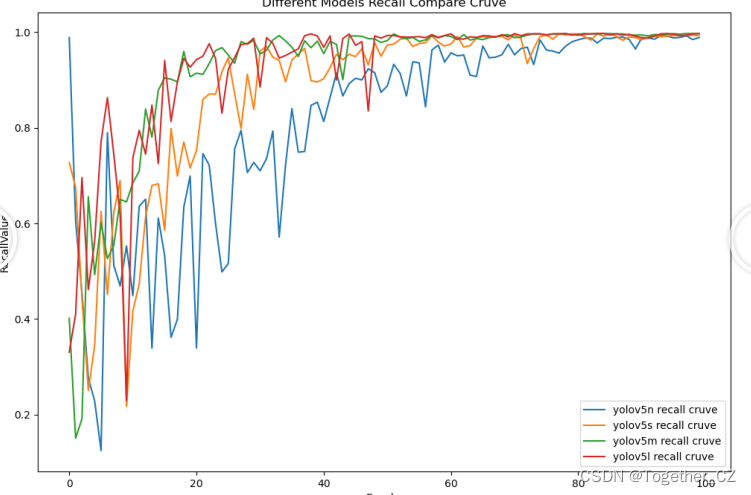
基于YOLOv5系列【n/s/m/l】模型开发构建人体手势目标检测识别分析系统
人体手势检测识别是指通过计算机视觉和深度学习技术,自动地识别和理解人体的手势动作。这项技术可以应用于各种领域,如人机交互、虚拟现实、智能监控等。
下面是一般的人体手势检测识别流程: 数据采集:首先需要收集包含手势动作的…
基于RetinaNet和TensorFlow Object Detection API实现目标检测(附源码)
文章目录 一、RetinaNet原理二、RetinaNet实现1. tf.train.CheckPoint简介2. RetinaNet的TensorFlow源码 一、RetinaNet原理 待补充
二、RetinaNet实现
1. tf.train.CheckPoint简介
待补充
2. RetinaNet的TensorFlow源码 Step 1:安装Tensorflow 2 Object Detect…

目标检测:3采用YOLOv8 API训练自己的模型
目录
1.YOLOv8 的新特性
2.如何使用 YOLOv8?
3使用YOLOv8训练模型
4.验证训练集
5.测试训练集
6.测验其他图片
7 其他问题
参考: 1.YOLOv8 的新特性 Ultralytics 为 YOLO 模型发布了一个全新的存储库。它被构建为 用于训练对象检测、实例分割和图像分类模型的统…
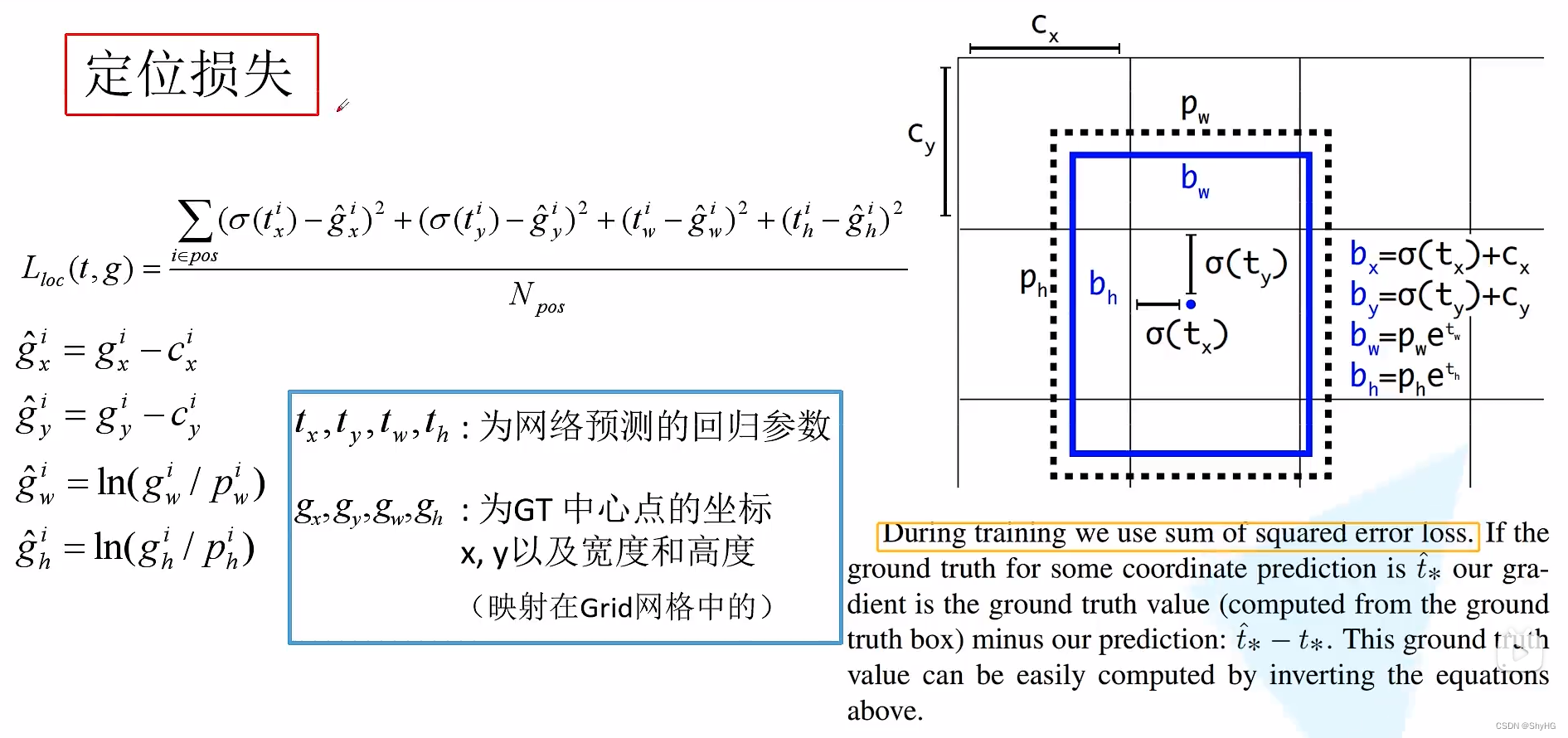
目标检测复盘 -- 5. YOLO v1-v3
YOLO v1
论文思想
应该怎么理解呢?其实相比较于RCNN系列,YOLO系列没有RPN这种模块了,而是直接输出或者叫做直接回归出来结果,最终的输出是一个特征图,大小为7 * 7 * [ (41) * 2 20],这个尺寸又怎么理解呢…
【计算机视觉 | 目标检测】术语理解6:ViT 变种( ViT-H、ViT-L ViT-B)、bbox(边界框)、边界框的绘制(含源代码)
文章目录 一、ViT & ViT变种1.1 ViT的介绍1.2 ViT 的变种 二、bbox(边界框)三、边界框的绘制 一、ViT & ViT变种
1.1 ViT的介绍
ViT,全称为Vision Transformer,是一种基于Transformer架构的视觉处理模型。传统的计算机视…
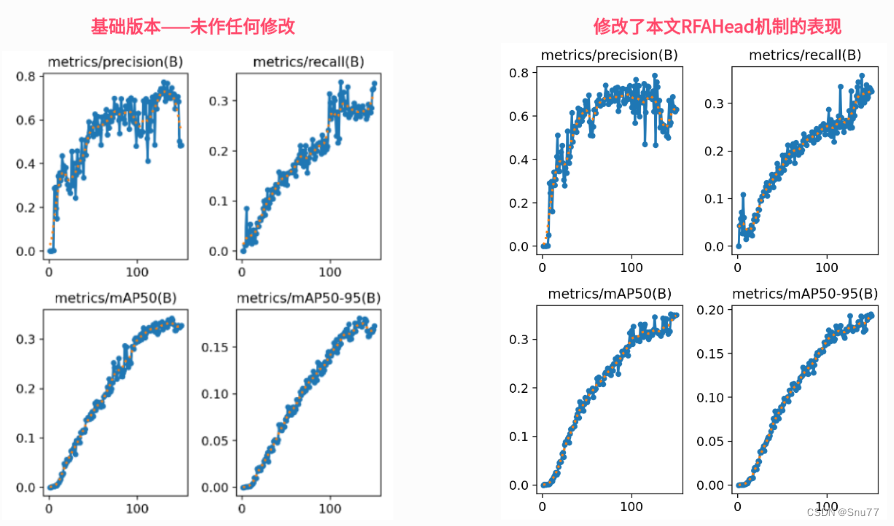
YOLOv8改进 | 检测头篇 | 独创RFAHead检测头超分辨率重构检测头(适用Pose、分割、目标检测)
一、本文介绍
本文给大家带来的改进机制是RFAHead,该检测头为我独家全网首发,本文主要利用将空间注意力机制与卷积操作相结合的卷积RFAConv来优化检测头,其核心在于优化卷积核的工作方式,特别是在处理感受野内的空间特征时。RFAConv主要的优点就是增加模型的特征提取能力,…

人工智能|深度学习——基于全局注意力的改进YOLOv7-AC的水下场景目标检测系统
代码下载: 基于全局注意力的改进YOLOv7-AC的水下场景目标检测系统.zip资源-CSDN文库 1.研究的背景 水下场景目标检测是水下机器人、水下无人机和水下监控等领域中的重要任务之一。然而,由于水下环境的复杂性和特殊性,水下目标检测面临着许多挑…

车牌识别系统完整商用级别设计流程
简介
车牌识别(License Plate Recognition)是一种通过计算机视觉技术识别和提取车辆车牌上字符信息的技术。它在交通管理、智慧停车、安防监控等领域有着广泛的应用。
本项目将带完整的了解车牌识别系统设计思路,以及实现流程。
算法部分应…

计算机视觉的应用4-目标检测任务:利用Faster R-cnn+Resnet50+FPN模型对目标进行预测
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用4-目标检测任务,利用Faster RcnnResnet50FPN模型对目标进行预测,目标检测是计算机视觉三大任务中应用较为广泛的,Faster R-CNN 是一个著名的目标检测网络&#x…
深度学习基本功3:NMS(Non-Maximum Suppression,非极大值抑制)算法原理及实现
文章目录 1. 为什么要使用NMS2. NMS算法原理2.1 IoU与置信度2.2 算法流程 3. Python代码实现 1. 为什么要使用NMS
大多数目标检测算法(稠密预测)在得到最终的预测结果时,特征图的每个位置都会输出多个检测结果,整个特征图上会出很…

目标检测数据预处理——部件截图,按一定比例进行外扩
本片是截图的篇的升级版本,简单版本的截图请参考根据目标框外扩一定比例进行截图(连带标签)。 对目标框(类别名称)进行分类,将同一类的目标框进行截图并分类保存在不同的文件夹中。 在本篇当中,…
【三维目标检测】SSN(一)
SSN是用于点云三维目标检测的模型算法,发表在ECCV 2020 《SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds》,论文地址为“https://arxiv.org/abs/2004.02774”。SSN核心在于提出了shape-aware heads grouping和shap…

PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
1. Motivation
现在存在的3D目标检测方法可以分为两种,一种是基于point-based,一种是基于grid-based(也就是voxel-based)。point-based可以获得更大的感受野,但是计算成本过高;voxel-based计算效率高,但是信息的损失较大。 因此本论文提出一…
MaskRCNN与注意力机制
Mask RCNN---two stage
mask rcnn是一个分割算法(实例分割),可用于: 目标检测 实例分割 关键点检测 本质上,mask R-CNN是在faster rcnn的基础上,加入了FCN模块,得到最终的分割结果。
先检测,再分割。不…

2020下半年上午题
2020下半年 d a b 小阶向大阶对齐 b b 平均cpi: MIPS: d c 公加验,私解签 加密防止被动攻击,认证防止主动攻击 a 访问控制包括:授权,确定存取权限,实施存取权限 c a c a 先申请先得 b b 著作权包括&…

YOLOv5【训练train.py逐行源码及参数调参解析】超详细解读!!!建议收藏✨✨!
之前的文章介绍了YOLOv5的网络结构🚀与目录结构源码🚀以及detect.py🚀的详细解读,今天带来的是YOLOv5的 train.py 代码参数逐行解读以及注释,废话不多说,让我们一起学习YOLOv5的 train.py 源码吧࿰…
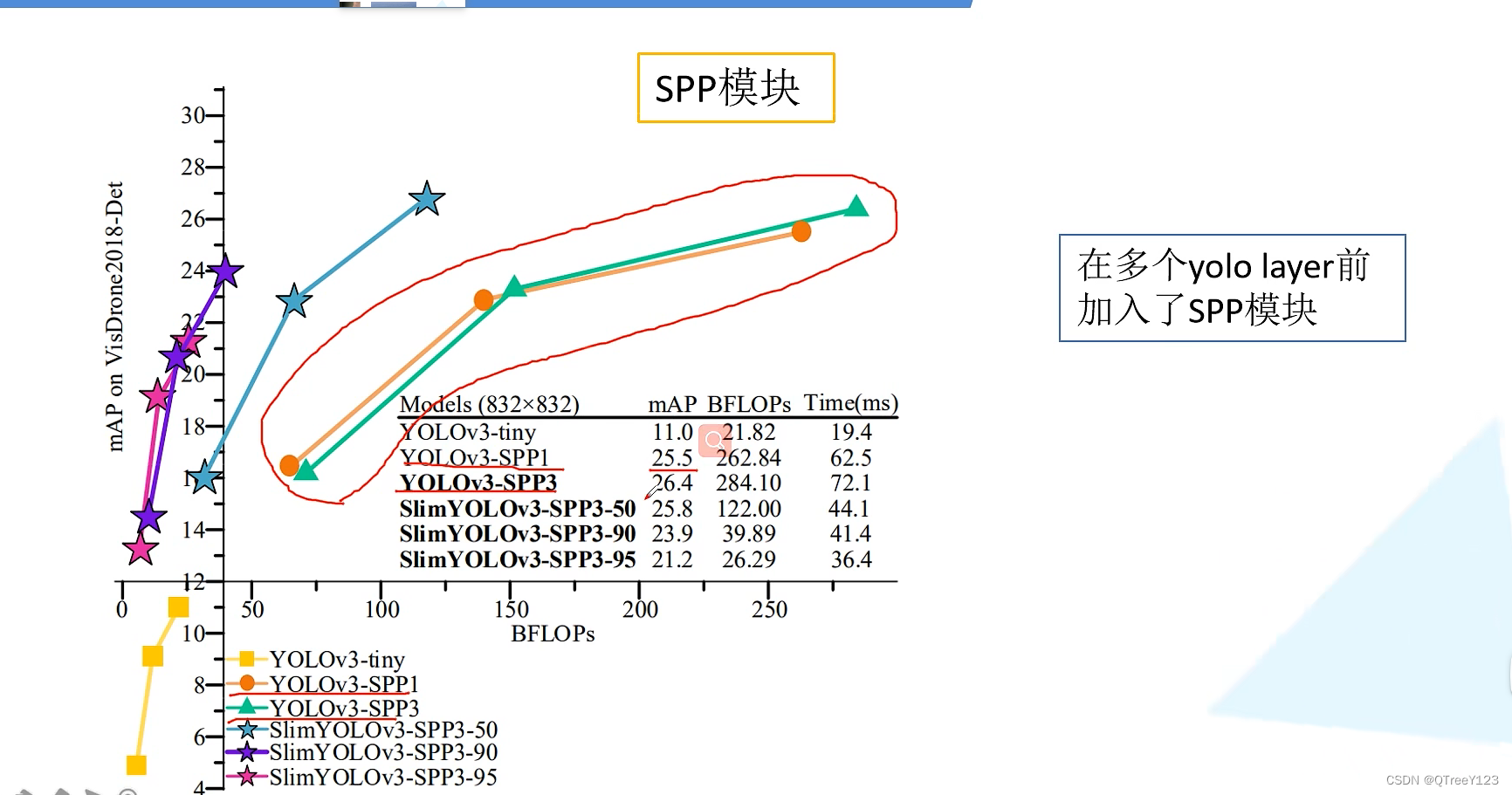
YOLOV3——你总能在这找到你想要的答案
目录
一:前言:
二:更快,更强
网络结构图
其他基础操作:
Darknet53的由来
三:最明显的特点:
四:多scale
五: 为什么vgg越深效果反而越差了?
六&#…
使用Java调用Yolo模型的准备工作与输入输出
当今社会,人工智能技术正日益成为各行各业的关键工具。其中,目标检测技术是计算机视觉领域中的一项重要任务。Yolo(You Only Look Once)是一种流行的目标检测算法,具有高效、准确的特点。本文将介绍如何使用Java语言调…
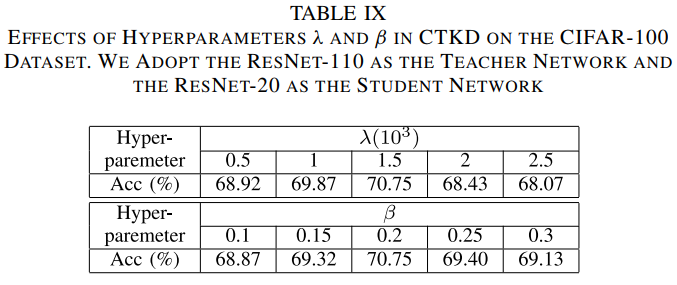
【论文翻译】Highlight Every Step: Knowledge Distillation via Collaborative Teaching
Highlight Every Step: Knowledge Distillation via Collaborative Teaching
强调每一步:通过协作教学提炼知识
摘要
High storage and computational costs obstruct deep neural networks to be deployed on resource-constrained devices. Knowledge distilla…

Open-Vocabulary Object Detection Using Captions(2021 CVPR)----论文解读
Open-Vocabulary Object Detection Using Captions[2021CVPR]----论文解读papercode1. AbstractOpen-Vocabulary Object Detection Using Captions2. Introduction设想与构思思路与做法OVD、ZSD、 WSD的区别?3. Related WorkZSDWSDObject detection using mixed sup…
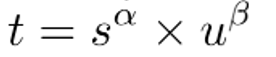
YOLOv8详解全流程捋清楚-每个步骤
从第一步,到最后一步,带着你捋
整体架构 Backbone: Feature Extractor提取特征的网络,其作用就是提取图片中的信息,供后面的网络使用 Neck : 放在backbone和head之间的,是为了更好的利用backbo…
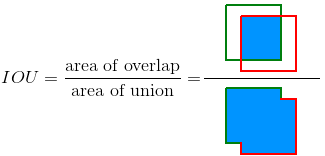
【评价方案】目标检测TP,FP,以及perception recall,以及AP,mAP
20230116:网上好多TP,FP,都感觉有点问题,特意研究了源代码,写下理解。
第一步:需要确定计算TP的准则
一般情况,我们设定Iou_threadhold 阈值∈[0.5,0.55,0.6,0.65,0.7,0.75,0.8,0.85,0.9,0.95…
【目标检测】YOLOv5推理加速实验:TensorRT加速
前言
前两篇博文分别讨论了YOLOv5检测算法的两种加速思路:采用多进程或批量检测,不过效果均收效甚微。本问将讨论使用TensorRT加速以及半精度推理/模型量化等优化策略对检测加速的实际影响。
测试环境
测试图片分辨率:13400x9528 GPU&…


有关深度学习打标签DIY的五种方式
有关深度学习打标签DIY的五种方式:Labelme、LabelImg、EISeg、Make Sence和CVat等 五种制作Label的方式:1.CVAT(Open Data Annotation Platform)2.EISeg(Efficient Interactive Segmentation)自动标注3.Mak…
Yolov8涨点神器:注意力机制---多头上下文集成(Context Aggregation)的广义构建模块,助力小目标检测,暴力涨点
🏆🏆🏆🏆🏆🏆Yolov8魔术师🏆🏆🏆🏆🏆🏆 ✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉定期更新不同数据集涨点情况 2.Context Aggregation介绍 论文:https://arxiv.org/abs/2106.01401 仅…

边缘计算那些事儿—边缘智能技术
0 背景 边缘智能是边缘计算中一个非常重要的方向。它将边缘计算和人工智能算法结合起来,在边缘设备上就近处理目标检测、物体跟踪,识别等任务。这种处理方式可以降低时延,减少数据上送云端对回传网络的冲击,同时保证数据的隐私和安…
Faster RCNN模型如何自定义损失函数
Faster RCNN模型如何自定义损失函数1. 代码分析:1.1 _fasterRCNN类:最基础的模型类1.2 resnet类:继承_fasterRCNN类1.3 vgg类:继承_fasterRCNN类1.4 如果要修改loss,一共需要修改哪些内容:1.4.1 模型代码&a…
YOLOv8与 DeepSORT 多目标检测的案例
这个YoLov8强大在于不用显卡也可以识别的很快,我是用10年前的笔记本 Core i7-4710 CPU8G内存
准备代码环境
git地址:https://github.com/MuhammadMoinFaisal/YOLOv8-DeepSORT-Object-Tracking
官方教程使用以下方法安装所需的环境
pip install -e .[…
YOLOv8改进检测头|增加卷积CNN小目标检测头、超多种Transformer小目标检测头
💡本篇内容:YOLOv8 改进检测头|增加多种CNN、超多种Transformer小目标检测头:小目标检测头 重点:🔥🔥🔥YOLOv8 使用这个 创新点 在数据集改进做实验:即插即用 小目标检测头
💡🚀🚀🚀本博客 内附的改进源代码改进,按步骤操作运行改进后的代码即可
读…
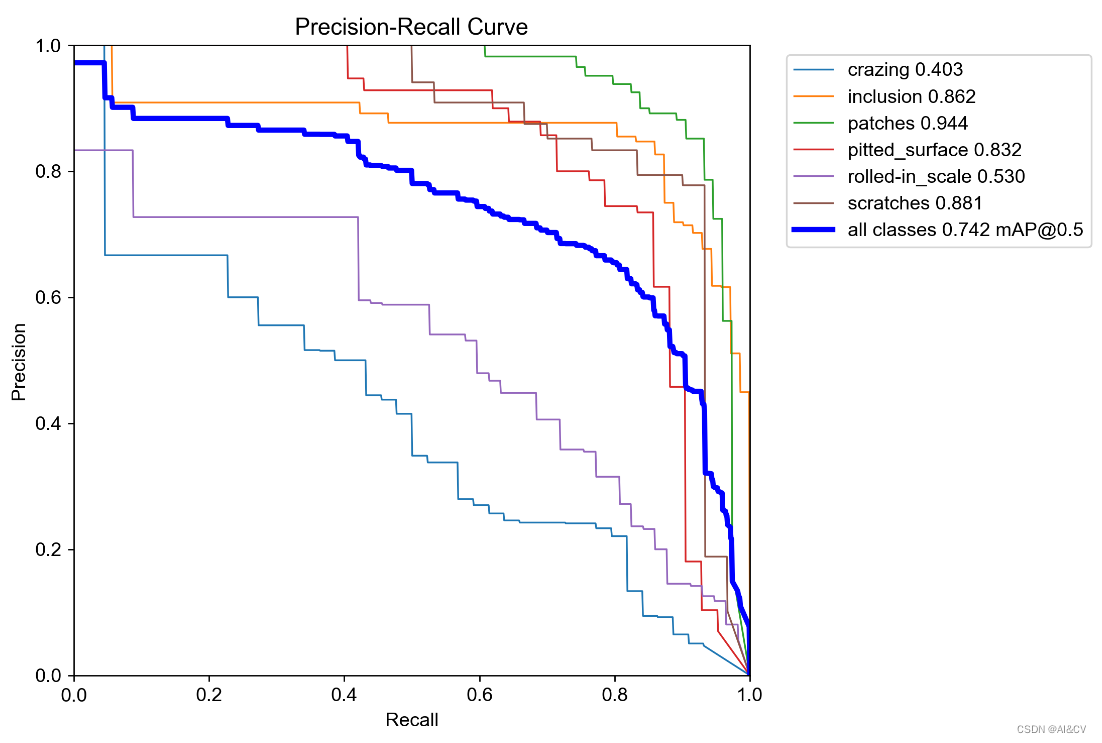
基于Yolov5的NEU-DET钢材表面缺陷检测,优化组合新颖程度较高:CVPR2023 DCNV3和InceptionNeXt,涨点明显
1.钢铁缺陷数据集介绍 NEU-DET钢材表面缺陷共有六大类,分别为:crazing,inclusion,patches,pitted_surface,rolled-in_scale,scratches
每个类别分布为: 训练结果如下:
2.基于yolov5s的训练
map值: 2.1 Inception-MetaNeXtStage
对应博客:https://cv2023.blog.csdn.n…
特征融合add,concat,attention
在深度学习的很多工作中(例如目标检测、图像分割),融合不同尺度的特征是提高性能的一个重要手段。低层特征分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。…
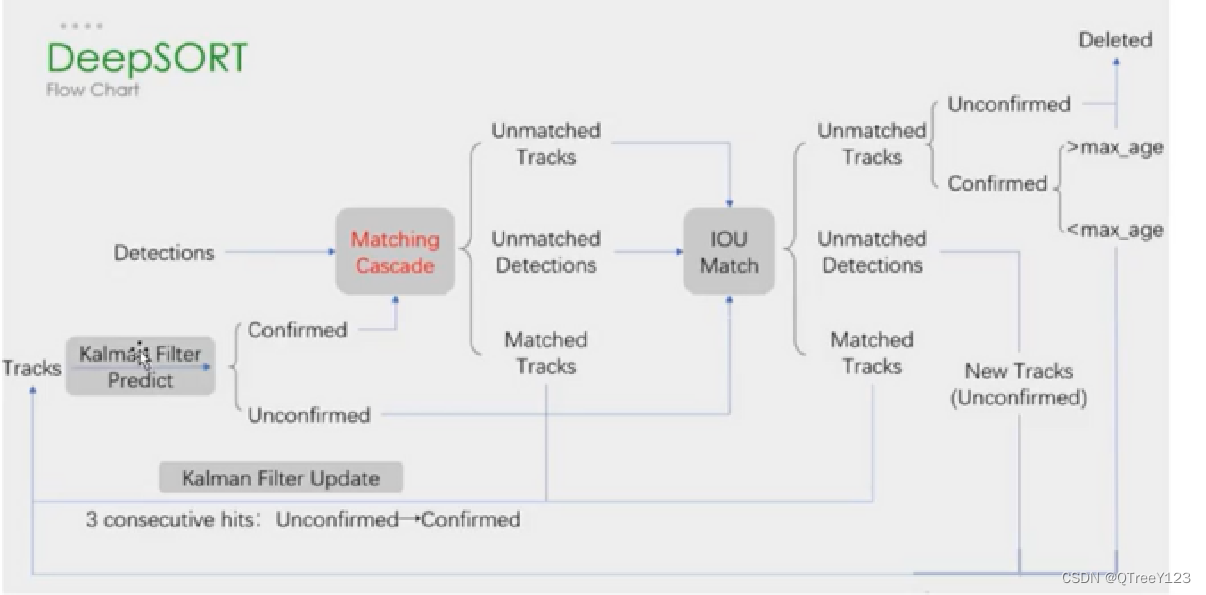
两万字深入浅出yolov5+deepsort实现目标跟踪,含完整代码, yolov,卡尔曼滤波估计,ReID目标重识别,匈牙利匹配KM算法匹配
目录
一:前言
二:跟踪部分:
ReID结构编辑
第一帧(生成track)
第二帧
更新先验的预测值
状态矩阵的初始化
对预测值进行更新(矫正):
匹配完成,进行矫正的更新&…
![[读论文]Referring Camouflaged Object Detection](https://img-blog.csdnimg.cn/77ad43e5bcf54278aac20875f214a926.png)
[读论文]Referring Camouflaged Object Detection
摘要 In this paper, we consider the problem of referring camouflaged object detection (Ref-COD), a new task that aims to segment specified camouflaged objects based on some form of reference, e.g. , image, text. We first assemble a large-scale dataset, ca…

yolov8训练进阶:自定义训练脚本,从配置文件载入训练超参数
yolov8官方教程提供了2种训练方式,一种是通过命令行启动训练,一种是通过写代码启动。 命令行的方式启动方便,通过传入参数可以方便的调整训练参数,但这种方式不方便记录训练参数和调试训练代码。 自行写训练代码的方式更灵活&am…

“记账”很麻烦,看这场竞赛中的队伍与合合信息是如何解决问题的
在我们日常生活中或多或少都会有记账的情况,以此来对自己的收支和消费习惯进行分析,来帮助自己减少不必要的开支,优化财务决策、合理分配资金,减少财务压力和不必要的浪费。
但记账这个动作本身就是一件比较麻烦的。虽然现阶段有…
【记录COCO数据集格式】实例分割的annotations.json的内部格式
在此记录一下实例分割coco的annotations.json的格式 annotations.json,整体是一个字典:
{
"info": {"description": null,"url": null, "version": null, "year": 2023, "contributor": null, "date_created…
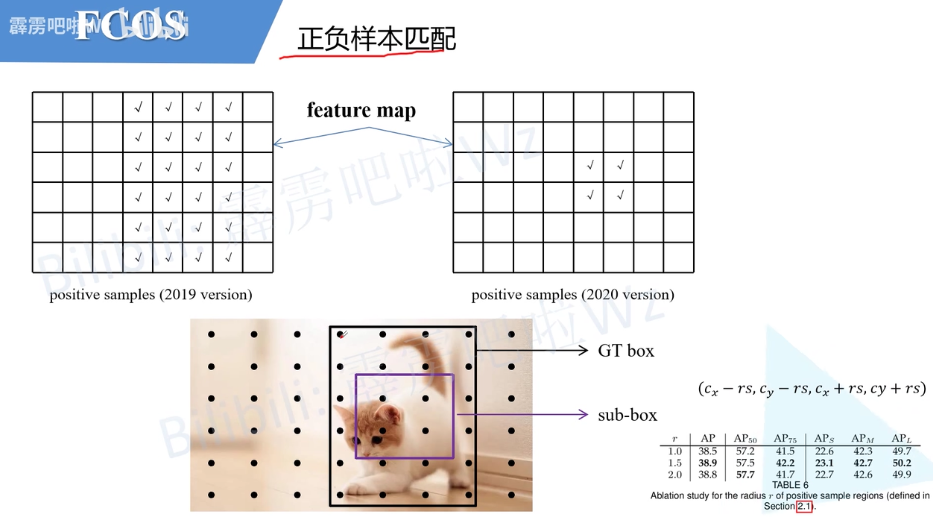
【目标检测】目标检测 相关学习笔记
目标检测算法
PASCALVOC2012数据集 挑战赛主要分为 图像分类 目标检测 目标分割 动作识别 数据集分为四个大类 交通(飞机 船 公交车 摩托车) 住房(杯子 椅子 餐桌 沙发) 动物(鸟 猫 奶牛 狗 马 羊) 其他&a…

YOLOv5基础知识入门(7)— NMS(非极大值抑制)原理解析
前言:Hello大家好,我是小哥谈。NMS是指非极大值抑制(non maximum suppression),它是一种常用于物体检测任务的算法。在物体检测中,通常会有多个预测框(bounding box)被提议出来&…
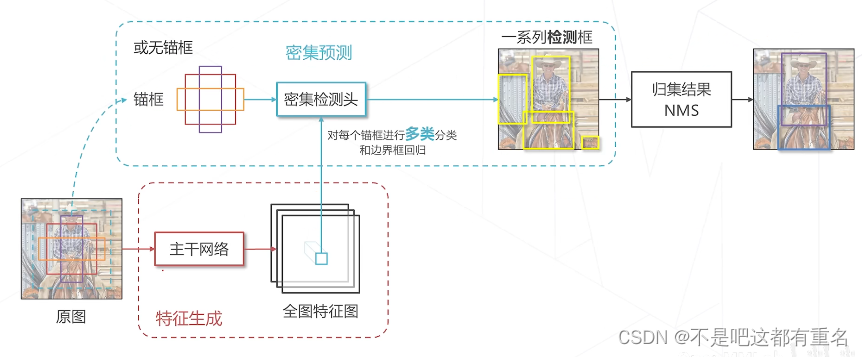
【OpenMMLab AI实战营二期笔记】第六天 目标检测和MMDetection
1.什么是目标检测? 目标检测 vs 图像分类 目标检测的应用
(1)人脸识别 (2)智慧城市 (3)自动驾驶 (4)下游视觉任务:场景文字识别、人体姿态估计
目标检测技术…
OpenCV项目开发实战--图像识别和目标检测之定向梯度直方图 (HOG)
什么是特征描述符?
特征描述符是图像或图像块的表示,它通过提取有用信息并丢弃无关信息来简化图像。
通常,特征描述符将大小为 width x height x 3 (channels ) 的图像转换为长度为 n 的特征向量/数组。在 HOG 特征描述符的情况下,输入图像的大小为 64 x 128 x 3,输出特…
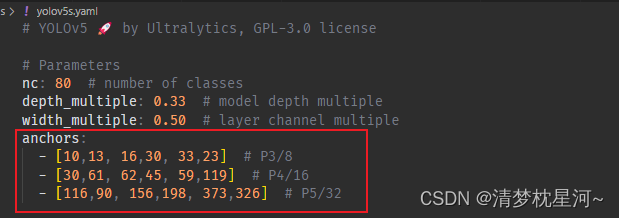
结合具体代码理解yolov5-7.0锚框(anchor)生成机制
最近对yolov5-7.0的学习有所深入,感觉官方代码也比较易读,所以对网络结构的理解更进一步,其中对锚框生成这块没太看明白细节,也想弄明白这块,于是前前后后好好看了代码。现在把我的学习收获做一下记录。个人见解&#…
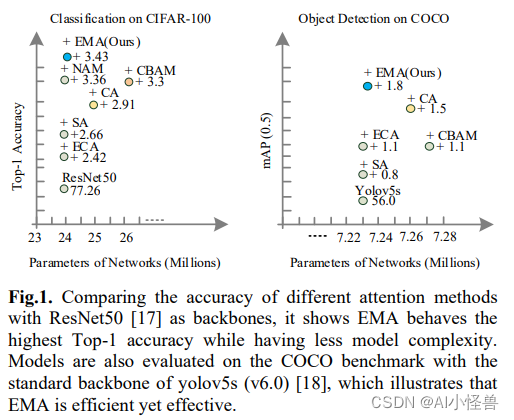
Yolov8改进---注意力机制:ICASSP2023 EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | 小目标涨点明显
1.EMA介绍 论文:https://arxiv.org/abs/2305.13563v1
录用:ICASSP2023 通过通道降维来建模跨通道关系可能会给提取深度视觉表示带来副作用。本文提出了一种新的高效的多尺度注意力(EMA)模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将…
论文提要Fast R-CNN
快速R-CNN,对R-CNN和SPPNet的加速,使用multi-task 进行单步训练,网络使用的是VGG16。R-CNN对每个proposal单独warp处理,SPPNet将warp放到最后一个卷积层的后面,将多个池化网格的结果串联到SPP中。SPPNet的微调算法只能…
3.3 无proposal检测方法(2): G-CNN: an Iterative Grid Based Object Detector
前言:博主目前的研究课题为“可见光遥感图像目标检测”,研究兴趣是大尺寸高分辨率遥感图像上多尺度目标及小物体检测。为了整理阅读过的文献,梳理研究思路,记录自己的理解感悟,遂开启一个“物体检测系列博客”。 …

PIXOR: Real-time 3D Object Detection from Point Clouds
PIXOR: Real-time 3D Object Detection from Point Clouds
背景
点云体素化做3D卷积计算量大,而且由于点云具有稀疏性,很多计算是不必要的。而将点云投影到一个平面上做2D卷积,点云会在离散化和投影的过程中产生信息丢失。因此作者提出一种…

语义分割Mask R-CNN
语义分割Mask R-CNN–潘登同学的深度学习笔记 文章目录语义分割Mask R-CNN--潘登同学的深度学习笔记上采样双线性插值转置卷积代码实现将双线性插值与转置卷积结合ROI AlignRoI PoolingRoIWrap PoolingROIAlign PoolingFPN思想图像金字塔(Featurized image pyramid)高斯金字塔拉…
目标框选之单阶段与两阶段目标检测区别
在目标检测算法中,目标边框从无到有以及边框变化的过程在一定程度上体现了检测是两阶段还是单阶段的。一定程度上体现了空间换时间
Two-stage:
第一阶段:专注于找出目标物体出现的位置,得到建议框,保证足够的准确率和…
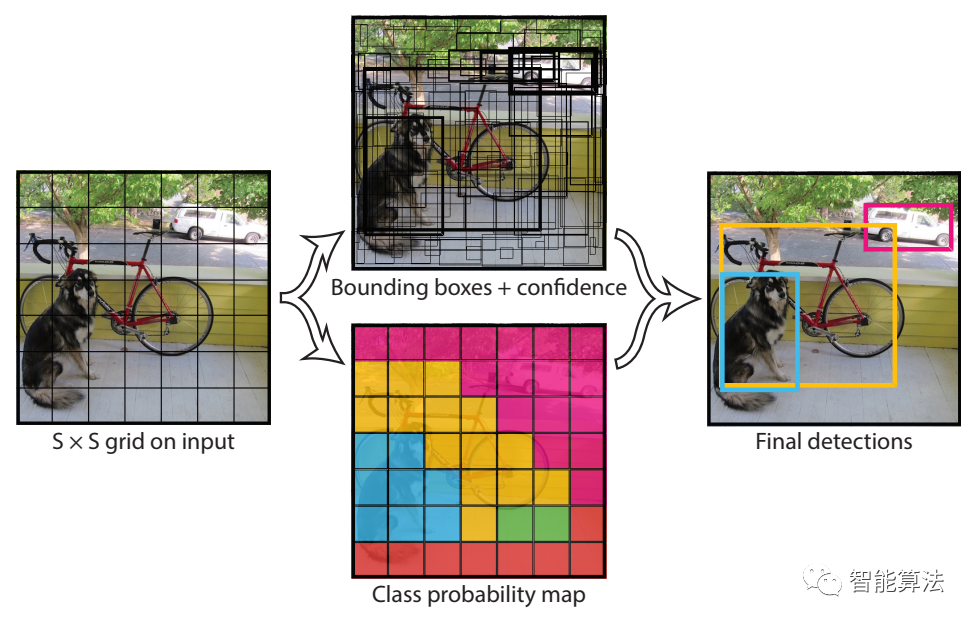
目标检测算法YOLO-V1算法详解
一、YOLO-V1结构剖析 YOLO-V1的核心思想:就是利用整张图作为网络的输入,将目标检测作为回归问题解决,直接在输出层回归预选框的位置及其所属的类别。YOLO和RCNN最大的区别就是去掉了RPN网络,去掉候选区这个步骤以后,YO…
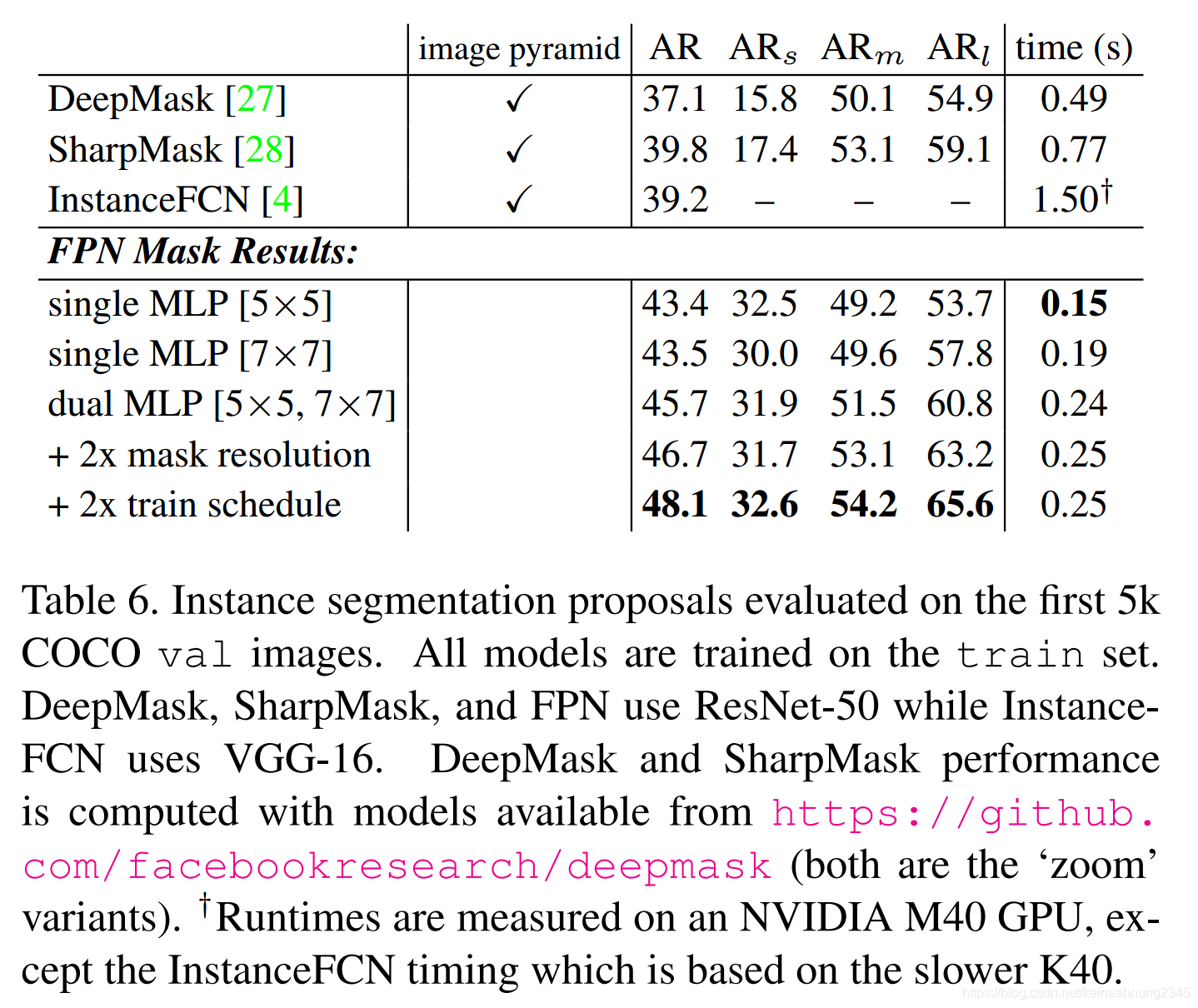
Feature Pyramid Networks for Object Detection論文研讀與問題討論
Feature Pyramid Networks for Object Detection論文研讀與問題討論前言(1)背景介紹Featurized Image PyramidsFast & Faster R-CNN使用deep ConvNet固有的feature hierarchySingle Shot DetectorFeature Pyramid Network(2)相…

目标检测算法:Faster-RCNN论文解读
目标检测算法:Faster-RCNN论文解读 前言 其实网上已经有很多很好的解读各种论文的文章了,但是我决定自己也写一写,当然,我的主要目的就是帮助自己梳理、深入理解论文,因为写文章,你必须把你所写的东西表…
目标追踪00-00:FairMOT(实时追踪)-目录-史上最新无死角讲解
接下来,我会为大家无死角的解析fast-reid(BoT-行人重识别),之前的文章,如下(以下是我工作的所有项目,每一个项目都是,我都做了百分百的详细解读,随着项目增多,为了方便不臃肿,所以给…

葡萄目标检测相关论文和数据集
文章目录 2018Computer Vision and Machine Learning for Viticulture Technology 2020Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association(Computers and Electronics in Agriculture) 2021Gr…
mmdetection使用指南
主要是目标检测方面的使用记录,mmdetection还有分类网络,分割等功能,但这篇博客主要关注目标检测,之后如果涉及到分割会再开一篇博客进行记录。 1. 安装
mmdetection需要的环境是cuda10.0为基础的环境,对驱动版本也有…
Detectron源码解读-roidb数据结构
roidb数据结构
roidb的类型是list, 其中的每个元素的数据类型都是dict, roidb列表的长度为数据集的数量(即图片的数量), roidb中每个元素的详细情况如下表所示:
for entry in roidb数据类型详细说明entry[id]int代表了当前image的img_identry[file_name]string表示当前图片的…
论文解读:YOLOv3
从这篇文章的写作风格可以看出,Joseph 这人是个幽默的老哥。。。
摘要
作者对YOLOv2进行了一些改进,使之在保持实时检测的同时,准确率又有所提升了。
介绍
作者说他这一年(18年)基本没干啥,就是打打电话…

R-CNN、Fast R-CNN、Faster R-CNN理论合集
目录R-CNN算法流程候选区域的生成对每个候选区域,使用深度网络提取特征特征送入每一类的SVM分类器,判定类别非极大值抑制剔除重叠建议框使用回归器精细修正候选框位置R-CNN框架R-CNN存在的问题Fast R-CNN算法流程与R-CNN的对比训练数据的采样ROI Pooling…

YOLOv5算法改进(1)— 如何去改进YOLOv5算法
前言:Hello大家好,我是小哥谈。YOLOv5基础知识入门系列、YOLOv5源码中的参数超详细解析系列和YOLOv5入门实践系列学习完成之后,接着就进入YOLOv5进阶改进算法系列了。🎉为了让大家能够清楚地了解如何去改进YOLOv5算法以及从哪几方…
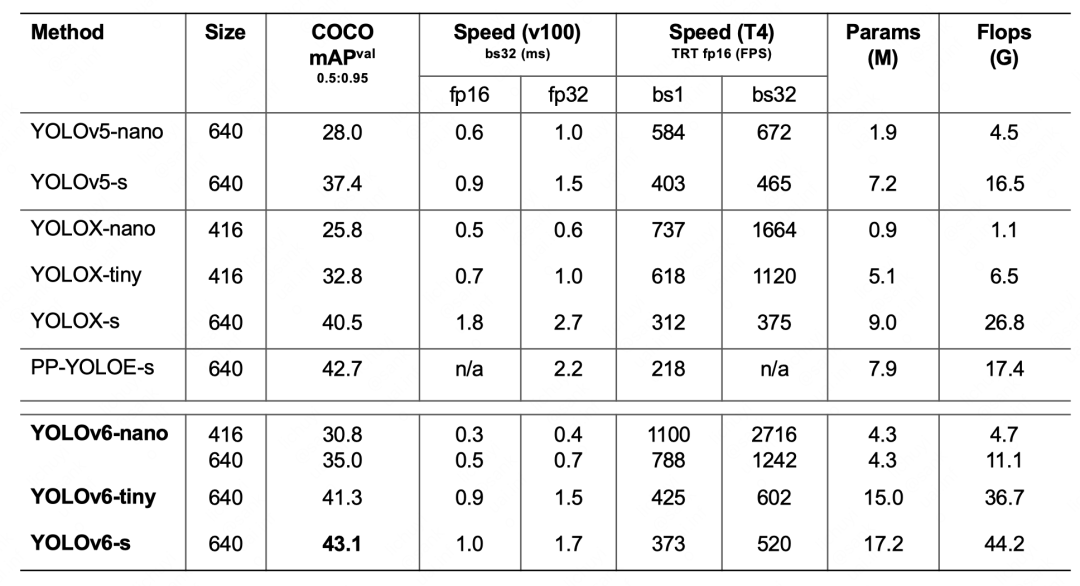
YOLOv6:又快又准的目标检测框架开源
目录
1. 概述
精度与速度远超 YOLOv5 和 YOLOX 的新框架
2. YOLOv6关键技术介绍
2.1 Hardware-friendly 的骨干网络设计
2.2 更简洁高效的 Decoupled Head
2.3 更有效的训练策略
3. 实验结果
4. 总结与展望
5. 参考文献 1. 概述
YOLOv6 是美团视觉智能部研发的一款目…
从0开始yolov8模型目标检测训练
从0开始yolov8模型目标检测训练
1 大环境
首先有大环境,即已经准备好了python、nvidia驱动、cuda、cudnn等。
2 yolov8的虚拟环境
2.1 创建虚拟环境
conda create -n yolov8 python3.102.2 激活虚拟环境
注意:激活虚拟环境的时候,需要清…
YOLOv5/v7 添加注意力机制,30多种模块分析⑤,SOCA模块 ,SimAM模块
目录 一、注意力机制介绍1、什么是注意力机制?2、注意力机制的分类3、注意力机制的核心 二、SOCA模块1、SOCA模块的原理2、实验结果3、应用示例 三、SimAM模块1、SimAM模块的原理2、实验结果3、应用示例 大家好,我是哪吒。
🏆本文收录于&…
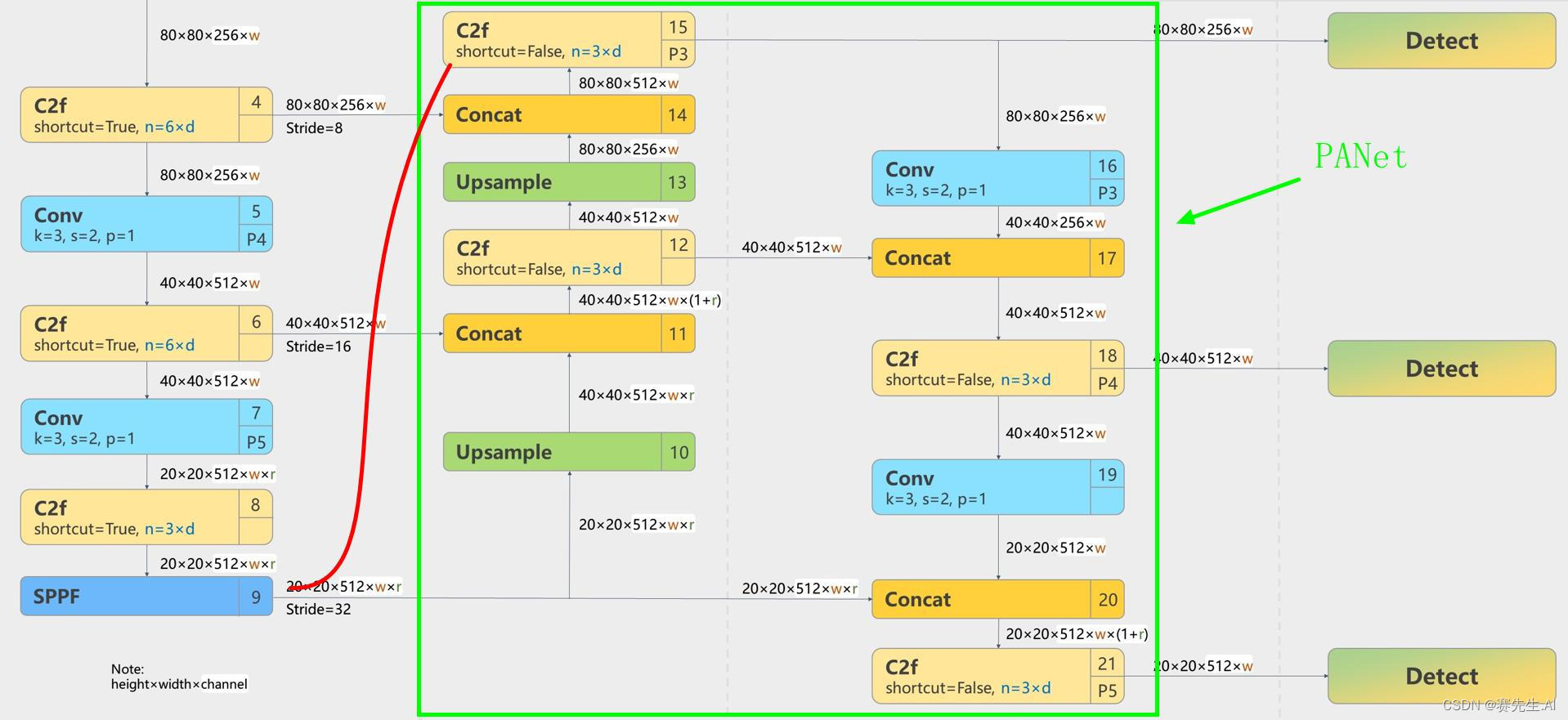
YOLOv8 : 网络结构
一. YOLOv8网络结构
1. Backbone
YOLOv8的Backbone同样参考了CSPDarkNet-53网络,我们可以称之为CSPDarkNet结构吧,与YOLOv5不同的是,YOLOv8使用C2f(CSPLayer_2Conv)代替了C3模块(如果你比较熟悉YOLOv5的网络结构,那YOLOv8的网络…

Lnton羚通关于【PyTorch】教程:torchvision 目标检测微调
torchvision 目标检测微调 本教程将使用Penn-Fudan Database for Pedestrian Detection and Segmentation 微调 预训练的Mask R-CNN 模型。 它包含 170 张图片,345 个行人实例。
定义数据集 用于训练目标检测、实例分割和人物关键点检测的参考脚本允许轻松支持添加…
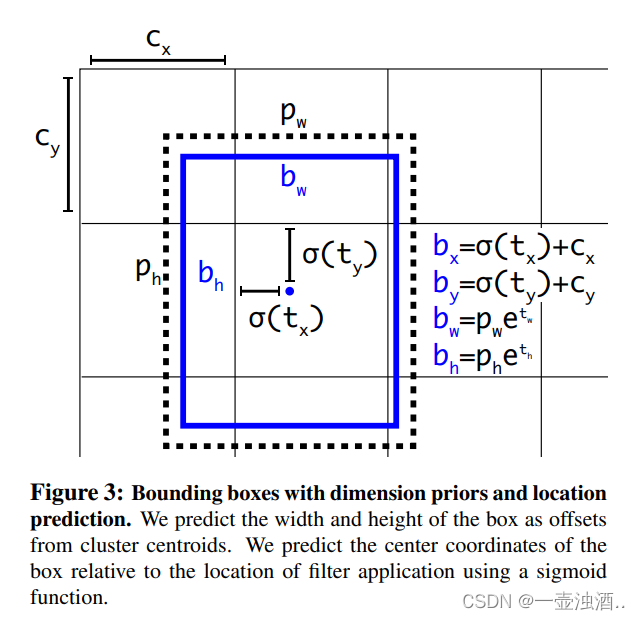

基于YOLOv8模型的五类动物目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的五类动物目标检测系统可用于日常生活中检测与定位动物目标(狼、鹿、猪、兔和浣熊),利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与…

目标检测 CenterNet 模型原理与论文精读(一)
文章目录简介Backbone如何制作数据集的Ground TruthCenter的设置如何计算Loss总结简介 Faster R-CNN和RetinaNet都是基于Anchor机制的。 Faster R-CNN是需要RPN进行预选框的筛选,300个框左右。 RetinaNet是one-stage的方法,没有RPN,直接暴力枚…
【YOLOv3】手把手教你打造一个汽车检测器
本文将带你打造一个汽车检测器,使用的算法是PyTorch版本的YOLOV3。我们不会讲解该算法的细节,而是专注于如何去实现自己的汽车检测器,主要包括数据下载,数据清洗,数据集制作以及训练和检测(图片检测&#x…
目标检测YOLO实战应用案例100讲-基于YOLO网络架构的无人机视角下的小目标检测算法研究与应用
目录
前言 基于YOLO-Drone的无人机视角下的小目标检测
2.1 问题描述
2.2 基于YOLO-Drone的小

目标检测——Mask R-CNN【请结合其他博客一起食用】
大家好 今天来到了我们Maskrcnn 的分享 由于MaskRCNN网络包含了很多之前介绍过的知识点,例如RPN,FPN,RoIPooling,RoIAlign,故这遍文章看上去显得比较‘单薄’,如果想弄清楚Mask RCNN网络,需要结…
目标检测YOLO实战应用案例100讲-基于超分辨率增强网络的小目标检测系统的研究与实现
目录
前言 目标检测
1.YOLO V4
2.Faster R-CNN
图像超分辨率在目标检测中的应用
YOLO目标检测算法训练过程学习记录
先前已经完成过YOLO系列目标检测算法的调试过程,今天主要是将所有的调试加以总结 这里的conda环境就不再赘述了,直接使用requirement.txt文件的即可,也可以参考YOLOX的配置过程5
数据集处理
YOLOv5有自己的数据集格式,博主的数据…
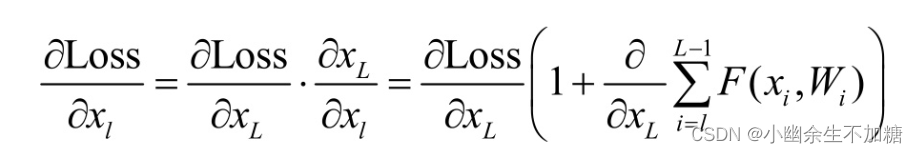
OpenCV实例(九)基于深度学习的运动目标检测(二)YOLOv2概述
基于深度学习的运动目标检测(二)YOLOv2&YOLOv3概述 1.YOLOv2概述2.YOLOv3概述2.1 新的基础网络结构:2.2 采用多尺度预测机制。2.3 使用简单的逻辑回归进行分类 1.YOLOv2概述
对YOLO存在的不足,业界又推出了YOLOv2。YOLOv2主要…

YOLOv5简易使用笔记
YOLOv5简易使用笔记 前言:
这篇博客只是简单记录下YOLOv5的使用方式,并不会详细介绍代码含义之类的。 更多文章:博客地址
环境: YOLOv5 Python 3.8.1
YOLOv5目录介绍
从Github上下载解压好最新的YOLOv5文件后的目录如下图 d…
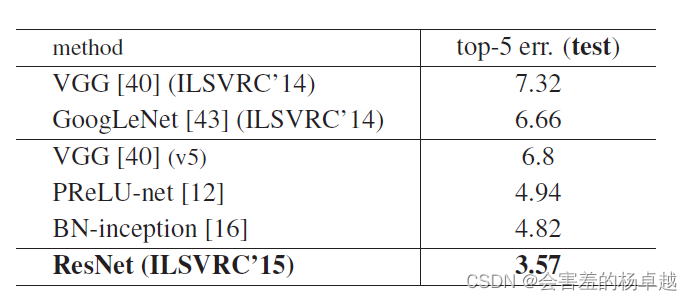
深度学习最强奠基作ResNet《Deep Residual Learning for Image Recognition》论文解读(上篇)
1、摘要
1.1 第一段
作者说深度神经网络是非常难以训练的,我们使用了一个残差学习框架的网络来使得训练非常深的网络比之前容易得很多。
把层作为一个残差学习函数相对于层输入的一个方法,而不是说跟之前一样的学习unreferenced functions
作者提供了…
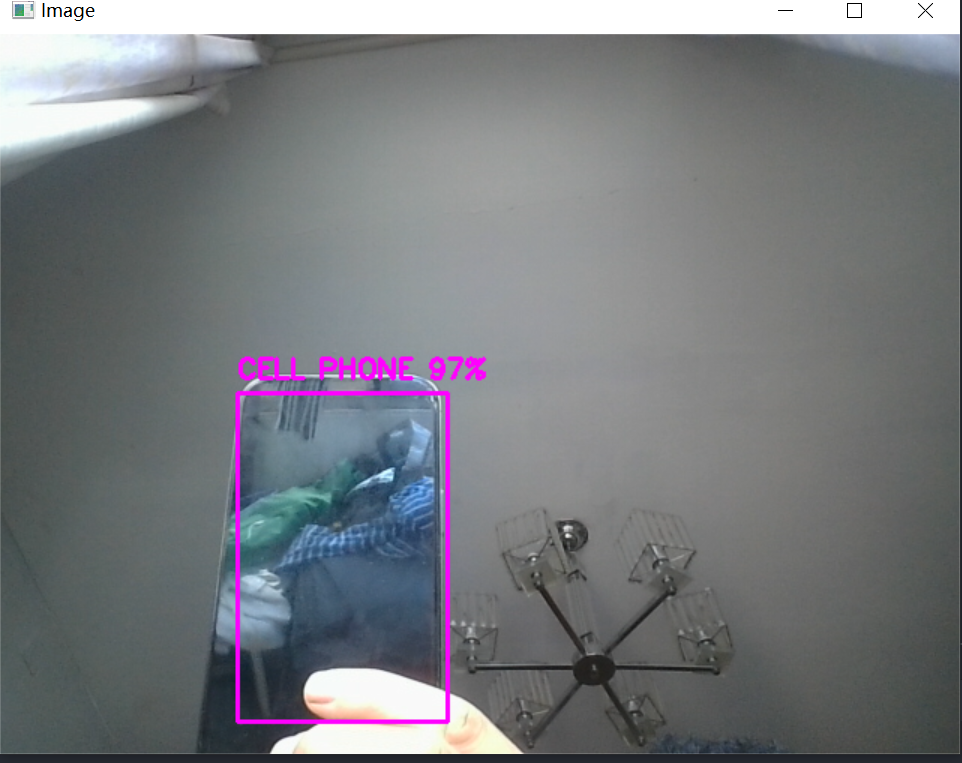
3分钟掌握实时目标检测:使用 OpenCV 和 YOLOv3 的手把手教程
实时目标检测:使用 OpenCV 和 YOLOv3
在这篇博客文章中,我们将探讨如何使用 OpenCV 和 YOLOv3 进行实时目标检测。我们将从头到尾演示整个过程,包括加载模型、处理图像和识别对象。
需要的库和工具
首先,我们需要导入以下库&am…
![[探地雷达]利用Faster RCNN对B-SCAN探地雷达数据进行目标检测](https://img-blog.csdnimg.cn/491979c290f04b53b67f55132951093d.png)
[探地雷达]利用Faster RCNN对B-SCAN探地雷达数据进行目标检测
引用量较高的一篇会议论文。
由于真实雷达图像较少,作者采用了GPR工具箱,使用不同配置,合成了部分模拟雷达图。然后采用Cifar-10数据(灰度图)对Faster RCNN进行预训练,再采用真实和合成数据进行微调。
论…
行人检测0-00:LFFD-目录-史上最新无死角解读
接下来,我会为大家无死角的解析LFFD(行人检测-注:该网络还可用于人脸检测),之前的文章,如下(以下是我工作的所有项目,每一个项目都是,我都做了百分百的详细解读,随着项目增多,为了方便不臃肿&am…
深度学习:经典卷积神经网络和目标检测网络
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的 个人博客,以及我的github。
本文主要讲解关于有关物体检测的相关网络,具体包括R-CNN,Fast R-CNN,Faster R-CNN和Mask R-CNN等。在此之前…
能给我总结所有的yolo模型和最新模型的资料吗?
当前,有许多不同版本的 YOLO (You Only Look Once) 模型。YOLO 是一种目标检测算法,旨在快速识别图像中的物体。 YOLO v1 是最早的版本,它发布于 2015 年。这个版本的模型被称为 YOLO9000,它可以在 COCO 和 ImageNet 数据集上进行…

2021-11-03
SS选择算法
ss算法是根据图像的颜色 纹理等 将一个图像差不多类似的部分结合在一起
SS算法是目标检测两步骤方法的一个方法,在目标检测中有用
出了fasterrcnn 采取anchor猫的理论实现外,具备较好的作用
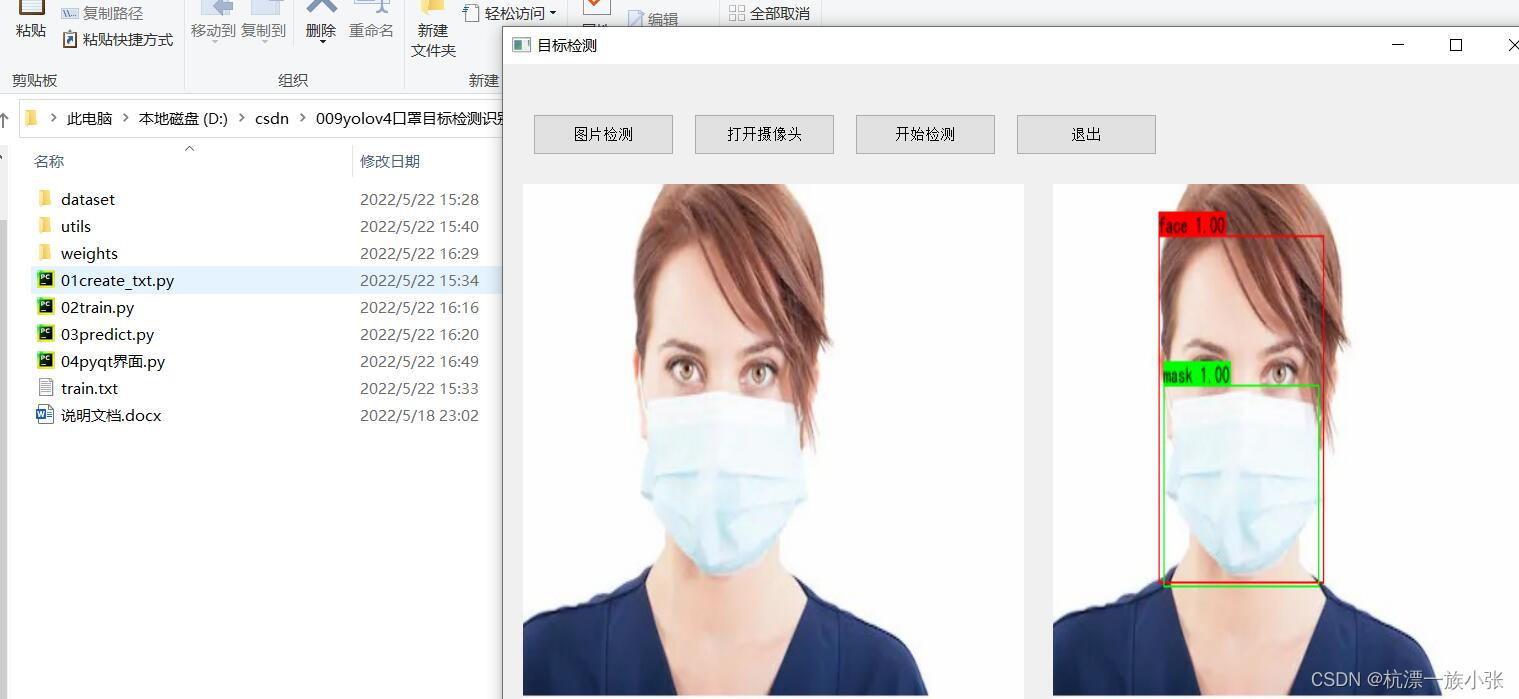
【教学】yolov4目标检测口罩+pyqt可视化界面_python代码
上效果图: 代码属于傻瓜式运行
本套代码的运行环境是python+pytorch
安装环境安装可参考博客:
在win10上安装pytorch-gpu版本_杭漂一族小张的博客-CSDN博客 算法部分
本次是口罩目标检测
数据集原图放在009yolov4口罩目标检测识别\dataset\JPEGImages路径下,
对应的xm…

yolox目标检测实现人脸识别换搞笑图
今天介绍的是一个使用yolox目标检测算法,实现换人脸的过程。 首先是换人脸视频的准备,我们可以找一些比较的热门视频作为素材,比如“华强买瓜”。
使用视频抽帧,将一个2分钟的视频,抽成200张左右,当然也可以抽成更多张。 以上就是视频抽帧的结果。
然后我们下载labelim…

pytorch-yolov5_deepsort目标跟踪行人车辆计数
看图就可以知道。穿过两条线,分别用于测上行人流和下行人流。
这个cpu和gpu版本都可以跑,cpu的话,安装好相应的库之后,运行会报
RuntimeError: “unfolded2d_copy“ not implemented for ‘Half‘
的错误,原因是模型是利用fp16混合精度计算对CPU进行推理,不安装gpu版本…

【两阶段目标检测】R-CNN论文精读与学习总结
目录0. 前言1. R-CNN大体介绍1.1 作者遇到的两个问题1.2 R-CNN的大体思路1.3 一些细节2. R-CNN的训练过程2.1 四个步骤2.2 训练过程的一些细节2.2.1 网络神经元学习效果可视化2.2.2 为什么迁移学习和训练SVM时正负类别定义不一样?2.2.3 为什么要用SVM进行分类&#…

【YOLO系列】YOLO V1 论文精读与学习总结
目录0. 前言1.YOLO V1 大体思路2. YOLO V1的训练过程2.1 YOLO V1网络结构2.2 具体训练过程2.2.1 把主干结构在ImageNet上进行预训练2.2.2 真正开始训练2.3 输出的7x7x30维张量代表含义2.3 损失函数设置3.YOLO V1推断过程(NMS后处理)4. YOLOV1 与其他模型…
美国站UL2849报告电动自行车的安全标准
目前国内很多大品牌电动车出口企业都已经通过UL2849的安全检测或已经在申请中了。目前,全球卖两款电动自行车SC-1,EB-7和高科时代电动自行车P10,P2都已经通过了美国UL2272&UL2849认证,率先进入了北美市场。电商平台亚马逊也对…
YoloV8优化:感受野注意力卷积运算(RFAConv),效果秒杀CBAM和CA等 | 即插即用系列
💡💡💡本文改进:感受野注意力卷积运算(RFAConv),解决卷积块注意力模块(CBAM)和协调注意力模块(CA)只关注空间特征,不能完全解决卷积核参数共享的问题
RFAConv| 亲测在多个数据集能够实现大幅涨点,有的数据集达到3个点以上
💡💡💡Yolov8魔术师,独家首…
掌握 yolo - 解码核心思想,v3、v4、v5上手不是梦....
文章目录0x01 背景0x02 编解码2.1 编码2.2 解码2.3 小脑袋有大大的问号0x03 Coding3.1 加载图片 & 推理3.2 解码3.3 置信度3.3.1 单个类别且只需要一个框3.3.2 多个类别参考资料0x01 背景 目的:识别出图片中概率最大的人形生物,并给出坐标 仅讨论 yo…
民安汇智(第三方旅游服务暗访)开展旅游景区度假区明察暗访复核检查服务
近日,民安汇智受客户委托对该市某旅游景区度假区进行明察暗访复核检查工作。
民安汇智通过实地调研、体验式暗访等各种方式对该市范围内3A级以上旅游景区、旅游度假区及2022年新创建的3A级以上旅游景区、旅游度假区进行明察暗访复核检查,对照《旅游景区…
基于PyTorch深度学习遥感影像地物分类与目标检测、分割及遥感影像问题深度学习优化
我国高分辨率对地观测系统重大专项已全面启动,高空间、高光谱、高时间分辨率和宽地面覆盖于一体的全球天空地一体化立体对地观测网逐步形成,将成为保障国家安全的基础性和战略性资源。未来10年全球每天获取的观测数据将超过10PB,遥感大数据时…

YOLOv5算法改进(4)— 添加CA注意力机制
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。在许多视觉任务中,输入数据通常由多个通道组成,例如图像中的RGB通道或…

YOLO目标检测——足球比赛中球员检测数据集下载分享
足球比赛中球员检测数据集,真实场景的高质量图片数据,数据场景丰富,图片格式为jpg,共500张图片 数据集点击下载:YOLO足球比赛中球员检测数据集500图片.rar
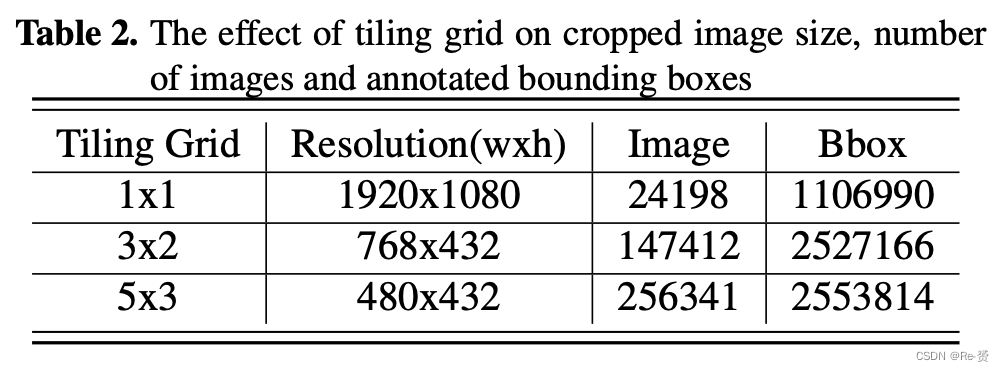
论文阅读 The Power of Tiling for Small Object Detection
The Power of Tiling for Small Object Detection
Abstract
基于深度神经网络的技术在目标检测和分类方面表现出色。但这些网络在适应移动平台时可能会降低准确性,因为图像分辨率的增加使问题变得更加困难。在低功耗移动设备上实现实时小物体检测一直是监控应用的…

OpenCV基础知识(9)— 视频处理(读取并显示摄像头视频、播放视频文件、保存视频文件等)
前言:Hello大家好,我是小哥谈。OpenCV不仅能够处理图像,还能够处理视频。视频是由大量的图像构成的,这些图像是以固定的时间间隔从视频中获取的。这样,就能够使用图像处理的方法对这些图像进行处理,进而达到…

Python使用 YOLO_NAS_S 模型进行目标检测并保存预测到的主体图片
一、前言:
使用 YOLO_NAS_S 模型进行目标检测,并保存预测到的主体图片
安装包:
pip install super_gradients
pip install omegaconf
pip install hydra-core
pip install boto3
pip install stringcase
pip install typing-extensions
pi…
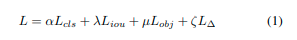
经典文献阅读之--EdgeYOLO(边缘设备YOLO目标检测)
0. 简介
Yolo家族从1-8,目前已经迭代了很多次,但是他们期望的仍然是能够以更低的算力去运行精度更高更快速的算法.目前《EdgeYOLO: An Edge-Real-Time Object Detector》提出了一种基于最先进的YOLO框架的高效、低复杂度和无锚点的目标检测器,可以在边缘计算平台上…

OK3588应用之——人脸和人脸关键点的检测(十四)
一、主机模型转换
采用FastDeploy来部署应用深度学习模型到OK3588板卡上
进入主机Ubuntu的虚拟环境 conda activate ok3588 主机环境搭建可以参考上一篇 《OK3588板卡实现人像抠图(十二)》
转换成RKNN模型
cd FastDeploy
wget https://bj.bcebos.co…

yolov5和yolov7部署的研究
1.结论
onnx推理比torch快3倍, openvino比onnx快一丢丢。 |
yolov7.pt 转 onnx
python export.py --weights best_31.pt --grid --end2end --simplify --topk-all 10 --iou-thres 0.65 --conf-thres 0.65 --img-size 320 320 --max-wh 200可以看到yolov7的 onnx是包括nms…
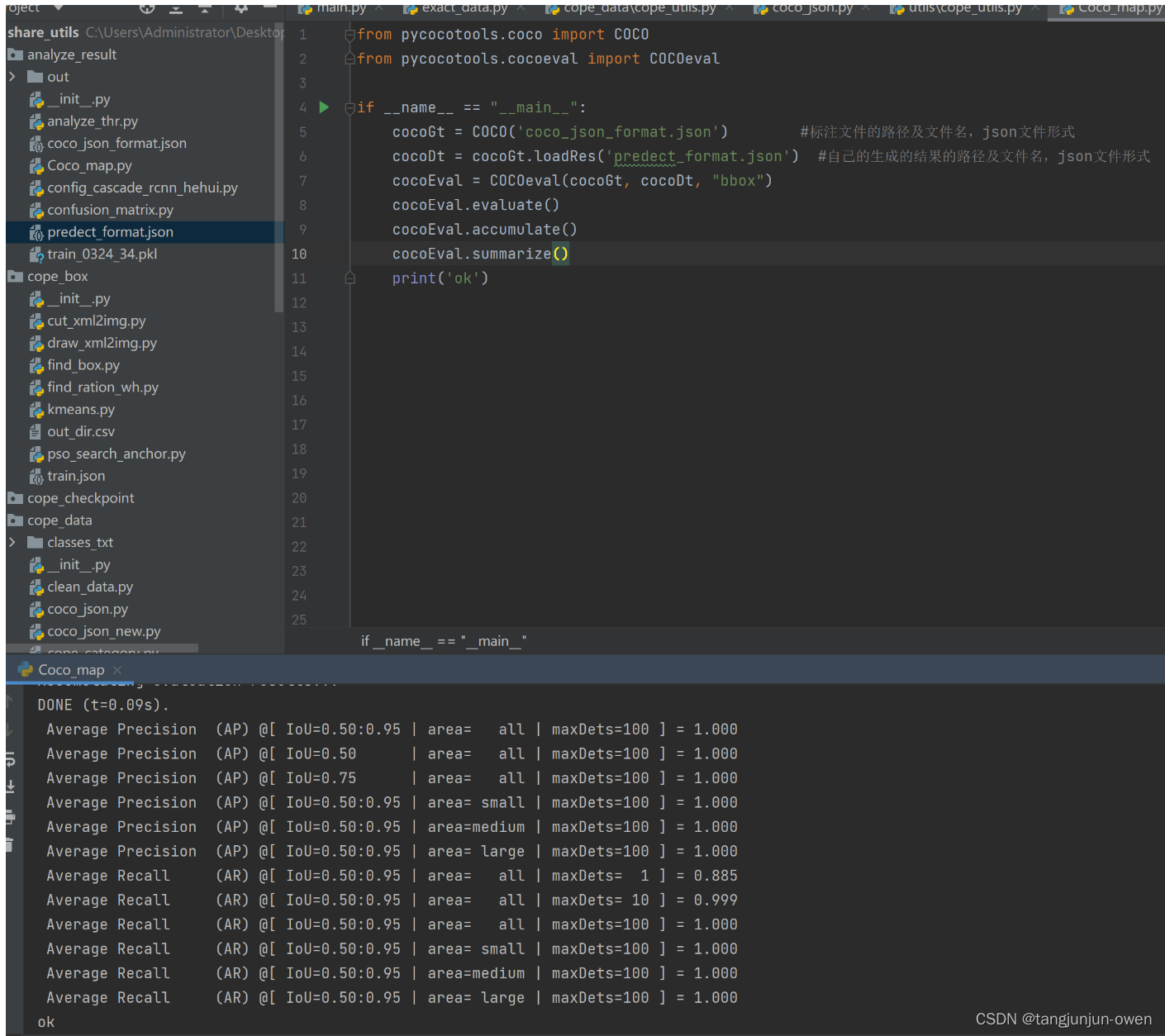
史上最全AP、mAP详解与代码实现
文章目录 前言一、mAP原理1、mAP概念2、准确率3、精确率4、召回率5、AP: Average Precision 二、mAP0.5与mAP0.5:0.951、mAP0.52、mAP0.5:0.95 三、mAP代码实现1、真实标签json文件格式2、模型预测标签json文件格式3、mAP代码实现4、mAP结果显示 四、模型集成mAP代码1、模型mai…

论文阅读 FCOS: Fully Convolutional One-Stage Object Detection
文章目录 FCOS: Fully Convolutional One-Stage Object DetectionAbstract1. Introduction2. Related Work3. Our Approach3.1. Fully Convolutional One-Stage Object Detector3.2. Multi-level Prediction with FPN for FCOS3.3. Center-ness for FCOS 4. Experiments4.1. Ab…

数据集学习笔记(七):不同任务数据集的标签介绍(包含目标检测、图像分割、行为分析)
文章目录 一、目标检测1.1 TXT1.2 COCO1.3 XML 二、图像分割2.1 json2.1 TXT2.1.1 json转txt 三、行为分析3.1 TXT3.2 JSON 一、目标检测
1.1 TXT 每行表示(类别,中心x相对坐标,中心y相对坐标,相对宽度、相对高度)
1…
(一)KITTI数据集用于3D目标检测
KITTI数据集介绍
数据基本情况
KITTI是德国卡尔斯鲁厄科技学院和丰田芝加哥研究院开源的数据集,最早发布于2012年03月20号。
对应的论文Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite发表在CVPR2012上。
KITTI数据集搜集自德国卡尔斯鲁厄市&…

YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
前言:Hello大家好,我是小哥谈。ShuffleNetV2 是一种轻量级的神经网络架构,适用于移动设备和嵌入式设备等资源受限的场景,旨在在计算资源有限的设备上提供高效的计算和推理能力,它通过引入通道重排操作和逐点组卷积来减…

目标检测矿石数据集图片下载分享
矿石图片,其中训练集包括“玄武岩”、“花岗岩”、“大理石”、“石英岩”、“煤”、“石灰石”、“砂岩”七种矿石图片。测试集包括24张相应的七种矿石图像。 数据集点击下载: 矿石数据集4500图片数据说明.rar
使用chatGPT做综述——以目标检测为例
尝试用chatGPT做综述。 备注:chatGPT的知识只到2021年。所以2022年以后的论文无法包含。
初次prompt
我的研究方向是深度学习相关的目标检测,你可以告诉我目标检测的发展脉络吗?将论文分类梳理同时给出经典的论文。
当谈到目标检测的发展脉…
YOLO目标检测——猫狗识别数据集下载分享
猫狗识别数据集是一个常用的用于猫和狗图像分类任务的数据集,包含了大量的猫和狗的图像样本 数据集点击下载:YOLO猫狗识别数据集5000图片.rar
![[软件工具]精灵标注助手目标检测数据集格式转VOC或者yolo](https://i1.hdslb.com/bfs/archive/785e751fd7911126cf12e5929d1ec80a0b2f8f0c.jpg@100w_100h_1c.png@57w_57h_1c.png)
[软件工具]精灵标注助手目标检测数据集格式转VOC或者yolo
有时候我们拿到一个数据集发现是xml文件格式如下:
<?xml version"1.0" ?>
<doc><path>C:\Users\Administrator\Desktop\test\000000000074.jpg</path><outputs><object><item><name>dog</name>…
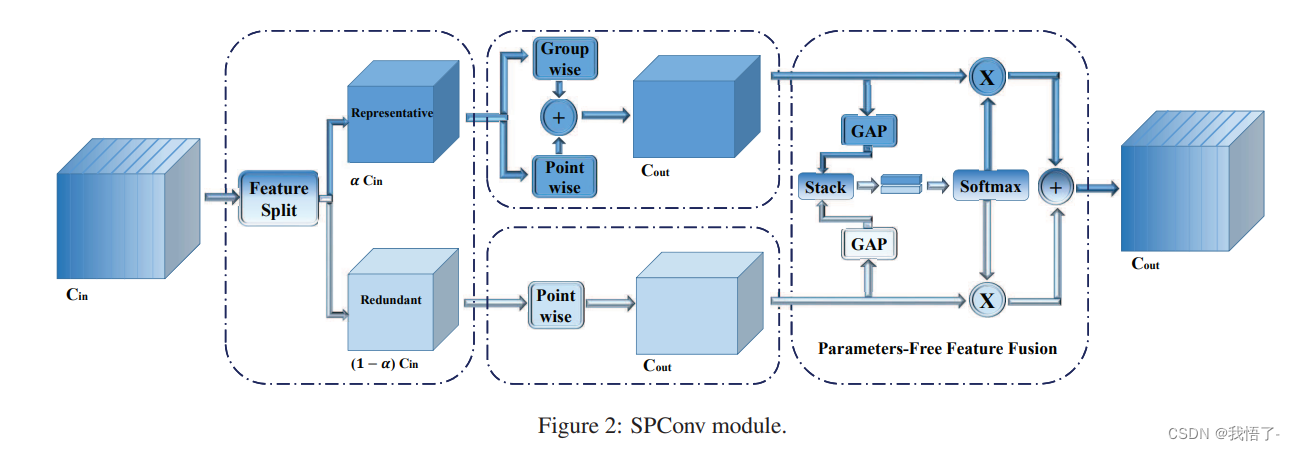
pytorch代码实现之SAConv卷积
SAConv卷积
SAConv卷积模块是一种精度更高、速度更快的“即插即用”卷积,目前很多方法被提出用于降低模型冗余、加速模型推理速度,然而这些方法往往关注于消除不重要的滤波器或构建高效计算单元,反而忽略了特征内部的模式冗余。 原文地址&am…
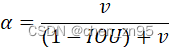
IOU、GIOU、DIOU、CIOU原理及代码介绍
一、IOU
论文:UnitBox: An Advanced Object Detection Network
定义
IOU的全称是Intersection over Union,即我们常说的交并比。IOU可以用作目标检测中正负样本的分配依据,也可用于衡量预测框与GT框之间的差异(目标检测中的AP&…
Yolov5/Yolov7损失函数改进:SlideLoss,解决简单样本和困难样本之间的不平衡问题
💡💡💡本文改进:SlideLoss,解决简单样本和困难样本之间的不平衡问题,并使用有效感受野的信息来设计Anchor。
SlideLoss| 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升也能够助力涨点。
💡💡💡Yolov5/Yolov7魔术师,独家首发创新(原创),适用于…
Yolov8红外弱小目标检测(8):微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测
💡💡💡本文改进:微小目标检测的上下文增强和特征细化网络ContextAggregation ContextAggregation | 亲测在红外弱小目标检测涨点明显,map@0.5 从0.755提升至0.759
💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,…

DCN v2阅读笔记
Deformable ConvNets v2: More Deformable, Better Results 是 Deformable Convolutional Networks 研究的续作,发表在 CVPR 2019上。
作者对 DCNv1 的自适应行为进行研究,观察到虽然其神经特征的空间支持比常规的卷积神经网络更符合物体结构࿰…

mmdetection基于 PyTorch 的目标检测开源工具箱 入门教程
安装环境
MMDetection 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.7 以上,CUDA 9.2 以上和 PyTorch 1.8 及其以上。
1、安装依赖
步骤 0. 从官方网站下载并安装 Miniconda。
步骤 1. 创建并激活一个 conda 环境。
conda create --name…

LabelImg制作自己的数据集
下载LabelImg工具: 链接:https://pan.baidu.com/s/1_py_dQ0vxm8WXLsHA_ekIw 提取码:oo6b
下载完成后点开labelImg.exe 打开后会弹出如下窗口:
然后点击Open dir选择图片所在路径 点击Change save dir 更改xml保存路径
几个常…

人工智能Java SDK:目标检测(支持voc数据集分类)
目标检测(支持voc数据集分类)SDK
检测图片中20个分类的目标。
支持分类如下:
aeroplanebicyclebirdboatbottlebuscarcatchaircowdiningtabledoghorsemotorbikepersonpottedplantsheepsofatraintvmonitor
点击下载
SDK包含两个检测器:
SSDResnet50D…
万字长文,YOLOv8 yaml 文件解析 | 一文搞定 YOLOv8 分类任务,检测任务,分割任务,关键点任务
之前写过一篇 YOLOv5/v7的 yaml 文件解析,大家反馈都不错,这篇主要介绍 YOLOv8 的 yaml 文件,
其实原本前几个版本的 YOLOv8 的 yaml 文件和 v5v7 的 yaml 一样的,但是更新了很多版之后,有了挺大的改变,
并且 YOLOv8 这个项目支持的算法和任务很多,所以这个 yaml 文件…

深度学习(十一)---zed 调用yolov5 进行识别目标并实时测距
1. 前言
zed 相机测距有2种方式:一种是根据点云数据进行测试,二是根据zed获取深度值进行测距。上篇文章 调用yolov5模型进行实时图像推理及网页端部署 我们讲述了zed调用yolov5进行目标识别,我们在此基础上进一步实现目标测距功能。
2.深度…
目标检测笔记(十三): 使用YOLOv5-7.0版本对图像进行目标检测完整版(从自定义数据集到测试验证的完整流程))
文章目录 一、目标检测介绍二、YOLOv5介绍2.1 和以往版本的区别三、代码获取3.1 视频代码介绍四、环境搭建五、数据集准备5.1 数据集转换5.2 数据集验证六、模型训练七、模型验证八、模型测试九、评价指标一、目标检测介绍
目标检测(Object Detection)是计算机视觉领域的一个…
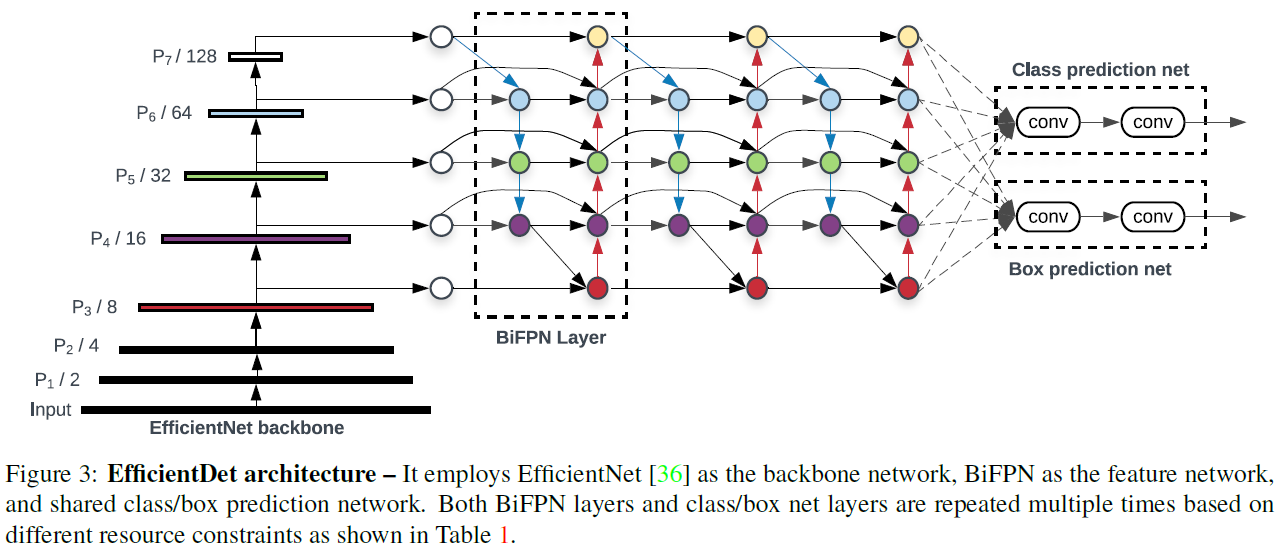
浅析目标检测入门算法:YOLOv1,SSD,YOLOv2,YOLOv3,CenterNet,EfficientDet,YOLOv4
本文致力于让读者对以下这些模型的创新点和设计思想有一个大体的认识,从而知晓YOLOv1到YOLOv4的发展源流和历史演进,进而对目标检测技术有更为宏观和深入的认知。本文讲解的模型包括:YOLOv1,SSD,YOLOv2,YOLOv3,CenterNet,EfficientDet,YOLOv4…

MobileViT v3论文超详细解读(翻译+精读)
前言
今天读一下MobileViT v3的论文《MOBILEVITV3: MOBILE-FRIENDLY VISION TRANS- FORMER WITH SIMPLE AND EFFECTIVE FUSION OF LOCAL, GLOBAL AND INPUT FEATURES》这篇论文的实验部分写得还是很不错的,很值得我们借鉴。 论文原文: https://arxiv.…
【深度学习】半监督学习 Efficient Teacher: Semi-Supervised Object Detection for YOLOv5
https://arxiv.org/abs/2302.07577 https://github.com/AlibabaResearch/efficientteacher 文章目录 AbstractIntroductionRelated WorkEfficient TeacherDense Detector Abstract
半监督目标检测(SSOD)在改善R-CNN系列和无锚点检测器的性能方面取得了成…

YOLOv5算法改进(6)— 添加SOCA注意力机制
前言:Hello大家好,我是小哥谈。SOCA(self-organizing competitive attention)是一种注意力机制,它模拟了人类视觉系统中的竞争性注意力机制。在视觉场景中,我们通常只关注某些特定的区域,而忽略…
目标检测(Object Detection):Fast R-CNN,YOLO v3
目录
目标检测(Object Detection)
R-CNN
SPPNet
Fast R-CNN
YOLO v1
YOLO v2
YOLO v3 目标检测(Object Detection)
任务是计算机视觉中非常重要的基础问题,也是解决图像分割、目标跟踪、图像描述等问题的基础。目标检测是检测输入图像是否存在给定类别的物体…
目标检测网络系列之R-CNN
文章目录 前言目标检测任务数据集任务区别评判标准的区别IoU 交并比P-R曲线mAPR-CNNR-CNN的基本逻辑候选框挑选Efficient Graph-Based Image Segmentation算法Selective Search for Object Recognition尺寸变换特征提取与非极大值抑制非极大值抑制(NMS, Non-maximum suppressio…
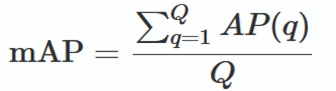
目标检测评估指标mAP:从Precision,Recall,PR曲线到AP
1. TP, FP, FN, TN
True Positive
满足以下三个条件被看做是TP 1. 置信度大于阈值(类别有阈值,IoU判断这个bouding box是否合适也有阈值) 2. 预测类型与标签类型相匹配(类别预测对了) 3. 预测的Bouding Box和Ground …
YOLO总结,从YOLOv1到YOLOv3
YOLOv1
论文链接:https://arxiv.org/abs/1506.02640
检测原理
将检测问题转换成回归问题,一个CNN就搞定。即得到一个框的中心坐标(x, y)和宽高w,h,然后作回归任务。 B是两个框,5是指参数量,x y w h是确定…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(9 月 8 日论文合集)
文章目录 一、检测相关(13篇)1.1 DiffusionEngine: Diffusion Model is Scalable Data Engine for Object Detection1.2 ClusterFusion: Leveraging Radar Spatial Features for Radar-Camera 3D Object Detection in Autonomous Vehicles1.3 Efficient Adaptive Human-Object …
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(十三)
文章目录 一、Drinking Waste Classification二、Drone vs Bird (Drone vs Bird Detection Challenge)三、EXPO-HD四、Embrapa ADD 256 (Embrapa Apples by Drones Detection Dataset)五、FGVD (Fine-Grained Vehicle Detection)六、FSVOD-500七、FracAtlas (A Dataset for Fra…

YOLO目标检测——口罩规范佩戴数据集+已标注xml和txt格式标签下载分享
实际项目应用:目标检测口罩佩戴检测数据集的应用场景涵盖了公共场所监控、疫情防控管理、安全管理与控制以及人员统计和分析等领域。这些应用场景可以帮助相关部门和机构更好地管理口罩佩戴情况,提高公共卫生和安全水平,保障人们的健康和安全…
目标检测后的图像上绘制边界框和标签
效果如图所示,有个遗憾就是CV2在图像上显示中文有点难,也不想用别的了,所以改成了英文,代码在下面了,一定要注意一点,就是标注文件的读取一定要根据自己的实际情况改一下,我的所有图像的标注文件…

opencv案例06-基于opencv图像匹配的消防通道障碍物检测与深度yolo检测的对比
基于图像匹配的消防通道障碍物检测
技术背景
消防通道是指在各种险情发生时,用于消防人员实施营救和被困人员疏散的通道。消防法规定任何单位和个人不得占用、堵塞、封闭消防通道。事实上,由于消防通道通常缺乏管理,导致各种垃圾࿰…

YOLOV8模型使用-检测-物体追踪
这个最新的物体检测模型,很厉害的样子,还有物体追踪的功能。 有官方的Python代码,直接上手试试就好,至于理论,有想研究在看论文了╮(╯_╰)╭ 简单介绍
YOLOv8 中可用的模型
YOLOv8 模型的每个类别中有五个模型用于检…

plt函数显示图片 在图片上画边界框 边界框坐标转换
一.读取图片并显示图片
%matplotlib inline
import torch
from d2l import torch as d2l读取图片
image_path ../data/images/cat_dog_new.jpg
# 创建画板
figure d2l.set_figsize()
image d2l.plt.imread(image_path)
d2l.plt.imshow(image);二.给出一个(x左上角,y左上角,…
目标检测YOLO算法,先从yolov1开始
学习资源
有一套配套的学习资料,才能让我们的学习事半功倍。
yolov1论文原址:You Only Look Once: Unified, Real-Time Object Detection
代码地址:darknet: Convolutional Neural Networks (github.com)
深度学习经典检测方法
one-stag…

YOLOv5算法改进(16)— 增加小目标检测层
前言:Hello大家好,我是小哥谈。小目标检测层是指在目标检测任务中用于检测小尺寸目标的特定网络层。由于小目标具有较小的尺寸和低分辨率,它们往往更加难以检测和定位。YOLOv5算法的检测速度与精度较为平衡,但是对于小目标的检测效…
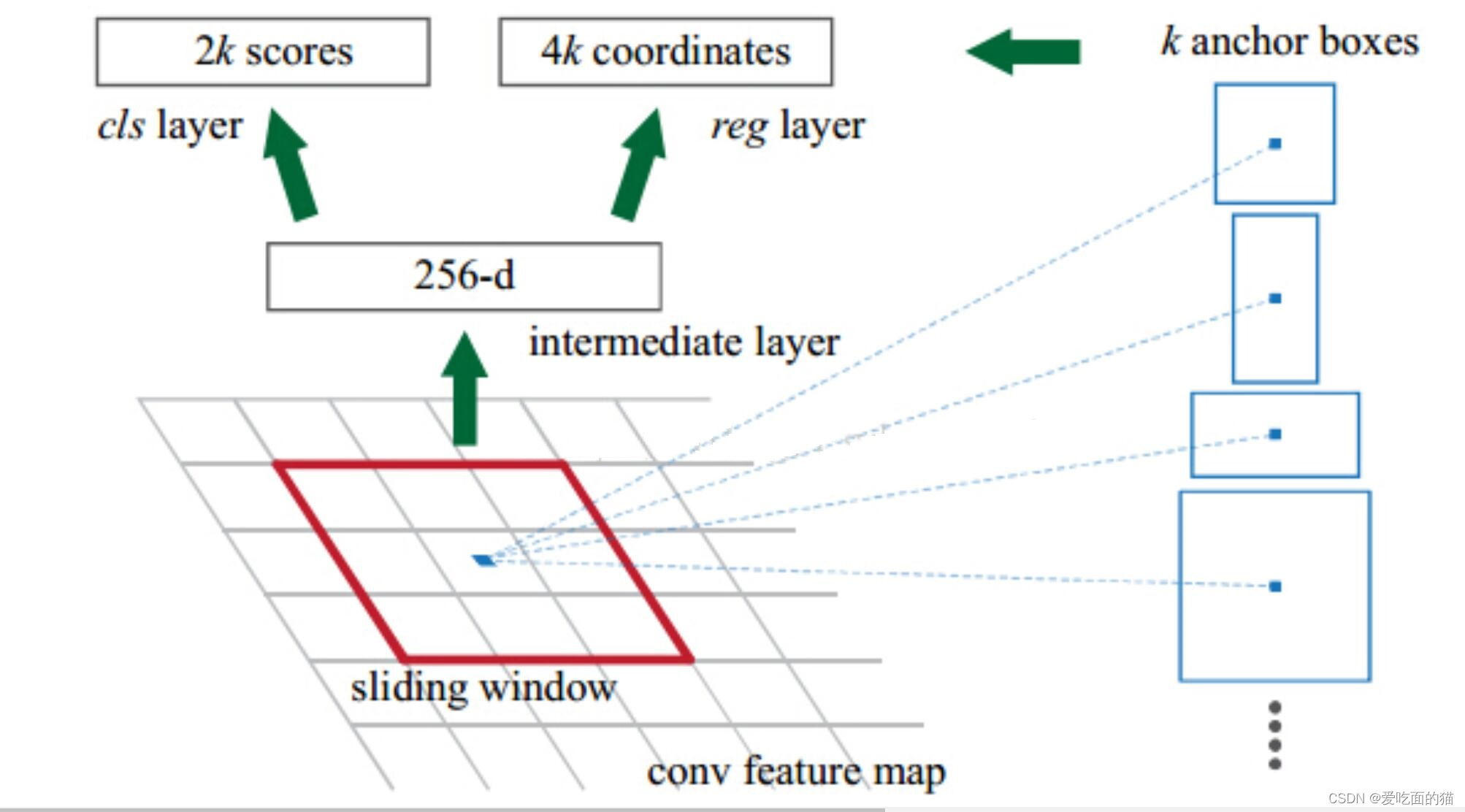
04深度学习-目标检测-深度学习方法详解-Two-stage的目标检测算法
一、 深度学习目标检测算法介绍 第二篇我们介绍了目标检测中传统的算法和目标检测的方式,第三篇我们对传统的目标检测算法和深度学习目标检测算法简单做了比较,此篇记录了深度学习目标检测算法内容,深入讲述一下深度学习算法在目标检测的原理…
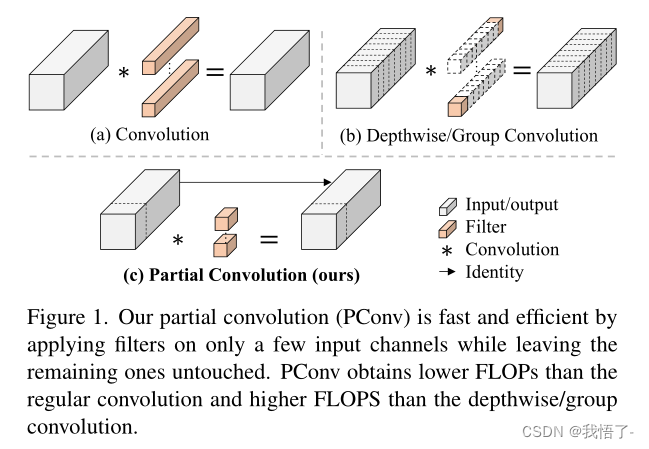
pytorch代码实现之Partial Convolution (PConv卷积)
Partial Convolution (PConv卷积)
Partial Convolution (PConv卷积),有助于提升模型对小目标检测的性能。目前许多研究都集中在减少浮点运算(FLOPs)的数量上。然而FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运…

FastDeploy部署(C++ Win10)
参考链接:FastDeploy C部署保姆级教程
FastDeploy是百度为了解决AI部署落地难题,发布的新一代面向产业实践的推理部署工具。它旨在为AI开发者提供模型部署最优解,具备全场景、简单易用、极致高效三大特点。项目地址:FastDeploy项…

YOLOv5算法改进(13)— 替换主干网络之PP-LCNet
前言:Hello大家好,我是小哥谈。PP-LCNet是一个由百度团队针对Intel-CPU端加速而设计的轻量高性能网络。它是一种基于MKLDNN加速策略的轻量级卷积神经网络,适用于多任务,并具有提高模型准确率的方法。与之前预测速度相近的模型相比…

瑞芯微:基于RK3568得人脸朝向检测
驾驶员监控系统是基于驾驶员面部图像处理来研究驾驶员状态的实时系统。首先挖掘出人在疲劳状态下的表情特征,然后将这些定性的表情特征进行量化,提取出面部特征点及特征指标作为判断依据,再结合实验数据总结出基于这些参数的识别方法…
YoloV8改进策略:NWD小目标检测新范式,助力YoloV5、V8在小目标上暴力涨点
文章目录 摘要官方代码Yolov8官方结果YoloV5改进策略改进方法测试结果YoloV8改进策略改进方法测试结果总结摘要
检测微小物体是一个极具挑战性的问题,因为微小物体只包含几个像素大小。由于缺乏外观信息,最先进的目标检测器在微小物体上无法产生令人满意的结果。由于,IoU(…

OpenCV实战(31)——基于级联Haar特征的目标检测
OpenCV实战(31)——基于级联Haar特征的目标检测 0. 前言1. Haar 特征图像表示2. 基于级联 Haar 特征的二分类分类器3. 级联分类器算法流程4. 使用 Haar 级联检测器进行人脸检测5. 完整代码小结系列链接 0. 前言
在机器学习基础一节中,我们介…
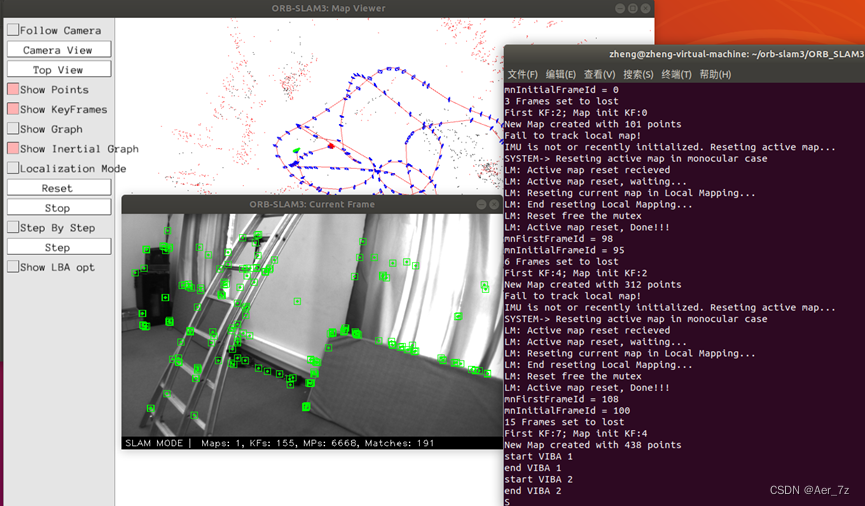
Ubuntu18.04版本下配置ORB-SLAM3和数据集测试方法
文章目录 环境说明必要配置一、Pangolin源码和库文件下载依赖安装和编译安装 二、Eigen3源码和库文件下载编译安装 三、Opencv源码和库文件下载编译安装 四、DBoW2 和 g2o五、boost源码和库文件下载编译安装 六、libssl-dev七、ORB-SLAM3源码和库文件下载编译安装 数据集测试数…

基于YOLOv8+PyQt5实现的共享自行车识别检测系统,含数据集+模型+精美GUI界面(可用于违规停放检测告警项目)
系列文章目录 文章目录 系列文章目录前言欢迎来到我的博客!我很高兴能与大家分享关于基于YOLOv8的共享自行车识别检测,违规停放告警系统的内容。 一、系统特点7. 带有训练部分标注好的数据集,训练集、验证集 二、环境配置2.anaconda环境导入p…

【Yolov5+Deepsort】训练自己的数据集(3)| 目标检测追踪 | 轨迹绘制 | 报错分析解决
📢前言:本篇是关于如何使用YoloV5Deepsort训练自己的数据集,从而实现目标检测与目标追踪,并绘制出物体的运动轨迹。本章讲解的为第三部分内容:数据集的制作、Deepsort模型的训练以及动物运动轨迹的绘制。本文中用到的数…
YOLO目标检测——赛马数据集下载分享
目标检测赛马数据集在马匹竞赛、马匹健康监测、马匹行为研究、马匹安全监控和马匹图像检索等应用场景中具有广泛的应用潜力,可以为马匹产业的发展和管理提供有力支持 数据集点击下载:YOLO赛马数据集640图片标框.rar
更多数据集下载和效果展示&#x…

YOLO目标检测——VOC2007数据集+已标注VOC格式标签下载分享
VOC2007数据集是一个经典的目标检测数据集,该数据集包含了20个常见的目标类别,涵盖了人、动物、交通工具等多个领域,共同11220图片。使用lableimg标注软件标注,标注框质量高,标签格式为VOC格式(即xml标签&a…
YOLOv8目标检测实战:TensorRT加速部署(视频教程)
课程链接:https://edu.csdn.net/course/detail/38956
PyTorch版的YOLOv8是先进的高性能实时目标检测方法。 TensorRT是针对英伟达GPU的加速工具。
本课程讲述如何使用TensorRT对YOLOv8目标检测进行加速和部署。
• 采用改进后的tensorrtx/yolov8的代码࿰…
基于YOLOV8模型的海上船只目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型的海上船只目标检测系统用于日常生活中检测与定位海上船只目标(散装货船(bulk cargo carrier)、集装箱船(container ship)、渔船(fishing boat)、普通货船&#…

YOLOv8『小目标』检测指南
前言
目前博主课题组在进行物体部件的异常检测项目,项目中需要先使用 YOLOv8 进行目标检测,然后进行图像切割,最后采用 WinCLIP 模型 进行部件异常检测
但是在实际操作过程中出现问题, YOLOv8 模型目标检测在大目标精确度不错&a…
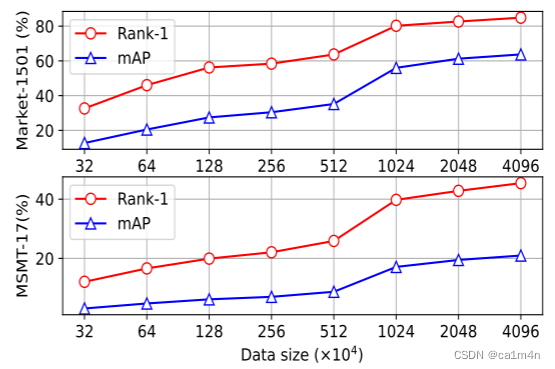
【自监督Re-ID】ICCV_2023_Oral | ISR论文阅读
Codehttps://github.com/dcp15/ISR_%20ICCV2023_Oral
面向泛化行人再识别的身份导向自监督表征学习,清华大学
目录
导读
摘要
相关工作
DG ReID
用于ReID的合成数据
无监督表征学习
Identity-Seeking Representation Learning
结果
消融实验 导读 新角度…
目标检测性能评价指标
文章目录 一.常见的模型评价术语True positives(TP)False positives(FP)False negatives(FN)True negatives(TN)P-R curveP-R曲线APmAPIOU(交并比)NMS(非极大抑制)检测速度 一.常见的模型评价术语
现在假设我们的分类目标只有两类,计为正例&…
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(十)
文章目录 一、ZeroWaste二、Aircraft Context Dataset三、BdSLImset (Bangladeshi Sign Language Image Dataset)四、COCO-Tasks五、Deep PCB (Deep Printed Circuit Board)5.1 DeepPCB:5.2 Dataset Description5.2.1 Image Collection5.2.2 Image Annotation5.2.3 Benchmarks…

基于Yolov8的中国交通标志(CCTSDB)识别检测系统
目录
1.Yolov8介绍
2.纸箱破损数据集介绍
2.1数据集划分
2.2 通过voc_label.py得到适合yolov8训练需要的
2.3生成内容如下
3.训练结果分析 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的&…
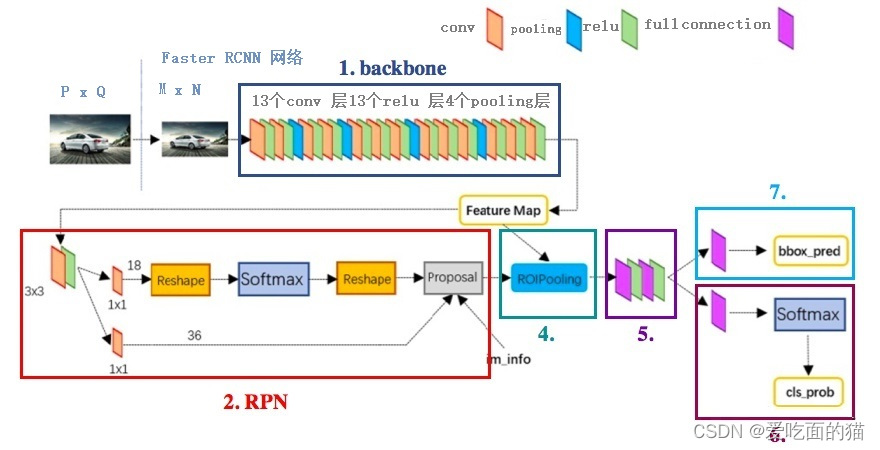
04目标检测-Two-stage的目标检测算法
一、 深度学习目标检测算法介绍 第二篇我们介绍了目标检测中传统的算法和目标检测的方式,第三篇我们对传统的目标检测算法和深度学习目标检测算法简单做了比较,此篇记录了深度学习目标检测算法内容,深入讲述一下深度学习算法在目标检测的原理…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(9 月 12 日论文合集)
文章目录 一、检测相关(13篇)1.1 An Effective Two-stage Training Paradigm Detector for Small Dataset1.2 CitDet: A Benchmark Dataset for Citrus Fruit Detection1.3 On the detection of Out-Of-Distribution samples in Multiple Instance Learning1.4 Zero-Shot Co-sa…
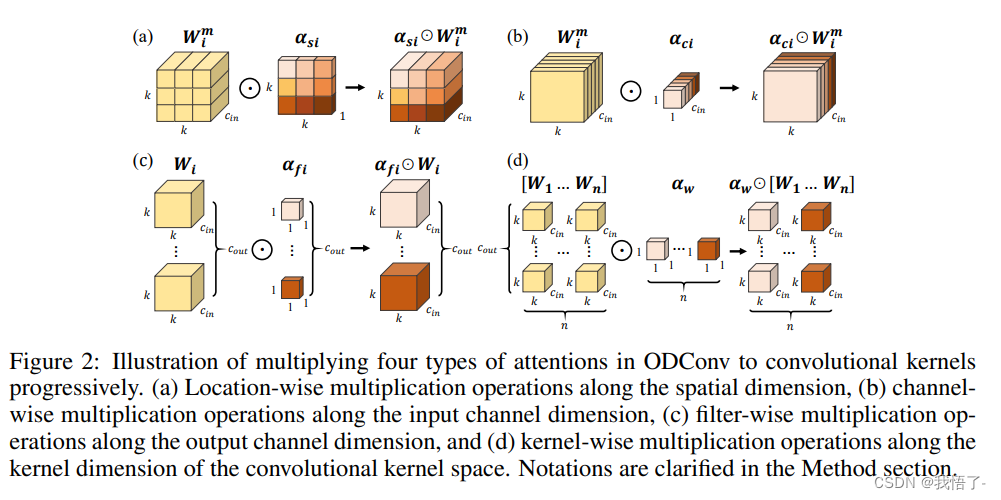
pytorch代码实现之动态卷积模块ODConv
ODConv动态卷积模块
ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度…
戴口罩 目标检测数据集-12000张
今天要介绍的数据集则是戴口罩 目标检测数据集:
数据集名称:戴口罩 目标检测数据集
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):以…

基于Yolov8的野外烟雾检测(2):多维协作注意模块MCA,效果秒杀ECA、SRM、CBAM等 | 2023.9最新发布
目录 1.Yolov8介绍
2.野外火灾烟雾数据集介绍
3.MCA介绍 4.训练结果分析
5.系列篇 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前…
(二十八)mmdetection实用工具: Visualization
目录 一、基础绘制接口二、基础存储接口三、任意点位进行可视化 一、基础绘制接口
可视化器(Visualizer):可视化器负责对模型的特征图、预测结果和训练过程中产生的结构化日志进行可视化,支持 Tensorboard 和 WanDB 等多种可视化…

基于PyTorch搭建FasterRCNN实现目标检测
基于PyTorch搭建FasterRCNN实现目标检测
1. 图像分类 vs. 目标检测 图像分类是一个我们为输入图像分配类标签的问题。例如,给定猫的输入图像,图像分类算法的输出是标签“猫”。
在目标检测中,我们不仅对输入图像中存在的对象感兴趣。我们还…
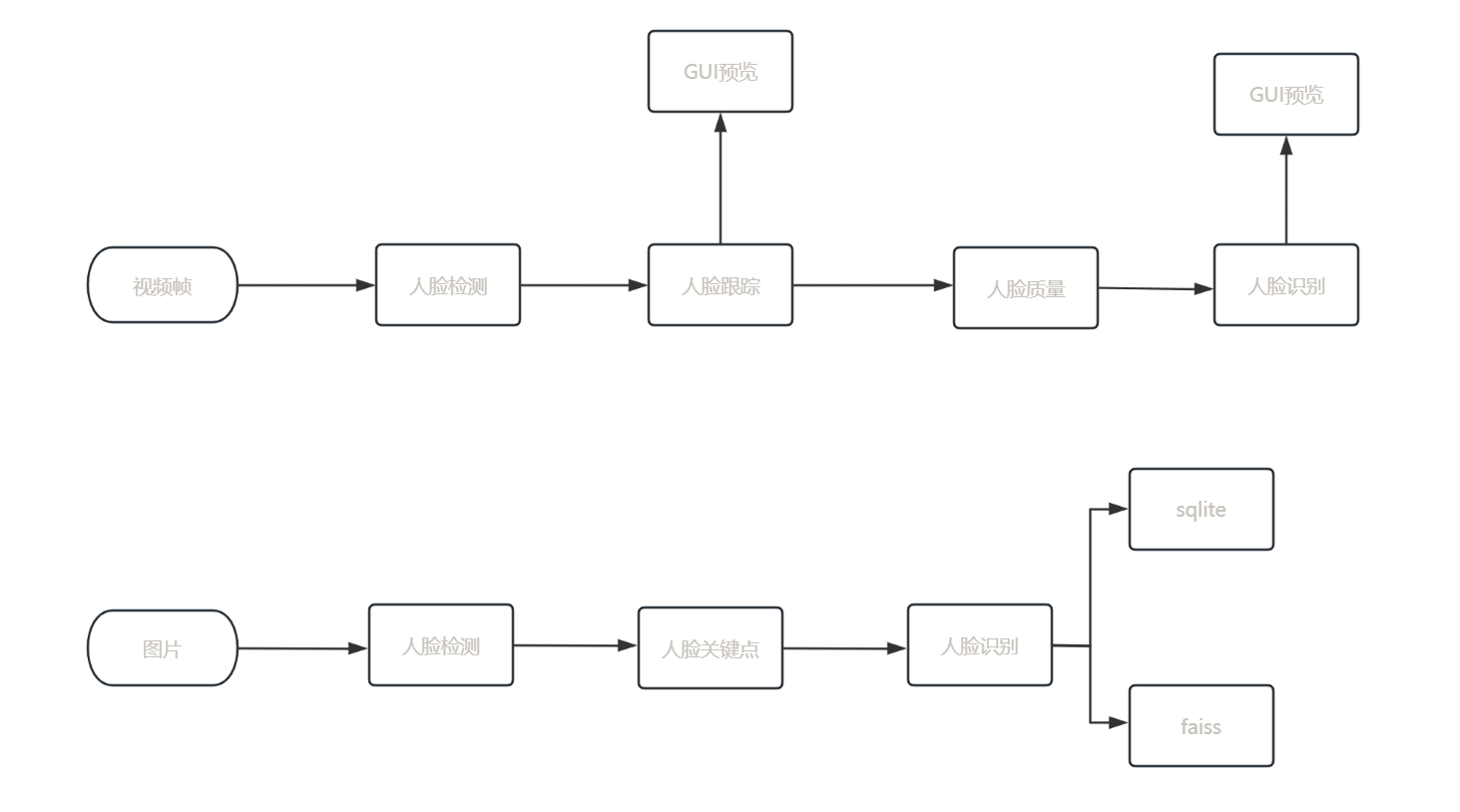
基于开源模型的实时人脸识别系统(九):软件说明
续 人脸识别_CodingInCV的博客-CSDN博客 文章目录 前言简介模型选择的要求总体流程图人脸检测人脸跟踪人脸质量人脸关键点人脸识别代码结构人脸识别的逻辑高阶设置 前言
前面的文章我们介绍了整个系统里的关键步骤,基于这些步骤我们就可以搭建出属于自己的人脸识别…

第1篇 目标检测概述 —(1)目标检测基础知识
前言:Hello大家好,我是小哥谈。目标检测是计算机视觉领域中的一项任务,旨在自动识别和定位图像或视频中的特定目标,目标可以是人、车辆、动物、物体等。目标检测的目标是从输入图像中确定目标的位置,并使用边界框将其标…
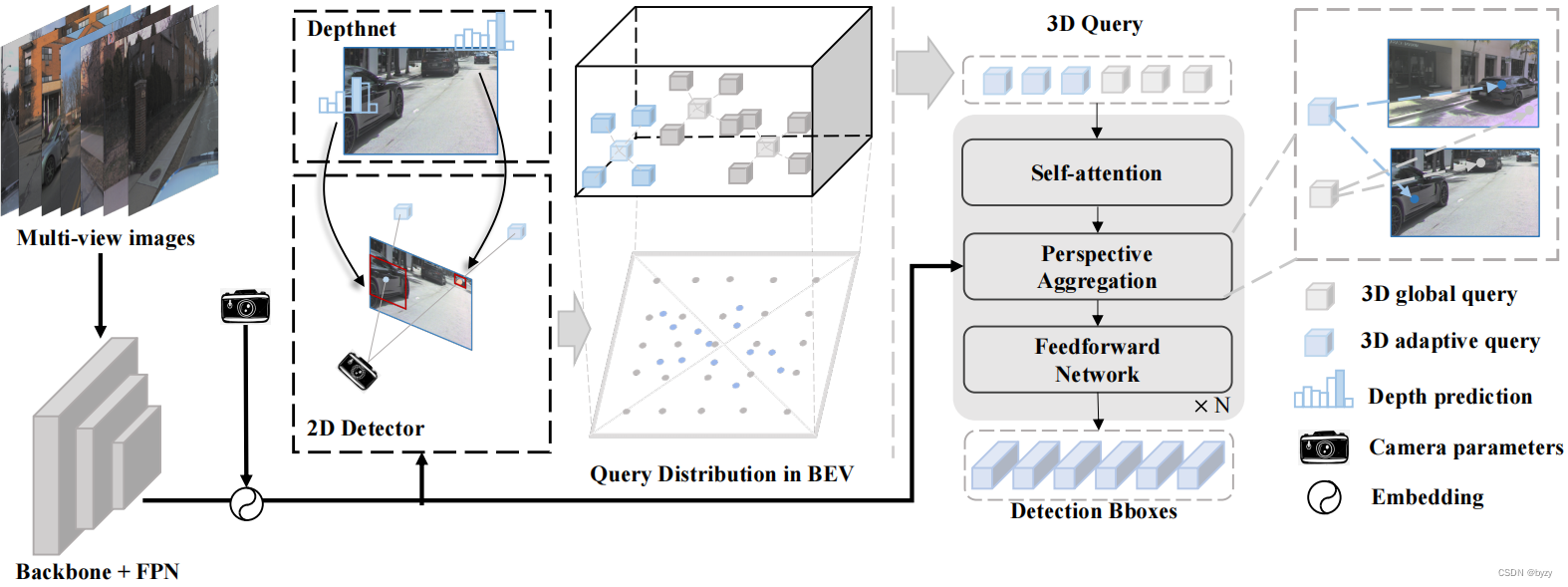
【论文笔记】Far3D: Expanding the Horizon for Surround-view 3D Object Detection
原文链接:https://arxiv.org/pdf/2308.09616.pdf
1. 引言
目前的环视图图像3D目标检测方法分为基于密集BEV的方法和基于稀疏查询的方法。前者需要较高的计算量,难以扩展到长距离检测。后者全局固定的查询不能适应动态场景,通常会丢失远距离…
YOLOV8目标检测——模型训练
文章目录 1下载yolov8([网址](https://github.com/ultralytics/ultralytics))2用pycharm打开文件3训练自己的YOLOV8数据集4run下运行完了之后没有best.pt文件5导出为onnx文件 本章内容主要解决如何训练自己的YOLOV8模型。 1下载yolov8(网址&a…

YOLO目标检测——密集人群人头检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:在公共场所,如车站、商场、景区等,可以通过人头目标检测技术来监测人群流量数据集说明:人头检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注…
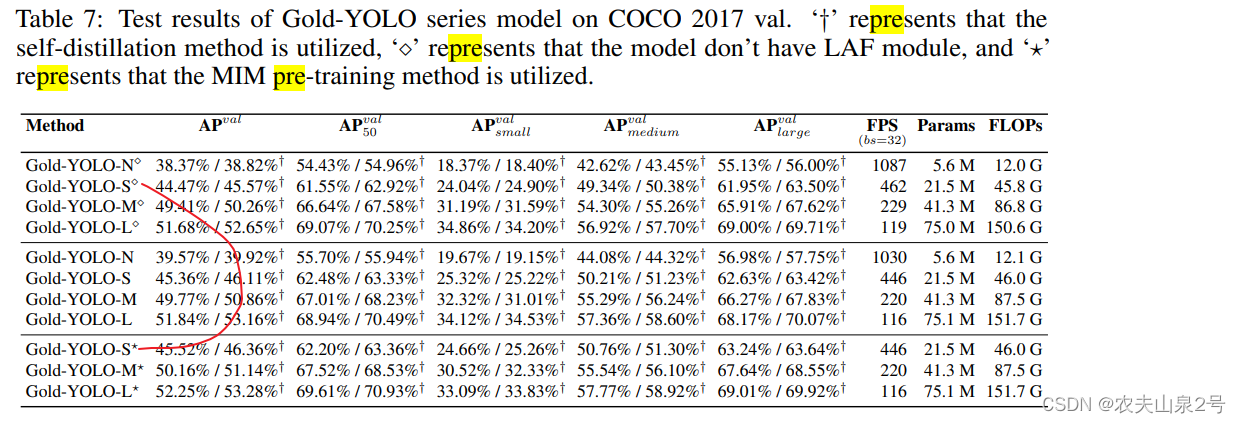
【目标检测】——Gold-YOLO为啥能超过YOLOV8
华为 https://arxiv.org/pdf/2309.11331.pdf 文章的出发点:FPN中的信息传输问题 1. 简介
基于全局信息融合的概念,提出了一种新的收集和分发机制(GD),用于在YOLO中进行有效的信息交换。通过全局融合多层特征并将全局信…
目标检测如何演变:从区域提议和 Haar 级联到零样本技术
目录
一、说明
二、目标检测路线图
2.1 路线图(一般)
2.2 路线图(更传统的方法)
2.3 路线图(深度学习方法)
2.4 对象检测指标的改进
三、传统检测方法
3.1 维奥拉-琼斯探测器 (2001)
3.2 HOG探测器…
4.迭代最近点ICP及非线性优化求解
使用非线性优化方法求解ICP 文章目录 使用非线性优化方法求解ICP前情提要ICP问题回顾对矩阵变量求导数 ICP问题的非线性解法代码示例 欢迎访问个人网络日志🌹🌹知行空间🌹🌹 前情提要
在迭代最近点算法ICP及SVD求解中介绍了ICP问…
FastestDet---原理介绍
1.测试指标 2.算法定位 FastestDet是设计用来接替yolo-fastest系列算法,相比于业界已有的轻量级目标检测算法如yolov5n, yolox-nano, nanoDet, pp-yolo-tiny, FastestDet和这些算法根本不是一个量级,FastestDet无论在速度还是参数量上,都是要小好几个数量级的,但是精度自然…
基于YOLOv8模型的蜜蜂目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的蜜蜂目标检测系统可用于日常生活中检测与定位蜜蜂目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…

YOLOv5算法改进(20)— 如何去写YOLOv5相关的论文(包括论文阅读+规律总结+写作方法)
前言:Hello大家好,我是小哥谈。最近一直在阅读关于YOLOv5的相关论文,读着读着我发现一条可以发论文的规律,特此简单总结一下,希望能够对同学们有所启迪!🌈 前期回顾: YOLOv5算法改进(1)— 如何去改进YOLOv5算法

YOLOV7改进-添加基于注意力机制的目标检测头(DYHEAD)
DYHEAD 复制到这: 1、models下新建文件 2、yolo.py中import一下 3、改IDetect这里 4、论文中说6的效果最好,但参数量不少,做一下工作量 5、在进入IDetect之前,会对RepConv做卷积 5、因为DYHEAD需要三个层输入的特征层一致&am…
目标检测网络系列——YOLO V1
文章目录 One Stage DectectionYOLO网络正向预测pipline反向传播过程理解grid和grid对应的B个预测框YOLO网络的限制对比实验与其他的real-time detection的对比VOC 2007数据集的错误分析YOLO和Fast RCNN的集成学习VOC 2012数据集结果YOLO模型的泛化性DEMOOne Stage Dectection …
看看谁还在看目标检测算法
🚀 作者 :“码上有钱”
🚀 文章简介 :AI-目标检测算法
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬简介
目标检测是计算机视觉领域的一个重要任务,它的目标是在图像或视频中识别并定位…
测试专项笔记(一): 通过算法能力接口返回的检测结果完成相关指标的计算(目标检测)
文章目录 一、任务描述二、指标分析2.1 TP/FP/FN/TN2.2 精准率2.3 召回率 三、接口处理四、数据集处理五、开始计算指标五、实用工具5.1 移动文件5.2 可视化JSON标签5.3 可视化TXT标签 一、任务描述
通过给定的算法接口,对算法的输出(置信度、检测框、告…
YOLOv5独家最新改进《新颖高效AsDDet检测头》VisDrone数据集mAP涨点1.4%,即插即用|检测头新颖改进,性能高效涨点
💡本篇内容:YOLOv5独家最新改进《新颖高效AsDDet检测头》VisDrone数据集mAP涨点1.4%,即插即用|检测头新颖改进,性能高效涨点
💡🚀🚀🚀本博客 YOLO系列 + 全新新颖原创高效AsDDet检测头
改进创新点改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可…
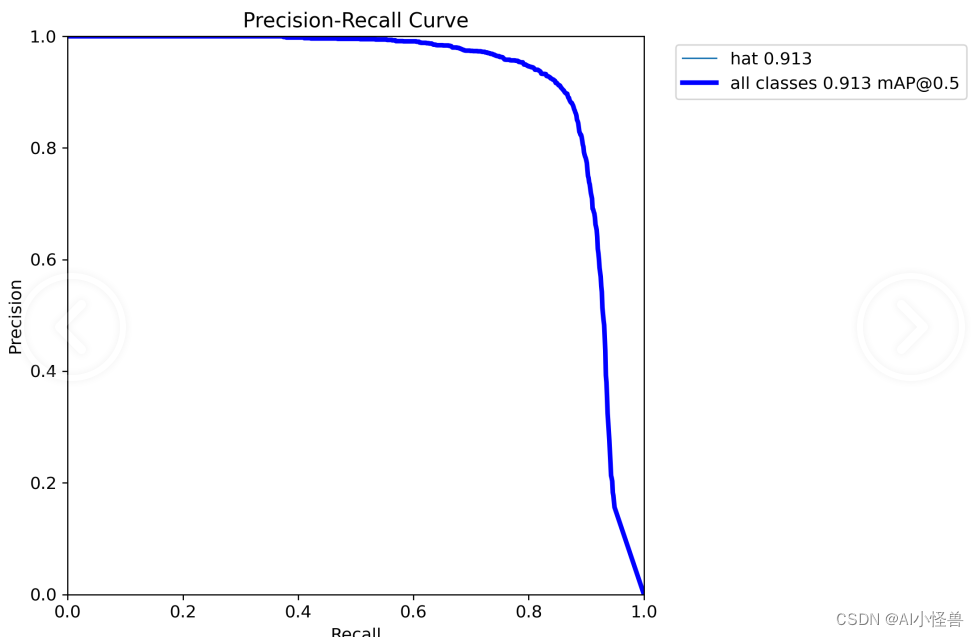
基于YOLOv8的安全帽检测系统(2):Gold-YOLO,遥遥领先,助力行为检测 | 华为诺亚NeurIPS23
目录 1.Yolov8介绍
2.安全帽数据集介绍
3.Gold-YOLO
4.训练结果分析 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功基础上…
LSKNet:大选择核网络在遥感目标检测中的应用
摘要
论文链接:https://arxiv.org/pdf/2303.09030.pdf 最近关于遥感目标检测的研究主要集中在改进有向边界框的表示,但忽略了遥感场景中呈现的独特先验知识。这种先验知识很有用,因为如果没有参考足够远的上下文,可能会错误地检测到微小的遥感对象,而不同类型对象所需的远…

YOLOv8轻量化模型:DCNV3结合c2f | CVPR2023
💡💡💡本文解决什么问题:模型轻量化创新引入CVPR20023 DCNV3,基于DCNv2算子,重新设计调整并提出DCNv3算子
DCNV3和C2f结合 | 轻量化的同时在数据集并有小幅涨点;
YOLO轻量化模型专栏:http://t.csdnimg.cn/AeaEF
1.InternImage介绍
论文:…
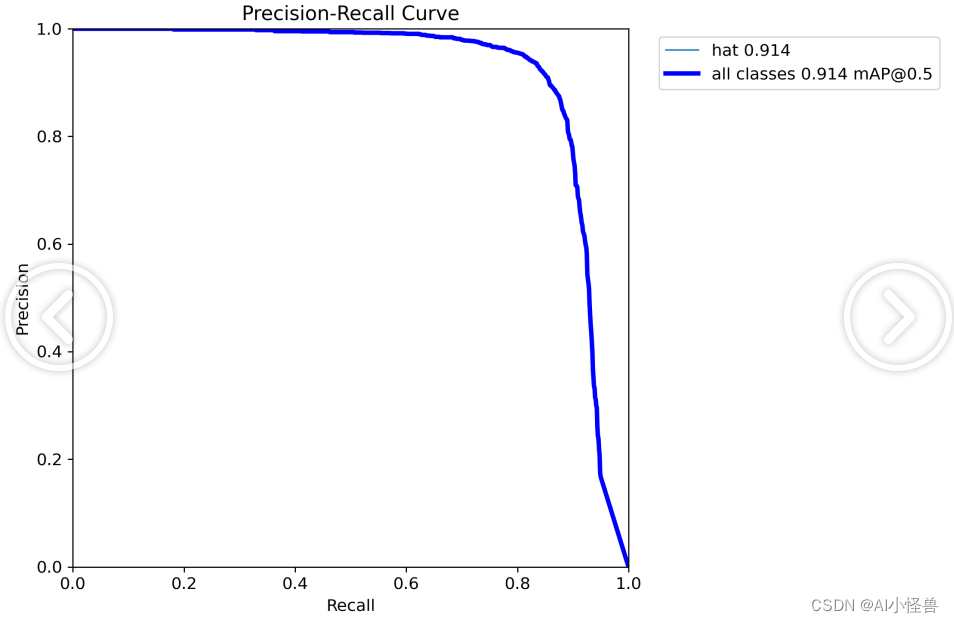
基于YOLOv8的安全帽检测系统(4):EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA,助力行为检测 | ICASSP2023
目录 1.Yolov8介绍
2.安全帽数据集介绍
3.EMA介绍
4.训练结果分析
5.系列篇 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO…
few shot object detection via feature reweight笔记
摘要部分
few shot很多用的都是faster R-CNN为基础,本文用的是one-stage 结构。 用了一个meta feature learner和reweighting模块。 和其他的few shot一样,先学习base数据集,再推广到novel数据集。 feature learner会从base数据集中提取meta…
YOLOv7改进:SPD-Conv,低分辨率图像和小物体涨点明显,涨点神器!!!
💡💡💡本文属于原创独家改进:SPD-Conv,优势:处理低分辨率图像和小物体等更困难的任务时性能更优
SPD-Conv | 亲测在多个数据集实现暴力涨点,尤其是小物体检测你值得拥有,强烈推荐,独家首发; 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨…
移动电源被亚马逊下架怎么办?UL2056认证解析
亚马逊下架移动电源isting突然被下架了,这到底怎么回事?移动电源UL2056认证怎么做? 卖家随后就咨询客服客服原因: 亚马逊在4月25日开始实行对于充电宝品类产品的销售限制。发布此限制的原因是基于安全因素:锂离子便携式…
AFPN:用于目标检测的渐近特征金字塔网络
文章目录 摘要1、介绍2、相关工作3、渐进特征金字塔网络4、实验5、结论摘要
在目标检测任务中, 多尺度特征在编码具有尺度方差的 目标方面具有重要意义。 多尺度特征提取的一种常见策略是采用经 典的自上而下和自下而上的特征金字塔网络。 然而, 这些方法存在 特征信息丢失或…
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
今天跟大家分享华南理工大学和阿里巴巴联合提出的将ViT模型用于下游任务的高效微调方法HSN,该方法在迁移学习、目标检测、实例分割、语义分割等多个下游任务中表现优秀,性能接近甚至在某些任务上超越全参数微调。 论文标题:Hierarchical Side…

YOLOv5算法改进(19)— Neck网络介绍(AFPN和BiFPN)
前言:Hello大家好,我是小哥谈。Neck网络是目标检测中的一个重要组成部分,主要用于对检测器提取的特征进行进一步处理和融合,以提高检测精度。通常,Neck网络由一系列卷积层、池化层、上采样层等组成,可以将不同层次的特征进行融合,同时也可以对特征进行降维和升维操作。本…

YOLOv5算法改进(4)— 如何去添加SE注意力机制(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。注意力机制可被应用于模型的不同层级,以便更好地捕捉图像中的细节和特征,这种模型在计算资源有限的情况下,可以实现更好的性能和效率。…

yolov7改进优化之蒸馏(一)
最近比较忙,有一段时间没更新了,最近yolov7用的比较多,总结一下。上一篇yolov5及yolov7实战之剪枝_CodingInCV的博客-CSDN博客 我们讲了通过剪枝来裁剪我们的模型,达到在精度损失不大的情况下,提高模型速度的目的。上一…

openvino系列教程之人脸检测 mobilenetv2
OpenVINO(开放式视觉推理和神经网络优化)是英特尔推出的一款用于加速计算机视觉应用开发的软件。它基于英特尔的深度学习技术,提供了一套完整的工具链,包括模型优化器、运行时库等,帮助开发者快速实现高性能的计算机视…
儿童带磁性写字板入驻亚马逊CPC认证怎么做?CPC认证是什么样子的解析
儿童卡通画板磁性写字板 婴幼儿1-3岁涂鸦绘画手写彩色画板桌玩具 。儿童带磁性写字板上架亚马逊需办理CPC认证。
一、Childrens product certificate是什么? 从去年开始,美国亚马逊平台开始严查儿童类目下的产品,让亚马逊商家人心惶惶&#…

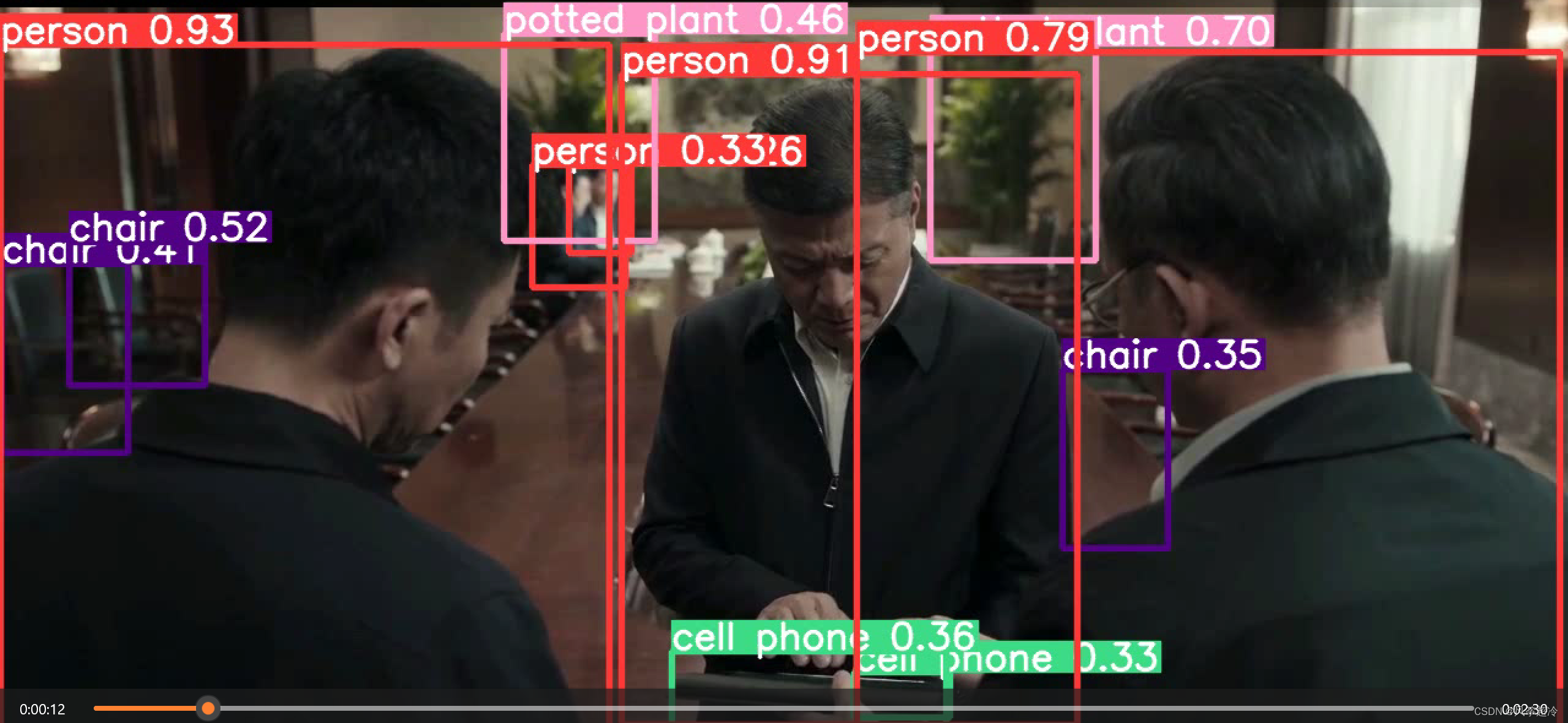
YOLOv5-调用官方权重进行检验(目标检测)
🍨 本文为[🔗365天深度学习训练营学习记录博客 🍦 参考文章:365天深度学习训练营-第7周:咖啡豆识别(训练营内部成员可读) 🍖 原作者:[K同学啊 | 接辅导、项目定制](https…

YOLOv8改进实战 | 更换主干网络Backbone(三)之轻量化模型ShuffleNetV2
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法:
网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个…

Python合并同类别且相交的矩形框
Python合并同类别且相交的矩形框 前言前提条件相关介绍实验环境Python合并同类别且相交的矩形框代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入Python日常小操作专栏、YOLO系列专栏、自然语言处理专栏或…

YOLOv5算法改进(14)— 如何去更换主干网络(3)(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。为了给后面YOLOv5算法的进阶改进奠定基础,本篇文章就继续通过案例的方式给大家讲解如何在YOLOv5算法中更换主干网络,本篇文章的特色就是比较浅显易懂,附加了很多的网络结构图,通过结构图的形式向大家娓娓道来,希望大家学习之后能够有所收获…
基于局部特征技术的航拍绝缘子图像检测和配准技术的研究
输电线路担负着电力传输的重要职责,对输电线路的定期巡检是有效保证输电线路及其设备安全运行的一项基础性工作。传统人工巡检的作业方式,越来越受到自然条件的限制,无法满足实际的需要。采用直升机或无人机输电线路巡检方式具有高效、快捷、…
【目标检测】Co-DETR:ATSS+Faster RCNN+DETR协作的先进检测器(ICCV 2023)
论文:DETRs with Collaborative Hybrid Assignments Training 代码**:https://github.com/Sense-X/Co-DETR 文章目录 摘要一、简介二、本文方法2.1.概述2.2.协同混合分配训练2.3. 定制的正 Query 生成2.4. Co-DETR为何有效1、丰富编码器的监督2、通过减少…

YOLOv5算法改进(15)— 如何去更换Neck网络(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。在学习完了如何去更换主干网络之后,接着就让我们通过案例的方式去学习下如何去更换Neck网络。本篇文章的特色就是比较浅显易懂,附加了很多的网络结构图,通过结构图的形式向大家娓娓道来,希望大家学习之后能够有所收获!🌈 前期回顾: YO…

目标检测 YOLOv5 预训练模型下载方法
目标检测 YOLOv5 预训练模型下载方法
flyfish
https://github.com/ultralytics/yolov5
https://github.com/ultralytics/yolov5/releases 可以选择自己需要的版本和不同任务类型的模型 后缀名是pt

YOLOv5算法改进(21)— 添加CA注意力机制 + 更换Neck网络之BiFPN + 更换损失函数之EIoU
前言:Hello大家好,我是小哥谈。通过上节课的学习,相信同学们一定了解了组合改进的核心。本节课开始,就让我们结合论文来对YOLOv5进行组合改进(添加CA注意力机制+更换Neck网络之BiFPN+更换损失函数之EIoU),希望同学们学完本节课可以有所启迪,并且后期可以自行进行YOLOv5…
经典目标检测神经网络 - RCNN、SSD、YOLO
文章目录 1. 目标检测算法分类2. 区域卷积神经网络2.1 R-CNN2.2 Fast R-CNN2.3 Faster R-CNN2.4 Mask R-CNN2.5 速度和精度比较 3. 单发多框检测(SSD)4. YOLO 1. 目标检测算法分类
目标检测算法主要分两类:One-Stage与Two-Stage。One-Stage与…
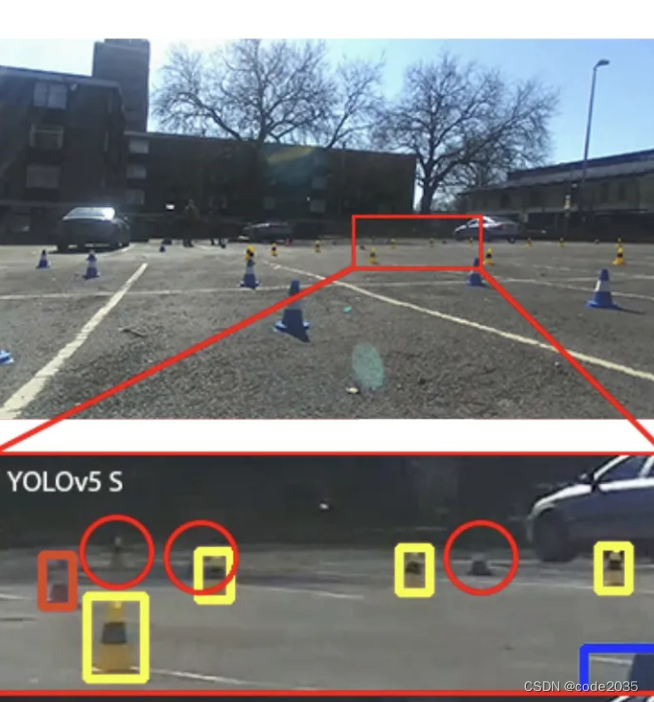
Yolo-Z:改进的YOLOv5用于小目标检测
目录
一、前言
二、背景
三、新思路
四、实验分析 论文地址:2112.11798.pdf (arxiv.org)
一、前言
随着自动驾驶汽车和自动驾驶赛车越来越受欢迎,对更快、更准确的检测器的需求也在增加。
虽然我们的肉眼几乎可以立即提取上下文信息,即…

独创改进 | RT-DETR 引入 Asymptotic Hybrid Encoder | 渐进混合特征解码结构
本专栏内容均为博主独家全网首发,未经授权,任何形式的复制、转载、洗稿或传播行为均属违法侵权行为,一经发现将采取法律手段维护合法权益。我们对所有未经授权传播行为保留追究责任的权利。请尊重原创,支持创作者的努力,共同维护网络知识产权。 文章目录 网络结构实验结果…

改进YOLOv3!IA-YOLO:恶劣天气下的目标检测
恶劣天气条件下从低质量图像中定位目标还是极具挑战性的任务。现有的方法要么难以平衡图像增强和目标检测任务,要么往往忽略有利于检测的潜在信息。本文提出了一种新的图像自适应YOLO (IA-YOLO)框架,可以对每张图像进行自适应增强,以提高检测…
YOLOv5改进之实验结果(四):将多种算法的Loss精度曲线图绘制到一张图上,便于YOLOv5系列模型对比实验获取更多精度数据,丰富实验数据
💡该教程为改进YOLO高阶指南,属于《芒果书》📚系列,包含大量的原创首发改进方式🚀 💡更多改进内容📚可以点击查看:YOLOv5改进、YOLOv7改进、YOLOv8改进、YOLOX改进原创目录 | 老师联袂推荐🏆 💡🚀🚀🚀本博客内含改进源代码,按步骤操作运行改进后的代码…
优化改进YOLOv5算法:加入SPD-Conv模块,让小目标无处遁形——(超详细)
1 SPD-Conv模块
论文:https://arxiv.org/pdf/2208.03641v1.pdf
摘要:卷积神经网络(CNNs)在计算即使觉任务中如图像分类和目标检测等取得了显著的成功。然而,当图像分辨率较低或物体较小时,它们的性能会灾难性下降。这是由于现有CNN常见的设计体系结构中有缺陷,即使用卷积…
Octave Convolution学习笔记 (附代码)
论文地址:https://export.arxiv.org/pdf/1904.05049
代码地址:https://gitcode.com/mirrors/lxtgh/octaveconv_pytorch/overview?utm_sourcecsdn_github_accelerator
1.是什么?
OctaveNet网络属于paper《Drop an Octave: Reducing Spatia…
目标检测新思路:DETR
Transformer是一种基于自注意力机制的神经网络架构,它能够从序列中提取重要信息,已被广泛应用于自然语言处理和语音识别等领域。随着Transformer的提出和发展,目标检测领域也开始使用Transformer来提高性能。 DETR是第一篇将Transformer应用于…
![单目3D目标检测[基于深度辅助篇]](https://img-blog.csdnimg.cn/d525c0bc93284695aa8c78cf1e9e521a.png)
单目3D目标检测[基于深度辅助篇]
基于深度辅助的方法
1. Pseudo-LiDAR
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving康奈尔大学https://zhuanlan.zhihu.com/p/52803631 首先利用DRON或PSMNET从单目 (Monocular)或双目 (Stereo)图像获取对应的…

Fast RCNN 目标检测网络学习记录 (附代码)
论文地址:https://arxiv.org/abs/1504.08083
代码地址:https://github.com/rbgirshick/fast-rcnn
1.是什么?
Fast RCNN是目标检测领域的一个算法框架,是RCNN的改进版。Fast RCNN的主要目的是解决RCNN算法中的瓶颈问题ÿ…
跨境出口亚马逊美国和加拿大市场水基灭火器UL测试报告审核解析
水基灭火器(Foam extinguisher),为绿色外观的灭火器,其灭火器机理为物理性灭火器原理,其主要成分包括碳氢表面活性剂、氟碳表面活性剂、阻燃剂和助剂等。水基灭火器出口需办理UL测试报告。
消防及其他安全用品
本政策…
基于YOLOv8模型的烟雾目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的烟雾目标检测系统可用于日常生活中检测与定位烟雾目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…
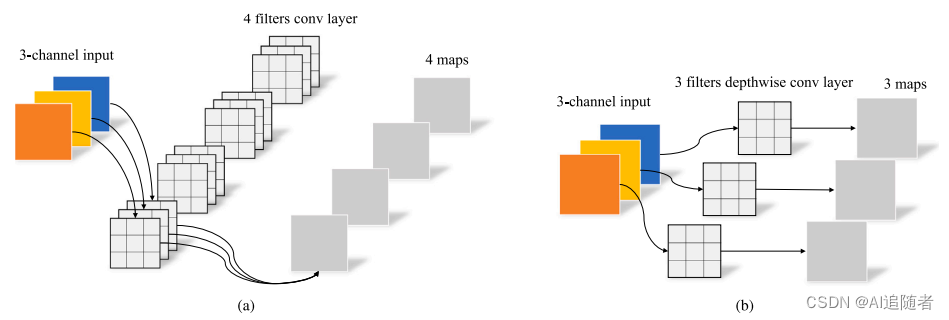
优化改进YOLOv5算法:加入ODConv+ConvNeXt提升小目标检测能力——(超详细)
为了提升无人机视角下目标检测效果,基于YOLOv5算法,在YOLOv5主干中实现了Omnidimensional Convolution(ODConv),以在不增加网络宽度和深度的情况下提高精度,还在YOLOv5骨干网中用ConvNeXt块替换了原始的C3块,以加快检测速度。 1 Omni-dimensional dynamic convolution
…
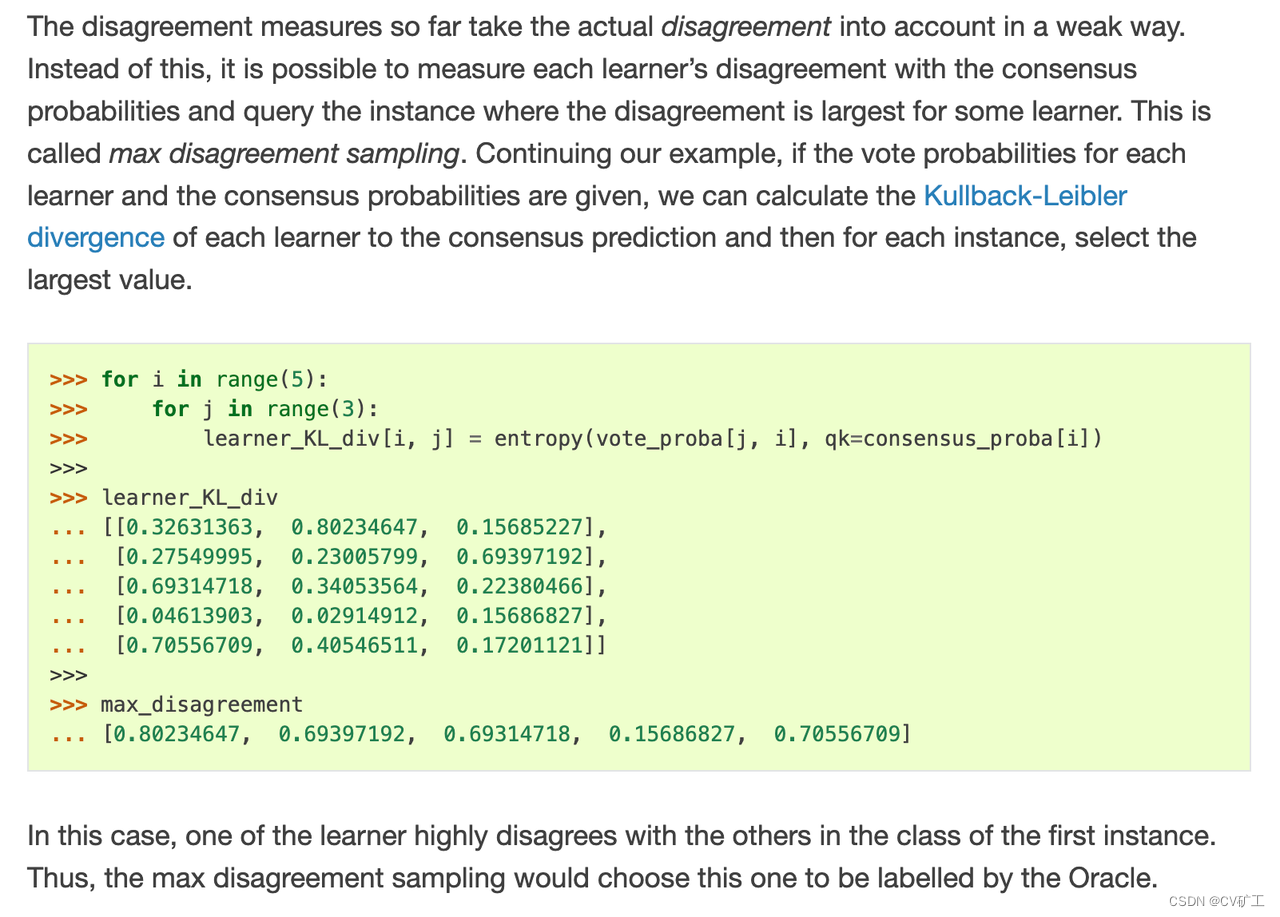
Active learning Tiny Review for autonomous driving
Introduction
阅读某一特定主题的一本书不会使你成为专家,阅读多本包含相似内容的书也不会。真正掌握一项技能或领域的知识需要来自多样化信息源的大量信息。 这对于自动驾驶和其他人工智能技术同样适用。 负责自动驾驶功能的深度神经网络需要经过详尽的训练&#…
![[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)](https://img-blog.csdnimg.cn/2d10cf012dfd44f3afc52db18d40ae65.png)
[论文阅读]Point Density-Aware Voxels for LiDAR 3D Object Detection(PDV)
PDV
Point Density-Aware Voxels for LiDAR 3D Object Detection 论文网址:PDV 论文代码:PDV
简读论文
摘要
LiDAR 已成为自动驾驶中主要的 3D 目标检测传感器之一。然而,激光雷达的发散点模式随着距离的增加而导致采样点云不均匀&#x…
![[论文阅读]MVF——基于 LiDAR 点云的 3D 目标检测的端到端多视图融合](https://img-blog.csdnimg.cn/7efb7e02d08042d99ff4171bcccfec9d.png)
[论文阅读]MVF——基于 LiDAR 点云的 3D 目标检测的端到端多视图融合
MVF
End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds 论文网址:MVF 论文代码:
简读论文
这篇论文提出了一个端到端的多视角融合(Multi-View Fusion, MVF)算法,用于在激光雷达点云中进行3D目标检测。论文的主要贡献有两个…
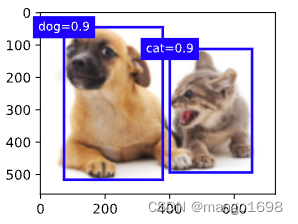
目标检测及锚框、IoU
1. 目标检测
物体检测(目标检测)是计算机视觉和数字图像处理的热门方向,意在判断一幅图像上是否存在感兴趣物体,并给出物体分类及位置等(What and Where)。本文主要进行物体检测研究背景、发展脉络、相关算…

YOLOv5-6.1源码详解之损失函数loss.py
目录
1 目标检测结果精确度的度量
2 YOLOv5-6.1损失函数
2.1 classification类别损失
2.2 confidence置信度损失
2.3 localization定位损失
3 YOLOv5-6.1损失函数loss.py代码解析
3.1 class ComputeLoss
3.1.1 __init__
3.1.2 build_targets
3.1.3 _call__
3.2 smo…
韩语图片文字如何转为纯文本?
如何将上图为韩语的图片转为文本文件?这个需要用到OCR程序,操作方法如下:
一、打开金鸣识别网站。 二、点击“点击添加图片/PDF”,将待识别的图片添加到列表。
三、识别模块点选“通用文字”,输出格式选择“纯文本输…
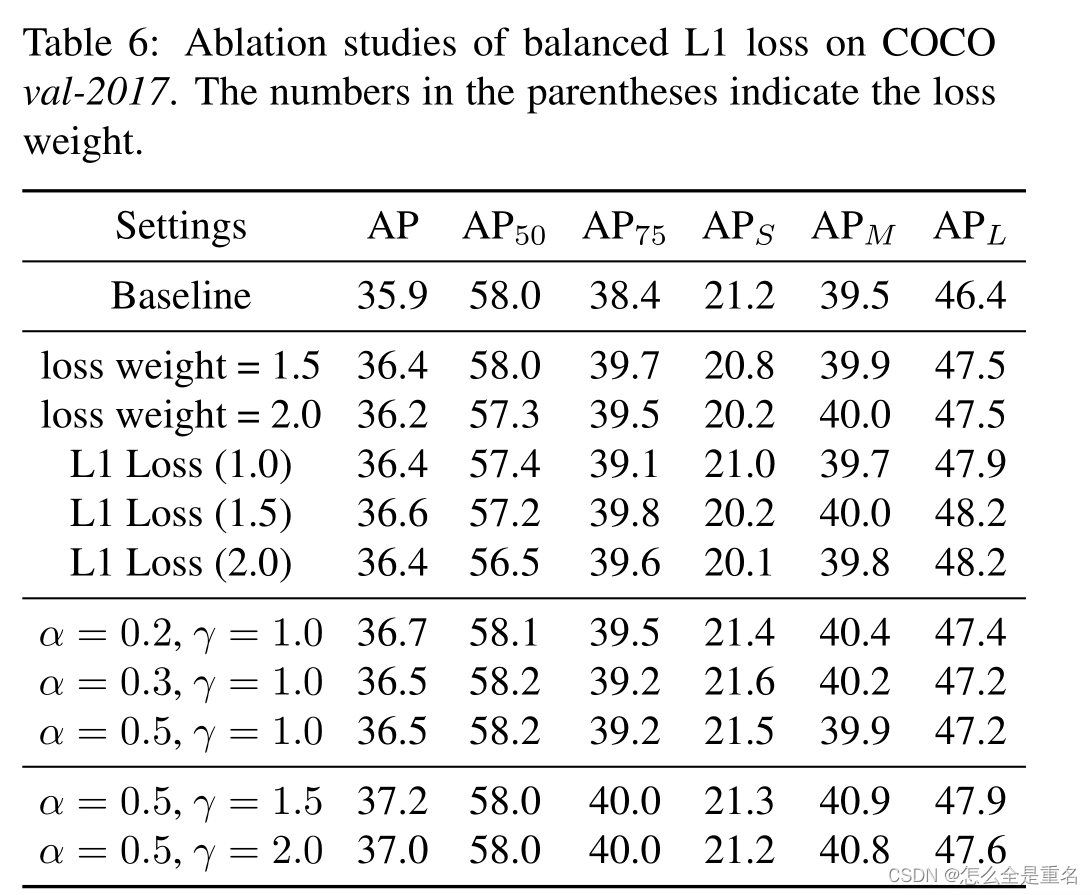
Libra R-CNN: Towards Balanced Learning for Object Detection(2019.4)
文章目录 AbstractIntroduction引入问题1) Sample level imbalance2) Feature level imbalance3) Objective level imbalance进行解决贡献 Related Work(他人的work,捎带与我们的对比)Model architectures for object detection&a…
划分VOC数据集,以及转换为划分后的COCO数据集格式
1.VOC数据集 LabelImg是一款广泛应用于图像标注的开源工具,主要用于构建目标检测模型所需的数据集。Visual Object Classes(VOC)数据集作为一种常见的目标检测数据集,通过labelimg工具在图像中标注边界框和类别标签,为…

目标检测最新创新点: EMS-YOLO:首个用于目标检测的直接训练脉冲神经网络
EMS-YOLO:第一个用于目标检测的深度直接训练脉冲神经网络,首次使用代理梯度训练深度 SNN 进行检测,并设计全脉冲残差块EMS-ResNet,代码刚刚开源!单位:国科大, 西安交大, 清华, 北大, 华为
脉冲神经网络 (S…

使用双动态令牌混合器学习全局和局部动态以进行视觉识别
TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition 1、问题与解决2、引言3、方法3.1 双动态令牌混合器(D- Mixer)3.2 IDConv(Input-dependent Depthwise Convolution)3.3 Overlapping Spatial Reduction Attention …
目标检测算法改进系列之添加EIOU,SIOU,AlphaIOU,FocalEIOU等
YOLOv8添加EIoU,SIoU,AlphaIoU,FocalEIoU,Wise-IoU等
yolov8中box_iou其默认用的是CIoU,其中代码还带有GIoU,DIoU,文件路径:ultralytics/yolo/utils/metrics.py,函数名为:bbox_iou
原始代码
def bbox_i…
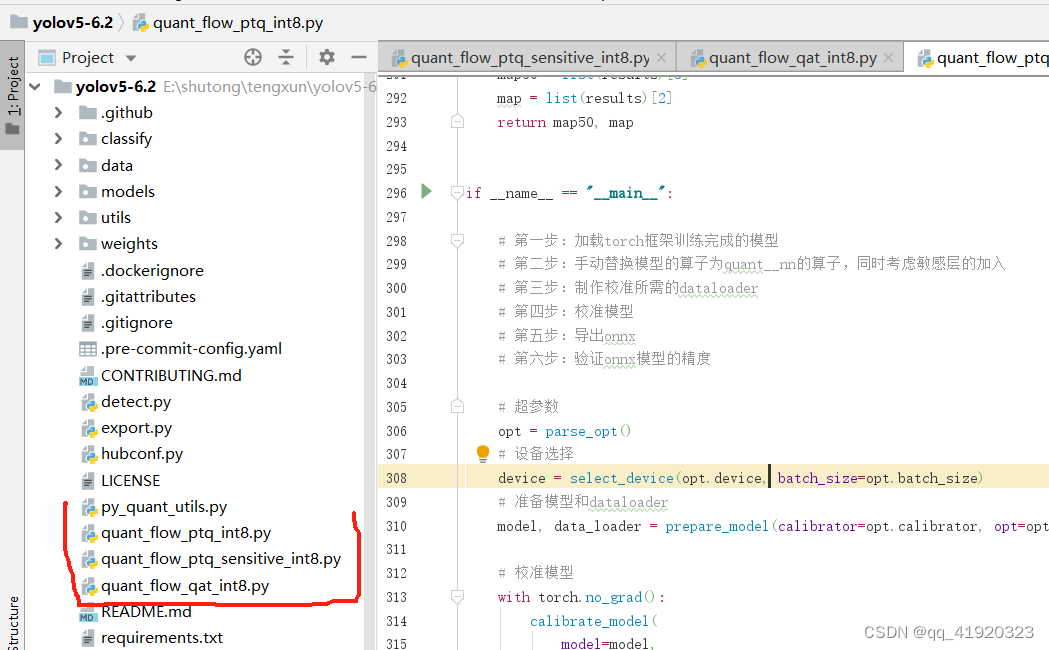
yolov5的ptq量化流程
本次试验是基于yolov5n的模型进行ptq、qat的量化以及敏感层分析的试验。 Post-Training-Quantization(PTQ)是目前常用的模型量化方法之一。以INT8量化为例,PTQ处理流程如下: 首先在数据集上以FP32精度进行模型训练,得到训练好的baseline模型; 使用小部分数据对FP32 basel…
YOLOv8芒果独家首发 | 改进新主干:改进版目标检测新范式骨干PPHGNetv2,百度出品,提升YOLOv8检测能力
💡本篇内容:YOLOv8改进新主干:目标检测新范式骨干PPHGNetv2改进版,百度出品,提升YOLOv8检测能力
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv8专属,充分结合YOLOv8和 PPHGNetv…
实力验证 | 求臻医学满分通过CAP及NCCL组织的国内外三项室间质评
近日,求臻医学以满分的优异成绩通过了由美国病理学家协会(College of American Pathologists,CAP)组织的NGS−A 2023:Next−Generation Sequencing (NGS) – Germline、NEO-B 2023 Neoplastic Cellularity能力验证项目…
目标检测 图像处理 计算机视觉 工业视觉
目标检测 图像处理 计算机视觉 工业视觉 工业表盘自动识别(指针型和数值型)智能水尺识别电梯中电动车识别,人数统计缺陷检测(半导体,电子元器件等)没带头盔检测基于dlib的人脸识别抽烟检测和睡岗检测/驾驶疲…

YOLOv7优化:独家创新(Partial_C_Detect)检测头结构创新,实现涨点 | 检测头新颖创新系列
💡💡💡本文独家改进:独家创新(Partial_C_Detect)检测头结构创新,适合科研创新度十足,强烈推荐
SC_C_Detect | 亲测在多个数据集能够实现大幅涨点 收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现
🚀🚀🚀YOLO…
Windows环境下使用VLC获取到大疆无人机的RTMP直播推流
1.环境准备
1.安装nginx 1.7.11.3 Gryphon
下载地址:http://nginx-win.ecsds.eu/download/
下载nginx 1.7.11.3 Gryphon.zip,解压后修改文件夹名称为nginx-1.7.11.3-Gryphon; 2.安装nginx-rtmp-module
下载地址:GitHub - arut…
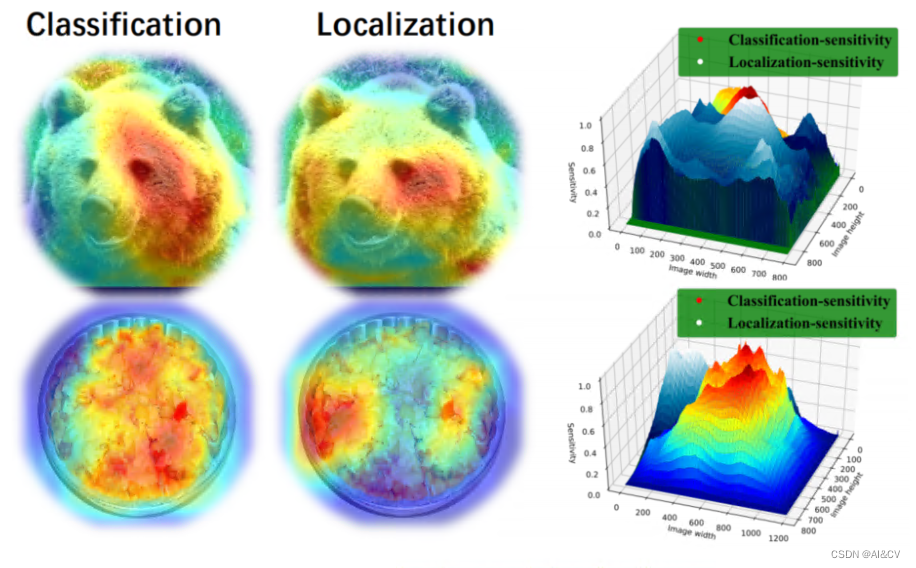
YOLOv7改进:加入解耦头Decoupled_Detect,涨点明显
💡💡💡本文全网首发独家改进:Decoupled_Detect,Hybrid Channels 策略重新设计了一个更高效的解耦头结构
Decoupled_Detect | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。
收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c…
YOLOv7改进:多头检测器助力小目标检测,实现暴力涨点
💡💡💡本文全网首发独家改进:多头检测器加入SOD检测头,提升小目标检测能力
多头检测器 | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。
收录:
YOLOv7高阶自研专栏介绍:
http://t.csdnimg.cn/tYI0c
✨✨✨前沿最新计算机顶会复现
�…

pix2tex - LaTeX OCR 安装使用记录
系列文章目录 文章目录 系列文章目录前言一、安装二、使用三、如果觉得内容不错,请点赞、收藏、关注 前言
项目地址:这儿 一、安装
版本要求 Python: 3.7 PyTorch: >1.7.1
安装:pip install "pix2tex[gui]"
注意:…
第二十六章 BEV感知系列三(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 BEV感知系列是对论文Delving into the De…

第二十五章 BEV感知系列二(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 BEV感知系列是对论文Delving into the De…

YOLO V1学习笔记
为什么要学YOLOV1_哔哩哔哩_bilibili
这个视频讲解的很好,建议在看这个之前看看卷积神经网络,会对卷积后的结果理解更加深刻一点。
一 背景
目标检测分为单阶段和两阶段模型。
之前的目标检测DPM、R-CNN、Fast-RCNN、Faster-RCNN都是双阶段模型&…

第96步 深度学习图像目标检测:FCOS建模
基于WIN10的64位系统演示
一、写在前面
本期开始,我们继续学习深度学习图像目标检测系列,FCOS(Fully Convolutional One-Stage Object Detection)模型。 二、FCOS简介
FCOS(Fully Convolutional One-Stage Object D…
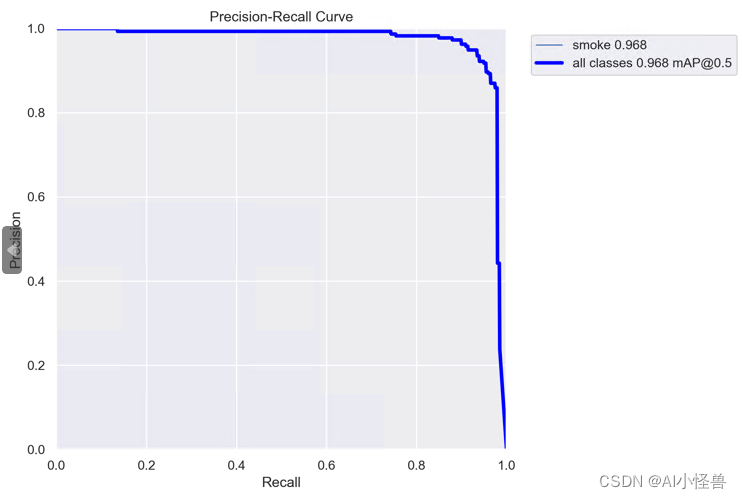
基于YOLOv8的烟雾检测:自研模块 BSAM注意力 PK CBAM注意力,提升一个多点
💡💡💡本文全网首发独家改进:提出新颖的注意力BSAM(BiLevel Spatial Attention Module),创新度极佳,适合科研创新,效果秒杀CBAM,Channel AttentionSpartial …
第二十三章 LaneAF框架结构以及接入MMDetection3D模型(车道线感知)
一 前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 二 LaneAF接入openlane数据集 2.1 Lan…

大神接力 | YOLOv4算法超详细解析(包括诞生背景+论文解析+技术原理等)
前言:Hello大家好,我是小哥谈。YOLOv4论文的发表背景是在原作者声名放弃更新YOLO算法后,俄罗斯的Alexey大神扛起了YOLOv4的大旗,因此,其诞生背景是为了进一步提高目标检测算法的性能和精度。本篇文章就简单讲述一下YOL…
【终端目标检测03】nanodet训练自己的数据集、NCNN部署到Android
nanodet训练自己的数据集、NCNN部署到Android 一、介绍二、训练自己的数据集1. 运行环境2. 数据集3. 配置文件4. 训练5. 训练可视化6. 测试 三、部署到android1. 使用官方权重文件部署1.1 下载权重文件1.2 使用Android Studio部署apk 2. 部署自己的模型【暂时存在问题】2.1 生成…
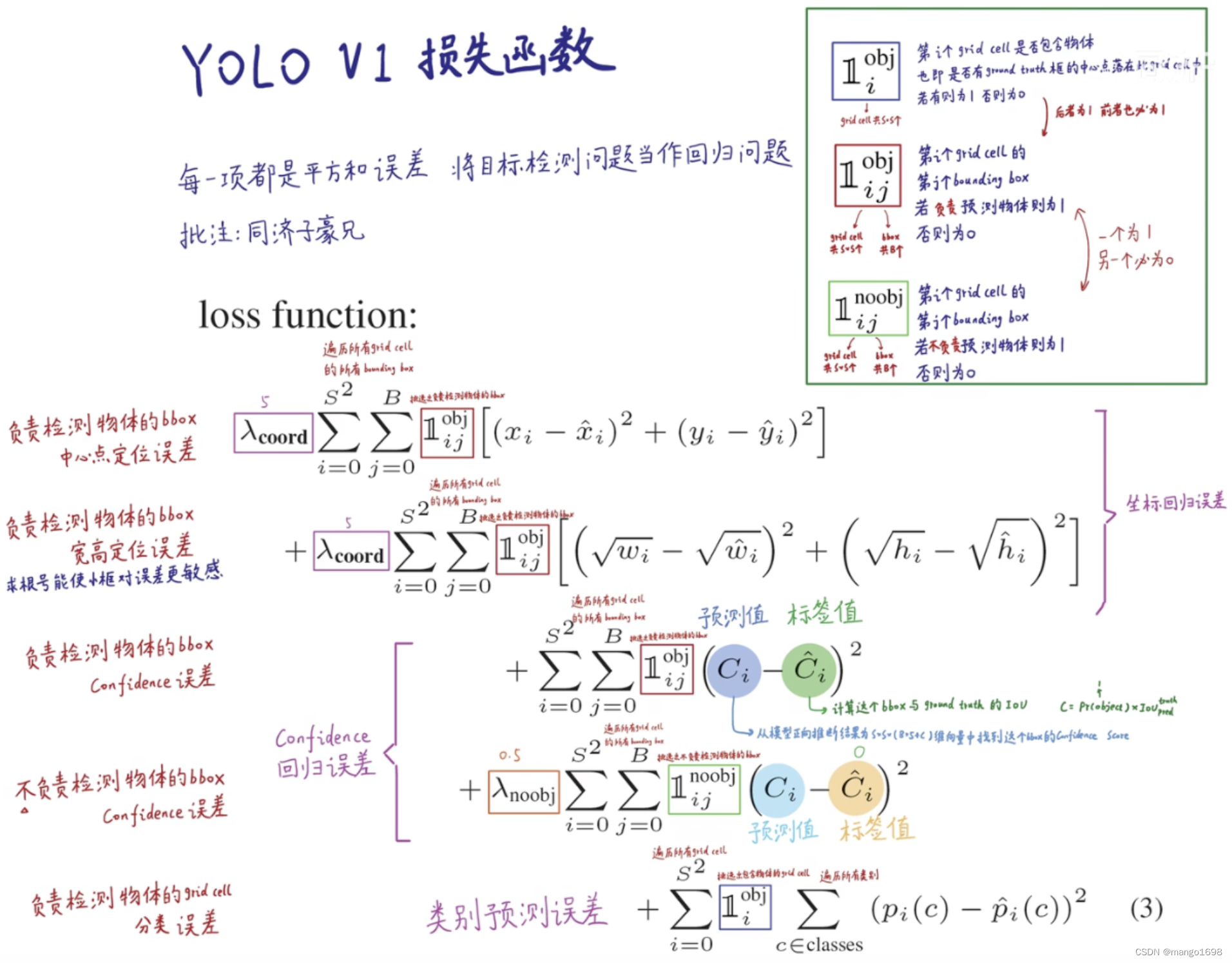
目标检测算法 - YOLOv1
文章目录 1. 作者简介2. 目标检测综述3. YOLOv1算法3.1 预测阶段3.2 预测阶段后处理3.3 训练阶段 YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。 YOLO是目标检测模型。目标检测是计算机视觉中比较简单的任务,用…

目标检测中的评价指标
目标检测中的评价指标
将检测目标分为正样本和负样本。
真阳性(true positives , TP) : 正样本被正确识别为正样本。
假阳性(false positives, FP): 负样本被错误识别为正样本。
假阴性(false negatives, FN&#…

第二十九章 目标检测中的测试模型评价指标(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 介绍
自动驾驶的一大前提是保证人的安全…
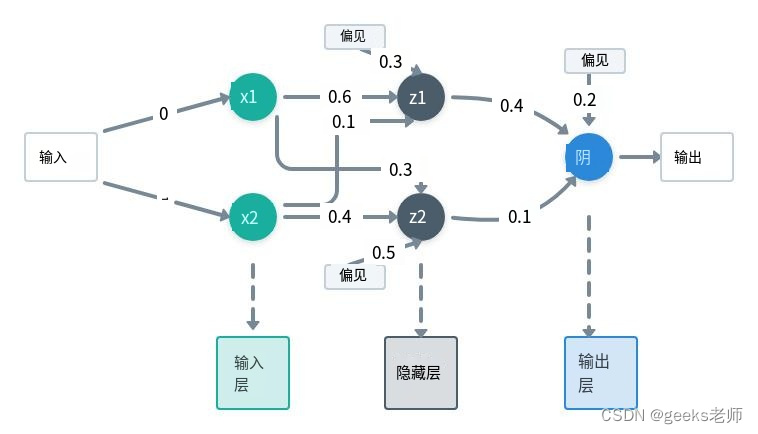
第三章:人工智能深度学习教程-基础神经网络(第五节-了解多层前馈网络)
让我们了解反向传播网络 (BPN) 中的误差是如何计算的以及权重是如何更新的。
考虑下图中的以下网络。 反向传播网络(BPN) 上图中的网络是一个简单的多层前馈网络或反向传播网络。它包含三层,输入层有两个神经元 x 1和 x 2,隐藏层有两个神经元 z 1和 z 2,输出层有一个神经…
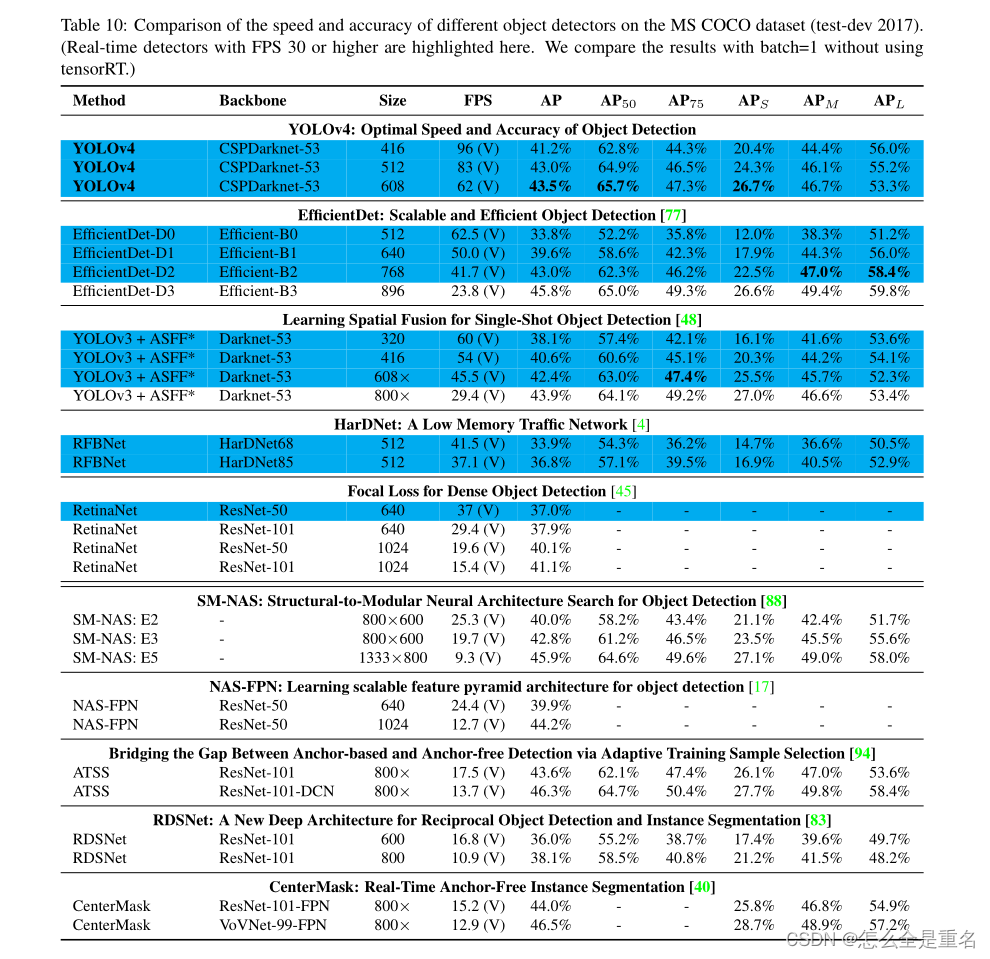
YOLOv4: Optimal Speed and Accuracy of Object Detection(2020.4)
文章目录 AbstractIntroductionRelated workObject detection modelsBag of freebiesBag of specials MethodologySelection of architectureSelection of BoF and BoSAdditional improvementsYOLOv4 ExperimentsResults表8列出了使用Maxwell GPU的帧率对比结果表9列出了使用Pa…
外贸出口游戏设备亚马逊CE认证电磁兼容性(EMC)测试解析
游戏设备上架亚马逊出口欧盟需办理CE认证电磁兼容性(EMC)测试。
CE认证,作为欧盟的一项标准,成为了游戏设备行业中最为重要的认证之一。CE认证不仅是游戏设备进入欧洲市场的必要条件,也是保证产品符合欧洲市场标准的重…
4.Swin Transformer目标检测——训练数据集
1.centos7 安装显卡驱动、cuda、cudnn-CSDN博客
2.安装conda python库-CSDN博客
3.Cenots Swin-Transformer-Object-Detection环境配置-CSDN博客
步骤1:准备待训练的coco数据集
下载地址:https://download.csdn.net/download/malingyu/88519420
htt…
Python实现从Labelme数据集中挑选出含有指定类别的数据集
Python实现从Labelme数据集中挑选出含有指定类别的数据集 前言前提条件相关介绍实验环境Labelme数据集中挑选出含有指定类别的数据集代码实现输出结果 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入Python日常小…

目标检测—YOLO系列(二 ) 全面解读论文与复现代码YOLOv1 PyTorch
精读论文
前言
从这篇开始,我们将进入YOLO的学习。YOLO是目前比较流行的目标检测算法,速度快且结构简单,其他的目标检测算法如RCNN系列,以后有时间的话再介绍。
本文主要介绍的是YOLOV1,这是由以Joseph Redmon为首的…
YOLO改进系列之注意力机制(EffectiveSE模型介绍)
模型结构
ESE(Effective Squeeze and Extraction) layer是CenterMask模型中的一个block,基于SE(Squeeze and Extraction)改进得到。与SE的区别在于,ESE block只有一个fc层,(CenterMask : Real-Time Anchor-Free Insta…
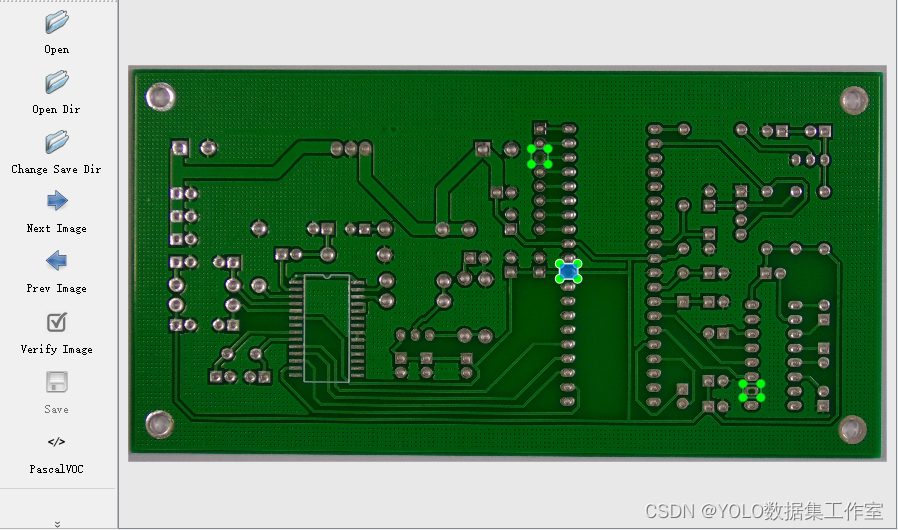
YOLO目标检测——PCB缺陷数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:电子制造过程的质量控制、生产线的自动化检测、以及产品可靠性验证等方面数据集说明:PCB缺陷检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量…

助力水泥基建裂痕自动化巡检,基于yolov5融合ASPP开发构建多尺度融合目标检测识别系统
道路场景下的自动化智能巡检、洞体场景下的壁体类建筑缺陷自动检测识别等等已经在现实生活中不断地落地应用了,在我们之前的很多博文中也已经有过很多相关的实践项目经历了,本文的核心目的是想要融合多尺度感受野技术到yolov5模型中以期在较低参数量的情…

YOLOv5项目实战(4)— 简单三步,教你按比例划分数据集
前言:Hello大家好,我是小哥谈。本节课就教大家如何去按照比例去划分数据集,希望大家学习之后可以有所收获!~🌈 前期回顾: YOLOv5项目实战(1)— 如何去训练模型 YOLOv5项目
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)(三)
目录
前言
几个高频面试题目
如何解决机器视觉稳定性差的问题?
知识储备
机器视觉基础知识点
阿秒脉冲
Inner-IoU:具有辅助边界框的更有效的交并比损失
文章目录 摘要1、简介2、相关工作3、方法4、实验5、结论摘要
随着检测器的快速发展,边界框回归(Bounding Box Regression,BBR)损失函数不断更新和优化。然而,现有的基于IoU的BBR仍然侧重于通过添加新的损失项来加速收敛,忽视了IoU损失项本身的局限性。尽管从理论上讲,I…
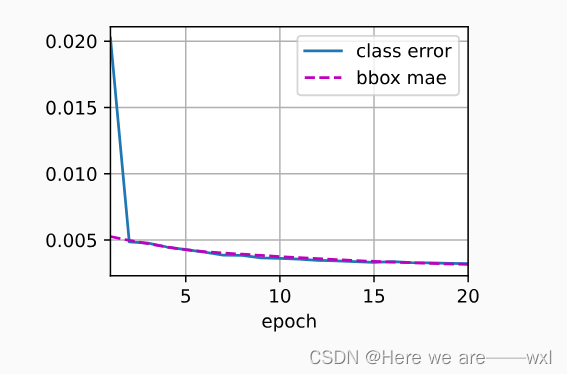
037、目标检测-SSD实现
之——简单实现
目录
之——简单实现
杂谈
正文
1.类别预测层
2.边界框预测
3.多尺度输出联结做预测(提高预测效率)
4.多尺度实现
5.基本网络块
6.完整模型 杂谈 原理查看:037、目标检测-算法速览-CSDN博客 正文
1.类别预测层 类别…

YOLO目标检测——水果检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:水果分类检测数据集的应用场景主要包括农贸市场监管、水果品质检测、超市零售管理等数据集说明:水果分类检测数据集,真实场景的高质量图片数据,数据场景丰富,含有苹果香蕉橙子图片标签说明:使…

改进YOLO系列 | YOLOv5/v7 引入Super Token Sampling ViT | 《CVPR 2023 最新论文》
论文地址:https://arxiv.org/abs/2211.11167 代码地址:https://github.com/hhb072/STViT
视觉变换器已经在许多视觉任务中取得了令人印象深刻的性能。然而,它在捕捉浅层的局部特征时可能会受到高度冗余的影响。因此,引入了局部自注意力或早期卷积,这些方法牺牲了捕捉长距…
手把手从零开始训练YOLOv8改进项目(官方ultralytics版本)教程
手把手从零开始训练 YOLOv8 改进项目 (Ultralytics版本) 教程,改进 YOLOv8 算法
本文以Windows服务器为例:从零开始使用Windows训练 YOLOv8 算法项目
《芒果 YOLOv8 目标检测算法 改进》 适用于芒果专栏改进 YOLOv8 算法 文章目录 官方 YOLOv8 算法介绍改进网络代码汇总第…

【计算机视觉】24-Object Detection
文章目录 24-Object Detection1. Introduction2. Methods2.1 Sliding Window2.2 R-CNN: Region-Based CNN2.3 Fast R-CNN2.4 Faster R-CNN: Learnable Region Proposals2.5 Results of objects detection 3. SummaryReference 24-Object Detection
1. Introduction Task Defin…

基础课10——自然语言生成
自然语言生成是让计算机自动或半自动地生成自然语言的文本。这个领域涉及到自然语言处理、语言学、计算机科学等多个领域的知识。
1.简介
自然语言生成系统可以分为基于规则的方法和基于统计的方法两大类。基于规则的方法主要依靠专家知识库和语言学规则来生成文本࿰…

亚马逊出口电热毯日本PSE认证需要什么资料解析
电热毯出口日本需要办理PSE认证,电热毯,又名电褥,是一种接触式电暖器具。 PSE认证介绍是日本强制性认证,包含安全及EMI,用以证明电子电气等产品符合日期电气用品安全法或国际IEC标准的要求。日本电气用品安全法规定&am…
第十一章 目标检测中的NMS
精度提升
众所周知,非极大值抑制NMS是目标检测常用的后处理算法,用于剔除冗余检测框,本文将对可以提升精度的各种NMS方法及其变体进行阶段性总结。 总体概要:
对NMS进行分类,大致可分为以下六种,这里是依…
中国毫米波雷达产业分析1——毫米波雷达行业概述
一、毫米波雷达简介 (一)产品定义 雷达是英文Radar的音译,源于Radio Detection and Ranging的缩写,原意是“无线电探测和测距”,即用无线电方法发现目标并测定它们在空间的位置。毫米波雷达是指一种工作在毫米波频段的…
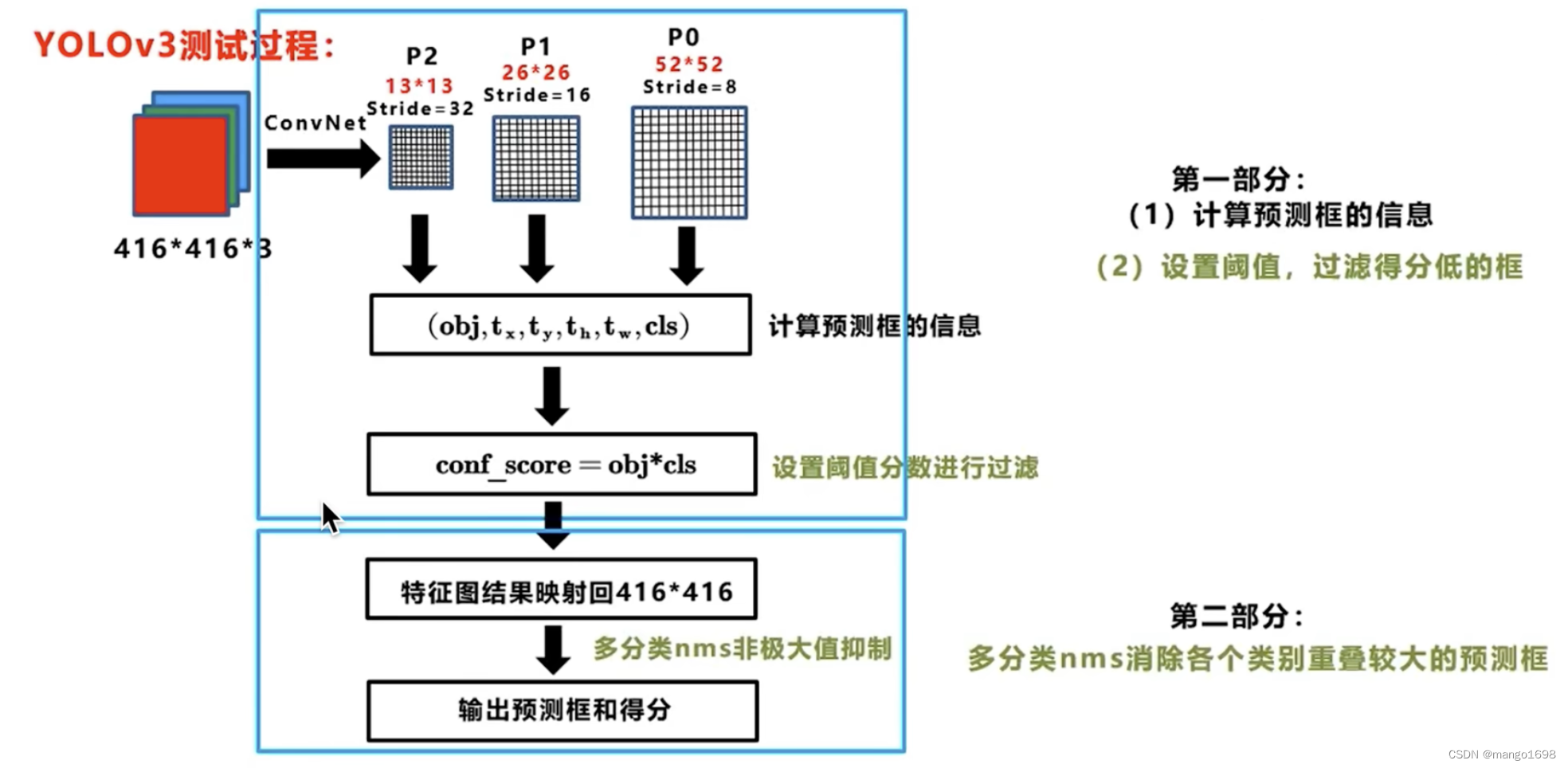
目标检测算法 - YOLOv3
YOLOv1、YOLOv2都是在CVPR这种正规的计算机视觉学术会议上发表的正式学术论文。
YOLOv3不算一篇严谨的学术论文,是作者随笔写的技术报告。
YOLOv3性能: 1. Backbone Darknet-53
YOLOv3在v2的基础上,更换了骨干网络,将Darknet-1…

OpenCV快速入门:目标检测——轮廓检测、轮廓的距、点集拟合和二维码检测
文章目录 前言一、轮廓检测1.1 图像轮廓的概念1.2 轮廓检测算法简介1.3 轮廓检测基本步骤1.4 轮廓检测函数说明1.4.1 轮廓发现1.4.2 轮廓面积1.4.3 轮廓周长1.4.4 轮廓外接多边形1.4.5 点到轮廓距离1.4.6 凸包检测 1.5 轮廓检测代码实现 二、轮廓的距2.1 几何距2.2 中心距2.3 H…

第95步 深度学习图像目标检测:Faster R-CNN建模
基于WIN10的64位系统演示
一、写在前面
本期开始,我们学习深度学习图像目标检测系列。
深度学习图像目标检测是计算机视觉领域的一个重要子领域,它的核心目标是利用深度学习模型来识别并定位图像中的特定目标。这些目标可以是物体、人、动物或其他可识…
第99步 深度学习图像目标检测:SSDlite建模
基于WIN10的64位系统演示
一、写在前面
本期,我们继续学习深度学习图像目标检测系列,SSD(Single Shot MultiBox Detector)模型的后续版本,SSDlite模型。 二、SSDlite简介
SSDLite 是 SSD 模型的一个变种,…

RT-DETR算法优化改进:Backbone改进 | HGBlock完美结合PPHGNetV2 RepConv
💡💡💡本文独家改进: PPHGNetV2助力RT-DETRHGBlock与PPHGNetV2 RepConv完美结合
推荐指数:五星
HGBlock_PPHGNetV2 | 亲测在多个数据集能够实现涨点
RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/category_12497375.html
✨✨✨魔改创新RT-DETR…

基于YOLO模型建筑工地个人防护设备目标检测
使用安全装备可以保护他们免受建筑工地的意外事故。据统计,每年有数以万计的工人在建筑工地受到严重伤害,造成终生困难。然而,通过自我监控来确保工人穿戴个人防护装备非常重要。在这方面,需要一个准确和快速的系统来检测工人是否…
YOLOv8改进 | SAConv可切换空洞卷积(附修改后的C2f+Bottleneck)
论文地址:官方论文地址
代码地址:官方代码地址 一、本文介绍
本文给大家带来的改进机制是可切换的空洞卷积(Switchable Atrous Convolution, SAC)是一种创新的卷积网络机制,专为增强物体检测和分割任务中的特征提取而…

yolov5检测(前向)输入视频输出(不在图上画标签形式的原)图片的方法,及设置每隔几帧保存的方式(不每帧保存减少重复)
这些天我忽然有个需求,要更新迭代一个场景的检测模型,甲方爸爸提供的新数据集是监控视频形式的(因为拍视频确实更加的方便),而我训练模型确实要标注好的图片形式。 根据这些条件的话,思路应该是要这样的:首先使用现有的…
Golang实现YOLO:高性能目标检测算法
引言
目标检测是计算机视觉领域的重要任务,它不仅可以识别图像中的物体,还可以标记出物体的位置和边界框。YOLO(You Only Look Once)是一种先进的目标检测算法,以其高精度和实时性而闻名。本文将介绍如何使用Golang实…

YOLOv5算法进阶改进(2)— 引入可变形卷积模块 | 涨点杀器
前言:Hello大家好,我是小哥谈。可变形卷积模块是一种改进的卷积操作,它可以更好地适应物体的形状和尺寸,提高模型的鲁棒性。可变形卷积模块的实现方式是在标准卷积操作中增加一个偏移量offset,使卷积核能够在训练过程中扩展到更大的范围,从而实现对尺度、长宽比和旋转等各…
RT-DETR算法优化改进:Backbone改进|RIFormer:无需TokenMixer也能达成SOTA性能的极简ViT架构 | CVPR2023
💡💡💡本文独家改进:RIFormer助力RT-DETR ,替换backbone, RIFormer-M36的吞吐量可达1185,同时精度高达82.6%;而PoolFormer-M36的吞吐量为109,精度为82.1%。
推荐指数:五星
RT-DETR魔术师专栏介绍:
https://blog.csdn.net/m0_63774211/category_12497375.html …
CE认证关于电动滑板车安全标准EN17128和电动自行车EN15194电磁兼容测试解析
本标准适用于有或没有自平衡系统的全部或部分由自给式电源供电的个人轻型电动汽车,除无人值守站值守站租用的电动汽车外。自平衡系统完全或部分由最高100VDC电池电压的独立电源供电,并配备或无输入电压高达240VAC的集成电池充电器。该标准规定了与个人轻…
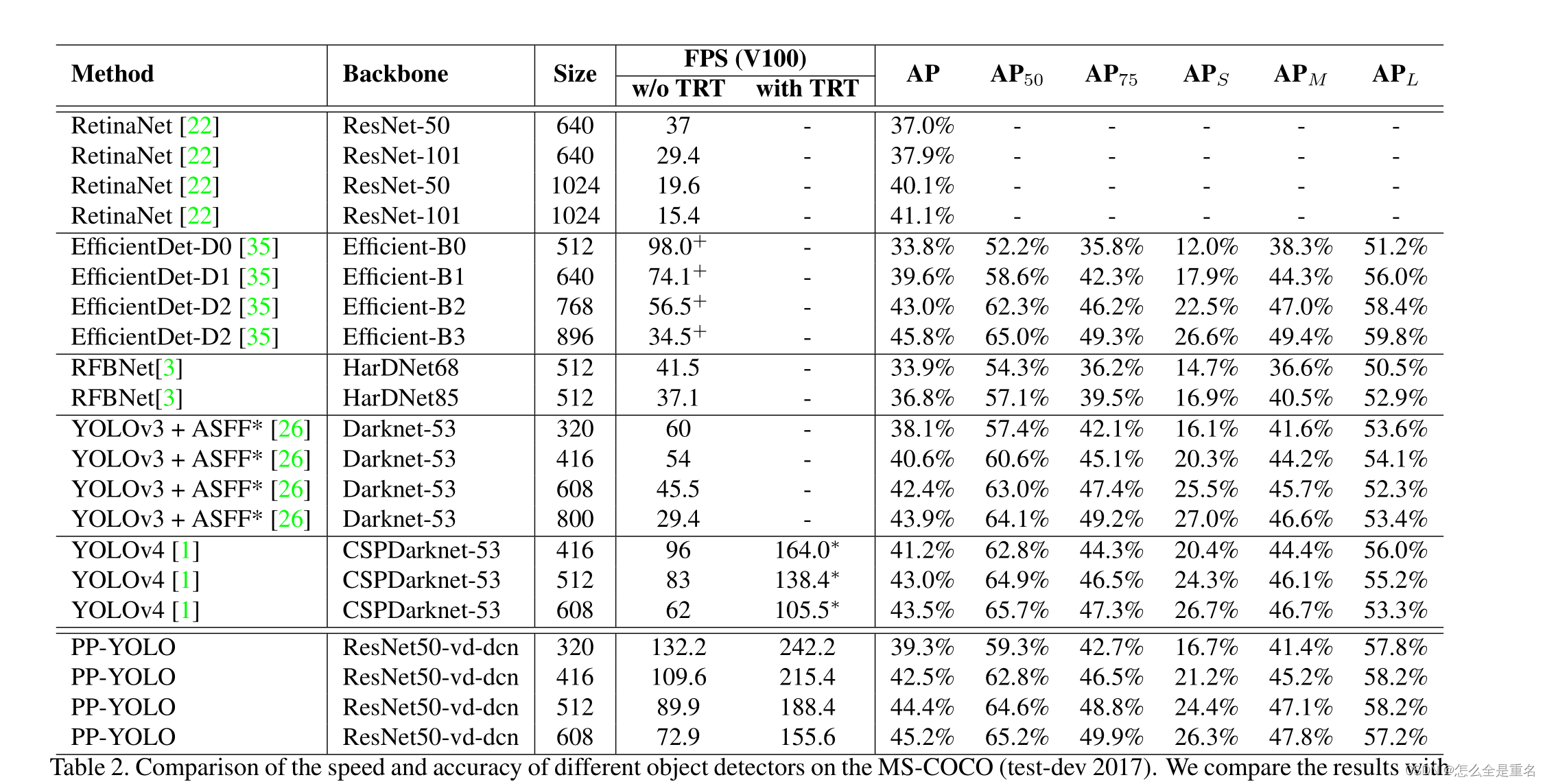
PP-YOLO: An Effective and Efficient Implementation of Object Detector(2020.8)
文章目录 Abstract1. Introduction先介绍了一堆前人的work自己的workexpect 2. Related Work先介绍别人的work与我们的区别 3.Method3.1. ArchitectureBackboneDetection NeckDetection Head 3.2. Selection of TricksLarger Batch SizeEMADropBlockIoULossIoU AwareGrid Sensi…

YOLOV8目标识别——详细记录从环境配置、自定义数据、模型训练到模型推理部署
一、概述
Yolov8建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性。Yolov8具有以下特点:
高效性:Yolov8采用了新的骨干网络、新的Ancher-Free检测头和新的损失函数,可在CPU到GPU的…
CVPR 2023 精选论文学习笔记:Delving Into Shape-Aware Zero-Shot Semantic Segmentation
基于MECE原则,我们给出以下四种分类标准:
标准 1:分割类型 语义分割:将图像中的每个像素分类为语义类别,例如“人”、“车”或“树”。这是最常见的分割类型,

YOLO目标检测——苹果缺陷检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:苹果质量检测和自动化分拣系统数据集说明:苹果缺陷检测数据集,真实场景的高质量图片数据,数据场景丰富,含有缺陷图片和没缺陷图片。标签说明:使用lableimg标注软件标注,标注框质量…

onnx快速部署YOLO模型
1、准备和环境 首先需要将yolov5模型训练好的最佳权重文件转化为.onnx格式以备使用。不会的小伙伴可以参考yolov5的官方文档,使用yolov5官方的 export.py 脚本进行转换,或者参考一些博客链接,这里不做详细解析。 基本环境配置,相…
SSD-Single Shot Detector
文章目录 SSD模型主要改进点模型说明训练Choosing scales and aspect ratios for default boxesMatching strategyTraining objectiveHard negative miningData augmentation实验结果基本网络参数PASCAL VOC2007模型消融实验PASCAL VOC2012COCO推理速度比较前面提到了两种经典的…
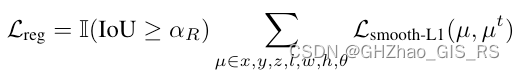
3D点云目标检测:CT3D解读(未完)
CT3D 一、RPN for 3D Proposal Generation二、Proposal-to-point Encoding Module2.1、Proposal-to-point Embedding2.2、Self-attention Encoding 三、Channel-wise Decoding Module3.1、Standard Decoding3.2、Channel-wise Re-weighting3.3、Channel-wise Decoding Module 四…
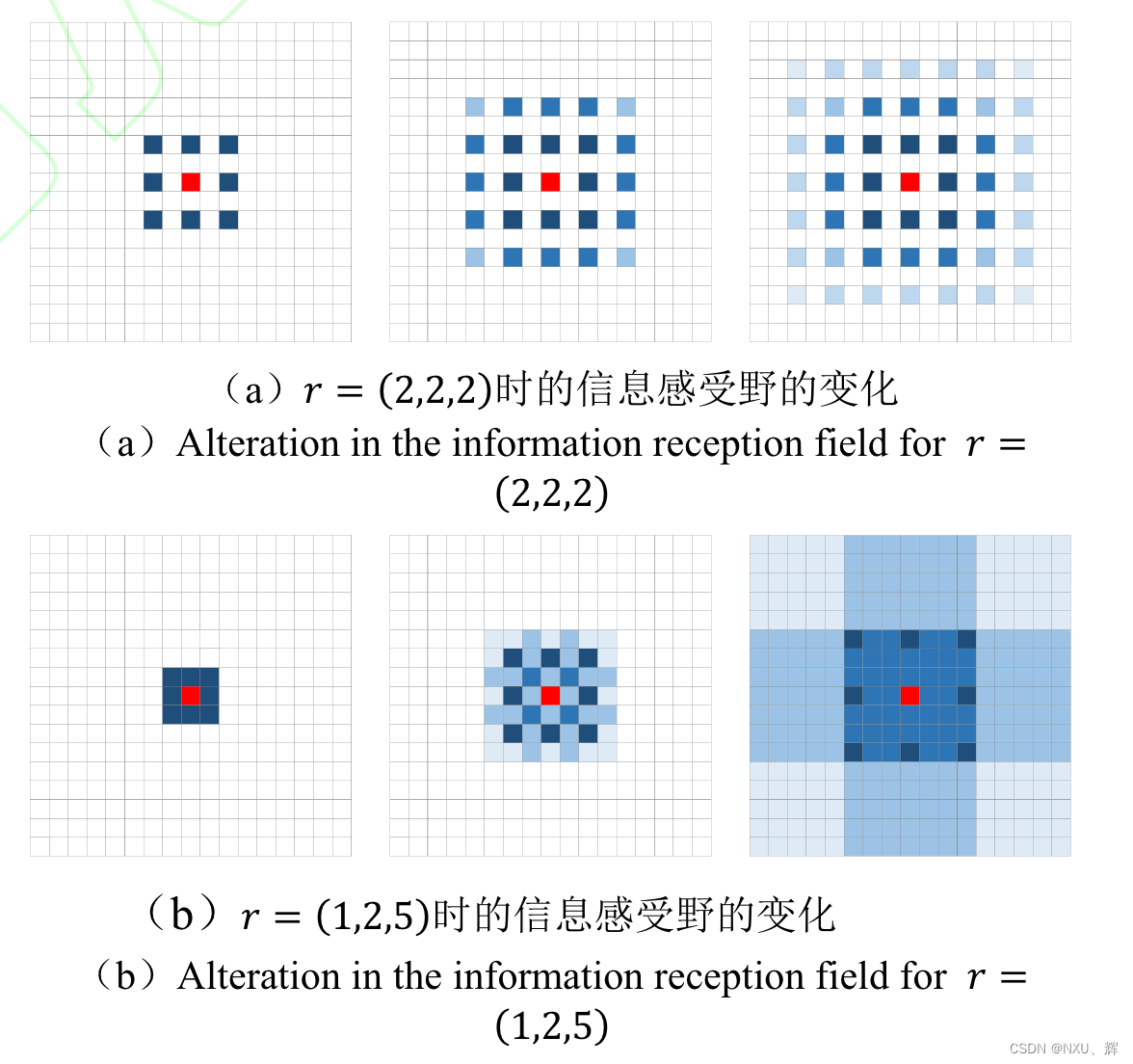
FSOD论文阅读 - 基于卷积和注意力机制的小样本目标检测
来源:知网
标题:基于卷积和注意力机制的小样本目标检测 作者:郭永红,牛海涛,史超,郭铖 郭永红,牛海涛,史超,郭铖.基于卷积和注意力机制的小样本目标检测 [J/OL].兵工学报. https://…
复现YOLO v1 PyTorch
复现YOLO v1 PyTorch
Paper: [1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org)
Github: EclipseR33/yolo_v1_pytorch (github.com)
数据集
VOC2007:The PASCAL Visual Object Classes Challenge 2007 (VOC2007)
VOC2012&…
目标检测YOLO实战应用案例100讲-基于改进YOLO v5的排水管网缺陷智能识别(续)
目录
3.3构建方法
3.3.1样本库框架
3.3.2总体流程
3.3.3图像获取
3.3.4质量控制
3.3.5数据扩增

中国毫米波雷达产业分析3——毫米波雷达市场分析(四、五、六)
四、康养雷达市场
(一)市场背景
1、政府出台系列政策提升智慧健康养老产品供给和应用 康养雷达是一种以老年人为主要监测对象,可以实现人体感应探测、跌倒检测报警、睡眠呼吸心率监测等重要养老监护功能的新型智慧健康养老产品。 随着我国经…
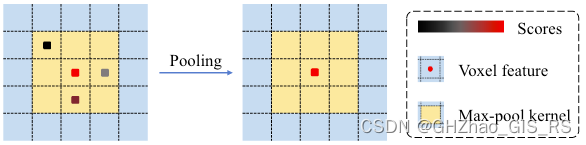
3D点云目标检测:VoxelNex解读
VoxelNext 通用检测器 vs VoxelNext一、3D稀疏卷积模块1.1、额外的两次下采样消融实验结果代码 1.2、稀疏体素删减消融实验:代码 二、稀疏体素高度压缩代码 三、稀疏预测head 通用检测器 vs VoxelNext 一、3D稀疏卷积模块
1.1、额外的两次下采样
使用通用的3D spa…

目标检测——Faster R-CNN算法解读
论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun 链接:https://arxiv.org/abs/1506.01497 代码:https://github.com/rbgirsh…
SHEIN出口儿童玩具加拿大站CCPSA安全标准办理解析
儿童玩具是为特定年龄组的儿童设计和制造的,其特点与儿童的年龄和智力阶段有关。儿童玩具的使用以一定的适应能力为前提。儿童玩具上亚马逊加拿大站需要办理CCPSA安全标准,才能在SHEIN\亚马逊上销售。
CCPSA安全标准,必须由 ISO 17025 认可的检测实验室…
YOLOv8改进 | 2023 | SCConv空间和通道重构卷积(精细化检测,又轻量又提点)
一、本文介绍
本文给大家带来的改进内容是SCConv,即空间和通道重构卷积,是一种发布于2023.9月份的一个新的改进机制。它的核心创新在于能够同时处理图像的空间(形状、结构)和通道(色彩、深度)信息…
22.Python 操作目录
目录) 1. 认识路径相对路径绝对路径 2. 拼接路径3.检测目录4.创建和删除目录5.遍历目录 1. 认识路径
目录也称文件夹,用于分层保护文件,通过目录可以分门别类地存放文件,也可以通过目录快速地找到想要的文件,在Python…

YOLOv8界面-目标检测+语义分割+追踪+姿态识别(姿态估计)+界面DeepSort/ByteTrack-PyQt-GUI
YOLOv8-DeepSort/ByteTrack-PyQt-GUI:全面解决方案,涵盖目标检测、跟踪和人体姿态估计
YOLOv8-DeepSort/ByteTrack-PyQt-GUI是一个多功能图形用户界面,旨在充分发挥YOLOv8在目标检测/跟踪和人体姿态估计/跟踪方面的能力,与图像、…
YOLOv8改进 | 2023 | 给YOLOv8换个RT-DETR的检测头(重塑目标检测前沿技术)
一、本文介绍
本文给大家带来是用最新的RT-DETR模型的检测头去替换YOLOv8中的检测头。RT-DETR号称是打败YOLO的检测模型,其作为一种基于Transformer的检测方法,相较于传统的基于卷积的检测方法,提供了更为全面和深入的特征理解,将…

【计算机视觉】基于OpenCV计算机视觉的摄像头测距技术设计与实现
基于计算机视觉的摄像头测距技术 文章目录 基于计算机视觉的摄像头测距技术导读引入技术实现原理技术实现细节Python-opencv实现方案获取目标轮廓步骤 1:图像处理步骤 2:找到轮廓步骤完整代码 计算图像距离前置技术背景与原理步骤 1:定义距离…

ImportError: cannot import name ‘metadata‘ from ‘importlib‘
yolov8 编译问题 ImportError: cannot import name ‘metadata’ from ‘importlib’ 将 from importlib import metadata 更改为 import importlib_metadata as metadata
目标检测VOC生成txt文件
VOC数据格式 首先生成ImageSets下的train.txt文件
get_list.py
import os
import random
import shutil# 设置随机种子
random.seed(1000)# 判断Annotations和JpegImages是否对应
train_precent = 0.8
label_path = "../../Annotations"
print(os.path.abspath(lab…
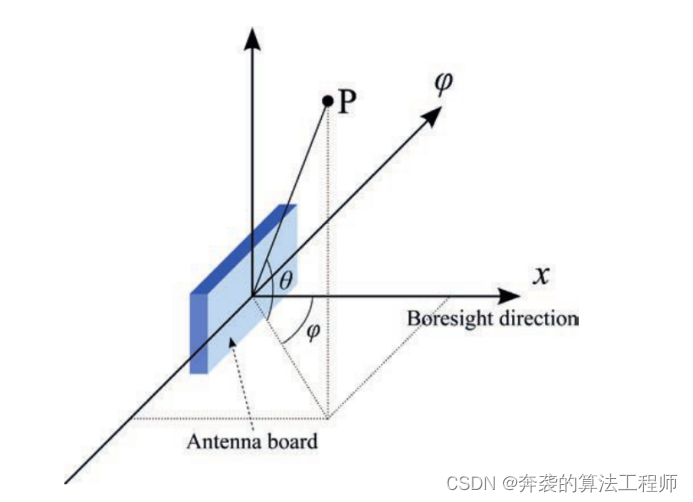
现代雷达车载应用——第2章 汽车雷达系统原理 2.1节
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
2.1 基本雷达功能 雷达系统通过天线或天线阵列向空间辐射电磁能量。辐射的电磁能量“照亮”周围的目标。“被照亮”的目标拦截一些辐射能量࿰…
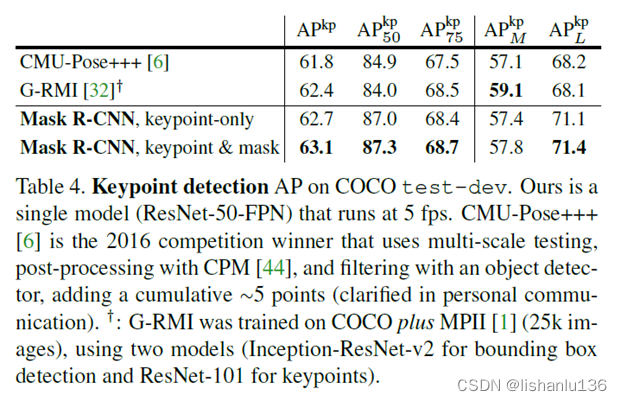
目标检测——Mask R-CNN算法解读
论文:Mask R-CNN 作者:Kaiming He Georgia Gkioxari Piotr Dollar Ross Girshick 链接:https://arxiv.org/abs/1703.06870 代码:https://github.com/facebookresearch/Detectron R-CNN系列其他文章:
R-CNN算法解读SPP…
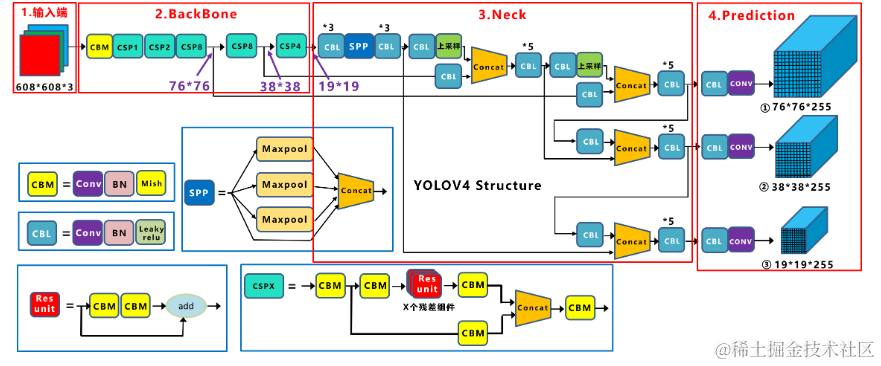
AI:92-基于深度学习的红外图像人体检测
🚀 本文选自专栏:人工智能领域200例教程专栏 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的核心代码,详细讲解供大家学习,希望可以帮到大家。欢迎订阅支持,正在不断更新…
基于YOLOv8深度学习的人脸面部口罩检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

计算机视觉-05-目标检测:LeNet的PyTorch复现(MNIST手写数据集篇)(包含数据和代码)
文章目录 0. 数据下载1. 背景描述2. 预测目的3. 数据总览4. 数据预处理4.1 下载并加载数据,并做出一定的预先处理4.2 搭建 LeNet-5 神经网络结构,并定义前向传播的过程4.3 将定义好的网络结构搭载到 GPU/CPU,并定义优化器4.4 定义训练过程4.5…

基于YOLOv8的目标检测与计数
目录方法1: Jupyter Notebook方法2: 部署到Streamllit云的Streamlit Web应用 已知限制 方法3:在Streamlit中进行本地部署代码演示更多演示 目录 最近,我研究了Roboflow提供的名为Supervision的计算机视觉工具,重点关注…
dToF直方图之美_激光雷达多目标检测
直方图提供了一种简单有效的方法来分析信号分布并识别与目标存在相对应的峰值,并且能够可视化大量数据,让测距数形结合。在车载激光雷达中,对于多目标检测,多峰算法统计等,有着区别于摄像头以及其他雷达方案的天然优势。
如下图,当中有着清晰可见的三个峰值,我们可以非…
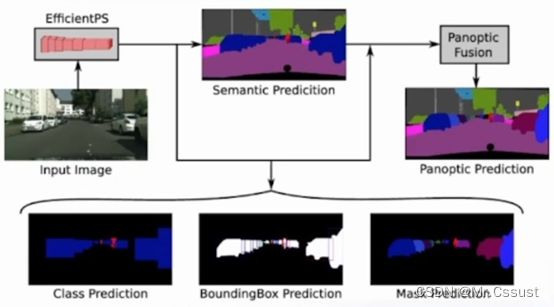
自动驾驶学习笔记(十七)——视觉感知
#Apollo开发者#
学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门
《Apollo 社区开发者圆桌会》免费报名—>传送门
文章目录
前言
分类
目标检测
语义分割
实例分割 …
深度学习测试和推断的区别
深度学习测试和推断是深度学习模型生命周期中的两个不同阶段,分别涉及到模型的验证和应用。以下是深度学习测试和推断的主要区别: 测试: 目的: 测试阶段旨在验证深度学习模型在训练之后对于独立测试数据的性能。数据: …
基于YOLOv8深度学习的西红柿成熟度检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

目标检测 YOLOv5 - 推理时的数据增强
目标检测 YOLOv5 - 推理时的数据增强
flyfish
版本 YOLOv5 6.2
参考地址
https://github.com/ultralytics/yolov5/issues/303在训练时可以使用数据增强,在推理阶段也可以使用数据增强 在测试使用数据增强有个名字叫做Test-Time Augmentation (TTA)
实际使用中使…
C# OpenCvSharp DNN 部署FastestDet
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN 部署FastestDet
效果 模型信息
Inputs ------------------------- name:input.1 tensor:Float[1, 3, 512, 512] ---------------------------------------------------------------
Outpu…
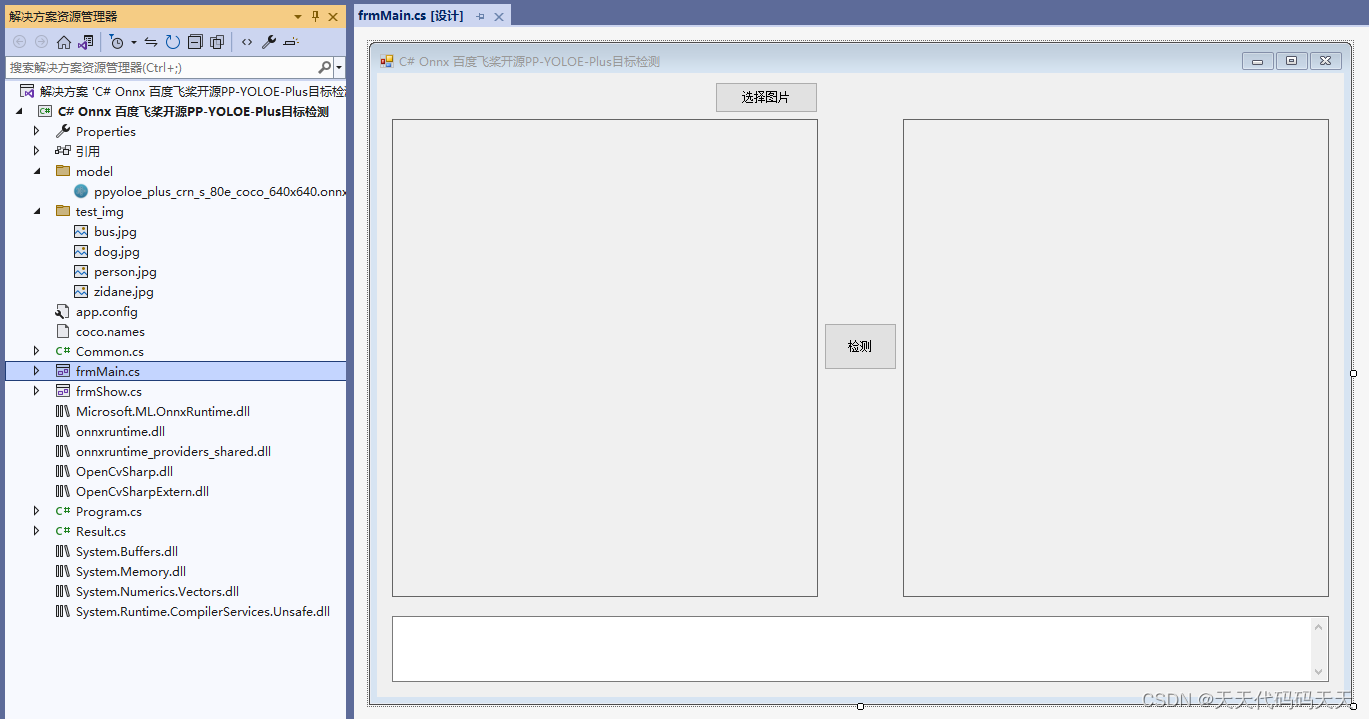
C# Onnx 百度飞桨开源PP-YOLOE-Plus目标检测
目录
效果
模型信息
项目
代码
下载 C# Onnx 百度飞桨开源PP-YOLOE-Plus目标检测
效果 模型信息
Inputs ------------------------- name:image tensor:Float[1, 3, 640, 640] name:scale_factor tensor:Float[1, 2] ----…
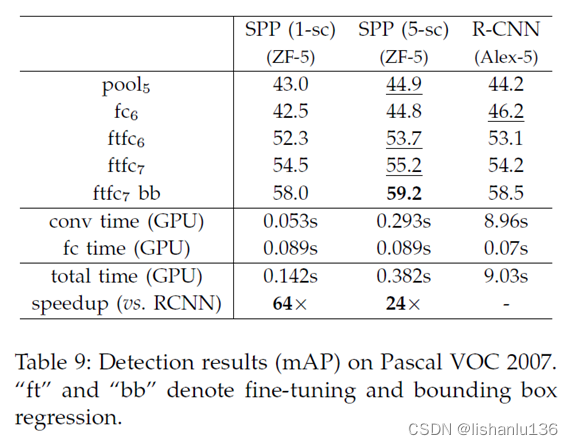
目标检测——SPPNet算法解读
论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 链接:https://arxiv.org/abs/1406.4729 目录 1、算法概述2、Deep Networks with Spatia…
![[论文阅读]VoxSet——Voxel Set Transformer](https://img-blog.csdnimg.cn/direct/3ac5184eebf3409ab1b15a933c212f63.png)
[论文阅读]VoxSet——Voxel Set Transformer
VoxSet
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds 论文网址:VoxSet 论文代码:VoxSet
简读论文
这篇论文提出了一个称为Voxel Set Transformer(VoxSeT)的3D目标检测模型,主要有以下几个亮点: 提出了基于…

esp32-s3部署yolox_nano进行目标检测
ESP32-S3部署yolox_nano进行目标检测 一、生成模型部署项目01 环境02 配置TVM包03 模型量化3.1预处理3.2 量化 04 生成项目 二、烧录程序 手上的是ESP32-S3-WROOM-1 N8R8芯片,整个链路跑通了,但是识别速度太慢了,20秒一张图,所以暂…

目标检测——OverFeat算法解读
论文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 作者:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun 链接:https://arxiv.org/abs/1312.6229 文章…

yolov8+tensorRT加速推理+部署-姿态识别-实力分割-目标检测
入门指南
这个项目演示了如何使用 TensorRT C++ API 运行 YoloV8 的 GPU 推理。它使用了我的另一个项目 tensorrt-cpp-api 在后台运行推理,因此请确保您熟悉该项目。
先决条件 在 Ubuntu 20.04 上测试并工作安装 CUDA,说明在这里。 推荐 >= 11.8安装 cuDNN,说明在这里。…

基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(一)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境Pycharm 环境Android环境 相关其它博客工程源代码下载其它资料下载 前言
本项目采用VGG-16网络模型,使用Kaggle开源数据集,旨在提取图片中的用户特征,最终在移…
基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(四)
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建3. 模型训练及保存4. 模型生成 系统测试1. 训练准确率2. 测试效果3. 模型应用 相关其它博客工程源代码下载其它资料下载 前言
本项目采用VGG-16网络模型,使用Kaggle开源数据集…
AI:99-基于深度学习的飞机故障检测与维修
🚀 本文选自专栏:人工智能领域200例教程专栏 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的核心代码,详细讲解供大家学习,希望可以帮到大家。欢迎订阅支持,正在不断更新…
现代雷达车载应用——第2章 汽车雷达系统原理 2.5节 检测基础
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
2.5 检测基础 对于要测试目标是否存在的雷达测量,可以假定下列两个假设之一为真: •H0:—测量结果仅为噪声。 •H1:—测量是噪…
大象elephant目标检测数据集VOC+YOLO格式2300张
大象是长鼻目象科的哺乳动物,有两个属,是世界上最大的陆生动物。其像柱子一样的四肢和宽厚的脚掌可以稳稳支撑住庞大的身体。巨大的头上长有蒲扇状的大耳朵和长且有弹性的鼻子。象耳上有丰富的血管,可以有效散热。鼻子和上唇合而为一的象鼻由…
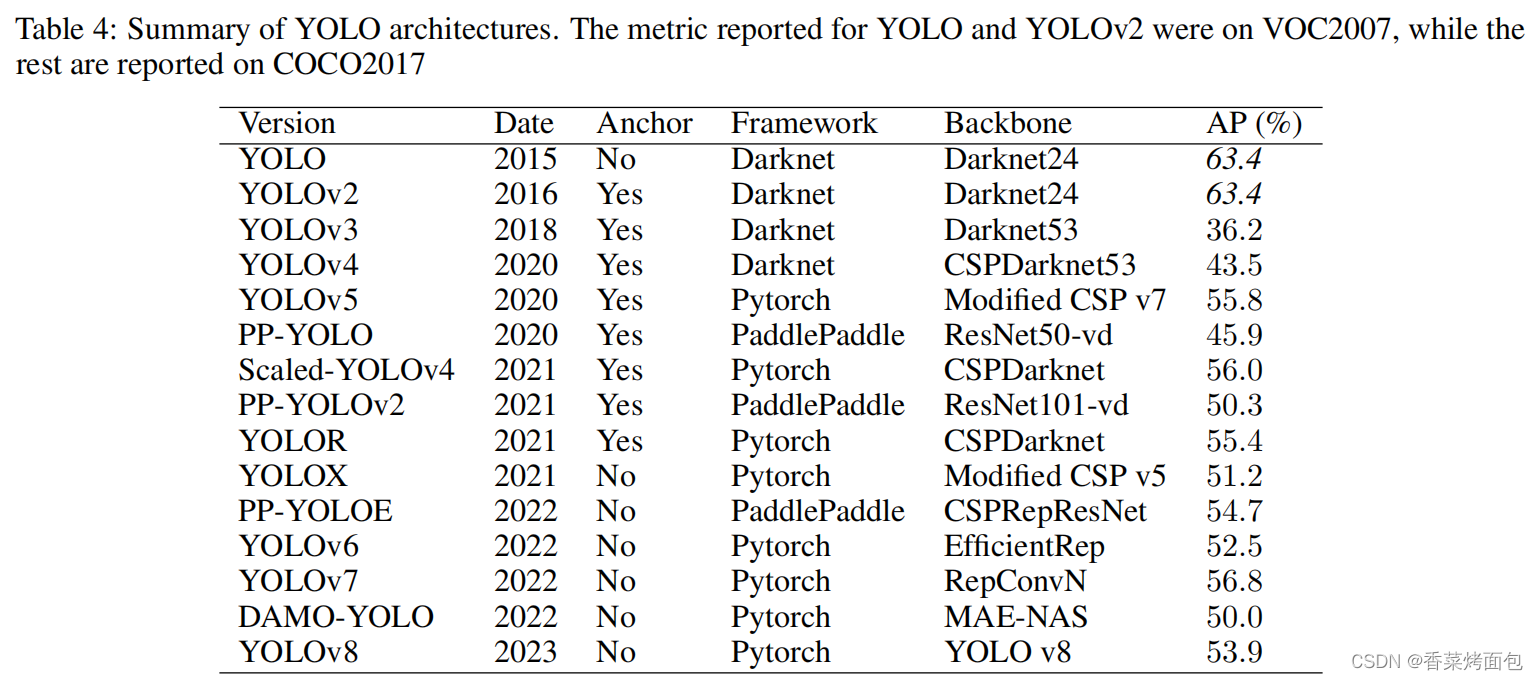
从YOLOv1到YOLOv8的YOLO系列最新综述【2023年4月】
作者:Juan R. Terven 、Diana M. Cordova-Esparaza
摘要:YOLO已经成为机器人、无人驾驶汽车和视频监控应用的核心实时物体检测系统。我们对YOLO的演变进行了全面的分析,研究了从最初的YOLO到YOLOv8每次迭代的创新和贡献。我们首先描述了标准…

【深度学习目标检测】五、基于深度学习的安全帽识别(python,目标检测)
深度学习目标检测方法则是利用深度神经网络模型进行目标检测,主要有以下几种: R-CNN系列:包括R-CNN、Fast R-CNN、Faster R-CNN等,通过候选区域法生成候选目标区域,然后使用卷积神经网络提取特征,并通过分类…
基于YOLOv8深度学习的高精度车辆行人检测与计数系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
Python移动未标注的图片数据集
Python移动未标注的图片数据集 前言前提条件相关介绍实验环境Python移动未标注的图片数据集情况一:有图,无标注文件代码实现输出结果 情况二:有图,有标注文件,但标注信息为空代码实现输出结果 情况一与情况二同时都考虑…

遥感论文 | Scientific Reports | 一种显著提升遥感影像小目标检测的网络!
论文题目:MwdpNet: towards improving the recognition accuracy of tiny targets in high-resolution remote sensing image论文网址:https://www.nature.com/articles/s41598-023-41021-8
摘要
提出MwdpNet,以提高对高分辨率遥感…
YOLOv8改进 | 检测头篇 | 利用DySnakeConv改进检测头专用于分割的检测头(全网独家首发,Seg)
一、本文改进
本文给大家带来的改进机制是一种我进行优化的专用于分割的检测头,在分割的过程中,最困难的无非就是边缘的检测,动态蛇形卷积(Dynamic Snake Convolution)通过自适应地聚焦于细长和迂回的局部结构,准确地捕捉管状结构的特征。这种卷积方法的核心思想是,通过…

yolov5目标检测
一、安装
1.源码下载
git clone git://github.com/ultralytics/yolov5.git
cd yolov5
2.环境配置
conda create -n yolov5 python3.8
conda activate yolov5
nvcc -V查看cuda版本
pytorch官网下载对应版本,例如当cuda版本为11.6
pip install torch1.13.1cu…

【深度学习目标检测】四、基于深度学习的抽烟识别(python,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…
[数据集][目标检测]人员持刀数据集VOC+YOLO格式6923张1类别重制版
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):6923 标注数量(xml文件个数):6923 标注数量(txt文件个数):6923 标注…
机器翻译:跨越语言边界的智能大使
导言 机器翻译作为人工智能领域的瑰宝,正在以前所未有的速度和精度,为全球沟通拓展新的可能性。本文将深入研究机器翻译的技术原理、应用场景以及对语言交流未来的影响。
1. 简介 机器翻译是一项致力于通过计算机自动将一种语言的文本翻译成另一种语言的…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】计算机视觉(基础篇)(三)
目录
几个高频面试题目
计算机视觉与图像处理、模式识别、机器学习学科之间的关系
全景图及计算机视觉技术
全景图的简易制作方式

【深度学习目标检测】九、基于yolov5的路标识别(python,目标检测)
YOLOv5是目标检测领域一种非常优秀的模型,其具有以下几个优势: 1. 高精度:YOLOv5相比于其前身YOLOv4,在目标检测精度上有了显著的提升。YOLOv5使用了一系列的改进,如更深的网络结构、更多的特征层和更高分辨率的输入图…
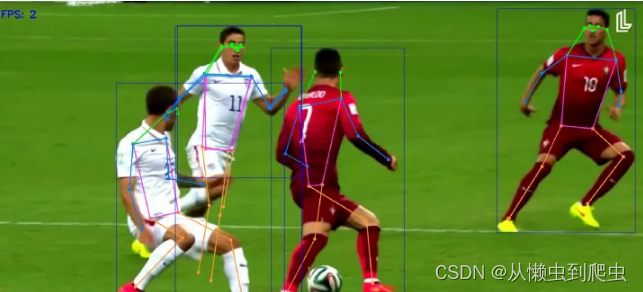
姿态识别、目标检测和跟踪的综合应用
引言: 近年来,随着人工智能技术的不断发展,姿态识别、目标检测和跟踪成为了计算机视觉领域的热门研究方向。这三个技术的综合应用为各个行业带来了巨大的变革和机遇。本文将分别介绍姿态识别、目标检测和跟踪的基本概念和算法,并探…
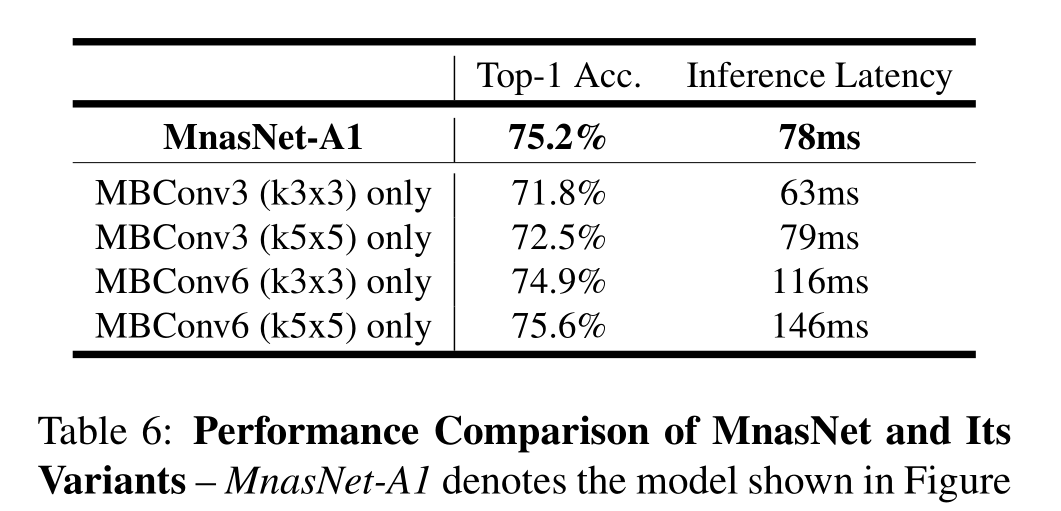
MnasNet: Platform-Aware Neural Architecture Search for Mobile(2019)
文章目录 Abstract存在的挑战给出方法实验支撑 Introduction目前的困境给出的方法主要贡献 Related WorkProblem FormulationMobile Neural Architecture SearchFactorized Hierarchical Search SpaceSearch Algorithm Experimental SetupResultsImageNet Classification Perfo…
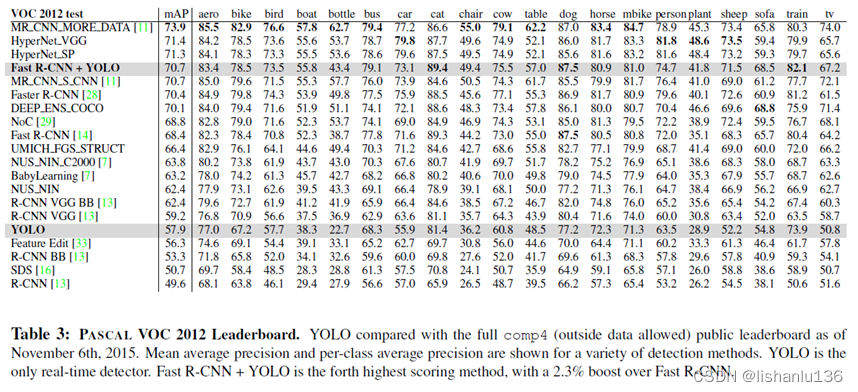
目标检测——YOLO算法解读(通俗易懂版)
论文:You Only Look Once: Unified, Real-Time Object Detection 作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi 链接:https://arxiv.org/abs/1506.02640 代码:http://pjreddie.com/yolo/ yolo系列检测算法开…
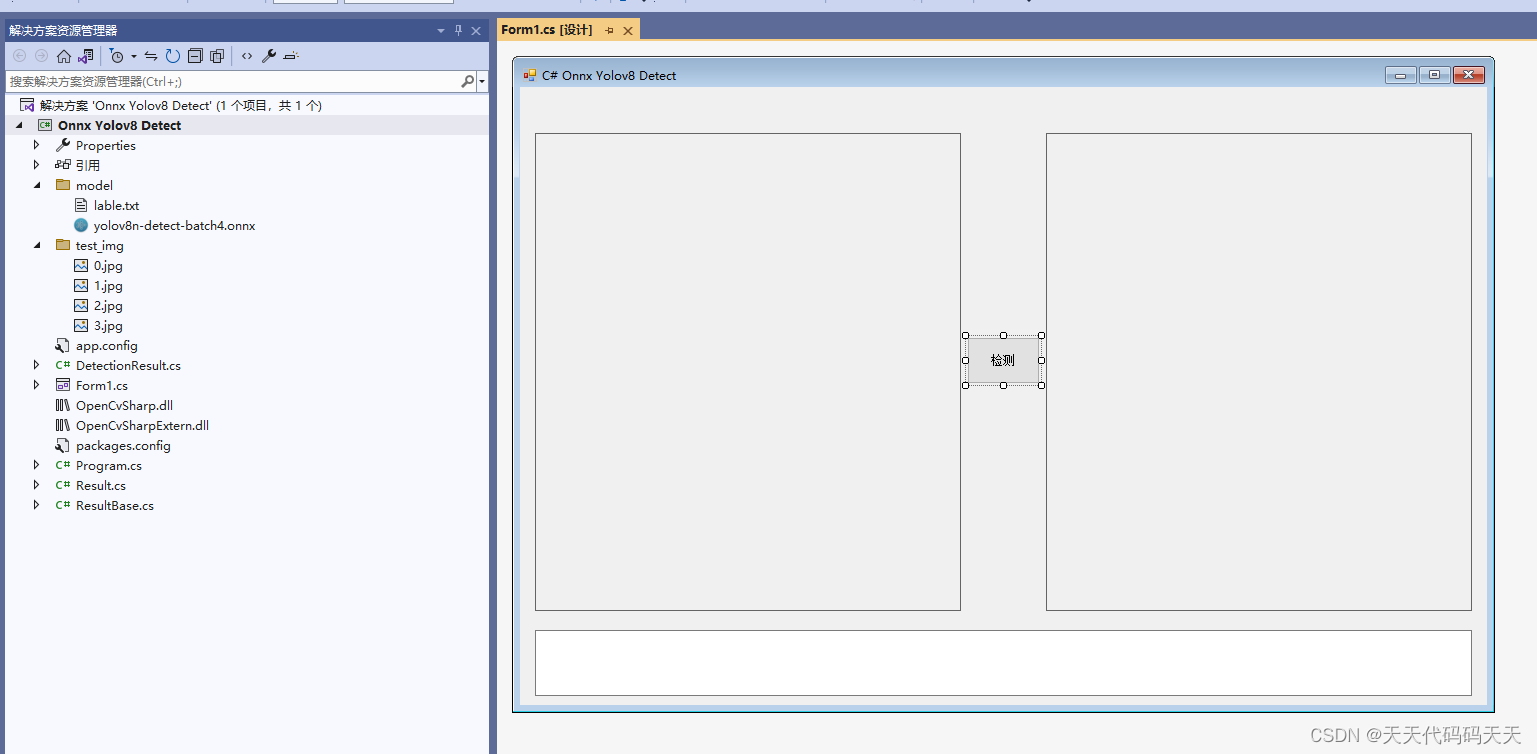
C# Onnx Yolov8 Detect 物体检测 多张图片同时推理
目录
效果
模型信息
项目
代码
下载 C# Onnx Yolov8 Detect 物体检测 多张图片同时推理
效果 模型信息
Model Properties ------------------------- date:2023-12-18T11:47:29.332397 description:Ultralytics YOLOv8n-detect model trained on …
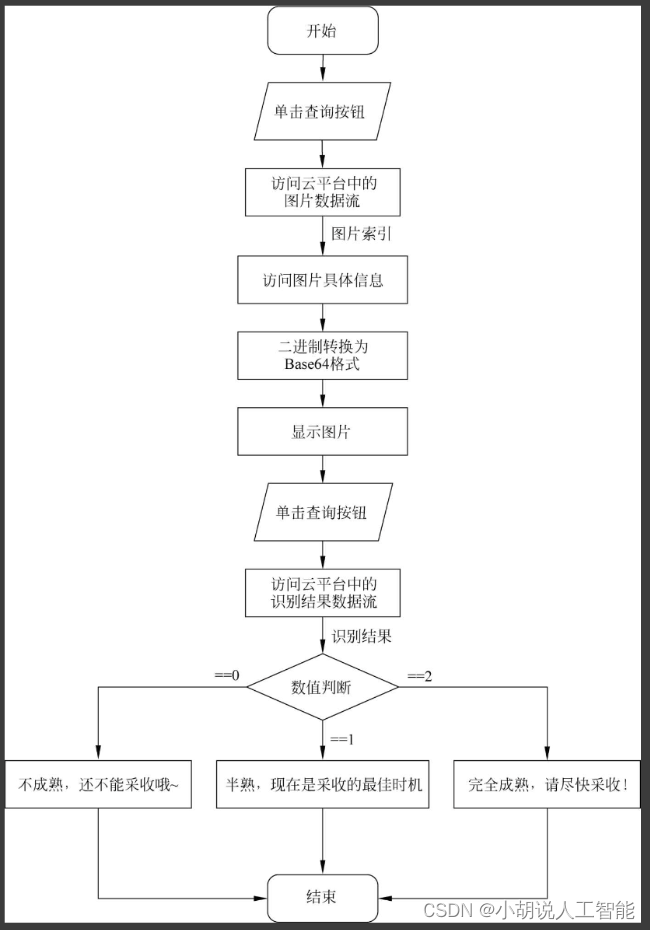
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(一)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境Jupyter Notebook环境Pycharm 环境 相关其它博客工程源代码下载其它资料下载 前言
本项目基于Keras框架,引入CNN进行模型训练,采用Dropout梯度下降算法,按比例…
YOLOv5 目标计数 | 图片上绘制计数结果
修改方法:
只需要改 detect.py
for path, im, im0s, vid_cap, s in dataset: 下新增一行 class_counts = {} class_counts[int(c)] = class_counts.get(int(c

【深度学习目标检测】九、基于yolov5的安全帽识别(python,目标检测)
YOLOv5是目标检测领域一种非常优秀的模型,其具有以下几个优势: 1. 高精度:YOLOv5相比于其前身YOLOv4,在目标检测精度上有了显著的提升。YOLOv5使用了一系列的改进,如更深的网络结构、更多的特征层和更高分辨率的输入图…

目标检测应用场景—数据集【NO.21】火灾检测数据集
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…
【RT-DETR有效改进】ShapeIoU、InnerShapeIoU关注边界框本身的IoU(包含二次创新)
前言
大家好,我是Snu77,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…
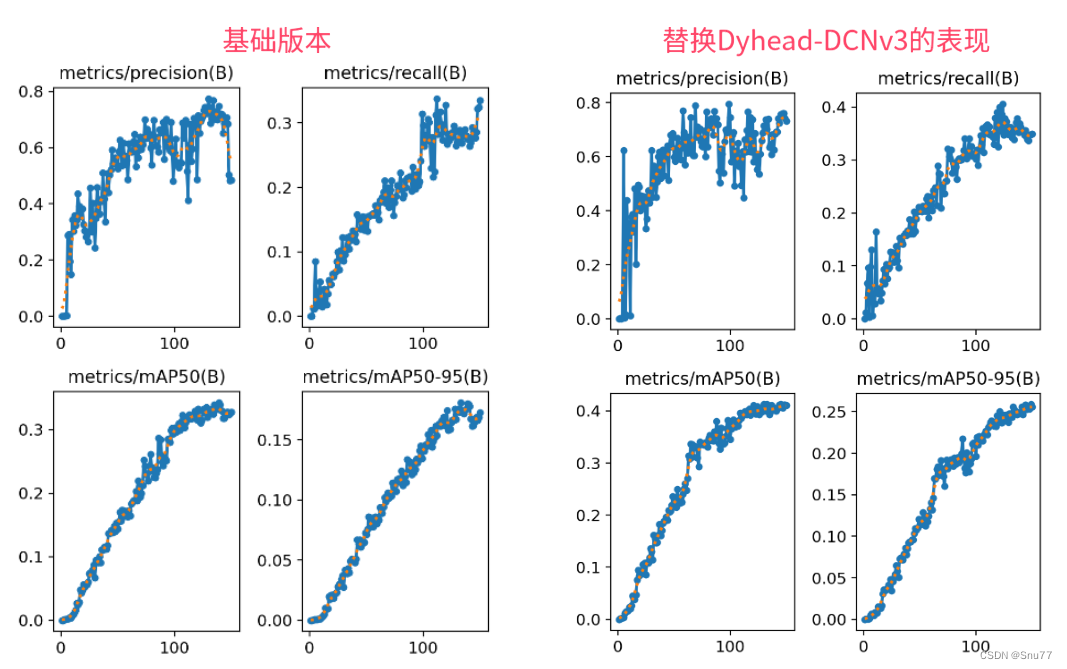
YOLOv5改进 | 二次创新篇 | 升级版本Dyhead检测头替换DCNv3 实现完美升级(全网独家首发)
一、本文介绍
本文给大家带来的改进机制是在DynamicHead上替换DCNv3模块,其中DynamicHead的核心为DCNv2,但是今年新更新了DCNv3其作为v2的升级版效果肯定是更好的,所以我将其中的核心机制替换为DCNv3给Dyhead相当于做了一个升级,效果也比之前的普通版本要好,这个机制我认…
YOLOv8改进 | 主干篇 | 低照度增强网络PE-YOLO改进主干(改进暗光条件下的物体检测模型)
一、本文介绍
本文给大家带来的改进机制是低照度图像增强网络PE-YOLO中的PENet,PENet通过拉普拉斯金字塔将图像分解成多个分辨率的组件,增强图像细节和低频信息。它包括一个细节处理模块(DPM),用于通过上下文分支和边缘分支增强图像细节,以及一个低频增强滤波器(LEF),…
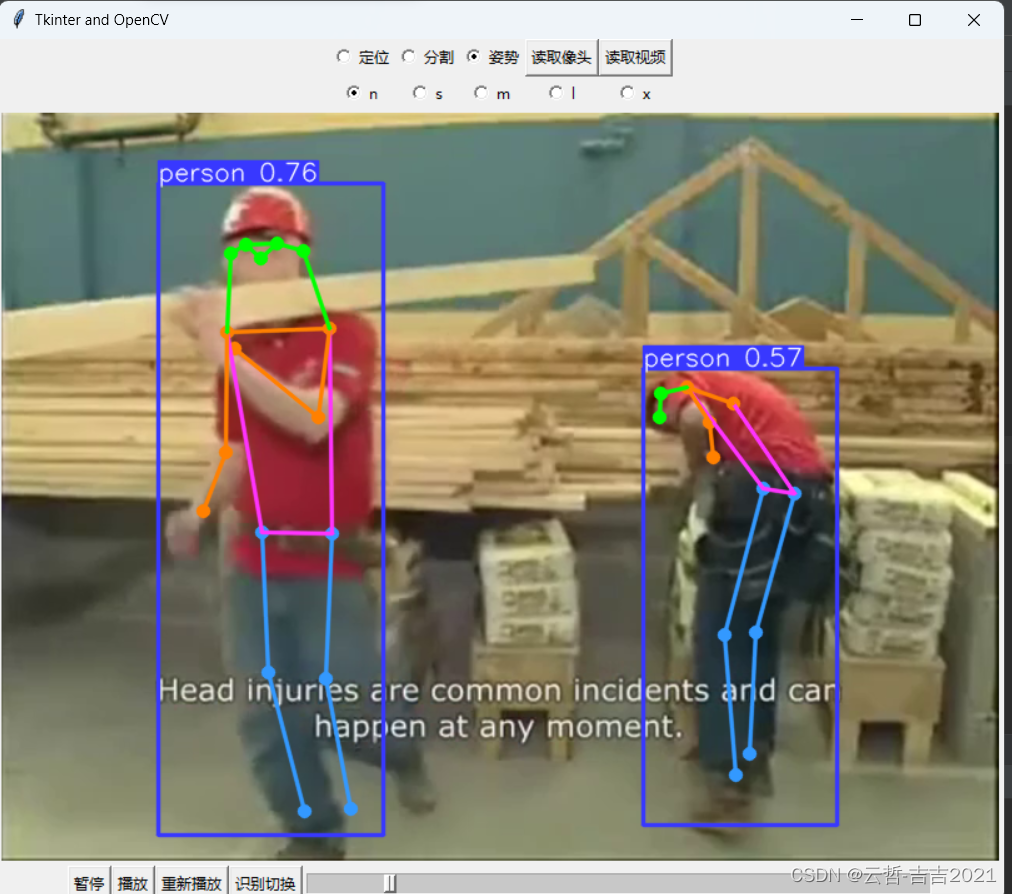
基于Tkinter和OpenCV的目标检测程序源码+权重文件,实现摄像头和视频文件的实时目标检测采用YOLOv8模型进行目标检测
基于Tkinter和OpenCV的目标检测程序源码权重文件,实现摄像头和视频文件的实时目标检测采用YOLOv8模型进行目标检测
项目描述
本项目是一个基于Tkinter和OpenCV的目标检测应用程序,实现了摄像头和视频文件的实时目标检测。通过YOLOv8模型进行目标检测&a…
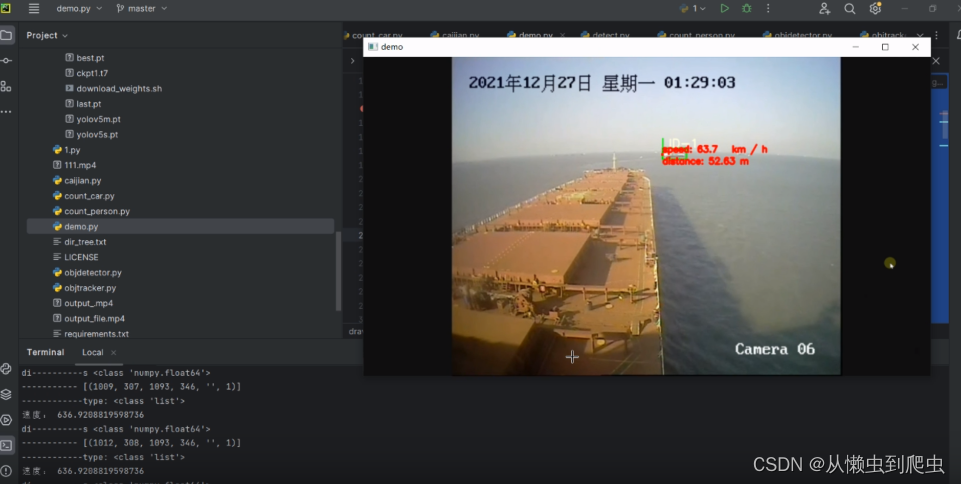
yolov5 deepsort-船舶目标检测+目标跟踪+单目测距+速度测量
目标跟踪是一种计算机视觉技术,通过分析图像或视频数据中的目标,实时追踪目标的位置和运动轨迹。在本文中,我们将详细介绍目标跟踪的原理、方法和应用,并探讨其在各个领域中的潜在价值。 1. 目标跟踪技术的基本原理 目标跟踪技术的…
【RT-DETR有效改进】利用MobileNetV3替换Backbone(轻量化网络结构,提点)
前言
大家好,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PP…

基于YOLOv8的目标识别、计数、电子围栏的项目开发过程
0 前言
用于生产环境中物体检测、识别、跟踪,人、车流量统计,越界安全识别
1 YOLOv8概述
YOLOv8 是Ultralytics的YOLO的最新版本。作为一种前沿、最先进(SOTA)的模型,YOLOv8在之前版本的成功基础上引入了新功能和改进,以提高性…

【单目测距】3D检测框测距
文章目录 一、前言二、2D框测距局限性三、3D框测距3.1、确定接地点3.2、测距结果对比3.3、代码3.4、代码解析 四、后记 一、前言
3D 检测模型用的 fcos3D。如何对 3D 框测距?3D 检测框测距对比 2D 检测框测距优势在哪? 二、2D框测距局限性
(1) 横向测距偏差。当目标有一定倾…
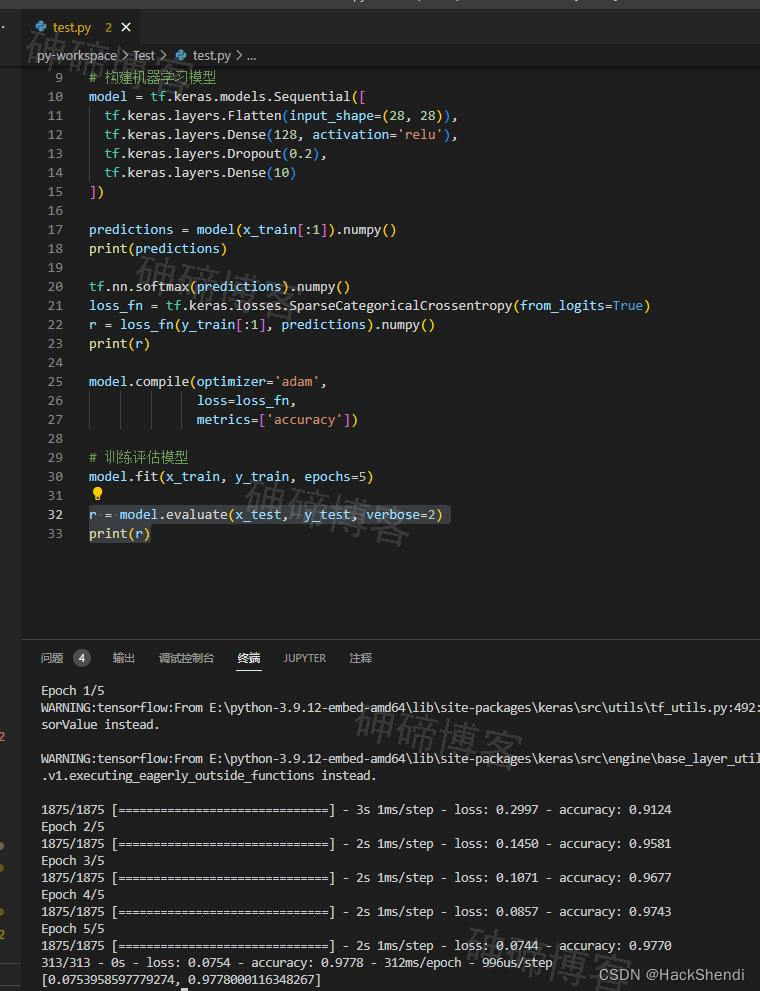
目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
Hi, I’m Shendi 1、目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估 在最近有了个物体识别的需求,于是开始学习
在一番比较与询问后,最终选择 TensorFlow。
对于编程语言,我比较偏向Java或nod…

【即插即用篇】YOLOv8改进实战 | 引入 RepVGG 重参数化结构,极简架构,SOTA性能,让VGG式模型再次伟大
YOLOv8专栏导航:点击此处跳转 一、RepVGG 2021 CVPR 论文链接:RepVGG: Making VGG-style ConvNets Great Again Pytorch code:DingXiaoH/RepVGG 所谓的 “VGG式” 指的是: 没有任何分支结构。即通常所说的plain或feed-forward架构。 仅使用
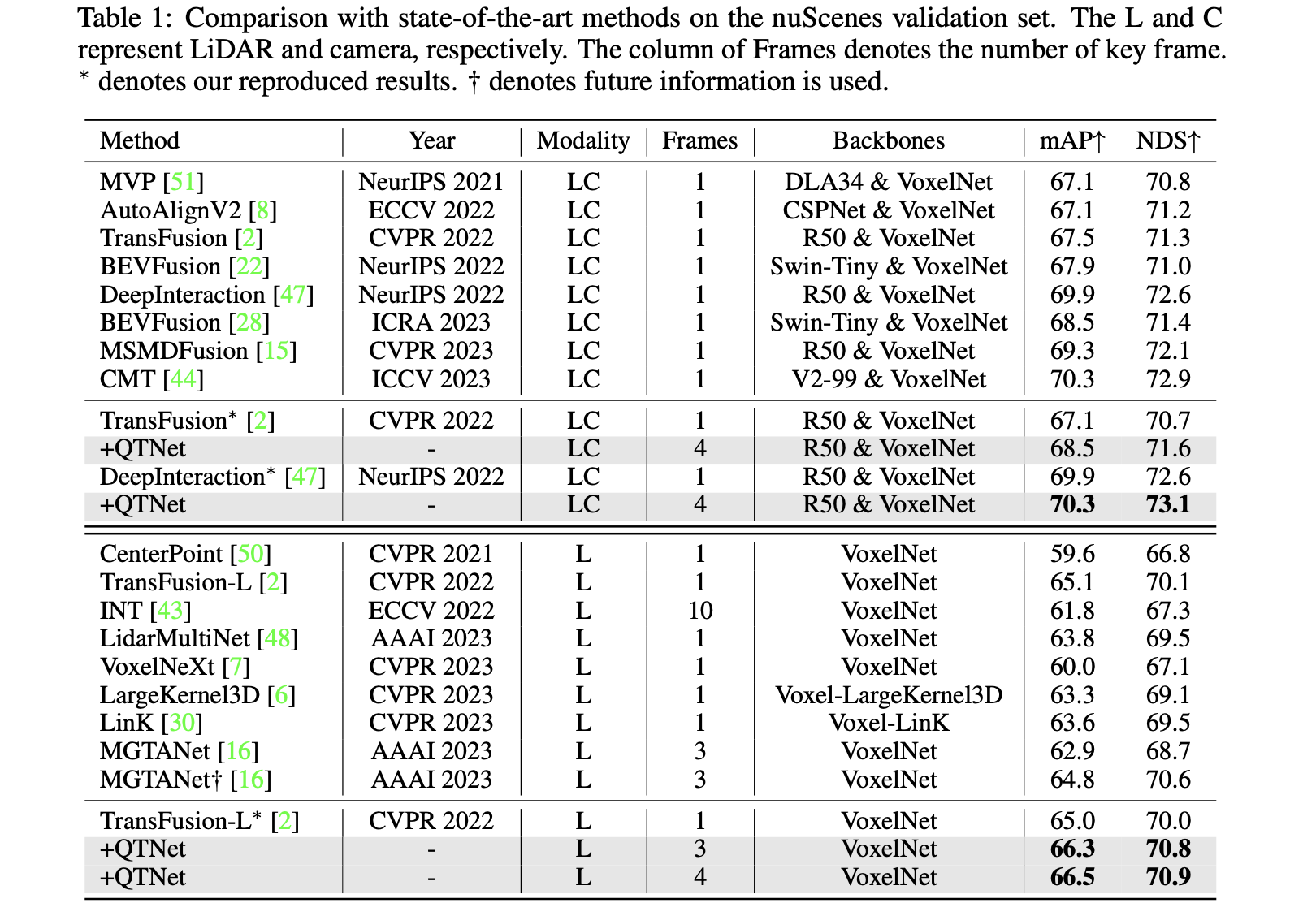
QTNet:Query-based Temporal Fusion with Explicit Motion for 3D Object Detection
参考代码:QTNet
动机和出发点 自动驾驶中时序信息对感知性能具有较大影响,如在感知稳定性维度上。对于常见的时序融合多是在feature的维度上做,这个维度的融合主要分为如下两个方案:
1)BEV-based方案:将之…
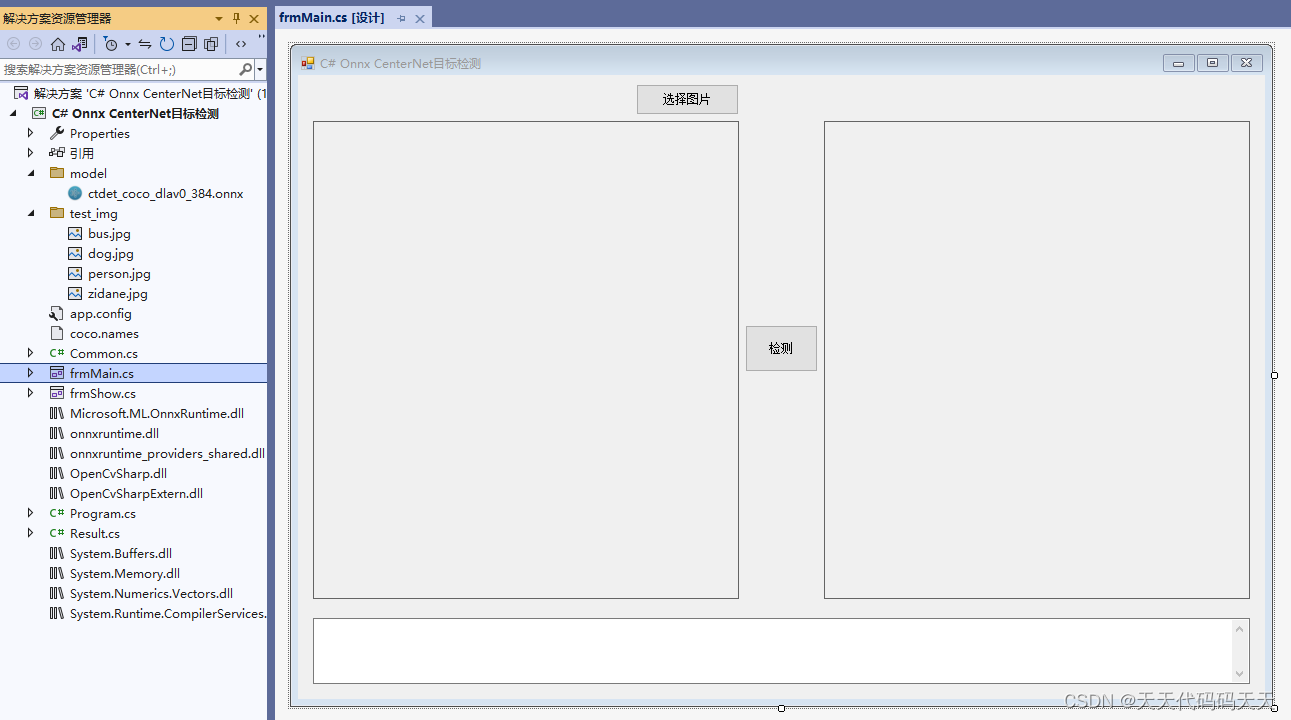
C# Onnx CenterNet目标检测
目录
效果
模型信息
项目
代码
下载 效果 模型信息
Inputs ------------------------- name:input.1 tensor:Float[1, 3, 384, 384] ---------------------------------------------------------------
Outputs ------------------------- name&a…
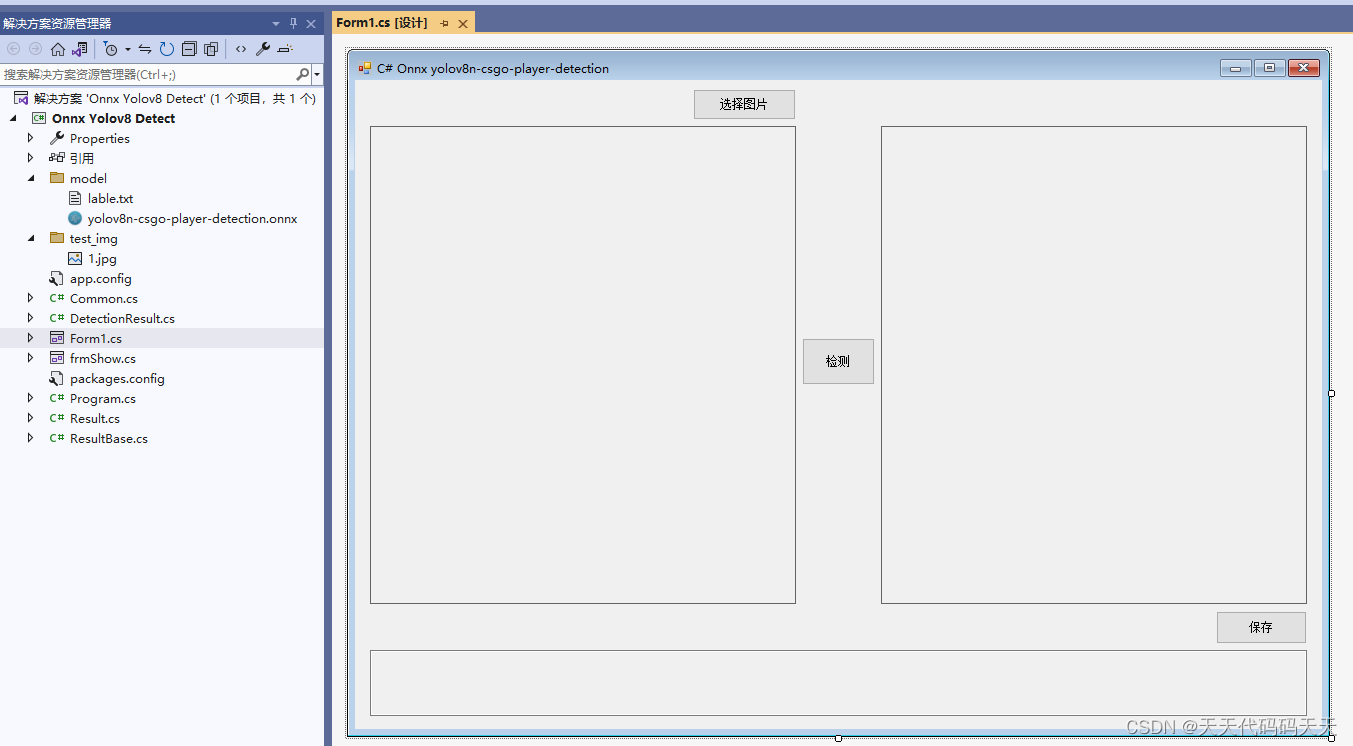
C# Onnx yolov8n csgo player detection
目录
效果
模型信息
项目
代码
下载 C# Onnx yolov8n csgo player detection
效果 模型信息
Model Properties ------------------------- date:2023-12-22T15:01:08.014205 author:Ultralytics task:detect license:AGPL-…

目标检测应用场景—数据集【NO.23】路面缺陷检测数据集
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…

目标追踪:使用ByteTrack进行目标检测和跟踪
BYTE算法是一种简单而有效的关联方法,通过关联几乎每个检测框而不仅仅是高分的检测框来跟踪对象。这篇博客的目标是介绍ByteTrack以及多目标跟踪(MOT)的技术。我们还将介绍在样本视频上使用ByteTrack跟踪运行YOLOv8目标检测。 多目标跟踪&…
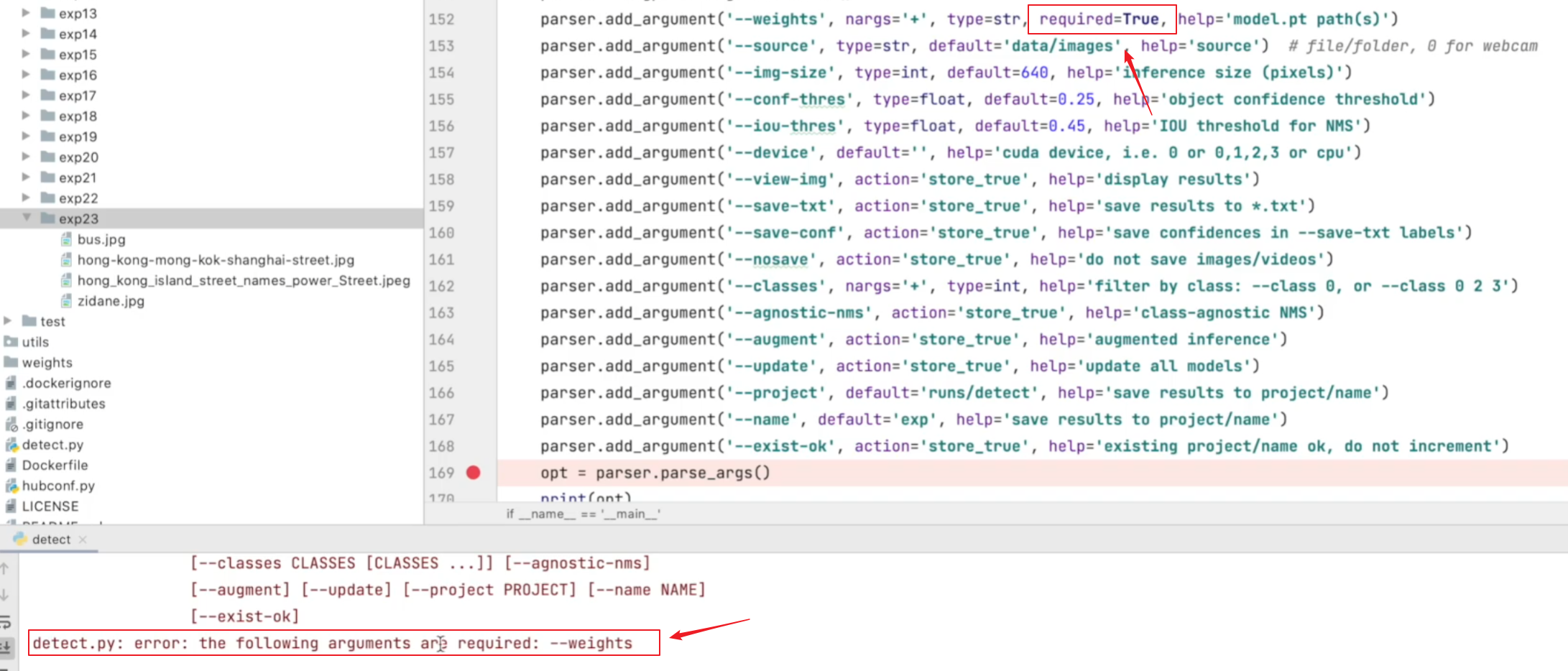
【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(2)-如何利用yolov5进行预测
如何利用yolov5进行预测 yolov5项目的简单描述模型对比图需要的包作者的教程环境inference 不用命令行,使用pycharm运行main函数部分运行程序来看一下 **detect.py**跑代码时遇到的一些问题,可以参考我的其他博客 一些参数说明--weightsdefaultyolov5s.p…
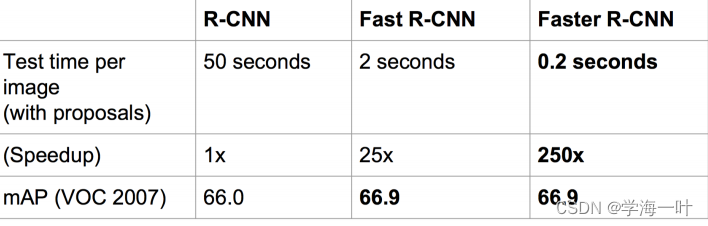
目标检测-Two Stage-Faster RCNN
文章目录 前言一、Faster RCNN的网络结构和流程Faster R-CNN的流程图Faster R-CNN网络结构图(以VGG为backbone): 二、Faster RCNN的创新点三、Faster RCNN的训练过程非极大值抑制(Non-Maximum Suppression,NMS…
C# 图标标注小工具-查看重复文件
目录
效果
项目
代码
下载 效果 项目 代码
using System;
using System.Collections.Generic;
using System.Data;
using System.IO;
using System.Linq;
using System.Security.Cryptography;
using System.Windows.Forms;namespace ImageDuplicate
{public partial clas…

【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(3)-训练yolov5模型(本地)
训练yolov5模型(本地) 训练文件 train.py训练如下图 一些参数的设置weights:对于weight参数,可以往Default参数中填入的参数有 cfg:(缩写)cfg参数可以选择的网络模型 data对于data hyp 超参数epochs 训练多…
深入理解 YOLOv8:解析.yaml 配置文件目标检测、实例分割、图像分类、姿态检测
目录
yolov8导航
YOLOv8(附带各种任务详细说明链接)
引言
YOLOv8配置文件概览
yolov8.yaml
1. nc
2. scales
3. backbone
4. head
yolov8-seg.yaml
1. 参数部分
2. 骨架(Backbone)部分
3. 头部(Head&…
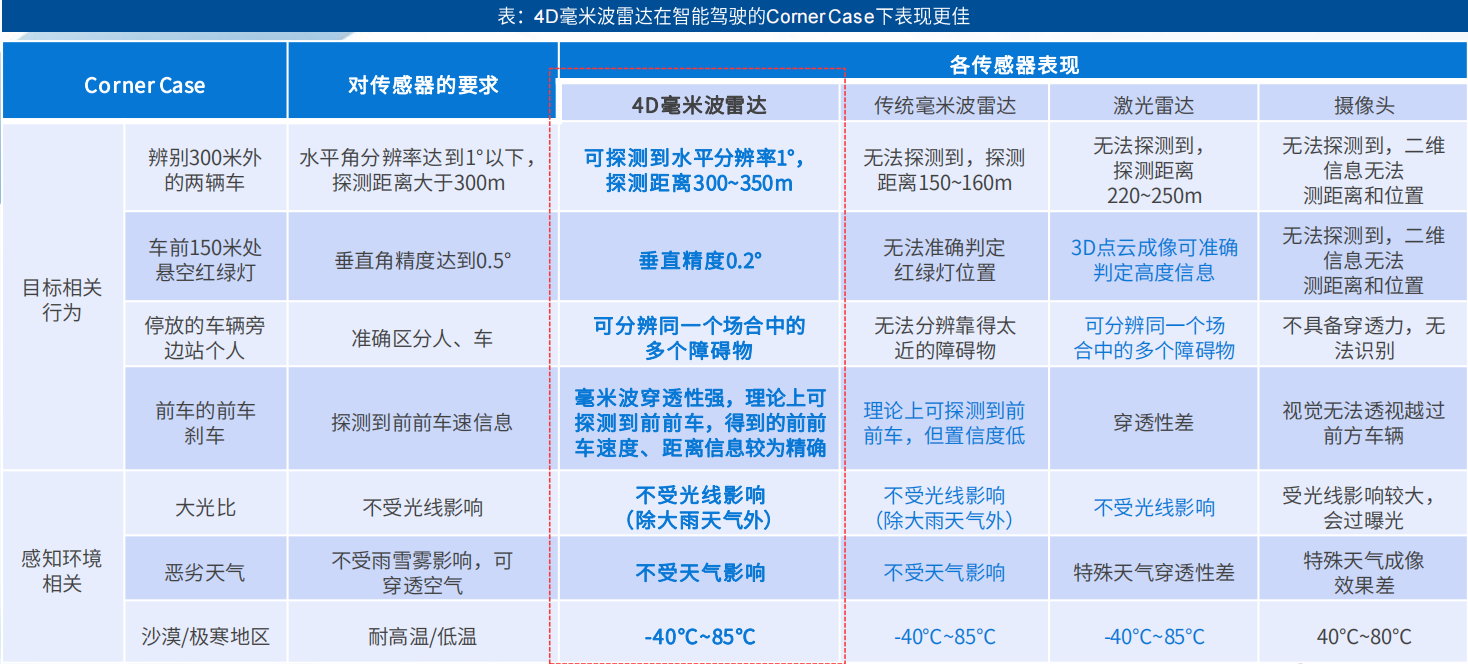
车载毫米波雷达及芯片新趋势研究2--“CMOS+AiP+SoC”与4D毫米波雷达推动产业越过大规模发展临界点
2.1 MMIC芯片工艺发展至CMOS时代,芯片集成度更高、体积与成本下降 MMIC芯片工艺经GaAs、SiGe已发展至CMOS时代,CMOS MMIC具有更低成本、更高集成度的优势。 工艺的主要变化发生在MMIC芯片的射频材料部分,目前SiGe仍为主流工艺。 SiGe虽在…
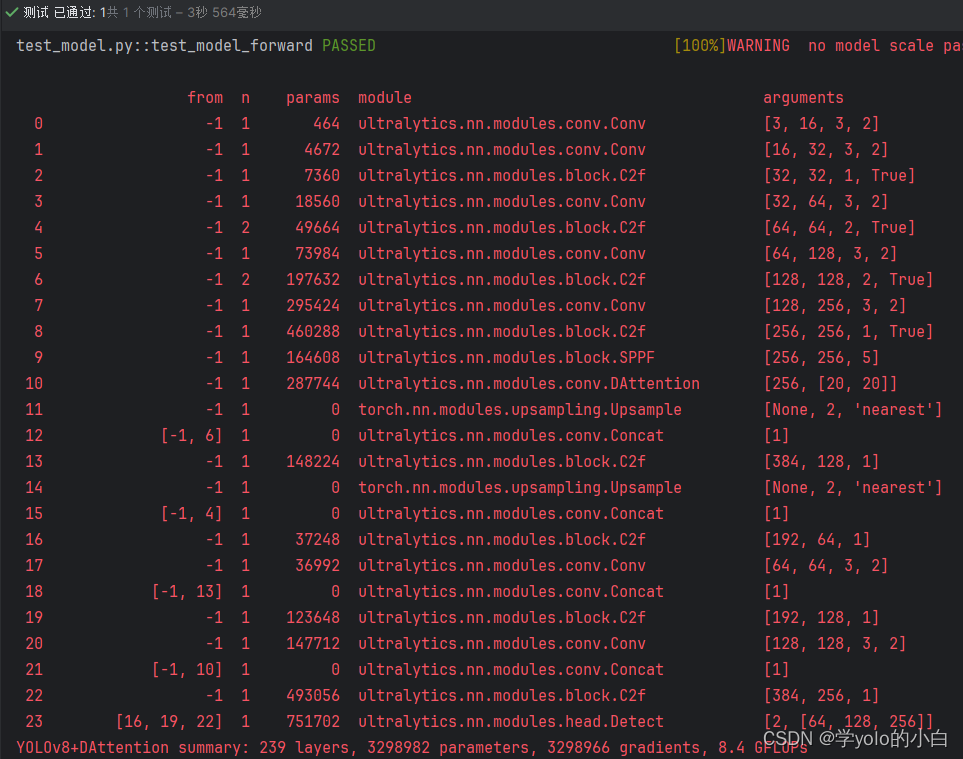
YOLOv8改进 添加可变形注意力机制DAttention
一、Deformable Attention Transformer论文 论文地址:arxiv.org/pdf/2201.00520.pdf
二、Deformable Attention Transformer注意力结构
Deformable Attention Transformer包含可变形注意力机制,允许模型根据输入的内容动态调整注意力权重。在传统的Tra…
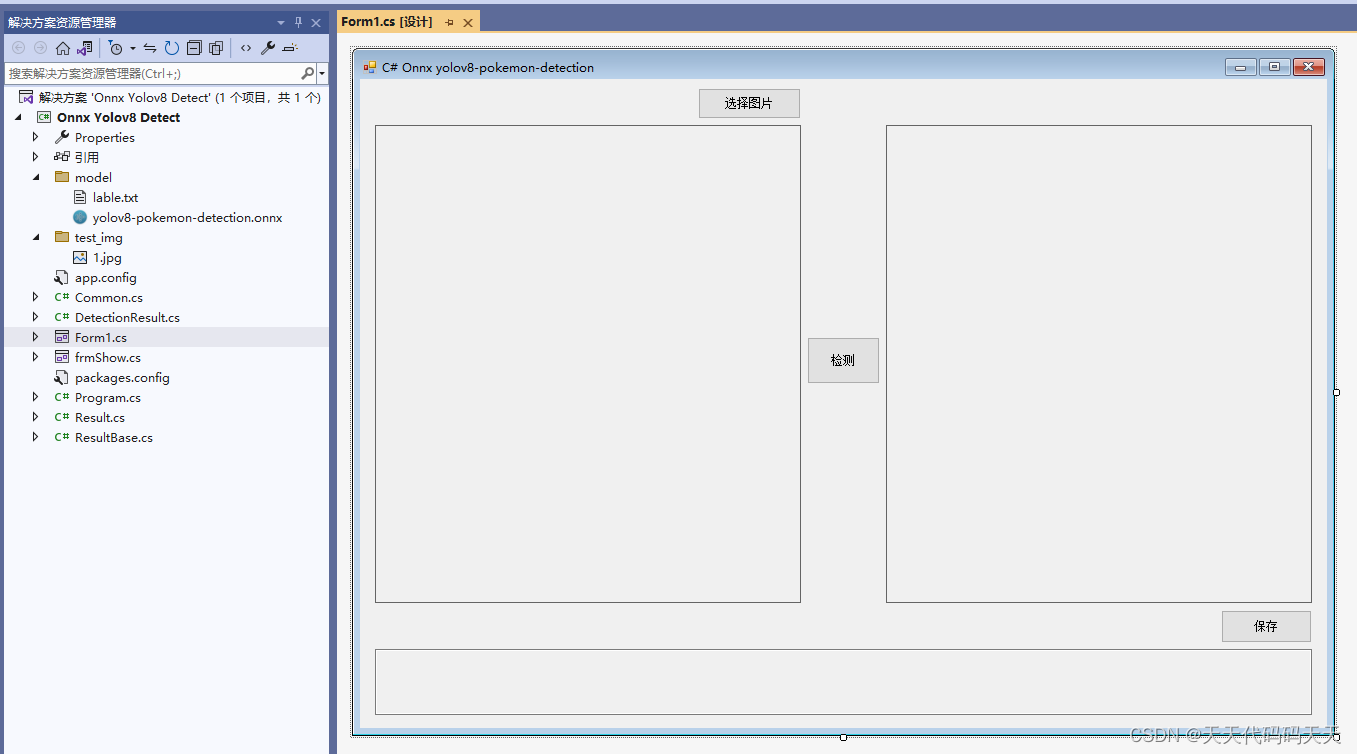
C# Onnx yolov8 pokemon detection
目录
效果
模型信息
项目
代码
下载 C# Onnx yolov8 pokemon detectio
效果 模型信息
Model Properties ------------------------- date:2023-12-25T17:55:44.583431 author:Ultralytics task:detect license:AGPL-3.0 h…
YOLO算法:实时目标检测的革命
第一部分:引言
在计算机视觉领域,目标检测是一个关键的任务,涉及到在图像或视频中识别和定位不同类别的物体。许多目标检测算法在追求准确性的同时牺牲了实时性,而You Only Look Once (YOLO)算法以其独特的设计理念成为了实时目标…
使用Python进行Yolo目标检测的带txt标签进行数据增强
yolov8导航 如果大家想要了解关于yolov8的其他任务和相关内容可以点击这个链接,我这边整理了许多其他任务的说明博文,后续也会持续更新,包括yolov8模型优化、sam等等的相关内容。
YOLOv8(附带各种任务详细说明链接)
…

GLEE:一个模型搞定目标检测/实例分割/定位/跟踪/交互式分割等任务!性能SOTA!
GLEE,这是一个面向目标级别的基础模型,用于定位和识别图像和视频中的目标。通过一个统一的框架,GLEE实现了对开放世界场景中任意目标的检测、分割、跟踪、定位和识别,适用于各种目标感知任务。采用了一种协同学习策略,…
YOLO5用于交通标志牌(TT100K数据集)的训练预测
共勉 一、数据集转换1.1、数据集下载1.2、数据集格式转换 二、训练预测三、写在最末 先贴下实验结果: 去年就做完了的一个工作,这会终于记录完毕啦。
另外如果是对口罩识别检测(可用于毕设、课程设计等等)感兴趣的同学也可参考…
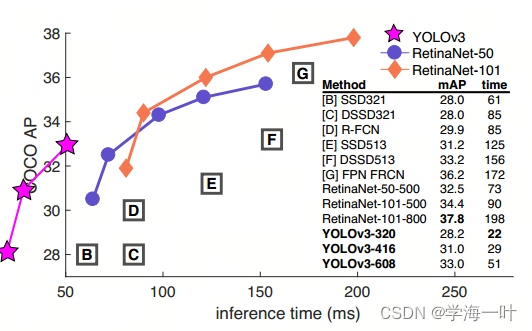
目标检测-One Stage-YOLO v3
文章目录 前言一、YOLO v3的网络结构和流程二、YOLO v3的创新点总结 前言
根据前文目标检测-One Stage-YOLOv2可以看出YOLOv2的速度和精度都有相当程度的提升,但是精度仍较低,YOLO v3基于一些先进的结构和思想对YOLO v2做了一些改进。 提示:…

基于YOLOv7算法的高精度实时19类动物目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时19类动物目标检测系统可用于日常生活中检测与定位19类动物目标(水牛、 斑马、 大象、 水豚、 海龟、 猫、 奶牛、 鹿、 狗、 火烈鸟、 长颈鹿、 捷豹、 袋鼠、 狮子、 鹦鹉、 企鹅、 犀牛、 羊和老虎)&#x…
实现目标检测中的数据格式自由(labelme json、voc、coco、yolo格式的相互转换)
在进行目标检测任务中,存在labelme json、voc、coco、yolo等格式。labelme json是由anylabeling、labelme等软件生成的标注格式、voc是通用目标检测框(mmdetection、paddledetection)所支持的格式,coco是通用目标检测框࿰…

WSL使用Ubuntu 20.04版本运行py-bottom-up-attention的记录,及其可能错误的解决方法
文章目录 1. 切换linux的镜像2. 安装gcc3. 查看显卡驱动4. 安装gcc版本5. wsl安装cuda 10.16. 新建虚拟环境8. 安装依赖包9. 运行代码错误运行的所有历史命令如下 WSL使用Ubuntu 20.04版本运行py-bottom-up-attention的记录,及其可能错误的解决方法
github代码地址…
C# OpenCvSharp DNN 部署yoloX
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN 部署yoloX
效果 模型信息
Inputs ------------------------- name:images tensor:Float[1, 3, 640, 640] ---------------------------------------------------------------
Outputs ---…

准备好迎接新兴的汽车雷达卫星架构了吗?(TI文档)
引言 随着全球新车评估计划的安全等级和法规对主动安全功能的要求越来越严格,安全是当今车辆的一个不容置疑的特征。全球汽车制造商正在满足这些安全要求,并通过不断增强车辆内的高级驾驶辅助系统(ADAS)功能,包括自动紧急制动(AEB)、自适应巡…

基于YOLOv7算法的高精度实时六类水果目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时六类水果目标检测系统可用于日常生活中检测与定位苹果(apple)、香蕉(banan)、葡萄(grape)、橘子(orange)、菠萝(pineapple&a…

目标检测应用场景—数据集【NO.25】牛行为检测数据集
写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享…

理解SIFT/SURF算法原理,并进行关键点检测
SIFT/SURF算法
1.1 SIFT原理
前面两节我们介绍了Harris和Shi-Tomasi角点检测算法,这两种算法具有旋转不变性,但不具有尺度不变性,以下图为例,在左侧小图中可以检测到角点,但是图像被放大后,在使用同样的窗…
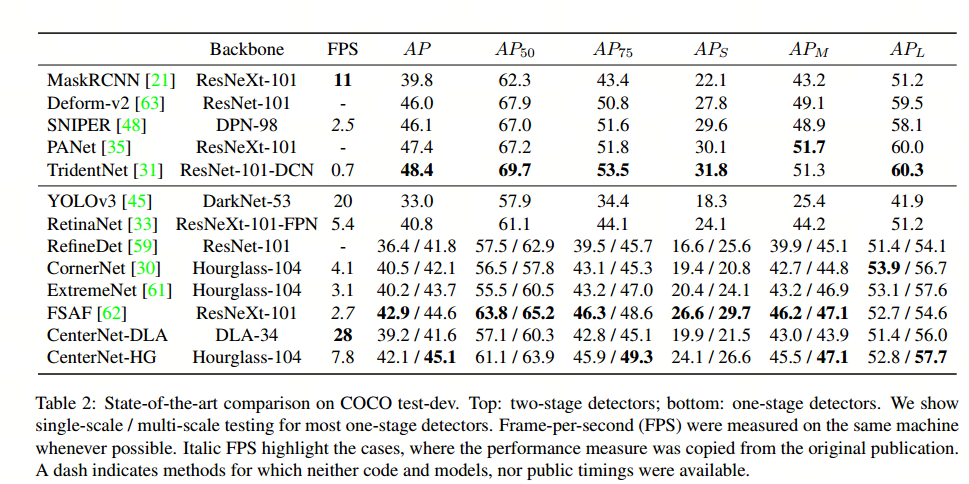
目标检测-One Stage-CenterNet
文章目录 前言一、CenterNet的网络结构和流程二、CenterNet的创新点总结 前言
前文提到的YOLOv3、YOLOv4、YOLOv5都是基于Anchor的算法(anchor-based),这类算法有如下缺点:
产生大量的预测框,计算量大正负样本不平衡…
YOLOv8目标检测中数据集各部分的作用
自学答疑使用,持续更新… 在目标检测任务中,通常将整个数据集划分为训练集(training set)、验证集(validation set)和测试集(test set)。这三个数据集在训练和评估过程中具有不同的…

即插即用篇 | YOLOv8 Gradio 前端展示页面 | 支持 【分类】【检测】【分割】【关键点】 任务
分类任务效果 分割任务效果 检测任务效果 关键点任务效果 使用方法
Gradio 是一个开源库,旨在为机器学习模型提供快速且易于使用的网页界面。它允许开发者和研究人员轻松地为他们的模型创建交互式的演示,使得无论技术背景如何的人都可以方便地试用和理解这些模型。使用Gradi…
![[C#]C# OpenVINO部署yolov8目标检测模型](https://img-blog.csdnimg.cn/direct/1d892b2efb894d4d86ecb9b9ce15f346.jpeg)
[C#]C# OpenVINO部署yolov8目标检测模型
【官方框架地址】
https://github.com/ultralytics/ultralytics.git 【算法介绍】
YOLOv8 抛弃了前几代模型的 Anchor-Base。
YOLO 是一种基于图像全局信息进行预测的目标检测系统。自 2015 年 Joseph Redmon、Ali Farhadi 等人提出初代模型以来,领域内的研究者们…
【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(4)-自制数据集及训练(使用makesense标注数据集)
如何制作和训练自己的数据集 看yolov5官网创建数据集1.搜索需要的图片2.创建标签标注数据集地址:放入图片后选择目标检测创建文档,每个标签写在单独的一行上传结果此处可以编辑类别把车框选选择类别即可导出数据 3.新建一个目录放数据写yaml文件 4. 测试…
目标检测数据集 - MS COCO
文章目录 1. 数据集介绍2. 使用pycocotools读取数据3. 验证mAP 论文:Microsoft COCO: Common Objects in Context 网址:https://arxiv.org/abs/1405.0312 官网:https://cocodataset.org/ 1. 数据集介绍
MS COCO是一个非常大型,且…

目标检测数据集 - 人脑肿瘤检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:人脑肿瘤检测数据集,真实 CT 场景高质量图片数据,涉及人脑 CT 图片数据集丰富;适用实际项目应用:CT 图片场景下人脑肿瘤检测项目,以及作为通用人脑检测数据集场景数据的补充;标注说明…

目标检测中类不平衡问题的解决方案分为两种方法:修正模型本身和直接处理数据。请解释一下修正模型本身和直接处理数据这两种方法的定义和特点。
问题描述:目标检测中类不平衡问题的解决方案分为两种方法:修正模型本身和直接处理数据。请解释一下修正模型本身和直接处理数据这两种方法的定义和特点。
问题解答:
在目标检测中,解决类别不平衡问题的方法可以分为修正模型本身和直接处理数…
Image Enhancement Guided Object Detection in Visually Degraded Scenes
Abstract
目标检测准确率在视觉退化场景下降严重。一个普遍的解决方法就是对退化图像进行增强然后再执行目标检测。但是,这是一种次优的方案,而且未必对目标检测的准确率有提升,因为图像增强和目标检测两个任务的不同。为了解决这个问题&…

【论文笔记】UniVision: A Unified Framework for Vision-Centric 3D Perception
原文链接:https://arxiv.org/pdf/2401.06994.pdf
1. 引言
目前,同时处理基于图像的3D检测任务和占用预测任务还未得到充分探索。3D占用预测需要细粒度信息,多使用体素表达;而3D检测多使用BEV表达,因其更加高效。
本…
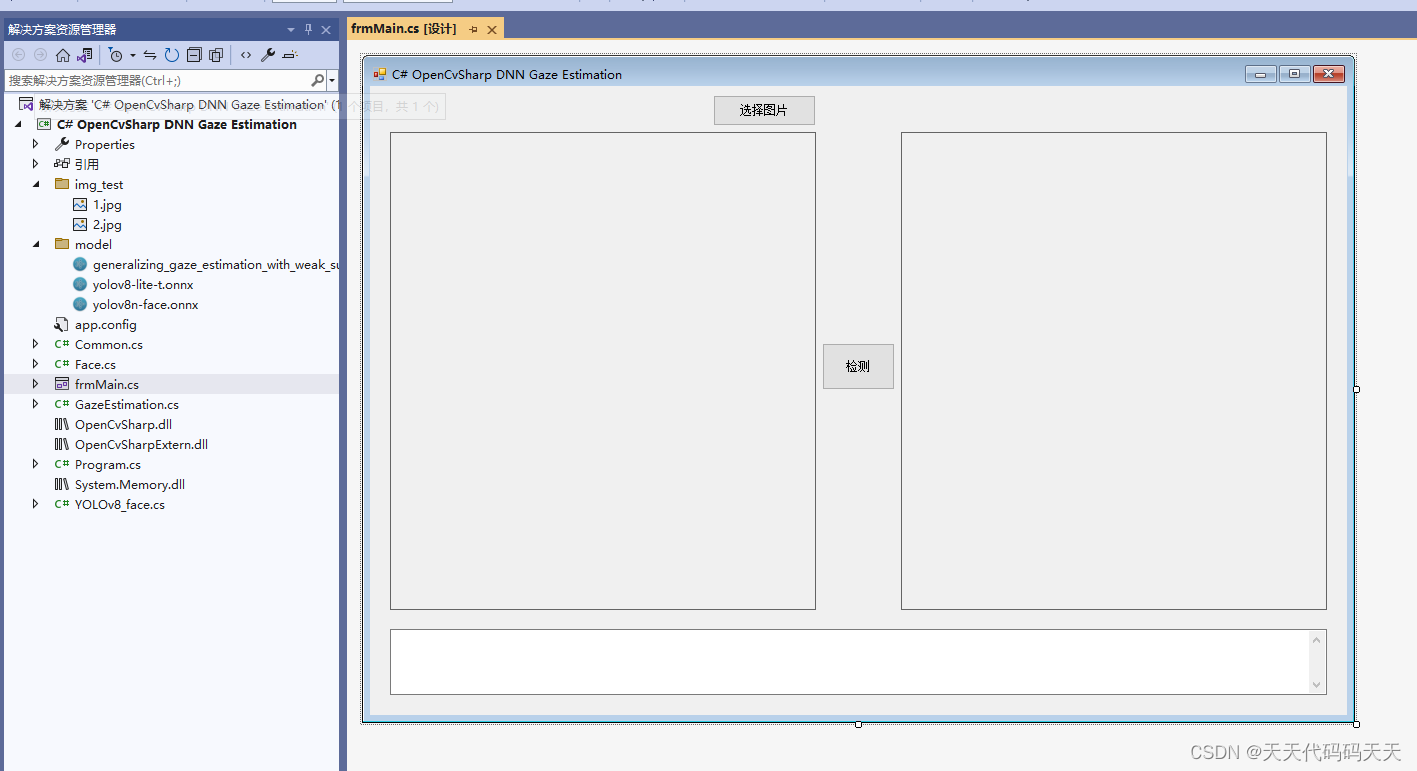
C# OpenCvSharp DNN Gaze Estimation 视线估计
目录
介绍
效果
模型信息
项目
代码
frmMain.cs
GazeEstimation.cs
下载 C# OpenCvSharp DNN Gaze Estimation
介绍
训练源码地址:https://github.com/deepinsight/insightface/tree/master/reconstruction/gaze
效果 模型信息
Inputs ----------------…

【论文解读】Collaboration Helps Camera Overtake LiDAR in 3D Detection
CoCa3D 摘要引言Collaborative Camera-Only 3D DetectionCollaborative depth estimationCollaborative detection feature learning 实验结论和局限 摘要
与基于 LiDAR 的检测系统相比,仅相机 3D 检测提供了一种经济的解决方案,具有简单的配置来定位 3…
分割头篇 | 原创自研 | YOLOv8 更换 SEResNeXtBottleneck 头 | 附详细结构图
左图:ResNet 的一个模块。右图:复杂度大致相同的 ResNeXt 模块,基数(cardinality)为32。图中的一层表示为(输入通道数,滤波器大小,输出通道数)。 1. 思路
ResNeXt是微软研究院在2017年发表的成果。它的设计灵感来自于经典的ResNet模型,但ResNeXt有个特别之处:它采用…

适用于汽车 4D 成像雷达的双器件毫米波级联参考设计(TI文档)
说明 该汽车雷达参考设计是一个 76GHz 至 81GHz 的级联雷达传感器模块。这包括由 AWR2243 器件和AM2732R 雷达处理器构成的双器件级联阵列。在这一级联雷达配置中,一个主器件向主器件和辅助器件分配20GHz 的本机振荡器 (LO) 信号,使这两个器件作为单个射…

目标检测的发展史及关键技术概述
目标检测的发展史及关键技术概述
目标检测是计算机视觉领域中的一个基础问题,它旨在识别出图像中所有感兴趣的目标,并给出它们的位置和类别。从早期的模板匹配到现代的深度学习方法,目标检测技术经历了多个发展阶段。本文将透过时间的迷雾&a…

目标检测 - 绘制bounding box
工具类
from PIL.Image import Image, fromarray
import PIL.ImageDraw as ImageDraw
import PIL.ImageFont as ImageFont
from PIL import ImageColor
import numpy as npSTANDARD_COLORS [AliceBlue, Chartreuse, Aqua, Aquamarine, Azure, Beige, Bisque,BlanchedAlmond, …

Faster-RCNN 和 Mask-RCNN详解
Faster-RCNN ,Mask-RCNN原理 一、摘要1.1 图像分割1.2 语义分割与实例分割 二、Faster-RCNN2.1 Faster-RCNN模型架构2.2 🍊深度卷积网络(backbone)2.3 🍎RPN(Region Proposal Network)2.4 &…
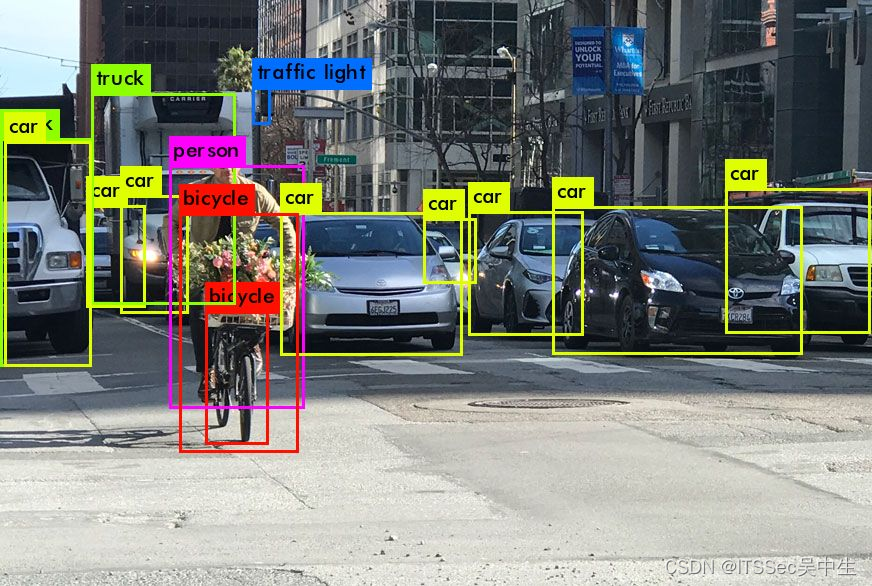
目标检测及相关算法介绍
文章目录 目标检测介绍目标检测算法分类目标检测算法模型组成经典目标检测论文 目标检测介绍
目标检测是计算机视觉领域中的一项重要任务,旨在识别图像或视频中的特定对象的位置并将其与不同类别中的对象进行分类。与图像分类任务不同,目标检测不仅需要…
即插即用篇 | UniRepLKNet:用于音频、视频、点云、时间序列和图像识别的通用感知大卷积神经网络 | DRepConv
大卷积神经网络(ConvNets)近来受到了广泛研究关注,但存在两个未解决且需要进一步研究的关键问题。1)现有大卷积神经网络的架构主要遵循传统ConvNets或变压器的设计原则,而针对大卷积神经网络的架构设计仍未得到解决。2)随着变压器在多个领域的主导地位,有待研究ConvNets…
雷达DoA估计的跨行业应用--麦克风阵列声源定位(Matlab仿真)
一、概述 麦克风阵列: 麦克风阵列是由一定数目的声学传感器(麦克风)按照一定规则排列的多麦克风系统,而基于麦克风阵列的声源定位是指用麦克风拾取声音信号,通过对麦克风阵列的各路输出信号进行分析和处理,…
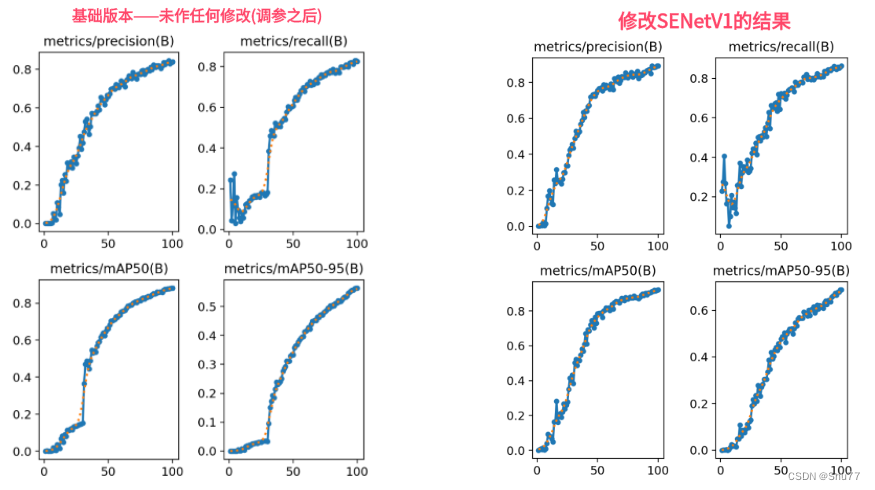
【RT-DETR有效改进】利用SENetV1重构化网络结构 (ILSVRC冠军得主)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文给大家带来的改进机制是SENet(Squeeze-and-Excitation Networks)其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何一个模型相结合…
End-to-End Object Detection with Transformers(DETR)
总结:这篇文档介绍了一个基于transformer和双分配匹配损失的新型目标检测系统(DETR)。传统的目标检测方法使用间接方法进行目标预测,而DETR将目标检测视为直接的集合预测问题,简化了检测流程,并减少了手动设…
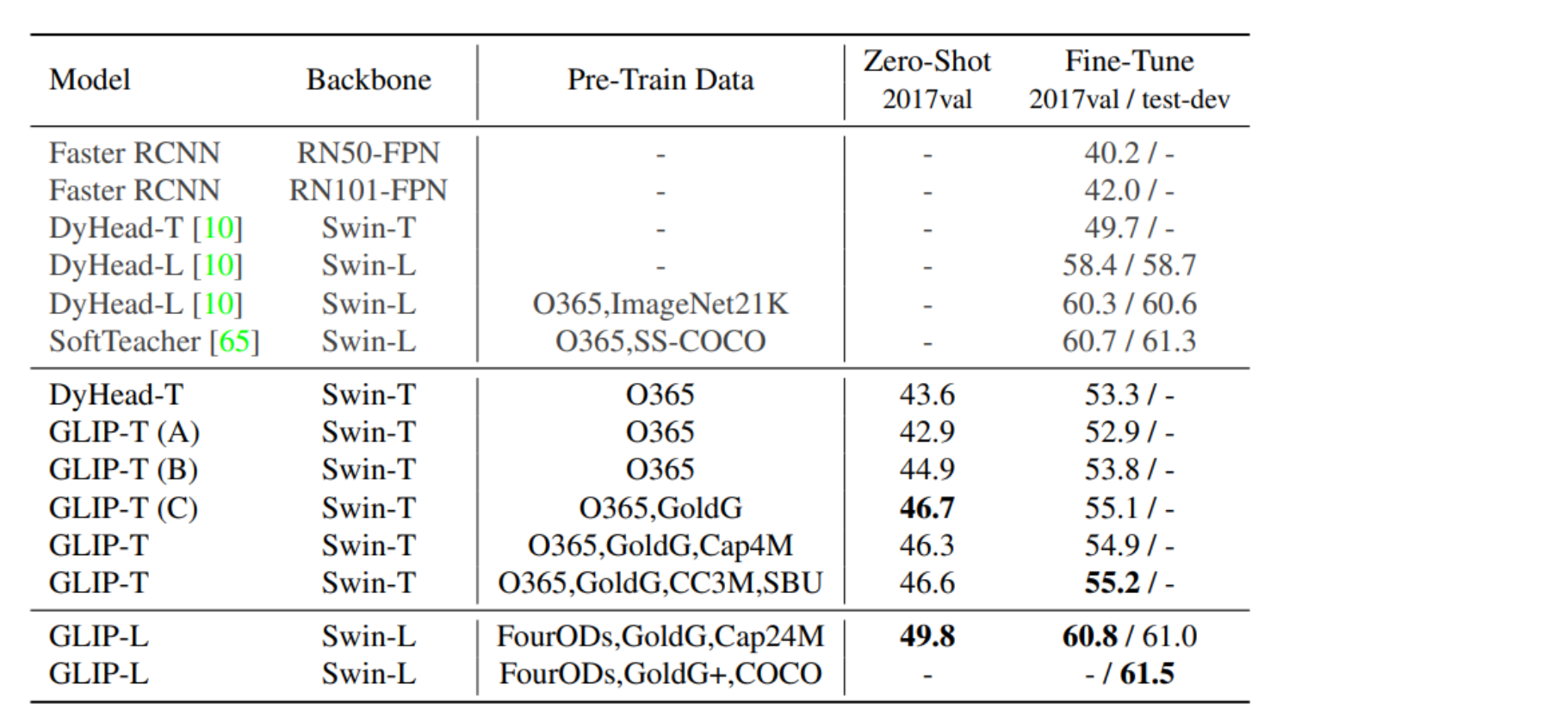
【多模态大模型】GLIP:零样本学习 + 目标检测 + 视觉语言大模型
GLIP 核心思想GLIP 对比 BLIP、BLIP-2、CLIP 主要问题: 如何构建一个能够在不同任务和领域中以零样本或少样本方式无缝迁移的预训练模型?统一的短语定位损失语言意识的深度融合预训练数据类型的结合语义丰富数据的扩展零样本和少样本迁移学习 效果 论文:…
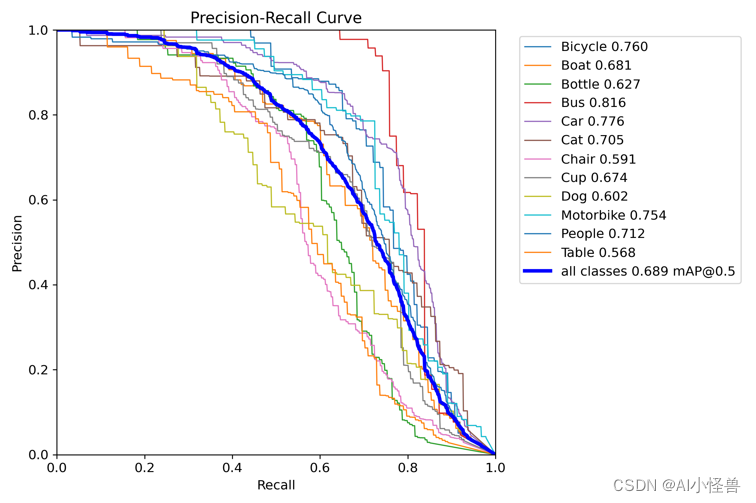
基于YOLOv8的暗光低光环境下(ExDark数据集)检测,加入多种优化方式---自研CPMS注意力,效果优于CBAM ,助力自动驾驶(二)
💡💡💡本文主要内容:详细介绍了暗光低光数据集检测整个过程,从数据集到训练模型到结果可视化分析,以及如何优化提升检测性能。
💡💡💡加入 自研CPMS注意力 mAP0.5由原始的0.682提升…
【RT-DETR进阶实战】利用RT-DETR进行视频划定区域目标统计计数
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
Hello,各位读者,最近会给大家发一些进阶实战的讲解,如何利用RT-DETR现有的一些功能进行一些实战, 让我们不仅会改进RT-DETR,也能够利用RT-DETR去做一些简单的小工作,后面我也会将这些功能利用PyQt或者是…
深度学习||YOLO(You Only Look Once)深度学习的实时目标检测算法(YOLOv1~YOLOv5)
目录
YOLOv1:
YOLOv2:
YOLOv3:
YOLOv4:
YOLOv5:
总结: YOLO(You Only Look Once)是一系列基于深度学习的实时目标检测算法。
自从2015年首次被提出以来,YOLO系列不断发展,推出了多个版本,包括YOLOv1, YOLOv2, YOLOv3, YOLOv4, 和YOLOv5等。下面是对YOLO系列的详解…
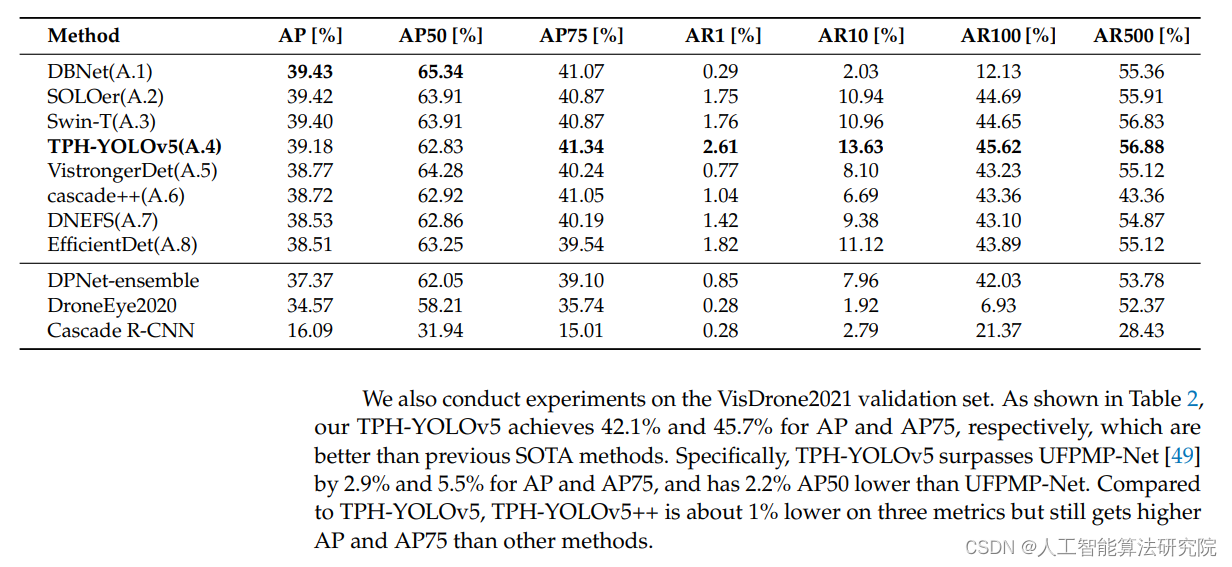
英文论文(sci)解读复现【NO.20】TPH-YOLOv5++:增强捕获无人机的目标检测跨层不对称变压器的场景
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…
目标检测教程视频指南大全
魔鬼面具-哔哩哔哩视频指南
必看干货系列(建议搞深度学习的小伙伴都看看,特别是图像相关)
深度学习常见实验问题与实验技巧(适用于所有模型,小白初学者必看!)还在迷茫深度学习中的改进实验应该从哪里开始改起的同学,一定要进来看看了!用自身…

YOLOv8-Openvino和ONNXRuntime推理【CPU】
1 环境:
CPU:i5-12500
2 安装Openvino和ONNXRuntime
2.1 Openvino简介
Openvino是由Intel开发的专门用于优化和部署人工智能推理的半开源的工具包,主要用于对深度推理做优化。
Openvino内部集成了Opencv、TensorFlow模块,除此…
![[杂记]mmdetection3.x中的数据流与基本流程详解(数据集读取, 数据增强, 训练)](https://img-blog.csdnimg.cn/direct/6e510634ee994db6b5b73d7bb42f58f7.png)
[杂记]mmdetection3.x中的数据流与基本流程详解(数据集读取, 数据增强, 训练)
之前跑了一下mmdetection 3.x自带的一些算法, 但是具体的代码细节总是看了就忘, 所以想做一些笔记, 方便初学者参考. 其实比较不能忍的是, 官网的文档还是空的… 这次想写其中的数据流是如何运作的, 包括从读取数据集的样本与真值, 到数据增强, 再到模型的forward当中. 0. MMDe…
YOLOv7改进PIoU损失函数:PIoU v2损失增强了专注于中等质量锚盒的能力,v1版本使用非单调聚焦机制更直接、更快的边界框回归损失
💡本篇内容:YOLOv7改进PIoU损失函数:PIoU v2损失增强了专注于中等质量锚盒的能力,v1版本使用非单调聚焦机制更直接、更快的边界框回归损失
💡附改进源代码及教程,用来改进🚀PIoU损失函数
Powerful-IoU损失函数论文地址:https://www.sciencedirect.com/science/art…

目标检测7-DETR算法剖析与实现
文章目录 端到端目标检测框架DETR背景介绍模型结构模块解析数据模型结构 动手实现DETR 欢迎访问个人网络日志🌹🌹知行空间🌹🌹 端到端目标检测框架DETR
背景介绍
DETR是Facebook AI的Nicolas Carion等于2020年05月提交的论文中提…
“目标检测”任务基础认识
“目标检测”任务基础认识
1.目标检测初识
目标检测任务关注的是图片中特定目标物体的位置。
目标检测最终目的:检测在一个窗口中是否有物体。 eg:以猫脸检测举例,当给出一张图片时,我们需要框出猫脸的位置并给出猫脸的大小,如…
目标检测YOLO实战应用案例100讲-基于图像增强的鸟类目标检测(续)
目录
SRGAN网络模型改进研究
3.1 SRGAN超分辨率模型
3.1.1 SRGAN网络结构
3.1.2 SRGAN的损失函数
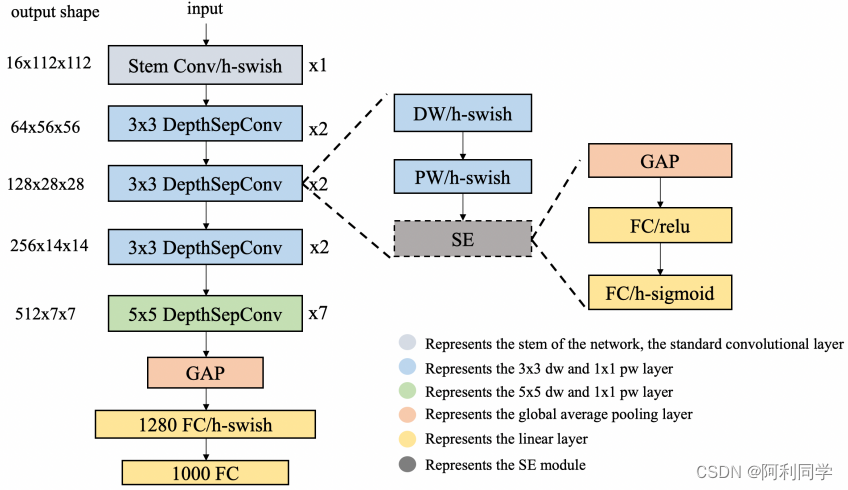
改进的yolov5目标检测-yolov5替换骨干网络-yolo剪枝(TensorRT及NCNN部署)
YOLOv5改进点 2022.10.30 复现TPH-YOLOv5 2022.10.31 完成替换backbone为Ghostnet 2022.11.02 完成替换backbone为Shufflenetv2 2022.11.05 完成替换backbone为Mobilenetv3Small 2022.11.10 完成EagleEye对YOLOv5系列剪枝支持 2022.11.14 完成MQBench对YOLOv5系列量化支持…
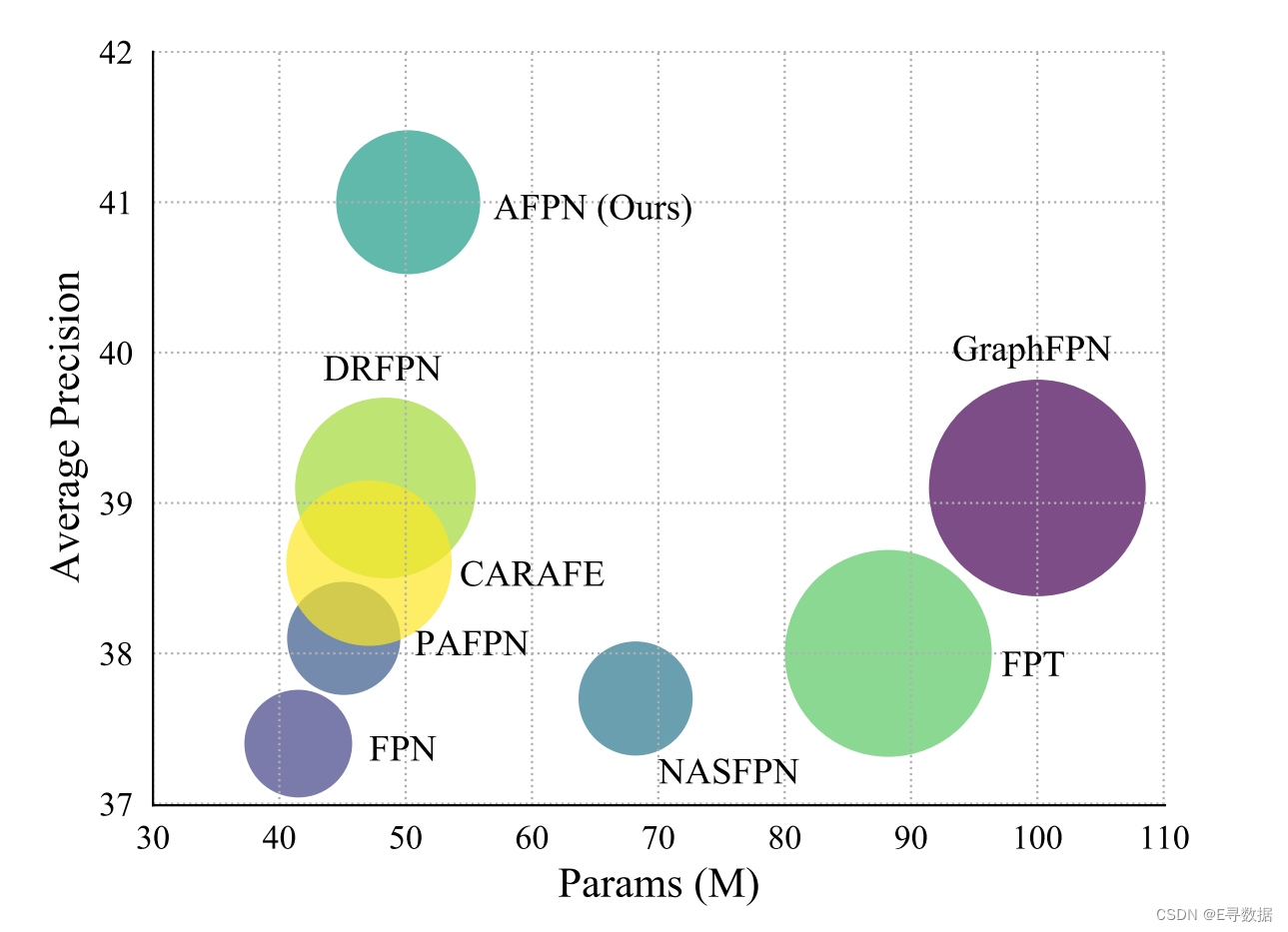
使用AFPN渐近特征金字塔网络优化YOLOv8改进小目标检测效果(不适合新手)
目录
简单概述
算法概述
优化效果
参考文献
文献地址:paper
废话少说,上demo源码链接: 简单概述 AFPN的核心思想:AFPN主要通过引入渐近的特征融合策略,逐步整合底层、高层和顶层的特征到目标检测过程中。这种融合…
引领时代的大模型chatgpt简介
目录 1. 引言
2. ChatGPT简介
2.1 名称的含义
2.2 特点
3. 发展历史
3.1 初始版本
3.2 后续发展
4. 应用领域
5. 参考文献
6. chatgpt新特性 1. 引言 在人工智能的迅猛发展中,聊天机器人成为了一个令人兴奋的领域。特别是OpenAI开发的ChatGPT,凭…
深入浅出理解目标检测的NMS非极大抑制
一、参考资料
物体检测中常用的几个概念迁移学习、IOU、NMS理解
目标定位和检测系列(3):交并比(IOU)和非极大值抑制(NMS)的python实现
Pytorch:目标检测网络-非极大值抑制(NMS)
…

NeurIPS 2023 Spotlight | VoxDet:基于3D体素表征学习的新颖实例检测器
本文提出基于3D体素表征学习的新颖实例检测器VoxDet。给定目标实例的多视图,VoxDet建立该实例的三维体素表征。在更加杂乱的测试图片上,VoxDet使用体素匹配算法检测目标实例。实验表明,VoxDet中的三维体素表征与匹配比多种二维特征与匹配要更…
基于YOLO的自动驾驶目标检测研究综述
摘要:自动驾驶是人工智能发展领域的一个重要方向,拥有良好的发展前景,而实时准确的目标检测与识别是保证自动驾驶汽车安全稳定运行的基础与关键。回顾自动驾驶和目标检测技术的发展历程,综述了YOLO算法在车辆、行人、交通标志、灯光、车道线等目标检测上的应用,同时对比分…

《YOLOv8:从入门到实战》报错解决 专栏答疑
前言:Hello大家好,我是小哥谈。《YOLOv8:从入门到实战》专栏上线后,部分同学在学习过程中提出了一些问题,笔者相信这些问题其他同学也有可能遇到。为了让大家可以更好地学习本专栏内容,笔者特意推出了该篇专…
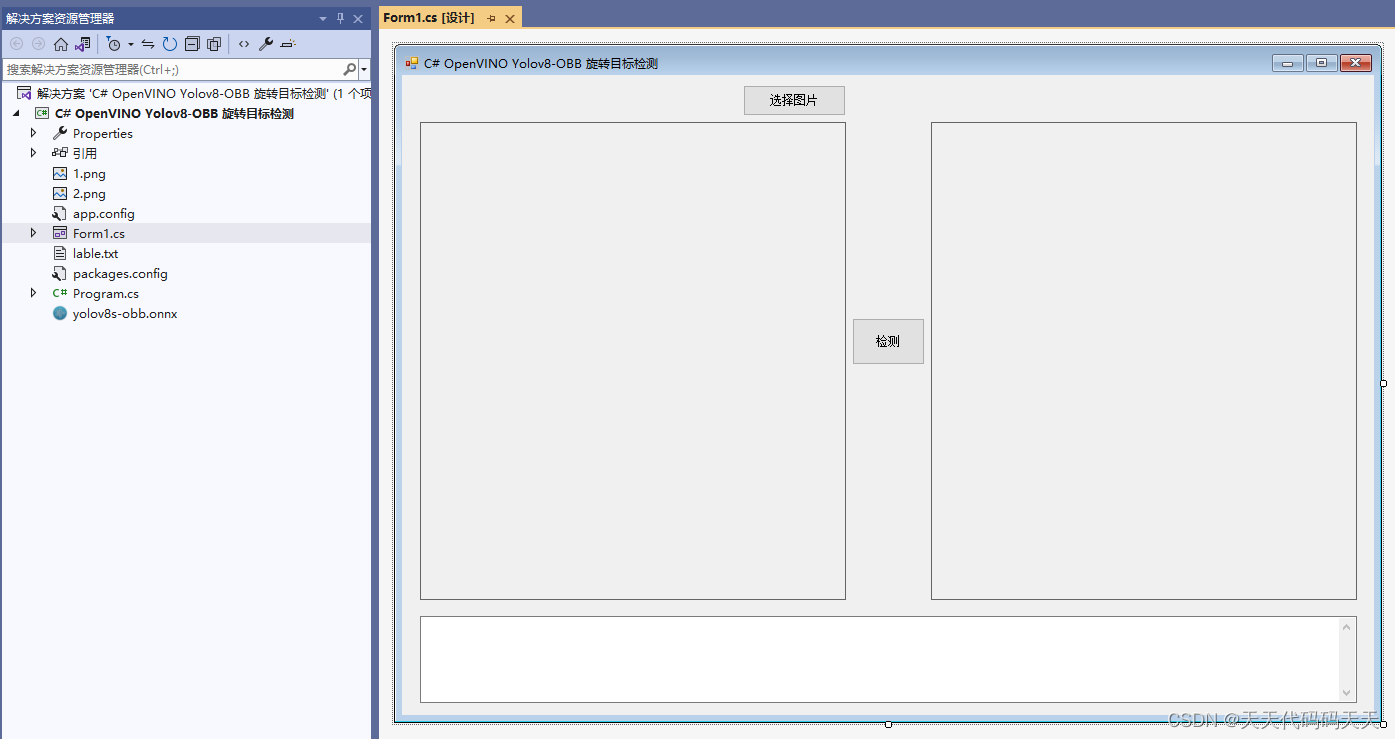
C# OpenVINO Yolov8-OBB 旋转目标检测
目录
效果
模型
项目
代码
下载 C# OpenVINO Yolov8-OBB 旋转目标检测
效果 模型
Model Properties ------------------------- date:2024-02-26T08:38:44.171849 description:Ultralytics YOLOv8s-obb model trained on runs/DOTAv1.0-ms.yaml …

特征融合篇 | YOLOv8 引入通用高效层聚合网络 GELAN | YOLOv9 新模块
今天的深度学习方法专注于如何设计最合适的目标函数,以使模型的预测结果最接近真实情况。同时,必须设计一个合适的架构,以便为预测提供足够的信息。现有方法忽视了一个事实,即当输入数据经过逐层特征提取和空间转换时,会丢失大量信息。本文将深入探讨数据通过深度网络传输…

yolov8训练目标检测模型
1.环境安装
conda安装(miniconda),配置环境变量 创建环境 conda create -n yolo python3.8安装ultralytics conda activate yolopip install ultralytics2.数据集标注
使用labelimg标注工具对图片进行标注:将标注产生的xml转为t…
![[数据集][目标检测]变电站缺陷检测数据集VOC+YOLO格式8307张17类别](https://img-blog.csdnimg.cn/direct/44f2f2347d5048bcac5a98cbcc9b2fce.png)
[数据集][目标检测]变电站缺陷检测数据集VOC+YOLO格式8307张17类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):8307 标注数量(xml文件个数):8307 标注数量(txt文件个数):8307 标注…
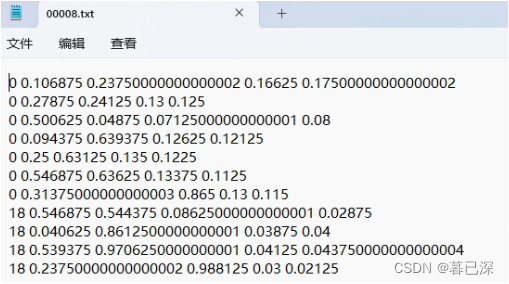
【目标检测-数据集准备】DIOR转为yolo训练所需格式
【目标检测】DIOR遥感影像数据集,转为yolo系列模型训练所需格式。 标签文件位于Annotations下,格式为xml,yolo系列模型训练所需格式为txt,格式为
class_id x_center,y_center,w,h其中,train,textÿ…
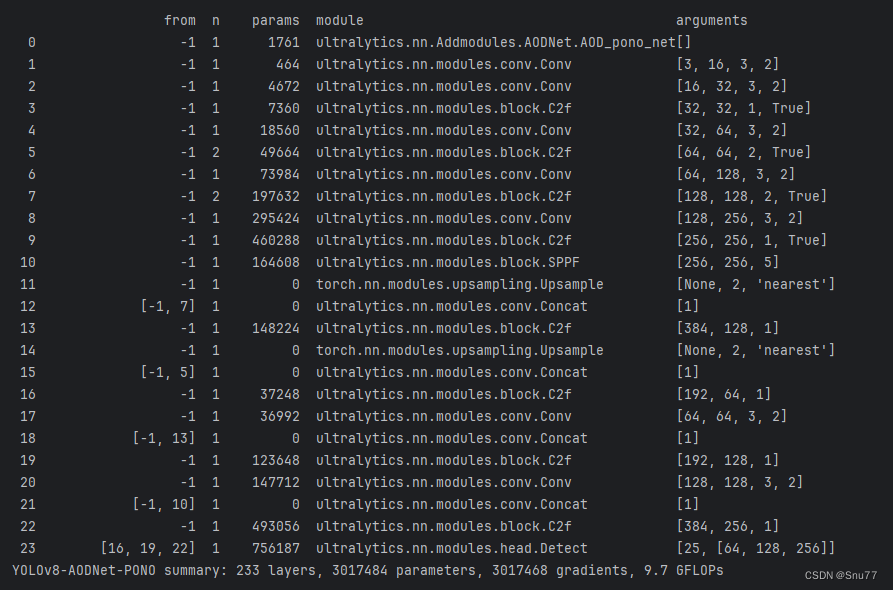
YOLOv8改进 | 图像去雾 | 利用图像去雾网络AOD-PONO-Net网络增改进图像物体检测
一、本文介绍
本文给大家带来的改进机制是利用AODNet图像去雾网络结合PONO机制实现二次增强,我将该网络结合YOLOv8针对图像进行去雾检测(也适用于一些模糊场景,图片不清晰的检测),同时本文的内容不影响其它的模块改进…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的交通信号灯识别系统(深度学习+UI界面+训练数据集+Python代码)
摘要:本研究详细介绍了一种采用深度学习技术的交通信号灯识别系统,该系统集成了最新的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等早期算法进行了性能评估对比。该系统能够在各种媒介——包括图像、视频文件、实时视频流及批量文件中——准确地…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的商品识别系统(深度学习+UI界面+训练数据集+Python代码)
摘要:在零售行业的技术进步中,开发商品识别系统扮演着关键角色。本博文详细阐述了如何利用深度学习技术搭建一个高效的商品识别系统,并分享了一套完整的代码实现。系统采用了性能强劲的YOLOv8算法,同时对YOLOv7、YOLOv6、YOLOv5等…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的障碍物检测系统(深度学习代码+UI界面+训练数据集)
摘要:开发障碍物检测系统对于道路安全性具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个障碍物检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模型间的性能…
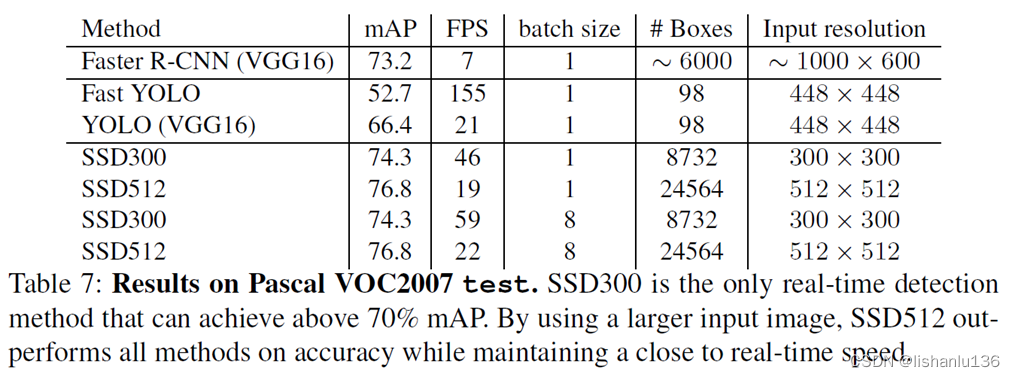
目标检测——SSD算法解读
论文:SSD: Single Shot MultiBox Detector 作者:Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg 链接:https://arxiv.org/abs/1512.02325 代码:https://github.co…

基于YOLOv5的手机顶盖焊缺陷检测系统
💡💡💡本文主要内容:详细介绍了工业手机顶盖焊缺陷测整个过程,从数据集到训练模型到结果可视化分析。 博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8优化创新,轻松涨点和模型…

YOLOv9目标识别——算法解读、环境配置、模型训练与模型推理部署
前言
YOLOv9引入了一种全新的计算机视觉模型架构,相比目前流行的YOLO模型(如YOLOv8、YOLOv7和YOLOv5),在MS COCO数据集上取得了更高的mAP(平均精度均值)。 YOLOv9是由Chien-Yao Wang、I-Hau Yeh和Hong-Yua…
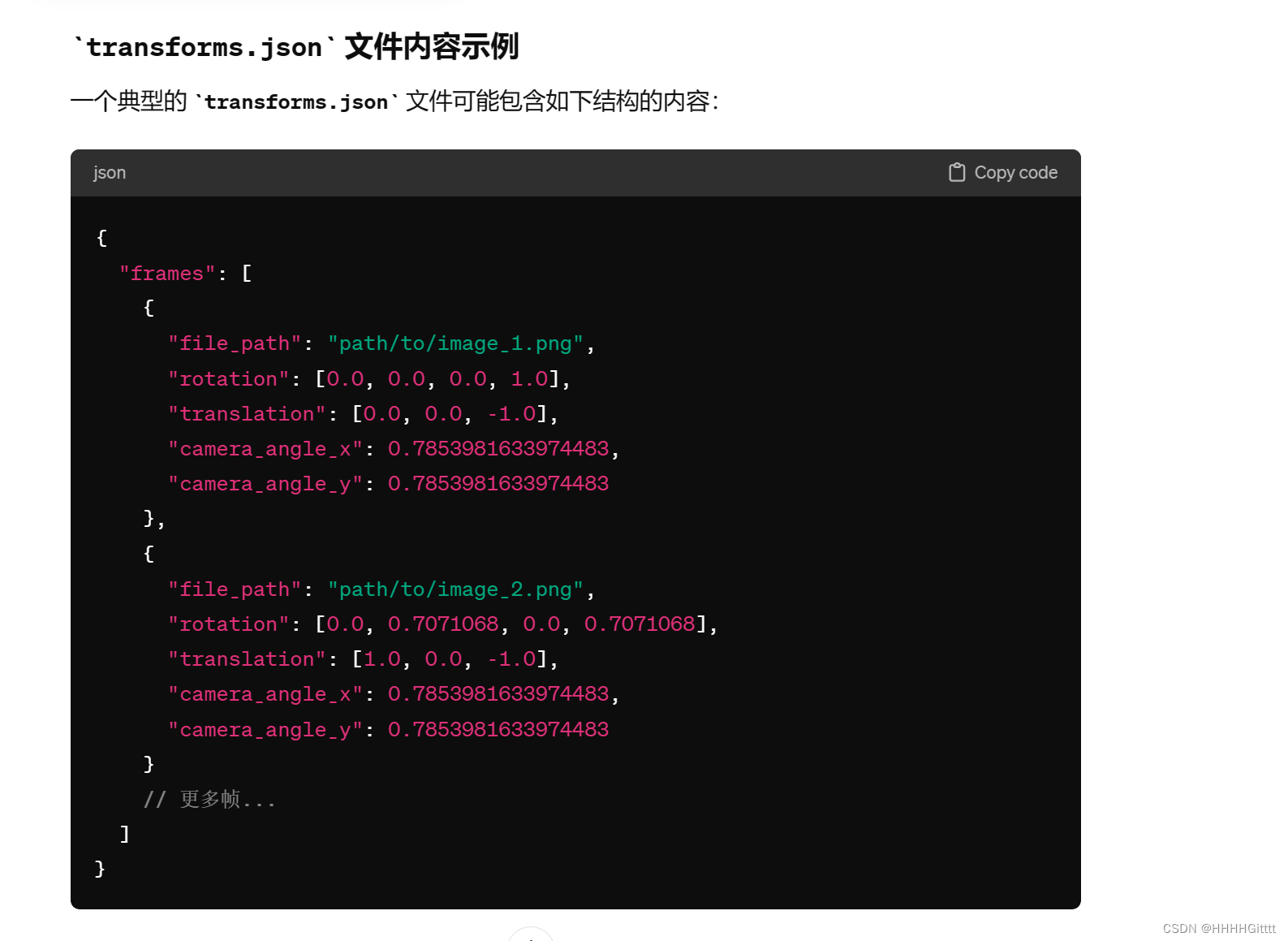
3d场景重建图像渲染 | 神经辐射场NeRF(Neural Radiance Fields)
神经辐射场NeRF(Neural Radiance Fields)
概念 NeRF(Neural Radiance Fields,神经辐射场)是一种用于3D场景重建和图像渲染的深度学习方法。它由Ben Mildenhall等人在2020年的论文《NeRF: Representing Scenes as Neur…
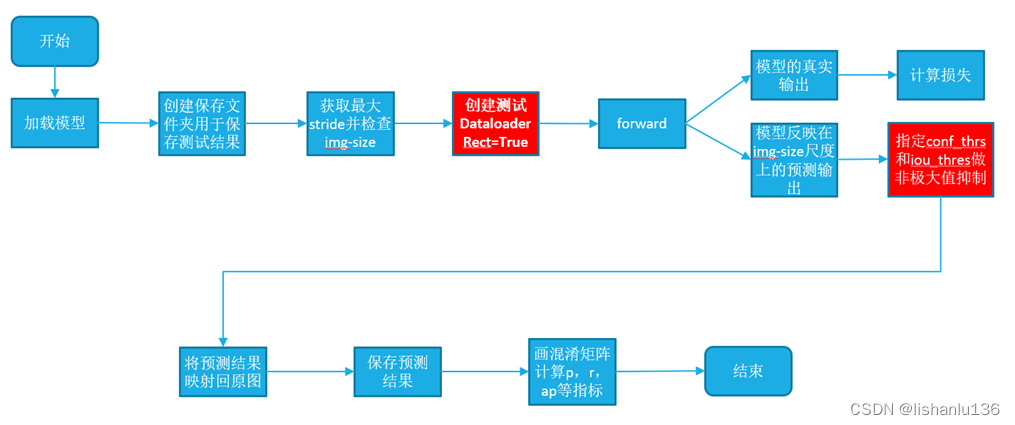
目标检测——YOLOv5算法解读
作者:UltralyticsLLC公司 代码:https://github.com/ultralytics/yolov5 YOLO系列其他文章:
YOLOv1通俗易懂版解读SSD算法解读YOLOv2算法解读YOLOv3算法解读YOLOv4算法解读 文章目录 1、算法概述2、YOLOv5细节2.1 YOLOv5损失函数2.2 YOLOv5边…

torchvision pytorch预训练模型目标检测使用
参考: https://pytorch.org/vision/0.13/models.html https://blog.csdn.net/weixin_42357472/article/details/131747022 有分类、检测、分割相关预训练模型
1、目标检测
https://pytorch.org/vision/0.13/models.html#object-detection-instance-segmentation-…
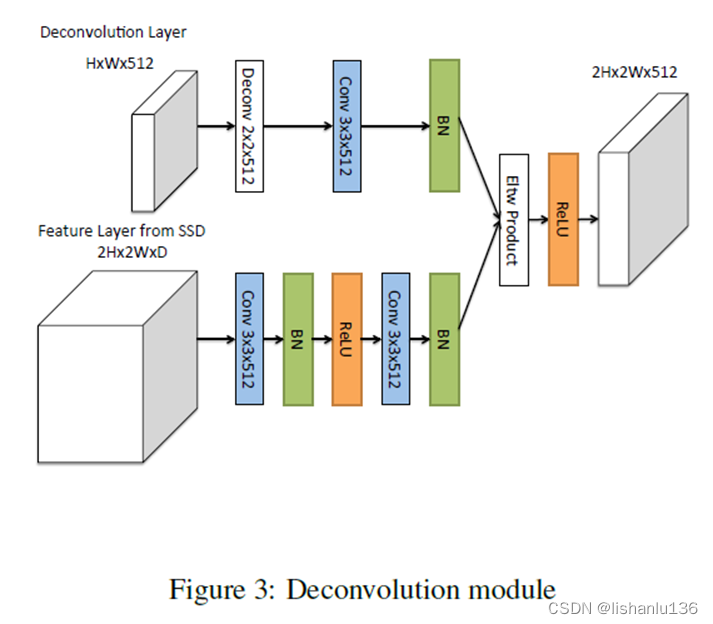
目标检测——FPN与DSSD算法解读
由于FPN和DSSD网络结构比较相似,且发布时间非常相近,所以放一起解读 按时间来算FPN是先于DSSD在arxiv上发布的,FPN第一版是2016年12月9日,DSSD第一版是2017年1月23日,前后相差一个月。 YOLO系列其他文章:
…
目标检测常见数据集格式(YOLO、VOC、COCO)
目录
1.YOLO格式数据
1.1数据格式
1.2YOLO格式数据示例
1.3YOLO格式可视化
2.COCO数据格式
2.1数据格式
2.2COCO格式数据示例
2.3COCO格式可视化
3.VOC数据格式
3.1数据格式
3.2VOC格式数据示例
3.3COCO格式可视化 🍓🍓1.YOLO格式数据
&…
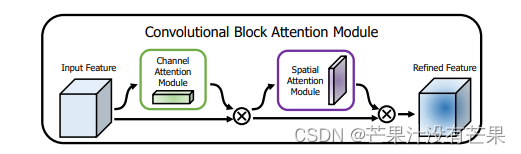
免费阅读篇 | 芒果YOLOv8改进111:注意力机制CBAM:轻量级卷积块注意力模块,无缝集成到任何CNN架构中,开销可以忽略不计
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
该专栏完整目录链接: 芒果YOLOv8深度改进教程 该篇博客为免费阅读内容,YOLOv8CBAM改进内容🚀🚀&am…
[数据集][目标检测]游泳者溺水数据集VOC+YOLO格式2类别895张
数据集制作单位:未来自主研究中心(FIRC) 数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):895 标注数量(xml文件个数):…

改进的yolo交通标志tt100k数据集目标检测(代码+原理+毕设可用)
YOLO TT100K: 基于YOLO训练的交通标志检测模型 在原始代码基础上:
修改数据加载类,支持CoCo格式(使用cocoapi);修改数据增强;validation增加mAP计算;修改anchor;
注: 实验开启weig…

【目标跟踪】相机运动补偿
文章目录 一、前言二、简介三、改进思路3.1、状态定义3.2、相机运动补偿3.3、iou和ReID融合3.4、改进总结 四、相机运动补偿 一、前言
目前 MOT (Multiple Object Tracking) 最有效的方法仍然是 Tracking-by-detection。今天给大家分享一篇论文 BoT-SORT。论文地址 ࿰…

YOLOv8改进涨点,添加GSConv+Slim Neck,有效提升目标检测效果,代码改进(超详细)
目录
摘要 主要想法
GSConv
GSConv代码实现 slim-neck slim-neck代码实现
yaml文件
完整代码分享
总结 摘要
目标检测是计算机视觉中重要的下游任务。对于车载边缘计算平台来说,巨大的模型很难达到实时检测的要求。而且,由大量深度可分离卷积层构…
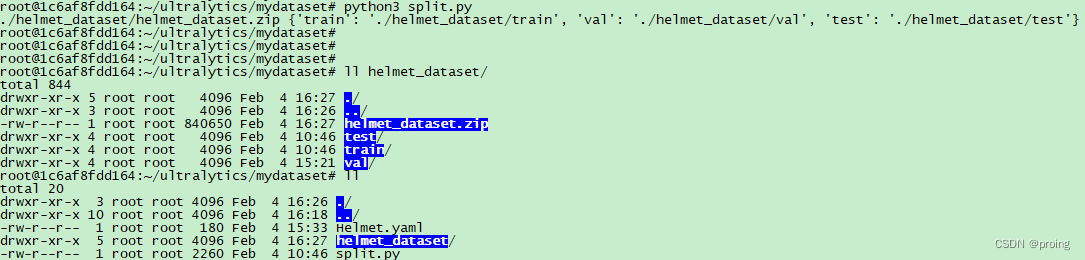
目标检测:2如何生成自己的数据集
目录
1. 数据采集
2. 图像标注
3. 开源已标记数据集
4. 数据集划分
参考: 1. 数据采集 数据采集是深度学习和人工智能任务中至关重要的一步,它为模型提供了必要的训练样本和测试数据。在实际应用中,数据采集的方法多种多样,每…
YOLOv6代码解读[05] yolov6/core/engine.py文件解读
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from ast import Pass
import os
import os.path as osp
import time
from copy import deepcopy
from tqdm import tqdm
import cv2
import numpy as np
import mathimport torch
from torch.cuda
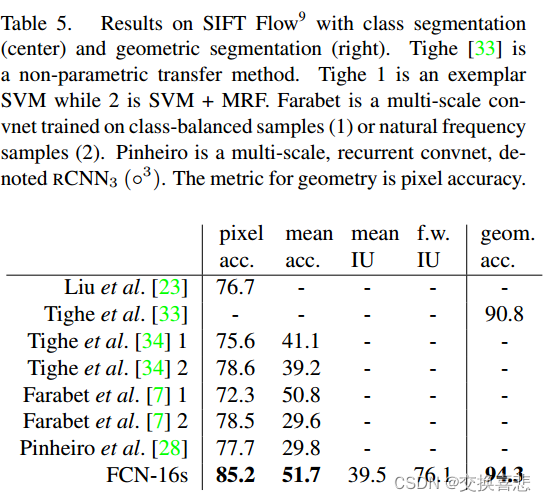
实例分割论文阅读之:FCN:《Fully Convolutional Networks for Semantica Segmentation》
论文地址:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf 代码链接:https://github.com/pytorch/vision
摘要
卷积网络是强大的视觉模型,可以产生特征层次结构。我们证明,…

目标检测 | 卷积神经网络(CNN)详细介绍及其原理详解
前言:Hello大家好,我是小哥谈。卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,主要用于图像识别和计算机视觉任务。它的设计灵感来自于生物学中视觉皮层的工作原理。CNN的核心思想是通…
PaddleDetection学习5——使用Paddle-Lite在 Android 上实现实时的人脸检测(C++)
使用Paddle-Lite在 Android 上实现实时的人脸检测 1 环境准备2. 部署步骤2.1 下载Paddle-Lite-Demo2.2 运行face_detection_demo项目3 使用Opencv对后处理进行优化4 开启手机摄像头进行人脸检测1 环境准备
参考前一篇在 Android 上使用Paddle-Lite实现实时的目标检测功能
2. …

无人机竞赛常用目标检测方法--色块检测
本次开源计划主要针对大学生无人机相关竞赛的视觉算法开发。 开源代码仓库链接:https://github.com/zzhmx/Using-color-gamut-limitations-such-as-HSV-and-RGB-for-object-detection.git 主要使用传统算法,如果想要使用进阶版机器学习算法,请…
【深度学习目标检测】十八、基于深度学习的人脸检测系统-含GUI和源码(python,yolov8)
人脸检测是计算机视觉中的一个重要方向,也是一个和人们生活息息相关的研究方向,因为人脸是人最重要的外貌特征。人脸检测技术的重要性主要体现在以下几个方面: 人脸识别与安全:人脸检测是人脸识别系统的一个关键部分,是…
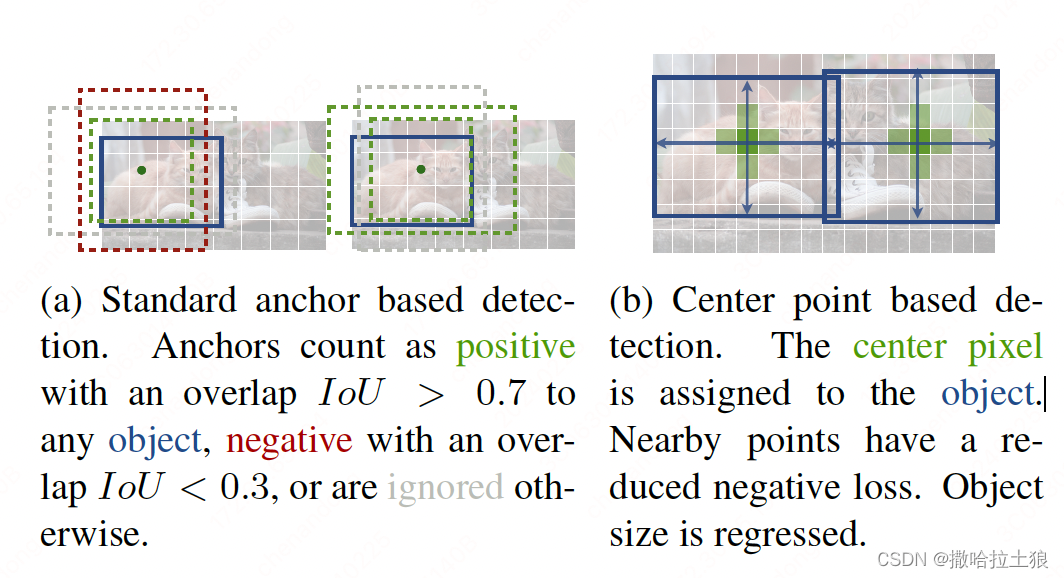
2D目标检测正负样本分配集合
一:CenterNet
Center point based正负样本分配方式:中心像素分配为当前目标。 如果同类的两个高斯核具有交叠的情况,我们逐元素【像素】的选取最大值。Center point based 正样本分配方式的缺点:如果两个不同的物体完美匹配&…
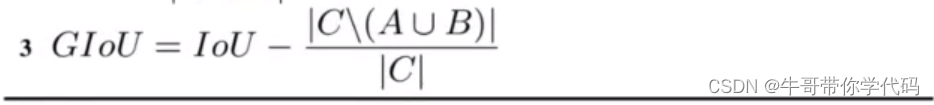
深度学习基础——YOLOv5目标检测
YOLO系列算法属于基于回归的单阶段目标检测算法,它将定位与分类两个任务整合成一个任务,直接通过CNN网络提取全局信息并预测图片上的目标。给目标检测算法提供了新的解决方案,并且图片检测速度准确率与召回率达到实时检测的要求。其中YOLOv1、…

基于YOLOv5+PySide6的火灾火情火焰检测系统设计深度学习
wx供重浩:创享日记 对话框发送:225火灾 获取完整源码源文件已标注的数据集(1553张)配置跑起来说明 可有偿49yuan一对一远程操作,在你电脑跑起来 效果展示: 数据集在下载的文件夹:yolov5-5.0\…

YOLOv7基础 | 第2种方式:简化网络结构之yolov7.yaml(由104层简化为30层)
前言:Hello大家好,我是小哥谈。通过下载YOLOv7源码可知,原始的yolov7.yaml文件是拆开写的,比较混乱,也不好理解,并且为后续改进增添了很多困难。基于此种情况,笔者就给大家介绍一种将yolov7.yaml文件简化的方法,将104层简化为30层,并且参数量和计算量和原来是一致的,…
[C++]使用C++部署yolov9的tensorrt模型进行目标检测
部署YOLOv9的TensorRT模型进行目标检测是一个涉及多个步骤的过程,主要包括准备环境、模型转换、编写代码和模型推理。
首先,确保你的开发环境已安装了NVIDIA的TensorRT。TensorRT是一个用于高效推理的SDK,它能对TensorFlow、PyTorch等框架训…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的铁轨缺陷检测系统(Python+PySide6界面+训练代码)
摘要:开发铁轨缺陷检测系统对于物流行业、制造业具有重要作用。本篇博客详细介绍了如何运用深度学习构建一个铁轨缺陷检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模…
YOLOv8改进 | 独家创新篇 | 结合SOTA思想利用双主干网络改进YOLOv8(全网独家创新,最重磅的更新)
一、本文介绍
本文给大家带来的改进机制是结合目前SOTAYOLOv9的思想利用双主干网络来改进YOLOv8(本专栏目前发布以来改进最大的内容,同时本文内容为我个人一手整理全网独家首发 | 就连V9官方不支持的模型宽度和深度修改我都均已提供,本文内容支持YOLOv8全系列模型从n到x均可…

传感器为智能化基础,L3车规落地打开激光雷达新空间(上)
1 智能化重新定义汽车,开启“新赛道”
1.1 新技术重新定义汽车,开启智能汽车时代 1.2 从整车看来,智能化产品带来汽车定位差异 颠覆性体验感打通消费者消费升级感受空间,用户对智能化功能需求度变高。未来车只分为“能自动驾驶…
[课程]yolov9目标检测封装成类调用
搞定系列:yolov9目标检测封装成类调用
课程地址:https://edu.csdn.net/course/detail/39352
课程介绍课程目录讨论留言
你将收获
学会yolov9封装基本技巧和大体思路
学会yolov9封装类的API调用技巧和自由扩展
学会使用Pycharm调试技巧和运行脚本技…
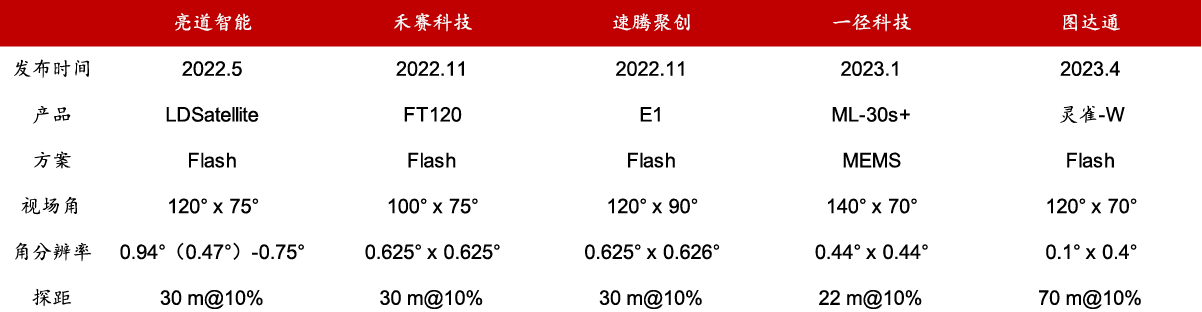
自动驾驶加速落地,激光雷达放量可期(下)
3 下游应用加速渗透,激光雷达出货提升
3.1 远期展望百亿美金市场,伴随自动驾驶快速成长 激光雷达是自动驾驶系统中一项关键技术,近年全球智能网联汽车产业进入加速发展新阶段,推动着激光雷达市场规模高速增长。2022 年全球激光雷…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的水果识别系统(Python+PySide6界面+训练代码)
摘要:本篇博客详尽介绍了一套基于深度学习的水果识别系统及其实现代码。系统采用了尖端的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等前代算法进行了详细的性能对比分析,提供在识别图像、视频、实时视频流和批量文件中水果方面的高效准确性。文…
基于YOLO家族最新模型YOLOv9开发构建自己的个性化目标检测系统从零构建模型完整训练、推理计算超详细教程【以自建数据酸枣病虫害检测为例】
在我前面的系列博文中,对于目标检测系列的任务写了很多超详细的教程,目的是能够读完文章即可实现自己完整地去开发构建自己的目标检测系统,感兴趣的话可以自行移步阅读:
《基于官方YOLOv4-u5【yolov5风格实现】开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为…
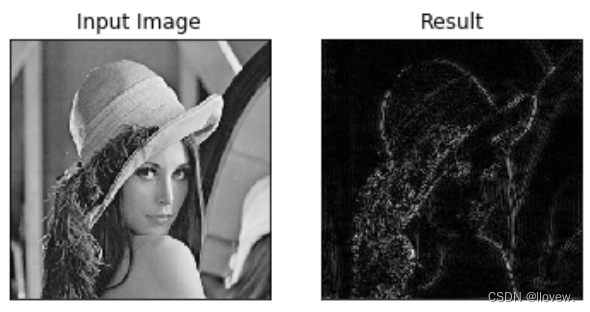
Opencv基本操作 (上)
目录
图像基本操作
阈值与平滑处理
图像阈值
图像平滑处理
图像形态学操作
图像梯度计算
Sobel 算子
Canny 边缘检测
图像金字塔与轮廓检测 图像轮廓
接口定义 轮廓绘制
轮廓特征与相似
模板匹配 傅里叶变换
傅里叶变换的作用
滤波
图像基本操作
读取图像&…
多模态3D目标检测-自动驾驶
【ECCV2022】|动态快读的多模态3D目标检测框架 | AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection|论文链接|代码链接 【ECCV2022】|同质多模态数据融合和交互用于3D目标检测 | Homogeneous Multi-modal Feature Fusion and Interac…
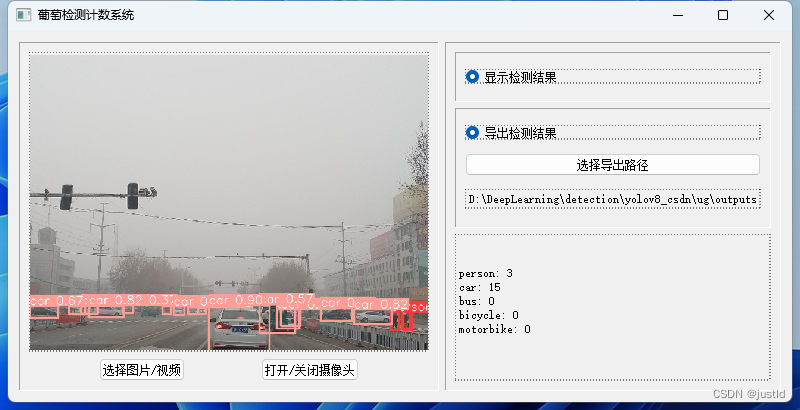
深度学习目标检测】二十、基于深度学习的雾天行人车辆检测系统-含数据集、GUI和源码(python,yolov8)
雾天车辆行人检测在多种场景中扮演着至关重要的角色。以下是其作用的几个主要方面: 安全性提升:雾天能见度低,视线受阻,这使得驾驶者和行人在道路上的感知能力大大降低。通过车辆行人检测技术,可以在雾天条件下及时发现…
[课程]训练自己的yolov9目标检测模型windows版
搞定系列:训练自己的yolov9目标检测模型windows版 课程地址:https://edu.csdn.net/course/detail/39354
课程介绍课程目录讨论留言
你将收获
学会安装yolov9环境
学会转换VOC格式数据集
学会如何训练自己目标检测模型
学会如何测试自己的模型
适用…
miniconda3彻底删除虚拟环境
退出虚拟环境:确保您不在要删除的虚拟环境中。如果在,使用命令 conda deactivate 来退出当前激活的虚拟环境。查看虚拟环境列表:运行命令 conda env list 或 conda info -e 来查看所有存在的虚拟环境及其路径。删除虚拟环境:使用命…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的停车位检测系统(Python+PySide6界面+训练代码)
摘要:开发停车位检测系统对于优化停车资源管理和提升用户体验至关重要。本篇博客详细介绍了如何利用深度学习构建一个停车位检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并结合了YOLOv7、YOLOv6、YOLOv5的性能对比…

YOLOv9独家原创改进|加入幽灵卷积Ghost Convolution模块,轻量化!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、论文摘要 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络是困难的。特征图中的冗余是那些成功的细胞神经网络的一个重要特征…
[数据集][目标检测]鸟类检测数据集VOC+YOLO格式11758张200类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):11758 标注数量(xml文件个数):11758 标注数量(txt文件个数):11758 标…
瑞芯微1808开发板目标识别模型运行环境的生成
修改后处理的头文件 头文件路径: rknn/rknpu-master/rknn/rknn_api/examples/rknn_yolov5_demo/include/postprocess.h该头文件中一部分代码如下: #ifndef _RKNN_ZERO_COPY_DEMO_POSTPROCESS_H_
#define _RKNN_ZERO_COPY_DEMO_POSTPROCESS_H_#include &l…

论文阅读《Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection》
论文地址:https://arxiv.org/abs/2203.13903 代码地址:https://github.com/facebookresearch/sylph-few-shot-detection 目录 1、存在的问题2、算法简介3、算法细节3.1、基础检测器3.2、小样本超网络3.2.1、支持集特征提取3.2.2、代码预测3.2.3、代码聚合…

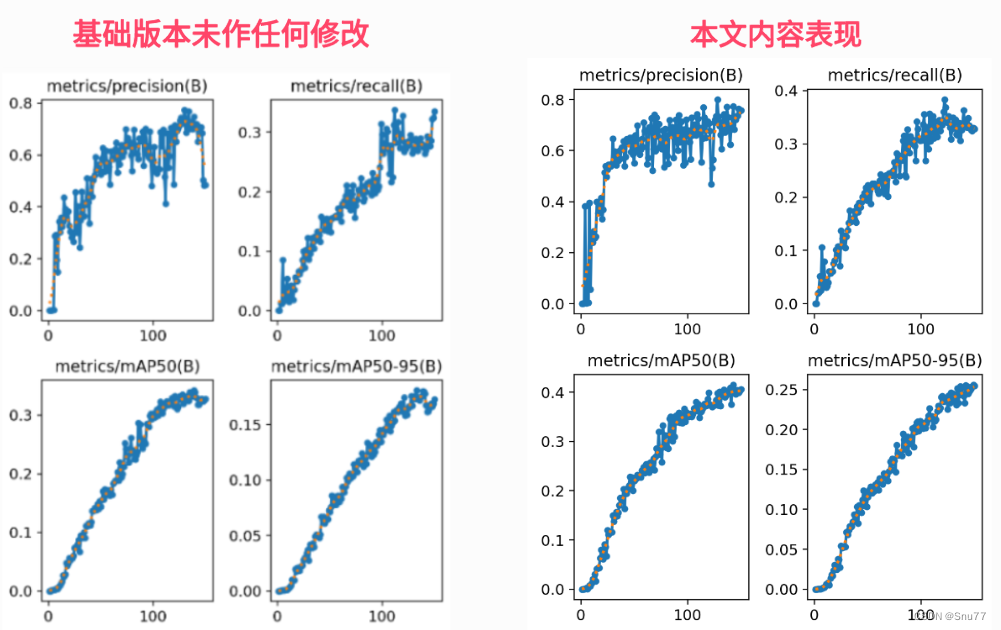
YOLOv8改进 | Conv篇 | 全新的SOATA轻量化下采样操作ADown(参数量下降百分之二十,附手撕结构图)
一、本文介绍
本文给大家带来的改进机制是利用2024/02/21号最新发布的YOLOv9其中提出的ADown模块来改进我们的Conv模块,其中YOLOv9针对于这个模块并没有介绍,只是在其项目文件中用到了,我将其整理出来用于我们的YOLOv8的项目,经过实验我发现该卷积模块(作为下采样模块)…

基于yolov5的电瓶车和自行车检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示:
基于yolov5的电瓶车和自行车检测系统_哔哩哔哩_bilibili
(一)简介
基于yolov5的电瓶车和自行车检测系统是在pytorch框架下实现的,这是一个完整的项目,包括代码,数据集,训练好的模型…
缺陷检测相关论文阅读总结(记录自己读过的论文主要内容/Ideas)
缺陷检测相关论文阅读总结(记录自己读过的论文主要内容)
Attention!!!
点击论文题目即可访问原文or下载原文PDF文件;每篇文章的内容包含:内容总结、文章Ideas;更多关于缺陷检测以及图像融合/拼接等方向的相关文章学习…
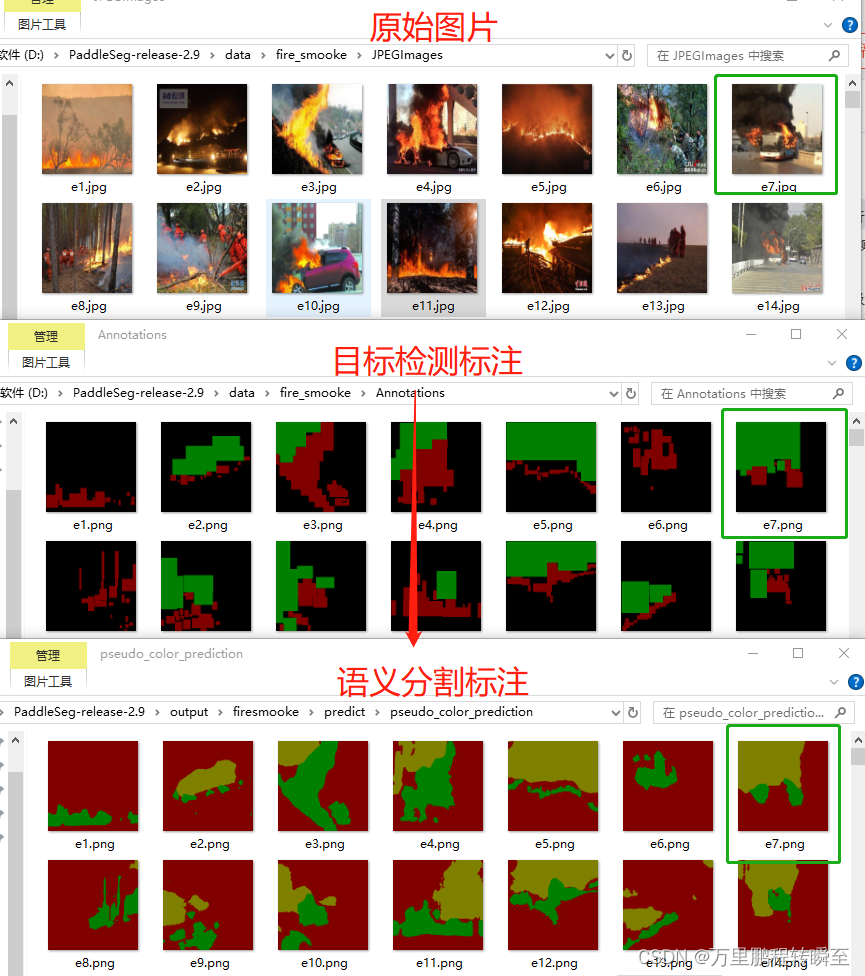
python工具方法 47 基于paddleseg将目标检测数据升级为语义分割数据
在进行项目研究时,通常需要搜集开源数据集。但是所能搜集到的数据集通常会存在形式上的差异,比如我想要的是语义分割数据,而搜集到的数据集却是目标检测数据;在这种情况下所搜集的数据就完成没有利用价值了么?不,其还存在价值,我们可以通过模型训练对数据标签的标注粒度…
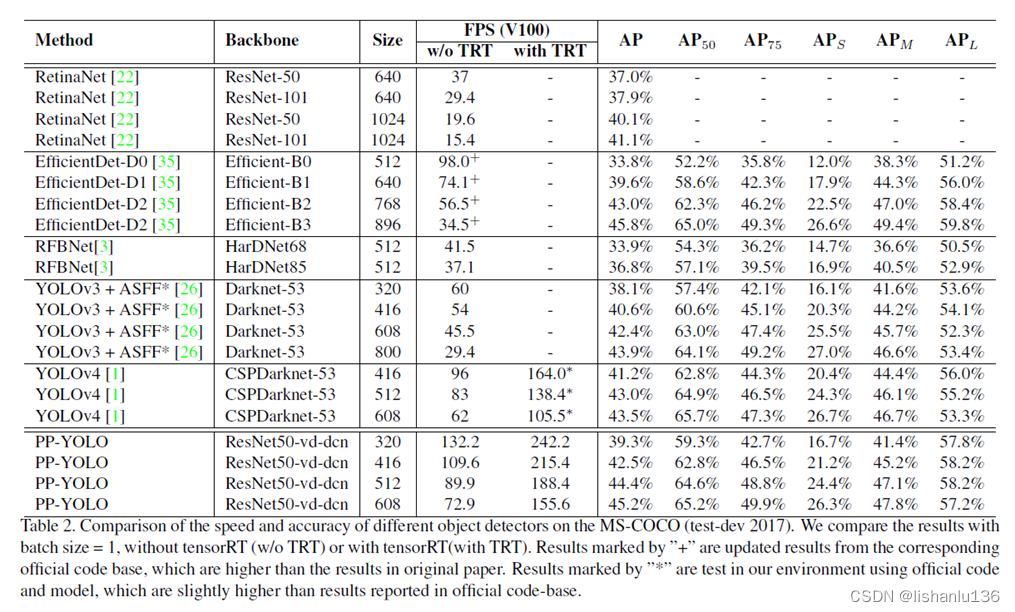
目标检测——PP-YOLO算法解读
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解…

如何在三个简单步骤中为对象检测标注图像
初始通过彻底清洗和处理原始图像数据来奠定有效对象检测注释的基础。选择适合的工具、方法和清晰的注释过程指南来建立注释工作空间。通过在图像中划定对象并附上类别标签来执行注释,随后进行细致的核验,以确保数据集的精确性和完整性。
图像注释是计算…
41 物体检测和目标检测数据集【李沐动手学深度学习v2课程笔记】
目录
1. 物体检测
2. 边缘框实现
3.数据集
4. 小结 1. 物体检测 2. 边缘框实现
%matplotlib inline
import torch
from d2l import torch as d2ld2l.set_figsize()
img d2l.plt.imread(../img/catdog.jpg)
d2l.plt.imshow(img);#save
def box_corner_to_center(boxes):&q…

利用autodl服务器跑模型
1. 租用服务器 本地改模型 服务器 将改进好的、数据集处理好的模型压缩为zip文件上传到阿里云盘打开服务器AUTODL服务器,在主页中选择容器实例 在此位置进行开关机操作,若停止服务器,必须关机,不然会一直扣钱
2. 运行模型 选择…
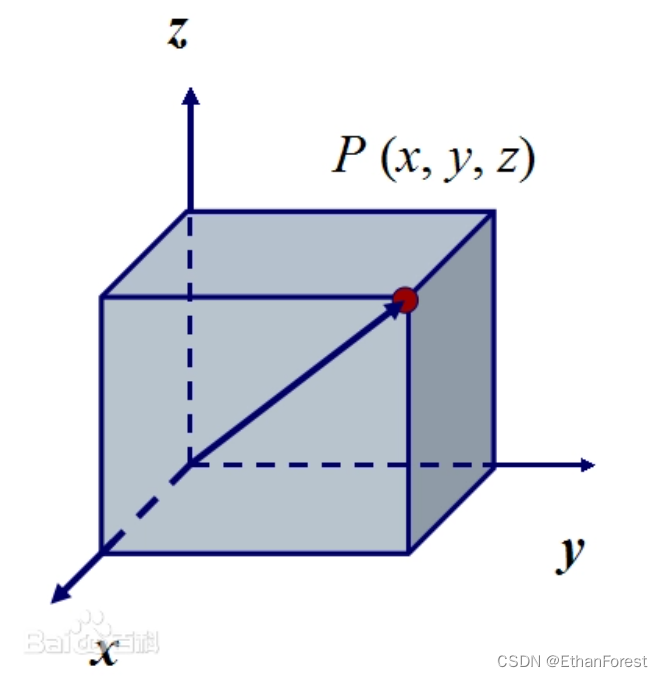
以目标检测和分类任务为例理解One-Hot Code
在目标检测和分类任务中,每一个类别都需要一个编码来表示,同时,这个编码会用来计算网络的loss。比如有猫,狗,猪三种动物,这三种动物相互独立,在分类中,将其中任意一种分类为其他都同…

YOLOv5创新改进:SPPF创新涨点篇 | SPPELAN:SPP创新结合ELAN ,效果优于SPP、SPPF| YOLOv9
💡💡💡本文独家改进:新颖SPPF创新涨点改进,SPP创新结合ELAN,来自于YOLOv9,助力YOLOv5,将SPPELAN代替原始的SPPF
💡💡💡在多个私有数据集和公开数据集VisDrone2019、PASCAL VOC实现涨点 收录
YOLOv5原创自研
https://blog.csdn.net/m0_63774211/category_12…

DCFL: for Oriented Tiny Object Detection
文章目录 AbstractIntroductionContributionRelated Work定向目标检测微小目标检测多尺度学习标签分配上下文信息特征增强MethodOverview动态先验Coarse Prior MatchingFiner Dynamic Posterior MatchingAblation StudyAnalysis不平衡问题的调解可视化速度Conclusionhh 源代码 …
YOLOv5全网首发改进: 注意力机制改进 | 上下文锚点注意力(CAA) | CVPR2024 PKINet 遥感图像目标检测
💡💡💡本文独家改进:引入了CAA模块来捕捉长距离的上下文信息,利用全局平均池化和1D条形卷积来增强中心区域的特征,从而提升检测精度,CAA和C3进行结合实现二次创新,改进思路来自CVPR2024 PKINet,2024年前沿最新改进,抢先使用 💡💡💡小目标数据集,涨点近两个…
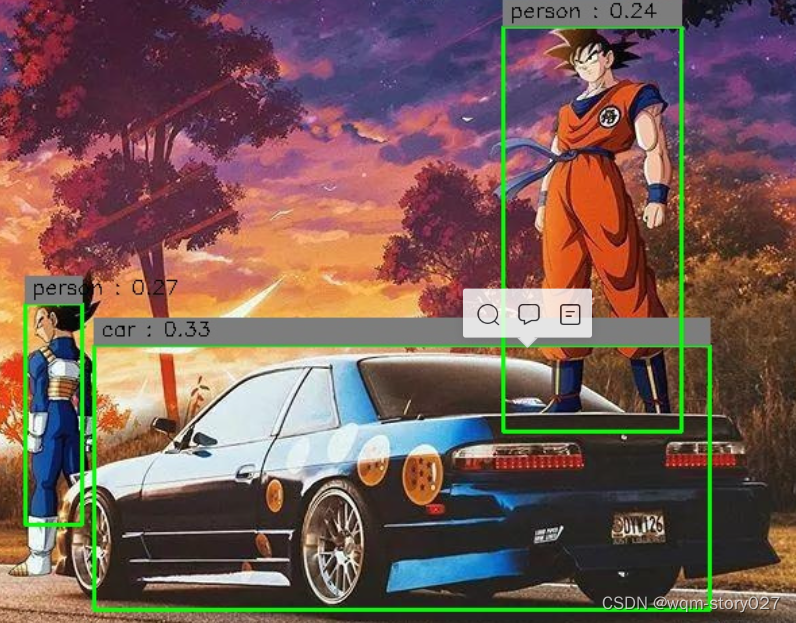
计算机视觉--flask部署 目标检测算法,并在局域网内远端访问
1.flask框架
Flask是一个轻量级的基于Python的web框架。static 文件夹来保存静态文件,templates 文件夹存放前端页面 安装:
pip install Flask框架代码:
from flask import *
from flask import Flaskapp Flask(__name__) //获取实例app.…
YoloV5+ECVBlock:基于YoloV5-ECVBlock的小目标检测训练
目录
1、前言
2、数据集
3、添加ECVBlock 4、BackBone+ECVBlock
5、Head+ECVBlock
6、训练结果

改进YOLOv5系列:增加Swin-Transformer小目标检测头
💡统一使用 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。🌟本项目包含大量的改进方式,降低改进难度,改进点包含【Backbone特征主干】、【Neck特征融合】、【Head检测头】、【注意力机制】、【IoU损失函数】、【NMS】、【Loss…

目标检测算法——遥感影像数据集资源汇总(附下载链接)
关注”PandaCVer“公众号
深度学习资料,第一时间送达
目录
一、用于 2-5 分类问题
1.UCAS-AOD 遥感影像数据集
2.Inria Aerial Image Labeling Dataset
3.RSOD-Dataset 物体检测数据集
二、用于 5-10 分类问题
1.RSSCN7 DataSet 遥感图像数据集
2.NWPU…
[数据集][目标检测]野生动物检测数据集VOC+YOLO格式1054张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1504 标注数量(xml文件个数):1504 标注数量(txt文件个数):1504 标注…
【深度学习】目标检测神经网络1/2
目标检测神经网络
概念
模型分类有三种:图像分类即输出图像类别和概率;单目标检测,输出目标的概率和位置;多目标检测,同时输出多个目标的分类、位置、概率。
位置检测分为两种形式:一种是矩形框…
[数据集][目标检测]芒果叶病害数据集VOC+YOLO格式4000张5类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4000 标注数量(xml文件个数):4000 标注数量(txt文件个数):4000 标注…

PyTorch搭建LeNet训练集详细实现
一、下载训练集
导包
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as npToTensor()函数:
把图像…
[数据集][目标检测]铁路工人工服安全帽检测数据集3065张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):3065 标注数量(xml文件个数):3065 标注数量(txt文件个数):3065 标注…
【AI】调用DarkNet C++接口来执行目标检测
AI学习目录汇总
1、DarkNet源码下载及编译
参见本人博客:【AI】YOLOv7部署在NVIDIA Jetson TX2上中第三节
2、编译C++库
2.1 修改Makefile
修改Makefile第七行,将 LIBSO 的值改为 1
LIBSO=1分析Makefile可知,使能LIBSO将会编译出库libdarknet.so和一个使用库的demo(u…
【目标检测】2. RCNN
接上篇 【目标检测】1. 目标检测概述_目标检测包括预测目标的位置吗?-CSDN博客
一、前言
CVPR201 4经典paper:《 Rich feature hierarchies for accurate object detection and semantic segmentation》,https://arxiv.org/abs/1311.2524, 这篇论文的算法思想被称…
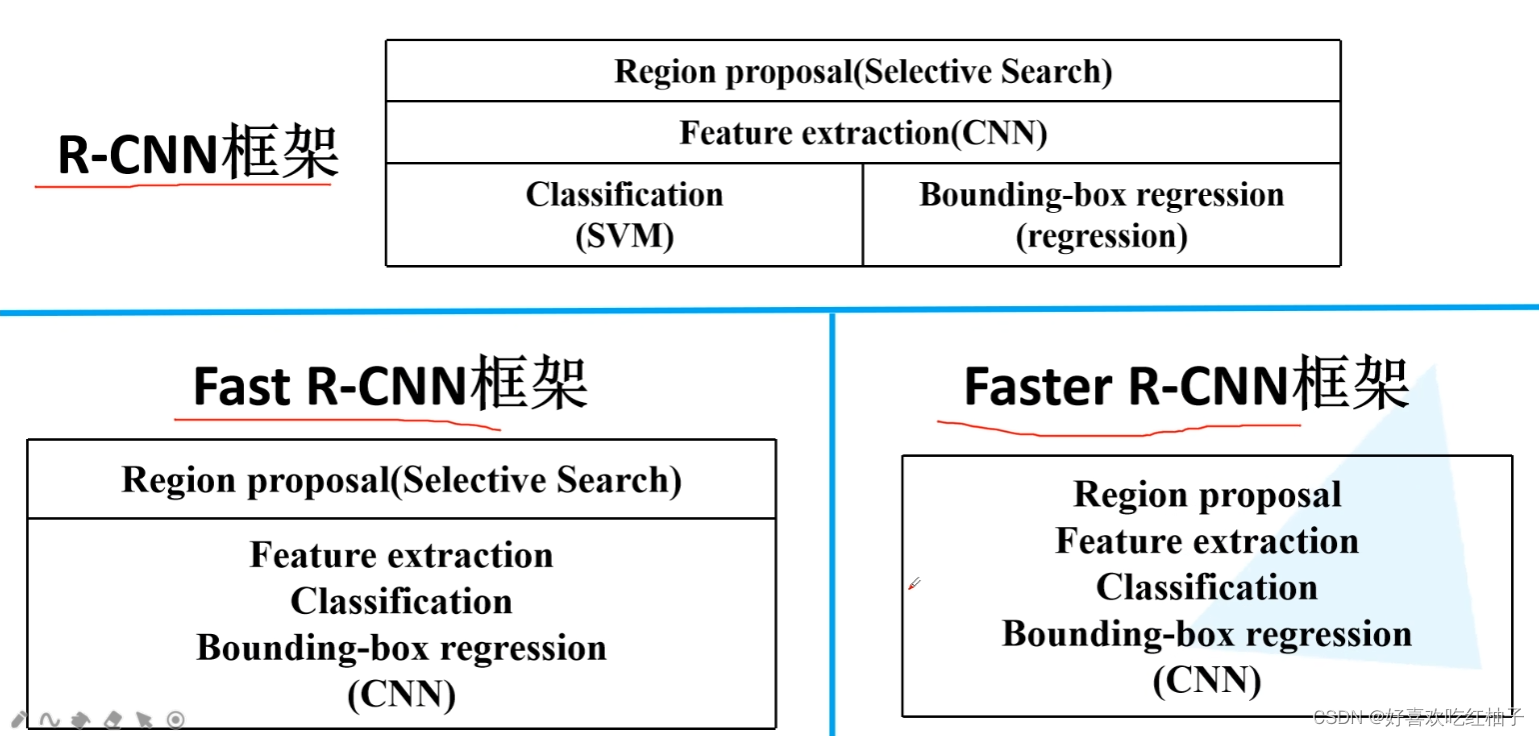
【目标检测经典算法】R-CNN、Fast R-CNN和Faster R-CNN详解系列三:Faster R-CNN图文详解
【目标检测经典算法】R-CNN、Fast R-CNN和Faster R-CNN详解系列二:Fast R-CNN图文详解
概念预设
感受野
感受野(Receptive Field) 是指特征图上的某个点能看到的输入图像的区域。
神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它…
[数据集][目标检测]牛羊检测数据集VOC+YOLO格式3393张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):3393 标注数量(xml文件个数):3393 标注数量(txt文件个数):3393 标注…
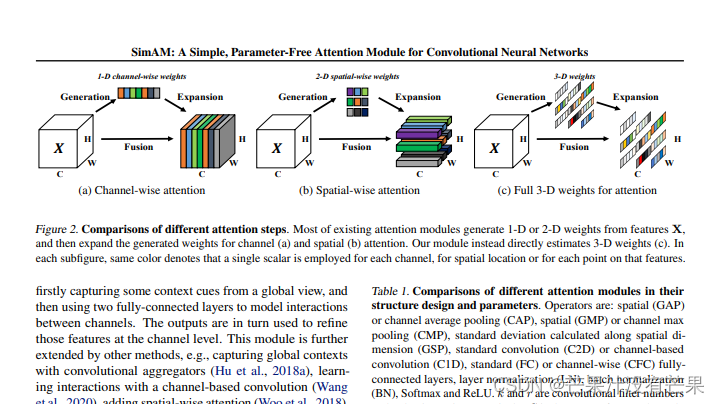
免费阅读篇 | 芒果YOLOv8改进109:注意力机制SimAM:用于卷积神经网络的简单、无参数注意力模块
免费阅读篇|芒果YOLOv8改进109:注意力机制篇SimAM:用于卷积神经网络的简单、无参数注意力模块
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
该专栏完整目录链接&#x…
Faster RCNN网络源码解读(Ⅺ) --- 预测结果后处理及预测过程(完结撒花)
目录 一、回顾以及本篇博客内容概述
二、代码解析
2.1 ROIHead类(承接上篇博客的2.1节)
2.1.1 初始化函数 __init__回顾
2.1.2 正向传播forward回顾及预测结果后处理
2.1.3 postprocess_detections
2.2 FasterRCNNBase类前向传播过程
2.3 Genera…

Opencv实战案例——模板匹配实现银行卡号识别(附详细介绍及完整代码下载地址)
Opencv目录1.项目意义2.模板匹配3.图像二值化3.1全局阈值3.2全局阈值代码即效果展示3.3 自适应阈值3.4自适应阈值代码即效果展示4.轮廓筛选4.1轮廓检测4.2绘制轮廓4.3轮廓筛选代码及效果展示5.形态学变化5.1腐蚀5.2膨胀5.3开运算和闭运算、礼帽和黑帽6.项目实战6.1读取图片转化…
论文投稿指南——中文核心期刊推荐(武器工业)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…
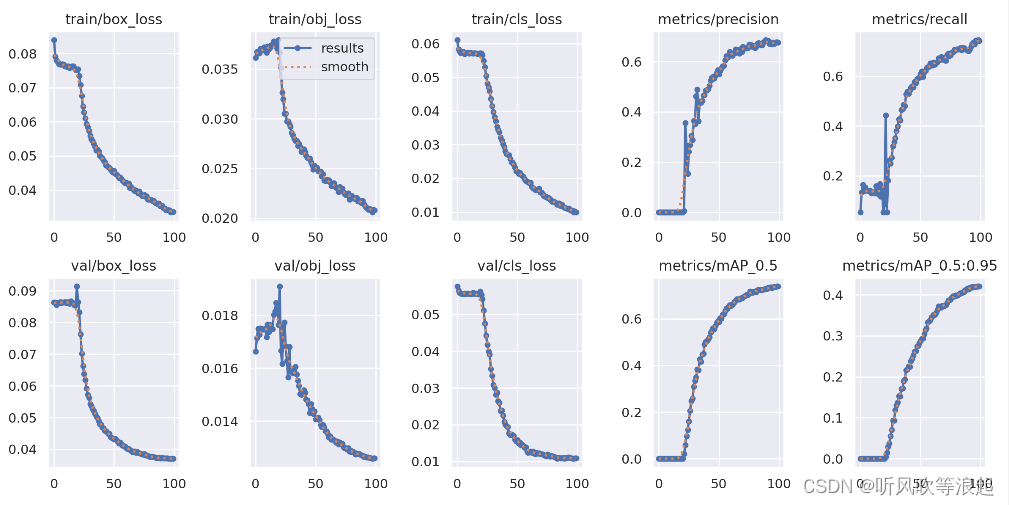
YOLOV5 改进:替换backbone为Vgg
1、前言
参考上一章的博文(YOLOV5 改进:替换backbone(MobileNet为例)-CSDN博客)将yolov5的backbone换成自定义的vgg网络 网络参数量很多,并且刚开始训练的时候精度很差,应该是没有迁移学习导致的。
大概经历了30-40多个epoch,网络才进行收敛, 加大epoch可以提升网络…
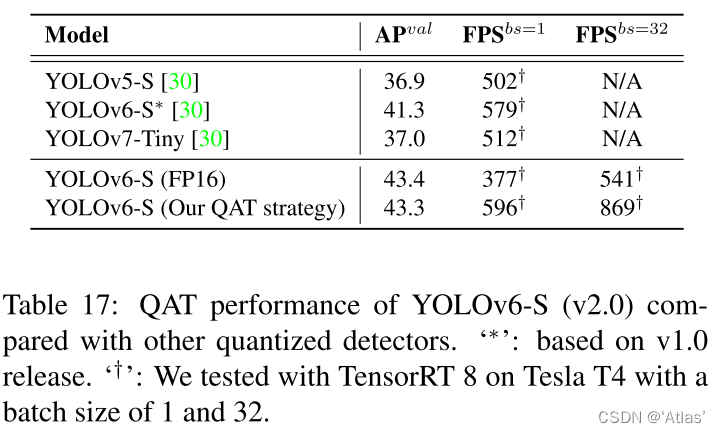
YOLOv6-目标检测论文解读
文章目录摘要问题算法网络设计BackboneNeckHead标签分配SimOTA(YOLOX提出):TAL(Task alignment learning,TOOD提出)损失函数分类损失框回归损失目标损失行业有用改进自蒸馏图像灰度边界填充量化及部署实验消…
自动驾驶目标检测项目实战(一)—基于深度学习框架yolov的交通标志检测
自动驾驶目标检测项目实战——基于深度学习框架yolov的交通标志检测
目前目标检测算法有很多,流行的就有faster-rnn和yolov,本文使用了几年前的yolov3框架进行训练,效果还是很好,当然也可以使用更高版本的Yolov进行实战。本代码使…
深度学习目标检测ui界面-交通标志检测识别
深度学习目标检测ui界面-交通标志检测识别
为了将算法封装起来,博主尝试了实验pyqt5的上位机界面进行封装,其中遇到了一些坑举给大家避开。这里加载的训练模型参考之前写的博客: 自动驾驶目标检测项目实战——基于深度学习框架yolov的交通标…

【YOLOv8/YOLOv7/YOLOv5/YOLOv4/Faster-rcnn系列算法改进NO.57】引入ASPP模块
前言作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍&…

行人车辆检测与计数系统(Python+YOLOv5深度学习模型+清新界面)
摘要:行人车辆检测与计数系统用于交通路口行人及车辆检测计数,道路人流量、车流量智能监测,方便记录、显示、查看和保存检测结果。本文详细介绍行人车辆检测,在介绍算法原理的同时,给出Python的实现代码、PyQt的UI界面…
基于yolov5的苹果成熟度检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示:
基于yolov5的苹果成熟度检测系统,系统既能够实现图像检测,也可以进行视屏和摄像实时检测_哔哩哔哩_bilibili
(一)简介
基于yolov5的苹果成熟度检测系统是在pytorch框架下实现的,这是一个完整的…
目标检测5:采用yolov8, RK3568上推理实时视频流
上一个效果图,海康球机对着电脑屏幕拍,清晰度不好。
RK3568接取RTSP视频流,通过解码,推理,编码,最终并把结果推出RTSP视频流。 数据集采用coco的80个种类集,通过从yovo8.pt,转换成R…
血细胞实时视频目标检测
目录
1. 写在前面
2. video_objection 实时目标检测代码
2.1 准备工作
2.2 ImageGrab.grab 函数
2.3 real time 目标检测

LFM雷达实现及USRP验证【章节2:LFM雷达测距】
目录
1. 参数设计
几个重要的约束关系
仿真参数设计
2. matlab雷达测距代码
完整源码
代码分析 回顾:LFM的基本原理请详见第一章
本章节将介绍LFM雷达测距的原理及实现
1. 参数设计 几个重要的约束关系
带通采样定理:
因此如果我们B80MHz时&a…
LeNet训练集详细实现
一、下载训练集
导包
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as npToTensor()函数:
把图像…

【目标检测】Mask RCNN的训练数据集是什么?(含labelimg和labelme的讲解)
文章目录一、训练数据集二、标注工具介绍2.1 labelimg介绍2.2 labelme介绍2.3 两者的对比三、制作数据案例在看完何凯明大神的Mask RCNN的时候,突然想到了一个问题,那就是Mask RCNN的训练数据集是什么?一、训练数据集
Mask R-CNN是一种基于F…

基于支持向量机的目标检测与识别
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…
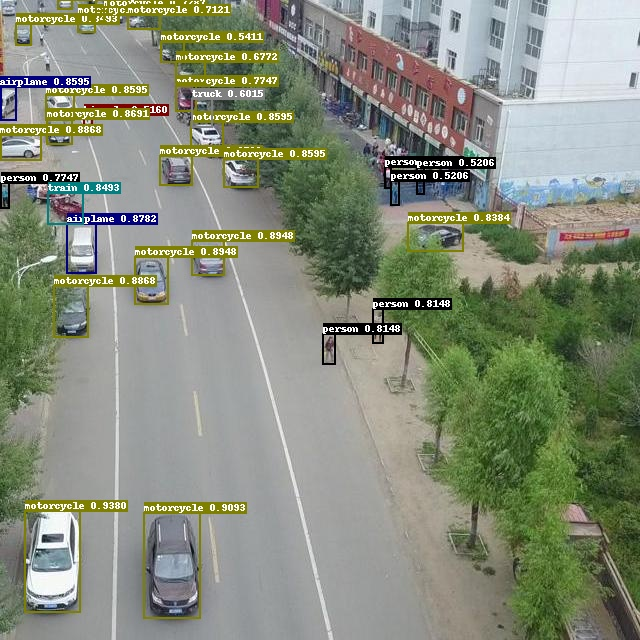
无人机巡检场景小目标检测与量化加速部署方案详解
在社会活动和社会生产中,巡检是一个必不可少的环节。然而,传统的人工巡检方式存在效率低下、成本高昂、安全风险大等问题,限制了巡检的效果和范围。无人机巡检因其高效、灵活、安全的特点被越来越多的企业采用。但是,如何在无…

【计算机视觉 | 目标检测】BARON:pseudo words 和 linear layer 的理解
文章目录一、问题二、个人的理解2.1 线性层的理解2.2 pseudo words的理解2.2.1 详细一点2.2.2 为什么可以使用文本嵌入空间中的技术?2.2.3 pseudo word的本质是什么?2.2.4 好处2.2.5 论文中的具体体现一、问题
在BARON中,有这样一个地方&…
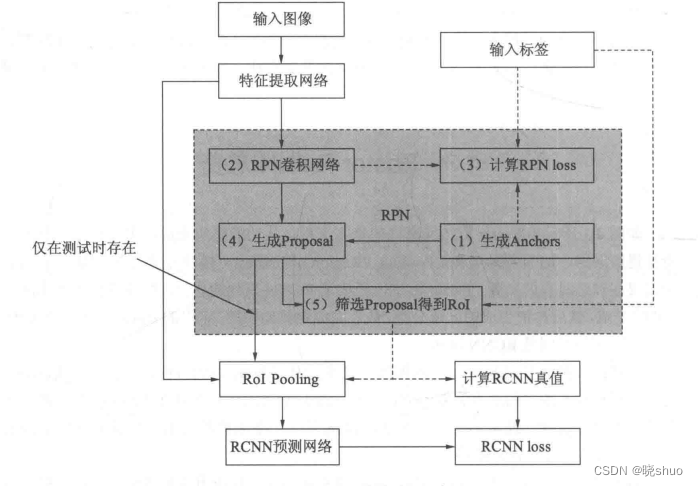
RCNN系列发展历程
1. RCNN RCNN发表于CVPR 2014。是将深度学习应用于目标检测领域的开山之作,凭借卷积神经网络较之传统CV方法的强大特征提取能力,将PASCAL VOC数据集检测率从35.1%提升到53.7%。 RCNN的算法流程如下图所示,其过程主要分为4步:
生成…
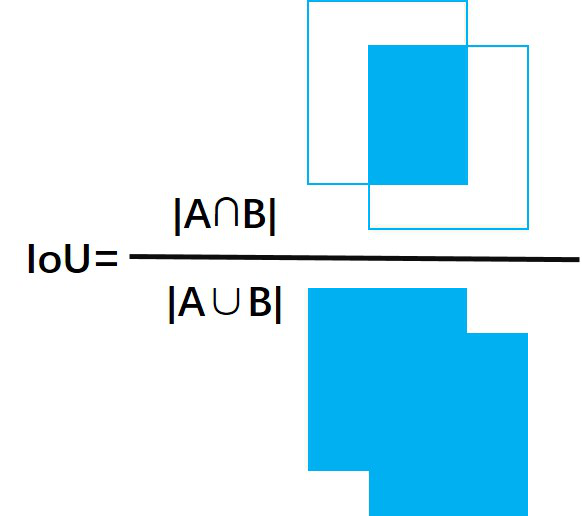
涨点技巧:IOU篇---Yolov8引入WIoU,SIoU,EIoU,α-IoU,不同数据集验证能涨点
1.IOU介绍
IoU其实是Intersection over Union的简称,也叫‘交并比’。IoU在目标检测以及语义分割中,都有着至关重要的作用。
首先,我们先来了解一下IoU的定义: 我们可以把IoU的值定为为两个图形面积的交集和并集的比值,如下图所示: 1.1 Yolov8自带IOU方法 GIoU, DIoU,…
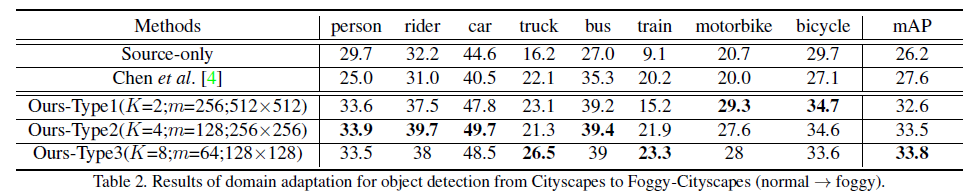
《Adapting Object Detectors via Selective Cross-Domain Alignment》笔记
Introduction
深度卷积网络模型的性能非常依赖数据集。如果数据集的数据分布与现实生活的数据分布一致,深度模型能够表现出优异的性能。但是,现有的基础数据集只覆盖了有限范围内的场景。在现实世界的模型部署中,环境条件的变化,…
RetinaNet Examples:NVIDIA 一站式训练、推理及模型转换解决方案
retinanet-examples 是英伟达提供的目标检测工程范例,针对端到端 GPU 处理进行了优化:
使用基于 Python 多进程的 apex.parallel.DistributedDataParallel 加速分布式训练;apex.amp 优化混合精度训练;NVIDIA DALI 加速数据预处理…

Faster R-CNN 与 RPN
Fast R-CNN 实现了候选框的特征图共享,大幅提高了训练及部署的效率。然而,网络输入仍然依赖 Selective Search 等方法,在整个系统中耗时占比较高且优化空间有限。
Faster R-CNN 使用 RPN 网络生成候选区域。RPN 与第2阶段的 Fast R-CNN 共享…

MegDet 与 Synchronized BatchNorm
旷视科技(Face)的 MegDet 网络取得了 COCO 2017 Challenge 竞赛的检测项目冠军,论文 MegDet: A Large Mini-Batch Object Detector 对该检测器进行了介绍。
摘要
深度学习时代的目标检测发展——从 R-CNN、Fast/Faster R-CNN 到最近的 Mask…

【NG DeepLearning视频笔记】目标检测
一 目标检测标签
1.1 bounding box标签
要训练一个目标检测网络,必然需要准备数据集的标签。每个目标的标签向量如下所示。 y[pcbxbybhbwc1c2c3](1)y \begin{bmatrix} pc \\ bx \\ by \\ bh \\ bw \\ c1 \\ c2 \\ c3 \\ \end{bmatrix} \tag{1} y⎣⎢⎢⎢⎢⎢⎢⎢⎢…

瑞芯微:基于RKNN3568得yolov8det部署
这段时间一直在搞rk3568,所以需要将yolov8det目标检测部署在rk3568里面。。。。 python import cv2
import numpy as npfrom rknn.api import RKNN
import osif __name__ __main__:platform rk3568exp yolov8nsegWidth 640Height 640MODEL_PATH ./onnx_models…
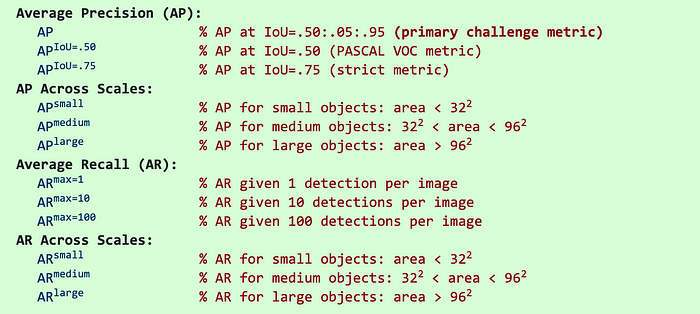

渣土车智能识别检测 yolov5
渣土车智能识别检测通过yolov5网络模型深度学习技术,渣土车智能识别检测对禁止渣土车通行现场画面中含有渣土车时进行自动识别监测,并自动抓拍告警。YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路࿰…
Kaggle往期赛 | 多目标推荐系统大赛baseline
来源:深度之眼 作者:比赛教研部 编辑:学姐 Kaggle OTTO – Multi-Objective Recommender System多目标推荐系统大赛 赛题分析baseline
1、赛题链接
https://www.kaggle.com/competitions/otto-recommender-system/overview
2、赛题描述
本…
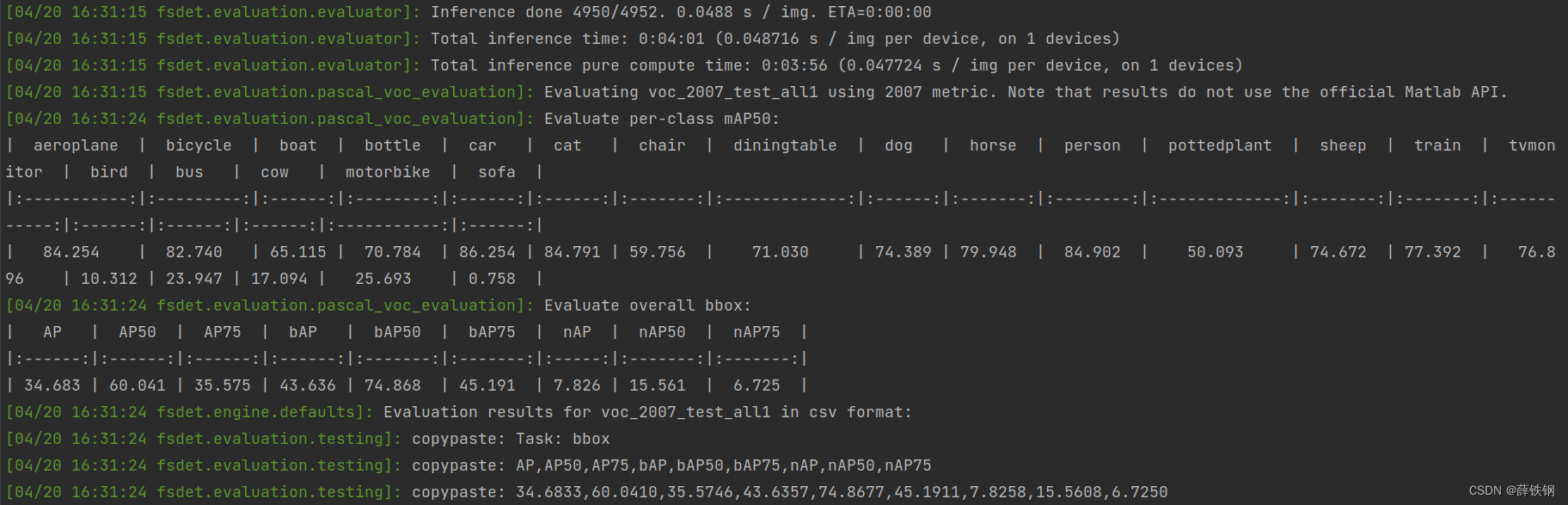
【代码调试】《Frustratingly Simple Few-Shot Object Detection》
更多问题可参考: https://blog.csdn.net/qiankendeNMY/article/details/128450196
论文地址:https://arxiv.org/abs/2003.06957 论文代码:https://github.com/ucbdrive/few-shot-object-detection
我的配置: Python :…
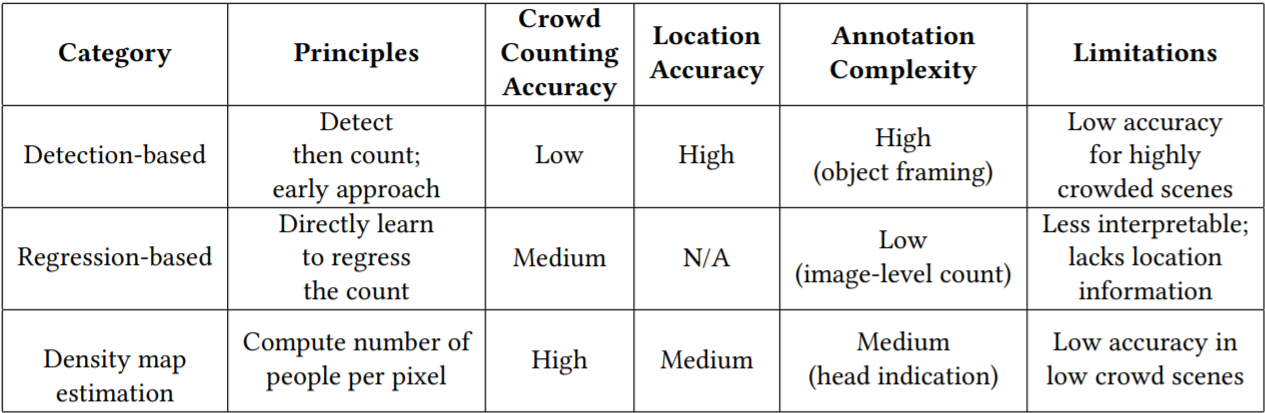
人群计数传统方法:object detection, regression-based
数据标注方式:
(1)人很少、人很大的时候用bounding box,把人从头到脚都框进长方形方框内,这个方框只用记录三个点的坐标,左下、左上、右下;测试集预测的时候,除了点的坐标还要输出这…

基于Transformer的DETR的注意力权重可视化,非CAM可视化技术
神经网络的可视化可以客观的解释 “黑盒” ,所以一直以来都是论文中必不可少的工作。对于深度卷积神经网络,一般用CAM进行可视化研究。遗憾的是,基于Transformer的神经网络可视化,CAM并不奏效。所以,本文章提供一套基于…

全网最最最轻量级检测网络 yolo-fastest 快速上手
文章目录0x01 Yolo-Fastest0x02 Preparestep1 clonestep2 makestep3 run darknet0x03 Trainstep1 获取权重文件step2 准备数据集step3 修改 data/voc.data 和 data/voc.namesstep4 trainstep5 mAP0x04 darknet 转 keras、tflitestep1 darknet 转 kerasstep2 keras 转 tfliteste…

Probabilistic and Geometric Depth: Detecting Objects in Perspective 论文学习
论文地址:Probabilistic and Geometric Depth: Detecting Objects in Perspective Github 地址:Probabilistic and Geometric Depth: Detecting Objects in Perspective
1. 解决了什么问题?
3D 目标检测在许多应用中发挥着重要作用…

Delving into Localization Errors for Monocular 3D Object Detection 论文学习
论文地址:Delving into Localization Errors for Monocular 3D Object Detection Github地址:Delving into Localization Errors for Monocular 3D Object Detection
1. 解决了什么问题?
从单目图像准确地估计 3D 框是自动驾驶领域的重要功…

05- 算法解读 R-CNN (目标检测)
要点:
R-CNN可以说是利用深度学习进行目标检测的开山之作。 一 R-CNN算法
R-CNN可以说是利用深度学习进行目标检测的开山之作。作者Ross Girshick多次 在PASCAL VOC的目标检测竞赛中折桂,曾在2010年带领团队获得终身成就奖。
RCNN算法流程可分为4个步…

《Scale-Aware Trident Networks for Object Detection》笔记
Introduction
特征金字塔有一个缺点,它每层的特征都是由不同的参数卷积得到的,这样做牺牲了不同尺度下特征的一致性,这会减低训练数据的影响和在每个尺度下有过拟合的风险。这篇论文的目标就是生成对所有尺度都有效率的有统一表征能力的特征…

论文阅读笔记 | 三维目标检测——AVOD算法
如有错误,恳请指出。 文章目录1. 背景2. 网络结构3. 实验结果paper:《Joint 3D Proposal Generation and Object Detection from View Aggregation》
1. 背景
AVOD同样是一个two-stage(使用了RPN提取候选框)、anchor-based网络结构。获得较高的召回率对…

YOLOv5改进系列(3)——添加CA注意力机制
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
YOLOv5改进系列(2)——添加CBAM注意力机制 目录 Ὠ…
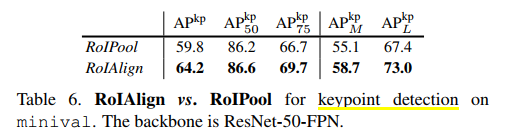
【AI面试】RoI Pooling 和 RoI Align 辨析
RoI Pooling和RoI Align是两种常用的目标检测中的RoI特征提取方法。它们的主要区别在于:如何将不同大小的RoI对齐到固定大小的特征图上,并在这个过程中保留更多的空间信息。
一、RoI Pooling
RoI Pooling最早是在Fast R-CNN中提出的,它的基…

【模式识别9】python计算目标检测IoU、TP、FP、FN、Precision、Recall指标
python计算目标检测IoU、TP、FP、FN、Precision、Recall指标 1. 基础概念1.1 TP、TN、FP、FN1.2 IoU1.3 Precision(P)、Recall(R)、F1-score 2. python代码3. 总结 代码资源:IoU_P_R.py 1. 基础概念
1.1 TP、TN、FP、…
FastDeploy:PaddleSeg C++部署方式(一)
1.FastDeploy介绍
⚡️FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具, 支持云边端部署。提供超过 🔥160+ Text,Vision, Speech和跨模态模型📦开箱即用的部署体验,并实现🔚端到端的推理性能优化,满足开发者多场景、多硬件、多平台的产业部署需求。 使…

YoloV5+TensorRT封装|C#调用dll实现V5+TRT目标检测
在目标检测得领域中,yolo系列无疑是最强得目标检测框架,而其中得yolov5更是扛把子得存在,虽然有着众多的yolo系列版本,但是在工业领域中yolov5还是用的最多,yolov5 yyds,,,先奉献上我…
ConvNeXt网络详解,最新ConvNeXt结合YOLO,催生YOLOv5目标检测巨变
目录 引言一、ConvNeXt的介绍1、目标检测的重要性2、YOLOv5的介绍3、ConvNeXt原理和特点4、ConvNeXt结构 二、相关研究综述1、目标检测的基础原理和流程2、YOLOv5的特点与局限性3、ConvNeXt技术在目标检测中的应用现状 三、ConvNeXt在YOLOv5中的应用与改进1、安装PyTorch和torc…
【计算机视觉 | 目标检测】术语理解4:OVD 训练的范式、半监督目标检测(SSOD)、弱监督目标检测(WSOD)、 余弦相似度
文章目录 一、OVD(开放词汇对象检测)训练的范式二、Semi-supervised Object Detection三、Weakly-supervised Object Detection四、余弦相似度 一、OVD(开放词汇对象检测)训练的范式
在OVD(开放词汇对象检测ÿ…

目标检测常用模型之R-CNN、Fast R-CNN、Faster R-CNN
文章目录 一、模型分类1. 一阶段目标检测2. 二阶段目标检测 二、常见模型1. R-CNN2. Fast R-CNN3. Faster R-CNN 一、模型分类 2012年卷积神经网络(Convolutional Neural Networks, CNNs)的兴起将目标检测领域推向了新的台阶。基于CNNs的目标检测算法主要有两条技术发展路线&am…

基于深度学习的高精度浣熊检测识别系统(PyTorch+Pyside6+模型)
摘要:基于深度学习的高精度浣熊检测(水牛、犀牛、斑马和大象)识别系统可用于日常生活中或野外来检测与定位浣熊目标,利用深度学习算法可实现图片、视频、摄像头等方式的浣熊目标检测识别,另外支持结果可视化与图片或视…

Faster-RCNN代码解读5:主要文件解读-上
Faster-RCNN代码解读5:主要文件解读-上 前言 因为最近打算尝试一下Faster-RCNN的复现,不要多想,我还没有厉害到可以一个人复现所有代码。所以,是参考别人的代码,进行自己的解读。
代码来自于B站的UP主ÿ…

论文精读 BlazePose结合LSTM 跌倒检测
Fall Detection for Shipboard Seafarers Based on Optimized BlazePose and LSTM
基于BlazePose-LSTM的海员跌倒检测 本博客通过全文翻译和总结的方式对论文进行精读。读完此论文颇受启发,比如: 视频中的时间序列问题;文章简单明了的整体脉…

论文投稿指南——中文核心期刊推荐(地球物理学)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…

论文解读:End-to-End Object Detection with Transformers
发表时间:2020 论文地址:https://arxiv.org/pdf/2005.12872.pdf 项目地址:https://github.com/facebookresearch/detr
提出了一种将对象检测视为集合预测问题的新方法。我们的方法简化了检测流程,有效地消除了许多手工设计的组件…

Anchor-free应用一览:目标检测、实例分割、多目标跟踪
作者|杨阳知乎 来源|https://zhuanlan.zhihu.com/p/163266388 本文整理了与Anchor free相关的一些工作。一方面是分享近期在目标检测领域中一些工作,另一方面,和大家一起梳理一下非常火热的网络模型CenterNet、FCOS,当…

CV——day75 读论文:基于差分特征融合CNN的轨道交通目标检测
Differential feature fusion convolutional neural network基于差分特征融合CNN的轨道交通目标检测I. INTRODUCTIONII. RELATED WORKSIII. NETWORK ARCHITECTUREA. Prior Detection ModuleB. Object-Detection ModuleV. CONCLUSION基于差分特征融合CNN的轨道交通目标检测
基于…

目标检测6--R-FCN中的Position-Sensitive RoI Pooling
文章目录1.介绍2.Position-Sensitive Score Map 和 Position-Sensitive RoI Pooling3.源码参考资料欢迎访问个人网络日志🌹🌹知行空间🌹🌹 1.介绍 论文: Region-based Fully Convolutional Networks 代码: R-FCN 本论文作者同9.De…
【roLabelImg】windows下旋转框标注软件安装、使用、rolabelimg打包成exe
主要参考:
roLabelImg安装、使用、数据格式roLabelImg在Win10系统下打包成exe - 问雪的文章 - 知乎
一、安装
1.1 直接下载exe运行
劝大家直接去下别人编译好的吧,本来是训练模型标记的,结果搞了半天去了解这个软件了,哎~
我…

Sparse Fuse Dense: 向高质量的深度补全3D检测迈进
点云的稀疏性:在远距离和遮挡区域提供的信息较差,导致难以生成精确的3D边界框。
出现了多模态融合。
图像和点云的不同表示方式使得它们难以融合,导致性能不佳。
论文提出了一种新颖的多模态框架SFD(Sparse Fuse Dense…
CenterMask paper笔记
CenterMask是一个anchor free的实例分割模型, 来自paper: CenterMask: Real-Time Anchor-Free Instance Segmentation
提起anchor free, 会想到FCOS模型,是用来目标检测的, 那么这里就用到了FCOS, 不过换了backbone,
在FCOS检测出目标框后&…

基于深度学习的高精度安全帽背心检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度安全帽背心检测识别系统可用于日常生活中或野外来检测与定位安全帽背心目标,利用深度学习算法可实现图片、视频、摄像头等方式的安全帽背心目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用…

目标检测模型中的Bells and wisthles
目标检测模型中的Bells and wisthles 目标检测模型中的Bells and wisthles1. Data augmentation 数据增强2. Multi-scale Training/Testing 多尺度训练/测试3. Global Context 全局语境4. Box Refinement/Voting 预测框微调/投票法5. OHEM 在线难例挖掘6. Soft NMS 软化非极大抑…
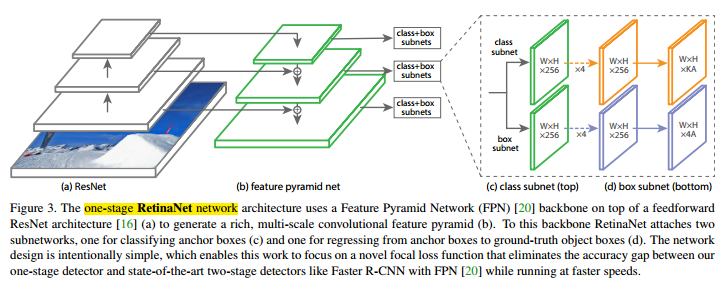
目标检测——Focal Loss
【Paper】Focal Loss for Dense Object Detection
1. Background of object detection
首先我们回顾单阶段目标检测(One-Stage)是如何实现的: 上图是YOLO的框架针对一张图片featuremap的变化,可以看到,网络输出的结果是对所有预设集合的分类…

基于深度学习的目标检测综述(单阶段、多阶段、FPN变体、旋转目标检测等)
随着深度学习的发展,基于深度学习的目标检测方法因其优异的性能已经得到广泛的使用。目前经典的目标检测方法主要包括单阶段(YOLO、SSD、RetinaNet,还有基于关键点的检测方法等)和多阶段方法(Fast RCNN、Faster RCNN、Cascade RCNN等)。下面主…

DeFCN:《End-to-End Object Detection with Fully Convolutional Network》复现:训练自己数据集
论文链接:https://arxiv.org/pdf/2012.03544.pdf代码链接:https://github.com/Megvii-BaseDetection/DeFCN论文解读:https://zhuanlan.zhihu.com/p/371594304
一. 环境搭建
1.1. 安装cvpods框架
git clone https://github.com/Megvii-Base…

《Libra R-CNN: Towards Balanced Learning for Object Detection》笔记
Introduction
这篇论文针对目标检测训练过程中的不平衡问题,提出了一种平衡化学习方法。关于目标检测中的不平衡问题,这篇博客有更详细的介绍。
这篇论文讨论的不平衡问题包括三种:
样本级别的不平衡:对于二阶段的目标检测算法…

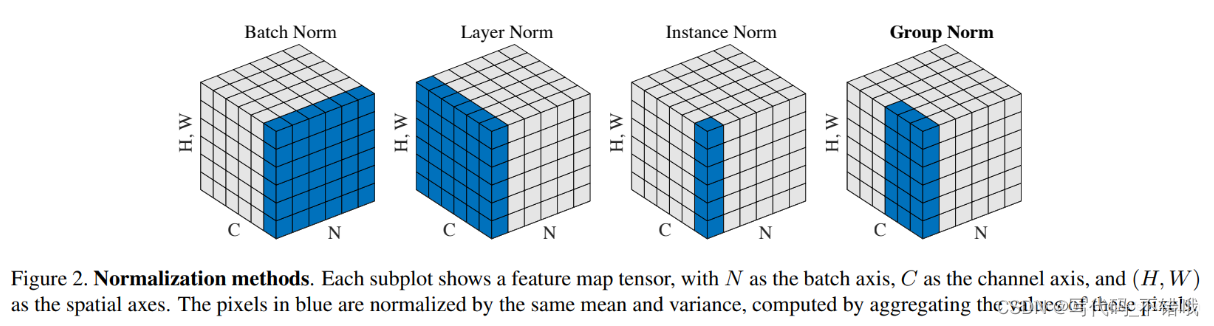
BN、LN、IN、GN的自我理解
目录
一、Batch Normal
二、Layer Normal
三、Instance Normal
四、Group Normal
五、参考 参考了这两三篇博客,终于理解了这几个概念。
一、Batch Normal
Batch Normal,举例来说:输入一个batch size,这个batch size中有2个…

【模式识别4】YOLO目标检测数据集xml格式转txt格式
YOLO目标检测数据集xml格式转txt格式 1. 转换前的xml格式2. xml格式转txt格式代码2.1 源代码2.2 需要修改的地方 3. 转换后的txt格式 代码资源:voc2txt.py
1. 转换前的xml格式
如果我们使用LabelImg工具标注数据集,生成的xml文件如下: xml…
Yolov8优化:引入Soft-NMS并结合各个IOU变体GIOU、DIOU、CIOU、EIOU、SIOU,进一步提升密集遮挡场景检测精度
目录 1.Soft-NMS介绍 2.IOU介绍
2.1 GIOU 2.2 DIoU(Distance-IoU)
2.3 CIoU
2.4 EIoU(Efficient-IoU)
Faster RCNN系列3——RPN的真值详解与损失值计算
Faster RCNN系列:
Faster RCNN系列1——Anchor生成过程 Faster RCNN系列2——RPN的真值与预测值概述 Faster RCNN系列3——RPN的真值详解与损失值计算 Faster RCNN系列4——生成Proposal与RoI Faster RCNN系列5——RoI Pooling与全连接层 目录 一、RPN真值详解二、…
【嵌入式模型转换】2. 算能盒子SE5 芯片板子BM1684 sophon-pipeline
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 前言
文章1,我们在SE5上实现了,SOC模式下的 C 和 python-sail的模型转换,本篇文章的目的是要走通一个pipeline。 这一段是…
MaskrcnnBenchmark 源码解析-模型定义(modeling)之骨架网络(backbone)
源码文件
不论是在训练脚本文件 train_net.py 还是在测试脚本文件 test_net.py 中, 都调用了 build_detection_model(cfg) 函数来创建模型, 该函数封装了模型定义的内部细节, 使得我们可以通过配置文件轻松的组合出不同类型的模型, 为了能够更好的了解模型的内部细节, 我们有必…
论文提要“Improving Object Detection with DCN via Bayesian Optimization and Structured Prediction”
2015年CVPR中的一篇文章,对R-CNN的改进和提升,主要贡献是:1)使用了贝叶斯优化提升Selective Search方法得到的proposal的准确度;2)使用了结构化的SVM框架训练CNN分类器。
1.使用贝叶斯优化对 bbox进行细粒…
【三维目标检测】3DSSD(二)
数据和源码请参考上一篇博文:【三维目标检测】3DSSD(一)_Coding的叶子的博客-CSDN博客。 3DSSD三维目标检测模型发表在CVPR2020《3DSSD: Point-based 3D Single Stage Object Detector》。目前,基于体素的 3D 单级检测器已经有很多…
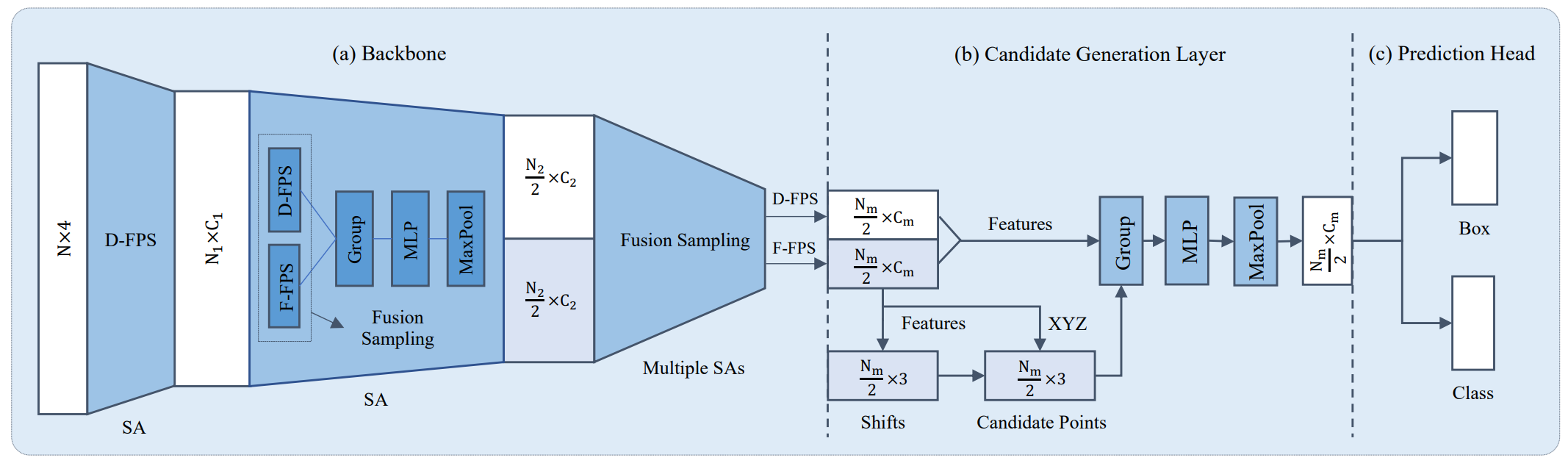
【三维目标检测】3DSSD(一)
3DSSD三维目标检测模型发表在CVPR2020《3DSSD: Point-based 3D Single Stage Object Detector》。目前,基于体素的 3D 单级检测器已经有很多种,而基于点的单级检测方法仍处于探索阶段。3DSSD是一种轻量级且有效的基于点的 3D 单级目标检测器,…
【三维目标检测】VoxelNet(二):数据处理
本节主要介绍VoxelNet的数据处理部分,数据下载及预处理部分请参考:三维点云目标检测 — VoxelNet详解crop.py (一)_Coding的叶子的博客-CSDN博客。 其他三维目标检测算法的数据处理,特别是基于KITTI的三维目标检测&…
SSD系列3——损失计算
SSD系列: SSD系列1——网络结构 SSD系列2——PriorBox SSD系列3——损失计算
一、确定正、负样本标签 损失计算的第一步是对所有的PriorBox赋予正、负样本的标签,并确定对应的真实物体标签。 在SSD的PriorBox生成过程中,一共生成了8732个Pri…

【深度学习 video detect】Towards High Performance Video Object Detection for Mobiles
文章目录 摘要IntroductionRevisiting Video Object Detection BaselinePractice for Mobiles Model Architecture for MobilesLight Flow 摘要
尽管在桌面GPU上取得了视频目标检测的最近成功,但其架构对于移动设备来说仍然过于沉重。目前尚不清楚在非常有限的计算…
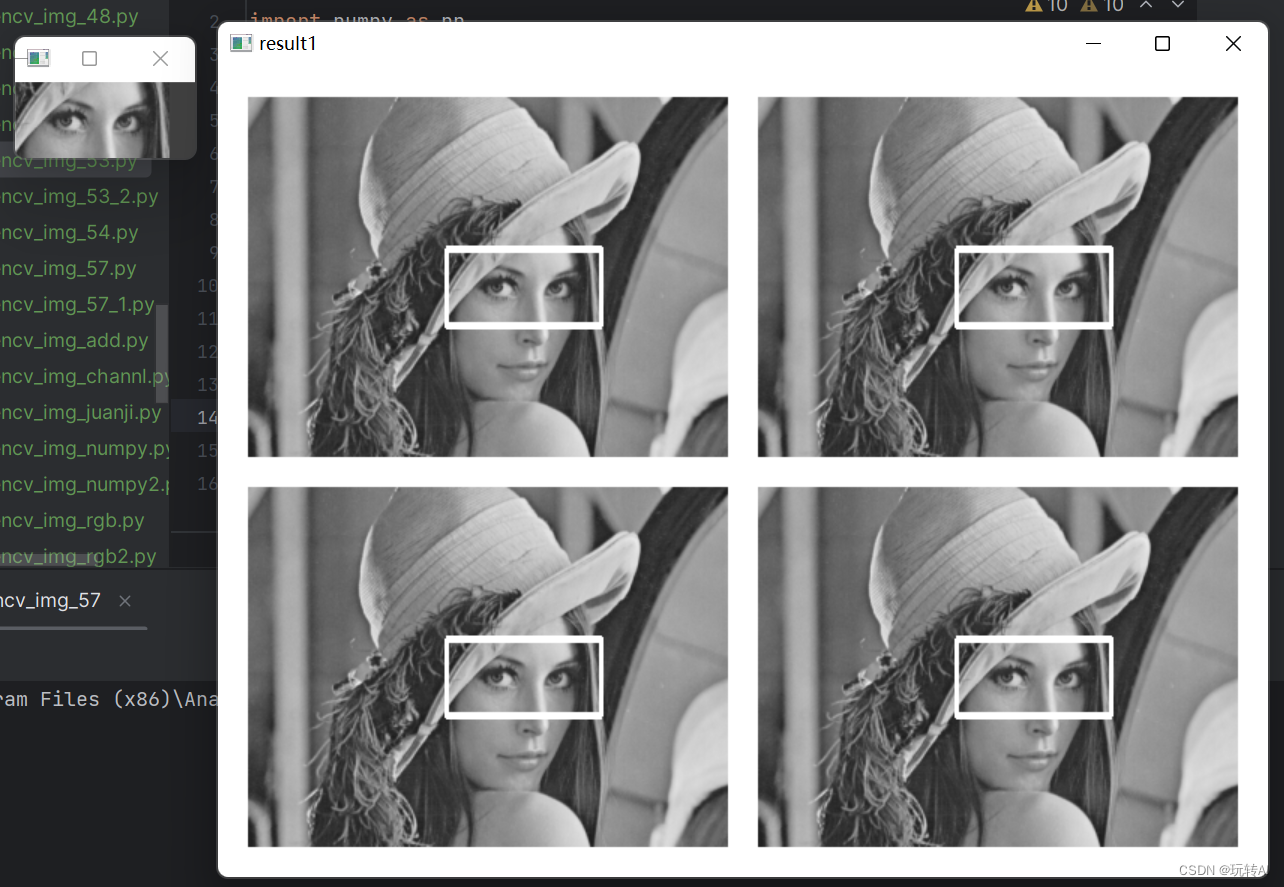
opencv基础57-模板匹配cv2.matchTemplate()->(目标检测、图像识别、特征提取)
OpenCV 提供了模板匹配(Template Matching)的功能,它允许你在图像中寻找特定模板(小图像)在目标图像中的匹配位置。模板匹配在计算机视觉中用于目标检测、图像识别、特征提取等领域。 以下是 OpenCV 中使用模板匹配的基…

Mask RCNN网络结构以及整体流程的详细解读
文章目录 1、概述2、Backbone3、RPN网络3.1、anchor的生成3.2、anchor的标注/分配3.3、分类预测和bbox回归3.4、NMS生成最终的anchor 4、ROI Head4.1、ROI Align4.2、cls head和bbox head4.3、mask head 1、概述
Mask RCNN是在Faster RCNN的基础上增加了mask head用于实例分割…
[数据集][目标检测]钢材表面缺陷目标检测数据集VOC格式2279张10类别
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):2279 标注数量(xml文件个数):2279 标注类别数:10 标注类别名称:["yueyawan",&…
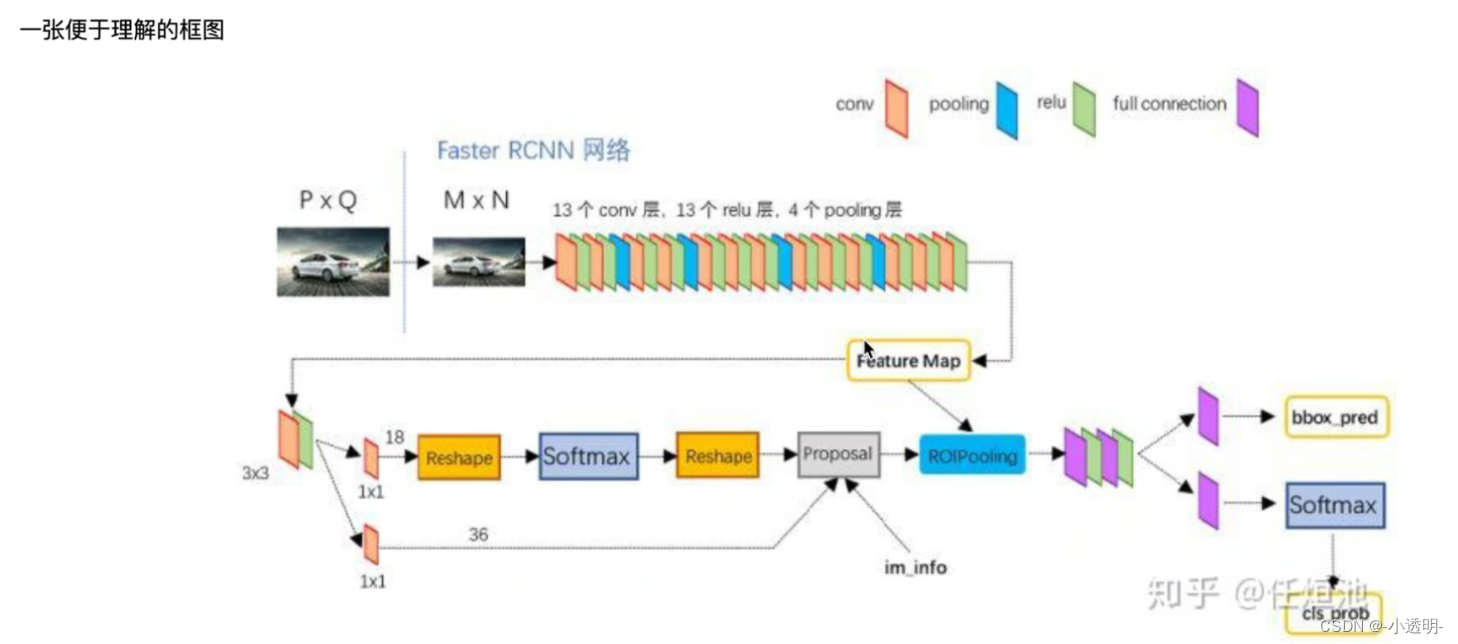
two-stage目标检测算法
R-CNN 现在,将目光穿越回2012年,hinton刚刚提出alexnet的时代。
此时,该如何审视目标检测任务?
当时的目标检测采用的是滑动窗口手动特征分类器的思路。
该方法的弱点包括 速度慢 精度差
精度差的问题是由手工特征造成的&am…

《Learning Rich Features at High-Speed for Single-Shot Object Detection》笔记
Introduction
论文针对目前一阶段目标检测方法在小物体检测的表现弱的问题,提出了一个新的一阶段目标检测框架。该框架主要的思路是在特征金字塔的过程中融入缺少的低级/中级特征,让低、中、高特征在各个级别的特征层上流动。另外,考虑到目标…
Yolov5/Yolov7改进---注意力机制:ShuffleAttention、ECA、EffectiveSE、SE
目录 1. ShuffleAttention 1.1 加入 common.py中
1.2 加入yolo.py中:
1.3 yolov5s_ShuffleAttention.yaml
2.ECA
![[数据集][目标检测]骑电动车摩托车不戴头盔数据集VOC格式1385张](https://i1.hdslb.com/bfs/archive/1b98ce6a0729dcac5bb74808fe3b79bf1eefb054.jpg@100w_100h_1c.png@57w_57h_1c.png)
[数据集][目标检测]骑电动车摩托车不戴头盔数据集VOC格式1385张
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):1385 标注数量(xml文件个数):1385 标注类别数:2 标注类别名称:["y","n&q…

Opencv 之ORB特征提取与匹配API简介及使用例程
Opencv 之ORB特征提取与匹配API简介及使用例程
ORB因其速度较快常被用于视觉SLAM中的位姿估计、视觉里程、图像处理中的特征提取与匹配及图像拼接等领域本文将详细给出使用例程及实现效果展示
1. API 简介
创建
static Ptr<ORB> cv::ORB::create (int nfeatures 500…

【深入了解PyTorch】PyTorch实战项目示例:深入探索图像分类、目标检测和情感分析
【深入了解PyTorch】PyTorch实战项目示例:深入探索图像分类、目标检测和情感分析 PyTorch实战项目示例:深入探索图像分类、目标检测和情感分析项目一:图像分类数据集准备构建模型训练模型模型评估和预测项目二:目标检测数据集准备构建模型训练模型模型评估和预测项目三:情…

基于YOLOv8模型和PCB电子线路板缺陷目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型PCB电子线路板缺陷目标检测系统可用于日常生活中检测与定位PCB线路板瑕疵,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检…

YOLOv5源码中的参数超详细解析(4)— 推理部分detect.py
前言:Hello大家好,我是小哥谈。YOLOv5是一种先进的目标检测算法,它可以实现快速和准确的目标检测。detect.py是YOLOv5项目目录结构中的一个重要的脚本文件,它用于执行目标检测任务,可以通过命令行参数指定要检测的图像…
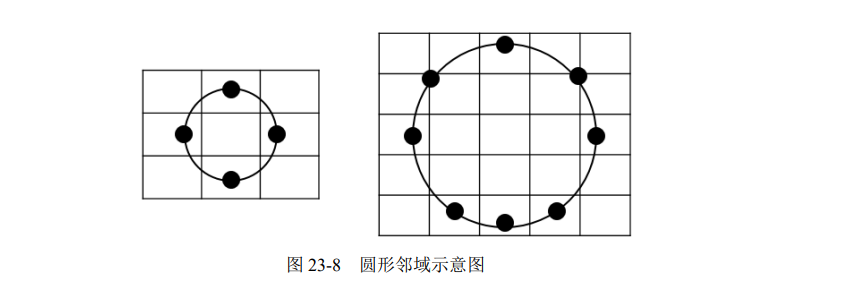
opencv进阶11-LBPH 人脸识别(人脸对比)
人脸识别的第一步,就是要找到一个模型可以用简洁又具有差异性的方式准确反映出每个人脸的特征。识别人脸时,先将当前人脸采用与前述同样的方式提取特征,再从已有特征集中找出当前特征的最邻近样本,从而得到当前人脸的标签。 OpenC…
深度学习(八)---zed调用yolov5之目标检测遇到的问题及解决
1.前言
zed调用yolov5进行目标检测时遇到的问题,记录下~~
2.环境信息
开发板:Jetson Xviewer NX
摄像头: zed2系统:Ubuntu18.043.问题及解决
问题1: RuntimeError: cuDNN error: CUDNN_STATUS_MAPPING_ERROR 原因&…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(8 月 15 日论文合集)
文章目录 一、检测相关(15篇)1.1 Diving with Penguins: Detecting Penguins and their Prey in Animal-borne Underwater Videos via Deep Learning1.2 Towards Robust Real-Time Scene Text Detection: From Semantic to Instance Representation Learning1.3 Survey on vide…
Yolov8小目标检测(1)
💡💡💡本文目标:通过原始基于yolov8的红外弱小目标检测,训练得到初版模型,进行问题点分析;
💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,带你轻松实现小目标检测涨点
💡💡…
目标检测常用的数据集格式
在目标检测领域,有三种常用的数据集:
数据集标注文件格式bbox格式vocxmlxmin, ymin, xmax, ymax:bbox左上角(xmin, ymin)和右下角(xmax, ymax)的坐标cocojsonx, y, w, h:bbox左上角坐标(x, y)以及宽(w)和高(h)yolotxtxcenter, ycenter, w, h:bbox的中心…

Towards Open World Object Detection【论文解析】
Towards Open World Object Detection 摘要1 介绍2 相关研究3 开放世界目标检测4 ORE:开放世界目标检测器4.1 对比聚类4.2 RPN自动标注未知类别4.3 基于能量的未知标识4.4 减少遗忘 5 实验5.1开放世界评估协议5.2 实现细节5.3 开放世界目标检测结果5.4 增量目标检测结果 6 讨论…
『LabelImg』使用小技巧
文件夹切换
需要注意我们在更换切换图像文件夹(Open Dir)之后,也要切换标注文件的保存文件夹(Change Save Dir)
快捷键
快捷键功能ctrl o打开文件ctrl 原始大小ctrl u打开目录ctrl F适应窗口ctrl r更改保存目录…
锚框【动手学深度学习】
生成多个锚框 假设输入图像高为h,宽为w,我们以图像每个像素为中心生成不同形状的锚框,缩放比
s∈(0,1],宽高比为r>0。那么锚框的宽度和高度分别为和。当中心位置给定时,
已知宽和高的锚框是确定的。缩放比为锚框高与图像高的比值,然后得到一个正方形锚框面积。 …

百度飞浆实战-手写数字识别
目录 参考建模过程1、数据加载和预处理2、模型的网络设计和开发模型组网 3、模型训练 代码实战1、打开aistudio找到项目 参考
视频教程 PaddleAPI DOC
建模过程
1、数据加载和预处理
飞桨框架帮助我们将MNIST数据集进行了内置 数据集名称: MNIST 数据集官网 &am…

基于YOLOV8模型的西红柿目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型的西红柿目标检测系统可用于日常生活中检测与定位西红柿目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数…

YOLOv5算法改进(10)— 替换主干网络之GhostNet
前言:Hello大家好,我是小哥谈。GhostNet是一种针对计算机视觉任务的深度神经网络架构,它于2020年由中国科学院大学的研究人员提出。GhostNet的设计目标是在保持高精度的同时,减少模型的计算和存储成本。GhostNet通过引入Ghost模块…

yolov8实战之torchserve服务化:使用yolov8x来预打标
前言
最近在做一个目标检测的任务,部署在边缘侧,对于模型的速度要求比较严格(yolov8n这种),所以模型的大小不能弄太大,所以原模型的性能受限,更多的重点放在增加数据上。实测yolov8x在数据集上…
基于YOLOv8模型和DarkFace数据集的黑夜人脸检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和DarkFace数据集的黑夜人脸检测系统可用于日常生活中检测与定位黑夜下的人脸,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目…

深度学习-4-二维目标检测-YOLOv5源码测试与训练
本文采用的YOLOv5源码是ultralytics发行版3.1 YOLOv5源码测试与训练
1.Anaconda环境配置
1.1安装Anaconda
Anaconda 是一个用于科学计算的 Python 发行版,支持 Linux, Mac, Windows, 包含了众多流行的科学计算、数据分析的 Python 包。
官方网址下载安装包&…

yolov5 应用整理
yolov5 应用整理
适用于0基础人员与有一定yolov5了解的人员食用.
关于yolov5参考:
yolov5 github源码链接 目前参与过yolov5的应用:
平台库x86/arm cpuncnnx86libtorch/pytorchBM1684算能标准库(需要进行模型转换)昇腾cann(ascend api)
https://gitee.com/Tencent/ncnn ht…

深度学习-4-二维目标检测-YOLOv3理论模型
单阶段目标检测模型YOLOv3
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并…
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(五)
文章目录 一、ModaNet二、SKU110K三、SceneNet四、VT5000五、Washington RGB-D六、Argoverse-HD七、CADC (Canadian Adverse Driving Conditions)八、ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer)九、MALF (Multi-Attribute Labelled Faces)十、Ti…
YOLO-NAS教程详细介绍如何使用 SuperGradients 训练 ResNet18 模型
在此示例中,我们将使用 SuperGradients 在 CIFAR10 图像分类数据集上从头开始训练 ResNet18 模型。我们还将通过迁移学习以及在 ImageNet 数据集上预先训练的权重来微调同一模型。 快速安装 对于这个例子,唯一必要的包是超级梯度。安装超级梯度还将安装运行本示例中的代码所需…

YOLO目标检测——人脸性别识别数据集下载分享
人脸性别识别数据集共同2300图片。在社交媒体分析、广告定向投放、零售业、安防系统以及健康和医疗领域等多个领域都具有广泛的应用潜力。通过准确识别人脸的性别,可以为这些领域提供更精准的数据分析和个性化的服务。 数据集点击下载:YOLO人脸性别识别数…
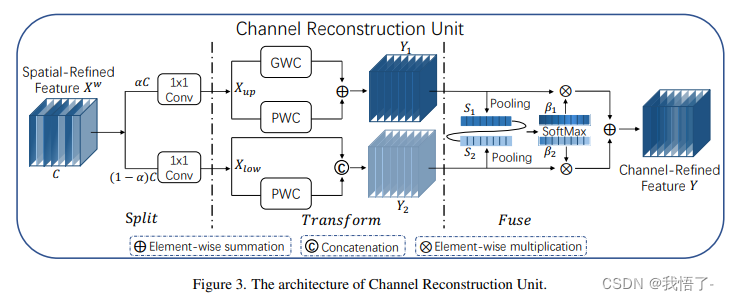
pytorch代码实现之空间通道重组卷积SCConv
空间通道重组卷积SCConv
空间通道重组卷积SCConv,全称Spatial and Channel Reconstruction Convolution,CPR2023年提出,可以即插即用,能够在减少参数的同时提升性能的模块。其核心思想是希望能够实现减少特征冗余从而提高算法的效…

Swin-Transformer-Object-Detection运行环境的搭建
swin transformer的表现就不用多说了,简单记录其目标检测的运行环境搭建过程。 目录创建Pycharm工程github下载源码安装第三方库运行测试代码运行效果问题及参考创建Pycharm工程 现在虚拟环境中只有以下几个包
github下载源码
https://github.com/SwinTransform…

YOLO目标检测——火焰烟雾数据集+已标注VOC和YOLO格式标签下载分享
实际项目应用:火灾预警系统、智能监控系统、工业安全管理、森林火灾监测以及城市规划和消防设计等应用场景中具有广泛的应用潜力,可以提高火灾检测的准确性和效率,保障人员和财产的安全。数据集说明:YOLO火焰目标检测数据集&#…
零基础教程:使用yolov8训练自己的目标检测数据集
1.前言
Ultralytics YOLOv8 是一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 设计快速、准确且易于使用,使其成为各种物体检测与跟踪、实例…


YOLO系列正负样本分配策略
1、YOLOv3
使用MaxIoUAssigner策略来给gt分配样本,基本上保证每个gt都有唯一的anchor对应,匹配的原则是该anchor与gt的IOU最大且大于FG_THRESH,这种分配制度会导致正样本比较少,cls和bbox分支训练起来可能比较慢。在剩余的anchor…
python工具方法 43 yolo|voc数据离线增强(实现数据类型平衡)
在众多的目标检测训练代码中都支持在线数据增强,但并不能妥善的解决数据不平衡的问题(比如yolob8,paddledetion都无法指定类别权重;使用focal loss也只是可以缓解bbox样本不平衡,并不能完全缓解类别间的不平衡),故此需要离线数据增强手段来实现数据类别的平衡。对yolo数…

Yolov8-pose关键点检测:模型轻量化创新 | BiLevelRoutingAttention 动态稀疏注意力 | CVPR2023 BiFormer
💡💡💡本文解决什么问题:BiLevelRoutingAttention ,通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ) BiLevelRoutingAttention | GFLOPs从9.6降低至8.5,参数量从6482kb降低至6134kb, mAP50从0.921提升至0.926
Yolov8…

基于深度学习的高精度老虎检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度老虎检测识别系统可用于日常生活中或野外来检测与定位老虎目标,利用深度学习算法可实现图片、视频、摄像头等方式的老虎目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型…

人工智能TensorFlow PyTorch物体分类和目标检测合集【持续更新】
1. 基于TensorFlow2.3.0的花卉识别
基于TensorFlow2.3.0的花卉识别Android APP设计_基于安卓的花卉识别_lilihewo的博客-CSDN博客 2. 基于TensorFlow2.3.0的垃圾分类
基于TensorFlow2.3.0的垃圾分类Android APP设计_def model_load(img_shape(224, 224, 3)_lilihewo的博客-CS…
深度学习与计算机视觉系列(下)--目标检测图像分割
深度学习与计算机视觉入门系列(下) 数据嗨客最近发布了一个深度学习系列,觉得还不错,主要对深度学习与计算机视觉相关内容做了系统的介绍,看了一遍,在这里做一下笔记。 目录 深度学习与计算机视觉入门系列&…
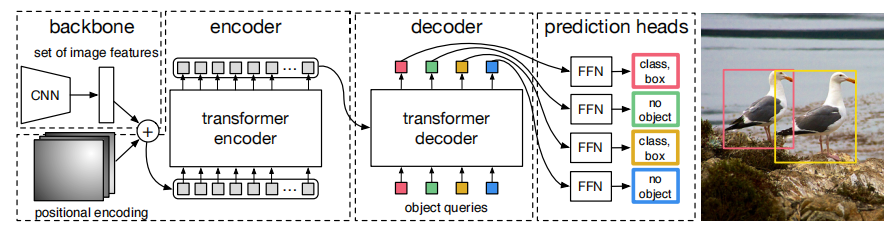
一文看懂DETR(二)
训练流程 1.输入图像经过CNN的backbone获得32倍下采样的深度特征; 2.将图片给拉直形成token,并添加位置编码送入encoder中; 3.将encoder的输出以及Object Query作为decoder的输入得到解码特征; 4.将解码后的特征传入FFN得到预测特…

海面漂浮物垃圾识别检测算法
海面漂浮物垃圾识别检测算法通过yolo系列网络框架模型算法,海面漂浮物垃圾识别检测算法一旦识别到海面的漂浮物垃圾,海面漂浮物垃圾识别检测算法立即发出预警信号。目标检测架构分为两种,一种是two-stage,一种是one-stage…
深度学习-4-二维目标检测-YOLOv3模型
单阶段目标检测模型YOLOv3
R-CNN系列算法需要先产生候选区域,再对候选区域做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。近几年,很多研究人员相继提出一系列单阶段的检测算法,只需要一个网络即可同时产生候选区域并…
Yolov8小目标检测(24):Gold-YOLO,遥遥领先,超越所有YOLO | 华为诺亚NeurIPS23
💡💡💡本文独家改进:提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,Gold-YOLO,替换yolov8 head部分 实现暴力涨点
Gold-YOLO | 亲测在红外弱小目标检测涨点明显,map@0.5 从0.755提升至0.768
💡💡💡Yolo小目标检测,独家首发创新(原…
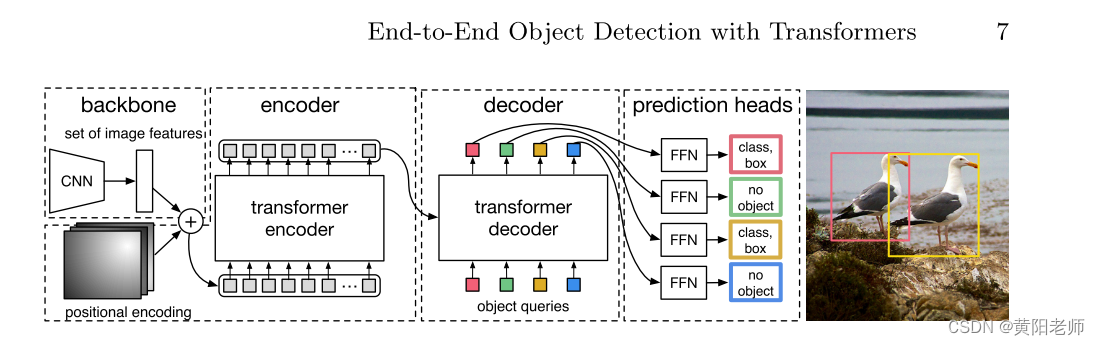
End-to-End Object Detection with Transformers(论文解析)
End-to-End Object Detection with Transformers 摘要介绍相关工作2.1 集合预测2.2 transformer和并行解码2.3 目标检测 3 DETR模型3.1 目标检测集设置预测损失3.2 DETR架构 摘要
我们提出了一种将目标检测视为直接集合预测问题的新方法。我们的方法简化了检测流程,…
opencv dnn模块 示例(16) 目标检测 object_detection 之 yolov4
博客【opencv dnn模块 示例(3) 目标检测 object_detection (2) YOLO object detection】 测试了yolov3 及之前系列的模型,有在博客【opencv dnn模块 示例(15) opencv4.2版本dnn支持cuda加速(vs2015异常解决)】 说明了如何使用dnn模块进行cuda…
![[论文必备]最强科研绘图分析工具Origin(1)——安装教程](https://img-blog.csdnimg.cn/70d88b7c6d8647fcb3cdf37f074d1b4d.gif)
[论文必备]最强科研绘图分析工具Origin(1)——安装教程
之前在论文中pr曲线和loss曲线对比用到了Origin这个最强科研绘图分析工具,被导师狠狠夸了,下面来分享一下~
本篇先带你手把手安装这个软件,可以先点再慢慢看哦~ 目录
📢一、软件简介
🌻二、安装教程
🎄…

弱监督目标检测:ALWOD: Active Learning for Weakly-Supervised Object Detection
论文作者:Yuting Wang,Velibor Ilic,Jiatong Li,Branislav Kisacanin,Vladimir Pavlovic
作者单位:Rutgers University;The Institute for Artificial Intelligence Research and Development of Serbia;Nvidia Corporation
论文链接:http:…

YOLO Magic - 强化YOLOv5的视觉任务框架
YOLO Magic🚀 - 强化YOLOv5的视觉任务框架 YOLO Magic🪄是一个基于Ultralytics YOLOv5 v7.0 版本的扩展,旨在为视觉任务提供更强大的功能和更简单的操作。它在YOLOv5的基础上引入了丰富的网络模块,并提供了直观易用的Web操作界面&…
实时车辆行人多目标检测与跟踪系统(含UI界面,Python代码)
算法架构:
目标检测:yolov5
目标跟踪:OCSort其中, Yolov5 带有详细的训练步骤,可以根据训练文档,训练自己的数据集,及其方便。 另外后续 目标检测会添加 yolov7 、yolox,目标跟踪会…
目标检测YOLO实战应用案例100讲-基于端到端的自动驾驶道路环境目标检测(续)
目录
3.1.2 多尺度小目标检测 3.1.3 Swin Transformer Layer 3.1.4 MCS-YOLO网络结构图
3.2 实验环境及参数设置

计算机视觉与深度学习-图像分割-视觉识别任务02-目标检测-【北邮鲁鹏】
目录标题 参考目标检测定义深度学习对目标检测的作用单目标检测多任务框架多任务损失预训练模型姿态估计 多目标检测问题滑动窗口(Sliding Window)滑动窗口缺点 AdaBoost(Adaptive Boosting)参考 区域建议 selective search 思想慢…

3-D HANet:一种用于目标检测的柔性三维 HeatMap 辅助网络
论文背景
室外场景感知使用 Lidar: 1.点云数据不受天气(雾、风暴、雨和雪)的影响,支持稳定的环境感知; 2.点云数据在很大程度上保留了原来中物体的空间结构特征。
3D 目标检测是室外场景感知的重要组成部分。 从一个不完整的点云空间结构中…
基于YOLOv8模型的条形码二维码检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的条形码二维码检测系统可用于日常生活中检测与定位条形码与二维码目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测…
第2篇 机器学习基础 —(1)机器学习方式及分类、回归
前言:Hello大家好,我是小哥谈。机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进…

【论文笔记】NeRF-RPN: A general framework for object detection in NeRFs
原文链接:https://arxiv.org/abs/2211.11646
1. 引言 NeRF模型能直接从给定的RGB图像和相机姿态学习3D场景的NeRF表达。本文提出NeRF-RPN,使用从NeRF模型提取的辐射场和密度,直接生成边界框提案。
3. 方法 如图所示,本文的方法有…
全网首发YOLOv8暴力涨点:Gold-YOLO,遥遥领先,超越所有YOLO | 华为诺亚NeurIPS23
💡💡💡本文独家改进:提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,Gold-YOLO,替换yolov8 head部分 实现暴力涨点
Gold-YOLO | 亲测在多个数据集能够实现大幅涨点
💡💡💡Yolov8魔术师,独家首发创新(原创),适用于Yolov5、Yolov7、…

基于知识蒸馏的夜间低照度图像增强及目标检测
源自:应用光学
作者:苗德邻, 刘磊, 莫涌超, 胡朝龙, 张益军, 钱芸生.
“人工智能技术与咨询” 发布
摘要
为了实现夜间低照度图像的增强,提高目标检测模型在夜间低照度条件下的检测精度并减小模型的计算成本,提出了一种基…
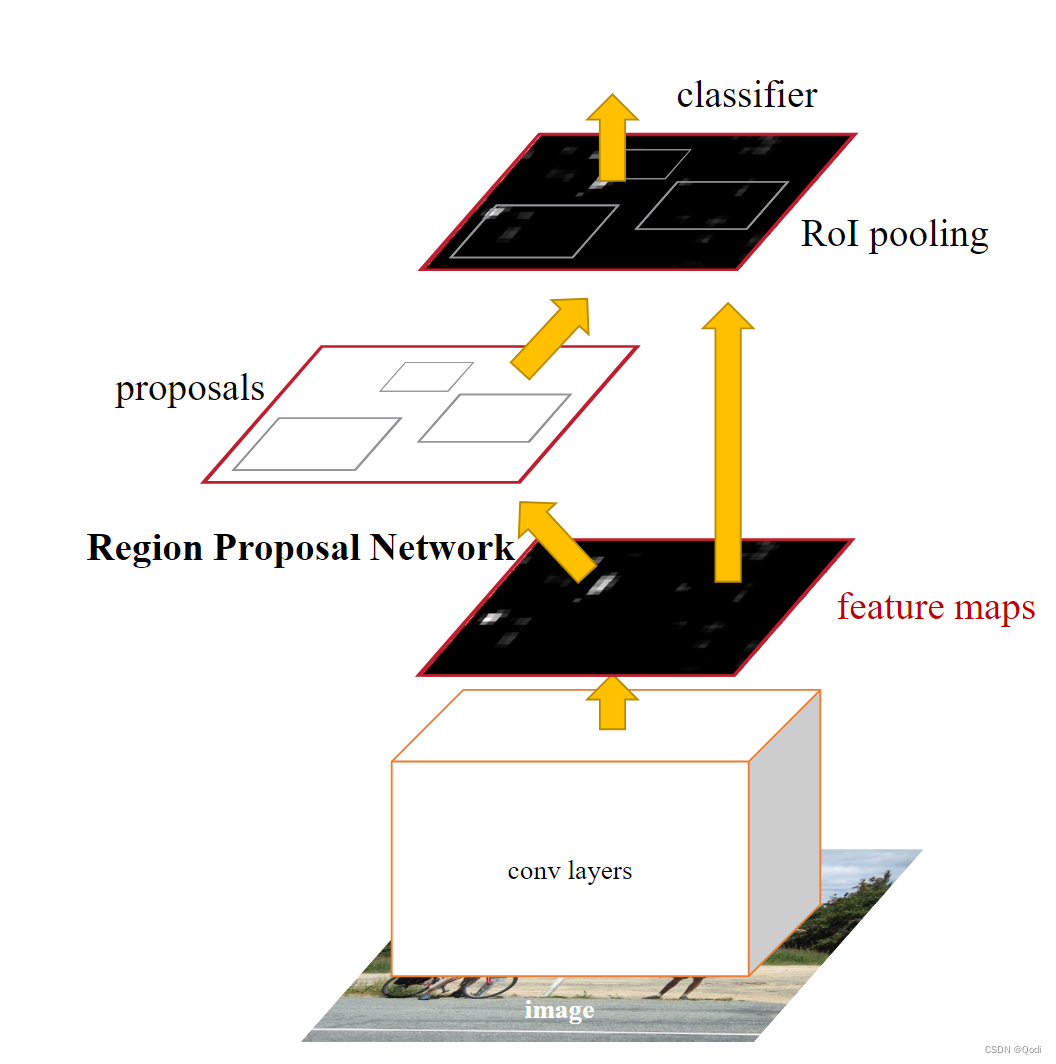
CV经典任务(二)目标检测 |单目标,多目标 非极大值抑制等
文章目录 1 目标检测1.1 单目标检测1.2 多目标检测3.2.1 阶段一 单像素点采样目标检测3.2.2 阶段二 多像素点采样目标检测3.2.3 阶段三 RNN3.2.4 阶段四 一阶段的目标检测 Yolo/SSD 1 目标检测
目标检测的重要任务是
目标定位:目标检测的首要任务是确定图像中对象…
传统目标检测算法【1】-Mean shift
传统目标检测算法【1】-Mean shift 一、均值漂移(MeanShift)二、 Mean shift 的opencv python实现三、 Python实现完整代码参考文献资料一、均值漂移(MeanShift)
该算法寻找离散样本的最大密度,并且重新计算下一帧的最大密度,这个算法的特点就是可以给出目标移动的方向。…

深度学习-4-二维目标检测-YOLOv5理论模型详解
YOLOv5理论模型详解
1.Yolov5四种网络模型
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。
YOLOv5系列的四个模型(YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x)在参数量和性…
目标检测前言,RCNN,Fast RCNN,Faster RCNN
一、RCNN: 找到概率最高的目标之后,与其他目标进行IOU交并比计算,若高于一定值,则说明这两张图片预测的是同一个目标,则把概率低的目标删掉 二、Fast RCNN 因为是直接得到特征图之后进行映射,所以不限制输入…

YOLO目标检测——棉花病虫害数据集+已标注txt格式标签下载分享
实际项目应用:目标检测棉花病虫害数据集的应用场景涵盖了棉花病虫害的识别与监测、研究与防治策略制定、农业智能决策支持以及农业教育和培训等领域。这些应用场景可以帮助农业从业者更好地管理棉花病虫害,提高棉花产量和质量,推动农业的可持…
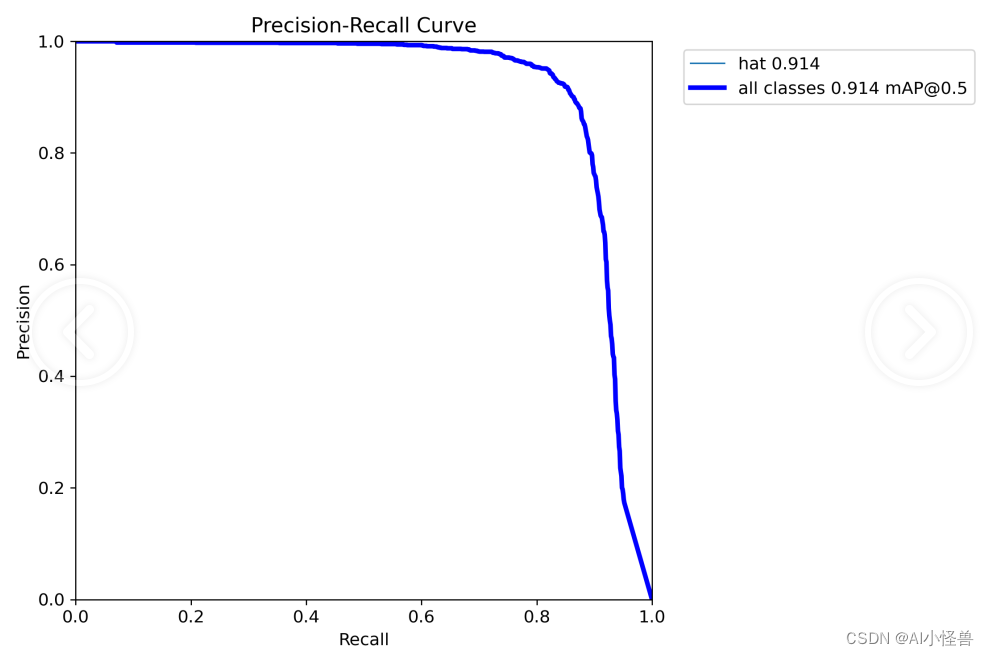
基于YOLOv8的安全帽检测系统(3):DCNv3可形变卷积,基于DCNv2优化,助力行为检测 | CVPR2023 InternImage
目录 1.Yolov8介绍
2.安全帽数据集介绍
3.InternImage介绍
4.训练结果分析 1.Yolov8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的(SOTA)模型,它建立在先前YOLO成功…

PyTorch深度学习实战(20)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现R-CNN目标检测 0. 前言1. R-CNN 目标检测模型1.1 核心思想1.2 算法流程 2. 实现 R-CNN 目标检测2.1 数据集准备2.2 获取区域提议和偏移量2.3 创建训练数据2.4 构建 R-CNN 架构 3. R-CNN目标检测模型测试小结系列…
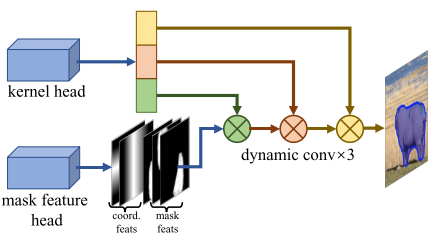
4.Mask R-CNN/YOLOV8/RTMDET三种实例分割方法推理逻辑对比
文章目录 Mask R-CNN/YOLOV8/RTMDET三种实例分割方法推理逻辑对比Mask R-CNNYOLOV5/8实例分割方法RTMDet中的实例分割 欢迎访问个人网络日志🌹🌹知行空间🌹🌹 Mask R-CNN/YOLOV8/RTMDET三种实例分割方法推理逻辑对比
实例分割是同…

使用目标之间的先验关系提升目标检测器性能
今天跟大家分享阿姆斯特丹大学等提出的用于提升目标检测和实例分割性能的新方法RP-FEM,该方法将目标之间位置的先验关系融入到feature中。 论文标题:Relational Prior Knowledge Graphs for Detection and Instance Segmentation机构:阿姆斯特…

Paper Reading:《Consistent-Teacher: 减少半监督目标检测中不一致的伪目标》
#pic_center 550x200 目录 简介工作重点方法ASA, adaptive anchor assignmentFAM-3D, 3D feature alignment moduleGMM, Gaussian Mixture Model实施细节 实验与SOTA的比较消融实验 总结 简介 题目:《Consistent-Teacher: Towards Reducing Inconsistent Pseudo-ta…

YOLOv5算法改进(13)— 如何去更换主干网络(2)(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。为了给后面YOLOv5算法的进阶改进奠定基础,本篇文章就继续通过案例的方式给大家讲解如何在YOLOv5算法中更换主干网络,本篇文章的特色就是比较浅显易懂,附加了很多的网络结构图,通过结构图的形式向大家娓娓道来,希望大家学习之后能够有所收获…
YOLOv8改进实战 | 更换主干网络Backbone(四)之轻量化模型MobileNetV3
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…
yolov5-6.0使用改进
代码版本V6.0 源码
YOLOv5 v6.0 release 改动速览
推出了新的 P5 和 P6 ‘Nano’ 模型: YOLOV5n和YOLOV5n6。 Nano 将 YOLOv5s 的深度倍数保持为 0.33,但将 YOLOv5 的宽度倍数从 0.50 降低到 0.25,从而将参数从 7.5M 降低到 1.9M࿰…
基于yolov5的目标检测和双目测距
目录
一.简介
1.双目视觉
2 YOLOv5
二.双目准备
1双目矫正
2.测距部分代码和函数
三.yolov5部分代码代码展示 效果展示 一.简介
1.双目视觉
双目视觉是通过两个摄像机同时拍摄同一场景,通过计算两幅图像的差异来获取深度信息的一种计算机视觉技术。在双目视…
YOLOv8 改进原创 HFAMPAN 结构,信息高阶特征对齐融合和注入,全局融合多级特征,将全局信息注入更高级别
💡本篇内容:YOLOv8 改进原创 HFAMPAN 结构,信息高阶特征对齐融合和注入,全局融合多级特征,将全局信息注入更高级别
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,YOLOv8 专属
论文理…

计算机视觉实战项目3(图像分类+目标检测+目标跟踪+姿态识别+车道线识别+车牌识别+无人机检测+A*路径规划+单目测距与测速+行人车辆计数等)
车辆跟踪及测距
该项目一个基于深度学习和目标跟踪算法的项目,主要用于实现视频中的目标检测和跟踪。该项目使用了 YOLOv5目标检测算法和 DeepSORT 目标跟踪算法,以及一些辅助工具和库,可以帮助用户快速地在本地或者云端上实现视频目标检测和…

opencv dnn模块 示例(19) 目标检测 object_detection 之 yolox
文章目录 0、前言1、网络介绍1.1、输入1.2、Backbone主干网络1.3、Neck1.4、Prediction预测输出1.4.1、Decoupled Head解耦头1.4.2、Anchor-Free1.4.3、标签分配1.4.4、Loss计算 1.5、Yolox-s、l、m、x系列1.6、轻量级网络研究1.6.1、轻量级网络1.6.2、数据增强的优缺点 1.7、Y…

卷积神经网络的感受野
经典目标检测和最新目标跟踪都用到了RPN(region proposal network),锚框(anchor)是RPN的基础,感受野(receptive field, RF)是anchor的基础。本文介绍感受野及其计算方法,和有效感受野概念。
1.感受野概念
在典型CNN结构中,FC层(…
win10下yolov6 tensorrt模型部署
TensorRT系列之 Win10下yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov8 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov7 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov6 tensorrt模型加速部署 TensorRT系列之 Linux下 yolov5 tensorrt模型加速部署…

YOLOv7改进:新颖的上下文解耦头TSCODE,即插即用,各个数据集下实现暴力涨点
💡💡💡本文属于原创独家改进:上下文解耦头TSCODE,进行深、浅层的特征融合,最后再分别输入到头部进行相应的解码输出,实现暴力暴力涨点
上下文解耦头TSCODE| 亲测在多个数据集实现暴力涨点,对遮挡场景、小目标场景提升也明显; 收录:
YOLOv7高阶自研专栏介绍: …

python项目部署代码汇总:目标检测类、人体姿态类
一、AI健身计数
1、图片视频检测 (cpu运行):
注:左上角为fps,左下角为次数统计。
1.哑铃弯举:12,14,16 详细环境安装教程:pyqt5AI健身CPU实时检测mediapipe 可视化界面…

我的创作纪念日--AI小怪兽打怪进阶路
目录
自我介绍
时间轴
收获
日常
成就
憧憬 自我介绍
希望您持续关注AI小怪兽的不断进化、打怪!!!
AI小怪兽:1)YOLO骨灰级玩家,YOLOv5、v7、v8优化创新,复现计算机视觉顶会,…
外贸须知音频设备亚马逊出口欧盟CE认证测试标准解析
音频设备主要是对音频输入输出设备的总称,其包括的产品类型也很多,一般可以分为功放机、音箱、多媒体控制台、数字调音台、音频采样卡、合成器、中高频音箱、话筒,PC中的声卡、耳机等。其他周边音频设备:专业话筒系列、耳机、收扩…


双目项目实战---测距(获取三维坐标和深度信息)
目录 1.简介
2.模块讲解
2.1 立体校正
2.1.1 校正目的
2.1.2 校正方法
2.2 立体匹配和视差计算
2.3 深度计算
3.完整代码 1.简介
双目视觉是一种通过两个摄像机(或者两个镜头)同时拍摄到同一个场景,再通过计算机算法来获取该场景深度…

YOLOv5算法改进(19)— 手把手教你去更换NMS(DIoU-NMS/CIoU-NMS/EIoU-NMS/GIoU-NMS/SIoU-NMS)
前言:Hello大家好,我是小哥谈。YOLOv5中的NMS指非极大值抑制(Non-Maximum Suppression),它是一种用于目标检测算法中的后处理技术。在检测到多个重叠的边界框时,NMS可以帮助选择最佳的边界框。NMS的工作原理是首先根据预测边界框的置信度对它们进行排序,然后从置信度最高…
OTA: Optimal Transport Assignment for Object Detection 论文和代码学习
OTA 原因步骤什么是最优传输策略标签分配的OT正标签分配负标签分配损失计算中心点距离保持稳定动态k的选取 整体流程代码使用 论文连接: 原因
1、全部按照一个策略如IOU来分配GT和Anchors不能得到全局最优,可能只能得到局部最优。 2、目前提出的ATSS和P…
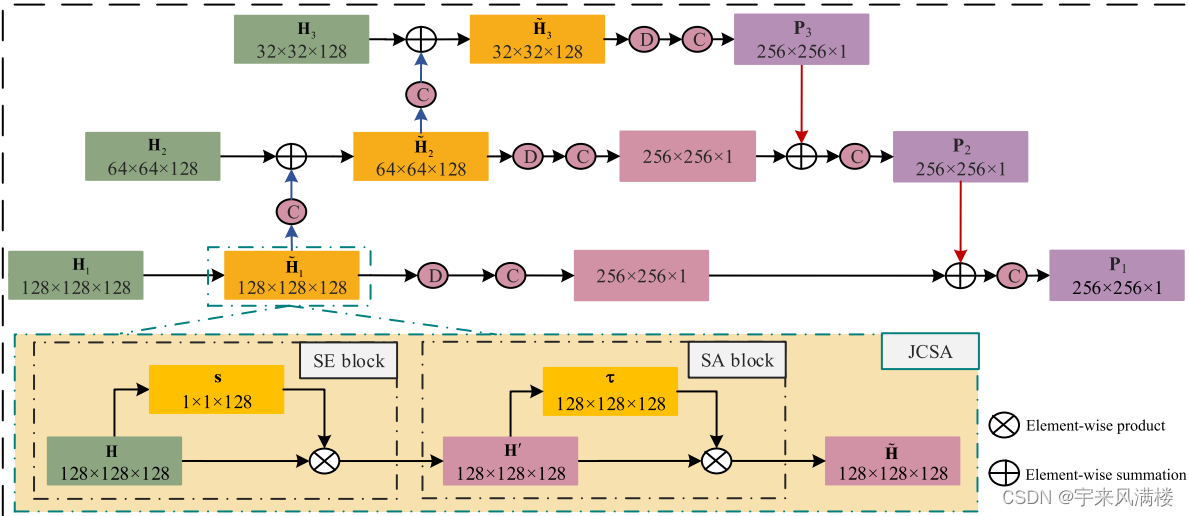
RGB-T Salient Object Detection via Fusing Multi-Level CNN Features
ADFC means ‘adjacent-depth feature combination’,MGF means ‘multi-branch group fusion’,JCSA means ‘joint channel-spatial attention’,JABMP means ‘joint attention guided bi-directional message passing’ 作者未提供代…

YOLO目标检测——红外车辆行人数据集【(含对应voc、coco和yolo三种格式标签+划分脚本+训练教程】
实际项目应用:智能驾驶、智能监控、军事应用监控通过红外传感器采集车辆和行人的红外图像,然后使用目标检测算法对图像进行处理和分析,以识别道路上的车辆和行人。数据集说明:,真实场景的高质量图片数据,数…

OpenCV技术应用(9)— 视频的暂停播放和继续播放
前言:Hello大家好,我是小哥谈。本节课就手把手教大家如何控制视频的暂停播放和继续播放,希望大家学习之后能够有所收获~!🌈 目录
🚀1.技术介绍
🚀2.实现代码 🚀1.技术介绍…

MATLAB Mobile - 使用预训练网络对手机拍摄的图像进行分类
系列文章目录 前言
此示例说明如何使用深度学习对移动设备摄像头采集的图像进行分类。
在您的移动设备上安装和设置 MATLAB Mobile™。然后,从 MATLAB Mobile 的“设置”登录 MathWorks Cloud。
在您的设备上启动 MATLAB Mobile。 一、在您的设备上安装 MATLAB M…
IoU、GIoU、CIoU和DIoU
IoU(Intersection over Union,交并比)、GIoU(Generalized IoU,广义交并比)、CIoU(Complete IoU,完全交并比)和DIoU(Distance IoU,距离交并比&…
“基于深度学习的目标检测跟工业机器人结合”实现过程
基于深度学习的目标检测技术在工业机器人中的应用,可以帮助机器人实现自动化的目标检测和识别任务。以下是基于深度学习的目标检测与工业机器人结合的一般实现过程: 1. 数据采集和准备: 首先,收集和准备用于训练深度学习模型的数据…
第二十四章 BEV感知系列一(车道线感知)
前言 近期参与到了手写AI的车道线检测的学习中去,以此系列笔记记录学习与思考的全过程。车道线检测系列会持续更新,力求完整精炼,引人启示。所需前期知识,可以结合手写AI进行系统的学习。 BEV感知系列是对论文Delving into the De…

YoloV8目标检测与实例分割——目标检测onnx模型推理
一、模型转换
1.onnxruntime
ONNX Runtime(ONNX Runtime或ORT)是一个开源的高性能推理引擎,用于部署和运行机器学习模型。它的设计目标是优化执行使用Open Neural Network Exchange(ONNX)格式定义的模型,…

YOLO目标检测——路标检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:路标检测数据集在自动驾驶、交通安全监控、导航系统、城市规划和车辆行为分析等领域都有广泛应用的潜力数据集说明:路标检测数据集,真实场景的高质量图片数据,数据场景丰富,含有停止标志、速度限制标志、…

YOLO目标检测——汽车头部尾部检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:用于训练自动驾驶系统中的车辆感知模块,以实现对周围车辆头部和尾部的准确检测和识别数据集说明:汽车头部尾部检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软…
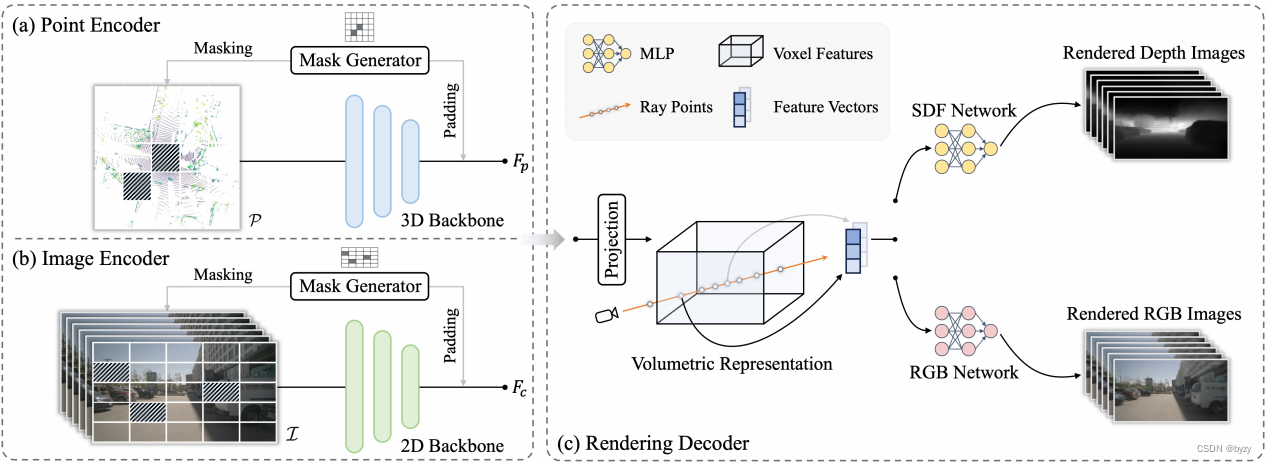
【论文笔记】UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
原文链接:https://arxiv.org/pdf/2310.08370.pdf
1. 引言
过去的3D场景理解预训练方法多采用2D图像领域中的想法,可大致分为基于对比的方法和基于MAE的方法。
基于对比的方法通过对比损失,在特征空间中将相似的3D点拉进而将不相似的点分开…
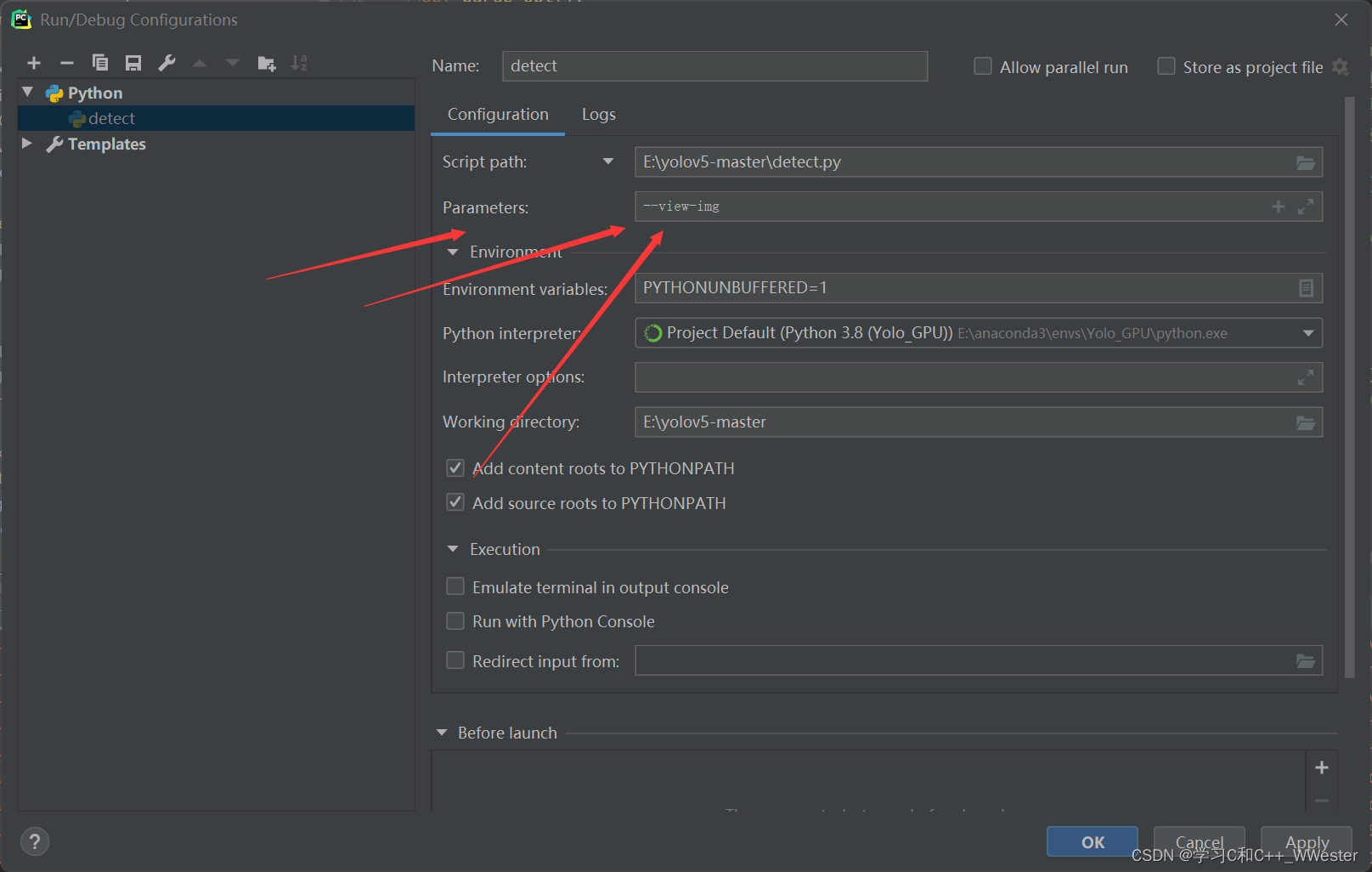
yolov5 通过视频进行目标检测
打开yolov5-master文件夹,可以看到一个名为data的文件夹,在data中创建一个新的文件夹,命名为videos。
打开yolov5-master中的detect.py可以看到一行代码(大概在245行左右)为
parser.add_argument(--source, typestr,…
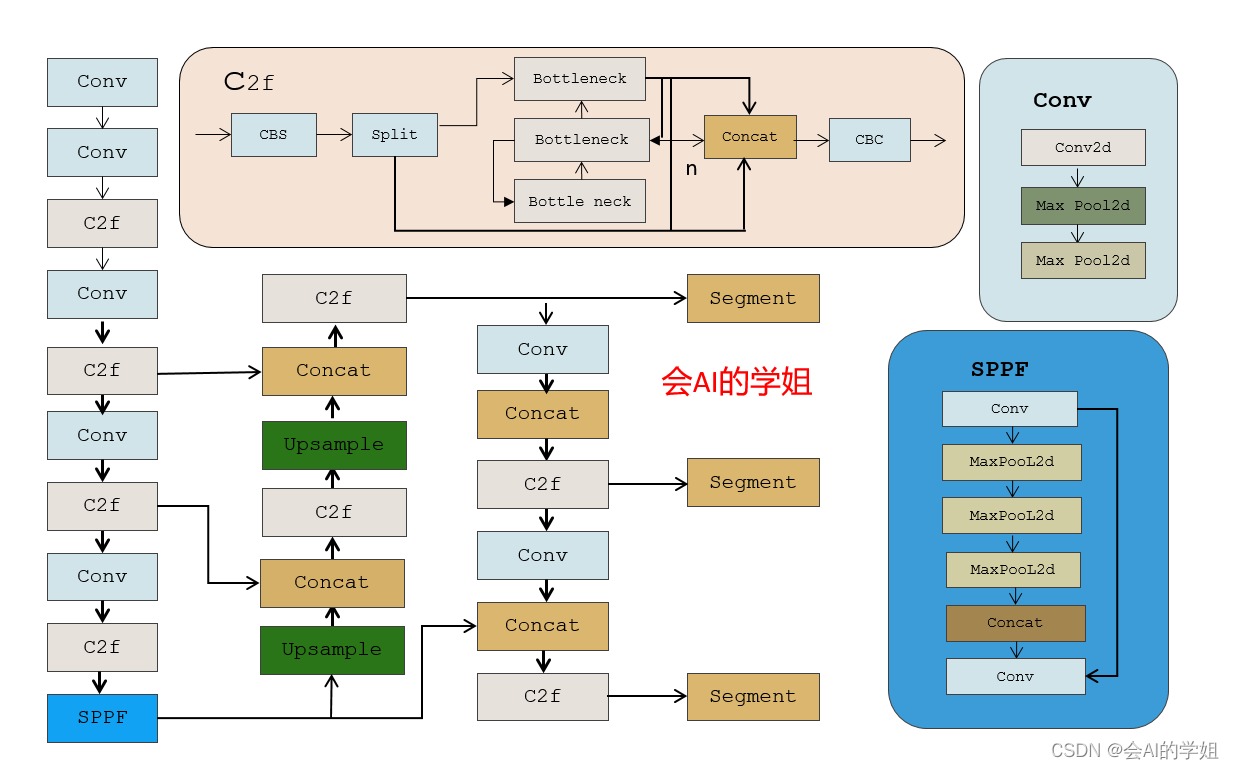
YOLOv8-Seg改进: 分割小目标系列篇 | SPD-Conv,提升分割小目标和弱小分割图精度
🚀🚀🚀本文改进:SPD-Conv由一个空间到深度(SPD)层和一个无卷积步长(Conv)层组成,可以应用于大多数CNN体系结构,特别是在处理低分辨率图像和分割小目标等更困难的任务时。
🚀🚀🚀SPD-Conv 分割小目标检测首选,暴力涨点 🚀🚀🚀YOLOv8-seg创新专栏:http:…

YOLO目标检测——猫狗目标检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:宠物识别、猫狗分类数据集说明:猫狗分类检测数据集,真实场景的高质量图片数据,数据场景丰富,含有猫和狗图片标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xm…
上线亚马逊出口美国审核CPC认证标准内容解析
儿童玩具产品、母婴产品出口美国都需要CPC认证证书和CPSIA报告进行过关清关。
一、什么是CPC认证? CPC认证是Children’sProduct Certificate的英文简称,CPC证书就类似于国内的质检报告,在通过相关检测,出具报告后同时可出具的一…
【目标检测】RCNN 的边界框回归损失函数
RCNN 这个网络,有好几个需要训练的部分,但是用到损失函数的部分就是边界框回归(bounding box regression)那里了。其实这个部分我看几篇文章讲得都挺不错的,所以我的这篇文章纯粹是当做阅读笔记来写了。
和 SSD 一样&…

RT-DETR算法优化改进:一种新颖的动态稀疏注意力(BiLevelRoutingAttention) | CVPR2023
💡💡💡本文独家改进: 提出了一种新颖的动态稀疏注意力(BiLevelRoutingAttention),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性 1)代替RepC3进行使用; 2)BiLevelRoutingAttention直接作为注意力进行使用;
推荐指数:五星
RT-DETR魔术师专栏介…
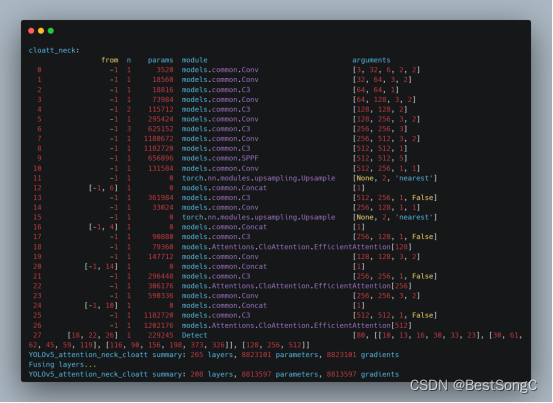
YOLO改进系列之注意力机制(CloAttention模型介绍)
CloAttention来自清华大学的团队提出的一篇论文CloFormer,作者从频域编码的角度认为现有的轻量级视觉Transformer中,大多数方法都只关注设计稀疏注意力,来有效地处理低频全局信息,而使用相对简单的方法处理高频局部信息。很少有方…

目标检测 详解SSD原理,数据处理与复现
原理详解
前言
今天我们要读的这篇VGGNet(《Very Deep Convolutional Networks For Large-Scale Image Recognition》),就是在AlexNet基础上对深度对网络性能的影响做了进一步的探索。它是ImageNet 2014年亚军,相比于AlexNet&am…

YOLO目标检测——钢表面缺陷检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
实际项目应用:钢材质量控制、钢材缺陷检测数据集说明:钢表面缺陷检测数据集,真实场景的高质量图片数据,数据场景丰富标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和…
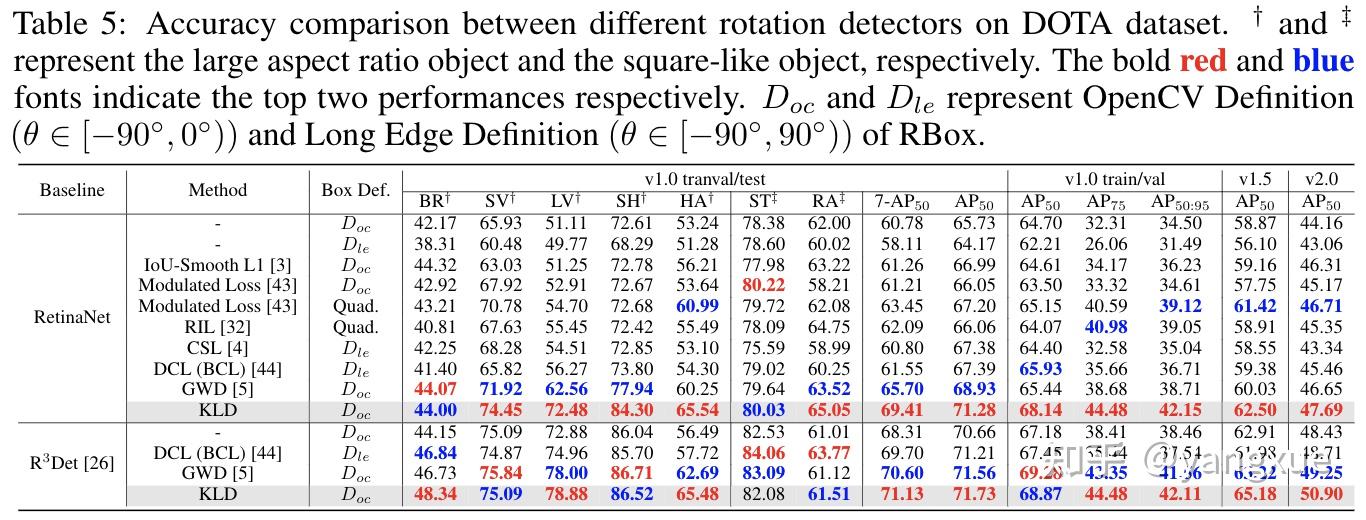
旋转框检测项目相关python库知识总结(mmrotate、ppyolo_r、yolov5_obb)
旋转框常用于检测带有角度信息的矩形框,即矩形框的宽和高不再与图像坐标轴平行。相较于水平矩形框,旋转矩形框一般包括更少的背景信息。旋转框检测常用于遥感等场景中,本博文简单的介绍了可应用于旋转框数据训练的开源库,数据结构…
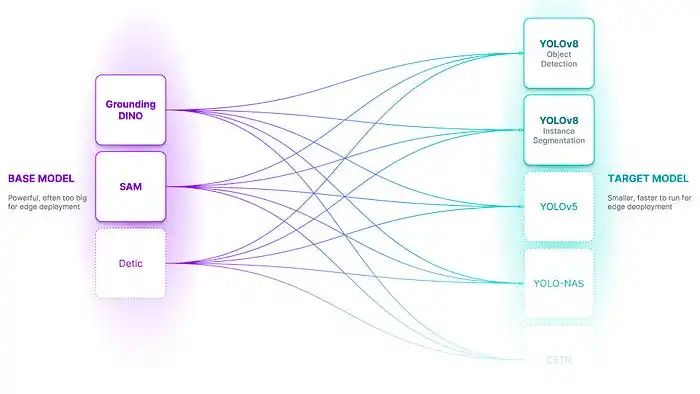
目标检测标注工具AutoDistill
引言
在快速发展的机器学习领域,有一个方面一直保持不变:繁琐和耗时的数据标注任务。无论是用于图像分类、目标检测还是语义分割,长期以来人工标记的数据集一直是监督学习的基础。 然而,由于一个创新性的工具 AutoDistill&#x…
目标检测—YOLO系列(二 ) 全面解读复现YOLOv1 PyTorch
精读论文
前言
从这篇开始,我们将进入YOLO的学习。YOLO是目前比较流行的目标检测算法,速度快且结构简单,其他的目标检测算法如RCNN系列,以后有时间的话再介绍。
本文主要介绍的是YOLOV1,这是由以Joseph Redmon为首的…
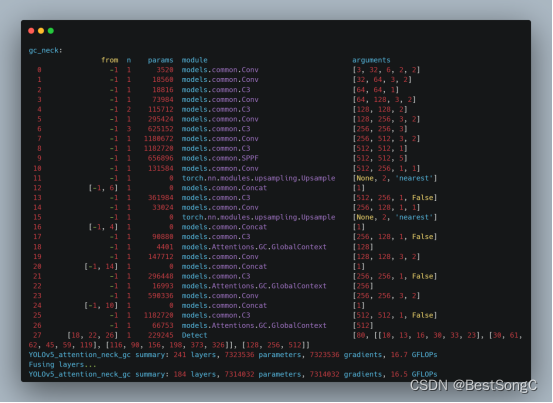
YOLO改进系列之注意力机制(GlobalContext模型介绍)
模型结构
通过捕获long-range dependency提取全局信息,对各种视觉任务都是很有帮助的,典型的方法是Non-local Network自注意力机制。对于每个查询位置(query position),Non-local network首先计算该位置和所有位置之间…
Atlas 200I DK目标检测与追踪技术记录
数据集
数据集采用MOT系列,MOT是多目标追踪常用数据集,MOT数据集对数据集进行了分帧,如要获得视频,需要先利用opencv里的cv2.VideoWriter模块便利图片文件夹,具体代码如下:
import os
import cv2img_path…
SHEIN出口亚马逊美国站圣诞节灯串灯饰UL588测试指南解析
圣诞节灯饰,万圣节灯饰,复活节灯饰,春节灯饰以及各种LED礼品灯饰的装饰灯。圣诞节灯饰需要出口到亚马逊美国站。为了满足亚马逊美国站的安全要求,上架的圣诞节灯饰需要有UL588测试报告
一、UL588检测报告办理流程 准备样品:按照美国站的要求,…

基于YOLOv8深度学习的生活垃圾分类目标检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

基于YOLOv7算法的的高精度实时通用目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时检测识别系统可用于日常生活中检测与定位多种目标,此系统可完成对输入图片、视频、文件夹以及摄像头方式的目标检测与识别,同时本系统还支持检测结果可视化与导出。本系统采用YOLOv7目标检测算法来训练数据集…

基于YOLOv8深度学习的120种犬类检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战、狗类检测、犬种识别
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

Object Detection in 20 Years: A Survey(2019.5)
文章目录 Abstract1. Introduction1.1. Difference from other related reviews1.2. Difficulties and Challenges in Object Detection 2. OBJECT DETECTION IN 20 YEARS2.1. 目标检测路线图2.1.1. 里程碑:传统探测器(粗略了解)2.1.2. 里程碑:基于CNN的…
YOLOv8改进 | 2023主干篇 | 利用RT-DETR特征提取网络PPHGNetV2改进YOLOv8(超级轻量化精度更高)
一、本文介绍
本文给大家带来利用RT-DETR模型主干HGNet去替换YOLOv8的主干,RT-DETR是今年由百度推出的第一款实时的ViT模型,其在实时检测的领域上号称是打败了YOLO系列,其利用两个主干一个是HGNet一个是ResNet,其中HGNet就是我们…
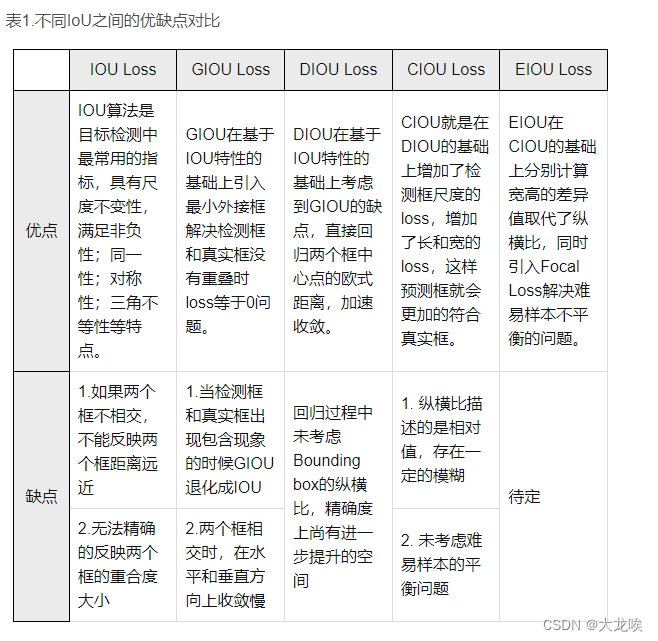
【目标检测算法】IOU、GIOU、DIOU、CIOU
目录
参考链接
前言
IOU(Intersection over Union) 优点
缺点
代码
存在的问题
GIOU(Generalized Intersection over Union)
来源
GIOU公式 实现代码
存在的问题
DIoU(Distance-IoU)
来源
DIOU公式 优点
实现代码
总结 参考链接
IoU系列(IoU, GIoU…
DSCNet:基于拓扑几何约束的动态蛇形卷积管状结构分割
文章目录 摘要1、简介2、相关研究2.1、基于网络设计的方法2.2、基于特征融合的方法2.3、基于损失函数的方法3、方法3.1、动态蛇形卷积(Dynamic Snake Convolution)3.2、多视图特征融合策略3.3、拓扑连续性约束损失4、实验配置4.1、数据集4.2、评估指标5、结果与讨论5.1、定量…
RoIAlign的作用
RoIAlign(Region of Interest Align)是一种用于在深度学习中处理感兴趣区域(Region of Interest,简称RoI)的操作。RoIAlign主要用于目标检测任务,特别是在Faster R-CNN等框架中。
在目标检测中,…
YOLOv5改进 | SPPF | 将RT-DETR模型AIFI模块和Conv模块结合替换SPPF(全网独家改进)
一、本文介绍
本文给大家带来是用最新的RT-DETR模型中的AIFI模块来替换YOLOv5中的SPPF。RT-DETR号称是打败YOLO的检测模型,其作为一种基于Transformer的检测方法,相较于传统的基于卷积的检测方法,提供了更为全面和深入的特征理解,…
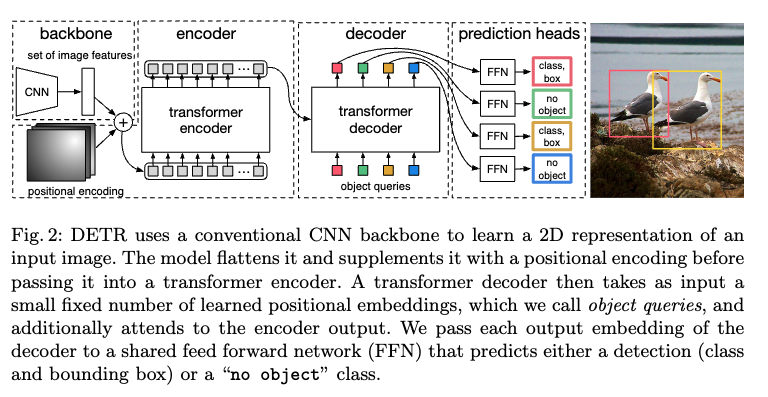
DETR 【目标检测里程碑的任务】
paper with code - DETR 标题
End-to-End Object Detection with Transformers end-to-end 意味着去掉了NMS的操作(生成很多的预测框,nms 去掉冗余的预测框)。因为有了NMS ,所以调参,训练都会多了一道工序,…
PaddleDetection训练目标检测模型
PaddleDetection训练目标检测模型 一,安装标注软件二,数据标注和清洗三,安装PaddleDetection环境四,修改配置文件,本文选择的是 PP-PicoDet算法五,训练模型六,训练完成之后导出模型七࿰…
YOLOv8独家原创改进:提出一种新的Shape IoU,更加关注边界框本身的形状和尺度,对小目标检测也很友好 | 2023.12.29收录
💡💡💡本文改进:一种新的Shape IoU方法,该方法可以通过关注边界框本身的形状和尺度来计算损失,解决边界盒的形状和规模等固有属性对边界盒回归的影响。 💡💡💡对小目标检测涨点明显,在VisDrone2019、PASCAL VOC均有涨点 收录
YOLOv8原创自研
https://blog.cs…

YOLOv8改进 更换层次化视觉变换器的网络结构
一、SwinTransformer论文 论文地址:arxiv.org/pdf/2103.14030.pdf
二、 SwinTransformer网络结构
SwinTransformer是一种基于transformer的图像分类网络结构。SwinTransformer是由微软亚洲研究院提出的,其特点是具有高效的计算和参数效率。
SwinTransformer的网络结构主要…
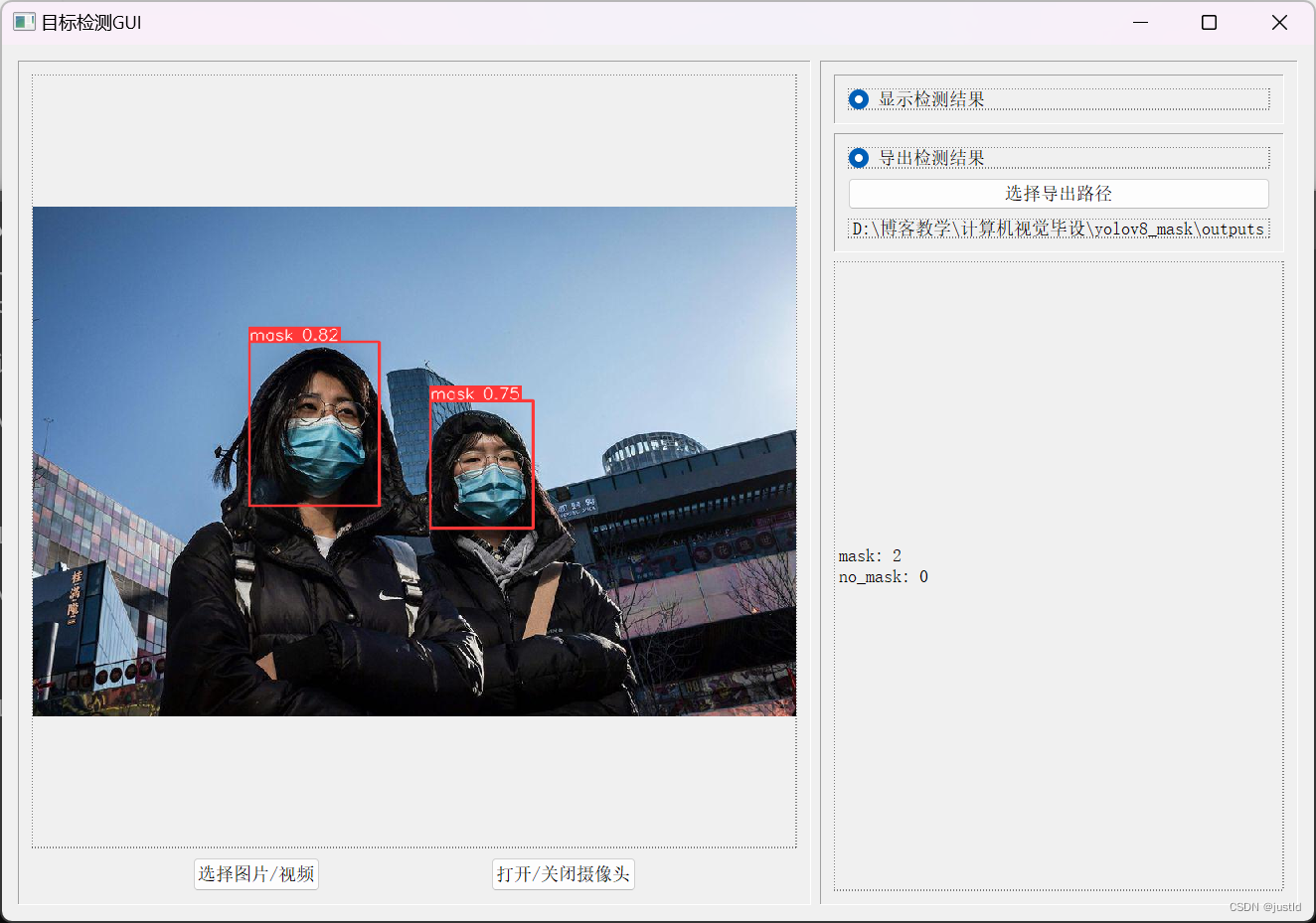
【深度学习目标检测】十五、基于深度学习的口罩检测系统-含GUI和源码(python,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…
YOLOv5改进 | 二次创新篇 | 结合iRMB和EMA形成全新的iEMA机制(全网独家创新)
一、本文介绍
本文给大家带来的改进机制是二次创新的机制,二次创新是我们发表论文中关键的一环,为什么这么说,从去年的三月份开始对于图像领域的论文发表其实是变难的了,在那之前大家可能搭搭积木的情况下就可以简单的发表一篇论文,但是从去年开始单纯的搭积木其实发表论…
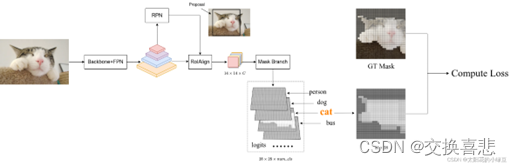
实例分割论文精读:Mask R-CNN
1.摘要
本文提出了一种概念简单、灵活、通用的实例分割方法,该方法在有效地检测图像中的物体同时,为每个物体实例生成一个实例分割模板,添加了一个分支,用于预测一个对象遮罩,与现有的分支并行,用于边界框…

【目标检测】YOLOv7算法实现(一):模型搭建
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本系列文章在YOLOv5算法实现的基础上,进一步完成YOLOv7算法的实现…
边缘检测——PidiNet网络训练自己数据集并优化推理测试(详细图文教程)
PiDiNet 是一种用于边缘检测的算法,它提出了一种简单、轻量级但有效的架构。PiDiNet 采用了新
颖的像素差卷积,将传统的边缘检测算子集成到现代 CNN 中流行的卷积运算中,以增强任务性能。
在 BSDS500、NYUD 和 Multicue 上进行了大量的实验…
YOLOv5改进 | 主干篇 | 12月份最新成果TransNeXt特征提取网络(全网首发)
一、本文介绍
本文给大家带来的改进机制是TransNeXt特征提取网络,其发表于2023年的12月份是一个最新最前沿的网络模型,将其应用在我们的特征提取网络来提取特征,同时本文给大家解决其自带的一个报错,通过结合聚合的像素聚焦注意力和卷积GLU&…

《YOLO算法:基础+进阶+改进》报错解决 专栏答疑
前言:Hello大家好,我是小哥谈。《YOLO算法:基础进阶改进》专栏上线后,部分同学在学习过程中提出了一些问题,笔者相信这些问题其他同学也有可能遇到。为了让大家可以更好地学习本专栏内容,笔者特意推出了该篇…
基于YOLOv8深度学习的葡萄簇目标检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…

2024年显著性检测论文及代码汇总(1)
ACM MM
Distortion-aware Transformer in 360 Salient Object Detection
code Abstacrt:现有的方法无法处理二维等矩投影引起的畸变。本文提出了一个基于Transformer的模型,即DATFormer。首先,引入两个畸变自适应模块。其一是畸变映射模块&…

【目标检测】YOLOv5算法实现(九):模型预测
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模…
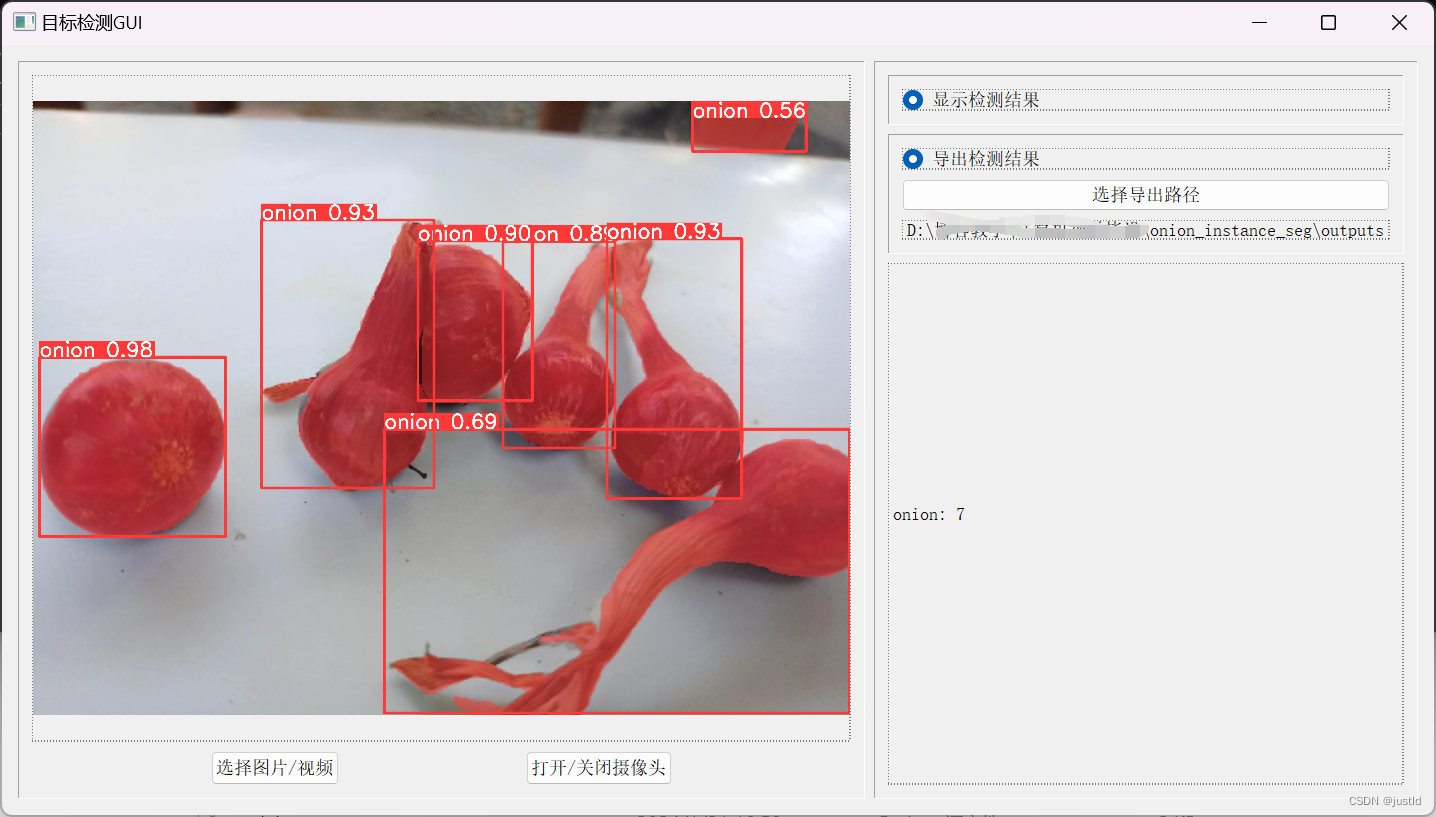
【深度学习目标检测】十七、基于深度学习的洋葱检测系统-含GUI和源码(python,yolov8)
使用AI实现洋葱检测对农业具有以下意义: 提高效率:AI技术可以快速、准确地检测出洋葱中的缺陷和问题,从而提高了检测效率,减少了人工检测的时间和人力成本。提高准确性:AI技术通过大量的数据学习和分析,能够…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的暴力行为检测系统(深度学习模型+UI界面+Python代码+训练数据集)
摘要:本篇博客深入介绍了如何利用深度学习技术构建暴力行为检测系统,并提供了完整的实现代码。本系统基于性能卓越的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等前代算法进行了详细的性能比较,关注了如mAP、F1 Score等关键性能指标。…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的石头剪刀布手势识别系统详解(深度学习模型+UI界面代码+训练数据集)
摘要:本篇博客深入探讨了使用深度学习技术开发石头剪刀布手势识别系统的过程,并分享了完整代码。该系统利用先进的YOLOv8、YOLOv7、YOLOv6、YOLOv5算法,并对这几个版本进行性能对比,如mAP、F1 Score等关键指标。文章详细阐述了YOL…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的跌倒检测系统详解(深度学习模型+UI界面代码+训练数据集)
摘要:本研究介绍了一个基于深度学习和YOLOv8算法的跌倒检测系统,并对比分析了包括YOLOv7、YOLOv6、YOLOv5在内的早期版本性能。该系统可在多种媒介如图像、视频文件、实时视频流中准确识别跌倒事件。文内详解了YOLOv8的工作机制,并提供了相应…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的田间杂草检测系统(深度学习模型+UI界面+Python代码+训练数据集)
摘要:开发用于田间杂草识别的系统对提高农业运营效率和提升作物产出至关重要。本篇文章详尽阐述了如何应用深度学习技术开发一个用于田间杂草识别的系统,并附上了完备的代码实现。该系统基于先进的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的车牌检测系统(Python+PySide6界面+训练代码)
摘要:本篇博客详细介绍了如何利用深度学习技术开发一个先进的车牌检测系统,并附上了完整的实现代码。系统核心采用了强大的YOLOv8算法,并对前代版本如YOLOv7、YOLOv6、YOLOv5进行了详尽的性能评估,包括mAP和F1 Score等关键指标的对…
![[论文精读]Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection](https://img-blog.csdnimg.cn/direct/44365d6ab5ce4781ba984c84ae0df9b5.png)
[论文精读]Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection
论文网址:[2304.08876] 用于定向微小目标检测的动态粗到细学习 (arxiv.org)
论文代码:https://github.com/ChaselTsui/mmrotate-dcfl
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误&…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的火焰与烟雾检测系统详解(深度学习模型+UI界面升级版+训练数据集)
摘要:本研究详细介绍了一种集成了最新YOLOv8算法的火焰与烟雾检测系统,并与YOLOv7、YOLOv6、YOLOv5等早期算法进行性能评估对比。该系统能够在包括图像、视频文件、实时视频流及批量文件中准确识别火焰与烟雾。文章深入探讨了YOLOv8算法的原理࿰…
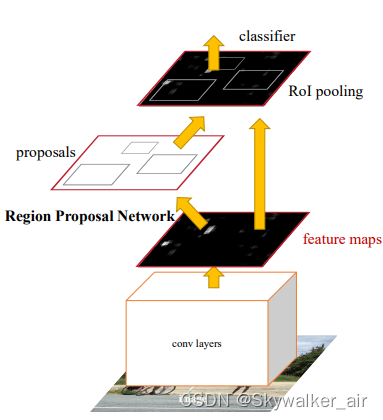
基于深度学习的目标检测算法概述
0. 写在前面 在开始目标检测算法学习之前,先建立基于深度学习的目标检测算法大局观,了解目标检测算法的发展史,在了解背景的前提下,能更好地提升代入感,让理论知识理解起来不会枯燥无味!废话不多说…

【深度学习笔记】9_5 多尺度目标检测
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 9.5 多尺度目标检测
在9.4节(锚框)中,我们在实验中以输入图像的每个像素为中心生成多个锚框。这些…
【Lidar】Lidar激光雷达一篇全(两万字激光雷达详细介绍)
【Lidar】Lidar激光雷达一篇全 1. 激光雷达测距原理1.1 三角测距1.2 飞行时间测距(TOF,Time of Flight) 2. 车载激光雷达类别2.1 机械旋转式2.2 固态2.2.1 相控阵 2.3 半固态(混合固态)2.3.2 微转镜/棱镜 3. 激光雷达性…

YOLOv9推理详解及部署实现
目录 前言零、YOLOv9简介一、YOLOv9推理(Python)1. YOLOv9预测2. YOLOv9预处理3. YOLOv9后处理4. YOLOv9推理 二、YOLOv9推理(C)1. ONNX导出2. YOLOv9预处理3. YOLOv9后处理4. YOLOv9推理 三、YOLOv9部署1. 源码下载2. 环境配置2.1 配置CMakeLists.txt2.2 配置Makefile 3. ONNX…

Python文件操作和异常处理:高效处理数据的利器
文章目录 一、引言1.1 文件操作和异常处理对于编程的重要性1.2 Python作为实现文件操作和异常处理的强大工具 二、为什么学习文件操作和异常处理2.1 处理各种文件格式:从文本到图像到音频等2.2 确保代码的鲁棒性:有效处理异常情况 三、文件读取和写入3.1…
【RT-DETR有效改进】 主干篇 | SwinTransformer替换Backbone(附代码 + 详细修改步骤 +原理介绍)
前言
大家好,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持ResNet32、ResNet101和PP…

【目标检测】YOLOv7算法实现(二):正样本匹配(SimOTA)与损失计算
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本篇文章在YOLOv5算法实现的基础上,进一步完成YOLOv7算法的实现。…
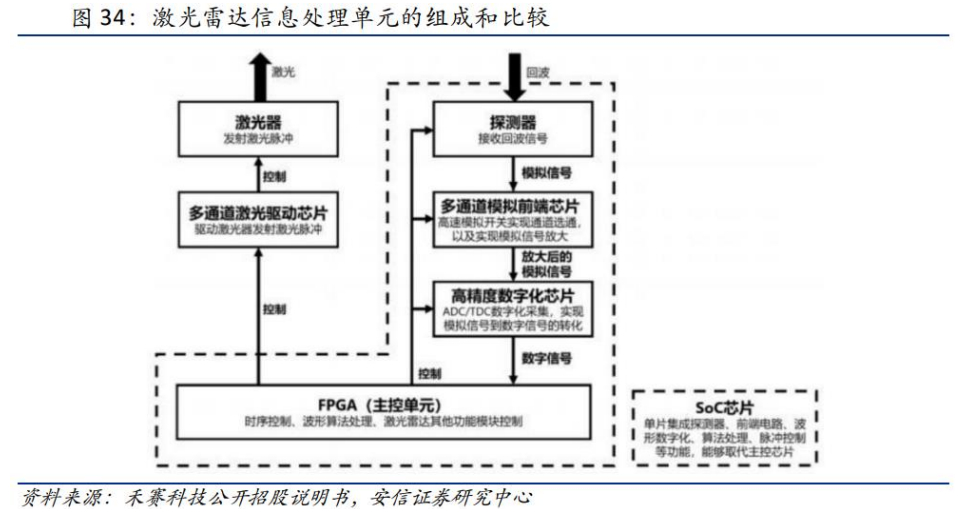
激光雷达行业梳理1-概述、市场、技术路线
激光雷达作为现代精确测距和感知技术的关键组成部分,在近几年里取得了令人瞩目的发展。作为自动驾驶感知层面的重要一环,相较摄像头、毫米波雷达等其他传感器具有“ 精准、快速、高效作业”的巨大优势,已成为自动驾驶的主传感器之一ÿ…
【YOLO系列算法俯视视角下舰船目标检测】
YOLO系列算法俯视视角下舰船目标检测 数据集和模型YOLO系列算法俯视视角下舰船目标检测YOLO系列算法俯视视角下舰船目标检测可视化结果 数据集和模型
数据和模型下载:
YOLOv6俯视视角下舰船目标检测训练好的舰船目标检测模型舰船目标检测数据YOLOv7俯视视角下舰船…

yolov8+多算法多目标追踪+实例分割+目标检测+姿态估计
YOLOv8是一种先进的目标检测算法,结合多种算法实现多目标追踪、实例分割和姿态估计功能。该算法在计算机视觉领域具有广泛的应用。
首先,YOLOv8算法采用了You Only Look Once(YOLO)的思想,通过单次前向传递将目标检测…

4D毫米波雷达分类和工程实现
4D毫米波目标检测信息丰富,可获得目标3维位置信息、径向速度vr和rcs等,能够对目标准确分类。 4D毫米波和激光做好时空同步,可以用激光目标给4D毫米波做标注,提升标注效率。
1 激光用做4D毫米波分类真值 128线激光推理的结果作为4…

Python面向对象编程:探索代码的结构之美
文章目录 一、引言二、为什么学习面向对象编程2.1 提高代码的可维护性:通过封装、继承和多态实现模块化设计2.2 提升代码的复用性:通过类和对象的创建实现代码的重用 三、类和对象的基本概念3.1 类和对象的定义和关系:类是对象的模板…
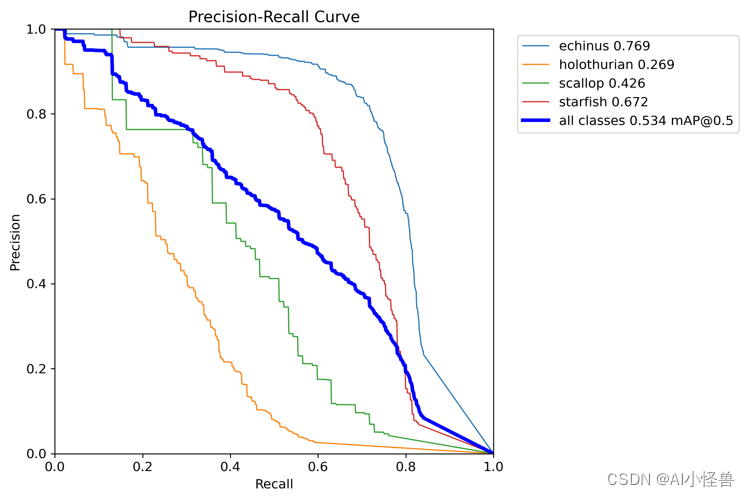
基于YOLOv8的水下生物检测,多种优化方法---MSAM(CBAM升级版)助力涨点(二)
💡💡💡本文主要内容:详细介绍了水下生物检测整个过程,从数据集到训练模型到结果可视化分析,以及如何优化提升检测性能。
💡💡💡加入自研注意力MSAM mAP0.5由原始的0.522提升至0.534…

【目标检测】对DETR的简单理解
【目标检测】对DETR的简单理解 文章目录 【目标检测】对DETR的简单理解1. Abs2. Intro3. Method3.1 模型结构3.2 Loss 4. Exp5. Discussion5.1 二分匹配5.2 注意力机制5.3 方法存在的问题 6. Conclusion参考 1. Abs
两句话概括:
第一个真正意义上的端到端检测器最…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】Transformer
目录 什么是 Transformer?
什么是注意力机制?
Transformer编码器 位置编码

电风扇目标检测数据集VOC格式1100张
电风扇的全方位介绍
一、功能特性
电风扇作为一种晋及化的家用电器,其主要功能是利用电机驱动扇叶旋转,从而产生风力,用干调节室内空气流通,达至降温、通风和改善室内环境的目的。此外,现代电风扇还具备定时、遥控、…
二维平面阵列波束赋形原理和Matlab仿真
1 波束赋形基本原理 实现波束赋形的最基本的方法是对各个天线阵元的信号进行适当延迟后相加,使目标方向的信号同相叠加得到增强,而其他方向均有不同程度的削弱,该方法通常用于模拟信号.数字信号可以通过对各个天线阵元的信号乘以复加权系数后…
GLIP:零样本学习 + 目标检测 + 视觉语言大模型
GLIP 核心思想GLIP 对比 BLIP、BLIP-2、CLIP 主要问题: 如何构建一个能够在不同任务和领域中以零样本或少样本方式无缝迁移的预训练模型?统一的短语定位损失语言意识的深度融合预训练数据类型的结合语义丰富数据的扩展零样本和少样本迁移学习 效果 论文:…
天线阵列车载应用——第1章 介绍 1.1节 汽车工业中的天线阵列:应用和频率范围
1.1 汽车工业中的天线阵列:应用和频率范围 无线通信系统的发展需要新的技术来支持更高质量的通信、新的服务和应用。近年来,汽车无线通信市场得到了极大的扩展。现代汽车使用不同的服务:AM/FM收音机、卫星广播(SDARS)、移动电话通信、数字音频广播(DAB)、远程无钥匙…
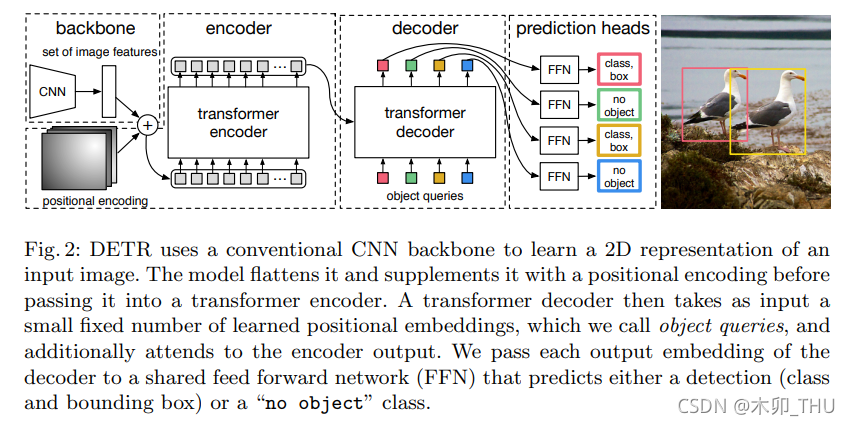
目标检测任务的调研与概述
目标检测任务的调研与概述 0 FQA1 目标检测任务基本知识:1.1 什么是目标检测?1.2 目标检测的损失函数都有那些?1.2.1 类别损失:1.2.2 位置损失: 1.3 目标检测的评价指标都有那些?1.4 目标检测有那些常见的数…

ICCV 2023 | 8篇论文看扩散模型diffusion用于图像检测任务:动作检测、目标检测、异常检测、deepfake检测...
1、动作检测 DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion 基于扩散方法提出一种新的时序动作检测(TAD)算法,简称DiffTAD。以随机时序proposals作为输入,可以在未修剪的长视频中准确生成动作proposals。…

蜥蜴目标检测数据集VOC格式1400张
蜥蜴,一种爬行动物,以其独特的形态和习性,成为了人们关注的焦点。
蜥蜴的外观多样,体型大小不一。它们通常拥有长条的身体、四肢和尾巴,鳞片覆盖全身,这使得它们能够在各种环境中轻松移动。大多数蜥蜴拥有…

浅谈语义分割、图像分类与目标检测中的TP、TN、FP、FN
语义分割 TP:正确地预测出了正类,即原本是正类,识别的也是正类
TN:正确地预测出了负类,即原本是负类,识别的也是负类
FP:错误地预测为了正类,即原本是负类,识别的是正类…
基于yolov5的水果成熟度检测,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示:
基于yolov5的水果成熟度检测系统,支持图像检测,视频检测和实时摄像检测功能_哔哩哔哩_bilibili
(一)简介
基于yolov5的水果成熟度检测系统是在pytorch框架下实现的,这是一个完整的项目&#x…

基于YOLOv8深度学习+Pyqt5的电动车头盔佩戴检测系统
wx供重浩:创享日记 对话框发送:225头盔 获取完整源码源文件已标注的数据集(1463张)源码各文件说明配置跑通说明文档 若需要一对一远程操作在你电脑跑通,有偿89yuan 效果展示 基于YOLOv8深度学习PyQT5的电动车头盔佩戴检…
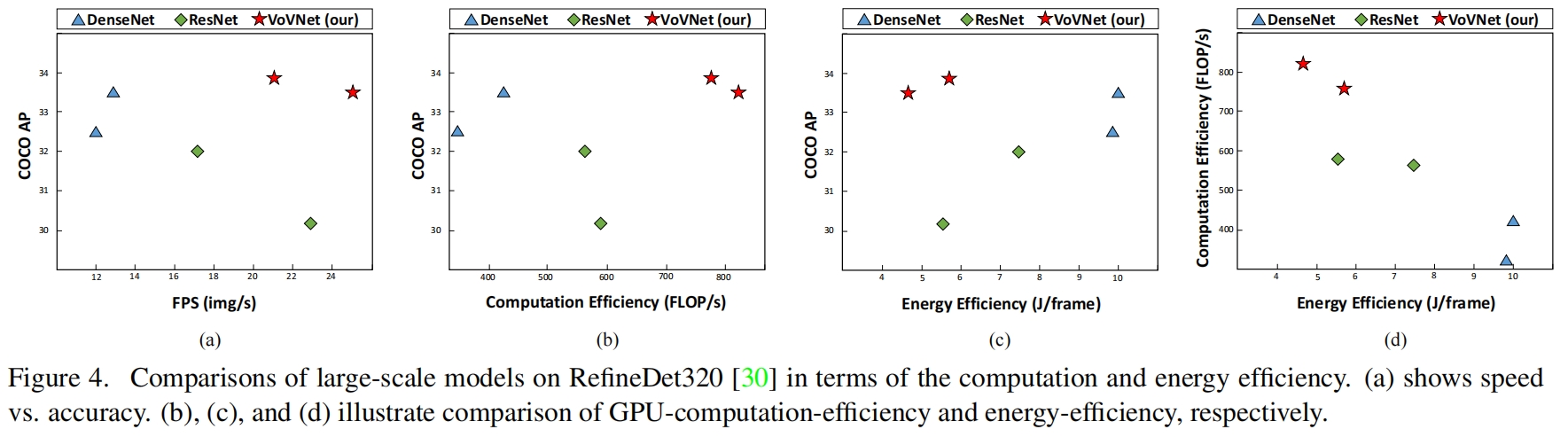
VoVNet(CVPR workshop 2019)原理与代码解析
paper:An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vovnet.py
存在的问题
DenseNet通过密…

网页实现-基于深度学习的车型识别与计数系统(YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的车型识别与计数,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Streamlit的…

pytorch yolov5+Deepsort实现目标检测和跟踪+单目测距
最近一直在整理单目测距的内容,想着检测单目测距都写完了,顺手也写个检测跟踪单目测距,算是总结下这部分内容吧,如果有错误,还请不吝赐教!! 参考文献: YOLOv5DeepSort实现目标跟踪 pytorch yolo…
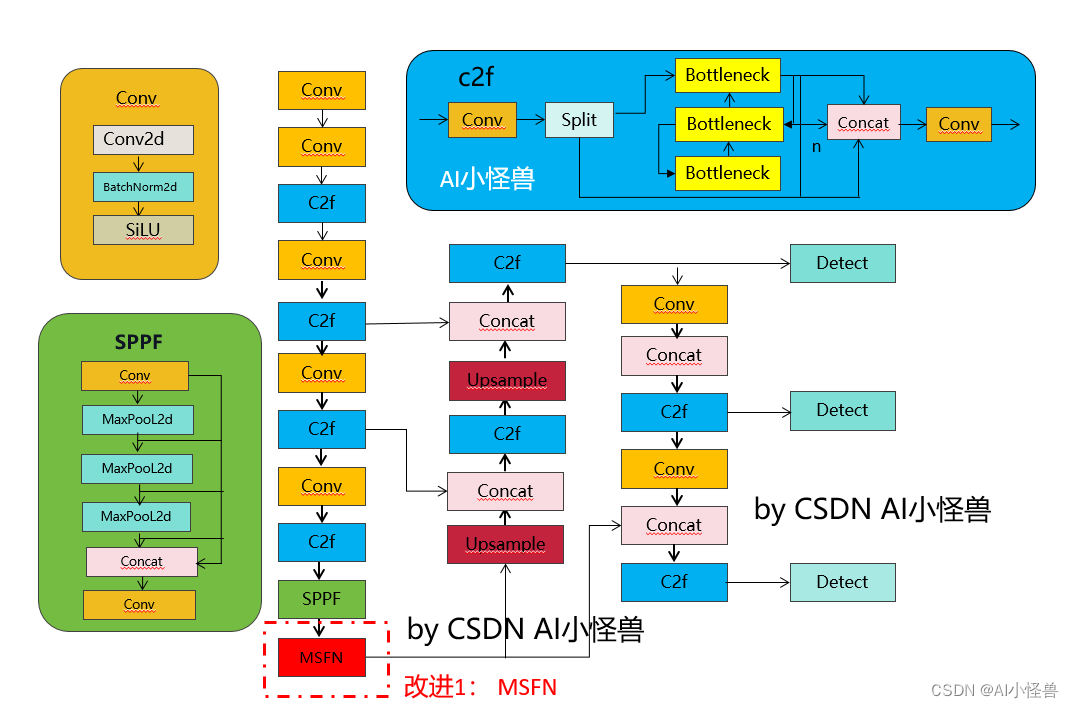
YOLOv8全网独家改进: 小目标 |新颖的多尺度前馈网络(MSFN) | 2024年4月最新成果
💡💡💡本文独家改进:多尺度前馈网络(MSFN),通过提取不同尺度的特征来增强特征提取能力,2024年最新的改进思路 💡💡💡创新点:多尺度前馈网络创新十足,抢先使用 💡💡💡如何跟YOLOv8结合:1)放在backbone后增强对全局和局部特征的提取能力;2)放在detect…
图像分割和目标检测技术的最新进展
图像分割和目标检测是计算机视觉领域的两个重要分支,它们各自有着不同的任务和挑战。
图像分割
图像分割是将数字图像细分为若干个区域或对象的过程。这些区域通常具有特定的特征,如颜色、亮度或纹理。最新的图像分割技术主要集中在提高分割的精确度和…
基于深度学习的机场航拍小目标检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:在本博客中介绍了基于YOLOv8/v7/v6/v5的机场航拍小目标检测系统。该系统的核心技术是采用YOLOv8,并整合了YOLOv7、YOLOv6、YOLOv5算法,从而进行性能指标的综合对比。我们详细介绍了国内外在机场航拍小目标检测领域的研究现状、数据集处理…
基于深度学习的商品标签识别系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的商品标签识别,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Streamlit的交…
基于深度学习的条形码二维码检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的条形码二维码检测系统。核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Streamlit的交互…
基于深度学习的钢材表面缺陷检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的钢材表面缺陷检测系统,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Strea…
运动伤害预防的实际案例
运动伤害预防是一个复杂的过程,涉及到运动员的体态分析、动作监测和潜在风险评估。在实际应用中,通常会结合传感器数据和图像识别技术来实现。以下是一个简化的案例,展示如何使用Python和OpenCV库来监测运动员的动作,并给出潜在伤…
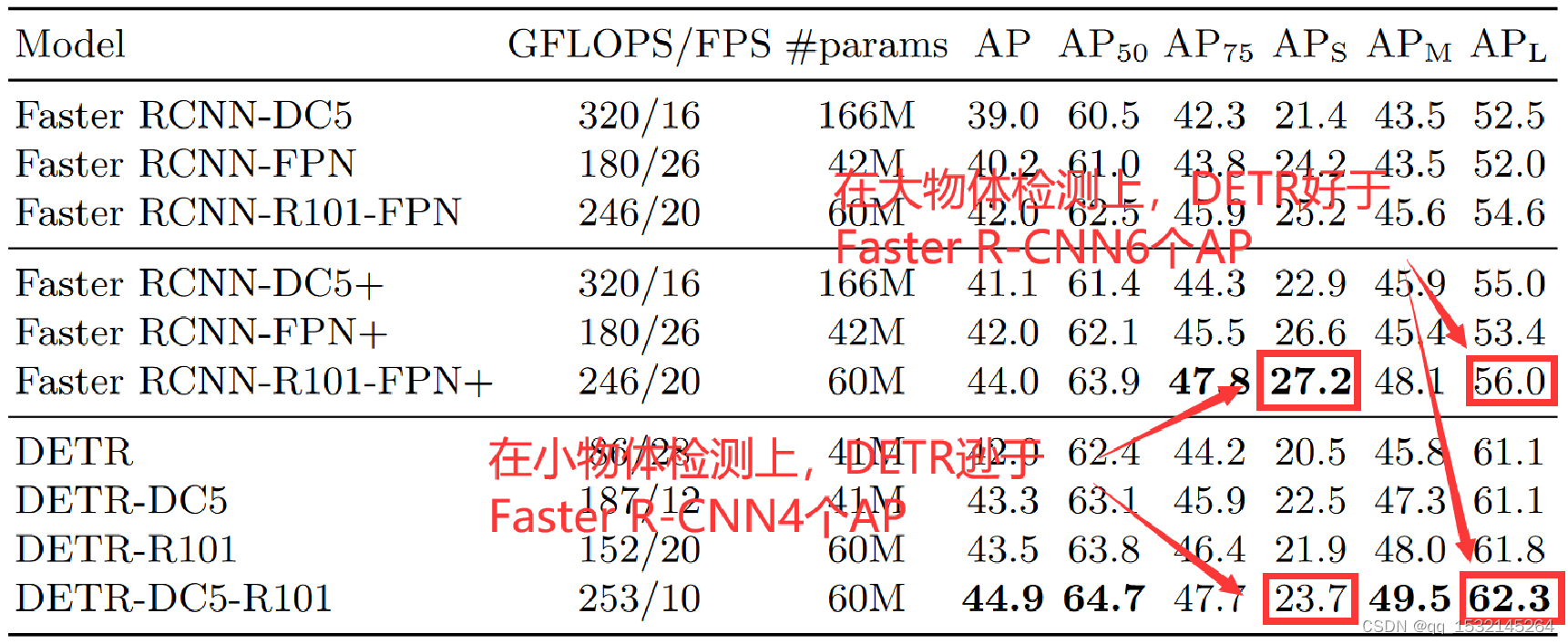
DETR【Transformer+目标检测】
End-to-End Object Detection with Transformers 2024 NVIDIA GTC,发布了地表最强的GPU B200,同时,黄仁勋对谈《Attention is All You Need》论文其中的7位作者,座谈的目的无非就是诉说,Transformer才是今天人工智能成…

目标检测——图像中提取文字
一、重要性及意义
图像提取文本,即光学字符识别(OCR)技术,在现代社会中的重要性和意义日益凸显。以下是关于图像提取文本的重要性和意义的几个关键方面:
信息获取的效率提升
快速处理大量文档:OCR技术可…
深度学习评价指标(1):目标检测的评价指标
1. 简述 在计算机视觉/深度学习领域,每一个方向都有属于自己的评价指标。通常在评估一个模型时,只需要计算出相应的评价指标,便可以评估算法的性能。同时,所谓SOTA,皆是基于某一评价指标进行的评估。 接下来࿰…
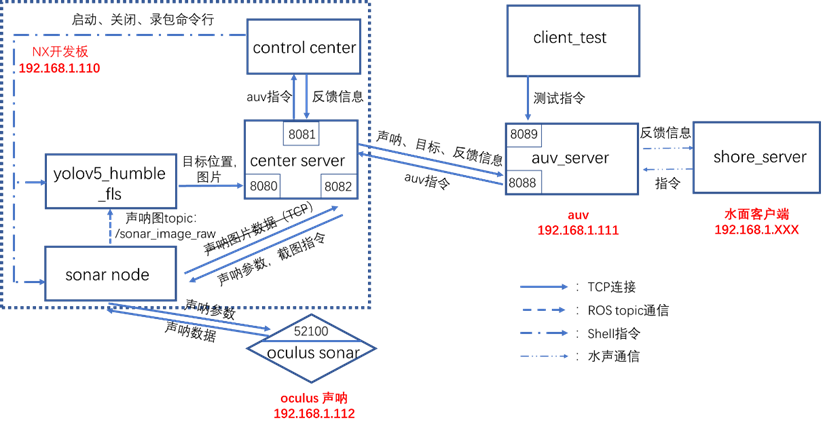
前视声呐目标识别定位(三)-部署至机器人
前视声呐目标识别定位(一)-基础知识
前视声呐目标识别定位(二)-目标识别定位模块 开发了多波束前视声呐目标识别定位模块后,自然期待能将声呐部署至AUV,实现AUV对目标的抵近观测。原本规划着定位模块不…
基于深度学习的商品识别系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:在本博客中,我们深入探讨了基于YOLOv8/v7/v6/v5的商品识别系统,其中核心技术基于YOLOv8,同时整合了YOLOv7、YOLOv6、YOLOv5的算法进行了细致的性能指标对比分析。我们全面回顾了国内外在商品识别领域的研究进展,详…

《YOLOv8:从入门到实战》专栏介绍 专栏目录
🌟YOLOv8:从入门到实战 | 目录 | 使用教程🌟
本专栏涵盖了丰富的YOLOv8基础知识源码解析入门实践算法改进项目实战系列教程,专为学习YOLOv8的同学而设计,堪称全网最详细的教程!该专栏针对YOLOv8内容的学习…
【YOLOV5 入门】——构建自己的数据集模型训练模型检验
一、准备工作
1、数据收集
图片类型数据不用多说;视频类型数据利用opencv进行抽帧保存为一张张图片,这里选取30s的名侦探柯南片段进行试验,确保环境解释器下安装了opencv(我使用的是另一个虚拟环境):
im…
【目标检测实验系列】YOLOv5模型改进:融合混合注意力机制CBAM,关注通道和空间特征,助力模型高效涨点!(内含源代码,超详细改进代码流程)
自我介绍:本人硕士期间全程放养,目前成果:一篇北大核心CSCD录用,两篇中科院三区已见刊,一篇中科院四区在投。如何找创新点,如何放养过程厚积薄发,如何写中英论文,找期刊等等。本人后续会以自己实战经验详细…
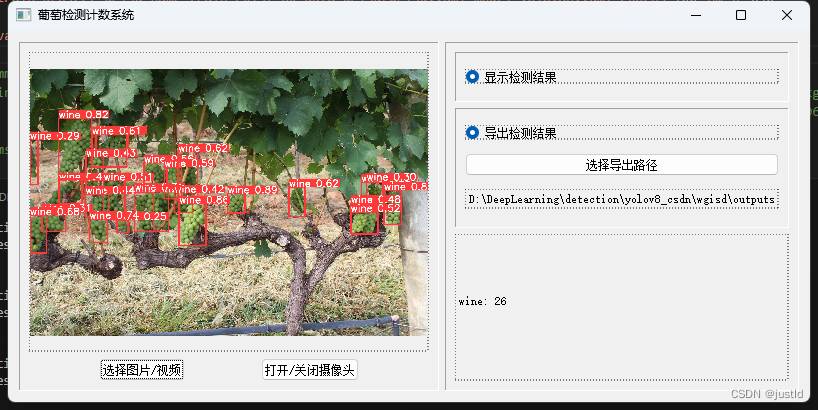
【深度学习目标检测】二十一、基于深度学习的葡萄检测系统-含数据集、GUI和源码(python,yolov8)
葡萄检测在农业中具有多方面的意义,具体来说如下: 首先,葡萄检测有助于保障农产品质量安全。通过对葡萄进行质量安全专项监测,可以确保葡萄中的农药残留、重金属等有害物质含量符合标准,从而保障消费者的健康。同时&am…
目标检测——服饰属性标签识别数据集
一、重要性及意义
首先,随着电商、时尚推荐等业务的发展,服饰属性标签识别已经成为一项关键的计算机视觉任务。这些标签,如颜色、款式、材质等,对于实现图像搜索、时尚推荐等业务需求至关重要。服饰属性标签识别数据集为此类任务…
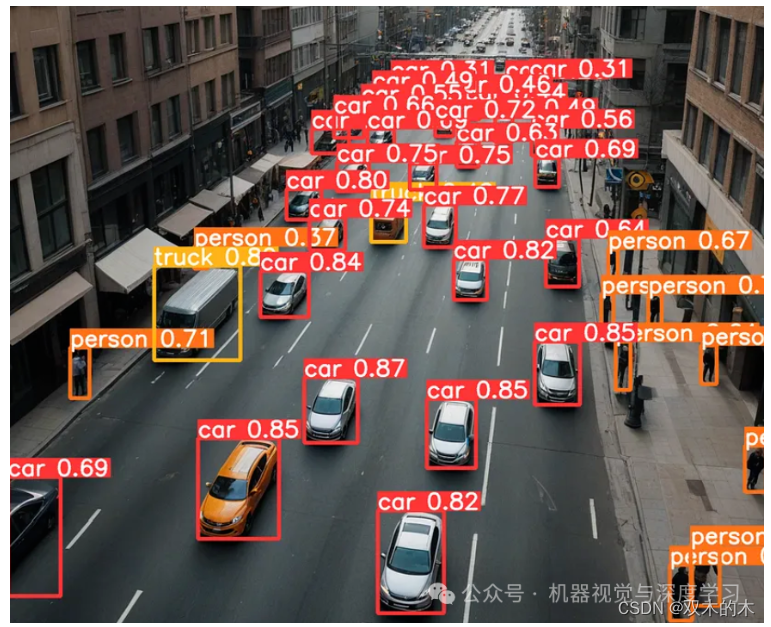
OpenCV与AI深度学习 | 如何使用YOLO-World做目标检测
本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:如何使用YOLO-World做目标检测 1 介绍 YOLO-World 是一种尖端的目标检测系统,在识别图像中物体的方式上开辟了新天地。与需要预定义…
渗透测试、人肉搜索算不算犯罪?
人肉搜索算不算犯罪? 根据《网络信息内容生态治理规定》,网络信息内容服务使用者和生产者、平台不得开展网络暴力、人肉搜索、深度伪造、流量造假、纵账号等违法活动。规定自2020年3月1日起施行。渗透测试 算不算犯罪? 《网络安全法》第二十六条开展网络…

番外篇 | 利用YOLOv5实现视频划定区域目标统计计数
前言:Hello大家好,我是小哥谈。视频划定区域目标统计计数是指在一个给定的视频中,通过划定一个特定的区域,对该区域内的目标进行统计计数的过程。这个过程通常涉及到目标检测和跟踪的技术。本篇文章就以YOLOv5算法为基础,实现视频划定区域目标统计计数!~🌈 目录…
【目标检测】从零开始进行yolov8目标检测环境搭建(详细版教程)
写在前面: 首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。(专栏订阅用户订阅专栏后免费提供数据集和源码一份,请各位帅哥美女一键三连,超级VIP用户不在服务范围之内) 路虽…
使用YOLOv8训练自己的【目标检测】数据集
文章目录 1.收集数据集1.1 使用开源已标记数据集1.2 爬取网络图像1.3 自己拍摄数据集1.4 使用数据增强生成数据集1.5 使用算法合成图像 2.标注数据集2.1确认标注格式2.2 开始标注 3.划分数据集4.配置训练环境4.1获取代码4.2安装环境 5.训练模型5.1新建一个数据集yaml文件5.2预测…

自动驾驶_交通标志识别:各目标检测算法评测
自动驾驶|交通标志识别:各目标检测算法评测
论文题目:Evaluation of Deep Neural Networks for traffic sign detection systems
开源代码:https://github.com/aarcosg/traffic-sign-detection 附赠自动驾驶学习资料和量产经验:…
DeepSort行人车辆识别系统(实现目标检测+跟踪+统计)
文章目录 1、前言2、源项目实现功能3、运行环境4、如何运行5、运行结果6、遇到问题7、使用框架8、目标检测系列文章 1、前言 1、本文基于YOLOv5DeepSort的行人车辆的检测,跟踪和计数。 2、该项目是基于github的黄老师傅,黄老师傅的项目输入视频后&#x…
目标检测——RCNN系列学习(二)Faster RCNN
接着上一篇文章:目标检测——RCNN系列学习(一)-CSDN博客
主要内容包含:Faster RCNN
废话不多说。 Faster RCNN
[1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)https://arxiv.…

头盔检测 | 基于Caffe-SSD目标检测算法实现的建筑工地头盔检测
项目应用场景 面向建筑工地头盔检测场景,使用深度学习 Caffe SSD 目标检测算法,基于 C 实现。
项目效果 项目细节 > 具体参见项目 README.md (1) 安装 Caffe SSD(2) 执行训练
sh examples/Hardhat/SSD300/train_SSD300.sh (3) 部署算法
项目获取 h…
模数转换器 SIG5533A 国产平替 CS5533AS,替代 CS5533AS
信格勒微电子的芯片产品已通过行业头部大厂导入验证,深受百万终端客户好评。 而且因为 fully compatible. 板子拿来,换个芯片, 性能更好 。MCU 不用改 c code。
SIG5531A/SIG5532A/SIG5533A/SIG5534A
1.6SPS to 3840SPS 16-bit/24-bit AD…

3D目标检测跟踪 | 基于kitti+waymo数据集的自动驾驶场景的3D目标检测+跟踪渲染可视化
项目应用场景 面向自动驾驶场景的 3D 目标检测目标跟踪,基于kittiwaymo数据集的自动驾驶场景的3D目标检测跟踪渲染可视化查看。
项目效果 项目细节 > 具体参见项目 README.md (1) Kitti detection 数据集结构
# For Kitti Detection Dataset
└── k…
YOLO算法改进Backbone系列之:PVT
摘要:尽管基于CNNs的backbone在多种视觉任务中取得重大进展,但本文提出了一个用于密集预测任务的、无CNN的的简单backbone——Pyramid Vision Transformer(PVT)。相比于ViT专门用于图像分类的设计,PVT将金字塔结构引入…

目标检测——RCNN系列学习(一)
前置知识
包括:非极大值抑制(NMS)、selective search等
RCNN
[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation (arxiv.org)https://arxiv.org/abs/1311.2524
1.网络训练 2.推理流程
3.总…
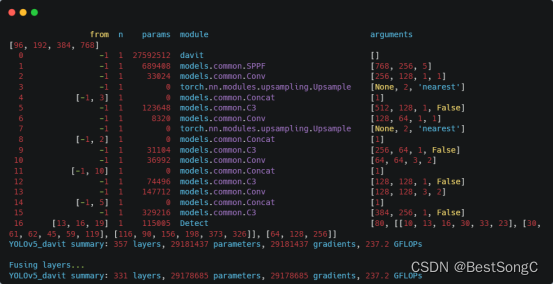
YOLO算法改进Backbone系列之DaViT
摘要:在这项工作中,我们介绍了双注意视觉变换器(DaViT),这是一个简单而有效的视觉变换器架构,能够在保持计算效率的同时捕捉全局环境。我们建议从一个正交的角度来处理这个问题:利用 "空间…
YOLOv9最新改进系列:YOLOv8融合BoTNet模块,融合CNN+自然语言处理技术的优势,有效提升检测效果!
YOLOv9最新改进系列:YOLOv9融合BoTNet模块,融合CNN自然语言处理技术的优势,有效提升检测效果!
YOLOv9原文链接戳这里,原文全文翻译请关注B站Ai学术叫叫首er
B站全文戳这里!
详细的改进教程以及源码&…
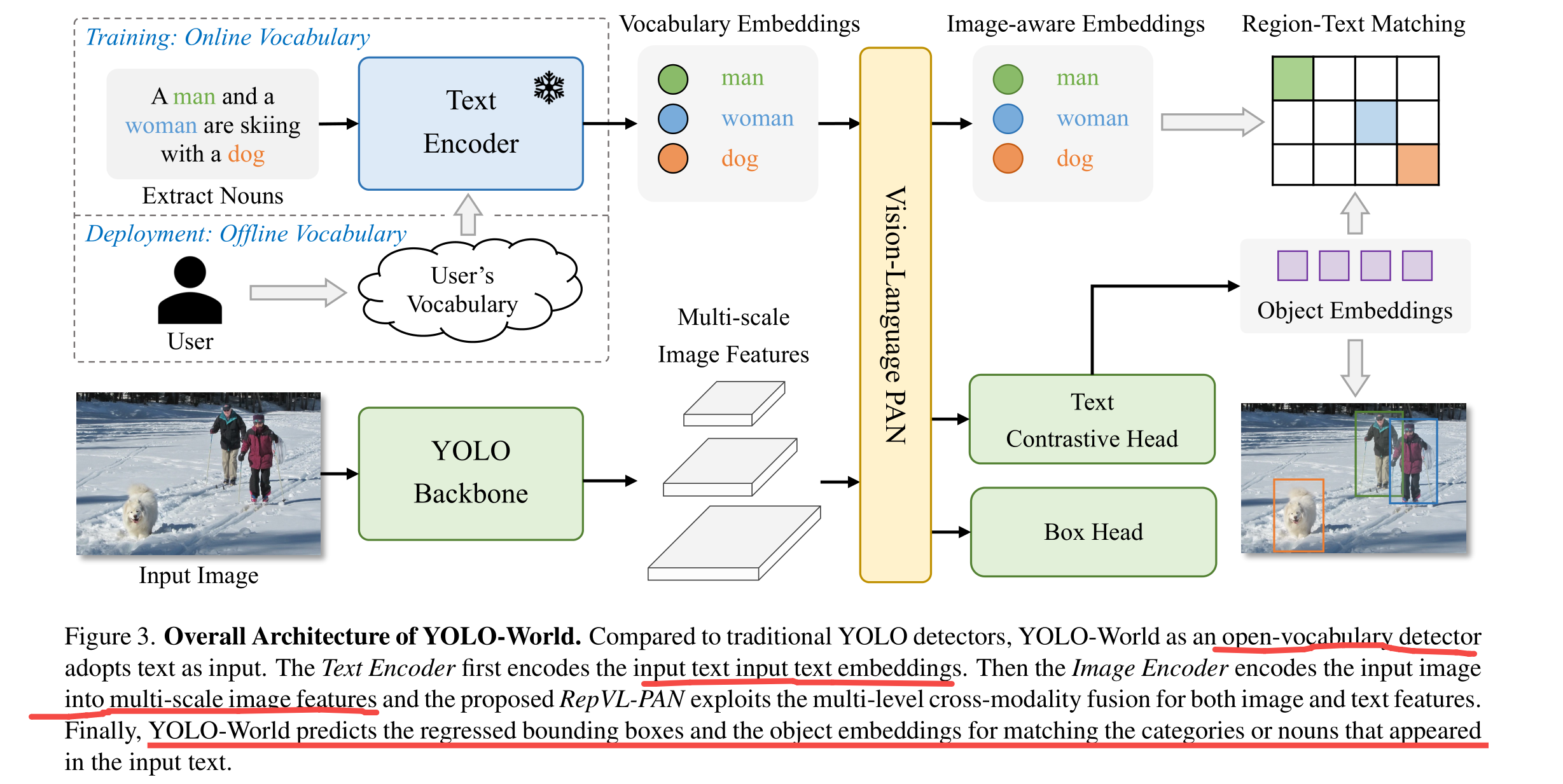
【深度学习】YOLO-World: Real-Time Open-Vocabulary Object Detection,目标检测
介绍一个酷炫的目标检测方式:
论文:https://arxiv.org/abs/2401.17270 代码:https://github.com/AILab-CVC/YOLO-World 文章目录 摘要Introduction第2章 相关工作2.1 传统目标检测2.2 开放词汇目标检测 第3章 方法3.1 预训练公式:…
YOLOv5全网独家改进: 卷积魔改 | 变形条状卷积,魔改DCNv3二次创新
💡💡💡本文独家改进: 变形条状卷积,DCNv3改进版本,不降低精度的前提下相比较DCNv3大幅度运算速度 💡💡💡强烈推荐:先到先得,paper级创新,直接使用; 💡💡💡创新点:1)去掉DCNv3中的Mask;2)空间域上的双线性插值转改为轴上的线性插值; 💡💡💡…

YOLOv9详细解读,改进提升全面分析(附YOLOv9结构图)
🥑 Welcome to Aedream同学 s blog! 🥑 文章目录 1. 概要1.1 模型结构上的改动:1.2 训练脚本上的改动: 2. 介绍2.1 背景2.2 主要贡献 3. 总体框架3.1 可编程梯度信息(PGI)3.1.1 辅助可逆分支3.1.2 多级辅助信息 3.2 Ge…

伪装目标检测论文阅读之:《Confidence-Aware Learning for Camouflaged Object Detection》
论文地址:link code:link 摘要: 任意不确定性捕获了观测结果中的噪声。对于伪装目标检测,由于伪装前景和背景的外观相似,很难获得高精度的注释,特别是目标边界周围的注释。我们认为直接使用“嘈杂”的伪装图进行训…
模数转换器 SIG7795 国产平替 AD7795,替代 AD7795
信格勒微电子的芯片产品已通过行业头部大厂导入验证,深受百万终端客户好评。 而且因为 fully compatible. 板子拿来,换个芯片, 性能更好 。MCU 不用改 c code。
SIG7794/SIG7795
4.17SPS to 890SPS ADC with PGA and Reference
Compatib…
[数据集][目标检测]鸡蛋破蛋数据集VOC+YOLO格式792张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):792 标注数量(xml文件个数):792 标注数量(txt文件个数):792 标注类别…

【YOLO系列】YOLOv9论文超详细解读(翻译 +学习笔记)
前言
时隔一年,YOLOv8还没捂热,YOLO系列最新版本——YOLOv9 终于闪亮登场! YOLOv9的一作和v7一样。v4也有他。
他于2017年获得台湾省National Central University计算机科学与信息工程博士学位,现在就职于该省Academia Sinica的…
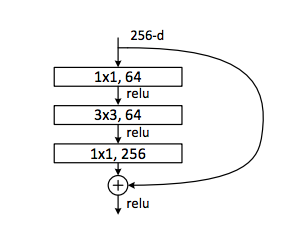
Feature Pyramid Networks for object detection
FPN 总述1.引言2.相关工作3. Feature Pyramid NetworksBottom-up pathwayTop-down pathway and lateral connections 4. 应用用于 RPN用于 Fast R-CNN 核心代码复现FPN网络结构ResNet Bottleneck完整代码 总述
下图中,蓝色边框表示的是特征图,边框越粗表…
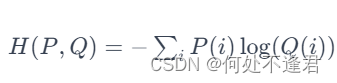
交叉熵在机器学习里做损失的意义
交叉熵是机器学习中常用的损失函数之一,特别适用于分类任务。其背后的核心思想是衡量两个概率分布之间的差异。在分类问题中,通常有一个真实分布(ground truth distribution)和一个模型预测的分布(predicted distribut…

YOLOv9有效提点|加入SE、CBAM、ECA、SimAM等几十种注意力机制(一)
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、本文介绍 本文将以SE注意力机制为例,演示如何在YOLOv9种添加注意力机制! 《Squeeze-and-Excitation Networks》 SENet提出…
C# OpenCvSharp DNN FreeYOLO 人脸检测
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN FreeYOLO 人脸检测
效果 模型信息
Inputs ------------------------- name:input tensor:Float[1, 3, 192, 320] ---------------------------------------------------------------
Outp…

Few-Shot目标检测数据集 | Few-Shot目标检测数据集_已经整理成MS-COCO数据格式_含60000+张图_可直接用于目标检测算法训练
项目应用场景 面向 Few-Shot 目标检测场景,项目提供 6000 张图,已经整理成 MS-COCO 数据格式,可用于 Few-Shot 目标检测的训练数据集,或作为 Few-Shot 目标检测数据集的补充。
数据集展示 数据集下载 > 具体参见项目 README.m…

【YOLOv9】完胜V8的SOTA模型Yolov9(论文阅读笔记)
官方论文地址: 论文地址点击即可跳转
官方代码地址: GitCode - 开发者的代码家园 官方代码地址点击即可跳转
1 总述
当输入数据经过各层的特征提取和变换的时候,都会丢失一定的信息。针对这一问题:

目标检测——车牌图像数据集
一、重要性及意义
车牌图像识别的重要性及意义主要体现在以下几个方面:
智能交通管理:车牌图像识别技术是智能交通系统(ITS)的核心组成部分。通过自动识别车辆车牌,可以实现对交通违章行为的自动记录和处理ÿ…
利用电动车进电梯检测系统识别电动车入楼行为,算法上实现的难点与方案
目前,我国电动自行车保有量已超过3.5亿辆。有限的充电场所难以满足日益增长的充电需求。许多人选择将电动车通过电梯带进家中充电。因此,火灾事故时有发生。数据显示,与电动车有关的起火事故占火灾总比35%。电梯空间狭小密闭,电动…
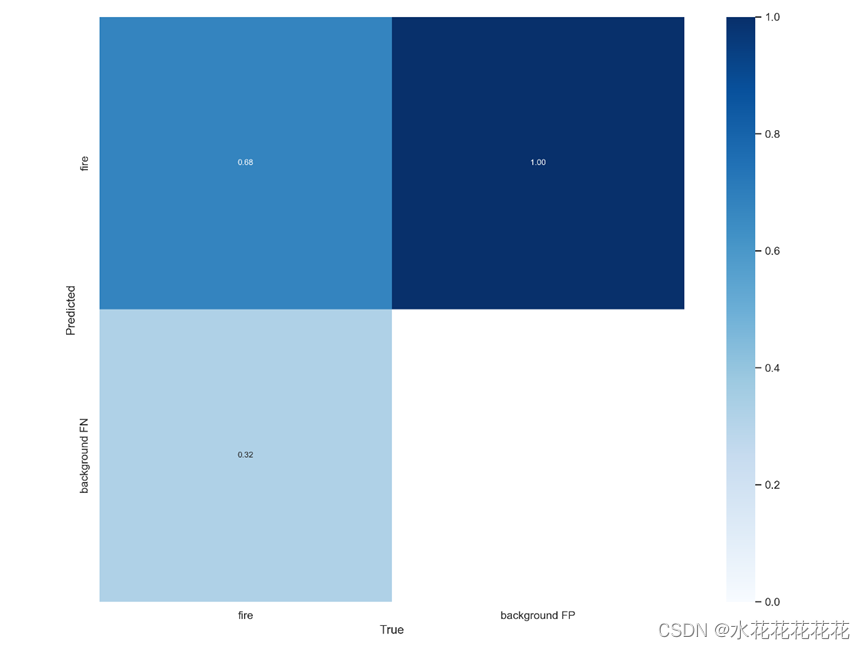
基于Yolov5的检测系统实战
文章目录
一、数据集
二、网络结构
三、完整文件目录介绍
四、测试分析 一、数据集
1、数据格式:图像数据(JPG格式),采用labelme标注后的图像(XML格式),训练需要的TXT格式 2、数据来源&…
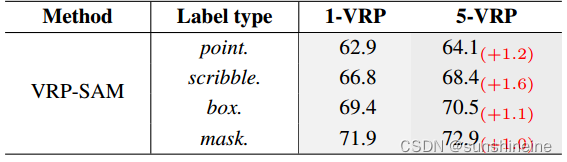
SAM功能改进VRP-SAM论文解读VRP-SAM: SAM with Visual Reference Prompt
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2024年3月30日
论文:
2402.17726.pdf (arxiv.org)https://arxiv.org/pdf/2402.17726.pdf代码:
syp2ysy/VRP-SAM (github.com)htt…

特征融合篇 | YOLOv8改进之将Neck网络更换为多级特征融合金字塔HS-FPN | 助力小目标检测
前言:Hello大家好,我是小哥谈。HS-FPN(Hierarchical Scale Feature Pyramid Network)是一种用于目标检测任务的网络结构。它是在传统的Feature Pyramid Network(FPN)基础上进行改进的。HS-FPN的主要目标是解决目标检测中存在的多尺度问题。在传统的FPN中,通过在不同层级…

基于激光雷达点云(lidar)的目标检测方法之BEV
基于激光雷达点云(lidar)的目标检测方法之BEV 附赠自动驾驶学习资料和量产经验:链接
基于lidar的目标检测方法可以分成3个部分:lidar representation,network backbone,detection head,如下图所…

防止狗上沙发,写一个浏览器实时识别目标检测功能
家里有一条狗🐶,很喜欢乘人不备睡沙发🛋️,恰好最近刚搬家 狗迎来了掉毛期 不想让沙发上很多毛。所以希望能识别到狗,然后播放“gun 下去”的音频📣。
需求分析 需要一个摄像头📷 利用 chrome…

目标检测——3D车道数据集
一、重要性及意义
3D车道检测在自动驾驶和智能交通领域具有极其重要的地位,其重要性和意义主要体现在以下几个方面:
首先,3D车道检测可以精确判断车辆在道路上的位置、方向和速度,从而预测潜在的危险情况并及时采取措施。这种能…

即插即用篇 | YOLOv5/v7引入Haar小波下采样 | 一种简单而有效的语义分割下采样模块
本改进已集成到 YOLOv5-Magic 框架。 下采样操作如最大池化或步幅卷积在卷积神经网络(CNNs)中被广泛应用,用于聚合局部特征、扩大感受野并减少计算负担。然而,对于语义分割任务,对局部邻域的特征进行池化可能导致重要的空间信息丢失,这有助于逐像素预测。为了解决这个问题…
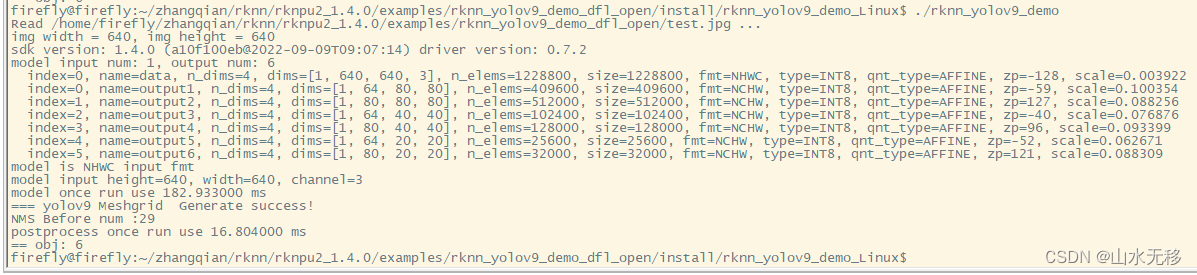
yolov9 瑞芯微芯片rknn部署、地平线芯片Horizon部署、TensorRT部署
特别说明:参考官方开源的yolov9代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。 模型和完整仿真测试代码,放在github上参考链接 模型和代码。 之前写过yolov8检测、分割、关键点模型的部署的多篇博文,y…

YOLOv9独家改进|动态蛇形卷积Dynamic Snake Convolution与空间和通道重建卷积SCConv与RepNCSPELAN4融合
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、改进点介绍 Dynamic Snake Convolution是一种针对细长微弱的局部结构特征与复杂多变的全局形态特征设计的卷积模块。 SCConv是一种即插即用的空间…

YOLOv5目标检测学习(1):yolo系列算法的基础概念
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、基于深度学习的目标检测需要哪些步骤?二、数据准备(即准备数据集)1.目标检测的数据集如何获取?2.数据集包括…
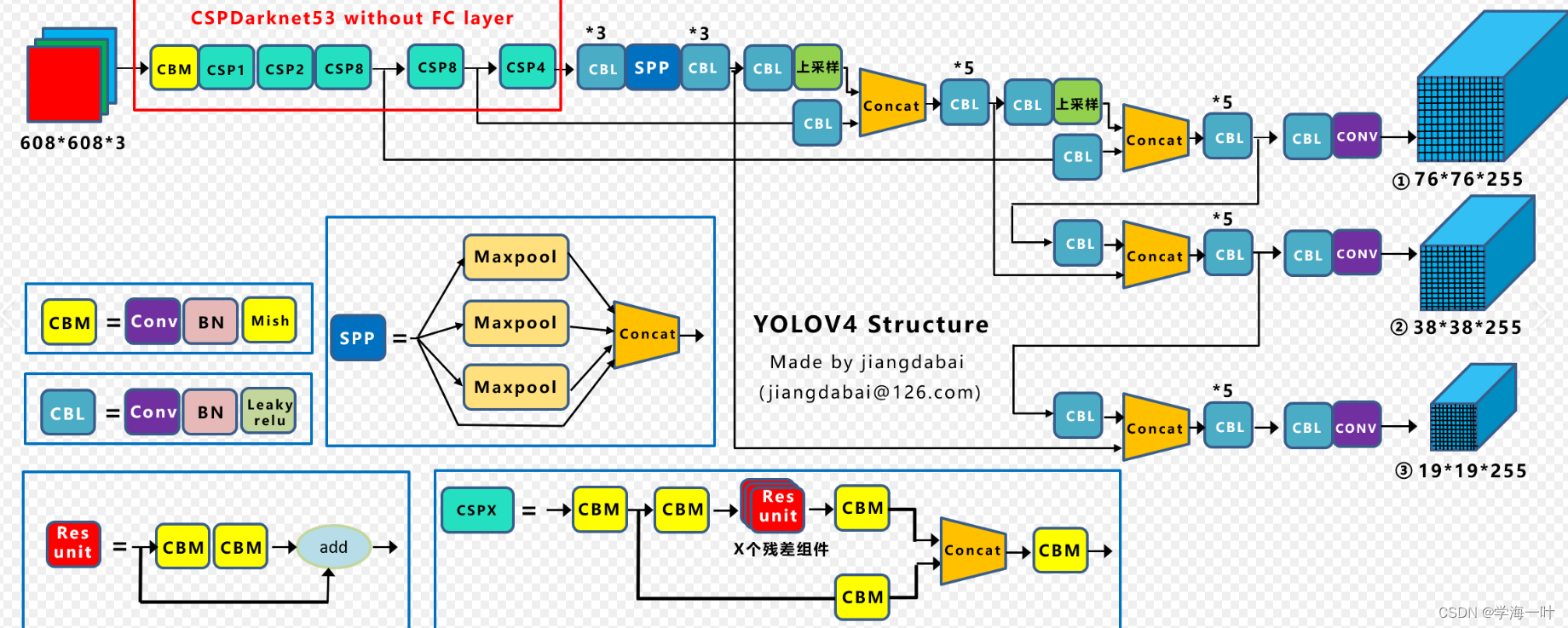
目标检测-One Stage-YOLOv4
文章目录 前言一、目标检测网络组成二、BoF(Bag of Freebies)1. 数据增强2.语义分布偏差问题3.损失函数IoUGIoUDIoUCIoU 三、BoS(Bag of Specials)增强感受野注意力机制特征融合激活函数后处理 四、YOLO v4的网络结构和创新点1.缓解过拟合(Bo…
极简sklearn上手教程,快速体验特性
文章目录 极简sklearn上手教程,快速体验特性1. **环境搭建与安装**2. **用户指南:监督学习模块 - 线性模型**3. **模型评估与选择 - 超参数调优**4. **数据预处理与转换 - 标准化**5. **统计检验与依赖分析 - 部分依赖图**6. **大规模计算与性能优化 - 并…

即插即用篇 | YOLOv8 引入 ParNetAttention 注意力机制 | 《NON-DEEP NETWORKS》
论文名称:《NON-DEEP NETWORKS》
论文地址:https://arxiv.org/pdf/2110.07641.pdf
代码地址:https://github.com/imankgoyal/NonDeepNetworks 文章目录 1 原理2 源代码3 添加方式4 模型 yaml 文件template-backbone.yamltemplate-small.yamltemplate-large.yaml
[数据集][目标检测]红外行人检测数据集VOC+YOLO格式5838张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):5838 标注数量(xml文件个数):5838 标注数量(txt文件个数):5838 标注…
[数据集][目标检测]垃圾检测数据集VOC+YOLO格式6004张18类别垃圾
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):6004 标注数量(xml文件个数):6004 标注数量(txt文件个数):6004 标注…
[数据集][目标检测]遥感图像游泳池检测数据集VOC+YOLO格式288张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):288 标注数量(xml文件个数):288 标注数量(txt文件个数):288 标注类别…
基于YOLOv8的手机摄像头的自动检测系统
文章大纲 数据集网络爬虫开源数据集标注目标定义标注标准标注工具标签更换脚本自制数据集下载地址自动检测系统设计与搭建模型训练与准确率代码仓库下载地址参考文献与学习路径随着移动通信技术的飞速发展,消费者对移动终端的要求也越来越高,各厂商纷纷提出自己的特色卖点,其…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的扑克牌识别软件(Python+PySide6界面+训练代码)
摘要:开发扑克牌识别软件对于智能辅助决策工具的建立具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个扑克牌识别软件,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同…
3d视觉笔记 | 神经辐射场NeRF(Neural Radiance Fields)
NeRF概念 NeRF(Neural Radiance Fields,神经辐射场)是一种用于3D场景重建和图像渲染的深度学习方法。它由Ben Mildenhall等人在2020年的论文《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》中首次提出。NeRF通过…
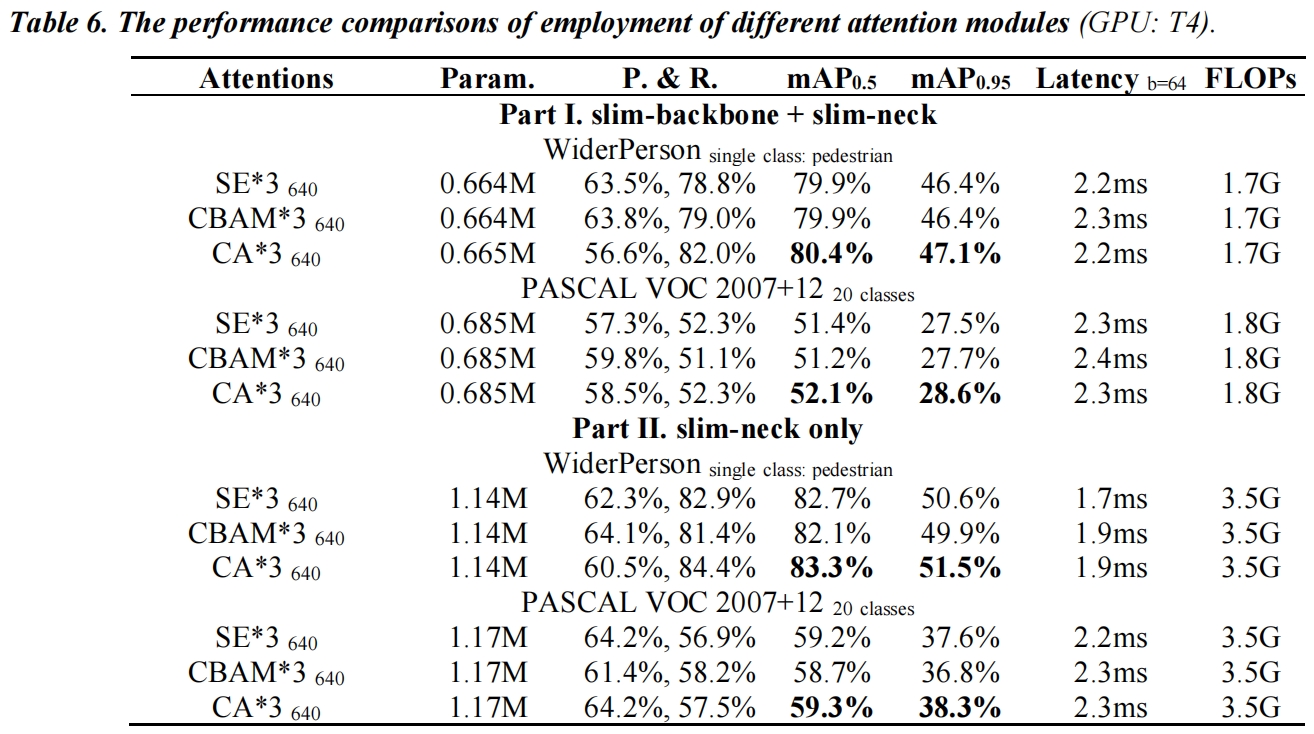
Slim-Neck by GSConv
paper:Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles
official implementation:https://github.com/alanli1997/slim-neck-by-gsconv
背景
目标检测是计算机视觉中一个重要的下游任务。对于车载…
YOLOv7 | 添加GSConv,VoVGSCSP等多种卷积,有效提升目标检测效果,代码改进(超详细)
⭐欢迎大家订阅我的专栏一起学习⭐
🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀 YOLOv5涨点专栏:http://t.csdnimg.cn/QdCj6
YOLOv7专栏: http://t.csdnimg.cn/dy…

单目测距的基本介绍和实现原理
单目测距的基本介绍和实现原理 单目测距是一种常用的测量技术,它通过单个摄像头来测量物体与摄像头的距离。在现代科技的推动下,单目测距术正在不断发展和应用于各个领域。本文将分点阐述关于单目测距的重要性、原理和方法、应用领域以及潜在的挑战和发展…

【YOLOv9】实战一:在 Windows 上使用LabVIEW OpenVINO工具包部署YOLOv9实现实时目标检测(含源码)
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主 🎄所属专栏:『仪酷LabVIEW目标检测工具包实战』 📑上期文章:『仪酷LabVIEW OD实战(3)——Object Detectiononnx工具包快速…
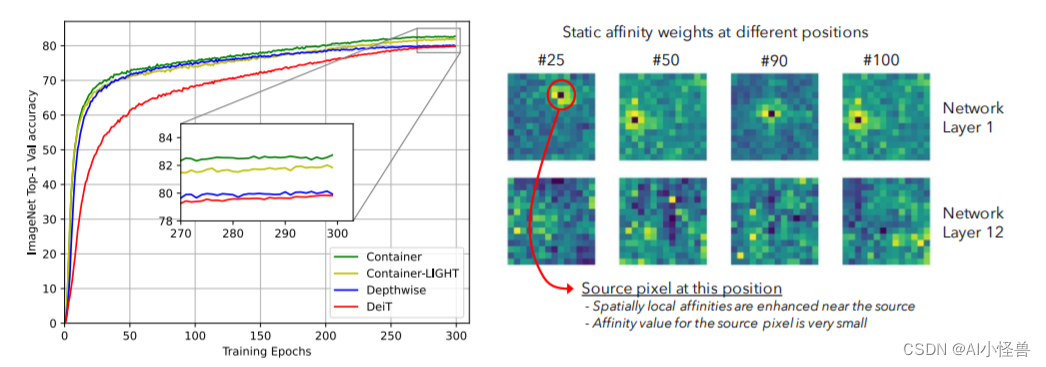
YOLOv9改进策略:注意力机制 | 用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测,暴力涨点
💡💡💡本文改进内容:用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测
yolov9-c-ContextAggregation summary: 971 layers, 51002153 parameters, 51002121 gradients, 238.9 GFLOPs 改…
DEYOv2: Rank Feature with Greedy Matchingfor End-to-End Object Detection
摘要 与前代类似, DEYOv2 采用渐进式推理方法 来加速模型训练并提高性能。该研究深入探讨了一对一匹配在优化器中的局限性,并提出了有效解决该问题的解决方案,如Rank 特征和贪婪匹配 。这种方法使DEYOv2的第三阶段能够最大限度地从第一和第二…
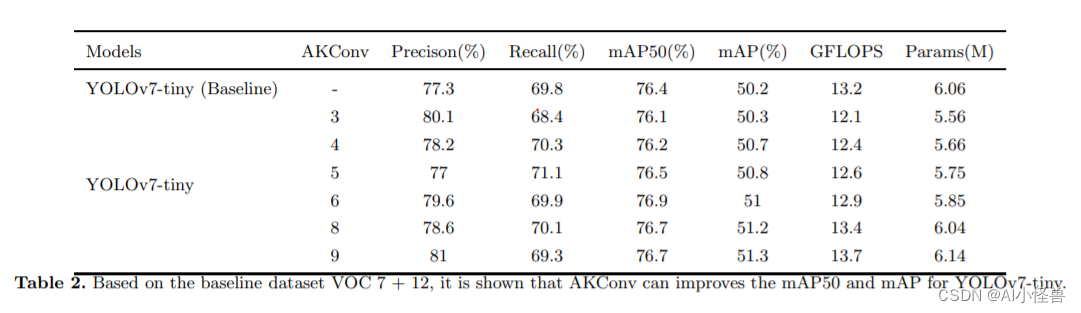
YOLOv9改进策略:卷积魔改 | AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv | 2023年11月最新发表
💡💡💡本文改进内容: YOLOv9如何魔改卷积进一步提升检测精度?AKConv 通过不规则卷积运算完成高效特征提取的过程,为卷积采样形状带来更多探索选择。 AKConv可以作为即插即用的卷积运算来替代卷积运算来提高…
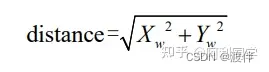
基于yolov5的单目测距实现与总结+相机模型+标定
写这篇文章的目的是为了总结我之前看的标定,相机模型以及单目测距的内容,如果有错误,还请不吝赐教。 参考链接: 相机模型、相机标定及基于yolov5的单目测距实现 深度学习目标检测目标追踪单目测距 单目测距代码部署(目…

【 yolo红外微小无人机-直升机-飞机-飞鸟目标检测】
yolo无人机-直升机-飞机-飞鸟目标检测 1. 小型旋翼无人机目标检测2. yolo红外微小无人机-直升机-飞机-飞鸟目标检测3. yolo细分类型飞机-鸟类-无人机检测4. yolo红外大尺度无人机检测5. 小型固定翼无人机检测6. 大型固定翼无人机检测7. yolo航空俯视场景下机场飞机检测 1. 小型…
YOLO算法改进Backbone系列之:CAT
Transformer广泛应用于NLP后,在CV领域也引起了广泛关注,但是将单词token替换为图像的patch使得Transformer计算量大幅增加。本文提出一种新的注意力机制Cross Attention,不再计算全局注意力而是将注意力的计算局限在patch内部来捕获局部信息&…
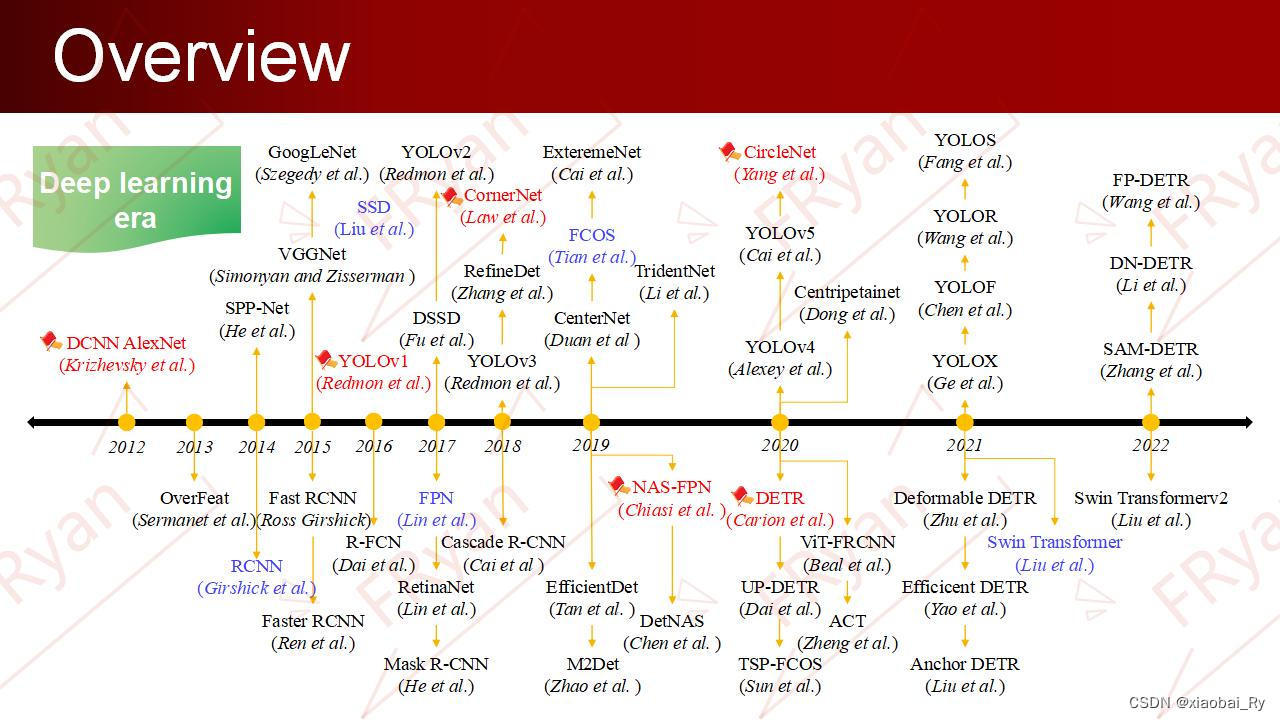
目标检测的相关模型图:YOLO系列和RCNN系列
目标检测的相关模型图:YOLO系列和RCNN系列 前言YOLO系列的图展示YOLOpassthroughYOLO2YOLO3YOLO4YOLO5 RCNN系列的图展示有关目标检测发展的 前言
最近好像大家也都在写毕业论文,前段时间跟朋友聊天,突然想起自己之前写画了一些关于YOLO、Fa…

【YOLOv5改进系列(6)】高效涨点----使用DAMO-YOLO中的Efficient RepGFPN模块替换yolov5中的Neck部分
文章目录 🚀🚀🚀前言一、1️⃣ 添加yolov5_GFPN.yaml文件二、2️⃣添加extra_modules.py代码三、3️⃣yolo.py文件添加内容3.1 🎓 添加CSPStage模块 四、4️⃣实验结果4.1 🎓 使用yolov5s.pt训练的结果对比4.2 ✨ 使用…
目标检测系列模型发展历程
常见数据集:
VOC-->COCO
VOC数据集
特点:
发布于2005-2012年,由多个项目(如VOC2007和VOC2012)组成。包含20个物体类别,涵盖动物、交通工具和日常物品等。提供了物体检测、物体分类、物体分割等任务的…
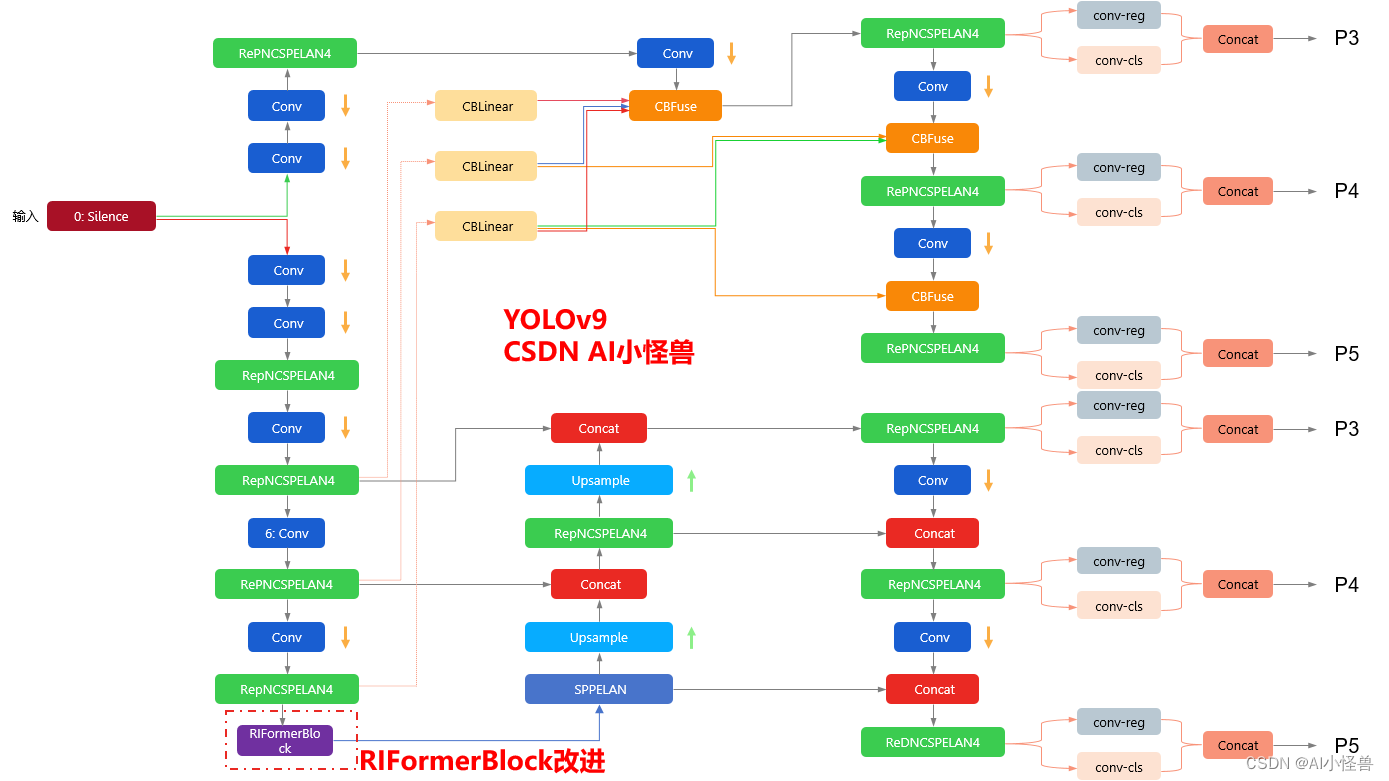
YOLOv9改进策略 :主干优化 | 无需TokenMixer也能达成SOTA性能的极简ViT架构 | CVPR2023 RIFormer
💡💡💡本文改进内容: token mixer被验证能够大幅度提升性能,但典型的token mixer为自注意力机制,推理耗时长,计算代价大,而RIFormers是无需TokenMixer也能达成SOTA性能的极简ViT架构 ,在保证性能的同时足够轻量化。 💡💡💡RIFormerBlock引入到YOLOv9,多个数…

目标检测——监控下的汽车
一、重要性及意义
首先,车辆检测技术是保证视频监控系统正常运行的基础。通过监控摄像头实时获取的图像,可以自动检测出图像中的车辆,并进行车辆类型的分类和识别。这对于优化城市交通管理、实现智能交通系统具有重要意义。此外,…

目标检测——车牌数据集
一、重要性及意义
交通安全与管理:车牌检测和识别技术有助于交通管理部门快速、准确地获取车辆信息,从而更有效地进行交通监控和执法。例如,在违规停车、超速行驶等交通违法行为中,该技术可以帮助交警迅速锁定违规车辆࿰…
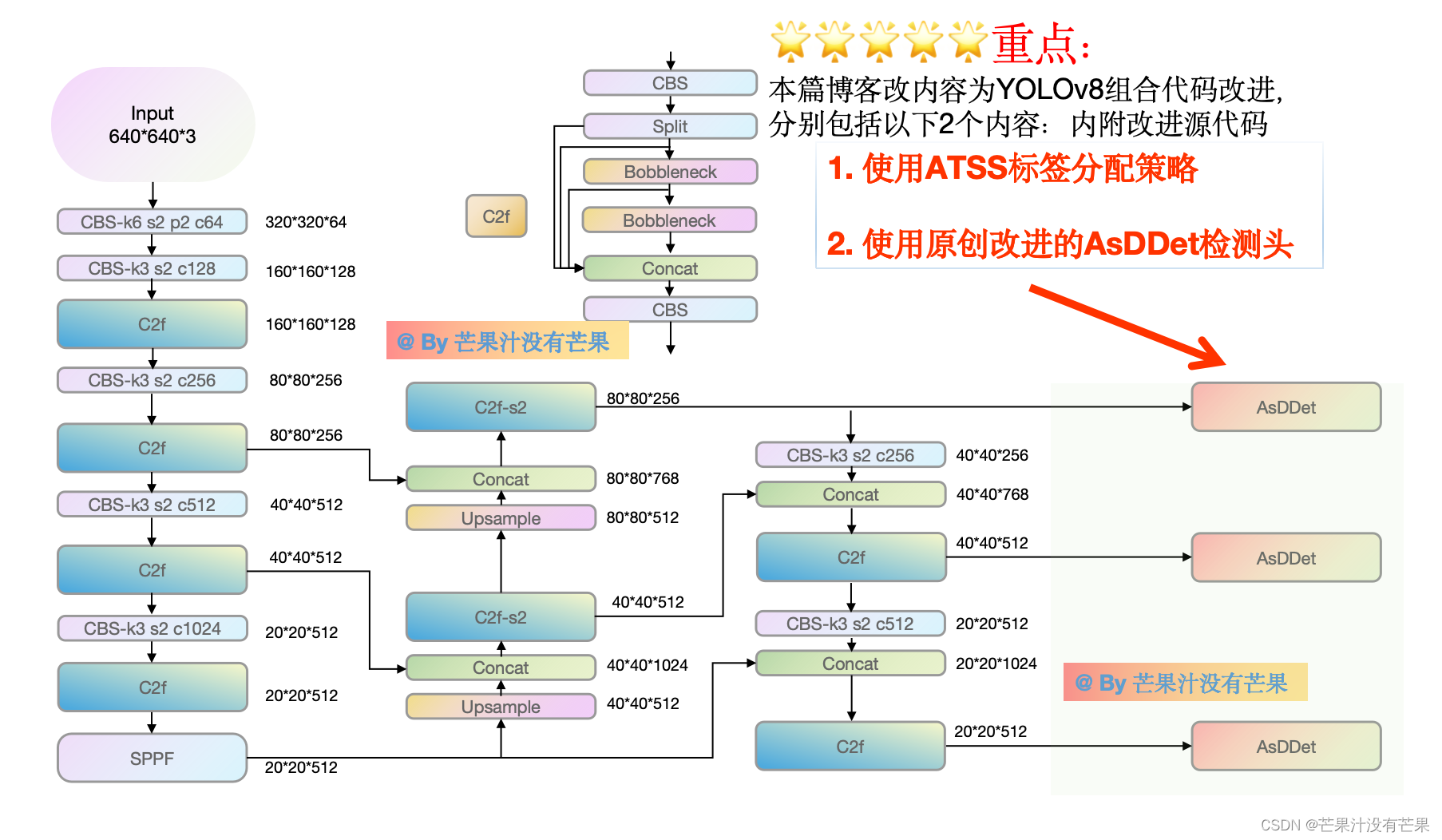
芒果YOLOv8改进组合157:动态标签分配ATSS+新颖高效AsDDet检测头组合改进,共同助力VisDrone涨点1.8%,小目标高效涨点
💡本篇内容:【芒果YOLOv8改进ATSS标签分配策略|第三集】芒果YOLOv8改进组合157:动态标签分配ATSS+新颖高效AsDDet检测头组合改进,共同助力VisDrone涨点1.8%,小目标高效涨点 💡🚀🚀🚀本博客 标签分配策略ATSS改进+ 新颖高效AsDDet检测头组合改进,适用于 YOLOv8 …
Focal Modulation Networks聚焦调制网络
摘要 我们提出了 焦点调制网络 (简称 FocalNets) ,其中 自注意( SA )被 Focal Modulation 替换,这种机制 包括三个组件:( 1 )通过 depth-wise Conv 提取分级的上下文信息࿰…
基于YOLOv8v7v6v5和LPRNet的中文车牌识别系统(深度学习代码+UI界面实现+训练数据集)
摘要:之前的中文车牌识别系统升级到v2.0版本,本文详细介绍使用深度学习实现的高效中文车牌识别系统完整代码,包括训练过程、原理介绍、模型对比、系统设计等部分。采用了最新的YOLOv8、YOLOv7、YOLOv6、YOLOv5目标检测算法进行车牌检测定位&a…
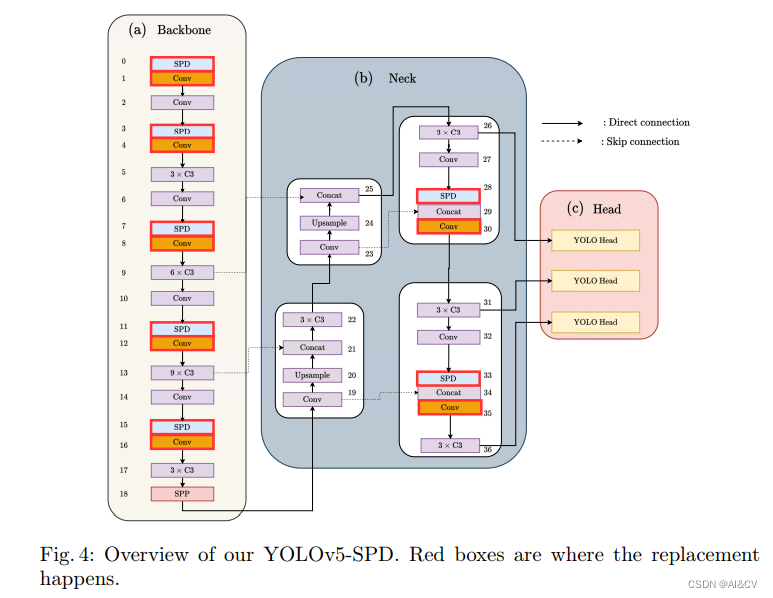
YOLOv9改进策略:卷积魔改 | SPD-Conv,低分辨率图像和小物体涨点明显
💡💡💡本文改进内容:SPD-Conv由一个空间到深度(SPD)层和一个无卷积步长(Conv)层组成,特别是在处理低分辨率图像和小物体等更困难的任务时。 💡💡💡SPD-Conv在多个数据集验证能够暴力涨点&#x…

yolov5+pyside6+登录+用户管理目标检测可视化源码
一、软件简介 这是基于yolov5目标检测实现的源码,提供了用户登录功能界面; 用户需要输入正确的用户名和密码才可以登录。如果是超级管理员,可以修改普通用户的信息,并且在检测界面的右上角显示【管理用户】按钮。 支持图片、视频、…
浅谈开放词汇目标检测
1. 引言
随着人工智能技术的快速发展,开放词汇物体检测(Open-Vocabulary Object Detection)已经成为计算机视觉领域的一个重要研究方向。开放词汇物体检测的目标是使机器能够识别并定位图像中未在训练集中出现的新类别的物体,这对于机器人技术、自动驾驶…
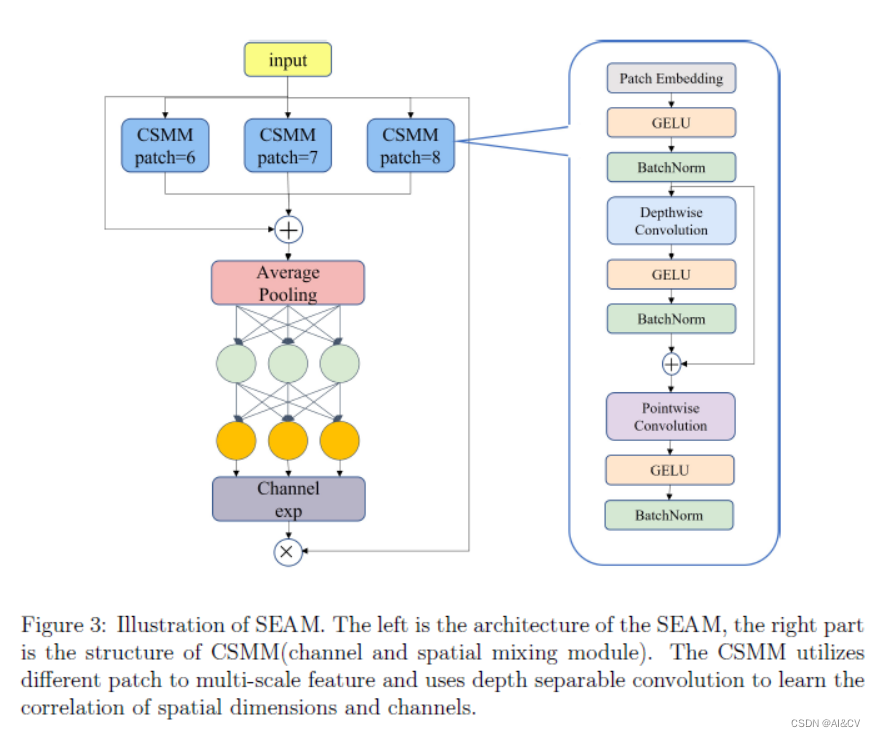
YOLOv9改进策略:block优化 | SEAM提升小目标遮挡物性能
💡💡💡本文改进内容:SEAM提升小目标遮挡物性能,在多个数据集得到很好的验证 改进结构图如下: YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️…
YOLOv9改进策略 :小目标 | 新颖的多尺度前馈网络(MSFN) | 2024年4月最新成果
💡💡💡本文独家改进:多尺度前馈网络(MSFN),通过提取不同尺度的特征来增强特征提取能力,2024年最新的改进思路 💡💡💡创新点:多尺度前馈网络创新十足,抢先使用 💡💡💡如何跟YOLOv8结合:1)放在backbone后增强对全局和局部特征的提取能力;2)放在detect…
人体跟随小车(旭日x3派、yolov5、目标检测)
人体跟随小车(yolov5、目标检测) 前言最终结果接线实现注意 前言
上板运行的后处理使用cython封装了,由于每个版本的yolo输出的形状不一样,这里只能用yolov5-6.2这个版本。 ①训练自己的模型并部署于旭日x3派参考: ht…
【目标检测】-入门知识
1、回归与分类问题
回归问题是指给定输入变量(特征)和一个连续的输出变量(标签),建立一个函数来预测输出变量的值。换句话说,回归问题的目标是预测一个连续的输出值,例如预测房价、股票价格、销售额等。回归问题通常使用回归分析技术,例如线性回归、多项式回归、决策树…

基于YOLOv8的摄像头下铁路工人安全作业检测系统
💡💡💡本文摘要:基于YOLOv8的铁路工人安全作业检测系统,属于小目标检测范畴,并阐述了整个数据制作和训练可视化过程,
博主简介
AI小怪兽,YOLO骨灰级玩家,1࿰…

基于ros的相机内参标定过程
基于ros的相机内参标定过程 1. 安装还对应相机的驱动2. 启动相机节点发布主题3. 下载camera_calibartion4. 将红框的文件夹复制在自己的工作空间里边,编译5. 标定完成以后,生成内参参数文件camera.yaml。将文件放在对应的路径下,修改config文…
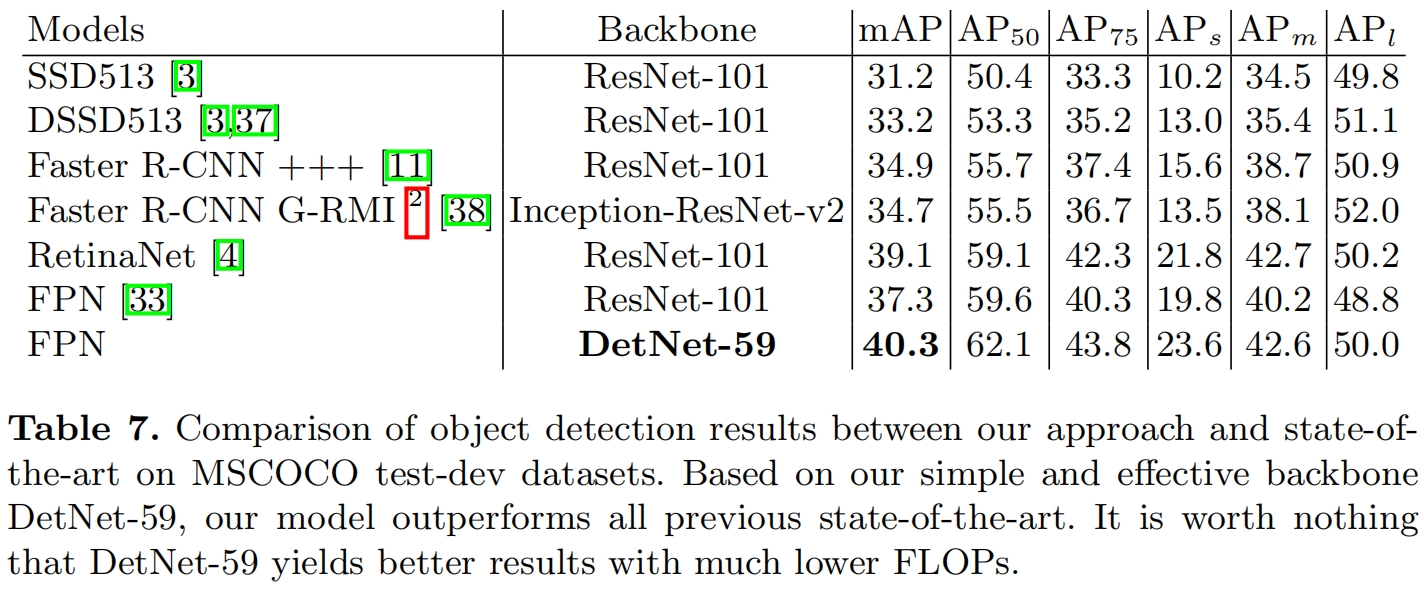
DetNet论文速读
paper:DetNet: A Backbone network for Object Detection
存在的问题
最近的目标检测模型通常依赖于在ImageNet分类数据集上预训练的骨干网络。由于ImageNet的分类任务不同于目标检测,后者不仅需要识别对象的类别,而且需要对边界框进行空间…
【目标检测】基于深度学习的垃圾桶满溢检测(yolov5算法,附代码和数据集)
写在前面: 首先感谢兄弟们的关注和订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。(专栏订阅用户订阅专栏后免费提供数据集和源码一份,超级VIP用户不在服务范围之内) 路虽远,行则将至;事虽难,做…
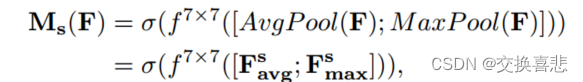
伪装目标检测之注意力CBAM:《Convolutional Block Attention Module》
论文地址:link 代码:link
摘要
我们提出了卷积块注意力模块(CBAM),这是一种简单而有效的用于前馈卷积神经网络的注意力模块。给定一个中间特征图,我们的模块依次推断沿着两个独立维度的注意力图ÿ…
YOLOv5独家改进:backbone改进 | 视觉新主干!RMT:RetNet遇见视觉Transformer | CVPR2024
💡💡💡本文独家改进:RMT:一种强大的视觉Backbone,灵活地将显式空间先验集成到具有线性复杂度的视觉主干中,在多个下游任务(分类/检测/分割)上性能表现出色!
💡💡💡Transformer 在各个领域验证了可行性,在多个数据集下能够实现涨点
改进结构图如下:
收…

目标检测中的mAP计算原理和源码实现
简介
在目标检测任务中,mAP(mean Average Precision,平均精度均值)是一个非常重要的评价指标,用于衡量模型在多个类别上的平均性能。它综合考虑了模型在不同召回率下的精确率,能够全面反映模型在检测任务中…
yoloV3的目标检测_3.11
目标
利用yolo模型进行目标检测的方法完成目标检测功能的实现 整个流程如下:
基于OPenCV中的DNN模块
加载已训练好的yolov3模型及其权重参数将要处理的图像转换成输入到模型中的blobs利用模型对目标进行检测遍历检测结果应用非极大值抑制绘制最终检测结果&#x…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的常见手势识别系统(深度学习模型+UI界面代码+训练数据集)
摘要:开发手势识别系统对于增强人机交互和智能家居控制领域的体验非常关键。本博客详尽阐述了通过深度学习技术构建手势识别系统的过程,并附上了全套实施代码。系统采用了先进的YOLOv8算法,并通过与YOLOv7、YOLOv6、YOLOv5的性能对比…

光伏便携式EL检测仪是什么?—科技助农
光伏便携式EL监测仪是一种专门用于检测光伏电池组件性能的高效、实用的设备。它利用电致发光(Electroluminescence,EL)原理,通过检测光伏板在受到光照后产生的电流所激发出的光线,来评估光伏板的性能。这种设备通常具有…
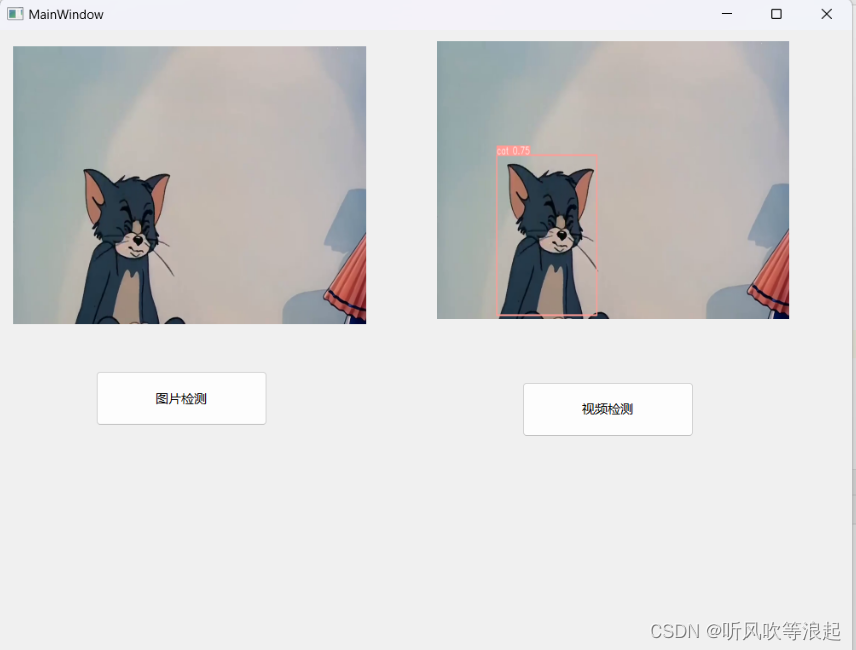
YOLOV5 部署:基于web网页的目标检测(本地、云端均可)
1、前言
YOLOV5推理的代码很复杂,大多数都是要通过命令行传入参数进行推理,不仅麻烦而且小白不便使用。 本章介绍的web推理,仅仅需要十几行代码就能实现本地推理,并且只需要更改单个参数就可以很方便的部署云端,外网也可以随时的使用 之前文章介绍了QT的可视化推理界面,…
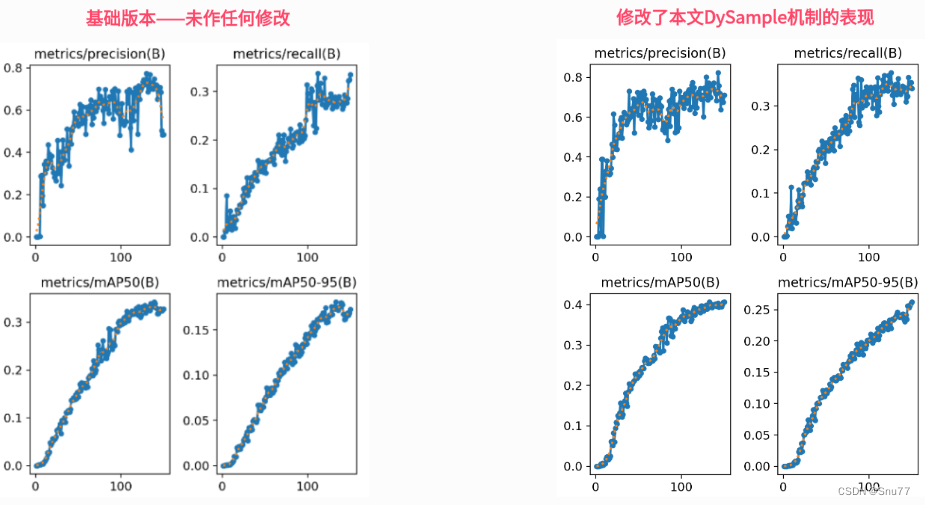
YOLOv8改进 | 细节涨点篇 | DySample一种超级轻量的动态上采样算子(效果完爆CARAFE)
一、 本文介绍
本文给大家带来的改进机制是一种号称超轻量级且有效的动态上采样器——DySample。与传统的基于内核的动态上采样器相比,DySample采用了一种基于点采样的方法,相比于以前的基于内核的动态上采样器,DySample具有更少的参数、浮点运算次数、GPU内存和延迟。此外…

计算机视觉实战项目4(单目测距与测速+摔倒检测+目标检测+目标跟踪+姿态识别+车道线识别+车牌识别+无人机检测+A_路径规划+行人车辆计数+动物识别等)
基于YOLOv5的无人机视频检测与计数系统 摘要: 无人机技术的快速发展和广泛应用给社会带来了巨大的便利,但也带来了一系列的安全隐患。为了实现对无人机的有效管理和监控,本文提出了一种基于YOLOv5的无人机视频检测与计数系统。该系统通过使用…
Days 24 Elfboard 读取摄像头视频进行目标检测
当前,将AI或深度学习算法(如分类、目标检测和轨迹追踪)部署到嵌入式设备,进而实现边缘计算,正成为轻量级深度学习算法发展的一个重要趋势。今天将与各位小伙伴分享一个实际案例:利用ChatGPT在ELF 1开发板上…
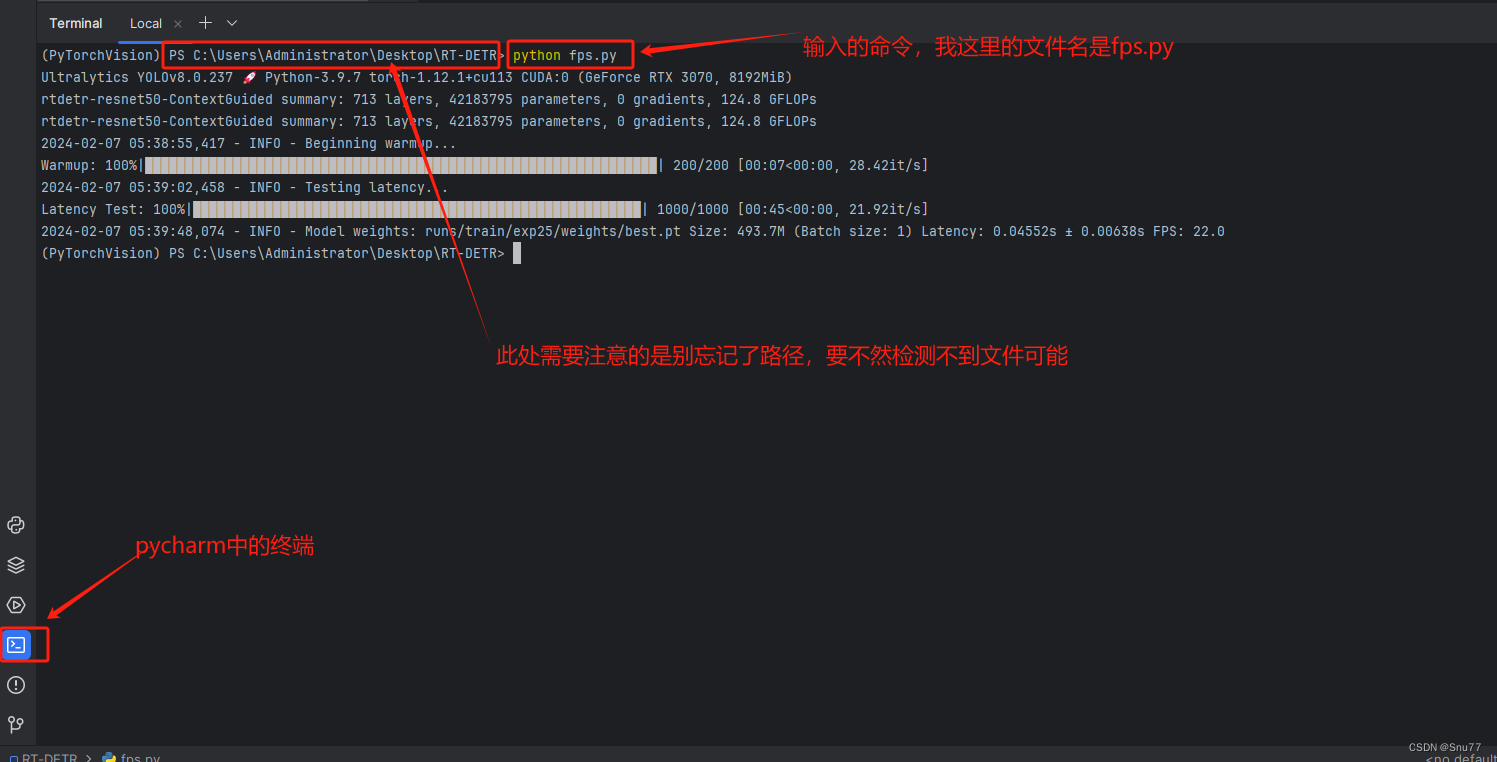
【RT-DETR有效改进】计算训练好权重文件对应的FPS、推理每张图片的平均时间(科研必备)
👑欢迎大家订阅本专栏,一起学习RT-DETR👑 一、本文介绍
本文给大家带来的改进机制是利用我们训练好的权重文件计算FPS,同时打印每张图片所利用的平均时间,模型大小(以MB为单位),同时支持batch_size功能的选择,对于轻量化模型的读者来说,本文的内容对你一定有…
YOLOv8改进 | 利用训练好权重文件计算YOLOv8的FPS、推理每张图片的平均时间(科研必备)
一、本文介绍
本文给大家带来的改进机制是利用我们训练好的权重文件计算FPS,同时打印每张图片所利用的平均时间,模型大小(以MB为单位),同时支持batch_size功能的选择,对于轻量化模型的读者来说,本文的内容对你一定有帮助,可以清晰帮你展示出模型速度性能的提升以及轻量…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的舰船检测与识别系统(Python+PySide6界面+训练代码)
摘要:开发高级的舰船检测与识别系统对于提升海上安全监控和航运管理至关重要。本篇博客详细阐述了如何应用深度学习技术构建舰船检测与识别系统,并提供了完整的实施代码。本系统采用了性能强大的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5进行了…
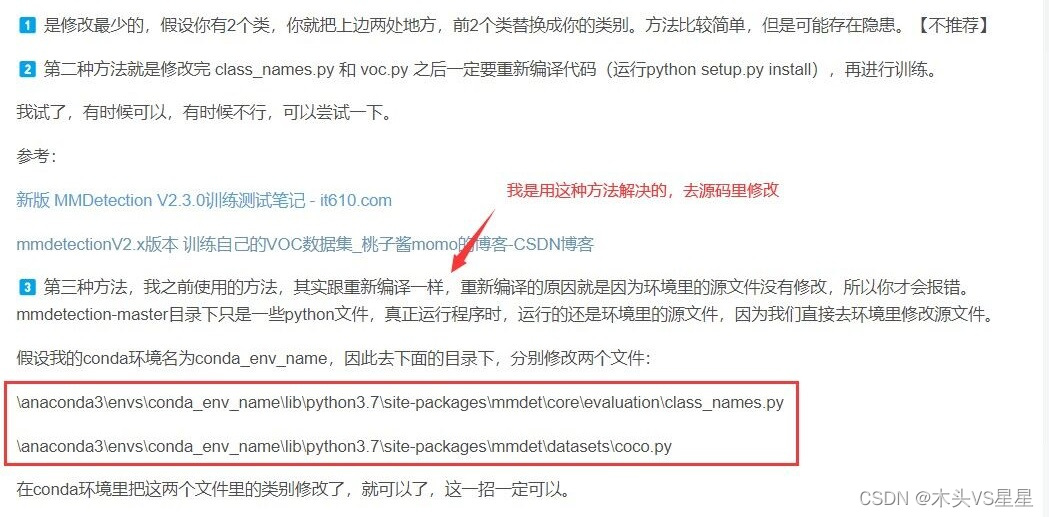
基于MMDetection训练VOC格式数据集
一 环境说明 基于前述安装MMDetection,数据集为VOC格式,主要版本如下:
Python:3.7.8
CUDA:11.3
cuDNN:8.4.0
torch:1.12.0
torchvision:0.13.0
mmcv-full:1.6.0
MMDetec…
YOLOv5改进 | 融合改进篇 | 华为VanillaNet + BiFPN突破涨点极限
一、本文介绍
本文给大家带来的改进机制是华为VanillaNet主干配合BiFPN实现融合涨点,这个主干是一种注重极简主义和效率的神经网络我也将其进行了实验, 其中的BiFPN不用介绍了从其发布到现在一直是比较热门的改进机制,其主要思想是通过多层级的特征金字塔和双向信息传递来提…
基于轻量级模型YOLOX-Nano的菜品识别系统
工程Gitee地址: https://gitee.com/zhong-liangtang/ncnn-android-yolox-nano
一、YOLOX简介
YOLOX是一个在2021年被旷视科技公司提出的高性能且无锚框(Anchor-free)的检测器,在YOLO系列的基础上吸收近年来目标检测学术界的最新…

compile error ESP32cam.h no such file or directory
解决方法 可以参考这篇文章:
But first, you will need to download the esp32cam.h library. For this go to Github and download the esp32cam Zip.
GitHub - yoursunny/esp32cam: OV2640 camera on ESP32-CAM, Arduino library 具体就是下面的这篇重要的文章 …
YOLOv5改进 | 一文汇总:如何在网络结构中添加注意力机制、C3、卷积、Neck、SPPF、检测头
一、本文介绍
本篇文章的内容是在大家得到一个改进版本的C3一个新的注意力机制、或者一个新的卷积模块、或者是检测头的时候如何替换我们YOLOv5模型中的原有的模块,从而用你的模块去进行训练模型或者检测。因为最近开了一个专栏里面涉及到挺多改进的地方,不能每篇文章都去讲…
YOLOv8改进 | Neck篇 | 当SDI碰上BiFPN形成全新的特征金字塔网络(全网独家创新)
一、本文介绍
本文给大家带来的改进机制是利用多层次特征融合模块(SDI)配上经典的加权双向特征金字塔网络Bi-FPN形成一种全新的Neck网络结构,从而达到二次创新的效果,其中(SDI)模块的主要思想是通过整合编码器生成的层级特征图来增强图像中的语义信息和细节信息。Bi-FPN…
13.5. 多尺度目标检测
这里是对那一节代码的通俗注释,希望对各位学习有帮助。 值得注意的是,multibox_prior函数的宽高计算网络上有争议,此处我仍认为作者的写法是正确的,如果读者有想法,可以在评论区留言,我们进行讨论。 import…
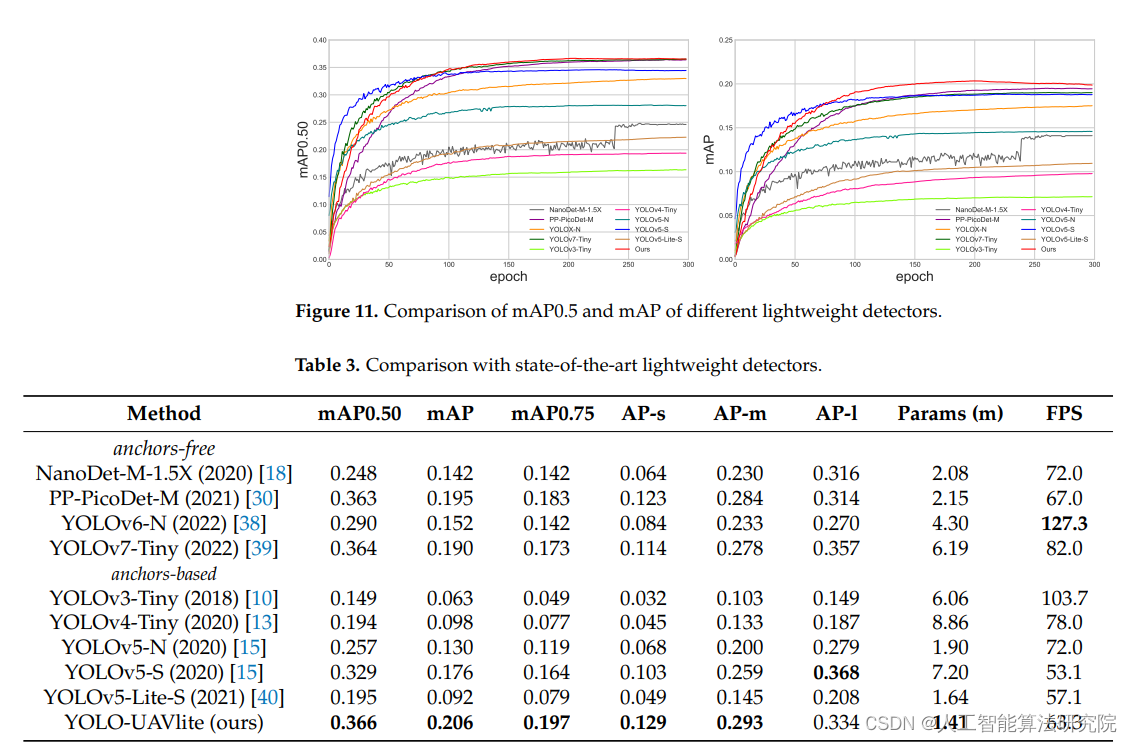
英文论文(sci)解读复现【NO.21】一种基于空间坐标的轻量级目标检测器无人机航空图像的自注意
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】机器视觉(基础篇)(十七)
目录
几个高频面试题目
如何选择合适的面扫相机
算法原理
分辨率与视野
像素尺寸与景深
像素尺寸
目标检测中AP50 AP75 APs APm APl 含义
目标检测中AP50 AP75 APs APm APl 含义 介绍 介绍
在目标检测领域,我们经常会遇到一些评价指标,这些指标有助于衡量模型的性能。让我来解释一下这些概念: AP (Average Precision):平均精度,用于衡量目标检测模型的准确…

YoloV8 +可视化界面+GUI+交互式界面目标检测与跟踪
YoloV8 可视化界面 GUI 本项目旨在基于 YoloV8 目标检测算法开发一个直观的可视化界面,使用户能够轻松上传图像或视频,并对其进行目标检测。通过图形用户界面,用户可以方便地调整检测参数、查看检测结果,并将结果保存或导出。同时…
处理目标检测中的类别不均衡问题
目标检测中,数据集中类别不均衡是一个常见的问题,其中一些类别的样本数量明显多于其他类别。这可能导致模型在训练和预测过程中对频繁出现的类别偏向,而忽略掉罕见的类别。本文将介绍如何处理目标检测中的类别不均衡问题,以提高模…
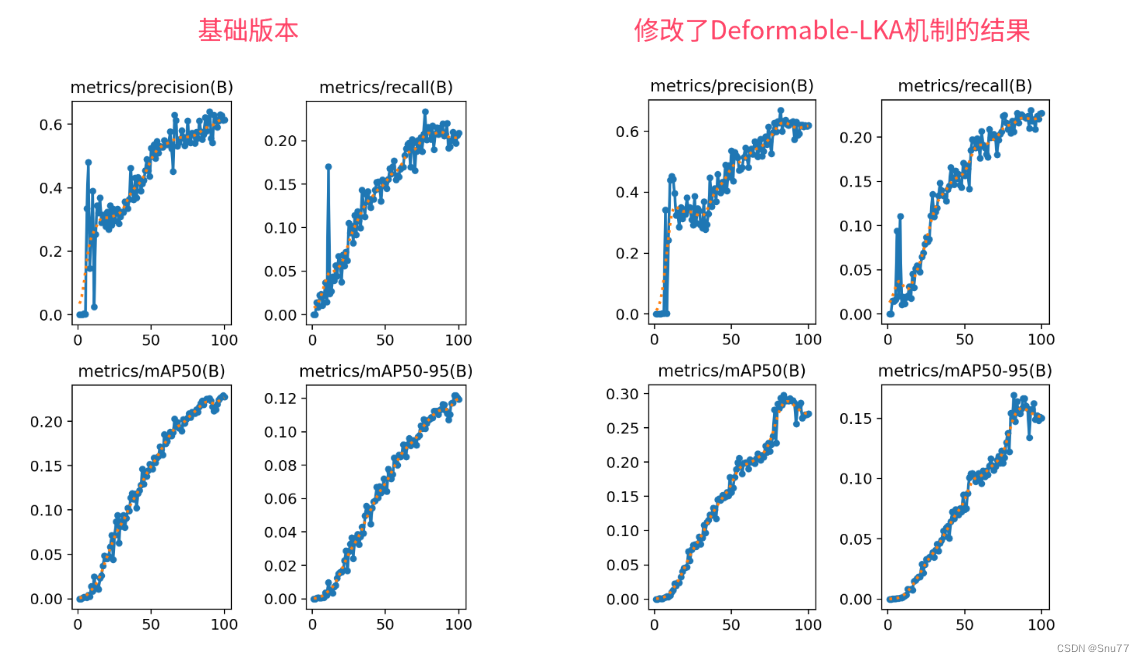
【RT-DETR有效改进】可变形大核注意力 | Deformable-LKA适用于复杂背景或不同光照场景
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
本文给大家带来的改进内容是Deformable-LKA(可变形大核注意力)。Deformable-LKA结合了大卷积核的广阔感受野和可变形卷积的灵活性,有效地处理复杂的视觉信息。这一机制通过动态调整卷积核的形状和大小来适…

Paddlepaddle使用自己的VOC数据集训练目标检测(0废话简易教程)
一 安装paddlepaddle和paddledection(略)
笔者使用的是自己的数据集
二 在dataset目录下新建自己的数据集文件,如下: 其中 xml文件内容如下: 另外新建一个createList.py文件:
# -- coding: UTF-8 --
imp…

YOLO-World:实时开放词汇目标检测
paper:https://arxiv.org/pdf/2401.17270.pdf Github:GitHub - AILab-CVC/YOLO-World: Real-Time Open-Vocabulary Object Detection online demo:https://huggingface.co/spaces/stevengrove/YOLO-World 目录
0. 摘要
1. 引言
2. 相关工…

YOLOv8改进 | 进阶实战篇 | 利用辅助超推理算法SAHI推理让小目标无所谓遁形(支持视频和图片)
欢迎大家订阅我的专栏一起学习YOLO!
一、本文介绍
本文给大家带来的是进阶实战篇,利用辅助超推理算法SAHI进行推理,同时官方提供的版本中支持视频,我将其进行改造后不仅支持视频同时支持图片的推理方式,SAHI主要的推理场景是针对于小目标检测(检测物体较大的不适用,…

遥感影像目标检测:从CNN(Faster-RCNN)到Transformer(DETR)
我国高分辨率对地观测系统重大专项已全面启动,高空间、高光谱、高时间分辨率和宽地面覆盖于一体的全球天空地一体化立体对地观测网逐步形成,将成为保障国家安全的基础性和战略性资源。未来10年全球每天获取的观测数据将超过10PB,遥感大数据时…
yolov9目标检测报错AttributeError: ‘list‘ object has no attribute ‘device‘
最近微智启软件工作室在运行yolov9目标检测的detect.py测试代码时,报错: File “G:\down\yolov9-main\yolov9-main\detect.py”, line 102, in run pred non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_detmax_det) Fil…
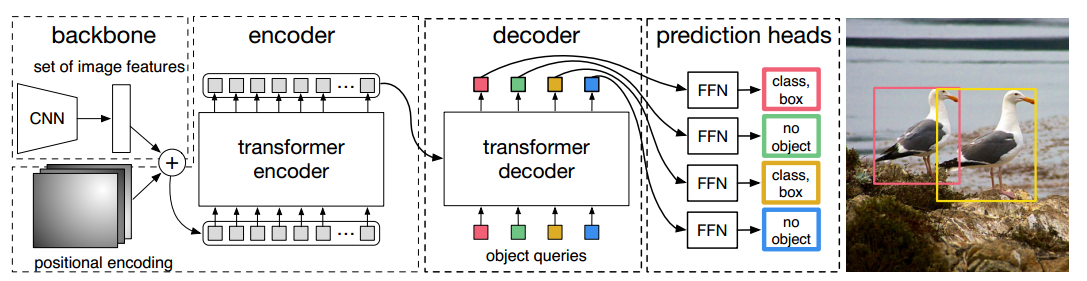
目标检测-Transformer-ViT和DETR
文章目录 前言一、ViT应用和结论结构及创新点 二、DETR应用和结论结构及创新点 总结 前言
随着Transformer爆火以来,NLP领域迎来了大模型时代,成为AI目前最先进和火爆的领域,介于Transformer的先进性,基于Transformer架构的CV模型…
YOLO(You Only Look Once)详细介绍
YOLO(You Only Look Once)是一种基于深度学习的目标检测方法,其核心思想是将目标检测任务转换为一个回归问题来解决。与传统的目标检测方法相比,YOLO具有更快的速度和更高的准确率,因此在实际应用中得到了广泛的关注和应用。
YOLO的检测过程是在一个单独的端到端网络中完…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的遥感目标检测系统(Python+PySide6界面+训练代码)
摘要:本文介绍了一种基于深度学习的遥感目标检测系统系统的代码,采用最先进的YOLOv8算法并对比YOLOv7、YOLOv6、YOLOv5等算法的结果,能够准确识别图像、视频、实时视频流以及批量文件中的遥感目标。文章详细解释了YOLOv8算法的原理࿰…
YOLOv5改进PIoU损失函数:PIoU v1版本使用非单调聚焦机制更直接、更快的边界框回归损失,PIoU v2版本损失增强了专注于中等质量锚盒的能力,
💡本篇内容:YOLOv5改进PIoU损失函数:PIoU v2损失增强了专注于中等质量锚盒的能力,v1版本使用非单调聚焦机制更直接、更快的边界框回归损失
💡附改进源代码及教程,用来改进🚀PIoU损失函数
Powerful-IoU损失函数论文地址:https://www.sciencedirect.com/science/art…

YOLOv5算法进阶改进(16)— 更换Neck网络之GFPN(源自DAMO-YOLO)
前言:Hello大家好,我是小哥谈。GFPN(Global Feature Pyramid Network)是一种用于目标检测的神经网络架构,它是在Faster R-CNN的基础上进行改进的,旨在提高目标检测的性能和效果。其核心思想是引入全局特征金字塔,通过多尺度的特征融合来提取更丰富的语义信息。具体来说,…
目标检测新SOTA:YOLOv9问世,新架构让传统卷积重焕生机(附代码)
在目标检测领域,YOLOv9 实现了一代更比一代强,利用新架构和方法让传统卷积在参数利用率方面胜过了深度卷积。
继 2023 年 1 月 YOLOv8 正式发布一年多以后,YOLOv9 终于来了!
我们知道,YOLO 是一种基于图像全局信息进行预测的目标检测系统。自 2015 年 Joseph Redmon、Al…
C# OpenCvSharp DNN Yolov8-OBB 旋转目标检测
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN Yolov8-OBB 旋转目标检测
效果 模型信息
Model Properties ------------------------- date:2024-02-26T08:38:44.171849 description:Ultralytics YOLOv8s-obb model trained on runs/DOT…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的无人机目标检测系统(Python+PySide6界面+训练代码)
摘要:本文详细介绍了一种利用深度学习技术的无人机目标检测系统,该系统基于前沿的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等先前版本进行了性能对比。本系统能够在不同媒介如单一图像、视频文件、实时视频流及批量处理文件中准确地检测和识别…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的生活垃圾检测与分类系统(Python+PySide6界面+训练代码)
摘要:本篇博客详细讲述了如何利用深度学习构建一个生活垃圾检测与分类系统,并且提供了完整的实现代码。该系统基于强大的YOLOv8算法,并进行了与前代算法YOLOv7、YOLOv6、YOLOv5的细致对比,展示了其在图像、视频、实时视频流和批量…
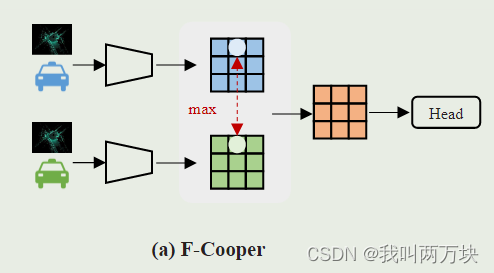
【代码解读】OpenCOOD框架之model模块(以PointPillarFCooper为例)
point_pillar_fcooper PointPillarFCooperPointPillarsPillarVFEPFNLayerPointPillarScatterBaseBEVBackboneDownsampleConvDoubleConv SpatialFusion检测头 (紧扣PointPillarFCooper的框架结构,一点一点看代码) PointPillarFCooper
# -*- c…
[数据集][目标检测]狗狗表情识别VOC+YOLO格式3971张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):3971 标注数量(xml文件个数):3971 标注数量(txt文件个数):3971 标注…
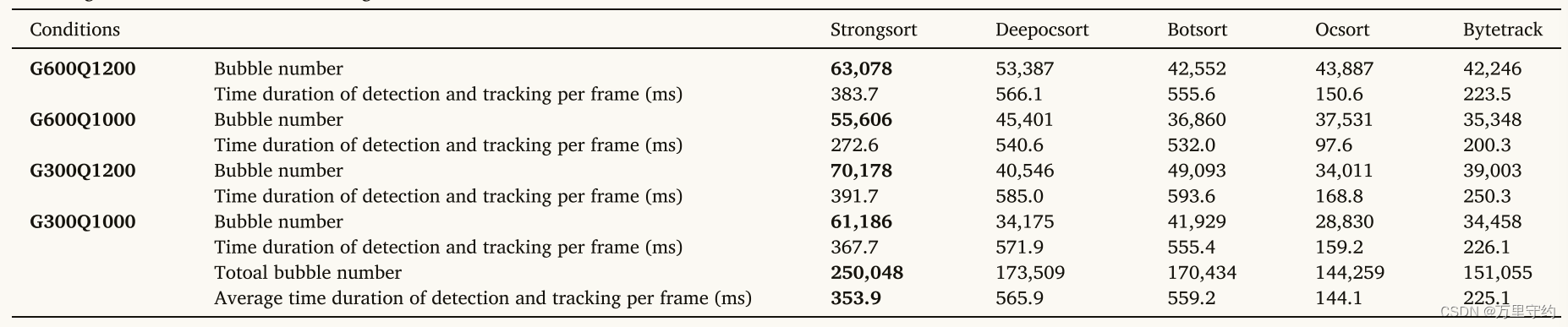
【论文阅读】基于人工智能目标检测与跟踪技术的过冷流沸腾气泡特征提取
Bubble feature extraction in subcooled flow boiling using AI-based object detection and tracking techniques 基于人工智能目标检测与跟踪技术的过冷流沸腾气泡特征提取 期刊信息:International Journal of Heat and Mass Transfer 2024 级别:EI检…
C# OpenVINO Crack Seg 裂缝分割 裂缝检测
目录
效果
模型信息
项目
代码
数据集
下载 C# OpenVINO Crack Seg 裂缝分割 裂缝检测
效果 模型信息
Model Properties ------------------------- date:2024-02-29T16:35:48.364242 author:Ultralytics task:segment version&…

目标检测 YOLOv5 - Rockchip rknn模型的测试 包括精度,召回率,mAP等详细信息
目标检测 YOLOv5 - Rockchip rknn模型的测试 包括精度,召回率,mAP等详细信息
flyfish
该测试是使用了自定义128张图片的测试结果,如果采用官网的coco128图片数据会比下列数值更好看。 以下是对比结果,pt模型的测试结果和rknn模型…

YOLOv8涨点技巧,添加SE注意力机制提升目标检测效果
目录
论文地址
摘要
SE结构图
代码实现
Squeeze Excitation
SE-Inception and SE-ResNet
yaml文件编写
完整代码分享
总结 论文地址
http://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.pdf
摘要
卷积神…
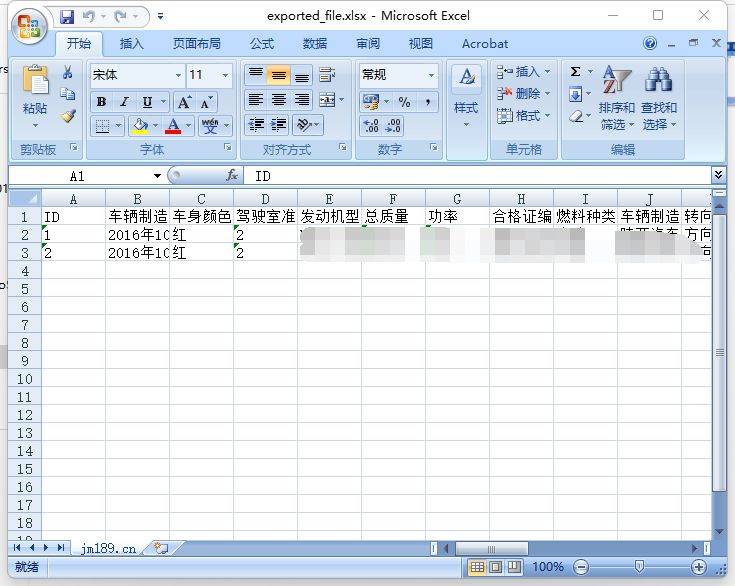
巧用眼精星票证识别系统将车辆合格证快速转为结构化excel数据,简单方便
眼精星票证识别系统是一款高效且精准的OCR软件,它的魔力在于能将纸质文档迅速转化为电子文档,并实现自动化的数据结构化处理。它拥有一双"火眼金睛",无论是各类发票、护照,还是车辆合格证等,都能一一识别。而…
基于yolov5的草莓成熟度检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示:
基于yolov5的草莓成熟度检测系统,系统既能够实现图像检测,也可以进行视屏和摄像实时检测_哔哩哔哩_bilibili
(一)简介
基于yolov5的草莓成熟度系统是在pytorch框架下实现的,这是一个完整的项目…

目标检测论文解读复现之十:基于YOLOv5的遥感图像目标检测
前言 此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文,…
基于Faster-RCNN的人脸口罩检测,可进行图像目标检测,也可进行视屏检测(pytorch框架)【python源码+UI界面+功能源码详解】
功能演示:
基于Faster-RCNN的口罩检测系统,支持图像检测和视频检测(pytorch框架)_哔哩哔哩_bilibili
(一)简介
基于Faster-RCNN的人脸口罩检测系统是在pytorch框架下实现的,这是一个完整的项…

【目标检测】YOLOv5在Android上的部署
前言
本篇博文用来研究YOLOv5在Android上部署的例程 主要参考的是Pytorch官方提供的Demo:https://github.com/pytorch/android-demo-app/tree/master/PyTorchDemoApp
功能简述
App主页如下图所示: 主要功能: 切换测试图片 在程序中直接指定…

项目实战 | YOLOv5 + Tesseract-OCR 实现车牌号文本识别
项目实战 | YOLOv5 Tesseract-OCR 实现车牌号文本识别 最近看到了各种各样的车牌识别,觉得挺有意思,自己也简单搞一个玩玩😼。 传统的图像处理算法我也不太会,就直接用深度学习的方法实现吧。 文章目录项目实战 | YOLOv5 Tesser…
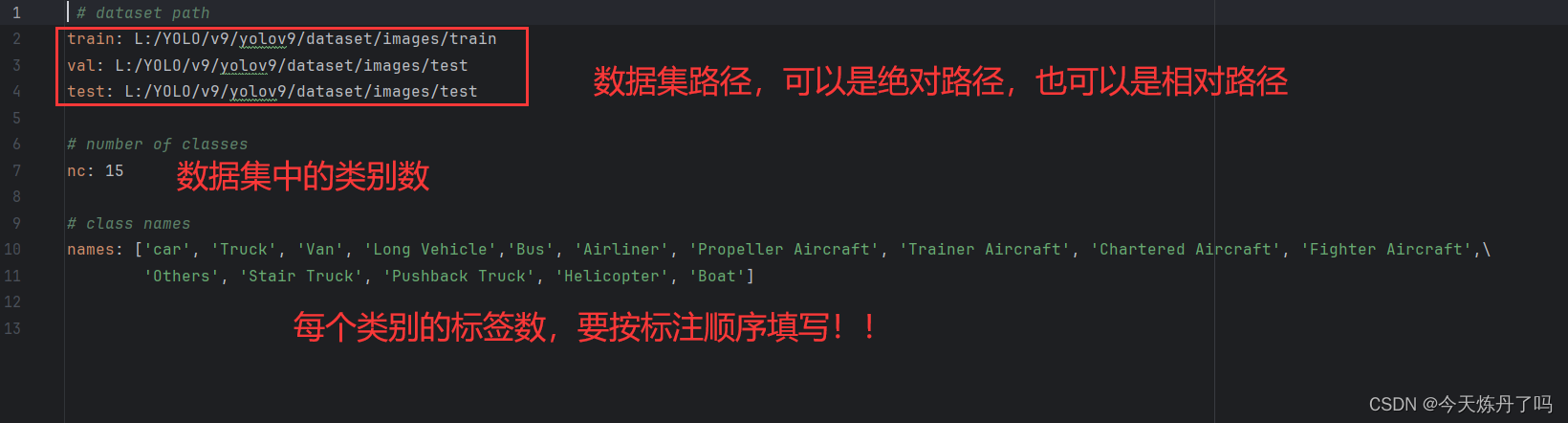
YOLO系列中的“data.yaml”详解!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、data.yaml介绍 YOLO系列中的data.yaml文件包含了YOLO系列模型运行所需要的数据集路径、数据集中的类别数及标签。数据集路径可以用绝对路径也可以…
基于pytorch预训练模型使用Faster RCNN调用摄像头进行目标检测【无敌详细!简单!超少代码!】
基于pytorch预训练模型使用Faster RCNN调用摄像头进行目标检测【无敌详细!简单!超少代码!】
详细完整项目链接:https://download.csdn.net/download/weixin_46570668/86954697?spm1001.2014.3001.5503
使用 Pytorch 自带的预训…

YOLOV9论文解读
代码:https://github.com/WongKinYiu/yolov9论文:https://arxiv.org/abs/2402.1361本文提出可编程梯度信息(PGI)和基于梯度路径规划的通用高效层聚合网络(GELAN),最终铸成YOLOv9目标检测全新工作!性能表现SOTA!在各个方…
YOLOv8创新改进:小目标涨点篇 | 一种新颖的轻量化网络,用于提升遥感图像中的小物体检测 | 2024年二区YOLOv5改进最新成果
💡💡💡本文独家改进:现将本文思想迁移到YOLOv8做二次创新 ,提出了三个创新的轻量级即插即用模块:特征增强模块(FEM)、特征融合模块(FFM)和空间上下文感知模块(SCAM),对标yolov5m,涨点的同时轻量化,GFLOPS从原始的47.9降低至37.6,MB从42.2降低至10.7 parame…
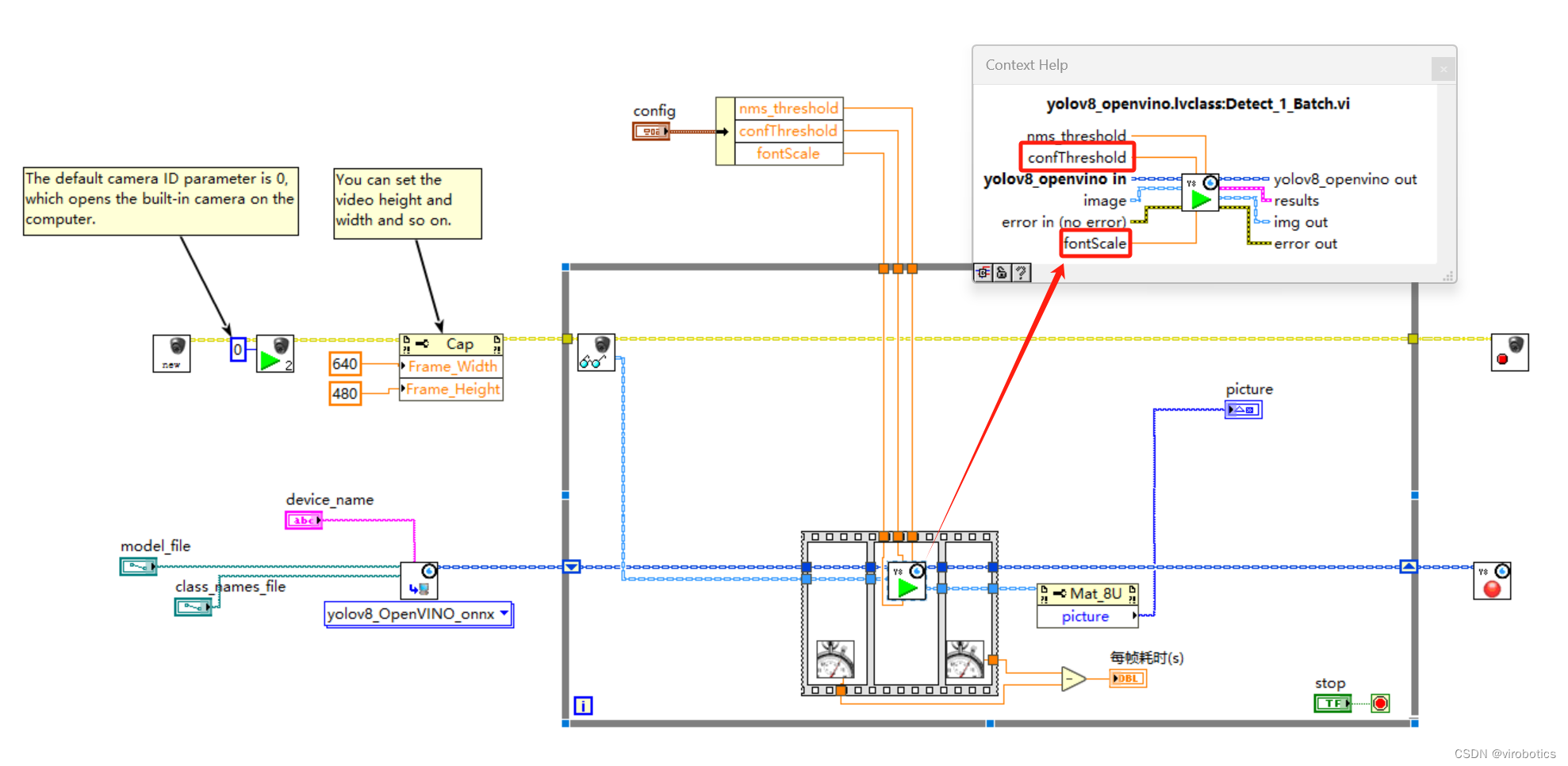
仪酷LabVIEW OD实战(4)——Object Detection+OpenVINO工具包快速实现yolo目标检测
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主 🎄所属专栏:『仪酷LabVIEW目标检测工具包实战』 📑上期文章:『仪酷LabVIEW OD实战(3)——Object Detectiononnx工具包快速…
YOLOv8改进 | 独家创新篇 | 利用DCNv3集合DLKA形成全新的注意力机制(全网独家创新)
一、本文介绍
本文给大家带来的机制是由我独家创新结合Deformable Large Kernel Attention (D-LKA) 注意力机制和DCNv3可变形卷积的全新注意力机制模块(算是二次创新),D-LKA的基本原理是结合了大卷积核和可变形卷积的注意力机制,通过采用大卷积核来模拟类似自我关注的感受…
YOLOFastestv2 训练自己的数据集---辛酸仨小时
我是训练的行人目标检测。
首先下载YOLOFastestv2:https://github.com/dog-qiuqiu/FastestDet
yolofastestv2需要这样的数据集:
.
├── category.names # .names category label file
├── train # train dataset
│ ├…
利用OpenCV 抽取视频的图片,并制作目标检测数据集
1、前言
目标检测中,图片的数据可以从视频中抽取,而OpenCV的VideoCapture可以实现这样的操作
需要的库文件 opencv
pip下载:
pip install opencv-contrib-python
更换镜像源下载:
pip install opencv-contrib-python -i htt…

YOLOv8改进 | 主干篇 | 轻量级的低照度图像增强网络IAT改进YOLOv8暗光检测(全网独家首发)
一、本文介绍
本文给大家带来的改进机制是轻量级的变换器模型:Illumination Adaptive Transformer (IAT),用于图像增强和曝光校正。其基本原理是通过分解图像信号处理器(ISP)管道到局部和全局图像组件,从而恢复在低光或过/欠曝光条件下的正常光照sRGB图像。具体来说,IAT…
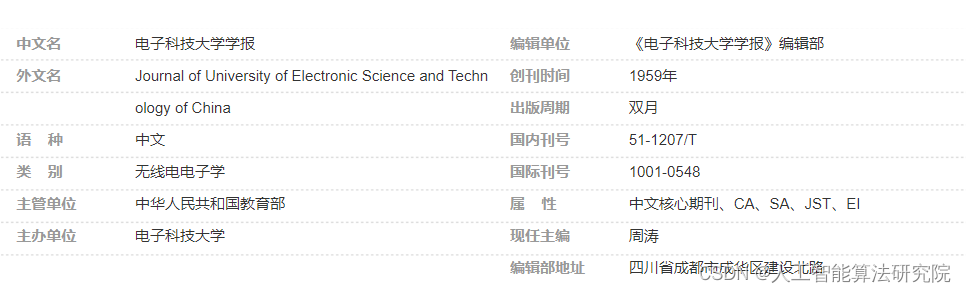
目标检测论文解读复现之十六:基于改进YOLOv5的小目标检测算法
前言 此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文,…
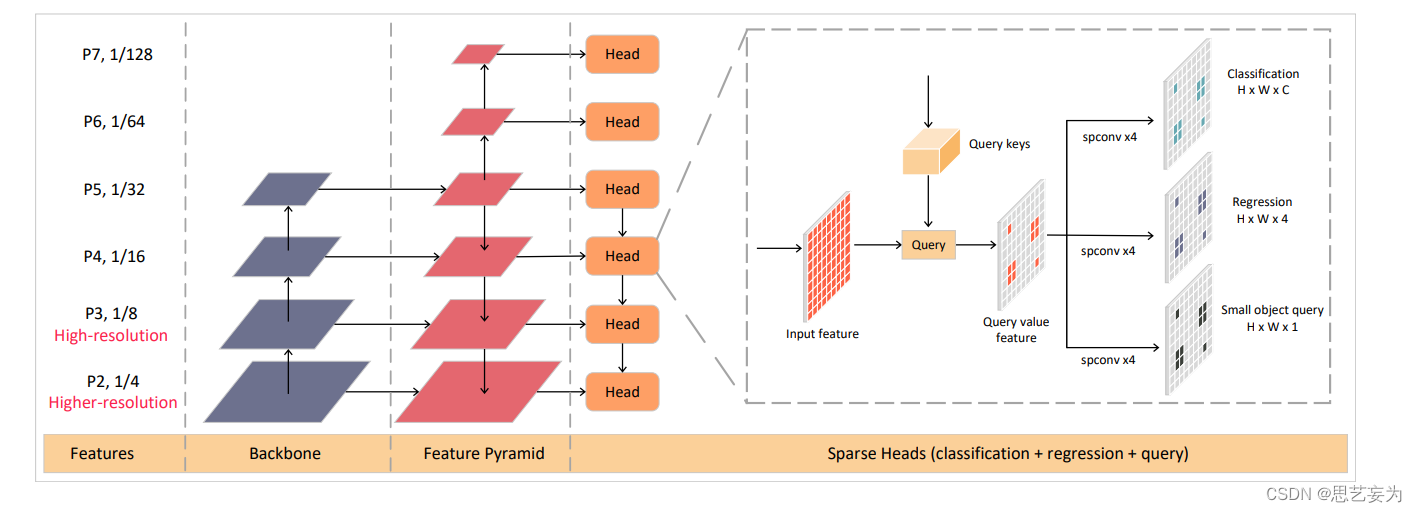
【CVPR 2022】QueryDet:加速高分辨率小目标检测
大连不负众望,疫情了,我们又封校了,可能初步封个5678天,微笑jpg
论文地址:https://arxiv.org/pdf/2103.09136.pdf 项目地址:https://github.com/ ChenhongyiYang/QueryDet-PyTorch
1. 简介
背景…
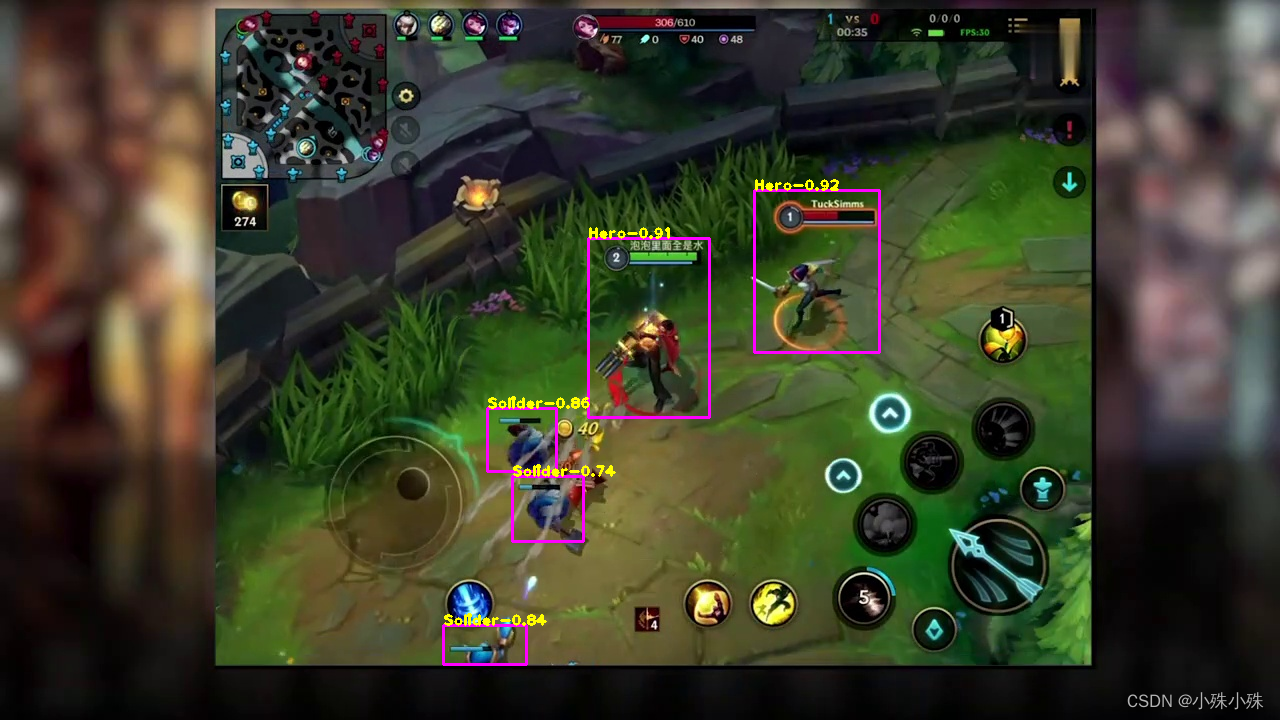
【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理
目录
一、项目介绍
二、项目结构
三、准备数据
1.数据标注
2.数据转换格式
四、执行训练
1.anchors文件
2.标签文件
3.预训练模型
4.训练数据
5.修改配置
6.执行训练
五、执行预测
1.检测图片
2.检测视频
3.heatmap
五、转换onnx
1.导出onnx文件
2.检测图片…

目标检测论文解读复现【NO.21】基于改进YOLOv7的小目标检测
前言
此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文࿰…

论文投稿指南——中文核心期刊推荐(航空、航天)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…
计算机视觉图像降噪实战:基于PyTorch实现图像去模糊任务详细教程
任务描述 相机的抖动、快速运动的物体都会导致拍摄出模糊的图像,景深变化也会使图像进一步模糊。对于传统方法来说,要想估计出每个像素点对应的 “blur kernel” 几乎是不可行的。因此,传统方法常常需要对模糊源作出假设,将 “blur kernel” 参数化。显然,这类方法不足以解…
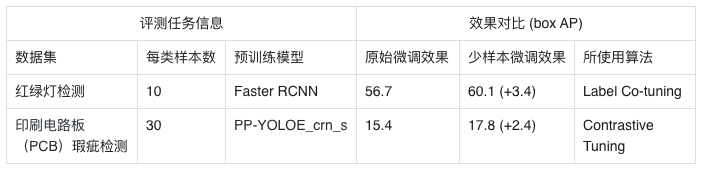
囿于数据少?泛化性差?PaddleDetection少样本迁移学习助你一键突围!
目标检测是非常基础和重要的计算机视觉任务,在各行业有非常广泛的应用。然而,在很多领域的实际落地过程中,由于样本稀缺、标注成本高或业务冷启动等困难,难以训练出可靠的模型。 在目标检测这类较为复杂的学习任务上,样…
![基于YOLOv5+C3CBAM+CBAM注意力的海底生物[海参、海胆、扇贝、海星]检测识别分析系统](https://img-blog.csdnimg.cn/img_convert/df21899986d75fb72e8d3291ac8b7a60.png)
基于YOLOv5+C3CBAM+CBAM注意力的海底生物[海参、海胆、扇贝、海星]检测识别分析系统
在我前面的一些文章中也有用到过很多次注意力的集成来提升原生检测模型的性能,这里同样是加入了注意力机制,区别在于,这里同时在两处加入了注意力机制,第一处是讲CBAM集成进入原生的C3模块中,在特征提取部分就可以发挥…
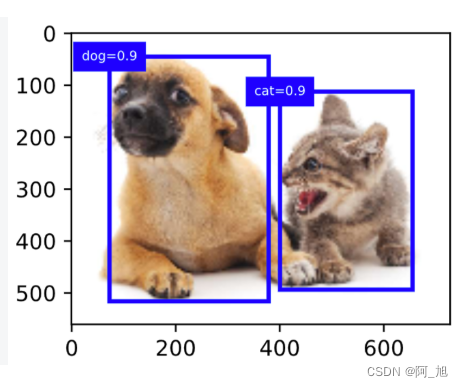
【从零开始学习深度学习】46. 目标检测中锚框的概念、计算方法、样本锚框标注方式及如何选取预测边界框
本文主要介绍目标检测中常用到的锚框相关概念、计算方式、样本标注及如何选取预测边界框并输出的相关内容。 目录1. 锚框介绍1.1 生成多个锚框2. 交并比--Jaccard系数3. 标注训练集的锚框4. 输出预测边界框---非极大值抑制方法总结1. 锚框介绍
在目标检测算法中通常会在输入图…
目标检测------损失函数=类别损失+位置损失
## 损失函数一般的目标检测模型包含两类损失函数:一类是类别损失(分类),另一类是位置损失(回归)。 这两类损失函数往往用于检测模型最后一部分,根据模型输出(类别和位置)和实际标注框(类别和位置)分别计算类别损失和位置损失。
1.类别损失
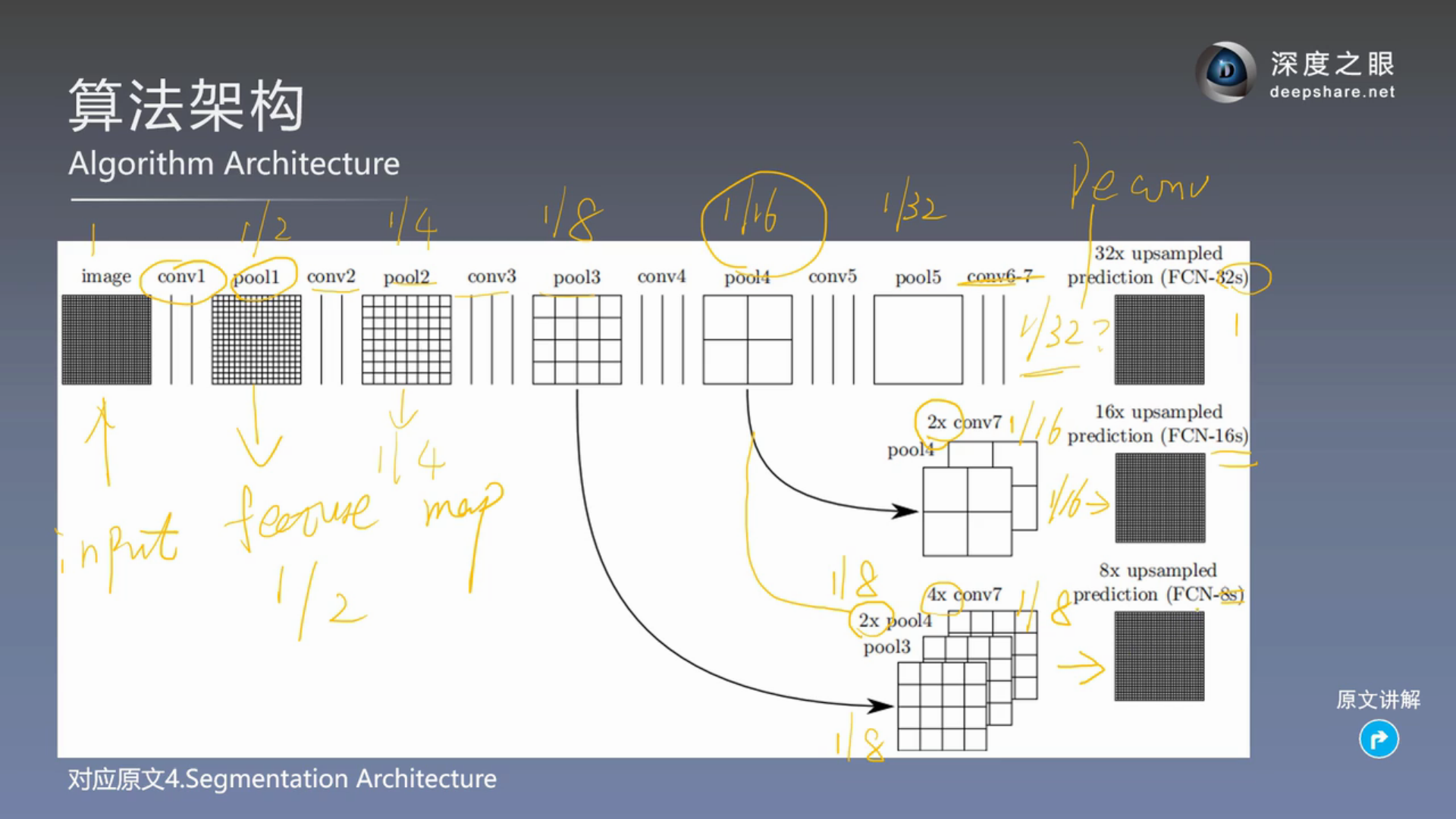
【深度学习笔记】全卷积网络FCN及 ROI Pooling 和 ROI Align 的区别
问题
FCN 是语义分割的开山之作,没理由不了解。最近发现学习最快的方式还是看别人的教学视频,很多时候博客看一大推,没几个能讲地明白的,确实啊,视频都得用四五十分钟的东西,一个博客得写得多详细才能覆盖到方方面面呀,以后还是先借助视频来学习,然后再根据源码进一步…
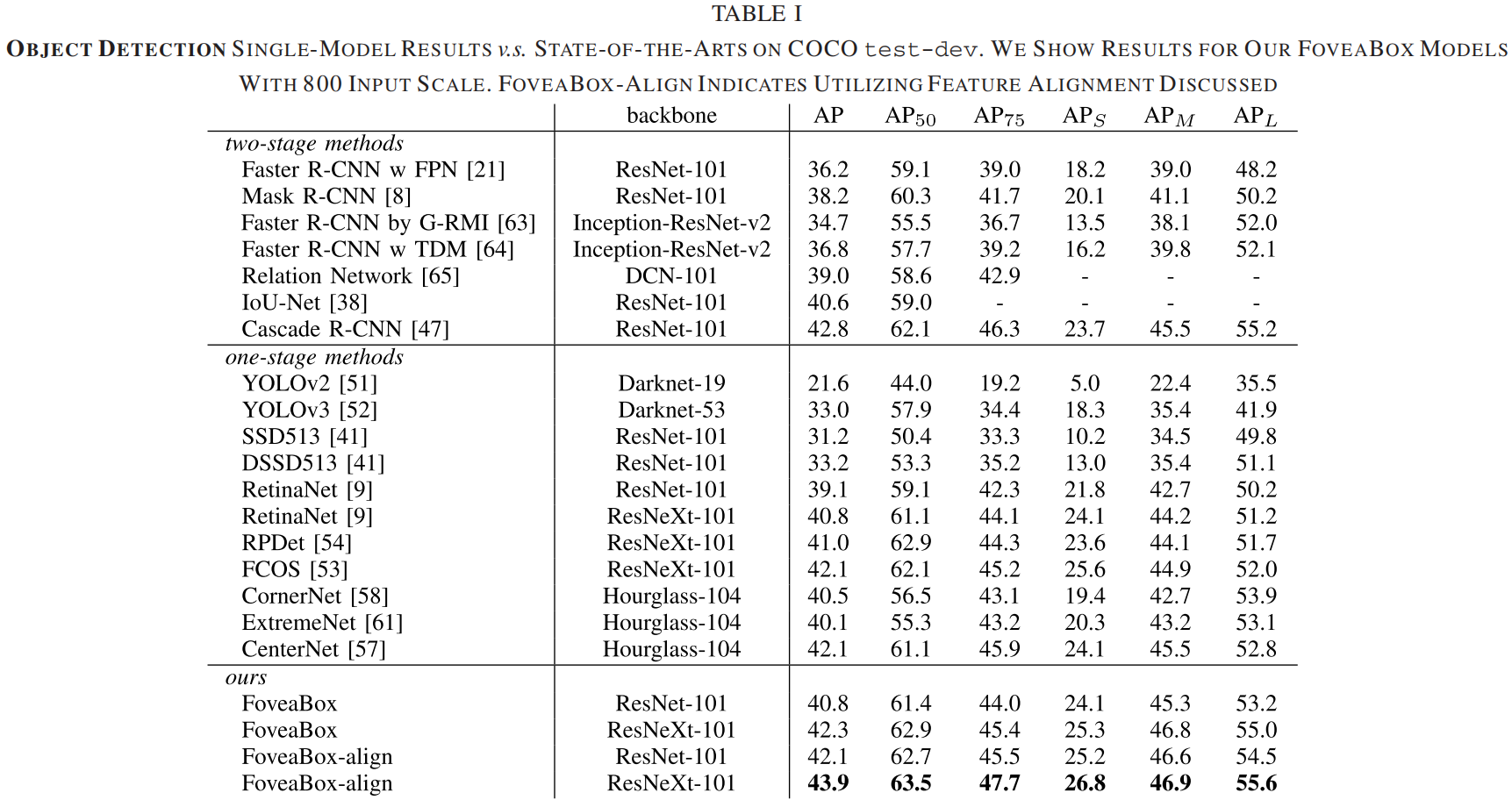
FoveaBox原理与代码解析
paper:FoveaBox: Beyond Anchor-based Object Detectorcode:https://github.com/taokong/FoveaBox背景基于anchor的检测模型需要仔细设计anchor,常用方法之一是根据特定数据集的统计结果确定anchor的number、scale、ratio等,但这种…
河道治理漂浮物识别监测系统 yolov7
河道治理漂浮物识别监测系统通过yolov7网络模型深度视觉分析技术,河道治理漂浮物识别监测算法模型实时检测着河道水面是否存在漂浮物、水浮莲以及生活垃圾等,识别到河道水面存在水藻垃圾等漂浮物,立即抓拍存档预警。You Only Look Once说的是…
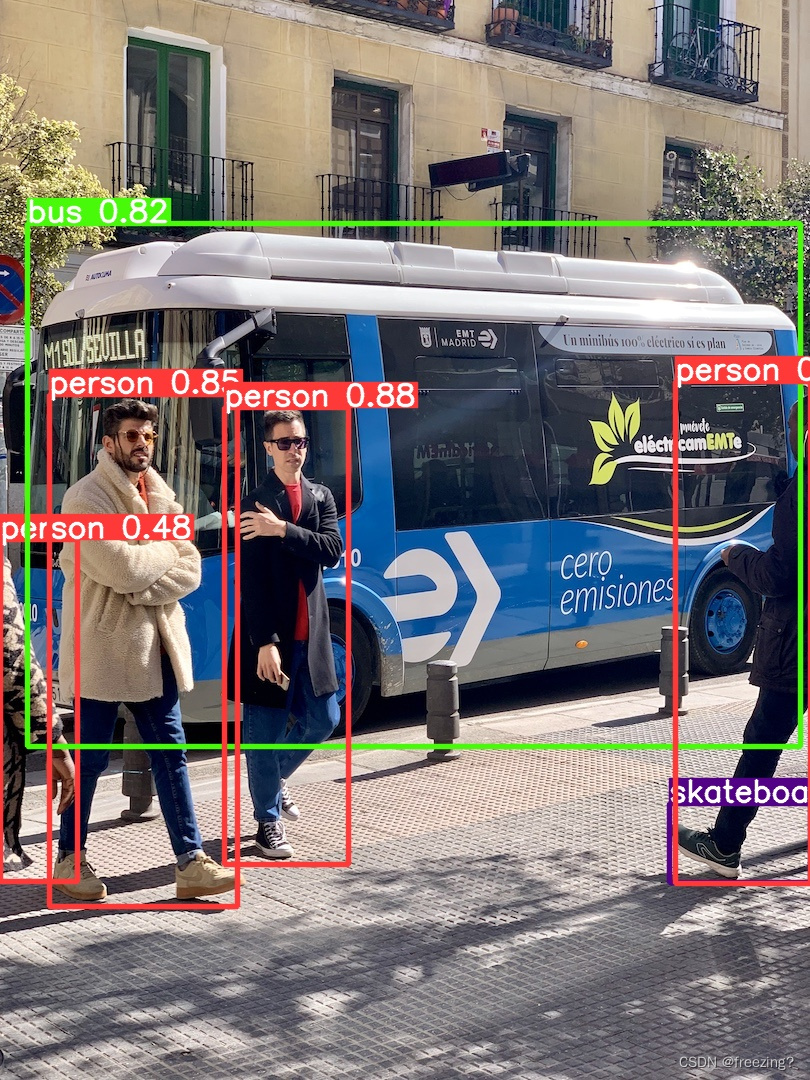
【yolov5】首次尝试目标检测利用prompt
1、打开prompt
2、切换到pytorch所在环境
conda activate freezing我的环境名是freezing,这里根据自己环境名去激活切换
3、进入到yolov5项目所在路径
激活完环境后立即执行指令当然是无效的,首先要进入到你的项目目录 首先看一下自己的项目在那个位…
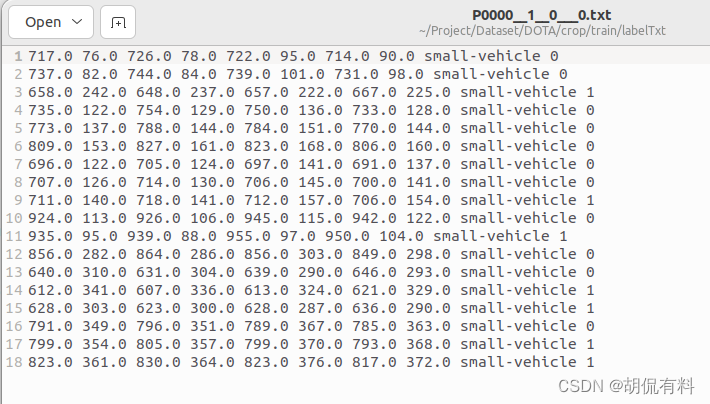
【DOTA】目标检测数据集介绍与使用
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog
0. 前言
DOTA 数据集简单介绍
1. 正文
1.1 简介
数据集包含来自不同的传感器和平台的航拍图。每张图像的像素尺寸在 800 800 到 20,000 20,000 之间…
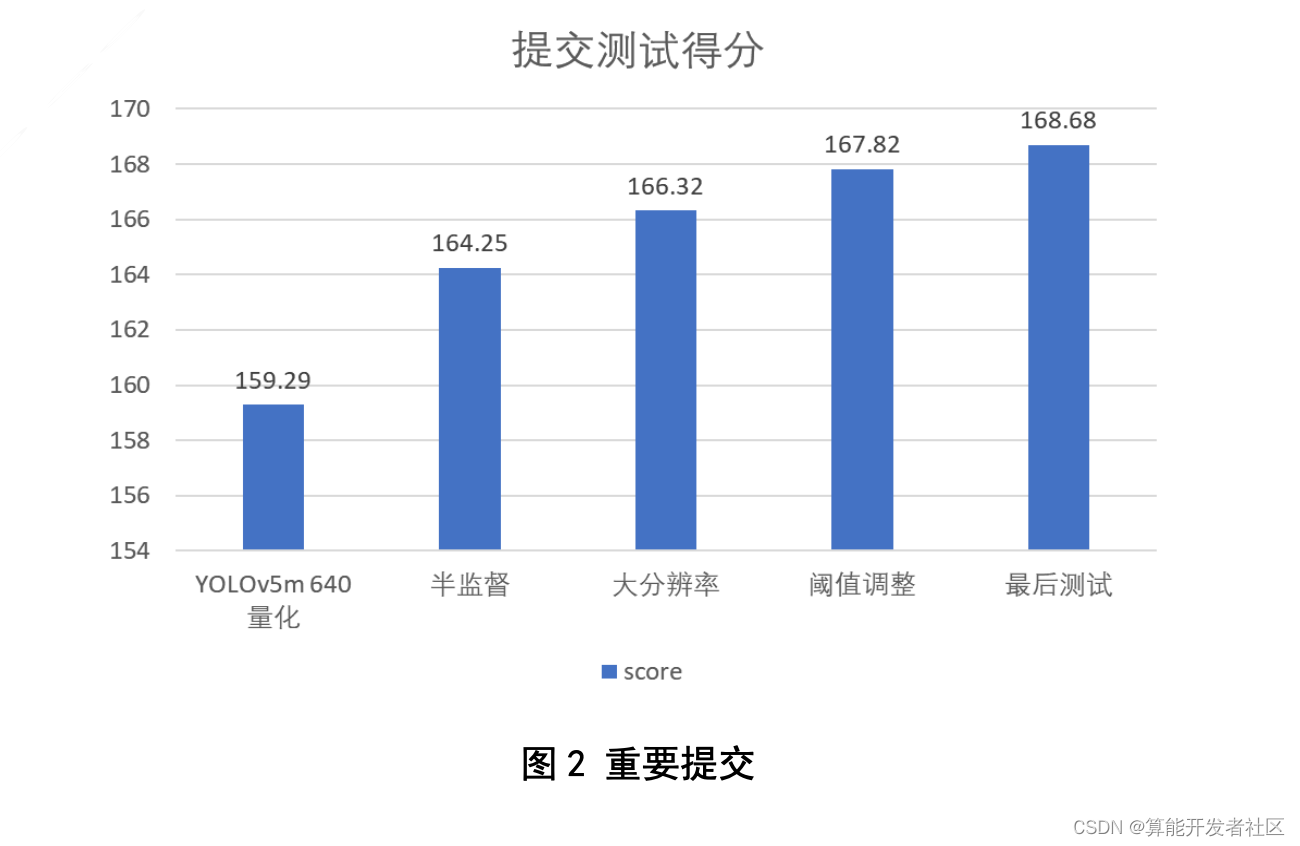
AI算法创新赛-人车目标检测竞赛总结03
团队简介AI0000032 团队成员均为从事计算机视觉领域的企业员工,热爱技术,勇于挑战,致力于更通用目标检测算法的研究与落地。团队由三人组成,队长何正海 主要负责整体方案设计与模型的量化工作,余洋主要负责模型训练与调…
论文投稿指南——中文核心期刊推荐(社会学)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…

YOLOv5全面解析教程⑤:计算mAP用到的Numpy函数详解
作者 | Fengwen、BBuf 本文主要介绍在One-YOLOv5项目中计算mAP用到的一些numpy操作,这些numpy操作使用在utils/metrics.py中。本文是《YOLOv5全面解析教程④:目标检测模型精确度评估》的补充,希望能帮助到小伙伴们。 欢迎Star、试用One-YOLOv…

TPU编程竞赛系列|算能赛道冠军SO-FAST团队获第十届CCF BDCI总决赛特等奖!
近日,第十届中国计算机学会(CCF)大数据与计算智能大赛总决赛暨颁奖典礼在苏州顺利落幕,算能赛道的冠军队伍SO-FAST从2万余支队伍中脱颖而出,获得了所有赛道综合评比特等奖! 本届CCF大赛吸引了来自全国的2万…
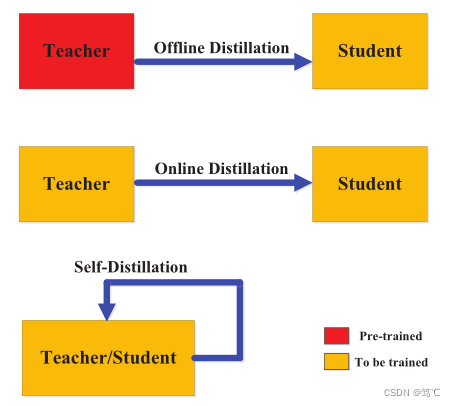
【知识蒸馏】什么是知识蒸馏、方法解读
【知识蒸馏】什么是知识蒸馏、方法解读 文章目录【知识蒸馏】什么是知识蒸馏、方法解读1. 前言1.1 由来1.2 定义1.3 可蒸馏(迁移)的知识2. 蒸馏方法介绍2.1 知识的种类、蒸馏的种类2.2 “知识”的种类2.2.1 基于响应的知识__Distilling the Knowledge in…
开荒手册4——Related work撰写
0 写在前面
最早读文献的时候,每每看到related work部分都会选择性的忽略,觉得是文献堆砌,等自己写过一篇,以及在写第二篇的时候回头看看,觉得related work还是值得回味的。
1 Related work架构
基本要求
主题相关…
315|如何构建持续性全过程质量管理体系?
1、构建全过程质量管理体系 为了保证软件开发质量,一般来说QA检查单按照检查阶段划分为:需求分析、系统设计、系统实现、系统测试、交付验收、系统运维。而QA检查单中的不符合项,需要实行闭环管理,并全过程跟踪不符合项的解决状态…

目标检测算法之R-CNN和SPPNet原理
一、R-CNN的原理 R-CNN的全称是Region-CNN,它可以说是第一个将深度学习应用到目标检测上的算法。后面将要学习的Fast R-CNN、Faster R-CNN全部都是建立在R-CNN基础上的。 传统的目标检测方法大多以图像识别为基础。一般可以在图片上使用穷举法选出所有物体可能出现的…

玩转肺癌目标检测数据集Lung-PET-CT-Dx ——②预览数据集,绘制锚框
文章目录数据集预览CT图片和xml文件的对应关系查看dcm文件信息将dcm图像与xml标注文件配对本文接着预览数据集的概况,看看图像文件和标注文件该如何处理。 本文所用代码: 我的Github
数据集预览
数据集分成三部分: Images 为我们需要下载的…
【计算机视觉 | 目标检测】常见的两种评价指标:AP50和APr的理解和对比
一、引言
平均精度(Average Precision,简称AP)是目标检测中广泛使用的一种评价指标,用于衡量模型的检测精度。AP的计算方式基于精度-召回曲线(precision-recall curve)。
精度-召回曲线是在不同的置信度阈…
yolov7目标检测:基于自定义数据集完成检测、训练、测试
文章目录前言一、环境与文件准备1.1、环境配置1.2、源码下载1.3、权重文件下载1.4、详解源码中的文件夹与文件1.5、详解配置参数二、检测模型(detect.py)2.1、自定义检测数据准备2.2、配置参数2.2.1、方式一:打开Pycharm,进入Term…
【计算机视觉 | 目标检测】BARON:“区域表征被映射到单词表征空间中”,该怎么理解?
一、前言
在看论文的过程中: 这句话不理解,直观翻译过来就是:将包中的区域嵌入投影到词嵌入空间。
The region embeddings in a bag are projected to the word embedding space
这个句子可以理解为:在一个包中,区域…
【计算机视觉 | 目标检测】术语理解2:Grounding 任务、MLM、ITM代理任务
文章目录 一、Grounding 任务二、word-region 级别的 grounding 任务三、MLM、ITM代理任务 一、Grounding 任务
Grounding 任务是指将自然语言文本与视觉场景之间进行对齐或连接的任务。在这个任务中,文本描述和视觉信息需要建立联系,以实现跨模态的理解…
【代码调试】《Multi-scale Positive Sample Refinement for Few-shot Object Detection》
论文地址:https://arxiv.org/abs/2007.09384#:~:textMulti-Scale%20Positive%20Sample%20Refinement%20for%20Few-Shot%20Object%20Detection.,previous%20attempts%20that%20exploit%20few-shot%20classification%20techniques%20 代码地址:https://git…
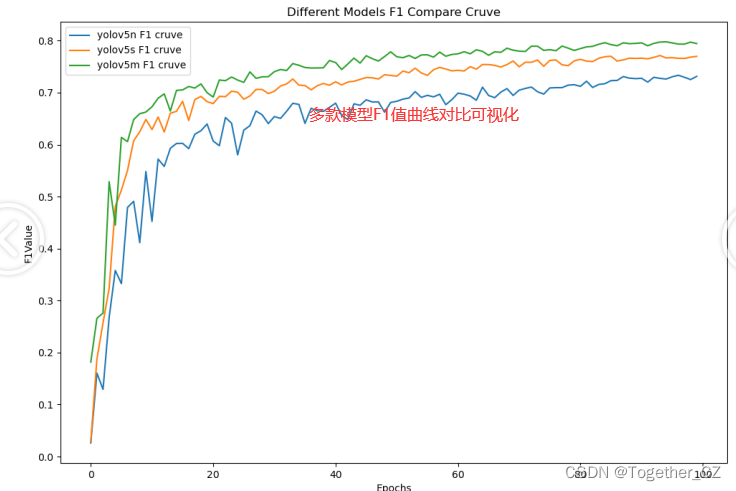
尝试探索水下目标检测,基于yolov5轻量级系列模型n/s/m开发构建海底生物检测系统
其实,水下目标检测相关的项目早在之前就已经做了几个了,但是没有系统性地对比过,感兴趣的话可以先看下之前的文章,如下:
《基于自建数据集【海底生物检测】使用YOLOv5-v6.1/2版本构建目标检测模型超详细教程》 《基于…
yolov3代码运行
目录
代码下载:ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite (github.com)
1:detect.py运行:
2:train.py运行
2.1:注意的一个很烦的点:wandb,这玩意一直报错&…

CV大一统模型的第一步!Segment Anything Model 最全解读!
Datawhale干货 作者:崔腾松,Datawhale成员前言Meta 开源万物可分割 AI 模型:segment anything model (SAM)。本文列举了一些资料,并从SAM的功能介绍、数据集、数据标注、图像分割方法介绍,研发思路以及对未来的展望来展…

RCNN网络原理详解
文章目录 一、前言二、R-CNN原理步骤2.1.Selective Search生成目标检测框2.2.对候选区域使用深度网络提取特征2.3.SVM分类2.4.使用回归器精细修正候选框位置 三、总结参考博客与学习视频 一、前言
学习目标检测当然要学习目标检测领域的开山之作R-CNN,本文为个人笔记。
二、…

论文投稿指南——中文核心期刊推荐(电子、通信技术3)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄🎈 核心期刊在国内的应用范围非常广,核心期刊发表很多是国内作者晋升中的硬性要求,在…
如何使用Django 结合WebSocket 进行实时目标检测呢?以yolov5 为例,实现:FPS 25+ (1: 后端)
文章大纲 web 框架 -- djangowebsocket 和 django 集成实时目标检测服务django后端搭建的主要步骤app 注册 和 添加路由django channel消息队列 与中间件redis问题:为什么发送一会就回中断? python websockets 断线重连实体的定义关键的consummerDjango 日志模块发送端:目标…
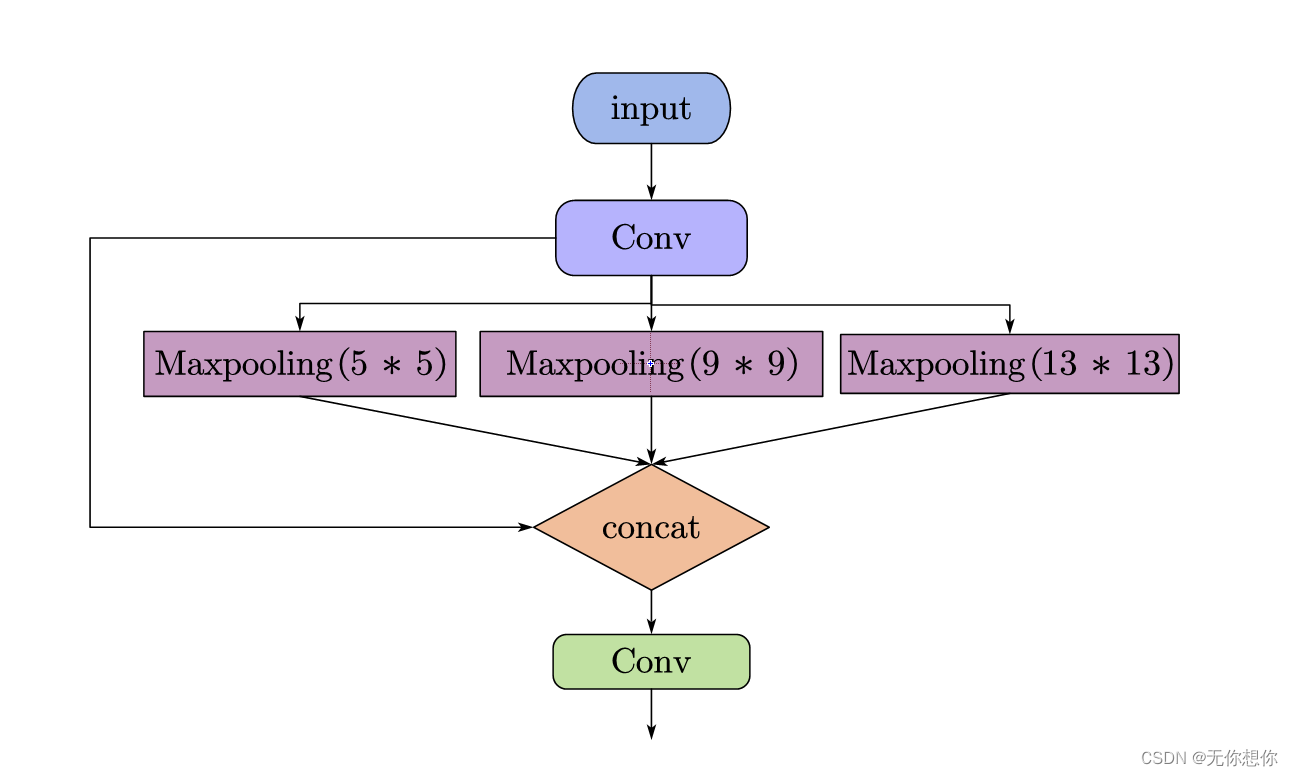
Yolov5之common.py文件解读
深度学习训练营原文链接前言0.导入需要的包以及基本配置1.基本组件1.1 autopad1.2 ConvDWConv模块1.3TransformerLayer模块1.4 Bottleneck和BottleneckCSPBottleneck模型结构1.5 CrossConv模块1.6 C3模块基于C3的改进1.7SPP1.8Focus模块1.9 Concat模块1.10 Contract和Expand1.1…
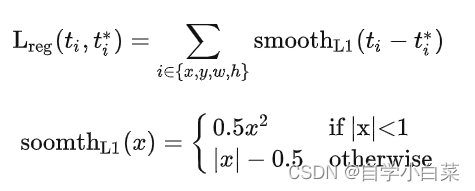
Faster-RCNN代码解读6:主要文件解读-中
Faster-RCNN代码解读6:主要文件解读-中 前言 因为最近打算尝试一下Faster-RCNN的复现,不要多想,我还没有厉害到可以一个人复现所有代码。所以,是参考别人的代码,进行自己的解读。
代码来自于B站的UP主ÿ…

Faster-RCNN代码解读7:主要文件解读-下
Faster-RCNN代码解读7:主要文件解读-下 前言 因为最近打算尝试一下Faster-RCNN的复现,不要多想,我还没有厉害到可以一个人复现所有代码。所以,是参考别人的代码,进行自己的解读。
代码来自于B站的UP主ÿ…
Faster-RCNN代码解读2:快速上手使用
Faster-RCNN代码解读2:快速上手使用 前言 因为最近打算尝试一下Faster-RCNN的复现,不要多想,我还没有厉害到可以一个人复现所有代码。所以,是参考别人的代码,进行自己的解读。
代码来自于B站的UP主(…
深度学习中的两阶段目标检测
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…
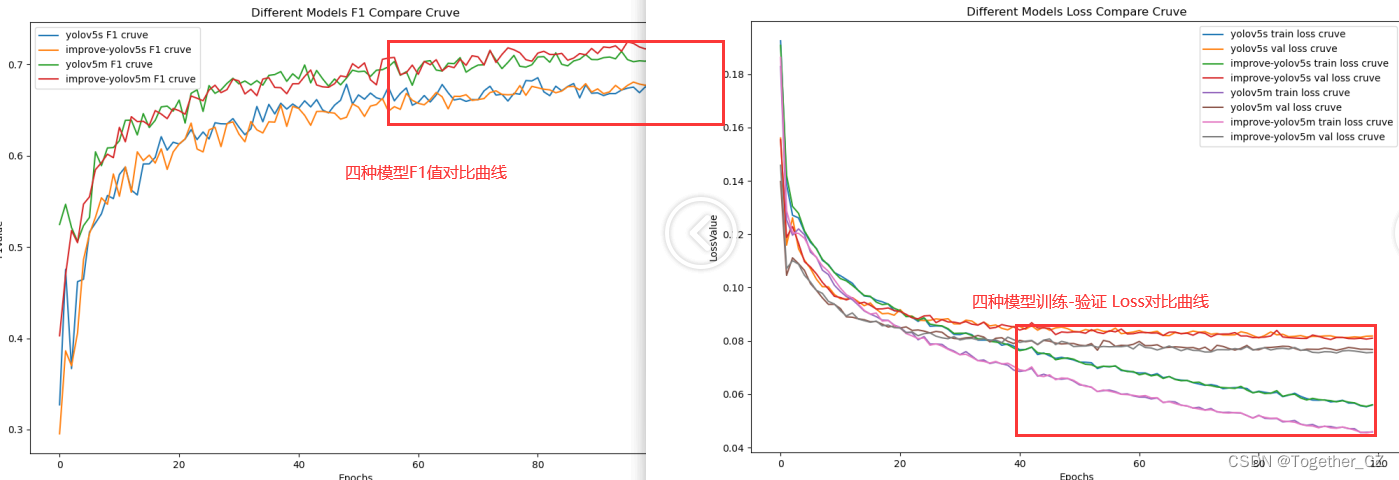
探索实践低光照场景下YOLOv5s模型上限,融合CBAM注意力机制开发构建基于改进YOLOv5s的低光照条件下目标检测识别分析系统
在现实生活场景里面,很多场景下光线光照条件都是比较差的,比如夜晚、室内等,这时候以往的目标检测模型是否还能够胜任我们所需的目标检测任务呢?这里主要的想法就是基于地光线条件下的数据集来开发构建目标检测系统,探…
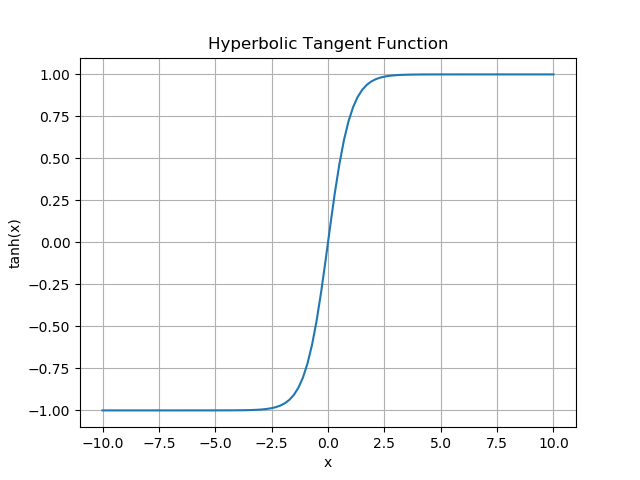
激活函数高频面试题集合
激活函数激活函数的作用是什么?常用的激活函数Relu引入Relu的原因Relu顺序relu在零点可导吗,不可导如何进行反向传播?Geluleaky relu优点缺点softmaxsigmoid缺陷tanh缺点如何选择激活函数Bert、GPT、GPT2中用的激活函数是什么?为什…

3D点云障碍物标注案例
3D点云标注内容
标注范围内的类别列表上的所有物体都需要标注,主要是道路上正在行驶和静止的参与者(包括行人、车辆等), 以及路上基本的交通设施
目标物ID
目标物 ID 应在前后帧中保持一致。一个对象只有一个目标ID,不能重复使用
标注要求…
论文投稿指南——中文核心期刊推荐(石油、天然气工业 2)
【前言】
🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…

目标检测框架yolov5环境搭建
目前,目标检测框架中,yolov5 是很火的,它基于pytorch框架,集成opencv等框架,项目地址:https://github.com/ultralytics/yolov5,对我来说,机器学习、深度学习才开始接触,本…
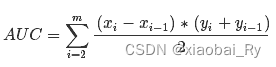
目标检测各常见评价指标详解
注:本文仅供学习,未经同意请勿转载 说明:该博客来源于xiaobai_Ry:2020年3月笔记 对应的PDF下载链接在:待上传
目录
常见的评价指标
准确率 (Accuracy)
混淆矩阵 (Confusion Matrixÿ…
【pytorch】nn.SmoothL1Loss 函数使用
SmoothL1 Loss1、Smooth L1 Loss2、nn.SmoothL1Loss 函数使用1、Smooth L1 Loss
本方法由微软rgb大神提出,Fast RCNN论文提出该方法
1)假设x为预测框和真实框之间的数值差异,常用的 L1 loss、L2 Loss 和 smooth L1 loss 定义分别为…

百度西交大大数据菁英班目标检测竞赛
来源:投稿 作者:LSC 编辑:学姐 数据介绍
数据集共包括40000张训练图像和1000张测试图像,每张训练图像对应xml标注文件: 共包含3类:0:head, 1:helmet, 2:person。
提交格式要求,提交名为pred_r…
基于深度学习的高精度安全背心检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度安全背心检测识别系统可用于日常生活中或野外来检测与定位安全背心目标,利用深度学习算法可实现图片、视频、摄像头等方式的安全背心目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5…

【Opencv项目实战】目标检测:自动检测出现的所有动态目标
文章目录一、项目思路二、算法详解2.1、计算两个数组或数组与标量之间的每个元素的绝对差。2.2、轮廓检测 绘制物体轮廓 绘制矩阵轮廓2.3、连续窗口显示2.4、读取视频,显示视频,保存视频三、项目实战:实时动态目标检测实时动态目标检测一、…

ubuntu搭建 自动驾驶单目3d检测smoke 环境
论文:SMOKE:Single-Stage Monocular 3D Object Detection via Keypoint Estimation 论文链接 源码 操作系统:ubuntu18.04 显卡:RTX2080TI
一、搭环境(前面和GitHub上一样,补上我踩的坑) 1.创建虚拟环境
conda create…

目标检测论文阅读:RepPoints算法笔记
标题:RepPoints: Point Set Representation for Object Detection 会议:ICCV2019 论文地址:https://ieeexplore.ieee.org/document/9009032/ 官方代码:https://github.com/microsoft/RepPoints 作者单位:北京大学、清华…
【开放域目标检测】一:Open-Vocabulary Object Detection Using Captions论文讲解
出发点是制定一种更加通用的目标检测问题,目的是借助于大量的image-caption数据来覆盖更多的object concept,使得object detection不再受限于带标注数据的少数类别,从而实现更加泛化的object detection,识别出更多novel的物体类别…
【计算机视觉】Visual grounding系列
文章目录一、任务简介二、Visual grounding常用数据集与评估指标2.1 常用数据集2.2 评估指标三、Visual grounding主流做法一、任务简介
Visual grounding涉及计算机视觉和自然语言处理两个模态。
简要来说,输入是图片(image)和对应的物体描…
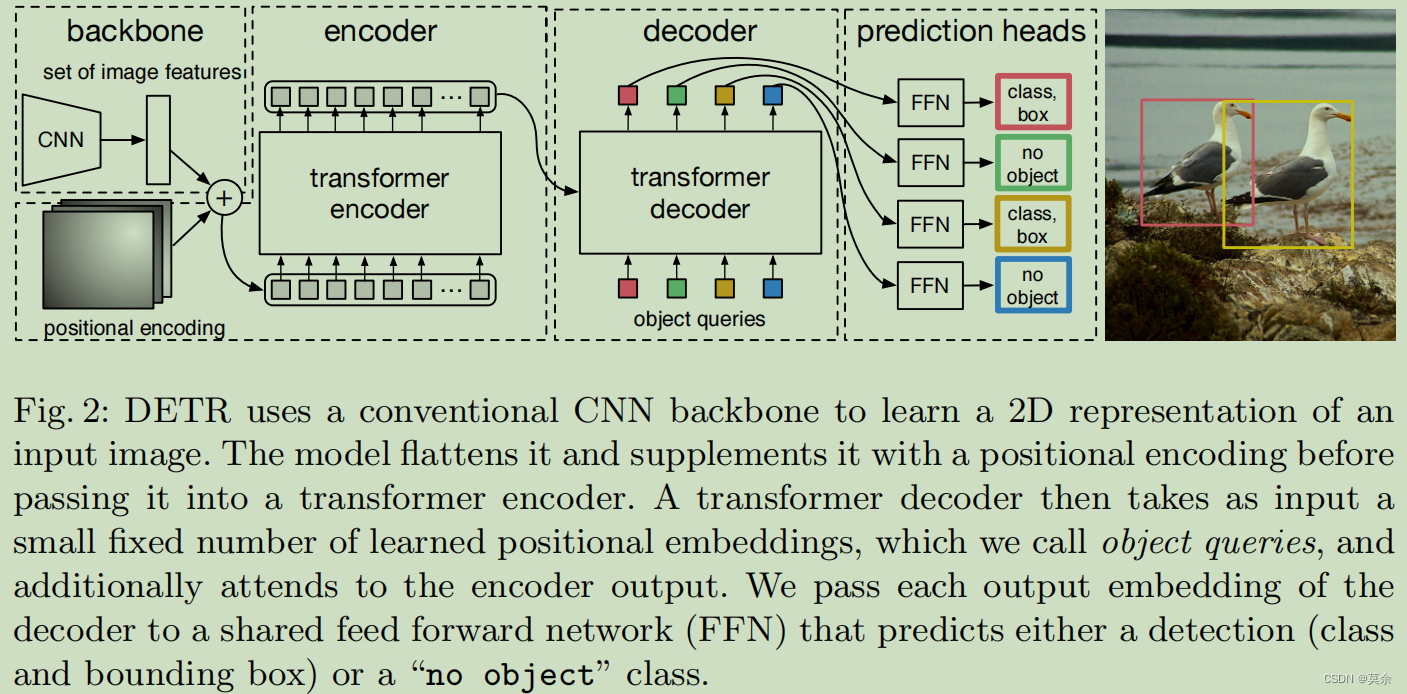
【目标检测 DETR】通俗理解 End-to-End Object Detection with Transformers,值得一品。
文章目录DETR1. 亮点工作1.1 E to E1.2 self-attention1.3 引入位置嵌入向量1.4 消除了候选框生成阶段2. Set Prediction2.1 N个对象2.2 Hungarian algorithm3. 实例剖析4. 代码4.1 配置文件4.1.1 数据集的类别数4.1.2 训练集和验证集的路径4.1.3 图片的大小4.1.4 训练时的批量…

Linux下查看图片中某点的像素X、Y坐标
在做目标检测、目标追踪的任务过程中,我们会用到一些开源的数据集,比如MOT16多目标追踪数据集。这些数据集会提供数据标注文件gt.txt,里面的内容如下1,1,912,484,97,109,0,7,12,1,912,484,97,109,0,7,13,1,912,484,97,109,0,7,14,1,912,484,97,109,0,7,1…
Yolov5目标检测算法解析:模型结构
Yolov5系列是Yolo家族新一代的模型,相比于之前的版本Yolov3和Yolov4,相同的是,它依然采用锚框(anchor)对目标的尺寸进行回归的思想,保持大中小多种尺度特征输出,所不同的是,Yolov5系…

DETR目标检测算法学习记录
引言
无论是One Stage中的YOLO还是Two-Stage中的Faster-RCNN,其虽然都在目标检测领域有着一席之地,但无一例外都是基于Anchor的模型算法,这就导致其在输出结果时不可避免的进行一些如非极大值抑制等操作来进一步选择最优解,这会带…

【netron】模型可视化工具netron
1、简介
在实际的项目中,经常会遇到各种网络模型,需要我们快速去了解网络结构。如果单纯的去看模型文件,脑海中很难直观的浮现网络的架构。这时,就可以使用netron可视化工具,可以清晰的看到每一层的输入输出ÿ…

【论文阅读总结】用于目标检测的特征金字塔网络(FPN)
Feature Pyramid Networks for Object Detection1.摘要2.引言2.1 低级特征对于检测小物体很重要2.2 算法目标3. 文献综述3.1 Hand-engineered features and early neural networks3.2 Deep ConvNet object detectors3.3 Methods using multiple layers4.Feature Pyramid Networ…

YOLOv5改进系列(1)——添加SE注意力机制
前言
从这篇开始我们进入YOLOv5改进系列。那就先从最简单的添加注意力机制开始吧!( ̄︶ ̄)↗
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分…
YOLO V1-V3 简单介绍
目录
1. YOLO
2. YOLO V1
3. YOLO V2
4. YOLO V3
5. YOLO V3 SPP网络
5.1 Mosaic 图像增强
5.2 SPP 模块
5.3 CIou Loss
5.4 Focal loss 1. YOLO
YOLO 是目标检测任务强大的算法,将目标检测的问题转换边界框和相关概率的回归问题,是目标检测…

【深一点学习】我用CPU也能跟着沐神实现单发多框检测(SSD),从底层了解目标检测任务的实现过程,需要什么样的方法调用。《动手学深度学习》Yes,沐神,Yes
目标检测近年来已经取得了很重要的进展,主流的算法主要分为两个类型[1611.06612] RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation (arxiv.org):(1)two-stage方法,如R-CNN系算法…
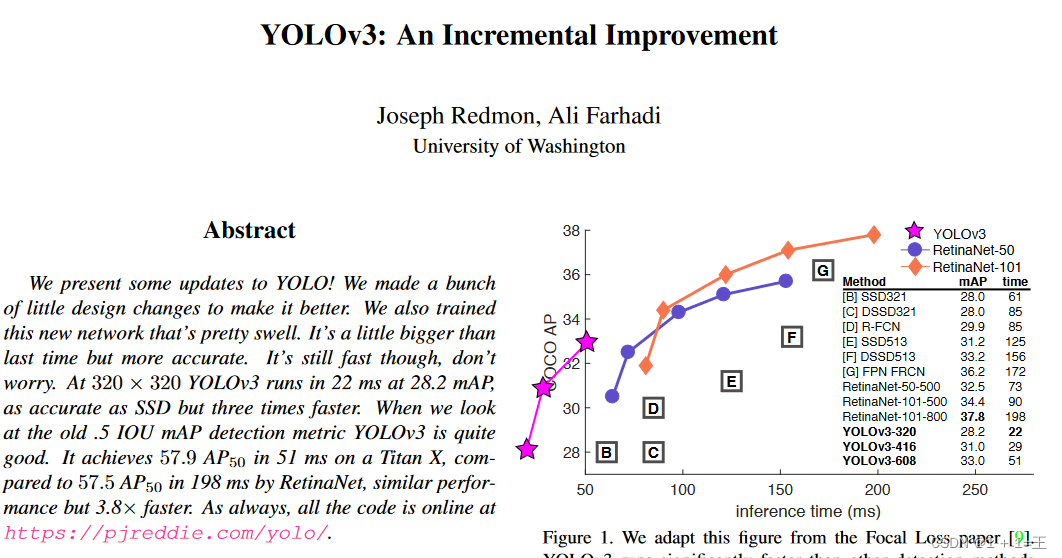
目标检测【Object Detection】
文章目录基本概念两阶段目标检测算法R-CNNFast R-CNNFaster R-CNNFPNMask R-CNN一阶段目标检测算法SSDYOLOv1YOLOv2YOLOv3目标检测的常用数据集目标检测的标注工具基本概念
目标检测是计算机视觉中的一个重要问题,它的目的是从图像或视频序列中识别出特定的目标&am…

Faster-RCNN网络详解
文章目录 一、前言二、Faster-RCNN算法原理2.1.RPN结构2.1.1感受野的计算与候选框的生成2.1.2正负样本 2.2.RPN的损失计算2.2.1对于分类损失2.2.2.边界回归参数 2.3.Fast-RCNN损失2.4.整体训练 三、总结四、参考博客、视频、论文地址4.1.B站优质UP视频4.2.系类论文地址4.3.个人…
Roboflow的使用
文章目录 前言一、使用labelimg标注数据集二、导入roboflow1.注册roboflow账户2.导入图片2.1 创建工作区workspace(非必须)2.2 创建项目 project2.3 导入 3、导出图片4、同一个数据集可以导出不同类型 前言
我自己也是一个小白不是很会,如果…
人工智能学习07--pytorch18--目标检测:Faster RCNN源码解析(pytorch)
参考博客: https://blog.csdn.net/weixin_46676835/article/details/130175898
VOC2012 1、代码的使用
查看pytorch中的faster-rcnn源码: 在pytorch中导入:
import torchvision.models.detection.faster_rcnn即可找到faster rcnn所实现的源…

目标检测——SPPNet【含全网最全翻译】
文章目录0. 摘要1. 简介2. 基于空间金字塔池化的深度网络2.1 卷积层和特征图2.2 空间金字塔池化层2.3 网络的训练2.3.1 单一尺寸训练2.3.2 多尺寸训练3. 用于图像分类的SPP-NET3.1 ImageNet 2012分类实验3.1.1 基准网络架构3.1.2 多层次池化提升准确度3.1.3 多尺寸训练提升准确…

UC-OWOD: Unknown-Classified Open World Object Detection(论文翻译)
文章目录 UC-OWOD: Unknown-Classified Open World Object Detection摘要1.介绍2.相关工作3.未知分类的开放世界目标检测3.1 问题定义3.2 整体架构3.3 未知物体的检测3.4基于相似性的未知分类3.5未知聚类优化3.6训练和优化 4:实验4.1准备工作4.2结果和分析4.3消融研…
目标检测——CornerNet
CornerNet是一个比较综合的目标检测论文,如果要详细看的话要补充好多的知识,所以像我们基础比较薄弱的看起来比较吃力,但是一点点慢慢来,总有一些事情是要坚持下去的,比如说…写博客。 【Paper】CornerNet:…
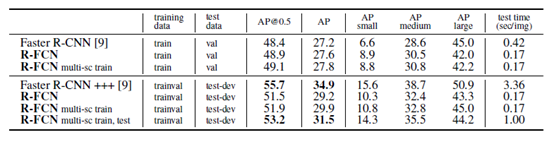
目标检测——R-FCN
Paper:R-FCN: Object Detection via Region-based Fully Convolutional Networks 作者:Jifeng Dai, Yi Li, Kaiming He, Jian Sun Visual Computing Group / Microsoft Research Asia 1 提出框架
首先说一说为什么提出了RFCN。作者分析此前的各种分类和…

DAB-DETR代码学习笔记
先上一张整体架构图 : 代码地址:GitHub - IDEA-Research/DAB-DETR: [ICLR 2022] DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR 论文地址: https://arxiv.org/pdf/2201.12329.pdf 文章全名《DYNAMIC ANCHOR BOXES ARE BETTER …

突破极限:YOLO9000 论文解读 - 构建更好、更快、更强大的实时检测系统
YOLOv2 论文全篇完整翻译 摘要
我们介绍了YOLO9000,这是一种先进的、实时的目标检测系统,可以检测超过9000个物体类别。首先,我们对YOLO检测方法进行了各种改进,包括新颖的方法和借鉴自先前工作的方法。改进后的模型YOLOv2在标准…
OPENCV训练模型
1.介绍
使用Cascade Classifier包括两个主要阶段:训练阶段和检测阶段。需要用到的OpenCV应用程序:opencv_createssamples, opencv_annotation, opencv_traincascade和opencv_visualisation。opencv_createssamples和opencv_traincascade自OpenCV 4.0以来被禁用,…
[数据集][目标检测]目标检测数据集大白菜数据集VOC格式1557张
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):1557 标注数量(xml文件个数):1557 标注类别数:1 标注类别名称:["cabbage"] 每…
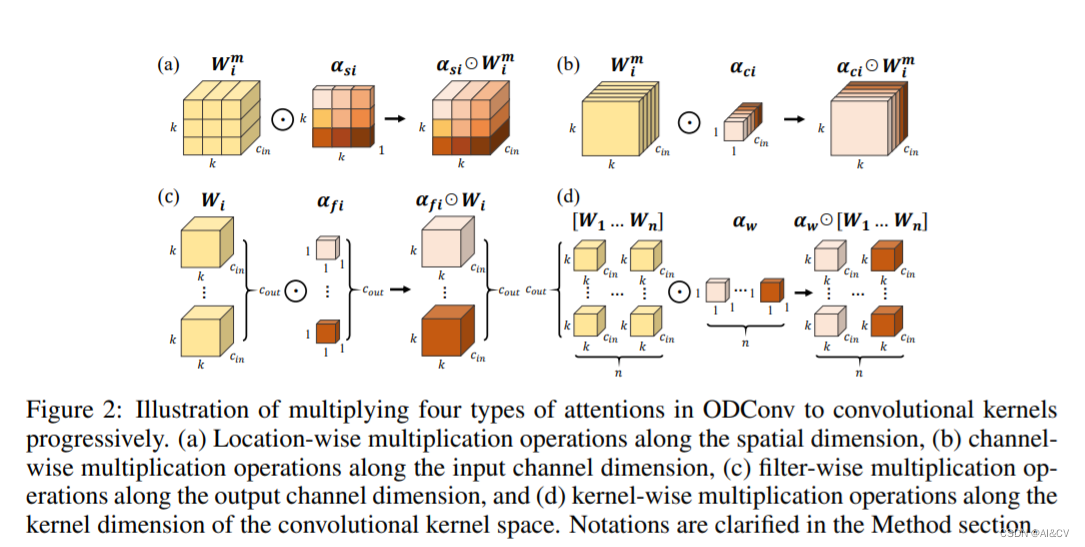
Yolov8涨点神器:ODConv+ConvNeXt提升小目标检测能力
1.涨点神器结合,助力YOLO 1.1 ICLR 2022涨点神器——即插即用的动态卷积ODConv 论文:Omni-Dimensional Dynamic Convolution
论文地址:Omni-Dimensional Dynamic Convolution | OpenReview ODConv通过并行策略引入一种多维注意力机制以对卷积核空间的四个维度学习更灵活的…
3D目标检测(室内)-TR3D
3D目标检测(室内)-TR3D 室内3D目标检测的数据集主要包括了ScanNet、SUN-RGBD和S3DIS。 TR3D是最新的SOTA模型,本文将介绍如何在MMdetection3D框架上对自己的数据进行处理、并用预训练好的TR3D等模型进行推理。 TR3D的github:https://github.com/SamsungL…
图片人群计数模型代码运行指南
PaperWithCode 八大数据集模型排名:https://paperswithcode.com/task/crowd-counting
搜索关键词
“人群计数”(crowd counting,crowd指的是人而不是拥挤的人;Counting People);“人流计数”;“人流量统计”(&#x…
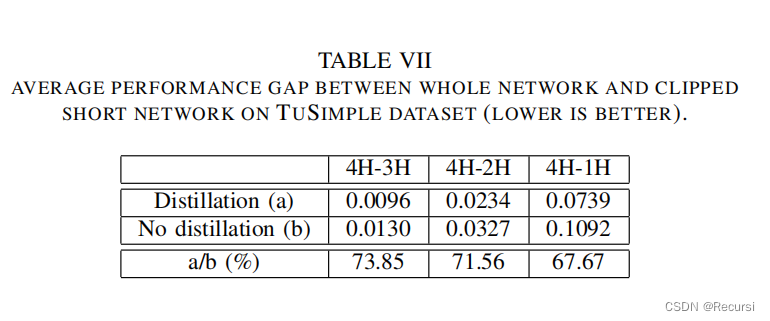
Key Points Estimation and Point Instance
Abstract 在交通线路检测的情况下,需要考虑一个基本的感知模块,但需要考虑许多条件,如交通线路的数量和目标系统的计算能力。为了解决这些问题,本文提出了一种交通线路检测方法,即点实例网络(PINet);该方法…

LaneATT代码阅读理解
LaneATT代码:https://github.com/lucastabelini/LaneATT
代码结构:
cfgs: 默认/预设配置文件figures:README用到的图片lib datasets culane.py : CULane数据集加载器lane_dataset.py : 将来自LaneDatasetLoader中的未经过处理的…

人群计数数据集汇总和详细介绍,全网最全,crowd counting datasets
Crowd Counting数据集汇总
视频监控video surveillance
https://github.com/gjy3035/Awesome-Crowd-Counting/blob/master/src/Datasets.md进展 | 密集人群分布检测与计数 :https://www.sohu.com/a/338406719_823210
Free-view
2022_Pedestrian Attribute Recognition
htt…
机器学习实践系列之9 - 视频结构化
视频结构化 是个沉重的话题,从 前背景建模 到 目标检测,再到目标跟踪,这里面涉及到的东西太多。目前各路安防厂商,视频分析团队 都在大打 结构化的大旗,公安行业也逐渐开始有了一定的应用,大华”睿智”、海…
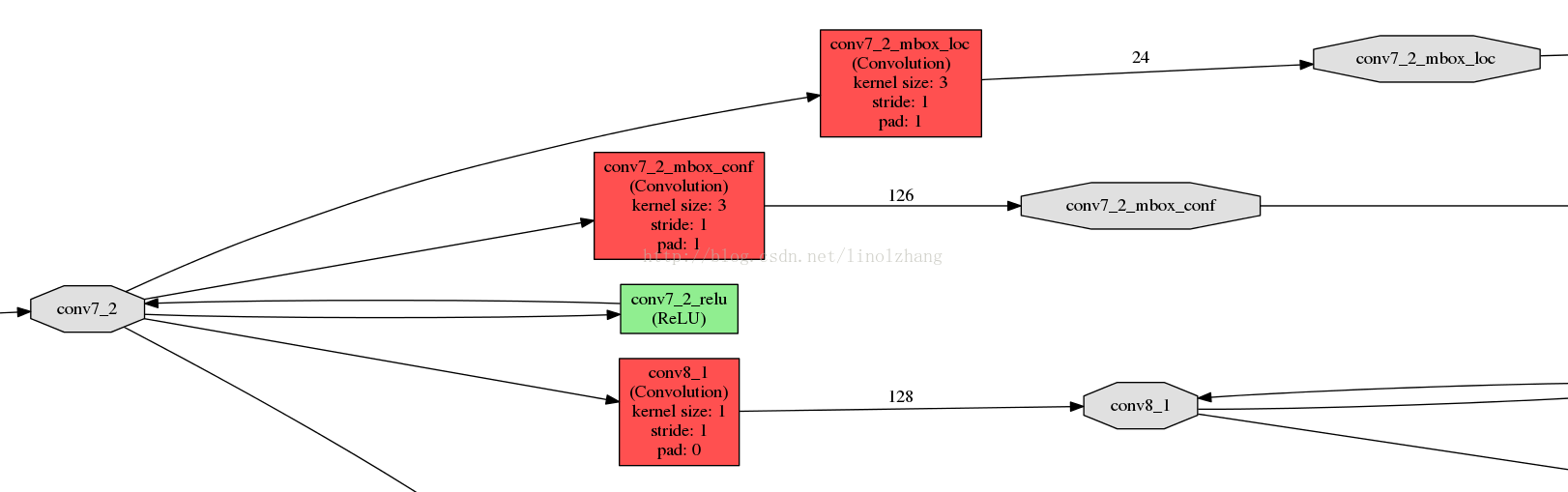
深度学习基础之 - 行人检测SSD
Faster-RCNN 虽然在效果上做到了 State-Of-The-Art,但效率问题无法做到实时,YOLO 在此基础上提出了改进:
一. Region Proposal Region Proposal 过程的优点是能够初步检测有效的 Candidate,缺点是带来效率的降低(Fast…

【YOLO系列】YOLOv6论文超详细解读(翻译 +学习笔记)
前言
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。论文题目是《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》。
本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中ÿ…
目标检测00-09:mmdetection(Foveabox为例)-源码无死角解析(2)-模型构建总览
以下链接是个人关于mmdetection(Foveabox-目标检测框架)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的…
行人检测0-06:LFFD源码无死角解析(1)-训练代码总览注释
以下链接是个人关于LFFD(行人检测)所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励,祝你…
YOLOv5改进系列(7)——添加SimAM注意力机制
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
计算机视觉 - 理论 - 从卷积到识别
计算机视觉 - 理论入门 前言一,导论:二,卷积:图像去噪:常值卷积:高斯卷积:椒盐去噪:锐化程度: 三,边缘检测:图像信号导数:求导算子:图…
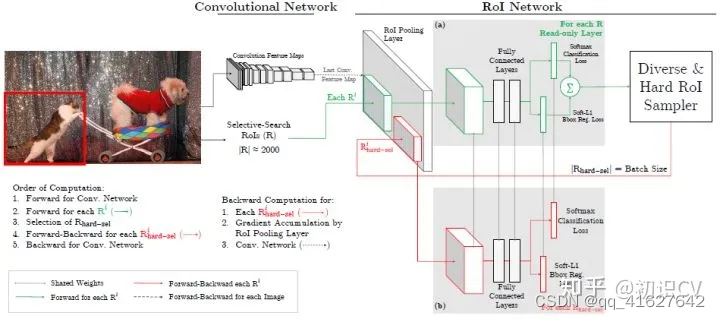
OpenMMLab MMdetection 目标检测模型系例文章(一)
(一)、MMDetection 学习和进阶路线(一)
1、不得不知的 MMDetection 学习路线(个人经验版)
2、轻松掌握 MMDetection 整体构建流程(一)
3、轻松掌握 MMDetection 整体构建流程(二)
4、轻松掌握 MMDetection 中 Head 流程
5、M…
YOLOv5/v7 添加注意力机制,30多种模块分析⑦,CCN模块,GAMAttention模块
目录 一、注意力机制介绍1、什么是注意力机制?2、注意力机制的分类3、注意力机制的核心 二、CCN模块1、CCN模块的原理2、实验结果3、应用示例 三、GAMAttention模块1、GAMAttention模块的原理2、实验结果3、应用示例 大家好,我是哪吒。
🏆本…
【OpenMMLab】AI实战营第二期Day6:目标检测与MMDetection
概要
这篇文章讨论了目标检测和MMDetection,并介绍了相关的基本思路和概念。
亮点
💡 单阶段算法是现在最广泛使用的一类算法。🕵️ 检测器可以检测到感兴趣的物体并在图像中框定它们。🤖 测量计算层次结构计算重叠框的成本比后…
YOLOv5改进系列(9)——替换主干网络之EfficientNetv2
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
基于深度学习的高精度鸽子检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度鸽子检测识别系统可用于日常生活中或野外来检测与定位鸽子目标,利用深度学习算法可实现图片、视频、摄像头等方式的鸽子目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型…
华为开源自研AI框架昇思MindSpore应用案例:SSD目标检测
目录 一、环境准备1.进入ModelArts官网2.使用CodeLab体验Notebook实例 SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络…
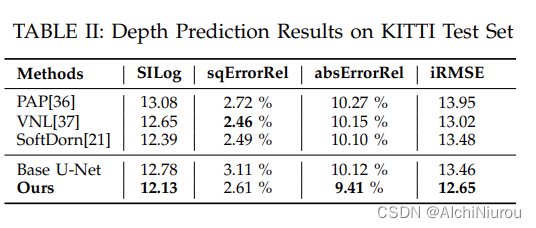
Ground-aware Monocular 3D Object Detection for Autonomous Driving论文
1 摘要
摘要:使用单个RGB相机估计环境中物体的3D位置和方向是低成本城市自主驾驶和移动机器人的一项至关重要的挑战性任务。大多数现有算法基于二维-三维对应中的几何约束,这源于一般的6D目标姿态估计。我们首先确定地平面如何在驾驶场景的深度推理中提…

多目标检测:基于Yolo优化的多目标检测(附论文下载)
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 计算机视觉研究院专栏 作者:Edison_G 为了解决目标检测任务中小目标检测精度低、误检、漏检率高等问题,有研究者提出了一种新…

使用yolov5训练自己的数据集并测试效果
1.源码下载链接
1.yolov5原模型以及权重文件
链接:https://pan.baidu.com/s/1XlvHIxlzJEqp2wlRx5Fb1w 提取码:xtkj
2.训练自己数据集的完整代码
链接:https://pan.baidu.com/s/1xdnah8ZLoT7E1YDm-RiGzQ 提取码:9261
2.训练…

目标检测 Chapter1 传统目标检测方法
文章目录目标检测问题定义介绍目标检测和图像分类、图像分割的区别目标检测问题方法传统目标检测深度学习目标检测传统 Vs 深度学习传统目标检测综述Viola-JonesHOGSVMDPMNMS 非极大值抑制目标检测问题定义
介绍 目标种类与数量问题:种类不同。种类越多,…

基于深度学习的目标检测的介绍(Introduction to object detection with deep learning)
物体检测的应用已经深入到我们的日常生活中,包括安全、自动车辆系统等。对象检测模型输入视觉效果(图像或视频),并在每个相应对象周围输出带有标记的版本。这说起来容易做起来难,因为目标检测模型需要考虑复杂的算法和数据集,这些…

【计算机视觉 | 目标检测】arxiv 计算机视觉关于分类和分割的学术速递(6月 22 日论文合集)
文章目录 一、分类相关(4篇)1.1 Annotating Ambiguous Images: General Annotation Strategy for Image Classification with Real-World Biomedical Validation on Vertebral Fracture Diagnosis1.2 Benchmark data to study the influence of pre-training on explanation pe…
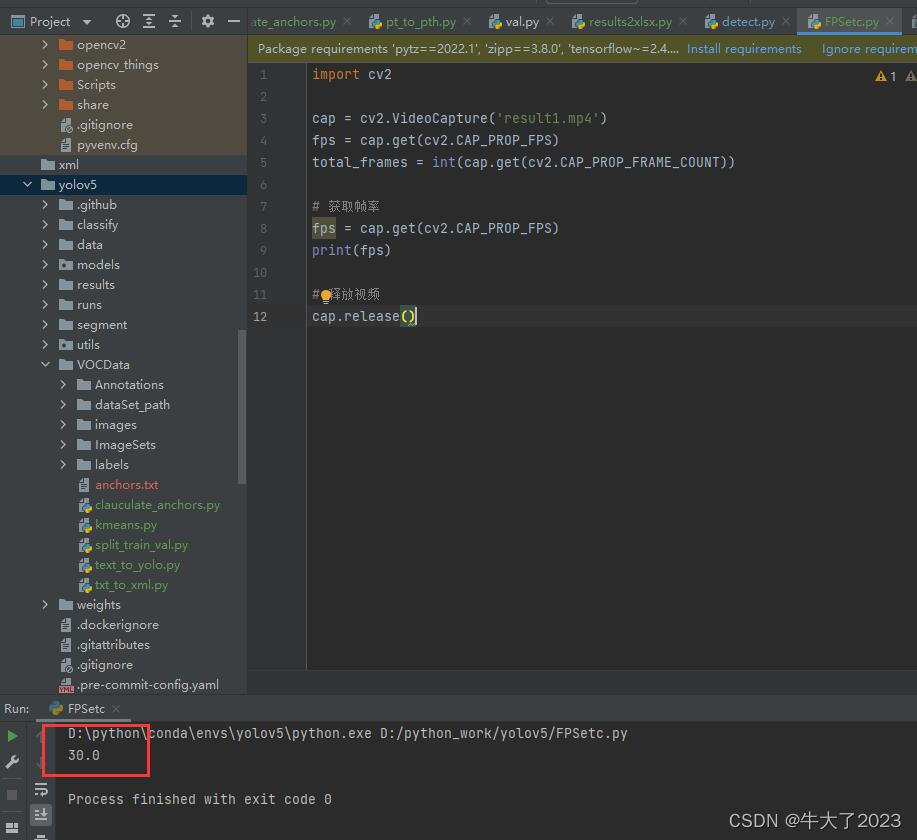
YOLOv5教程-如何使用他人的数据集进行训练+测试评估模型
目录
一、前言与数据集 二、划分数据集以及配置文件的修改
1.把图片和.txt标注文件放入对应VOCData文件夹下 2..txt文件转为.xml文件
3.在VOCData目录下创建程序 split_train_val.py 并运行
4.将xml格式转为yolo_txt格式
5.设置测试文件
6.配置文件
三、聚类获得先验框 …

改进YOLOv8 | 特征融合篇 | YOLOv8 应用 BiFPN 结构 | 《 EfficientDet: 可扩展和高效的目标检测》
模型效率在计算机视觉中变得越来越重要。在本文中,我们系统地研究了目标检测中的神经网络架构设计选择,并提出了几种关键的优化方法来提高效率。首先,我们提出了一种加权双向特征金字塔网络(BiFPN),它可以实现简单快速的多尺度特征融合;其次,我们提出了一种复合缩放方法…
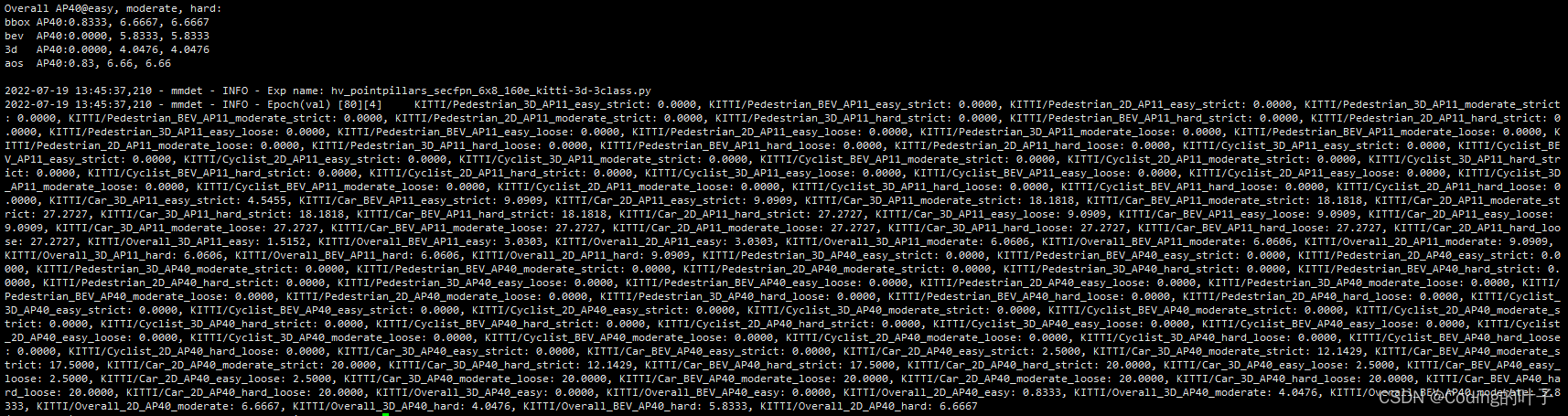
【三维目标检测】Pointpillars(二)
数据和源码请参考上一篇博文:【三维目标检测】Pointpillars(一)_Coding的叶子的博客-CSDN博客。 PointPillars是一种基于体素的三维目标检测算法,发表在CVPR2019《PointPillars: Fast Encoders for Object Detection from Point C…
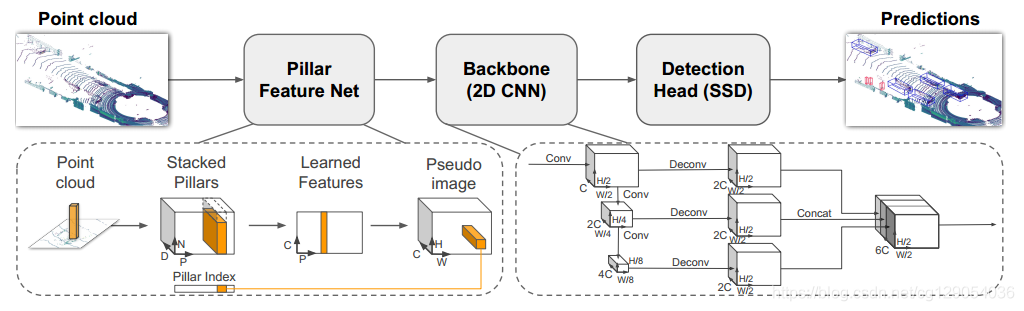
【三维目标检测】Pointpillars(一)
PointPillars是一种基于体素的三维目标检测算法,发表在CVPR2019《PointPillars: Fast Encoders for Object Detection from Point Clouds》。它的主要思想是把三维点云转换成2D伪图像以便用2D目标检测的方式进行目标检测。PointPillars在配置为Intel i7 CPU和1080ti…
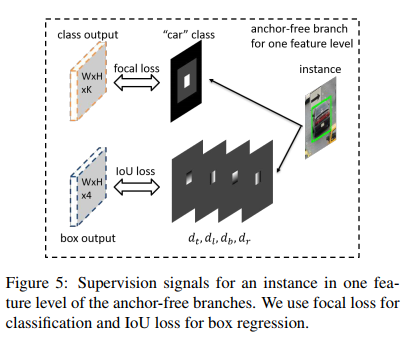
【AI面试】Anchor based 、 Anchor free 和 no anchor 的辨析
深度学习的目标检测算法,通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整(回归)区域边界,从而更准确地预测目标的真实边界框(ground-truth bounding box&…

无标签背景图(负样本)的拼图代码
训练目标检测模型有个很令人头疼的问题,就是有些特征与要训练的特征较为相似的背景区域也被误检出来(作为本应不该检测出来的负样本却被误检出为正样本的FP)。 根据这一问题的解决办法,除了可以对正样本特征较为模糊或者有歧义的样…

Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection
1. Motivation
point-base方法虽然识别率较高但是耗时过长;voxel-base方法虽然耗时较短但是识别率较差.经过相关实验可以知道原始点的精确定位并不是必要的,更粗的体素粒度也可以为该任务提供足够的空间上下文线索;voxel-base 方法将3D特征结构转换为BE…
mmrotate调研
mmrotate调研
MMrotate是什么?
在真实场景中,我们见到的图像不都是方方正正的,比如扫描的图书和遥感图像,需要检测的目标通常是有一定旋转角度的。这时候就需要用到旋转目标检测方法,对目标进行精确的定位&#x…

深度学习之目标检测Fast-RCNN模型算法流程详解说明(超详细理论篇)
1.Fast-RCNN论文背景 2. Fast-RCNN算法流程 3.Fast R-CNN 问题和缺点
这篇以对比RCNN来说明,如果你对RCNN网络没太熟悉,可访问这链接,快速了解,点下面链接
深度学习之目标检测R-CNN模型算法流程详解说明(超详细理论篇…
DETR系列:RT-DETR 论文解析
论文:《DETRs Beat YOLOs on Real-time Object Detection》 2023.4
DETRs Beat YOLOs on Real-time Object Detection:https://arxiv.org/pdf/2304.08069.pdf
源码地址:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/conf…

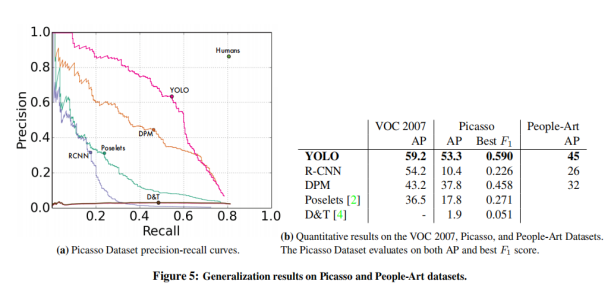
目标检测——Yolo v1
论文Paper:You Only Look Once: Unified, Real-Time Object Detection 论文地址:https://arxiv.org/pdf/1506.02640
0. 摘要
以前的目标检测:利用分类器来执行检测任务。而Yolo:
将目标检测看作关于边界框和相关的类别概率的回…
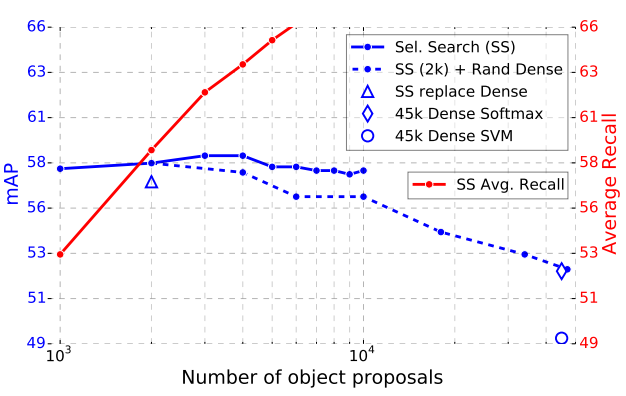
目标检测——Fast RCNN【你看这一篇就差不多了】
标题很酷炫,虽然说出来这句话有些虚~emmmmmmmm…【言归正传】SPPnet出来之后,RBG大神迅速回怼,抛出了更快更好的Fast-RCNN。新的思路是, 将之前的多阶段训练合并成了单阶段训练,面对灵活尺寸问题,大神借鉴了…

目标检测——RCNN
论文:Rich feature hierarchies for accurate object detection and semantic segmentation【用于精确物体定位和语义分割的丰富特征层次结构】 论文链接:https://arxiv.org/pdf/1311.2524v3.pdf 论文翻译:https://blog.csdn.net/v1_vivian/a…
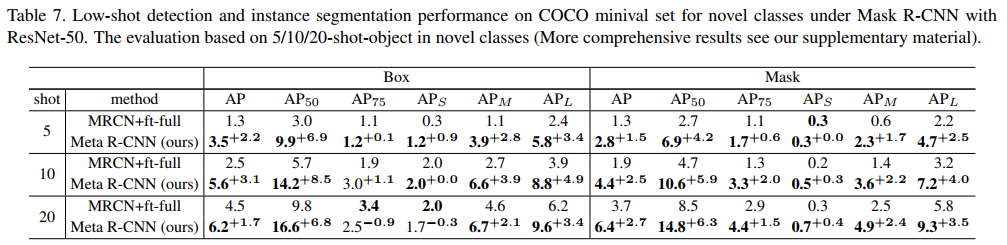
【论文翻译】Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning
Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning
Meta R-CNN:面向实例级小样本学习的通用解算器
论文地址:https://openaccess.thecvf.com/content_ICCV_2019/papers/Yan_Meta_R-CNN_Towards_General_Solver_for_Instance…
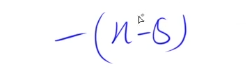

目标检测:Feature Pyramid Networks(FPN)
FPN:Feature Pyramid Networks,特征图金字塔网络
论文:feature pyramid networks for object detection (CVPR2017)论文链接:https://arxiv.org/abs/1612.03144 一、概述
原来多数的object detection算法都是只采用顶层特征做预…
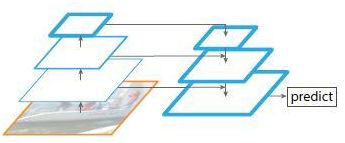
目标检测:各种网络结构对比
1、通常的CNN网络结构如下图所示 图1
上图网络是自底向上卷积,然后使用最后一层特征图进行预测,像SPP-Net,Fast R-CNN,Faster R-CNN就是采用这种方式,即仅采用网络最后一层的特征。
以VGG16为例子,假如fe…

目标检测:anchor box
目前,几乎所有流行的通用目标检测方法,如经典的两步方法Faster-RCNN,一步方法SSD和YOLO等,都需要根据经验设计不同尺度(可以看成是物体面积)和高宽比的anchor box(有的方法中叫做default box或p…
YOLOv3: An Incremental Improvement 全文翻译
YOLOv3 论文全篇完整翻译 摘要
本文介绍了YOLO的一些更新内容!我们进行了一系列小的设计改进,以使其更好。我们还训练了一个相当不错的新网络。它比上一版稍微大一些,但更加准确。不过不用担心,它依然保持了快速性能。在320320像…

目标检测:YOLO(You Only Look Once)
RCNN系列检测器奠定了检测模型two stage的网络结构,首先通过一系列方法(传统的selective search 即 RCNN,RPN结构即fasterRCNN)产生足够的区域候选,然后通过分类网络判别区域候选是否为目标并同时回归出目标的位置。这…

Anchor Free检测算法之FCOS
一.提出背景
2019 是 Anchor Free 大行其道的一年,从CornerNet 到 ExtremeNet,从FSAF到FCOS,层出不穷。
论文:FCOS: Fully Convolutional One-Stage Object Detection【paper】【github】
二.算法框架
FCOS框架比较简单&#…
目标检测00-00:mmdetection(Foveabox为例)-目录-史上最新无死角讲解
接下来,我会为大家无死角的解析mmdetection(Foveabox),之前的文章,如下(以下是我工作的所有项目,每一个项目都是,我都做了百分百的详细解读,随着项目增多,为了方便不臃肿,所以给出以…
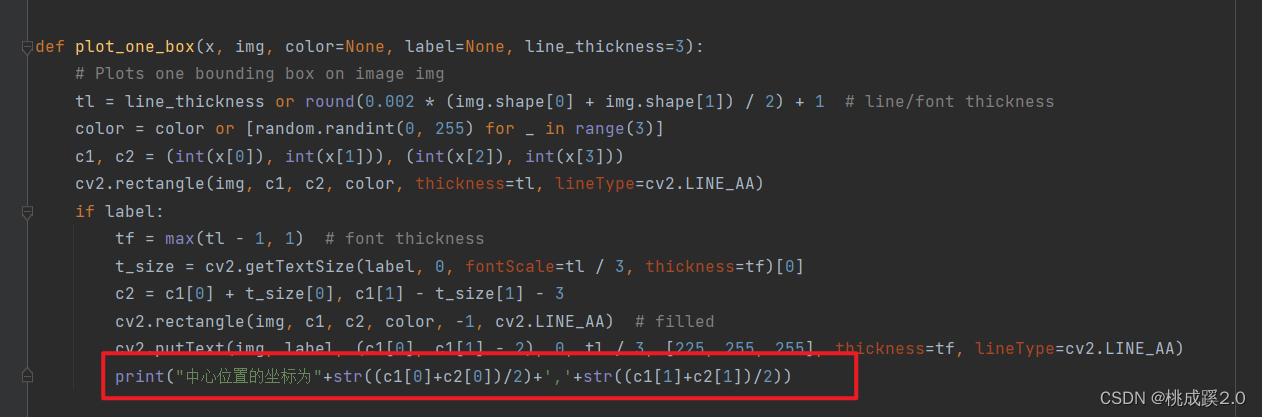
YOLOV5目标检测记录
文章目录1、运行官网YOLOV5代码1、下载源代码2、文件夹解析3、开始测试1、图片测试2、视频测试3、摄像头实时测试2、训练自己的神经网络模型1、数据集制作2、划分数据集3、开始训练4、训练参数5、使用训练好的模型进行预测3、获取目标中心坐标本文仅讨论YOLOV5的目标检测使用过…

PointPillars Fast Encoders for Object Detection from Point Clouds 论文学习
论文地址:PointPillars: Fast Encoders for Object Detection from Point Clouds Github 地址:PointPillars: Fast Encoders for Object Detection from Point Clouds
1. 解决了什么问题?
点云目标检测是自动驾驶领域的一个重要方向。自动…

一文打尽目标检测NMS(2): 效率提升篇
文章来自于:曲終人不散丶知乎, 连接:https://zhuanlan.zhihu.com/p/157900024, 本文仅用于学术分享,如有侵权,前联系后台做删文处理。 在笔者上一篇文章《一文打尽目标检测NMS——精度提升篇》中࿰…
DINO代码学习笔记(四)
DINO代码学习笔记(一)中已经将输入transformer之前的参数处理给捋了一遍
DINO代码学习笔记(二)中将encoder部分给捋了一遍
DINO代码学习笔记(三)中将decoder部分给捋了一遍,以上将DINO的主体部…
YOLOv5改进系列(12)——更换Neck之BiFPN
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制

基于深度学习的高精度鸡蛋检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度鸡蛋检测识别系统可用于日常生活中或野外来检测与定位鸡蛋目标,利用深度学习算法可实现图片、视频、摄像头等方式的鸡蛋目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型…

基于YOLOv4的目标检测系统(附MATLAB代码+GUI实现)
摘要:本文介绍了一种MATLAB实现的目标检测系统代码,采用 YOLOv4 检测网络作为核心模型,用于训练和检测各种任务下的目标,并在GUI界面中对各种目标检测结果可视化。文章详细介绍了YOLOv4的实现过程,包括算法原理、MATLA…
剑指YOLOv8改进VariFocalNet系列03:即插即用|最新改进VariFocal损失函数,全面提升密集场景下的目标检测,提升YOLOv8检测精度
剑指YOLOv8改进Loss系列:最新改进VariFocalNet损失函数,全面提升密集场景下的目标检测,提升YOLOv8检测精度
💡CSDN芒果汁没有芒果🥭:YOLOv8 最新首发创新点改进源代码!!
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作改进代码即可
💡论文地址…
基于深度学习的高精度抽烟行为检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度抽烟行为检测识别系统可用于日常生活中或野外来检测与定位抽烟行为目标,利用深度学习算法可实现图片、视频、摄像头等方式的抽烟行为目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5…

【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(6月19日论文合集)
文章目录 一、检测相关(7篇)1.1 Vehicle Occurrence-based Parking Space Detection1.2 Squeezing nnU-Nets with Knowledge Distillation for On-Board Cloud Detection1.3 MixedTeacher : Knowledge Distillation for fast inference textural anomaly detection1.4 Efficien…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(6月16日论文合集)
文章目录 一、检测相关(15篇)1.1 OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection1.2 Zero-Shot Anomaly Detection with Pre-trained Segmentation Models1.3 DEYOv2: Rank Feature with Greedy Matching for End-to-End Object Detection1.4 Winning So…
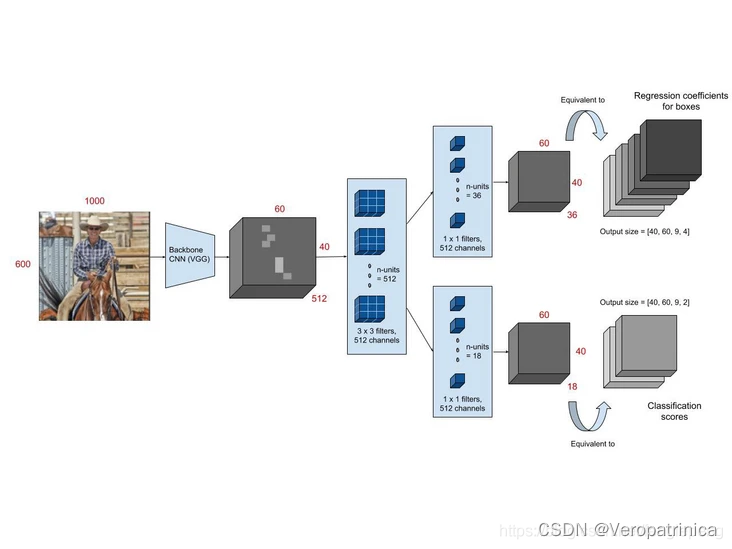
目标检测经典工作发展(超详细对比):R-CNN vs SPPNet vs Fast R-CNN vs Faster R-CNN
序
网上关于两阶段目标检测(two-stage object detection)的几个经典工作R-CNN,SPPNet,Fast R-CNN,Faster R-CNN的发展,各自的优缺点缺乏一个比较清楚的描述,大部分文章讲的比较细节,…

论文解读:DETRs Beat YOLOs on Real-time Object Detection
发表时间:2023 论文地址:https://arxiv.org/abs/2304.08069 项目地址:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr 【官方】 或 https://github.com/ultralytics/ultralytics/tree/main/ultralytics/vit/r…

【Adversarial Attack in Object Detection】物理对抗攻击和防御
目录 安全监控 **有无意义**无意义的补丁有意义的补丁 光学对抗攻击对抗灯干扰相机成像 攻击方法White-box attacksGradient-based attacks Optimization-based attacks Black-box attacksQuery-based attacksEvolution algorithm OUTLOOK 在计算机视觉中,根据实现…

基于深度学习的高精度绵羊检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度绵羊检测识别系统可用于日常生活中或野外来检测与定位绵羊目标,利用深度学习算法可实现图片、视频、摄像头等方式的绵羊目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检测模型…
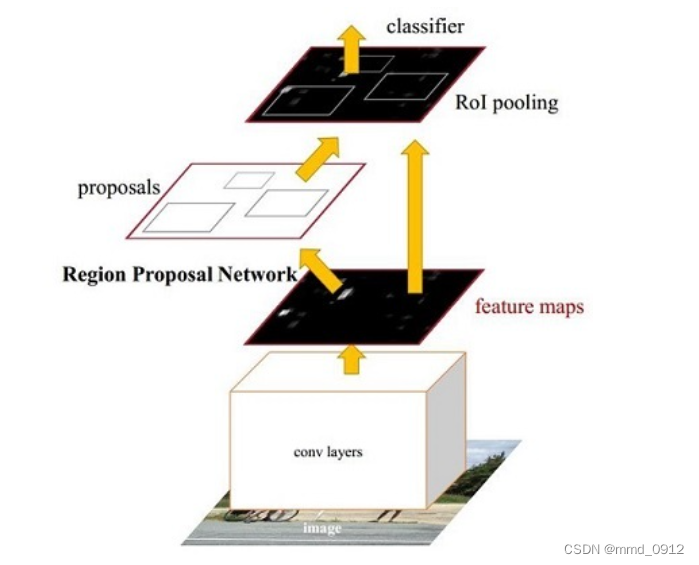
网络解析----faster rcnn
Faster R-CNN(Region-based Convolutional Neural Network)是一种基于区域的卷积神经网络用于目标检测任务的模型。它是一种两阶段的目标检测方法,主要包含以下几个步骤:
Region Proposal Network(RPN): F…

计算机视觉目标检测性能指标
目录
精确率(Precision)和召回率(Recall)
F1分数(F1 Score)
IoU(Intersection over Union)
P-R曲线(Precision-Recall Curve)和 AP
mAP(mean…
卷积神经网络教程 (CNN) – 使用 TensorFlow 在 Python 中开发图像分类器
在这篇博客中,让我们讨论什么是卷积神经网络 (CNN) 以及 卷积神经网络背后的架构——旨在解决 图像识别系统和分类问题。 卷积神经网络在图像和视频识别、推荐系统和自然语言处理方面有着广泛的应用。 目录 计算机如何读取图像? 为什么不是全连接网络?

基于YOLOv8模型和Caltech数据集的行人检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要
基于YOLOv8模型和Caltech数据集的行人检测系统可用于日常生活中检测与定位行人,利用深度学习算法可实现图片、视频、摄像头等方式的行人目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…

Yolov8改进---注意力机制: SimAM(无参Attention)和NAM(基于标准化的注意力模块),效果秒杀CBAM、SE
🏆🏆🏆🏆🏆🏆Yolov8魔术师🏆🏆🏆🏆🏆🏆 ✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🍉🍉🍉定期更新不同数据集涨点情况 1. SimAM:无参Attention 论文: http://proceedings.mlr.press/v139/yang…

MaskRCNN-ICCV2017 论文解读
文章: MaskRCNN 作者: Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick 备注: FAIR, ICCV best paper
核心亮点
1) 提出了一个简单,灵活,通用的实例分割模型框架 MaskRCNN 在 FasterRCNN 的基础上进行改进, 在模型的head部分引入了一个新的mask预测分支, 在训练阶…

机器视觉自动数据标注方法
目录
一、背景阅读
个人总结:
(半)自动数据标注的方法基本都是采用类似的思路,即通过少量标注数据进行训练后得到一个预训练模型,然后再次基础上对该网络的输出结果进行人工核验,并进一步地进行训练得…

计算机视觉 Computer Vision Chaper13 图像描述
文章目录深度语言模型RNN 原理解析LSTM 原理解析GRU 门控循环单元图说模型原理与结构Image Captioning 图说模型NIC Neural Image CaptionAttention 注意力机制SAT模型数据集介绍深度语言模型 RNN 原理解析 Y是一个概率vector,最大的概率是希望输出的词。 W其实是乘…

基于YOLOv5+Hough变换的目标检测和车道线检测
这学期做的一个大作业,实现了对行驶过程中车辆、行人以及车道线的检测。
1.B站视频演示 2.Github仓库链接 文章目录一、实现效果二、环境配置三、基于YOLOv5的目标检测四、基于Hough变换的车道线检测4.1 前置工作 Canny阈值设定4.2 前置工作 ROI标定4.3 Hough变换提…

【三维目标检测】Complex-Yolov4详解(二):模型结构
Complex-Yolo网络模型的核心思想是用鸟瞰图BEV替换Yolo网络输入的RGB图像。因此,在完成BEV处理之后,模型的训练和推理过程基本和Yolo完全一致。Yolov4中输入的RGB图片的尺寸维度为608x608x3,因此BEV的尺寸维度也为608x608x3,由强度…

【三维目标检测】Complex-Yolov4详解(一): 数据处理
前面分别介绍了基于点云的三维深度学习算法PointNet、PointNet,和基于体素的三维深度学习算法VoxelNet。本节将开始介绍基于投影的三维深度学习算法Complex-Yolov4。三维投影算法主要思想是用激光雷达点云的鸟瞰图(BEV)和前视图(F…

Frustum PointNets for 3D Object Detection from RGB-D Data
Frustum PointNets for 3D Object Detection from RGB-D Data
1.背景
3D的运用以及逐渐广泛,但是之前大多数的工作是将3D书转化为2D的数据或者对3D数据进行体素化处理,这样就失去了3D数据的一些空间特征以及其他的特性。 参考之前2D的工作,…
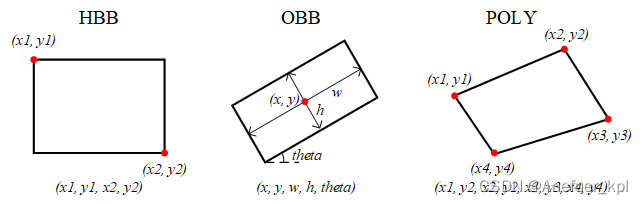
使用A100 GPU搭建OBBDetection的运行环境
项目场景:
最近需要复现一篇目标检测论文的代码,文章提供了代码,因此自己根据仓库的说明尝试配置环境运行代码,但遇到了非常多的困难 问题描述
比较老的代码加上比较的GPU,导致了环境在配置的时候困难重重 OBBDetect…

选择性搜索算法(Selective Search )——SS算法
文章目录 一、前言二、object Detection VS object Recognition(Selective Search的提出)2.1object recognition与object detection的关系2.2滑动窗口方法的局限性2.3Selective search算法的提出 三、Selective Search算法3.1什么是Selective Search&…

YOLOv7-Pose尝鲜,基于YOLOv7的关键点模型测评
【前言】
本文首发于GiantPandaCV,未经许可请勿转载!目前人体姿态估计总体分为Top-down和Bottom-up两种,与目标检测不同,无论是基于热力图或是基于检测器处理的关键点检测算法,都较为依赖计算资源,推理耗时…

自动驾驶-YOLOV5目标检测
1、环境:
操作系统:Ubuntu20.04
Python3.9
Pytorch1.10.2
IDE:(本人使用的是ECLIPSE)
显卡:NVIDIA GeForce GTX 1060 6GB
开源库地址:GitHub - ultralytics/yolov5: YOLOv5 🚀…
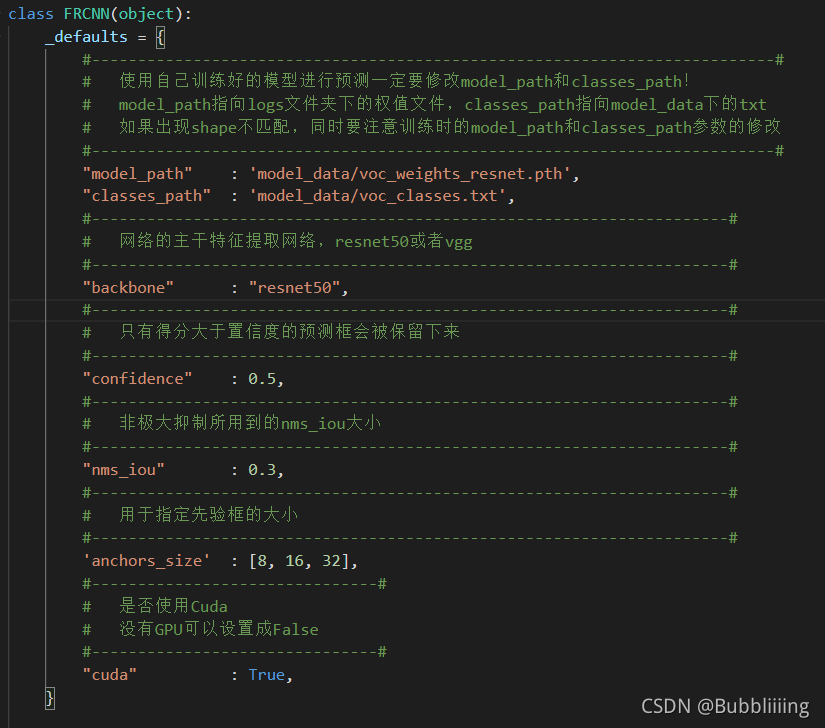
FasterRCNN目标检测算法
什么是FasterRCNN目标检测算法 Faster-RCNN是一个非常有效的目标检测算法,虽然是一个比较早的论文, 但它至今仍是许多目标检测算法的基础。
Faster-RCNN作为一种two-stage的算法,与one-stage的算法相比,two-stage的算法更加复杂且…
PP-Structure—表格数据提取
目录
简介
特性
效果展示
表格识别
版面分析和表格识别
版面恢复
关键信息抽取
快速开始
1. 准备环境
1.1 安装PaddlePaddle
1.2 安装PaddleOCR whl包
2 快速使用
3. 便捷使用
3.1 命令行使用
3.2 Python脚本使用
3.3 返回结果说明
分析总结 简介
PP-Stru…
不同学习任务的评价方法
图像识别分析数据集是一个多分类数据集,在预测结果评估过程中与需要注意一些问题[Everingham M]: 1. 在图像分类任务中,仅用一个标签标示样本,而图像中可能包含多个类别的物体。面对这种问题,可以借鉴图像检索的评估思路ÿ…
![[Paper Read] General Focal Loss](https://img-blog.csdnimg.cn/20210319001719146.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpYW5nZG9uZzIwMTQ=,size_16,color_FFFFFF,t_70)
[Paper Read] General Focal Loss
General Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection 目录General Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object DetectionCode && PaperBackground && Motivation不一致…
在线难例挖掘:Online Hard Example Mining (OHEM)
详细链接:https://erogol.com/online-hard-example-mining-pytorch/
OHEM通过减少计算成本来选择难例,提高网络性能。它主要用于目标检测。假设你想训练一个汽车检测器,并且你有正样本图像(图像中有汽车)和负样本图像(图像中没有汽车)。现在…

深度学习在目标检测进展
基于深度学习的目标检测目前主要是基于卷积神经网络和候选区域region proposal。本文将从四个方面对其进行阐述。
一、传统目标检测
主线:区域选择->特征提取->分类器 1、区域选取 采用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的尺…

【YOLOX】《YOLOX:Exceeding YOLO Series in 2021》
arXiv-2021 文章目录 1 Background and Motivation2 Related Work3 Advantages / Contributions4 Method5 Experiments5.1 Datasets and Metrics 6 Conclusion(own) 1 Background and Motivation
2 Related Work
3 Advantages / Contributions
4 Meth…

opencv动态目标检测
文章目录 前言一、效果展示二、实现方法构造形态学操作所需的核:创建背景减除模型:形态学操作:轮廓检测: 三、代码python代码C代码 总结参考文档 前言
很久没更新文章了,这次因为工作场景需要检测动态目标,特此记录一下。 一、效果展示 二、实现方法
基…
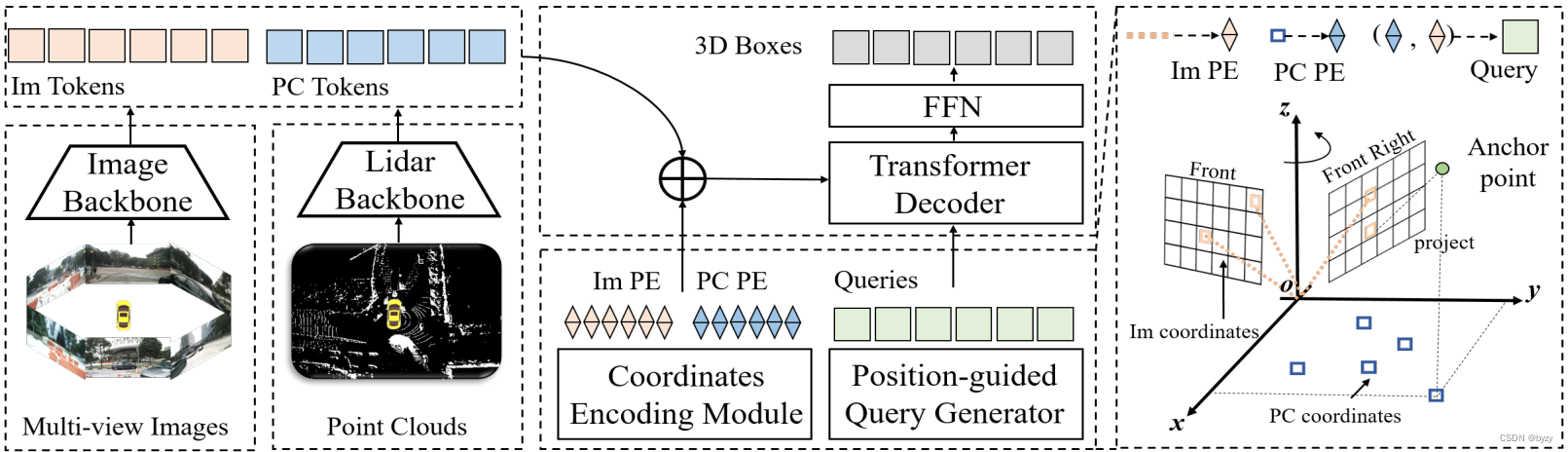
【论文笔记】Cross Modal Transformer: Towards Fast and Robust 3D Object Detection
原文链接:https://arxiv.org/abs/2301.01283
1. 引言 受到DETR启发,本文提出鲁棒的端到端多模态3D目标检测方法CMT(跨模态Transformer)。首先使用坐标编码模块(CEM),通过将3D点集隐式地编码为多…

opencv基础49-图像轮廓02-矩特征cv2.moments()->(形状分析、物体检测、图像识别、匹配)
矩特征(Moments Features)是用于图像分析和模式识别的一种特征表示方法,用来描述图像的形状、几何特征和统计信息。矩特征可以用于识别图像中的对象、检测形状以及进行图像分类等任务。 矩特征通过计算图像像素的高阶矩来提取特征。这些矩可以…

opencv 基础50-图像轮廓学习03-Hu矩函数介绍及示例-cv2.HuMoments()
什么是Hu 矩? Hu 矩(Hu Moments)是由计算机视觉领域的科学家Ming-Kuei Hu于1962年提出的一种图像特征描述方法。这些矩是用于描述图像形状和几何特征的不变特征,具有平移、旋转和尺度不变性,适用于图像识别、匹配和形状…
【目标检测系列】YOLOV1解读
前言
从R-CNN到Fast-RCNN,之前的目标检测工作都是分成两阶段,先提供位置信息在进行目标分类,精度很高但无法满足实时检测的要求。
而YoLo将目标检测看作回归问题,输入为一张图片,输出为S*S*(5*BC)的三维向量。该向量…

【Yolov5+Deepsort】训练自己的数据集(2)| 目标检测追踪 | 轨迹绘制
📢前言:本篇是关于如何使用YoloV5Deepsort训练自己的数据集,从而实现目标检测与目标追踪,并绘制出物体的运动轨迹。本章讲解的为第二部分内容:训练集的采集与划分,Yolov5模型的训练。本文中用到的数据集均为…
【目标检测系列】YOLOV2解读
为更好理解YOLOv2模型,请先移步,了解YOLOv1后才能更好的理解YOLOv2所做的改进。 前情回顾:【目标检测系列】YOLOV1解读_怀逸%的博客-CSDN博客 背景 通用的目标检测应该具备快速、准确且能过识别各种各样的目标的特点。自从引入神经网络以来&a…
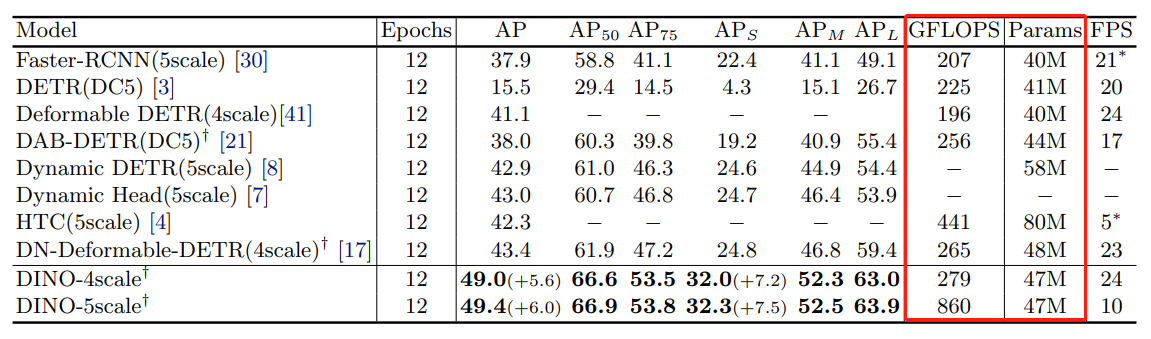
DETR模型计算量(FLOPs)参数量(Params)
前言
关于计算量(FLOPs)参数量(Params)的一个直观理解,便是计算量对应时间复杂度,参数量对应空间复杂度,即计算量要看网络执行时间的长短,参数量要看占用显存的量。 计算量: FLOPs,FLOP时指浮点运算次数&a…

YOLOv8“炼丹“之扑克牌识别
最近沉迷炼丹, 效果图:
框架Ultralytics YOLOv8
来自GitHub的介绍: Ultralytics YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost pe…
YOLOv8+ByteTrack多目标跟踪(行人车辆计数与越界识别)
课程链接:https://edu.csdn.net/course/detail/38901
ByteTrack是发表于2022年的ECCV国际会议的先进的多目标跟踪算法。YOLOv8代码中已集成了ByteTrack。本课程使用YOLOv8和ByteTrack对视频中的行人、车辆做多目标跟踪计数与越界识别,开展YOLOv8目标检测…

YOLOv5基础知识入门(5)— 损失函数(IoU、GIoU、DIoU、CIoU和EIoU)
前言:Hello大家好,我是小哥谈。使用YOLOv5训练模型阶段,需要用到损失函数。损失函数是用来衡量模型预测值和真实值不一样的程度,极大程度上决定了模型的性能。本节就给大家介绍IoU系列损失函数,希望大家学习之后能够有…

yolov5目标检测多线程Qt界面
上一篇文章:yolov5目标检测多线程C部署
V1 基本功能实现
mainwindow.h
#pragma once#include <iostream>#include <QMainWindow>
#include <QFileDialog>
#include <QThread>#include <opencv2/opencv.hpp>#include "yolov5.…
[数据集][目标检测]PCB板缺陷目标检测数据集VOC格式693张6类别
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):693 标注数量(xml文件个数):693 标注类别数:6 标注类别名称:["missing_hole",…

YOLOv8目标检测算法
YOLOv8目标检测算法相较于前几代YOLO系列算法具有如下的几点优势:
更友好的安装/运行方式速度更快、准确率更高新的backbone,将YOLOv5中的C3更换为C2FYOLO系列第一次尝试使用anchor-free新的损失函数
YOLOv8简介
YOLOv8 是 Ultralytics 公司继 YOLOv5…

Grounding dino + segment anything + stable diffusion 实现图片编辑
目录 总体介绍总体流程 模块介绍目标检测: grounding dino目标分割:Segment Anything Model (SAM)整体思路模型结构:数据引擎 图片绘制 集成样例 其他问题附录 总体介绍
总体流程
本方案用到了三个步骤,按顺序依次为:…
YOLOv5改进系列(21)——替换主干网络之RepViT(清华 ICCV 2023|最新开源移动端ViT)
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(1)——添加SE注意力机制
YOLOv5改进系列(2

YOLOv5基础知识入门(3)— 目标检测相关知识点
前言:Hello大家好,我是小哥谈。YOLO算法发展历程和YOLOv5核心基础知识学习完成之后,接下来我们就需要学习目标检测相关知识了。为了让大家后面可以顺利地用YOLOv5进行目标检测实战,本节课就带领大家学习一下目标检测的基础知识点&…

YOLOv5基础知识入门(6)— 激活函数(Mish、Sigmoid、Tanh、ReLU、Softmax、SiLU等)
前言:Hello大家好,我是小哥谈。激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数具有十分重要的作用。YOLOv5模型训练过程中即使用了激活函数,可以改善模型的训练速度和准确性。…
yolov5模型构建源码详细解读(yaml、parse_model等内容)
文章目录 前言一、yolov5文件说明二、yolov5调用模型构建位置三、模型yaml文件解析1、 yaml的backbone解读Conv模块参数解读C3模块参数解读 2、yaml的head解读Concat模块参数解读Detect模块参数解读 四、模型构建整体解读五、构建模型parse_model源码解读 前言
本文章记录yolo…
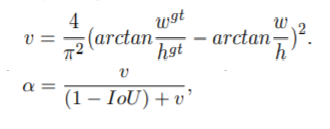
【目标检测中对IoU的改进】GIoU,DIoU,CIoU的详细介绍
文章目录 1、IoU2、GIoU(Generalized Intersection over Union)3、DIoU4、CIoU 1、IoU
IoU为交并比,即对于pred和Ground Truth:交集/并集 1、IoU可以作为评价指标使用,也可以用于构建IoU loss 1 - IoU 缺点: 2、对于pred和GT相…

2023年目标检测研究进展
综述
首先关于写这个笔记,我个人思考了很久关于以下几点。1:19年开始从做OCR用到图像和文本这种多模态联合处理的后,也就有意识的开始关注自然语言处理,这样的结果导致可能停留在前期图像上的学习和实践,停滞的研究如…
yolov8训练进阶:新增配置参数
续yolov8训练进阶:自定义训练脚本,从配置文件载入训练超参数_CodingInCV的博客-CSDN博客 尽管yolov8有很多参数可以设置,但难免我们训练过程中会需要增加自己的参数,如新的数据增强、自定义的一些条件。那么在yolov8中如何实现呢&…
YOLO目标检测——动漫头像数据集下载分享
动漫头像数据集是用于研究和分析动漫头像相关问题的数据集,它包含了大量的动漫风格的头像图像。动漫头像是指以动漫风格绘制的虚构人物的头像图像,常见于动画、漫画、游戏等媒体。 数据集点击下载:YOLO动漫头像数据集50800图片.rar
目标检测任务数据集的数据增强中,图像水平翻转和xml标注文件坐标调整
需求: 数据集的数据增强中,有时需要用到图像水平翻转的操作,图像水平翻转后,对应的xml标注文件也需要做坐标的调整。 解决方法: 使用pythonopencvimport xml.etree.ElementTree对图像水平翻转和xml标注…
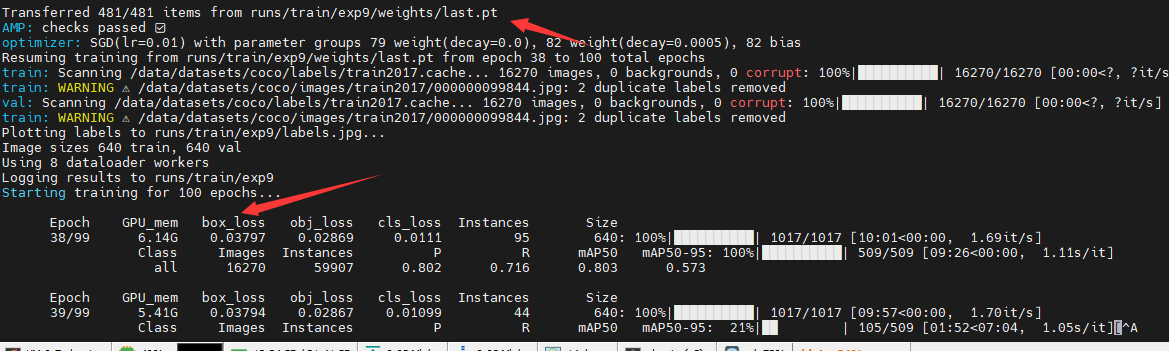
YOLO目标检测算法调试过程学习记录
先前已经完成过YOLO系列目标检测算法的调试过程,今天主要是将所有的调试加以总结 这里的conda环境就不再赘述了,直接使用requirement.txt文件的即可,也可以参考YOLOX的配置过程5
数据集处理
YOLOv5有自己的数据集格式,博主的数据…
YOLO目标检测——小狗图像数据集下载分享
小狗图像数据集 小狗图像数据集是一种常用的用于研究和分析狗狗图像分类问题的数据集,它包含了大量不同品种和姿势的小狗图像样本,用于训练和评估狗狗图像分类算法的性能,共同540张图片,8个不同类别小狗。 数据集点击下载…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(8 月 11 日论文合集)
文章目录 一、检测相关(11篇)1.1 Follow Anything: Open-set detection, tracking, and following in real-time1.2 YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection1.3 Adaptive Low Rank Adaptation of Segment Anything to Salien…

利用torchvision库实现目标检测与语义分割
一、介绍
利用torchvision库实现目标检测与语义分割。
二、代码
1、目标检测
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as T
import torchvision
import numpy as np
import cv2
import randomCOCO_INSTANCE_CATEGORY_NAMES …

基于YOLOV8模型的课堂场景下人脸目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型的课堂场景下人脸目标检测系统可用于日常生活中检测与定位课堂场景下人脸,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检…
目标检测任务数据集的数据增强中,图像垂直翻转和xml标注文件坐标调整
需求: 数据集的数据增强中,有时需要用到图像垂直翻转的操作,图像垂直翻转后,对应的xml标注文件也需要做坐标的调整。 解决方法: 使用pythonopencvimport xml.etree.ElementTree对图像垂直翻转和xml标…

基于YOLOV8模型和Kitti数据集的人工智能驾驶目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型和Kitti数据集的人工智能驾驶目标检测系统可用于日常生活中检测与定位车辆、汽车等目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用…
object detection with faster rCNN
Proposal and CropAndResize
1 custom plugin
config.py 是为convert_to_uff 命令定义的。config.py文件中应该通过修改op字段将自定义层映射到TensorRT中的插件名称。插件参数的名称也应该与TensorRT插件所期望的完全匹配。如果config.py定义正确。NvUffParser将能够解析网络…
object detection withSSD in python
SSD网络建立在VGG-16网络上,在单个前向传播网络中完成目标检测和定位。该网络将边界框的输出离散为一组默认框,其中每个特征框的位置具有不同的横纵比和尺寸。在预测目标时,网络为每个默认框中存在的每个对象类别生成分数,并对框进…

基于深度学习的高精度工人安全帽检测识别系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度工人安全帽检测识别系统可用于日常生活中或野外来检测与定位工人安全帽目标,利用深度学习算法可实现图片、视频、摄像头等方式的工人安全帽目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用…
Yolov8小目标检测(9): EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | ICASSP2023
💡💡💡本文改进: EMA基于跨空间学习的高效多尺度注意力 EMA | 亲测在红外弱小目标检测涨点,map@0.5 从0.755提升至0.766
💡💡💡Yolo小目标检测,独家首发创新(原创),适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,带你轻松实…
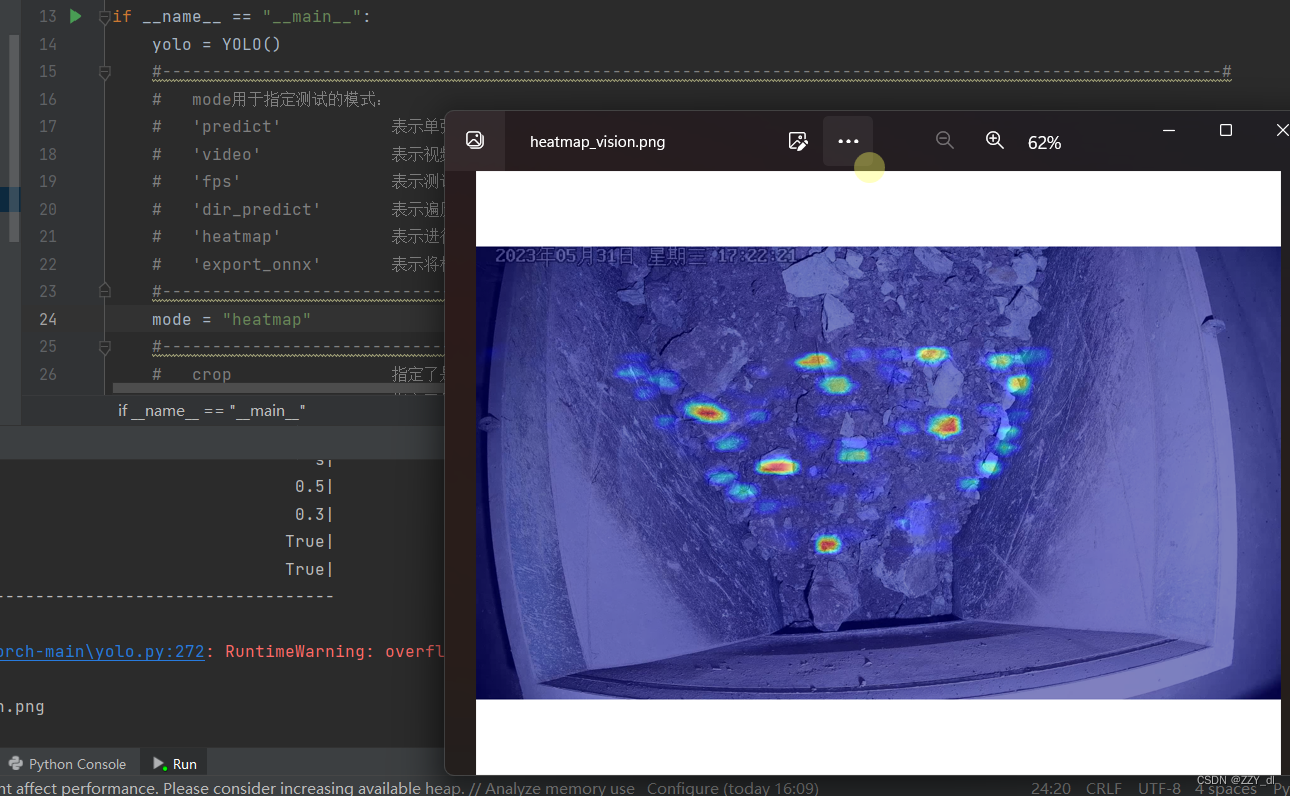
目标检测笔记(十五): 使用YOLOX完成对图像的目标检测任务(从数据准备到训练测试部署的完整流程)
文章目录 一、目标检测介绍二、YOLOX介绍三、源码获取四、环境搭建4.1 环境检测 五、数据集准备六、模型训练七、模型验证八、模型测试 一、目标检测介绍
目标检测(Object Detection)是计算机视觉领域的一项重要技术,旨在识别图像或视频中的…
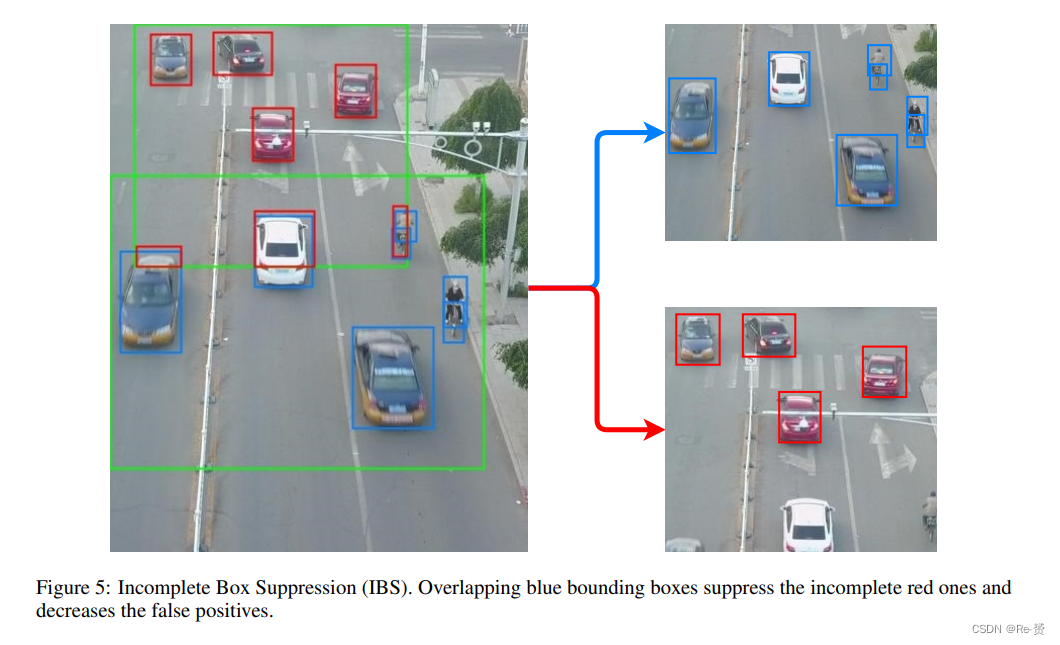
论文阅读 FOCUS-AND-DETECT: A SMALL OBJECT DETECTION FRAMEWORK FOR AERIAL IMAGES
文章目录 FOCUS-AND-DETECT: A SMALL OBJECT DETECTION FRAMEWORK FOR AERIAL IMAGESABSTRACT1 Introduction2 Related Work3 Focus-and-Detect3.1 Overview3.2 Focus Stage3.2.1 Generating Ground-Truth Boxes of Focal Regions Using Gaussian Mixture Model 3.3 Detection …
【动手学深度学习】--20.目标检测和边界框
文章目录 目标检测和边界框1.目标检测2.边界框 目标检测和边界框
学习视频:物体检测和数据集【动手学深度学习v2】
官方笔记:目标检测和边界框
在图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别…
目标检测笔记(十一):如何在特定区域进行人脸检测实操
文章目录 背景代码 背景
由于我们在做项目的时候可能会涉及到某个指定区域进行目标检测或者人脸识别等任务,所以这篇博客是为了探究如何在传统目标检测的基础上来结合特定区域进行检测,以Opencv自带的包为例。
代码
import cv2face_cascade cv2.Casc…

目标检测之遮挡物体检测
一、遮挡的类别
类内遮挡,目标被同一类别的目标遮挡类间遮挡,目标被其它类别的目标遮挡
二、解决方法
数据标注
精调遮挡目标的GT边界框
数据增强
cutout:在训练时,随机mask目标,提升模型对遮挡的应对能力mosaic…
YOLOv5原创改进之WDLA标签分配策略,最新改进Wasserstein Distance Label Assignment,提升小目标检测性能精度
💡该教程为改进进阶指南,属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 内容出品:@CSDN芒果汁没有芒果
💡🚀🚀🚀内含改进源代码,按步骤操作运行改进后的代码即可
重点:🔥🔥🔥YOLOv5原创改进之WDLA标签分配…

OpenMMLab MMYOLO目标检测环境搭建(一)
1、环境搭建
conda create -n mmyolo python3.7 -y #创建环境
conda activate mmyolo #激活环境
conda install pytorch torchvision torchaudio cudatoolkit10.2 -c pytorch #安装 PyTorch and torchvision (官方)#如果网不好,可以这样安装
pi…
基于YOLOv8模型的烟头目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的烟头目标检测系统可用于日常生活中检测与定位车辆目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…

YOLOv5算法改进(5)— 添加ECA注意力机制
前言:Hello大家好,我是小哥谈。ECA注意力机制是一种用于图像处理中的注意力机制,是在通道注意力机制的基础上做了进一步的改进。通道注意力机制主要是通过提取权重,作用在原特征图的通道维度上,而ECA注意力机制则使用了…
[数据集][目标检测]疲劳驾驶数据集VOC格式4类别-4362张
数据集格式:Pascal VOC格式(不包含分割的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):4362 标注数量(xml文件个数):4362 标注类别数:4 标注类别名称:["closed_eye","closed_mouth"…

目标检测(Object Detection)
计算机视觉包括图像分类、物体检测识别、语义分割、实例分割4个基本任务
其中
1)图像分类:一张图像中是否包含某种物体
2)物体检测识别:分为目标检测和目标识别两个部分,首先检测出图像中某一块存在的目标和位置&am…
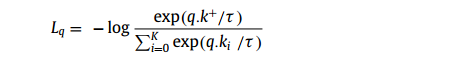
MIA文献阅读 —— 深度学习在医学图像分析中的最新进展及临床应用【2022】
目录 0 摘要1 引言2 深度学习方法概述2.1 监督式学习2.2 无监督学习2.2.1 自编码器 (Autoencoders)2.2.2 生成对抗网络(GANs)2.2.3 自监督学习 2.3. 半监督学习2.4 提高性能的策略2.4.1 注意力机制2.4.2 领域知识2.4.3 估计的不确定性 3 深度学习应用3.1 分类3.1.1 监督分类3.1…

YOLO目标检测——火灾和非火灾数据集下载分享
火灾和非火灾数据集应用场景:火灾预测和预警、火灾风险评估、火灾事故研究、智能消防系统等等 数据集点击下载:YOLO火灾和非火灾数据集1000图片.rar
YOLO目标检测——脑肿瘤检测数据集下载分享
脑肿瘤检测数据集是用于训练和评估脑肿瘤检测算法和模型的数据集,共同500张高清图像。 数据集点击下载:YOLO脑肿瘤检测数据集500图像.rar

安全帽人脸联动闸机开关算法
安全帽人脸联动闸机开关算法通过yolov7python网络模型深度学校框架 ,安全帽人脸联动闸机开关算法能够判断人员是否穿戴规定的工装是不是现场人员,当穿戴合规且为现场人员,闸机门禁才打开。YOLO的结构非常简单,就是单纯的卷积、池化…
亚马逊灯具具体需要什么认证?UL、FCC、CE、ROHSR等等
亚马逊灯具具体需要什么认证?
看了一些回答,都比较笼统,UL认证、FCC认证哪些是一定要的,哪些不是一定要的?(比如有的回答说UL不是一定要的,有的说是强制的)
如果灯具不带光源的话&…

基于OpenCV+LPR模型端对端智能车牌识别——深度学习和目标检测算法应用(含Python+Andriod全部工程源码)+CCPD数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境OpenCV环境Android环境1. 开发软件和开发包2. JDK设置3. NDK设置 模块实现1. 数据预处理2. 模型训练1)训练级联分类器2)训练无分割车牌字符识别模型 3. APP构建1)导入OpenCV库…

YOLOv5算法改进(11)— 替换主干网络之EfficientNetv2
前言:Hello大家好,我是小哥谈。EfficientNetV2是一个网络模型,旨在提供更小的模型和更快的训练速度。它是EfficientNetV1的改进版本。EfficientNetV2通过使用更小的模型参数和采用一种称为Progressive Learning的渐进学习策略来实现这一目标。…
机器学习笔记 - 【机器学习案例】基于KerasCV的预训练模型自定义多头+多标签预测
一、KerasCV KerasCV 是一个模块化计算机视觉组件库,可与 TensorFlow、JAX 或 PyTorch 原生配合使用。这些模型、层、指标、回调等基于Keras Core构建,可以在任何框架中进行训练和序列化,并在另一个框架中重复使用,而无需进行昂贵的迁 KerasCV 可以理解为 Keras API 的水平…

YOLO目标检测——室内场景识别数据集下载分享
目标检测室内场景识别数据集可以广泛应用于各种需要对室内场景进行目标识别和跟踪的领域,包括安防监控、智能家居、物流仓储管理等 数据集点击下载: YOLO室内场景识别数据集(一)5950图片26类别.rar YOLO室内场景识别数据集&#…
人工智能深度学习,100天掌握所有人工智能深度学习 –第二章:( 第 1 – 10 天第一节线性代数-线性方程组)
矩阵的迹:设A=[a ij ] nxn是n阶方阵,则对角元素之和称为矩阵的迹,记为tr(A)。tr(A) = a 11 + a 22 + a 33 + ……….+ a nn
矩阵迹的性质:设A和B为任意两个n阶方阵,则 tr(kA) = k tr(A) 其中 k 是标量。 tr(A+B) = tr(A)+tr(B) tr(AB) = tr(A)-tr(B) tr(AB) = tr(BA)…
化妆品HRIPT/RIPT斑贴测试报告办理流程详解
亚马逊要求化妆、美容类产品需做此测试为了确保在使用产品或原料后不会产生潜在的刺激或过敏。亚马逊要求化妆品,美容产品,指甲胶等需要做HRIPT /RIPT 多次重复封闭性皮肤斑贴测试报告。样品到达实验室后,测试物质会被给予一个独立的实验室测…
第十二章 YOLO的部署实战篇(中篇)
cuda教程目录
第一章 指针篇 第二章 CUDA原理篇 第三章 CUDA编译器环境配置篇 第四章 kernel函数基础篇 第五章 kernel索引(index)篇 第六章 kenel矩阵计算实战篇 第七章 kenel实战强化篇 第八章 CUDA内存应用与性能优化篇 第九章 CUDA原子(atomic)实战篇 第十章 CUDA流(strea…
目标检测框架MMDetection训练自定义数据集实验记录
在上一篇博文中,博主完成了MMDetection框架的环境部署与推理过程,下面进行该框架的训练过程,训练的入口文件为tools/train.py,我们需要配置的内容如下:
parser.add_argument(--config,default"/home/ubuntu/prog…

OpenCV基础知识(10)— 人脸识别(人脸跟踪、眼睛跟踪、行人跟踪、车牌跟踪和人脸识别)
前言:Hello大家好,我是小哥谈。人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术,也是计算机视觉重点发展的技术。机械学习算法诞生之后,计算机可以通过摄像头等输入设备自动分析图像中包含的内容信息,随…
YOLO-NAS详细教程-实现图像分割
SuperGradients 允许用户训练用于语义分割任务的模型。该库包含预先训练的模型,例如 Cityscapes PPLiteSeg 模型,并提供用于加载自定义数据集的简单界面。
模型动物园
SuperGradients 包括各种用于语义分割任务的预训练模型。 Model NameDatasetIoUTraining RecipeResoluti…
[数据集][目标检测]裸土识别裸土未覆盖目标检测数据集VOC格式857张2类别
数据集格式:Pascal VOC格式(不包含分割路径的txt文件和yolo格式的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):857 标注数量(xml文件个数):857 标注类别数:2 标注类别名称:["luotu","n…
【计算机视觉 | 目标检测】arxiv 计算机视觉关于目标检测的学术速递(8 月 29 日论文合集)
文章目录 一、检测相关(18篇)1.1 Neural Network Training Strategy to Enhance Anomaly Detection Performance: A Perspective on Reconstruction Loss Amplification1.2 SAAN: Similarity-aware attention flow network for change detection with VHR remote sensing image…
yolo源码注释4——yolo-py
代码基于yolov5 v6.0 目录:
yolo源码注释1——文件结构yolo源码注释2——数据集配置文件yolo源码注释3——模型配置文件yolo源码注释4——yolo-py
yolo.py 用于搭建 yolov5 的网络模型,主要包含 3 部分:
Detect:Detect 层Model…
yolo源码注释1——文件结构
代码基于yolov5 v6.0 目录:
yolo源码注释1——文件结构yolo源码注释2——数据集配置文件yolo源码注释3——模型配置文件yolo源码注释4——yolo-py datasets # 用于存放数据集的默认文件夹yolov5 data # 模型训练的超参数配置文件以及数据集配置文件 hyps # 存放超参…
(十)mmdetection源码解读:build_detector
目录 一、build_detector调用过程二、build_detector参数分析 一、build_detector调用过程
model build_detector(cfg.model, train_cfgcfg.get(train_cfg), test_cfgcfg.get(test_cfg))
#build_detector函数中
def build_detector(cfg, train_cfgNone, test_cfgNone):return…

YOLO目标检测——火焰检测数据集+已标注xml和txt格式标签下载分享
实际项目应用:火灾预警系统、智能监控系统、工业安全管理、森林火灾监测以及城市规划和消防设计等应用场景中具有广泛的应用潜力,可以提高火灾检测的准确性和效率,保障人员和财产的安全。数据集说明:YOLO火焰目标检测数据集&#…
目标检测YOLO实战应用案例100讲-基于非合作运动雷达辐射源的杂波建模方法与目标检测研究(续)
目录 3.2非合作雷达辐射源杂波建模
3.2.1杂波几何模型 3.2.2基于天线增益杂波模型
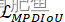
MPDIoU: A Loss for Efficient and Accurate Bounding BoxRegression
MPDIoU: A Loss for Efficient and Accurate Bounding BoxRegression MPDIoU:一个有效和准确的边界框损失回归函数 摘要 边界框回归(Bounding box regression, BBR)广泛应用于目标检测和实例分割,是目标定位的重要步骤。然而,当预测框与边界框具有相同的…
论文阅读——Co-Salient Object Detection with Co-Representation Purification
目录 基本信息标题摘要引言方法PCSRPP 实验 基本信息
期刊IEEE TPAMI年份2023论文地址https://arxiv.org/pdf/2303.07670.pdf代码地址https://github.com/ZZY816/CoRP
标题
具有共同表示净化的共同显著目标检测
摘要
共同显著目标检测(Co-SOD)旨在发…
将目标检测项目移植到linux上出现OSERROR
在windows上运行项目正常,但是在centos9上运行出现找到资源,第一次遇到这个问题,通过代码回找,一步一步发现,读取数据没问题,但是在预测的时候无法读取,查到的资料 说明显示字体问题,…
利用maskrcnn来实现目标检测与追踪
首先下载源代码仓库,链接地址如下:
maskrcnn
能够实现的效果如图所示: 该存储库包括:
基于FPN和ResNet101构建的Mask R-CNN的源代码。MS COCO 的训练代码MS COCO 的预训练砝码Jupyter 笔记本,用于可视化每一步的检测…
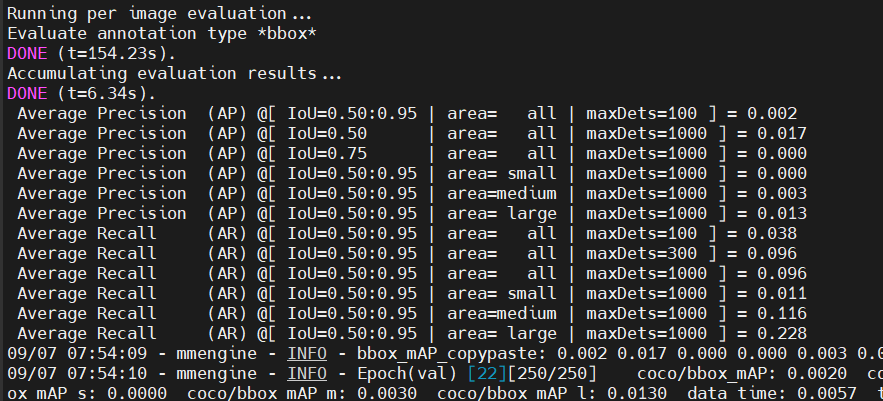
MMDetection实验记录踩坑记录
AP值始终为0
在实验MMDetection的DAB-DETR模型进行实验时,AP值始终上不去。 可以看到,在第22个epoch时的AP值仅为0.002 因为在此之前已经运行过YOLOX,Faster-RCNN等模型,所以数据集的设置肯定是没有问题的,而博主也只是修改了DAB…
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(九)
文章目录 一、CBC (Complete Blood Count)二、CURE-TSD (CURE Traffic Sign Detection)三、DUO (Detecting Underwater Objects)四、Duke Breast Cancer MRI (Dynamic contrast-enhanced magnetic resonance images of breast cancer patients with tumor locations)五、HS-SOD…

Voxel R-CNN:基于体素的高性能 3D 目标检测
论文地址:https://arxiv.org/abs/2012.15712 论文代码:https://github.com/djiajunustc/Voxel-R-CNN
论文背景
基于点的方法具有较高的检测精度,但基于点的方法通常效率较低,因为对于点集抽象来说,使用点表示来搜索最…
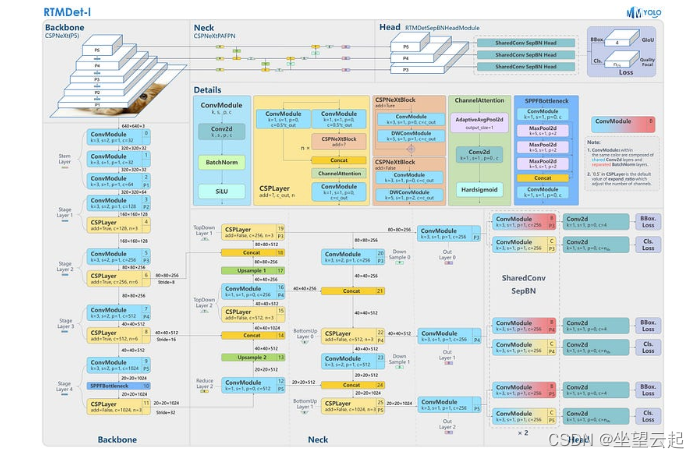
机器学习笔记 - 基于OpenMMLab在自定义数据集上训练RTMDet网络
一、什么是 RTMDet? RTMDet是一种高效的实时目标检测器,其自报告指标优于YOLO 系列。它在COCO上实现了52.8% 的 AP ,在 NVIDIA 3090 GPU 上实现了300+ FPS,使其成为当前号称最快、最准确的目标检测器之一。 RTMDet 与其他实时物体检测器的对比。 RTMDet 采用了一种…

YOLOv5算法改进(7)— 添加SimAM注意力机制
前言:Hello大家好,我是小哥谈。SimAM(Similarity-based Attention Mechanism)是一种基于相似度的注意力机制,它的原理是通过计算查询向量与每个键向量之间的相似度,从而确定每个键向量对于查询向量的重要性…

Python实现机器学习(上)— 基础知识介绍及环境部署
前言:Hello大家好,我是小哥谈。本门课程将介绍人工智能相关概念,重点讲解机器学习原理机器基本算法(监督学习及非监督学习)。使用python,结合sklearn、jupyter-notebook进行编程,介绍iris、匹马…
Yolov8魔术师:卷积变体大作战,涨点创新对比实验,提供CVPR2023、ICCV2023等改进方案
💡💡💡本文独家改进:提供各种卷积变体DCNV3、DCNV2、ODConv、SCConv、PConv、DynamicSnakeConvolution、DAT,引入CVPR2023、ICCV2023等改进方案,为Yolov8创新保驾护航,提供各种科研对比实验 &am…

OpenCV项目实战(1)— 如何去截取视频中的帧
前言:Hello大家好,我是小哥谈。针对一段视频,如何去截取视频中的帧呢?本节课就给大家介绍两种方式,一种方式是按一定间隔来截取视频帧,另一种方式是截取视频的所有帧。希望大家学习之后能够有所收获&#x…
yolov7简化yaml配置文件
yolov7代码结构简单,效果还好,但是动辄超过70几个模块的配置文件对于想要对网络进行魔改的朋友还是不怎么友好的,使用最小的tiny也有77个模块 代码的整体结构简单,直接将ELAN结构化写成一个类就能像yolov5一样仅仅只有20几个模块&…
【计算机视觉 | 目标检测】目标检测常用数据集及其介绍(十二)
文章目录 一、A Dataset of Multispectral Potato Plants Images二、Active Terahertz三、Apron Dataset四、AquaTrash五、BBBC041 (P. vivax (malaria) infected human blood smears)六、CLAD (Complex and Long Activities Dataset)七、COCO Object Detection VIPriors subse…
目标检测数据集:摄像头成像吸烟检测数据集(自己标注)
1.专栏介绍
✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨ 本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的…

few shot目标检测survey paper笔记(整体概念)
paper: Few-Shot Object Detection: A Comprehensive Survey (CVPR2021)
深度学习提高了目标检测的精度,但是它需要大量的训练数据。 对于训练数据集中没有见过的目标,是检测不了的,所以就限制了在实际中的应用。 如果想让模型去识别新的目标…
(十八)mmdetection源码解读:forward_train
目录 一、forward_train调用过程二、forward_train函数详解2.1、extract_feat2.2、self.rpn_head.forward_train2.3、self.roi_head.forward_train 一、forward_train调用过程
书接上文,在函数_call_impl中,最核心的训练过程,self.forward函…
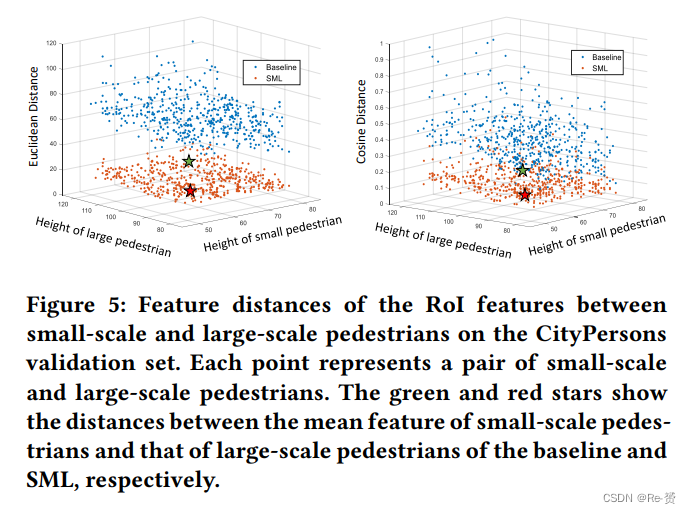
论文阅读 Self-Mimic Learning for Small-scale Pedestrian Detection
Self-Mimic Learning for Small-scale Pedestrian Detection
ABSTRACT
检测小尺度行人是行人检测中最具挑战性的问题之一。由于缺乏视觉细节,小尺度行人的 representations 往往难以与背景杂乱物区分开。本文深入分析了小尺度行人检测问题,揭示了小尺度…
(二十二)mmdetection源码解读:faster_rcnn_r50_fpn.py详解roi_head
目录 一、model配置文件->roi_head二、roi_head详解 一、model配置文件->roi_head
目标检测的ROI head是指在区域提议网络(Region Proposal Network,RPN)生成的候选区域中,对候选区域进行分类和边界框回归的神经网络模块。…
01目标检测-问题引入
目录
一、目标检测问题定义
二、目标检测过程中的常见的问题
三、目标检测VS图像分类区别
目标检测:
图像分类:
总结:
四、目标检测VS目标分割
目标分割: 目标检测是计算机视觉领域的一个重要任务,旨在从图像或…

few shot目标检测survey paper笔记(迁移学习)
paper: Few-Shot Object Detection: A Comprehensive Survey (CVPR2021)
meta learning需要复杂的情景训练,而迁移学习仅需在一个single-branch结构上做两步训练。 常用的结构是Faster R-CNN,下面是Faster R-CNN的结构图。 RPN的修改
当样本数量很少时…
基于YOLOv8模型的深海鱼目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和BDD数据集的自动驾驶目标检测系统可用于日常生活与海洋中检测与定位深海鱼目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv…
目标检测评估指标mAP:从Precision,Recall,到AP50-95【未完待续】
1. TP, FP, FN, TN
True Positive
满足以下三个条件被看做是TP 1. 置信度大于阈值(类别有阈值,IoU判断这个bouding box是否合适也有阈值) 2. 预测类型与标签类型相匹配(类别预测对了) 3. 预测的Bouding Box和Ground …
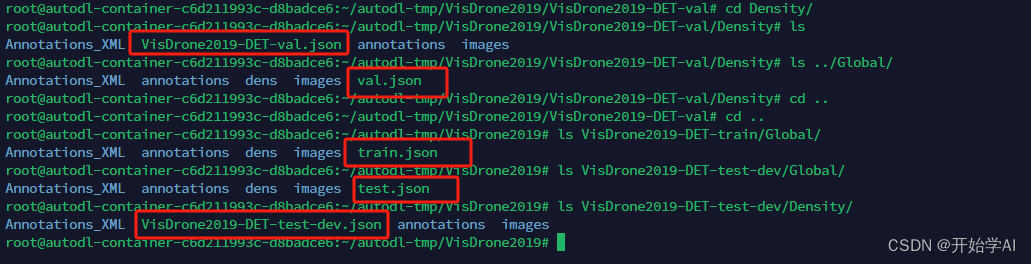
DMNet复现(一)之数据准备篇:Density map guided object detection in aerial image
一、生成密度图
密度图标签生成
采用以下代码,生成训练集密度图gt:
import cv2
import glob
import h5py
import scipy
import pickle
import numpy as np
from PIL import Image
from itertools import islice
from tqdm import tqdm
from matplotli…
PROB: Probabilistic Objectness for Open World Object Detection(论文解析)
PROB: Probabilistic Objectness for Open World Object Detection 摘要2 相关工作 摘要
开放世界目标检测(OWOD)是一个新的、具有挑战性的计算机视觉任务,它弥合了传统的目标检测(OD)基准和现实世界中的目标检测之间…

OpenCV之YOLOv2-tiny目标检测
💂 个人主页:风间琉璃🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦 目录
前言
一、YOLOv2-tiny介绍
二、预处理
三、模型加载与推理
四、解析输…

YOLOv5算法改进(18)— 更换激活函数(SiLU、ReLU、ELU、Hardswish、Mish、Softplus等)
前言:Hello大家好,我是小哥谈。激活函数在神经网络中起到引入非线性因素的作用。如果不使用激活函数,神经网络的每一层都只会做线性变换,多层输入叠加后仍然是线性变换。然而,线性模型的表达能力通常不够,因…
目标检测YOLO实战应用案例100讲-高分辨率显著性目标检测算法研究(续)
目录
3.2.3 空间细节路径
3.2.4 特征融合单元
3.3 实验及分析
3.3.1 高分辨率和低分辨率数据集
football 篮球数据集-目标检测548张
“篮球(basketball),是以手为中心的身体对抗性体育运动,是奥运会核心比赛项目。1891年12月21日,由美国马萨诸塞州斯普林菲尔德基督教青年会训练学校体育教师詹姆士奈史密斯发明。1896年,篮球运动传入中国天…
OpenCV之YOLOv4 目标检测
💂 个人主页:风间琉璃🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦 目录
前言
一、YOLOV4简介
二、预处理
1.获取分类名
2.获取输出层名称
3.…
基于YOLOv8模型的烟火目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的烟火目标检测系统可用于日常生活中检测与定位烟火目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…
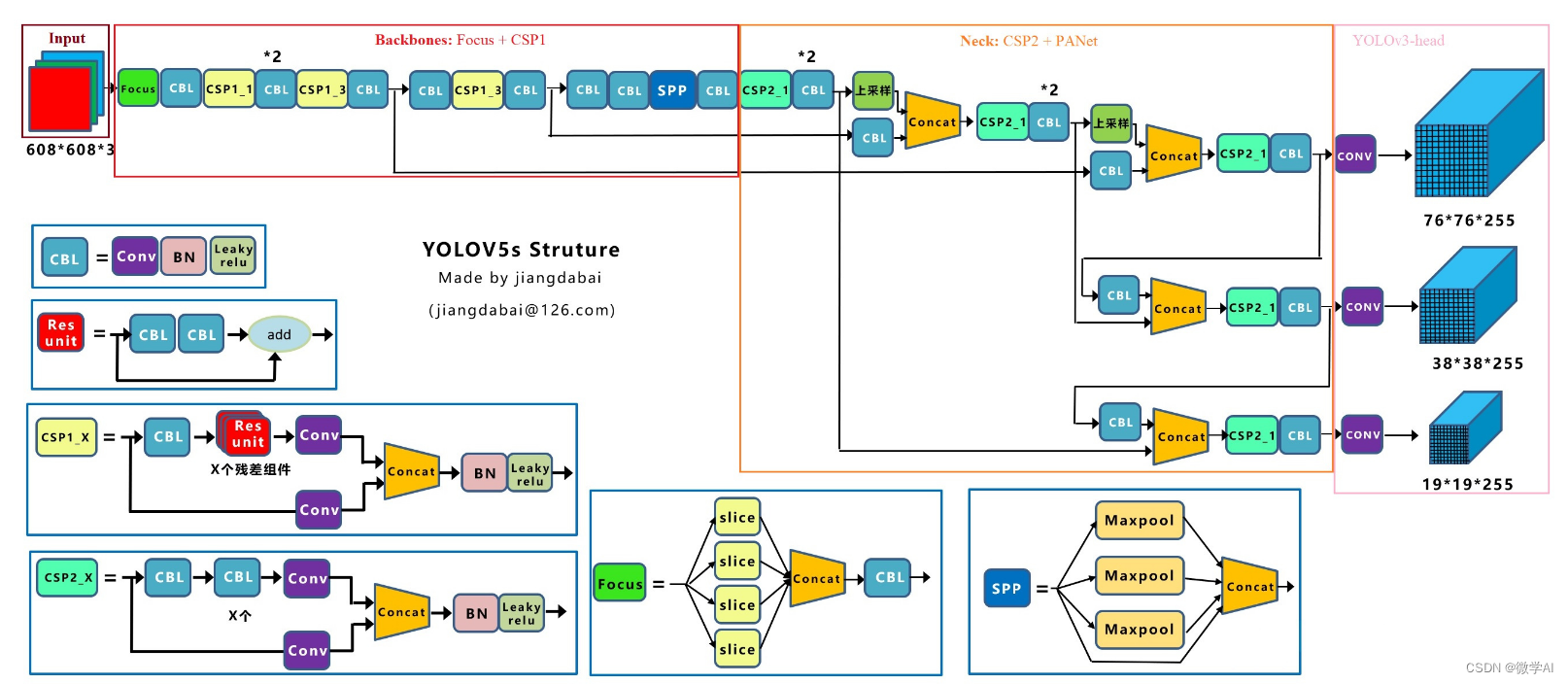
计算机视觉的应用14-目标检测经典算法之YOLOv1-YOLOv5的模型架构与改进过程详解,便于记忆
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用14-目标检测经典算法之YOLOv1-YOLOv5的模型架构与改进过程详解,便于记忆。YOLO(You Only Look Once)是一种目标检测深度学习模型。想象一下,传统的目…
基于Yolov8的工业端面小目标计数检测(1)
1.端面小目标计数数据集介绍
工业端面小目标计数类别:一类,类别名object
数据集大小:训练集864张,验证集98张
缺陷特点:小目标计数,检测难度大,如下图所示; 1.1 小目标定义
1)以物体检测领域的通用数据集COCO物体定义为例,小目标是指小于3232个像素点(中物体是指…

Deformable DETR(2020 ICLR)
Deformable DETR(2020 ICLR)
detr训练epochs缩小十倍,小目标性能更好
Deformable attention 结合变形卷积的稀疏空间采样和Transformer的关系建模能力 使用多层级特征层特征,不需要使用FPN的设计(直接使用backbone多层级输出&a…
(二十七)mmdetection实用工具: Visualization
目录 一、基础绘制接口二、基础存储接口三、任意点位进行可视化 一、基础绘制接口
可视化器(Visualizer):可视化器负责对模型的特征图、预测结果和训练过程中产生的结构化日志进行可视化,支持 Tensorboard 和 WanDB 等多种可视化…
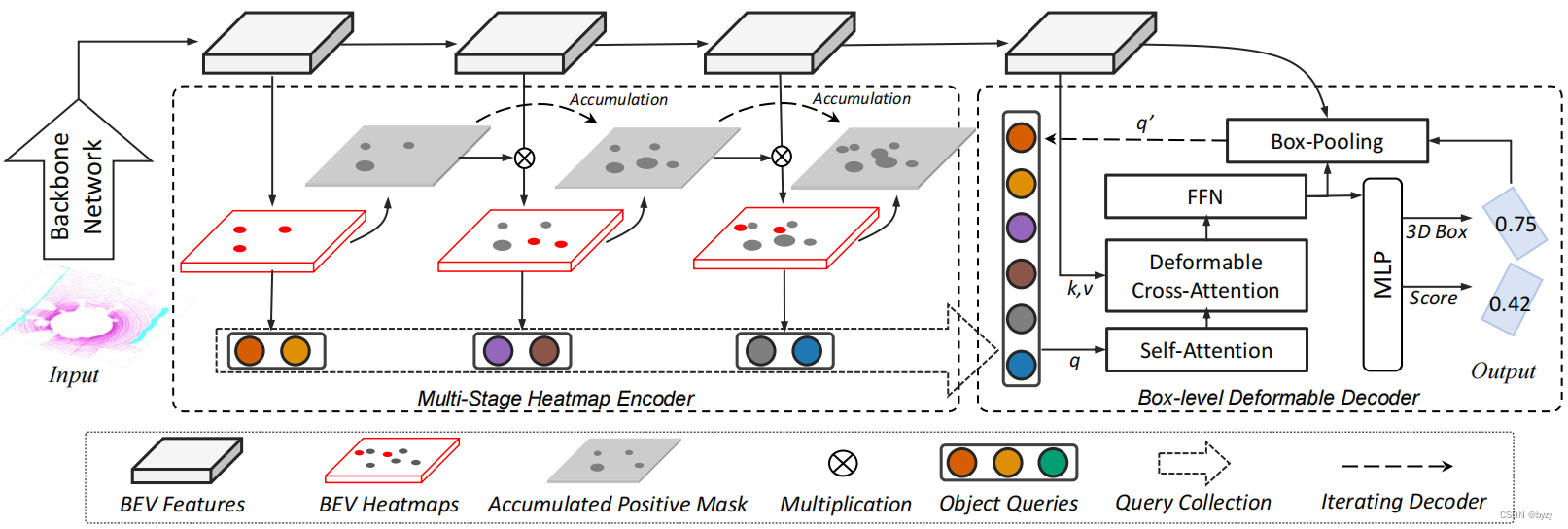
【ICCV 2023】FocalFormer3D : Focusing on Hard Instance for 3D Object Detection
原文链接:https://arxiv.org/abs/2308.04556
1. 引言 目前的3D目标检测方法没有显式地去考虑漏检问题。 本文提出了困难实例探测(HIP)。受目标检测的级联解码头启发,HIP逐步探测误检样本,极大提高召回率。在每个阶…

百度 RT-DETR 算法原理解析 | 超越YOLO的目标检测新高度?
文章目录 0. 前言1. RT-DETR结构设计1.1 主干网络1.2 颈部网络1.3 数据增强和训练策略 2. Query Selection 和 Decoder3. 实验结果3.1 设置3.2 与SOTA的比较3.3 关于混合编码器的消融研究3.4 关于IoU感知的查询选择的消融研究3.5 关于解码器的消融研究 总结参考文献 0. 前言 论…

基于Yolov8的工业小目标缺陷检测(5):大缺陷小缺陷一网打尽的轻量级目标检测器GiraffeDet,暴力提升工业缺陷检测能力
💡💡💡本文改进:大小缺陷一网打尽的GiraffeDet,提升处理低分辨率图像和小物体等更困难的检测能力。 GiraffeDet | 亲测在工业小目标缺陷涨点明显,原始mAP@0.5 0.679提升至0.727 收录专栏:
💡💡💡深度学习工业缺陷检测 :http://t.csdn.cn/fVSgs
✨✨✨提供…
YoloV5/YoloV7独家改进:Multi-Dconv Head Transposed Attention注意力,效果优于MHSA| CVPR2022
💡💡💡本文独家改进:为了降低计算量,构建了Multi-Dconv Head Transposed Attention,不在像素维度计算 attention,而是在通道维度计算。过程很简单,先用 point-wise conv 和 dconv 预处理,在通道维计算 atteniton
它有助于进行局部与非局部相关像素聚合,可以高效的…
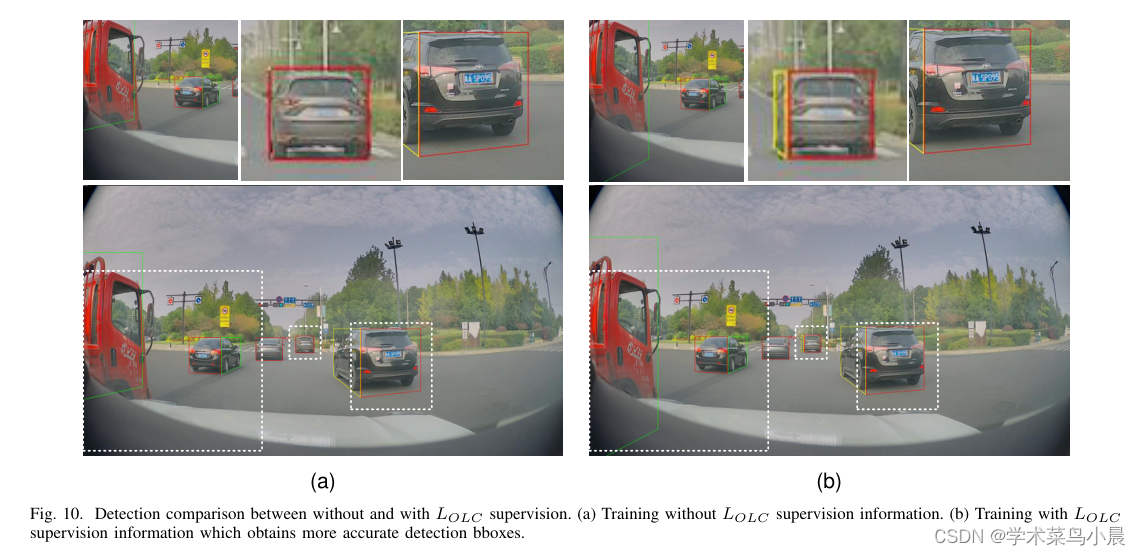
车辆检测:An Efficient Wide-Range Pseudo-3D Vehicle Detection Using A Single Camera
论文作者:Zhupeng Ye,Yinqi Li,Zejian Yuan
作者单位:Xian Jiaotong University
论文链接:http://arxiv.org/abs/2309.08369v1
项目链接:https://www.youtube.com/watch?v1gk1PmsQ5Q8
内容简介:
1)方…

FastestDet:比yolov5更快!更强!全新设计的超实时Anchor-free目标检测算法(附源代码下载)...
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 计算机视觉研究院专栏 作者:Edison_G 本篇文章转自于知乎——qiuqiuqiu,主要设计了一个新颖的轻量级网络! 代码地…
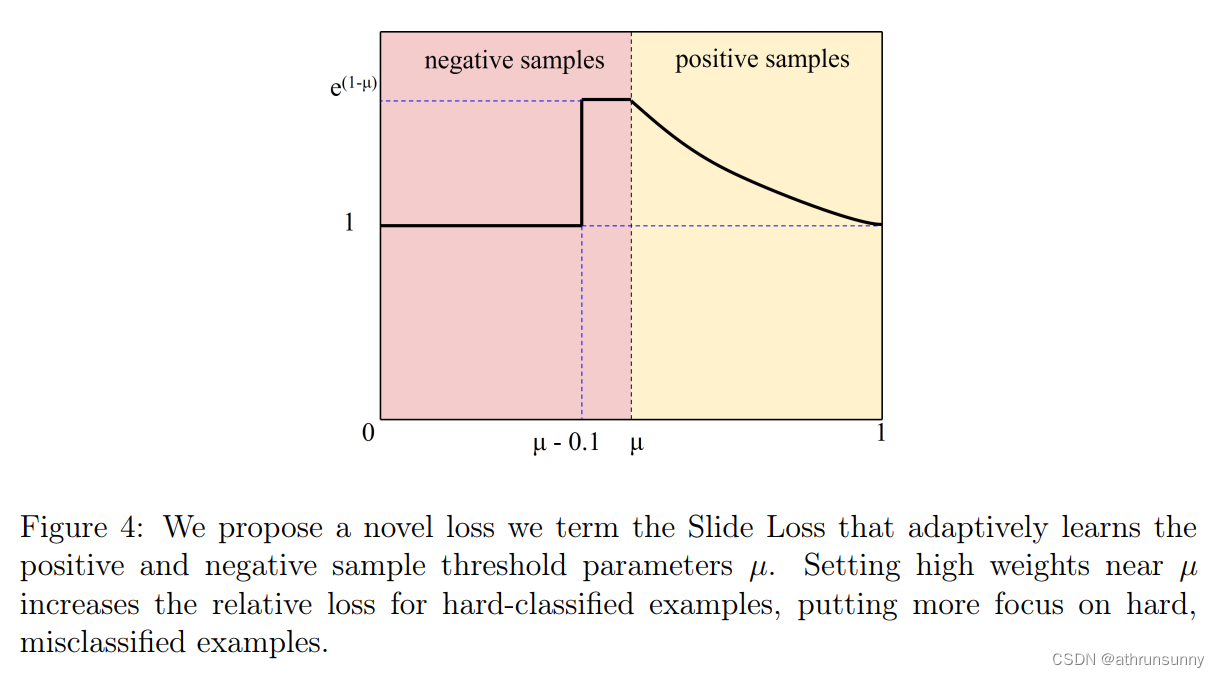
yolo增加slide loss,改善样本不平衡问题
slide loss的主要作用是让模型更加关注难例,可以轻微的改善模型在难例检测上的效果 论文地址:https://arxiv.org/pdf/2208.02019.pdf 代码:GitHub - Krasjet-Yu/YOLO-FaceV2: YOLO-FaceV2: A Scale and Occlusion Aware Face Detector 样本不…
DINO(ICLR 2023)
DINO(ICLR 2023)
DETR with Improved deNoising anchOr box DINO发展: Conditional DETR->DAB-DETR(4D,WH修正) DN-DETR(去噪训练,deNoising 稳定匹配过程) Deformable DETR&…
目标检测数据集:工业端面小目标缺陷计数数据集
✨✨✨✨✨✨目标检测数据集✨✨✨✨✨✨
本专栏提供各种场景的数据集,主要聚焦:工业缺陷检测数据集、小目标数据集、遥感数据集、红外小目标数据集,该专栏的数据集会在多个专栏进行验证,在多个数据集进行验证mAP涨点明显,尤其是小目标、遮挡物精度提升明显的数据集会在该…
UL588/UL1598/UL153/UL1573报告流程解析
一、什么是UL测试报告 UL是美国保险商试验所(Underwriter Laboratories Inc.)的简写。UL安全试验所是美国最有权威的,也是世界上从事安全试验和鉴定的较大的民间机构。 它是一个独立的、营利的、为公共安全做试验的专业机构。它采用科学的测试…

yolov5及yolov7实战之剪枝
之前有讲过一次yolov5的剪枝:yolov5实战之模型剪枝_yolov5模型剪枝-CSDN博客 当时基于的是比较老的yolov5版本,剪枝对整个训练代码的改动也比较多。最近发现一个比较好用的剪枝库,可以在不怎么改动原有训练代码的情况下,实现剪枝的…
基于Yolov8的工业小目标缺陷检测(9):Gold-YOLO,遥遥领先,超越所有YOLO | 华为诺亚NeurIPS23
💡💡💡本文独家全网首发改进:提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,Gold-YOLO,替换yolov8 head部分 实现暴力涨点
Gold-YOLO | 亲测在工业小目标缺陷涨点明显,原始mAP@0.5 0.679提升至0.712 收录专栏:
💡💡💡深度学习工业…

项目设计:YOLOv5目标检测+机构光相机(intel d455和d435i)测距
1.介绍
1.1 Intel D455
Intel D455 是一款基于结构光(Structured Light)技术的深度相机。
与ToF相机不同,结构光相机使用另一种方法来获取物体的深度信息。它通过投射可视光谱中的红外结构光图案,然后从被拍摄物体表面反射回来…
检测文件目录及其子文件到底的代码-实现可展开的目录列表和文件浏览功能的HTML代码
此实现了一个可展开的目录列表和文件浏览功能
该代码通过PHP实现了扫描指定目录下的文件和目录,并按照一定的排序规则进行展示。
用户可以点击目录名称,展开或折叠该目录下的子目录和文件列表。
对于文件,显示了文件名、修改时间和文件大小,并提供了文件链接以在新标签页…
基于YOLOv8模型的头盔行人检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的头盔行人检测系统可用于日常生活中检测与定位头盔与行人目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练…
全网首发YOLOv8暴力涨点:Dual-ViT:一种多尺度双视觉Transformer ,Dualattention助力检测| 顶刊TPAMI 2023
💡💡💡本文独家改进:DualViT:一种新的多尺度视觉Transformer主干,它在两种交互路径中对自注意力学习进行建模,即学习更精细像素级细节的像素路径和提取整体全局语义信息的语义路径,性能表现出色,Dualattention引入到YOLOv8实现创新涨点!!!
Dualattention | 亲…
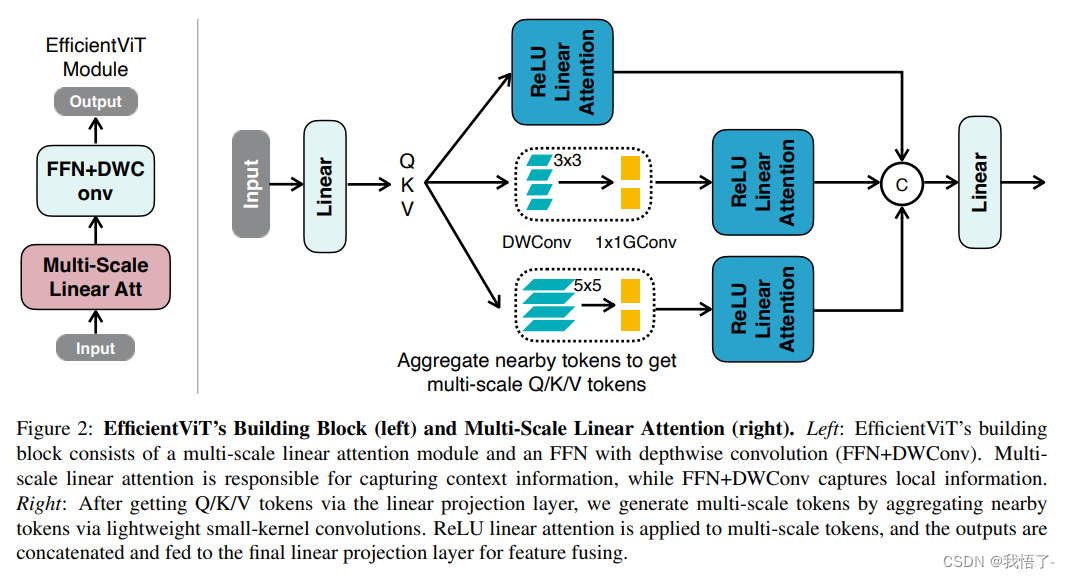
目标检测算法改进系列之Backbone替换为EfficientViT
EfficientViT
Vision Transformer (ViT) 在许多视觉任务中都取得了卓越的性能。然而,在针对高分辨率移动视觉应用时,ViT 不如卷积神经网络 (CNN)。 ViT 的关键计算瓶颈是 softmax 注意力模块,其计算复杂度与输入分辨率成二次方。降低 ViT 的…

Python如何优雅地可视化目标检测框
读入图像
img_name ./pikachu.jpg
img cv2.imread(img_name)
box [ 140, 16,468,390, "pikachu"]
box_color (255,0,255)
cv2.rectangle(img, (box[0], box[1]), (box[2], box[3]), colorbox_color, thickness2)标签美化
接下来我们来给矩形框添加标签,我们…

基于Yolov8的工业端面小目标计数检测(2):Gold-YOLO,遥遥领先,超越所有YOLO | 华为诺亚NeurIPS23
💡💡💡本文独家全网首发改进:提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,Gold-YOLO,替换yolov8 head部分 实现暴力涨点
Gold-YOLO | 亲测在工业端面小目标计数涨点明显,原始mAP@0.5 0.936提升至0.945 layers parametersGFLOPs mAP50mAP…
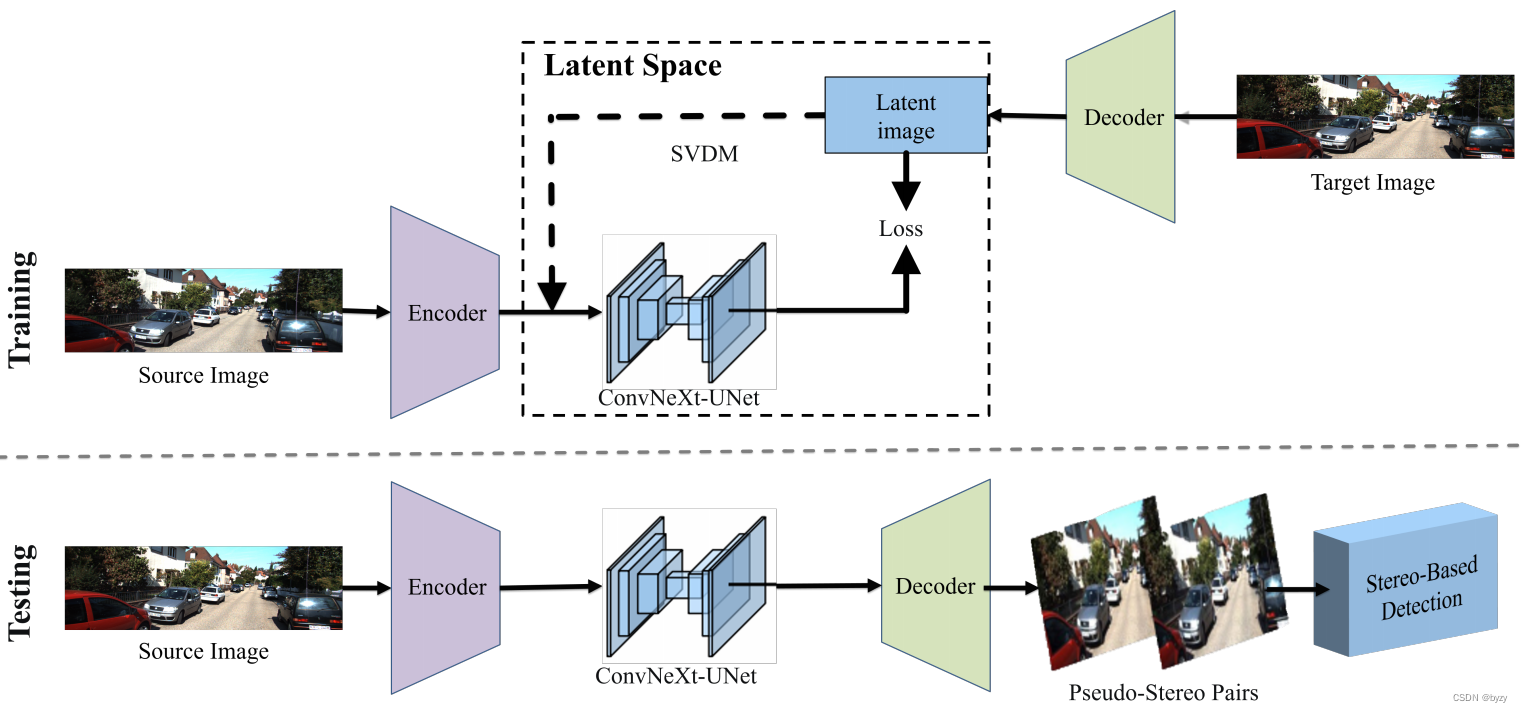
【论文笔记】SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
原文链接:https://arxiv.org/abs/2307.02270
1. 引言 目前的从单目相机生成伪传感器表达的方法依赖预训练的深度估计网络。这些方法需要深度标签来训练深度估计网络,且伪立体方法通过图像正向变形合成立体图像,会导致遮挡区域的像素伪影、扭…
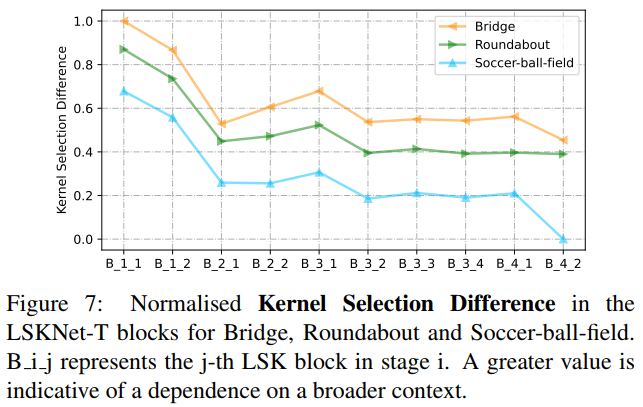
大选择核网络在遥感目标检测中的应用
摘要
论文链接:https://arxiv.org/pdf/2303.09030.pdf 最近关于遥感目标检测的研究主要集中在改进有向边界框的表示,但忽略了遥感场景中呈现的独特先验知识。这种先验知识很有用,因为如果没有参考足够远的上下文,可能会错误地检测…
来看看双阶段目标检测算法趴
🚀 作者 :“码上有钱”
🚀 文章简介 :AI-目标检测算法
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬简介
双阶段目标检测算法是一类深度学习算法,通常分为两个阶段来检测和识别图像中的…
(零)如何做机器视觉项目
文章目录 1 项目的前期准备1.1 从5个方面初步分析客户需求1.2 方案评估与验证1.3 签订合同 2 项目规划2.1 定义客户端的详细需求2.2 制定项目管理计划2.3 方案评审 3 详细设计3.1 硬件设备的选择与环境搭建3.2 软件开发平台与开发工具的选择3.3 机器视觉系统的整体框架与开发流…
![[论文必备]最强科研绘图分析工具Origin(2)——简单使用教程](https://img-blog.csdnimg.cn/dea0e6079dcc4dbaa8f0edb87d9fcd10.gif)
[论文必备]最强科研绘图分析工具Origin(2)——简单使用教程
本篇将介绍Origin的简单使用教程。
安装教程见上篇:[论文必备]最强科研绘图分析工具Origin(1)——安装教程
目录
📢一、工具栏介绍
📣1.1 行
1.1.1 标准栏
1.1.2 导入栏
1.1.3 工作表数据
1.1.4 图表数据
&a…

YOLO目标检测——红外人员数据集【含对应voc、coco和yolo三种格式标签+划分脚本】
实际项目应用:红外热像仪进行安全监控数据集说明:红外人员检测数据集,真实场景的高质量图片数据标签说明:使用lableimg标注软件标注,标注框质量高,含voc(xml)、coco(json)和yolo(txt)三种格式标签ÿ…

opencv dnn模块 示例(20) 目标检测 object_detection 之 yolor
文章目录 1、论文介绍1.1、YOLOR思想动机1.2、隐式知识学习1.2.1、隐式知识如何工作1.2.2、隐式知识统一网络建模 1.3、实验1.4、总结 2、测试2.1、opencv dnn2.1.1、代码2.1.2、结果 2.2、测试效率 YOLOR出自论文You Only Learn One Representation: Unified Network for Mult…
基于YOLOv8模型的船只目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的船只目标检测系统可用于日常生活中检测与定位船只目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…
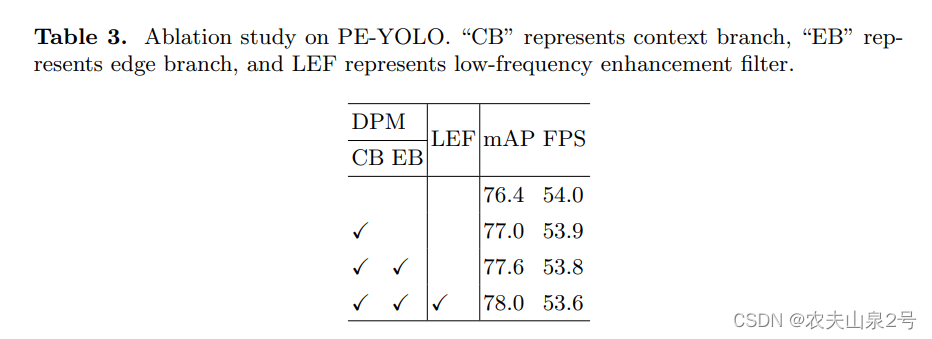
【目标检测】——PE-YOLO精读
yolo,暗光目标检测 论文:PE-YOLO 1. 简介
卷积神经网络(CNNs)在近年来如何推动了物体检测的发展。许多检测器已经被提出,而且在许多基准数据集上的性能正在不断提高。然而,大多数现有的检测器都是在正常条…

使用 labelImg 制作YOLO系列目标检测数据集(.xml文件)
文章转载自K同学,谨防原文失效 第一步: WIN键R 输入cmd 打开命令行窗口 第二步: 在命令行窗口中输入pip3 install labelImg,安装 labelImg 第三步: 输入labelImg 打开labelImg窗口 第四步: ✨ 标注小技巧…
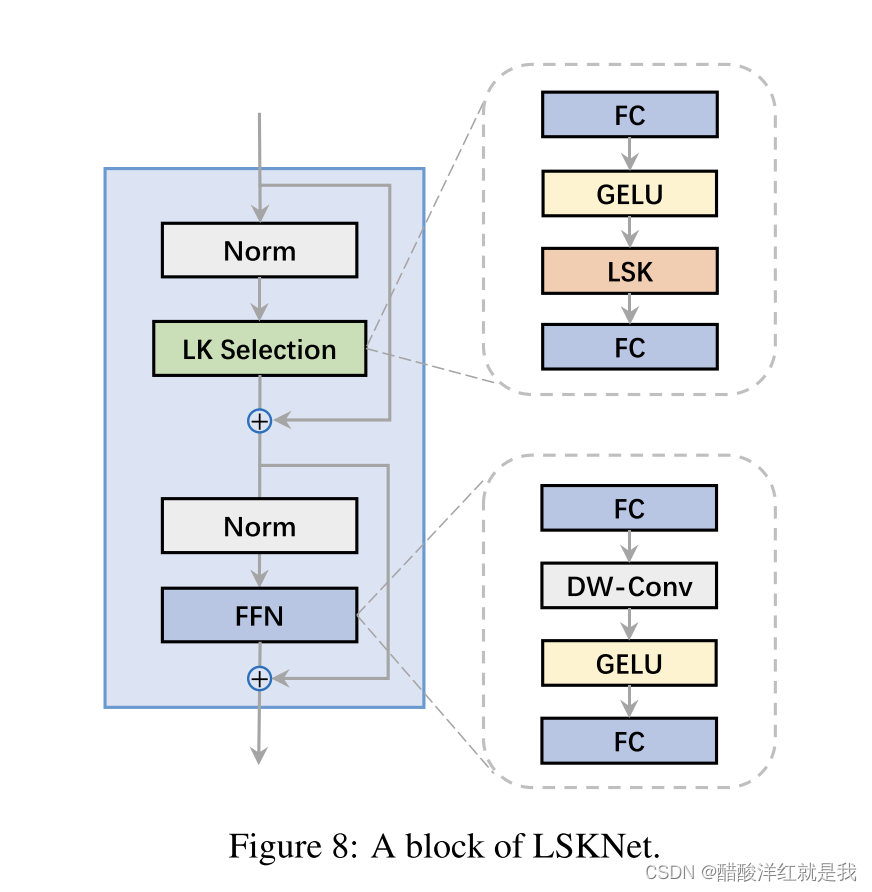
论文阅读——Large Selective Kernel Network for Remote Sensing Object Detection
目录 基本信息标题目前存在的问题改进网络结构另一个写的好的参考 基本信息
期刊CVPR年份2023论文地址https://arxiv.org/pdf/2303.09030.pdf代码地址https://github.com/zcablii/LSKNet
标题
遥感目标检测的大选择核网络
目前存在的问题
相对较少的工作考虑到强大的先验知…
yolo_tracking中osnet不支持.pth格式,而model_zoo中仅有.pth
yolo_traking-7.0中REID模块用到了osnet,track.py中模型文件不支持.pth,而model_zoo中仅有.pth,改动代码太麻烦了,网上查到的.pth文件转化为.pt文件都需要读取网络架构,不太可能实现。 读取osnet_x0_25_msmt17.pth发现…
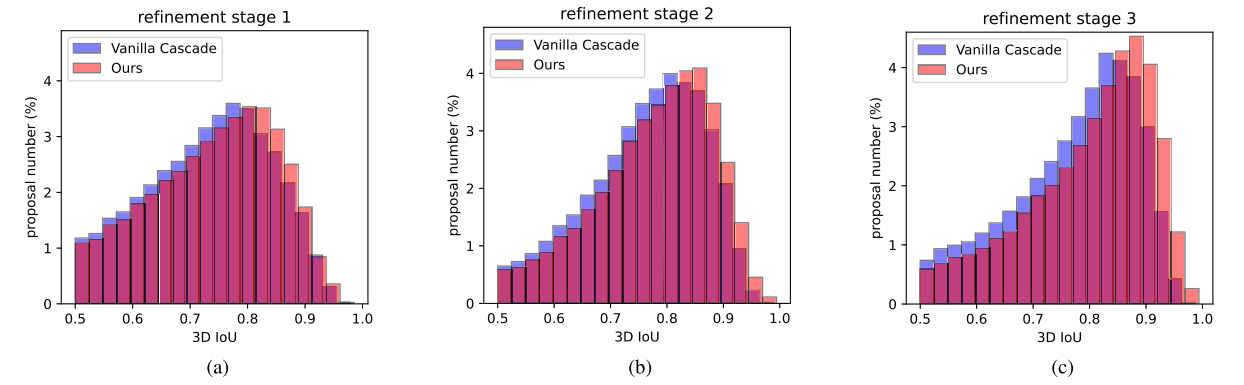
CasA:用于点云 3D 目标检测的级联注意力网络
论文摘要
LiDAR 收集的数据通常表现出稀疏和不规则的分布。 3D 空间中的 LiDAR 扫描并不均匀。近处和远处的物体之间存在巨大的分布差距。
CasA(Cascade Attention) 由 RPN(Region proposal Network)和 CRN(cascade refinement Network&…
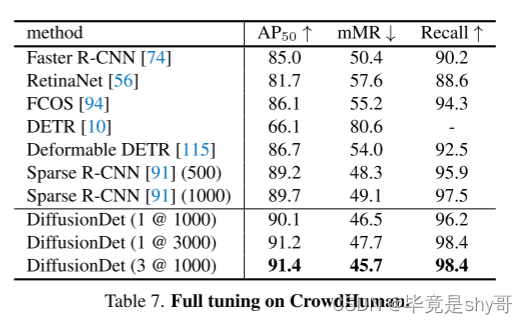
DiffusionDet:第一个用于物体检测的扩散模型(DiffusionDet: Diffusion Model for Object Detection)
提出了一种新的框架——DiffusionDet,它将目标检测定义为一个从有噪声的盒子到目标盒子的去噪扩散过程。在训练阶段,目标盒从真实值盒扩散到随机分布,模型学会了逆转这个噪声过程。 在推理中,该模型以渐进的方式将一组随机生成的框…

【Python深度学习】目标检测和语义分割的区别
在计算机视觉领域,语义分割和目标检测是两个关键的任务,它们都是对图像和视频进行分析,但它们之间存在着明显的区别。本文将通过图像示例,详细阐述语义分割和目标检测之间的差异。 一、基本概念 1.1 语义分割(Semantic…
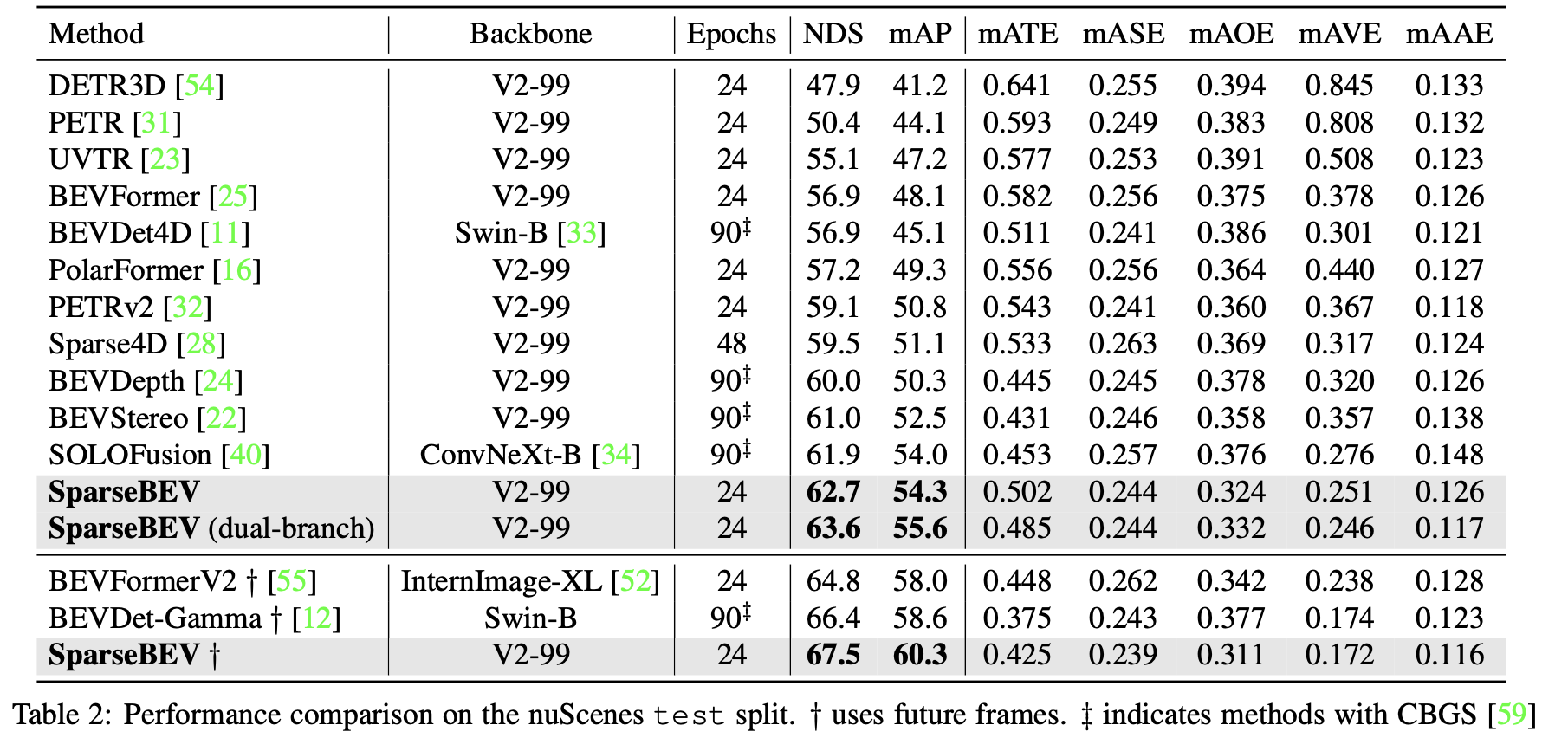
SparseBEV:High-Performance Sparse 3D Object Detection from Multi-Camera Videos
参考代码:SparseBEV
动机与主要贡献: BEV感知可以按照是否显式构建BEV特征进行划分,显式构建BEV特征的方法需要额外计算量用于特征构建,而类似query方案的方法则不需要这样做。比较两种类型的方法,前者需要更多计算资…
【Python目标识别】目标检测的原理及常见模型的介绍
1 概述 目标检测(Object Detection)是计算机视觉领域的一个重要研究方向,其目的是在图像或视频中定位并识别出特定的物体。目标检测模型通常需要同时确定物体的位置和类别。在深度学习之前,目标检测算法主要基于传统计算机视觉方法…
基于YOLOv8模型的二维码目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的二维码目标检测系统可用于日常生活中检测与定位车辆目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据…
热风梳被亚马逊下架是什么原因,UL859测试报告解析
近期受到亚马逊严查UL认证的影响,有卖家反映自己的产品被亚马逊下架了,并且收到了一份邮件通知,由于产品缺少UL认证被删除listing。 现在亚马逊平台竞争也愈显激烈,不合规范的操作也越来越多,随之平台要求越来越高&…

YOLOv5算法改进(10)— 如何去添加多层注意力机制(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。注意力机制可被应用于模型的不同层级,以便更好地捕捉图像中的细节和特征,这种模型在计算资源有限的情况下,可以实现更好的性能和效率。…

Python合并多个相交矩形框
Python合并多个相交矩形框 前言前提条件相关介绍实验环境Python合并多个相交矩形框代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入Python日常小操作专栏、YOLO系列专栏、自然语言处理专栏或我的个人主页…
YOLOv5算法改进(7)— 添加单层注意力机制(包括代码+添加步骤+网络结构图)
前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。注意力机制可被应用于模型的不同层级,以便更好地捕捉图像中的细节和特征,这种模型在计算资源有限的情况下,可以实现更好的性能和效率。…

小样本学习--(1)概论
目录
一、概述
二、小样本学习的数据集
1、Omniglot
2、MiniimageNet
三、孪生网络
四、三元组损失函数 一、概述 小样本学习用于处理训练数据集中样本数量少的情况,一般来说,小样本学习流程是这样的,从一个多种类少量样本的巨大数据集…
![[Python中常用的回归模型算法大全:从线性回归到XGBoost]](https://img-blog.csdnimg.cn/052452a4f41c4035bfb8352c5bc000ae.png)
[Python中常用的回归模型算法大全:从线性回归到XGBoost]
文章目录 概要保序回归:理论与实践多项式回归:探索数据曲线关系多输出回归的示例 概要
在数据科学和机器学习领域,回归分析是一项关键任务,用于预测连续型变量的数值。除了传统的线性回归模型外,Python提供了丰富多样…
基于YOLOv8模型的老虎目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型的老虎目标检测系统可用于日常生活中检测与定位老虎目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集…
YOLO目标检测——安全帽手套数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:主要应用于监控视频中工作人员是否佩戴安全帽或手套的场景。数据集说明:YOLO目标检测数据集,类别有:手套、头盔、非头盔、人、鞋、背心、赤膊,真实场景的高质量图片数据,数据场景丰富。使用la…

【yolov8系列】yolov8的目标检测、实例分割、关节点估计的原理解析
1 YOLO时间线 这里简单列下yolo的发展时间线,对每个版本的提出有个时间概念。 2 yolov8 的简介 工程链接:https://github.com/ultralytics/ultralytics 2.1 yolov8的特点 采用了anchor free方式,去除了先验设置可能不佳带来的影响借鉴Genera…

【yolov5目标检测】使用yolov5训练自己的训练集
数据集准备
首先得准备好数据集,你的数据集至少包含images和labels,严格来说你的images应该包含训练集train、验证集val和测试集test,不过为了简单说明使用步骤,其中test可以不要,val和train可以用同一个,…
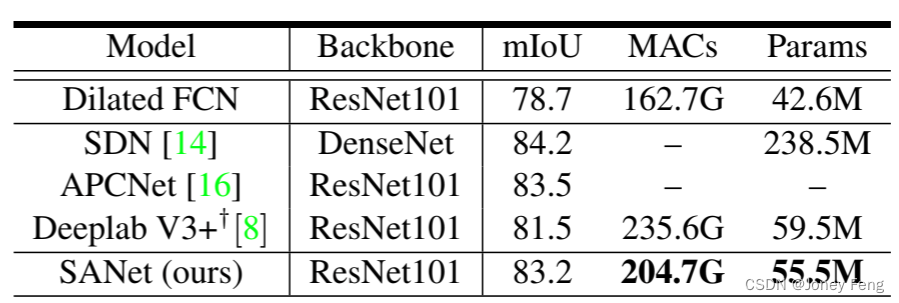
Squeeze-and-Attention Networks for Semantic Segmentation
0.摘要 最近,将注意力机制整合到分割网络中可以通过更重视提供更多信息的特征来提高它们的表征能力。然而,这些注意力机制忽视了语义分割的一个隐含子任务,并受到卷积核的网格结构的限制。在本文中,我们提出了一种新颖的squeeze-a…
YOLOv5改进实战 | 更换主干网络Backbone(四)之轻量化模型MobileNetV3
前言
轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操作,并将它们分别作用于输入的不…
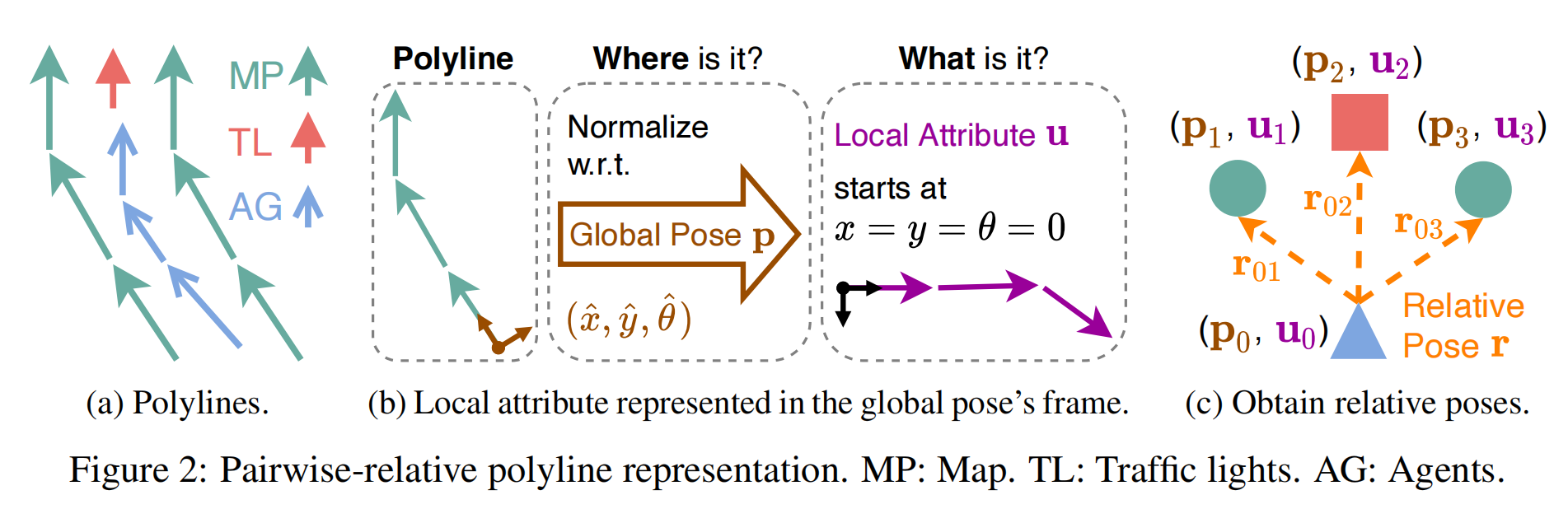
CV计算机视觉每日开源代码Paper with code速览-2023.10.20
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Click on Mask: A Labor-efficient Annotati…
YOLOv5:修改backbone为SPD-Conv
YOLOv5:修改backbone为SPD-Conv 前言前提条件相关介绍SPD-ConvYOLOv5修改backbone为SPD-Conv修改common.py修改yolo.py修改yolov5.yaml配置 参考 前言 记录在YOLOv5修改backbone操作,方便自己查阅。由于本人水平有限,难免出现错漏,…
基于YOLOv8模型和WiderPerson数据集的行人目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和WiderPerson数据集的行人目标检测系统可用于日常生活中检测与定位行人目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标…
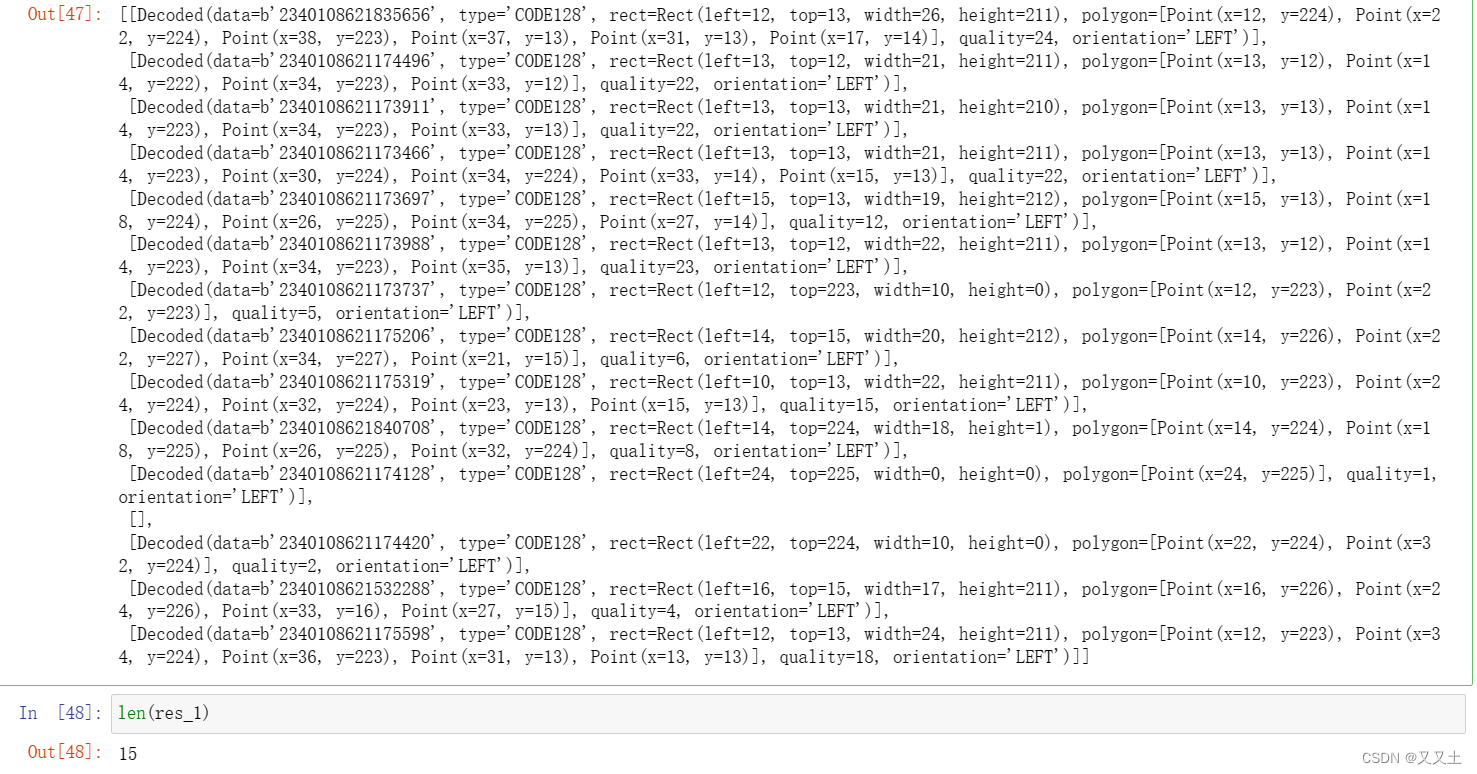
#1024 程序员节 大图像中的小目标检测——基于YOLOV8+OnnxRuntime部署+滑动窗口+Zbar的条码检测研究
文章目录 前言1 训练一个YOLOV8的一维码检测模型2 创建滑动窗口2.1 模块导入与测试图片展示2.2 创建滑动窗口检测,窗口大小为(640,640),滑动距离为640。对不足(640,640)的窗口进行填充 3 创建on…

YOLO目标检测——人脸识别数据集【对应voc、coco和yolo三种格式标签】
实际项目应用:安全监控、智能驾驶、人机交互、人脸门禁、人脸支付、人脸搜索数据集说明:人脸识别数据集,真实场景的高质量图片数据,数据场景丰富,含有人脸图片标签说明:使用lableimg标注软件标注࿰…
高效MMdetection(3.1.0)环境安装和训练自己数据集教程(实现于Linux(ubuntu),可在windows尝试)
很久没用mmdetection了,作为目标检测常见的几个深度学习框架,mmdetection用的人还是很多的,其中比较吸引人的一点就是mmdetection集成了非常多的算法,对于想做实验对比和算法学习的人来说,基于这个框架可以事半功倍。因…
YOLOV8目标检测——最全最完整模型训练过程记录
文章目录 前言1 下载yolov8([网址](https://github.com/ultralytics/ultralytics))2 配置conda环境3 用pycharm打开文件3 训练自己的YOLOV8数据集4 run下运行完了之后没有best.pt文件5 导出为onnx文件6 yolov8应用完整案例(免费且包含源代码、…
不断改进 | YOLOv2算法超详细解析(包括诞生背景+论文解析+技术原理等)
前言:Hello大家好,我是小哥谈。YOLOv2是YOLO(You Only Look Once)目标检测算法的第二个版本,它在YOLOv1的基础上做了很多改进,包括使用更深的卷积神经网络Darknet-19作为特征提取器、使用Batch Normalizati…
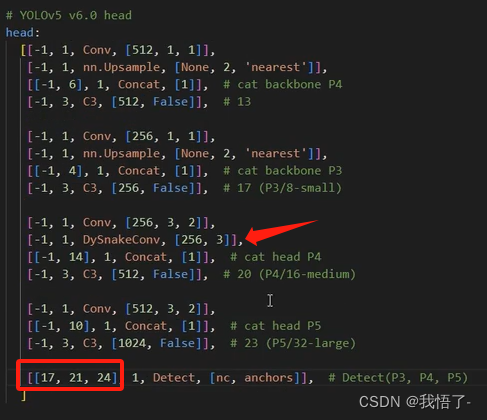
目标检测算法改进系列之嵌入动态蛇形卷积模块DySnakeConv
动态蛇形卷积模块DySnakeConv
血管、道路等拓扑管状结构的精确分割在各个领域都至关重要,确保下游任务的准确性和效率。 然而,许多因素使任务变得复杂,包括薄的局部结构和可变的全局形态。在这项工作中,我们注意到管状结构的特殊…

YOLOv7-QAT量化部署
目录 前言一、QAT量化浅析二、YOLOv7模型训练1. 项目的克隆和必要的环境依赖1.1 项目的克隆1.2 项目代码结构整体介绍1.3 环境安装 2. 数据集和预训练权重的准备2.1 数据集2.2 预训练权重准备 3. 训练模型3.1 修改模型配置文件3.2 修改数据配置文件3.3 训练模型3.4 mAP测试 三、…

从零开始的目标检测和关键点检测(一):用labelme标注数据集
从零开始的目标检测和关键点检测(一):用labelme标注数据集 1、可视化标注结果2、划分数据集3、Lableme2COCO,将json文件转换为MS COCO格式 前言:前段时间用到了mmlab的mmdetction和mmpose,因此以一个小的数…
YOLOv5/YOLOv7改进: AIFI (尺度内特征交互)助力YOLO | YOLO终结者?RT-DETR一探究竟
💡💡💡本文全网首发独家改进: AIFI (尺度内特征交互)助力YOLO ,提升尺度内和尺度间特征交互能力,同时降低多个尺度的特征之间进行注意力运算,计算消耗较大等问题
推荐指数:五星
AIFI | 亲测在多个数据集能够实现涨点
💡💡💡Yolov5/Yolov7魔术师,独家首…
16.ViT模型介绍
Vision Transformer
关于ViT
Transformer自2017年06月由谷歌团队在论文Attention Is All You Need中提出后,给自然语言处理领域带去了深远的影响,其并行化处理不定长序列的能力及自注意力机制表现亮眼。根据以往的惯例,一个新的机器学习方法往往先在NLP领域带来突破,然后…
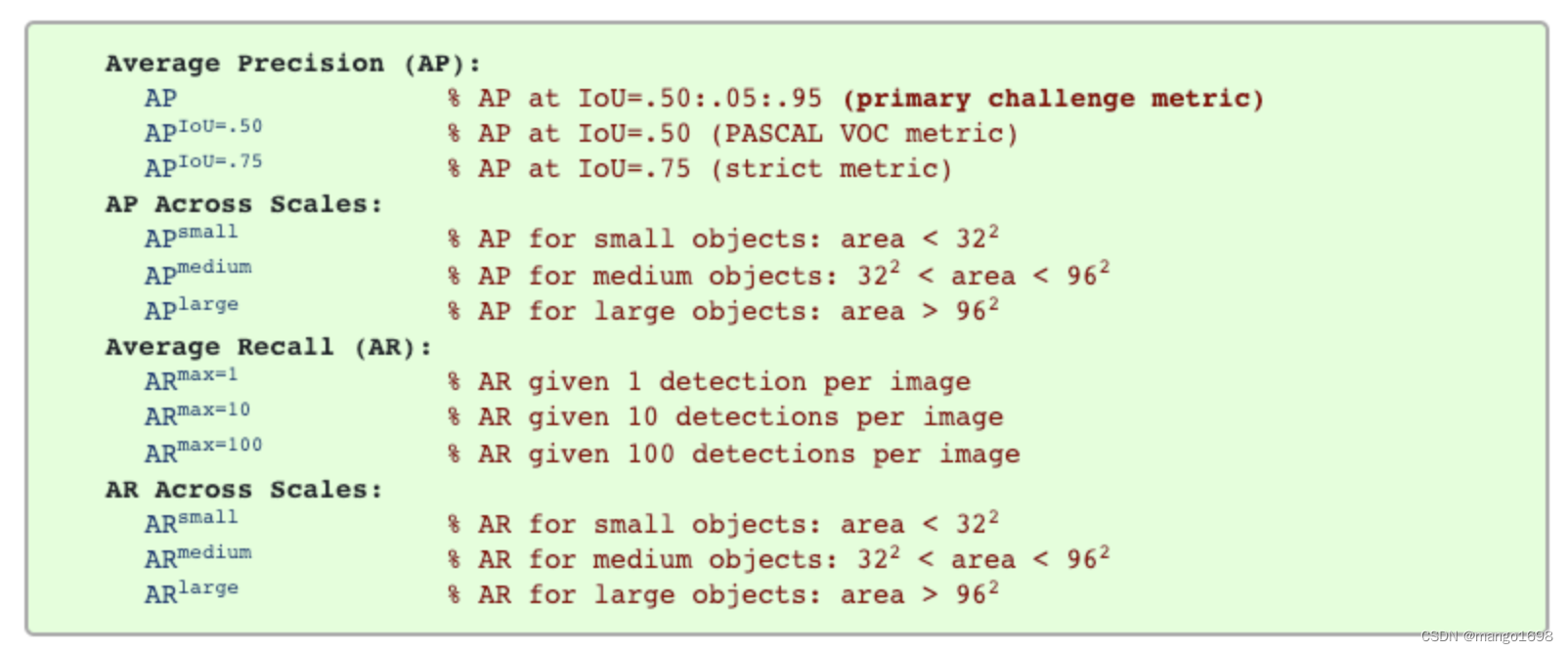
目标检测中常见指标 - mAP
文章目录 1. 评价指标2. 计算示例3. COCO评价指标 1. 评价指标
在目标检测领域,比较常用的两个公开数据集:pascal voc和coco。
目标检测与图像分类明显差距是很大的,在图像分类中,我们通常是统计在验证集当中,分类正…
海康多相机同步取流保存图片
话不多说,直接上代码。代码里包含了多窗口显示图像和保存图片。
#"rtsp://admin:123456qq192.168.10.192/stream1"
# rtsp://admin:Admin123192.168.100.103:554/Streaming/Channels/101
#rtsp://admin:Admin123192.168.100.103:554/cam/realmonitor?ch…
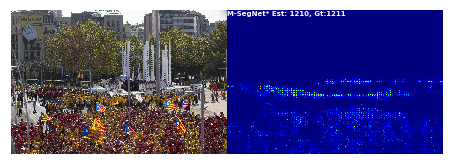
Variations-of-SFANet-for-Crowd-Counting可视化代码
前文对Variations-of-SFANet-for-Crowd-Counting做了一点基础梳理,链接如下:Variations-of-SFANet-for-Crowd-Counting记录-CSDN博客
本次对其中两个可视化代码进行梳理
1.Visualization_ShanghaiTech.ipynb
不太习惯用jupyter notebook, 这里改成了p…
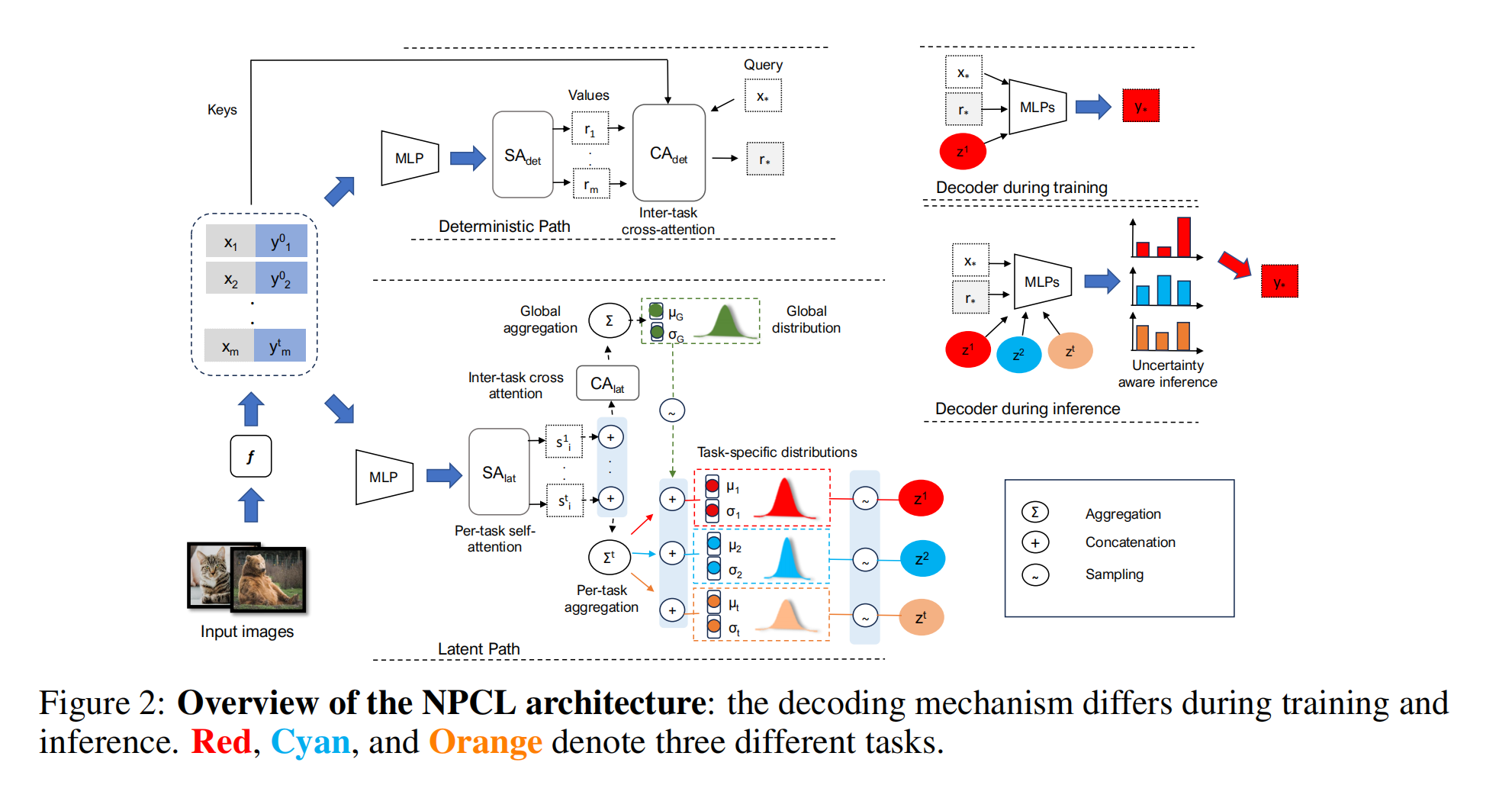
CV计算机视觉每日开源代码Paper with code速览-2023.10.31
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】(NeurIPS2023)Fa…
基于transformer的解码decode目标检测框架(修改DETR源码)
提示:transformer结构的目标检测解码器,包含loss计算,附有源码 文章目录 前言一、main函数代码解读1、整体结构认识2、main函数代码解读3、源码链接二、decode模块代码解读1、decoded的TransformerDec模块代码解读2、decoded的TransformerDecoder模块代码解读3、decoded的De…

YOLO目标检测——红外多目标检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:自动驾驶、安防监控等数据集说明:红外多目标检测数据集,真实场景的高质量图片数据,数据场景丰富,含有行人、汽车、自行车、摩托、消防栓、指示牌、狗等图片标签说明:使用lableimg标注软件标注…
YOLOv5:修改backbone为SPPCSPC
YOLOv5:修改backbone为SPPCSPC 前言前提条件相关介绍SPPCSPCYOLOv5修改backbone为SPPCSPC修改common.py修改yolo.py修改yolov5.yaml配置 参考 前言 记录在YOLOv5修改backbone操作,方便自己查阅。由于本人水平有限,难免出现错漏,敬…

YOLO目标检测——车辆分类检测数据集【含对应voc、coco和yolo三种格式标签】
实际项目应用:安全监控、智能驾驶、人机交互、智能城市数据集说明:车辆分类检测数据集,真实场景的高质量图片数据,数据场景丰富,含有图片汽车、公共汽车、摩托车、救护车和卡车等图片标签说明:使用lableimg…

独创改进 | RT-DETR 引入双向级联特征融合结构 RepBi-PAN | 附手绘结构图原图
本专栏内容均为博主独家全网首发,未经授权,任何形式的复制、转载、洗稿或传播行为均属违法侵权行为,一经发现将采取法律手段维护合法权益。我们对所有未经授权传播行为保留追究责任的权利。请尊重原创,支持创作者的努力,共同维护网络知识产权。 文章目录 YOLOv6贡献RepBi-…
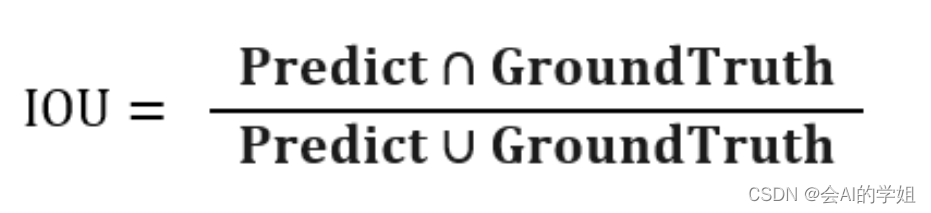
YOLOv8改进:IOU创新篇 | 引入MPDIou、WIoU、SIoU、EIoU、α-IoU,在不同场景实现涨点
🚀🚀🚀本文改进:引入MPDIou、WIoU、SIoU、EIoU、α-IoU,适配各个YOLO
🚀🚀🚀MPDIou、WIoU、SIoU、EIoU、α-IoU在各个场景都能够有效涨点
🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK
学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研; 1. …
YOLO目标检测数据集大全【含voc(xml)、coco(json)和yolo(txt)三种格式标签+划分脚本+训练教程】(持续更新建议收藏)
一、作者介绍:资深图像算法工程师,YOLO算法专业玩家;擅长目标检测、语义分割、OCR等。 二、数据集介绍: 真实场景的高质量图片数据,数据场景丰富,分享的绝大部分数据集已应用于各种实际落地项目。所有数据…

Google发布移动终端对象检测模型——mediapipe,无GPU依然飞快
对象检测模型最出名的当选YOLO系列,其YOLO系列已经更新到V8系列,但是现有的YOLO模型面临限制,如量化支持不足和准确性延迟权衡不足。 YOLO-NAS模型在包括COCO、Objects365和Roboflow 100在内的知名数据集上进行了预训练,使其非常适合生产环境中的下游对象检测任务。YOLO-NA…
YOLOv8-Seg改进:动态蛇形卷积(Dynamic Snake Convolution) | ICCV2023
🚀🚀🚀本文改进:动态蛇形卷积(Dynamic Snake Convolution),增强微小特征提取能力,引入到YOLOv8-Seg,与C2f结合实现二次创新
🚀🚀🚀Dynamic Snake Convolution亲测在番薯破损分割任务中,mask mAP@0.5 从原始的0.625提升至0.645 🚀🚀🚀YOLOv8-seg创新专…
CV计算机视觉每日开源代码Paper with code速览-2023.11.2
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Re-Scoring Using Image-Language Similarit…

YOLOv5算法改进(22)— 更换主干网络MobileNetv3 + 添加CA注意力机制
前言:Hello大家好,我是小哥谈。本节课就让我们结合论文来对YOLOv5进行组合改进(更换主干网络MobileNetv3 + 添加CA注意力机制),希望同学们学完本节课可以有所启迪,并且后期可以自行进行YOLOv5算法的改进!🌈 前期回顾: YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5/YOLOv7改进策略:一种新颖的可扩张残差(DWR)注意力模块,增强多尺度感受野特征,助力小目标检测
💡💡💡本文全网首发独家改进:一种新颖的可扩张残差(DWR)注意力模块,加强不同尺度特征提取能力,创新十足,独家首发适合科研 1)结合C3进行使用;
推荐指数:五星
DWR | 亲测在多个数据集能够实现涨点,多尺度特性在小目标检测表现也十分出色。
💡💡💡Yol…

BGF-YOLO | 增强版YOLOV8 | 用于脑瘤检测的多尺度注意力特征融合
基于You Only Look Once(YOLO)的目标检测器在自动脑瘤检测中展现出卓越的准确性。在本文中,我们开发了一种新的BGF-YOLO架构,通过将双层路由注意力(BRA)、广义特征金字塔网络(GFPN)和第四检测头整合到YOLOv8中来实现。BGF-YOLO包含了一个注意力机制,用于更加关注重要的…
Python实现Labelme的Json标注文件与YOLO格式的TXT标注文件相互转换
Python实现Labelme的Json标注文件与YOLO格式的TXT标注文件相互转换 前言前提条件相关介绍实验环境Labelme的Json标注文件与YOLO格式的TXT标注文件相互转换convert_labelme_json_to_txtjsons/000000000009.json代码实现输出结果labels/000000000009.txt convert_txt_to_labelme_…
YOLOv8-pose关键点检测:模型轻量化创新 |轻量级可重参化EfficientRepBiPAN
💡💡💡本文解决什么问题:轻量级可重参化EfficientRepBiPAN替换YOLOv8 neck部分
EfficientRepBiPAN | GFLOPs从9.6降低至8.5, mAP50从0.921下降至0.912,mAP50-95从0.697提升至0.779
Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_123…
RT-DETR 应用 BiFPN 结构 | 加权双向特征金字塔网络
模型效率在计算机视觉中变得越来越重要。在本文中,我们系统地研究了目标检测中的神经网络架构设计选择,并提出了几种关键的优化方法来提高效率。首先,我们提出了一种加权双向特征金字塔网络(BiFPN),它可以实现简单快速的多尺度特征融合;其次,我们提出了一种复合缩放方法…

YOLOv8推理详解及部署实现
目录 前言一、YOLOv8推理(Python)1. YOLOv8预测2. YOLOv8预处理3. YOLOv8后处理4. YOLOv8推理 二、YOLOv8推理(C)1. ONNX导出2. YOLOv8预处理3. YOLOv8后处理4. YOLOv8推理 三、YOLOv8部署1. 源码下载2. 环境配置2.1 配置CMakeLists.txt2.2 配置Makefile 3. ONNX导出4. 源码修改…
无需标注海量数据,目标检测新范式OVD
当前大火的多模态GPT-4在视觉能力上只具备目标识别的能力,还无法完成更高难度的目标检测任务。而识别出图像或视频中物体的类别、位置和大小信息,是现实生产中众多人工智能应用的关键,例如自动驾驶中的行人车辆识别、安防监控应用中的人脸锁定…
BAM(Bottleneck Attention Module)
BAM(Bottleneck Attention Module)是一种用于计算机视觉领域的深度学习模型结构,它旨在提高神经网络对图像的特征提取和感受野处理能力。BAM模块引入了通道注意力机制,能够自适应地加强或减弱不同通道的特征响应,从而提…
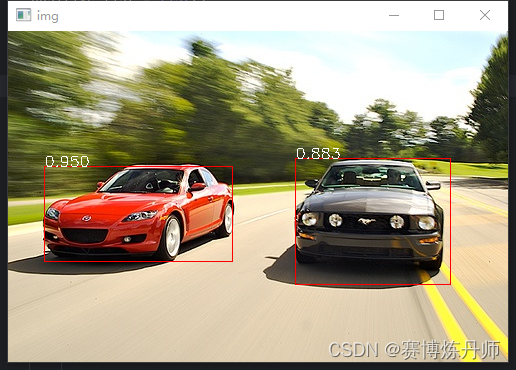
Pytorch R-CNN目标检测-汽车car
概述
目标检测(Object Detection)就是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,通俗点说就是给定一张图片要精确的定位到物体所在位置,并完成对物体类别的识别。其准确性和实时性是整个系统的一项重要能力。
R-CNN的全称是Region-CNN(区域卷积神经…
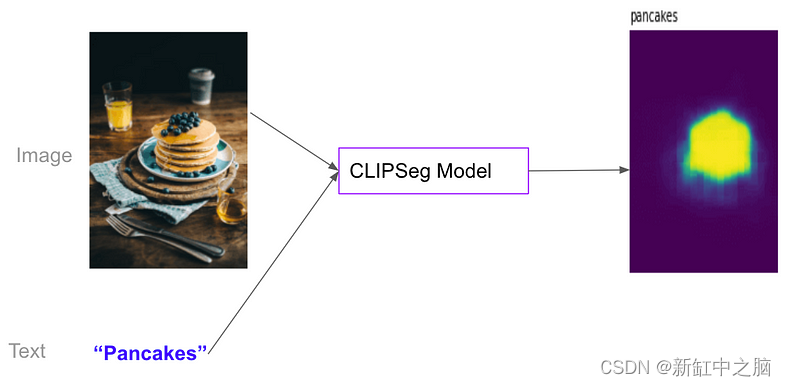
基于CLIP的图像分类、语义分割和目标检测
OpenAI CLIP模型是一个创造性的突破; 它以与文本相同的方式处理图像。 令人惊讶的是,如果进行大规模训练,效果非常好。 在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 3D…
【目标检测】SSD损失函数详解
文章目录 定位损失 L l o c L_{loc} Lloc偏移值的计算smooth L1 loss 置信率损失 L c o n f L_{conf} Lconf 最近看看这个古早的目标检测网络,看了好多文章,感觉对损失函数的部分讲得都是不很清楚得样子,所以自己捋一下。
首先&#x…
农业4.0中麦田的精确杂草检测:实现技术、方法和研究挑战的综述
Precision weed detection in wheat fields for agriculture 4.0: A survey of enabling technologies, methods, and research challenges 摘要1、引言2、相关工作3、麦田常见杂草的种类及分布特征3.1 天然麦田中常见的杂草3.2 杂草分布格局4、先进的麦田杂草检测技术4.1 光谱…
MATLAB算法实战应用案例精讲-【目标检测】YOLOV3
目录
知识储备 YOLO系列v1到v7
YOLO aka YOLOv1
YOLOv2 / YOLO9000
YOLOv3
YOLOv4, Scaled YOLOv4
Scaled YOLOv4
YOLOv5
YOLOv7改进全新Inner-IoU损失函数:全网首发|2023年11月最新论文|扩展到其他Inner-SIoU等主流损失函数,带辅助边界框的损失
💡本篇内容:YOLOv7改进全新Inner-IoU损失函数:全网首发|2023年11月最新论文|扩展到其他Inner-SIoU等主流损失函数,带辅助边界框的损失
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可 💡:重点:该专栏《剑指YOLOv7原创改进》只…
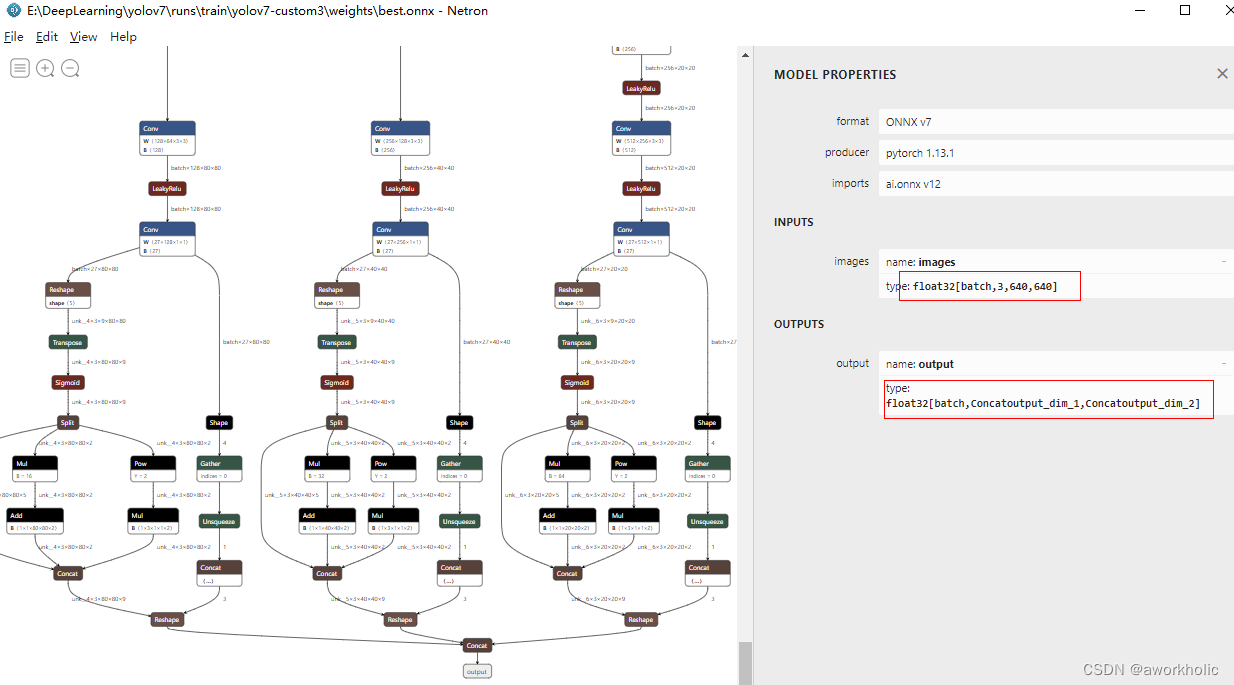
opencv dnn模块 示例(22) 目标检测 object_detection 之 yolov7
在YOLOv6 初版出来不久,YOLOv7就立马横空出世了。与YOLOv5、YOLOv6不同,YOLOv7是由YOLOv4团队的原班人马提出的(官方出品)。从论文的表上来看,目前YOLOv7无论是在实时性还是准确率上都已经超过了当时已知的所有目标检测…

YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型
YOLOv8 Ultralytics:使用Ultralytics框架训练RT-DETR实时目标检测模型 前言相关介绍前提条件实验环境安装环境项目地址LinuxWindows 制作自己的数据集训练自己的数据集创建自己数据集的yaml文件football.yaml文件内容 进行训练进行验证进行预测 数据集获取参考文献 …

超详细介绍对极几何和立体视觉及 Python 和 C++实现
您是否想过为什么戴着特殊的 3D 眼镜观看电影时可以体验到美妙的 3D 效果?或者为什么闭上一只眼睛很难接住板球?这一切都与立体视觉有关,立体视觉是我们用双眼感知深度的能力。这篇文章使用 OpenCV 和立体视觉为计算机提供这种感知深度的能力。代码以 Python 和 C++ 形式提供…
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】计算机视觉
目录
前言
算法原理
什么是计算机视觉(Computer Vision)
计算机视觉工作流程
计算机视觉领域常用迁移学习模型
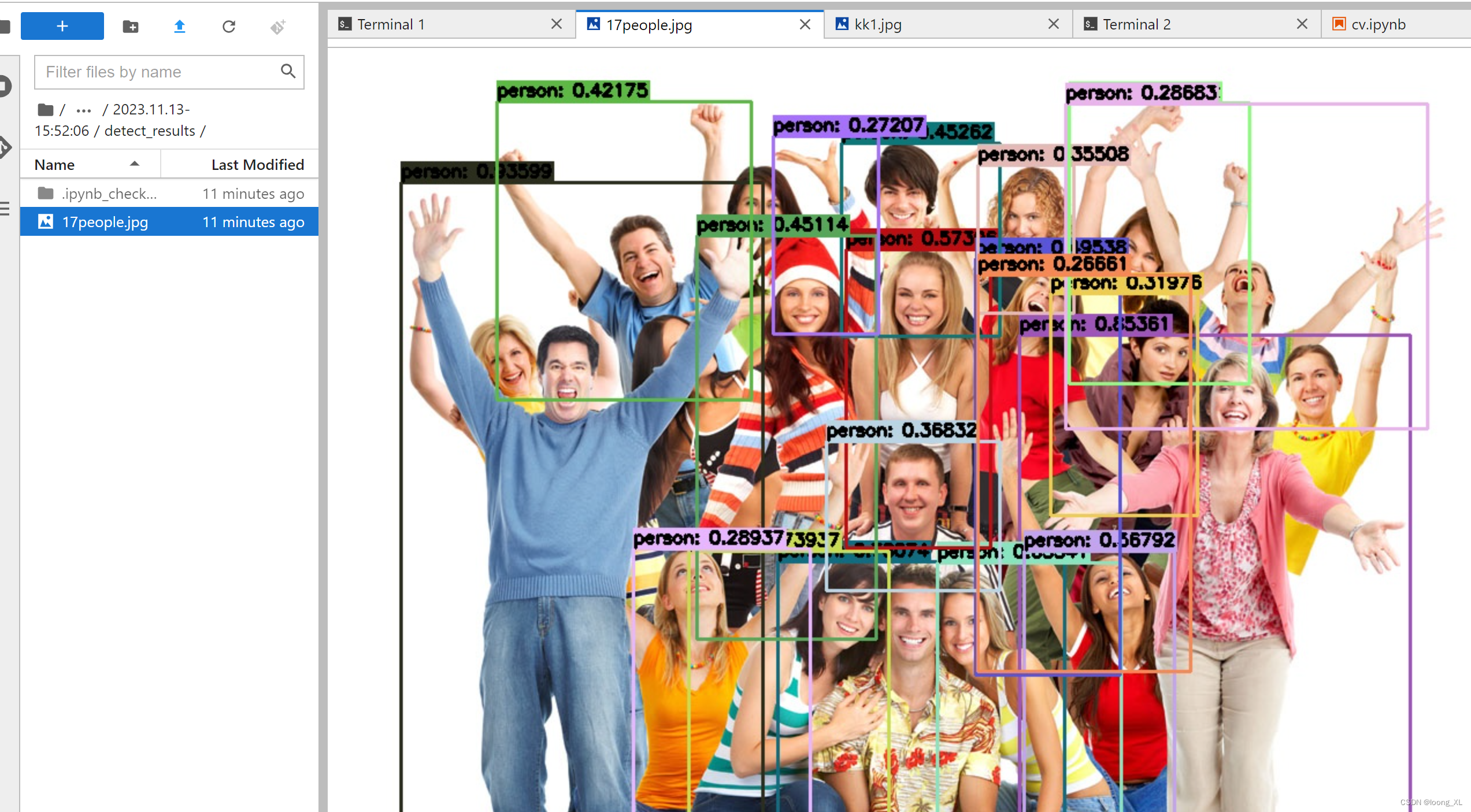
mindspore mindyolo目标检测华为昇腾上推理使用
参考: https://github.com/mindspore-lab/mindyolo
使用案例: https://github.com/mindspore-lab/mindyolo/blob/master/GETTING_STARTED.md
安装:
pip install mindyolo特别注意opencv-python、opencv-python-headless版本问题࿰…


YOLOv5算法进阶改进(3)— 引入深度可分离卷积C3模块 | 轻量化网络
前言:Hello大家好,我是小哥谈。深度可分离卷积是一种卷积神经网络中的卷积操作,它可以将标准卷积分解为两个较小的卷积操作:深度卷积和逐点卷积。深度卷积是在每个输入通道上分别执行卷积,而逐点卷积是在所有通道上执行卷积。这种分解可以大大减少计算量和参数数量,从而提…

yolo如何画框、如何变换目标检测框的颜色和粗细、如何运行detect脚本
这段代码是一个使用YOLO模型进行目标检测的Python脚本。下面我将逐步解释脚本的主要部分,并提供一些关于超参数的使用方法。
1. 脚本结构
导入相关库设置配置参数加载YOLO模型运行目标检测处理检测结果显示或保存结果
2. 超参数说明
--weights: 指定YOLO模型的…

原论文一比一复现 | 更换 RT-DETR 主干网络为 【ResNet-50】【ResNet-101】【ResNet-152】| 对比实验必备
本专栏内容均为博主独家全网首发,未经授权,任何形式的复制、转载、洗稿或传播行为均属违法侵权行为,一经发现将采取法律手段维护合法权益。我们对所有未经授权传播行为保留追究责任的权利。请尊重原创,支持创作者的努力,共同维护网络知识产权。 更深层的神经网络更难训练。…
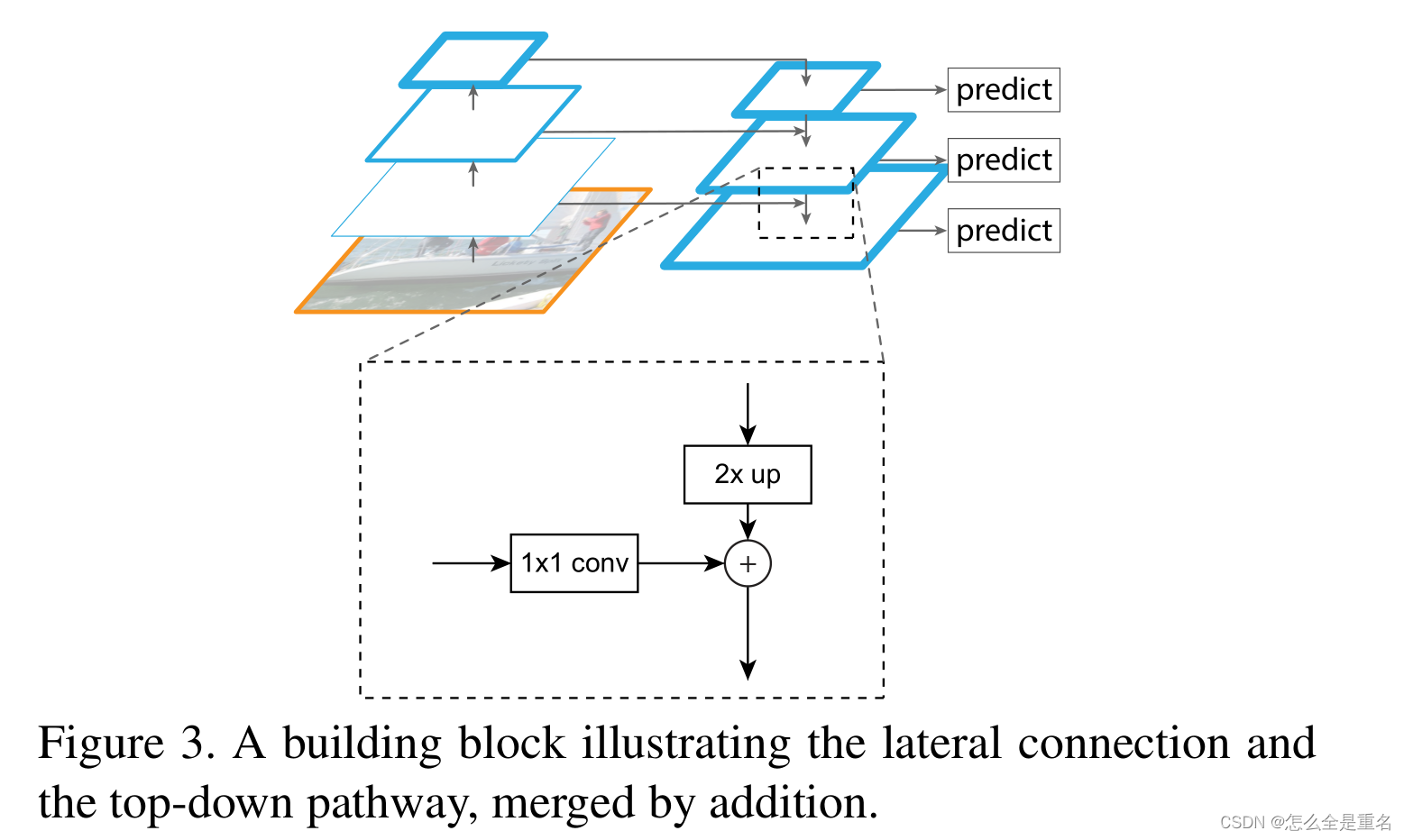
Feature Pyramid Networks for Object Detection(2017.4)
文章目录 Abstract1. Introduction3. Feature Pyramid NetworksBottom-up pathwayTop-down pathway and lateral connections 7. Conclusion FPN Abstract
特征金字塔是识别系统中检测不同尺度物体的基本组成部分。但最近的深度学习对象检测器避免了金字塔表示,部分…
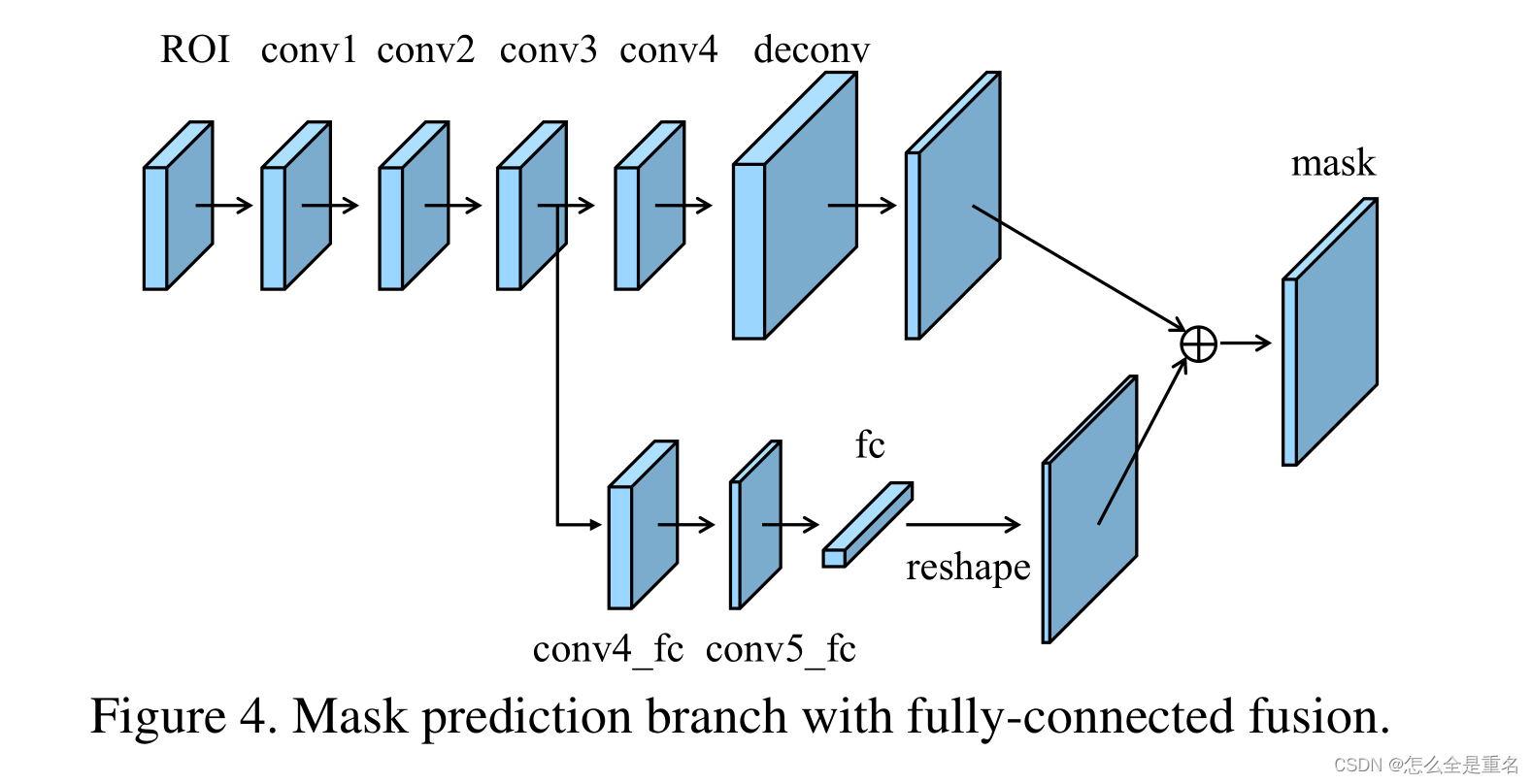
Path Aggregation Network for Instance Segmentation(2018.9)
文章目录 Abstract1. IntroductionOur FindingsOur Contributions 3. Framework3.1. Bottom-up Path AugmentationMotivationAugmented Bottom-up Structure 3.2. Adaptive Feature PoolingMotivationAdaptive Feature Pooling Structure 3.3. Fully-connected FusionMask Pred…
目标检测—YOLO系列(二 ) 解读论文与复现代码YOLOv1 PyTorch
精读论文
前言
从这篇开始,我们将进入YOLO的学习。YOLO是目前比较流行的目标检测算法,速度快且结构简单,其他的目标检测算法如RCNN系列,以后有时间的话再介绍。
本文主要介绍的是YOLOV1,这是由以Joseph Redmon为首的…

第五章 目标检测中K-means聚类生成Anchor box(工具)
第一种做法
在基于anchor的目标检测算法中,anchor一般都是通过人工设计的。例如,在SSD、Faster-RCNN中,设计了9个不同大小和宽高比的anchor。然而,通过人工设计的anchor存在一个弊端,就是并不能保证它们一定能很好的适…

新版mmdetection3d将3D bbox绘制到图像
环境信息
使用 python mmdet3d/utils/collect_env.py收集环境信息
sys.platform: linux
Python: 3.7.12 | packaged by conda-forge | (default, Oct 26 2021, 06:08:21) [GCC 9.4.0]
CUDA available: True
numpy_random_seed: 2147483648
GPU 0,1: NVIDIA GeForce RTX 3090
…

035、目标检测-物体和数据集
之——物体检测和数据集
目录
之——物体检测和数据集
杂谈
正文
1.目标检测
2.目标检测数据集
3.目标检测和边界框
4.目标检测数据集示例 杂谈 目标检测是计算机视觉中应用最为广泛的,之前所研究的图片分类等都需要基于目标检测完成。 在图像分类任务中&am…

目标检测框存在内嵌情况分析与解决
这里写目录标题 问题描述原因分析与解决方法:后续及思考参考文档 问题描述
目标检测模型输出的检测框存在内嵌情况。 原因分析与解决方法:
根据经验,第一感觉是后处理nms部分出了问题。来看下对应的代码:
static float CalcIou…
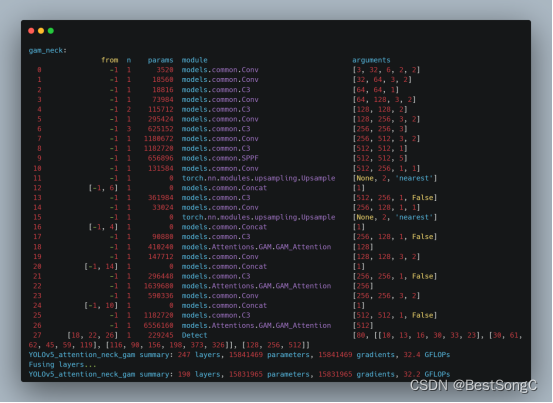
YOLO改进系列之注意力机制(GAM Attention模型介绍)
模型结构
为了提高计算机视觉任务的性能,人们研究了各种注意力机制。然而以往的方法忽略了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,liu提出了一种通过减少信息弥散和放大全局交互表示来提高深度神经网络性能的全局注意力机制。作者的目…

目标检测 Faster RCNN全面解读复现
Faster RCNN
解读
经过R-CNN和Fast RCNN的积淀,Ross B. Girshick在2016年提出了新的Faster RCNN,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine)&…

【精选】OpenCV多视角摄像头融合的目标检测系统:全面部署指南&源代码
1.研究背景与意义
随着计算机视觉和图像处理技术的快速发展,人们对于多摄像头拼接行人检测系统的需求日益增加。这种系统可以利用多个摄像头的视角,实时监测和跟踪行人的活动,为公共安全、交通管理、视频监控等领域提供重要的支持和帮助。
…

4D毫米波雷达和3D雷达、激光雷达全面对比
众所周知,传统3D毫米波雷达存在如下性能缺陷: 1)静止目标和地物杂波混在一起,难以区分; 2) 横穿车辆和行人多普勒为零或很低,难以检测; 3) 高处物体和地面目标不能区分,容易造成误刹…
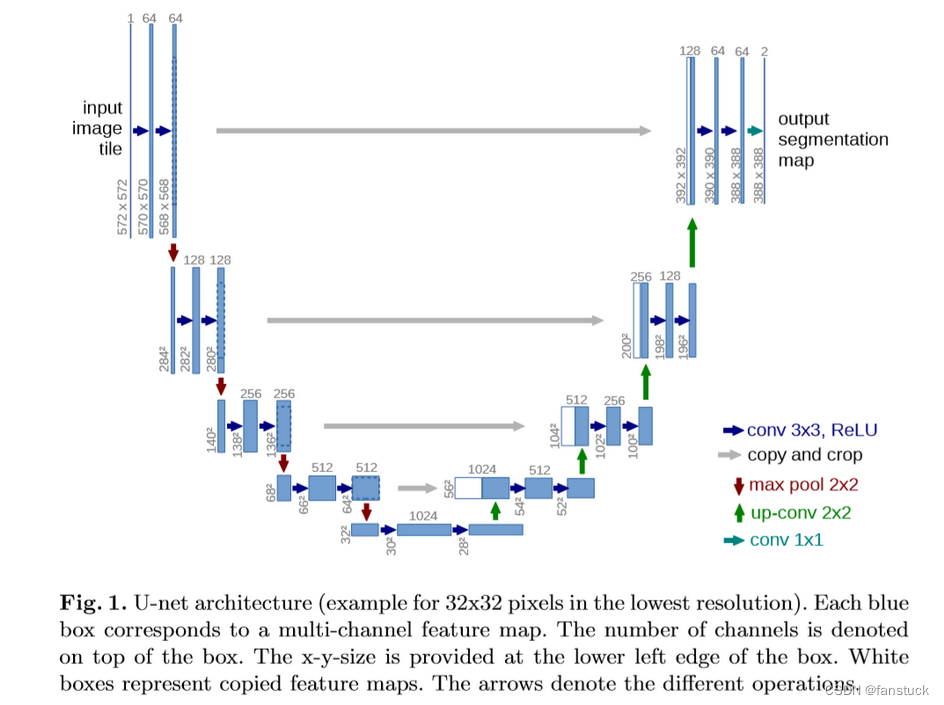
目标分割技术-语义分割总览
前言
博主现任高级人工智能工程师,曾发表多篇SCI且获得过多次国际竞赛奖项,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。目的就是为了让零基础快速使用各类代码模型,每一篇文章都包含实战项目以及可运行代码。欢迎大家订阅一…

【项目实战】犬只牵绳智能识别:源码详细解读与部署步骤
1.识别效果展示 2.视频演示
[YOLOv7]基于YOLOv7的犬只牵绳检测系统(源码&部署教程)_哔哩哔哩_bilibili
3.YOLOv7算法简介
YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器
并在 V100 上,30 FPS 的情况下达到实…
YOLOv8改进 | EIoU、SIoU、WIoU、DIoU、FoucsIOU等二十余种损失函数
一、本文介绍
这篇文章介绍了YOLOv8的重大改进,特别是在损失函数方面的创新。它不仅包括了多种IoU损失函数的改进和变体,如SIoU、WIoU、GIoU、DIoU、EIOU、CIoU,还融合了“Focus”思想,创造了一系列新的损失函数。这些组合形式的…
LabelImg(目标检测标注工具)的安装与使用教程
🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝🔝 🥰 博客首页:knighthood2001 😗 欢迎点赞👍评论ǵ…
SHEIN出口车钥匙扣REACH认证指南解析
钥匙扣的材料一般为金属、皮革、塑料、橡胶、木头等。此物精致小巧、造型千变万化是人们随身携带的日常用品。钥匙扣是挂在钥匙圈上的一种装饰物品。钥匙扣出口需要办理REACH认证。
一、什么是REACH认证? REACH认证是欧盟28个成员国对进入其市场的所有化学品,&…

【精选】改进的YOLOv5:红外遥感图像微型目标的高效识别系统
1.研究背景与意义
随着科技的不断发展,红外遥感技术在军事、安防、环境监测等领域中得到了广泛应用。红外遥感图像具有独特的优势,可以在夜间或恶劣天气条件下获取目标信息,因此在小目标检测方面具有重要的应用价值。然而,由于红…

【精选】通道热点加持的LW-ResNet:小麦病害智能诊断与防治系统
1.研究背景与意义
小麦是世界上最重要的粮食作物之一,但由于病害的侵袭,小麦产量和质量受到了严重的威胁。因此,开发一种高效准确的小麦病害识别分类防治系统对于保障粮食安全和农业可持续发展具有重要意义。
传统的小麦病害识别分类方法主…
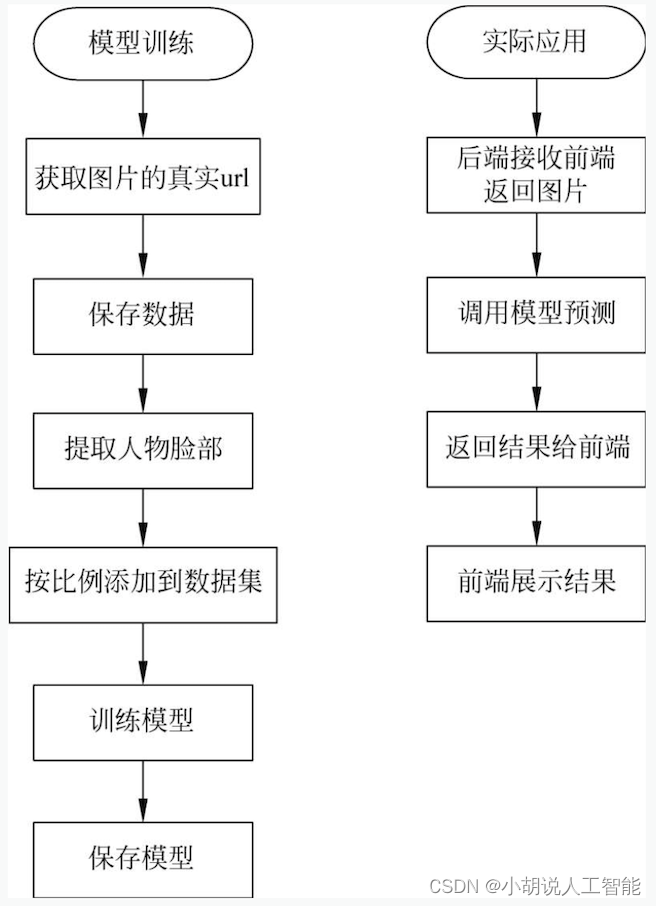
基于opencv+ImageAI+tensorflow的智能动漫人物识别系统——深度学习算法应用(含python、JS、模型源码)+数据集(一)
目录 前言总体设计系统整体结构图系统流程图 运行环境爬虫1.安装Anaconda2.安装Python3.63.更换pip源4.安装Python包5.下载phantomjs 模型训练1.安装依赖2.安装lmageAl 实际应用1.前端2.安装Flask3.安装Nginx 相关其它博客工程源代码下载其它资料下载 前言
本项目通过爬虫技术…
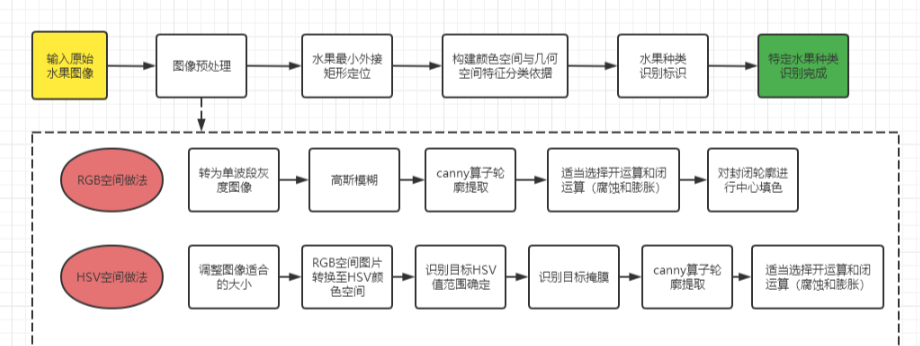
2023年亚太杯数学建模A题水果采摘机器人的图像识别功能(免费思路)
中国是世界上最大的苹果生产国,年产量约为 3500 万吨。同时,中国也是世界上最大的苹果出口国,世界上每两个苹果中就有一个出口到国。世界上每两个苹果中就有一个来自中国,中国出口的苹果占全球出口量的六分之一以上。来自中国。中…

昇腾Atlas 200I DK A2实现安全帽识别
文章目录 环境依赖编译测试总结 环境依赖
软件版本说明获取方式mxVision5.0.RC2mxVision软件包获取方式Ascend-CANN-toolkit6.2.RC2Ascend-cann-toolkit开发套件包获取方式Ubuntu22.04
代码仓库地址: https://gitee.com/ascend/ascend_community_projects/tree/31…

第97步 深度学习图像目标检测:RetinaNet建模
基于WIN10的64位系统演示
一、写在前面
本期开始,我们继续学习深度学习图像目标检测系列,RetinaNet模型。 二、RetinaNet简介
RetinaNet 是由 Facebook AI Research (FAIR) 的研究人员在 2017 年提出的一种目标检测模型。它是一种单阶段(o…

2023年亚太杯数学建模A题解题思路(*基于OpenCV的复杂背景下苹果目标的识别定位方法研究)
摘要 由于要求较高的时效性和劳力投入,果实采摘环节成为苹果生产作业中十分重要的一部分。而对于自然环境下生长的苹果,光照影响、枝叶遮挡和果实重叠等情况普遍存在,这严重影响了果实的准确识别以及采摘点的精确定位。针对在复杂背景下苹果的…
RT-DETR论文阅读笔记(包括YOLO版本训练和官方版本训练)
论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址 大家如果想看更详细训练、推理、部署、验证等教程可以看我的另一篇博客里面有更详细的介绍 内容回顾:详解RT-DETR网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署 目录
一…
YOLOv8独家原创改进:自研独家创新MSAM注意力,通道注意力升级,魔改CBAM
💡💡💡本文自研创新改进:MSAM(CBAM升级版):通道注意力具备多尺度性能,多分支深度卷积更好的提取多尺度特征,最后高效结合空间注意力 1)作为注意力MSAM使用;
推荐指数:五星
MSCA | 亲测在多个数据集能够实现涨点,对标CBAM。 在道路缺陷检测任务中,原始ma…
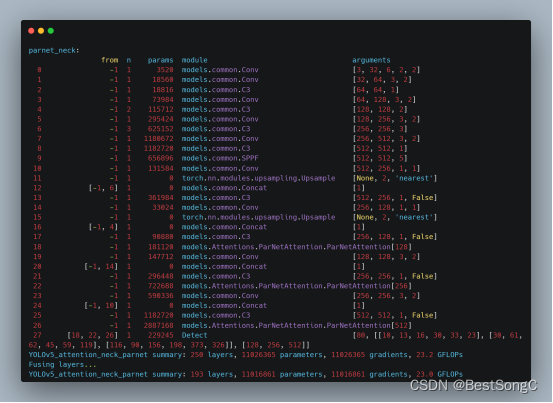
YOLO改进系列之ParNetAttention注意力机制
ParNet注意力是一种用于自然语言处理任务的注意力机制,它是由谷歌在2019年提出的。ParNet注意力旨在解决传统注意力机制在处理长序列时的效率问题。传统的注意力机制在计算注意力权重时,需要对所有输入序列的位置进行逐一计算,这导致了在长序…
基于YOLOv8深度学习的火焰烟雾检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
【目标检测实验系列】YOLOv5创新点改进实验:通过转置卷积,动态学习参数,减少上采用过程特征丢失,提高模型对目标的检测精度!(超详细改进代码流程)
1. 文章主要内容 本篇博客主要涉及两个主体内容。第一个:简单介绍转置卷积的原理。第二个:基于YOLOv5 6.x版本,将Neck部分的upSample改为nn.ConvTranspose2d转置卷积(通读本篇博客需要10分钟左右的时间)。 小提…

YOLOv5改进 | 添加ECA注意力机制 + 更换主干网络之ShuffleNetV2
前言:Hello大家好,我是小哥谈。本文给大家介绍一种轻量化部署改进方式,即在主干网络中添加ECA注意力机制和更换主干网络之ShuffleNetV2,希望大家学习之后,能够彻底理解其改进流程及方法~!🌈 目…
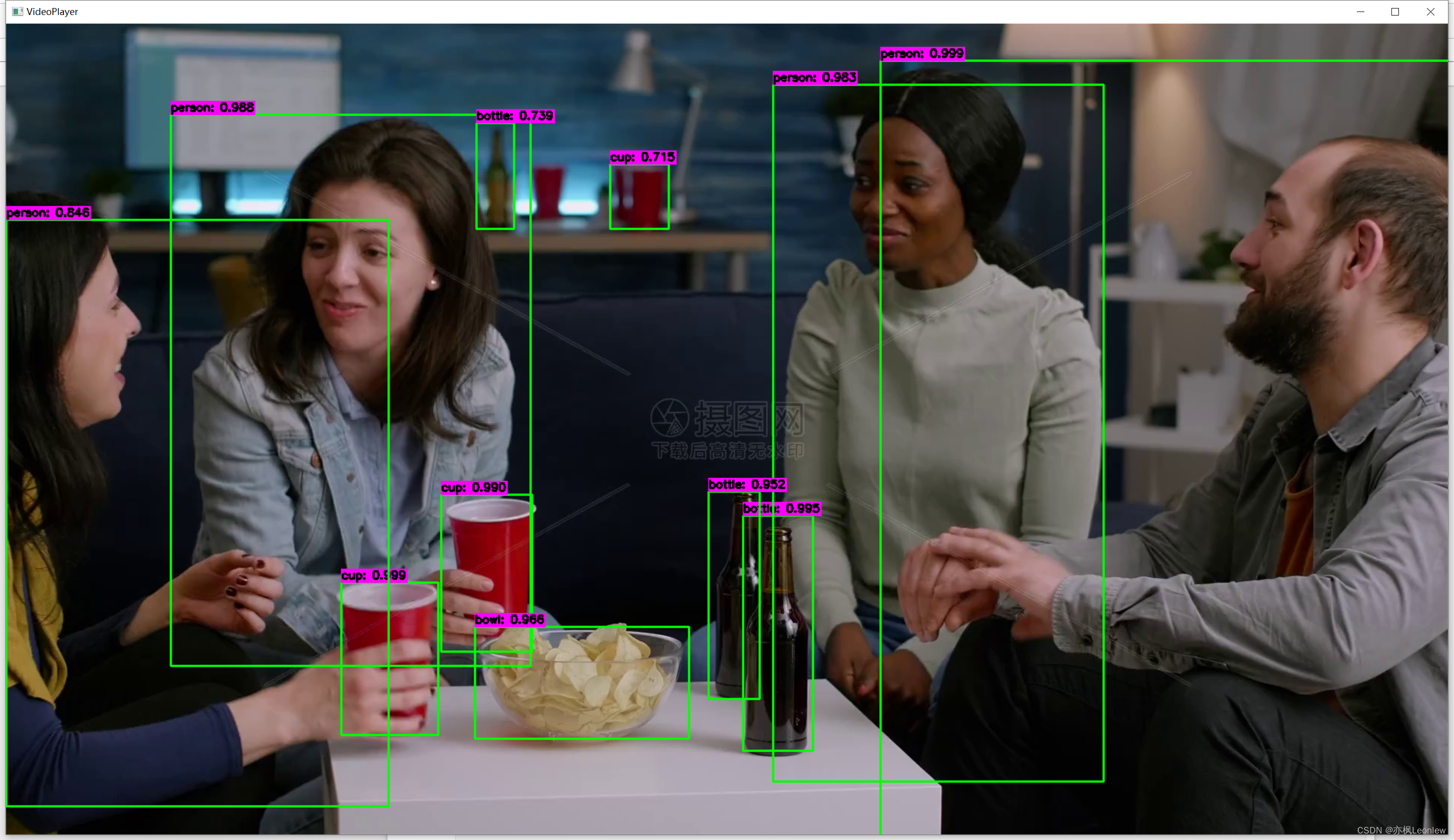
Python Opencv实践 - Yolov3目标检测
本文使用CPU来做运算,未使用GPU。练习项目,参考了网上部分资料。 如果要用TensorFlow做检测,可以参考这里
使用GPU运行基于pytorch的yolov3代码的准备工作_little han的博客-CSDN博客文章浏览阅读943次。记录一下自己刚拿到带独显的电脑&a…

YOLOv5项目实战(5)— 算法模型优化和服务器部署
前言:Hello大家好,我是小哥谈。近期,作者所负责项目中的算法模型检测存在很多误报情况,为了减少这种误报情况,作者一直在不断优化算法模型。鉴于此,本节课就给大家详细介绍一下实际工作场景中如何去优化算法模型和进行部署,另外为了方便大家进行模型训练,作者在文章中提…
CV计算机视觉每日开源代码Paper with code速览-2023.12.1
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】TransNeXt: Robust Foveal Visual Perception for Vision Transformers 论文地址:http…
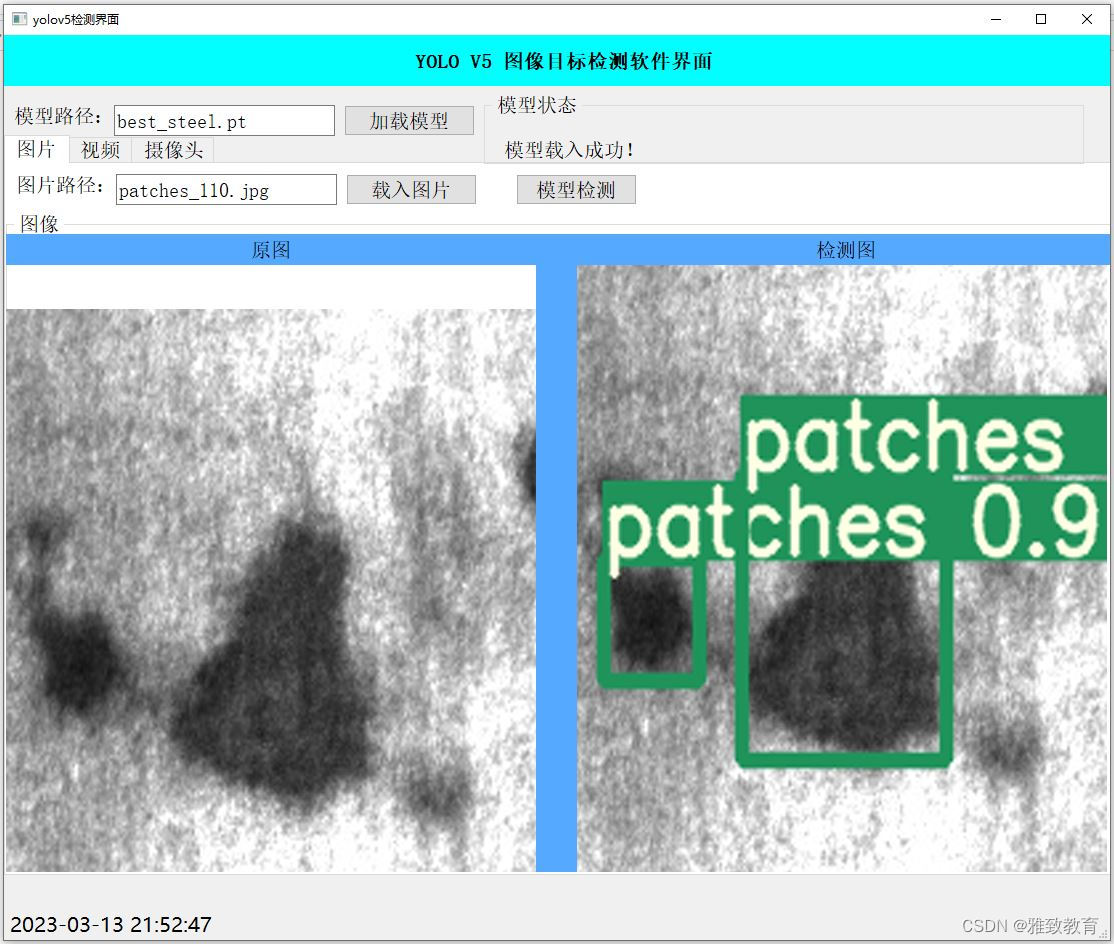
基于深度学习yolov5钢材瑕疵目标检测系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介简介YOLOv5钢材瑕疵目标检测系统特性1. 数据预处理2. 模型架构3. 训练策略4. 后处理 性能评估 二、功能三、系统四. 总结 一项目简介 # YOLOv5 钢材瑕疵目标…
DSGN:用于 3D 目标检测的深度立体几何网络
论文地址:https://www.jianshu.com/go-wild?ac2&urlhttps%3A%2F%2Farxiv.org%2Fpdf%2F2001.03398v3.pdf 论文代码:https://github.com/chenyilun95/DSGN
论文背景
大多数最先进的 3D 物体检测器严重依赖 LiDAR 传感器,因为基于图像的方…
AI:94-基于深度学习的微小目标检测与定位
🚀 本文选自专栏:人工智能领域200例教程专栏 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带有在本地跑过的核心代码,详细讲解供大家学习,希望可以帮到大家。欢迎订阅支持,正在不断更新…
目标检测:根据检测坐标取出图像数据
要从图像的目标框中提取数据,需要使用目标检测算法来识别目标并获取其边界框坐标。一旦您有了这些坐标,您可以使用图像处理库(例如OpenCV)来裁剪图像并提取目标框中的数据。
以下步骤完成此过程:
使用目标检测算法&a…
【论文笔记】DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
原文链接:https://arxiv.org/abs/2301.06051
1. 引言
本文提出DSVT,一种通用的、部署友好的、基于transformer的3D主干,可用于多种基于点云处理的3D感知任务中。
传统的稀疏点云特征提取方法,如PointNet系列和稀疏卷积…
道路坑洞数据集(坑洞目标检测)VOC+YOLO格式650张
路面坑洞的形成原因是由于设计、施工、养护处理不当、控制不适和受气候、环境、地质、水文等自然因素影响,以及车辆的运行和车辆超载运行导致路面破损,出现坑洞的现象。
路面坑洞的分类:
(1)路面混凝土板中坑洞&…
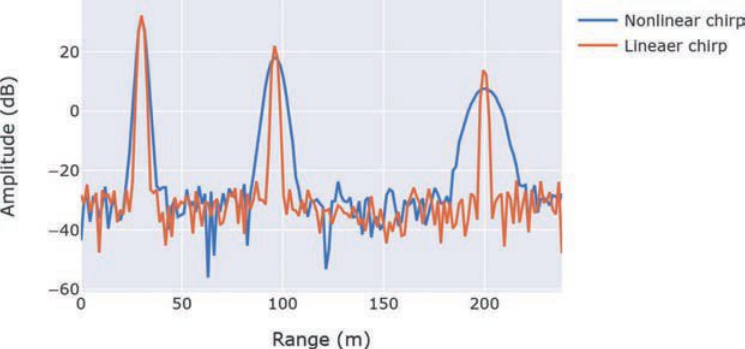
现代雷达车载应用——第2章 汽车雷达系统原理 2.6节 雷达设计考虑
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
2.6 雷达设计考虑 上述部分给出了汽车雷达基本原理的简要概述。在雷达系统的设计中,有几个方面是必不可少的,它们决定了雷达系…
C# OpenCvSharp DNN 部署yolov5不规则四边形目标检测
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN 部署yolov5不规则四边形目标检测
效果 模型信息
Inputs ------------------------- name:images tensor:Float[1, 3, 1024, 1024] -----------------------------------------------------…
基于YOLOv8深度学习的路面标志线检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
YOLOv5改进 | SPPF篇 | FocalModulation替换SPPF(精度更高的空间金字塔池化)
一、本文介绍
本文给大家带来的改进是用FocalModulation技术来替换了原有的SPPF(快速空间金字塔池化)模块。FocalModulation是今年新提出的特征增强方法,它利用注意力机制来聚焦于图像中的关键区域,从而提高模型对这些区域的识别…
【目标检测实验系列】YOLOv5创新点改进:融合高效轻量级网络结构GSConv,减轻模型复杂度的同时保持检测精度!(内含源代码,超详细改进代码流程)
自我介绍:本人硕士期间全程放养,目前成果:一篇北大核心CSCD录用,两篇中科院三区已见刊,一篇中科院三区在投。如何找创新点,如何放养过程厚积薄发,如何写中英论文,找期刊等等。本人后续会以自己实战经验详细…
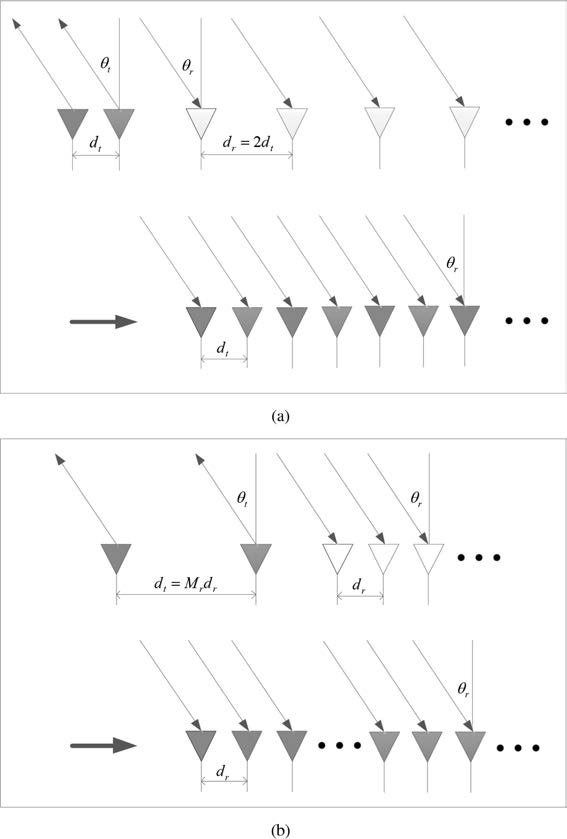
现代雷达车载应用——第3章 MIMO雷达技术 3.1节 基于MIMO雷达的虚拟阵列合成
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。
3 MIMO雷达技术 自20世纪90年代末以来,带有少量天线的汽车雷达已被用于高级驾驶员辅助系统(ADAS)的目的。这些早期的汽车雷达主要提供目标…
【halcon深度学习之那些封装好的库函数】determine_dl_model_detection_param
determine_dl_model_detection_param
目标检测的数据准备过程中的有一个库函数determine_dl_model_detection_param “determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。 这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议…
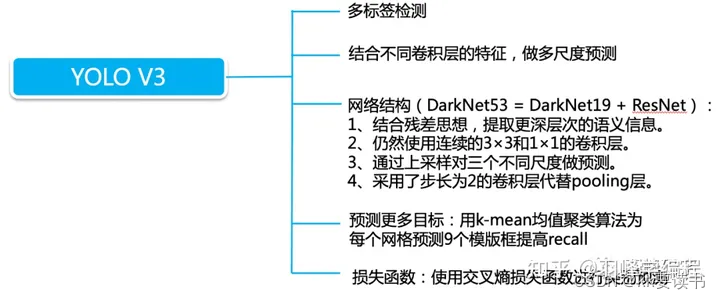
深度学习目标检测(2)yolov3设计思想
YOLOv3基础
YOLOv3算法基本思想可以分成两部分:
按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置…

esp32-s3训练自己的数据进行目标检测、图像分类
esp32-s3训练自己的数据进行目标检测、图像分类 一、下载项目二、环境三、训练和导出模型四、部署模型五、存在的问题 esp-idf的安装参考我前面的文章:
esp32cam和esp32-s3烧录human_face_detect实现人脸识别 一、下载项目
训练、转换模型:ModelAssist…
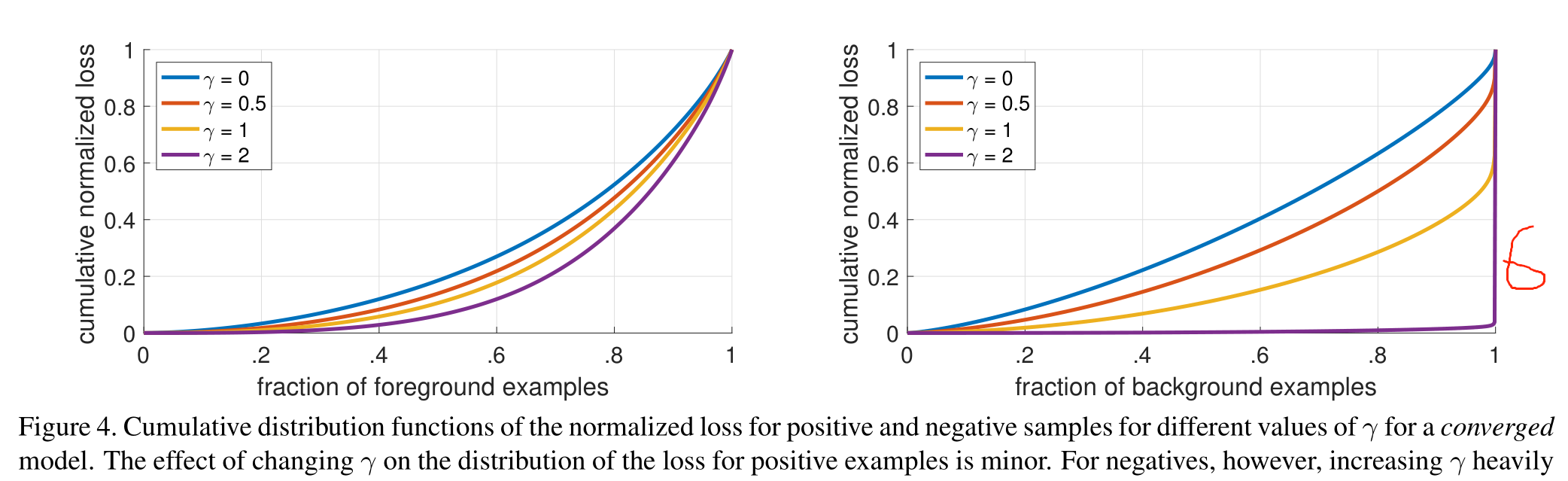
RetinaNet:Focal Loss for Dense Object Detection(CVPR2018)
文章目录 Abstract北京发现问题并给出方法成果 IntroductionRelated WorkRobust 评估 Focal LossBalanced Cross EntropyFocal Loss DefinitionClass Imbalance and Model InitializationClass Imbalance and Two-stage Detectors RetinaNet DetectorExperimentsConclusion hh …
在深度学习中,端到端的含义
在深度学习中,端到端(End-to-End)指的是整个系统从输入到输出的完整学习过程,而不需要明确定义和手动设计中间的特征提取或处理步骤。具体而言,端到端深度学习方法强调通过一个统一的、端到端的模型,直接从…
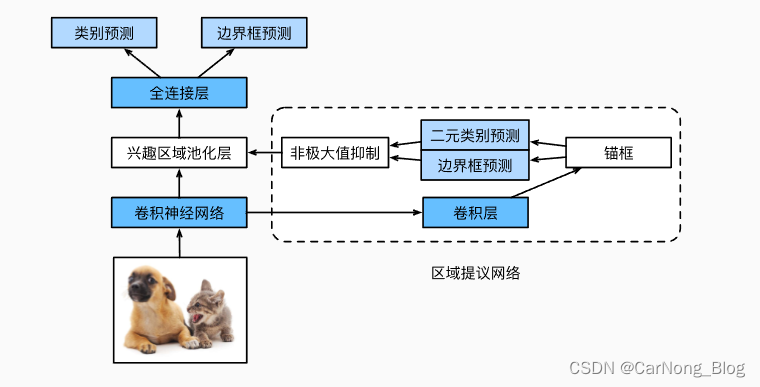
【深度学习-目标检测】03 - Faster R-CNN 论文学习与总结
论文地址:Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks
论文学习
1. 摘要与引言
研究背景与挑战:当前最先进的目标检测网络依赖于 区域提议(Region Proposals)来假设目标的位置,…
C# Onnx yolov8 竹签计数、一次性筷子计数
目录
效果
模型信息
项目
代码
数据集
下载 C# Onnx yolov8 竹签计数、一次性筷子计数
效果 模型信息
Model Properties ------------------------- date:2024-01-03T08:55:22.768617 author:Ultralytics task:detect license&#x…
YOLOv8改进 | 主干篇 | 利用SENetV1改进网络结构 (ILSVRC冠军得主)
一、本文介绍
本文给大家带来的改进机制是SENet(Squeeze-and-Excitation Networks)其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一…

开集目标检测-标签提示目标检测大模型(吊打YOLO系列-自动化检测标注)
背景
大多数现有的对象检测模型都经过训练来识别一组有限的预先确定的类别。将新类添加到可识别对象列表中需要收集和标记新数据,并从头开始重新训练模型,这是一个耗时且昂贵的过程。该大模型的目标是开发一个强大的系统来检测由人类语言输入指定的任意…
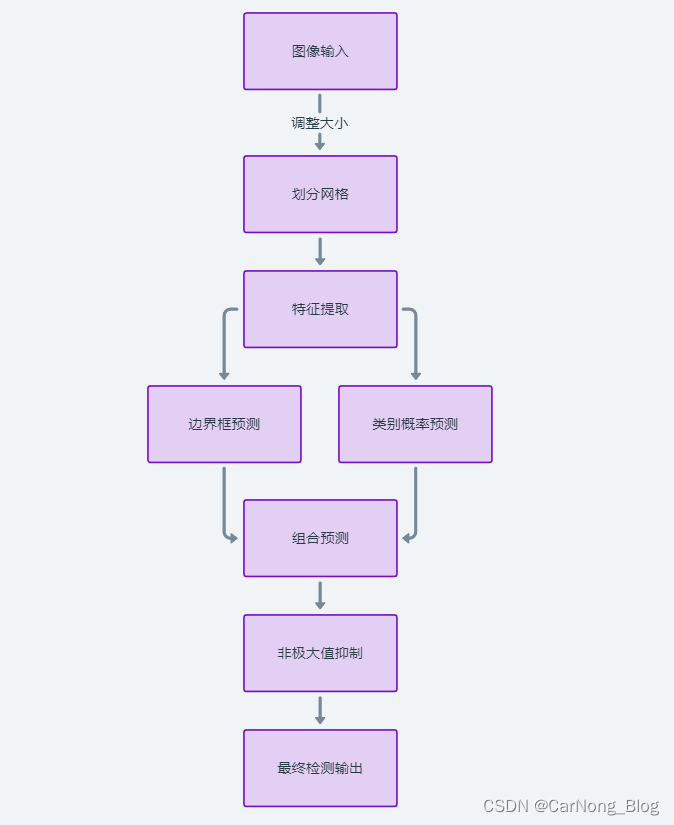
【深度学习-目标检测】05 - YOLOv1 论文学习与总结
论文地址:You Only Look Once:Unified, Real-Time Object Detection
论文学习 1. 摘要
YOLO的提出:作者提出了YOLO,这是一种新的目标检测方法。与传统的目标检测方法不同,YOLO将目标检测视为一个回归问题,直接从图像…
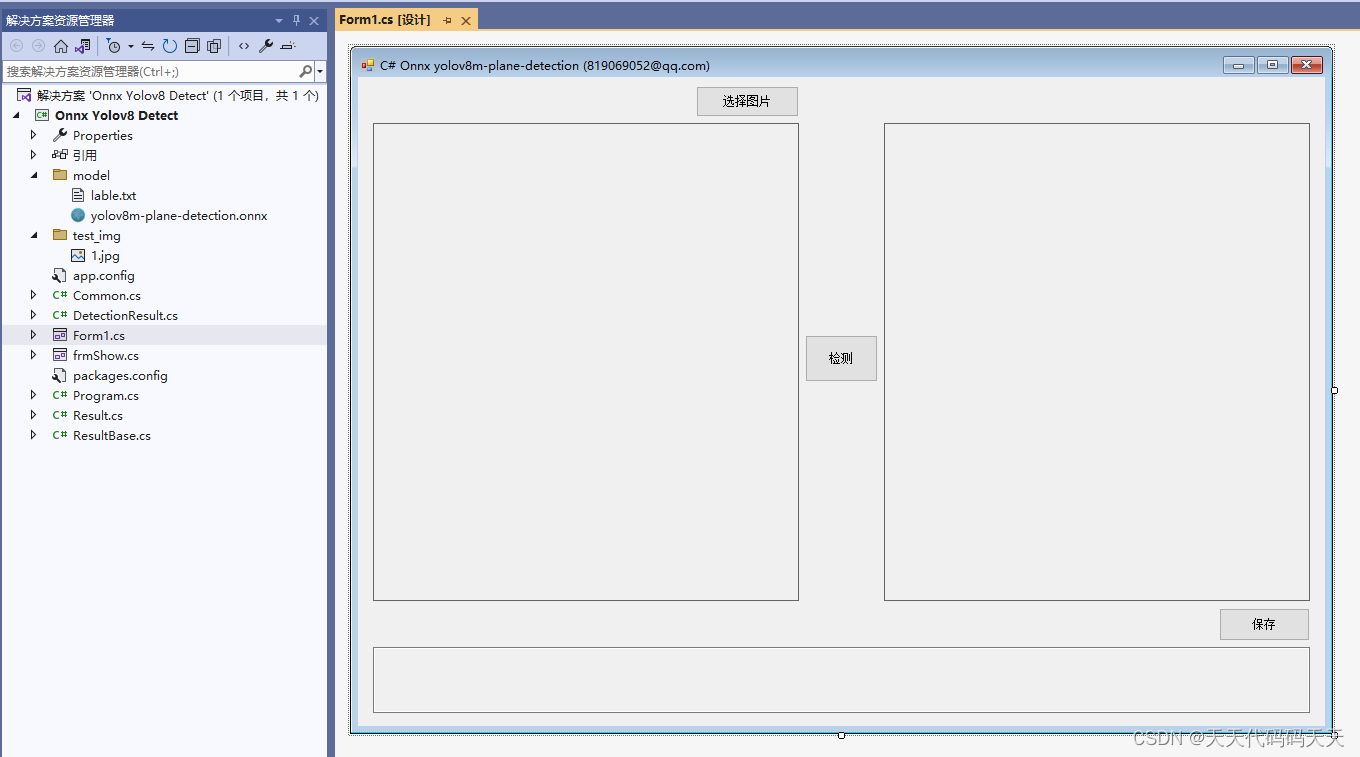
C# Onnx yolov8 plane detection
C# Onnx yolov8 plane detection
效果 模型信息
Model Properties ------------------------- date:2023-12-22T10:57:49.823820 author:Ultralytics task:detect license:AGPL-3.0 https://ultralytics.com/license version&am…
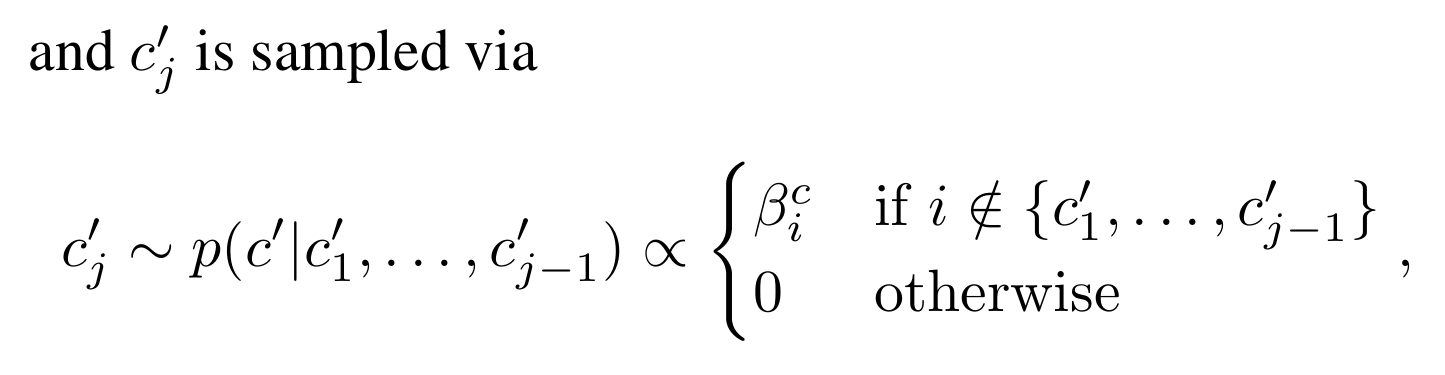
Efficient Classification of Very Large Images with Tiny Objects(CVPR2022待补)
文章目录 Abstract挑战此前的方法我们提出成果 IntroductionZoom-In NetworkTwo-stage Hierarchical Attention Sampling内存需求 Efficient Contrastive Learning with Attention Sampling Related WorkTiny object classificationAttentionComputational efficiencyIn-sample…
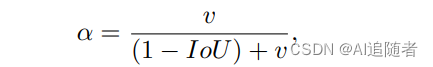
目标检测损失函数:IoU、GIoU、DIoU、CIoU、EIoU、alpha IoU、SIoU、WIoU原理及Pytorch实现
前言
损失函数是用来评价模型的预测值和真实值一致程度,损失函数越小,通常模型的性能越好。不同的模型用的损失函数一般也不一样。损失函数主要是用在模型的训练阶段,如果我们想让预测值无限接近于真实值,就需要将损失值降到最低…

yolov5旋转目标检测-遥感图像检测-无人机旋转目标检测-附代码和原理
综述
为了解决旋转目标检测问题,研究者们提出了多种方法和算法。以下是一些常见的旋转目标检测方法:
基于滑动窗口的方法:在图像上以不同的尺度和角度滑动窗口,通过分类器判断窗口中是否存在目标。这种方法简单直观,…
YOLOv8改进 | 细节创新篇 | iAFF迭代注意力特征融合助力多目标细节涨点
一、本文介绍
本文给大家带来的改进机制是iAFF(迭代注意力特征融合),其主要思想是通过改善特征融合过程来提高检测精度。传统的特征融合方法如加法或串联简单,未考虑到特定对象的融合适用性。iAFF通过引入多尺度通道注意力模块(我…

ValueError: operands could not be broadcast together with shapes (2,) (3,)
报错 这个有点离谱,明显的错误原作者故意留下的嘛,patch(h,w,c)三维size(x,y)二维 更改为注释即可

3D目标检测(教程+代码)
随着计算机视觉技术的不断发展,3D目标检测成为了一个备受关注的研究领域。与传统的2D目标检测相比,3D目标检测可以在三维空间中对物体进行定位和识别,具有更高的准确性和适用性。本文将介绍3D目标检测的相关概念、方法和代码实现。
一、3D目…

yolov5旋转目标检测-遥感图像检测-无人机旋转目标检测(附代码和原理)
目前,无人机技术的快速发展带来了遥感图像处理领域的革命性改变。然而,由于无人机在飞行时可能会出现旋转的情况,因此对于旋转目标的检测也成为了一个重要的问题。针对这个问题,yolov5可以提供一种高效的解决方案。 以下是介绍的分…
C# OpenCvSharp DNN FreeYOLO 目标检测
目录
效果
模型信息
项目
代码
下载 C# OpenCvSharp DNN FreeYOLO 目标检测
效果 模型信息
Inputs ------------------------- name:input tensor:Float[1, 3, 192, 320] ---------------------------------------------------------------
Outp…
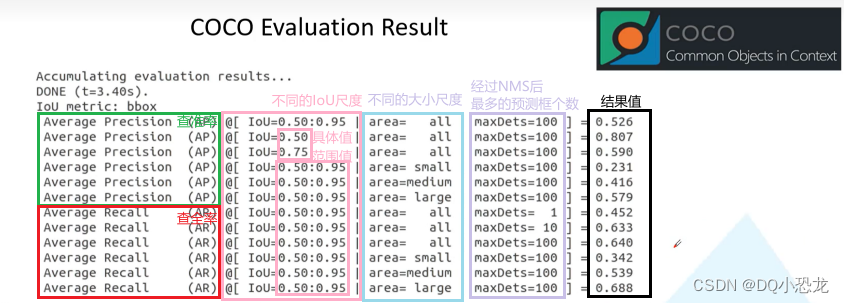
目标检测中的常见指标
概念引入:
TP:True Positive IoU > 阈值 检测框数量
FP: False Positive IoU < 阈值 检测框数量
FN: False Negative 漏检框数量
Precision:查准率 Recall:查全率(召回率) AP&am…
用opencv的DNN模块做Yolov5目标检测(纯干货,源码已上传Github)
最近在微信公众号里看到多篇讲解yolov5在openvino部署做目标检测文章,但是没看到过用opencv的dnn模块做yolov5目标检测的。于是,我就想着编写一套用opencv的dnn模块做yolov5目标检测的程序。在编写这套程序时,遇到的bug和解决办法,…
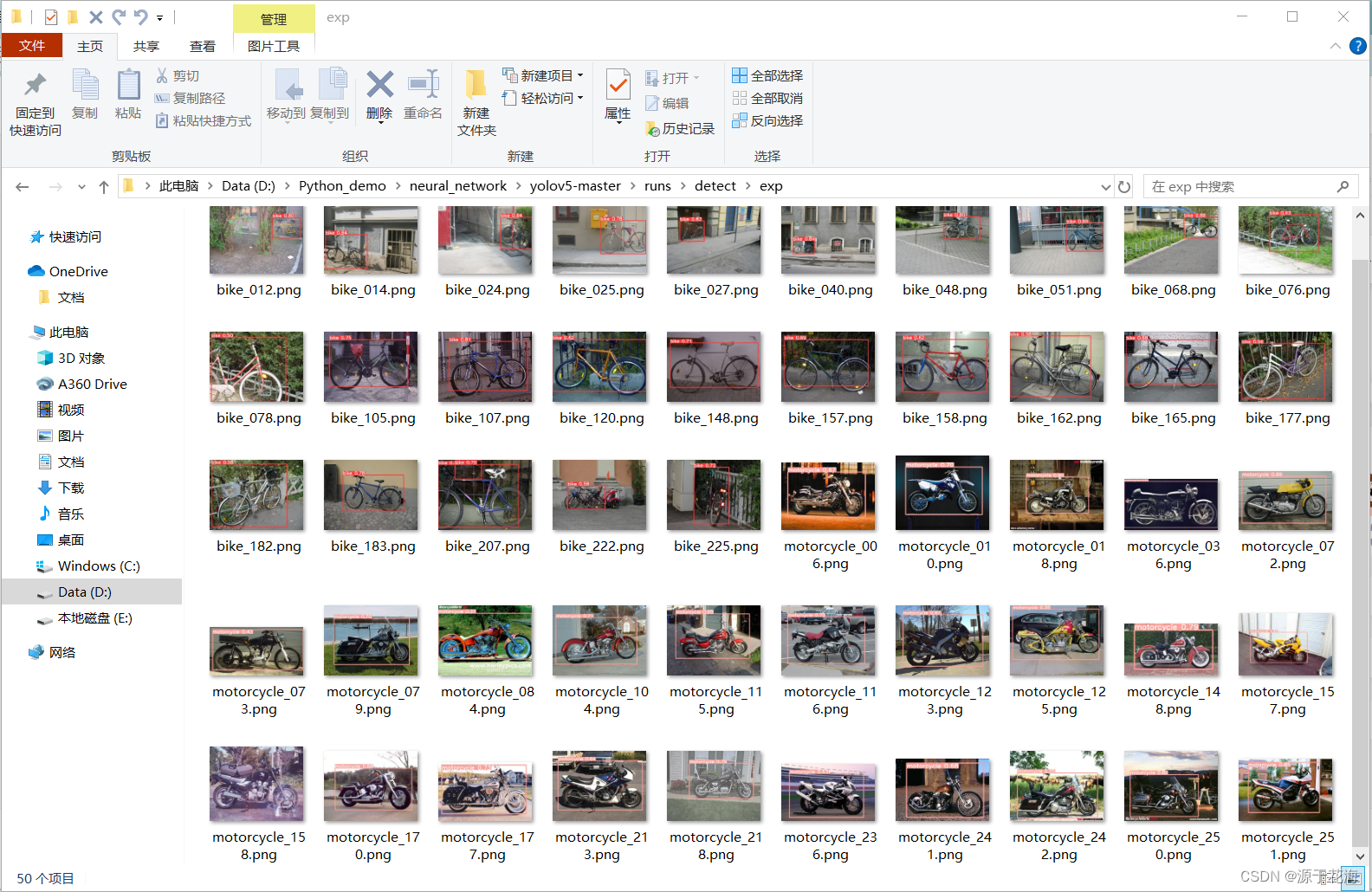
目标检测 | YOLOv5 训练自标注数据集实现迁移学习
Hi,大家好,我是源于花海。本文主要了解 YOLOv5 训练自标注数据集(自行车和摩托车两种图像)进行目标检测,实现迁移学习。YOLOv5 是一个非常流行的图像识别框架,这里介绍一下使用 YOLOv5 给使用 Labelme 标注…

Python+Torch+FasterCNN网络目标检测识别
程序示例精选 PythonTorchFasterCNN网络目标检测识别 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言
这篇博客针对《PythonTorchFasterCNN网络目标检测识别》编写代码,代码整洁,规…

目标检测数据集 - 夜间行人检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:夜间、低光行人检测数据集,真实场景高质量图片数据,涉及场景丰富,比如夜间街景行人、夜间道路行人、夜间遮挡行人、夜间严重遮挡行人数据;适用实际项目应用:公共场所监控场景下夜间行人检测项目…

从 YOLOv1 到 YOLO-NAS 的所有 YOLO 模型:论文解析
在计算机视觉的浩瀚领域,有一支耀眼的明星,她的名字传颂着革新与突破的传奇——YOLO(You Only Look Once)。回溯时光,走进这个引人注目的名字背后,我们仿佛穿越进一幅画卷,一幅展现创新魅力与技…
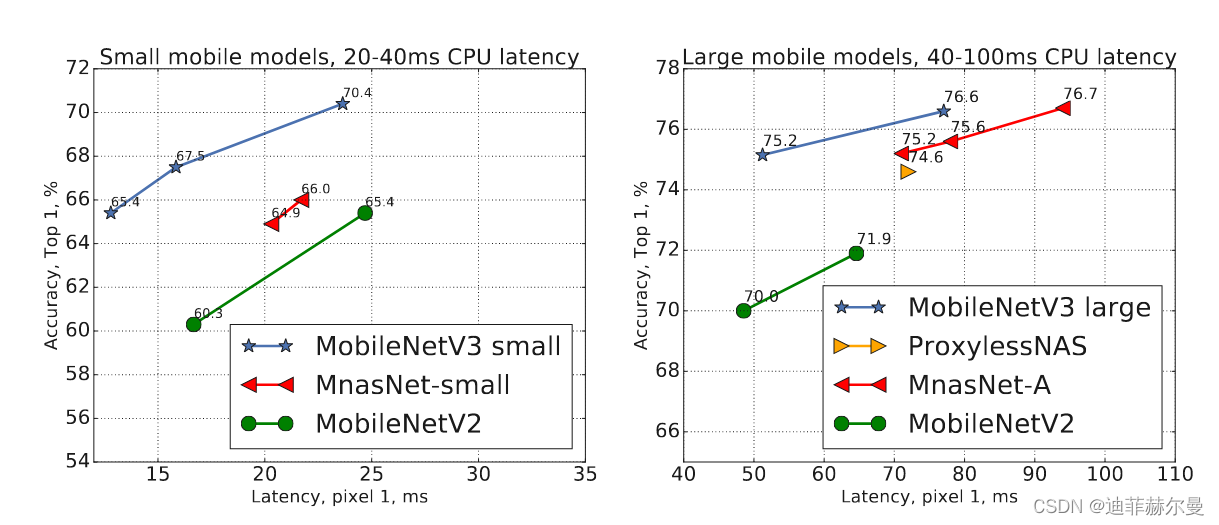
RT-DETR 更换骨干网络之 MobileNetV3 | 《搜寻 MobileNetV3》
论文地址:https://arxiv.org/abs/1905.02244 代码地址:https://github.com/xiaolai-sqlai/mobilenetv3
我们展示了基于互补搜索技术和新颖架构设计相结合的下一代 MobileNets。MobileNetV3通过结合硬件感知网络架构搜索(NAS)和 NetAdapt算法对移动设计如何协同工作,利用互…

猫头虎博主第9期赠书活动:《YOLO目标检测》计算机AI视觉实战YOLO人工智能目标检测与跟踪图像处理深度学习图像检测书籍
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通Golang》…
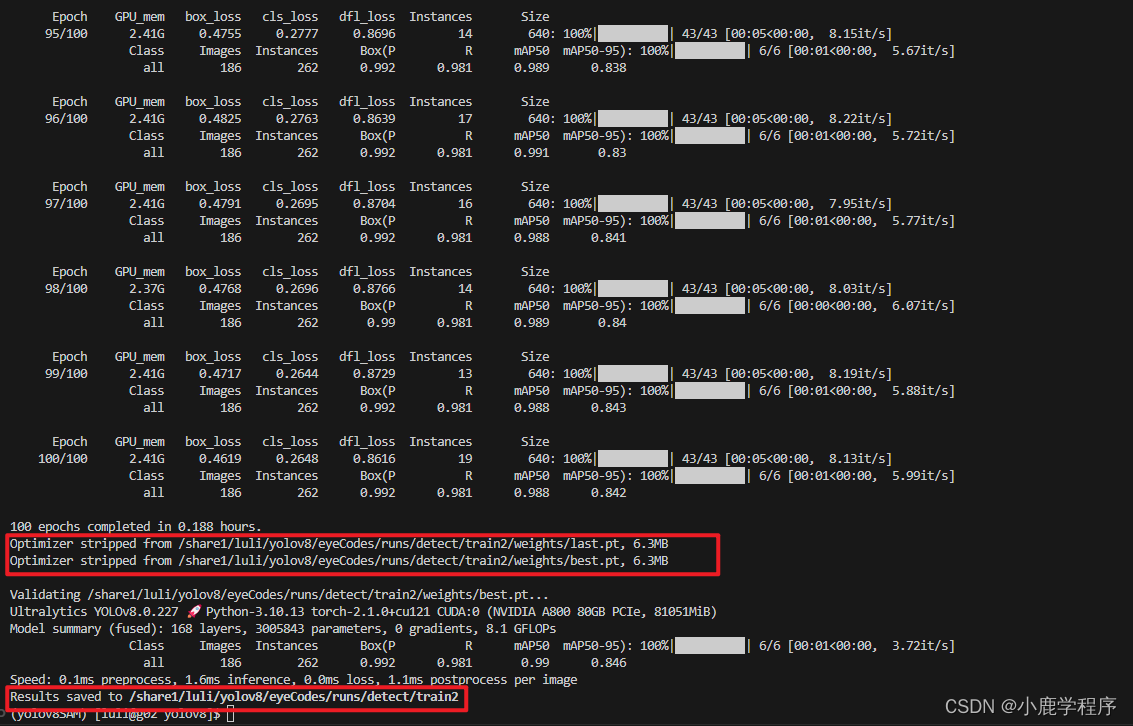
ylov8的训练和预测使用(目标检测)
首先要配置文文件
1-配置数据集的yaml文件:
目录在ultralytics/cfg/datasets/下面: 例如我的: (这里面的yaml文件在/ultralytics/cfg/datasets下面有很多,可以找几个参考一下)
path: /path/to/eye_datasets # dataset root di…

天鹅目标检测数据集VOC格式280张
天鹅,一种优雅而美丽的鸟类,以其洁白的羽毛、优美的身姿和动人的歌声而闻名。
天鹅属于鸟纲、鸭科,是一种大型水禽。它们的羽毛通常是白色、黑色或灰色,非常光滑且富有光泽。天鹅的头部和颈部非常细长,呈现出优雅的曲…

经典目标检测YOLO系列(二)YOLOv2算法详解
经典目标检测YOLO系列(二)YOLOv2算法详解
YOLO-V1以完全端到端的模式实现达到实时水平的目标检测。但是,YOLO-V1为追求速度而牺牲了部分检测精度,在检测速度广受赞誉的同时,其检测精度也饱受诟病。正是由于这个原因,YOLO团队在20…
【深度学习目标检测】十三、基于深度学习的血细胞识别(python,目标检测,yolov8)
血细胞计数是医学上一种重要的检测手段,用于评估患者的健康状况,诊断疾病,以及监测治疗效果。而目标检测是一种计算机视觉技术,用于在图像中识别和定位特定的目标。在血细胞计数中,目标检测技术可以发挥重要作用。 首先…
yolov8目标检测实战课程-训练自己的数据集
最近录制了关于yolov8目标检测的课程,对于初学者比较友好,可以点击课程试看。
可以说是从无到有的过程,手把手教会你训练自己的数据集。
课程地址:https://edu.csdn.net/course/detail/39213 你将收获 anaconda、pycharm、cuda、…
YOLOv8改进 | 二次创新篇 | 在Dyhead检测头的基础上替换DCNv3 (全网独家首发)
一、本文介绍
本文给大家带来的改进机制是在DynamicHead上替换DCNv3模块,其中DynamicHead的核心为DCNv2,但是今年新更新了DCNv3其作为v2的升级版效果肯定是更好的,所以我将其中的核心机制替换为DCNv3给Dyhead相当于做了一个升级,效果也比之前的普通版本要好,这个机制我认…

【目标检测】YOLOv5算法实现(七):模型训练
本系列文章记录本人硕士阶段YOLO系列目标检测算法自学及其代码实现的过程。其中算法具体实现借鉴于ultralytics YOLO源码Github,删减了源码中部分内容,满足个人科研需求。 本系列文章主要以YOLOv5为例完成算法的实现,后续修改、增加相关模…

使用Python和YOLOv8开发视频游戏的目标检测和鼠标重新定位
视频游戏已经走过了漫长的发展历程,从最初的谦卑起步到现在,先进的图形和游戏机制已经成为常态。现代游戏的一个显著发展方向是将人工智能和计算机视觉技术整合到游戏体验中。在本文中,我们将探讨如何使用Python和YOLOv8创建一个系统…
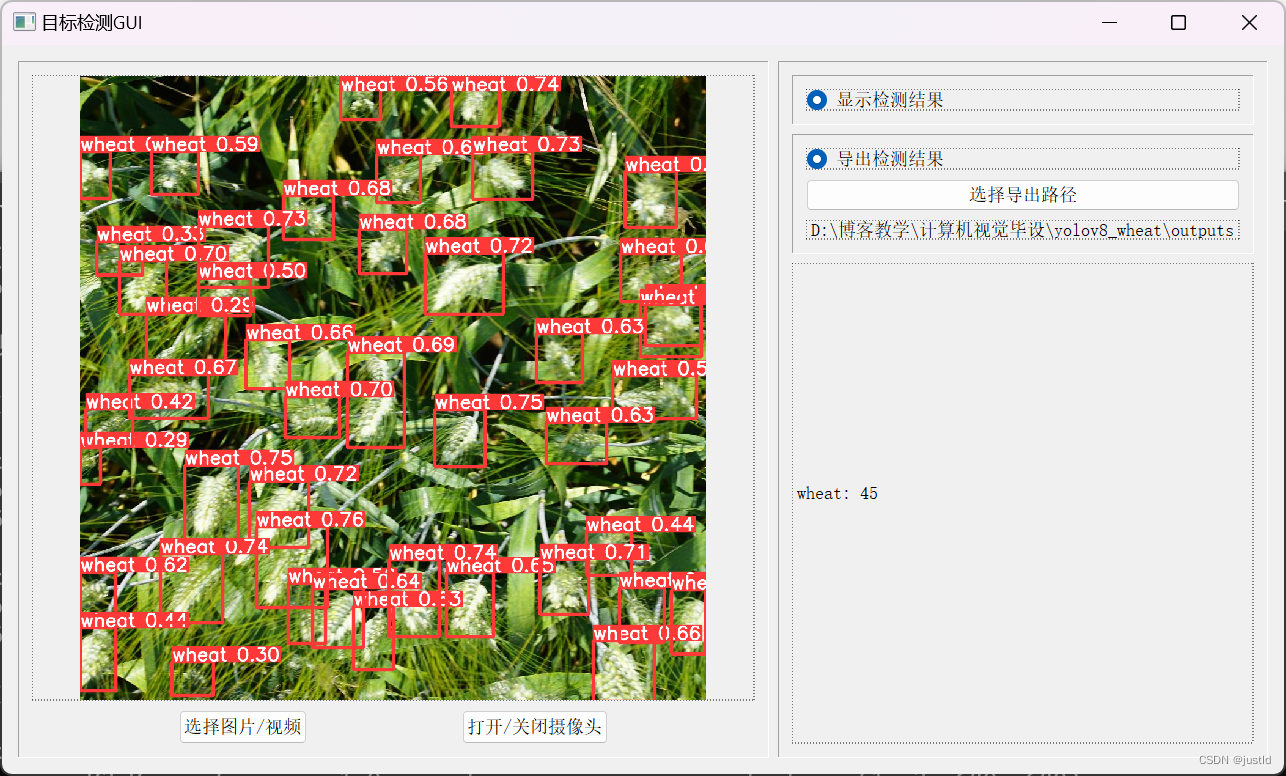
【深度学习目标检测】十六、基于深度学习的麦穗头系统-含GUI和源码(python,yolov8)
全球麦穗检测是植物表型分析领域的一个挑战,主要目标是检测图像中的小麦麦穗。这种检测在农业领域具有重要意义,可以帮助农民评估作物的健康状况和成熟度。然而,由于小麦麦穗在视觉上具有挑战性,准确检测它们是一项艰巨的任务。 全…

【论文阅读笔记】MobileSal: Extremely Efficient RGB-D Salient Object Detection
1.介绍
MobileSal: Extremely Efficient RGB-D Salient Object Detection MobileSal:极其高效的RGB-D显著对象检测 2021年发表在 IEEE Transactions on Pattern Analysis and Machine Intelligence。 Paper Code
2.摘要
神经网络的高计算成本阻碍了RGB-D显着对象…
YOLOv5改进 | 注意力篇 | CGAttention实现级联群体注意力机制 (全网首发改进)
一、本文介绍
本文给大家带来的改进机制是实现级联群体注意力机制CascadedGroupAttention,其主要思想为增强输入到注意力头的特征的多样性。与以前的自注意力不同,它为每个头提供不同的输入分割,并跨头级联输出特征。这种方法不仅减少了多头注意力中的计算冗余,而且通过增…

Grounding DINO:开放集目标检测,将基于Transformer的检测器DINO与真值预训练相结合
文章目录 背景知识补充CLIP (Contrastive Language-Image Pre-training):打破文字和图像之间的壁垒DINO(Data-INterpolating Neural Network):视觉 Transformer 的自监督学习Stable Diffusion:从文本描述中生成详细的图像Open-set Detector开…

YOLOv5源码中的参数超详细解析(7)— yolo.py
前言:Hello大家好,我是小哥谈。YOLOv5是一种先进的目标检测算法,它可以实现快速和准确的目标检测。yolo.py是YOLOv5项目中的一个Python文件,用于实现目标检测算法。该文件包含了YOLOv5模型的定义、训练和推理过程。本节课就结合源码对yolo.py文件进行逐行解析~!🌈 前期…
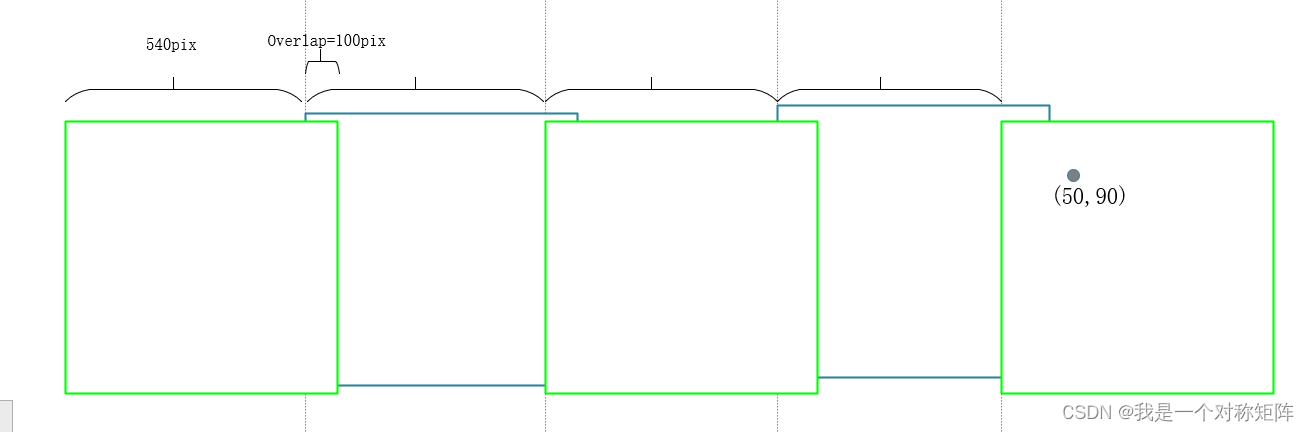
高分辨大尺寸图像的目标检测切图处理
对于yolo等目标检测框架,输入的尺寸通常为640x640,这对于常规的图片尺寸和常规目标检测足够了。但是在诸如航拍图像等任务上,图像尺寸通常几千x几千甚至上万,目标也是非常小的,如果resize到640的尺寸,显然目…
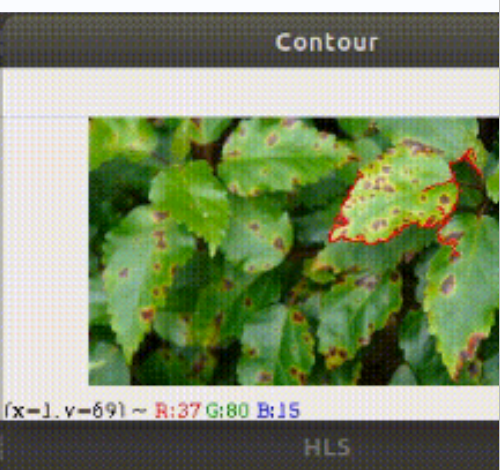
作物叶片病害识别系统
介绍 由于植物疾病的检测在农业领域中起着重要作用,因为植物疾病是相当自然的现象。 如果在这个领域不采取适当的护理措施,就会对植物产生严重影响,进而影响相关产品的质量、数量或产量。植物疾病会引起疾病的周期性爆发,导致大…
YOLOv5改进 | 融合改进篇 | CCFM + Dyhead完美融合突破极限涨点 (全网独家首发)
一、本文改进
本文给大家带来的改进机制是CCFM配合Dyhead检测头实现融合涨点,这个结构配合在一起只能说是完美的融合,看过我之前的检测头篇的读者都知道Dyhead官方版本支持的输入通道数是需要保持一致的,但是CCFM作为RT-DETR的Neck结构其输出通道数就是一致的,所以将这两种…
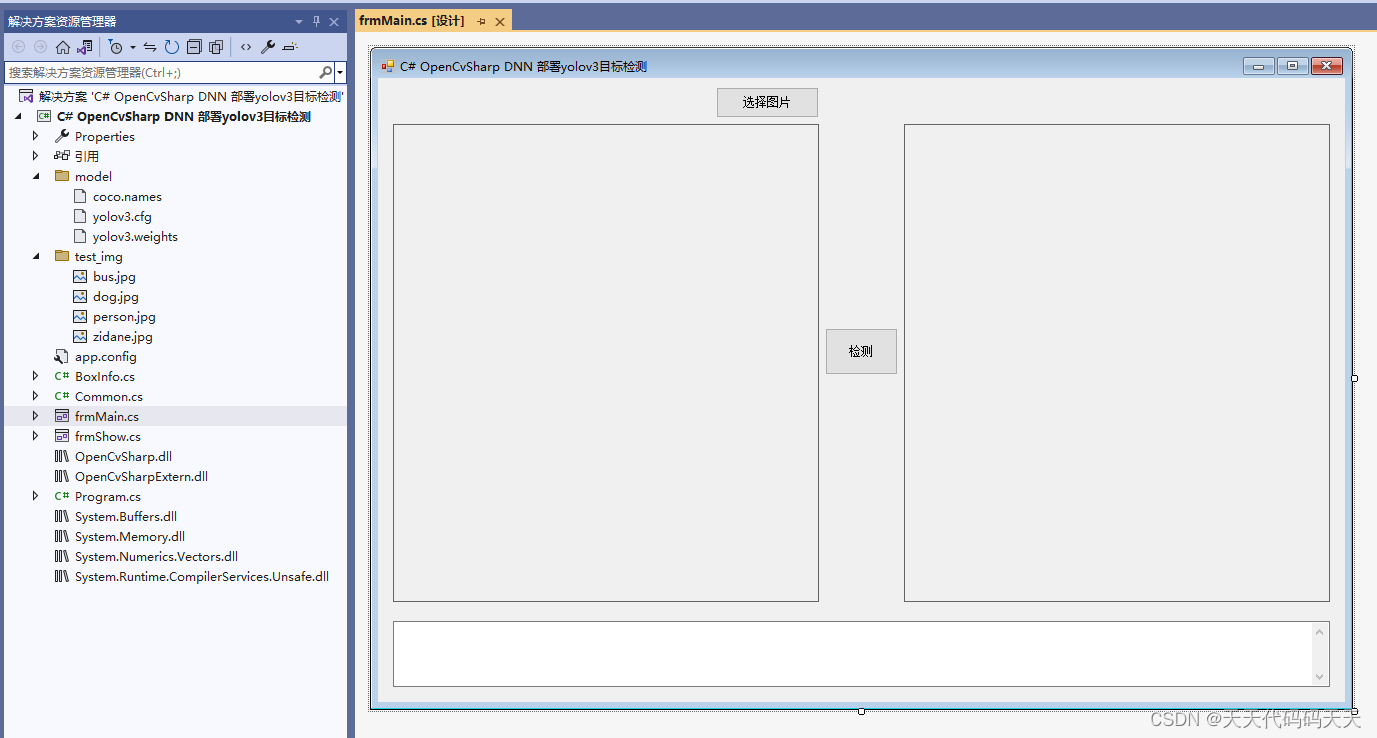
C# OpenCvSharp DNN 部署yolov3目标检测
目录
效果
yolov3.cfg
项目
代码
下载 C# OpenCvSharp DNN 部署yolov3目标检测
效果 yolov3.cfg
[net]
# Testing
#batch1
#subdivisions1
# Training
batch16
subdivisions1
width416
height416
channels3
momentum0.9
decay0.0005
angle0
saturation 1.5
exposure 1…

基于YOLOv7算法的高精度实时烟雾目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时烟雾目标检测系统可用于日常生活中检测与定位烟雾,此系统可完成对输入图片、视频、文件夹以及摄像头方式的目标检测与识别,同时本系统还支持检测结果可视化与导出。本系统采用YOLOv7目标检测算法来训练数据集…
目标检测中的数据增强
整个代码参考:bubbliiiing/object-detection-augmentation。 random_data.py
import cv2
import numpy as np
from PIL import Image, ImageDrawdef rand(a=0, b=1):return np.random.rand()*(b-a) + adef get_random_data(annotation_line, input_shape, jitter=.3, hue=.1…
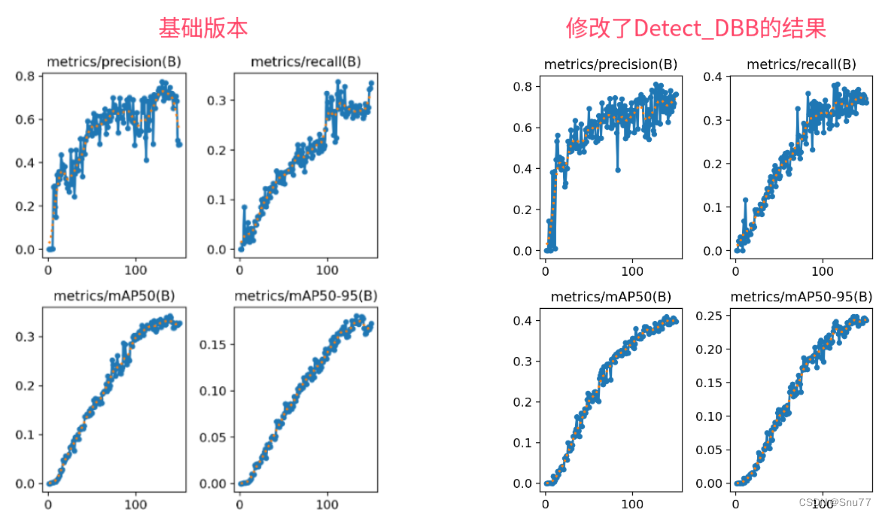
YOLOv8改进 | 检测头篇 | 利用DBB重参数化模块魔改检测头实现暴力涨点 (支持检测、分割、关键点检测)
一、本文介绍
本文给大家带来的改进机制是二次创新的机制,二次创新是我们发表论文中关键的一环,本文给大家带来的二次创新机制是通过DiverseBranchBlock(DBB)模块来改进我们的检测头形成一个新的检测头Detect_DBB,其中DBB是一种重参数化模块,其训练时采用复杂结构,推理时…
【RT-DETR改进涨点】MPDIoU、InnerMPDIoU损失函数中的No.1(包含二次创新)
前言
大家好,我是Snu77,这里是RT-DETR有效涨点专栏。
本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。
专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…
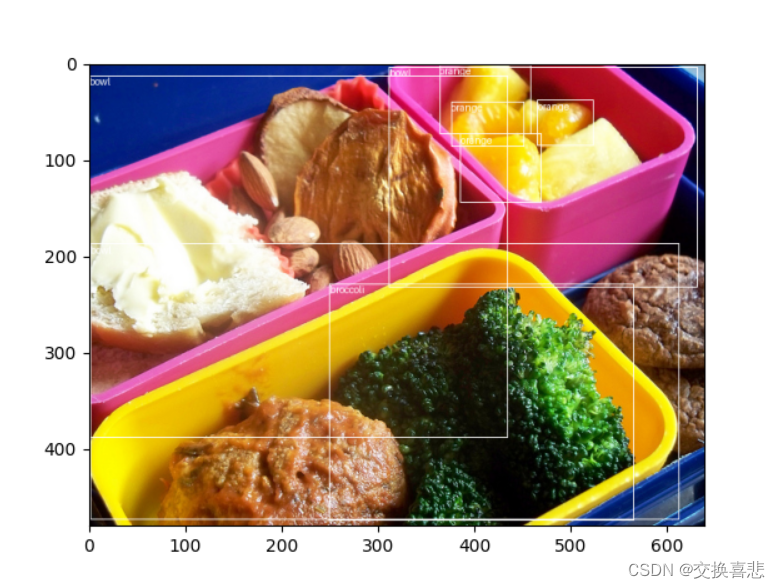
深度学习-标注文件处理(txt批量转换为json文件)
接上篇,根据脚本可将coco128的128张图片,按照比例划分成训练集、测试集、验证集,同时生成相应的标注的labels文件夹,最近再看实例分离比较火的mask rcnn模型,准备进行调试但由于实验室算力不足,网上自己租的…
【目标检测实验系列】YOLOv5模型改进:融入坐标注意力机制CA,多维度关注数据特征,高效涨点!(内含源代码,超详细改进代码流程)
自我介绍:本人硕士期间全程放养,目前成果:一篇北大核心CSCD录用,两篇中科院三区已见刊,一篇中科院四区在投。如何找创新点,如何放养过程厚积薄发,如何写中英论文,找期刊等等。本人后续会以自己实战经验详细…
![[论文阅读]DeepFusion](https://img-blog.csdnimg.cn/direct/7aea0198a8a6438c84b14e0fb4ff44b6.png)
[论文阅读]DeepFusion
DeepFusion
Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection 用于多模态 3D 物体检测的激光雷达相机深度融合 论文网址:DeepFusion 论文代码:DeepFusion
摘要
激光雷达和摄像头是关键传感器,可为自动驾驶中的 3D 检测提供补…

经典目标检测YOLO系列(二)YOLOV2的复现(2)正样本的匹配、损失函数的实现及模型训练
经典目标检测YOLO系列(二)YOLOV2的复现(2)正样本的匹配、损失函数的实现及模型训练
我们在之前实现YOLOv1的基础上,加入了先验框机制,快速的实现了YOLOv2的网络架构,并且实现了前向推理过程。
经典目标检测YOLO系列(二)YOLOV2的复现(1)总体…
目标检测难题 | 小目标检测策略汇总
大家好,在计算机视觉中,检测小目标是最有挑战的问题之一,本文给出了一些有效的策略。 从无人机上看到的小目标
为了提高模型在小目标上的性能,本文推荐以下技术: 提高图像采集的分辨率 增加模型的输入分辨率 tile你…
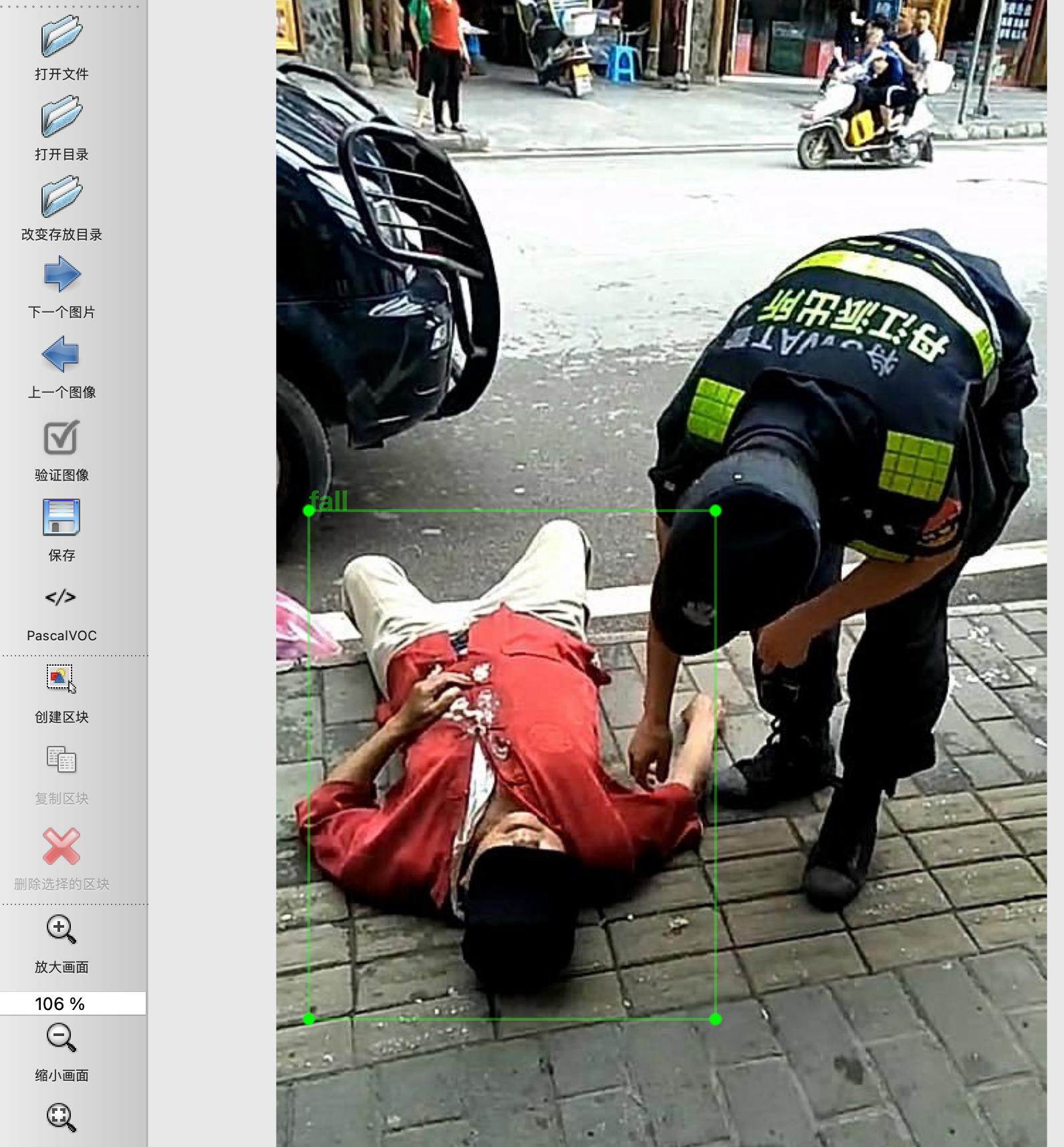
目标检测数据集 - 跌倒检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:跌倒检测数据集,真实场景高质量图片数据,涉及场景丰富,比如交通事故跌倒、打架跌倒、运动跌倒、楼梯跌倒、生病跌倒、遮挡行人跌倒、严重遮挡行人跌倒数据;适用实际项目应用:公共场所监控或室内…
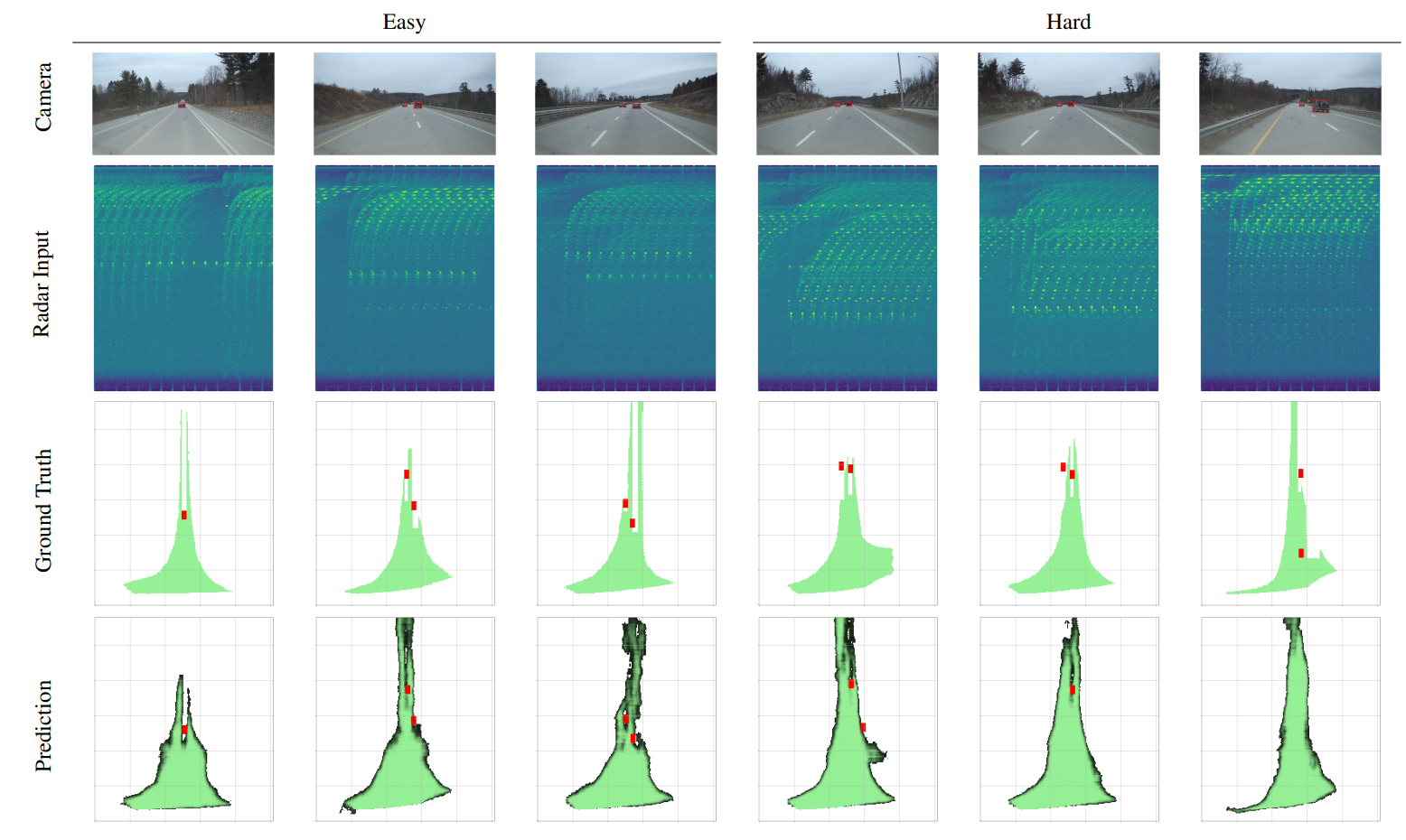
4D毫米波雷达——FFT-RadNet 目标检测与可行驶区域分割 CVPR2022
前言
本文介绍使用4D毫米波雷达,实现目标检测与可行驶区域分割,它是来自CVPR2022的。
会讲解论文整体思路、输入数据分析、模型框架、设计理念、损失函数等,还有结合代码进行分析。
论文地址:Raw High-Definition Radar for Mu…
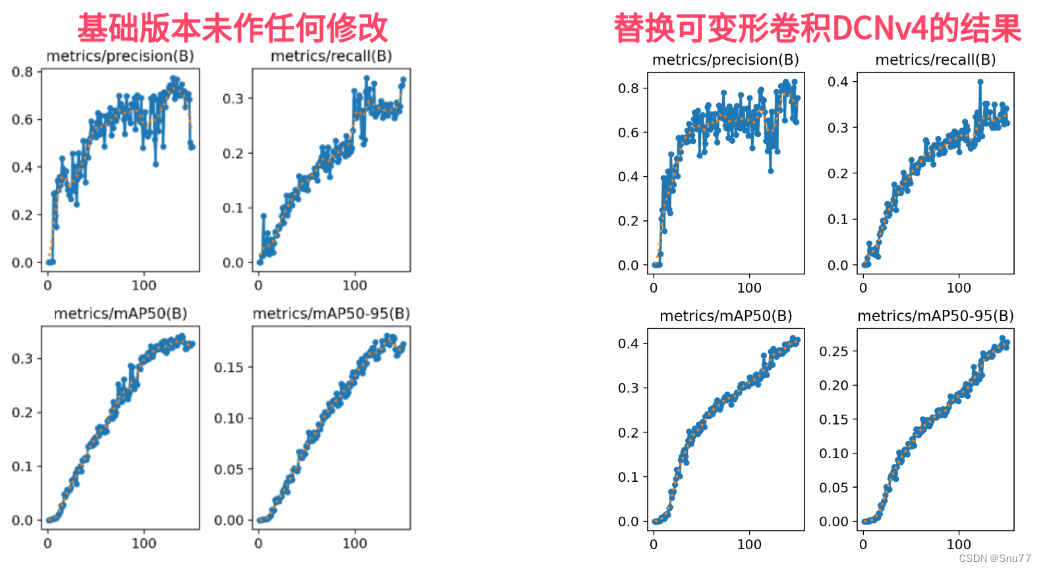
YOLOv8改进 | Conv篇 | 2024.1月最新成果可变形卷积DCNv4(适用检测、Seg、分类、Pose、OBB)
一、本文介绍
本文给大家带来的改进机制是2024-1月的最新成果DCNv4,其是DCNv3的升级版本,效果可以说是在目前的卷积中名列前茅了,同时该卷积具有轻量化的效果!一个DCNv4参数量下降越15Wparameters左右,。它主要通过两个方面对前一版本DCNv3进行改进:首先,它移除了空间聚…

树莓派也可以部署基于YOLO的目标检测
YOLO目标检测结果 在本文的第一部分中,我测试了YOLO(You Only Look Once)这一流行的目标检测库的“复古”版本。只使用OpenCV运行深度学习模型,而不使用“沉重”的框架如PyTorch或Keras,对于低功耗设备来说是有前途的&…
使用 LinkAi 打造自己的知识库和数字人
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录
其他系列文章导航
文章目录
前言
一、LinkAi 介绍
二、文档库
2.1 创建知识库
2.2 配置知识库
2.3 Ai配置
2.4 导入文档
2.5 接入微信
三、扩展
四、总结…
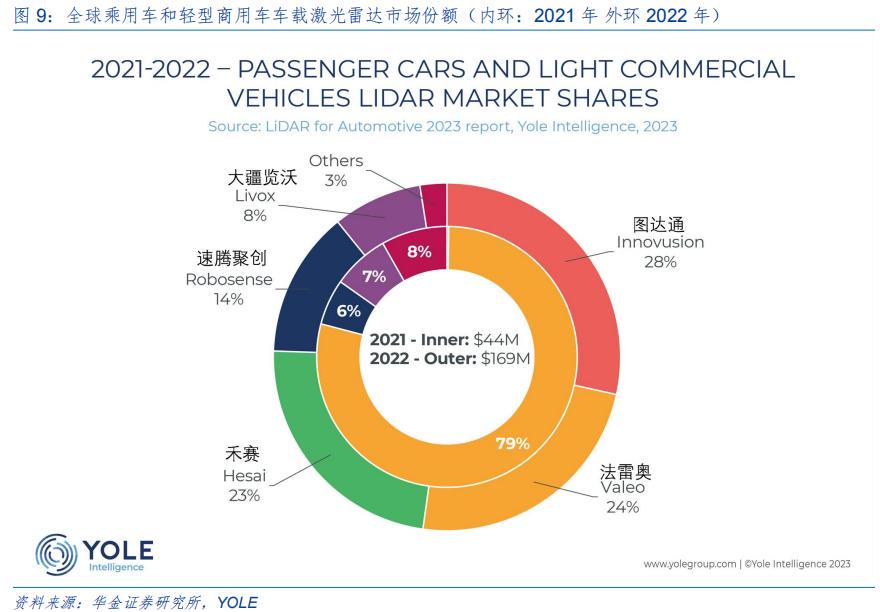
华为产业链之车载激光雷达
一、智能汽车 NOA 加快普及,L3 上路利好智能感知硬件
1、感知层是 ADAS 最重要的一环 先进驾驶辅助系统 (ADAS, Advanced driver-assistance system)分“感知层、决策层、执行层”三个层级,其中感知层是最重要的一环…

【01】深度学习——数学基础 | 线性代数 | 微积分 |概率
深度学习 1.线性代数1.1标量(scalar)1.2向量(Vector)1.2.1模长和范数1.2.2单位向量1.2.3向量的内积1.2.4向量的外积 1.3矩阵(Matrix)1.3.1矩阵转置1.3.2矩阵乘法1.3.3矩阵乘法的性质 1.4张量(Tensor) 2.微积分2.1极限2.2导数2.2.1导数和极限2.2.2导数和极…
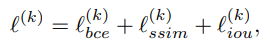
BASNet:Boundary-aware salient object detection
CVPR 2019开源论文 | BASNet:关注边界的显著性检测本文提出一种基于深度监督学习的前景提取构架BASNet,其在边缘感知上有优异的表现。https://mp.weixin.qq.com/s/fjq4UyDMN9Z9lvNZ7aNLWABASNet: Boundary-Aware Salient Object Detection论文学习_basne…

DCNv4:对视觉应用的动态和稀疏算子的重新思考
摘要
https://arxiv.org/pdf/2401.06197.pdf 我们介绍了可变形卷积v4(DCNv4),这是一种高效且有效的运算符,专为广泛的视觉应用而设计。DCNv4解决了其前身DCNv3的局限性,通过两个关键改进:1. 去除空间聚合中…
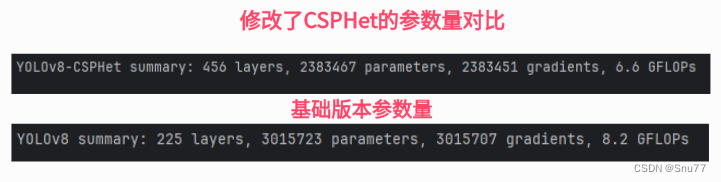
YOLOv8改进 | Conv篇 | 结合Dual思想利用HetConv创新一种全新轻量化结构CSPHet(参数量下降70W)
一、本文介绍
本文给大家带来的改进机制是我结合Dual的思想利用HetConv提出一种全新的结构CSPHet,我们将其用于替换我们的C2f结构,可以将参数降低越75W,GFLOPs降低至6.6GFLOPs,同时本文结构为我独家创新,全网无第二份,非常适合用于发表论文,该结构非常灵活,利用Dual卷…

经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程
经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构及前向处理过程
和之前实现的YOLOv2一样,根据《YOLO目标检测》(ISBN:9787115627094)一书,在不脱离YOLOv3的大部分核心理念的前提下,重构一款较新的YOLOv3检测器,来对YOLOv3有…
YOLOv5改进 | 检测头篇 | 利用DySnakeConv改进检测头专用于分割的检测头(全网独家首发,Seg)
一、本文改进
本文给大家带来的改进机制是一种我进行优化的专用于分割的检测头,在分割的过程中,最困难的无非就是边缘的检测,动态蛇形卷积(Dynamic Snake Convolution)通过自适应地聚焦于细长和迂回的局部结构,准确地捕捉管状结构的特征。这种卷积方法的核心思想是,通过…
经典目标检测YOLO系列(三)YOLOv3的复现(2)正样本的匹配、损失函数的实现
经典目标检测YOLO系列(三)YOLOv3的复现(2)正样本的匹配、损失函数的实现
我们在之前实现YOLOv2的基础上,加入了多级检测及FPN,快速的实现了YOLOv3的网络架构,并且实现了前向推理过程。
经典目标检测YOLO系列(三)YOLOV3的复现(1)总体网络架构…
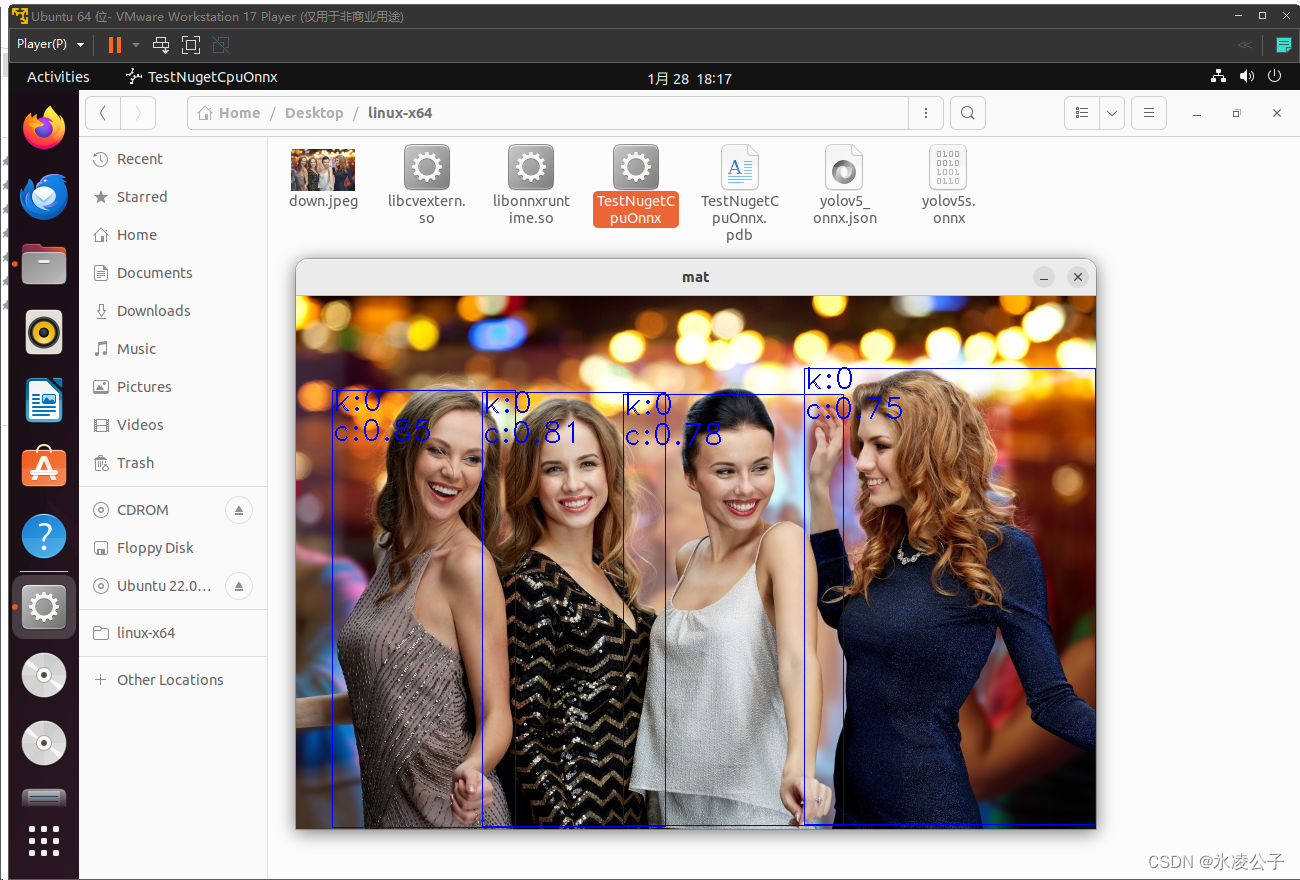
C#简单使用Yolov5的Onnx格式模型进行目标检测
背景
最近要离职了,同事需要了解一下C#如何使用yolov5系列onnx格式模型进行目标检测,由于其对C#不熟练,可能会影响公司后续的开发进度,所以趁着还在,赶紧把手尾搞好。
方案
1、创建一个C# DotNet 8 控制台项目[可千…

4D毫米波雷达——ADCNet 原始雷达数据 目标检测与可行驶区域分割
前言
本文介绍使用4D毫米波雷达,基于原始雷达数据,实现目标检测与可行驶区域分割,它是来自2023-12的论文。
会讲解论文整体思路、输入分析、模型框架、设计理念、损失函数等,还有结合代码进行分析。
论文地址:ADCNe…
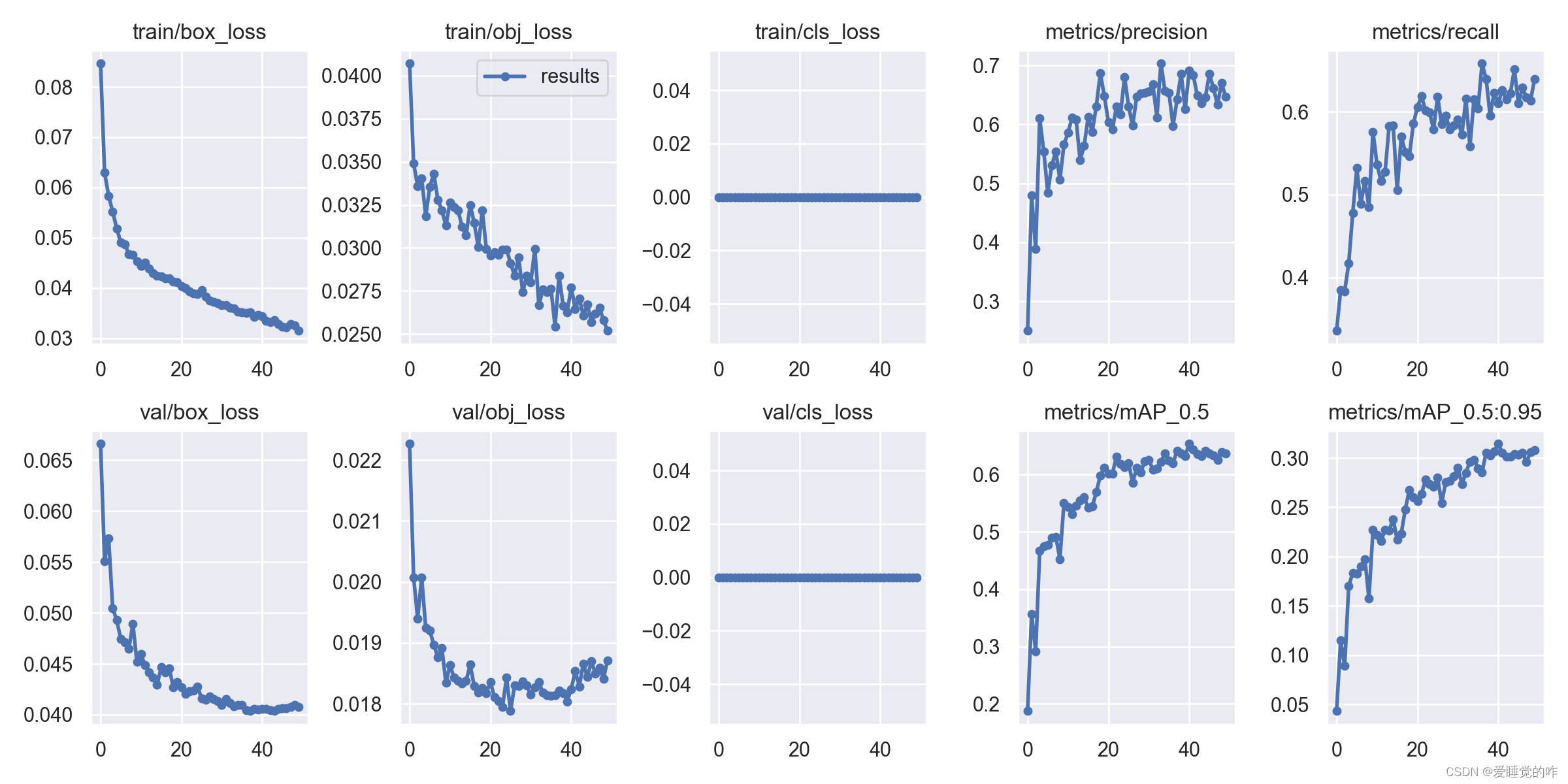
一文详解Yolov5——基于Yolov5的火灾检测系统
✨ 原创不易,还希望各位大佬支持一下 \textcolor{blue}{原创不易,还希望各位大佬支持一下} 原创不易,还希望各位大佬支持一下 👍 点赞,你的认可是我创作的动力! \textcolor{green}{点赞,你的认…
Revisiting image pyramid structure for high resolution salient object detection
accv2022的技术,在我测评的数据集上确实要明显好于basnet,rembg等一众方法。
1.Introduction 使用LR数据集训练的方法通过调整输入尺寸可以在HR图像上产生不错的结果。本文主要关注仅使用LR数据集进行训练以产生高质量的HR预测。HR的有效感受野ERFs和LR…
YOLO框架下(ultralytics) RTDETE 与 YOLOv8 目标检测对比
YOLO框架下(ultralytics) RTDETE 与 YOLOv8 目标检测对比 文章目录 YOLO框架下(ultralytics) RTDETE 与 YOLOv8 目标检测对比0 前言:1 RTDETE 训练l模型2 YOLOv8 训练l模型3 对比总结4 s的训练对比(无预训练权重)0 前言:
0.1 相同训练数据集和相同测试数据集下,采用R…

YOLOv5算法进阶改进(14)— 即插即用的动态卷积之ODConv | 助力涨点
前言:Hello大家好,我是小哥谈。动态卷积(Dynamic Convolution)是一种用于目标检测的卷积神经网络模块,其中ODConv(Object Detection Convolution)是其一种具体实现。动态卷积在传统的卷积操作上引入了动态权重,以适应不同目标的形状和尺度变化。本文将YOLOv5的主干网…

【深度学习:目标检测】深度学习中目标检测模型、用例和示例
【深度学习:目标检测】深度学习中目标检测模型、用例和示例 什么是物体检测?物体检测与图像分类物体检测与图像分割 计算机视觉中的目标检测物体检测的优点物体检测的缺点深度学习和目标检测人员检测 物体检测如何工作?一阶段与两阶段深度学习…

即插即用篇 | YOLOv8 引入 SKAttention 注意力机制 | 《Selective Kernel Networks》
论文名称:《Selective Kernel Networks》
论文地址:https://arxiv.org/pdf/1903.06586.pdf
代码地址:https://github.com/implus/SKNet 文章目录 1 原理2 源代码3 添加方式4 模型 yaml 文件template-backbone.yamltemplate-small.yamltemplate-large.yaml
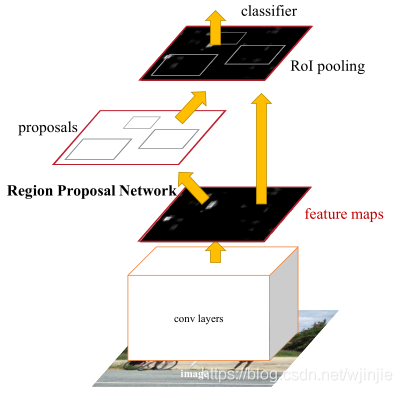
【计算机视觉】目标检测 |滑动窗口算法、YOLO、RCNN系列算法
一、概述
首先通过前面对计算机视觉领域中的卷积神经网络进行了解和学习,我们知道,可以通过卷积神经网络对图像进行分类。
如果还想继续深入,会涉及到目标定位(object location)的问题。在图像分类的基础上(Image classification)的基础上…
YOLOv5独家涨点技巧:FPN涨点篇 | 高层筛选特征金字塔网络(HS-FPN),助力医学、小目标检测 | 2024年最新论文
💡💡💡本文独家改进:高层筛选特征金字塔网络(HS-FPN),能够刷选出大小目标,增强模型表达不同尺度特征的能力,助力小目标检测
💡💡💡在BCCD医学数据集和私有多个数据集实现暴力涨点。
收录
YOLOv5原创自研
https://blog.csdn.net/m0_63774211/category…
使用mmrotate对自定义数据集进行检测
这里写自定义目录标题 安装虚拟环境创建与准备安装mmrotate 自定义数据集标注数据与格式转换数据集划分与大图像切片 训练与测试修改配置文件执行训练进行测试鸣谢 安装
mmrotate是一个自带工作目录的python工具箱,个人觉得,在不熟悉的情况下࿰…

YOLO-World——超级轻量级开放词汇目标检测方法
前言
目标检测一直是计算机视觉领域中不可忽视的基础挑战,对图像理解、机器人技术和自主驾驶等领域具有广泛应用。随着深度神经网络的发展,目标检测方面的研究取得了显著进展。尽管这些方法取得了成功,但它们存在一些限制,主要体…
C# OpenCvSharp DNN 部署yolov4目标检测
目录
效果
项目
代码
下载 效果 项目 代码
using OpenCvSharp;
using OpenCvSharp.Dnn;
using System;
using System.Collections.Generic;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Windows.Forms;namespace OpenCvSharp_DNN_Demo
{publ…
YOLOv5独家改进:上采样算子 | 超轻量高效动态上采样DySample,效果秒杀CAFFE,助力小目标检测
💡💡💡本文独家改进:一种超轻量高效动态上采样DySample, 具有更少的参数、FLOPs,效果秒杀CAFFE和YOLOv5网络中的nn.Upsample 💡💡💡在多个数据集下验证能够涨点,尤其在小目标检测领域涨点显著。 收录
YOLOv5原创自研
https://blog.csdn.net/m0_63774211/cate…
YOLOv5独家原创改进:大核卷积涨点系列| Shift-ConvNets,稀疏/移位操作让小卷积核也能达到大卷积核效果 | 2024年最新论文
💡💡💡本文独家改进:大的卷积核设计成为使卷积神经网络(CNNs)再次强大的理想解决方案,Shift-ConvNets稀疏/移位操作让小卷积核也能达到大卷积核效果,创新十足实现涨点,助力YOLOv8
💡💡💡在多个私有数据集和公开数据集VisDrone2019、PASCAL VOC实现涨点 收录…
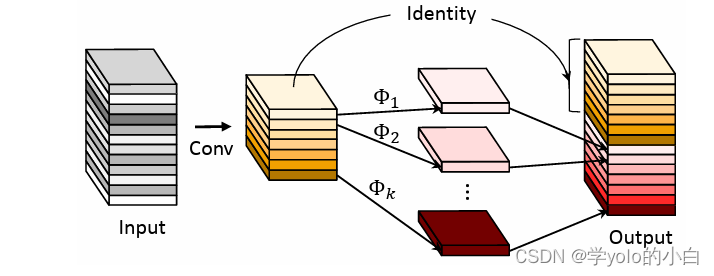
YOLOv8改进 更换轻量级网络结构
一、GhostNet论文 论文地址:1911.11907.pdf (arxiv.org)
二、 GhostNet结构
GhostNet是一种高效的目标检测网络,具有较低的计算复杂度和较高的准确性。该网络采用了轻量级的架构,可以在计算资源有限的设备上运行,并能够快速地实时检测图像中的目标物体。
GhostNet基于Mo…
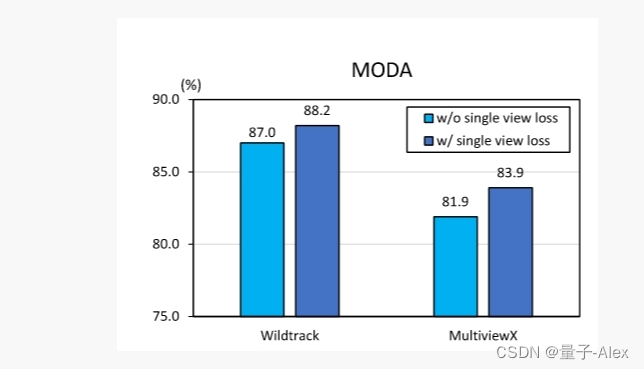
【CV论文精读】【MVDet】Multiview Detection with Feature Perspective Transformation
0.论文摘要
合并多个摄像机视图进行检测减轻了拥挤场景中遮挡的影响。在多视图检测系统中,我们需要回答两个重要问题。首先,我们应该如何从多个视图中聚合线索?第二,我们应该如何从空间上相邻的位置聚集信息?为了解决…
智慧自助餐饮系统(SpringBoot+MP+Vue+微信小程序+JNI+ncnn+YOLOX-Nano)
一、项目简介
本项目是配合智慧自助餐厅下的一套综合系统,该系统分为安卓端、微信小程序用户端以及后台管理系统。安卓端利用图像识别技术进行识别多种不同菜品,识别成功后安卓端显示该订单菜品以及价格并且生成进入小程序的二维码,用户扫描…
C# OpenVINO 图片旋转角度检测
目录
效果
项目
代码
下载 效果 项目 代码
using OpenCvSharp; using Sdcb.OpenVINO; using System; using System.Diagnostics; using System.Drawing; using System.Linq; using System.Runtime.InteropServices; using System.Security.Cryptography; using System.Te…

目标检测开源数据集——道路坑洼
一、危害
对车辆的影响:道路坑洼会导致车辆行驶不稳,增加车辆的颠簸,不仅影响乘坐舒适度,还可能对车辆的悬挂系统、轮胎等造成损害。长期在坑洼路面上行驶,车辆的减震系统、悬挂系统等关键部件容易受损,进…
多目标检测与跟踪技术详解
导言
在计算机视觉领域,多目标检测与跟踪(Multi-Object Tracking, MOT)是一个至关重要的研究方向。它涉及到在视频序列中同时跟踪多个目标,如行人、车辆等。本文将深入探讨多目标检测与跟踪的核心算法和相关挑战。
1. 基于检测的…
目标检测算法之YOLOv5的应用实例(零售业库存管理、无人机航拍分析、工业自动化领域应用的详解)
1.YOLOv5在"零售业库存管理"领域的应用
在零售业库存管理中,YOLOv5可以帮助自动化商品识别和库存盘点过程。通过使用深度学习模型来实时识别货架上的商品,零售商可以更高效地管理库存,减少人工盘点的时间和成本。以下是一个使用YOLOv5进行商品识别的Python脚本示…

【论文阅读|基于 YOLO 的红外小目标检测的逆向范例】
基于 YOLO 的红外小目标检测的逆向范例 摘要1 引言2 相关工作2.1 逆向推理2.2 物体检测方法 3 方法3.1 总体架构3.2 逆向标准的可微分积分 4 实验4.1 数据集和指标4.2 实验环境4.4 OL-NFA 为少样本环境带来稳健性 5 结论 论文题目: A Contrario Paradigm for YOLO-b…
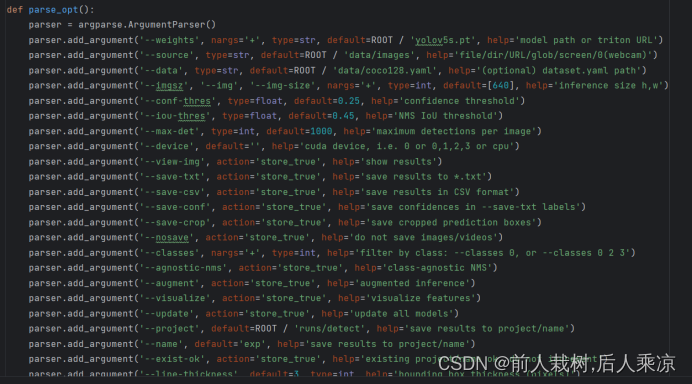
yolov5-tracking-xxxsort yolov5融合六种跟踪算法(二)--目标识别
本次开源计划主要针对大学生无人机相关竞赛的视觉算法开发。 开源代码仓库链接:https://github.com/zzhmx/yolov5-tracking-xxxsort.git 先按照之前的博客配置好环境: yolov5-tracking-xxxsort yolov5融合六种跟踪算法(一)–环境配…
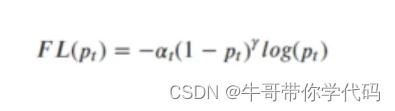
深度学习基础——SSD目标检测
SSD网络介绍
使用多个特征图作为特征预测层。
SSD (Single Shot MultiBox Detector)于2016年提出。当网络输入为300300大小时,在VOC2007测试集上达到74.3%的mAP;当输入是512512大小时,达到了76.9%的mAP SSD_Backbone部分介绍
不变的部分
特征提取网…

YOLOv9改进 | 一文带你了解全新的SOTA模型YOLOv9(论文阅读笔记,效果完爆YOLOv8)
官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转 图1. 在MS COCO数据集上实时对象检测器的比较。基于GELAN和PGI的对象检测方法在对象检测性能方面超越了所有以前的从头开始训练的方法。在准确性方面,新方法…

YOLOv9 | 利用YOLOv9训练自己的数据集 -> 推理、验证(源码解读 + 手撕结构图)
一、本文介绍
本文给大家带来的是全新的SOTA模型YOLOv9的基础使用教程,需要注意的是YOLOv9发布时间为2024年2月21日,截至最近的日期也没有过去几天,从其实验结果上来看,其效果无论是精度和参数量都要大于过去的一些实时检测模型&…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的犬种识别系统(附完整代码资源+UI界面+PyTorch代码)
摘要:本文介绍了一种基于深度学习的犬种识别系统系统的代码,采用最先进的YOLOv8算法并对比YOLOv7、YOLOv6、YOLOv5等算法的结果,能够准确识别图像、视频、实时视频流以及批量文件中的犬种。文章详细解释了YOLOv8算法的原理,并提供…
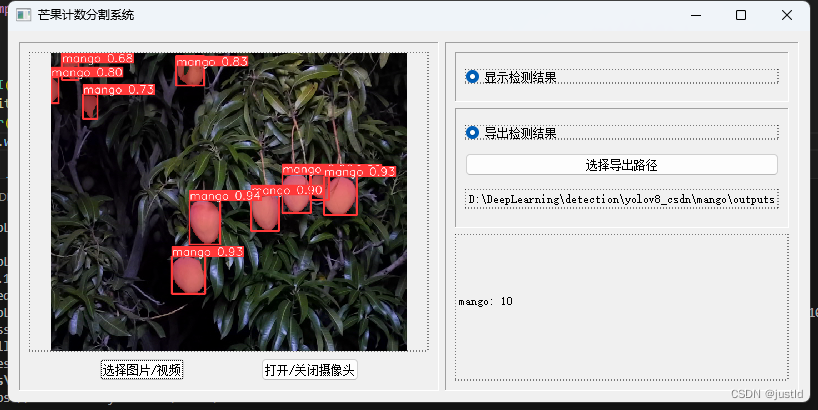
【深度学习目标检测】十九、基于深度学习的芒果计数分割系统-含数据集、GUI和源码(python,yolov8)
使用深度学习算法检测芒果具有显著的优势和应用价值。以下是几个主要原因: 特征学习的能力:深度学习,特别是卷积神经网络(CNN),能够从大量的芒果图像中自动学习和提取特征。这些特征可能是传统方法难以手动…

目标检测新SOTA:YOLOv9 问世,新架构让传统卷积重焕生机
在目标检测领域,YOLOv9 实现了一代更比一代强,利用新架构和方法让传统卷积在参数利用率方面胜过了深度卷积。 继 2023 年 1 月 YOLOv8 正式发布一年多以后,YOLOv9 终于来了!
我们知道,YOLO 是一种基于图像全局信息进行…

改进Yolov5目标检测与单目测距 yolo速度测量-pyqt界面-yolo添加注意力机制
当设计一个结合了 YOLOv5 目标检测、单目测距与速度测量以及 PyQt 界面的毕业设计时,需要考虑以下几个方面的具体细节:
计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,私聊会回复! YOLOv5 目标检测: 首先,选择…

番外篇 | YOLOv5+DeepSort实现行人目标跟踪检测
前言:Hello大家好,我是小哥谈。DeepSort是一种用于目标跟踪的深度学习算法。它结合了目标检测和目标跟踪的技术,能够在视频中准确地跟踪多个目标,并为每个目标分配一个唯一的ID。DeepSort的核心思想是将目标检测和目标跟踪两个任务进行联合训练,以提高跟踪的准确性和稳定性…
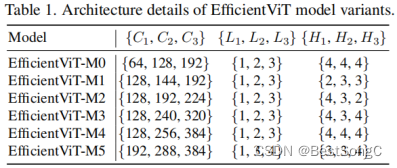
YOLO算法改进Backbone系列之:EfficientViT
EfficientViT: Memory Effificient Vision Transformer with Cascaded Group Attention 摘要:视觉transformer由于其高模型能力而取得了巨大的成功。然而,它们卓越的性能伴随着沉重的计算成本,这使得它们不适合实时应用。在这篇论文中&#x…

YOLOv9尝鲜测试五分钟极简配置
pip安装python包:
pip install yolov9pip在https://github.com/WongKinYiu/yolov9/tree/main中下载好权重文件yolov9-c.pt。 运行下面代码:
import yolov9model yolov9.load("yolov9-c.pt", device"cpu") # load pretrained or c…
C# OpenVINO Nail Seg 指甲分割 指甲检测
目录
效果
模型信息
项目
代码
数据集
下载 C# OpenVINO Nail Seg 指甲分割 指甲检测
效果 模型信息
Model Properties ------------------------- date:2024-02-29T16:41:28.273760 author:Ultralytics task:segment version&#…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的活体人脸检测系统(Python+PySide6界面+训练代码)
摘要:本篇博客详细讲述了如何利用深度学习构建一个活体人脸检测系统,并且提供了完整的实现代码。该系统基于强大的YOLOv8算法,并进行了与前代算法YOLOv7、YOLOv6、YOLOv5的细致对比,展示了其在图像、视频、实时视频流和批量文件处…
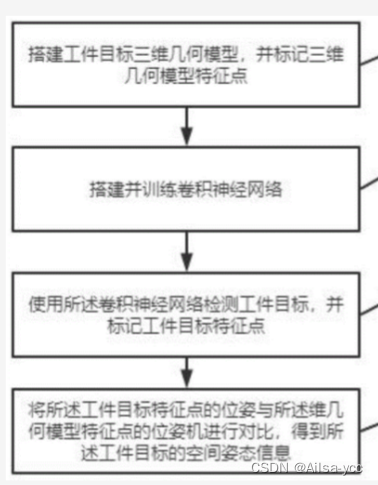
专利:基于2D工业相机的工件目标检测及三维姿态
本发明公开了一种基于2D工业相机的工件目标检测及三维姿态判定方法,首先根据待生产或是待加工工件目标搭建其三维几何模型,并标记该几何模型制定特征点,然后对通过两个2D工业相机分别获得的现场工件目标图像进行目标检测及特征识别࿰…

基于YOLOv8深度学习的复杂场景下船舶目标检测系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
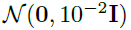
论文解读--Mutual Interference Mitigation in PMCW Automotive Radar
PMCW汽车雷达的相互干扰抑制
摘要 针对相位调制连续波(PMCW)毫米波(mmWave)汽车雷达系统中存在的相互干扰问题进行了研究。对先进驾驶辅助系统(ADAS)的需求日益增长,导致配备在同一频段工作的毫米波雷达系统的车辆激增,导致相互干扰,可能会降…
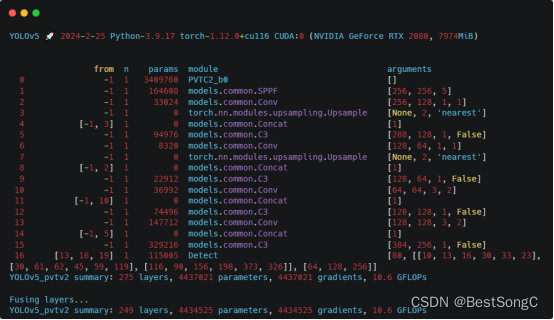
YOLO算法改进Backbone系列之:PVTv2
摘要:最近,Transformer在计算机视觉方面取得了令人鼓舞的进展。在本研究中,本文通过增加(1)线性复杂度注意层、(2)重叠贴片嵌入和(3)卷积前馈网络三种设计,改进了原始的金字塔视觉转换器(PVT v1),提出了新的基线。通过…
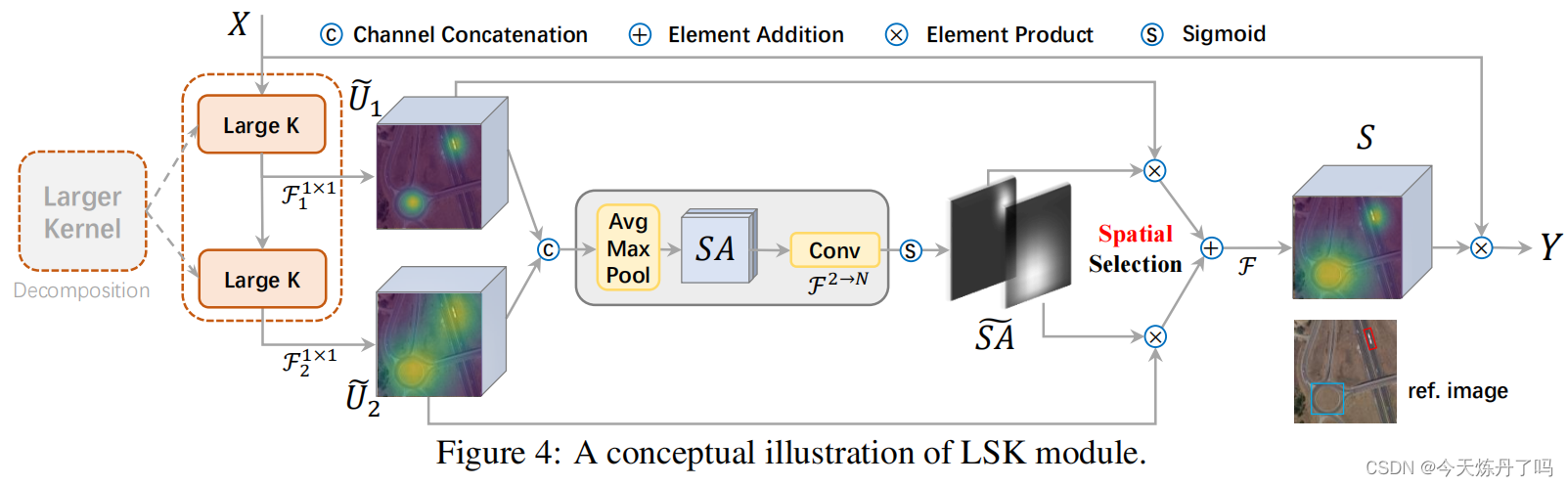
YOLOv9有效提点|加入BAM、CloFormer、Reversible Column Networks、Lskblock等几十种注意力机制(二)
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、本文介绍 本文只有代码及注意力模块简介,YOLOv9中的添加教程:可以看这篇文章。 YOLOv9有效提点|加入SE、CBAM、ECA、SimA…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的口罩识别系统(Python+PySide6界面+训练代码)
摘要:开发口罩识别系统对于提升公共卫生安全和疫情防控具有重要意义。本篇博客详细介绍了如何利用深度学习构建一个口罩识别系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并结合了YOLOv7、YOLOv6、YOLOv5的对比,给出…
【RT-DETR有效改进】Best Paper | DAttention (DAT)可变形注意力机制和动态采样点
一、本文介绍
本文给大家带来的是RT-DETR改进DAT(Vision Transformer with Deformable Attention)的教程,其发布于2022年CVPR2022上同时被评选为Best Paper,由此可以证明其是一种十分有效的改进机制,其主要的核心思想是:引入可变…
[数据集][目标检测]葡萄串检测数据集VOC+YOLO格式95张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):95 标注数量(xml文件个数):95 标注数量(txt文件个数):95 标注类别数…

【模型复现】自制数据集上复现目标检测域自适应 SSDA-YOLO
【模型复现】自制数据集上复现目标检测域自适应 SSDA-YOLO 1. 环境安装2. 数据集制作2.1 数据准备2.2 数据结构 3. 模型训练3.1 数据文件配置3.2 训练超参数配置3.3 模型训练 4. 模型验证4.1 验证超参数配置4.2 模型验证 5. 模型推理5.1 推理超参数配置5.2 模型推理 6. 踩坑记录…
通过esp32cam拍摄图片上传至PC并通过YOLO进行目标检测
通过esp32cam拍摄图片上传至PC并通过YOLO进行目标检测 一.通过esp32cam拍摄照片并上传至PC二.训练自己的数据集三.AutoDL AI算力云的使用1.账号注册2.GPU选取3.GPU使用4.开机训练 四.数据集的使用 一.通过esp32cam拍摄照片并上传至PC
文章链接: https://blog.csdn.net/qq_6297…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的交通标志识别系统详解(深度学习模型+UI界面代码+训练数据集)
摘要:本篇博客详细介绍了利用深度学习构建交通标志识别系统的过程,并提供了完整的实现代码。该系统采用了先进的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等早期版本进行了性能评估对比,分析了性能指标如mAP、F1 Score等。文章深入探…
深度学习基础知识之通道数channels
大多数的深度学习模型,模型上会展示图片的尺寸,如:352x352x3 这里面352x352表示的是像素大小,即高和宽都为352个像素,而3表示的是通道数,指输入的是3通道的RGB图像,每个颜色通道的取值范围为0-2…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的常见车型识别系统(Python+PySide6界面+训练代码)
摘要:本文深入探讨了如何应用深度学习技术开发一个先进的常见车型识别系统。该系统核心采用最新的YOLOv8算法,并与早期的YOLOv7、YOLOv6、YOLOv5等版本进行性能比较,主要评估指标包括mAP和F1 Score等。详细解析了YOLOv8的工作机制,…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的输电线路设备检测系统(深度学习+UI界面+Python代码+训练数据集)
摘要:本篇博客详细介绍了如何运用深度学习构建一个先进的输电线路设备检测系统,并附上了完整的实现代码。该系统利用了最新的YOLOv8算法作为其核心,同时也对之前版本的YOLOv7、YOLOv6、YOLOv5进行了性能比较,包括但不限于mAP&…

【YOLOv9】训练模型权重 YOLOv9.pt 重新参数化轻量转为 YOLOv9-converted.pt
【YOLOv9】训练模型权重 YOLOv9.pt 重新参数化轻量转为 YOLOv9-converted.pt 1. 模型权重准备2. 模型重新参数化2.1 文件准备2.2 参数修改2.3 重新参数化过程 3. 重新参数化后模型推理3.1 推理超参数配置3.2 模型推理及对比 4. onnx 模型导出(补充内容)4…
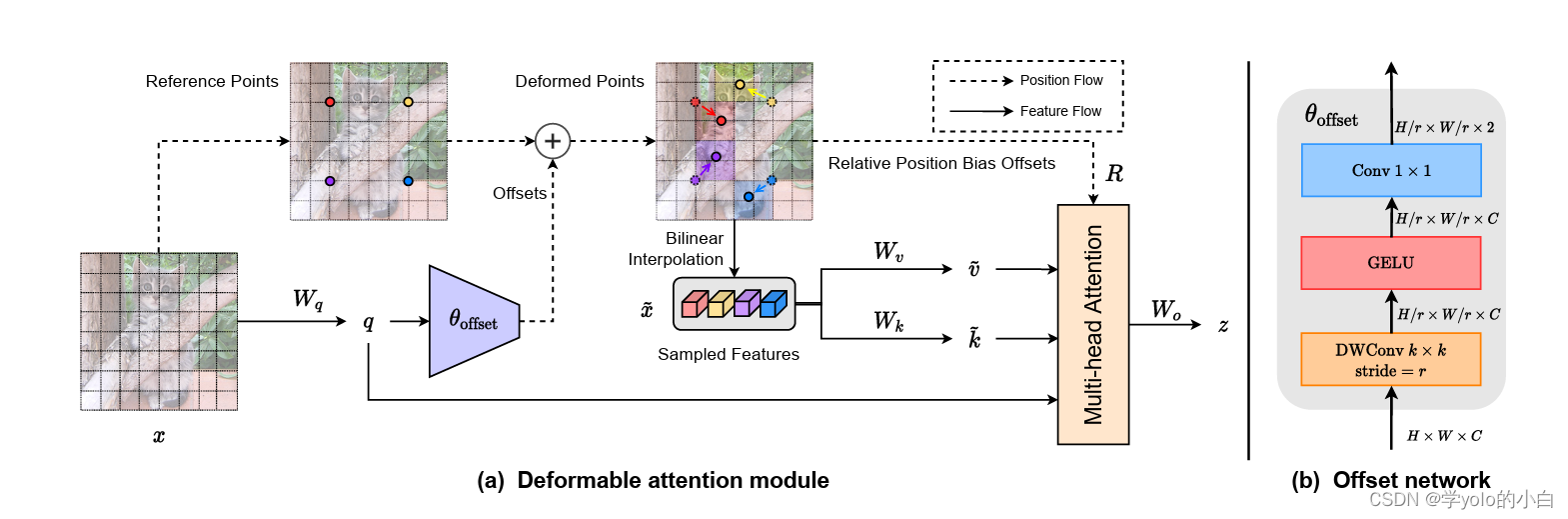
YOLOv9改进 添加可变形注意力机制DAttention
一、Deformable Attention Transformer论文 论文地址:arxiv.org/pdf/2201.00520.pdf
二、Deformable Attention Transformer注意力结构
Deformable Attention Transformer包含可变形注意力机制,允许模型根据输入的内容动态调整注意力权重。在传统的Transformer中,注意力是…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的夜间车辆检测系统(深度学习代码+UI界面+训练数据集)
摘要:开发夜间车辆检测系统对于自动驾驶技术具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个夜间车辆检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模型间…

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的水下目标检测系统(深度学习模型+UI界面+训练数据集)
摘要:本研究详述了一种采用深度学习技术的水下目标检测系统,该系统集成了最新的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5等早期算法进行了性能评估对比。该系统能够在各种媒介——包括图像、视频文件、实时视频流及批量文件中——准确地识别水…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的稻田虫害检测系统详解(深度学习+Python代码+UI界面+训练数据集)
摘要:本篇文章深入探讨了如何利用深度学习技术开发一个用于检测稻田虫害的系统,并且分享了完整的实现过程和资源代码下载。该系统采用了当前的YOLOv8、YOLOv7、YOLOv6、YOLOv5算法,对其进行了性能对比,包括mAP、F1 Score等关键指标…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的吸烟检测系统(深度学习+Python代码+PySide6界面+训练数据集)
摘要:本文详细说明了如何利用深度学习开发一个用于监测吸烟行为的系统,并分享了完整的代码实现。该系统采用了先进的YOLOv8算法,同时还使用YOLOv7、YOLOv6、YOLOv5算法,并对它们进行了性能比较,呈现了不同模型的性能指…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的远距离停车位检测系统(深度学习代码+UI界面+训练数据集)
摘要:开发远距离停车位检测系统对于提高停车效率具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个远距离停车位检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的木材表面缺陷检测系统(深度学习+Python代码+UI界面+训练数据集)
摘要:开发高效的木材表面缺陷检测系统对于提升木材加工行业的质量控制和生产效率至关重要。本篇博客详细介绍了如何运用深度学习技术构建一个木材表面缺陷检测系统,并提供了完整的实现代码。该系统采用了强大的YOLOv8算法,并对YOLOv7、YOLOv6…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的行人跌倒检测系统(深度学习+UI界面+完整训练数据集)
摘要:开发行人跌倒检测系统在确保老年人安全方面扮演着至关重要的角色。本篇文章详尽地阐述了如何利用深度学习技术构建一个行人跌倒检测系统,并附上了完整的代码实现。该系统采用了先进的YOLOv8算法,并对YOLOv7、YOLOv6、YOLOv5等先前版本进…

反无人机电子护栏:原理、算法及简单实现
随着无人机技术的快速发展,其在航拍、农业、物流等领域的应用日益广泛。然而,无人机的不规范使用也带来了安全隐患,如侵犯隐私、干扰航空秩序等。为了有效管理无人机,反无人机电子护栏技术应运而生。
目录
一、反无人机电子护栏…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的安全帽检测系统(深度学习模型+UI界面代码+训练数据集)
摘要:开发先进的安全帽识别系统对提升工作场所的安全性至关重要。本文详细介绍了使用深度学习技术创建此类系统的方法,并分享了完整的实现代码。系统采用了强大的YOLOv8算法,并对其与YOLOv7、YOLOv6、YOLOv5的性能进行了详细比较,…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的零售柜商品检测软件(Python+PySide6界面+训练代码)
摘要:开发高效的零售柜商品识别系统对于智能零售领域的进步至关重要。本文深入介绍了如何运用深度学习技术开发此类系统,并分享了全套实现代码。系统采用了领先的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5进行了性能比较,呈现了诸如…

目标检测C-RNN,Fast C-RNN,Faster C-RNN,SSD,Mask R-CNN 理论简单介绍
参考: https://zh-v2.d2l.ai/chapter_computer-vision/multiscale-object-detection.html
R-CNN 及系列
区域卷积神经网络 region-based CNN
R-CNN
R-CNN首先从输入图像中选取若干(例如2000个)提议区域,并标注它们的类别和边界…

opencv dnn模块 示例(25) 目标检测 object_detection 之 yolov9
文章目录 1、YOLOv9 介绍2、测试2.1、官方Python测试2.1.1、正确的脚本2.2、Opencv dnn测试2.2.1、导出onnx模型2.2.2、c测试代码 2.3、测试统计 3、自定义数据及训练3.1、准备工作3.2、训练3.3、模型重参数化 1、YOLOv9 介绍
YOLOv9 是 YOLOv7 研究团队推出的最新目标检测网络…

YOLOv5目标检测学习(5):源码解析之:推理部分dectet.py
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、导入相关包与路径、模块配置1.1 导入相关的python包1.2 获取当前文件的相对路径1.3 加载自定义模块1.4 总结 二、执行主体的main函数所以执行推理代码&…
重建3D结构方式 | 显式重建与隐式重建(Implicit Reconstruction)
在3D感知领域,包括3D目标检测在内,显式重建和隐式重建是两种不同的方法来表示和处理三维数据。它们各自有优势和局限,适用于不同的场景和需求。 显式重建(Explicit Reconstruction) 显式重建是指直接构建场景或物体的三…
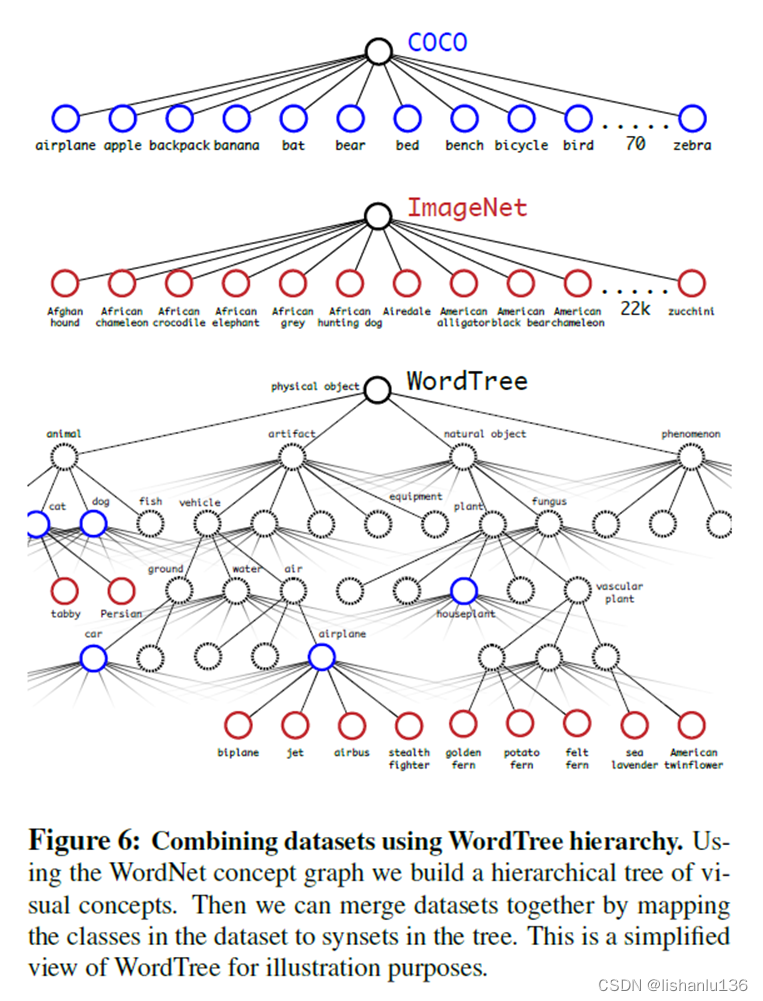
目标检测——YOLOv2算法解读
论文:YOLO9000: Better, Faster, Stronger 作者:Joseph Redmon, Ali Farhadi 链接:https://arxiv.org/pdf/1612.08242v1.pdf 代码:http://pjreddie.com/yolo9000/ YOLO系列其他文章:
YOLOv1通俗易懂版解读SSD算法解读…
[数据集][目标检测]螺丝螺母检测数据集VOC+YOLO格式2100张13类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2100 标注数量(xml文件个数):2100 标注数量(txt文件个数):2100 标注…
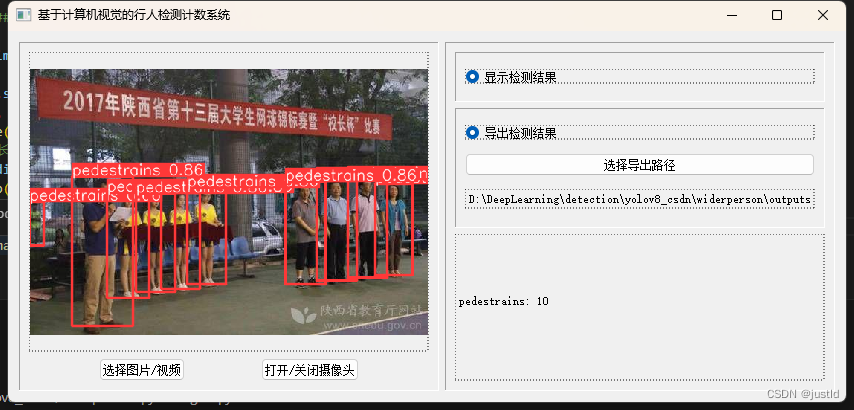
【深度学习目标检测】二十三、基于深度学习的行人检测计数系统-含数据集、GUI和源码(python,yolov8)
行人检测计数系统是一种重要的智能交通监控系统,它能够通过图像处理技术对行人进行实时检测、跟踪和计数,为城市交通规划、人流控制和安全管理提供重要数据支持。本系统基于先进的YOLOv8目标检测算法和PyQt5图形界面框架开发,具有高效、准确、…

芒果YOLOv8改进104:主干Backbone篇之DCNv3结构:即插即用|使用pytorch代码实现,并针对YOLOv8专门优化模块
💡本篇内容:YOLOv8原创改进DCNv3结构:即插即用|使用纯pytorch代码实现,不需要CUDA编译,并针对YOLOv8专门优化模块,基于可变形卷积的超强变种,优势:不需要编译!
💡附改进源代码及教程,用来改进🚀 DCNv3可变形网络结构 VisDrone有效涨点
关键词:DCNv3网络改进…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的癌症图像检测系统(深度学习模型+UI界面代码+训练数据集)
摘要:本篇博客深入介绍了如何借助深度学习技术开发癌症图像检测系统,以提高医疗诊断的精度和速度。系统基于先进的YOLOv8算法,并对比分析了YOLOv7、YOLOv6、YOLOv5的性能,如mAP和F1 Score。详细解释了YOLOv8的原理,并附…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的农作物害虫检测系统(深度学习模型+UI界面+训练数据集)
摘要:开发农作物害虫检测系统对于提高农业生产效率和作物产量具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个农作物害虫检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5࿰…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的人群密度检测系统(深度学习模型+UI界面+训练数据集)
摘要:开发人群密度检测系统对于公共安全等领域具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个人群密度检测系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模型…
![[数据集][目标检测]零售柜零食检测数据集VOC+YOLO格式5422张113类](https://img-blog.csdnimg.cn/direct/7a4d2cc4bc99494182c1537f7f797699.png)
[数据集][目标检测]零售柜零食检测数据集VOC+YOLO格式5422张113类
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):5422 标注数量(xml文件个数):5422 标注数量(txt文件个数):5422 标注…
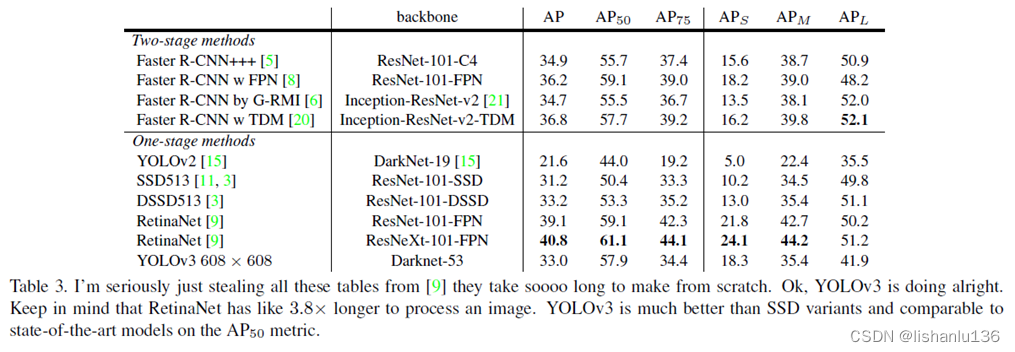
目标检测——YOLOv3算法解读
论文:YOLOv3:An Incremental Improvement 作者:Joseph Redmon, Ali Farhadi 链接:https://arxiv.org/abs/1804.02767 代码:http://pjreddie.com/yolo/ YOLO系列其他文章:
YOLOv1通俗易懂版解读SSD算法解读…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的日常场景下的人脸检测系统(深度学习模型+PySide6界面+训练数据集+Python代码)
摘要:开发用于日常环境中的人脸识别系统对增强安全监测和提供定制化服务极为关键。本篇文章详细描述了运用深度学习技术开发人脸识别系统的全过程,并附上了完整的代码。该系统搭建在强大的YOLOv8算法之上,并通过与YOLOv7、YOLOv6、YOLOv5的性…
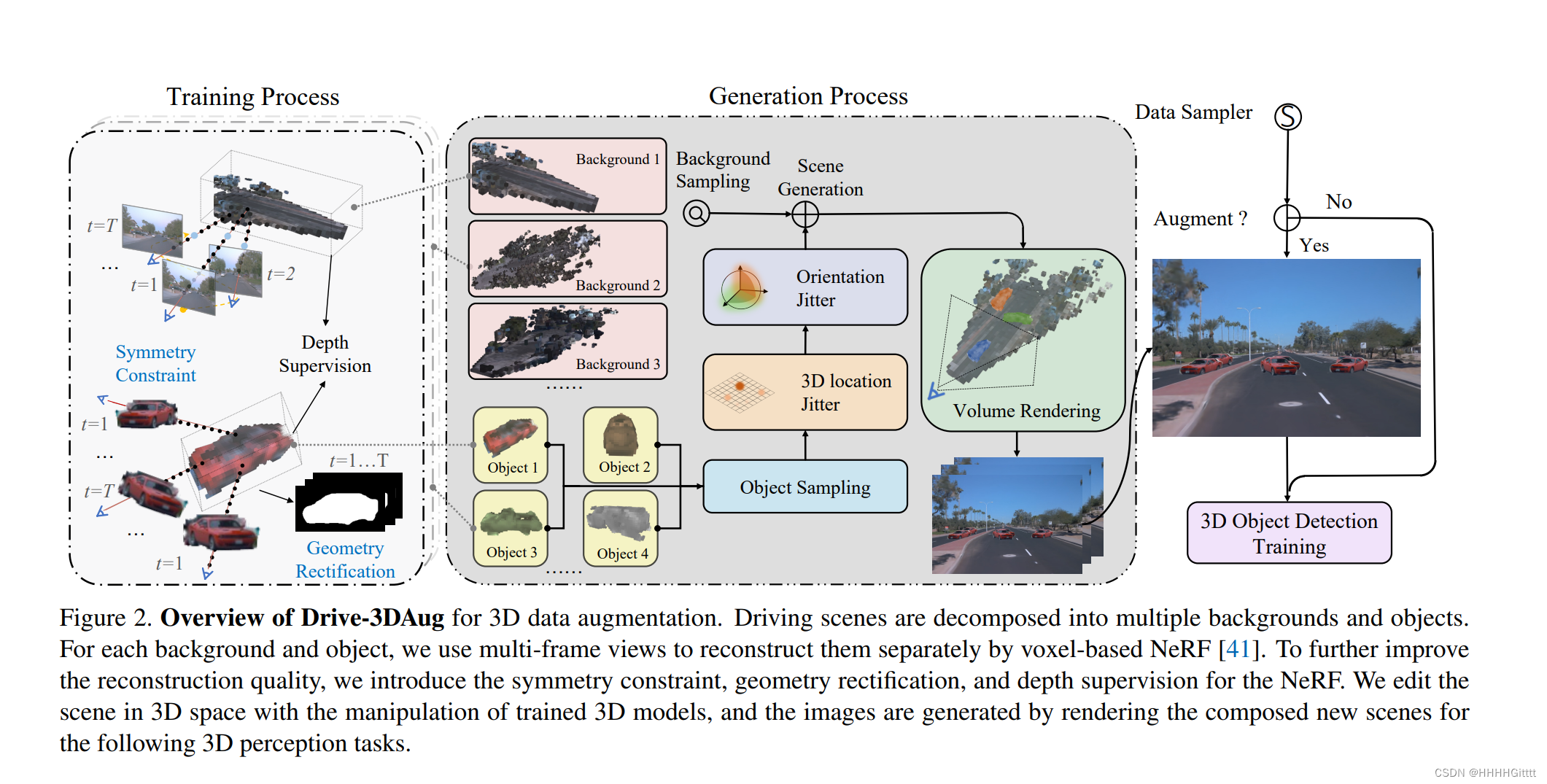
CVPR2023 | 3D Data Augmentation for Driving Scenes on Camera
3D Data Augmentation for Driving Scenes on Camera
摄像机驾驶场景的 3D 数据增强
摘要翻译
驾驶场景极其多样和复杂,仅靠人力不可能收集到所有情况。虽然数据扩增是丰富训练数据的有效技术,但自动驾驶应用中现有的摄像头数据扩增方法仅限于二维图像…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的手写数字和符号识别(深度学习训练+UI界面+训练数据集)
摘要:开发手写数字和符号识别对于智能交互系统具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个手写数字和符号识别,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5,展示了不同模…
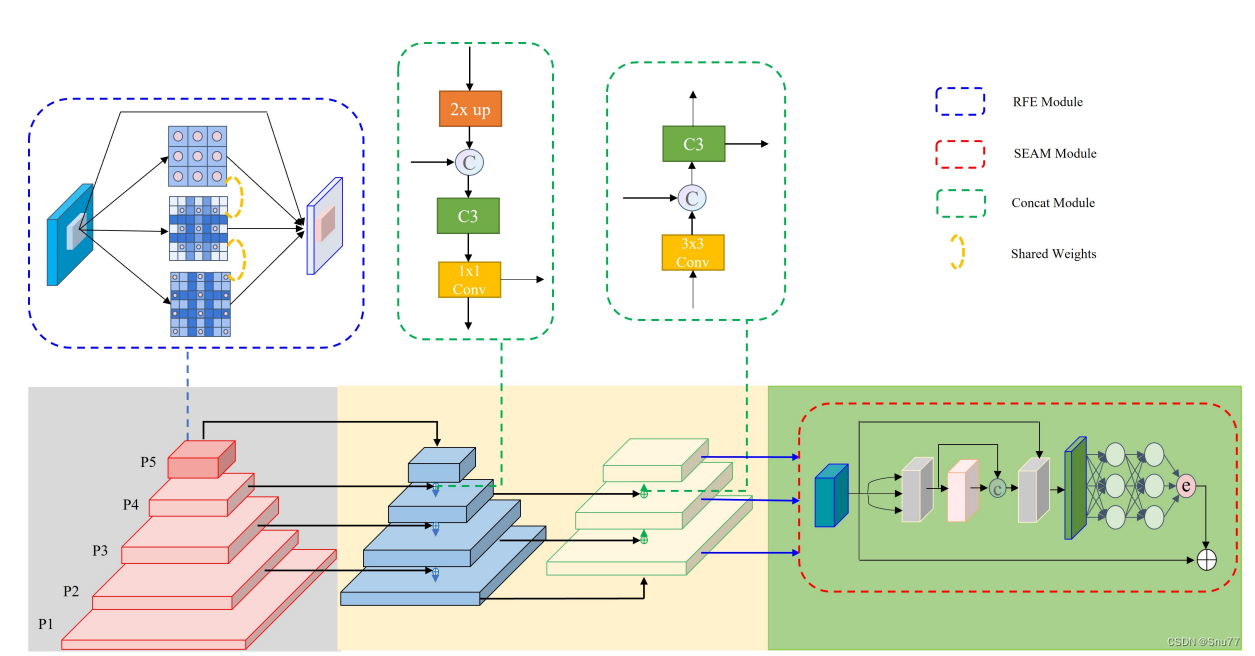
YOLOv8改进 | 注意力机制 | 添加YOLO-Face提出的SEAM注意力机制优化物体遮挡检测(附代码 + 修改教程)
一、本文介绍
本文给大家带来的改进机制是由YOLO-Face提出能够改善物体遮挡检测的注意力机制SEAM,SEAM(Spatially Enhanced Attention Module)注意力网络模块旨在补偿被遮挡面部的响应损失,通过增强未遮挡面部的响应来实现这一目标,其希望通过学习遮挡面和未遮挡面之间的…
物体检测-系列教程20:YOLOV5 源码解析10 (Model类前向传播、forward_once函数、_initialize_biases函数)
😎😎😎物体检测-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 点我下载源码 14、Model类
14.2 前向传播 def forward(self, x, augmentFalse, profileFalse):if augm…
【论文解读】Robust Collaborative 3D Object Detection in Presence of Pose Errors
CoAlign 摘要引言方法实验结论 摘要
协同3D对象检测利用多个代理之间的信息交换,以在存在诸如遮挡之类的传感器损伤的情况下提高对象检测的准确性。然而,在实践中,由于定位不完善而导致的姿态估计误差会导致空间消息错位,并显著降…
RT-DETR改进RepVGG结构:简单但功能强大的卷积神经网络架构
💡本篇内容:RT-DETR改进RepVGG结构:简单但功能强大的卷积神经网络架构
💡🚀🚀🚀本博客 改进源代码改进 适用于 RT-DETR 按步骤操作运行改进后的代码即可
💡本文提出改进 原创 方式:二次创新,RT-DETR专属
应部分读者要求,新增一篇RepVGG
论文理论部分 + 原…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的体育赛事目标检测系统(Python+PySide6界面+训练代码)
摘要:开发和研究体育赛事目标检测系统对于增强体育分析和观赏体验至关重要。本篇博客详细讲述了如何运用深度学习技术构建一个体育赛事目标检测系统,并提供了完整的实现代码。系统基于先进的YOLOv8算法,对比了YOLOv7、YOLOv6、YOLOv5的性能&a…

实战 | 使用YOLOv8图像分割实现路面坑洞检测(步骤 + 代码)
导 读 本文主要介绍使用YOLOv8图像分割实现路面坑洞检测(步骤 代码)。
背 景 如上图所示,现实生活中路面坑洞对车辆和驾驶员安全来说存在巨大隐患,本文将介绍如何使用YoloV8图像分割技术来检测路面坑洞,从而提示驾…
[数据集][目标检测]狗种类检测数据集VOC+YOLO格式20578张120类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):20578 标注数量(xml文件个数):20578 标注数量(txt文件个数):20578 标…

经典目标检测网络Yolo——原理部分
目标检测问题
分为两个子问题: 找到图片中哪些位置、哪些区域含有目标对象识别这些区域中的目标对象是什么基于CNN的目标检测算法能够很好的解决第二个问题,在一张图片仅含一个对象,且该对象占据了整张图片绝大部分面积时,基于CNN的对象识别算法具有很高的准确率。 一种定…
YOLOv9独家改进|使用HWD(小波下采样)模块改进ADown
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、改进点介绍 HWD是一种下采样模型,应用了小波变换的方法。 ADown是YOLOv9中的下采样模块,对不同的数据场景具有一定的可学…
[数据集][目标检测]无人机高空红外数据集VOC+YOLO格式2866张5类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2866 标注数量(xml文件个数):2866 标注数量(txt文件个数):2866 标注…
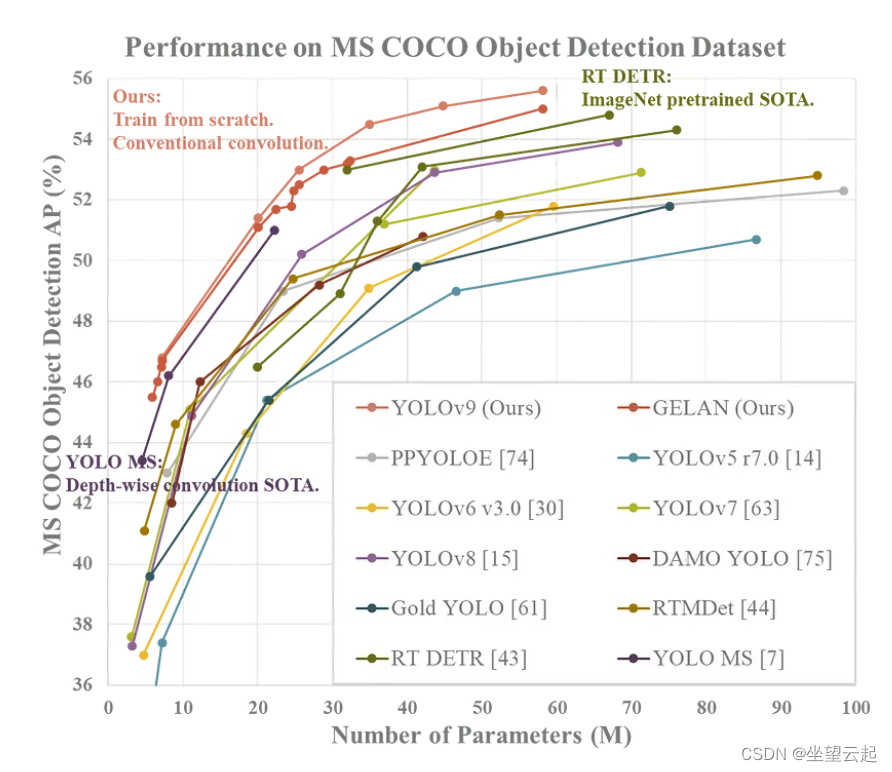
机器学习笔记 YOLOv9模型相关论文简读
一、YOLOv9简述 自 2015 年 Yolov1 推出以来,已经出现了多个版本。 基于Darknet的YOLOv2、YOLOv3和YOLOv4 YOLOv5 YOLOv8 基于 Ultralytics。 SCALED-YOLOv4 使用 Pytorch 而不是 Darknet。 YOLOR是YOLOv4的改进。 YOLOX是YOLOv3的改进。 YOLOv6专注于工业应用。 YOLOv7 来自 …

【论文精读】Mask R-CNN
摘要 基于Faster RCNN,做出如下改变:
添加了用于预测每个感兴趣区域(RoI)上的分割掩码分支,与用于分类和边界框回归的分支并行。mask分支是一个应用于每个RoI的FCN,以像素到像素的方式预测分割掩码,只增加了很小的计…
opencv dnn模块 示例(24) 目标检测 object_detection 之 yolov8-pose 和 yolov8-obb
前面博文【opencv dnn模块 示例(23) 目标检测 object_detection 之 yolov8】 已经已经详细介绍了yolov8网络和测试。本文继续说明使用yolov8 进行 人体姿态估计 pose 和 旋转目标检测 OBB 。 文章目录 1、Yolov8-pose 简单使用2、Yolov8-OBB2.1、python 命令行测试2.2、opencv…

Yolov8有效涨点,添加多种注意力机制,修改损失函数提高目标检测准确率
目录
简介
CBAM注意力机制原理及代码实现
原理 代码实现 GAM注意力机制
原理
代码实现
修改损失函数
YAML文件
完整代码 🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
http://t.csdnimg.c…

图解目标检测的现代历史
任务分类
图像分类 根据图像的主要对象对图像进行分类。
目标定位
预测包含主要对象的图像区域。然后,可以使用图像分类来识别该区域内的物体 目标检测 定位和分类出现在图像中的所有对象。这个任务通常包括:确定区域,然后对其中的对象进行…
【目标检测】旋转目标检测COCO格式标注转DOTAv1格式
DOTAv1数据集格式: imagesource:imagesource gsd:gsd x1, y1, x2, y2, x3, y3, x4, y4, category, difficult x1, y1, x2, y2, x3, y3, x4, y4, category, difficult ... imagesource: 图片来源 gsd: 分辨率 x1, y1, x2, y2, x3, y3, x4, y4:四边形的四…
【论文精读】【Yolov1】You Only Look Once Unified, Real-Time Object Detection
0.论文摘要
我们提出了YOLO,一种新的目标检测方法。先前关于目标检测的工作重新利用分类器来执行检测。相反,我们将目标检测框架确定为空间分离的边界框和相关类别概率的回归问题。单个神经网络在一次评估中直接从完整图像预测边界框和类别概率。由于整…

YOLOv8基础必需运用【目标检测、分割、姿势估计、跟踪和分类任务】
文章目录 前言1、环境安装2.1安装torch相关库2.2 获取yolov8最新版本,并安装依赖 3. 如何使用模型用于各种CV任务方式一:命令行形式方式二:python代码形式示例3.1 目标检测任务实现代码运行结果检测视频代码 3.2 分割任务实现代码运行效果分割…
DEYO: DETR with YOLO for End-to-End Object Detection论文翻译
DEYO:DETR与YOLO用于端到端目标检测
摘要 DETR的训练范式在很大程度上取决于在ImageNet数据集上预训练其骨干。然而,由图像分类任务和一对一匹配策略提供的有限监督信号导致DETR的预训练不充分的颈部。此外,在训练的早期阶段匹配的不稳定性会…
YOLOv5目标检测学习(2):运行一个yolo应用所需要配置的深度学习环境
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、CUDA、CUDNN的下载安装1.1 CUDA的安装1.2 cuDNN的配置 二、anaconda的安装1.卸载python2.安装anaconda 三、Pytorch、python虚拟环境安装1.创建虚拟环境2.安…

51-27 DirveVLM:自动驾驶与大型视觉语言模型的融合
本文由清华大学和理想汽车共同发布于2024年2月25日,论文名称DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models.
DriveVLM是一种新颖的自动驾驶系统,旨在针对场景理解挑战,利用最近的视觉语言模型VLM&…
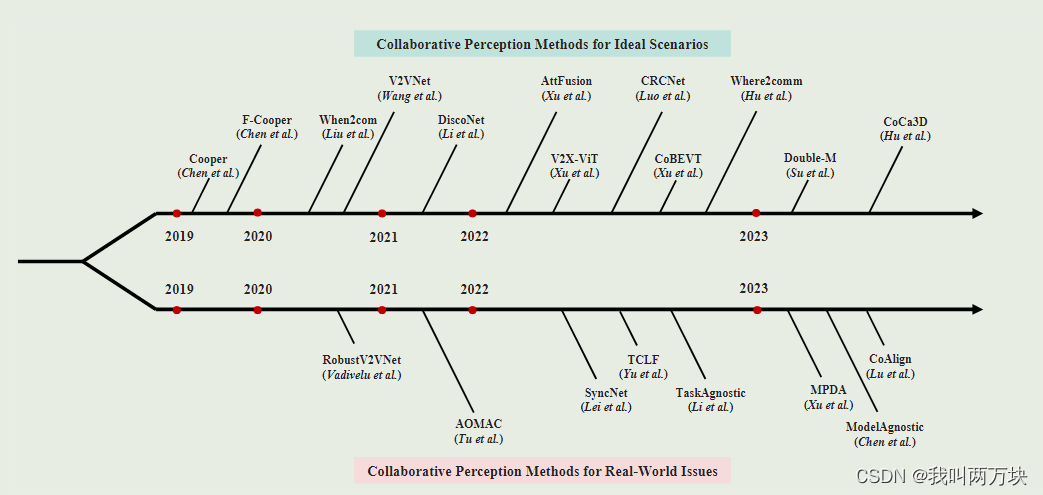
【论文整理】自动驾驶场景中Collaborative Methods多智能体协同感知文章创新点整理
Collaborative Methods F-CooperV2VNetWhen2commDiscoNetAttFusionV2X-ViTCRCNetCoBERTWhere2commDouble-MCoCa3D 这篇文章主要想整理一下,根据时间顺序这些文章是怎么说明自己的创新点的,又是怎么说明自己的文章比别的文章优越的。显然似乎很多文章只是…
目标检测——摩托车头盔检测数据集
一、简介
首先,摩托车作为一种交通工具,具有高速、开放和稳定性差的特点,其事故发生率高,伤亡率排在机动车辆损伤的首位。因此,摩托车乘员头盔对于保护驾乘人员头部安全至关重要。在驾乘突发状况、人体受冲击时&#…
YOLOv5原创改进:原创自研head创新 | 空间上下文感知模块(SCAM)结合超轻量高效动态上采样DySample | 小目标涨点系列
💡💡💡本文独家改进:YOLOV5 head创新,1)一种超轻量高效动态上采样DySample, 具有更少的参数、FLOPs,效果秒杀CAFFE和YOLOv8网络中的nn.Upsample;2)加入空间上下文感知模块(SCAM)进一步提升检测精度;
改进结构图如下: 💡💡💡在多个数据集下验证能够涨点…

植物病害识别:YOLO水稻病害识别数据集(11000多张,yolo标注)
YOLO水稻病害识别数据集,包含叶斑病,褐斑病,细菌性枯萎病,东格鲁病毒病4个常见病害类别,共11000多张图像,yolo标注完整,可直接训练。 适用于CV项目,毕设,科研,…
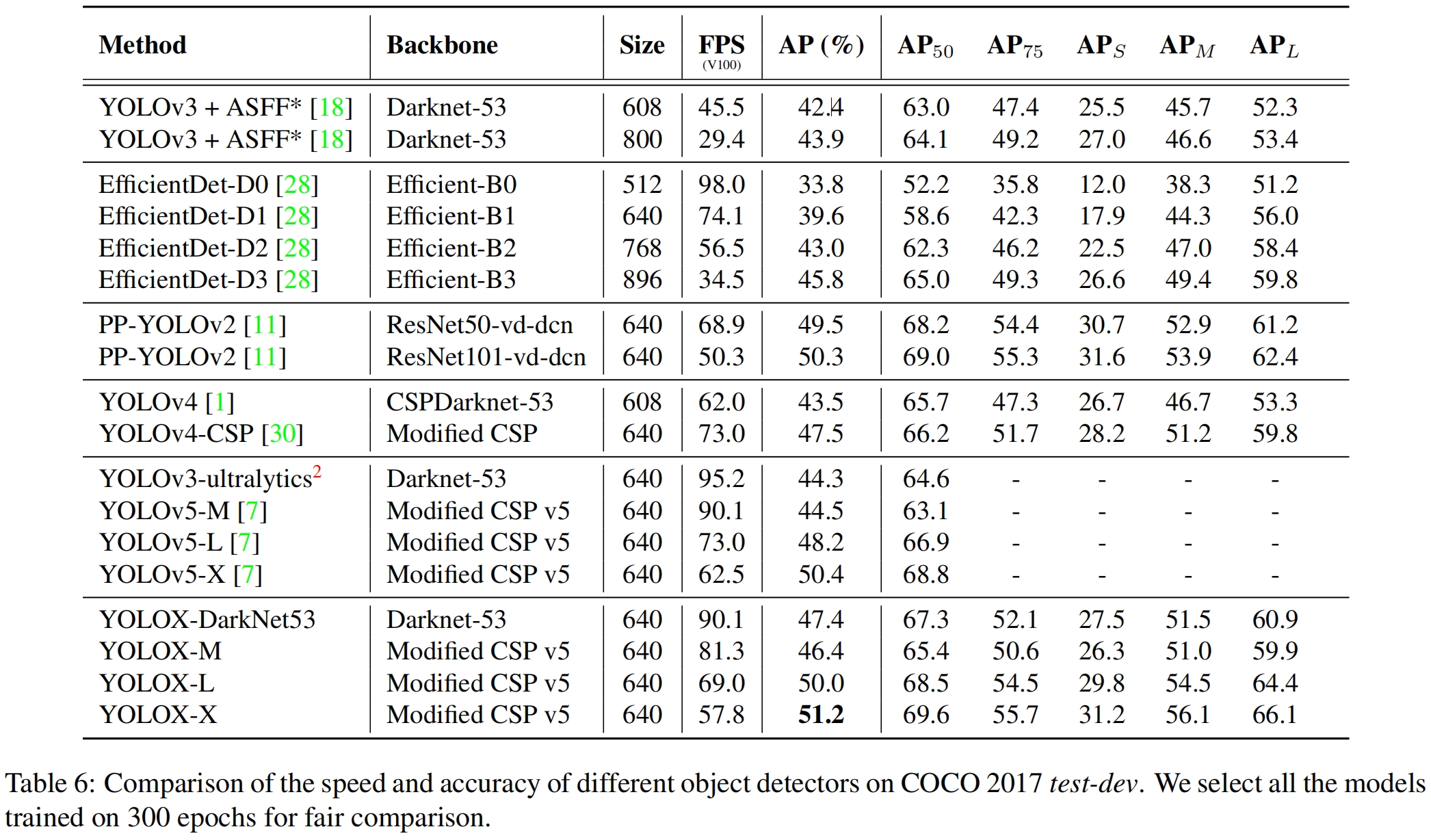

植物病虫害:YOLO玉米病虫害识别数据集
玉米病虫害识别数据集:玉米枯萎病,玉米灰斑病,玉米锈病叶,粘虫幼虫,玉米条斑病,黄二化螟,黄二化螟幼虫7类,yolo标注完整,3900多张图像,全部原始数据ÿ…
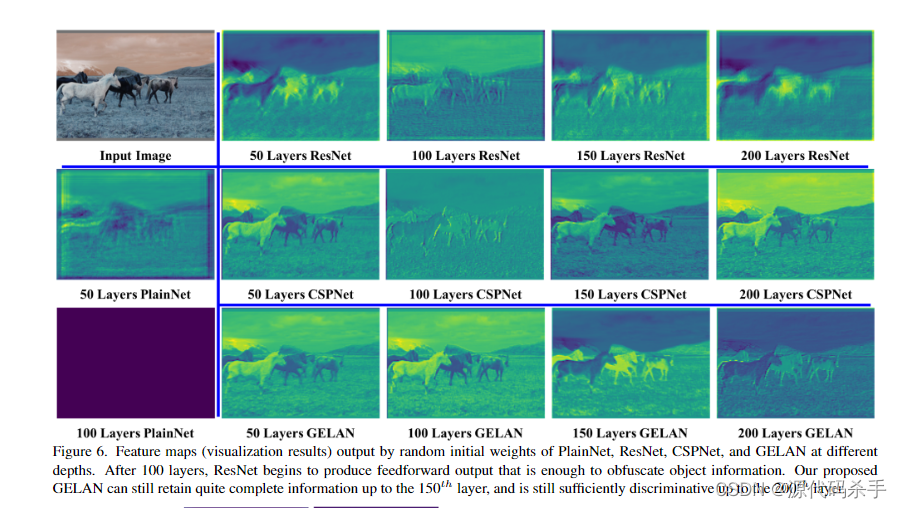
目标检测卷王YOLO卷出新高度:YOLOv9问世
论文摘要:如今的深度学习方法重点关注如何设计最合适的目标函数,使得模型的预测结果能够最接近真实情况。 同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。 现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。 本文将深…
目标检测:Anchor-Based Anchor-Free算法模型
Anchor-Based 目标检测: Anchor Boxes:Anchor-based 方法使用事先定义的一组锚框(Anchor Boxes)来作为候选框。这些锚框具有不同的尺度(大小)和长宽比(aspect ratio)。模型会预测每个…
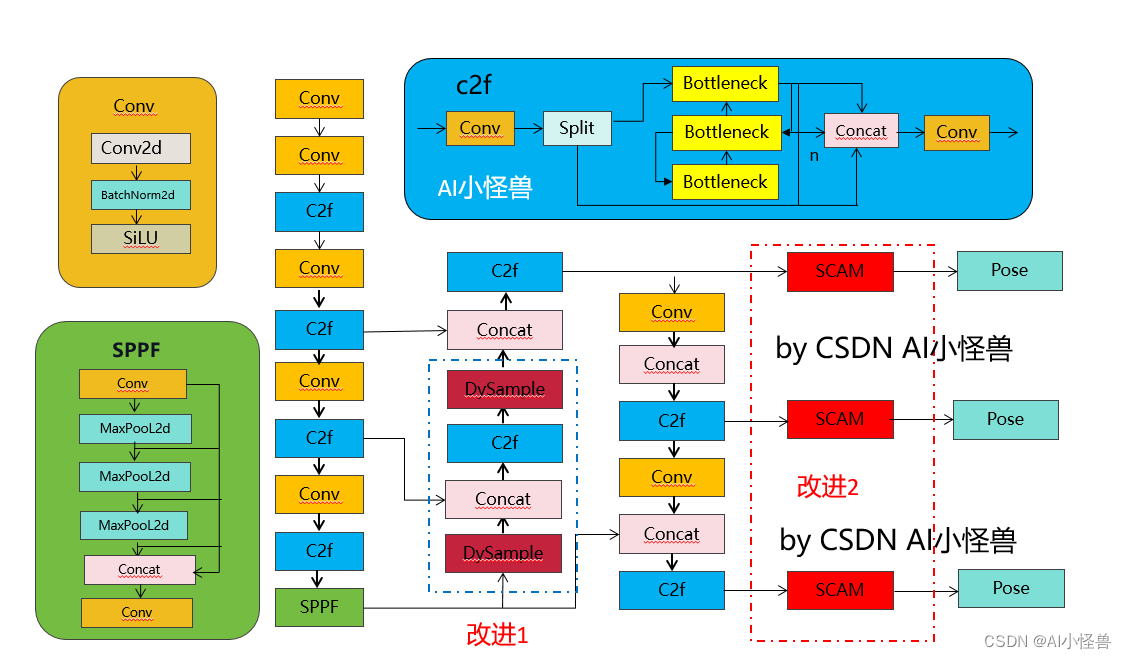
Yolov8-pose关键点检测:原创自研涨点系列篇 | 空间上下文感知模块(SCAM)结合超轻量高效动态上采样DySample
💡💡💡本文独家改进:YOLOV8-pose head创新,1)一种超轻量高效动态上采样DySample, 具有更少的参数、FLOPs,效果秒杀CAFFE和YOLOv8网络中的nn.Upsample;2)加入空间上下文感知模块(SCAM)进一步提升检测精度;
改进结构图如下: Yolov8-Pose关键点检测专栏介绍:ht…
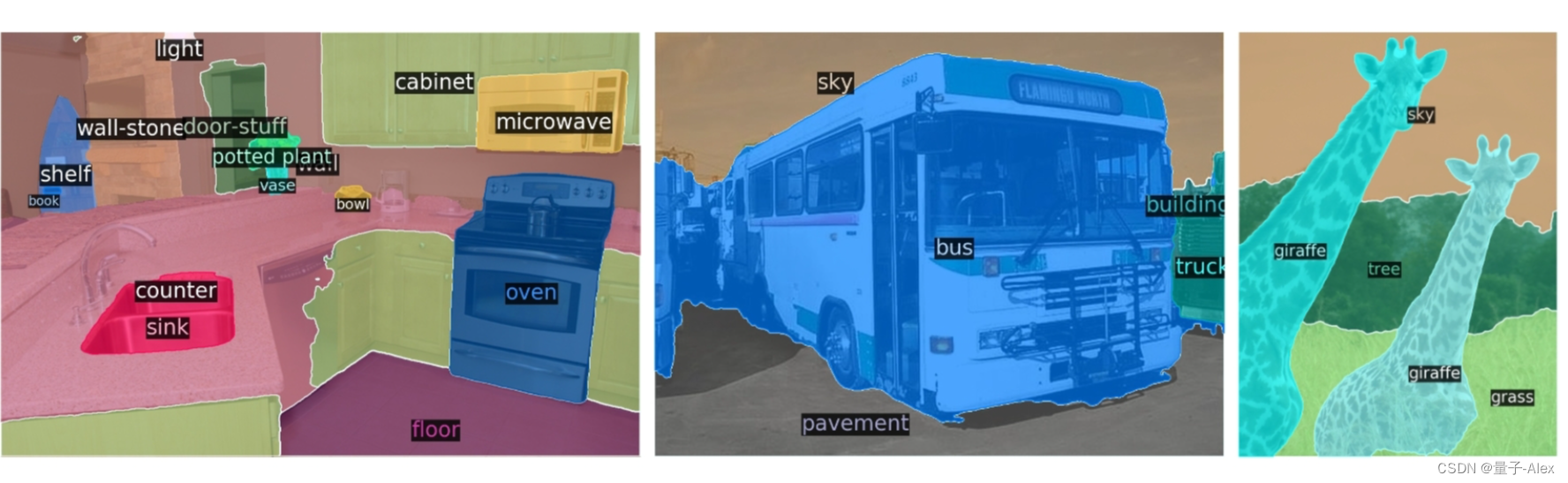
【论文精读】【DETR】End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers
0.论文摘要
我们提出了一种新的方法,将目标检测视为一个直接的集合预测问题。我们的方法简化了检测管道,有效地消除了对许多手工设计组件的需求,如非极大抑制程序或锚生成,它们…
[数据集][目标检测]光伏板太阳能板缺陷检测数据集VOC+YOLO格式2400张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2400 标注数量(xml文件个数):2400 标注数量(txt文件个数):2400 标注…

Yolov8-pose关键点检测:原创自研涨点系列篇 | 一种新颖的轻量化网络,用于提升遥感图像中的小物体检测 | 2024年二区YOLOv5改进最新成果
💡💡💡本文独家改进:现将本文思想迁移到YOLOv8-pose做二次创新 ,提出了三个创新的轻量级即插即用模块:特征增强模块(FEM)、特征融合模块(FFM)和空间上下文感知模块(SCAM) Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_12398833.…
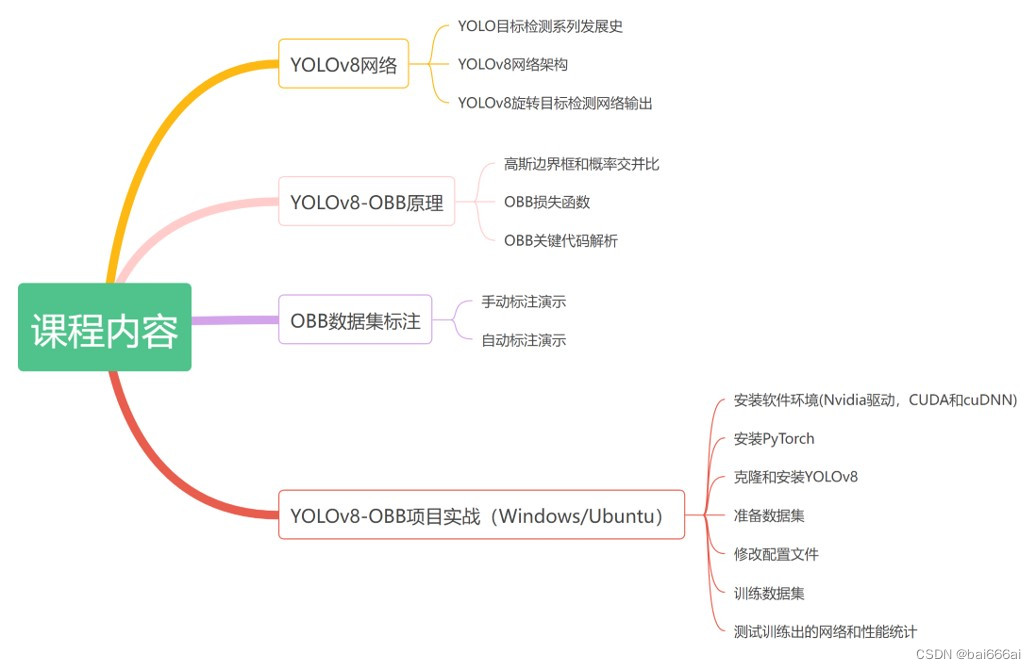
YOLOv8旋转目标检测实战:训练自己的数据集
课程链接:https://edu.csdn.net/course/detail/39393
旋转目标检测是计算机视觉领域的一个高级任务,它在传统目标检测的基础上进一步发展。传统目标检测技术主要关注于识别和定位图像中的物体,通常以水平边界框(HBB)来标识目标物体的位置。而…

机器学习评价指标(分类、目标检测)
https://zhuanlan.zhihu.com/p/364253497https://zhuanlan.zhihu.com/p/46714763https://blog.csdn.net/u013250861/article/details/123029585
1.1 混淆矩阵
在介绍评价指标之前,我们首先要介绍一下混淆矩阵(confusion matrix)。混淆矩阵…
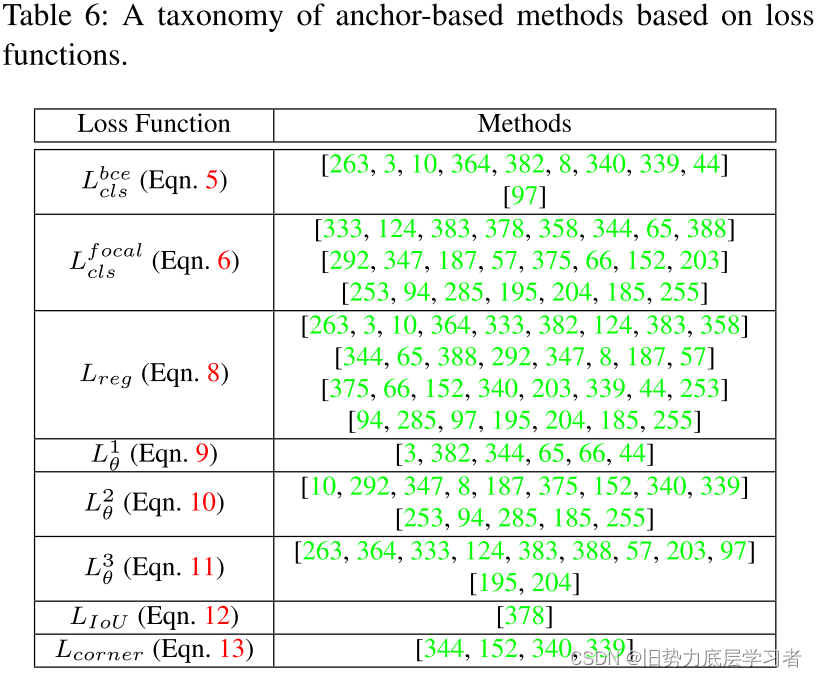
3D Object Detection for Autonomous Driving: A Comprehensive Survey文献阅读
目录
简言
文献地址:
重要网址(该项目持续更新中)
摘要
1、介绍
2、基础概念
2.1 3D object detection
2.2 Datasets
2.3 Evaluation metrics
2.3.1 评估指标类-1
2.3.2 评估指标类-2
2.3.3 评估指标对比
3、基于Lidar的…

浅谈OCR图片表格识别与目标检测的关系、异同与互相利用情况
随着数字化时代的到来,图像处理技术得到了广泛的应用。其中,OCR图片表格识别和目标检测作为图像处理中的重要技术,在很多领域都有广泛的应用。本文将对OCR图片表格识别与目标检测的关系与异同进行深入探讨,并分析互相的利用情况。…

YOLOv7-Openvino和ONNXRuntime推理【CPU】
纯检测系列: YOLOv5-Openvino和ONNXRuntime推理【CPU】 YOLOv6-Openvino和ONNXRuntime推理【CPU】 YOLOv8-Openvino和ONNXRuntime推理【CPU】 YOLOv7-Openvino和ONNXRuntime推理【CPU】 YOLOv9-Openvino和ONNXRuntime推理【CPU】 跟踪系列: YOLOv5/6/7-O…

植物病害识别:YOLO水稻病害识别数据集(3000多张,3个类别,yolo标注)
YOLO水稻病害识别数据集,包含细菌性枯萎病,水稻瘟疫,褐斑病3个常见病害类别,共3000多张图像,yolo标注完整,可直接训练。 适用于CV项目,毕设,科研,实验等
需要此数据集或…
目标检测:Anchor-free算法模型
Anchor-free概念 Anchor-free方法不依赖于预定义的锚框。它通过在图像或特征图上直接预测目标的位置和形状,而不是相对于锚框的偏移量。这意味着模型不需要提前定义锚框,可以更灵活地处理不同大小和形状的目标。Anchor-free模型简化了检测流程࿰…

4.1.CVAT——目标检测的标注详细步骤
文章目录 1. 进入任务1. 创建任务2. 已创建的task3. 进入标注界面 2. 选择标注类型2.1 选择标注类型2.2 进行标注2.3 遮挡 2.快捷键3.导出标注结果 1. 进入任务
登录后会看到如下图界面,CVAT的标注最小单位是Task,每个Task为一个标注任务。点击Task按钮…

目标检测论文模型笔记——YOLO系列
1. YOLOv1的核心思想:
YOLOv1:使用整张图作为输入,直接在输出层回归bounding box和类别;(one-stage)Faster RCNN:使用用整张图作为输入,但整体采用了RCNN: proposalclas…
Extended Feature Pyramid Network for SmallObject Detection
摘要 各种尺度的特征耦合会削弱小对象的性能,本文中,我们提出了具有超高分辨率金字塔的扩展特征金字塔网络(EFPN ),专门用于小目标检测。具体来说,我们设计了一个新模块,称为特征纹理转移&#…

计算机视觉——目标检测(R-CNN、Fast R-CNN、Faster R-CNN )
前言、相关知识
1.闭集和开集
开集:识别训练集不存在的样本类别。闭集:识别训练集已知的样本类别。
2.多模态信息融合
文本和图像,文本的语义信息映射成词向量,形成词典,嵌入到n维空间。 图片内容信息提取特征&…

YOLOv5目标检测学习(3):anaconda、虚拟环境、cuda、pytorch、pycharm之间的关系,以及配置时出现的问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、anaconda、虚拟环境、cuda、pytorch、pycharm之间的关系1.1 anaconda:python第三方包的安装和管理工具1.2 虚拟环境:可以使不同项目中使…

OpenCV目标检测与级联分类器的建立(Object Detect)
OpenCV目标检测与级联分类器的建立(Object Detect)
2023-03-23 ccc 在一般的目标检测中,级联分类器是基本的分类器,其中包括haar、hog、lbp等算法形成的分类器。然而,所谓的分类器实际上就是一个使用特定算法生成的xm…
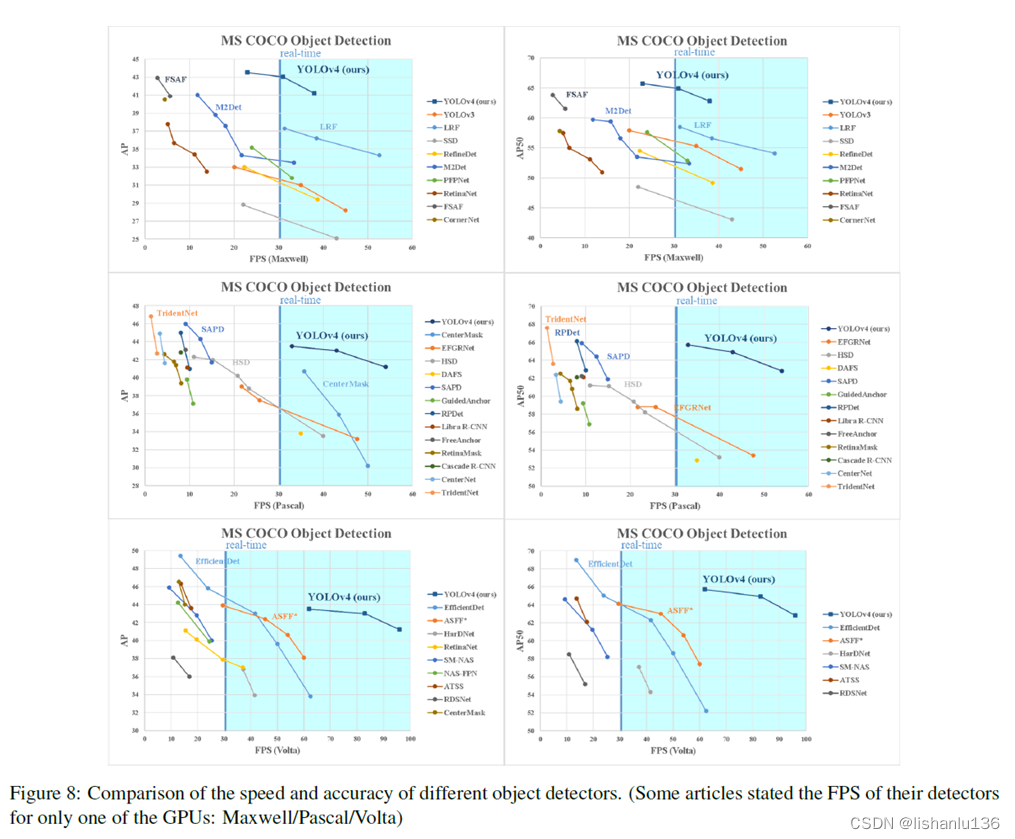
目标检测——YOLOv4算法解读
论文:YOLOv4:Optimal Speed and Accuracy of Object Detection 作者:Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao 链接:https://arxiv.org/pdf/2004.10934.pdf 代码:https://github.com/AlexeyAB/darkne…
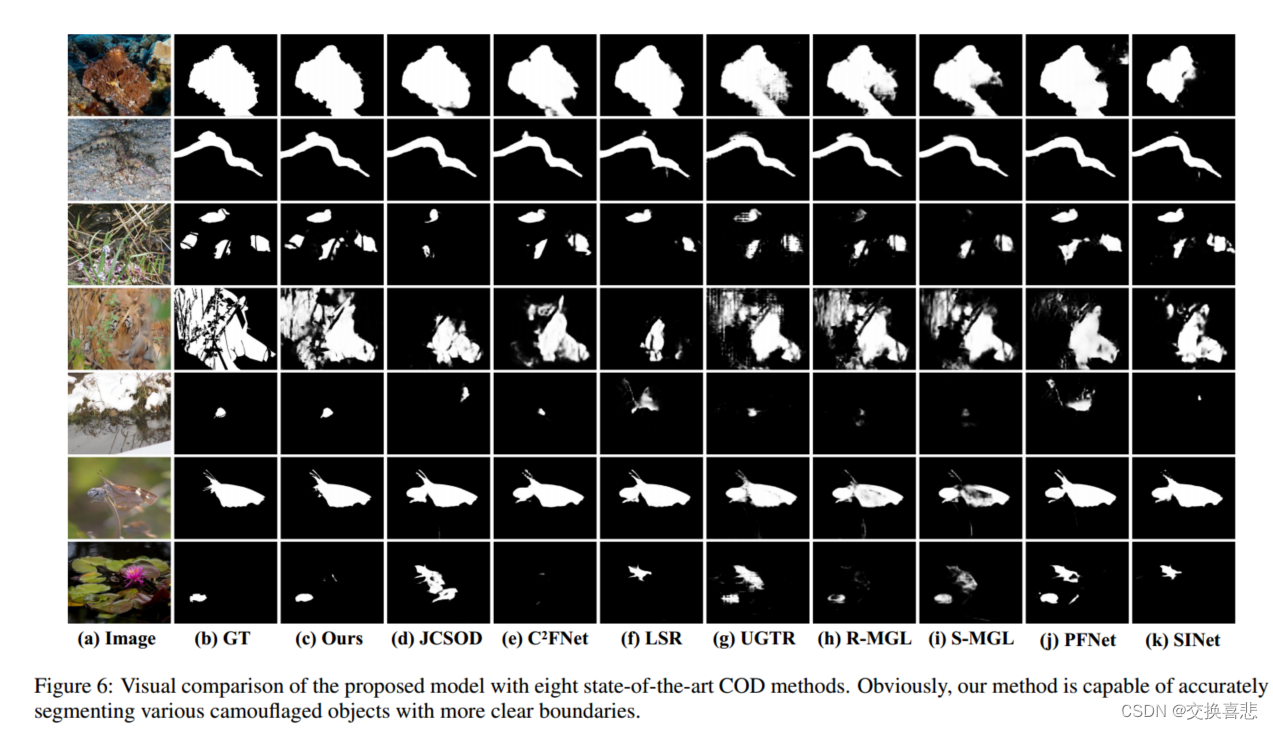
伪装目标检测论文BGNet:Boundary-Guided Camouflaged Object Detection
论文地址:link 代码地址:link 这篇论文是22年的CVPR收录的一篇关于伪装目标检测的文章,作者主要是用了一些通道注意力和Atrous卷积来实现边缘引导的伪装目标检测,模型并不复杂,看了两天的论文和代码,为了加深印象在这里…
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的草莓成熟度检测系统详解(深度学习模型+UI界面+Python代码+训练数据集)
摘要:本研究介绍了一个使用深度学习技术对草莓成熟度进行检测的系统,它采用了最新的YOLOv8算法,以及YOLOv7、YOLOv6、YOLOv5等前版本的算法,并对它们进行了性能对比。该系统能够在不同媒介上——如图像、视频文件、实时视频流和批…
【学习】目标检测中的anchor
参考知乎:anchor
简单理解
每个网格都会有一个自己的中心,每个小格子都可以抽象成为在自己的中心生成了一个指定大小为16个像素的矩形框,在这里,我们把这些中心称之为”锚点“,把每个锚点处的框称之为”锚框“。
锚…

【目标检测】原始的 YOLOv1 网络结构(GoogLeNet 作为 backbone 的实现)
现在看网上的很多 YOLOv1 的代码实现,基本都是使用新的 backbone,例如 ResNet 或者 VGG 来实现的,因为这些后面的通用的 backbone 可能比较方便的获得预训练模型,不需要从头开始训练。
但是我就是想看一下,一开始 YOL…

《计算机视觉中的深度学习》之目标检测算法原理
参考:《计算机视觉中的深度学习》
概述
目标检测的挑战:
减少目标定位的准确度减少背景干扰提高目标定位的准确度
目标检测系统常用评价指标:检测速度和精度
提高精度:有效排除背景,光照和噪声的影响 提高检测速度…
Task-balanced distillation for object detection用于
Task-balanced distillation for object detection用于目标检测的任务平衡蒸馏
摘要
主流的目标检测器通常由分类和回归两个子任务组成,由两个并行头部实现。这种经典的设计范式不可避免的导致分类得分和定位质量(IOU)之间的空间分布不一致…
[数据集][目标检测]城市道路垃圾检测数据集5266张33类别重制版
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):5266 标注数量(xml文件个数):5266 标注数量(txt文件个数):5266 标注…

【目标检测经典算法】R-CNN、Fast R-CNN和Faster R-CNN详解系列一:R-CNN图文详解
学习视频:Faster-RCNN理论合集
概念辨析
在目标检测中,proposals和anchors都是用于生成候选区域的概念,但它们在实现上有些许不同。 Anchors(锚框): 锚框是在图像中预定义的一组框,它们通常以…
芒果YOLOv8改进106:卷积Conv篇:DO-DConv卷积提高性能涨点,使用over-parameterized卷积层提高CNN性能
芒果YOLOv8改进106:卷积Conv篇:DO-DConv卷积提高性能涨点,使用over-parameterized卷积层提高CNN性能
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
该专栏完整目录链接: 芒果YOLOv8深度改进教程 文章目录 DO-DConv论文理论部分…
[数据集][目标检测]雾天行人车辆检测数据集VOC+YOLO格式4415张5类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4415 标注数量(xml文件个数):4415 标注数量(txt文件个数):4415 标注…
怎么判断发票扫描OCR软件好用不好用?
发票扫描OCR(Optical Character Recognition)是一种将纸质发票上的文字、数字等信息转化为可编辑的文本格式的技术。在现代企业中,随着数字化转型的推进,发票扫描OCR技术变得越来越重要。然而,面对市场上众多的发票扫描…
[数据集][目标检测]草莓成熟度检测数据集VOC+YOLO格式412张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):412 标注数量(xml文件个数):412 标注数量(txt文件个数):412 标注类别…

目标检测---IOU计算详细解读(IoU、GIoU、DIoU、CIoU、EIOU、Focal-EIOU、WIOU)
常见IoU解读与代码实现 一、✒️IoU(Intersection over Union)1.1 🔥IoU原理☀️ 优点⚡️缺点 1.2 🔥IoU计算1.3 📌IoU代码实现 二、✒️GIoU(Generalized IoU)2.1 GIoU原理☀️优点⚡️缺点 2…

YOLOv5 | 涨点复现!YOLOv5添加BiFPN有效提升目标检测精度
目录 🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀
介绍:
BiFPN
代码实现 ⭐欢迎大家订阅我的专栏一起学习⭐
🚀🚀🚀订阅专栏,更新及…

YOLOv8改进 更换分组卷积的网络结构模型
一、ConvNeXt V2论文 论文地址:2301.00808v1.pdf (arxiv.org)
二、ConvNeXt V2的结构 ConvNeXt V2是一种卷积神经网络模型,它是对ConvNeXt模型的改进和升级。ConvNeXt V2通过引入两种新的模块来提高模型的性能:逆残差连接和通道再分配模块。逆残差连接能够解决模型深度增加…
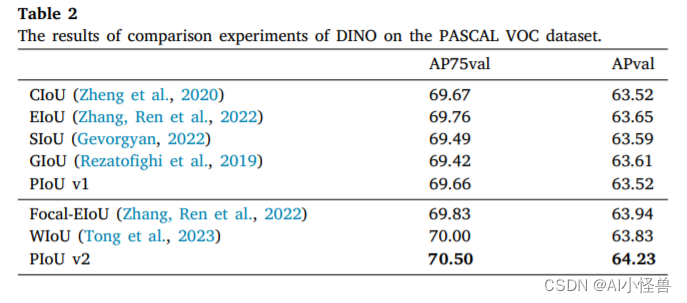
YOLOv9改进策略:IoU优化 | Powerful-IoU更好、更快的收敛IoU,效果秒杀CIoU、GIoU等 | 2024年最新IoU
💡💡💡本文独家改进:Powerful-IoU更好、更快的收敛IoU,是一种结合了目标尺寸自适应惩罚因子和基于锚框质量的梯度调节函数的损失函数
💡💡💡MS COCO和PASCAL VOC数据集实现涨点
YO…

小目标检测篇 | YOLOv8改进之增加小目标检测层(针对Neck网络为AFPN)
前言:Hello大家好,我是小哥谈。小目标检测是计算机视觉领域中的一个研究方向,旨在从图像或视频中准确地检测和定位尺寸较小的目标物体。相比于常规目标检测任务,小目标检测更具挑战性,因为小目标通常具有低分辨率、低对比度和模糊等特点,容易被背景干扰或遮挡。本篇文章就…
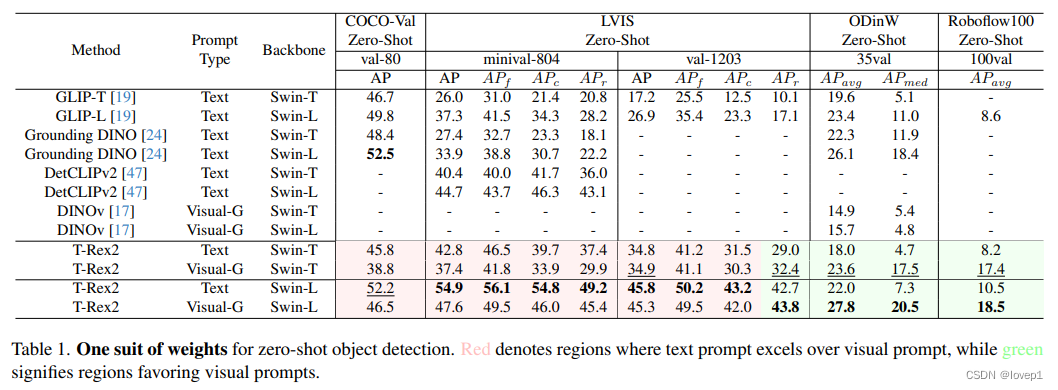
t-rex2开放集目标检测
论文链接:http://arxiv.org/abs/2403.14610v1
项目链接:https://github.com/IDEA-Research/T-Rex
这篇文章的工作是基于t-rex1的工作继续做的,核心亮点:
是支持图片/文本两种模态的prompt进行输入,甚至进一步利用两…
深入理解RCNN:区域建议与区域兴趣池化技术解析
引言
随着深度学习技术的发展,目标检测在计算机视觉领域扮演着越来越重要的角色。RCNN(Region-based Convolutional Neural Network)是一种经典的深度学习模型,它通过引入区域建议和区域兴趣池化技术,实现了对图像中目…
边缘计算【智能+安全检测】系列教程-- Jeton Agx Orin 基础环境搭建
1 .前期准备
Jetson Agx Orin 比Jetson Agx Orin Xavier的算力要高,性能要好通常用来做自动驾驶的AI推理,具体外观如下图
1.刷机软件sdkmanager:下载链接
NVIDIA账号需要注册,正常一步一步往下走就行。在ubuntu18以上的系统安…
FOCUS-AND-DETECT: A SMALL OBJECTDETECTION FRAMEWORK FOR AERIAL IMAGES
摘要 为了解决小对象检测问题,提出了一个叫做 Focus-and Detect 的检测框架,它是一个两阶段的框架。 第 一阶段包括由高斯混合模型监督的对象检测器网络,生成构成聚焦区域的对象簇 。 第二阶段 也是一个物体探测器网络,预测聚焦…

卷积篇 | YOLOv8改进之主干网络中引入可变形卷积DConv
前言:Hello大家好,我是小哥谈。可变形卷积模块是一种改进的卷积操作,它可以更好地适应物体的形状和尺寸,提高模型的鲁棒性。可变形卷积模块的实现方式是在标准卷积操作中增加一个偏移量offset,使卷积核能够在训练过程中扩展到更大的范围,从而实现对尺度、长宽比和旋转等各…
YOLOv8-ROS-noetic+USB-CAM目标检测
环境介绍 Ubuntu20.04 Ros1-noetic Anaconda-yolov8虚拟环境 本文假设ROS和anaconda虚拟环境都已经配备,如果不知道怎么配备可以参考: https://blog.csdn.net/weixin_45231460/article/details/132906916 创建工作空间
mkdir -p ~/catkin_ws/srccd ~/ca…

主干网络篇 | YOLOv8更换主干网络之GhostNet
前言:Hello大家好,我是小哥谈。GhostNet是2019年由华为诺亚方舟实验室发布的轻量级网络,速度和MobileNetV3相似,但是识别的准确率比MobileNetV3高,在ImageNet ILSVRC2012分类数据集的达到了75.7%的top-1精度。该论文提除了Ghost模块,通过廉价操作生成更多的特征图。基于一…
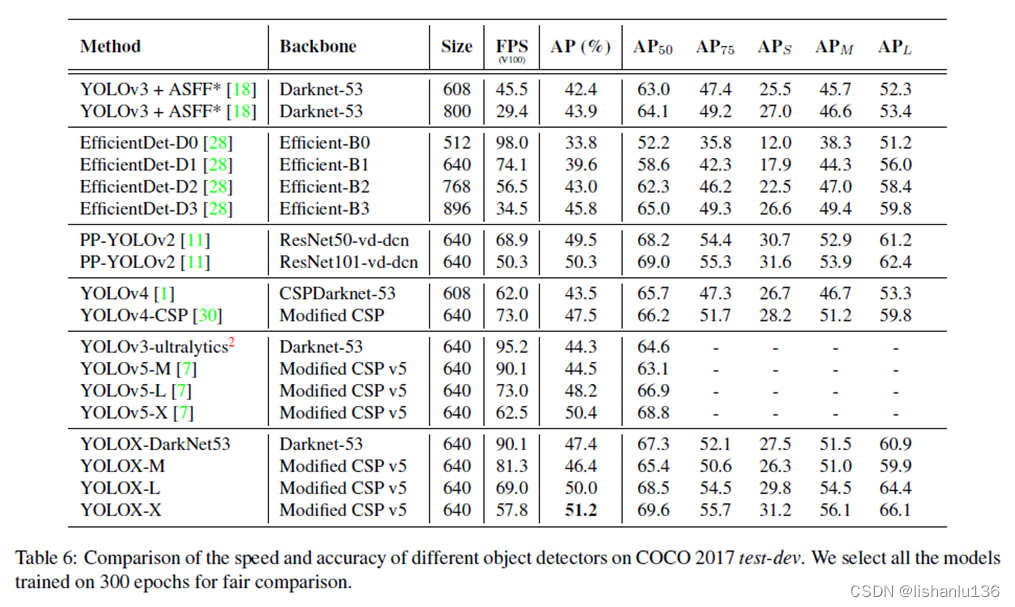
目标检测——YOLOX算法解读
论文:YOLOX: Exceeding YOLO Series in 2021(2021.7.18) 作者:Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun 链接:https://arxiv.org/abs/2107.08430 代码:https://github.com/Megvii-BaseDetection/YOLOX YOLO系列算法…
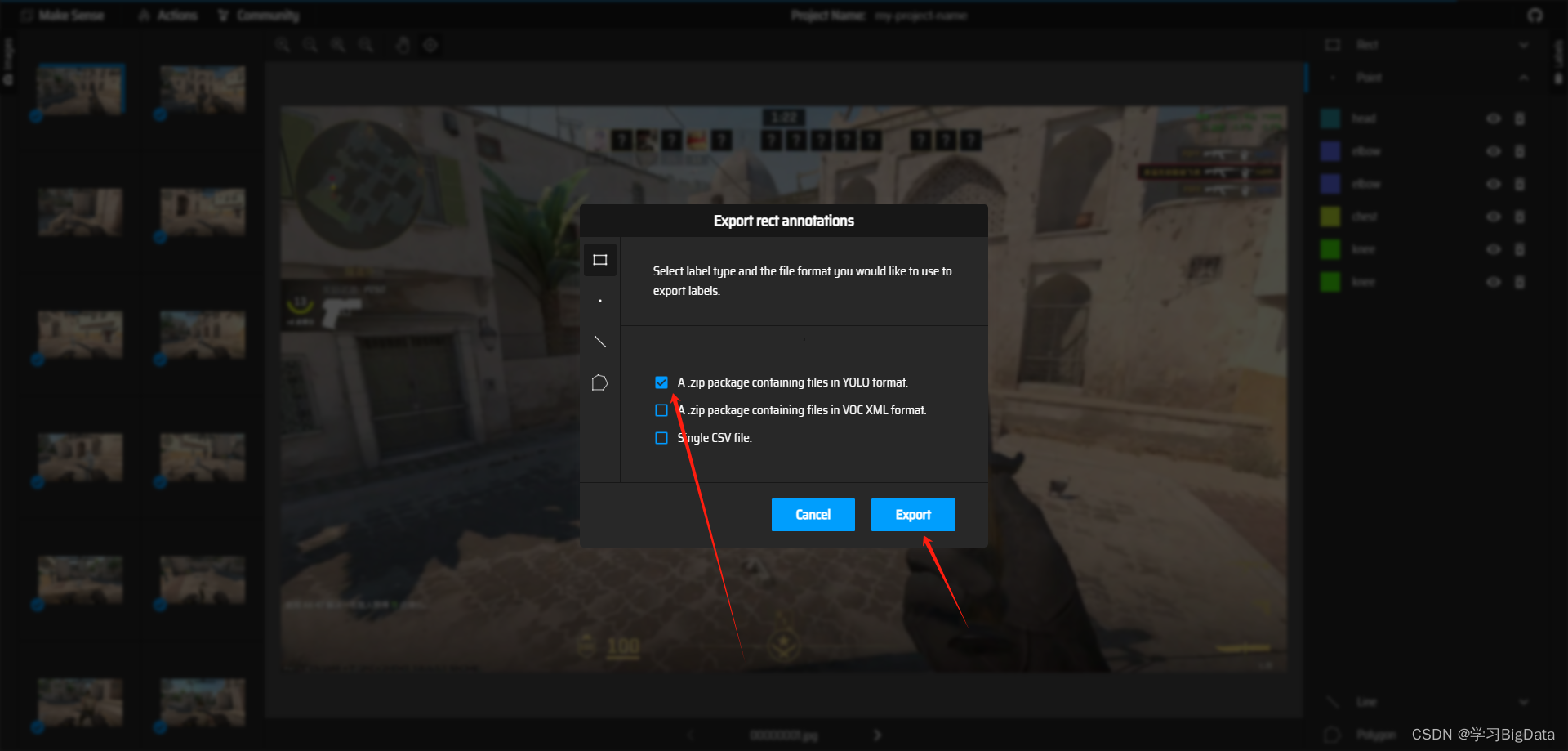
yolov8目标检测数据集制作——make sense
背景
在前几天我进行了录制视频以准备足够多的数据集,同时使用利用python自定义间隔帧数获取视频转存为图片,所以今天我准备对我要训练的数据集进行标注。我要做的是一个基于yolo的检测项目,在搜索资料后得知大家多是用labelme或者make sens…

目标检测预测框可视化python代码实现--OpenCV
import numpy as np
import cv2
import colorsys
from PIL import Image, ImageDraw, ImageFontdef puttext_cn(img, text, pt, color(255,0,0), size16):if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型img Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2…

自动驾驶感知新范式——BEV感知经典论文总结和对比(一)
自动驾驶感知新范式——BEV感知经典论文总结和对比(一)
博主之前的博客大多围绕自动驾驶视觉感知中的视觉深度估计(depth estimation)展开,包括单目针孔、单目鱼眼、环视针孔、环视鱼眼等,目标是只依赖于视…
YOLOv8独家改进:backbone改进 | 视觉新主干!RMT:RetNet遇见视觉Transformer | CVPR2024
💡💡💡本文独家改进:RMT:一种强大的视觉Backbone,灵活地将显式空间先验集成到具有线性复杂度的视觉主干中,在多个下游任务(分类/检测/分割)上性能表现出色!
💡💡💡Transformer 在各个领域验证了可行性,在多个数据集下能够实现涨点
改进结构图如下: 收录
…
yolov9目标检测可视化图形界面GUI源码
该系统是由微智启软件工作室基于yolov9pyside6开发的目标检测可视化界面系统 运行环境: window python3.8 安装依赖后,运行源码目录下的wzq.py启动 程序提供了ui源文件,可以拖动到Qt编辑器修改样式,然后通过pyside6把ui转成python…

【目标检测】YOLOv9理论解读与代码分析
前言
YOLO这个系列的故事已经很完备了,比如一些Decoupled-Head或者Anchor-Free等大的策略改动已经在YOLOv8固定下来,后面已经估计只有拿一些即插即用的tricks进行小改。
mmdetection框架的作者深度眸也在知乎上对“是否会有YOLOv9”这一观点发表看法&a…

【YOLOv8性能对比试验】YOLOv8n/s/m/l/x不同模型尺寸大小的实验结果对比及结论参考
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…
![[数据集][目标检测]高质量铁路轨道缺陷检测数据集VOC+YOLO格式1050张6类别](https://img-blog.csdnimg.cn/direct/be64bc4df32e4231884b0c2f9fdec1f8.jpeg)
[数据集][目标检测]高质量铁路轨道缺陷检测数据集VOC+YOLO格式1050张6类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1050 标注数量(xml文件个数):1050 标注数量(txt文件个数):1050 标注…
【目标检测-复制粘贴数据增强】
复制粘贴数据增强
在目标检测、分类和分割任务中,复制粘贴数据增强(Copy-Paste Data Augmentation)是一种创新的数据增广技术,它通过将训练集中的一部分物体实例复制并粘贴到其他图像的合理位置上,以生成新的训练样本…
【论文精读】OTA: Optimal Transport Assignment for Object Detection(物体探测的最优传输分配)
OTA最优传输 🚀🚀🚀摘要一、1️⃣ Introduction---介绍二、2️⃣Related Work---相关工作2.1 🎓 Fixed Label Assignment--静态标签分配2.2 ✨Dynamic Label Assignment--动态标签分配 三、3️⃣Method---论文方法3.1 Ἱ…
Semi-supervised Open-World Object Detection
Semi-supervised Open-World Object Detection 摘要1 介绍2.准备工作提出的SS-OWOD问题设置2.1 基础架构3 方法3.1整体架构摘要
传统的开放世界对象检测(OWOD)问题设置首先区分已知和未知类别,然后在后续任务中引入标签时逐步学习未知对象。然而,当前的OWOD公式在增量学习…
![[数据集][目标检测]铝片表面工业缺陷检测数据集VOC+YOLO格式400张4类别](https://img-blog.csdnimg.cn/direct/2e2d28a94e00470e8a69b0cce0c77c24.jpeg)
[数据集][目标检测]铝片表面工业缺陷检测数据集VOC+YOLO格式400张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):400 标注数量(xml文件个数):400 标注数量(txt文件个数):400 标注类别…
YOLOv5目标检测学习(7):验证部分val.py简要分析;训练、验证、推理三文件的关系
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、val.py的大致结构如下:1.0 准备工作1.获取文件路径2.存储预测信息为.txt文件3.存储预测信息为coco格式的.json文件 1.1 主函数main:…
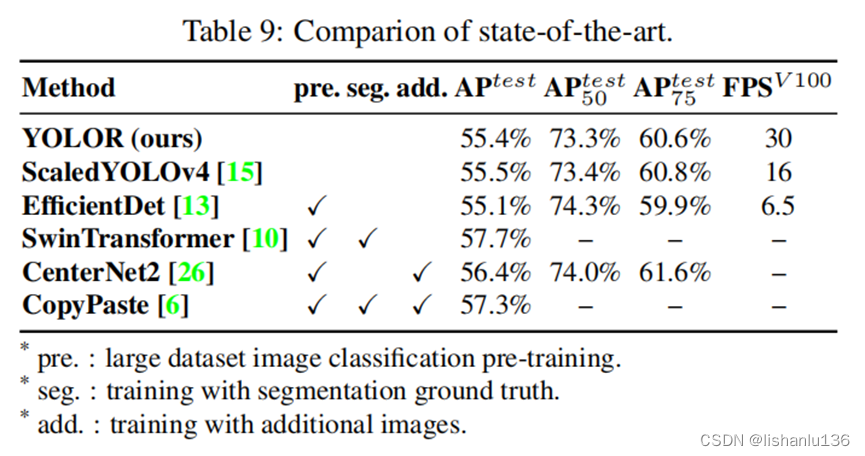
目标检测——YOLOR算法解读
论文:YOLOR-You Only Learn One Representation: Unifified Network for Multiple Tasks 作者:Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao 链接:https://arxiv.org/abs/2105.04206 代码:https://github.com/WongKinYiu/yolo…
目标检测---IOU计算详细解读(IoU、GIoU、DIoU、CIoU、EIOU、Focal-EIOU、SIOU、WIOU)
常见IoU解读与代码实现 一、✒️IoU(Intersection over Union)1.1 🔥IoU原理☀️ 优点⚡️缺点 1.2 🔥IoU计算1.3 📌IoU代码实现 二、✒️GIoU(Generalized IoU)2.1 GIoU原理☀️优点⚡️缺点 2…
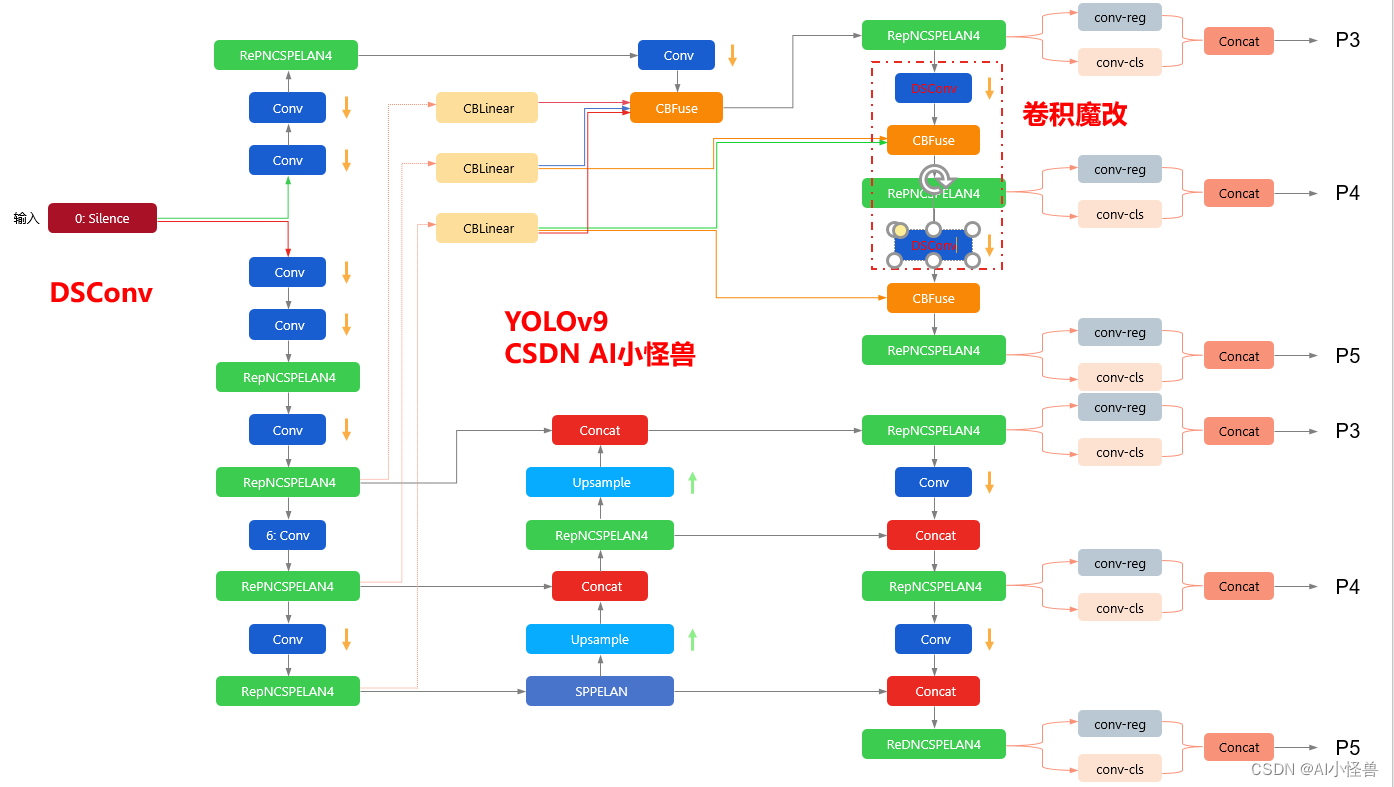
YOLOv9改进策略:卷积魔改 | 分布移位卷积(DSConv),提高卷积层的内存效率和速度
💡💡💡本文改进内容: YOLOv9如何魔改卷积进一步提升检测精度?提出了一种卷积的变体,称为DSConv(分布偏移卷积),其可以容易地替换进标准神经网络体系结构并且实现较低的存…

【目标检测基础篇】目标检测评价指标:mAP计算的超详细举例分析以及coco数据集标准详解(AP/AP50/APsmall.....))
学习视频: 霹雳吧啦Wz-目标检测mAP计算以及coco评价标准 【目标检测】指标介绍:mAP
1 TP/FP/FN
TP(True Positive) : IoU>0.5的检测框数量(同一Ground truth只计算一次)FP(False Positive) : IoU<0.5的检测框(或者是检测到同一个GT的多余检测框的…
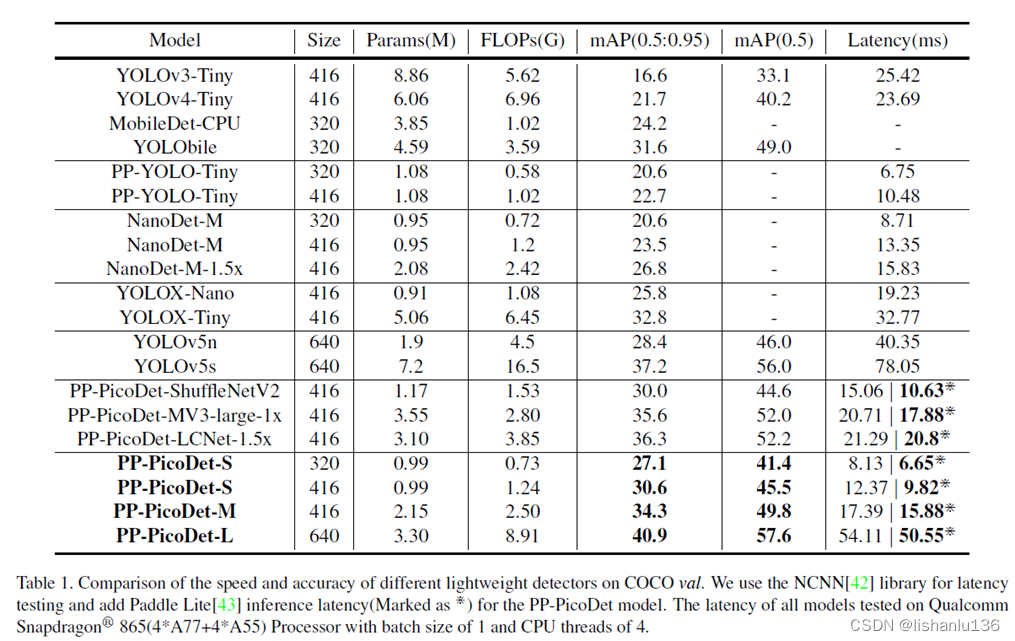
目标检测——PP-PicoDet算法解读
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解…
yolov7 gui 轻松通过GUI来实现车辆行人计数
YOLOv7 GUI 是一款用户友好型图形界面应用程序,专为简化基于YOLOv7(You Only Look Once version 7)的目标检测流程而设计。该工具允许用户无需深入掌握命令行操作和复杂编程细节,即可方便快捷地运行YOLOv7模型来检测图像或视频中的…

【目标检测】图解 YOLOv3 的网络结构(Darknet-53 作为 backbone)
到了 YOLOv3,backbone 从 YOLOv2 的 Darknet-19 升级到了 Darknet-53。
下面一张完整的结构示意图来一起理解一下 YOLOv3 的网络结构。 我们怎么理解最后输出的 3 个特征图(feature map)的这个 255?
同 YOLOv2 一样,…
目标检测——PP-YOLOE算法解读
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解…

产品推荐 | 基于XC7K325T的FMC接口万兆光纤网络验证平台
01、产品概述
TES307是一款基于XC7K325T FPGA的万兆光纤网络验证平台,板卡具有1个FMC(HPC)接口,4路SFP万兆光纤接口、4路SATA接口、1路USB3.0接口。
板载高性能的FPGA处理器可以实现光纤协议、SATA总线控制器、以及USB3.0高速串…
免费开源软件:思通数科舆情系统应对社会热点事件
本周末最炸裂的新闻:这起悲剧提醒我们,青少年心理健康教育和犯罪预防工作不容忽视。社会各界必须共同努力,为青少年创造一个安全、健康的成长环境。 对热点社会消息的实时追踪,真实得反应社会舆论走向,能极大的提高政务…
目标检测——PP-YOLOv2算法解读
PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解…

卷积篇 | YOLOv8改进之C2f模块融合SCConv | 即插即用的空间和通道维度重构卷积
前言:Hello大家好,我是小哥谈。SCConv是一种用于减少特征冗余的卷积神经网络模块。相对于其他流行的SOTA方法,SCConv可以以更低的计算成本获得更高的准确率。它通过在空间和通道维度上进行重构,从而减少了特征图中的冗余信息。这种模块的设计可以提高卷积神经网络的性能。本…
训练数据集(一):真实场景下采集的煤矸石目标检测数据集,可直接用于YOLOv5/v6/v7/v8训练
文章目录 数据集介绍数据集训练精度展示数据集获取方式 数据集介绍
煤矸石训练数据集:891张;验证数据数据集:404张 数据集类别:0代表煤炭(coal),1代表矸石(gangue)&…

注意力机制篇 | YOLOv8改进之添加CA注意力机制
前言:Hello大家好,我是小哥谈。CA(Channel Attention)注意力机制是一种用于计算机视觉任务的注意力机制,它可以通过学习通道之间的关系来提高模型的性能。本文所做出的改进即在YOLOv8主干网络中添加CA注意力机制!~🌈 目录
🚀1.基础概念
🚀2.网络结构<

免费阅读篇 | 芒果YOLOv8改进110:注意力机制GAM:用于保留信息以增强渠道空间互动
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可
该专栏完整目录链接: 芒果YOLOv8深度改进教程 该篇博客为免费阅读内容,直接改进即可🚀🚀…
[数据集][目标检测]番茄成熟度检测数据集VOC+YOLO格式277张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):277 标注数量(xml文件个数):277 标注数量(txt文件个数):277 标注类别…
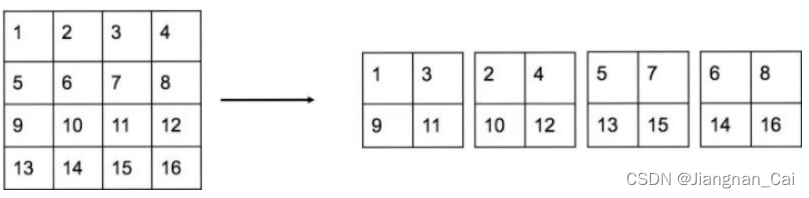
【目标检测】YOLOv2 网络结构(darknet-19 作为 backbone)
上一篇文章主要是写了一些 YOLOv1 的原版网络结构,这篇文章一样,目标是还原论文中原版的 YOLOv2 的网络结构,而不是后续各种魔改的版本。
YOLOv2 和 YOLOv1 不一样,开始使用 Darknet-19 来作为 backbone 了。论文中给出了 Darkne…

旭日x3派部署自己训练的模型(安全帽识别、视频流推理、yolov5-6.2)
旭日x3派部署自己训练的模型(安全帽识别、视频流推理、yolov5-6.2)windows,框架pytorch,python3.7 效果模型训练模型转换1、pt模型文件转onnx2、检查onnx模型3、准备校准数据4、onnx转bin 上板视频流推理1、图片推理2、视频流推理…

基于深度学习YOLOv8+Pyqt5的工地安全帽头盔佩戴检测识别系统(源码+跑通说明文件)
wx供重浩:创享日记 对话框发送:318安全帽 获取完整源码源文件7000张已标注的数据集训练好的模型配置说明文件 可有偿59yuan一对一远程操作配置环境跑通程序 效果展示(图片检测批量检测视频检测摄像头检测) 基于深度学习YOLOv8Pyqt…

目标检测算法 YOLOv8 原理解析|包揽目标检测、实例分割 SOTA
文章目录 YOLOv8算法简介YOLOv8 概述YOLOv8算法特点YOLOv8 网络模型结构图YOLOv8 网络模型结构设计YOLOv8 效果YOLOv8 和 YOLOv5 之间的综合比较YOLOv8 和 YOLOv5 目标检测模型对比 YOLOv8 Loss 计算YOLOv8 训练策略YOLOv8 算法总结 YOLOv8算法简介 YOLOv8作者:glen…

YOLO钢筋检测计数数据集(5000+图像,标注完整)
YOLO钢筋检测计数数据集,包含5125张真实场景下,密集钢筋图像,高精度yolo标注完整,全部原始图像,未使用增强。 适用于CV项目,毕设,科研,实验等
需要此数据集或其他任何数据集请私信
![[数据集][目标检测]焊接件表面缺陷检测数据集VOC+YOLO格式2292张10类别](https://img-blog.csdnimg.cn/direct/784231002051407cabd33a05f6c8ed38.jpeg)
[数据集][目标检测]焊接件表面缺陷检测数据集VOC+YOLO格式2292张10类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2292 标注数量(xml文件个数):2292 标注数量(txt文件个数):2292 标注…

与数据集偏差的十年之战:我们成功了吗?
论文地址:https://arxiv.org/pdf/2403.08632.pdf 代码地址:https://github.com/liuzhuang13/bias
1. Introduction 2011年,深度学习革命的黎明之前,Torralba 和 Efros 在十年之前呼吁 “数据集分类 (Dataset Classification)” 问题[1]&…
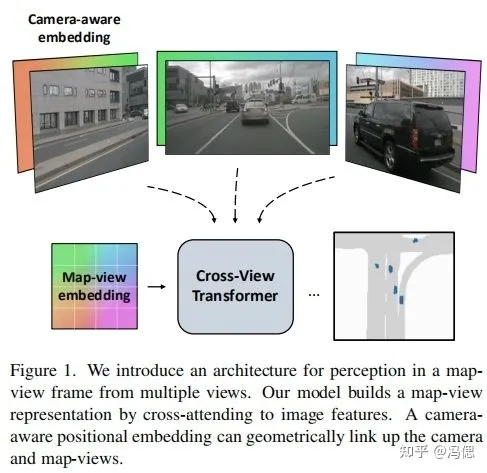
基于BEV的自动驾驶会颠覆现有的自动驾驶架构吗
基于BEV的自动驾驶会颠覆现有的自动驾驶架构吗 引言
很多人都有这样的疑问–基于BEV(Birds Eye View)的自动驾驶方案是什么?这个问题,目前学术界还没有统一的定义,但从我的开发经验上,尝试做一个解释:以鸟瞰视角为基础…

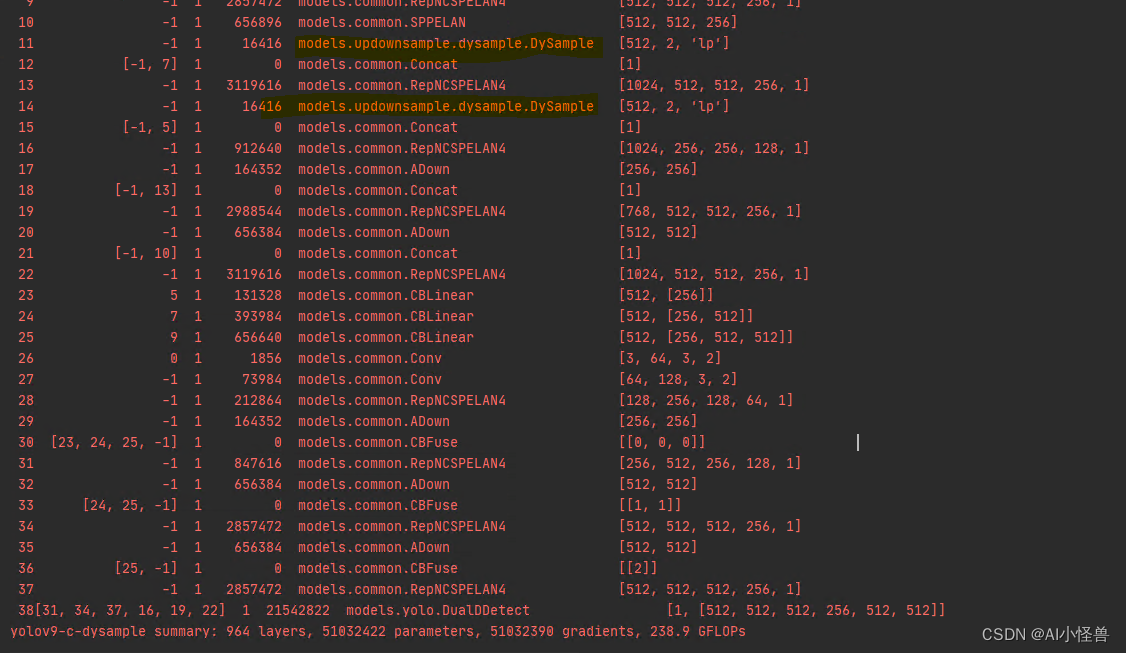
YOLOv9改进策略:上采样涨点系列 | 超轻量高效动态上采样DySample,效果秒杀CAFFE,助力小目标检测
💡💡💡本文独家改进:一种超轻量高效动态上采样DySample, 具有更少的参数、FLOPs,效果秒杀CAFFE和YOLOv9网络中的nn.Upsample 💡💡💡在多个数据集下验证能够涨点ÿ…

YOLOv8融入低照度图像增强算法---传统算法篇
YOLOv8n原图检测YOLOv8n增强后检测召回率和置信度都有提升 前言
这篇博客讲讲低照度,大家都催我出一些内容,没想到这么多同学搞这个,恰好我也做过这方面的一些工作,那今天就来讲解一些方法,低照度的图像增强大体分“传统算法”和“深度学习算法”;
目前低照度的图像增…

【目标检测】YOLOv6 的网络结构,图解RepBlock重参数化
YOLOv6 是美团推出的,在这个版本里面,不再使用之前 YOLOv4 和 YOLOv5 的带 CSP 结构的 CSPDarknet-53 作为 backbone 了,而是在 RepVGG 的启发下,推出了新的 EfficientRep 作为 YOLOv6 的 backbone。
RepVGG 最重要的一点是&…
红外弱小目标检测与跟踪
红外弱小目标检测与跟踪 1,红外弱小目标检测1.1 检测方法基于深度学习(数据驱动)基于传统方法(模型驱动)背景抑制局部对比度:最优化:1.2代码实现top-hat代码实现2,红外弱小目标跟踪根据国际光学工程学会的定义,在256256的图像中,红外小目标的像素面积不超过99。典型的…

67、yolov8目标检测和旋转目标检测算法batchsize=1/6部署Atlas 200I DK A2开发板上
基本思想:需求部署yolov8目标检测和旋转目标检测算法部署atlas 200dk 开发板上
一、转换模型 链接: https://pan.baidu.com/s/1hJPX2QvybI4AGgeJKO6QgQ?pwd=q2s5 提取码: q2s5
from ultralytics import YOLO# Load a model
model = YOLO("yolov8s.yaml") # buil…

主干网络篇 | YOLOv8改进之用RCS-OSA替换C2f(来源于RCS-YOLO)
前言:Hello大家好,我是小哥谈。RCS-YOLO是一种目标检测算法,它是基于YOLOv3算法的改进版本。通过查看RCS-YOLO的整体架构可知,其中包括RCS-OSA模块。RCS-OSA模块在模型中用于堆叠RCS模块,以确保特征的复用并加强不同层之间的信息流动。本文就给大家详细介绍如何将RCS-YOLO…
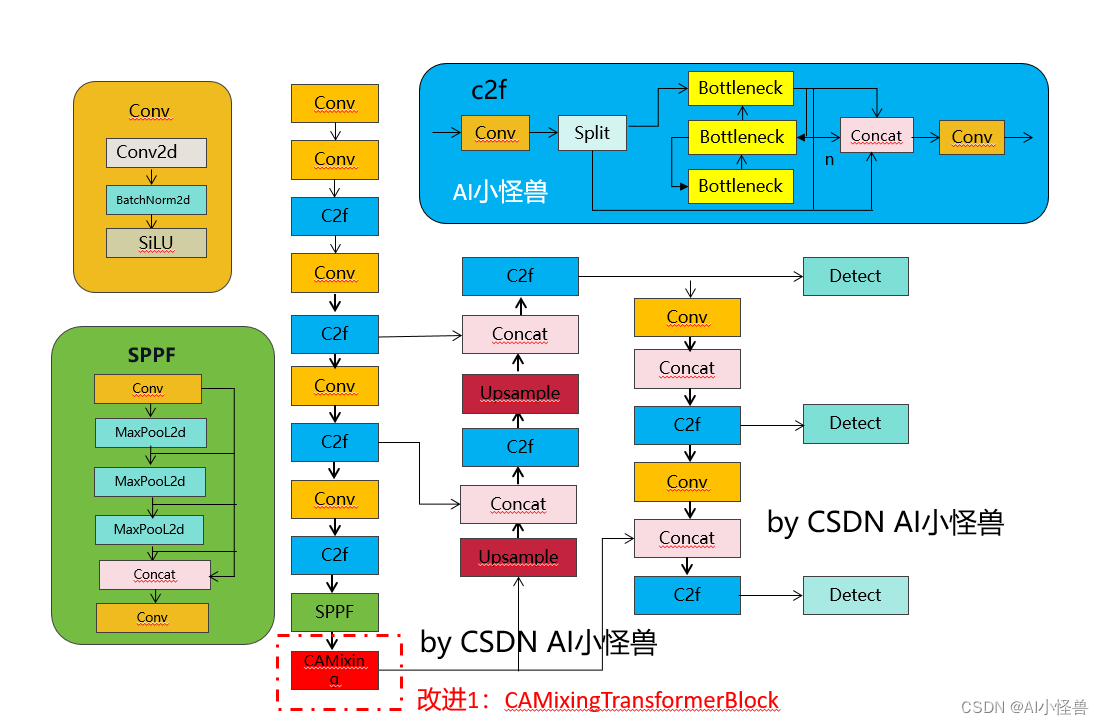
YOLOv8全网独家改进: 小目标 | CAMixing:卷积-注意融合模块和多尺度提取能力 | 2024年4月最新成果
💡💡💡本文独家改进:CAMixingBlock更好的提取全局上下文信息和局部特征,包括两个部分:卷积-注意融合模块和多尺度前馈网络; 💡💡💡红外小目标实现涨点,只有几个像素的小目标识别率提升明显 💡💡💡如何跟YOLOv8结合:1)放在backbone后增强对全局和局部特…

YOLOv8结合SCI低光照图像增强算法!让夜晚目标无处遁形!【含端到端推理脚本】
这里的"SCI"代表的并不是论文等级,而是论文采用的方法 — “自校准光照学习” ~ 左侧为SCI模型增强后图片的检测效果,右侧为原始v8n检测效果 这篇文章的主要内容是通过使用SCI模型和YOLOv8进行算法联调,最终实现了如上所示的效果:在增强图像可见度的同时,对图像…
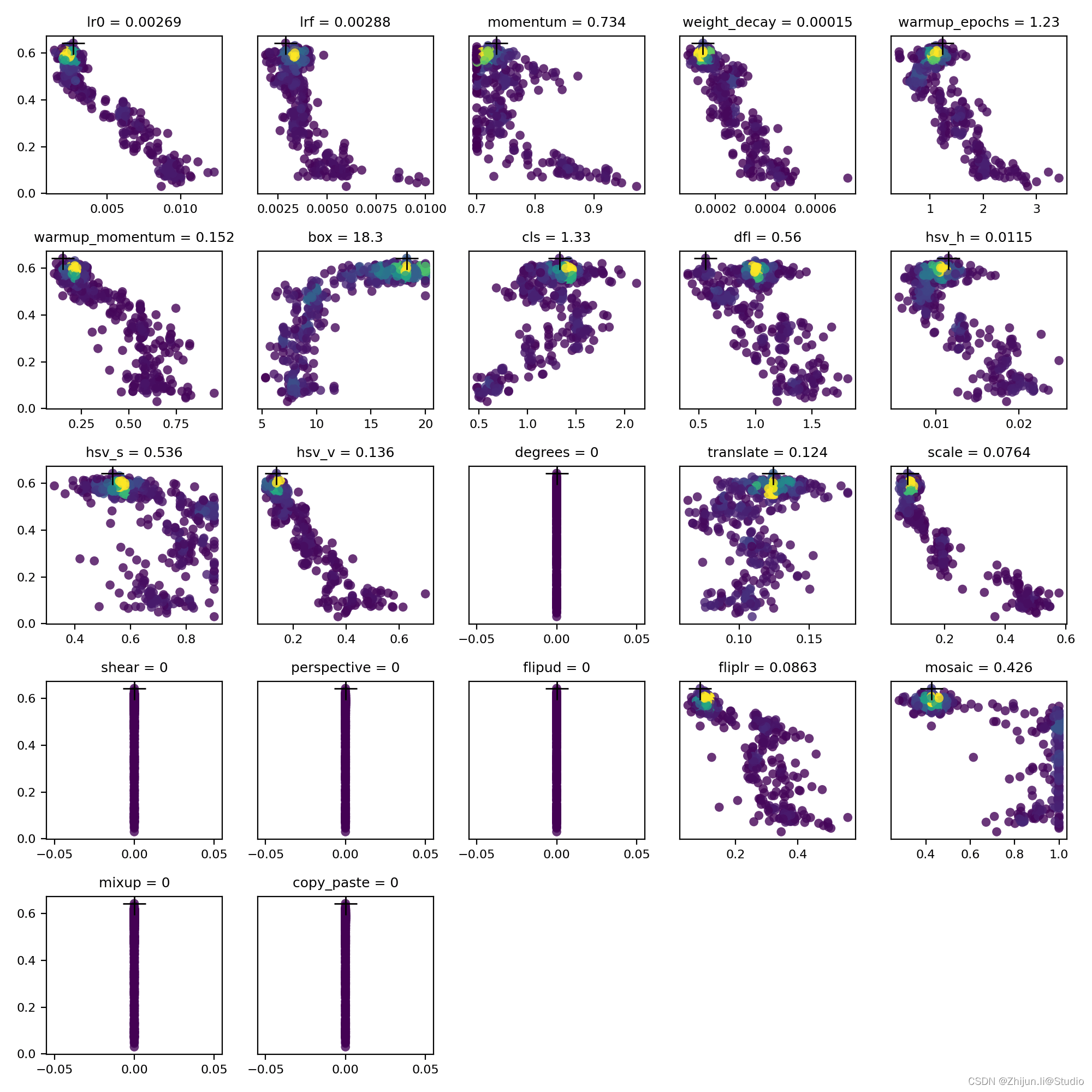
【最佳实践】高效调优目标检测模型
【最佳实践】高效调优目标检测模型 数据层面算法层面CNN还是Transformer?学习率和优化器损失函数的权重正负样本平衡模型微调与迁移学习模型性能监控与早停可视化与模型解释超参数进化其他方面总结 在深入繁复的计算机视觉领域,目标检测无疑是一项挑战且…
基于深度学习的危险物品检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文详细介绍基于YOLOv8/v7/v6/v5的危险物品检测技术。主要采用YOLOv8技术并整合了YOLOv7、YOLOv6、YOLOv5的算法,进行了细致的性能指标对比分析。博客详细介绍了国内外在危险物品检测方面的研究现状、数据集处理方法、算法原理、模型构建与训练代码…
基于深度学习的田间杂草检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本博客深入探讨了基于YOLOv8/v7/v6/v5的田间杂草检测系统,其中核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详细介绍了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,以及基…

NMS 系列:soft,softer,weighted,iou-guided, Diou, Adaptive
系列文章目录
IOU 系列:IOU,GIOU,DIOU,CIOU 文章目录 系列文章目录一、NMS简介(一)为什么要使用NMS(二)NMS的算法流程(三)NMS的置信度重置函数(四)NMS的局限性ÿ…

3D检测:从pointnet,voxelnet,pointpillar到centerpoint
记录centerpoint学习笔记。目前被引用1275次,非常高。
地址:Center-Based 3D Object Detection and Tracking (thecvf.com)
GitHub - tianweiy/CenterPoint
CenterPoint:三维点云目标检测算法梳理及最新进展(CVPR2021ÿ…
基于深度学习的吸烟检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5等深度学习模型的吸烟行为检测系统,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及…
基于深度学习的肿瘤图像检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:在本博客中,我们深入探讨了基于YOLOv8/v7/v6/v5的肿瘤图像检测系统。核心上,我们采用了最新的YOLOv8技术,并将其与YOLOv7、YOLOv6、YOLOv5算法进行了综合整合和性能指标对比分析。我们详细阐述了当前国内外在此领域的研究现状…
基于深度学习的植物叶片病害识别系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的植物叶片病害识别系统,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Strea…

树莓派部署yolov5实现目标检测(ubuntu22.04.3)
最近两天搞了一下树莓派部署yolov5,有点难搞(这个东西有点老,版本冲突有些包废弃了等等) 最后换到ubuntu系统弄了,下面是我的整体步骤(建议先使能一下ssh(最下面有),结合…

特征融合篇 | 结合内容引导注意力 DEA-Net 思想 实现双主干特征融合新方法 | IEEE TIP 2024
本篇改进已集成到 YOLOv8-Magic 框架。 摘要—单幅图像去雾是一个具有挑战性的不适定问题,它从观察到的雾化图像中估计潜在的无雾图像。一些现有的基于深度学习的方法致力于通过增加卷积的深度或宽度来改善模型性能。卷积神经网络(CNN)结构的学习能力仍然未被充分探索。本文…
mmdetection计算参数量和计算复杂度
参数量与图片尺寸无关
而计算复杂度(GFlops)与输入图片的尺寸有关,作比较的时候要确保,输入尺寸一致的,最新版本的mmdetection的tools/analysis_tools/get_flops.py中不支持更改输入图片尺寸,而是自己从数…
Streamlit 构建大语言模型 (LLM) web 界面
文章目录 Streamlit 构建大语言模型 (LLM) web 界面选择Streamlit的原因原理流程streamlit布局示例代码聊天机器人示例代码(简化版) Streamlit在ChatGLM3-6B中的应用 Streamlit 构建大语言模型 (LLM) web 界面
选择Streamlit的原因 易用性:S…
YoloV8实战:使用YoloV8实现水下目标检测(RUOD)
摘要
水下目标检测技术在生态监测、管道检修、沉船捕捞等任务中发挥着重要作用。常用的检测方法包括高清视像、侧扫声呐等。光学图像检测因高分辨率和灵活性,在近距离检测中优势显著。但水下图像受水体吸收、衰减、光源分布等影响,呈现蓝绿色࿰…
芒果YOLOv8改进组合156:动态标签分配ATSS + 损失函数NWDLoss组合改进,共同助力VisDrone小目标检测高效涨点
💡本篇内容:【芒果YOLOv8改进ATSS标签分配策略|第二集】动态标签分配ATSS + 损失函数NWDLoss组合改进,共同助力VisDrone小目标检测高效涨点
💡🚀🚀🚀本博客 标签分配策略ATSS改进+ 损失函数NWDLoss组合改进,源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码…

目标检测:数据集划分 XML数据集转YOLO标签
文章目录 1、前言:2、生成对应的类名3、xml转为yolo的label形式4、优化代码5、划分数据集6、画目录树7、目标检测系列文章 1、前言: 本文演示如何划分数据集,以及将VOC标注的xml数据转为YOLO标注的txt格式,且生成classes的txt文件…

交通标志识别项目 | 基于Tensorflow+SSD实现道路交通标志识别
项目应用场景 面向智能驾驶或自动驾驶场景道路道路交通标志的识别,在交通标志识别的基础上为下一步的智能决策提供前提
项目效果: 项目细节 > 具体参见项目 README.md (1) 安装依赖 Python3.5、TensorFlow v0.12.0、Pickle、OpenCV-Python、Matplotl…

【完整版!YOLOv9论文翻译】
目录 摘要1 引言2 相关工作2.1 实时目标检测2.2 可逆架构2.3 辅助监督 3 问题陈述3.1 信息瓶颈原理3.2 可逆函数 4 方法4.1 可编程梯度信息(PGI)4.1.1 辅助可逆分支4.1.2 多层次辅助信息 4.2 通用高效层聚合网络 Generalized ELAN 5 实验5.1 实验设置5.2…
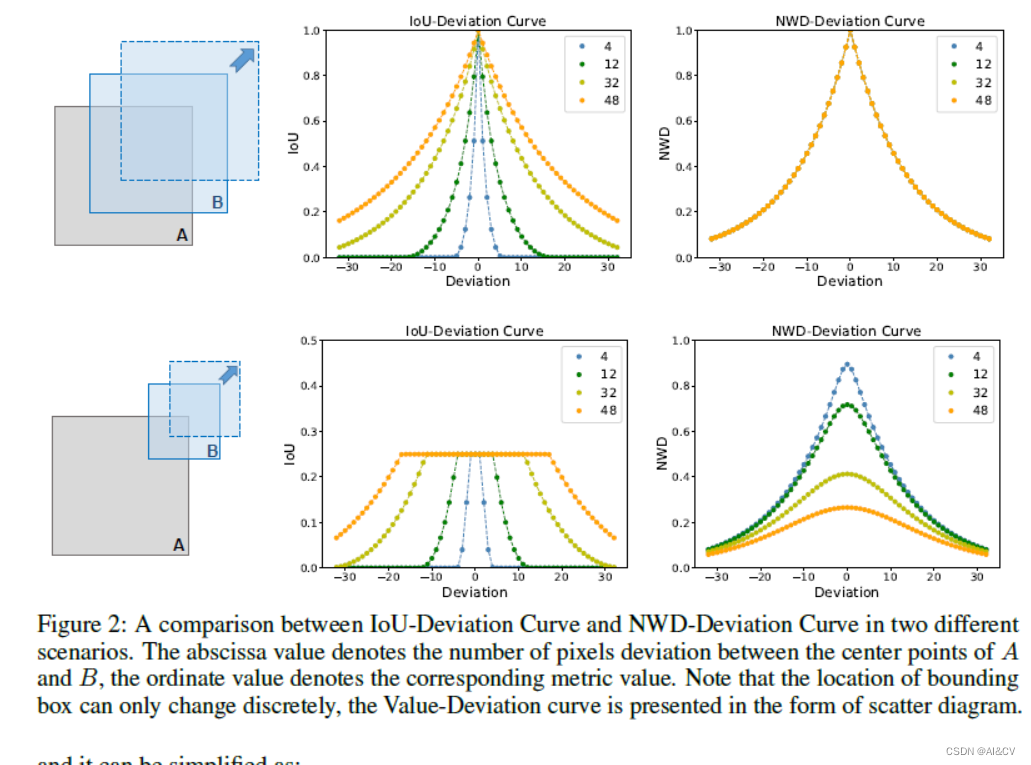
YOLOv9改进策略:IoU优化 | Wasserstein Distance Loss,助力小目标涨点
💡💡💡本文独家改进:基于Wasserstein距离的小目标检测评估方法
Wasserstein Distance Loss | 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升明显
💡💡💡MS COCO和PASC…
YOLOv8全网独家改进:红外小目标 | 注意力机制改进 | 维度感知选择性集成模块DASI,红外小目标暴力涨点| 2024年3月最新成果
💡💡💡本文独家改进:维度感知选择性集成模块DASI,解决目标的大小微小以及红外图像中通常具有复杂的背景的问题点,2024年3月最新成果 💡💡💡红外小目标实现暴力涨点,只有几个像素的小目标识别率大幅度提升
改进结构图如下: 收录
YOLOv8原创自研
https://blo…

【最新!红外小目标检测算法HCFNet】
文章目录 摘要1 引言2 相关工作2.1 传统方法2.2 深度学习方法 3 方法3.1 PPA3.2 维度感知选择性整合模块3.3 多稀释通道细化器模块3.4 损失函数设计 4 实验4.1 数据集与评估指标4.2 实现细节4.3 消融和对比 5 结论 论文:HCF-Net: Hierarchical Context Fusion Netwo…
【目标检测实验系列】AutoDL线上GPU服务器租用流程以及如何用Pycharm软件远程连接服务器进行模型训练 (以Pycharm远程训练Yolov5项目为例子 超详细)
目录 1. 文章主要内容2. 租用AutoDL服务器详细教程2.1 注册AutoDL账号,并申请学生认证(学生认证有优惠,如果不是学生可以忽略此点)2.2 算力市场选择GPU,并选择初始化配置环境2.3 控制台参数解析,并使用相关参数登录Xftp(Windows与…
[数据集][目标检测]道路交通事故检测数据集VOC+YOLO格式11819张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):11819 标注数量(xml文件个数):11819 标注数量(txt文件个数):11819 标…
YOLOv9改进策略 :neck优化 | 路径融合GFPN,小目标到大目标一网打尽 | 轻骨干重Neck的轻量级目标检测器GiraffeDet
💡💡💡本文改进内容:设计了一种新的路径融合GFPN:包含跳层与跨尺度连接,改进思路来自ICLR2022 GiraffeDet的核心思想。 💡💡💡GFPN和六个检测头结合,这种跳层…
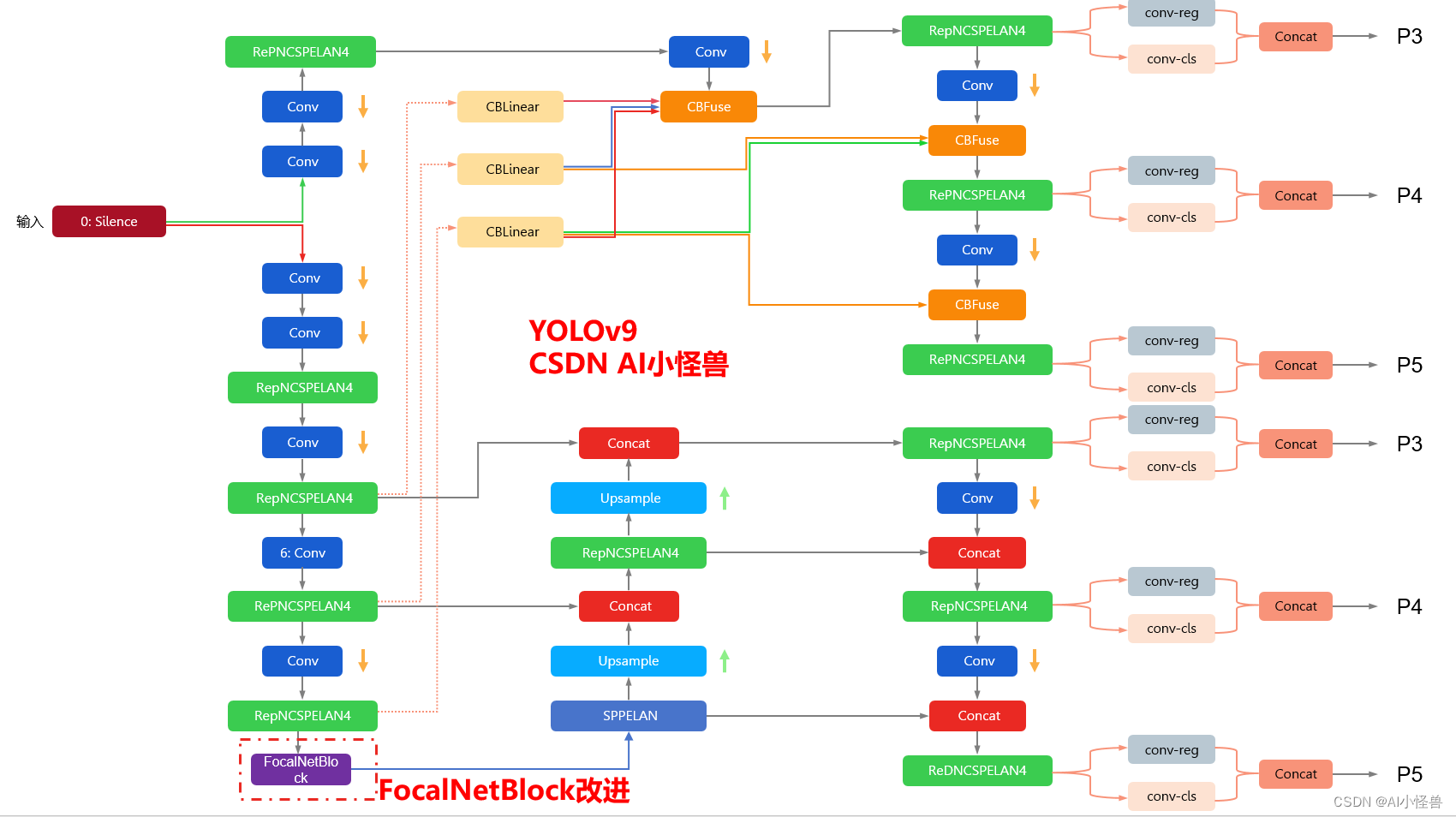
YOLOv9改进策略:注意力机制 | FocalNet焦点调制注意力取代自注意力
💡💡💡本文改进内容:由于自注意力二次的计算复杂度效率较低,尤其是对于高分辨率输入。因此,作者提出了focal modulation network(FocalNet)使用焦点调制模块来取代自注意力。 改进结…
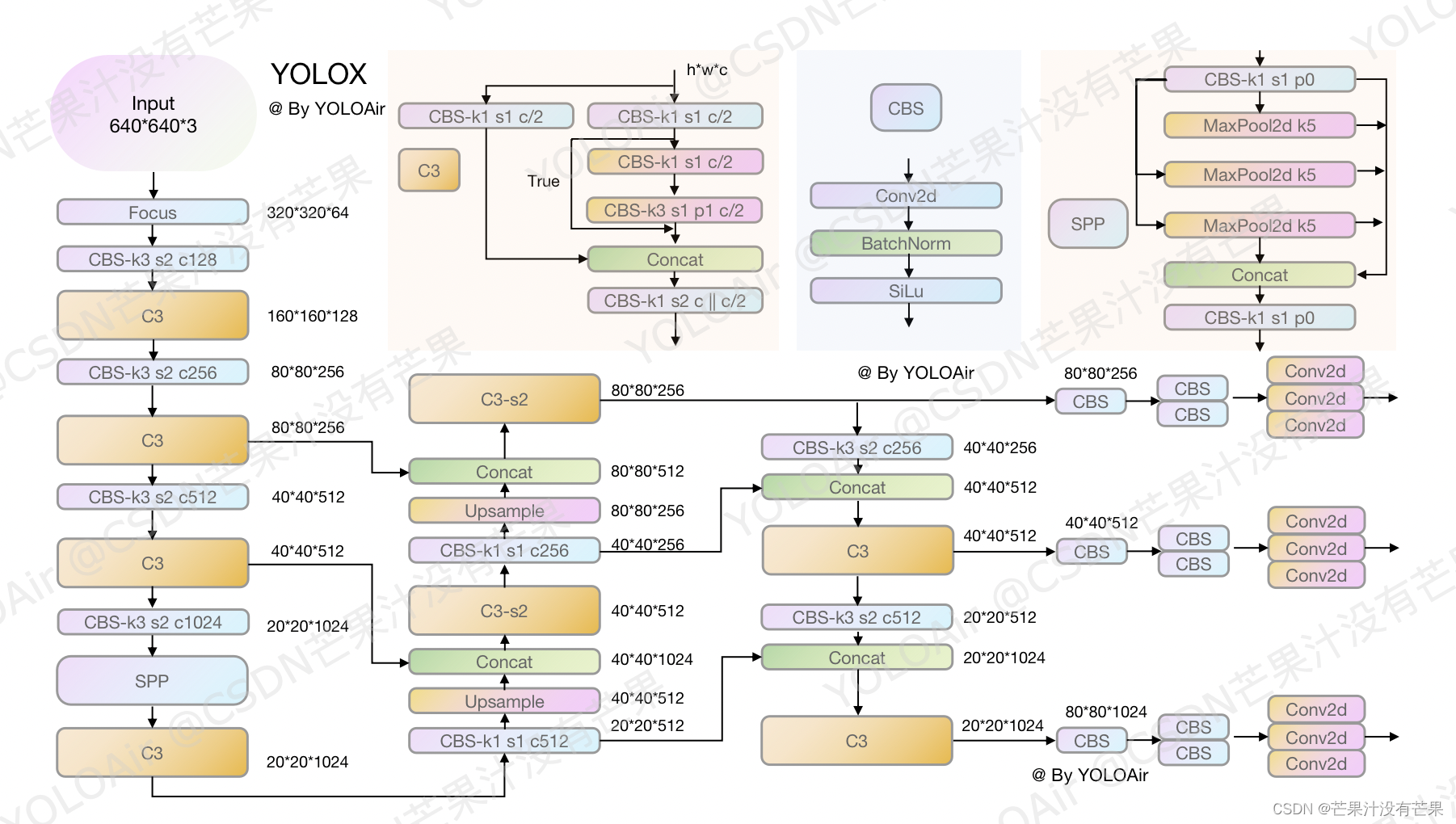
芒果YOLOv8改进145:全新风格原创YOLOv8网络结构解析图
💡本篇分享一下个人绘制的原创全新风格 YOLOv8网络结构图 感觉搭配还行,看着比较直观。
该专栏完整目录链接: 芒果YOLOv8深度改进教程
订阅了专栏的读者 可以获取一份 <可以自行修改 / 编辑> 的 YOLOv8结构图修改源文件 YOLOv8结构图…

DECO: Query-Based End-to-End Object Detection with ConvNets 学习笔记
论文地址:https://arxiv.org/pdf/2312.13735.pdf源码地址:https://github.com/xinghaochen/DECO 近年来,Detection Transformer (DETR) 及其变体在准确检测目标方面显示出巨大的潜力。对象查询机制使DETR系列能够直接获…
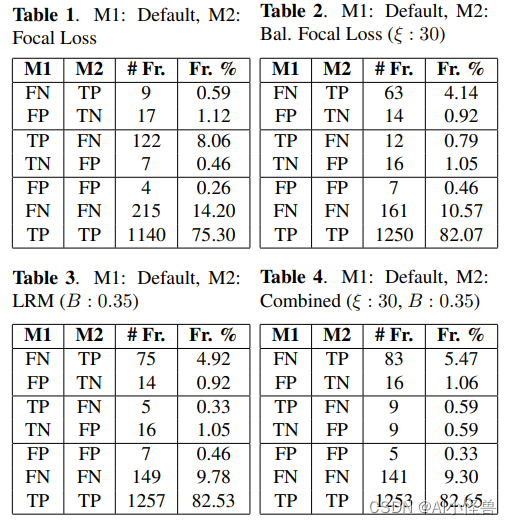
YOLOv9改进策略:loss优化 | LRM loss困难样本挖掘,提升难样本、遮挡物、低对比度等检测精度
💡💡💡本文改进内容:LRM loss困难样本挖掘引入到YOLOv9,性能优于Focal Loss 💡💡💡 LRM loss应用到能够大幅提升小目标、红外小目标、大幅度提升遮挡物性能,性能如下图所…
【YOLOv5改进系列(7)】高效涨点----使用yolov8中的C2F模块替换yolov5中的C3模块
文章目录 🚀🚀🚀前言一、1️⃣ C3模块和C2F模块详解1.1 🎓 C3模块1.2 ✨BottleNeck模块1.3 ⭐️C2F模块 二、2️⃣添加C2f和C2F_Bottleneck模块代码三、3️⃣新建yolov5s_C2F.yaml文件四、4️⃣修改yolo.py中的parse_model函数五…
【YOLOv5改进系列(8)】高效涨点----添加yolov7中Aux head 辅助训练头
文章目录 🚀🚀🚀前言一、1️⃣ Auxiliary head辅助头简单介绍二、2️⃣从损失函数和标签分配分析三、3️⃣正负样本标签分配四、4️⃣如何添加Aux head辅助训练头五、5️⃣实验部分(后续添加,还是跑模型,辅助头真是太慢…
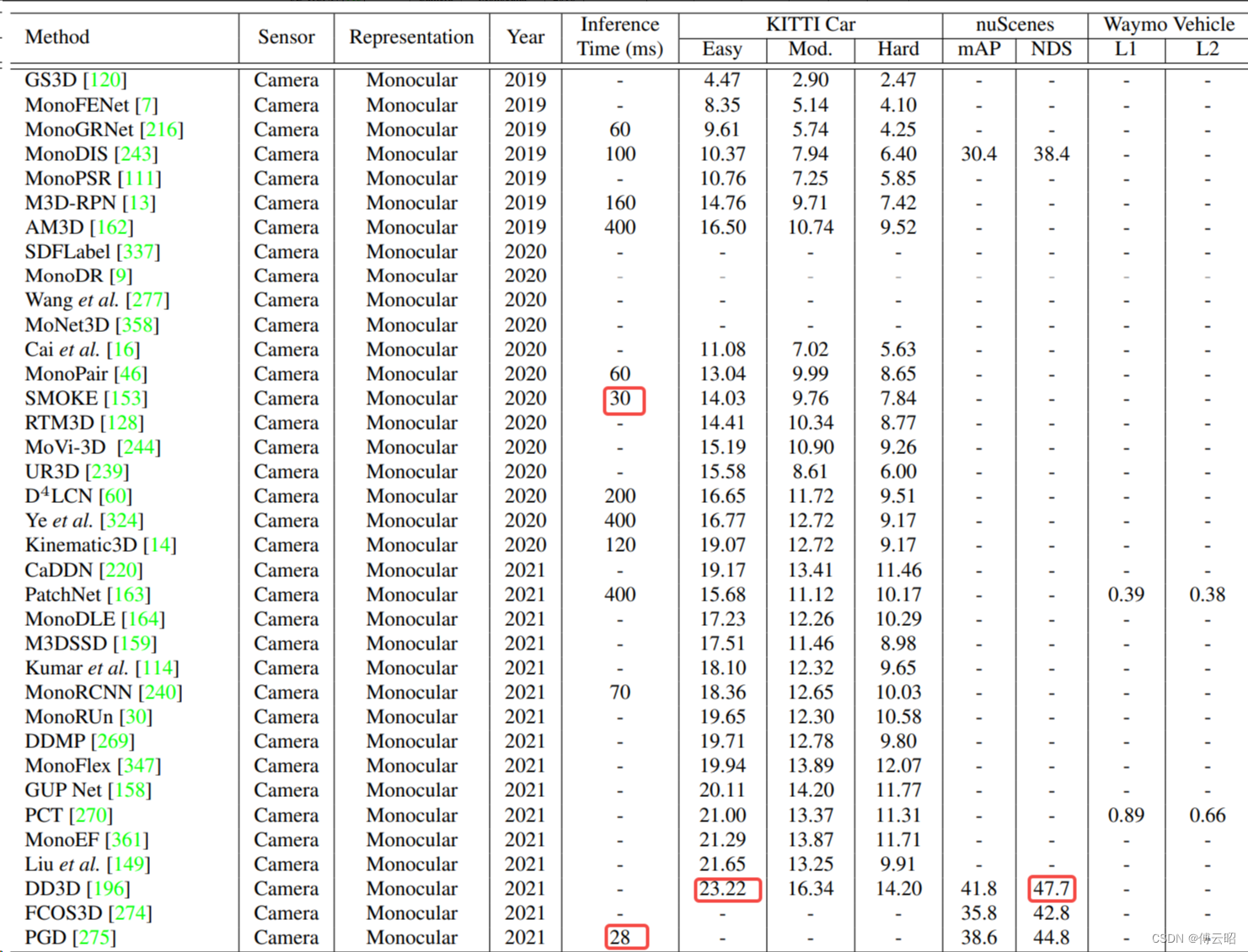
3D目标检测综述笔记
3D Object Detection for Autonomous Driving: A Review and New Outlooks
https://arxiv.org/pdf/2206.09474.pdf
目录
0.background编辑
1.1表示形式
1.2感知输入
1.3数据集
1.4评估指标
1. LiDAR-based 3D Object Detection
2.数据表征
2.1 point-based
2.1.…

数据增强项目 | 用于目标检测的训练数据增强
项目应用场景 面向增强目标检测训练数据集,采用 Horizontal Flipping、Scaling、Translation、Rotation、Shearing、Resizing 等方法进行数据集的增强和丰富,能够提高目标检测算法的鲁棒性
项目效果: 项目细节 > 具体参见项目 README.md …
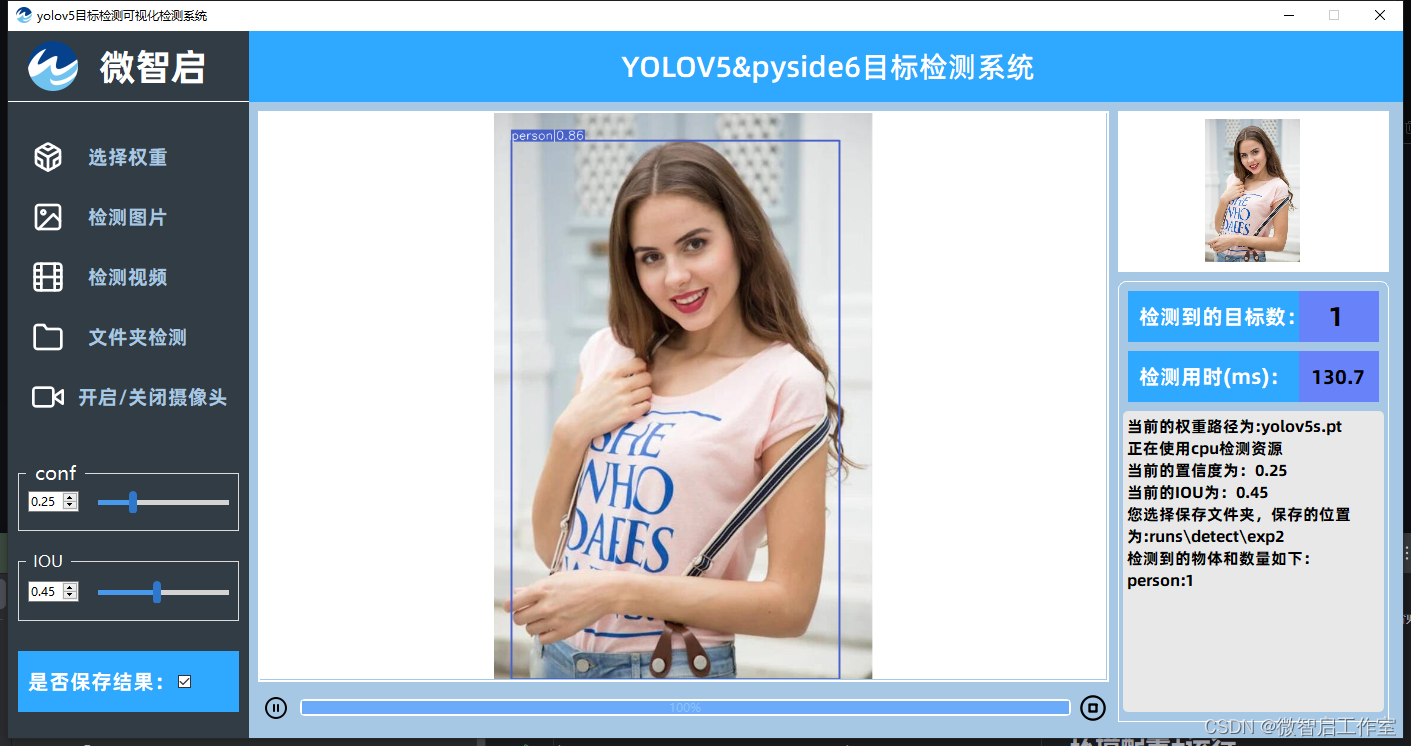
yolov5目标检测可视化界面pyside6源码(无登录版)
这个是yolov5pyside6实现目标检测可视化的代码,本套项目没有用户登录的功能,如需用户登录版,看另一篇文章:yolov5pyside6登录用户管理目标检测可视化源码_yolov5用户登入功能-CSDN博客

67、yolov8目标检测和旋转目标检测算法部署Atlas 200I DK A2开发板上
基本思想:需求部署yolov8目标检测和旋转目标检测算法部署atlas 200dk 开发板上
一、转换模型 链接: https://pan.baidu.com/s/1hJPX2QvybI4AGgeJKO6QgQ?pwdq2s5 提取码: q2s5
from ultralytics import YOLO# Load a model
model YOLO("yolov8s.yaml")…

主干网络篇 | YOLOv8更换主干网络之EfficientNet
前言:Hello大家好,我是小哥谈。EfficientNet是一种高效的卷积神经网络架构,由Mingxing Tan和Quoc V. Le在2019年提出,其设计思想是在不增加计算复杂度的情况下提高模型的准确性。它引入了一个称为"复合系数"的概念,该系数用于同时缩放网络的深度、宽度和分辨率。…
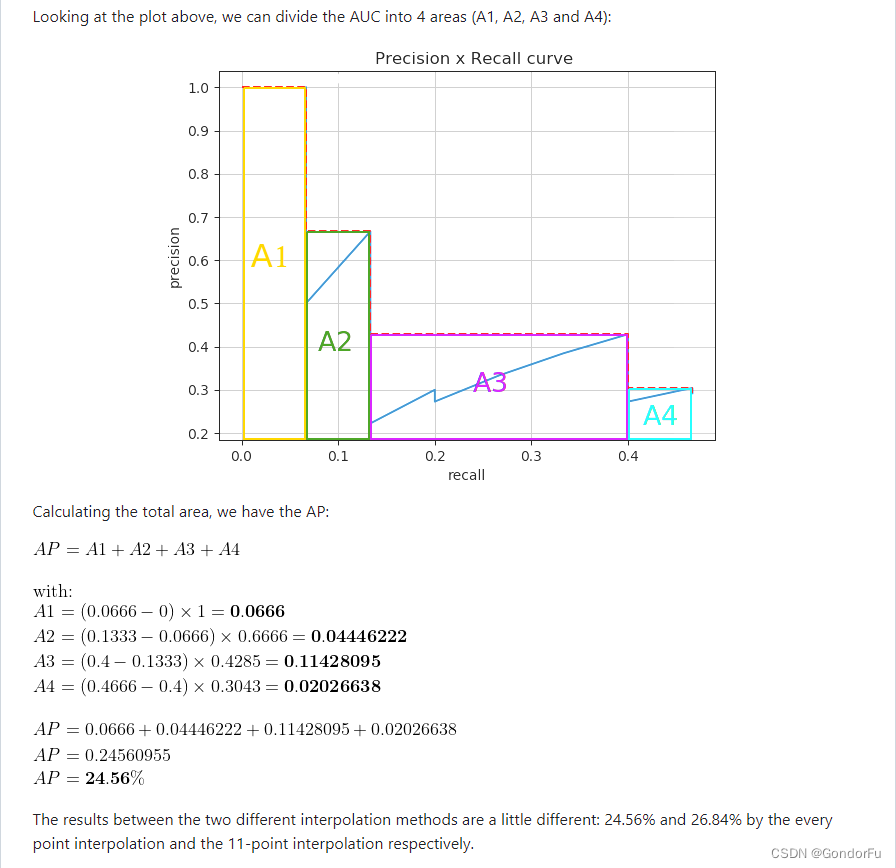

谈一谈BEV和Transformer在自动驾驶中的应用
谈一谈BEV和Transformer在自动驾驶中的应用
BEV和Transformer都这么火,这次就聊一聊。 结尾有资料连接
一 BEV有什么用
首先,鸟瞰图并不能带来新的功能,对规控也没有什么额外的好处。
从鸟瞰图这个名词就可以看出来,本来摄像头…

注意力机制篇 | YOLOv8改进之在C2f模块添加EMA注意力机制(附2种改进方法)
前言:Hello大家好,我是小哥谈。EMA(Exponential Moving Average)注意力机制是一种用于增强模型性能的注意力机制,它通过对模型的特征图进行加权平均来提取更有用的特征信息。具体来说,EMA注意力机制通过引入一个权重因子来调整特征图中每个位置的重要性,从而使模型能够更…
YOLOv9改进策略 :block优化 | 无需TokenMixer也能达成SOTA性能的极简ViT架构 | CVPR2023 RIFormer
💡💡💡本文改进内容: token mixer被验证能够大幅度提升性能,但典型的token mixer为自注意力机制,推理耗时长,计算代价大,而RIFormers是无需TokenMixer也能达成SOTA性能的极简ViT架构…
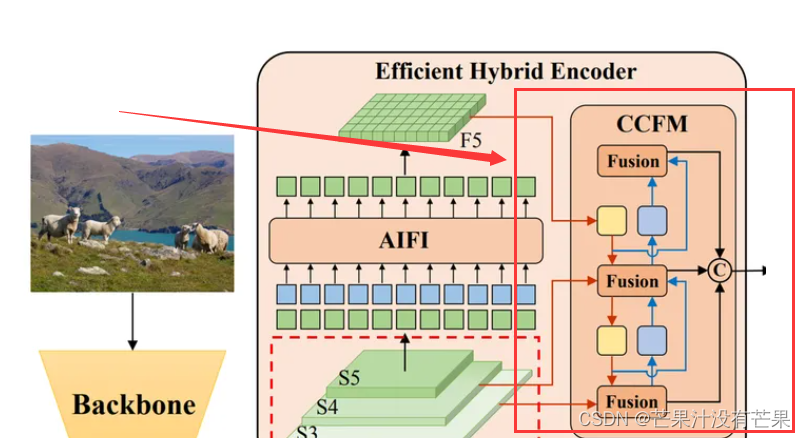
芒果YOLOv8改进130:Neck篇,即插即用,CCFM重构跨尺度特征融合模块,构建CCFM模块,助力小目标检测涨点
芒果专栏 基于 CCFM 的改进结构,改进源码教程 | 详情如下🥇 💡本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 即插即用 结构。博客 包括改进所需的 核心结构代码 文件
YOLOv8改进专栏完整目录链接:👉 芒果YOLOv8深度改进教程 | 🔥 订阅一个…
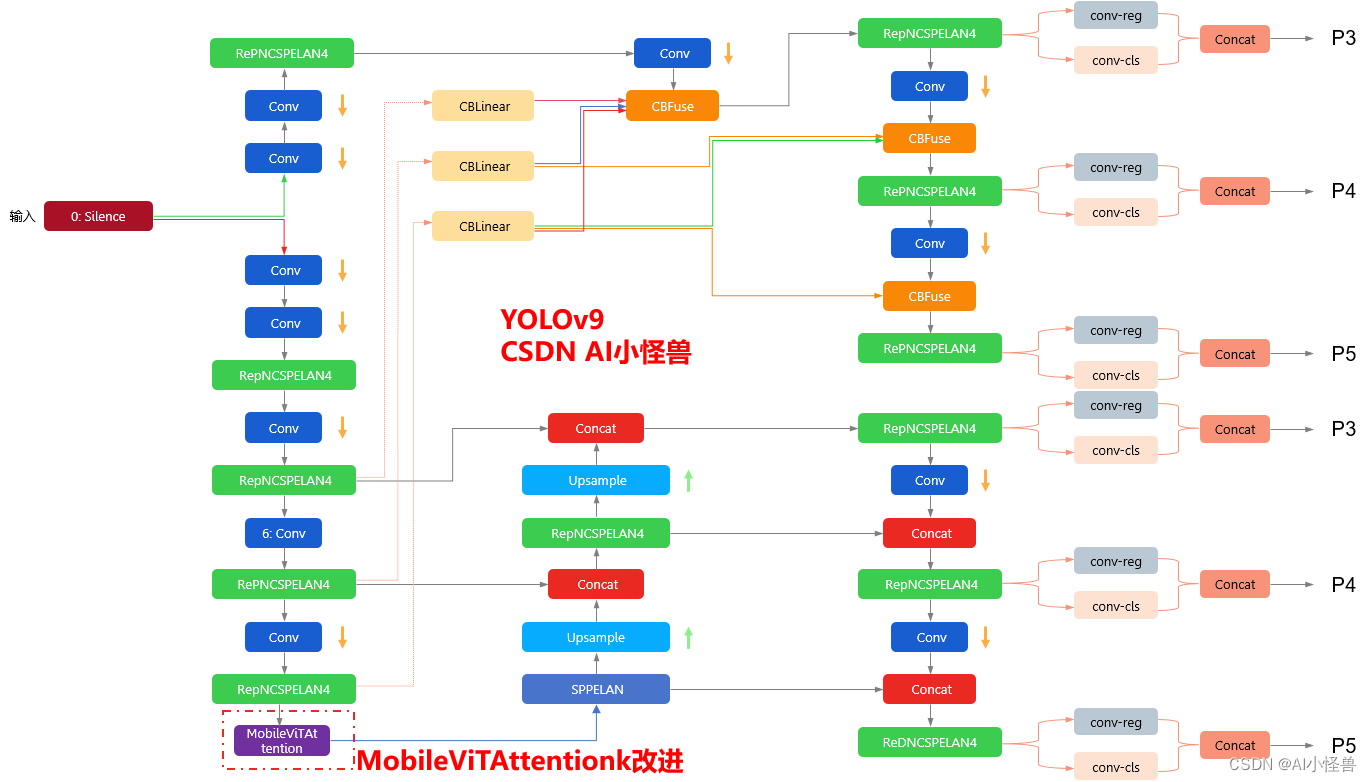
YOLOv9改进策略 :block优化 | MobileViTAttention自注意力,更小、更轻、精度更高 ,性能优于MobileNetV3等
💡💡💡本文改进内容:现有博客都是将MobileViT作为backbone引入YOLO,因此存在的问题点是训练显存要求巨大,因此本文引入自注意力(ViTs):MobileViTAttention,从而实现高效涨点
💡💡💡第一次基于轻量级CNN网络性能的轻量级ViT工作,性能SOTA!。性能优于MobileNe…

LabelConvert: 目标检测和图像分割数据集格式转换工具
LabelConvert
LabelConvert是一个目标检测和图像分割的数据集格式转换工具,支持labelme、labelImg与YOLO、VOC和COCO 数据集格式之间的相互转换。
支持的转换格式 安装
pip install label_convert具体使用方法
由于文章篇幅所限,请移步LabelConvert官…
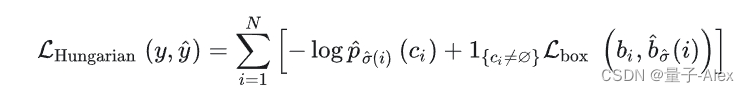
【DETR系列目标检测算法代码精讲】01 DETR算法01 DETR算法框架和网络结构介绍
为什么要有DETR
总所周知,传统的目标检测算法非常依赖于anchor和nms等手工设计操作,非常费时费力,自然而然的就产生了取消这些操作的想法。但是我们首先需要思考的是,为什么我们需要anchor和nms?
因为我们是没有指定…
【yolov5小技巧(1)】---可视化并统计目标检测中的TP、FP、FN
文章目录 🚀🚀🚀前言一、1️⃣相关名词解释二、2️⃣论文中案例三、3️⃣新建相关文件夹四、4️⃣detect.py推理五、5️⃣开始可视化六、6️⃣可视化结果分析 👀🎉📜系列文章目录
嘻嘻 暂时还没有~~~~
&a…
【保姆级教程】YOLOv3图像目标检测:训练自己的数据集
一、YOLOv3图像目标检测原理
二、YOLOv3代码及预训练权重下载
2.1 下载yolov3代码
这里使用的是B站大佬Bubbliiiing复现的yolov3代码 仓库地址: https://github.com/bubbliiiing/yolo3-pytorch
2.2 下载模型预训练权重unet_resnet_medical.pth
链接:…
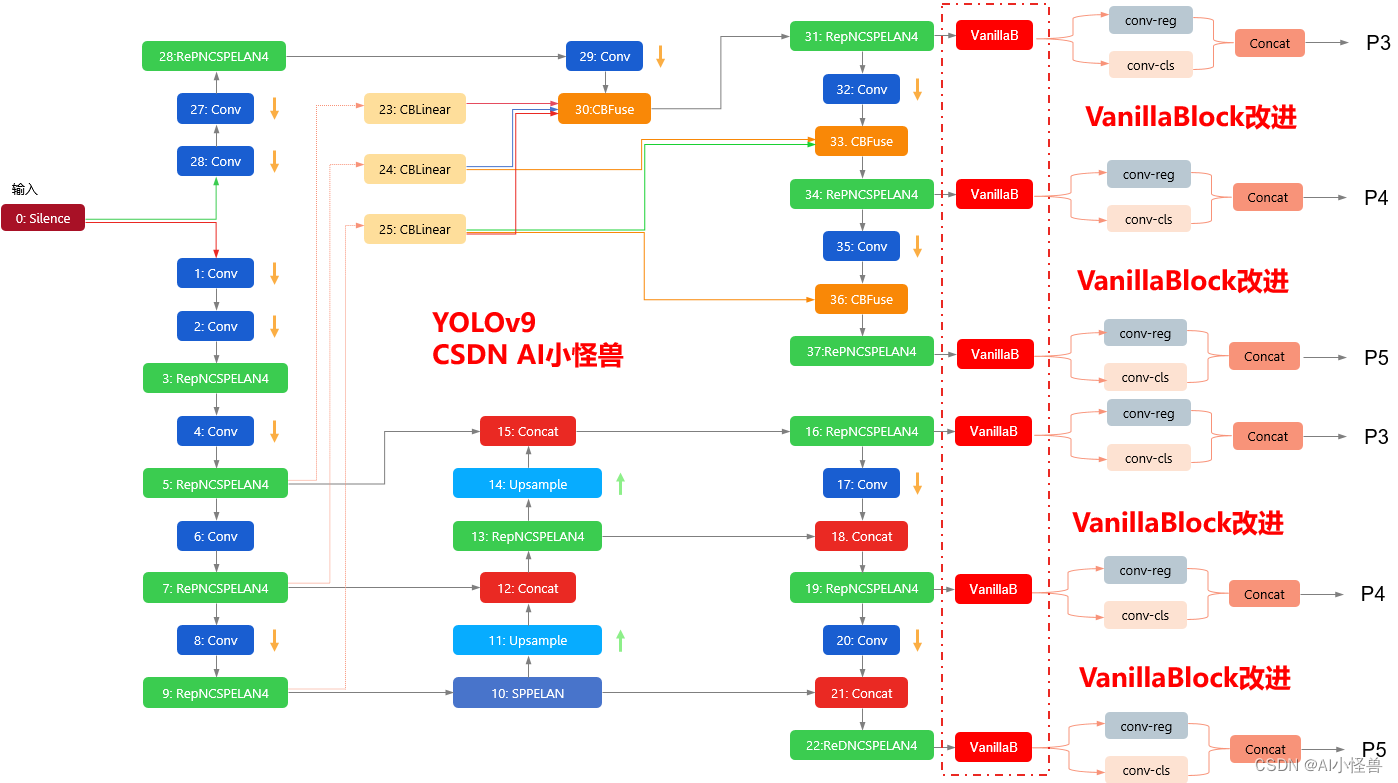
YOLOv9改进策略 :主干优化 | 极简的神经网络VanillaBlock 实现涨点 |华为诺亚 VanillaNet
💡💡💡本文改进内容: VanillaNet,是一种设计优雅的神经网络架构, 通过避免高深度、shortcuts和自注意力等复杂操作,VanillaNet 简洁明了但功能强大。 💡💡💡引入VanillaBlock GFLOPs从原始的238.9降低至 165.0 ,保持轻量级的同时在多个数据集验证能够高效涨点…
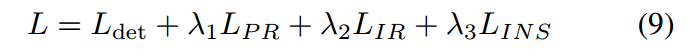
Dual Relation Knowledge Distillation for Object Detection用于目标检测的双关系知识蒸馏
摘要
有两个关键点导致检测任务的蒸馏性能不佳。一是前景和背景特征严重不平衡,二是小对象缺乏足够的特征表示。为了解决上述问题,我们提出了一种新的知识蒸馏方法——双关系知识蒸馏(DRKD),包括逐像素关系蒸馏和逐实…

【DETR系列目标检测算法代码精讲】01 DETR算法02 DETR算法数据预处理+图像增强+dataset代码精讲
今天这一节主要对DETR算法的数据预处理和数据增强部分的代码做逐行的精讲。 这一部分的代码主要的功能就是将COCO数据集中的原始图像和原始标注处理成能够输入到DETR网络中的图像和标注。
我首先采取任务流程逐行讲解的办法,然后再debug演示一下
准备
这个读取数…

基于YOLOv8的绝缘子检测系统
💡💡💡本文摘要:基于YOLOv8的绝缘子小目标检测,阐述了整个数据制作和训练可视化过程 1.YOLOv8介绍 Ultralytics YOLOv8是Ultralytics公司开发的YOLO目标检测和图像分割模型的最新版本。YOLOv8是一种尖端的、最先进的&a…
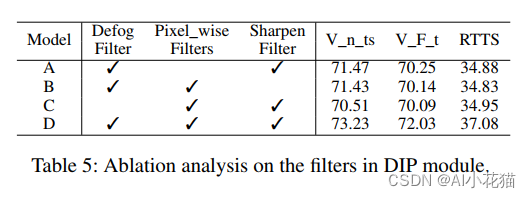
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions(IA-YOLO)
1、总体概述
基于深度学习的目标检测在常规条件的数据集可以获得不错的结果,但是在环境、场景、天气、照度、雾霾等自然条件的综合干扰下,深度学习模型的适应程度变低,检测结果也随之下降,因此研究在复杂气象条件下的目标检测方法…
YOLOv8改进:基础篇 | 手把手教程初学者入门 | 如何训练、验证、预测模型以及如何修改超参数
💡💡💡本文内容:手把手教程,教会你如何训练、验证、预测模型以及如何修改超参数 收录
YOLOv8原创自研
https://blog.csdn.net/m0_63774211/category_12511737.html?spm=1001.2014.3001.5482
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡…
目标检测——工业安全生产环境违规使用手机的识别
一、重要性及意义
首先,工业安全生产环境涉及到许多复杂的工艺和设备,这些设备和工艺往往需要高精度的操作和严格的监管。如果员工在生产过程中违规使用手机,不仅可能分散其注意力,降低工作效率,更可能因操作失误导致…
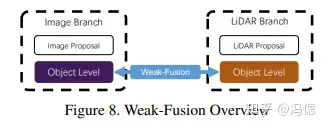
自动驾驶-如何进行多传感器的融合
自动驾驶-如何进行多传感器的融合 附赠自动驾驶学习资料和量产经验:链接
引言
自动驾驶中主要使用的感知传感器是摄像头和激光雷达,这两种模态的数据都可以进行目标检测和语义分割并用于自动驾驶中,但是如果只使用单一的传感器进行上述工作…
芒果YOLOv8改进128:卷积SPConv篇,即插即用,去除特征图中的冗余,FLOPs 和参数急剧下降,提升小目标检测
芒果专栏 基于 SPConv 的改进结构,改进源码教程 | 详情如下🥇 👉1. SPConv 结构、👉2. CfSPConv 结构 💡本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 即插即用 结构。博客 包括改进所需的 核心结构代码 文件
YOLOv8改进专栏完整目录链接:…
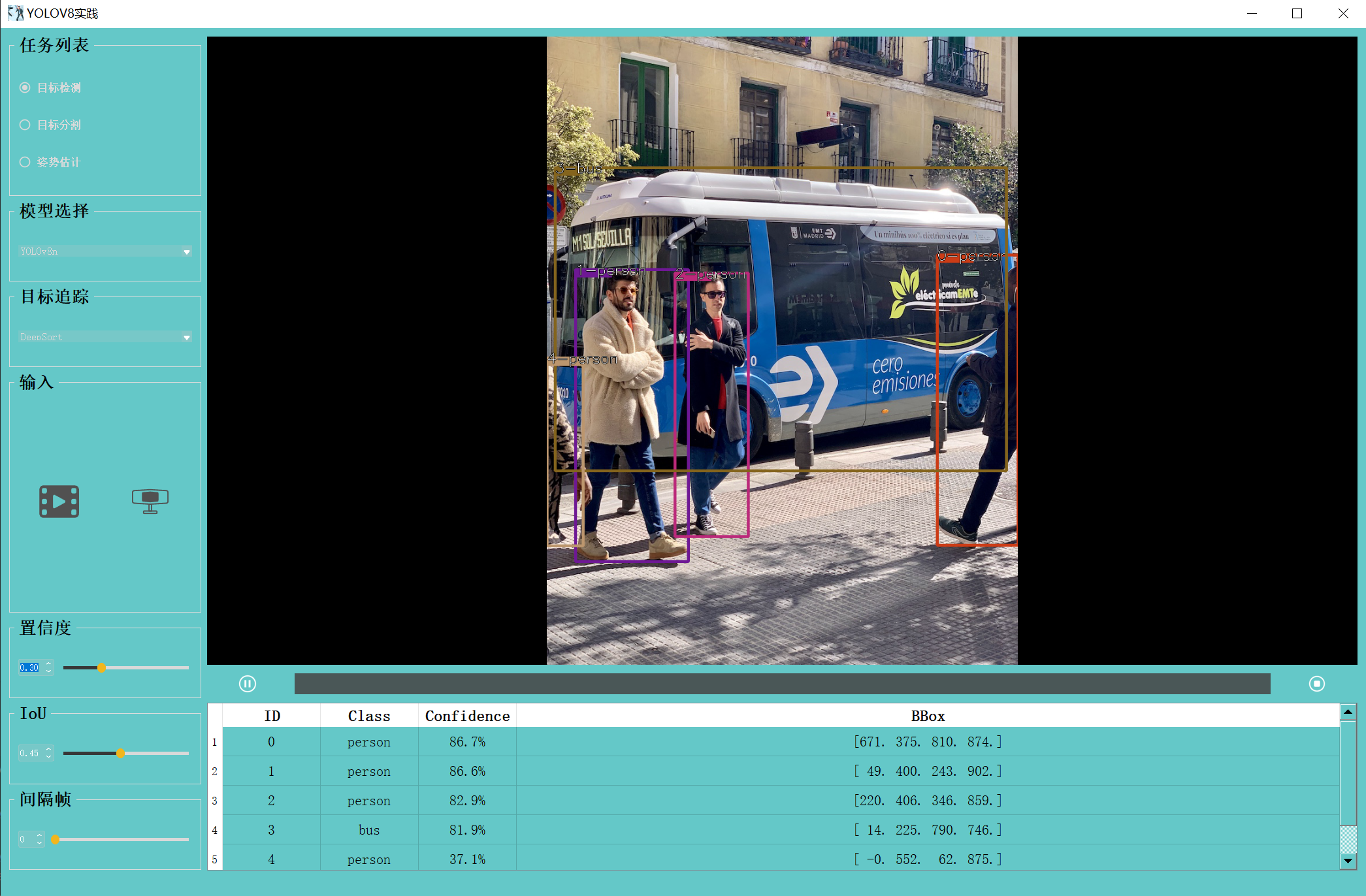
YOLOv8项目实践——目标检测、实例分割、姿态估计、目标追踪算法原理及模型部署(Python实现带界面)
简介
Ultralytics YOLOv8是一种前沿的、最先进的(SOTA)模型,它在前代YOLO版本的成功基础上进行了进一步的创新,引入了全新的特性和改进,以进一步提升性能和灵活性。作为一个高速、精准且易于操作的设计,YO…
[数据集][目标检测]道路行人车辆坑洞锥形桶检测数据集VOC+YOLO格式6275张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):6275 标注数量(xml文件个数):6275 标注数量(txt文件个数):6275 标注…

【EI会议征稿通知】电子、通信与智能科学国际会议(ECIS 2024)
电子、通信与智能科学国际会议(ECIS 2024)
The International Conference on Electronics, Communications and Intelligent Science
电子、通信与智能科学国际会议(ECIS 2024)将于2024年05月24日-05月27日在中国长沙召开。ECIS…

【3D目标检测】Det3d—SE-SSD模型训练(前篇):KITTI数据集训练
SE-SSD模型训练 1 基于Det3d搭建SE-SSD环境2 自定义数据准备2.1 自定义数据集标注2.2 训练数据生成2.3 数据集分割 3 训练KITTI数据集3.1 数据准备3.2 配置修改3.3 模型训练 1 基于Det3d搭建SE-SSD环境
Det3D环境搭建参考:【3D目标检测】环境搭建(OpenP…
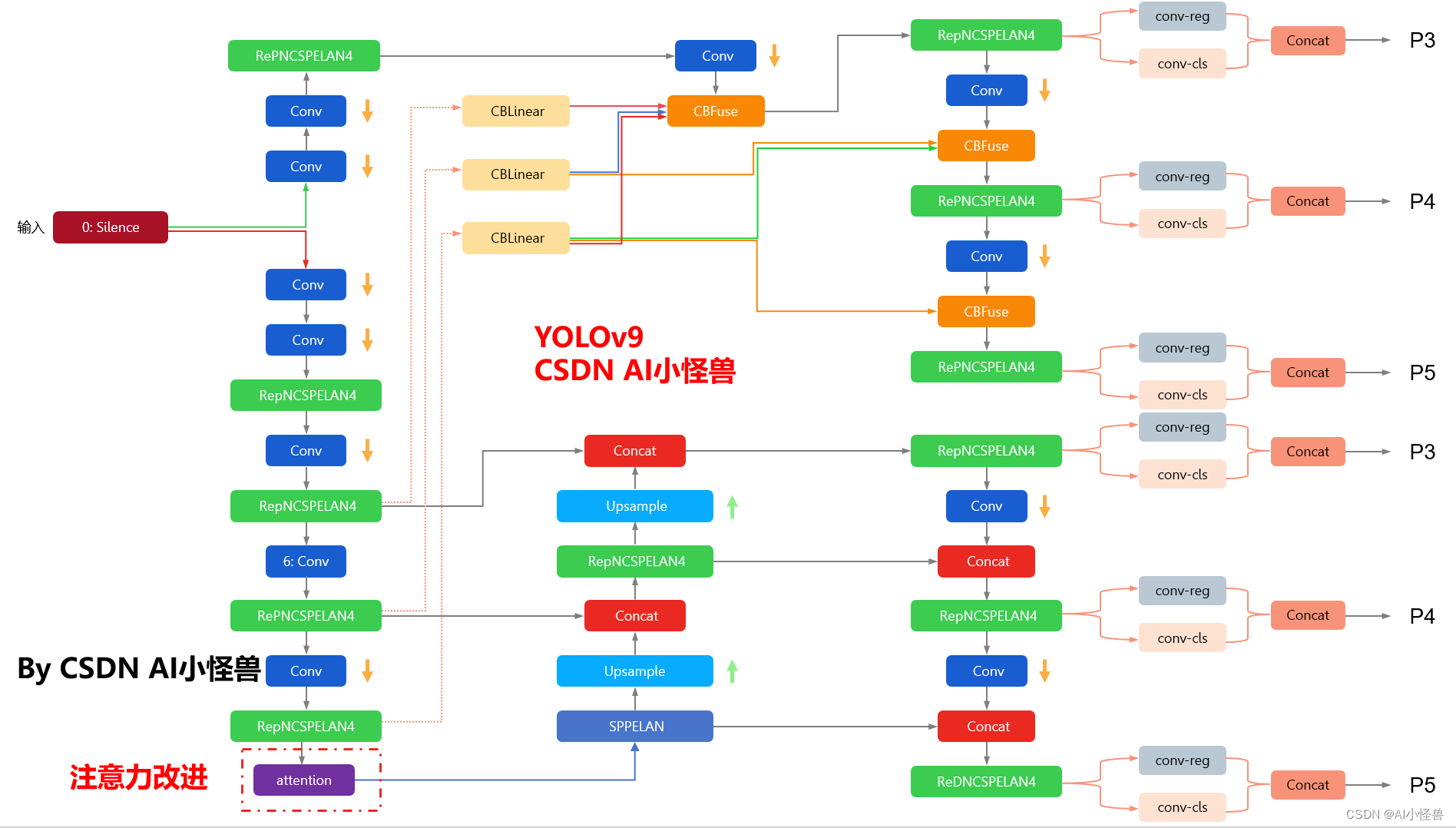
YOLOv9改进策略:注意力机制 | 二阶通道注意力机制(Second-order Channel Attention,SOCA),实现单图超分效果
💡💡💡本文改进内容:CVPR_2019 SOCA注意力,一种基于二阶通道注意力机制,能够单幅图像超分辨率,从原理角度分析能够在小目标检测领域实现大幅涨点效果!!!
&am…
[数据集][目标检测]公共场所危险物品检测数据集VOC+YOLO格式1431张6类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1431 标注数量(xml文件个数):1431 标注数量(txt文件个数):1431 标注…
芒果YOLOv5改进89:卷积SPConv篇,即插即用,去除特征图中的冗余,FLOPs 和参数急剧下降,提升小目标检测
芒果专栏 基于 SPConv 的改进结构,改进源码教程 | 详情如下🥇 👉1. SPConv 结构、👉2. CfSPConv 结构 💡本博客 改进源代码改进 适用于 YOLOv5 按步骤操作运行改进后的代码即可 即插即用 结构。博客 包括改进所需的 核心结构代码 文件
YOLOv5改进专栏完整目录链接:…
目标检测——植物病害图像数据集
一、重要性及意义
首先,植物病害图像是了解农业中植物生长和受病害情况的重要信息来源。通过对这些图像的分析,可以直观地观察到植物的生长状况,及时发现病害的存在。这不仅有助于农民和研究人员快速、准确地诊断植物病害,还能为…